cyberagentailab / cmaes Goto Github PK
View Code? Open in Web Editor NEWPython library for CMA Evolution Strategy.
Home Page: https://arxiv.org/abs/2402.01373
License: MIT License
Python library for CMA Evolution Strategy.
Home Page: https://arxiv.org/abs/2402.01373
License: MIT License





















































































































I have a dataset with features in the X dataframe, and the target in the y series. I am trying to select the features in X such that, when fitting a model, I reach the extreme of some objective function. Specifically, the model is linear regression, and the objective is BIC (Bayesian Information Criterion) - I'm trying to select the features in X so as to minimize BIC for the model.
X has a very large number of features, so exhaustive search of all feature combinations is not doable. But if you create a list of binary flags [1, 0, 0, 1, 1, 1, 0, 1, 0, 0, ...], one flag for each feature (0 means feature is not selected, 1 means feature is selected), then the problem becomes one of hyperparameter optimization: find the binary flag values that minimize BIC, by selecting the best features.
I've tried to use Optuna with CmaEsSampler(). I've also tried the cmaes library directly.
For some reason, Optuna with CmaEsSampler() finds a better solution (lower BIC), and does not get stuck, but is slow. The cmaes library, at least my implementation, only finds a slightly less good solution (slightly higher BIC), and appears to get stuck in a local minimum, but it iterates much faster.
I would like to use cmaes directly because it's so much faster, but I can't make it overcome the local minimum. What am I missing?
Optuna code:
def fs_objective(trial, X, y, features):
features = copy.deepcopy(features)
random.shuffle(features)
features_use = ['const'] + [f for f in features if trial.suggest_int(f, 0, 1) == 1]
lin_mod = sm.OLS(y, X[features_use], hasconst=True).fit()
return lin_mod.bic
features_select = [f for f in X.columns if f != 'const']
fs_sampler = optuna.samplers.CmaEsSampler(n_startup_trials=1, seed=0, with_margin=True)
study = optuna.create_study(sampler=fs_sampler, study_name=study_name, direction='minimize')
study.optimize(lambda trial: fs_objective(trial, X, y, features_select))My cmaes code, inspired from this link https://github.com/CyberAgentAILab/cmaes/blob/main/examples/cmaes_with_margin_binary.py
def cma_objective(fs):
features_use = ['const'] + [f for i, f in enumerate(features_select) if fs[i,] == 1]
lin_mod = sm.OLS(y, X[features_use], hasconst=True).fit()
return lin_mod.bic
features_select = [f for f in X.columns if f != 'const']
cma_bounds = np.tile([0, 1], (len(features_select), 1))
cma_steps = np.ones(len(features_select))
optimizer = CMAwM(mean=np.zeros(len(features_select)), sigma=2.0, bounds=cma_bounds, steps=cma_steps, seed=0)
pop_size = optimizer.population_size
gen_max = 10000
best_value = np.inf
best_gen = 0
best_sol_raw = None
history_values = np.full((gen_max,), np.nan)
history_values_best = np.full((gen_max,), np.nan)
for generation in tqdm(range(gen_max)):
best_value_gen = np.inf
sol = []
solutions = []
vals = np.full((pop_size,), np.nan)
for i in range(optimizer.population_size):
fs_for_eval, fs_for_tell = optimizer.ask()
solutions.append(fs_for_eval)
value = cma_objective(fs_for_eval)
vals[i] = value
sol.append((fs_for_tell, value))
optimizer.tell(sol)
best_value_gen = vals.min()
if best_value_gen < best_value:
best_value = best_value_gen
best_gen = generation
best_sol_raw = solutions[np.argmin(vals)]
print(f'gen: {best_gen:5n}, new best objective: {best_value:.4f}')
history_values[generation] = best_value_gen
history_values_best[generation] = best_value
if optimizer.should_stop():
break
gen_completed = generationFull code - this is the notebook with all the code, both Optuna and cmaes, along with other things I've attempted, and all required context (data loading, etc):
https://github.com/FlorinAndrei/feature_selection/blob/main/feature_selection.ipynb
Python 3.11.7
cmaes 0.10.0
optuna 3.5.0
Ubuntu 22.04
Optuna history:

cmaes history:

Why is there so much more variance in the Optuna trials? Why is it able to maintain that variance across many trials? It seems like the Optuna code would continue to find even better combinations if I let it run even more.



