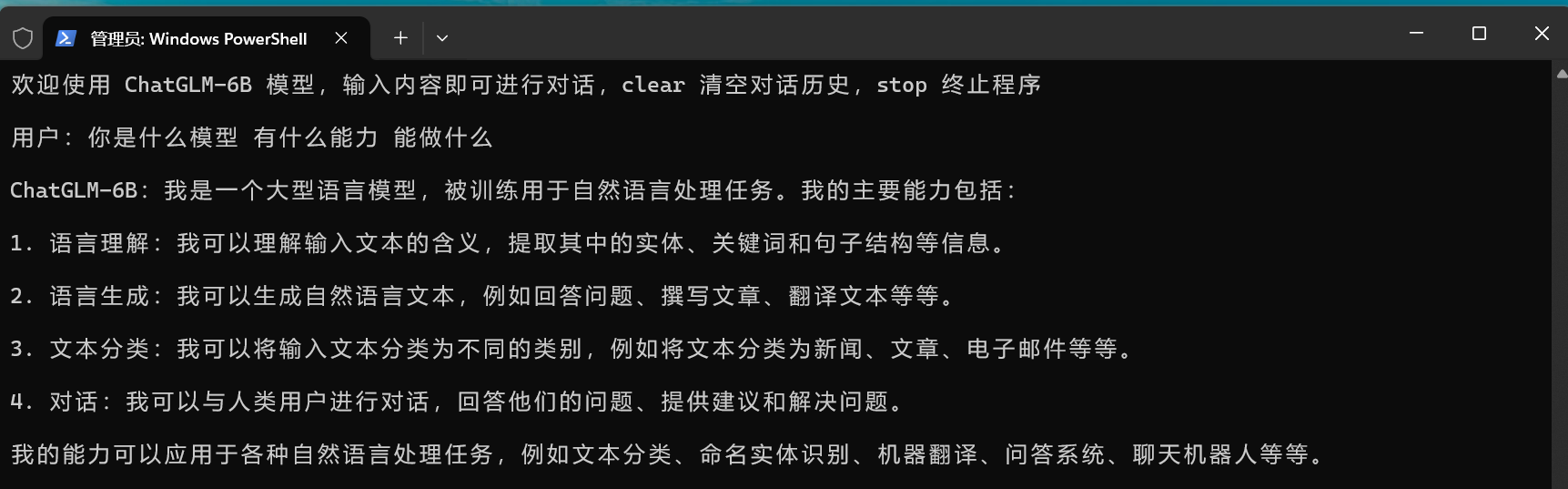
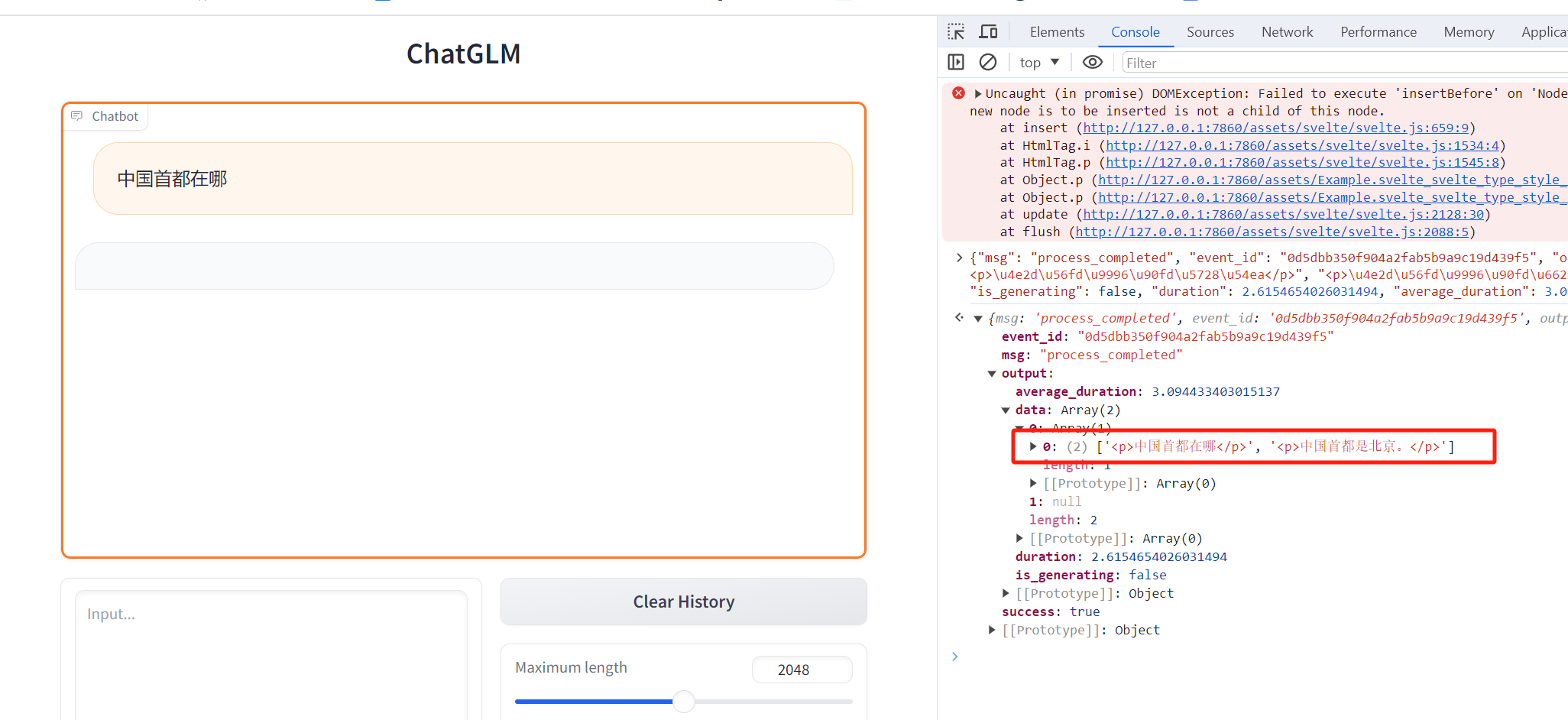
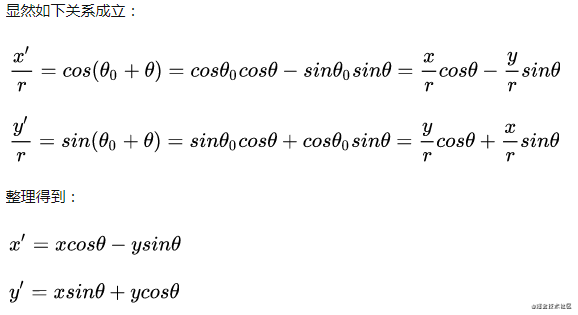woai3c / front-end-articles Goto Github PK
View Code? Open in Web Editor NEW分享我的编程经验和学习心得,订阅请点 watch
License: MIT License
分享我的编程经验和学习心得,订阅请点 watch
License: MIT License







































































































































































































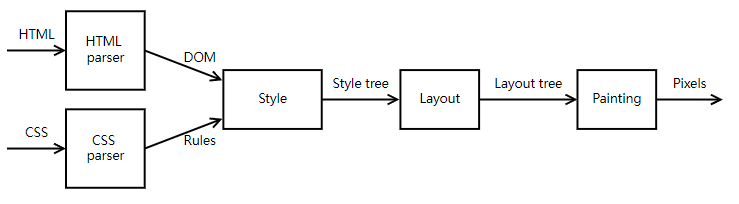
一个完整的前端监控平台包括三个部分:数据采集与上报、数据整理和存储、数据展示。
本文要讲的就是其中的第一个环节——数据采集与上报。下图是本文要讲述内容的大纲,大家可以先大致了解一下:


仅看理论知识是比较难以理解的,为此我结合本文要讲的技术要点写了一个简单的监控 SDK,可以用它来写一些简单的 DEMO,帮助加深理解。再结合本文一起阅读,效果更好。
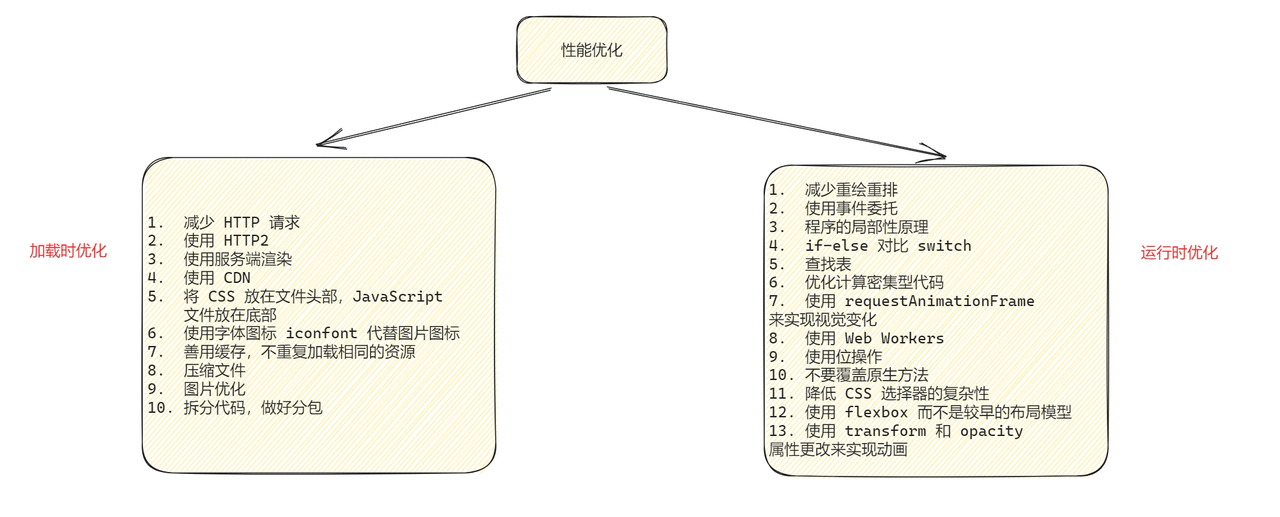
chrome 开发团队提出了一系列用于检测网页性能的指标:
这四个性能指标都需要通过 PerformanceObserver 来获取(也可以通过 performance.getEntriesByName() 获取,但它不是在事件触发时通知的)。PerformanceObserver 是一个性能监测对象,用于监测性能度量事件。
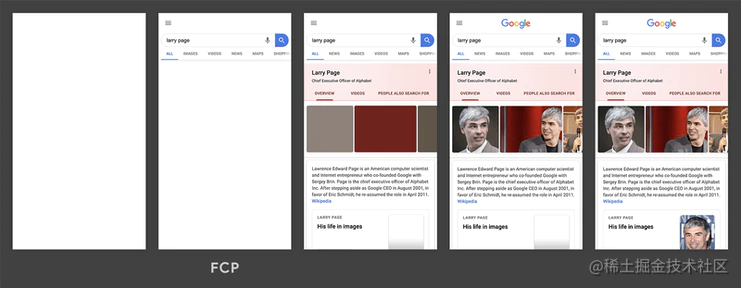
FP(first-paint),从页面加载开始到第一个像素绘制到屏幕上的时间。其实把 FP 理解成白屏时间也是没问题的。
测量代码如下:
const entryHandler = (list) => {
for (const entry of list.getEntries()) {
if (entry.name === 'first-paint') {
observer.disconnect()
}
console.log(entry)
}
}
const observer = new PerformanceObserver(entryHandler)
// buffered 属性表示是否观察缓存数据,也就是说观察代码添加时机比事情触发时机晚也没关系。
observer.observe({ type: 'paint', buffered: true })通过以上代码可以得到 FP 的内容:
{
duration: 0,
entryType: "paint",
name: "first-paint",
startTime: 359, // fp 时间
}其中 startTime 就是我们要的绘制时间。
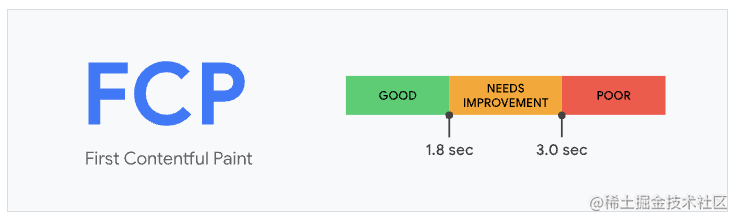
FCP(first-contentful-paint),从页面加载开始到页面内容的任何部分在屏幕上完成渲染的时间。对于该指标,"内容"指的是文本、图像(包括背景图像)、<svg>元素或非白色的<canvas>元素。
为了提供良好的用户体验,FCP 的分数应该控制在 1.8 秒以内。
测量代码:
const entryHandler = (list) => {
for (const entry of list.getEntries()) {
if (entry.name === 'first-contentful-paint') {
observer.disconnect()
}
console.log(entry)
}
}
const observer = new PerformanceObserver(entryHandler)
observer.observe({ type: 'paint', buffered: true })通过以上代码可以得到 FCP 的内容:
{
duration: 0,
entryType: "paint",
name: "first-contentful-paint",
startTime: 459, // fcp 时间
}其中 startTime 就是我们要的绘制时间。
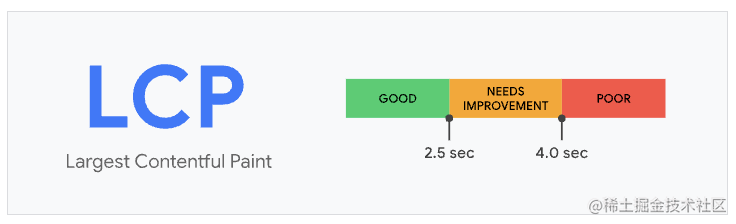
LCP(largest-contentful-paint),从页面加载开始到最大文本块或图像元素在屏幕上完成渲染的时间。LCP 指标会根据页面首次开始加载的时间点来报告可视区域内可见的最大图像或文本块完成渲染的相对时间。
一个良好的 LCP 分数应该控制在 2.5 秒以内。
测量代码:
const entryHandler = (list) => {
if (observer) {
observer.disconnect()
}
for (const entry of list.getEntries()) {
console.log(entry)
}
}
const observer = new PerformanceObserver(entryHandler)
observer.observe({ type: 'largest-contentful-paint', buffered: true })通过以上代码可以得到 LCP 的内容:
{
duration: 0,
element: p,
entryType: "largest-contentful-paint",
id: "",
loadTime: 0,
name: "",
renderTime: 1021.299,
size: 37932,
startTime: 1021.299,
url: "",
}其中 startTime 就是我们要的绘制时间。element 是指 LCP 绘制的 DOM 元素。
FCP 和 LCP 的区别是:FCP 只要任意内容绘制完成就触发,LCP 是最大内容渲染完成时触发。
LCP 考察的元素类型为:
<img>元素<svg>元素内的<image>元素<video>元素(使用封面图像)url()函数(而非使用CSS 渐变)加载的带有背景图像的元素CLS(layout-shift),从页面加载开始和其生命周期状态变为隐藏期间发生的所有意外布局偏移的累积分数。
布局偏移分数的计算方式如下:
布局偏移分数 = 影响分数 * 距离分数
影响分数测量不稳定元素对两帧之间的可视区域产生的影响。
距离分数指的是任何不稳定元素在一帧中位移的最大距离(水平或垂直)除以可视区域的最大尺寸维度(宽度或高度,以较大者为准)。
CLS 就是把所有布局偏移分数加起来的总和。
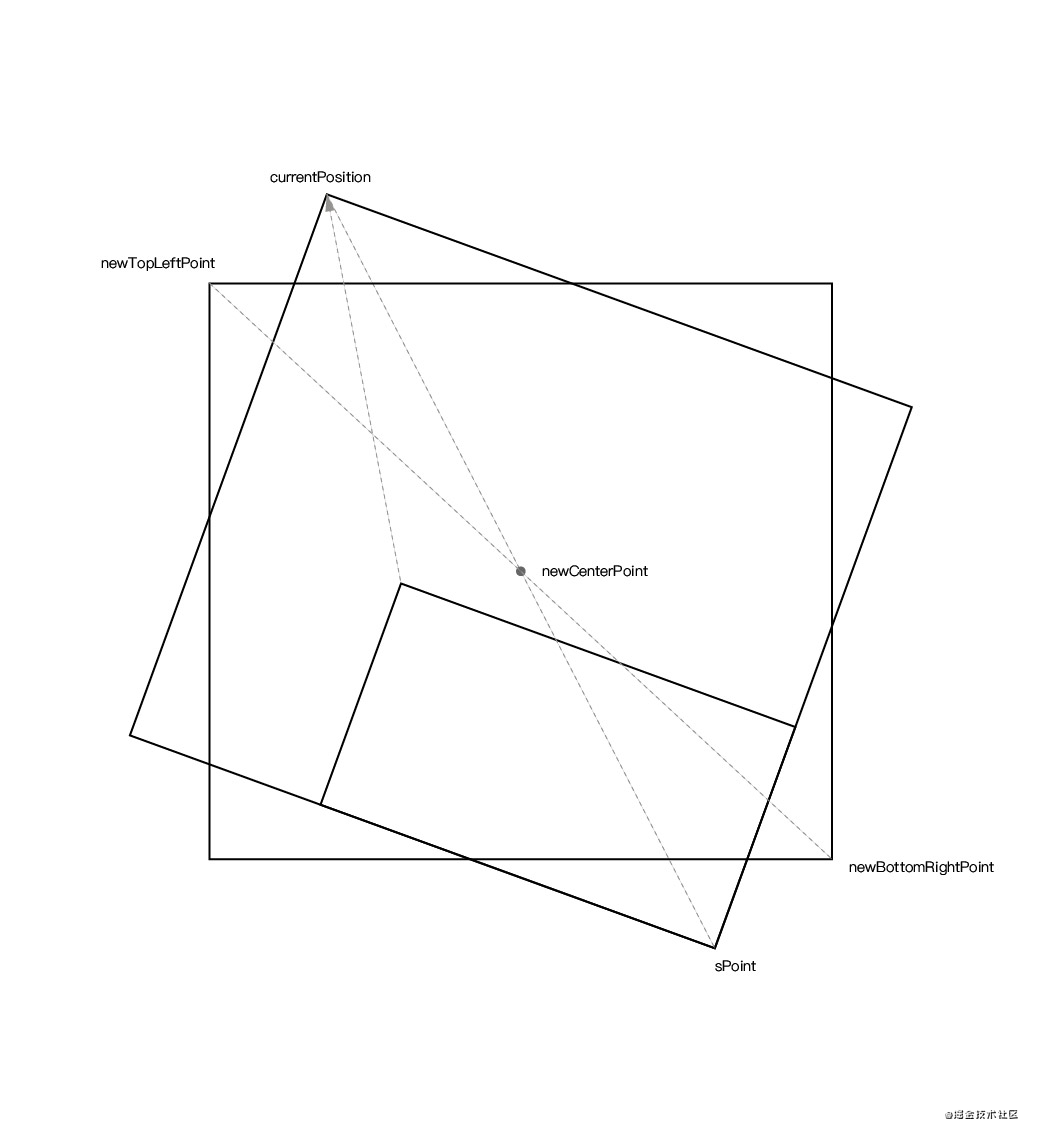
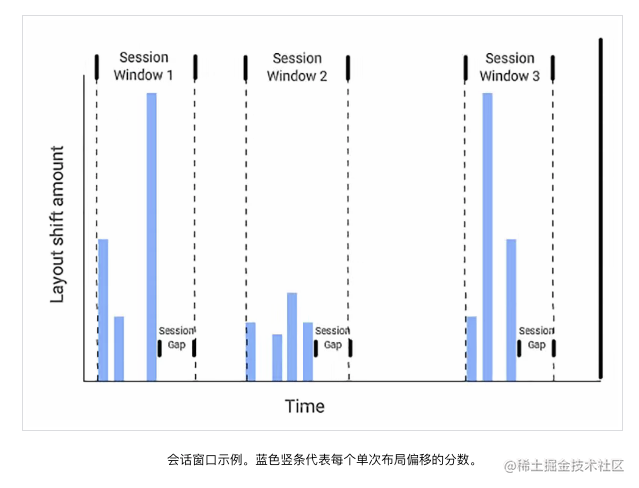
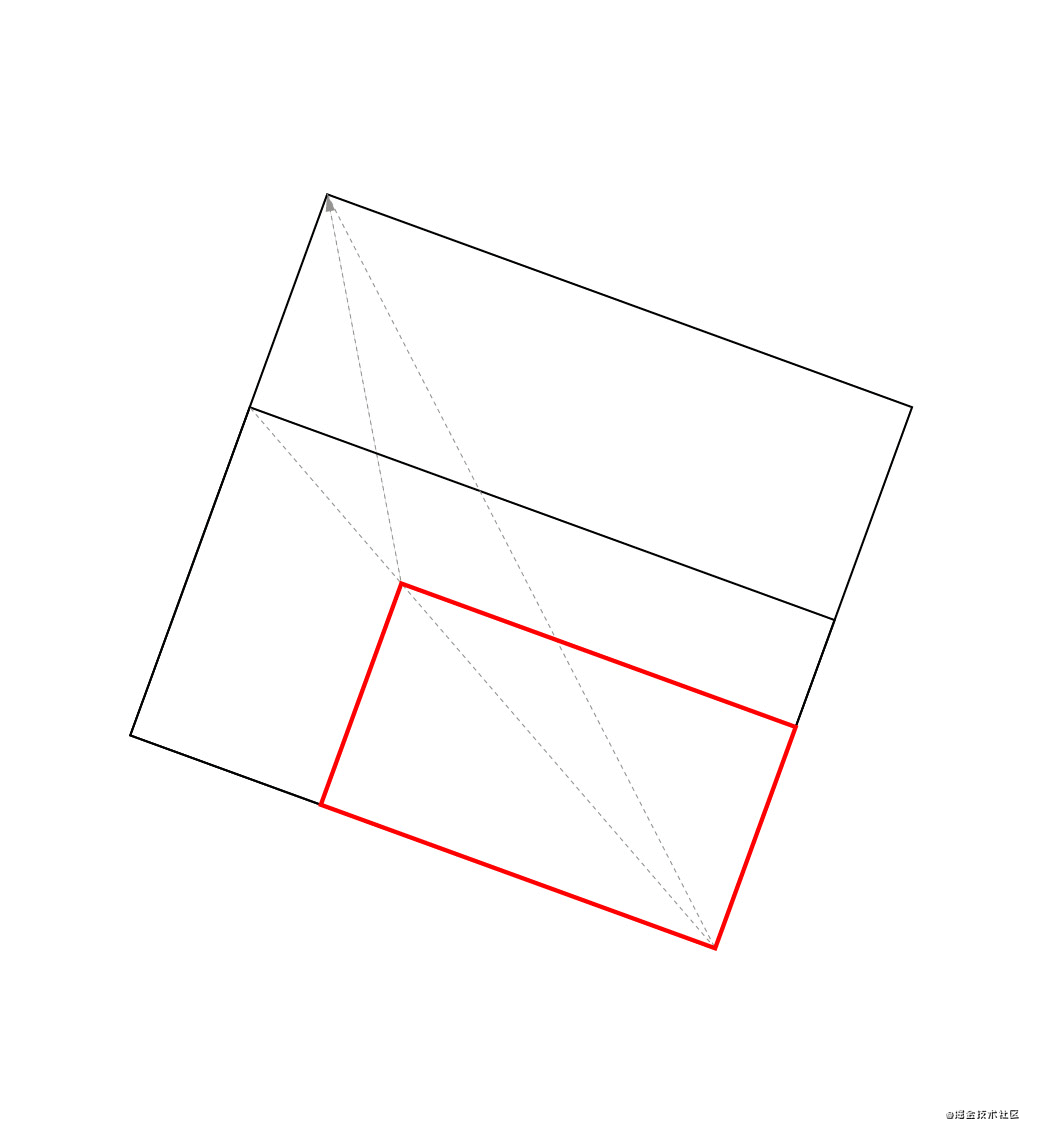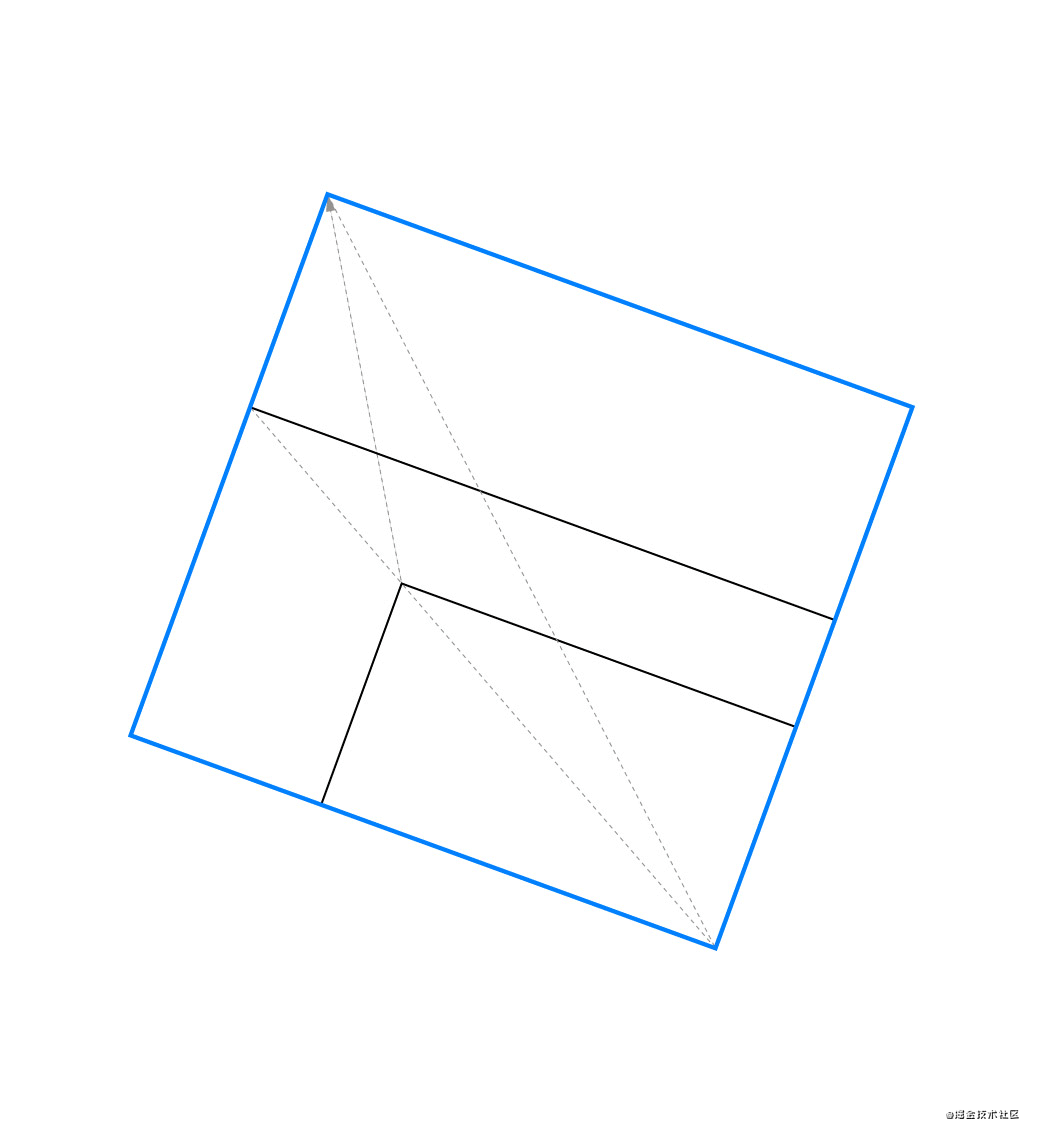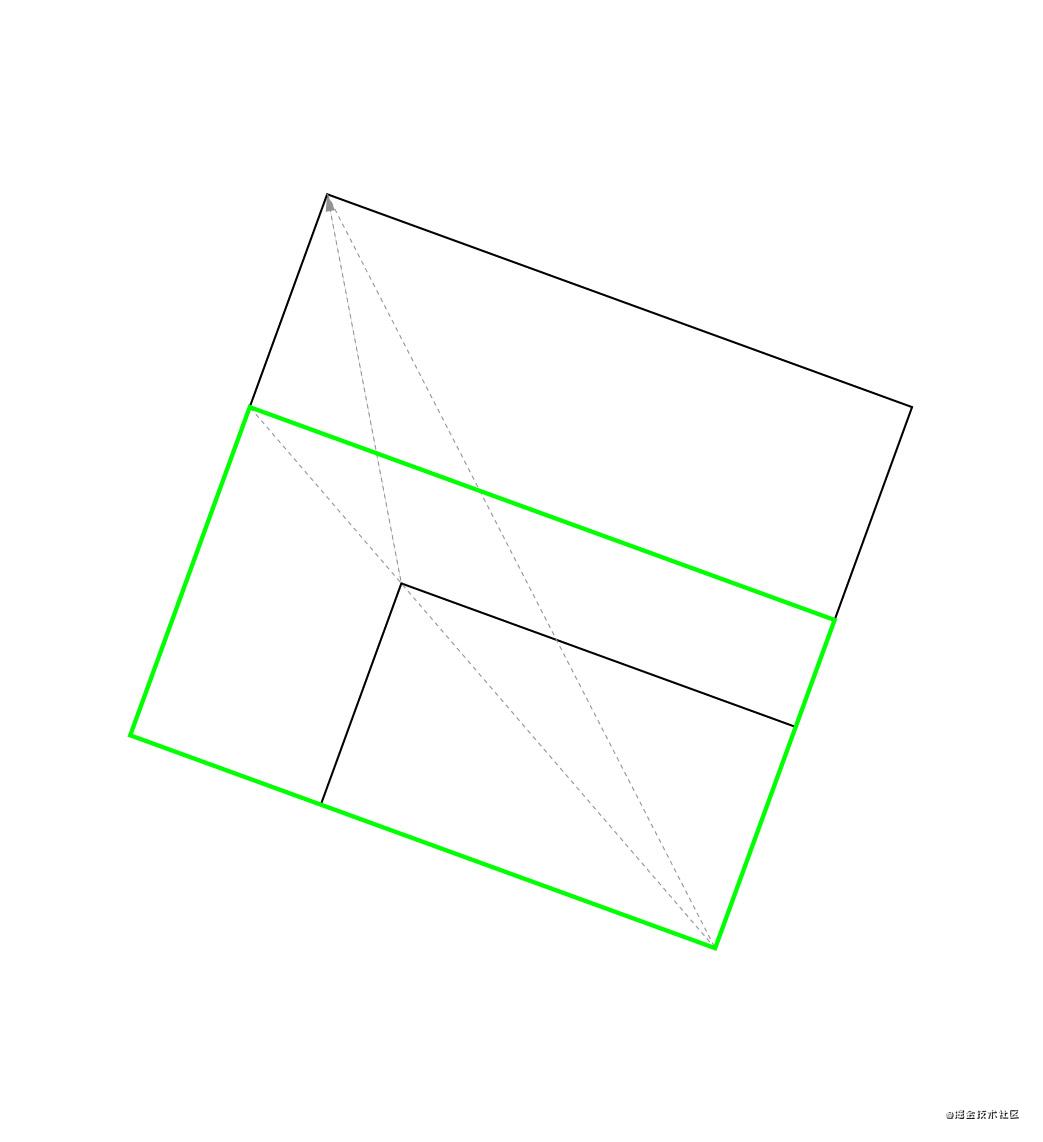
当一个 DOM 在两个渲染帧之间产生了位移,就会触发 CLS(如图所示)。
上图中的矩形从左上角移动到了右边,这就算是一次布局偏移。同时,在 CLS 中,有一个叫会话窗口的术语:一个或多个快速连续发生的单次布局偏移,每次偏移相隔的时间少于 1 秒,且整个窗口的最大持续时长为 5 秒。
例如上图中的第二个会话窗口,它里面有四次布局偏移,每一次偏移之间的间隔必须少于 1 秒,并且第一个偏移和最后一个偏移之间的时间不能超过 5 秒,这样才能算是一次会话窗口。如果不符合这个条件,就算是一个新的会话窗口。可能有人会问,为什么要这样规定?其实这是 chrome 团队根据大量的实验和研究得出的分析结果 Evolving the CLS metric。
CLS 一共有三种计算方式:
也就是把从页面加载开始的所有布局偏移分数加在一起。但是这种计算方式对生命周期长的页面不友好,页面存留时间越长,CLS 分数越高。
这种计算方式不是按单个布局偏移为单位,而是以会话窗口为单位。将所有会话窗口的值相加再取平均值。但是这种计算方式也有缺点。
从上图可以看出来,第一个会话窗口产生了比较大的 CLS 分数,第二个会话窗口产生了比较小的 CLS 分数。如果取它们的平均值来当做 CLS 分数,则根本看不出来页面的运行状况。原来页面是早期偏移多,后期偏移少,现在的平均值无法反映出这种情况。
这种方式是目前最优的计算方式,每次只取所有会话窗口的最大值,用来反映页面布局偏移的最差情况。详情请看 Evolving the CLS metric。
下面是第三种计算方式的测量代码:
let sessionValue = 0
let sessionEntries = []
const cls = {
subType: 'layout-shift',
name: 'layout-shift',
type: 'performance',
pageURL: getPageURL(),
value: 0,
}
const entryHandler = (list) => {
for (const entry of list.getEntries()) {
// Only count layout shifts without recent user input.
if (!entry.hadRecentInput) {
const firstSessionEntry = sessionEntries[0]
const lastSessionEntry = sessionEntries[sessionEntries.length - 1]
// If the entry occurred less than 1 second after the previous entry and
// less than 5 seconds after the first entry in the session, include the
// entry in the current session. Otherwise, start a new session.
if (
sessionValue
&& entry.startTime - lastSessionEntry.startTime < 1000
&& entry.startTime - firstSessionEntry.startTime < 5000
) {
sessionValue += entry.value
sessionEntries.push(formatCLSEntry(entry))
} else {
sessionValue = entry.value
sessionEntries = [formatCLSEntry(entry)]
}
// If the current session value is larger than the current CLS value,
// update CLS and the entries contributing to it.
if (sessionValue > cls.value) {
cls.value = sessionValue
cls.entries = sessionEntries
cls.startTime = performance.now()
lazyReportCache(deepCopy(cls))
}
}
}
}
const observer = new PerformanceObserver(entryHandler)
observer.observe({ type: 'layout-shift', buffered: true })在看完上面的文字描述后,再看代码就好理解了。一次布局偏移的测量内容如下:
{
duration: 0,
entryType: "layout-shift",
hadRecentInput: false,
lastInputTime: 0,
name: "",
sources: (2) [LayoutShiftAttribution, LayoutShiftAttribution],
startTime: 1176.199999999255,
value: 0.000005752046026677329,
}代码中的 value 字段就是布局偏移分数。
当纯 HTML 被完全加载以及解析时,DOMContentLoaded 事件会被触发,不用等待 css、img、iframe 加载完。
当整个页面及所有依赖资源如样式表和图片都已完成加载时,将触发 load 事件。
虽然这两个性能指标比较旧了,但是它们仍然能反映页面的一些情况。对于它们进行监听仍然是必要的。
import { lazyReportCache } from '../utils/report'
['load', 'DOMContentLoaded'].forEach(type => onEvent(type))
function onEvent(type) {
function callback() {
lazyReportCache({
type: 'performance',
subType: type.toLocaleLowerCase(),
startTime: performance.now(),
})
window.removeEventListener(type, callback, true)
}
window.addEventListener(type, callback, true)
}大多数情况下,首屏渲染时间可以通过 load 事件获取。除了一些特殊情况,例如异步加载的图片和 DOM。
<script>
setTimeout(() => {
document.body.innerHTML = `
<div>
<!-- 省略一堆代码... -->
</div>
`
}, 3000)
</script>像这种情况就无法通过 load 事件获取首屏渲染时间了。这时我们需要通过 MutationObserver 来获取首屏渲染时间。MutationObserver 在监听的 DOM 元素属性发生变化时会触发事件。
首屏渲染时间计算过程:
requestAnimationFrame() 回调函数中调用 performance.now() 获取当前时间,作为它的绘制时间。const next = window.requestAnimationFrame ? requestAnimationFrame : setTimeout
const ignoreDOMList = ['STYLE', 'SCRIPT', 'LINK']
observer = new MutationObserver(mutationList => {
const entry = {
children: [],
}
for (const mutation of mutationList) {
if (mutation.addedNodes.length && isInScreen(mutation.target)) {
// ...
}
}
if (entry.children.length) {
entries.push(entry)
next(() => {
entry.startTime = performance.now()
})
}
})
observer.observe(document, {
childList: true,
subtree: true,
})上面的代码就是监听 DOM 变化的代码,同时需要过滤掉 style、script、link 等标签。
一个页面的内容可能非常多,但用户最多只能看见一屏幕的内容。所以在统计首屏渲染时间的时候,需要限定范围,把渲染内容限定在当前屏幕内。
const viewportWidth = window.innerWidth
const viewportHeight = window.innerHeight
// dom 对象是否在屏幕内
function isInScreen(dom) {
const rectInfo = dom.getBoundingClientRect()
if (
rectInfo.left >= 0
&& rectInfo.left < viewportWidth
&& rectInfo.top >= 0
&& rectInfo.top < viewportHeight
) {
return true
}
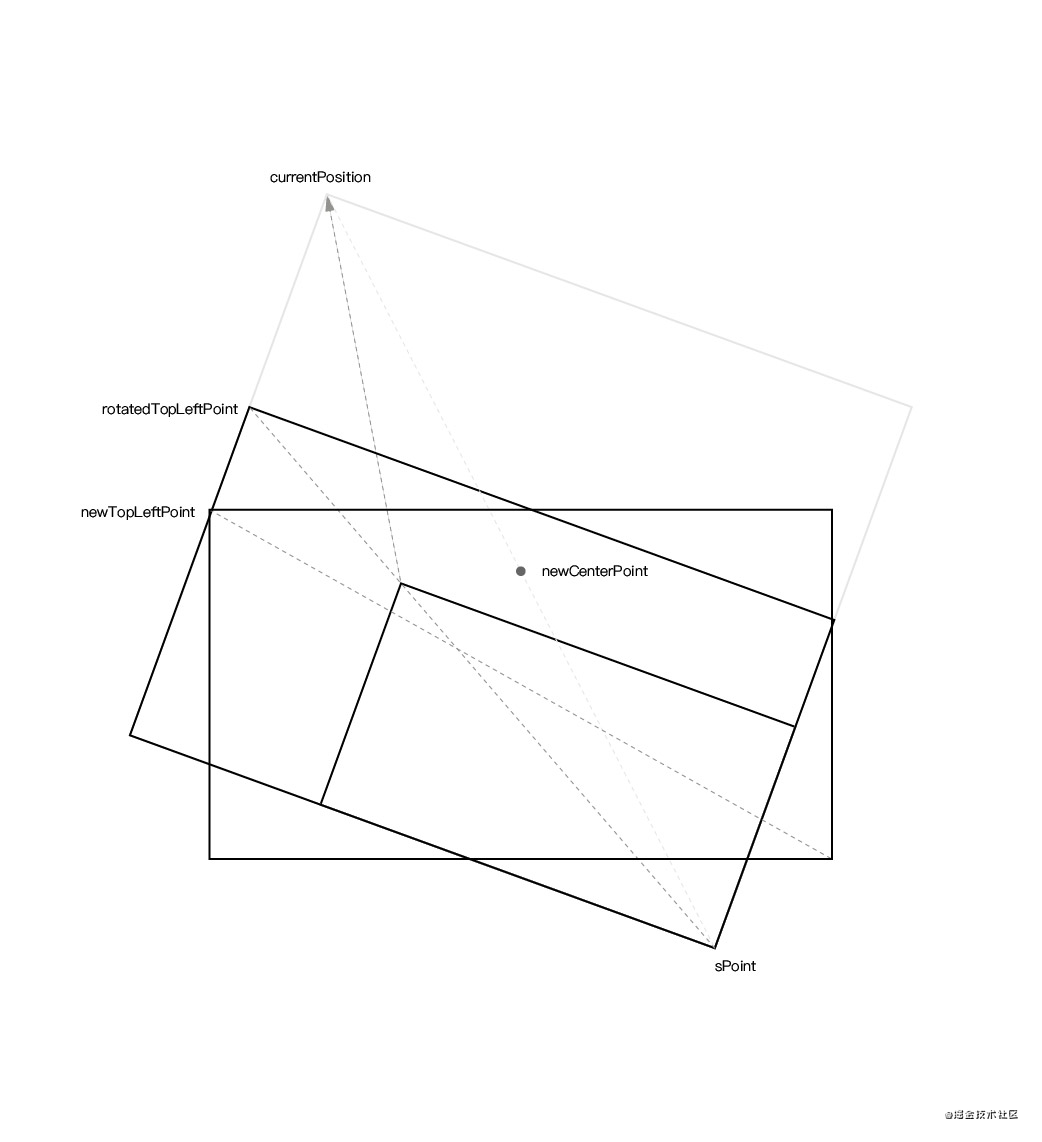
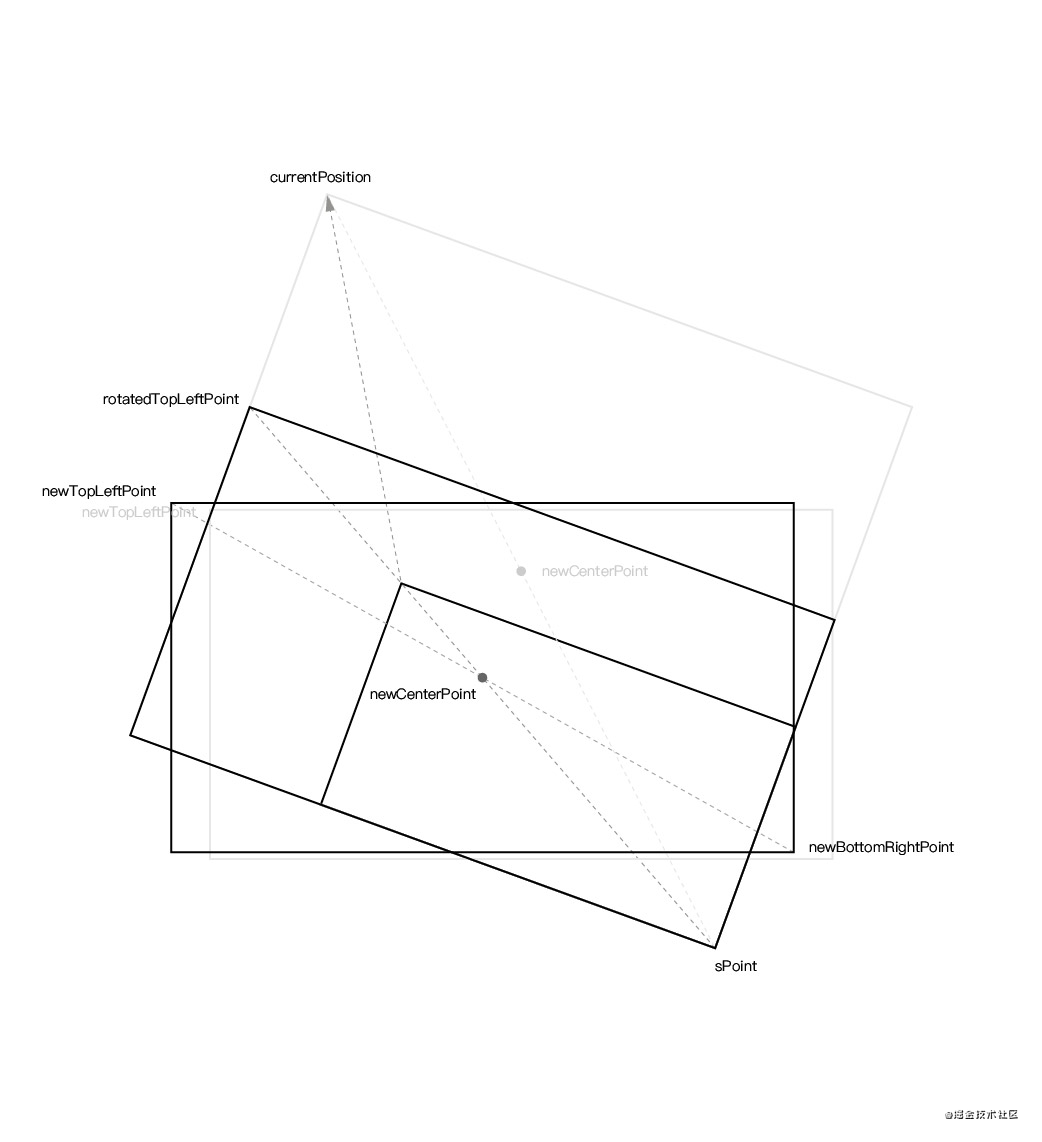
}requestAnimationFrame() 获取 DOM 绘制时间当 DOM 变更触发 MutationObserver 事件时,只是代表 DOM 内容可以被读取到,并不代表该 DOM 被绘制到了屏幕上。
从上图可以看出,当触发 MutationObserver 事件时,可以读取到 document.body 上已经有内容了,但实际上左边的屏幕并没有绘制任何内容。所以要调用 requestAnimationFrame() 在浏览器绘制成功后再获取当前时间作为 DOM 绘制时间。
function getRenderTime() {
let startTime = 0
entries.forEach(entry => {
if (entry.startTime > startTime) {
startTime = entry.startTime
}
})
// 需要和当前页面所有加载图片的时间做对比,取最大值
// 图片请求时间要小于 startTime,响应结束时间要大于 startTime
performance.getEntriesByType('resource').forEach(item => {
if (
item.initiatorType === 'img'
&& item.fetchStart < startTime
&& item.responseEnd > startTime
) {
startTime = item.responseEnd
}
})
return startTime
}现在的代码还没优化完,主要有两点注意事项:
第一点,必须要在 DOM 不再变化后再上报渲染时间,一般 load 事件触发后,DOM 就不再变化了。所以我们可以在这个时间点进行上报。
第二点,可以在 LCP 事件触发后再进行上报。不管是同步还是异步加载的 DOM,它都需要进行绘制,所以可以监听 LCP 事件,在该事件触发后才允许进行上报。
将以上两点方案结合在一起,就有了以下代码:
let isOnLoaded = false
executeAfterLoad(() => {
isOnLoaded = true
})
let timer
let observer
function checkDOMChange() {
clearTimeout(timer)
timer = setTimeout(() => {
// 等 load、lcp 事件触发后并且 DOM 树不再变化时,计算首屏渲染时间
if (isOnLoaded && isLCPDone()) {
observer && observer.disconnect()
lazyReportCache({
type: 'performance',
subType: 'first-screen-paint',
startTime: getRenderTime(),
pageURL: getPageURL(),
})
entries = null
} else {
checkDOMChange()
}
}, 500)
}checkDOMChange() 代码每次在触发 MutationObserver 事件时进行调用,需要用防抖函数进行处理。
接口请求耗时需要对 XMLHttpRequest 和 fetch 进行监听。
监听 XMLHttpRequest
originalProto.open = function newOpen(...args) {
this.url = args[1]
this.method = args[0]
originalOpen.apply(this, args)
}
originalProto.send = function newSend(...args) {
this.startTime = Date.now()
const onLoadend = () => {
this.endTime = Date.now()
this.duration = this.endTime - this.startTime
const { status, duration, startTime, endTime, url, method } = this
const reportData = {
status,
duration,
startTime,
endTime,
url,
method: (method || 'GET').toUpperCase(),
success: status >= 200 && status < 300,
subType: 'xhr',
type: 'performance',
}
lazyReportCache(reportData)
this.removeEventListener('loadend', onLoadend, true)
}
this.addEventListener('loadend', onLoadend, true)
originalSend.apply(this, args)
}如何判断 XML 请求是否成功?可以根据他的状态码是否在 200~299 之间。如果在,那就是成功,否则失败。
监听 fetch
const originalFetch = window.fetch
function overwriteFetch() {
window.fetch = function newFetch(url, config) {
const startTime = Date.now()
const reportData = {
startTime,
url,
method: (config?.method || 'GET').toUpperCase(),
subType: 'fetch',
type: 'performance',
}
return originalFetch(url, config)
.then(res => {
reportData.endTime = Date.now()
reportData.duration = reportData.endTime - reportData.startTime
const data = res.clone()
reportData.status = data.status
reportData.success = data.ok
lazyReportCache(reportData)
return res
})
.catch(err => {
reportData.endTime = Date.now()
reportData.duration = reportData.endTime - reportData.startTime
reportData.status = 0
reportData.success = false
lazyReportCache(reportData)
throw err
})
}
}对于 fetch,可以根据返回数据中的的 ok 字段判断请求是否成功,如果为 true 则请求成功,否则失败。
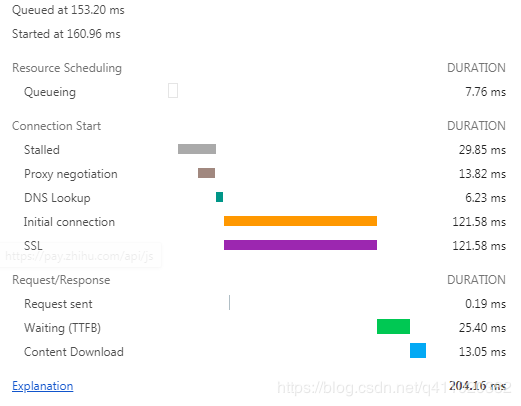
注意,监听到的接口请求时间和 chrome devtool 上检测到的时间可能不一样。这是因为 chrome devtool 上检测到的是 HTTP 请求发送和接口整个过程的时间。但是 xhr 和 fetch 是异步请求,接口请求成功后需要调用回调函数。事件触发时会把回调函数放到消息队列,然后浏览器再处理,这中间也有一个等待过程。
通过 PerformanceObserver 可以监听 resource 和 navigation 事件,如果浏览器不支持 PerformanceObserver,还可以通过 performance.getEntriesByType(entryType) 来进行降级处理。
当 resource 事件触发时,可以获取到对应的资源列表,每个资源对象包含以下一些字段:
从这些字段中我们可以提取到一些有用的信息:
{
name: entry.name, // 资源名称
subType: entryType,
type: 'performance',
sourceType: entry.initiatorType, // 资源类型
duration: entry.duration, // 资源加载耗时
dns: entry.domainLookupEnd - entry.domainLookupStart, // DNS 耗时
tcp: entry.connectEnd - entry.connectStart, // 建立 tcp 连接耗时
redirect: entry.redirectEnd - entry.redirectStart, // 重定向耗时
ttfb: entry.responseStart, // 首字节时间
protocol: entry.nextHopProtocol, // 请求协议
responseBodySize: entry.encodedBodySize, // 响应内容大小
responseHeaderSize: entry.transferSize - entry.encodedBodySize, // 响应头部大小
resourceSize: entry.decodedBodySize, // 资源解压后的大小
isCache: isCache(entry), // 是否命中缓存
startTime: performance.now(),
}判断该资源是否命中缓存
在这些资源对象中有一个 transferSize 字段,它表示获取资源的大小,包括响应头字段和响应数据的大小。如果这个值为 0,说明是从缓存中直接读取的(强制缓存)。如果这个值不为 0,但是 encodedBodySize 字段为 0,说明它走的是协商缓存(encodedBodySize 表示请求响应数据 body 的大小)。
function isCache(entry) {
// 直接从缓存读取或 304
return entry.transferSize === 0 || (entry.transferSize !== 0 && entry.encodedBodySize === 0)
}不符合以上条件的,说明未命中缓存。然后将所有命中缓存的数据/总数据就能得出缓存命中率。
bfcache 是一种内存缓存,它会将整个页面保存在内存中。当用户返回时可以马上看到整个页面,而不用再次刷新。据该文章 bfcache 介绍,firfox 和 safari 一直支持 bfc,chrome 只有在高版本的移动端浏览器支持。但我试了一下,只有 safari 浏览器支持,可能我的 firfox 版本不对。
但是 bfc 也是有缺点的,当用户返回并从 bfc 中恢复页面时,原来页面的代码不会再次执行。为此,浏览器提供了一个 pageshow 事件,可以把需要再次执行的代码放在里面。
window.addEventListener('pageshow', function(event) {
// 如果该属性为 true,表示是从 bfc 中恢复的页面
if (event.persisted) {
console.log('This page was restored from the bfcache.');
} else {
console.log('This page was loaded normally.');
}
});从 bfc 中恢复的页面,我们也需要收集他们的 FP、FCP、LCP 等各种时间。
onBFCacheRestore(event => {
requestAnimationFrame(() => {
['first-paint', 'first-contentful-paint'].forEach(type => {
lazyReportCache({
startTime: performance.now() - event.timeStamp,
name: type,
subType: type,
type: 'performance',
pageURL: getPageURL(),
bfc: true,
})
})
})
})上面的代码很好理解,在 pageshow 事件触发后,用当前时间减去事件触发时间,这个时间差值就是性能指标的绘制时间。注意,从 bfc 中恢复的页面的这些性能指标,值一般都很小,一般在 10 ms 左右。所以要给它们加个标识字段 bfc: true。这样在做性能统计时可以对它们进行忽略。
利用 requestAnimationFrame() 我们可以计算当前页面的 FPS。
const next = window.requestAnimationFrame
? requestAnimationFrame : (callback) => { setTimeout(callback, 1000 / 60) }
const frames = []
export default function fps() {
let frame = 0
let lastSecond = Date.now()
function calculateFPS() {
frame++
const now = Date.now()
if (lastSecond + 1000 <= now) {
// 由于 now - lastSecond 的单位是毫秒,所以 frame 要 * 1000
const fps = Math.round((frame * 1000) / (now - lastSecond))
frames.push(fps)
frame = 0
lastSecond = now
}
// 避免上报太快,缓存一定数量再上报
if (frames.length >= 60) {
report(deepCopy({
frames,
type: 'performace',
subType: 'fps',
}))
frames.length = 0
}
next(calculateFPS)
}
calculateFPS()
}代码逻辑如下:
requestAnimationFrame() 时,就将帧数加 1。过去一秒后用帧数/流逝的时间就能得到当前帧率。当连续三个低于 20 的 FPS 出现时,我们可以断定页面出现了卡顿,详情请看 如何监控网页的卡顿。
export function isBlocking(fpsList, below = 20, last = 3) {
let count = 0
for (let i = 0; i < fpsList.length; i++) {
if (fpsList[i] && fpsList[i] < below) {
count++
} else {
count = 0
}
if (count >= last) {
return true
}
}
return false
}首屏渲染时间我们已经知道如何计算了,但是如何计算 SPA 应用的页面路由切换导致的页面渲染时间呢?本文用 Vue 作为示例,讲一下我的思路。
export default function onVueRouter(Vue, router) {
let isFirst = true
let startTime
router.beforeEach((to, from, next) => {
// 首次进入页面已经有其他统计的渲染时间可用
if (isFirst) {
isFirst = false
return next()
}
// 给 router 新增一个字段,表示是否要计算渲染时间
// 只有路由跳转才需要计算
router.needCalculateRenderTime = true
startTime = performance.now()
next()
})
let timer
Vue.mixin({
mounted() {
if (!router.needCalculateRenderTime) return
this.$nextTick(() => {
// 仅在整个视图都被渲染之后才会运行的代码
const now = performance.now()
clearTimeout(timer)
timer = setTimeout(() => {
router.needCalculateRenderTime = false
lazyReportCache({
type: 'performance',
subType: 'vue-router-change-paint',
duration: now - startTime,
startTime: now,
pageURL: getPageURL(),
})
}, 1000)
})
},
})
}代码逻辑如下:
router.beforeEach() 钩子,在该钩子的回调函数里将当前时间记为渲染开始时间。Vue.mixin() 对所有组件的 mounted() 注入一个函数。每个函数都执行一个防抖函数。mounted() 触发时,就代表该路由下的所有组件已经挂载完毕。可以在 this.$nextTick() 回调函数中获取渲染时间。同时,还要考虑到一个情况。不切换路由时,也会有变更组件的情况,这时不应该在这些组件的 mounted() 里进行渲染时间计算。所以需要添加一个 needCalculateRenderTime 字段,当切换路由时将它设为 true,代表可以计算渲染时间了。
使用 addEventListener() 监听 error 事件,可以捕获到资源加载失败错误。
// 捕获资源加载失败错误 js css img...
