stephengineer / blog Goto Github PK
View Code? Open in Web Editor NEW:memo: Stephen's Blog
Home Page: https://stephengineer.github.io/Blog/
License: MIT License
:memo: Stephen's Blog
Home Page: https://stephengineer.github.io/Blog/
License: MIT License
Note: I will call the demo vue project as Edison for convenience in the following article.
To deploy a vue project as a remote server with Tomcat, to avoid run vue-cli project every time:
$ cd [to your checkout location]
# For example: cd C:\GitProjects\Edison
$ npm install
$ npm run dev
If you want to do so, please do the following steps
Clone Edison repository
$ git clone https://github.com/zhongqi1112/Edison.git
Configuration
Find Edison\config\index.js file change value of build.assetsPublicPath from '/' to './'

Package
$ cd [to your checkout location]
# For example: cd C:\GitProjects\Edison
$ npm install
$ npm run build
You will see a dist folder in the root. There are static folder and index.html inside, these two get ready to deploy to the server.

I introduced how to download, set up, and check the installation of Tomcat in another article, Installation of Tomcat, if you are not familiar with Tomcat please check it out.
Create a folder called Edison in Tomcat folder, for example, .\Tomcat 8.5\webapps\Edison
Copy static folder and index.html in .\Edison\dist, and paste to the folder just created: .\Tomcat 8.5\webapps\Edison

Go to the setup Tomcat server port, for example, http://localhost:8090/
Click on Manager App and enter the username and password you set up during installation

You will see Edison is running in the Applications list.

