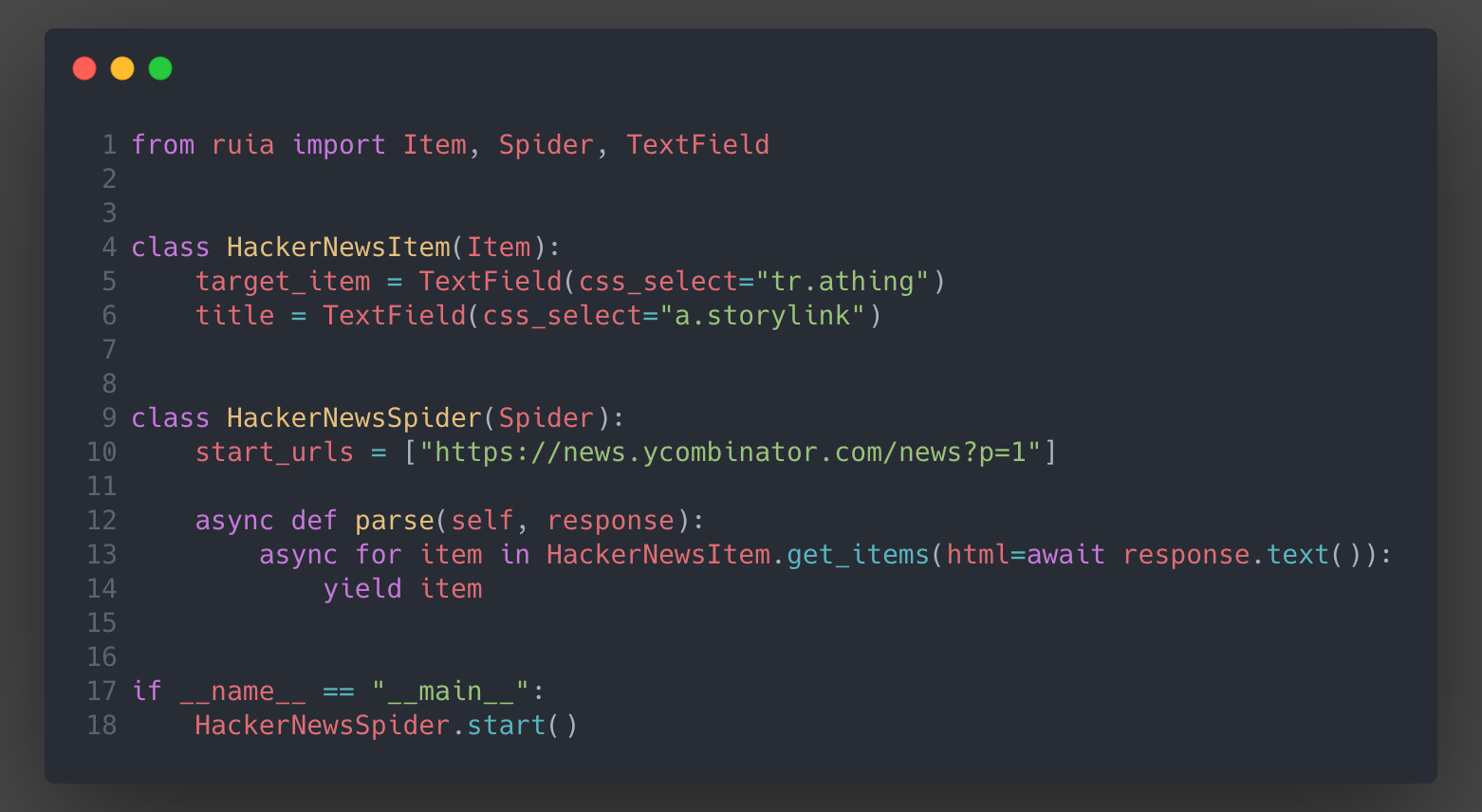
Mainly because the server rejected our request.
