scikit-learn-contrib / forest-confidence-interval Goto Github PK
View Code? Open in Web Editor NEWConfidence intervals for scikit-learn forest algorithms
Home Page: http://contrib.scikit-learn.org/forest-confidence-interval/
License: MIT License
Confidence intervals for scikit-learn forest algorithms
Home Page: http://contrib.scikit-learn.org/forest-confidence-interval/
License: MIT License
Hello, when trying to install through pip install sklforestci, got an error Could not find a version that satisfies the requirement sklforestci (from versions: ) No matching distribution found for sklforestci.
So I have to install it directly from github: pip install git+https://github.com/uwescience/sklearn-forest-ci.git.
Is module missing from pypi?
There is no clear statement of need is not provided in the README.md or in the paper
I remember there's supposed to be a publication describing this work; is it out somewhere?
Hi,
Running pip install will install version 0.1 from here https://pypi.python.org/pypi/forestci. The version on github and the documentation reflects changes in forestci 0.2. I suggest updating the versioning on pip or suggesting that users install the latest development version using:
pip install git+git://github.com/scikit-learn-contrib/forest-confidence-interval.git
Hi,
I was using the random_forest_error() function for a project of mine where the data is of the order of 10,000 and if I used it without a scaler, it started giving NaN values for all points. Why would this be happening?
Furthermore, if I then used a MinMaxScaler for the same, then it gives some values but it doesn't work with StandardScaler. Any idea why that would happen?
Another question that I had was that I need the variances in the same order as the original data, i.e. of the order of the original output data. How can I rescale the variance so that it matches the order of the original data?
Hi,
I am trying to generate confidence intervals for the below sample data. I am using RandomForestRegressor with bootstrapping enabled.
X_train shape (270, 7)
[[ 12. 20. 1. ... 300. 1. 0.]
[ 12. 20. 1. ... 300. 1. 0.]
[ 12. 20. 1. ... 300. 1. 0.]
...
[ 12. 30. 10. ... 300. 1. 0.]
[ 12. 30. 10. ... 300. 1. 0.]
[ 12. 30. 10. ... 300. 1. 0.]]
Test data shape (36,7)
[[ 12. 10. 1. 1. 300. 1. 0.]
[ 12. 10. 5. 1. 300. 1. 0.]
[ 12. 10. 10. 1. 300. 1. 0.]
...
[ 12. 10. 1. 4. 300. 1. 0.]
[ 12. 20. 1. 4. 300. 1. 0.]
[ 12. 30. 1. 4. 300. 1. 0.]]
I generate ci data as
ci_data = fci.random_forest_error(model, x_train, x_test, calibrate=True)
However, ci_data contains all zeroes
[1.89472718e-34 1.89472718e-34 1.89472718e-34 1.89472718e-34
1.89472718e-34 1.89472718e-34 1.89472718e-34 1.89472718e-34
1.89472718e-34 1.89472718e-34 1.89472718e-34 1.89472718e-34
1.89472718e-34 1.89472718e-34 1.89472718e-34 1.89472718e-34
1.89472718e-34 1.89472718e-34 1.89472718e-34 1.89472718e-34
1.89472718e-34 1.89472718e-34 1.89472718e-34 1.89472718e-34
1.89472718e-34 1.89472718e-34 1.89472718e-34 1.89472718e-34
1.89472718e-34 1.89472718e-34 1.89472718e-34 1.89472718e-34
1.89472718e-34 1.89472718e-34 1.89472718e-34 1.89472718e-34]
Do you have any pointers as to what could be going wrong here? Thanks.
A newer version of SciKit Learn modified _generate_sample_indices() to require an additional n_samples_bootstrap argument, thus the current version of the code will raise a TypeError: _generate_sample_indices() missing 1 required positional argument: 'n_samples_bootstrap' when running fci.random_forest_error(mpg_forest, mpg_X_train, mpg_X_test).
I couldn't install one of the dependencies, without root rights, please describe that this might be needed in the documentation.
On a toy problem, in which I am using Random Forests + ForestCI to prototype some ideas, I will randomly get NaNs in the V_IJ estimates.