window.addEventListener('error', e => {
const target = e.target
if (!target) return
if (target.src || target.href) {
const url = target.src || target.href
lazyReportCache({
url,
type: 'error',
subType: 'resource',
startTime: e.timeStamp,
html: target.outerHTML,
resourceType: target.tagName,
paths: e.path.map(item => item.tagName).filter(Boolean),
pageURL: getPageURL(),
})
}
}, true)使用 window.onerror 可以监听 js 错误。
// 监听 js 错误
window.onerror = (msg, url, line, column, error) => {
lazyReportCache({
msg,
line,
column,
error: error.stack,
subType: 'js',
pageURL: url,
type: 'error',
startTime: performance.now(),
})
}使用 addEventListener() 监听 unhandledrejection 事件,可以捕获到未处理的 promise 错误。
// 监听 promise 错误 缺点是获取不到列数据
window.addEventListener('unhandledrejection', e => {
lazyReportCache({
reason: e.reason?.stack,
subType: 'promise',
type: 'error',
startTime: e.timeStamp,
pageURL: getPageURL(),
})
})一般生产环境的代码都是经过压缩的,并且生产环境不会把 sourcemap 文件上传。所以生产环境上的代码报错信息是很难读的。因此,我们可以利用 source-map 来对这些压缩过的代码报错信息进行还原。
当代码报错时,我们可以获取到对应的文件名、行数、列数:
{
line: 1,
column: 17,
file: 'https:/www.xxx.com/bundlejs',
}然后调用下面的代码进行还原:
async function parse(error) {
const mapObj = JSON.parse(getMapFileContent(error.url))
const consumer = await new sourceMap.SourceMapConsumer(mapObj)
// 将 webpack://source-map-demo/./src/index.js 文件中的 ./ 去掉
const sources = mapObj.sources.map(item => format(item))
// 根据压缩后的报错信息得出未压缩前的报错行列数和源码文件
const originalInfo = consumer.originalPositionFor({ line: error.line, column: error.column })
// sourcesContent 中包含了各个文件的未压缩前的源码,根据文件名找出对应的源码
const originalFileContent = mapObj.sourcesContent[sources.indexOf(originalInfo.source)]
return {
file: originalInfo.source,
content: originalFileContent,
line: originalInfo.line,
column: originalInfo.column,
msg: error.msg,
error: error.error
}
}
function format(item) {
return item.replace(/(\.\/)*/g, '')
}
function getMapFileContent(url) {
return fs.readFileSync(path.resolve(__dirname, `./maps/${url.split('/').pop()}.map`), 'utf-8')
}每次项目打包时,如果开启了 sourcemap,那么每一个 js 文件都会有一个对应的 map 文件。
bundle.js
bundle.js.map
这时 js 文件放在静态服务器上供用户访问,map 文件存储在服务器,用于还原错误信息。source-map 库可以根据压缩过的代码报错信息还原出未压缩前的代码报错信息。例如压缩后报错位置为 1 行 47 列,还原后真正的位置可能为 4 行 10 列。除了位置信息,还可以获取到源码原文。
上图就是一个代码报错还原后的示例。鉴于这部分内容不属于 SDK 的范围,所以我另开了一个 仓库 来做这个事,有兴趣可以看看。
利用 window.onerror 是捕获不到 Vue 错误的,它需要使用 Vue 提供的 API 进行监听。
Vue.config.errorHandler = (err, vm, info) => {
// 将报错信息打印到控制台
console.error(err)
lazyReportCache({
info,
error: err.stack,
subType: 'vue',
type: 'error',
startTime: performance.now(),
pageURL: getPageURL(),
})
}PV(page view) 是页面浏览量,UV(Unique visitor)用户访问量。PV 只要访问一次页面就算一次,UV 同一天内多次访问只算一次。
对于前端来说,只要每次进入页面上报一次 PV 就行,UV 的统计放在服务端来做,主要是分析上报的数据来统计得出 UV。
export default function pv() {
lazyReportCache({
type: 'behavior',
subType: 'pv',
startTime: performance.now(),
pageURL: getPageURL(),
referrer: document.referrer,
uuid: getUUID(),
})
}用户进入页面记录一个初始时间,用户离开页面时用当前时间减去初始时间,就是用户停留时长。这个计算逻辑可以放在 beforeunload 事件里做。
export default function pageAccessDuration() {
onBeforeunload(() => {
report({
type: 'behavior',
subType: 'page-access-duration',
startTime: performance.now(),
pageURL: getPageURL(),
uuid: getUUID(),
}, true)
})
}记录页面访问深度是很有用的,例如不同的活动页面 a 和 b。a 平均访问深度只有 50%,b 平均访问深度有 80%,说明 b 更受用户喜欢,根据这一点可以有针对性的修改 a 活动页面。
除此之外还可以利用访问深度以及停留时长来鉴别电商刷单。例如有人进来页面后一下就把页面拉到底部然后等待一段时间后购买,有人是慢慢的往下滚动页面,最后再购买。虽然他们在页面的停留时间一样,但明显第一个人更像是刷单的。
页面访问深度计算过程稍微复杂一点:
scroll 事件,在回调函数中用第一点得到的数据算出页面访问深度和停留时长。具体代码请看:
let timer
let startTime = 0
let hasReport = false
let pageHeight = 0
let scrollTop = 0
let viewportHeight = 0
export default function pageAccessHeight() {
window.addEventListener('scroll', onScroll)
onBeforeunload(() => {
const now = performance.now()
report({
startTime: now,
duration: now - startTime,
type: 'behavior',
subType: 'page-access-height',
pageURL: getPageURL(),
value: toPercent((scrollTop + viewportHeight) / pageHeight),
uuid: getUUID(),
}, true)
})
// 页面加载完成后初始化记录当前访问高度、时间
executeAfterLoad(() => {
startTime = performance.now()
pageHeight = document.documentElement.scrollHeight || document.body.scrollHeight
scrollTop = document.documentElement.scrollTop || document.body.scrollTop
viewportHeight = window.innerHeight
})
}
function onScroll() {
clearTimeout(timer)
const now = performance.now()
if (!hasReport) {
hasReport = true
lazyReportCache({
startTime: now,
duration: now - startTime,
type: 'behavior',
subType: 'page-access-height',
pageURL: getPageURL(),
value: toPercent((scrollTop + viewportHeight) / pageHeight),
uuid: getUUID(),
})
}
timer = setTimeout(() => {
hasReport = false
startTime = now
pageHeight = document.documentElement.scrollHeight || document.body.scrollHeight
scrollTop = document.documentElement.scrollTop || document.body.scrollTop
viewportHeight = window.innerHeight
}, 500)
}
function toPercent(val) {
if (val >= 1) return '100%'
return (val * 100).toFixed(2) + '%'
}利用 addEventListener() 监听 mousedown、touchstart 事件,我们可以收集用户每一次点击区域的大小,点击坐标在整个页面中的具体位置,点击元素的内容等信息。
export default function onClick() {
['mousedown', 'touchstart'].forEach(eventType => {
let timer
window.addEventListener(eventType, event => {
clearTimeout(timer)
timer = setTimeout(() => {
const target = event.target
const { top, left } = target.getBoundingClientRect()
lazyReportCache({
top,
left,
eventType,
pageHeight: document.documentElement.scrollHeight || document.body.scrollHeight,
scrollTop: document.documentElement.scrollTop || document.body.scrollTop,
type: 'behavior',
subType: 'click',
target: target.tagName,
paths: event.path?.map(item => item.tagName).filter(Boolean),
startTime: event.timeStamp,
pageURL: getPageURL(),
outerHTML: target.outerHTML,
innerHTML: target.innerHTML,
width: target.offsetWidth,
height: target.offsetHeight,
viewport: {
width: window.innerWidth,
height: window.innerHeight,
},
uuid: getUUID(),
})
}, 500)
})
})
}利用 addEventListener() 监听 popstate、hashchange 页面跳转事件。需要注意的是调用history.pushState()或history.replaceState()不会触发popstate事件。只有在做出浏览器动作时,才会触发该事件,如用户点击浏览器的回退按钮(或者在Javascript代码中调用history.back()或者history.forward()方法)。同理,hashchange 也一样。
export default function pageChange() {
let from = ''
window.addEventListener('popstate', () => {
const to = getPageURL()
lazyReportCache({
from,
to,
type: 'behavior',
subType: 'popstate',
startTime: performance.now(),
uuid: getUUID(),
})
from = to
}, true)
let oldURL = ''
window.addEventListener('hashchange', event => {
const newURL = event.newURL
lazyReportCache({
from: oldURL,
to: newURL,
type: 'behavior',
subType: 'hashchange',
startTime: performance.now(),
uuid: getUUID(),
})
oldURL = newURL
}, true)
}Vue 可以利用 router.beforeEach 钩子进行路由变更的监听。
export default function onVueRouter(router) {
router.beforeEach((to, from, next) => {
// 首次加载页面不用统计
if (!from.name) {
return next()
}
const data = {
params: to.params,
query: to.query,
}
lazyReportCache({
data,
name: to.name || to.path,
type: 'behavior',
subType: ['vue-router-change', 'pv'],
startTime: performance.now(),
from: from.fullPath,
to: to.fullPath,
uuid: getUUID(),
})
next()
})
}数据上报可以使用以下几种方式:
我写的简易 SDK 采用的是第一、第二种方式相结合的方式进行上报。利用 sendBeacon 来进行上报的优势非常明显。
使用
sendBeacon()方法会使用户代理在有机会时异步地向服务器发送数据,同时不会延迟页面的卸载或影响下一导航的载入性能。这就解决了提交分析数据时的所有的问题:数据可靠,传输异步并且不会影响下一页面的加载。
在不支持 sendBeacon 的浏览器下我们可以使用 XMLHttpRequest 来进行上报。一个 HTTP 请求包含发送和接收两个步骤。其实对于上报来说,我们只要确保能发出去就可以了。也就是发送成功了就行,接不接收响应无所谓。为此,我做了个实验,在 beforeunload 用 XMLHttpRequest 传送了 30kb 的数据(一般的待上报数据很少会有这么大),换了不同的浏览器,都可以成功发出去。当然,这和硬件性能、网络状态也是有关联的。
上报时机有三种:
requestIdleCallback/setTimeout 延时上报。建议将三种方式结合一起上报:
requestIdleCallback/setTimeout 延时上报。仅看理论知识是比较难以理解的,为此我结合本文所讲的技术要点写了一个简单的监控 SDK,可以用它来写一些简单的 DEMO,帮助加深理解。再结合本文一起阅读,效果更好。
本文主要对以下技术要点进行分析:
为了让本文更加容易理解,我将以上技术要点结合在一起写了一个可视化拖拽组件库 DEMO:
建议结合源码一起阅读,效果更好(这个 DEMO 使用的是 Vue 技术栈)。
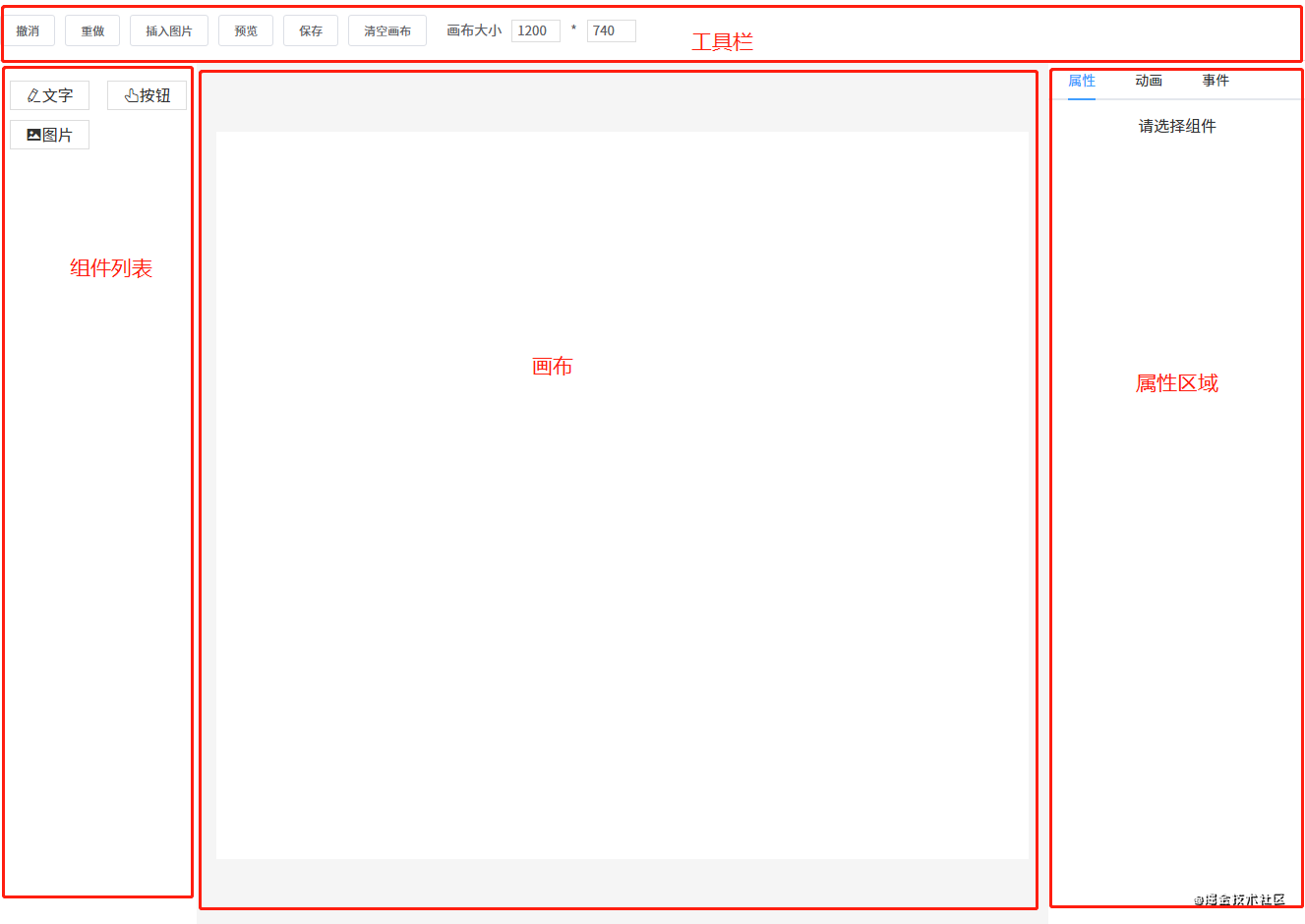
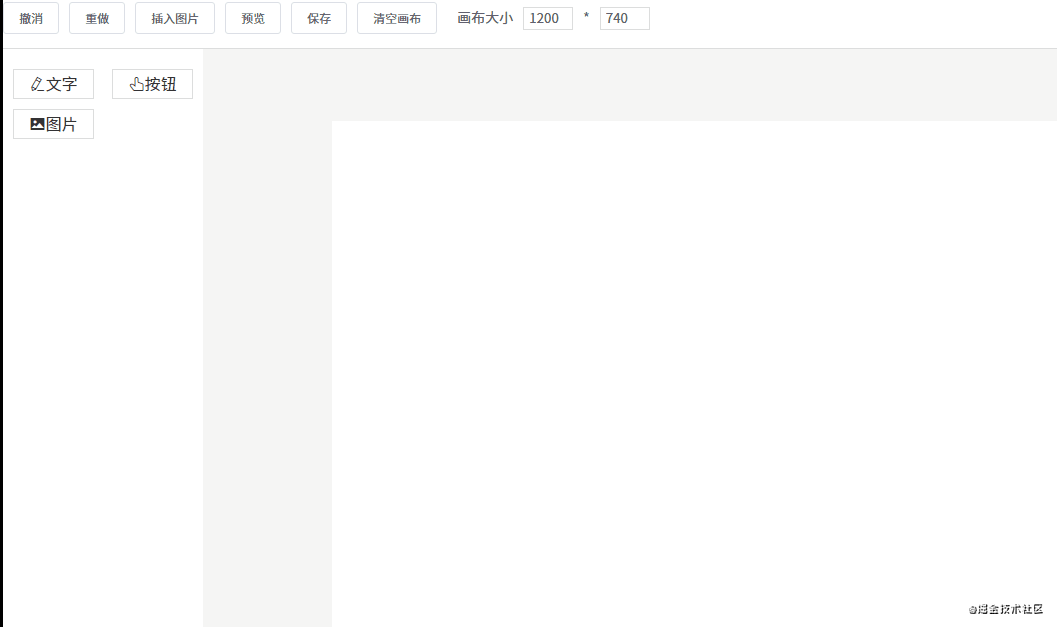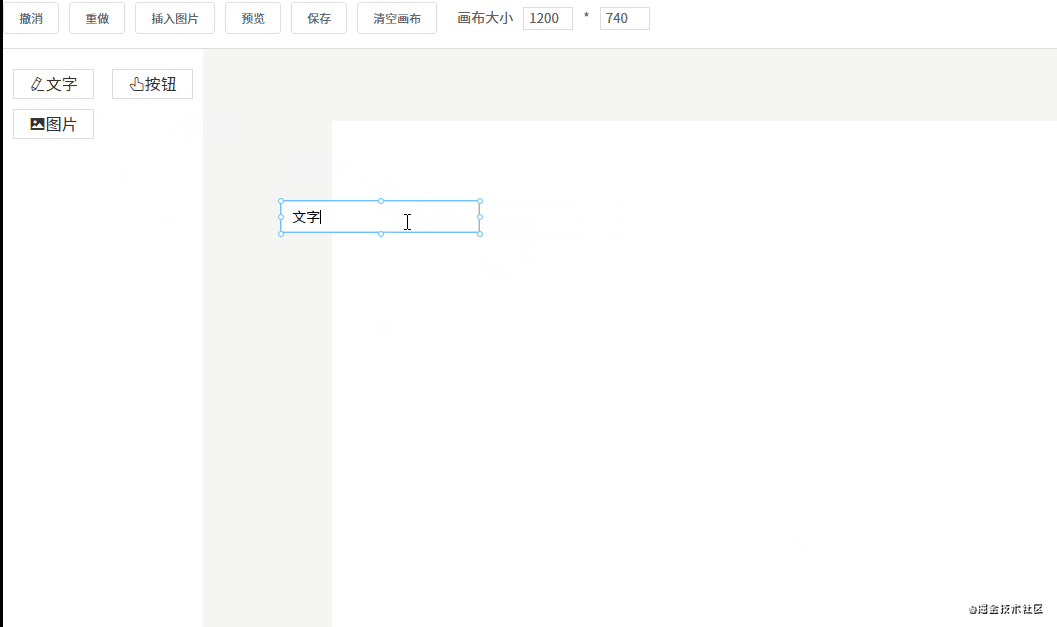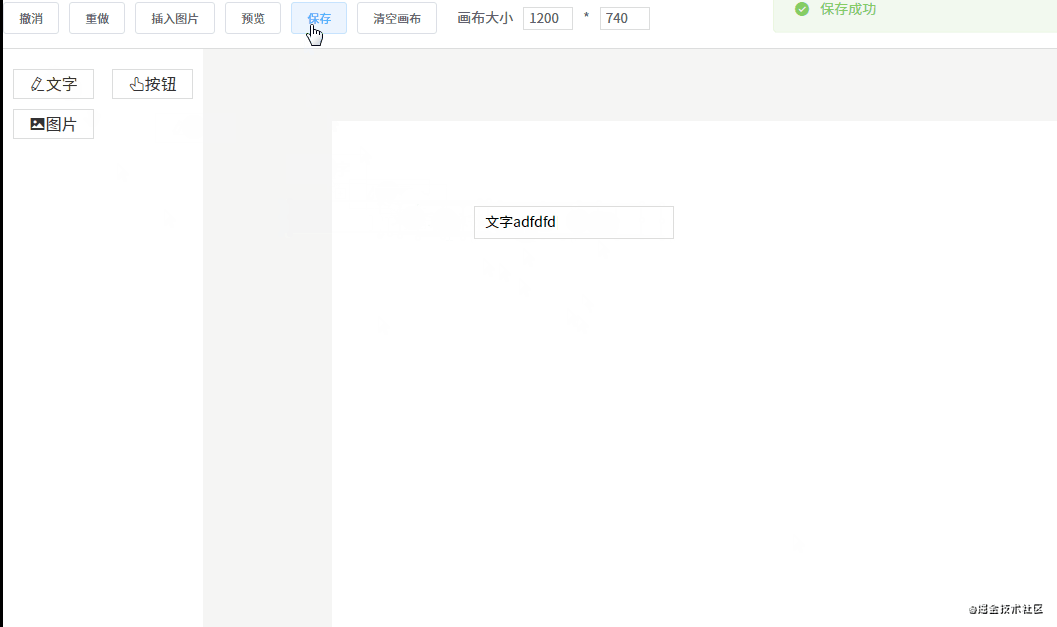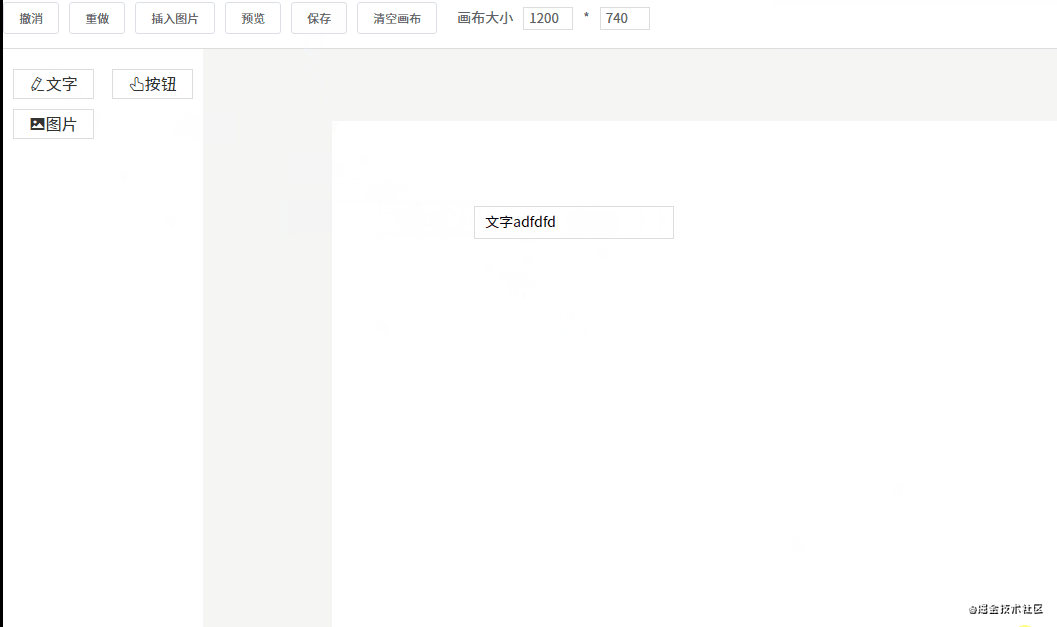
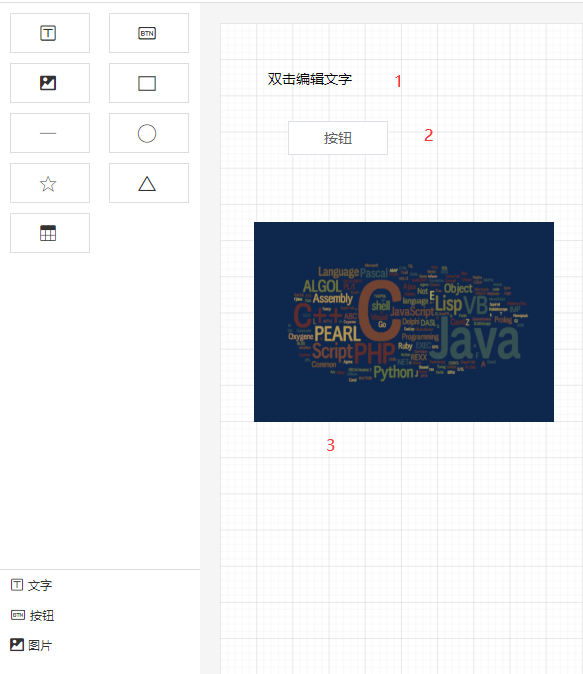
先来看一下页面的整体结构。
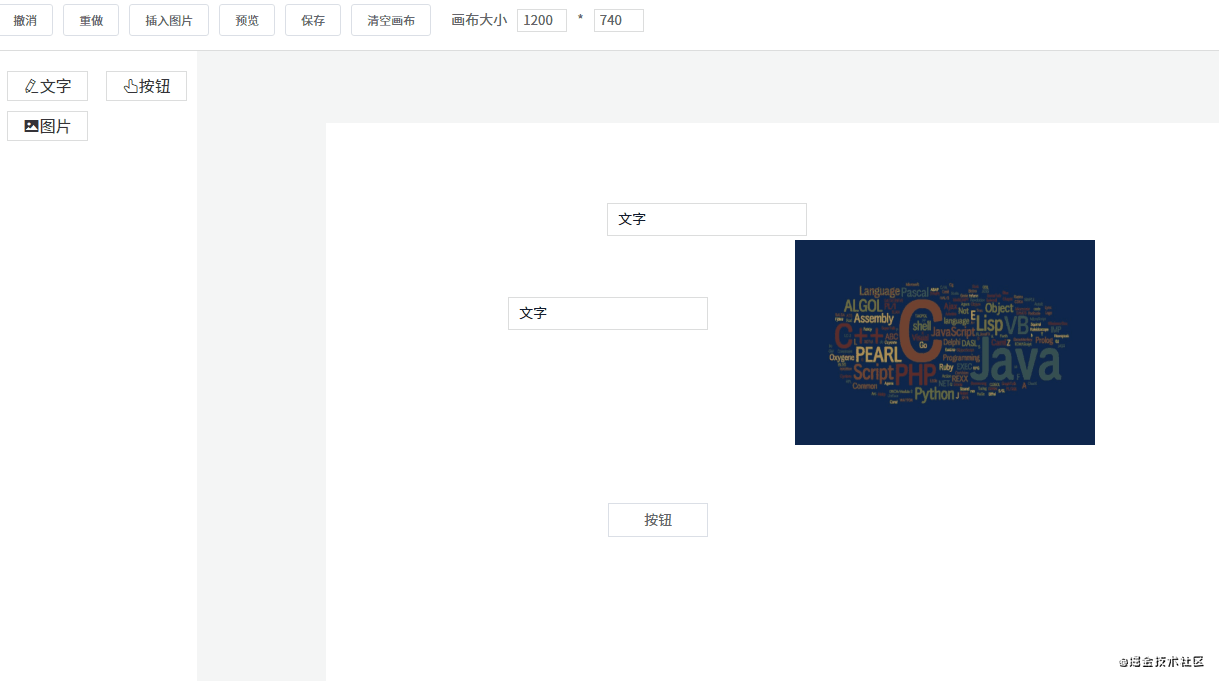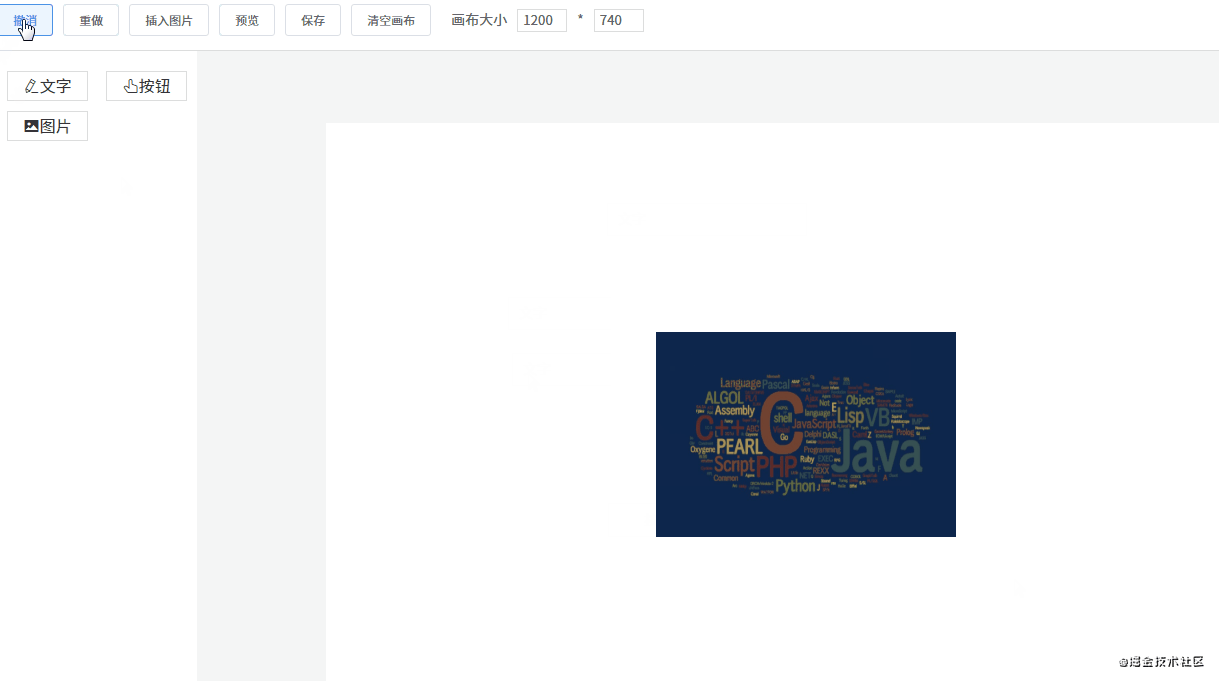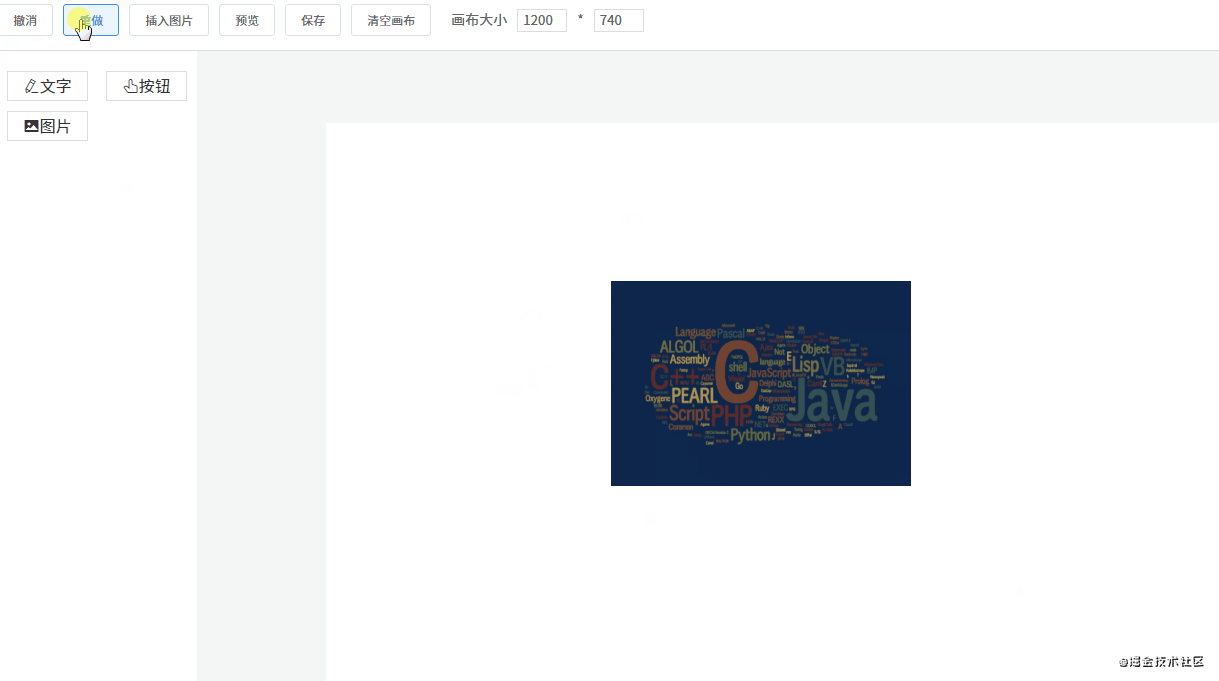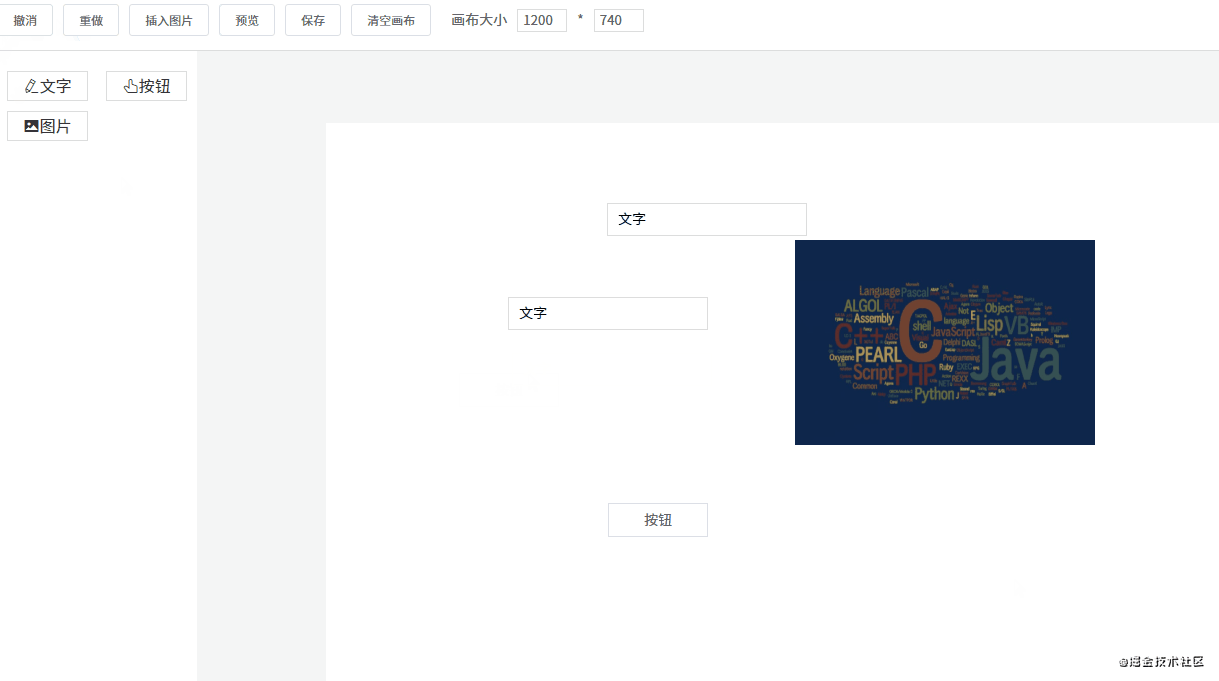
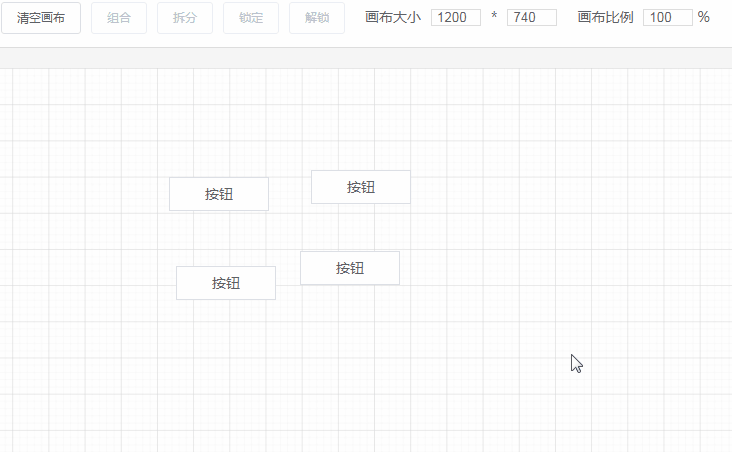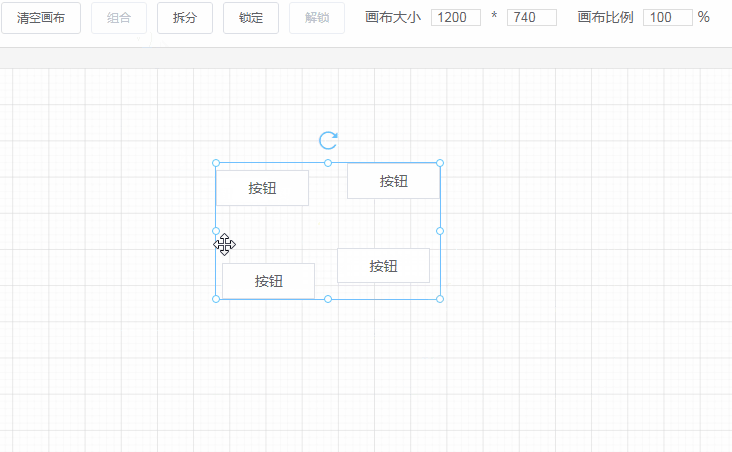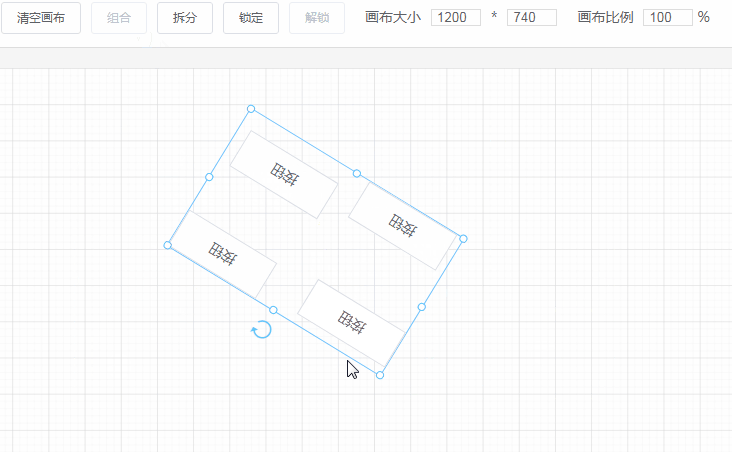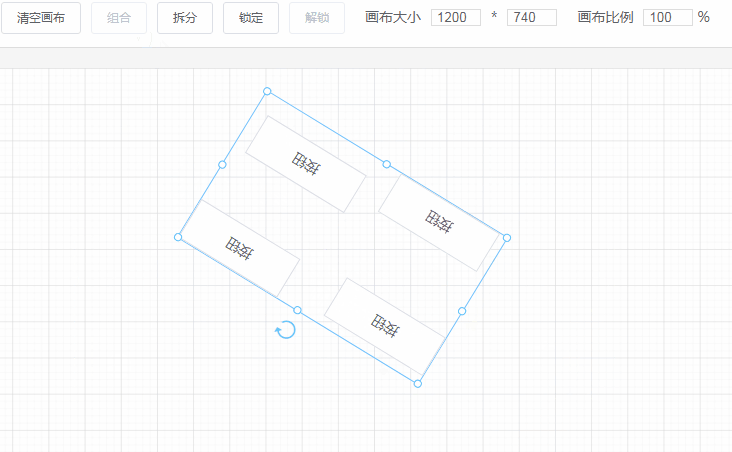
这一节要讲的编辑器其实就是中间的画布。它的作用是:当从左边组件列表拖拽出一个组件放到画布中时,画布要把这个组件渲染出来。
这个编辑器的实现思路是:
componentData 维护编辑器中的数据。push() 方法将新的组件数据添加到 componentData。v-for 指令遍历 componentData,将每个组件逐个渲染到画布(也可以使用 JSX 语法结合 render() 方法代替)。编辑器渲染的核心代码如下所示:
<component
v-for="item in componentData"
:key="item.id"
:is="item.component"
:style="item.style"
:propValue="item.propValue"
/>每个组件数据大概是这样:
{
component: 'v-text', // 组件名称,需要提前注册到 Vue
label: '文字', // 左侧组件列表中显示的名字
propValue: '文字', // 组件所使用的值
icon: 'el-icon-edit', // 左侧组件列表中显示的名字
animations: [], // 动画列表
events: {}, // 事件列表
style: { // 组件样式
width: 200,
height: 33,
fontSize: 14,
fontWeight: 500,
lineHeight: '',
letterSpacing: 0,
textAlign: '',
color: '',
},
}在遍历 componentData 组件数据时,主要靠 is 属性来识别出真正要渲染的是哪个组件。
例如要渲染的组件数据是 { component: 'v-text' },则 <component :is="item.component" /> 会被转换为 <v-text />。当然,你这个组件也要提前注册到 Vue 中。
如果你想了解更多 is 属性的资料,请查看官方文档。
原则上使用第三方组件也是可以的,但建议你最好封装一下。不管是第三方组件还是自定义组件,每个组件所需的属性可能都不一样,所以每个组件数据可以暴露出一个属性 propValue 用于传递值。
例如 a 组件只需要一个属性,你的 propValue 可以这样写:propValue: 'aaa'。如果需要多个属性,propValue 则可以是一个对象:
propValue: {
a: 1,
b: 'text'
}在这个 DEMO 组件库中我定义了三个组件。
图片组件 Picture:
<template>
<div style="overflow: hidden">
<img :src="propValue">
</div>
</template>
<script>
export default {
props: {
propValue: {
type: String,
require: true,
},
},
}
</script>按钮组件 VButton:
<template>
<button class="v-button">{{ propValue }}</button>
</template>
<script>
export default {
props: {
propValue: {
type: String,
default: '',
},
},
}
</script>文本组件 VText:
<template>
<textarea
v-if="editMode == 'edit'"
:value="propValue"
class="text textarea"
@input="handleInput"
ref="v-text"
></textarea>
<div v-else class="text disabled">
<div v-for="(text, index) in propValue.split('\n')" :key="index">{{ text }}</div>
</div>
</template>
<script>
import { mapState } from 'vuex'
export default {
props: {
propValue: {
type: String,
},
element: {
type: Object,
},
},
computed: mapState([
'editMode',
]),
methods: {
handleInput(e) {
this.$emit('input', this.element, e.target.value)
},
},
}
</script>一个元素如果要设为可拖拽,必须给它添加一个 draggable 属性。另外,在将组件列表中的组件拖拽到画布中,还有两个事件是起到关键作用的:
dragstart 事件,在拖拽刚开始时触发。它主要用于将拖拽的组件信息传递给画布。drop 事件,在拖拽结束时触发。主要用于接收拖拽的组件信息。先来看一下左侧组件列表的代码:
<div @dragstart="handleDragStart" class="component-list">
<div v-for="(item, index) in componentList" :key="index" class="list" draggable :data-index="index">
<i :class="item.icon"></i>
<span>{{ item.label }}</span>
</div>
</div>handleDragStart(e) {
e.dataTransfer.setData('index', e.target.dataset.index)
}可以看到给列表中的每一个组件都设置了 draggable 属性。另外,在触发 dragstart 事件时,使用 dataTransfer.setData() 传输数据。再来看一下接收数据的代码:
<div class="content" @drop="handleDrop" @dragover="handleDragOver" @click="deselectCurComponent">
<Editor />
</div>handleDrop(e) {
e.preventDefault()
e.stopPropagation()
const component = deepCopy(componentList[e.dataTransfer.getData('index')])
this.$store.commit('addComponent', component)
}触发 drop 事件时,使用 dataTransfer.getData() 接收传输过来的索引数据,然后根据索引找到对应的组件数据,再添加到画布,从而渲染组件。
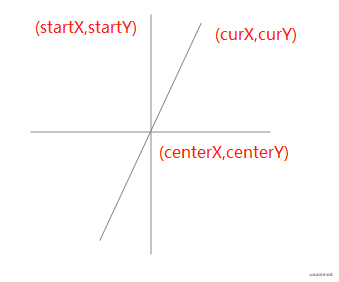
首先需要将画布设为相对定位 position: relative,然后将每个组件设为绝对定位 position: absolute。除了这一点外,还要通过监听三个事件来进行移动:
mousedown 事件,在组件上按下鼠标时,记录组件当前的位置,即 xy 坐标(为了方便讲解,这里使用的坐标轴,实际上 xy 对应的是 css 中的 left 和 top。mousemove 事件,每次鼠标移动时,都用当前最新的 xy 坐标减去最开始的 xy 坐标,从而计算出移动距离,再改变组件位置。mouseup 事件,鼠标抬起时结束移动。handleMouseDown(e) {
e.stopPropagation()
this.$store.commit('setCurComponent', { component: this.element, zIndex: this.zIndex })
const pos = { ...this.defaultStyle }
const startY = e.clientY
const startX = e.clientX
// 如果直接修改属性,值的类型会变为字符串,所以要转为数值型
const startTop = Number(pos.top)
const startLeft = Number(pos.left)
const move = (moveEvent) => {
const currX = moveEvent.clientX
const currY = moveEvent.clientY
pos.top = currY - startY + startTop
pos.left = currX - startX + startLeft
// 修改当前组件样式
this.$store.commit('setShapeStyle', pos)
}
const up = () => {
document.removeEventListener('mousemove', move)
document.removeEventListener('mouseup', up)
}
document.addEventListener('mousemove', move)
document.addEventListener('mouseup', up)
}PS: 有很多网友反馈拖拽的时候有卡顿现象,其实解决方案很简单,把浏览器的控制台关掉即可。
由于拖拽组件到画布中是有先后顺序的,所以可以按照数据顺序来分配图层层级。
例如画布新增了五个组件 abcde,那它们在画布数据中的顺序为 [a, b, c, d, e],图层层级和索引一一对应,即它们的 z-index 属性值是 01234(后来居上)。用代码表示如下:
<div v-for="(item, index) in componentData" :zIndex="index"></div>如果不了解 z-index 属性的,请看一下 MDN 文档。
理解了这一点之后,改变图层层级就很容易做到了。改变图层层级,即是改变组件数据在 componentData 数组中的顺序。例如有 [a, b, c] 三个组件,它们的图层层级从低到高顺序为 abc(索引越大,层级越高)。
如果要将 b 组件上移,只需将它和 c 调换顺序即可:
const temp = componentData[1]
componentData[1] = componentData[2]
componentData[2] = temp同理,置顶置底也是一样,例如我要将 a 组件置顶,只需将 a 和最后一个组件调换顺序即可:
const temp = componentData[0]
componentData[0] = componentData[componentData.lenght - 1]
componentData[componentData.lenght - 1] = temp删除组件非常简单,一行代码搞定:componentData.splice(index, 1)。
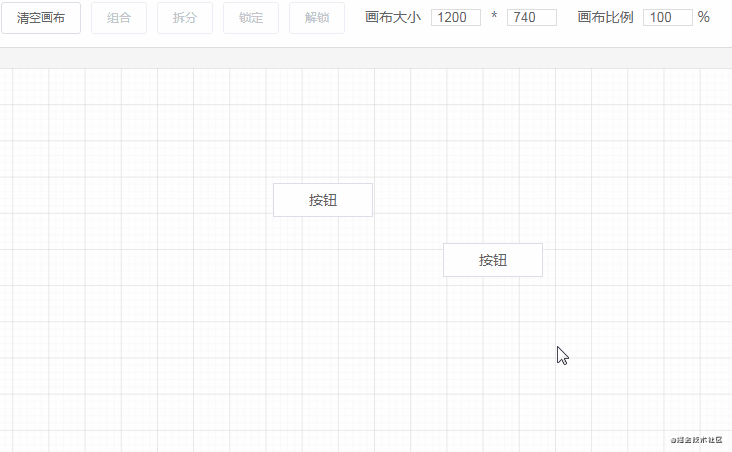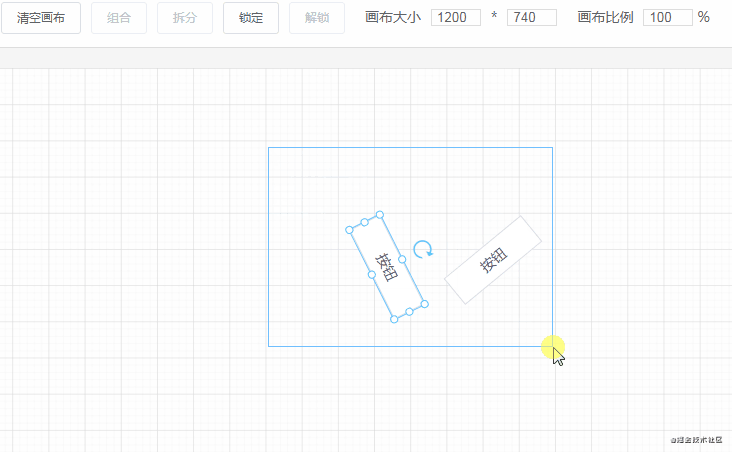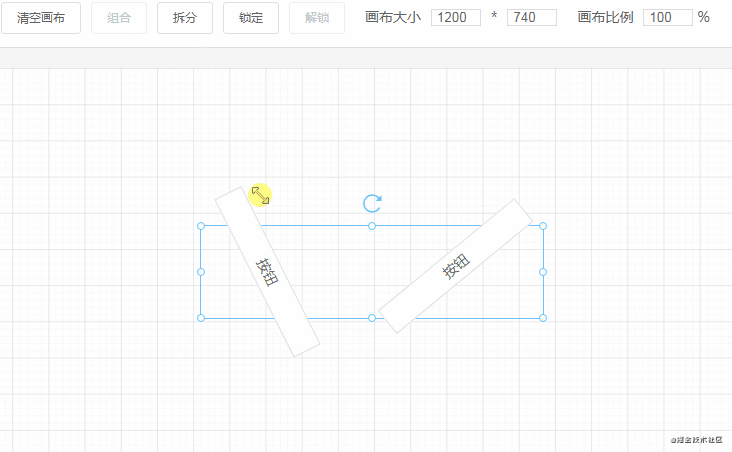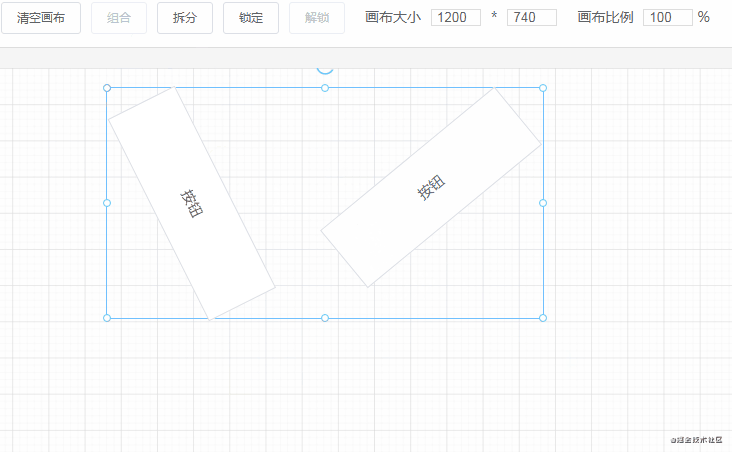
细心的网友可能会发现,点击画布上的组件时,组件上会出现 8 个小圆点。这 8 个小圆点就是用来放大缩小用的。实现原理如下:
Shape 组件,Shape 组件里包含 8 个小圆点和一个 <slot> 插槽,用于放置组件。<!--页面组件列表展示-->
<Shape v-for="(item, index) in componentData"
:defaultStyle="item.style"
:style="getShapeStyle(item.style, index)"
:key="item.id"
:active="item === curComponent"
:element="item"
:zIndex="index"
>
<component
class="component"
:is="item.component"
:style="getComponentStyle(item.style)"
:propValue="item.propValue"
/>
</Shape>Shape 组件内部结构:
<template>
<div class="shape" :class="{ active: this.active }" @click="selectCurComponent" @mousedown="handleMouseDown"
@contextmenu="handleContextMenu">
<div
class="shape-point"
v-for="(item, index) in (active? pointList : [])"
@mousedown="handleMouseDownOnPoint(item)"
:key="index"
:style="getPointStyle(item)">
</div>
<slot></slot>
</div>
</template>起作用的是这行代码 :active="item === curComponent"。
先来看一下计算小圆点位置的代码:
const pointList = ['t', 'r', 'b', 'l', 'lt', 'rt', 'lb', 'rb']
getPointStyle(point) {
const { width, height } = this.defaultStyle
const hasT = /t/.test(point)
const hasB = /b/.test(point)
const hasL = /l/.test(point)
const hasR = /r/.test(point)
let newLeft = 0
let newTop = 0
// 四个角的点
if (point.length === 2) {
newLeft = hasL? 0 : width
newTop = hasT? 0 : height
} else {
// 上下两点的点,宽度居中
if (hasT || hasB) {
newLeft = width / 2
newTop = hasT? 0 : height
}
// 左右两边的点,高度居中
if (hasL || hasR) {
newLeft = hasL? 0 : width
newTop = Math.floor(height / 2)
}
}
const style = {
marginLeft: hasR? '-4px' : '-3px',
marginTop: '-3px',
left: `${newLeft}px`,
top: `${newTop}px`,
cursor: point.split('').reverse().map(m => this.directionKey[m]).join('') + '-resize',
}
return style
}计算小圆点的位置需要获取一些信息:
height、宽度 width注意,小圆点也是绝对定位的,相对于 Shape 组件。所以有四个小圆点的位置很好确定:
left: 0, top: 0left: width, top: 0left: 0, top: heightleft: width, top: height另外的四个小圆点需要通过计算间接算出来。例如左边中间的小圆点,计算公式为 left: 0, top: height / 2,其他小圆点同理。
handleMouseDownOnPoint(point) {
const downEvent = window.event
downEvent.stopPropagation()
downEvent.preventDefault()
const pos = { ...this.defaultStyle }
const height = Number(pos.height)
const width = Number(pos.width)
const top = Number(pos.top)
const left = Number(pos.left)
const startX = downEvent.clientX
const startY = downEvent.clientY
// 是否需要保存快照
let needSave = false
const move = (moveEvent) => {
needSave = true
const currX = moveEvent.clientX
const currY = moveEvent.clientY
const disY = currY - startY
const disX = currX - startX
const hasT = /t/.test(point)
const hasB = /b/.test(point)
const hasL = /l/.test(point)
const hasR = /r/.test(point)
const newHeight = height + (hasT? -disY : hasB? disY : 0)
const newWidth = width + (hasL? -disX : hasR? disX : 0)
pos.height = newHeight > 0? newHeight : 0
pos.width = newWidth > 0? newWidth : 0
pos.left = left + (hasL? disX : 0)
pos.top = top + (hasT? disY : 0)
this.$store.commit('setShapeStyle', pos)
}
const up = () => {
document.removeEventListener('mousemove', move)
document.removeEventListener('mouseup', up)
needSave && this.$store.commit('recordSnapshot')
}
document.addEventListener('mousemove', move)
document.addEventListener('mouseup', up)
}它的原理是这样的:
撤销重做的实现原理其实挺简单的,先看一下代码:
snapshotData: [], // 编辑器快照数据
snapshotIndex: -1, // 快照索引
undo(state) {
if (state.snapshotIndex >= 0) {
state.snapshotIndex--
store.commit('setComponentData', deepCopy(state.snapshotData[state.snapshotIndex]))
}
},
redo(state) {
if (state.snapshotIndex < state.snapshotData.length - 1) {
state.snapshotIndex++
store.commit('setComponentData', deepCopy(state.snapshotData[state.snapshotIndex]))
}
},
setComponentData(state, componentData = []) {
Vue.set(state, 'componentData', componentData)
},
recordSnapshot(state) {
// 添加新的快照
state.snapshotData[++state.snapshotIndex] = deepCopy(state.componentData)
// 在 undo 过程中,添加新的快照时,要将它后面的快照清理掉
if (state.snapshotIndex < state.snapshotData.length - 1) {
state.snapshotData = state.snapshotData.slice(0, state.snapshotIndex + 1)
}
},用一个数组来保存编辑器的快照数据。保存快照就是不停地执行 push() 操作,将当前的编辑器数据推入 snapshotData 数组,并增加快照索引 snapshotIndex。目前以下几个动作会触发保存快照操作:
假设现在 snapshotData 保存了 4 个快照。即 [a, b, c, d],对应的快照索引为 3。如果这时进行了撤销操作,我们需要将快照索引减 1,然后将对应的快照数据赋值给画布。
例如当前画布数据是 d,进行撤销后,索引 -1,现在画布的数据是 c。
明白了撤销,那重做就很好理解了,就是将快照索引加 1,然后将对应的快照数据赋值给画布。
不过还有一点要注意,就是在撤销操作中进行了新的操作,要怎么办呢?有两种解决方案:
[a, b, c, d] 举例,假设现在进行了两次撤销操作,快照索引变为 1,对应的快照数据为 b,如果这时进行了新的操作,对应的快照数据为 e。那 e 会把 cd 顶掉,现在的快照数据为 [a, b, e]。[a, b, e, c, d]。我采用的是第一种方案。
什么是吸附?就是在拖拽组件时,如果它和另一个组件的距离比较接近,就会自动吸附在一起。
吸附的代码大概在 300 行左右,建议自己打开源码文件看(文件路径:src\components\Editor\MarkLine.vue)。这里不贴代码了,主要说说原理是怎么实现的。
在页面上创建 6 条线,分别是三横三竖。这 6 条线的作用是对齐,它们什么时候会出现呢?
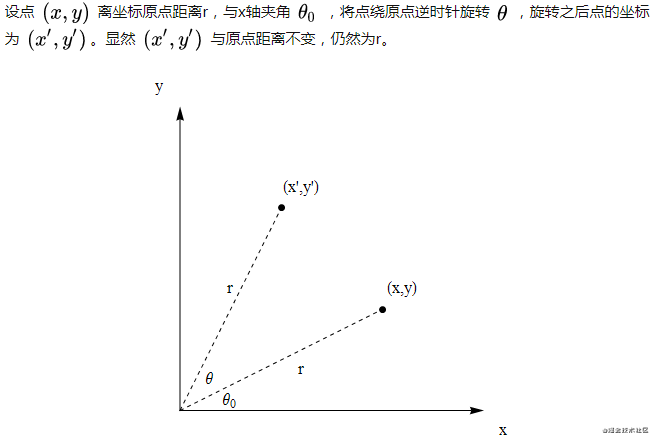
具体的计算公式主要是根据每个组件的 xy 坐标和宽度高度进行计算的。例如要判断 ab 两个组件的左边是否对齐,则要知道它们每个组件的 x 坐标;如果要知道它们右边是否对齐,除了要知道 x 坐标,还要知道它们各自的宽度。
// 左对齐的条件
a.x == b.x
// 右对齐的条件
a.x + a.width == b.x + b.width在对齐的时候,显示标线。
另外还要判断 ab 两个组件是否“足够”近。如果足够近,就吸附在一起。是否足够近要靠一个变量来判断:
diff: 3, // 相距 dff 像素将自动吸附小于等于 diff 像素则自动吸附。
吸附效果是怎么实现的呢?
假设现在有 ab 组件,a 组件坐标 xy 都是 0,宽高都是 100。现在假设 a 组件不动,我们正在拖拽 b 组件。当把 b 组件拖到坐标为 x: 0, y: 103 时,由于 103 - 100 <= 3(diff),所以可以判定它们已经接近得足够近。这时需要手动将 b 组件的 y 坐标值设为 100,这样就将 ab 组件吸附在一起了。
在拖拽时如果 6 条标线都显示出来会不太美观。所以我们可以做一下优化,在纵横方向上最多只同时显示一条线。实现原理如下:
可以发现,关键的地方是我们要知道两个组件的方向。即 ab 两个组件靠近,我们要知道到底 b 是在 a 的左边还是右边。
这一点可以通过鼠标移动事件来判断,之前在讲解拖拽的时候说过,mousedown 事件触发时会记录起点坐标。所以每次触发 mousemove 事件时,用当前坐标减去原来的坐标,就可以判断组件方向。例如 x 方向上,如果 b.x - a.x 的差值为正,说明是 b 在 a 右边,否则为左边。
// 触发元素移动事件,用于显示标线、吸附功能
// 后面两个参数代表鼠标移动方向
// currY - startY > 0 true 表示向下移动 false 表示向上移动
// currX - startX > 0 true 表示向右移动 false 表示向左移动
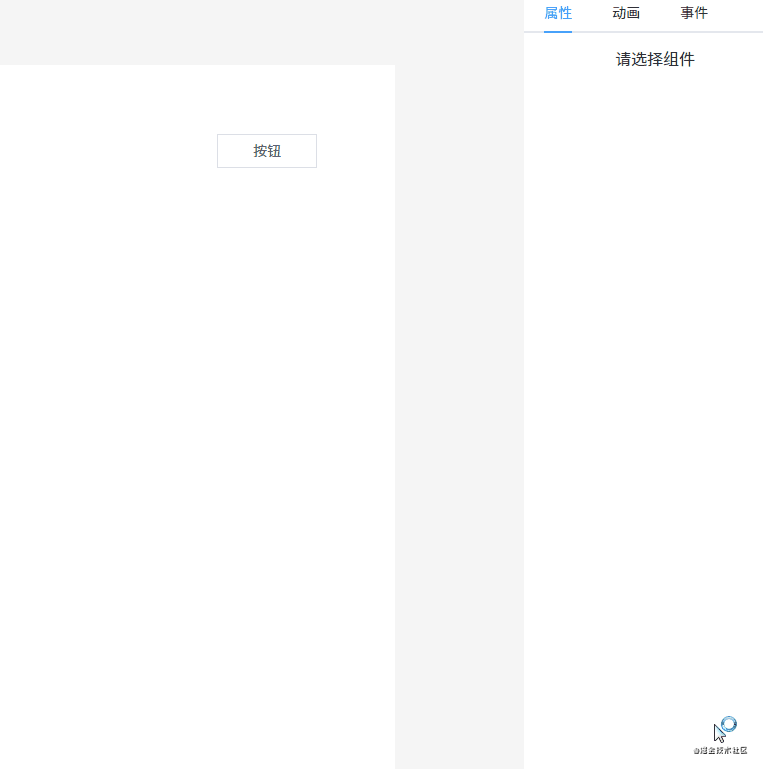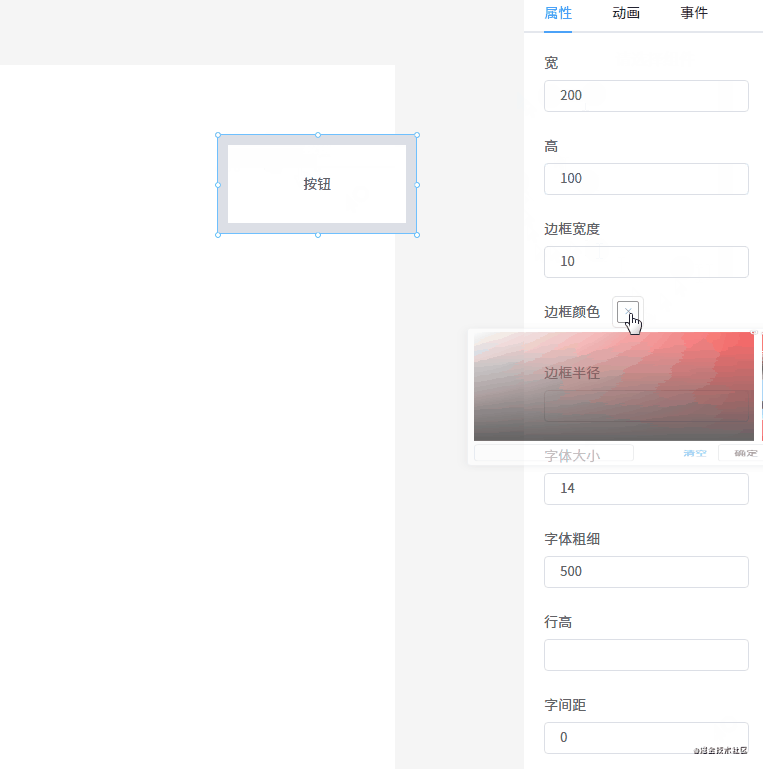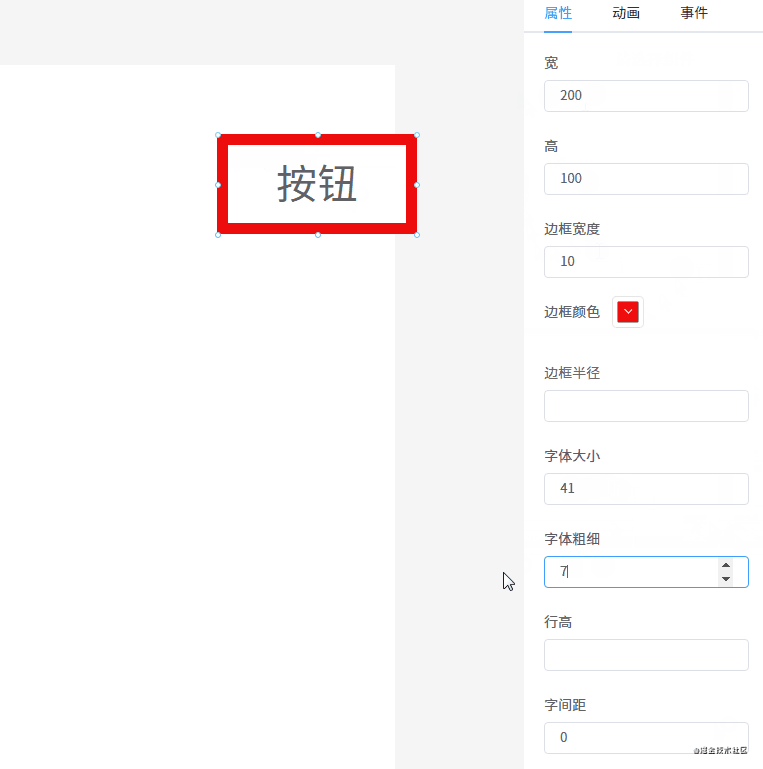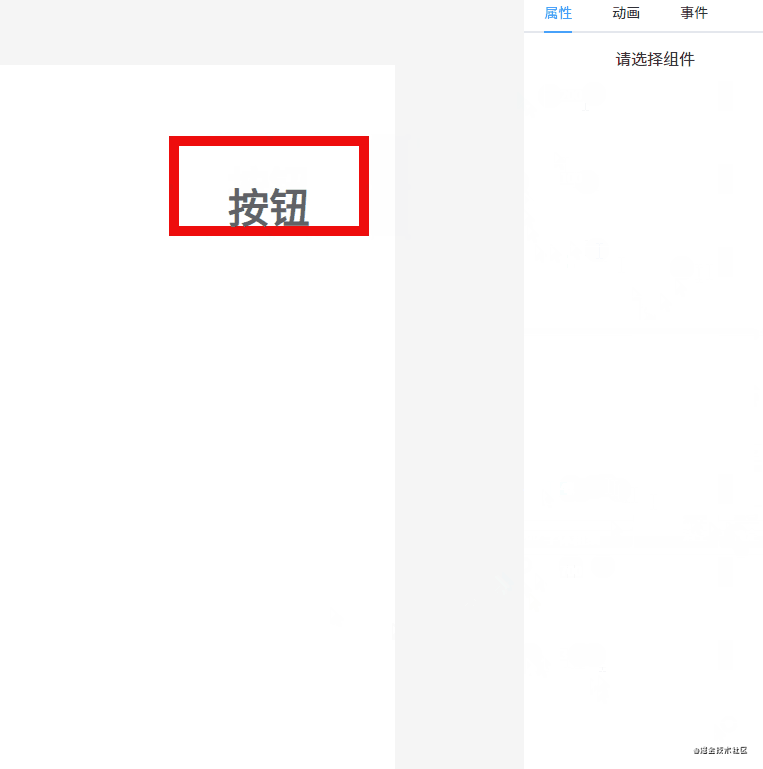
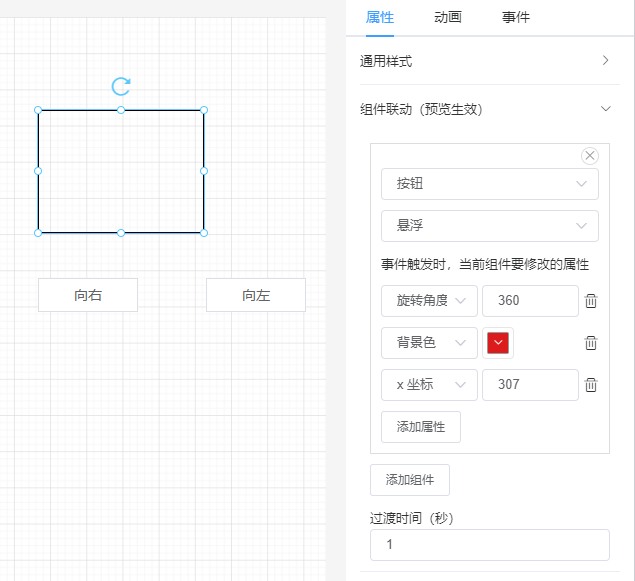
eventBus.$emit('move', this.$el, currY - startY > 0, currX - startX > 0)每个组件都有一些通用属性和独有的属性,我们需要提供一个能显示和修改属性的地方。
// 每个组件数据大概是这样
{
component: 'v-text', // 组件名称,需要提前注册到 Vue
label: '文字', // 左侧组件列表中显示的名字
propValue: '文字', // 组件所使用的值
icon: 'el-icon-edit', // 左侧组件列表中显示的名字
animations: [], // 动画列表
events: {}, // 事件列表
style: { // 组件样式
width: 200,
height: 33,
fontSize: 14,
fontWeight: 500,
lineHeight: '',
letterSpacing: 0,
textAlign: '',
color: '',
},
}我定义了一个 AttrList 组件,用于显示每个组件的属性。
<template>
<div class="attr-list">
<el-form>
<el-form-item v-for="(key, index) in styleKeys" :key="index" :label="map[key]">
<el-color-picker v-if="key == 'borderColor'" v-model="curComponent.style[key]"></el-color-picker>
<el-color-picker v-else-if="key == 'color'" v-model="curComponent.style[key]"></el-color-picker>
<el-color-picker v-else-if="key == 'backgroundColor'" v-model="curComponent.style[key]"></el-color-picker>
<el-select v-else-if="key == 'textAlign'" v-model="curComponent.style[key]">
<el-option
v-for="item in options"
:key="item.value"
:label="item.label"
:value="item.value"
></el-option>
</el-select>
<el-input type="number" v-else v-model="curComponent.style[key]" />
</el-form-item>
<el-form-item label="内容" v-if="curComponent && curComponent.propValue && !excludes.includes(curComponent.component)">
<el-input type="textarea" v-model="curComponent.propValue" />
</el-form-item>
</el-form>
</div>
</template>代码逻辑很简单,就是遍历组件的 style 对象,将每一个属性遍历出来。并且需要根据具体的属性用不同的组件显示出来,例如颜色属性,需要用颜色选择器显示;数值类的属性需要用 type=number 的 input 组件显示等等。
为了方便用户修改属性值,我使用 v-model 将组件和值绑定在一起。
预览和编辑的渲染原理是一样的,区别是不需要编辑功能。所以只需要将原先渲染组件的代码稍微改一下就可以了。
<!--页面组件列表展示-->
<Shape v-for="(item, index) in componentData"
:defaultStyle="item.style"
:style="getShapeStyle(item.style, index)"
:key="item.id"
:active="item === curComponent"
:element="item"
:zIndex="index"
>
<component
class="component"
:is="item.component"
:style="getComponentStyle(item.style)"
:propValue="item.propValue"
/>
</Shape>经过刚才的介绍,我们知道 Shape 组件具备了拖拽、放大缩小的功能。现在只需要将 Shape 组件去掉,外面改成套一个普通的 DIV 就可以了(其实不用这个 DIV 也行,但为了绑定事件这个功能,所以需要加上)。
<!--页面组件列表展示-->
<div v-for="(item, index) in componentData" :key="item.id">
<component
class="component"
:is="item.component"
:style="getComponentStyle(item.style)"
:propValue="item.propValue"
/>
</div>保存代码的功能也特别简单,只需要保存画布上的数据 componentData 即可。保存有两种选择:
在 DEMO 上我使用的 localStorage 保存在本地。
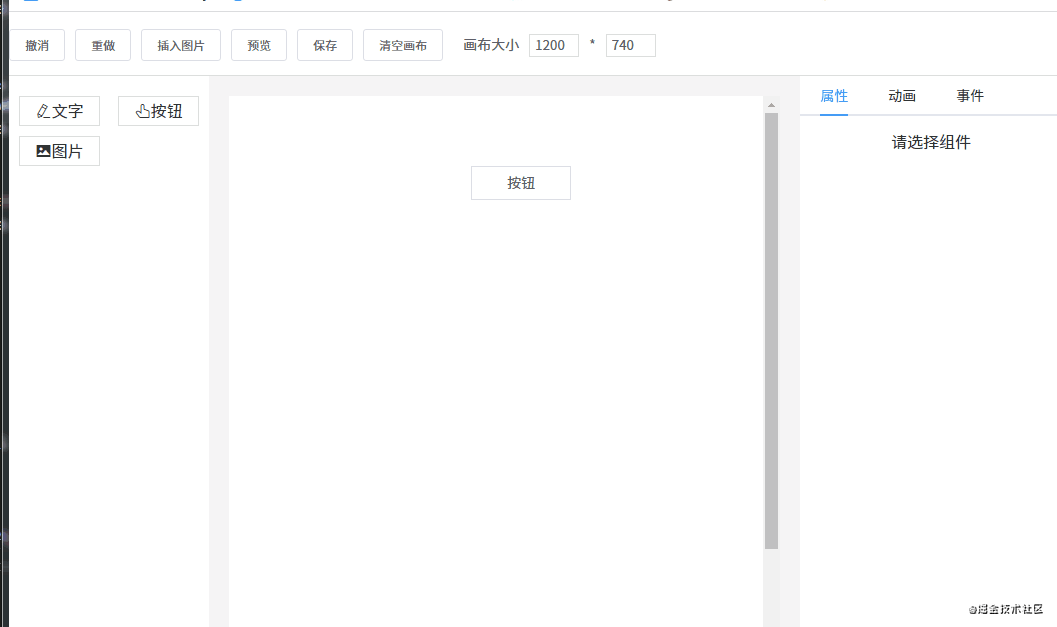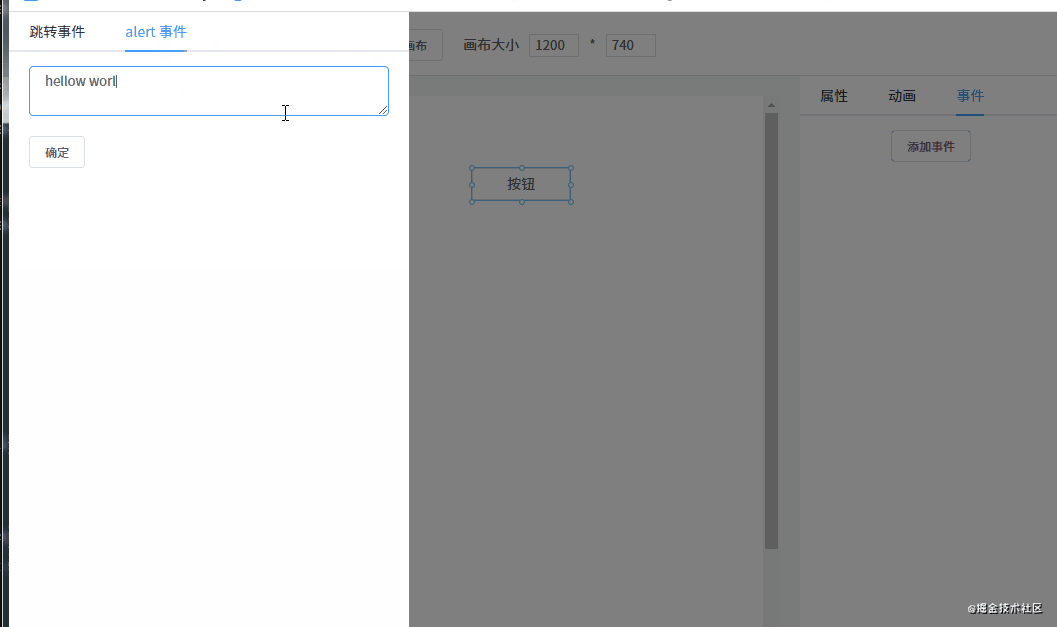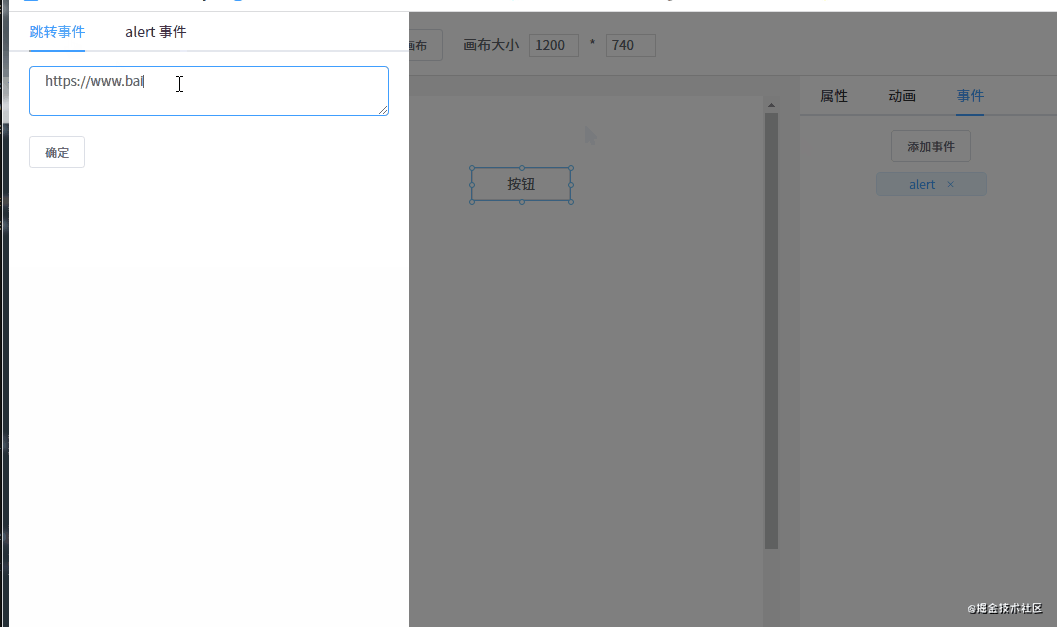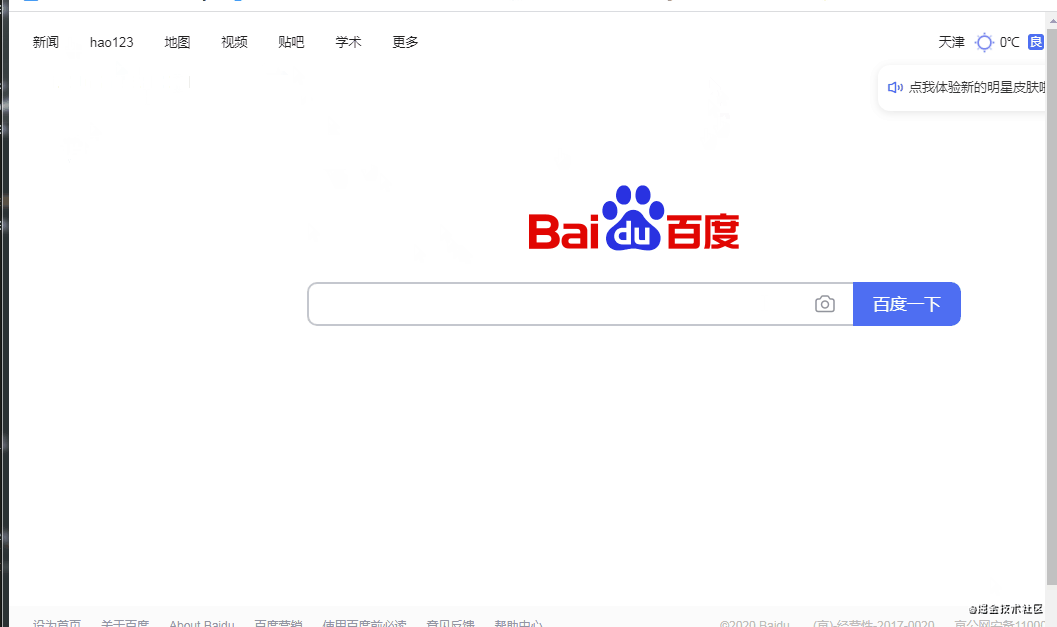
每个组件有一个 events 对象,用于存储绑定的事件。目前我只定义了两个事件:
// 编辑器自定义事件
const events = {
redirect(url) {
if (url) {
window.location.href = url
}
},
alert(msg) {
if (msg) {
alert(msg)
}
},
}
const mixins = {
methods: events,
}
const eventList = [
{
key: 'redirect',
label: '跳转事件',
event: events.redirect,
param: '',
},
{
key: 'alert',
label: 'alert 事件',
event: events.alert,
param: '',
},
]
export {
mixins,
events,
eventList,
}不过不能在编辑的时候触发,可以在预览的时候触发。
通过 v-for 指令将事件列表渲染出来:
<el-tabs v-model="eventActiveName">
<el-tab-pane v-for="item in eventList" :key="item.key" :label="item.label" :name="item.key" style="padding: 0 20px">
<el-input v-if="item.key == 'redirect'" v-model="item.param" type="textarea" placeholder="请输入完整的 URL" />
<el-input v-if="item.key == 'alert'" v-model="item.param" type="textarea" placeholder="请输入要 alert 的内容" />
<el-button style="margin-top: 20px;" @click="addEvent(item.key, item.param)">确定</el-button>
</el-tab-pane>
</el-tabs>选中事件时将事件添加到组件的 events 对象。
预览或真正渲染页面时,也需要在每个组件外面套一层 DIV,这样就可以在 DIV 上绑定一个点击事件,点击时触发我们刚才添加的事件。
<template>
<div @click="handleClick">
<component
class="conponent"
:is="config.component"
:style="getStyle(config.style)"
:propValue="config.propValue"
/>
</div>
</template>handleClick() {
const events = this.config.events
// 循环触发绑定的事件
Object.keys(events).forEach(event => {
this[event](events[event])
})
}动画和事件的原理是一样的,先将所有的动画通过 v-for 指令渲染出来,然后点击动画将对应的动画添加到组件的 animations 数组里。同事件一样,执行的时候也是遍历组件所有的动画并执行。
为了方便,我们使用了 animate.css 动画库。
// main.js
import '@/styles/animate.css'现在我们提前定义好所有的动画数据:
export default [
{
label: '进入',
children: [
{ label: '渐显', value: 'fadeIn' },
{ label: '向右进入', value: 'fadeInLeft' },
{ label: '向左进入', value: 'fadeInRight' },
{ label: '向上进入', value: 'fadeInUp' },
{ label: '向下进入', value: 'fadeInDown' },
{ label: '向右长距进入', value: 'fadeInLeftBig' },
{ label: '向左长距进入', value: 'fadeInRightBig' },
{ label: '向上长距进入', value: 'fadeInUpBig' },
{ label: '向下长距进入', value: 'fadeInDownBig' },
{ label: '旋转进入', value: 'rotateIn' },
{ label: '左顺时针旋转', value: 'rotateInDownLeft' },
{ label: '右逆时针旋转', value: 'rotateInDownRight' },
{ label: '左逆时针旋转', value: 'rotateInUpLeft' },
{ label: '右逆时针旋转', value: 'rotateInUpRight' },
{ label: '弹入', value: 'bounceIn' },
{ label: '向右弹入', value: 'bounceInLeft' },
{ label: '向左弹入', value: 'bounceInRight' },
{ label: '向上弹入', value: 'bounceInUp' },
{ label: '向下弹入', value: 'bounceInDown' },
{ label: '光速从右进入', value: 'lightSpeedInRight' },
{ label: '光速从左进入', value: 'lightSpeedInLeft' },
{ label: '光速从右退出', value: 'lightSpeedOutRight' },
{ label: '光速从左退出', value: 'lightSpeedOutLeft' },
{ label: 'Y轴旋转', value: 'flip' },
{ label: '中心X轴旋转', value: 'flipInX' },
{ label: '中心Y轴旋转', value: 'flipInY' },
{ label: '左长半径旋转', value: 'rollIn' },
{ label: '由小变大进入', value: 'zoomIn' },
{ label: '左变大进入', value: 'zoomInLeft' },
{ label: '右变大进入', value: 'zoomInRight' },
{ label: '向上变大进入', value: 'zoomInUp' },
{ label: '向下变大进入', value: 'zoomInDown' },
{ label: '向右滑动展开', value: 'slideInLeft' },
{ label: '向左滑动展开', value: 'slideInRight' },
{ label: '向上滑动展开', value: 'slideInUp' },
{ label: '向下滑动展开', value: 'slideInDown' },
],
},
{
label: '强调',
children: [
{ label: '弹跳', value: 'bounce' },
{ label: '闪烁', value: 'flash' },
{ label: '放大缩小', value: 'pulse' },
{ label: '放大缩小弹簧', value: 'rubberBand' },
{ label: '左右晃动', value: 'headShake' },
{ label: '左右扇形摇摆', value: 'swing' },
{ label: '放大晃动缩小', value: 'tada' },
{ label: '扇形摇摆', value: 'wobble' },
{ label: '左右上下晃动', value: 'jello' },
{ label: 'Y轴旋转', value: 'flip' },
],
},
{
label: '退出',
children: [
{ label: '渐隐', value: 'fadeOut' },
{ label: '向左退出', value: 'fadeOutLeft' },
{ label: '向右退出', value: 'fadeOutRight' },
{ label: '向上退出', value: 'fadeOutUp' },
{ label: '向下退出', value: 'fadeOutDown' },
{ label: '向左长距退出', value: 'fadeOutLeftBig' },
{ label: '向右长距退出', value: 'fadeOutRightBig' },
{ label: '向上长距退出', value: 'fadeOutUpBig' },
{ label: '向下长距退出', value: 'fadeOutDownBig' },
{ label: '旋转退出', value: 'rotateOut' },
{ label: '左顺时针旋转', value: 'rotateOutDownLeft' },
{ label: '右逆时针旋转', value: 'rotateOutDownRight' },
{ label: '左逆时针旋转', value: 'rotateOutUpLeft' },
{ label: '右逆时针旋转', value: 'rotateOutUpRight' },
{ label: '弹出', value: 'bounceOut' },
{ label: '向左弹出', value: 'bounceOutLeft' },
{ label: '向右弹出', value: 'bounceOutRight' },
{ label: '向上弹出', value: 'bounceOutUp' },
{ label: '向下弹出', value: 'bounceOutDown' },
{ label: '中心X轴旋转', value: 'flipOutX' },
{ label: '中心Y轴旋转', value: 'flipOutY' },
{ label: '左长半径旋转', value: 'rollOut' },
{ label: '由小变大退出', value: 'zoomOut' },
{ label: '左变大退出', value: 'zoomOutLeft' },
{ label: '右变大退出', value: 'zoomOutRight' },
{ label: '向上变大退出', value: 'zoomOutUp' },
{ label: '向下变大退出', value: 'zoomOutDown' },
{ label: '向左滑动收起', value: 'slideOutLeft' },
{ label: '向右滑动收起', value: 'slideOutRight' },
{ label: '向上滑动收起', value: 'slideOutUp' },
{ label: '向下滑动收起', value: 'slideOutDown' },
],
},
]然后用 v-for 指令渲染出来动画列表。
<el-tabs v-model="animationActiveName">
<el-tab-pane v-for="item in animationClassData" :key="item.label" :label="item.label" :name="item.label">
<el-scrollbar class="animate-container">
<div
class="animate"
v-for="(animate, index) in item.children"
:key="index"
@mouseover="hoverPreviewAnimate = animate.value"
@click="addAnimation(animate)"
>
<div :class="[hoverPreviewAnimate === animate.value && animate.value + ' animated']">
{{ animate.label }}
</div>
</div>
</el-scrollbar>
</el-tab-pane>
</el-tabs>点击动画将调用 addAnimation(animate) 将动画添加到组件的 animations 数组。
运行动画的代码:
export default async function runAnimation($el, animations = []) {
const play = (animation) => new Promise(resolve => {
$el.classList.add(animation.value, 'animated')
const removeAnimation = () => {
$el.removeEventListener('animationend', removeAnimation)
$el.removeEventListener('animationcancel', removeAnimation)
$el.classList.remove(animation.value, 'animated')
resolve()
}
$el.addEventListener('animationend', removeAnimation)
$el.addEventListener('animationcancel', removeAnimation)
})
for (let i = 0, len = animations.length; i < len; i++) {
await play(animations[i])
}
}运行动画需要两个参数:组件对应的 DOM 元素(在组件使用 this.$el 获取)和它的动画数据 animations。并且需要监听 animationend 事件和 animationcancel 事件:一个是动画结束时触发,一个是动画意外终止时触发。
利用这一点再配合 Promise 一起使用,就可以逐个运行组件的每个动画了。
由于时间关系,这个功能我还没做。现在简单的描述一下怎么做这个功能。那就是使用 psd.js 库,它可以解析 PSD 文件。
使用 psd 库解析 PSD 文件得出的数据如下:
{ children:
[ { type: 'group',
visible: false,
opacity: 1,
blendingMode: 'normal',
name: 'Version D',
left: 0,
right: 900,
top: 0,
bottom: 600,
height: 600,
width: 900,
children:
[ { type: 'layer',
visible: true,
opacity: 1,
blendingMode: 'normal',
name: 'Make a change and save.',
left: 275,
right: 636,
top: 435,
bottom: 466,
height: 31,
width: 361,
mask: {},
text:
{ value: 'Make a change and save.',
font:
{ name: 'HelveticaNeue-Light',
sizes: [ 33 ],
colors: [ [ 85, 96, 110, 255 ] ],
alignment: [ 'center' ] },
left: 0,
top: 0,
right: 0,
bottom: 0,
transform: { xx: 1, xy: 0, yx: 0, yy: 1, tx: 456, ty: 459 } },
image: {} } ] } ],
document:
{ width: 900,
height: 600,
resources:
{ layerComps:
[ { id: 692243163, name: 'Version A', capturedInfo: 1 },
{ id: 725235304, name: 'Version B', capturedInfo: 1 },
{ id: 730932877, name: 'Version C', capturedInfo: 1 } ],
guides: [],
slices: [] } } }从以上代码可以发现,这些数据和 css 非常像。根据这一点,只需要写一个转换函数,将这些数据转换成我们组件所需的数据,就能实现 PSD 文件转成渲染组件的功能。目前 quark-h5 和 luban-h5 都是这样实现的 PSD 转换功能。
由于画布是可以调整大小的,我们可以使用 iphone6 的分辨率来开发手机页面。
这样开发出来的页面也可以在手机下正常浏览,但可能会有样式偏差。因为我自定义的三个组件是没有做适配的,如果你需要开发手机页面,那自定义组件必须使用移动端的 UI 组件库。或者自己开发移动端专用的自定义组件。
由于 DEMO 的代码比较多,所以在讲解每一个功能点时,我只把关键代码贴上来。所以大家会发现 DEMO 的源码和我贴上来的代码会有些区别,请不必在意。
另外,DEMO 的样式也比较简陋,主要是最近事情比较多,没太多时间写好看点,请见谅。
i18n-replace 是一个能够自动替换中文并支持自动翻译的前端国际化辅助工具。
它具有以下功能:
自动翻译功能使用的是百度免费翻译 API,每秒只能调用一次,并且需要你注册百度翻译平台的账号。
然后将 appid 和密钥填入 i18n-replace 的配置文件 i18n.config.js,这个配置文件需要放置在你项目根目录下。
安装
npm i -g i18n-replace
全局安装后,打开你的项目,建立一个 i18n.config.js 文件,配置项如下:
module.exports = {
delay: 1500, // 自动翻译延时,必须大于 1000 ms,否则调用百度翻译 API 会失败
mapFile: '', // 需要生成默认 map 的文件
appid: '', // 百度翻译 appid
key: '', // 百度翻译密钥
output: 'i18n.data.js', // i18n 输出文件
indent: 4, // i18n 输出文件缩进
entry: '', // 要翻译的入口目录或文件,默认为命令行当前的 src 目录
prefix: '', // i18n 变量前缀 i18n 变量生成规则 prefix + id + suffix
suffix: '', // i18n 变量后缀
id: 0, // i18n 自增变量 id
translation: false, // 是否需要自动翻译中文
to: 'en', // 中文翻译的目标语言
mode: 1, // 0 翻译所有 i18n 数据,1 只翻译新数据
loader: 'loader.js',
pluginPrefix: '$t', // i18n 插件前缀 例如 vue-i18n: $t, react-i18next: t
include: [], // 需要翻译的目录或文件
exclude: [], // 不需要翻译的目录或文件 如果 exclude include 同时存在同样的目录或文件 则 exclude 优先级高
extra: /(\.a)|(\.b)$/, // 默认支持 .vue 和 .js 文件 如果需要支持其他类型的文件,请用正则描述 例如这个示例额外支持 .a .b 文件
}上面是 i18n-replace 工具的配置项,具体说明请看文档。
这些配置项都不是必要的,如果你需要翻译功能,一般只需要填入 appid、key 并且将 translation 设为 true。
设置完配置项后,执行 rep(这是一个全局命令),i18n-replace 就会对你的入口目录进行递归替换、翻译。
i18n-replace 能识别以下中文:
不能包含有空格,可以包含中文、中文符号,数字,-
测试123
测试-12-测试
几点了?12点。更多测试用例,请查看项目下的 test 目录。
翻译前
<div>
<input
type="二"
placeholder="一"
value="s 四 f"
/>
<MyComponent>
非常好 <header slot="header">测试</header> 非常好
非常好 <footer slot="footer">再一次测试</footer> 非常好
</MyComponent>
</div>翻译后
<div>
<input
type={this.$t('0')}
placeholder={this.$t('1')}
value={`s ${this.$t('2')} f`}
/>
<MyComponent>
{`${this.$t('3')} `}<header slot="header">{this.$t('4')}</header>{` ${this.$t('3')}`}
{`${this.$t('3')} `}<footer slot="footer">{this.$t('5')}</footer>{` ${this.$t('3')}`}
</MyComponent>
</div>翻译前
<template>
<div>
有人<div value="二" :val="abc + '三 afb'">一</div>在国
</div>
</template>
<script>
export default {
created() {
const test = '测试'
}
}
</script>翻译后
<template>
<div>
{{ $t('0') }}<div :value="$t('1')" :val="abc + $t('2') + ' afb'">{{ $t('3') }}</div>{{ $t('4') }}
</div>
</template>
<script>
export default {
created() {
const test = this.$t('5')
}
}
</script>在你的项目根目录下建立一个 i18n.config.js 文件,i18n-replace 将会根据配置项来执行不同的操作。
注意,所有配置项均为选填。
module.exports = {
delay: 1500, // 自动翻译延时,必须大于 1000 ms,否则调用百度翻译 API 会失败
mapFile: '国际化资源管理.xlsx', // 需要生成默认 map 的文件
appid: '', // 百度翻译 appid
key: '', // 百度翻译密钥
output: 'i18n.data.js', // i18n 输出文件
indent: 4, // i18n 输出文件缩进
entry: 'src', // 要翻译的入口目录或文件,默认为命令行当前的 src 目录
prefix: '', // i18n 变量前缀 i18n 变量生成规则 prefix + id + suffix
suffix: '', // i18n 变量后缀
id: 0, // i18n 自增变量 id
translation: true, // 是否需要自动翻译中文
to: 'en', // 中文翻译的目标语言
mode: 1, // 0 翻译所有 i18n 数据,1 只翻译新数据
loader: 'loader.js',
pluginPrefix: '$t', // i18n 插件前缀 例如 vue-i18n: $t, react-i18next: t
include: [], // 需要翻译的目录或文件,如果为空,将不进行任何操作。
exclude: [], // 不需要翻译的目录或文件 如果 exclude include 同时存在同样的目录或文件 则 exclude 优先级高
}appid: '', // 百度翻译 appid
key: '', // 百度翻译密钥这是百度免费翻译 API 的 appid 和密钥。
如果你需要自动翻译,这两个是必填项。
具体注册流程请看官网。
entry: 'src'入口目录或入口文件,默认为项目根目录下的 src 目录。
替换或翻译将从这里开始。
delay: 1500单位毫秒,默认 1500。
百度翻译 API 调用延时,由于免费的翻译 API 1 秒只能调用一次,所以该选项必须大于 1000。经过本人测试,该项设为 1500 比较稳定。
mapFile: 'data.js'如果你提供一个默认的映射文件(中文和变量之间的映射),本工具将根据映射文件将中文替换为对应的变量。
例如有这样的映射关系:
module.exports = {
zh: {
10000: '测试',
},
en: {},
}和一个源码文件:
const test = '一'启用工具后,源码文件中的 const test = '一' 将会被替换为 const test = this.$t('10000')。
所以如果你有默认的映射文件,请提供它的地址。
loader: 'src/loader.js'i18n-replace 提供了一个内置的 loader,以便将下面的数据:
module.exports = {
zh: {
10000: '测试',
},
en: {},
}转换成 i18n-replace 要求的映射数据格式:
{
"测试": "10000",
}所以为了能将其他文件翻译成这种格式,本工具提供了一个 loader 选项。
这个 loader 是一个本地文件地址,你提供的文件需要写一个转换函数,将其他格式的文件转换成 i18n-replace 要求的数据格式,就像下面这个函数一样:
const excelToJson = require('convert-excel-to-json')
function translateExcelData(file, done) {
const data = excelToJson({ sourceFile: file })
const result = {}
data.Sheet1.forEach(item => {
if (item.C == '中文') {
result[item.B] = item.A
}
})
done(result)
}
module.exports = translateExcelData它接收两个参数,分别是文件地址 file 和 完成函数 done()。
支持异步操作,只要在转换完成时调用 done(result) 即可。
如果你没有提供一个默认映射文件,i18n-replace 在将中文替换成变量时,将遵循下面的公式来生成变量:
prefix + id + suffix0,自动递增。pluginPrefix: '$t'翻译前缀,默认为 $t。请根据应用场景配置。
例如 vue-i18n 国际化工具使用的是 $t,而 react-i18next 使用的是 t。
是否需要自动翻译,默认为 false。
如果设为 true,将会调用百度免费翻译 API 进行翻译。
翻译的目标语言,默认为 en,即英语。
具体的配置项请查看百度翻译 API 文档。
翻译模式,默认为 1。
翻译模式有两种:0 和 1。
如果你提供了一个默认的映射文件:
{
"一": "10000",
"二": "10001",
}同时在替换过程中产生了两个新的变量,最后映射数据变成这样:
{
"一": "10000",
"二": "10001",
"三": "10002",
"四": "10003"
}这时,翻译模式为 0 将会对所有数据进行翻译。而翻译模式为 1 只对新产生的数据进行翻译。
翻译后的文件输出名称,默认为 i18n.data.js。
工具默认翻译入口目录下所有的文件,如果你提供了 include 选项,将只会翻译 include 指定的目录或指定的文件。
如果这个选项是一个空数组,将不会进行任何操作。
exclude 优先级比 include 高,如果有文件包含在 exclude 里面,它将不会被翻译。
生成文件的缩进,默认为 4。
由于 i18n-replace 默认只支持 .vue 和 .js 文件。
所以提供了一个 extra 选项,以支持其他的文件格式,它的值为正则表达式。
extra: /(\.a)|(\.b)$/例如使用上述的正则表达式,i18n-replace 将额外支持 .a .b 文件
最近的项目有一个加载远程组件的需求。基于此我对 Vue 加载远程组件的方案进行了研究,并且整理了两个可行的解决方案。
这个方案是最简单、最容易实现的。组件以 umd 的格式进行打包,然后在 HTML 文件中直接使用。
<div id="app">
<test-input></test-input>
</div>
<script src="https://unpkg.com/vue@3/dist/vue.global.js"></script>
<script>
// 将组件 URL 挂载到 script 标签上,然后通过 window 获取这个组件
await lodaScript('http://localhost/component/input/0.1.0/bundle.js')
app.component('TestInput', window.TestInput)
</script>但是这个方案不适合在大型项目中使用,效率比较低。
Vue 工程项目 + esm /umd 组件是我目前在使用的方案,但是在研究的过程中遇到了两个问题,逐一解决后,才把这个方案趟通了。
Relative references must start with either "/", "./", or "../"由于我们的项目不需要兼容 IE,所以打包组件采用的是 esm 格式。打包后的组件源码如下:
import { reactive } from 'vue'
// other code...然后在主项目中进行引用:
const { default: TestInput } = await import('http://localhost/component/input/0.1.0/bundle.mjs')在动态导入远程组件到项目时,提示报错 Relative references must start with either "/", "./", or "../"。这是因为在浏览器中不支持以 import { reactive } from 'vue' 的方式进行导入,得把 'vue' 改成 https://..../vue.js 或者 './vue.js' 的形式才可以。平时我们这样用没问题是因为有 vite、webpack 等构建工具帮忙解决了这个问题。
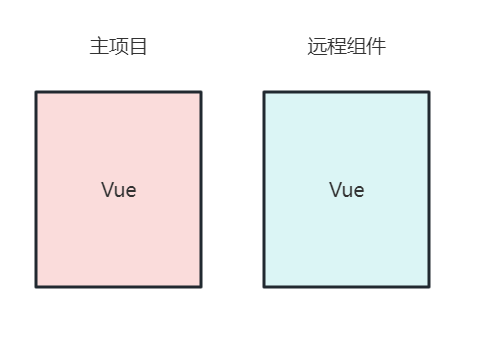
产生上面的问题是因为要引入依赖,如果打包组件时把相关依赖都打在一起,那不就没有 import 语句了。结果试了一下还是不行,因为当前的 Vue 主项目和打包好的 Vue 组件存在两个不同的 Vue 上下文。导致在加载组件时报错,比如提示 xxx 变量找不到 这种问题。
虽然主项目和远程组件使用的 Vue 方法都是一样的,但由于各自的 Vue 上下文不一样,导致主项目无法正常使用远程组件。
以上两个问题困扰了我一天的时间,但是睡醒一觉后,终于想到了如何解决这两个问题。首先在浏览器上不能直接使用 import { reactive } from 'vue' 这种语句,那把它改成 const { reactive } = Vue 就能解决这个问题了。至于第二个问题,打包时不把依赖打在一起,而是在 main.js 文件中直接把整个 Vue 引进来:
import * as Vue from 'vue'
window.Vue = Vue这样就能确保主项目和远程组件使用的是同一个 Vue 上下文。
为了解决代码转换问题,我写了一个 rollup-plugin-import-to-const 插件(支持 rollup、vite),打包 esm 组件时,它会自动的把 import { reactive } from 'vue' 转换成 const { reactive } = Vue 。
至此,就可以在主项目中加载远程 esm 组件了:
const { default: TestInput } = await import('http://localhost/component/input/0.1.0/bundle.mjs')其实只要能解决上面的两个问题,不管是 esm 还是 umd、cjs 等格式,都能够实现加载远程组件的方案。比如换成 umd 的格式来打包组件,就不需要引入 rollup 插件去转换代码了,并且还能支持 webpack。唯一要做的只是在 main.js 上把 Vue 全引进来挂到 window 下。
import * as Vue from 'vue'
window.Vue = Vue远程组件的方案其实不止上面两种,比如还有直接加载 .vue 文件的方案,有个现成的 vue3-sfc-loader 插件能用。 一般来说,加载远程组件的应用场景比较少,所以网上能搜到的讨论也比较少。目前比较常见的应用场景应该就是在低代码平台中加载远程组件了。
最近看了几个微前端框架的源码(single-spa、qiankun、micro-app),感觉收获良多。所以打算造一个迷你版的轮子,来加深自己对所学知识的了解。
这个轮子将分为五个版本,逐步的实现一个最小可用的微前端框架:
每一个版本的代码都是在上一个版本的基础上修改的,所以 V5 版本的代码是最终代码。
Github 项目地址:https://github.com/woai3c/mini-single-spa
V1 版本打算实现一个最简单的微前端框架,只要它能够正常加载、卸载子应用就行。如果将 V1 版本细分一下的话,它主要由以下两个功能组成:
一个 SPA 应用必不可少的功能就是监听页面 URL 的变化,然后根据不同的路由规则来渲染不同的路由组件。因此,微前端框架也可以根据页面 URL 的变化,来切换到不同的子应用:
// 当 location.pathname 以 /vue 为前缀时切换到 vue 子应用
https://www.example.com/vue/xxx
// 当 location.pathname 以 /react 为前缀时切换到 react 子应用
https://www.example.com/react/xxx这可以通过重写两个 API 和监听两个事件来完成:
其中 pushState()、replaceState() 方法可以修改浏览器的历史记录栈,所以我们可以重写这两个 API。当这两个 API 被 SPA 应用调用时,说明 URL 发生了变化,这时就可以根据当前已改变的 URL 判断是否要加载、卸载子应用。
// 执行下面代码后,浏览器的 URL 将从 https://www.xxx.com 变为 https://www.xxx.com/vue
window.history.pushState(null, '', '/vue')当用户手动点击浏览器上的前进后退按钮时,会触发 popstate 事件,所以需要对这个事件进行监听。同理,也需要监听 hashchange 事件。
这一段逻辑的代码如下所示:
import { loadApps } from '../application/apps'
const originalPushState = window.history.pushState
const originalReplaceState = window.history.replaceState
export default function overwriteEventsAndHistory() {
window.history.pushState = function (state: any, title: string, url: string) {
const result = originalPushState.call(this, state, title, url)
// 根据当前 url 加载或卸载 app
loadApps()
return result
}
window.history.replaceState = function (state: any, title: string, url: string) {
const result = originalReplaceState.call(this, state, title, url)
loadApps()
return result
}
window.addEventListener('popstate', () => {
loadApps()
}, true)
window.addEventListener('hashchange', () => {
loadApps()
}, true)
}从上面的代码可以看出来,每次 URL 改变时,都会调用 loadApps() 方法,这个方法的作用就是根据当前的 URL、子应用的触发规则去切换子应用的状态:
export async function loadApps() {
// 先卸载所有失活的子应用
const toUnMountApp = getAppsWithStatus(AppStatus.MOUNTED)
await Promise.all(toUnMountApp.map(unMountApp))
// 初始化所有刚注册的子应用
const toLoadApp = getAppsWithStatus(AppStatus.BEFORE_BOOTSTRAP)
await Promise.all(toLoadApp.map(bootstrapApp))
const toMountApp = [
...getAppsWithStatus(AppStatus.BOOTSTRAPPED),
...getAppsWithStatus(AppStatus.UNMOUNTED),
]
// 加载所有符合条件的子应用
await toMountApp.map(mountApp)
}这段代码的逻辑也比较简单:
为了支持不同框架的子应用,所以规定了子应用必须向外暴露 bootstrap() mount() unmount() 这三个方法。bootstrap() 方法在第一次加载子应用时触发,并且只会触发一次,另外两个方法在每次加载、卸载子应用时都会触发。
不管注册的是什么子应用,在 URL 符合加载条件时就调用子应用的 mount() 方法,能不能正常渲染交给子应用负责。在符合卸载条件时则调用子应用的 unmount() 方法。
registerApplication({
name: 'vue',
// 初始化子应用时执行该方法
loadApp() {
return {
mount() {
// 这里进行挂载子应用的操作
app.mount('#app')
},
unmount() {
// 这里进行卸载子应用的操作
app.unmount()
},
}
},
// 如果传入一个字符串会被转为一个参数为 location 的函数
// activeRule: '/vue' 会被转为 (location) => location.pathname === '/vue'
activeRule: (location) => location.hash === '#/vue'
})上面是一个简单的子应用注册示例,其中 activeRule() 方法用来判断该子应用是否激活(返回 true 表示激活)。每当页面 URL 发生变化,微前端框架就会调用 loadApps() 判断每个子应用是否激活,然后触发加载、卸载子应用的操作。�
首先我们将子应用的状态分为三种:
bootstrap,调用 registerApplication() 注册一个子应用后,它的状态默认为 bootstrap,下一个转换状态为 mount。mount,子应用挂载成功后的状态,它的下一个转换状态为 unmount。unmount,子应用卸载成功后的状态,它的下一个转换状态为 mount,即卸载后的应用可再次加载。现在我们来看看什么时候会加载一个子应用,当页面 URL 改变后,如果子应用满足以下两个条件,则需要加载该子应用:
activeRule() 的返回值为 true,例如 URL 从 / 变为 /vue,这时子应用 vue 为激活状态(假设它的激活规则为 /vue)。bootstrap 或 unmount,这样才能向 mount 状态转换。如果已经处于 mount 状态并且 activeRule() 返回值为 true,则不作任何处理。如果页面的 URL 改变后,子应用满足以下两个条件,则需要卸载该子应用:
activeRule() 的返回值为 false,例如 URL 从 /vue 变为 /,这时子应用 vue 为失活状态(假设它的激活规则为 /vue)。mount,也就是当前子应用必须处于加载状态(如果是其他状态,则不作任何处理)。然后 URL 改变导致失活了,所以需要卸载它,状态也从 mount 变为 unmount。V1 版本主要向外暴露了两个 API:
registerApplication(),注册子应用。start(),注册完所有的子应用后调用,在它的内部会执行 loadApps() 去加载子应用。registerApplication(Application) 接收的参数如下:
interface Application {
// 子应用名称
name: string
/**
* 激活规则,例如传入 /vue,当 url 的路径变为 /vue 时,激活当前子应用。
* 如果 activeRule 为函数,则会传入 location 作为参数,activeRule(location) 返回 true 时,激活当前子应用。
*/
activeRule: Function | string
// 传给子应用的自定义参数
props: AnyObject
/**
* loadApp() 必须返回一个 Promise,resolve() 后得到一个对象:
* {
* bootstrap: () => Promise<any>
* mount: (props: AnyObject) => Promise<any>
* unmount: (props: AnyObject) => Promise<any>
* }
*/
loadApp: () => Promise<any>
}现在我们来看一个比较完整的示例(代码在 V1 分支的 examples 目录):
let vueApp
registerApplication({
name: 'vue',
loadApp() {
return Promise.resolve({
bootstrap() {
console.log('vue bootstrap')
},
mount() {
console.log('vue mount')
vueApp = Vue.createApp({
data() {
return {
text: 'Vue App'
}
},
render() {
return Vue.h(
'div', // 标签名称
this.text // 标签内容
)
},
})
vueApp.mount('#app')
},
unmount() {
console.log('vue unmount')
vueApp.unmount()
},
})
},
activeRule:(location) => location.hash === '#/vue',
})
registerApplication({
name: 'react',
loadApp() {
return Promise.resolve({
bootstrap() {
console.log('react bootstrap')
},
mount() {
console.log('react mount')
ReactDOM.render(
React.createElement(LikeButton),
$('#app')
);
},
unmount() {
console.log('react unmount')
ReactDOM.unmountComponentAtNode($('#app'));
},
})
},
activeRule: (location) => location.hash === '#/react'
})
start()演示效果如下:
V1 版本的代码打包后才 100 多行,如果只是想了解微前端的最核心原理,只看 V1 版本的源码就可以了。
V1 版本的实现还是非常简陋的,能够适用的业务场景有限。从 V1 版本的示例可以看出,它要求子应用提前把资源都加载好(或者把整个子应用打包成一个 NPM 包,直接引入),这样才能在执行子应用的 mount() 方法时,能够正常渲染。
举个例子,假设我们在开发环境启动了一个 vue 应用。那么如何在主应用引入这个 vue 子应用的资源呢?首先排除掉 NPM 包的形式,因为每次修改代码都得打包,不现实。第二种方式就是手动在主应用引入子应用的资源。例如 vue 子应用的入口资源为:
那么我们可以在注册子应用时这样引入:
registerApplication({
name: 'vue',
loadApp() {
return Promise.resolve({
bootstrap() {
import('http://localhost:8001/js/chunk-vendors.js')
import('http://localhost:8001/js/app.js')
},
mount() {
// ...
