本项目主要用于互联网电商企业中使用Spark技术开发的大数据统计分析平台,对电商网站的各种用户行为(访问行为、购物行为、广告点击行为等)进行复杂的分析。用统计分析出来的数据辅助公司中的PM(产品经理)、数据分析师以及管理人员分析现有产品的情况,并根据用户行为分析结果持续改进产品的设计,以及调整公司的战略和业务。最终达到用大数据技术来帮助提升公司的业绩、营业额以及市场占有率的目标。
项目主要采用Spark,使用了Spark技术生态栈中最常用的三个技术框架,Spark Core、Spark SQL和Spark Streaming,进行离线计算和实时计算业务模块的开发。实现了包括用户访问session分析、页面单跳转化率统计、热门商品离线统计、广告流量实时统计4个业务模块。
通过合理的将实际业务模块进行技术整合与改造,该项目完全涵盖了Spark Core、Spark SQL和Spark Streaming这三个技术框架中,几乎所有的功能点、知识点以及性能优化点!重点讲解了实际企业项目中积累下来的宝贵的性能调优、troubleshooting以及数据倾斜等知识和技术,涵盖了项目开发全流程,包括需求分析、方案设计、数据设计、编码实现、测试以及性能调优等环节,全面还原真实大数据项目的开发流程。
在访问电商网站时,我们的一些访问行为会产生相应的埋点日志(例如点击、搜索、下单、购买等),这些埋点日志会被发送给电商的后台服务器,大数据部门会根据这些埋点日志中的数据分析用户的访问行为,并得出一系列的统计指标,借助这些统计指标指导电商平台中的商品推荐、广告推送和网站优化等工作。
上报到服务器的埋点日志数据会经过数据采集、过滤、存储、分析、可视化这一完整流程,电商平台通过对海量用户行为数据的分析,可以对用户建立精准的用户画像,同时,对于用户行为的分析,也可以帮助电商网站找到网站的优化思路,从而在海量用户数据的基础上对网站进行改进和完善。
1、用户访问session分析:该模块主要是对用户访问session进行统计分析,包括session的聚合指标计算、按时间比例随机抽取session、获取每天点击、下单和购买排名前10的品类、并获取top10品类的点击量排名前10的session。该模块可以让产品经理、数据分析师以及企业管理层形象地看到各种条件下的具体用户行为以及统计指标,从而对公司的产品设计以及业务发展战略做出调整。主要使用Spark Core实现。
2、页面单跳转化率统计:该模块主要是计算关键页面之间的单步跳转转化率,涉及到页面切片算法以及页面流匹配算法。该模块可以让产品经理、数据分析师以及企业管理层看到各个关键页面之间的转化率,从而对网页布局,进行更好的优化设计。主要使用Spark Core实现。
3、热门商品离线统计:该模块主要实现每天统计出各个区域的top3热门商品。然后使用Oozie进行离线统计任务的定时调度;使用Zeppeline进行数据可视化的报表展示。该模块可以让企业管理层看到公司售卖的商品的整体情况,从而对公司的商品相关的战略进行调整。主要使用Spark SQL实现。
4、广告流量实时统计:该模块负责实时统计公司的广告流量,包括广告展现流量和广告点击流量。实现动态黑名单机制,以及黑名单过滤;实现滑动窗口内的各城市的广告展现流量和广告点击流量的统计;实现每个区域每个广告的点击流量实时统计;实现每个区域top3点击量的广告的统计。主要使用Spark Streaming实现。
1、CentOS 6.6
2、CDH 5.3.6
3、Spark
4、Hadoop
5、ZooKeeper
6、Kafka
7、Flume
8、Java 1.8(Scala 2.11)
9、IDEA
本课程的编码实现采用Java。
1、因为Java语言具有高度的稳定性,语法简洁,更容易理解。
2、最重要的一点是,Java并不只是一门编程语言,而是一个生态体系!使用Java开发复杂的大型Spark工程项目,可以让Spark与Redis、Memcaced、Kafka、Solr、MongoDB、HBase、MySQL等第三方技术进行整合使用,因为Java就是一个生态系统,这些第三方的技术无一例外,全部都会包含了Java的API,可以无缝与Spark项目进行整合使用。
3、Java是目前最主流的语言,绝大多数公司里都有一批Java工程师。使用Java开发Spark工程,在项目进行交接、迁移、维护、新人加入时,只要懂得Java的人,都能快速接手和上手Spark开发和项目。更利于项目的交接与维护。
对于Scala仅仅会在部分重要技术点的使用,比如自定义Accumulator、二次排序等,用Scala辅助讲解一下如何实现。
1、Scala的高级语法复杂,学习曲线非常陡峭,不利于学习,容易造成迷惑。
2、Scala仅仅只是一门编程语言,而没有达到技术生态的程度。当Spark要与第三方技术,比如Redis、HBase等配合使用时,就只能混合使用Java。此时就会造成一个项目两种语言混编,可维护性与可扩展性大幅度降低。
3、Scala目前远远没有达到普及的程度,会的人很少,在进行项目交接时,如果是Scala的项目,交接过程会很痛苦,甚至导致项目出现问题。
数据从哪里来?