This toy problem is using a random forest to fit a 1D curve. Code to try reproducing the problem is below.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestRegressor
from forestci import random_forest_error
def func(x):
return x**2 + 3*x - 3
x_train = np.hstack([np.linspace(-10, -3, 10), np.linspace(3, 10, 10)])
x_test = np.linspace(-10, 10, 1000)
fig, axes = plt.subplots(nrows=2, ncols=5, figsize=(20, 8))
for i in range(10):
rfr = RandomForestRegressor(n_estimators=100, n_jobs=1)
rfr.fit(x_train.reshape(-1, 1), func(x_train))
preds = rfr.predict(x_test.reshape(-1, 1))
var_est = random_forest_error(rfr,
x_train.reshape(-1, 1),
x_test.reshape(-1, 1),
calibrate=True)
axes.flatten()[i].errorbar(x_test, preds, yerr=var_est)I noticed two observations. Firstly, the estimated errors are unstable. Please see image below.
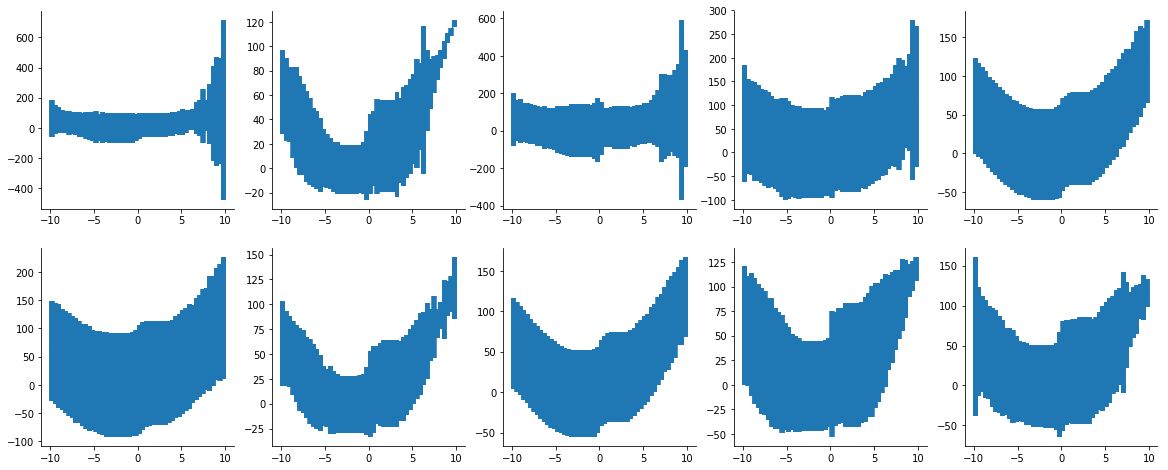
Is this a result of having few training samples (only 20 observations on the curve)? Or is there something else I'm missing conceptually?
Secondly, I will occasionally get NaNs in var_est (the estimate of V_IJ), hence the errors are unplottable.
I'm not quite sure how to diagnose what is happening here. Would you guys be able to provide some input on where I might be doing something wrong?
Submitting an error report here, just for record purposes.
With the following line:
pred_error = fci.random_forest_error(clf, X_train=X_train, X_test=X_test, inbag=None)
I get the following error:
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-60-79c18cb1c841> in <module>()
----> 1 pred_error = fci.random_forest_error(clf, X_train=X_train, X_test=X_test, inbag=None)
~/anaconda/envs/targetpred/lib/python3.6/site-packages/forestci/forestci.py in random_forest_error(forest, inbag, X_train, X_test)
115 pred_centered = pred - pred_mean
116 n_trees = forest.n_estimators
--> 117 V_IJ = _core_computation(X_train, X_test, inbag, pred_centered, n_trees)
118 V_IJ_unbiased = _bias_correction(V_IJ, inbag, pred_centered, n_trees)
119 return V_IJ_unbiased
~/anaconda/envs/targetpred/lib/python3.6/site-packages/forestci/forestci.py in _core_computation(X_train, X_test, inbag, pred_centered, n_trees)
57
58 for t_idx in range(n_trees):
---> 59 inbag_r = (inbag[:, t_idx] - 1).reshape(-1, 1)
60 pred_c_r = pred_centered.T[t_idx].reshape(1, -1)
61 cov_hat += np.dot(inbag_r, pred_c_r) / n_trees
TypeError: 'NoneType' object is not subscriptable
I am using version 0.1.0, installed from pip.
I think a new release is required; after inspecting the source code, I'm seeing that inbag=None is no longer a required keyword argument (contrary to what my installed version is saying), and that inbag=None is handled correctly in the GitHub version (contrary to how my installed version is working).
The submitting author: Kivan Polimis, has not institute listed, while the others have is this intentional ?
