100steps / blogs Goto Github PK
View Code? Open in Web Editor NEW:green_apple: 创新,只为与你分享。
:green_apple: 创新,只为与你分享。

















































































































































一堆废话
前前后后几个星期都在看理论,所以趁着放小长假就搭了一下 hadoop 的环境,虽然教程一抓一大把,但是对于 Mac 上的伪分布搭建基本都是不怎么能跑的,各种博客都是互相转载,所以在撸了一部分官方文档之后,结合一些有点用的博客,总算是把这个环境打好了,正所以环境都不会搭,还谈什么开发,也是为了防止自己玩崩 hadoop 忘了怎么装,就写了这个,有兴趣的也可以考虑坑一下,对于 Linux 的话,教程很多,如果有时间,会再出一篇,各位看官往下看吧。
Mac OS X EI Captian 10.11.4
java version "1.8.0_77"
Hadoop 2.7.2
Xcode 7.3
Homebrew 0.9.5
打开<终端>窗口, 粘贴以下脚本
/usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
Oracle 官网下载 JDK8 的 Mac OS X 安装包:Java SE Downloads
打开下载的 dmg 文件,双击包中的 pkg 文件进行安装
打开<终端>,输入
java -version
显示为
java version "1.8.0_77"
Java(TM) SE Runtime Environment (build 1.8.0_77-b03)
Java HotSpot(TM) 64-Bit Server VM (build 25.77-b03, mixed mode)
JDK目录为
/Library/Java/JavaVirtualMachines/jdk1.8.0_77.jdk/Contents/Home
打开 App Store 进行下载
PS:速度可能不是很快,但是官方的还是很安全
为了保证远程登录管理 Hadoop 及 Hadoop 节点用户共享的安全性,Hadoop 需要配置使用 SSH 协议
打开系统偏好设置-共享-远程登录-允许访问-所有用户
打开<终端>,分别输入
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub >>~/.ssh/authorized_keys
配置好之后,输入
ssh localhost
显示
Last login: Mon Apr 4 15:30:53 2016
或者类似时间信息,即配置完成
<终端>输入
brew install hadoop
显示如下即安装成功
==> Downloading https://www.apache.org/dyn/closer.cgi?path=hadoop/common/hadoop-
==> Best Mirror http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.7.2/hadoop-
######################################################################## 100.0%
==> Caveats
In Hadoop's config file:
/usr/local/Cellar/hadoop/2.7.2/libexec/etc/hadoop/hadoop-env.sh,
/usr/local/Cellar/hadoop/2.7.2/libexec/etc/hadoop/mapred-env.sh and
/usr/local/Cellar/hadoop/2.7.2/libexec/etc/hadoop/yarn-env.sh
$JAVA_HOME has been set to be the output of:
/usr/libexec/java_home
==> Summary
? /usr/local/Cellar/hadoop/2.7.2: 6,304 files, 309.8M, built in 2 minutes 43 seconds
<终端>输入
open /usr/local/Cellar/hadoop/2.7.2/libexec/etc/hadoop/hadoop-env.sh
将
export HADOOP_OPTS="$HADOOP_OPTS -Djava.net.preferIPv4Stack=true"
修改为
export HADOOP_OPTS="$HADOOP_OPTS -Djava.net.preferIPv4Stack=true -Djava.security.krb5.realm= -Djava.security.krb5.kdc="
<终端>输入
open /usr/local/Cellar/hadoop/2.7.2/libexec/etc/hadoop/yarn-env.sh
加入
YARN_OPTS="$YARN_OPTS -Djava.security.krb5.realm=OX.AC.UK -Djava.security.krb5.kdc=kdc0.ox.ac.uk:kdc1.ox.ac.uk"
<终端>输入
open /usr/local/Cellar/hadoop/2.7.2/libexec/etc/hadoop/core-site.xml
编辑
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<终端>输入
open /usr/local/Cellar/hadoop/2.7.2/libexec/etc/hadoop/hdfs-site.xml
编辑
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<终端>依次输入
cp /usr/local/Cellar/hadoop/2.7.2/libexec/etc/hadoop/mapred-site.xml.template /usr/local/Cellar/hadoop/2.7.2/libexec/etc/hadoop/mapred-site.xml
open /usr/local/Cellar/hadoop/2.7.2/libexec/etc/hadoop/mapred-site.xml
编辑
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<终端>输入
open /usr/local/Cellar/hadoop/2.7.2/libexec/etc/hadoop/yarn-site.xml
编辑
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<终端>输入
rm -rf /tmp/hadoop-tanjiti #如果之前安装过需要清除
hadoop namenode -format
找到sbin目录
cd /usr/local/Cellar/hadoop/2.7.2/sbin
./start-dfs.sh
./start-yarn.sh
jps
结果
6467 Jps
5991 DataNode
6343 NodeManager
6106 SecondaryNameNode
6251 ResourceManager
5901 NameNode
测算pi值的实例
hadoop jar /usr/local/Cellar/hadoop/2.7.2/libexec/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar pi 2 5
结果
Number of Maps = 2
Samples per Map = 5
16/04/04 16:34:51 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Wrote input for Map #0
Wrote input for Map #1
Starting Job
16/04/04 16:34:52 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
16/04/04 16:34:53 INFO input.FileInputFormat: Total input paths to process : 2
16/04/04 16:34:53 INFO mapreduce.JobSubmitter: number of splits:2
16/04/04 16:34:53 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1459758345965_0002
16/04/04 16:34:53 INFO impl.YarnClientImpl: Submitted application application_1459758345965_0002
16/04/04 16:34:53 INFO mapreduce.Job: The url to track the job: http://mbp.local:8088/proxy/application_1459758345965_0002/
16/04/04 16:34:53 INFO mapreduce.Job: Running job: job_1459758345965_0002
16/04/04 16:34:59 INFO mapreduce.Job: Job job_1459758345965_0002 running in uber mode : false
16/04/04 16:34:59 INFO mapreduce.Job: map 0% reduce 0%
16/04/04 16:35:06 INFO mapreduce.Job: map 100% reduce 0%
16/04/04 16:35:12 INFO mapreduce.Job: map 100% reduce 100%
16/04/04 16:35:12 INFO mapreduce.Job: Job job_1459758345965_0002 completed successfully
16/04/04 16:35:12 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=50
FILE: Number of bytes written=353319
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=526
HDFS: Number of bytes written=215
HDFS: Number of read operations=11
HDFS: Number of large read operations=0
HDFS: Number of write operations=3
Job Counters
Launched map tasks=2
Launched reduce tasks=1
Data-local map tasks=2
Total time spent by all maps in occupied slots (ms)=7821
Total time spent by all reduces in occupied slots (ms)=2600
Total time spent by all map tasks (ms)=7821
Total time spent by all reduce tasks (ms)=2600
Total vcore-milliseconds taken by all map tasks=7821
Total vcore-milliseconds taken by all reduce tasks=2600
Total megabyte-milliseconds taken by all map tasks=8008704
Total megabyte-milliseconds taken by all reduce tasks=2662400
Map-Reduce Framework
Map input records=2
Map output records=4
Map output bytes=36
Map output materialized bytes=56
Input split bytes=290
Combine input records=0
Combine output records=0
Reduce input groups=2
Reduce shuffle bytes=56
Reduce input records=4
Reduce output records=0
Spilled Records=8
Shuffled Maps =2
Failed Shuffles=0
Merged Map outputs=2
GC time elapsed (ms)=196
CPU time spent (ms)=0
Physical memory (bytes) snapshot=0
Virtual memory (bytes) snapshot=0
Total committed heap usage (bytes)=547356672
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=236
File Output Format Counters
Bytes Written=97
Job Finished in 20.021 seconds
Estimated value of Pi is 3.60000000000000000000
其实配置起来,如果按照上面的话,其实很快,但摸索的时候坑多,网速什么,路径什么,没事就会崩一崩。
环境搭好,继续撸理论,与一些也做这个的朋友们讨论了一下,还是要补一下统计学的知识,如果部门谁有兴趣,可以试一试哦。
Trie树,又称单词查找树、字典树,从字面意思即可理解,这种树的结构像英文字典一样,相邻的单词一般前缀相同,是一种用于快速检索的多叉树结构。典型应用是用于统计和排序大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。之所以时间复杂度低,是因为其采用了以空间换取时间的策略。
举个栗子:Trie树可以利用字符串的公共前缀来节约存储空间。如下图所示,该trie树用10个节点保存了6个字符串tea,ten,to,in,inn,int:
在该trie树中,字符串in,inn和int的公共前缀是“in”,因此可以只存储一份“in”以节省空间。当然,如果系统中存在大量字符串且这些字符串基本没有公共前缀,则相应的trie树将非常消耗内存,这也是trie树的一个缺点。
现在我们就可以归纳出trie树的三个基本特性:
可以看出:
trie基本操作有:查找、插入和删除。

可以采用双数组(Double-Array)实现。利用双数组可以大大减小内存使用量,具体实现细节见参考资料。
(1) 插入、查找的时间复杂度均为O(N),其中N为字符串长度。
(2) 空间复杂度是26^n级别的,非常庞大(可采用双数组实现改善)。
良玉最近遇到一个难题,老师交给他很多单词(只有小写字母组成,不会有重复的单词出现),现在老师要他统计出以某个字符串为前缀的单词数量(单词本身也是自己的前缀)
输入数据的第一部分是一张单词表,每行一个单词,单词的长度不超过10,它们代表的是老师交给良玉统计的单词,一个空行代表单词表的结束.第二部分是一连串的提问,每行一个提问,每个提问都是一个字符串.
(注意:本题只有一组测试数据,处理到文件结束.)
对于每个提问,给出以该字符串为前缀的单词的数量.
#include <iostream>
using namespace std;
typedef struct Trie
{
int v;
Trie *next[26];
}Trie;
Trie root;
void createTrie(char *str)
{
int len = strlen(str);
Trie *p = &root, *q;
for(int i=0; i<len; ++i)
{
int id = str[i]-'a';
if(p->next[id] == NULL)
{
q = (Trie *)malloc(sizeof(root));
q->v = 1;
for(int j=0; j<26; ++j)
q->next[j] = NULL;
p->next[id] = q;
p = p->next[id];
}
else
{
p->next[id]->v++;
p = p->next[id];
}
}
}
int findTrie(char *str)
{
int len = strlen(str);
Trie *p = &root;
for(int i=0; i<len; ++i)
{
int id = str[i]-'a';
p = p->next[id];
if(p == NULL) return 0;
}
return p->v;
}
int main()
{
//freopen("input.txt", "r", stdin);
char str[15];
int i;
for(i=0; i<26; ++i)
root.next[i] = NULL;
while(gets(str) && str[0]!='\0')
createTrie(str);
memset(str, 0, sizeof(str));
while(scanf("%s", str) != EOF)
{
int ans = findTrie(str);
printf("%d\n", ans);
}
return 0;
}/***************************************************
Name: Trie树的基本实现
Description: Trie树的基本实现,包括查找、插入和删除操作
***************************************************/
#include<algorithm>
#include<iostream>
using namespace std;
const int sonnum=26,base='a';
struct Trie
{
int num;//记录多少单词途径该节点,即多少单词拥有以该节点为末尾的前缀
bool terminal;//若terminal==true,该节点没有后续节点
int count;//记录单词的出现次数,此节点即一个完整单词的末尾字母
struct Trie *son[sonnum];//后续节点
};
/*********************************
创建一个新节点
*********************************/
Trie *NewTrie()
{
Trie *temp=new Trie;
temp->num=1;
temp->terminal=false;
temp->count=0;
for(int i=0;i<sonnum;++i)temp->son[i]=NULL;
return temp;
}
/*********************************
插入一个新词到字典树
pnt:树根
s :新词
len:新词长度
*********************************/
void Insert(Trie *pnt,char *s,int len)
{
Trie *temp=pnt;
for(int i=0;i<len;++i)
{
if(temp->son[s[i]-base]==NULL)temp->son[s[i]-base]=NewTrie();
else {temp->son[s[i]-base]->num++;temp->terminal=false;}
temp=temp->son[s[i]-base];
}
temp->terminal=true;
temp->count++;
}
/*********************************
删除整棵树
pnt:树根
*********************************/
void Delete(Trie *pnt)
{
if(pnt!=NULL)
{
for(int i=0;i<sonnum;++i)if(pnt->son[i]!=NULL)Delete(pnt->son[i]);
delete pnt;
pnt=NULL;
}
}
/*********************************
查找单词在字典树中的末尾节点
pnt:树根
s :单词
len:单词长度
*********************************/
Trie* Find(Trie *pnt,char *s,int len)
{
Trie *temp=pnt;
for(int i=0;i<len;++i)
if(temp->son[s[i]-base]!=NULL)temp=temp->son[s[i]-base];
else return NULL;
return temp;
}Trie树是一种非常重要的数据结构,它在信息检索,字符串匹配等领域有广泛的应用,同时,它也是很多算法和复杂数据结构的基础,如后缀树,AC自动机等。
wiki:http://en.wikipedia.org/wiki/Trie
Trie树:应用于统计和排序http://blog.csdn.net/hguisu/article/details/8131559
数据结构之Trie树:http://dongxicheng.org/structure/trietree/
Trie树http://www.cnblogs.com/huangxincheng/archive/2012/11/25/2788268.html
Trie树|字典树(字符串排序)
http://www.cnblogs.com/shuaiwhu/archive/2012/05/05/2484676.html
Trie(数字树、字典树、前缀树)http://blog.sina.com.cn/s/blog_72ef7bea0101drz3.html
HDOJ 1251 统计难题解http://www.wutianqi.com/?p=1364
字典树简介和简易应用http://blog.csdn.net/ly01kongjian/article/details/8743100
深入双数组Trie(Double-Array Trie)http://blog.csdn.net/zhoubl668/article/details/6957830
双数组Trie树(DoubleArrayTrie)Java实现http://www.hankcs.com/program/java/%E5%8F%8C%E6%95%B0%E7%BB%84trie%E6%A0%91doublearraytriejava%E5%AE%9E%E7%8E%B0.html
Android开发里自定义控件可以说是基础功了,尽管开源社区里有很多优秀的控件供我们使用,但毕竟不是所有我们想要的控件都能找到,这时就需要自己去自定义控件了。之前我也刚好在学习如何自定义空件,所以下面我就简单介绍一下如何自定义控件。
Android里所有控件都继承自View,而ViewGroup则是容纳这些组件的容器,其本身也是从View派生出来的,自定义View和自定义ViewGroup在实现上也有所不同。
自定义控件通常要实现以下三个构造函数。
第一个构造函数:当不需要使用xml声明或者不需要使用inflate动态加载时候,实现此构造函数即可
第二个构造函数:当需要在xml中声明此控件,则需要实现此构造函数。并且在构造函数中把自定义的属性与控件的数据成员连接起来。如果你有自定义XML属性,那么这些属性将会存放在参数中的attrs里。
第三个构造函数:接受一个style资源
这三个构造函数如果没特殊要求直接调用父类的构造函数就好。
除了构造函数,自定义控件最重要的是重写onMeasure(),onLayout(),onDraw()方法,运行时系统调用这三个方法的顺序是onMeasure()->onLayout()->onDraw(),不过它们其实都并非直接调用,而是先调用Measure(),Layout(),Draw()这三个方法,然后再由这三个方法去调用相应的方法。下面就重点介绍onMeasure(),onLayout(),onDraw()这三个方法。
onMeasure()这个方法是用来测量该控件的高和宽的,注意这里仅仅是测量大小,真正确定控件大小实际是在父控件里的OnLayout()里确定的,后面会提到onLayout()如何确定子控件大小。onMeasure()这里传入两个参数,注意到这两个参数名字后面都带有MeasureSpec,这里就要介绍一下MeasureSpec了。
MeasureSpec其实是父控件对子控件的布局要求,它其实是一个int类型的数据,不过它包含了两部分的信息,一个是大小,一个是模式,我们也不必知道它如何保存这两部分信息的,MeasurSpec类已经封装好提取和合成这两部分信息的方法了。
这里介绍一下MeasureSpec的三种模式:
这里要注意的是MeasureSpec仅仅是父控件对子控件的期盼,它其实是不具备任何实际约束力的,比如尽管传过来的模式是EXACTLY,你也可以让你自定义的控件测量得出来的是另外一个大小,不过多数情况下还是最好根据父控件给的期望去测量得出控件的大小。
说了那么多,onMeasure()又是如何测量控件大小的呢?
其实onMeasure最终目的是调用setMeasuredDimension(int measureWidth, int measureHeight)方法来确定测量的宽和高,当调用完这个方法之后,该控件的getMeasureWidth()和getMeasureHeight()方法将会获得相应的值,而父控件则会根据这两个方法得到的值去确定该控件的大小(如果没有调用setMeasuredDimension(),那么getMeasureWidth()和getMeasureHeight()方法得到的值便会是0)。
View和ViewGroup的onMeasure()实现有所不同,View只要测量自身大小就行了,而ViewGroup除了要测量自身大小外,还要调用子控件的Measure(int widthMeasureSpec, int heightMeasureSpec)方法来测量子控件的大小,参数里的MeasureSpec可由makeMeasureSpec()方法制作出来,这里要注意的是调用的是子控件的Measure(),而不是直接调用onMeasure()方法。我们可以先测量子控件的大小,然而再根据子控件的大小去确定ViewGroup测量的大小。
我们实现onMeasure()时可以调用控件的getLayoutParams()来获得XML布局里该控件的一些基础属性(比如长和宽),然后根据这些属性和父控件对该控件的期望来确定该控件的测量大小。
onLayout()这个方法是用来确定子控件的布局位置,这里传入了5个参数,第一个参数代表的是该控件的位置和大小有没有发生变化,通常情况下我们可以不用管。后面4个参数是该控件在父控件中的相对布局,也就是说其实这时候该控件的大小已经确定下来的了(比如宽便是right - left)。
onLayout()实际上只是用来确定子控件的布局位置即大小,所以View的这个方法是空白的,只有ViewGroup才需要重写这个方法。这4个参数实际上是是两个点的坐标X,Y值,再由这两个点确定一个的矩形既是该控件的布局范围,因为Android里X正向是向右,Y正向是向下,所以4个参数所代表的含义便成了左,上,右,下分别距离父控件左边或上面的大小。
在onLayout()里ViewGroup需要分别调用子控件的Layout()方法,需要传入4个参数来确定子控件在该控件中的相对布局位置及大小,而这4个参数的确定通常都要根据子控件的MeasureHeight和MeasureWidth来确定的,即需要根据子控件在onMeasure()方法中测量的大小来确定,当然你也可以不管子控件测量的大小去确定子控件的布局位置及大小。同样要注意的是这里调用的是子控件的Layout()方法而不是onLayout()。
onDraw()这个方法就是用来绘制图形了,要注意的是onDraw()绘制的只是该控件的图形,而不需要管子控件的图形,子控件的Draw()方法在ViewGroup的Draw()方法里已经调用了,所以并不需要我们再调用一次,所以如果实现的ViewGroup没有自带的外观就不用重写这方法了。
由于关于这方法如何描绘图形的内容比较多,所以我就不在这里介绍了,有兴趣的可以看一下后面我介绍的网址,里面有比较好的讲解,这里我们只需要知道onDraw()方法传入的画布大小与该控件的布局大小有关就好了。
关于自定义控件我了解的也不算深入,基本都是根据网上的一些博客自学的,上面的介绍算是我对之前在博客上学的知识的一些总结,有些细节我也没能总结出来,如果大家有兴趣的话可以到我下面介绍的博客去看一下。
学习自定义控件,除了看博客自学外,大家还可以去开源社区找一些别人做好的控件源码来看一下,可以更好地理解,然后最好可以自己尝试做一下。
之前没有看群公告,才知道接了分享这个锅,唔也没有什么准备的,就讲讲最近在看的react吧
唔由于本人也是才接触没多久,对与相关术语的接触及英文水平有限,有错误是必然的,欢迎各位大腿指正
react是最近几年很火的框架之一,其衍生品react native也是一个很火的框架(与react并不是一个东西),它期望通过写web app的方法来做到代替native app。这里不得不提一下Web app、Hybrid app与Native app的关系
Web app,顾名思义,直接在网页端写成的app,能跨平台使用,但是由于本身限制,各种性能捉鸡,也无法通过硬件进行优化。
Native意为本地的,天然的,Native app指原生app,也称本地app。即为平时我们用的大多数手机应用,如波板糖等。特点是其中的大部分UI框架,逻辑结构,数据内容已经写好并包含在整个应用里,用户无需联网也能使用其中的部分内容。
Hybrid意为混血的、杂种的,Hybrid app即指混合APP(简单理解就是将web view嵌套进app当中。当然,根据不同的需求我们可以选择不同的嵌套方式,此处关于嵌套方式不做赘述,有兴趣可以自行去了解更多内容)
native app的开发周期长,维护与更新也相对困难,无法实现跨平台,但是纯粹的web app虽然开发周期快,维护容易,但是也存在问题,即交互感受奇差(主要在于卡顿严重、掉帧明显,得不到良好的反馈,原因在之后进一步说明),无法调用部分设备硬件,无法调用系统通知等等。
比如native app可以调用GPU进行强制渲染(即使app本身并没有调用其进行渲染),提高流畅度,降低CPU负载,而web app无法做到这一点。所以Hybrid app可以说是顺应潮流而生,通过内嵌web view的形式,得到易于开发维护,但是仍然存在部分缺点。(但是据说web view shell已经支持硬件加速,似乎可以做到提高部分性能的要求,具体程度尚不清楚)
说了这么多,似乎有点跑题了,接下来进入我们的正题-->react(误)
React 起源于 Facebook 的内部项目,因为该公司对市场上所有 JavaScript MVC 框架,都不满意,就决定自己写一套,用来架设Instagram 的网站。做出来以后,发现这套东西很好用,就在2013年5月开源了。
与之几乎同知名度与同热度的还有Angular与Vue等一系列产品
AngularJS诞生于2009年,由Misko Hevery 等人创建,后为Google所收购。是一款优秀的前端JS框架,已经被用于Google的多款产品当中。AngularJS有着诸多特性,最为核心的是:MVVM、模块化、自动化双向数据绑定、语义化标签、依赖注入等等。
Vue.js 是一个用于创建 web 交互界面的库。
从技术角度讲,Vue.js 专注于 MVVM 模型的 ViewModel 层。它通过双向数据绑定把 View 层和 Model 层连接了起来。实际的 DOM 封装和输出格式都被抽象为了 Directives 和 Filters。
从哲学角度讲,Vue 希望通过一个尽量简单的 API 来提供反应式的数据绑定和可组合、复用的视图组件。它不是一个大而全的框架——它只是一个简单灵活的视图层。您可以独立使用它快速开发原型、也可以混合别的库做更多的事情。它同时和诸如 Firebase 这一类的 BaaS 服务有着天然的契合度。
三者可以说各有优劣,在不同的情况下的性能也都不一样。这三者中,Angular的适用领域相对窄一些,React可以拓展到服务端,移动端Native部分,而Vue因为比较轻量(至于多轻因为没具体用过我也说不出来),还能用于业务场景非常轻的页面中。
其中,Angular和Vue均是MVVM架构(我奤、大神和银峰老大之前均有详细说过这个架构,见第一篇分享)。
AngularJS主要考虑的是构建CRUD应用(增加Create、查询Retrieve、更新Update、删除Delete),在以下方面具有一定优势:
Vue的话更多地是看到是强调它的轻量级,特别是对比起react和angular这两个大而全的框架。
以下为作者 尤雨溪 的原话
合理使用 track-by 的情况下,Vue 甚至可以比 React 更快
使用场景上来说:React 配合严格的 Flux 架构,适合超大规模多人协作的复杂项目。理论上 Vue 配合类似架构也可以胜任这样的用例,但缺少类似 Flux 这样的官方架构。小快灵的项目上,Vue 和 React 的选择更多是开发风格的偏好。对于需要对 DOM 进行很多自定义操作的项目,Vue 的灵活性优于 React。
以下分别贴两种helloworld的demo,更多demo请自行翻阅官方文档
AngularJS
<!doctype html>
<html ng-app>
<head>
<script src="http://code.angularjs.org/angular-1.0.1.min.js"></script>
</head>
<body>
Hello {{'World'}}!
</body>
</html>
Vue
<div id="app">
{{ message }}
</div>
new Vue({
el: '#app',
data: {
message: 'Hello World!'
}
})
好了下面开始真正地讲react
在2015年年初的React开发者大会上,React项目经理Tom Occhino进一步阐述React诞生的初衷,在演讲中提到,React最大的价值究竟是什么?是高性能虚拟DOM、服务器端Render、封装过的事件机制、还是完善的错误提示信息?尽管每一点都足以重要。但他指出,其实React最有价值的是声明式的,直观的编程方式。
以上我们已经可以看出React的部分优点:
高性能虚拟DOM(Virtual DOM)
Virtual DOM的概念的提出是为了简化对DOM的操作:通过在内存中创建 Virtual DOM元素,利用 Virtual DOM来减少对实际DOM的操作从而提升性能。类似于真实的原生DOM,虚拟DOM也可以通过JavaScript来创建,但这样的代码可读性并不好,于是React发明了JSX,利用HTML语法来创建虚拟DOM。
那么Virtual DOM到底是如何简化操作,达到优化性能的目的的呢?这就不得不介绍一下它的DOM Diff算法了。
什么是DOM Diff算法
Web界面由DOM树来构成,当其中某一部分发生变化时,其实就是对应的某个DOM节点发生了变化。在React中,构建UI界面的思路是由当前状态决定界面。前后两个状态就对应两套界面,然后由React来比较两个界面的区别,这就需要对DOM树进行Diff算法分析。
即给定任意两棵树,找到最少的转换步骤。但是标准的的Diff算法复杂度需要O(n^3),这显然无法满足性能要求。要达到每次界面都可以整体刷新界面的目的,势必需要对算法进行优化。这看上去非常有难度,然而Facebook工程师却做到了,他们结合Web界面的特点做出了两个简单的假设,使得Diff算法复杂度直接降低到O(n)
- 两个相同组件产生类似的DOM结构,不同的组件产生不同的DOM结构;
- 对于同一层次的一组子节点,它们可以通过唯一的id进行区分。
算法上的优化是React整个界面Render的基础,事实也证明这两个假设是合理而精确的,保证了整体界面构建的性能。
当在DOM树中的同一位置前后输出了不同类型的节点,React直接删除前面的节点,然后创建并插入新的节点。这正是应用了第一个假设,不同的组件一般会产生不一样的DOM结构,与其浪费时间去比较它们基本上不会等价的DOM结构,还不如完全创建一个新的组件加上去。
(由于我已经扯了一大堆乱七八糟的东西,所以在此就不举更多例子进行说明。有兴趣的可以去百度更加详细的例子)
React对操作DOM树的算法其实非常简单,那就是两棵DOM树只会对同一层次的节点进行比较,对于不同层的节点,只有简单的创建和删除。
2.编程方式
React使用JSX进行编写,编程**类似于,将整个页面分解成若干个组件,每个组件又可以嵌套若干个子组件。于是一整个页面便被拆分成无数个小组件。组件并不是一个新的概念,它意味着某个独立功能或界面的封装,达到复用、或是业务逻辑分离的目的。
React将用户界面看做简单的状态机器。当组件处于某个状态时,那么就输出这个状态对应的界面。通过这种方式,就很容易去保证界面的一致性。
在React中,你简单的去更新某个组件的状态,然后输出基于新状态的整个界面。React负责以最高效的方式去比较两个界面并更新DOM树。
组件是React中构建用户界面的基本单位。它们和外界的交互除了状态(state)之外,还有就是属性(props)。事实上,状态更多的是一个组件内部去自己维护,而属性则由外部在初始化这个组件时传递进来(一般是组件需要管理的数据)。React认为属性应该是只读的,一旦赋值过去后就不应该变化。
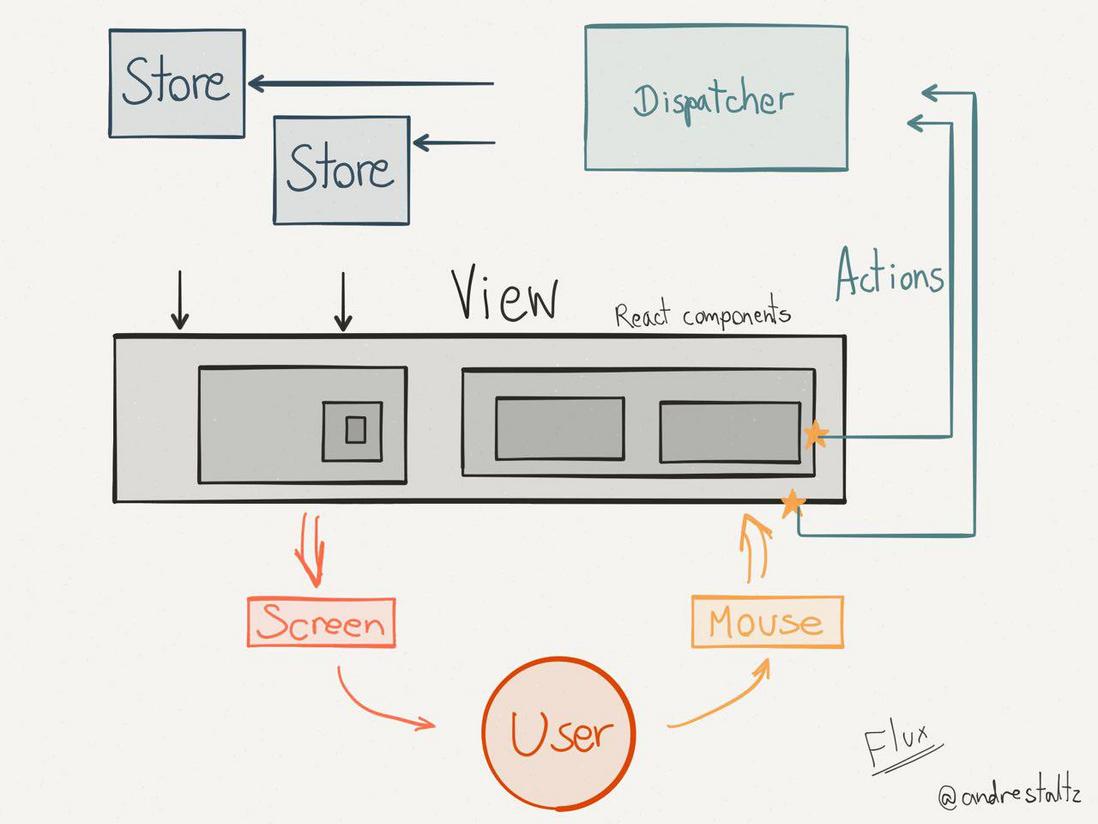
同时之前有提到过Angular和Vue使用的是MVVM方式,而React走的是另外一个流派,就是所谓的函数式。在这个里面,推崇的是单向数据流:给定原始界面(或数据),施加一个变化,就能推导出另外一个状态(界面或者数据的更新)。这就又涉及到另一样东西,Flux
Flux并不是什么非常复杂的东西,它仅仅是定义了一种单向数据流的方式,以此解决传统MVC框架中有可能出现的连锁更新现象。
在传统MVC框架中,通常使用双向绑定的方式来将Model的数据展现到View。当Model中的数据发生变化时,一个或多个View会发生变化;当View接受了用户输入时,Model中的数据则会发生变化。在实际的应用中,当一个Model中的数据发生变化时,也有可能另一个相关的Model中的数据会被同步更新。这样,很容易出现的一个现象就是连锁更新(Cascading Update),Model可以更新Model,Model可以更新View,View也可以更新Model。你很难去推断一个界面的变化究竟是由哪个局部的功能代码引起。
在MVC中,数据如何处理通常由Controller来完成,在Controller中实现大部分的业务逻辑来处理数据。而现在则被Flux清晰的定义在Store或者Action Creators中。
在Flux中,View完全是Store的展现形式,Store的更新则完全由Action触发。得益于React的View每次更新都是整体刷新的思路,我们可以完全不必关心Store的变化细节,只需要监听Store的onChange事件,每次变化都触发View的re-render,进行相应的更新。
那么Dispatcher和Action又是什么呢?简单来说,当View接受了用户的输入之后,它通过Dispatcher来分发一个特定的Action,而对应的Action处理函数会负责去更新Store。
说到这,那便不得不说一下最常与React一同提起的Redux
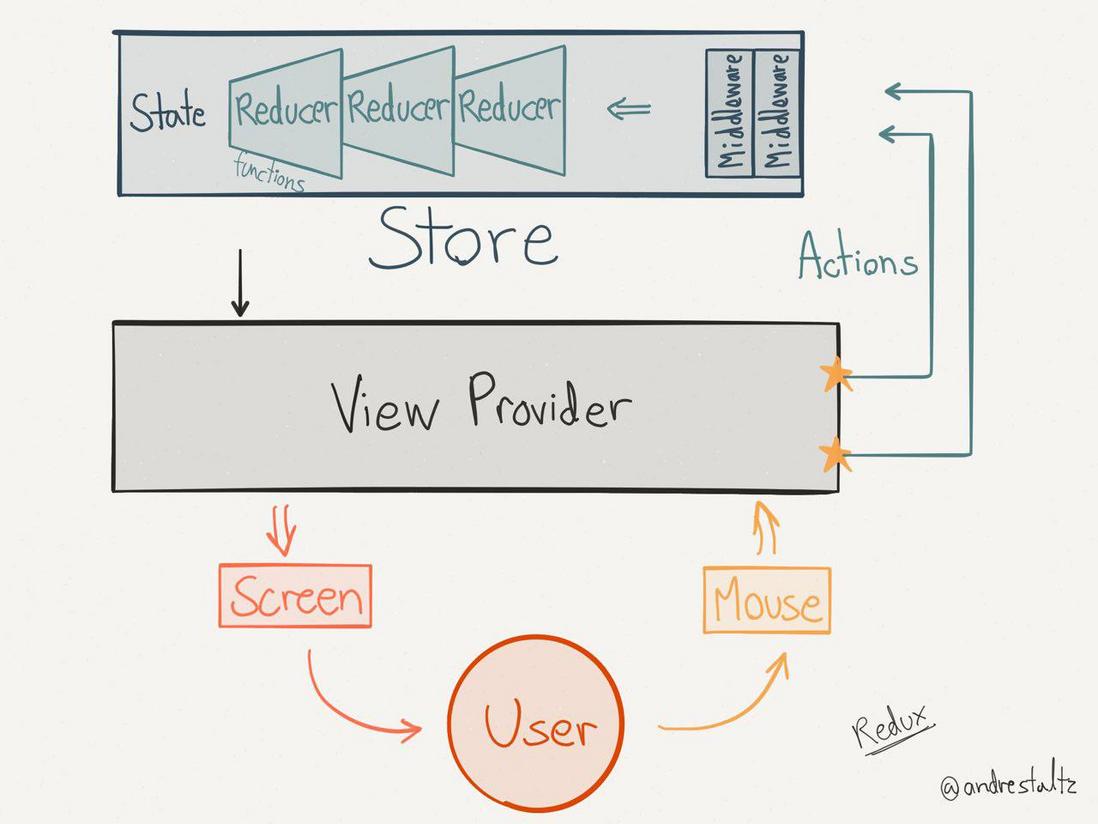
Redux是一种类Flux实现,他关注的重点是就是如何管理state。有必要强调的一点是,Redux 和 React 是没有必然关系的,Redux 用于管理 state,与具体的 View 框架无关(而React恰好是只做View的)。但是Redux特别适合React这种通过状态state来更新view的框架。
在React的思路中,UI就是一个状态机,每个确定的状态对应着一个确定的界面。对于一个小的组件,它的状态可能是在其内部进行维护;而对于多个组件组成的应用程序,如果某些状态需要在组件之间进行共享,则可以将这部分状态放到Store中进行维护。
其中state 可能包括:服务端的响应数据、本地对响应数据的缓存、本地创建的数据(比如,表单数据)以及一些 UI 的状态信息(比如,路由、选中的 tab、是否显示下拉列表、页码控制等等)。
需要强调的是,Redux只是类Flux实现,所以与上文中的Flux必定会有不同之处。以下是两者的流程图对比
我们可以看到其中与Flux不同的是Middleware、Store和Reducers。
- Action 可以理解为应用向 Store 传递的数据信息(一般为用户交互信息)。
- Reducer 实际上就是一个函数:
(previousState, action) => newState。用来执行根据指定 action 来更新 state 的逻辑。- Middleware 其实就是高阶函数,作用于 dispatch 返回一个新的 dispatch(附加了该中间件功能)。可以形式化为:
newDispatch = middleware1(middleware2(...(dispatch)...))
最后稍微再提一下JSX
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8" />
<title>Hello React!</title>
<script src="build/react.js"></script>
<script src="build/react-dom.js"></script>
<script src="https://cdnjs.cloudflare.com/ajax/libs/babel-core/5.8.23/browser.min.js"></script>
</head>
<body>
<div id="example"></div>
<script type="text/babel">
ReactDOM.render(
<h1>Hello, world!</h1>,
document.getElementById('example')
);
</script>
</body>
</html>
好了由于自己对react的了解也仅仅停留在看文档阶段,并没有大量使用过,对其认知也仅仅停留在看过的各种文章上,所以我的分享差不多就到这里了。以下是我在查阅资料的时候,看过的一些作者提到的我们对React的认知容易进入误区的地方
参考链接:
一看就懂的ReactJs入门教程
React官方文档
聊聊Web App、Hybrid App与Native App的设计差异
浅谈Hybrid技术的设计与实现
网上都说操作真实 DOM 慢,但测试结果却比 React 更快,为什么?-知乎
react.js,angular.js,vue.js学习哪个好?-知乎
vue、react和angular 2.x谁是2016年的主流?-知乎
颠覆式前端UI开发框架:React
深入浅出react系列
Redux核心概念
深入理解React、Redux
Redux 介绍
不止是UI:React的使用场景探索
flexbox 很受欢迎,以至于 CSS-TRICKS 的推荐搜索就是 flexbox