互联网行业:网站、app、系统(交易系统。。)
传统行业:电信,人们的上网、打电话、发短信等等数据
数据源:网站、app都要往我们的后台去发送请求,获取数据,执行业务逻辑;app获取要展现的商品数据;发送请求到后台进行交易和结账
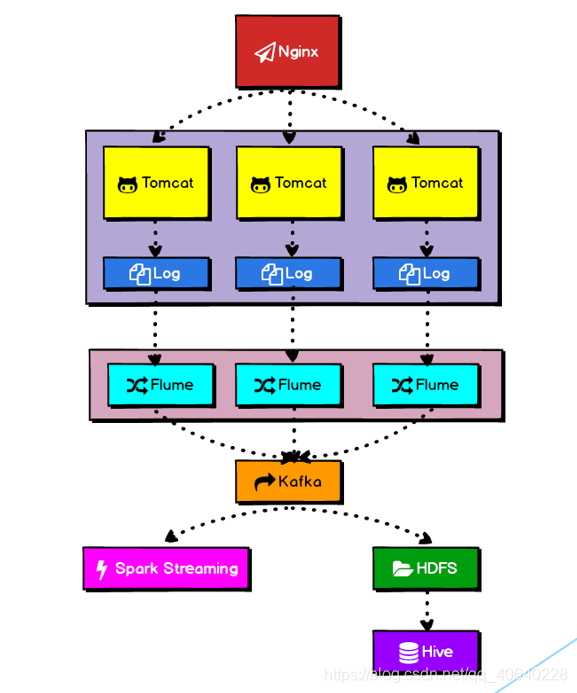
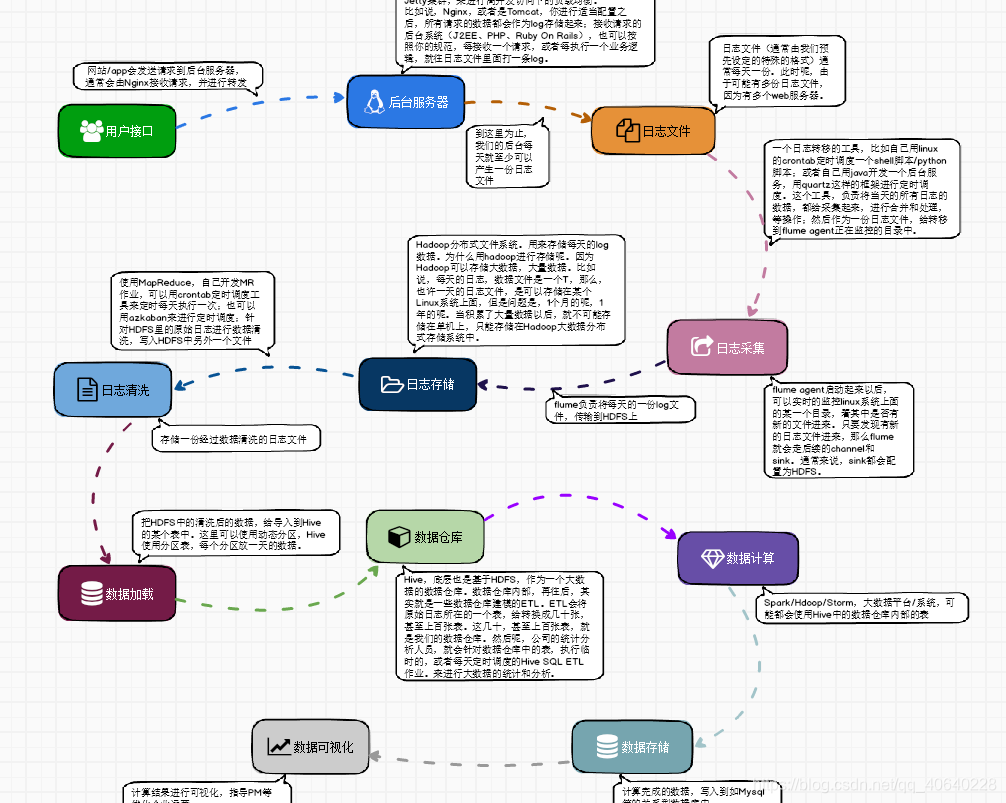
网站/app会发送请求到后台服务器,通常会由Nginx接收请求,并进行转发,在面向大量用户,高并发(每秒访问量过万)的情况下,通常都不会直接是用Tomcat来接收请求,这种时候通常都是用Nginx来接收请求,并且后端接入Tomcat集群/Jetty集群,来进行高并发访问下的负载均衡。Nginx或者Tomcat进行适当配置之后,所有请求的数据都会作为log存储起来;接收请求的后台系统(J2EE、PHP、Ruby On Rails),也可以按照你的规范,每接收一个请求,或者每执行一个业务逻辑,就往日志文件里面打一条log。日志文件(通常由我们预先设定的特殊的格式)通常每天一份,因为有多个web服务器,所以可能有多份日志文件。
可以通过一个日志转移工具,比如用linux的crontab定时调度一个shell脚本/python脚本,或者自己用java开发一个后台服务,用quartz这样的框架进行定时调度,负责将当天的所有日志的数据都给采集起来,进行合并和处理等操作,然后作为一份日志文件,给转移到flume agent正在监控的目录中,flume agent启动起来以后,可以实时的监控linux系统上面的某一个目录,看其中是否有新的文件进来。只要发现有新的日志文件进来,那么flume就会走后续的channel和sink。通常来说,sink都会配置为HDFS,flume负责将每天的一份log文件,传输到HDFS上,Hadoop HDFS中的原始的日志数据,会经过数据清洗。为什么要进行数据清洗?因为我们的数据中可能有很多是不符合预期的脏数据。, 把HDFS中的清洗后的数据,给导入到Hive的某个表中。这里可以使用动态分区,Hive使用分区表,每个分区放一天的数据。Spark/Hdoop/Storm,大数据平台/系统,可能都会使用Hive中的数据仓库内部的表。
实时数据,通常都是从分布式消息队列集群中读取的,比如Kafka;实时数据实时的写入到消息队列中,比如Kafka,然后由后端的实时数据处理程序(Storm、Spark Streaming),实时从Kafka中读取数据,log日志,然后进行实时的计算和处理。
如下是项目的日志采集架构:
如下是项目的数据处理流程:
如下是项目的部分需求图示:
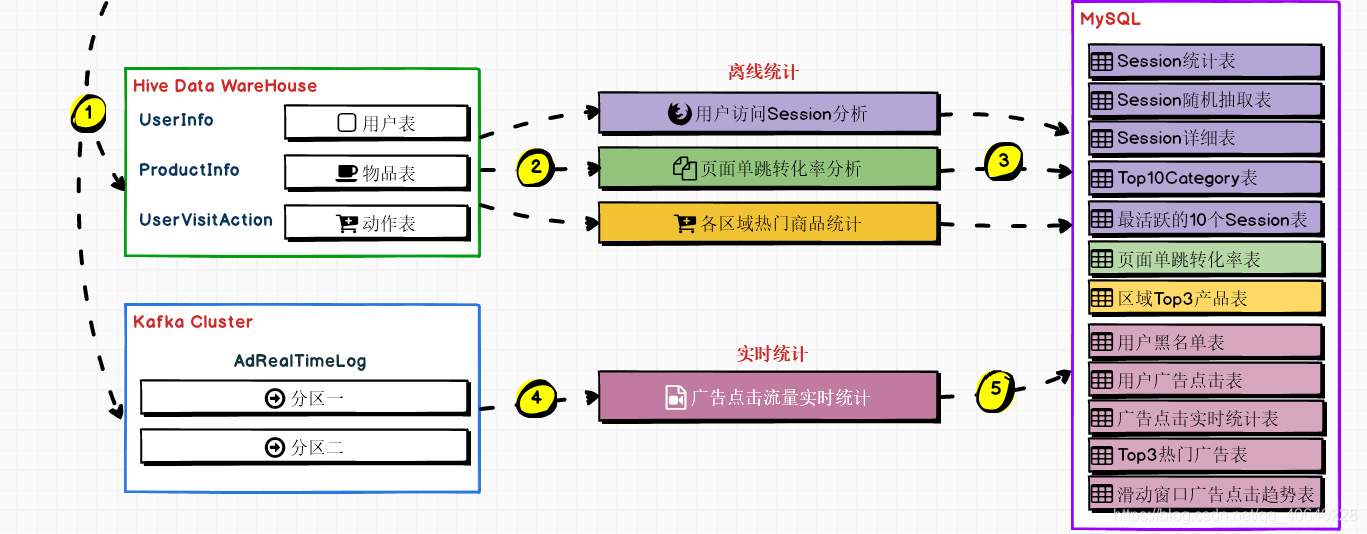
表名:user_visit_action(Hive表)
date:日期,代表这个用户点击行为是在哪一天发生的
user_id:代表这个点击行为是哪一个用户执行的
session_id :唯一标识了某个用户的一个访问session
page_id :点击了某些商品/品类,也可能是搜索了某个关键词,然后进入了某个页面,页面的id