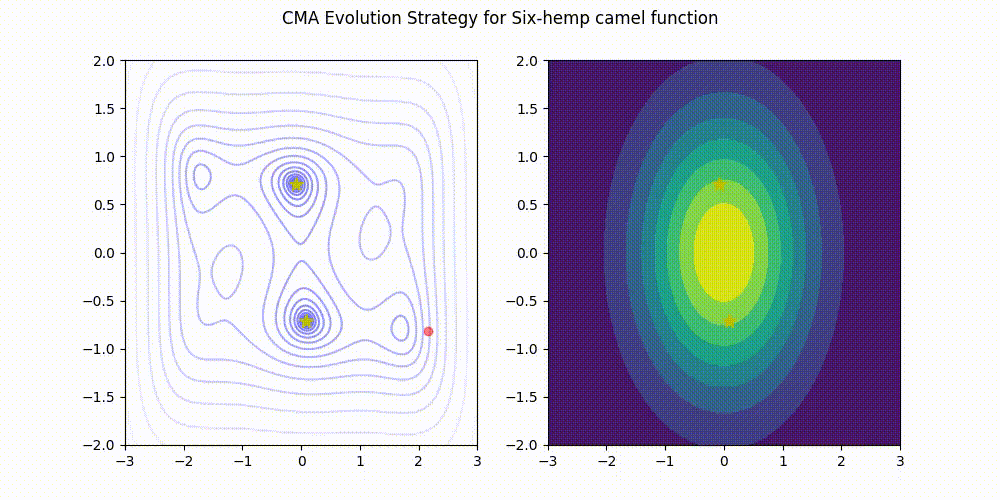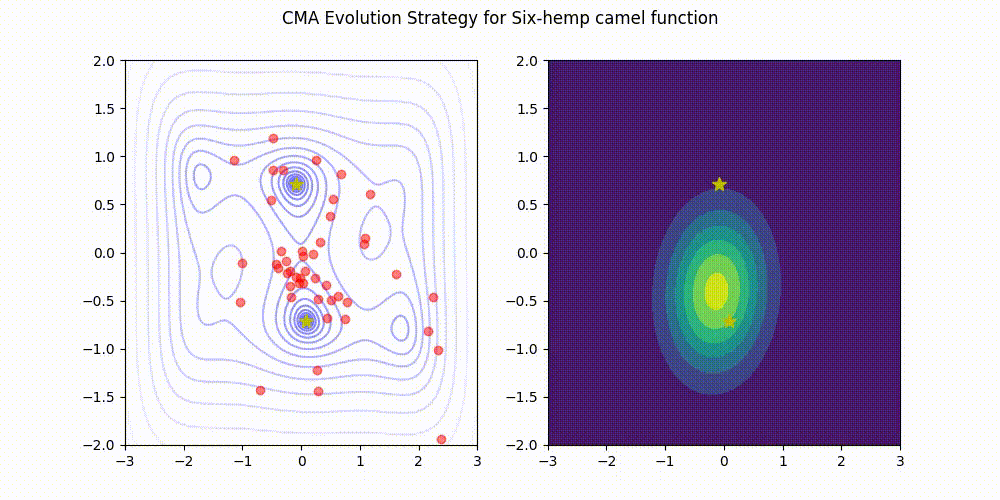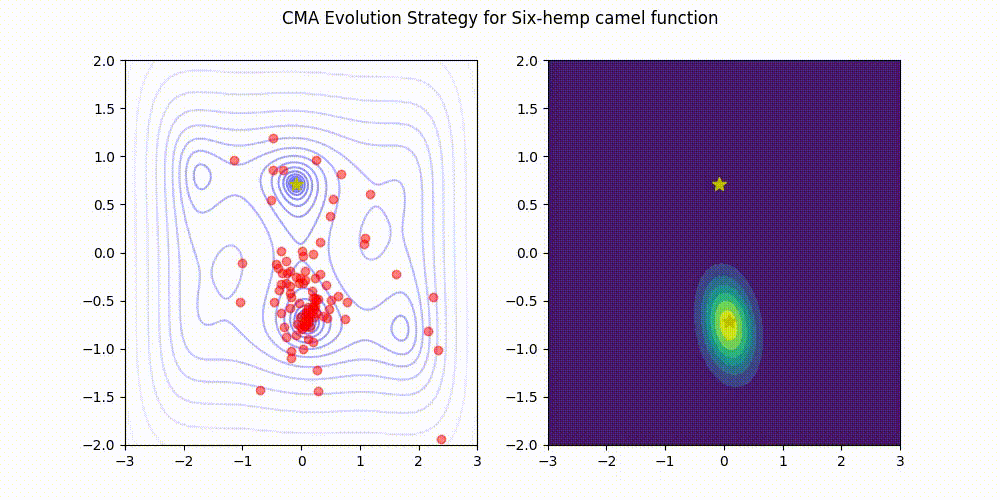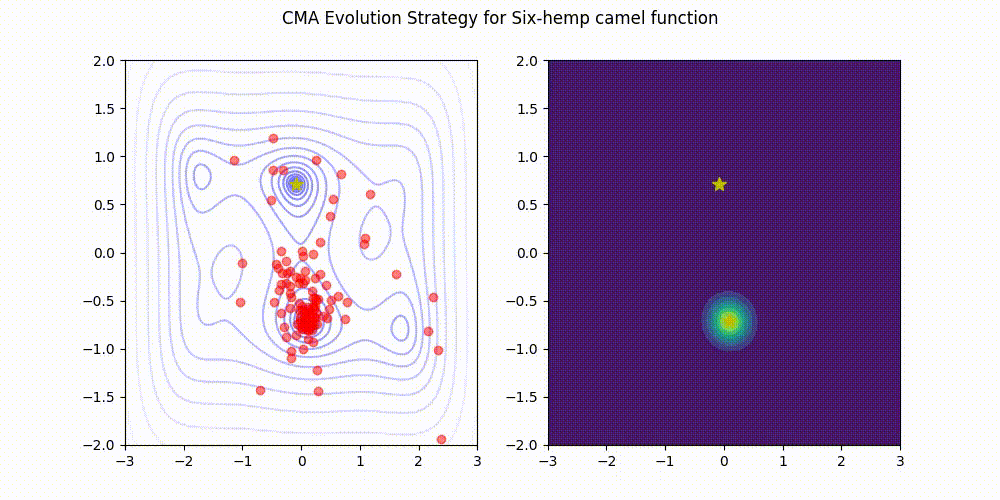



Are non-scalar values for an initial sigma supported by this implementation? I am interested in optimizing a problem where parameters have significantly different bounds and would like to specify a different initial sigma for each parameter via an array when I start the optimization. Thank you for your help!
An official built-in CMA-ES sampler using this library is available at Optuna v1.3.0.
So it's time to recommend the users to migrate to optuna.samplers.CmaEsSampler().
in cma.py CMA.tell() I somehow get to this point:
self._B, self._D = None, None
self._C =
[[ 8.14737017e-04 2.68770961e-02 -6.44404672e-03]
[ 2.68770961e-02 8.40956376e-01 -4.00553778e-01]
[ -6.44404672e-03 -4.00553778e-01 2.18242242e+00]]
D2 =
[ -6.44813495e-05 7.31257026e-01 2.29300099e+00]
D =
[ nan 0.85513568 1.51426582]
This leads to
self._C =
[[ nan nan nan]
[ nan nan nan]
[ nan nan nan]]
at the end of CMA.tell()
Then in CMA._sample_solution()
D2, B = np.linalg.eigh(self._C)
crashes for obvious reasons
LinAlgError: Eigenvalues did not converge
GitHub now supports mp4 and mov videos on comment areas.
