darrenburns / ward Goto Github PK
View Code? Open in Web Editor NEWWard is a modern test framework for Python with a focus on productivity and readability.
Home Page: https://ward.readthedocs.io
License: MIT License
Ward is a modern test framework for Python with a focus on productivity and readability.
Home Page: https://ward.readthedocs.io
License: MIT License
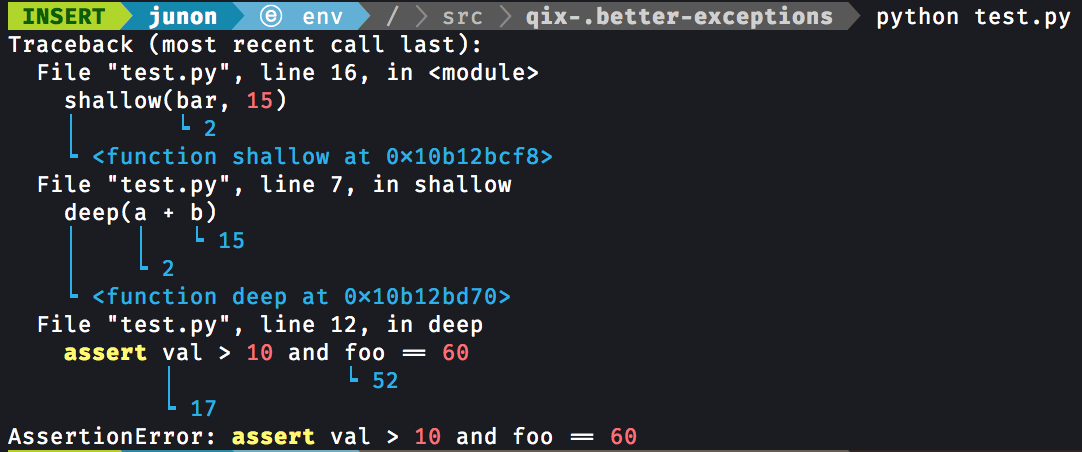
Right now, if an exception occurs in a test, the test is marked as a FAIL and a stack trace is printed as shown below. We should differentiate between tests that fail, and tests that raise uncaught exceptions by adding an ERROR/ERR outcome.

Jest has a really nice interactive "watch" mode, which will re-run any tests that change. If you change a file that tests depend on, Jest can walk the dependency tree and work out which tests to run as a result.
There is a clear distinction between describing a test and classifying it. They are semantically different things. The current method of 'tagging' or 'marking' tests is by patterns in the string descriptions. This not only mixes two things that probably shouldn't be but also causes some usability issues.
Even just a couple 'tags' can drown out the test descriptions, especially since they have to be formatted for reliable parsing for text search. They don't end up looking great in the output as the tags don't line up for easy human parsing. As alluded to before, text searching is clunky at best or unreliable.
So, I suggest adding a tags or similar attribute to tests and parameter to the test decorator to supplant the idea of tagging the descriptions. The --search CLI option could remain for text searching the descriptions, but a new --tags (or whatever name is chosen) option could be added. An implementation detail that would need to be ironed out is whether to support both 'or' and 'and' cases as well as how for multiple tags.
Is there a way we can disable output capturing when a debugger runs automatically?
Tracebacks may contain some frames that are internal to Ward:

Perhaps we could hide these as they're redundant information. I'm also interested in how we could format the exceptions better, to make them more readable. Right now, Ward adds some padding between frames and highlights the first line of each frame in blue, but I think we could do better. I got an exception in Poetry recently and noticed it was considerably easier to read due to the use of colours. There's also a couple of libraries that do some interesting things with errors, that could act as some inspiration:
There are certain directories that will exist in many projects that we should avoid looking in, as they may increase the test collection time drastically (e.g. node_modules, .git, etc.).
Ward should have a list of these directories, so that it knows to avoid them when searching for tests.
The code that looks for and collects tests can be found in collect.py:
Line 18 in 2cb07ad
Currently we use the blessings library to colour terminal output, but this library doesn't support Windows.
We should update to use termcolor + colorama (or any other library that will allow us to support Windows).
As tests are running, if the tests suite is large, it'd be nice to know how far through the run we are. Here are some ideas:
It'd be interesting to investigate assertion rewriting, to enable us to use assert statements instead of the expect API.
