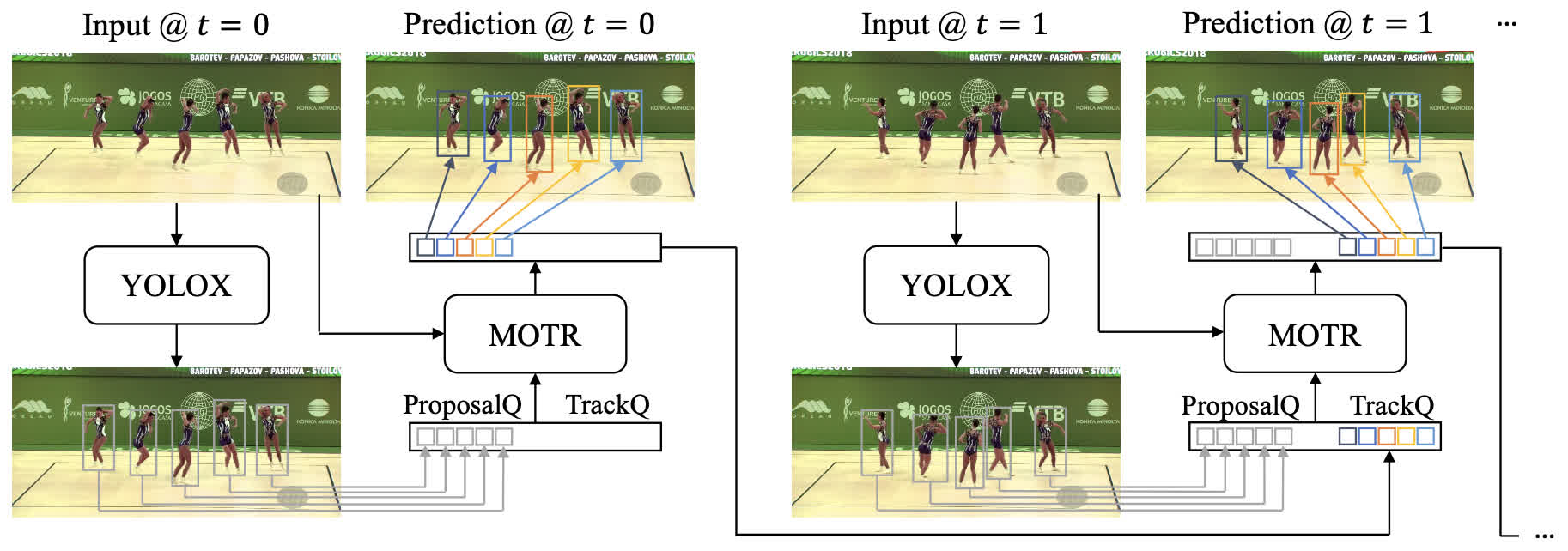
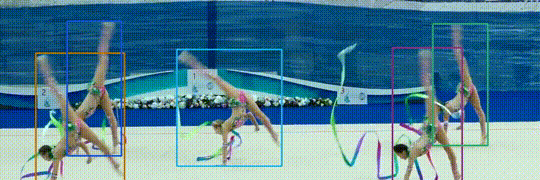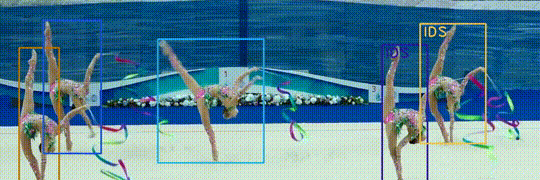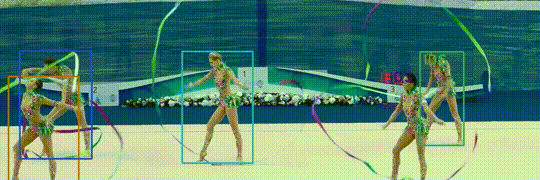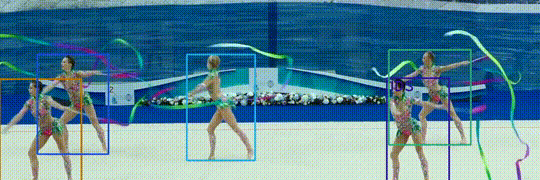Hi, I try to run the training code with command ./tools/train.sh configs/motrv2.args and there are some warnings when loading the pretrained detr weights as follows:
loaded /home/code/mot/MOTRv2/detr_pretrain/r50_deformable_detr_plus_iterative_bbox_refinement-checkpoint.pth Drop parameter transformer.reference_points.weight.If you see this, your model does not fully load the pre-trained weight. Please make sure you set the correct --num_classes for your own dataset. Drop parameter transformer.reference_points.bias.If you see this, your model does not fully load the pre-trained weight. Please make sure you set the correct --num_classes for your own dataset. Skip loading parameter class_embed.0.weight, required shapetorch.Size([1, 256]), loaded shapetorch.Size([91, 256]). If you see this, your model does not fully load the pre-trained weight. Please make sure you set the correct --num_classes for your own dataset. load class_embed: class_embed.0.weight shape=torch.Size([91, 256]) Skip loading parameter class_embed.0.bias, required shapetorch.Size([1]), loaded shapetorch.Size([91]). If you see this, your model does not fully load the pre-trained weight. Please make sure you set the correct --num_classes for your own dataset. load class_embed: class_embed.0.bias shape=torch.Size([91]) Skip loading parameter class_embed.1.weight, required shapetorch.Size([1, 256]), loaded shapetorch.Size([91, 256]). If you see this, your model does not fully load the pre-trained weight. Please make sure you set the correct --num_classes for your own dataset. load class_embed: class_embed.1.weight shape=torch.Size([91, 256]) Skip loading parameter class_embed.1.bias, required shapetorch.Size([1]), loaded shapetorch.Size([91]). If you see this, your model does not fully load the pre-trained weight. Please make sure you set the correct --num_classes for your own dataset. load class_embed: class_embed.1.bias shape=torch.Size([91]) Skip loading parameter class_embed.2.weight, required shapetorch.Size([1, 256]), loaded shapetorch.Size([91, 256]). If you see this, your model does not fully load the pre-trained weight. Please make sure you set the correct --num_classes for your own dataset. load class_embed: class_embed.2.weight shape=torch.Size([91, 256]) Skip loading parameter class_embed.2.bias, required shapetorch.Size([1]), loaded shapetorch.Size([91]). If you see this, your model does not fully load the pre-trained weight. Please make sure you set the correct --num_classes for your own dataset. load class_embed: class_embed.2.bias shape=torch.Size([91]) Skip loading parameter class_embed.3.weight, required shapetorch.Size([1, 256]), loaded shapetorch.Size([91, 256]). If you see this, your model does not fully load the