brave / adblock-rust Goto Github PK
View Code? Open in Web Editor NEWBrave's Rust-based adblock engine
License: Mozilla Public License 2.0
Brave's Rust-based adblock engine
License: Mozilla Public License 2.0
The blocker is not working under multiple rules with hostname regex.
For example, rules like
" ||alimc*.top^$domain=letv.com
||aa*.top^$domain=letv.com",
url like "https://r.alimc1.top/test.js" with domain "https://minisite.letv.com", which should matches but actually not.
I have figured out that the histogram of the tokens give the first fiter ("||alimc*.top^$domain=letv.com") the least count token "alimc", and url has the token "alimc1", so will not pick the bucket which contains the filter, then match failed.
I've tried to fix this by not recording the hostname of the filters with type of IS_HOSTNAME_REGEX .
In file network.rs:721
if !self.mask.contains(NetworkFilterMask::IS_HOSTNAME_REGEX) {
if let Some(hostname) = self.hostname.as_ref() {
let mut hostname_tokens = utils::tokenize(&hostname);
tokens.append(&mut hostname_tokens);
}
}
Related brave-core work - brave/brave-core#6632
The Brave browser has previously returned an empty response with HTTP 200 for blocked requests, and used the $explicitcancel option to actually fail the requests. While this is a cool unique capability offered by integrating the adblocker inside a browser rather than as an extension, it actually forces more maintenance overhead because most community adblock lists are not built with this behavior in mind. Some scripts have different behavior when a particular network request is blocked rather than successful with an empty body.
We're updating Brave to always cancel the requests, just like other adblockers - which means the $explicitcancel option has no meaning and should be removed.
Switch the VN filter list from Fanboy's to ABPVN, re https://www.reddit.com/r/brave_browser/comments/cjawig/suggestion_about_vietnamese_filters_list_on/ and conversation with @ryanbr
Calling check_network_urls with an empty source_url causes domain constrained rules, that has both negative plus positive, to match no matter what.
The problem is in check_options function in network.rs. The following code:
if let Some(included_domains) = filter.opt_domains.as_ref() {
if let Some(source_hashes) = request.source_hostname_hashes.as_ref() {
// If the union of included domains is recorded
if let Some(included_domains_union) = filter.opt_domains_union {
// If there isn't any source hash that matches the union, there's no match at all
if source_hashes.iter().all(|h| h & included_domains_union != *h) {
return false
}
}
if source_hashes.iter().all(|h| !utils::bin_lookup(&included_domains, *h)) {
return false
}
}
}
if let Some(excluded_domains) = filter.opt_not_domains.as_ref() {
if let Some(source_hashes) = request.source_hostname_hashes.as_ref() {
// If the union of excluded domains is recorded
if let Some(excluded_domains_union) = filter.opt_not_domains_union {
// If there's any source hash that matches the union, check the actual values
if source_hashes.iter().any(|h| (h & excluded_domains_union == *h) && utils::bin_lookup(&excluded_domains, *h)) {
return false
}
} else if source_hashes.iter().any(|h| utils::bin_lookup(&excluded_domains, *h)) {
return false
}
}
}Imagine the following use case
|http://$image,domain=domain.com|~sub.domain.com
This rule should match on images, coming from the domain domain.com with an exclusion for sub.domain.com.
The following check should pass, but it will block:
adblocker.check_network_urls(
url="http://some-website.com/image.jpg",
source_url="",
request_type="image",
)The solution should be and exclusion in the if statement. If there are domains inside filter.opt_domains and there is no request.source_hostname_hashes, it should never match.
This issue was previously listed at the bottom of the README. I've moved this to an issue to centralize TODO items.
Port existing ad-block tests to ensure no regressions from that engine:
https://github.com/brave/ad-block/blob/master/test/parser_test.cc
I want to deserialize the dat file to get the list, but the code doesn't provide an interface.
What should I do?
thanks!
As a forcing function to get us to keep pushing changes upstream, and to improve web compat, adblock-rust should by default use the exact same set of lists uBO does, plus braves single additions list.
So the full set of lists would be:
If just a TLD is specified in an adblock rule, e.g. ||foo.org$domain=com, requests from that TLD never match to it. Brave is interested in protecting users users from websites accessing local domains, and this is causing issues with the .local TLD.
