

|
我的技术公众号「iCSS 前端趣闻」,想 Get 到最有意思的 CSS 资讯,千万不要错过 😄
✏️ Recent Blog |

我的 CSS 书籍 - 「CSS 技术揭秘与实战通关」 |
自己博客园一些写得比较好的文章移植,欢迎订阅。
|
我的技术公众号「iCSS 前端趣闻」,想 Get 到最有意思的 CSS 资讯,千万不要错过 😄
✏️ Recent Blog |
我的 CSS 书籍 - 「CSS 技术揭秘与实战通关」 |










































































































































最近有关区块链的文章越来越多,发现现在很多人对区块链,比特币存在很多理解误差,遂打算好好全面的捋一捋相关知识。感兴趣可以继续读下去,可能会涉及到:
比特币是由一系列概念和技术作为基础构建的数字货币生态系统。
先介绍一些相关概念:
大部分人提及到区块链,第一反应肯定是比特币,只不过,区块链发展到现在,经历了区块链1.0 到 3.0 。甚至已经有打着区块链4.0口号的区块链应用出现。
区块链早已不再是比特币这么简单,我们通常习惯将不是比特币的其他区块链币种统称为山寨币,那么现在一共有多少种山寨币呢?
不完全统计,上非小号可以查询到的山寨币,截止至本文撰写的时候,已经达到了1900+ 多种。并且,这个数字还在以日为单位飞涨中。
那么,到底何为区块链呢?
区块链是一种不可篡改的、去中心化的、共享的数字化分布式账本,用于记录公有或私有对等网络中的交易。账本分发给网络中的所有成员节点,在通过哈希密码算法链接的区块的顺序链中,永久记录网络中的对等节点之间发生的资产交易的历史记录。
所有经过确认和证明的交易都从链的开头一直链接到最新的区块,因此得名区块链。区块链可以充当单一事实来源,而且区块链网络中的成员只能查看与他们相关的交易。
当然,区块链还有一些其他特定,譬如匿名性、全球性。
不可篡改这个很好理解,区块链记录的信息无法被篡改。对于传统中心化的服务来说,我们为客户提供服务,每个应用有自己的服务器,我们的信息存储在服务器的数据库上,要篡改我们的信息只需要修改数据库就好了。
那么区块链是如何做到不可篡改的?而且是 100% 无法篡改么?
不是,区块链的无法篡改,只是广义上的无法篡改。
一旦信息经过验证并添加至区块链,就会在区块的每一个节点永久的存储起来,除非能够同时控制住系统中超过51%的节点,否则单个节点上对数据库的修改是无效的,因此区块链的数据稳定性和可靠性极高。
所谓不可篡改也不是绝对的是因为,只要在从历史某一区块开始新开一个分支,并取得全网拥护即可。案例就是以太坊开发团队的以太币被黑客盗走后,为了挽回损失,团队新开了一个分支叫以太坊,被黑客盗币的那个分支现在叫以太坊经典。不过这件事也恰恰强调了区块链不可篡改的特性,毕竟以太坊开发团队并不能够在以太坊经典将黑客的以太币划拨到自己账户上。
所谓51%攻击,就是利用一些虚拟区块链货币使用算力作为竞争条件的特点,使用算力优势撤销自己已经发生的付款交易。如果有人掌握了50%以上的算力,他能够比其他人更快地找到开采区块需要的那个随机数,因此他实际上拥有了绝对那个区块的有效权利。
由于使用分布式核算和存储,不存在中心化的硬件或管理机构,任意节点的权利和义务都是均等的,系统中的数据块由整个系统中具有维护功能的节点来共同维护。
过去几年里,人们对区块链的最大误解可能就是对“去中心化”这个词的理解,按字面含义,去中心化就是节点的分散,数据的分散,矿工的分散,开发者的分散……甚至有人认为,矿工的分散(人人都能用个人电脑挖矿)是中本聪的初心,中本聪支持“一CPU一票”,即每个用户通过个人电脑、手机就能挖矿。还有人试图通过算法的改进,阻抗ASIC芯片的研发,避免算力的中心化,当然,这些努力都是掩耳盗铃,算法只能延缓专业化挖矿芯片的诞生,而不是阻止。
每个人都能通过自己的个人电脑、手机挖矿,这看起来是更公平、更去中心化的理想社会,可为什么区块链的安全性反而降低了呢?原因很简单,去中心化并不是一个描述状态的词,而是一个描述过程的词,状态的去中心化并不意味着过程的去中心化,僵尸网络的节点在状态上是分散的,但在行为模式上具有高度一致性。去中心化的本意是指,每个人参与共识的自由度。他有参与的权力,他也有退出的权力。在代码开源、信息对称的前提下,参与和决策的自由度,即意味着公平。
分布式账本是一种在网络成员之间共享、复制和同步的数据库。分布式账本记录网络参与者之间的交易,比如资产或数据的交换。
网络中的参与者根据共识原则来制约和协商对账本中的记录的更新。没有中间的第三方仲裁机构(比如金融机构或票据交换所)的参与。
“智能合约是一个在计算机系统上,当一定条件被满足的情况下,可以被自动执行的合约。”
智能合约看上去就是一段计算机执行程序,满足可准确自动执行即可,那么为什么用传统的技术为何很难实现,而需要区块链技术等新技术呢?
基于区块链技术的智能合约不仅可以发挥智能合约在成本效率方面的优势,而且可以避免恶意行为对合约正常执行的干扰。将智能合约以数字化的形式写入区块链中,由区块链技术的特性保障存储、读取、执行整个过程透明可跟踪、不可攥改。同时,由区块链自带的共识算法构建出一套状态机系统,使得智能合约能够高效地运行。
1、多方用户共同参与制定一份智能合约;
2、合约通过P2P网络扩散并存入区块链;
3、区块链构建的智能合约自动执行。
智能合约一定要在区块链技术之上实现吗?答案是否定的。
举个大家都熟悉的例子,就是信用卡的自动还款服务,我们就可以把它理解成一种智能合约。在具体的时间(信用卡还款日),当还款条件被满足(储蓄卡余额比信用卡还款金额要多的情况下),计算机系统会自动完成这笔交易(用最初设定的储蓄卡为信用卡还款)。然而这些服务仍是运行在传统的计算机系统之上,而这些系统并没有利用区块链技术。
区块链1.0是以比特币为代表的数字货币应用,其场景包括支付、流通等货币职能。
主要具备的是去中心化的数字货币和支付平台的功能,目标是为了去中心化。
当然,现在很多人对去中心化存在很大的理解偏差。
去中心化的英文单词是 Decentralized 。但其实翻译过来为分散,而非去中心化。
区块链是一种软件系统,而软件系统的网络架构一般有三种模式:单中心、多中心、分布式。单词 Decentralized 只是表明不是单中心模式,可能为多中心或弱中心,也可能是分布式的。
在****地区,大多将 Decentralized 翻译为“分散式的”而不是“去中心化”。
所以关于去中心化,绝大多数人还是误解颇深。
所谓的去中心化,并不是“消灭所有的中心”。在现实里,实际上是这样的:由“原本只有少量的大中心”,慢慢演化成“有大量的更小规模的中心”。也就是分散,Decentralized 的原意。
典型:
比特币的1M的区块大小导致在交易频次越来越高、人们需求越来越多的情况下,转账速度变得越来越慢。这个问题可以由扩容解决,所以出现了之后的比特现金和比特黄金,以及比特钻石等;
只满足数字货币的交易和支付功能使得该应用不能被大范围地普及到生活中,给日常生活带来的益处十分有限,区块链的概念也难以深入人心。
区块链2.0是数字货币与智能合约相结合,对金融领域更广泛的场景和流程进行优化的应用其。最大的升级之处在于有了智能合约。
智能合约是 1990s 年代由尼克萨博提出的理念,几乎与互联网同龄。由于缺少可信的执行环境,智能合约并没有被应用到实际产业中,自比特币诞生后,人们认识到比特币的底层技术区块链天生可以为智能合约提供可信的执行环境。
以太坊 ETH 首先看到了区块链和智能合约的契合,发布了白皮书《以太坊:下一代智能合约和去中心化应用平台》,并一直致力于将以太坊打造成最佳智能合约平台,所以比特币引领区块链,以太坊复活智能合约。
所谓智能合约,是指以数字形式定义的一系列承诺,包括合约参与方可以在上面执行这些承诺的协议。智能合约一旦设立指定后,能够无需中介的参与自动执行,并且没有人可以阻止它的运行。
可以这样通俗地说,通过智能合约建立起来的合约同时具备两个功能:一个是现实产生的合同;一个是不需要第三方的、去中心化的公正、超强行动力的执行者。
典型:
嗯。现在越来越多人开始提 区块链3.0了。区块链3.0的概念,已经超越货币、金融范围的区块链应用,涵盖了智能化物联网未来的各种应用场景。
体现为政府、健康、科学、工业、文化和艺术领域的应用。支持行业应用意味着区块链平台必须具备企业级属性。
采购方希望订立一个自动化的供货流程,追踪合约执行过程,并根据指定条件自动完成全额支付、部分支付、补贴、罚款。在此过程会涉及多个采购方、供货方、物流、银行等,需要对每一批次商品的供货过程有完整记录。通过采用区块链的方案,实现多方共同记账、共同监管,实现效率和透明度以及提高抗风险能力。
未来智能设备能够通过智能物联网代替人处理一些日常工作。例如汽车可以自动订购汽油、预定检修服务或清洗服务。冰箱可以自动化订购商品,甚至空调和冰箱可以谈判如何错峰用电。通过区块链的方案,可以在一个分布式的物联网建立信用机制,利用区块链的记录来监控、管理智能设备,同时利用智能合约来规范智能设备的行为。
客户希望知道购买的商品的供应链信息,例如消费者希望知道食品的生产、加工、经销、仓储、运输过程,原材料的来源等,整机集成商希望知道部件的厂商、渠道来源等。采用区块链的方案,可以登记每个商品的出处,提供一个共享的全局账本,追踪溯源所有引起变化的环境。
在游戏或某些行业,消费者会累积很多虚拟资产(点数、积分、奖励、装备、战力等),消费者希望能方便的将虚拟资产兑换或转移。比如游戏玩家希望游戏虚拟资产能从一个游戏转移到另一个游戏,或者玩家之间能够相互兑换这些虚拟资产。采用区块链的方案,可以实现虚拟资产的公开、公正的转移,不受第三方影响,自动到账。
包括不动产、动产、知识产权、物权、租赁使用权益、商标、执照、许可、各类票据、证书、身份、名称登记等在内的产权登记,都可以采用区块链技术来登记,以保障公正、防伪、不可篡改以及可审计等。
不断的学习,了解,才能更好的立足于区块链。
当然本文只是初浅对区块链1.0到3.0的进化过程进行科普,具体一些智能合约编程,详细算法等实现介绍,将在后续慢慢展开。
最后喜欢区块链的同学,可以进群一起交流:
互联网区块链交流群:483931379
作为前端,每日与 URL 打交道是必不可少的。但是也许每天只是单纯的用,对其只是一知半解,随着工作的展开,我发现在日常抓包调试,接口调用,浏览器兼容等许多方面,不深入去理解URL与URL编码则会踩到很多坑。故写下此篇文章,详解一下 URL 。
很多人会混淆这两个名词。
URL:(Uniform/Universal Resource Locator 的缩写,统一资源定位符)。
URI:(Uniform Resource Identifier 的缩写,统一资源标识符)。
关系:
URI 属于 URL 更低层次的抽象,一种字符串文本标准。
就是说,URI 属于父类,而 URL 属于 URI 的子类。URL 是 URI 的一个子集。
二者的区别在于,URI 表示请求服务器的路径,定义这么一个资源。而 URL 同时说明要如何访问这个资源(http://)。
何为端口?端口(Port),相当于一种数据的传输通道。用于接受某些数据,然后传输给相应的服务,而电脑将这些数据处理后,再将相应的回复通过开启的端口传给对方。
端口的作用:因为 IP 地址与网络服务的关系是一对多的关系。所以实际上因特网上是通过 IP 地址加上端口号来区分不同的服务的。
端口是通过端口号来标记的,端口号只有整数,范围是从0 到65535。
通常而言,我们所熟悉的 URL 的常见定义格式为:
scheme://host[:port#]/path/.../[;url-params][?query-string][#anchor]
scheme //有我们很熟悉的http、https、ftp以及著名的ed2k,迅雷的thunder等。
host //HTTP服务器的IP地址或者域名
port# //HTTP服务器的默认端口是80,这种情况下端口号可以省略。如果使用了别的端口,必须指明,例如tomcat的默认端口是8080 http://localhost:8080/
path //访问资源的路径
url-params //所带参数
query-string //发送给http服务器的数据
anchor //锚点定位开发当中一个很常见的场景是,需要从 URL 中提取一些需要的元素,譬如 host 、 请求参数等等。
通常的做法是写正则去匹配相应的字段,当然,这里要安利下述这种方法,来自 James 的 blog,原理是动态创建一个 a 标签,利用浏览器的一些原生方法及一些正则(为了健壮性正则还是要的),完美解析 URL ,获取我们想要的任意一个部分。
代码如下:
// This function creates a new anchor element and uses location
// properties (inherent) to get the desired URL data. Some String
// operations are used (to normalize results across browsers).
function parseURL(url) {
var a = document.createElement('a');
a.href = url;
return {
source: url,
protocol: a.protocol.replace(':',''),
host: a.hostname,
port: a.port,
query: a.search,
params: (function(){
var ret = {},
seg = a.search.replace(/^\?/,'').split('&'),
len = seg.length, i = 0, s;
for (;i<len;i++) {
if (!seg[i]) { continue; }
s = seg[i].split('=');
ret[s[0]] = s[1];
}
return ret;
})(),
file: (a.pathname.match(/([^/?#]+)$/i) || [,''])[1],
hash: a.hash.replace('#',''),
path: a.pathname.replace(/^([^/])/,'/$1'),
relative: (a.href.match(/tps?:\/[^/]+(.+)/) || [,''])[1],
segments: a.pathname.replace(/^\//,'').split('/')
};
}Usage 使用方法:
var myURL = parseURL('http://abc.com:8080/dir/index.html?id=255&m=hello#top');
myURL.file; // = 'index.html'
myURL.hash; // = 'top'
myURL.host; // = 'abc.com'
myURL.query; // = '?id=255&m=hello'
myURL.params; // = Object = { id: 255, m: hello }
myURL.path; // = '/dir/index.html'
myURL.segments; // = Array = ['dir', 'index.html']
myURL.port; // = '8080'
myURL.protocol; // = 'http'
myURL.source; // = 'http://abc.com:8080/dir/index.html?id=255利用上述方法,即可解析得到 URL 的任意部分。
为什么要进行URL编码?通常如果一样东西需要编码,说明这样东西并不适合直接进行传输。
那么如何编码?如下:
首先想声明的是,W3C把这个函数废弃了,身为一名前端如果还用这个函数是要打脸的。
escape只是对字符串进行编码(而其余两种是对URL进行编码),与URL编码无关。编码之后的效果是以 %XX 或者 %uXXXX 这种形式呈现的。它不会对 ASCII字符、数字 以及 @ * / + 进行编码。
根据 MDN 的说明,escape 应当换用为 encodeURI 或 encodeURIComponent;unescape 应当换用为 decodeURI 或 decodeURIComponent。escape 应该避免使用。举例如下:
encodeURI('https://www.baidu.com/ a b c')
// "https://www.baidu.com/%20a%20b%20c"
encodeURIComponent('https://www.baidu.com/ a b c')
// "https%3A%2F%2Fwww.baidu.com%2F%20a%20b%20c"
//而 escape 会编码成下面这样,eocode 了冒号却没 encode 斜杠,十分怪异,故废弃之
escape('https://www.baidu.com/ a b c')
// "https%3A//www.baidu.com/%20a%20b%20c" encodeURI() 是 Javascript 中真正用来对 URL 编码的函数。它着眼于对整个URL进行编码。
encodeURI("http://www.cnblogs.com/season-huang/some other thing");
//"http://www.cnblogs.com/season-huang/some%20other%20thing";编码后变为上述结果,可以看到空格被编码成了%20,而斜杠 / ,冒号 : 并没有被编码。
是的,它用于对整个 URL 直接编码,不会对 ASCII字母 、数字 、 ~ ! @ # $ & * ( ) = : / , ; ? + ' 进行编码。
encodeURI("~!@#$&*()=:/,;?+'")
// ~!@#$&*()=:/,;?+'嘿,有的时候,我们的 URL 长这样子,请求参数中带了另一个 URL :
var URL = "http://www.a.com?foo=http://www.b.com?t=123&s=456";直接对它进行 encodeURI 显然是不行的。因为 encodeURI 不会对冒号 : 及斜杠 / 进行转义,那么就会出现上述所说的服务器接受到之后解析会有歧义。
encodeURI(URL)
// "http://www.a.com?foo=http://www.b.com?t=123这个时候,就该用到 encodeURIComponent() 。它的作用是对 URL 中的参数进行编码,记住是对参数,而不是对整个 URL 进行编码。
因为它仅仅不对 ASCII字母、数字 ~ ! * ( ) ' 进行编码。
var URL = "http://www.a.com?foo=http://www.b.com?t=123&s=456";
encodeURIComponent(URL);
// "http%3A%2F%2Fwww.a.com%3Ffoo%3Dhttp%3A%2F%2Fwww.b.com%3Ft%3D123%26s%3D456"
// 错误的用法,看到第一个 http 的冒号及斜杠也被 encode 了 var param = "http://www.b.com?t=123&s=456"; // 要被编码的参数
URL = "http://www.a.com?foo="+encodeURIComponent(param);
//"http://www.a.com?foo=http%3A%2F%2Fwww.b.com%3Ft%3D123%26s%3D456"利用上述的使用标签解析 URL 以及根据业务场景配合 encodeURI() 与 encodeURIComponent() 便能够很好的处理 URL 的编码问题。
原创文章,文笔有限,才疏学浅,文中若有不正之处,万望告知。
关于 chrome 扩展的文章,很久之前也写过一篇。清除页面广告?身为前端,自己做一款简易的chrome扩展吧。
本篇文章重在分享一些制作扩展的过程中比较重要的知识及难点。
扩展程序是一些能够修改或增强 Chrome 浏览器功能的小程序。对于前端工程师而言,其最大的便利就是我们可以应用我们熟悉的 HTML、CSS 、 Javascript 等技术来制作扩展程序。
如下图所示,这些图标就是各种开发者提供的 chrome 扩展程序:

很多人会误称扩展程序为插件,这里有必要区分一下。
" 扩展 " 和 " 插件 ",其实都是软件组件的一种形式,Chrome 只不过是把两种类型的组件分别给与了专有名称,一个叫 " 扩展 ",另一个叫 " 插件 "。
指的是通过调用 Chrome 提供的 Chrome API 来扩展浏览器功能的一种组件,工作在浏览器层面,使用 HTML + Javascript 语言开发。比如著名的 Adblock plus。
指的是通过调用 Webkit 内核 NPAPI 来扩展内核功能的一种组件,工作在内核层面,理论上可以用任何一种生成本地二进制程序的语言开发,比如 C/C++、Delphi 等。比如 Flash player 插件,就属于这种类型。一般在网页中用 <object> 或者 <embed> 标签声明的部分,就要靠插件来渲染。
OK,简单了解完什么是扩展程序后,下面我们来看看如何开发一款扩展程序。
当然,首先我们要搞清楚为什么我们需要扩展程序,它有什么作用呢?
就我而言,最近我开发了一款简单的扩展程序 —— URLHelper 。你可以在 chrome 应用商店下载到它:
开发它的原因是因为,在我们的业务开发中,开发过程经常需要面对超长的 URL,带有 N 多个参数,它可能长这样:
http://tv.video.qq.com/xxx/xxx/xxx/index?rootdomain=test.tv.video.qq.com&guid=066de07bdd33422f95b7ddaf993b2004&tvid=0930DCE900E081E142ED006B56025BA7&appver=3.1.0&bid=31001&appid=101161688&vipbid=38&fromvipbid=38&cid=qk97pyegxz8kdug&vid=&pid=&mid=&from=501&qua_info=PT%3DSNMAPP%26CHID%3D10009%26VN%3D3.1.0%26PR%3DVIDEO%26TVKPlatform%3D670603%26SMARKET%3D&type=0&listid=&matchid=&channelid=&source1=747&source2=709&penid=D21D81E4489E43422F842235B52DD&access=82E8E64DDD4A531B6FFA3E0967F76&kt_login=qq&vuserid=&vusession=&oauth_consumer_key=101161688&kt_userid=924400965&kt_license_account=SNM_0059858531&main_login=qq&kt_login_support=qq%2Cwx%2Cph&kt_boss_channel=tx_snm&ott_flag=2&sop=9&actid=&tvactid=&tv_params=policy_id%3D88&disable_update=&dp=&du=&viewid=&dv=&pageid=&ptag=&redirect_url=http%3A%2F%2Ftest.tv.video.qq.com%2Fktweb%2Fpay%2Fphone%2Fscan%3Frootdomain%3Dtest.tv.video.qq.com%26guid%3D066de07bdd33422f95b7ddaf993b2004%26tvid%3D0930DCE900E081E142ED006B56025BA7%26appver%3D3.1.0%26bid%3D31001%26appid%3D101161688%26vipbid%3D38%26fromvipbid%3D38%26cid%3Dqk97pyegxz8kdug%26vid%3D%26pid%3D%26mid%3D%26from%3D501%26qua_info%3DPT%253DSNMAPP%2526CHID%253D10009%2526VN%253D3.1.0%2526PR%253DVIDEO%2526TVKPlatform%253D670603%2526SMARKET%253D%26type%3D0%26listid%3D%26matchid%3D%26channelid%3D%26source1%3D747%26source2%3D709%26openid%3DD21D81E44801E9E43422F842235B52DD%26access_token%3D82E8E64DDD4EDA531B6FFA3E09676F76%26kt_login%3Dqq%26vuserid%3D%26vusession%3D%26oauth_consumer_key%3D101161688%26kt_userid%3D924400965%26kt_license_account%3DSNM_0059858531%26main_login%3Dqq%26kt_login_support%3Dqq%252Cwx%252Cph%26kt_boss_channel%3Dtx_snm%26ott_flag%3D2%26sop%3D9%26actid%3D%26tvactid%3D%26tv_params%3Dpolicy_id%253D88%26disable_update%3D%26dp%3D%26du%3D%26viewid%3D%26dv%3D%26pageid%3D%26ptag%3D%26opres%3D0&%24from=201
不是开玩笑,真实情况可能比这个还长。
因为调试的需要,经常要找到某一个特定的参数,获取或者修改它的值。
读者可以尝试一下,贴到浏览器中,找到 cid 参数,修改为另外一个值。如果没有工具,这个过程是很痛苦的。一次还好,如果一天重复这个动作几十次,就有必要考虑借助工具了。
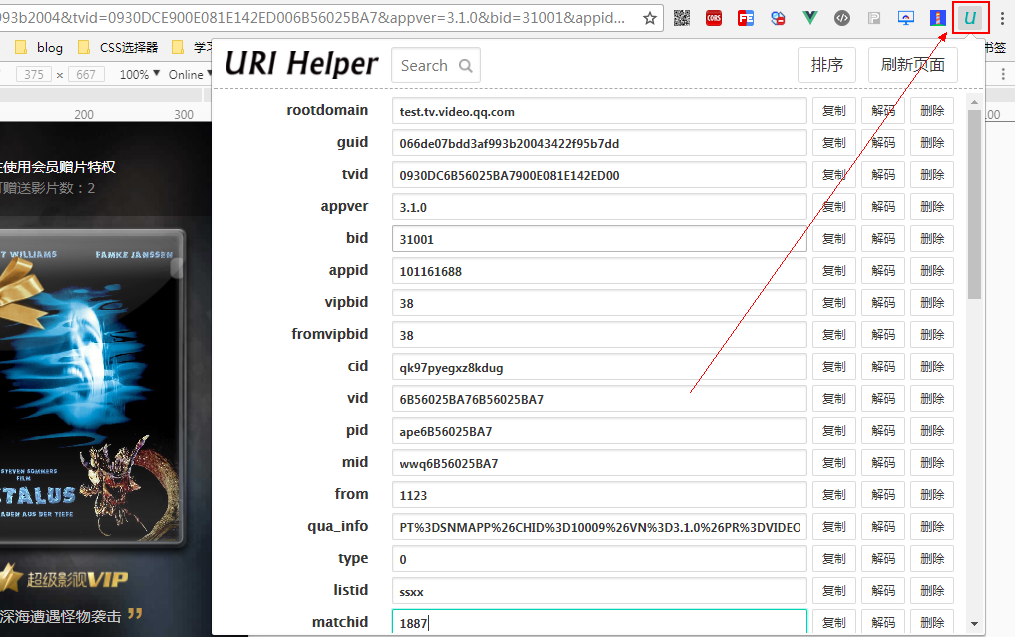
基于这个出发点,我制作了 URLHelper 这个扩展,它的界面大概长这个样子,可以非常方便的对 URL 参数进行删查改 pai 排序,修改参数刷新页面:
所以,扩展程序我觉得每个前端都可以开发,用于解决我们工作生活中在使用浏览器遇到的各种问题,譬如有名的 :
OK,接下来聊聊一些扩展程序开发相关的东西。
关于扩展程序的相关文档,可以看看这些文章:
首先,我觉得最重要的,是要了解整个扩展程序的基本架构,有几个非常重要的文件:
Content scripts 脚本是指能够在浏览器已经加载的页面内部运行的 javascript 脚本。可以将 content script 看作是网页的一部分,而不是它所在的扩展程序的一部分。
它可以实现的一些功能的例子及适用场景,大致如下:
我们可以这样理解它,在页面加载完毕之后,我们的扩展程序会向这个页面注入一个或者额多个脚本,这个脚本可以获得浏览器所访问的 web 页面的详细信息。也就是我们可以利用这个脚本收集页面上各种我们需要的信息。
以我上面的 URLHelper 为例子,在这个扩展中,content script 的作用就是拿到页面的 URL ,然后传递给扩展程序的 background 页面或者 popup 页面。
当然,如果你只需要一个脚本程序每次注入页面后获取页面相关的信息,然后上报到自己的服务器之类的功能,这个扩展程序只需要这一个 Content scripts 就够了。它不需要与其他界面或者脚本进行交互和信息传递,扩展帮你做的就是自动注入这个脚本而需要你每次手动注入。
popup 页面也非常好理解,在 manifest.json 的定义里它是 browser_action, 就是我们扩展程序的界面(弹窗页),就是上面的那张截图:

这个界面其实就是一个 Web 页面,点开任意一个扩展页面,右键都可以看到弹出检查选项,点击这个选项,就会弹出一个开发者工具,我们就可以愉快的开始对这个页面进行查看 DOM 结构、查看网络状态、 Debug 等任意
操作了:

然后:

重点,这个 popup 页面完全由我们控制,就像一个普通的 Web 页面,我们可以利用 Chrome 的消息传递机制利用这个页面和 Content scripts 进行交互,也就可以完成对页面的某些控制。
以我上面的 URLHelper 为例子,在这个扩展中,当我点击扩展程序界面中的刷新页面按钮的时候,会从扩展界面的 DOM 上将修改后参数取出拼好,并且通过Chrome 的消息传递机制 传递给Content scripts,然后Content scripts拿到新的参数,赋值给当前浏览器窗口页面 document.location.href,实现页面的刷新。
除了 popup 页面之外,还有一个 background 后台网页 。
chrome扩展程序将后台网页分为两种类型:
否持久存在是事件页面与后台网页之间的根本区别。(刚开始使用的时候可以理解为一个东西)
应用和扩展程序通常需要长时间运行的脚本来管理某些任务或状态,这就是后台页面的作用。事件页面只在需要时加载,当事件页面不活动时就会卸载,以便释放内存和其他系统资源,所以一般而言是推荐使用事件页面。
它存在的目的在于,在扩展的整个生命周期内需要长时间管理一些任务或状态。它的主要功能及适用场景,大致如下:
以我上面的 URLHelper 为例子,在这个扩展中,我使用的是持续运行的后台网页,当浏览器页面刷新第一次注入 Content Script 时,会获取到当前页面 url ,然后发送消息并带上 url 信息告诉给 background 后台网页, background 后台网页收到消息后,再转发给 popup 页面。
一个扩展程序最重要的我觉得就是上述的三块内容:

我们通过一个 manifest.json 的清单文件来配置它们及一些额外信息。关于 manifest.json 的详细信息,可以戳:manifest 。
接下来,我们的扩展要灵活地完成各种功能,最重要的就是互相间的通信!
信息数据在内容脚本、弹窗页面以及事件页面之间传递是一个扩展程序最重要的部分。
消息传递存在的必要性是因为内容脚本在网页而不是扩展程序的环境中运行,所以它们通常需要某种方式与扩展程序的其余部分通信。
扩展程序(弹窗页面和后台页面)和内容脚本间的通信使用消息传递的方式。两边均可以监听另一边发来的消息,并通过同样的通道回应。消息可以包含任何有效的 JSON 对象。
消息传递,主要使用了 Chrome 浏览器的内置 chrome 对象进行。打开浏览器,试一下,chrome 对象其实包含了非常多的功能:

各种类型的消息传递都是通过这个 chrome 对象进行,分为:
当然,对于通常而言的普通扩展程序而言,简单的一次性请求就足够我们使用了,举两个例子。
假设我们的 manifest.json 简单定义如下:
# manifest.json
{
"name": "Url Helper",
"version": "1.0.0",
"author": "Coco",
"manifest_version": 2,
"browser_action": {
"default_popup": "popup.html"
},
"background": {
"scripts": ["background.js"]
},
"content_scripts": [
{
"js": ["contentScript.js"]
}
]
}# contentScript.js
// 发送消息
chrome.runtime.sendMessage(
{
msg: '从 Content Script 向 事件页面 传递消息',
result: 1
},
function(response) {
if (response && response.msg) {
console.log(response.msg);
}
}
);#background.js
// 接收消息
chrome.runtime.onMessage.addListener(function(request, sender, sendResponse) {
if (request.result) {
sendResponse({
farewell: "ok"
});
}
});在发送端,我们可以使用 runtime.sendMessage 或 tabs.sendMessage 方法。这些方法分别允许您从内容脚本向扩展程序或者反过来发送可通过 JSON 序列化的消息,可选的 callback 参数允许您在需要的时候从另一边处理回应。
而在接收端,我们需要设置一个 runtime.onMessage 事件监听器来处理消息。
再举一个翻过来的例子,从 popup 弹窗页面 向 Content Script 传递消息。
# popup.html 页面内引入的 popup.js
let obj = {
msg: '从 popup 弹窗页面 向 Content Script 传递消息',
result: 0
};
// 发送消息
chrome.tabs.query({ active: true, currentWindow: true }, function(tabs) {
chrome.tabs.sendMessage(tabs[0].id, obj, function(response) {
console.log("Send Success");
});
});# contentScript.js
// 接收消息
chrome.runtime.onMessage.addListener(function(request, sender, sendResponse) {
console.log(sender.tab ? "来自内容脚本:" + sender.tab.url : "来自扩展程序");
if (request && !request.result) {
console.log(result.msg);
}
});这里有个问题需要注意,从 popup 弹窗页面 向 Content Script 传递消息时,由于浏览器可能同时打开多个 tab 页,所以需要指定一下传递的页面,指定发送至哪一个标签页。
使用 chrome.tabs.query({ active: true, currentWindow: true }, function(tabs) {}) 则能正确选中当前打开的标签页。
其他更多的消息传递方式,可以戳这里:消息传递。
扩展程序开发好了,希望供他人下载。那么当然需要发布到应用商店。流程大致如下:
首先,你需要有一个 Google 帐号,点击这里
,登录网上应用商店。
成功之后,将会登录到这个界面,: 
在这个界面我们选择添加新内容即可 : 
注意,要打包成 *.zip 格式,并且在根目录下有最重要的 manifest.json 文件,像我上传的整个目录结构,就非常简单:

选择文件并且成功上传之后,下一步非常重要。第一次发布扩展程序,谷歌会收取 $5 开发者注册费用,之后可以发布 20 个扩展程序 。


这里付款**内地的银行卡好像都不行,只能选择国外的 VISA 等储蓄卡、信用卡进行支付,地区选择美国即可。
OK,最后付款完成,就可以顺利发布了,稍等片刻,就可以搜索到我们自己开发扩展程序了!
当然,有些同学无法访问谷歌商店,或者扩展程序做出来仅仅是团队内部的一种工具,供私人使用。那么可以直接在 chrome 浏览器安装安装包。
扩展目录即是一个项目下的所有文件,开发调试的时候也是使用这个方法即可。
其实开发一款 Chrome 扩展程序真的不难,而且非常有意思。感兴趣但又怕麻烦的同学可以参考我这个小项目改改。Github -- URL Helper
本文其实应该叫,Web 用户体验设计提升指南。
一个 Web 页面,一个 APP,想让别人用的爽,也就是所谓的良好的用户体验,我觉得他可能包括但不限于:
所谓的用户体验设计,其实是一个比较虚的概念,是秉承着以用户为中心的**的一种设计手段,以用户需求为目标而进行的设计。设计过程注重以用户为中心,用户体验的概念从开发的最早期就开始进入整个流程,并贯穿始终。
良好的用户体验设计,是产品每一个环节共同努力的结果。
除去一些很难一蹴而就的,本文将就页面展示、交互细节、可访问性三个方面入手,罗列一些在实际的开发过程中,积攒的一些有益的经验。通过本文,你将能收获到:
就整个页面的展示,页面内容的呈现而言,有一些小细节是需要我们注意的。
先来看看一些布局相关的问题。
对于大部分 PC 端的项目,我们首先需要考虑的肯定是最外层的一层包裹。假设就是 .g-app-wrapper。
<div class="g-app-wrapper">
<!-- 内部内容 -->
</div>首先,对于 .g-app-wrapper,有几点,是我们在项目开发前必须弄清楚的:
对于定宽布局,就比较方便了,假设定宽为 1200px,那么:
.g-app-wrapper {
width: 1200px;
margin: 0 auto;
}利用 margin: 0 auto 实现布局的水平居中。在屏幕宽度大于 1200px 时,两侧留白,当然屏幕宽度小于 1200px 时,则出现滚动条,保证内部内容不乱。

对于现代布局,更多的是全屏布局。其实现在也更提倡这种布局,即使用可随用户设备的尺寸和能力而变化的自适应布局。
通常而言是左右两栏,左侧定宽,右侧自适应剩余宽度,当然,会有一个最小的宽度。那么,它的布局应该是这样:
<div class="g-app-wrapper">
<div class="g-sidebar"></div>
<div class="g-main"></div>
</div>.g-app-wrapper {
display: flex;
min-width: 1200px;
}
.g-sidebar {
flex-basis: 250px;
margin-right: 10px;
}
.g-main {
flex-grow: 1;
}
利用了 flex 布局下的 flex-grow: 1,让 .main 进行伸缩,占满剩余空间,利用 min-width 保证了整个容器的最小宽度。
当然,这是最基本的自适应布局。对于现代布局,我们应该尽可能的考虑更多的场景。做到:

下面一种情形也是非常常见的一个情景。
页面存在一个 footer 页脚部分,如果整个页面的内容高度小于视窗的高度,则 footer 固定在视窗底部,如果整个页面的内容高度大于视窗的高度,则 footer 正常流排布(也就是需要滚动到底部才能看到 footer)。
看看效果:

嗯,这个需求如果能够使用 flex 的话,使用 justify-content: space-between 可以很好的解决,同理使用 margin-top: auto 也非常容易完成:
<div class="g-container">
<div class="g-real-box">
...
</div>
<div class="g-footer"></div>
</div>.g-container {
height: 100vh;
display: flex;
flex-direction: column;
}
.g-footer {
margin-top: auto;
flex-shrink: 0;
height: 30px;
background: deeppink;
}Codepen Demo -- sticky footer by flex margin auto
当然,实现它的方法有很多,这里仅给出一种推荐的解法。
对于所有接收后端接口字段的文本展示类的界面。都需要考虑全面(防御性编程:所有的外部数据都是不可信的),正常情况如下,是没有问题的。

但是我们是否考虑到了文本会超长?超长了会折行还是换行?

