yygmind / blog Goto Github PK
View Code? Open in Web Editor NEW我是木易杨,公众号「高级前端进阶」作者,跟着我每周重点攻克一个前端面试重难点。接下来让我带你走进高级前端的世界,在进阶的路上,共勉!
Home Page: https://muyiy.cn/blog/
我是木易杨,公众号「高级前端进阶」作者,跟着我每周重点攻克一个前端面试重难点。接下来让我带你走进高级前端的世界,在进阶的路上,共勉!
Home Page: https://muyiy.cn/blog/









































































































































































































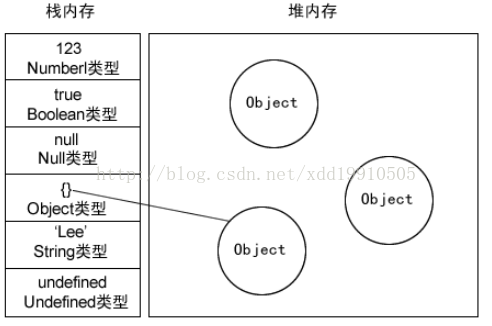
JavaScript深入之内存空间详细图解
https://muyiy.cn/blog/1/1.3.html#%E6%A0%88%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84
会导致内存溢出吧。
1、jsonp
2、CORS
对变量对象和激活对象这个有点不明白 这两个是不是ES3的概念呢 在ES5中通过 VariableEnvironment
LexicalEnvironment 这个些概念来表达了
Originally posted by @icantunderstand in #13 (comment)
本期的主题是调用堆栈,本计划一共28期,每期重点攻克一个面试重难点,如果你还不了解本进阶计划,文末点击查看全部文章。
如果觉得本系列不错,欢迎点赞、评论、转发,您的支持就是我坚持的最大动力。
JS内存空间分为栈(stack)、堆(heap)、池(一般也会归类为栈中)。 其中栈存放变量,堆存放复杂对象,池存放常量,所以也叫常量池。
昨天文章介绍了堆和栈,小结一下:
栈内存(不包含闭包中的变量)堆内存今日补充一个知识点,就是闭包中的变量并不保存中栈内存中,而是保存在堆内存中,这也就解释了函数之后之后为什么闭包还能引用到函数内的变量。
function A() {
let a = 1
function B() {
console.log(a)
}
return B
}闭包的简单定义是:函数 A 返回了一个函数 B,并且函数 B 中使用了函数 A 的变量,函数 B 就被称为闭包。
函数 A 弹出调用栈后,函数 A 中的变量这时候是存储在堆上的,所以函数B依旧能引用到函数A中的变量。现在的 JS 引擎可以通过逃逸分析辨别出哪些变量需要存储在堆上,哪些需要存储在栈上。
闭包的介绍点到为止,【进阶2期】 作用域闭包会详细介绍,敬请期待。
今天文章的重点是内存回收和内存泄漏。
JavaScript有自动垃圾收集机制,垃圾收集器会每隔一段时间就执行一次释放操作,找出那些不再继续使用的值,然后释放其占用的内存。
对垃圾回收算法来说,核心**就是如何判断内存已经不再使用,常用垃圾回收算法有下面两种。
引用计数算法定义“内存不再使用”的标准很简单,就是看一个对象是否有指向它的引用。如果没有其他对象指向它了,说明该对象已经不再需要了。
// 创建一个对象person,他有两个指向属性age和name的引用
var person = {
age: 12,
name: 'aaaa'
};
person.name = null; // 虽然name设置为null,但因为person对象还有指向name的引用,因此name不会回收
var p = person;
person = 1; //原来的person对象被赋值为1,但因为有新引用p指向原person对象,因此它不会被回收
p = null; //原person对象已经没有引用,很快会被回收引用计数有一个致命的问题,那就是循环引用
如果两个对象相互引用,尽管他们已不再使用,但是垃圾回收器不会进行回收,最终可能会导致内存泄露。
function cycle() {
var o1 = {};
var o2 = {};
o1.a = o2;
o2.a = o1;
return "cycle reference!"
}
cycle();cycle函数执行完成之后,对象o1和o2实际上已经不再需要了,但根据引用计数的原则,他们之间的相互引用依然存在,因此这部分内存不会被回收。所以现代浏览器不再使用这个算法。
但是IE依旧使用。
var div = document.createElement("div");
div.onclick = function() {
console.log("click");
};上面的写法很常见,但是上面的例子就是一个循环引用。
变量div有事件处理函数的引用,同时事件处理函数也有div的引用,因为div变量可在函数内被访问,所以循环引用就出现了。
标记清除算法将“不再使用的对象”定义为“无法到达的对象”。即从根部(在JS中就是全局对象)出发定时扫描内存中的对象,凡是能从根部到达的对象,保留。那些从根部出发无法触及到的对象被标记为不再使用,稍后进行回收。
无法触及的对象包含了没有引用的对象这个概念,但反之未必成立。
所以上面的例子就可以正确被垃圾回收处理了。
所以现在对于主流浏览器来说,只需要切断需要回收的对象与根部的联系。最常见的内存泄露一般都与DOM元素绑定有关:
email.message = document.createElement(“div”);
displayList.appendChild(email.message);
// 稍后从displayList中清除DOM元素
displayList.removeAllChildren();上面代码中,div元素已经从DOM树中清除,但是该div元素还绑定在email对象中,所以如果email对象存在,那么该div元素就会一直保存在内存中。
对于持续运行的服务进程(daemon),必须及时释放不再用到的内存。否则,内存占用越来越高,轻则影响系统性能,重则导致进程崩溃。 对于不再用到的内存,没有及时释放,就叫做内存泄漏(memory leak)
使用 Node 提供的 process.memoryUsage 方法。
console.log(process.memoryUsage());
// 输出
{
rss: 27709440, // resident set size,所有内存占用,包括指令区和堆栈
heapTotal: 5685248, // "堆"占用的内存,包括用到的和没用到的
heapUsed: 3449392, // 用到的堆的部分
external: 8772 // V8 引擎内部的 C++ 对象占用的内存
}判断内存泄漏,以heapUsed字段为准。
详细的JS内存分析将在【进阶20期】性能优化详细介绍,敬请期待。
ES6 新出的两种数据结构:WeakSet 和 WeakMap,表示这是弱引用,它们对于值的引用都是不计入垃圾回收机制的。
const wm = new WeakMap();
const element = document.getElementById('example');
wm.set(element, 'some information');
wm.get(element) // "some information"先新建一个 Weakmap 实例,然后将一个 DOM 节点作为键名存入该实例,并将一些附加信息作为键值,一起存放在 WeakMap 里面。这时,WeakMap 里面对element的引用就是弱引用,不会被计入垃圾回收机制。
昨天文章留了一道思考题,群里讨论很热烈,大家应该都知道原理了,现在来简单解答下。
var a = {n: 1};
var b = a;
a.x = a = {n: 2};
a.x // --> undefined
b.x // --> {n: 2}
答案已经写上面了,这道题的关键在于
.的优先级高于=,所以先执行a.x,堆内存中的{n: 1}就会变成{n: 1, x: undefined},改变之后相应的b.x也变化了,因为指向的是同一个对象。从右到左,所以先执行a = {n: 2},a的引用就被改变了,然后这个返回值又赋值给了a.x,需要注意的是这时候a.x是第一步中的{n: 1, x: undefined}那个对象,其实就是b.x,相当于b.x = {n: 2}问题一:
从内存来看 null 和 undefined 本质的区别是什么?
问题二:
ES6语法中的 const 声明一个只读的常量,那为什么下面可以修改const的值?
const foo = {};
foo = {}; // TypeError: "foo" is read-only
foo.prop = 123;
foo.prop // 123问题三:
哪些情况下容易产生内存泄漏?
进阶系列文章汇总:https://github.com/yygmind/blog,内有优质前端资料,欢迎领取,觉得不错点个star。
我是木易杨,网易高级前端工程师,跟着我每周重点攻克一个前端面试重难点。接下来让我带你走进高级前端的世界,在进阶的路上,共勉!

bind()方法会创建一个新函数,当这个新函数被调用时,它的this值是传递给bind()的第一个参数,传入bind方法的第二个以及以后的参数加上绑定函数运行时本身的参数按照顺序作为原函数的参数来调用原函数。bind返回的绑定函数也能使用new操作符创建对象:这种行为就像把原函数当成构造器,提供的this值被忽略,同时调用时的参数被提供给模拟函数。(来自参考1)
语法:fun.bind(thisArg[, arg1[, arg2[, ...]]])
bind 方法与 call / apply 最大的不同就是前者返回一个绑定上下文的函数,而后两者是直接执行了函数。
来个例子说明下
var value = 2;
var foo = {
value: 1
};
function bar(name, age) {
return {
value: this.value,
name: name,
age: age
}
};
bar.call(foo, "Jack", 20); // 直接执行了函数
// {value: 1, name: "Jack", age: 20}
var bindFoo1 = bar.bind(foo, "Jack", 20); // 返回一个函数
bindFoo1();
// {value: 1, name: "Jack", age: 20}
var bindFoo2 = bar.bind(foo, "Jack"); // 返回一个函数
bindFoo2(20);
// {value: 1, name: "Jack", age: 20}通过上述代码可以看出bind 有如下特性:
this经常有如下的业务场景
var nickname = "Kitty";
function Person(name){
this.nickname = name;
this.distractedGreeting = function() {
setTimeout(function(){
console.log("Hello, my name is " + this.nickname);
}, 500);
}
}
var person = new Person('jawil');
person.distractedGreeting();
//Hello, my name is Kitty这里输出的nickname是全局的,并不是我们创建 person 时传入的参数,因为 setTimeout 在全局环境中执行(不理解的查看【进阶3-1期】),所以 this 指向的是window。
这边把 setTimeout 换成异步回调也是一样的,比如接口请求回调。
解决方案有下面两种。
解决方案1:缓存 this值
var nickname = "Kitty";
function Person(name){
this.nickname = name;
this.distractedGreeting = function() {
var self = this; // added
setTimeout(function(){
console.log("Hello, my name is " + self.nickname); // changed
}, 500);
}
}
var person = new Person('jawil');
person.distractedGreeting();
// Hello, my name is jawil解决方案2:使用 bind
var nickname = "Kitty";
function Person(name){
this.nickname = name;
this.distractedGreeting = function() {
setTimeout(function(){
console.log("Hello, my name is " + this.nickname);
}.bind(this), 500);
}
}
var person = new Person('jawil');
person.distractedGreeting();
// Hello, my name is jawil完美!
【进阶3-3期】介绍了 call 的使用场景,这里重新回顾下。
function isArray(obj){
return Object.prototype.toString.call(obj) === '[object Array]';
}
isArray([1, 2, 3]);
// true
// 直接使用 toString()
[1, 2, 3].toString(); // "1,2,3"
"123".toString(); // "123"
123.toString(); // SyntaxError: Invalid or unexpected token
Number(123).toString(); // "123"
Object(123).toString(); // "123"可以通过toString() 来获取每个对象的类型,但是不同对象的 toString()有不同的实现,所以通过 Object.prototype.toString() 来检测,需要以 call() / apply() 的形式来调用,传递要检查的对象作为第一个参数。
另一个验证是否是数组的方法,这个方案的优点是可以直接使用改造后的 toStr。
var toStr = Function.prototype.call.bind(Object.prototype.toString);
function isArray(obj){
return toStr(obj) === '[object Array]';
}
isArray([1, 2, 3]);
// true
// 使用改造后的 toStr
toStr([1, 2, 3]); // "[object Array]"
toStr("123"); // "[object String]"
toStr(123); // "[object Number]"
toStr(Object(123)); // "[object Number]"上面方法首先使用 Function.prototype.call函数指定一个 this 值,然后 .bind 返回一个新的函数,始终将 Object.prototype.toString 设置为传入参数。其实等价于 Object.prototype.toString.call() 。
这里有一个前提是toString()方法没有被覆盖
Object.prototype.toString = function() {
return '';
}
isArray([1, 2, 3]);
// false只传递给函数一部分参数来调用它,让它返回一个函数去处理剩下的参数。
可以一次性地调用柯里化函数,也可以每次只传一个参数分多次调用。
var add = function(x) {
return function(y) {
return x + y;
};
};
var increment = add(1);
var addTen = add(10);
increment(2);
// 3
addTen(2);
// 12
add(1)(2);
// 3这里定义了一个 add 函数,它接受一个参数并返回一个新的函数。调用 add 之后,返回的函数就通过闭包的方式记住了 add 的第一个参数。所以说 bind 本身也是闭包的一种使用场景。
bind() 函数在 ES5 才被加入,所以并不是所有浏览器都支持,IE8及以下的版本中不被支持,如果需要兼容可以使用 Polyfill 来实现。
首先我们来实现以下四点特性:
this对于第 1 点,使用 call / apply 指定 this 。
对于第 2 点,使用 return 返回一个函数。
结合前面 2 点,可以写出第一版,代码如下:
// 第一版
Function.prototype.bind2 = function(context) {
var self = this; // this 指向调用者
return function () { // 实现第 2点
return self.apply(context); // 实现第 1 点
}
}测试一下
// 测试用例
var value = 2;
var foo = {
value: 1
};
function bar() {
return this.value;
}
var bindFoo = bar.bind2(foo);
bindFoo(); // 1对于第 3 点,使用 arguments 获取参数数组并作为 self.apply() 的第二个参数。
对于第 4 点,获取返回函数的参数,然后同第3点的参数合并成一个参数数组,并作为 self.apply() 的第二个参数。
// 第二版
Function.prototype.bind2 = function (context) {
var self = this;
// 实现第3点,因为第1个参数是指定的this,所以只截取第1个之后的参数
// arr.slice(begin); 即 [begin, end]
var args = Array.prototype.slice.call(arguments, 1);
return function () {
// 实现第4点,这时的arguments是指bind返回的函数传入的参数
// 即 return function 的参数
var bindArgs = Array.prototype.slice.call(arguments);
return self.apply( context, args.concat(bindArgs) );
}
}测试一下:
// 测试用例
var value = 2;
var foo = {
value: 1
};
function bar(name, age) {
return {
value: this.value,
name: name,
age: age
}
};
var bindFoo = bar.bind2(foo, "Jack");
bindFoo(20);
// {value: 1, name: "Jack", age: 20}到现在已经完成大部分了,但是还有一个难点,bind 有以下一个特性
一个绑定函数也能使用new操作符创建对象:这种行为就像把原函数当成构造器,提供的 this 值被忽略,同时调用时的参数被提供给模拟函数。
来个例子说明下:
var value = 2;
var foo = {
value: 1
};
function bar(name, age) {
this.habit = 'shopping';
console.log(this.value);
console.log(name);
console.log(age);
}
bar.prototype.friend = 'kevin';
var bindFoo = bar.bind(foo, 'Jack');
var obj = new bindFoo(20);
// undefined
// Jack
// 20
obj.habit;
// shopping
obj.friend;
// kevin上面例子中,运行结果this.value 输出为 undefined,这不是全局value 也不是foo对象中的value,这说明 bind 的 this 对象失效了,new 的实现中生成一个新的对象,这个时候的 this指向的是 obj。(【进阶3-1期】有介绍new的实现原理,下一期也会重点介绍)
这里可以通过修改返回函数的原型来实现,代码如下:
// 第三版
Function.prototype.bind2 = function (context) {
var self = this;
var args = Array.prototype.slice.call(arguments, 1);
var fBound = function () {
var bindArgs = Array.prototype.slice.call(arguments);
// 注释1
return self.apply(
this instanceof fBound ? this : context,
args.concat(bindArgs)
);
}
// 注释2
fBound.prototype = this.prototype;
return fBound;
}this instanceof fBound 结果为 true,可以让实例获得来自绑定函数的值,即上例中实例会具有 habit 属性。window,此时结果为 false,将绑定函数的 this 指向 contextprototype 为绑定函数的 prototype,实例就可以继承绑定函数的原型中的值,即上例中 obj 可以获取到 bar 原型上的 friend。注意:这边涉及到了原型、原型链和继承的知识点,可以看下我之前的文章。
上面实现中 fBound.prototype = this.prototype有一个缺点,直接修改 fBound.prototype 的时候,也会直接修改 this.prototype。
来个代码测试下:
// 测试用例
var value = 2;
var foo = {
value: 1
};
function bar(name, age) {
this.habit = 'shopping';
console.log(this.value);
console.log(name);
console.log(age);
}
bar.prototype.friend = 'kevin';
var bindFoo = bar.bind2(foo, 'Jack'); // bind2
var obj = new bindFoo(20); // 返回正确
// undefined
// Jack
// 20
obj.habit; // 返回正确
// shopping
obj.friend; // 返回正确
// kevin
obj.__proto__.friend = "Kitty"; // 修改原型
bar.prototype.friend; // 返回错误,这里被修改了
// Kitty解决方案是用一个空对象作为中介,把 fBound.prototype 赋值为空对象的实例(原型式继承)。
var fNOP = function () {}; // 创建一个空对象
fNOP.prototype = this.prototype; // 空对象的原型指向绑定函数的原型
fBound.prototype = new fNOP(); // 空对象的实例赋值给 fBound.prototype这边可以直接使用ES5的 Object.create()方法生成一个新对象
fBound.prototype = Object.create(this.prototype);不过 bind 和 Object.create()都是ES5方法,部分IE浏览器(IE < 9)并不支持,Polyfill中不能用 Object.create()实现 bind,不过原理是一样的。
第四版目前OK啦,代码如下:
// 第四版,已通过测试用例
Function.prototype.bind2 = function (context) {
var self = this;
var args = Array.prototype.slice.call(arguments, 1);
var fNOP = function () {};
var fBound = function () {
var bindArgs = Array.prototype.slice.call(arguments);
return self.apply(
this instanceof fNOP ? this : context,
args.concat(bindArgs)
);
}
fNOP.prototype = this.prototype;
fBound.prototype = new fNOP();
return fBound;
}到这里其实已经差不多了,但有一个问题是调用 bind 的不是函数,这时候需要抛出异常。
if (typeof this !== "function") {
throw new Error("Function.prototype.bind - what is trying to be bound is not callable");
}所以完整版模拟实现代码如下:
// 第五版
Function.prototype.bind2 = function (context) {
if (typeof this !== "function") {
throw new Error("Function.prototype.bind - what is trying to be bound is not callable");
}
var self = this;
var args = Array.prototype.slice.call(arguments, 1);
var fNOP = function () {};
var fBound = function () {
var bindArgs = Array.prototype.slice.call(arguments);
return self.apply(this instanceof fNOP ? this : context, args.concat(bindArgs));
}
fNOP.prototype = this.prototype;
fBound.prototype = new fNOP();
return fBound;
}// 1、赋值语句是右执行的,此时会先执行右侧的对象
var obj = {
// 2、say 是立即执行函数
say: function() {
function _say() {
// 5、输出 window
console.log(this);
}
// 3、编译阶段 obj 赋值为 undefined
console.log(obj);
// 4、obj是 undefined,bind 本身是 call实现,
// 【进阶3-3期】:call 接收 undefined 会绑定到 window。
return _say.bind(obj);
}(),
};
obj.say();call 的模拟实现如下,那有没有什么问题呢?
Function.prototype.call = function (context) {
context = context ? Object(context) : window;
context.fn = this;
var args = [];
for(var i = 1, len = arguments.length; i < len; i++) {
args.push('arguments[' + i + ']');
}
var result = eval('context.fn(' + args +')');
delete context.fn;
return result;
}当然是有问题的,其实这里假设 context 对象本身没有 fn 属性,这样肯定不行,我们必须保证 fn属性的唯一性。
解决方法也很简单,首先判断 context中是否存在属性 fn,如果存在那就随机生成一个属性fnxx,然后循环查询 context 对象中是否存在属性 fnxx。如果不存在则返回最终值。
一种循环方案实现代码如下:
function fnFactory(context) {
var unique_fn = "fn";
while (context.hasOwnProperty(unique_fn)) {
unique_fn = "fn" + Math.random(); // 循环判断并重新赋值
}
return unique_fn;
}一种递归方案实现代码如下:
function fnFactory(context) {
var unique_fn = "fn" + Math.random();
if(context.hasOwnProperty(unique_fn)) {
// return arguments.callee(context); ES5 开始禁止使用
return fnFactory(context); // 必须 return
} else {
return unique_fn;
}
}模拟实现完整代码如下:
function fnFactory(context) {
var unique_fn = "fn";
while (context.hasOwnProperty(unique_fn)) {
unique_fn = "fn" + Math.random(); // 循环判断并重新赋值
}
return unique_fn;
}
Function.prototype.call = function (context) {
context = context ? Object(context) : window;
var fn = fnFactory(context); // added
context[fn] = this; // changed
var args = [];
for(var i = 1, len = arguments.length; i < len; i++) {
args.push('arguments[' + i + ']');
}
var result = eval('context[fn](' + args +')'); // changed
delete context[fn]; // changed
return result;
}
// 测试用例在下面ES6有一个新的基本类型Symbol,表示独一无二的值,用法如下。
const symbol1 = Symbol();
const symbol2 = Symbol(42);
const symbol3 = Symbol('foo');
console.log(typeof symbol1); // "symbol"
console.log(symbol3.toString()); // "Symbol(foo)"
console.log(Symbol('foo') === Symbol('foo')); // false不能使用 new 命令,因为这是基本类型的值,不然会报错。
new Symbol();
// TypeError: Symbol is not a constructor模拟实现完整代码如下:
Function.prototype.call = function (context) {
context = context ? Object(context) : window;
var fn = Symbol(); // added
context[fn] = this; // changed
let args = [...arguments].slice(1);
let result = context[fn](...args); // changed
delete context[fn]; // changed
return result;
}
// 测试用例在下面测试用例在这里:
// 测试用例
var value = 2;
var obj = {
value: 1,
fn: 123
}
function bar(name, age) {
console.log(this.value);
return {
value: this.value,
name: name,
age: age
}
}
bar.call(null);
// 2
console.log(bar.call(obj, 'kevin', 18));
// 1
// {value: 1, name: "kevin", age: 18}
console.log(obj);
// {value: 1, fn: 123}有两种方案可以判断对象中是否存在某个属性。
var obj = {
a: 2
};
Object.prototype.b = function() {
return "hello b";
}in 操作符in 操作符会检查属性是否存在对象及其 [[Prototype]] 原型链中。
("a" in obj); // true
("b" in obj); // trueObject.hasOwnProperty(...)方法hasOwnProperty(...)只会检查属性是否存在对象中,不会向上检查其原型链。
obj.hasOwnProperty("a"); //true
obj.hasOwnProperty("b"); //false注意以下几点:
in 操作符可以检查容器内是否有某个值,实际上检查的是某个属性名是否存在。对于数组来说,4 in [2, 4, 6] 结果返回 false,因为 [2, 4, 6] 这个数组中包含的属性名是0,1,2 ,没有4。Object.prototype 的委托来访问 hasOwnProperty(...),但是对于一些特殊对象( Object.create(null) 创建)没有连接到 Object.prototype,这种情况必须使用 Object.prototype.hasOwnProperty.call(obj, "a"),显示绑定到 obj 上。又是一个 call 的用法。用 JS 实现一个无限累加的函数 add,示例如下:
add(1); // 1
add(1)(2); // 3
add(1)(2)(3); // 6
add(1)(2)(3)(4); // 10
// 以此类推不用 call 和 apply 方法模拟实现 ES5 的 bind 方法
进阶系列文章汇总如下,内有优质前端资料,觉得不错点个star。
我是木易杨,网易高级前端工程师,跟着我每周重点攻克一个前端面试重难点。接下来让我带你走进高级前端的世界,在进阶的路上,共勉!
本期的主题是调用堆栈,本计划一共28期,每期重点攻克一个面试重难点,如果你还不了解本进阶计划,文末点击查看全部文章。
如果觉得本系列不错,欢迎点赞、评论、转发,您的支持就是我坚持的最大动力。
执行上下文是当前 JavaScript 代码被解析和执行时所在环境的抽象概念。
执行上下文总共有三种类型
全局执行上下文:只有一个,浏览器中的全局对象就是 window 对象,this 指向这个全局对象。
函数执行上下文:存在无数个,只有在函数被调用的时候才会被创建,每次调用函数都会创建一个新的执行上下文。
Eval 函数执行上下文: 指的是运行在 eval 函数中的代码,很少用而且不建议使用。
执行栈,也叫调用栈,具有 LIFO(后进先出)结构,用于存储在代码执行期间创建的所有执行上下文。
首次运行JS代码时,会创建一个全局执行上下文并Push到当前的执行栈中。每当发生函数调用,引擎都会为该函数创建一个新的函数执行上下文并Push到当前执行栈的栈顶。
根据执行栈LIFO规则,当栈顶函数运行完成后,其对应的函数执行上下文将会从执行栈中Pop出,上下文控制权将移到当前执行栈的下一个执行上下文。
var a = 'Hello World!';
function first() {
console.log('Inside first function');
second();
console.log('Again inside first function');
}
function second() {
console.log('Inside second function');
}
first();
console.log('Inside Global Execution Context');
// Inside first function
// Inside second function
// Again inside first function
// Inside Global Execution Context执行上下文分两个阶段创建:1)创建阶段; 2)执行阶段
1、确定 this 的值,也被称为 This Binding。
2、LexicalEnvironment(词法环境) 组件被创建。
3、VariableEnvironment(变量环境) 组件被创建。
直接看伪代码可能更加直观
ExecutionContext = {
ThisBinding = <this value>, // 确定this
LexicalEnvironment = { ... }, // 词法环境
VariableEnvironment = { ... }, // 变量环境
}全局执行上下文中,this 的值指向全局对象,在浏览器中this 的值指向 window 对象,而在nodejs中指向这个文件的module对象。
函数执行上下文中,this 的值取决于函数的调用方式。具体有:默认绑定、隐式绑定、显式绑定(硬绑定)、new绑定、箭头函数,具体内容会在【this全面解析】部分详解。
词法环境有两个组成部分
1、环境记录:存储变量和函数声明的实际位置
2、对外部环境的引用:可以访问其外部词法环境
词法环境有两种类型
1、全局环境:是一个没有外部环境的词法环境,其外部环境引用为 null。拥有一个全局对象(window 对象)及其关联的方法和属性(例如数组方法)以及任何用户自定义的全局变量,this 的值指向这个全局对象。
2、函数环境:用户在函数中定义的变量被存储在环境记录中,包含了arguments 对象。对外部环境的引用可以是全局环境,也可以是包含内部函数的外部函数环境。
直接看伪代码可能更加直观
GlobalExectionContext = { // 全局执行上下文
LexicalEnvironment: { // 词法环境
EnvironmentRecord: { // 环境记录
Type: "Object", // 全局环境
// 标识符绑定在这里
outer: <null> // 对外部环境的引用
}
}
FunctionExectionContext = { // 函数执行上下文
LexicalEnvironment: { // 词法环境
EnvironmentRecord: { // 环境记录
Type: "Declarative", // 函数环境
// 标识符绑定在这里 // 对外部环境的引用
outer: <Global or outer function environment reference>
}
}变量环境也是一个词法环境,因此它具有上面定义的词法环境的所有属性。
在 ES6 中,词法 环境和 变量 环境的区别在于前者用于存储**函数声明和变量( let 和 const )绑定,而后者仅用于存储变量( var )**绑定。
使用例子进行介绍
let a = 20;
const b = 30;
var c;
function multiply(e, f) {
var g = 20;
return e * f * g;
}
c = multiply(20, 30);执行上下文如下所示
GlobalExectionContext = {
ThisBinding: <Global Object>,
LexicalEnvironment: {
EnvironmentRecord: {
Type: "Object",
// 标识符绑定在这里
a: < uninitialized >,
b: < uninitialized >,
multiply: < func >
}
outer: <null>
},
VariableEnvironment: {
EnvironmentRecord: {
Type: "Object",
// 标识符绑定在这里
c: undefined,
}
outer: <null>
}
}
FunctionExectionContext = {
ThisBinding: <Global Object>,
LexicalEnvironment: {
EnvironmentRecord: {
Type: "Declarative",
// 标识符绑定在这里
Arguments: {0: 20, 1: 30, length: 2},
},
outer: <GlobalLexicalEnvironment>
},
VariableEnvironment: {
EnvironmentRecord: {
Type: "Declarative",
// 标识符绑定在这里
g: undefined
},
outer: <GlobalLexicalEnvironment>
}
}变量提升的原因:在创建阶段,函数声明存储在环境中,而变量会被设置为 undefined(在 var 的情况下)或保持未初始化(在 let 和 const 的情况下)。所以这就是为什么可以在声明之前访问 var 定义的变量(尽管是 undefined ),但如果在声明之前访问 let 和 const 定义的变量就会提示引用错误的原因。这就是所谓的变量提升。
此阶段,完成对所有变量的分配,最后执行代码。
如果 Javascript 引擎在源代码中声明的实际位置找不到 let 变量的值,那么将为其分配 undefined 值。
进阶系列文章汇总:https://github.com/yygmind/blog,内有优质前端资料,欢迎领取,觉得不错点个star。
我是木易杨,网易高级前端工程师,跟着我每周重点攻克一个前端面试重难点。接下来让我带你走进高级前端的世界,在进阶的路上,共勉!
JavaScript语言是“动态”或“解释执行”语言,但事实上是一门编译语言。但它不是提前编译的,编译结果也不能在分布式系统中移植。
传统编译语言流程中,程序在执行之前会经历三个步骤,统称为“编译”。
分词/词法分析(Tokenizing/Lexing)
将由字符组成的字符串分解成(对编程语言来说)有意义的代码块。
var a = 2;上面这段程序会被分解成以下词法单元:var、a、=、2、;。
空格是否会被当做词法单元,取决于空格在这门语言中是否有意义。
解析/语法分析(Parsing)
将词法单元流(数组)转换成一个由元素逐级嵌套所组成的代表了程序语法结构的数。这个数被称作抽象语法树(Abstract Syntax Tree, AST)。
var a = 2;以上代码的抽象语法树如下所示:
代码生成
将AST转换成可执行代码的过程。过程与语言、目标平台等相关。
简单来说就是可以通过某种方法将var a = 2;的AST转化为一组机器指令。用来创建一个叫做a的变量(包括分配内存等),并将一个值存储在a中。
var a = 2;存在2个不同的声明。
1、编译器在编译时处理(var a):在当前作用域中声明一个变量(如果之前没有声明过)。
st=>start: Start
e=>end: End
op1=>operation: 分解成词法单元
op2=>operation: 解析成树结构AST
cond=>condition: 当前作用域存在变量a?
op3=>operation: 忽略此声明,继续编译
op4=>operation: 在当前作用域集合中声明新变量a
op5=>operation: 生成代码
st->op1->op2->cond
cond(yes)->op3->op5->e
cond(no)->op4->op5->e
2、引擎在运行时处理(a = 2):在作用域中查找该变量,如果找到就对变量赋值。
st=>start: Start
e=>end: End
cond=>condition: 当前作用域存在变量a?
cond2=>condition: 全局作用域?
op1=>operation: 引擎使用这个变量a
op2=>operation: 引擎向上一级作用域查找变量a
op3=>operation: 引擎把2赋值给变量a
op4=>operation: 举手示意,抛出异常
st->cond
cond(yes)->op1->op3->e
cond(no)->cond2(no)->op2(right)->cond
cond2(yes)->op4->e
L和R分别代表一个赋值操作的左侧和右侧,当变量出现在赋值操作的左侧时进行LHS查询,出现在赋值操作的**非左侧**时进行RHS查询。
retrieve his source value,即取到它的源值function foo(a) {
console.log( a ); // 2
}
foo(2);上述代码共有1处LHS查询,3处RHS查询。
LHS查询有:
a = 2中,在2被当做参数传递给foo(…)函数时,需要对参数a进行LHS查询RHS查询有:
最后一行foo(...)函数的调用需要对foo进行RHS查询
console.log( a );中对a进行RHS查询
console.log(...)本身对console对象进行RHS查询
遍历嵌套作用域链的规则:引擎从当前的执行作用域开始查找变量,如果找不到就向上一级继续查找。当抵达最外层的全局作用域时,无论找到还是没有找到,查找过程都会停止。
ReferenceError和作用域判别失败相关,TypeError表示作用域判别成功了,但是对结果的操作是非法或不合理的。
ReferenceError异常。ReferenceError异常TypeError异常。(比如对非函数类型的值进行函数调用,或者引用null或undefined类型的值中的属性)var a = 2被分解成2个独立的步骤。
var a在其作用域中声明新变量a = 2会LHS查询a,然后对其进行赋值词法作用域是定义在词法阶段的作用域,是由写代码时将变量和块作用域写在哪里来决定的,所以在词法分析器处理代码时会保持作用域不变。(不考虑欺骗词法作用域情况下)
作用域查找会在找到第一个匹配的标识符时停止。
遮蔽效应:在多层嵌套作用域中可以定义同名的标识符,内部的标识符会“遮蔽”外部的标识符。
全局变量会自动变成全局对象的属性,可以间接的通过对全局对象属性的引用来访问。通过这种技术可以访问那些被同名变量所遮蔽的全局变量,但是非全局的变量如果被遮蔽了,无论如何都无法被访问到。
window.a词法作用域只由函数被声明时所处的位置决定。
词法作用域查找只会查找一级标识符,比如a、b、c。对于foo.bar.baz,词法作用域只会查找foo标识符,找到之后,对象属性访问规则会分别接管对bar和baz属性的访问。
欺骗词法作用域会导致性能下降。以下两种方法不推荐使用
eval(..)函数可以接受一个字符串为参数,并将其中的内容视为好像在书写时就存在于程序中这个位置的代码。
function foo (str, a) {
eval( str ); // 欺骗!
console.log( a, b );
}
var b = 2;
foo( "var b = 3;", 1 ); // 1, 3eval('var b = 3')会被当做本来就在那里一样来处理。
eval(..)中所执行的代码包含一个或多个声明,会在运行期修改书写期的词法作用域。上述代码中在foo(..)内部创建了一个变量b,并遮蔽了外部作用域中的同名变量。eval(..)在运行时有自己的词法作用域,其中的声明无法修改作用域。function foo (str) {
"use strict";
eval( str );
console.log( a ); // ReferenceError: a is not defined
}
foo( "var a = 2;" ); setTimeout(..)和setInterval(..)的第一个参数可以是字符串,会被解释为一段动态生成的函数代码。已过时,不要使用new Function(..) 的最后一个参数可以接受代码字符串(前面的参数是新生成的函数的形参)。避免使用with通常被当做重复引用同一个对象中的多个属性的快捷方式,可以不需要重复引用对象本身。
var obj = {
a: 1,
b: 2,
c: 3
};
// 单调乏味的重复“obj”
obj.a = 2;
obj.b = 3;
obj.c = 4;
// 简单的快捷方式
with (obj) {
a = 3;
b = 4;
c = 5;
}with可以将一个没有或有多个属性的对象处理为一个完全隔离的词法作用域,这个对象的属性会被处理为定义在这个作用域中的词法标识符。
这个块内部正常的var声明并不会被限制在这个块的作用域中,而是被添加到with所处的函数作用域中。
function foo(obj) {
with (obj) {
a = 2;
}
}
var o1 = {
a: 3
};
var o2 = {
b : 3
}
foo( o1 );
console.log( o1.a ); // 2
foo( o2 );
console.log( o2.a ); // undefined
console.log( a ); // 2 -- 不好,a被泄露到全局作用域上了!上面例子中,创建了o1和o2两个对象。其中一个有a属性,另一个没有。在with(obj){..}内部是一个LHS引用,并将2赋值给它。
o1传递进去后,with声明的作用域是o1,a = 2赋值操作找到o1.a并将2赋值给它。o2传递进去后,作用域o2中并没有a属性,因此进行正常的LHS标识符查找,o2的作用域、foo(..)的作用域和全局作用域都没有找到标识符a,因此当a = 2执行时,自动创建了一个全局变量(非严格模式),所以o2.a保持undefined。eval(..)或with,它只能简单的假设关于标识符位置的判断都是无效的。因为无法在词法分析阶段明确知道eval(..)会接收到什么代码,这些代码会如何对作用域进行修改,也无法知道传递给with用来创建词法作用域的对象的内容到底是什么。eval(..)或with,所有的优化可能都是无意义的,最简单的做法就是完全不做任何优化。代码运行起来一定会变得非常慢。词法作用域意味着作用域是由书写代码时函数声明的位置来决定的。
编译的词法分析阶段基本能够知道全部标识符在哪里以及是如何声明的,从而能够预测在执行过程中如何对它们进行查找。
有以下两个机制可以“欺骗”词法作用域:
eval(..):对一段包含一个或多个声明的”代码“字符串进行演算,借此来修改已经存在的词法作用域(运行时)。with:将一个对象的引用当做作用域来处理,将对象的属性当做作用域中的标识符来处理,创建一个新的词法作用域(运行时)。副作用是引擎无法在编译时对作用域查找进行优化。因为引擎只能谨慎地认为这样的优化是无效的,使用任何一个都将导致代码运行变慢。不要使用它们
属于这个函数的全部变量都可以在整个函数的范围内使用及复用(事实上在嵌套的作用域中也可以使用)。
function foo(a) {
var b = 2;
// 一些代码
function bar() {
// ...
}
// 更多的代码
var c = 3;
}foo(..)作用域中包含了标识符(变量、函数)a、b、c和bar。无论标识符声明出现在作用域中的何处,这个标识符所代表的变量或函数都将附属于所处的作用域。
全局作用域只包含一个标识符:foo。
最小特权原则(最小授权或最小暴露原则):在软件设计中,应该最小限度地暴露必要内容,而将其他内容都”隐藏“起来,比如某个模块或对象的API设计。
function doSomething(a) {
function doSomethingElse(a) {
return a - 1;
}
var b;
b = a + doSomethingElse( a * 2 );
console.log( b * 3 );
}
doSomething( 2 ); // 15b和doSomethingElse(..)都无法从外部被访问,而只能被doSomething(..)所控制,设计上将具体内容私有化了。
”隐藏“作用域中的变量和函数带来的另一个好处是可以避免同名标识符之间的冲突。
function foo() {
function bar(a) {
i = 3; // 修改for循环所属作用域中的i
console.log( a + i );
}
for (var i = 0; i < 10; i++) {
bar( i * 2 ); // 糟糕,无限循环了!
}
}
foo();bar(..)内部的赋值表达式i = 3意外的覆盖了声明在foo(..)内部for循环中的i。
解决方案:
var i = 3。var j = 3。规避变量冲突的典型例子:
全局命名空间
第三方库会在全局作用域中声明一个名字足够独特的变量,通常是一个对象,这个对象被用作库的命名空间,所有需要暴露给外界的功能都会成为这个对象(命名空间)的属性,而不是将自己的标识符暴露在顶级的词法作用域中。
模块管理
任何库无需将标识符加入到全局作用域中,而是通过依赖管理器的机制将库的标识符显示的导入到另外一个特定的作用域中。
var a = 2;
function foo() { // <-- 添加这一行
var a = 3;
console.log( a ); // 3
} // <-- 以及这一行
foo(); // <-- 以及这一行
console.log( a ); // 2上述函数作用域虽然可以将内部的变量和函数定义”隐藏“起来,但是会导致以下2个额外问题。
foo(),意味着foo这个名称本身”污染“了所在的作用域。foo()调用这个函数才能运行其中的代码。解决方案:
var a = 2;
(function foo(){ // <-- 添加这一行
var a = 3;
console.log( a ); // 3
})(); // <-- 以及这一行
console.log( a ); // 2上述代码包装函数的声明以(function...开始,函数会被当做函数表达式而不是一个标准的函数声明来处理。
function是声明中的第一个词foo被绑定在所在作用域中,可以直接通过foo()来调用它。foo被绑定在函数表达式自身的函数中,而不是所在的作用域。(function foo(){ .. }中foo只能在..所代表的位置中被访问,外部作用域不行。foo变量名被隐藏在自身中意味着不会非必要地污染外部作用域。setTimeout( function() {
console.log("I wait 1 second!");
}, 1000 );上述是匿名函数表达式,因为function()..没有名称标识符。
函数表达式可以匿名,但函数声明不可以省略函数名。
匿名函数表达式有以下缺点:
arguments.callee引用
解决方案:
行内函数表达式可以解决上述问题,始终给函数表达式命名是一个最佳实践。
setTimeout( function timeoutHandler() { // <-- 快看,我有名字了!
console.log( "I waited 1 second!" );
}, 1000 );立即执行函数表达式(IIFE,Immediately Invoked Function Expression)
匿名/具名函数表达式
第一个( )将函数变成表达式,第二个( )执行了这个函数
var a = 2;
(function IIFE() {
var a = 3;
console.log( a ); // 3
})();
console.log( a ); // 2改进型(function(){ .. }())
用来调用的( )被移进了用来包装的( )中。
当做函数调用并传递参数进去
var a = 2;
(function IIFE( global ) {
var a = 3;
console.log( a ); // 3
console.log( global.a ); // 2
})( window );
console.log( a ); // 2解决undefined标识符的默认值被错误覆盖导致的异常
将一个参数命名为undefined,但是在对应的位置不传入任何值,这样就可以保证在代码块中undefined标识符的值真的是undefined。
undefined = true;
(function IIFE( undefined ) {
var a;
if (a === undefined) {
console.log("Undefined is safe here!");
}
})();倒置代码的运行顺序,将需要运行的函数放在第二位,在IIFE执行之后当做参数传递进去
函数表达式def定义在片段的第二部分,然后当做参数(这个参数也叫做def)被传递进IIFE函数定义的第一部分中。最后,参数def(也就是传递进去的函数)被调用,并将window传入当做global参数的值。
var a = 2;
(function IIFE( def ) {
def( window );
})(function def( global ) {
var a = 3;
console.log( a ); // 3
console.log( global.a ); // 2
});表面上看JavaScript并没有块作用域的相关功能,除非更加深入了解(with、try/catch 、let、const)。
for (var i = 0; i < 10; i++) {
console.log( i );
}上述代码中i会被绑定在外部作用域(函数或全局)中。
var foo = true;
if (foo) {
var bar = foo * 2;
bar = something( bar );
console.log( bar );
}上述代码中,当使用var声明变量时,它写在哪里都是一样的,因为它们最终都会属于外部作用域。
块作用域的一种形式,用with从对象中创建出的作用域仅在**with声明中**而非外部作用域中有效。
ES3规范中规定try/catch的catch分句会创建一个块作用域,其中声明的变量仅在catch中有效。
try {
undefined(); // 执行一个非法操作来强制制造一个异常
}
catch (err) {
console.log( err ); // 能够正常执行!
}
console.log( err ); // ReferenceError: err not found当同一个作用域中的两个或多个catch分句用同样的标识符名称声明错误变量时,很多静态检查工具还是会发出警告,实际上这并不是重复定义,因为所有变量都会安全地限制在块作用域内部。
ES6引入了let关键字,可以将变量绑定到所在的任意作用域中(通常是{ .. }内部),即let为其声明的变量隐式地劫持了所在的块作用域。
var foo = true;
if (foo) {
let bar = foo * 2;
bar = something( bar );
console.log( bar );
}
console.log( bar ); // ReferenceError存在的问题
用let将变量附加在一个已经存在的的块作用域上的行为是隐式的,如果习惯性的移动这些块或者将其包含在其他的块中,可能会导致代码混乱。
解决方案
为块作用域显示地创建块。显式的代码优于隐式或一些精巧但不清晰的代码。
var foo = true;
if (foo) {
{ // <-- 显式的块
let bar = foo * 2;
bar = something( bar );
console.log( bar );
}
}
console.log( bar ); // ReferenceError在if声明内部显式地创建了一个块,如果需要对其进行重构,整个块都可以被方便地移动而不会对外部if声明的位置和语义产生任何影响。
在let进行的声明不会在块作用域中进行提升
console.log( bar ); // ReferenceError
let bar = 2;1、垃圾收集
function process(data) {
// 在这里做点有趣的事情
}
var someReallyBigData = { .. };
process( someReallyBigData );
var btn = document.getElementById( "my_button" );
btn.addEventListener( "click", function click(evt) {
console.log("button clicked");
}, /*capturingPhase*/false );click函数的点击回调并不需要someReallyBigData。理论上当process(..)执行后,在内存中占用大量空间的数据结构就可以被垃圾回收了。但是,由于click函数形成了一个覆盖整个作用域的闭包,JS引擎极有可能依然保存着这个结构(取决于具体实现)。
2、let循环
for (let i = 0; i < 10; i++) {
console.log( i );
}
console.log( i ); // ReferenceErrorfor循环头部的let不仅将i绑定到了for循环的块中,事实上它将其重新绑定到了循环的每一个迭代中,确保使用上一个循环迭代结束时的值重新进行赋值。
{
let j;
for (j = 0; j < 10; j++) {
let i = j; // 每个迭代重新绑定!
console.log( i );
}
}ES6引用了const,可以创建块作用域变量,但其值是固定的(常量)
var foo = true;
if(foo) {
var a = 2;
const b = 3; // 包含在if中的块作用域常量
a = 3; // 正常!
b = 4; // 错误!
}
console.log( a ); // 3
console.log( b ); // ReferenceError!var a = 2;会被看成两个声明,var a;和a = 2;,第一个声明在编译阶段进行,第二个赋值声明会被留在原地等待执行阶段。a = 2;
var a;
console.log( a ); // 2
---------------------------------------
// 实际按如下形式进行处理
var a; // 编译阶段
a = 2; // 执行阶段
console.log( a ); // 2console.log( a ); // undefinde
var a = 2;
---------------------------------------
// 实际按如下形式进行处理
var a; // 编译
console.log( a ); // undefinde
a = 2; // 执行function foo() {
var a;
console.log( a ); // undefinde
a = 2;
}
foo();foo(); // 不是ReferenceError,而是TypeError!
var foo = function bar() {
// ...
};上面这段程序中,变量标识符foo()被提升并分配给所在作用域,因此foo()不会导致ReferenceError。此时foo并没有赋值(如果它是一个函数声明而不是函数表达式,那么就会赋值),foo()由于对undefined值进行函数调用而导致非法操作,因此抛出TypeError异常。
foo(); // TypeError
bar(); // ReferenceError
var foo = function bar() {
// ...
};
---------------------------------------
// 实际按如下形式进行处理
var foo;
foo(); // TypeError
bar(); // ReferenceError
foo = function() {
var bar = ...self...
// ...