LICENCE file is not an OSI approved licence
Hi, I was wondering if you will be ensuring compatibility with newer versions of scikit-learn? sklearn.ensemble.forest was renamed to sklearn.ensemble._forest in 2019 so I'm having this error
from sklearn.ensemble.forest import _generate_sample_indices, _get_n_samples_bootstrap
ModuleNotFoundError: No module named 'sklearn.ensemble.forest'
Trying to debug the problem of getting all NaN's from random_forest_error I found that the g_eta_raw array from
g_eta_main division throws the warning RuntimeWarning: invalid value encountered in true_divide.
This is probably related to #72, #78, #83, #88 and #92.
¿Any idea on why, despite np.exp(np.dot(XX, eta_hat)) and mask having some values different from 0, their product is a null matrix (all values are 0)? Of course it's because one of them is 0 in every pair of components (e.g. np.exp(np.dot(XX, eta_hat)[i] or mask[i] are 0 for every i in range(len(mask))). But why does this situation occur?
Hi there,
I believe the centered predictions are being computed incorrectly. Line 278 in forestci.py takes the average over the predictions, as opposed to the trees. The resulting shape of pred_mean is (forest.n_estimators,) when it should be (X_test.shape[0],). See below:
Thanks for the great package otherwise! :)
I have the following code:
df = pd.read_csv('data.csv', header=0, engine='c')
mat = df.as_matrix()
X = mat[:, 1:]
X_train, X_test = train_test_split(X, test_size = 0.2)
variance = forestci.random_forest_error(model, X_train, X_test)
When I run it, it throws the error TypeError: random_forest_error() takes exactly 4 arguments (3 given).
However, there are only three non-optional arguments listed in the documentation.
If I add a fourth argument for inbag, I then get an error saying that inbag is defined twice. Any ideas of what's causing this? I'm happy to write a PR if you point me towards the cause.
Hi,
first of all, great work, this is a great tool! I have a couple of questions based on issues I've encountered when playing with the package. Apologies if these reveal my misunderstanding rather than an actual issue with the coding.
When running the confidence interval calculation on a forest I trained, I encounter negative values of the unbiased variances. Additionally, the more trees my forest has, the more of these negative values appear. Could there be some kind of bias overcorrection?
The _bias_correction function in the module calculates n_var parameter, that it then applies to the bias correction vector. However, no such expression appears in Eqn. (7) of the Wagner et al. (2014), according to which the bias correction should be n_train_samples * boot_var / n_trees (using the variable names from the package code). Where does n_var come from?
I don't see any parameter regulating the number of bootstrap draws. Even though O(n) draws should be enough to take case of the Monte Carlo noise, it should still be possible to control this somehow. If I change the n_samples parameter, this clashes with the pred matrix, which is fixed to the number of trees in the forest. How to regulate the number of draws?
In fact, if I'm reading the paper right, the idea is to look at how the predictions from the individual trees change when using different bootstrap samples of the original data. That doesn't seem to be what the package is doing, which is using predictions from a single forest on a set of test data instead of predictions of multiple forests of a single new sample. Where is my understanding wrong?
Thanks and again, let me know if what I'm asking is off-topic for here.
Ondrej
Hi folks, I'm trying to use fci but when I run: import forestci as fci
I get:
/opt/conda/lib/python3.6/site-packages/forestci/forestci.py in
9 import copy
10 from .calibration import calibrateEB
---> 11 from sklearn.ensemble.forest import _generate_sample_indices, _get_n_samples_bootstrap
12 from .due import _due, _BibTeX
13
ImportError: cannot import name '_get_n_samples_bootstrap'
Please provide guidelines in the README.md file for others to
Hi,
I'm trying to create error estimates and am using RandomForestRegressor with bootstrapping enabled. I am using data with dimensions:
x_test [10,13]
x_train [90,13]
y_test [10,2]
y_train [90,2]
I then generate errors using:
y_error = fci.random_forest_error(self.model, self.x_train, self.x_test)
However I get the error:
Generating point estimates...
[Parallel(n_jobs=4)]: Using backend ThreadingBackend with 4 concurrent workers.