action_time :这个点击行为发生的时间点
search_keyword :如果用户执行的是一个搜索行为,比如说在网站/app中,搜索了某个关键词,然后会跳转到商品列表页面;搜索的关键词
click_category_id :可能是在网站首页,点击了某个品类(美食、电子设备、电脑)
click_product_id :可能是在网站首页,或者是在商品列表页,点击了某个商品(比如呷哺呷哺火锅XX路店3人套餐、iphone 6s)
order_category_ids :代表了可能将某些商品加入了购物车,然后一次性对购物车中的商品下了一个订单,这就代表了某次下单的行为中,有哪些
商品品类,可能有6个商品,但是就对应了2个品类,比如有3根火腿肠(食品品类),3个电池(日用品品类)
order_product_ids :某次下单,具体对哪些商品下的订单
pay_category_ids :代表的是,对某个订单,或者某几个订单,进行了一次支付的行为,对应了哪些品类
pay_product_ids:代表的,支付行为下,对应的哪些具体的商品
user_visit_action表其实就是放每天的点击流的数据。
表名:user_info(Hive表)
user_id:其实就是每一个用户的唯一标识,通常是自增长的Long类型,BigInt类型
username:是每个用户的登录名
name:每个用户自己的昵称、或者是真实姓名
age:用户的年龄
professional:用户的职业
city:用户所在的城市
user_info表,实际上,就是一张最普通的用户基础信息表;这张表里面放置了网站/app所有的注册用户的信息。
表名:task(MySQL表)
task_id:表的主键
task_name:任务名称
create_time:创建时间
start_time:开始运行的时间
finish_time:结束运行的时间
task_type:任务类型,就是说,在一套大数据平台中,肯定会有各种不同类型的统计分析任务,比如说用户访问session分析任务,页面单跳转化率统计任务;所以这个字段就标识了每个任务的类型
task_status:任务状态,任务对应的就是一次Spark作业的运行,这里就标识了,Spark作业是新建,还没运行,还是正在运行,还是已经运行完毕
task_param:最最重要,用来使用JSON的格式,来封装用户提交的任务对应的特殊的筛选参数
task表,其实是用来保存平台的使用者,通过J2EE系统,提交的基于特定筛选参数的分析任务的信息,就会通过J2EE系统保存到task表中来。之所以使用MySQL表,是因为J2EE系统是要实现快速的实时插入和查询的。
用户访问session介绍:
用户在电商网站上,通常会有很多的点击行为,首页通常都是进入首页;然后可能点击首页上的一些商品;点击首页上的一些品类;也可能随时在搜索框里面搜索关键词;还可能将一些商品加入购物车;对购物车中的多个商品下订单;最后对订单中的多个商品进行支付。
