livoras / blog Goto Github PK
View Code? Open in Web Editor NEWToo young, too simple. Sometimes, naive.
Home Page: https://livoras.com
Too young, too simple. Sometimes, naive.
Home Page: https://livoras.com









































































































































































































未经允许,请勿转载。
(如果对SPA概念不清楚的同学可以先自行了解相关概念)
平时喜欢做点小页面来玩玩,并且一直采用单页面应用(Single Page Application)的方式来进行开发。这种开发方式是在之前一年做的一个创业项目的经验和思考,一直想写篇博客来总结一下。
个人认为单页面应用的优势相当明显:
当然,SPA也有它自身的缺点,例如不利于搜索引擎优化等等,这些问题也有其相应的解决方案。
下面要介绍的这种方式可以说是一种模式或者工作流,和前端使用什么框架无关,也和后端使用什么语言、数据库无关。不能说是The Best Practice,我相信经过更多人的讨论和思考会有A Better Practice。:)
下图展示了这种模式的整个前后端及各自的主要组成:

看起来有点复杂,接下来会仔细地对上面每一个部分进行解释。看完本文,就应该能理解上图中的各部件之间的交互流程。
把上图的前端部分单独抽出来进行研究:

前端中大致分为四种类型的模块:
component指的是页面上的一个可复用UI交互单元,例如一个博客的评论功能:

我们可以把博客评论做为一个组件,这个组件有自己的结构(html),外观(css),交互逻辑(js),所以我们可以单独做一个叫comment的component,由以下文件组成:
(每个component可以想象成一个工程,甚至可以有自己的README、测试等)
一个component可以依赖另外一个component,这时候它们是父子关系;component之间也可以互相组合,它们就是兄弟关系。最后的结果就类似DOM tree,component可以组成components tree。
例如,现在要给这个博客添加两个功能:

我们构建两个组件,reply和user-info-card。因为每个comment都要有自己的回复列表,所以comment组件是依赖于reply组件的,comment和reply组件是嵌套关系。
而user-info-card可以出现在comment或者reply当中,并且为了以后让user-info-card复用性更强,它应该不属于任何一个组件,它和其他组件是组合关系。所以我们就得到一个简单的componenets tree:

怎么可以做到鼠标放到评论和回复的用户头像上显示名片呢?这其实牵涉到组件之间是如何进行通信的问题。
最佳的方式就是使用事件机制,所有组件之间可以通过一个叫eventbus通用组件进行信息的交互。所以,要做到上述功能:
user-info-card:show的事件。user-info-card:show事件。user-info-card:
var eventbus = require("eventbus")
eventbus.on("user-info-card:show", function(user) {
// 显示用户名片
})
comment or reply:
var eventbus = require("eventbus")
$avatar.on("mouseover", function(event) {
eventbus.emit("user-info-card:show", userData)
})
components之间用事件进行通信的优势在于:
总结:component之间有嵌套和组合的关系,构成components tree;component之间通过事件进行信息、数据的交换。
component的渲染和显示依赖于数据(model)。例如上面的评论,就会有一个评论列表的model。
comments: [
{user:.., content:.., createTime: ..},
{user:.., content:.., createTime: ..},
{user:.., content:.., createTime: ..}
]
每个评论的component会对应一个comment(comments数组中的对象)进行渲染,渲染完以后就会正确地显示在页面上。
因为可能在其他component中也会需要用到这些数据,所以comment component不会自己直接保存这些comment model。这些model都会保存在service当中,而component会从service拿取数据。components和services之间是多对多的关系:一个component可能会从不同的services中拿取数据,而一个service可能为多个components提供数据。
services除了用于缓存数据以外,还提供一系列对数据的一些操作接口。可以提供给components进行操作。这样的好处在于保持了数据的一直性,假如你使用的是MVVM框架进行component的开发,对数据的操作还可以直接对多个视图产生数据绑定,当services中的数据变化了,多个components的视图也会相应地得到更新。
总结:services是对前端数据(也就是model)的缓存和操作。
而services中缓存的数据是从哪里来的呢?当然也许想到的第一个方案是在services中直接发送Ajax请求去服务器中拉去数据。而这里建议不直接这样做,而是把各种和后端的API进行交互的接口封装到一个叫databus的模块当中,这里的databus相当于是“对后端数据进行原子操作的集合”。
如上面的comment service需要从后端进行拉取数据,它会这样做:
var databus = require("databus")
var comments = null
databus.getAllComments(function(cmts) { // 调用databus方法进行数据拉取
comments = cmts
})
而databus中则封装了一层Ajax:
databus.getAllCommetns = function(callback) {
utils.ajax({
url: "/comments",
method: "GET",
success: callback
})
}
这样做是因为,不同的services之间可能会用到同样的接口对后端进行操作,把操作封装起来可以提高接口的复用性。注意,如果databus中的某些操作不涉及到servcies的数据,这操作也可以被components所调用(例如退出、登录等)。
总结:databus封装了提供给services和component和后端API进行交互的接口。
这两个模块都可以被其他组件所依赖。
common,故名思议,组件之间的共用数据和一些程序参数可以缓存在这里。
utils,封装了一些可复用的函数,例如ajax等。
所有组件(特别是components之间)的通过事件机制进行数据、消息通信的接口。可以简单地使用EventEmitter这个库来实现。
传统的网页页面一般都是由后端进行页面的渲染,而在我们的架构当中,后端只渲染一个页面,其后,后端只是相当于一个Web Service,前端使用Ajax调用其接口进行数据的调取和操作,使用数据进行页面的渲染。
这样的好处就是,后端不仅仅能处理Web端的页面的请求,而且处理提供移动端、桌面端的请求或者作为第三方开放接口来使用。大大提高后端处理请求的灵活性。
后端对比起前端的架构来说会简单很多,但是这只是其中一种模式,对于不同复杂程度的应用可能会做相应的调整。后端大概分为三层:

例如上面的comments的例子,CGI可以接收到前端发送的请求,调用business层操作数据,返回结果:
var commentsBusiness = require("./businesses/comments")
app.get("/comments", function(req, res) {
// 此处调用comments的business数据库操作
commentsBusiness.getAllComments(function(comments) {
// 返回数据结果
res.json(comments)
})
})
后端的API可以采用更规范的RESTful API的方式,而RESTful不在本文的讨论范围内。有兴趣的可以参考Best Practices for Designing a Pragmatic RESTful API。
前后端的架构都基本清晰了,我们来看看文章开头的图:
看着图来,我们总结一下整个前后端的交互流程:
一个好的工作流可以让开发事半功倍。上面的这种单页面应用也有其相应的一种开发工作流,当然这种工作流也适合非单页面应用:
前后端分离开发。建议都可以采用TDD(测试驱动开发)的方式来单独测试、单独开发(关于Web APP测试这一块可以单独进行讨论研究),提高产品的可靠性、稳定性。
(完)
请问一下differ算法复杂度的n^3是怎么计算出来的?有参考文章吗?新人求教
mark
Originally posted by @Blueria in #8 (comment)
作者:戴嘉华
转载请注明出处,保留原文链接和作者信息
(本文假设各位已经对基本git的基本概念、操作有一定的理解,如无相关git知识,可以参考Pro Git这本书进行相关的学习和练习)
很多项目开发都会采用git这一优秀的分布式版本管理工具进行项目版本管理,使用github开源平台作为代码仓库托管平台。由于git的使用非常灵活,在实践当中衍生了很多种不同的工作流程,不同的项目、不同的团队会有不同的协作方式。
本文将介绍一种前人已经在各种大小项目中经过千锤百炼总结出来的一种比较成功的git工作流,这种工作流已经被成功用于许多团队开发当中。掌握git,掌握这种工作流,对大家以后的学习、开发工作大有好处。
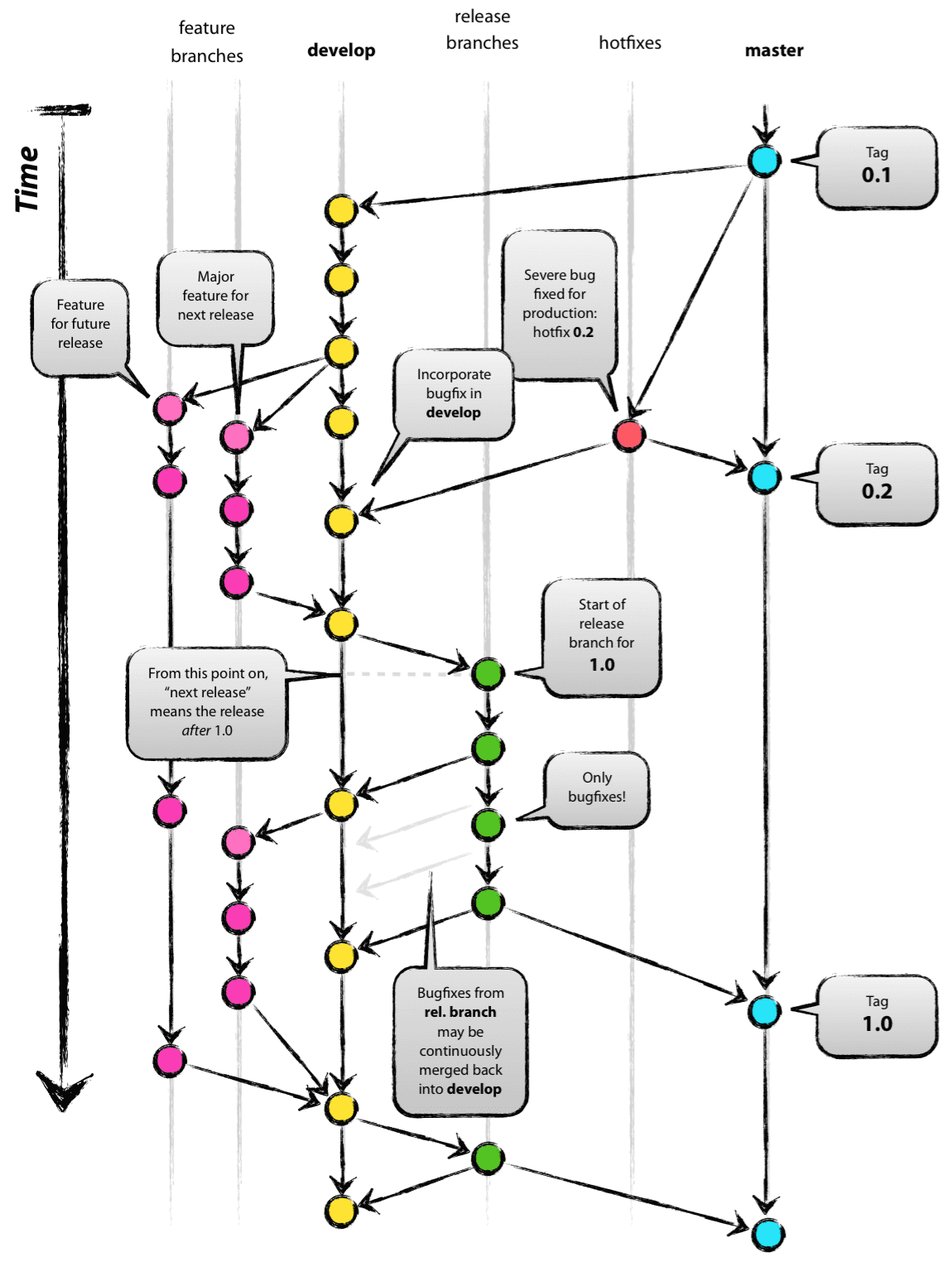
先上一张图吓大家一下:
上面一张图展示了一种使用git进行项目协同开发的模式,接下来会进行详细介绍。
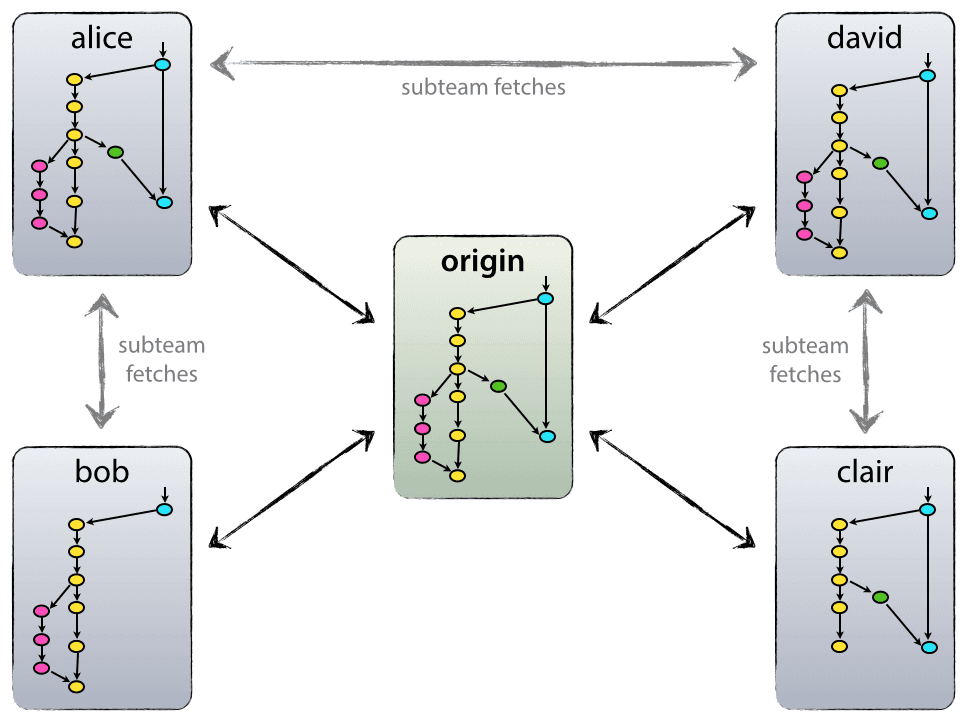
在项目的开始到结束,我们会有两种仓库。一种是源仓库(origin),一种是开发者仓库。上图中的每个矩形都表示一个仓库,正中间的是我们的源仓库,而其他围绕着源仓库的则是开发者仓库。
在项目的开始,项目的发起者构建起一个项目的最原始的仓库,我们把它称为origin,例如我们的PingHackers网站,origin就是这个PingHackers/blog了。源仓库的有两个作用:
源仓库应该是受保护的,开发者不应该直接对其进行开发工作。只有项目管理者(通常是项目发起人)能对其进行较高权限的操作。
上面说过,任何开发者都不会对源仓库进行直接的操作,源仓库建立以后,每个开发者需要做的事情就是把源仓库的“复制”一份,作为自己日常开发的仓库。这个复制,也就是github上面的fork。
每个开发者所fork的仓库是完全独立的,互不干扰,甚至与源仓库都无关。每个开发者仓库相当于一个源仓库实体的影像,开发者在这个影像中进行编码,提交到自己的仓库中,这样就可以轻易地实现团队成员之间的并行开发工作。而开发工作完成以后,开发者可以向源仓库发送pull request,请求管理员把自己的代码合并到源仓库中,这样就实现了分布式开发工作,和最后的集中式的管理。
分支是git中非常重要的一个概念,也是git这一个工具中的大杀器,必杀技。在其他集中式版本管理工具(SVN/CVS)把分支定位为高级技巧,而在git中,分支操作则是每个开发人员日常工作流。利用git的分支,可以非常方便地进行开发和测试,如果使用git没有让你感到轻松和愉悦,那是因为你还没有学会使用分支。不把分支用出一点翔来,不要轻易跟别人说你用过git。
在文章开头的那张图中,每一个矩形内部纷繁的枝蔓便是git的分支模型。可以看出,每个开发者的仓库都有自己的分支路线,而这些分支路线会通过代码汇总映射到源仓库中去。
我们为git定下一种分支模型,在这种模型中,分支有两类,五种
master branch:主分支develop branch:开发分支feature branch:功能分支release branch:预发布分支hotfix branch:bug修复分支永久性分支是寿命无限的分支,存在于整个项目的开始、开发、迭代、终止过程中。永久性分支只有两个master和develop。
master:主分支从项目一开始便存在,它用于存放经过测试,已经完全稳定代码;在项目开发以后的任何时刻当中,master存放的代码应该是可作为产品供用户使用的代码。所以,应该随时保持master仓库代码的清洁和稳定,确保入库之前是通过完全测试和代码reivew的。master分支是所有分支中最不活跃的,大概每个月或每两个月更新一次,每一次master更新的时候都应该用git打上tag,说明你的产品有新版本发布了。
develop:开发分支,一开始从master分支中分离出来,用于开发者存放基本稳定代码。之前说过,每个开发者的仓库相当于源仓库的一个镜像,每个开发者自己的仓库上也有master和develop。开发者把功能做好以后,是存放到自己的develop中,当测试完以后,可以向管理者发起一个pull request,请求把自己仓库的develop分支合并到源仓库的develop中。
所有开发者开发好的功能会在源仓库的develop分支中进行汇总,当develop中的代码经过不断的测试,已经逐渐趋于稳定了,接近产品目标了。这时候,我们就可以把develop分支合并到master分支中,发布一个新版本。所以,一个产品不断完善和发布过程就正如下图:
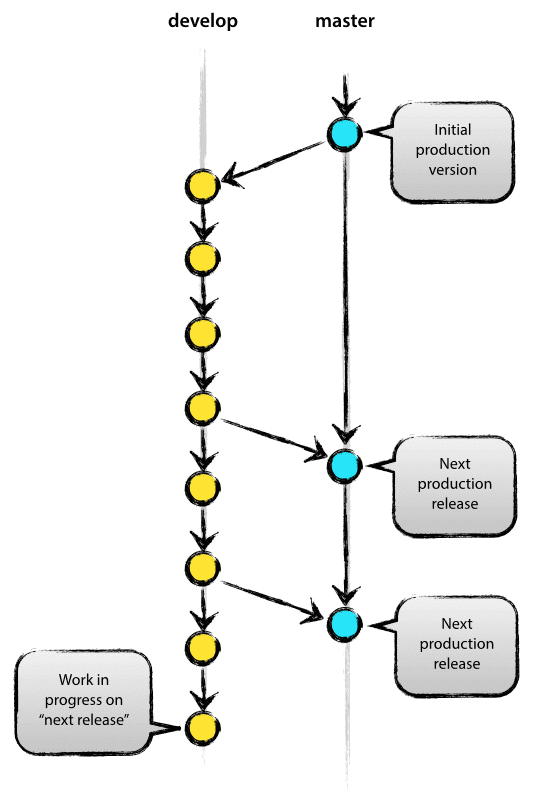
注意,任何人不应该向master直接进行无意义的合并、提交操作。正常情况下,master只应该接受develop的合并,也就是说,master所有代码更新应该源于合并develop的代码。
暂时性分支和永久性分支不同,暂时性分支在开发过程中是一定会被删除的。所有暂时性分支,一般源于develop,最终也一定会回归合并到develop。
feature:功能性分支,是用于开发项目的功能的分支,是开发者主要战斗阵地。开发者在本地仓库从develop分支分出功能分支,在该分支上进行功能的开发,开发完成以后再合并到develop分支上,这时候功能性分支已经完成任务,可以删除。功能性分支的命名一般为feature-*,*为需要开发的功能的名称。
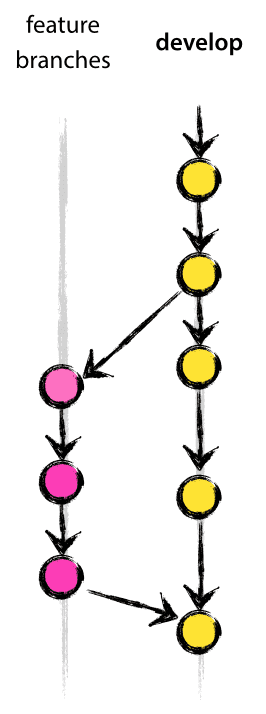
举一个例子,假设我是一名PingHackers网站的开发者,已经把源仓库fork了,并且clone到了本地。现在要开发PingHackers网站的“讨论”功能。我在本地仓库中可以这样做:
step 1: 切换到develop分支
>>> git checkout develop
step 2: 分出一个功能性分支
>>> git checkout -b feature-discuss
step 3: 在功能性分支上进行开发工作,多次commit,测试以后...
step 4: 把做好的功能合并到develop中
>>> git checkout develop
# 回到develop分支
>>> git merge --no-ff feature-discuss
# 把做好的功能合并到develop中
>>> git branch -d feature-discuss
# 删除功能性分支
>>> git push origin develop
# 把develop提交到自己的远程仓库中
这样,就完成一次功能的开发和提交。
release:预发布分支,当产品即将发布的时候,要进行最后的调整和测试,这时候就可以分出一个预发布分支,进行最后的bug fix。测试完全以后,发布新版本,就可以把预发布分支删除。预发布分支一般命名为release-*。
hotfix:修复bug分支,当产品已经发布了,突然出现了重大的bug。这时候就要新建一个hotfix分支,继续紧急的bug修复工作,当bug修复完以后,把该分支合并到master和develop以后,就可以把该分支删除。修复bug分支命名一般为hotfix-*
release和hotfix分支离我们还比较遥远。。就不详述,有兴趣的同学可以参考本文最后的参考资料进行学习。
啰嗦讲了这么多,概念永远是抽象的。对于新手来说,都喜欢一步一步的步骤傻瓜教程,接下来,我们就一步一步来操作上面所说的工作流程,大家感受一下:
这一步通常由项目发起人来操作,我们这里把管理员设为PingHackers,假设PingHackers已经为我们建立起了一个源仓库PingHackers/git-demo,并且已经初始化了两个永久性分支master和develop,如图:
源仓库建立以后,每个开发就可以去复制一份源仓库到自己的github账号中,然后作为自己开发所用的仓库。假设我是一个项目中的开发者,我就到PingHackers/git-demo项目主页上去fork:

fork完以后,我就可以在我自己的仓库列表中看到一个和源仓库一模一样的复制品。这时就应该感叹,你以后要和它相依为命了:
这一步应该不用教,git clone
进入仓库中,按照前面说所的构建功能分支的步骤,构建功能分支进行开发、合并,假设我现在要开发一个“讨论”功能:
>>> git checkout develop
# 切换到`develop`分支
>>> git checkout -b feature-discuss
# 分出一个功能性分支
>> touch discuss.js
# 假装discuss.js就是我们要开发的功能
>> git add .