[Parallel(n_jobs=4)]: Done 33 tasks | elapsed: 0.0s
[Parallel(n_jobs=4)]: Done 100 out of 100 | elapsed: 0.0s finished
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
/tmp/ipykernel_2626600/1096083143.py in <module>
----> 1 point_estimates = model.point_estimate(save_estimates=True, make_plots=False)
2 print(point_estimates)
/scratch/wiay/lara/galpro/galpro/model.py in point_estimate(self, save_estimates, make_plots)
158 # Use the model to make predictions on new objects
159 y_pred = self.model.predict(self.x_test)
--> 160 y_error = fci.random_forest_error(self.model, self.x_train, self.x_test)
161
162 # Update class variables
~/.local/lib/python3.7/site-packages/forestci/forestci.py in random_forest_error(forest, X_train, X_test, inbag, calibrate, memory_constrained, memory_limit)
279 n_trees = forest.n_estimators
280 V_IJ = _core_computation(
--> 281 X_train, X_test, inbag, pred_centered, n_trees, memory_constrained, memory_limit
282 )
283 V_IJ_unbiased = _bias_correction(V_IJ, inbag, pred_centered, n_trees)
~/.local/lib/python3.7/site-packages/forestci/forestci.py in _core_computation(X_train, X_test, inbag, pred_centered, n_trees, memory_constrained, memory_limit, test_mode)
135 """
136 if not memory_constrained:
--> 137 return np.sum((np.dot(inbag - 1, pred_centered.T) / n_trees) ** 2, 0)
138
139 if not memory_limit:
<__array_function__ internals> in dot(*args, **kwargs)
ValueError: shapes (90,100) and (100,10,2) not aligned: 100 (dim 1) != 10 (dim 1)
Does anyone have any idea what is going wrong here?? Thanks!
Hi! Great project! and welcome to scikit-learn-contrib :)
I could not find the information other than by looking at the code myself, but it would be good to specify precisely the variance of what statistical quantity is computed/approximated, and over which distribution. What is meant by "confidence interval" may otherwise be misleading/confusing.
Not sure whether this is an issue or not, but I thought I'd report it.
To the best of my knowledge, confidence intervals are, by definition, supposed to be positively-valued. However, I noticed that I am getting negative CIs. For example, after fitting a classifier and then obtaining confidence interval values, I see the following distribution:

When I check the range of the confidence intervals, I get:
>>> np.percentile(pred_error, [0, 1, 2, 5, 10, 57, 58])
array([ -6.44598321e-02, -3.91696053e-02, -2.07770770e-02,
-2.43449960e-03, -7.71852754e-04, -4.55220853e-05,
2.72525240e-05])
Negative values occur up to the 57th percentile.
Something didn't make sense w.r.t. negative CI values, thus I felt compelled to report this here. Hope it comes in handy.
Halo.
I started to use forest-confidence-interval. Thank you for implementing package.
After several interaction I converged to following usage:
errors = fci.random_forest_error(clf, k0_training,k0_test,memory_constrained=1, memory_limit=100, calibrate=0 )
for i in range(0,5):
errors = fci.random_forest_error(clf, k0_training,k0_test,memory_constrained=1, memory_limit=100, calibrate=1 )
print(i,errors[0:1000:200])
===>
(0, array([1.77080289, 1.77080289, 1.77080289, 1.77080289, 1.77080289]))
(1, array([1.60437205, 1.60437205, 1.60437205, 1.60437205, 1.60437205]))
(2, array([1.00765122, 1.00765122, 1.00765122, 1.00765122, 1.00765122]))
(3, array([1.55302694, 1.55302694, 1.55302694, 1.55302694, 1.55302694]))
(4, array([1.36027949, 1.36027949, 1.36027949, 1.36027949, 1.36027949]))
Regards
Marian
chlosyne:examples (master) $python plot_mpg.py
Traceback (most recent call last):
File "plot_mpg.py", line 51, in <module>
mpg_X_test)
File "/Users/arokem/source/forest-confidence-interval/forestci/forestci.py", line 221, in random_forest_error
memory_constrained, memory_limit)
File "/Users/arokem/source/forest-confidence-interval/forestci/forestci.py", line 98, in _core_computation
return np.sum((np.dot(inbag - 1, pred_centered.T) / n_trees) ** 2, 0)
ValueError: shapes (98,7) and (2000,294) not aligned: 7 (dim 1) != 2000 (dim 0)
chlosyne:examples (master) $python plot_spam.py
Traceback (most recent call last):
File "plot_spam.py", line 49, in <module>
spam_X_test)
File "/Users/arokem/source/forest-confidence-interval/forestci/forestci.py", line 221, in random_forest_error
memory_constrained, memory_limit)
File "/Users/arokem/source/forest-confidence-interval/forestci/forestci.py", line 98, in _core_computation
return np.sum((np.dot(inbag - 1, pred_centered.T) / n_trees) ** 2, 0)
ValueError: shapes (1000,20) and (500,4000) not aligned: 20 (dim 1) != 500 (dim 0)
I'm also experiencing the issue where my variances are (almost all) negative.
