fidler-lab / polyrnn-pp-pytorch Goto Github PK
View Code? Open in Web Editor NEWPyTorch training/tool code for Polygon-RNN++ (CVPR 2018)
PyTorch training/tool code for Polygon-RNN++ (CVPR 2018)






































































































































Hi, @amlankar. For some downstream usage, I'm trying to get the number of corrections when using the model to assist human annotation, which is exactly the evaluation metric mentioned in the paper. However, what I can only find is the function 'process_outputs' in 'generate_annotation.py', which simply assigns 0 to the value. Is the procedure of calculating the number of corrections included in the code? Can you provide it if not?
Thanks!
1.this command "python Scripts/prediction/generate_annotation.py --exp <path_to_corresponding_experiment> --reload <path_to_checkpoint> --output_dir <path_to_store_predictions>" I can't understand "<path_to_corresponding_experiment> ","<path_to_checkpoint>","<path_to_store_predictions> " refer to, respectively.
2.I have tested this command "python Scripts/data/change_paths.py --city_dir <path_to_downloaded_leftImg8bit_folder> --json_dir <path_to_downloaded_annotation_file> --output_dir <output_dir>" and finded the "output_dir" should be replaced by "out_dir".
3.similar with problem 2,"python Scripts/train/train_ce.py --exp Experiments/mle.json --reload <optional_if_resuming_training>" in this command can't work ,but if use "resume" replace "reload" i can worked well.
Hello,
I want to get code for training, but when I visit your website to sign up, there is a 503 problem, how can I deal with it?
Thank you!

Hello. Both the frontend and backend run normally, but the pictures on the page can't be displayed normally.

This is my front .
(ployrnn) gaoennan@gaoennan-MS-7D31:~/code/polyrnn/code/Tool/frontend$ python -m http.server
Serving HTTP on 0.0.0.0 port 8000 (http://0.0.0.0:8000/) ...
127.0.0.1 - - [11/Jan/2022 14:08:20] "GET / HTTP/1.1" 304 -
127.0.0.1 - - [11/Jan/2022 14:08:20] code 404, message File not found
127.0.0.1 - - [11/Jan/2022 14:08:20] "GET /static/js/jquery.svg.pan.zoom.js.map HTTP/1.1" 404 -
127.0.0.1 - - [11/Jan/2022 14:08:33] "GET / HTTP/1.1" 304 -
And a request of frontend is always failed.

They are in the config file of ggnn.
I have run the backend and frontend, and they have printed these content:
1.Backend
Building dataloaders
Dataset Options: {'batch_size': 1, 'max_poly_len': 71, 'grid_side': 28, 'img_side': 224, 'flip': False, 'random_start': False, 'random_context': [0.15, 0.15]}
Building polyrnnpp with opts:
{'mode': 'tool', 'max_poly_len': 71, 'temperature': 0.0, 'use_evaluator': True, 'use_bn_lstm': True, 'use_ggnn': True, 'ggnn_n_steps': 5, 'ggnn_state_dim': 1024, 'ggnn_grid_size': 112, 'ggnn_output_dim': 15, 'use_separate_encoder': False, 'return_attention': False, 'dataset': {'train_val': {'batch_size': 1, 'max_poly_len': 71, 'grid_side': 28, 'img_side': 224, 'flip': False, 'random_start': False, 'random_context': [0.15, 0.15]}}}
Building encoder
Building first vertex network
Building convlstm
Building Evaluator
Building GGNN
Building GGNN Feature Encoder
Reloading full model from: /data/weibo/code/polyrnn-pp-pytorch/models/mle_epoch9_step49000.pth
* Serving Flask app "tool" (lazy loading)
* Environment: production
WARNING: This is a development server. Do not use it in a production deployment.
Use a production WSGI server instead.
* Debug mode: off
* Running on http://0.0.0.0:8080/ (Press CTRL+C to quit)
2.Frontend
Serving HTTP on 0.0.0.0 port 8000 (http://0.0.0.0:8000/) ...
Then how can I label the images? For example, I run the server on 192.168.1.10, but I cannot get into the page like below by type 192.168.1.10:8080 or 192.168.1.10:8000 or 127.0.0.1:8000.