};foo(); // 1
var foo;
function foo() {
console.log( 1 );
};
foo = function() {
console.log( 2 );
};
---------------------------------------
// 实际按如下形式进行处理
function foo() { // 函数提升是整体提升,声明 + 赋值
console.log( 1 );
};
foo(); // 1
foo = function() {
console.log( 2 );
};var foo尽管出现在function foo()...的声明之前,但它是重复的声明,且函数声明会被提升到普通变量之前,因此被忽略foo(); // 3
function foo() {
console.log( 1 );
};
var foo = function() {
console.log( 2 );
};
function foo() {
console.log( 3 );
};foo(); // "b"
var a = true;
if (a) {
function foo() { console.log( "a" ); };
}
else {
function foo() { console.log( "b" ); };
}function foo() {
var a = 2;
function bar() {
console.log( a );
}
return bar;
}
var baz = foo();
baz(); // 2 ---- 这就是闭包的效果bar()在自己定义的词法作用域以外的地方执行。
bar()拥有覆盖foo()内部作用域的闭包,使得该作用域能够一直存活,以供bar()在之后任何时间进行引用,不会被垃圾回收器回收
bar()持有对foo()内部作用域的引用,这个引用就叫做闭包。// 对函数类型的值进行传递
function foo() {
var a = 2;
function baz() {
console.log( a ); // 2
}
bar( baz );
}
function bar(fn) {
fn(); // 这就是闭包
}
foo();baz传递给bar,当调用这个内部函数时(现在叫做fn),它覆盖的foo()内部作用域的闭包就形成了,因为它能够访问a。// 间接的传递函数
var fn;
function foo() {
var a = 2;
function baz() {
console.log( a );
}
fn = baz; // 将baz分配给全局变量
}
function bar() {
fn(); // 这就是闭包
}
foo();
bar(); // 2function wait(message) {
setTimeout( function timer() {
console.log( message );
}, 1000 );
}
wait( "Hello, closure!" );setTimeout(..)持有对一个参数的引用,这里参数叫做timer,引擎会调用这个函数,而词法作用域在这个过程中保持完整。这就是闭包// 典型的闭包例子:IIFE
var a = 2;
(function IIFE() {
console.log( a );
})();for (var i = 1; i <= 5; i++) {
setTimeout( function timer() {
console.log( i );
}, i * 1000 );
}
//输入五次6i的最终值。i尝试方案1:使用IIFE增加更多的闭包作用域
for (var i = 1; i <= 5; i++) {
(function() {
setTimeout( function timer() {
console.log( i );
}, i * 1000 );
})();
}
//失败,因为IIFE作用域是空的,需要包含一点实质内容才可以使用尝试方案2:IIFE增加变量
for (var i = 1; i <= 5; i++) {
(function() {
var j = i;
setTimeout( function timer() {
console.log( j );
}, j * 1000 );
})();
}
// 正常工作尝试方案3:改进型,将i作为参数传递给IIFE函数
for (var i = 1; i <= 5; i++) {
(function(j) {
setTimeout( function timer() {
console.log( j );
}, j * 1000 );
})( i );
}
// 正常工作let可以用来劫持块作用域,并且在这个块作用域中声明一个变量。for (var i = 1; i <= 5; i++) {
let j = i; // 闭包的块作用域!
setTimeout( function timer() {
console.log( j );
}, j * 1000 );
}
// 正常工作for循环头部的let声明会有一个特殊的行为。变量在循环过程中不止被声明一次,每次迭代都会声明。随后的每个迭代都会使用上一个迭代结束时的值来初始化这个变量。上面这句话参照3.4.3–---2.let循环,即以下
{
let j;
for (j = 0; j < 10; j++) {
let i = j; // 每个迭代重新绑定!
console.log( i );
}
}循环改进:
for (let i = 1; i <= 5; i++) {
setTimeout( function timer() {
console.log( i );
}, i * 1000 );
}
// 正常工作模块模式需要具备两个必要条件:
function CoolModule() {
var something = "cool";
var another = [1, 2, 3];
function doSomething() {
console.log( something );
}
function doAnother() {
console.log( another.join( " ! ") );
}
return {
doSomething: doSomething,
doAnother: doAnother
}
}
var foo = CoolModule();
foo.doSomething(); // cool
foo.doAnother(); // 1 ! 2 ! 3
// 1、必须通过调用CoolModule()来创建一个模块实例
// 2、CoolModule()返回一个对象字面量语法{ key: value, ... }表示的对象,对象中含有对内部函数而不是内部数据变量的引用。内部数据变量保持隐藏且私有的状态。立即调用这个函数并将返回值直接赋予给单例的模块标识符foo。
var foo = (function CoolModule() {
var something = "cool";
var another = [1, 2, 3];
function doSomething() {
console.log( something );
}
function doAnother() {
console.log( another.join( " ! ") );
}
return {
doSomething: doSomething,
doAnother: doAnother
}
})();
foo.doSomething(); // cool
foo.doAnother(); // 1 ! 2 ! 3大多数模块依赖加载器/管理器本质上是将这种模块定义封装进一个友好的API。
var MyModules = (function Manager() {
var modules = {};
function define(name, deps, impl) {
for (var i = 0; i < deps.length; i++ ) {
deps[i] = modules[deps[i]];
}
modules[name] = impl.apply( impl, deps ); // 核心,为了模块的定义引用了包装函数(可以传入任何依赖),并且将返回值(模块的API),储存在一个根据名字来管理的模块列表中。
}
function get(name) {
return modules[name];
}
return {
define: define,
get: get
};
})();使用上面的函数来定义模块:
MyModules.define( "bar", [], function() {
function hello(who) {
return "Let me introduct: " + who;
}
return {
hello: hello
};
} );
MyModules.define( "foo", ["bar"], function(bar) {
var hungry = "hippo";
function awesome() {
console.log( bar.hello( hungry ).toUpperCase() );
}
return {
awesome: awesome
};
} );
var bar = MyModules.get( "bar" );
var foo = MyModules.get( "foo" );
console.log(
bar.hello( "hippo" );
) // Let me introduct: hippo
foo.awesome(); // LET ME INTRODUCT: HIPPO在通过模块系统进行加载时,ES6会将文件当做独立的模块来处理。每个模块都可以导入其他模块或特定的API成员,同样可以导出自己的API成员。
ES6模块没有“行内”格式,必须被定义在独立的文件中(一个文件一个模块)
// bar.js
function hello(who) {
return "Let me introduct: " + who;
}
export hello;
// foo.js
// 仅从“bar”模块导入hello()
import hello from "bar";
var hungry = "hippo";
function awesome() {
console.log(
hello( hungry ).toUpperCase();
);
}
export awesome;
// baz.js
// 导入完整的“foo”和”bar“模块
module foo from "foo";
module bar from "bar";
console.log(
bar.hello( "rhino")
); // Let me introduct: rhino
foo.awesome(); // LET ME INTRODUCT: HIPPOimport:将一个模块中的一个或多个API导入到当前作用域中,并分别绑定在一个变量上module:将整个模块的API导入并绑定到一个变量上。export:将当前模块的一个标识符(变量、函数)导出为公共APIthis机制某种程度上很像动态作用域。// 词法作用域,关注函数在何处声明,a通过RHS引用到了全局作用域中的a
function foo() {
console.log( a ); // 2
}
function bar() {
var a = 3;
foo();
}
var a = 2;
bar();
-----------------------------
// 动态作用域,关注函数从何处调用,当foo()无法找到a的变量引用时,会顺着调用栈在调用foo()的地方查找a
function foo() {
console.log( a ); // 3(不是2!)
}
function bar() {
var a = 3;
foo();
}
var a = 2;
bar();ES3开始,JavaScript中就有了块作用域,包括with和catch分句。
// ES6环境
{
let a = 2;
console.log( a ); // 2
}
console.log( a ); // ReferenceError上述代码在ES6环境中可以正常工作,但是在ES6之前的环境中如何实现呢?
答案是使用catch分句,这是ES6中大部分功能迁移的首选方式。
try {
throw 2;
} catch (a) {
console.log( a ); // 2
}
console.log( a ); // ReferenceError// 代码转换成如下形式
{
try {
throw undefined;
} catch (a) {
a = 2;
console.log( a ); // 2
}
}
console.log( a ); // ReferenceErrorlet声明会创建一个显式的作用域并与其进行绑定,而不是隐式地劫持一个已经存在的作用域(对比前面的let定义)。
let (a = 2) {
console.log( a ); // 2
}
console.log( a ); // ReferenceError存在的问题:
let声明不包含在ES6中,Traceur编译器也不接受这种代码
/*let*/ { let a = 2;
console.log( a );
}
console.log( a ); // ReferenceError{
let a = 2;
console.log( a );
}
console.log( a ); // ReferenceError进阶系列文章汇总如下,内有优质前端资料,觉得不错点个star。
我是木易杨,网易高级前端工程师,跟着我每周重点攻克一个前端面试重难点。接下来让我带你走进高级前端的世界,在进阶的路上,共勉!
本期的主题是调用堆栈,本计划一共28期,每期重点攻克一个面试重难点,如果你还不了解本进阶计划,文末点击查看全部文章。
如果觉得本系列不错,欢迎点赞、评论、转发,您的支持就是我坚持的最大动力。
JS是单线程的语言,执行顺序肯定是顺序执行,但是JS 引擎并不是一行一行地分析和执行程序,而是一段一段地分析执行,会先进行编译阶段然后才是执行阶段。
翠花,上代码
例子一:变量提升
foo; // undefined
var foo = function () {
console.log('foo1');
}
foo(); // foo1,foo赋值
var foo = function () {
console.log('foo2');
}
foo(); // foo2,foo重新赋值例子二:函数提升
foo(); // foo2
function foo() {
console.log('foo1');
}
foo(); // foo2
function foo() {
console.log('foo2');
}
foo(); // foo2例子三:声明优先级,函数 > 变量
foo(); // foo2
var foo = function() {
console.log('foo1');
}
foo(); // foo1,foo重新赋值
function foo() {
console.log('foo2');
}
foo(); // foo1上面三个例子中,第一个例子是变量提升,第二个例子是函数提升,第三个例子是函数声明优先级高于变量声明。
需要注意的是同一作用域下存在多个同名函数声明,后面的会替换前面的函数声明。
执行上下文总共有三种类型
this 指向这个全局对象。eval 函数中的代码,很少用而且不建议使用。这部分内容在【进阶1-1期】中详细介绍了,点击查看【进阶1-1期】理解JavaScript 中的执行上下文和执行栈
因为JS引擎创建了很多的执行上下文,所以JS引擎创建了执行上下文栈(Execution context stack,ECS)来管理执行上下文。
当 JavaScript 初始化的时候会向执行上下文栈压入一个全局执行上下文,我们用 globalContext 表示它,并且只有当整个应用程序结束的时候,执行栈才会被清空,所以程序结束之前, 执行栈最底部永远有个 globalContext。
ECStack = [ // 使用数组模拟栈
globalContext
];具体执行过程如下图所示,这部分内容在【进阶1-1期】中详细介绍了,点击查看【进阶1-1期】理解JavaScript 中的执行上下文和执行栈
有如下两段代码,执行的结果是一样的,但是两段代码究竟有什么不同?
var scope = "global scope";
function checkscope(){
var scope = "local scope";
function f(){
return scope;
}
return f();
}
checkscope();var scope = "global scope";
function checkscope(){
var scope = "local scope";
function f(){
return scope;
}
return f;
}
checkscope()();答案是 执行上下文栈的变化不一样。
第一段代码:
ECStack.push(<checkscope> functionContext);
ECStack.push(<f> functionContext);
ECStack.pop();
ECStack.pop();第二段代码:
ECStack.push(<checkscope> functionContext);
ECStack.pop();
ECStack.push(<f> functionContext);
ECStack.pop();在函数上下文中,用活动对象(activation object, AO)来表示变量对象。
活动对象和变量对象的区别在于
调用函数时,会为其创建一个Arguments对象,并自动初始化局部变量arguments,指代该Arguments对象。所有作为参数传入的值都会成为Arguments对象的数组元素。
执行上下文的代码会分成两个阶段进行处理
1、进入执行上下文
2、代码执行
很明显,这个时候还没有执行代码
此时的变量对象会包括(如下顺序初始化):
上代码就直观了
function foo(a) {
var b = 2;
function c() {}
var d = function() {};
b = 3;
}
foo(1);对于上面的代码,这个时候的AO是
AO = {
arguments: {
0: 1,
length: 1
},
a: 1,
b: undefined,
c: reference to function c(){},
d: undefined
}形参arguments这时候已经有赋值了,但是变量还是undefined,只是初始化的值
这个阶段会顺序执行代码,修改变量对象的值,执行完成后AO如下
AO = {
arguments: {
0: 1,
length: 1
},
a: 1,
b: 3,
c: reference to function c(){},
d: reference to FunctionExpression "d"
}总结如下:
1、全局上下文的变量对象初始化是全局对象
2、函数上下文的变量对象初始化只包括 Arguments 对象
3、在进入执行上下文时会给变量对象添加形参、函数声明、变量声明等初始的属性值
4、在代码执行阶段,会再次修改变量对象的属性值
进阶系列文章汇总:https://github.com/yygmind/blog,内有优质前端资料,欢迎领取,觉得不错点个star。
我是木易杨,网易高级前端工程师,跟着我每周重点攻克一个前端面试重难点。接下来让我带你走进高级前端的世界,在进阶的路上,共勉!
本期的主题是作用域闭包,本计划一共28期,每期重点攻克一个面试重难点,如果你还不了解本进阶计划,文末点击查看全部文章。
如果觉得本系列不错,欢迎点赞、评论、转发,您的支持就是我坚持的最大动力。
红宝书(p178)上对于闭包的定义:闭包是指有权访问另外一个函数作用域中的变量的函数
关键在于下面两点:
对于闭包有下面三个特性:
function getOuter(){
var date = '815';
function getDate(str){
console.log(str + date); //访问外部的date
}
return getDate('今天是:'); //"今天是:815"
}
getOuter();function getOuter(){
var date = '815';
function getDate(str){
console.log(str + date); //访问外部的date
}
return getDate; //外部函数返回
}
var today = getOuter();
today('今天是:'); //"今天是:815"
today('明天不是:'); //"明天不是:815"function updateCount(){
var count = 0;
function getCount(val){
count = val;
console.log(count);
}
return getCount; //外部函数返回
}
var count = updateCount();
count(815); //815
count(816); //816Javascript中有一个执行上下文(execution context)的概念,它定义了变量或函数有权访问的其它数据,决定了他们各自的行为。每个执行环境都有一个与之关联的变量对象,环境中定义的所有变量和函数都保存在这个对象中。
详情查看 【进阶1-2期】JavaScript深入之执行上下文栈和变量对象
作用域链:当访问一个变量时,解释器会首先在当前作用域查找标示符,如果没有找到,就去父作用域找,直到找到该变量的标示符或者不在父作用域中,这就是作用域链。
作用域链和原型继承查找时的区别:如果去查找一个普通对象的属性,但是在当前对象和其原型中都找不到时,会返回undefined;但查找的属性在作用域链中不存在的话就会抛出ReferenceError。
作用域链的顶端是全局对象,在全局环境中定义的变量就会绑定到全局对象中。
// my_script.js
"use strict";
var foo = 1;
var bar = 2;
function myFunc() {
var a = 1;
var b = 2;
var foo = 3;
console.log("inside myFunc");
}
console.log("outside");
myFunc();定义时:当myFunc被定义的时候,myFunc的标识符(identifier)就被加到了全局对象中,这个标识符所引用的是一个函数对象(myFunc function object)。
内部属性[[scope]]指向当前的作用域对象,也就是函数的标识符被创建的时候,我们所能够直接访问的那个作用域对象(即全局对象)。
myFunc所引用的函数对象,其本身不仅仅含有函数的代码,并且还含有指向其被创建的时候的作用域对象。
调用时:当myFunc函数被调用的时候,一个新的作用域对象被创建了。新的作用域对象中包含myFunc函数所定义的本地变量,以及其参数(arguments)。这个新的作用域对象的父作用域对象就是在运行myFunc时能直接访问的那个作用域对象(即全局对象)。
当函数返回没有被引用的时候,就会被垃圾回收器回收。但是对于闭包,即使外部函数返回了,函数对象仍会引用它被创建时的作用域对象。
"use strict";
function createCounter(initial) {
var counter = initial;
function increment(value) {
counter += value;
}
function get() {
return counter;
}
return {
increment: increment,
get: get
};
}
var myCounter = createCounter(100);
console.log(myCounter.get()); // 返回 100
myCounter.increment(5);
console.log(myCounter.get()); // 返回 105当调用 createCounter(100) 时,内嵌函数increment和get都有指向createCounter(100) scope的引用。假设createCounter(100)没有任何返回值,那么createCounter(100) scope不再被引用,于是就可以被垃圾回收。
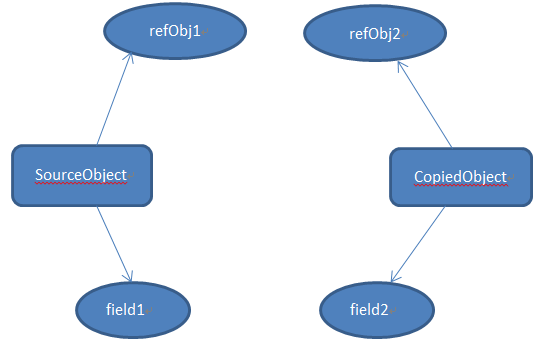
但是createCounter(100)实际上是有返回值的,并且返回值被存储在了myCounter中,所以对象之间的引用关系如下图:
即使createCounter(100)已经返回,但是其作用域仍在,并且只能被内联函数访问。可以通过调用myCounter.increment() 或 myCounter.get()来直接访问createCounter(100)的作用域。
当myCounter.increment() 或 myCounter.get()被调用时,新的作用域对象会被创建,并且该作用域对象的父作用域对象会是当前可以直接访问的作用域对象。
调用get()时,当执行到return counter时,在get()所在的作用域并没有找到对应的标示符,就会沿着作用域链往上找,直到找到变量counter,然后返回该变量。
单独调用increment(5)时,参数value保存在当前的作用域对象。当函数要访问counter时,没有找到,于是沿着作用域链向上查找,在createCounter(100)的作用域找到了对应的标示符,increment()就会修改counter的值。除此之外,没有其他方式来修改这个变量。闭包的强大也在于此,能够存贮私有数据。
创建两个函数:myCounter1和myCounter2
//my_script.js
"use strict";
function createCounter(initial) {
/* ... see the code from previous example ... */
}
//-- create counter objects
var myCounter1 = createCounter(100);
var myCounter2 = createCounter(200);
关系图如下
myCounter1.increment和myCounter2.increment的函数对象拥有着一样的代码以及一样的属性值(name,length等等),但是它们的[[scope]]指向的是不一样的作用域对象。
进阶系列文章汇总:https://github.com/yygmind/blog,内有优质前端资料,欢迎领取,觉得不错点个star。
我是木易杨,网易高级前端工程师,跟着我每周重点攻克一个前端面试重难点。接下来让我带你走进高级前端的世界,在进阶的路上,共勉!
上一节我们认识了节流函数 throttle,了解了它的定义、实现原理以及在 underscore 中的实现。这一小节会继续之前的篇幅聊聊防抖函数 debounce,结构是一样的,将分别介绍定义、实现原理并给出了 2 种实现代码并在最后介绍在 underscore 中的实现,欢迎大家拍砖。
有什么想法或者意见都可以在评论区留言,下图是本文的思维导图,高清思维导图和更多文章请看我的 Github。
防抖函数 debounce 指的是某个函数在某段时间内,无论触发了多少次回调,都只执行最后一次。假如我们设置了一个等待时间 3 秒的函数,在这 3 秒内如果遇到函数调用请求就重新计时 3 秒,直至新的 3 秒内没有函数调用请求,此时执行函数,不然就以此类推重新计时。
举一个小例子:假定在做公交车时,司机需等待最后一个人进入后再关门,每次新进一个人,司机就会把计时器清零并重新开始计时,重新等待 1 分钟再关门,如果后续 1 分钟内都没有乘客上车,司机会认为乘客都上来了,将关门发车。
此时「上车的乘客」就是我们频繁操作事件而不断涌入的回调任务;「1 分钟」就是计时器,它是司机决定「关门」的依据,如果有新的「乘客」上车,将清零并重新计时;「关门」就是最后需要执行的函数。
如果你还无法理解,看下面这张图就清晰多了,另外点击 这个页面 查看节流和防抖的可视化比较。其中 Regular 是不做任何处理的情况,throttle 是函数节流之后的结果(上一小节已介绍),debounce 是函数防抖之后的结果。
实现原理就是利用定时器,函数第一次执行时设定一个定时器,之后调用时发现已经设定过定时器就清空之前的定时器,并重新设定一个新的定时器,如果存在没有被清空的定时器,当定时器计时结束后触发函数执行。
// 实现 1
// fn 是需要防抖处理的函数
// wait 是时间间隔
function debounce(fn, wait = 50) {
// 通过闭包缓存一个定时器 id
let timer = null
// 将 debounce 处理结果当作函数返回
// 触发事件回调时执行这个返回函数
return function(...args) {
// 如果已经设定过定时器就清空上一次的定时器
if (timer) clearTimeout(timer)
// 开始设定一个新的定时器,定时器结束后执行传入的函数 fn
timer = setTimeout(() => {
fn.apply(this, args)
}, wait)
}
}
// DEMO
// 执行 debounce 函数返回新函数
const betterFn = debounce(() => console.log('fn 防抖执行了'), 1000)
// 停止滑动 1 秒后执行函数 () => console.log('fn 防抖执行了')
document.addEventListener('scroll', betterFn)上述实现方案已经可以解决大部分使用场景了,不过想要实现第一次触发回调事件就执行 fn 有点力不从心了,这时候我们来改写下 debounce 函数,加上第一次触发立即执行的功能。
// 实现 2
// immediate 表示第一次是否立即执行
function debounce(fn, wait = 50, immediate) {
let timer = null
return function(...args) {
if (timer) clearTimeout(timer)
// ------ 新增部分 start ------
// immediate 为 true 表示第一次触发后执行
// timer 为空表示首次触发
if (immediate && !timer) {
fn.apply(this, args)
}
// ------ 新增部分 end ------
timer = setTimeout(() => {
fn.apply(this, args)
}, wait)
}
}
// DEMO
// 执行 debounce 函数返回新函数
const betterFn = debounce(() => console.log('fn 防抖执行了'), 1000, true)
// 第一次触发 scroll 执行一次 fn,后续只有在停止滑动 1 秒后才执行函数 fn
document.addEventListener('scroll', betterFn)实现原理比较简单,判断传入的 immediate 是否为 true,另外需要额外判断是否是第一次执行防抖函数,判断依旧就是 timer 是否为空,所以只要 immediate && !timer 返回 true 就执行 fn 函数,即 fn.apply(this, args)。
现在考虑一种情况,如果用户的操作非常频繁,不等设置的延迟时间结束就进行下次操作,会频繁的清除计时器并重新生成,所以函数 fn 一直都没办法执行,导致用户操作迟迟得不到响应。
有一种**是将「节流」和「防抖」合二为一,变成加强版的节流函数,关键点在于「 wait 时间内,可以重新生成定时器,但只要 wait 的时间到了,必须给用户一个响应」。这种合体思路恰好可以解决上面提出的问题。
给出合二为一的代码之前先来回顾下 throttle 函数,上一小节中有详细的介绍。
// fn 是需要执行的函数
// wait 是时间间隔
const throttle = (fn, wait = 50) => {
// 上一次执行 fn 的时间
let previous = 0
// 将 throttle 处理结果当作函数返回
return function(...args) {
// 获取当前时间,转换成时间戳,单位毫秒
let now = +new Date()
// 将当前时间和上一次执行函数的时间进行对比
// 大于等待时间就把 previous 设置为当前时间并执行函数 fn
if (now - previous > wait) {
previous = now
fn.apply(this, args)
}
}
}结合 throttle 和 debounce 代码,加强版节流函数 throttle 如下,新增逻辑在于当前触发时间和上次触发的时间差小于时间间隔时,设立一个新的定时器,相当于把 debounce 代码放在了小于时间间隔部分。
// fn 是需要节流处理的函数
// wait 是时间间隔
function throttle(fn, wait) {
// previous 是上一次执行 fn 的时间
// timer 是定时器
let previous = 0, timer = null
// 将 throttle 处理结果当作函数返回
return function (...args) {
// 获取当前时间,转换成时间戳,单位毫秒
let now = +new Date()
// ------ 新增部分 start ------
// 判断上次触发的时间和本次触发的时间差是否小于时间间隔
if (now - previous < wait) {
// 如果小于,则为本次触发操作设立一个新的定时器
// 定时器时间结束后执行函数 fn
if (timer) clearTimeout(timer)
timer = setTimeout(() => {
previous = now
fn.apply(this, args)
}, wait)
// ------ 新增部分 end ------
} else {
// 第一次执行
// 或者时间间隔超出了设定的时间间隔,执行函数 fn
previous = now
fn.apply(this, args)
}
}
}
// DEMO
// 执行 throttle 函数返回新函数
const betterFn = throttle(() => console.log('fn 节流执行了'), 1000)
// 第一次触发 scroll 执行一次 fn,每隔 1 秒后执行一次函数 fn,停止滑动 1 秒后再执行函数 fn
document.addEventListener('scroll', betterFn)看完整段代码会发现这个**和上篇文章介绍的 underscore 中 throttle 的实现**非常相似。
看完了上文的基本版代码,感觉还是比较轻松的,现在来学习下 underscore 是如何实现 debounce 函数的,学习一下优秀的**,直接上代码和注释,本源码解析依赖于 underscore 1.9.1 版本实现。
// 此处的三个参数上文都有解释
_.debounce = function(func, wait, immediate) {
// timeout 表示定时器
// result 表示 func 执行返回值
var timeout, result;
// 定时器计时结束后
// 1、清空计时器,使之不影响下次连续事件的触发
// 2、触发执行 func
var later = function(context, args) {
timeout = null;
// if (args) 判断是为了过滤立即触发的
// 关联在于 _.delay 和 restArguments
if (args) result = func.apply(context, args);
};
// 将 debounce 处理结果当作函数返回
var debounced = restArguments(function(args) {
if (timeout) clearTimeout(timeout);
if (immediate) {
// 第一次触发后会设置 timeout,
// 根据 timeout 是否为空可以判断是否是首次触发
var callNow = !timeout;
timeout = setTimeout(later, wait);
if (callNow) result = func.apply(this, args);
} else {
// 设置定时器
timeout = _.delay(later, wait, this, args);
}
return result;
});
// 新增 手动取消
debounced.cancel = function() {
clearTimeout(timeout);
timeout = null;
};
return debounced;
};
// 根据给定的毫秒 wait 延迟执行函数 func
_.delay = restArguments(function(func, wait, args) {
return setTimeout(function() {
return func.apply(null, args);
}, wait);
});相比上文的基本版实现,underscore 多了以下几点功能。
函数节流和防抖都是「闭包」、「高阶函数」的应用
函数节流 throttle 指的是某个函数在一定时间间隔内(例如 3 秒)执行一次,在这 3 秒内 无视后来产生的函数调用请求
函数防抖 debounce 指的是某个函数在某段时间内,无论触发了多少次回调,都只执行最后一次
如果你觉得这篇内容对你挺有启发,我想邀请你帮我三个小忙:
上篇文章介绍了构造函数、原型和原型链的关系,并且说明了 prototype 、[[Prototype]] 和 __proto__ 之间的区别,今天这篇文章用图解的方式向大家介绍原型链及其继承方案,在介绍原型链继承的过程中讲解原型链运作机制以及属性遮蔽等知识。
建议阅读上篇文章后再来阅读本文,链接:【进阶5-1期】重新认识构造函数、原型和原型链
有什么想法或者意见都可以在评论区留言。下图是本文的思维导图,高清思维导图和更多文章请看我的 Github。
上篇文章中我们介绍了原型链的概念,即每个对象拥有一个原型对象,通过 __proto__ 指针指向上一个原型 ,并从中继承方法和属性,同时原型对象也可能拥有原型,这样一层一层,最终指向 null,这种关系被称为原型链(prototype chain)。
根据规范不建议直接使用 __proto__,推荐使用 Object.getPrototypeOf(),不过为了行文方便逻辑清晰,下面都以 __proto__ 代替。
注意上面的说法,原型上的方法和属性被 继承 到新对象中,并不是被复制到新对象,我们看下面这个例子。
// 木易杨
function Foo(name) {
this.name = name;
}
Foo.prototype.getName = function() {
return this.name;
}
Foo.prototype.length = 3;
let foo = new Foo('muyiy'); // 相当于 foo.__proto__ = Foo.prototype
console.dir(foo);原型上的属性和方法定义在 prototype 对象上,而非对象实例本身。当访问一个对象的属性 / 方法时,它不仅仅在该对象上查找,还会查找该对象的原型,以及该对象的原型的原型,一层一层向上查找,直到找到一个名字匹配的属性 / 方法或到达原型链的末尾(null)。
比如调用 foo.valueOf() 会发生什么?
foo 对象是否具有可用的 valueOf() 方法。foo 对象的原型对象(即 Foo.prototype)是否具有可用的 valueof() 方法。Foo.prototype 所指向的对象的原型对象(即 Object.prototype)是否具有可用的 valueOf() 方法。这里有这个方法,于是该方法被调用。prototype 和 __proto__上篇文章介绍了 prototype 和 __proto__ 的区别,其中原型对象 prototype 是构造函数的属性,__proto__ 是每个实例上都有的属性,这两个并不一样,但 foo.__proto__ 和 Foo.prototype 指向同一个对象。
这次我们再深入一点,原型链的构建是依赖于 prototype 还是 __proto__ 呢?
Foo.prototype 中的 prototype 并没有构建成一条原型链,其只是指向原型链中的某一处。原型链的构建依赖于 __proto__,如上图通过 foo.__proto__ 指向 Foo.prototype,foo.__proto__.__proto__ 指向 Bichon.prototype,如此一层一层最终链接到 null。
可以这么理解 Foo,我是一个 constructor,我也是一个 function,我身上有着 prototype 的 reference,只要随时调用 foo = new Foo(),我就会将
foo.__proto__指向到我的 prototype 对象。
不要使用 Bar.prototype = Foo,因为这不会执行 Foo 的原型,而是指向函数 Foo。 因此原型链将会回溯到 Function.prototype 而不是 Foo.prototype,因此 method 方法将不会在 Bar 的原型链上。
// 木易杨
function Foo() {
return 'foo';
}
Foo.prototype.method = function() {
return 'method';
}
function Bar() {
return 'bar';
}
Bar.prototype = Foo; // Bar.prototype 指向到函数
let bar = new Bar();
console.dir(bar);
bar.method(); // Uncaught TypeError: bar.method is not a functioninstanceof 运算符用来检测 constructor.prototype 是否存在于参数 object 的原型链上。
// 木易杨
function C(){}
function D(){}
var o = new C();
o instanceof C; // true,因为 Object.getPrototypeOf(o) === C.prototype
o instanceof D; // false,因为 D.prototype 不在 o 的原型链上instanceof 原理就是一层一层查找 __proto__,如果和 constructor.prototype 相等则返回 true,如果一直没有查找成功则返回 false。
instance.[__proto__...] === instance.constructor.prototype知道了原理后我们来实现 instanceof,代码如下。
// 木易杨
function instance_of(L, R) {//L 表示左表达式,R 表示右表达式
var O = R.prototype;// 取 R 的显示原型
L = L.__proto__;// 取 L 的隐式原型
while (true) {
// Object.prototype.__proto__ === null
if (L === null)
return false;
if (O === L)// 这里重点:当 O 严格等于 L 时,返回 true
return true;
L = L.__proto__;
}
}
// 测试
function C(){}
function D(){}
var o = new C();
instance_of(o, C); // true
instance_of(o, D); // false原型链继承的本质是重写原型对象,代之以一个新类型的实例。如下代码,新原型 Cat 不仅有 new Animal() 实例上的全部属性和方法,并且由于指向了 Animal 原型,所以还继承了Animal 原型上的属性和方法。
// 木易杨
function Animal() {
this.value = 'animal';
}
Animal.prototype.run = function() {
return this.value + ' is runing';
}
function Cat() {}
// 这里是关键,创建 Animal 的实例,并将该实例赋值给 Cat.prototype
// 相当于 Cat.prototype.__proto__ = Animal.prototype
Cat.prototype = new Animal();
var instance = new Cat();
instance.value = 'cat'; // 创建 instance 的自身属性 value
console.log(instance.run()); // cat is runing原型链继承方案有以下缺点:
原型链继承方案中,原型实际上会变成另一个类型的实例,如下代码,Cat.prototype 变成了 Animal 的一个实例,所以 Animal 的实例属性 names 就变成了 Cat.prototype 的属性。
而原型属性上的引用类型值会被所有实例共享,所以多个实例对引用类型的操作会被篡改。如下代码,改变了 instance1.names 后影响了 instance2。
// 木易杨
function Animal(){
this.names = ["cat", "dog"];
}
function Cat(){}
Cat.prototype = new Animal();
var instance1 = new Cat();
instance1.names.push("tiger");
console.log(instance1.names); // ["cat", "dog", "tiger"]
var instance2 = new Cat();
console.log(instance2.names); // ["cat", "dog", "tiger"]子类型原型上的 constructor 属性被重写了,执行 Cat.prototype = new Animal() 后原型被覆盖,Cat.prototype 上丢失了 constructor 属性, Cat.prototype 指向了 Animal.prototype,而 Animal.prototype.constructor 指向了 Animal,所以 Cat.prototype.constructor 指向了 Animal。
Cat.prototype = new Animal();
Cat.prototype.constructor === Animal
// true解决办法就是重写 Cat.prototype.constructor 属性,指向自己的构造函数 Cat。
// 木易杨
function Animal() {
this.value = 'animal';
}
Animal.prototype.run = function() {
return this.value + ' is runing';
}
function Cat() {}
Cat.prototype = new Animal();
// 新增,重写 Cat.prototype 的 constructor 属性,指向自己的构造函数 Cat
Cat.prototype.constructor = Cat; 给子类型原型添加属性和方法必须在替换原型之后,原因在第二点已经解释过了,因为子类型的原型会被覆盖。
// 木易杨
function Animal() {
this.value = 'animal';
}
Animal.prototype.run = function() {
return this.value + ' is runing';
}
function Cat() {}
Cat.prototype = new Animal();
Cat.prototype.constructor = Cat;
// 新增
Cat.prototype.getValue = function() {
return this.value;
}
var instance = new Cat();
instance.value = 'cat';
console.log(instance.getValue()); // cat改造上面的代码,在 Cat.prototype 上添加 run 方法,但是 Animal.prototype 上也有一个 run 方法,不过它不会被访问到,这种情况称为属性遮蔽 (property shadowing)。
// 木易杨
function Animal() {
this.value = 'animal';
}
Animal.prototype.run = function() {
return this.value + ' is runing';
}
function Cat() {}
Cat.prototype = new Animal();
Cat.prototype.constructor = Cat;
// 新增
Cat.prototype.run = function() {
return 'cat cat cat';
}
var instance = new Cat();
instance.value = 'cat';
console.log(instance.run()); // cat cat cat那如何访问被遮蔽的属性呢?通过 __proto__ 调用原型链上的属性即可。
// 接上
console.log(instance.__proto__.__proto__.run()); // undefined is runing原型链继承方案有很多问题,实践中很少会单独使用,日常工作中使用 ES6 Class extends(模拟原型)继承方案即可,更多更详细的继承方案可以阅读我之前写的一篇文章,欢迎拍砖。
点击阅读:JavaScript 常用八种继承方案
有以下 3 个判断数组的方法,请分别介绍它们之间的区别和优劣
Object.prototype.toString.call() 、 instanceof 以及 Array.isArray()
参考答案:点击查看
__proto__ 指针指向上一个原型 ,并从中继承方法和属性,同时原型对象也可能拥有原型,这样一层一层,最终指向 null,这种关系被称为**原型链 **null)。__proto__,一层一层最终链接到 null。__proto__,如果和 constructor.prototype 相等则返回 true,如果一直没有查找成功则返回 false。进阶系列文章汇总如下,内有优质前端资料,觉得不错点个star。
我是木易杨,公众号「高级前端进阶」作者,跟着我每周重点攻克一个前端面试重难点。接下来让我带你走进高级前端的世界,在进阶的路上,共勉!
几个常用数组方法的使用方式已经在【进阶 6-1 期】 中介绍过了,今天这篇文章主要看看 ECMA-262 规范中是如何定义这些方法的,并且在看完规范后我们用 JS 模拟实现下,透过源码探索一些底层的知识,希望本文对你有所帮助。
完整的结构是 Array.prototype.map(callbackfn[, thisArg]),map 函数接收两个参数,一个是必填项回调函数,另一个是可选项 callbackfn 函数执行时的 this 值。
map 方法的主要功能就是把原数组中的每个元素按顺序执行一次 callbackfn 函数,并且把所有返回的结果组合在一起生成一个新的数组,map 方法的返回值就是这个新数组。
ECMA-262 规范文档实现如下。
Array.prototype.map = function(callbackfn, thisArg) {
// 异常处理
if (this == null) {
throw new TypeError("Cannot read property 'map' of null or undefined");
}
// Step 1. 转成数组对象,有 length 属性和 K-V 键值对
let O = Object(this)
// Step 2. 无符号右移 0 位,左侧用 0 填充,结果非负
let len = O.length >>> 0
// Step 3. callbackfn 不是函数时抛出异常
if (typeof callbackfn !== 'function') {
throw new TypeError(callbackfn + ' is not a function')
}
// Step 4.
let T = thisArg
// Step 5.
let A = new Array(len)
// Step 6.
let k = 0
// Step 7.
while(k < len) {
// Step 7.1、7.2、7.3
// 检查 O 及其原型链是否包含属性 k
if (k in O) {
// Step 7.3.1
let kValue = O[k]
// Step 7.3.2 执行 callbackfn 函数
// 传入 this, 当前元素 element, 索引 index, 原数组对象 O
let mappedValue = callbackfn.call(T, kValue, k, O)
// Step 7.3.3 返回结果赋值给新生成数组
A[k] = mappedValue
}
// Step 7.4
k++
}
// Step 8. 返回新数组
return A
}
// 代码亲测已通过看完代码其实挺简单,核心就是在一个 while 循环中执行 callbackfn,并传入 4 个参数,回调函数具体的执行逻辑这里并不关心,只需要拿到返回结果并赋值给新数组就好了。
只有 O 及其原型链上包含属性 k 时才会执行 callbackfn 函数,所以对于稀疏数组 empty 元素或者使用 delete 删除后的索引则不会被调用。
let arr = [1, , 3, , 5]
console.log(0 in arr) // true
delete arr[0]
console.log(0 in arr) // false
console.log(arr) // [empty × 2, 3, empty, 5]
arr.map(ele => {
console.log(ele) // 3, 5
})map 并不会修改原数组,不过也不是绝对的,如果你在 callbackfn 中修改了原数组,那还是会改变。那问题来了,修改后会影响到 map 自身的执行吗?
答案是会的!不过得区分以下几种情况。
map 第一次执行时 length 已经确定了,所以不影响callbackfn 的元素是 map 遍历到它们那一瞬间的值,所以可能受影响
简单看下面几个例子,在 callbackfn 中不要改变原数组,不然会有意想不到的情况发生。
// 1、原数组新增元素,不受影响
let arr = [1, 2, 3]
let result = arr.map((ele, index, array) => {
array.push(4);
return ele * 2
})
console.log(result)
// 2, 4, 6
// ----------- 完美分割线 -----------
// 2、原数组修改当前索引之前的元素,不受影响
let arr = [1, 2, 3]
let result = arr.map((ele, index, array) => {
if (index === 1) {
array[0] = 4
}
return ele * 2
})
console.log(result)
// 2, 4, 6
// ----------- 完美分割线 -----------
// 3、原数组修改当前索引之后的元素,受影响
let arr = [1, 2, 3]
let result = arr.map((ele, index, array) => {
if (index === 1) {
array[2] = 4
}
return ele * 2
})
console.log(result)
// 2, 4, 8最后来说说 this,源码中有这么一段 callbackfn.call(T, kValue, k, O),其中 T 就是 thisArg 值,如果没有设置,那就是 undefined。
根据【进阶 3-3 期】 中对于 call 的解读,传入 undefined 时,非严格模式下指向 Window,严格模式下为 undefined。记住这时候回调函数不能用箭头函数,因为箭头函数是没有自己的 this 的。
// 1、传入 thisArg 但使用箭头函数
let name = 'Muyiy'
let obj = {
name: 'Hello',
callback: (ele) => {
return this.name + ele
}
}
let arr = [1, 2, 3]
let result = arr.map(obj.callback, obj);
console.log(result)
// ["1", "2", "3"],此时 this 指向 window
// 那为啥不是 "Muyiy1" 这样呢,不急,第 3 步介绍
// ----------- 完美分割线 -----------
// 2、传入 thisArg,使用普通函数
let name = 'Muyiy'
let obj = {
name: 'Hello',
callback: function (ele) {
return this.name + ele
}
}
let arr = [1, 2, 3]
let result = arr.map(obj.callback, obj);
console.log(result)
// ["Hello1", "Hello2", "Hello3"],完美
// ----------- 完美分割线 -----------
// 3、不传入 thisArg,name 使用 let 声明
let name = 'Muyiy'
let obj = {
name: 'Hello',
callback: function (ele) {
return this.name + ele
}
}
let arr = [1, 2, 3]
let result = arr.map(obj.callback);
console.log(result)
// ["1", "2", "3"]
// 为什么呢,因为 let 和 const 声明的变量不会挂载到 window 上
// ----------- 完美分割线 -----------
// 4、不传入 thisArg,name 使用 var 声明
var name = 'Muyiy'
let obj = {
name: 'Hello',
callback: function (ele) {
return this.name + ele
}
}
let arr = [1, 2, 3]
let result = arr.map(obj.callback);
console.log(result)
// ["Muyiy1", "Muyiy2", "Muyiy3"]
// 看看,改成 var 就好了
// ----------- 完美分割线 -----------
// 5、严格模式
'use strict'
var name = 'Muyiy'
let obj = {
name: 'Hello',
callback: function (ele) {
return this.name + ele
}
}
let arr = [1, 2, 3]
let result = arr.map(obj.callback);
console.log(result)
// TypeError: Cannot read property 'name' of undefined
// 因为严格模式下 this 指向 undefined上面这部分实操代码介绍了 5 种情况,分别是传入 thisArg 两种情况,非严格模式下两种情况,以及严格模式下一种情况。这部分的知识在之前的文章中都有介绍过,这里主要是温故下。如果这块知识不熟悉,可以详细看我的 博客
完整的结构是 Array.prototype.filter(callbackfn[, thisArg]),和 map 是一样的。
filter 字如其名,它的主要功能就是过滤,callbackfn 执行结果如果是 true 就返回当前元素,false 则不返回,返回的所有元素组合在一起生成新数组,并返回。如果没有任何元素通过测试,则返回空数组。
所以这部分源码相比 map 而言,多了一步判断 callbackfn 的返回值。
ECMA-262 规范文档实现如下。
Array.prototype.filter = function(callbackfn, thisArg) {
// 异常处理
if (this == null) {
throw new TypeError("Cannot read property 'map' of null or undefined");
}
if (typeof callbackfn !== 'function') {
throw new TypeError(callbackfn + ' is not a function')
}
let O = Object(this), len = O.length >>> 0,
T = thisArg, A = new Array(len), k = 0
// 新增,返回数组的索引
let to = 0
while(k < len) {
if (k in O) {
let kValue = O[k]
// 新增
if (callbackfn.call(T, kValue, k, O)) {
A[to++] = kValue;
}
}
k++
}
// 新增,修改 length,初始值为 len
A.length = to;
return A
}
// 代码亲测已通过看懂 map 再看这个实现就简单多了,改动点在于判断 callbackfn 返回值,新增索引 to,这样主要避免使用 k 时生成空元素,并在返回之前修改 length 值。
这部分源码还是挺有意思的,惊喜点在于 A.length = to,之前还没用过。
reduce 可以理解为「归一」,意为海纳百川,万剑归一,完整的结构是 Array.prototype.reduce(callbackfn[, initialValue]),这里第二个参数并不是 thisArg 了,而是初始值 initialValue,关于初始值之前有介绍过。
initialValue,那么第一次调用 callback 函数时,accumulator 使用原数组中的第一个元素,currentValue 即是数组中的第二个元素。initialValue,accumulator 将使用这个初始值,currentValue 使用原数组中的第一个元素。reduce 将报错。ECMA-262 规范文档实现如下。
Array.prototype.reduce = function(callbackfn, initialValue) {
// 异常处理
if (this == null) {
throw new TypeError("Cannot read property 'map' of null or undefined");
}
if (typeof callbackfn !== 'function') {
throw new TypeError(callbackfn + ' is not a function')
}
let O = Object(this)
let len = O.length >>> 0
let k = 0, accumulator
// 新增
if (initialValue) {
accumulator = initialValue
} else {
// Step 4.
if (len === 0) {
throw new TypeError('Reduce of empty array with no initial value');
}
// Step 8.
let kPresent = false
while(!kPresent && (k < len)) {
kPresent = k in O
if (kPresent) {
accumulator = O[k]
}
k++
}
}
while(k < len) {
if (k in O) {
let kValue = O[k]
accumulator = callbackfn.call(undefined, accumulator, kValue, k, O)
}
k++
}
return accumulator
}
// 代码亲测已通过这部分源码主要多了对于 initialValue 的处理,有初始值时比较简单,即 accumulator = initialValue ,kValue = O[0]。
无初始值处理在 Step 8,循环判断当 O 及其原型链上存在属性 k 时,accumulator = O[k] 并退出循环,因为 k++,所以 kValue = O[k++]。
更多的数组方法有 find、findIndex、forEach 等,其源码实现也是大同小异,无非就是在 callbackfn.call 这部分做些处理,有兴趣的可以看看 TC39 和 MDN 官网,参考部分链接直达。
forEach 的源码和 map 很相同,在 map 的源码基础上做些改造就是啦。
Array.prototype.forEach = function(callbackfn, thisArg) {
// 相同
...