用户的每一次操作,其实可以理解为一个action,比如点击、搜索、下单、支付,用户session,指的就是,从用户第一次进入首页,session就开始了。然后在一定时间范围内,直到最后操作完(可能做了几十次、甚至上百次操作)。离开网站,关闭浏览器,或者长时间没有做操作;那么session就结束了。以上用户在网站内的访问过程,就称之为一次session。简单理解,session就是某一天某一个时间段内,某个用户对网站从打开/进入,到做了大量操作到最后关闭浏览器的过程就叫做session。session实际上就是一个电商网站中最基本的数据,面向C端也就是customer--消费者,用户端的分析基本是最基本的就是面向用户访问行为/用户访问session。
在实际企业项目中的使用架构:
1、J2EE的平台(美观的前端页面),通过这个J2EE平台可以让使用者,提交各种各样的分析任务,其中就包括一个模块,就是用户访问session分析模块;可以指定各种各样的筛选条件,比如年龄范围、职业、城市等等。
2、J2EE平台接收到了执行统计分析任务的请求之后,会调用底层的封装了spark-submit的shell脚本(Runtime、Process),shell脚本进而提交我们编写的Spark作业。
3、Spark作业获取使用者指定的筛选参数,然后运行复杂的作业逻辑,进行该模块的统计和分析。
4、Spark作业统计和分析的结果,会写入MySQL中,指定的表
5、最后,J2EE平台,使用者可以通过前端页面(美观),以表格、图表的形式展示和查看MySQL中存储的该统计分析任务的结果数据。
模块的目标:对用户访问session进行分析
1、可以根据使用者指定的某些条件,筛选出指定的一些用户(有特定年龄、职业、城市);
2、对这些用户在指定日期范围内发起的session,进行聚合统计,比如,统计出访问时长在0~3s的session占总session数量的比例;
3、按时间比例,比如一天有24个小时,其中12:00 -- 13:00的session数量占当天总session数量的50%,当天总session数量是10000个,那么当天总共要抽取1000个session,12:00 -- 13:00的用户,就得抽取1000*50%=500。而且这500个需要随机抽取。
4、获取点击量、下单量和支付量都排名10的商品种类
5、获取top10的商品种类的点击数量排名前10的session
6、开发完毕了以上功能之后,需要进行大量、复杂、高端、全套的性能调优(大部分性能调优点,都是本人在实际开发过程中积累的经验,基本都是全网唯一)
7、十亿级数据量的troubleshooting(故障解决)的经验总结
8、数据倾斜的完美解决方案(全网唯一,非常高端,因为数据倾斜往往是大数据处理程序的性能杀手,很多人在遇到的时候,往往没有思路)
9、使用mock(模拟)的数据,对模块进行调试、运行和演示效果
需求分析
1、按条件筛选session
2、统计出符合条件的session中,访问时长在1s3s、4s6s、7s9s、10s30s、30s60s、1m3m、3m10m、10m30m、30m以上各个范围内的session占比;访问步长在13、46、79、1030、30~60、60以上各个范围内的session占比