Go and check it in the browser, http://localhost:8090/Edison, you will see vue project. Or use your IP address instead of localhost.
Note: Hosting config file external to Edison in Tomcat, and access the config file via relative URL. Since it's on the same server Edison can access it by relative URL.
static, this path should match with the config file in Edison repository, in the Tomcat folder, for example, Tomcat 8.5\webapps\staticewbmConfig.json in Edison\static, and paste to the folder just created: Tomcat 8.5\webapps\statichttp://localhost:8090/static/Config.jsonreload on both Edison and static in Tomcat.
I introduced how to change permissions of Tomcat, Change Tomcat users' information, change project port, and start or stop Tomcat server in my other article, Configuration of Tomcat
If you get any questions feel free to contact me.
On basis of the nature of the learning “signal” or “feedback” available to a learning system
Supervised learning: The computer is presented with example inputs and their desired outputs, given by a “teacher”, and the goal is to learn a general rule that maps inputs to outputs. The training process continues until the model achieves the desired level of accuracy on the training data. Some real-life examples are:
Unsupervised learning: No labels are given to the learning algorithm, leaving it on its own to find structure in its input. It is used for the clustering population in different groups. Unsupervised learning can be a goal in itself (discovering hidden patterns in data).
Semi-supervised learning: Problems where you have a large amount of input data and only some of the data is labeled, are called semi-supervised learning problems. These problems sit in between both supervised and unsupervised learning. For example, a photo archive where only some of the images are labeled, (e.g. dog, cat, person) and the majority are unlabeled.
Reinforcement learning: A computer program interacts with a dynamic environment in which it must perform a certain goal (such as driving a vehicle or playing a game against an opponent). The program is provided feedback in terms of rewards and punishments as it navigates its problem space.
On the basis of “output” desired from a machine-learned system
Some commonly used machine learning algorithms are Linear Regression, Logistic Regression, Decision Tree, SVM(Support vector machines), Naive Bayes, KNN(K nearest neighbors), K-Means, Random Forest, etc.
https://www.geeksforgeeks.org/getting-started-machine-learning/
Gradient Descent is an optimization algorithm used for minimizing the cost function in various machine learning algorithms. It is basically used for updating the parameters of the learning model.
Types of gradient Descent:
Linear regression is a statistical approach for modeling the relationship between a dependent variable with a given set of independent variables.
We refer to dependent variables as response and independent variables as features for simplicity.
Simple linear regression is an approach for predicting a response using a single feature.
Multiple linear regression attempts to model the relationship between two or more features and a response by fitting a linear equation to observed data. Clearly, it is nothing but an extension of Simple linear regression. Consider a dataset with p features(or independent variables) and one response(or dependent variable). Also, the dataset contains n rows/observations.
X (feature matrix) = a matrix of size n X p where x_{ij} denotes the values of jth feature for ith observation.
y (response vector) = a vector of size n where y_{i} denotes the value of response for ith observation.
https://www.geeksforgeeks.org/python-implementation-of-polynomial-regression/
In a classification problem, the target variable(or output), y, can take only discrete values for a given set of features(or inputs), X.
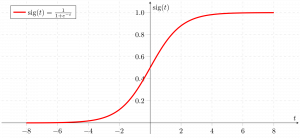
Contrary to popular belief, logistic regression IS a regression model. The model builds a regression model to predict the probability that a given data entry belongs to the category numbered as “1”. Just like Linear regression assumes that the data follows a linear function, Logistic regression models the data using the sigmoid function or *logistic function.
We can infer from the above graph that:
Logistic regression becomes a classification technique only when a decision threshold is brought into the picture. The setting of the threshold value is a very important aspect of Logistic regression and is dependent on the classification problem itself.
The decision for the value of the threshold value is majorly affected by the values of precision and recall. Ideally, we want both precision and recall to be 1, but this seldom is the case. In case of a Precision-Recall tradeoff we use the following arguments to decide upon the threshold:
Low Precision/High Recall: In applications where we want to reduce the number of false negatives without necessarily reducing the number of false positives, we choose a decision value that has a low value of Precision or a high value of Recall. For example, in a cancer diagnosis application, we do not want any affected patient to be classified as not affected without giving much heed to if the patient is being wrongfully diagnosed with cancer. This is because the absence of cancer can be detected by further medical diseases but the presence of the disease cannot be detected in an already rejected candidate.
High Precision/Low Recall: In applications where we want to reduce the number of false positives without necessarily reducing the number of false negatives, we choose a decision value that has a high value of Precision or a low value of Recall. For example, if we are classifying customers whether they will react positively or negatively to a personalized advertisement, we want to be absolutely sure that the customer will react positively to the advertisement because otherwise, a negative reaction can cause a loss of potential sales from the customer.
Based on the number of categories, Logistic regression can be classified as:
1. binomial: target variable can have only 2 possible types: “0” or “1” which may represent “win” vs “loss”, “pass” vs “fail”, “dead” vs “alive”, etc.
2. multinomial: target variable can have 3 or more possible types that are not ordered(i.e. types have no quantitative significance) like “disease A” vs “disease B” vs “disease C”.
3. ordinal: it deals with target variables with ordered categories. For example, a test score can be categorized as: “very poor”, “poor”, “good”, “very good”. Here, each category can be given a score like 0, 1, 2, 3.
A much better way to evaluate the performance of a classifier is to look at the confusion matrix. The general idea is to count the number of times instances of class A are classified as class B. Each row in a confusion matrix represents an actual class, while each column represents a predicted class. We want to predict some data using Classification in Machine Learning. Let the classifier be SVM, Decision Tree, Random Forest, Logistic Regression, and so on.
When we predict that something happens/occurs and it didn't happen/occurred.(rejection of a true null hypothesis) Example: We predict that an earthquake would occur which didn't happen.
When we predict that something won't happen/occur but it happens/occurs.(non-rejection of a false null hypothesis) Example: We predict that there might be no earthquake but there occurs an earthquake.
Usually, type I errors are considered to be not as critical as type II errors. But in fields like Medicine, Agriculture, both the errors might seem critical.
A 2x2 matrix denoting the right and wrong predictions might help us analyze the rate of success. This matrix is termed the Confusion Matrix.
| 0 | 1 | |
|---|---|---|
| 0 | TN | FP |
| 1 | FN | TP |
The horizontal axis corresponds to the predicted values(y-predicted) and the vertical axis corresponds to the actual values(y-actual).
Confusion Matrix can be used in python by importing the metrics module from sklearn.
from sklearn import metrics
cm = metrics.confusion_matrix(y_train, y_train_pred)from sklearn.metrics import accuracy_score
accuracy_score(y_train, y_train_pred)from sklearn.metrics import precision_score
precision_score(y_train, y_train_pred)from sklearn.metrics import recall_score
recall_score(y_train, y_train_pred)It is often convenient to combine precision and recall into a single metric called the F1 score, in particular, if you need a simple way to compare two classifiers. The F1 score is the harmonic mean of precision and recall.
# To compute the F1 score, simply call the f1_score() function:
from sklearn.metrics import f1_score