Requests should be checked against all segments up to and including the TLD.
Is it ever correct to "split" a multi-segmented TLD, or should they always be treated atomically? For example, should it be possible to write a rule with $domain=uk that will match on the co.uk TLD?
Support for the new abort-on-stack-trace scriptlet
From the related talk: AdguardTeam/Scriptlets#82
brave/uBlock@b735ac6
brave/uBlock@793e2c7
brave/uBlock@365b3f7
From https://adblockplus.org/filter-cheatsheet
Example rules Domain selection example.com##selector Active on, for example: Not active on:
http://example.com/ftp://subdomain.example.com/
- All other domains, including
http://example.edu/ftp://example.net/
An issue occurred where toolforge.org##+js(abort-on-property-read, noAdBlockers) wasn't being applied on https://pageviews.toolforge.org/?project=en.wikipedia.org&platform=all-access&agent=user&redirects=0&range=latest-20&pages=RStudio.
As it turns out, toolforge.org is actually a private TLD, and the rule should probably be made more specific. However, this is currently a difference from uBlock Origin, which would still apply the rule.
adblock-rust should be updated to match these cosmetic rules by arbitrary hostname segments, rather than being aware of the domain/TLD hierarchy.
Hello. Is this library thread safe? I'm using this library together with adblock-rust-ffi from Brave's repository and so far it was working well until I hit some crashes. Upon investigation I have achieved 100% reproducability when simply querying the engine_match(...) in a multithreaded code. I fixed this crash in my code by simply locking a mutex around engine_match(...)
It may just be that the library is not thread safe - given examples are of a single threaded code. Maybe my assumptions were just wrong :)
Crash details:
thread '<unnamed>' panicked at 'already borrowed: BorrowMutErrorthread '<unnamed>thread '<unnamed>' panicked at '' panicked at 'already borrowed: BorrowMutErroralready borrowed: BorrowMutErrorthread '<unnamed>thread '', <unnamed>' panicked at '', /rustc/a74d1862d4d87a56244958416fd05976c58ca1a8/src/libcore/cell.rs:-> 50
thread '/rustc/a74d1862d4d87a56244958416fd05976c58ca1a8/src/libcore/cell.rs878::878:9already borrowed: BorrowMutError
', /rustc/a74d1862d4d87a56244958416fd05976c58ca1a8/src/libcore/cell.rs:', 9878-> 51
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
' panicked at ':already borrowed: BorrowMutError', -> 52
/rustc/a74d1862d4d87a56244958416fd05976c58ca1a8/src/libcore/cell.rs:878:9
9
<unnamed>/rustc/a74d1862d4d87a56244958416fd05976c58ca1a8/src/libcore/cell.rs' panicked at 'already borrowed: BorrowMutError', /rustc/a74d1862d4d87a56244958416fd05976c58ca1a8/src/libcore/cell.rs:878:9
:878:9
SIGABRT: abort
PC=0x7fff6f4be2c2 m=9 sigcode=0
...
Currently, adblock-rust only deals with network filtering. There is no mechanism for parsing cosmetic rules and applying them in an efficient manner to pages as they load.
I'm currently working on integrating Brave's adblocker in Qutebrowser. See qutebrowser/qutebrowser#5317. I have a few questions regarding the BlockerResult struct:
pub struct BlockerResult {
pub matched: bool,
pub explicit_cancel: bool,
pub important: bool,
pub redirect: Option<String>,
pub exception: Option<String>,
pub filter: Option<String>,
pub error: Option<String>,
}None?redirect is set to Some(url) when the browser should redirect the request somewhere else?matched is true, does that mean that the browser should block the request?explicit_cancel and important?Thank you very much for your help!
Need to return a flag indicating that a request should be explicitly cancelled
Follow the logic of brave/ad-block brave-experiments/ad-block@d9377e2
The rule |ws://$domain=4shared.com should block all websocket connections made from pages on the domain 4shared.com. However, this rule ends up blocking all requests made from those pages.
The FROM_HTTP and FROM_HTTPS flags should not be set on network filters if a left-anchored ws:// protocol is specified.