Ward captures the message that appears in comparison assertions:
assert 1 == 2, "Message"Raises an AssertionError with a msg of "Message". Ward has access to this value as it writes output to the terminal. Are there any use-cases for this message being displayed, and if so, how should it be displayed?
Ward should integrate nicely with Hypothesis. I have already started work on this on the hypothesis branch.
Pytest has a fantastic plugin system and many community driven plugins which greatly enhance it.
Could we make use of pluggy or a similar project to bring plugin functionality to Ward?
I've been programming in Python for nearly 2 decades. For almost as long as that, I've been searching for something better than what the stdlib provided. In that search, I've tried out most Python CLI packages large and small. Yet I always ended up back at optparse and now argparse.
That not to say I'm evangelical one way or another; I always end up using what works best for me. Take two of my projects as examples: google-music-scripts and thorod. Both of them started out using docopt. When that became hard to maintain/didn't support something I needed, I siwtched them to click. Eventually that became hard to maintain/didn't support something I needed. So back to argparse. In fact, I was able to split out a good portion of the CLI stuff into my utility package for reusability. Now I don't have to copy/paste and test the code in every CLI app I make.
The warts of click start showing even with relatively small, simple scripts. And they come to a head once you reach a CLI of moderate size/complexity. Some of the issues I've run into:
There are more that I've run into involving subcommands that may not be applicable to ward. And I'm sure there's plenty I've forgotten. There are definitely some articles out there expressing these and more.
Just wanted to share my experiences from similar situations in case it strikes a chord.
** Example output of one of google-music-script's commands:
$ gms up -h
Usage: gms upload [OPTIONS] [INCLUDE_PATH]...
Upload song(s) to Google Music.
Options:
-h, --help Display help.
-V, --version Output version.
Action:
-n, --dry-run Output results without taking action.
Logging:
-v, --verbose Increase verbosity of output.
-q, --quiet Decrease verbosity of output.
--debug Output log messages from dependencies.
--log-to-stdout Log to stdout.
--no-log-to-stdout Don't log to stdout.
--log-to-file Log to file.
--no-log-to-file Don't log to file.
Identification:
-u USER, --username USER
Your Google username or e-mail address.
Used to separate saved credentials.
--uploader-id ID A unique id given as a MAC address (e.g. '00:11:22:33:AA:BB').
This should only be provided when the default does not work.
--device-id ID A mobile device id.
Local:
--no-recursion Disable recursion when scanning for local files.
Recursion is enabled by default.
--max-depth DEPTH Set maximum depth of recursion when scanning for local files.
Default is infinite recursion.
-xp PATH, --exclude-path PATH
Exclude filepaths.
Can be specified multiple times.
-xr RX, --exclude-regex RX
Exclude filepaths using regular expressions.
Can be specified multiple times.
-xg GP, --exclude-glob GP
Exclude filepaths using glob patterns.
Can be specified multiple times.
Absolute glob patterns not supported.
Filter:
-f FILTER, --filter FILTER
Metadata filters.
Can be specified multiple times.
--created-in DATE Include items created in year or year/month.
--created-on DATE Include items created on date.
--created-before DATE
Include items created before datetime.
--created-after DATE Include items created after datetime.
--modified-in DATE Include items created in year or year/month.
--modified-on DATE Include items created on date.
--modified-before DATE
Include items modified before datetime.
--modified-after DATE
Include items modified after datetime.
Misc:
--delete-on-success Delete successfully uploaded local files.
--no-sample Don't create audio sample with ffmpeg/avconv.
Send empty audio sample.
--album-art ART_PATHS
Comma-separated list of album art filepaths.
Can be relative filenames and/or absolute filepaths.
Sync:
--use-hash Use audio hash to sync songs.
--no-use-hash Don't use audio hash to sync songs.
--use-metadata Use metadata to sync songs.
--no-use-metadata Don't use metadata to sync songs.
Include:
PATH Local paths to include songs from.
When a test fails, we currently only output the module name and the line number.
Since the same module name may frequently appear more than once, when a test fails, we should include the full (relative or absolute?) path to the file that contains the test. I believe this information is already available within the Test object, which can be accessed via a TestResult object.
I was looking into creating a Visual Studio Code extension for ward. It's hard to parse the output that is printed to the terminal. A way to let ward output json (or any other structured format) would help to create integrations for all kinds of tools.