>> git commit -m 'finish discuss feature'
# 提交更改
>>> git checkout develop
# 回到develop分支
>>> git merge --no-ff feature-discuss
# 把做好的功能合并到develop中
>>> git branch -d feature-discuss
# 删除功能性分支
>>> git push origin develop
# 把develop提交到自己的远程仓库中
这时候,你上自己github的项目主页中develop分支中看看,已经有discuss.js这个文件了:
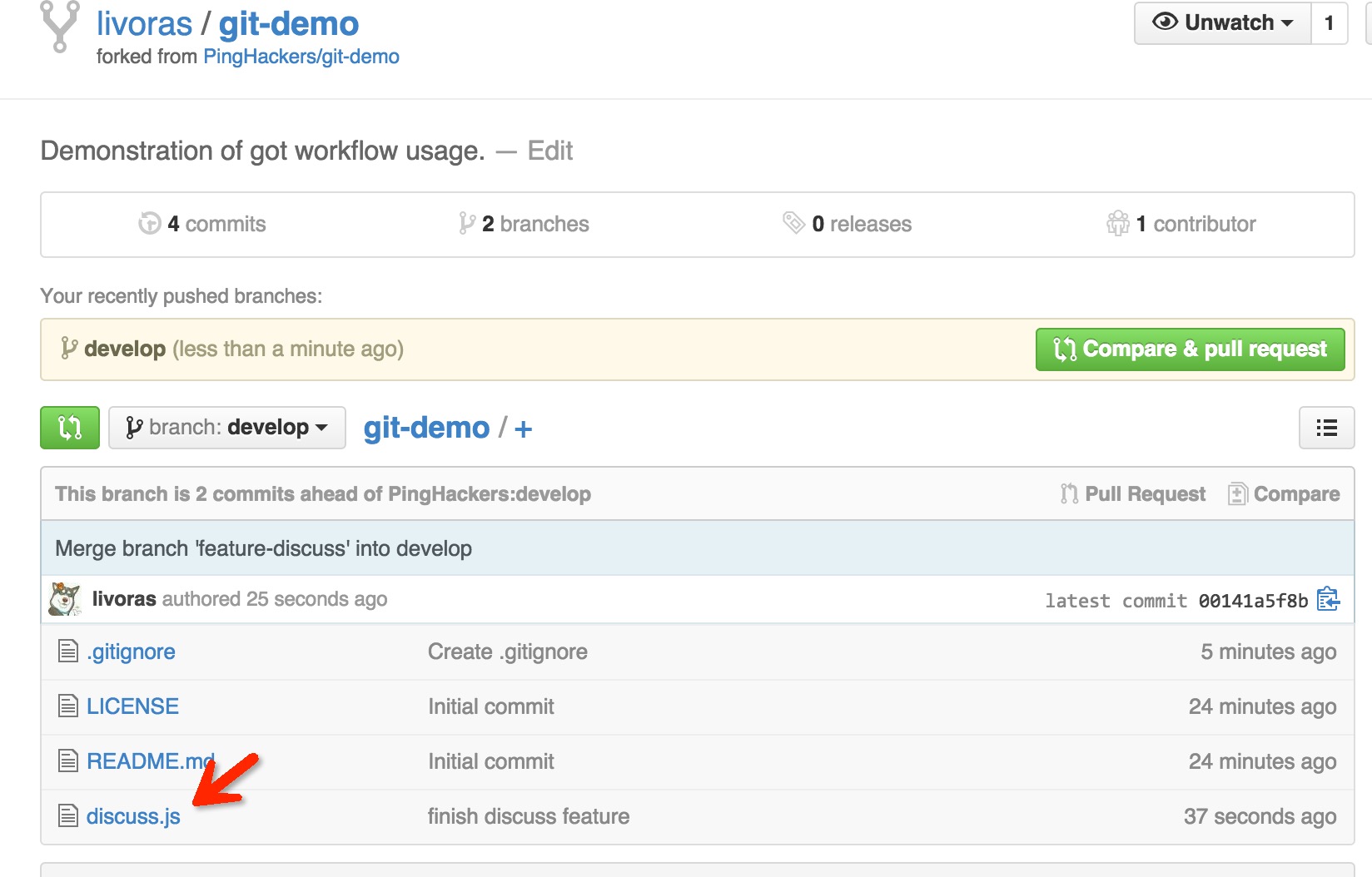
假设我完成了“讨论”功能(当然,你还可能对自己的develop进行了多次合并,完成了多个功能),经过测试以后,觉得没问题,就可以请求管理员把自己仓库的develop分支合并到源仓库的develop分支中,这就是传说中的pull request。
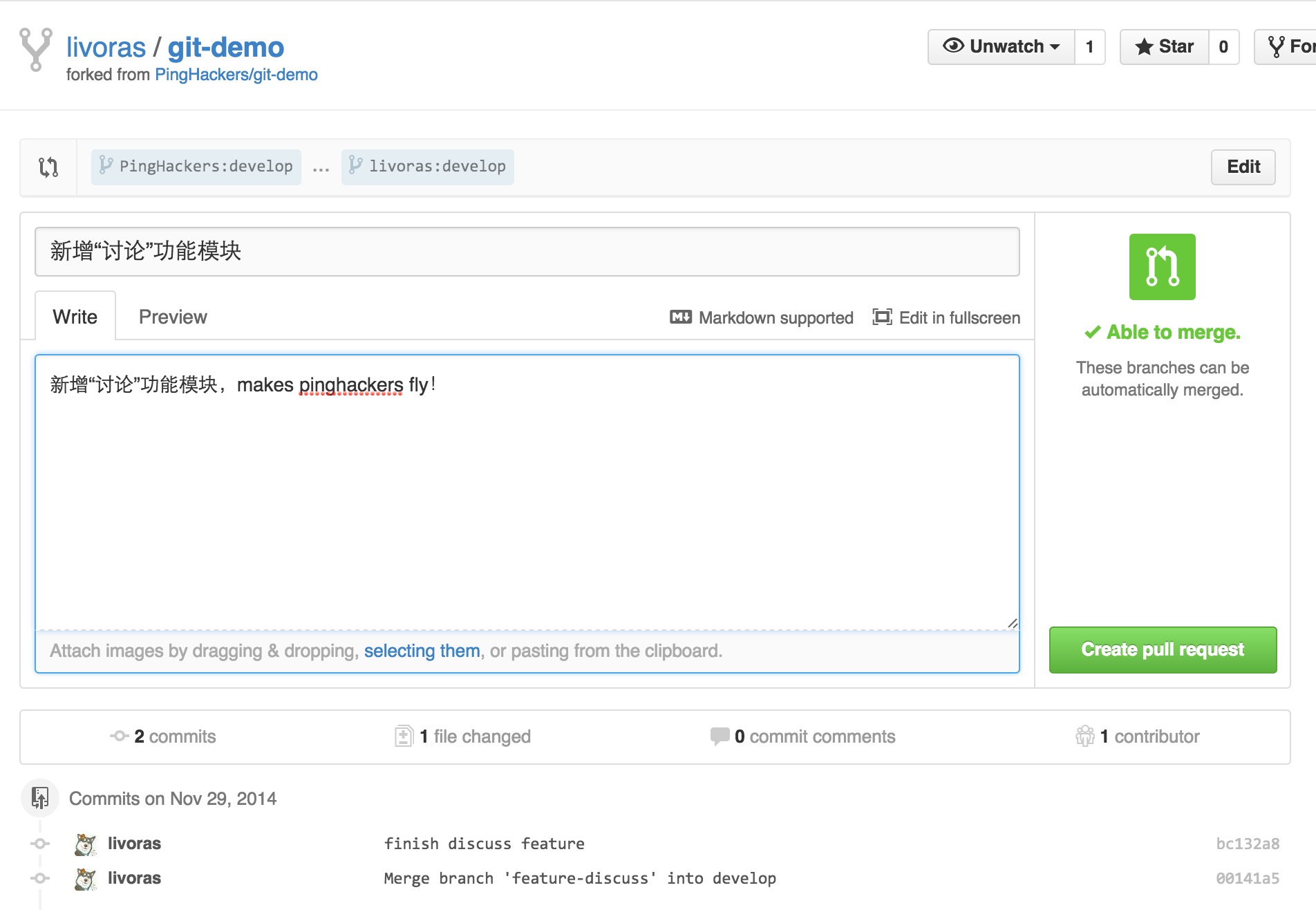
点击上图的绿色按钮,开发者就可以就可以静静地等待管理员对你的提交的评审了。
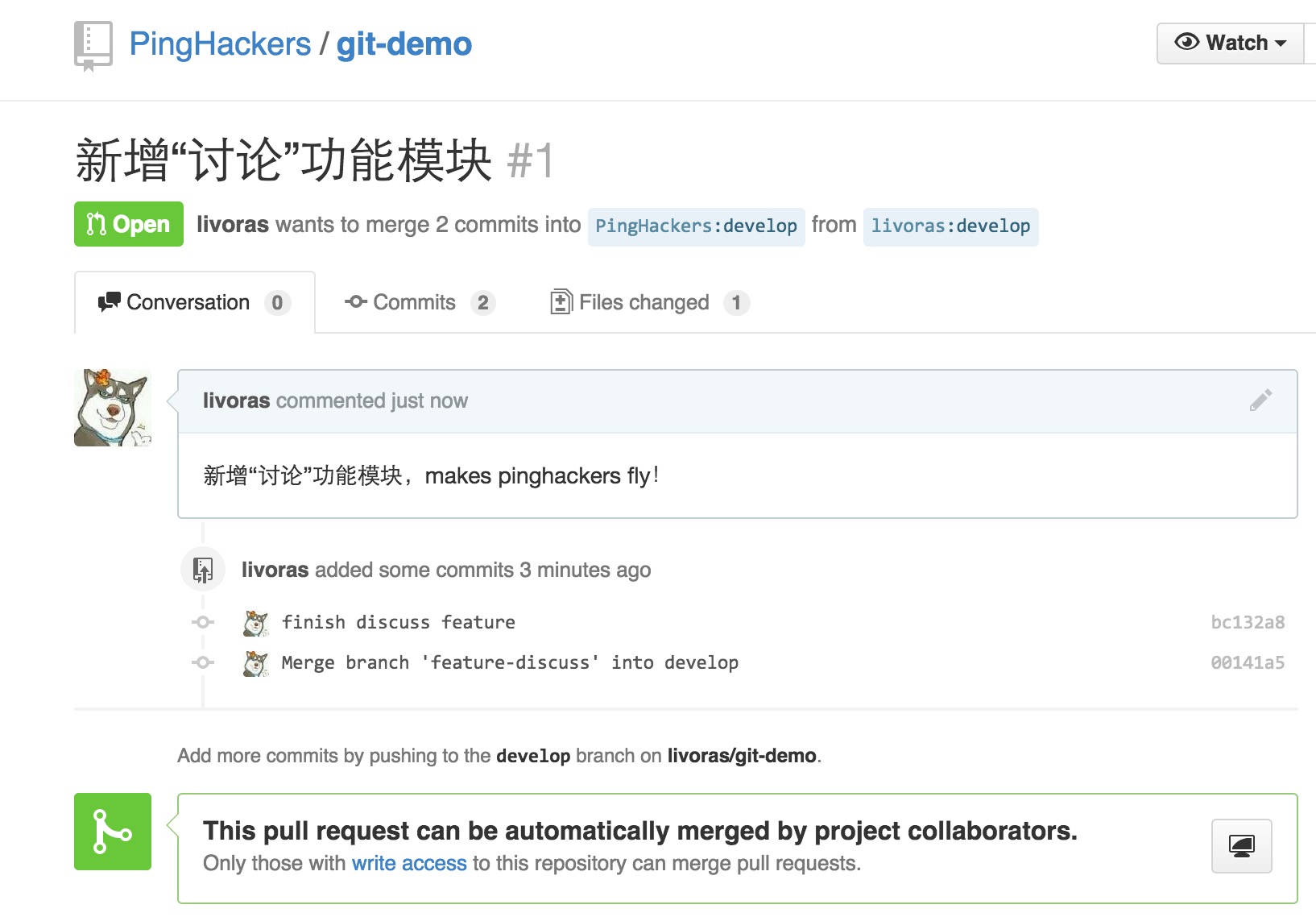
接下来就是管理员的操作了,作为管理员的PingHackers登陆github,便看到了我对源仓库发起的pull request。
这时候PingHackers需要做的事情就是:
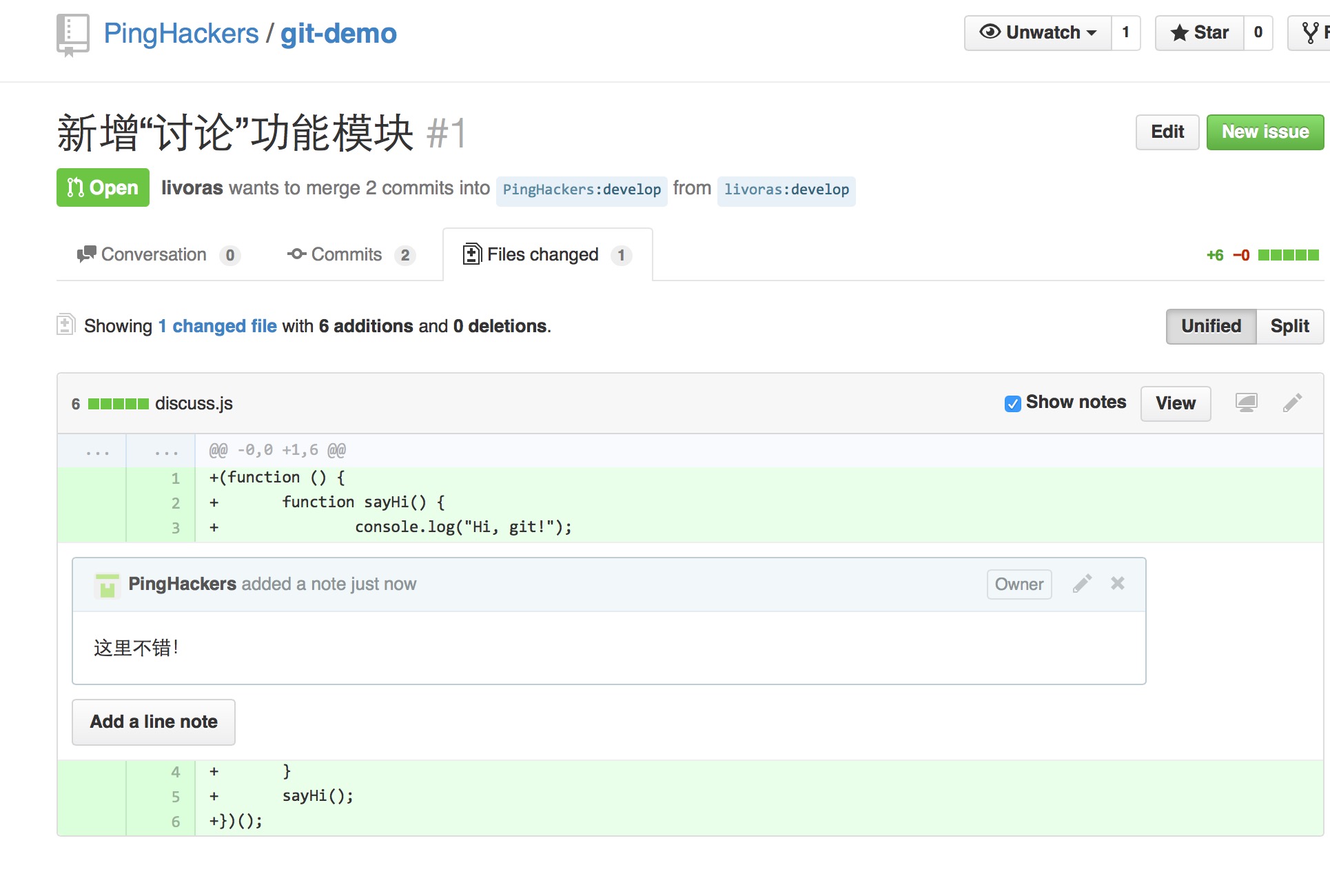
>> git checkout develop
# 进入他本地的develop分支
>> git checkout -b livoras-develop
# 从develop分支中分出一个叫livoras-develop的测试分支测试我的代码
>> git pull https://github.com/livoras/git-demo.git develop
# 把我的代码pull到测试分支中,进行测试
develop中,如果经过测试没问题,可以把我的代码合并到源仓库的develop中: >> git checkout develop
>> git merge --no-ff livoras-develop
>> git push origin develop
注意,PingHakers一直在操作的仓库是源仓库。所以我们经过上面一系列操作以后,就可以在源仓库主页中看到:
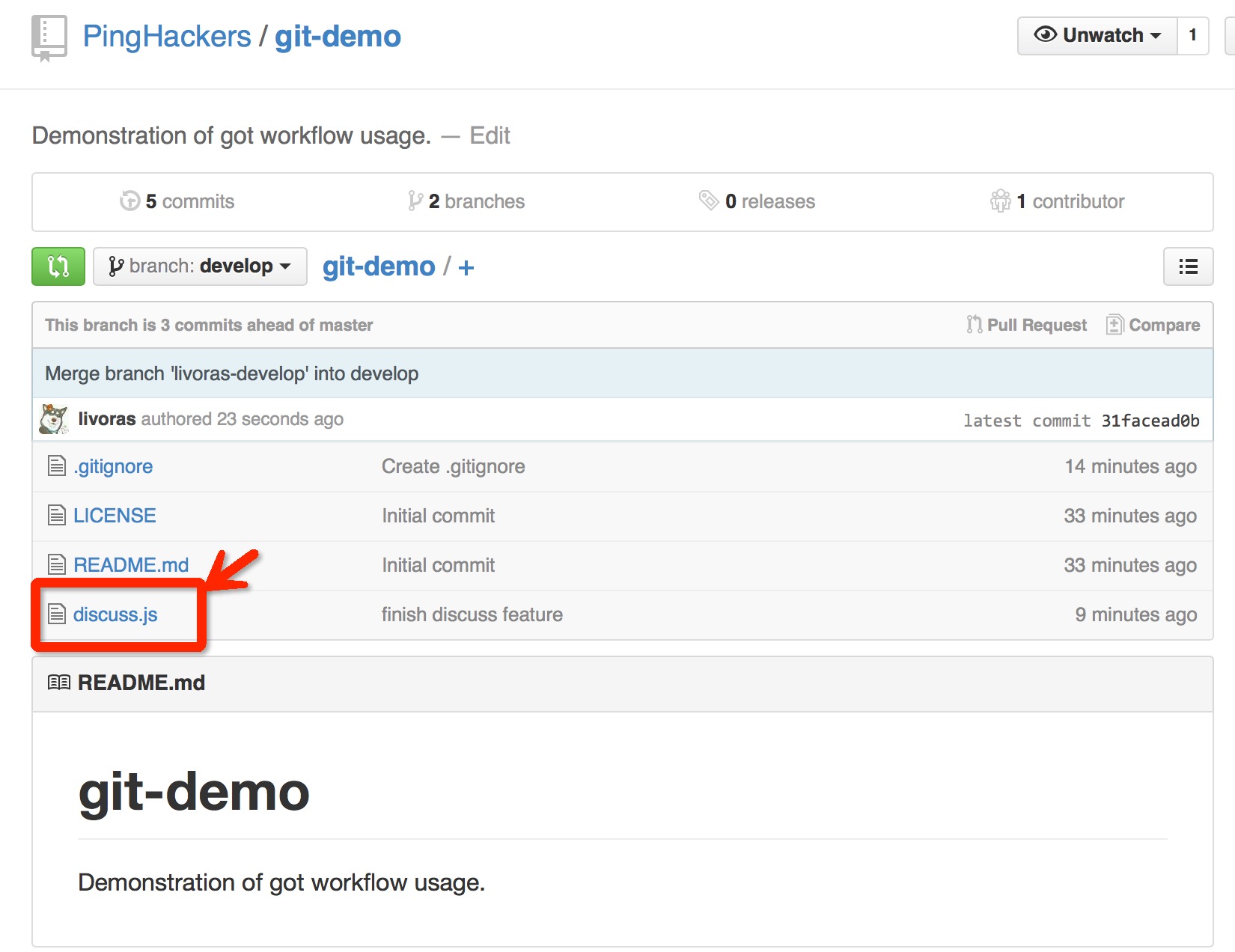
经过辗转曲折的路程,我们的discuss.js终于从我的开发仓库的功能分支到达了源仓库的develop分支中。以上,就是一个git & github协同工作流的基本步骤。
git这一个工具博大精深,使用如此恶心而又如此灵活和优雅的工具;此又为一神器,大家还是多动手,多查资料,让git成为自己的一项基本技能,帮助自己处理各种项目团队协同工作的问题,成为一个高效的开发者、优秀的项目的管理者。送大家一张神图,好好领悟:
最后给出一些参考资料,供参考学习。
@Y-WinDow 如果没有key的情况下,无法判断,所以如果两个节点tagName不一样会整棵子树替换掉;如果有key的话,关键点就是怎么用list-diff使得对比的时候两个节点是同一个节点了
Originally posted by @livoras in #13 (comment)
public 下面的 assets 在 git 里忽略掉啊...
无意中看到的项目,后面有时间关注一下下
Ok
作者:戴嘉华
转载请注明出处并保留原文链接( #14 )和作者信息。
本文尝试构建一个 Web 前端模板引擎,并且把这个引擎和 Virtual-DOM 进行结合。把传统模板引擎编译成 HTML 字符串的方式改进为编译成 Virtual-DOM 的 render 函数,可以有效地结合模板引擎的便利性和 Virtual-DOM 的性能。类似 ReactJS 中的 JSX。
阅读本文需要一些关于 ReactJS 实现原理或者 Virtual-DOM 的相关知识,可以先阅读这篇博客:深度剖析:如何实现一个 Virtual DOM 算法 , 进行相关知识的了解。
同时还需要对编译原理相关知识有基本的了解,包括 EBNF,LL(1),递归下降的方法等。
本人在就职的公司维护一个比较朴素的系统,前端渲染有两种方式:
当数据状态变更的时候,前端用 jQuery 修改页面元素状态,或者把局部界面用模板引擎重新渲染一遍。当页面状态很多的时候,用 jQuery 代码中会就混杂着很多的 DOM 操作,编码复杂且不便于维护;而重新渲染虽然省事,但是会导致一些性能、焦点消失的问题(具体可以看这篇博客介绍)。
因为习惯了 MVVM 数据绑定的编码方式,对于用 jQuery 选择器修改 wordings 等细枝末节的劳力操作个人感觉不甚习惯。于是就构思能否在这种朴素的编码方式上做一些改进,解放双手,提升开发效率。其实只要加入数据状态 -> 视图的 one-way data-binding 开发效率就会有较大的提升。
而这种已经在运作多年的多人维护系统,引入新的 MVVM 框架并不是一个非常好的选择,在兼容性和风险规避上大家都有诸多的考虑。于是就构思了一个方案,在前端模板引擎上做手脚。可以在几乎零学习成本的情况下,做到 one-way data-binding,大量减少 jQuery DOM 操作,提升开发效率。
考虑以下模板语法:
<div>
<h1>{title}</h1>
<ul>
{each users as user i}
<li class="user-item">
<img src="/avatars/{user.id}" />
<span>NO.{i + 1} - {user.name}</span>
{if user.isAdmin}
I am admin
{elseif user.isAuthor}
I am author
{else}
I am nobody
{/if}
</li>
{/each}
</ul>
</div>这只一个普通的模板引擎语法(类似 artTemplate),支持循环语句(each)、条件语句(if elseif else ..)、和文本填充({...}), 应该比较容易看懂,这里就不解释。当用下面数据渲染该模板的时候:
var data = {
title: 'Users List',
users: [
{id: 'user0', name: 'Jerry', isAdmin: true},
{id: 'user1', name: 'Lucy', isAuthor: true},
{id: 'user2', name: 'Tomy'}
]
}会得到下面的 HTML 字符串:
<div>
<h1>Users List</h1>
<ul>
<li class="user-item">
<img src="/avatars/user0" />
<span>NO.1 - Jerry</span>
I am admin
</li>
<li class="user-item">
<img src="/avatars/user1" />
<span>NO.2 - Lucy</span>
I am author
</li>
<li class="user-item">
<img src="/avatars/user2" />
<span>NO.3 - Tomy</span>
I am nobody
</li>
</ul>
</div>把这个字符串塞入文档当中就可以生成 DOM 。但是问题是如果数据变更了,例如data.title由Users List修改成Users,你只能用 jQuery 修改 DOM 或者直接重新渲染一个新的字符串塞入文档当中。
然而我们可以参考 ReactJS 的 JSX 的做法,不把模板编译成 HTML, 而是把模板编译成一个返回 Virtual-DOM 的 render 函数。render 函数会根据传入的 state 不同返回不一样的 Virtual-DOM ,然后就可以根据 Virtual-DOM 算法进行 diff 和 patch:
// setup codes
// ...
var render = template(tplString) // template 把模板编译成 render 函数而不是 HTML 字符串
var root1 = render(state1) // 根据初始状态返回的 virtual-dom
var dom = root.render() // 根据 virtual-dom 构建一个真正的 dom 元素
document.body.appendChild(dom)
var root2 = render(state2) // 状态变更,重新渲染另外一个 virtual-dom
var patches = diff(root1, root2) // virtual-dom 的 diff 算法
patch(dom, patches) // 更新真正的 dom 元素这样做好处就是:既保留了原来模板引擎的语法,又结合了 Virtual-DOM 特性:当状态改变的时候不再需要 jQuery 了,而是跑一遍 Virtual-DOM 算法把真正的 DOM 给patch了,达到了 one-way data-binding 的效果,总结流程就是:
(恩,其实就是一个类似于 JSX 的东西)
这里重点就是,如何能把模板语法编译成一个能够返回 Virtual-DOM 的 render 函数?例如上面的模板引擎,不再返回 HTML 字符串了,而是返回一个像下面那样的 render 函数:
function render (state) {
return el('div', {}, [
el('h1', {}, [state.title]),
el('ul', {}, state.users.map(function (user, i) {
return el('li', {"class": "user-item"}, [
el('img', {"src": "/avatars/" + user.id}, []),
el('span', {}, ['No.' + (i + 1) + ' - ' + user.name],
(user.isAdmin
? 'I am admin'
: uesr.isAuthor
? 'I am author'
: '')
])
}))
])
}前面的模板和这个 render 函数在语义上是一样的,只要能够实现“模板 -> render 函数”这个转换,就可以跑上面所说的 Virtual-DOM 的算法流程,这样就把模板引擎和 Virtual-DOM结合起来。为了方便起见,这里把这个结合体称为 Virtual-Template 。
网上关于模板引擎的实现原理介绍非常多。如果语法不是太复杂的话,可以直接通过对语法标签和代码片段进行分割,识别语法标签内的内容(循环、条件语句)然后拼装代码,具体可以参考这篇博客。其实就是正则表达式使用和字符串的操作,不需要对语法标签以外的内容做识别。
但是对于和 HTML 语法已经差别较大的模板语法(例如 Jade ),单纯的正则和字符串操作已经不够用了,因为其语法标签以外的代码片段根本不是合法的 HTML 。这种情况下一般需要编译器相关知识发挥用途:模板引擎本质上就是把一种语言编译成另外一种语言。
而对于 Virtual-Template 的情况,虽然其除了语法标签以外的代码都是合法的 HTML 字符串,但是我们的目的是把它编译成返回 Virtual-DOM 的 render 函数,在构建 Virtual-DOM 的时候,你需要知道元素的 tagName、属性等信息,所以就需要对 HTML 元素本身做识别。
因此 Virtual-Template 也需要借助编译原理(编译器前端)相关的知识,把一种语言(模板语法)编译成另外一种语言(一个叫 render 的 JavaScript 函数)。
CS 本科都教过编译原理,本文会用到编译器前端的一些概念。在实现模板到 render 函数的过程中,要经过几个步骤:
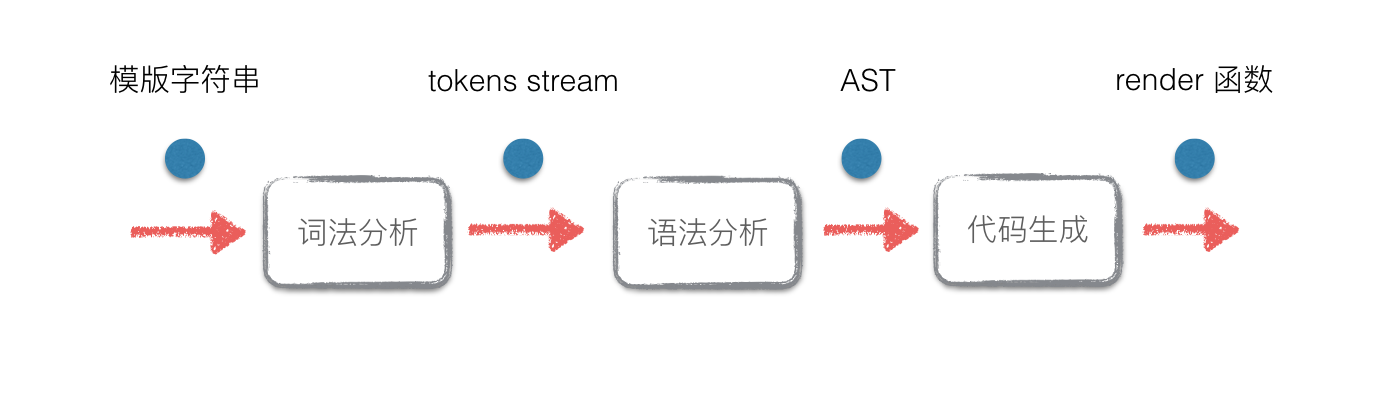
所以这个过程可以分成几个主要模块:tokenizer(词法分析器),parser(语法分析器),codegen(代码生成)。在此之前,还需要对模板的语法做文法定义,这是构建词法分析和语法分析的基础。
在计算机领域,对某种语言进行语法定义的时候,几乎都会用到 EBNF(扩展的巴科斯范式)。在定义模板引擎的语法的时候,也可以用到 EBNF。Virtual-Template 拥有非常简单的语法规则,支持上面所提到的 each、if 等语法:
{each users as user i }
<div> {user.name} </div>
...