f1_score(y_train, y_train_pred)The F1 score favors classifiers that have similar precision and recall. This is not always what you want: in some contexts, you mostly care about precision, and in other contexts, you really care about recall. For example, if you trained a classifier to detect videos that are safe for kids, you would probably prefer a classifier that rejects many good videos (low recall) but keeps only safe ones (high precision), rather than a classifier that has a much higher recall but lets a few terrible videos show up in your product (in such cases, you may even want to add a human pipeline to check the classifier’s video selection). On the other hand, suppose you train a classifier to detect shoplifters on surveillance images: it is probably fine if your classifier has only 30% precision as long as it has 99% recall (sure, the security guards will get a few false alerts, but almost all shoplifters will get caught). Unfortunately, you can’t have it both ways: increasing precision reduces recall and vice versa. This is called the precision/recall tradeoff.
https://www.geeksforgeeks.org/confusion-matrix-machine-learning/
https://github.com/Nitin1901/Confusion-Matrix
The likelihood is nothing but the probability of data(training examples), given a model and specific parameter values(here, regression coefficients). It measures the support provided by the data for each possible value of the regression coefficients. And for easier calculations, we take log(likelihood).
The cost function for logistic regression is proportional to the inverse of the likelihood of parameters so that the cost function is minimized using a gradient descent algorithm. where alpha is called learning rate and needs to be set explicitly.
Note: Gradient descent is one of the many ways to estimate regression coefficients.
Basically, these are more advanced algorithms that can be easily run in Python once you have defined your cost function and your gradients. These algorithms are:
In Multinomial Logistic Regression, the output variable can have more than two possible discrete outputs. Consider the Digit Dataset. Here, the output variable is the digit value which can take values out of (0, 12, 3, 4, 5, 6, 7, 8, 9).
At last, here are some points about Logistic regression to ponder upon:
The fundamental Naive Bayes assumption is that each feature makes an:
With relation to our dataset, this concept can be understood as:
Note: The assumptions made by Naive Bayes are not generally correct in real-world situations. In fact, the independence assumption is never correct but often works well in practice.
Other popular Naive Bayes classifiers are:
As we reach the end of this article, here are some important points to ponder upon:
An SVM model is a representation of the examples as points in space, mapped so that the examples of the separate categories are divided by a clear gap that is as wide as possible.
In addition to performing linear classification, SVMs can efficiently perform a non-linear classification, implicitly mapping their inputs into high-dimensional feature spaces.
Entropy is the measure of uncertainty of a random variable, it characterizes the impurity of an arbitrary collection of examples. The higher the entropy more the information content.
The essentials:
The border cases:
The most notable types of decision tree algorithms are:-
The strengths of decision tree methods are:
The weaknesses of decision tree methods :
https://www.geeksforgeeks.org/decision-tree-introduction-example/
https://www.geeksforgeeks.org/decision-tree/
A Random Forest is an ensemble technique capable of performing both regression and classification tasks with the use of multiple decision trees and a technique called Bootstrap and Aggregation, commonly known as bagging. The basic idea behind this is to combine multiple decision trees in determining the final output rather than relying on individual decision trees.
Random Forest has multiple decision trees as base learning models. We randomly perform row sampling and feature sampling from the dataset forming sample datasets for every model. This part is called Bootstrap.
We need to approach the Random Forest regression technique like any other machine learning technique
Ensemble learning helps improve machine learning results by combining several models. This approach allows the production of better predictive performance compared to a single model. Basic idea is to learn a set of classifiers (experts) and to allow them to vote.
The main challenge is not to obtain highly accurate base models, but rather to obtain base models which make different kinds of errors. For example, if ensembles are used for classification, high accuracies can be accomplished if different base models misclassify different training examples, even if the base classifier accuracy is low.
Reliable Classification: Meta-Classifier Approach
Co-Training and Self-Training
Bagging (Bootstrap Aggregation) is used to reduce the variance of a decision tree. Suppose a set D of d tuples, at each iteration i, a training set Di of d tuples is sampled with replacement from D (i.e., bootstrap). Then a classifier model Mi is learned for each training set D < i. Each classifier Mi returns its class prediction. The bagged classifier M* counts the votes and assigns the class with the most votes to X (unknown sample).
Random Forest is an extension over bagging. Each classifier in the ensemble is a decision tree classifier and is generated using a random selection of attributes at each node to determine the split. During classification, each tree votes, and the most popular class is returned.
A Voting Classifier is a machine learning model that trains on an ensemble of numerous models and predicts an output (class) based on their highest probability of chosen class as the output.
It simply aggregates the findings of each classifier passed into Voting Classifier and predicts the output class based on the highest majority of voting. The idea is instead of creating separate dedicated models and finding the accuracy for each of them, we create a single model that trains by these models and predicts output based on their combined majority of voting for each output class.
Voting Classifier supports two types of votings.
Welcome to The Unix Workbench!
echo 'Hello World!'# print the working directory
pwd
# list the files and folders in a directory
lsThe root directory (/) contains all of the folders and files on your computer.
Your home directory (~) is the directory where your terminal always starts.
To use cd to change your working directory to a directory other than your home directory, you need to provide cd with the path to another directory as an argument. You can specify a path as either a path:
# relative path to the Music folder
cd Music
# absolute path to the music folder
cd /users/stephen/music
cd ~/Music. is the path to your current working directory, so cd Music is the same as cd ./Music
.. is a relative path, going to the directory above the current working directory with the command cd ..
Use cd to any folder as long as know the absolute path to that folder. Remember that ~ is a shortcut for the path to your home folder, so cd /Users/stephen/Music is the same as cd ~/Music
Note: Pressing tab shows you a list of all files and folders inside of the current directory. Or add letters to the path, only folders with names that start with letters are listed.
# create a new folder
mkdir Photo
# create a new file
touch 2018.txt
# create a new file using output redirection
echo "I'm in the file." > 2018.txt
# append text to the end of a file
echo "I have been appended." >> 2018.txt
# long list
ls -l
# word count to display lines, words, and characters of file
wc 2018.txt
# print (concatenate) text files to the terminal
cat 2018.txt
cat 2018.txt 2018.txt
# view multi-page for large file
less 2018.txt
# glimpse the beginning or end of a text file
head 2018.txt
tail 2018.txt
# specify the number of lines printed
head -n 4 Documents/2018.txt
# file editor
nano
vim
emacs# move file to a folder
mv 2018.txt Journal
# move folder to folder
mv Journal Documents
# rename 2018.txt to todo.txt
mv 2018.txt todo.txt
# copy file
cp todo.txt Desktop
# copy folder
cp -r Documents Desktop
# remove file
rm todo.txt
# remove folder
rm -r Desktop/Documents# take a look at the documentation for the list
man ls
# to start a search
/
# get back to the prompt
q
# search all of the available commands and their descriptions
aproposThe * (“star”) wildcard represents zero or more of any character, and it can be used to match names of files and folders in the command line.
# list all of the files which have a name that starts with “2017”:
ls 2018*
# list only the files with names ending in .jpg:
ls *.jpg
# list containing 01 in the name:
ls *2018*
# move the files using wildcards:
mv 2018* 2018/
# list the files:
ls 2018/Regular expression, grep requires two arguments: a regular expression and a text file to search.
# search for the state names that contain the word “New”
grep "New" states.txt
## The "." (period) metacharacter, which represents any character.
# search for the character “i”, followed by any character, followed by the character “g”
grep "i.g" states.txt
## The "+" (plus) represents one or more occurrences of the proceeding expression.
# search for one or more “s” followed by “as”
grep "s+as" states.txt
## The "*" (star) metacharacter which represents zero or more occurrences of the preceding expression.
# search for zero or more “s” followed by “as”
grep "s*as" states.txt
## Curly brackets ({ }) to specify an exact number of occurrences of an expression.
# search for exactly two occurrences of the character “s”
grep "s{2}" states.txt
