
💡 We also have other video generation project that may interest you ✨.
Open-Sora-Plan
PKU-Yuan Lab and Tuzhan AI etc.


ChronoMagic-Bench
Shenghai Yuan, Jinfa Huang and Yujun Shi etc.



- ⏳⏳⏳ Training a stronger model with the support of Open-Sora Plan.
- ⏳⏳⏳ Release the training code of MagicTime.
- ⏳⏳⏳ Integrate MagicTime into Diffusers. 🙏 [Need your contribution]
[2024.07.29]We add batch inference to inference_magictime.py for easier usage.[2024.06.27]Excited to share our latest ChronoMagic-Bench, a benchmark for metamorphic evaluation of text-to-time-lapse video generation, and is fully open source! Please check out the paper.[2024.05.27]Excited to share our latest Open-Sora Plan v1.1.0, which significantly improves video quality and length, and is fully open source! Please check out the report.[2024.04.14]Thanks @camenduru and @ModelsLab for providing Jupyter Notebook and Replicate Demo.[2024.04.13]🔥 We have compressed the size of repo with less than 1.0 MB, so that everyone can clone easier and faster. You can click here to download, or usegit clone --depth=1command to obtain this repo.[2024.04.12]Thanks @Jukka Seppänen and @Baobao Wang for providing ComfyUI Extension ComfyUI-MagicTimeWrapper. If you find related work, please let us know.[2024.04.11]🔥 We release the Hugging Face Space of MagicTime, you can click here to have a try.[2024.04.10]🔥 We release the inference code and model weight of MagicTime.[2024.04.09]🔥 We release the arXiv paper for MagicTime, and you can click here to see more details.[2024.04.08]🔥 We release the subset of ChronoMagic dataset used to train MagicTime. The dataset includes 2,265 metamorphic video-text pairs and can be downloaded at HuggingFace Dataset or Google Drive.[2024.04.08]🔥 All codes & datasets are coming soon! Stay tuned 👀!
MagicTime shows excellent performance in metamorphic video generation.
Compared to general videos, metamorphic videos contain physical knowledge, long persistence, and strong variation, making them difficult to generate. We show compressed .gif on github, which loses some quality. The general videos are generated by the Animatediff and MagicTime.
| Type | "Bean sprouts grow and mature from seeds" | "[...] construction in a Minecraft virtual environment" | "Cupcakes baking in an oven [...]" | "[...] transitioning from a tightly closed bud to a fully bloomed state [...]" |
| General Videos |  |
 |
 |
 |
| Metamorphic Videos |  |
 |
 |
 |
We showcase some metamorphic videos generated by MagicTime, MakeLongVideo, ModelScopeT2V, VideoCrafter, ZeroScope, LaVie, T2V-Zero, Latte and Animatediff below.