Looking forward to your reply.
Hi, @amlankar. I try to train the model with Multi GPUs, beacause multi-gpus training not only can reduce trianing time hugely but also imporve the accurate with bigger batch size in theory.But i got an AssertionError unfortunately. The steps that i did as bellow:
I changed the model with nn.DataParaller() method like this:
model = polyrnnpp.PolyRNNpp(self.opts)
model = nn.DataParallel(model, device_ids=(0, 1)) # i have two 1080ti GPU devices
self.model = model.cuda()
for training, i put input data to cuda like this:
# Forward pass
output = self.model(data['img'].type(self.dtype).cuda(), data['fwd_poly'].type(self.dtype).cuda())
Then, the AssertionError occured:
Starting training
Saved model
/home/ztian5/.local/lib/python2.7/site-packages/torch/nn/functional.py:1006: UserWarning: nn.functional.sigmoid is deprecated. Use torch.sigmoid instead.
warnings.warn("nn.functional.sigmoid is deprecated. Use torch.sigmoid instead.")
/home/ztian5/.local/lib/python2.7/site-packages/torch/nn/functional.py:995: UserWarning: nn.functional.tanh is deprecated. Use torch.tanh instead.
warnings.warn("nn.functional.tanh is deprecated. Use torch.tanh instead.")
Traceback (most recent call last):
File "/mnt/data/polygonRNN_pluss/code/Scripts/train/train_ce.py", line 328, in <module>
trainer.loop()
File "/mnt/data/polygonRNN_pluss/code/Scripts/train/train_ce.py", line 148, in loop
self.train(epoch)
File "/mnt/data/polygonRNN_pluss/code/Scripts/train/train_ce.py", line 163, in train
output = self.model(data['img'].type(self.dtype).cuda(), data['fwd_poly'].type(self.dtype).cuda())
File "/home/ztian5/.local/lib/python2.7/site-packages/torch/nn/modules/module.py", line 477, in __call__
result = self.forward(*input, **kwargs)
File "/home/ztian5/.local/lib/python2.7/site-packages/torch/nn/parallel/data_parallel.py", line 124, in forward
return self.gather(outputs, self.output_device)
File "/home/ztian5/.local/lib/python2.7/site-packages/torch/nn/parallel/data_parallel.py", line 136, in gather
return gather(outputs, output_device, dim=self.dim)
File "/home/ztian5/.local/lib/python2.7/site-packages/torch/nn/parallel/scatter_gather.py", line 67, in gather
return gather_map(outputs)
File "/home/ztian5/.local/lib/python2.7/site-packages/torch/nn/parallel/scatter_gather.py", line 61, in gather_map
for k in out))
File "/home/ztian5/.local/lib/python2.7/site-packages/torch/nn/parallel/scatter_gather.py", line 61, in <genexpr>
for k in out))
File "/home/ztian5/.local/lib/python2.7/site-packages/torch/nn/parallel/scatter_gather.py", line 54, in gather_map
return Gather.apply(target_device, dim, *outputs)
File "/home/ztian5/.local/lib/python2.7/site-packages/torch/nn/parallel/_functions.py", line 52, in forward
assert all(map(lambda i: i.is_cuda, inputs))
AssertionError
Process finished with exit code 1
bty, i trained the network with single GPU fine, but when i use multi-gpu to train the network with 'nn.DataParaller()', the Error occured. Can you give me some advices on training the network with multi-gpu devices or what's wrong with i did ?
Appreciative for your reply ^_^.
Hi, @amlankar . When i try to visulize the MLE training network structure by add the **make_dot()** function from the package torchviz, the code i added in train(self, epoch) function of train_ce.py script as bellow:
def train(self, epoch):
print 'Starting training'
self.model.train()
accum = defaultdict(float)
# To accumulate stats for printing
for step, data in enumerate(self.train_loader):
if self.global_step % self.opts['val_freq'] == 0:
self.validate()
self.save_checkpoint(epoch)
# Forward pass
# data['img'] = Variable(data['img'], requires_grad=True)
# data['fwd_poly'] = Variable(data['fwd_poly'], requires_grad=True) # Variable data['fwd_poly'] used for correction interactive
input1 = data['img']
input2 = data['fwd_poly']
output = self.model(input1.to(device), input2.to(device))
## used for generating '.dot' format network structure graph
g = make_dot(output, params=dict(list(polyrnnpp.PolyRNNpp(self.opts).named_parameters())+[('input1', input1), ('input2', input2)]))
g.render('./graph', view=False)
Then i get the 'grad_fn' Error like this:
g = make_dot(output, params=dict(list(polyrnnpp.PolyRNNpp(self.opts).named_parameters())+[('input1', input1), ('input2', input2)]))
File "/home/tzq-lxj/softWare/anaconda3/envs/polygonRNNPP/lib/python2.7/site-packages/torchviz/dot.py", line 37, in make_dot
output_nodes = (var.grad_fn,) if not isinstance(var, tuple) else tuple(v.grad_fn for v in var)
AttributeError: 'dict' object has no attribute 'grad_fn'
Why the grad_fn of Variable output just gone when the make_dot() function called and how can i fix the 'grad_fn' Error ? And i try to use SummaryWriter of tensorboardX to do the same thing also, when testing by generate_annotation.py script and training by mle_ce.py script, I got the same Error. What's more important, if you have some other way to visulize the MLE network structure please let me konw. Thank you. Appreciative for your reply.
So to obtain this pytorch metagraph kinda thing did you trained just only one instance which included
MLE + Att + Evaluator + GGNN (Shared Encoder) ?? Or did you trained attention MLE + Att + Evaluator separately and incorporated with the GGNN .pth to obtain this final ggnn_epoch5_step14000.pth file? Sorry if this is a lame question. I didn't really gone completely through the training code :)
Dear authors,
Thanks for releasing the code! Would it be possible for you to provide a docker file for efficiently running your code?
Just like this project did: ritm_interactive_segmentation.
I am now trying to dockerize your code, but fail to get the results from the web browser.
My Docker file is shown below:
"FROM nvidia/cuda:9.0-cudnn7-devel-ubuntu16.04
RUN apt-get update && apt-get install -y
build-essential
git
curl
firefox
nano
RUN apt-get install -y
virtualenv
python2.7
libxrender1
libsm6
libxext6
"
But every time I draw the bounding box on the web browser, I get the error:
"RuntimeError: CUDNN_STATUS_EXECUTION_FAILED"
Thank you!
hi, @amlankar , when will you plan to publish the online tools of cvpr19 paper "curve-gcn". I'm very interested in your work^_^. Appreciative for your reply.
@ amlankar,hi,I had a problem preparing the json file,Could you help me find out what the problem is?
My input instructions are as follows:python Scripts/data/change_paths.py --city_dir /home/csy/polyrnnpp-pytorch/cityscapes/leftImg8bit --json_dir /home/csy/polyrnnpp-pytorch/cityscapes/gtFine --out_dir /home/csy/polyrnnpp-pytorch/json_out