Each test result is currently printed on its own line. For large projects this is unwieldy. Many other frameworks offer the ability to output each test as a . (representing a pass). The code that handles outputting each of these results is here:
Line 102 in e323f7a
Perhaps the user could pass in an option like --test-result-output=dots or something similar in order to control this? I'm open to suggestions :)
It would be nice to just list all tests ward found without directly running them.
Something like a --discover flag for the ward command.
It might be nice to have a JSON writer if this is part of a pipeline. It might also be nice to have a non-colored output. Currently the fields are easy to see on a colored terminal, because they're different colors. However, in some cases (maybe in Jenkins) you may not have access to colors, so it'd be easier to read with clear separators and no color codes.
Dependencies are too strict at the moment, meaning there's a high likelihood of a clash between ward itself and the dependencies of projects that use ward.
Line 21 in e7a9a4f
Brandon Rhodes has a great talk about his experimental Assay framework. It offers several features. Figured I'd mention them in case they inspire you :-).
From the slides:
Right now, you can mark tests with the @skip and @xfail decorators. These decorators do not take arguments:
Line 16 in e323f7a
Ideally, we'd be able to supply a "reason" argument, explaining why a test was marked with the decorator. It might look something like this:
from ward import skip
@xfail("external dependency not yet implemented")
def test_one_plus_one():
...This reason should be stored somewhere on the collected Test object, so that it can be printed out later. For example, if an xfail test unexpectedly passes, we may wish to output the reason we expected it to fail to aid understanding.
Hi!
Super excited about this project. I was hoping to ignore a certain directory/sub-directory, but I can't seem to figure out how to do this - is it possible?
My use case being that I oftentimes utilize a Jupyter Notebook to rapidly prototype. If I edit a test file in the jupyter editor, it will auto-generate a checkpoint/savepoint which has a similar name as the test file itself. /tests/.ipynb_checkpoints/test_<thing>-checkpoint.py
Is it possible to ignore directories ala git-ignore style or similar?
Thanks!
Right now Ward supports config through pyproject.toml, but there's nothing in the output that indicates that the defaults from that file are being used. If a pyproject.toml is used, we should tell the user.
Question: should this be hidden behind a flag (possibly a --verbose flag)?
This feels ready for at least a alpha release on PyI. https://pypi.org/project/python-tester/ is available.
When several failures occur, the individual errors can be a little difficult to find. For example, here's the last page of my terminal after three tests raise exceptions
___________________________________________________________________________________________________________________________________________________
Failure: search_generally query='fox' returns tests with 'fox' in the body
Traceback (most recent call last):
File "/home/tyler/Documents/git/ward/.venv/lib/python3.7/site-packages/ward/testing.py", line 132, in run
self.fn(**self.args)
File "tests/test_collect.py", line 45, in _
raise Exception
Exception
___________________________________________________________________________________________________________________________________________________
Failure: search_generally returns an empty generator when no tests match query
Traceback (most recent call last):
File "/home/tyler/Documents/git/ward/.venv/lib/python3.7/site-packages/ward/testing.py", line 132, in run
self.fn(**self.args)
File "tests/test_collect.py", line 52, in _
raise Exception
Exception
___________________________________________________________________________________________________________________________________________________
FFF................................................................................................................................................
FAILED in 0.63 seconds [ 3 failed 1 skipped 163 passed ]
I need to scroll up to see all the tests that failed, and from the traceback, it's not super easy to find which tests failed.
I thought of a few things that I think could make it easier
module:linenum [case] in detailed failure
Failure: <test description>; maybe there could be Failure: <module:linenum [case]> <description>details command
ward details or something similar$ ward
FAIL test_collect:35: search_generally matches on test name alone
FAIL test_collect:42: search_generally query='fox' returns tests with 'fox' in the body
FAIL test_collect:49: search_generally returns an empty generator when no tests match query
___________________________________________________________________________________________________________________________________________________
FFF................................................................................................................................................
FAILED in 0.63 seconds [ 3 failed 1 skipped 163 passed ]
$
$ ward details --search 'returns empty generator'
Failure: search_generally returns an empty generator when no tests match query
Traceback (most recent call last):
File "/home/tyler/Documents/git/ward/.venv/lib/python3.7/site-packages/ward/testing.py", line 132, in run
self.fn(**self.args)
File "tests/test_collect.py", line 52, in _
raise Exception
Exception
This may be helpful for people with colourblindness, and will allow Ward to be useful in terminals that don't support coloured output, such as many CI servers.
