yleo77 / notes Goto Github PK
View Code? Open in Web Editor NEWSomething about programming
License: MIT License
Something about programming
License: MIT License



















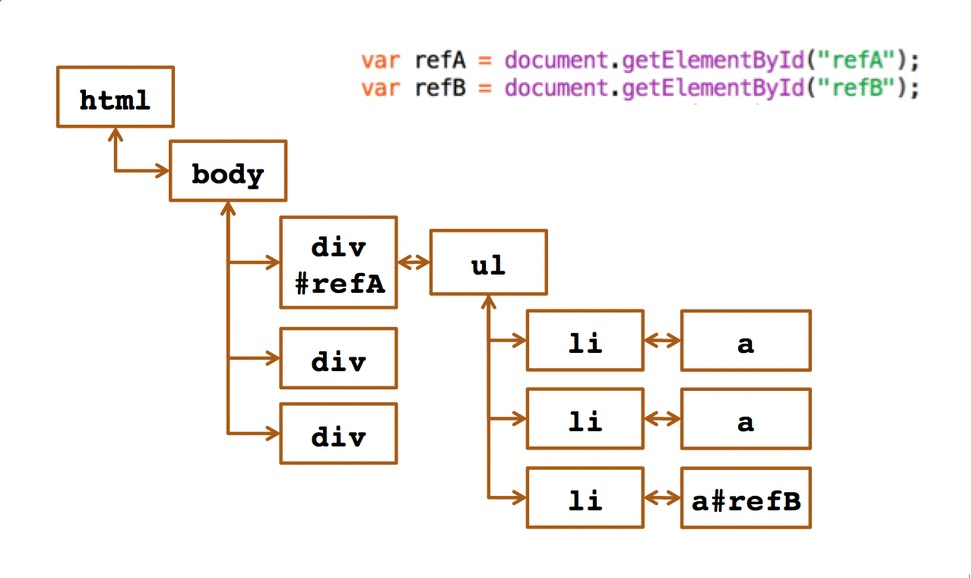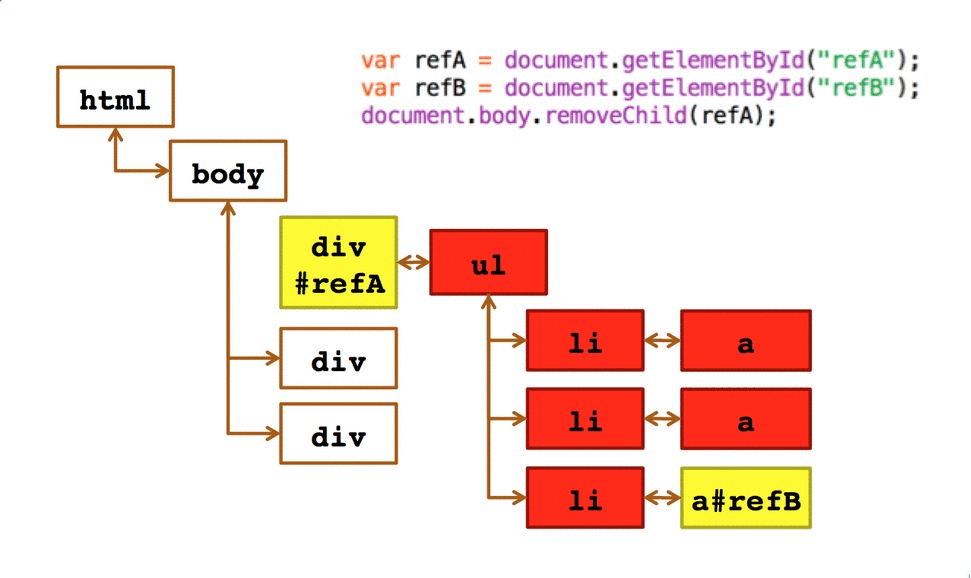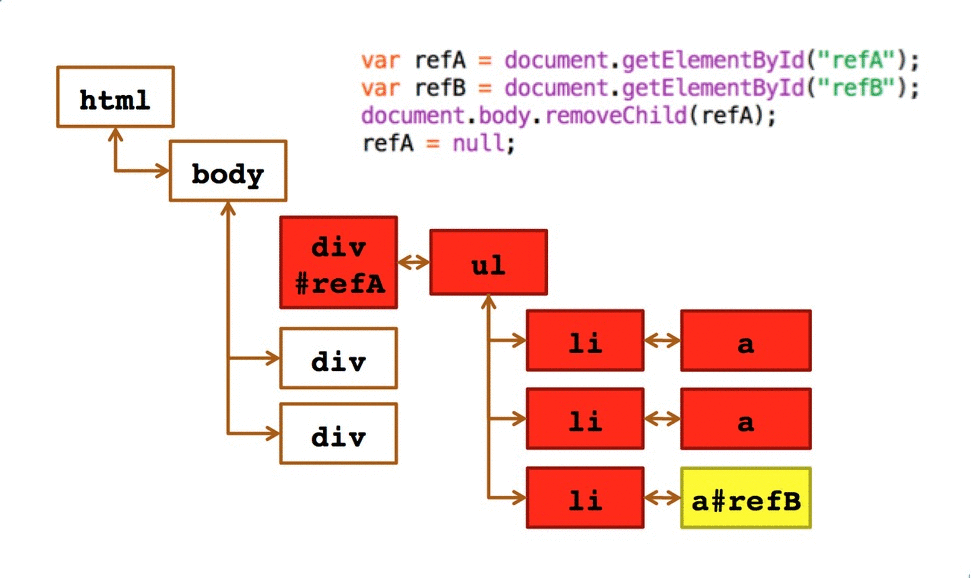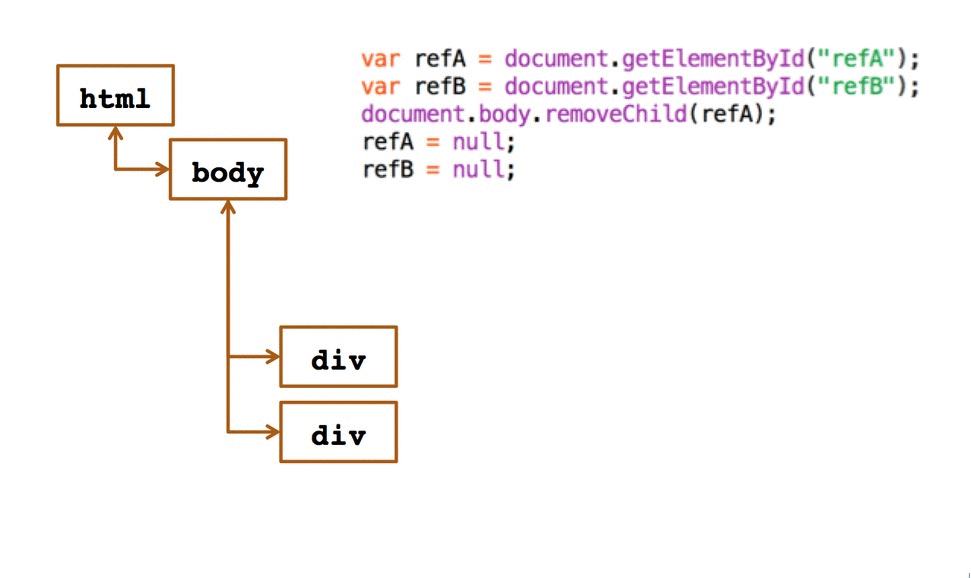
这篇文章是 2013 年在搜狐视频时为分享的一个 Topic 写的,主要从两个场景:获取跨域服务器相关资源和纯客户端页面和页面之间的跨域信息获取 以及在这两个场景下都有哪些技术方案可以选择。
因为 2014 年底和近期又遇到过两次和跨域有关的 Case,而且还是同一个, 所以就把这个 Case 当做一个知识点补充进来。
不存在完美的方案,只有适合特定场景的方案。
简单说就是因为 javascript 的同源策略限制,当域名不同时,安全考虑则禁止了彼此间的一个通信。
协议不同,端口不同,子域不同,都会造成跨域
前端交互开发中,往往需要往不同于当前域名的后端服务器获取/提交一些数据,或者是不同 window 之间的一个通信,但因为同源限制,导致 javascript 开发者不得不采取一些措施去解决这一技术问题,以下分别就这两个场景做一些技术总结。
因为 DOM 中可以插入第三方 javascript 文件并执行,所以利用这一特性,服务器在返回的数据上 wrap 一层函数名,以 javascript 函数调用的形式返回给客户端。
优点:
缺点:
需要注意的一个地方,其本质是通过往 head 里插入一个 script 节点,来让外域的 js 执行达到跨域这样一个目的,所以如果是一个频繁来获取数据的情况下,需要再该 js 节点执行完之后,移除该节点。
移除该节点的同时,其占用的内存事实上没有释放的,还需要删除一下该节点上的属性。一个最佳实践是最好创建一个 script 节点,然后去一次次改变它的 src 属性。via
另外,再移除节点的时候,需要注意 head 里是否有 base 节点的情况,如果存在 base 节点 并且是自闭合的写法的话,最好把 script 插在 head.firstChild 位置,或者移除节点的时候通过 script.parentNode.removeChild(script) 来完成,否则 IE6 会报错。 via
前端代码不做修改,还是以 ajax 形式从同域服务器获取数据,后端同学从 server 端去获取数据,然后返回给前端标准的 JSON 数据,这个情况是没有域这个概念。
优点:
缺点:
举个栗子
Nginx
location /cross_domain_api/ {
proxy_pass http://other.domain.com
}
Apache
# 加载 依赖的模块
LoadModule proxy_module modules/mod_proxy.so
LoadModule proxy_http_module modules/mod_proxy_http.so
# 配置
ProxyRequests Off
ProxyPass /cross_domain_api http://other.domain.com
生产环境的话,就需要根据各种不同的情况来进行配置,同时增加一些 header 的配置。
优点:
缺点:
HTML5 新增的特性,只要被请求的目标服务器配置 header
Access-Control-Allow-Origin: *
就可以了。这个的值写法比较奇葩,必须写 HTTP,还不支持通配符。
优点:
缺点
2015-04-26 更新
如果在一个不需要支持低版本浏览器的环境下,这个方案目前来看非常完善,但是有一个关于缓存的很重要的问题,需要注意:
问题现状是这样,在客户端缓存了一个需要跨域获取的资源时,因为第一次加载需要和服务器交互,服务器返回了跨域头,一切都正常,符合预期。但是在该资源未过期的前提下,当用户通过敲回车的形式加载页面再次请求该文件时,客户端不会向服务器发请求,直接返回200(from cache)的信息,但又因为该资源是需要跨域头的,现在本地的缓存是没有这个头,所以会直接报出跨域错误的信息。这个一定要注意。(文章开头提到的两个 Case 发生的原因就是这个,一个case 是因为用 Ajax 来获取的 js 资源,结果缓存后再通过 Ajax 获取发现是大量的 status 0,跨域错误的,导致页面出不来;另一个是 ajax 获取数据。)
补充的一点,ie虽说不支持标准,但勉为其难得ie8, 9支持 XDomainRequest 对象,权且当做对开发者的一点安慰吧。link
var xdr = new XDomainRequest();
xdr.open('get', 'url');
xdr.onload = function(){}
xdr.send();最后再补充一个小点,关于客户端在获取一个跨域资源时是否会和服务器端进行一次交互的问题,答案是会。客户端当识别这是个跨域资源时,会验证服务器的Response Header 中是否有关于跨域头的设置,如果没有就抛出跨域错误,如果有则资源正常加载。
从域名的角度来分两种情况, 跨子域,跨主域。
从使用场景来分,父窗口和子 iframe 之间的通信,以及 tab 和 tab 之间的通信。tab 和 tab 之间的通信有一个前置条件为 其中一个 tab 必须由前一个 tab 打开,也就是依赖一个句柄引用。
关于 iframe location 的读写限制,与导航相关属性的操作限制如下:
那关于 iframe 想读父窗口的 location.href 怎么办
top.location.href 来读在两个需要通信的页面上设置
document.domain = 'sohu.com'优点
缺点, 太多了
结论:先知其弊而避之;再知其弊而用之。
背景是这样:父页面 parent.com/p.html 和子页面 child.com/c.html 通信,c.html 需要向 p.html 传递数据。
思路: 此时需要在子页面中添加一个和 p.html 同域的 iframe 代理页面 meditor.html,数据通过该代理 iframe 的 location hash 进行传递。
优点
缺点
对于数据量比较大的情况,可以通过建立多个 iframe 来进行传递,举个栗子,c.html要传递 abcdef 长度为6的字符串,假设浏览器每次对 iframe 携带数据长度限制为2,怎么办呢?既要保证数据没有遗漏,又要保证在数据被拆分后,又能按照原始位置进行拼接完好?
也就是说 每个 iframe 都需要携带三部分数据: 1. 数据总长度; 2. 当前数据片要插入的位置;3. 数据分片.