It also might be able to use mp4 videos on readme.

Hello. I optimize the six degree of freedom task. Therefore, my goal is to set a Sigma for each channel. What should I do? I input a Sigma list, like this:
sigma = [1 , 15, 30, 25, 25, 50]
Thank you!
Links:
TODOs:
numpy v1.19.0 only supports python 3.6-3.9.
https://github.com/numpy/numpy/releases
This is a followup task for #87
Hi, I have a question about setting bounds in the Low-level interface. I want to set a [-1,1]^100 hypercube bounds, and my code are as below:
bounds = np.zeros((100,2))
for i in range(high_dim):
bounds[i][0] = -1
bounds[i][1] = 1
cma_es = CMA(bounds=bounds,mean=np.zeros(high_dim), sigma=1.3)However, this doesn't work when I run "x = cma_es.ask()"
Could you tell me the right way to set the bounds in Low-level interface?
dim in "get_warm_start_mgd" is defined as dim = len(source_solutions[0]). Since source_solutions[0] is tuple, this dim is always 2. I'm assuming dim = len(source_solutions[0][0]), otherwise get_warm_start_mgd won't work for higher dimensional data.
I have a question about the tell interface.
I think it is more intuitive to use the solution in x space (i.e. ~N(m, σ^2 C)) as an argument,
but why do you use the solution in z space (i.e. ~N(0, I)) as an argument now?
Please file a bug report here.
Please describe the behavior you are expecting
What is the current behavior? Please provide detailed steps or example for reproducing.
Please provide any relevant information about your setup. This is important in case the issue is not reproducible except for under certain conditions.
Sorry, it is not bug, but question about your imprementation.
I couldn't find the appropriate place, so I would like to ask a question here.
In the usage examples of xnes, an example of a minimization was shown. However, the original paper of xnes("Exponential Natural Evolution Strategies") deals with a maximization problem. I checked the code, but I couldn't find any specific changes from the original paper, and I couldn't understand where they switch between the maximization and minimization problems. I would be grateful if you could enlighten me how do you change maximize or minimize.
We will add an example of LRA-CMA.
Nikolaus Hansen. A Global Surrogate Assisted CMA-ES. GECCO 2019 - The Genetic and
Evolutionary Computation Conference, ACM, Jul 2019, Prague, Czech Republic. pp.664-672,
ff10.1145/3321707.3321842ff. ffhal-02143961f
https://hal.inria.fr/hal-02143961/document
mean is mutableI know this might technically not be a bug, more so than a slight inconvenience.
For a school project, I want to benchmark the CMA-ES, so I tried to do some repetitions with the same initial vector.
To my surprise, the optimiser seemed to "remember" the last optimal solution.
import SomePlot from .myplotscript
repetitions = 10
fmins = np.zeros(shape=(repetitions, pop_size))
X0 = np.arange(0, 100)
gen = 0
for rep in range(repetitions):
optimizer = CMA(mean=X0)
terminate = False
while not terminate:
# dosomestuff
best_fmin = ...
fmins[rep][gen] = best_fmin
gen += 1
SomePlot(fmins)I know that there is a very easy workaround, just changing mean=X0 to mean=X0.copy() does the trick.
I find this quite ugly though, and it might clear some confusion for other users if the copying would be done behind the screens.
It is not a pressing issue whatsoever, I just really like this project and I hope that me pointing out this issue might make the experience working with it even more enjoyable.
News partI'm new to Evolution Strategy and I don't understand the difference between a sampler and ask-and-tell interface. Can you give a more detailed explain?
I would like to empirically investigate reasonable box constraint handling in the continuous and discrete case in the CMA-ES.
This issue is related to #136.
Context: I am currently translating this code to Rust.
Issue: I want to understand a line of code:
# (eq.46)
w_io = self._weights * np.where(
self._weights >= 0,
1,
self._n_dim / (np.linalg.norm(C_2.dot(y_k.T), axis=0) ** 2 + _EPS),
)
So, when self.weights is less than zero, it'd happen that the operation would result in a in a vector, given the norm(..., axis=0)?
