No Language is an Island: Unifying Chinese and English in Financial Large Language Models, Instruction Data, and Benchmarks
免责声明
本资料库及其内容仅用于学术和教育目的。所有资料均不构成金融、法律或投资建议。不对内容的准确性、完整性或实用性提供任何明示或暗示的保证。作者和撰稿人不对任何错误、遗漏或因使用本网站信息而产生的任何后果负责。用户在做出任何财务、法律或投资决定之前,应自行判断并咨询专业人士。使用本资料库所含软件和信息的风险完全由用户自行承担。
使用或访问本资源库中的信息,即表示您同意对作者、撰稿人以及任何附属组织或个人的任何及所有索赔或损害进行赔偿、为其辩护并使其免受损害。
📢 更新 (Date: 2024/03/12)
🐹 我们很高兴与大家分享我们的论文, "No Language is an Island: Unifying Chinese and English in Financial Large Language Models, Instruction Data, and Benchmarks".
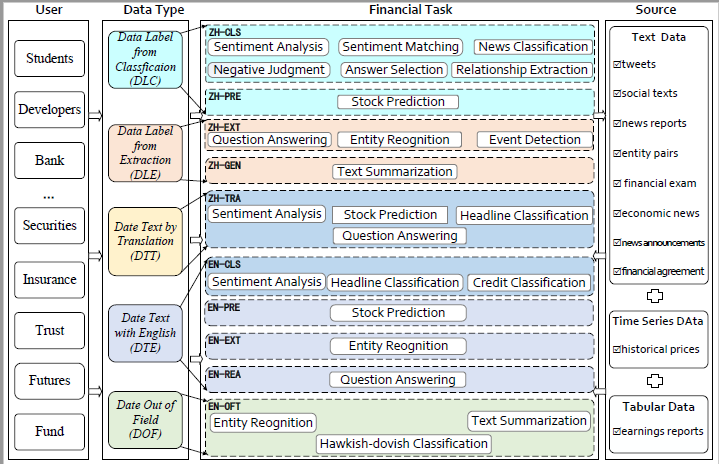
ICE-PIXIU 是我们推出的一个综合框架,包含首个跨语言双语金融指令数据集ICE-FIND、大语言模型 ICE-INTENT 和评估基准 ICE-FLARE。ICE-PIXIU 结合了各种中文分类、抽取、推理和预测的金融 NLP 任务,增强了训练和性能,从而弥补了中文金融 NLP 的不足。同时集成了一系列翻译和原始英文数据集,丰富了双语金融建模的广度和深度。它提供了对各种模型变体的不受限制的访问、大量不同的跨语言和多模式指令数据的汇编,以及带有专家注释的评估基准,包括 10 个 NLP 任务和 20 个双语特定任务。我们的全面评估强调了结合这些双语数据集的优势,尤其是在翻译任务和利用原始英语数据方面,从而提高了金融语境中的语言灵活性和分析敏锐性。
- 双语能力: ICE-INTENT 是 ICE-PIXIU 的一个组成部分,具有出色的中英双语能力,这对全球金融数据处理和分析至关重要。
- 多样化数据: ICE-PIXIU 结合了各种中文分类、提取、推理和预测 NLP 任务,加强了训练和性能,从而弥补了中文金融 NLP 的不足。
- 专家级提示: ICE-PIXIU 提供了一套多样化、高质量、经专家注释的提示,并采用了类似的微调说明,以增强对金融任务的理解。
- 多语言: ICE-PIXIU 通过纳入翻译任务和英语数据集来扩展其功能,从而加强其双语训练和应用。
- 跨语言评估: ICE-PIXIU 引入了 ICE-FLARE,这是一种严格的跨语言评估基准,可确保模型在不同语言环境中表现一致。
- 开放性: ICE-PIXIU 采用开放式访问方法,向研究社区提供资源,促进金融 NLP 的协同发展。
评测数据
我们所有的评测数据集合可以在这里找到。
数据集(Evaluation Test)
Sentiment Analysis(FinSA)
- ICE-FLARE (zh-FE)
- ICE-FLARE (zh-stockB)
- ICE-FLARE (zh-FPB)
- ICE-FLARE (zh-Fiqasa)
- ICE-FLARE (en-FPB)
- ICE-FLARE (en-Fiqasa)
Semantic Matching(FinSM)
News Classification(FinNS)
Negative Judgment(FinNJ)
Answer Selection(FinAS)
Relationship Extraction(FinRE)
Headline Classification(FinHC)
Credit Classification(FinCC)
Hawkish-dovish Classification(FinDC)
Event Detection(FinED)
Entity Recognition(FinER)
Question Answering(FinQA)
- ICE-FLARE (zh-QA)
- ICE-FLARE (zh-EnQA)
- ICE-FLARE (zh-ConvFinQa)
- ICE-FLARE (en-EnQA)
- ICE-FLARE (en-ConvFinQa)
Stock Prediction(FinSF)
- ICE-FLARE (zh-stockA)
- ICE-FLARE (zh-BigData)
- ICE-FLARE (zh-ACL)
- ICE-FLARE (zh-CIKM)
- ICE-FLARE (en-BigData)
- ICE-FLARE (en-ACL)
- ICE-FLARE (en-CIKM)
Text Summarization(FinTS)
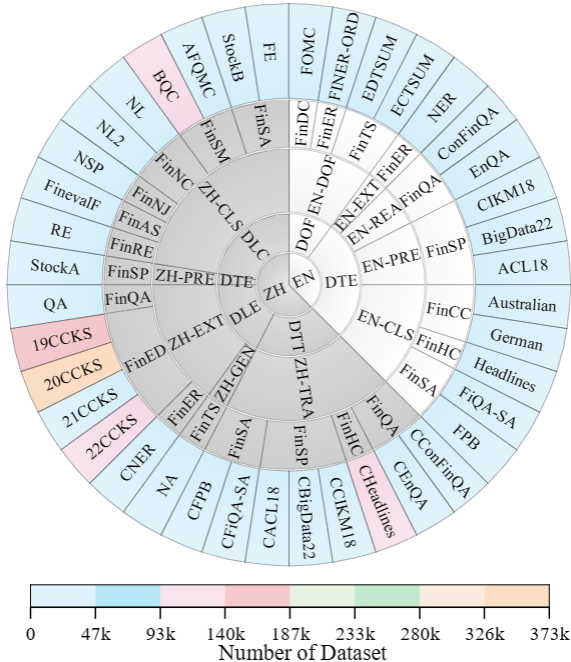
数据总表:中英文双语多任务金融教学和评估原始数据的详细信息包括语言能力(Lang)、数据类型(D_T)、NLP 任务(NLP_T)、特定任务(S_T)、数据集名称、指令数据大小、评估数据大小、数据源和许可证信息。