C:\Users\wolf\work\ruia\venv\Scripts\python.exe "C:\Program Files\JetBrains\PyCharm 2018.3.2\helpers\pydev\pydevd.py" --multiproc --qt-support=auto --client 127.0.0.1 --port 57124 --file C:/Users/wolf/work/ruia/examples/concise_hacker_news_spider/main.py
pydev debugger: process 9764 is connecting
Connected to pydev debugger (build 183.4886.43)
[2019:01:20 22:08:47]-Request-INFO request: <GET: https://news.ycombinator.com/news?p=1>
[2019:01:20 22:08:47]-Request-INFO request: <GET: https://news.ycombinator.com/news?p=2>
[2019:01:20 22:08:47]-Request-INFO request: <GET: https://news.ycombinator.com/news?p=3>
[2019:01:20 22:08:47]-Request-INFO request: <GET: https://news.ycombinator.com/news?p=4>
[2019:01:20 22:08:47]-Request-INFO request: <GET: https://news.ycombinator.com/news?p=5>
[2019:01:20 22:08:47]-Request-INFO request: <GET: https://news.ycombinator.com/news?p=6>
[2019:01:20 22:08:47]-Request-INFO request: <GET: https://news.ycombinator.com/news?p=7>
[2019:01:20 22:08:47]-Request-INFO request: <GET: https://news.ycombinator.com/news?p=8>
[2019:01:20 22:08:47]-Request-INFO request: <GET: https://news.ycombinator.com/news?p=9>
[2019:01:20 22:08:48]-Request-ERROR request: <Error: https://news.ycombinator.com/news?p=8 503 >
[2019:01:20 22:08:48]-Request-INFO request: <Retry url: https://news.ycombinator.com/news?p=8>, Retry times: 1
[2019:01:20 22:08:48]-Request-INFO request: <GET: https://news.ycombinator.com/news?p=8>
[2019:01:20 22:08:49]-Request-ERROR request: <Error: https://news.ycombinator.com/news?p=8 503 >
[2019:01:20 22:08:49]-Request-INFO request: <Retry url: https://news.ycombinator.com/news?p=8>, Retry times: 2
[2019:01:20 22:08:49]-Request-INFO request: <GET: https://news.ycombinator.com/news?p=8>
[2019:01:20 22:08:49]-Request-ERROR request: <Error: https://news.ycombinator.com/news?p=8 503 >
[2019:01:20 22:08:49]-Request-INFO request: <Retry url: https://news.ycombinator.com/news?p=8>, Retry times: 3
[2019:01:20 22:08:49]-Request-INFO request: <GET: https://news.ycombinator.com/news?p=8>
[2019:01:20 22:08:49]-Request-ERROR request: <Error: https://news.ycombinator.com/news?p=4 503 >
[2019:01:20 22:08:49]-Request-INFO request: <Retry url: https://news.ycombinator.com/news?p=4>, Retry times: 1
[2019:01:20 22:08:49]-Request-INFO request: <GET: https://news.ycombinator.com/news?p=4>
[2019:01:20 22:08:49]-Request-ERROR request: <Error: https://news.ycombinator.com/news?p=1 503 >
[2019:01:20 22:08:49]-Request-INFO request: <Retry url: https://news.ycombinator.com/news?p=1>, Retry times: 1
[2019:01:20 22:08:49]-Request-INFO request: <GET: https://news.ycombinator.com/news?p=1>
[2019:01:20 22:08:49]-Request-ERROR request: <Error: https://news.ycombinator.com/news?p=4 503 >
[2019:01:20 22:08:49]-Request-INFO request: <Retry url: https://news.ycombinator.com/news?p=4>, Retry times: 2
[2019:01:20 22:08:49]-Request-INFO request: <GET: https://news.ycombinator.com/news?p=4>
[2019:01:20 22:08:50]-Request-ERROR request: <Error: https://news.ycombinator.com/news?p=1 503 >
[2019:01:20 22:08:50]-Request-INFO request: <Retry url: https://news.ycombinator.com/news?p=1>, Retry times: 2
[2019:01:20 22:08:50]-Request-INFO request: <GET: https://news.ycombinator.com/news?p=1>
[2019:01:20 22:08:50]-Request-ERROR request: <Error: https://news.ycombinator.com/news?p=4 503 >
[2019:01:20 22:08:50]-Request-INFO request: <Retry url: https://news.ycombinator.com/news?p=4>, Retry times: 3
[2019:01:20 22:08:50]-Request-INFO request: <GET: https://news.ycombinator.com/news?p=4>
[2019:01:20 22:08:50]-Request-ERROR request: <Error: https://news.ycombinator.com/news?p=4 503 >
