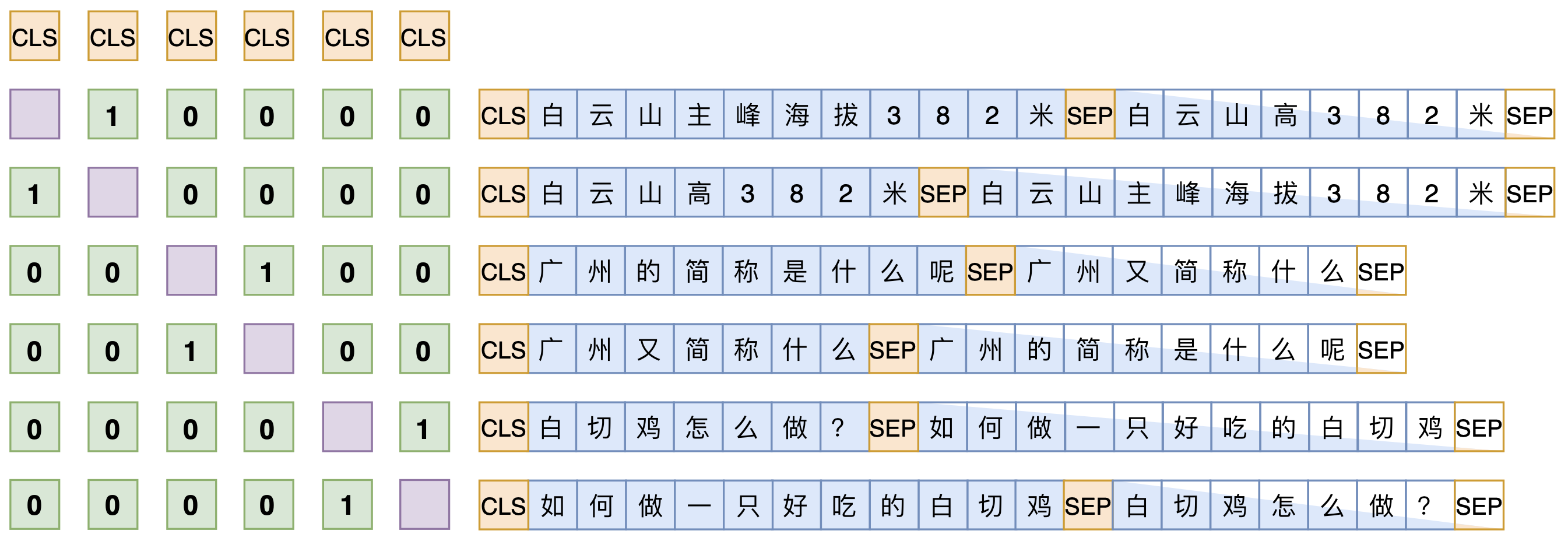
你好,
非常感谢作者提供了一个精巧的模型思路。请问如何让生成结果多样化一些?
比如说,这是我从通过您提供训练模型( https://open.zhuiyi.ai/releases/nlp/models/zhuiyi/chinese_simbert_L-6_H-384_A-12.zip)生成的同义句结果
问题 = u'女方提出离婚,我是不是是吃亏'
输出:
['女方提出离婚,我是不是吃亏',
'女方提出离婚我是不是吃亏',
'女方提出离婚,我是不是吃亏?',
'女方提出离婚,我是不是该吃亏',
'女方提出离婚,我们是不是吃亏了',
'女方提出离婚,我是不是要吃亏',
'女方提出离婚,是不是说明我吃亏',
'女方提出离婚是不是就是吃亏了',
'女方离婚,我是不是吃亏的',
'女方提出离婚,是吃亏,还是我吃亏',
'女方提出离婚,是不是吃亏?',
'女方提出离婚,女方是不是吃亏',
'女方提出离婚,女方是不是吃亏?',
'女方提出离婚,女方是不是吃亏,女方是吃亏?',
'女方提出离婚,是不是说明他吃亏了',
'离婚女方提出离婚是不是都是吃亏',
'女方提出离婚我们会是吃亏吗',
'男方提出离婚我是不是吃亏',
'女方提出离婚,女方是吃亏吗?',
'女方提出离婚,是不是吃亏了,我们该怎么办']
还有就是, 我造了一个英文数据集,用您的方法SIMBERT 对BERT BASE 模型bert_uncased_L-12_H-768_A-12进行微调,生成的结果也从存在单一性的问题,
比如
训练样本
{'synonyms': ['What singers performed in a concert in 2014?',
'Who sang in a concert in 2014?',
'Which singers sang in concert in 2014?',
'Who were the singers in a concert in 2014?.',
'What singers were present at the concert held in 2014.',
'What are the names of the singers who performed in a concert in '
'2014?',
'What are the names of the singers who performed in a concert in '
'2015?',
'Can you tell me the names of the singers who performed in the '
'concert held in 2014?'],
'text': 'What are the names of the singers who performed in a concert in '
'2014?'}
问题: gen_synonyms("Who were the singers in a concert in 2014?")
输出:['who were the singers in the concert in 2014?',
'which singers were in a concert in 2014?',
'who were the singers who performed the concert in 2014?',
'who were the singers in concerts in 2014?',
'which singers performed in the concert in 2014?',
'who singers in a concert in 2014?',
'show me the singers in concert in 2014?',
'who are the singers in concert in 2014?',
'which singers were in the concert in 2015?',
'which singers were the singers in the concert in 2014?',
'which singers were the singers that in concert in 2014?',
'which singers performed in 2014 in concert?',
'which singers sang at concert in the 2014?',
'what are the singers in concert in 2014?',
'which singers sang in concert in 2015?',
'what are the names of the singers and the singer in concert in 2014?',
'what are the names of the singers in concert in the 2014?',
'what are the singers who performed at a concert in concert',
'what are the singers in concert in 2013?',
'what are the names of singers in concert in 2014?']