juyong / caricatureface Goto Github PK
View Code? Open in Web Editor NEWThe source code for paper "Landmark Detection and 3D Face Reconstruction for Caricature using a Nonlinear Parametric Model".
The source code for paper "Landmark Detection and 3D Face Reconstruction for Caricature using a Nonlinear Parametric Model".










































































































































Hi, thansk for your great work. But I have a problem about function of
FittingIndicesPlus(euler_angle, scale, trans, points, parallel, best_51):
#V_NUM the number of vertices
#euler_angle a euler_angle tensor with size (m,3)
#scale a scale tensor with size (m,1)
#trans a translation matrix with size (m,2)
#points a point tensor with size (m,3,V_NUM)
#parallel a long tensor with size (17,4), you can read it from './parallel.txt' file.
#best_51 a long tensor with size (51), which represents the last 51 landmarks (68-17=51).
Can you provide a sample of vertices? When I use the exsiting mean_face.obj and /parallel.txt to visualize it, I found the landmark display is not right:

I crop and resize the images in your dataset to 224, and run test.sh using the pretrained model but get the error result.
Could you tell me where did I make a mistake?
I'm sorry i ask the question in the email yesterday, I run the project on win 10.

today, i install a ubuntu18.04,and the question remains.
I download CariFace_data.zip,CariFace_model.zip and CariFace_exp.zip then extract to directory ./CaricatureFace/data, ./CaricatureFace/model and ./CaricatureFace/exp. run command python train.py --no_train.
in the cariface.py file at line 346, i add code:
mesh = om.read_trimesh("mean_face.obj")
vertex = points.reshape(3,self.vertex_num).data.cpu().numpy()
for i in range(6144):
mesh.points()[i] = vertex[:, i]
om.write_mesh(str(vrecord[0])+".obj", mesh)

Hi,
I'm trying to explore the project by running the code and getting the outputs. I've successfully generate images with landmarks drawn on them. According to the paper, the next step should be to generate the 3D face mesh. I notice that in toy_example, it has 2 python files that converts a .npy file to a .obj file and the other way as well. I assume that in order to generate the 3D face mesh, we need a .npy file that is previously generated during the process of detecting landmarks. May I ask how to find the .npy file if my assumption is correct?
Thank you!
Can we provide a training data set? We want to refer to the format of the data set and make a data set of our own
There seems to be a typo in layer initialization.
torch.nn.init.kaiming_normal_(self.fc1.weight.data) # fc1 -> fc2The errors you see were fixed by renaming .
How do I fix the last error ?

All images in exp.zip are of size 224x224,but landmarks files seem not.
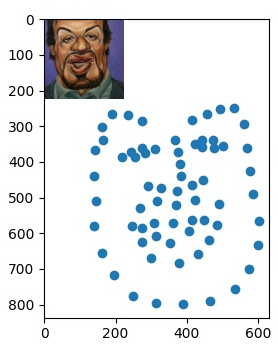
Hi, thank you for your cool work! I am trying to predict the 68 points landmark for the WebCaricatures dataset. When I tried to inference their data with your model, I got incorrect results. Seems I need to train your model on the WebCaricatures dataset. However, these's no vertex or ground-truth of WebCaricatures dataset.

Could you please give me some suggestions?
How to get the 3D coefficient of just one anime picture? Or a 3D face? Please give me a specific tutorial on how to use it

(cariface) C:\Users\HERO\git\CaricatureFace>python train.py --no_train
Traceback (most recent call last):
File "train.py", line 30, in
model.test()
File "C:\Users\HERO\git\CaricatureFace\cariface.py", line 273, in test
for img, landmark, lrecord, vrecord in self.test_loader:
File "C:\Users\HERO\anaconda3\envs\cariface\lib\site-packages\torch\utils\data\dataloader.py", line 279, in iter
return _MultiProcessingDataLoaderIter(self)
File "C:\Users\HERO\anaconda3\envs\cariface\lib\site-packages\torch\utils\data\dataloader.py", line 746, in init
self._try_put_index()
File "C:\Users\HERO\anaconda3\envs\cariface\lib\site-packages\torch\utils\data\dataloader.py", line 861, in _try_put_index
index = self._next_index()
File "C:\Users\HERO\anaconda3\envs\cariface\lib\site-packages\torch\utils\data\dataloader.py", line 339, in _next_index
return next(self._sampler_iter) # may raise StopIteration
File "C:\Users\HERO\anaconda3\envs\cariface\lib\site-packages\torch\utils\data\sampler.py", line 200, in iter
for idx in self.sampler:
File "C:\Users\HERO\anaconda3\envs\cariface\lib\site-packages\torch\utils\data\sampler.py", line 62, in iter
return iter(range(len(self.data_source)))
File "C:\Users\HERO\git\CaricatureFace\datagen.py", line 168, in len
return self.num_samples
AttributeError: 'TestSet' object has no attribute 'num_samples'
my linux environment:
torch:1.11.0+cu113
torchaudio: 0.11.0+cu113
torchvision: 0.12.0+cu113
cuda:11.3