所以,分解后的数据传递应该是这个样子
<iframe src="parent.com/meditor.html#3_0_ab"></iframe>
<iframe src="parent.com/meditor.html#3_1_cd"></iframe>
<iframe src="parent.com/meditor.html#3_2_ef"></iframe>之后装载数据便可。
// 2014-04-26 修改
// 一次组装
var ret = [];
var index = 0;
var data = location.hash.slice(1).splice('_');
ret[data[1]] = data[2];
index++;
// 当 ret 长度等于 data[0]时组装完成
if(index == data[0]){
// callback
}当对一个页面设置 window.name 后,即使改变该页面 url,window.name 也不会被重写。所以借助这一特点,可以实现跨域的数据传递。
// 2014-04-26 更新
关于 window.name 的一点补充
改写顶层页面 window.name 值后,通过改变页面 url,对于后续页面
另外一种情况,当设置子 iframe 中 window.name,当改变 iframe 的 location 后
window.name 不会因为改变页面 url (包括域不同)而恢复为初始值。当然了,如果父窗口想读取该值,那需要子 iframe 和父为同源。
这里,便是借助第二种情况这个特点,来实现跨域的数据传递。
背景没变,父页面parent.com/p.html和子页面child.com/c.html通信,c.html 需要向p.html传递数据。
原理大概是这样:在 c.html 中设置window.name的值 ,值为需要传递给 p.html的数据。设置完毕,p.html 重写 iframe.src, 使新的 src 指向和 p.html 为同一个域名的一个空白代理页, 当 iframe 加载完毕,读取该 iframe.contentWindow.name (这个时候已经是同域了).
优点
HTML5 新增的一个技术,IE 的支持情况呢 IE 分两个阶段 IE8+ 和 IE10+ 来讲。
No such interface supported对于第一点的不足,这里 其实也是给出了一些实现上的方法
另外说说 firefox
需要在网站根目录或相关目录下放置一个 crossdomain.xml 文件
<cross-domain-policy>
<!-- domain 是域名, secure 是是否加密访问 -->
<allow-access-from domain="*.sohu.com" secure="false" />
</cross-domain-policy>具体配置可以在网上搜搜
优点:
缺点:
两种情况
如果并不很在意跨域 post 提交结果的返回值,(比如,在能保证网络链接正常和程序无 bug的情况下,post 提交都会返回一个正常值。) 这个情况可以简单用 setTimeout 来搞
如果 post 提交会出现很多种情况,这种情况下,需要借助服务器端的跳转来完成。大致可以这样去解决:增加中转页面a.com/meditor.html, a.com 的页面提交数据通过 iframe 提交至 b.com 服务端后,服务端处理完后通过跳转到 a.com/meditor.html 并在中转页面的 location.hash 上附带服务器端处理结果,此时中转页就可以通过调用 parent 的函数来完成业务逻辑。
对 img 标签来说,增加了该属性,可以允许其他地方使用该图片,这样描述不太准确,想象一下 canvas.drawImage 可以根据一个图片来绘制,就是这个。当为第三方域的图片时,如果不加该属性,虽然说可以 drawImage 出来,但是当后续想访问该 canvas 的一些 function 时,例如我调用 toDataURL, toBlob, getImageData, 就会抛出一个SecurityError的异常
Uncaught SecurityError: Failed to execute 'toDataURL' on 'HTMLCanvasElement': Tainted canvases may not be exported
也是为了避免未经授权的图片信息不正当使用。
对于 script 标签来说,添加该属性后,可以将该脚本的一些信息暴露出来,比如 onerror 事件, 捕捉该事件时,同域的话,可以拿到相关信息,比如 message,line,type, 但跨域默认是拿不到的,只会抛出一个 Script error.
解决办法: 加了这个属性就可以拿到了。 当然了,需要搭配服务器返回 Access-Control-Allow-Origin: * 的 header
老版本的 firefox 中,当判断跨域的 css 文件是否加载完成用到的一个 error 事件,原理是当 css 加载完成并尝试访问node.sheet.cssRules时,会抛出NS_ERROR_DOM_SECURITY_ERR的这么一个 error,基于此便可以确定该不同域的 css 是否加载完成.
数十年以前, Sun 公司为了推广 Java 相关技术, 提出了一句 Slogon:
但是被 Web & Native 开发人员熟知却是在近年, 源于移动开发的兴起. Javascript 作为运行于浏览器端天然具有跨平台能力的语言, 自然被推到了前沿, 坊间一时兴起 Native 程序借助于 Webview 的形式完成 APP 的主要业务逻辑, 也就是上面那句 slogon 的那句含义了, coding 一次, 多端运行, 这期间也诞生了很多非常不错的工具库, 例如 cordova.
开发是省事了, 但用户体验实在是无法保证, 尤其是在五六年之前.
Learn once, write anywhere
这是 React Native 自诞生一来, 一直没变的 slogon. Facebook 重新出发, 和上面稍有区别, 没有变的是 Javascript, 变的是结合了实际情况(大多数情况是指 iOS 及 Android 俩个平台的差异), 在 React 基础上, 打造出 React Native, 利用 Javascript 来完成核心业务逻辑, 依赖于 React 和实际渲染层的解耦做到了利用 Native 来完成 UI 层绘制这一特性, 一定程度上保证了开发效率, 又兼顾了用户体验.
本文包含两部分:
本文适合以下人看
本文 不 包括以下话题:
对于前端开发人员来说, 可能对于 div 这个标签再熟悉不过了. 借助于 React 这个框架, 我们可以像写 HTML 标签 以及他们的嵌套一样使用已经写好的组件, 这一点也类似于 Vue. 在 React Native 中, 也有非常非常基础的一个 tag 就是 view (更准确得说这些都应该叫做UI 层组件, 这里为了和非常熟悉的知识建立链接, 先理解为 tag)
在普通的网页中, 我们可以通过 div 结合一些其他常用标签, 搭建出一个页面. 作为 React Native 的开始, 我们看看在 React Native 中怎么用这些 tag 搭建一个 Native 页面.
FYI, 和 WEB 稍有不同的是, 在 React Native 中想要显示文字片段, 必须用 Text 包裹, 这点需要注意.
OK, 先来看看环境配置相关.
环境配置分为两部分. iOS 的配置 和 Android的配置.
iOS 的配置延续了苹果家的一贯风格, 如果装好了 xcode 的话, 理论上不需要做任何配置.
Android 的配置较为麻烦些, 包括 模拟器的安装和 Android SDK 的安装配置.
Android SDK 的安装是通过在 Android Studio 中完成的, 安装完之后需要配置 SDK 的相关环境变量. 虚拟机推荐使用 Genymotion, 无它, 简单易用, 安装好之后只需要修改下 ADB 的路径.
关于 Android 更详细的配置, 可以查看官方文档: Getting Started
和开发网页较为类似, 需要熟知一些常用的 tag (先这么理解). 除了上面提到的 View, Text, 还有 Image, Button, 这几个对 Web 开发人员来说就再熟悉不过了. 再增加一个: StyleSheet, ScrollView.
最后这俩个标签如其名, 也都能猜到它们的作用, 一个是为了控制页面样式, 一个是创建了一个有滚动区域的视图, 这俩点 稍有不同于网页, 当内容多余既定宽高时可以自动出现滚动条.
# 安装 create-react-native-app
npm install -g create-react-native-app
# 创建项目
create-react-native-app react-native-simple-example
# 少不了的安装依赖
cd react-native-simple-example && npm i
# 依赖安装完毕后, 启动项目
npm start# 在开始前, 不妨将示例 git 库检出到本地, 该库包含了示例文件.
git clone https://github.com/jd-smart-fe/react-native-simple-example.git 根据提示, 按 i 在 iOS 模拟器中预览. 这个过程如果不出意外是自动的. 工具包会自动在 iOS 模拟器中安装Expo Client APP, 安装完毕后便可以预览我们的 APP 了. 接下来做一些较简单的修改.
打开 App.js, 将文件内容修改为和这个文件保持一致. 如果不出意外, 当保存文件时, iOS 模拟器会 自动刷新, 这是我们使用 React Native 的带来的一大好处, 免去了编译的麻烦. 当然了, 对前端工程师来说可能觉得这没什么, 但对于 Native 工程师来说可就完全不是这样了.
第一步的完成效果如下图所示, 用到了几个非常非常基础的标签, 同时点击 Enter Button 会在控制台打出 Clicked 类似的日志输出.

这一步完成后的代码示例: react-native-simple-example:v1.0.0
接下来, 为这个简单的页面增加类似 Native APP 常见的场景跳转功能. 这一步, 稍微麻烦一些, 因为我们调整了目录结构使之更合理化, 引入了新的包 react-navigation 来完成这一功能, 最终的源码文件可以通过这里看到. 也可以借助 git diff v2.0.0 v1.0.0 来查看本次的修改.
看 List.js 源码文件也会发现, 我们使用了一个变量存储了想要显示在 ui 中的数据. 在真实的世界中, 数据往往都会来源于服务器端, 而不是客户端, 在下面这一步我们就给这个 APP 增加 网络请求 这个功能.
这一步完成后的代码示例: react-native-simple-example:v2.0.0
完成后的代码可以通过这里看到, 得益于 React Native 的良好封装, Web 开发者不用再学习新的 API 就可以搞定. 代码中我们通过调用前端开发人员非常熟悉的 fetch API 来完成. 当然如果想使用 XMLHttpRequest 也 OK, 甚至于如果想使用更抽象的上层封装例如 axios 也没有任何问题. 此外, 这一步骤用到了新的模块 ActivityIndicator 来展示数据加载过程中的 Loading 状态.
这一步完成后的代码示例: react-native-simple-example:v3.0.0
再怎么强调 如何调试 的重要性都不为过. 就我自己的实际经验来看, 绝大多数人都将性能看的太过于重要, 总是经常提起这个这个影响性能, 那个提高性能等等, 反而忽视了如何调试应用程序的重要性.
打开菜单的快捷键, 必须熟知. iOS 为 CMD-D, Android 为 CMD-M.
按上面提到的菜单快捷键, 可以看到菜单中提供了一些较为常见的调试功能, 好奇哪个点哪个.
例如选择 Debug Remote JS 菜单项可以打开一个 Chrome Tab, 打开该 tab 的控制台可以看到一些它的基本信息, 包括应用的 log 输出, 网络请求等, 注意 Element Inspect 可不是在这里查看.
先看怎么查看这些最基本的 tag.
用 React 开发过网页的同学应该都知道 React Developer Tools 对开发调试的重要性, 这是一款 Chrome 插件, 能够查看网页组件树的层级结构, 每个组件持有的状态以及从上层传递过来的 props, 也包括了一些小 trick, 例如在插件提供的组件树面板(类似Chrome Devtool 的 Elements 面板), 当选中一个组件时, 此时在控制台按 $r 可以快速访问到该实例.
在 React Native 中同样有办法做到. 首先需要安装 react-devtools , 这是一个标准的 npm 包. npm install -g react-devtools 就可以了. 它提供了和上述 chrome 插件近乎一样的功能. 因为 chrome 插件只能运行在 chrome 浏览器中, 而该工具可不受这样的限制, 所以它的适用面就更光一些了, 比如移动端浏览器, webview 等.
使用方法呢, 安装好了, 直接命令行运行即可, 一般情况下会自动连接到所要调试的 React APP. 二般情况下呢, 根据提示在所要调试的页面中插入一段 js 代码即可.
效果如下:

默认情况下, 上面提到的Chrome 控制台中网络请求面板是看不到代码中发起的网络请求的. 但在开发过程中, 抓包查看 HTTP 返回的数据是经常需要做的事情, 这一点可以通过修改代码来满足这一调试需求.
// 将以下代码添加到程序入口处, 引入 react native 之后的地方
GLOBAL.XMLHttpRequest = GLOBAL.originalXMLHttpRequest || GLOBAL.XMLHttpRequest;效果如下:

补充, 做这样的设置之后, 可能需要在某些情况下, 服务器需要做 CORS 的配置, 如图中划线所示.
延伸讨论: Show network requests such as fetch, WebSocket etc. in chrome dev tools
待补充吧
以上通过一个简单例子, 来说明了如何开始使用 React Native 开发一款 APP, 涉及到了
距离最基本的一个 APP 还差很远, 例如 动画, 异步存储, 手势操作 等等等等, 也还差最后的一个闭环: 发布到应用商店, 后续把这部分加入进来.
首先回答为什么要有这一部分内容. 因为这篇文章的主旨是快速实际上手 React Native, 所以用到了create-react-native-app. 它和 create-react-app 的定位极其类似, 提供了最方便的方式来使我们快速启动一个 React Native 项目, 而不用关心它的配置, 当你不依赖 Native 自定义模块时甚至都不需要 xcode 或者 Android Studio.
create-react-native-app 某些功能依赖于 Expo, 所以这里也对 Expo 做一个简单的介绍.
Expo 是一个开发工具集合, 它囊括了开发原生 APP 过程中需要的 Tools, Library, Services.
用一句话概括,就是使用 Expo, 能让 开始开发 App 这一路径变得更短一些. 同时, 也可以利用 Expo 来 build 出可以直接发布到 Apple Store 或者 Google Play 商店的应用(不过有一定的限制).
