deepgraphlearning / torchdrug Goto Github PK
View Code? Open in Web Editor NEWA powerful and flexible machine learning platform for drug discovery
Home Page: https://torchdrug.ai/
License: Apache License 2.0
A powerful and flexible machine learning platform for drug discovery
Home Page: https://torchdrug.ai/
License: Apache License 2.0

































































































































I'm wondering if there is an intention to serve pretrained models directly through the API? It seems to me readily available pretrained models (eg large-scale trained molecular representation models) would be of great utility for many users and generally reduce waste.
See the huggingface transformers library as an example. There is vast demand for this type of interface...
Hi,
I tried to build a property prediction model using the OPV dataset. See code below.
Training a GIN model using all 8 tasks fails due to missing values in the 4 subtasks ending in _extrapolated.
However, model training does not stop even when all values get nan.
When the 4 subtasks with missing values are excluded model training works fine.
How does torchdrug deal with missing values in subtasks?
I'm asking as I would like to find out how robust multitask GIN models are to data sparsity.
See Effect of missing data on multitask prediction methods
import torch
from torchdrug import core, data, datasets, tasks, models
dataset = datasets.OPV("~/molecule-datasets/")
train_set, valid_set, test_set = dataset.split()
print(f"# Train/Valid/Test: {len(train_set)}/{len(valid_set)}/{len(test_set)}")
model = models.GIN(
input_dim=dataset.node_feature_dim,
hidden_dims=[300, 300, 300, 300],
short_cut=True,
batch_norm=True,
concat_hidden=True,
)
subtasks = (
"gap",
"homo",
"lumo",
"spectral_overlap",
# "homo_extrapolated", # task contains nan values
# "lumo_extrapolated", # task contains nan values
# "gap_extrapolated", # task contains nan values
# "optical_lumo_extrapolated", # task contains nan values
)
task = tasks.PropertyPrediction(
model, task=subtasks, criterion="mse", metric=("mae", "rmse"), verbose=1
)
optimizer = torch.optim.Adam(task.parameters(), lr=1e-3)
solver = core.Engine(
task,
train_set,
valid_set,
test_set,
optimizer,
gpus=[0],
batch_size=256,
)
solver.train(num_epoch=3)
solver.save("opv_gin_property_prediction.pth")
solver.evaluate("valid")
solver.evaluate("test")Thanks!
Hi, thanks for sharing this repo!
I am wondering how I could input arbitrary target/product for retrosynthesis analysis? What target format would the model required besides SMILES? In the notebook, it's performing prediction on USPTO dataset. I am interested in knowing how I could apply this model to the target outside of USPTO.
Thanks!!
import torchdrug will result in GUI of matplotlib use agg and the figure cant show. In general, the GUI of matplotlib use module://backend_interaggto show figure. Agg is non-GUI backend, so please tell why? In the graph.py, i find the function named visualize to show figure, but i cant find why change it. Hope to get your reply! Thanks!
Tip:
I find a solution to solve this problem.
under the all import, add matplotlib.use('module://backend_interagg') and import matplotlib.
I tried following the tutorial of GCPN. But when I execute model = models.RGCN(input_dim=dataset.node_feature_dim, num_relation=dataset.num_bond_type, hidden_dims=[256, 256, 256, 256], batch_norm=False), I got the following error:
Traceback (most recent call last):
File "gcpn.py", line 13, in <module>
num_relation=dataset.num_bond_type,
File "/opt/conda/lib/python3.8/site-packages/torchdrug/data/dataset.py", line 168, in num_bond_type
return len(self.bond_types)
File "/opt/conda/lib/python3.8/site-packages/torchdrug/utils/decorator.py", line 21, in __get__
result = self.func(obj)
File "/opt/conda/lib/python3.8/site-packages/torchdrug/data/dataset.py", line 183, in bond_types
bond_types.update(graph.edge_list[:, 2].tolist())
AttributeError: 'NoneType' object has no attribute 'edge_list'
I tried the dataset MOSES. It looks like in torchdrug/data/dataset.py, line 183, we have
for graph in self.data:
bond_types.update(graph.edge_list[:, 2].tolist())
and then the program complained about that graph is a NoneType, which may refer to self.data also has some problem. So I think there may be some bug in RGCN when interpreting the dataset. But I don't know how the inside works, could someone help solve this problem?
To reproduce this problem, I used nvidia docker:
nvidia-docker run -it --name=xxxxx nvcr.io/nvidia/pytorch:21.06-py3 /bin/bash
conda install -c milagraph -c conda-forge torchdrug
and then follow the tutorial.
When running the following code
from torchdrug import utils
from torch.nn import functional as F
samples = []
categories = set()
for sample in valid_set:
sample.pop("graph")
category = tuple(sample.values())
if category not in categories:
categories.add(category)
samples.append(sample)
samples = data.graph_collate(samples)
samples = utils.cuda(samples)
preds = F.sigmoid(task.predict(samples))
targets = task.target(samples)
titles = []
for pred, target in zip(preds, targets):
pred = ", ".join(["%.2f" % p for p in pred])
target = ", ".join(["%d" % t for t in target])
titles.append("predict: %s\ntarget: %s" % (pred, target))
graph = samples["graph"]
graph.visualize(titles, figure_size=(3, 3.5), num_row=1)
The following error occurred:
Traceback (most recent call last):
File "/home/ibmc-2/Projects/MNIST/mnist_data/5-2.py", line 46, in <module>
preds = F.sigmoid(task.predict(samples))
File "/home/ibmc-2/anaconda3/envs/td/lib/python3.8/site-packages/torchdrug-0.1.0-py3.8.egg/torchdrug/tasks/property_prediction.py", line 104, in predict
graph = batch["graph"]
KeyError: 'graph'
Since I'm just getting started, the question may be absurd. Thank you
Hi!
How to use the generation model to optimize specific molecules? For example, I have trained a generation model of QED and logP "GCPN"_ zinc250k_ 1epoch_ finetune. pkl ",and I have one or some smiles of known molecules. I want to generate some molecules with better QED and logP properties based on my own molecules through this generation model. How can I achieve it?
What's more, how is it implemented on the official website Tutorials: Molecule Generation? I don't have such output during and after the training
The results are as follows:
(5.63, 'CC=CC=CC=CC=CC=CC=CC=CC=CC=CC=CC=CC=CC=CC=CC=CC=C(I)C(C)(C)C')
(5.60, 'CCC=CC=CC=CC=CC=CC=CC=CC=CC=CC=CC=CC=CC=CC=CC=CC(C)(C)CCC')
(5.44, 'CC=CC=CC=CC(Cl)=CC=CC=CC=CC=CC=C(C)C=CC=CC=C(C)C=CC(Br)=CC=CCCC')
(5.35, 'CC=CC=CC=CC=CC=CC=CC=CC=CC=CC=CC=CC=CC=CC=CC=CC=C(CC)C(C)C')
...
Thank you very much!
Following the Get Started guide, the following error is thrown
import json
with open("clintox_gin.json", "w") as fout:
json.dump(solver.config_dict(), fout)
solver.save("clintox_gin.pth")
TypeError: Object of type Subset is not JSON serializable
dataset.num_bond_type
Traceback (most recent call last):
File "", line 1, in
File "/torchdrug/torchdrug/data/dataset.py", line 168, in num_bond_type
return len(self.bond_types)
File "torchdrug/torchdrug/utils/decorator.py", line 21, in get
result = self.func(obj)
File "torchdrug/torchdrug/data/dataset.py", line 183, in bond_types
bond_types.update(graph.edge_list[:, 2].tolist())
AttributeError: 'NoneType' object has no attribute 'edge_list'
import torch
from torchdrug import data, datasets
dataset = datasets.ChEMBLFiltered("~/molecule-datasets/")fails with
~/opt/anaconda3/envs/drugs/lib/python3.8/site-packages/torchdrug/datasets/chembl_filtered.py in _load_chembl_with_labels_dataset(root_path)
103 def _load_chembl_with_labels_dataset(root_path):
104 # 1. load folds and labels
--> 105 f=open(os.path.join(root_path, 'folds0.pckl'), 'rb')
106 folds=pickle.load(f)
107 f.close()
FileNotFoundError: [Errno 2] No such file or directory: './temp/chem_dataset/dataset/chembl_filtered/raw/folds0.pckl'
However, file folds0.pckl is written to
~/molecule-datasets/chem_dataset/dataset/chembl_filtered/raw/folds0.pckl
ChEMBLFiltered seems to download all MoleculeNet related datasets.
Is that intended behaviour?
import torch
from torchdrug import core, datasets, tasks, models
dataset = datasets.ZINC2m("~/molecule-datasets/", node_feature="pretrain", edge_feature="pretrain")~/opt/anaconda3/envs/drugs/lib/python3.8/site-packages/torchdrug/datasets/zinc2m.py in __init__(self, path, verbose, **kwargs)
44 reader = csv.reader(fin)
45 if verbose:
---> 46 reader = iter(tqdm(reader, "Loading %s" % path, utils.get_line_count(path)))
47 smiles_list = []
48
~/opt/anaconda3/envs/drugs/lib/python3.8/site-packages/torchdrug/utils/file.py in get_line_count(file_name, chunk_size)
112 """
113 count = 0
--> 114 with open(file_name, "rb") as fin:
115 chunk = fin.read(chunk_size)
116 while chunk:
IsADirectoryError: [Errno 21] Is a directory: '/username/molecule-datasets/'
I modified the code 'plt.switch_backend("agg")' in graph.py to 'plt.switch_backend("TkAgg")', and still can't show the image,what's the correct way?
the code 'command = ['ninja', '-v']' in file ~\Lib\site-packages\torch\utils\cpp_extension.py line 1631 report an error,then I modified to command = ['ninja', '--version'],an other error occured

how can I fix it?
Please add a description or tutorial how to load custom data.
I would like to use the clinical photosensitivity (PIH) data published by Schmidt et al Chem. Res. Toxicol. 2019, 32, 2338−2352.
The data can be downloaded as supplementary material EXCEL file tx9b00338_si_001.xls
Table S1 contains a column with the SMILES, the PIH value and a Set column, with indicates the splits.
Many thanks
This issue happens in torch 1.9.0 + python 3.7, but not in torch 1.8.0 + python 3.7.