对于单行文本,使用单行省略:
{
width: 200px;
white-space: nowrap;
overflow: hidden;
text-overflow: ellipsis;
}
当然,目前对于多行文本的超长省略,兼容性也已经非常好了:
{
width: 200px;
overflow : hidden;
text-overflow: ellipsis;
display: -webkit-box;
-webkit-line-clamp: 2;
-webkit-box-orient: vertical;
}
对于一些动态内容,我们经常使用 min/max-width 或 min/max-height 对容器的高宽限度进行合理的控制。
在使用它们的时候,也有一些细节需要考虑到。
譬如经常会使用 min-width 控制按钮的最小宽度:
.btn {
...
min-width: 120px;
}
当内容比较少的时候是没问题的,但是当内容比较长,就容易出现问题。使用了 min-width 却没考虑到按钮的过长的情况:

这里就需要配合 padding 一起:
.btn {
...
min-width: 88px;
padding: 0 16px
}借用Min and Max Width/Height in CSS中一张非常好的图,作为释义:

这个也是一个常常被忽略的地方。
页面经常会有列表搜索,列表展示。那么,既然存在有数据的正常情况,当然也会存在搜索不到结果或者列表无内容可展示的情形。
对于这种情况,一定要注意 0 结果页面的设计,同时也要知道,这也是引导用户的好地方。对于 0 结果页面,分清楚:
不同的情况可能对应不同的 0 结果页面,附带不同的操作引导。
譬如网络异常:

或者确实是 0 结果:

关于 0 结果页面设计,可以详细看看这篇文章:如何设计产品的空白页面?
小小总结一下,上述比较长的篇幅一直都在阐述一个道理,开发时,不能仅仅关注正常现象,要多考虑各种异常情况,思考全面。做好各种可能情况的处理。
图片在我们的业务中应该是非常的常见了。有一些小细节是需要注意的。
有的时候和产品、设计会商定,只能使用固定尺寸大小的图片,我们的布局可能是这样:

对应的布局:
<ul class="g-container">
<li>
<img src="http://placehold.it/150x100">
<p>图片描述</p>
</li>
</ul>ul li img {
width: 150px;
}当然,万一假设后端接口出现一张非正常大小的图片,上述不加保护的布局就会出问题:

所以对于图片,我们总是建议同时写上高和宽,避免因为图片尺寸错误带来的布局问题:
ul li img {
width: 150px;
height: 100px;
}同时,给 <img> 标签同时写上高宽,可以在图片未加载之前提前占住位置,避免图片从未加载状态到渲染完成状态高宽变化引起的重排问题。
object-fit当然,限制高宽也会出现问题,譬如图片被拉伸了,非常的难看:

这个时候,我们可以借助 object-fit,它能够指定可替换元素的内容(也就是图片)该如何适应它的父容器的高宽。
ul li img {
width: 150px;
height: 100px;
object-fit: cover;
}利用 object-fit: cover,使图片内容在保持其宽高比的同时填充元素的整个内容框。

object-fit 还有一个配套属性 object-position,它可以控制图片在其内容框中的位置。(类似于 background-position),m默认是 object-position: 50% 50%,如果你不希望图片居中展示,可以使用它去改变图片实际展示的 position 。
ul li img {
width: 150px;
height: 100px;
object-fit: cover;
object-position: 50% 100%;
}
像是这样,object-position: 100% 50% 指明从底部开始展示图片。这里有一个很好的 Demo 可以帮助你理解 object-position。
CodePen Demo -- Object position
正常情况下,图片的展示应该没有什么问题了。但是对于有图片可展示的情况下,我们还可以做的更好。
在移动端或者一些高清的 PC 屏幕(苹果的 MAC Book),屏幕的 dpr 可能大于 1。这种时候,我们可能还需要考虑利用多倍图去适配不同 dpr 的屏幕。
正好,<img> 标签是有提供相应的属性 srcset 让我们进行操作的。
<img src='[email protected]'
srcset='[email protected] 1x,
[email protected] 2x,
[email protected] 3x'
/>当然,这是比较旧的写法,srcset 新增了新的 w 宽度描述符,需要配合 sizes 一起使用,所以更好的写法是:
<img
src = "photo.png"
sizes = “(min-width: 600px) 600px, 300px"
srcset = “[email protected] 300w,
[email protected] 600w,
[email protected] 1200w,
>利用 srcset,我们可以给不同 dpr 的屏幕,提供最适合的图片。
上述出现了一些概念,dpr,图片的 srcset ,sizes 属性,不太了解的可以移步 前端基础知识概述
好了,当图片链接没问题时,已经处理好了。接下来还需要考虑,当图片链接挂了,应该如何处理。
处理的方式有很多种。最好的处理方式,是我最近在张鑫旭老师的这篇文章中 -- 图片加载失败后CSS样式处理最佳实践 看到的。这里简单讲下:
<img> 元素的 onerror 事件,给加载失败的 <img> 元素新增一个样式类<img> 元素的伪元素,展示默认兜底图的同时,还能一起展示 <img> 元素的 alt 信息<img src="test.png" alt="图片描述" onerror="this.classList.add('error');">img.error {
position: relative;
display: inline-block;
}
img.error::before {
content: "";
/** 定位代码 **/
background: url(error-default.png);
}
img.error::after {
content: attr(alt);
/** 定位代码 **/
}我们利用伪元素 before ,加载默认错误兜底图,利用伪元素 after,展示图片的 alt 信息:

OK,到此,完整的对图片的处理就算完成了,完整的 Demo 你可以戳这里看看:
接下来一个大环节是关于一些交互的细节。对于交互设计,一些比较通用的准则:
在我们的交互过程中,适当的增加过渡与动画,能够很好的让用户感知到页面的变化。
譬如我们页面上随处可见 loading 效果,其实就是这样一种作用,让用户感知页面正在加载,或者正在处理某些事务。

滚动也是操作网页中非常重要的一环。看看有哪些可以优化的点:
scroll-behavior: smooth 让滚动丝滑使用 scroll-behavior: smooth,可以让滚动框实现平稳的滚动,而不是突兀的跳动。看看效果,假设如下结构:
<div class="g-container">
<nav>
<a href="#1">1</a>
<a href="#2">2</a>
<a href="#3">3</a>
</nav>
<div class="scrolling-box">
<section id="1">First section</section>
<section id="2">Second section</section>
<section id="3">Third section</section>
</div>
</div>不使用 scroll-behavior: smooth,是突兀的跳动切换:

给可滚动容器添加 scroll-behavior: smooth,实现平滑滚动:
{
scroll-behavior: smooth;
}
scroll-snap-type 优化滚动效果sroll-snap-type 可能算得上是新的滚动规范里面最核心的一个属性样式。
scroll-snap-type:属性定义在滚动容器中的一个临时点(snap point)如何被严格的执行。
光看定义有点难理解,简单而言,这个属性规定了一个容器是否对内部滚动动作进行捕捉,并且规定了如何去处理滚动结束状态。让滚动操作结束后,元素停止在适合的位置。
看个简单示例:

当然,scroll-snap-type 用法非常多,可控制优化的点很多,限于篇幅无法一一展开,具体更详细的用法可以看看我的另外一篇文章 -- 使用 sroll-snap-type 优化滚动
这个优化可能稍微有一点难理解。需要了解 CSS 渲染优化的相关知识。
先说结论,控制滚动层级的意思是尽量让需要进行 CSS 动画(可以是元素的动画,也可以是容器的滚动)的元素的 z-index 保持在页面最上方,避免浏览器创建不必要的图形层(GraphicsLayer),能够很好的提升渲染性能。
这一点怎么理解呢,一个元素触发创建一个 Graphics Layer 层的其中一个因素是:
根据上述这点,我们对滚动性能进行优化的时候,需要注意两点:
如果你对这点还有点懵,可以看看这篇文章 -- 你所不知道的 CSS 动画技巧与细节
在用户点击交互方面,也有一些有意思的小细节。
cursor对于不同的内容,最好给与不同的 cursor 样式,CSS 原生提供非常多种常用的手势。
在不同的场景使用不同的鼠标手势,符合用户的习惯与预期,可以很好的提升用户的交互体验。
首先对于按钮,就至少会有 3 种不同的 cursor,分别是可点击,不可点击,等待中:
{
cursor: pointer; // 可点击
cursor: not-allowed; // 不可点击
cursor: wait; // loading
}
除此之外,还有一些常见的,对于一些可输入的 Input 框,使用 cursor: text,对于提示 Tips 类使用 cursor: help,放大缩小图片 zoom-in、zoom-out 等等:

一些常用的简单列一列:
cursor: pointercursor: not-allowedcursor: waitcursor: zoom-in/ zoom-out当然,实际 cursor 还支持非常多种,可以在 MDN 或者下面这个 CodePen Demo 中查看这里看完整的列表:
按钮是我们网页设计中十分重要的一环,而按钮的设计也与用户体验息息相关。
考虑这样一个场景,在摇晃的车厢上或者是单手操作着屏幕,有的时候一个按钮,死活也点不到。
让用户更容易的点击到按钮无疑能很好的增加用户体验及可提升页面的访问性,尤其是在移动端,按钮通常都很小,但是受限于设计稿或者整体 UI 风格,我们不能直接去改变按钮元素的高宽。
那么这个时候有什么办法在不改变按钮原本大小的情况下去增加他的点击热区呢?
这里,伪元素也是可以代表其宿主元素来响应的鼠标交互事件的。借助伪元素可以轻松帮我们实现,我们可以这样写:
.btn::before{
content:"";
position:absolute;
top:-10px;
right:-10px;
bottom:-10px;
left:-10px;
}当然,在 PC 端下这样子看起来有点奇怪,但是合理的用在点击区域较小的移动端则能取到十分好的效果,效果如下:

在按钮的伪元素没有其它用途的时候,这个方法确实是个很好的提升用户体验的点。
user-select: all操作系统或者浏览器通常会提供一些快速选取文本的功能,看看下面的示意图:

快速单击两次,可以选中单个单词,快速单击三次,可以选中一整行内容。但是如果有的时候我们的核心内容,被分隔符分割,或者潜藏在一整行中的一部分,这个时候选取起来就比较麻烦。
利用 user-select: all,可以将需要一次选中的内容进行包裹,用户只需要点击一次,就可以选中该段信息:
.g-select-all {
user-select: all
}给需要一次选中的信息,加上这个样式后的效果,这个细节作用在一些需要复制粘贴的场景,非常好用:

CodePen -- user-select: all 示例
::selection当然,如果你想更进一步,CSS 还有提供一个 ::selection 伪类,可以控制选中的文本的样式(只能控制color, background, text-shadow),进一步加深效果。

CodePen -- user-select: all && ::selection 控制选中样式
user-select: none有快速选择,也就会有它的对立面 -- 禁止选择。
对于一些可能频繁操作的按钮,可能出现如下尴尬的场景:


对于这种场景,我们需要把不可被选中元素设置为不可被选中,利用 CSS 可以快速的实现这一点:
{
-webkit-user-select: none; /* Safari */
-ms-user-select: none; /* IE 10 and IE 11 */
user-select: none; /* Standard syntax */
}这样,无论点击的频率多快,都不会出现尴尬的内容选中:

现阶段,单页应用(Single Page Application)的应用非常广泛,Vue 、React 等框架大行其道。但是一些常见的写法,也容易衍生一些小问题。
譬如,点击按钮、文本进行路由跳转。譬如,经常会出现这种代码:
<template>
...
<button @click="gotoDetail">
Detail
</button>
...
<template>
...
gotoDetail() {
this.$router.push({
name: 'xxxxx',
});
}
大致逻辑就是给按钮添加一个事件,点击之后,跳转到另外一个路由。当然,本身这个功能是没有任何问题的,但是没有考虑到用户实际使用的场景。
实际使用的时候,由于是一个页面跳转,很多时候,用户希望能够保留当前页面的内容,同时打开一个新的窗口,这个时候,他会尝试下的鼠标右键,选择在新标签页中打开页面,遗憾的是,上述的写法是不支持鼠标右键打开新页面的。
原因在于浏览器是通过读取 <a> 标签的 href 属性,来展示类似在新标签页中打开页面这种选项,对于上述的写法,浏览器是无法识别它是一个可以跳转的链接。简单的示意图如下:

所以,对于所有路由跳转按钮,建议都使用 <a> 标签,并且内置 href 属性,填写跳转的路由地址。实际渲染出来的 DOM 可能是需要类似这样:
<a href="/xx/detail">Detail</a>易用性也是交互设计中需要考虑的一个非常重要的环节,能做的有非常多。简单的罗列一下:
这一点非常的有意思,什么叫先探索后表态呢?就是我们不要一上来就强迫用户去做一些事情,譬如登录。
想一想一些常用网站的例子:
上述易用性和先探索,后表态的内容,部分来源于:Learn From What Leading Companies A/B Test,可以好好读一读。
字体的选择与使用其实是非常有讲究的。
如果网站没有强制必须使用某些字体。最新的规范建议我们更多的去使用系统默认字体。也就是 CSS Fonts Module Level 4 -- Generic font families 中新增的 font-family: system-ui 关键字。
font-family: system-ui 能够自动选择本操作系统下的默认系统字体。
默认使用特定操作系统的系统字体可以提高性能,因为浏览器或者 webview 不必去下载任何字体文件,而是使用已有的字体文件。 font-family: system-ui 字体设置的优势之处在于它与当前操作系统使用的字体相匹配,对于文本内容而言,它可以得到最恰当的展示。
举两个例子,天猫的字体定义与 Github 的字体定义:
font-family: "PingFang SC",miui,system-ui,-apple-system,BlinkMacSystemFont,Helvetica Neue,Helvetica,sans-serif;font-family: -apple-system,BlinkMacSystemFont,Segoe UI,Helvetica,Arial,sans-serif,Apple Color Emoji,Segoe UI Emoji,Segoe UI Symbol;简单而言,它们总体遵循了这样一个基本原则:
使用系统默认字体的主要原因是性能,并且系统字体的优点在于它与当前操作系统使用的相匹配,因此它的文本展示必然也是一个让人舒适展示效果。
中文或者西文(英文)都要考虑到。由于大部分中文字体也是带有英文部分的,但是英文部分又不怎么好看,但是英文字体中大多不包含中文。通常会先进行英文字体的声明,选择最优的英文字体,这样不会影响到中文字体的选择,中文字体声明则紧随其次。
选择字体的时候要考虑多操作系统。例如 MAC OS 下的很多中文字体在 Windows 都没有预装,为了保证 MAC 用户的体验,在定义中文字体的时候,先定义 MAC 用户的中文字体,再定义 Windows 用户的中文字体;
当使用一些非常新的字体时,要考虑向下兼容,兼顾到一些极旧的操作系统,使用字体族系列 serif 和 sans-serif 结尾总归是不错的选择。
对于上述的一些字体可能会有些懵,譬如 -apple-system, BlinkMacSystemFont,这是因为不同浏览器厂商对规范的实现有所不同,对于字体定义更多的相关细节,可以再看看这篇文章 -- Web 字体 font-family 再探秘
可访问性,在我们的网站中,属于非常重要的一环,但是大部分前端(其实应该是设计、前端、产品)同学都会忽视它。
我潜伏在一个叫无障碍设计小组的群里,其中包含了很多无障碍设计师以及患有一定程度视觉、听力、行动障碍的用户,他们在群里经常会表达出一个观点,就是国内的大部分 Web 网站及 APP 基本没有考虑过残障人士的使用(或者可访问性做的非常差),非常的令人揪心。
尤其在我们一些重交互、重逻辑的网站中,我们需要考虑用户的使用习惯、使用场景,从高可访问性的角度考虑,譬如假设用户没有鼠标,仅仅使用键盘,能否顺畅的使用我们的网站?
假设用户没有鼠标,这个真不一定是针对残障人士,很多情况下,用户拿鼠标的手可能在干其他事情,比如在吃东西,又或者在 TO B 类的业务,如超市收银、仓库收货,很可能用户拿鼠标的手操作着其他设备(扫码枪)等等。
本文不会专门阐述无障碍设计的方方面面,只是从一些我觉得前端工程师需要关注的,并且仅需要花费少量代价就能做好的一些无障碍设计细节。记住,无障碍设计对所有人都更友善。
颜色,也是我们天天需要打交道的属性。对于大部分视觉正常的用户,可能对页面的颜色敏感度还没那么高。但是对于一小部分色弱、色盲用户,他们对于网站的颜色会更加敏感,不好的设计会给他们访问网站带来极大的不便。
是否曾关心过页面内容的展示,使用的颜色是否恰当?色弱、色盲用户能否正常看清内容?良好的色彩使用,在任何时候都是有益的,而且不仅仅局限于对于色弱、色盲用户。在户外用手机、阳光很强看不清,符合无障碍标准的高清晰度、高对比度文字就更容易阅读。
这里就有一个概念 -- 颜色对比度,简单地说,描述就是两种颜色在亮度(Brightness)上的差别。运用到我们的页面上,大多数的情况就是背景色(background-color)与内容颜色(color)的对比差异。
最权威的互联网无障碍规范 —— WCAG AA规范规定,所有重要内容的色彩对比度需要达到 4.5:1 或以上(字号大于18号时达到 3:1 或以上),才算拥有较好的可读性。
借用一张图 -- 知乎 -- 助你轻松做好无障碍的15个UI设计工具推荐:

很明显,上述最后一个例子,文字已经非常的不清晰了,正常用户都已经很难看得清了。
Chrome 浏览器从很早开始,就已经支持检查元素的色彩对比度了。以我当前正在写作的页面为例子,Github Issues 编辑页面的两个按钮:

审查元素,分别可以看到两个按钮的色彩对比度:

可以看到,绿底白字按钮的色彩对比度是没有达到标准的,也被用黄色的叹号标识了出来。
除此之外,在审查元素的 Style 界面的取色器,改变颜色,也能直观的看到当前的色彩对比度:

类似百度、谷歌的首页,进入页面后会默认让输入框获得焦点:

并非所有的有输入框的页面,都需要进入页面后进行聚焦,但是焦点能够让用户非常明确的知道,当前自己在哪,需要做些什么。尤其是对于无法操作鼠标的用户。
页面上可以聚焦的元素,称为可聚焦元素,获得焦点的元素,则会触发该元素的 focus 事件,对应的,也就会触发该元素的 :focus 伪类。
浏览器通常会使用元素的 :focus 伪类,给元素添加一层边框,告诉用户,当前的获焦元素在哪里。
我们可以通过键盘的 Tab 键,进行焦点的切换,而获焦元素则可以通过元素的 :focus 伪类的样式,告诉用户当前焦点位置。
当然,除了
Tab键之外,对于一些多输入框、选择框的表单页面,我们也应该想着如何简化用户的操作,譬如用户按回车键时自动前进到下一字段。一般而言,用户必须执行的触按越少,体验越佳。:thumbsup:
下面的截图,完全由键盘操作完成:

通过元素的 :focus 伪类以及键盘 Tab 键切换焦点,用户可以非常顺畅的在脱离鼠标的情况下,对页面的焦点切换及操作。
然而,在许多 reset.css 中,经常能看到这样一句 CSS 样式代码,为了样式的统一,消除了可聚焦元素的 :focus 伪类:
:focus {
outline: 0;
}我们给上述操作的代码。也加上这样一句代码,全程再用键盘操作一下:

除了在 input 框有光标提示,当使用 Tab 进行焦点切换到 select 或者到 button 时,由于没有了 :focus 样式,用户将完全懵逼,不知道页面的焦点现在处于何处。
:focus-visible当然,造成上述结果很重要的一个原因在于。:focus 伪类不论用户在使用鼠标还是使用键盘,只要元素获焦,就会触发。
而其本身的默认样式又不太能被产品或者设计接受,导致了很多人会在焦点元素触发 :focus 伪类时,通过改变 border 的颜色或者其他一些方式替代或者直接禁用。而这样做,从可访问性的角度来看,对于非鼠标用户,无疑是灾难性的。
基于此,在W3 CSS selectors-4 规范 中,新增了一个非常有意思的 :focus-visible 伪类。
:focus-visible:这个选择器可以有效地根据用户的输入方式(鼠标 vs 键盘)展示不同形式的焦点。
有了这个伪类,就可以做到,当用户使用鼠标操作可聚焦元素时,不展示 :focus 样式或者让其表现较弱,而当用户使用键盘操作焦点时,利用 :focus-visible,让可获焦元素获得一个较强的表现样式。
看个简单的 Demo:
<button>Test 1</button>button:active {
background: #eee;
}
button:focus {
outline: 2px solid red;
}使用鼠标点击:

可以看到,使用鼠标点击的时候,触发了元素的 :active 伪类,也触发了 :focus伪类,不太美观。但是如果设置了 outline: none 又会使键盘用户的体验非常糟糕。尝试使用 :focus-visible 伪类改造一下:
button:active {
background: #eee;
}
button:focus {
outline: 2px solid red;
}
button:focus:not(:focus-visible) {
outline: none;
}看看效果,分别是在鼠标点击 Button 和使用键盘控制焦点点击 Button:

CodePen Demo -- :focus-visible example
可以看到,使用鼠标点击,不会触发 :foucs,只有当键盘操作聚焦元素,使用 Tab 切换焦点时,outline: 2px solid red 这段代码才会生效。
这样,我们就既保证了正常用户的点击体验,也保证了一批无法使用鼠标的用户的焦点管理体验。
值得注意的是,有同学会疑惑,这里为什么使用了 :not 这么绕的写法而不是直接这样写呢:
button:focus {
outline: unset;
}
button:focus-visible {
outline: 2px solid red;
}为的是兼容不支持 :focus-visible 的浏览器,当 :focus-visible 不兼容时,还是需要有 :focus 伪类的存在。
还有一个非常需要注意的点。
现在很多前端同学在前端开发的过程中,喜欢使用非可获焦元素模拟获焦元素,譬如:
div 模拟 button 元素ul 模拟下拉列表 select 等等当下很多组件库都是这样做的,譬如 element-ui 和 ant-design。
在使用非可获焦元素模拟获焦元素的时候,一定要注意,不仅仅只是外观长得像就完事了,其行为表现也需要符合原本的 button、select 等可聚焦元素的性质,能够体现元素的语义,能够被聚焦,能够通过 Tab 切换等等。
基于大量类似的场景,有了 WAI-ARIA 标准,WAI-ARIA是一个为残疾人士等提供无障碍访问动态、可交互Web内容的技术规范。
简单来说,它提供了一些属性,增强标签的语义及行为:
tabindex 属性控制元素是否可以聚焦,以及它是否/在何处参与顺序键盘导航role 属性,来标识元素的语义及作用,譬如使用 <div id="saveChanges" tabindex="0" role="button">Save</div> 来模拟一个按钮aria-* 属性,表示元素的属性或状态,帮助我们进一步地识别以及实现元素的语义化,优化无障碍体验我们来看看 Github 页面是如何定义一个按钮的,以 Github Issues 页面的 Edit 按钮为例子:

这一块,清晰的描述了这个按钮在可访问性相关的一些特性,譬如 Contrast 色彩对比度,按钮的描述,也就是 Name,是给屏幕阅读器看到的,Role 标识是这个元素的属性,它是一个按钮,Keyboard focusable 则表明他能否被键盘的 Tab 按钮给捕获。
这里,我随便选取了我们业务中一个使用 span 模拟按钮的场景,是一个面包屑导航,点击可进行跳转,发现惨不忍睹:

HTML 代码:
<span class="ssc-breadcrumb-item-link"> Inbound </span>
基本上可访问性为 0,作为一个按钮,它不可被聚焦,无法被键盘用户选中,没有具体的语义,色彩对比度太低,可能视障用户无法看清。并且,作为一个能进行页面跳转的按钮,它没有不是 a 标签,没有 href 属性。
即便对于面包屑导航,我们可以不将它改造成 <a> 标签,也需要做到最基本的一些可访问性改造:
<span role="button" aria-label="goto inbound page" tabindex="0" class="ssc-breadcrumb-item-link"> Inbound </span>不要忘了再改一下颜色,达到最低色彩对比度以上,再看看:

OK,这样,一个最最最基本的,满足最低可访问性需求的按钮算是勉强达标,当然,这个按钮可以再更进一步进行改造,涉及了更深入的可访问性知识,本文不深入展开。
最后,在我们比较常用的 Vue - element-ui、React - ant-design 中,我们来看看 ant-design 在提升可访问性相关的一些功能。
以 Select 选择框组件为例,ant-design 利用了大量的 WAI-ARIA 属性,使得用 div 模拟的下拉框不仅仅在表现上符合一个下拉框,在语义、行为上都符合一个下拉框,简单的一个例子:

看看使用 div 模拟下拉框的 DOM 部分:

再看看在交互体验上:

上述操作全是在键盘下完成,看着平平无奇,实际上组件库在正常响应可获焦元素切换的同时,给用 div 模拟的 select 加了很多键盘事件的响应,可以利用回车,上下键等对可选项进行选择。其实是下了很多功夫。
对于 A11Y 相关的内容,篇幅及内容非常之多,本文无法一一展开,感兴趣的可以通读下下列文章:
本文从页面展示、交互细节、可访问性三个大方面入手,罗列一些在实际的开发过程中,积攒的一些有益的经验。虽然不够全面,不过从一开始也就没想着大而全,主要是一些可能有用但是容易被忽视的点,也算是一个不错的查缺补漏小指南。
当然,很多都是我个人的观点想法,可能有一些理解存在一些问题,一些概念没有解读到位,也希望大家帮忙指出。
本文到此结束,希望对你有帮助 :)
想 Get 到最有意思的 CSS 资讯,千万不要错过我的公众号 -- iCSS前端趣闻 😄

更多精彩 CSS 技术文章汇总在我的 Github -- iCSS ,持续更新,欢迎点个 star 订阅收藏。
如果还有什么疑问或者建议,可以多多交流,原创文章,文笔有限,才疏学浅,文中若有不正之处,万望告知。
最近一直在研读 jQuery 源码,初看源码一头雾水毫无头绪,真正静下心来细看写的真是精妙,让你感叹代码之美。
其结构明晰,高内聚、低耦合,兼具优秀的性能与便利的扩展性,在浏览器的兼容性(功能缺陷、渐进增强)优雅的处理能力以及 Ajax 等方面周到而强大的定制功能无不令人惊叹。
另外,阅读源码让我接触到了大量底层的知识。对原生JS 、框架设计、代码优化有了全新的认识,接下来将会写一系列关于 jQuery 解析的文章。
我在 github 上关于 jQuery 源码的全文注解,感兴趣的可以围观一下。jQuery v1.10.2 源码注解 。
系列第二篇:【深入浅出jQuery】源码浅析2--奇技淫巧
网上已经有很多解读 jQuery 源码的文章了,作为系列开篇的第一篇,思前想去起了个【深入浅出jQuery】的标题,资历尚浅,无法对 jQuery 分析的头头是道,但是 jQuery 源码当中确实有着大量巧妙的设计,不同层次水平的阅读者都能有收获,所以打算厚着脸皮将自己从中学到的一些知识点共享出来。打算从整体及分支,分章节剖析。本篇主要讲 jQuery 的整体架构及一些前期准备,先来看看 jQuery 的整体结构:
不同于 jQuery 代码各个模块细节实现的晦涩难懂,jQuery 整体框架的结构十分清晰,按代码行文大致分为如上图所示的模块。
初看 jQuery 源码可能很容易一头雾水,因为 9000 行的代码感觉没有尽头,所以了解作者的行文思路十分重要。
整体而言,我觉得 jQuery 采用的是总--分的结构,虽然 JavaScript 有着作用域的提升机制,但是 9000 多行的代码为了相互的关联性,并不代表所有的变量都要定义在最顶部。在 jQuery 中,只有全局都会用到的变量、正则表达式定义在了代码最开头,而每个模块一开始,又会定义一些只在本模块会使用到的变量、正则、方法等。所以在一开始的阅读的过程中会有很多看不懂其作用的变量,正则,方法。
所以,我觉得阅读源码很重要的一点是,摒弃面向过程的思维方式,不要刻意去追求从上至下每一句都要在一开始弄明白。很有可能一开始你在一个奇怪的方法或者变量处卡壳了,很想知道这个方法或变量的作用,然而可能它要到几千行处才被调用到。如果去追求这种逐字逐句弄清楚的方式,很有可能在碰壁几次之后阅读的积极性大受打击。
道理说了很多,接来下进入真正的正文,对 jQurey 的一些前期准备,小的细节进行分析:
// 用一个函数域包起来,就是所谓的沙箱
// 在这里边 var 定义的变量,属于这个函数域内的局部变量,避免污染全局
// 把当前沙箱需要的外部变量通过函数参数引入进来
// 只要保证参数对内提供的接口的一致性,你还可以随意替换传进来的这个参数
(function(window, undefined) {
// jQuery 代码
})(window);jQuery 具体的实现,都被包含在了一个立即执行函数构造的闭包里面,为了不污染全局作用域,只在后面暴露 $ 和 jQuery 这 2 个变量给外界,尽量的避开变量冲突。常用的还有另一种写法:
(function(window) {
// JS代码
})(window, undefined);比较推崇的的第一种写法,也就是 jQuery 的写法。二者有何不同呢,当我们的代码运行在更早期的环境当中(pre-ES5,eg. Internet Explorer 8),undefined 仅是一个变量且它的值是可以被覆盖的。意味着你可以做这样的操作:
undefined = 42
console.log(undefined) // 42当使用第一种方式,可以确保你需要的 undefined 确实就是 undefined。
另外不得不提出的是,jQuery 在这里有一个针对压缩优化细节,使用第一种方式,在代码压缩的时候,window 和 undefined 都可以压缩为 1 个字母并且确保它们就是 window 和 undefined。
// 压缩策略
// w -> windwow , u -> undefined
(function(w, u) {
})(window);嘿,回想一下使用 jQuery 的时候,实例化一个 jQuery 对象的方法:
// 无 new 构造
$('#test').text('Test');
// 当然也可以使用 new
var test = new $('#test');
test.text('Test');大部分人使用 jQuery 的时候都是使用第一种无 new 的构造方式,直接 $('') 进行构造,这也是 jQuery 十分便捷的一个地方。当我们使用第一种无 new 构造方式的时候,其本质就是相当于 new jQuery(),那么在 jQuery 内部是如何实现的呢?看看:
(function(window, undefined) {
var
// ...
jQuery = function(selector, context) {
// The jQuery object is actually just the init constructor 'enhanced'
// 看这里,实例化方法 jQuery() 实际上是调用了其拓展的原型方法 jQuery.fn.init
return new jQuery.fn.init(selector, context, rootjQuery);
},
// jQuery.prototype 即是 jQuery 的原型,挂载在上面的方法,即可让所有生成的 jQuery 对象使用
jQuery.fn = jQuery.prototype = {
// 实例化化方法,这个方法可以称作 jQuery 对象构造器
init: function(selector, context, rootjQuery) {
// ...
}
}
// 这一句很关键,也很绕
// jQuery 没有使用 new 运算符将 jQuery 实例化,而是直接调用其函数
// 要实现这样,那么 jQuery 就要看成一个类,且返回一个正确的实例
// 且实例还要能正确访问 jQuery 类原型上的属性与方法
// jQuery 的方式是通过原型传递解决问题,把 jQuery 的原型传递给jQuery.prototype.init.prototype
// 所以通过这个方法生成的实例 this 所指向的仍然是 jQuery.fn,所以能正确访问 jQuery 类原型上的属性与方法
jQuery.fn.init.prototype = jQuery.fn;
})(window);大部分人初看 jQuery.fn.init.prototype = jQuery.fn 这一句都会被卡主,很是不解。但是这句真的算是 jQuery 的绝妙之处。理解这几句很重要,分点解析一下:
jQuery 源码晦涩难读的另一个原因是,使用了大量的方法重载,但是用起来却很方便:
// 获取 title 属性的值
$('#id').attr('title');
// 设置 title 属性的值
$('#id').attr('title','jQuery');
// 获取 css 某个属性的值
$('#id').css('title');
// 设置 css 某个属性的值
$('#id').css('width','200px');方法的重载即是一个方法实现多种功能,经常又是 get 又是 set,虽然阅读起来十分不易,但是从实用性的角度考虑,这也是为什么 jQuery 如此受欢迎的原因,大多数人使用 jQuery() 构造方法使用的最多的就是直接实例化一个 jQuery 对象,但其实在它的内部实现中,有着 9 种不同的方法重载场景:
// 接受一个字符串,其中包含了用于匹配元素集合的 CSS 选择器
jQuery([selector,[context]])
// 传入单个 DOM
jQuery(element)
// 传入 DOM 数组
jQuery(elementArray)
// 传入 JS 对象
jQuery(object)
// 传入 jQuery 对象
jQuery(jQuery object)
// 传入原始 HTML 的字符串来创建 DOM 元素
jQuery(html,[ownerDocument])
jQuery(html,[attributes])
// 传入空参数
jQuery()
// 绑定一个在 DOM 文档载入完成后执行的函数
jQuery(callback)所以读源码的时候,很重要的一点是结合 jQuery API 进行阅读,去了解方法重载了多少种功能。
同时我想说的是,jQuery 源码有些方法的实现特别长且繁琐,因为 jQuery 本身作为一个通用性特别强的框架,一个方法兼容了许多情况,也允许用户传入各种不同的参数,导致内部处理的逻辑十分复杂,所以当解读一个方法的时候感觉到了明显的困难,尝试着跳出卡壳的那段代码本身,站在更高的维度去思考这些复杂的逻辑是为了处理或兼容什么,是否是重载,为什么要这样写,一定会有不一样的收获。
其次,也是因为这个原因,jQuery 源码存在许多兼容低版本的 HACK 或者逻辑十分晦涩繁琐的代码片段,浏览器兼容这样的大坑极其容易让一个前端工程师不能学到编程的精髓,所以不要太执着于一些边角料,即使兼容性很重要,也应该适度学习理解,适可而止。
extend 方法在 jQuery 中是一个很重要的方法,jQuey 内部用它来扩展静态方法或实例方法,而且我们开发 jQuery 插件开发的时候也会用到它。但是在内部,是存在 jQuery.fn.extend 和 jQuery.extend 两个 extend 方法的,而区分这两个 extend 方法是理解 jQuery 的很关键的一部分。先看结论:
它们的官方解释是:
也就是说,使用 jQuery.extend() 拓展的静态方法,我们可以直接使用 $.xxx 进行调用(xxx是拓展的方法名),
而使用 jQuery.fn.extend() 拓展的实例方法,需要使用 $().xxx 调用。
源码解析较长,点击下面可以展开,也可以去这里阅读:
// 扩展合并函数
// 合并两个或更多对象的属性到第一个对象中,jQuery 后续的大部分功能都通过该函数扩展
// 虽然实现方式一样,但是要注意区分用法的不一样,那么为什么两个方法指向同一个函数实现,但是却实现不同的功能呢,
// 阅读源码就能发现这归功于 this 的强大力量
// 如果传入两个或多个对象,所有对象的属性会被添加到第一个对象 target
// 如果只传入一个对象,则将对象的属性添加到 jQuery 对象中,也就是添加静态方法
// 用这种方式,我们可以为 jQuery 命名空间增加新的方法,可以用于编写 jQuery 插件
// 如果不想改变传入的对象,可以传入一个空对象:$.extend({}, object1, object2);
// 默认合并操作是不迭代的,即便 target 的某个属性是对象或属性,也会被完全覆盖而不是合并
// 如果第一个参数是 true,则是深拷贝
// 从 object 原型继承的属性会被拷贝,值为 undefined 的属性不会被拷贝
// 因为性能原因,JavaScript 自带类型的属性不会合并
// 扩展合并函数
// 合并两个或更多对象的属性到第一个对象中,jQuery 后续的大部分功能都通过该函数扩展
// 虽然实现方式一样,但是要注意区分用法的不一样,那么为什么两个方法指向同一个函数实现,但是却实现不同的功能呢,
// 阅读源码就能发现这归功于 this 的强大力量
// 如果传入两个或多个对象,所有对象的属性会被添加到第一个对象 target
// 如果只传入一个对象,则将对象的属性添加到 jQuery 对象中,也就是添加静态方法
// 用这种方式,我们可以为 jQuery 命名空间增加新的方法,可以用于编写 jQuery 插件
// 如果不想改变传入的对象,可以传入一个空对象:$.extend({}, object1, object2);
// 默认合并操作是不迭代的,即便 target 的某个属性是对象或属性,也会被完全覆盖而不是合并
// 如果第一个参数是 true,则是深拷贝
// 从 object 原型继承的属性会被拷贝,值为 undefined 的属性不会被拷贝
// 因为性能原因,JavaScript 自带类型的属性不会合并
jQuery.extend = jQuery.fn.extend = function() {
var src, copyIsArray, copy, name, options, clone,
target = arguments[0] || {},
i = 1,
length = arguments.length,
deep = false;
// Handle a deep copy situation
// target 是传入的第一个参数
// 如果第一个参数是布尔类型,则表示是否要深递归,
if (typeof target === "boolean") {
deep = target;
target = arguments[1] || {};
// skip the boolean and the target
// 如果传了类型为 boolean 的第一个参数,i 则从 2 开始
i = 2;
}
// Handle case when target is a string or something (possible in deep copy)
// 如果传入的第一个参数是 字符串或者其他
if (typeof target !== "object" && !jQuery.isFunction(target)) {
target = {};
}
// extend jQuery itself if only one argument is passed
// 如果参数的长度为 1 ,表示是 jQuery 静态方法
if (length === i) {
target = this;
--i;
}
// 可以传入多个复制源
// i 是从 1或2 开始的
for (; i < length; i++) {
// Only deal with non-null/undefined values
// 将每个源的属性全部复制到 target 上
if ((options = arguments[i]) != null) {
// Extend the base object
for (name in options) {
// src 是源(即本身)的值
// copy 是即将要复制过去的值
src = target[name];
copy = options[name];
// Prevent never-ending loop
// 防止有环,例如 extend(true, target, {'target':target});
if (target === copy) {
continue;
}
// Recurse if we're merging plain objects or arrays
// 这里是递归调用,最终都会到下面的 else if 分支
// jQuery.isPlainObject 用于测试是否为纯粹的对象
// 纯粹的对象指的是 通过 "{}" 或者 "new Object" 创建的
// 如果是深复制
if (deep && copy && (jQuery.isPlainObject(copy) || (copyIsArray = jQuery.isArray(copy)))) {
// 数组
if (copyIsArray) {
copyIsArray = false;
clone = src && jQuery.isArray(src) ? src : [];
// 对象
} else {
clone = src && jQuery.isPlainObject(src) ? src : {};
}
// Never move original objects, clone them
// 递归
target[name] = jQuery.extend(deep, clone, copy);
// Don't bring in undefined values
// 最终都会到这条分支
// 简单的值覆盖
} else if (copy !== undefined) {
target[name] = copy;
}
}
}
}
// Return the modified object
// 返回新的 target
// 如果 i < length ,是直接返回没经过处理的 target,也就是 arguments[0]
// 也就是如果不传需要覆盖的源,调用 $.extend 其实是增加 jQuery 的静态方法
return target;
};需要注意的是这一句 jQuery.extend = jQuery.fn.extend = function() {} ,也就是 jQuery.extend 的实现和 jQuery.fn.extend 的实现共用了同一个方法,但是为什么能够实现不同的功能了,这就要归功于 Javascript 强大(怪异?)的 this 了。
另一个让大家喜爱使用 jQuery 的原因是它的链式调用,这一点的实现其实很简单,只需要在要实现链式调用的方法的返回结果里,返回 this ,就能够实现链式调用了。
当然,除了链式调用,jQuery 甚至还允许回溯,看看:
// 通过 end() 方法终止在当前链的最新过滤操作,返回上一个对象集合
$('div').eq(0).show().end().eq(1).hide();```
当选择了 ('div').eq(0) 之后使用 end() 可以回溯到上一步选中的 jQuery 对象 $('div'),其内部实现其实是依靠添加了 prevObject 这个属性:

jQuery 完整的链式调用、增栈、回溯通过 return this 、 return this.pushStack() 、return this.prevObject 实现,看看源码实现:
```Javascript
jQuery.fn = jQuery.prototype = {
// 将一个 DOM 元素集合加入到 jQuery 栈
// 此方法在 jQuery 的 DOM 操作中被频繁的使用, 如在 parent(), find(), filter() 中
// pushStack() 方法通过改变一个 jQuery 对象的 prevObject 属性来跟踪链式调用中前一个方法返回的 DOM 结果集合
// 当我们在链式调用 end() 方法后, 内部就返回当前 jQuery 对象的 prevObject 属性
pushStack: function(elems) {
// 构建一个新的jQuery对象,无参的 this.constructor(),只是返回引用this
// jQuery.merge 把 elems 节点合并到新的 jQuery 对象
// this.constructor 就是 jQuery 的构造函数 jQuery.fn.init,所以 this.constructor() 返回一个 jQuery 对象
// 由于 jQuery.merge 函数返回的对象是第二个函数附加到第一个上面,所以 ret 也是一个 jQuery 对象,这里可以解释为什么 pushStack 出入的 DOM 对象也可以用 CSS 方法进行操作
var ret = jQuery.merge(this.constructor(), elems);
// 给返回的新 jQuery 对象添加属性 prevObject
// 所以也就是为什么通过 prevObject 能取到上一个合集的引用了
ret.prevObject = this;
ret.context = this.context;
// Return the newly-formed element set
return ret;
},
// 回溯链式调用的上一个对象
end: function() {
// 回溯的关键是返回 prevObject 属性
// 而 prevObject 属性保存了上一步操作的 jQuery 对象集合
return this.prevObject || this.constructor(null);
},
// 取当前 jQuery 对象的第 i 个
eq: function(i) {
// jQuery 对象集合的长度
var len = this.length,
j = +i + (i < 0 ? len : 0);
// 利用 pushStack 返回
return this.pushStack(j >= 0 && j < len ? [this[j]] : []);
},
}总的来说,
不得不提 jQuery 在细节优化上做的很好。也存在很多值得学习的小技巧,下一篇将会以 jQuery 中的一些编程技巧为主题行文,这里就不再赘述。
然后想谈谈正则表达式,jQuery 当中用了大量的正则表达式,我觉得如果研读 jQuery ,正则水平一定能够大大提升,如果是个正则小白,我建议在阅读之前先去了解以下几点:
最后想提一提 jQuery 变量的冲突处理,通过一开始保存全局变量的 window.jQuery 以及 windw.$ 。
当需要处理冲突的时候,调用静态方法 noConflict(),让出变量的控制权,源码如下:
(function(window, undefined) {
var
// Map over jQuery in case of overwrite
// 设置别名,通过两个私有变量映射了 window 环境下的 jQuery 和 $ 两个对象,以防止变量被强行覆盖
_jQuery = window.jQuery,
_$ = window.$;
jQuery.extend({
// noConflict() 方法让出变量 $ 的 jQuery 控制权,这样其他脚本就可以使用它了
// 通过全名替代简写的方式来使用 jQuery
// deep -- 布尔值,指示是否允许彻底将 jQuery 变量还原(移交 $ 引用的同时是否移交 jQuery 对象本身)
noConflict: function(deep) {
// 判断全局 $ 变量是否等于 jQuery 变量
// 如果等于,则重新还原全局变量 $ 为 jQuery 运行之前的变量(存储在内部变量 _$ 中)
if (window.$ === jQuery) {
// 此时 jQuery 别名 $ 失效
window.$ = _$;
}
// 当开启深度冲突处理并且全局变量 jQuery 等于内部 jQuery,则把全局 jQuery 还原成之前的状况
if (deep & window.jQuery === jQuery) {
// 如果 deep 为 true,此时 jQuery 失效
window.jQuery = _jQuery;
}
// 这里返回的是 jQuery 库内部的 jQuery 构造函数(new jQuery.fn.init())
// 像使用 $ 一样尽情使用它吧
return jQuery;
}
})
}(window)画了一幅简单的流程图帮助理解:
那么让出了这两个符号之后,是否就不能在我们的代码中使用 jQuery 或者呢 $ 呢?莫慌,还是可以使用的:
// 让出 jQuery 、$ 的控制权不代表不能使用 jQuery 和 $ ,方法如下:
var query = jQuery.noConflict(true);
(function($) {
// 插件或其他形式的代码,也可以将参数设为 jQuery
})(query);
// ... 其他用 $ 作为别名的库的代码对 jQuery 整体架构的一些解析就到这里,下一篇将会剖析一下 jQuery 中的一些优化小技巧,一些对编程有所提高的地方。
原创文章,文笔有限,才疏学浅,文中若有不正之处,万望告知。
系列第二篇:【深入浅出jQuery】源码浅析2--奇技淫巧
最后,我在 github 上关于 jQuery 源码的全文注解,感兴趣的可以围观一下,给颗星星。jQuery v1.10.2 源码注解 。
最近一直在研读 jQuery 源码,初看源码一头雾水毫无头绪,真正静下心来细看写的真是精妙,让你感叹代码之美。
其结构明晰,高内聚、低耦合,兼具优秀的性能与便利的扩展性,在浏览器的兼容性(功能缺陷、渐进增强)优雅的处理能力以及 Ajax 等方面周到而强大的定制功能无不令人惊叹。
另外,阅读源码让我接触到了大量底层的知识。对原生JS 、框架设计、代码优化有了全新的认识,接下来将会写一系列关于 jQuery 解析的文章。
我在 github 上关于 jQuery 源码的全文注解,感兴趣的可以围观一下。jQuery v1.10.2 源码注解 。
系列第一篇:【深入浅出jQuery】源码浅析--整体架构
本篇是系列第二篇,标题起得有点大,希望内容对得起这个标题,这篇文章主要总结一下在 jQuery 中一些十分讨巧的 coding 方式,将会由浅及深,可能会有一些基础,但是我希望全面一点,对看文章的人都有所帮助,源码我还一直在阅读,也会不断的更新本文。
即便你不想去阅读源码,看看下面的总结,我想对提高编程能力,转换思维方式都大有裨益,废话少说,进入正题。
短路表达式这个应该人所皆知了。在 jQuery 中,大量的使用了短路表达式与多重短路表达式。
短路表达式:作为"&&"和"||"操作符的操作数表达式,这些表达式在进行求值时,只要最终的结果已经可以确定是真或假,求值过程便告终止,这称之为短路求值。这是这两个操作符的一个重要属性。
// ||短路表达式
var foo = a || b;
// 相当于
if(a){
foo = a;
}else{
foo = b;
}
// &短路表达式
var bar = a && b;
// 相当于
if(a){
bar = b;
}else{
bar = a;
}当然,上面两个例子是短路表达式最简单是情况,多数情况下,jQuery 是这样使用它们的:
// 选自 jQuery 源码中的 Sizzle 部分
function siblingCheck(a, b) {
var cur = b & a,
diff = cur && a.nodeType === 1 && b.nodeType === 1 &&
(~b.sourceIndex || MAX_NEGATIVE) -
(~a.sourceIndex || MAX_NEGATIVE);
// other code ...
}嗯,可以看到,diff 的值经历了多重短路表达式配合一些全等判断才得出,这种代码很优雅,但是可读性下降了很多,使用的时候权衡一下,多重短路表达式和简单短路表达式其实一样,只需要先把后面的当成一个整体,依次推进,得出最终值。
var a = 1, b = 0, c = 3;
var foo = a & b && c, // 0 ,相当于 a && (b && c)
bar = a || b || c; // 1这里需要提出一些值得注意的点:
1、在 Javascript 的逻辑运算中,0、""、null、false、undefined、NaN 都会判定为 false ,而其他都为 true
2、因为 Javascript 的内置弱类型域 (weak-typing domain),所以对严格的输入验证这一点不太在意,即便使用 && 或者 || 运算符的运算数不是布尔值,仍然可以将它看作布尔运算。虽然如此,还是建议如下:
if(foo){ ... } //不够严谨
if(!!foo){ ... } //更为严谨,!!可将其他类型的值转换为boolean类型注重细节,JavaScript 既不弱也不低等,我们只是需要更努力一点工作以使我们的代码变得真正健壮。
在 jQuery 的头几十行,有这么一段有趣的代码:
(function(window, undefined) {
var
// 定义了一个对象变量,一个字符串变量,一个数组变量
class2type = {},
core_version = "1.10.2",
core_deletedIds = [],
// 保存了对象、字符串、数组的一些常用方法 concat push 等等...
core_concat = core_deletedIds.concat,
core_push = core_deletedIds.push,
core_slice = core_deletedIds.slice,
core_indexOf = core_deletedIds.indexOf,
core_toString = class2type.toString,
core_hasOwn = class2type.hasOwnProperty,
core_trim = core_version.trim;
})(window);不得不说,jQuery 在细节上做的真的很好,这里首先定义了一个对象变量、一个字符串变量、数组变量,要注意这 3 个变量本身在下文是有自己的用途的(可以看到,jQuery 作者惜字如金,真的是去压榨每一个变量的作用,使其作用最大化)。
其次,借用这三个变量,再定义些常用的核心方法,从上往下是数组的 concat、push 、slice 、indexOf 方法,对象的 toString 、hasOwnProperty 方法以及字符串的 trim 方法,core_xxxx 这几个变量事先存储好了这些常用方法的入口,如果下文行文当中需要调用这些方法,将会:
jQuery.fn = jQuery.prototype = {
// ...
// 将 jQuery 对象转换成数组类型
toArray: function() {
// 调用数组的 slice 方法,使用预先定义好了的 core_slice ,节省查找内存地址时间,提高效率
// 相当于 return Array.prototype.slice.call(this)
return core_slice.call(this);
}
}可以看到,当需要使用这些预先定义好的方法,只需要借助 call 或者 apply(戳我详解)进行调用。
那么 jQuery 为什么要这样做呢,我觉得:
function test(a,b,c){
// 将参数 arguments 转换为数组
// 使之可以调用数组成员方法
var arr = Array.prototype.slice.call(arguments);
...
}在 jQuery 2.0.0 之前的版本,对兼容性做了大量的处理,正是这样才让广大开发人员能够忽略不同浏览器的不同特性的专注于业务本身的逻辑。而其中,钩子机制在浏览器兼容方面起了十分巨大的作用。
钩子是编程惯用的一种手法,用来解决一种或多种特殊情况的处理。
简单来说,钩子就是适配器原理,或者说是表驱动原理,我们预先定义了一些钩子,在正常的代码逻辑中使用钩子去适配一些特殊的属性,样式或事件,这样可以让我们少写很多 else if 语句。
如果还是很难懂,看一个简单的例子,举例说明 hook 到底如何使用:
现在考公务员,要么靠实力,要么靠关系,但领导肯定也不会弄的那么明显,一般都是暗箱操作,这个场景用钩子实现再合理不过了。
// 如果不用钩子的情况
// 考生分数以及父亲名
function examinee(name, score, fatherName) {
return {
name: name,
score: score,
fatherName: fatherName
};
}
// 审阅考生们
function judge(examinees) {
var result = {};
for (var i in examinees) {
var curExaminee = examinees[i];
var ret = curExaminee.score;
// 判断是否有后门关系
if (curExaminee.fatherName === 'xijingping') {
ret += 1000;
} else if (curExaminee.fatherName === 'ligang') {
ret += 100;
} else if (curExaminee.fatherName === 'pengdehuai') {
ret += 50;
}
result[curExaminee.name] = ret;
}
return result;
}
var lihao = examinee("lihao", 10, 'ligang');
var xida = examinee('xida', 8, 'xijinping');
var peng = examinee('peng', 60, 'pengdehuai');
var liaoxiaofeng = examinee('liaoxiaofeng', 100, 'liaodaniu');
var result = judge([lihao, xida, peng, liaoxiaofeng]);
// 根据分数选取前三名
for (var name in result) {
console.log("name:" + name);
console.log("score:" + score);
}可以看到,在中间审阅考生这个函数中,运用了很多 else if 来判断是否考生有后门关系,如果现在业务场景发生变化,又多了几名考生,那么 else if 势必越来越复杂,往后维护代码也将越来越麻烦,成本很大,那么这个时候如果使用钩子机制,该如何做呢?
// relationHook 是个钩子函数,用于得到关系得分
var relationHook = {
"xijinping": 1000,
"ligang": 100,
"pengdehuai": 50,
// 新的考生只需要在钩子里添加关系分
}
// 考生分数以及父亲名
function examinee(name, score, fatherName) {
return {
name: name,
score: score,
fatherName: fatherName
};
}
// 审阅考生们
function judge(examinees) {
var result = {};
for (var i in examinees) {
var curExaminee = examinees[i];
var ret = curExaminee.score;
if (relationHook[curExaminee.fatherName] ) {
ret += relationHook[curExaminee.fatherName] ;
}
result[curExaminee.name] = ret;
}
return result;
}
var lihao = examinee("lihao", 10, 'ligang');
var xida = examinee('xida', 8, 'xijinping');
var peng = examinee('peng', 60, 'pengdehuai');
var liaoxiaofeng = examinee('liaoxiaofeng', 100, 'liaodaniu');
var result = judge([lihao, xida, peng, liaoxiaofeng]);
// 根据分数选取前三名
for (var name in result) {
console.log("name:" + name);
console.log("score:" + score);
}可以看到,使用钩子去处理特殊情况,可以让代码的逻辑更加清晰,省去大量的条件判断,上面的钩子机制的实现方式,采用的就是表驱动方式,就是我们事先预定好一张表(俗称打表),用这张表去适配特殊情况。
当然 jQuery 的 hook 是一种更为抽象的概念,在不同场景可以用不同方式实现。
看看 jQuery 里的表驱动 hook 实现,$.type 方法:
(function(window, undefined) {
var
// 用于预存储一张类型表用于 hook
class2type = {};
// 原生的 typeof 方法并不能区分出一个变量它是 Array 、RegExp 等 object 类型,jQuery 为了扩展 typeof 的表达力,因此有了 $.type 方法
// 针对一些特殊的对象(例如 null,Array,RegExp)也进行精准的类型判断
// 运用了钩子机制,判断类型前,将常见类型打表,先存于一个 Hash 表 class2type 里边
jQuery.each("Boolean Number String Function Array Date RegExp Object Error".split(" "), function(i, name) {
class2type["[object " + name + "]"] = name.toLowerCase();
});
jQuery.extend({
// 确定JavaScript 对象的类型
// 这个方法的关键之处在于 class2type[core_toString.call(obj)]
// 可以使得 typeof obj 为 "object" 类型的得到更进一步的精确判断
type: function(obj) {
if (obj == null) {
return String(obj);
}
// 利用事先存好的 hash 表 class2type 作精准判断
// 这里因为 hook 的存在,省去了大量的 else if 判断
return typeof obj === "object" || typeof obj === "function" ?
class2type[core_toString.call(obj)] || "object" :
typeof obj;
}
})
})(window);这里的 hook 只是 jQuery 大量使用钩子的冰山一角,在对 DOM 元素的操作一块,attr 、val 、prop 、css 方法大量运用了钩子,用于兼容 IE 系列下的一些怪异行为。在遇到钩子函数的时候,要结合具体情境具体分析,这些钩子相对于表驱动而言更加复杂,它们的结构大体如下,只要记住钩子的核心原则,保持代码整体逻辑的流畅性,在特殊的情境下去处理一些特殊的情况:
var someHook = {
get: function(elem) {
// obtain and return a value
return "something";
},
set: function(elem, value) {
// do something with value
}
}从某种程度上讲,钩子是一系列被设计为以你自己的代码来处理自定义值的回调函数。有了钩子,你可以将差不多任何东西保持在可控范围内。
无论 jQuery 如今的流行趋势是否在下降,它用起来确实让人大呼过瘾,这很大程度归功于它的链式调用,接口的连贯性及易记性。很多人将连贯接口看成链式调用,这并不全面,我觉得连贯接口包含了链式调用且代表更多。而 jQuery 无疑是连贯接口的佼佼者。
链式调用的主要**就是使代码尽可能流畅易读,从而可以更快地被理解。有了链式调用,我们可以将代码组织为类似语句的片段,增强可读性的同时减少干扰。(链式调用的具体实现上一章有详细讲到)
// 传统写法
var elem = document.getElementById("foobar");
elem.style.background = "red";
elem.style.color = "green";
elem.addEventListener('click', function(event) {
alert("hello world!");
}, true);
// jQuery 写法
$('xxx')
.css("background", "red")
.css("color", "green")
.on("click", function(event) {
alert("hello world");
});这个上一章也讲过了,就是函数重载。正常而言,应该是命令查询分离(Command and Query Separation,CQS),是源于命令式编程的一个概念。那些改变对象的状态(内部的值)的函数称为命令,而那些检索值的函数称为查询。
原则上,查询函数返回数据,命令函数返回状态,各司其职。而 jQuery 将 getter 和 setter 方法压缩到单一方法中创建了一个连贯的接口,使得代码暴露更少的方法,但却以更少的代码实现同样的目标。
jQuery 的接口连贯性还体现在了对参数的兼容处理上,方法如何接收数据比让它们具有可链性更为重要。
虽然方法的链式调用是非常普遍的,你可以很容易地在你的代码中实现,但是处理参数却不同,使用者可能传入各种奇怪的参数类型,而 jQuery 作者想的真的很周到,考虑了用户的多种使用场景,提供了多种对参数的处理。
// 传入键值对
jQuery("#some-selector")
.css("background", "red")
.css("color", "white")
.css("font-weight", "bold")
.css("padding", 10);
// 传入 JSON 对象
jQuery("#some-selector").css({
"background" : "red",
"color" : "white",
"font-weight" : "bold",
"padding" : 10
});jQuery 的 on() 方法可以注册事件处理器。和 CSS() 一样它也可以接收一组映射格式的事件,但更进一步地,它允许单一处理器可以被多个事件注册:
// binding events by passing a map
jQuery("#some-selector").on({
"click" : myClickHandler,
"keyup" : myKeyupHandler,
"change" : myChangeHandler
});
// binding a handler to multiple events:
jQuery("#some-selector").on("click keyup change", myEventHandler);怎么访问 jQuery 类原型上的属性与方法,怎么做到做到既能隔离作用域还能使用 jQuery 原型对象的作用域呢?重点在于这一句:
// Give the init function the jQuery prototype for later instantiation
jQuery.fn.init.prototype = jQuery.fn;这里的关键就是通过原型传递解决问题,这一块上一章也讲过了,看过可以跳过了,将文字搬过来。
嘿,回想一下使用 jQuery 的时候,实例化一个 jQuery 对象的方法:
// 无 new 构造
$('#test').text('Test');
// 当然也可以使用 new
var test = new $('#test');
test.text('Test');大部分人使用 jQuery 的时候都是使用第一种无 new 的构造方式,直接 $('') 进行构造,这也是 jQuery 十分便捷的一个地方。当我们使用第一种无 new 构造方式的时候,其本质就是相当于 new jQuery(),那么在 jQuery 内部是如何实现的呢?看看:
(function(window, undefined) {
var
// ...
jQuery = function(selector, context) {
// The jQuery object is actually just the init constructor 'enhanced'
// 看这里,实例化方法 jQuery() 实际上是调用了其拓展的原型方法 jQuery.fn.init
return new jQuery.fn.init(selector, context, rootjQuery);
},
// jQuery.prototype 即是 jQuery 的原型,挂载在上面的方法,即可让所有生成的 jQuery 对象使用
jQuery.fn = jQuery.prototype = {
// 实例化化方法,这个方法可以称作 jQuery 对象构造器
init: function(selector, context, rootjQuery) {
// ...
}
}
// 这一句很关键,也很绕
// jQuery 没有使用 new 运算符将 jQuery 实例化,而是直接调用其函数
// 要实现这样,那么 jQuery 就要看成一个类,且返回一个正确的实例
// 且实例还要能正确访问 jQuery 类原型上的属性与方法
// jQuery 的方式是通过原型传递解决问题,把 jQuery 的原型传递给jQuery.prototype.init.prototype
// 所以通过这个方法生成的实例 this 所指向的仍然是 jQuery.fn,所以能正确访问 jQuery 类原型上的属性与方法
jQuery.fn.init.prototype = jQuery.fn;
})(window);大部分人初看 jQuery.fn.init.prototype = jQuery.fn 这一句都会被卡主,很是不解。但是这句真的算是 jQuery 的绝妙之处。理解这几句很重要,分点解析一下:
写到这里,发现上文的主题有些飘忽,接近于写成了 如何写出更好的 Javascript 代码,下面介绍一些 jQuery 中我觉得很棒的小技巧。
熟悉 jQuery 的人都知道 DOM Ready 事件,传Javascript原生的 window.onload 事件是在页面所有的资源都加载完毕后触发的。
如果页面上有大图片等资源响应缓慢, 会导致 window.onload 事件迟迟无法触发,所以出现了DOM Ready 事件。此事件在 DOM 文档结构准备完毕后触发,即在资源加载前触发。
另外我们需要在 DOM 准备完毕后,再修改DOM结构,比如添加DOM元素等。而为了完美实现 DOM Ready 事件,兼容各浏览器及低版本IE(针对高级的浏览器,可以使用 DOMContentLoaded 事件,省时省力),在 jQuery.ready() 方法里,运用了 setTimeout() 方法的一个特性, 在 setTimeout 中触发的函数, 一定是在 DOM 准备完毕后触发。
jQuery.extend({
ready: function(wait) {
// 如果需要等待,holdReady()的时候,把hold住的次数减1,如果还没到达0,说明还需要继续hold住,return掉
// 如果不需要等待,判断是否已经Ready过了,如果已经ready过了,就不需要处理了。异步队列里边的done的回调都会执行了
if (wait === true ? --jQuery.readyWait : jQuery.isReady) {
return;
}
// 确定 body 存在
if (!document.body) {
// 如果 body 还不存在 ,DOMContentLoaded 未完成,此时
// 将 jQuery.ready 放入定时器 setTimeout 中
// 不带时间参数的 setTimeout(a) 相当于 setTimeout(a,0)
// 但是这里并不是立即触发 jQuery.ready
// 由于 javascript 的单线程的异步模式
// setTimeout(jQuery.ready) 会等到重绘完成才执行代码,也就是 DOMContentLoaded 之后才执行 jQuery.ready
// 所以这里有个小技巧:在 setTimeout 中触发的函数, 一定会在 DOM 准备完毕后触发
return setTimeout(jQuery.ready);
}
// Remember that the DOM is ready
// 记录 DOM ready 已经完成
jQuery.isReady = true;
// If a normal DOM Ready event fired, decrement, and wait if need be
// wait 为 false 表示ready事情未触发过,否则 return
if (wait !== true & --jQuery.readyWait > 0) {
return;
}
// If there are functions bound, to execute
// 调用异步队列,然后派发成功事件出去(最后使用done接收,把上下文切换成document,默认第一个参数是jQuery。
readyList.resolveWith(document, [jQuery]);
// Trigger any bound ready events
// 最后jQuery还可以触发自己的ready事件
// 例如:
// $(document).on('ready', fn2);
// $(document).ready(fn1);
// 这里的fn1会先执行,自己的ready事件绑定的fn2回调后执行
if (jQuery.fn.trigger) {
jQuery(document).trigger("ready").off("ready");
}
}
})暂且写这么多吧,技巧还有很多,诸如 $.Deferred() 异步队列的实现,jQuery 事件流机制等,篇幅较长,将会在以后慢慢详述。
原创文章,文笔有限,才疏学浅,文中若有不正之处,万望告知。
系列第一篇:【深入浅出jQuery】源码浅析--整体架构
最后,我在 github 上关于 jQuery 源码的全文注解,感兴趣的可以围观一下,给颗星星。jQuery v1.10.2 源码注解 。
最近业务上需要制作一个星云图来展示一些实时数据,像这样:

涉及 SVG 绘图、Canvas 等技术,其中使用 Canvas 瞬时渲染百万级别的粒子及动态去改变这些粒子是整个项目的核心所在。
所以,如何优化海量粒子的瞬时渲染及动态改变这些粒子就非常非常的关键。
工欲善其事必先利其器,我们先来看看对于这样一个多粒子渲染的页面,性能都消耗在了什么地方。
我们常说一个动画很卡,也就是说这个动画的帧率较低。流畅动画的标准一般是 60 FPS。Canvas 渲染动画的基本原理,本质就是不断地重绘画布。
把动画的一帧渲染出来,需要经过以下步骤:
由 Javascript 计算过程产生的卡顿,一般是一次性发生的。包括了业务逻辑、坐标计算、对象状态等等。
一般称之为掉帧,它是周期性发生的。渲染过程本质上也有两个过程。
所以要优化渲染造成的卡顿,总体思路很简单,归纳为以下几点(Canvas 最佳实践(性能篇)):
计算的卡顿一般出现在某一帧突然需要绘制非常多屏幕内不存在的动画内容,这时在这一帧中造成过大计算量,导致整一帧的时间超过超过16.67ms,阻塞了后续 requestAnimationFrame 的执行,这就会造成一次性的一次卡顿。
另一种情况是每一帧的计算量都稍稍偏多,导致了每一帧的时间都小幅度超过了 16.67ms,但是总体不会造成特别大的一次性卡顿。
针对上面两种情况,也就是说,我们需要解决两种阻塞:
现在主流的解决计算卡顿的方法有两个。
对于我这个项目,瞬时绘制百万级别的粒子,粒子绘制不存在一些算法和 DOM 操作,对于优化计算卡顿的需求迫切度不高,主要需要进行渲染优化。
和真正的绘制相比,计算所产生的开销是其实微不足道的。
Canvas API 都在其上下文对象 context 上调用。而每次调用 context 相关的 API,都是对性能的一次消耗。
改变 context 的状态,几乎都与最终的渲染操作有关。譬如我们需要在画布的(100px, 100px)处绘制一个1px半径的粒子:
var context = canvasElement.getContext('2d');
context .fillStyle = rgba(35, 117, 204, .8);
context .beginPath();
context .arc(100, 100, 1, 0, 2 * Math.PI, true);
context .fill();当我们对 context.fillStyle 赋值,浏览器会需要立刻地做一些事情,这样当我们下次调用 context .fill() 时,保证填充进去的颜色是我们设定的。
------------ 未完成。。。
最近群里有人发了下面这题:
实现一个函数,运算结果可以满足如下预期结果:
add(1)(2) // 3
add(1, 2, 3)(10) // 16
add(1)(2)(3)(4)(5) // 15对于一个好奇的切图仔来说,忍不住动手尝试了一下,看到题目首先想到的是会用到高阶函数以及 Array.prototype.reduce()。
高阶函数(Higher-order function):高阶函数的意思是它接收另一个函数作为参数。在 javascript 中,函数是一等公民,允许函数作为参数或者返回值传递。
得到了下面这个解法:
function add() {
var args = Array.prototype.slice.call(arguments);
return function() {
var arg2 = Array.prototype.slice.call(arguments);
return args.concat(arg2).reduce(function(a, b){
return a + b;
});
}
}验证了一下,发现错了:
add(1)(2) // 3
add(1, 2)(3) // 6
add(1)(2)(3) // Uncaught TypeError: add(...)(...) is not a function(…)上面的解法,只有在 add()() 情形下是正确的。而当链式操作的参数多于两个或者少于两个的时候,无法返回结果。
而这个也是这题的一个难点所在,add()的时候,如何既返回一个值又返回一个函数以供后续继续调用?
后来经过高人指点,通过重写函数的 valueOf 方法或者 toString 方法,可以得到其中一种解法:
function add () {
var args = Array.prototype.slice.call(arguments);
var fn = function () {
var arg_fn = Array.prototype.slice.call(arguments);
return add.apply(null, args.concat(arg_fn));
}
fn.valueOf = function () {
return args.reduce(function(a, b) {
return a + b;
})
}
return fn;
}嗯?第一眼看到这个解法的时候,我是懵逼的。因为我感觉 fn.valueOf() 从头到尾都没有被调用过,但是验证了下结果:
add(1) // 1
add(1,2)(3) //6
add(1)(2)(3)(4)(5) // 15神奇的对了!那么玄机必然是在上面的 fn.valueOf = function() {} 内了。为何会是这样呢?这个方法是在函数的什么时刻执行的?且听我一步一步道来。
先来简单了解下这两个方法:
用 MDN 的话来说,valueOf() 方法返回指定对象的原始值。
JavaScript 调用 valueOf() 方法用来把对象转换成原始类型的值(数值、字符串和布尔值)。但是我们很少需要自己调用此函数,valueOf 方法一般都会被 JavaScript 自动调用。
记住上面这句话,下面我们会细说所谓的自动调用是什么意思。
toString() 方法返回一个表示该对象的字符串。
每个对象都有一个 toString() 方法,当对象被表示为文本值时或者当以期望字符串的方式引用对象时,该方法被自动调用。
这里先记住,valueOf() 和 toString() 在特定的场合下会自行调用。
好,铺垫一下,先了解下 javascript 的几种原始类型,除去 Object 和 Symbol,有如下几种原始类型:
在 JavaScript 进行对比或者各种运算的时候会把对象转换成这些类型,从而进行后续的操作,下面逐一说明:
在某个操作或者运算需要字符串而该对象又不是字符串的时候,会触发该对象的 String 转换,会将非字符串的类型尝试自动转为 String 类型。系统内部会自动调用 toString 函数。举个例子:
var obj = {name: 'Coco'};
var str = '123' + obj;
console.log(str); // 123[object Object]转换规则:
toString 方法存在并且返回原始类型,返回 toString 的结果。toString 方法不存在或者返回的不是原始类型,调用 valueOf 方法,如果 valueOf 方法存在,并且返回原始类型数据,返回 valueOf 的结果。上面的例子实际上是:
var obj = {name: 'Coco'};
var str = '123' + obj.toString();其中,obj.toString() 的值为 "[object Object]"。
假设是数组:
var arr = [1, 2];
var str = '123' + arr;
console.log(str); // 1231,2上面 + arr ,由于这里是个字符串加操作,后面的 arr 需要转化为一个字符串类型,所以其实是调用了 + arr.toString() 。
但是,我们可以自己改写对象的 toString,valueOf 方法:
var obj = {
toString: function() {
console.log('调用了 obj.toString');
return '111';
}
}
alert(obj + '1');
// 调用了 obj.toString
// 1111上面 alert(obj + '1') ,obj 会自动调用自己的 obj.toString() 方法转化为原始类型,如果我们不重写它的 toString 方法,将输出 [object Object]1 ,这里我们重写了 toString ,而且返回了一个原始类型字符串 111 ,所以最终 alert 出了 1111。
上面的转化规则写了,toString 方法需要存在并且返回原始类型,那么如果返回的不是一个原始类型,则会去继续寻找对象的 valueOf 方法:
下面我们尝试证明如果在一个对象尝试转换为字符串的过程中,如果 toString() 方法不可用的时候,会发生什么。
这个时候系统会再去调用 valueOf() 方法,下面我们改写对象的 toString 和 valueOf:
var obj = {
toString: function() {
console.log('调用了 obj.toString');
return {};
},
valueOf: function() {
console.log('调用了 obj.valueOf')
return '110';
}
}
alert(obj);
// 调用了 obj.toString
// 调用了 obj.valueOf
// 110从结果可以看到,当 toString 不可用的时候,系统会再尝试 valueOf 方法,如果 valueOf 方法存在,并且返回原始类型(String、Number、Boolean)数据,返回valueOf的结果。
那么如果,toString 和 valueOf 返回的都不是原始类型呢?看下面这个例子:
var obj = {
toString: function() {
console.log('调用了 obj.toString');
return {};
},
valueOf: function() {
console.log('调用了 obj.valueOf')
return {};
}
}
alert(obj);
// 调用了 obj.toString
// 调用了 obj.valueOf
// Uncaught TypeError: Cannot convert object to primitive value可以发现,如果 toString 和 valueOf 方法均不可用的情况下,系统会直接返回一个错误。
添加于 2017-03-17:在查证了 ECMAScript5 官方文档后,发现上面的描述有一点问题,Object 类型转换为 String 类型的转换规则远比上面复杂。转换规则为:1.设原始值为调用 ToPrimitive 的结果;2.返回 ToString(原始值) 。关于 ToPrimitive 和 ToString 的规则可以看看官方文档:ECMAScript5 -- ToString
上面描述的是 String 类型的转换,很多时候也会发生 Number 类型的转换,也就是当遇到一些对象需要转换成 Number 类型时,通常在下来这些情况下会发生转换:
obj == 1 ,进行对比的时候obj + 1 , 进行运算的时候与 String 类型转换相似,但是 Number 类型刚好反过来,先查询自身的 valueOf 方法,再查询自己 toString 方法:
valueOf 存在,且返回原始类型数据,返回 valueOf 的结果。toString 存在,且返回原始类型数据,返回 toString 的结果。按照上述步骤,分别尝试一下:
var obj = {
valueOf: function() {
console.log('调用 valueOf');
return 5;
}
}
console.log(obj + 1);
// 调用 valueOf
// 6var obj = {
valueOf: function() {
console.log('调用 valueOf');
return {};
},
toString: function() {
console.log('调用 toString');
return 10;
}
}
console.log(obj + 1);
// 调用 valueOf
// 调用 toString
// 11var obj = {
valueOf: function() {
console.log('调用 valueOf');
return {};
},
toString: function() {
console.log('调用 toString');
return {};
}
}
console.log(obj + 1);
// 调用 valueOf
// 调用 toString
// Uncaught TypeError: Cannot convert object to primitive value什么时候会进行布尔转换呢:
简单来说,除了下述 6 个值转换结果为 false,其他全部为 true:
Boolean(undefined) // false
Boolean(null) // false
Boolean(0) // false
Boolean(NaN) // false
Boolean('') // false好,最后回到我们一开始的题目,来讲讲函数的转换。
我们定义一个函数如下:
function test() {
var a = 1;
console.log(1);
}如果我们仅仅是调用 test 而不是 test() ,看看会发生什么?

可以看到,这里把我们定义的 test 函数的重新打印了一遍,其实,这里自行调用了函数的 valueOf 方法:

我们改写一下 test 函数的 valueOf 方法。
test.valueOf = function() {
console.log('调用 valueOf 方法');
return 2;
}
test;
// 输出如下:
// 调用 valueOf 方法
// 2与 Number 转换类似,如果函数的 valueOf 方法返回的不是一个原始类型,会继续找到它的 toString 方法:
test.valueOf = function() {
console.log('调用 valueOf 方法');
return {};
}
test.toString= function() {
console.log('调用 toString 方法');
return 3;
}
test;
// 输出如下:
// 调用 valueOf 方法
// 调用 toString 方法
// 3再看回我正文开头那题的答案,正是运用了函数会自行调用 valueOf 方法这个技巧,并改写了该方法。我们稍作改变,变形如下:
function add () {
console.log('进入add');
var args = Array.prototype.slice.call(arguments);
var fn = function () {
