dvlab-research / context-aware-consistency Goto Github PK
View Code? Open in Web Editor NEWSemi-supervised Semantic Segmentation with Directional Context-aware Consistency (CVPR 2021)
License: MIT License
Semi-supervised Semantic Segmentation with Directional Context-aware Consistency (CVPR 2021)
License: MIT License









































































































Hello, I was training your model using:
python3 train.py --config configs/voc_cac_deeplabv3+_resnet50_1over8_datalist0.json
The training starts but till 60 iterations of the 1st epoch the RAM explodes and the system crashes.
GPU: P100 16GB
CPU RAM: 25gb
Batch SIze: 2
As the subject.
Thanks!!
thanks for your work.
but i found an error when i try to test the code in VOC
`Checkpoint <E:\Context-Aware-Consistency-master\pretrained\voc_1over8_datalist0_deeplabv3+_resnet101.pth> (epoch 63) was loaded
0%| | 0/724 [00:17<?, ?it/s]
Traceback (most recent call last):
File "D:\ProgramData\Anaconda3\envs\cv\lib\runpy.py", line 193, in _run_module_as_main
"main", mod_spec)
File "D:\ProgramData\Anaconda3\envs\cv\lib\runpy.py", line 85, in run_code
exec(code, run_globals)
File "c:\Users\Administrator.vscode\extensions\ms-python.python-2020.7.96456\pythonFiles\lib\python\debugpy_main.py", line 45, in
cli.main()
File "c:\Users\Administrator.vscode\extensions\ms-python.python-2020.7.96456\pythonFiles\lib\python\debugpy/..\debugpy\server\cli.py", line 430, in main
run()
File "c:\Users\Administrator.vscode\extensions\ms-python.python-2020.7.96456\pythonFiles\lib\python\debugpy/..\debugpy\server\cli.py", line 267, in run_file
runpy.run_path(options.target, run_name=compat.force_str("main"))
File "D:\ProgramData\Anaconda3\envs\cv\lib\runpy.py", line 263, in run_path
pkg_name=pkg_name, script_name=fname)
File "D:\ProgramData\Anaconda3\envs\cv\lib\runpy.py", line 96, in _run_module_code
mod_name, mod_spec, pkg_name, script_name)
File "D:\ProgramData\Anaconda3\envs\cv\lib\runpy.py", line 85, in _run_code
exec(code, run_globals)
File "e:\Context-Aware-Consistency-master\train.py", line 128, in
main(config['n_gpu'], config['n_gpu'], config, args.resume, args.test)
File "e:\Context-Aware-Consistency-master\train.py", line 99, in main
trainer.train()
File "e:\Context-Aware-Consistency-master\base\base_trainer.py", line 105, in train
results = self._valid_epoch(0)
File "e:\Context-Aware-Consistency-master\trainer.py", line 145, in _valid_epoch
for batch_idx, (data, target) in enumerate(tbar):
File "D:\ProgramData\Anaconda3\envs\cv\lib\site-packages\tqdm\std.py", line 1185, in iter
for obj in iterable:
File "D:\ProgramData\Anaconda3\envs\cv\lib\site-packages\torch\utils\data\dataloader.py", line 435, in next
data = self._next_data()
File "D:\ProgramData\Anaconda3\envs\cv\lib\site-packages\torch\utils\data\dataloader.py", line 475, in _next_data
data = self._dataset_fetcher.fetch(index) # may raise StopIteration
File "D:\ProgramData\Anaconda3\envs\cv\lib\site-packages\torch\utils\data_utils\fetch.py", line 47, in fetch
return self.collate_fn(data)
File "D:\ProgramData\Anaconda3\envs\cv\lib\site-packages\torch\utils\data_utils\collate.py", line 83, in default_collate
return [default_collate(samples) for samples in transposed]
File "D:\ProgramData\Anaconda3\envs\cv\lib\site-packages\torch\utils\data_utils\collate.py", line 83, in
return [default_collate(samples) for samples in transposed]
File "D:\ProgramData\Anaconda3\envs\cv\lib\site-packages\torch\utils\data_utils\collate.py", line 55, in default_collate
return torch.stack(batch, 0, out=out)
RuntimeError: stack expects each tensor to be equal size, but got [3, 375, 500] at entry 0 and [3, 396, 500] at entry 1`
Hi,
as the question, why iters are fixed?
If it is fixed, and the iters to run over the epoch are less than the fixed number. Maybe it's not suitable to call that the whole training process runs 80 epochs.
An I also want to ask how much time it takes to train the models (80 epochs, fixed iters, voc/city dataset).
Thanks!!