Upgrading PyTorch from 1.4 to 1.5 has made the code work fine.
Thanks.
Originally posted by @sleeper2173 in #12 (comment)
I meet the same problem. Could you specify how did you upgrade the pytorch? I tried conda install pytorch==1.5.1 torchvision==0.6.1 cudatoolkit=10.1 -c pytorch but then got the error
File "/opt/conda/lib/python3.8/site-packages/torch_scatter/__init__.py", line 18, in <module>
raise RuntimeError(
RuntimeError: Expected PyTorch version 1.4 but found version 1.5.
Then I tried uninstall torch_scatter and install it again. But it didn't help.
I'm working on the nvidia docker image: docker nvidia-docker run -it --name torchDrug -v ~/shared:/home/shared nvcr.io/nvidia/pytorch:21.06-py3 /bin/bash and ran the command conda install -c milagraph -c conda-forge torchdrug after starting the container.
Hi,
I've installed torchdrug via conda. The installation updates already installed pytorch and pytorch_scatter. I don't know the backside of torchdrug yet, but it seems like to me maybe install (or update) too many the packages. Wouldn't it be safer, if some of the dependencies are already installed, for such dependencies not to update while installing torchdrug?
Whenever any model encounters functions like functional.generalized_spmm() or functional.generalized_rspmm() it crashes with a long stack trace saying that there are problems when JIT compiling the C++ code:
RuntimeError: Error building extension 'spmm': [1/3] c++ -MMD -MF spmm.o.d -DTORCH_EXTENSION_NAME=spmm -DTORCH_API_INCLUDE_EXTENSION_H -DPYBIND11_COMPILER_TYPE=\"_clang\" -DPYBIND11_STDLIB=\"_libcpp\" -DPYBIND11_BUILD_ABI=\"_cxxabi1002\" -isystem /Users/migalkin/opt/miniconda3/envs/nbf/lib/python3.8/site-packages/torch/include -isystem /Users/migalkin/opt/miniconda3/envs/nbf/lib/python3.8/site-packages/torch/include/torch/csrc/api/include -isystem /Users/migalkin/opt/miniconda3/envs/nbf/lib/python3.8/site-packages/torch/include/TH -isystem /Users/migalkin/opt/miniconda3/envs/nbf/lib/python3.8/site-packages/torch/include/THC -isystem /Users/migalkin/opt/miniconda3/envs/nbf/include/python3.8 -D_GLIBCXX_USE_CXX11_ABI=0 -fPIC -std=c++14 -g -Ofast -fopenmp -c /Users/migalkin/opt/miniconda3/envs/nbf/lib/python3.8/site-packages/torchdrug/layers/functional/extension/spmm.cpp -o spmm.o
FAILED: spmm.o
c++ -MMD -MF spmm.o.d -DTORCH_EXTENSION_NAME=spmm -DTORCH_API_INCLUDE_EXTENSION_H -DPYBIND11_COMPILER_TYPE=\"_clang\" -DPYBIND11_STDLIB=\"_libcpp\" -DPYBIND11_BUILD_ABI=\"_cxxabi1002\" -isystem /Users/migalkin/opt/miniconda3/envs/nbf/lib/python3.8/site-packages/torch/include -isystem /Users/migalkin/opt/miniconda3/envs/nbf/lib/python3.8/site-packages/torch/include/torch/csrc/api/include -isystem /Users/migalkin/opt/miniconda3/envs/nbf/lib/python3.8/site-packages/torch/include/TH -isystem /Users/migalkin/opt/miniconda3/envs/nbf/lib/python3.8/site-packages/torch/include/THC -isystem /Users/migalkin/opt/miniconda3/envs/nbf/include/python3.8 -D_GLIBCXX_USE_CXX11_ABI=0 -fPIC -std=c++14 -g -Ofast -fopenmp -c /Users/migalkin/opt/miniconda3/envs/nbf/lib/python3.8/site-packages/torchdrug/layers/functional/extension/spmm.cpp -o spmm.o
clang: error: unsupported option '-fopenmp'
[2/3] c++ -MMD -MF rspmm.o.d -DTORCH_EXTENSION_NAME=spmm -DTORCH_API_INCLUDE_EXTENSION_H -DPYBIND11_COMPILER_TYPE=\"_clang\" -DPYBIND11_STDLIB=\"_libcpp\" -DPYBIND11_BUILD_ABI=\"_cxxabi1002\" -isystem /Users/migalkin/opt/miniconda3/envs/nbf/lib/python3.8/site-packages/torch/include -isystem /Users/migalkin/opt/miniconda3/envs/nbf/lib/python3.8/site-packages/torch/include/torch/csrc/api/include -isystem /Users/migalkin/opt/miniconda3/envs/nbf/lib/python3.8/site-packages/torch/include/TH -isystem /Users/migalkin/opt/miniconda3/envs/nbf/lib/python3.8/site-packages/torch/include/THC -isystem /Users/migalkin/opt/miniconda3/envs/nbf/include/python3.8 -D_GLIBCXX_USE_CXX11_ABI=0 -fPIC -std=c++14 -g -Ofast -fopenmp -c /Users/migalkin/opt/miniconda3/envs/nbf/lib/python3.8/site-packages/torchdrug/layers/functional/extension/rspmm.cpp -o rspmm.o
FAILED: rspmm.o
c++ -MMD -MF rspmm.o.d -DTORCH_EXTENSION_NAME=spmm -DTORCH_API_INCLUDE_EXTENSION_H -DPYBIND11_COMPILER_TYPE=\"_clang\" -DPYBIND11_STDLIB=\"_libcpp\" -DPYBIND11_BUILD_ABI=\"_cxxabi1002\" -isystem /Users/migalkin/opt/miniconda3/envs/nbf/lib/python3.8/site-packages/torch/include -isystem /Users/migalkin/opt/miniconda3/envs/nbf/lib/python3.8/site-packages/torch/include/torch/csrc/api/include -isystem /Users/migalkin/opt/miniconda3/envs/nbf/lib/python3.8/site-packages/torch/include/TH -isystem /Users/migalkin/opt/miniconda3/envs/nbf/lib/python3.8/site-packages/torch/include/THC -isystem /Users/migalkin/opt/miniconda3/envs/nbf/include/python3.8 -D_GLIBCXX_USE_CXX11_ABI=0 -fPIC -std=c++14 -g -Ofast -fopenmp -c /Users/migalkin/opt/miniconda3/envs/nbf/lib/python3.8/site-packages/torchdrug/layers/functional/extension/rspmm.cpp -o rspmm.o
clang: error: unsupported option '-fopenmp'
ninja: build stopped: subcommand failed.
It seems that the problem is in the unsupported -fopenmp compiler flag for clang.
Torchdrug version is 0.1.0 h6151fa9. Python 3.8, torch 1.8.1.
I am running the code on macOS 11.2.1 (M1 CPU in the x86 compatibility mode, but it shouldn't matter I guess). clang version is:
Apple clang version 12.0.0 (clang-1200.0.32.29)
Target: x86_64-apple-darwin20.3.0
Thread model: posix
InstalledDir: /Library/Developer/CommandLineTools/usr/bin
The conda environment has the following packages:
attrs 21.2.0 pyhd8ed1ab_0 conda-forge
boost 1.74.0 py38h692b87f_3 conda-forge
boost-cpp 1.74.0 hff03dee_4 conda-forge
bzip2 1.0.8 h0d85af4_4 conda-forge
ca-certificates 2021.5.30 h033912b_0 conda-forge
cairo 1.16.0 he43a7df_1008 conda-forge
certifi 2021.5.30 py38h50d1736_0 conda-forge
cffi 1.14.6 py38h9688ba1_0 conda-forge
colorama 0.4.4 pyh9f0ad1d_0 conda-forge
coverage 5.5 py38h96a0964_0 conda-forge
cycler 0.10.0 py_2 conda-forge
decorator 4.4.2 py_0 conda-forge
easydict 1.9 pypi_0 pypi
fontconfig 2.13.1 h10f422b_1005 conda-forge
freetype 2.10.4 h4cff582_1 conda-forge
future 0.18.2 py38h50d1736_3 conda-forge
gettext 0.19.8.1 h7937167_1005 conda-forge
greenlet 1.1.1 py38ha048514_0 conda-forge
icu 68.1 h74dc148_0 conda-forge
iniconfig 1.1.1 pyh9f0ad1d_0 conda-forge
jbig 2.1 h0d85af4_2003 conda-forge
jinja2 3.0.1 pyhd8ed1ab_0 conda-forge
jpeg 9d hbcb3906_0 conda-forge
kiwisolver 1.3.2 py38h12bbefe_0 conda-forge
lcms2 2.12 h577c468_0 conda-forge
lerc 2.2.1 h046ec9c_0 conda-forge
libblas 3.9.0 11_osx64_mkl conda-forge
libcblas 3.9.0 11_osx64_mkl conda-forge
libcxx 12.0.1 habf9029_0 conda-forge
libdeflate 1.7 h35c211d_5 conda-forge
libffi 3.3 h046ec9c_2 conda-forge
libgfortran 5.0.0 9_3_0_h6c81a4c_23 conda-forge
libgfortran5 9.3.0 h6c81a4c_23 conda-forge
libglib 2.68.4 hd556434_0 conda-forge
libiconv 1.16 haf1e3a3_0 conda-forge
liblapack 3.9.0 11_osx64_mkl conda-forge
libpng 1.6.37 h7cec526_2 conda-forge
libprotobuf 3.16.0 hcf210ce_0 conda-forge
libtiff 4.3.0 h1167814_1 conda-forge
libwebp-base 1.2.1 h0d85af4_0 conda-forge
libxml2 2.9.12 h93ec3fd_0 conda-forge
llvm-openmp 12.0.1 hda6cdc1_1 conda-forge
lz4-c 1.9.3 he49afe7_1 conda-forge
markupsafe 2.0.1 py38h96a0964_0 conda-forge
matplotlib 3.4.3 py38h50d1736_0 conda-forge
matplotlib-base 3.4.3 py38hc7d2367_0 conda-forge
mkl 2021.3.0 h08c4f10_555 conda-forge
more-itertools 8.8.0 pyhd8ed1ab_0 conda-forge
ncurses 6.2 h2e338ed_4 conda-forge
networkx 2.6.2 pyhd8ed1ab_0 conda-forge
ninja 1.10.2 h9a9d8cb_0 conda-forge
numpy 1.21.2 py38h49b9922_0 conda-forge
olefile 0.46 pyh9f0ad1d_1 conda-forge
openjpeg 2.4.0 h6e7aa92_1 conda-forge
openssl 1.1.1l h0d85af4_0 conda-forge
packaging 21.0 pyhd8ed1ab_0 conda-forge
pandas 1.3.2 py38ha53d530_0 conda-forge
pcre 8.45 he49afe7_0 conda-forge
pillow 8.3.1 py38hee640a0_0 conda-forge
pip 21.2.4 pyhd8ed1ab_0 conda-forge
pixman 0.40.0 hbcb3906_0 conda-forge
pluggy 0.13.1 py38h50d1736_4 conda-forge
py 1.10.0 pyhd3deb0d_0 conda-forge
pycairo 1.20.1 py38h53d24c6_0 conda-forge
pycparser 2.20 pyh9f0ad1d_2 conda-forge
pyparsing 2.4.7 pyh9f0ad1d_0 conda-forge
pytest 6.2.5 py38h50d1736_0 conda-forge
pytest-cov 2.12.1 pyhd8ed1ab_0 conda-forge
python 3.8.11 h88f2d9e_1
python-dateutil 2.8.2 pyhd8ed1ab_0 conda-forge
python_abi 3.8 2_cp38 conda-forge
pytorch 1.9.0 cpu_py38h0529baa_2 conda-forge
pytorch-cpu 1.9.0 cpu_py38he781eb1_2 conda-forge
pytz 2021.1 pyhd8ed1ab_0 conda-forge
pyyaml 5.4.1 pypi_0 pypi
rdkit 2021.03.5 py38h0bd8f9b_0 conda-forge
readline 8.1 h05e3726_0 conda-forge
reportlab 3.5.68 py38hf6ac518_0 conda-forge
scipy 1.7.1 py38hd329d04_0 conda-forge
setuptools 57.4.0 py38h50d1736_0 conda-forge
six 1.16.0 pyh6c4a22f_0 conda-forge
sleef 3.5.1 h35c211d_1 conda-forge
sqlalchemy 1.4.23 py38h96a0964_0 conda-forge
sqlite 3.36.0 h23a322b_0 conda-forge
tbb 2021.3.0 h940c156_0 conda-forge
tk 8.6.11 h5dbffcc_1 conda-forge
toml 0.10.2 pyhd8ed1ab_0 conda-forge
torch 1.8.1 pypi_0 pypi
torch-scatter 2.0.8 pypi_0 pypi
torchdrug 0.1.0 h6151fa9 milagraph
tornado 6.1 py38h96a0964_1 conda-forge
tqdm 4.62.2 pyhd8ed1ab_0 conda-forge
typing_extensions 3.10.0.0 pyha770c72_0 conda-forge
wheel 0.37.0 pyhd8ed1ab_1 conda-forge
xz 5.2.5 haf1e3a3_1 conda-forge
zlib 1.2.11 h7795811_1010 conda-forge
zstd 1.5.0 h582d3a0_0 conda-forge
What would be the way to fix this?
