
The Move to Islandora Kit (MIK) converts source content files and accompanying metadata into ingest packages used by existing Islandora batch ingest modules, Islandora Batch, Islandora Newspaper Batch, Islandora Book Batch, and Islandora Compound Batch. In other words, it doesn’t import objects into Islandora, it prepares content for importing into Islandora:
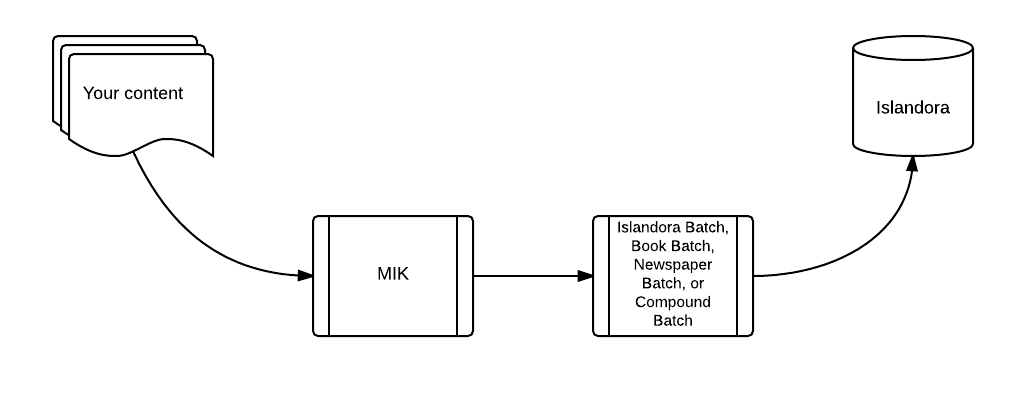
MIK is designed to be extensible. The base classes that convert the source metadata to XML files for importing into Islandora, and that convert the source content files into the required directory structure for importing, can be subclassed easily. MIK also uses plugins (known as "manipulators") and a set of "hook" scripts that allow functionality that can be turned off or on for specific jobs.
MIK was originally developed by staff at Simon Fraser University Library in support of their migration from CONTENTdm to Islandora, but its longer-term purpose is as a general toolkit for preparing content for importing content into Islandora. So MIK should really stand for "Move [content into] Islandora Kit."
We are continuing to improve our documentation, which is on the MIK wiki. Please let us know if you have any questions, suggestions or if you would like to assist.
If you have a question, please open an issue.
- Some collections in Arca
- Emily Carr University's Academic Calendars
- Emily Carr University's Wosk Masterworks Print Collection
- University of the Fraser Valley's Abbotsford Sumas and Matsqui News
- KORA, Kwantlen Polytechnic University's institutional repository
- Most of the newspapers in Simon Fraser University Library's Digitized Newspapers site
- Most of the collections in Simon Fraser University Library's Digitized Collections
- All of the collections initially launched in The Louisiana Digital Library. Some examples include:
Instructions are available on the wiki.
Typical workflow is to 1) configure your toolchain (defined below) by creating an .ini file, 2) check your configuration options and then 3) run MIK to perform the conversion of your source content into Islandora ingest packages. When MIK finishes running, you can import your content into Islandora using Islandora Batch, Islandora Newspaper Batch, Islandora Book Batch, or Islandora Compound Batch.
In a nutshell, this means create an .ini file for MIK. Details for available toolchaines are provided on the wiki.
To check your configuration options, run MIK and include the --checkconfig (or -cc) option with a value 'all':
./mik --config foo.ini --checkconfig all
You can also check specific types of configuration values as described in this Cookbook entry.
Note: if you are using null mappings for metadata manipulators, --checkconfig will return errors. Use --ignore_null_mappings to avoid these.
Once you have checked your configuration options, you can run MIK to perform the data conversion:
./mik --config foo.ini
On Windows, you'll need to run:
php mik --config foo.ini
The --config option is required, but you can also add a --limit option if you only want to create a specific number of import packages. This option is useful for testing. For example:
./mik --config foo.ini --limit 10
The above will generate 10 valid packages if possible. Check the problem_records log for any that were skipped due to errors.
Once MIK starts running, it will display its progress:
./mik --config foo.ini
Creating 10 Islandora ingest packages. Please be patient.
===================================================> 56%
and when finished will tell you where your ingest packages have been saved and where your log file is.
And you're done. In practice, you probably want to do some quality assurance on the Islandora ingest packages before you import them (and MIK provides some helper scripts to do that). If you're not happy with what MIK produced, you can always modify your configuration settings or your metadata mappings file and run MIK again.
We aim for a 1.0 release of MIK in fall 2017. Please note that the only differences between version 0.9 and 1.0 will be the addition of more features, automated tests, and code cleanup. Version 0.9 is already being used in production.
So far, we have "toolchains" (complete sets of MIK fetchers, metadata parsers, file getters, etc.) for creating Islandora import packages from the following:
- CONTENTdm
- single-file objects (images, audio, etc.)
- multi-file PDFs
- books
- newspapers
- non-book and non-newspaper compound objects
- CSV
- metadata and content files from a local filesystem for single-file objects (images, audio, etc.)
- metadata and content files from a local filesystem for compound objects
- metadata and content files from a local filesystem for books
- metadata and content files from a local filesystem for newspaper issues
- We also have an Excel fetcher and a Filesystem fetcher that can be used with CSV toolchains
- OAI-PMH
- metadata and one PDF per article from an Open Journal Systems journal
- metadata and one file per resource described in each OAI-PMH record if the record includes the URL to the file
We welcome community development partners. Some features that would be really great to see include:
- a graphical user interface on top of MIK
- tools for creating mappings files (in addition to the Metadata Mappings Helper)
- toolchains to migrate from DSpace and other repository platforms to Islandora (the OAI-PMH toolchain may already cover DSpace - testers welcome)
- a toolchain to generate Samvera import packages (yes, it's called Move to Islandora Kit but it's flexible enough to create other types of ingest packages and we'd love to collaborate with some Samvera friends)
- we have a sample CsvToJson toolchain that demonstrates that it's possible to write out packages that differ from those Islandora uses
MIK is designed to be extensible. If you have an idea for a useful manipulator or post-write hook script, please let us know.
CONTRIBUTING.md provides guidelines on how you can contribute to MIK. Our Information for Developers wiki page contains some information on coding standards, class structure, etc.
- Mark Jordan, Simon Fraser University Library
- Brandon Weigel, BC Electronic Library Network
- Marcus Barnes





