| Lang | D_T | NLP_T | S_T | Dataset | Raw | Instruction | Evaluation | Data Source | License |
| ZH | DLC | ZH-CLS | FinSA | FE | 18,177 | 18,177 | 2,020 | social texts | Public |
| StockB | 9,812 | 9,812 | 1,962 | social texts | Apache-2.0 | ||||
| FinSM | BQC | 120,000 | 110,000 | 10,000 | bank service logs | Public | |||
| AFQMC | 38,650 | 38,650 | 4,316 | online chat service | Apache-2.0 | ||||
| FinNC | NL | 7,955 | 7,955 | 884 | news articles | Public | |||
| NL2 | 7,955 | 7,955 | 884 | news articles | Public | ||||
| FinNJ | NSP | 4,499 | 4,499 | 500 | social texts | Public | |||
| FinAS | FinevalF | 1,115 | 1,115 | 222 | financial exam | Apache-2.0 | |||
| FinRE | RE | 14,973 | 14,973 | 1,489 | news, entity pairs | Public | |||
| ZH-PRE | FinSP | StockA | 14,769 | 14,769 | 1,477 | news, historical prices | Public | ||
| DLE | ZH-EXT | FinQA | QA | 22,375 | 22,375 | 2,469 | QA pairs of news | Public | |
| FinER | CNER | 1,685 | 1,685 | 337 | financial reports | Public | |||
| FinED | 19CCKS | 156,834 | 14,674 | 2,936 | social texts | CC BY-SA 4.0 | |||
| 20CCKS | 372,810 | 45,796 | 9,159 | news, reports | CC BY-SA 4.0 | ||||
| 21CCKS | 8,000 | 7,000 | 1,400 | news, reports | CC BY-SA 4.0 | ||||
| 22CCKS | 109,555 | 59,143 | 11,829 | news, reports | CC BY-SA 4.0 | ||||
| ZH-GEN | FinTS | NA | 32,400 | 32,400 | 3,600 | news, announcements | Public | ||
| DTT | ZH-TRA | FinSA | CFPB | 4,845 | 4,838 | 970 | economic news | MIT license | |
| CFiQA-SA | 1,173 | 1,143 | 233 | news headlines, tweets | MIT license | ||||
| FinSP | CACL | 27,056 | 2,555 | 511 | tweets, historical prices | MIT license | |||
| CBigdata | 7,167 | 798 | 159 | tweets, historical prices | MIT license | ||||
| CCIKM | 4,970 | 431 | 86 | tweets, historical prices | MIT license | ||||
| FinHC | CHeadlines | 102,708 | 10,256 | 2,051 | news headlines | MIT license | |||
| FinQA | CEnQA | 8,281 | 668 | 133 | earnings reports | MIT license | |||
| CConvFinQA | 12,594 | 1,189 | 237 | earnings reports | MIT license | ||||
| EN | DTE | EN-CLS | FinSA | FPB | 4,845 | 4,845 | 970 | economic news | CC BY-SA 3.0 |
| FiQA-SA | 1,173 | 1,173 | 235 | news headlines, tweets | Public | ||||
| FinHC | Headlines | 11,412 | 102,708 | 20,547 | news headlines | CC BY-SA 3.0 | |||