Thanks!
Dear sir:
I am trying to use torchdrug on Google Colab. Here is my code.
!pip install rdkit-pypi
!git clone https://github.com/DeepGraphLearning/torchdrug
!pip install -r /content/torchdrug/requirements.txt
!python /content/torchdrug/setup.py install
All seems to be well.
But when I run
import torchdrug as td
from torchdrug import data
edge_list = [[0, 1], [1, 2], [2, 3], [3, 4], [4, 5], [5, 0]]
graph = data.Graph(edge_list, num_node=6)
graph.visualize()
Then shows:
ImportError Traceback (most recent call last)
<ipython-input-10-bbad14b8be21> in <module>()
1 import torch
2 import torchdrug as td
----> 3 from torchdrug import data, datasets, core, models, tasks
4 get_ipython().magic('matplotlib inline')
5
ImportError: cannot import name 'data' from 'torchdrug' (unknown location)
---------------------------------------------------------------------------
NOTE: If your import is failing due to a missing package, you can
manually install dependencies using either !pip or !apt.
To view examples of installing some common dependencies, click the
"Open Examples" button below.
---------------------------------------------------------------------------
How can solve this probelm?
Running the retrosynthesis tutorial, the following error occurred
import torchdrug
print(torchdrug.__version__)0.1.0
from torchdrug import datasets
reaction_dataset = datasets.USPTO50k("~/Projects/drugs/molecule-datasets/",
node_feature="center_identification",
kekulize=True)
synthon_dataset = datasets.USPTO50k("~/Projects/drugs/molecule-datasets/", as_synthon=True,
node_feature="synthon_completion",
kekulize=True)
from torchdrug.utils import plot
for i in range(2):
sample = reaction_dataset[i]
reactant, product = sample["graph"]
reactants = reactant.connected_components()[0]
products = product.connected_components()[0]
plot.reaction(reactants, products)AttributeError: 'USPTO50k' object has no attribute 'lazy'
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
/var/folders/zq/yt7gftfj7_x_11psy591dtz00000gn/T/ipykernel_6673/2093549361.py in <module>
2
3 for i in range(2):
----> 4 sample = reaction_dataset[i]
5 reactant, product = sample["graph"]
6 reactants = reactant.connected_components()[0]
~/opt/anaconda3/envs/drugs/lib/python3.8/site-packages/torchdrug/data/dataset.py in __getitem__(self, index)
138 def __getitem__(self, index):
139 if isinstance(index, int):
--> 140 return self.get_item(index)
141
142 index = self._standarize_index(index, len(self))
~/opt/anaconda3/envs/drugs/lib/python3.8/site-packages/torchdrug/data/dataset.py in get_item(self, index)
127
128 def get_item(self, index):
--> 129 if self.lazy:
130 item = {"graph": data.Molecule.from_smiles(self.smiles_list[index], **self.kwargs)}
131 else:
AttributeError: 'USPTO50k' object has no attribute 'lazy'
Hello,
Thanks for sharing this library! The reproduced retrosynthesis results of G2Gs are different from the paper. Does this mean that the results of the G2Gs paper are not reproducible?
These are the reported results from the Torchdrug tutorial:
top-1 accuracy: 0.47541
top-3 accuracy: 0.741803
top-5 accuracy: 0.827869
top-10 accuracy: 0.879098
TorchDrug implements MOSES dataset, but doesn't distinguish between train / test / testSF which MOSES has. To train GCPN on Moses, I think the correct order is to pretrain the model by train dataset at first, then train it on test / testSF dataset and finally generate the molecules. But how to do this in TorchDrug? There's only one dataset named MOSES.
I have this question because when I generate molecules by MOSES, the statistics doesn't look correct if compared to other models on MOSEC, especially the Scaf/Test property in the table, which tries to find out if there are same scaffolds in test dataset and generated molecules. It's 0 for GCPN model after training on TorchDrug, following the tutorial. I think the problem is that TorchDrug only uses the train dataset but not test dataset. How can I explicitly use it? Thanks in advance!
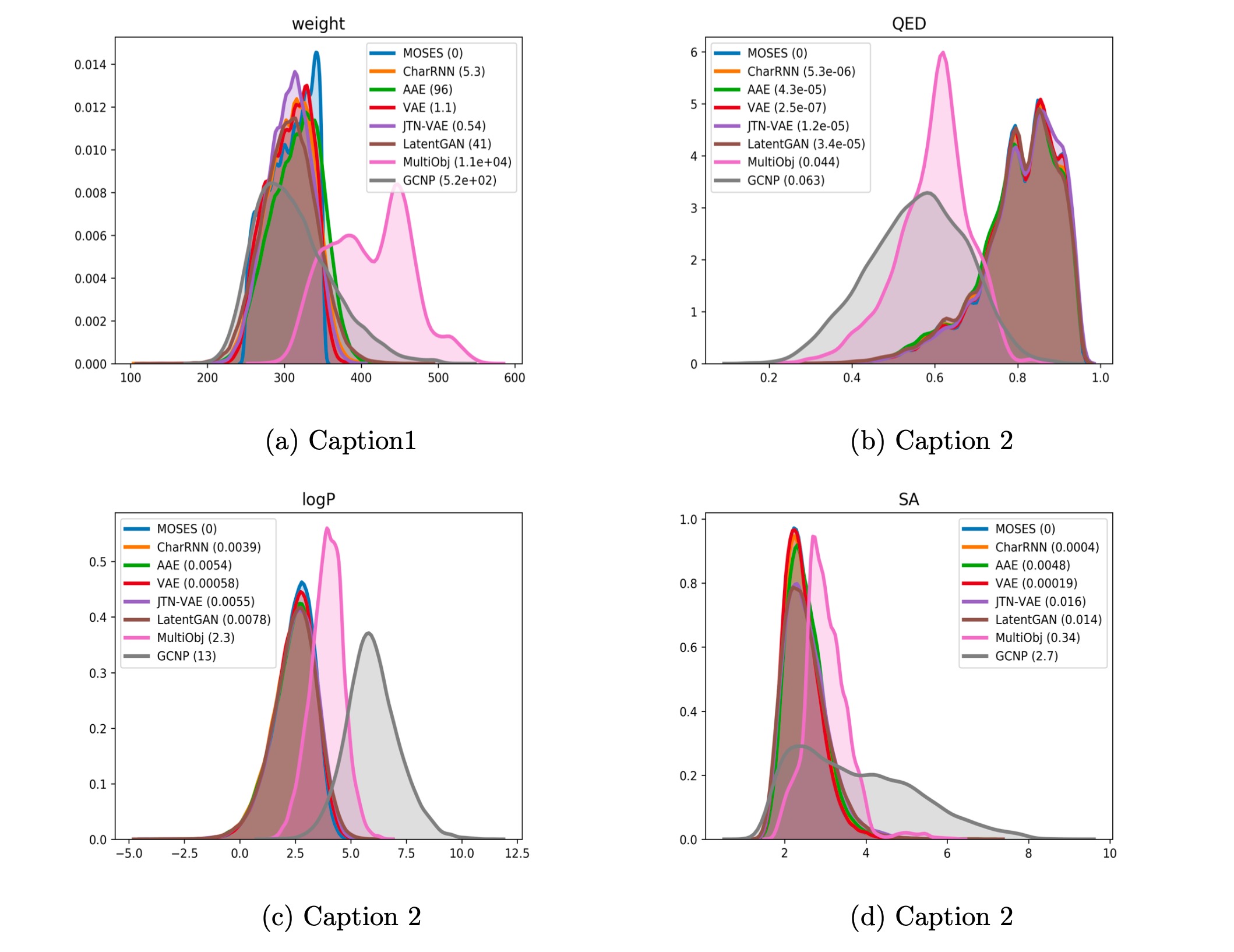

In the tutorial "Goal-directed molecule generation", the following error occurred
UnboundLocalError: local variable 'sascorer' referenced before assignment
import torchdrug
print(torchdrug.__version__)0.1.0
import os
import pickle
import torch
from torchdrug import core, datasets, models, tasks
from collections import defaultdict
# dataset = datasets.ZINC250k("~/Projects/drugs/molecule-datasets/", kekulize=True,
# node_feature="symbol")
filename = os.path.expanduser("~/Projects/drugs/molecule-datasets/zinc250k.pkl")
print(f"Loading {filename}")
with open(filename, "rb") as fin:
dataset = pickle.load(fin)
model = models.RGCN(input_dim=dataset.node_feature_dim,
num_relation=dataset.num_bond_type,
hidden_dims=[256, 256, 256, 256], batch_norm=False)
task = tasks.GCPNGeneration(model, dataset.atom_types,
max_edge_unroll=12, max_node=38,
task="plogp", criterion="ppo",
reward_temperature=1,
agent_update_interval=3, gamma=0.9)
optimizer = torch.optim.Adam(task.parameters(), lr=1e-5)
solver = core.Engine(task, dataset, None, None, optimizer,
#gpus=(0,),
batch_size=16, log_interval=10)
filename = os.path.expanduser("~/Projects/drugs/graphgeneration/gcpn_zinc250k_1epoch.pkl")
solver.load(filename,
load_optimizer=False)
# RL finetuning
solver.train(num_epoch=10)
filename = os.path.expanduser("~/Projects/drugs/graphgeneration/gcpn_zinc250k_1epoch_finetune.pkl")
solver.save(filename)UnboundLocalError: local variable 'sascorer' referenced before assignment
---------------------------------------------------------------------------
UnboundLocalError Traceback (most recent call last)
/var/folders/zq/yt7gftfj7_x_11psy591dtz00000gn/T/ipykernel_7569/599880889.py in <module>
39
40 # RL finetuning
---> 41 solver.train(num_epoch=10)
42 filename = os.path.expanduser("~/Projects/drugs/graphgeneration/gcpn_zinc250k_1epoch_finetune.pkl")
43 solver.save(filename)
~/opt/anaconda3/envs/drugs/lib/python3.8/site-packages/torchdrug/core/engine.py in train(self, num_epoch, batch_per_epoch)
141 batch = utils.cuda(batch, device=self.device)
142
--> 143 loss, metric = model(batch)
144 if not loss.requires_grad:
145 raise RuntimeError("Loss doesn't require grad. Did you define any loss in the task?")