while(k < len) {
if (k in O) {
let kValue = O[k]
// 这部分是 map
// let mappedValue = callbackfn.call(T, kValue, k, O)
// A[k] = mappedValue
// 这部分是 forEach
callbackfn.call(T, kValue, k, O)
}
k++
}
// 返回 undefined
// return undefined
}可以看到,不同之处在于不处理 callbackfn 执行的结果,也不返回。
特意指出来是因为在此之前看到过一种错误的说法,叫做「forEach 会跳过空,但是 map 不跳过」
为什么说 map 不跳过呢,因为原始数组有 empty 元素时,map 返回的结果也有 empty 元素,所以不跳过,但是这种说法并不正确。
let arr = [1, , 3, , 5]
console.log(arr) // [1, empty, 3, empty, 5]
let result = arr.map(ele => {
console.log(ele) // 1, 3, 5
return ele
})
console.log(result) // [1, empty, 3, empty, 5]看 ele 输出就会明白 map 也是跳空的,原因就在于源码中的 k in O,这里是检查 O 及其原型链是否包含属性 k,所以有的实现中用 hasOwnProperty 也是不正确的。
另外 callbackfn 中不可以使用 break 跳出循环,是因为 break 只能跳出循环,而 callbackfn 并不是循环体。如果有类似的需求可以使用for..of、for..in、 some、every 等。
熟悉源码之后很多问题就迎刃而解啦,感谢阅读。
如果你觉得这篇内容对你挺有启发,我想邀请你帮我三个小忙:
本期开始介绍 JavaScript 中的高阶函数,在 JavaScript 中,函数是一种特殊类型的对象,它们是 Function objects。那什么是高阶函数呢?本节将通过高阶函数的定义来展开介绍。
高阶函数英文叫 Higher-order function,它的定义很简单,就是至少满足下列一个条件的函数:
也就是说高阶函数是对其他函数进行操作的函数,可以将它们作为参数传递,或者是返回它们。 简单来说,高阶函数是一个接收函数作为参数传递或者将函数作为返回值输出的函数。
JavaScript 语言中内置了一些高阶函数,比如 Array.prototype.map,Array.prototype.filter 和 Array.prototype.reduce,它们接受一个函数作为参数,并应用这个函数到列表的每一个元素。我们来看看使用它们与不使用高阶函数的方案对比。
map() 方法创建一个新数组,其结果是该数组中的每个元素都调用一个提供的函数后返回的结果,原始数组不会改变。传递给 map 的回调函数(callback)接受三个参数,分别是 currentValue、index(可选)、array(可选),除了 callback 之外还可以接受 this 值(可选),用于执行 callback 函数时使用的this 值。
来个简单的例子方便理解,现在有一个数组 [1, 2, 3, 4],我们想要生成一个新数组,其每个元素皆是之前数组的两倍,那么我们有下面两种使用高阶和不使用高阶函数的方式来实现。
// 木易杨
const arr1 = [1, 2, 3, 4];
const arr2 = [];
for (let i = 0; i < arr1.length; i++) {
arr2.push( arr1[i] * 2);
}
console.log( arr2 );
// [2, 4, 6, 8]
console.log( arr1 );
// [1, 2, 3, 4]// 木易杨
const arr1 = [1, 2, 3, 4];
const arr2 = arr1.map(item => item * 2);
console.log( arr2 );
// [2, 4, 6, 8]
console.log( arr1 );
// [1, 2, 3, 4]filter() 方法创建一个新数组, 其包含通过提供函数实现的测试的所有元素,原始数组不会改变。接收的参数和 map 是一样的,其返回值是一个新数组、由通过测试的所有元素组成,如果没有任何数组元素通过测试,则返回空数组。
来个例子介绍下,现在有一个数组 [1, 2, 1, 2, 3, 5, 4, 5, 3, 4, 4, 4, 4],我们想要生成一个新数组,这个数组要求没有重复的内容,即为去重。
const arr1 = [1, 2, 1, 2, 3, 5, 4, 5, 3, 4, 4, 4, 4];
const arr2 = [];
for (let i = 0; i < arr1.length; i++) {
if (arr1.indexOf( arr1[i] ) === i) {
arr2.push( arr1[i] );
}
}
console.log( arr2 );
// [1, 2, 3, 5, 4]
console.log( arr1 );
// [1, 2, 1, 2, 3, 5, 4, 5, 3, 4, 4, 4, 4]const arr1 = [1, 2, 1, 2, 3, 5, 4, 5, 3, 4, 4, 4, 4];
const arr2 = arr1.filter( (element, index, self) => {
return self.indexOf( element ) === index;
});
console.log( arr2 );
// [1, 2, 3, 5, 4]
console.log( arr1 );
// [1, 2, 1, 2, 3, 5, 4, 5, 3, 4, 4, 4, 4]reduce() 方法对数组中的每个元素执行一个提供的 reducer 函数(升序执行),将其结果汇总为单个返回值。传递给 reduce 的回调函数(callback)接受四个参数,分别是累加器 accumulator、currentValue、currentIndex(可选)、array(可选),除了 callback 之外还可以接受初始值 initialValue 值(可选)。
如果没有提供 initialValue,那么第一次调用 callback 函数时,accumulator 使用原数组中的第一个元素,currentValue 即是数组中的第二个元素。 在没有初始值的空数组上调用 reduce 将报错。
如果提供了 initialValue,那么将作为第一次调用 callback 函数时的第一个参数的值,即 accumulator,currentValue 使用原数组中的第一个元素。
来个简单的例子介绍下,现在有一个数组 [0, 1, 2, 3, 4],需要计算数组元素的和,需求比较简单,来看下代码实现。
const arr = [0, 1, 2, 3, 4];
let sum = 0;
for (let i = 0; i < arr.length; i++) {
sum += arr[i];
}
console.log( sum );
// 10
console.log( arr );
// [0, 1, 2, 3, 4]const arr = [0, 1, 2, 3, 4];
let sum = arr.reduce((accumulator, currentValue, currentIndex, array) => {
return accumulator + currentValue;
});
console.log( sum );
// 10
console.log( arr );
// [0, 1, 2, 3, 4]上面是没有 initialValue 的情况,代码的执行过程如下,callback 总共调用四次。
| callback | accumulator | currentValue | currentIndex | array | return value |
|---|---|---|---|---|---|
| first call | 0 | 1 | 1 | [0, 1, 2, 3, 4] | 1 |
| second call | 1 | 2 | 2 | [0, 1, 2, 3, 4] | 3 |
| third call | 3 | 3 | 3 | [0, 1, 2, 3, 4] | 6 |
| fourth call | 6 | 4 | 4 | [0, 1, 2, 3, 4] | 10 |
我们再来看下有 initialValue 的情况,假设 initialValue 值为 10,我们看下代码。
const arr = [0, 1, 2, 3, 4];
let sum = arr.reduce((accumulator, currentValue, currentIndex, array) => {
return accumulator + currentValue;
}, 10);
console.log( sum );
// 20
console.log( arr );
// [0, 1, 2, 3, 4]代码的执行过程如下所示,callback 总共调用五次。
| callback | accumulator | currentValue | currentIndex | array | return value |
|---|---|---|---|---|---|
| first call | 10 | 0 | 0 | [0, 1, 2, 3, 4] | 10 |
| second call | 10 | 1 | 1 | [0, 1, 2, 3, 4] | 11 |
| third call | 11 | 2 | 2 | [0, 1, 2, 3, 4] | 13 |
| fourth call | 13 | 3 | 3 | [0, 1, 2, 3, 4] | 16 |
| fifth call | 16 | 4 | 4 | [0, 1, 2, 3, 4] | 20 |
这个很好理解,就是返回一个函数,下面直接看两个例子来加深理解。
我们知道在判断类型的时候可以通过 Object.prototype.toString.call 来获取对应对象返回的字符串,比如:
let isString = obj => Object.prototype.toString.call( obj ) === '[object String]';
let isArray = obj => Object.prototype.toString.call( obj ) === '[object Array]';
let isNumber = obj => Object.prototype.toString.call( obj ) === '[object Number]';可以发现上面三行代码有很多重复代码,只需要把具体的类型抽离出来就可以封装成一个判断类型的方法了,代码如下。
let isType = type => obj => {
return Object.prototype.toString.call( obj ) === '[object ' + type + ']';
}
isType('String')('123'); // true
isType('Array')([1, 2, 3]); // true
isType('Number')(123); // true这里就是一个高阶函数,因为 isType 函数将 obj => { ... } 这一函数作为返回值输出。
我们看一个常见的面试题,用 JS 实现一个无限累加的函数 add,示例如下:
add(1); // 1
add(1)(2); // 3
add(1)(2)(3); // 6
add(1)(2)(3)(4); // 10
// 以此类推我们可以看到结构和上面代码有些类似,都是将函数作为返回值输出,然后接收新的参数并进行计算。
我们知道打印函数时会自动调用 toString()方法,函数 add(a) 返回一个闭包 sum(b),函数 sum() 中累加计算 a = a + b,只需要重写sum.toString()方法返回变量 a 就可以了。
function add(a) {
function sum(b) { // 使用闭包
a = a + b; // 累加
return sum;
}
sum.toString = function() { // 重写toString()方法
return a;
}
return sum; // 返回一个函数
}
add(1); // 1
add(1)(2); // 3
add(1)(2)(3); // 6
add(1)(2)(3)(4); // 10 已知如下数组,编写一个程序将数组扁平化去并除其中重复部分数据,最终得到一个升序且不重复的数组
var arr = [ [1, 2, 2], [3, 4, 5, 5], [6, 7, 8, 9, [11, 12, [12, 13, [14] ] ] ], 10];
参考解析:扁平化并去重
进阶系列文章汇总如下,觉得不错点个Star,欢迎 加群 互相学习。
我是木易杨,公众号「高级前端进阶」作者,跟着我每周重点攻克一个前端面试重难点。接下来让我带你走进高级前端的世界,在进阶的路上,共勉!
本期的主题是this全面解析,本计划一共28期,每期重点攻克一个面试重难点,如果你还不了解本进阶计划,文末点击查看全部文章。
如果觉得本系列不错,欢迎点赞、评论、转发,您的支持就是我坚持的最大动力。
上篇文章详细的分析了各种this的情况,看过之后对this的概念就很清晰了,没看过的去看看。
我们知道this绑定规则一共有5种情况:
其实大部分情况下可以用一句话来概括,this总是指向调用该函数的对象。
但是对于箭头函数并不是这样,是根据外层(函数或者全局)作用域(词法作用域)来决定this。
对于箭头函数的this总结如下:
箭头函数不绑定this,箭头函数中的this相当于普通变量。
箭头函数的this寻值行为与普通变量相同,在作用域中逐级寻找。
箭头函数的this无法通过bind,call,apply来直接修改(可以间接修改)。
改变作用域中this的指向可以改变箭头函数的this。
eg. function closure(){()=>{//code }},在此例中,我们通过改变封包环境closure.bind(another)(),来改变箭头函数this的指向。
/**
* 非严格模式
*/
var name = 'window'
var person1 = {
name: 'person1',
show1: function () {
console.log(this.name)
},
show2: () => console.log(this.name),
show3: function () {
return function () {
console.log(this.name)
}
},
show4: function () {
return () => console.log(this.name)
}
}
var person2 = { name: 'person2' }
person1.show1()
person1.show1.call(person2)
person1.show2()
person1.show2.call(person2)
person1.show3()()
person1.show3().call(person2)
person1.show3.call(person2)()
person1.show4()()
person1.show4().call(person2)
person1.show4.call(person2)()空
白
占
位
符
正确答案如下:
person1.show1() // person1,隐式绑定,this指向调用者 person1
person1.show1.call(person2) // person2,显式绑定,this指向 person2
person1.show2() // window,箭头函数绑定,this指向外层作用域,即全局作用域
person1.show2.call(person2) // window,箭头函数绑定,this指向外层作用域,即全局作用域
person1.show3()() // window,默认绑定,这是一个高阶函数,调用者是window
// 类似于`var func = person1.show3()` 执行`func()`
person1.show3().call(person2) // person2,显式绑定,this指向 person2
person1.show3.call(person2)() // window,默认绑定,调用者是window
person1.show4()() // person1,箭头函数绑定,this指向外层作用域,即person1函数作用域
person1.show4().call(person2) // person1,箭头函数绑定,
// this指向外层作用域,即person1函数作用域
person1.show4.call(person2)() // person2最后一个person1.show4.call(person2)()有点复杂,我们来一层一层的剥开。
var func1 = person1.show4.call(person2),这是显式绑定,调用者是person2,show4函数指向的是person2。func1(),箭头函数绑定,this指向外层作用域,即person2函数作用域首先要说明的是,箭头函数绑定中,this指向外层作用域,并不一定是第一层,也不一定是第二层。
因为没有自身的this,所以只能根据作用域链往上层查找,直到找到一个绑定了this的函数作用域,并指向调用该普通函数的对象。
这次通过构造函数来创建一个对象,并执行相同的4个show方法。
/**
* 非严格模式
*/
var name = 'window'
function Person (name) {
this.name = name;
this.show1 = function () {
console.log(this.name)
}
this.show2 = () => console.log(this.name)
this.show3 = function () {
return function () {
console.log(this.name)
}
}
this.show4 = function () {
return () => console.log(this.name)
}
}
var personA = new Person('personA')
var personB = new Person('personB')
personA.show1()
personA.show1.call(personB)
personA.show2()
personA.show2.call(personB)
personA.show3()()
personA.show3().call(personB)
personA.show3.call(personB)()
personA.show4()()
personA.show4().call(personB)
personA.show4.call(personB)()空
白
占
位
符
正确答案如下:
personA.show1() // personA,隐式绑定,调用者是 personA
personA.show1.call(personB) // personB,显式绑定,调用者是 personB
personA.show2() // personA,首先personA是new绑定,产生了新的构造函数作用域,
// 然后是箭头函数绑定,this指向外层作用域,即personA函数作用域
personA.show2.call(personB) // personA,同上
personA.show3()() // window,默认绑定,调用者是window
personA.show3().call(personB) // personB,显式绑定,调用者是personB
personA.show3.call(personB)() // window,默认绑定,调用者是window
personA.show4()() // personA,箭头函数绑定,this指向外层作用域,即personA函数作用域
personA.show4().call(personB) // personA,箭头函数绑定,call并没有改变外层作用域,
// this指向外层作用域,即personA函数作用域
personA.show4.call(personB)() // personB,解析同题目1,最后是箭头函数绑定,
// this指向外层作用域,即改变后的person2函数作用域题目一和题目二的区别在于题目二使用了new操作符。
使用 new 操作符调用构造函数,实际上会经历一下4个步骤:
- 创建一个新对象;
- 将构造函数的作用域赋给新对象(因此this就指向了这个新对象);
- 执行构造函数中的代码(为这个新对象添加属性);
- 返回新对象。
依次给出console.log输出的数值。
var num = 1;
var myObject = {
num: 2,
add: function() {
this.num = 3;
(function() {
console.log(this.num);
this.num = 4;
})();
console.log(this.num);
},
sub: function() {
console.log(this.num)
}
}
myObject.add();
console.log(myObject.num);
console.log(num);
var sub = myObject.sub;
sub();答案有两种情况,分为严格模式和非严格模式。
TypeError: Cannot read property 'num' of undefined解答过程:
var num = 1;
var myObject = {
num: 2,
add: function() {
this.num = 3; // 隐式绑定 修改 myObject.num = 3
(function() {
console.log(this.num); // 默认绑定 输出 1
this.num = 4; // 默认绑定 修改 window.num = 4
})();
console.log(this.num); // 隐式绑定 输出 3
},
sub: function() {
console.log(this.num) // 因为丢失了隐式绑定的myObject,所以使用默认绑定 输出 4
}
}
myObject.add(); // 1 3
console.log(myObject.num); // 3
console.log(num); // 4
var sub = myObject.sub;// 丢失了隐式绑定的myObject
sub(); // 4内容来自评论区:【进阶3-1期】JavaScript深入之史上最全--5种this绑定全面解析
分别给出console.log输出的内容。
var obj = {
say: function () {
function _say() {
console.log(this);
}
console.log(obj);
return _say.bind(obj);
}()
}
obj.say()进阶系列文章汇总:https://github.com/yygmind/blog,内有优质前端资料,欢迎领取,觉得不错点个star。
我是木易杨,网易高级前端工程师,跟着我每周重点攻克一个前端面试重难点。接下来让我带你走进高级前端的世界,在进阶的路上,共勉!
1、对于框架的使用没必要花太多时间,应该多研究一下三大框架背后的设计**。
2、当一个程序员对算法、语言标准、底层、原生、英文文档这些词汇产生恐惧感的时候他的技术生命已经走到尽头。
3、前端架构主要解决的是高复用性,架构能力提升方向主要是组件库开发、前端框架实现等。
4、对于前端进阶这个问题,其实看书的作用和意义已经不太明显,需要寻找好的平台和合适的项目,在项目中不断克服难题并挑战自己,遇到问题再去查资料总结。如果只是闭门看书那很难成为高手,书只是基础而已,真正的应用还是在项目中。
5、寒冬中能做的只有提升自己,但是光靠技术是不行的。
6、推荐 TensorFlow、可视化切图、PWA、WebGL
1)
TensorFlow可以了解使用并做点东西出来,原理很难但不影响使用。2)
PWA有望进一步发展。3)
WebGL在未来会是一个很好的方向,它可以实现任何你想要的界面效果,但重点需要多掌握图形学的基础知识,它和算法,数据结构一样重要。4)
Weex和RN虽然都叫Hybird但不太一样,前者适合大厂主要是嵌入 APP 中使用,后者更适合创业公司。
7、不推荐 SSR、TypeScript、函数式编程
1)
SSR不太看好,其主要是用于SEO,不太建议用做服务端渲染,其能够使用的场景不多,而且成本代价太大。2)
TypeScript是好东西,是很有前景的语言,但适用于十万行以上代码级别的大型项目,小项目并不适合,反而徒增复杂。3)用 JS 做函数式编程并不靠谱,
Map/Reduce/Redux/Hooks等并不是函数式编程,只是长得像而已。
PS:笔记内容由自己和群友提供,仅供参考。
听完 Winter 老师直播后对其观点很是赞同,但因为是面对所有人讲解所以内容有点多范围有些广,但对个人来说还是找适合自己的方向,在自己相对熟悉的领域再去扩展去突破。横向只是拓宽你的眼界,纵向才是你的核心竞争力。
对我来说感触最大的就是 3、4、5 这几点,因为我一直在思考以下几个问题:
1、我现在是高级前端,但又感觉自身很弱,那我如何才能夯实我高级的地基然后成为资深前端呢?
2、项目迭代节奏快日常加班又多,那我如何做才能平衡工作和学习?
3、单单提升技术好像还是有很大瓶颈,那我如何提升我的职场核心竞争力?
结合 Winter 老师的直播和最近看的几篇文章,说说我对这几个问题的思考。
对于第一个问题,在 2 个多月前我还是不会写文章的小白,那个时候受到一些文章的触动,开办了「高级前端进阶」这个公众号,尝试把我的前端之路记录下来,后来经过几次调整开始了「进阶系列」。我的想法很简单,就是把前端进阶 28 期的重难点知识全部讲完,目前已经进行到第 4 期了,通过写作把知识通俗易懂的介绍给别人,在这个过程自己肯定会收获很多很多。这就是我目前在尝试的学习方式,通过写作建立自己的知识架构,并且在这个架构上不断地进行优化,时间到了自然就进阶了。
对于第二个问题,刚开始写作时精力充沛时间也很多,每天都会更新技术文章,但随着项目迭代压力增大,文章更新速度相应就变慢了一些,虽然文章质量提升了很多,但更新速度从日更变成了周更再变成了双周更,这个说实话我自身已经很难接受了,因为速度变慢导致我年初的计划要打折扣。所以说做项目和自我学习要如何权衡,是否说我要减少项目难度和时间并在工作中摸鱼去学习呢?我的结论是不,因为一句话,“最好的学习就是在项目中锻炼自己”。既然我有这么好的项目去锻炼,那为什么还要摸鱼去学习呢,这不就是南辕北辙嘛,道理很简单但不是所有人都懂。
我最近在执行的方法是专注 + 锻炼 + 利用周末。
专注即工作时专注于工作,努力做好每次迭代,遇到难题迎难而上,工作时不开微信,勤用笔记安排日常工作并整理文档;
锻炼即一周抽出三天时间每次去健身房锻炼1小时,强壮的体魄才能撑住高强度的工作和学习,因为网易有健身房所以冬天锻炼也没什么问题,没办法去健身房的小伙伴可以尝试跑步或者在瑜伽垫上做 Keep;
利用周末即加大周末和平常晚上熬夜的时间去写文章,减少娱乐的时间,正所谓时间挤一挤总会有的,但这件事情比较反人性,所以重在坚持。公众号写文章更容易坚持,原因在于文章发布后有正反馈,比如粉丝的增长,留言和鼓励,赞赏等等,这些都更能促使你坚持下去,时间长了自然就养成了习惯。
对于第三个问题,Winter 老师也说了,寒冬中光靠技术是不行的,那应该靠什么呢?幸好在最近看到的一篇文章中找到了答案,那就是表达能力。表达能力是形成自己的框架系统,有理有据并且逻辑清晰,而且能让外人听懂,大部分优秀的人都具备这样的能力。反观自己并没有这样的能力,所以我要努力提升这块,其中最重要的方法就是写作训练。
兜兜转转那么多,其实我一直在尝试的进阶方法就是通过写作建立自己的知识架构体系,同时提高自身的表达能力,通过正反馈机制和锻炼保证我长久的坚持下去并最终养成习惯,习惯这一模式之后变成优秀的人也只是时间问题罢了。
希望我的一些思考和尝试能对你有所帮助。
公众号回复「文章」领取最近看到的好文章
进阶系列文章汇总如下,内有优质前端资料,觉得不错点个star。
我是木易杨,网易高级前端工程师,跟着我每周重点攻克一个前端面试重难点。接下来让我带你走进高级前端的世界,在进阶的路上,共勉!
我用原生的bind试了obj.proto.friend = "Kitty"; // 修改原型
bar.prototype.friend; // 返回错误,这里被修改了// Kitty
发现也是会修改的,这个我有点蒙了哈
{friend: "Kitty", constructor: ƒ}
paste.html:68 {friend: "Kitty", constructor: ƒ},打印出来是一样的东西var Foot = bar.bind(foo, "Jack")
var a = new Foot(20);
a.proto.friend = "Kitty"; // 修改原型
console.log(bar.prototype.friend)
console.log(bar.prototype)
console.log(a.proto)
我也试了一下,不懂为啥会说是返回错误,原生的bind 也修改了原型,那这里出错的原因,作者也没有解释
Originally posted by @Pomelo1213 in #23 (comment)
Vue进阶系列汇总如下,欢迎阅读,欢迎加群讨论(文末)。
插件的详细使用方法详情看Vue官网
概括出来就是
Vue.use(MyPlugin)使用,本质上是调用MyPlugin.install(Vue)new Vue()启动应用之前完成,实例化之前就要配置好。Vue.use多次注册相同插件,那只会注册成功一次。Vue.use源码如下
Vue.use = function (plugin) {
// 忽略已注册插件
if (plugin.installed) {
return
}
// 集合转数组,并去除第一个参数
var args = toArray(arguments, 1);
// 把this(即Vue)添加到数组的第一个参数中
args.unshift(this);
// 调用install方法
if (typeof plugin.install === 'function') {
plugin.install.apply(plugin, args);
} else if (typeof plugin === 'function') {
plugin.apply(null, args);
}
// 注册成功
plugin.installed = true;
return this;
};Vue.use接受一个对象参数plugin,首先判断是否已注册,如果多次注册相同插件那么只会注册成功一次,在注册成功后设置plugin.installed = true。
然后执行toArray(arguments, 1)方法,arguments是一个表示所有参数的类数组对象,需要转换成数组之后才能使用数组的方法。
function toArray (list, start) {
start = start || 0;
var i = list.length - start;
var ret = new Array(i);
// 循环去除 前start元素
while (i--) {
ret[i] = list[i + start];
}
return ret
}上面进行了一次转换,假设list是[1, 2, 3, 4],start是1,首先创建一个包含3个元素的数组,依次执行ret[2] = list[ 2 + 1]、ret[1] = list[ 1 + 1]、ret[0] = list[ 0 + 1],实际上就是去除arguments的第一个参数然后把剩余的类数组赋值给新的数组,其实就是去除plugin参数,因为调用plugin.install的时候不需要这个参数。
还可以通过如下几种方式实现类数组转换成数组,但是使用slice会阻止某些JavaScript引擎中的优化(参考自MDN)。
// ES5
var args = Array.prototype.slice.call(arguments);
var args = [].slice.call(arguments);
// ES6
const args = Array.from(arguments);
const args = [...arguments];转换成数组之后调用args.unshift(this),把Vue对象添加到args的第一个参数中,这样就可以在调用plugin.install方法的时候把Vue对象传递过去。
要求创建一个告诉Vue组件处理自定义rules规则选项的插件,这个rules需要一个对象,该对象指定组件中的数据的验证规则。
示例:
const vm = new Vue({
data: { foo: 10 },
rules: {
foo: {
validate: value => value > 1,
message: 'foo must be greater than one'
}
}
})
vm.foo = 0 // 输出 foo must be greater than one第一步先不考虑插件,在已有的VueAPI中是没有rules这个公共方法的,如果要简单实现的话可以通过钩子函数来,即在created里面验证逻辑。
const vm = new Vue({
data: { foo: 10 },
rules: {
foo: {
validate: value => value > 1,
message: 'foo must be greater than one'
}
},
created: function () {
// 验证逻辑
const rules = this.$options.rules
if (rules) {
Object.keys(rules).forEach(key => {
// 取得所有规则
const { validate, message } = rules[key]
// 监听,键是变量,值是函数
this.$watch(key, newValue => {
// 验证规则
const valid = validate(newValue)
if (!valid) {
console.log(message)
}
})
})
}
}
})可以通过this.$options.rules获取到自定义的rules对象,然后对所有规则遍历,使用自定义的validate(newValue)验证规则。
第二步实现这个rules插件,为了在Vue中直接使用,可以通过Vue.mixin注入到Vue组件中,这样所有的Vue实例都可以使用。
按照插件的开发流程,应该有一个公开方法install,在install里面使用全局的mixin方法添加一些组件选项,mixin方法包含一个created钩子函数,在钩子函数中验证this.$options.rules。
实现代码如下:
import Vue from 'vue'
// 定义插件
const RulesPlugin = {
// 插件应该有一个公开方法install
// 第一个参数是Vue 构造器
// 第二个参数是一个可选的选项对象
install (Vue) {
// 注入组件
Vue.mixin({
// 钩子函数
created: function () {
// 验证逻辑
const rules = this.$options.rules
if (rules) {
Object.keys(rules).forEach(key => {
// 取得所有规则
const { validate, message } = rules[key]
// 监听,键是变量,值是函数
this.$watch(key, newValue => {
// 验证规则
const valid = validate(newValue)
if (!valid) {
console.log(message)
}
})
})
}
}
})
}
}
// 调用插件,实际上就是调用插件的install方法
// 即RulesPlugin.install(Vue)
Vue.use(RulesPlugin)本人Github链接如下,欢迎各位Star
http://github.com/yygmind/blog
我是木易杨,现在是网易高级前端工程师,目前维护了一个高级前端进阶群,欢迎加入。接下来让我带你走进高级前端的世界,在进阶的路上,共勉!
Vue进阶系列汇总如下,欢迎阅读,欢迎加高级前端进阶群一起学习(文末)。
根据第一篇文章介绍的响应式原理,如下图所示。
在初始化阶段,本质上发生在auto run函数中,然后通过render函数生成Virtual DOM,view根据Virtual DOM生成Actual DOM。因为render函数依赖于页面上所有的数据data,并且这些数据是响应式的,所有的数据作为组件render函数的依赖。一旦这些数据有所改变,那么render函数会被重新调用。
在更新阶段,render函数会重新调用并且返回一个新的Virtual Dom,新旧Virtual DOM之间会进行比较,把diff之后的最小改动应用到Actual DOM中。
Watcher负责收集依赖,清除依赖和通知依赖。在大型复杂的组件树结构下,由于采用了精确的依赖追踪系统,所以会避免组件的过度渲染。
Actual DOM 通过document.createElement('div')生成一个DOM节点。
document.createElement('div')
// 浏览器原生对象(开销大)
"[object HTMLDivElement]"Virtual DOM 通过 vm.$createElement('div')生成一个JS对象,VDOM对象有一个表示div的tag属性,有一个包含了所有可能特性的data属性,可能还有一个包含更多虚拟节点的children列表。
vm.$createElement('div')
// 纯JS对象(轻量)
{ tag: 'div', data: { attrs: {}, ...}, children: [] }因为Virtual DOM的渲染逻辑和Actual DOM解耦了,所以有能力运行在的非浏览器环境中,这就是为什么Virtual DOM出现之后混合开发开始流行的原因,React Native 和 Weex能够实现的原理就是这个。
JSX和Template都是用于声明DOM和state之间关系的一种方式,在Vue中,Template是默认推荐的方式,但是也可以使用JSX来做更灵活的事。
JSX更加动态化,对于使用编程语言是很有帮助的,可以做任何事,但是动态化使得编译优化更加复杂和困难。
Template更加静态化并且对于表达式有更多约束,但是可以快速复用已经存在的模板,模板约束意味着可以在编译时做更多的性能优化,相对于JSX在编译时间上有着更多优势。
要求使用如下
<example :tags="['h1', 'h2', 'h3']"></example>要求输出如下
<div>
<h1>0</h1>
<h2>1</h2>
<h3>2</h3>
</div>上面这个需求可以通过render函数来做,官方提供了createElement 函数用来生成模板。createElement('div', {}, [...])可接受的参数如下。
// @returns {VNode}
createElement(
// {String | Object | Function}
// 一个 HTML 标签字符串,组件选项对象,或者
// 解析上述任何一种的一个 async 异步函数。必需参数。
'div',
// {Object}
// 一个包含模板相关属性的数据对象
// 你可以在 template 中使用这些特性。可选参数。
{
},
// {String | Array}
// 子虚拟节点 (VNodes),由 `createElement()` 构建而成,
// 也可以使用字符串来生成“文本虚拟节点”。可选参数。
[
'先写一些文字',
createElement('h1', '一则头条'),
createElement(MyComponent, {
props: {
someProp: 'foobar'
}
})
]
)知道了用法之后,就可以在render中返回createElement生成的虚拟节点,外层是div,内层是三个锚点标题h1 h2 h3,所以内层需要遍历下,使用两个createElement就可以完成了。
通常使用h作为createElement的别名,这是Vue的通用惯例,也是JSX的要求。
实现如下
<!--引用-->
<script src="../node_modules/vue/dist/vue.js"></script>
<!--定义template -->
<div id="app">
<example :tags="['h1', 'h2', 'h3']"></example>
</div>
<script>
// 定义example组件
Vue.component('example', {
props: ['tags'],
render (h) {
// 第二个参数是一个包含模板相关属性的数据对象,可选参数
// 子虚拟节点(VNodes)参数可以传入字符串或者数字,
// 通过createElement生成,可选参数
return h('div', this.tags.map((tag, i) => h(tag, i)))
}
})
// 实例化
new Vue({ el: '#app' })
</script><example>组件要求如下
Foo组件渲染<div>foo</div>,实现一个Bar组件渲染<div>bar</div>。<example>组件,根据属性ok动态渲染Foo组件或者Bar组件。如果属性ok是true,那么最终的渲染应该是<div>foo</div>。ok,通过这个属性让<example>在Foo或者Bar之间切换。根据上面的要求,在模板中调用<example>组件,然后定义<button>组件,同时绑定属性ok。
实现如下
<!--引用-->
<script src="../node_modules/vue/dist/vue.js"></script>
<!--定义template -->
<div id="app">
<!--绑定属性ok-->
<example :ok="ok"></example>
<!--绑定点击事件-->
<button @click="ok = !ok">toggle</button>
</div>
<script>
// 定义Foo
const Foo = {
render (h) {
return h('div', 'foo')
}
}
// 定义Bar
const Bar = {
render (h) {
return h('div', 'bar')
}
}
// 定义example组件
// 根据ok属性动态切换
Vue.component('example', {
props: ['ok'],
render (h) {
return h(this.ok ? Foo : Bar)
}
})
// 实例化
new Vue({
el: '#app',
data: { ok: true }
})
</script>要求如下
withAvatarURL函数,要求传入一个带有url属性的组件,返回一个接收username属性的高阶组件,这个高阶组件主要负责获取相应的头像URL。http://via.placeholder.com/200x200传递给内部组件。例子如下
const SmartAvatar = withAvatarURL(Avatar)
// 使用这个方式
<smart-avatar username="vuejs"></smart-avatar>
// 替换下面的方式
<avatar url="/path/to/image.png"></avatar>withAvatarURL函数返回一个对象,接收username属性,在生命周期created获取头像URL。Avatar对象接收src属性,src的内容从withAvatarURL中获取,然后展示在上。实例化的时候,传入新定义的组件名
SmartAvatar。
实现如下
<!--引用-->
<script src="../node_modules/vue/dist/vue.js"></script>
<!--定义template-->
<div id="app">
<smart-avatar username="vuejs"></smart-avatar>
</div>
<script>
// 获取头像URL
function fetchURL (username, cb) {
setTimeout(() => {
// 获取头像并回传
cb('https://avatars3.githubusercontent.com/u/6128107?v=4&s=200')
}, 500)
}
// 传递的InnerComponent
const Avatar = {
props: ['src'],
template: `<img :src="src">`
}
function withAvatarURL (InnerComponent) {
return {
props: ['username'],
inheritAttrs: false, // 2.4 only,组件将不会把未被注册的props呈现为普通的HTML属性
data () {
return { url: null }
},
created () {
// 获取头像URL并回传给this.url
fetchURL(this.username, url => {
this.url = url
})
},
render (h) {
return h(InnerComponent, {
attrs: this.$attrs, // 2.4 only,获取到没有使用的注册属性
props: {
src: this.url || 'http://via.placeholder.com/200x200'
}
})
}
}
}
const SmartAvatar = withAvatarURL(Avatar)
// 实例化,新构造组件名为SmartAvatar或smart-avatar
new Vue({
el: '#app',
components: { SmartAvatar }
})
</script>本文内容参考自VUE作者尤大的付费视频
Vue官网之渲染函数 & JSX
本人Github链接如下,欢迎各位Star
http://github.com/yygmind/blog
我是木易杨,现在是网易高级前端工程师,目前维护了一个高级前端进阶群,欢迎加入。接下来让我带你走进高级前端的世界,在进阶的路上,共勉!
前端进阶系列已经到第 5 期啦,本期正式开始原型 Prototype 系列。
本篇文章重点介绍构造函数、原型和原型链相关知识,如果你还不知道 Symbol 是不是构造函数、constructor 属性是否只读、prototype 、[[Prototype]] 和 __proto__ 的区别、什么是原型链,建议你好好阅读本文,希望对你有所帮助。
下图是本文的思维导图,高清思维导图和更多文章请看我的 Github。
constructor 返回创建实例对象时构造函数的引用。此属性的值是对函数本身的引用,而不是一个包含函数名称的字符串。
// 木易杨
function Parent(age) {
this.age = age;
}
var p = new Parent(50);
p.constructor === Parent; // true
p.constructor === Object; // false构造函数本身就是一个函数,与普通函数没有任何区别,不过为了规范一般将其首字母大写。构造函数和普通函数的区别在于,使用 new 生成实例的函数就是构造函数,直接调用的就是普通函数。
那是不是意味着普通函数创建的实例没有 constructor 属性呢?不一定。
// 木易杨
// 普通函数
function parent2(age) {
this.age = age;
}
var p2 = parent2(50);
// undefined
// 普通函数
function parent3(age) {
return {
age: age
}
}
var p3 = parent3(50);
p3.constructor === Object; // trueMDN 是这样介绍 Symbol 的
The
Symbol()function returns a value of type symbol, has static properties that expose several members of built-in objects, has static methods that expose the global symbol registry, and resembles a built-in object class but is incomplete as a constructor because it does not support the syntax "new Symbol()".
Symbol 是基本数据类型,但作为构造函数来说它并不完整,因为它不支持语法 new Symbol(),Chrome 认为其不是构造函数,如果要生成实例直接使用 Symbol() 即可。(来自 MDN)
// 木易杨
new Symbol(123); // Symbol is not a constructor
Symbol(123); // Symbol(123)虽然是基本数据类型,但 Symbol(123) 实例可以获取 constructor 属性值。
// 木易杨
var sym = Symbol(123);
console.log( sym );
// Symbol(123)
console.log( sym.constructor );
// ƒ Symbol() { [native code] }这里的 constructor 属性来自哪里?其实是 Symbol 原型上的,即 Symbol.prototype.constructor 返回创建实例原型的函数, 默认为 Symbol 函数。
这个得分情况,对于引用类型来说 constructor 属性值是可以修改的,但是对于基本类型来说是只读的。
引用类型情况其值可修改这个很好理解,比如原型链继承方案中,就需要对 constructor重新赋值进行修正。
// 木易杨
function Foo() {
this.value = 42;
}
Foo.prototype = {
method: function() {}
};
function Bar() {}
// 设置 Bar 的 prototype 属性为 Foo 的实例对象
Bar.prototype = new Foo();
Bar.prototype.foo = 'Hello World';
Bar.prototype.constructor === Object;
// true
// 修正 Bar.prototype.constructor 为 Bar 本身
Bar.prototype.constructor = Bar;
var test = new Bar() // 创建 Bar 的一个新实例
console.log(test);对于基本类型来说是只读的,比如 1、“muyiy”、true、Symbol,当然 null 和 undefined 是没有 constructor 属性的。
// 木易杨
function Type() { };
var types = [1, "muyiy", true, Symbol(123)];
for(var i = 0; i < types.length; i++) {
types[i].constructor = Type;
types[i] = [ types[i].constructor, types[i] instanceof Type, types[i].toString() ];
};
console.log( types.join("\n") );
// function Number() { [native code] }, false, 1
// function String() { [native code] }, false, muyiy
// function Boolean() { [native code] }, false, true
// function Symbol() { [native code] }, false, Symbol(123)为什么呢?因为创建他们的是只读的原生构造函数(native constructors),这个例子也说明了依赖一个对象的 constructor 属性并不安全。
说到这里就要聊聊 new 的实现了,实现代码如下。
// 木易杨
function create() {
// 1、创建一个空的对象
var obj = new Object(),
// 2、获得构造函数,同时删除 arguments 中第一个参数
Con = [].shift.call(arguments);
// 3、链接到原型,obj 可以访问构造函数原型中的属性
Object.setPrototypeOf(obj, Con.prototype);
// 4、绑定 this 实现继承,obj 可以访问到构造函数中的属性
var ret = Con.apply(obj, arguments);
// 5、优先返回构造函数返回的对象
return ret instanceof Object ? ret : obj;
};之前写过一篇文章解析 new 的模拟实现过程,如果你对实现过程还不了解的话点击阅读。「【进阶3-5期】深度解析 new 原理及模拟实现」
prototypeJavaScript 是一种基于原型的语言 (prototype-based language),这个和 Java 等基于类的语言不一样。
每个对象拥有一个原型对象,对象以其原型为模板,从原型继承方法和属性,这些属性和方法定义在对象的构造器函数的 prototype 属性上,而非对象实例本身。
从上面这张图可以发现,Parent 对象有一个原型对象 Parent.prototype,其上有两个属性,分别是 constructor 和 __proto__,其中 __proto__ 已被弃用。
构造函数 Parent 有一个指向原型的指针,原型 Parent.prototype 有一个指向构造函数的指针 Parent.prototype.constructor,如上图所示,其实就是一个循环引用。
__proto__上图可以看到 Parent 原型( Parent.prototype )上有 __proto__ 属性,这是一个访问器属性(即 getter 函数和 setter 函数),通过它可以访问到对象的内部 [[Prototype]] (一个对象或 null )。
__proto__ 发音 dunder proto,最先被 Firefox使用,后来在 ES6 被列为 Javascript 的标准内建属性。
[[Prototype]] 是对象的一个内部属性,外部代码无法直接访问。
遵循 ECMAScript 标准,someObject.[[Prototype]] 符号用于指向 someObject 的原型。
这里用 p.__proto__ 获取对象的原型,__proto__ 是每个实例上都有的属性,prototype 是构造函数的属性,这两个并不一样,但 p.__proto__ 和 Parent.prototype 指向同一个对象。
// 木易杨
function Parent() {}
var p = new Parent();
p.__proto__ === Parent.prototype
// true所以构造函数 Parent、Parent.prototype 和 p 的关系如下图。
__proto__ 属性在 ES6 时才被标准化,以确保 Web 浏览器的兼容性,但是不推荐使用,除了标准化的原因之外还有性能问题。为了更好的支持,推荐使用 Object.getPrototypeOf()。
通过改变一个对象的
[[Prototype]]属性来改变和继承属性会对性能造成非常严重的影响,并且性能消耗的时间也不是简单的花费在obj.__proto__ = ...语句上, 它还会影响到所有继承自该[[Prototype]]的对象,如果你关心性能,你就不应该修改一个对象的[[Prototype]]。
如果要读取或修改对象的 [[Prototype]] 属性,建议使用如下方案,但是此时设置对象的 [[Prototype]] 依旧是一个缓慢的操作,如果性能是一个问题,就要避免这种操作。
// 木易杨
// 获取
Object.getPrototypeOf()
Reflect.getPrototypeOf()
// 修改
Object.setPrototypeOf()
Reflect.setPrototypeOf()如果要创建一个新对象,同时继承另一个对象的 [[Prototype]] ,推荐使用 Object.create()。
// 木易杨
function Parent() {
age: 50
};
var p = new Parent();
var child = Object.create(p);这里 child 是一个新的空对象,有一个指向对象 p 的指针 __proto__。
正如上面介绍的不建议使用 __proto__,所以我们使用 Object.create() 来模拟实现,优化后的代码如下。
// 木易杨
function create() {
// 1、获得构造函数,同时删除 arguments 中第一个参数
Con = [].shift.call(arguments);
// 2、创建一个空的对象并链接到原型,obj 可以访问构造函数原型中的属性
var obj = Object.create(Con.prototype);
// 3、绑定 this 实现继承,obj 可以访问到构造函数中的属性
var ret = Con.apply(obj, arguments);
// 4、优先返回构造函数返回的对象
return ret instanceof Object ? ret : obj;
};每个对象拥有一个原型对象,通过 __proto__ 指针指向上一个原型 ,并从中继承方法和属性,同时原型对象也可能拥有原型,这样一层一层,最终指向 null。这种关系被称为原型链 (prototype chain),通过原型链一个对象会拥有定义在其他对象中的属性和方法。
我们看下面一个例子
// 木易杨
function Parent(age) {
this.age = age;
}
var p = new Parent(50);
p.constructor === Parent; // true这里 p.constructor 指向 Parent,那是不是意味着 p 实例存在 constructor 属性呢?并不是。
我们打印下 p 值就知道了。
由图可以看到实例对象 p 本身没有 constructor 属性,是通过原型链向上查找 __proto__ ,最终查找到 constructor 属性,该属性指向 Parent。
// 木易杨
function Parent(age) {
this.age = age;
}
var p = new Parent(50);
p; // Parent {age: 50}
p.__proto__ === Parent.prototype; // true
p.__proto__.__proto__ === Object.prototype; // true
p.__proto__.__proto__.__proto__ === null; // true下图展示了原型链的运作机制。
Symbol 作为构造函数来说并不完整,因为不支持语法 new Symbol(),但其原型上拥有 constructor 属性,即 Symbol.prototype.constructor。constructor 属性值是可以修改的,但是对于基本类型来说是只读的,当然 null 和 undefined 没有 constructor 属性。__proto__ 是每个实例上都有的属性,prototype 是构造函数的属性,这两个并不一样,但 p.__proto__ 和 Parent.prototype 指向同一个对象。__proto__ 属性在 ES6 时被标准化,但因为性能问题并不推荐使用,推荐使用 Object.getPrototypeOf()。__proto__ 指针指向上一个原型 ,并从中继承方法和属性,同时原型对象也可能拥有原型,这样一层一层,最终指向 null,这就是原型链。进阶系列文章汇总如下,内有优质前端资料,觉得不错点个star。
我是木易杨,网易高级前端工程师,跟着我每周重点攻克一个前端面试重难点。接下来让我带你走进高级前端的世界,在进阶的路上,共勉!
本期的主题是调用堆栈,本计划一共28期,每期重点攻克一个面试重难点,如果你还不了解本进阶计划,文末点击查看全部文章。
如果觉得本系列不错,欢迎点赞、评论、转发,您的支持就是我坚持的最大动力。
堆栈的内容和执行顺序我就不说了,前面两篇已经介绍过了。
但是今天补充一个知识点:某些情况下,调用堆栈中函数调用的数量超出了调用堆栈的实际大小,浏览器会抛出一个错误终止运行。
对于下面的递归就会无限制的执行下去,直到超出调用堆栈的实际大小,这个是浏览器定义的。
function foo() {
foo();
}
foo();现在正式开始今天的主题,内存空间详解
栈的结构就是后进先出**(LIFO)**,如果读过前面两篇文章应该是相当熟悉了。文中使用乒乓球盒子的结构来解释。
处于盒子中最顶层的乒乓球5,它一定是最后被放进去,但可以最先被使用。而我们想要使用底层的乒乓球1,就必须将上面的4个乒乓球取出来,让乒乓球1处于盒子顶层。
堆数据结构是一种树状结构。它的存取数据的方式与书架和书非常相似。我们只需要知道书的名字就可以直接取出书了,并不需要把上面的书取出来。JSON格式的数据中,我们存储的key-value可以是无序的,因为顺序的不同并不影响我们的使用,我们只需要关心书的名字。
队列是一种先进先出(FIFO)的数据结构,这是事件循环(Event Loop)的基础结构,事件循环我们会在第8期详解介绍。
首先我们应该知道内存中有栈和堆,那么变量应该存放在哪里呢,堆?栈?
在计算机的数据结构中,栈比堆的运算速度快,Object是一个复杂的结构且可以扩展:数组可扩充,对象可添加属性,都可以增删改查。将他们放在堆中是为了不影响栈的效率。而是通过引用的方式查找到堆中的实际对象再进行操作。所以查找引用类型值的时候先去栈查找再去堆查找。
问题1:
var a = 20;
var b = a;
b = 30;
// 这时a的值是多少?问题2:
var a = { name: '前端开发' }
var b = a;
b.name = '进阶';
// 这时a.name的值是多少问题3:
var a = { name: '前端开发' }
var b = a;
a = null;
// 这时b的值是多少现在来解答一下,三个问题的答案分别是20、‘进阶’、{ name: '前端开发' }
b.name的值后,相应的a.name也就发生了改变。null是基本类型,a = null之后只是把a存储在栈内存中地址改变成了基本类型null,并不会影响堆内存中的对象,所以b的值不受影响。JavaScript的内存生命周期是
JavaScript有自动垃圾收集机制,最常用的是通过标记清除的算法来找到哪些对象是不再继续使用的,使用a = null其实仅仅只是做了一个释放引用的操作,让 a 原本对应的值失去引用,脱离执行环境,这个值会在下一次垃圾收集器执行操作时被找到并释放。
在局部作用域中,当函数执行完毕,局部变量也就没有存在的必要了,因此垃圾收集器很容易做出判断并回收。但是全局变量什么时候需要自动释放内存空间则很难判断,因此在开发中,需要尽量避免使用全局变量。
var a = {n: 1};
var b = a;
a.x = a = {n: 2};
a.x // 这时 a.x 的值是多少
b.x // 这时 b.x 的值是多少进阶系列文章汇总:https://github.com/yygmind/blog,内有优质前端资料,觉得不错点个star。
我是木易杨,网易高级前端工程师,跟着我每周重点攻克一个前端面试重难点。接下来让我带你走进高级前端的世界,在进阶的路上,共勉!