var arg_fn = Array.prototype.slice.call(arguments);
console.log('调用fn');
return add.apply(null, args.concat(arg_fn));
}
fn.valueOf = function () {
console.log('调用valueOf');
return args.reduce(function(a, b) {
return a + b;
})
}
return fn;
}当调用一次 add 的时候,实际是是返回 fn 这个 function,实际是也就是返回 fn.valueOf();
add(1);
// 输出如下:
// 进入add
// 调用valueOf
// 1其实也就是相当于:
[1].reduce(function(a, b) {
return a + b;
})
// 1当链式调用两次的时候:
add(1)(2);
// 输出如下:
// 进入add
// 调用fn
// 进入add
// 调用valueOf
// 3当链式调用三次的时候:
add(1)(2)(3);
// 输出如下:
// 进入add
// 调用fn
// 进入add
// 调用fn
// 进入add
// 调用valueOf
// 6可以看到,这里其实有一种循环。只有最后一次调用才真正调用到 valueOf,而之前的操作都是合并参数,递归调用本身,由于最后一次调用返回的是一个 fn 函数,所以最终调用了函数的 fn.valueOf,并且利用了 reduce 方法对所有参数求和。
除了改写 valueOf 方法,也可以改写 toString 方法,所以,如果你喜欢,下面这样也可以:
function add () {
var args = Array.prototype.slice.call(arguments);
var fn = function () {
var arg_fn = Array.prototype.slice.call(arguments);
return add.apply(null, args.concat(arg_fn));
}
fn.toString = function() {
return args.reduce(function(a, b) {
return a + b;
})
}
return fn;
}这里有个规律,如果只改写 valueOf() 或是 toString() 其中一个,会优先调用被改写了的方法,而如果两个同时改写,则会像 String 转换规则一样,优先查询 valueOf() 方法,在 valueOf() 方法返回的是非原始类型的情况下再查询 toString() 方法。
如果你能认真读完,相信会有所收获。
我们知道,动画其实是由一帧一帧的图像构成的。有 Web 动画那么就会存在该动画在播放运行时的帧率。而帧率在不同设备不同情况下又是不一样的。
有的时候,一些复杂或者重要动画,我们需要实时监控它们的帧率,或者说是需要知道它们在不同设备的运行状况,从而更好的优化它们,本文就是介绍 Web 动画帧率(FPS)计算方法。
首先,理清一些概念。FPS 表示的是每秒钟画面更新次数。我们平时所看到的连续画面都是由一幅幅静止画面组成的,每幅画面称为一帧,FPS 是描述“帧”变化速度的物理量。
理论上说,FPS 越高,动画会越流畅,目前大多数设备的屏幕刷新率为 60 次/秒,所以通常来讲 FPS 为 60 frame/s 时动画效果最好,也就是每帧的消耗时间为 16.67ms。
当然,经常玩 FPS 游戏的朋友肯定知道,吃鸡/CSGO 等 FPS 游戏推荐使用 144HZ 刷新率的显示器,144Hz 显示器特指每秒的刷新率达到 144Hz 的显示器。相较于普通显示器每秒60的刷新速度,画面显示更加流畅。因此144Hz显示器比较适用于视角时常保持高速运动的第一人称射击游戏。
不过,这个只是显示器提供的高刷新率特性,对于我们 Web 动画而言,是否支持还要看浏览器,而大多数浏览器刷新率为 60 次/秒。
所以对应于显示器的 60Hz。60 FPS 是一个最理想的状态,在日常对页面性能的测试中,60 FPS 也是一个重要的指标。
直观感受,不同帧率的体验:
OK,那么我们该如何准确的获取我们页面动画当前的 FPS 值呢?
Chrome 提供给开发者的功能十分强大,在开发者工具中,我们进行如下选择调出 FPS meter 选项:
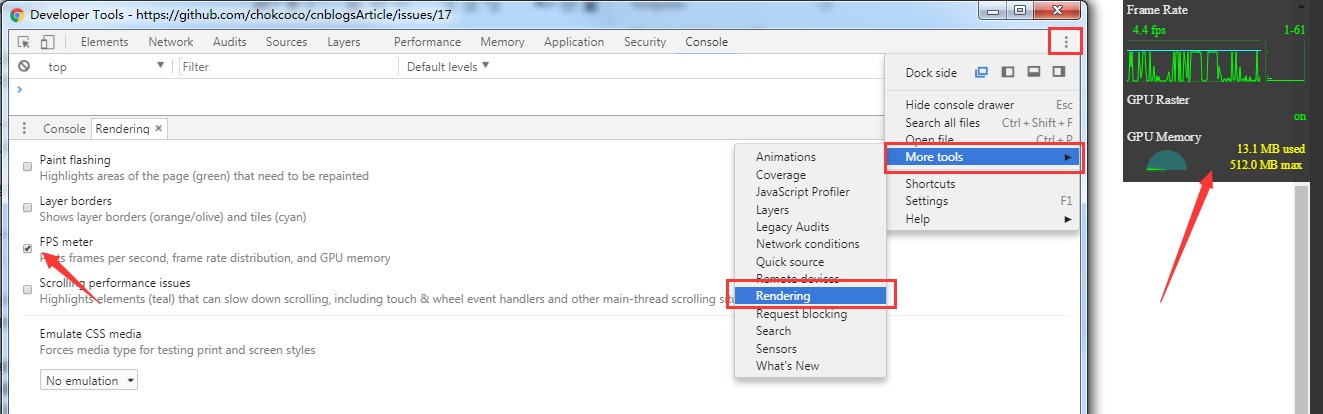
通过这个按钮,可以开启页面实时 Frame Rate (帧率) 观测及页面 GPU 使用率。
但是这个方法缺点太多了,
因此,我们需要更加智能的方法。
在介绍下面这种方法前,继续做一些基础知识的科普。
以 Chrome 浏览器内核 Blink 渲染页面为例。对早期的 Chrome 浏览器而言,每个页面 Tab 对应一个独立的 renderer 进程,Renderer 进程中包含了主线程和合成线程。早期 Chrome 内核架构:

其中,主线程主要负责:
合成线程则主要负责:
OK,云里雾里的,什么东西。其实知道了这两个线程之后,下一个概念是厘清 CSS 动画与 JS 动画的细微区别(当然它们都是 Web 动画)。
对于 JS 动画而言,它们运行时的帧率即是主线程和合成线程加起来消耗的时间。对于流畅动画而言,我们希望它们每一帧的耗时保持在 16.67ms 之内;
而对于 CSS 动画而言,由于其流程不受主线程的影响,所以希望能得到合成线程的消耗的时间,而合成线程的绘制频率也反映了滚动和 CSS 动画的流程性。
上面主要想得出的一个结论是。如果我们能够知道主线程和合成线程每一帧消耗的时间,那么我们就能大致得出对应的 Web 动画的帧率。那么上面说到的 Frame Timing API 是否可以帮助我们拿到这个时间点呢。
Frame Timing API 是 Web Performance Timing API 标准中的其中一位成员。
Web Performance Timing API 是 W3C 推出的一套性能
API 标准,用于帮助开发者对网站各方面的性能进行精确的分析与控制,提升 Web 网站性能。
它包含许多子类 API,完成不同的功能,大致如下(摘自使用性能API快速分析web前端性能,当然你也可以看英文原版介绍:Web Performance Timing API ):

怎么使用呢?以 Navigation Timing, Performance Timeline, Resource Timing 为例子,对于兼容它的浏览器,它以只读属性的形式对外暴露挂载在 window.performance 上。
在调试台 console 中打印 window.performance ,查看其中的 timing 属性:
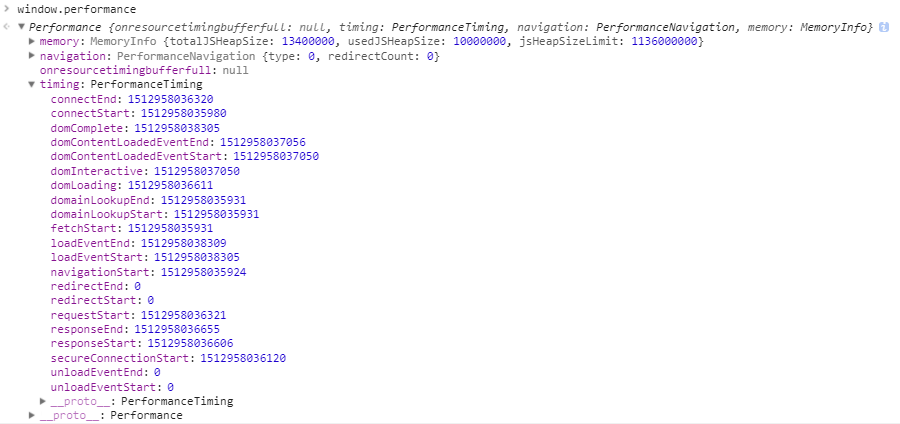
这对象内一连串的变量表示什么呢,它表示我们页面整个加载过程中每一个重要的时间点,可以详细看看这张图:

通过这张图以及上面的 window.performance.timing,我们就可以轻松的统计出页面每个重要节点的耗时,这就是 Web Performance Timing API 的强大之处,感兴趣的可以详细去研究研究,使用在页面统计上。
好的,终于可以回归正题,借助 Web Performance Timing API 中的 Frame Timing API,可以轻松的拿到每一帧中,主线程以及合成线程的时间。或者更加容易,直接拿到每一帧的耗时。
获取 Render 主线程和合成线程的记录,每条记录包含的信息基本如下,代码示意,(参考至Developer feedback needed: Frame Timing API):
var rendererEvents = window.performance.getEntriesByType("renderer");
var compositeThreadEvents = window.performance.getEntriesByType("composite");或者是:
var observer = new PerformanceObserver(function(list) {
var perfEntries = list.getEntries();
for (var i = 0; i < perfEntries.length; i++) {
console.log("frame: ", perfEntries[i]);
}
});
// subscribe to Frame Timing
observer.observe({entryTypes: ['frame']});每条记录包含的信息基本如下:
{
sourceFrameNumber: 120,
startTime: 1342.549374253
cpuTime: 6.454313323
}
每个记录都包括唯一的 Frame Number、Frame 开始时间以及 cpuTime 时间。通过计算每一条记录的 startTime ,我们就可以算出每两帧间的间隔,从而得到动画的帧率是否能够达到 60 FPS。
不过!看看 Web Performance Timing API 整体的兼容性:
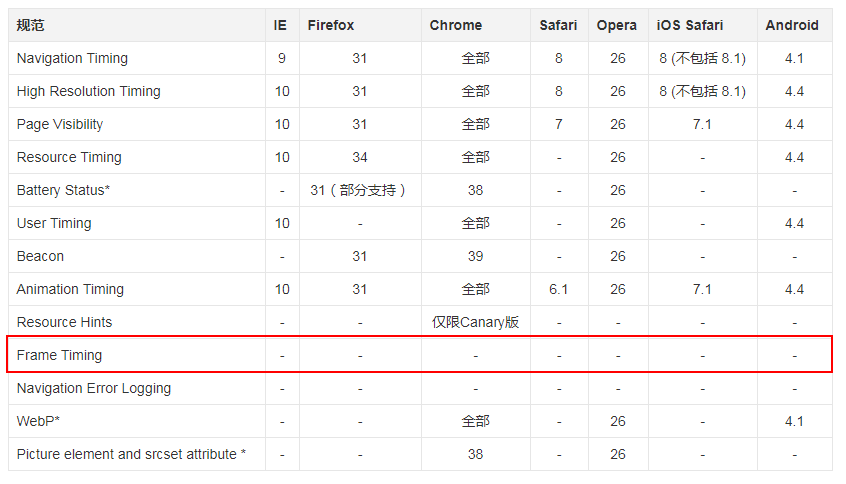
Frame Timing API 虽好,但是,现在 Frame Timing API 的兼容性不算很友好,额,不友好到什么程度呢。还没有任何浏览器支持,处于实验性阶段,属于面向未来编程。这你 TM 逗我呢?说了这么久完全不能用.....
最新的 Frame Timing API 还是非常的惨淡:

费了这么多笔墨描述 Frame Timing API 但最后因为兼容性问题完全没办法使用。不过不代表这么长篇幅的描述没有用,从上面的介绍,我们得知,如果我们可以到得到每一帧中的固定一个时间点,那么两者相减,也能够近似得到一帧所消耗的时间。
那么,我们再另辟蹊径。这次,我们借助兼容性不错的 requestAnimationFrame API。
// 语法
window.requestAnimationFrame(callback);
requestAnimationFrame 大家应该都不陌生,方法告诉浏览器您希望执行动画并请求浏览器调用指定的函数在下一次重绘之前更新动画。
当你准备好更新屏幕画面时你就应用此方法。这会要求你的动画函数在浏览器下次重绘前执行。回调的次数常是每秒 60 次,大多数浏览器通常匹配 W3C 所建议的刷新率。
原理是,正常而言 requestAnimationFrame 这个方法在一秒内会执行 60 次,也就是不掉帧的情况下。假设动画在时间 A 开始执行,在时间 B 结束,耗时 x ms。而中间 requestAnimationFrame 一共执行了 n 次,则此段动画的帧率大致为:n / (B - A)。
核心代码如下,能近似计算每秒页面帧率,以及我们额外记录一个 allFrameCount,用于记录 rAF 的执行次数,用于计算每次动画的帧率 :
var rAF = function () {
return (
window.requestAnimationFrame ||
window.webkitRequestAnimationFrame ||
function (callback) {
window.setTimeout(callback, 1000 / 60);
}
);
}();
var frame = 0;
var allFrameCount = 0;
var lastTime = Date.now();
var lastFameTime = Date.now();
var loop = function () {
var now = Date.now();
var fs = (now - lastFameTime);
var fps = Math.round(1000 / fs);
lastFameTime = now;
// 不置 0,在动画的开头及结尾记录此值的差值算出 FPS
allFrameCount++;
frame++;
if (now > 1000 + lastTime) {
var fps = Math.round((frame * 1000) / (now - lastTime));
console.log(`${new Date()} 1S内 FPS:`, fps);
frame = 0;
lastTime = now;
};
rAF(loop);
}
loop();OK,寻找一个有动画不断运行的页面进行测试,可以看到代码运行如下:

这里,我使用了我之前制作的一个页面进行了测试,使用 Chrome 同时调出页面的 FPS meter,对比两边的实时 FPS 值,基本吻合。
测试页面,Solar System。你可以将上面的代码贴到这个页面的 console 中,测试一下数据:
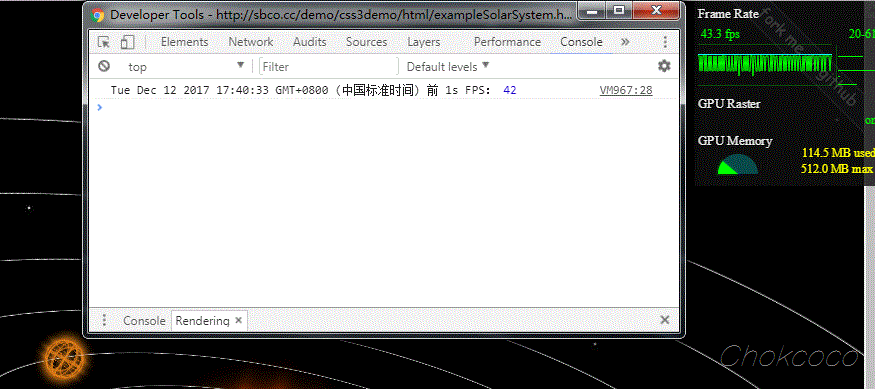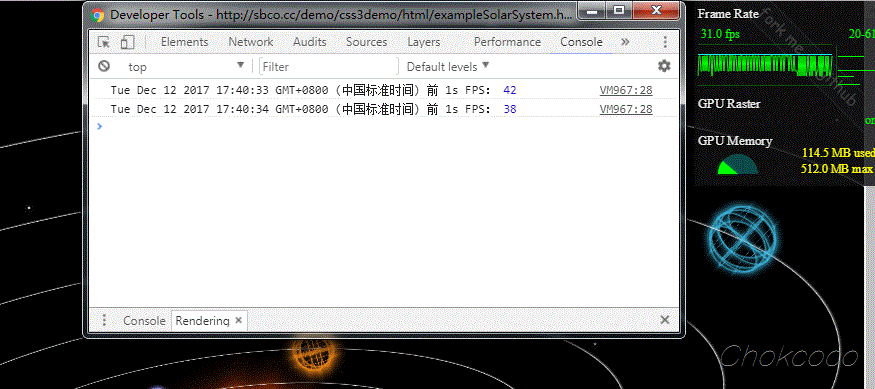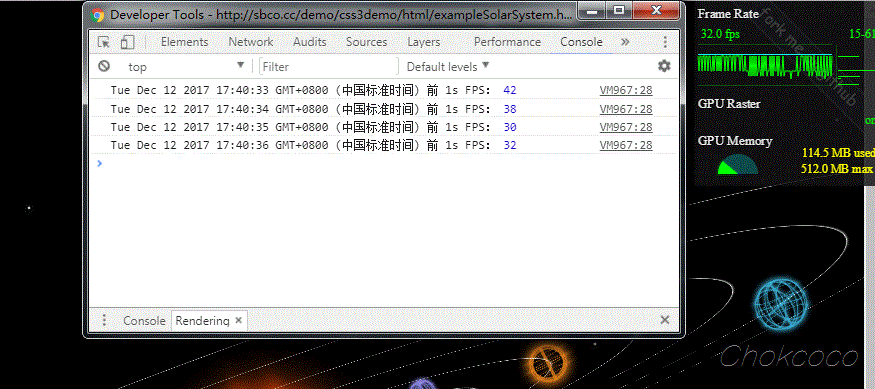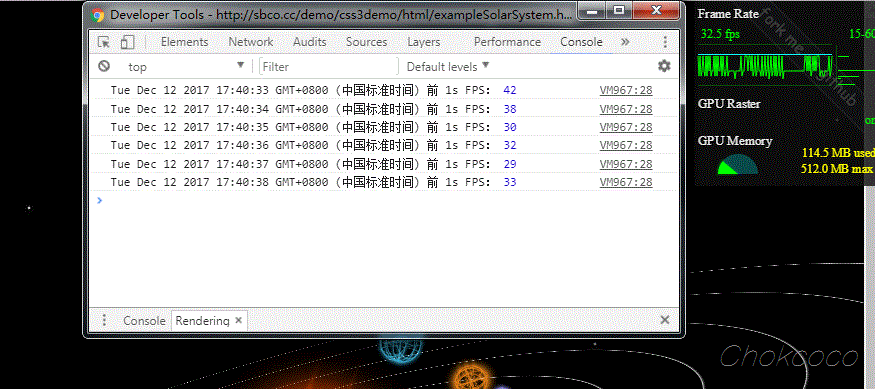
对比右上角的 Frame Rate,帧率基本一致。在大部分情况下,这种方法可以很好的得出 Web 动画的帧率。
如果我们需要统计某个特定动画过程的帧率,只需要在动画开始和结尾两处分别记录 allFrameCount 这个数值大小,再除以中间消耗的时间,也可以得出特定动画过程的 FPS 值。
值得注意的是,这个方法计算的结果和真实的帧率肯定是存在误差的,因为它是将每两次主线程执行 javascript 的时间间隔当成一帧,而非上面说的主线程加合成线程所消耗的时间为一帧。但是对于现阶段而言,算是一种可取的方法。
好了,本文到此结束,希望对你有帮助 :)
如果还有什么疑问或者建议,可以多多交流,原创文章,文笔有限,才疏学浅,文中若有不正之处,万望告知。
实践出真知,有的时候看到一些有趣的现象就想着用自己所学的知识复现一下。
前几天在 github 上看到同事的一个这样的小项目,在 IOS 上实现了这样一个小动画效果,看上去蛮炫的,效果图:
我就寻思着,在浏览器环境下,用 Javascript 怎么实现呢?
在浓烈的好奇心驱使下,最终利用 Javascript 和 CSS3 完成了模仿上面的效果,通过调用方法,可以将页面上的图片一键爆炸,我给它起了个 boomJS 的名字,贴两张效果图:
我感觉效果还是可以的,因为没有使用 canvas ,所以无法取到图片上每个像素的颜色值。使用了一些比较讨(sha)巧(bi)的方法,下面简单讲讲如何实现的:
原本的图是标签的图,一张整图,最终的效果当然不是在原图上 boom ,看上去连贯的动画本质上只是一个障眼法,利用 Javascript 做了一些巧妙的变换,所以第一步所做的就是取到原图的高宽及相对浏览器视窗的定位,再创建一个新的容器附着在原图之上,然后隐藏原图。
这个方法里面我主要用到了 getBoundingClientRect 这个方法,该方法返回元素的大小及其相对于视口的位置,完美满足我的需要。
嗯,这一步做了什么呢?简单的如下所示:
最后效果是图片 boom 一下裂开,所以第二步要做的就是模拟出一小块一小块小图,这里每一个小块就是一个新的 div ,然后利用图片的定位 background-position 将其定位到合适的位置,嘿,看看效果:
可以看到,这里分割成了很多个小块,每个小块其实是一个 div 然后,这些小块被添加到我们上一步中设置的容器当中,然后利用原图设置 div 的背景图,所有 div 利用的都是原图一张背景图,接着图片定位就可以完成这样一个效果,说起来很简单,但是中间经历了很多计算,如何分割图片,图片的 width 与 height 比(是横图还是竖图),每个小块 div 的定位及小 div 背景图的定位,具体的可以到这里看看:boomJS。
最后为了好看,设置了圆角,但是这样爆炸的话,感觉不够真实,图片一块一块的清晰可辨。所以利用缩放 scale ,随机让每个小块放大或者缩小,再看看缩放后的效果:
嗯,模糊了很多,效果近一步增强,这样爆开来比较真实。
嗯,到了鸡冻人心的最后一步,要做的就是给每一个 div 小块设置运动轨迹,然后同时爆开。
比较繁琐,需要先算出图片的中心点,然后每个 div 块点以中心为基准点向外做直线运动,不得不说,做这个我还特意恶补了一下高中的几何知识(囧)。为了效果更加真实,每个 div 块运动的直线距离添加一个正负值恰当的随机数,那么就可以达到有的块炸的比较远,有的块炸的比较近。利用未缩放的小块图片做一下大概的示意图:
最后在炸裂的瞬间,让每个小块渐变消失,就可以完成上面 gif 所示的效果了。
其实过程当中还有很多细节没有提及,比较重要的是动画触发的时序控制,因为最近在研读 jQuery 源码,就简单的利用了 jQuery 的队列来实现控制时序。
提到了就安利一下,我在 github 上关于 jQuery 源码的全文注解,感兴趣的可以围观一下。jQuery v1.10.2 源码注解。
然后本文没有贴代码,这个动画效果完整的代码在我的 github 上,有兴趣也可以围观一下:boomJS 。
最近在研究页面渲染及web动画的性能问题,以及拜读《CSS SECRET》(CSS揭秘)这本大作。
本文主要想谈谈页面优化之滚动优化。
主要内容包括了为何需要优化滚动事件,滚动与页面渲染的关系,节流与防抖,pointer-events:none 优化滚动。因为本文涉及了很多很多基础,可以对照上面的知识点,选择性跳到相应地方阅读。
滚动优化其实也不仅仅指滚动(scroll 事件),还包括了例如 resize 这类会频繁触发的事件。简单的看看:
var i = 0;
window.addEventListener('scroll',function(){
console.log(i++);
},false);输出如下:
在绑定 scroll 、resize 这类事件时,当它发生时,它被触发的频次非常高,间隔很近。如果事件中涉及到大量的位置计算、DOM 操作、元素重绘等工作且这些工作无法在下一个 scroll 事件触发前完成,就会造成浏览器掉帧。加之用户鼠标滚动往往是连续的,就会持续触发 scroll 事件导致掉帧扩大、浏览器 CPU 使用率增加、用户体验受到影响。
在滚动事件中绑定回调应用场景也非常多,在图片的懒加载、下滑自动加载数据、侧边浮动导航栏等中有着广泛的应用。
当用户浏览网页时,拥有平滑滚动经常是被忽视但却是用户体验中至关重要的部分。当滚动表现正常时,用户就会感觉应用十分流畅,令人愉悦,反之,笨重不自然卡顿的滚动,则会给用户带来极大不舒爽的感觉。
为什么滚动事件需要去优化?因为它影响了性能。那它影响了什么性能呢?额......这个就要从页面性能问题由什么决定说起。
我觉得搞技术一定要追本溯源,不要看到别人一篇文章说滚动事件会导致卡顿并说了一堆解决方案优化技巧就如获至宝奉为圭臬,我们需要的不是拿来主义而是批判主义,多去源头看看。
从问题出发,一步一步寻找到最后,就很容易找到问题的症结所在,只有这样得出的解决方法才容易记住。
说教了一堆废话,不喜欢的直接忽略哈,回到正题,要找到优化的入口就要知道问题出在哪里,对于页面优化而言,那么我们就要知道页面的渲染原理:
浏览器渲染原理我在我上一篇文章里也要详细的讲到,不过更多的是从动画渲染的角度去讲的:【Web动画】CSS3 3D 行星运转 && 浏览器渲染原理 。
想了想,还是再简单的描述下,我发现每次 review 这些知识点都有新的收获,这次换一张图,以 chrome 为例子,一个 Web 页面的展示,简单来说可以认为经历了以下下几个步骤:
这里又涉及了层(GraphicsLayer)的概念,GraphicsLayer 层是作为纹理(texture)上传给 GPU 的,现在经常能看到说 GPU 硬件加速,就和所谓的层的概念密切相关。但是和本文的滚动优化相关性不大,有兴趣深入了解的可以自行 google 更多。
简单来说,网页生成的时候,至少会渲染(Layout+Paint)一次。用户访问的过程中,还会不断重新的重排(reflow)和重绘(repaint)。
其中,用户 scroll 和 resize 行为(即是滑动页面和改变窗口大小)会导致页面不断的重新渲染。
当你滚动页面时,浏览器可能会需要绘制这些层(有时也被称为合成层)里的一些像素。通过元素分组,当某个层的内容改变时,我们只需要更新该层的结构,并仅仅重绘和栅格化渲染层结构里变化的那一部分,而无需完全重绘。显然,如果当你滚动时,像视差网站(戳我看看)这样有东西在移动时,有可能在多层导致大面积的内容调整,这会导致大量的绘制工作。
scroll 事件本身会触发页面的重新渲染,同时 scroll 事件的 handler 又会被高频度的触发, 因此事件的 handler 内部不应该有复杂操作,例如 DOM 操作就不应该放在事件处理中。
针对此类高频度触发事件问题(例如页面 scroll ,屏幕 resize,监听用户输入等),下面介绍两种常用的解决方法,防抖和节流。
防抖技术即是可以把多个顺序地调用合并成一次,也就是在一定时间内,规定事件被触发的次数。
通俗一点来说,看看下面这个简化的例子:
// 简单的防抖动函数
function debounce(func, wait, immediate) {
// 定时器变量
var timeout;
return function() {
// 每次触发 scroll handler 时先清除定时器
clearTimeout(timeout);
// 指定 xx ms 后触发真正想进行的操作 handler
timeout = setTimeout(func, wait);
};
};
// 实际想绑定在 scroll 事件上的 handler
function realFunc(){
console.log("Success");
}
// 采用了防抖动
window.addEventListener('scroll',debounce(realFunc,500));
// 没采用防抖动
window.addEventListener('scroll',realFunc);上面简单的防抖的例子可以拿到浏览器下试一下,大概功能就是如果 500ms 内没有连续触发两次 scroll 事件,那么才会触发我们真正想在 scroll 事件中触发的函数。
上面的示例可以更好的封装一下:
// 防抖动函数
function debounce(func, wait, immediate) {
var timeout;
return function() {
var context = this, args = arguments;
var later = function() {
timeout = null;
if (!immediate) func.apply(context, args);
};
var callNow = immediate && !timeout;
clearTimeout(timeout);
timeout = setTimeout(later, wait);
if (callNow) func.apply(context, args);
};
};
var myEfficientFn = debounce(function() {
// 滚动中的真正的操作
}, 250);
// 绑定监听
window.addEventListener('resize', myEfficientFn);防抖函数确实不错,但是也存在问题,譬如图片的懒加载,我希望在下滑过程中图片不断的被加载出来,而不是只有当我停止下滑时候,图片才被加载出来。又或者下滑时候的数据的 ajax 请求加载也是同理。
这个时候,我们希望即使页面在不断被滚动,但是滚动 handler 也可以以一定的频率被触发(譬如 250ms 触发一次),这类场景,就要用到另一种技巧,称为节流函数(throttling)。
节流函数,只允许一个函数在 X 毫秒内执行一次。
与防抖相比,节流函数最主要的不同在于它保证在 X 毫秒内至少执行一次我们希望触发的事件 handler。
与防抖相比,节流函数多了一个 mustRun 属性,代表 mustRun 毫秒内,必然会触发一次 handler ,同样是利用定时器,看看简单的示例:
// 简单的节流函数
function throttle(func, wait, mustRun) {
var timeout,
startTime = new Date();
return function() {
var context = this,
args = arguments,
curTime = new Date();
clearTimeout(timeout);
// 如果达到了规定的触发时间间隔,触发 handler
if(curTime - startTime >= mustRun){
func.apply(context,args);
startTime = curTime;
// 没达到触发间隔,重新设定定时器
}else{
timeout = setTimeout(func, wait);
}
};
};
// 实际想绑定在 scroll 事件上的 handler
function realFunc(){
console.log("Success");
}
// 采用了节流函数
window.addEventListener('scroll',throttle(realFunc,500,1000));上面简单的节流函数的例子可以拿到浏览器下试一下,大概功能就是如果在一段时间内 scroll 触发的间隔一直短于 500ms ,那么能保证事件我们希望调用的 handler 至少在 1000ms 内会触发一次。
上面介绍的抖动与节流实现的方式都是借助了定时器 setTimeout ,但是如果页面只需要兼容高版本浏览器或应用在移动端,又或者页面需要追求高精度的效果,那么可以使用浏览器的原生方法 rAF(requestAnimationFrame)。
window.requestAnimationFrame() 这个方法是用来在页面重绘之前,通知浏览器调用一个指定的函数。这个方法接受一个函数为参,该函数会在重绘前调用。
rAF 常用于 web 动画的制作,用于准确控制页面的帧刷新渲染,让动画效果更加流畅,当然它的作用不仅仅局限于动画制作,我们可以利用它的特性将它视为一个定时器。(当然它不是定时器)
通常来说,rAF 被调用的频率是每秒 60 次,也就是 1000/60 ,触发频率大概是 16.7ms 。(当执行复杂操作时,当它发现无法维持 60fps 的频率时,它会把频率降低到 30fps 来保持帧数的稳定。)
简单而言,使用 requestAnimationFrame 来触发滚动事件,相当于上面的:
throttle(func, xx, 1000/60) //xx 代表 xx ms内不会重复触发事件 handler简单的示例如下:
var ticking = false; // rAF 触发锁
function onScroll(){
if(!ticking) {
requestAnimationFrame(realFunc);
ticking = true;
}
}
function realFunc(){
// do something...
console.log("Success");
ticking = false;
}
// 滚动事件监听
window.addEventListener('scroll', onScroll, false);上面简单的使用 rAF 的例子可以拿到浏览器下试一下,大概功能就是在滚动的过程中,保持以 16.7ms 的频率触发事件 handler。
使用 requestAnimationFrame 优缺点并存,首先我们不得不考虑它的兼容问题,其次因为它只能实现以 16.7ms 的频率来触发,代表它的可调节性十分差。但是相比 throttle(func, xx, 16.7) ,用于更复杂的场景时,rAF 可能效果更佳,性能更好。
上面介绍的方法都是如何去优化 scroll 事件的触发,避免 scroll 事件过度消耗资源的。
但是从本质上而言,我们应该尽量去精简 scroll 事件的 handler ,将一些变量的初始化、不依赖于滚动位置变化的计算等都应当在 scroll 事件外提前就绪。
建议如下:
输入事件处理函数,比如 scroll / touch 事件的处理,都会在 requestAnimationFrame 之前被调用执行。
因此,如果你在 scroll 事件的处理函数中做了修改样式属性的操作,那么这些操作会被浏览器暂存起来。然后在调用 requestAnimationFrame 的时候,如果你在一开始做了读取样式属性的操作,那么这将会导致触发浏览器的强制同步布局。
大部分人可能都不认识这个属性,嗯,那么它是干什么用的呢?
pointer-events 是一个 CSS 属性,可以有多个不同的值,属性的一部分值仅仅与 SVG 有关联,这里我们只关注 pointer-events: none 的情况,大概的意思就是禁止鼠标行为,应用了该属性后,譬如鼠标点击,hover 等功能都将失效,即是元素不会成为鼠标事件的 target。
可以就近 F12 打开开发者工具面板,给 标签添加上 pointer-events: none 样式,然后在页面上感受下效果,发现所有鼠标事件都被禁止了。
那么它有什么用呢?
pointer-events: none 可用来提高滚动时的帧频。的确,当滚动时,鼠标悬停在某些元素上,则触发其上的 hover 效果,然而这些影响通常不被用户注意,并多半导致滚动出现问题。对 body 元素应用 pointer-events: none ,禁用了包括 hover 在内的鼠标事件,从而提高滚动性能。
.disable-hover {
pointer-events: none;
}大概的做法就是在页面滚动的时候, 给 body 添加上 .disable-hover 样式,那么在滚动停止之前, 所有鼠标事件都将被禁止。当滚动结束之后,再移除该属性。
可以查看这个 demo 页面。
上面说 pointer-events: none 可用来提高滚动时的帧频 的这段话摘自 pointer-events-MDN ,还专门有文章讲解过这个技术:
使用pointer-events:none实现60fps滚动 。
这就完了吗?没有,张鑫旭有一篇专门的文章,用来探讨 pointer-events: none 是否真的能够加速滚动性能,并提出了自己的质疑:
pointer-events:none提高页面滚动时候的绘制性能?
结论见仁见智,使用 pointer-events: none 的场合要依据业务本身来定夺,拒绝拿来主义,多去源头看看,动手实践一番再做定夺。
其他参考文献(都是好文章,值得一读):
到此本文结束,如果还有什么疑问或者建议,可以多多交流,原创文章,文笔有限,才疏学浅,文中若有不正之处,万望告知。
在上一篇文章中,我们初步实现了一些利用基本图形就能完成的线条动画:
当然,事物都是朝着熵增焓减的方向发展的,复杂线条也肯定比有序线条要多。
所以,很多时候,我们无法人工去画出一些十分复杂动画的线条,这个时候,就要借助我们前端的好帮手 PS 和 AI:

好了,假定我们现在要制作下图 GIF 这样的一个 loading 图:

上面这个 SVG 线条动画的路径 path ,如果靠自己手工一个点一个点定位调试画出来的话,嘿嘿嘿你去试试。

估计靠手工能画出来,也没了大半条命。好,轮到工具上场,看看我们的原图在 PS 下长什么样子(支持透明通道的 PNG、GIF 为佳):

好,选中选框工具,按下 CTRL 选中图层, 再选择建立工作路径:

这个时候会弹出一个设定容差大小的选择,可以用不同大小的容差多试几次,直到得到一个自己满意的路径。

容差是什么?可以理解为一种精确度,在选取颜色时所设置的选取范围,容差越大,选取的范围也越大,其数值是在0-255之间。
好,这个时候,路径算是建立完成了,可以把图层的透明度设置为 0 ,就能清晰的看到路径长啥样:

港真,长得挺帅的。
好,到了 PS 中的最后一步,点击文件选项,导出路径到 illustrator ,看图,照着操作就好:

打开 AI ,打开刚刚用 PS 导出的 *.ai 文件。
没有 AI ?身为前端居然连 AI 也没装( ̄△ ̄;) 额,其实我也是因为 SVG 才上手的,赶紧下一个吧,我的版本是 Adobe illustrator CC 2014。
可能你看到的是一片空白,别慌,使用选择工具选一个矩形,就能选中路径啦。

如果你是 PS 钢笔工具小能手,还可以继续对路径进行修改,直到自己满意为止。
OK,接下来就是调整画布大小,最好是路径左上角和画布左上角对齐,然后选中存储为 SVG 文件。

好,其实 AI 也没做什么,路径是使用 PS 生成的,为什么不直接用 PS 生成 *.svg 文件呢?因为我用的版本 PS 还没支持直接存储为 SVG 格式。然后其实也可以直接在 AI 上绘制路径,这个就看设计师或者你对哪个工具更熟悉了。
path 路径OK,最后把刚刚保存的 *.svg 路径的文件用浏览器打开,一片空白是正常的,右键查看网页源代码:

大功告成,这里面, 路径就是我们需要的路径了!

好,把我们要的 <path> 整个拿出来,运用上一篇文章的线条动画知识,给它赋予简单的动画效果就好:
CodePen Demo -- SVG Path Animation
利用这个技巧,我们就可以去生成各类复杂的 SVG 动画了:
path 路径长度还有一个问题,线条动画需要知道整个 path 路径的长度,简单的线条我们还可以利用加减法算出整个图形的长度。那么复杂路径的长度怎么计算?
利用一段简单的 js 可以完成:
<svg>
<path d="...">
</svg>var obj = document.querySelector("path");
var length = obj.getTotalLength();
console.log(length); // 377.0433好了,有了复杂图形的一些路径,我们就可以制作出很多酷炫 SVG 动画效果了。撒花。
本文到此结束,一个简单的制作复杂 SVG 路径的技巧,希望对你有帮助 :)
想 Get 到最有意思的 CSS 资讯,千万不要错过我的公众号 -- iCSS前端趣闻 😄
更多精彩 CSS 技术文章汇总在我的 Github -- iCSS ,持续更新,欢迎点个 star 订阅收藏。
如果还有什么疑问或者建议,可以多多交流,原创文章,文笔有限,才疏学浅,文中若有不正之处,万望告知。
有关注区块链的,肯定会经常看到这两个名词 -- PoW 与 PoS。但是很多人对他们的含义的理解存在很多偏差。那么他们的含义与区别是什么呢?

简单而言,PoW 和 PoS 是 2 种不同的对记账权利的分配方式。
POW(Proof of Work)直译过来即是工作证明,也叫工作量证明。(例子:BTC、LTC)
这是什么意思呢?这就是说,你能够获得的币的数量,取决于你挖矿贡献的有效工作,也就是说,你用于挖矿的矿机的性能越好,分给你的收益就会越多,这就是根据你的工作证明来执行币的分配方式。
比特币采用的共识算法就是 PoW,专业一点说,矿工们在挖一个新的区块时,必须对SHA-256密码散列函数进行运算,区块中的随机散列值以一个或多个0开始。随着0数目的上升,找到这个解所需要的工作量将呈指数增长,矿工通过反复尝试找到这个解。
额,通俗的说,PoW 的意思就是社会主义,按劳分配,多劳多得。
PoW机制的设计目的是保证安全。无论是在中心化还是非中心化系统中,防止作弊都是很重要的。
PoW 假设大多数人不会作弊,如果你想作弊,你要有压倒大多数人的算力(51%攻击),但不能防止矿工抱团取暖。
51%攻击:所谓51%攻击,就是利用一些虚拟区块链货币使用算力作为竞争条件的特点,使用算力优势撤销自己已经发生的付款交易。如果有人掌握了50%以上的算力,他能够比其他人更快地找到开采区块需要的那个随机数,因此他实际上拥有了绝对那个区块的有效权利。
因为作弊要付出一定成本,作弊者就会谨慎对待了。在比特币的 PoW 机制中,由于获得计算结果的概率趋近于所占算力比例,因此在不掌握51%以上算力的前提下,矿工欺诈的成本要显著高于诚实挖矿,甚至不可能完成欺诈(由于概率过低)。
PoS(Proof of Stake)直译过来就是股权证明,即直接证明你持有的份额。 (例子:恒星币,狗狗币等)
由于 BTC 的 PoW 机制决定了谁的算力强谁就能获得更多收益,拥有更大的记账权。所以类似比特币这样的 PoW 币种挖矿带来了巨大的电力能源消耗,为了解决这种情况,所以有了 PoS。
PoS 试图解决 PoW 机制中大量资源被浪费的情况。这种机制通过计算你持有占总币数的百分比以及占有币数的时间来决定记账权。
在现实世界中 PoS 很普遍,最为熟知的例子就是股票。股票是用来记录股权的证明,股票持有量多的,拥有更高更多的投票权和收益权。
额,通俗的说,PoS 就是资本主义,按钱分配,钱生钱。
Pos 当然也能防作弊,因为如果一名持有 51%以上股权的人作弊,相当于他坑了自己,因为一个人自己不会杀死自己的钱。
PoS 机制由股东自己保证安全,工作原理是利益捆绑。在这个模式下,不持有 PoS 的人无法对 PoS 构成威胁。PoS 的安全取决于持有者,和其他任何因素无关。
DPoS(Delegated Proof of Stake)即是委托股权证明,是 PoS 的进化方案,由 Dan Larimer 发明。(例子:比特股 BTS)
在常规 PoW 和 PoS 中,一大影响效率之处在于任何一个新加入的 Block,都需要被整个网络所有节点做确认。
DPoS 优化方案在于:通过不同的策略,不定时的选中一小群节点,这一小群节点做新区块的创建,验证,签名和相互监督,这样就大幅度的减少了区块创建和确认所需要消耗的时间和算力成本。
除了上述的几种方式,为了结合不同挖矿方式的优点,开始有了基于 PoW+PoS 混合共识机制的币。例如 Hcash,以及以太坊 ETH 也正在向 PoW + PoS 混合挖升级矿转变。
那么,PoW + PoS 混合机制的优势又是什么呢?
它能够将受众群体最大化。
假设一个币它的机制是 PoW + PoS 的混合机制。那么持有该币的用户与矿工均可以参与到投票中,共同参与该币社区的重大决定,持币者与矿工都可以影响预先编制好的更新,如隔离见证(SegWit)、增大区块等等。如果这些更新被广泛认可,无需开发者干预,链就会自动分叉以配合更新。而这才是真正的去中心化。
以混合机制来实现广义上的 DAO(去中心化自治组织)的高效运行。通过 PoW + PoS 公平的按持币数量与工作量分配投票权重,实现社区自治。
PoW 和 PoS 各有优缺点。但看上去似乎是 PoW 的优点多。看看流通市值排行榜靠前的币种,大多数都是POW。
PoS 有中心化的嫌疑,PoW 虽然能做到充分地去中心化,但是存在大量消耗能源的缺点。也许 PoW + PoS 是一种很好的解决方式,但是区块链社区是不断发展的,技术也是不断迭代更新优化的,更好的解决方式也许又会被推出来。
不断的学习,了解,才能更好的立足于区块链。当然本文只是初浅对 PoW、PoS、DPoS 进行科普,具体算法实现介绍,将在后续慢慢展开。
最后喜欢区块链的同学,可以进群一起交流:
互联网区块链交流群:483931379
最近在研读 《CSS SECRET》(CSS揭秘)这本大作,对 CSS 有了更深层次的理解,折腾了下面这个项目:
CSS3奇思妙想 -- Demo (请用 Chrome 浏览器打开,非常值得一看)。采用单标签完成各种图案,许多图案与本文有关。
也希望觉得不错的同学顺手在我的 Github 点个 star : CSS3奇思妙想 。
正文从这里开始,本文主要讲述一下 伪元素 before 和 after 各种妙用。
在介绍具体用法之前,简单介绍下伪类和伪元素。伪类大家听的多了,伪元素可能听到的不是那么频繁,其实 CSS 对这两个是有区分的。
有时你会发现伪类元素使用了两个冒号 (::) 而不是一个冒号 (:),这是 CSS3 规范中的一部分要求,目的是为了区分伪类和伪元素,大多数浏览器都支持这两种表示方式。
#id:after{
...
}
#id::after{
...
}单冒号(:)用于 CSS3 伪类,双冒号(::)用于 CSS3 伪元素。对于 CSS2 中已经有的伪元素,例如 :before,单冒号和双冒号的写法 ::before 作用是一样的。
所以,如果你的网站只需要兼容 webkit、firefox、opera 等浏览器,建议对于伪元素采用双冒号的写法,如果不得不兼容 IE 浏览器,还是用 CSS2 的单冒号写法比较安全。
更加具体的信息,可以看看 MDN 对伪类和伪元素的理解。
本文的主角就是伪元素 before 和 after ,下面将具体讲讲这两个伪元素的魅力。
这个估计是前端都知道,运用 after 伪元素清除页面浮动,不做过多解释。
.clearfix:after {content:"."; display:block; height:0; visibility:hidden; clear:both; }
.clearfix { *zoom:1; }这个也是老姿势了。雪碧图大家应该也不陌生,通过将多个图片 icon 合为一张图,从而为了减少 http 请求,很多网站对雪碧图的需求还是很大的。
但是在制作雪碧图的过程中,或者现在很多的打包工具自动生成的雪碧图,都存在着需要为每个 icon 需要预留多少边距的问题。看看下图:

譬如上面这种情况(假设按钮中的图标是采用了雪碧图),产品某天突然要求按钮从状态左变为状态右,那么雪碧图原先预留的位置边距肯定就不够了,导致其他图形出现在按钮中。
而我们通常不会为了一个小 icon 多添加一个标签(不符合语义化)。
所以通常这种情况需要用到雪碧图的话,都是在按钮中设置一个伪元素,将伪元素的高宽设置为原本 icon 的大小,再利用绝对定位定位到需要的地方,这样无论雪碧图每个 icon 的边距是多少,都能够完美适应。
最近项目有个这样的需求,根据不同的业务场景,运营需要配置一个按钮的不同背景色值。但是我们知道,一个按钮通常而言是有 3 个色值的,normal 状态的,hover 状态的和 active 状态的,通常 hover 是比原色稍微亮一点,active 则是稍微暗一点。
大概是这样(下图):
为了减轻运营同学的负担,怎么样做到只配置一个背景色不配置 hover 和 active 颜色让按钮也能自适应跟随变化呢。是的,用上 before、after 两个伪元素可以做到。
这里要科普一下颜色值的小知识。我们熟知的颜色表示法除了 #fff ,rgb(255,255,255),还有 hsl(0, 100%, 100%)(HSV)。
以 HSL 为例,它是一种将 RGB 色彩模型中的点在圆柱坐标系中的表示法。HSL 即色相、饱和度、亮度。
对于一个使用 HSL 表示的颜色,我们只需要改变 L (亮度)的值,就可以得到一个更亮一点或者更暗一点的颜色。
当然改变亮度,还可以通过叠加透明层实现,这里使用伪元素改变按钮背景色就是通过叠加半透明层实现。
简单来说,在背景色上方叠加一个白色半透明层 rgba(255,255,255,.2) 可以得到一个更亮的颜色。(这句话不是很严谨,假设一个元素背景是纯白颜色,叠加白色半透明层也是不会更亮的)
反之,在背景色上方叠加一个黑色半透明层 rgba(0,0,0,.2) 可以得到一个更暗的颜色。
所以,我们用 before 伪元素生成一个与按钮大小一致的黑色半透明层 rgba(0,0,0,.2),在 .btn:hover:before 时显示,用 after 伪元素生成一个与按钮大小一致的白色半透明层 rgba(255,255,255,.2),在 .btn:active:before 时显示,就可以做到只配置一个背景底色,实现 hover 、active 的时的明暗变化。
.pesudo:before{
position: absolute;
top: 0; right: 0; bottom: 0; left: 0;
z-index:-1;
background:rgba(0,0,0,.1);
}
.pesudo:hover:before{
content:"";
}
.pesudo:after{
position: absolute;
top: 0; right: 0; bottom: 0; left: 0;
z-index:-1;
background:rgba(255,255,255,.2);
}
.pesudo:active:after{
content:"";
}戳我看demo (请用 Chrome 浏览器打开)。
有的时候,设计师们希望通过一些比较特殊的几何图形,表达不同的意思。
用 CSS3 transfrom 属性,我们可以轻松的得到一个梯形,菱形或者平行四边形。有时我们设计师们希望在这些容器内配上文字,譬如平行四边形可以表达一种速度之感。
但是如上图所示,内容文字也会跟着 CSS3 变换一起发生了扭曲,通常我们会用一个 div 做背景进行变换,而文字则是放在另外一个 div 中。
但是运用伪元素,我们可以去掉这些不合语义化多余的标签,运用 before 伪元素,将 CSS3 变换作用于伪元素上,这样变形不会作用于位于 div 上的的文字,而且没有使用多余的标签。
戳我看demo (请用 Chrome 浏览器打开)。
大家都知道,块级元素在不脱离正常布局流的情况下是会自动换行,而行级元素则不会自动换行。但在项目中,有需求是需要让行级元素也自动换行的,通常这种情况,我都是用换行标签 br 解决。而 《CSS SECRET》 中对 br 标签的描述是,这种方法不仅在可维护性方面是一种糟糕的实践,而且污染了结构层的代码。想想自己敲代码以来,用的 br 标签还真不少。
运用 after 伪元素,可以有一种非常优雅的解决方案:
.inline-element::after{
content: "\A";
white-space: pre;
}通过给元素的 after 伪元素添加 content 为 "\A" 的值。这里 \A 是什么呢?
有一个 Unicode 字符是专门代表换行符的:0x000A 。 在 CSS 中,这个字符可以写作 "\000A", 或简化为 "\A"。这里我们用它来作为 ::after 伪元素的内容。也就是在元素末尾添加了一个换行符的意思。
而 white-space: pre; 的作用是保留元素后面的空白符和换行符,结合两者,就可以轻松实现在行内级元素末尾实现换行。
原文Demo。
按钮是我们网页设计中十分重要的一环,而按钮的设计也与用户体验息息相关。让用户更容易的点击到按钮无疑能很好的增加用户体验,尤其是在移动端,按钮通常都很小,但是有时由于设计稿限制,我们不能直接去改变按钮元素的高宽。那么这个时候有什么办法在不改变按钮原本大小的情况下去增加他的点击热区呢?
这里,伪元素也是可以代表其宿主元素来响应的鼠标交互事件的。借助伪元素可以轻松帮我们实现,我们可以这样写:
.btn::befoer{
content:"";
position:absolute;
top:-10px;
right:-10px;
bottom:-10px;
left:-10px;