| Method | "cherry blossoms transitioning [...]" | "dough balls baking process [...]" | "an ice cube is melting [...]" | "a simple modern house's construction [...]" |
| MakeLongVideo |  |
 |
 |
 |
| ModelScopeT2V |  |
 |
 |
 |
| VideoCrafter |  |
 |
 |
 |
| ZeroScope |  |
 |
 |
 |
| LaVie |  |
 |
 |
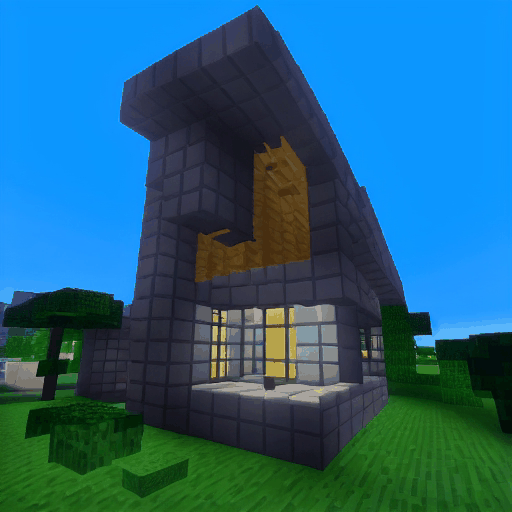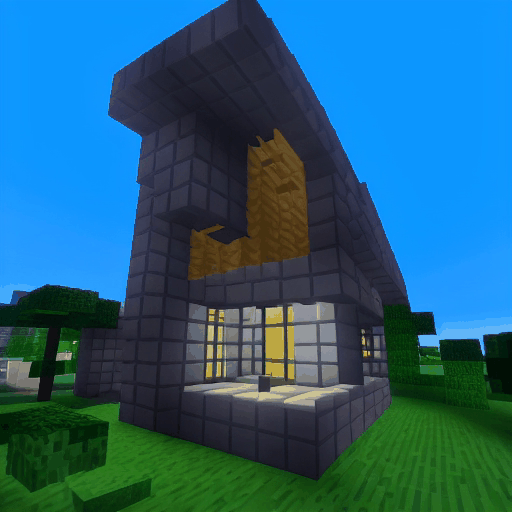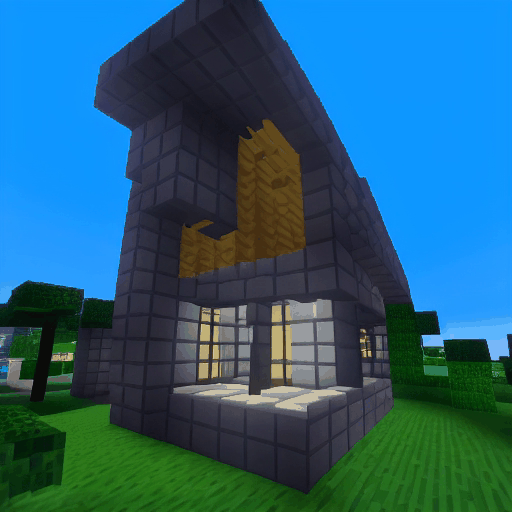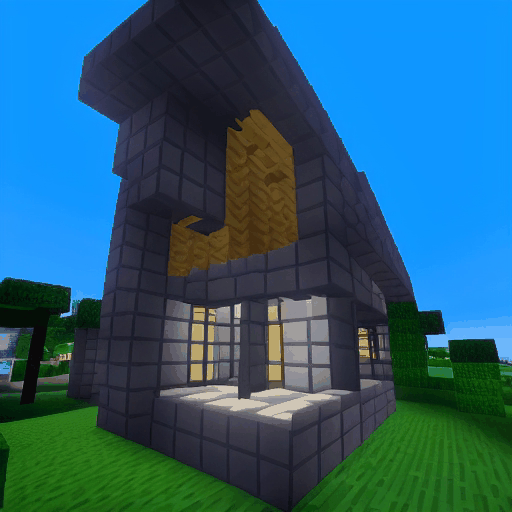 |
| T2V-Zero |  |
 |
 |
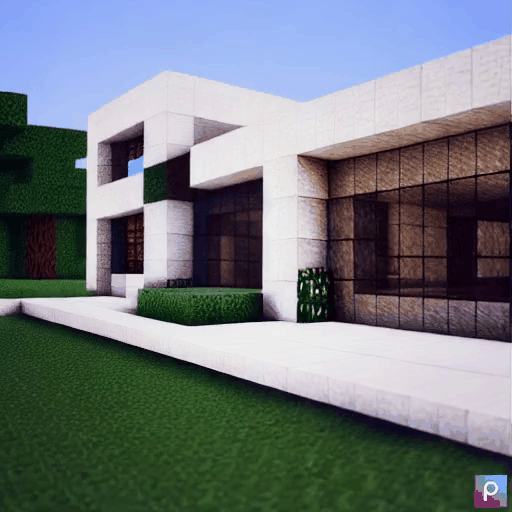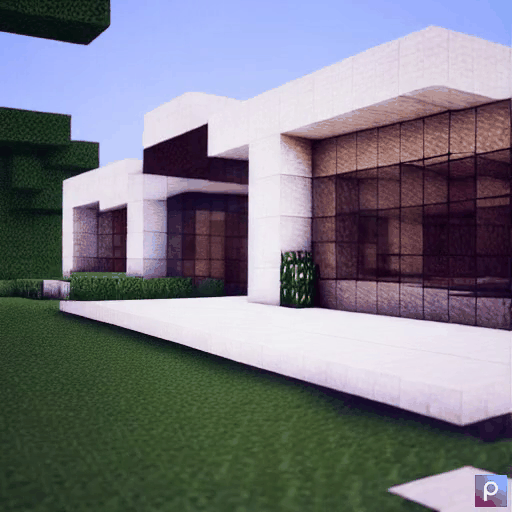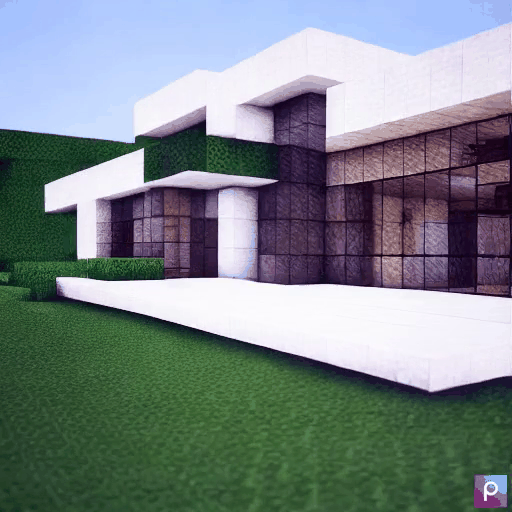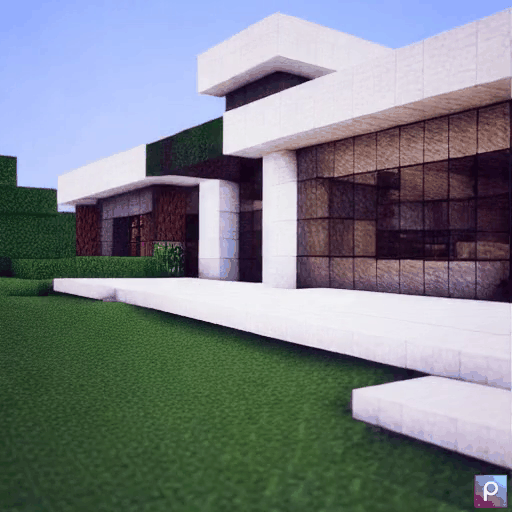 |
| Latte |  |
 |
 |
 |
| Animatediff |  |
 |
 |
