
![]()
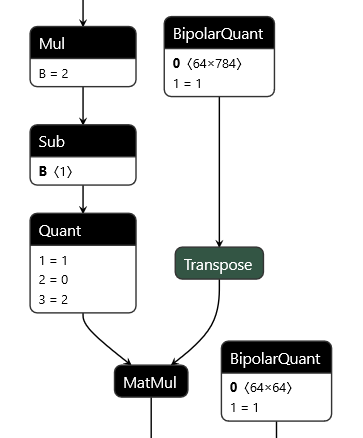
QONNX (Quantized ONNX) introduces three new custom operators -- Quant, BipolarQuant, and Trunc -- in order to represent arbitrary-precision uniform quantization in ONNX. This enables:
- Representation of binary, ternary, 3-bit, 4-bit, 6-bit or any other quantization.
- Quantization is an operator itself, and can be applied to any parameter or layer input.
- Flexible choices for scaling factor and zero-point granularity.
- Quantized values are carried using standard
floatdatatypes to remain ONNX protobuf-compatible.
This repository contains a set of Python utilities to work with QONNX models, including but not limited to:
- executing QONNX models for (slow) functional verification
- shape inference, constant folding and other basic optimizations
- summarizing the inference cost of a QONNX model in terms of mixed-precision MACs, parameter and activation volume
- Python infrastructure for writing transformations and defining executable, shape-inferencable custom ops
- (experimental) data layout conversion from standard ONNX NCHW to custom QONNX NHWC ops
- Quant for 2-to-arbitrary-bit quantization, with scaling and zero-point
- BipolarQuant for 1-bit (bipolar) quantization, with scaling and zero-point
- Trunc for truncating to a specified number of bits, with scaling and zero-point
pip install qonnx
The following quantization-aware training (QAT) frameworks support exporting to QONNX:
- Brevitas
- QKeras (beta, see this PR)
- HAWQ
- <your NN quantization framework here? please get in touch!>
The following NN inference frameworks support importing QONNX models for deployment:
- FINN (FPGA dataflow-style)
- hls4ml (FPGA dataflow-style)
- <your NN deployment framework here? please get in touch!>
Head to the QONNX model zoo to download pre-trained QONNX models on various datasets.
We recommend Netron for visualizing QONNX models.
Using the qonnx-exec command line utility, with top-level inputs supplied from in0.npy and in1.npy:
qonnx-exec my-qonnx-model.onnx in0.npy in1.npy
Using the Python API:
from qonnx.core.modelwrapper import ModelWrapper
from qonnx.core.onnx_exec import execute_onnx
model = ModelWrapper("my-qonnx-model.onnx")
idict = {"in0" : np.load("in0.npy), "in1" : np.load("in1.npy")}
odict = execute_onnx(idict)
Using the qonnx-inference-cost command line utility for the CNV_2W2A example:
qonnx-inference-cost CNV_2W2A.onnx
Which will print a inference cost dictionary like the following:
Inference cost for CNV_2W2A.onnx
{
"discount_sparsity": true, # discount MAC counts by layer sparsity (disregard zero-valued MACs and params)
# mem_o_X: number of layer outputs with datatype X
"mem_o_INT32": 142602.0, # number of INT32 output elements
# mem_o_X: number of layer parameters (weights) with datatype X
"mem_w_INT2": 908033.0, # number of INT2 parameters (weights)
# op_mac_X_Y: number of MAC operations, datatype X by datatype Y
# scaled integer datatypes have a tensor- or channelwise scale factor
"op_mac_SCALEDINT<8>_INT2": 1345500.0, # number of scaled int8 x int2 MACs
"op_mac_INT2_INT2": 35615771.0, # number of int2 x int2 MACs
"total_bops": 163991084.0, # total number of MACs normalized to bit-ops (BOPS)
"total_mem_o_bits": 4563264.0, # total number of bits for layer outputs
"total_mem_w_bits": 1816066.0, # total number of bits for layer parameters
"unsupported": "set()"
}
You can use the --cost-breakdown option to generate a more detailed report that covers per-node (by name) and per-op-type information.
You can read more about the BOPS metric in this paper, Section 4.2 Bit Operations.
Using the qonnx-convert command line utility you can convert from QONNX to QCDQ-style quantization:
qonnx-convert CNV_2W2A.onnx
This will convert Quant nodes to QuantizeLinear -> Clip -> DequantizeLinear nodes where possible.
Please see the documentation of the QuantToQCDQ transformation to learn more about the limitations.
Install in editable mode in a Python virtual environment:
git clone https://github.com/fastmachinelearning/qonnx
cd qonnx
virtualenv -p python3.8 venv
source venv/bin/activate
pip install --upgrade pip
pip install -e .[qkeras,testing]
Run entire test suite, parallelized across CPU cores:
pytest -n auto --verbose
Run a particular test and fall into pdb if it fails:
pytest --pdb -k "test_extend_partition.py::test_extend_partition[extend_id1-2]"
If you plan to make pull requests to the qonnx repo, linting will be required.
We use a pre-commit hook to auto-format Python code and check for issues. See https://pre-commit.com/ for installation. Once you have pre-commit,
you can install the hooks into your local clone of the qonnx repo:
cd qonnx
source venv/bin/activate
pip install pre-commit
pre-commit install
Every time you commit some code, the pre-commit hooks will first run, performing various checks and fixes. In some cases pre-commit won’t be able to fix the issues and you may have to fix it manually, then run git commit once again. The checks are configured in .pre-commit-config.yaml under the repo root.