},
unmount() {
// ...
},
})
},
activeRule: (location) => location.hash === '#/vue'
})这种方式也不靠谱,每次子应用的入口资源文件变了,主应用的代码也得跟着变。还好,我们有第三种方式,那就是在注册子应用的时候,把子应用的入口 URL 写上,由微前端来负责加载资源文件。
registerApplication({
// 子应用入口 URL
pageEntry: 'http://localhost:8081'
// ...
})现在我们来看一下如何自动加载子应用的入口文件(只在第一次加载子应用时执行):
export default function parseHTMLandLoadSources(app: Application) {
return new Promise<void>(async (resolve, reject) => {
const pageEntry = app.pageEntry
// load html
const html = await loadSourceText(pageEntry)
const domparser = new DOMParser()
const doc = domparser.parseFromString(html, 'text/html')
const { scripts, styles } = extractScriptsAndStyles(doc as unknown as Element, app)
// 提取了 script style 后剩下的 body 部分的 html 内容
app.pageBody = doc.body.innerHTML
let isStylesDone = false, isScriptsDone = false
// 加载 style script 的内容
Promise.all(loadStyles(styles))
.then(data => {
isStylesDone = true
// 将 style 样式添加到 document.head 标签
addStyles(data as string[])
if (isScriptsDone && isStylesDone) resolve()
})
.catch(err => reject(err))
Promise.all(loadScripts(scripts))
.then(data => {
isScriptsDone = true
// 执行 script 内容
executeScripts(data as string[])
if (isScriptsDone && isStylesDone) resolve()
})
.catch(err => reject(err))
})
}上面代码的逻辑:
script style 的内容或 URL,如果是 URL,则再次使用 ajax 拉取内容。最后得到入口页面所有的 script style 的内容document.head 下,script 代码直接执行下面再详细描述一下这四步是怎么做的。
export function loadSourceText(url: string) {
return new Promise<string>((resolve, reject) => {
const xhr = new XMLHttpRequest()
xhr.onload = (res: any) => {
resolve(res.target.response)
}
xhr.onerror = reject
xhr.onabort = reject
xhr.open('get', url)
xhr.send()
})
}代码逻辑很简单,使用 ajax 发起一个请求,得到 HTML 内容。
上图就是一个 vue 子应用的 HTML 内容,箭头所指的是要提取的资源,方框标记的内容要赋值给子应用所挂载的 DOM。
这需要使用一个 API DOMParser,它可以直接解析一个 HTML 字符串,并且不需要挂到 document 对象上。
const domparser = new DOMParser()
const doc = domparser.parseFromString(html, 'text/html')提取标签的函数 extractScriptsAndStyles(node: Element, app: Application) 代码比较多,这里就不贴代码了。这个函数主要的功能就是递归遍历上面生成的 DOM 树,提取里面所有的 style script 标签。
这一步比较简单,将所有提取的 style 标签添加到 document.head 下:
export function addStyles(styles: string[] | HTMLStyleElement[]) {
styles.forEach(item => {
if (typeof item === 'string') {
const node = createElement('style', {
type: 'text/css',
textContent: item,
})
head.appendChild(node)
} else {
head.appendChild(item)
}
})
}js 脚本代码则直接包在一个匿名函数内执行:
export function executeScripts(scripts: string[]) {
try {
scripts.forEach(code => {
new Function('window', code).call(window, window)
})
} catch (error) {
throw error
}
}为了保证子应用正常执行,需要将这部分的内容保存起来。然后每次在子应用 mount() 前,赋值到所挂载的 DOM 下。
// 保存 HTML 代码
app.pageBody = doc.body.innerHTML
// 加载子应用前赋值给挂载的 DOM
app.container.innerHTML = app.pageBody
app.mount()现在我们已经可以非常方便的加载子应用了,但是子应用还有一些东西需要修改一下。
在 V1 版本里,注册子应用的时候有一个 loadApp() 方法。微前端框架在第一次加载子应用时会执行这个方法,从而拿到子应用暴露的三个方法。现在实现了 pageEntry 功能,我们就不用把这个方法写在主应用里了,因为不再需要在主应用里引入子应用。
但是又得让微前端框架拿到子应用暴露出来的方法,所以我们可以换一种方式暴露子应用的方法:
// 每个子应用都需要这样暴露三个 API,该属性格式为 `mini-single-spa-${appName}`
window['mini-single-spa-vue'] = {
bootstrap,
mount,
unmount
}这样微前端也能拿到每个子应用暴露的方法,从而实现加载、卸载子应用的功能。
另外,子应用还得做两件事:
如果子应用是基于 webpack 进行开发的,可以这样配置:
module.exports = {
devServer: {
port: 8001, // 子应用访问端口
headers: {
'Access-Control-Allow-Origin': '*'
}
},
publicPath: "//localhost:8001/",
}示例代码在 examples 目录。
registerApplication({
name: 'vue',
pageEntry: 'http://localhost:8001',
activeRule: pathPrefix('/vue'),
container: $('#subapp-viewport')
})
registerApplication({
name: 'react',
pageEntry: 'http://localhost:8002',
activeRule:pathPrefix('/react'),
container: $('#subapp-viewport')
})
start()V3 版本主要添加以下两个功能:
在 V2 版本下,主应用及所有的子应用都共用一个 window 对象,这就导致了互相覆盖数据的问题:
// 先加载 a 子应用
window.name = 'a'
// 后加载 b 子应用
window.name = 'b'
// 这时再切换回 a 子应用,读取 window.name 得到的值却是 b
console.log(window.name) // b为了避免这种情况发生,我们可以使用 Proxy 来代理对子应用 window 对象的访问:
app.window = new Proxy({}, {
get(target, key) {
if (Reflect.has(target, key)) {
return Reflect.get(target, key)
}
const result = originalWindow[key]
// window 原生方法的 this 指向必须绑在 window 上运行,否则会报错 "TypeError: Illegal invocation"
// e.g: const obj = {}; obj.alert = alert; obj.alert();
return (isFunction(result) && needToBindOriginalWindow(result)) ? result.bind(window) : result
},
set: (target, key, value) => {
this.injectKeySet.add(key)
return Reflect.set(target, key, value)
}
})从上述代码可以看出,用 Proxy 对一个空对象做了代理,然后把这个代理对象作为子应用的 window 对象:
window.xxx 属性时,就会被这个代理对象拦截。它会先看看子应用的代理 window 对象有没有这个属性,如果找不到,就会从父应用里找,也就是在真正的 window 对象里找。那么问题来了,怎么让子应用里的代码读取/修改 window 时候,让它们访问的是子应用的代理 window 对象?
刚才 V2 版本介绍过,微前端框架会代替子应用拉取 js 资源,然后直接执行。我们可以在执行代码的时候使用 with 语句将代码包一下,让子应用的 window 指向代理对象:
export function executeScripts(scripts: string[], app: Application) {
try {
scripts.forEach(code => {
// ts 使用 with 会报错,所以需要这样包一下
// 将子应用的 js 代码全局 window 环境指向代理环境 proxyWindow
const warpCode = `
;(function(proxyWindow){
with (proxyWindow) {
(function(window){${code}\n}).call(proxyWindow, proxyWindow)
}
})(this);
`
new Function(warpCode).call(app.sandbox.proxyWindow)
})
} catch (error) {
throw error
}
}当子应用卸载时,需要对它的 window 代理对象进行清除。否则下一次子应用重新加载时,它的 window 代理对象会存有上一次加载的数据。刚才创建 Proxy 的代码中有一行代码 this.injectKeySet.add(key),这个 injectKeySet 是一个 Set 对象,存着每一个 window 代理对象的新增属性。所以在卸载时只需要遍历这个 Set,将 window 代理对象上对应的 key 删除即可:
for (const key of injectKeySet) {
Reflect.deleteProperty(microAppWindow, key as (string | symbol))
}通常情况下,一个子应用除了会修改 window 上的属性,还会在 window 上绑定一些全局事件。所以我们要把这些事件记录起来,在卸载子应用时清除这些事件。同理,各种定时器也一样,卸载时需要清除未执行的定时器。
下面的代码是记录事件、定时器的部分关键代码:
// 部分关键代码
microAppWindow.setTimeout = function setTimeout(callback: Function, timeout?: number | undefined, ...args: any[]): number {
const timer = originalWindow.setTimeout(callback, timeout, ...args)
timeoutSet.add(timer)
return timer
}
microAppWindow.clearTimeout = function clearTimeout(timer?: number): void {
if (timer === undefined) return
originalWindow.clearTimeout(timer)
timeoutSet.delete(timer)
}
microAppWindow.addEventListener = function addEventListener(
type: string,
listener: EventListenerOrEventListenerObject,
options?: boolean | AddEventListenerOptions | undefined,
) {
if (!windowEventMap.get(type)) {
windowEventMap.set(type, [])
}
windowEventMap.get(type)?.push({ listener, options })
return originalWindowAddEventListener.call(originalWindow, type, listener, options)
}
microAppWindow.removeEventListener = function removeEventListener(
type: string,
listener: EventListenerOrEventListenerObject,
options?: boolean | AddEventListenerOptions | undefined,
) {
const arr = windowEventMap.get(type) || []
for (let i = 0, len = arr.length; i < len; i++) {
if (arr[i].listener === listener) {
arr.splice(i, 1)
break
}
}
return originalWindowRemoveEventListener.call(originalWindow, type, listener, options)
}下面这段是清除事件、定时器的关键代码:
for (const timer of timeoutSet) {
originalWindow.clearTimeout(timer)
}
for (const [type, arr] of windowEventMap) {
for (const item of arr) {
originalWindowRemoveEventListener.call(originalWindow, type as string, item.listener, item.options)
}
}之前提到过子应用每次加载的时候会都执行 mount() 方法,由于每个 js 文件只会执行一次,所以在执行 mount() 方法之前的代码在下一次重新加载时不会再次执行。
举个例子:
window.name = 'test'
function bootstrap() { // ... }
function mount() { // ... }
function unmount() { // ... }上面是子应用入口文件的代码,在第一次执行 js 代码时,子应用可以读取 window.name 这个属性的值。但是子应用卸载时会把 name 这个属性清除掉。所以子应用下一次加载的时候,就读取不到这个属性了。
为了解决这个问题,我们可以在子应用初始化时(拉取了所有入口 js 文件并执行后)将当前的子应用 window 代理对象的属性、事件缓存起来,生成快照。下一次子应用重新加载时,将快照恢复回子应用上。
生成快照的部分代码:
const { windowSnapshot, microAppWindow } = this
const recordAttrs = windowSnapshot.get('attrs')!
const recordWindowEvents = windowSnapshot.get('windowEvents')!
// 缓存 window 属性
this.injectKeySet.forEach(key => {
recordAttrs.set(key, deepCopy(microAppWindow[key]))
})
// 缓存 window 事件
this.windowEventMap.forEach((arr, type) => {
recordWindowEvents.set(type, deepCopy(arr))
})恢复快照的部分代码:
const {
windowSnapshot,
injectKeySet,
microAppWindow,
windowEventMap,
onWindowEventMap,
} = this
const recordAttrs = windowSnapshot.get('attrs')!
const recordWindowEvents = windowSnapshot.get('windowEvents')!
recordAttrs.forEach((value, key) => {
injectKeySet.add(key)
microAppWindow[key] = deepCopy(value)
})
recordWindowEvents.forEach((arr, type) => {
windowEventMap.set(type, deepCopy(arr))
for (const item of arr) {
originalWindowAddEventListener.call(originalWindow, type as string, item.listener, item.options)
}
})我们在使用 document.querySelector() 或者其他查询 DOM 的 API 时,都会在整个页面的 document 对象上查询。如果在子应用上也这样查询,很有可能会查询到子应用范围外的 DOM 元素。为了解决这个问题,我们需要重写一下查询类的 DOM API:
// 将所有查询 dom 的范围限制在子应用挂载的 dom 容器上
Document.prototype.querySelector = function querySelector(this: Document, selector: string) {
const app = getCurrentApp()
if (!app || !selector || isUniqueElement(selector)) {
return originalQuerySelector.call(this, selector)
}
// 将查询范围限定在子应用挂载容器的 DOM 下
return app.container.querySelector(selector)
}
Document.prototype.getElementById = function getElementById(id: string) {
// ...
}将查询范围限定在子应用挂载容器的 DOM 下。另外,子应用卸载时也需要恢复重写的 API:
Document.prototype.querySelector = originalQuerySelector
Document.prototype.querySelectorAll = originalQuerySelectorAll
// ...除了查询 DOM 要限制子应用的范围,样式也要限制范围。假设在 vue 应用上有这样一个样式:
body {
color: red;
}当它作为一个子应用被加载时,这个样式需要被修改为:
/* body 被替换为子应用挂载 DOM 的 id 选择符 */
#app {
color: red;
}实现代码也比较简单,需要遍历每一条 css 规则,然后替换里面的 body、html 字符串:
const re = /^(\s|,)?(body|html)\b/g
// 将 body html 标签替换为子应用挂载容器的 id
cssText.replace(re, `#${app.container.id}`)V3 版本实现了 window 作用域隔离、元素隔离,在 V4 版本上我们将实现子应用样式隔离。
我们都知道创建 DOM 元素时使用的是 document.createElement() API,所以我们可以在创建 DOM 元素时,把当前子应用的名称当成属性写到 DOM 上:
Document.prototype.createElement = function createElement(
tagName: string,
options?: ElementCreationOptions,
): HTMLElement {
const appName = getCurrentAppName()
const element = originalCreateElement.call(this, tagName, options)
appName && element.setAttribute('single-spa-name', appName)
return element
}这样所有的 style 标签在创建时都会有当前子应用的名称属性。我们可以在子应用卸载时将当前子应用所有的 style 标签进行移除,再次挂载时将这些标签重新添加到 document.head 下。这样就实现了不同子应用之间的样式隔离。
移除子应用所有 style 标签的代码:
export function removeStyles(name: string) {
const styles = document.querySelectorAll(`style[single-spa-name=${name}]`)
styles.forEach(style => {
removeNode(style)
})
return styles as unknown as HTMLStyleElement[]
}第一版的样式作用域隔离完成后,它只能对每次只加载一个子应用的场景有效。例如先加载 a 子应用,卸载后再加载 b 子应用这种场景。在卸载 a 子应用时会把它的样式也卸载。如果同时加载多个子应用,第一版的样式隔离就不起作用了。
由于每个子应用下的 DOM 元素都有以自己名称作为值的 single-spa-name 属性(如果不知道这个名称是哪来的,请往上翻一下第一版的描述)。
所以我们可以给子应用的每个样式加上子应用名称,也就是将这样的样式:
div {
color: red;
}改成:
div[single-spa-name=vue] {
color: red;
}这样一来,就把样式作用域范围限制在对应的子应用所挂载的 DOM 下。
现在我们来看看具体要怎么添加作用域:
/**
* 给每一条 css 选择符添加对应的子应用作用域
* 1. a {} -> a[single-spa-name=${app.name}] {}
* 2. a b c {} -> a[single-spa-name=${app.name}] b c {}
* 3. a, b {} -> a[single-spa-name=${app.name}], b[single-spa-name=${app.name}] {}
* 4. body {} -> #${子应用挂载容器的 id}[single-spa-name=${app.name}] {}
* 5. @media @supports 特殊处理,其他规则直接返回 cssText
*/主要有以上五种情况。
通常情况下,每一条 css 选择符都是一个 css 规则,这可以通过 style.sheet.cssRules 获取:
拿到了每一条 css 规则之后,我们就可以对它们进行重写,然后再把它们重写挂载到 document.head 下:
function handleCSSRules(cssRules: CSSRuleList, app: Application) {
let result = ''
Array.from(cssRules).forEach(cssRule => {
const cssText = cssRule.cssText
const selectorText = (cssRule as CSSStyleRule).selectorText
result += cssRule.cssText.replace(
selectorText,
getNewSelectorText(selectorText, app),
)
})
return result
}
let count = 0
const re = /^(\s|,)?(body|html)\b/g
function getNewSelectorText(selectorText: string, app: Application) {
const arr = selectorText.split(',').map(text => {
const items = text.trim().split(' ')
items[0] = `${items[0]}[single-spa-name=${app.name}]`
return items.join(' ')
})
// 如果子应用挂载的容器没有 id,则随机生成一个 id
let id = app.container.id
if (!id) {
id = 'single-spa-id-' + count++
app.container.id = id
}
// 将 body html 标签替换为子应用挂载容器的 id
return arr.join(',').replace(re, `#${id}`)
}核心代码在 getNewSelectorText() 上,这个函数给每一个 css 规则都加上了 [single-spa-name=${app.name}]。这样就把样式作用域限制在了对应的子应用内了。
大家可以对比一下下面的两张图,这个示例同时加载了 vue、react 两个子应用。第一张图里的 vue 子应用部分字体被 react 子应用的样式影响了。第二张图是添加了样式作用域隔离的效果图,可以看到 vue 子应用的样式是正常的,没有被影响。
V5 版本主要添加了一个全局数据通信的功能,设计思路如下:
window.spaGlobalState,所有应用都可以对这个全局对象进行监听,每当有应用对它进行修改时,会触发 change 事件。下面是实现了第一点要求的部分关键代码:
export default class GlobalState extends EventBus {
private state: AnyObject = {}
private stateChangeCallbacksMap: Map<string, Array<Callback>> = new Map()
set(key: string, value: any) {
this.state[key] = value
this.emitChange('set', key)
}
get(key: string) {
return this.state[key]
}
onChange(callback: Callback) {
const appName = getCurrentAppName()
if (!appName) return
const { stateChangeCallbacksMap } = this
if (!stateChangeCallbacksMap.get(appName)) {
stateChangeCallbacksMap.set(appName, [])
}
stateChangeCallbacksMap.get(appName)?.push(callback)
}
emitChange(operator: string, key?: string) {
this.stateChangeCallbacksMap.forEach((callbacks, appName) => {
/**
* 如果是点击其他子应用或父应用触发全局数据变更,则当前打开的子应用获取到的 app 为 null
* 所以需要改成用 activeRule 来判断当前子应用是否运行
*/
const app = getApp(appName) as Application
if (!(isActive(app) && app.status === AppStatus.MOUNTED)) return
callbacks.forEach(callback => callback(this.state, operator, key))
})
}
}下面是实现了第二点要求的部分关键代码:
export default class EventBus {
private eventsMap: Map<string, Record<string, Array<Callback>>> = new Map()
on(event: string, callback: Callback) {
if (!isFunction(callback)) {
throw Error(`The second param ${typeof callback} is not a function`)
}
const appName = getCurrentAppName() || 'parent'
const { eventsMap } = this
if (!eventsMap.get(appName)) {
eventsMap.set(appName, {})
}
const events = eventsMap.get(appName)!
if (!events[event]) {
events[event] = []
}
events[event].push(callback)
}
emit(event: string, ...args: any) {
this.eventsMap.forEach((events, appName) => {
/**
* 如果是点击其他子应用或父应用触发全局数据变更,则当前打开的子应用获取到的 app 为 null
* 所以需要改成用 activeRule 来判断当前子应用是否运行
*/
const app = getApp(appName) as Application
if (appName === 'parent' || (isActive(app) && app.status === AppStatus.MOUNTED)) {
if (events[event]?.length) {
for (const callback of events[event]) {
callback.call(this, ...args)
}
}
}
})
}
}以上两段代码都有一个相同的地方,就是在保存监听回调函数的时候需要和对应的子应用关联起来。当某个子应用卸载时,需要把它关联的回调函数也清除掉。
全局数据修改示例代码:
// 父应用
window.spaGlobalState.set('msg', '父应用在 spa 全局状态上新增了一个 msg 属性')
// 子应用
window.spaGlobalState.onChange((state, operator, key) => {
alert(`vue 子应用监听到 spa 全局状态发生了变化: ${JSON.stringify(state)},操作: ${operator},变化的属性: ${key}`)
})全局事件示例代码:
// 父应用
window.spaGlobalState.emit('testEvent', '父应用发送了一个全局事件: testEvent')
// 子应用
window.spaGlobalState.on('testEvent', () => alert('vue 子应用监听到父应用发送了一个全局事件: testEvent'))至此,一个简易微前端框架的技术要点已经讲解完毕。强烈建议大家在看文档的同时,把 demo 运行起来跑一跑,这样能帮助你更好的理解代码。
如果你觉得我的文章写得不错,也可以看看我的其他一些技术文章或项目:
时隔三个月,终于有时间写脚手架系列第二篇文章了,在北京上班确实比天津忙多了,都没时间摸鱼。如果你没看过本系列的第一篇文章手把手教你写一个脚手架,建议先看一遍再来阅读本文,效果更好。
mini-cli 项目 github 地址:https://github.com/woai3c/mini-cli
v3 版本的代码在 v3 分支,v4 版本的代码在 v4 分支。
第三个版本主要添加了两个功能:
mvc add xxx 命令的方式来添加插件。首先来简单了解一下 monorepo 和 multirepo。它们都是项目管理的一种方式,multirepo 就是将不同的项目放在不同的 git 仓库维护,而 monorepo 将多个项目放在同一个 git 仓库中维护。在 v3 版本里,我要将 mini-cli 改造成 monorepo 的方式,把不同的插件当成一个个独立的项目来维护。
在将项目改造成 monorepo 后,目录如下所示:
├─packages
│ ├─@mvc
│ │ ├─cli # 核心插件
│ │ ├─cli-plugin-babel # babel 插件
│ │ ├─cli-plugin-linter # linter 插件
│ │ ├─cli-plugin-router # router 插件
│ │ ├─cli-plugin-vue # vue 插件
│ │ ├─cli-plugin-vuex # vuex 插件
│ │ └─cli-plugin-webpack # webpack 插件
└─scripts # commit message 验证脚本 和项目无关 不需关注
│─lerna.json
|─package.json
全局安装 lerna
npm install -g lerna
创建项目
git init mini-cli
初始化
cd mini-cli
lerna init
创建 package
lerna create xxx
由于 cli 是脚手架核心代码,在这里需要调用其他插件,因为要将其他插件添加到 @mvc/cli 的依赖项
# 如果是添加到 devDependencies,则需要在后面加上 --dev
# 下载第三方依赖也是同样的命令
lerna add @mvc/cli-plugin-babel --scope=@mvc/cli改造成 monorepo-repo 后的脚手架功能和第二版没有区别,只是将插件相关的代码独立成一个单独的 repo,后续可以将插件单独发布到 npm。
npm i 安装,才能使用。采用 monorepo 则没有这种烦恼,可以直接调用在 packages 目录里的其他插件,方便开发调试。lerna publish 时可以同时发布已经修改过的插件,不用每个单独发布。将项目改造成 monorepo-repo 的目的就是为了后续方便做扩展。例如生成的项目原来是不支持 router 的,在中途突然想加入 router 功能,就可以执行命令 mvc add router 添加 vue-router 依赖以及相关的模板代码。
先来看一下 add 命令的代码:
const path = require('path')
const inquirer = require('inquirer')
const Generator = require('./Generator')
const clearConsole = require('./utils/clearConsole')
const PackageManager = require('./PackageManager')
const getPackage = require('./utils/getPackage')
const readFiles = require('./utils/readFiles')
async function add(name) {
const targetDir = process.cwd()
const pkg = getPackage(targetDir)
// 清空控制台
clearConsole()
let answers = {}
try {
const pluginPrompts = require(`@mvc/cli-plugin-${name}/prompts`)
answers = await inquirer.prompt(pluginPrompts)
} catch (error) {
console.log(error)
}
const generator = new Generator(pkg, targetDir, await readFiles(targetDir))
const pm = new PackageManager(targetDir, answers.packageManager)
require(`@mvc/cli-plugin-${name}/generator`)(generator, answers)
await generator.generate()
// 下载依赖
await pm.install()
}
module.exports = add由于 v3 版本仍然是在本地开发的,所以没有将相关插件发布到 npm 上,因为可以直接引用插件,而不需执行 npm i 安装。在 v2 版本执行 create 命令创建项目时,所有的交互提示语都是放在 cli 插件下的,但是 add 命令是单独添加一个插件,因此还需要在每个插件下添加一个 prompts.js 文件(如果不需要,可以不加),里面是一些和用户交互的语句。例如用 add 命令添加 router 插件时,会询问是否选择 history 模式。
const chalk = require('chalk')
module.exports = [
{
name: 'historyMode',
type: 'confirm',
message: `Use history mode for router? ${chalk.yellow(`(Requires proper server setup for index fallback in production)`)}`,
description: `By using the HTML5 History API, the URLs don't need the '#' character anymore.`,
},
]从 add 命令的代码逻辑可以看出来,如果新加的插件有 prompts.js 文件就读取代码弹出交互语句。否则跳过,直接进行下载。
v4 版本主要将 webpack 的 dev 和 build 功能做成了动态,原来的脚手架生成的项目是有一个 build 目录,里面是 webpack 的一些配置代码。v4 版本的脚手架生成的项目是没有 build 目录的。
这一个功能通过新增的 mvc-cli-service 插件来实现,生成的项目中会有以下两个脚本命令:
scripts: {
serve: 'mvc-cli-service serve',
build: 'mvc-cli-service build',
},当运行 npm run serve 时,就会执行命令 mvc-cli-service serve。这一块的代码如下:
#!/usr/bin/env node
const webpack = require('webpack')
const WebpackDevServer = require('webpack-dev-server')
const devConfig = require('../lib/dev.config')
const buildConfig = require('../lib/pro.config')
const args = process.argv.slice(2)
if (args[0] === 'serve') {
const compiler = webpack(devConfig)
const server = new WebpackDevServer(compiler)
server.listen(8080, '0.0.0.0', err => {
console.log(err)
})
} else if (args[0] === 'build') {
webpack(buildConfig, (err, stats) => {
if (err) console.log(err)
if (stats.hasErrors()) {
console.log(new Error('Build failed with errors.'))
}
})
} else {
console.log('error command')
}原理如下(npm scripts 使用指南):
npm 脚本的原理非常简单。每当执行npm run,就会自动新建一个 Shell,在这个 Shell 里面执行指定的脚本命令。因此,只要是 Shell(一般是 Bash)可以运行的命令,就可以写在 npm 脚本里面。
比较特别的是,npm run新建的这个 Shell,会将当前目录的node_modules/.bin子目录加入PATH变量,执行结束后,再将PATH变量恢复原样。
上述代码对执行的命令进行了判断,如果是 serve,就 new 一个 WebpackDevServer 实例启动开发环境。如果是 build,就用 webpack 进行打包。
vue-cli 的 webpack 配置是动态的,使用了 chainwebpack 来动态添加不同的配置,我这个 demo 是直接写死的,主要是没时间,所以没有再深入研究。
下载 mini-cli 脚手架,其实下载的只是核心插件 mvc-cli。如果这个插件需要引用其他插件,则需要先进行安装,再调用。因此对 create add 命令需要做一些修改。下面看一下 create 命令代码的改动:
answers.features.forEach(feature => {
if (feature !== 'service') {
pkg.devDependencies[`mvc-cli-plugin-${feature}`] = '~1.0.0'
} else {
pkg.devDependencies['mvc-cli-service'] = '~1.0.0'
}
})
await writeFileTree(targetDir, {
'package.json': JSON.stringify(pkg, null, 2),
})
await pm.install()
// 根据用户选择的选项加载相应的模块,在 package.json 写入对应的依赖项
// 并且将对应的 template 模块渲染
answers.features.forEach(feature => {
if (feature !== 'service') {
require(`mvc-cli-plugin-${feature}/generator`)(generator, answers)
} else {
require(`mvc-cli-service/generator`)(generator, answers)
}
})
await generator.generate()
// 下载依赖
await pm.install()上面的代码就是新增的逻辑,在用户选择完需要的插件后,将这些插件写入到 pkg 对象,然后生成 package.json 文件,再执行 npm install 安装依赖。安装完插件后,再读取每个插件的 generator 目录/文件代码,从而生成模板或再次添加不同的依赖。然后再执行一次安装。
v3 版本的插件有一个前缀 @mvc,由于带有 @ 前缀的 npm 包会默认作为私人包,因此遇到了一些坑。花费了挺长的时间,后来懒得弄了,干脆将所有的插件重新改了前缀名,变成 mvc 开头的前缀。
本文是对《可视化拖拽组件库一些技术要点原理分析》的补充。上一篇文章主要讲解了以下几个功能点:
现在这篇文章会在此基础上再补充 4 个功能点,分别是:
和上篇文章一样,我已经将新功能的代码更新到了 github:
友善提醒:建议结合源码一起阅读,效果更好(这个 DEMO 使用的是 Vue 技术栈)。
在写上一篇文章时,原来的 DEMO 已经可以支持旋转功能了。但是这个旋转功能还有很多不完善的地方:
这一小节,我们将逐一解决这四个问题。
拖拽旋转需要使用 Math.atan2() 函数。
Math.atan2() 返回从原点(0,0)到(x,y)点的线段与x轴正方向之间的平面角度(弧度值),也就是Math.atan2(y,x)。Math.atan2(y,x)中的y和x都是相对于圆点(0,0)的距离。
简单的说就是以组件中心点为原点 (centerX,centerY),用户按下鼠标时的坐标设为 (startX,startY),鼠标移动时的坐标设为 (curX,curY)。旋转角度可以通过 (startX,startY) 和 (curX,curY) 计算得出。
那我们如何得到从点 (startX,startY) 到点 (curX,curY) 之间的旋转角度呢?
第一步,鼠标点击时的坐标设为 (startX,startY):
const startY = e.clientY
const startX = e.clientX第二步,算出组件中心点:
// 获取组件中心点位置
const rect = this.$el.getBoundingClientRect()
const centerX = rect.left + rect.width / 2
const centerY = rect.top + rect.height / 2第三步,按住鼠标移动时的坐标设为 (curX,curY):
const curX = moveEvent.clientX
const curY = moveEvent.clientY第四步,分别算出 (startX,startY) 和 (curX,curY) 对应的角度,再将它们相减得出旋转的角度。另外,还需要注意的就是 Math.atan2() 方法的返回值是一个弧度,因此还需要将弧度转化为角度。所以完整的代码为:
// 旋转前的角度
const rotateDegreeBefore = Math.atan2(startY - centerY, startX - centerX) / (Math.PI / 180)
// 旋转后的角度
const rotateDegreeAfter = Math.atan2(curY - centerY, curX - centerX) / (Math.PI / 180)
// 获取旋转的角度值, startRotate 为初始角度值
pos.rotate = startRotate + rotateDegreeAfter - rotateDegreeBefore组件旋转后的放大缩小会有 BUG。
从上图可以看到,放大缩小时会发生移位。另外伸缩的方向和我们拖动的方向也不对。造成这一 BUG 的原因是:当初设计放大缩小功能没有考虑到旋转的场景。所以无论旋转多少角度,放大缩小仍然是按没旋转时计算的。
下面再看一个具体的示例:
从上图可以看出,在没有旋转时,按住顶点往上拖动,只需用 y2 - y1 就可以得出拖动距离 s。这时将组件原来的高度加上 s 就能得出新的高度,同时将组件的 top、left 属性更新。
现在旋转 180 度,如果这时拖住顶点往下拖动,我们期待的结果是组件高度增加。但这时计算的方式和原来没旋转时是一样的,所以结果和我们期待的相反,组件的高度将会变小(如果不理解这个现象,可以想像一下没有旋转的那张图,按住顶点往下拖动)。
如何解决这个问题呢?我从 github 上的一个项目 snapping-demo 找到了解决方案:将放大缩小和旋转角度关联起来。
下面是一个已旋转一定角度的矩形,假设现在拖动它左上方的点进行拉伸。
现在我们将一步步分析如何得出拉伸后的组件的正确大小和位移。
第一步,按下鼠标时通过组件的坐标(无论旋转多少度,组件的 top left 属性不变)和大小算出组件中心点:
const center = {
x: style.left + style.width / 2,
y: style.top + style.height / 2,
}第二步,用当前点击坐标和组件中心点算出当前点击坐标的对称点坐标:
// 获取画布位移信息
const editorRectInfo = document.querySelector('#editor').getBoundingClientRect()
// 当前点击坐标
const curPoint = {
x: e.clientX - editorRectInfo.left,
y: e.clientY - editorRectInfo.top,
}
// 获取对称点的坐标
const symmetricPoint = {
x: center.x - (curPoint.x - center.x),
y: center.y - (curPoint.y - center.y),
}第三步,摁住组件左上角进行拉伸时,通过当前鼠标实时坐标和对称点计算出新的组件中心点:
const curPositon = {
x: moveEvent.clientX - editorRectInfo.left,
y: moveEvent.clientY - editorRectInfo.top,
}
const newCenterPoint = getCenterPoint(curPositon, symmetricPoint)
// 求两点之间的中点坐标
function getCenterPoint(p1, p2) {
return {
x: p1.x + ((p2.x - p1.x) / 2),
y: p1.y + ((p2.y - p1.y) / 2),
}
}由于组件处于旋转状态,即使你知道了拉伸时移动的 xy 距离,也不能直接对组件进行计算。否则就会出现 BUG,移位或者放大缩小方向不正确。因此,我们需要在组件未旋转的情况下对其进行计算。
第四步,根据已知的旋转角度、新的组件中心点、当前鼠标实时坐标可以算出当前鼠标实时坐标 currentPosition 在未旋转时的坐标 newTopLeftPoint。同时也能根据已知的旋转角度、新的组件中心点、对称点算出组件对称点 sPoint 在未旋转时的坐标 newBottomRightPoint。
对应的计算公式如下:
/**
* 计算根据圆心旋转后的点的坐标
* @param {Object} point 旋转前的点坐标
* @param {Object} center 旋转中心
* @param {Number} rotate 旋转的角度
* @return {Object} 旋转后的坐标
* https://www.zhihu.com/question/67425734/answer/252724399 旋转矩阵公式
*/
export function calculateRotatedPointCoordinate(point, center, rotate) {
/**
* 旋转公式:
* 点a(x, y)
* 旋转中心c(x, y)
* 旋转后点n(x, y)
* 旋转角度θ tan ??
* nx = cosθ * (ax - cx) - sinθ * (ay - cy) + cx
* ny = sinθ * (ax - cx) + cosθ * (ay - cy) + cy
*/
return {
x: (point.x - center.x) * Math.cos(angleToRadian(rotate)) - (point.y - center.y) * Math.sin(angleToRadian(rotate)) + center.x,
y: (point.x - center.x) * Math.sin(angleToRadian(rotate)) + (point.y - center.y) * Math.cos(angleToRadian(rotate)) + center.y,
}
}上面的公式涉及到线性代数中旋转矩阵的知识,对于一个没上过大学的人来说,实在太难了。还好我从知乎上的一个回答中找到了这一公式的推理过程,下面是回答的原文:
通过以上几个计算值,就可以得到组件新的位移值 top left 以及新的组件大小。对应的完整代码如下:
function calculateLeftTop(style, curPositon, pointInfo) {
const { symmetricPoint } = pointInfo
const newCenterPoint = getCenterPoint(curPositon, symmetricPoint)
const newTopLeftPoint = calculateRotatedPointCoordinate(curPositon, newCenterPoint, -style.rotate)
const newBottomRightPoint = calculateRotatedPointCoordinate(symmetricPoint, newCenterPoint, -style.rotate)
const newWidth = newBottomRightPoint.x - newTopLeftPoint.x
const newHeight = newBottomRightPoint.y - newTopLeftPoint.y
if (newWidth > 0 && newHeight > 0) {
style.width = Math.round(newWidth)
style.height = Math.round(newHeight)
style.left = Math.round(newTopLeftPoint.x)
style.top = Math.round(newTopLeftPoint.y)
}
}现在再来看一下旋转后的放大缩小:
自动吸附是根据组件的四个属性 top left width height 计算的,在将组件进行旋转后,这些属性的值是不会变的。所以无论组件旋转多少度,吸附时仍然按未旋转时计算。这样就会有一个问题,虽然实际上组件的 top left width height 属性没有变化。但在外观上却发生了变化。下面是两个同样的组件:一个没旋转,一个旋转了 45 度。
可以看出来旋转后按钮的 height 属性和我们从外观上看到的高度是不一样的,所以在这种情况下就出现了吸附不正确的 BUG。
如何解决这个问题?我们需要拿组件旋转后的大小及位移来做吸附对比。也就是说不要拿组件实际的属性来对比,而是拿我们看到的大小和位移做对比。
从上图可以看出,旋转后的组件在 x 轴上的投射长度为两条红线长度之和。这两条红线的长度可以通过正弦和余弦算出,左边的红线用正弦计算,右边的红线用余弦计算:
const newWidth = style.width * cos(style.rotate) + style.height * sin(style.rotate)同理,高度也是一样:
const newHeight = style.height * cos(style.rotate) + style.width * sin(style.rotate)新的宽度和高度有了,再根据组件原有的 top left 属性,可以得出组件旋转后新的 top left 属性。下面附上完整代码:
translateComponentStyle(style) {
style = { ...style }
if (style.rotate != 0) {
const newWidth = style.width * cos(style.rotate) + style.height * sin(style.rotate)
const diffX = (style.width - newWidth) / 2
style.left += diffX
style.right = style.left + newWidth
const newHeight = style.height * cos(style.rotate) + style.width * sin(style.rotate)
const diffY = (newHeight - style.height) / 2
style.top -= diffY
style.bottom = style.top + newHeight
style.width = newWidth
style.height = newHeight
} else {
style.bottom = style.top + style.height
style.right = style.left + style.width
}
return style
}经过修复后,吸附也可以正常显示了。
光标和可拖动的方向不对,是因为八个点的光标是固定设置的,没有随着角度变化而变化。
由于 360 / 8 = 45,所以可以为每一个方向分配 45 度的范围,每个范围对应一个光标。同时为每个方向设置一个初始角度,也就是未旋转时组件每个方向对应的角度。
pointList: ['lt', 't', 'rt', 'r', 'rb', 'b', 'lb', 'l'], // 八个方向
initialAngle: { // 每个点对应的初始角度
lt: 0,
t: 45,
rt: 90,
r: 135,
rb: 180,
b: 225,
lb: 270,
l: 315,
},
angleToCursor: [ // 每个范围的角度对应的光标
{ start: 338, end: 23, cursor: 'nw' },
{ start: 23, end: 68, cursor: 'n' },
{ start: 68, end: 113, cursor: 'ne' },
{ start: 113, end: 158, cursor: 'e' },
{ start: 158, end: 203, cursor: 'se' },
{ start: 203, end: 248, cursor: 's' },
{ start: 248, end: 293, cursor: 'sw' },
{ start: 293, end: 338, cursor: 'w' },
],
cursors: {},计算方式也很简单:
angleToCursor 数组,看看 b 在哪一个范围中,然后将对应的光标返回。经过上面三个步骤就可以计算出组件旋转后正确的光标方向。具体的代码如下:
getCursor() {
const { angleToCursor, initialAngle, pointList, curComponent } = this
const rotate = (curComponent.style.rotate + 360) % 360 // 防止角度有负数,所以 + 360
const result = {}
let lastMatchIndex = -1 // 从上一个命中的角度的索引开始匹配下一个,降低时间复杂度
pointList.forEach(point => {
const angle = (initialAngle[point] + rotate) % 360
const len = angleToCursor.length
while (true) {
lastMatchIndex = (lastMatchIndex + 1) % len
const angleLimit = angleToCursor[lastMatchIndex]
if (angle < 23 || angle >= 338) {
result[point] = 'nw-resize'
return
}
if (angleLimit.start <= angle && angle < angleLimit.end) {
result[point] = angleLimit.cursor + '-resize'
return
}
}
})
return result
},从上面的动图可以看出来,现在八个方向上的光标是可以正确显示的。
相对于拖拽旋转功能,复制粘贴就比较简单了。
const ctrlKey = 17, vKey = 86, cKey = 67, xKey = 88
let isCtrlDown = false
window.onkeydown = (e) => {
if (e.keyCode == ctrlKey) {
isCtrlDown = true
} else if (isCtrlDown && e.keyCode == cKey) {
this.$store.commit('copy')
} else if (isCtrlDown && e.keyCode == vKey) {
this.$store.commit('paste')
} else if (isCtrlDown && e.keyCode == xKey) {
this.$store.commit('cut')
}
}
window.onkeyup = (e) => {
if (e.keyCode == ctrlKey) {
isCtrlDown = false
}
}监听用户的按键操作,在按下特定按键时触发对应的操作。
在 vuex 中使用 copyData 来表示复制的数据。当用户按下 ctrl + c 时,将当前组件数据深拷贝到 copyData。
copy(state) {
state.copyData = {
data: deepCopy(state.curComponent),
index: state.curComponentIndex,
}
},同时需要将当前组件在组件数据中的索引记录起来,在剪切中要用到。
paste(state, isMouse) {
if (!state.copyData) {
toast('请选择组件')
return
}
const data = state.copyData.data
if (isMouse) {
data.style.top = state.menuTop
data.style.left = state.menuLeft
} else {
data.style.top += 10
data.style.left += 10
}
data.id = generateID()
store.commit('addComponent', { component: data })
store.commit('recordSnapshot')
state.copyData = null
},粘贴时,如果是按键操作 ctrl+v。则将组件的 top left 属性加 10,以免和原来的组件重叠在一起。如果是使用鼠标右键执行粘贴操作,则将复制的组件放到鼠标点击处。
cut(state) {
if (!state.curComponent) {
toast('请选择组件')
return
}
if (state.copyData) {
store.commit('addComponent', { component: state.copyData.data, index: state.copyData.index })
if (state.curComponentIndex >= state.copyData.index) {
// 如果当前组件索引大于等于插入索引,需要加一,因为当前组件往后移了一位
state.curComponentIndex++
}
}
store.commit('copy')
store.commit('deleteComponent')
},剪切操作本质上还是复制,只不过在执行复制后,需要将当前组件删除。为了避免用户执行剪切操作后,不执行粘贴操作,而是继续执行剪切。这时就需要将原先剪切的数据进行恢复。所以复制数据中记录的索引就起作用了,可以通过索引将原来的数据恢复到原来的位置中。
右键操作和按键操作是一样的,一个功能两种触发途径。
<li @click="copy" v-show="curComponent">复制</li>
<li @click="paste">粘贴</li>
<li @click="cut" v-show="curComponent">剪切</li>
cut() {
this.$store.commit('cut')
},
copy() {
this.$store.commit('copy')
},
paste() {
this.$store.commit('paste', true)
},提前写好一系列 ajax 请求API,点击组件时按需选择 API,选好 API 再填参数。例如下面这个组件,就展示了如何使用 ajax 请求向后台交互:
<template>
<div>{{ propValue.data }}</div>
</template>
<script>
export default {
// propValue: {
// api: {
// request: a,
// params,
// },
// data: null
// }
props: {
propValue: {
type: Object,
default: () => {},
},
},
created() {
this.propValue.api.request(this.propValue.api.params).then(res => {
this.propValue.data = res.data
})
},
}
</script>方式二适合纯展示的组件,例如有一个报警组件,可以根据后台传来的数据显示对应的颜色。在编辑页面的时候,可以通过 ajax 向后台请求页面能够使用的 websocket 数据:
const data = ['status', 'text'...]然后再为不同的组件添加上不同的属性。例如有 a 组件,它绑定的属性为 status。
// 组件能接收的数据
props: {
propValue: {
type: String,
},
element: {
type: Object,
},
wsKey: {
type: String,
default: '',
},
},
在组件中通过 wsKey 获取这个绑定的属性。等页面发布后或者预览时,通过 weboscket 向后台请求全局数据放在 vuex 上。组件就可以通过 wsKey 访问数据了。
<template>
<div>{{ wsData[wsKey] }}</div>
</template>
<script>
import { mapState } from 'vuex'
export default {
props: {
propValue: {
type: String,
},
element: {
type: Object,
},
wsKey: {
type: String,
default: '',
},
},
computed: mapState([
'wsData',
]),
</script>和后台交互的方式有很多种,不仅仅包括上面两种,我在这里仅提供一些思路,以供参考。
页面发布有两种方式:一是将组件数据渲染为一个单独的 HTML 页面;二是从本项目中抽取出一个最小运行时 runtime 作为一个单独的项目。
这里说一下第二种方式,本项目中的最小运行时其实就是预览页面加上自定义组件。将这些代码提取出来作为一个项目单独打包。发布页面时将组件数据以 JSON 的格式传给服务端,同时为每个页面生成一个唯一 ID。
假设现在有三个页面,发布页面生成的 ID 为 a、b、c。访问页面时只需要把 ID 带上,这样就可以根据 ID 获取每个页面对应的组件数据。
www.test.com/?id=a
www.test.com/?id=c
www.test.com/?id=b如果自定义组件过大,例如有数十个甚至上百个。这时可以将自定义组件用 import 的方式导入,做到按需加载,减少首屏渲染时间:
import Vue from 'vue'
const components = [
'Picture',
'VText',
'VButton',
]
components.forEach(key => {
Vue.component(key, () => import(`@/custom-component/${key}`))
})自定义组件有可能会有更新的情况。例如原来的组件使用了大半年,现在有功能变更,为了不影响原来的页面。建议在发布时带上组件的版本号:
- v-text
- v1.vue
- v2.vue
例如 v-text 组件有两个版本,在左侧组件列表区使用时就可以带上版本号:
{
component: 'v-text',
version: 'v1'
...
}这样导入组件时就可以根据组件版本号进行导入:
import Vue from 'vue'
import componentList from '@/custom-component/component-list`
componentList.forEach(component => {
Vue.component(component.name, () => import(`@/custom-component/${component.name}/${component.version}`))
})您好,请问导入PSD还没有实现是么? 那请问导入PSD文件之后,在画布上 以图层显示,实现的思路、方法 您可以详细描述一下么?
由于一直在使用 markdown 编辑器写技术文章,所以对于编写体验很敏感。我发现各大社区的 markdown 编辑器基本都有同步滚动功能。只不过有些做得好,有些做得马马虎虎。出于好奇,我就打算自己亲自实现一下这个功能。
思考了一段时间,最后想出来了三种方案:
假设现在正在滚动 a 屏,那 a 屏的滚动百分比计算方式为:a 屏的滚动高度 / a 屏的内容总高度,用代码表示 a.scrollTop / a.scrollHeight。当滚动 a 屏时,需要手动同步 b 屏的滚动高度,也就是根据 a 屏的滚动百分比算出 b 屏的滚动高度:
a.onscroll = () => {
b.scrollTo({ top: a.scrollTop / a.scrollHeight * b.scrollHeight })
}原理就是这么简单,可惜实现效果不太好。
从上面的动图可以看出,当我在第二个大标题处停留的时候,左右双屏的内容是同步的。但当我滚动到第三个大标题时,左右双屏的内容高度已经差了将近 300 像素了。所以说这个方案勉勉强强能用吧,聊胜于无。
双屏内容高度不一致,是因为 markdown 同一个元素渲染后的高度和渲染前会有差别。例如一个图片,用 markdown 写就一行代码的事,但渲染出来的图片有大有小,高度几十、几百像素的都有。如果 markdown 的图片代码双屏同时渲染,倒是能解决这个问题。
但是除了图片仍然有不少元素渲染前后的高度是有差距的,虽然没有图片这么夸张。譬如 h1 h2 这种,当文章内容越长,这种小差异带来的问题会越来越大,导致双屏内容高度的差距也会越来越大。所以说这种方案也不是很靠谱。
之前两个方案都属于勉强能用,不够好。现在这个第三方案就比前面两个强多了,几乎能做到精确同步每一行的内容。具体怎么做呢?
当把编辑框的 HTML 传给右边的框渲染时,需要把 data-index 赋值给渲染后的元素。这样就能通过 data-index 精确定位渲染前后的同一元素了。
在 a 屏进行滚动时,需要从上到下遍历 a 屏的所有元素,并且找到第一个在屏幕内的元素。找到第一个在屏幕内的元素 这句话的意思是因为在滚动过程中,有些元素会因为滚动跑到屏幕外面(原来在屏幕内,滚动到屏幕外),这些元素我们是不需要计算的。
判断一个元素是否在屏幕内:
// dom 是否在屏幕内
function isInScreen(dom) {
const { top, bottom } = dom.getBoundingClientRect()
return bottom >= 0 && top < window.innerHeight
}除了判断元素是否在屏幕内,还需要判断这个元素在屏幕内的部分占整个元素高度的百分比。譬如说一个图片的 markdown 字符串,由于滚动的原因,导致一半在屏幕内,一半在屏幕外。为了精确同步,那么渲染后的图片也必须有一半在屏幕内一半在屏幕外。
计算元素在屏幕内的百分比代码:
// dom 在当前屏幕展示内容的百分比
function percentOfdomInScreen(dom) {
// 已经通过另一个函数 isInScreen() 确定了这个 dom 在屏幕内,所以只需要计算它在屏幕内的百分比,而不需要考虑它是否在屏幕外
const { height, bottom } = dom.getBoundingClientRect()
if (bottom <= 0) return 0 // 不在屏幕内
if (bottom >= height) return 1 // 完全在屏幕内
return bottom / height // 部分在屏幕内
}现在我们就可以从上到下遍历 a 屏的所有元素,找到第一个在屏幕内的元素了:
// scrollContainer 即上面说的 a 屏,ShowContainer 是 b 屏
const nodes = Array.from(scrollContainer.children)
for (const node of nodes) {
// 从上往下遍历,找到第一个在屏幕内的元素
if (isInScreen(node) && percentOfdomInScreen(node) >= 0) {
const index = node.dataset.index
// 根据滚动元素的索引,找到它在渲染框中对应的元素
const dom = ShowContainer.querySelector(`[data-index="${index}"]`)
// 获取滚动元素在 a 屏中展示的内容百分比
const percent = percentOfdomInScreen(node)
// 计算这个对等元素在 b 屏中距离容器顶部的高度
const heightToTop = getHeightToTop(dom)
// 根据 percent 算出对等元素在 b 屏中需要隐藏的高度
const domNeedHideHeight = dom.offsetHeight * (1 - percent)
// scrollTo({ top: heightToTop }) 会把对等元素滚动到在 b 屏中恰好完全展示整个元素的位置
// 然后再滚动它需要隐藏的高度 domNeedHideHeight,组合起来就是 scrollTo({ top: heightToTop + domNeedHideHeight })
ShowContainer.scrollTo({ top: heightToTop + domNeedHideHeight })
break
}
}从动图来看,目前已经做到行内容的精确同步了。
有一些元素渲染后会变成嵌套元素,例如表格 table,渲染后的内容层级为:
<table>
<tbody>
<tr>
<td></td>
</tr>
</tbody>
</table>按照目前的渲染逻辑,假如我写了个表格:
|1|b|
...