我们来看看 flexbox 的各浏览器兼容情况

Flexbox Layout(Flexible Box) 的提出是为了提供一个更加有效的方式去完成页面布局、对齐、在组件间分配空间,甚至他们的尺寸是未知的或者是动态的。
flexbox是一整个模块,而不是单独的一个属性,其中包括容器(flex container)和其中的组件(flex items)。

其中有两个轴,主轴(main axis)和交叉轴(cross axis)。这两个轴可以决定 flex container 内 flex items 的排布方向。
flex container属性
display: flex; //定义了一个flex container
flex-direction: row | row-reverse | column | column-reverse; //定义items在container里的排布方向
flex-wrap: nowrap | wrap | wrap-reverse; //换行
justify-content: flex-start | flex-end | center | space-between | space-around; //定义对齐方式,帮助分配items间的空间
align-items: flex-start | flex-end | center | baseline | stretch; //定义在交叉轴上items是如何排布的,如果前面设置了 flex-direction 是 column 或者 column-reverse 的话,这里就是指 main axis 了
align-content: flex-start | flex-end | center | space-between | space-around | stretch; //多行 items 如何分配行间空间
flex items属性
order: <integer>; //人为安排 items 顺序,<integer> 越小排序越前
flex-grow: <number>; //定义 items 扩大
flex-shrink: <number>; //定义 items 收缩
flex-basis: <length> | auto; //分配 items 占据的主轴空间
flex: none | [ <'flex-grow'> <'flex-shrink'>? || <'flex-basis'> ]; //flex-grow, flex-shrink 和 flex-basis的简写,默认值为0 1 auto
align-self: auto | flex-start | flex-end | center | baseline | stretch; //允许单个 item 与其他 items 的对齐方式不一样
下面我们举例子:
1.怎样做到居中?
.parent {
display: flex;
height: 300px;
}
.child {
width: 100px;
height: 100px;
margin: auto;
}
或
.parent {
display: flex;
height: 300px;
align-items: center;
justify-content: center;
}
2.多个 items ,如何不用媒体查询就让 items 随浏览器尺寸变化而发生响应式排布呢?
.parent {
display: flex;
flex-flow: row wrap;
justify-content: space-around;
}
3.假设我们有一个右对齐的导航栏在页面顶部,当屏幕尺寸变小以后会变成居中,尺寸再变小导航栏会变成一列。
.parent {
display: flex;
flex-flow: row wrap;
justify-content: flex-end;
}
@media all and (max-width: 800px) {
.parent {
justify-content: space-around;
}
}
@media all and (max-width: 500px) {
.parent {
flex-direction: column;
}
}
4.列与列间存在间隔
.parent {
display: flex;
height: 300px;
justify-content: space-around;
}
还有由 flexbox 实现的栅格框架,比如 Flexbox Grid
参考资料
一、 写在前面

二、 开始吧!






三、小结。
学过概率论的同学都知道,概率分布有离散的,也有连续的,连续的概率分布有平均分布,也有正态分布,其中正态分布N(xi | μ,σ)又称为高斯分布,这个公式表示在高斯分布均值是μ,方差是σ的情况下,取得数值xi的概率密度。
利用高斯分布,我们可以很好地拟合生活中遇到的数据,然而,对于一个事物,往往一个数据是无法准确说明的,比如我们描述一个人,就需要提供身高,体重,年龄等数据。我们描述一段语音,则常用一种叫做MFCC的特征提取方法来提取语音段的特征,这个特征值是一个39维的向量。对于一个语音段,我们按一定的准则将其分割成前后有部分重叠的(部分重叠是为了考虑首尾数据,这个分割通常称为加窗)数据帧,那么对于一段较短的语音(如啊a哦o额e),就用四帧(经验值)39维的MFCC数据来刻画并建模,在此后我们利用概率的方法求输入MFCC帧序列与模型的匹配度实现语音识别。
对于一段语音,同个人说几次,每次的数据都是有细微差别的,趋近一个高维的高斯分布。那么我们如何利用高斯分布来拟合高维向量的分布呢?我们更改高斯分布的公式N(xi |μ,∑),后文都指的是这个公式。与一维相比,其中xi换成了向量xi,μ换成了均值向量μ,σ换成了协方差矩阵∑。对于一个多维的向量,引入公式 来计算其概率,这里用到了线性代数的矩阵运算。
来计算其概率,这里用到了线性代数的矩阵运算。
实际情况中,我们为了识别多个人的说话需要对以上的高斯模型加以扩展。由于每个人说话都是一个高斯分布,因此我们为了刻画一个音的模型,我们需要把多个高斯分布合并成一个概率密度函数。在实际操作中,为每个人都生成一个高斯分布并不实际,因此我们可以大致分成3~5个高斯分布,例如分成男人,女人和小孩三个类别,各自有高斯分布,然后合并成对同个音的混合高斯模型。合并高斯分布,我们采用加权求和的方法, ,其中P(Ni)是取第Ni个高斯分布的权重,来将多个高斯分布合并成一个。这样一来,对于同一段语音数据,我们就能用一个多峰的概率密度函数来匹配不同人群的语音特征,达到比对所有人的数据取均值得到的高斯分布更好的拟合效果。
,其中P(Ni)是取第Ni个高斯分布的权重,来将多个高斯分布合并成一个。这样一来,对于同一段语音数据,我们就能用一个多峰的概率密度函数来匹配不同人群的语音特征,达到比对所有人的数据取均值得到的高斯分布更好的拟合效果。
如图,多峰的混合高斯分布(本图取自网络)

