PyTorch Implementation of "Large-Scale Image Retrieval with Attentive Deep Local Features"
reference: https://arxiv.org/pdf/1612.06321.pdf
- PyTorch
- python3
- CUDA
There are 2 steps for DeLF training: (1) finetune stage, and (2) keypoint stage.
Finetune stage loads resnet50 model pretrained on ImageNet, and finetune.
Keypoint stage freezes the "base" network, and only update "attention" network for keypoint selection.
After the train process is done, model will be saved at repo/<expr>/keypoint/ckpt
$ cd train/
$ python main.py \
--stage 'finetune' \
--optim 'sgd' \
--gpu_id 6 \
--expr 'landmark' \
--ncls 586 \
--finetune_train_path <path to train data> \
--finetune_val_path <path to val data> \- load_from: absolute path to pytorch model you wish to load. (<model_name>.pth.tar)
- expr: name of experiment you wish to save as.
$ cd train/
$ python main.py \
--stage 'keypoint' \
--gpu_id 6 \
--ncls 586 \
--optim 'sgd' \
--use_random_gamma_scaling true \
--expr 'landmark' \
--load_from <path to model> \
--keypoint_train_path <path to train data> \
--keypoint_val_path <path to val data> \There are also two steps to extract DeLF: (1) train PCA, (2) extract dimension reduced DeLF.
IMPORTANT: YOU MUST CHANGE OR COPY THE NAME OF MODEL from repo/<expr>/keypoint/ckpt/bestshot.pth.tar to repo/<expr>/keypoint/ckpt/fix.pth.tar.
I intentionally added this to prevent the model from being updated after the PCA matrix is already calculated.
$ cd extract/
$ python extractor.py
--gpu_id 4 \
--load_expr 'delf' \
--mode 'pca' \
--stage 'inference' \
--batch_size 1 \
--input_path <path to train data>, but it is hardcoded.
--output_path <output path to save pca matrix>, but it is hardcoded.$ cd extract/
$ python extractor.py
--gpu_id 4 \
--load_expr 'delf' \
--mode 'delf' \
--stage 'inference' \
--batch_size 1 \
--attn_thres 0.31 \
--iou_thres 0.92 \
--top_k 1000 \
--use_pca True \
--pca_dims 40 \
--pca_parameters_path <path to pca matrix file.>, but it is hardcoded.
--input_path <path to train data>, but it is hardcoded.
--output_path <output path to save pca matrix>, but it is hardcoded.You can visualize DeLF matching batween two arbitrary query images. Let's assume there exist two images, test/img1.jpg, test/img2.jpg. Run visualize.ipynb using Jupyter Notebook, and run each cells. You may get the result like below.
1) RANSAC Matching (Correspondance Matching + Geometric Verification)