那么 |1|b| 上的 data-index 会对应到 table 上。
那这就会有个 bug,当 |1|b| 滚动到 50% 的时候,整个 table 也会滚动到 50%。这个现象如下图所示:
这和我们相要的效果不一样。a 屏连一行的内容都没滚完,b 屏整个内容已经滚动到一半了。
所以像这种嵌套的元素,在打 data-index 标记时,要把它打到真正的内容上。用表格 table 来做示例,就得把 data-index 的标记打在 tr 上。
这样一来,同步滚动就正常了。同理,其他的嵌套元素也一样(譬如 ul ol)。
完整的代码我已经放在 github 上了:
还有在线 DEMO:
如果在线 DEMO 比较慢,可以克隆项目后直接打开 html 文件访问。
在过去几年,我曾经写过几篇和性能优化相关的文章,例如有性能优化方法相关的,有性能监控相关的。但是都只关注于局部,没有从整体上去看待、分析性能优化。所以本文打算尝试从整体上去分析前端性能优化,从性能指标,性能分析,到性能优化这一整条链路来分析前端性能优化。
在做性能优化之前,首先要了解如何评价性能好坏,不能只凭主观感受来判断。因为每个人的感受都不一样,例如首屏加载时间,有人觉得 2 秒就够快了,有人觉得 5 秒也不错。为了避免这种情况,我们要建立一个性能评价系统,在统一的标准下,分析页面性能好坏。这可以通过一系列性能指标来实现,例如 FCP、LCP、CLS 等性能指标。
对性能指标有一定了解后,就可以开始编写 SDK 来收集性能数据了,当然,也可以使用开源的监控系统。一般的监控系统都会有一个监测平台用来查看性能数据。然后我们就可以分析出来页面的性能瓶颈在哪里,再使用对应的性能优化方法来解决性能问题。
以上,是关于如何做性能优化的方法论,下面来看一下具体如何做。
在优化性能的过程中,我们需要依赖一些具体的性能指标来对页面性能进行分析。然后通过对比优化前后的性能指标,我们可以准确判断性能优化的效果。对于性能指标,我们一般关注以下 9 个就可以了。
FP(first-paint),从页面加载开始到第一个像素绘制到屏幕上的时间。其实把 FP 理解成白屏时间也是没问题的。
FCP(first-contentful-paint),从页面加载开始到页面内容的任何部分在屏幕上完成渲染的时间。对于该指标,"内容"指的是文本、图像(包括背景图像)、<svg> 元素或非白色的 <canvas> 元素。
为了提供良好的用户体验,FCP 的分数应该控制在 1.8 秒以内。
LCP(largest-contentful-paint),从页面加载开始到最大文本块或图像元素在屏幕上完成渲染的时间。LCP 指标会根据页面首次开始加载的时间点来报告可视区域内可见的最大图像或文本块完成渲染的相对时间。
一个良好的 LCP 分数应该控制在 2.5 秒以内。
FCP 和 LCP 的区别是:FCP 只要任意内容绘制完成就触发,LCP 是最大内容渲染完成时触发。
LCP 考察的元素类型为:
<img>元素<svg>元素内的<image>元素<video>元素(使用封面图像)url()函数(而非使用CSS 渐变)加载的带有背景图像的元素CLS(layout-shift),从页面加载开始和其生命周期状态变为隐藏期间发生的所有意外布局偏移的累积分数。
布局偏移分数的计算方式如下:
布局偏移分数 = 影响分数 * 距离分数
影响分数测量不稳定元素对两帧之间的可视区域产生的影响。
距离分数指的是任何不稳定元素在一帧中位移的最大距离(水平或垂直)除以可视区域的最大尺寸维度(宽度或高度,以较大者为准)。
CLS 就是把所有布局偏移分数加起来的总和。
当一个 DOM 在两个渲染帧之间产生了位移,就会触发 CLS(如图所示)。
上图中的矩形从左上角移动到了右边,这就算是一次布局偏移。同时,在 CLS 中,有一个叫会话窗口的术语:一个或多个快速连续发生的单次布局偏移,每次偏移相隔的时间少于 1 秒,且整个窗口的最大持续时长为 5 秒。
例如上图中的第二个会话窗口,它里面有四次布局偏移,每一次偏移之间的间隔必须少于 1 秒,并且第一个偏移和最后一个偏移之间的时间不能超过 5 秒,这样才能算是一次会话窗口。如果不符合这个条件,就算是一个新的会话窗口。可能有人会问,为什么要这样规定?其实这是 chrome 团队根据大量的实验和研究得出的分析结果 Evolving the CLS metric。
CLS 一共有三种计算方式:
第三种方式是目前最优的计算方式,每次只取所有会话窗口的最大值,用来反映页面布局偏移的最差情况。详情请看 Evolving the CLS metric。
页面从加载开始到页面渲染完毕的时间,如果有些页面的内容特别多,我们可以只取当前屏幕展示的内容的加载时间作为首屏渲染时间。因为其他部分对于用户来说看不到,所以可以忽略那部分的加载时间。
页面的帧率就是每秒显示多少帧,一般使用 requestAnimationFrame() 来计算当前页面的 FPS。
资源加载时间指的是每个静态资源文件的加载时间,通过它可以找到哪些资源加载慢,然后再分析原因。
缓存命中率是用来分析你的缓存策略、内容分包机制做得好不好。一般缓存命中率越高,说明你缓存策略、内容分包机制做得越好。
通过接口请求耗时,可以分析哪些接口慢,然后再找出是服务器问题或者是接口内容过大或是网络问题。
通过这 9 个指标,我们就可以对页面做到一个全面的、客观的分析,进而知道性能瓶颈出在哪。例如资源加载时间比较慢,我们可以分析出来有可能是网络问题,再进而分析是不是 DNS 有问题、或者网络带宽问题、还是 CDN 有问题等等;也可以看看是不是资源体积过大,需要进行压缩或者拆包。
总的来说,了解性能指标可以提升你对性能优化的认识,帮助你更好的实现性能优化。
通过监控,我们可以拿到所需的性能指标数据。如果开发监控系统的压力过大,我们可以使用开源的监控系统,例如 sentry 就是一个很不错的监控平台,除了能收集性能数据,还能收集错误数据。不过如果不想使用这种大而全的监控平台,也可以选择自己开发一个监控平台,一个完整的监控平台包含了监控 SDK、数据清洗和存储、数据展示。两三个人花一两个月的时间就能开发出来一个够用的监控系统了,如果对监控 SDK 有兴趣的可以看看我这篇文章 前端监控 SDK 的一些技术要点原理分析。
如果不需要持续的监控页面性能,而只是想进行一次评测,那我们可以使用 chrome 浏览器自带的 lighthouse 工具来进行测试。
选择你想要收集的数据和所在平台,然后点击 Analyze page load 即可开始测试。
从上图可以看出,几个核心的性能指标都已经有了,并且还能看到整体页面和性能分数,非常的简单和直观。
收集性能数据的方式基本上就是两种:
通常情况下,测试工具就够用了,除非你的网站需要追求极致的性能和用户体验,否则不需要上监控平台。
性能监控、性能指标是用来收集数据、分析性能瓶颈用的,在找到性能瓶颈后,就得使用对应的性能方法去优化它。我觉得要做性能优化,可以从两方面入手:
所有的性能优化手段都可以归纳为以上两类。其中对性能影响最大、收益最大的是在页面加载时进行优化。
从上图可以看到,一共有 23 条性能优化方法,其中加载时优化有 10 条,运行时优化有 13 条。由于篇幅有限,这 23 条性能优化方法不能逐一展开细讲,就讲讲其中的一条吧 使用 CDN。
内容分发网络(CDN)是一组分布在多个不同地理位置的 Web 服务器。我们都知道,当服务器离用户越远时,延迟越高。CDN 就是为了解决这一问题,在多个位置部署服务器,让用户离服务器更近,从而缩短请求时间。
当用户访问一个网站时,如果没有 CDN,过程是这样的:
如果用户访问的网站部署了 CDN,过程是这样的:
由于篇幅有限,文中提及的一共 23 条性能优化方法可以看我的这篇文章前端性能优化 24 条建议(2020)。
在所有性能优化方法中,收益最大的有三个:压缩、懒加载和分包、缓存策略。绝大多数的应用做了这三个优化后,页面性能都能得到极大的提升。
压缩包含代码压缩和文件压缩,常用的代码压缩工具有 terser、uglify,文件压缩一般使用 gzip。1m 的文件使用 gzip 压缩后体积一般是 300-400kb。
压缩通常情况都是在前端打包的时候做,然后将打包好的文件上传到服务器。用户访问网站时,nginx 先查看用户访问的资源是否有 .gz 后缀的文件(gzip 压缩后的文件),如果有就返回,没有就自己压缩后再返回。这一块需要在 nginx 上进行配置才支持,默认不开启。尽量不要让 nginx 压缩,因为访问量高的时候,对服务器压力很大。
压缩是对整体项目的体积大小进行优化。
路由懒加载基本上每个前端都会,但是某些系统仍然需要手动优化。比如一些构建工具会默认把所有的第三方包都打在 verdor.js 文件里。但实际上并不是所有的页面都需要把所有的第三方包都加载进来,所以需要做好具体的分包策略来进行优化。分包主要是为了对打包好的资源进行拆分,让一些不是所有页面都要使用的资源做到懒加载。
懒加载和分包不改变项目的体积大小,而是将一些不是那么重要的资源放到后面再加载。比如有 10 个页面的资源,每个 1m,假设加载时间为 1 秒,都做成懒加载后,每次访问页面只需要一秒,而不是都打包在一起,首次访问要 10 秒。
浏览器缓存分为强制缓存和协商缓存,强制缓存就是缓存生效期间,浏览器会直接使用缓存的资源,而不会发起请求。协商缓存就是浏览器发起请求后,发现文件未变化,然后再使用缓存。
缓存策略就是围绕着强制缓存、协商缓存做的优化方案。在做优化之前,还要给大家再介绍一下缓存命中率。
缓存命中率=缓存命中的资源/所有请求的资源。缓存命中率越高,说明你的缓存策略做得越好。
缓存策略一般通过 nginx 来实现,当然也可以自己手写代码实现。现在常用的缓存策略是:
cache-control: no-cache,每次浏览器请求 html 时都要向服务器发起请求,查询 html 文件是否有变化,即协商缓存这样优化后,除了首次打开页面需要加载静态资源,后面再打开页面就不需要了,所以能在瞬间打开页面。当项目代码更新后,相关的 js、css 资源文件会发生变化,其他不变的部分,代码不会变化。当资源文件发生变化后,html 也会发生变化(引用的资源文件名称变了)。然后浏览器会重新加载 html 中发生变更的资源,没有变化的资源会使用缓存。目前只有 webpack 支持根据文件内容生成 hash,所以说 vite 是代替不了 webpack 的,它们会同时存在。
想了解如何利用 webpack 实现文件精确缓存的,可以看我这篇文章:webpack + express 实现文件精确缓存
现在我们再看一下其他比较知名的网站是怎么做缓存的。
一些比较好例子:
不好的例子:
为了避免不必要的问题,不好的示例还是不帖了,但是大家可以找一些小网站或者小公司的官网看看,基本上都没怎么做性能优化。
另外,有些细心的同学可能会发现即使没有设置 cache-control,浏览器也会进行缓存。这是因为没有设置 cache-control 响应头时,浏览器将自行选择缓存策略。
浏览器默认行为:即使响应头部中没有设置 Cache-Control 和 Expires,浏览器仍然会缓存某些资源,这是浏览器的默认行为,是为了提升性能进行的优化,每个浏览器的行为可能不一致,有些浏览器甚至没有这样的优化。
在绝大多数的单页面应用(SPA)中,页面采用懒加载的策略,并且通过打包工具实现代码压缩,基本上不会有性能问题。但是随着项目规模的扩大,可能会出现性能问题,这时就需要做性能优化了。
但是,性能优化并非无止境的进行。我们需要充分考虑优化的成本和收益,而不是盲目地采用所有可能的优化方法,因为这将带来过高的开发和维护成本。只有当项目的性能表现无法满足预设的性能指标时,我们才需要进行进一步的优化。这样,我们可以在保证项目性能的同时,也能控制好优化的成本。
举例,性能优化实战中说到 vite 不能实现按内容进行 hash。也可以打包时用 webpack 来替代 vite。但成本比较高,没什么必要,除非对性能有极端的要求。
如果做好了项目的整体架构设计(结合性能优化方法论、前端工程化、合理的研发流程、代码规范和 CodeReview),不好的代码对性能影响很小,除非写一些死循环代码。当然,前端工程化这些概念非常宽泛也不好理解,有兴趣可以看我写的这一本电子书:带你入门前端工程
举例,一个页面几千行代码会不会影响页面性能。如果这个页面确实需要这些代码,那说明代码总量不会变,再怎么拆分还是那么多代码。所有代码写在一个页面只会影响代码可读性,而不会影响性能。
关于性能优化的内容已经说完了,但是我还想说点别的,主要想说一下我们应该学习哪些技术才能让它更加保值。
在我看来,越偏向于应用层面的技术越容易过时,越偏向于底层的技术越不容易过时。 性能优化方法论是偏向于底层的,它不容易过时。为什么呢?
因为对于性能优化的理解和掌握,更接近于计算机科学的底层原理。这些原理包括但不限于算法复杂度、内存管理、数据结构的选择和使用、计算机网络知识等。这些基础理论并不会因为应用环境或者具体的技术实现的变化而变得过时。
虽然前端技术的发展非常快,也涌现出很多的框架(例如 HTML4 到 HTML5 的升级,或者从jQuery 到前端三大框架的转变),但是性能优化的基础理论是相对固定的。例如,无论在什么情况下,减少 HTTP 请求、合理利用浏览器缓存、代码压缩和合并、选择正确的数据结构和算法等都是通用的优化策略。
因此,从这个角度来看,理解和掌握性能优化的理论,是一种更为根本的、不易过时的技能。而且这种技能不仅适用于前端开发,也同样适用于其他计算机科学的领域。
我们学习技术也一样,应用层面的技术不要出一个新东西就去学,通常情况下只学对工作有用的就可以了,避免浪费时间。剩下的时间尽量去学习偏底层的技术,从前端的角度来看,可以学习脚手架、性能优化、微前端、监控、浏览器渲染原理等知识。当然,我更建议大家成为一个全栈,不要把自己的定位局限于前端。
低代码系列文章:
低代码相关仓库:
ChatGPT,作为一个先进的自然语言处理工具,可以理解和生成人类语言,提供智能编程建议,自动化代码生成,以及提供交互式编程教学。这些功能为开发者提供了前所未有的便利,大大减少了编程的时间和复杂性。
低代码平台则允许用户通过图形界面来构建应用,减少了对专业编程知识的依赖,在特定业务场景下能够提升开发效率。用户可以通过拖放组件和模型驱动的逻辑来快速地创建应用程序,而无需编写大量代码。
如果可以把 ChatGPT 和低代码平台结合起来使用,那么用户就可以通过对话来快速地创建应用程序,从而简化了搭建应用程序的过程,并且提升了用户体验。
低代码平台通常使用 JSON 格式的 DSL(领域特定语言 domain-specific language 指的是专注于某个应用程序领域的计算机语言) 来描述一个页面。用户拖拽组件、编辑页面,实际上是在和页面的 JSON 在进行交互。低代码平台通过渲染引擎把 JSON 数据渲染成为页面,至于页面要渲染成为 Vue、React 或者是纯粹的 HTML 页面,就得看各个低代码平台自己的实现了。一个应用程序一般会包含多个页面,然后通过路由来决定各个页面的跳转逻辑。
因此,我们可以向 ChatGPT 提出生成页面的需求,ChatGPT 再根据我们提供的 prompt 来生成一份符合低代码平台数据格式的 JSON。理论上,这是可行的,现在来看一下怎么实现这个功能。
首先,我们需要注册一个 openai 或者 azure 账号,在上面开通 api 服务(如何申请账号请自行搜索,网上有很多教程)。然后就可以使用这个 api 来和 ChatGPT 进行交互了。
另外,我们还需要一个低代码平台,因为生成的 JSON 需要一个低代码平台来验证生成 JSON 是否真实可用。刚好前几年我写了一个低代码平台教学项目,现在刚好可以用上。
首先,我们要知道每一个组件的 DSL 描述,下面的代码是一个文本组件的 DSL 描述:
{
"animations": [], // 动画属性
"events": {}, // 事件
"groupStyle": {}, // 组合组件样式
"isLock": false, // 是否锁定
"collapseName": "style",
"linkage": { // 联动组件
"duration": 0,
"data": [
{
"id": "",
"label": "",
"event": "",
"style": [
{
"key": "",
"value": ""
}
]
}
]
},
"component": "VText", // 组件类型
"label": "文字", // 组件名称
"propValue": "双击编辑文字", // 组件值
"icon": "wenben", // 组件图标
"request": { // 组件 API 请求
"method": "GET",
"data": [],
"url": "",
"series": false,
"time": 1000,
"paramType": "",
"requestCount": 0
},
"style": { // 组件样式
"rotate": 0,
"opacity": 1,
"width": 200,
"height": 28,
"fontSize": "",
"fontWeight": 400,
"lineHeight": "",
"letterSpacing": 0,
"textAlign": "",
"color": "",
"top": 157,
"left": 272
},
"id": "07l4byRWvsphAPo2uatxy" // 组件唯一 id
}每一个组件就是一个 JSON 数据,那么整个页面就是一个 JSON 数组,里面包含了多个组件:
// 页面 JSON
[
{ ... }, // 组件1
{ ... }, // 组件2
{ ... }, // 组件3
]要让 ChatGPT 来生成页面,那么我们要让 ChatGPT 知道页面、组件的数据结构,并且要给它提供示例。然后再向它提出页面生成的需求,从而为我们生成符合要求的页面。这个 prompt 的格式如下:
我有一个低代码平台项目,它可以根据符合规范的 JSON 数据生成页面,这个 JSON 数据是一个数组,里面的每一项都是一个 JSON 对象,每个 JSON 对象都对应着一个组件。
下面用 ### 包括起来的代码就是所有的组件列表。
###
---所有组件的 JSON 数据结构---
###
如果一个页面包含了一个文本和按钮组件,那么这个页面的 JSON 代码如下:
###
---示例页面 JSON 数据结构---
###
你作为一个技术专家,现在需要按照上面的规则来为我生成页面,并且生成的页面中每一个组件的属性都不能忽略,也不需要解释,只需要返回 JSON 数据即可。要注意的是,有些数值的单位是没有 px 的。
现在我需要生成一个海报页面,主要用于宣传编程有什么用。
由于篇幅有限,上面只展示了这个 prompt 的大纲,JSON 数据都省略了。完整的 prompt 请在 lowcode-llm-demo 上查看。
prompt 准备好了,现在我们需要调用 ChatGPT 的 api 来生成页面,示例代码如下:
import { AzureChatOpenAI } from '@langchain/azure-openai'
import 'dotenv/config'
import { readFileSync } from 'fs'
import { resolve, dirname } from 'path'
import { fileURLToPath } from 'url'
const model = new AzureChatOpenAI({
modelName: process.env.AZURE_OPENAI_API_MODEL_NAME,
azureOpenAIEndpoint: process.env.AZURE_OPENAI_API_ENDPOINT,
azureOpenAIApiKey: process.env.AZURE_OPENAI_API_KEY,
azureOpenAIEmbeddingsApiDeploymentName: process.env.AZURE_OPENAI_API_EMBEDDING_DEPLOYMENT_NAME,
azureOpenAIApiVersion: process.env.AZURE_OPENAI_API_VERSION,
})
const dirName = dirname(fileURLToPath(import.meta.url))
const prompt = readFileSync(resolve(dirName, '../prompts/prompt-compress.md'), 'utf-8')
const response = await model.invoke(prompt)
console.log(JSON.stringify(response)) // 返回 ChatGPT 的结果上面的代码执行后就能得到 ChatGPT 返回来的页面 JSON 数据。不过这个数据不能直接使用,还需要额外写点代码处理一下才能使用。下面的代码就是处理后的页面 JSON 数据结构:
[
{
"animations": [],
"events": {},
"groupStyle": {},
"isLock": false,
"collapseName": "style",
"linkage": {
"duration": 0,
"data": [
{
"id": "",
"label": "",
"event": "",
"style": [
{
"key": "",
"value": ""
}
]
}
]
},
"component": "Picture",
"label": "背景图片",
"propValue": {
"url": "img/programming_poster_bg.jpg" // 替换为自己的图片
},
"style": {
"rotate": 0,
"opacity": 1,
"width": 500,
"height": 700,
"top": 0,
"left": 0,
"position": "absolute",
"zIndex": 0
},
"id": "backgroundImage"
},
{
"animations": [],
"events": {},
"groupStyle": {},
"isLock": false,
"collapseName": "style",
"linkage": {
"duration": 0,
"data": [
{
"id": "",
"label": "",
"event": "",
"style": [
{
"key": "",
"value": ""
}
]
}
]
},
"component": "VText",
"label": "标题文字",
"propValue": "编程改变世界",
"icon": "wenben",
"style": {
"rotate": 0,
"opacity": 1,
"width": 450,
"height": 100,
"fontSize": "32px",
"fontWeight": 700,
"textAlign": "center",
"color": "rgba(16, 15, 15, 1)",
"top": 50,
"left": 25,
"position": "absolute",
"zIndex": 10
},
"id": "titleText"
},
{
"animations": [],
"events": {},
"groupStyle": {},
"isLock": false,
"collapseName": "style",
"linkage": {
"duration": 0,
"data": [
{
"id": "",
"label": "",
"event": "",
"style": [
{
"key": "",
"value": ""
}
]
}
]
},
"component": "VText",
"label": "描述文字",
"propValue": "通过编程,我们可以创建软件来解决问题、分析数据,甚至改善人们的生活。",
"icon": "wenben",
"style": {
"rotate": 0,
"opacity": 1,
"width": 400,
"height": 200,
"fontSize": "18px",
"fontWeight": 400,
"lineHeight": "1.5",
"textAlign": "center",
"color": "rgba(33, 31, 31, 1)",
"top": 180,
"left": 50,
"position": "absolute",
"zIndex": 10
},
"id": "descriptionText"
},
{
"animations": [],
"events": {},
"groupStyle": {},
"isLock": false,
"collapseName": "style",
"linkage": {
"duration": 0,
"data": [
{
"id": "",
"label": "",
"event": "",
"style": [
{
"key": "",
"value": ""
}
]
}
]
},
"component": "VButton",
"label": "行动按钮",
"propValue": "开始学习编程",
"icon": "button",
"style": {
"rotate": 0,
"opacity": 1,
"width": 200,
"height": 50,
"borderRadius": "25px",
"fontSize": "20px",
"fontWeight": 500,
"textAlign": "center",
"color": "#FFF",
"backgroundColor": "#f44336",
"top": 420,
"left": 150,
"position": "absolute",
"zIndex": 10
},
"id": "actionButton"
}
]将 JSON 导入到低代码平台后,生成的页面如下所示:
可以看到 ChatGPT 输出了一个半成品页面,背景图片的地址需要我们手动修改。ChatGPT 每次输出的页面都是随机的,下面是生成的另外一个页面。
ChatGPT 很好用,但是有一个缺点,太贵了。所以我们需要想一些办法来降低成本,下面是几个比较可行的办法:
ChatGPT 的 api 是通过 token 来收费的,所以最简单直接的方法就是优化 prompt。下面是一个未优化的 prompt 示例:
我需要一个用户管理系统的页面。在页面顶部,我需要一个添加用户的按钮。下面是一个表格,列出了所有用户的姓名、邮箱和注册日期。点击任何一个用户,将会打开一个包含完整用户信息的新页面,其中包含姓名、邮箱、注册日期、最后登录时间和用户角色。还需要有一个搜索栏,可以通过姓名或邮箱搜索用户。请基于这些要求为我的低代码平台生成代码。
现在将这个 prompt 优化一下:
生成页面:用户管理
组件:添加按钮,用户表格(姓名,邮箱,注册日期),用户详情(姓名,邮箱,注册日期,最后登录,角色),搜索栏(姓名,邮箱)
在这个例子中,我们简化了描述页面的需求,从而减少了 token 的数量。
在文章的开头,我展示了一个生成页面的 prompt 示例,并且可以看到这个 prompt 消耗的 token 数量非常大,因为它需要告诉 ChatGPT 每个组件的 JSON 数据结构是什么,以及一个完整的示例页面 JSON 数据结构是什么样的,这些示例都需要消耗大量的 token。
为了精简 prompt,同时又能达到未精简前的效果,这可以使用微调来实现。
微调是一种机器学习技术,它可以让你自定义机器学习模型以适应特定的任务或数据集。通过微调,您可以在一个预训练的模型(如ChatGPT)的基础上进一步训练它,使其更好地理解和执行特定的任务。这样,您可以创建一个专门为您的低代码平台生成页面的模型。
我们可以给 ChatGPT 提供大量的数据集进行微调训练,比如大量的低代码页面示例。这样你再让它生成一个“用于宣传编程的海报页面”,就不需要提供每个组件的数据结构了,因为这些数据 ChatGPT 已经通过微调学会了。
现在来看一下用于微调训练的数据集是什么样的:
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}上面是数据集的格式,现在我要提供大量的低代码平台数据集:
{"prompt":"生成一个带有矩形组件的页面","completion": "[{\"animations\":[],\"events\":{},\"groupStyle\":{},\"isLock\":false,\"collapseName\":\"style\",\"linkage\":{\"duration\":0,\"data\":[{\"id\":\"\",\"label\":\"\",\"event\":\"\",\"style\":[{\"key\":\"\",\"value\":\"\"}]}]},\"component\":\"RectShape\",\"label\":\"矩形\",\"propValue\":\"矩形\",\"icon\":\"juxing\",\"style\":{\"rotate\":0,\"opacity\":1,\"width\":200,\"height\":200,\"fontSize\":\"\",\"fontWeight\":400,\"lineHeight\":\"\",\"letterSpacing\":0,\"textAlign\":\"center\",\"color\":\"\",\"borderColor\":\"#000\",\"borderWidth\":1,\"backgroundColor\":\"\",\"borderStyle\":\"solid\",\"borderRadius\":\"\",\"verticalAlign\":\"middle\",\"top\":143,\"left\":379},\"id\":\"j3i41NnZw8Zcxu3BfbXwv\"}]"}
{"prompt":"生成一个带有文本组件的页面","completion": "[{\"animations\":[],\"events\":{},\"groupStyle\":{},\"isLock\":false,\"collapseName\":\"style\",\"linkage\":{\"duration\":0,\"data\":[{\"id\":\"\",\"label\":\"\",\"event\":\"\",\"style\":[{\"key\":\"\",\"value\":\"\"}]}]},\"component\":\"VText\",\"label\":\"文字\",\"propValue\":\"双击编辑文字\",\"icon\":\"wenben\",\"request\":{\"method\":\"GET\",\"data\":[],\"url\":\"\",\"series\":false,\"time\":1000,\"paramType\":\"\",\"requestCount\":0},\"style\":{\"rotate\":0,\"opacity\":1,\"width\":200,\"height\":28,\"fontSize\":\"\",\"fontWeight\":400,\"lineHeight\":\"\",\"letterSpacing\":0,\"textAlign\":\"\",\"color\":\"\",\"top\":145.3333282470703,\"left\":195},\"id\":\"WKqULBX4bKcmREgPJef3D\"}]"}
{"prompt":"生成一个带有按钮组件的页面","completion": "[{\"animations\":[],\"events\":{},\"groupStyle\":{},\"isLock\":false,\"collapseName\":\"style\",\"linkage\":{\"duration\":0,\"data\":[{\"id\":\"\",\"label\":\"\",\"event\":\"\",\"style\":[{\"key\":\"\",\"value\":\"\"}]}]},\"component\":\"VButton\",\"label\":\"按钮\",\"propValue\":\"按钮\",\"icon\":\"button\",\"style\":{\"rotate\":0,\"opacity\":1,\"width\":100,\"height\":34,\"borderWidth\":1,\"borderColor\":\"\",\"borderRadius\":\"\",\"fontSize\":\"\",\"fontWeight\":400,\"lineHeight\":\"\",\"letterSpacing\":0,\"textAlign\":\"\",\"color\":\"\",\"backgroundColor\":\"\",\"top\":126.33332824707031,\"left\":224},\"id\":\"6wgvR1wyRyNqIl37qs1iS\"}]"}
...通过微调训练后,ChatGPT 就变成了一个专门的低代码模型,它会更好地理解低代码的需求。后面我们再让 ChatGPT 生成页面就不需要大量的 prompt 了,可以直接让它生成一个“用于宣传编程的海报页面”。记住,微调是一个需要精心设计和执行的过程,需要我们不停的校正,才能达到最好的效果。
一个成功的低代码平台,一定会内置大量的模板,包括但不限于页面模板、应用模板等等。其实在大多数时候,用户提出生成页面的需求时,我们可以提取关键词,根据关键词找到符合用户需求的模板,再展示给用户选择。如果没有找到符合要求的模板,才使用 ChatGPT 来生成页面,这样不仅能节省成本,还避免了 ChatGPT 随机生成页面并且有可能生成错误页面的弊端。
现在我们来看看怎么做。首先,除了给模板命名,还需要给模板归类,比如打上几个类似于“医疗”、“后台管理系统”之类的标签。
当用户提出一个”生成用于宣传编程的页面“需求时,我们可以使用自然语言处理(NLP)库,如 natural 或者 compromise 进行关键词提取,然后再通过 Elasticsearch 来进行搜索,最后把搜索到的模板返回给用户。下面是代码示例:
const { Client } = require('@elastic/elasticsearch');
const { NlpManager } = require('node-nlp');
// 初始化Elasticsearch客户端
const client = new Client({ node: 'http://localhost:9200' });
// 初始化NLP管理器
const nlpManager = new NlpManager({ languages: ['en'], nlu: { useNoneFeature: false } });
// 假设我们有一些模板数据
const templates = [
{ name: 'Medical Service Promotion Page', tags: ['medical', 'promotion'] },
{ name: 'Programming Education Poster', tags: ['education', 'programming', 'poster'] },
{ name: 'Backend Management System Dashboard', tags: ['backend', 'management', 'system'] }
];
// 创建Elasticsearch索引
async function createIndex(indexName) {
// 省略创建索引代码
}
// 索引模板数据到Elasticsearch
async function indexTemplates(indexName, templates) {
// 省略索引数据代码
}
// 提取关键词
async function extractKeywords(text) {
const result = await nlpManager.extractEntities(text);
const keywords = result.entities.map(entity => entity.option || entity.utteranceText);
return keywords;
}
// 使用Elasticsearch进行搜索
async function searchTemplates(indexName, keywords) {
const { body } = await client.search({
index: indexName,
body: {
query: {
bool: {
should: [
{ match: { name: { query: keywords.join(' '), boost: 2 } } },
{ terms: { tags: keywords } }
]
}
}
}
});
return body.hits.hits.map(hit => hit._source);
}
// 主程序
async function main() {
const indexName = 'templates';
// 创建索引并索引数据
await createIndex(indexName);
await indexTemplates(indexName, templates);
// 用户输入
const userInput = "I want to create a poster page for programming promotion";
// 提取关键词
const keywords = await extractKeywords(userInput);
// 执行搜索
const results = await searchTemplates(indexName, keywords);
// 输出结果
console.log(results);
}
main().catch(console.error);对于无法使用外网或预算有限的项目,我们可以考虑使用开源的大语言模型。本文选了 ChatGLM-6B 开源模型来做演示。
ChatGLM-6B 本地部署的教程网上有很多,由于我的电脑是 Windows,并且没有 N 卡,所以我参考了这篇文章手把手教你本地部署清华大学KEG的ChatGLM-6B模型来部署 ChatGLM-6B。
这篇文章讲得很细致,按照流程走下来只出现了两个小问题,解决后就跑通了。这里也记录一下这两个问题及相应的解决办法。
按照文章中的要求安装了 TDM-GCC 后发现编译 quantization_kernels_parallel.c 文件错误,卸载 TDM-GCC 后换了 MinGW-w64 就好了,编译顺利通过。
这个问题排查了很久,经过不断的调试和重启,最后发现是系统资源不足(我的电脑 CPU 是 6800H,32G 内存,没有显卡)。在关掉无关程序后,只保留一个终端用于启动脚本后,就没有问题了。
ChatGLM-6B 的相关代码已经上传到了 Github ,大家可以把项目下载下来,然后按照仓库文档中的说明修改目录位置后,就可以执行 cli-demo.py 或者 web-demo.py 脚本和 ChatGLM-6B 进行交互了。下面的几张图片就是部署在我电脑上的 ChatGLM-6B 使用示例:
由于电脑配置不是特别好,ChatGLM-6B 在我电脑上运行起来比较慢,一个问题回答起来要花几分钟。像生成低代码页面的这个需求,就跑了十几分钟,最后程序直接崩了,只给我输出了一半的 JSON,不过数据结构是对的,所以换个好点的显卡后应该不是问题。
其实,大语言模型不仅能和低代码领域配合使用,经过训练后的模型可以和任何领域结合,从而生成该领域的专门模型。例如 Figma、即时设计、MasterGo 这种设计工具,它们存储的也是一份 JSON 数据。所以理论上也可以通过对话来生成设计页面。
还有其他的类似于 AI 客服、催收机器人都可以通过这种方法训练出来。
最近在给一个 nestjs 项目写单元测试(Unit Testing)和 e2e 测试(End-to-End Testing,端到端测试,简称 e2e 测试),这是我第一次给后端项目写测试,发现和之前给前端项目写测试还不太一样,导致在一开始写测试时感觉无从下手。后来在看了一些示例之后才想明白怎么写测试,所以打算写篇文章记录并分享一下,以帮助和我有相同困惑的人。
同时我也写了一个 demo 项目,相关的单元测试、e2e 测试都写好了,有兴趣可以看一下。代码已上传到 Github: nestjs-demo。
单元测试和 e2e 测试都是软件测试的方法,但它们的目标和范围有所不同。
单元测试是对软件中的最小可测试单元进行检查和验证。比如一个函数、一个方法都可以是一个单元。在单元测试中,你会对这个函数的各种输入给出预期的输出,并验证功能的正确性。单元测试的目标是快速发现函数内部的 bug,并且它们容易编写、快速执行。
而 e2e 测试通常通过模拟真实用户场景的方法来测试整个应用,例如前端通常使用浏览器或无头浏览器来进行测试,后端则是通过模拟对 API 的调用来进行测试。
在 nestjs 项目中,单元测试可能会测试某个服务(service)、某个控制器(controller)的一个方法,例如测试 Users 模块中的 update 方法是否能正确的更新一个用户。而一个 e2e 测试可能会测试一个完整的用户流程,如创建一个新用户,然后更新他们的密码,然后删除该用户。这涉及了多个服务和控制器。
为一个工具函数或者不涉及接口的方法编写单元测试,是非常简单的,你只需要考虑各种输入并编写相应的测试代码就可以了。但是一旦涉及到接口,那情况就复杂了。用代码来举例:
async validateUser(
username: string,
password: string,
): Promise<UserAccountDto> {
const entity = await this.usersService.findOne({ username });
if (!entity) {
throw new UnauthorizedException('User not found');
}
if (entity.lockUntil && entity.lockUntil > Date.now()) {
const diffInSeconds = Math.round((entity.lockUntil - Date.now()) / 1000);
let message = `The account is locked. Please try again in ${diffInSeconds} seconds.`;
if (diffInSeconds > 60) {
const diffInMinutes = Math.round(diffInSeconds / 60);
message = `The account is locked. Please try again in ${diffInMinutes} minutes.`;
}
throw new UnauthorizedException(message);
}
const passwordMatch = bcrypt.compareSync(password, entity.password);
if (!passwordMatch) {
// $inc update to increase failedLoginAttempts
const update = {
$inc: { failedLoginAttempts: 1 },
};
// lock account when the third try is failed
if (entity.failedLoginAttempts + 1 >= 3) {
// $set update to lock the account for 5 minutes
update['$set'] = { lockUntil: Date.now() + 5 * 60 * 1000 };
}
await this.usersService.update(entity._id, update);
throw new UnauthorizedException('Invalid password');
}
// if validation is sucessful, then reset failedLoginAttempts and lockUntil
if (
entity.failedLoginAttempts > 0 ||
(entity.lockUntil && entity.lockUntil > Date.now())
) {
await this.usersService.update(entity._id, {
$set: { failedLoginAttempts: 0, lockUntil: null },
});
}
return { userId: entity._id, username } as UserAccountDto;
}上面的代码是 auth.service.ts 文件里的一个方法 validateUser,主要用于验证登录时用户输入的账号密码是否正确。它包含的逻辑如下:
username 查看用户是否存在,如果不存在则抛出 401 异常(也可以是 404 异常)password 加密后和数据库中的密码进行对比,如果错误则抛出 401 异常(连续三次登录失败会被锁定账户 5 分钟)id 和 username 到下一阶段可以看到 validateUser 方法包含了 4 个处理逻辑,我们需要对这 4 点都编写对应的单元测试代码,以确定整个 validateUser 方法功能是正常的。
在开始编写单元测试时,我们会遇到一个问题,findOne 方法需要和数据库进行交互,它要通过 username 查找数据库中是否存在对应的用户。但如果每一个单元测试都得和数据库进行交互,那测试起来会非常麻烦。所以可以通过 mock 假数据来实现这一点。
举例,假如我们已经注册了一个 woai3c 的用户,那么当用户登录时,在 validateUser 方法中能够通过 const entity = await this.usersService.findOne({ username }); 拿到用户数据。所以只要确保这行代码能够返回想要的数据,即使不和数据库交互也是没有问题的。而这一点,我们能通过 mock 数据来实现。现在来看一下 validateUser 方法的相关测试代码:
import { Test } from '@nestjs/testing';
import { AuthService } from '@/modules/auth/auth.service';
import { UsersService } from '@/modules/users/users.service';
import { UnauthorizedException } from '@nestjs/common';
import { TEST_USER_NAME, TEST_USER_PASSWORD } from '@tests/constants';
describe('AuthService', () => {
let authService: AuthService; // Use the actual AuthService type
let usersService: Partial<Record<keyof UsersService, jest.Mock>>;
beforeEach(async () => {
usersService = {
findOne: jest.fn(),
};
const module = await Test.createTestingModule({
providers: [
AuthService,
{
provide: UsersService,
useValue: usersService,
},
],
}).compile();
authService = module.get<AuthService>(AuthService);
});
describe('validateUser', () => {
it('should throw an UnauthorizedException if user is not found', async () => {
await expect(
authService.validateUser(TEST_USER_NAME, TEST_USER_PASSWORD),
).rejects.toThrow(UnauthorizedException);
});
// other tests...
});
});我们通过调用 usersService 的 fineOne 方法来拿到用户数据,所以需要在测试代码中 mock usersService 的 fineOne 方法:
beforeEach(async () => {
usersService = {
findOne: jest.fn(), // 在这里 mock findOne 方法
};
const module = await Test.createTestingModule({
providers: [
AuthService, // 真实的 AuthService,因为我们要对它的方法进行测试
{
provide: UsersService, // 用 mock 的 usersService 代替真实的 usersService
useValue: usersService,
},
],
}).compile();
authService = module.get<AuthService>(AuthService);
});通过使用 jest.fn() 返回一个函数来代替真实的 usersService.findOne()。如果这时调用 usersService.findOne() 将不会有任何返回值,所以第一个单元测试用例就能通过了:
it('should throw an UnauthorizedException if user is not found', async () => {
await expect(
authService.validateUser(TEST_USER_NAME, TEST_USER_PASSWORD),
).rejects.toThrow(UnauthorizedException);
});因为在 validateUser 方法中调用 const entity = await this.usersService.findOne({ username }); 的 findOne 是 mock 的假函数,没有返回值,所以 validateUser 方法中的第 2-4 行代码就能执行到了:
if (!entity) {
throw new UnauthorizedException('User not found');
}抛出 401 错误,符合预期。
validateUser 方法中的第二个处理逻辑是判断用户是否锁定,对应的代码如下:
if (entity.lockUntil && entity.lockUntil > Date.now()) {
const diffInSeconds = Math.round((entity.lockUntil - Date.now()) / 1000);
let message = `The account is locked. Please try again in ${diffInSeconds} seconds.`;
if (diffInSeconds > 60) {
const diffInMinutes = Math.round(diffInSeconds / 60);
message = `The account is locked. Please try again in ${diffInMinutes} minutes.`;
}
throw new UnauthorizedException(message);
}可以看到如果用户数据里有锁定时间 lockUntil 并且锁定结束时间大于当前时间就可以判断当前账户处于锁定状态。所以需要 mock 一个具有 lockUntil 字段的用户数据:
it('should throw an UnauthorizedException if the account is locked', async () => {
const lockedUser = {
_id: TEST_USER_ID,
username: TEST_USER_NAME,
password: TEST_USER_PASSWORD,
lockUntil: Date.now() + 1000 * 60 * 5, // The account is locked for 5 minutes
};
usersService.findOne.mockResolvedValueOnce(lockedUser);
await expect(
authService.validateUser(TEST_USER_NAME, TEST_USER_PASSWORD),
).rejects.toThrow(UnauthorizedException);
});在上面的测试代码里,先定义了一个对象 lockedUser,这个对象里有我们想要的 lockUntil 字段,然后将它作为 findOne 的返回值,这通过 usersService.findOne.mockResolvedValueOnce(lockedUser); 实现。然后 validateUser 方法执行时,里面的用户数据就是 mock 出来的数据了,从而成功让第二个测试用例通过。
剩下的两个测试用例就不写了,原理都是一样的。如果剩下的两个测试不写,那么这个 validateUser 方法的单元测试覆盖率会是 50%,如果 4 个测试用例都写完了,那么 validateUser 方法的单元测试覆盖率将达到 100%。
单元测试覆盖率(Code Coverage)是一个度量,用于描述应用程序代码有多少被单元测试覆盖或测试过。它通常表示为百分比,表示在所有可能的代码路径中,有多少被测试用例覆盖。
单元测试覆盖率通常包括以下几种类型:
if/else 语句)。单元测试覆盖率是衡量单元测试质量的一个重要指标,但并不是唯一的指标。高的覆盖率可以帮助检测代码中的错误,但并不能保证代码的质量。覆盖率低可能意味着有未被测试的代码,可能存在未被发现的错误。
下图是 demo 项目的单元测试覆盖率结果:
像 service 和 controller 之类的文件,单元测试覆盖率一般尽量高点比较好,而像 module 这种文件就没有必要写单元测试了,也没法写,没有意义。上面的图片表示的是整个单元测试覆盖率的总体指标,如果你想查看某个函数的测试覆盖率,可以打开项目根目录下的 coverage/lcov-report/index.html 文件进行查看。例如我想查看 validateUser 方法具体的测试情况:
可以看到原来 validateUser 方法的单元测试覆盖率并不是 100%,还是有两行代码没有执行到,不过也无所谓了,不影响 4 个关键的处理节点,不要片面的追求高测试覆盖率。
在单元测试中我们展示了如何为 validateUser() 的每一个功能点编写单元测试,并且使用了 mock 数据的方法来确保每个功能点都能够被测试到。而在 e2e 测试中,我们需要模拟真实的用户场景,所以要连接数据库来进行测试。因此,这次测试的 auth.service.ts 模块里的方法都会和数据库进行交互。
auth 模块主要有以下几个功能:
e2e 测试需要将这六个功能都测试一遍,从注册开始,到删除用户结束。在测试时,我们可以建一个专门的测试用户来进行测试,测试完成后再删除这个测试用户,这样就不会在测试数据库中留下无用的信息了。
beforeAll(async () => {
const moduleFixture: TestingModule = await Test.createTestingModule({
imports: [AppModule],
}).compile()
app = moduleFixture.createNestApplication()
await app.init()
// 执行登录以获取令牌
const response = await request(app.getHttpServer())
.post('/auth/register')
.send({ username: TEST_USER_NAME, password: TEST_USER_PASSWORD })
.expect(201)
accessToken = response.body.access_token
refreshToken = response.body.refresh_token
})
afterAll(async () => {
await request(app.getHttpServer())
.delete('/auth/delete-user')
.set('Authorization', `Bearer ${accessToken}`)
.expect(200)
await app.close()
})beforeAll 钩子函数将在所有测试开始之前执行,所以我们可以在这里注册一个测试账号 TEST_USER_NAME。afterAll 钩子函数将在所有测试结束之后执行,所以在这删除测试账号 TEST_USER_NAME 是比较合适的,还能顺便对注册和删除两个功能进行测试。
在上一节的单元测试中,我们编写了关于 validateUser 方法的相关单元测试。其实这个方法是在登录时执行的,用于验证用户账号密码是否正确。所以这一次的 e2e 测试也将使用登录流程来展示如何编写 e2e 测试用例。
整个登录测试流程总共包含了五个小测试:
describe('login', () => {
it('/auth/login (POST)', () => {
// ...
})
it('/auth/login (POST) with user not found', () => {
// ...
})
it('/auth/login (POST) without username or password', async () => {
// ...
})
it('/auth/login (POST) with invalid password', () => {
// ...
})
it('/auth/login (POST) account lock after multiple failed attempts', async () => {
// ...
})
})这五个测试分别是:
现在我们开始编写 e2e 测试:
// 登录成功
it('/auth/login (POST)', () => {
return request(app.getHttpServer())
.post('/auth/login')
.send({ username: TEST_USER_NAME, password: TEST_USER_PASSWORD })
.expect(200)
})
// 如果用户不存在,应该抛出 401 异常
it('/auth/login (POST) with user not found', () => {
return request(app.getHttpServer())
.post('/auth/login')
.send({ username: TEST_USER_NAME2, password: TEST_USER_PASSWORD })
.expect(401) // Expect an unauthorized error
})e2e 的测试代码写起来比较简单,直接调用接口,然后验证结果就可以了。比如登录成功测试,我们只要验证返回结果是否是 200 即可。
前面四个测试都比较简单,现在我们看一个稍微复杂点的 e2e 测试,即验证账户是否被锁定。
it('/auth/login (POST) account lock after multiple failed attempts', async () => {
const moduleFixture: TestingModule = await Test.createTestingModule({
imports: [AppModule],
}).compile()
const app = moduleFixture.createNestApplication()
await app.init()
const registerResponse = await request(app.getHttpServer())
.post('/auth/register')
.send({ username: TEST_USER_NAME2, password: TEST_USER_PASSWORD })
const accessToken = registerResponse.body.access_token
const maxLoginAttempts = 3 // lock user when the third try is failed
for (let i = 0; i < maxLoginAttempts; i++) {
await request(app.getHttpServer())
.post('/auth/login')
.send({ username: TEST_USER_NAME2, password: 'InvalidPassword' })
}
// The account is locked after the third failed login attempt
await request(app.getHttpServer())
.post('/auth/login')
.send({ username: TEST_USER_NAME2, password: TEST_USER_PASSWORD })
.then((res) => {
expect(res.body.message).toContain(
'The account is locked. Please try again in 5 minutes.',
)
})
await request(app.getHttpServer())
.delete('/auth/delete-user')
.set('Authorization', `Bearer ${accessToken}`)
await app.close()
})当用户连续三次登录失败的时候,账户就会被锁定。所以在这个测试里,我们不能使用测试账号 TEST_USER_NAME,因为测试成功的话这个账户就会被锁定,无法继续进行下面的测试了。我们需要再注册一个新用户 TEST_USER_NAME2,专门用来测试账户锁定,测试成功后再删除这个用户。所以你可以看到这个 e2e 测试的代码非常多,需要做大量的前置、后置工作,其实真正的测试代码就这几行:
// 连续三次登录
for (let i = 0; i < maxLoginAttempts; i++) {
await request(app.getHttpServer())
.post('/auth/login')
.send({ username: TEST_USER_NAME2, password: 'InvalidPassword' })
}
// 测试账号是否被锁定
await request(app.getHttpServer())
.post('/auth/login')
.send({ username: TEST_USER_NAME2, password: TEST_USER_PASSWORD })
.then((res) => {
expect(res.body.message).toContain(
'The account is locked. Please try again in 5 minutes.',
)
})可以看到编写 e2e 测试代码还是相对比较简单的,不需要考虑 mock 数据,不需要考虑测试覆盖率,只要整个系统流程的运转情况符合预期就可以了。
如果有条件的话,我是比较建议大家写测试的。因为写测试可以提高系统的健壮性、可维护性和开发效率。
我们一般编写代码时,会关注于正常输入下的程序流程,确保核心功能正常运作。但是一些边缘情况,比如异常的输入,这些我们可能会经常忽略掉。但当我们开始编写测试时,情况就不一样了,这会逼迫你去考虑如何处理并提供相应的反馈,从而避免程序崩溃。可以说写测试实际上是在间接地提高系统健壮性。
当你接手一个新项目时,如果项目包含完善的测试,那将会是一件很幸福的事情。它们就像是项目的指南,帮你快速把握各个功能点。只看测试代码就能够轻松地了解每个功能的预期行为和边界条件,而不用你逐行的去查看每个功能的代码。
想象一下,一个长时间未更新的项目突然接到了新需求。改了代码后,你可能会担心引入 bug,如果没有测试,那就需要重新手动测试整个项目——浪费时间,效率低下。而有了完整的测试,一条命令就能得知代码更改有没有影响现有功能。即使出错了,也能够快速定位,找到问题点。
短期项目、需求迭代非常快的项目不建议写测试。比如某些活动项目,活动结束就没用了,这种项目就不需要写测试。另外,需求迭代非常快的项目也不要写测试,我刚才说写测试能提高开发效率是有前提条件的,就是功能迭代比较慢的情况下,写测试才能提高开发效率。如果你的功能今天刚写完,隔一两天就需求变更了要改功能,那相关的测试代码都得重写。所以干脆就别写了,靠团队里的测试人员测试就行了,因为写测试是非常耗时间的,没必要自讨苦吃。
根据我的经验来看,国内的绝大多数项目(尤其是政企类项目)都是没有必要写测试的,因为需求迭代太快,还老是推翻之前的需求,代码都得加班写,那有闲情逸致写测试。
在细致地讲解了如何为 Nestjs 项目编写单元测试及 e2e 测试之后,我还是想重申一下测试的重要性,它能够提高系统的健壮性、可维护性和开发效率。如果没有机会写测试,我建议大家可以自己搞个练习项目来写,或者说参加一些开源项目,给这些项目贡献代码,因为开源项目对于代码要求一般都比较严格。贡献代码可能需要编写新的测试用例或修改现有的测试用例。
最后,再推荐一下我的其他文章,如果你有兴趣,不妨一读:
2021 年已经结束,对于我来说,今年发生了不少的事情,所以我觉得写个年终总结很有必要,于是就有了这篇文章。
从转行开始,我就一直在天津工作。虽然当时转行已经 29 岁了,但是对于未来能做成什么事,要达到什么样的高度并没有清晰的认识,也没有规划。毕竟当时转行也只是为了混口饭吃,能让自己在天津活下去。
天津的互联网行业发展非常差,和北京比一个天一个地。而且大多数公司都是项目外包型公司,就是在外面接项目做来养活公司。基本上都是没什么技术含量的项目,一套模板能放在多个项目上用。我在天津工作的这几家公司全是项目外包型公司,所用技术也比较落后,只要能完成项目就行。所以在天津工作的这几年,我的技术提升只有第一年是靠工作,再往后的时间里,技术提升就全靠自学了。但是脱离于业务场景的学习,效果也不是很好。我在这几年时间里学到的很多知识点,基本上都没有机会落实到工作中(公司小,项目小),只能自己做个 DEMO 玩。
在天津工作四年后,随着技术提升与职业规划越来越清晰,我对现状也越来越不满。因此,在 2021 年初我做出了一个重大的决定——去北京发展。经过一个月的面试,在 2021 年 3 月,我跳槽去了北京狮桥,一家要向互联网转型的传统物流公司。刚来北京我就开始了差不多是 996 的生活,之前一直抱着吃瓜的心态在网上看广大网友讨论 996,没想到终于有机会体验了,此时此刻只能用两个字来形容——真累!不过所接触的项目确实是更有技术含量,不用再做后台管理系统了。
2022 年,我已经 34 了,满打满算,转前端也有五年了。在这五年里,业务上写过后台管理系统、移动端、小程序等,基础架构方面搞过监控、脚手架、CICD、低代码等等。慢慢的,也找到了自己喜欢的方向——基础架构。我越来越不喜欢写业务页面了,感觉写页面很枯燥。但是这不代表我不熟悉业务,一个好的程序员必须得懂业务,但是和写不写业务页面关系不大。
2021 年我在狮桥除了做基础架构,还开始带业务团队了。团队从一开始的 9 人,到后面的 18 人。从生疏到游刃有余花了不少时间,以前看别人当管理,觉得很轻松,心里经常有“我上我也行”的想法。但等自己真的当了管理,才发现管理特别的累,每天都有开不完的会,还得与其他部门协调沟通各种问题,保证项目的进度能顺利进行。除此之外,还有分配任务、负责招聘等等一堆的事情,根本没多少时间写代码。这时我才意识到,一个人能安安静静的写代码是一件多幸福的事。但是不得不说,当管理的这半年对我的提升非常大(非技术角度),感谢老领导给我的机会。
2021 年我跳槽了两次,一次是狮桥,一次是铂金智慧(现在就职的公司)。在这分享一下我找工作看重的点,其中有两点是比较重要的,一是薪资待遇,二是工作内容。薪资待遇就不说了,简单聊一下工作内容。我觉得程序员是一定要有职业规划的,要明白自己想要的是什么,然后找工作就根据自己的目标找契合度高的工作。拿我来说,我对技术比较感兴趣,喜欢钻研一些比较底层的技术。所以我找工作就比较偏向基础架构这一方面,例如在狮桥,除了管理外,我做的主要是关于前端工程化方面的事情。包括但不限于制定前端规范、写脚手架、写组件、推动 CICD 和监控在项目上的接入等等。在现在的公司,我主要做的事情是低代码平台。总的来说,我走的是技术专家路线。当然也有很多人比较喜欢业务,不太喜欢研究技术,那他们可以走业务专家路线。从国内的情况来看,业务专家更吃香。最后再强调一句,搞基础架构也需要懂业务,你得明白公司靠什么赚钱。
对了,找工作还有一点也很重要,那就是心态。面试是双向的选择,不是候选人在求着别人给工作,所以面试时不要把自己的位置放得太低。面试也是一件很讲运气的事,通过不了不一定是你技术不行,很有可能是问的问题刚好你不会(位置对调,面试官也有可能通过不了面试)、气场不合、价值观不符合等等。面试挂了做下复盘再准备下一次面试,不要在一棵树上吊死。
今年我的知乎和掘金都破万赞了,知乎关注者有 6k,掘金有 4k 多。看来之前费尽心思写的文章还是挺受读者欢迎的。
除此之外,我的一些 Github 开源项目也收获了不少 star,关注人数在**区排名来到了 350 名。
虽然对于大佬来说,这些不算什么。但对于我来,达成这些小成就花了不少的时间和精力,同时也激励着我以后写出更有深度的文章和开源项目。
18 年我学习了《计算机系统要素》这本书,并且写了个简单的编译器,自此我发现编译原理是一门非常有趣的计算机理论课程。后面一直想深入研究,苦于没有时间。所以今年我的目标就是学习编译原理,顺便研究一下 v8 和 nodejs。而且要是能搞懂 v8 、nodejs,对于我的前端生涯来说,也是非常有帮助的,一举三得。别的不多说了,加油干!
2022 年我的成考大专学历就下来了,估计到时简历通过率应该能稍微高点了。同时,自考本科也在进行中,目前已经通过了一半科目,还有一半估计得花两年时间慢慢考。毕竟工作太忙了,没多少时间去学习。
如果用一个词来总结 2021 年,那就是“不忘初心,稳中向好“。同时希望 2022 年更加顺利,争取技术水平更上一层楼。
先复习一下前、中、后遍历的顺序:
用递归来写二叉树遍历是非常简单的,例如前序遍历的代码如下:
const result = []
function preorderTraversal(node) {
if (!node) return null
result.push(node.val)
preorderTraversal(node.left)
preorderTraversal(node.right)
}
preorderTraversal(root)我们都知道,在调用函数时,系统会在栈中为每个函数维护相应的变量(参数、局部变量、返回地址等等)。
例如有 a,b,c 三个函数,先调用 a,a 又调用 b,b 最后调用 c。此时的调用栈如图所示:

为什么要说这个呢?因为递归遍历的执行过程就是这样的,只不过是函数不停的调用自身,直到遇到递归出口(终止条件)。
举个例子,现在要用递归前序遍历以下二叉树:
1
\
2
/
3
它的遍历顺序为 1-2-3,调用栈如图所示:

理解了递归调用栈的情况,再来看看怎么利用递归**实现前序迭代遍历:
function preorderTraversal(root) {
const result = []
// 用一个数组 stack 模拟调用栈
const stack = []
let node = root
while (stack.length || node) {
// 递归遍历节点的左子树,直到空为止
while (node) {
result.push(node.val)
stack.push(node)
node = node.left
}
// 跳出循环时 node 为空,由于前序遍历的特性
// 当前 node 节点的上一个节点必定是它的父亲节点
// 前序遍历是中-左-右,现在左子树已经到头了,该遍历父节点的右子树了
// 所以要弹出父节点,从它的右子树开始新一轮循环
node = stack.pop()
node = node.right
}
return result
}再看一个具体的示例,用迭代遍历跑一遍:
1
/ \
2 3
/ \ / \
4 5 6 7
stack == [1,2,4]看到这是不是已经发现了这个迭代遍历的过程和递归遍历的过程一模一样?
而且用递归的**来实现迭代遍历,优点在于好理解,以后再遇到这种问题马上就能想起来怎么做了。
中序遍历和前序遍历差不多,区别在于节点出栈时,才将节点的值推入到 result 中。
function inorderTraversal(root) {
const result = []
const stack = []
let node = root
while (stack.length || node) {
while (node) {
stack.push(node)
node = node.left
}
node = stack.pop()
result.push(node.val)
node = node.right
}
return result
}前序遍历过程为中-左-右,逆前序遍历过程就是将遍历左右子树的顺序调换一下,即中-右-左。
然后再看一下后序遍历的过程左-右-中,可以看出逆前序遍历顺序的倒序就是后序遍历的顺序。
利用这一特点写出的后序遍历代码如下:
function postorderTraversal(root) {
const result = []
const stack = []
let node = root
while (stack.length || node) {
while (node) {
result.push(node.val)
stack.push(node)
node = node.right // 原来是 node.left,这里换成 node.right
}
node = stack.pop()
node = node.left // 原来是 node.right,这里换成 node.left
}
return result.reverse() // 逆前序遍历顺序的倒序就是后序遍历的顺序
}为了学习 rollup 打包原理,我克隆了最新版(v2.26.5)的源码。然后发现打包器和我想像的不太一样,代码实在太多了,光看 d.ts 文件就看得头疼。为了看看源码到底有多少行,我写了个脚本,结果发现有 19650行,崩溃...
这就能打消我学习 rollup 的决心吗?不可能,退而求其次,我下载了 rollup 初版源码,才 1000 行左右。
我的目的是学习 rollup 怎么打包的,怎么做 tree-shaking 的。而初版源码已经实现了这两个功能(半成品),所以看初版源码已经足够了。
好了,下面开始正文。
rollup 使用了 acorn 和 magic-string 两个库。为了更好的阅读 rollup 源码,必须对它们有所了解。
下面我将简单的介绍一下这两个库的作用。
acorn 是一个 JavaScript 语法解析器,它将 JavaScript 字符串解析成语法抽象树 AST。
例如以下代码:
export default function add(a, b) { return a + b }将被解析为:
{
"type": "Program",
"start": 0,
"end": 50,
"body": [
{
"type": "ExportDefaultDeclaration",
"start": 0,
"end": 50,
"declaration": {
"type": "FunctionDeclaration",
"start": 15,
"end": 50,
"id": {
"type": "Identifier",
"start": 24,
"end": 27,
"name": "add"
},
"expression": false,
"generator": false,
"params": [
{
"type": "Identifier",
"start": 28,
"end": 29,
"name": "a"
},
{
"type": "Identifier",
"start": 31,
"end": 32,
"name": "b"
}
],
"body": {
"type": "BlockStatement",
"start": 34,
"end": 50,
"body": [
{
"type": "ReturnStatement",
"start": 36,
"end": 48,
"argument": {
"type": "BinaryExpression",
"start": 43,
"end": 48,
"left": {
"type": "Identifier",
"start": 43,
"end": 44,
"name": "a"
},
"operator": "+",
"right": {
"type": "Identifier",
"start": 47,
"end": 48,
"name": "b"
}
}
}
]
}
}
}
],
"sourceType": "module"
}可以看到这个 AST 的类型为 program,表明这是一个程序。body 则包含了这个程序下面所有语句对应的 AST 子节点。
每个节点都有一个 type 类型,例如 Identifier,说明这个节点是一个标识符;BlockStatement 则表明节点是块语句;ReturnStatement 则是 return 语句。
如果想了解更多详情 AST 节点的信息可以看一下这篇文章《使用 Acorn 来解析 JavaScript》。
magic-string 也是 rollup 作者写的一个关于字符串操作的库。下面是 github 上的示例:
var MagicString = require( 'magic-string' );
var s = new MagicString( 'problems = 99' );
s.overwrite( 0, 8, 'answer' );
s.toString(); // 'answer = 99'
s.overwrite( 11, 13, '42' ); // character indices always refer to the original string
s.toString(); // 'answer = 42'
s.prepend( 'var ' ).append( ';' ); // most methods are chainable
s.toString(); // 'var answer = 42;'
var map = s.generateMap({
source: 'source.js',
file: 'converted.js.map',
includeContent: true
}); // generates a v3 sourcemap
require( 'fs' ).writeFile( 'converted.js', s.toString() );
require( 'fs' ).writeFile( 'converted.js.map', map.toString() );从示例中可以看出来,这个库主要是对字符串一些常用方法进行了封装。这里就不多做介绍了。
│ bundle.js // Bundle 打包器,在打包过程中会生成一个 bundle 实例,用于收集其他模块的代码,最后再将收集的代码打包到一起。
│ external-module.js // ExternalModule 外部模块,例如引入了 'path' 模块,就会生成一个 ExternalModule 实例。
│ module.js // Module 模块,开发者自己写的代码文件,都是 module 实例。例如有 'foo.js' 文件,它就对应了一个 module 实例。
│ rollup.js // rollup 函数,一切的开始,调用它进行打包。
│
├─ast // ast 目录,包含了和 AST 相关的类和函数
│ analyse.js // 主要用于分析 AST 节点的作用域和依赖项。
│ Scope.js // 在分析 AST 节点时为每一个节点生成对应的 Scope 实例,主要是记录每个 AST 节点对应的作用域。
│ walk.js // walk 就是递归调用 AST 节点进行分析。
│
├─finalisers
│ cjs.js // 打包模式,目前只支持将代码打包成 common.js 格式
│ index.js
│
└─utils // 一些帮助函数
map-helpers.js
object.js
promise.js
replaceIdentifiers.js上面是初版源码的目录结构,在继续深入前,请仔细阅读上面的注释,了解一下每个文件的作用。
在 rollup 中,一个文件就是一个模块。每一个模块都会根据文件的代码生成一个 AST 语法抽象树,rollup 需要对每一个 AST 节点进行分析。
分析 AST 节点,就是看看这个节点有没有调用函数或方法。如果有,就查看所调用的函数或方法是否在当前作用域,如果不在就往上找,直到找到模块顶级作用域为止。
如果本模块都没找到,说明这个函数、方法依赖于其他模块,需要从其他模块引入。
例如 import foo from './foo.js',其中 foo() 就得从 ./foo.js 文件找。
在引入 foo() 函数的过程中,如果发现 foo() 函数依赖其他模块,就会递归读取其他模块,如此循环直到没有依赖的模块为止。
最后将所有引入的代码打包在一起。
上面例子的示例图:
接下来我们从一个具体的示例开始,一步步分析 rollup 是如何打包的。
以下两个文件是代码文件。
// main.js
import { foo1, foo2 } from './foo'
foo1()
function test() {
const a = 1
}
console.log(test())// foo.js
export function foo1() {}
export function foo2() {}下面是测试代码:
const rollup = require('../dist/rollup')
rollup(__dirname + '/main.js').then(res => {
res.wirte('bundle.js')
})main.js 入口文件。rollup() 首先生成一个 Bundle 实例,也就是打包器。然后根据入口文件路径去读取文件,最后根据文件内容生成一个 Module 实例。
fs.readFile(path, 'utf-8', (err, code) => {
if (err) reject(err)
const module = new Module({
code,
path,
bundle: this, // bundle 实例
})
})在 new 一个 Module 实例时,会调用 acorn 库的 parse() 方法将代码解析成 AST。
this.ast = parse(code, {
ecmaVersion: 6, // 要解析的 JavaScript 的 ECMA 版本,这里按 ES6 解析
sourceType: 'module', // sourceType值为 module 和 script。module 模式,可以使用 import/export 语法
})接下来需要对生成的 AST 进行分析。
第一步,分析导入和导出的模块,将引入的模块和导出的模块填入对应的对象。
每个 Module 实例都有一个 imports 和 exports 对象,作用是将该模块引入和导出的对象填进去,代码生成时要用到。
上述例子对应的 imports 和 exports 为:
// key 为要引入的具体对象,value 为对应的 AST 节点内容。
imports = {
foo1: { source: './foo', name: 'foo1', localName: 'foo1' },
foo2: { source: './foo', name: 'foo2', localName: 'foo2' }
}
// 由于没有导出的对象,所以为空
exports = {}第二步,分析每个 AST 节点间的作用域,找出每个 AST 节点定义的变量。
每遍历到一个 AST 节点,都会为它生成一个 Scope 实例。
// 作用域
class Scope {
constructor(options = {}) {
this.parent = options.parent // 父作用域
this.depth = this.parent ? this.parent.depth + 1 : 0 // 作用域层级
this.names = options.params || [] // 作用域内的变量
this.isBlockScope = !!options.block // 是否块作用域
}
add(name, isBlockDeclaration) {
if (!isBlockDeclaration && this.isBlockScope) {
// it's a `var` or function declaration, and this
// is a block scope, so we need to go up
this.parent.add(name, isBlockDeclaration)
} else {
this.names.push(name)
}
}
contains(name) {
return !!this.findDefiningScope(name)
}
findDefiningScope(name) {
if (this.names.includes(name)) {
return this
}
if (this.parent) {
return this.parent.findDefiningScope(name)
}
return null
}
}Scope 的作用很简单,它有一个 names 属性数组,用于保存这个 AST 节点内的变量。
例如下面这段代码:
function test() {
const a = 1
}打断点可以看出来,它生成的作用域对象,names 属性就会包含 a。并且因为它是模块下的一个函数,所以作用域层级为 1(模块顶级作用域为 0)。
第三步,分析标识符,并找出它们的依赖项。
什么是标识符?如变量名,函数名,属性名,都归为标识符。当解析到一个标识符时,rollup 会遍历它当前的作用域,看看有没这个标识符。如果没有找到,就往它的父级作用域找。如果一直找到模块顶级作用域都没找到,就说明这个函数、方法依赖于其它模块,需要从其他模块引入。如果一个函数、方法需要被引入,就将它添加到 Module 的 _dependsOn 对象里。
例如 test() 函数中的变量 a,能在当前作用域找到,它就不是一个依赖项。foo1() 在当前模块作用域找不到,它就是一个依赖项。
打断点也能发现 Module 的 _dependsOn 属性里就有 foo1。
这就是 rollup 的 tree-shaking 原理。
rollup 不看你引入了什么函数,而是看你调用了什么函数。如果调用的函数不在此模块中,就从其它模块引入。
换句话说,如果你手动在模块顶部引入函数,但又没调用。rollup 是不会引入的。从我们的示例中可以看出,一共引入了 foo1() foo2() 两个函数,_dependsOn 里却只有 foo1(),因为引入的 foo2() 没有调用。
_dependsOn 有什么用呢?后面生成代码时会根据 _dependsOn 里的值来引入文件。
从 _dependsOn 的值可以发现,我们需要引入 foo1() 函数。
这时第一步生成的 imports 就起作用了:
imports = {
foo1: { source: './foo', name: 'foo1', localName: 'foo1' },
foo2: { source: './foo', name: 'foo2', localName: 'foo2' }
}rollup 将 foo1 当成 key,找到它对应的文件。然后读取这个文件生成一个新的 Module 实例。由于 foo.js 文件导出了两个函数,所以这个新 Module 实例的 exports 属性是这样的:
exports = {
foo1: {
node: Node {
type: 'ExportNamedDeclaration',
start: 0,
end: 25,
declaration: [Node],
specifiers: [],
source: null
},
localName: 'foo1',
expression: Node {
type: 'FunctionDeclaration',
start: 7,
end: 25,
id: [Node],
expression: false,
generator: false,
params: [],
body: [Node]
}
},
foo2: {
node: Node {
type: 'ExportNamedDeclaration',
start: 27,
end: 52,
declaration: [Node],
specifiers: [],
source: null
},
localName: 'foo2',
expression: Node {
type: 'FunctionDeclaration',
start: 34,
end: 52,
id: [Node],
expression: false,
generator: false,
params: [],
body: [Node]
}
}
}这时,就会用 main.js 要导入的 foo1 当成 key 去匹配 foo.js 的 exports 对象。如果匹配成功,就把 foo1() 函数对应的 AST 节点提取出来,放到 Bundle 中。如果匹配失败,就会报错,提示 foo.js 没有导出这个函数。
由于已经引入了所有的函数。这时需要调用 Bundle 的 generate() 方法生成代码。
同时,在打包过程中,还需要对引入的函数做一些额外的操作。
移除额外代码
例如从 foo.js 中引入的 foo1() 函数代码是这样的:export function foo1() {}。rollup 会移除掉 export ,变成 function foo1() {}。因为它们就要打包在一起了,所以就不需要 export 了。
重命名
例如两个模块中都有一个同名函数 foo(),打包到一起时,会对其中一个函数重命名,变成 _foo(),以避免冲突。
好了,回到正文。
还记得文章一开始提到的 magic-string 库吗?在 generate() 中,会将每个 AST 节点对应的源代码添加到 magic-string 实例中:
magicString.addSource({
content: source,
separator: newLines
})这个操作本质上相当于拼字符串:
str += '这个操作相当于将每个 AST 的源代码当成字符串拼在一起,就像现在这样'最后将拼在一起的代码返回。
return { code: magicString.toString() }到这就已经结束了,如果你想把代码生成文件,可以调用 write() 方法生成文件:
rollup(__dirname + '/main.js').then(res => {
res.wirte('dist.js')
})这个方法是写在 rollup() 函数里的。
function rollup(entry, options = {}) {
const bundle = new Bundle({ entry, ...options })
return bundle.build().then(() => {
return {
generate: options => bundle.generate(options),
wirte(dest, options = {}) {
const { code } = bundle.generate({
dest,
format: options.format,
})
return fs.writeFile(dest, code, err => {
if (err) throw err
})
}
}
})
}本文对源码进行了抽象,所以很多实现细节都没说出来。如果对实现细节有兴趣,可以看一下源码。代码放在我的 github 上。
我已经对 rollup 初版源码进行了删减,并添加了大量注释,让代码更加易读。
Vue 的编译模块包含 4 个目录:
compiler-core
compiler-dom // 浏览器
compiler-sfc // 单文件组件
compiler-ssr // 服务端渲染其中 compiler-core 模块是 Vue 编译的核心模块,并且是平台无关的。而剩下的三个都是在 compiler-core 的基础上针对不同的平台作了适配处理。
Vue 的编译分为三个阶段,分别是:parse、transform、codegen。
其中 parse 阶段将模板字符串转化为语法抽象树 AST。transform 阶段则是对 AST 进行了一些转换处理。codegen 阶段根据 AST 生成对应的 render 函数字符串。
Vue 在解析模板字符串时,可分为两种情况:以 < 开头的字符串和不以 < 开头的字符串。
不以 < 开头的字符串有两种情况:它是文本节点或 {{ exp }} 插值表达式。
而以 < 开头的字符串又分为以下几种情况:
<div></div><!-- 123 --><!DOCTYPE html>用伪代码表示,大概过程如下:
while (s.length) {
if (startsWith(s, '{{')) {
// 如果以 '{{' 开头
node = parseInterpolation(context, mode)
} else if (s[0] === '<') {
// 以 < 标签开头
if (s[1] === '!') {
if (startsWith(s, '<!--')) {
// 注释
node = parseComment(context)
} else if (startsWith(s, '<!DOCTYPE')) {
// 文档声明,当成注释处理
node = parseBogusComment(context)
}
} else if (s[1] === '/') {
// 结束标签
parseTag(context, TagType.End, parent)
} else if (/[a-z]/i.test(s[1])) {
// 开始标签
node = parseElement(context, ancestors)
}
} else {
// 普通文本节点
node = parseText(context, mode)
}
}在源码中对应的几个函数分别是:
parseChildren(),主入口。parseInterpolation(),解析双花插值表达式。parseComment(),解析注释。parseBogusComment(),解析文档声明。parseTag(),解析标签。parseElement(),解析元素节点,它会在内部执行 parseTag()。parseText(),解析普通文本。parseAttribute(),解析属性。每解析完一个标签、文本、注释等节点时,Vue 就会生成对应的 AST 节点,并且会把已经解析完的字符串给截断。
对字符串进行截断使用的是 advanceBy(context, numberOfCharacters) 函数,context 是字符串的上下文对象,numberOfCharacters 是要截断的字符数。
我们用一个简单的例子来模拟一下截断操作:
<div name="test">
<p></p>
</div>首先解析 <div,然后执行 advanceBy(context, 4) 进行截断操作(内部执行的是 s = s.slice(4)),变成:
name="test">
<p></p>
</div>再解析属性,并截断,变成:
<p></p>
</div>同理,后面的截断情况为:
></p>
</div></div><!-- 所有字符串已经解析完 -->AST 节点
所有的 AST 节点定义都在 compiler-core/ast.ts 文件中,下面是一个元素节点的定义:
export interface BaseElementNode extends Node {
type: NodeTypes.ELEMENT // 类型
ns: Namespace // 命名空间 默认为 HTML,即 0
tag: string // 标签名
tagType: ElementTypes // 元素类型
isSelfClosing: boolean // 是否是自闭合标签 例如 <br/> <hr/>
props: Array<AttributeNode | DirectiveNode> // props 属性,包含 HTML 属性和指令
children: TemplateChildNode[] // 字节点
}一些简单的要点已经讲完了,下面我们再从一个比较复杂的例子来详细讲解一下 parse 的处理过程。
<div name="test">
<!-- 这是注释 -->
<p>{{ test }}</p>
一个文本节点
<div>good job!</div>
</div>上面的模板字符串假设为 s,第一个字符 s[0] 是 < 开头,那说明它只能是刚才所说的四种情况之一。
这时需要再看一下 s[1] 的字符是什么:
!,则调用字符串原生方法 startsWith() 看看是以 '<!--' 开头还是以 '<!DOCTYPE' 开头。虽然这两者对应的处理函数不一样,但它们最终都是解析为注释节点。/,则按结束标签处理。/,则按开始标签处理。从我们的示例来看,这是一个 <div> 开始标签。
这里还有一点要提一下,Vue 会用一个栈 stack 来保存解析到的元素标签。当它遇到开始标签时,会将这个标签推入栈,遇到结束标签时,将刚才的标签弹出栈。它的作用是保存当前已经解析了,但还没解析完的元素标签。这个栈还有另一个作用,在解析到某个字节点时,通过 stack[stack.length - 1] 可以获取它的父元素。
从我们的示例来看,它的出入栈顺序是这样的:
1. [div] // div 入栈
2. [div, p] // p 入栈
3. [div] // p 出栈
4. [div, div] // div 入栈
5. [div] // div 出栈
6. [] // 最后一个 div 出栈,模板字符串已解析完,这时栈为空接着上文继续分析我们的示例,这时已经知道是 div 标签了,接下来会把已经解析完的 <div 字符串截断,然后解析它的属性。
Vue 的属性有两种情况:
根据属性的不同生成的节点不同,HTML 普通属性节点 type 为 6,Vue 指令节点 type 为 7。
所有的节点类型值如下:
ROOT, // 根节点 0
ELEMENT, // 元素节点 1
TEXT, // 文本节点 2
COMMENT, // 注释节点 3
SIMPLE_EXPRESSION, // 表达式 4
INTERPOLATION, // 双花插值 {{ }} 5
ATTRIBUTE, // 属性 6
DIRECTIVE, // 指令 7属性解析完后,div 开始标签也就解析完了,<div name="test"> 这一行字符串已经被截断。现在剩下的字符串如下:
<!-- 这是注释 -->
<p>{{ test }}</p>
一个文本节点
<div>good job!</div>
</div>注释文本和普通文本节点解析规则都很简单,直接截断,生成节点。注释文本调用 parseComment() 函数处理,文本节点调用 parseText() 处理。
双花插值的字符串处理逻辑稍微复杂点,例如示例中的 {{ test }}:
test,再对它执行 trim(),去除空格。INTERPOLATION,type 为 5,表示它是双花插值。test,它会生成一个 SIMPLE_EXPRESSION 节点,type 为 4。return {
type: NodeTypes.INTERPOLATION, // 双花插值类型
content: {
type: NodeTypes.SIMPLE_EXPRESSION,
isStatic: false, // 非静态节点
isConstant: false,
content,
loc: getSelection(context, innerStart, innerEnd)
},
loc: getSelection(context, start)
}剩下的字符串解析逻辑和上文的差不多,就不解释了,最后这个示例解析出来的 AST 如下所示:
从 AST 上,我们还能看到某些节点上有一些别的属性:
{{ test }} 解析出来的节点会有一个 isStatic 属性,值为 false,表示这是一个动态节点。如果是静态节点,则只会生成一次,并且在后面的阶段一直复用同一个,不用进行 diff 比较。另外还有一个 tagType 属性,它有 4 个值:
export const enum ElementTypes {
ELEMENT, // 0 元素节点
COMPONENT, // 1 组件
SLOT, // 2 插槽
TEMPLATE // 3 模板
}主要用于区分上述四种类型节点。
在 transform 阶段,Vue 会对 AST 进行一些转换操作,主要是根据不同的 AST 节点添加不同的选项参数,这些参数在 codegen 阶段会用到。下面列举一些比较重要的选项:
如果 cacheHandlers 的值为 true,则表示开启事件函数缓存。例如 @click="foo" 默认编译为 { onClick: foo },如果开启了这个选项,则编译为
{ onClick: _cache[0] || (_cache[0] = e => _ctx.foo(e)) }hoistStatic 是一个标识符,表示要不要开启静态节点提升。如果值为 true,静态节点将被提升到 render() 函数外面生成,并被命名为 _hoisted_x 变量。
例如 一个文本节点 生成的代码为 const _hoisted_2 = /*#__PURE__*/_createTextVNode(" 一个文本节点 ")。
下面两张图,前者是 hoistStatic = false,后面是 hoistStatic = true。大家可以在网站上自己试一下。
这个参数的作用是用于代码生成。例如 {{ foo }} 在 module 模式下生成的代码为 _ctx.foo,而在 function 模式下是 with (this) { ... }。因为在 module 模式下,默认为严格模式,不能使用 with 语句。
transform 在对 AST 节点进行转换时,会打上 patchflag 参数,这个参数主要用于 diff 比较过程。当 DOM 节点有这个标志并且大于 0,就代表要更新,没有就跳过。
我们来看一下 patchflag 的取值范围:
export const enum PatchFlags {
// 动态文本节点
TEXT = 1,
// 动态 class
CLASS = 1 << 1, // 2
// 动态 style
STYLE = 1 << 2, // 4
// 动态属性,但不包含类名和样式
// 如果是组件,则可以包含类名和样式
PROPS = 1 << 3, // 8
// 具有动态 key 属性,当 key 改变时,需要进行完整的 diff 比较。
FULL_PROPS = 1 << 4, // 16
// 带有监听事件的节点
HYDRATE_EVENTS = 1 << 5, // 32
// 一个不会改变子节点顺序的 fragment
STABLE_FRAGMENT = 1 << 6, // 64
// 带有 key 属性的 fragment 或部分子字节有 key
KEYED_FRAGMENT = 1 << 7, // 128
// 子节点没有 key 的 fragment
UNKEYED_FRAGMENT = 1 << 8, // 256
// 一个节点只会进行非 props 比较
NEED_PATCH = 1 << 9, // 512
// 动态 slot
DYNAMIC_SLOTS = 1 << 10, // 1024
// 静态节点
HOISTED = -1,
// 指示在 diff 过程应该要退出优化模式
BAIL = -2
}从上述代码可以看出 patchflag 使用一个 11 位的位图来表示不同的值,每个值都有不同的含义。Vue 在 diff 过程会根据不同的 patchflag 使用不同的 patch 方法。
下图是经过 transform 后的 AST:
可以看到 codegenNode、helpers 和 hoists 已经被填充上了相应的值。codegenNode 是生成代码要用到的数据,hoists 存储的是静态节点,helpers 存储的是创建 VNode 的函数名称(其实是 Symbol)。
在正式开始 transform 前,需要创建一个 transformContext,即 transform 上下文。和这三个属性有关的数据和方法如下:
helpers: new Set(),
hoists: [],
// methods
helper(name) {
context.helpers.add(name)
return name
},
helperString(name) {
return `_${helperNameMap[context.helper(name)]}`
},
hoist(exp) {
context.hoists.push(exp)
const identifier = createSimpleExpression(
`_hoisted_${context.hoists.length}`,
false,
exp.loc,
true
)
identifier.hoisted = exp
return identifier
},我们来看一下具体的 transform 过程是怎样的,用 <p>{{ test }}</p> 来做示例。
这个节点对应的是 transformElement() 转换函数,由于 p 没有绑定动态属性,没有绑定指令,所以重点不在它,而是在 {{ test }} 上。{{ test }} 是一个双花插值表达式,所以将它的 patchFlag 设为 1(动态文本节点),对应的执行代码是 patchFlag |= 1。然后再执行 createVNodeCall() 函数,它的返回值就是这个节点的 codegenNode 值。
node.codegenNode = createVNodeCall(
context,
vnodeTag,
vnodeProps,
vnodeChildren,
vnodePatchFlag,
vnodeDynamicProps,
vnodeDirectives,
!!shouldUseBlock,
false /* disableTracking */,
node.loc
)createVNodeCall() 根据这个节点添加了一个 createVNode Symbol 符号,它放在 helpers 里。其实就是要在代码生成阶段引入的帮助函数。
// createVNodeCall() 内部执行过程,已删除多余的代码
context.helper(CREATE_VNODE)
return {
type: NodeTypes.VNODE_CALL,
tag,
props,
children,
patchFlag,
dynamicProps,
directives,
isBlock,
disableTracking,
loc
}一个节点是否添加到 hoists 中,主要看它是不是静态节点,并且需要将 hoistStatic 设为 true。
<div name="test"> // 属性静态节点
<!-- 这是注释 -->
<p>{{ test }}</p>
一个文本节点 // 静态节点
<div>good job!</div> // 静态节点
</div>可以看到,上面有三个静态节点,所以 hoists 数组有 3 个值。并且无论静态节点嵌套有多深,都会被提升到 hoists 中。
从上图可以看到,最外层的 div 的 type 原来为 1,经过 transform 生成的 codegenNode 中的 type 变成了 13。
这个 13 是代码生成对应的类型 VNODE_CALL。另外还有:
// codegen
VNODE_CALL, // 13
JS_CALL_EXPRESSION, // 14
JS_OBJECT_EXPRESSION, // 15
JS_PROPERTY, // 16
JS_ARRAY_EXPRESSION, // 17
JS_FUNCTION_EXPRESSION, // 18
JS_CONDITIONAL_EXPRESSION, // 19
JS_CACHE_EXPRESSION, // 20刚才提到的例子 {{ test }},它的 codegenNode 就是通过调用 createVNodeCall() 生成的:
return {
type: NodeTypes.VNODE_CALL,
tag,
props,
children,
patchFlag,
dynamicProps,
directives,
isBlock,
disableTracking,
loc
}可以从上述代码看到,type 被设置为 NodeTypes.VNODE_CALL,即 13。
每个不同的节点都由不同的 transform 函数来处理,由于篇幅有限,具体代码请自行查阅。
代码生成阶段最后生成了一个字符串,我们把字符串的双引号去掉,看一下具体的内容是什么:
const _Vue = Vue
const { createVNode: _createVNode, createCommentVNode: _createCommentVNode, createTextVNode: _createTextVNode } = _Vue
const _hoisted_1 = { name: "test" }
const _hoisted_2 = /*#__PURE__*/_createTextVNode(" 一个文本节点 ")
const _hoisted_3 = /*#__PURE__*/_createVNode("div", null, "good job!", -1 /* HOISTED */)
return function render(_ctx, _cache) {
with (_ctx) {
const { createCommentVNode: _createCommentVNode, toDisplayString: _toDisplayString, createVNode: _createVNode, createTextVNode: _createTextVNode, openBlock: _openBlock, createBlock: _createBlock } = _Vue
return (_openBlock(), _createBlock("div", _hoisted_1, [
_createCommentVNode(" 这是注释 "),
_createVNode("p", null, _toDisplayString(test), 1 /* TEXT */),
_hoisted_2,
_hoisted_3
]))
}
}可以看到上述代码最后返回一个 render() 函数,作用是生成对应的 VNode。
其实代码生成有两种模式:module 和 function,由标识符 prefixIdentifiers 决定使用哪种模式。
function 模式的特点是:使用 const { helpers... } = Vue 的方式来引入帮助函数,也就是是 createVode() createCommentVNode() 这些函数。向外导出使用 return 返回整个 render() 函数。
module 模式的特点是:使用 es6 模块来导入导出函数,也就是使用 import 和 export。
另外还有三个变量是用 _hoisted_ 命名的,后面跟着数字,代表这是第几个静态变量。
再看一下 parse 阶段的 HTML 模板字符串:
<div name="test">
<!-- 这是注释 -->
<p>{{ test }}</p>
一个文本节点
<div>good job!</div>
</div>这个示例只有一个动态节点,即 {{ test }},剩下的全是静态节点。从生成的代码中也可以看出,生成的节点和模板中的代码是一一对应的。静态节点的作用就是只生成一次,以后直接复用。
细心的网友可能发现了 _hoisted_2 和 _hoisted_3 变量中都有一个 /*#__PURE__*/ 注释。
这个注释的作用是表示这个函数是纯函数,没有副作用,主要用于 tree-shaking。压缩工具在打包时会将未被使用的代码直接删除(shaking 摇掉)。
再来看一下生成动态节点 {{ test }} 的代码: _createVNode("p", null, _toDisplayString(test), 1 /* TEXT */)。
其中 _toDisplayString(test) 的内部实现是:
return val == null
? ''
: isObject(val)
? JSON.stringify(val, replacer, 2)
: String(val)代码很简单,就是转成字符串输出。
而 _createVNode("p", null, _toDisplayString(test), 1 /* TEXT */) 最后一个参数 1 就是 transform 添加的 patchflag 了。
在 transform、codegen 这两个阶段,我们都能看到 helpers 的影子,到底 helpers 是干什么用的?
