shiqiyu / libfacedetection.train Goto Github PK
View Code? Open in Web Editor NEWThe training program for libfacedetection for face detection and 5-landmark detection.
License: Apache License 2.0
The training program for libfacedetection for face detection and 5-landmark detection.
License: Apache License 2.0





























































































































看到detect.py 只有图片和视频的,但是为尝试过拉流摄像头实时检测,发现不行,请问有相应的代码可以提供下吗?
谢谢,希望能够得到回复
老师,您好,我想问下为什么我按照你的redeme中的训练方法训练却出现如下的错误?您知道怎么解决吗?
Printing net...
Loading Dataset...
Printing net...
Printing net...
Printing net...
Printing net...
Printing net...
Printing net...
Printing net...
Printing net...
Traceback (most recent call last):
File "train.py", line 198, in
train()
File "train.py", line 133, in train
images, targets = next(batch_iterator)
File "C:\ProgramData\Anaconda3\envs\ozl\lib\site-packages\torch\utils\data\dataloader.py", line 637, in next
return self._process_next_batch(batch)
File "C:\ProgramData\Anaconda3\envs\ozl\lib\site-packages\torch\utils\data\dataloader.py", line 658, in _process_next_batch
raise batch.exc_type(batch.exc_msg)
AttributeError: Traceback (most recent call last):
File "C:\ProgramData\Anaconda3\envs\ozl\lib\site-packages\torch\utils\data\dataloader.py", line 138, in _worker_loop
samples = collate_fn([dataset[i] for i in batch_indices])
File "C:\ProgramData\Anaconda3\envs\ozl\lib\site-packages\torch\utils\data\dataloader.py", line 138, in
samples = collate_fn([dataset[i] for i in batch_indices])
File "F:\ozl\facenet\libfacedetection.train\src\data.py", line 325, in getitem
height, width, _ = img.shape
AttributeError: 'NoneType' object has no attribute 'shape'
How to get the face_rect_landmark.py? Thank you!
Hello!
I followed the suggested link to download "labelsv2" but after inserting the suggested password I cannot directly download the file because I am required some action with the QR-code (I don't speak Chinese)
What should I do?
Hello, can you write this code for training in C ++?
模型为640x640,但是为转onnx的时候尺寸改为641的大小也一样可以转onnx,请问这是为什么呢?不是规定了是640x640的大小吗?
余老师您好,我在下载了您的开源项目之后想要尝试把onnx模型部署到VUE上并做一个demo的展示。目前我使用的Node.js是1.16.1,onnxruntime是最新的1.12.1.在这个过程中我发现,使用项目自带的onnx会遇到两个问题:
1.需要把INT64转换成INT32.这个比较好处理。我在opset_version等参数不变的情况下,把模型的params和Nodes都换成了精度是INT32的。
2.然后,我就发现,您提供的ONNX似乎在JS上仍然不是很兼容。具体错误如下图:

我还尝试在您的代码上把上采样的方法改写,不进行任何操作而直接返回一个符合上采样尺寸大小的torch.ones()。但前端还是会出现Shape的错误。这个有什么好方法或者建议去解决吗?

//only 27 elements used for each pixel
create((imgHeight+1)/2, (imgWidth+1)/2, 32);
//since the pixel assignment cannot fill all the elements in the blob.
//some elements in the blob should be initialized to 0
setZero();
Issue:
Link for visualization of YuNet architecture from the README file does not point to the correct onnx file. The current link points to the onnx file based on the previous directory structure.
Screenshot:

Possible Fix:
Have to update the README file to point to the latest onnx file (From the 3 onnx files currently present).
Can I work on it and raise a PR ?
我在opencv 中使用这个模型,处理戴口罩图片提示检测不到人脸
请问大神,在data里面要导入的两个模块是什么?从哪里找到?
How can I solve this probelm? I'm using python3.6.5 torch 1.5.0+cuda92
您好,目前代码是支持训练固定次迭代,没有val集做early-stop个人认为会难以捕捉over-fitting的情况,请问后续有添加eval.py的计划吗?我自己写了一份eval.py,但是不知道对不对。
此致敬礼,顺颂时祺
Hello,
I would like to ask a few questions about this github repo.
请问余老师ConvDPUnit中的卷积部分如下代码:

为什么没有使用pointwise的操作进行降维呢?这样操作对速度和精度有什么作用吗?谢谢
python tools/yunet2onnx.py ./configs/yunet_n.py ./weights/yunet_n.pth --verify true
当转onnx的时候,验证pytorch模型推理和onnx推理时候出现问题。