}当然,在 PC 端下这样子看起来有点奇怪,但是合理的用在点击区域较小的移动端则能取到十分好的效果,效果如下:
上面介绍的是伪元素众多用法的一部分,伪元素的作用远不止于此。有了before 、after 两个伪元素。一个标签其实可以相当于 3 个标签来使用,而配合 CSS3 强大的 3D 变换、多重背景,多重阴影等手段,让单标签作画成为了可能,下面是我仅用单个标签,实现的一些动画效果:

CSS3奇思妙想,采用单标签完成各种图案 -- Demo (请用 Chrome 浏览器打开,非常值得一看)。
也希望觉得不错的同学顺手在我的 Github 点个 star : CSS3奇思妙想 。
希望这篇文章对大家有所帮助,尤其是在对问题解决的思维层面上。
到此本文结束,如果还有什么疑问或者建议,可以多多交流,原创文章,文笔有限,才疏学浅,文中若有不正之处,万望告知。
区块链在 2018 突然就爆发了,区块链工程师招聘也是异常火爆。长期混迹币圈,又是个人兴趣所向,遂打算学习一下区块链方面的编程技术。
如果你也感兴趣,可以和我一起,从零开始学习以太坊编程。
废话少说,直接开始教程。
Truffle 是一个以太坊智能合约开发框架,利用它可以方便地生成项目模板、编译合约、部署合约到区块链、测试合约等等。
truffle 支持使用 npm 安装。对于前端同学是个福音。
npm install -g truffle当然有些前提:
nodejs 版本要求大于 5.0,所以版本过低的同学需要更新一下。建议直接上 8.1.0 的稳定版本。Node.js 8.10.0 LTS
OK,我是 windows 下的环境,安装完成大概是这样:

OK,工具已经有了,接下来就是创建项目。
我们创建一个文件夹,在该文件夹下,使用 truffle init 指令创建一个新的项目。
> truffle init
上述命令之后,我们可以得到一个官方提供的简单脚手架 -- metacoin 项目。简单的目录示意如下:

truffle.js 是 Truffle 的配置文件当然,除了 truffle init 之外,官方还提供了一个简明教程项目 -- metacoin。安装它的方法如下:
> truffle unbox metacoin
两者都可以,目的是创建一个简单的脚手架。我们看到,脚手架提供的几个文件,后缀只有两个 *.js 或者是 *.sol。
*.js 这个大家都很熟悉,就是 JavaScript 脚本。
*.sol 是个啥呢?
.sol 后缀文件中的 sol 是 Solidity 的简称。Solidity 是基于以太坊虚拟机 Ethereum Virtual Machine (EVM)运行,面向智能合约,语法类似于 JavaScript 的高级编程语言。
语法类似于 JavaScript,前端工程师的福音。
这里先了解一下,后面会有更深入的讲解。
下面在正式编程之前,还有一些专业术语要了解一下。
什么是 Dapp?去中心化应用也被称为DApp(decentralized applications),是技术进化的下一个合乎逻辑的步骤。
一个分布式应用,类似以太坊上的智能合约,但也有关键不同。不像智能合约,Dapp不需仅围绕金融,还可将区块链技术用于可想到的任何用途。
有人将 Distributed App 翻译成去中心化应用,这个翻译其实并不准确。去中心化的英文单词是 Decentralized 或者是 Distributed 。但其实翻译过来为分散,而非去中心化。
区块链是一种软件系统,而软件系统的网络架构一般有三种模式:单中心、多中心、分布式。单词 Decentralized 只是表明不是单中心模式,可能为多中心或弱中心,也可能是分布式的。
经常看到说像 ETH 钱包支持 ERC20 标准代币。
那么所谓的 ERC20 是什么呢?
ERC-20 标准是在2015年11月份推出的,使用这种规则的代币,表现出一种通用的和可预测的方式,可以让以太坊区块链上的其他智能合约和分布式应用之间无缝交互。
简单地说,任何 ERC-20 代币都能立即兼容以太坊钱包。ERC20 是各个代币的标准接口。ERC20 代币仅仅是以太坊代币的子集。
ERC20 令牌存在的最大问题在于无法通过接收方合同处理传入的交易。在此基础上,有了 ERC223 标准。
自从引入 ERC20 令牌标准以来,几乎所有的基于以太坊的令牌都成功的接受了这个新标准。
然而其自身的缺点需要及时解决,这便是ERC223令牌诞生的原因。
ERC223 令牌标准将向现有的 ERC20 标准引入一个新功能,以防止意外转移的发生。ERC223 令牌标准可以防止令牌在以太坊网络上丢失。
我们知道,类似ETH,很多代币都是可以细分到小数点后面很多很多位数的。
譬如,我要可以只买卖 0.00000001 枚 ETH 。这就是 ERC20 的标准。Token 可以无限细分为 10^18 份。
而 ERC721 的 Token 最小的单位为 1,无法再分割。类似于我们见到的百度莱次狗、小米加密猫,这些阿猫阿狗正常来说都是一只一只的,我们不可能说去交易 0.000001 只加密猫。所以正常来说 莱次狗、加密猫 都应该是符合 ERC721 标准的代币。

ERC721(Non-Fungible Tokens),翻译为不可互换的 Token, 英文简写为"NFT",简单理解为每个 Token 都是独一无二的。也就是说 ERC721 的每个 Token 都拥有独立唯一的 tokenId 编号。
ERC20 是可置换的,意味着所有的 Token 直接没有区别,所有Token都是一样的,而符合 ERC721 的
Token 每个都具有独立唯一的 tokenId 编号。
举个例子,假设我的加密猫的 TokenId 为 888888888,是不是很具有收藏价值。可以类似对比车牌。
本期先带大家了解这多,下一期介绍 Go Ethereum 和直接开始一个简单和合约编程,敬请期待。
任何技术问题交流,或者有志学习 ETH 编程的,可以加 Q 群交流:互联网区块链技术交流 --483931379 。
stacking context 意为层叠上下文。
在浏览器的元素渲染过程中,除了水平的布局,还有一条沿着相对于用户的假想 Z 轴。
在水平的布局中,有块级上下文(BFC)等绘制规则,而在 Z 轴上,有层叠上下文(stacking context)的绘制规则。
层叠上下文是 HTML 元素的三维概念,这些 HTML 元素在一条假想的相对于面向(电脑屏幕的)视窗或者网页的用户的 z 轴上延伸,HTML 元素依据其自身属性按照优先级顺序占用层叠上下文的空间。
在某些时候,我们对某些元素使用 z-index ,导致某些元素的呈现顺序受其 z-index 值影响。发生这种情况是因为这些元素具有特殊的属性,这些属性导致它们形成了层叠上下文。从而可以根据 z-index 指定 Z 轴的优先级。
那么,如何触发一个元素生成层叠上下文呢?
MDN 上写的比较笼统,我们简单进行分类描述:
在以下情况下,文档中的任何元素只要拥有以下条件之一,即可形成堆叠上下文:
absolute 或者 relative ,并且 z-index 的值不为 auto 的元素fixed 或 sticky 的元素flex 容器的子元素,并且其 z-index 的值不是 auto。grid 容器的子元素,并且其 z-index 值不是auto。具有以下任一属性的元素,并且其值不是 none:
transformfilterperspectiveclip-path(裁剪)mask/ mask-image / mask-bordermix-blend-mode 的值不是 normal 的元素。isolation(隔离)的值为 isolate 的元素。(该属性就是可以主动申请一个 层叠上下文)-webkit-overflow-scrolling 的值为 touch 的元素。will-change 值不为初始值的元素(重要提示: will-change 旨在用作最后手段,以尝试解决现有的性能问题。不应将其用于预期性能问题。)。contain 的值 layout,或者 paint,或包括它们中的一个复合值(即 contain: strict,contain: content)。(这是一项实验性技术,请在生产中使用它之前仔细检查浏览器兼容性表。)综上:
层叠上下文可以被其他层叠上下文包含,并一起创建层叠上下文的层次结构;
每个层叠上下文和其兄弟独立开来,处理层叠上下文时仅考虑后代元素;
每个层叠上下文都是独立的,将元素的内容堆叠之后,将按照父层叠上下文的堆叠顺序考虑整个元素;
注意:比较堆叠顺序时,将只比较同级 DOM 的堆叠顺序,相同情况下再考虑子元素,直到一方比另一方大。
什么是层叠水平呢?就是有了层叠上下文后,还有一套规则把所有元素(有层叠上下文和没有层叠上下文的)放在一起进行层级优先级排列的,也就是大家非常熟悉的这张图:


前几天在公众号转发了好友 Vajoy 的一篇文章 -- 巧用 CSS 把图片马赛克风格化。
核心是利用了 CSS 中一个很有意思的属性 -- image-rendering,它可以用于设置图像缩放算法。
CSS 属性 image-rendering 用于设置图像缩放算法。它适用于元素本身,适用于元素其他属性中的图像,也应用于子元素。
语法比较简单:
{
image-rendering: auto; // 默认值,使用双线性(bilinear)算法进行重新采样(高质量)
image-rendering: smooth; // 使用能最大化图像客观观感的算法来缩放图像。让照片更“平滑”
image-rendering: crisp-edges; // 使用可有效保留对比度和图像中的边缘的算法来对图像进行缩放
image-rendering: pixelated; // 放大图像时, 使用最近邻居算法,因此,图像看着像是由大块像素组成的
}其中,image-rendering: pixelated 比较有意思,可以将一张低精度图像马赛克化。
譬如,假设我们有一张 300px x 300px 的图像,我们让他转换成 30px x 30px:

我们再把失真后的图片,放大到 300px x 300px:

在此基础上,我们给这张图片设置 image-rendering: pixelated,就能得到一张被马赛克化图片:
<img src="pic.jpeg?30x30" />img {
width: 300px;
height: 300px;
image-rendering: pixelated
}
OK,那么为什么需要先缩小再放大,然后才运用 image-rendering: pixelated 呢?我们来做个对比,直接给原图设置 image-rendering: pixelated:

直接给原图设置 image-rendering: pixelated 只会让图片变得更加有锯齿感,而不会直接产生马赛克的效果。
这也和 image-rendering: pixelated 的描述吻合,放大图像时, 使用最近邻居算法,因此,图像看着像是由大块像素组成的。
我们只有基于放大模糊后的图像,才能利用 image-rendering: pixelated 得到一张被马赛克的图片!
那么,假设我们只有一张清晰的原图,又想利用 CSS 得到一个马赛克效果,可行么?顺着这个思路,我们可以想到:
能否利用 CSS 将图片缩小后再放大,再运用 image-rendering: pixelated 呢?
不行。WEB 上的图片像极了 Photoshop 里的智能对象 —— 你可以任意修改它的尺寸(例如放大很多倍让其变模糊),但最后再把图片改回原本的大小时,图片会变回原来的样子(没有任何失真)。
所以,要想在只有一张原图的情况下,得到一张模糊的图像,就不得不求助于 Canvas,这样一来就稍显麻烦了。我们只是想要个马赛克效果而已。
这就可以引出今天的主角了,SVG 滤镜,使用几层 SVG 滤镜的叠加,其实可以非常轻松的实现一个马赛克效果滤镜。
并且,SVG 滤镜可以通过 CSS filter,轻松的引入。
代码其实也非常的简单,SVG 定义一个滤镜,利用多层滤镜的叠加效果实现一个马赛克效果,然后,通过 CSS filter 引入,可以运用在任何元素上:
<img src="任意无需缩放的原图.png" alt="">
<svg>
<filter id="pixelate" x="0" y="0">
<feFlood x="4" y="4" height="2" width="2"/>
<feComposite width="8" height="8"/>
<feTile result="a"/>
<feComposite in="SourceGraphic" in2="a" operator="in"/>
<feMorphology operator="dilate"radius="5"/>
</filter>
</svg>img {
width: 300px;
height: 300px;
filter: url(#pixelate);
}这样,我们就得到了一个马赛克效果:

如果你只是想使用这个效果,你甚至不需要去理解整个 SVG <filter> 到底做了什么事情,当然,如果你是一个一问到底的人,那么需要有一定的 SVG 基础,建议可以看看我的这几篇关于 SVG 滤镜的介绍:
当然,CSS/SVG 滤镜实现马赛克的局限性在于,如果你是不想给用户看到原图的,那么在客户端直接使用这个方式相当于直接把原图的暴露了。
因为 CSS/SVG 滤镜的方式是在前端进行图片马赛克化的,而且需要原图。
当然,利用上述的两个实现图片马赛克技巧,我们还是可以用于制作一些简单的交互效果的,像是这样:

上述的 DEMO 和 SVG 滤镜的全部代码,你都可以在这两个 DEMO 中找到:
好了,本文到此结束,希望对你有帮助 :)
想 Get 到最有意思的 CSS 资讯,千万不要错过我的公众号 -- iCSS前端趣闻 😄
更多精彩 CSS 技术文章汇总在我的 Github -- iCSS ,持续更新,欢迎点个 star 订阅收藏。
如果还有什么疑问或者建议,可以多多交流,原创文章,文笔有限,才疏学浅,文中若有不正之处,万望告知。
最近一直在研读 jQuery 源码,初看源码一头雾水毫无头绪,真正静下心来细看写的真是精妙,让你感叹代码之美。
其结构明晰,高内聚、低耦合,兼具优秀的性能与便利的扩展性,在浏览器的兼容性(功能缺陷、渐进增强)优雅的处理能力以及 Ajax 等方面周到而强大的定制功能无不令人惊叹。
另外,阅读源码让我接触到了大量底层的知识。对原生JS 、框架设计、代码优化有了全新的认识,接下来将会写一系列关于 jQuery 解析的文章。
我在 github 上关于 jQuery 源码的全文注解,感兴趣的可以围观一下。jQuery v1.10.2 源码注解 。
言归正传,本文讲的是原生 JS 获取、设置元素最终样式的方法。可能平时框架使用习惯了,以 jQuery 为例,使用 .css() 接口就能便捷的满足我们的要求。再看看今天要讲的 window.getComputedStyle ,就像刚接触 JS 的时候,看到 document.getElementById 一样,名字都这么长,顿生怯意。不过莫慌,我觉得如果我们不是只想做一个混饭吃的前端,那么越是底层的东西,如果能够吃透它,越是能让人进步。
getComputedStyle 为何物呢,DOM 中 getComputedStyle 方法可用来获取元素中所有可用的css属性列表,以数组形式返回,并且是只读的。IE678 中则用 currentStyle 代替 。
假设我们页面上存在一个 id 为 id 的元素,那么使用 getComputedStyle 获取元素样式就如下图所示:
// 语法:
// 在旧版本之前,第二个参数“伪类”是必需的,现代浏览器已经不是必需参数了
// 如果不是伪类,设置为null,
window.getComputedStyle("元素", "伪类");尝试一下之后可以看到,window.getComputedStyle 获取的是所有的样式,如果我们只是要获取单一样式,该怎么做呢。这个时候就要介绍另一个方法 -- getPropertyValue 。
用法也很简单:
// 语法:
// 使用 getPropertyValue 来指定获取的属性
window.getComputedStyle("元素", "伪类").getPropertyValue(style);说完常规浏览器,再来谈谈老朋友 IE ,与 getComputedStyle 对应,在 IE 中有自己特有的 currentStyle 属性,与 getPropertyValue 对应,IE 中使用 getAttribute 。
和 getComputedStyle 方法不同的是,currentStyle 要获得属性名的话必须采用驼峰式的写法。也就是如果我需要获取 font-size 属性,那么传入的参数应该是 fontSize。因此在IE 中要获得单个属性的值,就必须将属性名转为驼峰形式。
// IE 下语法:
// IE 下将 CSS 命名转换为驼峰表示法
// font-size --> fontSize
// 利用正则处理一下就可以了
function camelize(attr) {
// /\-(\w)/g 正则内的 (\w) 是一个捕获,捕获的内容对应后面 function 的 letter
// 意思是将 匹配到的 -x 结构的 x 转换为大写的 X (x 这里代表任意字母)
return attr.replace(/\-(\w)/g, function(all, letter) {
return letter.toUpperCase();
});
}
// 使用 currentStyle.getAttribute 获取元素 element 的 style 属性样式
element.currentStyle.getAttribute(camelize(style));必须要提出的是,我们使用 element.style 也可以获取元素的CSS样式声明对象,但是其与 getComputedStyle 方法还是有一些差异的。
首先,element.style 是可读可写的,而 getComputedStyle 为只读。
其次,element.style 只可以获取 style 样式上的属性值,而无法得到所有的 CSS 样式值,什么意思呢?回顾一下 CSS 基础,CSS 样式表的表现有三种方式,
而 element.style 只能获取被这些样式表定义了的样式,而 getComputedStyle 能获取到所有样式的值(在不同浏览器结果不一样,chrome 中是 264,在 Firefox 中是238),不管是否定义在样式表中,譬如:
#id{
width : 100px;
float:left;
}
var elem = document.getElementById('id');
elem.style.length // 2
window.getComputedStyle(elem, null).length // 264window.getComputedStyle 还有另一种写法,就是 document.defaultView.getComputedStyle 。
两者的用法完全一样,在 jQuery v1.10.2 中,使用的就是 window.getComputedStyle 。如下
也有特例,查看 stackoverflow ,上面提及到在 Firefox 3.6 ,不使用 document.defaultView.getComputedStyle 会出错。不过毕竟 FF3.6 已经随历史远去,现在可以放心的使用 window.getComputedStyle。
用一张图总结一下:
说了这么多,接下来将用原生 Javascript 实现一个小组件,实现 CSS 的 get 与 set,兼容所有浏览器。
完整的组件代码在我的 github 上,戳我直接看代码。
对于 CSS 的 set ,对于支持 window.getComputedStyle 的浏览器而言十分简单,只需要直接调用。
getStyle: function(elem, style) {
// 主流浏览器
if (win.getComputedStyle) {
return win.getComputedStyle(elem, null).getPropertyValue(style);
}
}反之,如果是 IE 浏览器,则有一些坑。
在早期的 IE 中要设置透明度的话,有两个方法:
因此在 IE 环境下,我们需要针对透明度做一些处理。先写一个 IE 下获取透明度的方法:
// IE 下获取透明度
function getIEOpacity(elem) {
var filter = null;
// 早期的 IE 中要设置透明度有两个方法:
// 1、alpha(opacity=0)
// 2、filter:progid:DXImageTransform.Microsoft.gradient( GradientType= 0 , startColorstr = ‘#ccccc’, endColorstr = ‘#ddddd’ );
// 利用正则匹配
filter = elem.style.filter.match(/progid:DXImageTransform.Microsoft.Alpha\(.?opacity=(.*).?\)/i) || elem.style.filter.match(/alpha\(opacity=(.*)\)/i);
if (filter) {
var value = parseFloat(filter);
if (!isNaN(value)) {
// 转化为标准结果
return value ? value / 100 : 0;
}
}
// 透明度的值默认返回 1
return 1;
}float 属性是比较重要的一个属性,但是由于 float 是 ECMAScript 的一个保留字。(ECMAScript保留字有哪些?戳这里)
所以在各浏览器中都会有代替的写法,比如说在标准浏览器中为 cssFloat,而在 IE678 中为 styleFloat 。经测试,在标准浏览器中直接使用 getPropertyValue("float") 也可以获取到 float 的值。而 IE678 则不行,所以针对 float ,也需要一个 HACK。
然后是元素的高宽,对于一个没有设定高宽的元素而言,在 IE678 下使用 getPropertyValue("width|height") 得到的是 auto 。而标准浏览器会直接返回它的 px 值,当然我们希望在 IE 下也返回 px 值。
这里的 HACK 方法是使用 element.getBoundingClientRect() 方法。
可以获得元素四个点相对于文档视图左上角的值 top、left、bottom、right ,通过计算就可以容易地获得准确的元素大小。
上文已经提及了,在IE下使用 currentStyle 要获得属性名的话必须采用驼峰式的写法。
OK,需要 HACK 的点已经提完了。那么在 IE 下,获取样式的写法:
getStyle: function(elem, style) {
// 主流浏览器
if (win.getComputedStyle) {
...
// 不支持 getComputedStyle
} else {
// IE 下获取透明度
if (style == "opacity") {
getIEOpacity(elem);
// IE687 下获取浮动使用 styleFloat
} else if (style == "float") {
return elem.currentStyle.getAttribute("styleFloat");
// 取高宽使用 getBoundingClientRect
} else if ((style == "width" || style == "height") & (elem.currentStyle[style] == "auto")) {
var clientRect = elem.getBoundingClientRect();
return (style == "width" ? clientRect.right - clientRect.left : clientRect.bottom - clientRect.top) + "px";
}
// 其他样式,无需特殊处理
return elem.currentStyle.getAttribute(camelize(style));
}
}说完 get ,再说说 setStyle ,相较于getStyle ,setStyle 则便捷很多,因为不管是标准浏览器还是 IE ,都可以使用 element.style.cssText 对元素进行样式的设置。
一种设置 CSS 样式的方法,但是它是一个销毁原样式并重建的过程,这种销毁和重建,会增加浏览器的开销。而且在 IE 中,如果 cssText(假如不为空),最后一个分号会被删掉,所以我们需要在其中添加的属性前加上一个 ”;” 。
只是在 IE 下的 opacity 需要额外的进行处理。明了易懂,直接贴代码:
// 设置样式
setStyle: function(elem, style, value) {
// 如果是设置 opacity ,需要特殊处理
if (style == "opacity") {
//IE7 bug:filter 滤镜要求 hasLayout=true 方可执行(否则没有效果)
if (!elem.currentStyle || !elem.currentStyle.hasLayout) {
// 设置 hasLayout=true 的一种方法
elem.style.zoom = 1;
}
// IE678 设置透明度叫 filter ,不是 opacity
style = "filter";
// !!转换为 boolean 类型进行判断
if (!!window.XDomainRequest) {
value = "progid:DXImageTransform.Microsoft.Alpha(style=0,opacity=" + value * 100 + ")";
} else {
value = "alpha(opacity=" + value * 100 + ")"
}
}
// 通用方法
elem.style.cssText += ';' + (style + ":" + value);
}到这里,原生 JS 实现的 getStyle 与 setStyle 就实现了,完整的代码可以戳这里查看。可以看到,一个简单接口的背后,都是有涉及了很多方面东西。虽然浏览器兼容性是一个坑,但是爬坑的过程却是我们沉淀自己的最好时机。
jQuery 这样的框架可以帮助我们走的更快,但是毫无疑问,去弄清底层实现,掌握原生 JS 的写法,可以让我们走得更远。
原创文章,文笔有限,才疏学浅,文中若有不正之处,万望告知。
最后,本文组件示例的代码贴在 我的github 上。
本文是内部的一次分享沉淀,偏向基础但是涉及了一些有意思的细节,文笔有限,才疏学浅,文中若有不正之处,万望告知。
前端的一大工作内容就是去兼容页面在不同内核的浏览器,不同的设备,不同的分辨率下的行为,使页面的能正常工作在各种各样的宿主环境当中。
而本文的主题 -- 移动端开发的兼容适配与性能优化,就是希望能从一些常见的移动端开发问题出发,厘清 Web 移动端开发的前前后后,一些技术的发展过程,一些问题的优化手段以及给出一些常见的兼容性问题的解决方案。
首先先聊聊响应式设计,这个与移动端开发有着密切的联系。
响应式设计即是 RWD,Responsive Web Design。
这里百度或者谷歌一下会有各种各样的答案。这里一段摘自知乎上我觉得很棒的一个答案:什么是响应式布局设计?
根据维基百科及其参考文献,理论上,响应式界面能够适应不同的设备。描述响应式界面最著名的一句话就是“Content is like water”,翻译成中文便是“如果将屏幕看作容器,那么内容就像水一样”。
为什么要费神地尝试统一所有设备呢?
可伸缩的内容区块:内容区块的在一定程度上能够自动调整,以确保填满整个页面
可自由排布的内容区块:当页面尺寸变动较大时,能够减少/增加排布的列数
适应页面尺寸的边距:到页面尺寸发生更大变化时,区块的边距也应该变化
能够适应比例变化的图片:对于常见的宽度调整,图片在隐去两侧部分时,依旧保持美观可用
能够自动隐藏/部分显示的内容:如在电脑上显示的的大段描述文本,在手机上就只能少量显示或全部隐藏
能自动折叠的导航和菜单:展开还是收起,应该根据页面尺寸来判断
放弃使用像素作为尺寸单位:用dp(对于前端来说,这里可能是rem)尺寸等方法来确保页面在分辨率相差很大的设备上,看起来也能保持一致。同时也要求提供的图片应该比预想的更大,才能适应高分辨率的屏幕
上面一段我觉得已经涵盖了响应式设计的绝大部分,简单总结起来,可以概括为:
响应式设计是 Responsive Web Design(RWD),自适应设计是 Adaptive Web Design(AWD)。经常有人会将两者混为一谈,或者其实根本也区分不了所谓的响应式与自适应。
其实在我写这篇文章的时候,我也无法很好的去区分两者。
RWD 和 AWD 两者都是为了适配各种不同的移动设备,致力于提升用户体验所产生的的技术。核心**是用技术来使网页适应从小到大(现在到超大)的不同分辨率的屏幕。通常认为,RWD 是 AWD 的子集。
RWD:Ethan Marcote 的文章是大家认为 RWD 的起源。他提出的 RWD 方案是通过 HTML 和 CSS 的媒体查询技术,配合流体布局实现。RWD 倾向于只改变元素的外观布局,而不大幅度改变内容。Jeffrey Zeldman 总结说,我们就把 RWD 定义为一切能用来为各种分辨率和设备性能优化视觉体验的技术。
AWD:Adaptive Design 是 Aaron Gustafson 的书的标题。他认为 AWD 在包括 RWD 的 CSS 媒体查询技术以外,也要用 Javascript 来操作 HTML 来更适应移动设备的能力。AWD 有可能会针对移动端用户减去内容,减去功能。AWD 可以在服务器端就进行优化,把优化过的内容送到终端上。
一图胜千言。

从定义上而言,RWD 是一套代码,适用于所有屏幕。而 AWD 则是多端多套代码。本文不会过多去纠结响应式与自适应区别,我觉得这两者的本质都是致力于适配不同设备,更好地提升用户体验。
Quora - Responsive Design vs. Adaptive Design?
zhihu -- Responsive design 和 Adaptive design 的区别
渐进增强(progressive enhancement):针对低版本浏览器进行构建页面,保证最基本的功能,然后再针对高级浏览器进行效果、交互等改进和追加功能达到更好的用户体验。
优雅降级(graceful degradation):一开始就构建完整的功能,然后再针对低版本浏览器进行兼容。
区别:优雅降级是从复杂的现状开始,并试图减少用户体验的供给,而渐进增强则是从一个非常基础的,能够起作用的版本开始,并不断扩充,以适应未来环境的需要。降级(功能衰减)意味着往回看;而渐进增强则意味着朝前看,同时保证其根基处于安全地带。
渐进增强/优雅降级通常是 AWD 会牵扯到的另一个技术术语。本质上而言即是随着屏幕的大小的改变,功能会一点一点增强。
也通常会用在一些高级 CSS3 属性上,我们对一些 CSS 属性进行特性检测,甚至不进行特性检测直接使用。后果是在支持它的网页上该属性正常展示,而不支持它的网页该属性不生效,但也不影响用户的基本使用。
典型的例子是 CSS3 逐渐被大众认可并被使用,PC端页面开始由 IE678 向兼容性更好的IE9+,chrome,firefox浏览器转变的时期。我们可以对页面元素直接使用阴影,圆角等属性。对于不支持它的低版本 IE 而言,没有什么损失,而对于支持它的高级浏览器而言,带给了用户更好的交互视觉体验,这就是渐进增强。
下面会针对一些具体的案例,展开讲讲。第一个是高保真还原设计稿,也就是如何适配移动端繁杂的屏幕大小。
通常而言,设计师只会给出单一分辨率下的设计稿,而我们要做的,就是以这个设计稿为基准,去适配所有不同大小的移动端设备。
在此之前,有一些基础概念需要理解。
一些概念性的东西,大部分人很难一次性记住,或者记了又忘,我觉得记忆这个东西比较看技巧,比如关联法,想象法,把这些生硬的概念与一些符合我们常识的知识关联在一起记忆,往往能够事半功倍。
以 iPhone6/7/8为例,这里我们打开 Chrome 开发者工具:

这里的 375 * 667 表示的是什么呢,表示的是设备独立像素(DIP),也可以理解为 CSS 像素,也称为逻辑像素:
设备独立像素 = CSS 像素 = 逻辑像素
如何记忆呢?这里使用 CSS 像素来记忆,也就是说。我们设定一个宽度为 375px 的 div,刚好可以充满这个设备的一行,配合高度 667px ,则 div 的大小刚好可以充满整个屏幕。
OK,那么,什么又是物理像素呢。我们到电商网站购买手机,都会看一看手机的参数,以 JD 上的 iPhone7 为例:

可以看到,iPhone7 的分辨率是 1334 x 750,这里描述的就是屏幕实际的物理像素。
物理像素,又称为设备像素。显示屏是由一个个物理像素点组成的,1334 x 750 表示手机分别在垂直和水平上所具有的像素点数。通过控制每个像素点的颜色,就可以使屏幕显示出不同的图像,屏幕从工厂出来那天起,它上面的物理像素点就固定不变了,单位为pt。
设备像素 = 物理像素
OK,有了上面两个概念,就可以顺理成章引出下一个概念。DPR(Device Pixel Ratio) 设备像素比,这个与我们通常说的视网膜屏(多倍屏,Retina屏)有关。
设备像素比描述的是未缩放状态下,物理像素和设备独立像素的初始比例关系。
简单的计算公式:
DPR = 物理像素 / 设备独立像素
我们套用一下上面 iPhone7 的数据(取设备的物理像素宽度与设备独立像素宽度进行计算):
iPhone7’s DPR = iPhone7’s 物理像素宽度 / iPhone7's 设备独立像素宽度 = 2
750 / 375 = 2
或者是 1334 / 667 = 2
可以得到 iPhone7 的 dpr 为 2。也就是我们常说的视网膜屏幕。
视网膜(Retina)屏幕是苹果公司"发明"的一个营销术语。 苹果公司将 dpr > 1 的屏幕称为视网膜屏幕。

在视网膜屏幕中,以 dpr = 2 为例,把 4(2x2) 个像素当 1 个像素使用,这样让屏幕看起来更精致,但是元素的大小本身却不会改变:

OK,我们再来看看 iPhone XS Max:

它的物理像素如上图是 2688 x 1242,

它的 CSS 像素是 896 x 414,很容易得出 iPhone XS Max 的 dpr 为 3。
上面三个概念(CSS像素、设备独立像素、DPR)是我觉得比较重要的,还有一些其他比较重要的概念 PPI、DPI 不影响后续的内容,可以自行去加深理解。
OK,到这里我们就完成了一个小的里程碑。我们通常说的H5手机适配也就是指的这两个维度:
适配不同屏幕大小,也就是适配不同屏幕下的 CSS 像素。最早移动端屏幕 CSS 像素适配方案是CSS媒体查询。但是无法做到高保真接近 100% 的还原。
适配不同屏幕大小其实只需要遵循一条原则,确保页面元素大小的与屏幕大小保持一定比例。也就是:按比例还原设计稿

假设我们现在拿到标注为 375*667 的大小的设计稿,其中一个元素的标注如下:


以页面宽度为基准的话,那么,
209/375 = 55.73%80/375 = 21.33%这样,无论屏幕的 CSS 像素宽度是 320px 还是 375px 还是 414px,按照等量百分比还原出来的界面总是正确的。
然而,理想很丰满,现实很骨感。实现上述百分比方案的核心需要一个全局通用的基准单位,让所有百分比展示以它为基准,但是在 CSS 中,根据CSS Values and Units Module Level 4的定义:
百分比值总要相对于另一个量,比如长度。每个允许使用百分比值的属性,同时也要定义百分比值参照的那个量。这个量可以是相同元素的另一个属性的值,也可以是祖先元素的某个属性的值,甚至是格式化上下文的一个度量(比如包含块的宽度)。
具体来说:
宽度(width)、间距(maring/padding)支持百分比值,但默认的相对参考值是包含块的宽度;
高度(height)百分比的大小是相对其父级元素高的大小;
边框(border)不支持百分值;
边框圆角半径(border-radius)支持百分比值,但水平方向相对参考值是盒子的宽度,垂直方向相对参考值是盒子的高度;
文本大小(font-size)支持百分比值,但相对参考值是父元素的font-size的值;
盒阴影(box-shadow)和文本阴影(text-shadow)不支持百分比值;
首先,支持百分比单位的度量属性有其各自的参照基准,其次并非所有度量属性都支持百分比单位。所以我们需要另辟蹊径。
在 vw 方案出来之前,最被大众接受的就是使用 rem 进行适配的方案,因为 rem 满足上面说的,可以是一个全局性的基准单位。
rem(font size of the root element),在 CSS Values and Units Module Level 3中的定义就是, 根据网页的根元素来设置字体大小,和 em(font size of the element)的区别是,em 是根据其父元素的字体大小来设置,而 rem 是根据网页的跟元素(html)来设置字体大小。
基于此,淘宝早年推行的一套以 rem 为基准的适配方案:lib-flexible。其核心做法在于:
<meta> 标签,设置 viewport 的缩放<html> 元素添加 data-dpr 属性,并且动态改写 data-dpr 的值document.documentElement.clientWidth 动态修改 <html> 的 font-size ,页面其他元素使用 rem 作为长度单位进行布局,从而实现页面的等比缩放关于头两点,其实现在的
lib-flexible库已经不这样做了,不再去缩放 Viewport,字体大小的设定也直接使用了 rem
hotcss 不是一个库,也不是一个框架。它是一个移动端布局开发解决方案。使用 hotcss 可以让移动端布局开发更容易。本质的**与 flexible 完全一致。
使用 flexible/hotcss 作为屏幕宽度适配解决方案,是存在一些问题的:
innerWidth/innerHeight 也会随之发生变化,如果业务逻辑有获取此类高宽进行其他计算的,可能会导致意想不到的错误;到今天,其实存在很多在 flexible 基础上演化而来的各种 rem 解决方案,有的不会对 Viewport 进行缩放处理,自行处理 1px 边框问题。
严格来说,使用 rem 进行页面适配其实是一种 hack 手段,rem 单位的初衷本身并不是用来进行移动端页面宽度适配的。
到了今天,有了一种更好的替代方案,使用 vw 进行适配 。
百分比适配方案的核心需要一个全局通用的基准单位,rem 是不错,但是需要借助 Javascript 进行动态修改根元素的 font-size,而 vw/vh(vmax/vmin) 的出现则很好弥补 rem 需要 JS 辅助的缺点。
根据 CSS Values and Units Module Level 4:vw等于初始包含块(html元素)宽度的1%,也就是
1vw 等于 window.innerWidth 的数值的 1%1vh 等于window.innerHeight 的数值的 1%再以上面设计稿图的元素为例,那么,
209/375 = 55.73% = 55.73vw80/375 = 21.33% = 21.33vw根据相关的测试,可以使用 vw 进行长度单位的有:
简单的一个页面,看看效果,完全是等比例缩放的效果:
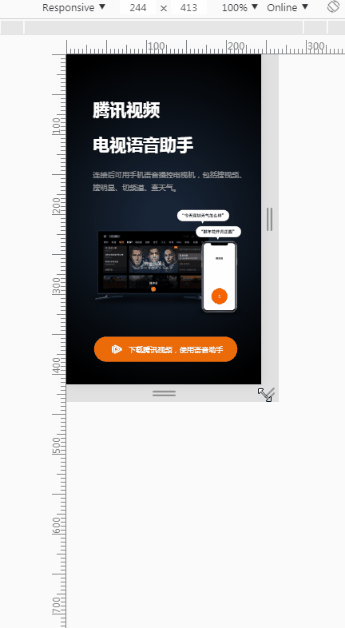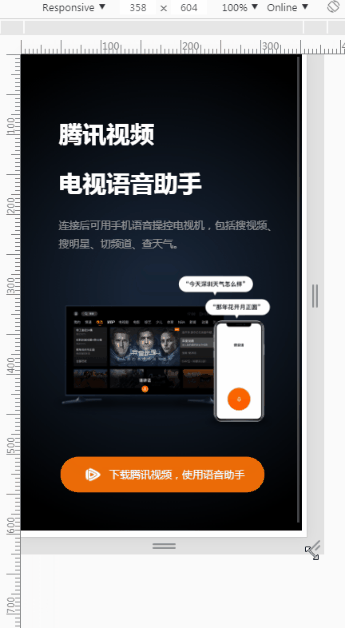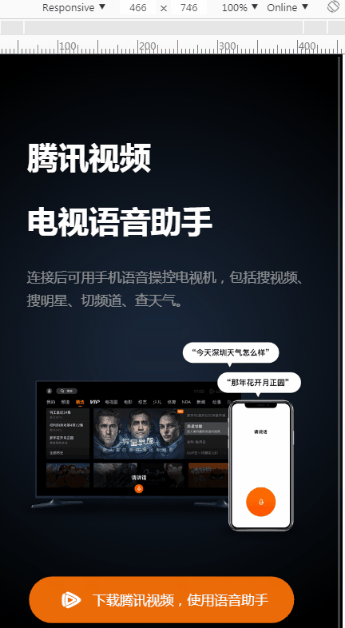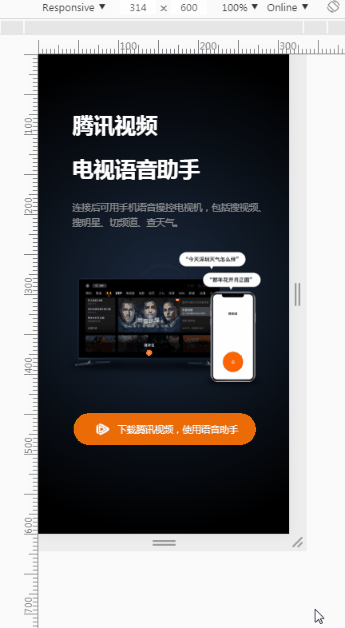
CodePen Demo(移动端打开):使用 vw 进行页面适配
当我们使用 rem 作为长度单位的时,通常会有借助 Sass/Less 实现一个转换函数,像是这样:
// 假设设计稿的宽度是 375px,假设取设计稿宽度下 1rem = 100px
$baseFontSize: 100;
@function px2rem($px) {
@return $px / $baseFontSize * 1rem;
}同理,在 vw 方案下,我们只需要去改写这个方法:
// 假设设计稿的宽度是 375px
@function px2vw($px) {
@return $px / 375 * 100vw;
}当然,我们还可以借助一些插件包去实现这个自动转换,提高效率,譬如 postcss-px-to-viewport
vw 现在毕竟还是存在兼容问题的,看看兼容性:

其实已经覆盖了绝大部分设备,那么如果业务使用了且又真的出现了兼容问题,应该怎么处理呢?有两种方式可以进行降级处理:
vw 确实看上去很不错,但是也是存在它的一些问题:
当然,两个方案现阶段其实都可以使用甚至一起搭配使用,更多详情可以读读:
上面说到使用 vw 适配屏幕大小方案,其中有一个缺点就是在 Retina 屏下,无法很好的展示真正的 1px 物理像素线条。
设计师想要的 retina 下 border: 1px,其实是 1 物理像素宽度,而不是 1 CSS 像素宽度,对于 CSS 而言:
border-width: 1px 这里的 1px 其实是 1 CSS像素宽度,等于 2 像素物理宽度,设计师其实想要的是 border-width: 0.5px;然而,并不是所有手机浏览器都能识别 border-width: 0.5px,在 iOS7 以下,Android 等其他系统里,小于 1px 的单位会被当成为 0px 处理,那么如何实现这 0.5px、0.33px 呢?
这里介绍几种方法:
图像通常占据了网页上下载资源绝的大部分。优化图像通常可以最大限度地减少从网站下载的字节数以及提高网站性能。
通常可以,有一些通用的优化手段:
本文重点关注如何在不同的 dpr 屏幕下,让图片看起来都不失真。
首先就是上述的第二点,尽可能利用 CSS3\SVG 矢量图像替代某些光栅图像。某些简单的几何图标,可以用 CSS3 快速实现的图形,都应该尽量避免使用光栅图像。这样能够保证它们在任何尺寸下都不会失真。
其次,实在到了必须使用光栅图像的地步,也是有许多方式能保证图像在各种场景下都不失真。
在移动端假设我们需要一张 CSS 像素为 300 x 200 的图像,考虑到现在已经有了 dpr = 3 的设备,那么要保证图片在 dpr = 3 的设备下也正常高清展示,我们最大可能需要一张 900 x 600 的原图。
这样,不管设备的 dpr 是否为 3,我们统一都使用 3 倍图。这样即使在 dpr = 1,dpr = 2 的设备上,也能非常好的展示图片。
当然这样并不可取,会造成大量带宽的浪费。现代浏览器,提供了更好的方式,让我们能够根据设备 dpr 的不同,提供不同尺寸的图片。
简单来说,srcset 可以根据不同的 dpr 拉取对应尺寸的图片:
<div class='illustration'>
<img src='illustration-small.png'
srcset='images/illustration-small.png 1x,
images/illustration-big.png 2x'
style='max-width: 500px'/>
</div>上面 srcset 里的 1x,2x 表示 像素密度描述符,表示
images/illustration-small.png 这张图images/illustration-big.png 这张图上面 1x,2x 的写法比较容易接受易于理解。
除此之外,srcset属性还有一个 w 宽度描述符,配合 sizes 属性一起使用,可以覆盖更多的面。
以下面这段代码为例子:
<img
sizes = “(min-width: 600px) 600px, 300px"
src = "photo.png"
srcset = “[email protected] 300w,
[email protected] 600w,
[email protected] 1200w,
>解析一下:
sizes = “(min-width: 600px) 600px, 300px" 的意思是,如果屏幕当前的 CSS 像素宽度大于或者等于 600px,则图片的 CSS 宽度为 600px,反之,则图片的 CSS 宽度为 300px。
也就是 sizes 属性声明了在不同宽度下图片的 CSS 宽度表现。这里可以理解为,大屏幕下图片宽度为 600px,小屏幕下图片宽度为 300px。(具体的媒体查询代码由 CSS 实现)
这里的 sizes 属性只是声明了在不同宽度下图片的 CSS 宽度表现,而具体使图片在大于600px的屏幕上展示为600px宽度的代码需要另外由 CSS 或者 JS 实现,有点绕。
srcset = “[email protected] 300w, [email protected] 600w, [email protected] 1200w 里面的 300w,600w,900w 叫宽度描述符。怎么确定当前场景会选取哪张图片呢?
当前屏幕 CSS 宽度为 375px,则图片 CSS 宽度为 300px。分别用上述 3 个宽度描述符的数值除以 300。
上面计算得到的 1、 2、 4 即是算出的有效的像素密度,换算成和 x 描述符等价的值 。这里 600w 算出的 2 即满足 dpr = 2 的情况,选择此张图。
当前屏幕 CSS 宽度为 414px,则图片 CSS 宽度仍为 300px。再计算一次:
因为 dpr = 3,2 已经不满足了,则此时会选择 1200w 这张图。
当前屏幕 CSS 宽度为 1920px,则图片 CSS 宽度变为了 600px。再计算一次:
因为 dpr = 1,所以此时会选择 600w 对应的图片。
具体的可以试下这个 Demo:CodePen Demo -- srcset属性配合w宽度描述符配合sizes属性
此方案的意义在于考虑到了响应性布局的复杂性与屏幕的多样性,利用上述规则,可以一次适配 PC 端大屏幕和移动端高清屏,一箭多雕。
CSS 有个类似的属性,
image-set(),搭配使用,效果更佳。
了解更多细节,推荐看看:
字体是很多前端开发同学容易忽略的一个点,但是其中也是有很多小知识点。
首先要知道,浏览器有最小字体限制:
如果小于最小字体,那么字体默认就是最小字体。
其次,很多早期的文章规范都建议不要使用奇数级单位来定义字体大小(如 13px,15px...),容易在一些低端设备上造成字体模糊,出现锯齿。
在字体适配上面,我们需要从性能和展示效果两个维度去考虑。