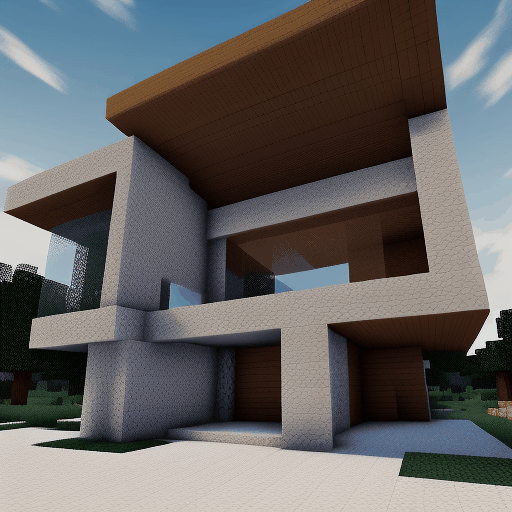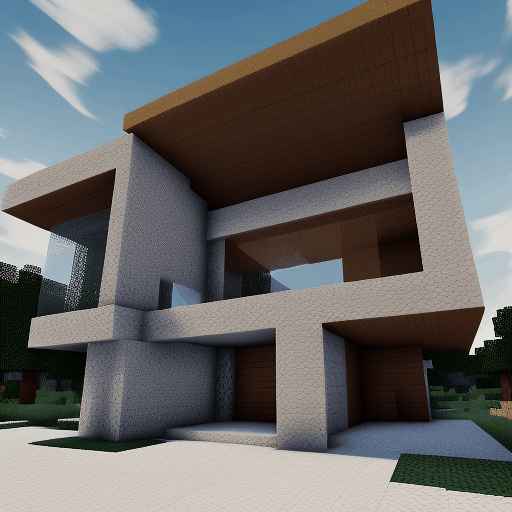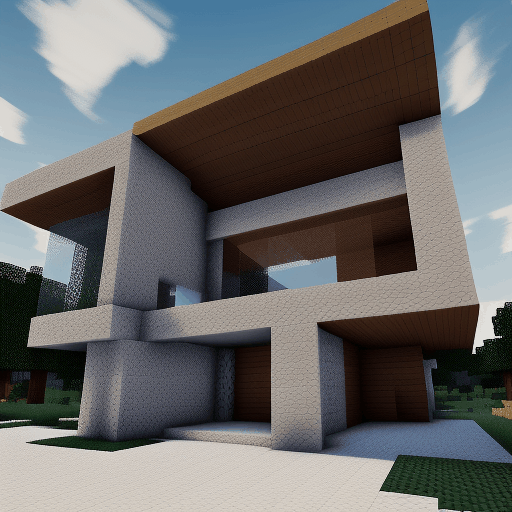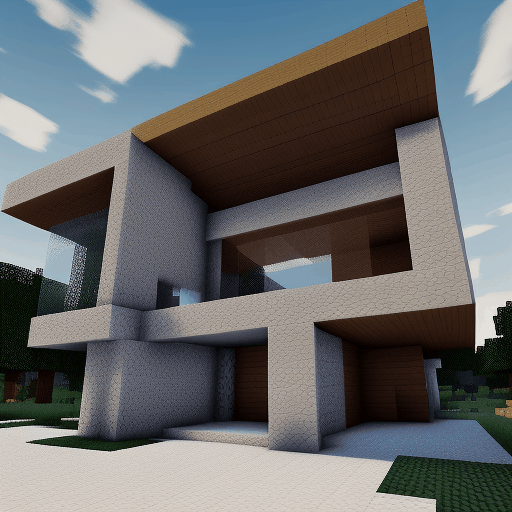 |
| Ours |  |
 |
 |
 |
We show more metamorphic videos generated by MagicTime with the help of Realistic, ToonYou and RcnzCartoon.
 |
 |
 |
| "[...] bean sprouts grow and mature from seeds" | "dough [...] swells and browns in the oven [...]" | "the construction [...] in Minecraft [...]" |
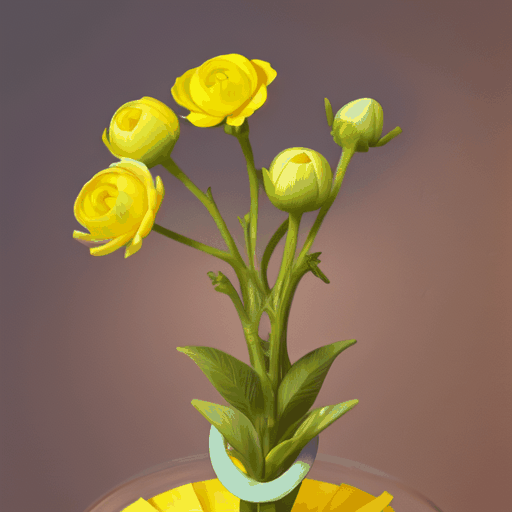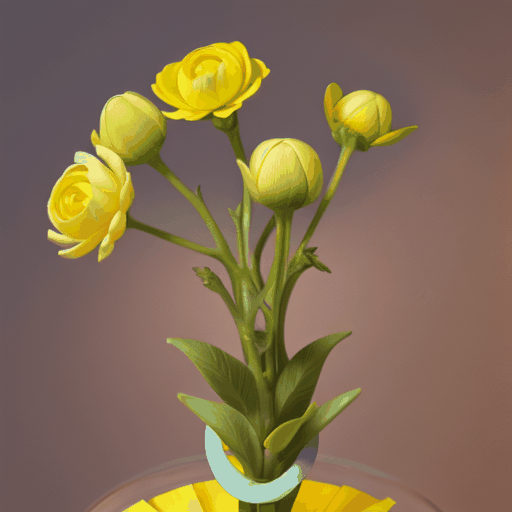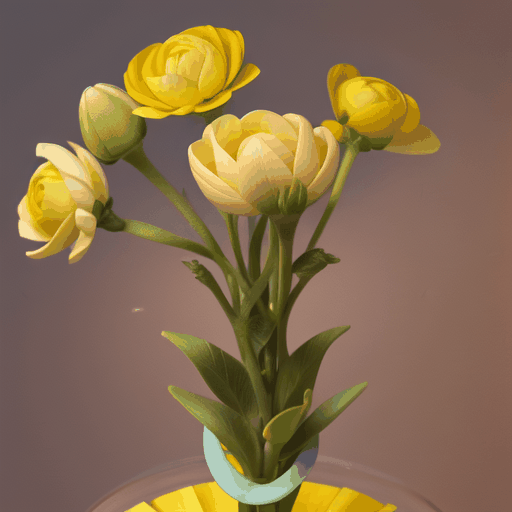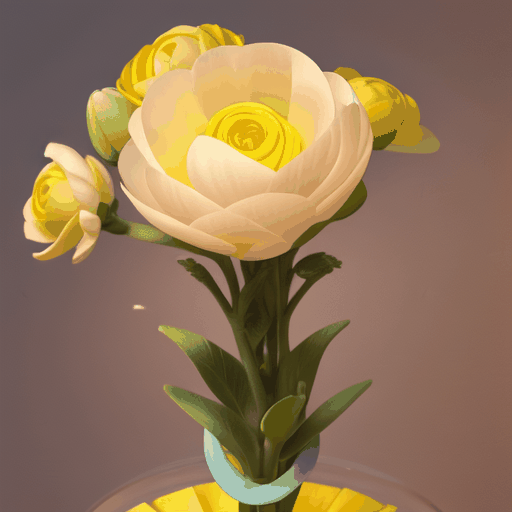 |
 |
 |
| "a bud transforms into a yellow flower" | "time-lapse of a plant germinating [...]" | "[...] a modern house being constructed in Minecraft [...]" |