2) Attention Map

Ranking Result on Oxf5k:
- glr1k, glr2k: Trained DeLF model with a subset of google-landmark-dataset on kaggle, which contains top-K instances sorted by the # of images included.
** ldmk: Trained DeLF model with landmark dataset. (exactly same with the paper)
glr1k ranking result

glr2k ranking result
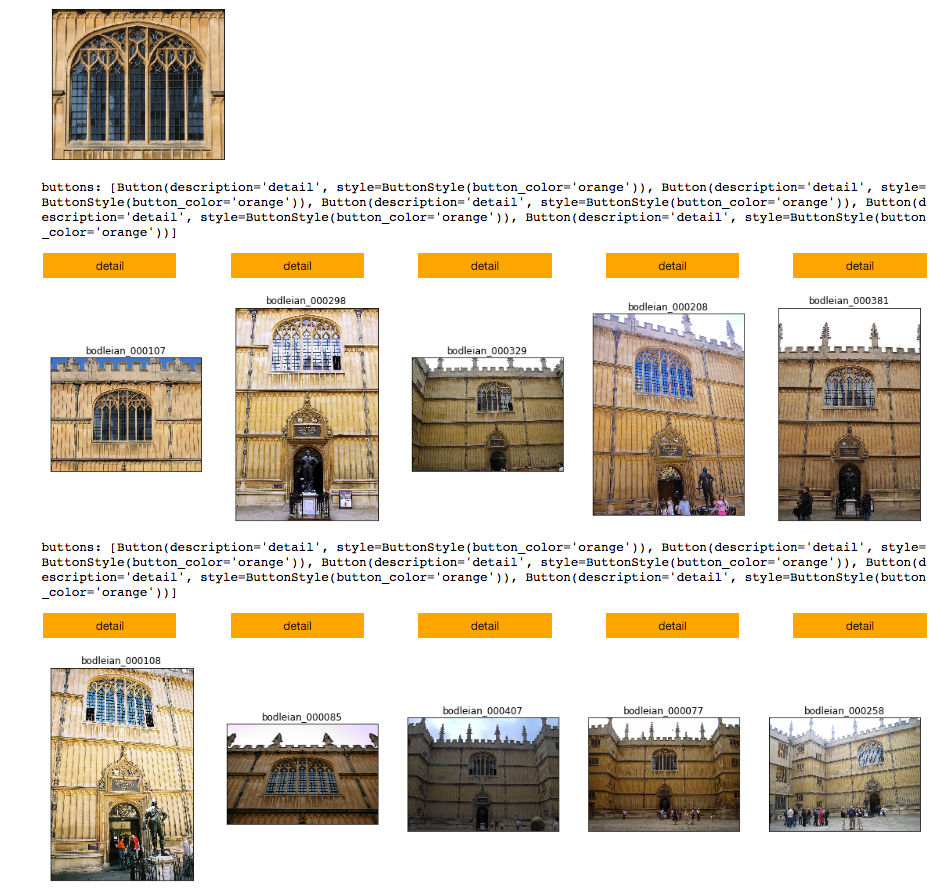
ldmk ranking result

Note: DELF_TF is the author's model, and the feature was extracted using this nice repo. (https://github.com/insikk/delf_enhanced)
PYTORCH_LDMK: Trained with landmark dataset.
PYTORCH_GLR1K: Trained with a subset of google-landmark-dataset with 1k instance classes.
PYTORCH_GLR1K: Trained with a subset of google-landmark-dataset with 2k instance classes.
PYTORCH_BNK_V3_BAL_HANA: Private currency dataset I personally own just for check.
| Classes | DELF_TF | PYTORCH_LDMK | PYTORCH_GLR1K | PYTORCH_GLR2K | PYTORCH_BNK_V3_BAL_HANA |
|---|---|---|---|---|---|
| mAP | 0.851307 | 0.849373 | 0.87828 | 0.866517 | 0.489614 |
| all_souls_1 | 0.751052 | 0.767453 | 0.916059 | 0.886243 | 0.0584418 |
| all_souls_2 | 0.517995 | 0.645628 | 0.708546 | 0.767904 | 0.287783 |
| all_souls_3 | 0.626499 | 0.760189 | 0.881578 | 0.903977 | 0.347261 |
| all_souls_4 | 0.968566 | 0.930445 | 0.967221 | 0.980288 | 0.515091 |
| all_souls_5 | 0.735256 | 0.827341 | 0.899803 | 0.911414 | 0.117378 |
| ashmolean_1 | 0.83206 | 0.768585 | 0.829522 | 0.860364 | 0.157126 |
| ashmolean_2 | 0.844329 | 0.803305 | 0.814522 | 0.88631 | 0.194069 |
| ashmolean_3 | 0.8407 | 0.863916 | 0.86428 | 0.841624 | 0.20158 |
| ashmolean_4 | 0.857416 | 0.730968 | 0.816007 | 0.829129 | 0.353456 |
| ashmolean_5 | 0.77901 | 0.84768 | 0.808717 | 0.875755 | 0.106619 |
| balliol_1 | 0.917435 | 0.818512 | 0.914453 | 0.857404 | 0.362258 |
| balliol_2 | 0.462124 | 0.5546 | 0.68825 | 0.632167 | 0.0984046 |
| balliol_3 | 0.710849 | 0.72742 | 0.80883 | 0.729275 | 0.209934 |
| balliol_4 | 0.658099 | 0.681549 | 0.749764 | 0.667446 | 0.342497 |
| balliol_5 | 0.739436 | 0.689549 | 0.80835 | 0.716029 | 0.319832 |
| bodleian_1 | 0.7943 | 0.797353 | 0.833887 | 0.851872 | 0.350422 |
| bodleian_2 | 0.828246 | 0.549165 | 0.520681 | 0.413119 | 0.643002 |
| bodleian_3 | 0.84655 | 0.844758 | 0.954003 | 0.841856 | 0.799652 |
| bodleian_4 | 0.726362 | 0.732197 | 0.916468 | 0.84604 | 0.476852 |
| bodleian_5 | 0.815629 | 0.864863 | 0.915992 | 0.847784 | 0.773505 |