pre-trained weight. Please make sure you set the correct --num_classes for your own dataset. load class_embed: class_embed.3.weight shape=torch.Size([91, 256]) Skip loading parameter class_embed.3.bias, required shapetorch.Size([1]), loaded shapetorch.Size([91]). If you see this, your model does not fully load the pre-trained weight. Please make sure you set the correct --num_classes for your own dataset. load class_embed: class_embed.3.bias shape=torch.Size([91]) Skip loading parameter class_embed.4.weight, required shapetorch.Size([1, 256]), loaded shapetorch.Size([91, 256]). If you see this, your model does not fully load the pre-trained weight. Please make sure you set the correct --num_classes for your own dataset. load class_embed: class_embed.4.weight shape=torch.Size([91, 256]) Skip loading parameter class_embed.4.bias, required shapetorch.Size([1]), loaded shapetorch.Size([91]). If you see this, your model does not fully load the pre-trained weight. Please make sure you set the correct --num_classes for your own dataset. load class_embed: class_embed.4.bias shape=torch.Size([91]) Skip loading parameter class_embed.5.weight, required shapetorch.Size([1, 256]), loaded shapetorch.Size([91, 256]). If you see this, your model does not fully load the pre-trained weight. Please make sure you set the correct --num_classes for your own dataset. load class_embed: class_embed.5.weight shape=torch.Size([91, 256]) Skip loading parameter class_embed.5.bias, required shapetorch.Size([1]), loaded shapetorch.Size([91]). If you see this, your model does not fully load the pre-trained weight. Please make sure you set the correct --num_classes for your own dataset. load class_embed: class_embed.5.bias shape=torch.Size([91]) Skip loading parameter query_embed.weight, required shapetorch.Size([10, 256]), loaded shapetorch.Size([300, 512]). If you see this, your model does not fully load the pre-trained weight. Please make sure you set the correct --num_classes for your own dataset. No param track_embed.self_attn.in_proj_weight.If you see this, your model does not fully load the pre-trained weight. Please make sure you set the correct --num_classes for your own dataset. No param track_embed.self_attn.in_proj_bias.If you see this, your model does not fully load the pre-trained weight. Please make sure you set the correct --num_classes for your own dataset. No param track_embed.self_attn.out_proj.weight.If you see this, your model does not fully load the pre-trained weight. Please make sure you set the correct --num_classes for your own dataset. No param track_embed.self_attn.out_proj.bias.If you see this, your model does not fully load the pre-trained weight. Please make sure you set the correct --num_classes for your own dataset. No param track_embed.linear1.weight.If you see this, your model does not fully load the pre-trained weight. Please make sure you set the correct --num_classes for your own dataset. No param