~/opt/anaconda3/envs/drugs/lib/python3.8/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
887 result = self._slow_forward(*input, **kwargs)
888 else:
--> 889 result = self.forward(*input, **kwargs)
890 for hook in itertools.chain(
891 _global_forward_hooks.values(),
~/opt/anaconda3/envs/drugs/lib/python3.8/site-packages/torchdrug/tasks/generation.py in forward(self, batch)
700 metric.update(_metric)
701 elif criterion == "ppo":
--> 702 _loss, _metric = self.reinforce_forward(batch)
703 all_loss += _loss * weight
704 metric.update(_metric)
~/opt/anaconda3/envs/drugs/lib/python3.8/site-packages/torchdrug/tasks/generation.py in reinforce_forward(self, batch)
811 for task in self.task:
812 if task == "plogp":
--> 813 plogp = metrics.penalized_logP(graph)
814 metric["Penalized logP"] = plogp.mean()
815 metric["Penalized logP (max)"] = plogp.max()
~/opt/anaconda3/envs/drugs/lib/python3.8/site-packages/torchdrug/metrics/metric.py in penalized_logP(pred)
117 Chem.GetSymmSSSR(mol)
118 logp = Descriptors.MolLogP(mol)
--> 119 sa = sascorer.calculateScore(mol)
120 logp = (logp - logp_mean) / logp_std
121 sa = (sa - sa_mean) / sa_std
UnboundLocalError: local variable 'sascorer' referenced before assignment
Hello. I was running the "quickstart" code on ubuntu20.04. I used torch = 1.9.0 and python = 3.8 with cuda = 11.1.
when I running the code followed:
optimizer = torch.optim.Adam(task.parameters(), lr=1e-3)
solver = core.Engine(task, train_set, valid_set, test_set, optimizer, gpus=[0],
batch_size=512) solver.train(num_epoch=100)
But:
RuntimeError Traceback (most recent call last)
/tmp/ipykernel_2887068/1406504193.py in <module>
----> 1 solver.train(num_epoch=100)
~/anaconda3/envs/torchDrug/lib/python3.8/site-packages/torchdrug-0.1.0-py3.8.egg/torchdrug/core/engine.py in train(self, num_epoch, batch_per_epoch)
141 batch = utils.cuda(batch, device=self.device)
142
--> 143 loss, metric = model(batch)
144 if not loss.requires_grad:
145 raise RuntimeError("Loss doesn't require grad. Did you define any loss in the task?")
~/anaconda3/envs/torchDrug/lib/python3.8/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
1049 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
1050 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1051 return forward_call(*input, **kwargs)
1052 # Do not call functions when jit is used
1053 full_backward_hooks, non_full_backward_hooks = [], []
~/anaconda3/envs/torchDrug/lib/python3.8/site-packages/torchdrug-0.1.0-py3.8.egg/torchdrug/tasks/property_prediction.py in forward(self, batch)
72 metric = {}
73
---> 74 pred = self.predict(batch, all_loss, metric)
75
76 if all([t not in batch for t in self.task]):
~/anaconda3/envs/torchDrug/lib/python3.8/site-packages/torchdrug-0.1.0-py3.8.egg/torchdrug/tasks/property_prediction.py in predict(self, batch, all_loss, metric)
103 def predict(self, batch, all_loss=None, metric=None):
104 graph = batch["graph"]
--> 105 output = self.model(graph, graph.node_feature.float(), all_loss=all_loss, metric=metric)
106 pred = self.linear(output["graph_feature"])
107 return pred
~/anaconda3/envs/torchDrug/lib/python3.8/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
1049 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
1050 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1051 return forward_call(*input, **kwargs)
1052 # Do not call functions when jit is used
1053 full_backward_hooks, non_full_backward_hooks = [], []
~/anaconda3/envs/torchDrug/lib/python3.8/site-packages/torchdrug-0.1.0-py3.8.egg/torchdrug/models/gin.py in forward(self, graph, input, all_loss, metric)
74
75 for layer in self.layers:
---> 76 hidden = layer(graph, layer_input)
77 if self.short_cut and hidden.shape == layer_input.shape:
78 hidden = hidden + layer_input
~/anaconda3/envs/torchDrug/lib/python3.8/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
1049 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
1050 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1051 return forward_call(*input, **kwargs)
1052 # Do not call functions when jit is used
1053 full_backward_hooks, non_full_backward_hooks = [], []
~/anaconda3/envs/torchDrug/lib/python3.8/site-packages/torchdrug-0.1.0-py3.8.egg/torchdrug/layers/conv.py in forward(self, graph, input)
89 update = checkpoint.checkpoint(self._message_and_aggregate, *graph.to_tensors(), input)
90 else:
---> 91 update = self.message_and_aggregate(graph, input)
92 output = self.combine(input, update)
93 return output
~/anaconda3/envs/torchDrug/lib/python3.8/site-packages/torchdrug-0.1.0-py3.8.egg/torchdrug/layers/conv.py in message_and_aggregate(self, graph, input)
338
339 def message_and_aggregate(self, graph, input):
--> 340 adjacency = utils.sparse_coo_tensor(graph.edge_list.t()[:2], graph.edge_weight,
341 (graph.num_node, graph.num_node))
342 update = torch.sparse.mm(adjacency.t(), input)
~/anaconda3/envs/torchDrug/lib/python3.8/site-packages/torchdrug-0.1.0-py3.8.egg/torchdrug/utils/torch.py in sparse_coo_tensor(indices, values, size)
160 size (list): size of the tensor
161 """
--> 162 return torch_ext.sparse_coo_tensor_unsafe(indices, values, size)
163
164
~/anaconda3/envs/torchDrug/lib/python3.8/site-packages/torchdrug-0.1.0-py3.8.egg/torchdrug/utils/torch.py in __getattr__(self, key)
26 def __getattr__(self, key):
27 if "module" not in self.__dict__:
---> 28 self.module = cpp_extension.load(self.name, self.sources, self.extra_cflags, self.extra_cuda_cflags,
29 self.extra_ldflags, self.extra_include_paths, self.build_directory,
30 self.verbose, **self.kwargs)
~/anaconda3/envs/torchDrug/lib/python3.8/site-packages/torch/utils/cpp_extension.py in load(name, sources, extra_cflags, extra_cuda_cflags, extra_ldflags, extra_include_paths, build_directory, verbose, with_cuda, is_python_module, is_standalone, keep_intermediates)
1078 verbose=True)
1079 '''
-> 1080 return _jit_compile(
1081 name,
1082 [sources] if isinstance(sources, str) else sources,
~/anaconda3/envs/torchDrug/lib/python3.8/site-packages/torch/utils/cpp_extension.py in _jit_compile(name, sources, extra_cflags, extra_cuda_cflags, extra_ldflags, extra_include_paths, build_directory, verbose, with_cuda, is_python_module, is_standalone, keep_intermediates)
1291 clean_ctx=clean_ctx
1292 )
-> 1293 _write_ninja_file_and_build_library(
1294 name=name,
1295 sources=sources,
~/anaconda3/envs/torchDrug/lib/python3.8/site-packages/torch/utils/cpp_extension.py in _write_ninja_file_and_build_library(name, sources, extra_cflags, extra_cuda_cflags, extra_ldflags, extra_include_paths, build_directory, verbose, with_cuda, is_standalone)
1372 with_cuda: Optional[bool],
1373 is_standalone: bool = False) -> None:
-> 1374 verify_ninja_availability()
1375 if IS_WINDOWS:
1376 compiler = os.environ.get('CXX', 'cl')
~/anaconda3/envs/torchDrug/lib/python3.8/site-packages/torch/utils/cpp_extension.py in verify_ninja_availability()
1428 '''
1429 if not is_ninja_available():
-> 1430 raise RuntimeError("Ninja is required to load C++ extensions")
1431
1432
RuntimeError: Ninja is required to load C++ extensions**
Ninja and other required package were installed.
Could you give me some advice to solve this problem?
Thank you!
Best wish!