完整的一个字体资源实在太大了,所以我们应该尽可能的使用用户设备上已有的字体,而不是额外去下载字体资源,从而使加载时间明显加快。
而从展示效果层面来说,使用系统字体能更好的与当前操作系统使用的相匹配,得到最佳的展示效果。所以我们在字体使用方面,有一个应该尽量去遵循的原则,也是现在大部分网站在字体适配上使用的策略:
使用各个支持平台上的默认系统字体。
常见的操作系统有 Windows、Windows Phone、Mac OS X、iPhone、Android Phone、Linux。当然对于普通用户而言,无须关注 Linux 系统。
下面就以 CSS-Trick 网站最新的 font-family 为例,看看他们是如何在字体选择上做到适配各个操作系统的
{
font-family:
system-ui,-apple-system,BlinkMacSystemFont,segoe ui,Roboto,
Helvetica,Arial,
sans-serif,apple color emoji,segoe ui emoji,segoe ui symbol;
}对于 CSS 中的 font-family 而言,它有两类取值。
一类是类似这样的具体的字体族名定义:font-family: Arial 这里定义了一个具体的字体样式,字体族名为 Arial;
一类是通用字体族名,它是一种备选机制,用于在指定的字体不可用时给出较好的字体,类似这样:font-family: sans-serif 。
其中,sans-serif 表无衬线字体族,例如, "Open Sans", "Arial" "微软雅黑" 等等。
关于通用字体族名,在 CSS Fonts Module Level 3 -- Basic Font Properties 中,定义了 5 个,也就是我们熟知的几个通用字体族名:
而在 CSS Fonts Module Level 4 -- Generic font families 中,新增了几个关键字:
我们看看用的最多的 system-ui。
简单而言,font-family: system-ui 的目的就是在不同的操作系统的 Web 页面下,自动选择本操作系统下的默认系统字体。
默认使用特定操作系统的系统字体可以提高性能,因为浏览器或者 webview 不必去下载任何字体文件,而是使用已有的字体文件。 font-family: system-ui 字体设置的优势之处在于它与当前操作系统使用的字体相匹配,对于文本内容而言,它可以得到最恰当的展示。
OK,简单了解了 system-ui 字体族。但是像 -apple-system、BlinkMacSystemFont 没有在最新的标准里出现。它们又代表什么意思呢?
在此之前,先了解下 San Francisco Fonts 。
San Francisco Fonts 又叫旧金山字体,是一款西文字体。随着 iOS 9 更新面世,在 WatchOS 中随 Apple Watch 一起悄然发售,并且还将在 Apple TV 上的新 tvOS 中使用。
San Francisco Fonts 在 iOS 系统上用于替代升级另外一款西文字体 Helvetica Neue。Apple 做了一些重要的改变,使其成为平台上更好的, 甚至是完美的西文字体。

话说回来。正如每个前端开发人员都知道的那样,将一个功能纳入规范是一回事,将其纳入浏览器又是另一回事。
幸运的是,system-ui 的普及很快。 Chrome 和 Safari 都可以在各种平台上完全支持它。只有 Mozilla 和 Windows 相对落后。
看看 system-ui 的兼容性,Can i Use -- system-ui(图片截取日 2019-08-13):

仔细看上图的最后两行:
考虑到不同平台及向后兼容,在 macOS 和 iOS 上,我们需要使用 -apple-system 及 BlinkMacSystemFont 来兼容适配 system-ui 标准。
Segoe UI 是 Windows 从 Vista 开始的默认西文字体族,只有西文,不支持汉字,属于无衬线体。
它也表示一个系列而不是某一款单一字体。使用 font-family: Segoe UI 可以在 Windows 平台及 Windows Phone 上选取最佳的西文字体展示。
Roboto 是为 Android 操作系统设计的一个无衬线字体家族。Google 描述该字体为“现代的、但平易近人”和“有感情”的。
这个字体家族包含Thin、Light、Regular、Medium、Bold、Black六种粗细及相配的斜体。
到此,我们可以总结一下了。以 CSS-Tricks 网站的 font-family 定义为例子:
{
font-family:
system-ui,-apple-system,BlinkMacSystemFont,segoe ui,Roboto,
Helvetica,Arial,
sans-serif,apple color emoji,segoe ui emoji,segoe ui symbol;
}上述 5 个字体族定义,优先级由高到底,可以看到,它们 5 个都并非某个特定字体,基本的核心**都是选择对应平台上的默认系统字体。
涵盖了 iOS、MAC OS X、Android、Windows、Windows Phone 基本所有用户经常使用的主流操作系统。
使用系统默认字体的主要原因是性能。字体通常是网站上加载的最大/最重的资源之一。如果我们可以使用用户机器上已有的字体,我们就完全不需要再去获取字体资源,从而使加载时间明显加快。
并且系统字体的优点在于它与当前操作系统使用的相匹配,因此它的文本展示必然也是一个让人舒适展示效果。
当然,上述 font-family 的定义不一定是最佳的。譬如天猫移动端在 font-family 最前面添加了 "PingFang SC",miui,..必定也有他们的业务上的考虑。但是一些 fallback 方案向后兼容的**都是一致的,值得参考学习。
更多的关于字体方面的细节知识,可以看看这几篇文章:
前端工程师的一大工作内容就是页面布局。无论在PC端还是移动端,页面布局的兼容适配都是重中之重。在整个前端发展的历程中,布局的方法也在不断的推陈出新。
简单来说,前端的布局发展历程经历了下面几个过程:
表格布局 --> 定位布局 --> 浮动布局 --> flexbox布局 --> gridbox布局
每一种布局在特定时期都发挥了重要的作用,而每一种新的布局方式的出现,往往都是因为现有的布局方式已经在该时期已经无法很好的满足开发者的需求,无法满足越来越潮流的页面布局的方式。
以 Flexbox 的出现为例子,在 Flexbox 被大家广为接受使用之前。我们一直在使用定位+浮动的布局方式。像下面这个布局:

容器宽度不定,内部三个元素,均分排列且占满整个空间,并且垂直居中。如果使用定位+浮动的布局方式,你无法很快想到最佳的解决方式。三个元素并排那么必然需要浮动或者绝对定位,容器宽度不定且中间元素始终居中,需要顾虑的方面就很多了。也许使用 text-align: justufy 可以 hack 实现,等等等等。
然而,使用 flexbox 布局的话,只需要:
.container {
display: flex;
justify-content: space-between;
align-items: center;
}flexbox 的出现,一次性解决了流动布局,弹性布局,排列方式等多个问题。并且它是简洁的,可控的。
再来看一个例子,水平垂直居中一个元素。使用 flexbox 也许是最便捷的:
.container {
display: flex;
}
.item {
margin: auto;
}OK,flexbox 已经足够优秀了,为什么 gird 网格布局的出现又是为什么?它解决了什么 flex 布局无法很好解决的问题?
看看下面这张图:

flexbox 是一维布局,他只能在一条直线上放置你的内容区块;而grid是一个二维布局。它除了可以灵活的控制水平方向之外,还能轻易的控制垂直方向的布局模式。对于上图那样的九宫格布局,它就可以轻而易举的完成。
一图以蔽之,flexbox:
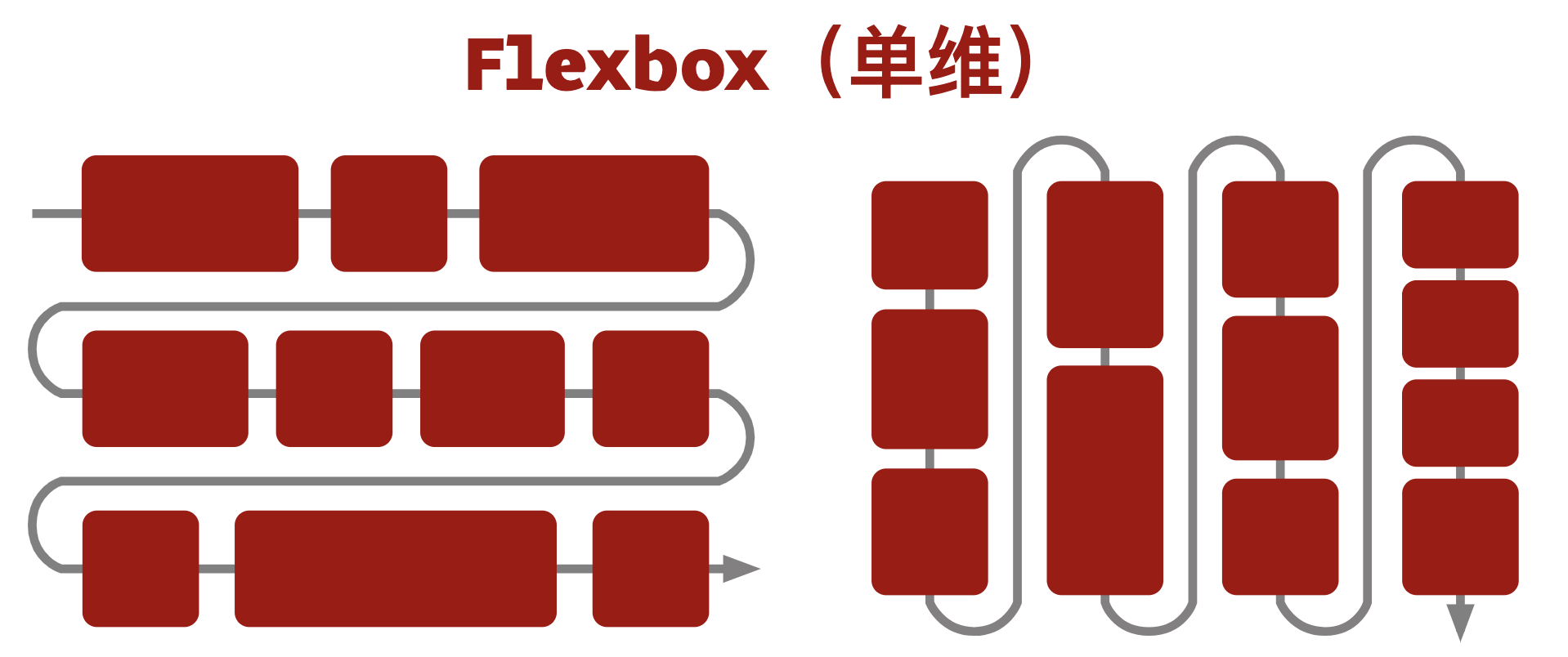
gridbox:
图片截取自陈慧晶老师在 2019 第五届 CSS 大会上的分享 -- 新时代CSS布局
在现阶段,移动端布局应当更多使用 flexbox 去完成(相对那些还在使用 float 布局的),而考虑到未来页面布局的推陈出新。对于 Grid 布局我们应当像前几年对待 flexbox 一样,重视起来,随着兼容性的普及,Grid 布局也会慢慢成为主流。
好了,本文到此结束,希望对你有帮助 :)
更多精彩技术文章汇总在我的 Github -- iCSS ,持续更新,欢迎点个 star 订阅收藏。
如果还有什么疑问或者建议,可以多多交流,原创文章,文笔有限,才疏学浅,文中若有不正之处,万望告知。
性能优化一直是前端工作中十分重要的一环,都说从 10 到 1 容易,从 1 到 0 很难。而随着前端技术的飞速发展,没有什么技术或者法则是金科玉律一沉不变的。
很佩服那些勇于挑战权威,推陈出新的勇者,是他们让我们的技术不断的变革更加的卓越。好像扯远了,本文主要想谈谈两个名词,域名发散和域名收敛。
这个很好理解,前端er都知道,PC 时代为了突破浏览器的域名并发限制,遵循这样一条定律:
嗯,为什么要这样做呢,目的是充分利用现代浏览器的多线程并发下载能力。
由于浏览器的限制,每个浏览器,允许对每个域名的连接数一般是有上限的,附图一枚:
上图展示了各浏览器的并行连接数(同域名),可以看到在一些现代浏览器内每个 hostname 的最大连接数基本都是6个,IE 稍显傲娇,总体而言并发数不高。
所以 PC 时代对静态资源优化时,通常将静态资源分布在几个不同域,保证资源最完美地分域名存储,以提供最大并行度,让客户端加载静态资源更为迅速。
另外,为什么浏览器要做并发限制呢?
本文的重点是想谈谈域名收敛,顾名思义,域名收敛的意思就是建议将静态资源只放在一个域名下面,而非发散情况下的多个域名下。
上面也说到了,域名发散可以突破浏览器的域名并发限制,那么为要反其道而行之呢?因为因地制宜,不同情况区别对待,域名发散是 PC 时代的产物,而现在进入移动互联网时代,通过无线设备访问网站,App的用户已占据了很大一部分比重,而域名发散正是在这种情况下提出的。且听我一步步分析。
首先要知道,使用一个 http 请求去请求一个资源时,会经历些什么。简单而言:
域名的结构(或者叫命名空间)是一个树状结构,有树就得有根,这个根是一个点‘.’(dot)。
以 www.example.com 为例,完整的形式应该是 www.example.com. ,注意最后一个点,就是根结点 root ,只不过平时是浏览器或者系统的解析器自动帮我们补全了。我们要想获取根域都有那些,可以在终端下直接使用 dig 命令(需要安装 dig 指令),如下:
可以看到有 13 个,大部分都是在国外,根节点之后就是顶级域名,就是.cn .com .gov 这些,顶级域划分为通用顶级域 (com、org、net 等)和国家与地区顶级域(cn、hk、us、tw 等)。我们可以继续使用 dig 查看一下 顶级域名的解析路径,加上 +trace 参数选项,意思是追踪 DNS 解析过程,如下:
可以看到是先到根节点,再查找到 com ,就是根结点会告知下一个结点 com 在哪:就是 com. 172800 IN NS [a-m].gtld-servers.net。
ok,顶级域之后就是我们熟知的一级域名,譬如 www.example.com 中的 example 就是一级域 。有兴趣的可以自己试着用 dig 指令再追踪一下:dig example.com. +trace ,可以看到是从根节点从右向左逐步查找的。
上面两张 dig 命令贴图中间出现了很多次 NS ,NS 即是 NameServer,大部分情况下又叫权威名称服务器简称权威。
什么是权威呢,通俗点讲其实是某些域的权威,也就是权威上面有这些域的最新,最全的数据,所有这些域的数据都应该以此为准(只有权威可以增删改这些域的数据),就像上面 dig com +trace 的结果可以看到,com 的权威是上面的 13 个根域。同理,所有的顶级域(cn、org、net 等等)的权威都是根域。
其实上面就是 DNS 解析的一个大致过程,即迭代解析,但是不是很详尽,一个完整的 DNS 解析过程如下:
到这里,我们大致就可以梳理一下,迭代查询的过程如下:
流程: . => com. => .exampl.com. => www.example.com. => IP adress
TTL 是 Time To Live 的缩写,该字段指定 IP 包被路由器丢弃之前允许通过的最大网段数量。TTL 是 IPv4 包头的一个 8 bit 字段。
简单的说它表示 DNS 记录在 DNS 服务器上缓存时间。
扯了这么多 http 请求, DNS 解析,回到正题域名收敛上,从上面可以看到,DNS 解析其实是一个很复杂的过程,在 PC 上,我们采用域名发散策略,是因为在 PC 端上,DNS 解析通常而言只需要几十 ms ,可以接受。而移动端,2G 网络,3G网络,4G网络/wifi 强网,而且移动 4G 容易在信号不理想的地段降级成 2G ,通过大量的数据采集和真实网络抓包分析(存在DNS解析的请求),DNS的消耗相当可观,2G网络大量5-10s,3G网络平均也要3-5s(数据来源于淘宝)。 下面附上在 2G,3G,4G, WIFI 情况下 DNS 递归解析的时间 (ms):
因为在增加域的同时,往往会给浏览器带来 DNS 解析的开销。所以在这种情况下,提出了域名收敛,减少域名数量可以降低 DNS 解析的成本。
下图是手机端页面加载数和域名分散数的关系(from Mobify Developer):
在 2 个域名分散条件下,网页的加载速度提升较大,而第 3 个以后就比较慢了。 所以,一般来说,域名分散的数量最好在 3 以下。
本来至此,本文应该结束了,谈了下域名发散与域名收敛。
但是,单纯的在移动端采用域名收敛并不能很大幅度的提升性能,很重要的一点是,在移动端建连的消耗非常大,而 SPDY 协议可以完成多路复用的加密全双工通道,显著提升非wifi环境下的网络体验。
俗话说,好刀配好鞘,好马配好鞍,当域名收敛配合 SPDY 才能最大程度发挥他们的效用,达到事半功倍。
SPDY,一种开放的网络传输协议,由Google开发,用来发送网页内容。基于传输控制协议(TCP)的应用层协议 ,是 HTTP/2 的前身。
SPDY 的作用就是,在不增加域名的情况下,解除最大连接数的限制。主要的特点就是多路复用,他的目的就是致力于取消并发连接上限。
SPDY 规定在一个 SPDY 连接内可以有无限个并行请求,即允许多个并发 HTTP 请求共用一个 TCP会话。这样 SPDY 通过复用在单个 TCP 连接上的多次请求,而非为每个请求单独开放连接,这样只需建立一个 TCP 连接就可以传送网页上所有资源,不仅可以减少消息交互往返的时间还可以避免创建新连接造成的延迟,使得 TCP 的效率更高。
此外,SPDY 的多路复用可以设置优先级,而不像传统 HTTP 那样严格按照先入先出一个一个处理请求,它会选择性的先传输 CSS 这样更重要的资源,然后再传输网站图标之类不太重要的资源,可以避免让非关键资源占用网络通道的问题,提升 TCP 的性能。
服务器可以主动向客户端发起通信向客户端推送数据,这种预加载可以使用户一直保持一个快速的网络。
舍弃掉了不必要的头信息,经过压缩之后可以节省多余数据传输所带来的等待时间和带宽。
Google 认为 Web 未来的发展方向必定是安全的网络连接,全部请求 SSL 加密后,信息传输更加安全。
看看 SPDY 的作用图:
SPDY 协议在性能上对 HTTP 做了很大的优化,其核心**是尽量减少连接个数,而对于 HTTP 的语义并没有做太大的修改。
具体来说是,SPDY 使用了 HTTP 的方法和页眉,但是删除了一些头并重写了 HTTP 中管理连接和数据转移格式的部分,所以基本上是兼容 HTTP 的。
写到这里,好想继续往下写 HTTP/2 ,因为 HTTP/2 的前身即是 SPDY 协议,但是感觉本文的内容已经很充实了,内容也很多,就不再继续往下,内容很多,希望有人能够耐心读完,对一些网络基础知识很好的巩固效果。
SPDY协议介绍
无线性能优化:域名收敛
谈谈HTTP/2对前端的影响
域名发散--前端优化(三)
15年双11手淘前端技术巡演 - H5性能最佳实践
Web前端优化最佳实践及工具集锦
本文接上篇文章。从零开始学习以太坊编程(一)-- 环境准备与基础知识
好的技术文章很难写,简单地介绍原理让大家都能懂的,也就仅仅只能局限于知道个原理,浮于表面。直接细读源码的,看似深入,实际上容易让人乏味,食之无味,枯燥的很,直接会把 90% 的人挡在门外。
我期望我的产出即是阳春白雪,又可如下里巴人,门外汉看得下去,凑个热闹学点基础,专业人士也可以从中学到很多东西。也希望大家多多支持。
OK,下面开始正文。
阅读本文,你需要:
本文将会是基础知识以及代码的混搭风格串讲。
早些时候,BTC 诞生之初。是没有智能合约这一说的,也就是我们传统所说的区块链1.0时代。
区块链1.0是以比特币为代表的分布式(去中心化)的数字货币数字货币应用。其场景包括支付、流通等货币职能。
区块链1.0的其中一个重大局限在于,只满足数字货币的交易和支付功能使得该应用不能被大范围地普及到生活中,给日常生活带来的益处十分有限,区块链的概念也难以深入人心。
直到 ETH 的出现,对智能合约的普及(也就是我们常说的区块链2.0时代)改变了区块链技术仅能类似 BTC 这样作为货币的局限。
智能合约并非 ETH 首创,只是由 ETH 发扬光大。
智能合约是 1990 年代由尼克萨博提出的理念,几乎与互联网同龄。由于缺少可信的执行环境,智能合约并没有被应用到实际产业中,自比特币诞生后,人们认识到比特币的底层技术区块链天生可以为智能合约提供可信的执行环境。
通俗的说,所谓智能合约,其实就是一段代码,它按照编写者设定的那样,运行在类似以太坊 ETH 这样的平台公链之上。
合约规定了什么时候达成什么条件执行什么,类似以太坊这样的平台为这段代码提供了一些重要的报障:
由于区块链的特性(去中心化的、天生可以为智能合约提供可信的执行环境),使得它与智能合约完美契合。
智能合约非常强大且有魅力。
OK,我们都知道,在使用 ETH 钱包转账的时候,每一笔都需要一笔矿工费。Why?
原因在于,转账行为本质上其实也是执行一段代码,用我们上文介绍所言,就是一条智能合约。
而在 ETH 平台上,每执行一条智能合约,都是需要消耗一定的 GAS 的。
怎么理解呢?智能合约在网络的各个节点上平稳运行,其实每时每刻都是在经历大量的计算(也就是我们常说的挖矿计算行为),而执行计算是需要花费金钱的,目的在于避免 DDoS 攻击,在 ETH 平台中花费的就是 GAS。在以太坊虚拟机(EVM)中的每个不同粒度级别的操作都需要花费一定量的 GAS 来执行。
OK,那么我们在使用钱包转账的时候,矿工费可以由我们自己调节。这表明 GAS 的价格是由市场决定,类似于比特币的交易费用。如果您支付更高的 GAS 价格,节点将优先处理您的交易。
好的,讲到这里,下面的内容将会越来越专业。上面提到了一下 EVM,即是以太坊虚拟机。
以太坊虚拟机 EVM 是智能合约的运行环境。它是一个完全独立的沙盒,合约代码在 EVM 内部运行,对外是完全隔离的。
为此,为了验证及测试编写的智能合约,我们需要下载以太坊虚拟机,亦就是 Go Ethereum。
Go Ethereum 是以太坊区块链项目的三个原始实现(以及 c++ 和 python )之一,使用 Go 语言实现,完全开源并使用开源协议 GNU LGPL v3 许可。 Geth 是其简称,也是可执行程序的默认名称。
接下来,我们可以在官方下载 Geth

这里我用的 windows 系统,所以选择 Geth 1.8.2 for Windows 。下载完成好,点击运行安装,勾选上 Geth 以及 Development tools 。

OK,得到如下目录文件夹。

在该文件夹下,打开命令行,输入 geth ,查看是否安装成功,如果展示如下信息,表示成功:

至此,所有相关环境都已经搭建完毕。下一节开始,将进入真正的编程环节。:)
任何技术问题交流,或者有志学习 ETH 编程的,可以加 Q 群交流:互联网区块链技术交流 -- 483931379
每天,我们都在和各种文档打交道,PRD、技术方案、个人笔记等等等。
其实文档排版有很多学问,就像我,对排版有强迫症,见不得英文与中文之间不加空格。
所以,最近在做这么一个谷歌扩展插件 chrome-extension-text-formatting,通过谷歌扩展,快速将选中文本,格式化为符合 中文文案排版指北 的文本。
emmm,什么是排版指南?简单来说它的目的在于统一中文文案、排版的相关用法,降低团队成员之间的沟通成本,增强网站气质。
举个例子:
正确:
在 LeanCloud 上,数据存储是围绕
AVObject进行的。
错误:
在LeanCloud上,数据存储是围绕
AVObject进行的。在 LeanCloud上,数据存储是围绕
AVObject进行的。
完整的正确用法:
在 LeanCloud 上,数据存储是围绕
AVObject进行的。每个AVObject都包含了与 JSON 兼容的 key-value 对应的数据。数据是 schema-free 的,你不需要在每个AVObject上提前指定存在哪些键,只要直接设定对应的 key-value 即可。
例外:「豆瓣FM」等产品名词,按照官方所定义的格式书写。
正确:
今天出去买菜花了 5000 元。
错误:
今天出去买菜花了 5000元。
今天出去买菜花了5000元。
当然,整个排版规范不仅仅局限于此,上面只是简单列出部分规范内容。而且,这玩意属于建议,很难强迫推广开来。所以,我就想着实现这么一个谷歌插件扩展,一键实现选中文本的格式化。
看个示意图:

适用于各种文本编辑框,当然 Excel 也可以:

当然,这都不是本文的重点。
因为各个文档平台存在一定的差异性,所以在扩展的制作过程,需要去兼容不同的文档平台(当然,更多的是我自己比较常用的一些文档平台,譬如谷歌文档、语雀、有道云、Github 等等)。
整体来说,整个扩展的功能非常简单,一个极简流程如下:
需要注意的是,上面的操作,大部分都是基于插入到页面的 JavaScript 脚本文件进行执行。
在兼容语雀文档的时候,遇到了这么个有趣的场景。
在上面的第 4 步执行完毕后,在我们对替换后的文本进行任意操作时,譬如重新获焦、重新编辑等,被修改的文本都会被进行替换复原,复原成修改前的状态!
什么意思呢?看看下面这张实际的截图:

总结一下,语雀这里这个操作是什么意思呢?
在脚本手动替换掉原选取文件后,当再次获焦文本,修改的内容再会被复原。
在一番测试后,我理清了语雀文档的逻辑:
Oh,这个功能确实是非常的有意思。它的强悍之处在于,它能够识别出内容的修改是常规正常操作,还是脚本、控制台修改等非常规操作。并且在非常规操作之后,回退到最近一次的正常操作版本。
那么,语雀它是如何做到这一点的呢?
由于线上编译混淆后的代码比较难以断点调试,所以我们大胆的猜测一下,如果我们需要去实现一个类似的功能,可能从什么方向入手。
首先,我们肯定需要用到 MutationObserver。
MutationObserver 是一个 JavaScript API,用于监视 DOM 的变化。它提供了一种异步观察 DOM 树的能力,并在发生变化时触发回调函数。
我们来构建一个在线文档的最小化场景:
<div id="g-container" contenteditable>
这是 Web 云文档的一段内容,如果直接编辑,可以编辑成功。如果使用控制台修改,数据将会被恢复。
</div>#g-container {
width: 400px;
padding: 20px;
line-height: 2;
border: 2px dashed #999;
}这里,我们利用 HTML 的 contenteditable 属性,实现了一个可编辑的 DIV 框:
接下来,我们就可以利用 MutationObserver,实现对这个 DOM 元素的监听,实现每当此元素的内容发生改变,就触发 MutationObserver 的事件回调,并且通过一个数组,记录下每一次元素改动的结果。
其大致代码如下:
const targetElement = document.getElementById("g-container");
// 记录初始数据
let cacheInitData = '';
function observeElementChanges(element) {
const changes = []; // 存储变化的数组
const targetElementCache = element.innerText;
// 缓存每次的初始数据
cacheInitData = targetElementCache;
// 创建 MutationObserver 实例
const observer = new MutationObserver((mutationsList, observer) => {
// 检查当前是否存在焦点
mutationsList.forEach((mutation) => {
console.log('observer', observer);
const { type, target, addedNodes, removedNodes } = mutation;
let realtimeText = "";
const change = {
type,
target,
addedNodes: [...addedNodes],
removedNodes: [...removedNodes],
realtimeText,
};
changes.push(change);
});
console.log("changes", changes);
});
// 配置 MutationObserver
const config = { childList: true, subtree: true, characterData: true };
// 开始观察元素的变化
observer.observe(element, config);
}
observeElementChanges(targetElement);上面的代码,阅读起来需要一点点时间。但是其本质是非常好理解的,我大致将其核心步骤列举一下:
创建一个 MutationObserver 实例来观察指定 DOM 元素的变化
定义一个配置对象 config,用于指定观察的选项。在这个例子中,配置对象中设置了
childList: true 表示观察子节点的变化subtree: true 表示观察所有后代节点的变化characterData: true 表示观察节点文本内容的变化将变化的信息存储在 changes 数组中
changes 数组中的每个元素记录了一次 DOM 变化的信息。每个变化对象包含以下属性:
type:表示变化的类型,可以是 "attributes"(属性变化)、"characterData"(文本内容变化)或 "childList"(子节点变化)。target:表示发生变化的目标元素。addedNodes:一个包含新增节点的数组,表示在变化中添加的节点。removedNodes:一个包含移除节点的数组,表示在变化中移除的节点。realtimeText:实时文本内容,可以根据具体需求进行设置。如此一来,我们尝试编辑 DOM 元素,打开控制台,看看每次 changes 输出了什么内容:

可以发现,每一次当 DIV 内的内容被更新,都会触发一次 MutationObserver 的回调。
我们详细展开数组中的两处进行说明:
其中 type 表示这次触发的是 MutationObserver 配置的 config 中的哪一类变化,命中了 characterData,也就是上面提到的文本内容的变化。而 addedNodes 和 removeDNodes 都为空,说明没有结构上的变化。
两组数据唯一的变化在于 realtimeText 我们利用了这个值记录了可编辑 DOM 元素内文本值内容。
。,所以 realtimeText 文本相比初始文本少了个句号复 字,所以 realtimeText 文本相比初始文本少了 复。后面的数据依次类推。可以看到,有了这个信息,其实我们相当于能够实现整个 DOM 结构的操作堆栈!
在此基础上,我们可以在整个监听之前,在 changes 数组中首先压入最开始未经过任何操作的数据。这也就意味着我们有能力将数据恢复到用户的操作过程中的任意一步。
有了上面的changes 数组,我们相当于有了用户操作的每一步的堆栈信息。
接下的核心就在于我们应该如何去运用它们。
在语雀这个例子中,它的核心点在于:
它能够识别出内容的修改是常规正常操作,还是脚本、控制台修改等非常规操作。并且在非常规操作之后,回退到最近一次的正常操作版本。
因此,我们接下来探索的问题就变成了如何识别一个可输入编辑框,它的内容修改是正常输入修改,还是非正常输入修改。
譬如,思考一下,当用户正常输入或者复制粘贴内容到编辑框,应该会有什么特征信息:
document.activeElement 拿到当前页面获焦的元素,因此可以在每次触发 Mutation 变化的时,多存储一份当前的获焦元素信息,对比内容被修改时的页面获焦元素是否是当前输入框foucs、blur 获焦及失焦等事件进行判断keydown 事件paste 事件childList 变化事件有了上面的思路,下面我们尝试一下,为了尽可能让 DEMO 好理解,我们稍微简化需求,实现:
基于此,下面我给出大致的伪代码:
<div id="g-container" contenteditable>这是 Web 云文档的一段内容,如果直接编辑,可以编辑成功。如果使用控制台修改,数据将会被恢复。</div>const targetElement = document.getElementById("g-container");
// 记录初始数据
let cacheInitData = '';
// 数据复位标志位
let data_fixed_flag = false;
// 复位缓存对象
let cacheObservingObject = null;
let cacheContainer = null;
let cacheData = '';
function eventBind() {
targetElement.addEventListener('focus', (e) => {
if (data_fixed_flag) {
cacheContainer.innerText = cacheData;
cacheObservingObject.disconnect();
observeElementChanges(targetElement);
data_fixed_flag = false;
}
});
}
function observeElementChanges(element) {
const changes = []; // 存储变化的数组
const targetElementCache = element.innerText;
// 缓存每次的初始数据
cacheInitData = targetElementCache;
// 创建 MutationObserver 实例
const observer = new MutationObserver((mutationsList, observer) => {
mutationsList.forEach((mutation) => {
// console.log('observer', observer);
const { type, target, addedNodes, removedNodes } = mutation;
let realtimeText = "";
if (type === "characterData") {
realtimeText = target.data;
}
const change = {
type,
target,
addedNodes: [...addedNodes],
removedNodes: [...removedNodes],
realtimeText,
activeElement: document.activeElement
};
changes.push(change);
});
let isFixed = false;
let container = null;
for (let i = changes.length - 1; i >= 0; i--) {
const item = changes[i];
// console.log('i', i);
if (item.activeElement === element) {
if (isFixed) {
cacheData = item.realtimeText;
}
break;
} else {
if (!isFixed) {
isFixed = true;
container = item.target.nodeType === 3 ? item.target.parentElement : item.target;
cacheContainer = container;
data_fixed_flag = true;
}
}
}
if (data_fixed_flag && cacheData === '') {
cacheData = cacheInitData;
}
cacheObservingObject = observer;
});
// 配置 MutationObserver
const config = { childList: true, subtree: true, characterData: true };
// 开始观察元素的变化
observer.observe(element, config);
eventBind();
// 返回停止观察并返回变化数组的函数
return () => {
observer.disconnect();
return changes;
};
}
observeElementChanges(targetElement);简单解释一下,大致流程如下
observeElementChanges 上文已经出现过,核心在于记录每一次 DOM 元素的变化,将变化内容记录在 changes 数组中
activeElement,表示每次 DOM 元素发生变化时,页面的焦点元素每次 changes 更新后,倒序遍历一次 changes 数组
isFixed 和 data_fixed_flag,此时继续向前寻找最近一次正常修改记录isFixed 用于向前寻找最近一次正常修改记录后,将最近一次修改的堆栈信息进行保存data_fixed_flag 标志位用于当元素被再次获焦时(触发 focus 事件),根据标志位判断是否需要回滚恢复数据
OK,此时,我们来看看整体效果:

这样,我们就成功的实现了识别非正常操作,并且恢复到上一次正常数据。
当然,实际场景肯定比这个复杂,并且需要考虑更多的细节,这里为了整体的可理解性,简化了整个 DEMO 的表达。
完整的 DEMO 效果,你可以戳这里体验:[CodePen Demo -- Editable Text Fixed]
至于这个功能有什么用?这个就见仁见智了,至少对于开发扩展插件的我而言,是一个非常棘手的问题,当然从语雀的角度而言,更多也许是从安全方面进行考量的。
当然,我们不应该局限于这个场景,思考一下,这个方案其实可以应用在非常多其它场景,举个例子:
当然,破解起来也有一些方式,对于扩展插件而言,我可以通过更早的向页面注入我的 content script,在页面加载渲染前,对全局的 MutationObserver 对象进行劫持。
总而言之,可以通过本文提供的思路,尝试进行更多有意思的前端交互限制。
好了,本文到此结束,希望对你有帮助 :)
想 Get 到最有意思的 CSS 资讯,千万不要错过我的公众号 -- iCSS前端趣闻 😄
更多精彩 CSS 技术文章汇总在我的 Github -- iCSS ,持续更新,欢迎点个 star 订阅收藏。
如果还有什么疑问或者建议,可以多多交流,原创文章,文笔有限,才疏学浅,文中若有不正之处,万望告知。
在区块链领域,我们经常会听到这些与链有关的名词:
这些区块链有着各自的特点和不同场景应用。本文作为科普文,带大家了解一下:
公有链是指全世界任何人都可以随时进入到系统中读取数据、发送可确认交易、竞争记账的区块链。公有链通常被认为是“完全去中心化”的,因为没有任何个人或者机构可以控制或篡改其中数据的读写。
公有链一般会通过代币机制来鼓励参与者竞争记账,来确保数据的安全性。比特币、以太坊都是典型的公有链。
举例说明:例如 比特币,以太坊,门罗币(Monero),达世币(Dash),莱特币(Litecoin),狗狗币(Dodgecoin)等等都是公有链。
适用场景:公有链适用于数字货币、电子商务、互联网金融、知识产权等应用场景。
私有链是指其写入权限由某个组织和机构控制的区块链,参与节点的资格会被严格限制。由于参与节点是有限和可控的,因此私有链往往可以有极快的交易速度、更好的隐私保护、更低的交易成本、不容易被恶意攻击,并且能做到身份认证等金融行业必需的要求。
相比中心化数据库,私有链能够防止机构内单节点故意隐瞒或者篡改数据,即使发生错误,也能够迅速发现来源。因此许多大型金融机构在目前更加倾向于使用私有链技术。
举例说明:例如 MONAX,Multichain
适用场景:私有链适用于企业、组织内部。
联盟链是指有若干个机构共同参与管理的区块链,每个机构都运行着一个或多个节点,其中的数据只允许系统内不同的机构进行读写和发送交易,并且共同来记录交易数据。
私有链和联盟链之间的设计隐私权限会有不同,联盟链中的权限设计要求往往会更为复杂。
适用场景:联盟链适用于行业协会、高级别机构组织、大型连锁企业对下属单位和分管机构的交易和监管。
一张图总结一下:

跨链,顾名思义,就是通过一个技术,能让价值跨过链和链之间的障碍,进行直接的流通。
区块链是分布式总账的一种。一条区块链就是一个独立的账本,两条不同的链,就是两个不同的独立的账本,两个账本没有关联。本质上价值没有办法在账本间转移,但是对于具体的某个用户,用户在一条区块链上存储的价值,能够变成另一条链上的价值,这就是价值的流通。
如果说共识机制是区块链的灵魂核心,那么对于区块链特别是联盟链及私链来看,跨链技术就是实现价值网络的关键,它是把联盟链从分散单独的孤岛中拯救出来的良药,是区块链向外拓展和连接的桥梁。
跨链技术本质上来说就是帮助一条链上的用户A找到另一条链上的愿意进行兑换的用户B。
通俗的说,跨链技术就是一个交易所,让用户能够到交易所里进行跨链交易。
交易所开展的不同类型数字货币之间的兑换,就是一种跨链价值转移的实现。其实,币币交易就是一个跨链技术的实现。
那什么又是侧链呢?这个概念来自比特币社区,2013 年 12 月提出。
侧链的诞生是由于比特币本身或者某一区块链本身的机制存在一些问题。但是直接在比特协议或者比特币链条上进行修改的话,又容易出错。而且比特币区块在一直不断运行,万一出错了涉及的资金量太大了。这个是不被允许的。
这种情况下,诞生了侧链。
本质上来说,侧链机制,就是一种使货币在两条区块链间移动的机制,它允许资产在比特币区块链和其它链之间互转。降低核心的区块链上发生交易的次数。
侧链(sidechains)实质上不是特指某个区块链,而是指遵守侧链协议的所有区块链,该名词是相对与比特币主链来说的。
侧链协议:可以让比特币安全地从比特币主链转移到其他区块链,又可以从其他区块链安全地返回比特币主链的一种协议。显然,只需符合侧链协议,所有现存的区块链,如以太坊、莱特币、暗网币等竞争区块链都可以成为侧链。
适用场景:侧链目前主要适用于代币发行。
侧链的存在,让使用该技术的虚拟货币在网络层面、资产层面都引入了额外的复杂度
侧链的存在,让一些不法之徒能够多了许多欺诈方式。
另外一个重要的顾虑是,引入带有矿工费的侧链是否会给矿工资源带来压力,产生比特币系统(挖矿)中心化的风险。
当然,侧链被提出,当然是有其独特的优越性的:
侧链架构的好处是代码和数据独立,不增加主链的负担,避免数据过度膨胀,实际上是一种天然的分片机制。
侧链的存在可以有效避免主链的膨胀和不可控(DAO事件)。而且侧链让所有的区块链参数是可以定制的
不增加货币总量,不会产生通膨的问题(山寨币都是加密币世界的通膨,所以储值用户支持的极少)
这篇文章实在是很难下笔,因为网上相关文章不胜枚举。
巧合的是前些天看到阮老师的一篇文章的一句话:
“对我来说,博客首先是一种知识管理工具,其次才是传播工具。我的技术文章,主要用来整理我还不懂的知识。我只写那些我还没有完全掌握的东西,那些我精通的东西,往往没有动力写。炫耀从来不是我的动机,好奇才是。"
对于这句话,不能赞同更多,也让我下决心好好写这篇,网上文章虽多,大多复制粘贴,且晦涩难懂,我希望能够通过这篇文章,能够清晰的提升对apply、call、bind的认识,并且列出一些它们的妙用加深记忆。
在 javascript 中,call 和 apply 都是为了改变某个函数运行时的上下文(context)而存在的,换句话说,就是为了改变函数体内部 this 的指向。
JavaScript 的一大特点是,函数存在「定义时上下文」和「运行时上下文」以及「上下文是可以改变的」这样的概念。
先来一个栗子:
function fruits() {}
fruits.prototype = {
color: "red",
say: function() {
console.log("My color is " + this.color);
}
}
var apple = new fruits;
apple.say(); //My color is red但是如果我们有一个对象banana= {color : "yellow"} ,我们不想对它重新定义 say 方法,那么我们可以通过 call 或 apply 用 apple 的 say 方法:
banana = {
color: "yellow"
}
apple.say.call(banana); //My color is yellow
apple.say.apply(banana); //My color is yellow所以,可以看出 call 和 apply 是为了动态改变 this 而出现的,当一个 object 没有某个方法(本栗子中banana没有say方法),但是其他的有(本栗子中apple有say方法),我们可以借助call或apply用其它对象的方法来操作。
对于 apply、call 二者而言,作用完全一样,只是接受参数的方式不太一样。例如,有一个函数定义如下:
var func = function(arg1, arg2) {
};就可以通过如下方式来调用:
func.call(this, arg1, arg2);
func.apply(this, [arg1, arg2])其中 this 是你想指定的上下文,他可以是任何一个 JavaScript 对象(JavaScript 中一切皆对象),call 需要把参数按顺序传递进去,而 apply 则是把参数放在数组里。
JavaScript 中,某个函数的参数数量是不固定的,因此要说适用条件的话,当你的参数是明确知道数量时用 call 。
而不确定的时候用 apply,然后把参数 push 进数组传递进去。当参数数量不确定时,函数内部也可以通过 arguments 这个伪数组来遍历所有的参数。
为了巩固加深记忆,下面列举一些常用用法:
var array1 = [12 , "foo" , {name "Joe"} , -2458];
var array2 = ["Doe" , 555 , 100];
Array.prototype.push.apply(array1, array2);
/* array1 值为 [12 , "foo" , {name "Joe"} , -2458 , "Doe" , 555 , 100] */var numbers = [5, 458 , 120 , -215 ];
var maxInNumbers = Math.max.apply(Math, numbers), //458
maxInNumbers = Math.max.call(Math,5, 458 , 120 , -215); //458functionisArray(obj){
return Object.prototype.toString.call(obj) === '[object Array]' ;
} var domNodes = Array.prototype.slice.call(document.getElementsByTagName("*"));Javascript中存在一种名为伪数组的对象结构。比较特别的是 arguments 对象,还有像调用 getElementsByTagName , document.childNodes 之类的,它们返回NodeList对象都属于伪数组。不能应用 Array下的 push , pop 等方法。
但是我们能通过 Array.prototype.slice.call 转换为真正的数组的带有 length 属性的对象,这样 domNodes 就可以应用 Array 下的所有方法了。
下面就借用一道面试题,来更深入的去理解下 apply 和 call 。
定义一个 log 方法,让它可以代理 console.log 方法,常见的解决方法是:
function log(msg) {
console.log(msg);
}
log(1); //1
log(1,2); //1上面方法可以解决最基本的需求,但是当传入参数的个数是不确定的时候,上面的方法就失效了,这个时候就可以考虑使用 apply 或者 call,注意这里传入多少个参数是不确定的,所以使用apply是最好的,方法如下:
function log(){
console.log.apply(console, arguments);
};
log(1); //1
log(1,2); //1 2接下来的要求是给每一个 log 消息添加一个"(app)"的前辍,比如:
log("hello world"); //(app)hello world该怎么做比较优雅呢?这个时候需要想到arguments参数是个伪数组,通过 Array.prototype.slice.call 转化为标准数组,再使用数组方法unshift,像这样:
function log(){
var args = Array.prototype.slice.call(arguments);
args.unshift('(app)');
console.log.apply(console, args);
};说完了 apply 和 call ,再来说说bind。bind() 方法与 apply 和 call 很相似,也是可以改变函数体内 this 的指向。