# search for having between two and three adjacent occurrences of the letter “s”
grep "s{2,3}" states.txt
## Parentheses ("( )") to create capturing groups within regular expressions.
# search for the string “iss” occurring twice
grep "(iss){2}" states.txt
# search for three occurrences of an “i” followed by two of any character:
grep "(i.{2}){3}" states.txt
## The \w metacharacter corresponds to all “word” characters. \W for non-words.
# search for characters
grep "\w" states.txt
# returned strings all contain non-word characters.
grep "\W" states.txt
## The -v flag (which stands for invert match) makes grep return all of the lines not matched by the regular expression.
# compliment of grep
grep -v "\w" states.txt
## The \d metacharacter corresponds to all “number” characters. \D for non-digits.
# search for numbers
grep "\d" states.txt
# search space
## The \s metacharacter corresponds to all “space” characters. \S for non-spaces.
grep "\s" states.txt
## Square brackets ([ ]) to create specific character sets.
# search for the set of vowels is [aeiou]
grep "[aeiou]" states.txt
## The complement of a set by including a caret (^) in the beginning of a set.
# search for contains at least one non-vowel
grep "[^aeiou]" states.txt
## Range of characters you can use a hyphen (-) inside of the square brackets.
# search for all of the lowercase letters between “e” and “q”
grep "[e-q]" states.txt
# search for all of the uppercase letters between “e” and “q”
grep "[E-Q]" states.txt
# search for all letters between “e” and “q” ignore case
grep "[e-qE-Q]" states.txt
## Backslash () before the plus sign in a regex, in order to “escape” the metacharacter functionality
grep "\+" states.txt
grep "\." states.txt
## The caret (^), which represents the start of a line, and the dollar sign ($) which represents the end of line.
grep "^M" states.txt
mnemonic: “First you get the power, then you get the money.” The caret character is used for exponentiation in many programming languages, so “power” (^) is used for the beginning of a line and “money” ($) is used for the end of a line.
## The “or” metacharacter (|), which is also called the “pipe” character.
grep "North|South" states.txt
grep "North|South|East|West" states.txt
## Display the line number that a match occurs on using the -n flag
grep -n "t$" states.txt
# can also grep multiple files at once by providing multiple file arguments
grep "New" states.txt canada.txt
# both begin and end with a vowel
grep "^[AEIOU]{1}.+[aeiou]{1}$" states.txt| Metacharacter | Meaning |
|---|---|
| . | Any Character |
| \w | A Word |
| \W | Not a Word |
| \d | A Digit |
| \D | Not a Digit |
| \s | Whitespace |
| \S | Not Whitespace |
| [def] | A Set of Characters |
| [^def] | Negation of Set |
| [e-q] | A Range of Characters |
| ^ | Beginning of String |
| $ | End of String |
| \n | Newline |
| + | One or More of Previous |
| * | Zero or More of Previous |
| ? | Zero or One of Previous |
| | | Either the Previous or the Following |
| {6} | Exactly 6 of Previous |
| {4, 6} | Between 4 and 6 or Previous |
| {4, } | More than 4 of Previous |
find . -name "states.txt"
find . -name "*.jpg"history
# take a look at the beginning of this file
head -n 5 ~/.bash_history
grep "canada" ~/.bash_history
# creates a shorter name for a command
# creates new command docs.
alias docs='cd ~/Documents'
# creates the command edbp (edit bash profile) so that you can quickly add aliases.
alias edbp='nano ~/.bash_profile'
# edit our ~/.bash_profile with nano. Add the line alias docs='cd ~/Documents', then save the file and quit nano.
# make the changes to our ~/.bash_profile take effect we need to run
source ~/.bash_profile# make two small simple text files in the Documents directory.
cd ~/Documents
head -n 4 states.txt > four.txt
head -n 6 states.txt > six.txt
# lines in these files are different we can use the diff
diff four.txt six.txt
# compare differing lines in a side-by-side comparison using sdiff:
sdiff four.txt six.txt## The pipe (|) takes the output of the program on its left side and directs the output to be the input for the program on its right side.
# cat canada.txt | head -n 5
cat canada.txt | head -n 5
# How many state names that end with a vowel,
grep "[aeiou]$" states.txt | wc -l
ls -al | grep "Feb" | lesscd ~/Documents/Journal
nano makefile
make draft_journal_entry.txt
# update our makefile with nano to automatically generate a readme.txt:
nano makefile
draft_journal_entry.txt:
touch draft_journal_entry.txt
readme.txt: toc.txt
echo "This journal contains the following number of entries:" > readme.txt
wc -l toc.txt | egrep -o "[0-9]+" >> readme.txt
make readme.txt
Rules
# Notice that there are no spaces on either side of the equals sign
chapter_number=5
# print the data in a variable
echo $chapter_number
# modify the value of a variable
let chapter_number=$chapter_number+1
# store strings in variables
the_empire_state="New York"
# store the result of that command in a variable
math_lines=$(cat math.sh | wc -l)
# Variable names with a dollar sign can also be used inside other strings
echo "I went to school in $the_empire_state."
# The first argument to your script is stored in $1, the second argument is stored in $2, etc, etc.
# An array of all of the arguments passed to your script is stored in $@
# The total number of arguments passed to your script is stored in $#
#!/usr/bin/env bash
# File: vars.sh
echo "Script arguments: $@"
echo "First arg: $1. Second arg: $2."
echo "Number of arguments: $#"
bash vars.sh red blue green
## Script arguments: red blue green
## First arg: red. Second arg: blue.
## Number of arguments: 3#!/usr/bin/env bash
# File: letsread.sh
echo "Type in a string and then press Enter:"
read response
echo "You entered: $response"# The exit status of a program is an integer, the exit status of the last program run is stored in the question mark variable ($?).
echo $?
# true has an exit status of 0 and false has an exit status of 1
true
echo $?
## 0
false
echo $?
## 1
# the program on the right hand side of && will only be executed if the program on the left hand side of && has an exit status of 0
true && echo "Program 1 was executed."
false && echo "Program 2 was executed."
false && true && echo Hello
echo 1 && false && echo 3
echo Athos && echo Porthos && echo Aramis
## Program 1 was executed.
## 1
## Athos
## Porthos
## Aramis
# Commands on the right-hand side of || are only executed if the command on the left-hand side fails
true || echo "Program 1 was executed."
false || echo "Program 2 was executed."
false || echo 1 || echo 2
echo 3 || false || echo 4
echo Athos || echo Porthos || echo Aramis
## Program 2 was executed.
## 1
## 3
## Athos
echo Athos || echo Porthos && echo Aramis
echo Gaspar && echo Balthasar || echo Melchior
## Athos
## Aramis
## Gaspar
## Balthasar
# Conditional expressions either compare two values, or they ask a question about one value. Conditional expressions are always between double brackets ([[ ]]), and they either use logical flags or logical operators.
[[ 4 -gt 3 ]]
echo $?
## 0
[[ 3 -gt 4 ]]
echo $?
## 1
# use the AND and OR operators so that an expression will print “t” if it’s true and “f” if its false:
[[ 4 -gt 3 ]] && echo t || echo f
[[ 3 -gt 4 ]] && echo t || echo f
## t
## fThere are several other varieties of logical flags
| Logical Flag | Meaning | Usage |
|---|---|---|
| -gt | Greater Than | [[ $planets -gt 8 ]] |
| -ge | Greater Than or Equal To | [[ $votes -ge 270 ]] |
| -eq | Equal | [[ $fingers -eq 10 ]] |
| -ne | Not Equal | [[ $pages -ne 0 ]] |
| -le | Less Than or Equal To | [[ $candles -le 9 ]] |
| -lt | Less Than | [[ $wives -lt 2 ]] |
| -e | A File Exists | [[ -e $taxes_2016 ]] |
| -d | A Directory Exists | [[ -d $photos ]] |
| -z | Length of String is Zero | [[ -z $name ]] |
| -n | Length of String is Non-Zero | [[ -n $name ]] |
Here’s a table of some of the useful logical operators in case you need to reference how they’re used later:
| Logical Operator | Meaning | Usage |
|---|---|---|
| =~ | Matches Regular Expression | [[ $consonants =~ [aeiou] ]] |
| = | String Equal To | [[ $password = "pegasus" ]] |
| != | String Not Equal To | [[ $fruit != "banana" ]] |
| ! | Not | [[ ! "apple" =~ ^b ]] |
One of the fundamental constructs in Bash programming is the IF statement.
#!/usr/bin/env bash
# File: nested.sh
if [[ $1 -gt 3 ]] && [[ $1 -lt 7 ]]
then
if [[ $1 -eq 4 ]]
then
echo "four"
elif [[ $1 -eq 5 ]]
then
echo "five"
else
echo "six"
fi
else
echo "You entered: $1, not what I was looking for."
fi
Arrays in Bash are ordered lists of values. Lists are created with parentheses (( )) with a space separating each element in the list.
plagues=(blood frogs lice flies sickness boils hail locusts darkness death)
# To get the first element of this array
echo ${plagues[0]}
# To get all of the elements of plagues use a star (*)
echo ${plagues[*]}
# change an individual elements
plagues[4]=disease
# get 3 array elements starting from the sixth element of the array (remember, the sixth element has an index of 5).
echo ${plagues[*]:5:3}
find the length of an array using the pound sign (#)
echo ${#plagues[*]}
# use the plus-equals operator (+=) to add an array onto the end of an array array
plagues+=(bashful dopey happy)