3、在符合条件的session中,按照时间比例随机抽取1000个session
4、在符合条件的session中,获取点击、下单和支付数量排名前10的品类
5、对于排名前10的品类,分别获取其点击次数排名前10的session
1、按条件筛选session,搜索过某些关键词的用户、访问时间在某个时间段内的用户、年龄在某个范围内的用户、职业在某个范围内的用户、所在某个城市的用户,发起的session。找到对应的这些用户的session,也就是我们所说的第一步,按条件筛选session。
这个功能,就最大的作用就是灵活。也就是说,可以让使用者,对感兴趣的和关系的用户群体,进行后续各种复杂业务逻辑的统计和分析,那么拿到的结果数据,就是只是针对特殊用户群体的分析结果;而不是对所有用户进行分析的泛泛的分析结果。比如说,现在某个企业高层,就是想看到用户群体中,28~35岁的,老师职业的群体,对应的一些统计和分析的结果数据,从而辅助高管进行公司战略上的决策制定。
2、统计出符合条件的session中,访问时长在1s3s、4s6s、7s9s、10s30s、30s60s、1m3m、3m10m、10m30m、30m以上各个范围内的session占比;访问步长在13、46、79、1030、30~60、60以上各个范围内的session占比
session访问时长,也就是说一个session对应的开始的action,到结束的action,之间的时间范围;还有,就是访问步长,指的是,一个session执行期间内,依次点击过多少个页面,比如说,一次session,维持了1分钟,那么访问时长就是1m,然后在这1分钟内,点击了10个页面,那么session的访问步长,就是10,比如说,符合第一步筛选出来的session的数量大概是有1000万个。那么里面,我们要计算出,访问时长在1s3s内的session的数量,并除以符合条件的总session数量(比如1000万),比如是100万/1000万,那么1s3s内的session占比就是10%。依次类推,这里说的统计,就是这个意思。这个功能的作用,其实就是,可以让人从全局的角度看到,符合某些条件的用户群体,使用我们的产品的一些习惯。比如大多数人,到底是会在产品中停留多长时间,大多数人,会在一次使用产品的过程中,访问多少个页面。那么对于使用者来说,有一个全局和清晰的认识。
3、在符合条件的session中,按照时间比例随机抽取1000个session,这个按照时间比例是什么意思呢?随机抽取本身是很简单的,但是按照时间比例,就很复杂了。比如说,这一天总共有1000万的session。那么我现在总共要从这1000万session中,随机抽取出来1000个session。但是这个随机不是那么简单的。需要做到如下几点要求:首先,如果这一天的12:00~13:00的session数量是100万,那么这个小时的session占比就是1/10,那么这个小时中的100万的session,我们就要抽取1/10 * 1000 = 100个。然后再从这个小时的100万session中,随机抽取出100个session。以此类推,其他小时的抽取也是这样做。这个功能的作用,是说,可以让使用者,能够对于符合条件的session,按照时间比例均匀的随机采样出1000个session,然后观察每个session具体的点击流/行为,比如先进入了首页、然后点击了食品品类、然后点击了雨润火腿肠商品、然后搜索了火腿肠罐头的关键词、接着对王中王火腿肠下了订单、最后对订单做了支付。之所以要做到按时间比例随机采用抽取,就是要做到,观察样本的公平性。