MDN的解释是:bind()方法会创建一个新函数,称为绑定函数,当调用这个绑定函数时,绑定函数会以创建它时传入 bind()方法的第一个参数作为 this,传入 bind() 方法的第二个以及以后的参数加上绑定函数运行时本身的参数按照顺序作为原函数的参数来调用原函数。
直接来看看具体如何使用,在常见的单体模式中,通常我们会使用 _this , that , self 等保存 this ,这样我们可以在改变了上下文之后继续引用到它。 像这样:
var foo = {
bar : 1,
eventBind: function(){
var _this = this;
$('.someClass').on('click',function(event) {
/* Act on the event */
console.log(_this.bar); //1
});
}
}由于 Javascript 特有的机制,上下文环境在 eventBind:function(){ } 过渡到 $('.someClass').on('click',function(event) { }) 发生了改变,上述使用变量保存 this 这些方式都是有用的,也没有什么问题。
当然使用 bind() 可以更加优雅的解决这个问题:
var foo = {
bar : 1,
eventBind: function(){
$('.someClass').on('click',function(event) {
/* Act on the event */
console.log(this.bar); //1
}.bind(this));
}
}在上述代码里,bind() 创建了一个函数,当这个click事件绑定在被调用的时候,它的 this 关键词会被设置成被传入的值(这里指调用bind()时传入的参数)。
因此,这里我们传入想要的上下文 this(其实就是 foo ),到 bind() 函数中。然后,当回调函数被执行的时候, this 便指向 foo 对象。再来一个简单的栗子:
var bar = function(){
console.log(this.x);
}
var foo = {
x:3
}
bar(); // undefined
var func = bar.bind(foo);
func(); // 3这里我们创建了一个新的函数 func,当使用 bind() 创建一个绑定函数之后,它被执行的时候,它的 this 会被设置成 foo , 而不是像我们调用 bar() 时的全局作用域。
有个有趣的问题,如果连续 bind() 两次,亦或者是连续 bind() 三次那么输出的值是什么呢?像这样:
var bar = function(){
console.log(this.x);
}
var foo = {
x:3
}
var sed = {
x:4
}
var func = bar.bind(foo).bind(sed);
func(); //?
var fiv = {
x:5
}
var func = bar.bind(foo).bind(sed).bind(fiv);
func(); //? 答案是,两次都仍将输出 3 ,而非期待中的 4 和 5 。
原因是,在Javascript中,多次 bind() 是无效的。更深层次的原因, bind() 的实现,相当于使用函数在内部包了一个 call / apply ,第二次 bind() 相当于再包住第一次 bind() ,故第二次以后的 bind 是无法生效的。
那么 apply、call、bind 三者相比较,之间又有什么异同呢?何时使用 apply、call,何时使用 bind 呢。简单的一个栗子:
var obj = {
x: 81,
};
var foo = {
getX: function() {
return this.x;
}
}
console.log(foo.getX.bind(obj)()); //81
console.log(foo.getX.call(obj)); //81
console.log(foo.getX.apply(obj)); //81三个输出的都是81,但是注意看使用 bind() 方法的,他后面多了对括号。
也就是说,区别是,当你希望改变上下文环境之后并非立即执行,而是回调执行的时候,使用 bind() 方法。而 apply/call 则会立即执行函数。
再总结一下:
本文实例出现的所有代码,在我的github上可以下载。
原创文章,文笔有限,才疏学浅,文中若有不正之处,万望告知。
承接上一篇:【CSS3进阶】酷炫的3D旋转透视 。
本文通过一个 3D Web 动画的实例,详细的捋一捋浏览器整个渲染页面的过程及原理。
CSS3 3D 行星运转 demo 页面请戳: Demo - CSS3 3D 行星运转 。
嗯,可能有些人打不开 demo 或者页面乱了,贴几张效果图:(图片有点大,耐心等待一会)

随机再截屏了一张:

强烈建议你点进 Demo - CSS3 3D 行星运转 页感受一下 CSS3 3D 的魅力,图片能展现的东西毕竟有限。
然后,这个 CSS3 3D 行星运转动画的制作过程不再详细赘述,本篇的重点放在 Web 动画介绍及性能优化方面。详细的 CSS3 3D 可以回看上一篇博客:【CSS3进阶】酷炫的3D旋转透视。简单的思路:
下面将进入本文的重点,从性能优化的角度讲讲浏览器渲染展示原理,浏览器的重绘与重排,动画的性能检测优化等:
小标题起得有点大,我们知道,不同浏览器的内核(渲染引擎,Rendering Engine)是不一样的,例如现在最主流的 chrome 浏览器的内核是 Blink 内核(在Chrome(28及往后版本)、Opera(15及往后版本)和Yandex浏览器中使用),火狐是 Gecko,IE 是 Trident 。
浏览器内核负责对网页语法的解释并渲染(显示)网页,不同浏览器内核的工作原理并不完全一致。
所以其实下面将主要讨论的是 chrome 浏览器下的渲染原理。因为 chrome 内核渲染可查证的资料较多,对于其他内核的浏览器不敢妄下定论,所以下面展开的讨论默认是针对 chrome 浏览器的。
首先,我要抛出一点结论:
这里谈到了 GPU 加速,为什么 GPU 能够加速 3D 变换?这一切又必须要从浏览器底层的渲染讲起,浏览器渲染展示网页的过程,老生常谈,面试必问,大致分为:
找到了一张很经典的图:

这个渲染过程作为一个基础知识,继续往下深入。
当页面加载并解析完毕后,它在浏览器内代表了一个大家十分熟悉的结构:DOM(Document Object Model,文档对象模型)。在浏览器渲染一个页面时,它使用了许多没有暴露给开发者的中间表现形式,其中最重要的结构便是层(layer)。
这个层就是本文重点要讨论的内容:
而在 Chrome 中,存在有不同类型的层: RenderLayer(负责 DOM 子树),GraphicsLayer(负责 RenderLayer 的子树)。接下来我们所讨论的将是 GraphicsLayer 层。
GraphicsLayer 层是作为纹理(texture)上传给 GPU 的。
这里这个纹理很重要,那么,
这里的纹理指的是 GPU 的一个术语:可以把它想象成一个从主存储器(例如 RAM)移动到图像存储器(例如 GPU 中的 VRAM)的位图图像(bitmap image)。一旦它被移动到 GPU 中,你可以将它匹配成一个网格几何体(mesh geometry),在 Chrome 中使用纹理来从 GPU 上获得大块的页面内容。
通过将纹理应用到一个非常简单的矩形网格就能很容易匹配不同的位置(position)和变形(transformation),这也就是 3D CSS 的工作原理。
说起来很难懂,直接看例子,在 chrome 中,我们是可以看到上文所述的 GraphicsLayer -- 层的概念。在开发者工具中,我们进行如下选择调出 show layer borders 选项:

在一个极简单的页面,我们可以看到如下所示,这个页面只有一个层。蓝色网格表示瓦片(tile),你可以把它们当作是层的单元(并不是层),Chrome 可以将它们作为一个大层的部分上传给 GPU:

因为上面的页面十分简单,所以并没有产生层,但是在很复杂的页面中,譬如我们给元素设置一个 3D CSS 属性来变换它,我们就能看到当元素拥有自己的层时是什么样子。
注意橘黄色的边框,它画出了该视图中层的轮廓:

上面示意图中黄色边框框住的层,就是 GraphicsLayer ,它对于我们的 Web 动画而言非常重要,通常,Chrome 会将一个层的内容在作为纹理上传到 GPU 前先绘制(paint)进一个位图中。如果内容不会改变,那么就没有必要重绘(repaint)层。
这样做的意义在于:花在重绘上的时间可以用来做别的事情,例如运行 JavaScript,如果绘制的时间很长,还会造成动画的故障与延迟。
那么一个元素什么时候会触发创建一个层?从目前来说,满足以下任意情况便会创建层:
对于静态 Web 页面而言,层在第一次被绘制出来之后将不会被改变,但对于 Web 动画,页面的 DOM 元素是在不断变换的,如果层的内容在变换过程中发生了改变,那么层将会被重绘(repaint)。
强大的 chrome 开发者工具提供了工具让我们可以查看到动画页面运行中,哪些内容被重新绘制了:

在旧版的 chrome 中,是有 show paint rects 这一个选项的,可以查看页面有哪些层被重绘了,并以红色边框标识出来。
但是新版的 chrome 貌似把这个选项移除了,现在的选项是 enable paint flashing ,其作用也是标识出网站动态变换的地方,并且以绿色边框标识出来。
看上面的示意图,可以看到页面中有几处绿色的框,表示发生了重绘。注意 Chrome 并不会始终重绘整个层,它会尝试智能的去重绘 DOM 中失效的部分。
按照道理,页面发生这么多动画,重绘应该很频繁才对,但是上图我的行星动画中我只看到了寥寥绿色重绘框,我的个人理解是,一是 GPU 优化,二是如果整个动画页面只有一个层,那么运用了 transform 进行变换,页面必然需要重绘,但是采用分层(GraphicsLayer )技术,也就是上面说符合情况的元素各自创建层,那么一个元素所创建的层运用 transform 变换,譬如 rotate 旋转,这个时候该层的旋转变换并没有影响到其他层,那么该层不一定需要被重绘。(个人之见,还请提出指正)。
了解层的重绘对 Web 动画的性能优化至关重要。
是什么原因导致失效(invalidation)进而强制重绘的呢?这个问题很难详尽回答,因为存在大量导致边界失效的情况。最常见的情况就是通过操作 CSS 样式来修改 DOM 或导致重排。
查找引发重绘和重排根源的最好办法就是使用开发者工具的时间轴和 enable paint flashing 工具,然后试着找出恰好在重绘/重排前修改了 DOM 的地方。
那么浏览器是如何从 DOM 元素到最终动画的展示呢?
Web 动画很大一部分开销在于层的重绘,以层为基础的复合模型对渲染性能有着深远的影响。当不需要绘制时,复合操作的开销可以忽略不计,因此在试着调试渲染性能问题时,首要目标就是要避免层的重绘。那么这就给动画的性能优化提供了方向,减少元素的重绘与回流。
这里首先要分清两个概念,重绘与回流。
当渲染树(render Tree)中的一部分(或全部)因为元素的规模尺寸,布局,隐藏等改变而需要重新构建。这就称为回流(reflow),也就是重新布局(relayout)。
每个页面至少需要一次回流,就是在页面第一次加载的时候。在回流的时候,浏览器会使渲染树中受到影响的部分失效,并重新构造这部分渲染树,完成回流后,浏览器会重新绘制受影响的部分到屏幕中,该过程成为重绘。
当render tree中的一些元素需要更新属性,而这些属性只是影响元素的外观,风格,而不会影响布局的,比如 background-color 。则就叫称为重绘。
值得注意的是,回流必将引起重绘,而重绘不一定会引起回流。
明显,回流的代价更大,简单而言,当操作元素会使元素修改它的大小或位置,那么就会发生回流。
所以对于页面而言,我们的宗旨就是尽量减少页面的回流重绘,简单的一个栗子:
// 下面这种方式将会导致回流reflow两次
var newWidth = aDiv.offsetWidth + 10; // Read
aDiv.style.width = newWidth + 'px'; // Write
var newHeight = aDiv.offsetHeight + 10; // Read
aDiv.style.height = newHeight + 'px'; // Write
// 下面这种方式更好,只会回流reflow一次
var newWidth = aDiv.offsetWidth + 10; // Read
var newHeight = aDiv.offsetHeight + 10; // Read
aDiv.style.width = newWidth + 'px'; // Write
aDiv.style.height = newHeight + 'px'; // Write上面四句,因为涉及了 offsetHeight 操作,浏览器强制 reflow 了两次,而下面四句合并了 offset 操作,所以减少了一次页面的回流。
减少回流、重绘其实就是需要减少对渲染树的操作(合并多次多DOM和样式的修改),并减少对一些style信息的请求,尽量利用好浏览器的优化策略。
其实浏览器自身是有优化策略的,如果每句 Javascript 都去操作 DOM 使之进行回流重绘的话,浏览器可能就会受不了。所以很多浏览器都会优化这些操作,浏览器会维护 1 个队列,把所有会引起回流、重绘的操作放入这个队列,等队列中的操作到了一定的数量或者到了一定的时间间隔,浏览器就会 flush 队列,进行一个批处理。这样就会让多次的回流、重绘变成一次回流重绘。
但是也有例外,因为有的时候我们需要精确获取某些样式信息,下面这些:
这个时候,浏览器为了反馈最精确的信息,需要立即回流重绘一次,确保给到我们的信息是准确的,所以可能导致 flush 队列提前执行了。
两者都可以在页面上隐藏节点。不同之处在于,
从性能的角度而言,即是回流与重绘的方面,
他们两者在优化中 visibility:hidden 会显得更好,因为我们不会因为它而去改变了文档中已经定义好的显示层次结构了。
对子元素的影响:
不同样式在消耗性能方面是不同的,譬如 box-shadow 从渲染角度来讲十分耗性能,原因就是与其他样式相比,它们的绘制代码执行时间过长。这就是说,如果一个耗性能严重的样式经常需要重绘,那么你就会遇到性能问题。其次你要知道,没有不变的事情,在今天性能很差的样式,可能明天就被优化,并且浏览器之间也存在差异。
因此关键在于,你要借助开发工具来分辨出性能瓶颈所在,然后设法减少浏览器的工作量。
好在 chrome 浏览器提供了许多强大的功能,让我们可以检测我们的动画性能,除了上面提到的,我们还可以通过勾选下面这个 show FPS meter 显示页面的 FPS 信息,以及 GPU 的使用率:

官方文档说,这是一个仍处于实验阶段的功能,所以在未来版本的浏览器中该功能的语法和行为可能随之改变。
will-change 为 web 开发者提供了一种告知浏览器该元素会有哪些变化的方法,这样浏览器可以在元素属性真正发生变化之前提前做好对应的优化准备工作。 这种优化可以将一部分复杂的计算工作提前准备好,使页面的反应更为快速灵敏。
看看 Can i Use - will-change,更新于 2021/03/31 :

使用方法示例:(具体每个取值的意义,去翻翻文档)
will-change: auto
will-change: scroll-position
will-change: contents
will-change: transform // Example of
will-change: opacity // Example of
will-change: left, top // Example of two
will-change: unset
will-change: initial
will-change: inherit
// 示例
.example{
will-change: transform;
}值得注意的是,用好这个属性并不是很容易:
3D transform 会启用GPU加速,例如 translate3D, scaleZ 之类,当然我们的页面可能并没有 3D 变换,但是不代表我们不能启用 GPU 加速,在非 3D 变换的页面也使用 3D transform 来操作,算是一种 hack 加速法。我们实际上不需要z轴的变化,但是还是假模假样地声明了,去欺骗浏览器。
参考文献:
好了,本文到此结束,希望对你有帮助 :)
想 Get 到最有意思的 CSS 资讯,千万不要错过我的公众号 -- iCSS前端趣闻 😄
如果还有什么疑问或者建议,可以多多交流,原创文章,文笔有限,才疏学浅,文中若有不正之处,万望告知。
之前学习 react+webpack ,偶然路过 webpack 官网 ,看到顶部的 LOGO ,就很感兴趣。
最近觉得自己 CSS3 过于薄弱,想着深入学习一番,遂以这个 LOGO 为切入口,好好研究学习了一下相关的 CSS3 属性。webpack 的 LOGO 动画效果乍看不是很难,深入了解之后,觉得内部其实大有学问,自己折腾了一番,做了一系列相关的 CSS3 动画效果。
先上 demo ,没有将精力放在兼容上,请用 chrome 打开。
本文完整的代码,以及更多的 CSS3 效果,在我 github 上可以看到,也希望大家可以点个 star。
嗯,可能有些人打不开 demo 或者页面乱了,贴几张效果图:(图片有点大,耐心等待一会)
可能上面的效果对精通 CSS3 的而言小菜一碟,写本文的目的也是我自己学习积累的一个过程,感兴趣的就可以一起往下看啦。
其实 CSS3 效果真的很强大,上面的效果都是纯 CSS 实现,个人感觉越是深入 CSS 的学习,越是觉得自己不懂 CSS ,不过话说回来,这些效果的实用场景不大,但是作为一个有追求的前端,我觉得还是有必要去好好了解一下这些属性。
所以本文接下来要讲的大概有:
要利用 CSS3 实现 3D 的效果,最主要的就是借助 transform-style 属性。transform-style 只有两个值可以选择:
// 语法:
transform-style: flat|preserve-3d;
transform-style: flat; // 默认,子元素将不保留其 3D 位置
transform-style: preserve-3d; // 子元素将保留其 3D 位置。当我们指定一个容器的 transform-style 的属性值为 preserve-3d 时,容器的后代元素便会具有 3D 效果,这样说有点抽象,也就是当前父容器设置了 preserve-3d 值后,它的子元素就可以相对于父元素所在的平面,进行 3D 变形操作。
当父元素设置了 transform-style:preserve-3d 后,就可以对子元素进行 3D 变形操作了,3D 变形和 2D 变形一样可以,使用 transform 属性来设置,或者可以通过制定的函数或者通过三维矩阵来对元素变型操作:
对于 API 的学习,我建议去源头看看,不要满足于消费别人的总结,transform-style API。
这里要特别提出的,3D 坐标轴,所谓的绕 X、Y、Z 轴的三个轴,这个不难,感觉空间想象困难的,照着 API 试试,绕每个轴都转一下就明白了:
了解过后,那么依靠上面所说的,其实我们就已经可以做一个立方体出来了。所谓实践出真知,下面就看看该如何一步步得到一个立方体。
这个好理解,正方体六个面,首先用 div 做出 6 个面,包裹在同一个父级容器下面,父级容器设置 transform-style:preserve-3d ,这样接下来就可以对 6 个面进行 3D 变换操作,为了方便演示,我用 6 个颜色不一样的面:
上面的图是示意有 6 个面,当然我们要把 6 个正方形 div 设置为绝对定位,重叠叠在一起,那么应该是这样的,只能看到一个面:
为了最后的看上去的效果好看,我们需要先对父容器进行变换,运用上面说的 rotate 属性,将容器的角度改变一下:
.cube-container{
-webkit-transform: rotateX(-33.5deg) rotateY(45deg);
transform: rotateX(-33.5deg) rotateY(45deg);
}那么,变换之后,得到这样一个图形:
嗯,这个时候,6 个 div 面仍然是重叠在一起的。
接下来就是对每个面进行 3D 变换了,运用 rotate 可以对 div 平面进行旋转,运用 translate 可以对 div 平面进行平移,而且要记住现在我们是在三维空间内变换,转啊转啊,我们可能会得到这样的形状:
算好旋转角度和偏移距离,最后上面的 6 个面就可以完美拼成一个立方体咯!为了效果更好,我给每个面增加一些透明度,最后得到一个完整的立方体:
为了更有立体感,我们可以调整父容器的旋转角度,旋转看上去更立体的角度:
至此,一个 3D 立方体就完成了。写这篇文章的时候,本来到这里,这一块应该就结束了,但是写到这里的时候,突然突发奇想,既然正方体可以(正六面体),那么正四面体,正八面体甚至球体应该也能做出来吧?
嗯,没有按住躁动的心,立马动手尝试了一番,最后做出了下面的两个:

就不再详细讨论如何一步一步得到这两个了,有兴趣的可以去我的 github 上看看源码,或者直接和我讨论交流,简单的谈谈思路:
和正方体一样,我们首先要准备 4 个三角形(下面会详细讲如何利用 CSS3 制作一个三角形 div),注意 4 个三角形应该是重叠在一起的,然后将其中三个分别沿着三条边的中心点旋转 70.5 度(正四面体临面夹角),就可以得到一个正四面体。
注意沿着三条边的中心点旋转 70.5 度这句话,意思是每个图形要定位一次旋转中心,也就是 transform-origin 属性,它允许我们设置旋转元素的基点位置。
上面的 GIF 图因为添加了 animation 动画效果,看上去很像一个球体在运动,其实只用了 4 个 div,每个 div 利用 border-radius:100% 设置为圆形,然后以中心点为基准,每个圆形 div 绕 Y 轴旋转不同的角度,再让整个圆形容器绕 Y 轴动起来,就可以得到这样一个效果了。
继续说 3D ,接下来要说的属性是 persepective 和 perspective-origin 。
// 语法
perspective: number|none;perspective 为一个元素设置三维透视的距离,仅作用于元素的后代,而不是其元素本身。
简单来说,当元素没有设置 perspective 时,也就是当 perspective:none/0 时所有后代元素被压缩在同一个二维平面上,不存在景深的效果。
而如果设置 perspective 后,将会看到三维的效果。
perspective-origin 表示 3D 元素透视视角的基点位置,默认的透视视角中心在容器是 perspective 所在的元素,而不是他的后代元素的中点,也就是 perspective-origin: 50% 50%。
// 语法
perspective-origin: x-axis y-axis;
// x-axis : 定义该视图在 x 轴上的位置。默认值:50%
// y-axis : 定义该视图在 y 轴上的位置。默认值:50%值得注意的是,CSS3 3D 变换中的透视的透视点是在浏览器的前方。
说总是很难理解,运用上面我们做出来的正方体试验一下,我设置了正方体的边长为 50 px ,这里设置正方体容器 cuber-inner 的 persepective 的为 100 px,而 perspective-origin 保持为默认值:
-webkit-perspective-origin: 50% 50%;
perspective-origin: 50% 50%;
-webkit-perspective: 100px;
perspective: 100px;上面这样设置,也就是相当于我站在 100px 的长度外去看这个立方体,效果如下:
通过调整 persepective 和 perspective-origin 的值,可以看到不一样的图形,这个很好理解,我们观测一个物体的角度和距离物体的距离不断发生改变,我们看的物体也是不一样的,嗯想象一下小学课文,杨桃和星星,就能容易明白了。
需要提出的是,我上面的几个正多面体图形和球形图形是没有加上 persepective 值的,感兴趣的可以加上试一下看看效果。
回到文章一开始我贴的那个 3D 照片墙,运用 transform-style: preserve-3d 和 persepective ,可以做出效果很好的这种 3D 照片墙旋转效果。
代码就不贴了,本文已经很长了,只是简单的谈谈原理,感兴趣的去扒源码看看。
这里要注意的一点是设置的 persepective 值和单个图片 translateZ(length) 的值,persepective 一定要比 translateZ(length) 的值大,否则就是相当于舞台跑你身后去了,肯定是看不到效果了。
本来想继续说
这些个可以让动画效果变得更赞的一些 CSS3 属性,但是觉得本文篇幅已经很长,而且这两个属性有点偏离主题,打算另起一文,再做深入探究。
再说两点本文没有谈到的,但是很有用处的小细节,感兴趣的可以去了解了解,也会在接下来进行详细探讨:
OK,本文到此结束,如果还有什么疑问或者建议,可以多多交流,原创文章,文笔有限,才疏学浅,文中若有不正之处,万望告知。
本文完整的代码,以及更多的 CSS3 效果,在我 github 上可以看到,也希望大家可以点个 star。
本文的 demo 戳我。
如果本文对你有帮助,请点下赞,写文章不容易。
前端同学可能向来对爬虫不是很感冒,觉得爬虫需要用偏后端的语言,诸如 php , python 等。
当然这是在 nodejs 前了,nodejs 的出现,使得 Javascript 也可以用来写爬虫了。由于 nodejs 强大的异步特性,让我们可以轻松以异步高并发去爬取网站,当然这里的轻松指的是 cpu 的开销。
要读懂本文,其实只需要有
本文较长且图多,但如果能耐下心读完本文,你会发现,简单的一个爬虫实现并不难,并且能从中学到很多东西。
本文中的完整的爬虫代码,在我的github上可以下载。主要的逻辑代码在 server.js 中,建议边对照代码边往下看。
在详细说爬虫前,先来简单看看要达成的最终目标,入口为 http://www.cnblogs.com/ ,博客园文章列表页每页有20篇文章,最多可以翻到200页。我这个爬虫要做的就是异步并发去爬取这4000篇文章的具体内容,拿到一些我们想要的关键数据。
看到了最终结果,那么我们接下来看看该如何一步一步通过一个简单的 nodejs 爬虫拿到我们想要的数据,首先简单科普一下爬虫的流程,要完成一个爬虫,主要的步骤分为:
爬虫爬虫,最重要的步骤就是如何把想要的页面抓取回来。并且能兼顾时间效率,能够并发的同时爬取多个页面。
同时,要获取目标内容,需要我们分析页面结构,因为 ajax 的盛行,许多页面内容并非是一个url就能请求的的回来的,通常一个页面的内容是经过多次请求异步生成的。所以这就要求我们能够利用抓包工具分析页面结构。
如果深入做下去,你会发现要面对不同的网页要求,比如有认证的,不同文件格式、编码处理,各种奇怪的url合规化处理、重复抓取问题、cookies 跟随问题、多线程多进程抓取、多节点抓取、抓取调度、资源压缩等一系列问题。
所以第一步就是拉网页回来,慢慢你会发现各种问题待你优化。
当把页面内容抓回来后,一般不会直接分析,而是用一定策略存下来,个人觉得更好的架构应该是把分析和抓取分离,更加松散,每个环节出了问题能够隔离另外一个环节可能出现的问题,好排查也好更新发布。
那么存文件系统、SQL or NOSQL 数据库、内存数据库,如何去存就是这个环节的重点。
对网页进行文本分析,提取链接也好,提取正文也好,总之看你的需求,但是一定要做的就是分析链接了。通常分析与存储会交替进行。可以用你认为最快最优的办法,比如正则表达式。然后将分析后的结果应用与其他环节。
要是你做了一堆事情,一点展示输出都没有,如何展现价值?
所以找到好的展示组件,去show出肌肉也是关键。
如果你为了做个站去写爬虫,抑或你要分析某个东西的数据,都不要忘了这个环节,更好地把结果展示出来给别人感受。
现在我们一步一步来完成我们的爬虫,目标是爬取博客园第1页至第200页内的4000篇文章,获取其中的作者信息,并保存分析。
共4000篇文章,所以首先我们要获得这个4000篇文章的入口,然后再异步并发的去请求4000篇文章的内容。但是这个4000篇文章的入口 URL 分布在200个页面中。所以我们要做的第一步是 从这个200个页面当中,提取出4000个 URL 。并且是通过异步并发的方式,当收集完4000个 URL 再进行下一步。那么现在我们的目标就很明确了:
要获取这么多 URL ,首先还是得从分析单页面开始,F12 打开 devtools 。很容易发现文章入口链接保存在 class 为 titlelnk 的 标签中,所以4000个 URL 就需要我们轮询 200个列表页 ,将每页的20个 链接保存起来。那么该如何异步并发的从200个页面去收集这4000个 URL 呢,继续寻找规律,看看每一页的列表页的 URL 结构:
那么,1~200页的列表页 URL 应该是这个样子的:
for(var i=1 ; i<= 200 ; i++){
pageUrls.push('http://www.cnblogs.com/#p'+i);
}有了存放200个文章列表页的 URL ,再要获取4000个文章入口就不难了,下面贴出关键代码,一些最基本的nodejs语法(譬如如何搭建一个http服务器)默认大家都已经会了:
// 一些依赖库
// 一些依赖库
var http = require("http"),
url = require("url"),
superagent = require("superagent"),
cheerio = require("cheerio"),
async = require("async"),
eventproxy = require('eventproxy');
var ep = new eventproxy(),
urlsArray = [], //存放爬取网址
pageUrls = [], //存放收集文章页面网站
pageNum = 200; //要爬取文章的页数
for(var i=1 ; i<= 200 ; i++){
pageUrls.push('http://www.cnblogs.com/#p'+i);
}
// 主start程序
function start(){
function onRequest(req, res){
// 轮询 所有文章列表页
pageUrls.forEach(function(pageUrl){
superagent.get(pageUrl)
.end(function(err,pres){
// pres.text 里面存储着请求返回的 html 内容,将它传给 cheerio.load 之后
// 就可以得到一个实现了 jquery 接口的变量,我们习惯性地将它命名为 `$`
// 剩下就都是利用$ 使用 jquery 的语法了
var $ = cheerio.load(pres.text);
var curPageUrls = $('.titlelnk');
for(var i = 0 ; i < curPageUrls.length ; i++){
var articleUrl = curPageUrls.eq(i).attr('href');
urlsArray.push(articleUrl);
// 相当于一个计数器
ep.emit('BlogArticleHtml', articleUrl);
}
});
});
ep.after('BlogArticleHtml', pageUrls.length*20 ,function(articleUrls){
// 当所有 'BlogArticleHtml' 事件完成后的回调触发下面事件
// ...
});
}
http.createServer(onRequest).listen(3000);
}
exports.start= start;这里我们用到了三个库,superagent 、 cheerio 、 eventproxy。
分别简单介绍一下:
superagent 是个轻量的的 http 方面的库,是nodejs里一个非常方便的客户端请求代理模块,当我们需要进行 get 、 post 、 head 等网络请求时,尝试下它吧。
cheerio 大家可以理解成一个 Node.js 版的 jquery,用来从网页中以 css selector 取数据,使用方式跟 jquery 一样一样的。
eventproxy 非常轻量的工具,但是能够带来一种事件式编程的思维变化。
用 js 写过异步的同学应该都知道,如果你要并发异步获取两三个地址的数据,并且要在获取到数据之后,对这些数据一起进行利用的话,常规的写法是自己维护一个计数器。
先定义一个 var count = 0,然后每次抓取成功以后,就 count++。如果你是要抓取三个源的数据,由于你根本不知道这些异步操作到底谁先完成,那么每次当抓取成功的时候,就判断一下count === 3。当值为真时,使用另一个函数继续完成操作。
而 eventproxy 就起到了这个计数器的作用,它来帮你管理到底这些异步操作是否完成,完成之后,它会自动调用你提供的处理函数,并将抓取到的数据当参数传过来。
OK,运行一下上面的函数,假设上面的内容我们保存在 server.js 中,而我们有一个这样的启动页面 index.js,
现在我们在回调里增加几行代码,打印出结果:
打开node命令行,键入指令,在浏览器打开 http://localhost:3000/ ,可以看到:
node index.js成功了!我们成功收集到了4000个 URL ,但是我将这个4000个 URL 去重后发现,只有20个 URL 剩下,也就是说我将每个 URL push 进数组了200次,一定是哪里错,看到200这个数字,我立马回头查看 200 个 文章列表页。
我发现,当我用 http://www.cnblogs.com/#p1 ~ 200 访问页面的时候,返回的都是博客园的首页。 而真正的列表页,藏在这个异步请求下面:
看看这个请求的参数:
把请求参数提取出来,我们试一下这个 URL,访问第15页列表页:http://www.cnblogs.com/?CategoryId=808&CategoryType=%22SiteHome%22&ItemListActionName=%22PostList%22&PageIndex=15&ParentCategoryId=0 。
成功了,那么我们稍微修改下上面的代码:
//for(var i=1 ; i<= 200 ; i++){
// pageUrls.push('http://www.cnblogs.com/#p'+i);
//}
//改为
for(var i=1 ; i<= 200 ; i++){
pageUrls.push('http://www.cnblogs.com/?CategoryId=808&CategoryType=%22SiteHome%22&ItemListActionName=%22PostList%22&PageIndex='+ i +'&ParentCategoryId=0');
}再试一次,发现这次成功收集到了 4000 个没有重复的 URL 。第二步完成!
获取到 4000 个 URL ,并且回调入口也有了,接下来我们只需要在回调函数里继续爬取4000个具体页面,并收集我们想要的信息就好了。其实刚刚我们已经经历了第一轮爬虫爬取,只是有一点做的不好的地方是我们刚刚并没有限制并发的数量,这也是我发现 cnblog 可以改善的一点,不然很容易被单IP的巨量 URL 请求攻击到崩溃。为了做一个好公民,也为了减轻网站的压力(其实为了不被封IP),这4000个URL 我限制了同时并发量最高为5。这里用到了另一个非常强大的库 async ,让我们控制并发量变得十分轻松,简单的介绍如下。
async 是一个流程控制工具包,提供了直接而强大的异步功能mapLimit(arr, limit, iterator, callback)。
这次我们要介绍的是 async 的 mapLimit(arr, limit, iterator, callback) 接口。另外,还有个常用的控制并发连接数的接口是 queue(worker, concurrency) ,大家可以去看看它的API。
继续我们的爬虫,进到具体的文章页面,发现我们想获取的信息也不在直接请求而来的 html 页面中,而是如下这个 ajax 请求异步生成的,不过庆幸的是我们上一步收集的 URL 包含了这个请求所需要的参数,所以我们仅仅需要多做一层处理,将这个参数从 URL 中取出来再重新拼接成一个ajax URL 请求。
下面,贴出代码,在我们刚刚的回调函数中,继续我们4000个页面的爬取,并且控制并发数为5:
ep.after('BlogArticleHtml',pageUrls.length*20,function(articleUrls){
// 当所有 'BlogArticleHtml' 事件完成后的回调触发下面事件
// 控制并发数
var curCount = 0;
var reptileMove = function(url,callback){
//延迟毫秒数
var delay = parseInt((Math.random() * 30000000) % 1000, 10);
curCount++;
console.log('现在的并发数是', curCount, ',正在抓取的是', url, ',耗时' + delay + '毫秒');
superagent.get(url)
.end(function(err,sres){
// sres.text 里面存储着请求返回的 html 内容
var $ = cheerio.load(sres.text);
// 收集数据
// 拼接URL
var currentBlogApp = url.split('/p/')[0].split('/')[3],
appUrl = "http://www.cnblogs.com/mvc/blog/news.aspx?blogApp="+ currentBlogApp;
// 具体收集函数
personInfo(appUrl);
});
setTimeout(function() {
curCount--;
callback(null,url +'Call back content');
}, delay);
};
// 使用async控制异步抓取
// mapLimit(arr, limit, iterator, [callback])
// 异步回调
async.mapLimit(articleUrls, 5 ,function (url, callback) {
reptileMove(url, callback);
}, function (err,result) {
// 4000 个 URL 访问完成的回调函数
// ...
});
});根据重新拼接而来的 URL ,再写一个具体的 personInfo(URL) 函数,具体获取我们要的昵称、园龄、粉丝数等信息。
这样,我们把抓取回来的信息以 JSON 串的形式存储在 catchDate 这个数组当中,
node index.js 运行一下程序,将结果打印出来,可以看到中间过程及结果:
至此,第三步就完成了,我们也收集到了4000条我们想要的原始数据。
本来想将爬来的数据存入 mongoDB ,但因为这里我只抓取了 4000 条数据,相对于动不动爬几百万几千万的量级而言不值一提,故就不添加额外的操作 mongoDB 代码,专注于爬虫本身。
收集到数据之后,就想看你想怎么展示了,这里推荐使用 Highcharts 纯JS图表库去展示我们的成果。当然这里我偷懒了没有做,直接用最原始的方法展示结果。
下面是我不同时间段爬取,经过简单处理后的的几张结果图:
(结果图的耗时均在并发量控制为 5 的情况下)
OK,至此,整个爬虫就完成了,其实代码量很少,我觉得写爬虫更多的时间是花在在处理各类问题,分析页面结构。
完整的爬虫代码,在我的github上可以下载。如果仍有疑问,可以把代码 down 到本地,重新从文章开头对照代码再实践一次,相信很多问题会迎刃而解。
参考文章:《Node.js 包教不包会》。
原创文章,文笔有限,才疏学浅,文中若有不正之处,万望告知。
从 Chrome 99+ 开始,新增了一个非常有用的 function -- showPicker(),它能够让多个 input 类型元素使用 showPicker() 方法。它们是:
type=datetype=monthtype=weektype=timetype=datetime-localtype=colortype=fileOK,那么新增的 showPicker() 到底有什么作用呢?
我们以 type=color 为例子。
<input type="color" />本文将介绍 HTML5 规范中,比较有意思的一个标签 <datalist>,通过它,我们可以
<datalist>经常制作表单的同学一定对下拉选框不陌生。
传统的下拉选框 select,类似于这样:
<label for="pet-select">Choose a pet:</label>
<select name="pets" id="pet-select">
<option value="">--Please choose an option--</option>
<option value="dog">Dog</option>
<option value="cat">Cat</option>
<option value="hamster">Hamster</option>
<option value="parrot">Parrot</option>
<option value="spider">Spider</option>
<option value="goldfish">Goldfish</option>
</select>
然而,这仅仅是最基础的用法。通常而言,业务中对一个下拉选框的要求会更多。
其中一项便是当选项特别多的时,需要有可搜索过滤的功能,譬如 Element-UI 封装的 Select 组件,就提供搜索的功能:

其实,HTML5 也原生提供了可以输入过滤的下拉选框,也就是本文将介绍的 -- <datalist>。
<datalist> 实现输入过滤的下拉选框使用 <datalist> 其实非常简单,它的核心就是提供了可输入过滤的下拉选框功能。
我们需要利用一个 <input> 标签和 <datalist> 关联起来,简单的示例如下:
<label>Choose a browser from this list:
<input list="browsers" name="myBrowser" /></label>
<datalist id="browsers">
<option value="Chrome">
<option value="Firefox">
<option value="Internet Explorer">
<option value="Opera">
<option value="Safari">
</datalist>上述代码通过了 <input> 内的 list 属性和定义的 <datalist> 关联起来,<input> 内的 list 属性的值为关联的 <datalist> 的 id。
这样,我们就能直接实现一个可输入过滤的下拉选框功能:

一看就懂,其实 <datalist> 使用起来还是非常简单。
<datalist> 使用的局限性<datalist> 其实成为标准已经很久了。然而,大家会发现这个标签的出镜率其实并不高。
限制了 <datalist> 被大规模使用的原因在于其 CSS 样式无法得到有效的修改,<datalist> 和 <select> 非常类似,很难用 CSS 进行高效的设计。
浏览给这类元素定义了默认样式,并且我们无法通过 CSS 去修改它们。最为致命的是,浏览器默认样式的表现在不同浏览器之间并不一致。这给追求稳定,UI 表现一致的业务来说,是灾难性的缺点!
所以我们日常中使用到业务中的这些复杂表单元素,通常都是使用了使用非语义元素 <div>、<ul> 等普通标签模拟 HTML 结构,使用了 JavaScript 添加行为,再使用 WAI-ARIA 来提供语义。
当然,这也不代表它们完全没有用武之地,在一些非业务环境下,合理使用 <datalist> 还是能够很少代码量的。
本文到此结束,希望对你有帮助 :)
想 Get 到最有意思的 CSS 资讯,千万不要错过我的公众号 -- iCSS前端趣闻 😄
更多精彩 CSS 技术文章汇总在我的 Github -- iCSS ,持续更新,欢迎点个 star 订阅收藏。
如果还有什么疑问或者建议,可以多多交流,原创文章,文笔有限,才疏学浅,文中若有不正之处,万望告知。

想写一篇关于 SVG 滤镜的文章已久,SVG 滤镜的存在,让本来就非常强大的 CSS 如虎添翼。让仅仅使用 CSS/HTML/SVG 创作的效果更上一层楼。题图为袁川老师使用 SVG 滤镜实现的云彩效果 -- CodePen Demo -- Cloud (SVG filter + CSS)。
系列另外两篇:
SVG 滤镜与 CSS 滤镜类似,是 SVG 中用于创建复杂效果的一种机制。很多人看到 SVG 滤镜复杂的语法容易心生退意。本文力图使用最简洁明了的方式让大家尽量弄懂 SVG 滤镜的使用方式。
本文默认读者已经掌握了一定 SVG 的基本概念和用法。
SVG 滤镜包括了:
feBlend
feColorMatrix
feComponentTransfer
feComposite
feConvolveMatrix
feDiffuseLighting
feDisplacementMap
feFlood
feGaussianBlur
feImage
feMerge
feMorphology
feOffset
feSpecularLighting
feTile
feTurbulence
feDistantLight
fePointLight
feSpotLight
看着内容很多,有点类似于 CSS 滤镜中的不同功能:blur()、contrast()、drop-shadow() 。
我们需要使用 <defs> 和 <filter> 标签来定义一个 SVG 滤镜。
通常所有的 SVG 滤镜元素都需要定义在 <defs> 标记内。
现在,基本上现代浏览器,即使不使用
<defs>包裹<filter>,也能够定义一个 SVG 滤镜。
这个 <defs> 标记是 definitions 这个单词的缩写,可以包含很多种其它标签,包括各种滤镜。
其次,使用 <filter> 标记用来定义 SVG 滤镜。 <filter> 标签需要一个 id 属性,它是这个滤镜的标志。SVG 图形使用这个 id 来引用滤镜。