Expo 之于 React-Native 就像 Rails 之于 Ruby, Sails 之于 Node. 能够让你快速着眼于业务开发.
具体一点, 它都提供了以下几点能力
等等.
via: frequently asked questions
换句话说, 如果在开发过程中, 确定不会用到自定义的 Native 模块, 那 Expo 完全可以覆盖到整个 APP 的开发生命周期, 直到上线.
这部分只涉及 Expo 相关的安装, 其他的一些和 react native 开发相关的安装依赖项, 例如 Node.js, watchman 等这里不做重复.
分两部分的安装, 桌面端的 Expo XDE 和手机端的 Expo APP.
XDE 是 Expo Development Environment 的缩写, 看名字也大概就知道它的作用了, 为开发者提供了一个桌面端的集成开发环境.
那 APP 又是什么鬼, 起初我看到它时的第一反映是我就是为了开发 APP, 怎么这里还有个 APP, 不禁好奇它的作用. 结合 Expo 的开发过程也就很容易理解了, 这个 APP 的作用可以理解为一个容器, 一个浏览器, 目的在于快速预览开发成果.
这个预览是如何做到的? 是这样的, 当我们在借助 Expo 开发 APP 时, 它会为应用提供一个类似 URL 可以实时预览效果的地址, 形如 exp://192.168.X.X:19000 , 通过手机端的 Expo APP 能够打开这样的地址并提供预效果, 和浏览器打开 URL 的过程非常类似. 因为 Expo 的预览功能是基于 ngrok 来完成的, 所以 Expo APP 和开发机即便不在一个局域网内, 也不会影响到它的预览功能.
其他的一些依赖, 在 react native 的安装中都有介绍, 不重复了.
和 Expo XDE 对应的有一个 cli 版本的工具 exp, 标准的 npm 包, 这里略过, 感兴趣可以看这里: exp Command-Line Interface.
先以一图作为这一小节的开端.

一图胜千言, 从图中基本上可以看到 expo 为开发者提供的功能了. 即可以通过它创建出新的项目, 也可以将已有的项目通过它 run 起来, 但是这有一定的条件.
如果正在开发的 APP 是以 create-react-native-app 创建出来的, 在项目目录下执行 npm start 之后, 根据对应的提示按 a (对应在 Android 模拟器中打开项目) 或者 i (在 iOS 模拟器中打开项目) 就可以在对应的模拟器中看到实际效果了. 打开 Expo XDE 选择刚才创建出来的 APP, 会看到这样的界面:

如提示, 左边为脚本 build 结果, 右边为设备 log 所输出的信息.
根据我这边的实际使用情况来看, 当希望在 iOS 模拟器中查看项目时, 直接按 i 即可; 但是在 Android 模拟器中查看时, 需要先将 Android 模拟器打开, 同时将 Expo APP 安装进模拟器才可以, 否则会报错, 这点和文档描述稍有出入, 需要注意.
这里先补充一个上面提到但用户可能感兴趣的话题: 如果想用 Expo, 但项目又依赖到 Native 自定义模块,怎么办? 两种办法:
以上, 对 Expo 做一个简单的介绍, 这里也只是就我的初步使用做一个简单入手介绍. 更多的介绍请移步官方文档描述: Expo - Quick Start.
这篇文章对 React Native 做了一个简单的介绍. 也是我第一次用 org-mode 来写文档, 真正感触到了 org-mode 的强大, 愈发觉得大纲模式对之于对写文档这件事情来说所提供的不可或缺的重要性, 犹如用过 vi 之后, 就再也接受不了不支持 类似 vi 移动编辑操作的编辑器了.
这是一篇简单的介绍 Service Worker 以及如何使用的文章,这个东西也不复杂。主要分背景,为什么它会出现 ,如何使用 以及总结 四部分。
当大家谈论 web 应用的时候,潜在里都清楚它有一个受限点:当没有网的时候,所有网站或应用打开都会出现「网页无法加载」或类似的文案提示,web 的这一特点,自它的诞生,一直持续到现在。
而现在,Service worker 的出现,正是为了解决这一天然缺陷,或者更准确得说叫做突破这一限制,使得 web 应用也能够如同 Native APP 一样,即使离线,页面也不会出现无法加载的局面。
源于现在绝大多数的 web HTML5 应用都是严重依赖于网络,没有网络 HTML5 便会完全瘫痪。而借助于 service worker,即使再没有网络的情况下,也可以方便打开 HTML5 应用。
那它和之前的 AppCache 又有什么区别?
总的来说,AppCache 还是不够宜上手,即便在浏览器都广泛支持的情况。
先附一张 Service worker 的流程图以及示例代码 ,可以结合下文对照着来看。
via: MDN
首先,在需要使用 service-worker 的页面中注册它。
// 主页面
// sw.js 为 service-worker 的主要代码。
navigator.serviceWorker.register('sw.js', {
// scope 的作用域,最上级目录不能超过当前目录
scope: './'
});注册好之后,页面便会尝试安装 service-worker, 此时会触发 service-worker 的 install 事件,一般会在该阶段做一些 初始化,例如缓存文件的操作;
// sw.js
this.addEventListener('install', function(event) {
event.waitUntil(caches.open('sw-storage').then(function(cache) {
return cache.addAll([
'./',
'script.js',
'style.css',
]);
}));
});我们看到了非常熟悉的 then 方法调用,没错 Service Worker 依赖于 Promise 的实现。那 caches 是什么?event.waitUntil 又是什么?未曾熟知的 API,一一来看。
caches 放在下面单独来看。event.waitUntil 如文档描述:
the ExtendableEvent.waitUntil() method extends the lifetime of the event
对比着来看,如果不借助于event.waitUntil,那么 install 回调函数中同步代码执行完毕后就会立刻改变 service worker 的状态;反之,会等待 install 回调函数中的 promise 被 resolve 或 reject 后才会改变。
备注:在 sw.js 的上下文中,service worker 的安装状态可以通过this.registration.installing拿到。
在 install 事件触发之后,便会到达 service-worker 的第二个事件响应: 激活 activate。在 activate 阶段,可以做一些删除旧缓存的操作;
this.addEventListener('activate', function(event) {
// console.log(‘ service worker: activate event is fired’ );
});此外,注册 Service Worker 的整个流程中,还有一个状态:redundant 当注册失败时会触发。
Service Worker 的初始化就算是马上就要完成了,还差最后一步:监听 fetch 事件。为什么 service-worker 能够不通过网络请求加载资源以及即便是离线状态下也可以使用的奥秘就在这里:
this.addEventListener('fetch', function(event) {
event.respondWith(
// 拦截fetch请求,从caches 中匹配并返回
caches.match(event.request).then(function(response) {
return response || fetch(event.request)
// 如果没有匹配到,则通过 fetch API 从网络获取
}).catch(function() {
return fetch(event.request);
})
);
});那么不监听fetch事件的后果是什么呢?所有的请求都走正常的网络请求了。
到此,以上的示例就展示了从注册到激活再到 监听,拦截 fetch 请求返回缓存的资源文件整个主体流程,但还差了一个重要环节:当网站静态资源更新之后,如何更新客户端中已经被缓存的静态资源?
先回顾下上面已经提到的两步: install -> activate 。
现在来看这个问题,每次页面刷新,都会去服务器请求 sw.js ,当发现服务器返回的该文件和本地不一致时,便会触发 service 的 install 事件监听,注意此时也只是安装,并不会激活。激活需要一个条件:当前不存在任何已经加载的页面再使用旧版本的 service-worker,当激活成功后,新版本的 service worker 便开始正常工作。
因为激活的条件,所以在实际的调试过程中,会发现,当新版本的注册好之后,我们需要关闭当前的已打开的标签页,必须通过重新开新标签页的形式才能完成激活。
基于我们上面 sw.js 代码的最简实现,每一次刷新页面,我们通过观察 Chrome Devtools 中 Network 面板的瀑布流时,会发现这样的现象:
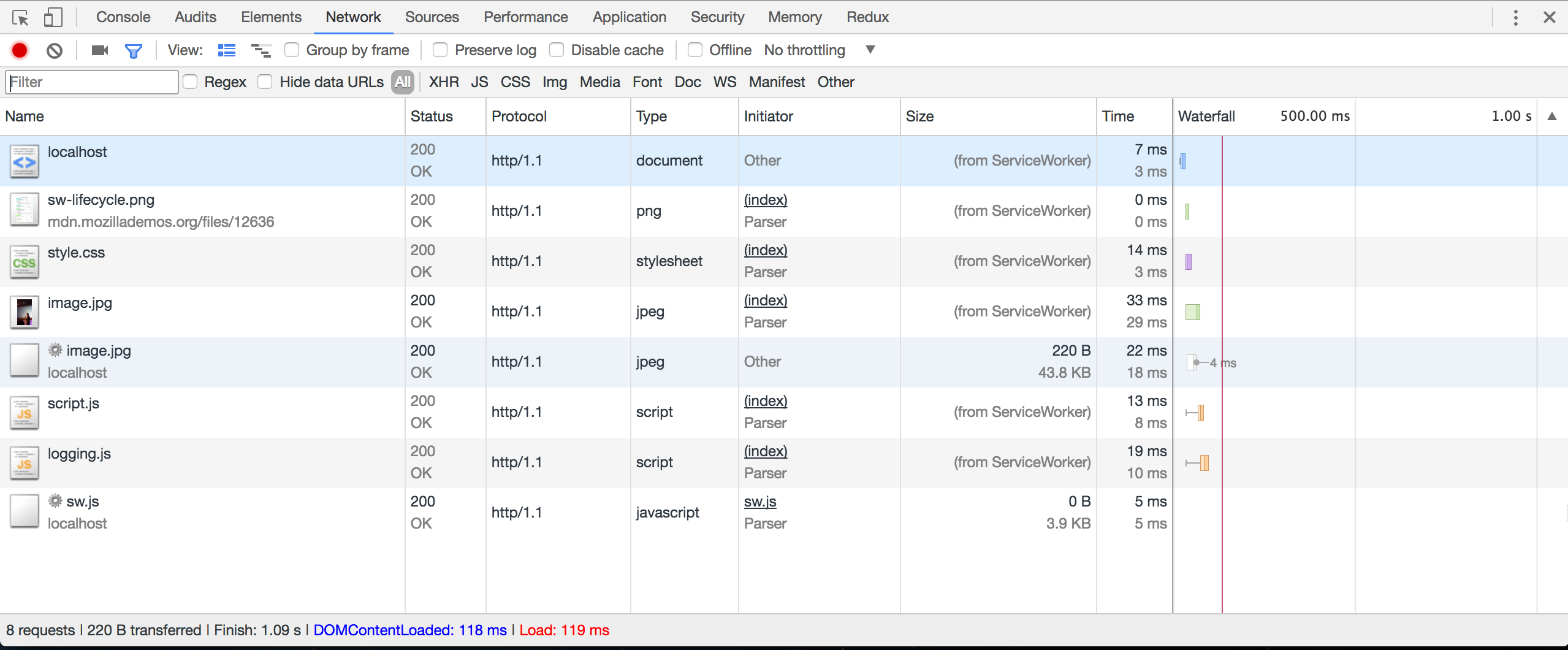
如上图所示,当使用了 Service worker 之后,fetch 会被 service worker 劫持,所以网络面板的请求,Size 一列都变成了from ServiceWorker。
在看官方例子的时候,可能大家已经注意到了,上面的代码示例中出现了cache.addAll 以及 caches.open 这样的方法调用,却也没有看到它的声明,这又是什么?从 caches 来入手。
caches 存在于在ServiceWorkerGlobalScope 作用域中(也就是上文提到的 sw.js 这个文件的执行环境),它是 CacheStorage 的一个快捷方式,关联着当前的 service worker,只读属性。CacheStorage 是什么?
The CacheStorage interface represents the storage for Cache objects. It provides a master directory of all the named caches that a ServiceWorker, other type of worker or window scope can access (you don't have to use it with service workers, even though that is the spec that defines it) and maintains a mapping of string names to corresponding Cache objects.