{/each}
{if user.isAdmin}
...
{elseif user.isAuthor}
...
{elseif user.isXXX}
...
{/if}
对于 {user.name} 这样的表达式插入,可以简单地看成是字符串,在代码生成的时候再做处理。这样我们的词法和语法分析就会简化很多,基本只需要对 each、if、HTML 元素进行处理。
Virtual-Template 的 EBNF:
Stat -> Frag Stat | ε
Frag -> IfStat | EachStat | Node | text
IfStat -> '{if ...}' Stat {ElseIf} [Else] '{/if}'
ElseIf -> '{elseif ...}' Stat
Else -> '{else}' Stat|e
EachStat -> '{each ...}' Stat '{/each}'
Node -> OpenTag NodeTail
OpenTag -> '/[\w\-\d]+/' {Attr}
NodeTail -> '>' Stat '/\<[\w\d]+\>/' | '/>'
Attr -> '/[\w\-\d]/+' Value
Value -> '=' '/"[\s\S]+"/' | ε
可以把该文法转换成 LL(1) 文法,方便我们写递归下降的 parser。这个语法还是比较简单的,没有出现复杂的左递归情况。简单进行展开和提取左公因子消除冲突获得下面的 LL(1) 文法。
LL(1) 文法:
Stat -> Frag Stat | ε
Frag -> IfStat | EachStat | Node | text
IfStat -> '{if ...}' Stat ElseIfs Else '{/if}'
ElseIfs -> ElseIf ElseIfs | ε
ElseIf -> '{elseif ...}' Stat
Else -> '{else}' Stat | ε
EachStat -> '{each ...}' Stat '{/each}'
Node -> OpenTag NodeTail
OpenTag -> '/[\w\-\d]+/' Attrs
NodeTail -> '>' Stat '/\<[\w\d]+\>/' | '/>'
Attrs -> Attr Attrs | ε
Attr -> '/[\w\-\d]/+' Value
Value -> '=' '/"[\s\S]+"/' | ε
根据上面获得的 EBNF ,单引号包含的都是非终结符,可以知道有以下几种词法单元:
module.exports = {
TK_TEXT: 1, // 文本节点
TK_IF: 2, // {if ...}
TK_END_IF: 3, // {/if}
TK_ELSE_IF: 4, // {elseif ...}
TK_ELSE: 5, // {else}
TK_EACH: 6, // {each ...}
TK_END_EACH: 7, // {/each}
TK_GT: 8, // >
TK_SLASH_GT: 9, // />
TK_TAG_NAME: 10, // <div|<span|<img|...
TK_ATTR_NAME: 11, // 属性名
TK_ATTR_EQUAL: 12, // =
TK_ATTR_STRING: 13, // "string"
TK_CLOSE_TAG: 13, // </div>|</span>|</a>|...
TK_EOF: 100 // end of file
}使用 JavaScript 自带的正则表达式引擎编写 tokenizer 很方便,把输入的模板字符串从左到右进行扫描,按照上面的 token 的类型进行分割:
function Tokenizer (input) {
this.input = input
this.index = 0
this.eof = false
}
var pp = Tokenizer.prototype
pp.nextToken = function () {
this.eatSpaces()
return (
this.readCloseTag() ||
this.readTagName() ||
this.readAttrName() ||
this.readAttrEqual() ||
this.readAttrString() ||
this.readGT() ||
this.readSlashGT() ||
this.readIF() ||
this.readElseIf() ||
this.readElse() ||
this.readEndIf() ||
this.readEach() ||
this.readEndEach() ||
this.readText() ||
this.readEOF() ||
this.error()
)
}
// read token methods
// ...Tokenizer 会存储一个 index,标记当前识别到哪个字符位置。每次调用 nextToken 会先跳过所有的空白字符,然后尝试某一种类型的 token ,识别失败就会尝试下一种,如果成功就直接返回,并且把 index 往前移;所有类型都试过都无法识别那么就是语法错误,直接抛出异常。
具体每个识别的函数其实就是正则表达式的使用,这里就不详细展开,有兴趣可以阅读源码 tokenizer.js
最后会把这样的文章开头的模板例子转换成下面的 tokens stream:
{ type: 10, label: 'div' }
{ type: 8, label: '>' }
{ type: 10, label: 'h1' }
{ type: 8, label: '>' }
{ type: 1, label: '{title}' }
{ type: 13, label: '</h1>' }
{ type: 10, label: 'ul' }
{ type: 8, label: '>' }
{ type: 6, label: '{each users as user i}' }
{ type: 10, label: 'li' }
{ type: 11, label: 'class' }
{ type: 12, label: '=' }
{ type: 13, label: 'user-item' }
{ type: 8, label: '>' }
{ type: 10, label: 'img' }
{ type: 11, label: 'src' }
{ type: 12, label: '=' }
{ type: 13, label: '/avatars/{user.id}' }
{ type: 9, label: '/>' }
{ type: 10, label: 'span' }
{ type: 8, label: '>' }
{ type: 1, label: 'NO.' }
{ type: 1, label: '{i + 1} - ' }
{ type: 1, label: '{user.name}' }
{ type: 13, label: '</span>' }
{ type: 2, label: '{if user.isAdmin}' }
{ type: 1, label: 'I am admin\r\n ' }
{ type: 4, label: '{elseif user.isAuthor}' }
{ type: 1, label: 'I am author\r\n ' }
{ type: 5, label: '{else}' }
{ type: 1, label: 'I am nobody\r\n ' }
{ type: 3, label: '{/if}' }
{ type: 13, label: '</li>' }
{ type: 7, label: '{/each}' }
{ type: 13, label: '</ul>' }
{ type: 13, label: '</div>' }
{ type: 100, label: '$' }拿到 tokens 以后就可以就可以按顺序读取 token,根据模板的 LL(1) 文法进行语法分析。语法分析器,也就是 parser,一般可以采取递归下降的方式来进行编写。LL(1) 不允许语法中有冲突( conflicts ),需要对文法中的产生式求解 FIRST 和 FOLLOW 集。
FIRST(Stat) = {TK_IF, TK_EACH, TK_TAG_NAME, TK_TEXT}
FOLLOW(Stat) = {TK_ELSE_IF, TK_END_IF, TK_ELSE, TK_END_EACH, TK_CLOSE_TAG, TK_EOF}
FIRST(Frag) = {TK_IF, TK_EACH, TK_TAG_NAME, TK_TEXT}
FIRST(IfStat) = {TK_IF}
FIRST(ElseIfs) = {TK_ELSE_IF}
FOLLOW(ElseIfs) = {TK_ELSE, TK_ELSE}
FIRST(ElseIf) = {TK_ELSE_IF}
FIRST(Else) = {TK_ELSE}
FOLLOW(Else) = {TK_END_IF}
FIRST(EachStat) = {TK_EACH}
FIRST(OpenTag) = {TK_TAG_NAME}
FIRST(NodeTail) = {TK_GT, TK_SLASH_GT}
FIRST(Attrs) = {TK_ATTR_NAME}
FOLLOW(Attrs) = {TK_GT, TK_SLASH_GT}
FIRST(Value) = {TK_ATTR_EQUAL}
FOLLOW(Value) = {TK_ATTR_NAME, TK_GT, TK_SLASH_GT}
上面只求出了一些必要的 FIRST 和 FOLLOW 集,对于一些不需要预测的产生式就省略求解了。有了 FIRST 和 FOLLOW 集,剩下的编写递归下降的 parser 只是填空式的体力活。
var Tokenizer = require('./tokenizer')
var types = require('./tokentypes')
function Parser (input) {
this.tokens = new Tokenizer(input)
this.parse()
}
var pp = Parser.prototype
pp.is = function (type) {
return (this.tokens.peekToken().type === type)
}
pp.parse = function () {
this.tokens.index = 0
this.parseStat()
this.eat(types.TK_EOF)
}
pp.parseStat = function () {
if (
this.is(types.TK_IF) ||
this.is(types.TK_EACH) ||
this.is(types.TK_TAG_NAME) ||
this.is(types.TK_TEXT)
) {
this.parseFrag()
this.parseStat()
} else {
// end
}
}
pp.parseFrag = function () {
if (this.is(types.TK_IF)) return this.parseIfStat()
else if (this.is(types.TK_EACH)) return this.parseEachStat()
else if (this.is(types.TK_TAG_NAME)) return this.parseNode()
else if (this.is(types.TK_TEXT)) {
var token = this.eat(types.TK_TEXT)
return token.label
} else {
this.parseError('parseFrag')
}
}
// ...完整的 parser 可以查看 parser.js。
递归下降进行语法分析的时候,可以同时构建模版语法的树状表示结构——抽象语法树,模板语法有以下的抽象语法树的节点类型:
Stat: {
type: 'Stat'
members: [IfStat | EachStat | Node | text, ...]
}
IfStat: {
type: 'IfStat'
label: <string>,
body: Stat
elifs: [ElseIf, ...]
elsebody: Stat
}
ElseIf: {
type: 'ElseIf'
label: <string>,
body: Stat
}
EachStat: {
type: 'EachStat'
label: <string>,
body: Stat
}
Node: {
type: 'Node'
name: <string>,
attributes: <object>,
body: Stat
}
因为 JavaScript 语法的灵活性,可以用字面量的 JavaScript 对象和数组直接表示语法树的树状结构。语法树构的建过程可以在语法分析阶段同时进行。最后,可以获取到如下图的语法树结构:
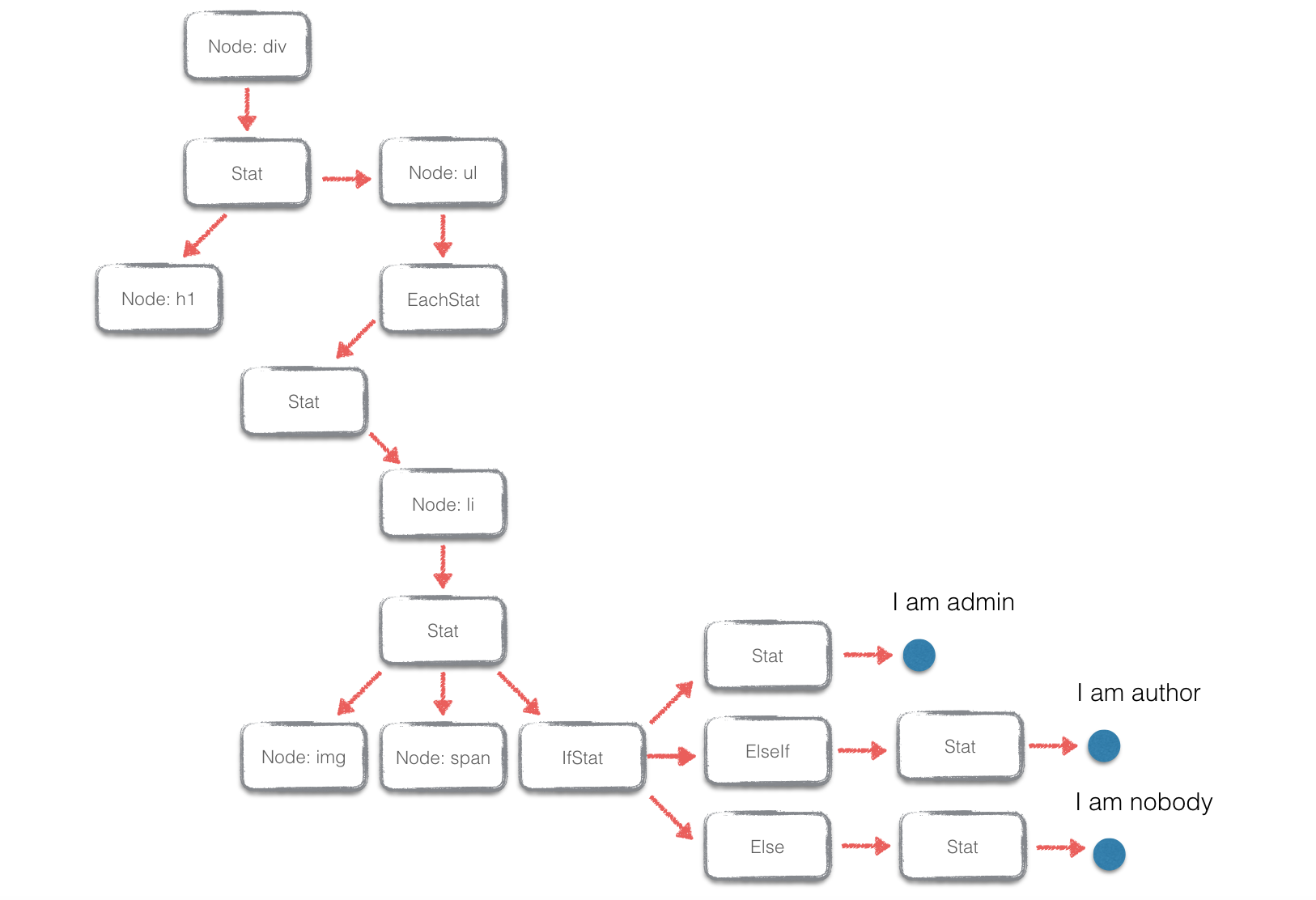
完整的语法树构建过程,可以查看 parser.js 。
从模版字符串到 tokens stream 再到 AST ,这个过程只需要对文本进行一次扫描,整个算法的时间复杂度为 O(n)。
至此,Virtual-Template 的编译器前端已经完成了。
JavaScript 从字符串中构建一个新的函数可以直接用 new Function 即可。例如:
var newFunc = new Function('a', 'b', 'return a + b')
newFunc(1, 2) // => 3这里需要通过语法树来还原 render 函数的函数体的内容,也就是 new Function 的第三个参数。
拿到模版语法的抽象语法树以后,生成相应的 JavaScript 函数代码就很好办了。只需要地对生成的 AST 进行深度优先遍历,遍历的同时维护一个数组,这个数组保存着 render 函数的每一行的代码:
function CodeGen (ast) {
this.lines = []
this.walk(ast)
this.body = this.lines.join('\n')
}
var pp = CodeGen.prototype
pp.walk = function (node) {
if (node.type === 'IfStat') {
this.genIfStat(node)
} else if (node.type === 'Stat') {
this.genStat(node)
} else if (node.type === 'EachStat') {
...
}
...
}
pp.genIfStat = function (node) {
var expr = node.label.replace(/(^\{\s*if\s*)|(\s*\}$)/g, '')
this.lines.push('if (' + expr + ') {')
if (node.body) {
this.walk(node.body)
}
if (node.elseifs) {
var self = this
_.each(node.elseifs, function (elseif) {
self.walk(elseif)
})
}
if (node.elsebody) {
this.lines.push(indent + '} else {')
this.walk(node.elsebody)
}
this.lines.push('}')
}
// ...CodeGen 类接受已经生成的 AST 的根节点,然后 this.walk(ast) 会对不同的节点类型进行解析。例如对于 IfStat 类型的节点:
{
type: 'IfStat',
label: '{if user.isAdmin}'
body: {...}
elseifs: [{...}, {...}, {...}],
elsebody: {...}
}genIfStat 会把 '{if user.isAdmin}' 中的 user.isAdmin 抽离出来,然后拼接 JavaScript 的 if 语句,push 到 this.lines 中:
var expr = node.label.replace(/(^\{\s*if\s*)|(\s*\}$)/g, '')
this.lines.push('if (' + expr + ') {')然后会递归的对 elseifs 和 elsebody 进行遍历和解析,最后给 if 语句补上 }。所以如果 elseifs 和 elsebody 都不存在,this.lines 上就会有:
['if (user.isAdmin) {', <body>, '}']其它的结构和 IfStat 同理的解析和拼接方式,例如 EachStat:
pp.genEachStat = function (node) {
var expr = node.label.replace(/(^\{\s*each\s*)|(\s*\}$)/g, '')
var tokens = expr.split(/\s+/)
var list = tokens[0]
var item = tokens[2]
var key = tokens[3]
this.lines.push(
'for (var ' + key + ' = 0, len = ' + list + '.length; ' + key + ' < len; ' + key + '++) {'
)
this.lines.push('var ' + item + ' = ' + list + '[' + key + '];')
if (node.body) {
this.walk(node.body)
}
this.lines.push('}')
}最后递归构造完成以后,this.lines.join('\n') 就把整个函数的体构建起来:
if (user.isAdmin) {
...
}
for (var ...) {
...
}这时候 render 函数的函数体就有了,直接通过 new Function 构建 render 函数:
var code = new CodeGen(ast)
var render = new Function('el', 'data', code.body)el 是需要注入的构建 Virtual-DOM 的构建函数,data 需要渲染的数据状态:
var svd = require('simple-virtual-dom')
var root = render(svd.el, {users: [{isAdmin: true}]})从模版 -> Virtual-DOM 的 render 函数 -> Virtual-DOM 的过程就完成了。完整的代码生成的过程可以参考:codegen.js
其实拿到 render 函数以后,每次手动进行 diff 和 patch 都是重复操作。可以把 diff 和 patch 也封装起来,只暴露一个 setData 的 API 。每次数据变更的时候,只需要 setData 就可以更新到 DOM 元素上(就像 ReactJS 的 setState):
// vTemplate.compile 编译模版字符串,返回一个函数
var usersListTpl = vTemplate.compile(tplStr)
// userListTpl 传入初始数据状态,返回一个实例
var usersList = usersListTpl({
title: 'Users List',
users: [
{id: 'user0', name: 'Jerry', isAdmin: true},
{id: 'user1', name: 'Lucy', isAuthor: true},
{id: 'user2', name: 'Tomy'}
]
})
// 返回的实例有 dom 元素和一个 setData 的 API
document.appendChild(usersList.dom)
// 需要变更数据的时候,setData 一下即可
usersList.setData({
title: 'Users',
users: [
{id: 'user1', name: 'Lucy', isAuthor: true},
{id: 'user2', name: 'Tomy'}
]
})完整的 Virtual-Template 源码托管在 github 。
这个过程其实和 ReactJS 的 JSX 差不多。就拿 Babel 的 JSX 语法实现而言,它的 parser 叫 babylon。而 babylon 基于一个叫 acorn 的 JavaScript 编写的 JavaScript 解释器和它的 JSX 插件 acorn-jsx。其实就是利用 acorn 把文本分割成 tokens,而 JSX 语法分析部分由 acorn-jsx 完成。
Virtual-Template 还不能应用于实际的生产环境,需要完善的东西还有很多。本文记录基本的分析和实现的过程,也有助于更好地理解和学习 ReactJS 的实现。
(全文完)
本博客可能会很少活跃了(其实也一直没怎么活跃,惭愧),本人的 github、知乎等各大基佬社交平台帐号也应该不会再活跃了。谢谢大家一直以来对本博客的支持和关注(其实我就写过那么几篇文章,是在受宠若惊[捂头])。
我还会在 Web 前端领域继续和大家一起学习、进步,也还会继续写东西——但是会以一种新的方式。如果有缘我们会再见。
再见了朋友们。:)
作者:戴嘉华
转载请注明出处,保留原文链接和作者信息
开发一个Web应用的时候我们一般都会简单地分为前端工程师和后端工程师(注:在一些比较复杂的系统中,前端可以细分为外观和逻辑,后端可以分为CGI和Server)。前端工程师负责浏览器端用户交互界面和逻辑等,后端负责数据的处理和存储等。前后端的关系可以浅显地概括为:后端提供数据,前端负责显示数据。
在这种前后端的分工下,会经常有一些疑惑:既然前端数据是由后端提供,那么后端数据接口还没有完成,前端是否就无法进行编码?怎么样才能做到前后端独立开发?