Hi,
Thanks for your work!
I'm wondering your result on this table is based on deeplabv3+ or not.

Cheers,
Hello, I use the config file you provide to reproduce on Pascal Voc dataset. But I got somehow slightly lower results in multiple dataset split setting. My reproduce result are as following.

And config file used in my experiment is as following.
{
"name": "CAC",
"experim_name": "cac_datalist0_1of8_3",
"dataset": "voc",
"data_dir": ###,
"datalist": 3,
"n_gpu": 4,
"n_labeled_examples": 10582,
"diff_lrs": true,
"ramp_up": 0.1,
"unsupervised_w": 30,
"ignore_index": 255,
"lr_scheduler": "Poly",
"use_weak_lables":false,
"weakly_loss_w": 0.4,
"pretrained": true,
"random_seed": 42,
"model":{
"supervised": false,
"semi": true,
"supervised_w": 1,
"sup_loss": "CE",
"layers": 101,
"downsample": true,
"proj_final_dim": 128,
"out_dim": 256,
"backbone": "deeplab_v3+",
"pos_thresh_value": 0.75,
"weight_unsup": 0.1,
"epoch_start_unsup": 5,
"selected_num": 3200,
"temp": 0.1,
"step_save": 2,
"stride": 8
},
"optimizer": {
"type": "SGD",
"args":{
"lr": 0.01,
"weight_decay": 1e-4,
"momentum": 0.9
}
},
"train_supervised": {
"batch_size": 8,
"crop_size": 320,
"shuffle": true,
"base_size": 400,
"scale": true,
"augment": true,
"flip": true,
"rotate": false,
"blur": false,
"split": "train_supervised",
"num_workers": 8
},
"train_unsupervised": {
"batch_size": 8,
"crop_size": 320,
"shuffle": true,
"base_size": 400,
"scale": true,
"augment": true,
"flip": true,
"rotate": false,
"blur": false,
"split": "train_unsupervised",
"num_workers": 8,
"iou_bound": [0.1, 1.0],
"stride": 8
},
"val_loader": {
"batch_size": 4,
"val": true,
"split": "val",
"shuffle": false,
"num_workers": 4
},
"trainer": {
"epochs": 80,
"save_dir": "saved/",
"save_period": 1,
"monitor": "max Mean_IoU",
"early_stop": 100,
"tensorboardX": true,
"log_dir": "saved/",
"log_per_iter": 20,
"val": true,
"val_per_epochs": 1
}
}
Could you give me some advice about how to correctly reproduce your results?
Thanks a lot.
你好,请问如何确定论文中随机选取的重叠区域刚好是目标所在的区域(伪标签的值)?如果选取的重叠区域不是目标所在,那对比损失还有意义吗?
I see that the algorithm uses labels for unsupervised data as well.
How to train without using the labels for unsupervised data ?
Thank you for your nice work!
I was a little wondering about :
Thank you for your nice work!
Would it be possible to provide the exact number of labeled data and unlabeled data with 1/16, 1/8, 1/4 setting of two datasets?
I get ValueError when I try to reproduce your paper results on Pascal Voc dataset. Concretely, it raises "ValueError: Cannot take a larger sample than population when 'replace=False'" when use default selected_num setting with value of 6400. And error aforementioned occurs at following line.
Context-Aware-Consistency/models/model.py
Line 174 in 4fdec7a

This error will be reported at 20% of the first round of training. Can you tell me the reason? How to solve it? My configuration is two pieces of 2080ti and 64g memory

May the learning rate used not 'poly'?
def get_lr(self): T = self.last_epoch * self.iters_per_epoch + self.cur_iter factor = pow((1 - 1.0 * T / self.N), 0.9) if self.warmup_iters > 0 and T < self.warmup_iters: factor = 1.0 * T / self.warmup_iters self.cur_iter %= self.iters_per_epoch self.cur_iter += 1 assert factor >= 0, 'error in lr_scheduler' return [base_lr * factor for base_lr in self.base_lrs]
However, the lr updated as follows,
self.lr_scheduler.step(epoch=epoch-1)
Is that a bug or a specific design?