// Name mapping for runtime helpers that need to be imported from 'vue' in
// generated code. Make sure these are correctly exported in the runtime!
// Using `any` here because TS doesn't allow symbols as index type.
export const helperNameMap: any = {
[FRAGMENT]: `Fragment`,
[TELEPORT]: `Teleport`,
[SUSPENSE]: `Suspense`,
[KEEP_ALIVE]: `KeepAlive`,
[BASE_TRANSITION]: `BaseTransition`,
[OPEN_BLOCK]: `openBlock`,
[CREATE_BLOCK]: `createBlock`,
[CREATE_VNODE]: `createVNode`,
[CREATE_COMMENT]: `createCommentVNode`,
[CREATE_TEXT]: `createTextVNode`,
[CREATE_STATIC]: `createStaticVNode`,
[RESOLVE_COMPONENT]: `resolveComponent`,
[RESOLVE_DYNAMIC_COMPONENT]: `resolveDynamicComponent`,
[RESOLVE_DIRECTIVE]: `resolveDirective`,
[WITH_DIRECTIVES]: `withDirectives`,
[RENDER_LIST]: `renderList`,
[RENDER_SLOT]: `renderSlot`,
[CREATE_SLOTS]: `createSlots`,
[TO_DISPLAY_STRING]: `toDisplayString`,
[MERGE_PROPS]: `mergeProps`,
[TO_HANDLERS]: `toHandlers`,
[CAMELIZE]: `camelize`,
[CAPITALIZE]: `capitalize`,
[SET_BLOCK_TRACKING]: `setBlockTracking`,
[PUSH_SCOPE_ID]: `pushScopeId`,
[POP_SCOPE_ID]: `popScopeId`,
[WITH_SCOPE_ID]: `withScopeId`,
[WITH_CTX]: `withCtx`
}
export function registerRuntimeHelpers(helpers: any) {
Object.getOwnPropertySymbols(helpers).forEach(s => {
helperNameMap[s] = helpers[s]
})
}其实帮助函数就是在代码生成时从 Vue 引入的一些函数,以便让程序正常执行,从上面生成的代码中就可以看出来。而 helperNameMap 是默认的映射表名称,这些名称就是要从 Vue 引入的函数名称。
另外,我们还能看到一个注册函数 registerRuntimeHelpers(helpers: any(),它是干什么用的呢?
我们知道编译模块 compiler-core 是平台无关的,而 compiler-dom 是浏览器相关的编译模块。为了能在浏览器正常运行 Vue 程序,就得把浏览器相关的 Vue 数据和函数导入进来。
registerRuntimeHelpers(helpers: any() 正是用来做这件事的,从 compiler-dom 的 runtimeHelpers.ts 文件就能看出来:
registerRuntimeHelpers({
[V_MODEL_RADIO]: `vModelRadio`,
[V_MODEL_CHECKBOX]: `vModelCheckbox`,
[V_MODEL_TEXT]: `vModelText`,
[V_MODEL_SELECT]: `vModelSelect`,
[V_MODEL_DYNAMIC]: `vModelDynamic`,
[V_ON_WITH_MODIFIERS]: `withModifiers`,
[V_ON_WITH_KEYS]: `withKeys`,
[V_SHOW]: `vShow`,
[TRANSITION]: `Transition`,
[TRANSITION_GROUP]: `TransitionGroup`
})它运行 registerRuntimeHelpers(helpers: any(),往映射表注入了浏览器相关的部分函数。
helpers 是怎么使用的呢?
在 parse 阶段,解析到不同节点时会生成对应的 type。
在 transform 阶段,会生成一个 helpers,它是一个 set 数据结构。每当它转换 AST 时,都会根据 AST 节点的 type 添加不同的 helper 函数。
例如,假设它现在正在转换的是一个注释节点,它会执行 context.helper(CREATE_COMMENT),内部实现相当于 helpers.add('createCommentVNode')。然后在 codegen 阶段,遍历 helpers,将程序需要的函数从 Vue 里导入,代码实现如下:
// 这是 module 模式
`import { ${ast.helpers
.map(s => `${helperNameMap[s]} as _${helperNameMap[s]}`)
.join(', ')} } from ${JSON.stringify(runtimeModuleName)}\n`从 codegen.ts 文件中,可以看到很多代码生成函数:
generate() // 代码生成入口文件
genFunctionExpression() // 生成函数表达式
genNode() // 生成 Vnode 节点
...生成代码则是根据不同的 AST 节点调用不同的代码生成函数,最终将代码字符串拼在一起,输出一个完整的代码字符串。
老规矩,还是看一个例子:
const _hoisted_1 = { name: "test" }
const _hoisted_2 = /*#__PURE__*/_createTextVNode(" 一个文本节点 ")
const _hoisted_3 = /*#__PURE__*/_createVNode("div", null, "good job!", -1 /* HOISTED */)看一下这段代码是怎么生成的,首先执行 genHoists(ast.hoists, context),将 transform 生成的静态节点数组 hoists 作为第一个参数。genHoists() 内部实现:
hoists.forEach((exp, i) => {
if (exp) {
push(`const _hoisted_${i + 1} = `);
genNode(exp, context);
newline();
}
})从上述代码可以看到,遍历 hoists 数组,调用 genNode(exp, context)。genNode() 根据不同的 type 执行不同的函数。
const _hoisted_1 = { name: "test" }这一行代码中的 const _hoisted_1 = 由 genHoists() 生成,{ name: "test" } 由 genObjectExpression() 生成。
同理,剩下的两行代码生成过程也是如此,只是最终调用的函数不同。
本文是可视化拖拽系列的第四篇,比起之前的三篇文章,这篇功能点要稍微少一点,总共有五点:
如果你对我之前的系列文章不是很了解,建议先把这三篇文章看一遍,再来阅读本文(否则没有上下文,不太好理解):
另附上项目、在线 DEMO 地址:
目前项目里提供的自定义组件都是支持自由放大缩小的,不过他们有一个共同点——都是规则形状。也就是说对它们放大缩小,直接改变宽高就可以实现了,无需做其他处理。但是不规则形状就不一样了,譬如一个五角星,你得考虑放大缩小时,如何成比例的改变尺寸。最终,我采用了 svg 的方案来实现(还考虑过用 iconfont 来实现,不过有缺陷,放弃了),下面让我们来看看具体的实现细节。
假设我们需要画一个 100 * 100 的五角星,它的代码是这样的:
<svg
version="1.1"
baseProfile="full"
xmlns="http://www.w3.org/2000/svg"
>
<polygon
points="50 0,62.5 37.5,100 37.5,75 62.5,87.5 100,50 75,12.5 100,25 62.5,0 37.5,37.5 37.5"
stroke="#000"
fill="rgba(255, 255, 255, 1)"
stroke-width="1"
></polygon>
</svg>svg 上的版本、命名空间之类的属性不是很重要,可以先忽略。重点是 polygon 这个元素,它在 svg 中定义了一个由一组首尾相连的直线线段构成的闭合多边形形状,最后一点连接到第一点。也就是说这个多边形由一系列坐标点组成,相连的点之间会自动连上。polygon 的 points 属性用来表示多边形的一系列坐标点,每个坐标点由 x y 坐标组成,每个坐标点之间用 ,逗号分隔。
上图就是一个用 svg 画的五角星,它由十个坐标点组成 50 0,62.5 37.5,100 37.5,75 62.5,87.5 100,50 75,12.5 100,25 62.5,0 37.5,37.5 37.5。由于这是一个 100*100 的五角星,所以我们能够很容易的根据每个坐标点的数值算出它们在五角星(坐标系)中所占的比例。譬如第一个点是 p1(50,0),那么它的 x y 坐标比例是 50%, 0;第二个点 p2(62.5,37.5),对应的比例是 62.5%, 37.5%...
// 五角星十个坐标点的比例集合
const points = [
[0.5, 0],
[0.625, 0.375],
[1, 0.375],
[0.75, 0.625],
[0.875, 1],
[0.5, 0.75],
[0.125, 1],
[0.25, 0.625],
[0, 0.375],
[0.375, 0.375],
]既然知道了五角星的比例,那么要画出其他尺寸的五角星也就易如反掌了。我们只需要在每次对五角星进行放大缩小,改变它的尺寸时,等比例的给出每个坐标点的具体数值即要。
<div class="svg-star-container">
<svg
version="1.1"
baseProfile="full"
xmlns="http://www.w3.org/2000/svg"
>
<polygon
ref="star"
:points="points"
:stroke="element.style.borderColor"
:fill="element.style.backgroundColor"
stroke-width="1"
/>
</svg>
<v-text :prop-value="element.propValue" :element="element" />
</div>
<script>
function drawPolygon(width, height) {
// 五角星十个坐标点的比例集合
const points = [
[0.5, 0],
[0.625, 0.375],
[1, 0.375],
[0.75, 0.625],
[0.875, 1],
[0.5, 0.75],
[0.125, 1],
[0.25, 0.625],
[0, 0.375],
[0.375, 0.375],
]
const coordinatePoints = points.map(point => width * point[0] + ' ' + height * point[1])
this.points = coordinatePoints.toString() // 得出五角星的 points 属性数据
}
</script>同理,要画其他类型的 svg 组件,我们只要知道它们坐标点所占的比例就可以了。如果你不知道一个 svg 怎么画,可以网上搜一下,先找一个能用的 svg 代码(这个五角星的 svg 代码,就是在网上找的)。然后再计算它们每个坐标点所占的比例,转成小数点的形式,最后把这些数据代入上面提供的 drawPolygon() 函数即可。譬如画一个三角形的代码是这样的:
function drawTriangle(width, height) {
const points = [
[0.5, 0.05],
[1, 0.95],
[0, 0.95],
]
const coordinatePoints = points.map(point => width * point[0] + ' ' + height * point[1])
this.points = coordinatePoints.toString() // 得出三角形的 points 属性数据
}目前所有自定义组件的属性面板都共用同一个 AttrList 组件。因此弊端很明显,需要在这里写很多 if 语句,因为不同的组件有不同的属性。例如矩形组件有 content 属性,但是图片没有,一个不同的属性就得写一个 if 语句。
<el-form-item v-if="name === 'rectShape'" label="内容">
<el-input />
</el-form-item>
<!-- 其他属性... -->幸好,这个问题的解决方案也不难。在本系列的第一篇文章中,有讲解过如何动态渲染自定义组件:
<component :is="item.component"></component> <!-- 动态渲染组件 -->在每个自定义组件的数据结构中都有一个 component 属性,这是该组件在 Vue 中注册的名称。因此,每个自定义组件的属性面板可以和组件本身一样(利用 component 属性),做成动态的:
<!-- 右侧属性列表 -->
<section class="right">
<el-tabs v-if="curComponent" v-model="activeName">
<el-tab-pane label="属性" name="attr">
<component :is="curComponent.component + 'Attr'" /> <!-- 动态渲染属性面板 -->
</el-tab-pane>
<el-tab-pane label="动画" name="animation" style="padding-top: 20px;">
<AnimationList />
</el-tab-pane>
<el-tab-pane label="事件" name="events" style="padding-top: 20px;">
<EventList />
</el-tab-pane>
</el-tabs>
<CanvasAttr v-else></CanvasAttr>
</section>同时,自定义组件的目录结构也需要做下调整,原来的目录结构为:
- VText.vue
- Picture.vue
...
调整后变为:
- VText
- Attr.vue <!-- 组件的属性面板 -->
- Component.vue <!-- 组件本身 -->
- Picture
- Attr.vue
- Component.vue现在每一个组件都包含了组件本身和它的属性面板。经过改造后,图片属性面板代码也更加精简了:
<template>
<div class="attr-list">
<CommonAttr></CommonAttr> <!-- 通用属性 -->
<el-form>
<el-form-item label="镜像翻转">
<div style="clear: both;">
<el-checkbox v-model="curComponent.propValue.flip.horizontal" label="horizontal">水平翻转</el-checkbox>
<el-checkbox v-model="curComponent.propValue.flip.vertical" label="vertical">垂直翻转</el-checkbox>
</div>
</el-form-item>
</el-form>
</div>
</template>这样一来,组件和对应的属性面板都变成动态的了。以后需要单独给某个自定义组件添加属性就非常方便了。
有些组件会有动态加载数据的需求,所以特地加了一个 Request 公共属性组件,用于请求数据。当一个自定义组件拥有 request 属性时,就会在属性面板上渲染接口请求的相关内容。至此,属性面板的公共组件已经有两个了:
-common
- Request.vue <!-- 接口请求 -->
- CommonAttr.vue <!-- 通用样式 -->// VText 自定义组件的数据结构
{
component: 'VText',
label: '文字',
propValue: '双击编辑文字',
icon: 'wenben',
request: { // 接口请求
method: 'GET',
data: [],
url: '',
series: false, // 是否定时发送请求
time: 1000, // 定时更新时间
paramType: '', // string object array
requestCount: 0, // 请求次数限制,0 为无限
},
style: { // 通用样式
width: 200,
height: 28,
fontSize: '',
fontWeight: 400,
lineHeight: '',
letterSpacing: 0,
textAlign: '',
color: '',
},
}
从上面的动图可以看出,api 请求的方法参数等都是可以手动修改的。但是怎么控制返回来的数据赋值给组件的某个属性呢?这可以在发出请求的时候把组件的整个数据对象 obj 以及要修改属性的 key 当成参数一起传进去,当数据返回来时,就可以直接使用 obj[key] = data 来修改数据了。
// 第二个参数是要修改数据的父对象,第三个参数是修改数据的 key,第四个数据修改数据的类型
this.cancelRequest = request(this.request, this.element, 'propValue', 'string')组件联动:当一个组件触发事件时,另一个组件会收到通知,并且做出相应的操作。
上面这个动图的矩形,它分别监听了下面两个按钮的悬浮事件,第一个按钮触发悬浮并广播事件,矩形执行回调向右旋转移动;第二个按钮则相反,向左旋转移动。
要实现这个功能,首先要给自定义组件加一个新属性 linkage,用来记录所有要联动的组件:
{
// 组件的其他属性...
linkage: {
duration: 0, // 过渡持续时间
data: [ // 组件联动
{
id: '', // 联动的组件 id
label: '', // 联动的组件名称
event: '', // 监听事件
style: [{ key: '', value: '' }], // 监听的事件触发时,需要改变的属性
},
],
}
}对应的属性面板为:
组件联动本质上就是订阅/发布模式的运用,每个组件在渲染时都会遍历它监听的所有组件。
<script>
import eventBus from '@/utils/eventBus'
export default {
props: {
linkage: {
type: Object,
default: () => {},
},
element: {
type: Object,
default: () => {},
},
},
created() {
if (this.linkage?.data?.length) {
eventBus.$on('v-click', this.onClick)
eventBus.$on('v-hover', this.onHover)
}
},
mounted() {
const { data, duration } = this.linkage || {}
if (data?.length) {
this.$el.style.transition = `all ${duration}s`
}
},
beforeDestroy() {
if (this.linkage?.data?.length) {
eventBus.$off('v-click', this.onClick)
eventBus.$off('v-hover', this.onHover)
}
},
methods: {
changeStyle(data = []) {
data.forEach(item => {
item.style.forEach(e => {
if (e.key) {
this.element.style[e.key] = e.value
}
})
})
},
onClick(componentId) {
const data = this.linkage.data.filter(item => item.id === componentId && item.event === 'v-click')
this.changeStyle(data)
},
onHover(componentId) {
const data = this.linkage.data.filter(item => item.id === componentId && item.event === 'v-hover')
this.changeStyle(data)
},
},
}
</script>从上述代码可以看出:
v-click v-hover 两个事件(目前只有点击、悬浮两个事件)<template>
<div @click="onClick" @mouseenter="onMouseEnter">
<component
:is="config.component"
ref="component"
class="component"
:style="getStyle(config.style)"
:prop-value="config.propValue"
:element="config"
:request="config.request"
:linkage="config.linkage"
/>
</div>
</template>
<script>
import eventBus from '@/utils/eventBus'
export default {
methods: {
onClick() {
const events = this.config.events
Object.keys(events).forEach(event => {
this[event](events[event])
})
eventBus.$emit('v-click', this.config.id)
},
onMouseEnter() {
eventBus.$emit('v-hover', this.config.id)
},
},
}
</script>从上述代码可以看出,在渲染组件时,每一个组件的最外层都监听了 click mouseenter 事件,当这些事件触发时,eventBus 就会触发对应的事件( v-click 或 v-hover ),并且把当前的组件 id 作为参数传过去。
最后再捊一遍整体逻辑:
目前这个项目本身是没有做按需加载的,但是我把实现方案用文字的形式写出来其实也差不多。
第一步需要把所有的自定义组件出离出来,单独存放。建议使用 monorepo 的方式来存放,所有的组件放在一个仓库里。每一个 package 就是一个组件,可以单独打包。
- node_modules
- packages
- v-text # 一个组件就是一个包
- v-button
- v-table
- package.json
- lerna.json建议每个组件都打包成一个 js 文件 ,例如叫 bundle.js。打包好直接调用上传接口放到服务器存起来(发布到 npm 也可以),每个组件都有一个唯一 id。前端每次渲染组件的时,通过这个组件 id 向服务器请求组件资源的 URL。
动态加载组件有两种方式:
import()<script> 标签第一种方式实现起来比较方便:
const name = 'v-text' // 组件名称
const component = await import('https://xxx.xxx/bundile.js')
Vue.component(name, component)但是兼容性上有点小问题,如果要支持一些旧的浏览器(例如 IE),可以使用 <script> 标签的形式来加载:
function loadjs(url) {
return new Promise((resolve, reject) => {
const script = document.createElement('script')
script.src = url
script.onload = resolve
script.onerror = reject
})
}
const name = 'v-text' // 组件名称
await loadjs('https://xxx.xxx/bundile.js')
// 这种方式加载组件,会直接将组件挂载在全局变量 window 下,所以 window[name] 取值后就是组件
Vue.component(name, window[name])为了同时支持这两种加载方式,在加载组件时需要判断一下浏览器是否支持 ES6。如果支持就用第一种方式,如果不支持就用第二种方式:
function isSupportES6() {
try {
new Function('const fn = () => {};')
} catch (error) {
return false
}
return true
}最后一点,打包也要同时兼容这两种加载方式:
import VText from './VText.vue'
if (typeof window !== 'undefined') {
window['VText'] = VText
}
export default VText同时导出组件和把组件挂在 window 下。
图片镜像翻转需要使用 canvas 来实现,主要使用的是 canvas 的 translate() scale() 两个方法。假设我们要对一个 100*100 的图片进行水平镜像翻转,它的代码是这样的:
<canvas width="100" height="100"></canvas>
<script>
const canvas = document.querySelector('canvas')
const ctx = canvas.getContext('2d')
const img = document.createElement('img')
const width = 100
const height = 100
img.src = 'https://avatars.githubusercontent.com/u/22117876?v=4'
img.onload = () => ctx.drawImage(img, 0, 0, width, height)
// 水平翻转
setTimeout(() => {
// 清除图片
ctx.clearRect(0, 0, width, height)
// 平移图片
ctx.translate(width, 0)
// 对称镜像
ctx.scale(-1, 1)
ctx.drawImage(img, 0, 0, width, height)
// 还原坐标点
ctx.setTransform(1, 0, 0, 1, 0, 0)
}, 2000)
</script>ctx.translate(width, 0) 这行代码的意思是把图片的 x 坐标往前移动 width 个像素,所以平移后,图片就刚好在画布外面。然后这时使用 ctx.scale(-1, 1) 对图片进行水平翻转,就能得到一个水平翻转后的图片了。
垂直翻转也是一样的原理,只不过参数不一样:
// 原来水平翻转是 ctx.translate(width, 0)
ctx.translate(0, height)
// 原来水平翻转是 ctx.scale(-1, 1)
ctx.scale(1, -1)画布中的每一个组件都是有层级的,但是每个组件的具体层级并不会实时显现出来。因此,就有了这个实时组件列表的功能。
这个功能实现起来并不难,它的原理和画布渲染组件是一样的,只不过这个列表只需要渲染图标和名称。
<div class="real-time-component-list">
<div
v-for="(item, index) in componentData"
:key="index"
class="list"
:class="{ actived: index === curComponentIndex }"
@click="onClick(index)"
>
<span class="iconfont" :class="'icon-' + getComponent(index).icon"></span>
<span>{{ getComponent(index).label }}</span>
</div>
</div>但是有一点要注意,在组件数据的数组里,越靠后的组件层级越高。所以不对数组的数据索引做处理的话,用户看到的场景是这样的(假设添加组件的顺序为文本、按钮、图片):
从用户的角度来看,层级最高的图片,在实时列表里排在最后。这跟我们平时的认知不太一样。所以,我们需要对组件数据做个 reverse() 翻转一下。譬如文字组件的索引为 0,层级最低,它应该显示在底部。那么每次在实时列表展示时,我们可以通过下面的代码转换一下,得到翻转后的索引,然后再渲染,这样的排序看起来就比较舒服了。
<div class="real-time-component-list">
<div
v-for="(item, index) in componentData"
:key="index"
class="list"
:class="{ actived: transformIndex(index) === curComponentIndex }"
@click="onClick(transformIndex(index))"
>
<span class="iconfont" :class="'icon-' + getComponent(index).icon"></span>
<span>{{ getComponent(index).label }}</span>
</div>
</div>
<script>
function getComponent(index) {
return componentData[componentData.length - 1 - index]
}
function transformIndex(index) {
return componentData.length - 1 - index
}
</script>
经过转换后,层级最高的图片在实时列表里排在最上面,完美!
至此,可视化拖拽系列的第四篇文章已经结束了,距离上一篇系列文章的发布时间(2021年02月15日)已经有一年多了。没想到这个项目这么受欢迎,在短短一年的时间里获得了很多网友的认可。所以希望本系列的第四篇文章还是能像之前一样,对大家有帮助,再次感谢!
最近在学习 vue-cli 的源码,获益良多。为了让自己理解得更加深刻,我决定模仿它造一个轮子,争取尽可能多的实现原有的功能。
我将这个轮子分成三个版本:
有人可能不懂脚手架是什么。按我的理解,脚手架就是帮助你把项目的基础架子搭好。例如项目依赖、模板、构建工具等等。让你不用从零开始配置一个项目,尽可能快的进行业务开发。
建议在阅读本文时,能够结合项目源码一起配合使用,效果更好。这是项目地址 mini-cli。项目中的每一个分支都对应一个版本,例如第一个版本对应的 git 分支为 v1。所以在阅读源码时,记得要切换到对应的分支。
第一个版本的功能比较简单,大致为:
package.json 文件,并添加对应的依赖项。index.html、main.js、App.vue 等文件)。npm install 命令安装依赖。项目目录树:
├─.vscode
├─bin
│ ├─mvc.js # mvc 全局命令
├─lib
│ ├─generator # 各个功能的模板
│ │ ├─babel # babel 模板
│ │ ├─linter # eslint 模板
│ │ ├─router # vue-router 模板
│ │ ├─vue # vue 模板
│ │ ├─vuex # vuex 模板
│ │ └─webpack # webpack 模板
│ ├─promptModules # 各个模块的交互提示语
│ └─utils # 一系列工具函数
│ ├─create.js # create 命令处理函数
│ ├─Creator.js # 处理交互提示
│ ├─Generator.js # 渲染模板
│ ├─PromptModuleAPI.js # 将各个功能的提示语注入 Creator
└─scripts # commit message 验证脚本 和项目无关 不需关注脚手架第一个功能就是处理用户的命令,这需要使用 commander.js。这个库的功能就是解析用户的命令,提取出用户的输入交给脚手架。例如这段代码:
#!/usr/bin/env node
const program = require('commander')
const create = require('../lib/create')
program
.version('0.1.0')
.command('create <name>')
.description('create a new project')
.action(name => {
create(name)
})
program.parse()它使用 commander 注册了一个 create 命令,并设置了脚手架的版本和描述。我将这段代码保存在项目下的 bin 目录,并命名为 mvc.js。然后在 package.json 文件添加这段代码:
"bin": {
"mvc": "./bin/mvc.js"
},再执行 npm link,就可以将 mvc 注册成全局命令。这样在电脑上的任何地方都能使用 mvc 命令了。实际上,就是用 mvc 命令来代替执行 node ./bin/mvc.js。
假设用户在命令行上输入 mvc create demo(实际上执行的是 node ./bin/mvc.js create demo),commander 解析到命令 create 和参数 demo。然后脚手架可以在 action 回调里取到参数 name(值为 demo)。
取到用户要创建的项目名称 demo 之后,就可以弹出交互选项,询问用户要创建的项目需要哪些功能。这需要用到
Inquirer.js。Inquirer.js 的功能就是弹出一个问题和一些选项,让用户选择。并且选项可以指定是多选、单选等等。
例如下面的代码:
const prompts = [
{
"name": "features", // 选项名称
"message": "Check the features needed for your project:", // 选项提示语
"pageSize": 10,
"type": "checkbox", // 选项类型 另外还有 confirm list 等
"choices": [ // 具体的选项
{
"name": "Babel",
"value": "babel",
"short": "Babel",
"description": "Transpile modern JavaScript to older versions (for compatibility)",
"link": "https://babeljs.io/",
"checked": true
},
{
"name": "Router",
"value": "router",
"description": "Structure the app with dynamic pages",
"link": "https://router.vuejs.org/"
},
]
}
]
inquirer.prompt(prompts)弹出的问题和选项如下:
问题的类型 "type": "checkbox" 是 checkbox 说明是多选。如果两个选项都进行选中的话,返回来的值为:
{ features: ['babel', 'router'] }其中 features 是上面问题中的 name 属性。features 数组中的值则是每个选项中的 value。
Inquirer.js 还可以提供具有相关性的问题,也就是上一个问题选择了指定的选项,下一个问题才会显示出来。例如下面的代码:
{
name: 'Router',
value: 'router',
description: 'Structure the app with dynamic pages',
link: 'https://router.vuejs.org/',
},
{
name: 'historyMode',
when: answers => answers.features.includes('router'),
type: 'confirm',
message: `Use history mode for router? ${chalk.yellow(`(Requires proper server setup for index fallback in production)`)}`,
description: `By using the HTML5 History API, the URLs don't need the '#' character anymore.`,
link: 'https://router.vuejs.org/guide/essentials/history-mode.html',
},第二个问题中有一个属性 when,它的值是一个函数 answers => answers.features.includes('router')。当函数的执行结果为 true,第二个问题才会显示出来。如果你在上一个问题中选择了 router,它的结果就会变为 true。弹出第二个问题:问你路由模式是否选择 history 模式。
大致了解 Inquirer.js 后,就可以明白这一步我们要做什么了。主要就是将脚手架支持的功能配合对应的问题、可选值在控制台上展示出来,供用户选择。获取到用户具体的选项值后,再渲染模板和依赖。
先来看一下第一个版本支持哪些功能:
由于这是一个 vue 相关的脚手架,所以 vue 是默认提供的,不需要用户选择。另外构建工具 webpack 提供了开发环境和打包的功能,也是必需的,不用用户进行选择。所以可供用户选择的功能只有 4 个:
现在我们先来看一下这 4 个功能对应的交互提示语相关的文件。它们全部放在 lib/promptModules 目录下:
-babel.js
-linter.js
-router.js
-vuex.js每个文件包含了和它相关的所有交互式问题。例如刚才的示例,说明 router 相关的问题有两个。下面再看一下 babel.js 的代码:
module.exports = (api) => {
api.injectFeature({
name: 'Babel',
value: 'babel',
short: 'Babel',
description: 'Transpile modern JavaScript to older versions (for compatibility)',
link: 'https://babeljs.io/',
checked: true,
})
}只有一个问题,就是问下用户需不需要 babel 功能,默认为 checked: true,也就是需要。
用户使用 create 命令后,脚手架需要将所有功能的交互提示语句聚合在一起:
// craete.js
const creator = new Creator()
// 获取各个模块的交互提示语
const promptModules = getPromptModules()
const promptAPI = new PromptModuleAPI(creator)
promptModules.forEach(m => m(promptAPI))
// 清空控制台
clearConsole()
// 弹出交互提示语并获取用户的选择
const answers = await inquirer.prompt(creator.getFinalPrompts())
function getPromptModules() {
return [
'babel',
'router',
'vuex',
'linter',
].map(file => require(`./promptModules/${file}`))
}
// Creator.js
class Creator {
constructor() {
this.featurePrompt = {
name: 'features',
message: 'Check the features needed for your project:',
pageSize: 10,
type: 'checkbox',
choices: [],
}
this.injectedPrompts = []
}
getFinalPrompts() {
this.injectedPrompts.forEach(prompt => {
const originalWhen = prompt.when || (() => true)
prompt.when = answers => originalWhen(answers)
})
const prompts = [
this.featurePrompt,
...this.injectedPrompts,
]
return prompts
}
}
module.exports = Creator
// PromptModuleAPI.js
module.exports = class PromptModuleAPI {
constructor(creator) {
this.creator = creator
}
injectFeature(feature) {
this.creator.featurePrompt.choices.push(feature)
}
injectPrompt(prompt) {
this.creator.injectedPrompts.push(prompt)
}
}以上代码的逻辑如下:
creator 对象getPromptModules() 获取所有功能的交互提示语PromptModuleAPI 将所有交互提示语注入到 creator 对象const answers = await inquirer.prompt(creator.getFinalPrompts()) 在控制台弹出交互语句,并将用户选择结果赋值给 answers 变量。如果所有功能都选上,answers 的值为:
{
features: [ 'vue', 'webpack', 'babel', 'router', 'vuex', 'linter' ], // 项目具有的功能
historyMode: true, // 路由是否使用 history 模式
eslintConfig: 'airbnb', // esilnt 校验代码的默认规则,可被覆盖
lintOn: [ 'save' ] // 保存代码时进行校验
}获取用户的选项后就该开始渲染模板和生成 package.json 文件了。先来看一下如何生成 package.json 文件:
// package.json 文件内容
const pkg = {
name,
version: '0.1.0',
dependencies: {},
devDependencies: {},
}先定义一个 pkg 变量来表示 package.json 文件,并设定一些默认值。
所有的项目模板都放在 lib/generator 目录下:
├─lib
│ ├─generator # 各个功能的模板
│ │ ├─babel # babel 模板
│ │ ├─linter # eslint 模板
│ │ ├─router # vue-router 模板
│ │ ├─vue # vue 模板
│ │ ├─vuex # vuex 模板
│ │ └─webpack # webpack 模板每个模板的功能都差不多:
pkg 变量注入依赖项下面是 babel 相关的代码:
module.exports = (generator) => {
generator.extendPackage({
babel: {
presets: ['@babel/preset-env'],
},
dependencies: {
'core-js': '^3.8.3',
},
devDependencies: {
'@babel/core': '^7.12.13',
'@babel/preset-env': '^7.12.13',
'babel-loader': '^8.2.2',
},
})
}可以看到,模板调用 generator 对象的 extendPackage() 方法向 pkg 变量注入了 babel 相关的所有依赖。
extendPackage(fields) {
const pkg = this.pkg
for (const key in fields) {
const value = fields[key]
const existing = pkg[key]
if (isObject(value) && (key === 'dependencies' || key === 'devDependencies' || key === 'scripts')) {
pkg[key] = Object.assign(existing || {}, value)
} else {
pkg[key] = value
}
}
}注入依赖的过程就是遍历所有用户已选择的模板,并调用 extendPackage() 注入依赖。
脚手架是怎么渲染模板的呢?用 vuex 举例,先看一下它的代码:
module.exports = (generator) => {
// 向入口文件 `src/main.js` 注入代码 import store from './store'
generator.injectImports(generator.entryFile, `import store from './store'`)
// 向入口文件 `src/main.js` 的 new Vue() 注入选项 store
generator.injectRootOptions(generator.entryFile, `store`)
// 注入依赖
generator.extendPackage({
dependencies: {
vuex: '^3.6.2',
},
})
// 渲染模板
generator.render('./template', {})
}可以看到渲染的代码为 generator.render('./template', {})。./template 是模板目录的路径:
所有的模板代码都放在 template 目录下,vuex 将会在用户创建的目录下的 src 目录生成 store 文件夹,里面有一个 index.js 文件。它的内容为:
import Vue from 'vue'
import Vuex from 'vuex'
Vue.use(Vuex)
export default new Vuex.Store({
state: {
},
mutations: {
},
actions: {
},
modules: {
},
})这里简单描述一下 generator.render() 的渲染过程。
第一步, 使用 globby 读取模板目录下的所有文件:
const _files = await globby(['**/*'], { cwd: source, dot: true })第二步,遍历所有读取的文件。如果文件是二进制文件,则不作处理,渲染时直接生成文件。否则读取文件内容,再调用 ejs 进行渲染:
// 返回文件内容
const template = fs.readFileSync(name, 'utf-8')
return ejs.render(template, data, ejsOptions)使用 ejs 的好处,就是可以结合变量来决定是否渲染某些代码。例如 webpack 的模板中有这样一段代码:
module: {
rules: [
<%_ if (hasBabel) { _%>
{
test: /\.js$/,
loader: 'babel-loader',
exclude: /node_modules/,
},
<%_ } _%>
],
},ejs 可以根据用户是否选择了 babel 来决定是否渲染这段代码。如果 hasBabel 为 false,则这段代码:
{
test: /\.js$/,
loader: 'babel-loader',
exclude: /node_modules/,
},将不会被渲染出来。hasBabel 的值是调用 render() 时用参数传过去的:
generator.render('./template', {
hasBabel: options.features.includes('babel'),
lintOnSave: options.lintOn.includes('save'),
})第三步,注入特定代码。回想一下刚才 vuex 中的:
// 向入口文件 `src/main.js` 注入代码 import store from './store'
generator.injectImports(generator.entryFile, `import store from './store'`)
// 向入口文件 `src/main.js` 的 new Vue() 注入选项 store
generator.injectRootOptions(generator.entryFile, `store`)这两行代码的作用是:在项目入口文件 src/main.js 中注入特定的代码。
vuex 是 vue 的一个状态管理库,属于 vue 全家桶中的一员。如果创建的项目没有选择 vuex 和 vue-router。则 src/main.js 的代码为:
import Vue from 'vue'
import App from './App.vue'
Vue.config.productionTip = false
new Vue({
render: (h) => h(App),
}).$mount('#app')如果选择了 vuex,它会注入上面所说的两行代码,现在 src/main.js 代码变为:
import Vue from 'vue'
import store from './store' // 注入的代码
import App from './App.vue'
Vue.config.productionTip = false
new Vue({
store, // 注入的代码
render: (h) => h(App),
}).$mount('#app')这里简单描述一下代码的注入过程:
package.json 的部分选项一些第三方库的配置项可以放在 package.json 文件,也可以自己独立生成一份文件。例如 babel 在 package.json 中注入的配置为:
babel: {
presets: ['@babel/preset-env'],
}我们可以调用 generator.extractConfigFiles() 将内容提取出来并生成 babel.config.js 文件:
module.exports = {
presets: ['@babel/preset-env'],
}渲染好的模板文件和 package.json 文件目前还是在内存中,并没有真正的在硬盘上创建。这时可以调用 writeFileTree() 将文件生成:
const fs = require('fs-extra')
const path = require('path')
module.exports = async function writeFileTree(dir, files) {
Object.keys(files).forEach((name) => {
const filePath = path.join(dir, name)
fs.ensureDirSync(path.dirname(filePath))
fs.writeFileSync(filePath, files[name])
})
}这段代码的逻辑如下:
例如现在一个文件路径为 src/test.js,第一次写入时,由于还没有 src 目录。所以会先生成 src 目录,再生成 test.js 文件。
webpack 需要提供开发环境下的热加载、编译等服务,还需要提供打包服务。目前 webpack 的代码比较少,功能比较简单。而且生成的项目中,webpack 配置代码是暴露出来的。这留待 v3 版本再改进。
添加一个新功能,需要在两个地方添加代码:分别是 lib/promptModules 和 lib/generator。在 lib/promptModules 中添加的是这个功能相关的交互提示语。在 lib/generator 中添加的是这个功能相关的依赖和模板代码。
不过不是所有的功能都需要添加模板代码的,例如 babel 就不需要。在添加新功能时,有可能会对已有的模板代码造成影响。例如我现在需要项目支持 ts。除了添加 ts 相关的依赖,还得在 webpack vue vue-router vuex linter 等功能中修改原有的模板代码。
举个例子,在 vue-router 中,如果支持 ts,则这段代码:
const routes = [ // ... ]需要修改为:
<%_ if (hasTypeScript) { _%>
const routes: Array<RouteConfig> = [ // ... ]
<%_ } else { _%>
const routes = [ // ... ]
<%_ } _%>因为 ts 的值有类型。
总之,添加的新功能越多,各个功能的模板代码也会越来越多。并且还需要考虑到各个功能之间的影响。
下载依赖需要使用 execa,它可以调用子进程执行命令。
const execa = require('execa')
module.exports = function executeCommand(command, cwd) {
return new Promise((resolve, reject) => {
const child = execa(command, [], {
cwd,
stdio: ['inherit', 'pipe', 'inherit'],
})
child.stdout.on('data', buffer => {
process.stdout.write(buffer)
})
child.on('close', code => {
if (code !== 0) {
reject(new Error(`command failed: ${command}`))
return
}
resolve()
})
})
}
// create.js 文件
console.log('\n正在下载依赖...\n')
// 下载依赖
await executeCommand('npm install', path.join(process.cwd(), name))
console.log('\n依赖下载完成! 执行下列命令开始开发:\n')
console.log(`cd ${name}`)
console.log(`npm run dev`)调用 executeCommand() 开始下载依赖,参数为 npm install 和用户创建的项目路径。为了能让用户看到下载依赖的过程,我们需要使用下面的代码将子进程的输出传给主进程,也就是输出到控制台:
child.stdout.on('data', buffer => {
process.stdout.write(buffer)
})下面我用动图演示一下 v1 版本的创建过程:
创建成功的项目截图:
第二个版本在 v1 的基础上添加了一些辅助功能:
创建项目时,先提前判断一下该项目是否存在:
const targetDir = path.join(process.cwd(), name)
// 如果目标目录已存在,询问是覆盖还是合并
if (fs.existsSync(targetDir)) {
// 清空控制台
clearConsole()
const { action } = await inquirer.prompt([
{
name: 'action',
type: 'list',
message: `Target directory ${chalk.cyan(targetDir)} already exists. Pick an action:`,
choices: [
{ name: 'Overwrite', value: 'overwrite' },
{ name: 'Merge', value: 'merge' },
],
},
])
if (action === 'overwrite') {
console.log(`\nRemoving ${chalk.cyan(targetDir)}...`)
await fs.remove(targetDir)
}
}如果选择 overwrite,则进行移除 fs.remove(targetDir)。
先在代码中提前把默认配置的代码写好:
exports.defaultPreset = {
features: ['babel', 'linter'],
historyMode: false,
eslintConfig: 'airbnb',
lintOn: ['save'],
}这个配置默认使用 babel 和 eslint。
然后生成交互提示语时,先调用 getDefaultPrompts() 方法获取默认配置。
getDefaultPrompts() {
const presets = this.getPresets()
const presetChoices = Object.entries(presets).map(([name, preset]) => {
let displayName = name
return {
name: `${displayName} (${preset.features})`,
value: name,
}
})
const presetPrompt = {
name: 'preset',
type: 'list',
message: `Please pick a preset:`,
choices: [
// 默认配置
...presetChoices,
// 这是手动模式提示语
{
name: 'Manually select features',
value: '__manual__',
},
],
}
const featurePrompt = {
name: 'features',
when: isManualMode,
type: 'checkbox',
message: 'Check the features needed for your project:',
choices: [],
pageSize: 10,
}
return {
presetPrompt,
featurePrompt,
}
}这样配置后,在用户选择功能前会先弹出这样的提示语:
在 vue-cli 创建项目时,会生成一个 .vuerc 文件,里面会记录一些关于项目的配置信息。例如使用哪个包管理器、npm 源是否使用淘宝源等等。为了避免和 vue-cli 冲突,本脚手架生成的配置文件为 .mvcrc。
这个 .mvcrc 文件保存在用户的 home 目录下(不同操作系统目录不同)。我的是 win10 操作系统,保存目录为 C:\Users\bin。获取用户的 home 目录可以通过以下代码获取:
const os = require('os')
os.homedir().mvcrc 文件还会保存用户创建项目的配置,这样当用户重新创建项目时,就可以直接选择以前创建过的配置,不用再一步步的选择项目功能。
在第一次创建项目时,.mvcrc 文件是不存在的。如果这时用户还安装了 yarn,脚手架就会提示用户要使用哪个包管理器:
// 读取 `.mvcrc` 文件
const savedOptions = loadOptions()
// 如果没有指定包管理器并且存在 yarn
if (!savedOptions.packageManager && hasYarn) {
const packageManagerChoices = []
if (hasYarn()) {
packageManagerChoices.push({
name: 'Use Yarn',
value: 'yarn',
short: 'Yarn',
})
}
packageManagerChoices.push({
name: 'Use NPM',
value: 'npm',
short: 'NPM',
})
otherPrompts.push({
name: 'packageManager',
type: 'list',
message: 'Pick the package manager to use when installing dependencies:',
choices: packageManagerChoices,
})
}当用户选择 yarn 后,下载依赖的命令就会变为 yarn;如果选择了 npm,下载命令则为 npm install:
const PACKAGE_MANAGER_CONFIG = {
npm: {
install: ['install'],
},
yarn: {
install: [],
},
}
await executeCommand(
this.bin, // 'yarn' or 'npm'
[
...PACKAGE_MANAGER_CONFIG[this.bin][command],
...(args || []),
],
this.context,
)当用户选择了项目功能后,会先调用 shouldUseTaobao() 方法判断是否需要切换淘宝源:
const execa = require('execa')
const chalk = require('chalk')
const request = require('./request')
const { hasYarn } = require('./env')
const inquirer = require('inquirer')
const registries = require('./registries')
const { loadOptions, saveOptions } = require('./options')
async function ping(registry) {
await request.get(`${registry}/vue-cli-version-marker/latest`)
return registry
}
function removeSlash(url) {
return url.replace(/\/$/, '')
}
let checked
let result
module.exports = async function shouldUseTaobao(command) {
if (!command) {
command = hasYarn() ? 'yarn' : 'npm'
}
// ensure this only gets called once.
if (checked) return result
checked = true
// previously saved preference
const saved = loadOptions().useTaobaoRegistry
if (typeof saved === 'boolean') {
return (result = saved)
}
const save = val => {
result = val
saveOptions({ useTaobaoRegistry: val })
return val
}
let userCurrent
try {
userCurrent = (await execa(command, ['config', 'get', 'registry'])).stdout
} catch (registryError) {
try {
// Yarn 2 uses `npmRegistryServer` instead of `registry`
userCurrent = (await execa(command, ['config', 'get', 'npmRegistryServer'])).stdout
} catch (npmRegistryServerError) {
return save(false)
}
}
const defaultRegistry = registries[command]
if (removeSlash(userCurrent) !== removeSlash(defaultRegistry)) {
// user has configured custom registry, respect that
return save(false)
}
let faster
try {
faster = await Promise.race([
ping(defaultRegistry),
ping(registries.taobao),
])
} catch (e) {
return save(false)
}
if (faster !== registries.taobao) {
// default is already faster
return save(false)
}
if (process.env.VUE_CLI_API_MODE) {
return save(true)
}
// ask and save preference
const { useTaobaoRegistry } = await inquirer.prompt([
{
name: 'useTaobaoRegistry',
type: 'confirm',
message: chalk.yellow(
` Your connection to the default ${command} registry seems to be slow.\n`
+ ` Use ${chalk.cyan(registries.taobao)} for faster installation?`,
),
},
])
// 注册淘宝源
if (useTaobaoRegistry) {
await execa(command, ['config', 'set', 'registry', registries.taobao])
}
return save(useTaobaoRegistry)
}上面代码的逻辑为:
.mvcrc 是否有 useTaobaoRegistry 选项。如果有,直接将结果返回,无需判断。get 请求,通过 Promise.race() 来调用。这样更快的那个请求会先返回,从而知道是默认源还是淘宝源速度更快。await execa(command, ['config', 'set', 'registry', registries.taobao]) 将当前 npm 的源改为淘宝源,即 npm config set registry https://registry.npm.taobao.org。如果是 yarn,则命令为 yarn config set registry https://registry.npm.taobao.org。其实 vue-cli 是没有这段代码的:
// 注册淘宝源
if (useTaobaoRegistry) {
await execa(command, ['config', 'set', 'registry', registries.taobao])
}这是我自己加的。主要是我没有在 vue-cli 中找到显式注册淘宝源的代码,它只是从配置文件读取出是否使用淘宝源,或者将是否使用淘宝源这个选项写入配置文件。另外 npm 的配置文件 .npmrc 是可以更改默认源的,如果在 .npmrc 文件直接写入淘宝的镜像地址,那 npm 就会使用淘宝源下载依赖。但 npm 肯定不会去读取 .vuerc 的配置来决定是否使用淘宝源。
对于这一点我没搞明白,所以在用户选择了淘宝源之后,手动调用命令注册一遍。
如果用户创建项目时选择手动模式,在选择完一系列功能后,会弹出下面的提示语:
询问用户是否将这次的项目选择保存为默认配置,如果用户选择是,则弹出下一个提示语:
让用户输入保存配置的名称。
这两句提示语相关的代码为:
const otherPrompts = [
{
name: 'save',
when: isManualMode,
type: 'confirm',
message: 'Save this as a preset for future projects?',
default: false,
},
{
name: 'saveName',
when: answers => answers.save,
type: 'input',
message: 'Save preset as:',
},
]保存配置的代码为:
exports.saveOptions = (toSave) => {
const options = Object.assign(cloneDeep(exports.loadOptions()), toSave)
for (const key in options) {
if (!(key in exports.defaults)) {
delete options[key]
}
}
cachedOptions = options
try {
fs.writeFileSync(rcPath, JSON.stringify(options, null, 2))
return true
} catch (e) {
error(
`Error saving preferences: `
+ `make sure you have write access to ${rcPath}.\n`
+ `(${e.message})`,
)
}
}
exports.savePreset = (name, preset) => {
const presets = cloneDeep(exports.loadOptions().presets || {})
presets[name] = preset
return exports.saveOptions({ presets })
}以上代码直接将用户的配置保存到 .mvcrc 文件中。下面是我电脑上的 .mvcrc 的内容:
{
"packageManager": "npm",
"presets": {
"test": {
"features": [
"babel",
"linter"
],
"eslintConfig": "airbnb",
"lintOn": [
"save"
]
},
"demo": {
"features": [
"babel",
"linter"
],
"eslintConfig": "airbnb",
"lintOn": [
"save"
]
}
},
"useTaobaoRegistry": true
}下次再创建项目时,脚手架就会先读取这个配置文件的内容,让用户决定是否使用已有的配置来创建项目。
至此,v2 版本的内容就介绍完了。
由于 vue-cli 关于插件的源码我还没有看完,所以这篇文章只讲解前两个版本的源码。v3 版本等我看完 vue-cli 的源码再回来填坑,预计在 3 月初就可以完成。
如果你想了解更多关于前端工程化的文章,可以看一下我写的《带你入门前端工程》。 这里是全文目录:
如:iPhone 安卓 ipad,以及各种尺寸的电视机
建议先阅读官方指南——Vue.js 服务器端渲染指南,再回到本文开始阅读。
本文将分成以下两部分:
好了,下面开始正文。
<div id="app"></div> 的 HTML 文件。new Vue() 开始实例化并渲染页面。asyncData() 函数,就会执行它进行数据预取并填充到 HTML 文件里,最后返回这个 HTML 页面。new Vue() 开始实例化并接管页面。从上述两个过程中,可以看出,区别就在于第二步。客户端渲染的网站会直接返回 HTML 文件,而服务端渲染的网站则会渲染完页面再返回这个 HTML 文件。
这样做的好处是什么?是更快的内容到达时间 (time-to-content)。
假设你的网站需要加载完 abcd 四个文件才能渲染完毕。并且每个文件大小为 1 M。
这样一算:客户端渲染的网站需要加载 4 个文件和 HTML 文件才能完成首页渲染,总计大小为 4M(忽略 HTML 文件大小)。而服务端渲染的网站只需要加载一个渲染完毕的 HTML 文件就能完成首页渲染,总计大小为已经渲染完毕的 HTML 文件(这种文件不会太大,一般为几百K,我的个人博客网站(SSR)加载的 HTML 文件为 400K)。这就是服务端渲染更快的原因。
对于服务端返回来的 HTML 文件,客户端必须进行接管,对其进行 new Vue() 实例化,用户才能正常使用页面。
如果不对其进行激活的话,里面的内容只是一串字符串而已,例如下面的代码,点击是无效的:
<button @click="sayHi">如果不进行激活,点我是不会触发事件的</button>那客户端如何接管页面呢?下面引用一篇文章中的内容:
客户端 new Vue() 时,客户端会和服务端生成的DOM进行Hydration对比(判断这个DOM和自己即将生成的DOM是否相同(vuex store 数据同步才能保持一致)
如果相同就调用app.$mount('#app')将客户端的vue实例挂载到这个DOM上,即去“激活”这些服务端渲染的HTML之后,其变成了由Vue动态管理的DOM,以便响应后续数据的变化,即之后所有的交互和vue-router不同页面之间的跳转将全部在浏览器端运行。
如果客户端构建的虚拟 DOM 树与服务器渲染返回的HTML结构不一致,这时候,客户端会请求一次服务器再渲染整个应用程序,这使得ssr失效了,达不到服务端渲染的目的了
不管是客户端渲染还是服务端渲染,都需要等待客户端执行 new Vue() 之后,用户才能进行交互操作。但服务端渲染的网站能让用户更快的看见页面。
webpack 配置文件共有 3 个:
webpack.base.config.js,基础配置文件,客户端与服务端都需要它。webpack.client.config.js,客户端配置文件,用于生成客户端所需的资源。webpack.server.config.js,服务端配置文件,用于生成服务端所需的资源。webpack.base.config.js 基础配置文件const path = require('path')
const { VueLoaderPlugin } = require('vue-loader')
const isProd = process.env.NODE_ENV === 'production'
function resolve(dir) {
return path.join(__dirname, '..', dir)
}
module.exports = {
context: path.resolve(__dirname, '../'),
devtool: isProd ? 'source-map' : '#cheap-module-source-map',
output: {
path: path.resolve(__dirname, '../dist'),
publicPath: '/dist/',
// chunkhash 同属一个 chunk 中的文件修改了,文件名会发生变化
// contenthash 只有文件自己的内容变化了,文件名才会变化
filename: '[name].[contenthash].js',
// 此选项给打包后的非入口js文件命名,与 SplitChunksPlugin 配合使用
chunkFilename: '[name].[contenthash].js',
},
resolve: {
extensions: ['.js', '.vue', '.json', '.css'],
alias: {
public: resolve('public'),
'@': resolve('src')
}
},
module: {
// https://juejin.im/post/6844903689103081485
// 使用 `mini-css-extract-plugin` 插件打包的的 `server bundle` 会使用到 document。
// 由于 node 环境中不存在 document 对象,所以报错。
// 解决方案:样式相关的 loader 不要放在 `webpack.base.config.js` 文件
// 将其分拆到 `webpack.client.config.js` 和 `webpack.client.server.js` 文件
// 其中 `mini-css-extract-plugin` 插件要放在 `webpack.client.config.js` 文件配置。
rules: [
{
test: /\.vue$/,
loader: 'vue-loader',
options: {
compilerOptions: {
preserveWhitespace: false
}
}
},
{
test: /\.js$/,
loader: 'babel-loader',
exclude: /node_modules/
},
{
test: /\.(png|svg|jpg|gif|ico)$/,
use: ['file-loader']
},
{
test: /\.(woff|eot|ttf)\??.*$/,
loader: 'url-loader?name=fonts/[name].[md5:hash:hex:7].[ext]'
},
]
},
plugins: [new VueLoaderPlugin()],
}基础配置文件比较简单,output 属性的意思是打包时根据文件内容生成文件名称。module 属性配置不同文件的解析 loader。
webpack.client.config.js 客户端配置文件const webpack = require('webpack')
const merge = require('webpack-merge')
const base = require('./webpack.base.config')
const CompressionPlugin = require('compression-webpack-plugin')
const WebpackBar = require('webpackbar')
const VueSSRClientPlugin = require('vue-server-renderer/client-plugin')
const MiniCssExtractPlugin = require('mini-css-extract-plugin')
const CssMinimizerPlugin = require('css-minimizer-webpack-plugin')
const isProd = process.env.NODE_ENV === 'production'
const plugins = [
new webpack.DefinePlugin({
'process.env.NODE_ENV': JSON.stringify(
process.env.NODE_ENV || 'development'
),
'process.env.VUE_ENV': '"client"'
}),
new VueSSRClientPlugin(),
new MiniCssExtractPlugin({
filename: 'style.css'
})
]
if (isProd) {
plugins.push(
// 开启 gzip 压缩 https://github.com/woai3c/node-blog/blob/master/doc/optimize.md
new CompressionPlugin(),
// 该插件会根据模块的相对路径生成一个四位数的hash作为模块id, 用于生产环境。
new webpack.HashedModuleIdsPlugin(),
new WebpackBar(),
)
}
const config = {
entry: {
app: './src/entry-client.js'
},
plugins,
optimization: {
runtimeChunk: {
name: 'manifest'
},
splitChunks: {
cacheGroups: {
vendor: {
name: 'chunk-vendors',
test: /[\\/]node_modules[\\/]/,
priority: -10,
chunks: 'initial',
},
common: {
name: 'chunk-common',
minChunks: 2,
priority: -20,
chunks: 'initial',
reuseExistingChunk: true
}
},
}
},
module: {
rules: [
{
test: /\.css$/,
use: [
{
loader: MiniCssExtractPlugin.loader,
options: {
// 解决 export 'default' (imported as 'mod') was not found
// 启用 CommonJS 语法
esModule: false,
},
},
'css-loader'
]
}
]
},
}
if (isProd) {
// 压缩 css
config.optimization.minimizer = [
new CssMinimizerPlugin(),
]
}
module.exports = merge(base, config)客户端配置文件中的 config.optimization 属性是打包时分割代码用的。它的作用是将第三方库都打包在一起。
其他插件作用:
MiniCssExtractPlugin 插件, 将 css 提取出来单独打包。CssMinimizerPlugin 插件,压缩 css。CompressionPlugin 插件,将资源压缩成 gzip 格式(大大提升传输效率)。另外还需要在 node 服务器上引入 compression 插件配合使用。WebpackBar 插件,打包时显示进度条。webpack.server.config.js 服务端配置文件const webpack = require('webpack')
const merge = require('webpack-merge')
const base = require('./webpack.base.config')
const nodeExternals = require('webpack-node-externals') // Webpack allows you to define externals - modules that should not be bundled.