考虑这么一个场景:Alex和Bob是一对好基友,他们有个可以颠覆世界的idea,准备把它实现出来,但是他们不需要程序员,因为他们就是程序员。说干就干,两个就干上了。Alex写前端,Bob写后端。
Alex和Bob都经过良好的训练,按部就班地把产品的主要功能设计,交互原型,视觉设计做好了,然后他们根据产品功能和交互制定了一堆叼炸天的前后端交互的API,这套API就类似于一套前后端开发的“协议”,Alex和Bob开发的时候都需要遵守。例如其中一个发表评论的功能:
// API: Create New Comment v2
// Ajax, JSON, RESTful
url: /comments
type: POST
request: {content: "comment content.", userId: 123456}
response:
- status: 200
data: {result: "SUCCESS", msg: "The comment has been created."}
- status: 404
data: {result: "failed", msg: "User is not found."}
Alex的前端需要向/comments这个url以POST的方式发送类似于{content: "comment content.", userId: 123456}这样的JSON请求数据;Bob的服务端识别后以后,操作成功则返回200状态和上面的JSON的数据,不同的操作状态有不同的响应数据(为了简单起见只列出了两种,200和404)。
API制定完以后,Alex和Bob就开始编码了。Alex把评论都外观和交互写完了,但是写到发表评论功能就纳闷了:Alex现在需要发Ajax过去,但是只能把Ajax代码写好,因为是本地服务器,却无法获取到数据:
// jQuery Ajax
$.ajax({ // 这个ajax直接报错,因为这个是Alex的前端服务器,请求无法获取数据;
url: "/comments",
type: "POST",
data: {content: content, userId: userId},
success: funtion(data) {
// 这里不会被执行
}
})
相比起来Bob就没有这个烦恼,因为后端是基于测试驱动开发,且后端可以轻易地模拟前端发送请求,可以对前端没有依赖地进行开发和测试。
Alex把这种情况和Bob说了,Bob就说,要不我们把代码弄到你本地前后端连接一下,这不就可以测试了吗。Alex觉得Bob简直是天才。
他们把前后端代码代码都部署到Alex的本地服务器以后,经过一系列的测试,调试,终于把这个API连接成功了。但是他们发现这个方法简直不科学:难道每写一个API都要把前后端链接测试一遍吗?而且,Alex的如果需要测试某个API,而Bob的这个API还没写好,Alex这个功能模块的进度就“阻塞”了。
后面还有168个API需要写,不能这么做。Alex和Bob就开始思考这个问题的解决方案。
在这个场景下,前后端是有比较强的数据依赖的关系,后端依赖前端的请求,前端依赖后端的响应。而后端可以轻松模拟前端请求(基本上能写后端的语言都可以直接发送HTTP请求),前端没有一个比较明显的方案来可以做到模拟响应,所以这里的需要解决的点就是:如何给前端模拟的响应数据。
先来一句非常形而上的话:如果两个对象具有强耦合的关系,我们一般只要引入第三个对象就可以打破这种强耦合的关系。
+---------+ +---------+
| | | |
| Object1 | <--------> | Object2 |
| | | |
+---------+ +---------+
Before
+---------+ +---------+
| | | |
| Object1 | <-- ✕ ---> | Object2 |
| | | |
+---+-----+ +-----+---+
| |
| |
| |
| |
| |
| +---------+ |
| | | |
+-----> | Object3 | <------+
| |
+---------+
After
在我们上述开发的过程中,前后端的耦合性太强了,我们需要借助额外的东西来打破它们的耦合性。所以,在前后端接口定下来以后,我们根据接口构建另外一个Server,这个Server会一一响应前端的请求,并且根据接口返回数据。当然这些数据都是假数据。我们把这个Server叫做_Mock Server_,而Bob真正在开发的Server叫做_Real Server_。
+-------------------+ +-------------------+
| | +-------- ✕ ------> | |
| Browser | | Real Server |
| | <---+ | |
+--------------+----+ | +-------------------+
| |
| |
| |
| |
Request Response
| |
| |
| |
| +----+--------------+
+---> | |
| Mock Server |
| |
+-------------------+
Mock Server是根据API实现的,但是是没有数据逻辑的,只是非常简单地返回数据。例如上面Alex和Bob的发表评论的接口在Mock Server上是这样的:
// Mock Server
// Create New Comment API
route.post("/comments", function(req, res) {
res.send(200, {result: "Success"});
})
Alex在开发的时候向Mock Server发出请求,而不是向Bob的服务器发出请求:
// Sending Request to Mock Server
// jQuery Ajax
$.ajax({
url: config.HOST + "/comments",
type: "POST",
data: {content: content, userId: userId},
success: funtion(data) {
// OK
}
})
注意上面的config.HOST,我们把服务器配置放在一个全局共用的模块当中:
// Front-end Configuration Module
var config = modules.exports;
config.HOST = "http://192.169.10.20" // Mock Server IP
那么上面我们其实是向IP为http://192.169.10.20的Mock Server发出请求http://192.169.10.20/comments发出POST的请求。
当Alex和Bob都代码写好了以后,需要连接调试了,Alex只要简单地改一下配置文件即可把所有的请求都转向Bob所开发的Real Server:
// Front-end Configuration Module
var config = module.exports;
// config.HOST = "http://192.169.10.20" // Mock Server IP
config.HOST = "http://changing-world-app.com" // Real Server Domain
然后Alex和Bob就可以愉快地分离独立开发,而最后只需要联合调试就可以了。
总结一下基本上前后端分离开发包括下面几个步骤:
当然要注意,如果接口修改了,Mock Server要同步修改。
Mock Server具体应该如何构建?应该存放在哪里?应该怎么维护?
前后端是不同的两个工程,它们各自占用一个仓库。Mock Server应该和它们分离出来,独立进行开发和维护,也就是说会有三个仓库,Mock Server是一个单独的工程。
Mock Server可以部署在本地,也可以部署到远程服务器,两者之间各有优劣。
做法:把Mock Server工程部署到一个远程的always on的远程服务器上,前端开发的时候向该服务器发请求。
优点:
缺点:
(在写这篇博客的时候,逛Hacker News,刚好看到有人做了一个开发辅助工具(http://reqr.es/),可以用于开发时响应前端请求,其实也就是这里所说的远程Mock Server。真是不能再巧更多。)
做法:前端把Mock Server克隆到本地,开发的时候,开启前端工程服务器和Mock Server,所有的请求都发向本地服务器,获取到Mock数据。
优点:
缺点:
Mock Server工程一般可以由后端开发人员来维护。因为在开发的过程中,后端因为各种原因可能需要修改API,后端人员是最熟悉请求的响应数据和格式的人,可以同步维护Mock Server和Real Server,更好保证数据的一致。Mock Server维护起来并不复杂,对于比较大多工程来说,这样的前期准备和过程的维护是非常值得的。
所以要点就是:根据API构建可以模拟服务器响应的Mock Server,用于前端请求模拟数据进行测试。
再重复总结一下前后端分离开发包括下面几个步骤:
当开发只有我一个人的时候,我更喜欢后端独立开发,开发前端的时候开个Real Server来做响应。又爽又快。其实如果团队的人是full-stack的话,完全可以按照功能模块来划分任务,而不是分为前端工程师和后端工程师。
但一般来说还是会选择前后端职能划分,对于这种情况下的多人开发的工程来说,前后端分离开发的方式确实需要考虑和构建的,可以更好帮助我们构建一个高效,规范化,流程化的开发流程。
还是那句话,没有银弹,所有的东西都需要根据实际情况来构建独特的流程。
无
(全文完)
(前言:本文写的是”经历“,不是”经验“,废话很多,没什么干货,所以建议不要看)
在所有大公司实习生都招完以后再来找实习简直就是作死,而我绝对是作死中的楷模。
还好我有一堆堆在阿里、腾讯等大公司实习的师兄大大们,叫他们内推一下应该不成问题。于是我就找了微信黄思程大大内推我去微信做Web前端实习生,当晚就交了简历。
第二天就有声音甜美媲美10086客服的HR妹子打电话给我:“请问是戴嘉华同学吗。”她问了我一些问题,为什么这么晚才找实习,为什么要从之前的创业团队离开,课能不能修完,然后最后问我意向去微信还是邮箱(广研就这两个部门)。我说微信,然后她说微信满人了(那还问个蛋啊),我说最好是微信,如果不行的话邮箱也可以。
过了两天她告诉我微信确实满人了,只能去邮箱。因为前些天同时也让陈学家大大内推去阿里,考虑到与其去邮箱还不如去阿里,然后我就说很抱歉我不能去了,挂了电话,就一心去阿里了。第二天HR妹妹又告诉我微信有童鞋毁约了,现在有个位置,问我去不去,我当然说去,然后就给我发了三天以后面试的通知。
后来阿里那边实习生也已经招满了,跟我们说校招的时候再来。好在有个微信有个家伙毁约了,不然两头不着岸就GG了。
三天时间不知道在干嘛,想准备一下也不知道从何准备,胡乱地看了一通http、js、性能优化之类的。听说微信前端面试有时候会有搞后端的面试官,突然感觉受到了恐吓,还去学了几个排序算法,感觉时间太短也做不了什么大的准备,最后只好作罢。
约了三天后下午3点的时间,我知道自己一定会迷路,所以就提早了点,果不然,去的时候坐过了站,回来的时候又坐过了站,天才。
乘坐广州地铁到客村站A出口,走几步就可以到达伪文艺逼格如画的T.I.T创意园,腾讯广研独自占据了里面4、5座红砖建筑,沿着一条干净的小道,两遍是各种咖啡屋,精品店,还有买不知道什么东西的店,阳光斜斜地洒下来,几个扫地大伯时而低头,时而驻足,无不让人联想起宫崎骏《侧耳倾听》里面那只诡异的大肥猫消失的长廊。
穿过玻璃大门,必须承认果然是大公司,前台妹子都这么漂亮,前台妹子让我在咖啡厅里面等,她联系面试官,后来我才发现妹子长得漂亮是腾讯的公司文化,因为包括咖啡厅里面、咖啡厅外面、和端咖啡的妹子都很漂亮#不知道为什么#。
咖啡厅整体格调昏黄,装修得很有范儿,门口摆放着星球大战里面的机器人的半身铜像,不知道是干嘛用的,几个沙发,几张桌子,一个吧台,有喝的有吃的,一个落地玻璃大门,门外的几张桌子也是咖啡厅的一部分,里外都有休闲的人,除了差了点音乐,一切都完美了。如果不时有短裤拖鞋脚毛大叔经过,我真以为我来到了一个高端洋气的酒吧。
不一会儿,面试官来了,一个胖胖的大哥哥,露着可爱的笑容,我很喜欢他。还以为他会带我到什么奇奇怪怪的地方,原来直接就在咖啡厅里面坐下来了,就开始了面试。
大哥哥:看你的简历,你说你有两年的Web经验,据我所知现在的学校都没有教这些东西,你可以说说你的经验吗。
我(内心:为什么没有让我自我介绍,准备的台词都木有聊):我从大一开始学习Web编程的,学校教的都是C/C++,我一直觉得没有什么意思,只到有一天看到一个师兄在捣鼓CSS,我突然感觉被雷劈了一样,才发现原来编程可以这样子,然后就自己捣鼓起来。。。。blablabla
他针对我简历上的一些项目问了我一些问题,我就跟他侃我做过的项目,在项目中用到的一些框架,我们遇到什么问题,怎么解决的,基本上就是这篇博客的内容。侃前端的架构,框架,测试,性能,版本管理,项目管理,模块划分,各种侃,非常高兴地看到话题一直停留在我熟悉的领域,说到大哥哥有共鸣的地方,大哥哥都给我露出了赞许笑容。最后问了一下在项目中我有没有遇到什么性能问题,怎么解决的,我就说我们怎么用requirejs做开发,自己构建脚本进行打包压缩代码,控制Cache-controll,怎么用调试工具找出应用中的性能瓶颈,使用内存池提高性能ect。看到我做过浏览器tab同步的类库,就问我用了什么原理,怎么做的。问的基本都是简历上相关项目的问题,没什么特别难的算法、智力题之类的,都是在我认知范围内的东西,大哥哥也是前端的,长吁了一口气。
最后大哥哥说比较喜欢我会质疑、会思考,遇到问题能够尽力地解决和优化,他很喜欢我这点。然后他让我等一下,他去找他leader来。额,我以为这就完了,原来要轮着来,看了手机,大概过了半个小时。
不一会儿,他就带着一个造型炫酷的大叔叔,留着可爱的小辫子,满脸的络腮胡子,带着一顶小麦子,WoW,LoL,简直酷!我一眼就喜欢上他了,但是大叔叔一直都没有露出什么感情,感觉干干的,不过这不妨碍我们又侃了半个小时。叔叔来了,哥哥就走了,叔叔坐下来,
大叔叔:你是黄思程推荐的吧(后来才知道原来他也是思程大大的leader)
我:是
大叔叔:你自我介绍一下吧。
我(内心:妈蛋,台词终于用上了,哈哈哈哈):我叫戴嘉华,是中山大学软件学院三年级学生,blabla。。。
我跟大叔叔侃的内容和大哥哥侃的差不多,各种前端模块划分,架构之类的。大叔叔问了一个问题:“如果我让你做一个编辑器,你会怎么设计、构建它的组件”,然后拿了一支笔,让我画图。我没什么急才,感觉要毁了,就随便画了一个富文本编辑器,分析是怎么构建它的组件的,每个组件的功能划分,组件是怎么组合、关联起来的。叔叔说:“如果我现在要你添加一个功能,xxxx”,然后我就在我设计的基础上跟他说可以通过编辑器接口构建插件,来进行功能的添加,讲了一下具体的方案,大叔叔听完以后没什么表情,也不知道满不满意。这个问题算是过了。
大叔叔也问了一些性能问题,安全问题,就侃了一下XSS、DDoS攻击啥的;他看到简历上说我阅读过Seajs源码并且写过自己的模块加载器,让我说一下模块加载器的原理和架构,那是一年前的事情了,早就忘了七七八八,硬生生挤出一点东西,随便侃了一下过去了。
跟大叔叔侃了半个小时左右,大叔叔最后酷酷地说,跟我来。这时候我口已经干到苦了,感叹终于可以休息一下。
大叔叔带我到另外一栋腾讯办公楼,那是微信的办公所在地,路上他问了我现在大三课多不,毕设怎么样云云,随便聊了几句。
进了办公楼,他让我到茶水间坐一下,酷炫地指了一下饮水机。哈利路亚,活了这么多年,我终于明白了穿越沙漠很久没有水喝的人见到水以后是什么赶脚。
怒喝了两三杯,饱暖思淫欲,就开始悠闲地看着微信的办公区,好多白色的办公桌,以一种难以名状的方式摆放着,每张桌子上都有一个巨大的高端台灯(估计是用来熬夜的),男人居多,有一些不大不小的讨论声,感觉是是一个适合工作的地方。
我一边心里暗思:不会还要面吧...?于是又喝了几杯,储存弹药防口干。
不一会儿,大叔叔貌似打了个电话乱搞了一下什么的,就走过来告诉我我可以走了,过两天就有消息。我说哦,庆幸了一下没有后续面试,然后就走了。
然后就在等消息。过了一天就收到面试通过的短信,让我过两天去第二轮面试。
第二轮面试考了一道简单的算法题和一道智力题,然后就HR面。
有过两天就拿到offer了。
经验就是:面试的时候要引导话题到你能熟知的领域并且尽量停留,那是你能侃下去的资本。
(全文完)
UPDATE(2015-10-29):更新MV*关于业务逻辑的描述,此处感谢 @LuoPQ @finian 指出错误
作者:戴嘉华
转载请注明出处并保留原文链接( #11 )和作者信息。
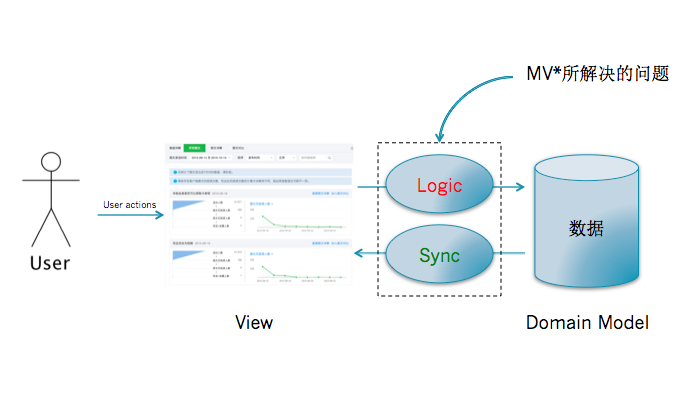
做客户端开发、前端开发对MVC、MVP、MVVM这些名词不了解也应该大致听过,都是为了解决图形界面应用程序复杂性管理问题而产生的应用架构模式。网上很多文章关于这方面的讨论比较杂乱,各种MV模式之间的区别分不清,甚至有些描述都是错误的。本文追根溯源,从最经典的Smalltalk-80 MVC模式开始逐步还原图形界面之下最真实的MV模式。
图形界面的应用程序提供给用户可视化的操作界面,这个界面提供给数据和信息。用户输入行为(键盘,鼠标等)会执行一些应用逻辑,应用逻辑(application logic)可能会触发一定的业务逻辑(business logic)对应用程序数据的变更,数据的变更自然需要用户界面的同步变更以提供最准确的信息。例如用户对一个电子表格重新排序的操作,应用程序需要响应用户操作,对数据进行排序,然后需要同步到界面上。
在开发应用程序的时候,以求更好的管理应用程序的复杂性,基于**职责分离(Speration of Duties)**的**都会对应用程序进行分层。在开发图形界面应用程序的时候,会把管理用户界面的层次称为View,应用程序的数据为Model(注意这里的Model指的是Domain Model,这个应用程序对需要解决的问题的数据抽象,不包含应用的状态,可以简单理解为对象)。Model提供数据操作的接口,执行相应的业务逻辑。
有了View和Model的分层,那么问题就来了:View如何同步Model的变更,View和Model之间如何粘合在一起。
带着这个问题开始探索MV模式,会发现这些模式之间的差异可以归纳为对这个问题处理的方式的不同。而几乎所有的MV模式都是经典的Smalltalk-80 MVC的修改版。
早在上个世纪70年代,美国的施乐公司(Xerox)的工程师研发了Smalltalk编程语言,并且开始用它编写图形界面的应用程序。而在Smalltalk-80这个版本的时候,一位叫Trygve Reenskaug的工程师设计了MVC图形应用程序的架构模式,极大地降低了图形应用程序的管理难度。而在四人帮(GoF)的设计模式当中并没有把MVC当做是设计模式,而仅仅是把它看成解决问题的一些类的集合。Smalltalk-80 MVC和GoF描述的MVC是最经典的MVC模式。
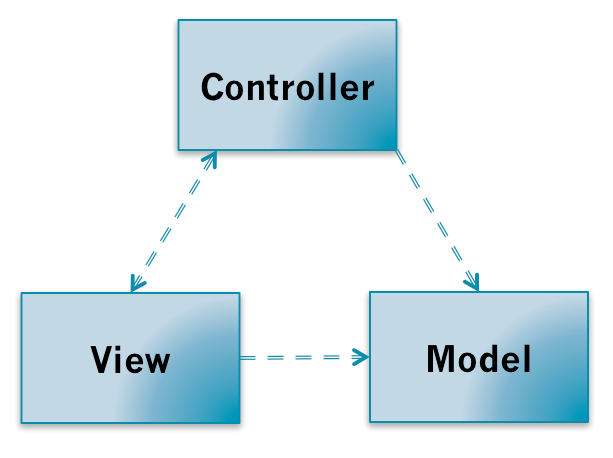
MVC出了把应用程序分成View、Model层,还额外的加了一个Controller层,它的职责为进行Model和View之间的协作(路由、输入预处理等)的应用逻辑(application logic);Model进行处理业务逻辑。Model、View、Controller三个层次的依赖关系如下:
Controller和View都依赖Model层,Controller和View可以互相依赖。在一些网上的资料Controller和View之间的依赖关系可能不一样,有些是单向依赖,有些是双向依赖,这个其实关系不大,后面会看到它们的依赖关系都是为了把处理用户行为触发的事件处理权交给Controller。
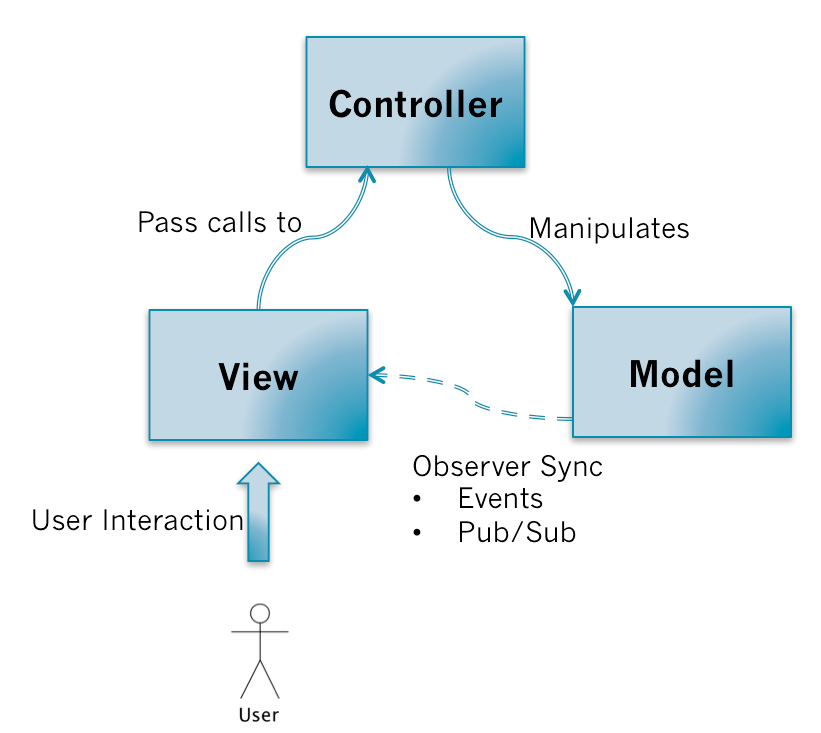