See the build log for the newly released 0.2.7: https://docs.rs/crate/adblock/0.2.7/builds/237004
It contains the error message:
[INFO] [stderr] error: proc-macro derive panicked
[INFO] [stderr] --> /opt/rustwide/cargo-home/registry/src/github.com-1ecc6299db9ec823/psl-0.4.1/src/list.rs:6:10
[INFO] [stderr] |
[INFO] [stderr] 6 | #[derive(Psl, Copy, Clone, Eq, PartialEq, Ord, PartialOrd, Hash, Debug, Default)]
[INFO] [stderr] | ^^^
[INFO] [stderr] |
[INFO] [stderr] = help: message: failed to download the list: failed to lookup address information: Temporary failure in name resolution
[INFO] [stderr]
[INFO] [stderr] error[E0599]: no method named `domain` found for struct `list::List` in the current scope
[INFO] [stderr] --> /opt/rustwide/cargo-home/registry/src/github.com-1ecc6299db9ec823/psl-0.4.1/src/list.rs:28:20
[INFO] [stderr] |
[INFO] [stderr] 7 | pub struct List;
[INFO] [stderr] | ---------------- method `domain` not found for this
[INFO] [stderr] ...
[INFO] [stderr] 28 | match List.domain(input) {
[INFO] [stderr] | ^^^^^^ method not found in `list::List`
[INFO] [stderr] |
[INFO] [stderr] = help: items from traits can only be used if the trait is implemented and in scope
[INFO] [stderr] note: `Psl` defines an item `domain`, perhaps you need to implement it
[INFO] [stderr] --> /opt/rustwide/cargo-home/registry/src/github.com-1ecc6299db9ec823/psl-0.4.1/src/lib.rs:48:1
[INFO] [stderr] |
[INFO] [stderr] 48 | pub trait Psl {
[INFO] [stderr] | ^^^^^^^^^^^^^
[INFO] [stderr]
[INFO] [stderr] error[E0599]: no method named `suffix` found for struct `list::List` in the current scope
[INFO] [stderr] --> /opt/rustwide/cargo-home/registry/src/github.com-1ecc6299db9ec823/psl-0.4.1/src/list.rs:51:20
[INFO] [stderr] |
[INFO] [stderr] 7 | pub struct List;
[INFO] [stderr] | ---------------- method `suffix` not found for this
[INFO] [stderr] ...
[INFO] [stderr] 51 | match List.suffix(input) {
[INFO] [stderr] | ^^^^^^ method not found in `list::List`
[INFO] [stderr] |
[INFO] [stderr] = help: items from traits can only be used if the trait is implemented and in scope
[INFO] [stderr] note: `Psl` defines an item `suffix`, perhaps you need to implement it
[INFO] [stderr] --> /opt/rustwide/cargo-home/registry/src/github.com-1ecc6299db9ec823/psl-0.4.1/src/lib.rs:48:1
[INFO] [stderr] |
[INFO] [stderr] 48 | pub trait Psl {
[INFO] [stderr] | ^^^^^^^^^^^^^
[INFO] [stderr]
[INFO] [stderr] error: aborting due to 3 previous errors
[INFO] [stderr]
[INFO] [stderr] For more information about this error, try `rustc --explain E0599`.
[INFO] [stderr] error: could not compile `psl`.
[INFO] [stderr]
[INFO] [stderr] To learn more, run the command again with --verbose.
[INFO] [stderr] warning: build failed, waiting for other jobs to finish...
[INFO] [stderr] error: build failed
[INFO] running `"docker" "inspect" "1a583d3b205a1d35ca294c083e029718f790f76ef98f367be6181f879fdfafe8"`
[INFO] running `"docker" "rm" "-f" "1a583d3b205a1d35ca294c083e029718f790f76ef98f367be6181f879fdfafe8"`
[INFO] [stdout] 1a583d3b205a1d35ca294c083e029718f790f76ef98f367be6181f879fdfafe8
Currently the set of filter lists served in the Brave browser are compiled into adblock-rust, and maintained in this repository. While adblock-rust is usable without those lists, we'd like to make adblock-rust as supportive as possible of community usage. Moving them out would make the library more generic, and limits the version bump churning.
Ideally, they can go into https://github.com/brave/adblock-resources, which is already used to host custom webcompat scriptlets for Brave. They'll need to be served as a "catalog" of regional filters along with the default set of lists before they can be fully removed from this repository.