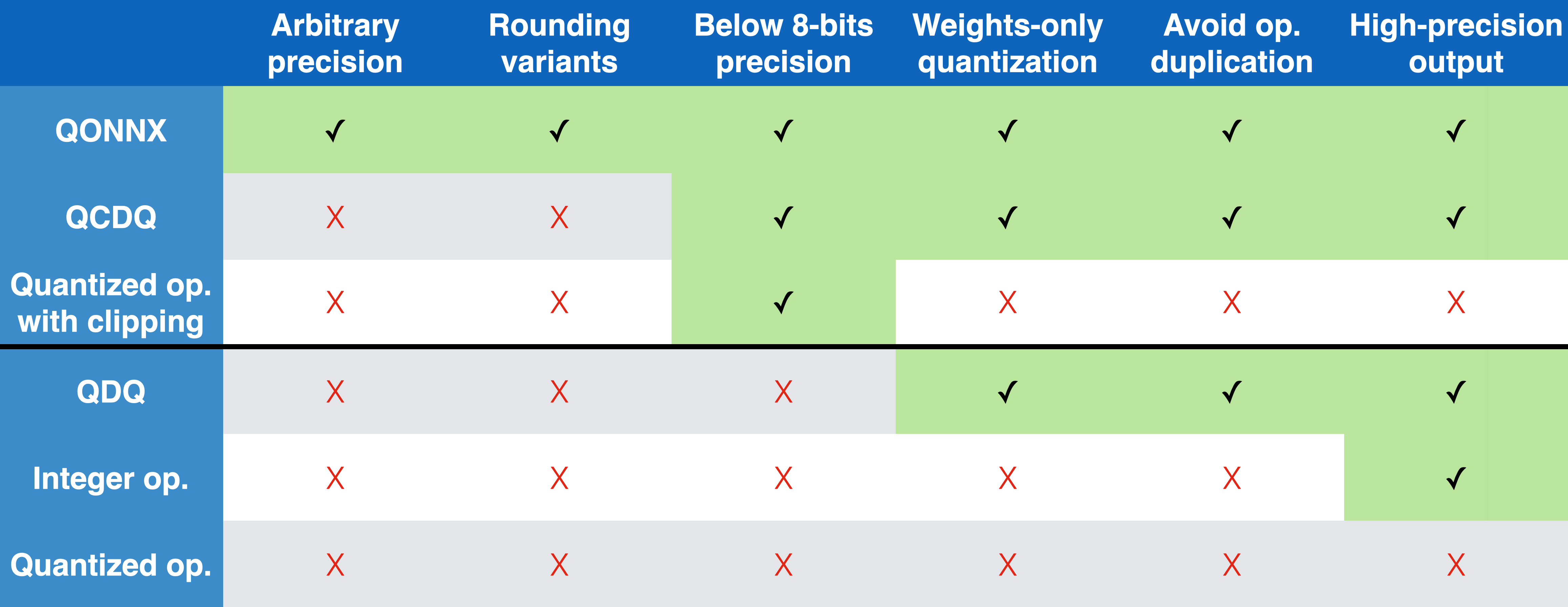
The QONNX representation has several advantages compared to other alternatives, as summarized in the table below. These include a compact but flexible, single-node quantization representation that avoids operator duplication and can support arbitrary precision up to the container datatype limit.
The QONNX efforts were started by the FINN and hls4ml communities working together to create a common, arbitrary-precision representation that both frameworks could ingest. However, QONNX aims to build an open-source community for practitioners and researchers working with mixed-precision quantized neural networks by providing useful tools and a discussion forum.
You can read more about QONNX in this paper. If you find QONNX useful in your work, please consider citing:
@inproceedings{Pappalardo:2022nxk,
author = "Pappalardo, Alessandro and Umuroglu, Yaman and Blott, Michaela and Mitrevski, Jovan and Hawks, Ben and Tran, Nhan and Loncar, Vladimir and Summers, Sioni and Borras, Hendrik and Muhizi, Jules and Trahms, Matthew and Hsu, Shih-Chieh Hsu and Hauck, Scott and Duarte, Javier"
title = "{QONNX: Representing Arbitrary-Precision Quantized Neural Networks}",
booktitle = "{4th Workshop on Accelerated Machine Learning (AccML) at HiPEAC 2022 Conference}",
eprint = "2206.07527",
archivePrefix = "arXiv",
primaryClass = "cs.LG",
reportNumber = "FERMILAB-CONF-22-471-SCD",
month = "6",
year = "2022",
url = "https://accml.dcs.gla.ac.uk/papers/2022/4thAccML_paper_1(12).pdf"
}
@software{yaman_umuroglu_2023_7622236,
author = "Umuroglu, Yaman and Borras, Hendrik and Loncar, Vladimir, and Summers, Sioni and Duarte, Javier",
title = "fastmachinelearning/qonnx",
month = {06},
year = 2022,
publisher = {Zenodo},
doi = {10.5281/zenodo.7622236},
url = {https://github.com/fastmachinelearning/qonnx}
}
























































































