# Brace expansion uses the curly brackets and two periods ({ .. }) to create a sequence of letters or numbers.
echo {0..9}
echo {a..e}
echo {W..Z}
echo a{0..4}
echo b{0..4}c
echo {1..3}{A..C}
## 1A 1B 1C 2A 2B 2C 3A 3B 3C
start=4
end=9
echo {$start..$end}
eval echo {$start..$end}
## {4..9}
## 4 5 6 7 8 9
echo { {1..3}, {a..c} }
## 1 2 3 a b c
echo {Who,What,Why,When,How}?
## Who? What? Why? When? How?# File: forloop.sh
echo "Before Loop"
for i in {1..3}
do
echo "i is equal to $i"
done
for the picture in img001.jpg img002.jpg img451.jpg
do
echo "picture is equal to $picture"
done
echo ""
echo "Array:"
stooges=(curly larry moe)
for stooge in ${stooges[*]}
do
echo "Current stooge: $stooge"
done
echo ""
echo "Command substitution:"
for code in $(ls)
do
echo "$code is a bash script"
done
echo "After Loop"
# File: whileloop.sh
count=3
while [[ $count -gt 0 ]]
do
echo "count is equal to $count"
let count=$count-1
done
# File: nestedloops.sh
for number in {1..3}
do
for letter in a b
do
echo "number is $number, letter is $letter"
done
done
# File: ifloop.sh
for number in {1..10}
do
if [[ $number -lt 3 ]] || [[ $number -gt 8 ]]
then
echo $number
fi
donefunction [name of function] {
# code here
}
# File: hello.sh
function hello {
echo "Hello"
}
# File: addseq.sh
function addseq {
sum=0
for element in $@
do
let sum=sum+$element
done
echo $sum
}
# we’re going to start using the source command, which allows us to use function definitions in bash scripts as command-line commands.
source addseq.sh
# The local keyword ensures that variables outside of our function are not overwritten by our function.
# File: addseq2.sh
function addseq2 {
local sum=0
for element in $@
do
let sum=sum+$element
done
echo $sum
}ls -l | head -n 3
## -rw-rw-r-- 1 sean sean 138 Jun 26 12:51 addseq.sh
## -rw-rw-r-- 1 sean sean 146 Jun 26 14:45 addseq2.sh
## -rw-rw-r-- 1 sean sean 140 Jan 29 10:06 bigmath.sh
# make this file executable and we’re the owner of this file
chmod u+x short
# To run an executable file we need to specify the path to the file, even if the path is in the current directory, meaning we need to prepend ./ to short.
./shortExcluding the first hyphen, we have the following string: rw-rw-r--. This string reflects the permissions that are set up for this file. There are three permissions that we can grant: the ability to read the file (r), write to or edit the file (w), or execute the file (x) as a program.
These three permissions can be granted on three different levels of access which correspond to each of the three sets of rwx in the permissions string: the owner of the file, the group that the file belongs to, and everyone other than the owner and the members of a group.
Set the permissions for files that you own using the chmod command. The chmod command takes two arguments. The first argument is a string that specifies how we’re going to change permissions for a file, and the second argument is the path to the file.
First, we can specify which set of users we’re going to change permissions for:
| Character | Meaning |
|---|---|
| u | The owner of the file |
| g | The group that the file belongs to |
| o | Everyone else |
| a | Everyone above |
We then need to specify whether we’re going to add, remove, or set the permission:
| Character | Meaning |
|---|---|
| + | Add permission |
| - | Remove permission |
| = | Set permission |
Finally, we specify what permission we’re changing:
| Character | Meaning |
|---|---|
| r | Read a file |
| w | Write to or edit a file |
| x | Execute a file |
To use our scripts and functions as shell commands.
The PATH variable contains a sequence of paths on our computer separated by colons. When the shell starts it searches these paths for executable files, and then makes those executable commands available in our shell.
One approach to making our scripts available is to add a directory to the PATH. Bash scripts in the directory that are executable can be used as commands. We need to modify PATH every time we start a shell, so we can amend our ~/.bash_profile so that our directory for executable scripts is always in the PATH. To modify an environmental variable we need to use the export keyword.
# HOME variable contains the path to our home directory.
echo $HOME
# PWD variable contains the path to our current directory.
echo $PWD
# If we want one of our functions to be available always as a command then we need to change the PATH variable.
echo $PATH
# create a new directory called Commands in our Code directory and add a line to our ~/.bash_profile so that Commands are added to the PATH.
mkdir Commands
nano ~/.bash_profile
alias docs='cd ~/Documents'
alias edbp='nano ~/.bash_profile'
export PATH=~/Code/Commands:$PATH
# Save ~/.bash_profile and close nano. Now let’s source our Bash profile (we only need to do this once) and move short into the Commands directory. Then we should be able to use short as a command!
source ~/.bash_profile
short
# Alternatively to making individual scripts executable we can add a source command to our ~/.bash_profile so that we can use a Bash function on the command line.
nano ~/.bash_profile
alias docs='cd ~/Documents'
alias edbp='nano ~/.bash_profile'
export PATH=~/Code/Commands:$PATH
source ~/Code/addseq2.sh
# Save the ~/.bash_profile, quit nano, and now let’s source our ~/.bash_profile so we can test if we can use addseq2.
source ~/.bash_profile
addseq2 9 8 7Difference between let and var.
let gives you the privilege to declare variables that are limited in scope to the block, statement of expression, unlike var.
var is rather a keyword that defines a variable globally regardless of block scope.
Even if the let variable is defined as the same as the var variable globally, the let variable will not be added to the global window object.
var varVariable = “this is a var variable”;
let letVariable = “this is a let variable”;
console.log(window.varVariable); //this is a var variable
console.log(window.letVariable); //undefinedThus let variables cannot be accessed in the window object because they cannot be globally accessed.
let variables are usually used when there is limited use of those variables. Say, in for loops, while loops or inside the scope of if conditions, etc. Basically, where ever the scope of the variable has to be limited.
For loop using let variable:
for(let i=0;i<10;i++){
console.log(i); //i is visible thus is logged in the console as 0,1,2,....,9
}
console.log(i); //throws an error as "i is not defined" because i is not visibleFor loop using var variable:
for(var i=0; i<10; i++){
console.log(i); //i is visible thus is logged in the console as 0,1,2,....,9
}
console.log(i); //i is visible here too. thus is logged as 10.let variables cannot be re-declared while var variable can be re-declared in the same scope.
Assume we are using strict mode:
'use strict';
var temp = "this is a temp variable";
var temp = "this is a second temp variable"; //replaced easilyWe cannot do the same thing with let:
'use strict';
let temp = "this is a temp variable";
let temp = "this is a second temp variable" //SyntaxError: temp is already declaredlet and var variables work the same way when used in a function block.
function aSampleFunction(){
let letVariable = "Hey! What's up? I am let variable.";
var varVariable = "Hey! How are you? I am var variable.";
console.log(letVariable); //Hey! What's up? I am let variable.
console.log(varVariable); //Hey! How are you? I am var variable.
}Thank Krish S Bhanushali for providing the reference.
Condition of loop can not change
while(left<=right) {} // [left, right]while(left< right) {} // [left, right)977. Squares of a Sorted Array
209. Minimum Size Subarray Sum
203. Remove Linked List Elements
19. Remove Nth Node From End of List
160. Intersection of Two Linked Lists
When we encounter the need to quickly determine whether an element appears in a set, we must consider the hash table.
349. Intersection of Two Arrays
Note: I will call the demo Maven project as Maxwell for convenience in the following article.
To deploy a maven project as a remote server with Tomcat, to avoid run maven project every time:
$ cd [to your checkout location]
# For example, cd C:\GitProjects\Maxwell
$ mvn spring-boot:run
If you want to do so, please do the following steps
pom.xml <packaging>war</packaging>
pom.xml <dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-tomcat</artifactId>
<scope>provided</scope>
</dependency>
SpringBootApplication.java class has to extend SpringBootServletInitializer@SpringBootApplication
public class Application extends SpringBootServletInitializer {
public static void main(String[] args) {
SpringApplication.run(BookingDemoApplication.class, args);
}
@Override
protected SpringApplicationBuilder configure(SpringApplicationBuilder builder) {
return builder.sources(Application.class);
}
}
pom.xml<build>
<finalName>Maxwell</finalName>
</build>
Clone maven project repository
$ git clone https://github.com/zhongqi1112/Maxwell.git
Package Maxwell
$ cd [to your checkout location]
# For example: cd C:\GitProjects\Maxwell
$ mvn package
A Maxwell.war file will be generated in .\Maxwell\target to get ready to deploy to the server.
Tomcat 8.5.32: we are going to use Tomcat 8.5.32 as a server, click 32-bit/64-bit Windows Service Installer