[2019:01:20 22:08:50]-Request-ERROR request: <Error: https://news.ycombinator.com/news?p=9 0 >
[2019:01:20 22:08:50]-Request-INFO request: <Retry url: https://news.ycombinator.com/news?p=9>, Retry times: 1
[2019:01:20 22:08:50]-Request-INFO request: <GET: https://news.ycombinator.com/news?p=9>
[2019:01:20 22:08:50]-Request-ERROR request: <Error: https://news.ycombinator.com/news?p=8 0 >
[2019:01:20 22:08:50]-Request-ERROR request: <Error: https://news.ycombinator.com/news?p=5 0 >
[2019:01:20 22:08:50]-Request-INFO request: <Retry url: https://news.ycombinator.com/news?p=5>, Retry times: 1
[2019:01:20 22:08:50]-Request-INFO request: <GET: https://news.ycombinator.com/news?p=5>
[2019:01:20 22:08:50]-Request-ERROR request: <Error: https://news.ycombinator.com/news?p=3 0 >
[2019:01:20 22:08:50]-Request-INFO request: <Retry url: https://news.ycombinator.com/news?p=3>, Retry times: 1
[2019:01:20 22:08:50]-Request-INFO request: <GET: https://news.ycombinator.com/news?p=3>
[2019:01:20 22:08:50]-Request-ERROR request: <Error: https://news.ycombinator.com/news?p=2 0 >
[2019:01:20 22:08:50]-Request-INFO request: <Retry url: https://news.ycombinator.com/news?p=2>, Retry times: 1
[2019:01:20 22:08:50]-Request-INFO request: <GET: https://news.ycombinator.com/news?p=2>
[2019:01:20 22:08:50]-Request-ERROR request: <Error: https://news.ycombinator.com/news?p=1 0 >
[2019:01:20 22:08:50]-Request-INFO request: <Retry url: https://news.ycombinator.com/news?p=1>, Retry times: 3
[2019:01:20 22:08:50]-Request-INFO request: <GET: https://news.ycombinator.com/news?p=1>
[2019:01:20 22:08:52]-Request-ERROR request: <Error: https://news.ycombinator.com/news?p=1 503 >
[2019:01:20 22:08:53]-Request-ERROR request: <Error: https://news.ycombinator.com/news?p=9 503 >
[2019:01:20 22:08:53]-Request-INFO request: <Retry url: https://news.ycombinator.com/news?p=9>, Retry times: 2
[2019:01:20 22:08:53]-Request-INFO request: <GET: https://news.ycombinator.com/news?p=9>
[2019:01:20 22:08:57]-asyncio-ERROR base_events: unhandled exception during asyncio.run() shutdown
task: <Task finished coro=<parse_one_page() done, defined at C:/Users/wolf/work/ruia/examples/concise_hacker_news_spider/main.py:11> exception=ValueError('can only parse strings')>
Traceback (most recent call last):
File "C:\Program Files\Python37\lib\asyncio\runners.py", line 43, in run
return loop.run_until_complete(main)
File "C:\Program Files\Python37\lib\asyncio\base_events.py", line 584, in run_until_complete
return future.result()
File "C:/Users/wolf/work/ruia/examples/concise_hacker_news_spider/main.py", line 18, in main
result = await asyncio.gather(*coroutine_list)
File "C:/Users/wolf/work/ruia/examples/concise_hacker_news_spider/main.py", line 13, in parse_one_page
return await HackerNewsItem.get_items(url=url)
File "C:\Users\wolf\work\ruia\ruia\item.py", line 53, in get_items
html_etree = await cls._get_html(html, url, **kwargs)
File "C:\Users\wolf\work\ruia\ruia\item.py", line 41, in _get_html
return etree.HTML(html)
File "src\lxml\etree.pyx", line 3159, in lxml.etree.HTML
File "src\lxml\parser.pxi", line 1876, in lxml.etree._parseMemoryDocument
ValueError: can only parse strings
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "C:/Users/wolf/work/ruia/examples/concise_hacker_news_spider/main.py", line 13, in parse_one_page
return await HackerNewsItem.get_items(url=url)
File "C:\Users\wolf\work\ruia\ruia\item.py", line 53, in get_items
html_etree = await cls._get_html(html, url, **kwargs)
File "C:\Users\wolf\work\ruia\ruia\item.py", line 41, in _get_html
return etree.HTML(html)