直白得说,它就和 localStorage 一样,只是它专门用来缓存 HTTP 的 Response 对象。它的规范也是定义在 Service Worker 中,这意味着它的使用脱离不了 Service Worker 的上下文。
cache 则是 CacheStorage 通过调用 open 方法生成的一个 Cache 实例。在该实例上便可通过调用 add 或者 put 方法进行存储 Response。
// 在 ServiceWorkerGlobalScope 中
caches.open('sw-storage').then(function(cache) {
return cache.add('script.js');
})那么,如何在现有的项目中集成进 Service Worker呢?也是 So easy,将代码示例中的部分片段做少许调整就可以。当然了有更方便的方法:
service-worker.js 文件,之后引入在 html 中就大功告成。BYW,第一种方案也是基于sw-precache 实现的。
遗憾的是 Service Worker 各个浏览器支持的并不太好。截至到 iOS 11,也尚未支持,Android 倒好一些。几乎可以肯定的是,一旦这项技术被广大浏览器厂商支持,那么它对 Web 应用将会带来质的飞跃,激进得看,甚至会因此而将 Web 从此划分为两个时代。
自从习惯了 Chrome 作为日常浏览器之后,在开发过程中也一直在使用 Chrome 的 Devtool 作为调试工具,发现了其中很多好用的地方,这篇文章对这些功能以面板维度为区分做一个回顾和引述。
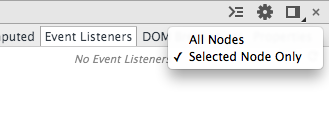
有时候我们需要查看某一个特定元素绑定的事件,在这个面板可以直接查看到(或者借助 Command Line API: getEventListener),选择 Elements 面板右侧的 Event Listeners,这里会显示出所有可以发生在这个元素的事件(捕获和冒泡),但是这往往不是大多数场景下我们想要的,大部分场景想要的是查看自身绑定的事件,也是可以做到的,只需要在最右侧下拉中选择 Selected Node Only 的选项就可以了,如图。
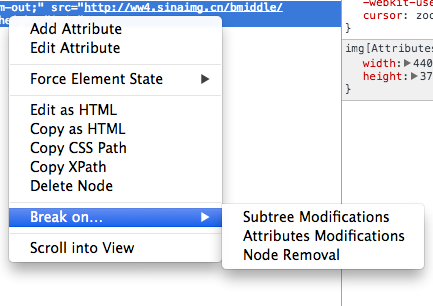
因为浏览器里的编程大多数是和 DOM 紧密结合在一起的,JS 中也往往会存在一些改变 DOM 树结构有关 UI 的业务逻辑,所以调试过程中我们就经常需要去检查 DOM 的改变情况以及程序后续所做出的逻辑响应,那么这个时候可以借助 Break on 功能来辅助 debug。
当选中一个元素右键查看 Break on 的子选项时,可以看到这里提供 几个 DOM Level 3 的事件监听选项以及节点被移除时的中断。分别对应 DOMSubtreeModified,DOMNodeRemoved 和 DOMAttrModified,虽然说现在的大部分业务代码不太会监听这样的事件,但是断点监听调试的场景是非常多的。
肯定所有人都知道右键选择 Edit as HTML 可以编辑选中部分的 HTML 源代码,这个功能应该是非常常用了,是吧,既然常用,就记住快捷键吧 F2,按F2进入编辑模式,再按F2进入普通模式(N 久前不知道的时候习惯了编辑完按 ESC 真是抓狂)。
另外,CMD + F 是用来根据关键字搜 HTML ,但它还支持 CSS Selector的形式。
在 Sources 面板的右侧,大部分情况下,我们最常用的可能是_Watch Expressions_ , Breakpoints 但除了常用的这几个, 其还包括 Event listener breakpoints,Dom Breakpoints, xhr breakpoints, workers 这几大类
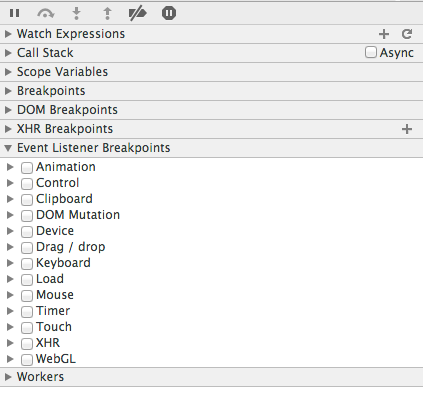
见上图,比如 Event Listener Breakpoints 区域, 当触发什么事件时中断,事件可以除了常规的键盘事件,鼠标事件,还有几大类,Animation,Clipboard,Device,DOM Mutation,Touch,XHR,Load,甚至还有 Timer(在 setTimeout setInterval 处理函数开始执行时中断),看图估计就都会用了。
XHR Breakpoints 区域,简而言之就是当 ajax 时中断,对开发便利之处是,这里可以添加规则,当 url 包含某些字符时自动中断。以及 workers 中断。
DOM Breakpoints 则对应的就是在 Elements 面板中添加的被 Break on 的元素了。
定位基本是通过快捷键来完成,并且这些快捷键大多数情况下是和其他工具相通的。
cmd + o 或者 cmd + p (对应于 sublime 的 cmd + p)Ctrl + g ,其实是 cmd + p,再输入 : 的简写。 (对应于 sublime 的 Ctrl + g)cmd + Shift + p (或者 cmd + Shift + o ) (对应于 st 的 cmd + r)Sources 面板提供了就地编辑 js 和 css 的功能(不能编辑 html 中的内联资源,html 的编辑是通过 elements 面板进行的),当cmd + s 保存后,会立即生效。需要区分的是 内联的 css 编辑完之后可以生效的,但 js 不可以。
全局搜索 cmd + opt + f, 可以搜索当前页面中的任意 js,css,html 中的关键字,还支持正则。
基本的一点,蓝线是 DOMContentLoaded,文档解析完毕;红线是初始资源都已经下载完毕,load 事件触发。
看下图,以一个截图为例,前端开发者可能天天都会看,注意其中画线的三个部分。

可以看到 Size 和 Time 列有两行数据。那有什么区别呢。
先看 Size 列,下面是 Content,两者的区别在于,第一行数字仅仅是 Response 的 size,包括了 header 和 body 的大小,而第二行才是真正的内容的大小。
通常情况下,因为 web 上访问静态资源都会经过 gzip 的压缩,所以看到的 Content 一般都是要大于 Size 的,但是当内容没有经过 gzip 压缩时,两者可能就是相等的。
以三个例子来分明说明三种情况。



当然也有Size 大于 Content 的情况,比如说 Response Header 中携带了大量的 Cookie 时候。
现在看 Time 列。上行 Time 数字代表获取 Response 总的时间,第二排 Latency 数字代表从开始传输数据到结束总的耗时,所以可以肯定是,第一行数字,永远是大于等于第二行数字的,两者的消耗时间比例也可以从右侧(上图中箭头所指的位置)来看出大概的比例,颜色稍浅的部分等同于 Latency。
这个面板好像也没什么好说的了。
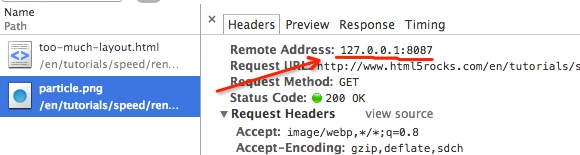
想起有一点改进提一下,点击每个资源,在 Chrome 32 版本 中新增加了 Remote Address(资源远程地址,firefox firebug 一直有这个信息),这个信息对于经常切换 host,调试 cdn 的朋友估计很有用,来查看确认当前返回的资源是从哪个服务器 IP 来的。以前没有这个 feature 的时候,基本都是通过 Chrome Extension 的形式解决。现在方便多了。如图:
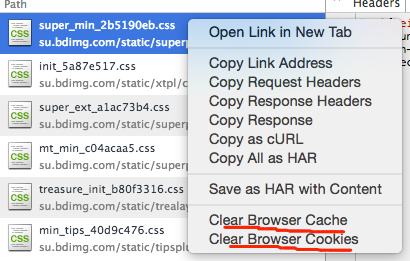
补充一个坑,看图。右键请求,会有 Clear Browser Cache 和 Clear Browser Cookies, 功效确实如其名,清除的是浏览器的cache 和 cookie,我最初理解的是出现在这个位置的清除维度应该对应的是当前域名或者是该资源,因为上下文嘛。太容易混淆了,坑死窝了,引以为戒。
平时开发的过程中,可能和 Timeline 面板接触比较少,但是当需要做页面优化或者动画的时候,TImeline 的强大就可以发挥出来了,先以一个简单的例子为入口。
// code 1
var h1 = f.clientHeight;
f.style.height = (h1 + 10) + 'px';
var h2 = b.clientHeight;
b.style.height = (h2 + 10) + 'px';
var h3 = z.clientHeight;
z.style.height = (h3 + 10) + 'px';
// code 2
var h1 = f.clientHeight;
var h2 = b.clientHeight;
var h3 = z.clientHeight;
f.style.height = (h1 + 10) + 'px';
b.style.height = (h2 + 10) + 'px';
z.style.height = (h3 + 10) + 'px';没有什么区别,都是做获取高度,设置高度的事情,但在执行层面上效率的实际情况呢。运行一下,在 Timeline 两者对比一下就知道了。
code 1 的运行图片。
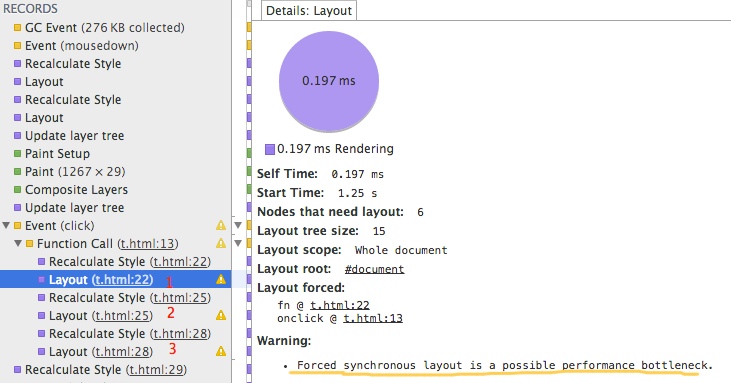
可以看到 触发了 3 次 layout。
再看 code 2 的
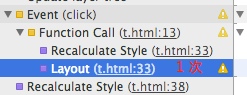
只有 1 次。 (备注: 不同的 chrome 版本截图可能会有区别)
原因呢,简单来说就是,尽量避免频繁触发 layout,最佳实践就是分离读写,这个这里不多提到,具体查阅如何减少不必要的layout,paint 方面的文章。现在再来看 Timeline 的作用,显而易见了是吧,它帮我们记住了浏览器从开始加载网页到任意时间段的每一个阶段的执行细节。
通过 Timeline 我们以一个基本的网页来示例梳理从加载到渲染到计算机屏幕都经过了哪些步骤。
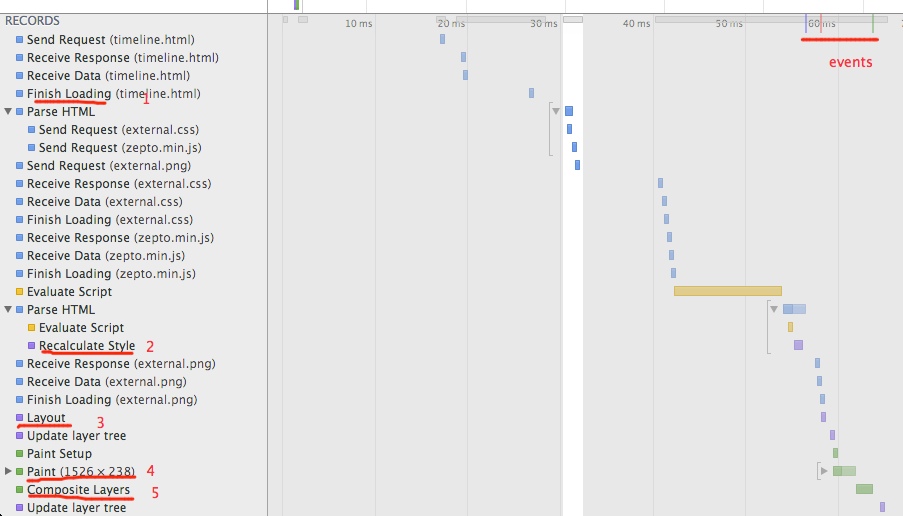
第一阶段: Send Request - > Receive Response -> Receive Data -> Finish Loading. 完成页面自身的加载。
第二阶段: Parse HTML,生成一棵 DOM Tree,如果 HTML 中存在内联脚本就执行,外联脚本或者 CSS 就发请求去加载,并执行,最终在 Recalculate Style 后生成一棵 Render Tree。
第三阶段: Layout 根据元素 width,height, margin, left, top 等信息构造出布局。
第四阶段: Paint 根据元素 color,box-shadow,border-radius,background 等属性渲染元素。
第五阶段/最终完成:Composite Layers, 混合生成位图信息,发送至GPU,渲染到屏幕。
右上角中,三条线 分别给开发者指名了 domready,load 和 first paint 的事件触发时间(分先后顺序)。
来,通过一个精简版本的 timeline 直观看到哪些属性分别是在哪一阶段完成。
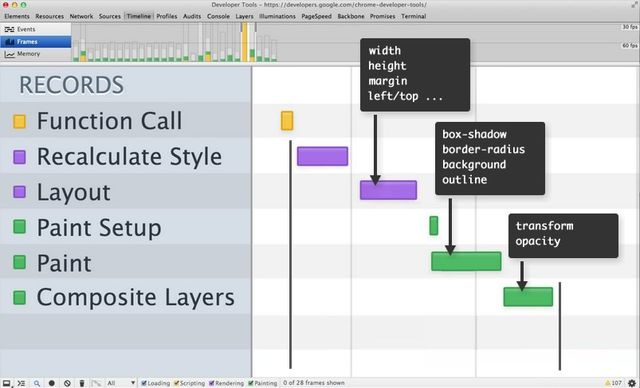
引自: https://developer.chrome.com
更具体的,关于哪些属性是在 layout 中完成,哪些属性是在 paint 中完成,可以见这里 。换句换说也就是当我们修改了元素的哪些属性,就会触发相对应的阶段,所以说,
The higher up you start on the timeline waterfall the more work the browser has to do to get pixels on to the screen.