const VueSSRServerPlugin = require('vue-server-renderer/server-plugin')
const WebpackBar = require('webpackbar')
const plugins = [
new webpack.DefinePlugin({
'process.env.NODE_ENV': JSON.stringify(process.env.NODE_ENV || 'development'),
'process.env.VUE_ENV': '"server"'
}),
new VueSSRServerPlugin()
]
if (process.env.NODE_ENV == 'production') {
plugins.push(
new WebpackBar()
)
}
module.exports = merge(base, {
target: 'node',
devtool: '#source-map',
entry: './src/entry-server.js',
output: {
filename: 'server-bundle.js',
libraryTarget: 'commonjs2'
},
externals: nodeExternals({
allowlist: /\.css$/ // 防止将某些 import 的包(package)打包到 bundle 中,而是在运行时(runtime)再去从外部获取这些扩展依赖
}),
plugins,
module: {
rules: [
{
test: /\.css$/,
use: [
'vue-style-loader',
'css-loader'
]
}
]
},
})服务端打包和客户端不同,它将所有文件一起打包成一个文件 server-bundle.js。同时解析 css 需要使用 vue-style-loader,这一点在官方指南中有说明:
pro-server.js 生产环境服务器配置文件
const fs = require('fs')
const path = require('path')
const express = require('express')
const setApi = require('./api')
const LRU = require('lru-cache') // 缓存
const { createBundleRenderer } = require('vue-server-renderer')
const favicon = require('serve-favicon')
const resolve = file => path.resolve(__dirname, file)
const app = express()
// 开启 gzip 压缩 https://github.com/woai3c/node-blog/blob/master/doc/optimize.md
const compression = require('compression')
app.use(compression())
// 设置 favicon
app.use(favicon(resolve('../public/favicon.ico')))
// 新版本 需要加 new,旧版本不用
const microCache = new LRU({
max: 100,
maxAge: 60 * 60 * 24 * 1000 // 重要提示:缓存资源将在 1 天后过期。
})
const serve = (path) => {
return express.static(resolve(path), {
maxAge: 1000 * 60 * 60 * 24 * 30
})
}
app.use('/dist', serve('../dist', true))
function createRenderer(bundle, options) {
return createBundleRenderer(
bundle,
Object.assign(options, {
basedir: resolve('../dist'),
runInNewContext: false
})
)
}
function render(req, res) {
const hit = microCache.get(req.url)
if (hit) {
console.log('Response from cache')
return res.end(hit)
}
res.setHeader('Content-Type', 'text/html')
const handleError = err => {
if (err.url) {
res.redirect(err.url)
} else if (err.code === 404) {
res.status(404).send('404 | Page Not Found')
} else {
res.status(500).send('500 | Internal Server Error~')
console.log(err)
}
}
const context = {
title: 'SSR 测试', // default title
url: req.url
}
renderer.renderToString(context, (err, html) => {
if (err) {
return handleError(err)
}
microCache.set(req.url, html)
res.send(html)
})
}
const templatePath = resolve('../public/index.template.html')
const template = fs.readFileSync(templatePath, 'utf-8')
const bundle = require('../dist/vue-ssr-server-bundle.json')
const clientManifest = require('../dist/vue-ssr-client-manifest.json') // 将js文件注入到页面中
const renderer = createRenderer(bundle, {
template,
clientManifest
})
const port = 8080
app.listen(port, () => {
console.log(`server started at localhost:${ port }`)
})
setApi(app)
app.get('*', render)从代码中可以看到,当首次加载页面时,需要调用 createBundleRenderer() 生成一个 renderer,它的参数是打包生成的 vue-ssr-server-bundle.json 和 vue-ssr-client-manifest.json 文件。当返回 HTML 文件后,页面将会被客户端接管。
在文件的最后有一行代码 app.get('*', render),它表示所有匹配不到的请求都交给它处理。所以如果你写了 ajax 请求处理函数必须放在前面,就像下面这样:
app.get('/fetchData', (req, res) => { ... })
app.post('/changeData', (req, res) => { ... })
app.get('*', render)否则你的页面会打不开。
开发环境的服务器配置和生产环境没什么不同,区别在于开发环境下的服务器有热更新。
一般用 webpack 进行开发时,简单的配置一下 dev server 参数就可以使用热更新了,但是 SSR 项目需要自己配置。
由于 SSR 开发环境服务器的配置文件 setup-dev-server.js 代码太多,我对其进行简化后,大致代码如下:
// dev-server.js
const express = require('express')
const webpack = require('webpack')
const webpackConfig = require('../build/webpack.dev') // 获取 webpack 配置文件
const compiler = webpack(webpackConfig)
const app = express()
app.use(require('webpack-hot-middleware')(compiler))
app.use(require('webpack-dev-middleware')(compiler, {
noInfo: true,
stats: {
colors: true
}
}))同时需要在 webpack 的入口文件加上这一行代码 webpack-hot-middleware/client?reload=true。
// webpack.dev.js
const merge = require('webpack-merge')
const webpackBaseConfig = require('./webpack.base.config.js') // 这个配置和热更新无关,可忽略
module.exports = merge(webpackBaseConfig, {
mode: 'development',
entry: {
app: ['webpack-hot-middleware/client?reload=true' , './client/main.js'] // 开启热模块更新
},
plugins: [new webpack.HotModuleReplacementPlugin()]
})然后使用 node dev-server.js 来开启前端代码热更新。
热更新主要使用了两个插件:webpack-dev-middleware 和 webpack-hot-middleware。顾名思义,看名称就知道它们的作用,
webpack-dev-middleware 的作用是生成一个与 webpack 的 compiler 绑定的中间件,然后在 express 启动的 app 中调用这个中间件。
这个中间件的作用呢,简单总结为以下三点:通过watch mode,监听资源的变更,然后自动打包; 快速编译,走内存;返回中间件,支持express 的 use 格式。
webpack-hot-middleware 插件的作用就是热更新,它需要配合 HotModuleReplacementPlugin 和 webpack-dev-middleware 一起使用。
vue-ssr-client-manifest.json 和 vue-ssr-server-bundle.jsonwebpack 需要对源码打包两次,一次是为客户端环境打包的,一次是为服务端环境打包的。
为客户端环境打包的文件,和以前我们打包的资源一样,不过多出了一个 vue-ssr-client-manifest.json 文件。服务端环境打包只输出一个 vue-ssr-server-bundle.json 文件。
vue-ssr-client-manifest.json 包含了客户端环境所需的资源名称:
从上图中可以看到有三个关键词:
vue-ssr-server-bundle.json 文件:
[vue-router] failed to resolve async component default: referenceerror: window is not defined由于在一些文件或第三方文件中可能会用到 window 对象,并且 node 中不存在 window 对象,所以会报错。
此时可在 src/app.js 文件加上以下代码进行判断:
// 在 app.js 文件添加上这段代码,对环境进行判断
if (typeof window === 'undefined') {
global.window = {}
}mini-css-extract-plugin 插件造成 ReferenceError: document is not defined使用 mini-css-extract-plugin 插件打包的的 server bundle, 会使用到 document。由于 node 环境中不存在 document 对象,所以报错。
解决方案:样式相关的 loader 不要放在 webpack.base.config.js 文件,将其分拆到 webpack.client.config.js 和 webpack.client.server.js 文件。其中 mini-css-extract-plugin 插件要放在 webpack.client.config.js 文件配置。
base
module: {
rules: [
{
test: /\.vue$/,
loader: 'vue-loader',
options: {
compilerOptions: {
preserveWhitespace: false
}
}
},
{
test: /\.js$/,
loader: 'babel-loader',
exclude: /node_modules/
},
{
test: /\.(png|svg|jpg|gif|ico)$/,
use: ['file-loader']
},
{
test: /\.(woff|eot|ttf)\??.*$/,
loader: 'url-loader?name=fonts/[name].[md5:hash:hex:7].[ext]'
},
]
}client
module: {
rules: [
{
test: /\.css$/,
use: [
{
loader: MiniCssExtractPlugin.loader,
options: {
// 解决 export 'default' (imported as 'mod') was not found
esModule: false,
},
},
'css-loader'
]
}
]
}server
module: {
rules: [
{
test: /\.css$/,
use: [
'vue-style-loader',
'css-loader'
]
}
]
}由于开发环境使用的是 memory-fs 插件,打包文件是放在内存中的。如果此时 dist 文件夹有刚才打包留下的资源,就会使用 dist 文件夹中的资源,而不是内存中的资源。并且开发环境和打包环境生成的资源名称是不一样的,所以就造成了这个 BUG。
解决方法是执行 npm run dev 时,删除 dist 文件夹。所以要在 npm run dev 对应的脚本中加上 rimraf dist。
"dev": "rimraf dist && node ./server/dev-server.js --mode development",[vue-router] Failed to resolve async component default: ReferenceError: document is not defined不要在有可能使用到服务端渲染的页面访问 DOM,如果有这种操作请放在 mounted() 钩子函数里。
如果你引入的数据或者接口有访问 DOM 的操作也会报这种错,在这种情况下可以使用 require()。因为 require() 是运行时加载的,所以可以这样使用:
<script>
// 原来报错的操作,这个接口有 DOM 操作,所以这样使用的时候在服务端会报错。
import { fetchArticles } from '@/api/client'
export default {
methods: {
getAppointArticles() {
fetchArticles({
tags: this.tags,
pageSize: this.pageSize,
pageIndex: this.pageIndex,
})
.then(res => {
this.$store.commit('setArticles', res)
})
},
}
}
</script>修改后:
<script>
// 先定义一个外部变量,在 mounted() 钩子里赋值
let fetchArticles
export default {
mounted() {
// 由于服务端渲染不会有 mounted() 钩子,所以在这里可以保证是在客户端的情况下引入接口
fetchArticles = require('@/api/client').fetchArticles
},
methods: {
getAppointArticles() {
fetchArticles({
tags: this.tags,
pageSize: this.pageSize,
pageIndex: this.pageIndex,
})
.then(res => {
this.$store.commit('setArticles', res)
})
},
}
}
</script>修改后可以正常使用。
这个坑其实是有报错信息的,但是没有输出,导致以为没有错误。
在 setup-dev-server.js 文件中有一行代码 if (stats.errors.length) return,如果有报错就直接返回,不执行后续的操作。导致服务器没任何反应,所以我们可以在这打一个 console.log 语句,打印报错信息。
这个 DEMO 是基于官方 DEMO vue-hackernews-2.0 改造的。不过官方 DEMO 发表于 4 年前,最近修改时间是 2 年前,很多选项参数已经过时了。并且官方 DEMO 需要翻墙才能使用。所以我在此基础上对其进行了改造,改造后的 DEMO 放在 Github 上,它是一个比较完善的 DEMO,可以在此基础上进行二次开发。
如果你不仅仅满足于一个 DEMO,建议看一看我的个人博客项目,它原来是客户端渲染的项目,后来重构为服务端渲染,绝对实战。
浏览器渲染原理作为前端必须要了解的知识点之一,在面试中经常会被问到。在一些前端书籍或者培训课程里也会经常被提及,比如 MDN 文档中就有渲染原理的相关描述。
作为一名工作多年的前端,我对于渲染原理自然也是了解的,但是对于它的理解只停留在理论知识层面。所以我决定自己动手实现一个玩具版的渲染引擎。
渲染引擎是浏览器的一部分,它负责将网页内容(HTML、CSS、JavaScript 等)转化为用户可阅读、观看、听到的形式。但是要独自实现一个完整的渲染引擎工作量实在太大了,而且也很困难。于是我决定退一步,打算实现一个玩具版的渲染引擎。刚好 Github 上有一个开源的用 Rust 写的玩具版渲染引擎 robinson,于是决定模仿其源码自己用 JavaScript 实现一遍,并且也在 Github 上开源了 从零开始实现一个玩具版浏览器渲染引擎。
这个玩具版的渲染引擎一共分为五个阶段:
分别是:
每个阶段的代码我在仓库上都用一个分支来表示。由于直接看整个渲染引擎的代码可能会比较困难,所以我建议大家从第一个分支开始进行学习,从易到难,这样学习效果更好。
现在我们先看一下如何编写一个 HTML 解析器。
HTML 解析器的作用就是将一连串的 HTML 文本解析为 DOM 树。比如将这样的 HTML 文本:
<div class="lightblue test" id=" div " data-index="1">test!</div>解析为一个 DOM 树:
{
"tagName": "div",
"attributes": {
"class": "lightblue test",
"id": "div",
"data-index": "1"
},
"children": [
{
"nodeValue": "test!",
"nodeType": 3
}
],
"nodeType": 1
}写解析器需要懂一些编译原理的知识,比如词法分析、语法分析什么的。但是我们的玩具版解析器非常简单,即使不懂也没有关系,大家看源码就能明白了。
再回到上面的那段 HTML 文本,它的整个解析过程可以用下面的图来表示,每一段 HTML 文本都有对应的方法去解析。
为了让解析器实现起来简单一点,我们需要对 HTML 的功能进行约束:
<div>...</div><div class="test">...</div>Element 和 Text对解析器的功能进行约束后,代码实现就变得简单多了,现在让我们继续吧。
首先,为这两种节点 Element 和 Text 定一个适当的数据结构:
export enum NodeType {
Element = 1,
Text = 3,
}
export interface Element {
tagName: string
attributes: Record<string, string>
children: Node[]
nodeType: NodeType.Element
}
interface Text {
nodeValue: string
nodeType: NodeType.Text
}
export type Node = Element | Text然后为这两种节点各写一个生成函数:
export function element(tagName: string) {
return {
tagName,
attributes: {},
children: [],
nodeType: NodeType.Element,
} as Element
}
export function text(data: string) {
return {
nodeValue: data,
nodeType: NodeType.Text,
} as Text
}这两个函数在解析到元素节点或者文本节点时调用,调用后会返回对应的 DOM 节点。
下面这张图就是整个 HTML 解析器的执行过程:
HTML 解析器的入口方法为 parse(),从这开始执行直到遍历完所有 HTML 文本为止:
<,如果是,则当作元素节点来解析,调用 parseElement(),否则调用 parseText()parseText() 比较简单,一直往前遍历字符串,直至遇到 < 字符为止。然后将之前遍历过的所有字符当作 Text 节点的值。parseElement() 则相对复杂一点,它首先要解析出当前的元素标签名称,这段文本用 parseTag() 来解析。parseAttrs() 方法,判断是否有属性节点,如果该节点有 class 或者其他 HTML 属性,则会调用 parseAttr() 把 HTML 属性或者 class 解析出来。parseTag(),看看结束标签名和元素节点的开始标签名是否相同,如果相同,则 parseElement() 或者 parse() 结束,否则报错。HTML 的入口方法是 parse(rawText)
parse(rawText: string) {
this.rawText = rawText.trim()
this.len = this.rawText.length
this.index = 0
this.stack = []
const root = element('root')
while (this.index < this.len) {
this.removeSpaces()
if (this.rawText[this.index].startsWith('<')) {
this.index++
this.parseElement(root)
} else {
this.parseText(root)
}
}
}入口方法需要遍历所有文本,在一开始它需要判断当前字符是否是 <,如果是,则将它当作元素节点来解析,调用 parseElement(),否则将当前字符作为文本来解析,调用 parseText()。
parseElement()private parseElement(parent: Element) {
// 解析标签
const tag = this.parseTag()
// 生成元素节点
const ele = element(tag)
this.stack.push(tag)
parent.children.push(ele)
// 解析属性
this.parseAttrs(ele)
while (this.index < this.len) {
this.removeSpaces()
if (this.rawText[this.index].startsWith('<')) {
this.index++
this.removeSpaces()
// 判断是否是结束标签
if (this.rawText[this.index].startsWith('/')) {
this.index++
const startTag = this.stack[this.stack.length - 1]
// 结束标签
const endTag = this.parseTag()
if (startTag !== endTag) {
throw Error(`The end tagName ${endTag} does not match start tagName ${startTag}`)
}
this.stack.pop()
while (this.index < this.len && this.rawText[this.index] !== '>') {
this.index++
}
break
} else {
this.parseElement(ele)
}
} else {
this.parseText(ele)
}
}
this.index++
}parseElement() 会依次调用 parseTag() parseAttrs() 解析标签和属性,然后再递归解析子节点,终止条件是遍历完所有的 HTML 文本。
parseText()private parseText(parent: Element) {
let str = ''
while (
this.index < this.len
&& !(this.rawText[this.index] === '<' && /\w|\//.test(this.rawText[this.index + 1]))
) {
str += this.rawText[this.index]
this.index++
}
this.sliceText()
parent.children.push(text(removeExtraSpaces(str)))
}解析文本相对简单一点,它会一直往前遍历,直至遇到 < 为止。比如这段文本 <div>test!</div>,经过 parseText() 解析后拿到的文本是 test!。
parseTag()在进入 parseElement() 后,首先调用就是 parseTag(),它的作用是解析标签名:
private parseTag() {
let tag = ''
this.removeSpaces()
// get tag name
while (this.index < this.len && this.rawText[this.index] !== ' ' && this.rawText[this.index] !== '>') {
tag += this.rawText[this.index]
this.index++
}
this.sliceText()
return tag
}比如这段文本 <div>test!</div>,经过 parseTag() 解析后拿到的标签名是 div。
parseAttrs()解析完标签名后,接着再解析属性节点:
// 解析元素节点的所有属性
private parseAttrs(ele: Element) {
// 一直遍历文本,直至遇到 '>' 字符为止,代表 <div ....> 这一段文本已经解析完了
while (this.index < this.len && this.rawText[this.index] !== '>') {
this.removeSpaces()
this.parseAttr(ele)
this.removeSpaces()
}
this.index++
}
// 解析单个属性,例如 class="foo bar"
private parseAttr(ele: Element) {
let attr = ''
let value = ''
while (this.index < this.len && this.rawText[this.index] !== '=' && this.rawText[this.index] !== '>') {
attr += this.rawText[this.index++]
}
this.sliceText()
attr = attr.trim()
if (!attr.trim()) return
this.index++
let startSymbol = ''
if (this.rawText[this.index] === "'" || this.rawText[this.index] === '"') {
startSymbol = this.rawText[this.index++]
}
while (this.index < this.len && this.rawText[this.index] !== startSymbol) {
value += this.rawText[this.index++]
}
this.index++
ele.attributes[attr] = value.trim()
this.sliceText()
}parseAttr() 可以将这样的文本 class="test" 解析为一个对象 { class: "test" }。
有时不同的节点、属性之间有很多多余的空格,所以需要写一个方法将多余的空格清除掉。
protected removeSpaces() {
while (this.index < this.len && (this.rawText[this.index] === ' ' || this.rawText[this.index] === '\n')) {
this.index++
}
this.sliceText()
}同时为了方便调试,开发者经常需要打断点看当前正在遍历的字符是什么。如果以前遍历过的字符串还在,那么是比较难调试的,因为开发者需要根据 index 的值自己去找当前遍历的字符是什么。所以所有解析完的 HTML 文本,都需要截取掉,确保当前的 HTML 文本都是没有被遍历:
protected sliceText() {
this.rawText = this.rawText.slice(this.index)
this.len = this.rawText.length
this.index = 0
}sliceText() 方法的作用就是截取已经遍历过的 HTML 文本。用下图来做例子,假设当前要解析 div 这个标签名:
那么解析后需要对 HTML 文本进行截取,就像下图这样:
至此,整个 HTML 解析器的逻辑已经讲完了,所有代码加起来 200 行左右,如果不算 TS 各种类型声明,代码只有 100 多行。
CSS 样式表是一系列的 CSS 规则集合,而 CSS 解析器的作用就是将 CSS 文本解析为 CSS 规则集合。
div, p {
font-size: 88px;
color: #000;
}例如上面的 CSS 文本,经过解析器解析后,会生成下面的 CSS 规则集合:
[
{
"selectors": [
{
"id": "",
"class": "",
"tagName": "div"
},
{
"id": "",
"class": "",
"tagName": "p"
}
],
"declarations": [
{
"name": "font-size",
"value": "88px"
},
{
"name": "color",
"value": "#000"
}
]
}
]每个规则都有一个 selector 和 declarations 属性,其中 selectors 表示 CSS 选择器,declarations 表示 CSS 的属性描述集合。
export interface Rule {
selectors: Selector[]
declarations: Declaration[]
}
export interface Selector {
tagName: string
id: string
class: string
}
export interface Declaration {
name: string
value: string | number
}每一条 CSS 规则都可以包含多个选择器和多个 CSS 属性。
parseRule()private parseRule() {
const rule: Rule = {
selectors: [],
declarations: [],
}
rule.selectors = this.parseSelectors()
rule.declarations = this.parseDeclarations()
return rule
}在 parseRule() 里,它分别调用了 parseSelectors() 去解析 CSS 选择器,然后再对剩余的 CSS 文本执行 parseDeclarations() 去解析 CSS 属性。
parseSelector()private parseSelector() {
const selector: Selector = {
id: '',
class: '',
tagName: '',
}
switch (this.rawText[this.index]) {
case '.':
this.index++
selector.class = this.parseIdentifier()
break
case '#':
this.index++
selector.id = this.parseIdentifier()
break
case '*':
this.index++
selector.tagName = '*'
break
default:
selector.tagName = this.parseIdentifier()
}
return selector
}
private parseIdentifier() {
let result = ''
while (this.index < this.len && this.identifierRE.test(this.rawText[this.index])) {
result += this.rawText[this.index++]
}
this.sliceText()
return result
}选择器我们只支持标签名称、前缀为 # 的 ID 、前缀为任意数量的类名 . 或上述的某种组合。如果标签名称为 *,则表示它是一个通用选择器,可以匹配任何标签。
标准的 CSS 解析器在遇到无法识别的部分时,会将它丢掉,然后继续解析其余部分。主要是为了兼容旧浏览器和防止发生错误导致程序中断。我们的 CSS 解析器为了实现简单,没有做这方面的做错误处理。
parseDeclaration()private parseDeclaration() {
const declaration: Declaration = { name: '', value: '' }
this.removeSpaces()
declaration.name = this.parseIdentifier()
this.removeSpaces()
while (this.index < this.len && this.rawText[this.index] !== ':') {
this.index++
}
this.index++ // clear :
this.removeSpaces()
declaration.value = this.parseValue()
this.removeSpaces()
return declaration
}parseDeclaration() 会将 color: red; 解析为一个对象 { name: "color", value: "red" }。
CSS 解析器相对来说简单多了,因为很多知识点在 HTML 解析器中已经讲到。整个 CSS 解析器的代码大概 100 多行,如果你阅读过 HTML 解析器的源码,相信看 CSS 解析器的源码会更轻松。
本阶段的目标是写一个样式构建器,输入 DOM 树和 CSS 规则集合,生成一棵样式树 Style tree。
样式树的每一个节点都包含了 CSS 属性值以及它对应的 DOM 节点引用:
interface AnyObject {
[key: string]: any
}
export interface StyleNode {
node: Node // DOM 节点
values: AnyObject // style 属性值
children: StyleNode[] // style 子节点
}先来看一个简单的示例:
<div>test</div>div {
font-size: 88px;
color: #000;
}上述的 HTML、CSS 文本在经过样式树构建器处理后生成的样式树如下:
{
"node": { // DOM 节点
"tagName": "div",
"attributes": {},
"children": [
{
"nodeValue": "test",
"nodeType": 3
}
],
"nodeType": 1
},
"values": { // CSS 属性值
"font-size": "88px",
"color": "#000"
},
"children": [ // style tree 子节点
{
"node": {
"nodeValue": "test",
"nodeType": 3
},
"values": { // text 节点继承了父节点样式
"font-size": "88px",
"color": "#000"
},
"children": []
}
]
}现在我们需要遍历 DOM 树。对于 DOM 树中的每个节点,我们都要在样式树中查找是否有匹配的 CSS 规则。
export function getStyleTree(eles: Node | Node[], cssRules: Rule[], parent?: StyleNode) {
if (Array.isArray(eles)) {
return eles.map((ele) => getStyleNode(ele, cssRules, parent))
}
return getStyleNode(eles, cssRules, parent)
}匹配选择器实现起来非常容易,因为我们的CSS 解析器仅支持简单的选择器。 只需要查看元素本身即可判断选择器是否与元素匹配。
/**
* css 选择器是否匹配元素
*/
function isMatch(ele: Element, selectors: Selector[]) {
return selectors.some((selector) => {
// 通配符
if (selector.tagName === '*') return true
if (selector.tagName === ele.tagName) return true
if (ele.attributes.id === selector.id) return true
if (ele.attributes.class) {
const classes = ele.attributes.class.split(' ').filter(Boolean)
const classes2 = selector.class.split(' ').filter(Boolean)
for (const name of classes) {
if (classes2.includes(name)) return true
}
}
return false
})
}当查找到匹配的 DOM 节点后,再将 DOM 节点和它匹配的 CSS 属性组合在一起,生成样式树节点 styleNode:
function getStyleNode(ele: Node, cssRules: Rule[], parent?: StyleNode) {
const styleNode: StyleNode = {
node: ele,
values: getStyleValues(ele, cssRules, parent),
children: [],
}
if (ele.nodeType === NodeType.Element) {
// 合并内联样式
if (ele.attributes.style) {
styleNode.values = { ...styleNode.values, ...getInlineStyle(ele.attributes.style) }
}
styleNode.children = ele.children.map((e) => getStyleNode(e, cssRules, styleNode)) as unknown as StyleNode[]
}
return styleNode
}
function getStyleValues(ele: Node, cssRules: Rule[], parent?: StyleNode) {
const inheritableAttrValue = getInheritableAttrValues(parent)
// 文本节点继承父元素的可继承属性
if (ele.nodeType === NodeType.Text) return inheritableAttrValue
return cssRules.reduce((result: AnyObject, rule) => {
if (isMatch(ele as Element, rule.selectors)) {
result = { ...result, ...cssValueArrToObject(rule.declarations) }
}
return result
}, inheritableAttrValue)
}在 CSS 选择器中,不同的选择器优先级是不同的,比如 id 选择器就比类选择器的优先级要高。但是我们这里没有实现选择器优先级,为了实现简单,所有的选择器优先级是一样的。
文本节点无法匹配选择器,那它的样式从哪来?答案就是继承,它可以继承父节点的样式。
在 CSS 中存在很多继承属性,即使子元素没有声明这些属性,也可以从父节点里继承。比如字体颜色、字体家族等属性,都是可以被继承的。为了实现简单,这里只支持继承父节点的 color、font-size 属性。
// 子元素可继承的属性,这里只写了两个,实际上还有很多
const inheritableAttrs = ['color', 'font-size']
/**
* 获取父元素可继承的属性值
*/
function getInheritableAttrValues(parent?: StyleNode) {
if (!parent) return {}
const keys = Object.keys(parent.values)
return keys.reduce((result: AnyObject, key) => {
if (inheritableAttrs.includes(key)) {
result[key] = parent.values[key]
}
return result
}, {})
}在 CSS 中,内联样式的优先级是除了 !important 之外最高的。
<span style="color: red; background: yellow;">我们可以在调用 getStyleValues() 函数获得当前 DOM 节点的 CSS 属性值后,再去取当前节点的内联样式值。并对当前 DOM 节点的 CSS 样式值进行覆盖。
styleNode.values = { ...styleNode.values, ...getInlineStyle(ele.attributes.style) }
function getInlineStyle(str: string) {
str = str.trim()
if (!str) return {}
const arr = str.split(';')
if (!arr.length) return {}
return arr.reduce((result: AnyObject, item: string) => {
const data = item.split(':')
if (data.length === 2) {
result[data[0].trim()] = data[1].trim()
}
return result
}, {})
}第四阶段讲的是如何将样式树转化为布局树,也是整个渲染引擎相对比较复杂的部分。
在 CSS 中,所有的 DOM 节点都可以当作一个盒子。这个盒子模型包含了内容、内边距、边框、外边距以及在页面中的位置信息。
我们可以用以下的数据结构来表示盒子模型:
export default class Dimensions {
content: Rect
padding: EdgeSizes
border: EdgeSizes
margin: EdgeSizes
}
export default class Rect {
x: number
y: number
width: number
height: number
}
export interface EdgeSizes {
top: number
right: number
bottom: number
left: number
}CSS 的 display 属性决定了盒子在页面中的布局方式。display 的类型有很多种,例如 block、inline、flex 等等,但这里只支持 block 和 inline 两种布局方式,并且所有盒子的默认布局方式为 display: inline。
我会用伪 HTML 代码来描述它们之间的区别:
<container>
<a></a>
<b></b>
<c></c>
<d></d>
</container>块布局会将盒子从上至下的垂直排列。
内联布局则会将盒子从左至右的水平排列。
如果容器内同时存在块布局和内联布局,则会用一个匿名布局将内联布局包裹起来。
这样就能将内联布局的盒子和其他块布局的盒子区别开来。
通常情况下内容是垂直增长的。也就是说,在容器中添加子节点通常会使容器更高,而不是更宽。另一种说法是,默认情况下,子节点的宽度取决于其容器的宽度,而容器的高度取决于其子节点的高度。
布局树是所有盒子节点的集合。
export default class LayoutBox {
dimensions: Dimensions
boxType: BoxType
children: LayoutBox[]
styleNode: StyleNode
}盒子节点的类型可以是 block、inilne 和 anonymous。
export enum BoxType {
BlockNode = 'BlockNode',
InlineNode = 'InlineNode',
AnonymousBlock = 'AnonymousBlock',
}我们构建样式树时,需要根据每一个 DOM 节点的 display 属性来生成对应的盒子节点。
export function getDisplayValue(styleNode: StyleNode) {
return styleNode.values?.display ?? Display.Inline
}如果 DOM 节点 display 属性的值为 none,则在构建布局树的过程中,无需将这个 DOM 节点添加到布局树上,直接忽略它就可以了。
如果一个块节点包含一个内联子节点,则需要创建一个匿名块(实际上就是块节点)来包含它。如果一行中有多个子节点,则将它们全部放在同一个匿名容器中。
function buildLayoutTree(styleNode: StyleNode) {
if (getDisplayValue(styleNode) === Display.None) {
throw new Error('Root node has display: none.')
}
const layoutBox = new LayoutBox(styleNode)
let anonymousBlock: LayoutBox | undefined
for (const child of styleNode.children) {
const childDisplay = getDisplayValue(child)
// 如果 DOM 节点 display 属性值为 none,直接跳过
if (childDisplay === Display.None) continue
if (childDisplay === Display.Block) {
anonymousBlock = undefined
layoutBox.children.push(buildLayoutTree(child))
} else {
// 创建一个匿名容器,用于容纳内联节点
if (!anonymousBlock) {
anonymousBlock = new LayoutBox()
layoutBox.children.push(anonymousBlock)
}
anonymousBlock.children.push(buildLayoutTree(child))
}
}
return layoutBox
}现在开始构建布局树,入口函数是 getLayoutTree():
export function getLayoutTree(styleNode: StyleNode, parentBlock: Dimensions) {
parentBlock.content.height = 0
const root = buildLayoutTree(styleNode)
root.layout(parentBlock)
return root
}它将遍历样式树,利用样式树节点提供的相关信息,生成一个 LayoutBox 对象,然后调用 layout() 方法。计算每个盒子节点的位置、尺寸信息。
在本节内容的开头有提到过,盒子的宽度取决于其父节点,而高度取决于子节点。这意味着,我们的代码在计算宽度时需要自上而下遍历树,这样它就可以在知道父节点的宽度后设置子节点的宽度。然后自下而上遍历以计算高度,这样父节点的高度就可以在计算子节点的相关信息后进行计算。
layout(parentBlock: Dimensions) {
// 子节点的宽度依赖于父节点的宽度,所以要先计算当前节点的宽度,再遍历子节点
this.calculateBlockWidth(parentBlock)
// 计算盒子节点的位置
this.calculateBlockPosition(parentBlock)
// 遍历子节点并计算对位置、尺寸信息
this.layoutBlockChildren()
// 父节点的高度依赖于其子节点的高度,所以计算子节点的高度后,再计算自己的高度
this.calculateBlockHeight()
}这个方法执行布局树的单次遍历,向下执行宽度计算,向上执行高度计算。一个真正的布局引擎可能会执行几次树遍历,有些是自上而下的,有些是自下而上的。
现在,我们先来计算盒子节点的宽度,这部分比较复杂,需要详细的讲解。
首先,我们要拿到当前节点的 width padding border margin 等信息:
calculateBlockWidth(parentBlock: Dimensions) {
// 初始值
const styleValues = this.styleNode?.values || {}
// 初始值为 auto
let width = styleValues.width ?? 'auto'
let marginLeft = styleValues['margin-left'] || styleValues.margin || 0
let marginRight = styleValues['margin-right'] || styleValues.margin || 0
let borderLeft = styleValues['border-left'] || styleValues.border || 0
let borderRight = styleValues['border-right'] || styleValues.border || 0
let paddingLeft = styleValues['padding-left'] || styleValues.padding || 0
let paddingRight = styleValues['padding-right'] || styleValues.padding || 0
// 拿到父节点的宽度,如果某个属性为 'auto',则将它设为 0
let totalWidth = sum(width, marginLeft, marginRight, borderLeft, borderRight, paddingLeft, paddingRight)
// ...如果这些属性没有设置,就使用 0 作为默认值。拿到当前节点的总宽度后,还需要和父节点对比一下是否相等。如果宽度或边距设置为 auto,则可以对这两个属性进行适当展开或收缩以适应可用空间。所以现在需要对当前节点的宽度进行检查。
const isWidthAuto = width === 'auto'
const isMarginLeftAuto = marginLeft === 'auto'
const isMarginRightAuto = marginRight === 'auto'
// 当前块的宽度如果超过了父元素宽度,则将它的可扩展外边距设为 0
if (!isWidthAuto && totalWidth > parentWidth) {
if (isMarginLeftAuto) {
marginLeft = 0
}
if (isMarginRightAuto) {
marginRight = 0
}
}
// 根据父子元素宽度的差值,去调整当前元素的宽度
const underflow = parentWidth - totalWidth
// 如果三者都有值,则将差值填充到 marginRight
if (!isWidthAuto && !isMarginLeftAuto && !isMarginRightAuto) {
marginRight += underflow
} else if (!isWidthAuto && !isMarginLeftAuto && isMarginRightAuto) {
// 如果右边距是 auto,则将 marginRight 设为差值
marginRight = underflow
} else if (!isWidthAuto && isMarginLeftAuto && !isMarginRightAuto) {
// 如果左边距是 auto,则将 marginLeft 设为差值
marginLeft = underflow
} else if (isWidthAuto) {
// 如果只有 width 是 auto,则将另外两个值设为 0
if (isMarginLeftAuto) {
marginLeft = 0
}
if (isMarginRightAuto) {
marginRight = 0
}
if (underflow >= 0) {
// 展开宽度,填充剩余空间,原来的宽度是 auto,作为 0 来计算的
width = underflow
} else {
// 宽度不能为负数,所以需要调整 marginRight 来代替
width = 0
// underflow 为负数,相加实际上就是缩小当前节点的宽度
marginRight += underflow
}
} else if (!isWidthAuto && isMarginLeftAuto && isMarginRightAuto) {
// 如果只有 marginLeft 和 marginRight 是 auto,则将两者设为 underflow 的一半
marginLeft = underflow / 2
marginRight = underflow / 2
}详细的计算过程请看上述代码,重要的地方都已经标上注释了。
通过对比当前节点和父节点的宽度,我们可以拿到一个差值:
// 根据父子元素宽度的差值,去调整当前元素的宽度
const underflow = parentWidth - totalWidth如果这个差值为正数,说明子节点宽度小于父节点;如果差值为负数,说明子节点大于父节。上面这段代码逻辑其实就是根据 underflow width padding margin 等值对子节点的宽度、边距进行调整,以适应父节点的宽度。
计算当前节点的位置相对来说简单一点。这个方法会根据当前节点的 margin border padding 样式以及父节点的位置信息对当前节点进行定位:
calculateBlockPosition(parentBlock: Dimensions) {
const styleValues = this.styleNode?.values || {}
const { x, y, height } = parentBlock.content
const dimensions = this.dimensions
dimensions.margin.top = transformValueSafe(styleValues['margin-top'] || styleValues.margin || 0)
dimensions.margin.bottom = transformValueSafe(styleValues['margin-bottom'] || styleValues.margin || 0)
dimensions.border.top = transformValueSafe(styleValues['border-top'] || styleValues.border || 0)
dimensions.border.bottom = transformValueSafe(styleValues['border-bottom'] || styleValues.border || 0)
dimensions.padding.top = transformValueSafe(styleValues['padding-top'] || styleValues.padding || 0)
dimensions.padding.bottom = transformValueSafe(styleValues['padding-bottom'] || styleValues.padding || 0)
dimensions.content.x = x + dimensions.margin.left + dimensions.border.left + dimensions.padding.left
dimensions.content.y = y + height + dimensions.margin.top + dimensions.border.top + dimensions.padding.top
}
function transformValueSafe(val: number | string) {
if (val === 'auto') return 0
return parseInt(String(val))
}比如获取当前节点内容区域的 x 坐标,计算方式如下:
dimensions.content.x = x + dimensions.margin.left + dimensions.border.left + dimensions.padding.left在计算高度之前,需要先遍历子节点,因为父节点的高度需要根据它下面子节点的高度进行适配。
layoutBlockChildren() {
const { dimensions } = this
for (const child of this.children) {
child.layout(dimensions)
// 遍历子节点后,再计算父节点的高度
dimensions.content.height += child.dimensions.marginBox().height
}
}每个节点的高度就是它上下两个外边距之间的差值,所以可以通过 marginBox() 获得高度:
export default class Dimensions {
content: Rect
padding: EdgeSizes
border: EdgeSizes
margin: EdgeSizes
constructor() {
const initValue = {
top: 0,
right: 0,
bottom: 0,
left: 0,
}
this.content = new Rect()
this.padding = { ...initValue }
this.border = { ...initValue }
this.margin = { ...initValue }
}
paddingBox() {
return this.content.expandedBy(this.padding)
}
borderBox() {
return this.paddingBox().expandedBy(this.border)
}
marginBox() {
return this.borderBox().expandedBy(this.margin)
}
}export default class Rect {
x: number
y: number
width: number
height: number
constructor() {
this.x = 0
this.y = 0
this.width = 0
this.height = 0
}
expandedBy(edge: EdgeSizes) {
const rect = new Rect()
rect.x = this.x - edge.left
rect.y = this.y - edge.top
rect.width = this.width + edge.left + edge.right
rect.height = this.height + edge.top + edge.bottom
return rect
}
}遍历子节点并执行完相关计算方法后,再将各个子节点的高度进行相加,得到父节点的高度。
默认情况下,节点的高度等于其内容的高度。但如果手动设置了 height 属性,则需要将节点的高度设为指定的高度:
calculateBlockHeight() {
// 如果元素设置了 height,则使用 height,否则使用 layoutBlockChildren() 计算出来的高度
const height = this.styleNode?.values.height
if (height) {
this.dimensions.content.height = parseInt(height)
}
}为了简单起见,我们不需要实现外边距折叠。
布局树是渲染引擎最复杂的部分,这一阶段结束后,我们就了解了布局树中每个盒子节点在页面中的具体位置和尺寸信息。下一步,就是如何把布局树渲染到页面上了。
绘制阶段主要是根据布局树中各个节点的位置、尺寸信息将它们绘制到页面。目前大多数计算机使用光栅(raster,也称为位图)显示技术。将布局树各个节点绘制到页面的这个过程也被称为“光栅化”。
浏览器通常在图形API和库(如Skia、Cairo、Direct2D等)的帮助下实现光栅化。这些API提供绘制多边形、直线、曲线、渐变和文本的功能。
实际上绘制才是最难的部分,但是这一步我们有现成的 canvas 库可以用,不用自己实现一个光栅器,所以相对来说就变得简单了。在真正开始绘制阶段之前,我们先来学习一些关于计算机如何绘制图像、文本的基础知识,有助于我们理解光栅化的具体实现过程。
在计算机底层进行像素绘制属于硬件操作,它依赖于屏幕和显卡接口的具体细节。为了简单起点,我们可以用一段内存区域来表示屏幕,内存的一个 bit 就代表了屏幕中的一个像素。比如在屏幕中的 (x,y) 坐标绘制一个像素,可以用 memory[x + y * rowSize] = 1 来表示。从屏幕左上角开始,列是从左至右开始计数,行是从上至下开始计数。因此屏幕最左上角的坐标是 (0,0)。
为了简单起见,我们用 1 bit 来表示屏幕的一个像素,0 代表白色,1 代表黑色。屏幕每一行的长度用变量 rowSzie 表示,每一列的高度用 colSize 表示。
如果我们要在计算机上绘制一条直线,那么只要知道计算机的起点坐标 (x1,y1) 和终点坐标 (x2,y2) 就可以了。
然后根据 memory[x + y * rowSize] = 1 公式,将 (x1,y1) 至 (x2,y2) 之间对应的内存区域置为 1,这样就画出来了一条直线。
为了在屏幕上显示文本,首先必须将物理上基于像素点的屏幕,在逻辑上以字符为单位划分成若干区域,每个区域能输出单个完整的字符。假设有一个 256 行 512 列的屏幕,如果为每个字符分配一个 11*8 像素的网格,那么屏幕上总共能显示 23 行,每行 64 个字符(还有 3 行像素没使用)。
有了这些前提条件后,我们现在打算在屏幕上画一个 A:
上图的 A 在内存区域中用 11*8 像素的网格表示。为了在内存区域中绘制它,我们可以用一个二维数组来表示它:
const charA = [
[0, 0, 1, 1, 0, 0, 0, 0], // 按从左至右的顺序来读取 bit,转换成十进制数字就是 12
[0, 1, 1, 1, 1, 0, 0, 0], // 30
[1, 1, 0, 0, 1, 1, 0, 0], // 51
[1, 1, 0, 0, 1, 1, 0, 0], // 51
[1, 1, 1, 1, 1, 1, 0, 0], // 63
[1, 1, 0, 0, 1, 1, 0, 0], // 51
[1, 1, 0, 0, 1, 1, 0, 0], // 51
[1, 1, 0, 0, 1, 1, 0, 0], // 51
[1, 1, 0, 0, 1, 1, 0, 0], // 51
[0, 0, 0, 0, 0, 0, 0, 0], // 0
[0, 0, 0, 0, 0, 0, 0, 0], // 0
]上面二维数组的第一项,代表了第一行内存区域每个 bit 的取值。一共 11 行,画出了一个字母 A。
如果我们为 26 个字母都建一个映射表,按 ascii 的编码来排序,那么 charsMap[65] 就代表字符 A,当用户在键盘上按下 A 键时,就把 charsMap[65] 对应的数据输出到内存区域上,这样屏幕上就显示了一个字符 A。
科普完关于绘制屏幕的基础知识后,我们现在正式开始绘制布局树(为了方便,我们使用 node-canvas 库)。
首先要遍历整个布局树,然后逐个节点进行绘制:
function renderLayoutBox(layoutBox: LayoutBox, ctx: CanvasRenderingContext2D, parent?: LayoutBox) {
renderBackground(layoutBox, ctx)
renderBorder(layoutBox, ctx)
renderText(layoutBox, ctx, parent)
for (const child of layoutBox.children) {
renderLayoutBox(child, ctx, layoutBox)
}
}这个函数对每个节点依次绘制背景色、边框、文本,然后再递归绘制所有子节点。
默认情况下,HTML 元素按照它们出现的顺序进行绘制。如果两个元素重叠,则后一个元素将绘制在前一个元素之上。这种排序反映在我们的布局树中,它将按照元素在 DOM 树中出现的顺序绘制元素。
function renderBackground(layoutBox: LayoutBox, ctx: CanvasRenderingContext2D) {
const { width, height, x, y } = layoutBox.dimensions.borderBox()
ctx.fillStyle = getStyleValue(layoutBox, 'background')
ctx.fillRect(x, y, width, height)
}首先拿到布局节点的位置、尺寸信息,以 x,y 作为起点,绘制矩形区域。并且以 CSS 属性 background 的值作为背景色进行填充。
function renderBorder(layoutBox: LayoutBox, ctx: CanvasRenderingContext2D) {
const { width, height, x, y } = layoutBox.dimensions.borderBox()
const { left, top, right, bottom } = layoutBox.dimensions.border
const borderColor = getStyleValue(layoutBox, 'border-color')
if (!borderColor) return
ctx.fillStyle = borderColor
// left
ctx.fillRect(x, y, left, height)
// top
ctx.fillRect(x, y, width, top)
// right
ctx.fillRect(x + width - right, y, right, height)
// bottom
ctx.fillRect(x, y + height - bottom, width, bottom)
}绘制边框,其实我们绘制的是四个矩形,每一个矩形就是一条边框。
function renderText(layoutBox: LayoutBox, ctx: CanvasRenderingContext2D, parent?: LayoutBox) {
if (layoutBox.styleNode?.node.nodeType === NodeType.Text) {
// get AnonymousBlock x y
const { x = 0, y = 0, width } = parent?.dimensions.content || {}
const styles = layoutBox.styleNode?.values || {}
const fontSize = styles['font-size'] || '14px'
const fontFamily = styles['font-family'] || 'serif'
const fontWeight = styles['font-weight'] || 'normal'
const fontStyle = styles['font-style'] || 'normal'
ctx.fillStyle = styles.color
ctx.font = `${fontStyle} ${fontWeight} ${fontSize} ${fontFamily}`
ctx.fillText(layoutBox.styleNode?.node.nodeValue, x, y + parseInt(fontSize), width)
}
}通过 canvas 的 fillText() 方法,我们可以很方便的绘制带有字体风格、大小、颜色的文本。
绘制完成后,我们可以借助 canvas 的 API 输出图片。下面用一个简单的示例来演示一下:
<html>
<body id=" body " data-index="1" style="color: red; background: yellow;">
<div>
<div class="lightblue test">test1!</div>
<div class="lightblue test">
<div class="foo">foo</div>
</div>
</div>
</body>
</html>* {
display: block;
}
div {
font-size: 14px;
width: 400px;
background: #fff;
margin-bottom: 20px;
display: block;
background: lightblue;
}
.lightblue {
font-size: 16px;
display: block;
width: 200px;
height: 200px;
background: blue;
border-color: green;
border: 10px;
}
.foo {
width: 100px;
height: 100px;
background: red;
color: yellow;
margin-left: 50px;
}
body {
display: block;
font-size: 88px;
color: #000;
}上面这段 HTML、CSS 代码经过渲染引擎程序解析后生成的图片如下:
至此,这个玩具版的渲染引擎就完成了。虽然这个玩具并没有什么用,但如果能通过实现它来了解真实的渲染引擎是如何运作的,从这个角度来看,它还是“有用”的。
我看issue里面有人提到好几次swiper. 可否考虑把这个做成一个标配功能.类似于ps里面的图层给他加个眼睛可以点开/关闭 一个一个进行编辑
另外 每个swiper项可能包含好几个元素 比如总的背景.标题. 以及标题和背景的切换动画
因为混得不好。
在成为程序员之前,我干过很多工作。由于学历的问题(高中),我的工作基本上都是体力活。包括但不限于:工厂普工、销售(没有干销售的才能)、搬运工、摆地摊等,转行前最后一份工作是修电脑。这么多年,月薪没高过 3300...
后来偶然一个机会我发现了知乎这个网站,在上面了解到程序员的各种优点。于是,我下定决心转行(2016 年,当时 28 了),辞职在家自学编程。并且也得到了媳妇的支持,感谢我的媳妇。
转行选择前端也是在知乎上看网友分析的,比后端好入门。
最好在网上多查查资料,找评价高的或者去豆瓣上找评分高的书。
我在网上查了很多资料,最终确定 HTML、CSS 在 w3cschool 学习。JavaScript 则选择了JavaScript 高级程序设计第三版(俗称红宝书,现在已经有第四版了)。
光看不练是学不好编程的,我非常幸运的遇到了百度前端技术学院。它从易到难设置了 52 个任务,共分为四个阶段。任务难度循序渐进,每一个任务都有清晰的讲解和学习参考资料。它还怕你不会做,允许你查看其他人上传的任务答案。
我先学习了 HTML、CSS,做完了第一阶段任务。再看完红宝书前十三章,做完了第二阶段任务。然后把红宝石剩下的全看完,做到第三阶段的任务四十五。后面的任务对于当时的我来说实在太难了,就没往下做。在 1 月的时候,又学习了 ajax,了解了前后端如何相互通信。
我从 16 年 11 月开始自学前端,一直到 17 年 2 月。历时 3 个月,平均每天学习 3-4 个小时。中间有好几次因为太难想过放弃,不过最后还是坚持下来了。
找工作的过程非常艰难,我在网上各大招聘平台投了很多简历,但由于没学历、没经验,所以一个回复都没有。最后还是我媳妇工作的公司在招前端,给了我一个内推的机会,才有了第一次面试。并且第一次面试也很顺利,居然过了,这是我没想到的。直到多年后我和面试官又在一个公司的时候,才知道原因。他的意思是:看在我这么努力自学编程的份上,愿意给我一个机会。
虽然人生很艰难,但很有可能,遇到一个愿意给你机会的人,就能改变你的命运。
在正式的项目中写代码和在学习时写代码是不一样的。你必须得考虑这样写安不安全,会不会引起 BUG,会不会引起性能问题。在工作的第一年,写业务代码对我的提升非常大。
第一年的主要任务,就是提升前端基础能力。因此我看了很多 JavaScript 的书籍来提升自己的水平:
这些书都是非常经典的书籍,有几本我还看了好几篇。
除了看书外,我还做了百度前端技术学院 2017 年的任务,它比 2016 年的任务(转行时做的是 2016 年的任务)更有难度和深度,非常适合进阶。
另外还学习了 jquery 和 nodejs。jquery 是工作中要用,nodejs 则是出于兴趣学习的,没有多深入。
到了第二年,写业务代码对于我来说,已经提升不大了,就像一个熟练工一样。而且感觉前端方面掌握的知识已经足够把工作做好了。于是我就想,为了成为一名顶尖的程序员,还需要做什么。我在网上查了很多资料,看了很多前辈的回答,最后决定自学计算机专业。
我制定了一个自学计算机专业的计划,并且减少花在前端上的时间。因为说到底,基础是地基。基础打好了,楼才能建得高。
计算机系统要素是我制订计划后开始学习的第一本书。它主要讲解了计算机原理(1-5章)、编译原理(6-11章)、操作系统相关知识(12章)。不要看内容这么多,其实这本书的内容非常通俗易懂,翻译也很给力。每一章后面都有相关的实验,需要你手写代码去完成,堪称理论与实践结合的经典。
这里引用一下书里的简介,大家可以感受一下:
本书通过展现简单但功能强大的计算机系统之构建过程,为读者呈现了一幅完整、严格的计算机应用科学大图景。本书作者认为,理解计算机工作原理的最好方法就是亲自动手,从零开始构建计算机系统。
通过12个章节和项目来引领读者从头开始,本书逐步地构建一个基本的硬件平台和现代软件阶层体系。在这个过程中,读者能够获得关于硬件体系结构、操作系统、编程语言、编译器、数据结构、算法以及软件工程的详实知识。通过这种逐步构造的方法,本书揭示了计算机科学知识中的重要成分,并展示其它课程中所介绍的理论和应用技术如何融入这幅全局大图景当中去。
全书基于“先抽象再实现”的阐述模式,每一章都介绍一个关键的硬件或软件抽象,一种实现方式以及一个实际的项目。完成这些项目所必要的计算机科学知识在本书中都有涵盖,只要求读者具备程序设计经验。本书配套的支持网站提供了书中描述的用于构建所有硬件和软件系统所必需的工具和资料,以及用于12个项目的200个测试程序。
全书内容广泛、涉猎全面,适合计算机及相关专业本科生、研究生、技术开发人员、教师以及技术爱好者参考和学习。
做完这些实验,让我有了一个质的提升。以前感觉计算机就是一个黑盒,但现在不一样了。我开始了解计算机内部是如何运作的。明白了自己写的代码是怎么经过编译变成指令,最后在 CPU 中执行的。也明白了指令、数据怎么在 CPU 和内存之间流转的。
这本书所有实验的答案我都放在了 github 上,有兴趣不妨了解一下。
这一年还学会了 Vue。除了熟读文档外,还为了研究源码而模仿 Vue1.0 版本写了一个 mini-vue。不过学习源码对于我写业务代码并没有什么帮助。如果不是出于兴趣去研究源码,最好不要去学,熟读文档就能完全应付工作了。如果是为了面试,那也不需要阅读源码。只需要在网上找一些质量高的源码分析文章看一看,作一下笔记就 OK 了。
为什么我不建议阅读源码?因为阅读源码效率太低,而且相对于你的付出,收益并不大。到后面 Vue 出了 3.0 版本时,我也是有选择地阅读部分源码。
第三年有大半年的时间浪费在王者荣耀上,那会天天只想着冲荣耀,根本没心思学习。后来终于醒悟过来了,王者荣耀是我成为顶级程序员的阻碍。于是痛定思痛,给戒掉了。
由于打王者的原因,第三年没学习多少新知识。基本上只做了三件事:
数据结构和算法有什么用?学了算法后,我觉得至少会懂得去分析程序的性能问题。
一个程序的性能有问题,需要你去优化。如果学过数据结构和算法,你会从时间复杂度和空间复杂度去分析代码,然后解决问题。如果没学过,你只能靠猜、碰运气来解决问题。
理论知识上,我主要看的是算法这本书,课后习题没做,改成用刷 leetcode 代替。目前已经刷了 300+ 道题,还在继续刷。不过由于数学差,稍微复杂一点的算法知识都看不懂,效果不是很好。
第四年,也就是今年(2020),是我重新奋斗的一年。今年比以往的任何一年都要努力,每天保证 3 小时以上的学习时间。如果实在太忙了,达不到要求,那就改天把时间补上。附上我今年的学习时长图(记录软件为 Now Then):
今年我做了非常多的事情:
研究前端工程化的目的,就是为了提高团队的开发效率。为此我看了很多书和资料:
研究了一年的时间,写了一篇质量较高的入门教程——手把手带你入门前端工程化——超详细教程。除此之外,还有其他工程化相关的一系列文章:
操作系统是管理计算机硬件与软件资源的计算机程序。通常情况下,程序是运行在操作系统上的,而不是直接和硬件交互。一个程序如果想和硬件交互就得通过操作系统。
如果你掌握了操作系统的知识,你就知道程序是怎么和硬件交互的。
例如你知道申请内存,释放内存的内部过程是怎样的;当你按下 k 键,你也知道 k 是怎么出现在屏幕上的;知道文件是怎么读出、写入的。
对于操作系统,我主要学习了以下书籍:
然后做 MIT6.828 的实验,实现了一个简单的操作系统内核。
计算机网络的作用主要是解决计算机之间如何通信的问题。
例如 A 地区和 B 地区的的计算机怎么通信?同一局域网的两台电脑又如何通信?学习计算机网络知识就是了解它们是怎么通信的以及怎么将它们联通起来。
对于计算机网络,我主要学习了以下书籍:
并且做了计算机网络--自顶向下的实验。
软件工程是一门研究用工程化方法构建和维护有效的、实用的和高质量的软件的学科。它涉及程序设计语言、数据库、软件开发工具、系统平台、标准、设计模式等方面。
学习以下书籍:
软件工程是一门非常庞大的学科,我只学习了一点皮毛。主要学习的是关于代码怎么写得更好、结构组织更合理的知识,这需要一边学习一边在工作中运用。
学习 C++ 其实是为了研究 nodejs 源码用的,看的这本书C++ Primer 中文版(第 5 版)。
我从转行开始就一直在学习英语,不过今年花的时间比较多。
英语对于程序员的好处非常非常多,就我知道的有:
在我转行前英语词汇量只有几百,三年多过去了,现在词汇量有 6000(都是用百词斩测的)。
写作的好处是非常多的,越早写越好。我还记得第一篇文章是 2017 年 2 月发表的,是我工作后的第 13 天,发表在 CSDN 上。
个人认为写作的好处有三点:
总之一句话,写作对你只有好处,没有坏处。
我觉得学习一定要有非常清晰的目标,知道你要学什么,怎么学。对于前端来说,我认为很多框架和库都是不用学的。例如前端三大框架,没有必要三个都学,把你工作中要用的那个掌握好就行。
比如你公司用的是 Vue,就深入学习 Vue,如果要看源码就只看重点部分的源码。例如模板编译、Diff 算法、Vue 原生组件实现、指令实现等等。
剩下的两个框架 React、Angular 做个 DEMO 熟悉一下就行,毕竟原理都是相通的。等你公司要上这两个再深入学习,不过也不建议阅读源码了,太累。看别人写的现成的源码分析文章就好。
其他的,像 easyui、Backbone.js、各种小程序... 用不到的坚决不学,浪费时间。用的时候看文档就行了,当然,如果有兴趣了解如何实现也是可以的。
我觉得好的学习方法非常重要,对我比较有用的两个是:
费曼学习法在《写作》一节中已经说过了,这里着重说说第二个。
你有没有过这种感觉:觉得自己会的东西很多,但其实掌握的知识很多都停留在表面上,别人要是往深一问,就懵逼了。
我以前就有过这种感觉,主要问题出在对知识的学习仅停留在浅尝即止的状态。就是学习新知识,能写个 DEMO,就觉得自己学得差不多了。这种学习方法是很有害的,首先知识存留度不高,其次是浪费时间,因为很快就会忘掉。
后来我尝试改正这种状态,在学习新的知识点时,时常问自己三个问题:
当然,不是所有问题都能适用灵魂三问,但它适用大多数情况。
举个例子:看过性能优化相关文章的同学应该知道有这么一条规则,要减少页面上的 HTTP 请求。
先了解一下 HTTP 请求是啥,查资料发现原来是向服务器请求资源用的。
查资料发现:HTTP 请求需要经历 DNS 查找,TCP 握手,SSL 握手(如果有的话)等一系列过程,才能真正发出这个请求。并且现代浏览器对于 TCP 并发数也是有限制的,超过 TCP 并发数的 HTTP 请求只能等前面的请求完成了才能继续发送。
我们可以打开 chrome 开发者工具看一下一个 HTTP 请求所花费的具体时间。
这是一个 HTTP 请求,请求的文件大小为 28.4KB。
名词解释:
13.05 / 204.16 = 6.39%。文件越小,这个比例越小,文件越大,比例就越高。这就是为什么要建议将多个小文件合并为一个大文件,从而减少 HTTP 请求次数的原因。使用 HTTP2,所有的请求都可以放在一个 TCP 连接上发送。HTTP2 还有好多东西要学,这里不深入讲解了。
经过灵魂三问后,是不是这条优化规则的来龙去脉全都理清了,并且在你查资料动手的过程中,知识会理解得更加深刻。
掌握了这种学习方法,并且时刻运用在学习中、工作中,突破瓶颈只是时间的问题。
下面提前回答一下可能会有的问题。
百度前端技术学院 2017 年及往后的任务,如果没有报名,那就只能做部分任务。2016 年的任务则由于百度服务器的问题,很多题的示例图都裂了。这个其实是有解决方案的,那就是看别人的答案。把别人的源码下载下来,用浏览器打开 html 文件当示例图看。这两年的任务我都做了大部分,附上答案:
我从 18 年开始,已经报考了成人高考大专,19 年报了自考本科。大专明年 1 月就能毕业,自考本科比较难,可能 2021 年或 2022 年才能考下来。
从转行到现在,已经过去 3 年多了。不得不说转行当程序员给了我人生第二次机会,我也很喜欢这个职业。不过这几年一直都是在小公司,导致自己的技术和视野得不到很大的提升。所以现在的目标除了学习计算机专业外,就是进大厂,希望有一天能实现。
虽然今年已经 32 了,但我对未来仍然充满希望。努力地学习,努力地提升自己,为了成为一名顶尖的程序员而努力。
编译器是一个程序,作用是将一门语言翻译成另一门语言。
例如 babel 就是一个编译器,它将 es6 版本的 js 翻译成 es5 版本的 js。从这个角度来看,将英语翻译成中文的翻译软件也属于编译器。
一般的程序,CPU 是无法直接执行的,因为 CPU 只能识别机器指令。所以要想执行一个程序,首先要将高级语言编写的程序翻译为汇编代码(Java 还多了一个步骤,将高级语言翻译成字节码),再将汇编代码翻译为机器指令,这样 CPU 才能识别并执行。
由于汇编语言和机器语言一一对应,并且汇编语言更具有可读性。所以计算机原理的教材在讲解机器指令时一般会用汇编语言来代替机器语言讲解。
本文所要写的四则运算编译器需要将 1 + 1 这样的四则运算表达式翻译成机器指令并执行。具体过程请看示例:
// CPU 无法识别
10 + 5
// 翻译成汇编语言
push 10
push 5
add
// 最后翻译为机器指令,汇编代码和机器指令一一对应
// 机器指令由 1 和 0 组成,以下指令非真实指令,只做演示用
0011101001010101
1101010011100101
0010100111100001四则运算编译器,虽然说功能很简单,只能编译四则运算表达式。但是编译原理的前端部分几乎都有涉及:词法分析、语法分析。另外还有编译原理后端部分的代码生成。不管是简单的、复杂的编译器,编译步骤是差不多的,只是复杂的编译器实现上会更困难。
可能有人会问,学会编译原理有什么好处?
我认为对编译过程内部原理的掌握将会使你成为更好的高级程序员。另外在这引用一下知乎网友-随心所往的回答,更加具体:
好了,下面让我们看一下如何写一个四则运算编译器。
程序其实就是保存在文本文件中的一系列字符,词法分析的作用是将这一系列字符按照某种规则分解成一个个字元(token,也称为终结符),忽略空格和注释。
示例:
// 程序代码
10 + 5 + 6
// 词法分析后得到的 token
10
+
5
+
6终结符就是语言中用到的基本元素,它不能再被分解。
四则运算中的终结符包括符号和整数常量(暂不支持一元操作符和浮点运算)。
+ - * / ( )function lexicalAnalysis(expression) {
const symbol = ['(', ')', '+', '-', '*', '/']
const re = /\d/
const tokens = []
const chars = expression.trim().split('')
let token = ''
chars.forEach(c => {
if (re.test(c)) {
token += c
} else if (c == ' ' && token) {
tokens.push(token)
token = ''
} else if (symbol.includes(c)) {
if (token) {
tokens.push(token)
token = ''
}
tokens.push(c)
}
})
if (token) {
tokens.push(token)
}
return tokens
}
console.log(lexicalAnalysis('100 + 23 + 34 * 10 / 2'))
// ["100", "+", "23", "+", "34", "*", "10", "/", "2"]x*, 表示 x 出现零次或多次x | y, 表示 x 或 y 将出现( ) 圆括号,用于语言构词的分组以下规则从左往右看,表示左边的表达式还能继续往下细分成右边的表达式,一直细分到不可再分为止。
+ - * /addExpression 对应 + - 表达式,mulExpression 对应 * / 表达式。
如果你看不太懂以上的规则,那就先放下,继续往下看。看看怎么用代码实现语法分析。
对输入的文本按照语法规则进行分析并确定其语法结构的一种过程,称为语法分析。
一般语法分析的输出为抽象语法树(AST)或语法分析树(parse tree)。但由于四则运算比较简单,所以这里采取的方案是即时地进行代码生成和错误报告,这样就不需要在内存中保存整个程序结构。
先来看看怎么分析一个四则运算表达式 1 + 2 * 3。
首先匹配的是 expression,由于目前 expression 往下分只有一种可能,即 addExpression,所以分解为 addExpression。
依次类推,接下来的顺序为 mulExpression、term、1(integerConstant)、+(op)、mulExpression、term、2(integerConstant)、*(op)、mulExpression、term、3(integerConstant)。
如下图所示:
这里可能会有人有疑问,为什么一个表达式搞得这么复杂,expression 下面有 addExpression,addExpression 下面还有 mulExpression。
其实这里是为了考虑运算符优先级而设的,mulExpr 比 addExpr 表达式运算级要高。
1 + 2 * 3
compileExpression
| compileAddExpr
| | compileMultExpr
| | | compileTerm
| | | |_ matches integerConstant push 1
| | |_
| | matches '+'
| | compileMultExpr
| | | compileTerm
| | | |_ matches integerConstant push 2
| | | matches '*'
| | | compileTerm
| | | |_ matches integerConstant push 3
| | |_ compileOp('*') *
| |_ compileOp('+') +
|_
有很多算法可用来构建语法分析树,这里只讲两种算法。
递归下降分析法,也称为自顶向下分析法。按照语法规则一步步递归地分析 token 流,如果遇到非终结符,则继续往下分析,直到终结符为止。
递归下降分析法是简单高效的算法,LL(0)在此基础上多了一个步骤,当第一个 token 不足以确定元素类型时,对下一个字元采取“提前查看”,有可能会解决这种不确定性。
以上是对这两种算法的简介,具体实现请看下方的代码实现。
我们通常用的四则运算表达式是中缀表达式,但是对于计算机来说中缀表达式不便于计算。所以在代码生成阶段,要将中缀表达式转换为后缀表达式。
后缀表达式,又称逆波兰式,指的是不包含括号,运算符放在两个运算对象的后面,所有的计算按运算符出现的顺序,严格从左向右进行(不再考虑运算符的优先规则)。
示例:
中缀表达式: 5 + 5 转换为后缀表达式:5 5 +,然后再根据后缀表达式生成代码。
// 5 + 5 转换为 5 5 + 再生成代码
push 5
push 5
add编译原理的理论知识像天书,经常让人看得云里雾里,但真正动手做起来,你会发现,其实还挺简单的。
如果上面的理论知识看不太懂,没关系,先看代码实现,然后再和理论知识结合起来看。
注意:这里需要引入刚才的词法分析代码。
// 汇编代码生成器
function AssemblyWriter() {
this.output = ''
}
AssemblyWriter.prototype = {
writePush(digit) {
this.output += `push ${digit}\r\n`
},
writeOP(op) {
this.output += op + '\r\n'
},
//输出汇编代码
outputStr() {
return this.output
}
}
// 语法分析器
function Parser(tokens, writer) {
this.writer = writer
this.tokens = tokens
// tokens 数组索引
this.i = -1
this.opMap1 = {
'+': 'add',
'-': 'sub',
}
this.opMap2 = {
'/': 'div',
'*': 'mul'
}
this.init()
}
Parser.prototype = {
init() {
this.compileExpression()
},
compileExpression() {
this.compileAddExpr()
},
compileAddExpr() {
this.compileMultExpr()
while (true) {
this.getNextToken()
if (this.opMap1[this.token]) {
let op = this.opMap1[this.token]
this.compileMultExpr()
this.writer.writeOP(op)
} else {
// 没有匹配上相应的操作符 这里为没有匹配上 + -
// 将 token 索引后退一位
this.i--
break
}
}
},
compileMultExpr() {
this.compileTerm()
while (true) {
this.getNextToken()
if (this.opMap2[this.token]) {
let op = this.opMap2[this.token]
this.compileTerm()
this.writer.writeOP(op)
} else {
// 没有匹配上相应的操作符 这里为没有匹配上 * /
// 将 token 索引后退一位
this.i--
break
}
}
},
compileTerm() {
this.getNextToken()
if (this.token == '(') {
this.compileExpression()
this.getNextToken()
if (this.token != ')') {
throw '缺少右括号:)'
}
} else if (/^\d+$/.test(this.token)) {
this.writer.writePush(this.token)
} else {
throw '错误的 token:第 ' + (this.i + 1) + ' 个 token (' + this.token + ')'
}
},
getNextToken() {
this.token = this.tokens[++this.i]
},
getInstructions() {
return this.writer.outputStr()
}
}
const tokens = lexicalAnalysis('100+10*10')
const writer = new AssemblyWriter()
const parser = new Parser(tokens, writer)
const instructions = parser.getInstructions()
console.log(instructions) // 输出生成的汇编代码
/*
push 100
push 10
push 10
mul
add
*/现在来模拟一下 CPU 执行机器指令的情况,由于汇编代码和机器指令一一对应,所以我们可以创建一个直接执行汇编代码的模拟器。
在创建模拟器前,先来讲解一下相关指令的操作。
在内存中,栈的特点是只能在同一端进行插入和删除的操作,即只有 push 和 pop 两种操作。
push 指令的作用是将一个操作数推入栈中。
pop 指令的作用是将一个操作数弹出栈。
add 指令的作用是执行两次 pop 操作,弹出两个操作数 a 和 b,然后执行 a + b,再将结果 push 到栈中。
sub 指令的作用是执行两次 pop 操作,弹出两个操作数 a 和 b,然后执行 a - b,再将结果 push 到栈中。
mul 指令的作用是执行两次 pop 操作,弹出两个操作数 a 和 b,然后执行 a * b,再将结果 push 到栈中。
sub 指令的作用是执行两次 pop 操作,弹出两个操作数 a 和 b,然后执行 a / b,再将结果 push 到栈中。
四则运算的所有指令已经讲解完毕了,是不是觉得很简单?
注意:需要引入词法分析和语法分析的代码
function CpuEmulator(instructions) {
this.ins = instructions.split('\r\n')
this.memory = []
this.re = /^(push)\s\w+/
this.execute()
}
CpuEmulator.prototype = {
execute() {
this.ins.forEach(i => {
switch (i) {
case 'add':
this.add()
break
case 'sub':
this.sub()
break
case 'mul':
this.mul()
break
case 'div':
this.div()
break
default:
if (this.re.test(i)) {
this.push(i.split(' ')[1])
}
}
})
},
add() {
const b = this.pop()
const a = this.pop()
this.memory.push(a + b)
},
sub() {
const b = this.pop()
const a = this.pop()
this.memory.push(a - b)
},
mul() {
const b = this.pop()
const a = this.pop()
this.memory.push(a * b)
},
div() {
const b = this.pop()
const a = this.pop()
// 不支持浮点运算,所以在这要取整
this.memory.push(Math.floor(a / b))
},
push(x) {
this.memory.push(parseInt(x))
},
pop() {
return this.memory.pop()
},
getResult() {
return this.memory[0]
}
}
const tokens = lexicalAnalysis('(100+ 10)* 10-100/ 10 +8* (4+2)')
const writer = new AssemblyWriter()
const parser = new Parser(tokens, writer)
const instructions = parser.getInstructions()
const emulator = new CpuEmulator(instructions)
console.log(emulator.getResult()) // 1138一个简单的四则运算编译器已经实现了。我们再来写一个测试函数跑一跑,看看运行结果是否和我们期待的一样:
function assert(expression, result) {
const tokens = lexicalAnalysis(expression)
const writer = new AssemblyWriter()
const parser = new Parser(tokens, writer)
const instructions = parser.getInstructions()
const emulator = new CpuEmulator(instructions)
return emulator.getResult() == result
}
console.log(assert('1 + 2 + 3', 6)) // true
console.log(assert('1 + 2 * 3', 7)) // true
console.log(assert('10 / 2 * 3', 15)) // true
console.log(assert('(10 + 10) / 2', 10)) // true测试全部正确。另外附上完整的源码,建议没看懂的同学再看多两遍。
对于工业级编译器来说,这个四则运算编译器属于玩具中的玩具。但是人不可能一口吃成个胖子,所以学习编译原理最好采取循序渐进的方式去学习。下面来介绍一个高级一点的编译器,这个编译器可以编译一个 Jack 语言(类 Java 语言),它的语法大概是这样的:
class Generate {
field String str;
static String str1;
constructor Generate new(String s) {
let str = s;
return this;
}
method String getString() {
return str;
}
}
class Main {
function void main() {
var Generate str;
let str = Generate.new("this is a test");
do Output.printString(str.getString());
return;
}
}上面代码的输出结果为:this is a test。
想不想实现这样的一个编译器?
这个编译器出自一本书《计算机系统要素》,它从第 6 章开始,一直到第 11 章讲解了汇编编译器(将汇编语言转换为机器语言)、VM 编译器(将类似于字节码的 VM 语言翻译成汇编语言)、Jack 语言编译器(将高级语言 Jack 翻译成 VM 语言)。每一章都有详细的知识点讲解和实验,只要你一步一步跟着做实验,就能最终实现这样的一个编译器。
如果编译器写完了,最后机器语言在哪执行呢?
这本书已经为你考虑好了,它从第 1 章到第 5 章,一共五章的内容。教你从逻辑门开始,逐步组建出算术逻辑单元 ALU、CPU、内存,最终搭建出一个现代计算机。然后让你用编译器编译出来的程序运行在这台计算机之上。
另外,这本书的第 12 章会教你写操作系统的各种库函数,例如 Math 库(包含各种数学运算)、Keyboard 库(按下键盘是怎么输出到屏幕上的)、内存管理等等。
想看一看全书共 12 章的实验做完之后是怎么样的吗?我这里提供几张这台模拟计算机运行程序的 DEMO GIF,供大家参考参考。
这几张图中的右上角是“计算机”的屏幕,其他部分是“计算机”的堆栈区和指令区。
这本书的所有实验我都已经做完了(每天花 3 小时,两个月就能做完),答案放在我的 github 上,有兴趣的话可以看看。
hello 大佬,文章【前端性能和错误监控】写的很不错啊,可以授权公众号 全栈修炼 转载吗?会注明作者及来源的,谢谢。
你好,已star,前端性能优化 24 条建议(2020)可以转载到公众号高级前端进阶上吗?会标明作者与来源,感谢
组合功能只有在画布上操作才可以实现,在其他组件上操作会拖动组件,可以在其他逐渐锁定的情况下进行拖拽组合吗
hello 作者,文章有离线版吗
通常情况下,一个 git 仓库就是一个项目,只需要配置一套 git hooks 脚本就可以执行各种校验任务。对于 monorepo 项目也是如此,monorepo 项目下的多个 packages 之间,它们是有关联的,可以互相引用,所以当成一个项目也没问题。
但是也有一种情况,一个 git 仓库下的多个项目之间是彼此独立的,比如 git 仓库下存在前端项目、后端项目、文档项目等等。这时候就需要为每个项目配置不同的 git hooks 脚本了,因为不同的项目有可能校验规则不一样。
本文主要探讨一下如何为不同的项目配置 git hooks 脚本。
PS:配置 git hooks 脚本使用 huksy。
假设仓库拥前后端两个项目:
frontend
backend那么我们需要在每个项目下安装 husky,同时要在 package.json 中配置一下 prepare 脚本(这里以前端项目为示例):
# package.json
{
"scripts" {
"prepare": "cd .. && husky install frontend/.husky"
}
}然后按照 husky 文档创建 pre-commit 和 commit-msg 钩子文件:
#!/usr/bin/env sh
. "$(dirname -- "$0")/_/husky.sh"
# pre-commit
cd frontend
npx lint-staged#!/usr/bin/env sh
. "$(dirname -- "$0")/_/husky.sh"
# commit-msg
cd frontend
FORCE_COLOR=1 node scripts/verifyCommitMsg.mjs $1上面展示的是前端项目的 git hooks 创建过程,后端项目按照同样的过程创建即可。目前仓库的目录结构如下:
frontend
.husky
- pre-commit
- commit-msg
backend
.husky
- pre-commit
- commit-msg运行一段时间后,发现这个方案有问题,那就是每次触发的 git hooks 脚本都是前端项目的,后端项目提交代码根本不触发 git hooks。排查问题后发现是 git 仓库的配置引起的,打开 .git/config 文件:
[core]
hooksPath = frontend/.husky上面 hooksPath 路径对应的就是 git hooks 的目录位置,目前 git 只支持指定一个目录作为 git hooks 的位置。所以第一个方案不靠谱,达不到我们想要的效果。
第二个方案是将 git hooks 放在项目根目录下,统一在根目录里执行各个子项目的校验脚本。这个方案有以下几个步骤:
在每个项目下安装 husky 时,要把 git hooks 钩子目录设置在根目录:
# package.json
{
"scripts" {
"prepare": "cd .. && husky install .husky" # 放到根目录
}
}同时 .git/config 文件也要修改一下:
[core]
hooksPath = .husky # 改为根目录这里以 commit-msg 作为示例编写一个脚本:
#!/usr/bin/env sh
. "$(dirname -- "$0")/_/husky.sh"
# 拿到所有改动的文件名
changedFiles=$(git diff --cached --name-only --diff-filter=ACM)
# 判断目录是否改动
isBackendChanged=false
isFrontendChanged=false
for file in $changedFiles
do
if [[ $file == frontend/* ]]
then
isFrontendChanged=true
elif [[ $file == backend/* ]]
then
isBackendChanged=true
fi
done
# 改动的目录需要执行校验命令
# $1 $2 代表传给函数的第一个、第二个参数
execTask() {
echo "root $1 commit-msg"
cd $1
FORCE_COLOR=1 node scripts/verifyCommitMsg.mjs $2
}
if $isFrontendChanged
then
execTask "frontend" $1 & # 使用 & 让任务在后台执行
task1=$! # 保存任务 id
fi
if $isBackendChanged
then
execTask "backend" $1 &
task2=$!
fi
if [[ -n $task1 ]]; then
wait $task1
fi
if [[ -n $task2 ]]; then
wait $task2
fi
echo "All tasks finished."上面脚本的逻辑是这样的:
All tasks finished.pre-push 脚本编写与 pre-commit 和 commit-msg 不同,在 pre-push 钩子中需要通过其他方式来拿到发生改动的文件,大家直接看代码:
#!/usr/bin/env sh
. "$(dirname -- "$0")/_/husky.sh"
# 判断目录是否改动
isFrontendChanged=false
isComponentTemplateChanged=false
isComponentAttrPanelChanged=false
# 获取远程仓库的名字和 URL
remote="$1"
url="$2"
# 定义一个空的 git 哈希值
z40=0000000000000000000000000000000000000000
# 这个循环从 stdin 读取数据,这些数据是 git 在调用 pre-push 钩子时传递的。
# 每一行数据包括 4 个字段:本地引用名,本地最新的提交哈希值,远程引用名,远程最新的提交哈希值。
while read local_ref local_sha remote_ref remote_sha
do
# 这段代码检查是否正在删除一个引用(例如,删除一个分支)。如果是,那么本地的 sha 值将被设置为一个空哈希值。
if [ "$local_sha" = $z40 ]
then
# Handle delete
:
else
# 这段代码确定要检查哪些提交。如果远程的 sha 值是一个空哈希值,那么我们正在创建一个新的引用,所以我们需要检查所有的提交。
# 否则,我们正在更新一个已经存在的引用,所以我们只需要检查新的提交。
if [ "$remote_sha" = $z40 ]
then
# New branch, examine all commits
range="$local_sha"
else
# Update to existing branch, examine new commits
range="$remote_sha..$local_sha"
fi
# 这个循环对每一个包含在 range 变量中的提交执行 git rev-list 命令,这个命令会返回一系列的提交哈希值。
# 然后,对每个提交,我们使用 git diff-tree 命令来找到在那个提交中修改的文件。这些文件的名字被存储在 files 变量中。
for commit in $(git rev-list "$range"); do
# 拿到所有改动的文件名
files=$(git diff-tree --no-commit-id --name-only -r $commit)
for file in $files
do
if [[ $file == frontend/* ]]
then
isFrontendChanged=true
elif [[ $file == component-attr-panel/* ]]
then
isComponentAttrPanelChanged=true
elif [[ $file == component-template/* ]]
then
isComponentTemplateChanged=true
fi
done
done
fi
done
# 改动的目录需要执行校验命令
execTask() {
echo "root $1 pre-push"
cd $1
npm run type-check
}
if $isFrontendChanged
then
execTask "frontend" & # 使用 & 让任务在后台执行
task1=$! # 保存任务 id
fi
if $isComponentTemplateChanged
then
execTask "component-template" &
task2=$!
fi
if $isComponentAttrPanelChanged
then
execTask "component-attr-panel" &
task3=$!
fi
if [[ -n $task1 ]]; then
wait $task1
fi
if [[ -n $task2 ]]; then
wait $task2
fi
if [[ -n $task3 ]]; then
wait $task3
fi
echo "All tasks finished."测试一段时间后,发现第二个方案没发生什么问题,完全满足需求。
PS:在写脚本的时候要注意各个任务是否能并发执行,比如 lint-staged 这个任务就不能并发执行,所以在编写 pre-commit 脚本执行代码校验的时候,得改为串行。
> > > > 你好,关于发布的部分可以详细说明下吗?
如何生成.vue或者.html文件,如何打包,如何发布之类的
或者在代码里更新下这部分的功能,我最近正好在做可视化布局相关的项目可以从现有项目提取一个最小运行时,只包含自定义组件和预览页面相关的代码。单独打包成一个项目运行。这样就有两个项目,A 项目是用户拖拽的,B 是直接用于渲染的最小运行时。当 A 项目点击发布时,就把当前的组件数据发布到服务器,同时生成对应的 ID。在访问 B 项目时把 ID 带上,后台把组件数据返回,在 B 项目上渲染。
你说的这个方式我懂了。
我现在遇到个需求。
在A项目拖拽排布生成预览页面,点击一个按钮,生成一个文件夹或者文件并下载。下载之后得到的这个文件可以放到服务器进行部署,出来的就是之前排好的页面。
所以我会问如何生成.vue或者.html文件,如何打包。
对于这个需求,期待你的建议这个目前我也没有好的思路。
我现在有个方案,拿出来分享一下。
1、在public文件夹下新建一个文件夹,里面放上所有的静态资源、组件之类的,跟最小运行时有点像。这些文件,会被vue-cli自动复制一份。
2、写一个函数,接收一个json数据,返回一个模板字符串,这个字符串内容是html,会引入public里面的那些静态资源,例如vue.js、normalize.css、组件……就是把东西都引入。然后script里面new一个Vue,把拿到的json数据放进data里面。这里我引入了http-vue-loader.js,这样就可以把.vue拿来用了。
3、使用axios、jszip、file-saver。把html模板字符串用window.URL.createObjectURL转一下,然后和之前放在public里面的文件一起打包给用户。最终用户就可以得到一个zip包,解压之后是index.html和一堆静态文件,这些东西直接拖到服务器,就成了一个静态页面。
Originally posted by @longqizhu in #20 (comment)
学习 Vue3.0 源码必须对以下知识有所了解:
这些知识可以看一下阮一峰老师的《ES6 入门教程》。
如果不会 ts,我觉得影响不大,了解一下泛型就可以了。因为我就没用过 TS,但是不影响看代码。
阅读源码,建议先过一遍该模块下的 API,了解一下有哪些功能。然后再看一遍相关的单元测试,单元测试一般会把所有的功能细节都测一边。对源码的功能有所了解后,再去阅读源码的细节,效果更好。
const p = new Proxy(target, handler)在阅读源码的过程中,要时刻问自己三个问题:
正所谓知其然,知其所以然。
阅读源码除了要了解一个库具有什么特性,还要了解它为什么要这样设计,并且要问自己能不能用更好的方式去实现它。
如果只是单纯的停留在“是什么”这个阶段,对你可能没有什么帮助。就像看流水账似的,看完就忘,你得去思考,才能理解得更加深刻。
reactivity 模块是 Vue3.0 的响应式系统,它有以下几个文件:
baseHandlers.ts
collectionHandlers.ts
computed.ts
effect.ts
index.ts
operations.ts
reactive.ts
ref.ts
接下来按重要程度顺序来讲解一下各个文件的 API 用法和实现。
在 Vue.2x 中,使用 Object.defineProperty() 对对象进行监听。而在 Vue3.0 中,改用 Proxy 进行监听。Proxy 比起 Object.defineProperty() 有如下优势:
reactive() 的作用主要是将目标转化为响应式的 proxy 实例。例如:
const obj = {
count: 0
}
const proxy = reactive(obj)如果是嵌套的对象,会继续递归将子对象转为响应式对象。
reactive() 是向用户暴露的 API,它真正执行的是 createReactiveObject() 函数:
// 根据 target 生成 proxy 实例
function createReactiveObject(
target: Target,
isReadonly: boolean,
baseHandlers: ProxyHandler<any>,
collectionHandlers: ProxyHandler<any>
) {
if (!isObject(target)) {
if (__DEV__) {
console.warn(`value cannot be made reactive: ${String(target)}`)
}
return target
}
// target is already a Proxy, return it.