File "src\lxml\etree.pyx", line 3159, in lxml.etree.HTML
File "src\lxml\parser.pxi", line 1876, in lxml.etree._parseMemoryDocument
ValueError: can only parse strings
[2019:01:20 22:08:57]-asyncio-ERROR base_events: unhandled exception during asyncio.run() shutdown
task: <Task finished coro=<parse_one_page() done, defined at C:/Users/wolf/work/ruia/examples/concise_hacker_news_spider/main.py:11> exception=ValueError('can only parse strings')>
Traceback (most recent call last):
File "C:\Program Files\Python37\lib\asyncio\runners.py", line 43, in run
return loop.run_until_complete(main)
File "C:\Program Files\Python37\lib\asyncio\base_events.py", line 584, in run_until_complete
return future.result()
File "C:/Users/wolf/work/ruia/examples/concise_hacker_news_spider/main.py", line 18, in main
result = await asyncio.gather(*coroutine_list)
File "C:/Users/wolf/work/ruia/examples/concise_hacker_news_spider/main.py", line 13, in parse_one_page
return await HackerNewsItem.get_items(url=url)
File "C:\Users\wolf\work\ruia\ruia\item.py", line 53, in get_items
html_etree = await cls._get_html(html, url, **kwargs)
File "C:\Users\wolf\work\ruia\ruia\item.py", line 41, in _get_html
return etree.HTML(html)
File "src\lxml\etree.pyx", line 3159, in lxml.etree.HTML
File "src\lxml\parser.pxi", line 1876, in lxml.etree._parseMemoryDocument
ValueError: can only parse strings
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "C:/Users/wolf/work/ruia/examples/concise_hacker_news_spider/main.py", line 13, in parse_one_page
return await HackerNewsItem.get_items(url=url)
File "C:\Users\wolf\work\ruia\ruia\item.py", line 53, in get_items
html_etree = await cls._get_html(html, url, **kwargs)
File "C:\Users\wolf\work\ruia\ruia\item.py", line 41, in _get_html
return etree.HTML(html)
File "src\lxml\etree.pyx", line 3159, in lxml.etree.HTML
File "src\lxml\parser.pxi", line 1876, in lxml.etree._parseMemoryDocument
ValueError: can only parse strings
Traceback (most recent call last):
File "C:\Program Files\JetBrains\PyCharm 2018.3.2\helpers\pydev\pydevd.py", line 1741, in <module>
main()
File "C:\Program Files\JetBrains\PyCharm 2018.3.2\helpers\pydev\pydevd.py", line 1735, in main
globals = debugger.run(setup['file'], None, None, is_module)
File "C:\Program Files\JetBrains\PyCharm 2018.3.2\helpers\pydev\pydevd.py", line 1135, in run
pydev_imports.execfile(file, globals, locals) # execute the script
File "C:\Program Files\JetBrains\PyCharm 2018.3.2\helpers\pydev\_pydev_imps\_pydev_execfile.py", line 18, in execfile
exec(compile(contents+"\n", file, 'exec'), glob, loc)
File "C:/Users/wolf/work/ruia/examples/concise_hacker_news_spider/main.py", line 27, in <module>
asyncio.run(main())
File "C:\Program Files\Python37\lib\asyncio\runners.py", line 43, in run
return loop.run_until_complete(main)
File "C:\Program Files\Python37\lib\asyncio\base_events.py", line 584, in run_until_complete
return future.result()
File "C:/Users/wolf/work/ruia/examples/concise_hacker_news_spider/main.py", line 18, in main
result = await asyncio.gather(*coroutine_list)
File "C:/Users/wolf/work/ruia/examples/concise_hacker_news_spider/main.py", line 13, in parse_one_page
return await HackerNewsItem.get_items(url=url)
File "C:\Users\wolf\work\ruia\ruia\item.py", line 53, in get_items
html_etree = await cls._get_html(html, url, **kwargs)
File "C:\Users\wolf\work\ruia\ruia\item.py", line 41, in _get_html
return etree.HTML(html)
File "src\lxml\etree.pyx", line 3159, in lxml.etree.HTML
File "src\lxml\parser.pxi", line 1876, in lxml.etree._parseMemoryDocument
ValueError: can only parse strings