Select Full type of install

Set three available ports, the default port is 8085, I set 8090 as the HTTP connector port.
Set username and password for the administrator to manage

Select the correct path of JRE, for example, C:\Program Files\Java\Jre1.8.0

Select the path to install Tomcat, if you install in C:\Program Files you need to change permissions when you want to modify the configuration.

Go to the window search bar and search services, you will see Apache Tomcat 8.5 in the services list, right-click and select Properties. You will see Tomcat is Running and startup Automatic

Go to the setup port to check install Tomcat successfully, for example, http://localhost:8090/, you will see the window like this:

Go to the setup Tomcat server port, for example, http://localhost:8090/
Click on Manager App and enter the username and password you set up during installation

Click on Choose File, selecting the Maxwell.war was generated, and then click on Deploy.
Wait for a few seconds, you will see Maxwell is running in the Applications list.

Go and check it in the browser, http://localhost:8090/Maxwell/uciMessageType, you will see all UCI messages in the database. Or use your IP address instead of localhost.
Go to the folder installed Tomcat, C:\Program Files\Apache Software Foundation
Right click on Tomcat8.5 folder, select Properties -> Security -> Edit
Allow Full control
C:\Program Files\Apache Software Foundation\Tomcat 8.5\conftomcat-users.xml to modify users' username or password, for example<user username="tomcat" password="tomcat" roles="admin-gui,manager-gui" />stop and start server.Go to the folder installed Tomcat, C:\Program Files\Apache Software Foundation\Tomcat 8.5\conf
Open server.xml, approximate line 69, you could change the port 8090 of the server to any available port.
<Connector port="8090" protocol="HTTP/1.1" connectionTimeout="20000" redirectPort="8443" />
If you reset the port of the server, you need to stop and start server.
$ cd [the appropriate subdirectory of the EDQP Tomcat installation directory]
# For example, C:\Program Files\Apache Software Foundation\Tomcat 8.5\bin
$ startup.bat
# Verify that the service was started correctly by looking for the final server startup messages.
$ cd [the appropriate subdirectory of the EDQP Tomcat installation directory]
# For example, C:\Program Files\Apache Software Foundation\Tomcat 8.5\bin
$ shutdown.bat
# Verify that the service was stopped correctly by looking for the final server shutdown messages.
You could check the youtube video I found online, thanks to Romanian Coder for providing the video.
if you get any questions feel free to email me.
To install Apache Maven on Windows, you just need to download the Maven’s zip file and Unzip it to the directory you wish to install and configure the Windows environment variables.
Tools Used
Note
Maven 3.2 requires JDK 1.6 or above, while Maven 3.0/3.1 requires JDK 1.5 or above
Make sure JDK is installed, and the "JAVA_HOME" variable is added as the Windows environment variable.
Type "environment" in the search bar.
click on -> Edit the system environment variables -> Advanced -> Environment Variables => Pop up following window

Visit Maven official website, download the Maven zip file, for example : apache-maven-3.5.3-bin.zip. Unzip it to the folder you want to install Maven.
Assume you unzip to this folder - C:\Program Files\Apache\maven
Note
That is all, just folders and files, installation is NOT required.
Add both M2_HOME and MAVEN_HOME variables in the Windows environment, and point it to your Maven folder.

M2_HOME or MAVEN_HOME
Maven document said add M2_HOME only, but some programs still reference Maven folder with MAVEN_HOME, so, it’s safer to add both.
Update the PATH variable, append Maven bin folder – %M2_HOME%\bin, so that you can run the Maven’s command everywhere.

Done, to verify it, run mvn –version in the command prompt.
$ mvn -version
Apache Maven 3.5.3 (138edd61fd100ec658bfa2d307c43b76940a5d7d; 2017-10-18T00:58:13-07:00)
Maven home: Maven home: C:\Program Files\Apache\maven
Java version: 1.8.0_151, vendor: Oracle Corporation
Java home: C:\Program Files\Java\jdk1.8.0_151\jre
Default locale: en_US, platform encoding: Cp1252
OS name: "windows 10", version: "10.0", arch: "amd64", family: "windows"
If you see a similar message, means the Apache Maven is installed successfully on Windows.
Thanks mkyong for reference.
Git is a free and open-source distributed version control system designed to handle everything from small to very large projects with speed and efficiency.
Git is easy to learn and has a tiny footprint with lightning-fast performance. It outclasses SCM tools like Subversion, CVS, Perforce, and ClearCase with features like cheap local branching, convenient staging areas, and multiple workflows.
Download Git from git official website.