Hi, when I use forstci, which is great, I get the following warning, which is harmless for now:
The sklearn.ensemble.forest module is deprecated in version 0.22 and will be removed in version 0.24. The corresponding classes / functions should instead be imported from sklearn.ensemble. Anything that cannot be imported from sklearn.ensemble is now part of the private API.
It might hit us in the future
When I use this on my Random forest model it only works when I use 200 or more trees in the parameters.
n_trees = 200
forest = RandomForestRegressor(n_estimators=n_trees, random_state=42)
my optimal amount of trees is 29 but then (and not with the 200 trees) I get a warning:
RuntimeWarning: invalid value encountered in true_divide g_eta_main = g_eta_raw / sum(g_eta_raw)
I also can't get a confidence interval around my predicted points because of the error.
I'm a missing something, why you need such an excessive amount of trees?
Edit: minimum amount of trees needed to make it work
I’m looking at using random forest regressors to perform hyperparameter tuning in a Bayesian optimization setup. While you can use the upper confidence bound to explore your state space, Thompson sampling performs better and eliminates the need for tuning the hyper-hyperparameter of the confidence interval used for selection. One solution is to obtain an empirical Bayesian posterior by training many random forest regressors on bootstrapped data, but this seems like overkill (ensembles of ensembles!). Would appreciate any input on the subject thank you! (For more discussion see this review of using CART decision trees to pull off the goal: https://arxiv.org/pdf/1706.04687.pdf)
I have encountered this warning message when executing forestci.random_forest_error(regressor, x_train, x_test)
RuntimeWarning: invalid value encountered in true_divide g_eta_main = g_eta_raw / sum(g_eta_raw)
and the results are
array([nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan,
nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan,
nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan,
nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan,
nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan,
nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan,
nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan,
nan, nan, nan, nan, nan, nan])
Is it something related to zero division?
See the bottom of README.md
In discussing with @arokem, we couldn't find a reason for this method not to apply to generalized bagging estimators, e.g. an sklearn.ensemble.BaggingRegressor composed of sklearn.svm.SVR() instances. The Wager paper delays any mention of forests until section three.
I tried to blindly use a BaggingRegressor on one of the examples:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.svm import SVR
from sklearn.datasets import fetch_openml
from sklearn.ensemble import BaggingRegressor
from sklearn.linear_model import LassoCV
from sklearn.model_selection import train_test_split
import forestci as fci
# Build the bagging regressors, one using SVR and one using LassoCV
# retreive mpg data from machine learning library
mpg_data = fetch_openml('autompg')
# separate mpg data into predictors and outcome variable
mpg_X = mpg_data["data"]
mpg_y = mpg_data["target"]
# remove rows where the data is nan
not_null_sel = np.invert(np.sum(np.isnan(mpg_data["data"]), axis=1).astype(bool))
mpg_X = mpg_X[not_null_sel]
mpg_y = mpg_y[not_null_sel]
# split mpg data into training and test set
mpg_X_train, mpg_X_test, mpg_y_train, mpg_y_test = train_test_split(
mpg_X, mpg_y,
test_size=0.25,
random_state=42,
)
# Create BaggingRegressor
n_estimators = 1000
svr_bagger = BaggingRegressor(
base_estimator=SVR(),
n_estimators=n_estimators,
random_state=42,
n_jobs=-1,
# max_samples=0.99999
)
lasso_bagger = BaggingRegressor(
base_estimator=LassoCV(cv=3),
n_estimators=n_estimators,
random_state=42,
n_jobs=-1,
# max_samples=0.99999
)
svr_bagger.fit(mpg_X_train, mpg_y_train)
lasso_bagger.fit(mpg_X_train, mpg_y_train)
svr_y_hat = svr_bagger.predict(mpg_X_test)
lasso_y_hat = lasso_bagger.predict(mpg_X_test)
# Calculate the variance
svr_V_IJ_unbiased = fci.random_forest_error(
svr_bagger, mpg_X_train, mpg_X_test
)
lasso_V_IJ_unbiased = fci.random_forest_error(
lasso_bagger, mpg_X_train, mpg_X_test
)
But I got the following error:
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-3-482cfbc9365b> in <module>
13
14 # Calculate the variance
---> 15 svr_V_IJ_unbiased = fci.random_forest_error(
16 svr_bagger, mpg_X_train, mpg_X_test
17 )
~/projects/forest-confidence-interval/forestci/forestci.py in random_forest_error(forest, X_train, X_test, inbag, calibrate, memory_constrained, memory_limit)
234 """
235 if inbag is None:
--> 236 inbag = calc_inbag(X_train.shape[0], forest)
237
238 pred = np.array([tree.predict(X_test) for tree in forest]).T
~/projects/forest-confidence-interval/forestci/forestci.py in calc_inbag(n_samples, forest)
60 inbag = np.zeros((n_samples, n_trees))
61 sample_idx = []
---> 62 n_samples_bootstrap = _get_n_samples_bootstrap(
63 n_samples, forest.max_samples
64 )
~/miniconda3/envs/forestci/lib/python3.8/site-packages/sklearn/ensemble/_forest.py in _get_n_samples_bootstrap(n_samples, max_samples)
107 if not (0 < max_samples < 1):
108 msg = "`max_samples` must be in range (0, 1) but got value {}"
--> 109 raise ValueError(msg.format(max_samples))
110 return int(round(n_samples * max_samples))
111
ValueError: `max_samples` must be in range (0, 1) but got value 1.0
This is because RandomForestRegressor and BaggingRegressor have different validation subroutines for max_samples. forestci uses the private routines in sklearn.ensemble._forest to get the number of bootstrap samples, which validates the max_samples parameter as if it were supplied to RandomForestRegressor. So some work might have to be done to accommodate generalized bagging regressors/classifiers.