Can you explain that?
I will introduce CR-FM-NES, which is suited for high-dimensional problems.
CR-FM-NES shows better performance than scalable baseline methods such as VD-CMA and Sep-CMA in typical benchmark problems with d=200, 600, 1000.
After the introduction of CMA-ES with Margin (wip in #115), I will send this PR.

Now I'm trying to introduce CMA-ES with Margin, and I'm thinking of putting scipy dependency into this repository.
Specifically, I'd like to use chi2.ppf in the following.
https://github.com/scipy/scipy/blob/v1.9.1/scipy/stats/_continuous_distns.py#L1343-L1407
It might be possible to implement chi2.ppf without scipy, but it seems to be a bit difficult (at least for me).
Optuna, which employs this repository for using CMA-ES, already requires scipy, so I think this doesn't become a problem.
https://github.com/optuna/optuna/blob/master/setup.py#L39
Thank you to the developers for a nice implementation of the CMA-ES optimizer.
I have used your implementation in a project, and want to acknowledge it. What is the best way to reference your implementation? Is there a paper that could be cited?
With Optuna, if I use CmaEsSampler() with restart_strategy='ipop' then the recommended inc_popsize (according to the documentation) is 2.
But what if I use restart_strategy='bipop'? Is inc_popsize=2 still optimal? And what is the optimal popsize in that case?
The documentation should provide some hints, the way it does for inc_popsize.
The documentation does not provide hints.
To uncover bugs, I use hypothesis for coverage-guided fuzzing.
import hypothesis.extra.numpy as npst
import unittest
from hypothesis import given, strategies as st
from cmaes import CMA
class TestFuzzing(unittest.TestCase):
@given(
data=st.data(),
)
def test_cma_tell(self, data):
dim = data.draw(st.integers(min_value=2, max_value=100))
mean = data.draw(npst.arrays(dtype=float, shape=dim))
sigma = data.draw(st.floats(min_value=1e-16))
n_iterations = data.draw(st.integers(min_value=1))
optimizer = CMA(mean, sigma)
popsize = optimizer.population_size
for _ in range(n_iterations):
tell_solutions = data.draw(
st.lists(st.tuples(npst.arrays(dtype=float, shape=dim), st.floats()),
min_size=popsize, max_size=popsize)
)
optimizer.ask()
optimizer.tell(tell_solutions)
optimizer.ask()(venv) $ py.test tests/test_fuzzing.py
===================================================================================== test session starts =====================================================================================
platform darwin -- Python 3.9.0, pytest-6.2.2, py-1.9.0, pluggy-0.13.1
rootdir: /Users/a14737/go/src/github.com/CyberAgent/cmaes
plugins: hypothesis-6.6.0
collected 1 item
tests/test_fuzzing.py F [100%]
========================================================================================== FAILURES ===========================================================================================
__________________________________________________________________________________ TestFuzzing.test_cma_tell __________________________________________________________________________________
self = <tests.test_fuzzing.TestFuzzing testMethod=test_cma_tell>
@given(
> data=st.data(),
)
tests/test_fuzzing.py:10:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
tests/test_fuzzing.py:26: in test_cma_tell
optimizer.ask()
cmaes/_cma.py:238: in ask
x = self._sample_solution()
cmaes/_cma.py:258: in _sample_solution
B, D = self._eigen_decomposition()
cmaes/_cma.py:250: in _eigen_decomposition
D2, B = np.linalg.eigh(self._C)
<__array_function__ internals>:5: in eigh
???