I am an ex-Safari user who switched to Brave once Apple neutered extension support (which is purported to be coming back using WebExtensions). I’ve been reading up in detail about how Apple implements Intelligent Tracking Protection in WebKit, the open-source counterpart to Safari (akin to Chromium for Google Chrome). ITP uses statistical methods to classify third-party domains as trackers, and gradually reduce their access to the user‘s browser the longer the user has gone without visiting their domain directly.
For those interested, I found a 2017 Apple blog post about the technology that does a pretty good job of explaining the feature, and why it works so well. The following snippet is of particular interest:
Out of the various statistics collected, three vectors turned out to have strong signal for classification based on current tracking practices: subresource under number of unique domains, sub frame under number of unique domains, and number of unique domains redirected to.
If the user has not interacted with example.com in the last 30 days, example.com website data and cookies are immediately purged and continue to be purged if new data is added.
However, if the user interacts with example.com as the top domain, often referred to as a first-party domain, Intelligent Tracking Prevention considers it a signal that the user is interested in the website and temporarily adjusts its behavior as depicted in this timeline:
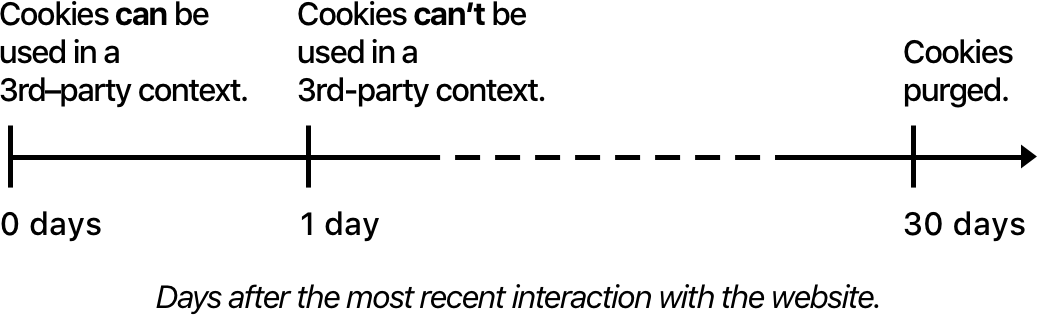
If the user interacted with example.com the last 24 hours, its cookies will be available when example.com is a third-party. This allows for “Sign in with my X account on Y” login scenarios.
On the technical side, I found a page of documentation, and the feature’s location within the mirrored source tree. (Here is the Trac viewer for the original repository.)
To the best of my knowledge, that portion of WebKit’s source is licensed under a BSD-like license, while this repository is licensed under the MPL, as per Rust rules I presume. I’m not as familiar with cross-licensing as I’d like, but perhaps it would be possible to learn from Apple’s technology and incorporate something like Intelligent Tracking Protection in Brave? In the meantime, I am doubling up on Brave’s tracking protection using Privacy Badger.
Hi, our website speakol.com is listed in the blocked domains as "||speakol.com^$third-party".
While we are serving ads through the platform, the website itself doesn't contain ads. This is badly impacting the user experience as our users can't access their dashboards (advertisers.speakol.com) when using brave browser. Could you please help out with explaining the reason and how to overcome this?
Examples:
adv$domain=example.com|~foo.example.com should match:
http://example.net/adv from source http://example.combut not match:
http://example.net/adv from source http://foo.example.comhttp://example.net/adv", from source http://www.foo.example.comadv$domain=~example.com|foo.example.com should match:
http://example.net/adv from source http://foo.example.comhttp://example.net/adv", from source http://www.foo.example.combut not match:
http://example.net/adv from source http://example.comUnicode not always properly handled, crashing on \##+js(,ݍ (uncovered with fuzzing in #80)
Current WIP-branch for fuzz-testing uncovered issues is fuzzing
Currently, adblock-rust only accepts ABP/uBO-style filter rule list formats. It would be useful to support other list formats as well, such as those used for hostname-level blocking.
This would likely entail creating a new enum of supported formats, which can be used to add annotations to our existing list library and be used as a parameter in parsing methods to signal how adblock-rust should interpret the input.