https://github.com/pytorch/pytorch/blob/41054f2ab5bb39d28a3eb8497f1a65b42385a996/torch/optim/lr_scheduler.py#L155
I try to train the model by only one GPU. But the process is ended by the following error :
Traceback (most recent call last):
File "train.py", line 127, in
mp.spawn(main, nprocs=config['n_gpu'], args=(config['n_gpu'], config, args.resume, args.test))
File "/home/ders/anaconda3/envs/sdp/lib/python3.6/site-packages/torch/multiprocessing/spawn.py", line 230, in spawn
return start_processes(fn, args, nprocs, join, daemon, start_method='spawn')
File "/home/ders/anaconda3/envs/sdp/lib/python3.6/site-packages/torch/multiprocessing/spawn.py", line 188, in start_processes
while not context.join():
File "/home/ders/anaconda3/envs/sdp/lib/python3.6/site-packages/torch/multiprocessing/spawn.py", line 150, in join
raise ProcessRaisedException(msg, error_index, failed_process.pid)
torch.multiprocessing.spawn.ProcessRaisedException:
-- Process 0 terminated with the following error:
Traceback (most recent call last):
File "/home/ders/anaconda3/envs/sdp/lib/python3.6/site-packages/torch/multiprocessing/spawn.py", line 59, in _wrap
fn(i, *args)
File "/media/ders/sundingpeng/paper_code/Context-Aware-Consistency-master-2/train.py", line 98, in main
trainer.train()
File "/media/ders/sundingpeng/paper_code/Context-Aware-Consistency-master-2/base/base_trainer.py", line 115, in train
results = self._valid_epoch(epoch)
File "/media/ders/sundingpeng/paper_code/Context-Aware-Consistency-master-2/trainer.py", line 145, in _valid_epoch
for batch_idx, (data, target) in enumerate(tbar):
File "/home/ders/anaconda3/envs/sdp/lib/python3.6/site-packages/tqdm/std.py", line 1178, in iter
for obj in iterable:
File "/home/ders/anaconda3/envs/sdp/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 517, in next
data = self._next_data()
File "/home/ders/anaconda3/envs/sdp/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 1199, in _next_data
return self._process_data(data)
File "/home/ders/anaconda3/envs/sdp/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 1225, in _process_data
data.reraise()
File "/home/ders/anaconda3/envs/sdp/lib/python3.6/site-packages/torch/_utils.py", line 429, in reraise
raise self.exc_type(msg)
RuntimeError: Caught RuntimeError in DataLoader worker process 0.
Original Traceback (most recent call last):
File "/home/ders/anaconda3/envs/sdp/lib/python3.6/site-packages/torch/utils/data/_utils/worker.py", line 202, in _worker_loop
data = fetcher.fetch(index)
File "/home/ders/anaconda3/envs/sdp/lib/python3.6/site-packages/torch/utils/data/_utils/fetch.py", line 47, in fetch
return self.collate_fn(data)
File "/home/ders/anaconda3/envs/sdp/lib/python3.6/site-packages/torch/utils/data/_utils/collate.py", line 83, in default_collate
return [default_collate(samples) for samples in transposed]
File "/home/ders/anaconda3/envs/sdp/lib/python3.6/site-packages/torch/utils/data/_utils/collate.py", line 83, in
return [default_collate(samples) for samples in transposed]
File "/home/ders/anaconda3/envs/sdp/lib/python3.6/site-packages/torch/utils/data/_utils/collate.py", line 55, in default_collate
return torch.stack(batch, 0, out=out)
RuntimeError: stack expects each tensor to be equal size, but got [3, 366, 500] at entry 0 and [3, 335, 500] at entry 1
if self.mode == 'supervised':
# dataloader = iter(self.supervised_loader)
# tbar = tqdm(range(len(self.supervised_loader)), ncols=135)
dataloader = iter(cycle(self.supervised_loader))
tbar = tqdm(range(self.iter_per_epoch), ncols=135)
else:
dataloader = iter(zip(cycle(self.supervised_loader), cycle(self.unsupervised_loader)))
tbar = tqdm(range(self.iter_per_epoch), ncols=135)
The comment part is your original code.
In the semi-supervised method, 'cycle' was used to expand the number of iterations of labeled images. Obviously the number of iterations in the fully-supervised is much less. I think this comparison may be unfair. What is your opinion or modification plan? Looking forward to your answer, thanks!
Hey @X-Lai ,
Thank you for sharing your work!
I was able to set up the repository and run the experiments in accordance with the steps provided. However , I am finding it difficult to understand some part of the code related to unsupervised data loader. Please find my queries below:
dataloaders/voc.py: overlap1_ul = [max(0, y2-y1), max(0, x2-x1)]
overlap1_br = [min(self.crop_size, self.crop_size+y2-y1, h//self.stride * self.stride), min(self.crop_size, self.crop_size+x2-x1, w//self.stride * self.stride)]
overlap2_ul = [max(0, y1-y2), max(0, x1-x2)]
overlap2_br = [min(self.crop_size, self.crop_size+y1-y2, h//self.stride * self.stride), min(self.crop_size, self.crop_size+x1-x2, w//self.stride * self.stride)]
I am not quite able to understand the utility of self.stride, why is this necessary and what exactly does overlap1_ul and overlap1_br represent
Regards
Nitin
Hi, thank you for your great work!
Could you please give me some advice on using weak labels? Are the classification model are first pre-trained on ImageNet are next fine-tuned on specific weak-annotated datasets like CityScapes?
when use "python3 train.py --config configs/voc_cac_deeplabv3+_resnet50_1over8_datalist0.json" with two GPUS to run , i find that one GPUS imput image size is (1,3,335,500) while another is (1,3,366,500) . in this case ,i can run to end.
but ,when i run with only one GPU,the problem of diffrent size is occr.
how is go ???