Can i just do some 3D landmark detction on a 3D mesh?
Thanks for your attention.
You could try to change codes in lines 145 and 146 of "cariface.py" as below:
ck1 = torch.load(model1_path, map_location='cuda:0')
and
ck2 = torch.load(model2_path, map_location='cuda:0')
You can modify the number '0' to your existing device.
This may help you.
Originally posted by @RainbowRui in #2 (comment)
hello,the caricatureface work is great,i am very intersted with it ,I checked the readme,run and debug the code.some file from data dir confused me a few days!I am a new at the field,can you guide me with how to generate the pca_pri.npy,logR_S_meana.npy and A_pinv.npy,i am looking forward you reply,Senior!
Hello, I'm a novice, how can I reconstruct my comic pictures? Do the landmarks files in the code need to be generated by themselves?
Thanks for your nice research!
When I run your code, I figured out that the result changes according to how to crop caricature image. So, I will be really grateful if you inform me how you cropped caricature image.
Hello teacher, your work is very good, I am deeply inspired, but during the training, I encountered a problem, how to get
exp / train_ Image.txt file.
My goal is to interpolate between real face and its caricture face in 3D. And I want to first reconstruct these two face, and interpolate between their latent vector, then reconstruct using it.
However, when I test, I find this model seems not reconstruct real face very well. In principle, it shouldn't, because the real face is also a type of caricature.
Have you tested this before? Maybe there is someting with my experiment.
Thank you!
Traceback (most recent call last):
File "train.py", line 29, in
opt.model1_path, opt.model2_path)
File "/content/CaricatureFace/cariface.py", line 145, in load_model
ck1 = torch.load(model1_path)
File "/usr/local/lib/python3.6/site-packages/torch/serialization.py", line 529, in load
return _legacy_load(opened_file, map_location, pickle_module, **pickle_load_args)
File "/usr/local/lib/python3.6/site-packages/torch/serialization.py", line 702, in _legacy_load
result = unpickler.load()
File "/usr/local/lib/python3.6/site-packages/torch/serialization.py", line 665, in persistent_load
deserialized_objects[root_key] = restore_location(obj, location)
File "/usr/local/lib/python3.6/site-packages/torch/serialization.py", line 156, in default_restore_location
result = fn(storage, location)
File "/usr/local/lib/python3.6/site-packages/torch/serialization.py", line 132, in _cuda_deserialize
device = validate_cuda_device(location)
File "/usr/local/lib/python3.6/site-packages/torch/serialization.py", line 126, in validate_cuda_device
device, torch.cuda.device_count()))
RuntimeError: Attempting to deserialize object on CUDA device 1 but torch.cuda.device_count() is 1. Please use torch.load with map_location to map your storages to an existing device.
I tried to duplicate your code, but I encountered an error:Error 2.No such file or dictionary:'data/pca_pri.npy'.
So could you help me solve this problem? Thanks a lot.
Hi, thank you for your brilliant paper and work.
During running your source code, I have run the test code with pre-trained model successfully, however I met some trouble when running the train code with the following command in readme:
python train.py --no_premodel
The error printed is as below:
Traceback (most recent call last):
File "train.py", line 12, in <module>
opt.batch_size, opt.num_workers)
File "/root/3dface/CaricatureFace/cariface.py", line 130, in load_train_data
trainset = TrainSet(image_path, landmark_path, vertex_path, self.landmark_num, self.vertex_num)
File "/root/3dface/CaricatureFace/datagen.py", line 74, in __init__
file = open(image_path,'r')
FileNotFoundError: [Errno 2] No such file or directory: 'exp/train_images.txt'
At first, I wonder if any file for training is forgotten to put into this repository by the developer. However, I notice that the readme of the repo writes "Firstly, prepare a training set. ...". So I also wonder, if no file is forgotten to put into the repo, how could I build up a training set by the data files provided (those in form of links) in readme?
Great gratitudes if you could give some help.
Nice works, I want to recover the head mesh from the submesh, Can you share the vertices of submesh in original head mesh?
Thanks a lot.
I test the pretrained model with the exp data, but I do not get good enough result. Is there something wrong?