根据上面提到的,补充两点:
上图 Panel 中,各个颜色代表是不同的,如下图所示。概括一下就是 蓝色是网络事件,黄色是js 事件,紫色和绿色是 layout 和 render 事件。

引自: https://developer.chrome.com
另外,结合 Console API : console.timeStamp() 可以手动向 timeline 中插入一条记录。
OK,是时候来看 Timeline 面板还提供了哪些功能。
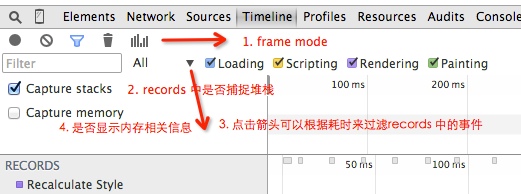
假设前三个的作用你已经知道(开始记录,清空,过滤), 第四个垃圾桶的图标是 强制执行一次GC。图中 3 是点击沙漏图标(过滤)后可以根据耗时来选择显示在 RECORDS 里的事件默认提供了 > 1ms 和 > 15 ms,可以根据此来过滤出比较耗时间的事务。
现在看看其他三个。
在前阵子 Chrome 版本的的 Dev Tool 中,是分为三种维度来显示记录,events、frame、memory,之后的升级将 events 模式变为默认的记录方式(所以本节刚开始部分都是 events 模式下的示例),其他两种通过图中标识进行激活。
在 frame 模式下,记录面板将会以 每一帧 的形式记录下来在这一帧中浏览器所处理的所有细节。

根据业界数据普遍公认的一些信息,如果想得到一个平滑的动画,那么,尽可能得将帧率保持在 60 FPS 左右。
直观查看帧的 layer,以及数据情况可以通过下图的方式来看。
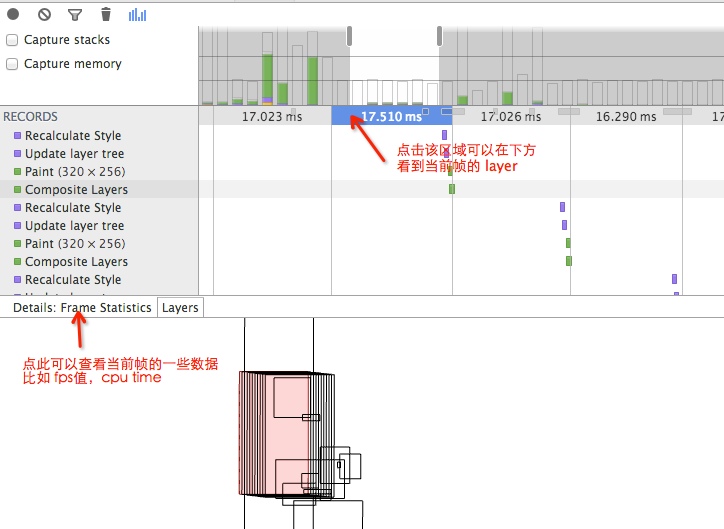
一个鲜活的 demo: Timeline demo: Diagnosing forced synchronous layouts
这个模式可以协助你查看当前应用已经分配到的内存情况,注意是没有被垃圾回收的。
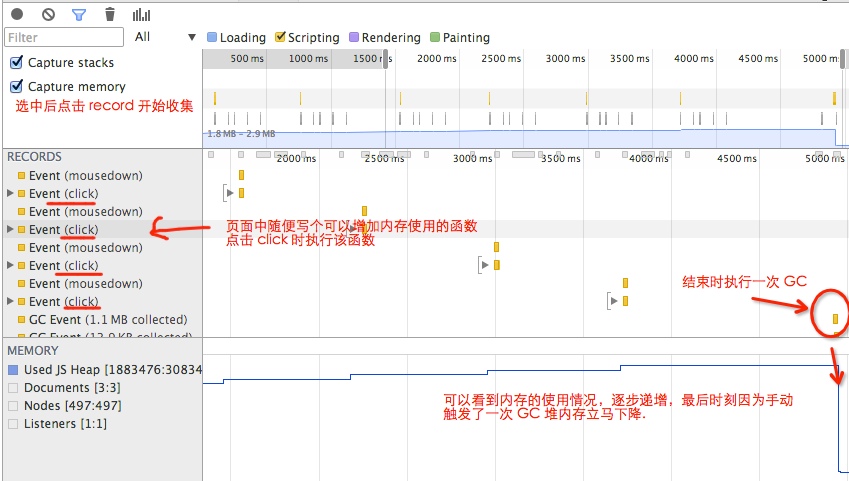
这是一个常见的网页查看内存使用情况,由上图可以看到 memory 的内存使用轨迹,再搭配 Records 中的 事件记录以及 call stack,我们可以很容易直观得看到程序执行过程中堆内存使用情况。
借由此,便可以初步检测 应用是否存在内存泄露情况,比如说 内存曲线始终是逐步攀升的,通过观测几分钟后(Records 中应该会触发多次 GC,或者手动触发一次 GC),内存使用情况依然居高不下,甚至是节节上升态,那么很有可能应用程序存在内存泄露。所以,可能下一步就需要 Profiles 面板的更精确的定位了。
那么正常情况下应该是什么样子呢,看下图,这是一个网页打开后在接近一分钟内的内存使用情况,可以看出常态基本拿捏于一个平缓的幅度中,只是在页面加载执行时内存使用会稍微多一些而已。
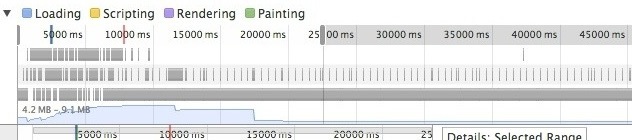
想要了解更详细一点的看官方的帮助:Performance profiling with the Timeline 。
简而言之,通过它可以收集到程序运行时记录的函数调用的耗时和内存使用情况,来让我们更方便得了解程序的时间和空间消耗情况。早期这里也可以收集到 CSS 选择器生成 Render Tree 的情况,不过后来被移除了,因为在 Timeline 里通过查看 Style Recalculation 的信息来完成。
在CPU Profile 下,可以看到函数的调用堆栈以及每个函数的性能。查看 DEMO,按一下操作流程开始。
现在来看录制结果。
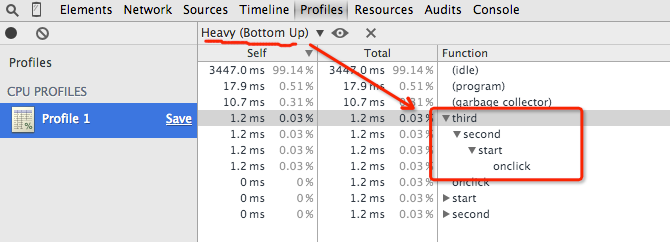
对比一下代码,其实有点点 console.trace(); 的意思。在 CPU Profiles 模式中,如上图,当选中划横线部分 Heavy(Bottom Up)后,展示出来的就是函数调用的堆栈信息。与之对应的,还有一个 Tree(Top Down)的选项,看字面意思,就是从顶向下了,应该知道是什么用途了吧,从函数调用堆栈的顶部向下开始展示函数的执行轨迹, 也就是断点调试的 step in的节奏。
还是看上图,图中显示的三列: Self,Total,Function。Self 和 Total 单位都为 ms,代表当前执行耗时,Function 指代目标函数名称。Self 是当前函数自身执行耗时,而 Total 的时间包括了当前函数调用以及它所调用其他函数的总耗时。
了解了 js 执行的耗时了,接下来应该看看占用的内存情况了。
简单说,它可以抓去一份当前页面的内存快照, 它包含了当前网页 js运行时用到的所有对象,相关 dom 节点的所使用的内存信息。
它能解决的问题是,我们可以通过对 js 内存的快照对比来分析排查当前网页哪里存在内存泄露,不要忘了 Timeline 的 Memory View 也是可以查看内存的使用情况,往往这两者是搭配使用,先用 Timeline 来查看是否有内存泄露,比如说内存是否一直是处于增长状态,DOM Node 的数量等。
下图是 Summary view 模式下的一个快照
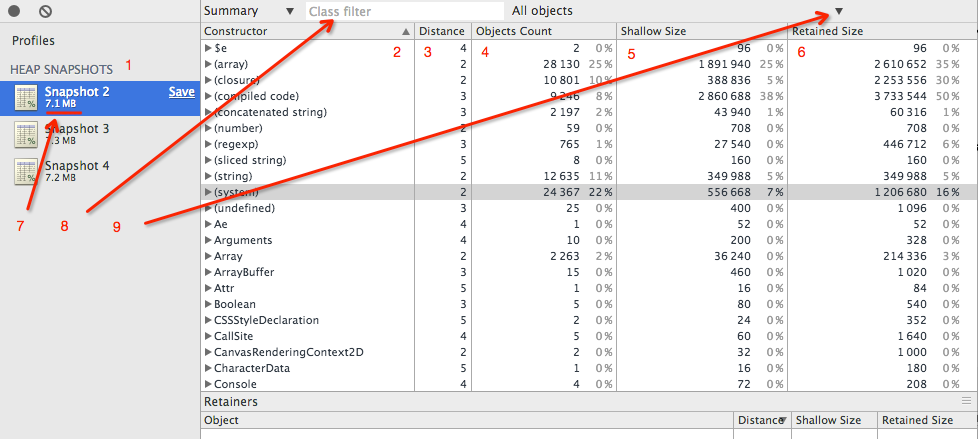
从图中序号开始先了解一下各列的含义。
这里引用一下官方对Shallow Size 和 Retained Size 的解释来加深理解: Memory Analysis 101
The size of memory that is held by the object itself is called shallow size. Typical JavaScript objects have some memory reserved for their description and for storing immediate values.
Usually, only arrays and strings can have significant shallow sizes. However, strings often have their main storage in renderer memory, exposing only a small wrapper object on the JavaScript heap.
Nevertheless, even a small object can hold a large amount of memory indirectly, by preventing other objects from being disposed by the automatic garbage collection process. The size of memory that will be freed, when the object itself is deleted, and its dependent objects made unreachable from GC roots, is called retained size.
备注: 5 和 6 的单位都为 Byte.