I train this network using default parameters in train.py, then use final.pth to test on widerface val set scales=[1.], confidence_threshold=0.3.
The scores I get are
Easy Val AP: 0.7902144778486827
Medium Val AP: 0.7513014930849016
Hard Val AP: 0.5267147634247762
Do you use some other tricks while training?
为什么我训练的时候利用率很低呢,我的cuda环境也配置好了
Is the fine-tuned model covered by MIT license as well? If so, was it trained on WIDER FACE or another dataset?
Asking because your C++ code is BSD-3-clause, and int8data.cpp is a direct derivative of the fine-tuned model.
于老师,您好
我采用默认的命令python tools/detect_image.py ./configs/yunet_n.py ./weights/yunet_n.pth ./image.jpg 去检测图像,结果好像有问题,结果如下:

Hi, I am trying to repeat your experiment by running your train.py in one gpu and four gpus, it turns out 4 gpus require longer time than one gpu, 150+ hours versus 60+ hours. I am using 2080Ti on ubuntu 16, cuda 10.1, nvidia 430, pytorch 1.2.0. Did you encounter the same problem on your side? Thanks.
Hi,
I manually label custom datasets following the COCO format.
May I ask if is it possible for you to publish the code to convert to NVIDIA Dali (which is used in this repo)?
Thanks
Hello, I would like to ask how the new annotation txt file is written. From my understanding, 1st line is file name, 2nd line is number of faces, however 3rd/4th lines have 15 numbers, the last number i assume is visibility or opacity, however I do not know what the 14 other numbers represent because I assumed it was 5 facial landmarks thus 10 points.
Thank you
Hello, I'm kijoong lee, a LG Electronics SW Developer.
We are developing a TFLite-based hardware-accelerated AI inference framework on webOS.
Recently, we judged YuNet to be the most suitable for face detection models through benchmarks. And, by converting the face_detection_yunet_2022mar.onnx model included in opencv dnn into a tflite model, a face detector with good performance was obtained. For reference, we used the xnnpack accelerated method.
However, we need a model larger than 160x120 that can be accelerated by GPU(or NPU), so we tried to convert the model included in https://github.com/ShiqiYu/libfacedetection.train/tree/master/onnx and use it, but it didn't work. .
The reasons we analyzed are as follows.
(face_detection_yunet_2022mar_float32.tflite)
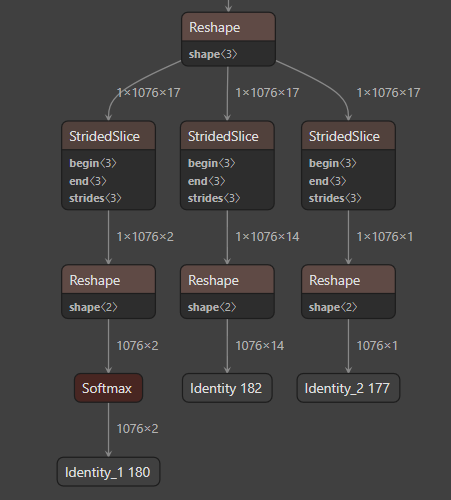
(yunet_yunet_final_320_320_simplify_float32.tflite)
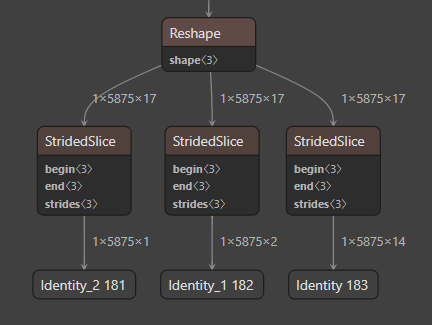
As you can see in the two figures above, the output shapes of the two models are different. A well-behaved model includes a reshaping part into a two-dimensional tensor and a Softmax operation.
How can we make a model with an input size larger than face_detection_yunet_2022mar.onnx? Or could you please fix this problem?
I firstly used my custom dataset and trained a model. Since I use the config yunet_n.py, all 'img_scale' and 'size' are (640, 640); but the input_shape of my exported onnx file is (1, 3, 736, 1280). I successfully convert this onnx file to tensorrt engine and get recall 83% on my own testing set.
However, all my custom dataset and testing set are formed of (height, width) = (720, 1080) or (1080, 1920) pictures. Hence I thought maybe I should adjust all 'img_scale' and 'size' to (736, 1280) in order to get a better model for my task.
Unfortunately, the model which trained with size (736, 1280) only get recall 50%, I also trained two models with size (1280, 1280) and (352, 640), and only get recall 70% and 50%. (all the input_shape of exported onnx files are (1, 3, 736, 1280))
Did I ignore somewhere also need to be adjusted if I don't want to use default size = (640, 640)?
The ordering of 'img_scale' and 'size' in the config and the the ordering of flag 'shape' in yunet2onnx.py are all (height, width), right?
按照readme.md配置好后,在训练完一个epoch后没反应,等了一个多小时也没有新的日志信息打印。这是为何。
日志信息如下:
LM:False || Epoch:0/500 || iter: 800/803 || L: 0.58(0.57) IOU: 0.13(0.17) LM: 277.46(232.85) C: 2.30(2.46) All: 3.02(3.20) || LR: 0.01000000