Thank you
Appreciative for your reply.
Hi, @amlankar. When I try to run Tool on my own server follow the part tool:
There are my command lines that running the backent and frontent separately:
python Tool/tool.py --exp /mnt/data/polygonRNN_pluss/code/Experiments/tool.json --reload /mnt/data/polygonRNN_pluss/models/ggnn_epoch5_step14000.pth --port 5001 --image_dir /mnt/data/polygonRNN_pluss/code/Tool/frontend/static/img/python -m SimpleHTTPServer
the page above showed when i draw a box around an object like a car. The page just stoped when i draw a box around an object, and the progress bar just rolling endless.
the log at frontent terminal like this:

the log at backent as follow:
Building dataloaders
Dataset Options: {u'img_side': 224, u'random_context': [0.15, 0.15], u'flip': False, u'batch_size': 1, u'random_start': False, u'grid_side': 28, u'max_poly_len': 71}
Building polyrnnpp with opts:
{u'ggnn_n_steps': 5, u'temperature': 0.0, u'ggnn_grid_size': 112, u'ggnn_output_dim': 15, u'use_bn_lstm': True, u'ggnn_state_dim': 1024, u'return_attention': False, u'mode': u'tool', u'use_evaluator': True, u'dataset': {u'train_val': {u'img_side': 224, u'random_context': [0.15, 0.15], u'flip': False, u'batch_size': 1, u'random_start': False, u'grid_side': 28, u'max_poly_len': 71}}, u'use_ggnn': True, u'use_separate_encoder': False, u'max_poly_len': 71}
Building encoder
Building first vertex network
Building convlstm
Building Evaluator
Building GGNN
Building GGNN Feature Encoder
Reloading full model from: /mnt/data/polygonRNN_pluss/models/ggnn_epoch5_step14000.pth
* Serving Flask app "tool" (lazy loading)
* Environment: development
* Debug mode: on
* Running on http://0.0.0.0:5001/ (Press CTRL+C to quit)
* Restarting with stat
Building dataloaders
Dataset Options: {u'img_side': 224, u'random_context': [0.15, 0.15], u'flip': False, u'batch_size': 1, u'random_start': False, u'grid_side': 28, u'max_poly_len': 71}
Building polyrnnpp with opts:
{u'ggnn_n_steps': 5, u'temperature': 0.0, u'ggnn_grid_size': 112, u'ggnn_output_dim': 15, u'use_bn_lstm': True, u'ggnn_state_dim': 1024, u'return_attention': False, u'mode': u'tool', u'use_evaluator': True, u'dataset': {u'train_val': {u'img_side': 224, u'random_context': [0.15, 0.15], u'flip': False, u'batch_size': 1, u'random_start': False, u'grid_side': 28, u'max_poly_len': 71}}, u'use_ggnn': True, u'use_separate_encoder': False, u'max_poly_len': 71}
Building encoder
Building first vertex network
Building convlstm
Building Evaluator
Building GGNN
Building GGNN Feature Encoder
Reloading full model from: /mnt/data/polygonRNN_pluss/models/ggnn_epoch5_step14000.pth
* Debugger is active!
* Debugger PIN: 294-205-619
I can't get the annotation file of the tool and see the polygon on the page when i draw a bbox around an object.Can you give me some advice about this? Much appreciated for your reply.
What's more , when i try to see the backend with chrome browser by localhost:5001, i get 404 respond like bellow:
127.0.0.1 -- "GET / HTTP/1.1" 404 -
Does that means the backent not work?
I find that the epoch is very small, like 'ggnn_epoch8_step21000.pth', but the epochs you have set in the config is about 200.
Hi 1)when I run the tool.py ,there is alaways a error at "self.model.reload(args.reload, strict=False)" (line 46),
the error is "PermissionError: [Errno 13] Permission denied: 'E:/Work/polyrnnpp-pytorch/models/',Is there something I should pay attention to?
2) And I'm a little confused about the whole process of the project,(train->prediction->tool, is it ?)
I was trying to do the demo of code using the model : ../models/ggnn_epoch5_step14000.pth and while running the code I encountered to GPU out of memory. I am having an Nvidia Quadro 2 GB GPU.
Hey I was thinking of using a bounding box detector which detects all the bounding boxes for the object instances in the image. I have seen in the paper that you guys used faster rcnn for the same. Was there any particular reason for using the faster rcnn for bounding box. Is that the best option for detecting the bounding box with faster response time. I really want to use an automatic bbox detector for some evaluation for my master thesis. It would be great if you guys could shed some light on this. :)
I change the data path, edit the path in ggnn.json, and test it with torch1.2/ptyhon3, got a mIoU 69, which is a bit lower than the result published in the paper - 71.38.
And I cannot load the 'ggnn_epoch8', can you give me a json file for it?
Thanks for you great work!
Did you guys tried any new encoding techniques other than resnet. Can I expect something new this year? Like an improved version of the polyrnn++. I was just curious :)
Hello,
It is fantastic, so cool.
Following to your guide, I try to test pre-trained model but I am not sure my result is right or not.
Step1. which path do these arguments(--exp, --reload) have? "Mine" command line is right, or not? if excite with mine, I don't get any in "out" directory. If you are possible, I hope you show example.
(Guide) python Scripts/prediction/generate_annotation.py --exp <path_to_corresponding_experiment> --reload <path_to_checkpoint> --output_dir <path_to_store_predictions>
(Mine) (env) charles@charles-ubuntu:~/Documents/polyrnnpp/polyrnn-pp-pytorch/code$ python Scripts/prediction/generate_annotation.py --exp Experiments/rl.json --reload ../models/rl_epoch1_step3000.pth --output_dir out/
Step2. which path do these arguments(--pred,--output) have? If you are possible, I hope you show example.
(Guide) python Scripts/get_scores.py --pred <path_to_preds> --output <path_to_file_to_save_results>
(Mine) (env) charles@charles-ubuntu:~/Documents/polyrnnpp/polyrnn-pp-pytorch/code$ python Scripts/get_scores.py --pred out/ --output out/
hi, @amlankar , I got an error while training my own data set. It may be that my own data set has errors, but I can't find the error.Can you give me a standard format for the data set?