4、在符合条件的session中,获取点击、下单和支付数量排名前10的品类,什么意思呢,对于这些session,每个session可能都会对一些品类的商品进行点击、下单和支付等等行为。那么现在就需要获取这些session点击、下单和支付数量排名前10的最热门的品类。也就是说,要计算出所有这些session对各个品类的点击、下单和支付的次数,然后按照这三个属性进行排序,获取前10个品类。这个功能,很重要,就可以让我们明白,就是符合条件的用户,他们最感兴趣的商品是什么种类。这个可以让公司里的人,清晰地了解到不同层次、不同类型的用户的心理和喜好。
5、对于排名前10的品类,分别获取其点击次数排名前10的session,这个就是说,对于top10的品类,每一个都要获取对它点击次数排名前10的session,这个功能,可以让我们看到,对某个用户群体最感兴趣的品类,各个品类最感兴趣最典型的用户的session的行为。
技术方案设计
1、按条件筛选session,这里首先提出第一个问题,你要按条件筛选session,但是这个筛选的粒度是不同的,比如说搜索词、访问时间,那么这个都是session粒度的,甚至是action粒度的;那么还有,就是针对用户的基础信息进行筛选,年龄、性别、职业;所以说筛选粒度是不统一的。
第二个问题,就是说,我们的每天的用户访问数据量是很大的,因为user_visit_action这个表,一行就代表了用户的一个行为,比如点击或者搜索;那么在国内一个大的电商企业里面,如果每天的活跃用户数量在千万级别的话。那么可以告诉大家,这个user_visit_action表,每天的数据量大概在至少5亿以上,在10亿左右。
那么针对这个筛选粒度不统一的问题,以及数据量巨大(10亿/day),可能会有两个问题;首先第一个,就是,如果不统一筛选粒度的话,那么就必须得对所有的数据进行全量的扫描;第二个,就是全量扫描的话,量实在太大了,一天如果在10亿左右,那么10天呢(100亿),100呢,1000亿。量太大的话,会导致Spark作业的运行速度大幅度降低。极大的影响平台使用者的用户体验。
所以为了解决这个问题,那么我们选择在这里,对原始的数据,进行聚合,什么粒度的聚合呢?session粒度的聚合。也就是说,用一些最基本的筛选条件,比如时间范围,从hive表中提取数据,然后呢,按照session_id这个字段进行聚合,那么聚合后的一条记录,就是一个用户的某个session在指定时间内的访问的记录,比如搜索过的所有的关键词、点击过的所有的品类id、session对应的userid关联的用户的基础信息。
