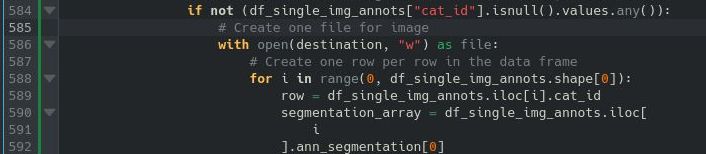
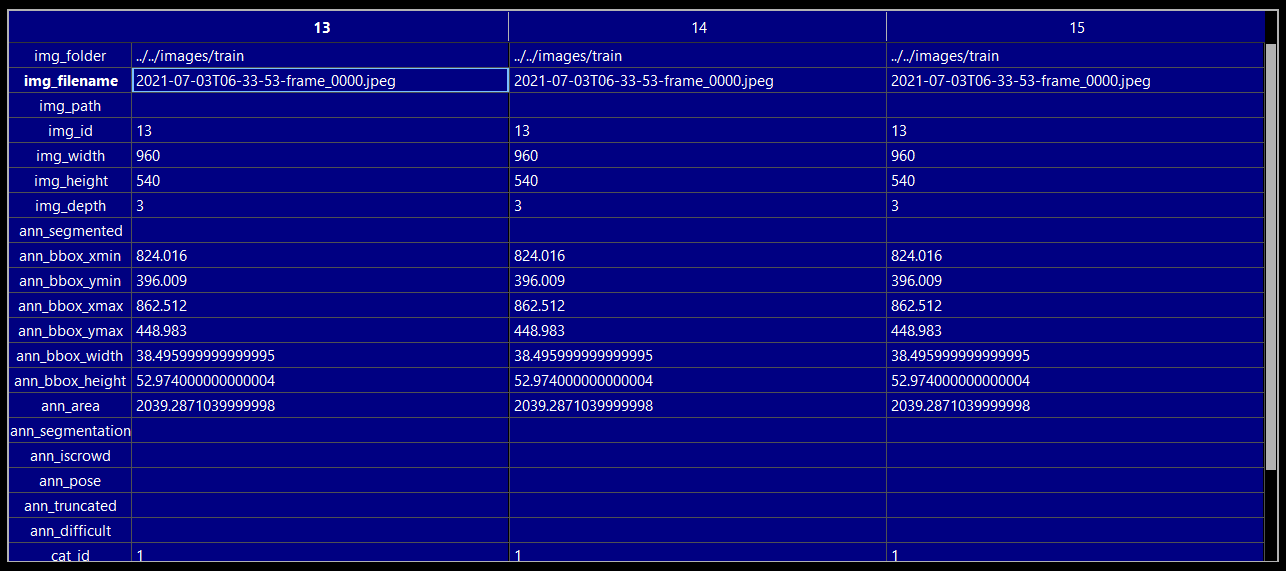
PyLabel is a Python package to help you prepare image datasets for computer vision models including PyTorch and YOLOv5. It can translate bounding box annotations between different formats. (For example, COCO to YOLO.) And it includes an AI-assisted labeling tool that runs in a Jupyter notebook.
- Translate: Convert annotation formats with a single line of code:
importer.ImportCoco(path_to_annotations).export.ExportToYoloV5() - Analyze: PyLabel stores annotatations in a pandas dataframe so you can easily perform analysis on image datasets.
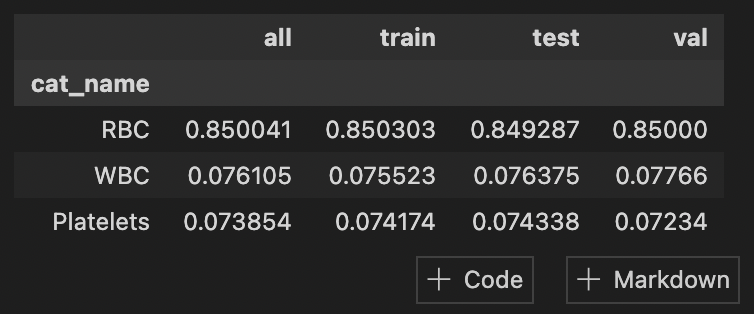
- Split: Divide image datasets into train, test, and val with stratification to get consistent class distribution.
- Label: PyLabel also includes an image labeling tool that runs in a Jupyter notebook that can annotate images manually or perform automatic labeling using a pre-trained model.
