toodef / neural-pipeline Goto Github PK
View Code? Open in Web Editor NEWNeural networks training pipeline based on PyTorch
Home Page: https://neural-pipeline.readthedocs.io
License: MIT License
Neural networks training pipeline based on PyTorch
Home Page: https://neural-pipeline.readthedocs.io
License: MIT License













































































































This need after 0.2 performance increase release.
Need to add to documentation guide about how to use Neural Pipeline more effective.
It's really useful to manage and customize console output by separated class.
Also, this makes possible to include some info to console:
The idea is cpu and gpu occupancy monitoring for analyse code pervormance
serialisation ---> serialization
initialisation ---> initialization
For solving this issue these steps needed:
enable_grads_acumulation(steps_num: int) to Trainer classFor do this test need to provide same data input to model and same weights in model (last can be done by flushing weights to file).
I was wondering when saw strange results of my metrics. I have custom metrics-wrappers around sklearn metrics:
from neural_pipeline.train_config import AbstractMetric, MetricsProcessor, MetricsGroup
from sklearn.metrics import precision_score, recall_score, accuracy_score
class Metric(AbstractMetric):
def __init__(self, name, function):
super().__init__(name)
self.function = function
def calc(self, output: torch.Tensor, target: torch.Tensor) -> np.ndarray or float:
predicted = output.gt(0.5)
return self.function(target, predicted)
class Metrics(MetricsProcessor):
def __init__(self, stage_name: str):
super().__init__()
accuracy = Metric('accuracy', accuracy_score)
precision = Metric('precision', precision_score)
recall = Metric('recall', recall_score)
self.add_metrics_group(MetricsGroup(stage_name).\
add(accuracy).\
add(precision).\
add(recall))Configuration is following:
train_batch_size = 32
val_batch_size = len(X_test)
train_dataset = DataProducer([Dataset(X_train, y_train)], batch_size=train_batch_size)
validation_dataset = DataProducer([Dataset(X_test, y_test)], batch_size=val_batch_size)
train_stages = [TrainStage(train_dataset, Metrics('train')),
ValidationStage(validation_dataset, Metrics('validation'))]
loss = nn.BCELoss()
optimizer = optim.Adam(model.parameters(), lr=1e-3)
train_config = TrainConfig(train_stages, loss, optimizer)
fsm = FileStructManager(base_dir='data', is_continue=False)
epochs = 1
trainer = Trainer(model, train_config, fsm, device).set_epoch_num(epochs)
trainer.monitor_hub.add_monitor(TensorboardMonitor(fsm, is_continue=False))\
.add_monitor(LogMonitor(fsm))
trainer.train()After training I load the metrics from data/monitors/metrics_log/metrics_log.json I got following results for validation data:

But I did same manually and got different result
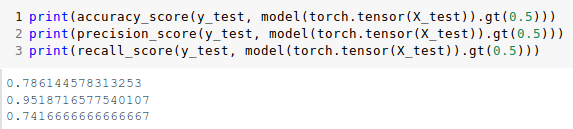
I understand that if I used the batch_size that is not equal to the len of validation dataset I would get a different result. But here this is not the case. Another problem that I also found is result of last training step also differ from those computed manually no matter what value for epochs is used. I can't find error in the code, but it seems to me as magic
Separate Predictor to Predictor and DataProducerPredictor. Predictor just init model and provide an interface to predict one item, DataProducerPredictor - provides an interface to predict all data from DataProducer object.
Also DataProducerPredictor can have interfaces:
Frequently we need to extract part of dataset for test network for example.
We need to implement this feature in DataProducer, cause it'll make possible to not change dataset class. Also, DataProsucer has flushing and loading indices interfaces.
Requirements:
Need to add continue from best checkpoint option to Predictor
There is traceback on screenshot, which happen after resuming train process with "resume" method of Trainer class in the end of last epoch.

Now in np user do Trainer(..., device=torch.device('cuda)).
It's good but bad when we try to pass unexpected data to device.
Need to make possible use callback for this + create some predefinitions.
Need an example for multitask learning to show why train stages needed
TensorboardMonitor "is_continue" flag should be set True
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.