 |
 |
 |
| "an ice cube is melting" | "bean plant sprouts grow and mature from the soil" | "time-lapse of delicate pink plum blossoms [...]" |
Prompts are trimmed for display, see here for full prompts.
The mission of this project is to help reproduce Sora and provide high-quality video-text data and data annotation pipelines, to support Open-Sora-Plan or other DiT-based T2V models. To this end, we take an initial step to integrate our MagicTime scheme into the DiT-based Framework. Specifically, our method supports the Open-Sora-Plan v1.0.0 for fine-tuning. We first scale up with additional metamorphic landscape time-lapse videos in the same annotation framework to get the ChronoMagic-Landscape dataset. Then, we fine-tune the Open-Sora-Plan v1.0.0 with the ChronoMagic-Landscape dataset to get the MagicTime-DiT model. The results are as follows (257×512×512 (10s)):
 |
 |
 |
 |
| "Time-lapse of a coastal landscape [...]" | "Display the serene beauty of twilight [...]" | "Sunrise Splendor: Capture the breathtaking moment [...]" | "Nightfall Elegance: Embrace the tranquil beauty [...]" |
 |
 |
 |
 |
| "The sun descending below the horizon [...]" | "[...] daylight fades into the embrace of the night [...]" | "Time-lapse of the dynamic formations of clouds [...]" | "Capture the dynamic formations of clouds [...]" |
Prompts are trimmed for display, see here for full prompts.
