sampsyo / bril Goto Github PK
View Code? Open in Web Editor NEWan educational compiler intermediate representation
Home Page: https://capra.cs.cornell.edu/bril/
License: MIT License
an educational compiler intermediate representation
Home Page: https://capra.cs.cornell.edu/bril/
License: MIT License












































































































































The current feature difference between the reference interpreter, brili, and its Rust counter-part brilirs is that brilirs does not implement the speculative execution extension. The implementation semantics can probably be borrowed from brili and converted to rust. However, brilir uses iterators along basic block sequences instead of random access of the entire function which is more performant but may be an issue when trying to commit, and then return to an instruction part of the way through a code block. Use of the speculation extension is rare, so it would be nice to do this with a limited performance penalty on the longer running benchmarks.
Hi,
It looks like on line 27 of sieve.bril there is a reference to a ptr<book>... not sure that this is valid Bril!
It would be nice if bril-ts, including the language definition and builder, could be used independently of the TypeScript compiler and possibly also the interpreter. This would help facilitate independent projects written in TS that want to depend on our utilities, and it would set a precedent for other similar independent language definitions/tools in other languages.
The current implementation of constant folding via local value numbering in lvn.py crashes when the program divides by zero. Instead of crashing, the compiler should bail on folding constants when there are dynamic errors.
Minimal example:
void main() {
entry:
zero : int = const 0;
one : int = const 1;
baddiv : int = div one zero;
print baddiv;
}
Stack trace:
Traceback (most recent call last):
File "examples/lvn.py", line 243, in <module>
lvn(bril, '-p' in sys.argv, '-c' in sys.argv, '-f' in sys.argv)
File "examples/lvn.py", line 236, in lvn
fold=_fold if fold else lambda n2c, v: None,
File "examples/lvn.py", line 160, in lvn_block
const = fold(num2const, val)
File "examples/lvn.py", line 211, in _fold
return FOLDABLE_OPS[value.op](*const_args)
File "examples/lvn.py", line 197, in <lambda>
'div': lambda a, b: a // b,
ZeroDivisionError: integer division or modulo by zero
Consider:
@main {
five: int = const 5;
x: ptr<int> = alloc five;
print x;
free x;
}
Currently, brili outputs [object Object] and brilirs outputs Pointer { base: 0, offset: 0 }, essentially just spitting out their internal representations. Given that https://www.cs.cornell.edu/courses/cs6120/2019fa/blog/manually-managed-memory/ says that "the representation of data in memory is abstract", this seems like not great behavior.
I was wondering if this behavior should be further specified? One could of course just keep it implementation defined, it could be "bad program" for which a nice interpreter would return an error, or it could print out the contents of the array either just at that index or from there untill the end(Which a couple benchmarks have written implementations for so this is desirable behavior but requires a compliant implementation to know the bounds of the array).
There is the following text in https://capra.cs.cornell.edu/bril/lang/syntax.html#instruction section:
op, a string: the opcode that determines what the instruction does. (See the Operations section, below.)
But there is no "operations" section so the link leads to nowhere. And therefore there is no place where all operations are described.
Bril is supposed to be extensible, but that extensibility is currently pretty ad hoc: you just add whatever you want to the language. It would be nice to codify some standard way to package up extensions to Bril. There wouldn't need to be a machine-readable description of what an extension consists of, but maybe there should be a way in a Bril program to describe the extensions that the program relies on.
This would require that extensions get assigned (string) names. We would probably want to organize the documentation around a minimal "base" language and individual extensions.
Most of the tests we run in CI rely on the reference interpreter, which is (by design) extremely permissive. Plenty of type errors are forgiven, for example. As @Pat-Lafon has valiantly pointed out lately, however (e.g., #154 (comment) and #152 (comment)), this makes it easy for hand-written code with type errors to sneak into the benchmarks and other tests.
It would be awesome to set up automated checking in CI for all the Bril programs we have in tree. We could do this with brilirs's own --check mode or the type inference tool.
Bonus points for pointing out the line where the error occurs and adding a check annotation on the offending line in a given PR… but that can come in a subsequent phase!