聚合过后,针对session粒度的数据,按照使用者指定的筛选条件,进行数据的筛选。筛选出来符合条件的用session粒度的数据。其实就是我们想要的那些session了。
2、聚合统计
如果要做这个事情,那么首先要明确,我们的spark作业是分布式的。所以也就是说,每个spark task在执行我们的统计逻辑的时候,可能就需要对一个全局的变量,进行累加操作。比如代表访问时长在1s3s的session数量,初始是0,然后呢分布式处理所有的session,判断每个session的访问时长,如果是1s3s内的话,那么就给1s~3s内的session计数器,累加1。
那么在spark中,要实现分布式安全的累加操作,基本上只有一个最好的选择,就是Accumulator变量。但是,问题又来了,如果是基础的Accumulator变量,那么可能需要将近20个Accumulator变量,1s3s、4s6s。。。。;但是这样的话,就会导致代码中充斥了大量的Accumulator变量,导致维护变得更加复杂,在修改代码的时候,很可能会导致错误。比如说判断出一个session访问时长在4s6s,但是代码中不小心写了一个bug(由于Accumulator太多了),比如说,更新了1s3s的范围的Accumulator变量。导致统计出错。
所以,对于这个情况,那么我们就可以使用自定义Accumulator的技术,来实现复杂的分布式计算。也就是说,就用一个Accumulator,来计算所有的指标。
3、在符合条件的session中,按照时间比例随机抽取1000个session
这个呢,需求上已经明确了。那么剩下的就是具体的实现了。具体的实现这里不多说,技术上来说,就是要综合运用Spark的countByKey、groupByKey、mapToPair等算子,来开发一个复杂的按时间比例随机均匀采样抽取的算法。(大数据算法)
4、在符合条件的session中,获取点击、下单和支付数量排名前10的品类
这里的话呢,需要对每个品类的点击、下单和支付的数量都进行计算。然后呢,使用Spark的自定义Key二次排序算法的技术,来实现所有品类,按照三个字段,点击数量、下单数量、支付数量依次进行排序,首先比较点击数量,如果相同的话,那么比较下单数量,如果还是相同,那么比较支付数量。
5、对于排名前10的品类,分别获取其点击次数排名前10的session
这个需求,需要使用Spark的分组取TopN的算法来进行实现。也就是说对排名前10的品类对应的数据,按照品类id进行分组,然后求出每组点击数量排名前10的session。
最后总结一下,通过学习这个模块,通过业务功能的开发,还不说性能调优、troubleshooting、数据倾斜方面的东西。仅仅是业务功能的开发,可以掌握到的技术点:
1、通过底层数据聚合,来减少spark作业处理数据量,从而提升spark作业的性能(从根本上提升spark性能的技巧)
2、自定义Accumulator实现复杂分布式计算的技术
3、Spark按时间比例随机抽取算法
4、Spark自定义key二次排序技术
5、Spark分组取TopN算法
6、通过Spark的各种功能和技术点,进行各种聚合、采样、排序、取TopN业务的实现