| FinCC | German | 1,000 | 1,000 | 200 | credit records | CC BY-SA 4.0 | |||
| Australian | 690 | 690 | 139 | credit records | CC BY-SA 4.0 | ||||
| EN-PRE | FinSP | ACL18 | 27,053 | 27,053 | 3,720 | tweets, historical prices | MIT License | ||
| BigData22 | 7,164 | 7,164 | 1,472 | tweets, historical prices | Public | ||||
| CIKM18 | 4,967 | 4,967 | 1,143 | tweets, historical prices | Public | ||||
| EN-EXT | FinER | NER | 609 | 609 | 98 | financial agreements | CC BY-SA-3.0 | ||
| EN-REA | FinQA | EnQA | 8,281 | 8,281 | 1,147 | earnings reports | MIT License | ||
| ConvFinQA | 3,458 | 12,594 | 1,490 | earnings reports | MIT License | ||||
| DOF | EN-DOF | FinER | Finer-Ord | 1,075 | - | 1,075 | news articles | CC BY-SA 4.0 | |
| FinTS | ECTSUM | 495 | - | 495 | earning call transcripts | Public | |||
| EDTSUM | 2,000 | - | 2,000 | news articles | Public | ||||
| FinDC | FOMC | 496 | - | 496 | FOMC transcripts | CC BY-SA 4.0 |
- ICE-INTERN-7B (包含所有DLC的指令数据微调模型)
- ICE-INTERN-7B (包含所有DCL+DLE的指令数据微调模型)
- ICE-INTERN-7B (包含所有DCL+DLE+DTT的数据微调模型)
- ICE-INTERN-7B (包含所有指令数据的微调模型)
在微调过程中,我们采用了QLoRA,这是一种高效的参数调整技术,使用统一的2048标记序列长度。微调过程使用了AdamW优化器,初始学习率为5e-5,权重衰减为1e-5,另外还进行了1%的总步数预热。所有模型在八块A100 40GB GPU上批量为24进行了一轮的微调,使用了一致的超参数设置。
为了与其他通用大模型(包括 Baichuan、ChatGPT、Qwen 等)和金融大模型进行对比分析,我们选择了一系列任务和指标,涵盖了金融自然语言处理和金融预测的各个方面。
| Data | Task | Raw | Data Types | Modalities | License | Paper |
|---|---|---|---|---|---|---|
| AFQMC | 语义匹配 | 38,650 | 提问数据, 对话 | 文本 | Apache-2.0 | [1] |
| corpus | 语义匹配 | 120,000 | 提问数据, 对话 | 文本 | Public | [2] |
| stockA | 股票分类 | 14,769 | 新闻, 历史价格 | 文本, 时间序列 | Public | [3] |
| Fineval | 多项选择 | 1,115 | 金融考试 | 文本 | Apache-2.0 | [4] |
| NL | 新闻分类 | 7,955 | 新闻报道 | 文本 | Public | [5] |
| NL2 | 新闻分类 | 7,955 | 新闻报道 | 文本 | Public | [5] |
| NSP | 负面新闻判断 | 4,499 | 新闻、社交媒体文本 | 文本 | Public | [5] |
| RE | 关系识别 | 14,973 | 新闻、实体对 | 文本 | Public | [5] |
| FE | 情感分析 | 18,177 | 金融社交媒体文本 | 文本 | Public | [5] |
| stockB | 情感分析 | 9,812 | 金融社交媒体文本 | 文本 | Apache-2.0 | [6] |
| QA | 金融问答 | 22,375 | 财经新闻公告 | 文本, 表格 | Public | [5] |
| NA | 文本摘要 | 32,400 | 新闻文章、公告 | 文本 | Public | [5] |
| 19CCKS | 事件主体提取 | 156,834 | 新闻报道 | 文本 | CC BY-SA 4.0 | [7] |
| 20CCKS | 事件主体提取 | 372,810 | 新闻报道 | 文本 | CC BY-SA 4.0 | [8] |
| 21CCKS | 事件因果关系抽取 | 8,000 | 新闻报道 | 文本 | CC BY-SA 4.0 | [9] |