本期的主题是作用域闭包,本计划一共28期,每期重点攻克一个面试重难点,如果你还不了解本进阶计划,文末点击查看全部文章。
如果觉得本系列不错,欢迎点赞、评论、转发,您的支持就是我坚持的最大动力。
作用域指的是一个变量和函数的作用范围,JS中函数内声明的所有变量在函数体内始终是可见的,在ES6前有全局作用域和局部作用域,但是没有块级作用域(catch只在其内部生效),局部变量的优先级高于全局变量。
var scope="global";
function scopeTest(){
console.log(scope);
var scope="local"
}
scopeTest(); //undefined上面的代码输出是undefined,这是因为局部变量scope变量提升了,等效于下面
var scope="global";
function scopeTest(){
var scope;
console.log(scope);
scope="local"
}
scopeTest(); //undefined注意,如果在局部作用域中忘记var,那么变量就被声明为全局变量。
var data = [];
for (var i = 0; i < 3; i++) {
data[i] = function () {
console.log(i);
};
}
data[0](); // 3
data[1](); // 3
data[2](); // 3上篇文章已经介绍过了,【进阶2-2期】JavaScript深入之从作用域链理解闭包
每个函数都有自己的执行上下文环境,当代码在这个环境中执行时,会创建变量对象的作用域链,作用域链是一个对象列表或对象链,它保证了变量对象的有序访问。
作用域链的开始是当前代码执行环境的变量对象,常被称之为“活跃对象”(AO),变量的查找会从第一个链的对象开始,如果对象中包含变量属性,那么就停止查找,如果没有就会继续向上级作用域链查找,直到找到全局对象中
function createClosure(){
var name = "jack";
return {
setStr:function(){
name = "rose";
},
getStr:function(){
return name + ":hello";
}
}
}
var builder = new createClosure();
builder.setStr();
console.log(builder.getStr()); //rose:hello上面在函数中返回了两个闭包,这两个闭包都维持着对外部作用域的引用。闭包中会将外部函数的自由对象添加到自己的作用域链中,所以可以通过内部函数访问外部函数的属性,这也是javascript模拟私有变量的一种方式。
由于作用域链机制的影响,闭包只能取得内部函数的最后一个值,这引起的一个副作用就是如果内部函数在一个循环中,那么变量的值始终为最后一个值。
这个代码已经贴过了,怕你们忘记,就再贴一遍
var data = [];
for (var i = 0; i < 3; i++) {
data[i] = function () {
console.log(i);
};
}
data[0](); // 3
data[1](); // 3
data[2](); // 3如果要强制返回预期的结果,怎么办???
for (var i = 0; i < 3; i++) {
(function(num) {
setTimeout(function() {
console.log(num);
}, 1000);
})(i);
}
// 0
// 1
// 2var data = [];
for (var i = 0; i < 3; i++) {
data[i] = (function (num) {
return function(){
console.log(num);
}
})(i);
}
data[0](); // 0
data[1](); // 1
data[2](); // 2无论是立即执行函数还是返回一个匿名函数赋值,原理上都是因为变量的按值传递,所以会将变量i的值复制给实参num,在匿名函数的内部又创建了一个用于访问num的匿名函数,这样每个函数都有了一个num的副本,互不影响了。
var data = [];
for (let i = 0; i < 3; i++) {
data[i] = function () {
console.log(i);
};
}
data[0]();
data[1]();
data[2]();解释下原理:
var data = [];// 创建一个数组data;
// 进入第一次循环
{
let i = 0; // 注意:因为使用let使得for循环为块级作用域
// 此次 let i = 0 在这个块级作用域中,而不是在全局环境中
data[0] = function() {
console.log(i);
};
}循环时,let声明i,所以整个块是块级作用域,那么data[0]这个函数就成了一个闭包。这里用{}表达并不符合语法,只是希望通过它来说明let存在时,这个for循环块是块级作用域,而不是全局作用域。
上面的块级作用域,就像函数作用域一样,函数执行完毕,其中的变量会被销毁,但是因为这个代码块中存在一个闭包,闭包的作用域链中引用着块级作用域,所以在闭包被调用之前,这个块级作用域内部的变量不会被销毁。
// 进入第二次循环
{
let i = 1; // 因为 let i = 1 和上面的 let i = 0
// 在不同的作用域中,所以不会相互影响
data[1] = function(){
console.log(i);
};
}当执行data[1]()时,进入下面的执行环境。
{
let i = 1;
data[1] = function(){
console.log(i);
};
}在上面这个执行环境中,它会首先寻找该执行环境中是否存在i,没有找到,就沿着作用域链继续向上到了其所在的块作用域执行环境,找到了i = 1,于是输出了1。
代码1:
var scope = "global scope";
function checkscope(){
var scope = "local scope";
function f(){
return scope;
}
return f;
}
checkscope()(); 代码2:
var scope = "global scope";
function checkscope(){
var scope = "local scope";
function f(){
return scope;
}
return f;
}
var foo = checkscope();
foo(); 上面的两个代码中,checkscope()执行完成后,闭包f所引用的自由变量scope会被垃圾回收吗?为什么?
进阶系列文章汇总:https://github.com/yygmind/blog,内有优质前端资料,欢迎领取,觉得不错点个star。
我是木易杨,网易高级前端工程师,跟着我每周重点攻克一个前端面试重难点。接下来让我带你走进高级前端的世界,在进阶的路上,共勉!
上篇文章用图解的方式向大家介绍了原型链及其继承方案,在介绍原型链继承的过程中讲解原型链运作机制以及属性遮蔽等知识,今天这篇文章就来深入探究下 Function.__proto__ === Function.prototype 引起的鸡生蛋蛋生鸡问题,并在这个过程中深入了解 Object.prototype、Function.prototype、function Object 、function Function 之间的关系。
我们先来看看 ECMAScript 上的定义(15.2.4)。
The value of the [[Prototype]] internal property of the Object prototype object is null, the value of the [[Class]] internal property is
"Object", and the initial value of the [[Extensible]] internal property is true.
Object.prototype 表示 Object 的原型对象,其 [[Prototype]] 属性是 null,访问器属性 __proto__ 暴露了一个对象的内部 [[Prototype]] 。 Object.prototype 并不是通过 Object 函数创建的,为什么呢?看如下代码
function Foo() {
this.value = 'foo';
}
let f = new Foo();
f.__proto__ === Foo.prototype;
// true实例对象的 __proto__ 指向构造函数的 prototype,即 f.__proto__ 指向 Foo.prototype,但是 Object.prototype.__proto__ 是 null,所以 Object.prototype 并不是通过 Object 函数创建的,那它如何生成的?其实 Object.prototype 是浏览器底层根据 ECMAScript 规范创造的一个对象。
Object.prototype 就是原型链的顶端(不考虑 null 的情况下),所有对象继承了它的 toString 等方法和属性。
我们先来看看 ECMAScript 上的定义(15.3.4)。
The Function prototype object is itself a Function object (its [[Class]] is
"Function").The value of the [[Prototype]] internal property of the Function prototype object is the standard built-in Object prototype object.
The Function prototype object does not have a
valueOfproperty of its own; however, it inherits thevalueOfproperty from the Object prototype Object.
Function.prototype 对象是一个函数(对象),其 [[Prototype]] 内部属性值指向内建对象 Object.prototype。Function.prototype 对象自身没有 valueOf 属性,其从 Object.prototype 对象继承了 valueOf 属性。
Function.prototype 的 [[Class]] 属性是 Function,所以这是一个函数,但又不大一样。为什么这么说呢?因为我们知道只有函数才有 prototype 属性,但并不是所有函数都有这个属性,因为 Function.prototype 这个函数就没有。
Function.prototype
// ƒ () { [native code] }
Function.prototype.prototype
// undefined当然你会发现下面这个函数也没有 prototype 属性。
let fun = Function.prototype.bind()
// ƒ () { [native code] }
fun.prototype
// undefined为什么没有呢,我的理解是 Function.prototype 是引擎创建出来的函数,引擎认为不需要给这个函数对象添加 prototype 属性,不然 Function.prototype.prototype… 将无休无止并且没有存在的意义。
我们先来看看 ECMAScript 上的定义(15.2.3)。
The value of the [[Prototype]] internal property of the Object constructor is the standard built-in Function prototype object.
Object 作为构造函数时,其 [[Prototype]] 内部属性值指向 Function.prototype,即
Object.__proto__ === Function.prototype
// true使用 new Object() 创建新对象时,这个新对象的 [[Prototype]] 内部属性指向构造函数的 prototype 属性,对应上图就是 Object.prototype。
当然也可以通过对象字面量等方式创建对象。
[[Prototype]] 值是 Object.prototype。[[Prototype]] 值是 Array.prototype。function f(){} 函数创建的对象,其 [[Prototype]] 值是 Function.prototype。new fun() 创建的对象,其中 fun 是由 JavaScript 提供的内建构造器函数之一(Object, Function, Array, Boolean, Date, Number, String 等等),其 [[Prototype]] 值是 fun.prototype。[[Prototype]] 值就是该构造器函数的 prototype 属性。let o = {a: 1};
// 原型链: o ---> Object.prototype ---> null
let a = ["yo", "whadup", "?"];
// 原型链: a ---> Array.prototype ---> Object.prototype ---> null
function f(){
return 2;
}
// 原型链: f ---> Function.prototype ---> Object.prototype ---> null
let fun = new Function();
// 原型链: fun ---> Function.prototype ---> Object.prototype ---> null
function Foo() {}
let foo = new Foo();
// 原型链: foo ---> Foo.prototype ---> Object.prototype ---> null
function Foo() {
return {};
}
let foo = new Foo();
// 原型链: foo ---> Object.prototype ---> null我们先来看看 ECMAScript 上的定义(15.3.3)。
The Function constructor is itself a Function object and its [[Class]] is
"Function". The value of the [[Prototype]] internal property of the Function constructor is the standard built-in Function prototype object.
Function 构造函数是一个函数对象,其 [[Class]] 属性是 Function。Function 的 [[Prototype]] 属性指向了 Function.prototype,即
Function.__proto__ === Function.prototype
// true到这里就有意思了,我们看下鸡生蛋蛋生鸡问题。
我们看下面这段代码
Object instanceof Function // true
Function instanceof Object // true
Object instanceof Object // true
Function instanceof Function // trueObject 构造函数继承了 Function.prototype,同时 Function 构造函数继承了Object.prototype。这里就产生了 鸡和蛋 的问题。为什么会出现这种问题,因为 Function.prototype 和 Function.__proto__ 都指向 Function.prototype。
// Object instanceof Function 即
Object.__proto__ === Function.prototype // true
// Function instanceof Object 即
Function.__proto__.__proto__ === Object.prototype // true
// Object instanceof Object 即
Object.__proto__.__proto__ === Object.prototype // true
// Function instanceof Function 即
Function.__proto__ === Function.prototype // true对于 Function.__proto__ === Function.prototype 这一现象有 2 种解释,争论点在于 Function 对象是不是由 Function 构造函数创建的一个实例?
解释 1、YES:按照 JavaScript 中“实例”的定义,a 是 b 的实例即 a instanceof b 为 true,默认判断条件就是 b.prototype 在 a 的原型链上。而 Function instanceof Function 为 true,本质上即 Object.getPrototypeOf(Function) === Function.prototype,正符合此定义。
解释 2、NO:Function 是 built-in 的对象,也就是并不存在“Function对象由Function构造函数创建”这样显然会造成鸡生蛋蛋生鸡的问题。实际上,当你直接写一个函数时(如 function f() {} 或 x => x),也不存在调用 Function 构造器,只有在显式调用 Function 构造器时(如 new Function('x', 'return x') )才有。
我个人偏向于第二种解释,即先有 Function.prototype 然后有的 function Function() ,所以就不存在鸡生蛋蛋生鸡问题了,把 Function.__proto__ 指向 Function.prototype 是为了保证原型链的完整,让 Function 可以获取定义在 Object.prototype 上的方法。
最后给一个完整的图,看懂这张图原型就没问题了。
JavaScript 内置类型是浏览器内核自带的,浏览器底层对 JavaScript 的实现基于 C/C++,那么浏览器在初始化 JavaScript 环境时都发生了什么?
没找到官方文档,下文参考自 https://segmentfault.com/a/1190000005754797。对于其观点比较认同,欢迎小伙伴提出不同观点。
1、用 C/C++ 构造内部数据结构创建一个 OP 即 (Object.prototype) 以及初始化其内部属性但不包括行为。
2、用 C/C++ 构造内部数据结构创建一个 FP 即 (Function.prototype) 以及初始化其内部属性但不包括行为。
3、将 FP 的 [[Prototype]] 指向 OP。
4、用 C/C++ 构造内部数据结构创建各种内置引用类型。
5、将各内置引用类型的[[Prototype]]指向 FP。
6、将 Function 的 prototype 指向 FP。
7、将 Object 的 prototype 指向 OP。
8、用 Function 实例化出 OP,FP,以及 Object 的行为并挂载。
9、用 Object 实例化出除 Object 以及 Function 的其他内置引用类型的 prototype 属性对象。
10、用 Function 实例化出除Object 以及 Function 的其他内置引用类型的 prototype 属性对象的行为并挂载。
11、实例化内置对象 Math 以及 Grobal
至此,所有内置类型构建完成。
从探究Function.__proto__===Function.prototype过程中的一些收获
进阶系列文章汇总如下,觉得不错点个Star,欢迎 加群 互相学习。
我是木易杨,公众号「高级前端进阶」作者,跟着我每周重点攻克一个前端面试重难点。接下来让我带你走进高级前端的世界,在进阶的路上,共勉!
this的绑定规则总共有下面5种。
调用位置就是函数在代码中被调用的位置(而不是声明的位置)。
查找方法:
分析调用栈:调用位置就是当前正在执行的函数的前一个调用中
function baz() {
// 当前调用栈是:baz
// 因此,当前调用位置是全局作用域
console.log( "baz" );
bar(); // <-- bar的调用位置
}
function bar() {
// 当前调用栈是:baz --> bar
// 因此,当前调用位置在baz中
console.log( "bar" );
foo(); // <-- foo的调用位置
}
function foo() {
// 当前调用栈是:baz --> bar --> foo
// 因此,当前调用位置在bar中
console.log( "foo" );
}
baz(); // <-- baz的调用位置使用开发者工具得到调用栈:
设置断点或者插入debugger;语句,运行时调试器会在那个位置暂停,同时展示当前位置的函数调用列表,这就是调用栈。找到栈中的第二个元素,这就是真正的调用位置。
undefined。只有函数运行在非严格模式下,默认绑定才能绑定到全局对象。在严格模式下调用函数则不影响默认绑定。function foo() { // 运行在严格模式下,this会绑定到undefined
"use strict";
console.log( this.a );
}
var a = 2;
// 调用
foo(); // TypeError: Cannot read property 'a' of undefined
// --------------------------------------
function foo() { // 运行
console.log( this.a );
}
var a = 2;
(function() { // 严格模式下调用函数则不影响默认绑定
"use strict";
foo(); // 2
})();当函数引用有上下文对象时,隐式绑定规则会把函数中的this绑定到这个上下文对象。对象属性引用链中只有上一层或者说最后一层在调用中起作用。
function foo() {
console.log( this.a );
}
var obj = {
a: 2,
foo: foo
};
obj.foo(); // 2隐式丢失
被隐式绑定的函数特定情况下会丢失绑定对象,应用默认绑定,把this绑定到全局对象或者undefined上。
// 虽然bar是obj.foo的一个引用,但是实际上,它引用的是foo函数本身。
// bar()是一个不带任何修饰的函数调用,应用默认绑定。
function foo() {
console.log( this.a );
}
var obj = {
a: 2,
foo: foo
};
var bar = obj.foo; // 函数别名
var a = "oops, global"; // a是全局对象的属性
bar(); // "oops, global"参数传递就是一种隐式赋值,传入函数时也会被隐式赋值。回调函数丢失this绑定是非常常见的。
function foo() {
console.log( this.a );
}
function doFoo(fn) {
// fn其实引用的是foo
fn(); // <-- 调用位置!
}
var obj = {
a: 2,
foo: foo
};
var a = "oops, global"; // a是全局对象的属性
doFoo( obj.foo ); // "oops, global"
// ----------------------------------------
// JS环境中内置的setTimeout()函数实现和下面的伪代码类似:
function setTimeout(fn, delay) {
// 等待delay毫秒
fn(); // <-- 调用位置!
}通过call(..) 或者 apply(..)方法。第一个参数是一个对象,在调用函数时将这个对象绑定到this。因为直接指定this的绑定对象,称之为显示绑定。
function foo() {
console.log( this.a );
}
var obj = {
a: 2
};
foo.call( obj ); // 2 调用foo时强制把foo的this绑定到obj上显示绑定无法解决丢失绑定问题。
解决方案:
创建函数bar(),并在它的内部手动调用foo.call(obj),强制把foo的this绑定到了obj。这种方式让我想起了借用构造函数继承,没看过的可以点击查看 JavaScript常用八种继承方案
function foo() {
console.log( this.a );
}
var obj = {
a: 2
};
var bar = function() {
foo.call( obj );
};
bar(); // 2
setTimeout( bar, 100 ); // 2
// 硬绑定的bar不可能再修改它的this
bar.call( window ); // 2典型应用场景是创建一个包裹函数,负责接收参数并返回值。
function foo(something) {
console.log( this.a, something );
return this.a + something;
}
var obj = {
a: 2
};
var bar = function() {
return foo.apply( obj, arguments );
};
var b = bar( 3 ); // 2 3
console.log( b ); // 5创建一个可以重复使用的辅助函数。
function foo(something) {
console.log( this.a, something );
return this.a + something;
}
// 简单的辅助绑定函数
function bind(fn, obj) {
return function() {
return fn.apply( obj, arguments );
}
}
var obj = {
a: 2
};
var bar = bind( foo, obj );
var b = bar( 3 ); // 2 3
console.log( b ); // 5ES5内置了Function.prototype.bind,bind会返回一个硬绑定的新函数,用法如下。
function foo(something) {
console.log( this.a, something );
return this.a + something;
}
var obj = {
a: 2
};
var bar = foo.bind( obj );
var b = bar( 3 ); // 2 3
console.log( b ); // 5JS许多内置函数提供了一个可选参数,被称之为“上下文”(context),其作用和bind(..)一样,确保回调函数使用指定的this。这些函数实际上通过call(..)和apply(..)实现了显式绑定。
function foo(el) {
console.log( el, this.id );
}
var obj = {
id: "awesome"
}
var myArray = [1, 2, 3]
// 调用foo(..)时把this绑定到obj
myArray.forEach( foo, obj );
// 1 awesome 2 awesome 3 awesome构造函数只是使用new操作符时被调用的普通函数,他们不属于某个类,也不会实例化一个类。Number(..))在内的所有函数都可以用new来调用,这种函数调用被称为构造函数调用。使用new来调用函数,或者说发生构造函数调用时,会自动执行下面的操作。
[[Prototype]]连接。this。new表达式中的函数调用会自动返回这个新对象。使用new来调用foo(..)时,会构造一个新对象并把它(bar)绑定到foo(..)调用中的this。
function foo(a) {
this.a = a;
}
var bar = new foo(2); // bar和foo(..)调用中的this进行绑定
console.log( bar.a ); // 2手写一个new实现
function create() {
// 创建一个空的对象
var obj = new Object(),
// 获得构造函数,arguments中去除第一个参数
Con = [].shift.call(arguments);
// 链接到原型,obj 可以访问到构造函数原型中的属性
obj.__proto__ = Con.prototype;
// 绑定 this 实现继承,obj 可以访问到构造函数中的属性
var ret = Con.apply(obj, arguments);
// 优先返回构造函数返回的对象
return ret instanceof Object ? ret : obj;
};使用这个手写的new
function Person() {...}
// 使用内置函数new
var person = new Person(...)
// 使用手写的new,即create
var person = create(Person, ...)代码原理解析:
1、用new Object() 的方式新建了一个对象obj
2、取出第一个参数,就是我们要传入的构造函数。此外因为 shift 会修改原数组,所以 arguments 会被去除第一个参数
3、将 obj 的原型指向构造函数,这样obj就可以访问到构造函数原型中的属性
4、使用 apply,改变构造函数 this 的指向到新建的对象,这样 obj 就可以访问到构造函数中的属性
5、返回 obj
st=>start: Start
e=>end: End
cond1=>condition: new绑定
op1=>operation: this绑定新创建的对象,
var bar = new foo()
cond2=>condition: 显示绑定
op2=>operation: this绑定指定的对象,
var bar = foo.call(obj2)
cond3=>condition: 隐式绑定
op3=>operation: this绑定上下文对象,
var bar = obj1.foo()
op4=>operation: 默认绑定
op5=>operation: 函数体严格模式下绑定到undefined,
否则绑定到全局对象,
var bar = foo()
st->cond1
cond1(yes)->op1->e
cond1(no)->cond2
cond2(yes)->op2->e
cond2(no)->cond3
cond3(yes)->op3->e
cond3(no)->op4->op5->e
在new中使用硬绑定函数的目的是预先设置函数的一些参数,这样在使用new进行初始化时就可以只传入其余的参数(柯里化)。
function foo(p1, p2) {
this.val = p1 + p2;
}
// 之所以使用null是因为在本例中我们并不关心硬绑定的this是什么
// 反正使用new时this会被修改
var bar = foo.bind( null, "p1" );
var baz = new bar( "p2" );
baz.val; // p1p2把null或者undefined作为this的绑定对象传入call、apply或者bind,这些值在调用时会被忽略,实际应用的是默认规则。
下面两种情况下会传入null
apply(..)来“展开”一个数组,并当作参数传入一个函数bind(..)可以对参数进行柯里化(预先设置一些参数)function foo(a, b) {
console.log( "a:" + a + ",b:" + b );
}
// 把数组”展开“成参数
foo.apply( null, [2, 3] ); // a:2,b:3
// 使用bind(..)进行柯里化
var bar = foo.bind( null, 2 );
bar( 3 ); // a:2,b:3 总是传入null来忽略this绑定可能产生一些副作用。如果某个函数确实使用了this,那默认绑定规则会把this绑定到全局对象中。
更安全的this
安全的做法就是传入一个特殊的对象(空对象),把this绑定到这个对象不会对你的程序产生任何副作用。
JS中创建一个空对象最简单的方法是**Object.create(null)**,这个和{}很像,但是并不会创建Object.prototype这个委托,所以比{}更空。
function foo(a, b) {
console.log( "a:" + a + ",b:" + b );
}
// 我们的空对象
var ø = Object.create( null );
// 把数组”展开“成参数
foo.apply( ø, [2, 3] ); // a:2,b:3
// 使用bind(..)进行柯里化
var bar = foo.bind( ø, 2 );
bar( 3 ); // a:2,b:3 间接引用下,调用这个函数会应用默认绑定规则。间接引用最容易在赋值时发生。
// p.foo = o.foo的返回值是目标函数的引用,所以调用位置是foo()而不是p.foo()或者o.foo()
function foo() {
console.log( this.a );
}
var a = 2;
var o = { a: 3, foo: foo };
var p = { a: 4};
o.foo(); // 3
(p.foo = o.foo)(); // 2new除外),防止函数调用应用默认绑定规则。但是会降低函数的灵活性,使用硬绑定之后就无法使用隐式绑定或者显式绑定来修改this。// 默认绑定规则,优先级排最后
// 如果this绑定到全局对象或者undefined,那就把指定的默认对象obj绑定到this,否则不会修改this
if(!Function.prototype.softBind) {
Function.prototype.softBind = function(obj) {
var fn = this;
// 捕获所有curried参数
var curried = [].slice.call( arguments, 1 );
var bound = function() {
return fn.apply(
(!this || this === (window || global)) ?
obj : this,
curried.concat.apply( curried, arguments )
);
};
bound.prototype = Object.create( fn.prototype );
return bound;
};
}使用:软绑定版本的foo()可以手动将this绑定到obj2或者obj3上,但如果应用默认绑定,则会将this绑定到obj。
function foo() {
console.log("name:" + this.name);
}
var obj = { name: "obj" },
obj2 = { name: "obj2" },
obj3 = { name: "obj3" };
// 默认绑定,应用软绑定,软绑定把this绑定到默认对象obj
var fooOBJ = foo.softBind( obj );
fooOBJ(); // name: obj
// 隐式绑定规则
obj2.foo = foo.softBind( obj );
obj2.foo(); // name: obj2 <---- 看!!!
// 显式绑定规则
fooOBJ.call( obj3 ); // name: obj3 <---- 看!!!
// 绑定丢失,应用软绑定
setTimeout( obj2.foo, 10 ); // name: objES6新增一种特殊函数类型:箭头函数,箭头函数无法使用上述四条规则,而是根据外层(函数或者全局)作用域(词法作用域)来决定this。
foo()内部创建的箭头函数会捕获调用时foo()的this。由于foo()的this绑定到obj1,bar(引用箭头函数)的this也会绑定到obj1,箭头函数的绑定无法被修改(new也不行)。function foo() {
// 返回一个箭头函数
return (a) => {
// this继承自foo()
console.log( this.a );
};
}
var obj1 = {
a: 2
};
var obj2 = {
a: 3
}
var bar = foo.call( obj1 );
bar.call( obj2 ); // 2,不是3!ES6之前和箭头函数类似的模式,采用的是词法作用域取代了传统的this机制。
function foo() {
var self = this; // lexical capture of this
setTimeout( function() {
console.log( self.a ); // self只是继承了foo()函数的this绑定
}, 100 );
}
var obj = {
a: 2
};
foo.call(obj); // 2代码风格统一问题:如果既有this风格的代码,还会使用 seft = this 或者箭头函数来否定this机制。
bind(..),尽量避免使用 self = this 和箭头函数。代码1:
var scope = "global scope";
function checkscope(){
var scope = "local scope";
function f(){
return scope;
}
return f;
}
checkscope()(); 代码2:
var scope = "global scope";
function checkscope(){
var scope = "local scope";
function f(){
return scope;
}
return f;
}
var foo = checkscope();
foo(); 上面的两个代码中,checkscope()执行完成后,闭包f所引用的自由变量scope会被垃圾回收吗?为什么?
解答:
checkscope()执行完成后,代码1中自由变量特定时间之后回收,代码2中自由变量不回收。
首先要说明的是,现在主流浏览器的垃圾回收算法是标记清除,标记清除并非是标记执行栈的进出,而是从根开始遍历,也是一个找引用关系的过程,但是因为从根开始,相互引用的情况不会被计入。所以当垃圾回收开始时,从Root(全局对象)开始寻找这个对象的引用是否可达,如果引用链断裂,那么这个对象就会回收。
闭包中的作用域链中 parentContext.vo 是对象,被放在堆中,栈中的变量会随着执行环境进出而销毁,堆中需要垃圾回收,闭包内的自由变量会被分配到堆上,所以当外部方法执行完毕后,对其的引用并没有丢。
每次进入函数执行时,会重新创建可执行环境和活动对象,但函数的[[Scope]]是函数定义时就已经定义好的(词法作用域规则),不可更改。
checkscope()执行时,将checkscope对象指针压入栈中,其执行环境变量如下
checkscopeContext:{
AO:{
arguments:
scope:
f:
},
this,
[[Scope]]:[AO, globalContext.VO]
}执行完毕后出栈,该对象没有绑定给谁,从Root开始查找无法可达,此活动对象一段时间后会被回收
checkscope()执行后,返回的是f对象,其执行环境变量如下
fContext:{
AO:{
arguments:
},
this,
[[Scope]]:[AO, checkscopeContext.AO, globalContext.VO]
}此对象赋值给var foo = checkscope();,将foo 压入栈中,foo 指向堆中的f活动对象,对于Root来说可达,不会被回收。
如果一定要自由变量scope回收,那么该怎么办???
很简单,foo = null;,把引用断开就可以了。
依次给出console.log输出的数值。
var num = 1;
var myObject = {
num: 2,
add: function() {
this.num = 3;
(function() {
console.log(this.num);
this.num = 4;
})();
console.log(this.num);
},
sub: function() {
console.log(this.num)
}
}
myObject.add();
console.log(myObject.num);
console.log(num);
var sub = myObject.sub;
sub();进阶系列文章汇总如下,内有优质前端资料,觉得不错点个star。
我是木易杨,网易高级前端工程师,跟着我每周重点攻克一个前端面试重难点。接下来让我带你走进高级前端的世界,在进阶的路上,共勉!
new 运算符创建一个用户定义的对象类型的实例或具有构造函数的内置对象的实例。 ——(来自于MDN)
举个栗子
function Car(color) {
this.color = color;
}
Car.prototype.start = function() {
console.log(this.color + " car start");
}
var car = new Car("black");
car.color; // 访问构造函数里的属性
// black
car.start(); // 访问原型里的属性
// black car start可以看出 new 创建的实例有以下 2 个特性
ES6新增 symbol 类型,不可以使用 new Symbol(),因为 symbol 是基本数据类型,每个从Symbol()返回的 symbol 值都是唯一的。
Number("123"); // 123
String(123); // "123"
Boolean(123); // true
Symbol(123); // Symbol(123)
new Number("123"); // Number {123}
new String(123); // String {"123"}
new Boolean(true); // Boolean {true}
new Symbol(123); // Symbol is not a constructor当代码 new Foo(...) 执行时,会发生以下事情:
Foo.prototype 的新对象被创建。Foo ,并将 this 绑定到新创建的对象。new Foo 等同于 new Foo(),也就是没有指定参数列表,Foo 不带任何参数调用的情况。new 表达式的结果。如果构造函数没有显式返回一个对象,则使用步骤1创建的对象。new 是关键词,不可以直接覆盖。这里使用 create 来模拟实现 new 的效果。
new 返回一个新对象,通过 obj.__proto__ = Con.prototype 继承构造函数的原型,同时通过 Con.apply(obj, arguments)调用父构造函数实现继承,获取构造函数上的属性(【进阶3-3期】)。
实现代码如下
// 第一版
function create() {
// 创建一个空的对象
var obj = new Object(),
// 获得构造函数,arguments中去除第一个参数
Con = [].shift.call(arguments);
// 链接到原型,obj 可以访问到构造函数原型中的属性
obj.__proto__ = Con.prototype;
// 绑定 this 实现继承,obj 可以访问到构造函数中的属性
Con.apply(obj, arguments);
// 返回对象
return obj;
};测试一下
// 测试用例
function Car(color) {
this.color = color;
}
Car.prototype.start = function() {
console.log(this.color + " car start");
}
var car = create(Car, "black");
car.color;
// black
car.start();
// black car start完美!
不熟悉 apply / call 的点击查看:【进阶3-3期】深度解析 call 和 apply 原理、使用场景及实现
不熟悉继承的点击查看:JavaScript常用八种继承方案
上面的代码已经实现了 80%,现在继续优化。
构造函数返回值有如下三种情况:
return,即返回 undefinedundefined 以外的基本类型情况1:返回一个对象
function Car(color, name) {
this.color = color;
return {
name: name
}
}
var car = new Car("black", "BMW");
car.color;
// undefined
car.name;
// "BMW"实例 car 中只能访问到返回对象中的属性。
情况2:没有 return,即返回 undefined
function Car(color, name) {
this.color = color;
}
var car = new Car("black", "BMW");
car.color;
// black
car.name;
// undefined实例 car 中只能访问到构造函数中的属性,和情况1完全相反。
情况3:返回undefined 以外的基本类型
function Car(color, name) {
this.color = color;
return "new car";
}
var car = new Car("black", "BMW");
car.color;
// black
car.name;
// undefined实例 car 中只能访问到构造函数中的属性,和情况1完全相反,结果相当于没有返回值。
所以需要判断下返回的值是不是一个对象,如果是对象则返回这个对象,不然返回新创建的 obj对象。
所以实现代码如下:
// 第二版
function create() {
// 创建一个空的对象
var obj = new Object(),
// 获得构造函数,arguments中去除第一个参数
Con = [].shift.call(arguments);
// 链接到原型,obj 可以访问到构造函数原型中的属性
obj.__proto__ = Con.prototype;
// 绑定 this 实现继承,obj 可以访问到构造函数中的属性
var ret = Con.apply(obj, arguments);
// 优先返回构造函数返回的对象
return ret instanceof Object ? ret : obj;
};问题:用 JS 实现一个无限累加的函数 add,示例如下:
add(1); // 1
add(1)(2); // 3
add(1)(2)(3); // 6
add(1)(2)(3)(4); // 10
// 以此类推实现:
function add(a) {
function sum(b) { // 使用闭包
a = a + b; // 累加
return sum;
}
sum.toString = function() { // 重写toString()方法
return a;
}
return sum; // 返回一个函数
}
add(1); // 1
add(1)(2); // 3
add(1)(2)(3); // 6
add(1)(2)(3)(4); // 10 我们知道打印函数时会自动调用 toString()方法,函数 add(a) 返回一个闭包 sum(b),函数 sum() 中累加计算 a = a + b,只需要重写sum.toString()方法返回变量 a 就OK了。
进阶系列文章汇总如下,内有优质前端资料,觉得不错点个star。
https://github.com/yygmind/blog
我是木易杨,网易高级前端工程师,跟着我每周重点攻克一个前端面试重难点。接下来让我带你走进高级前端的世界,在进阶的路上,共勉!
要点:
1、await并不阻塞线程
2、async对异步错误处理是使用try/catch
3、使用Promise.all()可以将多个await操作并行
之前文章详细介绍了 this 的使用,不了解的查看【进阶3-1期】。
call() 方法调用一个函数, 其具有一个指定的
this值和分别地提供的参数(参数的列表)。
call() 和 apply()的区别在于,call()方法接受的是若干个参数的列表,而apply()方法接受的是一个包含多个参数的数组
举个例子:
var func = function(arg1, arg2) {
...
};
func.call(this, arg1, arg2); // 使用 call,参数列表
func.apply(this, [arg1, arg2]) // 使用 apply,参数数组下面列举一些常用用法:
var vegetables = ['parsnip', 'potato'];
var moreVegs = ['celery', 'beetroot'];
// 将第二个数组融合进第一个数组
// 相当于 vegetables.push('celery', 'beetroot');
Array.prototype.push.apply(vegetables, moreVegs);
// 4
vegetables;
// ['parsnip', 'potato', 'celery', 'beetroot']当第二个数组(如示例中的 moreVegs )太大时不要使用这个方法来合并数组,因为一个函数能够接受的参数个数是有限制的。不同的引擎有不同的限制,JS核心限制在 65535,有些引擎会抛出异常,有些不抛出异常但丢失多余参数。
如何解决呢?方法就是将参数数组切块后循环传入目标方法
function concatOfArray(arr1, arr2) {
var QUANTUM = 32768;
for (var i = 0, len = arr2.length; i < len; i += QUANTUM) {
Array.prototype.push.apply(
arr1,
arr2.slice(i, Math.min(i + QUANTUM, len) )
);
}
return arr1;
}
// 验证代码
var arr1 = [-3, -2, -1];
var arr2 = [];
for(var i = 0; i < 1000000; i++) {
arr2.push(i);
}
Array.prototype.push.apply(arr1, arr2);
// Uncaught RangeError: Maximum call stack size exceeded
concatOfArray(arr1, arr2);
// (1000003) [-3, -2, -1, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, ...]var numbers = [5, 458 , 120 , -215 ];
Math.max.apply(Math, numbers); //458
Math.max.call(Math, 5, 458 , 120 , -215); //458
// ES6
Math.max.call(Math, ...numbers); // 458为什么要这么用呢,因为数组 numbers 本身没有 max 方法,但是 Math 有呀,所以这里就是借助 call / apply 使用 Math.max 方法。
function isArray(obj){
return Object.prototype.toString.call(obj) === '[object Array]';
}
isArray([1, 2, 3]);
// true
// 直接使用 toString()
[1, 2, 3].toString(); // "1,2,3"
"123".toString(); // "123"
123.toString(); // SyntaxError: Invalid or unexpected token
Number(123).toString(); // "123"
Object(123).toString(); // "123"可以通过toString() 来获取每个对象的类型,但是不同对象的 toString()有不同的实现,所以通过 Object.prototype.toString() 来检测,需要以 call() / apply() 的形式来调用,传递要检查的对象作为第一个参数。
另一个验证是否是数组的方法
var toStr = Function.prototype.call.bind(Object.prototype.toString);
function isArray(obj){
return toStr(obj) === '[object Array]';
}
isArray([1, 2, 3]);
// true
// 使用改造后的 toStr
toStr([1, 2, 3]); // "[object Array]"
toStr("123"); // "[object String]"
toStr(123); // "[object Number]"
toStr(Object(123)); // "[object Number]"上面方法首先使用 Function.prototype.call函数指定一个 this 值,然后 .bind 返回一个新的函数,始终将 Object.prototype.toString 设置为传入参数。其实等价于 Object.prototype.toString.call() 。
这里有一个前提是toString()方法没有被覆盖
Object.prototype.toString = function() {
return '';
}
isArray([1, 2, 3]);
// falsevar domNodes = document.getElementsByTagName("*");
domNodes.unshift("h1");
// TypeError: domNodes.unshift is not a function
var domNodeArrays = Array.prototype.slice.call(domNodes);
domNodeArrays.unshift("h1"); // 505 不同环境下数据不同
// (505) ["h1", html.gr__hujiang_com, head, meta, ...] 类数组对象有下面两个特性
length 属性push 、shift、 forEach 以及 indexOf 等数组对象具有的方法要说明的是,类数组对象是一个对象。JS中存在一种名为类数组的对象结构,比如 arguments 对象,还有DOM API 返回的 NodeList 对象都属于类数组对象,类数组对象不能使用 push/pop/shift/unshift 等数组方法,通过 Array.prototype.slice.call 转换成真正的数组,就可以使用 Array下所有方法。
类数组对象转数组的其他方法:
// 上面代码等同于
var arr = [].slice.call(arguments);
ES6:
let arr = Array.from(arguments);
let arr = [...arguments]; Array.from() 可以将两类对象转为真正的数组:类数组对象和可遍历(iterable)对象(包括ES6新增的数据结构 Set 和 Map)。
PS扩展一:为什么通过 Array.prototype.slice.call() 就可以把类数组对象转换成数组?
其实很简单,slice 将 Array-like 对象通过下标操作放进了新的 Array 里面。
下面代码是 MDN 关于 slice 的Polyfill,链接 Array.prototype.slice()
Array.prototype.slice = function(begin, end) {
end = (typeof end !== 'undefined') ? end : this.length;
// For array like object we handle it ourselves.
var i, cloned = [],
size, len = this.length;
// Handle negative value for "begin"
var start = begin || 0;
start = (start >= 0) ? start : Math.max(0, len + start);
// Handle negative value for "end"
var upTo = (typeof end == 'number') ? Math.min(end, len) : len;
if (end < 0) {
upTo = len + end;
}
// Actual expected size of the slice
size = upTo - start;
if (size > 0) {
cloned = new Array(size);
if (this.charAt) {
for (i = 0; i < size; i++) {
cloned[i] = this.charAt(start + i);
}
} else {
for (i = 0; i < size; i++) {
cloned[i] = this[start + i];
}
}
}
return cloned;
};
}PS扩展二:通过 Array.prototype.slice.call() 就足够了吗?存在什么问题?
在低版本IE下不支持通过Array.prototype.slice.call(args)将类数组对象转换成数组,因为低版本IE(IE < 9)下的DOM对象是以 com 对象的形式实现的,js对象与 com 对象不能进行转换。
兼容写法如下:
function toArray(nodes){
try {
// works in every browser except IE
return Array.prototype.slice.call(nodes);
} catch(err) {
// Fails in IE < 9
var arr = [],
length = nodes.length;
for(var i = 0; i < length; i++){
// arr.push(nodes[i]); // 两种都可以
arr[i] = nodes[i];
}
return arr;
}
}PS 扩展三:为什么要有类数组对象呢?或者说类数组对象是为什么解决什么问题才出现的?
JavaScript类型化数组是一种类似数组的对象,并提供了一种用于访问原始二进制数据的机制。
Array存储的对象能动态增多和减少,并且可以存储任何JavaScript值。JavaScript引擎会做一些内部优化,以便对数组的操作可以很快。然而,随着Web应用程序变得越来越强大,尤其一些新增加的功能例如:音频视频编辑,访问WebSockets的原始数据等,很明显有些时候如果使用JavaScript代码可以快速方便地通过类型化数组来操作原始的二进制数据,这将会非常有帮助。
一句话就是,可以更快的操作复杂数据。
function SuperType(){
this.color=["red", "green", "blue"];
}
function SubType(){
// 核心代码,继承自SuperType
SuperType.call(this);
}
var instance1 = new SubType();
instance1.color.push("black");
console.log(instance1.color);
// ["red", "green", "blue", "black"]
var instance2 = new SubType();
console.log(instance2.color);
// ["red", "green", "blue"]在子构造函数中,通过调用父构造函数的call方法来实现继承,于是SubType的每个实例都会将SuperType 中的属性复制一份。
缺点:
更多继承方案查看我之前的文章。JavaScript常用八种继承方案
以下内容参考自 JavaScript深入之call和apply的模拟实现
先看下面一个简单的例子
var value = 1;
var foo = {
value: 1
};
function bar() {
console.log(this.value);
}
bar.call(foo); // 1通过上面的介绍我们知道,call()主要有以下两点
call()改变了this的指向bar 执行了如果在调用call()的时候把函数 bar()添加到foo()对象中,即如下
var foo = {
value: 1,
bar: function() {
console.log(this.value);
}
};
foo.bar(); // 1这个改动就可以实现:改变了this的指向并且执行了函数bar。
但是这样写是有副作用的,即给foo额外添加了一个属性,怎么解决呢?
解决方法很简单,用 delete 删掉就好了。
所以只要实现下面3步就可以模拟实现了。
foo.fn = barfoo.fn()delete foo.fn代码实现如下:
// 第一版
Function.prototype.call2 = function(context) {
// 首先要获取调用call的函数,用this可以获取
context.fn = this; // foo.fn = bar
context.fn(); // foo.fn()
delete context.fn; // delete foo.fn
}
// 测试一下
var foo = {
value: 1
};
function bar() {
console.log(this.value);
}
bar.call2(foo); // 1完美!
第一版有一个问题,那就是函数 bar 不能接收参数,所以我们可以从 arguments中获取参数,取出第二个到最后一个参数放到数组中,为什么要抛弃第一个参数呢,因为第一个参数是 this。
类数组对象转成数组的方法上面已经介绍过了,但是这边使用ES3的方案来做。
var args = [];
for(var i = 1, len = arguments.length; i < len; i++) {
args.push('arguments[' + i + ']');
}参数数组搞定了,接下来要做的就是执行函数 context.fn()。
context.fn( args.join(',') ); // 这样不行上面直接调用肯定不行,args.join(',')会返回一个字符串,并不会执行。
这边采用 eval方法来实现,拼成一个函数。
eval('context.fn(' + args +')')上面代码中args 会自动调用 args.toString() 方法,因为'context.fn(' + args +')'本质上是字符串拼接,会自动调用toString()方法,如下代码:
var args = ["a1", "b2", "c3"];
console.log(args);
// ["a1", "b2", "c3"]
console.log(args.toString());
// a1,b2,c3
console.log("" + args);
// a1,b2,c3所以说第二个版本就实现了,代码如下:
// 第二版
Function.prototype.call2 = function(context) {
context.fn = this;
var args = [];
for(var i = 1, len = arguments.length; i < len; i++) {
args.push('arguments[' + i + ']');
}
eval('context.fn(' + args +')');
delete context.fn;
}
// 测试一下
var foo = {
value: 1
};
function bar(name, age) {
console.log(name)
console.log(age)
console.log(this.value);
}
bar.call2(foo, 'kevin', 18);
// kevin
// 18
// 1完美!!
还有2个细节需要注意:
null 或者 undefined,此时 this 指向 window实现上面的三点很简单,代码如下
// 第三版
Function.prototype.call2 = function (context) {
context = context ? Object(context) : window; // 实现细节 1 和 2
context.fn = this;
var args = [];
for(var i = 1, len = arguments.length; i < len; i++) {
args.push('arguments[' + i + ']');
}
var result = eval('context.fn(' + args +')');
delete context.fn
return result; // 实现细节 2
}
// 测试一下
var value = 2;
var obj = {
value: 1
}
function bar(name, age) {
console.log(this.value);
return {
value: this.value,
name: name,
age: age
}
}
function foo() {
console.log(this);
}
bar.call2(null); // 2
foo.call2(123); // Number {123, fn: ƒ}
bar.call2(obj, 'kevin', 18);
// 1
// {
// value: 1,
// name: 'kevin',
// age: 18
// }完美!!!
ES3:
Function.prototype.call = function (context) {
context = context ? Object(context) : window;
context.fn = this;
var args = [];
for(var i = 1, len = arguments.length; i < len; i++) {
args.push('arguments[' + i + ']');
}
var result = eval('context.fn(' + args +')');
delete context.fn
return result;
}ES6:
Function.prototype.call = function (context) {
context = context ? Object(context) : window;
context.fn = this;
let args = [...arguments].slice(1);
let result = context.fn(...args);
delete context.fn
return result;
}ES3:
Function.prototype.apply = function (context, arr) {
context = context ? Object(context) : window;
context.fn = this;
var result;
// 判断是否存在第二个参数
if (!arr) {
result = context.fn();
} else {
var args = [];
for (var i = 0, len = arr.length; i < len; i++) {
args.push('arr[' + i + ']');
}
result = eval('context.fn(' + args + ')');
}
delete context.fn
return result;
}ES6:
Function.prototype.apply = function (context, arr) {
context = context ? Object(context) : window;
context.fn = this;
let result;
if (!arr) {
result = context.fn();
} else {
result = context.fn(...arr);
}
delete context.fn
return result;
}call 和 apply 的模拟实现有没有问题?欢迎思考评论。
PS: 上期思考题留到下一期讲解,下一期介绍重点介绍 bind 原理及实现
进阶系列文章汇总如下,内有优质前端资料,觉得不错点个star。
我是木易杨,网易高级前端工程师,跟着我每周重点攻克一个前端面试重难点。接下来让我带你走进高级前端的世界,在进阶的路上,共勉!