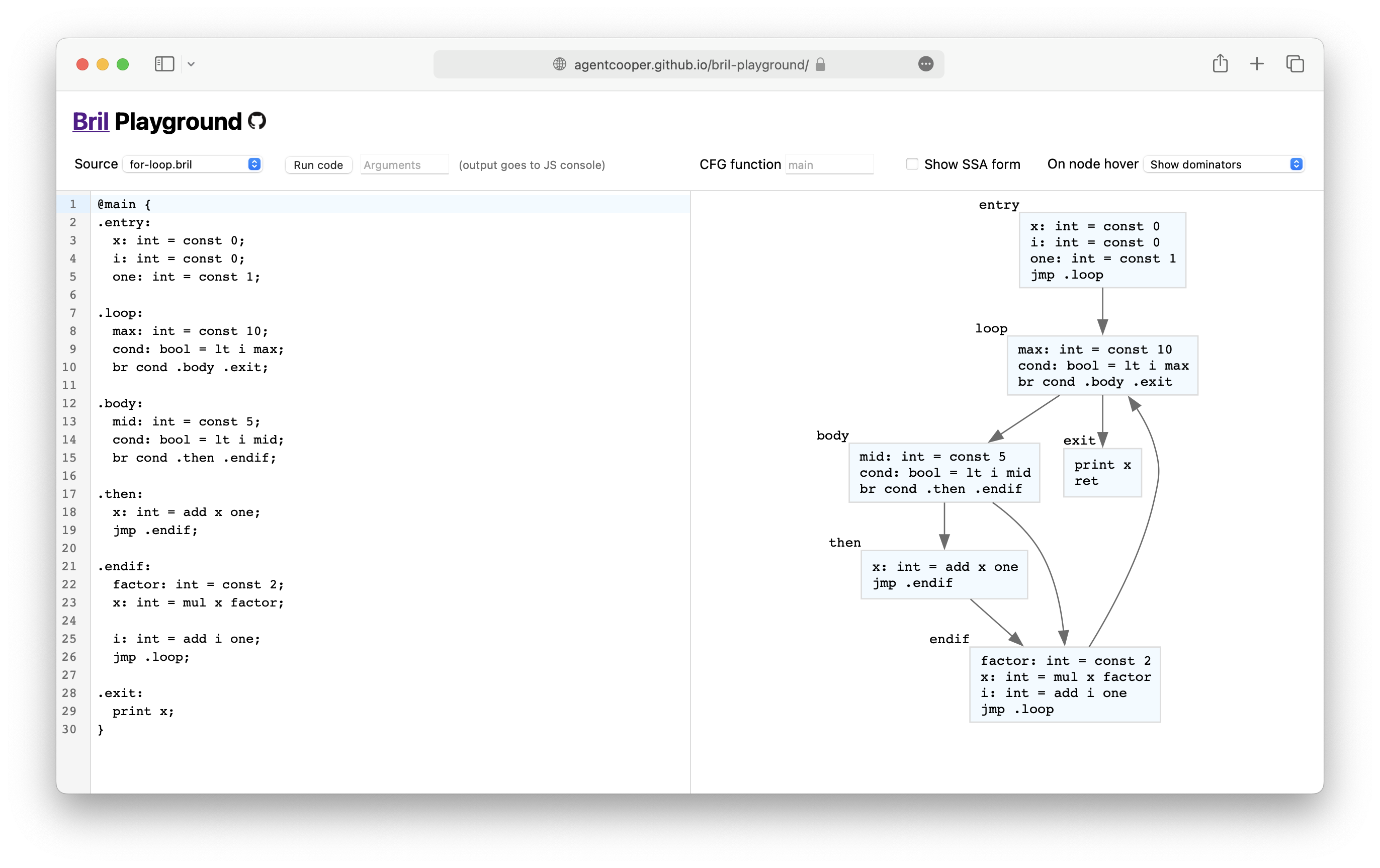
I've created a web playground for Bril to visualize the CFG and dominators. And it embeds the interpreter. I am also open to suggestions on what can be added/changed.
https://agentcooper.github.io/bril-playground/
The Bril docs don't say anything about what divide-by-zero should do, either in the core instructions or in the floating point extension. Options include:
Crashing with an exception is in some ways the most reasonable thing to do (and models many real languages), but it has two drawbacks:
div and fdiv instructions.Of course, you can see the latter disadvantage as an advantage, pedagogically speaking… since it introduces an extra nuance, especially for speculative optimizations, that otherwise wouldn't exist in the language.