| christ_church_1 | 0.953197 | 0.97743 | 0.96955 | 0.987822 | 0.866622 |
| christ_church_2 | 0.960692 | 0.950959 | 0.975525 | 0.979186 | 0.783949 |
| christ_church_3 | 0.932694 | 0.951987 | 0.940492 | 0.942081 | 0.263114 |
| christ_church_4 | 0.965374 | 0.979779 | 0.970264 | 0.981529 | 0.784185 |
| christ_church_5 | 0.971503 | 0.971411 | 0.976488 | 0.983004 | 0.312071 |
| cornmarket_1 | 0.690551 | 0.722799 | 0.692261 | 0.681911 | 0.492891 |
| cornmarket_2 | 0.727338 | 0.382168 | 0.32282 | 0.184599 | 0.169908 |
| cornmarket_3 | 0.707911 | 0.650324 | 0.696718 | 0.672553 | 0.379656 |
| cornmarket_4 | 0.65958 | 0.789562 | 0.656362 | 0.669228 | 0.273514 |
| cornmarket_5 | 0.68901 | 0.814039 | 0.606983 | 0.558519 | 0.19587 |
| hertford_1 | 0.92893 | 0.915811 | 0.957557 | 0.951947 | 0.562145 |
| hertford_2 | 0.960313 | 0.942536 | 0.937546 | 0.951293 | 0.524951 |
| hertford_3 | 0.936073 | 0.959108 | 0.97494 | 0.941641 | 0.570177 |
| hertford_4 | 0.898146 | 0.914434 | 0.924889 | 0.927225 | 0.679879 |
| hertford_5 | 0.975377 | 0.929499 | 0.946097 | 0.94726 | 0.235865 |
| keble_1 | 1 | 1 | 1 | 1 | 0.954762 |
| keble_2 | 1 | 0.944161 | 1 | 1 | 0.921088 |
| keble_3 | 1 | 0.932568 | 1 | 1 | 0.931319 |
| keble_4 | 1 | 1 | 1 | 1 | 0.331796 |
| keble_5 | 1 | 0.87432 | 1 | 1 | 0.944161 |
| magdalen_1 | 0.710288 | 0.766209 | 0.819577 | 0.861361 | 0.109972 |
| magdalen_2 | 0.830566 | 0.928487 | 0.914451 | 0.926896 | 0.164253 |
| magdalen_3 | 0.759041 | 0.832379 | 0.872577 | 0.896532 | 0.168931 |
| magdalen_4 | 0.853145 | 0.877747 | 0.880979 | 0.844535 | 0.0728258 |
| magdalen_5 | 0.761443 | 0.77776 | 0.841862 | 0.791102 | 0.175314 |
| pitt_rivers_1 | 1 | 1 | 1 | 1 | 0.647935 |
| pitt_rivers_2 | 1 | 1 | 1 | 1 | 1 |
| pitt_rivers_3 | 1 | 1 | 1 | 1 | 0.746479 |
| pitt_rivers_4 | 1 | 1 | 1 | 1 | 0.599398 |
| pitt_rivers_5 | 1 | 1 | 1 | 1 | 1 |
| radcliffe_camera_1 | 0.93144 | 0.916562 | 0.943584 | 0.95298 | 0.860801 |
| radcliffe_camera_2 | 0.961224 | 0.980161 | 0.980304 | 0.982237 | 0.936467 |
| radcliffe_camera_3 | 0.925759 | 0.908404 | 0.949748 | 0.959252 | 0.871228 |
| radcliffe_camera_4 | 0.979608 | 0.98273 | 0.983941 | 0.988227 | 0.787773 |
| radcliffe_camera_5 | 0.90082 | 0.936742 | 0.952967 | 0.949522 | 0.894346 |
Minchul Shin(@nashory)
contact: [email protected]















































































