$ git help [verb]
$ git [verb] --help
$ git --version
# set proxy
$ git config --global http.proxy http://64.128.256.512
$ git config --global https.proxy http://64.128.256.512
# remove proxy
$ git config --global --unset http.proxy
$ git config --global --unset https.proxy
Configure user information for all local repositories
# Sets the name and email you want attached to your commit transactions
$ git config --global user.name "StephenWang"
$ git config --global user.email “[email protected]”
# check configure list of git
$ git config --list
Start a new repository or obtain one from an existing URL
# Start a repository from existing code
$ cd c:/Git Projects/project
$ git init
# Creates a new local repository with the specified name
$ git init [project-name]
# Downloads a project and its entire version history
$ git clone [url]
Relocate and remove versioned files
# Create new file
$ touch [file]
# Deletes the file from the working directory and stages the deletion
$ git rm [file]
# Removes the file from version control but preserves the file locally
$ git rm --cached [file]
# Changes the file name and prepare it for commit
$ git mv [file-original] [file-renamed]
# Removes directory
$ rmdir [directory]
Shelve and restore incomplete changes
# Temporarily stores all modified tracked files
$ git stash
# Restores the most recently stashed files
$ git stash pop
# Lists all stashed changesets
$ git stash list
# Discards the most recently stashed changeset
$ git stash drop
Review edits and craft a commit transaction
# Lists all new or modified files to be committed
$ git status
# Shows file differences not yet staged
$ git diff
# Snapshots the file in preparation for versioning
$ git add [file]
# Add files to staging area
$ git add .
# Shows file differences between staging and the last file version
$ git diff --staged
# Unstaged the file, but preserves its contents
$ git reset [file]
# Records file snapshots permanently in the version history
$ git commit -m"[descriptive message]"
# Push the changes in the local repository to Github
$ git remote add origin [url]
$ git push origin master
$ git push [url] master
Name a series of commits and combine completed efforts
# Viewing infomation about the remote repository
$ git remote -v
# Lists all local branches in the current repository
$ git branch
# Creates a new branch
$ git branch [branch-name]
# Switches to the specified branch and updates working directory
$ git checkout [branch-name]
# Combines the specified branch’s history into the current branch
$ git merge [branch-name]
# Deletes the specified branch
$ git branch -d [branch-name]
Browse and inspect the evolution of project files
# Lists version history for the current branch
$ git log
# Lists version history for the file, including renames
$ git log --follow [file]
# Shows content differences between two branches
$ git diff [first-branch]...[second-branch]
# Outputs metadata and content changes of the specified commit
$ git show [commit]
Erase mistakes and craft replacement history
# Undoes all commits after [commit], preserving changes locally
$ git reset [commit]
# Discards all history and changes back to the specified commit
$ git reset --hard [commit]
Register a remote (URL) and exchange repository history
# Downloads all history from the remote repository
$ git fetch [remote]
# Combines the remote branch into the current local branch
$ git merge [remote]/[branch]
# Uploads all local branch commits to GitHub
$ git push [remote] [branch]
# Downloads bookmark history and incorporates changes
$ git pull
# DELETING A BRANCH
$ git branch -d [branch]
$ git branch -D [branch]
Note: There is an official git cheat sheet. you could look at it, I will explain in detail.
GitHub provides desktop clients that include a graphical user interface for the most common repository actions and an automatically updating command line edition of Git for advanced scenarios.
There is an online tutorial on YouTube by The Net Ninja.
I recommend you use TortoiseGit instead of Git command prompt. TortoiseGit provides overlay icons showing the file status, a powerful context menu for Git and much more!
add or remove proxy command prompt
# install npm
$ npm install
# check configure of npm
$ npm config list
# remove proxy
$ npm config delete proxy
$ npm config delete http-proxy
$ npm config delete https-proxy
# set proxy (using DevlLAN)
$ npm config set proxy http://64.128.256.512
$ npm config set https-proxy http://64.128.256.512
# compile
$ npm run dev
add or remove proxy command prompt
# install yarn
$ yarn install
# check configure of yarn
$ yarn config list
# disable ssl with
$ yarn config set strict-ssl false
# remove proxy
$ yarn config delete proxy
$ yarn config delete http-proxy
$ yarn config delete https-proxy
# set proxy (using DevlLAN)
$ yarn config set proxy http://64.128.256.512
$ yarn config set https-proxy http://64.128.256.512
# compile
$ yarn run dev
Static is a non-access modifier in Java which is applicable for the following:
When a member(block, variable, method, nested class) is declared static, it can be accessed before any objects of its class are created, and without reference to any object.
If you need to do the computation in order to initialize your static variables, you can declare a static block that gets executed exactly once, when the first time you make an object of that class or the first time you access a static member of that class (even if you never make an object of that class). Also, static blocks are executed before constructors.
When a variable is declared as static, then a single copy of the variable is created and shared among all objects at class level. Static variables are, essentially, global variables. All instances of the class share the same static variable.
Important points for static variables:
When a method is declared with a static keyword, it is known as a static method. The most common example of a static method is main( ) method. As discussed above, Any static member can be accessed before any objects of its class are created, and without reference to any object. Methods declared as static have several restrictions:
When to use static variables and methods?
Use the static variable for the property that is common to all objects. For example, in class Student, students share the same college name. Use static methods for changing static variables.
Can a class be static in Java ?
The answer is YES, we can have a static class in java. In java, we have static instance variables as well as static methods and also static blocks. Classes can also be made static in Java.
Java allows us to define a class within another class. Such a class is called a nested class. The class which enclosed the nested class is known as the Outer class. In java, we can’t make Top-level class static. Only nested classes can be static.
n java, it is possible to define a class within another class, such classes are known as nestedclasses. They enable you to logically group classes that are only used in one place, thus this increases the use of encapsulation, and create more readable and maintainable code.
Syntax:
class OuterClass
{
...
class NestedClass
{
...
}
}As with class methods and variables, a static nested class is associated with its outer class. And like static class methods, a static nested class cannot refer directly to instance variables or methods defined in its enclosing class: it can use them only through an object reference.
They are accessed using the enclosing class name.
OuterClass.StaticNestedClassFor example, to create an object for the static nested class, use this syntax:
OuterClass.StaticNestedClass nestedObject =
new OuterClass.StaticNestedClass();To instantiate an inner class, you must first instantiate the outer class. Then, create the inner object within the outer object with this syntax:
OuterClass.InnerClass innerObject = outerObject.new InnerClass();There are two special kinds of inner classes:
What are the differences between static and non-static nested (inner) classes?
The following are major differences between the static nested class and non-static nested class. A non-static nested class is also called Inner Class.
1) Nested static class doesn’t need a reference to Outer class, but Non-static nested class or Inner class requires Outer class reference.
2) Inner class(or non-static nested class) can access both static and non-static members of the Outer class. A static class cannot access non-static members of the Outer class. It can access only static members of the Outer class.
3) An instance of Inner class cannot be created without an instance of the outer class and an Inner class can reference data and methods defined in Outer class in which it nests, so we don’t need to pass the reference of an object to the constructor of the Inner class. For this reason, Inner classes can make the program simple and concise.
final keyword is used in different contexts. First of all, final is a non-access modifier applicable only to a variable, a method, or a class. The following are different contexts where the final is used.
When a variable is declared with final keyword, its value can’t be modified, essentially, a constant. This also means that you must initialize a final variable. If the final variable is a reference, this means that the variable cannot be re-bound to reference another object, but an internal state of the object pointed by that reference variable can be changed i.e. you can add or remove elements from a final array or final collection. It is good practice to represent final variables in all uppercase, using underscore to separate words.
