htsget-rs
![]()
A server implementation of the htsget protocol for bioinformatics in Rust. It is:
- Fully-featured: supports BAM and CRAM for reads, and VCF and BCF for variants, as well as other aspects of the protocol such as TLS, and CORS.
- Serverless: supports local server instances using Actix Web, and serverless instances using AWS Lambda Rust Runtime.
- Storage interchangeable: supports local filesystem storage as well as objects via Minio and AWS S3.
- Thoroughly tested and benchmarked: tested using a purpose-built test suite and benchmarked using criterion-rs.
To get started, see Usage.
Note: htsget-rs is still experimental, and subject to change.
Overview
Htsget-rs implements the htsget protocol, which is an HTTP-based protocol for querying bioinformatics files. The htsget protocol outlines how a htsget server should behave, and it is an effective way to fetch regions of large bioinformatics files.
A htsget server responds to queries which ask for regions of bioinformatics files. It does this by returning an array of URL tickets, that the client must fetch and concatenate. This process is outlined in the diagram below:
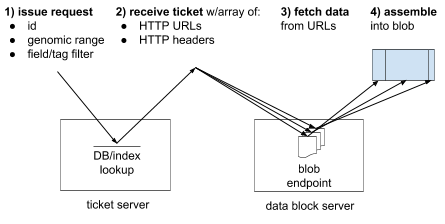
htsget-rs implements this process as closely as possible, and aims to return byte ranges that are as small as possible. htsget-rs is written asynchronously using the Tokio runtime. It aims to be as efficient and safe as possible, having a thorough set of tests and benchmarks.
htsget-rs implements the following components of the protocol:
GETrequests.POSTrequests.- BAM and CRAM for the
readsendpoint. - VCF and BCF for the
variantsendpoint. service-infoendpoint.- TLS on the data block server.
- CORS support on the ticket and data block servers.
Usage
Htsget-rs is configured using environment variables, for details on how to set them, see htsget-config.
Local
To run a local instance htsget-rs, run htsget-actix by executing the following:
cargo run -p htsget-actixUsing the default configuration, this will start a ticket server on 127.0.0.1:8080 and a data block server on 127.0.0.1:8081
with data accessible from the data directory. See htsget-actix for more information.
Cloud
Cloud based htsget-rs uses htsget-lambda. For more information and an example deployment of this crate see deploy.
Tests
Tests can be run tests by executing:
cargo test --all-featuresTo run benchmarks, see the benchmark sections of htsget-actix and htsget-search.
Project Layout
This repository consists of a workspace composed of the following crates:
- htsget-config: Configuration of the server.
- htsget-actix: Local instance of the htsget server. Contains framework dependent code using Actix Web.
- htsget-http: Handling of htsget HTTP requests. Framework independent code.
- htsget-lambda: Cloud based instance of the htsget server. Contains framework dependent code using the Rust Runtime for AWS Lambda.
- htsget-search: Core logic needed to search bioinformatics files based on htsget queries.
- htsget-test: Test suite used by other crates in the project.
Other directories contain further applications or data:
- data: Contains example data files which can be used by htsget-rs, in folders denoting the file type.
This directory also contains example events used by a cloud instance of htsget-rs in the
eventssubdirectory. - deploy: An example deployment of htsget-lambda.
In htsget-rs the ticket server handled by htsget-actix or htsget-lambda, and the data
block server is handled by the storage backend, either locally, or using AWS S3.
This project layout is structured to allow for extensibility and modularity. For example, a new ticket server and data server could
be implemented using Cloudflare Workers in a htsget-http-workers crate and Cloudflare R2 in htsget-search.
See the htsget-search overview for more information on the storage backend.
Contributing
Thanks for your interest in contributing, we would love to have you! See the contributing guide for more information.
License
This project is licensed under the MIT license.



![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")
![github-actions[bot] avatar](https://avatars.githubusercontent.com/in/15368?v=4 "github-actions[bot]")
![github-merge-queue[bot] avatar](https://avatars.githubusercontent.com/u/9919?v=4 "github-merge-queue[bot]")