用户的对View操作以后,View捕获到这个操作,会把处理的权利交移给Controller(Pass calls);Controller会对来自View数据进行预处理、决定调用哪个Model的接口;然后由Model执行相关的业务逻辑;当Model变更了以后,会通过观察者模式(Observer Pattern)通知View;View通过观察者模式收到Model变更的消息以后,会向Model请求最新的数据,然后重新更新界面。如下图:
看似没有什么特别的地方,但是由几个需要特别关注的关键点:
需要特别注意的是MVC模式的精髓在于第三点:Model的更新是通过观察者模式告知View的,具体表现形式可以是Pub/Sub或者是触发Events。而网上很多对于MVC的描述都没有强调这一点。通过观察者模式的好处就是:不同的MVC三角关系可能会有共同的Model,一个MVC三角中的Controller操作了Model以后,两个MVC三角的View都会接受到通知,然后更新自己。保持了依赖同一块Model的不同View显示数据的实时性和准确性。我们每天都在用的观察者模式,在几十年前就已经被大神们整合到MVC的架构当中。
这里有一个MVC模式的JavaScript Demo,实现了一个小的TodoList应用程序。经典的Smalltalk-80 MVC不需要任何框架支持就可以实现。目前Web前端框架当中只有一个号称是严格遵循Smalltalk-80 MVC模式的:maria.js。
优点:
缺点:
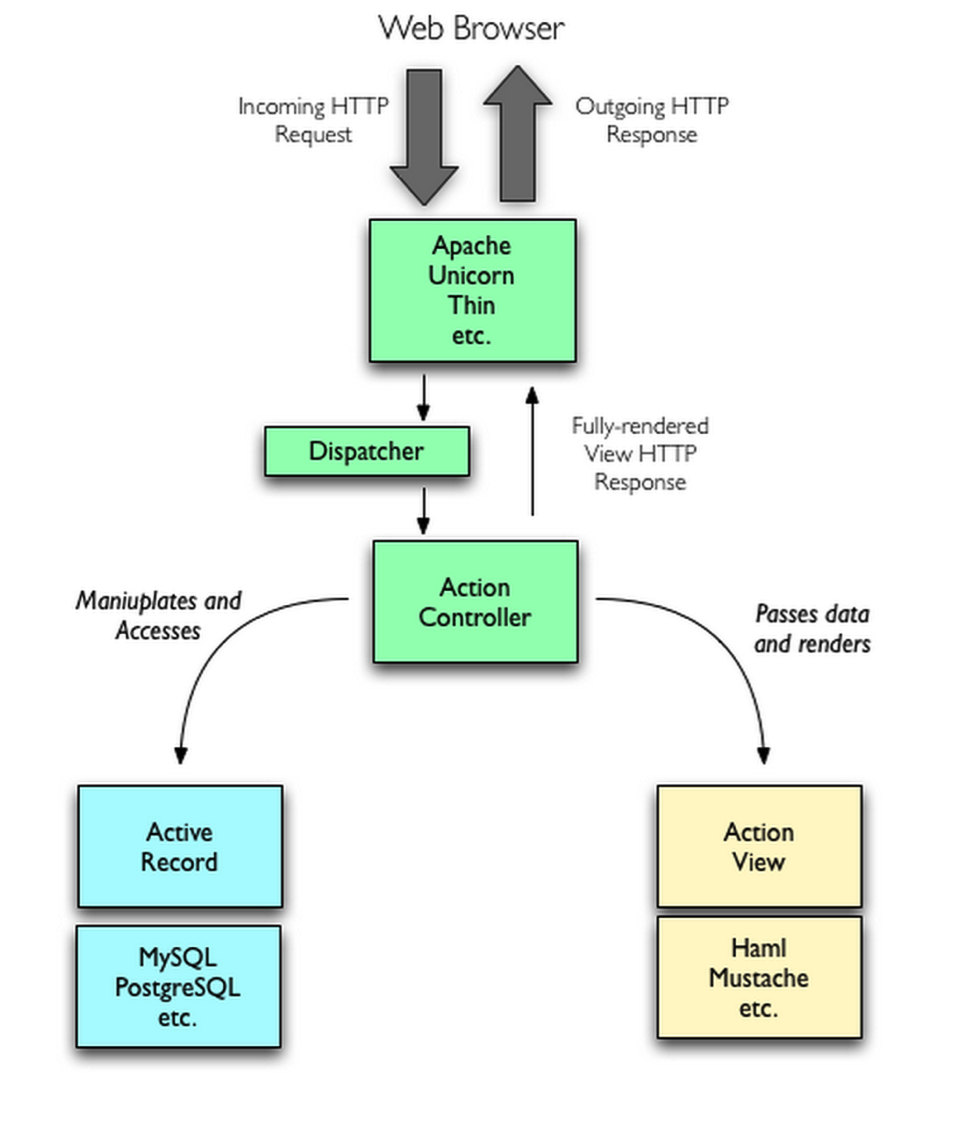
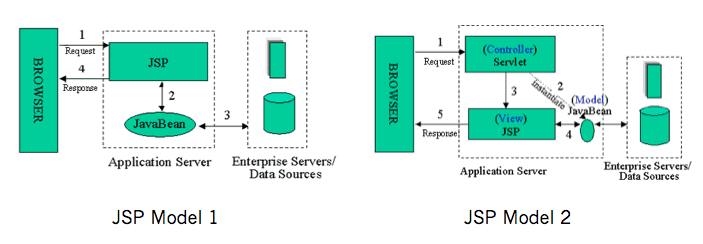
在Web服务端开发的时候也会接触到MVC模式,而这种MVC模式不能严格称为MVC模式。经典的MVC模式只是解决客户端图形界面应用程序的问题,而对服务端无效。服务端的MVC模式又自己特定的名字:MVC Model 2,或者叫JSP Model 2,或者直接就是Model 2 。Model 2客户端服务端的交互模式如下:
服务端接收到来自客户端的请求,服务端通过路由规则把这个请求交由给特定的Controller进行处理,Controller执行相应的应用逻辑,对Model进行操作,Model执行业务逻辑以后;然后用数据去渲染特定的模版,返回给客户端。
因为HTTP协议是单工协议并且是无状态的,服务器无法直接给客户端推送数据。除非客户端再次发起请求,否则服务器端的Model的变更就无法告知客户端。所以可以看到经典的Smalltalk-80 MVC中Model通过观察者模式告知View更新这一环被无情地打破,不能称为严格的MVC。
Model 2模式最早在1998年应用在JSP应用程序当中,JSP Model 1应用管理的混乱诱发了JSP参考了客户端MVC模式,催生了Model 2。
后来这种模式几乎被应用在所有语言的Web开发框架当中。PHP的ThinkPHP,Python的Dijango、Flask,NodeJS的Express,Ruby的RoR,基本都采纳了这种模式。平常所讲的MVC基本是这种服务端的MVC。
MVP模式有两种:
而大多数情况下讨论的都是Passive View模式。本文会对PV模式进行较为详细的介绍,而SC模式则简单提及。
MVP模式是MVC模式的改良。在上个世纪90年代,IBM旗下的子公司Taligent在用C/C++开发一个叫CommonPoint的图形界面应用系统的时候提出来的。
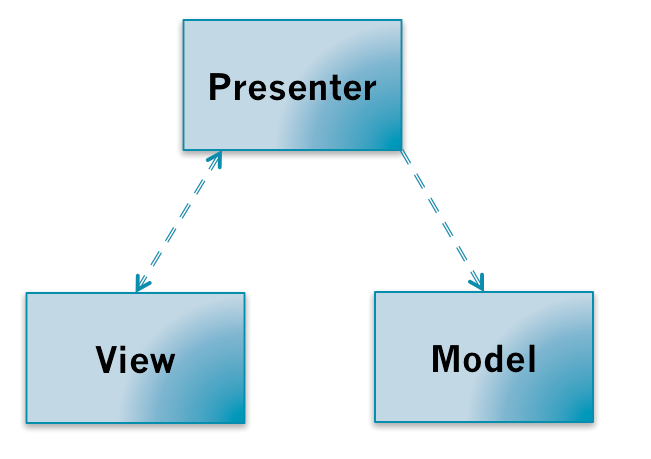
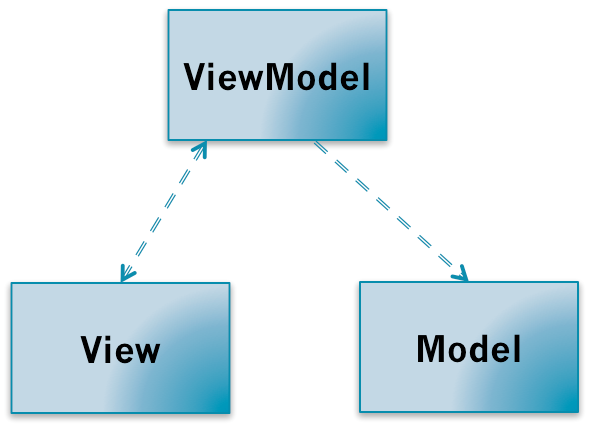
MVP模式把MVC模式中的Controller换成了Presenter。MVP层次之间的依赖关系如下:
MVP打破了View原来对于Model的依赖,其余的依赖关系和MVC模式一致。
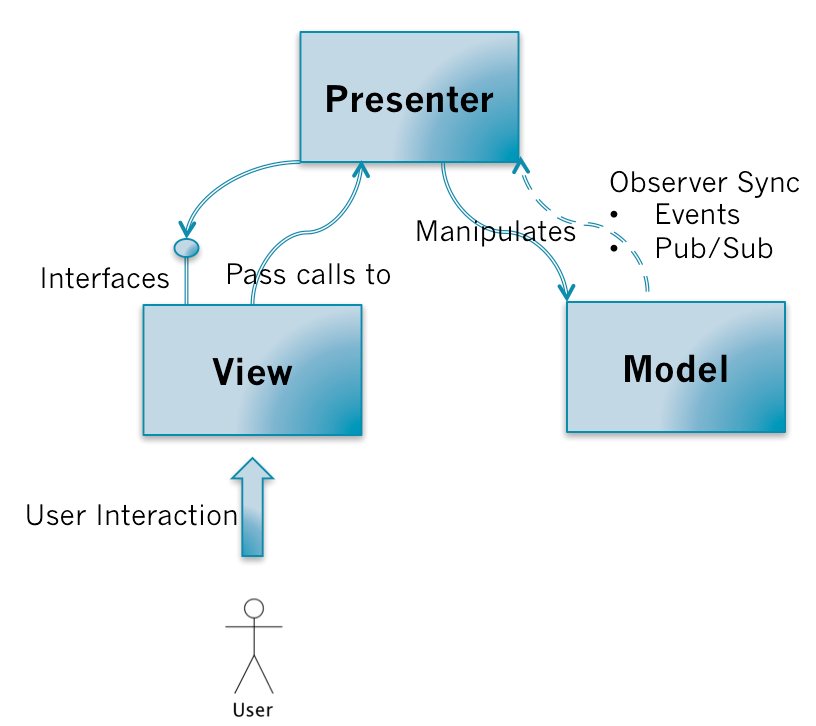
既然View对Model的依赖被打破了,那View如何同步Model的变更?看看MVP的调用关系:
和MVC模式一样,用户对View的操作都会从View交移给Presenter。Presenter会执行相应的应用程序逻辑,并且对Model进行相应的操作;而这时候Model执行完业务逻辑以后,也是通过观察者模式把自己变更的消息传递出去,但是是传给Presenter而不是View。Presenter获取到Model变更的消息以后,通过View提供的接口更新界面。
关键点:
对比在MVC中,Controller是不能操作View的,View也没有提供相应的接口;而在MVP当中,Presenter可以操作View,View需要提供一组对界面操作的接口给Presenter进行调用;Model仍然通过事件广播自己的变更,但由Presenter监听而不是View。
MVP模式,这里也提供一个用JavaScript编写的例子。
优点:
缺点:
上面讲的是MVP的Passive View模式,该模式下View非常Passive,它几乎什么都不知道,Presenter让它干什么它就干什么。而Supervising Controller模式中,Presenter会把一部分简单的同步逻辑交给View自己去做,Presenter只负责比较复杂的、高层次的UI操作,所以可以把它看成一个Supervising Controller。
Supervising Controller模式下的依赖和调用关系:
因为Supervising Controller用得比较少,对它的讨论就到这里为止。
MVVM可以看作是一种特殊的MVP(Passive View)模式,或者说是对MVP模式的一种改良。
MVVM模式最早是微软公司提出,并且了大量使用在.NET的WPF和Sliverlight中。2005年微软工程师John Gossman在自己的博客上首次公布了MVVM模式。
MVVM代表的是Model-View-ViewModel,这里需要解释一下什么是ViewModel。ViewModel的含义就是 "Model of View",视图的模型。它的含义包含了领域模型(Domain Model)和视图的状态(State)。 在图形界面应用程序当中,界面所提供的信息可能不仅仅包含应用程序的领域模型。还可能包含一些领域模型不包含的视图状态,例如电子表格程序上需要显示当前排序的状态是顺序的还是逆序的,而这是Domain Model所不包含的,但也是需要显示的信息。
可以简单把ViewModel理解为页面上所显示内容的数据抽象,和Domain Model不一样,ViewModel更适合用来描述View。
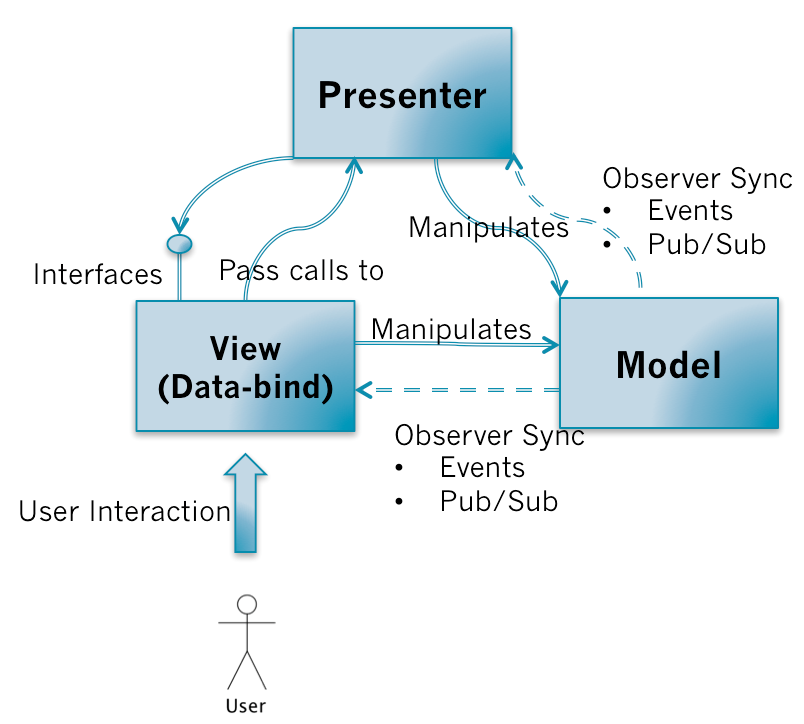
MVVM的依赖关系和MVP依赖,只不过是把P换成了VM。
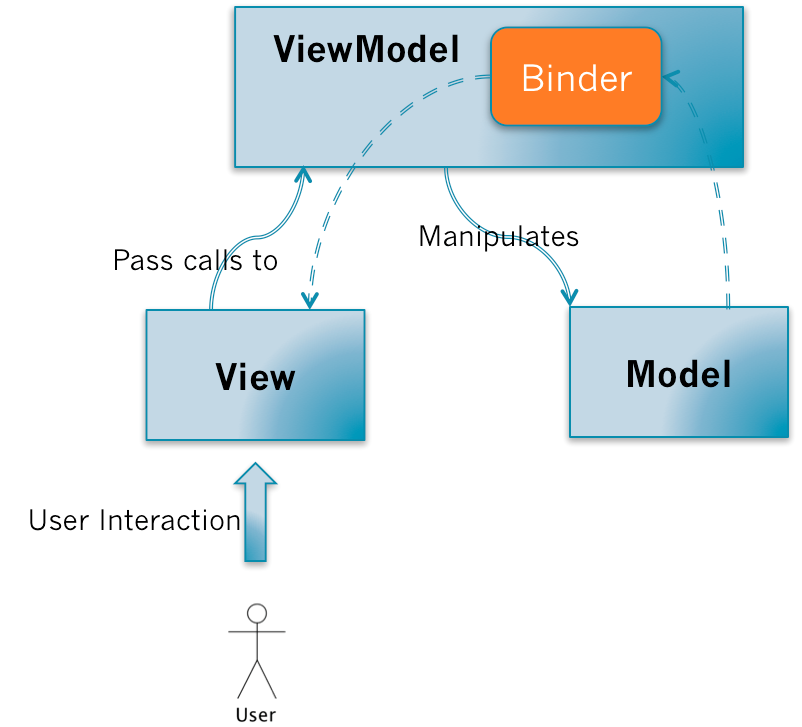
MVVM的调用关系和MVP一样。但是,在ViewModel当中会有一个叫Binder,或者是Data-binding engine的东西。以前全部由Presenter负责的View和Model之间数据同步操作交由给Binder处理。你只需要在View的模版语法当中,指令式地声明View上的显示的内容是和Model的哪一块数据绑定的。当ViewModel对进行Model更新的时候,Binder会自动把数据更新到View上去,当用户对View进行操作(例如表单输入),Binder也会自动把数据更新到Model上去。这种方式称为:Two-way data-binding,双向数据绑定。可以简单而不恰当地理解为一个模版引擎,但是会根据数据变更实时渲染。
也就是说,MVVM把View和Model的同步逻辑自动化了。以前Presenter负责的View和Model同步不再手动地进行操作,而是交由框架所提供的Binder进行负责。只需要告诉Binder,View显示的数据对应的是Model哪一部分即可。
这里有一个JavaScript MVVM的例子,因为MVVM需要Binder引擎。所以例子中使用了一个MVVM的库:Vue.js。
优点:
缺点:
可以看到,从MVC->MVP->MVVM,就像一个打怪升级的过程。后者解决了前者遗留的问题,把前者的缺点优化成了优点。同样的Demo功能,代码从最开始的一堆文件,优化成了最后只需要20几行代码就完成。MV*模式之间的区分还是蛮清晰的,希望可以给对这些模式理解比较模糊的同学带来一些参考和思路。
小广告:欢迎follow关注个人github:https://github.com/livoras
的
麻烦不是主题相关的讨论就不要回复了,这么多人都watch了这个issuse,无意义的评论都要通知到每个人。不要把issuse当论坛帖子灌水。
Originally posted by @RyanLiu0235 in #13 (comment)
作者:戴嘉华
转载请注明出处并保留原文链接( #13 )和作者信息。
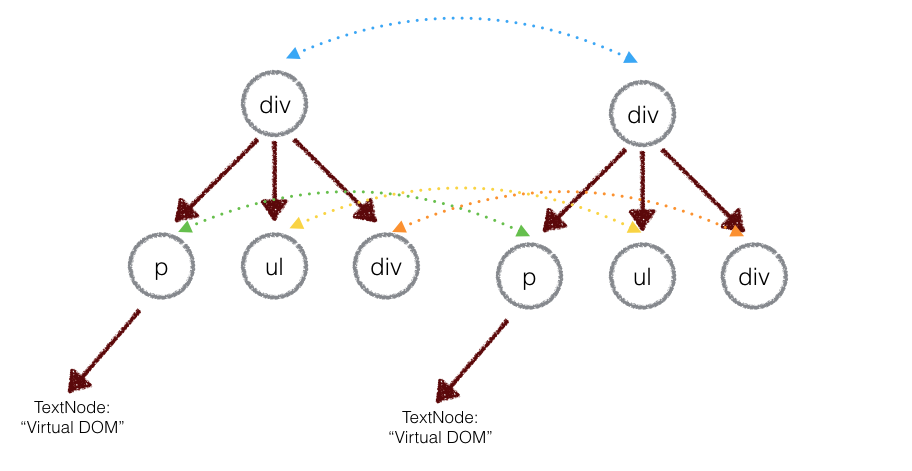
本文会在教你怎么用 300~400 行代码实现一个基本的 Virtual DOM 算法,并且尝试尽量把 Virtual DOM 的算法思路阐述清楚。希望在阅读本文后,能让你深入理解 Virtual DOM 算法,给你现有前端的编程提供一些新的思考。
本文所实现的完整代码存放在 Github。
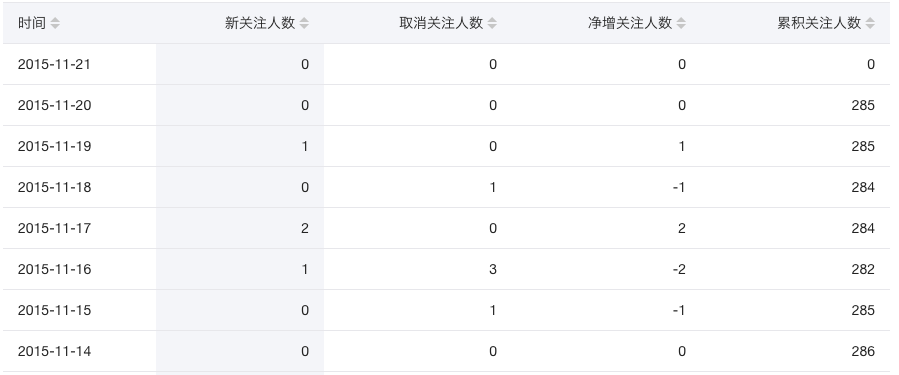
假如现在你需要写一个像下面一样的表格的应用程序,这个表格可以根据不同的字段进行升序或者降序的展示。
这个应用程序看起来很简单,你可以想出好几种不同的方式来写。最容易想到的可能是,在你的 JavaScript 代码里面存储这样的数据:
var sortKey = "new" // 排序的字段,新增(new)、取消(cancel)、净关注(gain)、累积(cumulate)人数
var sortType = 1 // 升序还是逆序
var data = [{...}, {...}, {..}, ..] // 表格数据用三个字段分别存储当前排序的字段、排序方向、还有表格数据;然后给表格头部加点击事件:当用户点击特定的字段的时候,根据上面几个字段存储的内容来对内容进行排序,然后用 JS 或者 jQuery 操作 DOM,更新页面的排序状态(表头的那几个箭头表示当前排序状态,也需要更新)和表格内容。
这样做会导致的后果就是,随着应用程序越来越复杂,需要在JS里面维护的字段也越来越多,需要监听事件和在事件回调用更新页面的DOM操作也越来越多,应用程序会变得非常难维护。后来人们使用了 MVC、MVP 的架构模式,希望能从代码组织方式来降低维护这种复杂应用程序的难度。但是 MVC 架构没办法减少你所维护的状态,也没有降低状态更新你需要对页面的更新操作(前端来说就是DOM操作),你需要操作的DOM还是需要操作,只是换了个地方。
既然状态改变了要操作相应的DOM元素,为什么不做一个东西可以让视图和状态进行绑定,状态变更了视图自动变更,就不用手动更新页面了。这就是后来人们想出了 MVVM 模式,只要在模版中声明视图组件是和什么状态进行绑定的,双向绑定引擎就会在状态更新的时候自动更新视图(关于MV*模式的内容,可以看这篇介绍)。
MVVM 可以很好的降低我们维护状态 -> 视图的复杂程度(大大减少代码中的视图更新逻辑)。但是这不是唯一的办法,还有一个非常直观的方法,可以大大降低视图更新的操作:一旦状态发生了变化,就用模版引擎重新渲染整个视图,然后用新的视图更换掉旧的视图。就像上面的表格,当用户点击的时候,还是在JS里面更新状态,但是页面更新就不用手动操作 DOM 了,直接把整个表格用模版引擎重新渲染一遍,然后设置一下innerHTML就完事了。
听到这样的做法,经验丰富的你一定第一时间意识这样的做法会导致很多的问题。最大的问题就是这样做会很慢,因为即使一个小小的状态变更都要重新构造整棵 DOM,性价比太低;而且这样做的话,input和textarea的会失去原有的焦点。最后的结论会是:对于局部的小视图的更新,没有问题(Backbone就是这么干的);但是对于大型视图,如全局应用状态变更的时候,需要更新页面较多局部视图的时候,这样的做法不可取。
但是这里要明白和记住这种做法,因为后面你会发现,其实 Virtual DOM 就是这么做的,只是加了一些特别的步骤来避免了整棵 DOM 树变更。
另外一点需要注意的就是,上面提供的几种方法,其实都在解决同一个问题:维护状态,更新视图。在一般的应用当中,如果能够很好方案来应对这个问题,那么就几乎降低了大部分复杂性。
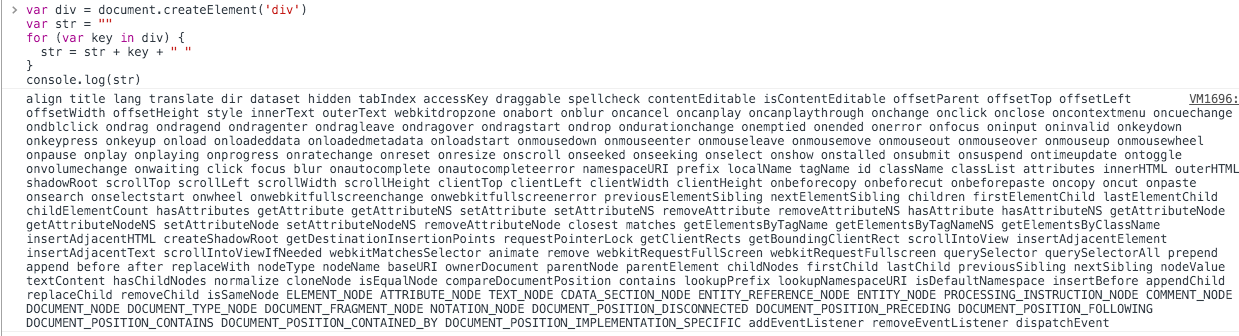
DOM是很慢的。如果我们把一个简单的div元素的属性都打印出来,你会看到:
而这仅仅是第一层。真正的 DOM 元素非常庞大,这是因为标准就是这么设计的。而且操作它们的时候你要小心翼翼,轻微的触碰可能就会导致页面重排,这可是杀死性能的罪魁祸首。
相对于 DOM 对象,原生的 JavaScript 对象处理起来更快,而且更简单。DOM 树上的结构、属性信息我们都可以很容易地用 JavaScript 对象表示出来:
var element = {
tagName: 'ul', // 节点标签名
props: { // DOM的属性,用一个对象存储键值对
id: 'list'
},
children: [ // 该节点的子节点
{tagName: 'li', props: {class: 'item'}, children: ["Item 1"]},
{tagName: 'li', props: {class: 'item'}, children: ["Item 2"]},
{tagName: 'li', props: {class: 'item'}, children: ["Item 3"]},
]
}上面对应的HTML写法是:
<ul id='list'>
<li class='item'>Item 1</li>
<li class='item'>Item 2</li>
<li class='item'>Item 3</li>
</ul>既然原来 DOM 树的信息都可以用 JavaScript 对象来表示,反过来,你就可以根据这个用 JavaScript 对象表示的树结构来构建一棵真正的DOM树。
之前的章节所说的,状态变更->重新渲染整个视图的方式可以稍微修改一下:用 JavaScript 对象表示 DOM 信息和结构,当状态变更的时候,重新渲染这个 JavaScript 的对象结构。当然这样做其实没什么卵用,因为真正的页面其实没有改变。
但是可以用新渲染的对象树去和旧的树进行对比,记录这两棵树差异。记录下来的不同就是我们需要对页面真正的 DOM 操作,然后把它们应用在真正的 DOM 树上,页面就变更了。这样就可以做到:视图的结构确实是整个全新渲染了,但是最后操作DOM的时候确实只变更有不同的地方。
这就是所谓的 Virtual DOM 算法。包括几个步骤:
Virtual DOM 本质上就是在 JS 和 DOM 之间做了一个缓存。可以类比 CPU 和硬盘,既然硬盘这么慢,我们就在它们之间加个缓存:既然 DOM 这么慢,我们就在它们 JS 和 DOM 之间加个缓存。CPU(JS)只操作内存(Virtual DOM),最后的时候再把变更写入硬盘(DOM)。
用 JavaScript 来表示一个 DOM 节点是很简单的事情,你只需要记录它的节点类型、属性,还有子节点:
element.js
function Element (tagName, props, children) {
this.tagName = tagName
this.props = props
this.children = children
}
module.exports = function (tagName, props, children) {
return new Element(tagName, props, children)
}例如上面的 DOM 结构就可以简单的表示:
var el = require('./element')
var ul = el('ul', {id: 'list'}, [
el('li', {class: 'item'}, ['Item 1']),
el('li', {class: 'item'}, ['Item 2']),
el('li', {class: 'item'}, ['Item 3'])
])现在ul只是一个 JavaScript 对象表示的 DOM 结构,页面上并没有这个结构。我们可以根据这个ul构建真正的<ul>:
Element.prototype.render = function () {
var el = document.createElement(this.tagName) // 根据tagName构建
var props = this.props
for (var propName in props) { // 设置节点的DOM属性
var propValue = props[propName]
el.setAttribute(propName, propValue)
}
var children = this.children || []
children.forEach(function (child) {
var childEl = (child instanceof Element)
? child.render() // 如果子节点也是虚拟DOM,递归构建DOM节点
: document.createTextNode(child) // 如果字符串,只构建文本节点
el.appendChild(childEl)
})
return el
}render方法会根据tagName构建一个真正的DOM节点,然后设置这个节点的属性,最后递归地把自己的子节点也构建起来。所以只需要:
var ulRoot = ul.render()
document.body.appendChild(ulRoot)上面的ulRoot是真正的DOM节点,把它塞入文档中,这样body里面就有了真正的<ul>的DOM结构:
<ul id='list'>
<li class='item'>Item 1</li>
<li class='item'>Item 2</li>
<li class='item'>Item 3</li>
</ul>完整代码可见 element.js。
正如你所预料的,比较两棵DOM树的差异是 Virtual DOM 算法最核心的部分,这也是所谓的 Virtual DOM 的 diff 算法。两个树的完全的 diff 算法是一个时间复杂度为 O(n^3) 的问题。但是在前端当中,你很少会跨越层级地移动DOM元素。所以 Virtual DOM 只会对同一个层级的元素进行对比:
上面的div只会和同一层级的div对比,第二层级的只会跟第二层级对比。这样算法复杂度就可以达到 O(n)。
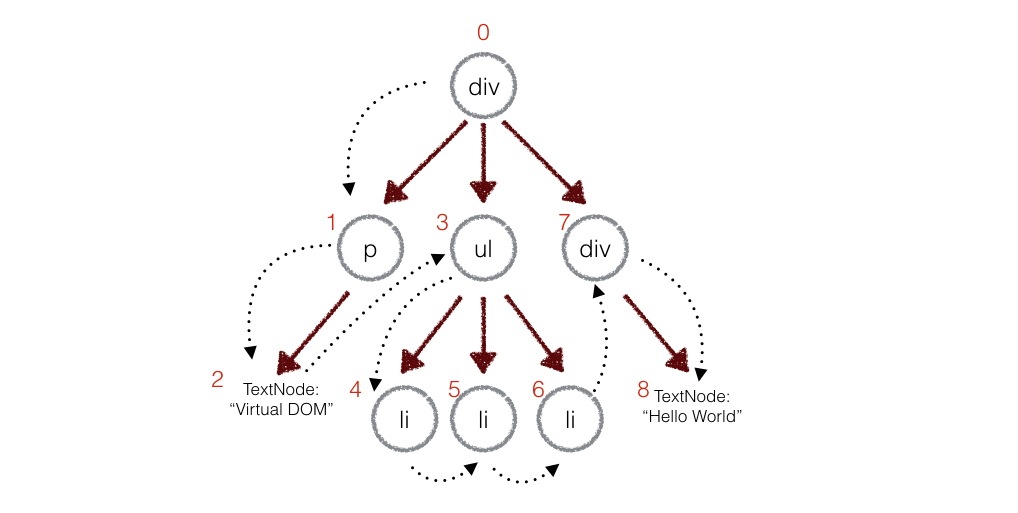
在实际的代码中,会对新旧两棵树进行一个深度优先的遍历,这样每个节点都会有一个唯一的标记:
在深度优先遍历的时候,每遍历到一个节点就把该节点和新的的树进行对比。如果有差异的话就记录到一个对象里面。
// diff 函数,对比两棵树
function diff (oldTree, newTree) {
var index = 0 // 当前节点的标志
var patches = {} // 用来记录每个节点差异的对象
dfsWalk(oldTree, newTree, index, patches)
return patches
}
// 对两棵树进行深度优先遍历
function dfsWalk (oldNode, newNode, index, patches) {
// 对比oldNode和newNode的不同,记录下来
patches[index] = [...]