Can you explain a bit more explicit how you solve the path error, cuz I run into the exact same error, even though I edited the global path, I use the global search and there is even no "/ais/gobi6/amlan/poly_rnn_demo_images/test.jpg" in all code, I feel frustrated.
Thanks
Thank you very much for your reply. I've solved the path problem
But I haven't solved the problem related to #14.
The back-end server terminal displays as follows.
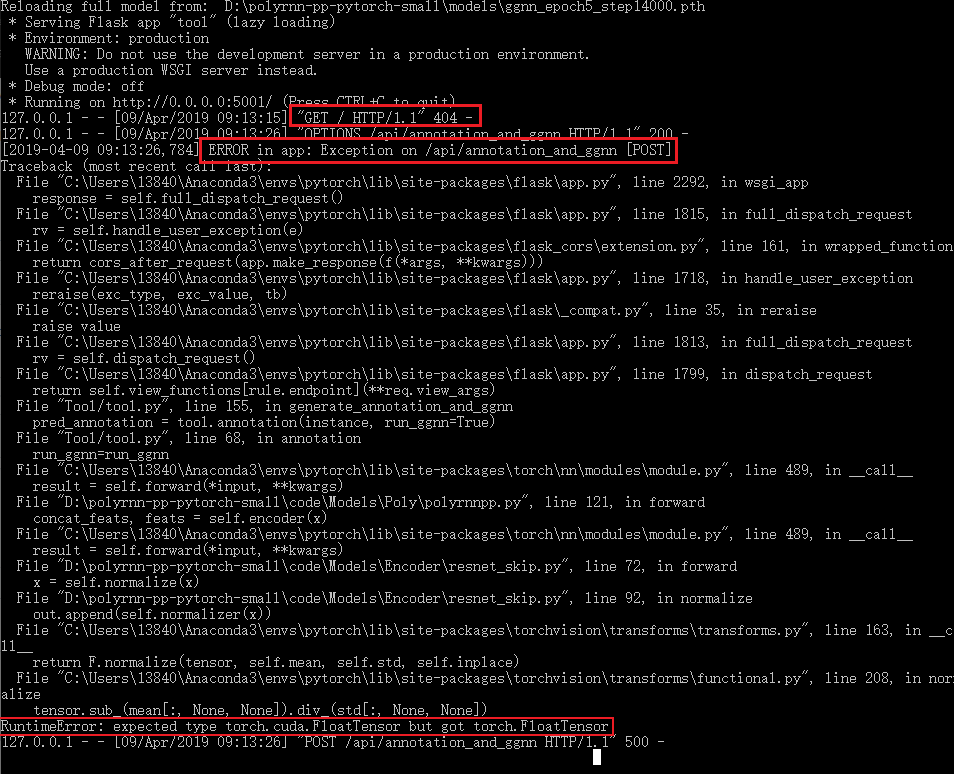
Can you help me? I can't find the reason for this mistake
Can you help me with this problem? Thank you
Appreciative for your reply.
Originally posted by @CSYslient in #5 (comment)
Thanks for sharing the code of this great work. I have a question while using the code regarding the performance at different checkpoints (files in the shared models folder).
I loaded each model and used it to annotate a car in the supplied Road image. It seems that results from mle, rl and evaluator all look very bad. Some predicted vertices are not even on the edges. The result from ggnn, on the other hand, works really well. I'm wondering if that's an expected behaviour or I did something wrong.
Below are snapshots to explain what I meant.
result from mle