I succeeded to run test.sh,
but now I wan to see the mesh result,
can you explain how to do that?
if i want use my own training data, how can i generate the relate data
Thanks a lot.
I receive this erro. What to do?
Traceback (most recent call last):
File "train.py", line 29, in
opt.model1_path, opt.model2_path)
File "D:\Anaconda\Caricature\cariface.py", line 145, in load_model
ck1 = torch.load(model1_path)
File "C:\Users\BrenoSilva.conda\envs\Cariface\lib\site-packages\torch\serialization.py", line 529, in load
return _legacy_load(opened_file, map_location, pickle_module, **pickle_load_args)
File "C:\Users\BrenoSilva.conda\envs\Cariface\lib\site-packages\torch\serialization.py", line 702, in _legacy_load
result = unpickler.load()
File "C:\Users\BrenoSilva.conda\envs\Cariface\lib\site-packages\torch\serialization.py", line 665, in persistent_load
deserialized_objects[root_key] = restore_location(obj, location)
File "C:\Users\BrenoSilva.conda\envs\Cariface\lib\site-packages\torch\serialization.py", line 156, in default_restore_location
result = fn(storage, location)
File "C:\Users\BrenoSilva.conda\envs\Cariface\lib\site-packages\torch\serialization.py", line 132, in _cuda_deserialize
device = validate_cuda_device(location)
File "C:\Users\BrenoSilva.conda\envs\Cariface\lib\site-packages\torch\serialization.py", line 126, in validate_cuda_device
device, torch.cuda.device_count()))
RuntimeError: Attempting to deserialize object on CUDA device 1 but torch.cuda.device_count() is 1. Please use torch.load with map_location to map your storages to an existing device.
When training to 500 epochs, the following error is reported because the vertices used to calculate the keypoint loss use the target:

What is the reason for this and how should I deal it?
Hi, thanks for your great work!
I notice that a landmark file (.npy) for a caricature image is required for testing (test.sh), However, I don't know how to get these labels. Should I label it manually, or is there a way to generate landmarks?
Hi, thanks for your work.
I tried running it with the pre-trained weights - and got the following error:
python3 train.py --no_train
FileNotFoundError: [Errno 2] No such file or directory: 'data/pca_pri.npy'
Can you add the missing npy file?
When I try to evalute your results on the testest provided by you in Google Drive
Use python cal_error/cal_error.py
The results is
the mean error: 5.822952259763909
the mean error(pupil): 0.08047147811848179
the mean error(ocular): 0.054439231366942696
the mean error(diagnal): 0.024300979350562503
Why is it so different from the Table 1 in your paper?
您好,我是刚接触这个研究方面,我按照您GitHub上的操作步骤,最终得出的结果是loss_land:5.934936 ,我想请教一下,怎么让测试图片 的可视化呢?
I try torch==1.7 and torch==1.9, and run test.sh as readme shows. No warning. But, the result is so bad:

Same as #32
However, when I switch to torch==1.4, the result is as good as paper shows.
I spend so much time on this problem but can not find why
It is so strange......
Hello,
thanks for sharing this great paper and code.
I have a question: is it possible to do animation of the mesh output?
for example, BFM basis enables animation using manipulating of expressions.
is it possible to achieve this effect over the this model? if so, how?
Thanks,
Ofer
FileNotFoundError: [Errno 2] No such file or directory: 'data/pca_pri.npy'
Nice jobs. I am instreasted in the process of making train data. Will you share the code?
Hello! Thank you for your splendid work! But I do not know how to test my own data using your model? Could you give me some advise? Thanks for your reply!
can you explain how to run a test on my image?
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.