venv/lib/python3.9/site-packages/numpy/linalg/linalg.py:1471: in eigh
w, vt = gufunc(a, signature=signature, extobj=extobj)
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
err = 'invalid value', flag = 8
def _raise_linalgerror_eigenvalues_nonconvergence(err, flag):
> raise LinAlgError("Eigenvalues did not converge")
E numpy.linalg.LinAlgError: Eigenvalues did not converge
venv/lib/python3.9/site-packages/numpy/linalg/linalg.py:94: LinAlgError
----------------------------------------------------------------------------------------- Hypothesis ------------------------------------------------------------------------------------------
Falsifying example: test_cma_tell(
self=<tests.test_fuzzing.TestFuzzing testMethod=test_cma_tell>,
data=data(...),
)
Draw 1: 3
Draw 2: array([1.34078079e+138, 1.34078079e+138, 1.34078079e+138])
Draw 3: 1e-16
Draw 4: 1
Draw 5: [(array([0., 0., 0.]), 0.0), (array([0., 0., 0.]), 0.0), (array([0., 0., 0.]), 0.0), (array([0., 0., 0.]), 0.0), (array([0., 0., 0.]), 0.0), (array([0., 0., 0.]), 0.0), (array([0., 0., 0.]), 0.0)]
====================================================================================== warnings summary =======================================================================================
tests/test_fuzzing.py::TestFuzzing::test_cma_tell
/Users/a14737/go/src/github.com/CyberAgent/cmaes/venv/lib/python3.9/site-packages/numpy/core/fromnumeric.py:87: RuntimeWarning: invalid value encountered in reduce
return ufunc.reduce(obj, axis, dtype, out, **passkwargs)
tests/test_fuzzing.py::TestFuzzing::test_cma_tell
/Users/a14737/go/src/github.com/CyberAgent/cmaes/cmaes/_cma.py:300: RuntimeWarning: overflow encountered in true_divide
y_k = (x_k - self._mean) / self._sigma # ~ N(0, C)
tests/test_fuzzing.py::TestFuzzing::test_cma_tell
/Users/a14737/go/src/github.com/CyberAgent/cmaes/cmaes/_cma.py:328: RuntimeWarning: invalid value encountered in multiply
self._pc = (1 - self._cc) * self._pc + h_sigma * math.sqrt(
tests/test_fuzzing.py::TestFuzzing::test_cma_tell
/Users/a14737/go/src/github.com/CyberAgent/cmaes/venv/lib/python3.9/site-packages/numpy/linalg/linalg.py:2560: RuntimeWarning: overflow encountered in multiply
s = (x.conj() * x).real
tests/test_fuzzing.py::TestFuzzing::test_cma_tell
/Users/a14737/go/src/github.com/CyberAgent/cmaes/venv/lib/python3.9/site-packages/numpy/core/numeric.py:909: RuntimeWarning: overflow encountered in multiply
return multiply(a.ravel()[:, newaxis], b.ravel()[newaxis, :], out)
tests/test_fuzzing.py::TestFuzzing::test_cma_tell
/Users/a14737/go/src/github.com/CyberAgent/cmaes/cmaes/_cma.py:345: RuntimeWarning: invalid value encountered in multiply
np.array([w * np.outer(y, y) for w, y in zip(w_io, y_k)]), axis=0
tests/test_fuzzing.py::TestFuzzing::test_cma_tell
/Users/a14737/go/src/github.com/CyberAgent/cmaes/cmaes/_cma.py:261: RuntimeWarning: overflow encountered in multiply
x = self._mean + self._sigma * y # ~ N(m, σ^2 C)
tests/test_fuzzing.py::TestFuzzing::test_cma_tell
/Users/a14737/go/src/github.com/CyberAgent/cmaes/cmaes/_cma.py:261: RuntimeWarning: invalid value encountered in add
x = self._mean + self._sigma * y # ~ N(m, σ^2 C)
tests/test_fuzzing.py::TestFuzzing::test_cma_tell
/Users/a14737/go/src/github.com/CyberAgent/cmaes/cmaes/_cma.py:300: RuntimeWarning: invalid value encountered in subtract
y_k = (x_k - self._mean) / self._sigma # ~ N(0, C)
tests/test_fuzzing.py::TestFuzzing::test_cma_tell
/Users/a14737/go/src/github.com/CyberAgent/cmaes/cmaes/_cma.py:304: RuntimeWarning: invalid value encountered in add
self._mean += self._cm * self._sigma * y_w
tests/test_fuzzing.py::TestFuzzing::test_cma_tell
/Users/a14737/go/src/github.com/CyberAgent/cmaes/venv/lib/python3.9/site-packages/numpy/core/numeric.py:909: RuntimeWarning: invalid value encountered in multiply
return multiply(a.ravel()[:, newaxis], b.ravel()[newaxis, :], out)
tests/test_fuzzing.py::TestFuzzing::test_cma_tell
/Users/a14737/go/src/github.com/CyberAgent/cmaes/cmaes/_cma.py:315: RuntimeWarning: overflow encountered in exp
self._sigma *= np.exp(