I tried again by setting max_samples = 0.999 and it worked. But this is a bit hacky and it would be better to write code that inspects the "forest" to see if it inherits from BaseForest or from BaseBagging. I will submit a PR to this effect.
I'm getting a ValueError when using a random forest estimator trained on multi-dimensional output:
fci.random_forest_error(est, X_train, X_test)
Traceback (most recent call last):
File "<ipython-input-46-91c6f1ac565a>", line 1, in <module>
fci.random_forest_error(est, X_train, X_test)
File "/home/matt/anaconda3/lib/python3.6/site-packages/forestci/forestci.py", line 163, in random_forest_error
memory_constrained, memory_limit)
File "/home/matt/anaconda3/lib/python3.6/site-packages/forestci/forestci.py", line 64, in _core_computation
return np.sum((np.dot(inbag-1,pred_centered.T)/n_trees)**2,0)
ValueError: shapes (135,10) and (10,34,96) not aligned: 10 (dim 1) != 34 (dim 1)
For reference,
X_train.shape
>>> (135, 1252)
y_test.shape
>>> (34, 96)
I would expect the returned variance array to be of shape (34,96).
I am on version 0.2 of forestci.
I'm substituting my own Data into this but running this code and receiving the above titled error??
import numpy as np
from matplotlib import pyplot as plt
from sklearn.ensemble import RandomForestRegressor
import sklearn.cross_validation as xval
from sklearn.datasets.mldata import fetch_mldata
import forestci as fci
# create RandomForestRegressor
n_trees = 2000
mpg_forest = RandomForestRegressor(n_estimators=n_trees, random_state=42)
mpg_forest.fit(X, y)
mpg_y_hat = mpg_forest.predict(X2)
# calculate inbag and unbiased variance
mpg_inbag = fci.calc_inbag(X.shape[0], mpg_forest)
mpg_V_IJ_unbiased = fci.random_forest_error(mpg_forest, X,
X2)
# Plot error bars for predicted MPG using unbiased variance
plt.errorbar(y2, mpg_y_hat, yerr=np.sqrt(mpg_V_IJ_unbiased), fmt='o')
plt.plot([5, 45], [5, 45], '--')
plt.xlabel('Reported MPG')
plt.ylabel('Predicted MPG')
TypeError: random_forest_error() takes exactly 4 arguments (3 given)
Hi,
Firstly, thanks for the amazing work! I just have a question that how we support to use the error bar? Specifically for the RandomForestClassifier. The example only uses the result for plotting ...
Thanks and look forward to hearing from you
Hello,
I am trying to compare the RF error on train and test data for a regression problem. After fitting the model (rf_model), I estimate the error as follows (np for numpy)-
test_std = np.sqrt(fci.random_forest_error(rf_model, train_dataset.X, test_dataset.X)) train_std = np.sqrt(fci.random_forest_error(rf_model, train_dataset.X, train_dataset.X))
But from the results I see that the standard deviation for test data is very small compared to the standard deviation for the train dataset which is weird. I am thinking is it because I am passing the same dataset to calculate the standard deviation for training dataset?
I would really appreciate some help.
Thank you!
Hi. I am trying to get a CI for a new x value that was not in the training set.
X_train.shape = 2000, 1
X_test.shape = 1, 1
X_test = [10]
V_IJ_unbiased = fci.random_forest_error (model, X_train, X_test)
At the same time, V_IJ_unbiased = [0.]