| 22CCKS | 事件主体提取 | 109,555 | 新闻报道 | 文本 | CC BY-SA 4.0 | [10] |
| CNER | 命名实体识别 | 1,685 | 新闻报道 | 文本 | Public | [11] |
| CFPB | 情感分析 | 4,845 | 新闻 | 文本 | MIT license | [12] |
| CFIQASA | 情感分析 | 1,173 | 新闻头条、推文 | 文本 | MIT license | [12] |
| CHeadlines | 新闻标题分类 | 11,412 | 新闻头条 | 文本 | MIT license | [12] |
| CBigData | 股票走势预测 | 7,164 | 推文、历史价格 | 文本, 时间序列 | MIT license | [12] |
| CACL | 股票走势预测 | 27,053 | 推文、历史价格 | 文本, 时间序列 | MIT license | [12] |
| CCIKM | 股票走势预测 | 4,967 | 推文、历史价格 | 文本, 时间序列 | MIT license | [12] |
| CFinQA | 金融问答 | 14,900 | 收益报告 | 文本, 表格 | MIT license | [12] |
| CConvFinQA | 多轮问答 | 48,364 | 收益报告 | 文本, 表格 | MIT license | [12] |
- Xu L, Hu H, Zhang X, et al. CLUE: A Chinese language understanding evaluation benchmark[J]. arXiv preprint arXiv:2004.05986, 2020.
- Jing Chen, Qingcai Chen, Xin Liu, Haijun Yang, Daohe Lu, and Buzhou Tang. 2018. The BQ Corpus: A Large-scale Domain-specific Chinese Corpus For Sentence Semantic Equivalence Identification. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 4946–4951, Brussels, Belgium. Association for Computational Linguistics.
- Jinan Zou, Haiyao Cao, Lingqiao Liu, Yuhao Lin, Ehsan Abbasnejad, and Javen Qinfeng Shi. 2022. Astock: A New Dataset and Automated Stock Trading based on Stock-specific News Analyzing Model. In Proceedings of the Fourth Workshop on Financial Technology and Natural Language Processing (FinNLP), pages 178–186, Abu Dhabi, United Arab Emirates (Hybrid). Association for Computational Linguistics.
- Zhang L, Cai W, Liu Z, et al. FinEval: A Chinese Financial Domain Knowledge Evaluation Benchmark for Large Language Models[J]. arxiv preprint arxiv:2308.09975, 2023.
- Lu D, Liang J, Xu Y, et al. BBT-Fin: Comprehensive Construction of Chinese Financial Domain Pre-trained Language Model, Corpus and Benchmark[J]. arxiv preprint arxiv:2302.09432, 2023.
- https://huggingface.co/datasets/kuroneko5943/stock11
- https://www.biendata.xyz/competition/ccks_2019_4/
- https://www.biendata.xyz/competition/ccks_2020_4_1/
- https://www.biendata.xyz/competition/ccks_2021_task6_2/
- https://www.biendata.xyz/competition/ccks2022_eventext/
- Jia C, Shi Y, Yang Q, et al. Entity enhanced BERT pre-training for Chinese NER[C]//Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020: 6384-6396.