diffChildren(oldNode.children, newNode.children, index, patches)
}
// 遍历子节点
function diffChildren (oldChildren, newChildren, index, patches) {
var leftNode = null
var currentNodeIndex = index
oldChildren.forEach(function (child, i) {
var newChild = newChildren[i]
currentNodeIndex = (leftNode && leftNode.count) // 计算节点的标识
? currentNodeIndex + leftNode.count + 1
: currentNodeIndex + 1
dfsWalk(child, newChild, currentNodeIndex, patches) // 深度遍历子节点
leftNode = child
})
}例如,上面的div和新的div有差异,当前的标记是0,那么:
patches[0] = [{difference}, {difference}, ...] // 用数组存储新旧节点的不同同理p是patches[1],ul是patches[3],类推。
上面说的节点的差异指的是什么呢?对 DOM 操作可能会:
div换成了sectiondiv的子节点,把p和ul顺序互换Virtual DOM 2。所以我们定义了几种差异类型:
var REPLACE = 0
var REORDER = 1
var PROPS = 2
var TEXT = 3对于节点替换,很简单。判断新旧节点的tagName和是不是一样的,如果不一样的说明需要替换掉。如div换成section,就记录下:
patches[0] = [{
type: REPALCE,
node: newNode // el('section', props, children)
}]如果给div新增了属性id为container,就记录下:
patches[0] = [{
type: REPALCE,
node: newNode // el('section', props, children)
}, {
type: PROPS,
props: {
id: "container"
}
}]如果是文本节点,如上面的文本节点2,就记录下:
patches[2] = [{
type: TEXT,
content: "Virtual DOM2"
}]那如果把我div的子节点重新排序呢?例如p, ul, div的顺序换成了div, p, ul。这个该怎么对比?如果按照同层级进行顺序对比的话,它们都会被替换掉。如p和div的tagName不同,p会被div所替代。最终,三个节点都会被替换,这样DOM开销就非常大。而实际上是不需要替换节点,而只需要经过节点移动就可以达到,我们只需知道怎么进行移动。
这牵涉到两个列表的对比算法,需要另外起一个小节来讨论。
假设现在可以英文字母唯一地标识每一个子节点:
旧的节点顺序:
a b c d e f g h i
现在对节点进行了删除、插入、移动的操作。新增j节点,删除e节点,移动h节点:
新的节点顺序:
a b c h d f g i j
现在知道了新旧的顺序,求最小的插入、删除操作(移动可以看成是删除和插入操作的结合)。这个问题抽象出来其实是字符串的最小编辑距离问题(Edition Distance),最常见的解决算法是 Levenshtein Distance,通过动态规划求解,时间复杂度为 O(M * N)。但是我们并不需要真的达到最小的操作,我们只需要优化一些比较常见的移动情况,牺牲一定DOM操作,让算法时间复杂度达到线性的(O(max(M, N))。具体算法细节比较多,这里不累述,有兴趣可以参考代码。
我们能够获取到某个父节点的子节点的操作,就可以记录下来:
patches[0] = [{
type: REORDER,
moves: [{remove or insert}, {remove or insert}, ...]
}]但是要注意的是,因为tagName是可重复的,不能用这个来进行对比。所以需要给子节点加上唯一标识key,列表对比的时候,使用key进行对比,这样才能复用老的 DOM 树上的节点。
这样,我们就可以通过深度优先遍历两棵树,每层的节点进行对比,记录下每个节点的差异了。完整 diff 算法代码可见 diff.js。
因为步骤一所构建的 JavaScript 对象树和render出来真正的DOM树的信息、结构是一样的。所以我们可以对那棵DOM树也进行深度优先的遍历,遍历的时候从步骤二生成的patches对象中找出当前遍历的节点差异,然后进行 DOM 操作。
function patch (node, patches) {
var walker = {index: 0}
dfsWalk(node, walker, patches)
}
function dfsWalk (node, walker, patches) {
var currentPatches = patches[walker.index] // 从patches拿出当前节点的差异
var len = node.childNodes
? node.childNodes.length
: 0
for (var i = 0; i < len; i++) { // 深度遍历子节点
var child = node.childNodes[i]
walker.index++
dfsWalk(child, walker, patches)
}
if (currentPatches) {
applyPatches(node, currentPatches) // 对当前节点进行DOM操作
}
}applyPatches,根据不同类型的差异对当前节点进行 DOM 操作:
function applyPatches (node, currentPatches) {
currentPatches.forEach(function (currentPatch) {
switch (currentPatch.type) {
case REPLACE:
node.parentNode.replaceChild(currentPatch.node.render(), node)
break
case REORDER:
reorderChildren(node, currentPatch.moves)
break
case PROPS:
setProps(node, currentPatch.props)
break
case TEXT:
node.textContent = currentPatch.content
break
default:
throw new Error('Unknown patch type ' + currentPatch.type)
}
})
}完整代码可见 patch.js。
Virtual DOM 算法主要是实现上面步骤的三个函数:element,diff,patch。然后就可以实际的进行使用:
// 1. 构建虚拟DOM
var tree = el('div', {'id': 'container'}, [
el('h1', {style: 'color: blue'}, ['simple virtal dom']),
el('p', ['Hello, virtual-dom']),
el('ul', [el('li')])
])
// 2. 通过虚拟DOM构建真正的DOM
var root = tree.render()
document.body.appendChild(root)
// 3. 生成新的虚拟DOM
var newTree = el('div', {'id': 'container'}, [
el('h1', {style: 'color: red'}, ['simple virtal dom']),
el('p', ['Hello, virtual-dom']),
el('ul', [el('li'), el('li')])
])
// 4. 比较两棵虚拟DOM树的不同
var patches = diff(tree, newTree)
// 5. 在真正的DOM元素上应用变更
patch(root, patches)当然这是非常粗糙的实践,实际中还需要处理事件监听等;生成虚拟 DOM 的时候也可以加入 JSX 语法。这些事情都做了的话,就可以构造一个简单的ReactJS了。
本文所实现的完整代码存放在 Github,仅供学习。
https://github.com/Matt-Esch/virtual-dom/blob/master/vtree/diff.js
有几点疑惑,希望大家能予以解答:
作者:戴嘉华
转载请注明出处,保留原文链接和作者信息
最近面试季,有不少同学在面试前端的时候遇到一些问题来问我的的时候,才发现之前博客里面介绍的关于前端架构有些东西没有说清楚,特别是关于如何使用事件巧妙地进行模块的解耦。特意写这篇博客详细说一下。
本来想一篇写完,但是写着写着发现废话比较多。决定开个系列分2~3篇来写,本文主要介绍:
这算是(一),接下来的(二)会介绍事件在前端游戏开发中的应用。
(了解的同学可以直接跳过这一节)
在构建前端应用的时候免不了要和事件打交道,有些同学可能觉得事件不就是鼠标点击执行特定的函数之类的吗?
此“事件”非彼“事件”。这里的“事件”,实际上是指“观察者模式(Observer Pattern)”在前端的一种呈现方式。所谓观察者模式可以类比博客“订阅/推送”,你通过RSS订阅了某个博客,那么这个博客有新的博文就会自动推送给你;当你退订阅这个博客,那么就不会再推送给你。
用JavaScript代码可以怎么表示这么一个场景?
var blog = new Blog; // 假设已有一个Blog类实现subscribe、publish、unsubscribe方法
var readerFunc1 = function(blogContent) {
console.log(blogContent + " will be shown here.");
}
var readerFunc2 = function(blogContent) {
console.log(blogContent + " will be shown here, too.");
}
blog.subscribe(readerFunc1); // 读者1订阅博客
blog.subscribe(readerFunc2); // 读者2订阅博客
blog.publish("This is blog content."); // 发布博客内容,上面的两个读者的函数都会被调用
blog.unsubscribe(readerFunc1); // 读者1取消订阅
blog.publish("This is another blog content."); // readerFunc1函数不再调用,readerFunc2继续调用
可以把上面的“新文章”看成是一个事件,“订阅文章”则是“监听”这个事件,“发布新文章”则是“触发”这个事件,“取消订阅文章”就是“取消监听”“新文章”这个事件。假如“监听”用on来表示,“触发”用emit来表示,“取消监听”用off来表示,那么上面的代码可以重新表示为:
var blog = new Blog; // 假设已有一个Blog类实现on、emit、off方法
var readerFunc1 = function(blogContent) {
console.log(blogContent + " will be shown here.");
}
var readerFunc2 = function(blogContent) {
console.log(blogContent + " will be shown here, too.");
}
blog.on("new post", readerFunc1); // 读者1监听事件
blog.on("new post", readerFunc2); // 读者2监听事件
blog.emit("new post", "This is blog content."); // 发布博客内容,触发事件,上面的两个读者的函数都会被调用
blog.off("new post", readerFunc1); // 读者1取消监听事件
blog.emit("new post", "This is another blog content."); // readerFunc1函数不再调用,readerFunc2继续调用
这就是前端中观察者模式的一种具体的表现,使用on来监听特定的事件,emit触发特定的事件,off取消监听特定的事件。再举一个场景“小猫听到小狗叫就会跑”:
var dog = new Dog;
var cat = new Cat;
dog.on("park", function() {
cat.run();
});
dog.emit("park");
巧妙利用观察者模式可以让前端应用开发耦合性变得更加低,开发效率更高。可能说“变得更有趣”会显得有点不专业,但确实会变得有趣。
上面可能比较疑惑的一个点就是,on、emit、off函数该怎么实现?
如果要自己实现一遍也不很复杂:每个“事件名”对应的就是一个函数数组,每次on某个事件的时候就是把函数压到对应的函数数组当中;每次emit的时候相当于把事件名对应的函数数组遍历一遍进行调用;每次off的时候把目标函数从数组当中剔除。这里有个简单的实现,有兴趣的可以了解一下。
重复发明轮子的事情就不要做了,其实现成有很多JavaScript的事件库,直接拿来用就好了。比较流行、常用的就是EventEmitter2这个事件库,本文主要使用这个库来展开对观察者模式在前端应用中的讨论。但实际上,你可以使用任何自己构建的或者第三方的事件库来实践本文所提及的应用方式。
EventEmitter本来是Node.js中自带的events模块中的一个类,可见Node.js文档。可供开发者自定义事件,后来有人把它重新实现了一遍,优化了实现方式,提高了性能,新增了一些方便的API,这就是EventEmitter2。当然,后来陆续出现了EventEmitter3,EventEmitter4。可见没有女朋友的程序员也是比较无聊地只好重复发明和优化轮子。
EventEmitter2可以供浏览器、或者Node.js使用。安装过程和API就不在这里累述,参照官方文档即可。使用Browserify或者Node.js可以非常方便地引用EvenEmitter2,只需要require即可。示例:
var EventEmitter2 = require('eventemitter2').EventEmitter2;
var emitter = new EventEmitter2;
emitter.on("Hello World", function() {
console.log("Somebody said: Hello world.");
});
emitter.emit("Hello World"); // 输出 Somebody said: Hello world.
但在实际应用当中,很少单纯EventEmitter直接实例化来使用。比较多的应用场景是,为某些已有的类添加事件的功能。如上面的第一章中的“小猫听到小狗叫就会跑”的例子,Cat和Dog类本身就有自己的类属性、方法,需要的是为已有的Cat、Dog添加事件功能。这里就需要让EventEmitter作为其他类的父类进行继承。
var EventEmitter2 = require('eventemitter2').EventEmitter2;
// Cat子类继承父类构造字
function Cat() {
EventEmitter2.apply(this);
// Cat 构造子,属性初始化等
}
// 原型继承
Cat.prototype = Object.create(EventEmitter2.prototype);
Cat.prototype.constructor = Cat;
// Cat类方法
Cat.prototype.run = function () {
console.log("This cat is running...");
}
var cat = new Cat;
console.assert(typeof cat.on == "function"); // => true
console.assert(typeof cat.run == "function"); // => true
很棒是吧,这样就可以即有EventEmitter2的原型方法,也可以定义Cat自身的方法。
这一点都不棒!每次定义一个类都要重新写一堆啰嗦的东西,下面做个继承的改进:构建一个函数,只需要传入已经定义好的类就可以在不影响类原有功能的情况下,让其拥有EventEmitter2的功能:
// Function `eventify`: Making a class get power of EventEmitter2!
// @copyright: Livoras
// @date: 2015/3/27
// All rights reserve!
function eventify(klass) {
if (klass.prototype instanceof EventEmitter2) {
console.warn("Class has been eventified!");
return klass;
}
function Tempt() {
klass.apply(this, arguments);
EventEmitter2.call(this);
};
function Tempt2() {};
Tempt2.prototype = Object.create(EventEmitter2.prototype)
Tempt2.prototype.constructor = EventEmitter2;
var temptProp = Object.create(Tempt2.prototype);
var klassProp = klass.prototype;
for (var attr in klassProp) {
temptProp[attr] = klassProp[attr];
}
Tempt.prototype = temptProp;
Tempt.prototype.constructor = klass;
return Tempt;
}
上面的代码可以的实现原理在这里并不重要的,有兴趣的可以接下来的博客,会继续讨论eventify的实现原理。在这里只需要知道,有了eventify就可以很方便的给类添加EventEmitter2的功能,使用方法如下:
// Dog类的构造函数和原型方法定义
function Dog(name) {
this.name = name;
}
Dog.prototype.park = function() {
console.log(this.name + " parking....");
}
// 使Dog具有EventEmitter2功能
Dog = eventify(Dog);
var dog = new Dog("Jerry");
dog.on("somebody is coming", function() {
dog.park();
})
dog.emit("somebody is coming") // 输出 Jerry is parking....
如上面的代码,现在没有必要为Dog类重新书写类继承代码,只需要按正常的方式定义好Dog类,然后传入eventify函数即可使Dog获取EventEmitter2的功能。本文接下来的讨论会持续使用eventify函数。
注意:如果你正在使用CoffeeScript,直接使用CoffeeScript自带的extends进行类继承即可,无需上面复杂的代码:
class Dog extends EventEmitter2
constructor: ->
super.apply @, arguments
park: ->
// ...
当一个前端应用足够复杂的时候,往往需要对应用进行“组件化”。所谓组件化,就是把一个大的应用拆分成多个小的应用。每个“应用”具有自己独特的结构和内容、样式和业务逻辑,这些小的应用称为“组件”(Component)。组件的复用性一般很强,是DRY原则的应用典范,多个组件的嵌套、组合,构建成了一个完成而复杂的应用。
举我在《一种SPA(单页面应用)架构》举过的例子,博客的评论功能组件:
这个评论组件的功能大概如此:可显示多条评论(comment);每条评论多条有自己的回复(reply);评论或者回复都会显示有用户头像,鼠标放到用户头像上会显示该用户的信息(类似微博的功能)。
这里可以把这个功能分好几个组件:
组件这样的关系可以用树的结构来表示:
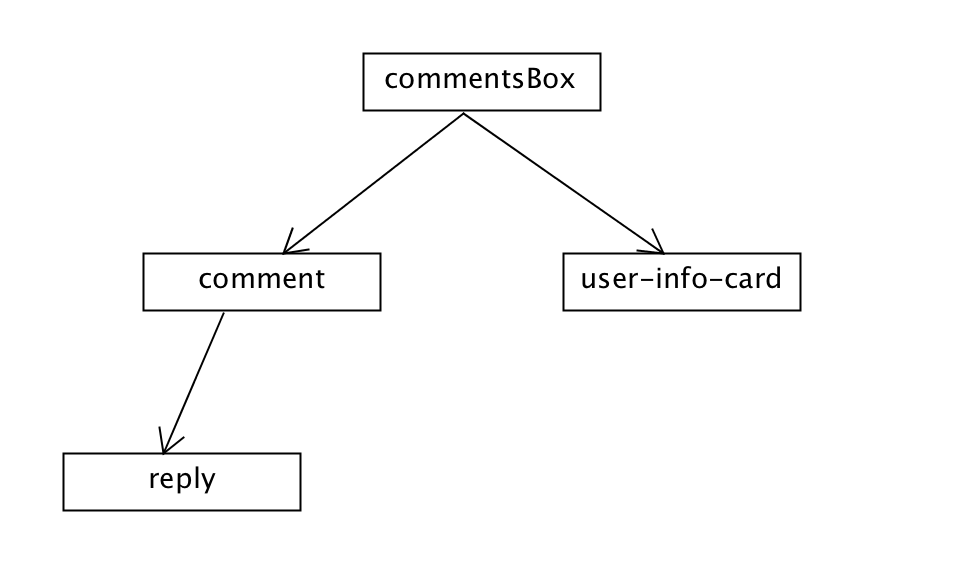
这里要注意的是组件之间的关系一般有两种:嵌套和组合。嵌套,如,每个commentBox有comment和user-info-card,comment和user-info-card是嵌套在commentBox当中的,所以这两个组件和commentBox之间都是嵌套的关系;组合,comment和user-info-card都是作为commentBox的子组件存在,他们两个互为兄弟,是组合的关系。处理组件之间的嵌套和组合关系是架构层面需要解决的最重要的问题之一,不在本文讨论范围内,故不累述。但接下来我们讨论的“组件之间以事件的形式进行消息传递”和这些组件之间的关系密切相关。
当开始按照上面的设计进行组件化的时候,我们首先要做的是为每个组件构建一个超类,所有的组件都应该继承这个超类:
component.js:
eventify = require("./eventify.js");
// Component构造函数
function Component(parent) {
this.$el = $("...")
this.parent = parent;
}
// Component原型方法
Component.prototype.init = function () {/* ... */};
module.exports = eventify(Component);
这里为了方便起见,Component基本什么内容都没有,几乎只是一个“空”的类,而它通过eventify函数获得了“超能力”,所以继承Component的类同样具有事件的功能。
注意Component构造函数,每个Component在示例化的时候应该传入一个它所属的父组件的实例parent,接下来会看到,组件之间的消息通信可以通过这个实例来完成。而$el可以看作是该组件所负责的HTML元素。
现在把注意力放在commentsBox、comment、user-info-card三个组件上,暂且忽略reply。
目前要实现的功能是:鼠标放到comment组件的用户头像上,就会显示用户信息。要把这个功能完成大概是这么一个事件流程:comment组件监听用户鼠标放在头像上的交互事件,然后通过this.parent向父组件(commentsBox)传递该事件(this.parent就是commentsBox),commentsBox获取到该事件以后触发一个事件给user-info-card,user-info-card可以通过this.parent监听到该事件,显示用户信息。
// comment-component.js
// 从Component类中继承获得Comment类
// ...
// 原型方法
Comment.prototype.init = function () {
var that = this;
this.$el.find("div.avatar").on("mouseover", function () {
// 这里的that.parent相当于父组件CommentsBox,在Comment组件被示例化的时候传入
that.parent.emit("comment:user-mouse-on-avatar", this.userId);
})
}
上述代码为当用户把鼠标放到用户头像的时候触发一个事件comment:user-mouse-on-avatar,这里需要注意的是,通过组件名:事件名给这样的事件命名方式可以区分事件的来源组件或目标组件,是一种比较好的编程习惯。
// comments-box-component.js
// 从Component类中继承获得CommentsBox类
// ...
// 原型方法
CommentsBox.prototype.init = function() {
var that = this;
this.on("comment:user-mouse-on-avatar", function (userId) { // 这里接受到来自Comment组件的事件
that.emit("user-info-card:show-user-info", userId); // 把这个事件传递给user-info-card组件
});
}
上述代码中commentsBox获取到来自comment组件的comment:user-mouse-on-avatar事件,由于user-info-card组件也同时拥有commentsBox的实例,所以commentsBox可以通过触发自身的事件user-info-card:show-user-info来给user-info-card组件传递事件。再一次注意这里到事件名,user-info-card:前缀说明这个事件是由user-info-card组件所接收的。
// user-info-card-component.js
// 从Component类中继承获得UserInfoCard类
// ...