By nature of being an adblocking library, the primary use case for adblock-rust is for it to be embedded within a browser. Browsers already ship with a lot of network primitives and utilities; including adblock-rust as a dependency should not require fetching and including a unique instance of the large list of top-level domains used for domain name parsing.
It should be possible to run adblock-rust without the dependency on psl. eTLD+1 parsing behavior should be possible to access from an external source, likely through a callback mechanism.
Of course, adblock-rust has valid use-cases outside of the browser, and it should still be possible to retain the current behavior with an embedded psl dependency.
Currently there is no difference between trailing ^ and | characters on network rules, e.g. the parsed version fo the ||gateway.reddit.com| rule from EasyPrivacy is indistinguishable from a hypothetical ||gateway.reddit.com^ rule.
A request to https://gateway.reddit.com/example.html should be allowed by the first rule and blocked by the second. Currently both rules block this request.
Currently adblock-rust treats any redirect filters distinctly from blocking filters, and important is used as a precedence-increase for any kinds of rules. It appears uBO has slightly different semantics for these two options, and we should make sure we are treating both the same way.
uBlockOrigin/uBlock-issues#1224 has more details.
Since youtube has a specifically target css ad element, youtube.com##ytd-display-ad-renderer:upward(2) in brave/brave-browser#11955
Filters.txt (Upward 39 lines, nth-of-type: 26 lines)
Filters-2020.txt (Upward 10 lines, nth-of-type: 10 lines)
A simple cargo fmt (a community auto formatter for Rust) results in around 3000 additions and less than 2000 deletions across 34 files.
rustfmt, which cargo uses for the fmt command, can be customized with a rustfmt.toml in the repository root which can contain 0 or more options listed here.
If formatting changes are to be kept to a minimum, custom formatting would need to be specified via a rustfmt.toml file. Otherwise, to go with the community standard, no file is needed, but all the roughly 5000 line changes would need to be applied.
ABP Japanese filters has a lot of bugs and Japanese ad-blocking users often use 280blocker (https://280blocker.net/files/280blocker_adblock.txt) or mochi filter (https://pokapoka.shoooter.net/) instead.
They are also updated frequently, so consider changing it.
Or add a feature like ublock origin that lets users subscribe to and sync their favorite ad filters. (Related Issue: brave/browser-laptop#9711)
In the following Python code, I call Engine's add_filter_list method on the string contents of each downloaded block list.
try:
download.fileobj.seek(0)
text = io.TextIOWrapper(download.fileobj, encoding="utf-8")
self._engine.add_filter_list(text.read())
text.close()
except UnicodeDecodeError:
message.info("Block list is not valid utf-8")
finally:
download.fileobj.close()When I run said code on a few popular blocklists, the console is filled with Filter already exists:
...
Filter already exists
Filter already exists
Filter already exists
Filter already exists
Filter already exists
Filter already exists
17:14:30 INFO: Block lists have been successfully imported
Those particular messages come from src/engine.rs#L166 where the library prints to the console in case of an error. I'm personally not a fan of this kind of "logging", since there's no way for me as a consumer of the library to tell it not to print to the console.
@AndriusA Do you agree that another method of logging errors should be used? If so, what would be your preferred alternative approach? I'd be happy to make a PR.
I've tried to share an instance of Engine across threads and encountered that it can not be shared across threads as it is not thread-safe. Can you please replace Rc and RefCell with Arc and RwLock/Mutex so we can use this library in threads? Thanks!
uBo extends Adblock Plus filter syntax with the badfilter option to disable an existing filter. Sometimes, disabling an existing blocking filter is better than creating an exception filter: https://github.com/gorhill/uBlock/wiki/Static-filter-syntax#badfilter
For example we've seen issues caused for youtube videos by the EasyPrivacy rule /log_event?. Which in uBo unbreak list is disabled with /log_event?$badfilter.