Let's assemble a ready-made Bril benchmark suite for measuring the impact of performance. Some places to start:
Line 52 in 57877b1
Take this program for example (modified from interp test):
@print(n: int): int {
}
@main: int {
v: int = const 4;
jmp .somewhere;
v: int = const 2;
.somewhere:
tmp: int = call @print v;
ret v;
}
Applying to_ssa creates this wrong output
@print(n: int): int {
}
@main: int {
.b1:
v.0: int = const 4;
jmp .somewhere;
.b2:
v.1: int = const 2;
jmp .somewhere;
.somewhere:
tmp.0: int = phi __undefined tmp.1 .b1 .b2;
tmp.1: int = call @print v.0;
ret v.0;
}
Note the garbage phi instruction tmp.0. This happens because dominators are computed as follows in dom.py (which is then used by to_ssa.py)
{'b1': {'b1'}, 'b2': {'somewhere', 'b1'}, 'somewhere': {'somewhere', 'b1'}}
This is obviously wrong. This happens because get_dom algorithm fails when there's a node/basic block that doesn't have any predecessor that is not reachable from entry.
store instruction raises error when writing to a float pointer.
@main() {
one: int = const 1;
seed: float = const 109658.0;
rng: ptr<float> = alloc one;
store rng seed;
}
../bril/bril-ts/build/brili.js:789
process.on('unhandledRejection', e => { throw e; });
^
store argument 1 must be a Pointer
As far as I understand, if two values have the same value number, they are guaranteed to be the same at runtime. As a result, for operator eq, if both operands have the same value number (even if they are not constants) we could fold the operator to a constant true.
A "fun" task for any Rustaceans out there: #49 introduced a breaking syntax change, and the brilirs interpreter needs updating to match. In particular, the main necessary change is looking for labels in an instruction's labels key rather than in args.
Consider a typescript program looks like this:
let value = 8;
let result = 1;
for (let i = value; i > 0; i = i - 1) {
if (i>5){
result = result * i;
}
}
The if statement of this program will be translated to bril like this
br v10 then.7 else.7;
then.7:
v11: int = id result;
v12: int = id i;
v13: int = mul v11 v12;
result: int = id v13;
jmp endif.7;
else.7:
endif.7:
v14: int = id i;
...
The translation is correct. But block else.7 is empty.
However, because in our own project we would like to take use of add_terminators in cfg.py, we find block[-1]['op'] not in TERMINATORS does not work since block length of else.7 is empty and there is no block[-1].
It would be better to modify the function to
def add_terminators(blocks):
for i, block in enumerate(blocks.values()):
if len(block) == 0:
dest = list(blocks.keys())[i + 1]
block.append({'op': 'jmp', 'args': [dest]})
elif block[-1]['op'] not in TERMINATORS:
...
ts2bril throws an error when it encounters a boolean constant instruction.
For example, the line var x : boolean = true; makes it throw the error: unimplemented type boolean. This occurs with or without the type annotation in the code.
Should other parts of floating point be specified as well, specifically how a compliant interpreter/runtime outputs Nan/Infinity?
Originally posted by @Pat-Lafon in #214 (comment)
Also, we should specify that printing "normal" floats should always use 17 decimal digits, as discussed in #214 (comment).
This input, which is exactly if-ssa.bril except the .exit label is renamed to .xit causes buggy SSA to be generated by to_ssa.py:
@main(cond: bool) {
.entry:
a.1: int = const 47;
br cond .left .right;
.left:
a.2: int = add a.1 a.1;
jmp .xit;
.right:
a.3: int = mul a.1 a.1;
jmp .xit;
.xit:
a.4: int = phi .left a.2 .right a.3;
print a.4;
}
The generated SSA is:
@main(cond: bool) {
.entry:
a.1.0: int = const 47;
br cond .left .right;
.left:
a.2.0: int = add a.1.0 a.1.0;
jmp .xit;
.right:
a.3.0: int = mul a.1.0 a.1.0;
jmp .xit;
.xit:
a.2.1: int = phi a.2.0 a.2.0 .left .right;
a.4.0: int = phi a.2.1 a.3.1 .left .right;
print a.4.0;
ret;
}
The buggy line is a.4.0: int = phi a.2.1 a.3.1 .left .right;. When called with cond = false the variable a.3.1 is not defined, causing a.4.0 to be undefined.