result from rl

result from evaluator

result from ggnn_epoch5

PS: ggnn_epoch8_step21000.pth cannot be loaded. It seems the shared checkpoint is not compatible with the defined model.
RuntimeError: Error(s) in loading state_dict for PolyRNNpp:
While copying the parameter named "ggnn.encoder.conv_final.0.weight", whose dimensions in the model are torch.Size([256, 256, 3, 3]) and whose dimensions in the checkpoint are torch.Size([128, 256, 3, 3]).
thanks for your contribution.
I would like to ask you some question.
Firstly, what version of cudnn did you used?
Secondly, I cant run you Tool code in my computer. it show that there are some questions at CUDNN.
the error show that:
[2020-01-10 20:31:07,787] ERROR in app: Exception on /api/annotation_and_ggnn [POST]
Traceback (most recent call last):
File "/home/lyx/code/PolygonRNN/polyrnn-pp-pytorch/env/local/lib/python2.7/site-packages/flask/app.py", line 2292, in wsgi_app
response = self.full_dispatch_request()
File "/home/lyx/code/PolygonRNN/polyrnn-pp-pytorch/env/local/lib/python2.7/site-packages/flask/app.py", line 1815, in full_dispatch_request
rv = self.handle_user_exception(e)
File "/home/lyx/code/PolygonRNN/polyrnn-pp-pytorch/env/local/lib/python2.7/site-packages/flask_cors/extension.py", line 161, in wrapped_function
return cors_after_request(app.make_response(f(*args, **kwargs)))
File "/home/lyx/code/PolygonRNN/polyrnn-pp-pytorch/env/local/lib/python2.7/site-packages/flask/app.py", line 1718, in handle_user_exception
reraise(exc_type, exc_value, tb)
File "/home/lyx/code/PolygonRNN/polyrnn-pp-pytorch/env/local/lib/python2.7/site-packages/flask/app.py", line 1813, in full_dispatch_request
rv = self.dispatch_request()
File "/home/lyx/code/PolygonRNN/polyrnn-pp-pytorch/env/local/lib/python2.7/site-packages/flask/app.py", line 1799, in dispatch_request
return self.view_functionsrule.endpoint
File "Tool/tool.py", line 153, in generate_annotation_and_ggnn
pred_annotation = tool.annotation(instance, run_ggnn=True)
File "Tool/tool.py", line 66, in annotation
run_ggnn=run_ggnn
File "/home/lyx/code/PolygonRNN/polyrnn-pp-pytorch/env/local/lib/python2.7/site-packages/torch/nn/modules/module.py", line 491, in call
result = self.forward(*input, **kwargs)
File "/home/lyx/code/PolygonRNN/polyrnn-pp-pytorch/code/Models/Poly/polyrnnpp.py", line 121, in forward
concat_feats, feats = self.encoder(x)
File "/home/lyx/code/PolygonRNN/polyrnn-pp-pytorch/env/local/lib/python2.7/site-packages/torch/nn/modules/module.py", line 491, in call
result = self.forward(*input, **kwargs)
File "/home/lyx/code/PolygonRNN/polyrnn-pp-pytorch/code/Models/Encoder/resnet_skip.py", line 73, in forward
fc_f, conv1_f, layer1_f, layer2_f, layer3_f, layer4_f = self.resnet(x)
File "/home/lyx/code/PolygonRNN/polyrnn-pp-pytorch/env/local/lib/python2.7/site-packages/torch/nn/modules/module.py", line 491, in call
result = self.forward(*input, **kwargs)
File "/home/lyx/code/PolygonRNN/polyrnn-pp-pytorch/code/Models/Encoder/resnet.py", line 89, in forward
x = self.conv1(x)
File "/home/lyx/code/PolygonRNN/polyrnn-pp-pytorch/env/local/lib/python2.7/site-packages/torch/nn/modules/module.py", line 491, in call
result = self.forward(*input, **kwargs)
File "/home/lyx/code/PolygonRNN/polyrnn-pp-pytorch/env/local/lib/python2.7/site-packages/torch/nn/modules/conv.py", line 301, in forward
self.padding, self.dilation, self.groups)
RuntimeError: CUDNN_STATUS_EXECUTION_FAILED
I strictly used the same version with you:Ubuntu 16.04, Python 2.7.12, Pytorch 0.4.0, CUDA 9.0,TITAN XP.
So can you answer my questions?
I am hope for your reply.
I changed the global folder to my image directory containing the required images in the polygon.js, but when running the frontend and backend I am not able to label an image nor upload a photo, there is an infinite loop for labeling and error message appears when a image is attempted to be uploaded. No output is produced on the terminal, except for on the frontend when refreshing the page. I've included the terminals below.


Also I changed the globalFolder variable to be set to:
var globalFolder = '/home/myusername/Downloads/polyrnn-pp-pytorch/code/Tool/frontend/static/img'
After filling the form, getting the following error:
SQL Connection failed: Connection refused
Please contact [email protected]
Please look into it.
Could you explain how to test the models on custom data. What all things need to be prepared in the code to run inference/testing on custom data. I have images with bounding box labels and I would like to run the model to generate a segmentation mask. Thank you.
Hi! First of all, thanks for a very interesting article!
Hope you don't mind me asking.
I am currently learning about recurrent neural networks, and I was wondering whether you could elaborate on how the EOS-token is implemented. You say that you one-hot-encode vertices as a DxD + 1 dimensional vector, where the last element signifies that the polygon is closed, i.e., that the current predicted vertex is equal to the first predicted vertex.
How is this implemented? Do you do a check of equality between current predicted and first predicted at every time step, and set the bit accordingly?
What happens after the EOS-token has been reached? Does the network keep predicting vertices until the max_sequence_length number of vertices has been predicted, or does the network stop in some way? In the former case, how do you "discard" the extra vertices generated after the EOS-token?
Cheers in advance!
I wanted to try out the annotation tool before setting it up locally, but the web demo hosted at http://www.cs.toronto.edu/~amlan/demo/ does not seem to work. I believe the problem is with the backend since I keep seeing the 3 dots forever (as in the ss below).

