![]()
![]()



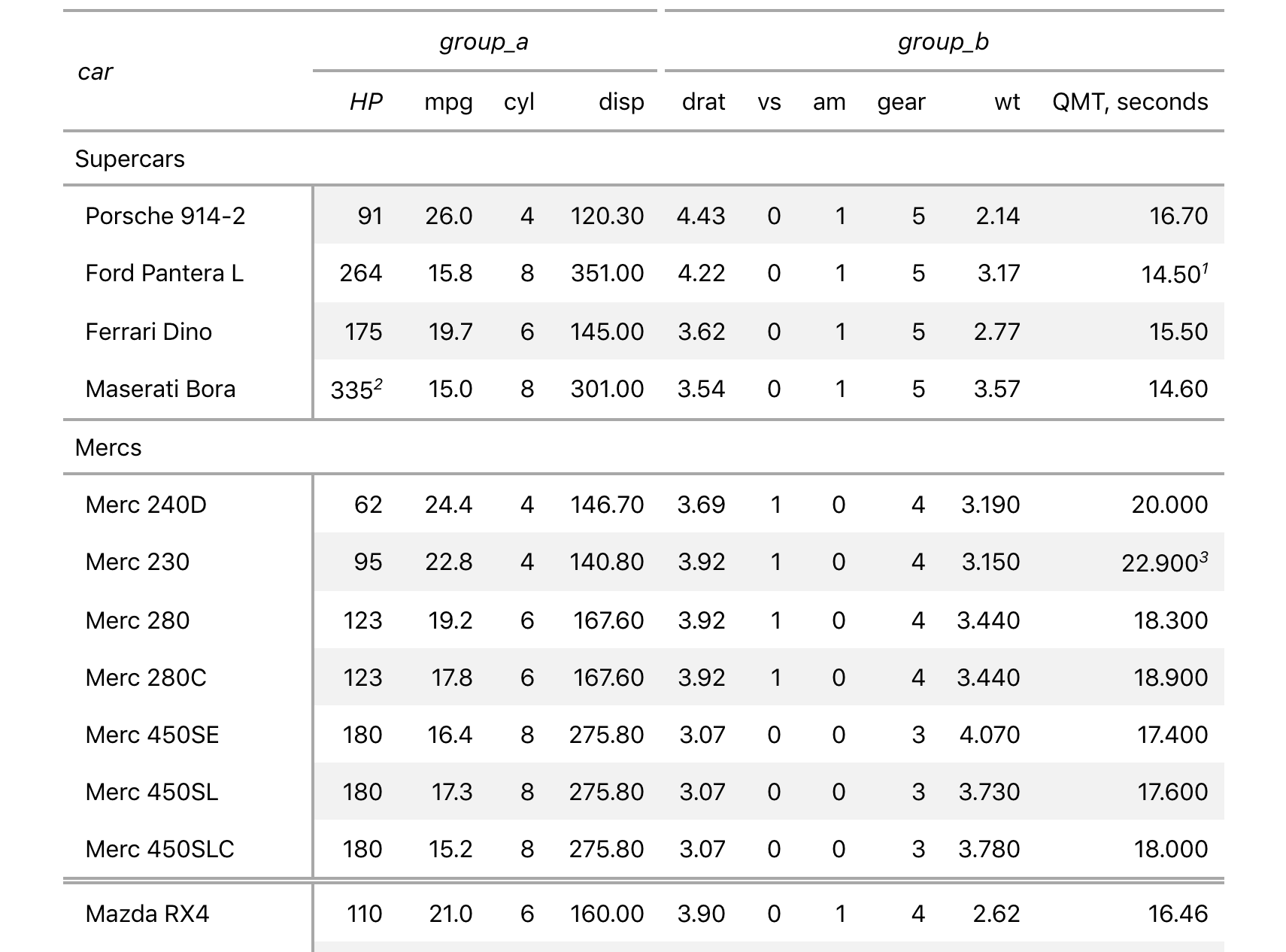
With the gt package, anyone can make wonderful-looking tables using the R programming language. The gt philosophy: we can construct a wide variety of useful tables with a cohesive set of table parts. These include the table header, the stub, the column labels and spanner column labels, the table body, and the table footer.

It all begins with table data (be it a tibble or a data frame). You
then decide how to compose your gt table with the elements and
formatting you need for the task at hand. Finally, the table is rendered
by printing it at the console, including it in an R Markdown document,
or exporting to a file using gtsave(). Currently, gt supports the
HTML, LaTeX, and RTF output formats.

The gt package is designed to be both straightforward yet powerful.
The emphasis is on simple functions for the everyday display table
needs. Here is a brief example of how to use gt to create a table
from the included sp500 dataset:
library(gt)
# Define the start and end dates for the data range
start_date <- "2010-06-07"
end_date <- "2010-06-14"
# Create a gt table based on preprocessed
# `sp500` table data
sp500 |>
dplyr::filter(date >= start_date & date <= end_date) |>
dplyr::select(-adj_close) |>
gt() |>
tab_header(
title = "S&P 500",
subtitle = glue::glue("{start_date} to {end_date}")
) |>
fmt_currency() |>
fmt_date(columns = date, date_style = "wd_m_day_year") |>
fmt_number(columns = volume, suffixing = TRUE)
There are twelve datasets provided by gt: countrypops, sza, gtcars, sp500, pizzaplace, exibble, towny, metro, constants, illness, rx_adsl, and rx_addv.












All of this tabular data is great for experimenting with gt’s functions and we make extensive use of these datasets in our documentation.
Beyond the functions shown in the simple sp500-based example, there are many functions available in gt for creating super-customized tables. Check out the documentation website to get started via introductory articles for making gt tables. There's a handy Reference section that has detailed help for every function in the package.
With the gt Test Drive, you can try gt in the Posit Cloud environment that features the RStudio IDE and a large collection of ready-to-run examples. Visit the publicly available Posit Cloud project and try out the package in your browser. There's no charge to use this platform and you'll learn a lot about what the package can do!

Let's talk about making tables with gt! There are a few locations where there is much potential for discussion.
One such place is in GitHub Discussions. This discussion board is especially great for Q&A, and many people have had their problems solved in there.
Another fine venue for discussion is in the gt_package Discord server. This is a good option for asking about the development of gt, pitching ideas that may become features, and sharing your table creations!
Finally, there is the gt_package Twitter account. There you'll find tweets about gt (including sneak previews about in-development features) and other table-generation packages.
These are all great places to ask questions about how to use the package, discuss some ideas, engage with others, and much more!
The gt package can be installed from CRAN with:
install.packages("gt")You can also choose to install the development version of gt from GitHub:
devtools::install_github("rstudio/gt")If you encounter a bug, have usage questions, or want to share ideas to make this package better, please feel free to file an issue.
There are several R packages that either use gt to generate tabular outputs or extend gt in amazing ways. Here is a short list of some of these great packages:
- gtsummary (GITHUB, WEBSITE)
- gtExtras (GITHUB, WEBSITE)
- pointblank (GITHUB, WEBSITE)
- tfrmt (GITHUB, WEBSITE)
- gto (GITHUB)
Please note that the gt project is released with a contributor code of
conduct.
By
participating in this project you agree to abide by its terms.
gt is licensed under the MIT license. See the
LICENSE.md file for more details.
© Posit Software, PBC.
This project is primarily maintained by Rich Iannone. Other authors may occasionally assist with some of these duties.