引入混合高斯模型以后,我们可以求得一个特征向量属于该模型的概率,从而得之语音数据的匹配程度。为了确定模型各项的参数,我们需要利用EM算法来训练数据,这里不再介绍。
主要是根据上次琦哥说到的计算机网络中几点展开,是我正好趁着这次干事分享学习后的个人体会,因为是在网上快速学习的,没看过系统的书,理解错的地方请大佬们直接指出哦~(弱弱地飘过~)
举个栗子:从前有个人开了家征婚事务所,有一位叫杰艾斯的男子看中了她脑内写码的技能,想要一张征婚报名表,并要求在10:00之前送到A4二楼。
在这个场景里,征婚报名表就是请求的报文体,而10:00,A4,名叫艾杰斯这类附加信息就是报文头。
常见请求报文头属性:
Accept:请求内容的类型
Referrer:完整的url
Cache-control:缓存的时间选择
Cookie:包含sessionid,是服务器区别多个客户端的重要凭证。
响应状态码:
1xx 请求已收到,正在处理中
2xx 处理成功
3xx 重定向到其它地方
4xx 错误在客户端,如客户端的请求一个不存在的资源,客户端未被授权,禁止访问等。
5xx 错误在服务端,如服务端抛出异常,路由出错,HTTP版本不支持等
常见的响应状态码有:
200: 处理成功
303 see others: 重定向到其他页面
304 not modified: 该资源以前请求过了,提示用户直接使用本地的缓存
(补充:last-Modified If-Modified-Since,当第一次请求资源时,会生成一个last-modified时间标识,客户端通过查询该标识来确认是否以前请求过该资源)
404 not found: 该页面不存在等
500 internal server error: 服务端抛出异常等
响应报文头属性:
ETag:实体标签,是一种随状态而随时改变的资源状态标识。形式多样,廉洁的时间戳,复杂的哈希算法等。
Location:重定向页面的url,指示了303响应状态码所跳转的页面。
Set-cookie: 指示用户更新sessionid
e.g: customer=huangxp;path=/foo;domain=.ibm.com;
expires= Wednesday, 19-OCT-05 23:12:40 GMT; [secure]
customer为一个“名称 = 值”对。
path = /foo 表示控制访问路径,只有访问/foo下的网页cookie才被发送。
domain = .ibm.com 非空时指定发送到具体服务器,为空时为默认的链接服务器。
Expires = …指定cookie失效的时间
Secure 开启SSL加密模式
先了解一些在TCP协议中的常见状态:
SYN表示建立连接,
FIN表示关闭连接,
ACK表示响应,
PSH表示有 DATA数据传输,
RST表示连接重置。
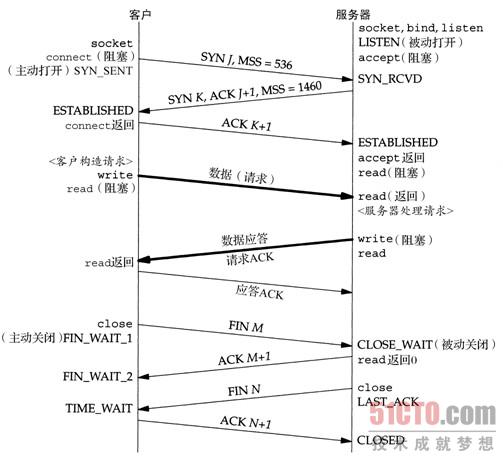
第一次握手:客户端发送位码为syn=1,随机产生seq number=1234567的数据包到服务器,服务器由SYN=1知道,客户端要求建立联机;
第二次握手:服务器收到请求后要确认联机信息,向客户端发送ack number=seq+1,syn=1,ack=1,随机产生seq number=7654321的包,即发送ACK+SYN包;
第三次握手:客户端收到后检查ack number是否正确,即第一次发送的seq number+1,以及位码ack是否为1,若正确,客户端会再发送ack number=seq+1,ack=1,服务器收到后确认seq值与ack=1则连接建立成功。客户端和服务器进入ESTABLISHED状态,完成三次握手。
目的:
防止已经失效的连接请求又传到了服务端。如果客户端与服务器是直接传输直接接受的关系,那么服务器端会接受已经失效的连接请求,认为双方已经建立了联系,所以一直
等待数据从客户端发来,这样会拖慢服务器进程,浪费资源。
第一次挥手:主动关闭方调用close,发送一个FIN给被动方
第二次挥手:被动关闭方接收到FIN,并发送确认包ACK给主动方
第三次挥手:一段时间后,被动方也调用close,发送一个FIN给原主动方
第四次挥手:主动方接收确认这个FIN,并发出确认包(TIME_WAIT)
总过程图:
状态时序图:
概念:
又称2MSL状态,而MSL是任何报文段被丢弃前在网络内的最长时间。当TCP连接完成四个报文段的交换时,即使两端的应用程序结束,主动关闭的一方还将继续等待一定时间(2-4分钟)才关闭连接。
原因:
其一,保证发送的ACK会成功发送到对方。如果ACK丢失,则服务器将重新发送它的最终FIN值,因此客户必须维护状态信息,以允许它重新发送最终那个ACK。要是客户不维护状态信息,它将响应以一个RST,该分节将被服务器解释成一个错误。这也说明了为什么执行主动关闭的那一端是处于TIME_WAIT状态的那一端,因为可能不得不重传最终那个ACK的就是那一端。
其二,防止新的连接被老的连接干扰。 当老的连接断开之后,在相同的服务器与客户端建立新的连接,由于它们的IP地址与端口都相同,曾经的连接很有可能干扰新建立的连接,所以需要有TIME_WAIT状态,使老的连接在2MSL的持续时间内失效而被丢弃。
HTTPS较HTTP的特点:
HTTP+SSL证书加密,安全性高。
参考资料:
http报文详解
tcp的连接与断开
https工作原理
https工作原理与tcp握手机制
by 汤雪儿
第一次线上分享~~
ContentProvider为Android四大组件之一,之前并没有使用过,所以趁着这次分享赶紧看看这是什么东东。
问了一下度娘,ContentProvider主要用来应用程序之间的数据共享,一个应用程序用ContentProvider将分享给其他应用访问。google doc说数据可以存储于文件系统、SQLite数据库或其它方式,内容提供者继承于ContentProvider 基类,为其它应用程序取用和存储它管理的数据实现了一套标准方法。然而,应用程序并不直接调用这些方法,而是使用一个 ContentResolver 对象,调用它的方法作为替代。而ContentResolver可以与任意内容提供者进行会话,与其合作来对所有相关交互通讯进行管理。
1.ContentProvider主要方法:
public boolean onCreate() 在创建ContentProvider时调用;
public Cursor query(Uri, String[], String, String[], String) 用于查询指定Uri的ContentProvider,返回一个Cursor;
public Uri insert(Uri, ContentValues) 用于添加数据到指定Uri的ContentProvider中;
public int update(Uri, ContentValues, String, String[]) 用于更新指定Uri的ContentProvider中的数据;
public int delete(Uri, String, String[]) 用于从指定Uri的ContentProvider中删除数据;
public String getType(Uri) 用于返回指定的Uri中的数据的MIME类型;
2..ContentResolver
要获取ContentResolver对象,可以使用Context提供的getContentResolver()方法,主要操作方法有对数据的增删改查。
public Uri insert(Uri uri, ContentValues values) 用于添加数据到指定Uri的ContentProvider中。
public int delete(Uri uri, String selection, String[] selectionArgs) 用于从指定Uri的ContentProvider中删除数据。
public int update(Uri uri, ContentValues values, String selection, String[] selectionArgs) 用于更新指定Uri的ContentProvider中的数据。
public Cursor query(Uri uri, String[] projection, String selection, String[] selectionArgs, String sortOrder) 用于查询指定Uri的ContentProvider。
3.Uri类
例:Uri uri = Uri.parse("content://contacts/people")
Uri由3部分组成。把Uri比作网址,第一部分是"content://",可以看作是网址中的"http://"。第二部分是主机名或authority,用于唯一标识这个ContentProvider,外部应用需要根据这个标识来找到它。可以看作是网址中的主机名。第三部分是路径名,用来表示将要操作的数据。可以看作网址中细分的内容路径。
以下是一些示例URI:
content://media/internal/images 这个URI将返回设备上存储的所有图片
content://contacts/people/ 这个URI将返回设备上的所有联系人信息
content://contacts/people/45 这个URI返回单个结果(联系人信息中ID为45的联系人记录)
具体的代码还没有写过。看了网上的几个demo还看得懂,应该不难。总的来说就是应用通过provider使数据暴露出来,然后另一个应用通过resolver来实现对数据的增删改查操作,当然前提是获取了一定权限!
最近帮忙做毕业季的小游戏,收获了很多,和大家分享一下。
我做的部分是布局和动画,这次主要说动画。
因为以前没有写移动端动画的经历,所以一开始并不知道怎么下手。之后选了jquery。
(其实在这之前还用canvas写了一个做测试,因为这个没完整测试,就不说了)
就是animate()这个函数,为什么用这个呢?简单粗暴!还有回调函数!然而事实证明,这TM就是个坑。。。在电脑上的测试fps大概是48 在手机上就更不用说了。在某些手机上很卡(其实就是安卓机)。这是第一个测试版。
然后昊杰告诉我可以用纯css3动画。于是,我开始了我的重写之路。
其实之前也很少写css动画,于是我开始上网资料。
发现了这些文章
http://www.w3cplus.com/content/css3-transform
http://www.w3cplus.com/content/css3-transition
http://www.w3cplus.com/content/css3-animation
居然有三种!!!
当时用了脑抽的排除法排除了前面两个。。。
现在来讲讲css3的animate是怎么回事。
这个据说是真正的css3动画,前面两个并不是严格意义上的动画。
要用这个东东,首先要定义关键帧,就是初末位置或中间过程的样式,然后绑定某个元素,设置运动时间,运动速率函数之类的参数,然后就可以动了。要了解具体语法可以上w3school
结果,当然是比jquery的效果要好。记得电脑上的fps大概是52左右。然而这并没有什么卵用,该卡的还是卡。。。
这时候正式上线了。
然后,达仔提醒:from...to这种写法不是很好
还有我用jq修改css3属性的方式可能会有性能问题
其实这里我用css3修改动画时间等参数是为了传参
达仔的建议是添加类
开始我也有想过,这样的话每个动画还要写一个类,太麻烦了。。。
要是到这里没别的办法我也就弃坑了,但是,css3动画还有两种没试呢!!
当初排除前面两种的原因:
第一种,只能设置变化值。。。这就比较尴尬了。。
第二种,看起来比帧动画麻烦。。。
事实上,translate(第一种)设置的变化值可以当做参数传给transition(第二种)。。叫你不好好看文档!!
此时,我找到了一篇关于移动端写动画的文章。。。(怎么之前没找到呢Orz)
http://blog.sina.com.cn/s/blog_3f1fc8950102v0un.html
所以,再一次重写。。。
根据文章作者多次试验的结果,在移动端transform的效果比animate的效果要好
正确的使用方式:
在要移动的元素上先设置初始值比如
-webkit-transform:translateY(100%);
-webkit-transition:-webkit-transform 0s 0s;
然后用用js改变这些值,会比用添加类的方法更加高效
据说是因为浏览器有预先渲染功能,就是当要触发某些动画样式的时候,最好浏览器事先有过渲染
这就是我的改代码之路。至于我的代码,写的太烂就不贴了(其实是懒得整理)
顺便提一下:
网上查到的最多关于动画优化的方法就是开启gpu加速,gpu是为了加速3d渲染用的
其中一个的网址https://www.qianduan.net/high-performance-css3-animations/
那要怎么开呢??
其实就是达仔给的那张图。只要使用了上面的属性,浏览器就会自动开启gpu
就算没有使用上面的属性,也有个流氓的办法:-webkit-transform: translate3d(0, 0, 0);
假装有3d变化= =
还有一些优化的方法,应该说该注意的地方:
1.要移动的元素不要在文档布局流内
2.减小移动面积
3.减少layout,就像之前canvas优化那样,描述所有图形的路径,再一次画出
还有到现在还没解决的闪烁问题
有方法是:
-webkit-backface-visibility: hidden;
-moz-backface-visibility: hidden;
-ms-backface-visibility: hidden;
backface-visibility: hidden;
-webkit-perspective: 1000;
-moz-perspective: 1000;
-ms-perspective: 1000;
perspective: 1000;
然并卵。。。
预加载估计是写崩了。。。
有说错的地方欢迎大神改正补充
真·结尾
想必每个程序员都对游戏编程有着或多或少的向往吧,虽然现在用canvas, js就能写出一些小游戏,但真正的游戏开发比想象中的复杂多了,下面就与憧憬于游戏编程的同学分享一下游戏开发的基础要素与学习方法,也请技术大牛们对文章的错误之处加以指正,积极分享你们的经验。
////////////////////////////////////////////////////////////////////////////////
PC单机平台游戏(Windows)
PC网络平台游戏(Windows,Linux)
移动平台游戏(J2ME,Symbian,Plam…)
掌上游戏机平台游戏(GB,GBA,NDS,3DS,PSP,PSV…)
家用游戏机平台游戏(PS1/2/3/4,Xbox,Wii…)
网页游戏(HTML,Flash)
智能移动设备平台游戏(iOS,Android)
大型游戏:基础 --- C++\C
进阶 --- 汇编语言,CPU硬件指令,高级SHADER语言
小型游戏:C#\JAVA
Android手游:JAVA
iPhone手游:Objective-c
重点掌握数学,c和c++,汇编,数据结构,线性代数,空间解析几何
基本掌握计算机体系结构,离散数学,编译原理,计算机网络,操作系统,软件工程,数据库,人工智能
游戏引擎是指一些已编写好的可编辑电脑游戏系统或者一些交互式实时图像应用程序的核心组件。这些系统为游戏设计者提供各种编写游戏所需的各种工具,其目的在于让游戏设计者能容易和快速地做出游戏程式而不用由零开始。大部分都支持多种操作平台,如Linux、Mac OS X、微软Windows。
游戏引擎包含以下系统:渲染引擎(即“渲染器”,含二维图像引擎和三维图像引擎)、物理引擎、碰撞检测系统、音效、脚本引擎、电脑动画、人工智能、网络引擎以及场景管理。
引擎相当于游戏的框架,框架打好后,关卡设计师、建模师、动画师只要往里填充内容就可以了。因此,在3D游戏的开发过程中,引擎的制作往往会占用非常多的时间。出于节约成本、缩短周期和降低风险这三方面的考虑,越来越多的开发者倾向于使用第三方的现成引擎制作自己的游戏。
列一个公式就是:
游戏=引擎(程序代码)+资源(图象,声音,动画等)
时下流行的优秀游戏引擎:
Unity3D:全面整合的3D专业游戏引擎,支持C#,JS。代表作品《神庙逃亡》,《纪念碑谷》,《仙剑6》
Cocos2d-x:开源的移动2D跨平台游戏引擎,支持C++,lua(嵌入式脚本语言)。代表作品《保卫萝卜》,《梦幻西游》。
是**的在github上有名的大型开源项目:https://github.com/cocos2d/cocos2d-x
Orge:开源的图形解决方案,可与其他子系统库如物理库等整合。国内大型3D网游多用。
Unreal:AAA级顶尖游戏制作引擎,支持C++,代表作品《剑灵》,《无尽之剑》
Gamebryo:专业级游戏制作引擎,支持C++,lua脚本,其渲染引擎部分是私有的,但允许使用者添加自己的图形绘制代码,代表作品《古剑奇谭》,《上古卷轴5》
BigWorld:在线网络游戏引擎,支持C++,python脚本,代表作品《魔兽世界》,《天下2》
DirectX
OpenGL
他们是一个函数库,函数库为我们做了一些最基本的和底层打交道的处理,其他还提供了一些常用的3D函数库,算是一个2次开发。最大功劳在于充分调度和发挥了显卡性能,把显卡的特性用接口的形式提供出来。
3D游戏处理可以分成2个部分,一个是3D空间数据处理,经过纹理映射把象素写到屏幕缓冲,接下来其他特效处理都是归结到2D问题,所以学习3D游戏的基础是真正了解游戏图象处理过程,也就是学习2D原理。
而2D游戏主要学习像素图像处理,颜色模式与2D动画系统。书本推荐《WINDOWS游戏编程大师技巧》。
3D游戏开发需要无比的耐力与勇气,你需要学习基础的3D数学,3D流水线(3D游戏的脊柱),D3D流水线。书本推荐《3D游戏编程大师技巧》。
a.游戏逻辑开发程序员:
主要集中于游戏逻辑的编写。
游戏逻辑开发是集中力量只开发游戏中剧情部分,你只需要做的是什么时候显示什么,什么时候放出什么声音,什么时候通过网络传输什么数据,什么时候这个物体或者人物做什么动作。
初学时可运用4)的一个引擎(鄙人现在刚开始接触cocos2d-x),选择其支持的一门语言,学习理解游戏中的场景管理,资源管理,状态机,AI和网络这些模块的编写。
b.游戏引擎开发程序员:
主要是自主设计编写游戏引擎。
基本包括:(1)图形引擎(2)声音引擎(3)网络引擎(4)脚本引擎(5)GUI(图形用户接口)(6)人工智能引擎(7)物理引擎
其中,(6)(7)在开发小型游戏中并不必要,而图形引擎是最难的,它基本要处理游戏引擎中70-80%的工作量,主要任务是负责图形高效显示,包括速度和精度。
初学时可先选用4)中的一个引擎,仔细剖析它的内部工作原理,学习5)的一个图形接口以及参照6)学习2D,3D游戏的编写。
以上许多信息都是鄙人从度娘上搜索整合出来的,在这个过程中也是受益良多。可以看出游戏开发所需的知识面及其广袤,原理繁杂且专深,入门容易,精通却要大量时间与精力的投入。如果真正要向游戏开发发展的话势必要下一番苦工(所以部门里没有游戏方向?),不过,做游戏开发无论在物质上还是精神上都有着非常可观的收益,当在游戏上做出一定成果时,对程序员来说一定有莫大的buff加成(勾搭妹子,哄女票什么的 ⁄(⁄ ⁄•⁄ω⁄•⁄ ⁄)⁄…)。
//////////////////////////////////////////////////////////////////////////////////////////////////
下面是本文部分资料的出处与推荐阅读的文章:
这是篇很好的关于如何做好游戏编程的文章:
http://blog.csdn.net/rabbit729/article/details/7014170
这篇主要讲游戏引擎:
https://www.zhihu.com/question/32063728
游戏开发论坛,有各种各样游戏开发相关的干货:
http://www.gameres.com/
by 汤雪儿
近日遇到了青阳大神,和他聊起了微软研究院的面试。我没去试试还是有点后悔,不过机会总是留给有准备的人,建议大家平时多多学习算法吧,leetcode是个很好的平台。青阳谈到了哈希表,我觉得这十分有趣 / 我孤陋寡闻,因此特地学习了一下并写了这篇笔记。
哈希表即散列表(hash=散列),是一种提供了某种表映射关系的数据结构,哈希表算法则是一种以空间为代价换取时间的算法,在以前存储空间紧张的时候,哈希表算法难以进行,而随着现在内存空间越来越大,哈希表被越来越广泛地应用。特别地,哈希表算法尤其受到ACM(国际大学生程序设计竞赛)的欢迎,因为它具有极其优秀的效率,相比于队列O(n)的查找时间,他只需要O(1)就可以定位内存。
哈希表的原理。首先我们需要定义一种映射关系,例如从字符串到整形数据的映射(MD5也是一种映射),这种映射通常是稀疏的(并不是所有的字符串都是有意义的单词 / 频繁出现)因此,对于一对一的映射,映射后的整形也是稀疏的,为了提高空间利用率,我们对映射后的数据求余,把整形限制在一个区间内,如果这个区间足够大,那么可以认为不存在冲突。如果我们把整形数据作为内存数组的下标来寻址、访问内存空间,那么就实现了从字符串到内存地址的映射。假设我们维护的是一个结构类型,那么我们可以根据指针找回原字符串,实现双向的映射。
一些待解决的问题。由于哈希表做的是一种求余后的映射,所以必然会有许多地址从未被访问、有许多字符串具有相同的哈希值访问相同的地址,产生冲突。由于哈希表是一种以空间换时间的算法,所以空间浪费是可以牺牲的,而对于冲突的问题,我们可以在产生冲突后额外维护一个链表,在访问到内存后继续做一个小的链表查找。由于当内存大小足够大时,冲突是小概率事件,他不会对整个代码的运行效率有多少影响。
哈希表的应用。哈希表最优秀的地方在于其搜索时间,而缺点在于其实现复杂度,因此特别适用于需要巨量搜索的场合,例如微软面试中提到的一个题,假设电脑中所有文件都是文章,里面含有大量的英文单词,要求统计英文单词的出现频率(这里把无关的部分省略了)。那么我们就可以维护一个哈希表,然后每得到一个单词,就进行一次映射(哈希、求余),并把访问的地址里的数据加一。
(例:mapInt=hash(charArr)%10000;buff[mapInt]++)
最后我们再遍历哈希表,根据结构指针找回原来的字符串,然后再输出对应的频率即可(哈希映射后顺序会被打乱,如果需要按字典序输出,需要另外排序)。
设n为单词总量相对于队列O(n^2)、字典树O(nlogn)的复杂度,哈希表只有O(n)的复杂度。
先说Laravel的版本,最新版的是5.3,为常规发布版本,相比5.2又加了一些新特性&一些部分进行了调整,虽然看不太懂但是反正会好用一些就没错了。
关于文档,目前5.3的中文文档还在更新中,基本还是可以参照5.2的去看,注意一下就ok,反正有变化的地方写代码的时候就会发现了。
讲一下Laravel的安装。虽然官方提供了一键安装包,但这里我们还是使用Composer会比较好。
Composer是php用来管理依赖关系的工具,就是包管理工具,当项目中需要用到某个包的时候直接引入即可,很方便。
Composer可以直接在官方下载.exe文件进行安装:
Download and run Composer-Setup.exe - it will install the latest composer version whenever it is executed.
安装过程中选好自己的php路径即可,完成后在控制台check一下顺便看看版本。
关于Laravel Homestead,这是个啥玩意呢:
Laravel 旨在让 PHP 开发变得简单和有趣,为此 Laravel 为开发者提供了打包好的一站式开发环境 —— Laravel Homestead,Homestead 实际上是一个虚拟机,我们使用 Vagrant 管理该虚拟机,并且在该虚拟机底层,我们使用 VirtualBox 提供其与主机操作系统之间的交互。
我理解来看,Homestead就是一个黑匣子,里面集成了一堆可能用到可能用不到的东西,比如PHP、MySQL、Nginx、Ubuntu等等。暂时还没怎么用过,主要是开启Homestead的速度太感人,homestead up之后需要默默地等待几个小时..总之可以先装好放着,本地暂时不用它,简单粗暴用wamp就好了:)
Wamp下载就在官网,安装完成之后记得配置一下环境变量。
同样的,对于前端资源,我们也可以直接拿现有的东西,用到的时候引入即可。这里我们使用bower,就是一个前端的包管理工具。先装好node,之后安装gulp,再装bower。
然后使用composer安装Laravel安装器,命令行:
composer global require "laravel/installer=~1.1"
后面的是版本号,不添加就安装最新版的,关于版本可以在packagist查看:
https://packagist.org/packages/laravel/installer
以后我们用到的依赖都是从这里来的,按照这种方式引入即可。
准备工作到这里就结束,之后就是正式创建一个项目开始工作,我们使用laravel安装器创建一个名为test的项目的骨架: laravel new test
如果这条命令瓦特了,可以使用composer:
composer create-project laravel/laravel test --prefer-dist
在相应的目录下就会自动创建一个项目骨架,然后就可以开工了。
Laravel自己添加了很多为了方便开发者的玩意,可以一个个去尝试,像是模型工厂功能,在进行测试的时候,如果要手动添加数据还是挺麻烦的,这个功能可以随机快速生成数据填充表单,方便进行测试。或是新建一个Controller、模型、服务类、任务类等,通过相应的指令就能自动生成一个包含了默认内容的文件,比如类声明、默认方法等,数据库迁移也可以通过migrate操作实现。
毕竟是为web艺术家创造的php框架,还是挺优雅的,但这建立在会用的前提之上。
入门的话可以看一看视频,文档还是挺迷的,laravist还可以,有些教程因为版本略有偏差所以当跟着教程搞出bug的时候就要考虑是不是框架版本的问题了…
放链接: https://laravist.com/
前面提过composer是个包管理工具,它提供的包在这里查询: https://packagist.org/
引入某些包的时候注意版本,因为它可能自带bug。
另外,Laravel有一些自带的辅助函数,可以在这里查询: http://laravelacademy.org/post/3230.html
最后,ide还是推荐phpstorm,有很多方便的地方。
写的挺乱的,大概先这样,也还在摸索中。
唔,并不知道写啥,就写写最基础的东西吧。(其实数据结构应该有讲这种东西?
DFS和BFS分别是深度优先搜索与广度优先搜索,顾名思义即为搜索算法
适用范围:
DFS主要适用于寻找最长路径,比方说从某个节点出发,能到的最远的节点这种。
BFS适用于最短路径,比方说从某个节点出发,如何最快走进死胡同这种。。
值得注意的是,两种搜索方法的差异不仅仅是在优先度上面,它们的搜索结果本身是不一样的。
比方说有ABC三个节点。
A->B
B->C
A->C
深度优先搜索得到的AC距离是2,而广度优先搜索得到的AC距离是1,就这样。
实现:
BFS主要通过遍历访问所有相邻节点,再对所有被访问的节点重复上一步以实现。
很明显,因为要遍历访问所有节点,因此你刚访问完一个节点,就得去访问下一个,不能马上对该节点的相邻节点进行遍历访问,所以通常用先进先出的堆以实现。
另外,为了保证是最短路径(以及避免死循环),会维护一个表以保证不重复访问。
queue.push(origin_node)
while(cur_node=queue.shift)//取出队列的第一个值
cur_node.next_nodes.each do |visiting_node| //对cur_node的每个相邻节点进行访问,当前的被访问节点为visited_node
//只要当前节点还没被访问,就加入队列,它离原点的距离比cur_node多一。
next if visiting_node.visited?
visiting_node.visited? = true
visiting_node.length_to_origin = cur_node.length_to_origin + 1
queue.push(visiting_node)
end
end
就这样。搜索完成后,你只要访问任意一个节点的length_to_origin属性,就知道其与原点的最短距离了。
当然,不一定要完全搜索,比方说你只想找一个最短的死胡同,你只要在while下一行加一个
return cur_node unless cur_node.next_nodes (unless condition = if !condition)
比方说该代码应用于之前说的三节点情况时时,假设origin_node是A。origin_node.length_to_origin = 0。
那么(A,B,C) => (0,1,1)
DFS在很多意义上都与BFS正好相反
BFS先访问完再挨个遍历
DFS则是挨个访问并遍历
BFS的计数是以原点为基准,这样可以保证由近到远进行遍历
DFS则是以终点作为基准,保证其储存的是每个点离最远终点的距离
由于BFS要维持visited?(虽然我的代码中把它当节点的自带属性了,但通常是用一个数组来维护的
还有那些已访问但待遍历的点,
所以迭代比较自然
而DFS则由于要从终点从后往前算,递归比较自然。
BFS中起点很重要,不同的起点整个结果完全不一样,
DFS中起点是浮云,甚至就是要把所有的节点都作为起点遍历一次才保证完成
先上结构。
比方说之前说的三节点结构,应表示为:
(define a (delay (list b c)))
(define b (delay (list c)))
(define c (delay null))
(define l (list a b c))
其中a,b,c是节点,l是储存所有节点的表
然后是DFS实现
(define (DFS-l l)
(define (DFS-n n)
(define next_nodes (force n))
(if (null? next_nodes)
0
(+ 1 (apply max (map DFS-n next_nodes)))))
(map DFS-n l))
当然这十分低效,实际写的时候应当加上缓存。
就是在把在完成(+1 ...)那行代码后缓存当前节点的值
唔,那么运行 (DFS-l l)的结果是(2 1 0)
显然与BFS的(0 1 1)有明显差别。。
其差别如上文所说,就是AC之间的距离。
唔,DFS和BFS和冒泡算法类似,本身只是一个非常简单的思路,但实际运用中往往只是算法中的一个中间步骤,其实际代码肯定是要根据需求灵活改动的。
网上的代码各种i,j,k看的我一愣一愣的,所以自己写了一下。。写完才发现。。好像也好不到哪去。。
还是伪代码好懂啊。。
另外BFS的代码我自己比较懒没跑过的= =
有错误欢迎指出
先介绍一下什么是socket,它的英文翻译是套接字,用通俗的语言来理解,就是操作系统提供的一组接口,开发人员可以去调用它,来实现程序之间、或者程序与网络的通信——本质上说它是对TCP/IP协议的封装和应用。一般我们所说的socket编程,则是在Linux操作系统下的服务端软件开发,使用语言多为C,当然也可以用python之类的。常见的比如Apache、php-fpm、Memcached、Nginx、MySQL等都是通过这种方式写出来的,因为对外提供服务基本上要通过网络嘛。
实际上socket编程算是比较底层开发了,需要考虑多线程、内存管理、读写锁等等一系列问题,所以用C是比较合理的一种选择,当然代码量相对也比较庞大;另外一点就是,它是和各种协议密切相关的,特别是在通信方面,所以了解网络模型是学习socket编程的首要任务。
呃, 其实socket编程只是服务端软件开发的一部分,其它的逻辑实现还得另外写,既然大家都学过C语言我就不多说了。最后再解释一下,我以前讲过的监听端口,实际上就是通过socket相关函数来启动的,同理当你在访问某个端口的时候,就会触发相应的socket操作,以达到与程序通信的目的……比如获取网页的请求。
总的来说,学习socket编程可以加深你对诸如网络协议、通信模型等一系列概念的理解,也鼓励大家去看一看我刚才提到那些软件的源码哟(⊙o⊙)
以下是两个相关的资料,请自行阅读:
http://www.cnblogs.com/fuchongjundream/p/3914696.html
http://blog.csdn.net/hguisu/article/details/7445768/
PS:java有这方面的库可以用,所以也可以用它来开发相关的软件呢~详情请见:
http://www.cnblogs.com/linzheng/archive/2011/01/23/1942328.html
最近重构天气预报,试了一下material design的控件。嗯比原生好看多了。
首先在AS里新建工程,可以直接新建一个带有其他控件的项目,当然这样代码会多一点,你需要去了解一下它的初始架构。

我这里分享的是一个带有抽屉的activity,其中NavigationView,Toolbar,FloatingActionButton,DrawerLayout的使用我就不多说了。
这里讲一下在这个应用中加入下拉刷新列表的方法。
以前使用下拉刷新的话一般使用开源库,但是google推出了SwipeRefreshLayout和RecyclerView,可以完美替代开源库的作用,而且也有动画效果,很推荐使用。
首先在xml里加入控件嵌套使用就可以了。
<android.support.v4.widget.SwipeRefreshLayout
android:layout_width="match_parent"
android:layout_height="match_parent"
android:id="@+id/swipe">
<android.support.v7.widget.RecyclerView
android:layout_width="match_parent"
android:layout_height="match_parent"
android:id="@+id/recycler"/>
</android.support.v4.widget.SwipeRefreshLayout>
接着在java中声明控件,要注意的是RecyclerView需要配置一个LayoutManager。
SwipeRefreshLayout swipeRefreshLayout = (SwipeRefreshLayout) findViewById(R.id.swipe);
swipeRefreshLayout.setOnRefreshListener(new SwipeRefreshLayout.OnRefreshListener() {
@Override
public void onRefresh() {
}
});
RecyclerView recyclerView = (RecyclerView) findViewById(R.id.recycler);
recyclerView.setLayoutManager(new LinearLayoutManager(this));
recyclerView.setAdapter(new RecyclerAdapter());
SwipeRefreshLayout的使用比较简单,就是在onRefresh里写刷新的操作就可以的了。主要介绍一下RecyclerView的使用。
整体上看RecyclerView架构,提供了一种插拔式的体验,高度的解耦,异常的灵活,通过设置它提供的不同LayoutManager,ItemDecoration , ItemAnimator实现令人瞠目的效果。
你想要控制其显示的方式,请通过布局管理器LayoutManager
你想要控制Item间的间隔(可绘制),请通过ItemDecoration
你想要控制Item增删的动画,请通过ItemAnimator
(复制粘贴了一波。。。)
目前SDK中提供了三种自带的LayoutManager,能够实现三种不同布局:
LinearLayoutManager 线性管理器,支持横向、纵向。
GridLayoutManager 网格布局管理器
StaggeredGridLayoutManager 瀑布流式布局管理器
ItemDecoration可以绘制分割线,当然你也可以添加其他东西作为间隔,提高了我们的设计自由度。
ItemAnimator可以设置增删的动画效果,而且也有默认动画,还不错。
接下来是Adapter了。RecyclerView自带Adapter,引入了ViewHolder提高性能。话不多说看代码
public class RecyclerAdapter extends RecyclerView.Adapter<RecyclerAdapter.ViewHolder> {
public String[] datas = null;
public RecyclerAdapter(String[] datas) {
this.datas = datas;
}
//创建新View,被LayoutManager所调用
@Override
public ViewHolder onCreateViewHolder(ViewGroup viewGroup, int viewType) {
View view = LayoutInflater.from(viewGroup.getContext()).inflate(R.layout.item,viewGroup,false);
ViewHolder vh = new ViewHolder(view);
return vh;
}
//将数据与界面进行绑定的操作
@Override
public void onBindViewHolder(ViewHolder viewHolder, int position) {
viewHolder.mTextView.setText(datas[position]);
}
//获取数据的数量
@Override
public int getItemCount() {
return datas.length;
}
//自定义的ViewHolder,持有每个Item的的所有界面元素
public static class ViewHolder extends RecyclerView.ViewHolder {
public TextView mTextView;
public ViewHolder(View view){
super(view);
mTextView = (TextView) view.findViewById(R.id.text);
}
}
}
这就是最简单的使用方法了,创建一个ViewHolder,包含了你的item里面的控件,onCreateViewHolder就在绘制时创建ViewHolder,而onBindViewHolder是用来绑定数据的。
而RecyclerView还有一个特点就是可以很方便的使用多种布局作为item。通过getItemViewType方法,使每个位置的item返回不同的type,在onCreateViewHolder中通过不同的type创建不同的ViewHolder,就可以实现显示不同的布局了。
推荐两篇RecyclerView的文章
http://www.jcodecraeer.com/a/anzhuokaifa/androidkaifa/2014/1118/2004.html
http://blog.csdn.net/lmj623565791/article/details/45059587
这两个控件还有很多使用技巧,后面慢慢更新吧。
我们都知道,前端语义化已经成为了一个趋势,语义化的标签可以让代码更具有可读性(包括机器和人).例如在H5中有这么几个标签header footer sidebar以及其他一些标签,这些标签清晰地指出了html代码中每一部分的具体的作用,便于代码的维护和团队合作.
过去我们常用添加类名或是id亦或是写注释来达到这个目的.确实,这很大程度上解决了"人"对于代码的阅读需求,然而,对于机器(搜索引擎)来说这就是一个巨大的问题了.例如:我们使用<h1>标签包裹页面标题信息就是为了让机器识别
为了解决这个问题,我们就要用一个特定的规范去描述我们的页面.在HTML和CSS Javascript三者中,html主要是负责数据的结构与呈现,于是microdata利用这一特点,在HTML标签中增加一系列的属性来告诉机器这些文字或是数据分别是什么含义.