I looked for a contact link on the demo page itself, but couldn't find one, so apologies in advance if this is no place for demo-related issues.
I downloaded the file but can't find the path_to_downloaded_annotation_file. What should it be?
Code Signup failed
Hello, thanks for releasing the training script! I've got some suggestions on the code:
Again, thanks for releasing the code!
Useful resources:
Hi, I'm trying to update the code to use python 3 and pytorch 1.3.
When running inference, I'm getting a different output than python 2 and pytorch 0.4.
Do you know what needs to change?
SkipResnet output matches when I set Upsample(align_corners=False)
PolyGGNN has a different output
I was going through the polygonrnn and polygonnrnnpp paper once again and a question was striking me about the output resolution. 28x28 output resolution in the first version and 128x128 output resolution in the second version. Is that the resolution of the grid size which fits the cropped image of res 224x224?? Does it mean like the cropped image res 224x224 is downscaled to the grid-size so the grid points fits over it. I saw there was some functions which converts the grid values to the coordinates value. But was a little bit confused on the concept.
Lovasz softmax as described in this paper (https://arxiv.org/pdf/1705.08790.pdf) is differentiable loss and can be used to optimize the intersection over union. Did you try to use it instead of RL fine-tuning? What can we expect if we use this instead of the RL finetuning?
I was interested in the fixing method while testing the model. Especially about the variable 'instance['fwd_poly']'. I just initially thought this variable is the new value which is generated after the user does the correction interactively. But after printing this fwd_poly of instance it seems like some floating point numbers with values less than 100. If you don't mind can you elaborate how this fwd_poly is populated?
Thanks for open source this project.
I am looking for a tool to automatically semantically segment videos instead of frame by frame. This tool is good in that it has transferable learning to automatically segment one instance, but it still takes time to label (1) all instances in one frame one by one. (2) same instance through multiple frames. It will be really cool if I can segment all instances of the same category in one frame by one click, and automatically segment the same instances in the following frames.
when i run the command of Launch backend(flash server) in the terminal, the error appears.
The whole information is :File "Tool/tool.py",line 12 ,in
from Utils import utils
ImportError:No module named Utils
Please help me!
Hi, @amlankar . When i work through the code of you published, I find the method of sampling the GT vertexs when training stage is : if the length of GT vertex smaller than the parameter opts['max_poly_len'] ,then taking all the GT vertex when training, otherwise, taking poly[:opts['max_poly_len']] when training. The code of sampling GT vertex in cityscapes.py script as followed:
len_to_keep = min(len(fwd_poly), self.opts['max_poly_len'])
arr_fwd_poly[:len_to_keep] = fwd_poly[:len_to_keep]
arr_bwd_poly[:len_to_keep] = bwd_poly[:len_to_keep]
The understanding about sampling the GT vertex when training, dose it right? If not, can you tell me how? thank U~
I fully followed the guidelines; after running both backend and frontend codes, the web page(localhost:8000) is brought up correctly. But once I click and choose a vehicle object in the default road image, the progress bar keeps updating but hang there for ever.
The detailed traces are copied below.
127.0.0.1 - - [23/Aug/2018 19:30:16] "OPTIONS /api/annotation_and_ggnn HTTP/1.1" 200 -
[2018-08-23 19:30:16,432] ERROR in app: Exception on /api/annotation_and_ggnn [POST]
Traceback (most recent call last):
File "/home/xiaojun/tfenv_xj/venv/lib/python3.5/site-packages/flask/app.py", line 2292, in wsgi_app
response = self.full_dispatch_request()
File "/home/xiaojun/tfenv_xj/venv/lib/python3.5/site-packages/flask/app.py", line 1815, in full_dispatch_request
rv = self.handle_user_exception(e)
File "/home/xiaojun/tfenv_xj/venv/lib/python3.5/site-packages/flask_cors/extension.py", line 161, in wrapped_function
return cors_after_request(app.make_response(f(*args, **kwargs)))
File "/home/xiaojun/tfenv_xj/venv/lib/python3.5/site-packages/flask/app.py", line 1718, in handle_user_exception
reraise(exc_type, exc_value, tb)
File "/home/xiaojun/tfenv_xj/venv/lib/python3.5/site-packages/flask/_compat.py", line 35, in reraise
raise value
File "/home/xiaojun/tfenv_xj/venv/lib/python3.5/site-packages/flask/app.py", line 1813, in full_dispatch_request
rv = self.dispatch_request()
File "/home/xiaojun/tfenv_xj/venv/lib/python3.5/site-packages/flask/app.py", line 1799, in dispatch_request
return self.view_functionsrule.endpoint
File "Tool/tool.py", line 151, in generate_annotation_and_ggnn
instance = tool.data_loader.prepare_component(instance, component)
File "/home/xiaojun/data/polyrnn-pp-pytorch/code/DataProvider/cityscapes.py", line 166, in prepare_component
crop_info = self.extract_crop(component, instance, context_expansion)
File "/home/xiaojun/data/polyrnn-pp-pytorch/code/DataProvider/cityscapes.py", line 245, in extract_crop
img = utils.rgb_img_read(instance['img_path'])
File "/home/xiaojun/data/polyrnn-pp-pytorch/code/Utils/utils.py", line 55, in rgb_img_read
img = imread(img_path)
File "/home/xiaojun/tfenv_xj/venv/lib/python3.5/site-packages/skimage/io/_io.py", line 62, in imread
img = call_plugin('imread', fname, plugin=plugin, **plugin_args)
File "/home/xiaojun/tfenv_xj/venv/lib/python3.5/site-packages/skimage/io/manage_plugins.py", line 214, in call_plugin
return func(*args, **kwargs)
File "/home/xiaojun/tfenv_xj/venv/lib/python3.5/site-packages/skimage/io/_plugins/pil_plugin.py", line 35, in imread
with open(fname, 'rb') as f:
FileNotFoundError: [Errno 2] No such file or directory: '/ais/gobi6/amlan/poly_rnn_demo_images/city1.png'
127.0.0.1 - - [23/Aug/2018 19:30:16] "POST /api/annotation_and_ggnn HTTP/1.1" 500 -
Hi, @amlankar , I don't understant that you said in your paper CVPR17: "Here, we fix the polygon to always follow the clockwise orientation,".But how you did it in your code?, In other words, How can you control the orientation to be clockwise always? I looked into the rnn_step with attention mechanism of your code like :
att_feats, att = self.attention(feats, rnn_state)
att_feats_bak, att_bak = self.attention(feats, rnn_state_back)
input_t = torch.cat((att_feats, v_prev2, v_prev1, v_first), dim=1)
Does the 'catination' order of 'v_prev2, v_prev2, v_first' make clockwise orientation? Apprecaitive for your reply, thank U~.
Hi,
When I tried to sign up to get your code, I met HTTP Error 500 (as showed in the picture below). What should I do to solve this problem and successfully get your code?