Dear Author,
Thanks so much for your excellent work, and the code. I'm just get into the semi-supervised segmentation field, and I'm really interested for your Grad-CAM visualization, which is shown in your first page of the paper.
Could you give me some advice to visualize it? Any advice/pseudo-code could be really helpful!
Thanks again!
Hi, thanks for your nice work!
You have listed some results of other methods (such as CCT), have you just re-implement the method under your settings?
As we know, the splits of dataset differ in those semi-sup papers.
Thanks.
Thanks for your great work!
but i wonder how to visualize the result?Are there any codes?I try to solve it for several days,but can not figure it out...
It seems that you only provide 1323 label supervised experiment. How can I reimplement your 1/4 and full part?? Thanks
Hi X-Lai,
Thank you very much for sharing your well-organized code and I'm trying to use your Directional Contrastive Loss in my work. I have a question on the calculation of Directional Contrastive Loss.
Equation 1 in your conference paper has two items in the denominator, while the calculation in your code is as following:
logits1 = torch.exp(pos1 - neg_max1).squeeze(-1) / (logits1_down + eps) # in model.py Line 231.
Should it be 'torch.exp(pos1 - neg_max1).squeeze(-1) / (torch.exp(pos1 - eg_max1).squeeze(-1)+logits1_down + eps)'? Or 'torch.exp(pos1 - neg_max1).squeeze(-1)' is already added up to logits1_down.
Ps: Is 'neg_max1' for normalization?
I'm looking forward to your reply!
Thanks for your nice work!
Will scripts and pre-trained models for cityscapes be published?
in addition,iteration per epoch is constant in train.py code , 'iter_per_epoch = 1157', can i set it with 'len(unsupervised_loader)', thank you!
Thank you for your excellent work. How to visualize the results?
I try to train the model as your guide ( python3 train.py --config configs/voc_cac_deeplabv3+_resnet50_1over8_datalist0.json
), but the program is ended with an error. Can you give me some suggestions?
The error :
Traceback (most recent call last):
File "/home/anaconda3/envs/sdp36/lib/python3.6/site-packages/torch/multiprocessing/spawn.py", line 59, in _wrap
fn(i, *args)
File "/home/sundingpeng/paper_code/Context-Aware-Consistency-master/train.py", line 98, in main
trainer.train()
File "/home/sundingpeng/paper_code/Context-Aware-Consistency-master/base/base_trainer.py", line 113, in train
self._train_epoch(epoch)
File "/home/sundingpeng/paper_code/Context-Aware-Consistency-master/trainer.py", line 81, in _train_epoch
curr_iter=batch_idx, target_ul=target_ul, epoch=epoch-1, **kargs)
File "/home/anaconda3/envs/sdp36/lib/python3.6/site-packages/torch/nn/modules/module.py", line 1051, in _call_impl
return forward_call(*input, **kwargs)
File "/home/anaconda3/envs/sdp36/lib/python3.6/site-packages/torch/nn/parallel/distributed.py", line 799, in forward
output = self.module(inputs[0], **kwargs[0])
File "/home/anaconda3/envs/sdp36/lib/python3.6/site-packages/torch/nn/modules/module.py", line 1051, in _call_impl
return forward_call(input, **kwargs)
File "/home/sundingpeng/paper_code/Context-Aware-Consistency-master/models/model.py", line 174, in forward
selected_idx1 = np.random.choice(range(bhw), selected_num, replace=False)
File "mtrand.pyx", line 954, in numpy.random.mtrand.RandomState.choice
ValueError: Cannot take a larger sample than population when 'replace=False'
Thank you for your amazing job.
I have one question about your ablation results. As in Table 3,
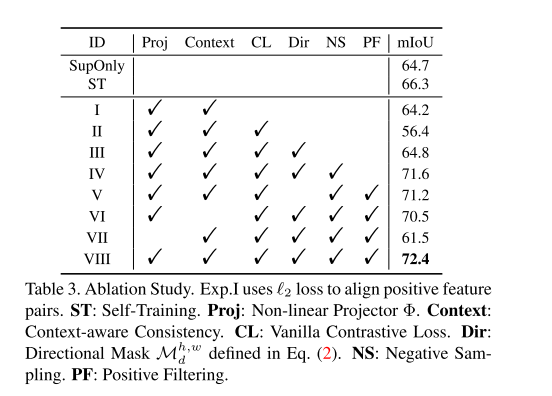
you applied Proj+Context+L2 regularization in Exp.1. However, the performance is lower than SupOnly.
Could you please give me some more explanation about this phenomenon?
def _train_epoch(self, epoch):
raise NotImplementedError
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.