Copied over from brave-experiments/ad-block#113
This would help squeeze out some more stuff out of the some of the filters that are already used and it would make it possible to implement even more filters in the future. The new syntax is an extension of ABP Filter Syntax and should (in theory) not be too hard to implement. More info on it can be found here: https://github.com/gorhill/uBlock/wiki/Static-filter-syntax#extended-syntax
In general, there is some value in supporting ABP specific additions, more so on network rules but possibly on cosmetic rules too. Low priority but would be "nice to have"
A few options are not currently handled from easylist and easyprivacy:
popup - Include pages opened in a new tab or windowgenerichide - Used to prevent applying global element rules on a page (e.g. @@||example.com^$generichide)document - Used to whitelist the page itself (e.g. @@||example.com^$document)webrtc - Include or exclude connections opened via RTCPeerConnection instances to ICE serverselemhide - Used to prevent element rules from applying on a page (e.g. @@||example.com^$elemhide)genericblock - Used to prevent applying global blocking rules on a page (e.g. @@||example.com^$genericblock)I've noticed that twitch ads still show up on brave with shields on. However ublock Origin does block twitch ads.
Version: Version 1.8.86 Chromium: 81.0.4044.129 (Official Build) unknown (64-bit)
Doesn't block twitch ads on linux and windows.
YouTube ads appear without the possibility of being skipped. Cleaning browsing data (cache, cookies, whatever else) doesn't work.
The issue started about 10 days ago.
The only way to skip the ads is reloading the website.
Similar, but distinct to #27, would be neat if uBO could handle cases like this:
https://github.com/gorhill/uBlock/wiki/Static-filter-syntax#scriptlet-injection
https://github.com/brave/adblock-rust/blob/master/src/filters/network.rs#L1020
This method always go out of bounds if find_str(url, hostname) condition is not met.
A bounds check or an early return method with better fallback should be added to prevent it
Currently, IPv6 addresses in network rules must be surrounded with square brackets. This doesn't match the IPv6 spec, which only surrounds them in square brackets as part of a resource identifier - but more importantly, it doesn't match the behavior of other adblockers, which leave off the square brackets.
I would love the ability to add in a pre-existing filter which will add pages and keep itself updated, just like I can in ublock. So far there is no mechanism to do this under the current Brave Adblock page, unless we individually copy and paste the sites into the free text box.
We already support the $tag option on network filters, to conditionally enable or disable certain sets of rules based on a boolean engine configuration. It would be great to support these on cosmetic rules as well, at least for scriptlets.
Cosmetic rules currently don't have anywhere to specify filter options, so we'd have to introduce new syntax for this.
HTML filters are rare, but a category of their own, separate from network and from cosmetic filters.
E.g. example.org$$script[data-src="banner"] should delete script element with matching data-src attribute
Currently lifeguard is using a language feature that has been deprecated since Rust 1.39, which is technically a source of undefined behavior.
This is detected at runtime as of 1.49.0-nightly, which causes runtime panics during network rule matching:
'attempted to leave type `std::mem::ManuallyDrop<std::vec::Vec<u64>>` uninitialized, which is invalid'
lifeguard should be updated as soon as a version with the fix is published.
Relevant lifeguard issue: zslayton/lifeguard#25
Copied demo example.
Downloaded rule lists and got an error:
index.js:10
client.updateResources(resources);
^
Error: Error(Msg("invalid type: string \"image/gif\", expected a borrowed string"), State { next_error: None, backtrace: InternalBacktrace { backtrace: None } })
at Object.<anonymous> (index.js:10:8)
at Module._compile (module.js:643:30)
at Object.Module._extensions..js (module.js:654:10)
at Module.load (module.js:556:32)
at tryModuleLoad (module.js:499:12)
at Function.Module._load (module.js:491:3)
at Function.Module.runMain (module.js:684:10)
at startup (bootstrap_node.js:187:16)
at bootstrap_node.js:608:3
After getting it, I tried many versions of uBlock libs from repo: https://github.com/gorhill/uBlock with no success.
Right now the lib prints errors out (e.g. Error parsing request, returning no match) but doesn't show the error to the calling code. This seems like kinda a worst of all words situation.
It would be better to change the api to allow the caller to (optionally) receive feedback if an error occurred, and print nothing (since my code has no way of replying to the error anyway). Possibly an optional throw exception on error parameter for any option that might have such an error?
uBO defines polyfills, or alternate content bodies that should be returned for resources from a URL that matches a pattern. The bodies of these responses, and identifiers for them, are given here:
https://github.com/uBlockOrigin/uAssets/blob/master/filters/resources.txt
Rules then reference these polyfils with the redirect=<identifier> option on rules.
It would be good if adblock-rust both could
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.