- Xie Q, Han W, Zhang X, et al. PIXIU: A Large Language Model, Instruction Data and Evaluation Benchmark for Finance[J]. arXiv preprint arXiv:2306.05443, 2023.
git clone https://github.com/chancefocus/PIXIU.git --recursive
cd PIXIU
pip install -r requirements.txt
cd PIXIU/src/financial-evaluation
pip install -e .[multilingual]sudo bash scripts/docker_run.sh以上命令会启动一个 docker 容器,你可以根据自己的环境修改 docker_run.sh。我们通过运行 sudo docker pull tothemoon/pixiu:latest 来提供预编译镜像。
docker run --gpus all --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 \
--network host \
--env https_proxy=$https_proxy \
--env http_proxy=$http_proxy \
--env all_proxy=$all_proxy \
--env HF_HOME=$hf_home \
-it [--rm] \
--name pixiu \
-v $pixiu_path:$pixiu_path \
-v $hf_home:$hf_home \
-v $ssh_pub_key:/root/.ssh/authorized_keys \
-w $workdir \
$docker_user/pixiu:$tag \
[--sshd_port 2201 --cmd "echo 'Hello, world!' && /bin/bash"]参数说明:
[]表示可忽略的参数HF_HOME: huggingface 缓存目录sshd_port: 容器的 sshd 端口,可以运行ssh -i private_key -p $sshd_port root@$ip来连接容器,默认为 22001--rm: 退出容器时移除容器(即CTRL + D)
在评估前, 请下载 punto de control BART 到 src/metrics/BARTScore/bart_score.pth.
如需进行自动评估,请按照以下说明操作:
- Transformador Huggingface
要评估 HuggingFace Hub 上托管的模型(例如,ICE-INTERN-Full-7B),请使用此命令:
python eval.py \
--model "hf-causal-llama" \
--model_args "use_accelerate=True,pretrained=chancefocus/finma-7b-full,tokenizer=chancefocus/finma-7b-full,use_fast=False" \
--tasks "flare_ner,flare_sm_acl,flare_fpb"更多详情,请参阅 lm_eval 文档。
- 商用接口
请注意,对于 NER 等任务,自动评估是基于特定模式进行的。这可能无法提取零镜头设置中的相关信息,导致性能相对低于之前的人工标注结果。
export OPENAI_API_SECRET_KEY=YOUR_KEY_HERE
python eval.py \
--model gpt-4 \
--tasks flare_zh_fe,flare_cner,flare_sm_acl3.自托管评估
要运行推理后端,请执行以下操作:
bash scripts/run_interface.sh注意,请根据您的环境要求调整run_interface.sh。
| Task | Metric | Illustration |
|---|---|---|
| 分类 | Accuracy | 该指标表示正确预测的观测数据与总观测数据的比率。计算公式为(正确预测结果 + 错误预测结果)/总观测数据 |
| 分类 | F1 Score | F1 分数代表精确度和召回率的调和平均值,从而在这两个因素之间达成平衡。事实证明,在一个因素比另一个因素更重要的情况下,它特别有用。分数范围从 0 到 1,1 表示精确度和召回率均为满分,0 表示最差情况。此外,我们还提供了 F1 分数的 "加权 "和 "宏观 "版本。 |
| 分类 | Missing Ratio | 此指标计算任务中给定选项中未返回任何选项的响应比例。 |
| 分类 | Matthews Correlation Coefficient (MCC) | MCC 是一种评估二元分类质量的指标,其得分范围从 -1 到 +1 不等。得分 +1 表示完美预测,0 表示预测结果不优于随机概率,-1 表示预测结果完全相反。 |