This is caused by the function prune_phis():
Lines 91 to 126 in d65455d
This bug is triggered with the new input, and not triggered by if-ssa.bril because of the sorting done on this line:
Line 79 in d65455d
I believe that this optimization is not sound, even in the case when the input does not have phi instructions. Imagine the input:
@main() {
cond: bool = const true;
br cond .true .false;
.true:
a: int = const 0;
jmp .zexit;
.false:
b: int = const 1;
jmp .zexit;
.zexit:
print a;
}
Because cond is always true, a is always defined. But, to_ssa.py generates incorrect code similar to before:
@main {
.b1:
cond.0: bool = const true;
br cond.0 .true .false;
.true:
a.0: int = const 0;
jmp .zexit;
.false:
b.0: int = const 1;
jmp .zexit;
.zexit:
b.1: int = phi b.0 b.0 .false .true;
print a.1;
ret;
}
You could also argue that variables MUST be defined on all paths for the bril program to be well-formed. But, I don't think that is a reasonable requirement. And instead it should instead be undefined behavior to read from an undefined variable. That leaves the prune_phis optimization as it is currently implemented unsound.
Instead, prune_phis() should probably insert undefined variables like __undefined, or read from the output variable.
In the examples, lvn.py -p currently fails for this example:
@main {
a: int = const 42;
.lbl:
b: int = id a;
a: int = const 5;
print b;
}
The optimization incorrectly changes the last line to print a.
The problem is the interaction between copy (id) propagation and basic block inputs (i.e., the fact that a is read before it is written in the second block). One annoying but cleanish solution would be to copy a to a fresh variable right as the block begins because it is read before it is written. Another, much less clean solution would be to detect the first overwrite of a and do the renaming at that point, or to somehow avoid doing copy propagation for the id because the value will be clobbered later.
Here's an example bril for interp test add-overflow
@pow(base: int, exp: int): int {
out: int = const 1;
one: int = const 1;
.loop:
end: bool = lt exp one;
br end .ret .body;
.body:
out: int = mul out base;
exp: int = sub exp one;
jmp .loop;
.ret:
ret out;
}
Converting this to ssa using to_ssa.py gives following output
@pow(base: int, exp: int): int {
.b1:
out.0: int = const 1;
one.0: int = const 1;
jmp .loop;
.loop:
out.1: int = phi out.0 out.2 .b1 .body;
exp.0: int = phi exp exp.1 .b1 .body;
end.0: bool = phi __undefined end.1 .b1 .body;
end.1: bool = lt exp.0 one.0;
br end.1 .ret .body;
.body:
out.2: int = mul out.1 base;
exp.1: int = sub exp.0 one.0;
jmp .loop;
.ret:
ret out.1;
}
Note how end.0: bool = phi __undefined end.1 .b1 .body; is inserted and it's not necessary to have done that. In fact it's not used anywhere and tdce would remove it.
I will try to figure out where this issue is coming from.
Processing the IR is significantly more annoying because of the syntactic simplicity in Bril 1.0: in jmp foo, the foo argument, which is a label, looks exactly the same as bar and baz in add bar baz. Special-case handling is required to separate actual variable references from labels and function names.
We should separate these in the syntax. This change will break plenty of stuff but is probably worth it.
I was checking my implementation against the examples, and found this:
bril2json < overwritten-variable.bril | python3 examples/lvn.py -p -c -f | bril2txt
@main {
v1: int = const 4;
v2: int = const 0;
mul1: int = mul v1 v2;
v2: int = const 3;
}
Lowers to:
@main {
v1: int = const 4;
lvn.2: int = const 0;
mul1: int = mul v1 lvn.2; // <-- This should be folded.
v2: int = const 3;
}
Expected output:
@main {
v1: int = const 4;
lvn.2: int = const 0;
mul1: int = const 0;
v2: int = const 3;
}
main {
v0: int = const 9;
v1: int = const -20;
res: int = div v0 v1;
print res;
}
This code produces -0.45 rather than 0 as expected.
# bril2json < p.bril | python3 ../../df.py defined
@main(awesome_integer: int) {
.entry:
print awesome_integer;
}
entry:
in: ∅
out: ∅
awesome_integer should be defined in .entry.
entry:
in: awesome_integer
out: awesome_integer
I think the issue here is two-fold.
There's no simple way to pass in arguments to the analyses. Here, we pass in an analysis with a defaulted (empty) data structure. However, for an analysis such as reaching definitions or defined analysis, we want to pass in the function arguments to the first block.