I tried to run the code of Molecule Generation in the Tutorials.
from torchdrug import datasets, core, models, tasks
from torch import optim
dataset = datasets.ZINC250k("~/molecule-datasets/", kekulize=True,
node_feature="symbol")
model = models.RGCN(input_dim=dataset.node_feature_dim,
num_relation=dataset.num_bond_type,
hidden_dims=[256, 256, 256, 256], batch_norm=False)
task = tasks.GCPNGeneration(model, dataset.atom_types, max_edge_unroll=12,
max_node=38, criterion="nll")
optimizer = optim.Adam(task.parameters(), lr = 1e-3)
solver = core.Engine(task, dataset, None, None, optimizer,
gpus=(0,), batch_size=128, log_interval=10)
solver.train(num_epoch=1)
solver.save("gcpn_zinc250k_1epoch.pkl")
results = task.generate(num_sample=32, max_resample=5)
And I got the error.
Traceback (most recent call last):
File "./test.py", line 18, in <module>
results = task.generate(num_sample=32, max_resample=5)
File "/home/foo/opt/anaconda3/lib/python3.7/site-packages/torch/autograd/grad_mode.py", line 49, in decorate_no_grad return func(*args, **kwargs)
File "/home/foo/opt/anaconda3/lib/python3.7/site-packages/torchdrug-0.1.0-py3.7.egg/torchdrug/tasks/generation.py", line 1369, in generate
new_graph = self._apply_action(graph, off_policy, max_resample, verbose=1)
File "/home/foo/opt/anaconda3/lib/python3.7/site-packages/torch/autograd/grad_mode.py", line 49, in decorate_no_grad
return func(*args, **kwargs)
File "/home/foo/opt/anaconda3/lib/python3.7/site-packages/torchdrug-0.1.0-py3.7.egg/torchdrug/tasks/generation.py", line 1248, in _apply_action
bond_type[is_modified_edge] = edge_action[has_modified_edge]
RuntimeError: shape mismatch: value tensor of shape [28] cannot be broadcast to indexing result of shape [0]
My environment : torch==1.4.0 ,python==3.7.4, rdkit==2020.03.3
Thanks.
Hi: I have some questions about KnowledgeBaseGraphAttentionNetwork model, the code at kbgat.py , the kbgat inherit GAT method. But in the original paper, there is also attention code for different relations, but at kbgat.py can not find attention for multi-type relations, maybe I miss something for this code, or kbgat.py did not fully code refer to the original paper? thanks
synthon_optimizer = torch.optim.Adam(synthon_task.parameters(), lr=1e-3)
synthon_solver = core.Engine(synthon_task, synthon_train, synthon_valid,
synthon_test, synthon_optimizer,
gpus=[0], batch_size=128)
synthon_solver.train(num_epoch=10)
synthon_solver.evaluate("valid")
synthon_solver.save("g2gs_synthon_model.pth")

I tried to run the code in the Quick Start. When I got to this step,
optimizer = torch.optim.Adam(task.parameters(), lr=1e-3)
solver = core.Engine(task, train_set, valid_set, test_set, optimizer,
batch_size=1024)
solver.train(num_epoch=5)
I got the bug
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-8-46cb357a6598> in <module>
2 solver = core.Engine(task, train_set, valid_set, test_set, optimizer,
3 batch_size=1024)
----> 4 solver.train(num_epoch=5)
~/torch_drug_test/torchdrug/torchdrug/core/engine.py in train(self, num_epoch, batch_per_epoch)
129 model.train()
130
--> 131 for epoch in self.meter(num_epoch):
132 sampler.set_epoch(epoch)
133
~/torch_drug_test/torchdrug/torchdrug/core/meter.py in __call__(self, num_epoch)
100 logger.warning(pretty.separator)
101 logger.warning("Epoch %d end" % epoch)
--> 102 self.step()
~/torch_drug_test/torchdrug/torchdrug/core/meter.py in step(self)
82 logger.warning("ETA: %s" % pretty.time(eta))
83 logger.warning("max GPU memory: %.1f MiB" % (torch.cuda.max_memory_allocated() / 1e6))
---> 84 torch.cuda.reset_peak_memory_stats()
85
86 logger.warning(pretty.line)
~/anaconda3/envs/torchdrug/lib/python3.8/site-packages/torch/cuda/memory.py in reset_peak_memory_stats(device)
236 """
237 device = _get_device_index(device, optional=True)
--> 238 return torch._C._cuda_resetPeakMemoryStats(device)
239
240
AttributeError: module 'torch._C' has no attribute '_cuda_resetPeakMemoryStats'
It's likely because I'm using the CPU install, and it was easy enough for me to comment out the line
torch.cuda.reset_peak_memory_stats()
in
/torchdrug/core/meter.py. So perhaps one could just add an if statement to see if the GPU is enabled?
Broadly speaking, is this code repo robust for CPU users or is it targeted at GPU only?
Hi!
Are you going to add functionality for the interpretation of GNN models to torchdrug?
There are benchmarks datasets Benchmarks for interpretation of QSAR models
and there is a whole bunch of different methods Explainability in Graph Neural Networks: A Taxonomic Survey.
Unfortunately, I haven't seen a method which directly combines explainability and uncertainty quantification (like evidential deep learning).
That would be really helpful for our medicinal chemists to understand why a decision was made by a model und how certain the model is about the decision.
Thanks
i use conda install -c milagraph -c conda-forge torchdrug to install torchdrug, but it show this. Can u tell what cause this problem? Thanks u. in my environment : torch==1.8 ,py ==3.6
项目开始介绍页使用的 td.CARBON 没有引用来源,无法展示项目功能
Dear Torchdrug team,
Can you please add a reader for the PCQM4M-LSC dataset?
See https://ogb.stanford.edu/kddcup2021/pcqm4m/
Many thanks!
torchdrug/torchdrug/layers/conv.py
Lines 154 to 174 in 5bf0a50
torchdrug/torchdrug/layers/conv.py
Lines 170 to 171 in 5bf0a50
torchdrug.version: 0.1.1
import json
import torch
from torchdrug import core, datasets, tasks, models
dataset = datasets.OPV("~/molecule-datasets/")
train_set, valid_set, test_set = dataset.split()
print(f"# Train/Valid/Test: {len(train_set)}/{len(valid_set)}/{len(test_set)}")
model = models.GIN(
input_dim=dataset.node_feature_dim,
hidden_dims=[300, 300, 300, 300],
short_cut=True,
batch_norm=True,
concat_hidden=True,
)
subtasks = (
"gap",
"homo",
"lumo",
"spectral_overlap",
)
task = tasks.PropertyPrediction(
model, task=subtasks, criterion="mse", metric=("mae", "rmse"), verbose=1
)
optimizer = torch.optim.Adam(task.parameters(), lr=1e-3)
solver = core.Engine(
task,
train_set,
valid_set,
test_set,
optimizer,
gpus=[0],
batch_size=256,
)
with open("opv_gin.json", "w") as fout:
json.dump(solver.config_dict(), fout)Traceback (most recent call last):
File "~/opv-gin-property-prediction.py", line 40, in <module>
json.dump(solver.config_dict(), fout)
File "~/opt/anaconda3/envs/drugs/lib/python3.8/json/__init__.py", line 179, in dump
for chunk in iterable:
File "~/opt/anaconda3/envs/drugs/lib/python3.8/json/encoder.py", line 431, in _iterencode
yield from _iterencode_dict(o, _current_indent_level)
File "~/opt/anaconda3/envs/drugs/lib/python3.8/json/encoder.py", line 405, in _iterencode_dict
yield from chunks
File "~/opt/anaconda3/envs/drugs/lib/python3.8/json/encoder.py", line 438, in _iterencode
o = _default(o)
File "~/opt/anaconda3/envs/drugs/lib/python3.8/json/encoder.py", line 179, in default
raise TypeError(f'Object of type {o.__class__.__name__} '
TypeError: Object of type Subset is not JSON serializable
opv_gin.json
{
"class": "core.Engine",
"task": {
"class": "tasks.PropertyPrediction",
"model": {
"class": "models.GIN",
"input_dim": 69,
"hidden_dims": [
300,
300,
300,
300
],
"edge_input_dim": null,
"num_mlp_layer": 2,
"eps": 0,
"learn_eps": false,
"short_cut": true,
"batch_norm": true,
"activation": "relu",
"concat_hidden": true,
"readout": "sum"
},
"task": [
"gap",
"homo",
"lumo",
"spectral_overlap"
],
"criterion": "mse",
"metric": [
"mae",
"rmse"
],
"verbose": 1
},
"train_set":Writing of the file opv_gin.json stops with the error above.
from torchdrug import data
edge_list = [[0, 1], [1, 2], [2, 3], [3, 4], [4, 5], [5, 0]]
graph = data.Graph(edge_list, num_node=6)
graph = graph.cuda()
the error is :
TypeError: metaclass conflict: the metaclass of a derived class must be a (non-strict) subclass of the metaclasses of all its bases


how can I fix it
Dear everyone,
I have install torchdrug correctly, and then follow the tutorial https://torchdrug.ai/docs/tutorials/retrosynthesis.html
When I run the code as below:
from torchdrug import datasets
reaction_dataset = datasets.USPTO50k("D:/test/molecule-datasets/",
node_feature="reaction_reaction_identification",
kekulize=True)
synthon_dataset = datasets.USPTO50k("D:/test/molecule-dataset/", as_synthon=True,
node_feature="synthon_completion",
kekulize=True)It happens error as follows:
Loading D:/test/molecule-datasets/data_processed.csv: 100%|██████████| 50017/50017 [00:00<00:00, 92358.37it/s]
Constructing molecules from SMILES: 0%| | 0/50016 [00:00<?, ?it/s]
Traceback (most recent call last):
File "F:/workdir/pycharm/Retrosynthesis/main.py", line 5, in <module>
kekulize=True)
File "D:\soft\Anaconda3\envs\py37\lib\site-packages\decorator.py", line 232, in fun
return caller(func, *(extras + args), **kw)
File "D:\soft\Anaconda3\envs\py37\lib\site-packages\torchdrug-0.1.0-py3.7.egg\torchdrug\core\core.py", line 282, in wrapper
return init(self, *args, **kwargs)
File "D:\soft\Anaconda3\envs\py37\lib\site-packages\torchdrug-0.1.0-py3.7.egg\torchdrug\datasets\uspto50k.py", line 63, in __init__
**kwargs)
File "D:\soft\Anaconda3\envs\py37\lib\site-packages\torchdrug-0.1.0-py3.7.egg\torchdrug\data\dataset.py", line 112, in load_csv
self.load_smiles(smiles, targets, verbose=verbose, **kwargs)
File "D:\soft\Anaconda3\envs\py37\lib\site-packages\torchdrug-0.1.0-py3.7.egg\torchdrug\data\dataset.py", line 232, in load_smiles
mol = data.Molecule.from_molecule(mol, **kwargs)
File "D:\soft\Anaconda3\envs\py37\lib\site-packages\torchdrug-0.1.0-py3.7.egg\torchdrug\data\molecule.py", line 183, in from_molecule
func = R.get("features.atom.%s" % name)
File "D:\soft\Anaconda3\envs\py37\lib\site-packages\torchdrug-0.1.0-py3.7.egg\torchdrug\core\core.py", line 208, in get
raise KeyError("Can't find `%s` in `%s`" % (key, ".".join(keys[:i])))
KeyError: "Can't find `reaction_reaction_identification` in `features.atom`"what is the problem? could you help me to solve it?