本人于7-8月开始准备面试,过五关斩六将,最终抱得网易归,深深感受到高级前端面试的套路。以下是自己整理的面试题汇总,不敢藏私,统统贡献出来。
面试的公司分别是:阿里、网易、滴滴、今日头条、有赞、挖财、沪江、饿了么、携程、喜马拉雅、兑吧、微医、寺库、宝宝树、海康威视、蘑菇街、酷家乐、百分点和海风教育。
PS:文末有GitHub链接,欢迎各位Star。
使用过的koa2中间件
koa-body原理
介绍自己写过的中间件
有没有涉及到Cluster
介绍pm2
master挂了的话pm2怎么处理
如何和MySQL进行通信
React声明周期及自己的理解
如何配置React-Router
路由的动态加载模块
服务端渲染SSR
介绍路由的history
介绍Redux数据流的流程
Redux如何实现多个组件之间的通信,多个组件使用相同状态如何进行管理
多个组件之间如何拆分各自的state,每块小的组件有自己的状态,它们之间还有一些公共的状态需要维护,如何思考这块
使用过的Redux中间件
如何解决跨域的问题
常见Http请求头
移动端适配1px的问题
介绍flex布局
其他css方式设置垂直居中
居中为什么要使用transform(为什么不使用marginLeft/Top)
使用过webpack里面哪些plugin和loader
webpack里面的插件是怎么实现的
dev-server是怎么跑起来
项目优化
抽取公共文件是怎么配置的
项目中如何处理安全问题
怎么实现this对象的深拷贝
<Link>标签和<a>标签有什么区别<a>标签默认事件禁掉之后做了什么才实现了跳转import { Button } from 'antd' ,打包的时候只打包button,分模块加载,是怎么做到的import时,webpack对node_modules里的依赖会做什么cookie放哪里,cookie能做的事情和存在的价值cookie和token都存放在header里面,为什么只劫持前者cookie和session有哪些方面的区别React中Dom结构发生变化后内部经历了哪些变化React挂载的时候有3个组件,textComponent、composeComponent、domComponent,区别和关系,Dom结构发生变化时怎么区分data的变化,怎么更新,更新怎么调度,如果更新的时候还有其他任务存在怎么处理shouldComponentUpdate是为了解决什么问题——proto——区别_construct是什么new是怎么实现的rem、flex的区别(root em)em和px的区别var a = {name: "前端开发"}; var b = a; a = null那么b输出什么var a = {b: 1} 存放在哪里var a = {b: {c: 1}}存放在哪里let块作用域是怎么实现的setState后发生了什么setState为什么默认是异步setState什么时候是同步的node接口转发有无做什么优化node起服务如何保证稳定性,平缓降级,重启等<b>和<strong>的区别对react看法,它的优缺点
使用过程中遇到的问题,如何解决的
react的理念是什么(拿函数式编程来做页面渲染)
JS是什么范式语言(面向对象还是函数式编程)
koa原理,为什么要用koa(express和koa对比)
使用的koa中间件
ES6使用的语法
Promise 和 async/await 和 callback的区别
Promise有没有解决异步的问题(promise链是真正强大的地方)
Promise和setTimeout的区别(Event Loop)
进程和线程的区别(一个node实例就是一个进程,node是单线程,通过事件循环来实现异步
)
介绍下DFS深度优先
介绍下观察者模式
观察者模式里面使用的数据结构(不具备顺序 ,是一个list)
欢迎加我微信进一步交流或者找我内推,前行的路上,共勉!
concat()
连接两个或多个数组,两边的原始数组都不会变化,返回被连接数组的一个副本。
join()
把数组中所有元素放入一个字符串中,返回字符串。
slice()
从开始到结束(不包括结束)选择数组的一部分浅拷贝到一个新数组。
map()
创建一个新数组并返回,其中新数组的每个元素由调用原始数组中的每一个元素执行提供的函数得来,原始数组不会改变。
every()
对数组中的每个元素都执行一次指定的回调函数,直到回调函数返回false,此时every()返回false并不再继续执行。如果回调函数对每个元素都返回true,那么every()将返回true。
some()
对数组中的每个元素都执行一次指定的回调函数,直到回调函数返回true,此时some()返回true并不再继续执行。如果回调函数对每个元素都返回false,那么some()将返回false。
filter()
创建一个新数组, 其包含通过所提供函数实现的测试的所有元素。
forEach()
针对每一个元素执行提供的函数。会修改原来的数组,不会返回执行结果,返回undefined。
pop()
删除数组最后一个元素,返回被删除的元素。如果数组为空,则不改变数组,返回undefined。
push()
向数组末尾添加一个或多个元素,返回改变后数组的长度。
reverse()
颠倒数组中元素的位置,返回该数组的引用。
shift()
从数组中删除第一个元素,并返回该元素的值。此方法更改数组的长度。
unshift()
将一个或多个元素添加到数组的开头,并返回新数组的长度。
sort()
对数组的元素进行排序,并返回数组。排序不一定是稳定的。默认排序顺序是根据字符串Unicode码点。
splice()
向数组中添加/删除项目,然后返回被删除项目的新数组。
for..in 和 object.keys()的区别for..in语句:遍历对象的可枚举属性名列表,包括[[Prototype]]原型链。
propertyIsEnumerable(..):只检查属性名是否在对象中并且enumerable:true。Object.keys(..):只查找属性名是否在对象中,返回一个数组,包含所有可枚举属性名。Object.getOwnPropertyNames(..):只查找属性名是否在对象中,返回一个数组,包含所有属性名,无论是否可枚举。for..of和object.values()for..of语句:遍历可迭代对象的可枚举属性的值列表,包括[[Prototype]]原型链。object.values():返回一个给定对象自身的所有可枚举属性的值的数组,不包括原型链new Map创建一个map
// new Map创建一个map
let map = new Map([[1,"one"], [2,"two"], [3,"three"]]);
map.set(4, "four");
// 获取所有键值对
console.log("获取key")
console.log([...map.keys()]) // 输出[1, 2, 3, 4]
console.log("获取value")
console.log([...map.values()]) // 输出[one, two, three, four]
console.log("获取map数组")
console.log([...map]) // 输出[[1, "one"], [2, "two"], [3, "three"], [4, "four"]]function merge(left, right){
let result = [],
il = 0,
ir = 0;
while (il < left.length && ir < right.length) {
result.push(left[il] < right[ir] ? left[il++] : right[ir++]);
}
return result.concat(left.slice(il)).concat(right.slice(ir));
}public class Solution {
// m, n 是数组长度
public void merge(int[] nums1, int m, int[] nums2, int n) {
int i = m - 1, j = n - 1, writeIdx = m + n - 1;
while (i >= 0 && j >= 0)
nums1[writeIdx--] = nums1[i] > nums2[j]? nums1[i--] : nums2[j--];
while (j >= 0)
nums1[writeIdx--] = nums2[j--];
}
}const distinct = arr => arr.sort().reduce( (init, current) => {
if (init.length === 0 || init[init.length - 1] !== current) {
init.push( current );
}
return init;
}, []);
let arr = [1,2,1,2,3,5,4,5,3,4,4,4,4];
distinct(arr); // [1, 2, 3, 4, 5]const distinct = arr => arr.filter( (element, index, self) => {
return self.indexOf( element ) === index;
});
let arr = [1,2,1,2,3,5,4,5,3,4,4,4,4];
distinct(arr); // [1, 2, 3, 5, 4]const flattenDeep = arr => Array.isArray(arr)
? arr.reduce( (a, b) => [...a, ...flattenDeep(b)] , [])
: [arr]
flattenDeep([1, [[2], [3, [4]], 5]]); // [1, 2, 3, 4, 5]给定两个数组,写一个方法来计算它们的交集。
例如:
给定 nums1 = [1, 2, 2, 1], nums2 = [2, 2], 返回 [2, 2].
注意:
跟进:
解法:
/**
* @param {number[]} nums1
* @param {number[]} nums2
* @return {number[]}
*/
var intersect = function(nums1, nums2) {
var map1 = new Map();
var number = [];
for(var i = 0; i < nums1.length; i++) {
var map1Value = map1.get(nums1[i]);
map1.set( nums1[i], ( map1Value ? map1Value : 0 ) + 1 );
}
for(var i = 0; i < nums2.length; i++) {
if( map1.has(nums2[i]) && map1.get(nums2[i]) != 0 ) {
number.push(nums2[i]);
map1.set( nums2[i], map1.get(nums2[i]) - 1 );
}
}
return number;
};
/**
* @param {number[]} nums
* @return {number}
*/
var removeDuplicates = function(nums) {
if(!nums || nums.length == 0) return 0;
let len = 0;
for(let i = 1; i < nums.length; i++) {
if (nums[len] != nums[i]) {
nums[++ len] = nums[i];
}
}
return len + 1;
};给定一个非空整数数组,除了某个元素只出现一次以外,其余每个元素均出现两次。找出那个只出现了一次的元素
/**
* @param {number[]} nums
* @return {number}
*/
var singleNumber = function(nums) {
let number = 0;
for(let i = 0; i < nums.length; i++) {
number ^= nums[i];
}
return number;
};
参考资料:https://blog.csdn.net/qq_35546040/article/details/80284079
给定一个整数数组和一个目标值,找出数组中和为目标值的两个数。
你可以假设每个输入只对应一种答案,且同样的元素不能被重复利用。
示例:
给定 nums = [2, 7, 11, 15], target = 9
因为 nums[0] + nums[1] = 2 + 7 = 9
所以返回 [0, 1]解法:
/**
* @param {number[]} nums
* @param {number} target
* @return {number[]}
*/
var twoSum = function(nums, target) {
var map = new Map();
var number = [];
for(var i = 0; i < nums.length; i ++) {
if(map.has(target - nums[i])) {
number.push(i, map.get(target - nums[i]));
break;
}
map.set(nums[i], i);
}
return number;
};给定一个数组,将数组中的元素向右移动 k 个位置,其中 k 是非负数。
示例 1:
输入: [1,2,3,4,5,6,7] 和 k = 3
输出: [5,6,7,1,2,3,4]
解释:
向右旋转 1 步: [7,1,2,3,4,5,6]
向右旋转 2 步: [6,7,1,2,3,4,5]
向右旋转 3 步: [5,6,7,1,2,3,4]示例 2:
输入: [-1,-100,3,99] 和 k = 2
输出: [3,99,-1,-100]
解释:
向右旋转 1 步: [99,-1,-100,3]
向右旋转 2 步: [3,99,-1,-100]说明:
解法:
/**
* @param {number[]} nums
* @param {number} k
* @return {void} Do not return anything, modify nums in-place instead.
*/
var rotate = function(nums, k) {
var k = k % nums.length;
reverse(nums, 0, nums.length - 1);
reverse(nums, k, nums.length - 1);
reverse(nums, 0, k - 1);
};
var reverse = function(nums, i, j) {
while(i < j) {
swap(nums, i++, j--);
}
}
var swap = function(nums, i, j) {
var temp = nums[i];
nums[i] = nums[j];
nums[j] = temp;
}给定一个非负整数组成的非空数组,在该数的基础上加一,返回一个新的数组。
最高位数字存放在数组的首位, 数组中每个元素只存储一个数字。
你可以假设除了整数 0 之外,这个整数不会以零开头。
示例 1:
输入: [1,2,3]
输出: [1,2,4]
解释: 输入数组表示数字 123。示例 2:
输入: [4,3,2,1]
输出: [4,3,2,2]
解释: 输入数组表示数字 4321。解法:
/**
* @param {number[]} digits
* @return {number[]}
*/
var plusOne = function(digits) {
if(digits.length == 0) return digits;
var carry = 1;
var res = [1];
for(var i = digits.length - 1; i >= 0; i--) {
if(carry == 0) return digits;
var sum = carry + digits[i];
digits[i] = sum % 10;
carry = parseInt(sum / 10);
}
for(let i = digits.length - 1; i >= 0; i--) {
res.push(0);
}
return carry == 0 ? digits : res;
};给定一个整数数组,判断是否存在重复元素。
如果任何值在数组中出现至少两次,函数返回 true。如果数组中每个元素都不相同,则返回 false。
示例 1:
输入: [1,2,3,1]
输出: true示例 2:
输入: [1,2,3,4]
输出: false示例 3:
输入: [1,1,1,3,3,4,3,2,4,2]
输出: true解法 :
/**
* @param {number[]} nums
* @return {boolean}
*/
var containsDuplicate = function(nums) {
let hashMap = new Map();
for(let i = 0; i < nums.length; i++) {
if( hashMap.has(nums[i]) ) {
return true;
}
hashMap.set(nums[i], 1);
}
return false;
};给定一个数组 nums,编写一个函数将所有 0 移动到数组的末尾,同时保持非零元素的相对顺序。
示例:
输入: [0,1,0,3,12]
输出: [1,3,12,0,0]
说明:
解法1:
/**
* @param {number[]} nums
* @return {void} Do not return anything, modify nums in-place instead.
*/
let moveZeroes = function(nums) {
let n = nums.length;
let slow = -1; // 指针索引
let fast = 0; // 指针索引
let x = 0;
while(slow < fast && fast < n) {
if (nums[fast] != x) {
slow ++;
swap(nums, slow, fast);
}
fast ++;
}
};
let swap = function(nums, i, j) {
let temp = nums[i];
nums[i] = nums[j];
nums[j] = temp;
}解法2:
/**
* @param {number[]} nums
* @return {void} Do not return anything, modify nums in-place instead.
*/
let moveZeroes = function(nums) {
let n = nums.length;
let one = 0;
let x = 0;
for(let i = 0; i < n; i ++) {
if (nums[i] != x) {
nums[one ++] = nums[i];
}
}
for(let i = one; i < n; i ++) {
nums[i] = x;
}
};欢迎加我微信进一步交流或者找我内推,前行的路上,共勉!
上一节我们学习了 Lodash 中防抖和节流函数是如何实现的,并对源码浅析一二,今天这篇文章会通过七个小例子为切入点,换种方式继续解读源码。其中源码解析上篇文章已经非常详细介绍了,这里就不再重复,建议本文配合上文一起服用,猛戳这里学习
有什么想法或者意见都可以在评论区留言,欢迎大家拍砖。
我们先来看一张图,这张图充分说明了 Throttle(节流)和 Debounce(防抖)的区别,以及在不同配置下产生的不同效果,其中 mousemove 事件每 50 ms 触发一次,即下图中的每一小隔是 50 ms。今天这篇文章就从下面这张图开始介绍。
lodash.throttle(fn, 200, {leading: true, trailing: true})
先来看下 throttle 源码
function throttle(func, wait, options) {
// 首尾调用默认为 true
let leading = true
let trailing = true
if (typeof func !== 'function') {
throw new TypeError('Expected a function')
}
// options 是否是对象
if (isObject(options)) {
leading = 'leading' in options ? !!options.leading : leading
trailing = 'trailing' in options ? !!options.trailing : trailing
}
// maxWait 为 wait 的防抖函数
return debounce(func, wait, {
leading,
trailing,
'maxWait': wait,
})
}所以 throttle(fn, 200, {leading: true, trailing: true}) 返回内容是 debounce(fn, 200, {leading: true, trailing: true, maxWait: 200}),多了 maxWait: 200 这部分。
先打个预防针,后面即将开始比较难的部分,看下 debounce 入口函数。
// 入口函数,返回此函数
function debounced(...args) {
// 获取当前时间
const time = Date.now()
// 判断此时是否应该执行 func 函数
const isInvoking = shouldInvoke(time)
// 赋值给闭包,用于其他函数调用
lastArgs = args
lastThis = this
lastCallTime = time
// 执行
if (isInvoking) {
// 无 timerId 的情况有两种:
// 1、首次调用
// 2、trailingEdge 执行过函数
if (timerId === undefined) {
return leadingEdge(lastCallTime)
}
// 如果设置了最大等待时间,则立即执行 func
// 1、开启定时器,到时间后触发 trailingEdge 这个函数。
// 2、执行 func,并返回结果
if (maxing) {
// 循环定时器中处理调用
timerId = startTimer(timerExpired, wait)
return invokeFunc(lastCallTime)
}
}
// 一种特殊情况,trailing 设置为 true 时,前一个 wait 的 trailingEdge 已经执行了函数
// 此时函数被调用时 shouldInvoke 返回 false,所以要开启定时器
if (timerId === undefined) {
timerId = startTimer(timerExpired, wait)
}
// 不需要执行时,返回结果
return result
}对于 debounce(fn, 200, {leading: true, trailing: true, maxWait: 200}) 来说,会经历如下过程。
shouldInvoke(time) 中,因为满足条件 lastCallTime === undefined,所以返回 truelastCallTime = time,所以 lastCallTime 等于当前时间,假设为 0timerId === undefined 满足,执行 leadingEdge(lastCallTime) 方法// 执行连续事件刚开始的那次回调
function leadingEdge(time) {
// 1、设置上一次执行 func 的时间
lastInvokeTime = time
// 2、开启定时器,为了事件结束后的那次回调
timerId = startTimer(timerExpired, wait)
// 3、如果配置了 leading 执行传入函数 func
// leading 来源自 !!options.leading
return leading ? invokeFunc(time) : result
}leadingEdge(time) 中,设置 lastInvokeTime 为当前时间即 0,开启 200 毫秒定时器,执行 invokeFunc(time) 并返回// 执行 Func 函数
function invokeFunc(time) {
// 获取上一次执行 debounced 的参数
const args = lastArgs
// 获取上一次的 this
const thisArg = lastThis
// 重置
lastArgs = lastThis = undefined
lastInvokeTime = time
result = func.apply(thisArg, args)
return result
}invokeFunc(time) 中,执行 func.apply(thisArg, args),即 fn 函数第一次执行,并把结果赋值给 result,便于后续触发时直接返回。同时重置 lastInvokeTime 为当前时间即 0,清空 lastArgs 和 lastThis。lastCallTime 和 lastInvokeTime 都为 0,200 毫秒的定时器还在运行中。50 毫秒后第二次触发到来,此时当前时间 time 为 50,wait 为 200, maxWait 为 200,maxing 为 true,lastCallTime 和 lastInvokeTime 都为 0,timerId 定时器存在,我们来看下执行步骤。
function shouldInvoke(time) {
// 当前时间距离上一次调用 debounce 的时间差
const timeSinceLastCall = time - lastCallTime
// 当前时间距离上一次执行 func 的时间差
const timeSinceLastInvoke = time - lastInvokeTime
// 下述 4 种情况返回 true
return ( lastCallTime === undefined ||
(timeSinceLastCall >= wait) ||
(timeSinceLastCall < 0) ||
(maxing && timeSinceLastInvoke >= maxWait) )
}shouldInvoke(time) 中,timeSinceLastCall 为 50,timeSinceLastInvoke 为 50,4 种条件都不满足,返回 false。isInvoking 为 false,同时 timerId === undefined 不满足,直接返回第一次触发时的 resultresult距第一次触发 200 毫秒后第五次触发到来,此时当前时间 time 为 200,wait 为 200, maxWait 为 200,maxing 为 true,lastCallTime 为 150, lastInvokeTime 为 0,timerId 定时器存在,我们来看下执行步骤。
shouldInvoke(time) 中,timeSinceLastInvoke 为 200,满足 (maxing && timeSinceLastInvoke >= maxWait),所以返回 true// debounced 方法中执行到这部分
if (maxing) {
// 循环定时器中处理调用
timerId = startTimer(timerExpired, wait)
return invokeFunc(lastCallTime)
}maxing 条件,重新开启 200 毫秒的定时器,并执行 invokeFunc(lastCallTime) 函数invokeFunc(time) 中,重置 lastInvokeTime 为当前时间即 200,清空 lastArgs 和 lastThis假设第八次触发之后就停止了滚动,在第八次触发时 time 为 350,所以如果有第九次触发,那么此时是应该执行fn 的,但是此时 mousemove 已经停止了触发,那么还会执行 fn 吗?答案是依旧执行,因为最开始设置了 {trailing: true}。
// 开启定时器
function startTimer(pendingFunc, wait) {
// 没传 wait 时调用 window.requestAnimationFrame()
if (useRAF) {
// 若想在浏览器下次重绘之前继续更新下一帧动画
// 那么回调函数自身必须再次调用 window.requestAnimationFrame()
root.cancelAnimationFrame(timerId);
return root.requestAnimationFrame(pendingFunc)
}
// 不使用 RAF 时开启定时器
return setTimeout(pendingFunc, wait)
}在第五次触发时开启了 200 毫秒的定时器,所以在时间 time 到 400 时会执行 pendingFunc,此时的 pendingFunc 就是 timerExpired 函数,来看下具体的代码。
// 定时器回调函数,表示定时结束后的操作
function timerExpired() {
const time = Date.now()
// 1、是否需要执行
// 执行事件结束后的那次回调,否则重启定时器
if (shouldInvoke(time)) {
return trailingEdge(time)
}
// 2、否则 计算剩余等待时间,重启定时器,保证下一次时延的末尾触发
timerId = startTimer(timerExpired, remainingWait(time))
}此时在 shouldInvoke(time) 中,time 为 400,lastInvokeTime 为 200,timeSinceLastInvoke 为 200,满足 (maxing && timeSinceLastInvoke >= maxWait),所以返回 true。
// 执行连续事件结束后的那次回调
function trailingEdge(time) {
// 清空定时器
timerId = undefined
// trailing 和 lastArgs 两者同时存在时执行
// trailing 来源自 'trailing' in options ? !!options.trailing : trailing
// lastArgs 标记位的作用,意味着 debounce 至少执行过一次
if (trailing && lastArgs) {
return invokeFunc(time)
}
// 清空参数
lastArgs = lastThis = undefined
return result
}之后执行 trailingEdge(time),在这个函数中判断 trailing 和 lastArgs ,此时这两个条件都是 true,所以会执行 invokeFunc(time),最终执行函数 fn。
这里需要说明以下两点
{trailing: false},那么最后一次是不会执行的。对于 throttle 和 debounce 来说,默认值是 true,所以如果没有特意指定 trailing,那么最后一次是一定会执行的。lastArgs 来说,执行 debounced 时会赋值,即每次触发都会重新赋值一次,那什么时候清空呢,在 invokeFunc(time) 中执行 fn 函数时重置为 undefined,所以如果 debounced 只触发了一次,即使设置了 {trailing: true} 那也不会再执行 fn 函数,这个就解答了上篇文章留下的第一道思考题。lodash.throttle(fn, 200, {leading: true, trailing: false})
在「角度 1 之 mousemove 停止触发」这部分中说到,如果不设置 trailing 和设置 {trailing: true} 效果是一样的,事件回调结束后都会再执行一次传入函数 fn,但是如果设置了{trailing: false},那么事件回调结束后是不会再执行 fn 的。
此时的配置对比角度 1 来说,区别在于设置了{trailing: false},所以实际效果对比 1 来说,就是最后不会额外再执行一次,效果见第一张图。
lodash.throttle(fn, 200, {leading: false, trailing: true})
此时的配置和角度 1 相比,区别在于设置了 {leading: false},所以直接看 leadingEdge(time) 方法就可以了。
// 执行连续事件刚开始的那次回调
function leadingEdge(time) {
// 1、设置上一次执行 func 的时间
lastInvokeTime = time
// 2、开启定时器,为了事件结束后的那次回调
timerId = startTimer(timerExpired, wait)
// 3、如果配置了 leading 执行传入函数 func
// leading 来源自 !!options.leading
return leading ? invokeFunc(time) : result
}在这里,会开启 200 毫秒的定时器,同时因为 leading 为 false,所以并不会执行 invokeFunc(time) ,只会返回 result,此时的 result 值是 undefined。
这里开启一个定时器的目的是为了事件结束后的那次回调,即如果设置了 {trailing: true} 那么最后一次回调将执行传入函数 fn,哪怕 debounced 函数只触发一次。
这里指定了 {leading: false},那么 leading 的初始值是什么呢?在 debounce 中是 false,在 throttle 中是 true。所以在 throttle 中不需要刚开始就触发时,必须指定 {leading: false},在 debounce 中就不需要了,默认不触发。
lodash.debounce(fn, 200, {leading: false, trailing: true})
此时相比较 throttle 来说,缺少了 maxWait 值,所以具体触发过程中的判断就不一样了,来详细看一遍。
debounced 中,执行 shouldInvoke(time),前面讨论过因为第一次触发所以会返回 true,之后执行 leadingEdge(lastCallTime)。// 执行连续事件刚开始的那次回调
function leadingEdge(time) {
// 1、设置上一次执行 func 的时间
lastInvokeTime = time
// 2、开启定时器,为了事件结束后的那次回调
timerId = startTimer(timerExpired, wait)
// 3、如果配置了 leading 执行传入函数 func
// leading 来源自 !!options.leading
return leading ? invokeFunc(time) : result
}leadingEdge 中,因为 leading 为 false,所以并不执行 fn,只开启 200 毫秒的定时器,并返回 undefined。此时 lastInvokeTime 为当前时间,假设为 0。// 判断此时是否应该执行 func 函数
function shouldInvoke(time) {
// 当前时间距离上一次调用 debounce 的时间差
const timeSinceLastCall = time - lastCallTime
// 当前时间距离上一次执行 func 的时间差
const timeSinceLastInvoke = time - lastInvokeTime
// 下述 4 种情况返回 true
return ( lastCallTime === undefined ||
(timeSinceLastCall >= wait) ||
(timeSinceLastCall < 0) ||
(maxing && timeSinceLastInvoke >= maxWait) )
}timeSinceLastCall 总是为 50 毫秒,maxing 为 false,所以 shouldInvoke(time) 总是返回 false,并不会执行传入函数 fn,只返回 result,即为 undefined。timerExpired 函数// 定时器回调函数,表示定时结束后的操作
function timerExpired() {
const time = Date.now()
// 1、是否需要执行
// 执行事件结束后的那次回调,否则重启定时器
if (shouldInvoke(time)) {
return trailingEdge(time)
}
// 2、否则 计算剩余等待时间,重启定时器,保证下一次时延的末尾触发
timerId = startTimer(timerExpired, remainingWait(time))
}mousemove 事件一直在触发,根据前面介绍 shouldInvoke(time) 会返回 false,之后就将计算剩余等待时间,重启定时器。时间计算公式为 wait - (time - lastCallTime),即 200 - 50,所以只要 shouldInvoke(time) 返回 false,就每隔 150 毫秒后执行一次 timerExpired()。mousemove 事件不再触发,因为 timerExpired() 在循环执行,所以肯定会存在一种情况满足 timeSinceLastCall >= wait,即 shouldInvoke(time) 返回 true,终结 timerExpired() 的循环,并执行 trailingEdge(time)。// 执行连续事件结束后的那次回调
function trailingEdge(time) {
// 清空定时器
timerId = undefined
// trailing 和 lastArgs 两者同时存在时执行
// trailing 来源自 'trailing' in options ? !!options.trailing : trailing
// lastArgs 标记位的作用,意味着 debounce 至少执行过一次
if (trailing && lastArgs) {
return invokeFunc(time)
}
// 清空参数
lastArgs = lastThis = undefined
return result
}trailingEdge 中 trailing 和 lastArgs 都是 true,所以会执行 invokeFunc(time),即执行传入函数 fn。lodash.debounce(fn, 200, {leading: true, trailing: false})
此时相比角度 4 来说,差异在于 {leading: true, trailing: false},但是 wait 和 maxWait 都和角度 4 一致,所以只存在下面 2 种区别,效果同上面第一张图所示。
leadingEdge 中会执行传入函数 fntrailingEdge 中不再执行传入函数 fnlodash.debounce(fn, 200, {leading: true, trailing: true})
此时相比角度 4 来说,差异仅仅在于设置了 {leading: true},所以只存在一个区别,那就是在 leadingEdge 中会执行传入函数 fn,当然在 trailingEdge 中依旧执行传入函数 fn,所以会出现在 mousemove 事件触发过程中首尾都会执行的情况,效果同上面第一张图所示。
当然一种情况除外,那就是 mousemove 事件永远只触发一次的情况,关键在于 lastArgs 变量。
对于 lastArgs 变量来说,在入口函数 debounced 中赋值,即每次触发都会重新赋值一次,那什么时候清空呢,在 invokeFunc(time) 中重置为 undefined,所以如果 debounced 只触发了一次,而且在 {leading: true} 时执行过一次 fn,那么即使设置了 {trailing: true} 也不会再执行传入函数 fn。
lodash.debounce(fn, 200, {leading: false, trailing: true, maxWait: 400})
此时 wait 为 200,maxWait 为 400,maxing 为 true,我们来看下执行过程。
{leading: false},所以肯定不会执行 fn,此时开启了一个 200 毫秒的定时器。// 判断此时是否应该执行 func 函数
function shouldInvoke(time) {
// 当前时间距离上一次调用 debounce 的时间差
const timeSinceLastCall = time - lastCallTime
// 当前时间距离上一次执行 func 的时间差
const timeSinceLastInvoke = time - lastInvokeTime
// 下述 4 种情况返回 true
return ( lastCallTime === undefined ||
(timeSinceLastCall >= wait) ||
(timeSinceLastCall < 0) ||
(maxing && timeSinceLastInvoke >= maxWait) )
}shouldInvoke(time) 函数,只有在第 400 毫秒时,才会满足 maxing && timeSinceLastInvoke >= maxWait,返回 true。// 计算仍需等待的时间
function remainingWait(time) {
// 当前时间距离上一次调用 debounce 的时间差
const timeSinceLastCall = time - lastCallTime
// 当前时间距离上一次执行 func 的时间差
const timeSinceLastInvoke = time - lastInvokeTime
// 剩余等待时间
const timeWaiting = wait - timeSinceLastCall
// 是否设置了最大等待时间
// 是(节流):返回「剩余等待时间」和「距上次执行 func 的剩余等待时间」中的最小值
// 否:返回剩余等待时间
return maxing
? Math.min(timeWaiting, maxWait - timeSinceLastInvoke)
: timeWaiting
}timerExpired,因为此时 shouldInvoke(time) 返回 false,所以会重新计算剩余等待时间并重启计时器,其中 timeWaiting 是 150 毫秒,maxWait - timeSinceLastInvoke 是 200 毫秒,所以计算结果是150 毫秒。timeWaiting 依旧是 150 毫秒,maxWait - timeSinceLastInvoke 是 50 毫秒,所以重新开启 50 毫秒的定时器,即在第 400 毫秒时触发。shouldInvoke(time) 中返回 true 的时间也是在第 400 毫秒,为什么要这样呢?这样会冲突吗?首先定时器剩余时间判断和 shouldInvoke(time) 判断中,只要有一处满足执行 fn 条件,就会立马执行,同时 lastInvokeTime 值也会发生改变,所以另一处判断就不会生效了。另外本身定时器是不精准的,所以通过 Math.min(timeWaiting, maxWait - timeSinceLastInvoke) 取最小值的方式来减少误差。if (timerId === undefined) {timerId = startTimer(timerExpired, wait)},避免 trailingEdge 执行后定时器被清空。问:如果 leading 和 trailing 选项都是 true,在 wait 期间只调用了一次 debounced 函数时,总共会调用几次 func,1 次还是 2 次,为什么?
答案是 1 次,为什么?文中已给出详细解答,详情请看角度 1 和角度 6。
问:如何给 debounce(func, time, options) 中的 func 传参数?
第一种方案,因为 debounced 函数可以接受参数,所以可以用高阶函数的方式传参,如下
const params = 'muyiy';
const debounced = lodash.debounce(func, 200)(params)
window.addEventListener('mousemove', debounced);不过这种方式不太友好,params 会将原来的 event 覆盖掉,此时就拿不到 scroll 或者 mousemove 等事件对象 event 了。
第二种方案,在监听函数上处理,使用闭包保存传入参数并返回需要执行的函数即可。
function onMove(param) {
console.log('param:', param); // muyiy
function func(event) {
console.log('param:', param); // muyiy
console.log('event:', event); // event
}
return func;
}使用时如下
const params = 'muyiy';
const debounced = lodash.debounce(onMove(params), 200)
window.addEventListener('mousemove', debounced);如果你觉得这篇内容对你挺有启发,我想邀请你帮我三个小忙:
在上一篇文章中介绍了如何实现一个深拷贝,分别说明了对象、数组、循环引用、引用丢失、Symbol 和递归爆栈等情况下的深拷贝实践,今天我们来看看 Lodash 如何实现上述之外的函数、正则、Date、Buffer、Map、Set、原型链等情况下的深拷贝实践。本篇文章源码基于 Lodash 4.17.11 版本。
更多内容请查看 GitHub
入口文件是 cloneDeep.js,直接调用核心文件 baseClone.js 的方法。
// 木易杨
const CLONE_DEEP_FLAG = 1
const CLONE_SYMBOLS_FLAG = 4
function cloneDeep(value) {
return baseClone(value, CLONE_DEEP_FLAG | CLONE_SYMBOLS_FLAG)
}第一个参数是需要拷贝的对象,第二个是位掩码(Bitwise),关于位掩码的详细介绍请看下面拓展部分。
然后我们进入 ./.internal/baseClone.js 路径查看具体方法,主要实现逻辑都在这个方法里。
先介绍下该方法的参数 baseClone(value, bitmask, customizer, key, object, stack)
value:需要拷贝的对象
bitmask:位掩码,其中 1 是深拷贝,2 拷贝原型链上的属性,4 是拷贝 Symbols 属性
customizer:定制的 clone 函数
key:传入 value 值的 key
object:传入 value 值的父对象
stack:Stack 栈,用来处理循环引用
我将分成以下几部分进行讲解,可以选择自己感兴趣的部分阅读。
clone 函数这部分就是核心代码了,各功能分割如下,详细功能实现部分将对各个功能详细解读。
// 木易杨
function baseClone(value, bitmask, customizer, key, object, stack) {
let result
// 标志位
const isDeep = bitmask & CLONE_DEEP_FLAG // 深拷贝,true
const isFlat = bitmask & CLONE_FLAT_FLAG // 拷贝原型链,false
const isFull = bitmask & CLONE_SYMBOLS_FLAG // 拷贝 Symbol,true
// 自定义 clone 函数
if (customizer) {
result = object ? customizer(value, key, object, stack) : customizer(value)
}
if (result !== undefined) {
return result
}
// 非对象
if (!isObject(value)) {
return value
}
const isArr = Array.isArray(value)
const tag = getTag(value)
if (isArr) {
// 数组
result = initCloneArray(value)
if (!isDeep) {
return copyArray(value, result)
}
} else {
// 对象
const isFunc = typeof value == 'function'
if (isBuffer(value)) {
return cloneBuffer(value, isDeep)
}
if (tag == objectTag || tag == argsTag || (isFunc && !object)) {
result = (isFlat || isFunc) ? {} : initCloneObject(value)
if (!isDeep) {
return isFlat
? copySymbolsIn(value, copyObject(value, keysIn(value), result))
: copySymbols(value, Object.assign(result, value))
}
} else {
if (isFunc || !cloneableTags[tag]) {
return object ? value : {}
}
result = initCloneByTag(value, tag, isDeep)
}
}
// 循环引用
stack || (stack = new Stack)
const stacked = stack.get(value)
if (stacked) {
return stacked
}
stack.set(value, result)
// Map
if (tag == mapTag) {
value.forEach((subValue, key) => {
result.set(key, baseClone(subValue, bitmask, customizer, key, value, stack))
})
return result
}
// Set
if (tag == setTag) {
value.forEach((subValue) => {
result.add(baseClone(subValue, bitmask, customizer, subValue, value, stack))
})
return result
}
// TypedArray
if (isTypedArray(value)) {
return result
}
// Symbol & 原型链
const keysFunc = isFull
? (isFlat ? getAllKeysIn : getAllKeys)
: (isFlat ? keysIn : keys)
const props = isArr ? undefined : keysFunc(value)
// 遍历赋值
arrayEach(props || value, (subValue, key) => {
if (props) {
key = subValue
subValue = value[key]
}
assignValue(result, key, baseClone(subValue, bitmask, customizer, key, value, stack))
})
// 返回结果
return result
}上面简单介绍了位掩码,参数定义如下。
// 木易杨
// 主线代码
const CLONE_DEEP_FLAG = 1 // 1 即 0001,深拷贝标志位
const CLONE_FLAT_FLAG = 2 // 2 即 0010,拷贝原型链标志位,
const CLONE_SYMBOLS_FLAG = 4 // 4 即 0100,拷贝 Symbols 标志位位掩码用于处理同时存在多个布尔选项的情况,其中掩码中的每个选项的值都等于 2 的幂。相比直接使用变量来说,优点是可以节省内存(1/32)(来自MDN)
// 木易杨
// 主线代码
// cloneDeep.js 添加标志位,1 | 4 即 0001 | 0100 即 0101 即 5
CLONE_DEEP_FLAG | CLONE_SYMBOLS_FLAG
// baseClone.js 取出标志位
let result // 初始化返回结果,后续代码需要,和位掩码无关
const isDeep = bitmask & CLONE_DEEP_FLAG // 5 & 1 即 1 即 true
const isFlat = bitmask & CLONE_FLAT_FLAG // 5 & 2 即 0 即 false
const isFull = bitmask & CLONE_SYMBOLS_FLAG // 5 & 4 即 4 即 true常用的基本操作如下
a | b:添加标志位 a 和 bmask & a:取出标志位 amask & ~a:清除标志位 amask ^ a:取出与 a 的不同部分// 木易杨
var FLAG_A = 1; // 0001
var FLAG_B = 4; // 0100
// 添加标志位 a 和 b => a | b
var mask = FLAG_A | FLAG_B => 0101 => 5
// 取出标志位 a => mask & a
mask & FLAG_A => 0001 => 1
mask & FLAG_B => 0100 => 4
// 清除标记位 a => mask & ~a
mask & ~FLAG_A => 0100 => 4
// 取出与 a 的不同部分 => mask ^ a
mask ^ FLAG_A => 0100 => 4
mask ^ FLAG_B => 0001 => 1
FLAG_A ^ FLAG_B => 0101 => 5clone 函数// 木易杨
// 主线代码
if (customizer) {
result = object ? customizer(value, key, object, stack) : customizer(value)
}
if (result !== undefined) {
return result
}上面代码比较清晰,存在定制 clone 函数时,如果存在 value 值的父对象,就传入 value、key、object、stack 这些值,不存在父对象直接传入 value 执行定制函数。函数返回值 result 不为空则返回执行结果。
这部分是为了定制 clone 函数暴露出来的方法。
// 木易杨
// 主线代码
//判断要拷贝的值是否是对象,非对象直接返回本来的值
if (!isObject(value)) {
return value;
}
// ../isObject.js
function isObject(value) {
const type = typeof value;
return value != null && (type == 'object' || type ='function');
}这里的处理和我在【进阶3-3】的处理一样,有一点不同在于对象的判断中加入了 function,对于函数的拷贝详见下面函数部分。
// 木易杨
// 主线代码
const isArr = Array.isArray(value)
const hasOwnProperty = Object.prototype.hasOwnProperty
if (isArr) {
// 数组
result = initCloneArray(value)
if (!isDeep) {
return copyArray(value, result)
}
} else {
... // 非数组,后面解析
}
// 初始化一个数组
function initCloneArray(array) {
const { length } = array
// 构造相同长度的新数组
const result = new array.constructor(length)
// 正则 `RegExp#exec` 返回的数组
if (length && typeof array[0] == 'string' && hasOwnProperty.call(array, 'index')) {
result.index = array.index
result.input = array.input
}
return result
}
// ... 未完待续,最后部分有数组遍历赋值 传入的对象是数组时,构造一个相同长度的数组 new array.constructor(length),这里相当于 new Array(length),因为 array.constructor === Array。
// 木易杨
var a = [];
a.constructor === Array; // true
var a = new Array;
a.constructor === Array // true如果存在正则 RegExp#exec 返回的数组,拷贝属性 index 和 input。判断逻辑是 1、数组长度大于 0,2、数组第一个元素是字符串类型,3、数组存在 index 属性。
// 木易杨
if (length && typeof array[0] == 'string' && hasOwnProperty.call(array, 'index')) {
result.index = array.index
result.input = array.input
}其中正则表达式 regexObj.exec(str) 匹配成功时,返回一个数组,并更新正则表达式对象的属性。返回的数组将完全匹配成功的文本作为第一项,将正则括号里匹配成功的作为数组填充到后面。匹配失败时返回 null。
// 木易杨
var re = /quick\s(brown).+?(jumps)/ig;
var result = re.exec('The Quick Brown Fox Jumps Over The Lazy Dog');
console.log(result);
// [
// 0: "Quick Brown Fox Jumps" // 匹配的全部字符串
// 1: "Brown" // 括号中的分组捕获
// 2: "Jumps"
// groups: undefined
// index: 4 // 匹配到的字符位于原始字符串的基于0的索引值
// input: "The Quick Brown Fox Jumps Over The Lazy Dog" // 原始字符串
// length: 3
// ]如果不是深拷贝,传入value 和 result,直接返回浅拷贝后的数组。这里的浅拷贝方式就是循环然后复制。
// 木易杨
if (!isDeep) {
return copyArray(value, result)
}
// 浅拷贝数组
function copyArray(source, array) {
let index = -1
const length = source.length
array || (array = new Array(length))
while (++index < length) {
array[index] = source[index]
}
return array
}// 木易杨
// 主线代码
const isArr = Array.isArray(value)
const tag = getTag(value)
if (isArr) {
... // 数组情况,详见上面解析
} else {
// 函数
const isFunc = typeof value == 'function'
// 如果是 Buffer 对象,拷贝并返回
if (isBuffer(value)) {
return cloneBuffer(value, isDeep)
}
// Object 对象、类数组、或者是函数但没有父对象
if (tag == objectTag || tag == argsTag || (isFunc && !object)) {
// 拷贝原型链或者 value 是函数时,返回 {},不然初始化对象
result = (isFlat || isFunc) ? {} : initCloneObject(value)
if (!isDeep) {
return isFlat
? copySymbolsIn(value, copyObject(value, keysIn(value), result))
: copySymbols(value, Object.assign(result, value))
}
} else {
// 在 cloneableTags 中,只有 error 和 weakmap 返回 false
// 函数或者 error 或者 weakmap 时,
if (isFunc || !cloneableTags[tag]) {
// 存在父对象返回value,不然返回空对象 {}
return object ? value : {}
}
// 初始化非常规类型
result = initCloneByTag(value, tag, isDeep)
}
}通过上面代码可以发现,函数、error 和 weakmap 时返回空对象 {},并不会真正拷贝函数。
value 类型是 Object 对象和类数组时,调用 initCloneObject 初始化对象,最终调用 Object.create 生成新对象。
// 木易杨
function initCloneObject(object) {
// 构造函数并且自己不在自己的原型链上
return (typeof object.constructor == 'function' && !isPrototype(object))
? Object.create(Object.getPrototypeOf(object))
: {}
}
// 本质上实现了一个instanceof,用来测试自己是否在自己的原型链上
function isPrototype(value) {
const Ctor = value && value.constructor
// 寻找对应原型
const proto = (typeof Ctor == 'function' && Ctor.prototype) || Object.prototype
return value === proto
}其中 Object 的构造函数是一个函数对象。
// 木易杨
var obj = new Object();
typeof obj.constructor;
// 'function'
var obj2 = {};
typeof obj2.constructor;
// 'function'对于非常规类型对象,通过各自类型分别进行初始化。
// 木易杨
function initCloneByTag(object, tag, isDeep) {
const Ctor = object.constructor
switch (tag) {
case arrayBufferTag:
return cloneArrayBuffer(object)
case boolTag: // 布尔与时间类型
case dateTag:
return new Ctor(+object) // + 转换为数字
case dataViewTag:
return cloneDataView(object, isDeep)
case float32Tag: case float64Tag:
case int8Tag: case int16Tag: case int32Tag:
case uint8Tag: case uint8ClampedTag: case uint16Tag: case uint32Tag:
return cloneTypedArray(object, isDeep)
case mapTag: // Map 类型
return new Ctor
case numberTag: // 数字和字符串类型
case stringTag:
return new Ctor(object)
case regexpTag: // 正则
return cloneRegExp(object)
case setTag: // Set 类型
return new Ctor
case symbolTag: // Symbol 类型
return cloneSymbol(object)
}
}拷贝正则类型
// 木易杨
// \w 用于匹配字母,数字或下划线字符,相当于[A-Za-z0-9_]
const reFlags = /\w*$/
function cloneRegExp(regexp) {
// 返回当前匹配的文本
const result = new regexp.constructor(regexp.source, reFlags.exec(regexp))
// 下一次匹配的起始索引
result.lastIndex = regexp.lastIndex
return result
}初始化 Symbol 类型
// 木易杨
const symbolValueOf = Symbol.prototype.valueOf
function cloneSymbol(symbol) {
return Object(symbolValueOf.call(symbol))
}构造了一个栈用来解决循环引用的问题。
// 木易杨
// 主线代码
stack || (stack = new Stack)
const stacked = stack.get(value)
// 已存在
if (stacked) {
return stacked
}
stack.set(value, result)如果当前需要拷贝的值已存在于栈中,说明有环,直接返回即可。栈中没有该值时保存到栈中,传入 value 和 result。这里的 result 是一个对象引用,后续对 result 的修改也会反应到栈中。
value 值是 Map 类型时,遍历 value 并递归其 subValue,遍历完成返回 result 结果。
// 木易杨
// 主线代码
if (tag == mapTag) {
value.forEach((subValue, key) => {
result.set(key, baseClone(subValue, bitmask, customizer, key, value, stack))
})
return result
}value 值是 Set 类型时,遍历 value 并递归其 subValue,遍历完成返回 result 结果。
// 木易杨
// 主线代码
if (tag == setTag) {
value.forEach((subValue) => {
result.add(baseClone(subValue, bitmask, customizer, subValue, value, stack))
})
return result
}上面的区别在于添加元素的 API 不同,即 Map.set 和 Set.add。
这里我们介绍下 Symbol 和 原型链属性的拷贝,通过标志位 isFull 和 isFlat 来控制是否拷贝。
// 木易杨
// 主线代码
// 类型化数组对象
if (isTypedArray(value)) {
return result
}
const keysFunc = isFull // 拷贝 Symbol 标志位
? (isFlat // 拷贝原型链属性标志位
? getAllKeysIn // 包含自身和原型链上可枚举属性名以及 Symbol
: getAllKeys) // 仅包含自身可枚举属性名以及 Symbol
: (isFlat
? keysIn // 包含自身和原型链上可枚举属性名的数组
: keys) // 仅包含自身可枚举属性名的数组
const props = isArr ? undefined : keysFunc(value)
arrayEach(props || value, (subValue, key) => {
if (props) {
key = subValue
subValue = value[key]
}
// 递归拷贝(易受调用堆栈限制)
assignValue(result, key, baseClone(subValue, bitmask, customizer, key, value, stack))
})
return result我们先来看下怎么获取自身、原型链、Symbol 这几种属性名组成的数组 keys。
// 木易杨
// 创建一个包含自身和原型链上可枚举属性名以及 Symbol 的数组
// 使用 for...in 遍历
function getAllKeysIn(object) {
const result = keysIn(object)
if (!Array.isArray(object)) {
result.push(...getSymbolsIn(object))
}
return result
}
// 创建一个仅包含自身可枚举属性名以及 Symbol 的数组
// 非 ArrayLike 数组使用 Object.keys
function getAllKeys(object) {
const result = keys(object)
if (!Array.isArray(object)) {
result.push(...getSymbols(object))
}
return result
}上面通过 keysIn 和 keys 获取常规可枚举属性,通过 getSymbolsIn 和 getSymbols 获取 Symbol 可枚举属性。
// 木易杨
// 创建一个包含自身和原型链上可枚举属性名的数组
// 使用 for...in 遍历
function keysIn(object) {
const result = []
for (const key in object) {
result.push(key)
}
return result
}
// 创建一个仅包含自身可枚举属性名的数组
// 非 ArrayLike 数组使用 Object.keys
function keys(object) {
return isArrayLike(object)
? arrayLikeKeys(object)
: Object.keys(Object(object))
}
// 测试代码
function Foo() {
this.a = 1
this.b = 2
}
Foo.prototype.c = 3
keysIn(new Foo)
// ['a', 'b', 'c'] (迭代顺序无法保证)
keys(new Foo)
// ['a', 'b'] (迭代顺序无法保证)常规属性遍历原型链用的是 for.. in,那么 Symbol 是如何遍历原型链的呢,这里通过循环以及使用 Object.getPrototypeOf 获取原型链上的 Symbol。
// 木易杨
// 创建一个包含自身和原型链上可枚举 Symbol 的数组
// 通过循环和使用 Object.getPrototypeOf 获取原型链上的 Symbol
function getSymbolsIn (object) {
const result = []
while (object) { // 循环
result.push(...getSymbols(object))
object = Object.getPrototypeOf(Object(object))
}
return result
}
// 创建一个仅包含自身可枚举 Symbol 的数组
// 通过 Object.getOwnPropertySymbols 获取 Symbol 属性
const nativeGetSymbols = Object.getOwnPropertySymbols
const propertyIsEnumerable = Object.prototype.propertyIsEnumerable
function getSymbols (object) {
if (object == null) { // 判空
return []
}
object = Object(object)
return nativeGetSymbols(object)
.filter((symbol) => propertyIsEnumerable.call(object, symbol))
}我们回到主线代码,获取到 keys 组成的 props 数组之后,遍历并递归。
// 木易杨
// 主线代码
const props = isArr ? undefined : keysFunc(value)
arrayEach(props || value, (subValue, key) => {
// props 时替换 key 和 subValue,因为 props 里面的 subValue 只是 value 的 key
if (props) {
key = subValue
subValue = value[key]
}
// 递归拷贝(易受调用堆栈限制)
assignValue(result, key, baseClone(subValue, bitmask, customizer, key, value, stack))
})
// 返回结果,主线结束
return result我们看下 arrayEach 的实现,主要实现了一个遍历,并在 iteratee 返回为 false 时退出。
// 木易杨
// 迭代数组
// iteratee 是每次迭代调用的函数
function arrayEach(array, iteratee) {
let index = -1
const length = array.length
while (++index < length) {
if (iteratee(array[index], index, array) === false) {
break
}
}
return array
}我们看下 assignValue 的实现,在值不相等情况下,将 value 分配给 object[key]。
// 木易杨
const hasOwnProperty = Object.prototype.hasOwnProperty
// 如果现有值不相等,则将 value 分配给 object[key]。
function assignValue(object, key, value) {
const objValue = object[key]
// 不相等
if (! (hasOwnProperty.call(object, key) && eq(objValue, value)) ) {
// 值可用
if (value !== 0 || (1 / value) == (1 / objValue)) {
baseAssignValue(object, key, value)
}
// 值未定义而且键 key 不在对象中
} else if (value === undefined && !(key in object)) {
baseAssignValue(object, key, value)
}
}
// 赋值基本实现,其中没有值检查。
function baseAssignValue(object, key, value) {
if (key == '__proto__') {
Object.defineProperty(object, key, {
'configurable': true,
'enumerable': true,
'value': value,
'writable': true
})
} else {
object[key] = value
}
}
// 比较两个值是否相等
// (value !== value && other !== other) 是为了判断 NaN
function eq(value, other) {
return value === other || (value !== value && other !== other)
}进阶系列文章汇总如下,内有优质前端资料,觉得不错点个star。
我是木易杨,网易高级前端工程师,跟着我每周重点攻克一个前端面试重难点。接下来让我带你走进高级前端的世界,在进阶的路上,共勉!
