vaticle / typedb-ml Goto Github PK
View Code? Open in Web Editor NEWTypeDB-ML is the Machine Learning integrations library for TypeDB
Home Page: https://vaticle.com
License: Apache License 2.0
TypeDB-ML is the Machine Learning integrations library for TypeDB
Home Page: https://vaticle.com
License: Apache License 2.0


















































































































































Walk the schema to find schemas concept types and their hierarchies. This is required in order to encode information about these types in the TensorFlow pipeline, so that the framework has the capacity to learn the impact of a node having a particular type, and the influence of that type's super-types.
Needed by #13
This issue was originally posted by @sorsaffari on 2018-09-17 19:49.
Based on the response(s) returned from the API, as implemented here, the schema for the Grakn knowledge graph needs to be defined and loaded into a keyspace.
Write an interface to allow users to easily create a KGCN instance for their own purposes.
Needed by #13
This issue was originally posted by @kasper-piskorski on 2018-08-30 13:22.
Same problem as the related ticker but at the core API level (attributes, owners calls)
The README.md describes what KGCN is, but it does not describe how it will be beneficial for users.
We should have a use-case section describing the kind of problems in which KGCN makes sense as a solution.
At present, the approach used is close to the approach described in GraphSAGE, which assumes homogenous data.
The downside of this approach are:
A, but 10,000 of Type B, how do we choose to sample these?Working on Grakn, we have type information that allows us to understand the nature of the neighbours a Thing has. The network architecture should make use of this.
Ingest data that describes the traversals from a batch of starting concepts and build float tensors to feed into the main trunk of the pipeline.
Requires:
Right now the deployment test:
pip installThese tests do not verify whether the Pip package are well-formed therefore we should have a test which performs basic sanity checks on the installed package, for example, by attempting to import and instantiate the kglib from a real Python program.
Take Grakn traversals and from these build sets of numpy arrays to act as initial feed tensors for TensorFlow.
Needed by #13
If there are 2 workflows running at the same time, since date is used as the VERSION number for test PyPi, and the highest number is used as the latest, then the wrong version may be used by the next job in one of those workflows. That job is end-to-end-test.
This issue was originally posted by @jmsfltchr on 2018-09-12 17:07.
Research into how to represent graph structure as a vector for use as input to machine learning pipelines.
This issue was originally posted by @jmsfltchr on 2018-09-14 12:42.
Why:
Expert Systems are critical for a variety of domains, including chatbots, and medical diagnostics (for their transparency over ML systems)
How:
Research and disseminate how to build a general ES framework for Grakn to demonstrate Grakn's usefulness in this domain.
TensorFlow Hub components can take some time to download the pre-trained network. This happens silently which makes it look as if the program has hung.
Hi there! This is neither a bug report nor a feature request, so I hope you don't mind me posting this here.
My name is Reed, and I'm a software engineering researcher at Sandia National Laboratories in the US. I've created an issue on your repo just to ask a quick question. If you don't have time or don't care to respond, feel free to ignore me and/or delete this issue.
Where I work, we have a very diverse ecosystem of cutting-edge research codes spanning every discipline you could imagine. I'm part of our software engineering research department, and it's our job to keep that ecosystem robust and healthy. Part of that means helping scientists to adopt good software practices. Right now, my mind has been on software versioning/release schemes (e.g. semantic versioning).
In order to build a case for/against getting my people on-board with the practice, I figured I should ask people who already use versioning to release their software to see what they think. So I gathered up a list of scientific software repositories on GitHub, then I selected those that tracked versioned releases, that were reasonably active, etc. Finally, I picked a handful of those repos and decided to reach out to them. You were on that list.
Anyway, here's the question:
What do you believe are the benefits (or drawbacks) of having versioned releases of your software (i.e. 1.0.0, 1.1.0, 2.0.0...)? When should someone start thinking about versioning/releasing their code?
Just a sentence or two, that's all I need. For context, imagine the preceding sentence is this: "But don't just take my word for it, just listen to what these accomplished researchers have to say!".
Thank you so much!
Reed Milewicz
[email protected]
The objective is to prototype a method of building vector representations of Concepts in a Knowledge Graph. These vectors can then subsequently be used in machine learning pipelines in order to perform learning across the graph.