Thank you for your work.
The command for training the RL model is
"python Scripts/train/train_rl.py --exp Experiments/mle.json --resume <optional_if_resuming_training>"
Why do we change the paths in rl.json and then train with the mle.json configuration. We are supposed to train the rl model with rl.json right?
Hi, @amlankar , when i try to train RL model on my own dataset which include prostate MRI with different image size 512x512 and 320x320 , then i got the Value Error as bellow:
Exception NameError: "global name 'FileNotFoundError' is not defined" in <bound method _DataLoaderIter.__del__ of <torch.utils.data.dataloader._DataLoaderIter object at 0x7f5964cd7c90>> ignored
Traceback (most recent call last):
File "/home/tzq-lxj/workStation/polygonRNN_pluss/code/Scripts/train/train_rl.py", line 304, in <module>
trainer.loop()
File "/home/tzq-lxj/workStation/polygonRNN_pluss/code/Scripts/train/train_rl.py", line 119, in loop
self.train(epoch)
File "/home/tzq-lxj/workStation/polygonRNN_pluss/code/Scripts/train/train_rl.py", line 179, in train
sampling_ious[i] = metrics.iou_from_mask(sampling_masks[i], gt_mask)
File "/home/tzq-lxj/workStation/polygonRNN_pluss/code/Evaluation/metrics.py", line 72, in iou_from_mask
false_negatives = np.count_nonzero(np.logical_and(gt, np.logical_not(pred)))
ValueError: operands could not be broadcast together with shapes (256,256) (512,512)
So, dose the error means the train images that input to the RL network must be the same size?
How can i handle the problem by changing the RL code without changing the image size when the training dataset with different image size or i get something wrong ?
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.