上一节介绍了高阶函数的定义,并结合实例说明了使用高阶函数和不使用高阶函数的情况。后面几部分将结合实际应用场景介绍高阶函数的应用,本节先来聊聊函数柯里化,通过介绍其定义、比较常见的三种柯里化应用、并在最后实现一个通用的 currying 函数,带你认识完整的函数柯里化。
有什么想法或者意见都可以在评论区留言,下图是本文的思维导图,高清思维导图和更多文章请看我的 Github。
函数柯里化又叫部分求值,维基百科中对柯里化 (Currying) 的定义为:
在数学和计算机科学中,柯里化是一种将使用多个参数的函数转换成一系列使用一个参数的函数,并且返回接受余下的参数而且返回结果的新函数的技术。
用大白话来说就是只传递给函数一部分参数来调用它,让它返回一个新函数去处理剩下的参数。使用一个简单的例子来介绍下,最常用的就是 add 函数了。
// 木易杨
const add = (...args) => args.reduce((a, b) => a + b);
// 传入多个参数,执行 add 函数
add(1, 2) // 3
// 假设我们实现了一个 currying 函数,支持一次传入一个参数
let sum = currying(add);
// 封装第一个参数,方便重用
let addCurryOne = sum(1);
addCurryOne(2) // 3
addCurryOne(3) // 4我们看下面的部分求和例子,很好的说明了延迟计算这个情况。
// 木易杨
const add = (...args) => args.reduce((a, b) => a + b);
// 简化写法
function currying(func) {
const args = [];
return function result(...rest) {
if (rest.length === 0) {
return func(...args);
} else {
args.push(...rest);
return result;
}
}
}
const sum = currying(add);
sum(1,2)(3); // 未真正求值
sum(4); // 未真正求值
sum(); // 输出 10上面的代码理解起来很容易,就是「用闭包把传入参数保存起来,当传入参数的数量足够执行函数时,就开始执行函数」。上面的 currying 函数是一种简化写法,判断传入的参数长度是否为 0,若为 0 执行函数,否则收集参数。
另一种常见的应用是 bind 函数,我们看下 bind 的使用。
// 木易杨
let obj = {
name: 'muyiy'
}
const fun = function () {
console.log(this.name);
}.bind(obj);
fun(); // muyiy这里 bind 用来改变函数执行时候的上下文,但是函数本身并不执行,所以本质上是延迟计算,这一点和 call / apply 直接执行有所不同。
我们看下 bind 模拟实现,其本身就是一种柯里化,我们在最后的实现部分会发现,bind 的模拟实现和柯理化函数的实现,其核心代码都是一致的。
以下实现方案是简化版实现,完整版实现过程和代码解读请看我之前写的一篇文章,【进阶3-4期】深度解析bind原理、使用场景及模拟实现。
// 木易杨
// 简化实现,完整版实现中的第 2 步
Function.prototype.bind = function (context) {
var self = this;
// 第 1 个参数是指定的 this,截取保存第 1 个之后的参数
// arr.slice(begin); 即 [begin, end]
var args = Array.prototype.slice.call(arguments, 1);
return function () {
// 此时的 arguments 是指 bind 返回的函数调用时接收的参数
// 即 return function 的参数,和上面那个不同
// 类数组转成数组
var bindArgs = Array.prototype.slice.call(arguments);
// 执行函数
return self.apply( context, args.concat(bindArgs) );
}
}有一种典型的应用情景是这样的,每次调用函数都需要进行一次判断,但其实第一次判断计算之后,后续调用并不需要再次判断,这种情况下就非常适合使用柯里化方案来处理。即第一次判断之后,动态创建一个新函数用于处理后续传入的参数,并返回这个新函数。当然也可以使用惰性函数来处理,本例最后一个方案会有所介绍。
我们看下面的这个例子,在 DOM 中添加事件时需要兼容现代浏览器和 IE 浏览器(IE < 9),方法就是对浏览器环境进行判断,看浏览器是否支持,简化写法如下。
// 简化写法
function addEvent (type, el, fn, capture = false) {
if (window.addEventListener) {
el.addEventListener(type, fn, capture);
}
else if(window.attachEvent){
el.attachEvent('on' + type, fn);
}
}但是这种写法有一个问题,就是每次添加事件都会调用做一次判断,那么有没有什么办法只判断一次呢,可以利用闭包和立即调用函数表达式(IIFE)来处理。
const addEvent = (function(){
if (window.addEventListener) {
return function (type, el, fn, capture) {
el.addEventListener(type, fn, capture);
}
}
else if(window.attachEvent){
return function (type, el, fn) {
el.attachEvent('on' + type, fn);
}
}
})();上面这种实现方案就是一种典型的柯里化应用,在第一次的 if...else if... 判断之后完成部分计算,动态创建新的函数用于处理后续传入的参数,这样做的好处就是之后调用就不需要再次计算了。
当然可以使用惰性函数来实现这一功能,原理很简单,就是重写函数。
function addEvent (type, el, fn, capture = false) {
// 重写函数
if (window.addEventListener) {
addEvent = function (type, el, fn, capture) {
el.addEventListener(type, fn, capture);
}
}
else if(window.attachEvent){
addEvent = function (type, el, fn) {
el.attachEvent('on' + type, fn);
}
}
// 执行函数,有循环爆栈风险
addEvent(type, el, fn, capture);
}第一次调用 addEvent 函数后,会进行一次环境判断,在这之后 addEvent 函数被重写,所以下次调用时就不会再次判断环境,可以说很完美了。
我们知道调用 toString() 可以获取每个对象的类型,但是不同对象的 toString() 有不同的实现,所以需要通过 Object.prototype.toString() 来获取 Object 上的实现,同时以 call() / apply() 的形式来调用,并传递要检查的对象作为第一个参数,例如下面这个例子。
function isArray(obj) {
return Object.prototype.toString.call(obj) === '[object Array]';
}
function isNumber(obj) {
return Object.prototype.toString.call(obj) === '[object Number]';
}
function isString(obj) {
return Object.prototype.toString.call(obj) === '[object String]';
}
// Test
isArray([1, 2, 3]); // true
isNumber(123); // true
isString('123'); // true但是上面方案有一个问题,那就是每种类型都需要定义一个方法,这里我们可以使用 bind 来扩展,优点是可以直接使用改造后的 toStr。
const toStr = Function.prototype.call.bind(Object.prototype.toString);
// 改造前
[1, 2, 3].toString(); // "1,2,3"
'123'.toString(); // "123"
123.toString(); // SyntaxError: Invalid or unexpected token
Object(123).toString(); // "123"
// 改造后
toStr([1, 2, 3]); // "[object Array]"
toStr('123'); // "[object String]"
toStr(123); // "[object Number]"
toStr(Object(123)); // "[object Number]"上面例子首先使用 Function.prototype.call 函数指定一个 this 值,然后 .bind 返回一个新的函数,始终将 Object.prototype.toString 设置为传入参数,其实等价于 Object.prototype.toString.call() 。
我们可以理解所谓的柯里化函数,就是封装「一系列的处理步骤」,通过闭包将参数集中起来计算,最后再把需要处理的参数传进去。那如何实现 currying 函数呢?
实现原理就是「用闭包把传入参数保存起来,当传入参数的数量足够执行函数时,就开始执行函数」。上面延迟计算部分已经实现了一个简化版的 currying 函数。
下面我们来实现一个更加健壮的的 currying 函数。
// 木易杨
function currying(fn, length) {
length = length || fn.length; // 注释 1
return function (...args) { // 注释 2
return args.length >= length // 注释 3
? fn.apply(this, args) // 注释 4
: currying(fn.bind(this, ...args), length - args.length) // 注释 5
}
}
// Test
const fn = currying(function(a, b, c) {
console.log([a, b, c]);
});
fn("a", "b", "c") // ["a", "b", "c"]
fn("a", "b")("c") // ["a", "b", "c"]
fn("a")("b")("c") // ["a", "b", "c"]
fn("a")("b", "c") // ["a", "b", "c"]注释 1:第一次调用获取函数 fn 参数的长度,后续调用获取 fn 剩余参数的长度
注释 2:currying 包裹之后返回一个新函数,接收参数为 ...args
注释 3:新函数接收的参数长度是否大于等于 fn 剩余参数需要接收的长度
注释 4:满足要求,执行 fn 函数,传入新函数的参数
注释 5:不满足要求,递归 currying 函数,新的 fn 为 bind 返回的新函数(bind 绑定了 ...args 参数,未执行),新的 length 为 fn 剩余参数的长度
上面使用的是 ES5 和 ES6 的混合语法,那我不想使用 call/apply/bind 这些方法呢,自然是可以的,看下面的 ES6 极简写法,更加简洁也更加易懂。
// 参考自 segmentfault 的@大笑平
const currying = fn =>
judge = (...args) =>
args.length >= fn.length
? fn(...args)
: (...arg) => judge(...args, ...arg)
// Test
const fn = currying(function(a, b, c) {
console.log([a, b, c]);
});
fn("a", "b", "c") // ["a", "b", "c"]
fn("a", "b")("c") // ["a", "b", "c"]
fn("a")("b")("c") // ["a", "b", "c"]
fn("a")("b", "c") // ["a", "b", "c"]如果你还无法理解,看完下面例子你就更加容易理解了,要求实现一个 add 方法,需要满足如下预期。
add(1, 2, 3) // 6
add(1, 2)(3) // 6
add(1)(2)(3) // 6
add(1)(2, 3) // 6我们可以看到,计算结果就是所有参数的和,如果我们分两次调用时 add(1)(2),可以写出如下代码。
function add(a) {
return function(b) {
return a + b;
}
}
add(1)(2) // 3add 方法第一次调用后返回一个新函数,通过闭包保存之前的参数,第二次调用时满足参数长度要求然后执行函数。
如果分三次调用时 add(1)(2)(3),可以写出如下代码。
function add(a) {
return function(b) {
return function (c) {
return a + b + c;
}
}
}
console.log(add(1)(2)(3)); // 6前面两次调用每次返回一个新函数,第三次调用后满足参数长度要求然后执行函数。
这时候我们再来看 currying 实现函数,其实就是判断当前参数长度够不够,参数够了就立马执行,不够就返回一个新函数,这个新函数并不执行,并且通过 bind 或者闭包保存之前传入的参数。
// 注释同上
function currying(fn, length) {
length = length || fn.length;
return function (...args) {
return args.length >= length
? fn.apply(this, args)
: currying(fn.bind(this, ...args), length - args.length)
}
}函数 currying 的实现中,使用了 fn.length 来表示函数参数的个数,那 fn.length 表示函数的所有参数个数吗?并不是。
函数的 length 属性获取的是形参的个数,但是形参的数量不包括剩余参数个数,而且仅包括第一个具有默认值之前的参数个数,看下面的例子。
((a, b, c) => {}).length;
// 3
((a, b, c = 3) => {}).length;
// 2
((a, b = 2, c) => {}).length;
// 1
((a = 1, b, c) => {}).length;
// 0
((...args) => {}).length;
// 0
const fn = (...args) => {
console.log(args.length);
}
fn(1, 2, 3)
// 3所以在柯里化的场景中,不建议使用 ES6 的函数参数默认值。
const fn = currying((a = 1, b, c) => {
console.log([a, b, c]);
});
fn();
// [1, undefined, undefined]
fn()(2)(3);
// Uncaught TypeError: fn(...) is not a function我们期望函数 fn 输出 [1, 2, 3],但是实际上调用柯里化函数时 ((a = 1, b, c) => {}).length === 0,所以调用 fn() 时就已经执行并输出了 [1, undefined, undefined],而不是理想中的返回闭包函数,所以后续调用 fn()(2)(3) 将会报错。
我们通过定义认识了什么是柯里化函数,并且介绍了三种实际的应用场景:延迟计算、动态创建函数、参数复用,然后实现了强大的通用化 currying 函数,不过更像是柯里化 (currying) 和偏函数 (partial application) 的综合应用,并且在最后介绍了函数的 length,算是意外之喜。
Function.prototype.call.bind(Object.prototype.toString)进阶系列文章汇总如下,觉得不错点个Star,欢迎 加群 互相学习。
我是木易杨,公众号「高级前端进阶」作者,跟着我每周重点攻克一个前端面试重难点。接下来让我带你走进高级前端的世界,在进阶的路上,共勉!

本期的主题是调用堆栈,本计划一共28期,每期重点攻克一个面试重难点,如果你还不了解本进阶计划,文末点击查看全部文章。
如果觉得本系列不错,欢迎点赞、评论、转发,您的支持就是我坚持的最大动力。
上篇文章详细介绍了内存回收和内存泄漏,今天我们继续这个篇幅,不过重点是内存泄漏可能发生的原因。
常用垃圾回收算法叫做**标记清除 (Mark-and-sweep) **,算法由以下几步组成:
1、垃圾回收器创建了一个“roots”列表。roots 通常是代码中全局变量的引用。JavaScript 中,“window” 对象是一个全局变量,被当作 root 。window 对象总是存在,因此垃圾回收器可以检查它和它的所有子对象是否存在(即不是垃圾);
2、所有的 roots 被检查和标记为激活(即不是垃圾)。所有的子对象也被递归地检查。从 root 开始的所有对象如果是可达的,它就不被当作垃圾。
3、所有未被标记的内存会被当做垃圾,收集器现在可以释放内存,归还给操作系统了。
现代的垃圾回收器改良了算法,但是本质是相同的:可达内存被标记,其余的被当作垃圾回收。
划重点 这是个考点
未定义的变量会在全局对象创建一个新变量,如下。
function foo(arg) {
bar = "this is a hidden global variable";
}函数 foo 内部忘记使用 var ,实际上JS会把bar挂载到全局对象上,意外创建一个全局变量。
function foo(arg) {
window.bar = "this is an explicit global variable";
}另一个意外的全局变量可能由 this 创建。
function foo() {
this.variable = "potential accidental global";
}
// Foo 调用自己,this 指向了全局对象(window)
// 而不是 undefined
foo();解决方法:
在 JavaScript 文件头部加上 'use strict',使用严格模式避免意外的全局变量,此时上例中的this指向undefined。如果必须使用全局变量存储大量数据时,确保用完以后把它设置为 null 或者重新定义。
计时器setInterval代码很常见
var someResource = getData();
setInterval(function() {
var node = document.getElementById('Node');
if(node) {
// 处理 node 和 someResource
node.innerHTML = JSON.stringify(someResource));
}
}, 1000);上面的例子表明,在节点node或者数据不再需要时,定时器依旧指向这些数据。所以哪怕当node节点被移除后,interval 仍旧存活并且垃圾回收器没办法回收,它的依赖也没办法被回收,除非终止定时器。
var element = document.getElementById('button');
function onClick(event) {
element.innerHTML = 'text';
}
element.addEventListener('click', onClick);对于上面观察者的例子,一旦它们不再需要(或者关联的对象变成不可达),明确地移除它们非常重要。老的 IE 6 是无法处理循环引用的。因为老版本的 IE 是无法检测 DOM 节点与 JavaScript 代码之间的循环引用,会导致内存泄漏。
但是,现代的浏览器(包括 IE 和 Microsoft Edge)使用了更先进的垃圾回收算法(标记清除),已经可以正确检测和处理循环引用了。即回收节点内存时,不必非要调用 removeEventListener 了。
如果把DOM 存成字典(JSON 键值对)或者数组,此时,同样的 DOM 元素存在两个引用:一个在 DOM 树中,另一个在字典中。那么将来需要把两个引用都清除。
var elements = {
button: document.getElementById('button'),
image: document.getElementById('image'),
text: document.getElementById('text')
};
function doStuff() {
image.src = 'http://some.url/image';
button.click();
console.log(text.innerHTML);
// 更多逻辑
}
function removeButton() {
// 按钮是 body 的后代元素
document.body.removeChild(document.getElementById('button'));
// 此时,仍旧存在一个全局的 #button 的引用
// elements 字典。button 元素仍旧在内存中,不能被 GC 回收。
}如果代码中保存了表格某一个 <td> 的引用。将来决定删除整个表格的时候,直觉认为 GC 会回收除了已保存的 <td> 以外的其它节点。实际情况并非如此:此 <td> 是表格的子节点,子元素与父元素是引用关系。由于代码保留了 <td> 的引用,导致整个表格仍待在内存中。所以保存 DOM 元素引用的时候,要小心谨慎。
闭包的关键是匿名函数可以访问父级作用域的变量。
var theThing = null;
var replaceThing = function () {
var originalThing = theThing;
var unused = function () {
if (originalThing)
console.log("hi");
};
theThing = {
longStr: new Array(1000000).join('*'),
someMethod: function () {
console.log(someMessage);
}
};
};
setInterval(replaceThing, 1000);每次调用 replaceThing ,theThing 得到一个包含一个大数组和一个新闭包(someMethod)的新对象。同时,变量 unused 是一个引用 originalThing 的闭包(先前的 replaceThing 又调用了 theThing )。someMethod 可以通过 theThing 使用,someMethod 与 unused 分享闭包作用域,尽管 unused 从未使用,它引用的 originalThing 迫使它保留在内存中(防止被回收)。
解决方法:
在 replaceThing 的最后添加 originalThing = null 。
PS:今晚弄到很晚,由于时间问题,就不再详细介绍Chrome 内存剖析工具,有兴趣的大家去原文查看。
周末汇总将在周日早上发送,周六会发送其他类型的文章,敬请期待。
问题一:
从内存来看 null 和 undefined 本质的区别是什么?
解答:
给一个全局变量赋值为null,相当于将这个变量的指针对象以及值清空,如果是给对象的属性 赋值为null,或者局部变量赋值为null,相当于给这个属性分配了一块空的内存,然后值为null, JS会回收全局变量为null的对象。
给一个全局变量赋值为undefined,相当于将这个对象的值清空,但是这个对象依旧存在,如果是给对象的属性赋值 为undefined,说明这个值为空值
扩展下:
声明了一个变量,但未对其初始化时,这个变量的值就是undefined,它是 JavaScript 基本类型 之一。
var data;
console.log(data === undefined); //true对于尚未声明过的变量,只能执行一项操作,即使用typeof操作符检测其数据类型,使用其他的操作都会报错。
//data变量未定义
console.log(typeof data); // "undefined"
console.log(data === undefined); //报错值 null 特指对象的值未设置,它是 JavaScript 基本类型 之一。
值 null 是一个字面量,它不像undefined 是全局对象的一个属性。null 是表示缺少的标识,指示变量未指向任何对象。
// foo不存在,它从来没有被定义过或者是初始化过:
foo;
"ReferenceError: foo is not defined"
// foo现在已经是知存在的,但是它没有类型或者是值:
var foo = null;
console.log(foo); // null问题二:
ES6语法中的 const 声明一个只读的常量,那为什么下面可以修改const的值?
const foo = {};
// 为 foo 添加一个属性,可以成功
foo.prop = 123;
foo.prop // 123
// 将 foo 指向另一个对象,就会报错
foo = {}; // TypeError: "foo" is read-only解答:
const实际上保证的,并不是变量的值不得改动,而是变量指向的那个内存地址所保存的数据不得改动。对于简单类型的数据(数值、字符串、布尔值),值就保存在变量指向的那个内存地址,因此等同于常量。但对于复合类型的数据(主要是对象和数组),变量指向的内存地址,保存的只是一个指向实际数据的指针,const只能保证这个指针是固定的(即总是指向另一个固定的地址),至于它指向的数据结构是不是可变的,就完全不能控制了。因此,将一个对象声明为常量必须非常小心。
<script>
console.log(fun)
console.log(person)
</script>
<script>
console.log(person)
console.log(fun)
var person = "Eric";
console.log(person)
function fun() {
console.log(person)
var person = "Tom";
console.log(person)
}
fun()
console.log(person)
</script>上面代码的执行结果是什么?先自己分析,然后再到浏览器中执行。
进阶系列文章汇总:https://github.com/yygmind/blog,内有优质前端资料,欢迎领取,觉得不错点个star。
我是木易杨,网易高级前端工程师,跟着我每周重点攻克一个前端面试重难点。接下来让我带你走进高级前端的世界,在进阶的路上,共勉!
上篇文章介绍了赋值、浅拷贝和深拷贝,其中介绍了很多赋值和浅拷贝的相关知识以及两者区别,限于篇幅只介绍了一种常用深拷贝方案。
本篇文章会先介绍浅拷贝 Object.assign 的实现原理,然后带你手动实现一个浅拷贝,并在文末留下一道面试题,期待你的评论。
Object.assign上篇文章介绍了其定义和使用,主要是将所有可枚举属性的值从一个或多个源对象复制到目标对象,同时返回目标对象。(来自 MDN)
语法如下所示:
Object.assign(target, ...sources)
其中 target 是目标对象,sources 是源对象,可以有多个,返回修改后的目标对象 target。
如果目标对象中的属性具有相同的键,则属性将被源对象中的属性覆盖。后来的源对象的属性将类似地覆盖早先的属性。
我们知道浅拷贝就是拷贝第一层的基本类型值,以及第一层的引用类型地址。
// 木易杨
// 第一步
let a = {
name: "advanced",
age: 18
}
let b = {
name: "muyiy",
book: {
title: "You Don't Know JS",
price: "45"
}
}
let c = Object.assign(a, b);
console.log(c);
// {
// name: "muyiy",
// age: 18,
// book: {title: "You Don't Know JS", price: "45"}
// }
console.log(a === c);
// true
// 第二步
b.name = "change";
b.book.price = "55";
console.log(b);
// {
// name: "change",
// book: {title: "You Don't Know JS", price: "55"}
// }
// 第三步
console.log(a);
// {
// name: "muyiy",
// age: 18,
// book: {title: "You Don't Know JS", price: "55"}
// } 1、在第一步中,使用 Object.assign 把源对象 b 的值复制到目标对象 a 中,这里把返回值定义为对象 c,可以看出 b 会替换掉 a 中具有相同键的值,即如果目标对象(a)中的属性具有相同的键,则属性将被源对象(b)中的属性覆盖。这里需要注意下,返回对象 c 就是 目标对象 a。
2、在第二步中,修改源对象 b 的基本类型值(name)和引用类型值(book)。
3、在第三步中,浅拷贝之后目标对象 a 的基本类型值没有改变,但是引用类型值发生了改变,因为 Object.assign() 拷贝的是属性值。假如源对象的属性值是一个指向对象的引用,它也只拷贝那个引用地址。
String 类型和 Symbol 类型的属性都会被拷贝,而且不会跳过那些值为 null 或 undefined 的源对象。
// 木易杨
// 第一步
let a = {
name: "muyiy",
age: 18
}
let b = {
b1: Symbol("muyiy"),
b2: null,
b3: undefined
}
let c = Object.assign(a, b);
console.log(c);
// {
// name: "muyiy",
// age: 18,
// b1: Symbol(muyiy),
// b2: null,
// b3: undefined
// }
console.log(a === c);
// trueObject.assign 模拟实现实现一个 Object.assign 大致思路如下:
1、判断原生 Object 是否支持该函数,如果不存在的话创建一个函数 assign,并使用 Object.defineProperty 将该函数绑定到 Object 上。
2、判断参数是否正确(目标对象不能为空,我们可以直接设置{}传递进去,但必须设置值)。
3、使用 Object() 转成对象,并保存为 to,最后返回这个对象 to。
4、使用 for..in 循环遍历出所有可枚举的自有属性。并复制给新的目标对象(使用 hasOwnProperty 获取自有属性,即非原型链上的属性)。
实现代码如下,这里为了验证方便,使用 assign2 代替 assign。注意此模拟实现不支持 symbol 属性,因为ES5 中根本没有 symbol 。
// 木易杨
if (typeof Object.assign2 != 'function') {
// Attention 1
Object.defineProperty(Object, "assign2", {
value: function (target) {
'use strict';
if (target == null) { // Attention 2
throw new TypeError('Cannot convert undefined or null to object');
}
// Attention 3
var to = Object(target);
for (var index = 1; index < arguments.length; index++) {
var nextSource = arguments[index];
if (nextSource != null) { // Attention 2
// Attention 4
for (var nextKey in nextSource) {
if (Object.prototype.hasOwnProperty.call(nextSource, nextKey)) {
to[nextKey] = nextSource[nextKey];
}
}
}
}
return to;
},
writable: true,
configurable: true
});
}测试一下
// 木易杨
// 测试用例
let a = {
name: "advanced",
age: 18
}
let b = {
name: "muyiy",
book: {
title: "You Don't Know JS",
price: "45"
}
}
let c = Object.assign2(a, b);
console.log(c);
// {
// name: "muyiy",
// age: 18,
// book: {title: "You Don't Know JS", price: "45"}
// }
console.log(a === c);
// true针对上面的代码做如下扩展。
原生情况下挂载在 Object 上的属性是不可枚举的,但是直接在 Object 上挂载属性 a 之后是可枚举的,所以这里必须使用 Object.defineProperty,并设置 enumerable: false 以及 writable: true, configurable: true。
// 木易杨
for(var i in Object) {
console.log(Object[i]);
}
// 无输出
Object.keys( Object );
// []上面代码说明原生 Object 上的属性不可枚举。
我们可以使用 2 种方法查看 Object.assign 是否可枚举,使用 Object.getOwnPropertyDescriptor 或者 Object.propertyIsEnumerable 都可以,其中propertyIsEnumerable(..) 会检查给定的属性名是否直接存在于对象中(而不是在原型链上)并且满足 enumerable: true。具体用法如下:
// 木易杨
// 方法1
Object.getOwnPropertyDescriptor(Object, "assign");
// {
// value: ƒ,
// writable: true, // 可写
// enumerable: false, // 不可枚举,注意这里是 false
// configurable: true // 可配置
// }
// 方法2
Object.propertyIsEnumerable("assign");
// false上面代码说明 Object.assign 是不可枚举的。
介绍这么多是因为直接在 Object 上挂载属性 a 之后是可枚举的,我们来看如下代码。
// 木易杨
Object.a = function () {
console.log("log a");
}
Object.getOwnPropertyDescriptor(Object, "a");
// {
// value: ƒ,
// writable: true,
// enumerable: true, // 注意这里是 true
// configurable: true
// }
Object.propertyIsEnumerable("a");
// true所以要实现 Object.assign 必须使用 Object.defineProperty,并设置 writable: true, enumerable: false, configurable: true,当然默认情况下不设置就是 false。
// 木易杨
Object.defineProperty(Object, "b", {
value: function() {
console.log("log b");
}
});
Object.getOwnPropertyDescriptor(Object, "b");
// {
// value: ƒ,
// writable: false, // 注意这里是 false
// enumerable: false, // 注意这里是 false
// configurable: false // 注意这里是 false
// }所以具体到本次模拟实现中,相关代码如下。
// 木易杨
// 判断原生 Object 中是否存在函数 assign2
if (typeof Object.assign2 != 'function') {
// 使用属性描述符定义新属性 assign2
Object.defineProperty(Object, "assign2", {
value: function (target) {
...
},
// 默认值是 false,即 enumerable: false
writable: true,
configurable: true
});
}有些文章判断参数是否正确是这样的。
// 木易杨
if (target === undefined || target === null) {
throw new TypeError('Cannot convert undefined or null to object');
}这样肯定没问题,但是这样写没有必要,因为 undefined 和 null 是相等的(高程 3 P52 ),即 undefined == null 返回 true,只需要按照如下方式判断就好了。
// 木易杨
if (target == null) { // TypeError if undefined or null
throw new TypeError('Cannot convert undefined or null to object');
}// 木易杨
var v1 = "abc";
var v2 = true;
var v3 = 10;
var v4 = Symbol("foo");
var obj = Object.assign({}, v1, null, v2, undefined, v3, v4);
// 原始类型会被包装,null 和 undefined 会被忽略。
// 注意,只有字符串的包装对象才可能有自身可枚举属性。
console.log(obj);
// { "0": "a", "1": "b", "2": "c" }上面代码中的源对象 v2、v3、v4 实际上被忽略了,原因在于他们自身没有可枚举属性。
// 木易杨
var v1 = "abc";
var v2 = true;
var v3 = 10;
var v4 = Symbol("foo");
var v5 = null;
// Object.keys(..) 返回一个数组,包含所有可枚举属性
// 只会查找对象直接包含的属性,不查找[[Prototype]]链
Object.keys( v1 ); // [ '0', '1', '2' ]
Object.keys( v2 ); // []
Object.keys( v3 ); // []
Object.keys( v4 ); // []
Object.keys( v5 );
// TypeError: Cannot convert undefined or null to object
// Object.getOwnPropertyNames(..) 返回一个数组,包含所有属性,无论它们是否可枚举
// 只会查找对象直接包含的属性,不查找[[Prototype]]链
Object.getOwnPropertyNames( v1 ); // [ '0', '1', '2', 'length' ]
Object.getOwnPropertyNames( v2 ); // []
Object.getOwnPropertyNames( v3 ); // []
Object.getOwnPropertyNames( v4 ); // []
Object.getOwnPropertyNames( v5 );
// TypeError: Cannot convert undefined or null to object但是下面的代码是可以执行的。
// 木易杨
var a = "abc";
var b = {
v1: "def",
v2: true,
v3: 10,
v4: Symbol("foo"),
v5: null,
v6: undefined
}
var obj = Object.assign(a, b);
console.log(obj);
// {
// [String: 'abc']
// v1: 'def',
// v2: true,
// v3: 10,
// v4: Symbol(foo),
// v5: null,
// v6: undefined
// }原因很简单,因为此时 undefined、true 等不是作为对象,而是作为对象 b 的属性值,对象 b 是可枚举的。
// 木易杨
// 接上面的代码
Object.keys( b ); // [ 'v1', 'v2', 'v3', 'v4', 'v5', 'v6' ]这里其实又可以看出一个问题来,那就是目标对象是原始类型,会包装成对象,对应上面的代码就是目标对象 a 会被包装成 [String: 'abc'],那模拟实现时应该如何处理呢?很简单,使用 Object(..) 就可以了。
// 木易杨
var a = "abc";
console.log( Object(a) );
// [String: 'abc']到这里已经介绍很多知识了,让我们再来延伸一下,看看下面的代码能不能执行。
// 木易杨
var a = "abc";
var b = "def";
Object.assign(a, b); 答案是否定的,会提示以下错误。
// 木易杨
TypeError: Cannot assign to read only property '0' of object '[object String]'原因在于 Object("abc") 时,其属性描述符为不可写,即 writable: false。
// 木易杨
var myObject = Object( "abc" );
Object.getOwnPropertyNames( myObject );
// [ '0', '1', '2', 'length' ]
Object.getOwnPropertyDescriptor(myObject, "0");
// {
// value: 'a',
// writable: false, // 注意这里
// enumerable: true,
// configurable: false
// }同理,下面的代码也会报错。
// 木易杨
var a = "abc";
var b = {
0: "d"
};
Object.assign(a, b);
// TypeError: Cannot assign to read only property '0' of object '[object String]'但是并不是说只要 writable: false 就会报错,看下面的代码。
// 木易杨
var myObject = Object('abc');
Object.getOwnPropertyDescriptor(myObject, '0');
// {
// value: 'a',
// writable: false, // 注意这里
// enumerable: true,
// configurable: false
// }
myObject[0] = 'd';
// 'd'
myObject[0];
// 'a'这里并没有报错,原因在于 JS 对于不可写的属性值的修改静默失败(silently failed),在严格模式下才会提示错误。
// 木易杨
'use strict'
var myObject = Object('abc');
myObject[0] = 'd';
// TypeError: Cannot assign to read only property '0' of object '[object String]'所以我们在模拟实现 Object.assign 时需要使用严格模式。
如何在不访问属性值的情况下判断对象中是否存在某个属性呢,看下面的代码。
// 木易杨
var anotherObject = {
a: 1
};
// 创建一个关联到 anotherObject 的对象
var myObject = Object.create( anotherObject );
myObject.b = 2;
("a" in myObject); // true
("b" in myObject); // true
myObject.hasOwnProperty( "a" ); // false
myObject.hasOwnProperty( "b" ); // true这边使用了 in 操作符和 hasOwnProperty 方法,区别如下(你不知道的JS上卷 P119):
1、in 操作符会检查属性是否在对象及其 [[Prototype]] 原型链中。
2、hasOwnProperty(..) 只会检查属性是否在 myObject 对象中,不会检查 [[Prototype]] 原型链。
Object.assign 方法肯定不会拷贝原型链上的属性,所以模拟实现时需要用 hasOwnProperty(..) 判断处理下,但是直接使用 myObject.hasOwnProperty(..) 是有问题的,因为有的对象可能没有连接到 Object.prototype 上(比如通过 Object.create(null) 来创建),这种情况下,使用 myObject.hasOwnProperty(..) 就会失败。
// 木易杨
var myObject = Object.create( null );
myObject.b = 2;
("b" in myObject);
// true
myObject.hasOwnProperty( "b" );
// TypeError: myObject.hasOwnProperty is not a function解决方法也很简单,使用我们在【进阶3-3期】中介绍的 call 就可以了,使用如下。
// 木易杨
var myObject = Object.create( null );
myObject.b = 2;
Object.prototype.hasOwnProperty.call(myObject, "b");
// true所以具体到本次模拟实现中,相关代码如下。
// 木易杨
// 使用 for..in 遍历对象 nextSource 获取属性值
// 此处会同时检查其原型链上的属性
for (var nextKey in nextSource) {
// 使用 hasOwnProperty 判断对象 nextSource 中是否存在属性 nextKey
// 过滤其原型链上的属性
if (Object.prototype.hasOwnProperty.call(nextSource, nextKey)) {
// 赋值给对象 to,并在遍历结束后返回对象 to
to[nextKey] = nextSource[nextKey];
}
}如何实现一个深拷贝?
进阶系列文章汇总如下,内有优质前端资料,觉得不错点个star。
我是木易杨,网易高级前端工程师,跟着我每周重点攻克一个前端面试重难点。接下来让我带你走进高级前端的世界,在进阶的路上,共勉!
原文 Improve Your React App Performance by Using Throttling and Debouncing
使用 React 构建应用程序时,我们总是会遇到一些限制问题,比如大量的调用、异步网络请求和 DOM 更新等,我们可以使用 React 提供的功能来检查这些。
shouldComponentUpdate(...) 生命周期钩子React.PureComponentReact.memouseState, useMemo, useContext, useReducer, 等)在这篇文章中,我们将研究如何在不使用 React 提供的功能下来改进 React 应用程序性能,我们将使用一种不仅仅适用于 React 的技术:节流(Throttle)和防抖(Debounce)。
下面这个例子可以很好的解释节流和防抖带给我们的好处,假设我们有一个 autocomp 组件
import React from 'react';
import './autocomp.css';class autocomp extends React.Component {
constructor(props) {
super(props);
this.state= {
results: []
}
} handleInput = evt => {
const value = evt.target.value
fetch(`/api/users`)
.then(res => res.json())
.then(result => this.setState({ results: result.users }))
} render() {
let { results } = this.state;
return (
<div className='autocomp_wrapper'>
<input placeholder="Enter your search.." onChange={this.handleInput} />
<div>
{results.map(item=>{item})}
</div>
</div>
);
}
}
export default autocomp;在我们的 autocomp 组件中,一旦我们在输入框中输入一个单词,它就会请求 api/users 获取要显示的用户列表。 在每个字母输入后,触发异步网络请求,并且成功后通过 this.setState 更新DOM。
现在,想象一下输入 fidudusola 尝试搜索结果 fidudusolanke,将有许多名称与 fidudusola 一起出现。
1. f
2. fi
3. fid
4. fidu
5. fidud
6. fidudu
7. fidudus
8. fiduduso
9. fidudusol
10. fidudusola这个名字有 10 个字母,所以我们将有 10 次 API 请求和 10 次 DOM 更新,这只是一个用户而已!! 输入完成后最终看到我们预期的名字 fidudusolanke 和其他结果一起出现。
即使 autocomp 可以在没有网络请求的情况下完成(例如,内存中有一个本地“数据库”),仍然需要为输入的每个字符/单词进行昂贵的 DOM 更新。
const data = [
{
name: 'nnamdi'
},
{
name: 'fidudusola'
},
{
name: 'fashola'
},
{
name: 'fidudusolanke'
},
// ... up to 10,000 records
]class autocomp extends React.Component {
constructor(props) {
super(props);
this.state= {
results: []
}
} handleInput = evt => {
const value = evt.target.value
const filteredRes = data.filter((item)=> {
// algorithm to search through the `data` array
})
this.setState({ results: filteredRes })
} render() {
let { results } = this.state;
return (
<div className='autocomp_wrapper'>
<input placeholder="Enter your search.." onChange={this.handleInput} />
<div>
{results.map(result=>{result})}
</div>
</div>
);
}
}另一个例子是使用 resize 和 scroll 等事件。大多数情况下,网站每秒滚动 1000 次,想象一下在 scroll 事件中添加一个事件处理。
document.body.addEventListener('scroll', ()=> {
console.log('Scrolled !!!')
})你会发现这个函数每秒被执行 1000 次!如果这个事件处理函数执行大量计算或大量 DOM 操作,将面临最坏的情况。
function longOp(ms) {
var now = Date.now()
var end = now + ms
while(now < end) {
now = Date.now()
}
}document.body.addEventListener('scroll', ()=> {
// simulating a heavy operation
longOp(9000)
console.log('Scrolled !!!')
})我们有一个需要 9 秒才能完成的操作,最后输出 Scrolled !!!,假设我们滚动 5000 像素会有 200 多个事件被触发。 因此,需要 9 秒才能完成一次的事件,大约需要 9 * 200 = 1800s 来运行全部的 200 个事件。 因此,全部完成需要 30 分钟(半小时)。
所以肯定会发现一个滞后且无响应的浏览器,因此编写的事件处理函数最好在较短的时间内执行完成。
我们发现这会在我们的应用程序中产生巨大的性能瓶颈,我们不需要在输入的每个字母上执行 API 请求和 DOM 更新,我们需要等到用户停止输入或者输入一段时间之后,等到用户停止滚动或者滚动一段时间之后,再去执行事件处理函数。
所有这些确保我们的应用程序有良好性能,让我们看看如何使用节流和防抖来避免这种性能瓶颈。
节流强制一个函数在一段时间内可以调用的最大次数,例如每 100 毫秒最多执行一次函数。
节流是指在指定的时间内执行一次给定的函数。这限制了函数被调用的次数,所以重复的函数调用不会重置任何数据。
假设我们通常以 1000 次 / 20 秒的速度调用函数。 如果我们使用节流将它限制为每 500 毫秒执行一次,我们会看到函数在 20 秒内将执行 40 次。
1000 * 20 secs = 20,000ms
20,000ms / 500ms = 40 times这是从 1000 次到 40 次的极大优化。
下面将介绍在 React 中使用节流的例子,将分别使用 underscore 、 lodash 、RxJS 以及自定义实现。
我们将使用 underscore 提供的节流函数处理我们的 autocomp 组件。
先安装依赖。
npm i underscore然后在组件中导入它:
// ...
import * as _ from underscore;class autocomp extends React.Component {
constructor(props) {
super(props);
this.state = {
results: []
}
this.handleInputThrottled = _.throttle(this.handleInput, 1000)
} handleInput = evt => {
const value = evt.target.value
const filteredRes = data.filter((item)=> {
// algorithm to search through the `data` array
})
this.setState({ results: filteredRes })
} render() {
let { results } = this.state;
return (
<div className='autocomp_wrapper'>
<input placeholder="Enter your search.." onChange={this.handleInputThrottled} />
<div>
{results.map(result=>{result})}
</div>
</div>
);
}
}节流函数接收两个参数,分别是需要被限制的函数和时间差,返回一个节流处理后的函数。 在我们的例子中,handleInput 方法被传递给 throttle 函数,时间差为 1000ms。
现在,假设我们以每 200ms 1 个字母的正常速度输入 fidudusola,输入完成需要10 * 200ms =(2000ms)2s,这时 handleInput 方法将只调用 2(2000ms / 1000ms = 2)次而不是最初的 10 次。
lodash 也提供了一个 throttle 函数,我们可以在 JS 程序中使用它。
首先,我们需要安装依赖。
npm i lodash使用 lodash,我们的 autocomp 将是这样的。
// ...
import { throttle } from lodash;class autocomp extends React.Component {
constructor(props) {
super(props);
this.state = {
results: []
}
this.handleInputThrottled = throttle(this.handleInput, 100)
} handleInput = evt => {
const value = evt.target.value
const filteredRes = data.filter((item)=> {
// algorithm to search through the `data` array
})
this.setState({ results: filteredRes })
} render() {
let { results } = this.state;
return (
<div className='autocomp_wrapper'>
<input placeholder="Enter your search.." onChange={this.handleInputThrottled} />
<div>
{results.map(result=>{result})}
</div>
</div>
);
}
}和 underscore 一样的效果,没有其他区别。
JS 中的 Reactive Extensions 提供了一个节流运算符,我们可以使用它来实现功能。
首先,我们安装 rxjs 。
npm i rxjs我们从 rxjs 库导入 throttle
// ...
import { BehaviorSubject } from 'rxjs';
import { throttle } from 'rxjs/operators';class autocomp extends React.Component {
constructor(props) {
super(props);
this.state = {
results: []
}
this.inputStream = new BehaviorSubject()
} componentDidMount() {
this.inputStream
.pipe(
throttle(1000)
)
.subscribe(v => {
const filteredRes = data.filter((item)=> {
// algorithm to search through the `data` array
})
this.setState({ results: filteredRes })
})
} render() {
let { results } = this.state;
return (
<div className='autocomp_wrapper'>
<input placeholder="Enter your search.." onChange={e => this.inputStream.next(e.target.value)} />
<div>
{results.map(result => { result })}
</div>
</div>
);
}
}我们从 rxjs 中导入了 throttle 和 BehaviorSubject,初始化了一个 BehaviorSubject 实例保存在 inputStream 属性,在 componentDidMount 中,我们将 inputStream 流传递给节流操作符,传入 1000,表示 RxJS 节流控制为 1000ms,节流操作返回的流被订阅以获得流值。
因为在组件加载时订阅了 inputStream,所以我们开始输入时,输入的内容就被发送到 inputStream 流中。 刚开始时,由于 throttle 操作符 1000ms 内不会发送内容,在这之后发送最新值, 发送之后就开始计算得到结果。
如果我们以 200ms 1 个字母的速度输入 fidudusola ,该组件将重新渲染 2000ms / 1000ms = 2次。
我们实现自己的节流函数,方便更好的理解节流如何工作。
我们知道在一个节流控制的函数中,它会根据指定的时间间隔调用,我们将使用 setTimeout 函数实现这一点。
function throttle(fn, ms) {
let timeout
function exec() {
fn.apply()
}
function clear() {
timeout == undefined ? null : clearTimeout(timeout)
}
if(fn !== undefined && ms !== undefined) {
timeout = setTimeout(exec, ms)
} else {
console.error('callback function and the timeout must be supplied')
}
// API to clear the timeout
throttle.clearTimeout = function() {
clear();
}
}注:原文自定义实现的节流函数有问题,节流函数的详细实现和解析可以查看我的另一篇文章,点击查看
我的实现如下:
// fn 是需要执行的函数
// wait 是时间间隔
const throttle = (fn, wait = 50) => {
// 上一次执行 fn 的时间
let previous = 0
// 将 throttle 处理结果当作函数返回
return function(...args) {
// 获取当前时间,转换成时间戳,单位毫秒
let now = +new Date()
// 将当前时间和上一次执行函数的时间进行对比
// 大于等待时间就把 previous 设置为当前时间并执行函数 fn
if (now - previous > wait) {
previous = now
fn.apply(this, args)
}
}
}上面的实现非常简单,在 React 项目中使用方式如下。
// ...
class autocomp extends React.Component {
constructor(props) {
super(props);
this.state = {
results: []
}
this.handleInputThrottled = throttle(this.handleInput, 100)
} handleInput = evt => {
const value = evt.target.value
const filteredRes = data.filter((item)=> {
// algorithm to search through the `data` array
})
this.setState({ results: filteredRes })
} render() {
let { results } = this.state;
return (
<div className='autocomp_wrapper'>
<input placeholder="Enter your search.." onChange={this.handleInputThrottled} />
<div>
{results.map(result=>{result})}
</div>
</div>
);
}
}防抖会强制自上次调用后经过一定时间才会再次调用函数,例如只有在没有被调用的情况下经过一段时间之后(例如100毫秒)才执行该函数。
在防抖时,它忽略对函数的所有调用,直到函数停止调用一段时间之后才会再次执行。
下面将介绍在项目中使用 debounce 的例子。
// ...
import * as _ from 'underscore';
class autocomp extends React.Component {
constructor(props) {
super(props);
this.state = {
results: []
}
this.handleInputThrottled = _.debounce(this.handleInput, 100)
}
handleInput = evt => {
const value = evt.target.value
const filteredRes = data.filter((item)=> {
// algorithm to search through the `data` array
})
this.setState({ results: filteredRes })
}
render() {
let { results } = this.state;
return (
<div className='autocomp_wrapper'>
<input placeholder="Enter your search.." onChange={this.handleInputThrottled} />
<div>
{results.map(result=>{result})}
</div>
</div>
);
}
}// ...
import { debounce } from 'lodash';
class autocomp extends React.Component {
constructor(props) {
super(props);
this.state = {
results: []
}
this.handleInputThrottled = debounce(this.handleInput, 100)
}
handleInput = evt => {
const value = evt.target.value
const filteredRes = data.filter((item)=> {
// algorithm to search through the `data` array
})
this.setState({ results: filteredRes })
}
render() {
let { results } = this.state;
return (
<div className='autocomp_wrapper'>
<input placeholder="Enter your search.." onChange={this.handleInputThrottled} />
<div>
{results.map(result=>{result})}
</div>
</div>
);
}
}// ...