// exception: calling readonly() on a reactive object
if (
target[ReactiveFlags.raw] &&
!(isReadonly && target[ReactiveFlags.isReactive])
) {
return target
}
// target already has corresponding Proxy
if (
hasOwn(target, isReadonly ? ReactiveFlags.readonly : ReactiveFlags.reactive)
) {
return isReadonly
? target[ReactiveFlags.readonly]
: target[ReactiveFlags.reactive]
}
// only a whitelist of value types can be observed.
if (!canObserve(target)) {
return target
}
const observed = new Proxy(
target,
// 根据是否 Set, Map, WeakMap, WeakSet 来决定 proxy 的 handler 参数
collectionTypes.has(target.constructor) ? collectionHandlers : baseHandlers
)
// 在原始对象上定义一个属性(只读则为 "__v_readonly",否则为 "__v_reactive"),这个属性的值就是根据原始对象生成的 proxy 实例。
def(
target,
isReadonly ? ReactiveFlags.readonly : ReactiveFlags.reactive,
observed
)
return observed
}这个函数的处理逻辑如下:
__v_readonly,否则为 __v_reactive),指向这个 proxy 实例,最后返回这个实例。添加这个属性就是为了在第 2 步做判断用的,防止对同一对象重复监听。其中第 3、4 点需要单独拎出来讲一讲。
const canObserve = (value: Target): boolean => {
return (
!value[ReactiveFlags.skip] &&
isObservableType(toRawType(value)) &&
!Object.isFrozen(value)
)
}canObserve() 函数就是用来判断 value 是否是可观察的对象,满足以下条件才是可观察的对象:
__v_skip,__v_skip 是用来定义这个对象是否可跳过,即不监听。Object,Array,Map,Set,WeakMap,WeakSet 才可被监听。根据上面的代码可以看出来,在生成 proxy 实例时,处理器对象是根据一个三元表达式产生的:
// collectionTypes 的值为 Set, Map, WeakMap, WeakSet
collectionTypes.has(target.constructor) ? collectionHandlers : baseHandlers这个三元表达式非常简单,如果是普通的对象 Object 或 Array,处理器对象就使用 baseHandlers;如果是 Set, Map, WeakMap, WeakSet 中的一个,就使用 collectionHandlers。
collectionHandlers 和 baseHandlers 是从 collectionHandlers.ts 和 baseHandlers.ts 处引入的,这里先放一放,接下来再讲。
createReactiveObject() 根据不同的参数,可以创建多种不同的 proxy 实例:
reactive()。浅层响应的 proxy 实例是什么?
之所以有浅层响应的 proxy 实例,是因为 proxy 只代理对象的第一层属性,更深层的属性是不会代理的。如果确实需要生成完全响应式的 proxy 实例,就得递归调用 reactive()。不过这个过程是内部自动执行的,用户感知不到。
// 判断 value 是否是响应式的
export function isReactive(value: unknown): boolean {
if (isReadonly(value)) {
return isReactive((value as Target)[ReactiveFlags.raw])
}
return !!(value && (value as Target)[ReactiveFlags.isReactive])
}
// 判断 value 是否是只读的
export function isReadonly(value: unknown): boolean {
return !!(value && (value as Target)[ReactiveFlags.isReadonly])
}
// 判断 value 是否是 proxy 实例
export function isProxy(value: unknown): boolean {
return isReactive(value) || isReadonly(value)
}
// 将响应式数据转为原始数据,如果不是响应数据,则返回源数据
export function toRaw<T>(observed: T): T {
return (
(observed && toRaw((observed as Target)[ReactiveFlags.raw])) || observed
)
}
// 给 value 设置 skip 属性,跳过代理,让数据不可被代理
export function markRaw<T extends object>(value: T): T {
def(value, ReactiveFlags.skip, true)
return value
}在 baseHandlers.ts 文件中针对 4 种 proxy 实例定义了不对的处理器。
由于它们之间差别不大,所以在这只讲解完全响应式的处理器对象:
export const mutableHandlers: ProxyHandler<object> = {
get,
set,
deleteProperty,
has,
ownKeys
}处理器对五种操作进行了拦截,分别是:
其中 ownKeys 可拦截以下操作:
Object.getOwnPropertyNames()Object.getOwnPropertySymbols()Object.keys()Reflect.ownKeys()其中 get、has、ownKeys 操作会收集依赖,set、deleteProperty 操作会触发依赖。
get 属性的处理器是用 createGetter() 函数创建的:
// /*#__PURE__*/ 标识此为纯函数 不会有副作用 方便做 tree-shaking
const get = /*#__PURE__*/ createGetter()
function createGetter(isReadonly = false, shallow = false) {
return function get(target: object, key: string | symbol, receiver: object) {
// target 是否是响应式对象
if (key === ReactiveFlags.isReactive) {
return !isReadonly
// target 是否是只读对象
} else if (key === ReactiveFlags.isReadonly) {
return isReadonly
} else if (
// 如果访问的 key 是 __v_raw,并且 receiver == target.__v_readonly || receiver == target.__v_reactive
// 则直接返回 target
key === ReactiveFlags.raw &&
receiver ===
(isReadonly
? (target as any).__v_readonly
: (target as any).__v_reactive)
) {
return target
}
const targetIsArray = isArray(target)
// 如果 target 是数组并且 key 属于三个方法之一 ['includes', 'indexOf', 'lastIndexOf'],即触发了这三个操作之一
if (targetIsArray && hasOwn(arrayInstrumentations, key)) {
return Reflect.get(arrayInstrumentations, key, receiver)
}
// 不管Proxy怎么修改默认行为,你总可以在Reflect上获取默认行为。
// 如果不用 Reflect 来获取,在监听数组时可以会有某些地方会出错
// 具体请看文章《Vue3 中的数据侦测》——https://juejin.im/post/5d99be7c6fb9a04e1e7baa34#heading-10
const res = Reflect.get(target, key, receiver)
// 如果 key 是 symbol 并且属于 symbol 的内置方法之一,或者访问的是原型对象,直接返回结果,不收集依赖。
if ((isSymbol(key) && builtInSymbols.has(key)) || key === '__proto__') {
return res
}
// 只读对象不收集依赖
if (!isReadonly) {
track(target, TrackOpTypes.GET, key)
}
// 浅层响应立即返回,不递归调用 reactive()
if (shallow) {
return res
}
// 如果是 ref 对象,则返回真正的值,即 ref.value,数组除外。
if (isRef(res)) {
// ref unwrapping, only for Objects, not for Arrays.
return targetIsArray ? res : res.value
}
if (isObject(res)) {
// 由于 proxy 只能代理一层,所以 target[key] 的值如果是对象,就继续对其进行代理
return isReadonly ? readonly(res) : reactive(res)
}
return res
}
}这个函数的处理逻辑看代码注释应该就能明白,其中有几个点需要单独说一下:
Reflect.get()builtInSymbols.has(key) 为 true 或原型对象不收集依赖Reflect.get() 方法与从对象 (target[key]) 中读取属性类似,但它是通过一个函数执行来操作的。
为什么直接用 target[key] 就能得到值,却还要用 Reflect.get(target, key, receiver) 来多倒一手呢?
先来看个简单的示例:
const p = new Proxy([1, 2, 3], {
get(target, key, receiver) {
return target[key]
},
set(target, key, value, receiver) {
target[key] = value
}
})
p.push(100)运行这段代码会报错:
Uncaught TypeError: 'set' on proxy: trap returned falsish for property '3'但做一些小改动就能够正常运行:
const p = new Proxy([1, 2, 3], {
get(target, key, receiver) {
return target[key]
},
set(target, key, value, receiver) {
target[key] = value
return true // 新增一行 return true
}
})
p.push(100)这段代码可以正常运行。为什么呢?
区别在于新的这段代码在 set() 方法上多了一个 return true。我在 MDN 上查找到的解释是这样的:
set() 方法应当返回一个布尔值。
true 代表属性设置成功。set() 方法返回 false,那么会抛出一个 TypeError 异常。这时我又试了一下直接执行 p[3] = 100,发现能正常运行,只有执行 push 方法才报错。到这一步,我心中已经有答案了。为了验证我的猜想,我在代码上加了 console.log(),把代码执行过程的一些属性打印出来。
const p = new Proxy([1, 2, 3], {
get(target, key, receiver) {
console.log('get: ', key)
return target[key]
},
set(target, key, value, receiver) {
console.log('set: ', key, value)
target[key] = value
return true
}
})
p.push(100)
// get: push
// get: length
// set: 3 100
// set: length 4从上面的代码可以发现执行 push 操作时,还会访问 length 属性。推测执行过程如下:根据 length 的值,得出最后的索引,再设置新的置,最后再改变 length。
结合 MDN 的解释,我的推测是数组的原生方法应该是运行在严格模式下的(如果有网友知道真相,请在评论区留言)。因为在 JS 中很多代码在非严格模式和严格模式下都能正常运行,只是严格模式会给你报个错。就跟这次情况一样,最后设置 length 属性的时候报错,但结果还是正常的。如果不想报错,就得每次都返回 true。
然后再看一下 Reflect.set() 的返回值说明:
返回一个 Boolean 值表明是否成功设置属性。
所以上面代码可以改成这样:
const p = new Proxy([1, 2, 3], {
get(target, key, receiver) {
console.log('get: ', key)
return Reflect.get(target, key, receiver)
},
set(target, key, value, receiver) {
console.log('set: ', key, value)
return Reflect.set(target, key, value, receiver)
}
})
p.push(100)另外,不管 Proxy 怎么修改默认行为,你总可以在 Reflect 上获取默认行为。
通过上面的示例,不难理解为什么要通过 Reflect.set() 来代替 Proxy 完成默认操作了。同理,Reflect.get() 也一样。
// 如果 target 是数组并且 key 属于三个方法之一 ['includes', 'indexOf', 'lastIndexOf'],即触发了这三个操作之一
if (targetIsArray && hasOwn(arrayInstrumentations, key)) {
return Reflect.get(arrayInstrumentations, key, receiver)
}在执行数组的 includes, indexOf, lastIndexOf 方法时,会把目标对象转为 arrayInstrumentations 再执行。
const arrayInstrumentations: Record<string, Function> = {}
;['includes', 'indexOf', 'lastIndexOf'].forEach(key => {
arrayInstrumentations[key] = function(...args: any[]): any {
// 如果 target 对象中指定了 getter,receiver 则为 getter 调用时的 this 值。
// 所以这里的 this 指向 receiver,即 proxy 实例,toRaw 为了取得原始数据
const arr = toRaw(this) as any
// 对数组的每个值进行 track 操作,收集依赖
for (let i = 0, l = (this as any).length; i < l; i++) {
track(arr, TrackOpTypes.GET, i + '')
}
// we run the method using the original args first (which may be reactive)
// 参数有可能是响应式的,函数执行后返回值为 -1 或 false,那就用参数的原始值再试一遍
const res = arr[key](...args)
if (res === -1 || res === false) {
// if that didn't work, run it again using raw values.
return arr[key](...args.map(toRaw))
} else {
return res
}
}
})从上述代码可以看出,Vue3.0 对 includes, indexOf, lastIndexOf 进行了封装,除了返回原有方法的结果外,还会对数组的每个值进行依赖收集。
builtInSymbols.has(key) 为 true 或原型对象不收集依赖const p = new Proxy({}, {
get(target, key, receiver) {
console.log('get: ', key)
return Reflect.get(target, key, receiver)
},
set(target, key, value, receiver) {
console.log('set: ', key, value)
return Reflect.set(target, key, value, receiver)
}
})
p.toString() // get: toString
// get: Symbol(Symbol.toStringTag)
p.__proto__ // get: __proto__从 p.toString() 的执行结果来看,它会触发两次 get,一次是我们想要的,一次是我们不想要的(我还没搞明白为什么会有 Symbol(Symbol.toStringTag),如果有网友知道,请在评论区留言)。所以就有了这个判断: builtInSymbols.has(key) 为 true 就直接返回,防止重复收集依赖。
再看 p.__proto__ 的执行结果,也触发了一次 get 操作。一般来说,没有场景需要单独访问原型,访问原型都是为了访问原型上的方法,例如 p.__proto__.toString() 这样使用,所以 key 为 __proto__ 的时候也要跳过,不收集依赖。
const set = /*#__PURE__*/ createSetter()
// 参考文档《Vue3 中的数据侦测》——https://juejin.im/post/5d99be7c6fb9a04e1e7baa34#heading-10
function createSetter(shallow = false) {
return function set(
target: object,
key: string | symbol,
value: unknown,
receiver: object
): boolean {
const oldValue = (target as any)[key]
if (!shallow) {
value = toRaw(value)
// 如果原来的值是 ref,但新的值不是,将新的值赋给 ref.value 即可。
if (!isArray(target) && isRef(oldValue) && !isRef(value)) {
oldValue.value = value
return true
}
} else {
// in shallow mode, objects are set as-is regardless of reactive or not
}
const hadKey = hasOwn(target, key)
const result = Reflect.set(target, key, value, receiver)
// don't trigger if target is something up in the prototype chain of original
if (target === toRaw(receiver)) {
if (!hadKey) {
// 如果 target 没有 key,就代表是新增操作,需要触发依赖
trigger(target, TriggerOpTypes.ADD, key, value)
} else if (hasChanged(value, oldValue)) {
// 如果新旧值不相等,才触发依赖
// 什么时候会有新旧值相等的情况?例如监听一个数组,执行 push 操作,会触发多次 setter
// 第一次 setter 是新加的值 第二次是由于新加的值导致 length 改变
// 但由于 length 也是自身属性,所以 value === oldValue
trigger(target, TriggerOpTypes.SET, key, value, oldValue)
}
}
return result
}
}set() 的函数处理逻辑反而没那么难,看注释即可。track() 和 trigger() 将放在下面和 effect.ts 文件一起讲解。
function deleteProperty(target: object, key: string | symbol): boolean {
const hadKey = hasOwn(target, key)
const oldValue = (target as any)[key]
const result = Reflect.deleteProperty(target, key)
// 如果删除结果为 true 并且 target 拥有这个 key 就触发依赖
if (result && hadKey) {
trigger(target, TriggerOpTypes.DELETE, key, undefined, oldValue)
}
return result
}
function has(target: object, key: string | symbol): boolean {
const result = Reflect.has(target, key)
track(target, TrackOpTypes.HAS, key)
return result
}
function ownKeys(target: object): (string | number | symbol)[] {
track(target, TrackOpTypes.ITERATE, ITERATE_KEY)
return Reflect.ownKeys(target)
}这三个函数比较简单,看代码即可。
等把 effect.ts 文件讲解完,响应式模块基本上差不多结束了。
effect() 主要和响应式的对象结合使用。
export function effect<T = any>(
fn: () => T,
options: ReactiveEffectOptions = EMPTY_OBJ
): ReactiveEffect<T> {
// 如果已经是 effect 函数,取得原来的 fn
if (isEffect(fn)) {
fn = fn.raw
}
const effect = createReactiveEffect(fn, options)
// 如果 lazy 为 false,马上执行一次
// 计算属性的 lazy 为 true
if (!options.lazy) {
effect()
}
return effect
}真正创建 effect 的是 createReactiveEffect() 函数。
let uid = 0
function createReactiveEffect<T = any>(
fn: (...args: any[]) => T,
options: ReactiveEffectOptions
): ReactiveEffect<T> {
// reactiveEffect() 返回一个新的 effect,这个新的 effect 执行后
// 会将自己设为 activeEffect,然后再执行 fn 函数,如果在 fn 函数里对响应式属性进行读取
// 会触发响应式属性 get 操作,从而收集依赖,而收集的这个依赖函数就是 activeEffect
const effect = function reactiveEffect(...args: unknown[]): unknown {
if (!effect.active) {
return options.scheduler ? undefined : fn(...args)
}
// 为了避免递归循环,所以要检测一下
if (!effectStack.includes(effect)) {
// 清空依赖
cleanup(effect)
try {
enableTracking()
effectStack.push(effect)
activeEffect = effect
return fn(...args)
} finally {
// track 将依赖函数 activeEffect 添加到对应的 dep 中,然后在 finally 中将 activeEffect
// 重置为上一个 effect 的值
effectStack.pop()
resetTracking()
activeEffect = effectStack[effectStack.length - 1]
}
}
} as ReactiveEffect
effect.id = uid++
effect._isEffect = true
effect.active = true // 用于判断当前 effect 是否激活,有一个 stop() 来将它设为 false
effect.raw = fn
effect.deps = []
effect.options = options
return effect
}其中 cleanup(effect) 的作用是让 effect 关联下的所有 dep 实例清空 effect,即清除这个依赖函数。
function cleanup(effect: ReactiveEffect) {
const { deps } = effect
if (deps.length) {
for (let i = 0; i < deps.length; i++) {
deps[i].delete(effect)
}
deps.length = 0
}
}从代码中可以看出来,真正的依赖函数是 activeEffect。执行 track() 收集的依赖就是 activeEffect。
趁热打铁,现在我们再来看一下 track() 和 trigger() 函数。
// 依赖收集
export function track(target: object, type: TrackOpTypes, key: unknown) {
// activeEffect 为空,代表没有依赖,直接返回
if (!shouldTrack || activeEffect === undefined) {
return
}
// targetMap 依赖管理中心,用于收集依赖和触发依赖
let depsMap = targetMap.get(target)
// targetMap 为每个 target 建立一个 map
// 每个 target 的 key 对应着一个 dep
// 然后用 dep 来收集依赖函数,当监听的 key 值发生变化时,触发 dep 中的依赖函数
// 类似于这样
// targetMap(weakmap) = {
// target1(map): {
// key1(dep): (fn1,fn2,fn3...)
// key2(dep): (fn1,fn2,fn3...)
// },
// target2(map): {
// key1(dep): (fn1,fn2,fn3...)
// key2(dep): (fn1,fn2,fn3...)
// },
// }
if (!depsMap) {
targetMap.set(target, (depsMap = new Map()))
}
let dep = depsMap.get(key)
if (!dep) {
depsMap.set(key, (dep = new Set()))
}
if (!dep.has(activeEffect)) {
dep.add(activeEffect)
activeEffect.deps.push(dep)
// 开发环境下会触发 onTrack 事件
if (__DEV__ && activeEffect.options.onTrack) {
activeEffect.options.onTrack({
effect: activeEffect,
target,
type,
key
})
}
}
}targetMap 是一个 WeakMap 实例。
WeakMap 对象是一组键/值对的集合,其中的键是弱引用的。其键必须是对象,而值可以是任意的。
弱引用是什么意思呢?
let obj = { a: 1 }
const map = new WeakMap()
map.set(obj, '测试')
obj = null当 obj 置为空后,对于 { a: 1 } 的引用已经为零了,下一次垃圾回收时就会把 weakmap 中的对象回收。
但如果把 weakmap 换成 map 数据结构,即使把 obj 置空,{ a: 1 } 依然不会被回收,因为 map 数据结构是强引用,它现在还被 map 引用着。
// 触发依赖
export function trigger(
target: object,
type: TriggerOpTypes,
key?: unknown,
newValue?: unknown,
oldValue?: unknown,
oldTarget?: Map<unknown, unknown> | Set<unknown>
) {
const depsMap = targetMap.get(target)
// 如果没有收集过依赖,直接返回
if (!depsMap) {
// never been tracked
return
}
// 对收集的依赖进行分类,分为普通的依赖或计算属性依赖
// effects 收集的是普通的依赖 computedRunners 收集的是计算属性的依赖
// 两个队列都是 set 结构,为了避免重复收集依赖
const effects = new Set<ReactiveEffect>()
const computedRunners = new Set<ReactiveEffect>()
const add = (effectsToAdd: Set<ReactiveEffect> | undefined) => {
if (effectsToAdd) {
effectsToAdd.forEach(effect => {
// effect !== activeEffect 避免重复收集依赖
if (effect !== activeEffect || !shouldTrack) {
// 计算属性
if (effect.options.computed) {
computedRunners.add(effect)
} else {
effects.add(effect)
}
} else {
// the effect mutated its own dependency during its execution.
// this can be caused by operations like foo.value++
// do not trigger or we end in an infinite loop
}
})
}
}
// 在值被清空前,往相应的队列添加 target 所有的依赖
if (type === TriggerOpTypes.CLEAR) {
// collection being cleared
// trigger all effects for target
depsMap.forEach(add)
} else if (key === 'length' && isArray(target)) { // 当数组的 length 属性变化时触发
depsMap.forEach((dep, key) => {
if (key === 'length' || key >= (newValue as number)) {
add(dep)
}
})
} else {
// schedule runs for SET | ADD | DELETE
// 如果不符合以上两个 if 条件,并且 key !== undefined,往相应的队列添加依赖
if (key !== void 0) {
add(depsMap.get(key))
}
// also run for iteration key on ADD | DELETE | Map.SET
const isAddOrDelete =
type === TriggerOpTypes.ADD ||
(type === TriggerOpTypes.DELETE && !isArray(target))
if (
isAddOrDelete ||
(type === TriggerOpTypes.SET && target instanceof Map)
) {
add(depsMap.get(isArray(target) ? 'length' : ITERATE_KEY))
}
if (isAddOrDelete && target instanceof Map) {
add(depsMap.get(MAP_KEY_ITERATE_KEY))
}
}
const run = (effect: ReactiveEffect) => {
if (__DEV__ && effect.options.onTrigger) {
effect.options.onTrigger({
effect,
target,
key,
type,
newValue,
oldValue,
oldTarget
})
}
if (effect.options.scheduler) {
// 如果 scheduler 存在则调用 scheduler,计算属性拥有 scheduler
effect.options.scheduler(effect)
} else {
effect()
}
}
// Important: computed effects must be run first so that computed getters
// can be invalidated before any normal effects that depend on them are run.
computedRunners.forEach(run)
// 触发依赖函数
effects.forEach(run)
}对依赖函数进行分类后,需要先运行计算属性的依赖,因为其他普通的依赖函数可能包含了计算属性。先执行计算属性的依赖能保证普通依赖执行时能得到最新的计算属性的值。
这个 type 取值范围就定义在 operations.ts 文件中:
// track 的类型
export const enum TrackOpTypes {
GET = 'get', // get 操作
HAS = 'has', // has 操作
ITERATE = 'iterate' // ownKeys 操作
}
// trigger 的类型
export const enum TriggerOpTypes {
SET = 'set', // 设置操作,将旧值设置为新值
ADD = 'add', // 新增操作,添加一个新的值 例如给对象新增一个值 数组的 push 操作
DELETE = 'delete', // 删除操作 例如对象的 delete 操作,数组的 pop 操作
CLEAR = 'clear' // 用于 Map 和 Set 的 clear 操作。
}type 主要用于标识 track() 和 trigger() 的类型。
if (key !== void 0) {
add(depsMap.get(key))
}
// also run for iteration key on ADD | DELETE | Map.SET
const isAddOrDelete =
type === TriggerOpTypes.ADD ||
(type === TriggerOpTypes.DELETE && !isArray(target))
if (
isAddOrDelete ||
(type === TriggerOpTypes.SET && target instanceof Map)
) {
add(depsMap.get(isArray(target) ? 'length' : ITERATE_KEY))
}
if (isAddOrDelete && target instanceof Map) {
add(depsMap.get(MAP_KEY_ITERATE_KEY))
}在 trigger() 中有这么一段连续判断的代码,它们作用是什么呢?其实它们是用于判断数组/集合这种数据结构比较特别的操作。
看个示例:
let dummy
const counter = reactive([])
effect(() => (dummy = counter.join()))
counter.push(1)effect(() => (dummy = counter.join())) 生成一个依赖,并且自执行一次。
在执行函数里的代码 counter.join() 时,会访问数组的多个属性,分别是 join 和 length,同时触发 track() 收集依赖。也就是说,数组的 join length 属性都收集了一个依赖。
当执行 counter.push(1) 这段代码时,实际上是将数组的索引 0 对应的值设为 1。这一点,可以通过打 debugger 从上下文环境看出来,其中 key 为 0,即数组的索引,值为 1。
设置值后,由于是新增操作,执行 trigger(target, TriggerOpTypes.ADD, key, value)。但由上文可知,只有数组的 key 为 join length 时,才有依赖,key 为 0 是没有依赖的。
从上面两个图可以看出来,只有 join length 属性才有对应的依赖。
这个时候,trigger() 的一连串 if 语句就起作用了,其中有一个 if 语句是这样的:
if (
isAddOrDelete ||
(type === TriggerOpTypes.SET && target instanceof Map)
) {
add(depsMap.get(isArray(target) ? 'length' : ITERATE_KEY))
}如果 target 是一个数组,就添加 length 属性对应的依赖到队列中。也就是说 key 为 0 的情况下使用 length 对应的依赖。
另外,还有一个巧妙的地方。待执行依赖的队列是一个 set 数据结构。如果 key 为 0 有对应的依赖,同时 length 也有对应的依赖,就会添加两次依赖,但由于队列是 set,具有自动去重的效果,避免了重复执行。
仅看代码和文字,是很难理解响应式数据和 track() trigger() 是怎么配合的。所以我们要配合示例来理解:
let dummy
const counter = reactive({ num: 0 })
effect(() => (dummy = counter.num))
console.log(dummy == 0)
counter.num = 7
console.log(dummy == 7)上述代码执行过程如下:
{ num: 0 } 进行监听,返回一个 proxy 实例,即 counter。effect(fn) 创建一个依赖,并且在创建时会执行一次 fn。fn() 读取 num 的值,并赋值给 dummy。counter.num = 7 这个操作会触发 proxy 的属性设置拦截操作,在这个拦截操作里,除了把新的值返回,还会触发刚才收集的依赖。在这个依赖里把 counter.num 赋值给 dummy(num 的值已经变为 7)。用图来表示,大概这样的:
collectionHandlers.ts 文件包含了 Map WeakMap Set WeakSet 的处理器对象,分别对应完全响应式的 proxy 实例、浅层响应的 proxy 实例、只读 proxy 实例。这里只讲解对应完全响应式的 proxy 实例的处理器对象:
export const mutableCollectionHandlers: ProxyHandler<CollectionTypes> = {
get: createInstrumentationGetter(false, false)
}为什么只监听 get 操作,set has 等操作呢?不着急,先看一个示例:
const p = new Proxy(new Map(), {
get(target, key, receiver) {
console.log('get: ', key)
return Reflect.get(target, key, receiver)
},
set(target, key, value, receiver) {
console.log('set: ', key, value)
return Reflect.set(target, key, value, receiver)
}
})
p.set('ab', 100) // Uncaught TypeError: Method Map.prototype.set called on incompatible receiver [object Object]运行上面的代码会报错。其实这和 Map Set 的内部实现有关,必须通过 this 才能访问它们的数据。但是通过 Reflect 反射的时候,target 内部的 this 其实是指向 proxy 实例的,所以就不难理解为什么会报错了。
那怎么解决这个问题?通过源码可以发现,在 Vue3.0 中是通过代理的方式来实现对 Map Set 等数据结构监听的:
function createInstrumentationGetter(isReadonly: boolean, shallow: boolean) {
const instrumentations = shallow
? shallowInstrumentations
: isReadonly
? readonlyInstrumentations
: mutableInstrumentations
return (
target: CollectionTypes,
key: string | symbol,
receiver: CollectionTypes
) => {
// 这三个 if 判断和 baseHandlers 的处理方式一样
if (key === ReactiveFlags.isReactive) {
return !isReadonly
} else if (key === ReactiveFlags.isReadonly) {
return isReadonly
} else if (key === ReactiveFlags.raw) {
return target
}
return Reflect.get(
hasOwn(instrumentations, key) && key in target
? instrumentations
: target,
key,
receiver
)
}
}把最后一行代码简化一下:
target = hasOwn(instrumentations, key) && key in target? instrumentations : target
return Reflect.get(target, key, receiver);其中 instrumentations 的内容是:
const mutableInstrumentations: Record<string, Function> = {
get(this: MapTypes, key: unknown) {
return get(this, key, toReactive)
},
get size() {
return size((this as unknown) as IterableCollections)
},
has,
add,
set,
delete: deleteEntry,
clear,
forEach: createForEach(false, false)
}从代码可以看到,原来真正的处理器对象是 mutableInstrumentations。现在再看一个示例:
const proxy = reactive(new Map())
proxy.set('key', 100)生成 proxy 实例后,执行 proxy.set('key', 100)。proxy.set 这个操作会触发 proxy 的属性读取拦截操作。
打断点可以看到,此时的 key 为 set。拦截了 set 操作后,调用 Reflect.get(target, key, receiver),这个时候的 target 已经不是原来的 target 了,而是 mutableInstrumentations 对象。也就是说,最终执行的是 mutableInstrumentations.set()。
接下来再看看 mutableInstrumentations 的各个处理器逻辑。
// 如果 value 是对象,则返回一个响应式对象(`reactive(value)`),否则直接返回 value。
const toReactive = <T extends unknown>(value: T): T =>
isObject(value) ? reactive(value) : value
get(this: MapTypes, key: unknown) {
// this 指向 proxy
return get(this, key, toReactive)
}
function get(
target: MapTypes,
key: unknown,
wrap: typeof toReactive | typeof toReadonly | typeof toShallow
) {
target = toRaw(target)
const rawKey = toRaw(key)
// 如果 key 是响应式的,额外收集一次依赖
if (key !== rawKey) {
track(target, TrackOpTypes.GET, key)
}
track(target, TrackOpTypes.GET, rawKey)
// 使用 target 原型上的方法
const { has, get } = getProto(target)
// 原始 key 和响应式的 key 都试一遍
if (has.call(target, key)) {
// 读取的值要使用包装函数处理一下
return wrap(get.call(target, key))
} else if (has.call(target, rawKey)) {
return wrap(get.call(target, rawKey))
}
}get 的处理逻辑很简单,拦截 get 之后,调用 get(this, key, toReactive)。
function set(this: MapTypes, key: unknown, value: unknown) {
value = toRaw(value)
// 取得原始数据
const target = toRaw(this)
// 使用 target 原型上的方法
const { has, get, set } = getProto(target)
let hadKey = has.call(target, key)
if (!hadKey) {
key = toRaw(key)
hadKey = has.call(target, key)
} else if (__DEV__) {
checkIdentityKeys(target, has, key)
}
const oldValue = get.call(target, key)
const result = set.call(target, key, value)
// 防止重复触发依赖,如果 key 已存在就不触发依赖
if (!hadKey) {
trigger(target, TriggerOpTypes.ADD, key, value)
} else if (hasChanged(value, oldValue)) {
// 如果新旧值相等,也不会触发依赖
trigger(target, TriggerOpTypes.SET, key, value, oldValue)
}
return result
}set 的处理逻辑也较为简单,配合注释一目了然。
还有剩下的 has add delete 等方法就不讲解了,代码行数比较少,逻辑也很简单,建议自行阅读。
const convert = <T extends unknown>(val: T): T =>
isObject(val) ? reactive(val) : val
export function ref(value?: unknown) {
return createRef(value)
}
function createRef(rawValue: unknown, shallow = false) {
// 如果已经是 ref 对象了,直接返回原值
if (isRef(rawValue)) {
return rawValue
}
// 如果不是浅层响应并且 rawValue 是个对象,调用 reactive(rawValue)
let value = shallow ? rawValue : convert(rawValue)
const r = {
__v_isRef: true, // 用于标识这是一个 ref 对象,防止重复监听 ref 对象
get value() {
// 读取值时收集依赖
track(r, TrackOpTypes.GET, 'value')
return value
},
set value(newVal) {
if (hasChanged(toRaw(newVal), rawValue)) {
rawValue = newVal
value = shallow ? newVal : convert(newVal)
// 设置值时触发依赖
trigger(
r,
TriggerOpTypes.SET,
'value',
__DEV__ ? { newValue: newVal } : void 0
)
}
}
}
return r
}在 Vue2.x 中,基本数值类型是不能监听的。但在 Vue3.0 中通过 ref() 可以实现这一效果。
const r = ref(0)
effect(() => console.log(r.value)) // 打印 0
r.value++ // 打印 1ref() 会把 0 转成一个 ref 对象。如果给 ref(value) 传的值是个对象,在函数内部会调用 reactive(value) 将其转为 proxy 实例。
export function computed<T>(
options: WritableComputedOptions<T>
): WritableComputedRef<T>
export function computed<T>(
getterOrOptions: ComputedGetter<T> | WritableComputedOptions<T>
) {
let getter: ComputedGetter<T>
let setter: ComputedSetter<T>
// 如果 getterOrOptions 是个函数,则是不可被配置的,setter 设为空函数
if (isFunction(getterOrOptions)) {
getter = getterOrOptions
setter = __DEV__
? () => {
console.warn('Write operation failed: computed value is readonly')
}
: NOOP
} else {
// 如果是个对象,则可读可写
getter = getterOrOptions.get
setter = getterOrOptions.set
}
// dirty 用于判断计算属性依赖的响应式属性有没有被改变
let dirty = true
let value: T
let computed: ComputedRef<T>
const runner = effect(getter, {
lazy: true, // lazy 为 true,生成的 effect 不会马上执行
// mark effect as computed so that it gets priority during trigger
computed: true,
scheduler: () => { // 调度器
// trigger 时,计算属性执行的是 effect.options.scheduler(effect) 而不是 effect()
if (!dirty) {
dirty = true
trigger(computed, TriggerOpTypes.SET, 'value')
}
}
})
computed = {
__v_isRef: true,
// expose effect so computed can be stopped
effect: runner,
get value() {
if (dirty) {
value = runner()
dirty = false
}
track(computed, TrackOpTypes.GET, 'value')
return value
},
set value(newValue: T) {
setter(newValue)
}
} as any
return computed
}下面通过一个示例,来讲解一下 computed 是怎么运作的:
const value = reactive({})
const cValue = computed(() => value.foo)
console.log(cValue.value === undefined)
value.foo = 1
console.log(cValue.value === 1)computed() 生成计算属性对象,当对 cValue 进行取值时(cValue.value),根据 dirty 判断是否需要运行 effect 函数进行取值,如果 dirty 为 false,直接把值返回。() => value.foo) 取值。在取值过程中,读取 foo 的值(value.foo)。value.foo = 1),就会 trigger 这个 activeEffect 函数。scheduler() 将 dirty 设为 true,这样 computed 下次求值时会重新执行 effect 函数进行取值。index.ts 文件向外导出 reactivity 模块的 API。
仅吧store的数据放在module里面,通过this.$store.state.dataA.xxxx获取,其他代码都一样,就是在点击的时候没有出现8点,右边的属性栏也没有显示,请各位又遇到的人士指点
Git 能在特定的重要动作发生时触发自定义脚本,其中比较常用的有:pre-commit、commit-msg、pre-push 等钩子(hooks)。我们可以在 pre-commit 触发时进行代码格式验证,在 commit-msg 触发时对 commit 消息和提交用户进行验证,在 pre-push 触发时进行单元测试、e2e 测试等操作。
Git 在执行 git init 进行初始化时,会在 .git/hooks 目录生成一系列的 hooks 脚本:
从上图可以看到每个脚本的后缀都是以 .sample 结尾的,在这个时候,脚本是不会自动执行的。我们需要把后缀去掉之后才会生效,即将 pre-commit.sample 变成 pre-commit 才会起作用。
本文主要是想介绍一下如何编写 git hooks 脚本,并且会编写两个 pre-commit、commit-msg 脚本作为示例,帮助大家更好的理解 git hooks 脚本。当然,在工作中还是建议使用现成的、开源的解决方案 husky。
用于编写 git hooks 的脚本语言是没有限制的,你可以用 nodejs、shell、python、ruby等脚本语言,非常的灵活方便。
下面我将用 shell 语言来演示一下如何编写 pre-commit 和 commit-msg 脚本。另外要注意的是,在执行这些脚本时,如果以非零的值退出程序,将会中断 git 的提交/推送流程。所以在 hooks 脚本中验证消息/代码不通过时,就可以用非零值进行退出,中断 git 流程。
exit 1在 pre-commit 钩子中要做的事情特别简单,只对要提交的代码格式进行检查,因此脚本代码比较少:
#!/bin/sh
npm run lint
# 获取上面脚本的退出码
exitCode="$?"
exit $exitCode由于我在项目中已经配置好了相关的 eslint 配置以及 npm 脚本,因此在 pre-commit 中执行相关的 lint 命令就可以了,并且判断一下是否正常退出。
// 在 package.json 文件中已配置好 lint 命令
"scripts": {
"lint": "eslint --ext .js src/"
},下面看一个动图,当代码格式不正确的时候,进行 commit 就报错了:
在修改代码格式后再进行提交,这时就不报错了:
从动图中可以看出,这次 commit 已正常提交了。
在 commit-msg hooks 中,我们需要对 commit 消息和用户进行校验。
#!/bin/sh
# 用 `` 可以将命令的输出结果赋值给变量
# 获取当前提交的 commit msg
commit_msg=`cat $1`
# 获取用户 email
email=`git config user.email`
msg_re="^(feat|fix|docs|style|refactor|perf|test|workflow|build|ci|chore|release|workflow)(\(.+\))?: .{1,100}"
if [[ ! $commit_msg =~ $msg_re ]]
then
echo "\n不合法的 commit 消息提交格式,请使用正确的格式:\
\nfeat: add comments\
\nfix: handle events on blur (close #28)\
\n详情请查看 git commit 提交规范:https://github.com/woai3c/Front-end-articles/blob/master/git%20commit%20style.md"
# 异常退出
exit 1
fi在 commit-msg 钩子触发时,对应的脚本会接收到一个参数,这个参数就是 commit 消息,通过 cat $1 获取,并赋值给 commit_msg 变量。
验证 commit 消息的正则比较简单,看代码即可。如果对 commit 提交规范有兴趣,可以看看我另一篇文章。
对用户权限做判断则比较简单,只需要检查用户的邮箱或用户名就可以了(假设现在只有 abc 公司的员工才有权限提交代码)。
email_re="@abc\.com"
if [[ ! $email =~ $email_re ]]
then
echo "此用户没有权限,具有权限的用户为: [email protected]"
# 异常退出
exit 1
fi下面用两个动图来分别演示一下校验 commit 消息和判断用户权限的过程:
脚本可以正常执行只是第一步,还有一个问题是必须要解决的,那就是如何和同一项目的其他开发人员共享 git hooks 配置。因为 .git/hooks 目录不会随着提交一起推送到远程仓库。对于这个问题有两种解决方案:第一种是模仿 husky 做一个 npm 插件,在安装的时候自动在 .git/hooks 目录添加 hooks 脚本;第二种是将 hooks 脚本单独写在项目中的某个目录,然后在该项目安装依赖时,自动将该目录设置为 git 的 hooks 目录。
接下来详细说说第二种方法的实现过程:
npm install 执行完成后,自动执行 git config core.hooksPath hooks 命令。git config core.hooksPath hooks 命令将 git hooks 目录设置为项目根目录下的 hooks 目录。"scripts": {
"lint": "eslint --ext .js src/",
"postinstall": "git config core.hooksPath hooks"
},demo 源码在 windows 上是可以正常运行的,后来换成 mac 之后就不行了,提交时报错:
hint: The 'hooks/pre-commit' hook was ignored because it's not set as executable.原因是 hooks 脚本默认为不可执行,所以需要将它设为可执行:
chmod 700 hooks/*为了避免每次克隆项目都得修改,最好将这个命令在 npm 脚本上加上:
"scripts": {
"lint": "eslint --ext .js src/",
"postinstall": "git config core.hooksPath hooks && chmod 700 hooks/*"
},当然,如果是 windows 就不用加后半段代码了。
为了帮助前端同学更好的理解 git hooks 脚本,我用 nodejs 又重写了一版。
pre-commit
#!/usr/bin/env node
const childProcess = require('child_process');
try {
childProcess.execSync('npm run lint');
} catch (error) {
console.log(error.stdout.toString());
process.exit(1);
}commit-msg
#!/usr/bin/env node
const childProcess = require('child_process');
const fs = require('fs');
const email = childProcess.execSync('git config user.email').toString().trim();
const msg = fs.readFileSync(process.argv[2], 'utf-8').trim(); // 索引 2 对应的 commit 消息文件
const commitRE = /^(feat|fix|docs|style|refactor|perf|test|workflow|build|ci|chore|release|workflow)(\(.+\))?: .{1,100}/;
if (!commitRE.test(msg)) {
console.log();
console.error('不合法的 commit 消息格式,请使用正确的提交格式:');
console.error('feat: add \'comments\' option');
console.error('fix: handle events on blur (close #28)');
console.error('详情请查看 git commit 提交规范:https://github.com/woai3c/Front-end-articles/blob/master/git%20commit%20style.md。');
process.exit(1);
}
if (!/@qq\.com$/.test(email)) {
console.error('此用户没有权限,具有权限的用户为: [email protected]');
process.exit(1);
}其实本文适用的范围不仅仅局限于前端,而是适用于所有使用了 git 作为版本控制的项目。例如安卓、ios、Java 等等。只是本文选择了前端项目作为示例。
最近附上项目源码:https://github.com/woai3c/git-hooks-demo
大佬考虑写一个在线协同文档的demo吗
作者你好 如果你左边是一个套件怎么处理 这个套件拖拽到中间显示是两个选项而且两个选项是有联动效果的
官网上的定义:
loader 是一个转换器,用于对源代码进行转换。
例如 babel-loader 可以将 ES6 代码转换为 ES5 代码;sass-loader 将 sass 代码转换为 css 代码。
一般 loader 的配置代码如下:
module: {
rules: [
{
test: /\.js$/,
use: [
// loader 的执行顺序从下到上
{
loader: path.resolve('./src/loader2.js'),
},
{
loader: path.resolve('./src/loader1.js'),
},
]
}
]
},rules 数组包含了一个个匹配规则和具体的 loader 文件。
上述代码中的 test: /\.js$/ 就是匹配规则,表示对 js 文件使用下面的两个 loader。
而 loader 的处理顺序是自下向上的,即先用 loader1 处理源码,然后将处理后的代码再传给 loader2。
loader2 处理后的代码就是最终的打包代码。
loader 其实是一个函数,它的参数是匹配文件的源码,返回结果是处理后的源码。下面是一个最简单的 loader,它什么都没做:
module.exports = function (source) {
return source
}这么简单的 loader 没有挑战性,我们可以写一个稍微复杂一点的 loader,它的作用是将 var 关键词替换为 const:
module.exports = function (source) {
return source.replace(/var/g, 'const')
}写完之后,我们来测试一下,测试文件为:
function test() {
var a = 1;
var b = 2;
var c = 3;
console.log(a, b, c);
}
test()wepback.config.js 配置文件为:
const path = require('path')
module.exports = {
mode: 'development',
entry: {
main: './src/index.js'
},
output: {
filename: 'bundle.js',
path: path.resolve(__dirname, 'dist')
},
module: {
rules: [
{
test: /\.js$/,
use: [
{
loader: path.resolve('./src/loader1.js'),
},
]
}
]
},
}运行 npm run build,得到打包文件 bundle.js,我们来看一看打包后的代码:
eval("function test() {\r\n const a = 1;\r\n const b = 2;\r\n const c = 3;\r\n console.log(a, b, c);\r\n}\r\n\r\ntest()\n\n//# sourceURL=webpack:///./src/index.js?");可以看到,代码中的 var 已经变成了 const。
刚才实现的 loader 是一个同步 loader,在处理完源码后用 return 返回。
下面我们来实现一个异步 loader:
module.exports = function (source) {
const callback = this.async()
// 由于有 3 秒延迟,所以打包时需要 3+ 秒的时间
setTimeout(() => {
callback(null, `${source.replace(/;/g, '')}`)
}, 3000)
}异步 loader 需要调用 webpack 的 async() 生成一个 callback,它的第一个参数是 error,这里可设为 null,第二个参数就是处理后的源码。当你异步处理完源码后,调用 callback 即可。
下面来试一下异步 loader 到底有没生效,这里设置了一个 3 秒延迟。我们来对比一下打包时间:
上图是调用同步 loader 的打包时间,为 141 ms;下图是调用异步 loader 的打包时间,为 3105 ms,说明异步 loader 生效了。
如果想看完整 demo 源码,请点击我的 github。
webpack 在整个编译周期中会触发很多不同的事件,plugin 可以监听这些事件,并且可以调用 webpack 的 API 对输出资源进行处理。
这是它和 loader 的不同之处,loader 一般只能对源文件代码进行转换,而 plugin 可以做得更多。plugin 在整个编译周期中都可以被调用,只要监听事件。
对于 webpack 编译,有两个重要的对象需要了解一下:
Compiler 和 Compilation
在插件开发中最重要的两个资源就是 compiler 和 compilation 对象。理解它们的角色是扩展 webpack 引擎重要的第一步。
compiler 对象代表了完整的 webpack 环境配置。这个对象在启动 webpack 时被一次性建立,并配置好所有可操作的设置,包括 options,loader 和 plugin。当在 webpack 环境中应用一个插件时,插件将收到此 compiler 对象的引用。可以使用它来访问 webpack 的主环境。
compilation 对象代表了一次资源版本构建。当运行 webpack 开发环境中间件时,每当检测到一个文件变化,就会创建一个新的 compilation,从而生成一组新的编译资源。一个 compilation 对象表现了当前的模块资源、编译生成资源、变化的文件、以及被跟踪依赖的状态信息。compilation 对象也提供了很多关键时机的回调,以供插件做自定义处理时选择使用。
这两个组件是任何 webpack 插件不可或缺的部分(特别是 compilation),因此,开发者在阅读源码,并熟悉它们之后,会感到获益匪浅。
我们看一下官网的定义,webpack 插件由以下部分组成:
简单的说,一个具有 apply 方法的函数就是一个插件,并且它要监听 webpack 的某个事件。下面来看一个简单的示例:
function Plugin(options) { }
Plugin.prototype.apply = function (compiler) {
// 所有文件资源都被 loader 处理后触发这个事件
compiler.plugin('emit', function (compilation, callback) {
// 功能完成后调用 webpack 提供的回调
console.log('Hello World')
callback()
})
}
module.exports = Plugin写完插件后要怎么调用呢?
先在 webpack 配置文件中引入插件,然后在 plugins 选项中配置:
const Plugin = require('./src/plugin')
module.exports = {
...
plugins: [
new Plugin()
]
}这就是一个简单的插件了。
下面我们再来写一个复杂点的插件,它的作用是将经过 loader 处理后的打包文件 bundle.js 引入到 index.html 中:
function Plugin(options) { }
Plugin.prototype.apply = function (compiler) {
// 所有文件资源经过不同的 loader 处理后触发这个事件
compiler.plugin('emit', function (compilation, callback) {
// 获取打包后的 js 文件名
const filename = compiler.options.output.filename
// 生成一个 index.html 并引入打包后的 js 文件
const html = `<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<script src="${filename}"></script>
</head>
<body>
</body>
</html>`
// 所有处理后的资源都放在 compilation.assets 中
// 添加一个 index.html 文件
compilation.assets['index.html'] = {
source: function () {
return html
},
size: function () {
return html.length
}
}
// 功能完成后调用 webpack 提供的回调
callback()
})
}
module.exports = PluginOK,执行一下,看看效果。
完美,和预测的结果一模一样。
完整 demo 源码,请看我的 github。
想了解更多的事件,请看官网介绍 compiler 钩子。
本文是可视化拖拽系列的第三篇,之前的两篇文章一共对 17 个功能点的技术原理进行了分析:
本文在此基础上,将对以下几个功能点的技术原理进行分析:
如果你对我之前的两篇文章不是很了解,建议先把这两篇文章看一遍,再来阅读此文:
虽然我这个可视化拖拽组件库只是一个 DEMO,但对比了一下市面上的一些现成产品(例如 processon、墨刀),就基础功能来说,我这个 DEMO 实现了绝大部分的功能。
如果你对于低代码平台有兴趣,但又不了解的话。强烈建议将我的三篇文章结合项目源码一起阅读,相信对你的收获绝对不小。另附上项目、在线 DEMO 地址:
组合和拆分的技术点相对来说比较多,共有以下 4 个:
在将多个组件组合之前,需要先选中它们。利用鼠标事件可以很方便的将选中区域展示出来:
mousedown 记录起点坐标mousemove 将当前坐标和起点坐标进行计算得出移动区域// 获取编辑器的位移信息
const rectInfo = this.editor.getBoundingClientRect()
this.editorX = rectInfo.x
this.editorY = rectInfo.y
const startX = e.clientX
const startY = e.clientY
this.start.x = startX - this.editorX
this.start.y = startY - this.editorY
// 展示选中区域
this.isShowArea = true
const move = (moveEvent) => {
this.width = Math.abs(moveEvent.clientX - startX)
this.height = Math.abs(moveEvent.clientY - startY)
if (moveEvent.clientX < startX) {
this.start.x = moveEvent.clientX - this.editorX
}
if (moveEvent.clientY < startY) {
this.start.y = moveEvent.clientY - this.editorY
}
}在 mouseup 事件触发时,需要对选中区域内的所有组件的位移大小信息进行计算,得出一个能包含区域内所有组件的最小区域。这个效果如下图所示:
这个计算过程的代码:
createGroup() {
// 获取选中区域的组件数据
const areaData = this.getSelectArea()
if (areaData.length <= 1) {
this.hideArea()
return
}
// 根据选中区域和区域中每个组件的位移信息来创建 Group 组件
// 要遍历选择区域的每个组件,获取它们的 left top right bottom 信息来进行比较
let top = Infinity, left = Infinity
let right = -Infinity, bottom = -Infinity
areaData.forEach(component => {
let style = {}
if (component.component == 'Group') {
component.propValue.forEach(item => {
const rectInfo = $(`#component${item.id}`).getBoundingClientRect()
style.left = rectInfo.left - this.editorX
style.top = rectInfo.top - this.editorY
style.right = rectInfo.right - this.editorX
style.bottom = rectInfo.bottom - this.editorY
if (style.left < left) left = style.left
if (style.top < top) top = style.top
if (style.right > right) right = style.right
if (style.bottom > bottom) bottom = style.bottom
})
} else {
style = getComponentRotatedStyle(component.style)
}
if (style.left < left) left = style.left
if (style.top < top) top = style.top
if (style.right > right) right = style.right
if (style.bottom > bottom) bottom = style.bottom
})
this.start.x = left
this.start.y = top
this.width = right - left
this.height = bottom - top
// 设置选中区域位移大小信息和区域内的组件数据
this.$store.commit('setAreaData', {
style: {
left,
top,
width: this.width,
height: this.height,
},
components: areaData,
})
},
getSelectArea() {
const result = []
// 区域起点坐标
const { x, y } = this.start
// 计算所有的组件数据,判断是否在选中区域内
this.componentData.forEach(component => {
if (component.isLock) return
const { left, top, width, height } = component.style
if (x <= left && y <= top && (left + width <= x + this.width) && (top + height <= y + this.height)) {
result.push(component)
}
})
// 返回在选中区域内的所有组件
return result
}简单描述一下这段代码的处理逻辑:
left top right bottom。Group 组合组件,则需要对它里面的子组件进行计算,而不是对组合组件进行计算。为了方便将多个组件一起进行移动、旋转、放大缩小等操作,我新创建了一个 Group 组合组件:
<template>
<div class="group">
<div>
<template v-for="item in propValue">
<component
class="component"
:is="item.component"
:style="item.groupStyle"
:propValue="item.propValue"
:key="item.id"
:id="'component' + item.id"
:element="item"
/>
</template>
</div>
</div>
</template>
<script>
import { getStyle } from '@/utils/style'
export default {
props: {
propValue: {
type: Array,
default: () => [],
},
element: {
type: Object,
},
},
created() {
const parentStyle = this.element.style
this.propValue.forEach(component => {
// component.groupStyle 的 top left 是相对于 group 组件的位置
// 如果已存在 component.groupStyle,说明已经计算过一次了。不需要再次计算
if (!Object.keys(component.groupStyle).length) {
const style = { ...component.style }
component.groupStyle = getStyle(style)
component.groupStyle.left = this.toPercent((style.left - parentStyle.left) / parentStyle.width)
component.groupStyle.top = this.toPercent((style.top - parentStyle.top) / parentStyle.height)
component.groupStyle.width = this.toPercent(style.width / parentStyle.width)
component.groupStyle.height = this.toPercent(style.height / parentStyle.height)
}
})
},
methods: {
toPercent(val) {
return val * 100 + '%'
},
},
}
</script>
<style lang="scss" scoped>
.group {
& > div {
position: relative;
width: 100%;
height: 100%;
.component {
position: absolute;
}
}
}
</style>Group 组件的作用就是将区域内的组件放到它下面,成为子组件。并且在创建 Group 组件时,获取每个子组件在 Group 组件内的相对位移和相对大小:
created() {
const parentStyle = this.element.style
this.propValue.forEach(component => {
// component.groupStyle 的 top left 是相对于 group 组件的位置
// 如果已存在 component.groupStyle,说明已经计算过一次了。不需要再次计算
if (!Object.keys(component.groupStyle).length) {
const style = { ...component.style }
component.groupStyle = getStyle(style)
component.groupStyle.left = this.toPercent((style.left - parentStyle.left) / parentStyle.width)
component.groupStyle.top = this.toPercent((style.top - parentStyle.top) / parentStyle.height)
component.groupStyle.width = this.toPercent(style.width / parentStyle.width)
component.groupStyle.height = this.toPercent(style.height / parentStyle.height)
}
})
},
methods: {
toPercent(val) {
return val * 100 + '%'
},
},也就是将子组件的 left top width height 等属性转成以 % 结尾的相对数值。
为什么不使用绝对数值?
如果使用绝对数值,那么在移动 Group 组件时,除了对 Group 组件的属性进行计算外,还需要对它的每个子组件进行计算。并且 Group 包含子组件太多的话,在进行移动、放大缩小时,计算量会非常大,有可能会造成页面卡顿。如果改成相对数值,则只需要在 Group 创建时计算一次。然后在 Group 组件进行移动、旋转时也不用管 Group 的子组件,只对它自己计算即可。
组合后的放大缩小是个大问题,主要是因为有旋转角度的存在。首先来看一下各个子组件没旋转时的放大缩小:
从动图可以看出,效果非常完美。各个子组件的大小是跟随 Group 组件的大小而改变的。
现在试着给子组件加上旋转角度,再看一下效果:
为什么会出现这个问题?
主要是因为一个组件无论旋不旋转,它的 top left 属性都是不变的。这样就会有一个问题,虽然实际上组件的 top left width height 属性没有变化。但在外观上却发生了变化。下面是两个同样的组件:一个没旋转,一个旋转了 45 度。
可以看出来旋转后按钮的 top left width height 属性和我们从外观上看到的是不一样的。
接下来再看一个具体的示例:
上面是一个 Group 组件,它左边的子组件属性为:
transform: rotate(-75.1967deg);
width: 51.2267%;
height: 32.2679%;
top: 33.8661%;
left: -10.6496%;可以看到 width 的值为 51.2267%,但从外观上来看,这个子组件最多占 Group 组件宽度的三分之一。所以这就是放大缩小不正常的问题所在。
一开始我想的是,先算出它相对浏览器视口的 top left width height 属性,再算出这几个属性在 Group 组件上的相对数值。这可以通过 getBoundingClientRect() API 实现。只要维持外观上的各个属性占比不变,这样 Group 组件在放大缩小时,再通过旋转角度,利用旋转矩阵的知识(这一点在第二篇有详细描述)获取它未旋转前的 top left width height 属性。这样就可以做到子组件动态调整了。
但是这有个问题,通过 getBoundingClientRect() API 只能获取组件外观上的 top left right bottom width height 属性。再加上一个角度,参数还是不够,所以无法计算出组件实际的 top left width height 属性。
就像上面的这张图,只知道原点 O(x,y) w h 和旋转角度,无法算出按钮的宽高。
这是无意中发现的,我在对 Group 组件进行放大缩小时,发现只要保持 Group 组件的宽高比例,子组件就能做到根据比例放大缩小。那么现在问题就转变成了如何让 Group 组件放大缩小时保持宽高比例。我在网上找到了这一篇文章,它详细描述了一个旋转组件如何保持宽高比来进行放大缩小,并配有源码示例。
现在我尝试简单描述一下如何保持宽高比对一个旋转组件进行放大缩小(建议还是看看原文)。下面是一个已旋转一定角度的矩形,假设现在拖动它左上方的点进行拉伸。
第一步,算出组件宽高比,以及按下鼠标时通过组件的坐标(无论旋转多少度,组件的 top left 属性不变)和大小算出组件中心点:
// 组件宽高比
const proportion = style.width / style.height
const center = {
x: style.left + style.width / 2,
y: style.top + style.height / 2,
}第二步,用当前点击坐标和组件中心点算出当前点击坐标的对称点坐标:
// 获取画布位移信息
const editorRectInfo = document.querySelector('#editor').getBoundingClientRect()
// 当前点击坐标
const curPoint = {
x: e.clientX - editorRectInfo.left,
y: e.clientY - editorRectInfo.top,
}
// 获取对称点的坐标
const symmetricPoint = {
x: center.x - (curPoint.x - center.x),
y: center.y - (curPoint.y - center.y),
}第三步,摁住组件左上角进行拉伸时,通过当前鼠标实时坐标和对称点计算出新的组件中心点:
const curPositon = {
x: moveEvent.clientX - editorRectInfo.left,
y: moveEvent.clientY - editorRectInfo.top,
}
const newCenterPoint = getCenterPoint(curPositon, symmetricPoint)
// 求两点之间的中点坐标
function getCenterPoint(p1, p2) {
return {
x: p1.x + ((p2.x - p1.x) / 2),
y: p1.y + ((p2.y - p1.y) / 2),
}
}由于组件处于旋转状态,即使你知道了拉伸时移动的 xy 距离,也不能直接对组件进行计算。否则就会出现 BUG,移位或者放大缩小方向不正确。因此,我们需要在组件未旋转的情况下对其进行计算。
第四步,根据已知的旋转角度、新的组件中心点、当前鼠标实时坐标可以算出当前鼠标实时坐标 currentPosition 在未旋转时的坐标 newTopLeftPoint。同时也能根据已知的旋转角度、新的组件中心点、对称点算出组件对称点 sPoint 在未旋转时的坐标 newBottomRightPoint。
对应的计算公式如下:
/**
* 计算根据圆心旋转后的点的坐标
* @param {Object} point 旋转前的点坐标
* @param {Object} center 旋转中心
* @param {Number} rotate 旋转的角度
* @return {Object} 旋转后的坐标
* https://www.zhihu.com/question/67425734/answer/252724399 旋转矩阵公式
*/
export function calculateRotatedPointCoordinate(point, center, rotate) {
/**
* 旋转公式:
* 点a(x, y)
* 旋转中心c(x, y)
* 旋转后点n(x, y)
* 旋转角度θ tan ??
* nx = cosθ * (ax - cx) - sinθ * (ay - cy) + cx
* ny = sinθ * (ax - cx) + cosθ * (ay - cy) + cy
*/
return {
x: (point.x - center.x) * Math.cos(angleToRadian(rotate)) - (point.y - center.y) * Math.sin(angleToRadian(rotate)) + center.x,
y: (point.x - center.x) * Math.sin(angleToRadian(rotate)) + (point.y - center.y) * Math.cos(angleToRadian(rotate)) + center.y,
}
}上面的公式涉及到线性代数中旋转矩阵的知识,对于一个没上过大学的人来说,实在太难了。还好我从知乎上的一个回答中找到了这一公式的推理过程,下面是回答的原文:
通过以上几个计算值,就可以得到组件新的位移值 top left 以及新的组件大小。对应的完整代码如下:
function calculateLeftTop(style, curPositon, pointInfo) {
const { symmetricPoint } = pointInfo
const newCenterPoint = getCenterPoint(curPositon, symmetricPoint)
const newTopLeftPoint = calculateRotatedPointCoordinate(curPositon, newCenterPoint, -style.rotate)
const newBottomRightPoint = calculateRotatedPointCoordinate(symmetricPoint, newCenterPoint, -style.rotate)
const newWidth = newBottomRightPoint.x - newTopLeftPoint.x
const newHeight = newBottomRightPoint.y - newTopLeftPoint.y
if (newWidth > 0 && newHeight > 0) {
style.width = Math.round(newWidth)
style.height = Math.round(newHeight)
style.left = Math.round(newTopLeftPoint.x)
style.top = Math.round(newTopLeftPoint.y)
}
}现在再来看一下旋转后的放大缩小:
第五步,由于我们现在需要的是锁定宽高比来进行放大缩小,所以需要重新计算拉伸后的图形的左上角坐标。
这里先确定好几个形状的命名:
在第四步中算出组件未旋转前的 newTopLeftPoint newBottomRightPoint newWidth newHeight 后,需要根据宽高比 proportion 来算出新的宽度或高度。
上图就是一个需要改变高度的示例,计算过程如下:
if (newWidth / newHeight > proportion) {
newTopLeftPoint.x += Math.abs(newWidth - newHeight * proportion)
newWidth = newHeight * proportion
} else {
newTopLeftPoint.y += Math.abs(newHeight - newWidth / proportion)
newHeight = newWidth / proportion
}由于现在求的未旋转前的坐标是以没按比例缩减宽高前的坐标来计算的,所以缩减宽高后,需要按照原来的中心点旋转回去,获得缩减宽高并旋转后对应的坐标。然后以这个坐标和对称点获得新的中心点,并重新计算未旋转前的坐标。
经过修改后的完整代码如下:
function calculateLeftTop(style, curPositon, proportion, needLockProportion, pointInfo) {
const { symmetricPoint } = pointInfo
let newCenterPoint = getCenterPoint(curPositon, symmetricPoint)
let newTopLeftPoint = calculateRotatedPointCoordinate(curPositon, newCenterPoint, -style.rotate)
let newBottomRightPoint = calculateRotatedPointCoordinate(symmetricPoint, newCenterPoint, -style.rotate)
let newWidth = newBottomRightPoint.x - newTopLeftPoint.x
let newHeight = newBottomRightPoint.y - newTopLeftPoint.y
if (needLockProportion) {
if (newWidth / newHeight > proportion) {
newTopLeftPoint.x += Math.abs(newWidth - newHeight * proportion)
newWidth = newHeight * proportion
} else {
newTopLeftPoint.y += Math.abs(newHeight - newWidth / proportion)
newHeight = newWidth / proportion
}
// 由于现在求的未旋转前的坐标是以没按比例缩减宽高前的坐标来计算的
// 所以缩减宽高后,需要按照原来的中心点旋转回去,获得缩减宽高并旋转后对应的坐标
// 然后以这个坐标和对称点获得新的中心点,并重新计算未旋转前的坐标
const rotatedTopLeftPoint = calculateRotatedPointCoordinate(newTopLeftPoint, newCenterPoint, style.rotate)
newCenterPoint = getCenterPoint(rotatedTopLeftPoint, symmetricPoint)
newTopLeftPoint = calculateRotatedPointCoordinate(rotatedTopLeftPoint, newCenterPoint, -style.rotate)
newBottomRightPoint = calculateRotatedPointCoordinate(symmetricPoint, newCenterPoint, -style.rotate)
newWidth = newBottomRightPoint.x - newTopLeftPoint.x
newHeight = newBottomRightPoint.y - newTopLeftPoint.y
}
if (newWidth > 0 && newHeight > 0) {
style.width = Math.round(newWidth)
style.height = Math.round(newHeight)
style.left = Math.round(newTopLeftPoint.x)
style.top = Math.round(newTopLeftPoint.y)
}
}保持宽高比进行放大缩小的效果如下:
当 Group 组件有旋转的子组件时,才需要保持宽高比进行放大缩小。所以在创建 Group 组件时可以判断一下子组件是否有旋转角度。如果没有,就不需要保持宽度比进行放大缩小。
isNeedLockProportion() {
if (this.element.component != 'Group') return false
const ratates = [0, 90, 180, 360]
for (const component of this.element.propValue) {
if (!ratates.includes(mod360(parseInt(component.style.rotate)))) {
return true
}
}
return false
}将多个组件组合在一起只是第一步,第二步是将 Group 组件进行拆分并恢复各个子组件的样式。保证拆分后的子组件在外观上的属性不变。
计算代码如下:
// store
decompose({ curComponent, editor }) {
const parentStyle = { ...curComponent.style }
const components = curComponent.propValue
const editorRect = editor.getBoundingClientRect()
store.commit('deleteComponent')
components.forEach(component => {
decomposeComponent(component, editorRect, parentStyle)
store.commit('addComponent', { component })
})
}
// 将组合中的各个子组件拆分出来,并计算它们新的 style
export default function decomposeComponent(component, editorRect, parentStyle) {
// 子组件相对于浏览器视口的样式
const componentRect = $(`#component${component.id}`).getBoundingClientRect()
// 获取元素的中心点坐标
const center = {
x: componentRect.left - editorRect.left + componentRect.width / 2,
y: componentRect.top - editorRect.top + componentRect.height / 2,
}
component.style.rotate = mod360(component.style.rotate + parentStyle.rotate)
component.style.width = parseFloat(component.groupStyle.width) / 100 * parentStyle.width
component.style.height = parseFloat(component.groupStyle.height) / 100 * parentStyle.height
// 计算出元素新的 top left 坐标
component.style.left = center.x - component.style.width / 2
component.style.top = center.y - component.style.height / 2
component.groupStyle = {}
}这段代码的处理逻辑为:
Group 的子组件并恢复它们的样式getBoundingClientRect() API 获取子组件相对于浏览器视口的 left top width height 属性。width height 属性是相对于 Group 组件的,所以将它们的百分比值和 Group 相乘得出具体数值。center(x, y) 减去子组件宽高的一半得出它的 left top 属性。至此,组合和拆分就讲解完了。
文本组件 VText 之前就已经实现过了,但不完美。例如无法对文字进行选中。现在我对它进行了重写,让它支持选中功能。
<template>
<div v-if="editMode == 'edit'" class="v-text" @keydown="handleKeydown" @keyup="handleKeyup">
<!-- tabindex >= 0 使得双击时聚集该元素 -->
<div :contenteditable="canEdit" :class="{ canEdit }" @dblclick="setEdit" :tabindex="element.id" @paste="clearStyle"
@mousedown="handleMousedown" @blur="handleBlur" ref="text" v-html="element.propValue" @input="handleInput"
:style="{ verticalAlign: element.style.verticalAlign }"
></div>
</div>
<div v-else class="v-text">
<div v-html="element.propValue" :style="{ verticalAlign: element.style.verticalAlign }"></div>
</div>
</template>
<script>
import { mapState } from 'vuex'
import { keycodes } from '@/utils/shortcutKey.js'
export default {
props: {
propValue: {
type: String,
require: true,
},
element: {
type: Object,
},
},
data() {
return {
canEdit: false,
ctrlKey: 17,
isCtrlDown: false,
}
},
computed: {
...mapState([
'editMode',
]),
},
methods: {
handleInput(e) {
this.$emit('input', this.element, e.target.innerHTML)
},
handleKeydown(e) {
if (e.keyCode == this.ctrlKey) {
this.isCtrlDown = true
} else if (this.isCtrlDown && this.canEdit && keycodes.includes(e.keyCode)) {
e.stopPropagation()
} else if (e.keyCode == 46) { // deleteKey
e.stopPropagation()
}
},
handleKeyup(e) {
if (e.keyCode == this.ctrlKey) {
this.isCtrlDown = false
}
},
handleMousedown(e) {
if (this.canEdit) {
e.stopPropagation()
}
},
clearStyle(e) {
e.preventDefault()
const clp = e.clipboardData
const text = clp.getData('text/plain') || ''
if (text !== '') {
document.execCommand('insertText', false, text)
}
this.$emit('input', this.element, e.target.innerHTML)
},
handleBlur(e) {
this.element.propValue = e.target.innerHTML || ' '
this.canEdit = false
},
setEdit() {
this.canEdit = true
// 全选
this.selectText(this.$refs.text)
},
selectText(element) {
const selection = window.getSelection()
const range = document.createRange()
range.selectNodeContents(element)
selection.removeAllRanges()
selection.addRange(range)
},
},
}
</script>
<style lang="scss" scoped>
.v-text {
width: 100%;
height: 100%;
display: table;
div {
display: table-cell;
width: 100%;
height: 100%;
outline: none;
}
.canEdit {
cursor: text;
height: 100%;
}
}
</style>改造后的 VText 组件功能如下:

矩形组件其实就是一个内嵌 VText 文本组件的一个 DIV。
<template>
<div class="rect-shape">
<v-text :propValue="element.propValue" :element="element" />
</div>
</template>
<script>
export default {
props: {
element: {
type: Object,
},
},
}
</script>
<style lang="scss" scoped>
.rect-shape {
width: 100%;
height: 100%;
overflow: auto;
}
</style>VText 文本组件有的功能它都有,并且可以任意放大缩小。

锁定组件主要是看到 processon 和墨刀有这个功能,于是我顺便实现了。锁定组件的具体需求为:不能移动、放大缩小、旋转、复制、粘贴等,只能进行解锁操作。
它的实现原理也不难:
isLock 属性,表示是否锁定组件。isLock 是否为 true 来隐藏组件上的八个点和旋转图标。相关代码如下:
export const commonAttr = {
animations: [],
events: {},
groupStyle: {}, // 当一个组件成为 Group 的子组件时使用
isLock: false, // 是否锁定组件
}<el-button @click="decompose"
:disabled="!curComponent || curComponent.isLock || curComponent.component != 'Group'">拆分</el-button>
<el-button @click="lock" :disabled="!curComponent || curComponent.isLock">锁定</el-button>
<el-button @click="unlock" :disabled="!curComponent || !curComponent.isLock">解锁</el-button><template>
<div class="contextmenu" v-show="menuShow" :style="{ top: menuTop + 'px', left: menuLeft + 'px' }">
<ul @mouseup="handleMouseUp">
<template v-if="curComponent">
<template v-if="!curComponent.isLock">
<li @click="copy">复制</li>
<li @click="paste">粘贴</li>
<li @click="cut">剪切</li>
<li @click="deleteComponent">删除</li>
<li @click="lock">锁定</li>
<li @click="topComponent">置顶</li>
<li @click="bottomComponent">置底</li>
<li @click="upComponent">上移</li>
<li @click="downComponent">下移</li>
</template>
<li v-else @click="unlock">解锁</li>
</template>
<li v-else @click="paste">粘贴</li>
</ul>
</div>
</template>
支持快捷键主要是为了提升开发效率,用鼠标点点点毕竟没有按键盘快。目前快捷键支持的功能如下:
const ctrlKey = 17,
vKey = 86, // 粘贴
cKey = 67, // 复制
xKey = 88, // 剪切
yKey = 89, // 重做
zKey = 90, // 撤销
gKey = 71, // 组合
bKey = 66, // 拆分
lKey = 76, // 锁定
uKey = 85, // 解锁
sKey = 83, // 保存
pKey = 80, // 预览
dKey = 68, // 删除
deleteKey = 46, // 删除
eKey = 69 // 清空画布实现原理主要是利用 window 全局监听按键事件,在符合条件的按键触发时执行对应的操作:
// 与组件状态无关的操作
const basemap = {
[vKey]: paste,
[yKey]: redo,
[zKey]: undo,
[sKey]: save,
[pKey]: preview,
[eKey]: clearCanvas,
}
// 组件锁定状态下可以执行的操作
const lockMap = {
...basemap,
[uKey]: unlock,
}
// 组件未锁定状态下可以执行的操作
const unlockMap = {
...basemap,
[cKey]: copy,
[xKey]: cut,
[gKey]: compose,
[bKey]: decompose,
[dKey]: deleteComponent,
[deleteKey]: deleteComponent,
[lKey]: lock,
}
let isCtrlDown = false
// 全局监听按键操作并执行相应命令
export function listenGlobalKeyDown() {
window.onkeydown = (e) => {
const { curComponent } = store.state
if (e.keyCode == ctrlKey) {
isCtrlDown = true
} else if (e.keyCode == deleteKey && curComponent) {
store.commit('deleteComponent')
store.commit('recordSnapshot')
} else if (isCtrlDown) {
if (!curComponent || !curComponent.isLock) {
e.preventDefault()
unlockMap[e.keyCode] && unlockMap[e.keyCode]()
} else if (curComponent && curComponent.isLock) {
e.preventDefault()
lockMap[e.keyCode] && lockMap[e.keyCode]()
}
}
}
window.onkeyup = (e) => {
if (e.keyCode == ctrlKey) {
isCtrlDown = false
}
}
}为了防止和浏览器默认快捷键冲突,所以需要加上 e.preventDefault()。
网格线功能使用 SVG 来实现:
<template>
<svg class="grid" width="100%" height="100%" xmlns="http://www.w3.org/2000/svg">
<defs>
<pattern id="smallGrid" width="7.236328125" height="7.236328125" patternUnits="userSpaceOnUse">
<path
d="M 7.236328125 0 L 0 0 0 7.236328125"
fill="none"
stroke="rgba(207, 207, 207, 0.3)"
stroke-width="1">
</path>
</pattern>
<pattern id="grid" width="36.181640625" height="36.181640625" patternUnits="userSpaceOnUse">
<rect width="36.181640625" height="36.181640625" fill="url(#smallGrid)"></rect>
<path
d="M 36.181640625 0 L 0 0 0 36.181640625"
fill="none"
stroke="rgba(186, 186, 186, 0.5)"
stroke-width="1">
</path>
</pattern>
</defs>
<rect width="100%" height="100%" fill="url(#grid)"></rect>
</svg>
</template>
<style lang="scss" scoped>
.grid {
position: absolute;
top: 0;
left: 0;
}
</style>对 SVG 不太懂的,建议看一下 MDN 的教程。
在系列文章的第一篇中,我已经分析过快照的实现原理。
snapshotData: [], // 编辑器快照数据
snapshotIndex: -1, // 快照索引
undo(state) {
if (state.snapshotIndex >= 0) {
state.snapshotIndex--
store.commit('setComponentData', deepCopy(state.snapshotData[state.snapshotIndex]))
}
},
redo(state) {
if (state.snapshotIndex < state.snapshotData.length - 1) {
state.snapshotIndex++
store.commit('setComponentData', deepCopy(state.snapshotData[state.snapshotIndex]))
}
},
setComponentData(state, componentData = []) {
Vue.set(state, 'componentData', componentData)
},
recordSnapshot(state) {
// 添加新的快照
state.snapshotData[++state.snapshotIndex] = deepCopy(state.componentData)
// 在 undo 过程中,添加新的快照时,要将它后面的快照清理掉
if (state.snapshotIndex < state.snapshotData.length - 1) {
state.snapshotData = state.snapshotData.slice(0, state.snapshotIndex + 1)
}
},用一个数组来保存编辑器的快照数据。保存快照就是不停地执行 push() 操作,将当前的编辑器数据推入 snapshotData 数组,并增加快照索引 snapshotIndex。
由于每一次添加快照都是将当前编辑器的所有组件数据推入 snapshotData,保存的快照数据越多占用的内存就越多。对此有两个解决方案:
现在详细描述一下第二个解决方案。
假设依次往画布上添加 a b c d 四个组件,在原来的实现中,对应的 snapshotData 数据为:
// snapshotData
[
[a],
[a, b],
[a, b, c],
[a, b, c, d],
]从上面的代码可以发现,每一相邻的快照中,只有一个数据是不同的。所以我们可以为每一步的快照添加一个类型字段,用来表示此次操作是添加还是删除。
那么上面添加四个组件的操作,所对应的 snapshotData 数据为:
// snapshotData
[
[{ type: 'add', value: a }],
[{ type: 'add', value: b }],
[{ type: 'add', value: c }],
[{ type: 'add', value: d }],
]
如果我们要删除 c 组件,那么 snapshotData 数据将变为:
// snapshotData
[
[{ type: 'add', value: a }],
[{ type: 'add', value: b }],
[{ type: 'add', value: c }],
[{ type: 'add', value: d }],
[{ type: 'remove', value: c }],
]
那如何使用现在的快照数据呢?