LM:False || Epoch:0/500 || iter: 802/803 || L: 0.57(0.57) IOU: 0.12(0.17) LM: 64.95(232.43) C: 2.30(2.46) All: 2.99(3.20) || LR: 0.01000000
Epoch time: 11.31 minutes; Time left: 94.09 hours
这样做是为了便于部署时候进行预处理吗?
In file config/yufacedet.yaml
anchor:
min_sizes: [[10, 16, 24], [32, 48], [64, 96], [128, 192, 256]]
steps: [8, 16, 32, 64]
ratio: [1.]
clip: False
These parameters are based on the weights/yunet_final.pth model .
But when i use the model with a fixed input size eg.onnx/yunet_yunet_final_320_320_simplify.onnx , this set of parameters will not match.
I wish to get a set of parameters which is able to adapt to the onnx model.
Thanks
As i am testing the model, i encounter it creates a lot of false positive detection on hands and necks with high confidence, can you tell me how to add negative sample images.
Thanks
Is this a one-stage test or a two-stage test?
请问这是属于单阶段检测还是两阶段检测呢?
Thanks for your great work!
The libfacedetection-v3 has many differences from v2, such as DSC and less width.
So will you release train codes for v3?
Currently, I have some problems converting the model trained by this repo, but successfully convert the model at the OpenCV GitHub repo.
So I wonder if the training code is still around?
于老师您好,我之前跑过您开源的caffe模型(https://github.com/ShiqiYu/libfacedetection/tree/master/models/caffe/yufacedetectnet-open-v1.caffemodel)
,效果挺好的。
现在想重新训练,但是开源的是pytorch版本,所以想问:
谢谢!
Hi. I saw the new version of libfacedetection.train, which is switched to the mmdet framework. But both the yunet_n.py and yunet_s.py are little bit different from the original model structure. That means the converted libfacedetection-data.cpp will not be compatible with the project libfacedetection, in which libfacedetection-model.cpp has different inferencing code. Then will you update the corresponding cpp code in the project libfacedetection? What should we do if we want to use libfacedetection on new trainning?
Thanks in advance!
安装了nvidia-dali-cuda102==1.5.0 和nvidia-dali-tf-plugin-cuda102==1.5.0
运行python train.py
报错如下:
Traceback (most recent call last):
File "train.py", line 18, in
from data import get_train_loader
File "/app/code/face_recognition/libface/libfacedetection.train/tasks/task1/../../src/data.py", line 11, in
from nvidia.dali import _DaliBaseIterator
ImportError: cannot import name '_DaliBaseIterator' from 'nvidia.dali' (/root/anaconda3/envs/libface/lib/python3.7/site-packages/nvidia/dali/init.py)
1.why set rgb_mean=(0,0,0)
2.why start trainning landmarks unitl 100 epoch later?
3.why trainning landmarks in every 2 epochs after 100 epoch?
看到训练中利用到关键点信息,有关键点相关的loss,模型推理是否支持关键点的输出呢?
在做实验的时候用到了您的代码,现在在写论文,怎么去引用您的文献?
请问现在检测最小人脸框是10x10吗,如何修改大小?
尝试通过python tools/yunet2onnx.py ./configs/yunet_n.py ./weights/yunet_n.pth 进行onnx转换,发现转换失败,我的mmcv安装版本是1.6

how to convert pytorch model to openvino model?
The bounding boxes are not same in dataset_rect and dataset_landmark, the face count in dataset_rect are larger than the one in dataset_landmark. Would tiny faces in dataset_landmark be seriously restrained during training?
Hi Mr Yu,
How can I find the requirements.txt file?
Hello, i'm currently training the model using the wider face data set and your annotations, however after 300 epochs the IoU and L just fluctuates and does not go down. IoU is also extremely low. I have attached the terminal output of the first 40 epochs
training_log.txt
Hi, thanks for sharing your project. Yunet does detact faces fast and accurately than other baselines.
I try to re-train Yunet, but I wonder where can we get datasets with the-five-key-point to train the models?
Thank you in advance if you can give some advice or directions that can help me to re-train Yunet with key-points prediction ability.
于老师,您好
我在使用项目中提供的训练脚本得到的模型性能比您开源的模型性能要差1~1.5个点.请问开源模型是否在训练时进行了别的参数调优,还是仅仅是因为数据shuffle不同导致的? 此外,还想请教一下,如果我们不需要输出人脸关键点预测,那么在训练时删除人脸关键点,对于人脸检测性能会有帮助吗?
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.