以官方一个实际例子来看。example4
打开页面,按一下步骤操作
ok,操作结束。(因为我已经抓取过,所以我的图示例索引为 6,7,8)
现在来看第一次抓取到的快照,通过搜索快速定位到 DocumentFragment 搜索没结果;切换到快照2,可以看到有我们代码中创建的 DocumentFragment, Object Count 是 11 个,不用在乎最下面那一个,从它的数据也可以看出它不属于我们创建的,(Distance 是 4,Shallow Size 是16)。注意节点颜色是黄色的。
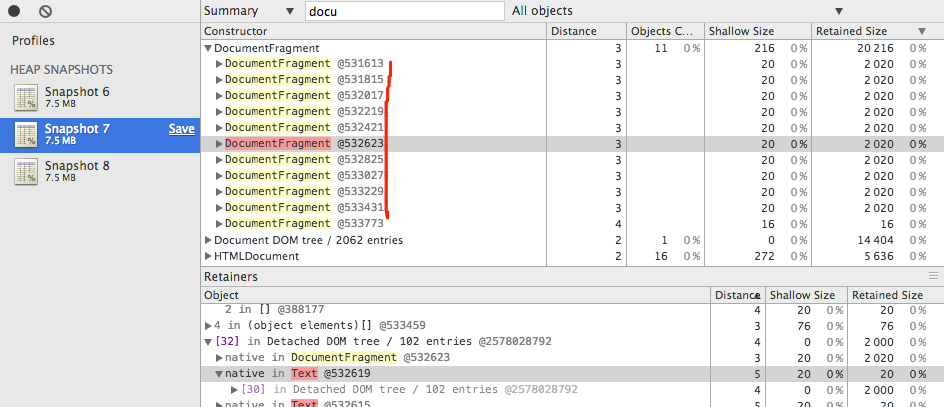
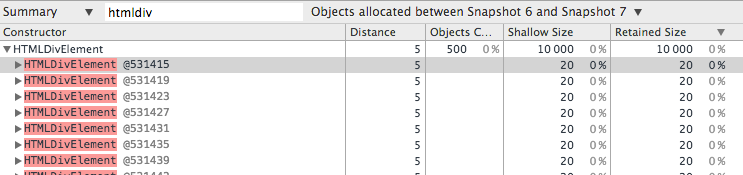
切换上图中提到的9过滤选项为Objects allocated between Snapshot 1 and 2 ,再来搜索 HtmlDivElement, 一共 500 个。
注意这里的背景颜色是红色的,普通情况下是没有背景色的。
插播一下, 红色和黄色背景标识的对象都代表 该节点是 Detached DOM tree 的一部分,但两者的区别在于红色 node 不存在直接的 javascript 对象引用,而黄色存在。
用一个官方示例的 gif 图来直观了解一下
引自: https://developer.chrome.com
回来看 点了_Clean detached nodes_ 之后的内存快照 3,来验证一下对红色和黄色的理解。代码中
frags.length = 0;相当于已经切断了 节点与 js 对象之间的引用,红色和黄色所标识的节点应该都不会存在才对。
切换快照3的过滤选项到 Object allocated between Snapshoot 1 and 2(其实切换到其他的过滤选项也是可以的),再通过搜索 documentfragment 或者 htmlDivElement 都没有我们创建的节点了。

空空如也。
这个 Heap Profiles 里还有太多东西一一列举不到了(事实是我还没看到),想看时可以继续看 JavaScript Memory Profiling。
这两个面板好像都没什么可说的。一个是当前页面的相关资源,一个是给出优化建议。
这个应该也属于用的非常非常多的一个面板。这里把 Console 提供的 api 结合 Command Line API 共同过一下,这两者的 api 有时候还是互通的。我只摘一些我经常用到或者感觉有可能用到的 api 列举一下,完整的请看官方文档。
Console 提供的功能不仅仅有 log,warn,error,还有很多,比如 assert,group(groupEnd),time(timeEnd),timeStamp,profile(profileEnd)
单列出两个, count 和 trace,前者统计某一段代码执行次数,后者可以打印出函数调用堆栈,调试时常用到,根据堆栈排查 bug 对前端来说也是一件容易的事儿。
Command Line API 里,
$0 , $1, $2, $3, $4 $0 指代 element 面板上当前选中的元素, $1 指代上一次选中的元素,依次类推。
$() 等价于 document.querySelector,$$() 是 document.querySelectorAll,$x() 则提供了 用 xpath 的方式访问 DOM 树的功能。
getEventListeners 获取给定对象上绑定的事件;monitorEvents(object [,event]) 监听事件,事件触发后控制台会打出一条 log,比较有用的是 event 参数所支持的形式,比如 monitorEvents(window, [“key"]) 当所有和按键有关的事件触发时都会打出 log。
全部的 api 看这里:
Source 面板中加了断点后,代码在中断执行模式下,此时 Console 里输入的代码执行上下文和断点所在的函数保持一致。
在 Console 里执行的代码一般是不能加断点的,有两种方法,一种是借助 Command Line API 提供的 debug 函数;一种是通过在所要执行的代码中加入 //@ sourceURL=filename.js ,此后就可以在 source 面板通过 filename 来找到这部分代码了,断点就可以随便打了。举个栗子,将以下代码放入 Console 里执行后,去看看 source 面板是不是多了一个叫 abc.js 的文件。
function a(){}
//@ sourceURL=abc.js借助这个特性,也就可以调试 localStorage 里的代码了, 每个保存在 localStorage 里的 js code 字符串末尾都加上 sourceURL 的 filename 映射,h5开发的代码很多都是保存在 localStorage 里,碰到问题想调试却无发 debug code 的 case 就解决了。
同借助这个特性,也就可以和其他普通的 js 文件一样,支持动态修改。
另外一个,也是和调试相关的书写代码习惯方面的 case,看下面两段匿名函数的代码书写:
// code 1
(function() {
// body
})();
// code 2
(function loop() {
// body
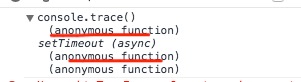
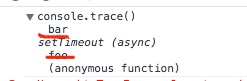
})(); 两段代码唯一区别就是 code 2 中函数表达式中同时有了函数名,那这两者的写法和 Chrome Dev Tools 这个有什么关系呢。这样书写,对于调试代码,可以给开发者跟踪 Call Stack 来说有很大的好处,举一个简单的栗子。
// code 1
(function(){
setTimeout(function(){
console.trace();
}, 10)
})();
// code 2
(function foo(){
setTimeout(function bar(){
console.trace();
}, 10)
})();
在 Dev Tools 中调试过程中的区别: 左边是 code 1, 右边是 code 2。很明显能看出区别。在复杂的 web 工程开发中,对关键部位的匿名函数增加函数名,可以对调试有很大的帮助(这一点也是在有些开源项目中发现的)。
一个是右上角齿轮,一个是按 Esc 呼出的,定期看看,更新还是蛮快的,尤其是 Canary 版本。
最后,给自己一个建议,每隔两三个月打开一次 chrome 控制台的setting窗口,撸一遍设置/快捷键,其他工具也是类似了,想一气呵成记住很多亮眼的 feature,最后可能起反作用容易搞混,所以我一般都需要每过一定时期再来翻翻我常用的软件的设置窗口看看是不是有什么进阶的功能我应该能用到但还没用到的,或者去相关官网有没有新增加并且我认为对我有用的特性,以及会订阅一些关于该软件信息的 maillist。如果是这样的话,我就会择几个先记在 evernote 里,把它用起来,工具只有在用熟练之后,才能闪现出它的光芒。
EOF
Koa 是一个非常小巧且轻量级的由 Node.js 完成的 web框架,底层借助于 co 解决了繁琐的回调嵌套,充分发挥了 Generator 的优势。目前该 team 已经尝试将 async/await 引入其中,不过还在 Alpha 阶段。
关于 Koa,还有一个关键字:Middleware。
这篇文章主要是在边看 Koa 源码边做的一个整理笔记。
先通过代码看一段简单示例。
var koa = require('koa');
var app = koa();
// x-response-time
app.use(function *(next){
var start = new Date;
yield next;
var ms = new Date - start;
this.set('X-Response-Time', ms + 'ms');
});
// logger
app.use(function *(next){
var start = new Date;
yield next;
var ms = new Date - start;
console.log('%s %s - %s', this.method, this.url, ms);
});
// response
app.use(function *(){
this.body = 'Hello World';
});
app.listen(3000);如果细心看这段代码的话,对代码有一些直觉的同学到此就应该能大致了解一些,比如 app.use 中的函数会一个个执行,执行的方式大概是利用 yield next 触发的吧,next 那大概应该指向的是下一个中间件吧?
没错,是这样的。但是这就有一个疑问,如果 next 指向的是下一个中间件,那 next 的类型是什么,应该还是和 Generator 有关的吧,比如 Generator函数?比如 Iterator Object?
也没错。那可是在 Generator 内部,如果 yield 后面跟的还是 Generator,根据规范,这样是不会执行到内部 Generator 的吧?
恩,那 Koa 是怎么做到的呢?这个就当做 谜1 吧。
看完这篇文章就有答案了。
考虑到篇幅,后续文中出现的源码会删掉不重要且不影响关键逻辑部分的代码,比如调试信息。
通过上面的实例结合 koa 的两个最重要的 api 看源码。入口文件 lib/application.js。
module.exports = Application // exports 出来的是一个构造函数
原型链上有两个比较重要的 API,也是经常会看到的。
listen 方法很简短,源码备注已经说的很明白了,就是
http.createServer(app.callback()).listen(...)的简写,但这里有个方法需要后续了解一下,就是 Application#callback,这个放在 Application#use 之后讲,一步步来,先看 Application#use 。
Application#use 方法源码:
app.use = function(fn){
if (!this.experimental) {
// 如果没有打开`experimental`,那么 fn 必须为 generator
assert(fn && 'GeneratorFunction' == fn.constructor.name, 'app.use() requires a generator function');
}
// 将 fn 压入 middleware 中,稍后会利用到,这是 koa 最重要的部分,需要多少个中间件,就多次使用 use 方法,传入 fn 即可。
this.middleware.push(fn);
return this;
};现在来看 Application#callback。
app.callback = function(){
// 先对这些中间件做一次包装,包装是通过 compose 和 co 的方式完成的,具体实现方式放到最后再讲。
// fn 的执行结果始终是一个 Promise.
var fn = this.experimental
? compose_es7(this.middleware)
: co.wrap(compose(this.middleware));
var self = this;
if (!this.listeners('error').length) this.on('error', this.onerror);
// 返回的是一个函数,也就是 httpCreateServer 的回调。
return function(req, res){
// 默认的 statusCode 值,之后会在 set body 中修正该值。
res.statusCode = 404;
// 创建this上下文,供后续使用。
// ctx 上携带着大量 shortcut 的方法,例如req 上的accept,header 之类。
var ctx = self.createContext(req, res);
onFinished(res, ctx.onerror);
// 中间件 和 respond 的执行都是在 ctx 这个上下文中。
fn.call(ctx).then(function () {
respond.call(ctx);
}).catch(ctx.onerror);
}
}按从上到下,应该先看 Koa 是如何处理中间件的。但是这里需要投入大量的篇幅,而另外一个问题中间件执行完之后 respond 的源码实现相对来说就简短多了,只需要大概撇一眼即可,所以这里先看 respond 的实现,接下来再重点看 Koa 对中间件的处理。
// 这个方法没有太多需要介绍的。
function respond() {
if (false === this.respond) return;
var res = this.res;
if (res.headersSent || !this.writable) return;
var body = this.body;
var code = this.status;
// 有些 statuscode 可以不用设置 body,直接结束 res,比如204(reset content),205(partial content),304(not modified)
if (statuses.empty[code]) {
this.body = null;
return res.end();
}
// 设置 `Content-Length`,正常情况下 length 的设置是在 this.body 中,但这个逻辑分支下需要修正。
if ('HEAD' == this.method) {
if (isJSON(body)) this.length = Buffer.byteLength(JSON.stringify(body));
return res.end();
}
// 如果 body 为 null,则将 body 设置为statusMessage。
if (null == body) {
this.type = 'text';
body = this.message || String(code);
this.length = Buffer.byteLength(body);
return res.end(body);
}
// 设置 body,并结束响应
if (Buffer.isBuffer(body)) return res.end(body);
if ('string' == typeof body) return res.end(body);
if (body instanceof Stream) return body.pipe(res);
body = JSON.stringify(body);
this.length = Buffer.byteLength(body);
res.end(body);
}现在,重头戏才刚刚开始。这也是我认为的 koa 最有价值的地方,看看 koa 是如何处理这些中间件的。
var fn = this.experimental
? compose_es7(this.middleware)
: co.wrap(compose(this.middleware));兵分两路,先看 compose_es7 的方式。但是在这之前,需要先介绍一个概念,compose。
通俗得来说 Compose 做的事情就是将多个函数组合成一个函数的过程。这里借用 Ramda 库的 compose 官方示例来说明它的作用。
var f = R.compose(R.inc, R.negate, Math.pow);
f(3, 4); // -(3^4) + 1试想一下要完成这一个需求场景如果在不用 R.compose 库的时候会是什么样子。
R.inc(R.negate(Math.pow(3, 4)))再试想一下在经常可以看到的业务场景之下的对比,对一串 JSON 做一些处理,比如根据 id 排序,根据日期过滤,摘取其中的 content 和 id 字段等等。
借助 compose
var f = R.compose(sort(item => item.id),
filter(item => item.date >= 20160101),
map(item => {item.id, item.content})
);
f(json);
不借助 compose,怎么写呢?这该用多少行代码才能做到并且还要在满足可复用性的前提下。
这样子的处理有什么好处呢?后者,数据混淆在逻辑之中,很难做到两者的分离,对于再复杂一点的业务来说,更是增加了抽象的难度。
而先通过 compose 的形式组合出一套完整的公式再等待数据的输入更有利于处理逻辑和数据的分离。这其实正是体现了函数式编程的**所在:先有公式,再把数据塞给公式处理,返回结果,而不是算好一个值,再给另一个公式。公式有一个简单,那公式有多个怎么办,compose 一下变成一个。
这也是这里没有用 underscore 中 compose 的原因,underscore 虽然是函数式,但它总需要先传入数据,然后再有函数的链式调用,它更像是以容器为中心对操作的串联,更像是 jQuery 的变形,这个和真正的函数式有点脱节。
如果你有看过 Redux 源码的话,不知道有没有留意到 Redux 中applyMiddleWare部分也是借用了 compose 这一理念来实现的,这一部分,其实又和 Koa 是类似的。把一个个的中间件,经过 compose 组合成一条流水线(一个函数),然后将需要处理的数据传入这条流水线,顺次加工处理。
// redux 中 compose 的源码
// FYI,这部分也是我认为 Redux 处理的最漂亮的地方
function compose(...funcs) {
return (...args) => {
if (funcs.length === 0) {
return args[0]
}
const last = funcs[funcs.length - 1]
const rest = funcs.slice(0, -1)
return rest.reduceRight((composed, f) => f(composed), last(...args))
}
}现在回到主题,继续看 Koa。
Koa 中 compose_es7 依赖于另一个库完成的: composition,主要的任务是借助 compose 的**将多个函数组合成一个,废话嘛,当然这不是该库存在的意义,它的真正价值在于对异步(比如Generator, Async/Await,Promise)的支持。。 代码量也不多,一共151行代码,它的执行结果最终返回的是既支持 Promise 也支持 Generator 的对象,这个在 koa 的源码中也可以看出来。
实现看代码,这里只看 Promise 的处理方式,其他的类似。通过结合使用例子来看源码,先例子。
// compose 例子
var compose = require('composition');
var stack = [];
stack.push(function (next) {
console.log('first');
return next.then(function(){
console.log('first is ok');
})
});
stack.push(function () {
console.log('second');
return new Promise(function(resolve){
setTimeout(function(){
console.log('second is ok');
resolve()
});
});
});
// 被 composition 组装之后的样子,它的**执行结果**为一个 promise。
compose(stack)().then(function (val) {
console.log(' ---- final -----');
});再源码。
// 对外exports 出去的接口
function compose(middleware) {
return function (next) {
next = next || new Wrap(noop);
var i = middleware.length;
// 注意:这里的 next,作为参数传入到Wrap 中去。
while (i--) next = new Wrap(middleware[i], this, next);
// 最终返回的是 **第一个** 被包装过的对象。
return next
}
}
// constructor,then, 和 _getPromise() 都没啥可说的。
function Wrap(fn, ctx, next) {
if (typeof fn !== 'function') throw TypeError('Not a function!');
this._fn = fn;
this._ctx = ctx;
this._next = next;
this._called = false;
this._value = undefined;
this._promise = undefined;
this._generator = undefined;
}
Wrap.prototype.then = function (resolve, reject) {
return this._getPromise().then(resolve, reject);
}
Wrap.prototype._getPromise = function () {
if (this._promise === undefined) {
var value = this._getValue();
this._promise = isGenerator(value)
? co.call(this._ctx, value)
: Promise.resolve(value);
}
return this._promise
}
// 注意:真正的执行最初压入 stack 的函数是在这里执行的;其次,将 next 当做参数传入到所要执行的 fn 中,记不记得 Koa 中使用的时候,总是 `yield next`,next 就是在这里作为参数传入的。
Wrap.prototype._getValue = function () {
if (!this._called) {
this._called = true;
try {
this._value = this._fn.call(this._ctx, this._next);
} catch (e) {
this._value = Promise.reject(e);
}
}
return this._value
};对 Generator 的处理大同小异吧,这里略过。正是因为源码中多了 Promise 和 Generator 的互转,所以完成了同时满足这两种异步编程风格的使命。
细心的人可能会发现,Composition 源码部分_getPromise也有用到co,承担了把 Generator 转化为 Promise 的功能。那在 koa 中呢?