看一个简单的 DEMO:
<div class="cssFilter"></div>
<div class="svgFilter"></div>
<svg>
<defs>
<filter id="blur">
<feGaussianBlur in="SourceGraphic" stdDeviation="5" />
</filter>
</defs>
</svg>div {
width: 100px;
height: 100px;
background: #000;
}
.cssblur {
filter: blur(5px);
}
.svgFilter{
filter: url(#blur);
}这里,我们在 defs 的 filter 标签内,运用了 SVG 的 feGaussianBlur 滤镜,也就是模糊滤镜, 该滤镜有两个属性 in 和 stdDeviation。其中 in="SourceGraphic" 属性指明了模糊效果要应用于整个图片,stdDeviation 属性定义了模糊的程度。最后,在 CSS 中,使用了 filter: url(#blur) 去调用 HTML 中定义的 id 为 blur 的滤镜。
为了方便理解,也使用 CSS 滤镜 filter: blur(5px) 实现了一个类似的滤镜,方便比较,结果图如下:

嘿,可以看到,使用 SVG 的模糊滤镜,实现了一个和 CSS 模糊滤镜一样的效果。
上文的例子中使用了 filter: url(#blur) 这种模式引入了一个 SVG 滤镜效果,url 是 CSS 滤镜属性的关键字之一,url 模式是 CSS 滤镜提供的能力之一,允许我们引入特定的 SVG 过滤器,这极大的增强 CSS 中滤镜的能力。
相当于所有通过 SVG 实现的滤镜效果,都可以快速的通过 CSS 滤镜 URL 模式一键引入。
和 CSS 滤镜一样,SVG 滤镜也是支持多个滤镜搭配混合使用的。
所以我们经常能看到一个 <filter> 标签内有大量的代码。很容易就懵了~
再来看个简单的例子:
<div></div>
<svg>
<defs>
<!-- Filter declaration -->
<filter id="MyFilter">
<!-- offsetBlur -->
<feGaussianBlur in="SourceAlpha" stdDeviation="5" result="blur" />
<feOffset in="blur" dx="10" dy="10" result="offsetBlur" />
<!-- merge SourceGraphic + offsetBlur -->
<feMerge>
<feMergeNode in="offsetBlur" />
<feMergeNode in="SourceGraphic" />
</feMerge>
</filter>
</defs>
</svg>div {
width: 200px;
height: 200px;
background: url(xxx);
filter: url(#MyFilter);
}我们先来看看整个滤镜的最终结果,结果长这样:

CSS 可能一行代码就能实现的事情,SVG 居然用了这么多代码。(当然,这里 CSS 也不好实现,不是简单容器的阴影,而是 PNG 图片图形的轮廓阴影)
首先看这一段:
<!-- offsetBlur -->
<feGaussianBlur in="SourceAlpha" stdDeviation="5" result="blur" />
<feOffset in="blur" dx="10" dy="10" result="offsetBlur" />首先 <feGaussianBlur in="SourceAlpha" stdDeviation="5" result="blur" /> 这一段,我们上面也讲到了,会生成一个模糊效果,这里多了一个新的属性 result='blur',这个就是 SVG 的一个特性,不同滤镜作用的效果可以通过 result 产出一个中间结果(也称为 primitives 图元),其他滤镜可以使用 in 属性导入不同滤镜产出的 result,继续操作。
紧接着,<feOffset> 滤镜还是很好理解的,使用 in 拿到了上一步的结果 result = 'blur',然后做了一个简单的位移。
这里就有一个非常重要的知识点:在不同滤镜中利用 result 和 in 属性,可以实现在前一个基本变换操作上建立另一个操作,比如我们的例子中就是添加模糊后又添加位移效果。
结合两个滤镜,产生的图形效果,其实是这样的:

实际效果中还出现了原图,所以这里我们还使用了 <feMerge> 标签,合并了多个效果。也就是上述这段代码:
<!-- merge SourceGraphic + offsetBlur -->
<feMerge>
<feMergeNode in="offsetBlur" />
<feMergeNode in="SourceGraphic" />
</feMerge>feMerge 滤镜允许同时应用滤镜效果而不是按顺序应用滤镜效果。利用 result 存储别的滤镜的输出可以实现这一点,然后在一个 <feMergeNode> 子元素中访问它。
<feMergeNode in="offsetBlur" /> 表示了上述两个滤镜的最终输出结果 offsetBlur ,也就是阴影的部分<feMergeNode in="SourceGraphic" /> 中的 in="SourceGraphic" 关键词表示图形元素自身将作为 <filter> 原语的原始输入整体再遵循后输入的层级越高的原则,最终得到上述结果。示意流程图如下:

至此,基本就掌握了 SVG 滤镜的工作原理,及多个滤镜如何搭配使用。接下来,只需要搞懂不同的滤镜能产生什么样的效果,有什么不同的属性,就能大致对 SVG 滤镜有个基本的掌握!
上面大致过了一下 SVG 滤镜的使用流程,过程中提到了一些属性,可能也漏掉了一些属性的讲解,本章节将补充说明一下。
有一些属性是每一个滤镜标签都有,都可以进行设置的。
| 属性 | 作用 |
|---|---|
| x, y | 提供左上角的坐标来定义在哪里渲染滤镜效果。 (默认值:0) |
| width, height | 绘制滤镜容器框的高宽(默认都为 100%) |
| result | 用于定义一个滤镜效果的输出名字,以便将其用作另一个滤镜效果的输入(in) |
| in | 指定滤镜效果的输入源,可以是某个滤镜导出的 result,也可以是下面 6 个值 |
SVG filter 中的 in 属性,指定滤镜效果的输入源,可以是某个滤镜导出的 result,也可以是下面 6 个值:
in 取值 |
作用 |
|---|---|
| SourceGraphic | 该关键词表示图形元素自身将作为 <filter> 原语的原始输入 |
| SourceAlpha | 该关键词表示图形元素自身将作为 <filter> 原语的原始输入。SourceAlpha 与 SourceGraphic 具有相同的规则除了 SourceAlpha 只使用元素的非透明部分 |
| BackgroundImage | 与 SourceGraphic 类似,但可在背景上使用。 需要显式设置 |
| BackgroundAlpha | 与 SourceAlpha 类似,但可在背景上使用。 需要显式设置 |
| FillPaint | 将其放置在无限平面上一样使用填充油漆 |
| StrokePaint | 将其放在无限平面上一样使用描边绘画 |
后 4 个基本用不上~
上面已经提到了几个滤镜,我们简单回顾下:
<feGaussianBlur > - 模糊滤镜<feOffset > - 位移滤镜<feMerge> - 多滤镜叠加滤镜接下来再介绍一些比较常见,有意思的 SVG 滤镜。
<feBlend> 为混合模式滤镜,与 CSS 中的混合模式相类似。
在 CSS 中,我们有混合模式 mix-blend-mode 和 background-blend-mode 。我有过非常多篇关于 CSS 混合模式相关的一些应用。如果你还不太了解 CSS 中的混合模式,可以先看看这几篇文章:
SVG 中的混合模式种类比 CSS 中的要少一些,只有 5 个,其作用与 CSS 混合模式完全一致:
简单一个 Demo,我们有两张图,利用不同的混合模式,可以得到不一样的混合结果 :
<div></div>
<svg>
<defs>
<filter id="lighten" x="0" y="0" width="200" height="250">
<feImage width="200" height="250" xlink:href="image1.jpg" result="img1" />
<feImage width="200" height="250" xlink:href="image2.jpg" result="img2" />
<feBlend mode="lighten" in="img1" in2="img2"/>
</filter>
</defs>
</svg>.container {
width: 200px;
height: 250px;
filter: url(#lighten);
}这里还用到了一个 <feImage> 滤镜,它的作用是提供像素数据作为输出,如果外部来源是一个 SVG 图像,这个图像将被栅格化。

上述运用了 feBlend 滤镜中的 mode="lighten" 后的结果,两个图像叠加作用了 lighten 混合模式:

看看全部 5 中混合模式的效果:

CodePen Demo -- SVG Filter feBlend Demo
<feColorMatrix> 滤镜也是 SVG 滤镜中非常有意思的一个滤镜,顾名思义,它的名字中包含了矩阵这个单词,表示该滤镜基于转换矩阵对颜色进行变换。每一像素的颜色值(一个表示为[红,绿,蓝,透明度] 的矢量) 都经过矩阵乘法 (matrix multiplated) 计算出的新颜色。
这个滤镜稍微有点复杂,我们一步一步来看。
<feColorMatrix> 滤镜有 2 个私有属性 type 和 values,type 它支持 4 种不同的类型:saturate | hueRotate | luminanceToAlpha | matrix,其中部分与 CSS Filter 中的一些滤镜效果类似。
type 类型 |
作用 | values 的取值范围 |
|---|---|---|
| saturate | 转换图像饱和度 | 0.0 - 1.0 |
| hueRotate | 转换图像色相 | 0.0 - 360 |
| luminanceToAlpha | 阿尔法通道亮度(不知道如何翻译 :sad) | 只有一个效果,无需改变 values 的值 |
| matrix | 使用矩阵函数进行色彩变换 | 需要应用一个 4 x 5 的矩阵 |
在这里,我做了一个简单的关于 <feColorMatrix> 前 3 个属性 saturate | hueRotate | luminanceToAlpha 的效果示意 DEMO -- CodePen - feColorMatrix Demo,可以感受下它们的具体的效果:

saturate、hueRotate 滤镜和 CSS 中的 filter 中的 saturate、hue-rotate 的作用是一模一样的。
feColorMatrix 中的 type=matrix 理解起来要稍微更复杂点,它的 values 需要传入一个 4x5 的矩阵。
像是这样:
<filter id="colorMatrix">
<feColorMatrix type="matrix" values="1 0 0 0 0, 0 1 0 0 0, 0 0 1 0 0, 0 0 0 1 0"/>
</filter>要理解如何运用这些填写矩阵,就不得不直面另外一个问题 -- 图像的表示。
数字图像的本质是一个多维矩阵。在图像显示时,我们把图像的 R 分量放进红色通道里,B 分量放进蓝色通道里,G 分量放进绿色通道里。经过一系列处理,显示在屏幕上的就是我们所看到的彩色图像了。
而 feColorMatrix 中的 matrix 矩阵,就是用来表示不同通道的值每一个分量的值,最终通过计算得到我们熟知的 rgba() 值。
计算逻辑为:
/* R G B A 1 */
1 0 0 0 0 // R = 1*R + 0*G + 0*B + 0*A + 0
0 1 0 0 0 // G = 0*R + 1*G + 0*B + 0*A + 0
0 0 1 0 0 // B = 0*R + 0*G + 1*B + 0*A + 0
0 0 0 1 0 // A = 0*R + 0*G + 0*B + 1*A + 0中文的文章,对 feColorMatrix 的 matrix 讲解最好的应该就是大漠老师的这篇 -- 详解feColorMatrix,对具体的表示法感兴趣的可以看看。
仅仅是使用的话,这里还有一个可视化的 DEMO -- CodePen - feColorMatrix Demo,帮助大家理解记忆:

到目前为止,大部分 SVG 滤镜的展示讲解都是 CSS 现有能力能够实现的,那 SVG 滤镜的独特与魅力到底在哪呢?有什么是 CSS 能力无法做到的么?下面来看看另外几个有意思的 SVG 滤镜。
feSpecularLighting 与 feDiffuseLighting 都意为光照滤镜,使用它们可以照亮一个源图形,不同的是,feSpecularLighting 为镜面照明,而 feDiffuseLighting 为散射光照明。
简单看其中一个 Demo,代码看着有点多,但是一步一步也很好理解:
<div></div>
<div class="svg-filter"></div>
<svg>
<defs>
<filter id="filter">
<!--Lighting effect-->
<feSpecularLighting in="SourceGraphic" specularExponent="20" specularConstant="0.75" result="spec">
<fePointLight x="0" y="0" z="200" />
</feSpecularLighting>
<!--Composition of inputs-->
<feComposite in="SourceGraphic" in2="spec" operator="arithmetic" k1="0" k2="1" k3="1" k4="0" />
</filter>
</defs>
</svg>div {
background: url(avator.png);
}
.svg-filter {
filter: url(#filter);
}左边是原图,右边是应用了光照滤镜之后的效果。

CodePen - feSpotLight SVG Light Source
feMorphology 为形态滤镜,它的输入源通常是图形的 alpha 通道,用来它的两个操作可以使源图形腐蚀(变薄)或扩张(加粗)。
使用属性 operator 确定是要腐蚀效果还是扩张效果。使用属性 radius 表示效果的程度,可以理解为笔触的大小。
erode 腐蚀模式,dilate 为扩张模式,默认为 erode我们将这个滤镜简单的应用到文字上看看效果:
<div class="g-text">
<p>Normal Text</p>
<p class="dilate">Normal Text</p>
<p class="erode">Normal Text</p>
</div>
<svg width="0" height="0">
<filter id="dilate">
<feMorphology in="SourceAlpha" result="DILATED" operator="dilate" radius="3"></feMorphology>
</filter>
<filter id="erode">
<feMorphology in="SourceAlpha" result="ERODE" operator="erode" radius="1"></feMorphology>
</filter>
</svg>p {
font-size: 64px;
}
.dilate {
filter: url(#dilate);
}
.erode {
filter: url(#erode);
}效果如下:最左边的是正常文字,中间的是扩张的模式,右边的是腐蚀模式,看看效果,非常好理解:

当然,我们还可以将其运用在图片之上,这时,并非是简单的让图像的笔触变粗或者变细,
erode 模式,会将图片的每一个像素向更暗更透明的方向变化,dilate 模式,则是将每个向像素周围附近更亮更不透明的方向变化简单看个示例动画 DEMO,我们有两张图,分别作用 operator="erode" 和 operator="dilate",并且动态的去改变它们的 radius,其中一个的代码示意如下:
<svg width="450" height="300" viewBox="0 0 450 300">
<filter id="morphology">
<feMorphology operator="erode" radius="0">
<animate attributeName="radius" from="0" to="5" dur="5s" repeatCount="indefinite" />
</feMorphology>
</filter>
<image xlink:href="image.jpg" width="90%" height="90%" x="10" y="10" filter="url(#morphology)"></image>
</svg>
上图左边是扩张模式,右边是腐蚀模式:
CodePen Demo -- SVG feMorphology Animation
turbulence 意为湍流,不稳定气流,而 SVG <feTurbulence> 滤镜能够实现半透明的烟熏或波状图像。 通常用于实现一些特殊的纹理。滤镜利用 Perlin 噪声函数创建了一个图像。噪声在模拟云雾效果时非常有用,能产生非常复杂的质感,利用它可以实现了人造纹理比如说云纹、大理石纹的合成。
有了 feTurbulence,我们可以自使用 SVG 创建纹理图形作为置换图,而不需要借助外部图形的纹理效果,即可创建复杂的图形效果。
这个滤镜,我个人认为是 SVG 滤镜中最有意思的一个,因为它允许我们自己去创造出一些纹理,并且叠加在其他效果之上,生成出非常有意思的动效。
feTurbulence 有三个属性是我们特别需要注意的:type、baseFrequency、numOctaves:
这里有一个非常好的网站,用于示意 feTurbulence 所产生的两种噪声的效果:http://apike.ca/ - feTurbulence
两种噪声的代码基本一致,只是 type 类型不同:
<filter id="fractal" >
<feTurbulence id="fe-turb-fractal" type="fractalNoise" baseFrequency="0.00025" numOctaves="1"/>
</filter>
<filter id="turbu">
<feTurbulence id="fe-turb-turbulence" type="turbulence" baseFrequency="0.00025" numOctaves="1"/>
</filter>我们通过改变 baseFrequency 和 numOctaves 参数看看实际产生的两种噪声的效果:

同时,baseFrequency 允许我们传入两个值,我们可以只改变某一方向上的频率,具体的你可以戳这个 Demo 看看:CodePen -- feTurbulence baseFrequency & numOctaves
单单一个 <feTurbulence> 滤镜其实是比较难搞懂这滤镜想干什么的,需要将这个滤镜作为纹理或者输入,和其他滤镜一起搭配使用,实现一些效果,下面我们来看看:
首先,尝试将 feTurbulence 所产生的纹理和文字相结合。
简单的代码如下:
<div>Coco</div>
<div class="turbulence">Coco</div>
<svg>
<filter id="fractal" filterUnits="objectBoundingBox" x="0%" y="0%" width="100%" height="100%">
<feTurbulence id="turbulence" type="fractalNoise" baseFrequency="0.03" numOctaves="1" />
<feDisplacementMap in="SourceGraphic" scale="50"></feDisplacementMap>
</filter>
</svg>.turbulence {
filter: url(#fractal);
}左边是正常的效果,后边是应用了 <feTurbulence> 的效果,你可以试着点进 Demo,更改 baseFrequency 和 numOctaves 参数的大小,可以看到不同的效果:

CodePen Demo -- feTurbulence text demo
上面的 Demo 还用到了 feDisplacementMap 滤镜,也需要简单的讲解下。
feDisplacementMap 为映射置换滤镜,想要用好这个滤镜不太容易,需要掌握非常多的关于 PhotoShop 纹理创建或者是图形色彩相关的知识。该滤镜用来自图像中从 in2 的输入值到空间的像素值置换图像从 in 输入值到空间的像素值。
说人话就是 feDisplacementMap 实际上是用于改变元素和图形的像素位置的。该滤镜通过遍历原图形的所有像素点,使用 feDisplacementMap 重新映射到一个新的位置,形成一个新的图形。
在上述的 feTurbulence 滤镜与文字的结合使用中,我们通过 feTurbulence 噪声得到了噪声图形,然后通过 feDisplacementMap 滤镜根据 feTurbulence 所产生的噪声图形进行形变,扭曲,液化,得到最终的效果。
在 MDN 上有这个滤镜转化的一个公式(感兴趣的可以研究下,我啃不动了):
P'(x,y) ← P( x + scale * (XC(x,y) - 0.5), y + scale * (YC(x,y) - 0.5))
好,我们继续 feTurbulence ,使用这个滤镜,我们可以生成各种不同的纹理,我们可以尝试使用 feTurbulence 滤镜搭配光照滤镜实现褶皱的纸张纹理效果,代码也非常少:
<div></div>
<svg>
<filter id='roughpaper'>
<feTurbulence type="fractalNoise" baseFrequency='0.04' result='noise' numOctaves="5" />
<feDiffuseLighting in='noise' lighting-color='#fff' surfaceScale='2'>
<feDistantLight azimuth='45' elevation='60' />
</feDiffuseLighting>
</filter>
</svg>div {
width: 650px;
height: 500px;
filter: url(#roughpaper);
}效果如下:

CodePen Demo -- Rough Paper Texture with SVG Filters
你可以在 Sara Soueidan 的一次关于 SVG Filter 的分享上,找到制作它的教程:Youtube -- SVG Filters Crash Course
使用 feTurbulence 滤镜搭配 feDisplacementMap 滤镜,还可以制作一些非常有意思的按钮效果。
尝试实现一些故障风格的按钮,其中一个按钮的代码如下:
<div class="fe1">Button</div>
<div class="fe2">Button</div>
<svg>
<defs>
<filter id="fe1">
<feTurbulence id="animation" type="fractalNoise" baseFrequency="0.00001 9.9999999" numOctaves="1" result="warp">
<animate attributeName="baseFrequency" from="0.00001 9.9999" to="0.00001 0.001" dur="2s" repeatCount="indefinite"/>
</feTurbulence>
<feOffset dx="-90" dy="-90" result="warpOffset"></feOffset>
<feDisplacementMap xChannelSelector="R" yChannelSelector="G" scale="30" in="SourceGraphic" in2="warpOffset"></feDisplacementMap>
</filter>
</defs>
</svg>.fe1 {
width: 200px;
height: 64px;
outline: 200px solid transparent;
}
.fe1:hover {
filter: url(#fe1);
}通过 hover 按钮的时候,给按钮添加滤镜效果,并且滤镜本身带有一个无限循环的动画:

完整的代码你可以戳这里:CodePen Demo - SVG Filter Button Effects
最后,我们回到题图上的云彩效果,使用 feTurbulence 滤镜,我们可以非常逼真的使用 SVG 模拟出真实的云彩效果。
首先,通过随机生成的多重 box-shadow,实现这一一个图形:
<div></div>div {
width: 1px;
height: 1px;
box-shadow: rgb(240 255 243) 80vw 11vh 34vmin 16vmin, rgb(17 203 215) 33vw 71vh 23vmin 1vmin, rgb(250 70 89) 4vw 85vh 21vmin 9vmin, rgb(198 241 231) 8vw 4vh 22vmin 12vmin, rgb(198 241 231) 89vw 11vh 31vmin 19vmin, rgb(240 255 243) 5vw 22vh 38vmin 19vmin, rgb(250 70 89) 97vw 35vh 33vmin 16vmin, rgb(250 70 89) 51vw 8vh 35vmin 14vmin, rgb(17 203 215) 75vw 57vh 40vmin 4vmin, rgb(250 70 89) 28vw 18vh 31vmin 11vmin, rgb(250 70 89) 8vw 89vh 31vmin 2vmin, rgb(17 203 215) 13vw 8vh 26vmin 19vmin, rgb(240 255 243) 98vw 12vh 35vmin 5vmin, rgb(17 203 215) 35vw 29vh 27vmin 18vmin, rgb(17 203 215) 67vw 58vh 22vmin 15vmin, rgb(198 241 231) 67vw 24vh 25vmin 7vmin, rgb(17 203 215) 76vw 52vh 22vmin 7vmin, rgb(250 70 89) 46vw 86vh 26vmin 20vmin, rgb(240 255 243) 50vw 20vh 25vmin 1vmin, rgb(250 70 89) 74vw 14vh 25vmin 16vmin, rgb(240 255 243) 31vw 100vh 29vmin 20vmin
}这个工作,你可以交给 SASS、LESS 或者 JavaScript 这些能够有循环函数能力的语言去生成,它的效果大概是这样:

紧接着,通过 feTurbulence 产生分形噪声图形,使用 feDisplacementMap 进行映射置换,最后给图形叠加上这个滤镜效果。
<svg width="0">
<filter id="filter">
<feTurbulence type="fractalNoise" baseFrequency=".01" numOctaves="10" />
<feDisplacementMap in="SourceGraphic" scale="240" />
</filter>
</svg>div {
filter: url(#filter);
}即可得到这样的云彩效果:

完整的代码,你可以戳这里到袁川老师的 CodePen 观看:Cloud (SVG filter + CSS)
关于 SVG 滤镜入门的第一篇总算差不多了,本文简单的介绍了一下 SVG 滤镜的使用方式以及一些常见的 SVG 滤镜并给出了最简单的一些使用效果,希望大家看完能对 SVG 滤镜有一个简单的认识。
本文罗列的滤镜效果更多的是单个效果或者很少几个组合在一起的效果,实际的使用或者应用到应用场景下其实会是更多滤镜的的组合产生出的一个效果。
后面的文章将会更加细致的去探讨分析多个 SVG 滤镜组合效果,探讨更复杂的排列组合。
文章的题目叫SVG 滤镜从入门到放弃因为 SVG 滤镜学起来确实太繁琐太累了,它不像 CSS 滤镜或者混合模式那么容易上手那么简单。当然也由于 SVG 滤镜的功能非常强大,定制化能力强以及它已经存在了非常之久有关。SVG 滤镜的兼容性也很好,它们其实是早于 CSS3 一些特殊效果之前就已经存在的。
CSS 其实一直在向 SVG 的一些特殊能力靠拢,用更简单的语法让人更易上手,不过 SVG 滤镜还是有其独特的魅力所在。后续将会有更多关于 SVG 滤镜的文章。也希望读到这里的同学不要放弃!
好了,本文到此结束,希望对你有帮助 :)
更多精彩 CSS 技术文章汇总在我的 Github -- iCSS ,持续更新,欢迎点个 star 订阅收藏。
想 Get 到最有意思的 CSS 资讯,千万不要错过我的公众号 -- iCSS前端趣闻 😄
如果还有什么疑问或者建议,可以多多交流,原创文章,文笔有限,才疏学浅,文中若有不正之处,万望告知。
写这篇文章的缘由是因为看到了这个页面:

运用 CSS3 完成的 3D 视角,虽然有一些晕3D,但是使人置身于其中的交互体验感觉非常棒,运用在移动端制作一些 H5 页面可谓十分博人眼球。
并且掌握原理之后制作起来也并不算废力,好好的研究了一番后将一些学习过程共享给大家。下面进入正文。
先直观感受一下上述我所说的效果的简化版本:

这里我使用了带背景色的 Div 作为示例,我们的视角处于一个正方体中,正方体的旋转动画让我们有了 3D 的感觉。
那么原本的图长什么样呢?我们把距离拉远,一探究竟:

静态图如下,是这样的:
相较于第一种效果,其实所做的只是将我们的视角推进到了正方体当中,有了一种身临其景的感觉。
而合理的运用 CSS3 所提供的一些 3D 属性,很容易就能达到上述的效果。
制作这样一个 3D 图形,我在之前的文章已经很详细的讲述了过程,感兴趣的可以戳进去看看:
再简单复述一下,主要是运用到了两个 CSS 属性:
要利用 CSS3 实现 3D 的效果,最主要的就是借助 transform-style 属性。
transform-style 只有两个值可以选择:
// 语法:
transform-style: flat|preserve-3d;
transform-style: flat; // 默认,子元素将不保留其 3D 位置
transform-style: preserve-3d; // 子元素将保留其 3D 位置。当父元素设置了 transform-style:preserve-3d 后,就可以对子元素进行 3D 变形操作了,3D 变形和 2D 变形一样可以,使用 transform 属性来设置,或者可以通过制定的函数或者通过三维矩阵来对元素变型操作:当我们指定一个容器的 transform-style 的属性值为 preserve-3d 时,容器的后代元素便会具有 3D 效果,这样说有点抽象,也就是当前父容器设置了 preserve-3d 值后,它的子元素就可以相对于父元素所在的平面,进行 3D 变形操作。
translateX(length) 、translateY(length)、 translateZ(length) 来进行 3D 位移操作,与 2D 操作一样,对元素进行位移操作,也可以合并为 translate3d(x,y,z) 这种写法;scaleX() 、scaleY() 、scaleY() 来进行3D 缩放操作,也可以合并为 scale3d(number,number,number) 这种写法;rotateX(angle) 、rotateY(angle) 、rotateZ(angle) 来进行 3D 旋转操作,也可以合并为 rotate3d(Xangle,Yangle,Zangle) 这种写法。perspective 的语法如下:
{
perspective: number|none;
}简单来说,当元素没有设置 perspective 时,也就是当 perspective:none/0 时所有后代元素被压缩在同一个二维平面上,不存在景深的效果。perspective 为一个元素设置三维透视的距离,仅作用于元素的后代,而不是其元素本身。
而如果设置 perspective 后,将会看到三维的效果。
我们上面之所以能够在正方体外围看到正方体,以及深入正方体内,都是因为 perspective 这个属性。它让我们能够选择推进视角,还是远离视角,因此便有了 3D 的感觉。
为了完成这样一个效果,需要一个灵活的布局,去控制整个 3D 效果的展示。
下面是我觉得比较好的一种方式:
<!-- 最外层容器,控制图形的位置及在整个页面上的布局-->
<div class="container">
<!-- 舞台层,设置 preserve-3d 与 perspective 视距 -->
<div class="stage">
<!-- 控制层,动画的控制层,通过这一层可以添加旋转动画或者触摸动画 -->
<div class="control">
<!-- 图片层,装入我们要拼接的图片 -->
<div class="imgWrap">
<div class="img img1"></div>
<div class="img img2"></div>
<div class="img img3"></div>
<div class="img img4"></div>
</div>
</div>
</div>
</div>其中:
container ,控制图形的位置及在整个页面上的布局;stage 层,舞台层,从这里开始设置 3D 景深效果,添加 perspective 视距;control 层,动画的控制层,通过这一层可以添加旋转动画或者在移动端的触摸动画,通过更改 translateZ 属性也可以拉近拉远视角;imgWrap 层,图片层,装入我们要拼接的图片,下文会提及。图片拼接其实才是个技术活,需要许多的计算。
以上述 Demo 中的正方体为例子,class 为 img 的 div 块的高宽为 400px*400px。那么要利用 4 个 这样的 div 拼接成一个正方体,需要分别将 4 个 div 绕 Y 轴旋转 [90°, 180°, 270°, 360°],再 translateY(200px) 。
值得注意的是,一定是先旋转角度,再偏移距离,这个顺序很重要。
看看俯视图,也就是这个意思:
这是最简单的情况了,都是直角。
如果是一张图需要分割成八份,假设每张图分割出来的高宽为 400 400 , 8 张图需要做的操作是依次绕 Y 轴旋转 [45°, 90°, 135°, 180°, 225°, 270°, 315°, 360°] ,偏移的距离为 translateY(482.84px) ,也就是 (200 + 200√2)。
看看俯视图:
效果图:

上面的示例都是使用的带背景色的 div 块,现在我们选取一张真正的图片,将其拼接成一个柱体。
下面这张图,大小为 3480px * 2000px :
我们把它分割为 20 份,拼成一个正 20 边形,当然不用一块一块切图下来,利用 background-position 就可以完成了。而且分割的份数越多,最终做出来的效果越像一个圆柱,效果也更加真实。
正 20 边形,需要 20 个 div ,假设容器是 .img-bg1 ~ .img-bg20 ,那么每块图片的宽度为 174px,依次需要递增的角度为 18° ,并且我们需要计算出需要偏移的距离为 translateZ(543px)。
可以利用一些 CSS 预处理器处理这段代码,下面是 Sass 的写法:
// Sass 的写法
$imgCount : 20 !default;
@for $i from 1 through $imgCount {
.img-bg#{$i}{
background-position:($i * -174px + 174px) 0;
transform: rotateY($i * 18deg) translateZ(543px);
}
}看看效果:
可以看到,图中近视为一个圆柱形,不过有一些小问题:
control 层,进入到圆柱画面内做到这一步,只剩下最后一步,就是推进我们的视角,进入到圆柱内部,产生 3D 视图的感觉。
我们通过 class 为 control 这个 div 控制这个效果,不过这里控制我们进入圆柱内部的属性不是调整修改 perspective 属性,而是调整 translateZ 属性。通过控制 translateZ 得到的画面更加真实,可以自己尝试一下分别控制 perspective 与 translateZ 得到的效果,便会有深刻的感受。
最后的效果,整个效果图太大,只截取了部分制作成 GIF:
Demo可以戳这里,Demo -- 3D View
还有一个小问题,那就是进入到圆柱内部之后,整个图片都反了过来,所以我们可能需要利用PS将原图进行一次左右翻转,这样进入内部之后,看到的就是原图效果。
至此,整个页面就算完工了,接下来的就是添加一些 touch 事件,增添一些细节。可能写的过程中遗漏了一些细节,有什么很难一下理解过来的地方可以在评论留言。
好了,本文到此结束,希望对你有帮助 :)
想 Get 到最有意思的 CSS 资讯,千万不要错过我的公众号 -- iCSS前端趣闻 😄
更多精彩 CSS 技术文章汇总在我的 Github -- iCSS ,持续更新,欢迎点个 star 订阅收藏。
如果还有什么疑问或者建议,可以多多交流,原创文章,文笔有限,才疏学浅,文中若有不正之处,万望告知。
更加优质的阅读效果,能看到 CodePen 示例,移步我的博客园:
通常我们说的 Web 动画,包含了三大类。
CSS3 动画javascript 动画(canvas)html 动画(SVG)个人认为 3 种动画各有优劣,实际应用中根据掌握情况作出取舍,本文讨论的是我认为 SVG 中在实际项目中非常有应用价值 SVG 线条动画。
SVG 线条动画,在一些特定的场合下可以解决使用 CSS 无法完成的动画。尤其是在进度条方面,看看最近项目里的一个小需求,一个这种形状的进度条:

把里面的进度条单独拿出来,也就是需要实现这样一个效果:

脑洞大开一下,使用 CSS3 如何实现这样一个进度条呢。
CSS3 是可以做到的,就是很麻烦。但是如果采用 SVG 的话,迎刃而解。
<iframe height='265' scrolling='no' title='不规则进度条' src='//codepen.io/Chokcoco/embed/WogpWd/?height=265&theme-id=0&default-tab=css,result&embed-version=2' frameborder='no' allowtransparency='true' allowfullscreen='true' style='width: 100%;'>See the Pen 不规则进度条 by Chokcoco (@Chokcoco) on CodePen. </iframe>我们假定你在阅读本文的时候有了一定的 SVG 基础,上面代码看看就懂了,好了,本文到此结束。

好吧,还是稍微解释下,上面进度条的主要 SVG 代码如下:
<svg version="1.1" xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" xml:space="preserve" class="circle-load-rect-svg" width="300" height="200" viewbox="0 0 600 400">
<polyline points="5 5, 575 5, 575 200, 5 200" class="g-rect-path"/>
<polyline points="5 5, 575 5, 575 200, 5 200" class="g-rect-fill"/>
</svg>SVG 为何可缩放矢量图形,即SVG,是W3C XML的分枝语言之一,用于标记可缩放的矢量图形。(摘自MDN)
上面代码中,先谈谈 svg 标签:
version: 表示 <svg> 的版本,目前只有 1.0,1.1 两种xmlns:http://www.w3.org/2000/svg 固定值xmlns:xlink:http://www.w3.org/1999/xlink 固定值xml:space:preserve 固定值,上述三个值固定,表示命名空间,当数据单独存在svg文件内时,这3个值不能省略class:就是我们熟悉的 classwidth | height: 定义 svg 画布的大小viewbox: 定义了画布上可以显示的区域,当 viewBox 的大小和 svg 不同时,viewBox 在屏幕上的显示会缩放至 svg 同等大小(暂时可以不用理解)有了 svg 标签,我们就可以愉快的在内部添加 SVG 图形了,上面,我在 svg 中定义了两个 polyline 标签。
SVG 基本形状polyline:是SVG的一个基本形状,用来创建一系列直线连接多个点。
其实,polyline 是一个比较不常用的形状,比较常用的是path,rect,circle 等。这里我使用 polyline 的原因是需要使用 stroke-linejoin 和 stroke-linecap 属性,在线段连接处创建圆滑过渡角。
SVG 中定义了一些基本形状:

SVG 线条动画好,终于到本文的重点了。

上面,我们给两个 polyline 都设置了 class,SVG 图形的一个好处就是部分属性样式可以使用 CSS 的方式书写,更重要的是可以配合 CSS 动画一起使用。
上面,主要的 CSS 代码:
.g-rect-path{
fill: none;
stroke-width:10;
stroke:#d3dce6;
stroke-linejoin:round;
stroke-linecap:round;
}
.g-rect-fill{
fill: none;
stroke-width:10;
stroke:#ff7700;
stroke-linejoin:round;
stroke-linecap:round;
stroke-dasharray: 0, 1370;
stroke-dashoffset: 0;
animation: lineMove 2s ease-out infinite;
}
@keyframes lineMove {
0%{
stroke-dasharray: 0, 1350;
}
100%{
stroke-dasharray: 1350, 1350;
}
}这尼玛是什么 CSS?怎么除了 animation 全都不认识? 
莫慌,其实很多和 CSS 对比一下非常好理解,只是换了个名字:
fill:类比 css 中的 background-color,给 svg 图形填充颜色;stroke-width:类比 css 中的 border-width,给 svg 图形设定边框宽度;stroke:类比 css 中的 border-color,给 svg 图形设定边框颜色;stroke-linejoin | stroke-linecap:上文稍微提到过,设定线段连接处的样式;stroke-dasharray:值是一组数组,没数量上限,每个数字交替表示划线与间隔的宽度;stroke-dashoffset:则是虚线的偏移量重点讲讲能够实现线条动画的关键属性 stroke-dasharray 。
上面,填充进度条,使用了下面这个动画 :
@keyframes lineMove {
0%{
stroke-dasharray: 0, 1350;
}
100%{
stroke-dasharray: 1350, 1350;
}
}stroke-dasharray: 0, 1350;,表示线框短划线和缺口的长度分别为 0 和 1350,所以一开始整个图形都是被缺口占据,所以是在视觉效果上长度为 0。
然后过渡到 stroke-dasharray: 1350, 1350,表示线框短划线和缺口的长度分别为 1350 和 1350,因为整个图形的长度就是 1350,所以整个进度条会被慢慢填充满。
掌握了这个技巧后,就可以使用 stroke-dasharray 和 stroke-dashoffset 制作很多不错的交互场景:
SVG 线条动画实现按钮交互
SVG 线条动画实现圆形进度条SVG 图形线条动画配合之前我司一个 h5 里面应用过的,多SVG 图形线条动画配合,可以制作一些比较酷炫的动画,很有科技感。

本文到此结束,我在我的 Github 上,使用 SVG 实现了一些图形 -- SVG奇思妙想,Demo可以戳这里。
下篇文章将会详述非规则图形,如何使用 PS + AI 生成 path 路径,实现 SVG 动画,放个 Demo,敬请期待。

A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.















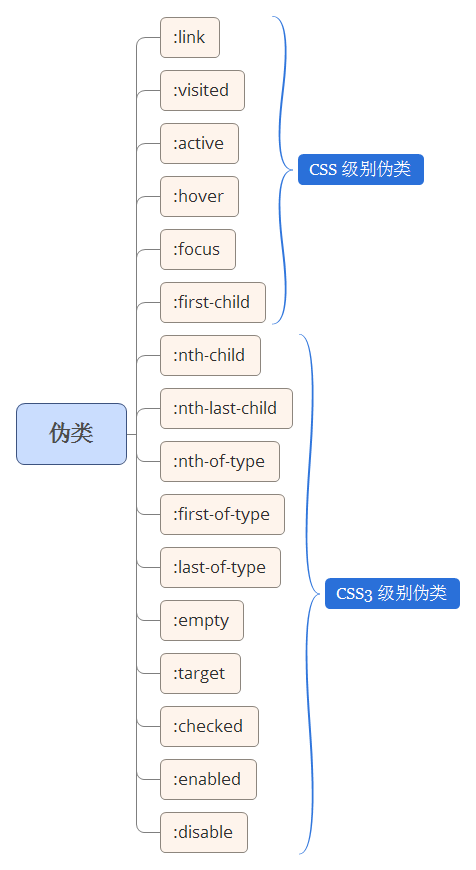
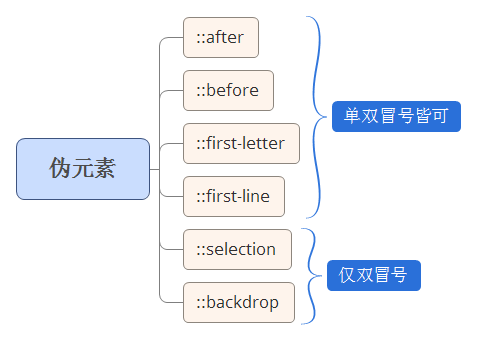

























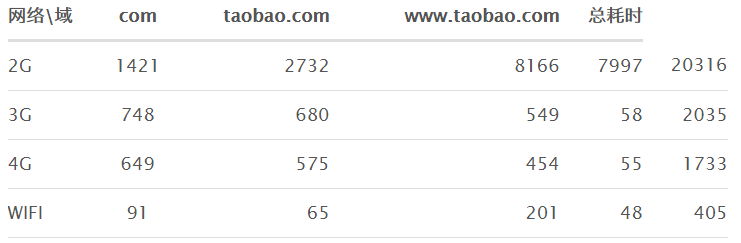

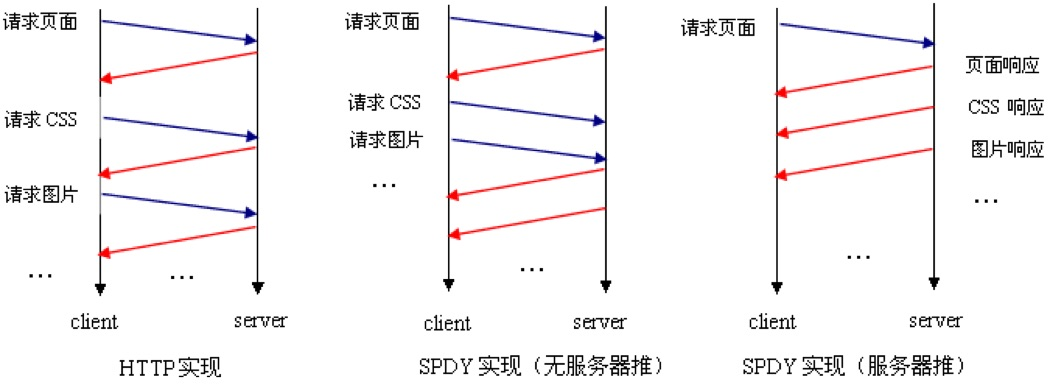





































{kind=link}