我们最常看到用这一特性的就是meta标签了
<meta name="keywords" content="HTML,ASP,PHP,SQL">
我们说要描述的数据不仅如此,我们要描述一个电影,必然要说清楚这个电影的名称,男猪脚和女猪脚是谁?那个导演导演的?啥时候上映?对于商家来说还要说这部影片什么时候在哪里排片情况如何.我的影院的电话号码是多少,在哪里,官网是什么等等一系列的问题.这些问题光靠meta标签怕是有些困难
我们看看下面的一段代码,看看MicroData是怎么解决的:
<div itemscope itemtype="http://schema.org/Movie">
<h1 itemprop="name">美国队长3</h1>
<div itemprop="description">
该片根据<span itemprop="about">漫威2006年出版的漫画大事件《内战》</span>
改编,背景故事承接于《复仇者联盟2:奥创纪元》事件的余波中,讲述了奥创事件
后引发的一系列政治问题导致复仇者之间内部矛盾激化的故事。
</div>
<span itemprop="director" itemscope itemtype="http://schema.org/Person">
<span itemprop="name">安东尼·罗素</span>
/
<span itemprop = "name">乔·罗素兄弟</span>
</span>
<span itemprop="locationCreated">美国</span>
<span itemprop="publisher">漫威影业公司</span>
<p>时长
<span itemprop="duration">147 min</span>
</p>
<span itemprop="aggregateRating" itemscope itemtype="http://schema.org/AggregateRating">
<span itemprop="ratingCount">***</span>
<span itemprop="reviewCount">*****</span>
<span itemprop="ratingValue">4.5</span>
/
<span itemprop="bestRating">5</span>
</span>
</p>
</div>
在这里先用itemscope声明microdata的编辑区域,然后用itemtype来声明你所使用的词汇库.在其下面,我们用itemprop来指定属性的值.具体语法将在下面给个传送门.
词汇表是干啥用的呢?它定义了itemprop可以使用的值,我们上面的例子用的是Google丰富网页摘要词汇表要用的时候可以到里面查询具体的词汇表
这种写法似乎有违于HTML要求的简介清晰明了的特点,上面的一大堆,看起来一点也不优雅.有一个好消息
2014年1月16日,W3C的资源描述框架(RDF)工作组发布了JSON-LD 1.0及JSON-LD 1.0处理算法和API(JSON-LD 1.0 Processing Algorithms and API)两份正式推荐标准(W3C Recommendation)。
看看google给的示例
<script type="application/ld+json">
[{
"@context" : "http://schema.org",
"@type" : "MusicEvent",
"name" : "B.B. King",
"startDate" : "2014-04-12T19:30",
"location" : {
"@type" : "Place",
"name" : "Lupo's Heartbreak Hotel",
"address" : "79 Washington St., Providence, RI"
},
"offers" : {
"@type" : "Offer",
"url" : "https://www.etix.com/ticket/1771656"
}
},
{
"@context" : "http://schema.org",
"@type" : "MusicEvent",
"name" : "B.B. King",
"startDate" : "2014-04-13T20:00",
"location" : {
"@type" : "Place",
"name" : "Lynn Auditorium",
"address" : "Lynn, MA, 01901"
},
"offers" : {
"@type" : "Offer",
"url" : "http://frontgatetickets.com/venue.php?id=11766"
}
}]
这种表示方法更加的直观,与html的耦合程度更低易于书写,(JSON-LD也是最近才看到的,日后补充吧)
附录:
马上部门就要开始毕业季的项目开发啦~这也是大多数15级的小朋友第一次正式参与开发的部门项目。经过一学期的学习,相信大家对于git的使用已经不太陌生,但不知道大家对于git的分支管理是否也有足够的了解呢?
分支管理是git作为版本控制工具最强大的优势之一。怎么协调管理团队开发中每个人的开发工作,怎么管理一个项目各个阶段的版本迭代,这与这个团队是否懂得合理运用分支进行项目管理息息相关。相信准备参与毕业季开发的小朋友最近都已经加入到部门的gitlab中了,大家也可以走走看看以前的项目都是怎么进行版本管理的。
废话说完了,下面是正题:
首先我们先来看看一张比较典型的git分支管理图
是不是感觉看得有点晕?其实在一般的需要进行版本迭代的项目中,日常的分支只需要master和develop两条就够了,其他都是临时性的分支。如果是仅使用一段时间的比较小的短期项目(比如治愈系、毕业季等),那可能就连dev分支都没必要了。但像波板糖这种需要长期维护的项目,dev分支还是必须的。
下面我们一条条来讲各个分支的功能。
这个分支大家一点都不陌生了,初建立版本仓库时默认新建的就是这个分支。
主分支也就是发布分支。无论何时,主分支都是必须的。而且绝大多数时候,一个项目的主分支都只会有一个。这条分支上,存放的是所有给用户正式使用的发布版本。对于需要不断迭代更新版本的项目,我们都会习惯给主分支上的每个版本设立一个tag,用来标注它的版本号,方便进行版本的回退操作。
主分支是用来发布正式版本的,而日常的开发则是发布在develop分支上(有时我们也会简写成dev分支)。当一个版本开发完毕,打算正式发布时,我们就会将该分支上的版本merge到master分支上。但有时开发完成后我们并不会直接发布,而是还要再经过一个预发布的测试过程,这种情况后文再提。
在这里再重提下合并分支时no fastforward的问题。不知道大家是否还记得上学期柏晓培训git时提到的--no-ff参数?默认情况下的git merge dev是快进式合并,合并后master分支会直接指向dev分支。为了保证版本演进的清晰,强烈建议采用git merge --no-ff dev的方式。下面两张图对比下:
前面提到了有时候开发完一个版本后,我们不会立马上线,而是会先测试一段时间。这时候我们会选择新建一个临时的release分支,专门用来在版本测试中对代码进行修复和完善。待版本测试完毕后,再将可以发布的版本分别合并到master分支和develop分支上,最后再根据需要删除该临时分支。预发布分支可以采用“release-版本号”的方式命名。至于图片我就不放了,大家参考最上面的那张大图。
有时候bug并不一定出现在开发过程中,也可能是已发布的版本中发现有bug。此时在dev分支正在开发新版本的情况下,我们并不方便将bug放到下一个新版本中再修复。这时就需要从master分支上新建一个临时分支,用来针对已发布的版本进行bug的修复。同样,修复完成后的版本要分别合并到master分支和dev分支上。
这其实是一个比较少用到的分支。曾经在部门的某次项目开发中,因为项目中包含好几个功能模块,开发组成员的工作又是按功能模块划分的,于是gitlab的分支上一下出现了五六个以功能命名的分支。更崩溃的是,这个开发组其实只有3个人。对于这种想撞墙的分支管理方式,我给出的回应是:“来,我们来聊聊人生。”
功能分支。顾名思义,是为了开发某种特定功能而从dev上延伸出来的临时分支。但是请注意:这里的功能并不是在版本规划内的功能。换句话说,只是这个项目有开发这个功能的需要,但它并不在版本计划内,它有可能会在下次版本发布,也有可能在下下次版本中发布,甚至也可能在开发到一半时被cancel掉了。这取决于这个功能的开发进度和功能设计的完善程度,只有当这个功能稳定下来,被考虑进新一个版本的计划中时,它才会被合并回dev分支,并最终发布到master上。
五种分支介绍完啦~现在大家是不是觉得清晰了很多?
但是实际开发中还是有很多各种各样的情况,下面我针对有可能碰到的问题进行一个探讨。当然这些观点更多是从我的经验角度看的,而且大多是来源于网页开发的经验。如果其他老人们有其他建议或者不一样的观点,欢迎跟帖留言。或者是有自己在开发中遇到的问题也可以发上来一起讨论下。
bomb后端云是什么?
是一个baas平台。
baas平台是什么?
baas(后端即服务:Backend as a Service),公司为移动应用开发者提供整合云后端的边界服务。
注意:是bomb,不是bmob!
然后附一个娱乐大众的文章。
好,说正经的。。。
http://www.bmob.cn/docs
就这一个网址,里面讲解十分详细。
各个方向的都可以看一下。
主要给移动端的看看,可以多给黄登一些时间和妹子相处,少写点api。
问题提出:在做博客时会出现一个页面要显示的数据在多个不同的表中,有时需要将一个表的一个搜索结果作为另一个搜索的条件。举个例子:在登陆时,你可以输入你的是用户名登陆,但是在数据库里用password和id在表basic里,id,user_name,nickname,sex,age,email,phone....在basic_information里。如果有人用aaaa为用户名登陆,我就要搜索表basic_information找到aaaa对应的id,然后把这个搜索结果放到表basic里搜索password并进行匹配,这样会有很多问题。首先逻辑不易判断,要考虑在两个表间传递时可能出现的各种错误,而且性能上问题也会比较严重,所以引入“视图”。
先给一个基本定义:计算机数据库中的视图是一个虚拟表,其内容由查询定义。同真实的表一样,视图包含一系列带有名称的列和行数据。但是,视图并不在数据库中以存储的数据值集形式存在。行和列数据来自由定义视图的查询所引用的表,并且在引用视图时动态生成。(baike.baidu.com/link?url=KcZfe4OHUMZLAbXh1c4G8NPc1wkldMGec1s1i53jh3Q6vag4k596FUH9s8Yqts-6gR0OOzDQ-Q8Dyd18YryU1_)
还用我这个例子,我建立一个视图,将表basic和basic_information建立视图,
create algorithm=temptable view log_in (id,password,user_name) as select basic.id ,basic.password ,basic_information.user_name from basic ,basic_information where basic.id=basic_information.id;
tips:括号内的可以省略不写。
接着我只要搜索这个虚拟表log_in就可以了,这样就跳过了id这个中介,直接让买家(user_name)找到了卖家(password),你就能省下一笔中介费。
select * frm where user_name = "aaaa";
再从中提取出password进行匹配就OK了。
最后我们来删除这个没有用的视图,毕竟让一个存有用户名和密码的表存在是很危险的
Drop view log_in;
这样就算是彻底优化了我的登录功能。
现在我们知道视图是什么了,那么我们再来看看他都有什么功能:
1.合并多表:现阶段我们用的最多的功能。就像我这个例子,把多个表合并在一起提高搜索效率并简化查询语句。
2.权限控制:在开放权限时,可以只开放这个视图的权限,他们就不知道nickname,sex,age,email,phone....的信息,如果哪天有人让我提供昵称,我可再做一个视图而不用改我的整个表了。
3.大数据分表:表的行数据超过200万行时,速度就会变慢。如果我的博客系统做的很成功,有400万人用,那我为了兼顾效率,就要进行分表出处理,但是我不能在他们登陆时一个一个表去找啊,所以用视图把4个100万条数据的表组合起来
create view basic_informations as select * from basic_information1 union select * from basic_information2 union select * from basic_information3 union select * from basic_information4;
4.....(等待你们补充哦!)
made by mzt
本文参考引用:
http://www.cnblogs.com/zzwlovegfj/archive/2012/06/23/2559596.html
baike.baidu.com/link?url=KcZfe4OHUMZLAbXh1c4G8NPc1wkldMGec1s1i53jh3Q6vag4k596FUH9s8Yqts-6gR0OOzDQ-Q8Dyd18YryU1_
http://www.cnblogs.com/wangtao_20/archive/2011/02/24/1964276.html
http://blog.itpub.net/28194062/viewspace-772902/
随着移动互联网技术的兴起,各式各样的应用层出不穷,一个app能否在众多应用中脱颖而出,在浪潮中站稳脚跟,除了其功能是否能适应当代人的需求以外,还有就是良好的用户体验,而良好的用户体验又主要取决于UI设计,所以,一款优秀的app的UI设计得是否良好(此处应@ui狂魔我奤),很大程度上决定了它能走得多高,多远。
众所周知,如今移动端的两大巨头之一的安卓,一直饱受UI体验不足iOS的诟病(此处再@iOS痴迷粉我奤),这是由安卓系统本身的开源性所决定的,因为开源,所以设计规范上得不到统一,所以导致整个app的UI设计趋于凌乱,也正是为了改变这种现状,两年前,Larry Page 就任谷歌 CEO 后下的第一个命令就是将谷歌所有的产品重新设计一遍。于是谷歌搜索首席设计师 Jon Wiley 花了两个月时间将谷歌系列产品改头换面。从那时起,谷歌开始重视设计,Material Design 的概念自此呼之欲出。
Material Design 是一套非常拟物的设计逻辑,提取自卡片的材质和真实的光影,符合现实世界的物理反馈,在 UI 设计上提取出具体的物理细节,只保留物理特效、光影和层次。它的核心**,就是把物理世界的体验带进屏幕。去掉现实中的杂质和随机性,保留其最原始纯净的形态、空间关系、变化与过渡,配合虚拟世界的灵活特性,还原最贴近真实的体验,达到简洁与直观的效果。


具体有关于Material Design的更多细节,有兴趣的同学可以看看
Material Design 提出至今已经有两年了,在国内的大部分的app身上仅仅体现了一小部分,就算是BAT中移动端老大腾讯的两条腿,微信和qq均未使用Material Design,当然,这样并非代表Material Design效果不好,而是任何新技术的更新发展,直到大规模使用还需要一定的时间周期,特别是对于一些业务相对成熟的大公司,在考虑应用新技术的时候都会考虑到开发成本,和维护稳定的成本的。虽然Material Design 在大型App上未看见其身影,但是现在越来越多的小中型应用开始采用这种设计,目前我在用的就有WPS,知乎,天天动听等等,还有一些是只是小部分使用的应用是360手机助手,百度地图等。
曾经看过一个国外的产品经理来到**后使用应用后感受国内外差距最大的设计观念就是,国外的app是越简单越好,而国内的是拼命想把越多东西塞到应用里面去。这也侧面说明了Material Design在国内推广的困难,一些应用,例如美团,淘宝等需要大量堆积信息的应用,如果使用了Material Design这样简洁的风格,就很难实现其自己的业务需求了。所以Material Design很多出现在了一些信息需求不是很大,的轻量级应用身上。
为什么Material Design没在国产App中流行起来?



最后的话,好像这篇东西更适合设计的人员看,但是作为一个有情怀的app开发人员,都有一颗UI狂魔的心。然后我就回去继续撸波板糖了,希望第二版能把UI改得更好看点。大家有兴趣的话可以自行百度一下~
这个锅本来是若花的,然而不知不觉就甩我背上了。你说我一个学电气的,怎么就跑来写验证码识别了呢。波小跟我说,组织上决定了,由我来写这个。我当时就念了两句代码,print "苟....
言归正传,验证码识别主要分两部分:图像分割和识别。其中,分割验证码是最麻烦的,因为基本没有一劳永逸的分割方法。
本文基于opencv2.4,有兴趣的可以去了解一下。
我们先来看看教务的验证码。

可以看到,是个72x27像素的矩形,而且每个字符的颜色都是一样的,所以只要提取那个颜色的像素就可以分离出字符了。听起来很简单是不是?
首先我要表扬一下若花,因为若花的项目虽然tj了,里面用到的分割算法确是非常赞的。那么我们先来看一下若花是怎样做的。

这个GIF所演示的就大致是若花的算法了,若花当时对我说的是“染色”,也就是油漆桶算法(又叫种子填充算法,Floodfill)。说实话看了若花的代码,我深有感触。首先,若花自己一个人写了前端和后台,前端用了npm、bootstrap,还用了ajax,要是让我来写。。。。。。估计又要在群上喊耀宗了。其次是算法的实现都是若花都是用php写的,php在这方面有点先天弱势,但是若花还是写出来了,所以要给若花点个赞。
但是说了这么多,我最终还是没有采用这个算法。为什么呢?
因为这个算法有个致命的问题,对于ij这样带有非联通区域的字母,会把上面的点漏掉。。。。。。这就很尴尬了。我一开始想,能不能先给出每个字母的最小区间,再对区间内的字符颜色的像素染色,这样就有很大几率可以把点也染上,因为写过原生的php生成验证码的代码,知道字符虽然有旋转和位移,一开始的位置还是有规律的。如果想分离出单个字符,可以直接使用RGB中R的通道,第一个字符就+1,第二个+2,第三个+4,第四个+8,这样数一下R的大小就可以把字符分开,还可以知道哪些字符相连,然后相连字符再重新分隔。
但是后来我又放弃了,因为我比若花还要懒找到了更好的方法。之前的方案要统计一定数量的验证码来确定每个字符的最小染色起始区间,还要把php写的染色算法改写成python。
所以最后,我使用了opencv自带的k-means算法。这个算法的好处在于有现成的函数可以偷懒不但可以分割提取字符,还可以找出每个字符的中心点。中心点可是个好东西,不但可以确定字符的次序,还可以对每个字符标准化,方便后续的特征提取。

说到特征提取,若花好像就是卡在这一步。他的分类器好像都基本写完了,而且是php写的,说实话真的很厉害。。。
我这里使用了ocr例程里的方向梯度直方图Histogram of Oriented Gradients (HOG)作为特征向量。在计算 HOG 前还要使用图片的二阶矩对其进行抗扭斜(deskew)处理,然后把每个字符分成4块,我这里把27x27的字符分成了14x14的小方块,然后计算图像 X 方向和 Y 方向的 Sobel 导数(这个不是很懂,如果有人知道请告诉我)。然后计算得到每个像素的梯度的方向和大小。把这个梯度转换成 16 位的整数。将图像分为 4 个小的方块,对每一个小方块计算它们的朝向直方图(16 个 bin),使用梯度的大小做权重。这样每一个小方块都会得到一个含有 16 个成员的向量。4 个小方块的 4 个向量就组成了这个图像的特征向量(包含 64 个成员)。这就是我们要训练数据的特征向量。
这里我用在knn和svm中选用了svm。knn每次识别都要遍历一遍现有数据,随着数据的增加识别速度会下降,而svm就没有这个问题。svm有很多相关资料可以查,比如前面给的链接,这里就不细说。而且opencv自带的svm并不是最好的,3.0版还有bug,无法导入训练好的模型:(

识别速度还算令人满意。
Service是Android四大组件之一,主要用于在后台运行处理数据,可以在APP不在前台的时候依旧运行。这里我就简单介绍一下Service。
Service的生命周期比Activity简单,主要有OnCraate(),OnStart(),OnStartCommand(),OnDestroy()这四个流程,其中OnStart()和OnStartCommand()其实是一样的,只不过OnStartCommand()是Onstart()更加好的实现,OnStart()方法现在也基本废弃了,我们只关注OnStartCommand()就好了。
当第一次启动Service时,先后调用了onCreate(),OnStartCommand()这两个方法,当停止Service时,则执行onDestroy()方法,这里需要注意的是,如果Service已经启动了,当我们再次启动Service时,不会在执行onCreate()方法,而是直接执行onStart()方法。另外要注意的是每个Service只有一个实例,也就是说不同Acitvity启动同一个Service时调用的都是同一个对象的方法。
Service的启动方法有两种,一种是bindService(),另一种是startService(),下面讲讲这两种方法的区别。
startService()只需要我们传入一个Intent参数就可以了,和我们启动Activity差不多。当我们使用了startService()后,系统会调用相应Service的onStart()方法,并且我们每一次调用startService()系统都会调用一次,我们Service主要进行工作的地方便是在onStart()方法里了。
比起startService(),bindService()就相对复杂一点了。我们注意到当我们创建一个Service类时编辑器会要求我们重写OnBind()方法,而这个OnBind()方法实际上就是为bindService()服务的,这里要求我们返回一个IBinder,通常我们都是在Service里创建一个类继承Binder类然后返回一个这个类的实例。注意到bindService()要求传入的参数里有个ServiceConnection类,这个类也是需要我们自己去实现的,ServiceConnection类主要实现两个方法,onServiceConnected()和onServiceDisconnected(),onServiceConnection()传入的参数里有一个IBinder类,而这个IBinder类就是Service里OnBind()方法返回的那个对象。
说了那么多,那么这个IBinder类有什么用呢?我们知道当我们要启动Acitvity或者Service的时候不是我们直接new一个对象出来的,而是调用Android自带的方法去启动,并且这个方法启动是不会返回创建的对象的,也就是说我们不能直接在当前Acitvity持有我们启动的Activity或Service对象,也就无法直接调用我们启动的Service里面的方法了,所以这时候便需要IBinder了。如上面所说的,我们是在Service里创建IBender对象的,所以这个IBender对象可以直接调用Service里的方法,并且我们会通过ServiceConnection将这个对象传递到Activity里,进而我们可以在Activity里通过IBinder这个对象调用Service里的方法了。
要注意的一点是当我们调用bindService()时,系统并不会调用onStartCommand()方法,只会去调用onBind()方法。
说完了Service的启动,现在说一下Service的停止。
当我们调用了startService()和bindService()方法后,Service就会启动并调用相应的方法,但在这之后Service并不会销毁并调用onDestroy(),而是需要我们在启动Service的Acitvity里相应调用StopService()或unbindService()方法后才会停止并销毁。
stopService()方法对应着startService()方法,我们需要在每一个调用了startService()的地方调用stopService()方法后Service才会进行销毁。除了StopService()外Service自己内部里还有一个stopSelf()方法,这个stopSelf()方法相当于在每个调用startService的地方调用一次stopService()。
bindService()方法对应着unbindService()方法,我们也是需要在每一个调用了bindService()的Activity调用unbindService()方法后Service才会销毁。和startService()不同的是,当我们调用了bindService()的Activity销毁的时候Activity会自动调用unbindService()方法,而不会调用stopService()方法。
需要注意的是如果我们同时调用了bindService()和startService()方法,那么只有我们unbindService()方法和stopService()方法都调用了Service才会销毁,只调用一种方法的话Service是不会停止的。
前面有提到onStartCommand()方法是onStart()方法改进,那么onStartCommand()方法究竟与onStart()方法有什么不同呢?细心的话我们可以注意到onStartCommand()方法的传入参数比onStart()方法多了一个flags参数,并且onStartCommand()有返回值而onStart()方法没有返回值。这两个地方都与Service的重启有关,也就是说onStartCommand()方法比起onStart()方法更优在于它可以在一定程度上控制Service的重启。
onStartCommand()方法的返回值有4种,分别是:
需要注意一下的是onStartCommand()默认的返回值为START_STICKY,也就是说当Service被系统异常kill掉后是默认会重启的。
onStartCommand()的传入的flags值有3种,分别是:
我们上面说到了Service的停止是需要我们调用方法去停止的,它自身是不会自动停止的,那么如果我们忘记停止Service会有什么后果呢?当我们退出APP的时候,如果Service没有停止,那么系统将会首先将这个Service异常kill掉一次(并且这时候Service是不会调用onDestroy()方法的!!!),然而我们上面说了只要我们在Service里onStartCommand()方法的返回值不是START_NOT_STICKY那么当Service被异常kill掉后便会自动重启,也就是说尽管我们已经退掉APP了但是我们的Service会依旧在后台运行着,这样便会白白占用我们手机的内存了。这里值得一提的是我们国产的一些安卓手机会对这行为进行拦截,会阻止这种情况下的Service的重启,然而这不见得是好事,因为当有时我们需要在APP退出后Service继续在后台运行也会遭到拦截。
我想很多初学者都搞不懂Service和Thread的区别,因为他们两个都是用于处理一些耗时的操作,我这里就简单地说一下我的理解。
我们知道Android里面主线程也就是UI线程是不能进行耗时操作的,一但进行耗时操作就会出现失帧的情况,而Service里onStartCommand()方法是在主线程中运行的。这里就有个问题了,既然onStartCommand()方法是在主线程中运行的,那么Service要进行耗时操作就必然会用到Thread,既然如此我为什么不直接用Thread呢?那是因为其实Service和Thread是完全是两样不同的东西,并不能将它们俩相提并论,我们可以简单地理解为Thread是一种工具,而Service是这种工具的其中一个持有者。
我们知道在Android里我们不能直接持有Acitvity对象,那么我们是很难做到在Activity之间传递Thread对象的,所以如果我们直接在Activity里使用Thread的话,那么当Activity被销毁后我们将不能够再次获取该Thread对象,也就是说Thread对象只能存活在Activity的生命周期里,当Acitvity被销毁的时候该Thread对象也应该要进行销毁,不然我们将会失去对该Thread对象的控制。所以如果我们需要进行一些贯穿整个APP的耗时操作便不能直接在Activity里使用Thread,这时候便需要Service来操纵Thread,因为Service是可以保证在APP存活期间一直运行着的。
波板糖一直出现的白盒测试的问题,过程中有很多想法
排序算法,大家应该都很熟悉了,常见的排序算法有:
在这么多算法中,我认为归并排序是最优雅的,首先,它拥有一个十分简洁的表达形式而且几乎在任何情况都适用,下面来看一下对比与分析:
归并排序算法的步骤:
从归并排序的步骤里可以看出,这是有递归、分治的**在里面的,而这种**非常适合多核运算:我可以很方便地把一个问题均分为四份然后当作四个独立的子任务交由四个CPU进行。
合并的过程是有序的(从前往后顺推),因此可以很方便的对巨大的表进行合并:可以每次只从硬盘读出一小部分数据到内存进行合并,这样可以避免过于集中的IO调用以及过重内存占用。
对比其他的合并方式:
总结一下,数据结构并不是越复杂越高端越好,很多时候,伟大的规律总是简洁而深刻
“小程序是⼀种不需要下载安装即可使用的应⽤,它实现了应用「触手可及」的梦想,用户扫⼀扫或者搜⼀下即可打开应用。也体现了「⽤完即走」的理念,⽤户不用关心是否安装太多应⽤用的问题。应⽤将无处不在,随时可用,但⼜无需安装卸载。” --张小龙
通过这段文字我们可以提炼出几个关键词来理解一下他到底想做出一个怎样的产品?
触手可及 通过扫一扫或者搜索你就能打开。
用完即走 没有主动*扰,不希望过度黏住用户。没有关注,没有群发。
无需安装卸载 不占空间,不费流量,不流垃圾。
这段东西我的理解是:这是一个不用下载安装,不会在后台吃内存的一个APP。
但这真的是一个全新的东西吗?
并不是,在13年,百度就退出了一个轻应用,而它的介绍是
LAPP (Light App) 即轻应用是一种无需下载、即搜即用的全功能 App,既有媲美甚至超越native app的用户体验,又具备webapp的可被检索与智能分发的特性,将有效解决优质应用和服务与移动用户需求对接的问题。
谷歌也提出了一个Progressive Web Apps的项目,它具有的特性是