Thanks.
HI,When I run to this part "Goal-Directed Molecule Generation with Reinforcement Learning: GCPN"
import torch
import pickle
from torchdrug import core, datasets, models, tasks
from torch import nn, optim
from collections import defaultdict
with open("/home/ibmc-2/Projects/torchdrug/zinc250k.pkl", "rb") as fin:
dataset = pickle.load(fin)
model = models.RGCN(input_dim=dataset.node_feature_dim,
num_relation=dataset.num_bond_type,
hidden_dims=[256, 256, 256, 256], batch_norm=False)
task = tasks.GCPNGeneration(model, dataset.atom_types,
max_edge_unroll=12, max_node=38,
task="plogp", criterion="ppo",
reward_temperature=1,
agent_update_interval=3, gamma=0.9)
optimizer = optim.Adam(task.parameters(), lr=1e-5)
solver = core.Engine(task, dataset, None, None, optimizer,
gpus=(0,), batch_size=16, log_interval=10)
solver.load("/home/ibmc-2/Projects/torchdrug/gcpn_zinc250k_1epoch.pkl",
load_optimizer=False)
The above part works normally,but an error is reported when running to fine-tuning
solver.train(num_epoch=10)
solver.save("/home/ibmc-2/Projects/torchdrug/gcpn_zinc250k_1epoch_finetune.pkl")
as follow
solver.train(num_epoch=10)
19:16:03 >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
19:16:03 Epoch 0 begin
/home/ibmc-2/anaconda3/envs/td/lib/python3.8/site-packages/torchdrug-0.1.0-py3.8.egg/torchdrug/data/molecule.py:103: UserWarning: Try to apply masks on molecules with stereo bonds. This may produce invalid molecules. To discard stereo information, call `mol.bond_stereo[:] = 0` before applying masks.
warnings.warn("Try to apply masks on molecules with stereo bonds. This may produce invalid molecules. "
/home/ibmc-2/anaconda3/envs/td/lib/python3.8/site-packages/torch/nn/functional.py:1698: UserWarning: nn.functional.tanh is deprecated. Use torch.tanh instead.
warnings.warn("nn.functional.tanh is deprecated. Use torch.tanh instead.")
Traceback (most recent call last):
File "/home/ibmc-2/anaconda3/envs/td/lib/python3.8/site-packages/IPython/core/interactiveshell.py", line 3441, in run_code
exec(code_obj, self.user_global_ns, self.user_ns)
File "<ipython-input-17-451bfe7c53dc>", line 1, in <module>
solver.train(num_epoch=10)
File "/home/ibmc-2/anaconda3/envs/td/lib/python3.8/site-packages/torchdrug-0.1.0-py3.8.egg/torchdrug/core/engine.py", line 143, in train
loss, metric = model(batch)
File "/home/ibmc-2/anaconda3/envs/td/lib/python3.8/site-packages/torch/nn/modules/module.py", line 889, in _call_impl
result = self.forward(*input, **kwargs)
File "/home/ibmc-2/anaconda3/envs/td/lib/python3.8/site-packages/torchdrug-0.1.0-py3.8.egg/torchdrug/tasks/generation.py", line 702, in forward
_loss, _metric = self.reinforce_forward(batch)
File "/home/ibmc-2/anaconda3/envs/td/lib/python3.8/site-packages/torchdrug-0.1.0-py3.8.egg/torchdrug/tasks/generation.py", line 813, in reinforce_forward
plogp = metrics.penalized_logP(graph)
File "/home/ibmc-2/anaconda3/envs/td/lib/python3.8/site-packages/torchdrug-0.1.0-py3.8.egg/torchdrug/metrics/metric.py", line 119, in penalized_logP
#sa = sascorer.calculateScore(mol)
UnboundLocalError: local variable 'sascorer' referenced before assignment
By the way, is it normal that UserWarning: Unknown value Tl or Mn or Cr appears when downloading the ClinTox data set, thank you!
I installed torchdrug with
conda install -c milagraph -c conda-forge torchdrugI've performed the verification for pytorch https://pytorch.org/get-started/locally/#linux-verification
This is the error I get when I try import torchdrug:
OSError: <redacted>/.venv/lib/python3.8/site-packages/torch_scatter/_scatter_cuda.so: undefined symbol: _ZNK2at6Tensor6deviceEvOperating system: ArchLinux
How to get the SMILES leading to a RDKit error during data loading?
Like:
Constructing molecules from SMILES: 22%|██▏ | 305/1417 [00:00<00:02, 465.19it/s]
RDKit ERROR: [11:20:56] Explicit valence for atom # 7 O, 3, is greater than permitted
[11:20:56] Explicit valence for atom # 7 O, 3, is greater than permitted
Constructing molecules from SMILES: 33%|███▎ | 473/1417 [00:01<00:03, 308.42it/s]
~/opt/anaconda3/envs/drugs/lib/python3.8/site-packages/torchdrug/data/feature.py:37: UserWarning: Unknown value `As`
warnings.warn("Unknown value `%s`" % x)
Constructing molecules from SMILES: 56%|█████▌ | 788/1417 [00:06<00:11, 55.14it/s]
RDKit ERROR: [11:21:02] Explicit valence for atom # 3 O, 3, is greater than permitted
There are arsenic-based drugs. Are these correctly processed in feature.py?
See for example: https://go.drugbank.com/categories/DBCAT001515
I wanted to ask are GCPN and GRAPHAF the only two graph generative models used, can I integrate other models like ZINC, ORGAN and JT VAE for molecular generation?
Hi all,
I come across a problem while I cannot find the answer in tutorial or document.
Is there any candidate pool for the value of "node_feature" and "edge_feature"?
In someplace, the "node_feature" is "default", "pretrain" or other values. So I wonder if there is any difference between these values? From where, I can find the whole candidates for the value?
Thank you! Looking forward to your apply!
Best,
For example, after train a model for 3 epochs and save it as model_3epoch.pkl, how to load model_3epoch.pkl and train it for more epochs?
Besides that, if we train model_3epoch.pkl with the training dataset, can we load it and train it with the test dataset then?
The question was asked here at first.
What is the simplest way to install it with pip on Ubuntu 18.04 please?
I have successfully installed all requirements, however, it can't find the RDKit:
ModuleNotFoundError: No module named 'rdkit'
To install it, I used: sudo apt-get install python-rdkit librdkit1 rdkit-data as per RDKit
Any ideas, how to run this awesome library without Anaconda please?
Hi torchdrug team, thank you for the awesome project! I am playing with molecule generation models, and am interested in trying to reproduce the benchmarks posted here: https://torchdrug.ai/docs/benchmark/generation.html
I am able to follow the tutorial for molecule generation: https://torchdrug.ai/docs/tutorials/generation.html
But I found that there was no mention of how we can evaluate models once they are fully trained. Is there any evaluator class or oracle that can be called to obtain the metrics as in your benchmark?
Additionally, do you have any advice on how to set the hyperparameters to fairly reproduce/compare to the GCPN or GraphAF papers?
I am facing installation issues. Note, my installation is in a fresh conda environment, and my only manual installs were numpy and pytorch before running
conda install -c milagraph -c conda-forge torchdrug
Details below, and happy to provide more info. Thanks!