import { BehaviorSubject } from 'rxjs';
import { debounce } from 'rxjs/operators';
class autocomp extends React.Component {
constructor(props) {
super(props);
this.state = {
results: []
}
this.inputStream = new BehaviorSubject()
}
componentDidMount() {
this.inputStream
.pipe(
debounce(100)
)
.subscribe(v => {
const filteredRes = data.filter((item)=> {
// algorithm to search through the `data` array
})
this.setState({ results: filteredRes })
})
}
render() {
let { results } = this.state;
return (
<div className='autocomp_wrapper'>
<input placeholder="Enter your search.." onChange={e => this.inputStream.next(e.target.value)} />
<div>
{results.map(result => { result })}
</div>
</div>
);
}
}有很多情况需要使用节流和防抖,其中最需要的领域是游戏。游戏中最常用的动作是在电脑键盘或者游戏手柄中按键,玩家可能经常按同一个键多次(每 20 秒 40 次,即每秒 2 次)例如射击、加速这样的动作,但无论玩家按下射击键的次数有多少,它只会发射一次(比如说每秒)。 所以使用节流控制为 1 秒,这样第二次按下按钮将被忽略。
我们看到了节流和防抖如何提高 React 应用程序的性能,以及重复调用会影响性能,因为组件及其子树将不必要地重新渲染,所以应该避免在 React 应用中重复调用方法。在小型程序中不会引起注意,但在大型程序中效果会很明显。
如果你觉得这篇内容对你挺有启发,我想邀请你帮我三个小忙:
赋值是将某一数值或对象赋给某个变量的过程,分为下面 2 部分
对基本类型进行赋值操作,两个变量互不影响。
// 木易杨
let a = "muyiy";
let b = a;
console.log(b);
// muyiy
a = "change";
console.log(a);
// change
console.log(b);
// muyiy对引用类型进行赋址操作,两个变量指向同一个对象,改变变量 a 之后会影响变量 b,哪怕改变的只是对象 a 中的基本类型数据。
// 木易杨
let a = {
name: "muyiy",
book: {
title: "You Don't Know JS",
price: "45"
}
}
let b = a;
console.log(b);
// {
// name: "muyiy",
// book: {title: "You Don't Know JS", price: "45"}
// }
a.name = "change";
a.book.price = "55";
console.log(a);
// {
// name: "change",
// book: {title: "You Don't Know JS", price: "55"}
// }
console.log(b);
// {
// name: "change",
// book: {title: "You Don't Know JS", price: "55"}
// } 通常在开发中并不希望改变变量 a 之后会影响到变量 b,这时就需要用到浅拷贝和深拷贝。
创建一个新对象,这个对象有着原始对象属性值的一份精确拷贝。如果属性是基本类型,拷贝的就是基本类型的值,如果属性是引用类型,拷贝的就是内存地址 ,所以如果其中一个对象改变了这个地址,就会影响到另一个对象。
上图中,SourceObject 是原对象,其中包含基本类型属性 field1 和引用类型属性 refObj。浅拷贝之后基本类型数据 field2 和 filed1 是不同属性,互不影响。但引用类型 refObj 仍然是同一个,改变之后会对另一个对象产生影响。
简单来说可以理解为浅拷贝只解决了第一层的问题,拷贝第一层的基本类型值,以及第一层的引用类型地址。
Object.assign()Object.assign() 方法用于将所有可枚举属性的值从一个或多个源对象复制到目标对象。它将返回目标对象。
有些文章说Object.assign() 是深拷贝,其实这是不正确的。
// 木易杨
let a = {
name: "muyiy",
book: {
title: "You Don't Know JS",
price: "45"
}
}
let b = Object.assign({}, a);
console.log(b);
// {
// name: "muyiy",
// book: {title: "You Don't Know JS", price: "45"}
// }
a.name = "change";
a.book.price = "55";
console.log(a);
// {
// name: "change",
// book: {title: "You Don't Know JS", price: "55"}
// }
console.log(b);
// {
// name: "muyiy",
// book: {title: "You Don't Know JS", price: "55"}
// } 上面代码改变对象 a 之后,对象 b 的基本属性保持不变。但是当改变对象 a 中的对象 book 时,对象 b 相应的位置也发生了变化。
Spread// 木易杨
let a = {
name: "muyiy",
book: {
title: "You Don't Know JS",
price: "45"
}
}
let b = {...a};
console.log(b);
// {
// name: "muyiy",
// book: {title: "You Don't Know JS", price: "45"}
// }
a.name = "change";
a.book.price = "55";
console.log(a);
// {
// name: "change",
// book: {title: "You Don't Know JS", price: "55"}
// }
console.log(b);
// {
// name: "muyiy",
// book: {title: "You Don't Know JS", price: "55"}
// } 通过代码可以看出实际效果和 Object.assign() 是一样的。
Array.prototype.slice()slice() 方法返回一个新的数组对象,这一对象是一个由 begin和 end(不包括end)决定的原数组的浅拷贝。原始数组不会被改变。
// 木易杨
let a = [0, "1", [2, 3]];
let b = a.slice(1);
console.log(b);
// ["1", [2, 3]]
a[1] = "99";
a[2][0] = 4;
console.log(a);
// [0, "99", [4, 3]]
console.log(b);
// ["1", [4, 3]]可以看出,改变 a[1] 之后 b[0] 的值并没有发生变化,但改变 a[2][0] 之后,相应的 b[1][0] 的值也发生变化。说明 slice() 方法是浅拷贝,相应的还有concat等,在工作中面对复杂数组结构要额外注意。
深拷贝会拷贝所有的属性,并拷贝属性指向的动态分配的内存。当对象和它所引用的对象一起拷贝时即发生深拷贝。深拷贝相比于浅拷贝速度较慢并且花销较大。拷贝前后两个对象互不影响。
JSON.parse(JSON.stringify(object))
// 木易杨
let a = {
name: "muyiy",
book: {
title: "You Don't Know JS",
price: "45"
}
}
let b = JSON.parse(JSON.stringify(a));
console.log(b);
// {
// name: "muyiy",
// book: {title: "You Don't Know JS", price: "45"}
// }
a.name = "change";
a.book.price = "55";
console.log(a);
// {
// name: "change",
// book: {title: "You Don't Know JS", price: "55"}
// }
console.log(b);
// {
// name: "muyiy",
// book: {title: "You Don't Know JS", price: "45"}
// } 完全改变变量 a 之后对 b 没有任何影响,这就是深拷贝的魔力。
我们看下对数组深拷贝效果如何。
// 木易杨
let a = [0, "1", [2, 3]];
let b = JSON.parse(JSON.stringify( a.slice(1) ));
console.log(b);
// ["1", [2, 3]]
a[1] = "99";
a[2][0] = 4;
console.log(a);
// [0, "99", [4, 3]]
console.log(b);
// ["1", [2, 3]]对数组深拷贝之后,改变原数组不会影响到拷贝之后的数组。
但是该方法有以下几个问题。
1、会忽略 undefined
2、会忽略 symbol
3、不能序列化函数
4、不能解决循环引用的对象
5、不能正确处理new Date()
6、不能处理正则
undefined、symbol 和函数这三种情况,会直接忽略。// 木易杨
let obj = {
name: 'muyiy',
a: undefined,
b: Symbol('muyiy'),
c: function() {}
}
console.log(obj);
// {
// name: "muyiy",
// a: undefined,
// b: Symbol(muyiy),
// c: ƒ ()
// }
let b = JSON.parse(JSON.stringify(obj));
console.log(b);
// {name: "muyiy"}// 木易杨
let obj = {
a: 1,
b: {
c: 2,
d: 3
}
}
obj.a = obj.b;
obj.b.c = obj.a;
let b = JSON.parse(JSON.stringify(obj));
// Uncaught TypeError: Converting circular structure to JSONnew Date 情况下,转换结果不正确。// 木易杨
new Date();
// Mon Dec 24 2018 10:59:14 GMT+0800 (China Standard Time)
JSON.stringify(new Date());
// ""2018-12-24T02:59:25.776Z""
JSON.parse(JSON.stringify(new Date()));
// "2018-12-24T02:59:41.523Z"解决方法转成字符串或者时间戳就好了。
// 木易杨
let date = (new Date()).valueOf();
// 1545620645915
JSON.stringify(date);
// "1545620673267"
JSON.parse(JSON.stringify(date));
// 1545620658688// 木易杨
let obj = {
name: "muyiy",
a: /'123'/
}
console.log(obj);
// {name: "muyiy", a: /'123'/}
let b = JSON.parse(JSON.stringify(obj));
console.log(b);
// {name: "muyiy", a: {}}PS:为什么会存在这些问题可以学习一下 JSON。
除了上面介绍的深拷贝方法,常用的还有jQuery.extend() 和 lodash.cloneDeep(),后面文章会详细介绍源码实现,敬请期待!
| -- | 和原数据是否指向同一对象 | 第一层数据为基本数据类型 | 原数据中包含子对象 |
|---|---|---|---|
| 赋值 | 是 | 改变会使原数据一同改变 | 改变会使原数据一同改变 |
| 浅拷贝 | 否 | 改变不会使原数据一同改变 | 改变会使原数据一同改变 |
| 深拷贝 | 否 | 改变不会使原数据一同改变 | 改变不会使原数据一同改变 |
进阶系列文章汇总:https://github.com/yygmind/blog,内有优质前端资料,觉得不错点个star。
我是木易杨,网易高级前端工程师,跟着我每周重点攻克一个前端面试重难点。接下来让我带你走进高级前端的世界,在进阶的路上,共勉!
1、对于框架的使用没必要花太多时间,应该多研究一下三大框架背后的设计**。
2、当一个程序员对算法、语言标准、底层、原生、英文文档这些词汇产生恐惧感的时候他的技术生命已经走到尽头。
3、前端架构主要解决的是高复用性,架构能力提升方向主要是组件库开发、前端框架实现等。
4、对于前端进阶这个问题,其实看书的作用和意义已经不太明显,需要寻找好的平台和合适的项目,在项目中不断克服难题并挑战自己,遇到问题再去查资料总结。如果只是闭门看书那很难成为高手,书只是基础而已,真正的应用还是在项目中。
5、寒冬中能做的只有提升自己,但是光靠技术是不行的。
6、推荐 TensorFlow、可视化切图、PWA、WebGL
1)
TensorFlow可以了解使用并做点东西出来,原理很难但不影响使用。2)
PWA有望进一步发展。3)
WebGL在未来会是一个很好的方向,它可以实现任何你想要的界面效果,但重点需要多掌握图形学的基础知识,它和算法,数据结构一样重要。4)
Weex和RN虽然都叫Hybrid但不太一样,前者适合大厂主要是嵌入 APP 中使用,后者更适合创业公司。
7、不推荐 SSR、TypeScript、函数式编程
1)
SSR不太看好,其主要是用于SEO,不太建议用做服务端渲染,其能够使用的场景不多,而且成本代价太大。2)
TypeScript是好东西,是很有前景的语言,但适用于十万行以上代码级别的大型项目,小项目并不适合,反而徒增复杂。3)用 JS 做函数式编程并不靠谱,
Map/Reduce/Redux/Hooks等并不是函数式编程,只是长得像而已。
PS:笔记内容由自己和群友提供,仅供参考。
听完 Winter 老师直播后对其观点很是赞同,但因为是面对所有人讲解所以内容有点多范围有些广,但对个人来说还是找适合自己的方向,在自己相对熟悉的领域再去扩展去突破。横向只是拓宽你的眼界,纵向才是你的核心竞争力。
对我来说感触最大的就是 3、4、5 这几点,因为我一直在思考以下几个问题:
1、我现在是高级前端,但又感觉自身很弱,那我如何才能夯实我高级的地基然后成为资深前端呢?
2、项目迭代节奏快日常加班又多,那我如何做才能平衡工作和学习?
3、单单提升技术好像还是有很大瓶颈,那我如何提升我的职场核心竞争力?
结合 Winter 老师的直播和最近看的几篇文章,说说我对这几个问题的思考。
对于第一个问题,在 2 个多月前我还是不会写文章的小白,那个时候受到一些文章的触动,开办了「高级前端进阶」这个公众号,尝试把我的前端之路记录下来,后来经过几次调整开始了「进阶系列」。我的想法很简单,就是把前端进阶 28 期的重难点知识全部讲完,目前已经进行到第 4 期了,通过写作把知识通俗易懂的介绍给别人,在这个过程自己肯定会收获很多很多。这就是我目前在尝试的学习方式,通过写作建立自己的知识架构,并且在这个架构上不断地进行优化,时间到了自然就进阶了。
对于第二个问题,刚开始写作时精力充沛时间也很多,每天都会更新技术文章,但随着项目迭代压力增大,文章更新速度相应就变慢了一些,虽然文章质量提升了很多,但更新速度从日更变成了周更再变成了双周更,这个说实话我自身已经很难接受了,因为速度变慢导致我年初的计划要打折扣。所以说做项目和自我学习要如何权衡,是否说我要减少项目难度和时间并在工作中摸鱼去学习呢?我的结论是不,因为一句话,“最好的学习就是在项目中锻炼自己”。既然我有这么好的项目去锻炼,那为什么还要摸鱼去学习呢,这不就是南辕北辙嘛,道理很简单但不是所有人都懂。
我最近在执行的方法是专注 + 锻炼 + 利用周末。
专注即工作时专注于工作,努力做好每次迭代,遇到难题迎难而上,工作时不开微信,勤用笔记安排日常工作并整理文档;
锻炼即一周抽出三天时间每次去健身房锻炼1小时,强壮的体魄才能撑住高强度的工作和学习,因为网易有健身房所以冬天锻炼也没什么问题,没办法去健身房的小伙伴可以尝试跑步或者在瑜伽垫上做 Keep;
利用周末即加大周末和平常晚上熬夜的时间去写文章,减少娱乐的时间,正所谓时间挤一挤总会有的,但这件事情比较反人性,所以重在坚持。公众号写文章更容易坚持,原因在于文章发布后有正反馈,比如粉丝的增长,留言和鼓励,赞赏等等,这些都更能促使你坚持下去,时间长了自然就养成了习惯。
对于第三个问题,Winter 老师也说了,寒冬中光靠技术是不行的,那应该靠什么呢?幸好在最近看到的一篇文章中找到了答案,那就是表达能力。表达能力是形成自己的框架系统,有理有据并且逻辑清晰,而且能让外人听懂,大部分优秀的人都具备这样的能力。反观自己并没有这样的能力,所以我要努力提升这块,其中最重要的方法就是写作训练。
兜兜转转那么多,其实我一直在尝试的进阶方法就是通过写作建立自己的知识架构体系,同时提高自身的表达能力,通过正反馈机制和锻炼保证我长久的坚持下去并最终养成习惯,习惯这一模式之后变成优秀的人也只是时间问题罢了。
希望我的一些思考和尝试能对你有所帮助。
公众号回复「文章」领取最近看到的好文章
进阶系列文章汇总如下,内有优质前端资料,觉得不错点个star。
我是木易杨,公众号「高级前端进阶」作者,跟着我每周重点攻克一个前端面试重难点。接下来让我带你走进高级前端的世界,在进阶的路上,共勉!
对于现代浏览器来说,css中指定的width就是content width。
对于IE5.x和6来说,在怪异模式中width等于content、左右padding和左右border。
其中padding和margin的4种写法。
1、上 右 下 左
padding:10px 5px 15px 20px;2、上 右左 下
padding:10px 5px 15px;3、上下 右左
padding:10px 5px;4、四边一致
padding:10px;display和position介绍
display规定元素应该生成的框的类型。| 值 | 描述 |
|---|---|
| flex | 设置弹性容器 |
| block | 此元素将显示为块级元素,此元素前后会带有换行符。 |
| inline | 默认。此元素会被显示为内联元素,元素前后没有换行符。 |
| inline-block | 行内块元素。(CSS2.1 新增的值) |
| none | 此元素不会被显示。 |
| list-item | 此元素会作为列表显示。 |
| 值 | 描述 |
|---|---|
| absolute | 生成绝对定位的元素,相对于 static 定位以外的第一个父元素进行定位。 元素的位置通过 "left", "top", "right" 以及 "bottom" 属性进行规定。 |
| fixed | 生成绝对定位的元素,相对于浏览器窗口进行定位。 元素的位置通过 "left", "top", "right" 以及 "bottom" 属性进行规定。 |
| relative | 生成相对定位的元素,相对于其正常位置进行定位。 因此,"left:20" 会向元素的 left 位置添加 20 像素。 |
| static | 默认值。没有定位,元素出现在正常的流中 (忽略 top, bottom, left, right 或者 z-index 声明)。 |
| inherit | 规定应该从父元素继承 position 属性的值。 |
CSS选择器分类
不同级别:排序:!important > 行内样式 > ID选择器 > 类选择器 > 标签 > 通配符 > 继承 > 浏览器默认属性。
同一级别:后写的会覆盖先写的。
em和strong的区别
使元素消失的方法
opacity:0:该元素隐藏起来,但不会改变页面布局,如果该元素绑定了事件会触发。visibility:hidden:该元素隐藏起来,但不会改变页面布局,不会触发该元素已经绑定的事件。display:node:把元素隐藏起来,并且会改变页面布局,可以理解成在页面中把该元素删掉。如何画一个三角形
左右边框设置为透明,长度为底部边框的一半。左右边框长度必须设置,不设置则只有底部一条边框,是不能展示的。
.child{
width: 0;
height: 0;
border-bottom: 100px solid cyan;
border-left: 50px solid transparent;
border-right: 50px solid transparent;
}浮动相关
为什么要清除浮动
主要是为了解决父元素高度坍陷问题。
一个块级元素如果没有设置height,其height由子元素撑开,对子元素使用了浮动之后,子元素就会脱离文档流。那么父元素中没有内容撑开其高度,这样父元素的height就会被忽略。
如何清除
1、父元素设置overflow: hidden(少用)
2、clearfix:使用内容生成的方式清除浮动,不会破坏文档流。
.clearfix: after { // :after选择器向选定的元素之后插入内容
content:""; // 生成内容为空
display: block; // 块级元素显示
clear:both; // 清除前面元素
}行内元素居中
.parent {
text-align: center
}DIV居中问题
1、使用flex
.parent {
height: 600px;
border: 1px solid red;
display: flex;
justify-content: center;
align-items: center;
}
.child {
border: 1px solid green;
width: 300px;
}2、使用transform
.parent{
height: 600px;
border: 1px solid red;
position: relative;
}
.child{
border: 1px solid green;
position: absolute;
top: 50%;
left: 50%;
transform: translate(-50%,-50%);
}3、使用margin-top -一半的高度
.parent{
height: 600px;
border: 1px solid red;
position: relative;
}
.child{
border: 1px solid green;
width: 300px;
height: 100px;
position: absolute;
top: 50%;
left: 50%;
margin-left: -150px;
margin-top: -50px;
}4、使用绝对布局absolute和margin:auto
.parent{
height: 600px;
border: 1px solid red;
position: relative;
}
.child{
border: 1px solid green;
position: absolute;
width: 300px;
height: 200px;
margin: auto;
top: 0;
bottom: 0;
left: 0;
right: 0;
}三栏布局
要求两边两栏宽度固定,中间栏宽度自适应
方案一:position绝对定位法
center的div需要放到后面,将左右两边使用absolute定位,因为绝对定位使其脱离文档流,最后面的center会显示在正常文档流中,然后设置margin属性,留出左右两边的宽度。
.parent {
border: 1px solid red;
position: relative;
}
.child_left {
width: 100px;
height: 100px;
border: 1px solid gray;
position: absolute;
}
.child_right {
width: 100px;
height: 100px;
border: 1px solid green;
position: absolute;
right: 0;
}
// div在html中必须放在left和right之后
.child_center {
height: 100px;
border: 1px solid black;
margin: 0 100px;
}方案二:float 自身浮动法
center的div需要放到后面,对左右使用float:left和float:right,float使左右两个元素脱离文档流,中间的正常文档流中,然后设置margin属性,留出左右两边的宽度。
.parent {
border: 1px solid red;
position: relative;
}
.child_left {
width: 100px;
height: 100px;
border: 1px solid gray;
float: left;
}
.child_right {
width: 100px;
height: 100px;
border: 1px solid green;
float: right;
}
.child_center {
height: 100px;
border: 1px solid black;
margin: 0 100px;
}介绍BFC
BFC是CSS布局的一个概念,是一块独立的渲染区域,是一个环境,里面的元素不会影响到外部的元素 。
如何生成BFC:(即脱离文档流)
BFC布局规则:
1.内部的Box会在垂直方向,一个接一个地放置。
2.属于同一个BFC的两个相邻的Box的margin会发生重叠
3.BFC就是页面上的一个隔离的独立容器,容器里面的子元素不会影响到外面的元素。反之也如此, 文字环绕效果,设置float
4.BFC的区域不会与float box重叠。
5.计算BFC的高度,浮动元素也参与计算
BFC作用:
CSS3特性 vh和vw
vh 相对于视窗的高度,视窗高度是100vhvw 相对于视窗的宽度,视窗宽度是100vw这里是视窗指的是浏览器内部的可视区域大小,即window.innerWidth/window.innerHeight大小,不包含任务栏标题栏以及底部工具栏的浏览器区域大小。
@supports (property: value){
element {
property: value;
}
}
// 例
@supports (display: flex){
.flex {
display: flex;
float: none;
}
}本人Github链接如下,欢迎各位Star
http://github.com/yygmind/blog
欢迎加我微信进一步交流或者找我内推,前行的路上,共勉!
[TOC]
构造函数、原型和实例之间的关系:每个构造函数都有一个原型对象,原型对象都包含一个指向构造函数的指针,而实例都包含一个原型对象的指针。
继承的本质就是复制,即重写原型对象,代之以一个新类型的实例。
function SuperType() {
this.property = true;
}
SuperType.prototype.getSuperValue = function() {
return this.property;
}
function SubType() {
this.subproperty = false;
}
// 这里是关键,创建SuperType的实例,并将该实例赋值给SubType.prototype
SubType.prototype = new SuperType();
SubType.prototype.getSubValue = function() {
return this.subproperty;
}
var instance = new SubType();
console.log(instance.getSuperValue()); // true原型链方案存在的缺点:多个实例对引用类型的操作会被篡改。
function SuperType(){
this.colors = ["red", "blue", "green"];
}
function SubType(){}
SubType.prototype = new SuperType();
var instance1 = new SubType();
instance1.colors.push("black");
alert(instance1.colors); //"red,blue,green,black"
var instance2 = new SubType();
alert(instance2.colors); //"red,blue,green,black"使用父类的构造函数来增强子类实例,等同于复制父类的实例给子类(不使用原型)
function SuperType(){
this.color=["red","green","blue"];
}
function SubType(){
//继承自SuperType
SuperType.call(this);
}
var instance1 = new SubType();
instance1.color.push("black");
alert(instance1.color);//"red,green,blue,black"
var instance2 = new SubType();
alert(instance2.color);//"red,green,blue"核心代码是SuperType.call(this),创建子类实例时调用SuperType构造函数,于是SubType的每个实例都会将SuperType中的属性复制一份。
缺点:
组合上述两种方法就是组合继承。用原型链实现对原型属性和方法的继承,用借用构造函数技术来实现实例属性的继承。
function SuperType(name){
this.name = name;
this.colors = ["red", "blue", "green"];
}
SuperType.prototype.sayName = function(){
alert(this.name);
};
function SubType(name, age){
// 继承属性
// 第二次调用SuperType()
SuperType.call(this, name);
this.age = age;
}
// 继承方法
// 构建原型链
// 第一次调用SuperType()
SubType.prototype = new SuperType();
// 重写SubType.prototype的constructor属性,指向自己的构造函数SubType
SubType.prototype.constructor = SubType;
SubType.prototype.sayAge = function(){
alert(this.age);
};
var instance1 = new SubType("Nicholas", 29);
instance1.colors.push("black");
alert(instance1.colors); //"red,blue,green,black"
instance1.sayName(); //"Nicholas";
instance1.sayAge(); //29
var instance2 = new SubType("Greg", 27);
alert(instance2.colors); //"red,blue,green"
instance2.sayName(); //"Greg";
instance2.sayAge(); //27缺点:
SuperType():给SubType.prototype写入两个属性name,color。SuperType():给instance1写入两个属性name,color。实例对象instance1上的两个属性就屏蔽了其原型对象SubType.prototype的两个同名属性。所以,组合模式的缺点就是在使用子类创建实例对象时,其原型中会存在两份相同的属性/方法。
利用一个空对象作为中介,将某个对象直接赋值给空对象构造函数的原型。
function object(obj){
function F(){}
F.prototype = obj;
return new F();
}object()对传入其中的对象执行了一次浅复制,将构造函数F的原型直接指向传入的对象。
var person = {
name: "Nicholas",
friends: ["Shelby", "Court", "Van"]
};
var anotherPerson = object(person);
anotherPerson.name = "Greg";
anotherPerson.friends.push("Rob");
var yetAnotherPerson = object(person);
yetAnotherPerson.name = "Linda";
yetAnotherPerson.friends.push("Barbie");
alert(person.friends); //"Shelby,Court,Van,Rob,Barbie"缺点:
另外,ES5中存在Object.create()的方法,能够代替上面的object方法。
核心:在原型式继承的基础上,增强对象,返回构造函数
function createAnother(original){
var clone = object(original); // 通过调用 object() 函数创建一个新对象
clone.sayHi = function(){ // 以某种方式来增强对象
alert("hi");
};
return clone; // 返回这个对象
}函数的主要作用是为构造函数新增属性和方法,以增强函数
var person = {
name: "Nicholas",
friends: ["Shelby", "Court", "Van"]
};
var anotherPerson = createAnother(person);
anotherPerson.sayHi(); //"hi"缺点(同原型式继承):
结合借用构造函数传递参数和寄生模式实现继承
function inheritPrototype(subType, superType){
var prototype = Object.create(superType.prototype); // 创建对象,创建父类原型的一个副本
prototype.constructor = subType; // 增强对象,弥补因重写原型而失去的默认的constructor 属性
subType.prototype = prototype; // 指定对象,将新创建的对象赋值给子类的原型
}
// 父类初始化实例属性和原型属性
function SuperType(name){
this.name = name;
this.colors = ["red", "blue", "green"];
}
SuperType.prototype.sayName = function(){
alert(this.name);
};
// 借用构造函数传递增强子类实例属性(支持传参和避免篡改)
function SubType(name, age){
SuperType.call(this, name);
this.age = age;
}
// 将父类原型指向子类
inheritPrototype(SubType, SuperType);
// 新增子类原型属性
SubType.prototype.sayAge = function(){
alert(this.age);
}
var instance1 = new SubType("xyc", 23);
var instance2 = new SubType("lxy", 23);
instance1.colors.push("2"); // ["red", "blue", "green", "2"]
instance2.colors.push("3"); // ["red", "blue", "green", "3"]这个例子的高效率体现在它只调用了一次SuperType 构造函数,并且因此避免了在SubType.prototype 上创建不必要的、多余的属性。于此同时,原型链还能保持不变;因此,还能够正常使用instanceof 和isPrototypeOf()
这是最成熟的方法,也是现在库实现的方法
function MyClass() {
SuperClass.call(this);
OtherSuperClass.call(this);
}
// 继承一个类
MyClass.prototype = Object.create(SuperClass.prototype);
// 混合其它
Object.assign(MyClass.prototype, OtherSuperClass.prototype);
// 重新指定constructor
MyClass.prototype.constructor = MyClass;
MyClass.prototype.myMethod = function() {
// do something
};Object.assign会把 OtherSuperClass原型上的函数拷贝到 MyClass原型上,使 MyClass 的所有实例都可用 OtherSuperClass 的方法。
extends关键字主要用于类声明或者类表达式中,以创建一个类,该类是另一个类的子类。其中constructor表示构造函数,一个类中只能有一个构造函数,有多个会报出SyntaxError错误,如果没有显式指定构造方法,则会添加默认的 constructor方法,使用例子如下。
class Rectangle {
// constructor
constructor(height, width) {
this.height = height;
this.width = width;
}
// Getter
get area() {
return this.calcArea()
}
// Method
calcArea() {
return this.height * this.width;
}
}
const rectangle = new Rectangle(10, 20);
console.log(rectangle.area);
// 输出 200
-----------------------------------------------------------------
// 继承
class Square extends Rectangle {
constructor(length) {
super(length, length);
// 如果子类中存在构造函数,则需要在使用“this”之前首先调用 super()。
this.name = 'Square';
}
get area() {
return this.height * this.width;
}
}
const square = new Square(10);
console.log(square.area);
// 输出 100extends继承的核心代码如下,其实现和上述的寄生组合式继承方式一样
function _inherits(subType, superType) {
// 创建对象,创建父类原型的一个副本
// 增强对象,弥补因重写原型而失去的默认的constructor 属性
// 指定对象,将新创建的对象赋值给子类的原型
subType.prototype = Object.create(superType && superType.prototype, {
constructor: {
value: subType,
enumerable: false,
writable: true,
configurable: true
}
});
if (superType) {
Object.setPrototypeOf
? Object.setPrototypeOf(subType, superType)
: subType.__proto__ = superType;
}
}1、函数声明和类声明的区别
函数声明会提升,类声明不会。首先需要声明你的类,然后访问它,否则像下面的代码会抛出一个ReferenceError。
let p = new Rectangle();
// ReferenceError
class Rectangle {}2、ES5继承和ES6继承的区别
ES5的继承实质上是先创建子类的实例对象,然后再将父类的方法添加到this上(Parent.call(this)).
ES6的继承有所不同,实质上是先创建父类的实例对象this,然后再用子类的构造函数修改this。因为子类没有自己的this对象,所以必须先调用父类的super()方法,否则新建实例报错。
本人Github链接如下,欢迎各位Star
http://github.com/yygmind/blog
我是木易杨,网易高级前端工程师,跟着我每周重点攻克一个前端面试重难点。接下来让我带你走进高级前端的世界,在进阶的路上,共勉!
如果你想加群讨论每期面试知识点,公众号回复[加群]即可
本期的主题是作用域闭包,本计划一共28期,每期重点攻克一个面试重难点,如果你还不了解本进阶计划,文末点击查看全部文章。
如果觉得本系列不错,欢迎点赞、评论、转发,您的支持就是我坚持的最大动力。
红宝书(p178)上对于闭包的定义:闭包是指有权访问另外一个函数作用域中的变量的函数,
MDN 对闭包的定义为:闭包是指那些能够访问自由变量的函数。
其中自由变量,指在函数中使用的,但既不是函数参数arguments也不是函数的局部变量的变量,其实就是另外一个函数作用域中的变量。
使用上一篇文章的例子来说明下自由变量
function getOuter(){
var date = '1127';
function getDate(str){
console.log(str + date); //访问外部的date
}
return getDate('今天是:'); //"今天是:1127"
}
getOuter();其中date既不是参数arguments,也不是局部变量,所以date是自由变量。
总结起来就是下面两点:
首先来一个简单的例子
var scope = "global scope";
function checkscope(){
var scope = "local scope";
function f(){
return scope;
}
return f;
}
var foo = checkscope(); // foo指向函数f
foo(); // 调用函数f()简要的执行过程如下:
进入全局代码,创建全局执行上下文,全局执行上下文压入执行上下文栈
全局执行上下文初始化
执行 checkscope 函数,创建 checkscope 函数执行上下文,checkscope 执行上下文被压入执行上下文栈
checkscope 执行上下文初始化,创建变量对象、作用域链、this等
checkscope 函数执行完毕,checkscope 执行上下文从执行上下文栈中弹出
执行 f 函数,创建 f 函数执行上下文,f 执行上下文被压入执行上下文栈
f 执行上下文初始化,创建变量对象、作用域链、this等
f 函数执行完毕,f 函数上下文从执行上下文栈中弹出
那么问题来了, 函数f 执行的时候,checkscope 函数上下文已经被销毁了,那函数f是如何获取到scope变量的呢?
上文(【进阶2-1期】深入浅出图解作用域链和闭包)介绍过,函数f 执行上下文维护了一个作用域链,会指向指向checkscope作用域,作用域链是一个数组,结构如下。
fContext = {
Scope: [AO, checkscopeContext.AO, globalContext.VO],
}所以指向关系是当前作用域 --> checkscope作用域--> 全局作用域,即使 checkscopeContext 被销毁了,但是 JavaScript 依然会让 checkscopeContext.AO(活动对象) 活在内存中,f 函数依然可以通过 f 函数的作用域链找到它,这就是闭包实现的关键。
上面介绍的是实践角度,其实闭包有很多种介绍,说法不一。
汤姆大叔翻译的关于闭包的文章中的定义,ECMAScript中,闭包指的是:
1、从理论角度:所有的函数。因为它们都在创建的时候就将上层上下文的数据保存起来了。哪怕是简单的全局变量也是如此,因为函数中访问全局变量就相当于是在访问自由变量,这个时候使用最外层的作用域。
2、从实践角度:以下函数才算是闭包:
var data = [];
for (var i = 0; i < 3; i++) {
data[i] = function () {
console.log(i);
};
}
data[0]();
data[1]();
data[2]();如果知道闭包的,答案就很明显了,都是3
循环结束后,全局执行上下文的VO是
globalContext = {
VO: {
data: [...],
i: 3
}
}执行 data[0] 函数的时候,data[0] 函数的作用域链为:
data[0]Context = {
Scope: [AO, globalContext.VO]
}由于其自身没有i变量,就会向上查找,所有从全局上下文查找到i为3,data[1] 和 data[2] 是一样的。
改成闭包,方法就是data[i]返回一个函数,并访问变量i
var data = [];
for (var i = 0; i < 3; i++) {
data[i] = (function (i) {
return function(){
console.log(i);
}
})(i);
}
data[0](); // 0
data[1](); // 1
data[2](); // 2循环结束后的全局执行上下文没有变化。
执行 data[0] 函数的时候,data[0] 函数的作用域链发生了改变:
data[0]Context = {
Scope: [AO, 匿名函数Context.AO, globalContext.VO]
}
匿名函数执行上下文的AO为:
匿名函数Context = {
AO: {
arguments: {
0: 0,
length: 1
},
i: 0
}
}因为闭包执行上下文中贮存了变量i,所以根据作用域链会在globalContext.VO中查找到变量i,并输出0。
上面必刷题改动一个地方,把for循环中的var i = 0,改成let i = 0。结果是什么,为什么???
var data = [];
for (let i = 0; i < 3; i++) {
data[i] = function () {
console.log(i);
};
}
data[0]();
data[1]();
data[2]();进阶系列文章汇总:https://github.com/yygmind/blog,内有优质前端资料,欢迎领取,觉得不错点个star。
我是木易杨,网易高级前端工程师,跟着我每周重点攻克一个前端面试重难点。接下来让我带你走进高级前端的世界,在进阶的路上,共勉!
上一节我们详细聊了聊高阶函数之柯里化,通过介绍其定义和三种柯里化应用,并在最后实现了一个通用的 currying 函数。这一小节会继续之前的篇幅聊聊函数节流 throttle,给出这种高阶函数的定义、实现原理以及在 underscore 中的实现,欢迎大家拍砖。
有什么想法或者意见都可以在评论区留言,下图是本文的思维导图,高清思维导图和更多文章请看我的 Github。
函数节流指的是某个函数在一定时间间隔内(例如 3 秒)只执行一次,在这 3 秒内 无视后来产生的函数调用请求,也不会延长时间间隔。3 秒间隔结束后第一次遇到新的函数调用会触发执行,然后在这新的 3 秒内依旧无视后来产生的函数调用请求,以此类推。
举一个小例子,不知道大家小时候有没有养过小金鱼啥的,养金鱼肯定少不了接水,刚开始接水时管道中水流很大,水到半满时开始拧紧水龙头,减少水流的速度变成 3 秒一滴,通过滴水给小金鱼增加氧气。
此时「管道中的水」就是我们频繁操作事件而不断涌入的回调任务,它需要接受「水龙头」安排;「水龙头」就是节流阀,控制水的流速,过滤无效的回调任务;「滴水」就是每隔一段时间执行一次函数,「3 秒」就是间隔时间,它是「水龙头」决定「滴水」的依据。
如果你还无法理解,看下面这张图就清晰多了,另外点击 这个页面 查看节流和防抖的可视化比较。其中 Regular 是不做任何处理的情况,throttle 是函数节流之后的结果,debounce 是函数防抖之后的结果(下一小节介绍)。
函数节流非常适用于函数被频繁调用的场景,例如:window.onresize() 事件、mousemove 事件、上传进度等情况。使用 throttle API 很简单,那应该如何实现 throttle 这个函数呢?
实现方案有以下两种
这里我们采用第一种方案来实现,通过闭包保存一个 previous 变量,每次触发 throttle 函数时判断当前时间和 previous 的时间差,如果这段时间差小于等待时间,那就忽略本次事件触发。如果大于等待时间就把 previous 设置为当前时间并执行函数 fn。
我们来一步步实现,首先实现用闭包保存 previous 变量。
const throttle = (fn, wait) => {
// 上一次执行该函数的时间
let previous = 0
return function(...args) {
console.log(previous)
...
}
}执行 throttle 函数后会返回一个新的 function,我们命名为 betterFn。
const betterFn = function(...args) {
console.log(previous)
...
}betterFn 函数中可以获取到 previous 变量值也可以修改,在回调监听或事件触发时就会执行 betterFn,即 betterFn(),所以在这个新函数内判断当前时间和 previous 的时间差即可。
const betterFn = function(...args) {
let now = +new Date();
if (now - previous > wait) {
previous = now
// 执行 fn 函数
fn.apply(this, args)
}
}结合上面两段代码就实现了节流函数,所以完整的实现如下。
// fn 是需要执行的函数
// wait 是时间间隔
const throttle = (fn, wait = 50) => {
// 上一次执行 fn 的时间
let previous = 0
// 将 throttle 处理结果当作函数返回
return function(...args) {
// 获取当前时间,转换成时间戳,单位毫秒
let now = +new Date()
// 将当前时间和上一次执行函数的时间进行对比
// 大于等待时间就把 previous 设置为当前时间并执行函数 fn
if (now - previous > wait) {
previous = now
fn.apply(this, args)
}
}
}
// DEMO
// 执行 throttle 函数返回新函数
const betterFn = throttle(() => console.log('fn 函数执行了'), 1000)
// 每 10 毫秒执行一次 betterFn 函数,但是只有时间差大于 1000 时才会执行 fn
setInterval(betterFn, 10)上述代码实现了一个简单的节流函数,不过 underscore 实现了更高级的功能,即新增了两个功能
配置 { leading: false } 时,事件刚开始的那次回调不执行;配置 { trailing: false } 时,事件结束后的那次回调不执行,不过需要注意的是,这两者不能同时配置。
所以在 underscore 中的节流函数有 3 种调用方式,默认的(有头有尾),设置 { leading: false } 的,以及设置 { trailing: false } 的。上面说过实现 throttle 的方案有 2 种,一种是通过时间戳判断,另一种是通过定时器创建和销毁来控制。
第一种方案实现这 3 种调用方式存在一个问题,即事件停止触发时无法响应回调,所以 { trailing: true } 时无法生效。
第二种方案来实现也存在一个问题,因为定时器是延迟执行的,所以事件停止触发时必然会响应回调,所以 { trailing: false } 时无法生效。
underscore 采用的方案是两种方案搭配使用来实现这个功能。
const throttle = function(func, wait, options) {
var timeout, context, args, result;
// 上一次执行回调的时间戳
var previous = 0;
// 无传入参数时,初始化 options 为空对象
if (!options) options = {};
var later = function() {
// 当设置 { leading: false } 时
// 每次触发回调函数后设置 previous 为 0
// 不然为当前时间
previous = options.leading === false ? 0 : _.now();
// 防止内存泄漏,置为 null 便于后面根据 !timeout 设置新的 timeout
timeout = null;
// 执行函数
result = func.apply(context, args);
if (!timeout) context = args = null;
};
// 每次触发事件回调都执行这个函数
// 函数内判断是否执行 func
// func 才是我们业务层代码想要执行的函数
var throttled = function() {
// 记录当前时间
var now = _.now();
// 第一次执行时(此时 previous 为 0,之后为上一次时间戳)
// 并且设置了 { leading: false }(表示第一次回调不执行)
// 此时设置 previous 为当前值,表示刚执行过,本次就不执行了
if (!previous && options.leading === false) previous = now;
// 距离下次触发 func 还需要等待的时间
var remaining = wait - (now - previous);
context = this;
args = arguments;
// 要么是到了间隔时间了,随即触发方法(remaining <= 0)
// 要么是没有传入 {leading: false},且第一次触发回调,即立即触发
// 此时 previous 为 0,wait - (now - previous) 也满足 <= 0
// 之后便会把 previous 值迅速置为 now
if (remaining <= 0 || remaining > wait) {
if (timeout) {
clearTimeout(timeout);
// clearTimeout(timeout) 并不会把 timeout 设为 null
// 手动设置,便于后续判断
timeout = null;
}
// 设置 previous 为当前时间
previous = now;
// 执行 func 函数
result = func.apply(context, args);
if (!timeout) context = args = null;
} else if (!timeout && options.trailing !== false) {
// 最后一次需要触发的情况
// 如果已经存在一个定时器,则不会进入该 if 分支
// 如果 {trailing: false},即最后一次不需要触发了,也不会进入这个分支
// 间隔 remaining milliseconds 后触发 later 方法
timeout = setTimeout(later, remaining);
}
return result;
};
// 手动取消
throttled.cancel = function() {
clearTimeout(timeout);
previous = 0;
timeout = context = args = null;
};
// 执行 _.throttle 返回 throttled 函数
return throttled;
};函数节流指的是某个函数在一定时间间隔内(例如 3 秒)只执行一次,在这 3 秒内 无视后来产生的函数调用请求
节流可以理解为养金鱼时拧紧水龙头放水,3 秒一滴
节流实现方案有 2 种
如果你觉得这篇内容对你挺有启发,我想邀请你帮我三个小忙:
前面几节我们学习了节流函数 throttle,防抖函数 debounce,以及各自如何在 React 项目中进行应用,今天这篇文章主要聊聊 Lodash 中防抖和节流函数是如何实现的,并对源码浅析一二。下篇文章会举几个小例子为切入点,换种方式继续解读源码,敬请期待。
有什么想法或者意见都可以在评论区留言,欢迎大家拍砖。
Lodash 中节流函数比较简单,直接调用防抖函数,传入一些配置就摇身一变成了节流函数,所以我们先来看看其中防抖函数是如何实现的,弄懂了防抖,那节流自然就容易理解了。
防抖函数的定义和自定义实现我就不再介绍了,之前专门写过一篇文章,戳这里学习
进入正文,我们看下 debounce 源码,源码不多,总共 100 多行,为了方便理解就先列出代码结构,然后再从入口函数着手一个一个的介绍。
function debounce(func, wait, options) {
// 通过闭包保存一些变量
let lastArgs, // 上一次执行 debounced 的 arguments,
// 起一个标记位的作用,用于 trailingEdge 方法中,invokeFunc 后清空
lastThis, // 保存上一次 this
maxWait, // 最大等待时间,数据来源于 options,实现节流效果,保证大于一定时间后一定能执行
result, // 函数 func 执行后的返回值,多次触发但未满足执行 func 条件时,返回 result
timerId, // setTimeout 生成的定时器句柄
lastCallTime // 上一次调用 debounce 的时间
let lastInvokeTime = 0 // 上一次执行 func 的时间,配合 maxWait 多用于节流相关
let leading = false // 是否响应事件刚开始的那次回调,即第一次触发,false 时忽略
let maxing = false // 是否有最大等待时间,配合 maxWait 多用于节流相关
let trailing = true // 是否响应事件结束后的那次回调,即最后一次触发,false 时忽略
// 没传 wait 时调用 window.requestAnimationFrame()
// window.requestAnimationFrame() 告诉浏览器希望执行动画并请求浏览器在下一次重绘之前调用指定的函数来更新动画,差不多 16ms 执行一次
const useRAF = (!wait && wait !== 0 && typeof root.requestAnimationFrame === 'function')
// 保证输入的 func 是函数,否则报错
if (typeof func !== 'function') {
throw new TypeError('Expected a function')
}
// 转成 Number 类型
wait = +wait || 0
// 获取用户传入的配置 options
if (isObject(options)) {
leading = !!options.leading
// options 中是否有 maxWait 属性,节流函数预留
maxing = 'maxWait' in options
// maxWait 为设置的 maxWait 和 wait 中最大的,如果 maxWait 小于 wait,那 maxWait 就没有意义了
maxWait = maxing ? Math.max(+options.maxWait || 0, wait) : maxWait
trailing = 'trailing' in options ? !!options.trailing : trailing
}
// ----------- 开闭定时器 -----------
// 开启定时器
function startTimer(pendingFunc, wait) {}
// 取消定时器
function cancelTimer(id) {}
// 定时器回调函数,表示定时结束后的操作
function timerExpired() {}
// 计算仍需等待的时间
function remainingWait(time) {}
// ----------- 执行传入函数 -----------
// 执行连续事件刚开始的那次回调
function leadingEdge(time) {}
// 执行连续事件结束后的那次回调
function trailingEdge(time) {}
// 执行 func 函数
function invokeFunc(time) {}
// 判断此时是否应该执行 func 函数
function shouldInvoke(time) {}
// ----------- 对外 3 个方法 -----------
// 取消函数延迟执行
function cancel() {}
// 立即执行 func
function flush() {}
// 检查当前是否在计时中
function pending() {}
// ----------- 入口函数 -----------
function debounced(...args) {}
// 绑定方法
debounced.cancel = cancel
debounced.flush = flush
debounced.pending = pending
// 返回入口函数
return debounced
}debounce(func, wait, options) 方法提供了 3 个参数,第一个是我们想要执行的函数,为方便理解文中统一称为传入函数 func,第二个是超时时间 wait,第三个是可选参数,分别是 leading、trailing 和 maxWait。
debounce 函数最终返回了 debounced,返回的这个函数就是入口函数了,事件每次触发后都会执行 debounced 函数,而且会频繁的执行,所以在这个方法里需要「判断是否应该执行传入函数 func」,然后根据条件开启定时器,debounced 函数做的就是这件事。
// 入口函数,返回此函数
function debounced(...args) {
// 获取当前时间
const time = Date.now()
// 判断此时是否应该执行 func 函数
const isInvoking = shouldInvoke(time)
// 赋值给闭包,用于其他函数调用
lastArgs = args
lastThis = this
lastCallTime = time
// 执行
if (isInvoking) {
// 无 timerId 的情况有两种:
// 1、首次调用
// 2、trailingEdge 执行过函数
if (timerId === undefined) {
return leadingEdge(lastCallTime)
}
// 如果设置了最大等待时间,则立即执行 func
// 1、开启定时器,到时间后触发 trailingEdge 这个函数。
// 2、执行 func,并返回结果
if (maxing) {
// 循环定时器中处理调用
timerId = startTimer(timerExpired, wait)
return invokeFunc(lastCallTime)
}
}
// 一种特殊情况,trailing 设置为 true 时,前一个 wait 的 trailingEdge 已经执行了函数
// 此时函数被调用时 shouldInvoke 返回 false,所以要开启定时器
if (timerId === undefined) {
timerId = startTimer(timerExpired, wait)
}
// 不需要执行时,返回结果
return result
}入口函数中多次使用了 startTimer、timerExpired 这些方法,都是和定时器以及时间计算相关的,除了这两个方法外还有 cancelTimer 和 remainingWait。
这个就是开启定时器了,防抖和节流的核心还是使用定时器,当事件触发时,设置一个指定超时时间的定时器,并传入回调函数,此时的回调函数 pendingFunc 其实就是 timerExpired。这里区分两种情况,一种是使用 requestAnimationFrame,另一种是使用 setTimeout。
// 开启定时器
function startTimer(pendingFunc, wait) {
// 没传 wait 时调用 window.requestAnimationFrame()
if (useRAF) {
// 若想在浏览器下次重绘之前继续更新下一帧动画
// 那么回调函数自身必须再次调用 window.requestAnimationFrame()
root.cancelAnimationFrame(timerId);
return root.requestAnimationFrame(pendingFunc)
}
// 不使用 RAF 时开启定时器
return setTimeout(pendingFunc, wait)
}定时器有开启自然就需要关闭,关闭很简单,只要区分好 RAF 和非 RAF 时的情况即可,取消时传入时间 id。
// 取消定时器
function cancelTimer(id) {
if (useRAF) {
return root.cancelAnimationFrame(id)
}
clearTimeout(id)
}startTimer 函数中传入的回调函数 pendingFunc 其实就是定时器回调函数 timerExpired,表示定时结束后的操作。
定时结束后无非两种情况,一种是执行传入函数 func,另一种就是不执行。对于第一种需要判断下是否需要执行传入函数 func,需要的时候执行最后一次回调。对于第二种计算剩余等待时间并重启定时器,保证下一次时延的末尾触发。
// 定时器回调函数,表示定时结束后的操作
function timerExpired() {
const time = Date.now()
// 1、是否需要执行
// 执行事件结束后的那次回调,否则重启定时器
if (shouldInvoke(time)) {
return trailingEdge(time)
}
// 2、否则 计算剩余等待时间,重启定时器,保证下一次时延的末尾触发
timerId = startTimer(timerExpired, remainingWait(time))
}这里计算仍然需要等待的时间,使用的变量有点多,足足有 9 个,我们先看看各个变量的含义。
maxWait in optionsmaxWait - timeSinceLastInvoke 距上次执行 func 的剩余等待时间变量是真的多,没看明白建议再看一遍,当然核心是下面这部分,根据 maxing 判断具体应该返回的剩余等待时间。
// 是否设置了 maxing
// 是(节流):返回「剩余等待时间」和「距上次执行 func 的剩余等待时间」中的最小值
// 否:返回 剩余等待时间
return maxing
? Math.min(timeWaiting, maxWait - timeSinceLastInvoke)
: timeWaiting这部分比较核心,完整的代码注释如下。
// 计算仍需等待的时间
function remainingWait(time) {
// 当前时间距离上一次调用 debounce 的时间差
const timeSinceLastCall = time - lastCallTime
// 当前时间距离上一次执行 func 的时间差
const timeSinceLastInvoke = time - lastInvokeTime
// 剩余等待时间
const timeWaiting = wait - timeSinceLastCall
// 是否设置了最大等待时间
// 是(节流):返回「剩余等待时间」和「距上次执行 func 的剩余等待时间」中的最小值
// 否:返回剩余等待时间
return maxing
? Math.min(timeWaiting, maxWait - timeSinceLastInvoke)
: timeWaiting
}聊完定时器和时间相关的函数后,这部分源码解析已经进行了大半,接下来我们看一下执行传入函数 func 的逻辑,分为执行刚开始的那次回调 leadingEdge,执行结束后的那次回调 trailingEdge,正常执行 func 函数 invokeFunc,以及判断是否应该执行 func 函数 shouldInvoke。
执行事件刚开始的那次回调,即事件刚触发就执行,不再等待 wait 时间之后,在这个方法里主要有三步。
lastInvokeTime// 执行连续事件刚开始的那次回调
function leadingEdge(time) {
// 1、设置上一次执行 func 的时间
lastInvokeTime = time
// 2、开启定时器,为了事件结束后的那次回调
timerId = startTimer(timerExpired, wait)
// 3、如果配置了 leading 执行传入函数 func
// leading 来源自 !!options.leading
return leading ? invokeFunc(time) : result
}这里就是执行事件结束后的回调了,这里做的事情很简单,就是执行 func 函数,以及清空参数。
// 执行连续事件结束后的那次回调
function trailingEdge(time) {
// 清空定时器
timerId = undefined
// trailing 和 lastArgs 两者同时存在时执行
// trailing 来源自 'trailing' in options ? !!options.trailing : trailing
// lastArgs 标记位的作用,意味着 debounce 至少执行过一次
if (trailing && lastArgs) {
return invokeFunc(time)
}
// 清空参数
lastArgs = lastThis = undefined
return result
}说了那么多次执行 func 函数,那么具体是如何执行的呢?真的很简单,就是 func.apply(thisArg, args),除此之外需要重置部分参数。
// 执行 Func 函数
function invokeFunc(time) {
// 获取上一次执行 debounced 的参数
const args = lastArgs
// 获取上一次的 this
const thisArg = lastThis
// 重置
lastArgs = lastThis = undefined
lastInvokeTime = time
result = func.apply(thisArg, args)
return result
}在入口函数中执行 invokeFunc 时会先判断下是否应该执行,我们来详细看下具体逻辑,和 remainingWait 中类似,变量有点多,先来回顾下这些变量。
maxWait in options我们来一步一步看下判断的核心代码,总共有 4 种逻辑。
return ( lastCallTime === undefined ||
(timeSinceLastCall >= wait) ||
(timeSinceLastCall < 0) ||
(maxing && timeSinceLastInvoke >= maxWait) )会发现一共有 4 种情况返回 true,区分开看也比较理解。
lastCallTime === undefined 第一次调用时timeSinceLastCall >= wait 超过超时时间 wait,处理事件结束后的那次回调timeSinceLastCall < 0 当前时间 - 上次调用时间小于 0,即更改了系统时间maxing && timeSinceLastInvoke >= maxWait 超过最大等待时间// 判断此时是否应该执行 func 函数
function shouldInvoke(time) {
// 当前时间距离上一次调用 debounce 的时间差
const timeSinceLastCall = time - lastCallTime
// 当前时间距离上一次执行 func 的时间差
const timeSinceLastInvoke = time - lastInvokeTime
// 上述 4 种情况返回 true
return (lastCallTime === undefined || (timeSinceLastCall >= wait) ||
(timeSinceLastCall < 0) || (maxing && timeSinceLastInvoke >= maxWait))
}debounced 函数提供了 3 个方法,分别是cancel、flush 和 pending,通过如下方式提供属性进行绑定。
// 绑定方法
debounced.cancel = cancel
debounced.flush = flush
debounced.pending = pending这个就是取消执行,取消主要做的就是清除定时器,然后清除必要的闭包变量,回归初始状态。
// 取消函数延迟执行
function cancel() {
// 清除定时器
if (timerId !== undefined) {
cancelTimer(timerId)
}
// 清除闭包变量
lastInvokeTime = 0
lastArgs = lastCallTime = lastThis = timerId = undefined
}这个是对外提供的立即执行方法,方便需要的时候调用。
result 结果trailingEdge,执行完成后会清空定时器id,lastArgs 和 lastThis// 立即执行 func
function flush() {
return timerId === undefined ? result : trailingEdge(Date.now())
}获取当前状态,检查当前是否在计时中,存在定时器 id timerId 意味着正在计时中。
// 检查当前是否在计时中
function pending() {
return timerId !== undefined
}节流函数的定义和自定义实现我就不再介绍了,之前专门写过一篇文章,戳这里学习
这部分源码比较简单,相比防抖来说只是触发条件不同,说白了就是 maxWait 为 wait 的防抖函数。
function throttle(func, wait, options) {
// 首尾调用默认为 true
let leading = true
let trailing = true
if (typeof func !== 'function') {
throw new TypeError('Expected a function')
}
// options 是否是对象
if (isObject(options)) {
leading = 'leading' in options ? !!options.leading : leading
trailing = 'trailing' in options ? !!options.trailing : trailing
}
// maxWait 为 wait 的防抖函数
return debounce(func, wait, {
leading,
trailing,
'maxWait': wait,
})
}上面使用了 isObject 判断是否是一个对象,原理就是 typeof value,如果是 object 或者 function 时返回 true。
function isObject(value) {
const type = typeof value
return value != null && (type == 'object' || type == 'function')
}举几个小例子说明下
isObject({})
// => true
isObject([1, 2, 3])
// => true
isObject(Function)
// => true
isObject(null)
// => false源码解析已经完成,那你真的理解了吗,留下几道思考题给大家,欢迎作答,答案会在下篇文章中给出。
leading 和 trailing 选项都是 true,在 wait 期间只调用了一次 debounced 函数时,总共会调用几次 func,1 次还是 2 次,为什么?debounce(func, time, options) 中的 func 传参数?如果你觉得这篇内容对你挺有启发,我想邀请你帮我三个小忙:
干得漂亮
Vue进阶系列汇总如下,欢迎阅读,欢迎加群讨论(文末)。
Reactivity表示一个状态改变之后,如何动态改变整个系统,在实际项目应用场景中即数据如何动态改变Dom。
现在有一个需求,有a和b两个变量,要求b一直是a的10倍,怎么做?