Initializing a final variable:
We must initialize a final variable, otherwise, the compiler will throw compile-time error. A final variable can only be initialized once, either via an initializer or an assignment statement. There are three ways to initialize a final variable :
Let us see above different ways of initializing a final variable through an example.
//Java program to demonstrate differently
// ways of initializing a final variable
class Gfg
{
// a final variable
// direct initialize
final int THRESHOLD = 5;
// a blank final variable
final int CAPACITY;
// another blank final variable
final int MINIMUM;
// a final static variable PI
// direct initialize
static final double PI = 3.141592653589793;
// a blank final static variable
static final double EULERCONSTANT;
// instance initializer block for
// initializing CAPACITY
{
CAPACITY = 25;
}
// static initializer block for
// initializing EULERCONSTANT
static{
EULERCONSTANT = 2.3;
}
// constructor for initializing MINIMUM
// Note that if there are more than one
// constructor, you must initialize MINIMUM
// in them also
public GFG()
{
MINIMUM = -1;
}
} When to use a final variable:
The only difference between a normal variable and a final variable is that we can re-assign value to a normal variable but we cannot change the value of a final variable once assigned. Hence final variables must be used only for the values that we want to remain constant throughout the execution of the program.
Reference final variable:
When a final variable is a reference to an object, then this final variable is called reference final variable. For example, a final StringBuffer variable looks like
final StringBuffer sb;
As you know that a final variable cannot be re-assign. But in the case of a reference final variable, the internal state of the object pointed by that reference variable can be changed. Note that this is not re-assigning. This property of final is called non-transitivity.
The non-transitivity property also applies to arrays, because arrays are objects in the java. Arrays with the final keyword are also called final arrays.
Note:
As discussed above, a final variable cannot be reassigned.
When a final variable is created inside a method/constructor/block, it is called the local final variable, and it must initialize once where it is created. See the below program for the local final variable.
Note the difference between C++ const variables and Java final variables. const variables in C++ must be assigned a value when declared. For final variables in Java, it is not necessary as we see in the above examples. A final variable can be assigned value later, but only once.
final with foreach loop: final with for-each statement is a legal statement.
Explanation: Since the i variable goes out of scope with each iteration of the loop, it is actually re-declaration each iteration, allowing the same token (i.e. i) to be used to represent multiple variables.
When a class is declared with final keyword, it is called a final class. A final class cannot be extended(inherited). There are two uses of a final class :
When a method is declared with final keyword, it is called a final method. A final method cannot be overridden. The Object class does this—a number of its methods are final. We must declare methods with the final keyword for which we required to follow the same implementation throughout all the derived classes.
The scope of a variable is the part of the program where the variable is accessible.
These must be declared inside the class (outside any function). They can be directly accessed anywhere in the class.
Modifier Package Subclass World
public Yes Yes Yes
protected Yes Yes No
Default (no
modifier) Yes No No
private No No NoVariables declared inside a method have the method-level scope and can’t be accessed outside the method.
Note: Local variables don’t exist after the method’s execution is over. Except the variable got passed in as a parameter to the method
A variable declared inside pair of brackets “{” and “}” in a method has scope within the brackets only.
Some Important Points about Variable scope in Java:
MIT License Copyright (c) 2018 By Stephen Wang
References:
I am going to show you how to create a WebSocket project using the spring boot framework.
Create a maven project and add WebSocket as a dependency on pom.xml
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-websocket</artifactId>
</dependency>
Create a WebSocketConfig.java class
package com.company.websocket;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.socket.WebSocketHandler;
import org.springframework.web.socket.config.annotation.EnableWebSocket;
import org.springframework.web.socket.config.annotation.WebSocketConfigurer;
import org.springframework.web.socket.config.annotation.WebSocketHandlerRegistry;
/**
* WebSocket configuration
*/
@Configuration
@EnableWebSocket
public class WebSocketConfig implements WebSocketConfigurer {
/**
* WebSocket declaration for service.
*
* @return client connection handler.
*/
@Bean
public WebSocketHandler clientHandler() {
return new WebSocketHandler();
}
@Override
public final void registerWebSocketHandlers(
final WebSocketHandlerRegistry registry) {
registry.addHandler(clientHandler(), "/websocketserver").setAllowedOrigins("*");
}
}
Create a WebSocketHandler.java class in the same folder
package com.company.websocket;
import java.util.Map;
import java.util.Set;
import java.util.concurrent.ConcurrentHashMap;
import org.springframework.stereotype.Component;
import org.springframework.web.socket.CloseStatus;
import org.springframework.web.socket.TextMessage;
import org.springframework.web.socket.WebSocketSession;
import org.springframework.web.socket.handler.TextWebSocketHandler;
@Component
public class WebSocketHandler extends TextWebSocketHandler {
private final static Map<String, WebSocketSession> sessions;
static {
sessions = new ConcurrentHashMap<String, WebSocketSession>(30);
}
@Override
public void afterConnectionEstablished(WebSocketSession session) throws Exception {
this.sessions.put(session.getId(), session);
System.out.println("New WebSocket user {} is connected", () -> session.getId());
}
@Override
public void afterConnectionClosed(WebSocketSession session, CloseStatus status) throws Exception {
System.out.println("WebSocket user {} is disconnected", () -> session.getId());
this.sessions.remove(session.getId());
}
@Override
protected void handleTextMessage(WebSocketSession session, TextMessage message) throws Exception {
String payload = message.getPayload();
System.out.println("Receive message from user {}, message is: {}", () -> session.getId(), () -> payload);
}
@Override
public void handleTransportError(WebSocketSession session, Throwable exception) throws Exception {
System.out.println("Transport Error: {}", () -> exception.getMessage());
}
/**
* Send a message to a designated WebSocket client
*
* @param userId every user connect to the WebSocket server have an identify id used for user-id
* @param contents message need to be sent to the user
*/
public void sendMessageToUser(String userId, String contents) {
WebSocketSession session = sessions.get(userId);
if (session != null && session.isOpen()) {
try {
TextMessage message = new TextMessage(contents);
session.sendMessage(message);
System.out.println("WebSocket send message to user {}, the message is: {}", () -> session.getId(), () -> contents);
} catch (IOException e) {
e.printStackTrace();
}
}
}
/**
* Send a message to all WebSocket client
*
* @param contents message need to be sent to the user
*/
public void sendMessageToAllUsers(String contents) {
Set<String> userIds = sessions.keySet();
System.out.println("WebSocket send message to all users, the message is: {}", () -> contents);
userIds.forEach((userId) -> {
this.sendMessageToUser(userId, contents);
});
}
}
Create a js file to handle the WebSocket client side.
export default () => {
var websocket = null
// if browser supports WebSocket
if ('WebSocket' in window) {
websocket = new WebSocket(webSocketUrl)
console.log('Connecting to WebSocket Server')
} else {
// if browser does not support WebSocket
console.error('Browser does not support WebSocket')
};
/**
* an event listener for when WebSocket connection is error
*/
websocket.onerror = function () {
console.error('WebSocket connection Error')
}
/**
* an event listener for when WebSocket connection is open
*/
websocket.onopen = function (event) {
console.log('WebSocket connection opened. URL: ' + event.target.url)
websocket.send("This is an user connecting to Websocket")
}
/**
* an event listener for when a message is received from the WebSocket server
*/
websocket.onmessage = function (event) {
console.log('Message received from WebSocket server: ' + event.data)
var jsonObject = JSON.parse(event.data)
console.log(jsonObject)
}
/**
* an event listener for when WebSocket connection is close
*/
websocket.onclose = function () {
console.log('WebSocket connection closed.')
}
/**
* close WebSocket connection when close window
*/
window.onbeforeunload = function () {
console.log('WebSocket connection closed due to Window closed.')
websocket.close()
}
/**
* this function should be called when users want to send any command to the server via WebSocket in JSON.
* @message the message send to the WebSocket server from the client
*/
function sendMessageObject (message) {
var messageObject = JSON.stringify(message)
console.log('Send message to server: ' + messageObject)
websocket.send(messageObject)
}
}
You could use any user GUI to hold this websocket.js to see messages in the console.
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.