还是看这行代码
var fn = this.experimental
? compose_es7(this.middleware)
: co.wrap(compose(this.middleware));那就从 co.wrap(compose(this.middleware)) 开始看起吧。co.wrap 可以将一个 generator 形式转化为 promise。在这里先对 middleware 做了组合处理,翻翻 compose 的源码。
function compose(middleware){
return function* (next){
var i = middleware.length;
var prev = next || noop();
var curr;
// 通过循环展开中间件
while (i--) {
// 获取当前索引下的 generator 并调用该 generator(不是真正的执行),同时为它准备 next 参数。next 参数的值就是队列中当前 i+1 的Iterator Object。
curr = middleware[i];
prev = curr.call(this, prev);
}
// 最终返回的,便是在队列首部并且已经准备就绪的 Iterator Object。
yield* prev;
}
}单独看这段代码,还不能充分理解,结合一段示例代码来充分消化 compose 的妙处。
var stack = [];
stack.push(function* (next){
console.log('first-before');
// 注意:这里使用的是 yield*,不是 yield。
yield* next;
console.log('first-after');
});
stack.push(function* (next){
console.log('second-before');
yield* next;
console.log('second-after');
});
stack.push(function* (){
console.log('third');
});
var fn = compose(stack);
for(var ret of fn()) {
console.log(ret.value);
}
/**
///////////////// 输出
first-before
second-before
third
second-after
first-after
**/当 fn 开始执行时,会从第一个 Generator 生成的 Iterator Object 开始执行,并带有 next 参数。就像拨洋葱一样,一层一层深入,再一层层出来,回忆一下 Koa 官网的那个配图。
compose 的最后一行 yield* prev 和 yield prev 区别是什么呢?从概念上就可以看出两者的区别:
如果需要在 Generator 函数 内部,调用另一个 Generator 函数,则必须使用yield*,否则没有效果。换句话说,yield*等于在外层的 Generator 函数内部,部署了内层 Generator 函数的 for of 循环。
看例子。
function* inner() {
yield 'inner';
}
function* outer_without_asterisk() {
yield 'outer - begin';
yield inner();
yield 'outer - after';
}
function* outer_with_asterisk() {
yield 'outer - begin';
yield* inner();
yield 'outer - after';
}
for(var val of outer_without_asterisk()) {
console.log(val);
}
/**
///////// 输出。 并没看到 inner 迭代器的输出,因为 `yield inner() 这里返回的只是 Iterator Object.
outer - begin
{}
outer - after
**/
for(var val of outer_with_asterisk()) {
console.log(val);
}
/**
///////// 输出。 并没看到 inner 迭代器的输出,因为 `yield inner() 这里返回的只是 Iterator Object.
outer - begin
inner
outer - after
**/Ok,在回到主线任务前,还有一个问题,还没展开,就是
Koa 官网中的中间件使用的方式还记得吗?
app.use(function* (next) {
yield next;
});而在我刚才的示例代码中是
stack.push(function* (next){
// ...
yield* next;
// ...
});前者使用的是 yield(前者也可以使用 yield_),后者必须使用 yield_ 这是为什么?这个问题当做 谜2 放在 co 的源码分析完之后自会有答案。
现在回头再看,发现compose其实和上面 composition 差不了太多,区别比较大的地方是是这里返回的是 Generator。返回后的 Generator 交给 co.wrap 进一步处理。
// 如上面提到的,只是将 generator 转化为 promise。
co.wrap = function (fn) {
// 缓存着原始的 generator,以备不时之需。
createPromise.__generatorFunction__ = fn;
return createPromise;
function createPromise() {
return co.call(this, fn.apply(this, arguments));
}
};真正的 co 函数长什么样子,打开这个传颂很久的神秘盒子看看。
function co(gen) {
var ctx = this;
var args = slice.call(arguments, 1)
return new Promise(function(resolve, reject) {
if (typeof gen === 'function') gen = gen.apply(ctx, args);
if (!gen || typeof gen.next !== 'function') return resolve(gen);
// 启动 generator
onFulfilled();
function onFulfilled(res) {
var ret;
try {
ret = gen.next(res);
} catch (e) {
return reject(e);
}
// 将执行结果传入 next
next(ret);
}
// 异常处理代码略掉...
function next(ret) {
// 根据 ret 的各种情况进行分别处理。
// 如果迭代器已经执行完毕,则通过 Promise 的 resove 函数触发改变 Promise 的状态。
if (ret.done) return resolve(ret.value);
// 将迭代器上一步的返回值进行 promise 化处理。
var value = toPromise.call(ctx, ret.value);
if (value && isPromise(value)) return value.then(onFulfilled, onRejected);
return onRejected(new TypeError('You may only yield a function, promise, generator, array, or object, '
+ 'but the following object was passed: "' + String(ret.value) + '"'));
}
});上一步中,对迭代器每一步的返回值都进行 toPromise 转变。
// 根据obj 的不同类型进行不同方式的 promise 形式的转变。比如数组时,对象时,或者函数,还有当是 Generator 时。
function toPromise(obj) {
if (!obj) return obj;
if (isPromise(obj)) return obj;
// 当为 generator 时,再调用 co 对该 obj 做一次转化为 promise 的操作。
if (isGeneratorFunction(obj) || isGenerator(obj)) return co.call(this, obj);
if ('function' == typeof obj) return thunkToPromise.call(this, obj);
if (Array.isArray(obj)) return arrayToPromise.call(this, obj);
if (isObject(obj)) return objectToPromise.call(this, obj);
return obj;
}看到这里是不是有点拨开云雾见天日的感觉呢。在对 obj 做 toPromise 的转变时,如果 obj 为 Generator,那就再 obj 上再调用一次 co,co 函数内部会执行这个 Generator,并通过返回的 promise 跟踪状态,触发相关逻辑(回想上面的 co 函数源码)。对外部的好处,统一了编程风格,自然也就不用再去 care yield 关键字后面到底是个异步任务呢,还是个 Generator 呢。
谜1和谜2 的疑团是不是解开了呢。不过话说回来,多一次的调用,自然就多出一点额外的性能损耗,如果追求极致的性能,那就明确指名使用 yield* next,如果需要统一的风格,那大可以直接用 yield next 的形式。via: promote yield* next instead of yield next
到这里,Koa 的源码基本粗略得过完了,肯定还有一些比较细节但处理比较好的地方尚未顾及到,等再有机会 review 时再做补充吧。
有没有发现什么值得学习借鉴的地方,或者好的**,有,三点。
去年在看 Ruby on Rails 时非常喜欢它的简洁高效,后来也迷上了 Ruby 这门语言,感觉它就像一个魔法盒子一样,总是能看到很多得意于 Ruby 这门语言的自身大量特性而独有的一些解决问题的方式,所谓处处都是 Magic。
最近找来「Ruby 元编程」这本书,边看边做一些 Note 当做备忘。
元编程是什么,直白一点得说:就是编写能写代码的代码。程序世界的语言解释为
编写在运行时操纵语言构件的代码。
Ruby 的 class 关键字和别的编程语言有个很大的区别点,它更像是一个作用域操作符而不是类型声明语句,核心作用是把你带到类的上下文中,让你可以在类中定义方法,通俗点就是当类不存在时定义类,当类存在时重新打开(不会覆盖原有的定义),并在原有类的基础上进行修改,这个也叫 打开类技术(Open Class)。
obj.instance_variables 来查看obj.methods 或者 Module.instance_methods区别:一个对象的实例变量存在于对象自身,方法存在于类中。所以对象共享方法,但不共享变量。
Class.instance_methods(false) # 查看对象非继承来的方法模块就是一组实例方法,而类则是一个增加了若干功能(superclass, new)的模块,实例化对象,类,模块这几个的关系可以在下面的图谱中看到。
如何选择这俩者,如果希望它被别处包含(或者当成命名空间),应该选择模块;如果希望它被实例化或者继承,应该选择类。
在类外面,可以这样引用常量:
MyModule::MyClass::MyConstant
MyModule.constants # 查看当前模块都有哪些常量插播一个 Sidebar 的知识点,require 和 load 区别: 前者用来导入一个类库,后者用来执行一段代码。所以 load 有第二个参数可以控制执行代码的作用域。
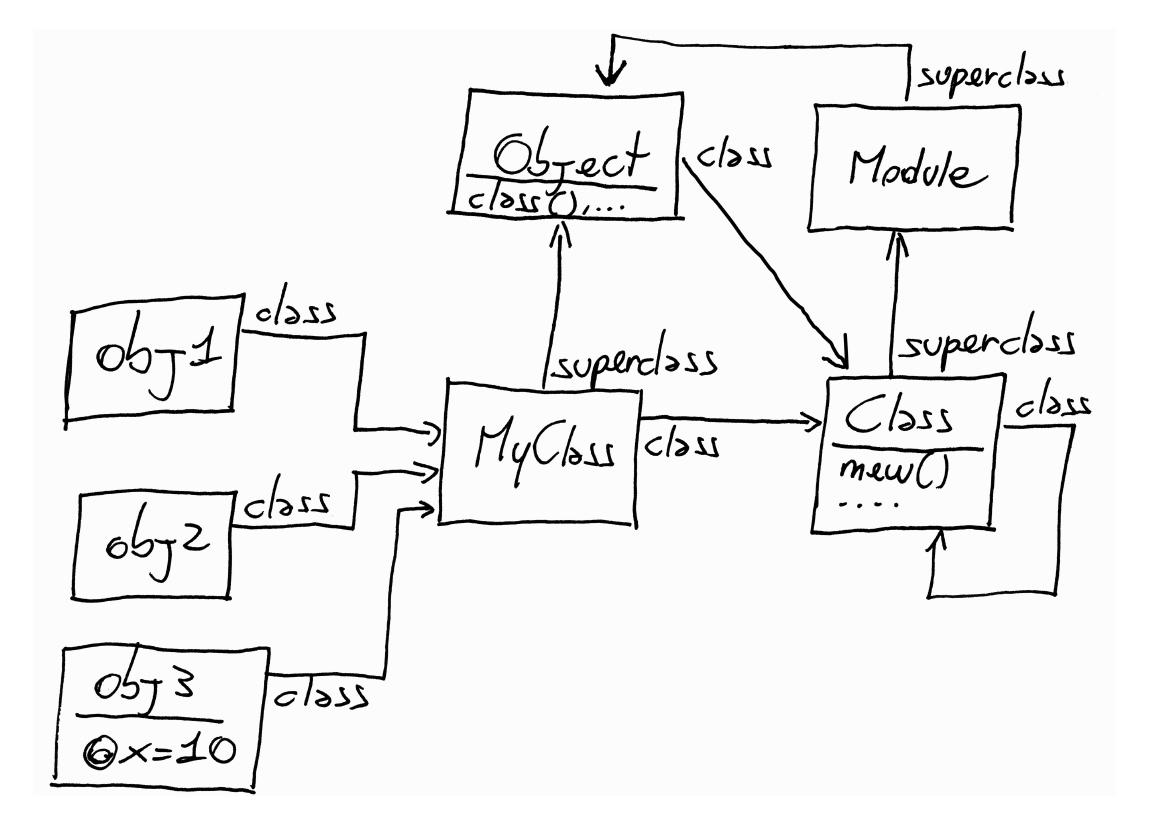
第一步,方法查找,第二步 执行这个方法。当执行的时候 ruby 需要一个 self 的东西。
接收者:调用方法所在的对象。祖先链: 从那个当前类移动到超类,依次直到 Object,Kernel,最后到达 BasicObject. 通过在一个 class 上调用 ancestors 可以查看到该类的祖先链。
Kernel 模块,比如看起来像关键字的 print 其实就是在 Kernel 里定义的。
Kernel.private_instance_methods.grep /^p/ 顶级上下文:当开始运行程序时,Ruby 会创建一个 main 的对象,self 就指向的 main。self 的角色,通常由最后一个接收到方法调用的对象来充当。
私有方法,好零散,私有方法只能被隐含接收者调用。也就是说不能在私有方法调用时传递一个接收者(这是规则,自然也就有打破规则的方法,下文会提到)。
静态语言和动态语言,在前者中,在对象上调用一个不存在的方法,编译器这一关就不会通过;而在动态语言中,只有当真正执行到时才会检查,不存在时会报错。基于这两者的区别,所以这也是我为什么一直喜欢动态语言的原因之一:灵活。
以 obj.send 的形式调用对象方法,好处是对象调用的方法名可以当做一个参数,这样的意义是可以在运行期间来动态决定调用的是对象的哪一个方法。使用场景想想 javascript 中的 obj[prop] 就知道了。这个技术有个很 cool 的名字 动态派发(Dynamic Dispatch)。
插播广告,关于符号,简单补充下两者区别:
其实没有太大意义的区别,两者也是可以进行互相转换(String#to_sym()和Symbol.to_s() )的。但是存在一个最佳实践,符号用于标识一个事物的名字,尤其是和元编程相关的名字,比如方法名。另外一点区别,符号是不可变的,而字符串是可以动态变换的,这也意味着两者的速度可能稍微有些区别。
回到这里, obj.send 调用时,根据方法名是否确定来选择是字符串 or 符号。
有了动态派发,少不了一个**动态定义方法(Dynamic Method)**的组合,就完美了。 Module#define_method
class MyClass
define_method :m do |arg|
arg * 3
end
endObject#send 有个杀手锏功能,这玩意破天荒得可以在外部 call 对象的私有方法,所以有时候会借用这个方法来打破封装。 Rails - ActiveRecord/validations.rb 把 ActiveSupport::Callbacks 模块扩充到ActiveRecord 上就借用了这个妙招。
Object#send很酷炫,method_missing 叼炸天。
被 method_missing 处理的消息,从调用者的角度来看是没有区别的,但是接收者其实没有对应的方法,这个叫做幽灵方法(Ghost Method)
一个代码例子:
class MyClass
def initialize
@attributes = {}
end
def method_missing name, *args
attribute = name.to_s
if attribute =~ /=$/
@attributes[attribute.chop] = args[0]
else
@attributes[attribute]
end
end
end
nick = MyClass.new
nick.name = 'nick'
nick.nameRails 中的 ActiveRecord 就是使用了这个特性把数据库中的表和 model 进行了关联。强大,自然也会容易难以控制。一定需要注意,绝大多数,当不满足特定条件时需要通过 super 的形式把信息传递到 Kernel#method_missing 上,否则程序出错都不知道是哪里的问题了。
相关的两个点:
当幽灵方法和真实存在的方法冲突时,后者会胜出(废话嘛, 只有当方法不存在才会产生幽灵方法),基于这个情况,有时候可能需要一个白板(Blank State)类,BasicObject 就是了。
EOF
康威定律中提到一点, 设计系统的组织产生的设计和架构等价于组织间的沟通结构. 类比得说, 一个有章可循的组织所产生的代码也应当是可读性良好的, 反之也成立.