System information
Ubuntu 20.04.2 LTS, 64-bit
No GPU
python --version
> Python 3.8.8
conda --version
> conda 4.10.3
conda --list
># Name Version Build Channel
_libgcc_mutex 0.1 main
_openmp_mutex 4.5 1_gnu
alsa-lib 1.2.3 h516909a_0 conda-forge
boost 1.74.0 py38hc10631b_3 conda-forge
boost-cpp 1.74.0 h312852a_4 conda-forge
bzip2 1.0.8 h7f98852_4 conda-forge
ca-certificates 2021.5.30 ha878542_0 conda-forge
cairo 1.16.0 h6cf1ce9_1008 conda-forge
certifi 2021.5.30 py38h578d9bd_0 conda-forge
colorama 0.4.4 pyh9f0ad1d_0 conda-forge
cpuonly 1.0 0 pytorch
cycler 0.10.0 py_2 conda-forge
dbus 1.13.6 h48d8840_2 conda-forge
decorator 5.0.9 pyhd8ed1ab_0 conda-forge
expat 2.4.1 h9c3ff4c_0 conda-forge
fontconfig 2.13.1 hba837de_1005 conda-forge
freetype 2.10.4 h0708190_1 conda-forge
gettext 0.19.8.1 h0b5b191_1005 conda-forge
glib 2.68.3 h9c3ff4c_0 conda-forge
glib-tools 2.68.3 h9c3ff4c_0 conda-forge
greenlet 1.1.0 py38h709712a_0 conda-forge
gst-plugins-base 1.18.4 hf529b03_2 conda-forge
gstreamer 1.18.4 h76c114f_2 conda-forge
icu 68.1 h58526e2_0 conda-forge
intel-openmp 2021.3.0 h06a4308_3350
jbig 2.1 h7f98852_2003 conda-forge
jinja2 3.0.1 pyhd8ed1ab_0 conda-forge
jpeg 9d h36c2ea0_0 conda-forge
kiwisolver 1.3.1 py38h1fd1430_1 conda-forge
krb5 1.19.2 hcc1bbae_0 conda-forge
lcms2 2.12 hddcbb42_0 conda-forge
ld_impl_linux-64 2.35.1 h7274673_9
lerc 2.2.1 h9c3ff4c_0 conda-forge
libblas 3.9.0 11_linux64_openblas conda-forge
libcblas 3.9.0 11_linux64_openblas conda-forge
libclang 11.1.0 default_ha53f305_1 conda-forge
libdeflate 1.7 h7f98852_5 conda-forge
libedit 3.1.20191231 he28a2e2_2 conda-forge
libevent 2.1.10 hcdb4288_3 conda-forge
libffi 3.3 he6710b0_2
libgcc-ng 9.3.0 h5101ec6_17
libgfortran-ng 11.1.0 h69a702a_8 conda-forge
libgfortran5 11.1.0 h6c583b3_8 conda-forge
libglib 2.68.3 h3e27bee_0 conda-forge
libgomp 9.3.0 h5101ec6_17
libiconv 1.16 h516909a_0 conda-forge
liblapack 3.9.0 11_linux64_openblas conda-forge
libllvm11 11.1.0 hf817b99_2 conda-forge
libogg 1.3.4 h7f98852_1 conda-forge
libopenblas 0.3.17 pthreads_h8fe5266_1 conda-forge
libopus 1.3.1 h7f98852_1 conda-forge
libpng 1.6.37 h21135ba_2 conda-forge
libpq 13.3 hd57d9b9_0 conda-forge
libstdcxx-ng 9.3.0 hd4cf53a_17
libtiff 4.3.0 hf544144_1 conda-forge
libuuid 2.32.1 h7f98852_1000 conda-forge
libvorbis 1.3.7 h9c3ff4c_0 conda-forge
libwebp-base 1.2.0 h7f98852_2 conda-forge
libxcb 1.13 h7f98852_1003 conda-forge
libxkbcommon 1.0.3 he3ba5ed_0 conda-forge
libxml2 2.9.12 h72842e0_0 conda-forge
lz4-c 1.9.3 h9c3ff4c_1 conda-forge
markupsafe 2.0.1 py38h497a2fe_0 conda-forge
matplotlib 3.4.2 py38h578d9bd_0 conda-forge
matplotlib-base 3.4.2 py38hcc49a3a_0 conda-forge
mkl 2021.3.0 h06a4308_520
mysql-common 8.0.25 ha770c72_2 conda-forge
mysql-libs 8.0.25 hfa10184_2 conda-forge
ncurses 6.2 he6710b0_1
networkx 2.5 py_0 conda-forge
ninja 1.10.2 h4bd325d_0 conda-forge
nspr 4.30 h9c3ff4c_0 conda-forge
nss 3.67 hb5efdd6_0 conda-forge
numpy 1.21.1 py38h9894fe3_0 conda-forge
olefile 0.46 pyh9f0ad1d_1 conda-forge
openjpeg 2.4.0 hb52868f_1 conda-forge
openssl 1.1.1k h7f98852_0 conda-forge
pandas 1.3.1 py38h1abd341_0 conda-forge
pcre 8.45 h9c3ff4c_0 conda-forge
pillow 8.3.1 py38h8e6f84c_0 conda-forge
pip 21.2.3 pyhd8ed1ab_0 conda-forge
pixman 0.40.0 h36c2ea0_0 conda-forge
pthread-stubs 0.4 h36c2ea0_1001 conda-forge
pycairo 1.20.1 py38hf61ee4a_0 conda-forge
pyparsing 2.4.7 pyh9f0ad1d_0 conda-forge
pyqt 5.12.3 py38h578d9bd_7 conda-forge
pyqt-impl 5.12.3 py38h7400c14_7 conda-forge
pyqt5-sip 4.19.18 py38h709712a_7 conda-forge
pyqtchart 5.12 py38h7400c14_7 conda-forge
pyqtwebengine 5.12.1 py38h7400c14_7 conda-forge
python 3.8.11 h12debd9_0_cpython
python-dateutil 2.8.2 pyhd8ed1ab_0 conda-forge
python_abi 3.8 2_cp38 conda-forge
pytorch 1.4.0 py3.8_cpu_0 [cpuonly] pytorch
pytorch_scatter 2.0.4 py38h9235441_1 conda-forge
pytz 2021.1 pyhd8ed1ab_0 conda-forge
qt 5.12.9 hda022c4_4 conda-forge
rdkit 2021.03.4 py38hf8acc3d_0 conda-forge
readline 8.1 h27cfd23_0
reportlab 3.5.68 py38hadf75a6_0 conda-forge
setuptools 52.0.0 py38h06a4308_0
six 1.16.0 pyh6c4a22f_0 conda-forge
sqlalchemy 1.4.22 py38h497a2fe_0 conda-forge
sqlite 3.36.0 hc218d9a_0
tk 8.6.10 hbc83047_0
torchaudio 0.4.0 py38 pytorch
torchdrug 0.1.0 h39ad8c7 milagraph
torchvision 0.5.0 py38_cpu [cpuonly] pytorch
tornado 6.1 py38h497a2fe_1 conda-forge
tqdm 4.62.0 pyhd8ed1ab_0 conda-forge
wheel 0.36.2 pyhd3eb1b0_0
xorg-kbproto 1.0.7 h7f98852_1002 conda-forge
xorg-libice 1.0.10 h7f98852_0 conda-forge
xorg-libsm 1.2.3 hd9c2040_1000 conda-forge
xorg-libx11 1.7.2 h7f98852_0 conda-forge
xorg-libxau 1.0.9 h7f98852_0 conda-forge
xorg-libxdmcp 1.1.3 h7f98852_0 conda-forge
xorg-libxext 1.3.4 h7f98852_1 conda-forge
xorg-libxrender 0.9.10 h7f98852_1003 conda-forge
xorg-renderproto 0.11.1 h7f98852_1002 conda-forge
xorg-xextproto 7.3.0 h7f98852_1002 conda-forge
xorg-xproto 7.0.31 h7f98852_1007 conda-forge
xz 5.2.5 h7b6447c_0
zlib 1.2.11 h7b6447c_3
zstd 1.5.0 ha95c52a_0 conda-forge
Here is the error:
(torchdrug) 1_Projects $ python
Python 3.8.11 (default, Aug 3 2021, 15:09:35)
[GCC 7.5.0] :: Anaconda, Inc. on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import torchdrug
Traceback (most recent call last):
File "/home/murph213/anaconda3/envs/torchdrug/lib/python3.8/site-packages/torch_scatter/__init__.py", line 12, in <module>
torch.ops.load_library(importlib.machinery.PathFinder().find_spec(
File "/home/murph213/anaconda3/envs/torchdrug/lib/python3.8/site-packages/torch/_ops.py", line 106, in load_library
ctypes.CDLL(path)
File "/home/murph213/anaconda3/envs/torchdrug/lib/python3.8/ctypes/__init__.py", line 373, in __init__
self._handle = _dlopen(self._name, mode)
OSError: /home/murph213/anaconda3/envs/torchdrug/lib/python3.8/site-packages/torch_scatter/_version.so: undefined symbol: _ZN5torch3jit17parseSchemaOrNameERKNSt7__cxx1112basic_stringIcSt11char_traitsIcESaIcEEE
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/murph213/anaconda3/envs/torchdrug/lib/python3.8/site-packages/torchdrug/__init__.py", line 1, in <module>
from . import patch
File "/home/murph213/anaconda3/envs/torchdrug/lib/python3.8/site-packages/torchdrug/patch.py", line 12, in <module>
from torchdrug import core, data
File "/home/murph213/anaconda3/envs/torchdrug/lib/python3.8/site-packages/torchdrug/core/__init__.py", line 2, in <module>
from .engine import Engine
File "/home/murph213/anaconda3/envs/torchdrug/lib/python3.8/site-packages/torchdrug/core/engine.py", line 10, in <module>
from torchdrug import data, core, utils
File "/home/murph213/anaconda3/envs/torchdrug/lib/python3.8/site-packages/torchdrug/data/__init__.py", line 1, in <module>
from .graph import Graph, PackedGraph, cat
File "/home/murph213/anaconda3/envs/torchdrug/lib/python3.8/site-packages/torchdrug/data/graph.py", line 9, in <module>
from torch_scatter import scatter_add, scatter_min
File "/home/murph213/anaconda3/envs/torchdrug/lib/python3.8/site-packages/torch_scatter/__init__.py", line 21, in <module>
raise OSError(e)
OSError: /home/murph213/anaconda3/envs/torchdrug/lib/python3.8/site-packages/torch_scatter/_version.so: undefined symbol: _ZN5torch3jit17parseSchemaOrNameERKNSt7__cxx1112basic_stringIcSt11char_traitsIcESaIcEEE
Hi, I was running the "quickstart" code on my win10. I used torch = 1.8.0 and python = 3.7 with cuda = 10.2.
The problems happened when I tried training the model in Jupyter:
optimizer = torch.optim.Adam(task.parameters(), lr=1e-3)
solver = core.Engine(task, train_set, valid_set, test_set, optimizer, gpus=[0],
batch_size=512) solver.train(num_epoch=100)
And this turned to:
---------------------------------------------------------------------------
ImportError Traceback (most recent call last)
~\AppData\Local\Temp/ipykernel_19744/1406504193.py in <module>
----> 1 solver.train(num_epoch=100)
d:\conda\envs\torchdrug\lib\site-packages\torchdrug-0.1.0-py3.7.egg\torchdrug\core\engine.py in train(self, num_epoch, batch_per_epoch)
141 batch = utils.cuda(batch, device=self.device)
142
--> 143 loss, metric = model(batch)
144 if not loss.requires_grad:
145 raise RuntimeError("Loss doesn't require grad. Did you define any loss in the task?")