Within any fixture or test, you should be able to retrieve things like "what test is currently running" etc.
The recent addition of output capturing resulted in a bug where when you run PDB during a test session, all of the output that PDB tries to write to the terminal is also captured lost. This makes debugging impossible.
If you pass a path to a file, e.g.: ward --tests/test_something.py, Ward won't find any tests. The command line API is defined in run.py, and the actual collection of modules and tests happens in collect.py.
TestResult.test.fn must traverse decorators to find the test.
This would be so all of the output for these tests line up when the total tests has more digits than some of the test indexes. E.g:
PASS test_api:41 [ 1/22]: [determine_format] Filepath (test-flac-0-duration.flac)
PASS test_api:41 [ 2/22]: [determine_format] Filepath (test-flac-application.flac)
PASS test_api:41 [ 3/22]: [determine_format] Filepath (test-flac-cuesheet.flac)
PASS test_api:41 [ 4/22]: [determine_format] Filepath (test-flac-padding.flac)
PASS test_api:41 [ 5/22]: [determine_format] Filepath (test-flac-seektable.flac)
PASS test_api:41 [ 6/22]: [determine_format] Filepath (test-flac-vorbis-id3v24.flac)
PASS test_api:41 [ 7/22]: [determine_format] Filepath (test-flac-vorbis.flac)
PASS test_api:41 [ 8/22]: [determine_format] Filepath (test-mp3-apev2.mp3)
PASS test_api:41 [ 9/22]: [determine_format] Filepath (test-mp3-cbr-2-frames.mp3)
PASS test_api:41 [10/22]: [determine_format] Filepath (test-mp3-id3v1.mp3)
PASS test_api:41 [11/22]: [determine_format] Filepath (test-mp3-id3v22.mp3)
PASS test_api:41 [12/22]: [determine_format] Filepath (test-mp3-id3v23.mp3)
PASS test_api:41 [13/22]: [determine_format] Filepath (test-mp3-id3v24.mp3)
PASS test_api:41 [14/22]: [determine_format] Filepath (test-mp3-lame-abr.mp3)
PASS test_api:41 [15/22]: [determine_format] Filepath (test-mp3-lame-cbr.mp3)
PASS test_api:41 [16/22]: [determine_format] Filepath (test-mp3-lame-no-bitrate-mode.mp3)
PASS test_api:41 [17/22]: [determine_format] Filepath (test-mp3-lame-vbr.mp3)
PASS test_api:41 [18/22]: [determine_format] Filepath (test-mp3-sync-branch.mp3)
PASS test_api:41 [19/22]: [determine_format] Filepath (test-mp3-vbri.mp3)
PASS test_api:41 [20/22]: [determine_format] Filepath (test-mp3-xing-0-num-frames.mp3)
PASS test_api:41 [21/22]: [determine_format] Filepath (test-wav-id3v23.wav)
PASS test_api:41 [22/22]: [determine_format] Filepath (test-wav-riff.wav)
vs the current:
PASS test_api:41 [1/22]: [determine_format] Filepath (test-flac-0-duration.flac)
PASS test_api:41 [2/22]: [determine_format] Filepath (test-flac-application.flac)
PASS test_api:41 [3/22]: [determine_format] Filepath (test-flac-cuesheet.flac)
PASS test_api:41 [4/22]: [determine_format] Filepath (test-flac-padding.flac)
PASS test_api:41 [5/22]: [determine_format] Filepath (test-flac-seektable.flac)
PASS test_api:41 [6/22]: [determine_format] Filepath (test-flac-vorbis-id3v24.flac)
PASS test_api:41 [7/22]: [determine_format] Filepath (test-flac-vorbis.flac)
PASS test_api:41 [8/22]: [determine_format] Filepath (test-mp3-apev2.mp3)
PASS test_api:41 [9/22]: [determine_format] Filepath (test-mp3-cbr-2-frames.mp3)
PASS test_api:41 [10/22]: [determine_format] Filepath (test-mp3-id3v1.mp3)
PASS test_api:41 [11/22]: [determine_format] Filepath (test-mp3-id3v22.mp3)
PASS test_api:41 [12/22]: [determine_format] Filepath (test-mp3-id3v23.mp3)
PASS test_api:41 [13/22]: [determine_format] Filepath (test-mp3-id3v24.mp3)
PASS test_api:41 [14/22]: [determine_format] Filepath (test-mp3-lame-abr.mp3)
PASS test_api:41 [15/22]: [determine_format] Filepath (test-mp3-lame-cbr.mp3)
PASS test_api:41 [16/22]: [determine_format] Filepath (test-mp3-lame-no-bitrate-mode.mp3)
PASS test_api:41 [17/22]: [determine_format] Filepath (test-mp3-lame-vbr.mp3)
PASS test_api:41 [18/22]: [determine_format] Filepath (test-mp3-sync-branch.mp3)
PASS test_api:41 [19/22]: [determine_format] Filepath (test-mp3-vbri.mp3)
PASS test_api:41 [20/22]: [determine_format] Filepath (test-mp3-xing-0-num-frames.mp3)
PASS test_api:41 [21/22]: [determine_format] Filepath (test-wav-id3v23.wav)
PASS test_api:41 [22/22]: [determine_format] Filepath (test-wav-riff.wav)
A small annoyance, to be sure. But it's something I always do for my numbered output if the total number is known ahead of time.