But if I use X_test.shape = [2, 1] - everything is fine.
example
X_test = [10, 23]
How can I get the CI for the new value of X_test ?
In the implementation of both, random_forest_error() and _core_computation(), the complete X_train data is passed but only X_train.shape[0] is ever used. Why is the complete data being taken instead of just the length then? Wouldn't this be an issue if there is a huge training data array but can be solved if just its length is passed?
@owlas @arokem I'm running fci.random_forest_error on a fairly large dataset.
train: 3334431, 200
test: 13703350, 200
(train is smaller after undersampling)
I'm trying to use both the memory_constrained version and the low_memory version (#74).
I ran the memory_constrained version on a m5.24xlarge EC2 instance with 384.0 GiB of memory and 96 vCPUs. I gave it a memory_limit of 100000 MB (100 GB). This only utilized about half of the memory on the instance and it ran for over 48 hours until I just terminated the instance.
I'm currently running the low_memory option on a m5.12xlarge (192 GiB memory, 48 vCPU) which has been running for 15 hours straight and hasn't finished yet. Using top I do see that all of the CPUs are being utilized to 100%.
I have a few questions:
how can I estimate the ideal size of memory_limit? I understand its the max size of the intermediate matrices from the docs but it wasn't clear to me how many intermediate matricies are being created at a time? Is it sequential, i.e. do I just give it the whole RAM?
is the memory_constrained version faster than the low_memory option given large enough memory limit? It wasn't clear to me which one I should be expecting to complete.
Is there any way to show a progress indicator (even if I have to hack in a print for now)? I'd like to know how close I am to completion with jobs that seem to take multiple days to run.
Overall, I'm looking to precompute as much as possible and then run this model on live predictions one at a time. Looking at the code I believe this should be possible- does this sound do-able to you?
Any other advice you can offer would be most helpful.
Thanks!
EDIT: I'm trying the low_memory option again with a memory_limit of 300000 (300 GiB). I believe that limit does indeed appear to be sequential. The memory slowly crawls up to the max, all the cores kick in for a few minutes, and then the memory comes back down again.
Notably, while the memory is slowly filling up, only one core is being. Only when the memory fills up all the way, most of the cores kick into action for about 2 minutes. Then it takes 1 minute for the memory to go back down with a single core being used. The cycle then starts again.
Is there perhaps some optimization that can allow all the cores to be used more efficiently? It seems the majority of time is currently spent waiting until the memory limit is reached and only then some computation occurs.
As mentioned before, the low_memory option, on the other hand, is constantly using all cores at 100%.
First of all many thanks for the very nice repository and clean code!
I was wondering whether this method would be applicable to non-binary classification tasks. By looking at the code, I imagine it could make sense if the class is an ordinal variable, but in the general case the mean over the predicted classes would not be meaningful.
The original paper does not discuss this, and it seems to me the extension to multi-class problems is not super trivial. However, as your code imposes no restrictions on the number of classes, I was wondering if you have considered this problem, and whether you know of a good workaround. Would running the code on the predicted probability of each class make sense? That is, computing the variance of the output of predict_proba instead of predict.
Many thanks!
There is no mention of tests, or how to run the tests in the documentation. Also the level of test coverage for this package is unknown
Training set is of the form (n_training_samples, n_features) = (14175.34)
Testing set is of the form (n_testing_samples, n_features) = (4725,34)
Running - forestci.random_forest_error(randomFor, X_train, X_test)
Yields the following error;
ValueError Traceback (most recent call last)
in
21 print(X_test.shape)
22 mpg_V_IJ_unbiased = forestci.random_forest_error(randomFor, X_train,
---> 23 X_test)
24 hat = randomFor.predict(X_test)
25 print(' The score for is {}'.format(score[-13::]))
~\Anaconda3\lib\site-packages\forestci\forestci.py in random_forest_error(forest, X_train, X_test, inbag, calibrate, memory_constrained, memory_limit)
241 n_trees = forest.n_estimators
242 V_IJ = _core_computation(X_train, X_test, inbag, pred_centered, n_trees,
--> 243 memory_constrained, memory_limit)
244 V_IJ_unbiased = _bias_correction(V_IJ, inbag, pred_centered, n_trees)
245
~\Anaconda3\lib\site-packages\forestci\forestci.py in _core_computation(X_train, X_test, inbag, pred_centered, n_trees, memory_constrained, memory_limit, test_mode)
110 """
111 if not memory_constrained:
--> 112 return np.sum((np.dot(inbag - 1, pred_centered.T) / n_trees) ** 2, 0)
113
114 if not memory_limit:
<array_function internals> in dot(*args, **kwargs)
ValueError: shapes (14175,700) and (700,4725,2) not aligned: 700 (dim 1) != 4725 (dim 1)
Hey guys,
Current example in docs no longer runs with latest version from pip, producing the error:
mpg_V_IJ_unbiased = fci.random_forest_error(mpg_forest, mpg_X_train, mpg_X_test)
TypeError: random_forest_error() takes exactly 4 arguments (3 given)
This is because the random_forest_error method inputs have changed to request the in_bag argument second.