d:\conda\envs\torchdrug\lib\site-packages\torch\nn\modules\module.py in _call_impl(self, *input, **kwargs)
887 result = self._slow_forward(*input, **kwargs)
888 else:
--> 889 result = self.forward(*input, **kwargs)
890 for hook in itertools.chain(
891 _global_forward_hooks.values(),
d:\conda\envs\torchdrug\lib\site-packages\torchdrug-0.1.0-py3.7.egg\torchdrug\tasks\property_prediction.py in forward(self, batch)
72 metric = {}
73
---> 74 pred = self.predict(batch, all_loss, metric)
75
76 if all([t not in batch for t in self.task]):
d:\conda\envs\torchdrug\lib\site-packages\torchdrug-0.1.0-py3.7.egg\torchdrug\tasks\property_prediction.py in predict(self, batch, all_loss, metric)
103 def predict(self, batch, all_loss=None, metric=None):
104 graph = batch["graph"]
--> 105 output = self.model(graph, graph.node_feature.float(), all_loss=all_loss, metric=metric)
106 pred = self.linear(output["graph_feature"])
107 return pred
d:\conda\envs\torchdrug\lib\site-packages\torch\nn\modules\module.py in _call_impl(self, *input, **kwargs)
887 result = self._slow_forward(*input, **kwargs)
888 else:
--> 889 result = self.forward(*input, **kwargs)
890 for hook in itertools.chain(
891 _global_forward_hooks.values(),
d:\conda\envs\torchdrug\lib\site-packages\torchdrug-0.1.0-py3.7.egg\torchdrug\models\gin.py in forward(self, graph, input, all_loss, metric)
74
75 for layer in self.layers:
---> 76 hidden = layer(graph, layer_input)
77 if self.short_cut and hidden.shape == layer_input.shape:
78 hidden = hidden + layer_input
d:\conda\envs\torchdrug\lib\site-packages\torch\nn\modules\module.py in _call_impl(self, *input, **kwargs)
887 result = self._slow_forward(*input, **kwargs)
888 else:
--> 889 result = self.forward(*input, **kwargs)
890 for hook in itertools.chain(
891 _global_forward_hooks.values(),
d:\conda\envs\torchdrug\lib\site-packages\torchdrug-0.1.0-py3.7.egg\torchdrug\layers\conv.py in forward(self, graph, input)
89 update = checkpoint.checkpoint(self._message_and_aggregate, *graph.to_tensors(), input)
90 else:
---> 91 update = self.message_and_aggregate(graph, input)
92 output = self.combine(input, update)
93 return output
d:\conda\envs\torchdrug\lib\site-packages\torchdrug-0.1.0-py3.7.egg\torchdrug\layers\conv.py in message_and_aggregate(self, graph, input)
339 def message_and_aggregate(self, graph, input):
340 adjacency = utils.sparse_coo_tensor(graph.edge_list.t()[:2], graph.edge_weight,
--> 341 (graph.num_node, graph.num_node))
342 update = torch.sparse.mm(adjacency.t(), input)
343 if self.edge_linear:
d:\conda\envs\torchdrug\lib\site-packages\torchdrug-0.1.0-py3.7.egg\torchdrug\utils\torch.py in sparse_coo_tensor(indices, values, size)
160 size (list): size of the tensor
161 """
--> 162 return torch_ext.sparse_coo_tensor_unsafe(indices, values, size)
163
164
d:\conda\envs\torchdrug\lib\site-packages\torchdrug-0.1.0-py3.7.egg\torchdrug\utils\torch.py in __getattr__(self, key)
28 self.module = cpp_extension.load(self.name, self.sources, self.extra_cflags, self.extra_cuda_cflags,
29 self.extra_ldflags, self.extra_include_paths, self.build_directory,
---> 30 self.verbose, **self.kwargs)
31 return getattr(self.module, key)
32
d:\conda\envs\torchdrug\lib\site-packages\torch\utils\cpp_extension.py in load(name, sources, extra_cflags, extra_cuda_cflags, extra_ldflags, extra_include_paths, build_directory, verbose, with_cuda, is_python_module, is_standalone, keep_intermediates)
1089 is_python_module,
1090 is_standalone,
-> 1091 keep_intermediates=keep_intermediates)
1092
1093
d:\conda\envs\torchdrug\lib\site-packages\torch\utils\cpp_extension.py in _jit_compile(name, sources, extra_cflags, extra_cuda_cflags, extra_ldflags, extra_include_paths, build_directory, verbose, with_cuda, is_python_module, is_standalone, keep_intermediates)
1315 return _get_exec_path(name, build_directory)
1316
-> 1317 return _import_module_from_library(name, build_directory, is_python_module)
1318
1319
d:\conda\envs\torchdrug\lib\site-packages\torch\utils\cpp_extension.py in _import_module_from_library(module_name, path, is_python_module)
1697 def _import_module_from_library(module_name, path, is_python_module):
1698 # https://stackoverflow.com/questions/67631/how-to-import-a-module-given-the-full-path
-> 1699 file, path, description = imp.find_module(module_name, [path])
1700 # Close the .so file after load.
1701 with file:
d:\conda\envs\torchdrug\lib\imp.py in find_module(name, path)
294 break # Break out of outer loop when breaking out of inner loop.
295 else:
--> 296 raise ImportError(_ERR_MSG.format(name), name=name)
297
298 encoding = None
ImportError: No module named 'torch_ext'
The same code works well in Colab and I suspect this is because I couldn't install rdkit-pypi and installed rdkit on conda instead.
Following the tutorial in the doc, I got error on this line.
synthon_solver = core.Engine(synthon_task, synthon_train, synthon_valid, synthon_test, synthon_optimizer , gpus=[0], batch_size=128)
The error message is
****
Pre-condition Violation
bgnIdx not connected to begin atom of bond
Violation occurred on line 292 in file /opt/conda/conda-bld/rdkit_1603173682698/work/Code/GraphMol/Bond.cpp
Failed Expression: getOwningMol().getBondBetweenAtoms(getBeginAtomIdx(), bgnIdx) != nullptr
****
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/zhuzhaoc/torchdrug/torchdrug/core/engine.py", line 143, in train
loss, metric = model(batch)
File "/home/zhuzhaoc/.local/envs/ogb/lib/python3.7/site-packages/torch/nn/modules/module.py", line 889, in _call_impl
result = self.forward(*input, **kwargs)
File "/home/zhuzhaoc/torchdrug/torchdrug/tasks/retrosynthesis.py", line 596, in forward
pred, target = self.predict_and_target(batch, all_loss, metric)
File "/home/zhuzhaoc/torchdrug/torchdrug/tasks/retrosynthesis.py", line 993, in predict_and_target
graph2, node_in_target2, node_out_target2, bond_target2, stop_target2 = self.all_stop(reactant, synthon)
File "/home/zhuzhaoc/.local/envs/ogb/lib/python3.7/site-packages/torch/autograd/grad_mode.py", line 27, in decorate_context
return func(*args, **kwargs)
File "/home/zhuzhaoc/torchdrug/torchdrug/tasks/retrosynthesis.py", line 586, in all_stop
graph, feature_valid = self._update_molecule_feature(graph)
File "/home/zhuzhaoc/torchdrug/torchdrug/tasks/retrosynthesis.py", line 385, in _update_molecule_feature
mols = graphs.to_molecule(ignore_error=True)
File "/home/zhuzhaoc/torchdrug/torchdrug/data/molecule.py", line 788, in to_molecule
bond.SetStereoAtoms(*stereo_atoms[j])
RuntimeError: Pre-condition Violation
bgnIdx not connected to begin atom of bond
Violation occurred on line 292 in file Code/GraphMol/Bond.cpp
Failed Expression: getOwningMol().getBondBetweenAtoms(getBeginAtomIdx(), bgnIdx) != nullptr
RDKIT: 2020.09.1
BOOST: 1_73
This is because some molecules in USPTO50k have stereo bonds.
I followed the instruction to install the TorchDrug properly and meet the Runtime Error when preparing the USPTO-50 dataset:
from torchdrug import datasets
reaction_dataset = datasets.USPTO50k("~/molecule-datasets/", node_feature="center_identification", kekulize=True)
The error log was:
reaction_dataset = datasets.USPTO50k("~/data/molecule-datasets/",
node_feature="center_identification",
kekulize=True)
Loading /home/masa/data/molecule-datasets/data_processed.csv: 100%|█| 50017/50017 [00:00<00:00, 11396
Constructing molecules from SMILES: 100%|█████████████████████| 50016/50016 [03:31<00:00, 236.07it/s]
Computing reaction centers: 0%| | 0/50016 [00:00<?, ?it/s]/home/masa/.conda/envs/td/lib/python3.7/site-packages/torchdrug-0.1.0-py3.7.egg/torchdrug/data/graph.py:411: UserWarning: This overload of nonzero is deprecated:
nonzero()
Consider using one of the following signatures instead:
nonzero(*, bool as_tuple) (Triggered internally at /pytorch/torch/csrc/utils/python_arg_parser.cpp:882.)
return match.nonzero().flatten()
[21:52:07]
Pre-condition Violation
getNumImplicitHs() called without preceding call to calcImplicitValence()
Violation occurred on line 188 in file /home/conda/feedstock_root/build_artifacts/rdkit_1629841762512/work/Code/GraphMol/Atom.cpp
Failed Expression: d_implicitValence > -1
Computing reaction centers: 0%| | 0/50016 [00:00<?, ?it/s]
Traceback (most recent call last):
File "", line 1, in
File "/home/masa/.conda/envs/td/lib/python3.7/site-packages/decorator.py", line 232, in fun
return caller(func, *(extras + args), **kw)
File "/home/masa/.conda/envs/td/lib/python3.7/site-packages/torchdrug-0.1.0-py3.7.egg/torchdrug/core/core.py", line 282, in wrapper
return init(self, *args, **kwargs)
File "/home/masa/.conda/envs/td/lib/python3.7/site-packages/torchdrug-0.1.0-py3.7.egg/torchdrug/datasets/uspto50k.py", line 83, in init
reactants, products = process_fn(reactant, product)
File "/home/masa/.conda/envs/td/lib/python3.7/site-packages/torchdrug-0.1.0-py3.7.egg/torchdrug/datasets/uspto50k.py", line 142, in _get_reaction_center
reactant_hs = torch.tensor([atom.GetTotalNumHs() for atom in reactant.to_molecule().GetAtoms()])
File "/home/masa/.conda/envs/td/lib/python3.7/site-packages/torchdrug-0.1.0-py3.7.egg/torchdrug/data/molecule.py", line 332, in to_molecule
Chem.AssignStereochemistry(mol)
RuntimeError: Pre-condition Violation
getNumImplicitHs() called without preceding call to calcImplicitValence()
Violation occurred on line 188 in file Code/GraphMol/Atom.cpp
Failed Expression: d_implicitValence > -1
RDKIT: 2021.03.5
BOOST: 1_74
My env setting was python=3.7, torch=1.7.1, CUDA=11.0, and RDKit=2021.03.5.
I have defined the mse loss but it's still useless.
Here comes the codes:
train_set, valid_set, test_set, dataset = load_dataset('Caco-2-Permeability.csv')
model = models.GIN(input_dim=dataset.node_feature_dim,
hidden_dims=[256, 256, 256, 256],
short_cut=True, batch_norm=True, concat_hidden=True)
task = tasks.PropertyPrediction(model, task=(),
criterion="mse", metric="rmse")
optimizer = torch.optim.Adam(task.parameters(), lr=1e-3)
solver = core.Engine(task, train_set, valid_set, test_set, optimizer,
gpus=[0], batch_size=1024)
solver.train(num_epoch=100)
solver.evaluate("valid")
solver.save("clintox_gin_infograph.pth")
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.