A Makefile would be very useful to capture common commands like black ., ward --path tests and commands that are used in the build and release GitHub Actions.
It can be useful to record the durations of individual tests in order to find identify those which are slow.
Pytest has the --durations=N option, which will print the N slowest tests. It records the time taken to the fixtures a test depends on too.
Ward should support pyproject.toml files for specifying config.
Any of the options provided via the CLI should also be able to be used inside pyproject.toml.
The black project has a nice implementation of this feature.
This was discovered after merging #80, which adds a Makefile which creates a venv inside the project directory. During test collection, ward recurses directories and may stumble across test modules not intended for it. Looking inside the virtualenv caused ward to fail. Running ward --path tests worked because it excluded the virtualenv from test collection.

I'm wondering whether it makes sense for ward to ignore virtualenvs or folders in the .gitignore when it looks for tests?
Defining the following test raises IndentationError: unexpected indent during (I assume) collection:
if True:
@test("Testing indent")
def _():
passI believe the relevant line in the traceback is "ward/rewrite.py", line 96, in rewrite_assertion, tree = ast.parse(code).
This tends to happen when ast.parse is called on indented code and can be fixed by using textwrap.dedent, although that would probably mess up column numbers in the resulting AST. An alternative dirty, dirty hack may be to prepend if True: to the code if the first non-empty line starts with a space, and then extracting the if body prior to the transform, which would preserve correct column numbers.
Hi,
Very nice piece of software! :-)
I was playing with tests including a call to fork and behavior seems a bit strange to me.
@test("My test that forks")
def test_minimalFork():
import time
fatherPid = os.getpid()
pid = os.fork()
if pid == 0:
# Do stuff
time.sleep(1)
import signal
os.kill(fatherPid, signal.SIGINT)
expect(True).equals(True)
else:
# Do stuff that hangs
time.sleep(20)
expect(False).equals(True)% ward --search Fork
Ward collected 1 tests in 0.17 seconds.
[WARD] Run cancelled - results for tests that ran shown below.
NO_TESTS_FOUND in 1.18 seconds
PASS test_SSH:69: My test that forks
..............................................................................................................................................................................................
SUCCESS in 1.24 seconds [ 1 passed ]
Given output, it seems that fork is handled as being two different tests (or two instances of ward?).
Obviously, tests running in child process (testing True == True) passes and test in father process (testing False == True) does not raises and thus is correctly killed by child process.
Only get the pass verdict and not the "NO_TEST_FOUND" and "Run cancelled".
First, if there a "good" way to kill the process according to ward?
If not, is there a way to specify in the killed process that ward shouldn't look for a test here (thus we only get the pass verdict and not the "NO_TEST_FOUND" and "Run cancelled"?
I'd by happy to contribute if needed ;-)
Cheers
Sometimes failures don't include the "Location" header, which indicates the module and line number an assertion failed on:

Right now, this header is only printed for assertions containing comparisons e.g. assert x == y, assert x in y, etc (because these are the types of assertions that are rewritten using AST transformation). This header should be printed for all AssertionErrors. This doesn't mean we need to rewrite all assertions for now, we could probably just catch the raised AssertionErrors.