Highly recommend trying out our web demo by the following command, which incorporates all features currently supported by MagicTime. We also provide online demo in Hugging Face Spaces.
python app.py# For Realistic
python inference_magictime.py --config sample_configs/RealisticVision.yaml --human
# or you can directly run the .sh
sh inference_cli.shwarning: It is worth noting that even if we use the same seed and prompt but we change a machine, the results will be different.
We recommend the requirements as follows.
git clone --depth=1 https://github.com/PKU-YuanGroup/MagicTime.git
cd MagicTime
conda create -n magictime python=3.10.13
conda activate magictime
pip install -r requirements.txtsh prepare_weights/down_base_model.sh
sh prepare_weights/down_dreambooth.shsh prepare_weights/down_magictime_module.shThe training code is coming soon!
For inference, some examples are shown below:
# For Realistic
python inference_magictime.py --config sample_configs/RealisticVision.yaml
# For ToonYou
python inference_magictime.py --config sample_configs/ToonYou.yaml
# For RcnzCartoon
python inference_magictime.py --config sample_configs/RcnzCartoon.yaml
# or you can directly run the .sh
sh inference.shYou can also put all your custom prompts in a .txt file and run:
# For Realistic
python inference_magictime.py --config sample_configs/RealisticVision.yaml --run-txt XXX.txt --batch-size 2
# For ToonYou
python inference_magictime.py --config sample_configs/ToonYou.yaml --run-txt XXX.txt --batch-size 2
# For RcnzCartoon
python inference_magictime.py --config sample_configs/RcnzCartoon.yaml --run-txt XXX.txt --batch-size 2We found some plugins created by community developers. Thanks for their efforts:
- ComfyUI Extension. ComfyUI-MagicTimeWrapper (by @Jukka Seppänen). And you can click here to view the installation tutorial.
- Replicate Demo & Cloud API. Replicate-MagicTime (by @camenduru).
- Jupyter Notebook. Jupyter-MagicTime (by @ModelsLab).
- Diffusers. We need your help to integrate MagicTime into Diffusers. 🙏 [Need your contribution]
If you find related work, please let us know.
ChronoMagic with 2265 metamorphic time-lapse videos, each accompanied by a detailed caption. We released the subset of ChronoMagic used to train MagicTime. The dataset can be downloaded at HuggingFace Dataset, or you can download it with the following command. Some samples can be found on our Project Page.
huggingface-cli download --repo-type dataset \
--resume-download BestWishYsh/ChronoMagic \
--local-dir BestWishYsh/ChronoMagic \
--local-dir-use-symlinks False-
Animatediff The codebase we built upon and it is a strong U-Net-based text-to-video generation model.
-
Open-Sora-Plan The codebase we built upon and it is a simple and scalable DiT-based text-to-video generation repo, to reproduce Sora.
- The majority of this project is released under the Apache 2.0 license as found in the LICENSE file.
- The service is a research preview. Please contact us if you find any potential violations.
If you find our paper and code useful in your research, please consider giving a star ⭐ and citation 📝.
@article{yuan2024magictime,
title={MagicTime: Time-lapse Video Generation Models as Metamorphic Simulators},
author={Yuan, Shenghai and Huang, Jinfa and Shi, Yujun and Xu, Yongqi and Zhu, Ruijie and Lin, Bin and Cheng, Xinhua and Yuan, Li and Luo, Jiebo},
journal={arXiv preprint arXiv:2404.05014},
year={2024}
}






























































































