tests/test_fuzzing.py::TestFuzzing::test_cma_tell
/Users/a14737/go/src/github.com/CyberAgent/cmaes/cmaes/_cma.py:310: RuntimeWarning: overflow encountered in multiply
self._p_sigma = (1 - self._c_sigma) * self._p_sigma + math.sqrt(
tests/test_fuzzing.py::TestFuzzing::test_cma_tell
/Users/a14737/go/src/github.com/CyberAgent/cmaes/venv/lib/python3.9/site-packages/numpy/linalg/linalg.py:2561: RuntimeWarning: overflow encountered in reduce
return sqrt(add.reduce(s, axis=axis, keepdims=keepdims))
-- Docs: https://docs.pytest.org/en/stable/warnings.html
=================================================================================== short test summary info ===================================================================================
FAILED tests/test_fuzzing.py::TestFuzzing::test_cma_tell - numpy.linalg.LinAlgError: Eigenvalues did not converge
=============================================================================== 1 failed, 14 warnings in 6.53s ================================================================================
Does not raise exception.
Please provide any relevant information about your setup. This is important in case the issue is not reproducible except for under certain conditions.
hypothesis branch)In this report we describe two small modifications of CMA-ES that are sometimes useful and sometimes even essential in order to apply the method to mixed-integer problems.
This problem is solved by introducing an integer mutation for components where the variance appears to be small. The integer mutation is disregarded for the update of any state variable but the mean. Additionally, for step-size adaptation, components where the integer mutation is dominating are out-masked.

In the current ask-and-tell interface, it may be difficult to implement mirrored sampling because ask returns only one solution.
Additionaly, updating based on z vector is also difficult, as ask returns only x vector rather than z.
So adding the new API (e.g optimize()) that includes ask and tell is helpful to implement such features.
This is related to #117.
To implement CMA-ES variants, it is better to provide a protocol for optimizer API (See PEP 544 or Python docs for details).
Probably, the protocol will be like this:
import numpy as np
from typing import List, Optional, Tuple
try:
from typing import Protocol
except ImportError:
from typing_extensions import Protocol
class Optimizer(Protocol):
@property
def dim(self) -> int:
"""A number of dimensions"""
@property
def generation(self) -> int:
"""Generation number which is monotonically incremented
when multi-variate gaussian distribution is updated."""
@property
def population_size(self) -> int:
"""A population size"""
def ask(self) -> np.ndarray:
"""Sample a parameter"""
def tell(self, solutions: List[Tuple[np.ndarray, float]]) -> None:
"""Tell evaluation values"""
def set_bounds(self, bounds: Optional[np.ndarray]) -> None:
"""Update boundary constraints"""It would be good to get the local optimums together with the "global". Is this already possible? If yes how can I do it?
In some cases, one might want to choose a local optimum that is, in some sense, "more robust" than the global one. For this reason having a list of local optimums as well would be useful
I observed the figure of CMA with Margin was not working before the authentication of CyberAgent organization.
Anyway one easy idea to fix is to include the figure itself, rather than link.
Hello, currently I'm trying to implement the local meta-model CMAES algorithm from this paper with the help of your repository. I already plotted to see how the algorithm works.
Here is the link to my implementation in my fork: https://github.com/joshnah/cmaes/blob/main/test-LMM-CMAES.py
I would like to make use of your folder benchmark (with kurobako) do some performance tests with the original algorithm CMAES but I didn't succeed. Could you please give me some advices or instructions on this benchmark? Thank you in advance.
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.