let a = 3;
let b = a * 10;
console.log(b); // 30乍一看好像满足要求,但此时b的值是固定的,不管怎么修改a,b并不会跟着一起改变。也就是说b并没有和a保持数据上的同步。只有在a变化之后重新定义b的值,b才会变化。
a = 4;
console.log(a); // 4
console.log(b); // 30
b = a * 10;
console.log(b); // 40将a和b的关系定义在函数内,那么在改变a之后执行这个函数,b的值就会改变。伪代码如下。
onAChanged(() => {
b = a * 10;
})所以现在的问题就变成了如何实现onAChanged函数,当a改变之后自动执行onAChanged,请看后续。
现在把a、b和view页面相结合,此时a对应于数据,b对应于页面。业务场景很简单,改变数据a之后就改变页面b。
<span class="cell b"></span>
document
.querySelector('.cell.b')
.textContent = state.a * 10现在建立数据a和页面b的关系,用函数包裹之后建立以下关系。
<span class="cell b"></span>
onStateChanged(() => {
document
.querySelector(‘.cell.b’)
.textContent = state.a * 10
})再次抽象之后如下所示。
<span class="cell b">
{{ state.a * 10 }}
</span>
onStateChanged(() => {
view = render(state)
})view = render(state)是所有的页面渲染的高级抽象。这里暂不考虑view = render(state)的实现,因为需要涉及到DOM结构及其实现等一系列技术细节。这边需要的是onStateChanged的实现。
实现方式是通过Object.defineProperty中的getter和setter方法。具体使用方法参考如下链接。
需要注意的是get和set函数是存取描述符,value和writable函数是数据描述符。描述符必须是这两种形式之一,但二者不能共存,不然会出现异常。
convert()函数要求如下:
obj作为参数Object.defineProperty转换对象的所有属性示例:
const obj = { foo: 123 }
convert(obj)
obj.foo // 输出 getting key "foo": 123
obj.foo = 234 // 输出 setting key "foo" to 234
obj.foo // 输出 getting key "foo": 234在了解Object.defineProperty中getter和setter的使用方法之后,通过修改get和set函数就可以实现onAChanged和onStateChanged。
实现:
function convert (obj) {
// 迭代对象的所有属性
// 并使用Object.defineProperty()转换成getter/setters
Object.keys(obj).forEach(key => {
// 保存原始值
let internalValue = obj[key]
Object.defineProperty(obj, key, {
get () {
console.log(`getting key "${key}": ${internalValue}`)
return internalValue
},
set (newValue) {
console.log(`setting key "${key}" to: ${newValue}`)
internalValue = newValue
}
})
})
}Dep类要求如下:
Dep类,包含两个方法:depend和notifyautorun函数,传入一个update函数作为参数update函数中调用dep.depend(),显式依赖于Dep实例dep.notify()触发update函数重新运行示例:
const dep = new Dep()
autorun(() => {
dep.depend()
console.log('updated')
})
// 注册订阅者,输出 updated
dep.notify()
// 通知改变,输出 updated首先需要定义autorun函数,接收update函数作为参数。因为调用autorun时要在Dep中注册订阅者,同时调用dep.notify()时要重新执行update函数,所以Dep中必须持有update引用,这里使用变量activeUpdate表示包裹update的函数。
实现代码如下。
let activeUpdate = null
function autorun (update) {
const wrappedUpdate = () => {
activeUpdate = wrappedUpdate // 引用赋值给activeUpdate
update() // 调用update,即调用内部的dep.depend
activeUpdate = null // 绑定成功之后清除引用
}
wrappedUpdate() // 调用
}wrappedUpdate本质是一个闭包,update函数内部可以获取到activeUpdate变量,同理dep.depend()内部也可以获取到activeUpdate变量,所以Dep的实现就很简单了。
实现代码如下。
class Dep {
// 初始化
constructor () {
this.subscribers = new Set()
}
// 订阅update函数列表
depend () {
if (activeUpdate) {
this.subscribers.add(activeUpdate)
}
}
// 所有update函数重新运行
notify () {
this.subscribers.forEach(sub => sub())
}
}结合上面两部分就是完整实现。
要求如下:
convert()重命名为观察者observe()observe()转换对象的属性使之响应式,对于每个转换后的属性,它会被分配一个Dep实例,该实例跟踪订阅update函数列表,并在调用setter时触发它们重新运行autorun()接收update函数作为参数,并在update函数订阅的属性发生变化时重新运行。示例:
const state = {
count: 0
}
observe(state)
autorun(() => {
console.log(state.count)
})
// 输出 count is: 0
state.count++
// 输出 count is: 1结合实例1和实例2之后就可以实现上述要求,observe中修改obj属性的同时分配Dep的实例,并在get中注册订阅者,在set中通知改变。autorun函数保存不变。
实现如下:
class Dep {
// 初始化
constructor () {
this.subscribers = new Set()
}
// 订阅update函数列表
depend () {
if (activeUpdate) {
this.subscribers.add(activeUpdate)
}
}
// 所有update函数重新运行
notify () {
this.subscribers.forEach(sub => sub())
}
}
function observe (obj) {
// 迭代对象的所有属性
// 并使用Object.defineProperty()转换成getter/setters
Object.keys(obj).forEach(key => {
let internalValue = obj[key]
// 每个属性分配一个Dep实例
const dep = new Dep()
Object.defineProperty(obj, key, {
// getter负责注册订阅者
get () {
dep.depend()
return internalValue
},
// setter负责通知改变
set (newVal) {
const changed = internalValue !== newVal
internalValue = newVal
// 触发后重新计算
if (changed) {
dep.notify()
}
}
})
})
return obj
}
let activeUpdate = null
function autorun (update) {
// 包裹update函数到"wrappedUpdate"函数中,
// "wrappedUpdate"函数执行时注册和注销自身
const wrappedUpdate = () => {
activeUpdate = wrappedUpdate
update()
activeUpdate = null
}
wrappedUpdate()
}Job Done!!!
本文内容参考自VUE作者尤大的付费视频
欢迎加我微信进一步交流或者找我内推,前行的路上,共勉!
大家好,我是依扬,在蚂蚁一直是面试官,负责招聘正式员工和合作伙伴的面试,大家对大厂面试、内推、校招相关的都可以找我哈!
这是面试直播系列文章,每周更新一篇,下一篇将通过案例来演示简历如何写,才能获得面试官的青睐,大家记得关注我,更新后会收到推送!
1、简历三大原则:清晰,简短,必要,给面试官留下好印象
2、技术能力匹配:满足招聘方的要求,技术水平要达标
3、突出项目亮点:10 秒以内要让面试官发现亮点,有问下去的动力
一份好简历应该满足以下三个特征:清晰,简短,必要
1)清晰:简历是易于理解的,排版简单,不会模棱两可
比如学校和毕业时间,工作多少年,相应行业的工作经验,求职岗位等需要清晰明确。
社招时有的人会把实习时间算上去,这个工作时间就对不上了,社招的话不用写实习相关内容了,除非内容特别好。
还有的人会把毕业学校放到简历最后面,有的毕业时间都没有让面试官来猜,真的是蜜汁操作。这种一般就默认简历不行,求职者自己都不自信,面试官继续看简历的心情是没有的。
2) 简短:在工作汇报或者面试跳槽中,「突出重点」是非常重要的能力,有利于让面试官一下就明白你想表达的重点内容。非常重要的部分可以适当加粗,然后简历不要超过 2 页。
这部分不知道怎么做的话,推荐大家看看 《金字塔原理》这本书,非常棒,职场人必备。
3)必要:简历上面只需要有必要的信息,能够帮助彼此最大化的节约时间,提升效率。保证简历里面的内容都是面试官感兴趣的。
基本信息包括姓名、邮箱、手机号、工作年限、意向城市等基本信息,像籍贯这些对面试来说不重要的内容就不用写了。
有的人会在简历中放上 GitHub 或者博客链接,如果博客内容充实可以放上去,如果没什么内容,只是几个面经笔记的话,这种链接就不要放了,反而降分。
贴了博客链接的话,面试官一般都会去看一眼的,所以博客内容要准备一下,避免忘记后面试时尴尬。
有的人会把项目经历中相似的项目全部列出来,比如 A 管理后台、B 管理后台,其实这些工作内容没有多大差异性,写一个有代表性的就可以了。
这部分突出深入的领域和掌握的核心技能,比如对性能优化、监控、工程化等有经验,掌握了 Vue / React 源码,掌握网络、浏览器等原理,熟悉数据结构和算法等。
突出这些内容可以引导面试官向着你预设的战场前进,不至于突然抛几道不会的面试题导致慌张。
需要非常精简的把一个项目经历写出来,推荐使用【STAR】法则来完善项目的介绍,STAR法则是情境(situation)、任务(task)、行动(action)、结果(result)。
简单来说就是【S】这个项目的背景是什么,可以是项目介绍也可以是遇到的问题和难点,【T】需要做的工作是什么,在其中担任什么职责,【A】通过什么方式来解决这些问题的,【R】以及取得了什么指标可衡量的结果。
从项目中的一些点切入,把自己的价值做出来就值得写进简历中。
工作分为两种,一种是偏业务方向,另一种是偏基础架构方向
如果你的团队本身就是基础架构团队,那只要把你的项目系统的整理出来就可以了,从为什么做,怎么做,技术难点和业务价值这些说出来就可以。
如果你的团队是业务方向,那就需要在平常的工作中,去主动挖掘技术点。这个要看团队的支持度,最好的方式是推动团队去挖掘技术点,做一些业务价值提升点。
可以做的方向还是很多的,找准一个方向做个一年以上,拿到结果之后再考虑跳槽这种事情。
脚手架系统、营销配置平台、发布 / 发码平台、微前端、低代码、提效工具等等都是可以的。最好还是结合业务来做,做完后可以带来业务价值,对绩效和面试都有很大的帮助。
虽然很多人吐槽这个,但是没有办法,市场就是这样。面试时常规题型都回答不上来,很难进入到后面的环节。
常规题型其实就那么多,包含了 HTML、CSS、JS、异步、浏览器、网络、安全、框架、数据结构和算法、性能优化以及参加的手写题。
现在很多公司都会在一面的时候安排编程能力考查,所以编程题和算法题需要好好准备下,可以去 https://muyiy.cn 面试网站学习。
复习简历上列的知识点和项目,简历上的知识点将是接下来你面试时非常高频的面试题,这些必须牢牢掌握。
对于你简历上没有写的知识,那就不用准备了。比如你没接触过小程序,那就不用看。比如你的项目是 React,那就不用准备 Vue。一切以你的简历为主。
如果说面试时遇到了你没写到的知识点,这时候只要如实说这块没怎么接触过就好了,面试是为了挖掘你的潜力和你的亮点,不是为了为难你,所以有些点没回答上来是没有问题的。
统一用 PDF 格式,很多人喜欢发 Word 格式,但是不同设备下查看会乱掉。
排版简洁明了就行,白底黑字,使用常见的表格、标题、列表,不用过于花哨。
面试官一般会问离职原因,如果最近几家跳槽很频繁的话需要注意了。如果目标是进入大厂的话,最好在最近这一家待满 3 年以上,5 年内最好不要超过 3 家,不然就比较危险了。
有的人喜欢问什么答什么,这其实是不好的。一问一答会被面试官带节奏,另外会显得你没有思考,看起来像背的。
这里需要突出跟问题相关的思考、框架原理或技术细节这些,要展现出来你与别人不同的地方。把你的技术亮点主要抛出来,引导面试官来问。
遇到不会的问题,就实话实说这个技术点不会,没有深入了解过,然后把自己的理解说一下,切记胡乱猜测。
有的人喜欢胡乱瞎扯,回答问题说一大堆,但是没有重点没有主次,会让面试官觉得你思路不清晰。
面试其实找的是同路人,除了技术水平外还会考察沟通水平如何,逻辑混乱的话,这种人一般不适合招进来培养。
这个非常不好,太流利不符合正常人情况,面试官都知道大家是有准备的,但是肆无忌惮的大段背诵,会给人一种只是背下来但没有理解问题本质的感觉。
这块需要有适当的停顿,要有思考,过程中最好是看着面试官眼睛来,有眼神上的互动。
// fn 是需要节流处理的函数
// wait 是时间间隔
function throttle(fn, wait) {
// previous 是上一次执行 fn 的时间
// timer 是定时器
let previous = 0, timer = null
```javascript
// 将 throttle 处理结果当作函数返回
return function (...args) {
// 获取当前时间,转换成时间戳,单位毫秒
let now = +new Date()
// ------ 新增部分 start ------
// 判断上次触发的时间和本次触发的时间差是否小于时间间隔
if (now - previous < wait) {
// 如果小于,则为本次触发操作设立一个新的定时器
// 定时器时间结束后执行函数 fn
if (timer) clearTimeout(timer)
timer = setTimeout(() => {
previous = now
fn.apply(this, args)
}, wait)
// ------ 新增部分 end ------
} else {
// 第一次执行
// 或者时间间隔超出了设定的时间间隔,执行函数 fn
previous = now
fn.apply(this, args)
}
}
}如果throttle 和 debounce都用同一个wait那就没有意义了吧?(和单纯throttle不就一样了吗?)
请教大佬解答
半年时间,几千人参与,精选大厂前端面试高频 100 题,这就是「壹题」。
在 2019 年 1 月 21 日这天,「壹题」项目正式开始,在这之后每个工作日都会出一道高频面试题,主要涵盖阿里、腾讯、头条、百度、网易等大公司和常见题型。得益于大家热情参与,现在每道题都有很多答案,提供的解题思路和答案也大大增长了我的见识,到现在已累积 100 道题目,『 8000+ 』Star 了,可以说你面试中遇到过的题目,在这里肯定能发现熟悉的身影。
后期计划除了持续更新「壹题」之外,还将整理非常详细的答案解析,提供完整的思考链路,帮助大家更好的理解题目,以及题目背后的知识,「我们的目标不是背题,而是通过题目查漏补缺,温故知新」。
更多更全更详细的每日一题和答案解析,戳这里查看
解析:第 1 题
['1', '2', '3'].map(parseInt) what & why ?解析:第 2 题
解析:第 3 题
解析:第 4 题
解析:第 5 题
解析:第 6 题
解析:第 7 题
解析:第 8 题
解析:第 9 题
请写出下面代码的运行结果
async function async1() {
console.log('async1 start');
await async2();
console.log('async1 end');
}
async function async2() {
console.log('async2');
}
console.log('script start');
setTimeout(function() {
console.log('setTimeout');
}, 0)
async1();
new Promise(function(resolve) {
console.log('promise1');
resolve();
}).then(function() {
console.log('promise2');
});
console.log('script end');解析:第 10 题
已知如下数组:
var arr = [ [1, 2, 2], [3, 4, 5, 5], [6, 7, 8, 9, [11, 12, [12, 13, [14] ] ] ], 10];
编写一个程序将数组扁平化去并除其中重复部分数据,最终得到一个升序且不重复的数组
解析:第 11 题
解析:第 12 题
解析:第 13 题
解析:第 14 题
解析:第 15 题
解析:第 16 题
如果A 与 B 建立了正常连接后,从未相互发过数据,这个时候 B 突然机器重启,问 A 此时处于 TCP 什么状态?如何消除服务器程序中的这个状态?(超纲题,了解即可)
解析:第 17 题
解析:第 18 题
class Example extends React.Component {
constructor() {
super();
this.state = {
val: 0
};
}
componentDidMount() {
this.setState({val: this.state.val + 1});
console.log(this.state.val); // 第 1 次 log
this.setState({val: this.state.val + 1});
console.log(this.state.val); // 第 2 次 log
setTimeout(() => {
this.setState({val: this.state.val + 1});
console.log(this.state.val); // 第 3 次 log
this.setState({val: this.state.val + 1});
console.log(this.state.val); // 第 4 次 log
}, 0);
}
render() {
return null;
}
};解析:第 19 题
解析:第 20 题
Object.prototype.toString.call() 、 instanceof 以及 Array.isArray()
解析:第 21 题
解析:第 22 题
解析:第 23 题
解析:第 24 题
解析:第 25 题
可从IIFE、AMD、CMD、CommonJS、UMD、webpack(require.ensure)、ES Module、<script type="module"> 这几个角度考虑。
解析:第 26 题
解析:第 27 题
解析:第 28 题
解析:第 29 题
请把两个数组 ['A1', 'A2', 'B1', 'B2', 'C1', 'C2', 'D1', 'D2'] 和 ['A', 'B', 'C', 'D'],合并为 ['A1', 'A2', 'A', 'B1', 'B2', 'B', 'C1', 'C2', 'C', 'D1', 'D2', 'D']。
解析: 第 30 题
for (var i = 0; i< 10; i++){
setTimeout(() => {
console.log(i);
}, 1000)
}解析:第 31 题
解析:第 32 题
var b = 10;
(function b(){
b = 20;
console.log(b);
})();解析:第 33 题
var b = 10;
(function b(){
b = 20;
console.log(b);
})();解析:第 34 题
可以分成 Service Worker、Memory Cache、Disk Cache 和 Push Cache,那请求的时候 from memory cache 和 from disk cache 的依据是什么,哪些数据什么时候存放在 Memory Cache 和 Disk Cache中?
解析:第 35 题
解析:第 36 题
解析:第 37 题
var a = ?;
if(a == 1 && a == 2 && a == 3){
console.log(1);
}解析:第 38 题
解析:第 39 题
如果修改了,Vue 是如何监控到属性的修改并给出警告的。
解析:第 40 题
var a = 10;
(function () {
console.log(a)
a = 5
console.log(window.a)
var a = 20;
console.log(a)
})()解析:第 41题
比如 sleep(1000) 意味着等待1000毫秒,可从 Promise、Generator、Async/Await 等角度实现
解析:第 42 题
解析:第 43 题
解析:第 44 题
解析:第 45 题
var obj = {
'2': 3,
'3': 4,
'length': 2,
'splice': Array.prototype.splice,
'push': Array.prototype.push
}
obj.push(1)
obj.push(2)
console.log(obj)解析:第 46 题
解析:第 47 题
解析:第 48 题
解析:第 49 题
例: 5 + 3 - 2,结果为 6
解析:第 50 题
为什么在 Vue3.0 采用了 Proxy,抛弃了 Object.defineProperty?
解析:第 51 题
解析:第 52 题
var a = {n: 1};
var b = a;
a.x = a = {n: 2};
console.log(a.x)
console.log(b.x)解析:第 53 题
解析:第 54 题
如下:{1:222, 2:123, 5:888},请把数据处理为如下结构:[222, 123, null, null, 888, null, null, null, null, null, null, null]。
解析:第 55 题
LazyMan('Tony');
// Hi I am Tony
LazyMan('Tony').sleep(10).eat('lunch');
// Hi I am Tony
// 等待了10秒...
// I am eating lunch
LazyMan('Tony').eat('lunch').sleep(10).eat('dinner');
// Hi I am Tony
// I am eating lunch
// 等待了10秒...
// I am eating diner
LazyMan('Tony').eat('lunch').eat('dinner').sleepFirst(5).sleep(10).eat('junk food');
// Hi I am Tony
// 等待了5秒...
// I am eating lunch
// I am eating dinner
// 等待了10秒...
// I am eating junk food解析:第 56 题
解析:第 57 题
解析:第 58 题
例如:给定 nums1 = [1, 2, 2, 1],nums2 = [2, 2],返回 [2, 2]。
解析:第 59 题
<img src="1.jpg" style="width:480px!important;”>
解析:第 60 题
解析:第 61 题
解析:第 62 题
解析:第 63 题
解析:第 64 题
a.b.c.d 和 a['b']['c']['d'],哪个性能更高?解析:第 65 题
解析:第 66 题
随机生成一个长度为 10 的整数类型的数组,例如 [2, 10, 3, 4, 5, 11, 10, 11, 20],将其排列成一个新数组,要求新数组形式如下,例如 [[2, 3, 4, 5], [10, 11], [20]]。
解析:第 67 题
解析:第 68 题
解析:第 69 题
解析:第 70 题
解析:第 71 题
for 循环的性能远远高于 forEach 的性能,请解释其中的原因。解析:第 72 题
解析:第 73 题
解析:第 74 题
解析:第 75 题
// example 1
var a={}, b='123', c=123;
a[b]='b';
a[c]='c';
console.log(a[b]);
---------------------
// example 2
var a={}, b=Symbol('123'), c=Symbol('123');
a[b]='b';
a[c]='c';
console.log(a[b]);
---------------------
// example 3
var a={}, b={key:'123'}, c={key:'456'};
a[b]='b';
a[c]='c';
console.log(a[b]);解析:第 76 题
给定一个数组,将数组中的元素向右移动 k 个位置,其中 k 是非负数。
示例 1:
输入: [1, 2, 3, 4, 5, 6, 7] 和 k = 3
输出: [5, 6, 7, 1, 2, 3, 4]
解释:
向右旋转 1 步: [7, 1, 2, 3, 4, 5, 6]
向右旋转 2 步: [6, 7, 1, 2, 3, 4, 5]
向右旋转 3 步: [5, 6, 7, 1, 2, 3, 4]示例 2:
输入: [-1, -100, 3, 99] 和 k = 2
输出: [3, 99, -1, -100]
解释:
向右旋转 1 步: [99, -1, -100, 3]
向右旋转 2 步: [3, 99, -1, -100]解析:第 77 题
解析:第 78 题
解析:第 79 题
解析:第 80 题
例如:121、1331 等
解析:第 81 题
给定一个数组 nums,编写一个函数将所有 0 移动到数组的末尾,同时保持非零元素的相对顺序。
示例:
输入: [0,1,0,3,12] 输出: [1,3,12,0,0]说明:
- 必须在原数组上操作,不能拷贝额外的数组。
- 尽量减少操作次数。
解析:第 82 题
解析:第 83 题
add(1); // 1 add(1)(2); // 3 add(1)(2)(3);// 6 add(1)(2, 3); // 6 add(1, 2)(3); // 6 add(1, 2, 3); // 6
解析:第 84 题
<Link> 标签和 <a> 标签有什么区别如何禁掉
<a>标签默认事件,禁掉之后如何实现跳转。
解析:第 85 题
给定一个整数数组和一个目标值,找出数组中和为目标值的两个数。
你可以假设每个输入只对应一种答案,且同样的元素不能被重复利用。
示例:
给定 nums = [2, 7, 11, 15], target = 9
因为 nums[0] + nums[1] = 2 + 7 = 9
所以返回 [0, 1]解析:第 86 题
解析:第 87 题
以下数据结构中,id 代表部门编号,name 是部门名称,parentId 是父部门编号,为 0 代表一级部门,现在要求实现一个 convert 方法,把原始 list 转换成树形结构,parentId 为多少就挂载在该 id 的属性 children 数组下,结构如下:
// 原始 list 如下
let list =[
{id:1,name:'部门A',parentId:0},
{id:2,name:'部门B',parentId:0},
{id:3,name:'部门C',parentId:1},
{id:4,name:'部门D',parentId:1},
{id:5,name:'部门E',parentId:2},
{id:6,name:'部门F',parentId:3},
{id:7,name:'部门G',parentId:2},
{id:8,name:'部门H',parentId:4}
];
const result = convert(list, ...);
// 转换后的结果如下
let result = [
{
id: 1,
name: '部门A',
parentId: 0,
children: [
{
id: 3,
name: '部门C',
parentId: 1,
children: [
{
id: 6,
name: '部门F',
parentId: 3
}, {
id: 16,
name: '部门L',
parentId: 3
}
]
},
{
id: 4,
name: '部门D',
parentId: 1,
children: [
{
id: 8,
name: '部门H',
parentId: 4
}
]
}
]
},
···
];解析:第 88 题
解析:第 89 题
解析:第 90 题
解析:第 91 题
const value = '112' const fn = (value) => { ... } fn(value) // 输出 [1, 11, 112]
解析:第 92 题
示例 1:
nums1 = [1, 3]
nums2 = [2]中位数是 2.0
示例 2:
nums1 = [1, 2]
nums2 = [3, 4]中位数是(2 + 3) / 2 = 2.5
解析:第 93 题
解析:第 94 题
解析:第 95 题
解析:第 96 题
解析:第 97 题
function changeObjProperty(o) {
o.siteUrl = "http://www.baidu.com"
o = new Object()
o.siteUrl = "http://www.google.com"
}
let webSite = new Object();
changeObjProperty(webSite);
console.log(webSite.siteUrl);解析:第 98 题
用 JavaScript 写一个函数,输入 int 型,返回整数逆序后的字符串。如:输入整型 1234,返回字符串“4321”。要求必须使用递归函数调用,不能用全局变量,输入函数必须只有一个参数传入,必须返回字符串。
解析:第 99 题
function Foo() { Foo.a = function() { console.log(1) } this.a = function() { console.log(2) } } Foo.prototype.a = function() { console.log(3) } Foo.a = function() { console.log(4) } Foo.a(); let obj = new Foo(); obj.a(); Foo.a();
解析:第 100 题
如果你觉得这篇内容对你挺有启发,我想邀请你帮我三个小忙:
上篇文章详细介绍了浅拷贝 Object.assign,并对其进行了模拟实现,在实现的过程中,介绍了很多基础知识。今天这篇文章我们来看看一道必会面试题,即如何实现一个深拷贝。本文会详细介绍对象、数组、循环引用、引用丢失、Symbol 和递归爆栈等情况下的深拷贝实践,欢迎阅读。
其实深拷贝可以拆分成 2 步,浅拷贝 + 递归,浅拷贝时判断属性值是否是对象,如果是对象就进行递归操作,两个一结合就实现了深拷贝。
根据上篇文章内容,我们可以写出简单浅拷贝代码如下。
// 木易杨
function cloneShallow(source) {
var target = {};
for (var key in source) {
if (Object.prototype.hasOwnProperty.call(source, key)) {
target[key] = source[key];
}
}
return target;
}
// 测试用例
var a = {
name: "muyiy",
book: {
title: "You Don't Know JS",
price: "45"
},
a1: undefined,
a2: null,
a3: 123
}
var b = cloneShallow(a);
a.name = "高级前端进阶";
a.book.price = "55";
console.log(b);
// {
// name: 'muyiy',
// book: { title: 'You Don\'t Know JS', price: '55' },
// a1: undefined,
// a2: null,
// a3: 123
// }上面代码是浅拷贝实现,只要稍微改动下,加上是否是对象的判断并在相应的位置使用递归就可以实现简单深拷贝。
// 木易杨
function cloneDeep1(source) {
var target = {};
for(var key in source) {
if (Object.prototype.hasOwnProperty.call(source, key)) {
if (typeof source[key] === 'object') {
target[key] = cloneDeep1(source[key]); // 注意这里
} else {
target[key] = source[key];
}
}
}
return target;
}
// 使用上面测试用例测试一下
var b = cloneDeep1(a);
console.log(b);
// {
// name: 'muyiy',
// book: { title: 'You Don\'t Know JS', price: '45' },
// a1: undefined,
// a2: {},
// a3: 123
// }一个简单的深拷贝就完成了,但是这个实现还存在很多问题。
1、没有对传入参数进行校验,传入 null 时应该返回 null 而不是 {}
2、对于对象的判断逻辑不严谨,因为 typeof null === 'object'
3、没有考虑数组的兼容
我们来看下对于对象的判断,之前在【进阶3-3期】有过介绍,判断方案如下。
// 木易杨
function isObject(obj) {
return Object.prototype.toString.call(obj) === '[object Object]';
}但是用在这里并不合适,因为我们要保留数组这种情况,所以这里使用 typeof 来处理。
// 木易杨
typeof null //"object"
typeof {} //"object"
typeof [] //"object"
typeof function foo(){} //"function" (特殊情况)改动过后的 isObject 判断逻辑如下。
// 木易杨
function isObject(obj) {
return typeof obj === 'object' && obj != null;
}所以兼容数组的写法如下。
// 木易杨
function cloneDeep2(source) {
if (!isObject(source)) return source; // 非对象返回自身
var target = Array.isArray(source) ? [] : {};
for(var key in source) {
if (Object.prototype.hasOwnProperty.call(source, key)) {
if (isObject(source[key])) {
target[key] = cloneDeep2(source[key]); // 注意这里
} else {
target[key] = source[key];
}
}
}
return target;
}
// 使用上面测试用例测试一下
var b = cloneDeep2(a);
console.log(b);
// {
// name: 'muyiy',
// book: { title: 'You Don\'t Know JS', price: '45' },
// a1: undefined,
// a2: null,
// a3: 123
// }我们知道 JSON 无法深拷贝循环引用,遇到这种情况会抛出异常。
// 木易杨
// 此处 a 是文章开始的测试用例
a.circleRef = a;
JSON.parse(JSON.stringify(a));
// TypeError: Converting circular structure to JSON解决方案很简单,其实就是循环检测,我们设置一个数组或者哈希表存储已拷贝过的对象,当检测到当前对象已存在于哈希表中时,取出该值并返回即可。
// 木易杨
function cloneDeep3(source, hash = new WeakMap()) {
if (!isObject(source)) return source;
if (hash.has(source)) return hash.get(source); // 新增代码,查哈希表
var target = Array.isArray(source) ? [] : {};
hash.set(source, target); // 新增代码,哈希表设值
for(var key in source) {
if (Object.prototype.hasOwnProperty.call(source, key)) {
if (isObject(source[key])) {
target[key] = cloneDeep3(source[key], hash); // 新增代码,传入哈希表
} else {
target[key] = source[key];
}
}
}
return target;
}测试一下,看看效果如何。
// 木易杨
// 此处 a 是文章开始的测试用例
a.circleRef = a;
var b = cloneDeep3(a);
console.log(b);
// {
// name: "muyiy",
// a1: undefined,
// a2: null,
// a3: 123,
// book: {title: "You Don't Know JS", price: "45"},
// circleRef: {name: "muyiy", book: {…}, a1: undefined, a2: null, a3: 123, …}
// }完美!
这里使用了 ES6 中的 WeakMap 来处理,那在 ES5 下应该如何处理呢?
也很简单,使用数组来处理就好啦,代码如下。
// 木易杨
function cloneDeep3(source, uniqueList) {
if (!isObject(source)) return source;
if (!uniqueList) uniqueList = []; // 新增代码,初始化数组
var target = Array.isArray(source) ? [] : {};
// ============= 新增代码
// 数据已经存在,返回保存的数据
var uniqueData = find(uniqueList, source);
if (uniqueData) {
return uniqueData.target;
};
// 数据不存在,保存源数据,以及对应的引用
uniqueList.push({
source: source,
target: target
});
// =============
for(var key in source) {
if (Object.prototype.hasOwnProperty.call(source, key)) {
if (isObject(source[key])) {
target[key] = cloneDeep3(source[key], uniqueList); // 新增代码,传入数组
} else {
target[key] = source[key];
}
}
}
return target;
}
// 新增方法,用于查找
function find(arr, item) {
for(var i = 0; i < arr.length; i++) {
if (arr[i].source === item) {
return arr[i];
}
}
return null;
}
// 用上面测试用例已测试通过现在已经很完美的解决了循环引用这种情况,那其实还是一种情况是引用丢失,我们看下面的例子。
// 木易杨
var obj1 = {};
var obj2 = {a: obj1, b: obj1};
obj2.a === obj2.b;
// true
var obj3 = cloneDeep2(obj2);
obj3.a === obj3.b;
// false引用丢失在某些情况下是有问题的,比如上面的对象 obj2,obj2 的键值 a 和 b 同时引用了同一个对象 obj1,使用 cloneDeep2 进行深拷贝后就丢失了引用关系变成了两个不同的对象,那如何处理呢。
其实你有没有发现,我们的 cloneDeep3 已经解决了这个问题,因为只要存储已拷贝过的对象就可以了。
// 木易杨
var obj3 = cloneDeep3(obj2);
obj3.a === obj3.b;
// true完美!
Symbol这个时候可能要搞事情了,那我们能不能拷贝 Symol 类型呢?
当然可以,不过 Symbol 在 ES6 下才有,我们需要一些方法来检测出 Symble 类型。
方法一:Object.getOwnPropertySymbols(...)
方法二:Reflect.ownKeys(...)
对于方法一可以查找一个给定对象的符号属性时返回一个 ?symbol 类型的数组。注意,每个初始化的对象都是没有自己的 symbol 属性的,因此这个数组可能为空,除非你已经在对象上设置了 symbol 属性。(来自MDN)
var obj = {};
var a = Symbol("a"); // 创建新的symbol类型
var b = Symbol.for("b"); // 从全局的symbol注册?表设置和取得symbol
obj[a] = "localSymbol";
obj[b] = "globalSymbol";
var objectSymbols = Object.getOwnPropertySymbols(obj);
console.log(objectSymbols.length); // 2
console.log(objectSymbols) // [Symbol(a), Symbol(b)]
console.log(objectSymbols[0]) // Symbol(a)对于方法二返回一个由目标对象自身的属性键组成的数组。它的返回值等同于Object.getOwnPropertyNames(target).concat(Object.getOwnPropertySymbols(target))。(来自MDN)
Reflect.ownKeys({z: 3, y: 2, x: 1}); // [ "z", "y", "x" ]
Reflect.ownKeys([]); // ["length"]
var sym = Symbol.for("comet");
var sym2 = Symbol.for("meteor");
var obj = {[sym]: 0, "str": 0, "773": 0, "0": 0,
[sym2]: 0, "-1": 0, "8": 0, "second str": 0};
Reflect.ownKeys(obj);
// [ "0", "8", "773", "str", "-1", "second str", Symbol(comet), Symbol(meteor) ]
// 注意顺序
// Indexes in numeric order,
// strings in insertion order,
// symbols in insertion order思路就是先查找有没有 Symbol 属性,如果查找到则先遍历处理 Symbol 情况,然后再处理正常情况,多出来的逻辑就是下面的新增代码。
// 木易杨
function cloneDeep4(source, hash = new WeakMap()) {
if (!isObject(source)) return source;
if (hash.has(source)) return hash.get(source);
let target = Array.isArray(source) ? [] : {};
hash.set(source, target);
// ============= 新增代码
let symKeys = Object.getOwnPropertySymbols(source); // 查找
if (symKeys.length) { // 查找成功
symKeys.forEach(symKey => {
if (isObject(source[symKey])) {
target[symKey] = cloneDeep4(source[symKey], hash);
} else {
target[symKey] = source[symKey];
}
});
}
// =============
for(let key in source) {
if (Object.prototype.hasOwnProperty.call(source, key)) {
if (isObject(source[key])) {
target[key] = cloneDeep4(source[key], hash);
} else {
target[key] = source[key];
}
}
}
return target;
}测试下效果
// 木易杨
// 此处 a 是文章开始的测试用例
var sym1 = Symbol("a"); // 创建新的symbol类型
var sym2 = Symbol.for("b"); // 从全局的symbol注册?表设置和取得symbol
a[sym1] = "localSymbol";
a[sym2] = "globalSymbol";
var b = cloneDeep4(a);
console.log(b);
// {
// name: "muyiy",
// a1: undefined,
// a2: null,
// a3: 123,
// book: {title: "You Don't Know JS", price: "45"},
// circleRef: {name: "muyiy", book: {…}, a1: undefined, a2: null, a3: 123, …},
// [Symbol(a)]: 'localSymbol',
// [Symbol(b)]: 'globalSymbol'
// }完美!
// 木易杨
function cloneDeep4(source, hash = new WeakMap()) {
if (!isObject(source)) return source;
if (hash.has(source)) return hash.get(source);
let target = Array.isArray(source) ? [] : {};
hash.set(source, target);
Reflect.ownKeys(source).forEach(key => { // 改动
if (isObject(source[key])) {
target[key] = cloneDeep4(source[key], hash);
} else {
target[key] = source[key];
}
});
return target;
}
// 测试已通过这里使用了 Reflect.ownKeys() 获取所有的键值,同时包括 Symbol,对 source 遍历赋值即可。
写到这里已经差不多了,我们再延伸下,对于 target 换一种写法,改动如下。
// 木易杨
function cloneDeep4(source, hash = new WeakMap()) {
if (!isObject(source)) return source;
if (hash.has(source)) return hash.get(source);
let target = Array.isArray(source) ? [...source] : { ...source }; // 改动 1
hash.set(source, target);
Reflect.ownKeys(target).forEach(key => { // 改动 2
if (isObject(source[key])) {
target[key] = cloneDeep4(source[key], hash);
} else {
target[key] = source[key];
}
});
return target;
}
// 测试已通过在改动 1 中,返回一个新数组或者新对象,获取到源对象之后就可以如改动 2 所示传入 target 遍历赋值即可。
Reflect.ownKeys() 这种方式的问题在于不能深拷贝原型链上的数据,因为返回的是目标对象自身的属性键组成的数组。如果想深拷贝原型链上的数据怎么办,那用 for..in 就可以了。
我们再介绍下两个知识点,分别是构造字面量数组时使用展开语法和构造字面量对象时使用展开语法。(以下代码示例来源于 MDN)
这是 ES2015 (ES6) 才有的语法,可以通过字面量方式, 构造新数组,而不再需要组合使用 push, splice, concat 等方法。
var parts = ['shoulders', 'knees'];
var lyrics = ['head', ...parts, 'and', 'toes'];
// ["head", "shoulders", "knees", "and", "toes"]这里的使用方法和参数列表的展开有点类似。
function myFunction(v, w, x, y, z) { }
var args = [0, 1];
myFunction(-1, ...args, 2, ...[3]);返回的是新数组,对新数组修改之后不会影响到旧数组,类似于 arr.slice()。
var arr = [1, 2, 3];
var arr2 = [...arr]; // like arr.slice()
arr2.push(4);
// arr2 此时变成 [1, 2, 3, 4]
// arr 不受影响展开语法和 Object.assign() 行为一致, 执行的都是浅拷贝(即只遍历一层)。
var a = [[1], [2], [3]];
var b = [...a];
b.shift().shift(); // 1
// [[], [2], [3]]这里 a 是多层数组,b 只拷贝了第一层,对于第二层依旧和 a 持有同一个地址,所以对 b 的修改会影响到 a。
这是 ES2018 才有的语法,将已有对象的所有可枚举属性拷贝到新构造的对象中,类似于 Object.assign() 方法。
var obj1 = { foo: 'bar', x: 42 };
var obj2 = { foo: 'baz', y: 13 };
var clonedObj = { ...obj1 };
// { foo: "bar", x: 42 }
var mergedObj = { ...obj1, ...obj2 };
// { foo: "baz", x: 42, y: 13 }Object.assign() 函数会触发 setters,而展开语法不会。有时候不能替换或者模拟 Object.assign() 函数,因为会得到意想不到的结果,如下所示。
var obj1 = { foo: 'bar', x: 42 };
var obj2 = { foo: 'baz', y: 13 };
const merge = ( ...objects ) => ( { ...objects } );
var mergedObj = merge ( obj1, obj2);
// { 0: { foo: 'bar', x: 42 }, 1: { foo: 'baz', y: 13 } }
var mergedObj = merge ( {}, obj1, obj2);
// { 0: {}, 1: { foo: 'bar', x: 42 }, 2: { foo: 'baz', y: 13 } }这里实际上是将多个解构变为剩余参数( rest ),然后再将剩余参数展开为字面量对象.
上面四步使用的都是递归方法,但是有一个问题在于会爆栈,错误提示如下。
// RangeError: Maximum call stack size exceeded那应该如何解决呢?其实我们使用循环就可以了,代码如下。
function cloneDeep5(x) {
const root = {};
// 栈
const loopList = [
{
parent: root,
key: undefined,
data: x,
}
];
while(loopList.length) {
// 广度优先
const node = loopList.pop();
const parent = node.parent;
const key = node.key;
const data = node.data;
// 初始化赋值目标,key为undefined则拷贝到父元素,否则拷贝到子元素
let res = parent;
if (typeof key !== 'undefined') {
res = parent[key] = {};
}
for(let k in data) {
if (data.hasOwnProperty(k)) {
if (typeof data[k] === 'object') {
// 下一次循环
loopList.push({
parent: res,
key: k,
data: data[k],
});
} else {
res[k] = data[k];
}
}
}
}
return root;
}由于篇幅问题就不过多介绍了,详情请参考下面这篇文章。
如何用 JS 实现 JSON.parse?
进阶系列文章汇总如下,内有优质前端资料,觉得不错点个star。
我是木易杨,公众号「高级前端进阶」作者,跟着我每周重点攻克一个前端面试重难点。接下来让我带你走进高级前端的世界,在进阶的路上,共勉!
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.

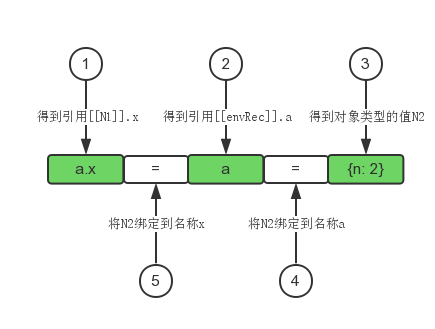







.png)