// 原型方法
UserInfoCard.prototype.init = function () {
var that = this;
this.parent.on("user-info-card:show-user-info", function (userId) {
$.ajax({ // 通过ajax获取用户数据
url: "/users/" + userId,
method: "GET"
}).success(function(data) {
that.render(data); // 渲染用户信息
that.show(); // 显示信息
})
});
}
上述代码中,user-info-card组件通过this.parent获取到来自其父组件(也就是commentsBox)的事件user-info-card:show-user-info,并且得到所传入的用户id;然后通过ajax向服务器发送用户id,请求用户数据渲染页面数据然后显示。
这样,消息就通过事件机制从comment到达了它的父组件commentsBox,然后通过commentsBox到达它的兄弟组件user-info-card。完成了一个父子组件之间、兄弟之间的消息传递过程:
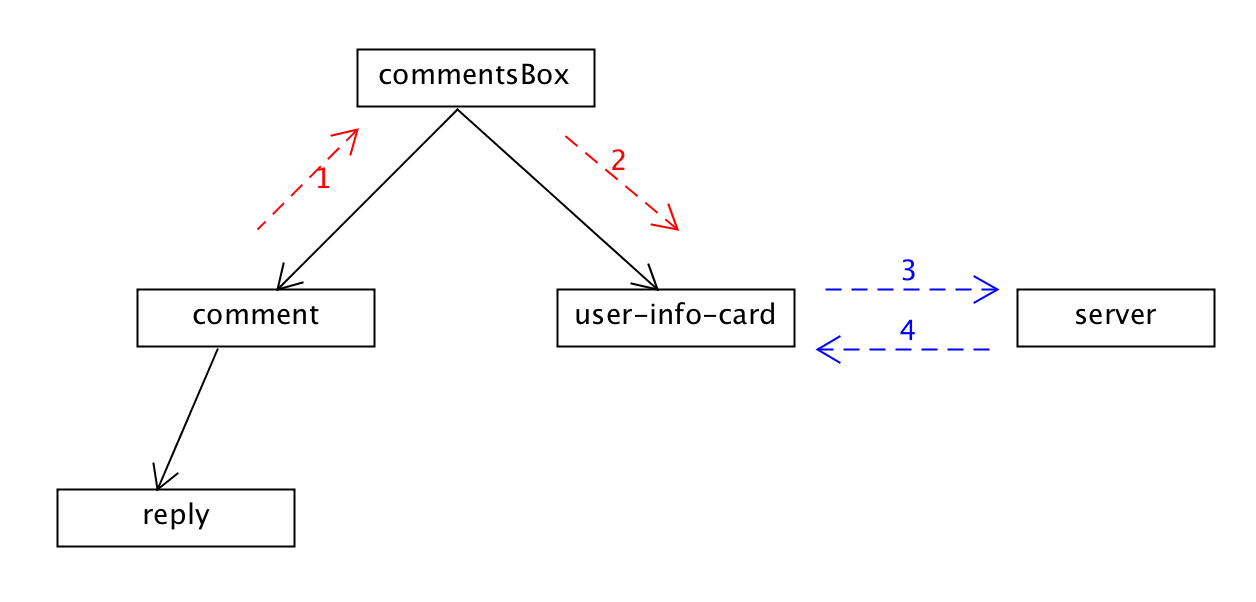
按照这种消息传递方式的事件有四种类型:
每个组件只要hold住一个其父组件实例,就可以完成:
两个功能。
现在可以把注意力放到reply组件上,reply作为comment的子组件,负责显示这条评论下的回复。类似地,它有回复者的用户头像,鼠标放上去以后也可以显示用户的信息。
user-info-card是commentsBox的子组件,reply是comment的子组件;user-info-card和reply既不是父子也不是兄弟节点关系,reply无法按照上面的方式比较直接地把事件传递给它;reply的鼠标放到头像上的事件需要先传递给其父组件comment,然后经过comment传递给commentsBox,最后通过commentsBox传递给user-info-card组件。如下:
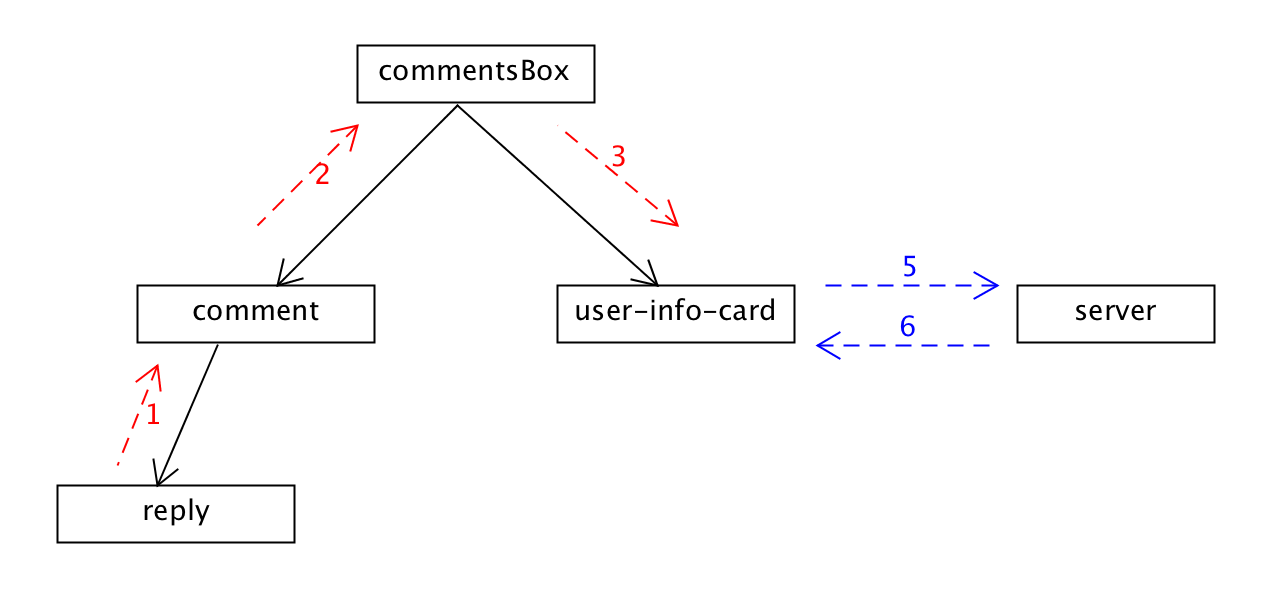
看起来好像比较麻烦,reply离它根组件commentsBox高度为二,嵌套了两层。假设reply嵌套了很多层,那么事件的传递就类似浏览器的事件冒泡一样,需要先冒泡到根节点commentsBox,再由跟节点把事件发送给user-info-card。
如果要真的这样写会带来相当大的维护成本,当组件之间的交互方式更改了甚至只是单单修改了事件名,中间层的负责事件转发的都需要把代码重新修改。而且,这些负责转发的组件需要维护和自己业务逻辑并不相关的逻辑,违反单一职责原则。
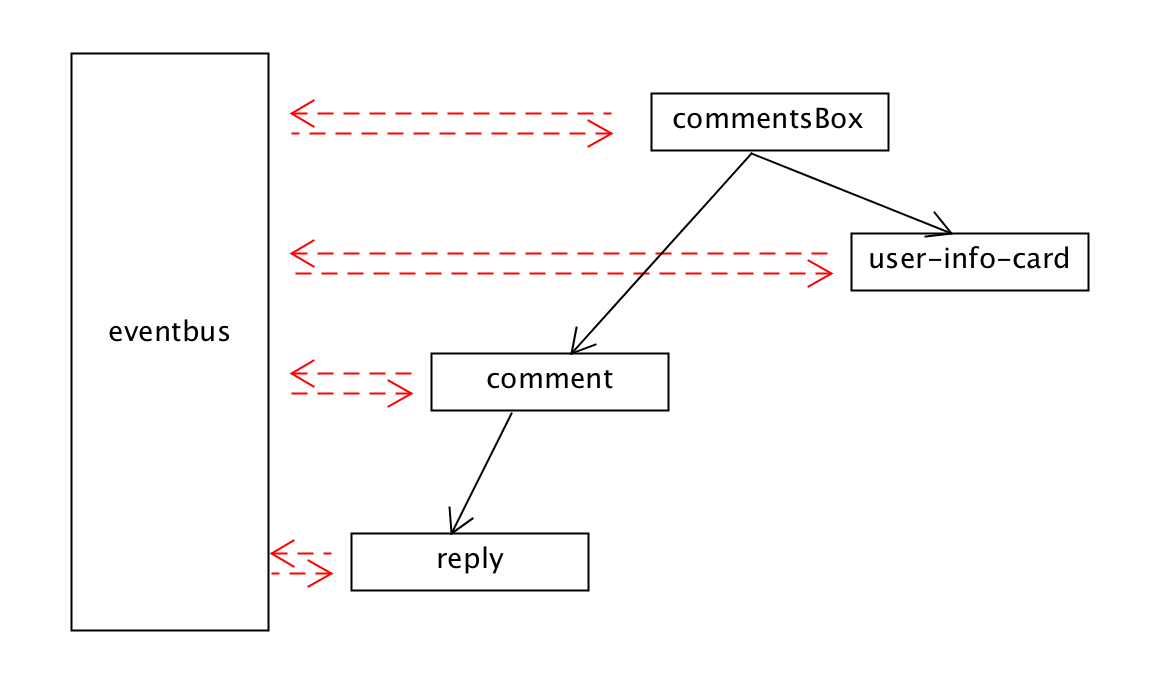
解决这个问题的方式就是:**提供一个组件之间共享的事件对象eventbus,可以负责跨组件之间的事件传递。**所有的组件都可以从这个这个总线上触发事件,也可以从这个总线上监听事件。
commom/eventbus.js
var EventEmitter2 = require('eventemitter2').EventEmitter2;
module.exports = new EventEmitter2; // eventbus是一个简单的EventEmitter2对象
那么reply组件和user-info-card就可以通过eventbus进行之间的信息交换,在reply组件中:
// reply.js
// 从Component类中继承获得Reply类
// ...
eventbus = require("../common/eventbus.js");
// 原型方法
Reply.prototype.init = function () {
var that = this;
this.$el.find("div.avatar").on("mouseover", function () {
// 触发eventbus上的事件user-info-card:show-user-info
eventbus.emit("user-info-card:show-user-info", that.userId);
})
}
在user-info-card组件当中:
// user-info-card-component.js
// 从Component类中继承获得UserInfoCard类
// ...
eventbus = require("../common/eventbus.js");
// 原型方法
UserInfoCard.prototype.init = function () {
var that = this;
// 原来的逻辑不变
this.parent.on("user-info-card:show-user-info", getUserInfoAndShow);
// 新增获取eventbus的事件
eventbus.on("user-info-card:show-user-info", getUserInfoAndShow);
function getUserInfoAndShow (userId) {
$.ajax({ // 通过ajax获取用户数据
url: "/users/" + userId,
method: "GET"
}).success(function(data) {
that.render(data); // 渲染用户信息
that.show(); // 显示信息
});
};
};
这样user-info-card和就跨越了组件嵌套组合的关系,直接进行组件之间的信息事件的交互。
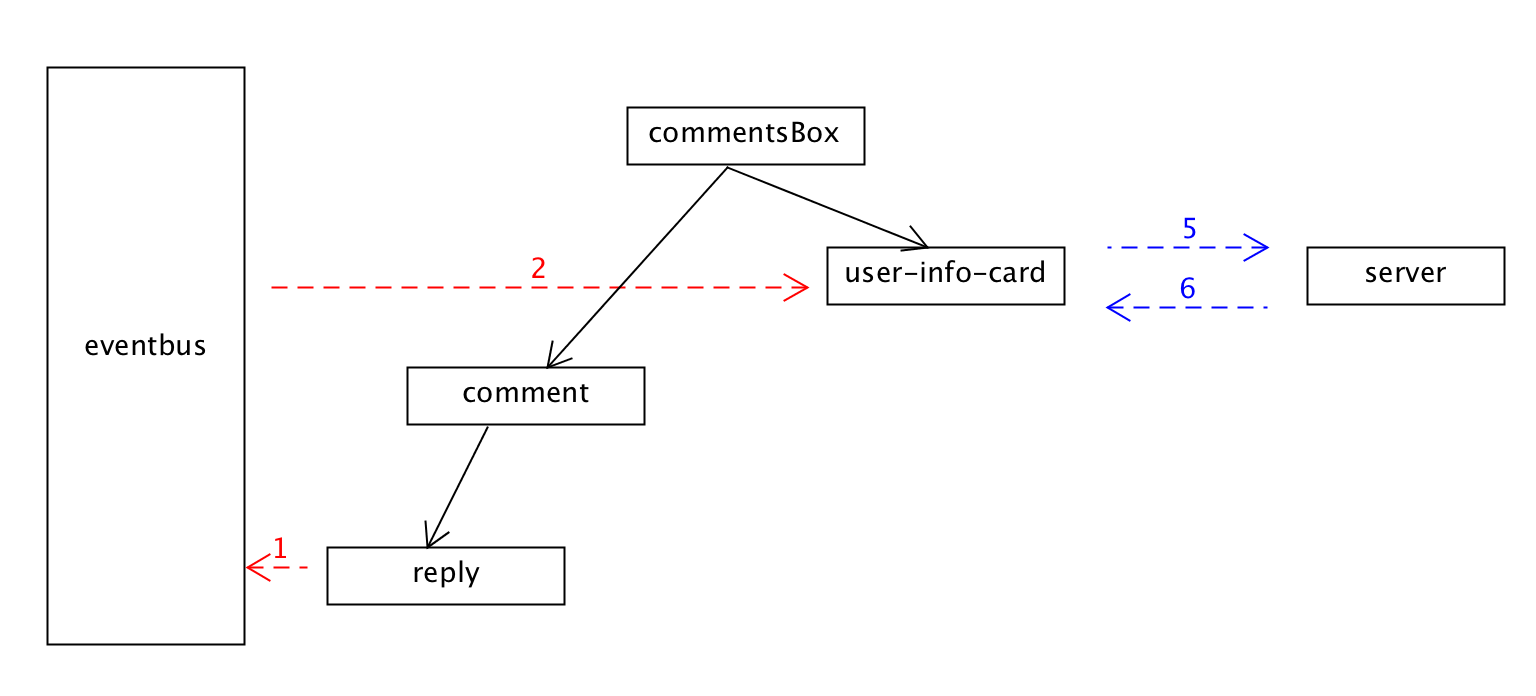
那么问题就来了:
如果所有的组件都往eventbus上post事件,那么就会带来eventbus上事件的维护的困难;我们可以类比一下JavaScript里面的全局变量,假如所有函数都不自己维护局部变量,而都使用全局变量会带来什么问题?想想都觉得可怕。既然这个事件交互只是在局部组件之间交互的,那么就尽量不要把它post到eventbus,eventbus上的事件应该尽量少,越少越好。
那什么时候使用eventbus上的事件?这里给出一个原则:当组件嵌套了三层以上的时候,带来局部事件转发维护困难的时候,就可以考虑祭出eventbus。而在实际当中很少会出现三层事件传播这种情况,也可保持eventbus事件的简洁。(按照这个原则上面的reply是不需要使用eventbus的,但是为了阐述eventbus而使用,这点要注意。)
(系列待续)
这是一个系列的文章,通过分析 nestscript,一个基于虚拟机的 JavaScript 小程序动态执行的方案。讲述如何使用编译原理技术使得小程序可以动态执行代码,让大家理解程序编译的过程,涉及到代码语法、代码生成、虚拟机的实现原理等。可以让你对代码的运行机制,计算机的原理有更深入的了解。
众所周知,原生小程序里面 JavaScript 是没办法动态加载的,微信甚至禁止了 eval 和 new Function 的能力。
但是这并不能阻止人们想出各种千奇百怪的方案来在小程序上做到动态加载,例如很多方案都是通过动态加载 JavaScript 文本字符串,然后通过 parser 分析成 AST,然后做一个 AST 解析运行器。
这么做会比较慢,需要在前端做 AST 的解析,而且基于 AST 的运行可以优化空间比较小。其实可以仿照成熟的编程语言的实现方式:把 AST 编译成二进制字节码,然后在前端做一个虚拟机,网络下载直接运行字节码。可以在运行时减少程序的编译成 AST 的过程。
本文已经做出一个实现 https://github.com/livoras/nestscript , 并且已经成功编译了一些经典的第三方库,例如 moment.js、lodash.js、mqtt.js,并且应用在了百万级日活的产品上。
nestscript 的实现涉及了较多的编译原理相关的知识(主要是编译后端,例如虚拟机相关),Web 开发的同学可能对这一块比较陌生。所以这系列文章除了介绍 nestscript 以外,也是由浅入深地介绍编译原理的相关知识,让大家对程序的编译过程、运行机制有更深入的认识。
因为本人水平有限,在实现的过程中也没有用到了特别专业的优化手法,有些细节可能比较粗糙。请读者见谅。如果有什么好的建议,也希望能评论指出、发 issue 和 PR 都可以。
为了展示它的效果,我们编译了一个开源的的伪 3D 游戏 javascript-racer。可以通过这个网址查看:https://livoras.github.io/nestscript-demo/index.html
打开控制台可以看到,页面只有一个 nestscript 的虚拟机文件。然后通过网络请求下载了一个二进制文件 game,接着通过虚拟机解析、运行。
game 是个二进制文件:
这个 game 二进制文件,其实是包含了游戏的所有逻辑。是 nestscript 把原有 javascript-racer 的几个 JavaScript 文件编译而成。类似我们把 C 语言编译成的可执行的二进制文件一样,只不过它的执行不是在机器的 CPU 上执行,而是我们编写的一个虚拟机上执行。
可以对比一下,原有的游戏页面和编译后的游戏页面,效果一样:
如何把 JavaScript 语言变成可执行的二进制文件?
二进制文件就像是一个数组,它是一系列的 01010... 罢了。它是一种扁平的连续的结构,而我们 JavaScript 代码却是有很多嵌套结构的,例如函数、if else、循环等,怎么可能用一个扁平的结构来描述这么复杂多变的嵌套结构?
其实如果不知道一些计算机的原理的知识的话,确实很难理解。但实际上,任何的程序逻辑,到了 CPU 层面执行的时候,都是这么一系列可以用扁平的数组描述的指令,毕竟我们的内存也是这么一条扁平而连续的结构。CPU 只会连续地从扁平的内存一条条指令进行读取、解析、执行。所谓的虚拟机,不过就是模拟一个 CPU 执行连续指令的过程。这里不做过多的解释,具体的原理会在后续的文章中提及。
为了让 JavaScript 更方便地变成连续的指令,我们需要设计一套没有嵌套结构、连续的中间语言,类似于汇编。我们这里也设计了一套,把它叫做 nestscript IR,例如一个计算斐波那契的程序:
function fibonacci(n) {
if (n < 1) { return 0 }
if (n <= 2) { return 1 }
return fibonacci(n - 1) + fibonacci(n - 2);
}
fibonacci(10)用 nestscript IR 来描述:
func @@main() {
CLS @fibonacci;
REG %r0;
FUNC $RET @@f0;
FUNC @fibonacci @@f0;
MOV %r0 10;
PUSH %r0;
CALL_REG @fibonacci 1 false;
}
func @@f0(.n) {
REG %r0;
REG %r1;
REG %r2;
REG %r3;
MOV %r0 .n;
MOV %r1 1;
LT %r0 %r1;
JF %r0 _l1_;
MOV %r1 0;
MOV $RET %r1;
RET;
JMP _l0_;
LABEL _l1_:
LABEL _l0_:
MOV %r0 .n;
MOV %r1 2;
LE %r0 %r1;
JF %r0 _l3_;
MOV %r1 1;
MOV $RET %r1;
RET;
JMP _l2_;
LABEL _l3_:
LABEL _l2_:
MOV %r2 .n;
MOV %r3 1;
SUB %r2 %r3;
PUSH %r2;
CALL_REG @fibonacci 1 false;
MOV %r0 $RET;
MOV %r2 .n;
MOV %r3 2;
SUB %r2 %r3;
PUSH %r2;
CALL_REG @fibonacci 1 false;
MOV %r1 $RET;
ADD %r0 %r1;
MOV $RET %r0;
RET;
}
里面的内容可以先不看。总直观上看出来,用 IR 表示的程序逻辑,除了函数以外,都是扁平化的。我们可以用扁平化的结构来描述任意复杂嵌套的程序逻辑。我们可以把 JavaScript 变成 AST,然后把 AST 编译成这种连续扁平的中间语言,这个过程我们把它叫代码生成(code generation)。
为什么要把 AST 变成中间代码(IR)?因为这种序列化的结构可以让我们更好地生成序列化的二进制文件。并且这种代码比较简单,结构不复杂,可以针对这种 IR 代码做代码的代码优化,让生成的二进制运行起来更高效。
有了代码的 IR 表示形式,就可以把经过优化的 IR 代码生成二进制,我们会把这种二进制叫做字节码。这个过程需要设计一套指令映射成二进制的方案,例如 MOV %r2 1,可以用三个字节来表示。第一个字节表示操作符,后面两个字节表示操作数。这里面的设计也非常讲究,操作数的数量会发生改变,操作数的内容长度也会发生改变。怎么让生成的代码体积更小,更紧凑,但又不影响使用是一个比较大的话题。这里面还涉及字符串,需要用特殊的段来存储字符串。这里不详细展开,会在以后的文章中提及。
有了字节码,就可以用 JavaScript 写一个虚拟机,解析运行字节码。所谓虚拟机就是一个虚拟的 CPU,就是用代码模拟一个 CPU 解析执行二进制代码的过程。像 JavaScript 的 V8 引擎、Java、Python、Lua 都是使用了虚拟机来运行字节码。它大致的框架很简单,不过就是一个疯狂的 CPU,疯狂地循环地从字节码中取指令,识别是什么指令,然后执行不同的操作:
const byteCode: ArrayBuffer = ...
while (true) {
const operator = nextOperator()
switch (operator) {
case MOV:
...
case ADD:
...
case SUB:
...
}
}只要你的环境中包含了这个用 JavaScript 编写的虚拟机代码,就可以通过网络下载编译好的字节码,然后让它来执行。nestscript 的虚拟机完整实现在:https://github.com/livoras/nestscript/blob/master/src/vm/vm.ts
本文只是粗略描述了 nestscript 的实现,介绍的同时给大家一个原理上的全貌,后续会慢慢展开,对各种细节进行描述。希望看完以后你也可以实现一门编程语言。
(待续未完....)
Hypers 在招优秀的前端工程师,如果你有意向,欢迎你加入。
翻译自:Unix Philosophy and Node.js,未经允许,转载打屁屁(我说真的)。
[译注]
大一的时候玩过Linux,当时懵懵懂懂(现在也是),好多东西不知道是干diao用的,糊里糊涂地学了一堆命令;最后除了帮隔壁宿舍的后现代主义抠脚大师装系统的时候装X用一下以外基本没有发挥太大的用途。
后来断断续续使用Linux,也没有很深地钻研进去。最近捡回来看了一下,惊异地发现,原来一直以来那些编码中所用到的概念其实很多都源于Unix当中古老的设计。JS中的事件、Node.js中的Stream、多线程(进程)、管道、socket等等,都一一可以在这些古老的设计中找到源头。虽然没有非常深入了解到其中深奥的机制,但是带给我的感觉整个世界就像《三体》里面的三维生物在二维平面展开,很多细节都清晰明了。
在软件这个迭代更新迅速的领域,Unix不得不说是一个奇葩中的奇葩,自从设计完成以后以来基本上没有做过太多的修改,但是却持续地发光发热了几十年,支撑它的不仅仅是它精妙的设计,还有前辈们因为Unix而奠定的Unix哲学,影响了不仅仅是一个操作系统,而是几代Hackers的对程序的理解,对架构的设计。你几乎可以在那些最优秀的Hackers写的每一行代码中看到Unix哲学的身影。
本文的作者isz是npm(Node.js包管理器)的主要代码贡献者,在他的文章中,可以窥见Unix哲学对Node.js设计,文化所产生的影响。

以下是正文:
在TxJS的另外一天,我做了一个演讲,提到了Unix哲学是Node.js的模式、主张、和文化很重要的一部分。像往常一样,在视频流出之前,我提前把展示用到的幻灯片放网上。
出于某些原因,简短地提及“Unix哲学”引起了一些人的忿怒。当时我只有25分钟,但是我讲的每一页幻灯片都可以单出拿出来做一个演讲,所以我只好尽量地把精华抽出来讲。视频不能很好地还原当时的场景。但是我的目的是能够引起大家的讨论,所以如果它引起了一些批评,也许我的目标就达到了。毕竟,无知地唱高调只适合说教,我想我最好解释一下。
Eirc S. Raymond在他的_The Art Of Unix Programming_收集了一些关于Unix哲学的最佳阐述。他详细讨论了17条特定的原则,但是我最喜欢的关于Unix哲学的阐述是Salus在他的_A Quarter Century of Unix_引用Doug McIlroy的简洁的陈述:
这就是Unix的哲学:
写只做一件事并且把这件事做好的程序。
写能组合在一起运作的程序。
写能处理文本流的程序,因为文本流是通用的接口。
McIlroy接下来稍微详细地给出了4点自己的陈述:
(i) 每个程序只做好一件事情。当需要完成新的任务的时候,写一个新的程序而不是原有程序上添加新功能。
(ii) 让每一个程序的输出可以成为另外一个程序的输入,甚至是未知的程序的输入。不要在输入中混杂着无用的信息。避免严格按列排列二进制的输入格式。不要依赖交互式输入。
(iii) 在设计和编写软件,甚至是操作系统的时候,要尽快地尝试,最好是在几个星期之内就完成。要毫无顾虑地删掉笨拙的地方和重写它们。(译注:深有体会,绝B认同。)
(iv) 使用工具而不是蹩脚的编码来减轻编程任务,即使你知道你最后还是不得不自己来构建这些工具或者要放弃它们。
在X桌面系统(译注:X是Linux下的桌面系统,没有它Linux就没有界面了)Mike Gancarz把Unix哲学总结成了9点:
- 精小就是优雅。
- 让每个程序只做好一件事情。
- 尽快地完成原型。
- 可移植性高于效率。
- 用纯文本来存放数据。
- 使用软件来加强你的优势。
- 使用Shell脚本来提高利用率和可移植性。
- 不要迷恋界面。
- 让每一个程序都成为过滤器。
最后一点和Ryan Dahl(译注:Node.js作者)经常说的“一切程序都是代理”(Every program is a proxy)产生了强烈的共鸣。前三点其实是James Halliday(译注:花名substack,疯了一样贡献了几百个Node.js模块,Node.js届无人不知的巨巨)的赖以生存的法则。
人们经常错误地迷失在Unix哲学的某些方面,而通常一叶障目不见森林。Unix哲学并不是一种特定的程序实现,或某种Unix操作系统或程序特有的东西。它并不是文件描述符,管道,套接字,或者信号量。这些误解就像是,除非一个人说Pali语,否则就不是佛教徒一样。
Unix哲学是软件开发的曙光,而不是软件中的一种特定技术开发。它是一种值得我们追求的理想境界,也许听起来有点讽刺:它是一种让指引我们要注重实用性而不是理想主义的理想境界。
在Node里面,人们之间分享和交互基本的构建的单元不是命令行中的二进制数据,而是通过require加载进来的模块。文本流_是_通用的接口,在Node.js里面其实就是JavaScript流对象,而不是标准输入输出中的管道。(标准输入输出的管道当然也在JavaScript流对象中体现出来了,因为它是我们通用的接口,我们还有其他选择吗?)