track_embed.linear1.bias.If you see this, your model does not fully load the pre-trained weight. Please make sure you set the correct --num_classes for your own dataset. No param track_embed.linear2.weight.If you see this, your model does not fully load the pre-trained weight. Please make sure you set the correct --num_classes for your own dataset. No param track_embed.linear2.bias.If you see this, your model does not fully load the pre-trained weight. Please make sure you set the correct --num_classes for your own dataset. No param track_embed.linear_feat1.weight.If you see this, your model does not fully load the pre-trained weight. Please make sure you set the correct --num_classes for your own dataset. No param track_embed.linear_feat1.bias.If you see this, your model does not fully load the pre-trained weight. Please make sure you set the correct --num_classes for your own dataset. No param track_embed.linear_feat2.weight.If you see this, your model does not fully load the pre-trained weight. Please make sure you set the correct --num_classes for your own dataset. No param track_embed.linear_feat2.bias.If you see this, your model does not fully load the pre-trained weight. Please make sure you set the correct --num_classes for your own dataset. No param track_embed.norm_feat.weight.If you see this, your model does not fully load the pre-trained weight. Please make sure you set the correct --num_classes for your own dataset. No param track_embed.norm_feat.bias.If you see this, your model does not fully load the pre-trained weight. Please make sure you set the correct --num_classes for your own dataset. No param track_embed.norm1.weight.If you see this, your model does not fully load the pre-trained weight. Please make sure you set the correct --num_classes for your own dataset. No param track_embed.norm1.bias.If you see this, your model does not fully load the pre-trained weight. Please make sure you set the correct --num_classes for your own dataset. No param track_embed.norm2.weight.If you see this, your model does not fully load the pre-trained weight. Please make sure you set the correct --num_classes for your own dataset. No param track_embed.norm2.bias.If you see this, your model does not fully load the pre-trained weight. Please make sure you set the correct --num_classes for your own dataset. No param position.weight.If you see this, your model does not fully load the pre-trained weight. Please make sure you set the correct --num_classes for your own dataset. No param yolox_embed.weight.If you see this, your model does not fully load the pre-trained weight. Please make sure you set the correct --num_classes for your own dataset. No param refine_embed.weight.If you see this, your model does not fully load the pre-trained weight. Please make sure you set the correct --num_classes for your own dataset. Start training
Does this matter? Should I change any configurations or code?
Thanks!