As below, the dataset has been hard-coded. Ideally we shouldn't piggyback on release data for testing.
http_file(
name = "animaltrade_dist",
urls = ["https://github.com/graknlabs/kglib/releases/download/v0.1a1/grakn-animaltrade.zip", # TODO How to update to the latest relase each time?
]
)
Presently it is very difficult to architect a concise way to normalise attribute values.
Current problems include:
long, double, string, date and boolean in case they are an Attribute. In the case that a Thing is an Attribute, then only one of these values will be set to non-default.preprocessing.StandardScaler() of scikit-learnShould be made easier to accomplish by solving #51
We require a way to test that kglib can be imported via pip. This requires a dedicated test that can be run independent of other typical tests. This test, using bazel, should depend on the latest deployment to the test PyPI server.
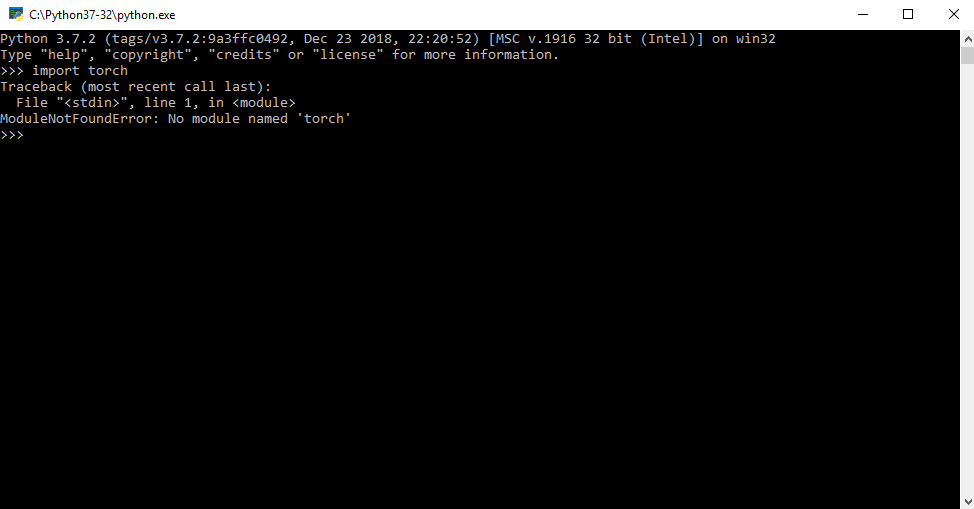
I try to install pytorch and after days of trying Im here with a big, big problem. I read a lot of articles of "how to install pytorch" I try to install with pip install but dont work for me and after I install it with Anaconda, but in anaconda is pytorch install, when I type: conda list, he is there like this form: pytorch 1.0.1 py3.7_cuda100_cudnn7_1 pytorch, I have python 3.7, when I run a code with import torch this show me a message like this:
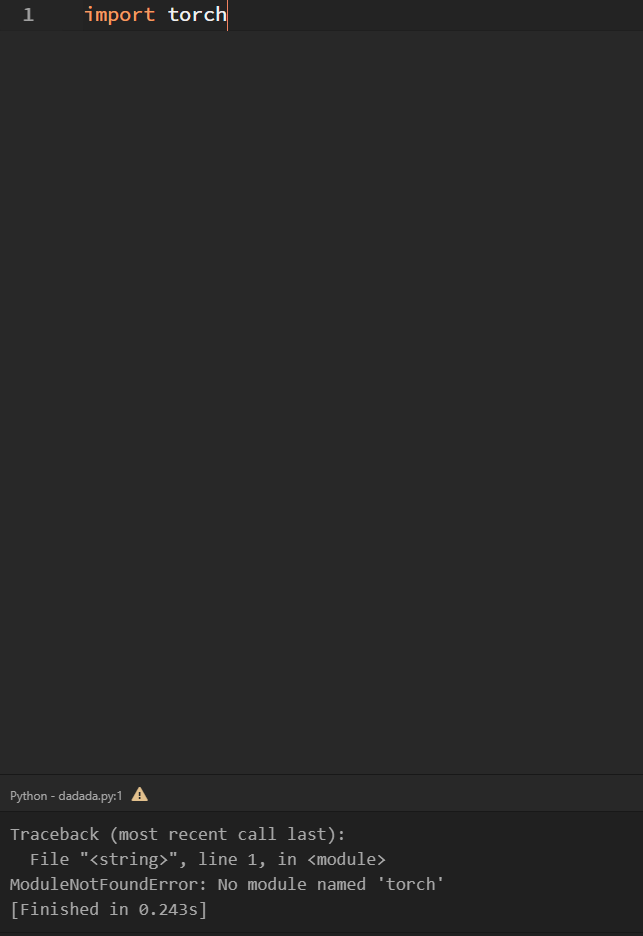
And when i try to import torch in python 3.7:
Pip install error:
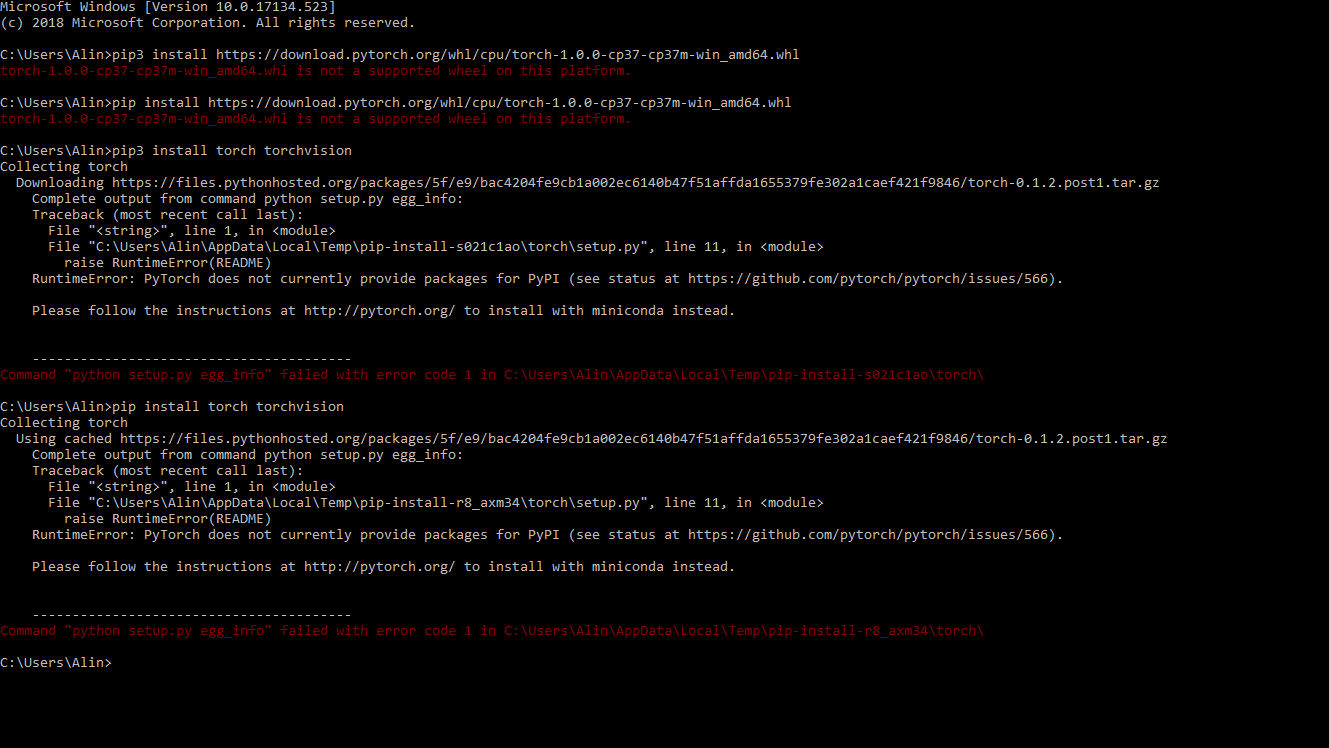
How to pass this errors? Please Help, thx.
This issue was originally posted by @tomassabat on 2018-08-22 17:12.
Write a biomedical white paper to outline the value proposition of Grakn in the biomed field. This is done by building a BioGrakn knowledge graph, and using examples demonstrating why Grakn is valuable to use for bioinformaticians.
The animal trade example currently sits in a sub-directory of kglib, which means it is accessible when importing via pip. This should not be the case.
Hi,
do you plan to add support for pytorch models?
Revisit neighbourhood traversals. Tests are currently insufficient for this module to be trustworthy.
Needed by #13
Given that KGLIB's codebase is still in its infancy right now, it's good to start putting a code quality system enforce early on. Let's add this as part of PR and master workflow.
Feature values once encoded need to be normalised relative to the other values for the same attribute type. This is necessary since we can expect that different attribute types (of the same datatype) will have wildly different distributions.
Needed by #13
This issue was originally posted by @jmsfltchr on 2018-09-17 14:14.
This issue was originally posted by @jmsfltchr on 2018-08-31 17:29.
Why
To explore the benefits of combining Grakn with Machine Learning
How
Investigate the integration of machine learning with Grakn.
Efforts to include:
This issue was originally posted by @jmsfltchr on 2018-08-31 17:27.