Lines 82 to 92 in dbbd8e8
Even if we do pass in the correct function arguments,
Lines 48 to 49 in dbbd8e8
inval = analysis.merge(out[n] for n in in_edges[node]) # in_edges[.entry] == []
So, even though in_[.entry] is initialized correctly, it is over-written afterward.
As usual, let me know if I'm off-target.
I am also interested in the following:
If there should be 2 additional operators to the floating point extension, isnan and isinf, which would match similar behavior as seen in Python. Though I guess that this could be implemented as a small function calls in a Bril program and then used via the import extension in the niche cases that would want them.
If Bril should allow conversion between integers and floating point values with an operator like toint/tofloat.
Originally posted by @Pat-Lafon in #214 (comment)
To reproduce:
❯ cat test/overflow.bril
@main() {
x: int = const 9223372036854775807;
one: int = const 1;
three: int = const 3;
y: int = add x one;
print y;
y: int = mul x three;
print y;
}
❯
❯ bril2json < test/overflow.bril | brili
-9223372036854775807
-9223372036854775808
❯ bril2json < test/overflow.bril | brilirs
-9223372036854775808
9223372036854775805
❯
The Bril documentation on integers writes:
int: 64-bit, two’s complement, signed integers.
I wonder which one is correct?
2 benchmarks (perfect.bril and digital-root.bril) have ret instructions at the end of their main functions that return values despite them not having a return type. I guess this is a type error?
A more general question. From the type system perspective, if a function both returns a value and has a side effect, does it need to be called as a Value operation (because it returns something) or can it be called as an Effect operation (and just ignore the return value)?
Line 16 in 421042a
I believe this should say that not takes 1 argument instead of 2.
Please mentione in doc that user must install ts2bril in order to run tests:
$ deno install ts2bril.ts --allow-all
$ deno install brilck.ts --allow-all
And probably fix existing instruction for brili:
$ deno install brili.ts --allow-all
Consider replacing --allow-all with more granular permissionns.
As was shown in #189 (comment). The current memory extension implementation for brilirs is surprisingly slow.
Currently, there are no good benchmarks that are memory intensive enough which makes it difficult to know what to optimize for. The closest program seems to be test/mem/alloc_large.bril which only allocates and frees the same sized chunk of memory in a loop.
The current implementation of Heap which supports the memory extension in brilirs is ported from brili and could be greatly improved.
A couple of possible pain points include.
Heap is implemented as a map from the "base" of the pointer to a Vec<Value>. This is nice in that it grows and shrinks with the amount of memory in use at any given. However, the use of maps like HashMap<usize, Vec<Value>> has historically been a performance hit in brilirs due to needing to hash the key and perform the lookup.
Vec<Vec<Value>> or aVec<Value> with the "base" of the pointer just indexing into the start of it's allocation in the array. In either case we will want the ability to reuse indexes as allocations are freed up.Vec<Vec<Value>> is probably slower than the alternative because it will require two array access to read/write to a value. However, it's probably easier to implement.Vec<Value> is more along the lines of implementing something like malloc which gives all of the performance benefits / fragmentation complexities involved.
Heap needs to still enforce errors on buffer over/underflows, use after frees, use of uninitialized memory, and memory leaks.Vec<Value> on every call to alloc. Ideally, brilirs should be able to reuse previously freed allocations. This would especially target alloc_large.bril and potentially provide a significant improvement over brili.
Heap as just one large Vec<Value> or using something like a slab allocator and delegating this reuse to an external library.Heap to use during the course of interpretation.
brilirs already employs some static analysis for type checking and it would be interesting if it could use a data flow analysis to get a very rough estimate on whether it should start out with a small or large Heap size. Some programs don't use the memory extension or use it sparingly which is the default case. On the other hand, we also want to optimize for programs which make of intense use of memory.Hi! Checking my results against the examples again.
From the lecture notes,
We say A's domination frontier contains B if
A does not strictly dominate* BA dominates a predecessor of B.*I think this was just dominates rather than strictly dominates in the video lecture. However it is defined correctly in the Gist
bril2json < class-example.bril | python3 examples/dom.py front
# Example used for Global Analysis in L5.
@main {
.entry:
x: int = const 0;
i: int = const 0;
one: int = const 1;
jmp .loop;
.loop:
max: int = const 10;
cond: bool = lt i max;
br cond .body .exit;
.body:
mid: int = const 5;
cond: bool = lt i mid;
br cond .then .endif;
.then:
x: int = add x one;
jmp .endif;
.endif:
factor: int = const 2;
x: int = mul x factor;
i: int = add i one;
jmp .loop;
.exit:
print x;
ret;
}
Results in:
# Frontiers
{
"body": [
"loop"
],
"endif": [
"loop"
],
"entry": [],
"exit": [],
"loop": [
"loop" # ???