This is a cool library, not sure how this normally works but want me to amend the docs?
When using random_forest_error() with a dataset in which the features range between 0 and 1 and of datatype float64, I get a bunch of overflow errors like so:
/Users/erictaw/forest-confidence-interval/forestci/calibration.py:86: RuntimeWarning: overflow encountered in exp
g_eta_raw = np.exp(np.dot(XX, eta)) * mask
/Users/erictaw/forest-confidence-interval/forestci/calibration.py:101: RuntimeWarning: overflow encountered in exp
g_eta_raw = np.exp(np.dot(XX, eta_hat)) * mask
/Users/erictaw/forest-confidence-interval/forestci/calibration.py:102: RuntimeWarning: invalid value encountered in true_divide
g_eta_main = g_eta_raw / sum(g_eta_raw)
Turning off calibration eliminates these errors, of course. Is this something I should be worried about?
I ran the plot_mpg notebook code:
# Regression Forest Example
import numpy as np
from matplotlib import pyplot as plt
from sklearn.ensemble import RandomForestRegressor
import sklearn.cross_validation as xval
from sklearn.datasets.mldata import fetch_mldata
import forestci as fci
# retreive mpg data from machine learning library
mpg_data = fetch_mldata('mpg')
# separate mpg data into predictors and outcome variable
mpg_X = mpg_data["data"]
mpg_y = mpg_data["target"]
# split mpg data into training and test set
mpg_X_train, mpg_X_test, mpg_y_train, mpg_y_test = xval.train_test_split(
mpg_X, mpg_y,
test_size=0.25,
random_state=42
)
# create RandomForestRegressor
n_trees = 2000
mpg_forest = RandomForestRegressor(n_estimators=n_trees, random_state=42)
mpg_forest.fit(mpg_X_train, mpg_y_train)
mpg_y_hat = mpg_forest.predict(mpg_X_test)
# calculate inbag and unbiased variance
mpg_inbag = fci.calc_inbag(mpg_X_train.shape[0], mpg_forest)
mpg_V_IJ_unbiased = fci.random_forest_error(mpg_forest, mpg_X_train,
mpg_X_test)
# Plot error bars for predicted MPG using unbiased variance
plt.errorbar(mpg_y_test, mpg_y_hat, yerr=np.sqrt(mpg_V_IJ_unbiased), fmt='o')
plt.plot([5, 45], [5, 45], '--')
plt.xlabel('Reported MPG')
plt.ylabel('Predicted MPG')
plt.show()
and got the following error:
TypeError Traceback (most recent call last)
<ipython-input-2-a0d96d55b892> in <module>()
30 mpg_inbag = fci.calc_inbag(mpg_X_train.shape[0], mpg_forest)
31 mpg_V_IJ_unbiased = fci.random_forest_error(mpg_forest, mpg_X_train,
---> 32 mpg_X_test)
33
34 # Plot error bars for predicted MPG using unbiased variance
TypeError: random_forest_error() missing 1 required positional argument: 'X_test'
My environment is Anaconda python 4.3.1.
Charles
Both references (wager_confidence_2014 and wager_randomforestci_2016) are missing a DOI
For my dataset, I tried correlating the CIs to absolute error on the test set, and didn't find a relationship. I do get a relationship if I use the standard deviation of the predictions from individual decision trees. Do you see this with other datasets?
The software makes no performance claims, a performance comparison against the original R-code would be interesting to add
This is the result when I try to pip uninstall forestci:
Can't uninstall 'forestci'. No files were found to uninstall.
Any idea what might be causing this?
The examples use two standard datasets from another package, however it is not explained in which
format the users own data needs to be presented before it can be used.
Please provide links to the relevant documentations.
The two examples do not show before and after plots of the dataset, as
such it is not clear why the user should use this routine.
There is no description of what settings can be used in the calculation of inbag and unbiased variance and how these influence the results
This package provides 2 functions to the user, which have been documented. However there are also 2 undocumented internal functions, which should be documented.
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.