Is it possible to create a random forest that sits inside Grakn so that it can be used for classification/regression at query-time? This experiment has not yet gone far enough to determine feasibility in terms of speed. The blocker that was encountered before this was being able to perform aggregations in rules, because we need to do aggregate mode inside a rule in order to implement the majority voting of trees in a forest to classify an example. Performing this operation outside Grakn seems to defeat the point of embedding the forest in Grakn at all. I have made no effort to consider how to build or "train" (*1) the forest. This training (*1) could be done in application code and then the tree translated into Grakn. *1 by "training" I mean that the trees are not built totally randomly, the discrimination boundary picked for each node (and which feature to use, picked from a random set?) is picked based upon the basis of what divides the data the most.
This issue was originally posted by @jmsfltchr on 2018-09-03 12:09.
Write a guide on how to build a schema that we can use for our own reference, and to point the community towards.
KGLIB should be automatically updated to depend upon the latest commit
Currently the dependencies must be updated manually.
Have Grabl automatically update the commits that are depended upon.
Scope of the CI pipeline:
All tests rerun from cold, which is unnecessary if large amounts of source code are unchanged.
Ignore this computational penalty
Use RBE with bazel to cache test results
Hi,
Is this framework usable on any RDF graph or is it only for grakn graphs ?
Thanks
In KGLIB we wish to conduct tests in CI against the latest releases of graknlabs/client-python and graknlabs/grakn. This is to ensure that user experience is aligned with the testing conditions in CI. We wish to do this by depending upon git repositories by tag with bazel, using sync-dependencies to auto-update the tags to reflect the latest releases.
It is common that the latest release of graknlabs/client-python and the latest release of graknlabs/grakn depend upon different commits of graknlabs/build-tools. Using bazel there is no way to use graknlabs/build-tools with two different versions. This is due to the fact that both of these repositories refer to graknlabs/build-tools as @graknlabs_build_tools.
This transitive dependency misalignment makes it impossible to both use bazel and test against the latest releases of graknlabs/client-python and graknlabs/grakn.
Depend upon graknlabs/client-python and graknlabs/grakn by commit and use sync-dependencies, in which case they both use the same version of graknlabs/build-tools, hence resolving the conflict.
In this case we only test against the latest releases of graknlabs/client-python and graknlabs/grakn in the test-deployment-pip job in CI, when we use a deployed snapshot of KGLIB, which will depend upon a released version of client-python. This version must be manually updated in install_requires of assemble_pip.
This test will also use a released version of Grakn, retrieved as a zip.
Add functionality to bazel to permit including transitive dependencies in a scoped way, such that graknlabs/client-python, graknlabs/grakn and graknlabs/kglib can each depend upon a different version of graknlabs/build-tools without conflicting.
This issue was originally posted by @sorsaffari on 2018-09-05 18:39.
As the first step in writing an example to illustrate how BLAST can be used with a Grakn Knowledge Graph. - try with a single protein sequence - try with a file containing multiple protein sequences - assess the result
Translate the approach of GraphSAGE to the context of Grakn, taking inspiration from the author's code where applicable. Implement first cut implementation for inference, loss and optimisation. Test using dummy data as a stand-in for an encoding pipeline.
needed by #13
Maybe there is a clerical error that exists in the sentence :"Delete all appendix attributes from both animaltrade_train and animaltrade_test keyspaces. This is the label we will predict in this example, so it should not be present in Grakn otherwise the network can cheat"
Here the animaltrade_train may should be animaltrade_eval. Just let me know if that's right.
This issue was originally posted by @jmsfltchr on 2018-09-11 11:34.
Track the papers of interest found during my research into how to do ML over a knowledge graph. Develop a schema sophisticated enough to capture this information fully.
Build a classification example using KGCN to predict attribute labels on our Animal Trade dataset
A CI workflow which reaches an approval step, where approval is not given, is indicated as pending (orange). This is misleading as it gives the impression that tests have not passed. Approval is only given when releasing, so this problem is very common.
Inspect the pending flag to see how far the workflow progressed
Use a custom approval system
I can't get to install grakn-kglib. After I run "pip3 install grakn-kglib" (inside a new venv), I receive this error:
Could not find a version that satisfies the requirement tensorflow==1.11.0 (from grakn-kglib) (from versions: ) No matching distribution found for tensorflow==1.11.0 (from grakn-kglib)
I'm running python 3.7.1.
This link is presently relative and should be made absolute.
At present there are several terms that may need explaining to avoid confusion. For example:
neighbourhoodexample is (either a Thing we want to embed/classify or example code)This will be used to build a cohesive architecture for the project.
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.