是不是感觉很眼熟~但是轻应用失败了,而谷歌在墙外,所以微信小程序在我们看来是全新的,但实际上并不是。
因为它叫微信小程序,我们从后面3个字来分析一下它的特性:
1.小
小程序的小体现在程序包小,微信目前给的限制是:1024KB程序包限制(打包后)、10M本地存储限制、5层跳转。这样的限制应该是为了满足触手可及的要求。而由于这个限制,小程序所能实现的功能也变小了。
2.程序
作为程序,与公众号最大的区别就是使用的是C/S架构而不是B/S架构,它的本质更倾向于一个APP而不是H5应用,(其实它是需要安装的,不过因为程序小的原因它可以让你察觉不到它的安装过程。)但是为什么说微信小程序跟前端方向比较接近呢?因为它在技术上借鉴了HTML+CSS+JS的模式,技术框架MINA则借鉴了REACT、VUE、ANGULAR等框架,借鉴了前端模块化开发的理念。所以微信小程序的开发更偏向于前端而不是移动端。

受限于体积限制,它能做的事情有限,而且因为调用的系统api是微信给的二手api,所以他也不能做跟系统有关的东西。
小程序的实现其实是Native跟Web的结合,它在Web View的基础上,用Native对地图等几类块级元素进行绘制和交互。如果按技术架构拆分的话我们可以将它拆解成三层。
上层 Native 是用于平衡性能;下层的 JSSDK,为微信的 Web view 提供 Native 功能,实现上传文件、获取设备、定位等功能,而中层的Web View则解决主要的渲染工作,在这里它使用了Virtual dom技术。
另外,微信小程序不支持Dom、Window和Document,也就是说,他没有alert...如果你要alert的话,你可以引用目前微信提供的官方组件或者自己写。而且在目前,微信不支持引入第三方的库。如果想引入的话只能复制源码...
毕竟我也没接触过,想看更多关于技术方面的还是要去看各位大牛。
对我们部门来说,能放到微信小程序这上面的项目应该是目前的线上活动如治愈系、毕业季、光音等。
个人感觉我们可以将波板糖APP资讯那里和华工百步梯公众号结合起来,做一个类似网易新闻那样的小程序,不过这样做的话,我们的APP地位就更加尴尬了。(给我一个下APP的理由!)
参考资料
http://www.w2bc.com/article/181803
http://mp.weixin.qq.com/s?__biz=MzI2MDE0MjA5MQ==&mid=2247483793&idx=1&sn=b0dc6abe454688a8c514c365b60c375f&chksm=ea6f64f5dd18ede32c00de9363c7cd74a0ffded195e3334eed818b2fd3ec5ddf83a31006b318&mpshare=1&scene=1&srcid=1030WLmzALyWXmmB8VRtlIL9#wechat_redirect
http://jianggaowang.com/events/33-techparty-guang-zhou-10-yue-wei-xin-xiao-cheng-xu-zhuan-chang
欣(bei)然(bi)接受师父要求,做一个canvas优化的个人见解的小分享
(认识较浅,只能聊一点点,装不了比)
春招选了萝卜大战洞穴的题目,在动画展示上用到了canvas,做完以后在pc端运行当然很流畅,但是一到移动端实验就呵呵excuse me了。动画各种卡,各种掉帧。
然后就必须要进行canvas优化了,师父给我这个网站,以下是见解
用一种很low的方式来测试canvas性能
优化前
var start_time = (new Date()).getTime();
var canvas = document.getElementById("canvas");
canvas.width = 400;
canvas.height = 400;
var ctx = canvas.getContext("2d");
for (var i = 0; i < 400; i++) {
for (var j = 0; j < 400; j++) {
ctx.beginPath();
ctx.moveTo(i, j);
ctx.lineTo(i, j+1);
ctx.stroke();
}
}
var end_time = (new Date()).getTime();
console.log(end_time - start_time); // 平均330+
优化后
var start_time = (new Date()).getTime();
var canvas = document.getElementById("canvas");
canvas.width = 400;
canvas.height = 400;
var ctx = canvas.getContext("2d");
ctx.beginPath();
for (var i = 0; i < 400; i++) {
for (var j = 0; j < 400; j++) {
ctx.moveTo(i, j);
ctx.lineTo(i, j+1);
}
}
ctx.stroke();
var end_time = (new Date()).getTime();
console.log(end_time - start_time); // 平均32+
对这个我有很深的体会,因为那个任务里我主要用了这个优化方法。
比如在那个游戏里面,我渲染了上下两个边界,加之因为是像素级别的操作,所以调用api次数非常多。
换个角度思考,只渲染两个边界的中间部分,调用api的次数变为原来的一半。
优化前
var start_time = (new Date()).getTime();
var canvas = document.getElementById("canvas");
canvas.width = 1000;
canvas.height = 1000;
var ctx = canvas.getContext("2d");
for (var i = 0; i < 500 ; i++) {
for (var j = 0; j < 500 ; j++) {
ctx.fillStyle = (j % 2 ? '#ff5252' : '#1976d2');
ctx.fillRect(j * 2, i * 2, 2, 2);
}
}
var end_time = (new Date()).getTime();
console.log(end_time - start_time); // 平均220+
优化后
var start_time = (new Date()).getTime();
var canvas = document.getElementById("canvas");
canvas.width = 1000;
canvas.height = 1000;
var ctx = canvas.getContext("2d");
ctx.fillStyle = '#ff5252';
for (var i = 0; i < 500; i++) {
for (var j = 0; j < 500 / 2; j++) {
ctx.fillRect((j * 2) * 2, i * 2, 2, 2);
}
}
ctx.fillStyle = '#1976d2';
for (var i = 0; i < 500; i++) {
for (var j = 0; j < 500 / 2; j++) {
ctx.fillRect((j * 2 + 1) * 2, i * 2, 2, 2);
}
}
var end_time = (new Date()).getTime();
console.log(end_time - start_time); // 平均120+
这个当然会优化,所以就不举例了~
优化前
var start_time = (new Date()).getTime();
var canvas = document.getElementById("canvas");
canvas.width = 1000;
canvas.height = 1000;
var ctx = canvas.getContext("2d");
ctx.shadowOffsetX = 2;
ctx.shadowOffsetY = 2;
ctx.shadowBlur = 2;
ctx.shadowColor = 'rgba(255, 0, 0, 0.5)';
for (var i = 0; i < 300 ; i++) {
for (var j = 0; j < 300 ; j++) {
ctx.fillRect(j * 2, i * 2, 2, 2);
}
}
var end_time = (new Date()).getTime();
console.log(end_time - start_time); // 平均2800+
优化后
var start_time = (new Date()).getTime();
var canvas = document.getElementById("canvas");
canvas.width = 1000;
canvas.height = 1000;
var ctx = canvas.getContext("2d");
for (var i = 0; i < 300 ; i++) {
for (var j = 0; j < 300 ; j++) {
ctx.fillRect(j * 2, i * 2, 2, 2);
}
}
var end_time = (new Date()).getTime();
console.log(end_time - start_time); // 平均40+
优化前
var start_time = (new Date()).getTime();
var canvas = document.getElementById("canvas");
canvas.width = 1000;
canvas.height = 1000;
var ctx = canvas.getContext("2d");
for (var i = 0; i < 1000 ; i++) {
for (var j = 0; j < 1000 ; j++) {
ctx.fillRect(j * 0.99, i * 0.99, 0.99, 0.99);
}
}
var end_time = (new Date()).getTime();
console.log(end_time - start_time); // 平均1200+
意外发现这个渲染出来是这样子

优化后
var start_time = (new Date()).getTime();
var canvas = document.getElementById("canvas");
canvas.width = 1000;
canvas.height = 1000;
var ctx = canvas.getContext("2d");
for (var i = 0; i < 1000 ; i++) {
for (var j = 0; j < 1000 ; j++) {
ctx.fillRect(j * 1, i * 1, 1, 1);
}
}
var end_time = (new Date()).getTime();
console.log(end_time - start_time); // 平均440+
无
最近在看《游戏脚本高级编程》,所以想向大家分享一下书里的内容。不过书已经暂时还回广图,所以我不能翻书,只能全凭记忆写这篇分享,因此如有错误敬请提出。
一个游戏主要包括游戏引擎,游戏脚本,美术和音乐等游戏材料。
游戏引擎,是一个很复杂的系统,包括图形渲染系统、物理碰撞系统等等。而像游戏引擎里的物理碰撞系统,简单来说就是计算两个物体是否碰撞在一起,例如枪战游戏里人物是否中弹啦、哪个部位中弹啦。所以游戏引擎,就是负责一个游戏的计算和渲染的大型程序。
游戏脚本,就是控制剧情和每一个游戏角色行为的背后程序。例如一个NPC,他的行为就是不断行走,然后遇到人就说:“你好。“这就是背后一个程序脚本来控制他的行为。又例如,你已经把小boss打败,下面该打大boss了,剧情脚本就会控制切换画面、更换音乐、导入大boos的脚本。所以游戏脚本,就是控制剧情和控制人物的行为的多个程序。
现在多数游戏引擎都由C++写出,当你把一个人物的所有属性都写进游戏引擎时,你编译整个游戏程序将耗费大量时间,所以解决办法就是把各个部分都分离,把一个游戏变成一个个互不相同的模块。于是细分下去,就把剧情任务、人物行为这一部分和游戏引擎那一部分分离了开来。
而且,因为已经有了游戏引擎,若想增加新的剧情,你就可以只写游戏脚本,这样游戏公司就降低了很多成本。就例如有些游戏发布一些新的副本。
对于脚本系统,最流行的实现方法有两种,一是像python一样的运行在虚拟机上的动态语言,二是利用游戏引擎提供的接口控制游戏的二进制dll动态链接程序。
对于第一种实现方法,例子有《梦幻西游》。《梦幻西游》的游戏脚本语言是云风修改lua源码后得到的一种lua方言,所以它和正版lua不兼容,又因为lua是一种小众语言,所以使得开发外挂变得困难,这在当时是很成功的。这种实现方法,所有游戏脚本程序都是运行在虚拟机上面的,并不是运行在本地电脑上的二进制程序。
对于第二种实现方法,例子有经典游戏CS。CS是由外国玩家写的mod,他利用《半条命》提供的接口构造了另一种玩法,而这个mod本身是运行在本地电脑上的二进制程序,所以就是相当于插件一样。还有一个著名例子就是Dota啦。
对于虚拟机的实现方法,在运行速度上肯定比不过动态链接程序。但是在编写上更容易,因为虚拟机上运行的是解释型的语言,所以修改后不用编译就马上可以看到改动效果,而动态链接程序还需要编译时间。
在安全性上,动态链接程序因为运行在本地电脑上,所以这个程序的作者可以写一些恶意的代码,例如去扫描你的所有文件,也可以去攻击服务器。同时如果代码质量差,动态链接程序还会容易奔溃,影响到本地电脑。所以动态链接程序安全性应该说是比较差的。
而对于虚拟机的实现方法,因为脚本都运行在虚拟机里,是比较安全的。因为虚拟机可以禁止脚本去访问那些不能访问的地方,而且如果脚本奔溃了还可以没有负担地重启脚本。
例如现有一个类似C++的动态语言,写了一个箱子类
class box
{
function move(event);
function explode(event);
var x;
var y;
};
当人物行走时,游戏引擎会计算人物与箱子的距离,如果人物当前位置和箱子的位置重合了,游戏引擎就会调用箱子的move方法,向move方法发送event。event是一个结构体,是游戏引擎调用脚本方法时发送给脚本的,里面的变量告诉箱子脚本很多信息,包括碰撞力的方向与大小、发出力的物体等等。然后move方法就会根据event结构体来改变box的位置,同时调用游戏引擎的物理系统来计算轨迹,调用渲染系统来显示箱子移动的效果。而控制爆炸的方法explode也是同样的道理,只是调用渲染系统来显示的是爆炸效果,爆炸效果结束后调用渲染系统使自己不再显示,最后脚本退出。
本来想说内存泄漏和优化。。发现自己根本看不懂。。还是说点简单的东西吧
最近刚发现的android studio的插件,利用好插件可以帮我们完成一些繁琐的工作,提高我们的代码效率。
首先先说一下插件安装方法
打开目录file->settings->plugins

列表里显示的就是已经安装好了的插件,而要安装新的插件就是browse respositories里面就有所有的插件,搜索后点击install就可以了。
接下来就是我推荐的几个插件了
1.先安利一下genymotion。
没错它就是最强大的虚拟机。速度甩开原生虚拟机一条街。不过as的genymotion插件实际上也只是在as界面添加一个快捷启动虚拟机的按钮而已。。
genymotion的使用就简单介绍一下吧(需要翻墙就自行解决吧)
在genymotion官网注册一个账号,然后在官网上下载对应安装包。可能一般需要下载带有virtual box的安装包。然后启动后添加下载虚拟机就可以了
2.Android Code Generator
这是一个可以自动形成findVIewById的插件,只需要设计好xml界面,写好相应的属性什么的(id啊位置啊),然后在xml界面右击如下

然后就会生成对应的activity,你可以选择复制代码使用,也可以直接让它帮你生成一个activity。

这能够帮我们省很多时间,特别是控件特别多的时候。。比如注册账号界面。。。
当然他的缺点是代码跟你习惯不太一样,比如button他并没有生成一个button控件。。
2.1 android-butterknife-zelezny
这是一个与上面插件类似功能的插件,但是生成的代码更加与我们的习惯不一样,不过他生成的代码很简洁,可以学习使用

3.Gson Format
这是一个超级强大的json解析插件。
使用方法就是在你新建的bean类中右键选择generate然后把json格式示例数据复制到下面的框框,然后就能帮你生成对应的java对象,get,set方法都能帮你写好,特别方便,无论多少数据多复杂的嵌套都可以解决。也可以对生成的数据的变量名进行修改。


这是自己写的一个简单的Json解析后的结果。然后就可以对数据进行调用啦。
4.FindBugs-IDEA
5.LeakCanary
为什么这两个一起介绍呢
因为我不会用。 @NeroLoh 这就交给罗大腿去使用了
findbugs是可以用来自动检测bug的。给链接看吧
LeakCanary是用来检测内存泄漏的。刚好拿去检测波板糖吧。英文文档 中文文档
用完记得分享一下教我们怎么用。。
呐这篇水水的分享就结束啦。。实在憋不出来啦。。
可以慢慢再盖楼分享新的方便的插件啦。
在群里看到的一份抽签代码:
#!/bin/env python3
import sys,os,random
f = open("list.txt","r+")
flist = f.readlines()
random.shuffle(flist)
saturday = flist.pop()
sunday = flist.pop()
print(saturday.strip())
print(sunday.strip())
f = open("list.txt","w+")
f.writelines(flist)不妨思考一下,得出以下疑点:
然后问题来了,大家可以思考下答案:
关于这个问题,实际上是因为在参与开发毕业季小游戏的时候,遇到了一些性能方面的问题。虽然小游戏不是传统意义上的web界面,仍然有许多问题可以推广到一般的Web前端性能优化问题上。由于这个问题涉及太广,我就根据自己所见和一些资料简单讨论一下,主要讲的是关于加载的优化,然而仅仅只是涉及前端优化这片汪洋大海中的一粒水滴而已。
首先是近来Web前端的技术被炒得越来越火,人们不再能够接受2000年时候那样简陋的网页设计,各类UI交互和动画,以及为了实时改变页面频繁操作的Ajax请求都使得网页的操作量比之前高了许多;同时,主战场逐渐向移动端转型的Web页面,也不得不重新面对不同浏览器、机型、系统的兼容和支持问题。
大部分情况下,移动端的硬件性能本身就弱于PC端,并且不少情况下移动端可能是通过3G/4G信号连接的,因此经常会出现明明在PC端非常流畅的页面,在移动端测试时会卡的一比的情况(不排除某浏览器辣鸡的可能)。在暂时没有办法通过代码优化进一步提升性能的情况下,最容易考虑到的就是为移动端专门布置一个页面,这样保留了PC端的强大交互,也能让移动端有一个能够接受的基本的内容和视觉效果。
这里所说的即『渐进增强(progressive enhancement)』和『优雅降级(graceful degradation)』的观点:
渐进增强 progressive enhancement:针对低版本浏览器进行构建页面,保证最基本的功能,然后再针对高级浏览器进行效果、交互等改进和追加功能达到更好的用户体验。渐进增强”观点则认为应关注于内容本身。
内容是我们建立网站的诱因。有的网站展示它,有的则收集它,有的寻求,有的操作,还有的网站甚至会包含以上的种种,但相同点是它们全都涉及到内容。这使得“渐进增强”成为一种更为合理的设计范例。这也是它立即被 Yahoo! 所采纳并用以构建其“分级式浏览器支持 (Graded Browser Support)”策略的原因所在。
优雅降级 graceful degradation:一开始就构建完整的功能,然后再针对低版本浏览器进行兼容。“优雅降级”观点认为应该针对那些最高级、最完善的浏览器来设计网站。而将那些被认为“过时”或有功能缺失的浏览器下的测试工作安排在开发周期的最后阶段,并把测试对象限定为主流浏览器(如 IE、Mozilla 等)的前一个版本。在这种设计范例下,旧版的浏览器被认为仅能提供“简陋却无妨 (poor, but passable)” 的浏览体验。你可以做一些小的调整来适应某个特定的浏览器。但由于它们并非我们所关注的焦点,因此除了修复较大的错误之外,其它的差异将被直接忽略。
区别:优雅降级是从复杂的现状开始,并试图减少用户体验的供给,而渐进增强则是从一个非常基础的,能够起作用的版本开始,并不断扩充,以适应未来环境的需要。降级(功能衰减)意味着往回看;而渐进增强则意味着朝前看,同时保证其根基处于安全地带。
举个栗子,慕课网(http://www.imooc.com/) 对于PC端和移动端给出了几乎完全不同的的页面,不仅仅是布局上,移动端在首页提供的内容也大幅减少,而且在PC上的动画效果和照片墙也全部移除,只保留最基本的登录和进入内容的交互。
至于需要参考哪一种逻辑,就要根据网站的核心是在什么地方而定的了,慕课网的在线测试等等均在PC端上实现,并且考虑到代码工作是在PC上完成,因此其采用了优雅降级的**,只为移动端保留最最基本的页面,这样自欺欺人地做了针对移动端的优化(并没有)。
加载一直是个令人头疼的问题。有数据表明,如果用户打开一个网站,等待3-4 秒还没有任何反应,他们会变得急躁,焦虑,抱怨,甚至关闭网页并且不再访问,这是非常糟糕的情况。这次在完成毕业季小游戏的时候,相继出现了梯仔闪烁、加载页面文字不出来,以及部分机型的样式还没实现渲染出来就显示了的问题(@林键,手动滑稽)。由于各个资源的加载顺序并不是能够完美控制的,有时会出现问题,比如:
以上是添加了毕业季小游戏加载界面(已经没什么人玩了的时候才添加的没用的页面)后的加载顺序,因为加载页面时就要使用外部字体,因此优先级很高,然而不管怎么提程,仍然会出现文字加载不出来的情况,后来看了一下Timeline:
由于字体文件相对太大(1.9M),即使优先加载也会耗费很长的时间,这段时间是无法显示带字体的文字的。本来打算精简字库(通过将要使用的文字全部提取出来),但是有字库审核还要一段时间,所以简单处理了一下,把页面加载需要用到的几个文字做成png放了上去。不过真正来说,如果时间允许,做成精简字库应该会大大减少字体文件的体积,从而优化加载速度,缺点则是每次改动文案都需要重新生成一个字库文件。
这里可以看出其中一个优化加载速度的方法就是尽量减少每一个资源的体积。这里通常有如下的方法:

除了减少每一个资源的体积以外,另一个很有必要的优化则是尽量减少同一域下的HTTP请求数。在每个资源并不是非常大的情况下,减少HTTP请求数能显著提高加载速度。这里分两个部分来说。
第一个部分是同一域。浏览器常常限制了对相同域名发起的并发连接数的上限。举个栗子,IE6/7和Firefox2(无视我举了这么远古的例子,然而目前还是有很多人用这些浏览器的,哭)设定了同时只能对一个域名发起两个并发连接,新版本的一些浏览器则普遍设置为4-8个。这里澄清一下的是,浏览器作为一个善意的客户端,限制连接数上限是为了保证服务器不会压力过大,否则就变成了DDoS攻击的说。如果需要对某个域建立更多的连接,则需要在当前传输结束后,重复使用或者重新建立TCP连接。
在确保服务器不会压力过大时,为了提高资源传输速度,可以把静态资源放在非主域名下。这样做的好处不仅仅是可以增加浏览器资源请求的并发,还可以减少HTTP请求中所携带的不必要的cookie数据(即使是子域名也会被认为是不同的域名,从而不携带主域名的cookie)。
第二个部分是请求数。之前在看昊杰他们开发治愈系的时候曾经有一个小BUG,按钮定位有偏差导致出现了两个不完整的按钮显示在一个位置上,之前不能理解为什么会出现这样的图片,现在知道这是雪碧图(Sprite Image),即把许多小图拼接在一起,通过CSS定位来显示雪碧图的特定部分,从而有效减少了需要请求的资源数。
其他减少请求数的方法比如删去不必要的HTTP请求,例如将小型css内嵌处理、设置缓存等等,最终目的都是优化HTTP请求数,这样在优化前端加载时间的同时,也能大大减轻对服务器的压力。
下面提一个估计我们暂时用不到的东西。之前雪儿讲了关于HTTP的内容,这个部分在页面首次加载的时候流程是:客户端建立连接,服务器同意连接,客户端发起请求,服务器返回数据,客户端接受并处理数据,这里常常有两个问题:

Facebook公司作为前端的弄潮儿之一,为了应对他们大量数据的情况,开发了BigPipe这一非阻塞的模型,能够解决上面两个问题。通俗来讲,BigPipe首先将HTML分为很多部分,然后在服务器和浏览器之间建立一条管道,通过这条管道,一个框架性的HTML结构首先被传输,其定义了不同的Pagelet模块的位置和宽高(实际上是空的)。服务器传输完成后,紧接着告诉浏览器:这次请求还未结束,保持连接不断开,但浏览器可以先渲染这个“混凝土框架”,空内容显示为“正在加载“。页面渲染的同时,服务器仍然通过这条“管道”源源不断地把资源传输过来,根据重要程度优先传输和渲染(比如主要的用户框架优先显示),并且边渲染边传输,直到将优先度较低的内容传输完成。以下为BigPipe的非阻塞模型。
顺便一提,BigPipe是通过HTTP1.1中的分块传输编码实现的。其允许服务器为动态生成的内容维持HTTP长连接,只要设置HTTP消息的Transfer-Encoding消息头值为chunked,即告知在连接结束前,可以发送任意块,以大小为0的块作为结束标志。不过目前我们的产品需要动态生成的内容并不是那么多,因此这个貌似没并有什么卵用(真要做的话重构太麻烦了坑就给下一届吧)
嗯之前耀宗已经详细的讲了关于缓存的部分,因此这里简单提提就好。(总算可以偷懒了)
缓存对优化起到举足轻重的作用,有些时候优化算法、压缩图片,效果都比不上优化缓存。关于优化缓存的部分暂不赞述,这里提一个问题:文件有可能在运营商服务器上被劫持。比如说我们缓存的一个main.js?version=1,当下次更新后更改Query String,改为main.js?version=2,按照HTTP规范理应重新请求,但是运营商仍然可能拿自己节点服务器上缓存的main.js?version=1来代替。所以为了保证更新,最好还是使用更改文件名的方式,而不是修改Query String。
Web优化的部分实在太多,水平、时间有限难以一一提及,这里推荐一本书《高性能网站建设指南》 ,非常详细地介绍了Web优化的内容,前后端的同学都可以看看哟。
(完)
by 张海鑫
举个例子吧,我去世博天津包子那里买早餐,柜台里一个有着娃娃脸的小哥在刷卡机上打了3.5元,在我把卡放上刷卡机的一瞬间,机子完成了:
共计两个操作。如果我的卡余额被扣世博的账户却没有钱进账,或者世博的账户余额增加了但是我的卡却没有被扣钱,都是一件很尴尬的事。
不过数据库事务这种东西的诞生就是为了不让这样的尴尬事出现。
拿Mysql来举例的话,stepA和stepB可以分别对应一条SQL语句,现在启动一个事务,然后分别加载stepA和stepB两条SQL语句。提交事务后,如果有其中任何一条不成功,整个事务就会回滚,就是说我的学生卡的余额和世博账户的余额都会恢复到我刷卡之前的样子。
然后给出事务处理的定义:(虽然并不知道例子有没有用,但是我还是举了。只是单纯的想举一下而已)
数据库事务(Database Transaction) ,是指作为单个逻辑工作单元执行的一系列操作,要么完全地执行,要么完全地不执行。 事务处理可以确保除非事务性单元内的所有操作都成功完成,否则不会永久更新面向数据的资源。通过将一组相关操作组合为一个要么全部成功要么全部失败的单元,可以简化错误恢复并使应用程序更加可靠。一个逻辑工作单元要成为事务,必须满足所谓的ACID(原子性、一致性、隔离性和持久性)属性。事务是数据库运行中的一个逻辑工作单位,由DBMS中的事务管理子系统负责事务的处理。(百度百科上找的* ^ *)
以下使用PDO来处理(Mysqli我自己用起来自己也不习惯_^_),虽然代码是抄的,不过自己打了一遍貌似有用。
代码来源http://www.oschina.net/code/snippet_561584_12903
还有数据库的存储引擎(Storage Engine)记得设置为InnoDB,貌似MyISAM不支持哎,然而它居然是MySql默认的引擎(╯-_-)╯╧╧
<?php
//pdo 实现mysql 事务处理 简单示例
/*
实现向数据库中写入多条数据的事务
insert into test values ('test123', 'test123')
*/
$type = 'mysql'; //要连接的数据库类型
$host = 'localhost'; //数据库主机
$dbname = 'test'; //要选择的数据库名称
$password = '';
$username = 'root';
$dsn = "{$type}:dbname={$dbname};host={$host}";
try{
//连接数据库
$pdo = new PDO($dsn, $username, $password);
//编码
$pdo->exec("set names utf8");
//设置错误提示方式
$pdo->setAttribute(PDO::ATTR_ERRMODE,PDO::ERRMODE_EXCEPTION);
//开启标准事务
$pdo->beginTransaction();
//构造sql语句
//$sql = "insert into test values (?,?)";
$sql = "insert into test values (:user, :password)";
//或者使用此sql语句 :user :password 与问号功能相似 绑定参数
$stmt = $pdo->prepare($sql);
//为sql语句中的变量绑定变量
$stmt->bindParam(':user', $username);
$stmt->bindParam(':password', $password);
//为sql语句中的变量 赋值
$username = 'test123';
$password = '123456';
$stmt->execute();
$rows = $stmt->rowCount();
if($rows<1){
//如果失败则抛出异常
throw new PDOexception('第一句sql语句执行失败!', '01');
}
$username = 'hello123';
$password = '123456';
$stmt->execute();
$rows = $stmt->rowCount();
if($rows<1){
//如果失败则抛出异常
throw new PDOexception('第二句sql语句执行失败!', '02');
}
$username = 'world123';
$password = '123456';
$stmt->execute();
$rows = $stmt->rowCount();
if($rows<1){
//如果失败则抛出异常
throw new PDOexception('第三句sql语句执行失败!', '02');
}
//如果没有异常被抛出则 sql语句全部执行成功 提交事务
$pdo->commit();
}catch(PDOexception $e){
//如果有异常被抛出 则事务失败 执行事务回滚
$pdo->rollback();
//输出异常信息
echo $e->getCode().'-----'.$e->getMessage();
$pdo = null;
}
?>在官方文档(ThinkPHP5.0)里面看到了,顺便贴上来。
官方文档http://www.kancloud.cn/manual/thinkphp5/139063
Db::transaction(function(){
Db::table('think_user')->find(1);
Db::table('think_user')->delete(1);
});// 启动事务
Db::startTrans();
try{
Db::table('think_user')->find(1);
Db::table('think_user')->delete(1);
// 提交事务
Db::commit();
catch (\PDOException $e) {
// 回滚事务
Db::rollback();
}// 启动事务
Db::startTrans('UserTrans');
try{
Db::table('think_user')->find(1);
Db::table('think_user')->delete(1);
// 提交事务
Db::commit('UserTrans');
catch (\PDOException $e) {
// 回滚事务
Db::rollback();
}
就酱把。
因为学的少,接触的数据库和语言也不多,所以只好放上这些了。
这篇文章有点复杂,但是看上去有点意思http://blog.csdn.net/zdwzzu2006/article/details/5947062
由于在app中webview的广泛使用,移动端如何与前端交互是一个需要我们考虑的问题,在这里介绍一下iOS开发中OC与js交互的问题。
首先我们需要知道js方法名,比如js方法名为:JSFunc(),那么我们可以通过以下代码来调用
UIWebView *webview=[[UIWebView alloc]init];
[webView stringByEvaluatingJavaScriptFromString:@"JSFunc()"];
注:这个方法是同步的
同样的我们需要知道js方法名,比如js方法名为:JSFunc()
WKWebView *webview=[[WKWebView alloc]init];
[webview evaluateJavaScript:@"JSFunc()" completionHandler:^(id _Nullable script, NSError * _Nullable error) {
}];
参数1:@param 是调用的js方法,并传值
参数2:如果JavaScript 代码出错, 可以在completionHandler 进行处理.
注:WKWebView在iOS8之后才可以使用,推荐用其代替UIWebView
比起OC中一行就可以调用js方法,js调用OC的方法比较复杂,iOS7引入了JavaScriptCore框架,使得调用变得简单,在这里只介绍JavaScriptCore的使用方法
JSValue: 代表一个JavaScript实体,一个JSValue可以表示很多JavaScript原始类型例如boolean, integers, doubles,甚至包括对象和函数。
JSContext: 代表JavaScript的运行环境,你需要用JSContext来执行JavaScript代码。所有的JSValue都是捆绑在一个JSContext上的。
JSExport: 这是一个协议,可以用这个协议来将原生对象导出给JavaScript,这样原生对象的属性或方法就成为了JavaScript的属性或方法,非常神奇。
首先写一个简单的js方法
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>test javascript</title>
</head>
<body>
<div>
<button onclick="ttf.OCFunc('JS与OC交互');">点击我然后看xcode的log</button>
</div>
</body>
</html>
然后在OC中新建一个类
//首先引入框架
#import <JavaScriptCore/JavaScriptCore.h>
//定义一个协议继承JSExport协议
@protocol PersonJSExport <JSExport>
- (void)OCFunc:(NSString *)str; //协议里面要声明调用的方法
@end
//我们的自定义类要遵循我们自己定义的这个协议
@interface MyJSObject() <PersonJSExport>
- (void)OCFunc:(NSString *)str;
@end
@implementation MyJSObject
- (void)OCFunc:(NSString *)str {
NSLog(@"%@", str);
}
@end
向UIWebView对象拿JSContext环境对象,并注入刚才新建的对象
JSContext *context = [self.webView valueForKeyPath:@"documentView.webView.mainFrame.javaScriptContext"];
MyJSObject *jsObject = [MyJSObject new];
context[@"ttf"] = jsObject; //将对象注入这个context中
这样就完成了!
这里只介绍了比较简单的实现方式
详情可以看这篇文章:http://www.jianshu.com/p/59242a92d4f2
7. Reverse Integer
Total Accepted: 180058
Total Submissions: 759486
Difficulty: Easy
Contributors: Admin
Reverse digits of an integer.
Example1: x = 123, return 321
Example2: x = -123, return -321
input : x
int reverse=0;
for(int num;x;x/=10)
{
num=x%10;
reverse=reverse*10+num;
}
return reverse;
class Solution
{
public:
int reverse(int x)
{
int max=2147483647;//有符号int最大值
int min=-2147483648;//有符号int最小值
//转换为正数
if(x==min)return 0;//x=mix不方便去符号,手动判断排除
bool sign=x>0?true:false;
if(sign==false)x=-x;
int reverse=0;
for(int num,tmp;x;x/=10)
{
num=x%10;
tmp=reverse*10+num;
if(reverse<=(max-num)/10) //a*b+c>max=>a>(max-c)/b
{
reverse=tmp;
}
else
{
return 0;
}
}
return sign?reverse:-reverse;
}
};
class Solution
{
public:
const int max=2147483647;//有符号int最大值
const int min=-2147483648;//有符号int最小值
int reverse(int x) {
//转换为正数
if(x==min)return 0;//x=mix不方便去符号,手动判断排除
bool sign=x>0?true:false;
if(sign==false)x=-x;
int reverse=0;
for(int num,tmp,count=0;x;x/=10)
{
num=x%10;
if(++count==10)//减少判断频率节约时间,只有在长度在10位才有可能溢出
{
tmp=reverse*10+num;
if(reverse<=(max-num)/10) //a*b+c>max=>a>(max-c)/b
{
reverse=tmp;
}
else
{
return 0;
}
}
else
{
reverse=reverse*10+num;
}
}
return sign?reverse:-reverse;
}
};
这星期在捣鼓这个游戏引擎,就说说这个引擎吧
前言
自己从学习数据挖掘这个方向到现在也有几周,一开始上手权威指南这本书是挺难接受里面的内容,于是花了几天去知乎和 GitHub 上搜集了一些的资料,并且从 Conan 的 blog 上找到了一个比较好的学习路线,于是整理一下拿出来分享。自己也在继续学习,如果有错误请指出!

Hadoop 家族中,常用的项目包括 Hadoop,Hive,Pig,HBase,Sqoop,Mahout,Zookeeper,Avro,Ambari,Chukwa,新增项目包括 YARN,Hcatalog,Oozie,Cassandra,Hama,Whirr,Flume,Bigtop,Crunch,Hue,Giraph等。

虽然这样看起来 Hadoop 家族比较庞大,但是作为适应多种目标要求的工具,还是比较适合我们去学习的。
这是一个老生常谈的问题,网上一抓一大把的教程,书店一抓一大把的书,难道真的撸完所有教程和书就入门了吗?作为一个新入坑的少年,自己这几周也算是走了一阵的弯路,毕竟身边没有很好的指导,而且数据挖掘这个行业虽然看似很热门很潜力,也是在黑暗中摸索的。
尽量去官网看文档,英文不是问题,毕竟它也只是一种工具,我们在学习的也是一类工具,对于一个工具学习的时间跨度可以很长,但是入门的话,推荐学几个自己喜欢或者与自己处理的数据相关的工具,项目导向要比纯学习向上手快得多。
接下来开始继续学习,关于具体的学习情况会持续更新。
注:部分内容出处来自 http://blog.fens.me/hadoop-family-roadmap/
大家都知道,程序员喜欢造轮子。那么如果我们想用别人的轮子,应该怎么办呢?最简单的方法当然是到github里去找,但我们需要手动将其clone|download下来,再整合到自己的项目中,所以从开发者的角度来看,那只能叫代码仓库而并非一个很好的项目构建&管理工具。
另一方面,在项目的开发阶段,可能会引用到一些第三方的库,而它们可能又依赖于其它的库,如果我们自己去找这些依赖关系的话,势必会花费一定的时间和精力。那么能否通过一种工具,自动安装我们想要的库和相关依赖呢?答案是肯定的。
为了解决项目构建自动化以及安装包依赖的问题,一些猿引入了包管理工具。对于现代语言,它们基本上是不可或缺的了,下面列举了部分对应关系:
以npm为例,由于Nodejs是以模块化为标榜,每一个文件对应一个模块,所以如何在项目中进行布局,使得整个结构有层次感,就需要好好的考虑了(特别是模块之间的依赖比较多的时候)。而npm提供了一种通用的解决方案,以统一的依赖描述和引入方式来进行管理,同时也对库的版本作了规定。下面介绍两个比较重要的东西:
package.json:项目的描述文档,用于声明依赖并自动构建项目
{
"name": "demo",
"version": "1.0.0",
"description": "",
"main": "index.js",
"dependencies": {
"express": "*"
},
"author": "tugui"
}
node_modules:存储第三方模块的文件夹,以平面的方式来组织依赖关系,好处是可以实现包依赖的重用,同时避免一些多重嵌套的情况

上面是原始依赖关系,下面为经过重新组织之后的结构。

我们可以看到,对于express(Nodejs的一个框架)来说,它所依赖的模块是相当多的,而使用npm进行安装的话却只需要一条命令就能够完成。另外,包管理器还可以替我们做一些重复性的工作,比如对某些库进行更新/卸载,或者是对项目的重新构建,当然还有某些必要文件的生成(LICENSE等),它们的命令格式大同小异,大家可以自行去了解。
npm makes it easy for Javascript developers to share the code that they've created to solve particular problems, and for other developers to reuse that code in their own applications.
值得一提的是,它们都维护有一个官方的仓库,开发者可以在这个平台上与他人交换轮子,形成了良好的生态系统。在软件规模越来越大的现在,对于第三方库/包的管理显得十分必要,而上面讲到的这些工具,很好地将规范与实践结合了起来,为我们的开发提供了一定的方便。

另外,对于软件的安装也存在相互依赖的情况,所以在一些操作系统提供了方便的解决方案供人们使用,比较常见的有Ubuntu下的apt-get、Red Hat/CentOS/Fedora有yum、MacOS自然就是homebrew了,在使用这些工具时只需要输入一条命令,就可以按顺序下载并安装相关的依赖包了(其中的软件包列表是由对应的开发商进行维护的)。
最后借着Composer 1.0.0版本发布的余热,我引用其创始人Jordi Boggiano的一段话作为结语:
... I can barely remember what it was like to write PHP code without having a whole ecosystem at my fingertips.
使用包管理工具还有一个好处,就是在进行项目版本控制的过程中,不需要包含第三方的库文件,而是在项目的构建阶段才进行相关依赖的安装,这样即使想对库版本进行升级,也可以保证整个版本控制的干净(要知道有些库体积是十分庞大的,每次改动会给git仓库造成不必要的压力)……这样我们只需要对package.json进行修改和管理就可以了。
然后这里有一篇关于Composer的介绍,有兴趣的可以看看:
在前端开发中,性能一直都是被大家所重视的一点,而判断一个网站的性能最直观的就是看网页打开的速度。其中提高网页反应速度的一个方式就是使用缓存。一个优秀的缓存策略可以缩短网页请求资源的距离,减少延迟,并且由于缓存文件可以重复利用,还可以减少带宽,降低网络负荷。
缓存的种类:
web缓存分为很多种,比如数据库缓存、代理服务器缓存、还有我们熟悉的CDN缓存,以及浏览器缓存。
首先讲一下浏览器缓存
页面的缓存状态是由header决定的,header的参数有四种:
一、Cache-Control:
1、max-age(单位为s)指定设置缓存最大的有效时间,定义的是时间长短。当浏览器向服务器发送请求后,在max-age这段时间里浏览器就不会再向服务器发送请求了。
2、s-maxage(单位为s)同max-age,只用于共享缓存(比如CDN缓存)。
3、public 指定响应会被缓存,并且在多用户间共享。也就是下图的意思。如果没有指定public还是private,则默认为public。
4、private 响应只作为私有的缓存,不能在用户间共享。如果要求HTTP认证,响应会自动设置为private。
5、no-cache 指定不缓存响应,表明资源不进行缓存,但是设置了no-cache之后并不代表浏览器不缓存,而是在缓存前要向服务器确认资源是否被更改。因此有的时候只设置no-cache防止缓存还是不够保险,还可以加上private指令,将过期时间设为过去的时间。
6、no-store 绝对禁止缓存,一看就知道如果用了这个命令当然就是不会进行缓存,每次请求资源都要从服务器重新获取。
7、must-revalidate指定如果页面是过期的,则去服务器进行获取。这个指令并不常用,就不做过多的讨论了。
二、Expires
缓存过期时间,用来指定资源到期的时间,是服务器端的具体的时间点。也就是说,Expires=max-age + 请求时间,需要和Last-modified结合使用。但在上面我们提到过,cache-control的优先级更高。 Expires是Web服务器响应消息头字段,在响应http请求时告诉浏览器在过期时间前浏览器可以直接从浏览器缓存取数据,而无需再次请求。
不过不推荐使用Expires,因为它指定的是具体的过期日期而不是秒数。由于很多服务器跟客户端存在时钟不一致的情况,所以最好还是使用Cache-Control.
三、Last-modified
服务器端文件的最后修改时间,需要和cache-control共同使用,是检查服务器端资源是否更新的一种方式。当浏览器再次进行请求时,会向服务器传送If-Modified-Since报头,询问Last-Modified时间点之后资源是否被修改过。如果没有修改,则返回码为304,使用缓存;如果修改过,则再次去服务器请求资源,返回码和首次请求相同为200,资源为服务器最新资源。
四、ETag
根据实体内容生成一段hash字符串,标识资源的状态,由服务端产生。浏览器会将这串字符串传回服务器,验证资源是否已经修改,如果没有修改,过程如下:

使用ETag可以解决Last-modified存在的一些问题:
a、某些服务器不能精确得到资源的最后修改时间,这样就无法通过最后修改时间判断资源是否更新
b、如果资源修改非常频繁,在秒以下的时间内进行修改,而Last-modified只能精确到秒
c、一些资源的最后修改时间改变了,但是内容没改变,使用ETag就认为资源还是没有修改的。
PS:由于Etag有服务器构造,所以在集群环境中一定要保证Etag的唯一性
使用缓存流程

cache-control指令使用

另外,还有两种缓存方式,LocalStorage和sessionStorage。
LocalStorage是一种本地存储的公共资源,域名下很多应用共享这份资源会有风险;LocalStorage是以页面域名划分的,如果有多个等价域名之间的LocalStorage不互通,则会造成缓存多份浪费。
LocalStorage在PC上的兼容性不太好,而且当网络速度快、协商缓存响应快时使用localStorage的速度比不上304。并且不能缓存css文件。而移动端由于网速慢,使用localStorage要快于304。
而相对LocalStorage来说,SessionStorage的数据只存储到特定的会话中,不属于持久化的存储,所以关闭浏览器会清除数据。和localstorage具有相同的方法。
然后稍微讲一下代理服务器缓存
公有缓存会接受来自多个用户的访问,所以通过它能够更好的减少冗余流量。
下图中每个客户端都会重复的向服务器访问一个资源(此时还不在私有缓存中),这样它会多次访问服务器,增加服务器压力。而使用共享的公有缓存时,缓存只需要从服务器取一次,以后不用再经过服务器,能够显著减轻服务器压力。

事实上在实际应用中通常采用层次化的公有缓存,基本**是在靠近客户端的地方使用小型廉价缓存,而更高层次中,则逐步采用更大、功能更强的缓存在装载多用户共享的资源。
缓存处理流程

就这样啦~
用工厂方法或者类来实例化对象,而不是直接new。
首先我们需要创建一个工厂类,比如Factory.php。如果不使用工厂模式的,我们需要一个对象的时候通常需要
new Inexistence\girlfriend();
然而我们一般不只在一个地方需要这个对象,这个时候一旦对象发生变更,或者对象的某些属性发生变化,我们就需要一个一个的来改,非常麻烦。这个时候我们引入工厂类,在Factory.php中
<?php
namespace Imagination;
class Factory
{
static function getGirlfriend()
{
$GF = new girlfriend;
return $GF;
}
}然后每次调用时$GF1 = Imagination\Factory::getGirlfriend()就可以避免四处修改的问题。
在Laravel中这样的设计模式很常见。
class CommentsController extends Controller {
/**
* Store a newly created resource in storage.
*
* @return Response
*/
public function store()
{
if (Comment::create(Input::all())) {
return Redirect::back();
} else {
return Redirect::back()->withInput()->withErrors('Fail to comment!');
}
}
}即确保某个类的对象仅被创建一次。比如我们在database里面存了很多女生的联系方式,如果我们用pdo的话每次查找都会new一个对象,势必会造成资源的浪费。所以我们就在connect之前做个判断。
class Database
{
static private $db;
private function __construct()
{
}
static function getInstance()
{
if (empty(self::$db)) {
self::$db = new self;
return self::$db;
} else {
return self::$db;
}
}
function where($where)
{
return $this;
}
function order($order)
{
return $this;
}
function limit($limit)
{
return $this;
}
function query($sql)
{
echo "SQL: $sql\n";
}
}这里面比较关键的地方在于声明了一个私有变量和私有的构造方法,然后再在这个类里面new自己,就避免了在其他地方重复实例化的问题。这个时候我们已经没法直接new Database了,我们只能通过调用get Instance方法来建立连接。这里顺带讲一下PHP的链式操作的实现。在很多框架比如用完26个字母就不知道怎么办的thinkPHP和Laravel中对数据库的操作可以使用链式操作,这样可以使代码更为优雅。具体实现就是使用return this;,这样就可以用where($where)->order($order)->limit(1);来代替多行语句。
Laravel使用了三目运算符来代替if,显得更为优雅。
public function hasMany($related, $foreignKey = null, $localKey = null)
{
$foreignKey = $foreignKey ?: $this->getForeignKey();
$instance = new $related();
$localKey = $localKey ?: $this->getKeyName();
return new HasMany($instance->newQuery(), $this, $instance->getTable() . '.' . $foreignKey, $localKey);
}解决全局共享和交换对象的问题。实际上就是把实例好的对象放进一个数组,在任何地方要用的时候就去出来。就好比有一课树,我们把new好的$GF1,$GF2。。。一个一个挂上去,要用的时候再取出来。
class Register
{
protected static $objects;
/**
* 把对象映射到树上
* @param string $alias 对象的别名
* @param array $object 储存所有对象
*/
static function set($alias, $object)
{
self::$objects[$alias] = $object;
}
/**
* 把对象从树上移除
* @param string $alias 对象的别名
* @return [type] [description]
*/
function _unset($alias)
{
unset(self::$objects[$alias]);
}
}unset在PHP中是关键字,所以用_unset代替。这样的话我们就要在工厂类中用一下Register::set()方法,把new好的对象挂树上。为了调用方便,Register中还需要一个get()方法来取对象。
static function get($key)
{
if (!isset(self::$objects[$key]))
{
return false;
}
return self::$objects[$key];
}这样我们也就不用再去使用单例模式了,直接从注册器中取Register::get()。
Laravel中用了更优雅的方式。
<?php namespace Illuminate\Contracts\Auth;
interface Registrar {
/**
* Get a validator for an incoming registration request.
*
* @param array $data
* @return \Illuminate\Contracts\Validation\Validator
*/
public function validator(array $data);
/**
* Create a new user instance after a valid registration.
*
* @param array $data
* @return User
*/
public function create(array $data);
}PHP还有很多有用的设计模式,比如观察者模式、代理模式、装饰器模式等,因为时间不够就不写了。有兴趣的可以自行了解。Laravel的源码遵循PSR规范,建议先了解再来看源码。
(此步可被代码代替,但使用可视化工具更加便捷)
主场景:
先添加图片资源,创建基础容器 root,在 root 子树上添加一系列静态元素,这里除了菜单按钮需要用户交互外其他都是图片类型(Cocos Studio中图片与精灵区别不大)。修改相应元素的名称,以便在写代码时做对应操作。
菜单层:
因为菜单是在主场景的基础上跳出来的,所以作为一个层来处理。同样添加所需的元素。
(1) 类的定义(工厂模式)
先创建游戏所需场景MainScene,所需层MenuLayer的 .cpp 与 .h 文件,又由于2048游戏主要体现在对卡片的操作上,且比较复杂,所以这里再创建 CardSprite 的 .cpp 与 .h 文件。
主场景:
class MainScene : public cocos2d::Layer
{
public:
static cocos2d::Scene* createScene();
virtual bool init();
CREATE_FUNC(MainScene);
static void ClearData(); //清除上次游戏数据,用于重新开始private:
void LoadBackground(); //加载背景音乐
void MenuTouch(cocos2d::Ref *pSender, Widget::TouchEventType type); //点击弹出菜单事件
void SetScore(); //设置分数
Size GetVisibleSize(); //获取可视化大小
void SetTouchListener(); //调用手势识别的事件监听器,添加事件监听
void createCardSprite(cocos2d::Size size); //创建卡片精灵
virtual bool onTouchBegan(cocos2d::Touch *touch, cocos2d::Event *unused_event); //触摸事件开始
virtual void onTouchEnded(cocos2d::Touch *touch, cocos2d::Event *unused_event); //触摸事件结束
bool doLeft(); //向左
bool doRight(); //向右
bool doUp(); //向上
bool doDown(); //向下
void autoCreateCardNumber(); //自动生成随机数初始卡片
void doCheckGameOver(); //判断游戏是否结束Layout* root;
ImageView* imgIcon;
ImageView* imgScorelast;
ImageView* imgScoremax;
Button* btnMenu;
int firstX, firstY, endX, endY;
CardSprite *cardArr[4][4]; //二维数组存放16张卡片格
int lastScore; //最新分数
int maxScore; //历史最高分数
LabelTTF *labelTTFCardNumber;
LabelTTF *labelTTFlastScore;
LabelTTF *labelTTFmaxScore;};
菜单层:
class MenuLayer : public cocos2d::Layer
{
public:
virtual bool init();
CREATE_FUNC(MenuLayer);
static void playEffect(const std::string &effectName, bool force); //播放音效private:
void SetBackground(); //获取studio ui场景
void SetButton(); //设置菜单选项按钮
void ContinueTouch(cocos2d::Ref pSender, Widget::TouchEventType type); //继续按钮点击事件
void RestartTouch(cocos2d::Ref *pSender, Widget::TouchEventType type); //重新开始按钮点击事件
void Close(Node pSender); //关闭菜单层
void loadSoundMenu(); //加载声音菜单
void soundMenuCallback(Ref *sender); //声音菜单回调函数Layout* root;
ImageView* imgBack;
ImageView* imgMenu;
Button* btnContinue;
Button* btnRestart;
CheckBox* checkBox;};
卡片精灵:
class CardSprite : public cocos2d::Sprite
{public:
static CardSprite *createCardSprite(int numbers, int width, int height, float CardSpriteX, float CardSpriteY); //初始化卡片
virtual bool init();
CREATE_FUNC(CardSprite);
void setNumber(int num); //设置数字
int getNumber(); //获取数字private:
void enemyInit(int numbers, int width, int height, float CardSpriteX, float CardSpriteY); //结合卡片与数字
int number;
cocos2d::LabelTTF *labTTFCardNumber;
cocos2d::LayerColor *layerColorBG;
};
(2) 方法定义
Cocos2d-x是个功能强大的集成库,其提供的方法可满足大部分游戏的需求,写代码时配合官方文档食用风味更佳。
获取 Cocos Studio 的UI页面
void MainScene::LoadBackground()
{
auto rootNode = CSLoader::createNode("MainScene.csb");
root = (Layout_)rootNode->getChildByName("root");
imgIcon = (ImageView_)Helper::seekWidgetByName(root, "imgIcon");
imgScorelast = (ImageView_)Helper::seekWidgetByName(root, "imgScorelast");
imgScoremax = (ImageView_)Helper::seekWidgetByName(root, "imgScoremax");
btnMenu = (Button*)Helper::seekWidgetByName(root, "btnMenu");
//加载控件
btnMenu->addTouchEventListener(CC_CALLBACK_2(MainScene::MenuTouch, this));
//菜单按钮点击事件
addChild(rootNode);
}
2048游戏的特色在于识别上下左右手势,对卡片进行移动或合并操作。(这里有点要注意,当初困扰了我一天,一定要把Cocos Studio中除按钮外的控件取消交互性,否则会和手势识别冲突。)
//调用手势识别的事件监听器,添加事件监听
void MainScene::SetTouchListener()
{
auto touchListener = EventListenerTouchOneByOne::create();
touchListener->onTouchBegan = CC_CALLBACK_2(MainScene::onTouchBegan, this);
touchListener->onTouchEnded = CC_CALLBACK_2(MainScene::onTouchEnded, this);_eventDispatcher->addEventListenerWithSceneGraphPriority(touchListener, this);
}//触摸事件开始
bool MainScene::onTouchBegan(cocos2d::Touch *touch, cocos2d::Event *unused_event) {
Point touchP0 = touch->getLocation(); //触摸点
firstX = touchP0.x;
firstY = touchP0.y;
return true;
}//触摸结束触发
void MainScene::onTouchEnded(cocos2d::Touch *touch, cocos2d::Event *unused_event) {
// 获取触摸点位置
Point touchP0 = touch->getLocation();
// 获取X轴和Y轴的移动距离
endX = firstX - touchP0.x;
endY = firstY - touchP0.y;// 判断X轴和Y轴的移动距离,如果X轴的绝对值大于Y轴的绝对值就是左右否则是上下
if (abs(endX) > abs(endY)) {
// 左右
if (endX + 5 > 0) {
// 左边
if (doLeft()) {
MenuLayer::playEffect("Sound/move.wav", false);
autoCreateCardNumber();
doCheckGameOver();
}//右,上,下省略
}
}
}
有卡片的游戏中初始化卡片的套路
CardSprite* CardSprite::createCardSprite(int numbers, int width, int height, float CardSpriteX, float CardSpriteY)
{
// 初始化卡片精灵
CardSprite *enemy = new CardSprite();
if (enemy && enemy->init()) {
enemy->autorelease();
enemy->enemyInit(numbers, width, height, CardSpriteX, CardSpriteY);
return enemy;
}
CC_SAFE_DELETE(enemy);
return NULL;
}
该游戏开发的难点在于识别手势后卡片的逻辑
//向左
bool MainScene::doLeft() {
//log("doLeft");
bool isdo = false;
// 最外层循环为4*4迭代
for (int y = 0; y < 4; y++) {
for (int x = 0; x < 4; x++) {
//判断卡片是合并还是清空
for (int x1 = x + 1; x1 < 4; x1++) {
if (cardArr[x1][y]->getNumber() > 0) {//有数字
if (cardArr[x][y]->getNumber() <= 0) { //为空
//设置为右边卡片的数值
cardArr[x][y]->setNumber(cardArr[x1][y]->getNumber());
cardArr[x1][y]->setNumber(0);
x--;
isdo = true;
}
else if (cardArr[x][y]->getNumber() == cardArr[x1][y]->getNumber()) {
//当前卡片的值与其比较卡片的值相等,设置为其的2倍
cardArr[x][y]->setNumber(cardArr[x][y]->getNumber() * 2);
cardArr[x1][y]->setNumber(0);
MenuLayer::playEffect("Sound/merge.wav", false);
cardArr[x][y]->runAction(Sequence::create(ScaleTo::create(0.05, 1.1), ScaleTo::create(0.05, 1.0), NULL));
//设置分数
lastScore += cardArr[x][y]->getNumber();
if (lastScore > maxScore)
{
maxScore = lastScore;
}
labelTTFlastScore->setString(__String::createWithFormat("%i", lastScore)->getCString());
labelTTFmaxScore->setString(__String::createWithFormat("%i", maxScore)->getCString());
isdo = true;
}
break; //跳出,否则无法运行
}
}
}
}
return isdo;
}
菜单层中的继续按钮与重新开始按钮的动效不同,前者是缩小到消失,后者是清空变黑
//继续按钮
void MenuLayer::ContinueTouch(cocos2d::Ref *pSender, Widget::TouchEventType type)
{
switch (type)
{
case Widget::TouchEventType::ENDED:
MenuLayer::playEffect("Sound/move.wav",false); //点击的音效
auto seq = Sequence::create(ScaleTo::create(0.2, 0), CallFuncN::create(CC_CALLBACK_1(MenuLayer::Close, this)), NULL);
//弹窗关闭动画 0.2s逐渐缩小到消失
imgBack->runAction(seq);
break;
}
}//关闭菜单层
void MenuLayer::Close(Node* pSender)
{
this->removeFromParentAndCleanup(true);//把该层从父空间清空
}//重新开始按钮
void MenuLayer::RestartTouch(cocos2d::Ref *pSender, Widget::TouchEventType type)
{
switch (type)
{
case Widget::TouchEventType::ENDED:
MenuLayer::playEffect("Sound/move.wav",false); //点击的音效
MainScene::ClearData();
Director::getInstance()->replaceScene(TransitionFade::create(0.5f, MainScene::createScene()));
//清空变黑,场景替换
break;
}
}
制作一个高仿的2048游戏是十分简单基础的,还有动画,音效等设置的代码就不贴了。这里格式有些乱,我的github上有源码,网上也有参考教程,有兴趣的同学可以进一步了解。
最后,cocos2d-x 推荐学习路线:
1.麦子学院,极客学院 cocos 入门教学视频系列
2 .cocos 官方文档,教程
3.小游戏项目实战
4. lua 脚本
5.极客学院物理引擎,数据操作,绘图 API 等进阶视频
6. cocos2d-x 底层源码
7.大项目实战
......
蟹妖!(笑)
作为部门里近年来为数不多的选择了 Web 前端开发 作为职业起点的师兄,在这里开个帖,跟各位师弟师妹分享一下我的前端工程师之路。
我准备就以下问题,结合亲身经历讲讲自己的看法,欢迎各位补充提问并提出建议。
AlertDialog Builder
虽然前面大部分都是很简单基础的,就当凑个完整。
1.一个最简单的应用,就是弹出一个消息框,在android中可以这样实现
new AlertDialog.Builder(self)
.setTitle("标题")
.setMessage("简单消息框")
.setPositiveButton("确定", null)
.show();
效果如下:

Builder方法的参数 self其实是Activity对象的引用,根据你所处的上下文来传入相应的引用就可以了。例如在onCreate方法中调用,只需传入this即 可。
2.带确认和取消按钮的对话框:
new AlertDialog.Builder(self)
.setTitle("确认")
.setMessage("确定吗?")
.setPositiveButton("是", null)
.setNegativeButton("否", null)
.show();

这里有两个null参数,这里要放的其实是这两个按钮点击的监听程序.这里不需要监听这些动作,所以传入null值简单忽略掉,但是实际开发的时候一般都是需要传入监听器的,用来响应用户的操作。
3.一个可以输入文本的对话框
new AlertDialog.Builder(self)
.setTitle("请输入")
.setIcon(android.R.drawable.ic_dialog_info)
.setView(new EditText(self))
.setPositiveButton("确定", null)
.setNegativeButton("取消", null)
.show();

4.单选框
new AlertDialog.Builder(self)
.setTitle("请选择")
.setIcon(android.R.drawable.ic_dialog_info)
.setSingleChoiceItems(new String[] {"选项1","选项2","选项3","选项4"}, 0,
new DialogInterface.OnClickListener() {
public void onClick(DialogInterface dialog, int which) {
dialog.dismiss();
}
}
)
.setNegativeButton("取消", null)
.show();

5.多选框
new AlertDialog.Builder(self)
.setTitle("多选框")
.setMultiChoiceItems(new String[] {"选项1","选项2","选项3","选项4"}, null, null)
.setPositiveButton("确定", null)
.setNegativeButton("取消", null)
.show();

6.列表框
new AlertDialog.Builder(self)
.setTitle("列表框")
.setItems(new String[] {"列表项1","列表项2","列表项3"}, null)
.setNegativeButton("确定", null)
.show();

7.显示图片
ImageView img = new ImageView(self);
img.setImageResource(R.drawable.icon);
new AlertDialog.Builder(self)
.setTitle("图片框")
.setView(img)
.setPositiveButton("确定", null)
.show();

建一个Dialog了。
另外:只有一个Activity才能添加一个窗体
将new AlertDialog.Builder(Context context)中的参数用Activity.this(Activity是你的Activity的名称)来填充就可以正确的创建一个Dialog了。

8.可以用来设置时间,弹出时间选择框。如图:

public void setDate(final TextView text) {
calendar = Calendar.getInstance();
// 通过自定义控件AlertDialog实现
AlertDialog.Builder builder = new AlertDialog.Builder(context);
View view = (LinearLayout) LayoutInflater.from(context).inflate(R.layout.dialog_date, null);
final DatePicker datePicker = (DatePicker) view.findViewById(R.id.date_picker);
// 设置日期简略显示 否则详细显示 包括:星期周
datePicker.setCalendarViewShown(false);
// 初始化当前日期
calendar.setTimeInMillis(System.currentTimeMillis());
datePicker.init(calendar.get(Calendar.YEAR),
calendar.get(Calendar.MONTH),
calendar.get(Calendar.DAY_OF_MONTH), null);
// 设置date布局
builder.setView(view);
builder.setTitle("设置日期信息");
builder.setNegativeButton("确 定",
new DialogInterface.OnClickListener() {
@Override
public void onClick(DialogInterface dialog, int which) {
// 日期格式
StringBuffer sb = new StringBuffer();
sb.append(String.format("%d-%02d-%02d",
datePicker.getYear(),
datePicker.getMonth() + 1,
datePicker.getDayOfMonth()));
text.setText(sb);
dialog.cancel();
}
});
builder.setPositiveButton("取 消",
new DialogInterface.OnClickListener() {
@Override
public void onClick(DialogInterface dialog, int which) {
dialog.cancel();
}
});
builder.create().show();
}
也可自定义弹出时间框
// 自定义控件
AlertDialog.Builder builder = new AlertDialog.Builder(context);
View view = (LinearLayout) LayoutInflater.from(context).inflate(R.layout.dialog_time, null);
final TimePicker timePicker = (TimePicker) view.findViewById(R.id.time_picker);
// 初始化时间
calendar.setTimeInMillis(System.currentTimeMillis());
timePicker.setIs24HourView(false);
timePicker.setCurrentHour(calendar.get(Calendar.HOUR_OF_DAY));
timePicker.setCurrentMinute(calendar.get(Calendar.MINUTE));
// 设置time布局
builder.setView(view);
builder.setTitle("设置时间信息");
builder.setNegativeButton("确定",
new DialogInterface.OnClickListener() {
@OverRide
public void onClick(DialogInterface dialog, int which) {
hour = timePicker.getCurrentHour();
minute = timePicker.getCurrentMinute();
// 时间小于10的数字 前面补0 如01:12:00
text.setText(new StringBuilder()
.append(hour < 10 ? "0" + hour : hour)
.append(":")
.append(minute < 10 ? "0" + minute : minute)
.append(":00"));
dialog.cancel();
MainActivity.instance.setTimeClock(text.getText().toString().trim());
}
});
大家都进入了技术部,那我们首先get一个新的技能使用GitHub来管理自己的项目,至少应该知道GitHub,并能够使用,因为用github来管理自己的项目是个不错的选择,而且github上有很多开源项目,大家也可以学习借鉴。
GitHub 是一家公司,位于旧金山,由 Chris Wanstrath, PJ Hyett 与 Tom Preston-Werner 三位开发者在2008年4月创办,主要提供基于git的版本托管服务。
Git 是一款免费、开源的分布式版本控制系统,他是著名的 Linux 发明者 Linus Torvalds 开发的。
总结:Git只是一个对GitHub上托管的项目进行版本控制的工具,而GitHub的功能还有很多(比如:搭建博客、写作等)。
1.协同开发:一个项目,需要好几个人同时开发,彼此之间修改的代码互不影响,同时需要同步别人的代码。
2.防止代码丢失:同步本地的代码和服务端的代码,本地代码丢失还可以从服务端拉取(有好事者(我)就问了:服务端的代码也没有了怎么办? 答:自求多福!)
3.代码回滚:有很多时候,提交上去的代码可能产生了更多的Bug,这个时候就需要回滚到之前的代码,不然怎么知道自己到底改了哪些地方。
4.精确的记录:每次修改完提交至服务端时,都会记录一条修改了什么地方,这样很方便自己或协作者找到差异之处。
Mac上会默认安装了Xcode这个软件(用phpstorm也行),它本身就集成了Git,所以一般Mac上是不用安装Git的。
要是你的Mac上没有Git,你可以用两个方式安装:
下载一个.exe文件就可以一键安装了。
安装完了之后,在桌面上右键找到gitBash或者在开始菜单里Git->gitBash,弹出了一个类似Cmd的命令窗口,就说明安装成功。
没有人用的话我就省略了哈。。。
以下是在Mac环境下进行的操作(谁让我用的是mac呢),Windows和Linux环境下的小伙伴,请自己选择合适的方法操作(比如创建文件夹,Windows用户可以右键新建),其中git命令通用。
$ mkdir mywork
$ cd mywork/
$ git init
Initialized empty Git repository in/Users/AaronYi/Desktop/github/mywork/.git/
$ ls -ah
. .. .git
现在就已经将git仓库建好了,但仓库里边除了一个.git文件夹(不要随便动它,否则就会破坏这个库)外,没有其他东西。
在mywork文件夹中新建一个文件(可以是.txt或.md等,需使用纯文本and编码为UTF-8,这样更好),命令如下:
$ touch readme.md
虽然之前是在mywork仓库文件夹中创建了readme.md文件,但是并没有提交的仓库中去,这里先看一下没有提交的状态。
查看状态命令,之后常用的一个命令:
$ git status
On branch master
Initial commit
Untracked files:
(use "git add <file>..." to include in what will be committed)
readme.md
nothing added to commit but untracked files present (use "git add" to track)
看英文,Untracked files这个文件没被跟踪和提交,叫我们用git add 这个命令去添加这个文件,下面我们就顺其之意,先添加然后看状态变化:
$ git add readme.md
$ git status
On branch master
Initial commit
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: readme.md
再看英文,先忽略git rm这个命令,我们看见了new file: xxxx,这就说明已经添加上去了,但是这还不够,Changes to be committed说明这是一个待提交的文件。
使用命令将文件提交到仓库:
$ git commit -m "nothing"
[master (root-commit) 483c022] nothing
1 file changed, 0 insertions(+), 0 deletions(-)
create mode 100644 readme.md
解释一下这个命令中的-m,就是message的意思,这个可以任意写你想要写的文字,但是作为项目版本管理库使用,最好是填入自己修改了什么,添加了什么等有用方便日后自己回顾与管理的文字。
总结:两步完成文件的提交,好事者(当初的我)又问了,干嘛还需要git add 这个命令,这是因为commit一次可以提交多个文件,所以可以添加add多个文件了。
下面我们给readme.md文件中写入hello ,boy or gril,然后使用上述命令对其进行操作,并学习一个新的命令git diff用来查看修改了哪些内容。
$ git status
On branch master
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: readme.md
no changes added to commit (use "git add" and/or "git commit -a")
上边提示说这是一个已经修改过但是没有被提交的文件,为了以防万一我们还可以在提交之前看一下更改了什么地方,使用新命令git diff
$ git diff readme.md
diff --git a/readme.md b/readme.md
index e69de29..4646a13 100644
--- a/readme.md
+++ b/readme.md
@@ -0,0 +1 @@
+hello,boy or gril
\ No newline at end of file
细心的伙伴就看见了+hello,boy or gril我们刚添加的文字,但是前面怎么多了一个+号呢?+表示我们添加了的内容,-表示我们删除了的内容,当然现在去修改文件中的内容,不会生效,因为还没有提交的仓库。
$ git add readme.md
$ git commit -m "添加了文字"
[master 3467800] 添加了文字
1 file changed, 2 insertions(+)
$ git status
On branch master
nothing to commit, working directory clean
此时,提示仓库没有什么要提交的,工作目录干净。对了git status这个命令真的使用很频繁。
下面我们重复上述内容,再一次对文件内容进行修改,看看变化,会不会出现-。
$ git diff readme.md
diff --git a/readme.md b/readme.md
index 7072e56..111e182 100644
--- a/readme.md
+++ b/readme.md
@@ -1,2 +1 @@
now,we can see.
-on boy no gril
\ No newline at end of file
看有了吧,后边仍需要两步提交,可不要忘记了,自己动手完成吧。
也需到这里,有部分小伙伴懵逼了,mywork文件夹明明就是个仓库啊,为什么还需要提交文件。其实,mywork文件夹只是一个工作区,其中的.git文件夹才是版本库,在.git文件夹中又包含有缓存区,主分支master和指向主分支的指针HEAD。所以git add 是将工作区的文件存到缓存区,git commit -m "xxx"是将缓存区的文件提交到当前分支。最后,需要注意的是当你add之后,又对文件进行了修改,那么你还得add一次,然后再commit,不然第二次修改的内容不会存到缓存区,当然也就不会提交到当前分支上去了。
刚才我们只是对readme.md这一个文件做了两次更改,想必大家都能记住,但是文件一多改的地方也多,单凭回忆一般是记不住的(除非你是像大神那样能脑补编译的天才),下面我们使用git log命令的帮助我们回忆吧。
$ git log
commit 8cb96e943c3a0c1f2cc04598639a01ad8c78e77a
Author: Aaron <[email protected]>
Date: Tue Sep 20 23:57:51 2016 +0800
rm -boy or gril
commit 3467800f630c8647814a8b83a4fce4b2fc0f35dc
Author: Aaron <[email protected]>
Date: Tue Sep 20 23:49:51 2016 +0800
添加了文字
可以看到出现了git commit -m "xxx"提交的文字(所以说提交的时候要好好表达自己做了哪些改动),这样是不是一目了然呢。
可是说了半天,版本回滚到底是个什么?版本又是怎么回滚呢?各位体验过电脑蓝屏吧,再次启动的时候,你是否注意到恢复到上一次正常启动时状态的字样,版本回滚就和这差不多,要是不小心删了重要的文件,我们还可以回退到之前的状态。
在上边的提交历史中,我们注意到每次提交都有commit 3467800f630c8647814a8b83a4fce4b2fc0f35dc这个字段,这个就是我们回到过去用到的时光机器。
使用命令git reset --hard commit_id,commit_id只需要填写前面6-7位就好了,强迫症可以填完整:
$ git reset --hard 3467800
HEAD is now at 3467800 添加了文字
$ cat readme.md
now,we can see.
cat查看文件内容。
我现在反悔了,需要返回到未来,依然可以根据commit_id来回去,如下:
$ git reset --hard 8cb96e
HEAD is now at 8cb96e9 rm -boy or gril
BUT我们刚刚关了之前的命令窗,根本不记得commit_id了。*年,你莫慌,Git提供了一个命令git reflog用来记录你的每一次命令:
$ git reflog
8cb96e9 HEAD@{0}: reset: moving to 8cb96e
3467800 HEAD@{1}: reset: moving to 3467800
8cb96e9 HEAD@{2}: commit: rm -boy or gril
3467800 HEAD@{3}: commit: 添加了文字
483c022 HEAD@{4}: commit (initial): nothing
至此我们又可以搭乘时光机器回到未来了。
(1)丢弃工作区的修改
你看我随便改了些什么:
$ cat readme.md
now,we can see.
Z柏晓脸真大
这个时候,不想出现中文,可以手动删除,也可以使用命令:
$ git status
On branch master
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: readme.md
no changes added to commit (use "git add" and/or "git commit -a")
现在,我们在提示中看见了一个新的命令git checkout -- ,意思是丢弃工作区的修改,事不宜迟,试一把:
$ git checkout -- readme.md
$ cat readme.md
now,we can see.
OK,成功了!(成功删除了柏晓脸大的这个事实。)
(2)丢弃已经添加到缓存区的修改
如果你已经将文件add进去了:
$ git status
On branch master
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
modified: readme.md
根据提示,我们可以使用git reset HEAD 撤销缓存区的修改,重新放回到工作区,现在就可以操作(1)来撤销工作区的修改了,自己动手燥起来吧。
(3)丢弃已经添加到当前分支的修改
这时就只能通过commit_id来回滚了。
(4)处理已经删除的文件(真想删或误删)
首先,我们来回顾之前的命令,创建并提交一个文件到版本库,动手燥起来。
现在,我们手动或者使用rm命令将这个文件删除了,虽然该文件在工作区已经不存在了,但是依然存在于版本库,导致两者不一致,那么现在该怎么办呢?憋着急,git status命令来告诉你。
$ git status
On branch master
Changes not staged for commit:
(use "git add/rm <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
deleted: text.md
no changes added to commit (use "git add" and/or "git commit -a")
见到这样的提示,应该很亲切了吧。现在需要选择是真删除还是将其恢复,根据提示命令完成。
真删(就是讲版本库中的也删了):
$ git rm text.md
rm 'text.md'
误删:
$ git checkout -- text.md
此时,刚刚误删的文件又会跑回到工作区了。
说了这么多(大部分都是从网上找的),基本也把常用的Git操作说了一下,希望能给大家的学习提供帮助。
An Adapter object acts as a bridge between an AdapterView and the underlying data for that view. The Adapter provides access to the data items. The Adapter is also responsible for making a View for each item in the data set.
翻译过来,简单理解就是adapter是view和数据的桥梁。在一个ListView或者GridView中,你不可能手动给每一个格子都新建一个view,所以这时候就需要Adapter的帮忙,它会帮你自动绘制view并且填充数据。
从英文就可以知道了,最基础的Adapter,也就是说,它可以做所有的事情。所以为什么说最实用最常用,原因就在于它的全能性,不会像ArrayAdapter等的封装好的类有那么多局限性,但是这样的话,使用起来自然会更加麻烦一点。但是这篇文章就会告诉你怎么熟练使用它。
在ListView、GridView或者其他的view中,使用setAdapter方法传入我们的baseAdapter就可以用了。
listView.setAdapter(mBaseAdapter);
问题就出在这个mBaseAdapter要怎么写了。重点终于来了。
可以新建一个java文件MyBaseAdapter,继承自BaseAdapter,并且实现它的4个基础方法。
public class MyBaseAdapter extends BaseAdapter {
@Override
public int getCount() {
return 0;
}
@Override
public Object getItem(int position) {
return null;
}
@Override
public long getItemId(int position) {
return 0;
}
@Override
public View getView(int position, View convertView, ViewGroup parent) {
return null;
}
}
默认实现这4个方法后,接下来我们就要重写这4个方法了。那么具体这4个方法有什么用呢?我们在后面再讲。
MyBaseAdapter这个类写好后,我们就新建一个mBaseAdapter,在setAdapter方法的时候传进去就好了。
MyBaseAdapter mBaseAdapter = new MyBaseAdapter();
这样的三步法就可以实现BaseAdapter的使用了。
但是,这当然没完。因为现在你还没告诉你的BaseAdapter你要叫它干什么呢。所以接下来我们就要修改MyBaseAdapter了。
学会BaseAdapter其实只需要掌握四个方法:
getCount, getItem, getItemId, getView
可以简单的理解为,adapter先从getCount里确定数量,然后循环执行getView方法将条目一个一个绘制出来,所以必须重写的是getCount和getView方法。而getItem和getItemId是调用某些函数才会触发的方法,如果不需要使用可以暂时不修改。
首先在MyBaseAdapter中添加super()方法,用来将数据源传入MyBaseAdapter中。其中this.data = data;的意思是将传入的形参赋值给我们的私有变量以供使用。mContext是在后面要调用到,这里先不解释。
private String[] data;
private Context mContext;
public MyBaseAdapter(Context mContext, String[] data) {
super();
this.mContext = mContext;
this.data = data;
}
然后就可以将getCount的返回值修改为我们的数据源的长度,要显示几个条目,我们就传入多长的数据源就可以了。
public int getCount() {
return data.length;
}
接着将getView的方法改为显示出我们数据源的字符串。
public View getView(int position, View convertView, ViewGroup parent) {
TextView textView = new TextView(mContext);
textView.setText(data[position]);
return textView;
}
这里为每一个条目新建一个TextView用来显示字符串,新建的时候就需要传入一个Context,就用到了我们之前的mContext。
这样我们就可以使用MyBaseAdapter来显示一个字符串数组了。不过还需要在前面修改一下,在新建mBaseAdapter的时候要传入context和数据源。
String[] strings = {"a","b","c"};
MyBaseAdapter mBaseAdapter = new MyBaseAdapter(getApplicationContext(),strings);
接下来贴一下完整的代码吧。ListView的新建我就不讲了。
import android.support.v7.app.AppCompatActivity;
import android.os.Bundle;
import android.widget.ListView;
public class MainActivity extends AppCompatActivity {
private ListView listView;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
listView = (ListView) findViewById(R.id.listView);
String[] strings = {"a","b","c"};
MyBaseAdapter mBaseAdapter = new MyBaseAdapter(getApplicationContext(),strings);
listView.setAdapter(mBaseAdapter);
}
}
import android.content.Context;
import android.view.View;
import android.view.ViewGroup;
import android.widget.BaseAdapter;
import android.widget.TextView;
public class MyBaseAdapter extends BaseAdapter {
private String[] data;
private Context mContext;
public MyBaseAdapter(Context mContext, String[] data) {
super();
this.mContext = mContext;
this.data = data;
}
@Override
public int getCount() {
return data.length;
}
@Override
public Object getItem(int position) {
return null;
}
@Override
public long getItemId(int position) {
return 0;
}
@Override
public View getView(int position, View convertView, ViewGroup parent) {
TextView textView = new TextView(mContext);
textView.setText(data[position]);
return textView;
}
}
当然一个TextView显然满足不了我们的需要,这也完全不能显示BaseAdapter的全能性。那接下来,就来展示一下如何用BaseAdapter显示一个自定义布局。
<?xml version="1.0" encoding="utf-8"?>
<LinearLayout xmlns:android="http://schemas.android.com/apk/res/android"
xmlns:app="http://schemas.android.com/apk/res-auto"
android:orientation="horizontal" android:layout_width="match_parent"
android:layout_height="match_parent">
<ImageView
android:layout_width="wrap_content"
android:layout_height="wrap_content"
app:srcCompat="@mipmap/ic_launcher"
android:id="@+id/imageView" />
<Button
android:text="Button"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:id="@+id/button" />
<TextView
android:text="TextView"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:id="@+id/textView" />
</LinearLayout>
public View getView(int position, View convertView, ViewGroup parent) {
LayoutInflater inflater = LayoutInflater.from(mContext);
View view = inflater.inflate(R.layout.item,null);
final TextView textView = (TextView) view.findViewById(R.id.textView);
Button button = (Button) view.findViewById(R.id.button);
ImageView imageView = (ImageView) view.findViewById(R.id.imageView);
imageView.setImageResource(R.mipmap.ic_launcher);
button.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View v) {
textView.append("!");
}
});
textView.setText(data[position]);
return view;
}
主要讲解一下前两句。LayoutInflater是用来加载布局的,用LayoutInflater的inflate方法就可以将你的item布局绘制出来。其中getView方法中的三个参数,position是指现在是第几个条目;convertView是旧视图,就是绘制好了的视图;parent是父级视图,也就是ListView之类的。
用inflate方法绘制好后的view最后return返回给getView方法就可以了。
上面的convertView是旧视图是什么意思呢?就是listview如果超出了屏幕,滑动的时候会隐藏掉一部分,这时候就将隐藏掉的部分保存到convertView中。那么如果是我们之前的写法,每次返回的时候就没有使用convertView,重新创建了一个View,这样子浪费了系统资源。那要怎么利用convertView优化呢?
同样我们还是对getView进行进一步修改。
static class ViewHolder{
TextView textView;
ImageView imageView;
Button button;
}
public View getView(int position, View convertView, ViewGroup parent) {
LayoutInflater inflater = LayoutInflater.from(mContext);
ViewHolder holder = null;
if (convertView == null) {
convertView = inflater.inflate(R.layout.item, null);
holder = new ViewHolder();
holder.button = (Button) convertView.findViewById(R.id.button);
holder.textView = (TextView) convertView.findViewById(R.id.textView);
holder.imageView = (ImageView) convertView.findViewById(R.id.imageView);
convertView.setTag(holder);
} else {
holder = (ViewHolder) convertView.getTag();
}
holder.imageView.setImageResource(R.mipmap.ic_launcher);
holder.button.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View v) {
Log.d("click","button");
}
});
holder.textView.setText(data[position]);
return convertView;
}
先判断convertView是否为空,是的话就创建ViewHolder,不是的话就取出ViewHolder,这样就可以实现复用convertView了。
这篇文章仅仅只是自己的理解,希望能够帮助新手更好的理解BaseAdapter,如果有意见欢迎指出。
每一个Android应用程序在运行时,对于底层的Linux Kernel而言都是一个单独的进程,但是对于Android系统而言,因为局限于手机画面的大小与使用的考虑,不能把每一个运行中的应用程序窗口都显示出来。
所以通常手机系统的界面一次仅显示一个应用程序窗口,Android使用了Activity的概念来表示界面。
运行中的应用程序分为五大类,分别是:
前景模式:foreground process
可见模式:visible process
背景模式:background process
空白模式:empty process
服务模式:service process
除了最后一个,貌似service process是Service的事情了。其他都与Activity相关。(我没用过不清楚,泽铭用过具体问他吧)
Android系统会判断应用程序Activity是属于哪一个类,给予不同的Activity生命周期。
Activity的生命周期也是它所在进程的生命周期。
Activity生命周期的运行如图:

在Android系统中,即使不关掉程序,当应用程序处于某种进程类时,也有可能被系统kill掉。
Android系统通过运行机制,依照哪些画面或消息对使用者最重要以及当前内存使用状况,而做出是否kill Activity的决定。
foreground process(前景模式)是当前显示于手机屏幕上的应用程序画面,被定义为前景模式的进程,其中由onCreate()、onStart() 、onResume() 函数调用的Activity都会变成foreground process正在运行的Activity。
visible process(可见模式):visible process最常发生的情况是当应用程序弹出对话框要与用户交互时,原应用程序就会变成透明(不可见)的,而对话窗口就会变成前景。
当对话窗口退出后,原应用程序马上就又变回原前景模式了。
在Activity窗口画面变为透明时,就会由onPause()函数掌控进入暂停状态。
当前景进程退出时,该Activity就会再度被拉到前景模式,由onResume() 函数唤醒。
background process是在Activity窗口画面被其他Activity完全盖掉,窗口画面已经完全看不见时,则会进入onStop()停止状态。
这种情况通常发生在两个不同的应用程序开启时,后开启的应用程序会覆盖掉原应用程序。
此时对background process Activity的处理有两种选择:一是直接被onDestroy()退出,该程序将完全关闭,无法再使用任何返回键回到该程序;另一个处理方式是当其他Activity需要内存时,这个background process会先被清除掉,释放出内存。
如果使用者再度浏览刚刚被清除掉的background process,则Android系统会自动再运行onCreate()重新启动该Activity,所以当系统需要内存时,就会暂时将背景进程清除,让它变成empty process(空白模式) , 所以空白进程最重要的目的就是暂时释放出内存,直到使用者再度唤醒该empty process Activity时,才会将空白进程变成前景进程。
(Service相关)service process(服务模式进程)是由startService()所产生的,虽然服务进程有点类似背景进程在背景状态运行,但是它的运行等级和前景进程几乎一样高。
服务模式进程是持续运行的,虽然使用者看不到任何运行画面,Android系统不会自动关闭此类的服务进程,除非使用者自行关闭。

Activity生命周期的每一个阶段都表示为金字塔上的一个台阶,当系统创建一个新的activity时,每一个回调函数都把activity的状态网上挪一步。
金子塔的最顶层就是activity运行在前景模式下,用户可与之交互。
当用户离开activity时,系统调用另一些回调函数,将activity的状态从金字塔中一步一步移下来。有些情况下,activity只移动一部分,并没有完全到底,这些情况下仍然可以移动回顶部。
注意这些状态中只有三个状态是静态(static)的,意味着activity只有在这三个状态下能停留一段时间:
Resumed:foreground,用户可交互running state
Paused:部分被遮挡,不能接收用户输入也不能执行代码,另一个半透明或者小的activity正挡在前面。
Stopped:activity完全被遮挡,不能被用户看到,activity被认为在background,当Stopped的时候,activity实例的状态信息被保留,但是不能执行任何代码。
其他状态都是转换状态,系统会很快调用其他相应的回调函数离开这些状态。比如系统调用onCreate()之后,会很快调用onStart(),之后是 onResume()。
覆写这些回调函数时,首先要记得一定要调用基类的回调函数,即最开始一行永远是super.onXXX();
onPause()和onResume()中的动作应该互逆,比如说onPause()中释放了相机,那么onResume()中就要重新初始化相机。
Stopped状态下,UI对用户完全不可见,此时用户焦点在另一个activity或者另一个程序上。
onStop()中需要释放资源,因为有时候系统会kill掉Stopped状态的进程,如果有资源没有被释放,会造成内存泄露。
onStop()中还应该包括一些关闭操作,比如向数据库写信息。
当从Stopped状态回到前景时,首先需要调用onRestart(),这个函数做一些恢复工作,恢复停止但是并没有被销毁的activity;然后系统会接着调用onStart(),因为每次activity变为可见时都要调用onStart()。
可以把onStart()和onStop()看成一对,因为在一开始启动时和重新启动时都需要做一些初始化工作。
c,但有一个例外的情况:如果在onCreate()中调用finish()方法,系统将会立即调用onDestroy()而不用经过生命周期中的其他阶段。
如果activity是自己销毁的,实例就永远消失了,但是如果系统因为资源限制销毁了activity,虽然这个实例已经不在了,但是当用户返回到它时,系统会利用这个activity被销毁时存储的数据,重新创建一个实例。
Activity的销毁分为两种:
第一种是正常的销毁,比如用户按下Back按钮或者是activity自己调用了finish()方法;
另一种是由于activity处于stopped状态,并且它长期未被使用,或者前台的activity需要更多的资源,这些情况下系统就会关闭后台的进程,以恢复一些内存。
需要注意的是这其中有一种情况就是屏幕旋转的问题,当用户旋转手机屏幕,每一次都会导致activity的销毁和重新建立。
在第二种情况下,尽管实际的activity实例已经被销毁,但是系统仍然记得它的存在,当用户返回到它的时候,系统会创建出一个新的实例来代替它,这里需要利用旧实例被销毁时候存下来的数据。这些数据被称为“instance state”,是一个存在Bundle对象中的键值对集合。
缺省状态下,系统会把每一个View对象保存起来(比如EditText对象中的文本,ListView中的滚动条位置等),即如果activity实例被销毁和重建,那么不需要你编码,layout状态会恢复到前次状态。
但是如果你的activity需要恢复更多的信息,比如成员变量信息,则需要自己动手写了。
如果要存储额外的数据,必须覆写回调函数onSaveInstanceState().
系统会在用户离开activity的时候调用这个函数,并且传递给它一个Bundle object,如果系统稍后需要重建这个activity实例,它会传递同一个Bundle object到onRestoreInstanceState() 和 onCreate() 方法中去。
当系统停止activity时,它会调用onSaveInstanceState()(过程1),如果activity被销毁了,但是需要创建同样的实例,系统会把过程1中的状态数据传给onCreate()和onRestoreInstanceState()(图中标出的2和3)。

当系统停止activity时,系统会调用onSaveInstanceState(),状态信息会以键值对的形式存储下来。
默认的实现中存储了activity的view系列的状态,比如文本和滚动条位置等。
要存储额外的信息,必须自己实现onSaveInstanceState(),并且给Bundle object加上键值对。
比如:
static final String STATE_SCORE = "playerScore";static final String STATE_LEVEL = "playerLevel";
...
@Overridepublic void onSaveInstanceState(Bundle savedInstanceState) {
// Save the user's current game state savedInstanceState.putInt(STATE_SCORE, mCurrentScore);
savedInstanceState.putInt(STATE_LEVEL, mCurrentLevel);
// Always call the superclass so it can save the view hierarchy state
super.onSaveInstanceState(savedInstanceState);
}
要记得调用基类的实现,以实现默认的实现。
当activity重建时,需要根据Bundle中的状态信息数据恢复activity。
onCreate() 和onRestoreInstanceState()回调函数都会接收到这个Bundle。
因为每次创建新的activity实例的或重建一个实例的时候都会调用onCreate()方法,所以必须先检查是否Bundle是null,如果是null,则表明是要创建一个全新的对象,而不是重建一个上次被销毁的对象。
比如onCreate()方法可以这么写:
@Overrideprotected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState); // Always call the superclass first
// Check whether we're recreating a previously destroyed instance
if (savedInstanceState != null) {
// Restore value of members from saved state
mCurrentScore = savedInstanceState.getInt(STATE_SCORE);
mCurrentLevel = savedInstanceState.getInt(STATE_LEVEL);
} else {
// Probably initialize members with default values for a new instance }
...
}
除了在onCreate()中恢复状态外,也可以选择在onRestoreInstanceState()中实现,这个函数在onStart()之后调用。
只有在有数据要恢复的时候系统会调用onRestoreInstanceState(),所以不必检查Bundle是否为null。
public void onRestoreInstanceState(Bundle savedInstanceState) {
// Always call the superclass so it can restore the view hierarchy
super.onRestoreInstanceState(savedInstanceState);
// Restore state members from saved instance
mCurrentScore = savedInstanceState.getInt(STATE_SCORE);
mCurrentLevel = savedInstanceState.getInt(STATE_LEVEL);
}
此处要注意,不要忘记调用基类实现。
下面是acitivity跳转代码





新建一个empty activity 或 blank activity,命名BAcitivity

系统显示具体运行流程:

最后 System out : A onStop
结束。
刚好最近看到关于浏览器内核的文章,当一回搬运工,大家就当科普文来看吧~
浏览器内核又可以分成两部分:渲染引擎(layout engineer 或者 Rendering Engine)和 JS 引擎。它负责取得网页的内容(HTML、XML、图像等等)、整理讯息(例如加入 CSS 等),以及计算网页的显示方式,然后会输出至显示器或打印机。浏览器的内核的不同对于网页的语法解释会有不同,所以渲染的效果也不相同。所有网页浏览器、电子邮件客户端以及其它需要编辑、显示网络内容的应用程序都需要内核。JS 引擎则是解析 Javascript 语言,执行 javascript 语言来实现网页的动态效果。
最开始渲染引擎和 JS 引擎并没有区分的很明确,后来 JS 引擎越来越独立,内核就倾向于只指渲染引擎。有一个网页标准计划小组制作了一个 ACID 来测试引擎的兼容性和性能。内核的种类很多,如加上没什么人使用的非商业的免费内核,可能会有 10 多种,但是常见的浏览器内核可以分这四种:Trident、Gecko、Blink、Webkit。
Trident(IE内核):该内核程序在 1997 年的 IE4 中首次被采用,是微软在 Mosaic("马赛克",这是人类历史上第一个浏览器,从此网页可以在图形界面的窗口浏览) 代码的基础之上修改而来的,并沿用到 IE11,也被普遍称作 "IE内核"。
Trident实际上是一款开放的内核,其接口内核设计的相当成熟,因此才有许多采用 IE 内核而非 IE 的浏览器(壳浏览器)涌现。由于 IE 本身的 "垄断性"(虽然名义上 IE 并非垄断,但实际上,特别是从 Windows 95 年代一直到 XP 初期,就市场占有率来说 IE 的确借助 Windows 的东风处于 "垄断" 的地位)而使得 Trident 内核的长期一家独大,微软很长时间都并没有更新 Trident 内核,这导致了两个后果——一是 Trident 内核曾经几乎与 W3C 标准脱节(2005年),二是 Trident 内核的大量 Bug 等安全性问题没有得到及时解决,然后加上一些致力于开源的开发者和一些学者们公开自己认为 IE 浏览器不安全的观点,也有很多用户转向了其他浏览器,Firefox 和 Opera 就是这个时候兴起的。非 Trident 内核浏览器的市场占有率大幅提高也致使许多网页开发人员开始注意网页标准和非 IE浏览器的浏览效果问题。
补充:IE 从版本 11 开始,初步支持 WebGL 技术。IE8 的 JavaScript 引擎是 Jscript,IE9 开始用 Chakra,这两个版本区别很大,Chakra 无论是速度和标准化方面都很出色。
国内很多的双核浏览器的其中一核便是 Trident,美其名曰 "兼容模式"。
Window10 发布后,IE 将其内置浏览器命名为 Edge,Edge 最显著的特点就是新内核 EdgeHTML。
Trident各版本更新信息:

除Trident之外,微软还有另一个网页浏览器排版引擎,称为Tasman,它是使用在「Internet Explorer for Mac」的排版引擎。相较于Trident,Tasman引擎对网页标准有较佳的支持,但微软自04年开始已经停止了Mac计算机版本的 Internet Explorer的开发。
Gecko(Firefox 内核):Netscape6 开始采用的内核,后来的 Mozilla FireFox(火狐浏览器) 也采用了该内核,Gecko 的特点是代码完全公开,因此,其可开发程度很高,全世界的程序员都可以为其编写代码,增加功能。因为这是个开源内核,因此受到许多人的青睐,Gecko 内核的浏览器也很多,这也是 Gecko 内核虽然年轻但市场占有率能够迅速提高的重要原因。
事实上,Gecko 引擎的由来跟 IE 不无关系,前面说过 IE 没有使用 W3C 的标准,这导致了微软内部一些开发人员的不满;他们与当时已经停止更新了的 Netscape 的一些员工一起创办了 Mozilla,以当时的 Mosaic 内核为基础重新编写内核,于是开发出了 Gecko。不过事实上,Gecko 内核的浏览器仍然还是 Firefox (火狐) 用户最多,所以有时也会被称为 Firefox 内核。此外 Gecko 也是一个跨平台内核,可以在Windows、 BSD、Linux 和 Mac OS X 中使用。
一提到 webkit,首先想到的便是 chrome,可以说,chrome 将 Webkit内核 深入人心,殊不知,Webkit 的鼻祖其实是 Safari。现在很多人错误地把 webkit 叫做 chrome内核(即使 chrome内核已经是 blink 了),苹果都哭瞎了有木有。
Safari 是苹果公司开发的浏览器,使用了KDE(Linux桌面系统)的 KHTML 作为浏览器的内核,Safari 所用浏览器内核的名称是大名鼎鼎的 WebKit。 Safari 在 2003 年 1 月 7 日首度发行测试版,并成为 Mac OS X v10.3 与之后版本的默认浏览器,也成为苹果其它系列产品的指定浏览器(也已支持 Windows 平台)。
如上述可知,WebKit 前身是 KDE 小组的 KHTML 引擎,可以说 WebKit 是 KHTML 的一个开源的分支。当年苹果在比较了 Gecko 和 KHTML 后,选择了后者来做引擎开发,是因为 KHTML 拥有清晰的源码结构和极快的渲染速度。
Webkit内核 可以说是以硬件盈利为主的苹果公司给软件行业的最大贡献之一。随后,2008 年谷歌公司发布 chrome 浏览器,采用的 chromium 内核便 fork 了 Webkit。
需要了解的是,虽然我们称WebKit为浏览器内核(或浏览器引擎),但不太适合直接称之为我们开头提到的Rendering Engine(渲染引擎),因为WebKit本身主要是由两个引擎构成的,一个正是渲染引擎“WebCore”,另一个则是javascript解释引擎“JSCore”,它们均是从KDE的渲染引擎KHTML及javascript解释引擎KJS衍生而来。
2008 年,谷歌公司发布了 chrome 浏览器,浏览器使用的内核被命名为 chromium。
chromium fork 自开源引擎 webkit,却把 WebKit 的代码梳理得可读性提高很多,所以以前可能需要一天进行编译的代码,现在只要两个小时就能搞定。因此 Chromium 引擎和其它基于 WebKit 的引擎所渲染页面的效果也是有出入的。所以有些地方会把 chromium 引擎和 webkit 区分开来单独介绍,而有的文章把 chromium 归入 webkit 引擎中,都是有一定道理的。
谷歌公司还研发了自己的 Javascript 引擎,V8,极大地提高了 Javascript 的运算速度。
chromium 问世后,带动了国产浏览器行业的发展。一些基于 chromium 的单核,双核浏览器如雨后春笋般拔地而起,例如 搜狗、360、QQ浏览器等等,无一不是套着不同的外壳用着相同的内核。
然而 2013 年 4 月 3 日,谷歌在 Chromium Blog 上发表 博客,称将与苹果的开源浏览器核心 Webkit 分道扬镳,在 Chromium 项目中研发 Blink 渲染引擎(即浏览器核心),内置于 Chrome 浏览器之中。
webkit 用的好好的,为何要投入到一个新的内核中去呢?
Blink 其实是 WebKit 的分支,如同 WebKit 是 KHTML 的分支。Google 的 Chromium 项目此前一直使用 WebKit(WebCore) 作为渲染引擎,但出于某种原因,并没有将其多进程架构移植入Webkit。
后来,由于苹果推出的 WebKit2 与 Chromium 的沙箱设计存在冲突,所以 Chromium 一直停留在 WebKit,并使用移植的方式来实现和主线 WebKit2 的对接。这增加了 Chromium 的复杂性,且在一定程度上影响了 Chromium 的架构移植工作。
基于以上原因,Google 决定从 WebKit 衍生出自己的 Blink 引擎(后由 Google 和 Opera Software 共同研发),将在 WebKit 代码的基础上研发更加快速和简约的渲染引擎,并逐步脱离 WebKit 的影响,创造一个完全独立的 Blink 引擎。这样以来,唯一一条维系 Google 和苹果之间技术关系的纽带就这样被切断了。
这里顺便介绍下Chrome和Chromium两个浏览器的区别——Chromium浏览器是谷歌为发展自家的浏览器Chrome而开启的计划,所以Chromium相当于Chrome的工程版或称实验版(尽管Chrome自身也有β版阶段),新功能会率先在Chromium上实现,待验证后才会应用在Chrome上。Chromium一天最多可以更新十几二十个版本,实验性的新特性都会现在这里放出,但是Chromium本身其实并不稳定;而Chrome总共有四个更新分支:Canary、Dev、Beta、Stable,稳定性依次增强。
Presto 是挪威产浏览器 opera 的 "前任" 内核,为何说是 "前任",因为最新的 opera 浏览器早已将之抛弃从而投入到了谷歌大本营。
Opera 的一个里程碑作品是 Opera7.0,因为它使用了 Opera Software 自主开发的 Presto 渲染引擎,取代了旧版 Opera 4 至 6 版本使用的 Elektra 排版引擎。该款引擎的特点就是渲染速度的优化达到了极致,然而代价是牺牲了网页的兼容性。
Presto 加入了动态功能,例如网页或其部分可随着 DOM 及 Script 语法的事件而重新排版。Presto 在推出后不断有更新版本推出,使不少错误得以修正,以及阅读 Javascript 效能得以最佳化,并成为当时速度最快的引擎。
然而为了减少研发成本,Opera 在 2013 年 2 月宣布放弃 Presto,转而跟随 Chrome 使用 WebKit 分支的 Chromium 引擎作为自家浏览器核心引擎,Presto 内核的 Opera 浏览器版本永远的停留在了 12.17。在 Chrome 于 2013 年推出 Blink 引擎之后,Opera 也紧跟其脚步表示将转而使用 Blink 作为浏览器核心引擎。
Presto 与开源的 WebKit 和经过谷歌加持的 Chromium 系列相比毫无推广上的优势,这是 Opera 转投 WebKit 的主要原因,并且使用 WebKit 内核的 Opera 浏览器可以兼容谷歌 Chrome 浏览器海量的插件资源。但是换内核的代价对于 Opera 来说过于惨痛。使用谷歌的 WebKit 内核之后,原本快速,轻量化,稳定的 Opera 浏览器变得异常的卡顿,而且表现不稳定,Opera 原本旧内核浏览器书签同步到新内核上的工作 Opera 花了整整两年时间,期间很多 Opera 的用户纷纷转投谷歌浏览器和其他浏览器,造成了众多的用户流失。时至今日现在还有上千万人在使用老版本的 Opera。
很多人都认为 Opera 浏览器终止在了 12.17,此后所更新的 Opera 版本号不再是原来那个 Opera。
移动端的浏览器内核主要说的是系统内置浏览器的内核。
目前移动设备浏览器上常用的内核有 Webkit,Blink,Trident,Gecko 等,其中 iPhone 和 iPad 等苹果 iOS 平台主要是 WebKit,Android 4.4 之前的 Android 系统浏览器内核是 WebKit,Android4.4 系统浏览器切换到了Chromium,内核是 Webkit 的分支 Blink,Windows Phone 8 系统浏览器内核是 Trident。
—————————————————————————————————————————————
再谈谈javascript引擎(后面统称JS引擎)。我们上述的渲染引擎主要是负责HTML、CSS以及其他一些东西的渲染,而JS引擎则主要负责对javascript的渲染,一个JS引擎的好坏决定了一个浏览器对脚本的加载和执行速度,也影响了其跑分。
Firefox:
SpiderMonkey:第一款JavaScript引擎,由Brendan Eich在Netscape Communications时编写,用于Mozilla Firefox 1.0~3.0版本。
Rhino:由Mozilla基金会管理,开放源代码,完全以Java编写。
TraceMonkey:基于实时编译的引擎,其中部份代码取自Tamarin引擎,用于Mozilla Firefox 3.5~3.6版本。
JaegerMonkey:德文Jäger原意为猎人,结合追踪和组合码技术大幅提高性能,部分技术借凿了V8、JavaScriptCore、WebKit:用于Mozilla Firefox 4.0以上版本。
IonMonkey:可以对JavaScript编译后的结果进行优化,用于Mozilla Firefox 18.0以上版本。
OdinMonkey:可以对asm.js进行优化,用于Mozilla Firefox 22.0以上版本。
Chrome:
V8:开源,由Google丹麦开发,是Google Chrome的一部分。
注:我们上面提到Chrome是基于WebKit的分支,而WebKit又由渲染引擎“WebCore”和JS解释引擎“JSCore”组成,可能会让你搞不清V8和JSCore的关系。你可以这样理解——WebKit是一块主板,JSCore是一块可拆卸的内存条,谷歌实际上认为Webkit中的JSCore不够好,才自己搞了一个V8 JS引擎,这就是Chrome比Safari在某些JS测试中效率更高的原因。
IE:
Chakra:中文译名为查克拉,用于Internet Explorer 9的32位版本及IE10+。
Opera:
Linear A:用于Opera 4.0~6.1版本。
Linear B:用于Opera 7.0~9.2版本。
Futhark:用于Opera 9.5~10.2版本。
Carakan:由Opera软件公司编写,自Opera10.50版本开始使用。
其它:
KJS:KDE的ECMAScript/JavaScript引擎,最初由Harri Porten开发,用于KDE项目的Konqueror网页浏览器中。
Narcissus:开放源代码,由Brendan Eich编写(他也参与编写了第一个SpiderMonkey)。
Tamarin:由Adobe Labs编写,Flash Player 9所使用的引擎。
Nitro(原名SquirrelFish):为Safari 4编写。
原文地址:http://www.cnblogs.com/zichi/p/5116764.html
http://www.cnblogs.com/vajoy/p/3735553.html
前段时间学了点canvas,写了些代码。发现自己写的代码有些动画运行的时候会有卡顿,闪烁,掉帧这些现象,应该是我太菜了,所以上网找了找解决办法。然后发现了一篇文章,里面总结了一些提高canvas性能的方法,还是比较全面的,所以拿过来和大家分享。
原文地址:
如果你对canvas不了解或没兴趣不想看原文,那我下面就把文章中的方法简单提一下。希望对你在运用其他平台做动画的时候能有所启示。
1.预渲染
先把图像渲染在一个不可见的canvas上,再把不可见的canvas渲染到可见的canvas上。
2.用一个长的指令集载入将绘图状态机载入,然后再一次性的全部写入到video缓冲区。
例如,当需要画多条线时先创建一条包含所有线条的路经然后用一个draw调用将比分别单独地画每一条线条要高效的多。
3.减少操纵状态机
例如:为了渲染一副条纹的图案,你可以这样渲染:用一种颜色渲染一条线条,然后改变颜色,渲染下一条线条,如此反复;也可以先用一种颜色渲染所有的偶数线条再用另外一种染色渲染所有的奇数线条,而第一种方法会慢得多。
(总之减少调用canvasAPI)
4.尽量避免全屏重绘
重绘时如果只有少量的差异你可以通过仅仅重绘差异部分来获得显著的性能提升。
5.用叠在一起的多个canvas绘制
6.减少阴影效果
因为阴影效果相当耗费资源
7.用不同的方法清理canvas
原文中提到clearRect()和重置画布宽度两种方法,不过我查过之后发现重置画布宽度是为了避免不同的方法都调用同一个canvas时,只调用clearRect()之后,再次绘制会的出现偏移现象。不知道是什么意思。。。希望大神解释
8.避免浮点坐标
用Math.floor或者Math.round把浮点坐标转化成整数坐标。文中还提供了一个转化坐标的办法。
9.运用requestAnimationFrame API
据说这个才是动画的最佳循环,而不是setTimeout或setInterval。
最后,这篇文章很老了,可能有些方法不能用了。。。
我在上网查找怎么优化canvas性能的时候,有人说用双缓冲(一听就高大上是不是)来解决闪烁问题。原文是这么说的”创建一个临时canvas,先把下一帧动画绘制到临时canvas上。在每次真正绘制的时候,擦除正式canvas后,用drawImage把临时canvas的内容copy过去,而这个copy过程是非常非常高效的,所以基本可以杜绝闪烁。”是不是看起来很眼熟。。。跟上面的预渲染很像。。。后来,又发现一篇文章,作者表示canvas没有双缓冲这种东东。。。原文:”使用缓存也就是用离屏canvas进行预渲染了,原理很简单,就是先绘制到一个离屏canvas中,然后再通过drawImage把离屏canvas画到主canvas中。可能看到这很多人就会误解,这不是写游戏里面用的很多的双缓冲机制么?其实不然,双缓冲机制是游戏编程中为了防止画面闪烁,因此会有一个显示在用户面前的画布以及一个后台画布,进行绘制时会先将画面内容绘制到后台画布中,再将后台画布里的数据绘制到前台画布中。这就是双缓冲,但是canvas中是没有双缓冲的,因为现代浏览器基本上都是内置了双缓冲机制。所以,使用离屏canvas并不是双缓冲,而是把离屏canvas当成一个缓存区。把需要重复绘制的画面数据进行缓存起来,减少调用canvas的API的消耗。”好了,我也懵了。。。希望大神解释一下。不过可能名字不同,方法还是那样,凑合着用吧。
其实写一些小游戏的话,canvas还是挺好用的。有什么不足之处希望大神补充。
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.