所以就从JavaScript的角度来说,我会说一下我是怎么表述Unix哲学的。哎~可惜我不是McIlroy,我也没有时间和能力去把它写得更精简,大家就将就一下吧:
写只做好一件事的模块。写新的模块而不是增加旧的模块的复杂性。
写鼓励组合而不是鼓励扩展的模块。
写能够处理数据流的模块,因为它是通用的接口。
写对数据来源和去向都无知的模块。
写某块来解决你知道的问题,那么你就可以知道哪些问题你是不知道的。
写小的模块。迅速地迭代。无情地重构。勇敢地重写。
迅速地写模块来满足你的需求,写几个测试来合乎规范。避免臃肿的文档。为你fix掉的每个bug写测试。
能工作优于完美
功能专注优于功能丰富
兼容性优于纯粹性
简单优于任何东西
Unix哲学是一种实用主义意识形态。是关于如何在写_好的软件_和写_任何软件_这两种需求中取得平衡。它是一套实用的建议,牺牲开发成本中的稳健性来获取更低的维护成本。
在现实世界当中,作为人类,我们在编写和调试程序的时候面临这一种相当不公平的约束,编码和调试的成本永远不可能降低到0。这种观念是有情景的,并且可以应用到所有的层次当中。我们都承认,我们没有聪明到写一次就知道如何把我们要写的软件写对,因为只有当我们把问题解决的时候我们才能完全理解问题。
**不是所有规则都是神圣不可侵犯的!**事实上,在很多情景下面,这些规则都是有争议甚至有时候是完全相反的。即便这样,如果我们把让我们程序的单元保持精小,加以简单通用的接口,我们就可以把所有零散的部件组合成一个高品质的齿轮,那么在我们滚动的时候,可以轻松自在地把笨拙的部分换出去。
没有线索清晰地表明Unix哲学和软件分享文化有什么关系。但是,它无疑是来自于我们一直在其中讨论如何让我们的软件更加自由的社区。根据这些原则来开发的软件,会更加容易地被分享,重用,重改和维护。
(完)
还是觉得用Github的issue来做博客方便一点:
所以,原来的博客搬到这里了!
之前的文章不打算搬过来了,也没什么东西,一切重新开始吧~!
作者:戴嘉华
转载请注明出处,保留原文链接和作者信息
前段时间无聊或有聊地做了几个移动端的HTML5游戏。放在不同的移动端平台上进行测试后有了诡异的发现,有些手机的动画会“快”一点,有些手机的动画会“慢”一点,有些慢得还不是一两点。
通过查找资料发现,基于帧的算法(Frame-based)来实现动画会导致不同帧率的平台体验不一致,而基于时间(Time-based)的动画算法可以很好地改良这种情况,让不同帧率的情况下都能达到较为统一的速度上的体验。
本文介绍的就是基于帧动画算法和基于时间动画算法的差异,以及对基于时间算法的改良。
相信做过前端的人对使用JavaScript实现动画的原理都很熟悉。现在让你实现一个让一个div从左到右来回移动的JS代码,你可能嗖嗖就写出来了:
function moveDiv(div, fps) {
var left = 0;
var param = 1;
function loop () {
update();
draw();
}
function update() {
left += param * 2;
if (left > 300) {
left = 300;
param = -1;
} else if (left < 0) {
left = 0;
param = 1;
}
}
function draw() {
div.style.left = left + "px";
}
setInterval(loop, 1000 / fps);
}
moveDiv(document.getElementById("div1"), 60);效果如下:
http://jsfiddle.net/livoras/4taf9hhs/embedded/result,js,html,css/
看看代码,我们让一个div在0 ~ 300px区间内左右来回移动。update计算更新描绘div的位置,draw重新描绘页面上的div。为了方便起见,这里直接使用setInterval作为定时器,实际情况下可以采用你喜欢的setTimeout或者requestAnimationFrame。这里设置每秒钟到更新60次,60fps是人尽皆知的比较适合做动画的帧率。
地球人都知道,JavaScript中的定时器是不准确的。由于JavaScript运行时需要耗费时间,而JavaScript又是单线程的,所以如果一个定时器如果比较耗时的话,是会阻塞下一个定时器的执行。所以即使你这里设置了1000 / 60每秒60帧的帧率,在不同的浏览器平台的差异也会导致实际上你的没有60fps的帧率。
所以上面代码在一个手机上执行的时候可能有60fps的帧率,在另外一个手机上可能就只有30fps,更甚可能只有10fps。
我们模拟一下这种情况会有什么效果发生:
http://jsfiddle.net/livoras/Lcv1jm53/embedded/result,js,html,css/
这完全不对大头!
可以看到三个方块移动速度根本不在同一个channel上。想象一下一个超级马里奥游戏在10fps的情况会怎么样?按跳跃一下,你会看到马里奥以一种太空漫游的姿态在空中抛弧线。
导致这种情况的原因很简单,因为我们计算和绘制每个div位置的时候是在每帧更新,每帧移动2px。在60fps的情况下,我们1秒钟会执行60帧,所以小块每秒钟会移动60 * 2 = 120px;如果是30fps,小块每秒就移动30 * 2 = 60px,以此类推10fps就是每秒移动20px。
三个小块在单位时间内移动的距离不一样!
假如你现在要做一个超级马里奥的游戏,怎么做到可以在不同帧率的情况下让马里奥看起来还是那么迅速且帅气?
解决方案很明显。虽然不同的浏览器平台上的运行差异可能会导致帧率的不一致,但是有一样东西是在任何平台上都一致的,那就是时间。所以我们可以改良我们的算法,不是以帧为基准来更新方块的位置,而是以时间为单位更新。也就是说,我们之前是px/frame,现在换成px/ms。
这就是接下来要说的基于时间(Time-based)的动画算法。
其实思路和实现都很简单。我们计算每一帧离上一帧过去了多少时间,然后根据过去的时间来更新方块的位置。
例如,上面的方块应该每秒钟移动120px,每毫秒移动120 / 1000 = 0.12像素(12px/ms)。如果上一帧方块的位置在left为10px的位置,到了这一帧的时候,假设相对于上一帧来说时间过去了200ms,那在时间上来说在这一帧方块应该移动200ms * 0.12px/ms = 240px。最终位置应该为10 + 240 = 250px。其实就是left = left + detalTime * speed。代码如下:
function moveDivTimeBased(div, fps) {
var left = 0;
var current = +new Date;
var previous = +new Date;
var param = 1;
function loop() {
var current = +new Date;
var dt = current - previous; // 计算时间差
previous = current;
update(dt);
draw()
}
function update(dt) {
left += param * (dt * 0.12); // 根据时间差更新位置
if (left > 300) {
left = 300;
param = -1;
} else if (left < 0) {
left = 0;
param = 1;
}
}
function draw() {
div.style.left = left + "px";
}
setInterval(loop, 1000 / fps);
}看看效果如何:
http://jsfiddle.net/livoras/8da1nssL/embedded/result,js,html,css/
看起来比上面的好多了,30fps和10fps好像能勉强赶上60fps的步伐。但是时间久了会发现30fps和10fps越来越落后于60fps。(建议先刷新再看看效果会更加明显)
这是因为**每次小方块碰到边缘的时候,都会损失掉一部分时间,而且帧率越低的损失越大。**看看我们上面的update函数:
function update(dt) {
left += param * (dt * 0.12); // 根据时间差更新位置
if (left > 300) {
left = 300;
param = -1;
} else if (left < 0) {
left = 0;
param = 1;
}
}假如我们现在方块的位置在left为290px的位置,这一帧传入的dt为100ms,那么我们left为290 + 100 * 0.12 = 302,但是302大于300,所以left会被设置为300。那么本来用来移动2px的时间就会白白被“抛弃”掉。dt越大,浪费得越多,所以30fps和10fps会比60fps越来越慢。
为了解决这个问题,我们对已有的算法进行改良。
解决思路如下:不一次算整块的时间(dt)移动的距离,而是把dt分成固定的时间片,通过多次update固定的时间片来计算dt时间后应该到什么位置。
比较抽象,我们直接看代码:
function moveDivTimeBasedImprove(div, fps) {
var left = 0;
var current = +new Date;
var previous = +new Date;
var dt = 1000 / 60;
var acc = 0;
var param = 1;
function loop() {
var current = +new Date;
var passed = current - previous;
previous = current;
acc += passed; // 累积过去的时间
while(acc >= dt) { // 当时间大于我们的固定的时间片的时候可以进行更新
update(dt); // 分片更新时间
acc -= dt;
}
draw();
}
// update 和 draw 函数不变
setInterval(loop, 1000 / fps);
}我们先确定一个固定更新的时间片,如固定为60fps时一帧的时间:1000 / 60 = 0.167ms。然后积累过去的时间,然后根据固定时间片分片进行更新。也就说,即使这一帧和上一帧相差过去了100ms,我也会把这100ms分成很多个0.167ms来执行update函数。这样做有两个好处:
看上面的代码,update和draw函数保持不变,而loop函数中,对过去的时间进行了累加,当时间超过固定的片就可以执行update。while循环可以保证更新直到把积累的时间都更新完。
对时间进行积累,然后分固定片更新。这种方式还有一个非常大的好处,如果你的帧率超过了60fps,如达到100fps或者200fps,这时候passed会小于0.167ms,时间就会被积累,积累大于0.167才会执行更新。碉堡的效果就是:不管你的帧率是高还是低,移动速度都可以和60fps情况下的速度同步。
看看最后的效果:
http://jsfiddle.net/livoras/25nut92z/embedded/result,js,html,css/
还是蛮不错的。
基于帧的动画算法会在帧率不同的情况下导致动画体验有较大的差异,所有动画都应该基于时间进行执行。而基于时间的动画算法要注意边缘时间的损失,最好采取积累时间,然后分固定片更新动画的方式。
作者:戴嘉华
转载请注明出处,保留原文链接和作者信息
每种项目都有自己特定的开发流程、工作流程。从需求分析、设计、编码、测试、发布,一个整个开发流程中,会根据不同的情况形成自己独特的步骤和流程。一个工作流的过程不是一开始就固定的,而是随着项目的深入而不断地改进,期间甚至会形成一些工具。例如当年大神们在Linux写C语言,觉得每次编译好多文件好麻烦,就发明了makefile。不同代码的管理好麻烦,然后就发明了git、SVN等等。
一个工作流程的好坏会影响你开发的效率、开发的流程程度,然后间接影响心情,打击编码积极性。所以我认为开发一个项目的时候,编码前把工作流程梳理清楚确定下来是一个非常重要的步骤。并且这个流程要在真实环境中不停的改进。
对于要负责页面结构和内容、外观、逻辑的前端来说,一个好的工作流至关重要。而且这里中没有银弹。要根据具体项目所使用的框架、应用场景来进行调整独特的工作流。
我会介绍一个我经常使用的前端工作流,这个工作流只是一个原始的流程,一般来说,我会根据不同项目的不同来在这个基础上进行调整,形成每个项目独特的流程。所以这里的重点是领会构建工作流的思路,然后学会举一反三。
一个前端自动化开发流程中,我觉得至少需要做到以下几点:
能用机器的地方就不要自己动手,除了上述必备的几点,有时候要根据特定的情况编写一些Python、Nodejs、Shell脚本来避免重复的操作。好好呵护你的F5和稀疏的脑神经,男人要对自己好一点。
在正式介绍之前会先做一些储备知识的介绍,也会略过一些你可能不懂的知识。懂的话可以跳过,遇到不懂的可以自己Google,不要百度。
我的工程目录一般是这个样的:
├─assets/
│ └─images/
├─bin/
├─dist/
├─lib/
├─src/
│ ├─coffee/
│ │ └─main.coffee
│ └─less/
│ └─main.less
├─test/
│ └─specs/
├─node_modules/
├─index.html
├─Gruntfile.coffee
├─package.json
├─.gitignore
└─README.md
所有子目录名称很多都其实源于古老的C语言工程。
assets:一般存放的是图片、音频、视频、字体等代码无关的静态资源,我一般只有图片,有时候也会新建一个fonts文件夹什么的。
bin:binary的缩写,这个名字来历于我们古老的C语言工程,因为一般C语言要编译成可执行的二进制文件什么的,后来基本成为了一种默认的标注。所以前端编译好的文件也会存放在bin/目录下。
dist:distribution的缩写,编译好的bin中的文件并不会直接用于发布,而是会经过一系列的优化操作,例如打包压缩等。最终能够部署到发布环境的文件都会存放在dist里面,所以dist里面是能够直接用到生产环境的代码。
lib:library的缩写,存放的是第三方库文件。例如你喜欢的jquery、fastclick什么的。但是接下来你会看到,在我们的模块化方式中,这个文件夹一般是比较鸡肋的存在。
src:source的缩写,所有需要开发的源代码的存放地,我们一般操作地最多的就是这个文件夹。简单地分为coffee、less两个文件夹,存的是逻辑代码和样式(我一般用CoffeeScript和LessCss,当然你也可以改成你喜欢的语言,JS,TS,LS,SASS,思路是一样的)。你看到两个文件夹下分别有main.coffe、main.less,这其实是逻辑代码和样式代码的主要入口文件,会把其他模块和样式引进来,通过某种机制合成一个文件。接下来会详细解释。
另外,这个目录的组织方式会根据实际情况多变。有时候你会需要html模板,可能会多一个tpl/目录。也许你的目录不是这种基于文件类型的层次组织,而是基于页面部件的组织,就可能出现components/目录,然后下面有很多个页面部件的目录,每个子目录有自己的coffee、less、html。(这种形式也变得逐渐流行。因为基于文件类型目录,当工程复杂起来的时候,就会变得异常难以维护,基于部件就会相当方便)。
test:使用测试驱动(TDD)开发进行编程,这里存放的都是测试样例。
index.html:页面文件
接下来几个文件都不解释,不了解的可以先预习NodeJS、Git、Grunt这几个东西。
说起前端模块化又是一个可以长篇大论话题。前端模块化的方式有很多种,年轻人最喜欢用的就是RequireJS、SeaJS什么的,看到这些模块化工具的时候感觉就像自己的第一双滑板鞋那样那么兴奋。其实这种AMD、CMD都需要引进一个库文件来做模块化工具,而且配置复杂,各种异步加载问题多多。后来我发现其实最clean、直接、方便、强大模块化方式当属substack大神的真.Browserify。
它可以基于NodeJS平台实现模块化的工具,你可以像组织NodeJS代码那样组织自己的前端工程,所有的模块都可以像NodeJS那样直接require进来。提供一个入口文件(如上的main.coffee)给Browserify,它会把这个入口文件的所有依赖模块都打包成一个文件。最终的文件不依赖于Browserify,最终的文件就是你的逻辑代码的组合。
而且Browserify和NodeJS的模块兼容性很好,一些NodeJS自带的模块例如util、path都可以用到前端中。你用npm安装的库,也可以通过Browserify用到前端中!例如我想用jQuery,我只需要:npm install jquery --save。然后在main.coffee中:
$ = require "jquery"
// play with jquery
相当贴心。
(Browserify具体用法查看官网文档)
其实自动化方式可以有很多种,你可以:
前两种方式更适合NodeJS开发服务端的应用场景,前端一般更适合用后两种。
目前使用的是Grunt,选择它是因为它社区大、插件多、成熟。但是我更看好Gulp基于流(Stream)的机理,这种继承于Unix**的无与伦比的实现方式着实可以让它在性能上和Grunt拉开差距。Grunt基于文件实现方式是在是:太!慢!了!
(Grunt具体用法可以见官网文档)
测试又是一个庞大的话题。在国外,前端TDD、BDD开发已经相当成熟,各种酷炫的工具Jasmine、Mocha、Tape等等,可能是我比较孤陋寡闻,貌似国内很少见到这些工具的使用。
其实前端是很难做到完全测试驱动开发的,它本身涉及到许多主观判断因素,例如动画是不是按照预想的那样移动等等。但是逻辑代码和前后端接口逻辑是可以测试的。所以引进测试驱动开发的一个非常大的好处就是:只要接口确定了,前后端可以分离开发,前端不用再“等后端API实现”了。
在我们的工作流中,使用MochaJS作为测试套件,ChaiJS作为断言库,Sinon做为数据mocking和函数spy。具体用法可以看各自的官网。
(对前端测试驱动开发不了解的同学可以Google相关资料或查阅相关书籍)
这个工作流的模版已经存放到了github上,大家可以clone下来进行本地测试一下:https://github.com/livoras/feb.git
运行步骤:
电脑上必须先按安装好Nodejs和npm
安装browswerify,coffeescript,和grunt:
npm install browswerify coffee-script grunt-cli -g
把仓库fork到本地,进入工程目录,安装依赖:
npm install
然后运行grunt命令
运气好的话你可以看到这样的界面:
然后,你会发现工程目录下多了一个bin文件夹,那就是我们刚编译好的文件存放在bin中。
然后打开浏览器,进入http://localhost:3000 ,可以看到:
现在我们修改src/less/main.less文件,把body改成黑色看看:

然后回到浏览器看看:
说变就变,非常哦妹子(amazing)是不是?
工作流分两个简单的步骤:
现在来介绍一下。
我们来看看gruntfile的100~108行:
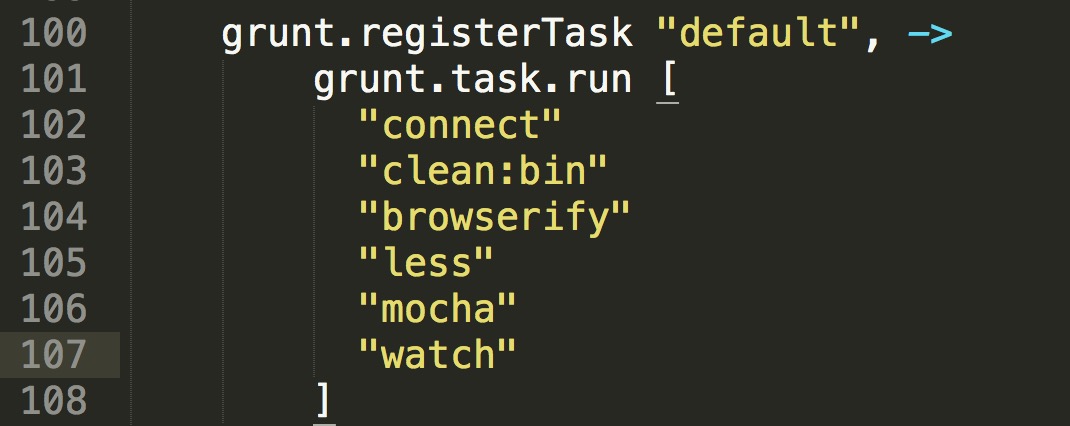
其实grunt干了这么几件事:
import)。所以我们的样式也是萌萌哒模块化了。有了这么一个流程,你就可以很轻松地写前端的逻辑和样式,并且都是以模块化的方式。
好了,代码都写完了。我需要把我的代码部署到服务器上。很简单,只需要命令行中执行:
grunt build
你就会发现工程目录下多了一个dist文件夹,进入里面,可以看到:
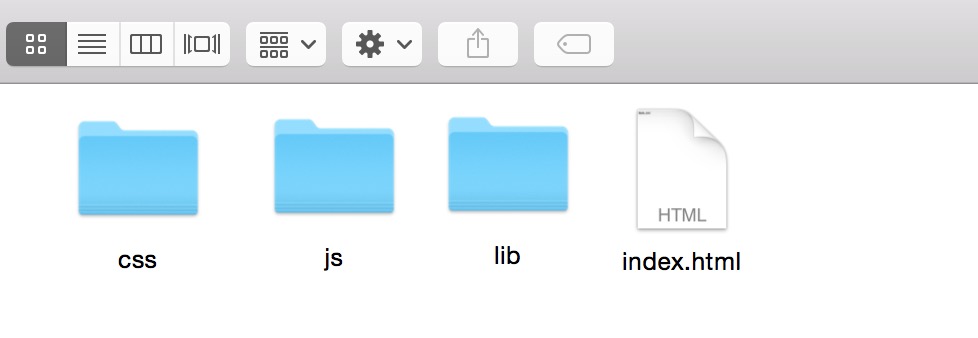
直接打开index.html:
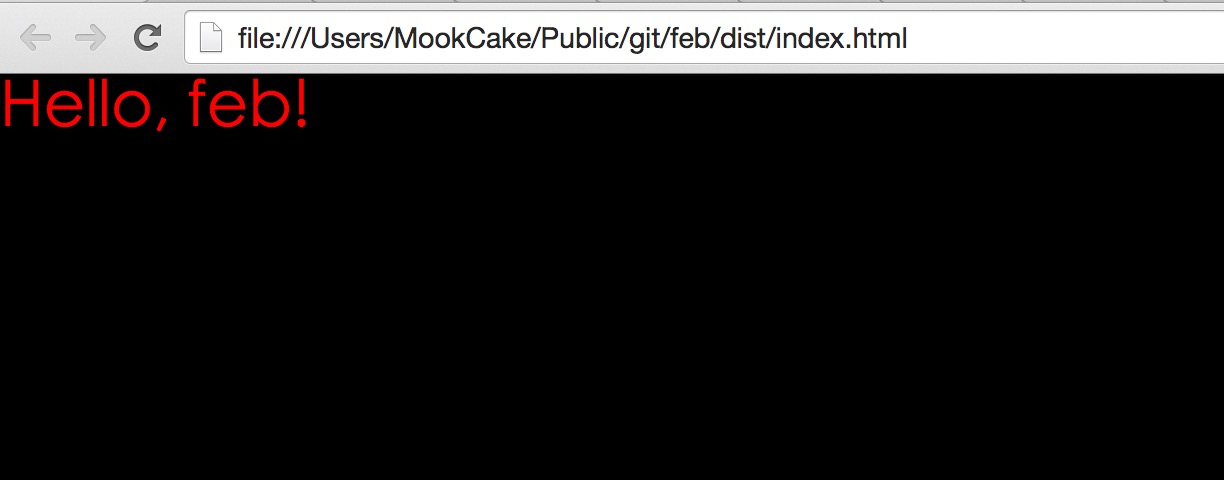
居然可以直接打开,也是非常哦妹子是不是?
我们看看grunt的build任务:
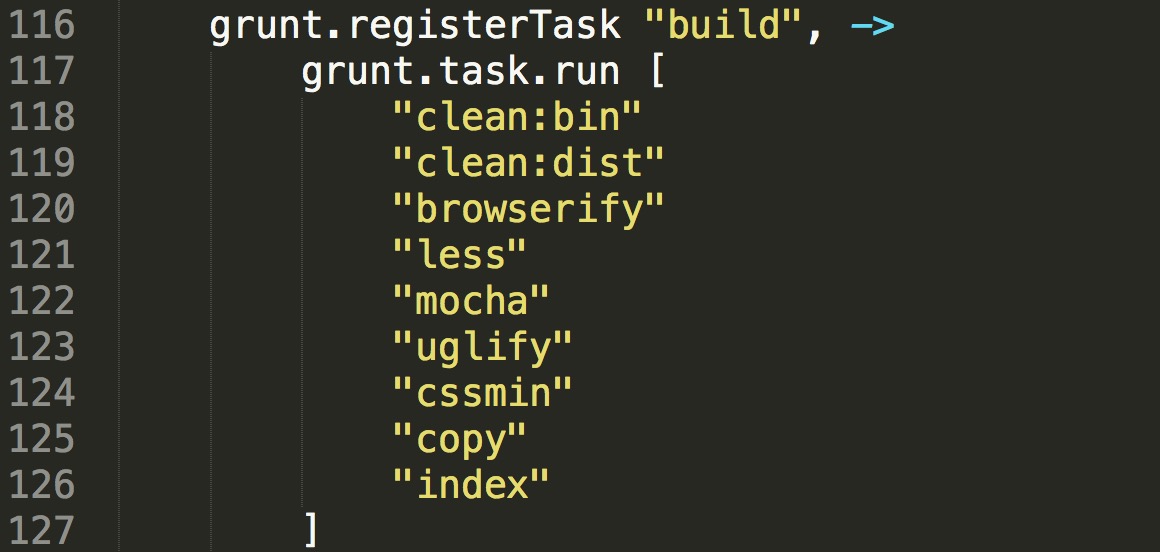
grunt build干了这么几件事情:
你可以看到dist目录下的文件js和css文件都是经过压缩的,现在dist中的文件夹已经ready了,你随时都可以直接放到服务器上了。
上面其实是一个非常简陋的流程,在实际要做的流程化要比这个复杂多,例如要考虑组建目录自动化构建,版本管理自动化,部署自动化,图片合并优化等等。主要有这个意识:* 不要做任何重复的工作,能自动化到地方都可以想法设法做到自动化 *。
上面也跳过了很多基础知识,这些是你需要知道的:
我甚至直接跳过了构建整个流程的过程,也跳过了测试如何编写。其实其中很多细节都可以拓展来讲,测试,模块化等,接下来博客也许会往这个方向去写。
(全文完)
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.