我们需要遍历一遍快照数据,来生成编辑器的组件数据 componentData。假设在上面的数据基础上执行了 undo 撤销操作:
// snapshotData
// 快照索引 snapshotIndex 此时为 3
[
[{ type: 'add', value: a }],
[{ type: 'add', value: b }],
[{ type: 'add', value: c }],
[{ type: 'add', value: d }],
[{ type: 'remove', value: c }],
]
snapshotData[0] 类型为 add,将组件 a 添加到 componentData 中,此时 componentData 为 [a][a, b][a, b, c][a, b, c, d]如果这时执行 redo 重做操作,快照索引 snapshotIndex 变为 4。对应的快照数据类型为 type: 'remove', 移除组件 c。则数组数据为 [a, b, d]。
这种方法其实就是时间换空间,虽然每一次保存的快照数据只有一项,但每次都得遍历一遍所有的快照数据。两种方法都不完美,要使用哪种取决于你,目前我仍在使用第一种方法。
从造轮子的角度来看,这是我目前造的第四个比较满意的轮子,其他三个为:
造轮子是一个很好的提升自己技术水平的方法,但造轮子一定要造有意义、有难度的轮子,并且同类型的轮子只造一个。造完轮子后,还需要写总结,最好输出成文章分享出去。
例如我想查看元素触发 hover 时的 css 样式。先选中该元素,然后按下图操作:
document.body.contentEditable="true"在控制台输入 document.body.contentEditable="true",就可以对页面直接进行编辑。
现在可以查看元素的 placeholder 样式了:
下面是测试报告:
参考资料:
一般 Network 会显示加载资源的详细信息,但它默认只显示部分信息。如果我想查询网页资源是通过 HTTP1.1 还是 HTTP2 加载的,要怎么做呢?
从 GIF 中可以看出,除了 HTTP 协议版本外,还可以查看其他信息,例如 HTTP 请求的方法、域名等等。
鼠标移到 handler 上,可查看具体的函数代码。
打开开发者工具,点击 Console 标签,按 ESC 弹出:
点击左边竖形排列的三个小点,选择 Search:
点击搜索结果,会跳到具体的源码文件。它会搜索该网页下所有引入的文件。
打开开发者工具,点击 Performance 标签:
点击左上角的 Record 按钮开始记录,然后你模拟正常用户使用网页。测试完毕后,点击 Stop。
可以看到右上角分别有 FPS、CPU、NET、HEAP:
NET 最好点击下面的 Network 查看,可以看到具体的加载资源等。
一般根据这些信息就能判断出网页性能问题出在哪。
如果想了解更多,请查看下面的参考资料,需要翻 qiang。或者用搜索引擎搜索 chrome performance,也有很多讲解使用方法的文章。
参考资料
打开开发者工具,点击 Console 标签,按 ESC 弹出:
点击左边竖形排列的三个小点,选择 Rendering:
下面是比较实用的功能:
从图中看到,在 Application 标签下可以查到本页面很多信息。拿 localStorage 举例,现在我执行代码 localStorage.setItem('token', '123'),然后打开 Application:
不出意外,能看到新增的 localStorage 信息。
webpack 是一个模块打包器,在它看来,每一个文件都是一个模块。
无论你开发使用的是 CommonJS 规范还是 ES6 模块规范,打包后的文件都统一使用 webpack 自定义的模块规范来管理、加载模块。本文将从一个简单的示例开始,来讲解 webpack 模块加载原理。
假设现在有如下两个文件:
// index.js
const test2 = require('./test2')
function test() {}
test()
test2()// test2.js
function test2() {}
module.exports = test2以上两个文件使用 CommonJS 规范来导入导出文件,打包后的代码如下(已经删除了不必要的注释):
(function(modules) { // webpackBootstrap
// The module cache
// 模块缓存对象
var installedModules = {};
// The require function
// webpack 实现的 require() 函数
function __webpack_require__(moduleId) {
// Check if module is in cache
// 如果模块已经加载过,直接返回缓存
if(installedModules[moduleId]) {
return installedModules[moduleId].exports;
}
// Create a new module (and put it into the cache)
// 创建一个新模块,并放入缓存
var module = installedModules[moduleId] = {
i: moduleId,
l: false,
exports: {}
};
// Execute the module function
// 执行模块函数
modules[moduleId].call(module.exports, module, module.exports, __webpack_require__);
// Flag the module as loaded
// 将模块标识为已加载
module.l = true;
// Return the exports of the module
return module.exports;
}
// expose the modules object (__webpack_modules__)
// 将所有的模块挂载到 require() 函数上
__webpack_require__.m = modules;
// expose the module cache
// 将缓存对象挂载到 require() 函数上
__webpack_require__.c = installedModules;
// define getter function for harmony exports
__webpack_require__.d = function(exports, name, getter) {
if(!__webpack_require__.o(exports, name)) {
Object.defineProperty(exports, name, { enumerable: true, get: getter });
}
};
// define __esModule on exports
__webpack_require__.r = function(exports) {
if(typeof Symbol !== 'undefined' && Symbol.toStringTag) {
Object.defineProperty(exports, Symbol.toStringTag, { value: 'Module' });
}
Object.defineProperty(exports, '__esModule', { value: true });
};
// create a fake namespace object
// mode & 1: value is a module id, require it
// mode & 2: merge all properties of value into the ns
// mode & 4: return value when already ns object
// mode & 8|1: behave like require
__webpack_require__.t = function(value, mode) {
if(mode & 1) value = __webpack_require__(value);
if(mode & 8) return value;
if((mode & 4) && typeof value === 'object' && value && value.__esModule) return value;
var ns = Object.create(null);
__webpack_require__.r(ns);
Object.defineProperty(ns, 'default', { enumerable: true, value: value });
if(mode & 2 && typeof value != 'string') for(var key in value) __webpack_require__.d(ns, key, function(key) { return value[key]; }.bind(null, key));
return ns;
};
// getDefaultExport function for compatibility with non-harmony modules
__webpack_require__.n = function(module) {
var getter = module && module.__esModule ?
function getDefault() { return module['default']; } :
function getModuleExports() { return module; };
__webpack_require__.d(getter, 'a', getter);
return getter;
};
// Object.prototype.hasOwnProperty.call
__webpack_require__.o = function(object, property) { return Object.prototype.hasOwnProperty.call(object, property); };
// __webpack_public_path__
__webpack_require__.p = "";
// Load entry module and return exports
// 加载入口模块,并返回模块对象
return __webpack_require__(__webpack_require__.s = "./src/index.js");
})({
"./src/index.js": (function(module, exports, __webpack_require__) {
eval("const test2 = __webpack_require__(/*! ./test2 */ \"./src/test2.js\")\r\n\r\nfunction test() {}\r\n\r\ntest()\r\ntest2()\n\n//# sourceURL=webpack:///./src/index.js?");
}),
"./src/test2.js": (function(module, exports) {
eval("function test2() {}\r\n\r\nmodule.exports = test2\n\n//# sourceURL=webpack:///./src/test2.js?");
})
});可以看到 webpack 实现的模块加载系统非常简单,仅仅只有一百行代码。
打包后的代码其实是一个立即执行函数,传入的参数是一个对象。这个对象以文件路径为 key,以文件内容为 value,它包含了所有打包后的模块。
{
"./src/index.js": (function(module, exports, __webpack_require__) {
eval("const test2 = __webpack_require__(/*! ./test2 */ \"./src/test2.js\")\r\n\r\nfunction test() {}\r\n\r\ntest()\r\ntest2()\n\n//# sourceURL=webpack:///./src/index.js?");
}),
"./src/test2.js": (function(module, exports) {
eval("function test2() {}\r\n\r\nmodule.exports = test2\n\n//# sourceURL=webpack:///./src/test2.js?");
})
}将这个立即函数化简一下,相当于:
(function(modules){
// ...
})({
path1: function1,
path2: function2
})再看一下这个立即函数做了什么:
installedModules,作用是缓存已经加载过的模块。__webpack_require__()。__webpack_require__() 加载入口模块。其中的核心就是 __webpack_require__() 函数,它接收的参数是 moduleId,其实就是文件路径。
它的执行过程如下:
export 对象,即 module.exports。module,并放入缓存。exports 对象。 // The require function
// webpack 实现的 require() 函数
function __webpack_require__(moduleId) {
// Check if module is in cache
// 如果模块已经加载过,直接返回缓存
if(installedModules[moduleId]) {
return installedModules[moduleId].exports;
}
// Create a new module (and put it into the cache)
// 创建一个新模块,并放入缓存
var module = installedModules[moduleId] = {
i: moduleId,
l: false,
exports: {}
};
// Execute the module function
// 执行模块函数
modules[moduleId].call(module.exports, module, module.exports, __webpack_require__);
// Flag the module as loaded
// 将模块标识为已加载
module.l = true;
// Return the exports of the module
return module.exports;
}从上述代码可以看到,在执行模块函数时传入了三个参数,分别为 module、module.exports、__webpack_require__。
其中 module、module.exports 的作用和 CommonJS 中的 module、module.exports 的作用是一样的,而 __webpack_require__ 相当于 CommonJS 中的 require。
在立即函数的最后,使用了 __webpack_require__() 加载入口模块。并传入了入口模块的路径 ./src/index.js。
__webpack_require__(__webpack_require__.s = "./src/index.js");我们再来分析一下入口模块的内容。
(function(module, exports, __webpack_require__) {
eval("const test2 = __webpack_require__(/*! ./test2 */ \"./src/test2.js\")\r\n\r\nfunction test() {}\r\n\r\ntest()\r\ntest2()\n\n//# sourceURL=webpack:///./src/index.js?");
})入口模块函数的参数正好是刚才所说的那三个参数,而 eval 函数的内容美化一下后和下面内容一样:
const test2 = __webpack_require__("./src/test2.js")
function test() {}
test()
test2()
//# sourceURL=webpack:///./src/index.js?将打包后的模块代码和原模块的代码进行对比,可以发现仅有一个地方发生了变化,那就是 require 变成了 __webpack_require__。
再看一下 test2.js 的代码:
function test2() {}
module.exports = test2
//# sourceURL=webpack:///./src/test2.js?从刚才的分析可知,__webpack_require__() 加载模块后,会先执行模块对应的函数,然后返回该模块的 exports 对象。而 test2.js 的导出对象 module.exports 就是 test2() 函数。所以入口模块能通过 __webpack_require__() 引入 test2() 函数并执行。
到目前为止可以发现 webpack 自定义的模块规范完美适配 CommonJS 规范。
将刚才用 CommonJS 规范编写的两个文件换成用 ES6 module 规范来写,再执行打包。
// index.js
import test2 from './test2'
function test() {}
test()
test2()// test2.js
export default function test2() {}使用 ES6 module 规范打包后的代码和使用 CommonJS 规范打包后的代码绝大部分都是一样的。
一样的地方是指 webpack 自定义模块规范的代码一样,唯一不同的是上面两个文件打包后的代码不同。
{
"./src/index.js":(function(module, __webpack_exports__, __webpack_require__) {
"use strict";
eval("__webpack_require__.r(__webpack_exports__);\n/* harmony import */ var _test2__WEBPACK_IMPORTED_MODULE_0__ = __webpack_require__(/*! ./test2 */ \"./src/test2.js\");\n\r\n\r\nfunction test() {}\r\n\r\ntest()\r\nObject(_test2__WEBPACK_IMPORTED_MODULE_0__[\"default\"])()\n\n//# sourceURL=webpack:///./src/index.js?");
}),
"./src/test2.js": (function(module, __webpack_exports__, __webpack_require__) {
"use strict";
eval("__webpack_require__.r(__webpack_exports__);\n/* harmony export (binding) */ __webpack_require__.d(__webpack_exports__, \"default\", function() { return test2; });\nfunction test2() {}\n\n//# sourceURL=webpack:///./src/test2.js?");
})
}可以看到传入的第二个参数是 __webpack_exports__,而 CommonJS 规范对应的第二个参数是 exports。将这两个模块代码的内容美化一下:
// index.js
__webpack_require__.r(__webpack_exports__);
var _test2__WEBPACK_IMPORTED_MODULE_0__ = __webpack_require__("./src/test2.js");
function test() {}
test()
Object(_test2__WEBPACK_IMPORTED_MODULE_0__["default"])()
//# sourceURL=webpack:///./src/index.js?// test2.js
__webpack_require__.r(__webpack_exports__);
__webpack_require__.d(__webpack_exports__, "default", function() { return test2; });
function test2() {}
//# sourceURL=webpack:///./src/test2.js?可以发现,在每个模块的开头都执行了一个 __webpack_require__.r(__webpack_exports__) 语句。并且 test2.js 还多了一个 __webpack_require__.d() 函数。
我们先来看看 __webpack_require__.r() 和 __webpack_require__.d() 是什么。
// define getter function for harmony exports
__webpack_require__.d = function(exports, name, getter) {
if(!__webpack_require__.o(exports, name)) {
Object.defineProperty(exports, name, { enumerable: true, get: getter });
}
};原来 __webpack_require__.d() 是给 __webpack_exports__ 定义导出变量用的。例如下面这行代码:
__webpack_require__.d(__webpack_exports__, "default", function() { return test2; });它的作用相当于 __webpack_exports__["default"] = test2。这个 "default" 是因为你使用 export default 来导出函数,如果这样导出函数:
export function test2() {}它就会变成 __webpack_require__.d(__webpack_exports__, "test2", function() { return test2; });
// define __esModule on exports
__webpack_require__.r = function(exports) {
if(typeof Symbol !== 'undefined' && Symbol.toStringTag) {
Object.defineProperty(exports, Symbol.toStringTag, { value: 'Module' });
}
Object.defineProperty(exports, '__esModule', { value: true });
};__webpack_require__.r() 函数的作用是给 __webpack_exports__ 添加一个 __esModule 为 true 的属性,表示这是一个 ES6 module。
添加这个属性有什么用呢?
主要是为了处理混合使用 ES6 module 和 CommonJS 的情况。
例如导出使用 CommonJS module.export = test2 导出函数,导入使用 ES6 module import test2 from './test2。
打包后的代码如下:
// index.js
__webpack_require__.r(__webpack_exports__);
var _test2__WEBPACK_IMPORTED_MODULE_0__ = __webpack_require__("./src/test2.js");
var _test2__WEBPACK_IMPORTED_MODULE_0___default = __webpack_require__.n(_test2__WEBPACK_IMPORTED_MODULE_0__);
function test() {}
test()
_test2__WEBPACK_IMPORTED_MODULE_0___default()()
//# sourceURL=webpack:///./src/index.js?// test2.js
function test2() {}
module.exports = test2
//# sourceURL=webpack:///./src/test2.js?从上述代码可以发现,又多了一个 __webpack_require__.n() 函数:
__webpack_require__.n = function(module) {
var getter = module && module.__esModule ?
function getDefault() { return module['default']; } :
function getModuleExports() { return module; };
__webpack_require__.d(getter, 'a', getter);
return getter;
};先来分析一下入口模块的处理逻辑:
__webpack_exports__ 导出对象标识为 ES6 module。test2.js 模块,并将该模块的导出对象作为参数传入 __webpack_require__.n() 函数。__webpack_require__.n 分析该 export 对象是否是 ES6 module,如果是则返回 module['default'] 即 export default 对应的变量。如果不是 ES6 module 则直接返回 export。按需加载,也叫异步加载、动态导入,即只在有需要的时候才去下载相应的资源文件。
在 webpack 中可以使用 import 和 require.ensure 来引入需要动态导入的代码,例如下面这个示例:
// index.js
function test() {}
test()
import('./test2')// test2.js
export default function test2() {}其中使用 import 导入的 test2.js 文件在打包时会被单独打包成一个文件,而不是和 index.js 一起打包到 bundle.js。
这个 0.bundle.js 对应的代码就是动态导入的 test2.js 的代码。
接下来看看这两个打包文件的内容:
// bundle.js
(function(modules) { // webpackBootstrap
// install a JSONP callback for chunk loading
function webpackJsonpCallback(data) {
var chunkIds = data[0];
var moreModules = data[1];
// add "moreModules" to the modules object,
// then flag all "chunkIds" as loaded and fire callback
var moduleId, chunkId, i = 0, resolves = [];
for(;i < chunkIds.length; i++) {
chunkId = chunkIds[i];
if(Object.prototype.hasOwnProperty.call(installedChunks, chunkId) && installedChunks[chunkId]) {
resolves.push(installedChunks[chunkId][0]);
}
installedChunks[chunkId] = 0;
}
for(moduleId in moreModules) {
if(Object.prototype.hasOwnProperty.call(moreModules, moduleId)) {
modules[moduleId] = moreModules[moduleId];
}
}
if(parentJsonpFunction) parentJsonpFunction(data);
while(resolves.length) {
resolves.shift()();
}
};
// The module cache
var installedModules = {};
// object to store loaded and loading chunks
// undefined = chunk not loaded, null = chunk preloaded/prefetched
// Promise = chunk loading, 0 = chunk loaded
var installedChunks = {
"main": 0
};
// script path function
function jsonpScriptSrc(chunkId) {
return __webpack_require__.p + "" + chunkId + ".bundle.js"
}
// The require function
function __webpack_require__(moduleId) {
// Check if module is in cache
if(installedModules[moduleId]) {
return installedModules[moduleId].exports;
}
// Create a new module (and put it into the cache)
var module = installedModules[moduleId] = {
i: moduleId,
l: false,
exports: {}
};
// Execute the module function
modules[moduleId].call(module.exports, module, module.exports, __webpack_require__);
// Flag the module as loaded
module.l = true;
// Return the exports of the module
return module.exports;
}
// This file contains only the entry chunk.
// The chunk loading function for additional chunks
__webpack_require__.e = function requireEnsure(chunkId) {
var promises = [];
// JSONP chunk loading for javascript
var installedChunkData = installedChunks[chunkId];
if(installedChunkData !== 0) { // 0 means "already installed".
// a Promise means "currently loading".
if(installedChunkData) {
promises.push(installedChunkData[2]);
} else {
// setup Promise in chunk cache
var promise = new Promise(function(resolve, reject) {
installedChunkData = installedChunks[chunkId] = [resolve, reject];
});
promises.push(installedChunkData[2] = promise);
// start chunk loading
var script = document.createElement('script');
var onScriptComplete;
script.charset = 'utf-8';
script.timeout = 120;
if (__webpack_require__.nc) {
script.setAttribute("nonce", __webpack_require__.nc);
}
script.src = jsonpScriptSrc(chunkId);
// create error before stack unwound to get useful stacktrace later
var error = new Error();
onScriptComplete = function (event) {
// avoid mem leaks in IE.
script.onerror = script.onload = null;
clearTimeout(timeout);
var chunk = installedChunks[chunkId];
if(chunk !== 0) {
if(chunk) {
var errorType = event && (event.type === 'load' ? 'missing' : event.type);
var realSrc = event && event.target && event.target.src;
error.message = 'Loading chunk ' + chunkId + ' failed.\n(' + errorType + ': ' + realSrc + ')';
error.name = 'ChunkLoadError';
error.type = errorType;
error.request = realSrc;
chunk[1](error);
}
installedChunks[chunkId] = undefined;
}
};
var timeout = setTimeout(function(){
onScriptComplete({ type: 'timeout', target: script });
}, 120000);
script.onerror = script.onload = onScriptComplete;
document.head.appendChild(script);
}
}
return Promise.all(promises);
};
// expose the modules object (__webpack_modules__)
__webpack_require__.m = modules;
// expose the module cache
__webpack_require__.c = installedModules;
// define getter function for harmony exports
__webpack_require__.d = function(exports, name, getter) {
if(!__webpack_require__.o(exports, name)) {
Object.defineProperty(exports, name, { enumerable: true, get: getter });
}
};
// define __esModule on exports
__webpack_require__.r = function(exports) {
if(typeof Symbol !== 'undefined' && Symbol.toStringTag) {
Object.defineProperty(exports, Symbol.toStringTag, { value: 'Module' });
}
Object.defineProperty(exports, '__esModule', { value: true });
};
// create a fake namespace object
// mode & 1: value is a module id, require it
// mode & 2: merge all properties of value into the ns
// mode & 4: return value when already ns object
// mode & 8|1: behave like require
__webpack_require__.t = function(value, mode) {
if(mode & 1) value = __webpack_require__(value);
if(mode & 8) return value;
if((mode & 4) && typeof value === 'object' && value && value.__esModule) return value;
var ns = Object.create(null);
__webpack_require__.r(ns);
Object.defineProperty(ns, 'default', { enumerable: true, value: value });
if(mode & 2 && typeof value != 'string') for(var key in value) __webpack_require__.d(ns, key, function(key) { return value[key]; }.bind(null, key));
return ns;
};
// getDefaultExport function for compatibility with non-harmony modules
__webpack_require__.n = function(module) {
var getter = module && module.__esModule ?
function getDefault() { return module['default']; } :
function getModuleExports() { return module; };
__webpack_require__.d(getter, 'a', getter);
return getter;
};
// Object.prototype.hasOwnProperty.call
__webpack_require__.o = function(object, property) { return Object.prototype.hasOwnProperty.call(object, property); };
// __webpack_public_path__
__webpack_require__.p = "";
// on error function for async loading
__webpack_require__.oe = function(err) { console.error(err); throw err; };
var jsonpArray = window["webpackJsonp"] = window["webpackJsonp"] || [];
var oldJsonpFunction = jsonpArray.push.bind(jsonpArray);
jsonpArray.push = webpackJsonpCallback;
jsonpArray = jsonpArray.slice();
for(var i = 0; i < jsonpArray.length; i++) webpackJsonpCallback(jsonpArray[i]);
var parentJsonpFunction = oldJsonpFunction;
// Load entry module and return exports
return __webpack_require__(__webpack_require__.s = "./src/index.js");
})({
"./src/index.js":(function(module, exports, __webpack_require__) {
eval("function test() {}\r\n\r\ntest()\r\n__webpack_require__.e(/*! import() */ 0).then(__webpack_require__.bind(null, /*! ./test2 */ \"./src/test2.js\"))\n\n//# sourceURL=webpack:///./src/index.js?");
})
});// 0.bundle.js
(window["webpackJsonp"] = window["webpackJsonp"] || []).push(
[
[0],
{
"./src/test2.js":(function(module, __webpack_exports__, __webpack_require__) {
"use strict";
eval("__webpack_require__.r(__webpack_exports__);\n/* harmony export (binding) */ __webpack_require__.d(__webpack_exports__, \"default\", function() { return test2; });\nfunction test2() {}\n\n//# sourceURL=webpack:///./src/test2.js?");
})
}
]
);这次打包的代码量有点膨胀,bundle.js 代码居然有 200 行。我们来看看相比于同步加载的 webpack 模块规范,它有哪些不同:
installedChunks,作用是缓存动态模块。jsonpScriptSrc(),作用是根据模块 ID 生成 URL。__webpack_require__.e() 和 webpackJsonpCallback()。window["webpackJsonp"] = [],它的作用是存储需要动态导入的模块。window["webpackJsonp"] 数组的 push() 方法为 webpackJsonpCallback()。也就是说 window["webpackJsonp"].push() 其实执行的是 webpackJsonpCallback()。而从 0.bundle.js 文件可以发现,它正是使用 window["webpackJsonp"].push() 来放入动态模块的。动态模块数据项有两个值,第一个是 [0],它是模块的 ID;第二个值是模块的路径名和模块内容。
然后我们再看一下打包后的入口模块的代码,经过美化后:
function test() {}
test()
__webpack_require__.e(0).then(__webpack_require__.bind(null, "./src/test2.js"))
//# sourceURL=webpack:///./src/index.js?原来模块代码中的 import('./test2') 被翻译成了 __webpack_require__.e(0).then(__webpack_require__.bind(null, "./src/test2.js"))。
那 __webpack_require__.e() 的作用是什么呢?
__webpack_require__.e = function requireEnsure(chunkId) {
var promises = [];
// JSONP chunk loading for javascript
var installedChunkData = installedChunks[chunkId];
if(installedChunkData !== 0) { // 0 means "already installed".
// a Promise means "currently loading".
if(installedChunkData) {
promises.push(installedChunkData[2]);
} else {
// setup Promise in chunk cache
var promise = new Promise(function(resolve, reject) {
installedChunkData = installedChunks[chunkId] = [resolve, reject];
});
promises.push(installedChunkData[2] = promise);
// start chunk loading
var script = document.createElement('script');
var onScriptComplete;
script.charset = 'utf-8';
script.timeout = 120;
if (__webpack_require__.nc) {
script.setAttribute("nonce", __webpack_require__.nc);
}
script.src = jsonpScriptSrc(chunkId);
// create error before stack unwound to get useful stacktrace later
var error = new Error();
onScriptComplete = function (event) {
// avoid mem leaks in IE.
script.onerror = script.onload = null;
clearTimeout(timeout);
var chunk = installedChunks[chunkId];
if(chunk !== 0) {
if(chunk) {
var errorType = event && (event.type === 'load' ? 'missing' : event.type);
var realSrc = event && event.target && event.target.src;
error.message = 'Loading chunk ' + chunkId + ' failed.\n(' + errorType + ': ' + realSrc + ')';
error.name = 'ChunkLoadError';
error.type = errorType;
error.request = realSrc;
chunk[1](error);
}
installedChunks[chunkId] = undefined;
}
};
var timeout = setTimeout(function(){
onScriptComplete({ type: 'timeout', target: script });
}, 120000);
script.onerror = script.onload = onScriptComplete;
document.head.appendChild(script);
}
}
return Promise.all(promises);
};它的处理逻辑如下:
undefined。undefined 代表已经是加载中的状态。然后将这个加载中的 Promise 推入 promises 数组。undefined 就新建一个 Promise,用于加载需要动态导入的模块。script 标签,URL 使用 jsonpScriptSrc(chunkId) 生成,即需要动态导入模块的 URL。script 标签设置一个 2 分钟的超时时间,并设置一个 onScriptComplete() 函数,用于处理超时错误。document.head.appendChild(script),开始加载模块。promises 数组。当 JS 文件下载完成后,会自动执行文件内容。也就是说下载完 0.bundle.js 后,会执行 window["webpackJsonp"].push()。
由于 window["webpackJsonp"].push() 已被重置为 webpackJsonpCallback() 函数。所以这一操作就是执行 webpackJsonpCallback() ,接下来我们看看 webpackJsonpCallback() 做了哪些事情。
对这个模块 ID 对应的 Promise 执行 resolve(),同时将缓存对象中的值置为 0,表示已经加载完成了。相比于 __webpack_require__.e(),这个函数还是挺好理解的。
总的来说,动态导入的逻辑如下:
window["webpackJsonp"].push() 方法。__webpack_require__.e() 下载动态资源。window["webpackJsonp"].push(),即 webpackJsonpCallback()。resolve()。__webpack_require__.e(0).then(__webpack_require__.bind(null, "./src/test2.js")),下载完成后执行 then() 方法,调用 __webpack_require__() 真正开始加载代码,__webpack_require__() 在上文已经讲解过,如果不了解,建议再阅读一遍。本文将分成以下 7 个小节:
部分小节提供了非常详细的实战教程,让大家动手实践。
另外我还写了一个前端工程化 demo 放在 github 上。这个 demo 包含了 js、css、git 验证,其中 js、css 验证需要安装 VSCode,具体教程在下文中会有提及。
对于前端来说,技术选型挺简单的。就是做选择题,三大框架中选一个。个人认为可以依据以下两个特点来选:
第二点对于小公司来说,特别重要。本来小公司就不好招人,要是还选一个市场占有率不高的框架(例如 Angular),简历你都看不到几个...
UI 组件库更简单,github 上哪个 star 多就用哪个。star 多,说明用的人就多,很多坑别人都替你踩过了,省事。
先来看看统一代码规范的好处:
当团队的成员都严格按照代码规范来写代码时,可以保证每个人的代码看起来都像是一个人写的,看别人的代码就像是在看自己的代码。更重要的是我们能够认识到规范的重要性,并坚持规范的开发习惯。
建议找一份好的代码规范,在此基础上结合团队的需求作个性化修改。
下面列举一些 star 较多的 js 代码规范:
css 代码规范也有不少,例如:
使用 eslint 可以检查代码符不符合团队制订的规范,下面来看一下如何配置 eslint 来检查代码。
// eslint-config-airbnb-base 使用 airbnb 代码规范
npm i -D babel-eslint eslint eslint-config-airbnb-base eslint-plugin-import
.eslintrc 文件{
"parserOptions": {
"ecmaVersion": 2019
},
"env": {
"es6": true,
},
"parser": "babel-eslint",
"extends": "airbnb-base",
}
package.json 的 scripts 加上这行代码 "lint": "eslint --ext .js test/ src/"。然后执行 npm run lint 即可开始验证代码。代码中的 test/ src/ 是指你要进行校验的代码目录,这里指明了要检查 test、src 目录下的代码。不过这样检查代码效率太低,每次都得手动检查。并且报错了还得手动修改代码。
为了改善以上缺点,我们可以使用 VSCode。使用它并加上适当的配置可以在每次保存代码的时候,自动验证代码并进行格式化,省去了动手的麻烦。
css 检查代码规范则使用 stylelint 插件。
由于篇幅有限,具体如何配置请看我的另一篇文章ESlint + stylelint + VSCode自动格式化代码(2020)。
git 规范包括两点:分支管理规范、git commit 规范。
一般项目分主分支(master)和其他分支。
当有团队成员要开发新功能或改 BUG 时,就从 master 分支开一个新的分支。例如项目要从客户端渲染改成服务端渲染,就开一个分支叫 ssr,开发完了再合并回 master 分支。
如果改一个 BUG,也可以从 master 分支开一个新分支,并用 BUG 号命名(不过我们小团队嫌麻烦,没这样做,除非有特别大的 BUG)。
<type>(<scope>): <subject>
<BLANK LINE>
<body>
<BLANK LINE>
<footer>大致分为三个部分(使用空行分割):
示例
如果修复的这个BUG只影响当前修改的文件,可不加范围。如果影响的范围比较大,要加上范围描述。
例如这次 BUG 修复影响到全局,可以加个 global。如果影响的是某个目录或某个功能,可以加上该目录的路径,或者对应的功能名称。
// 示例1
fix(global):修复checkbox不能复选的问题
// 示例2 下面圆括号里的 common 为通用管理的名称
fix(common): 修复字体过小的BUG,将通用管理下所有页面的默认字体大小修改为 14px
// 示例3
fix: value.length -> values.lengthfeat: 添加网站主页静态页面
这是一个示例,假设对点检任务静态页面进行了一些描述。
这里是备注,可以是放BUG链接或者一些重要性的东西。chore 的中文翻译为日常事务、例行工作,顾名思义,即不在其他 commit 类型中的修改,都可以用 chore 表示。
chore: 将表格中的查看详情改为详情其他类型的 commit 和上面三个示例差不多,就不说了。
验证 git commit 规范,主要通过 git 的 pre-commit 钩子函数来进行。当然,你还需要下载一个辅助工具来帮助你进行验证。
下载辅助工具
npm i -D husky
在 package.json 加上下面的代码
"husky": {
"hooks": {
"pre-commit": "npm run lint",
"commit-msg": "node script/verify-commit.js",
"pre-push": "npm test"
}
}然后在你项目根目录下新建一个文件夹 script,并在下面新建一个文件 verify-commit.js,输入以下代码:
const msgPath = process.env.HUSKY_GIT_PARAMS
const msg = require('fs')
.readFileSync(msgPath, 'utf-8')
.trim()
const commitRE = /^(feat|fix|docs|style|refactor|perf|test|workflow|build|ci|chore|release|workflow)(\(.+\))?: .{1,50}/
if (!commitRE.test(msg)) {
console.log()
console.error(`
不合法的 commit 消息格式。
请查看 git commit 提交规范:https://github.com/woai3c/Front-end-articles/blob/master/git%20commit%20style.md
`)
process.exit(1)
}现在来解释下各个钩子的含义:
"pre-commit": "npm run lint",在 git commit 前执行 npm run lint 检查代码格式。"commit-msg": "node script/verify-commit.js",在 git commit 时执行脚本 verify-commit.js 验证 commit 消息。如果不符合脚本中定义的格式,将会报错。"pre-push": "npm test",在你执行 git push 将代码推送到远程仓库前,执行 npm test 进行测试。如果测试失败,将不会执行这次推送。主要是项目文件的组织方式和命名方式。
用我们的 Vue 项目举个例子。
├─public
├─src
├─test
一个项目包含 public(公共资源,不会被 webpack 处理)、src(源码)、test(测试代码),其中 src 目录,又可以细分。
├─api (接口)
├─assets (静态资源)
├─components (公共组件)
├─styles (公共样式)
├─router (路由)
├─store (vuex 全局数据)
├─utils (工具函数)
└─views (页面)
文件名称如果过长则用 - 隔开。
UI 规范需要前端、UI、产品沟通,互相商量,最后制定下来,建议使用统一的 UI 组件库。
制定 UI 规范的好处:
测试是前端工程化建设必不可少的一部分,它的作用就是找出 bug,越早发现 bug,所需要付出的成本就越低。并且,它更重要的作用是在将来,而不是当下。
设想一下半年后,你的项目要加一个新功能。在加完新功能后,你不确定有没有影响到原有的功能,需要测试一下。由于时间过去太久,你对项目的代码已经不了解了。在这种情况下,如果没有写测试,你就得手动一遍一遍的去试。而如果写了测试,你只需要跑一遍测试代码就 OK 了,省时省力。
写测试还可以让你修改代码时没有心理负担,不用一直想着改这里有没有问题?会不会引起 BUG?而写了测试就没有这种担心了。
在前端用得最多的就是单元测试(主要是端到端测试我用得很少,不熟),这里着重讲解一下。
单元测试就是对一个函数、一个组件、一个类做的测试,它针对的粒度比较小。
它应该怎么写呢?
例如一个取绝对值的函数 abs(),输入 1,2,结果应该与输入相同;输入 -1,-2,结果应该与输入相反。如果输入非数字,例如 "abc",应该抛出一个类型错误。
假设有这样一个类:
class Math {
abs() {
}
sqrt() {
}
pow() {
}
...
}
单元测试,必须把这个类的所有方法都测一遍。
组件测试比较难,因为很多组件都涉及了 DOM 操作。
例如一个上传图片组件,它有一个将图片转成 base64 码的方法,那要怎么测试呢?一般测试都是跑在 node 环境下的,而 node 环境没有 DOM 对象。
我们先来回顾一下上传图片的过程:
<input type="file" />,选择图片上传。input 的 change 事件,获取 file 对象。FileReader 将图片转换成 base64 码。这个过程和下面的代码是一样的:
document.querySelector('input').onchange = function fileChangeHandler(e) {
const file = e.target.files[0]
const reader = new FileReader()
reader.onload = (res) => {
const fileResult = res.target.result
console.log(fileResult) // 输出 base64 码
}
reader.readAsDataURL(file)
}上面的代码只是模拟,真实情况下应该是这样使用
document.querySelector('input').onchange = function fileChangeHandler(e) {
const file = e.target.files[0]
tobase64(file)
}
function tobase64(file) {
return new Promise((resolve, reject) => {
const reader = new FileReader()
reader.onload = (res) => {
const fileResult = res.target.result
resolve(fileResult) // 输出 base64 码
}
reader.readAsDataURL(file)
})
}可以看到,上面代码出现了 window 的事件对象 event、FileReader。也就是说,只要我们能够提供这两个对象,就可以在任何环境下运行它。所以我们可以在测试环境下加上这两个对象:
// 重写 File
window.File = function () {}
// 重写 FileReader
window.FileReader = function () {
this.readAsDataURL = function () {
this.onload
&& this.onload({
target: {
result: fileData,
},
})
}
}然后测试可以这样写:
// 提前写好文件内容
const fileData = 'data:image/test'
// 提供一个假的 file 对象给 tobase64() 函数
function test() {
const file = new File()
const event = { target: { files: [file] } }
file.type = 'image/png'
file.name = 'test.png'
file.size = 1024
it('file content', (done) => {
tobase64(file).then(base64 => {
expect(base64).toEqual(fileData) // 'data:image/test'
done()
})
})
}
// 执行测试
test()通过这种 hack 的方式,我们就实现了对涉及 DOM 操作的组件的测试。我的 vue-upload-imgs 库就是通过这种方式写的单元测试,有兴趣可以了解一下。
TDD 就是根据需求提前把测试代码写好,然后根据测试代码实现功能。
TDD 的初衷是好的,但如果你的需求经常变(你懂的),那就不是一件好事了。很有可能你天天都在改测试代码,业务代码反而没怎么动。
所以到现在为止,三年多的程序员生涯,我还没尝试过 TDD 开发。
虽然环境如此艰难,但有条件的情况下还是应该试一下 TDD 的。例如在你自己负责一个项目又不忙的时候,可以采用此方法编写测试用例。
我常用的测试框架是 jest,好处是有中文文档,API 清晰明了,一看就知道是干什么用的。
在没有学会自动部署前,我是这样部署项目的:
npm run test。npm run build。一次两次还行,如果天天都这样,就会把很多时间浪费在重复的操作上。所以我们要学会自动部署,彻底解放双手。
自动部署(又叫持续部署 Continuous Deployment,英文缩写 CD)一般有两种触发方式:
webhook 事件。轮询,就是构建软件每隔一段时间自动执行打包、部署操作。
这种方式不太好,很有可能软件刚部署完我就改代码了。为了看到新的页面效果,不得不等到下一次构建开始。
另外还有一个副作用,假如我一天都没更改代码,构建软件还是会不停的执行打包、部署操作,白白的浪费资源。
所以现在的构建软件基本采用监听 webhook 事件的方式来进行部署。
webhook 事件webhook 钩子函数,就是在你的构建软件上进行设置,监听某一个事件(一般是监听 push 事件),当事件触发时,自动执行定义好的脚本。
例如 Github Actions,就有这个功能。
对于新人来说,仅看我这一段讲解是不可能学会自动部署的。为此我特地写了一篇自动化部署教程,不需要你提前学习自动化部署的知识,只要照着指引做,就能实现前端项目自动化部署。
前端项目自动化部署——超详细教程(Jenkins、Github Actions),教程已经奉上,各位大佬看完后要是觉得有用,不要忘了点赞,感激不尽。
监控,又分性能监控和错误监控,它的作用是预警和追踪定位问题。
性能监控一般利用 window.performance 来进行数据采集。
Performance 接口可以获取到当前页面中与性能相关的信息,它是 High Resolution Time API 的一部分,同时也融合了 Performance Timeline API、Navigation Timing API、 User Timing API 和 Resource Timing API。
这个 API 的属性 timing,包含了页面加载各个阶段的起始及结束时间。
为了方便大家理解 timing 各个属性的意义,我在知乎找到一位网友对于 timing 写的简介(忘了姓名,后来找不到了,见谅),在此转载一下。
timing: {
// 同一个浏览器上一个页面卸载(unload)结束时的时间戳。如果没有上一个页面,这个值会和fetchStart相同。
navigationStart: 1543806782096,
// 上一个页面unload事件抛出时的时间戳。如果没有上一个页面,这个值会返回0。
unloadEventStart: 1543806782523,
// 和 unloadEventStart 相对应,unload事件处理完成时的时间戳。如果没有上一个页面,这个值会返回0。
unloadEventEnd: 1543806782523,
// 第一个HTTP重定向开始时的时间戳。如果没有重定向,或者重定向中的一个不同源,这个值会返回0。
redirectStart: 0,
// 最后一个HTTP重定向完成时(也就是说是HTTP响应的最后一个比特直接被收到的时间)的时间戳。
// 如果没有重定向,或者重定向中的一个不同源,这个值会返回0.
redirectEnd: 0,
// 浏览器准备好使用HTTP请求来获取(fetch)文档的时间戳。这个时间点会在检查任何应用缓存之前。
fetchStart: 1543806782096,
// DNS 域名查询开始的UNIX时间戳。
//如果使用了持续连接(persistent connection),或者这个信息存储到了缓存或者本地资源上,这个值将和fetchStart一致。
domainLookupStart: 1543806782096,
// DNS 域名查询完成的时间.
//如果使用了本地缓存(即无 DNS 查询)或持久连接,则与 fetchStart 值相等
domainLookupEnd: 1543806782096,
// HTTP(TCP) 域名查询结束的时间戳。
//如果使用了持续连接(persistent connection),或者这个信息存储到了缓存或者本地资源上,这个值将和 fetchStart一致。
connectStart: 1543806782099,
// HTTP(TCP) 返回浏览器与服务器之间的连接建立时的时间戳。
// 如果建立的是持久连接,则返回值等同于fetchStart属性的值。连接建立指的是所有握手和认证过程全部结束。
connectEnd: 1543806782227,
// HTTPS 返回浏览器与服务器开始安全链接的握手时的时间戳。如果当前网页不要求安全连接,则返回0。
secureConnectionStart: 1543806782162,
// 返回浏览器向服务器发出HTTP请求时(或开始读取本地缓存时)的时间戳。
requestStart: 1543806782241,
// 返回浏览器从服务器收到(或从本地缓存读取)第一个字节时的时间戳。
//如果传输层在开始请求之后失败并且连接被重开,该属性将会被数制成新的请求的相对应的发起时间。
responseStart: 1543806782516,
// 返回浏览器从服务器收到(或从本地缓存读取,或从本地资源读取)最后一个字节时
//(如果在此之前HTTP连接已经关闭,则返回关闭时)的时间戳。
responseEnd: 1543806782537,
// 当前网页DOM结构开始解析时(即Document.readyState属性变为“loading”、相应的 readystatechange事件触发时)的时间戳。
domLoading: 1543806782573,
// 当前网页DOM结构结束解析、开始加载内嵌资源时(即Document.readyState属性变为“interactive”、相应的readystatechange事件触发时)的时间戳。
domInteractive: 1543806783203,
// 当解析器发送DOMContentLoaded 事件,即所有需要被执行的脚本已经被解析时的时间戳。
domContentLoadedEventStart: 1543806783203,
// 当所有需要立即执行的脚本已经被执行(不论执行顺序)时的时间戳。
domContentLoadedEventEnd: 1543806783216,
// 当前文档解析完成,即Document.readyState 变为 'complete'且相对应的readystatechange 被触发时的时间戳
domComplete: 1543806783796,
// load事件被发送时的时间戳。如果这个事件还未被发送,它的值将会是0。
loadEventStart: 1543806783796,
// 当load事件结束,即加载事件完成时的时间戳。如果这个事件还未被发送,或者尚未完成,它的值将会是0.
loadEventEnd: 1543806783802
}通过以上数据,我们可以得到几个有用的时间
// 重定向耗时
redirect: timing.redirectEnd - timing.redirectStart,
// DOM 渲染耗时
dom: timing.domComplete - timing.domLoading,
// 页面加载耗时
load: timing.loadEventEnd - timing.navigationStart,
// 页面卸载耗时
unload: timing.unloadEventEnd - timing.unloadEventStart,
// 请求耗时
request: timing.responseEnd - timing.requestStart,
// 获取性能信息时当前时间
time: new Date().getTime(),还有一个比较重要的时间就是白屏时间,它指从输入网址,到页面开始显示内容的时间。
将以下脚本放在 </head> 前面就能获取白屏时间。
<script>
whiteScreen = new Date() - performance.timing.navigationStart
</script>通过这几个时间,就可以得知页面首屏加载性能如何了。
另外,通过 window.performance.getEntriesByType('resource') 这个方法,我们还可以获取相关资源(js、css、img...)的加载时间,它会返回页面当前所加载的所有资源。
它一般包括以下几个类型
我们只需用到以下几个信息
// 资源的名称
name: item.name,
// 资源加载耗时
duration: item.duration.toFixed(2),
// 资源大小
size: item.transferSize,
// 资源所用协议
protocol: item.nextHopProtocol,现在,写几行代码来收集这些数据。
// 收集性能信息
const getPerformance = () => {
if (!window.performance) return
const timing = window.performance.timing
const performance = {
// 重定向耗时
redirect: timing.redirectEnd - timing.redirectStart,
// 白屏时间
whiteScreen: whiteScreen,
// DOM 渲染耗时
dom: timing.domComplete - timing.domLoading,
// 页面加载耗时
load: timing.loadEventEnd - timing.navigationStart,
// 页面卸载耗时
unload: timing.unloadEventEnd - timing.unloadEventStart,
// 请求耗时
request: timing.responseEnd - timing.requestStart,
// 获取性能信息时当前时间
time: new Date().getTime(),
}
return performance
}
// 获取资源信息
const getResources = () => {
if (!window.performance) return
const data = window.performance.getEntriesByType('resource')
const resource = {
xmlhttprequest: [],
css: [],
other: [],
script: [],
img: [],
link: [],
fetch: [],
// 获取资源信息时当前时间
time: new Date().getTime(),
}
data.forEach(item => {
const arry = resource[item.initiatorType]
arry && arry.push({
// 资源的名称
name: item.name,
// 资源加载耗时
duration: item.duration.toFixed(2),
// 资源大小
size: item.transferSize,
// 资源所用协议
protocol: item.nextHopProtocol,
})
})
return resource
}通过对性能及资源信息的解读,我们可以判断出页面加载慢有以下几个原因:
除了用户网速过慢,我们没办法之外,其他两个原因都是有办法解决的,性能优化将在下一节《性能优化》中会讲到。
现在能捕捉的错误有三种。
addEventListener('error', callback, true) 在捕获阶段捕捉资源加载失败错误。window.onerror 捕捉 js 错误。addEventListener('unhandledrejection', callback)捕捉 promise 错误,但是没有发生错误的行数,列数等信息,只能手动抛出相关错误信息。我们可以建一个错误数组变量 errors 在错误发生时,将错误的相关信息添加到数组,然后在某个阶段统一上报,具体如何操作请看代码
// 捕获资源加载失败错误 js css img...
addEventListener('error', e => {
const target = e.target
if (target != window) {
monitor.errors.push({
type: target.localName,
url: target.src || target.href,
msg: (target.src || target.href) + ' is load error',
// 错误发生的时间
time: new Date().getTime(),
})
}
}, true)
// 监听 js 错误
window.onerror = function(msg, url, row, col, error) {
monitor.errors.push({
type: 'javascript',
row: row,
col: col,
msg: error && error.stack? error.stack : msg,
url: url,
// 错误发生的时间
time: new Date().getTime(),
})
}
// 监听 promise 错误 缺点是获取不到行数数据
addEventListener('unhandledrejection', e => {
monitor.errors.push({
type: 'promise',
msg: (e.reason && e.reason.msg) || e.reason || '',
// 错误发生的时间
time: new Date().getTime(),
})
})通过错误收集,可以了解到网站错误发生的类型及数量,从而可以做相应的调整,以减少错误发生。
完整代码和 DEMO 请看我另一篇文章前端性能和错误监控的末尾,大家可以复制代码(HTML文件)在本地测试一下。
性能数据可以在页面加载完之后上报,尽量不要对页面性能造成影响。
window.onload = () => {
// 在浏览器空闲时间获取性能及资源信息
// https://developer.mozilla.org/zh-CN/docs/Web/API/Window/requestIdleCallback
if (window.requestIdleCallback) {
window.requestIdleCallback(() => {
monitor.performance = getPerformance()
monitor.resources = getResources()
})
} else {
setTimeout(() => {
monitor.performance = getPerformance()
monitor.resources = getResources()
}, 0)
}
}当然,你也可以设一个定时器,循环上报。不过每次上报最好做一下对比去重再上报,避免同样的数据重复上报。
我在DEMO里提供的代码,是用一个 errors 数组收集所有的错误,再在某一阶段统一上报(延时上报)。
其实,也可以改成在错误发生时上报(即时上报)。这样可以避免在收集完错误延时上报还没触发,用户却已经关掉网页导致错误数据丢失的问题。
// 监听 js 错误
window.onerror = function(msg, url, row, col, error) {
const data = {
type: 'javascript',
row: row,
col: col,
msg: error && error.stack? error.stack : msg,
url: url,
// 错误发生的时间
time: new Date().getTime(),
}
// 即时上报
axios.post({ url: 'xxx', data, })
}window.performance API 是有缺点的,在 SPA 切换路由时,window.performance.timing 的数据不会更新。
所以我们需要另想办法来统计切换路由到加载完成的时间。
拿 Vue 举例,一个可行的办法就是切换路由时,在路由的全局前置守卫 beforeEach 里获取开始时间,在组件的 mounted 钩子里执行 vm.$nextTick 函数来获取组件的渲染完毕时间。
router.beforeEach((to, from, next) => {
store.commit('setPageLoadedStartTime', new Date())
})mounted() {
this.$nextTick(() => {
this.$store.commit('setPageLoadedTime', new Date() - this.$store.state.pageLoadedStartTime)
})
}除了性能和错误监控,其实我们还可以做得更多。
使用 window.navigator 可以收集到用户的设备信息,操作系统,浏览器信息...
是指通过互联网访问、浏览这个网页的自然人。访问您网站的一台电脑客户端为一个访客。00:00-24:00内相同的客户端只被计算一次。一天内同个访客多次访问仅计算一个UV。
在用户访问网站时,可以生成一个随机字符串+时间日期,保存在本地。在网页发生请求时(如果超过当天24小时,则重新生成),把这些参数传到后端,后端利用这些信息生成 UV 统计报告。
即页面浏览量或点击量,用户每1次对网站中的每个网页访问均被记录1个PV。用户对同一页面的多次访问,访问量累计,用以衡量网站用户访问的网页数量。
传统网站
用户在进入 A 页面时,通过后台请求把用户进入页面的时间捎上。过了 10 分钟,用户进入 B 页面,这时后台可以通过接口捎带的参数可以判断出用户在 A 页面停留了 10 分钟。
SPA
可以利用 router 来获取用户停留时间,拿 Vue 举例,通过 router.beforeEach destroyed 这两个钩子函数来获取用户停留该路由组件的时间。
通过 document.documentElement.scrollTop 属性以及屏幕高度,可以判断用户是否浏览完网站内容。
通过 document.referrer 属性,可以知道用户是从哪个网站跳转而来。
通过分析用户数据,我们可以了解到用户的浏览习惯、爱好等等信息,想想真是恐怖,毫无隐私可言。
前面说的都是监控原理,但要实现还是得自己动手写代码。为了避免麻烦,我们可以用现有的工具 sentry 去做这件事。
sentry 是一个用 python 写的性能和错误监控工具,你可以使用 sentry 提供的服务(免费功能少),也可以自己部署服务。现在来看一下如何使用 sentry 提供的服务实现监控。
打开 https://sentry.io/signup/ 网站,进行注册。
选择项目,我选的 Vue。
选完项目,下面会有具体的 sentry 依赖安装指南。
根据提示,在你的 Vue 项目执行这段代码 npm install --save @sentry/browser @sentry/integrations @sentry/tracing,安装 sentry 所需的依赖。
再将下面的代码拷到你的 main.js,放在 new Vue() 之前。
import * as Sentry from "@sentry/browser";
import { Vue as VueIntegration } from "@sentry/integrations";
import { Integrations } from "@sentry/tracing";
Sentry.init({
dsn: "xxxxx", // 这里是你的 dsn 地址,注册完就有
integrations: [
new VueIntegration({
Vue,
tracing: true,
}),
new Integrations.BrowserTracing(),
],
// We recommend adjusting this value in production, or using tracesSampler
// for finer control
tracesSampleRate: 1.0,
});然后点击第一步中的 skip this onboarding,进入控制台页面。
如果忘了自己的 DSN,请点击左边的菜单栏选择 Settings -> Projects -> 点击自己的项目 -> Client Keys(DSN)。
在你的 Vue 项目执行一个打印语句 console.log(b)。
这时点开 sentry 主页的 issues 一项,可以发现有一个报错信息 b is not defined:
这个报错信息包含了错误的具体信息,还有你的 IP、浏览器信息等等。
但奇怪的是,我们的浏览器控制台并没有输出报错信息。
这是因为被 sentry 屏蔽了,所以我们需要加上一个选项 logErrors: true。
然后再查看页面,发现控制台也有报错信息了:
一般打包后的代码都是经过压缩的,如果没有 sourcemap,即使有报错信息,你也很难根据提示找到对应的源码在哪。
下面来看一下如何上传 sourcemap。
首先创建 auth token。
这个生成的 token 一会要用到。
安装 sentry-cli 和 @sentry/webpack-plugin:
npm install sentry-cli-binary -g
npm install --save-dev @sentry/webpack-plugin
安装完上面两个插件后,在项目根目录创建一个 .sentryclirc 文件(不要忘了在 .gitignore 把这个文件添加上,以免暴露 token),内容如下:
[auth]
token=xxx
[defaults]
url=https://sentry.io/
org=woai3c
project=woai3c
把 xxx 替换成刚才生成的 token。
org 是你的组织名称。
project 是你的项目名称,根据下面的提示可以找到。
在项目下新建 vue.config.js 文件,把下面的内容填进去:
const SentryWebpackPlugin = require('@sentry/webpack-plugin')
const config = {
configureWebpack: {
plugins: [
new SentryWebpackPlugin({
include: './dist', // 打包后的目录
ignore: ['node_modules', 'vue.config.js', 'babel.config.js'],
}),
],
},
}
// 只在生产环境下上传 sourcemap
module.exports = process.env.NODE_ENV == 'production'? config : {}填完以后,执行 npm run build,就可以看到 sourcemap 的上传结果了。
我们再来看一下没上传 sourcemap 和上传之后的报错信息对比。
未上传 sourcemap
已上传 sourcemap
可以看到,上传 sourcemap 后的报错信息更加准确。
选完刷新即可。
打开 performance 选项,就能看到你每个项目的运行情况。具体的参数解释请看文档 Performance Monitoring。
性能优化主要分为两类:
例如压缩文件、使用 CDN 就属于加载时优化;减少 DOM 操作,使用事件委托属于运行时优化。
在解决问题之前,必须先找出问题,否则无从下手。所以在做性能优化之前,最好先调查一下网站的加载性能和运行性能。
一个网站加载性能如何主要看白屏时间和首屏时间。
将以下脚本放在 </head> 前面就能获取白屏时间。
<script>
new Date() - performance.timing.navigationStart
</script>在 window.onload 事件里执行 new Date() - performance.timing.navigationStart 即可获取首屏时间。
配合 chrome 的开发者工具,我们可以查看网站在运行时的性能。
打开网站,按 F12 选择 performance,点击左上角的灰色圆点,变成红色就代表开始记录了。这时可以模仿用户使用网站,在使用完毕后,点击 stop,然后你就能看到网站运行期间的性能报告。如果有红色的块,代表有掉帧的情况;如果是绿色,则代表 FPS 很好。
另外,在 performance 标签下,按 ESC 会弹出来一个小框。点击小框左边的三个点,把 rendering 勾出来。
这两个选项,第一个是高亮重绘区域,另一个是显示帧渲染信息。把这两个选项勾上,然后浏览网页,可以实时的看到你网页渲染变化。
可以部署一个前端监控系统来监控网站性能,上一节中讲到的 sentry 就属于这一类。
如果你安装了 Chrome 52+ 版本,请按 F12 打开开发者工具。
它不仅会对你网站的性能打分,还会对 SEO 打分。
网上关于性能优化的文章和书籍多不胜数,但有很多优化规则已经过时了。所以我写了一篇性能优化文章前端性能优化 24 条建议(2020),分析总结出了 24 条性能优化建议,强烈推荐。
《重构2》一书中对重构进行了定义:
所谓重构(refactoring)是这样一个过程:在不改变代码外在行为的前提下,对代码做出修改,以改进程序的内部结构。重构是一种经千锤百炼形成的有条不紊的程序整理方法,可以最大限度地减小整理过程中引入错误的概率。本质上说,重构就是在代码写好之后改进它的设计。
重构和性能优化有相同点,也有不同点。
相同的地方是它们都在不改变程序功能的情况下修改代码;不同的地方是重构为了让代码变得更加易读、理解,性能优化则是为了让程序运行得更快。
重构可以一边写代码一边重构,也可以在程序写完后,拿出一段时间专门去做重构。没有说哪个方式更好,视个人情况而定。
如果你专门拿一段时间来做重构,建议你在重构一段代码后,立即进行测试。这样可以避免修改代码太多,在出错时找不到错误点。
在《重构2》这本书中,介绍了多达上百个重构手法。但我觉得有两个是比较常用的:
假设有一个查询数据的接口 /getUserData?age=17&city=beijing。现在需要做的是把用户数据:{ age: 17, city: 'beijing' } 转成 URL 参数的形式:
let result = ''
const keys = Object.keys(data) // { age: 17, city: 'beijing' }
keys.forEach(key => {
result += '&' + key + '=' + data[key]
})
result.substr(1) // age=17&city=beijing如果只有这一个接口需要转换,不封装成函数是没问题的。但如果有多个接口都有这种需求,那就得把它封装成函数了:
function JSON2Params(data) {
let result = ''
const keys = Object.keys(data)
keys.forEach(key => {
result += '&' + key + '=' + data[key]
})
return result.substr(1)
}假设现在有一个注册功能,用伪代码表示:
function register(data) {
// 1. 验证用户数据是否合法
/**
* 验证账号
* 验证密码
* 验证短信验证码
* 验证身份证
* 验证邮箱
*/
// 2. 如果用户上传了头像,则将用户头像转成 base64 码保存
/**
* 新建 FileReader 对象
* 将图片转换成 base64 码
*/
// 3. 调用注册接口
// ...
}这个函数包含了三个功能,验证、转换、注册。其中验证和转换功能是可以提取出来单独封装成函数的:
function register(data) {
// 1. 验证用户数据是否合法
// verify()
// 2. 如果用户上传了头像,则将用户头像转成 base64 码保存
// tobase64()
// 3. 调用注册接口
// ...
}如果你对重构有兴趣,强烈推荐你阅读《重构2》这本书。
参考资料:
写这篇文章主要是为了对我这一年多工作经验作总结,因为我基本上都在研究前端工程化以及如何提升团队的开发效率。希望这篇文章能帮助一些对前端工程化没有经验的新手,通过这篇文章入门前端工程化。
如果这篇文章对你有帮助,请点一下赞,感激不尽。
本教程主要讲解了怎么使用 Jenkins 和 Github Actions 部署前端项目。
阅读本教程并不需要你提前了解 Jenkins 和 Github Actions 的知识,只要按照本教程的指引,就能够实现自动化部署项目。
PS:本人所用电脑操作系统为 windows,即以下所有的操作均在 windows 下运行。其他操作系统的配置大同小异,不会有太大差别。
Gitea 用于构建 Git 局域网服务器,Jenkins 是 CI/CD 工具,用于部署前端项目。
gitea-1.13-windows-4.0-amd64.exe 下载。localhost:3000 就能看到 Gitea 已经运行在你的电脑上了。SQLite3。另外把 localhost 改成你电脑的局域网地址,例如我的电脑 IP 为 192.168.0.118。
5. 填完信息后,点击立即安装,等待一会,即可完成配置。
6. 继续点击注册用户,第一个注册的用户将会成会管理员。
7. 打开 Gitea 的安装目录,找到 custom\conf\app.ini,在里面加上一行代码 START_SSH_SERVER = true。这时就可以使用 ssh 进行 push 操作了。
8. 如果使用 http 的方式无法克隆项目,请取消 git 代理。
git config --global --unset http.proxy
git config --global --unset https.proxy

Logon Type 时,选择第一个。http://localhost:8000 网站,这时需要等待一会,进行初始化。
6. 安装插件,选择第一个。
8. 配置完成后自动进入首页,这时点击 Manage Jenkins -> Manage plugins 安装插件。
9. 点击 可选插件,输入 nodejs,搜索插件,然后安装。
10. 安装完成后回到首页,点击 Manage Jenkins -> Global Tool Configuration 配置 nodejs。如果你的电脑是 win7 的话,nodejs 版本最好不要太高,选择 v12 左右的就行。
npm init -y,初始化项目。npm i express 下载 express。server.js 文件,代码如下:const express = require('express')
const app = express()
const port = 8080
app.use(express.static('dist'))
app.listen(port, () => {
console.log(`Example app listening at http://localhost:${port}`)
})它将当前目录下的 dist 文件夹设为静态服务器资源目录,然后执行 node server.js 启动服务器。
由于现在没有 dist 文件夹,所以访问网站是空页面。
不过不要着急,一会就能看到内容了。
2. 打开 Jenkins 首页,点击 新建 Item 创建项目。
3. 选择源码管理,输入你的 Gitea 上的仓库地址。


execute windows batch command,linux 要选 execute shell。
npm i && npm run build && xcopy .\build\* G:\node-server\dist\ /s/e/y,这行命令的作用是安装依赖,构建项目,并将构建后的静态资源复制到指定目录 G:\node-server\dist\ 。这个目录是静态服务器资源目录。
build now。
10. 构建成功,打开 http://localhost:8080/ 看一下结果。
11. 由于刚才设置了每 5 分钟构建一次,我们可以改变一下网站的内容,然后什么都不做,等待一会再打开网站看看。
12. 把修改的内容提交到 Gitea 服务器,稍等一会。打开网站,发现内容已经发生了变化。
使用流水线构建项目可以结合 Gitea 的 webhook 钩子,以便在执行 git push 的时候,自动构建项目。
点击首页右上角的用户名,选择设置。
添加 token,记得将 token 保存起来。
打开 Jenkins 首页,点击 新建 Item 创建项目。
4. 点击构建触发器,选择触发远程构建,填入刚才创建的 token。
5. 选择流水线,按照提示输入内容,然后点击保存。
6. 打开 Jenkins 安装目录下的 jenkins.xml 文件,找到 <arguments> 标签,在里面加上 -Dhudson.security.csrf.GlobalCrumbIssuerConfiguration.DISABLE_CSRF_PROTECTION=true。它的作用是关闭 CSRF 验证,不关的话,Gitea 的 webhook 会一直报 403 错误,无法使用。加好参数后,在该目录命令行下输入 jenkins.exe restart 重启 Jenkins。
7. 回到首页,配置全局安全选项。勾上匿名用户具有可读权限,再保存。
仓库设置。
管理 web 钩子,添加 web 钩子,钩子选项选择 Gitea。添加 web 钩子。
11. 点击创建好的 web 钩子,拉到下方,点击测试推送。不出意外,应该能看到推送成功的消息,此时回到 Jenkins 首页,发现已经在构建项目了。
12. 由于没有配置 Jenkinsfile 文件,此时构建是不会成功的。所以接下来需要配置一下 Jenkinsfile 文件。将以下代码复制到你 Gitea 项目下的 Jenkinsfile 文件。jenkins 在构建时会自动读取文件的内容执行构建及部署操作。
pipeline {
agent any
stages {
stage('Build') {
steps { // window 使用 bat, linux 使用 sh
bat 'npm i'
bat 'npm run build'
}
}
stage('Deploy') {
steps {
bat 'xcopy .\\build\\* D:\\node-server\\dist\\ /s/e/y' // 这里需要改成你的静态服务器资源目录
}
}
}
}
push 操作时,Gitea 都会通过 webhook 发送一个 post 请求给 Jenkins,让它执行构建及部署操作。
如果你的操作系统是 Linux,可以在 Jenkins 打包完成后,使用 ssh 远程登录到阿里云,将打包后的文件复制到阿里云上的静态服务器上,这样就能实现阿里云自动部署了。具体怎么远程登录到阿里云,请看下文中的 《Github Actions 部署到阿里云》 一节。
如果你的项目是 Github 项目,那么使用 Github Actions 也许是更好的选择。
接下来看一下如何使用 Github Actions 部署到 Github Page。
在你需要部署到 Github Page 的项目下,建立一个 yml 文件,放在 .github/workflow 目录下。你可以命名为 ci.yml,它类似于 Jenkins 的 Jenkinsfile 文件,里面包含的是要自动执行的脚本代码。
这个 yml 文件的内容如下:
name: Build and Deploy
on: # 监听 master 分支上的 push 事件
push:
branches:
- master
jobs:
build-and-deploy:
runs-on: ubuntu-latest # 构建环境使用 ubuntu
steps:
- name: Checkout
uses: actions/[email protected]
with:
persist-credentials: false
- name: Install and Build # 下载依赖 打包项目
run: |
npm install
npm run build
- name: Deploy # 将打包内容发布到 github page
uses: JamesIves/[email protected] # 使用别人写好的 actions
with: # 自定义环境变量
ACCESS_TOKEN: ${{ secrets.VUE_ADMIN_TEMPLATE }} # VUE_ADMIN_TEMPLATE 是我的 secret 名称,需要替换成你的
BRANCH: master
FOLDER: dist
REPOSITORY_NAME: woai3c/woai3c.github.io # 这是我的 github page 仓库
TARGET_FOLDER: github-actions-demo # 打包的文件将放到静态服务器 github-actions-demo 目录下
上面有一个 ACCESS_TOKEN 变量需要自己配置。
settings。
developer settings。
Personal access tokens(个人访问令牌)。
Generate new token(生成新令牌)。
repo。
Generate token,并将生成的 token 保存起来。
7. 打开你的 Github 项目,点击 settings。
点击 secrets->new secret。
创建一个密钥,名称随便填(中间用下划线隔开),内容填入刚才创建的 token。
将上文代码中的 ACCESS_TOKEN: ${{ secrets.VUE_ADMIN_TEMPLATE }} 替换成刚才创建的 secret 名字,替换后代码如下 ACCESS_TOKEN: ${{ secrets.TEST_A_B }}。保存后,提交到 Github。
以后你的项目只要执行 git push,Github Actions 就会自动构建项目并发布到你的 Github Page 上。
Github Actions 的执行详情点击仓库中的 Actions 选项查看。
具体详情可以参考一下我的 demo 项目 github-actions-demo。
构建成功后,打开 Github Page 网站,可以发现内容已经发布成功。
root(默认用户名),密码为你刚才重置的实例密码sudo apt-get update && sudo apt-get upgrade -ysudo apt-get install npmsudo npm install -g nsudo n stablemkdir node-server // 创建 node-server 文件夹
cd node-server // 进入 node-server 文件夹
npm init -y // 初始化项目
npm i express
touch server.js // 创建 server.js 文件
vim server.js // 编辑 server.js 文件将以下代码输入进去(用 vim 进入文件后按 i 进行编辑,保存时按 esc 然后输入 :wq,再按 enter),更多使用方法请自行搜索。
const express = require('express')
const app = express()
const port = 3388 // 填入自己的阿里云映射端口,在网络安全组配置。
app.use(express.static('dist'))
app.listen(port, '0.0.0.0', () => {
console.log(`listening`)
})执行 node server.js 开始监听,由于暂时没有 dist 目录,先不要着急。
注意,监听 IP 必须为 0.0.0.0 ,详情请看部署Node.js项目注意事项。
阿里云入端口要在网络安全组中查看与配置。
请参考创建SSH密钥对和绑定SSH密钥对 ,将你的 ECS 服务器实例和密钥绑定,然后将私钥保存到你的电脑(例如保存在 ecs.pem 文件)。
打开你要部署到阿里云的 Github 项目,点击 setting->secrets。
点击 new secret
secret 名称为 SERVER_SSH_KEY,并将刚才的阿里云密钥填入内容。
点击 add secret 完成。
在你项目下建立 .github\workflows\ci.yml 文件,填入以下内容:
name: Build app and deploy to aliyun
on:
#监听push操作
push:
branches:
# master分支,你也可以改成其他分支
- master
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v1
- name: Install Node.js
uses: actions/setup-node@v1
with:
node-version: '12.16.2'
- name: Install npm dependencies
run: npm install
- name: Run build task
run: npm run build
- name: Deploy to Server
uses: easingthemes/[email protected]
env:
SSH_PRIVATE_KEY: ${{ secrets.SERVER_SSH_KEY }}
ARGS: '-rltgoDzvO --delete'
SOURCE: dist # 这是要复制到阿里云静态服务器的文件夹名称
REMOTE_HOST: '118.190.217.8' # 你的阿里云公网地址
REMOTE_USER: root # 阿里云登录后默认为 root 用户,并且所在文件夹为 root
TARGET: /root/node-server # 打包后的 dist 文件夹将放在 /root/node-server保存,推送到 Github 上。
以后只要你的项目执行 git push 操作,就会自动执行 ci.yml 定义的脚本,将打包文件放到你的阿里云静态服务器上。
这个 Actions 主要做了两件事:
如果还是不懂,建议看一下我的 demo。
ci.yml 配置文件讲解name,表示这个工作流程(workflow)的名称。on,表示监听的意思,后面可以加上各种事件,例如 push 事件。下面这段代码表示要监听 master 分支的 push 事件。当 Github Actions 监听到 push 事件发生时,它就会执行下面 jobs 定义的一系列操作。
name: Build app and deploy to aliyun
on:
#监听push操作
push:
branches:
# master分支,你也可以改成其他分支
- master
jobs:
...jobs,看字面意思就是一系列的作业,你可以在 jobs 字段下面定义很多作业,例如 job1、job2 等等,并且它们是并行执行的。jobs:
job1:
...
job2:
...
job3:
...回头看一下 ci.yml 文件,它只有一个作业,即 build,作业的名称是自己定义的,你叫 good 也可以。
runs-on,表示你这个工作流程要运行在什么操作系统上,ci.yml 文件定义的是最新稳定版的 ubuntu。除了 ubuntu,它还可以选择 Mac 或 Windows。
steps,看字面意思就是一系列的步骤,也就是说这个作业由一系列的步骤完成。例如先执行 step1,再执行 step2...
setps 步骤讲解setps 其实是一个数组,在 YAML 语法中,以 - 开始就是一个数组项。例如 ['a', 'b', 'c'] 用 YAML 语法表示为:
- a
- b
- c所以 setps 就是一个步骤数组,从上到下开始执行。从 ci.yml 文件来看,每一个小步骤都有几个相关选项:
name,小步骤的名称。uses,小步骤使用的 actions 库名称或路径,Github Actions 允许你使用别人写好的 Actions 库。run,小步骤要执行的 shell 命令。env,设置与小步骤相关的环境变量。with,提供参数。综上所述,ci.yml 文件中的 setps 就很好理解了,下面从头到尾解释一边:
steps:
- uses: actions/checkout@v1
- name: Install Node.js
uses: actions/setup-node@v1
with:
node-version: '12.16.2'
- name: Install npm dependencies
run: npm install
- name: Run build task
run: npm run build
- name: Deploy to Server
uses: easingthemes/[email protected]
env:
SSH_PRIVATE_KEY: ${{ secrets.SERVER_SSH_KEY }}
ARGS: '-rltgoDzvO --delete'
SOURCE: dist # 这是要复制到阿里云静态服务器的文件夹名称
REMOTE_HOST: '118.190.217.8' # 你的阿里云公网地址
REMOTE_USER: root # 阿里云登录后默认为 root 用户,并且所在文件夹为 root
TARGET: /root/node-server # 打包后的 dist 文件夹将放在 /root/node-serveractions/checkout@v1 库克隆代码到 ubuntu 上。actions/setup-node@v1 库安装 nodejs,with 提供了一个参数 node-version 表示要安装的 nodejs 版本。ubuntu 的 shell 上执行 npm install 下载依赖。npm run build 打包项目。easingthemes/[email protected] 库,这个库的作用就是用 SSH 的方式远程登录到阿里云服务器,将打包好的文件夹复制到阿里云指定的目录上。从 env 上可以看到,这个 actions 库要求我们提供几个环境变量:
SSH_PRIVATE_KEY: 阿里云密钥对中的私钥(需要你提前写在 github secrets 上),ARGS: '-rltgoDzvO --delete',没仔细研究,我猜是复制完文件就删除掉。SOURCE:打包后的文件夹名称REMOTE_HOST: 阿里云公网 IP 地址REMOTE_USER: 阿里云服务器的用户名TARGET: 你要拷贝到阿里云服务器指定目录的名称如果你想了解一下其他 actions 库的实现,可以直接复制 actions 库的名称去搜索引擎搜索一下,例如搜索 actions/checkout 的结果为:
都看到这了,给个赞再走吧。
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.