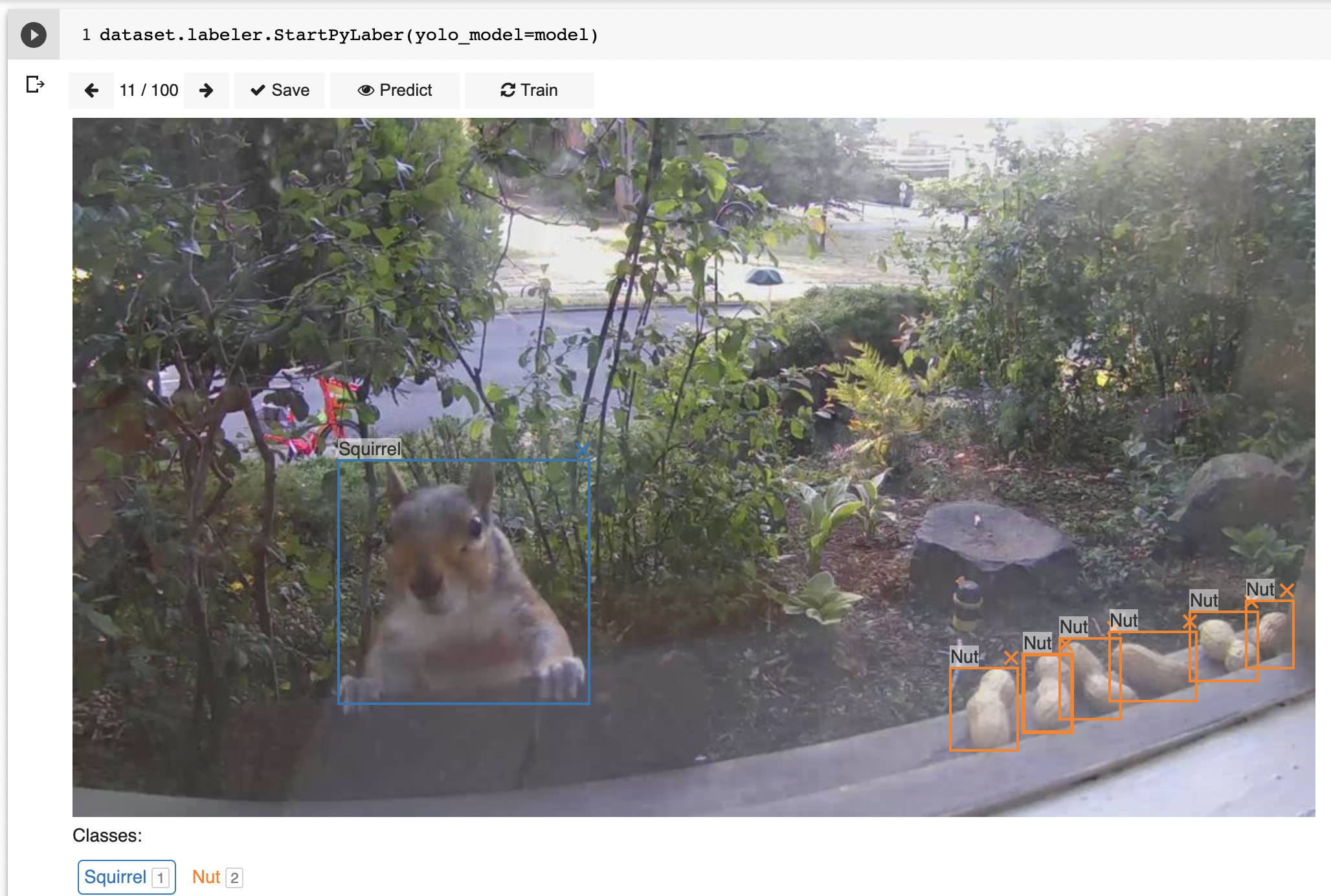
- Visualize: Render images from your dataset with bounding boxes overlaid so you can confirm the accuracy of the annotations.
See PyLabel in action in these sample Jupyter notebooks:
- Convert COCO to YOLO
- Convert COCO to VOC
- Convert VOC to COCO
- Convert YOLO to COCO
- Convert YOLO to VOC
- Import a YOLO YAML File
- Splitting Images Datasets into Train, Test, Val
- Labeling Tool Demo with AI Assisted Labeling
Find more docs at https://pylabel.readthedocs.io.
PyLabel was developed by Jeremy Fraenkel, Alex Heaton, and Derek Topper as the Capstope project for the Master of Information and Data Science (MIDS) at the UC Berkeley School of Information. If you have any questions or feedback please create an issue. Please let us know how we can make PyLabel more useful.