],
"then": [
"endif"
]
}
Does B = loop meet the frontier criteria for A = loop?
loop does not strictly dominate loop <-- does hold since, loop == loop.loop dominates an immediate predecessor of loop. <-- does not hold. The only predecessor to loop is entry, which is not dominated.Let me know if something looks off with my explanation.
The typescript compiler doesn't seem to handle for loops right now.
It seems like one way to handle it would be to:
One issue I guess with adding for loops is that it's not super obvious which loops users should expect to work or not, and so it might create a lot of implied work (to handle other loops), but maybe a decent way of handling it would just be to see if the user seems to be using some type of loop, and have the error message explain which type of loop they can do.
A cool thing to add to the brili reference interpreter would be more informative messages about error locations. We can't give source locations, because the interpreter runs on ASTs instead of source code, but we could indicate which instruction index inside which function produced the error.
Hi,
So I'm not very familiar with the project, but I've done a fair bit of Rust and one of my friends is currently taking 6120, so I looked a little bit through the code. It seems some of the Brilrs code isn't using the commonly accepted Rust definitions of unsafe, which means that one could accidentally run into undefined behavior. Now these issues aren't actually being realized at the moment, but it might be good to conform to Rust standards to ensure correctness in the future.
The commonly accepted Rust standard is to say that
A function should be marked as
unsafeif it's possible to cause undefined behavior by calling it from safe code.
If one were to do (in entirely safe code)
let bbprog: BBProgram = prog.try_into()?;
interp::execute_main(&bbprog, out, &input_args, profiling)?;one could actually cause undefined behavior if the program passed into execute_main is not a valid program. This is because (if I'm reading correctly) execute_main assumes the program has been type-checked
Lines 184 to 218 in 30c836c
There's a couple possible solutions to this, if it is worth solving:
type_check return some sort of TypedProgram, and execute_main can only take in a TypedProgram, guaranteeing that the program has been type-checked. This solution makes the most sense to me.execute_main as unsafe. This is probably the least work but is very sad.The current interpreter for Bril does not support float arguments to main.
Here's a simple piece of code:
@main (x1 : int, x2: float) {
print x1;
print x2;
}
The output of this is as follows:
$ bril2json < floats.bril | brili 2 3.0
2
error: undefined variable x2
x1 got printed successfully because it's an int, but it seems like the argument x2 results in an error because it's a float.
Does this line do anything?
Line 184 in 104bc00
The interpreter tests are not currently broken down into directories based on the Bril extensions they use. (Except for the mem directory, which dates back to the original Fall 2019 project that implemented it.) We should do that—each extension should get its own directory. That will make it easer to differentially test against other interpreter implementations that don't support all the extensions, such as the Rust interpreter, as discussed in #104 (comment).
As part of my dataflow analysis lesson task, I came up with some funky Bril programs to stress the worklist algorithm. The following program (which is easier to understand when the order of the basic blocks is reversed) fails with brilirs -p false false but passes brili -p false false and brilck. It also seems to obey the list of rules given in the Bril documentation.
@main(b0: bool, b1: bool) {
jmp .start;
.end:
print x_0_2;
print x_1_2;
ret;
.l_1_3:
jmp .end;
.l_1_2:
x_1_2 : int = const 0;
jmp .l_1_3;
.l_1_1:
x_1_1 : int = const 1;
jmp .l_1_3;
.l_0_3:
br b1 .l_1_1 .l_1_2;
.l_0_2:
x_0_2 : int = const 2;
jmp .l_0_3;
.l_0_1:
x_0_1 : int = const 3;
jmp .l_0_3;
.start:
br b0 .l_0_1 .l_0_2;
}
For reference, here is the Python code I used to generate the program. brilirs has been super useful thus far, but I'm not super familiar with Rust so it'd be nice if a Rustacean could help us out here :)
#98 brought the fast Rust interpreter up to date. It currently supports all of the core language except function calls, i.e., the call instruction. We should add that someday!
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.