| 序列标记 | F1 score | 在 "顺序标签 "任务中,我们使用了由 "seqeval "库计算的 F1 分数,这是一个强大的实体级评估指标。该指标要求预测实体和地面实况实体之间的实体跨度和类型完全匹配,以获得正确的评价。真阳性(TP)表示预测正确的实体,假阳性(FP)表示预测错误的实体或跨度/类型不匹配的实体,假阴性(FN)表示从地面实况中遗漏的实体。然后利用这些数量计算精确度、召回率和 F1 分数,其中 F1 分数代表精确度和召回率的调和平均值。 |
| 序列标记 | Label F1 score | 该指标仅根据预测标签的正确性来评估模型性能,而不考虑实体跨度。 |
| 关系抽取 | Precision | 精度衡量正确预测的关系在所有预测关系中的比例。它的计算方法是真阳性 (TP) 数除以真阳性和假阳性 (FP) 的总和。 |
| 关系抽取 | Recall | 召回率衡量的是在所有实际关系中正确预测关系的比例。它的计算方法是真阳性(TP)的数量除以真阳性和假阴性(FN)的总和。 |
| 关系抽取 | F1 score | F1 分数是精确度和召回率的调和平均值,它能在这两个指标之间取得平衡。F1 分数在 1(精确度和召回率均为满分)时最佳,在 0 时最差。 |
| 提取和抽象总结 | Rouge-L | 该指标评估系统与参考摘要之间的最长共同子序列(LCS)。LCS 自然考虑到了句子级结构的相似性,并自动识别最长的共现同序 n-gram。 |
| 提取和抽象总结 | Rouge-N | 它测量的是系统生成的摘要与参考摘要之间 N 个词组(给定文本样本中 N 个项目的连续序列)的重叠度。N "可以是 1、2 或更多,ROUGE-1 和 ROUGE-2 通常分别用于评估单语法重叠和大语法重叠。 |
| 问答 | EmACC | EMACC 对模型生成的答案与参考答案之间的精确匹配进行评估。换句话说,只有当模型生成的答案与参考答案一字不差地完全匹配时,模型生成的答案才被认为是正确的。 |
在问题解答(FinQA)、文本摘要(FinTS)、关系提取(FinRE)、事件检测(FinED)、实体识别(FinER)和新闻分类(FinNC)等特定金融任务中,各种 LLM 的输入和响应示例。
| Task | Query | Baichuan-7B | GPT-4 | ICE-INTERN-full-7B |
|---|---|---|---|---|
| FinQA | 浦东建设公告,公司子公司上海市浦东新区建设(集团)有限公司、上海浦兴路桥建设工程有限公司中标多项重大工程项目,中标金额总计为10.94亿元。请问中标事件对应的主体有哪些? | 浦东建设、浦兴路桥、浦东建设(集团) | 中标事件对应的主体有上海市浦东新区建设(集团)有限公司 | 上海市浦东新区建设(集团)有限公司,上海浦兴路桥建设工程有限公司 |
| FinTS | 市场普遍预期日本央行将维持其超宽松货币政策不变,但知情人士表示,周二将公布的经济展望报告中,可能上调4月起财政年度的通胀预估。能源和原材料成本的上涨已将批发价格推高至40年来的最高水平,企业已开始将上涨的成本转嫁给消费者。近期通胀温和上升,主要是投入成本上升和日元疲软推动的,而不是强劲的国内需求。日本央行行长黑田东彦曾表示,物价上涨应该伴随着工资的强劲增长。请对上述金融报道进行总结,给出具有中心主旨的摘要,回答要求尽量简短。 | 日本央行行长黑田东彦曾表示,物价上涨应该伴随着工资的强劲增长。 | 日本央行预计将上调4月起的通胀预估,尽管市场普遍预期货币政策将保持超宽松。成本上涨推高批发价格,企业已将涨成本转嫁给消费者,但通胀主要由投入成本上升和日元疲软推动,而非国内需求强劲。 | 知情人士:日本央行可能上调4月起财政年度的通胀预估。 |
| FinRE | 新希望集团销售额约为上市公司倍有余,由于背靠农业帝国“希望系”, 资本市场一直预期集团能够向新希望股份注入农业资产, 如果集团资产整合启动, 新希望股份的股。请分析上述涉及实体对(新希望股份,新希望集团)的关系。 | 被收购 | 被注资 | 自己 |
| FinED | 大智慧(601519)信披违规遭调查“互联网+”炒作或终结金鹰等多家基金公司高管离职 基民担忧业绩波动。请分析上述金融报道中的事件类型及及其事件主体,并以‘事件类型,事件主体’的格式输出。 | 套现约1.5亿元 | 交易违规, 大智慧 | 信批违规, 大智慧 |
| FinER | 本公司非执行董事孙月英女士不再担任**远洋海运集团有限公司总会计师和中远财务有限责任公司董事长。请给出上述金融报道中存在的个人(’PER’)、组 织(’ORG’)或地点(’LOC’)的特定命 名实体,回答应遵循的格式’实体名称, 实体类型’。 | **远洋海运集团有限公司,ORG | 中远海运发展股份有限公司, ORG | 孙月英, PER;**远洋海运集团有限公司, ORG;中远财务有限责任公司, ORG |
| FinNC | WTI原油涨幅回升至0.5%,现报75.58美元/桶。请对该金融报道进行分类,具体属于['**','外国','国际','公司','行业','大盘','经济','政策','政治','期货','债券','房地产','外汇','虚拟货币','新冠','能源']中的哪些类别? | 国际,能源 | 国际期货 |
如果您在项目中使用了ICE-PIXIU,请引用我们的文章。
ICE-PIXIU 采用 [MIT] 许可。有关详细信息,请参阅 MIT 文件。