Modifying global or module scoped fixtures in between tests is dangerous and should be avoided.
The --path option currently only supports a single argument. This means if you have two sibling directories of tests, you'd have to specify a path of . in order for them to be found. This is really inefficient, because it means ward will spend a lot of time looking in places for tests where they won't be found.
A better interface would be e.g.
ward --path ./test_dir_one ./test_dir_two
Command line input in this project is handled by the click library, which supports this functionality out of the box: https://click.palletsprojects.com/en/7.x/options/#multi-value-options
To implement this change, one option would be to alter the get_info_for_modules to take a List[str] instead of a str argument:
Line 16 in e323f7a
Then passing that list through to pkgutil.iter_modules:
Line 18 in e323f7a
Test function docstrings are a great place to put a description of the test. I am wondering if it is better to keep the test description in there instead of in the decorator@test("...").
When fixtures are collected, they're stored inside a FixtureRegistry. The FixtureRegistry essentially just wraps a dictionary which maps fixture names to Fixture objects (Dict[str, Fixture]).
Line 71 in 795b918
The name of a Fixture, and therefore the key used to access it from the FixtureRegistry, is just the name of the function. For example, the fixture below has the name bob:
@fixture
def bob():
return "bob"A side effect of just using the function name to identify a fixture is that if two fixtures of the same name are collected in a single ward run, the run will fail even if the fixtures are defined in different files (specifically we raise a CollectionError). If we didn't fail the run, the key in the wrapped dict could get overwritten, and we might inject the wrong fixture. Here's where the failure happens:
Line 84 in 795b918
These are just some of the questions raised by this issue, which will require lots of thought on the most sensible approach.
The teardown code for generator fixtures is only ran for those fixtures directly injected into a test. If a generator fixture is not the root of the tree of fixtures being injected for a single arg, it will not have its teardown code executed.
Add --coverage, which will use coverage.py to monitor test code coverage.
Could we use PrettyErrors, or add our own implementation of it to make errors easier to read?
Is this necessary, or is the existing colouration and added spacing that we do enough? (See example of existing output below).
Here's an example of PrettyErrors (I'd probably want the full path to the files to be displayed, rather than just the filename, but am interested to know if anyone has other thoughts):
Hello and thank you for Ward!
In the process of converting my Pytest tests to Ward, I realized that my project relies heavily on ValueError with some message (instead of, for example, having a large exception class hierarchy under MyProjectError). Accordingly, many tests look like this:
def test_it_raises_on_empty_X():
with pytest.raises(ValueError, match="empty"):
X.parse("{}")I can easily convert this test to:
@test("X.parse should raise on empty inputs")
def _():
with ward.raises(ValueError):
X.parse("{}")but that test is less precise than the original (the reported error message could be related to something else). In Pytest, the match keyword-argument to raises allows me to specify a regex the raised exception's message should satisfy.
What would you suggest in that case? My first reflex was to look at the code of ward.raises and be enthused over how easy it would be to add the same Pytest feature. My understanding is however that "become a Pytest clone" is not high on the list of Ward's goals (nor do I think it should be), so I shelved my pull-request for now, and I'm very curious about other ideas regular users of Ward could have about this use-case.
Ideally I would have in Ward an intuitive way to specify that my code raised an exception with some keywords in the exception's message. Rewriting the application to use a custom exception class hierarchy would solve the problem today, but would create other problems and would basically be a reason to keep Pytest alongside Ward. Please let me know how I can help!
To view which fixtures have been discovered, it'd be good if users could run a ward fixtures subcommand. Ward uses the Click package for handling command line input, and luckily it has built in support for this kind of thing!
User runs the command as follows:
ward fixtures
Output could look something like:
module_one.fixture_one
module_one.fixture_two(fixture_one)
module_two.fixture_three(fixture_one, fixture_two)
This output says module_one contains two fixtures: fixture_one and fixture_two. fixture_two depends on fixture_one.
Here's where the available command line options are set up:
Line 21 in b4f11a2
You can find the available fixtures inside the fixture_registry object, which has been imported into that file (run.py). It has the type FixtureRegistry, which is wrapper class around a dict, defined here:
Line 71 in b4f11a2
This issue is related to #39, which will likely change the structure of the FixtureRegistry.
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.