其次, 无规则不成方圆. 同样在一个组织中, 无规范无法成就一份便于团队共享, 交流的代码, 所以有了这篇文档.
这份文档的目的, 并不在于将前端开发中的方方面面都有所提及, 而是会有所侧重, 同时也包含一些最佳化实践, 未来也会不断更新. 另外, 老生常态的一些规则不会从该文中出现或者只是简单略过.
包含四部分: 常规性, HTML, CSS及Javascript 相关, Git 相关.
以上部分可以借助 EditorConfig 来完成, 在其中找到对应的自己所使用的编辑器插件, 下载安装. 其次, 在项目根目录下配置 .editorconfig 文件即可.
<!DOCTYPE html> 来声明文档类型(有想过为什么 HTML5 的文档头部声明这么短吗);div 和 p 的不同场景, 清楚 em 和 strong 的区别;j-作为前缀, 指代它作为一个 Hook 存在;item-btn;background-image 的 URL 时, 需要省略掉 http:, 目的是为了让协议自适应。ml10 指代 margin-left: 10px, u-fr 指代 float: right;u-开头, 例如u-center 居中;t- 作为前缀;以 switch 组件为例
// c-switch 为switch 组件的根节点类名
// c-switch-disabled 指名当前组件处于禁用状态
// c-switch-button 为组件中子元素的类名
<div class="c-switch c-switch-disabled" >
<span class="c-switch-button"></span>
</div>首先, 是时候要拥抱 ECMAScript 2016(ES7)了, 任何时候将目光朝向未来, 都不会存在大的方向性的错.
c- 开始;Body 节点下;git rebase master 的方式, 会得到一个线性的提交记录, 如果不小心使用了 git merge master 的方式, 会将开发分支的 commit 历史变得混乱, 试想一下, 先把 master merge 到分支上, 未来也是会要把该分支 merge 到 master 上, 结果是不是会很糟糕呢;const messagebus = new Vue();
// 监听事件
messagebus.$on('button.clicked', () => { ... });
// 触发事件
messagebus.$emit('button.clicked');当你看完全文, 可能会发现, 本篇文章并没有全文都着笔于代码规范上, 在这之外, 也添加了很多个人认为的最佳实践与见解.
在程序优化中有一条法则是
永远不要优化代码,直到你真正需要
对于程序的设计也是依然如此, 保证不要引入不必要的复杂.
持续更新中...
Grunt 是一款基于 Nodejs 的任务工具,并不如大多数文章介绍的只局限于前端自动化工具,只是大多数情况下应用于前端的重复性任务。大多数场景下,Nodejs 可以干什么,它也就可以干什么。
这篇文章从 介绍,新手入门,核心源码分析,进阶 - Grunt 的卡顿缘何引起? 以及 其他 这五个节组成,最后一节是填坑。
选择一个目录,新建项目目录,并进入
$ mkdir grunt-tutorial && cd grunt-tutorial创建 src 目录,并在其中新建 grunt-tutorial.js
$ mkdir src && cd src && echo 'console.log("foo");' > grunt-tutorial.js第一步,安装全局 grunt-cli 模块
$ npm install grunt-cli -g第二步 安装项目所要用到的 grunt 模块
$ npm install grunt --save-dev第三步 编写 Gruntfile.js
假设项目根目录下已经有了_package.json_, 如果没有请先运行npm init补上该文件。
Gruntfile.js 是个 js 文件,所以,按写 js 的形式,想怎么写,就怎么写。但是如果新手想知道如何上手,和上面一样,我建议,按照官方给出的例子,复制一份。
这个环节涉及到的知识点
-g, 一个却是--save-dev。挖坑,下面会提到。附送一个官方教程: Getting started
接下来看实际应用。
假设你现在的 Gruntfile.js 是从官方 copy 的,长下面这个样子,这是前提。
module.exports = function(grunt) {
// 项目配置和任务配置
// 每个任务以 该任务的名称为key 作为 initConfig 的参数对象的属性配置.
grunt.initConfig({
pkg: grunt.file.readJSON('package.json'),
uglify: {
options: {
banner: '/*! <%= pkg.name %> <%= grunt.template.today("yyyy-mm-dd") %> */\n'
},
build: {
src: 'src/<%= pkg.name %>.js',
dest: 'build/<%= pkg.name %>.min.js'
}
}
});
// 利用 *grunt.loadNpmTasks* 来加载插件
grunt.loadNpmTasks('grunt-contrib-uglify');
// 通过 *grunt.registerTask* 来注册任务名
// 当第一个参数为 default 时,命令行可以直接以 *grunt* 的形式来来启动该任务
// 第二个参数为所要执行的任务数组.
grunt.registerTask('default', ['uglify']);
};那么现在安装所要执行任务的依赖插件 grunt-contrib-uglify
$ npm install grunt-contrib-uglify --save-dev执行完毕后,就是使用了
# 或者直接 grunt. 原因代码中注释说了,因为调用 registerTask 时已经将 uglify 任务作为默认任务了
$ grunt uglify
命令行应该会输出DONE, without errors字样,OK。
这个环节用到的知识点
在 grunt-tutorial 目录下新建目录 custom-tasks, 创建文件 frog.js,内容如下
module.exports = function(grunt) {
grunt.registerTask('frog', 'custom task - frog', function(color) {
color = color || 'green';
console.log('the %s frog said guagua', color);
});
};打开 Gruntfile.js,在grunt.loadNpmTasks('grunt-contrib-uglify');下面添加一行
grunt.loadTasks('./custom-tasks');现在可以在命令行中执行
$ grunt frog:white这个时候,应该也是会输出一下信息的。
Running "frog:white" (frog) task
the white frog said guagua
Done, without errors
这个环节的知识点
本节提到的三个 API是使用 Grunt 的过程中非常重要。
到这里我想,大部分人应该说是可以达到会用 grunt 的程度了,但是还差一步,不做这一步,依然无法畅快使用 Grunt。那就是熟悉常用的 API,除了上面提到的几个,包括但不限于:
最好在使用的过程中把 API 列表都看一遍,混个眼熟,在用的时候能想起来就可以。
grunt 的安装使用分为两个组成,一个是全局的 grunt-cli,为了区分暂时叫做global-grunt。一个是项目目录下的 grunt 模块,叫做 local-grunt 吧。
不算命令行补全的话,只做了一件事:通过 resolve 和 findup 来查找当前目录的 grunt 模块,并启动。
关键几行代码,从这里可以看出,查找到项目 grunt 模块后,直接调用cli API来启动local-grunt。
// 同步版本的 findup。
var findup = require('findup-sync');
// resolve 模块和 require.resolve 类似,但前者支持的更广,比如支持同步和异步,支持指定目录
var resolve = require('resolve').sync;
//basedir 也支持自定义配置
var basedir = process.cwd();
// 获取 local-grunt模块
try {
// 通过 resolve 模块 在basedir目录下查找 grunt 模块的文件路径
gruntpath = resolve('grunt', {basedir: basedir});
} catch (ex) {
// 从当前目录往上查找 grunt 模块文件路径.
gruntpath = findup('lib/grunt.js');
// 如果没找到,退出提示用户未找到 代码略
if (!gruntpath) { /** 代码略 **/ }
}
// 通过 cli API 来启动 local-grunt
require(gruntpath).cli();剩余所有的事情都是由 local-grunt 中处理完成的。
最关键的是解析命令行参数,并传递给相应任务并启动任务,输出执行结果。
这里代码比较多,摘重要的一点点来看。下面是关键部分的目录结构
$ tree -L 3
├── lib
│ ├── grunt
│ │ ├── cli.js
│ │ ├── ...
│ │ ├── task.js
│ │ └── template.js
│ ├── grunt.js
│ └── util
│ └── task.js因为 global-grunt 调用了local-grunt 中 /lib/grunt.js 的 cli 接口,就从这里开始入口。
// ...
// Expose internal grunt libs.
function gRequire(name) {
return grunt[name] = require('./grunt/' + name);
}
// ...
gRequire('cli');
// ...cli 是在 /lib/grunt/cli.js 定义的,负责解析命令行相关的逻辑,比如接收并格式化处理命令行传递进来的参数。
var cli = module.exports = function(options, done) {
// ...处理 options
// 执行 grunt.tasks, 根据配置 cli.options 启动相关任务 cli.tasks
grunt.tasks(cli.tasks, cli.options, done);
};
// 通过第三方 nopt 模块 解析命令行参数,赋值给相应变量: cli.tasks 和 cli.options
var parsed = nopt(known, aliases, process.argv, 2);
// 例如 grunt -v foo baz
// cli.tasks 就为 ['foo', 'baz']
// cli.options 就为 {verbose: true, ...}
cli.tasks = parsed.argv.remain;
cli.options = parsed;接下来,我们转回/lib/grunt.js ,看看 grunt.tasks 都干了什么。
grunt.tasks = function(tasks, options, done) {
// 版本, 帮助, 日志 相关略过.
// 如果传了任务名 task 就执行任务 task,否则执行 default 任务
var tasksSpecified = tasks && tasks.length > 0;
tasks = task.parseArgs([tasksSpecified ? tasks : 'default']);
// 初始化
// 加载 tasks, 执行Gruntfile.js。
task.init(tasks);
var uncaughtHandler = function(e) {
fail.fatal(e, fail.code.TASK_FAILURE);
};
process.on('uncaughtException', uncaughtHandler);
// 设置 task error 和 done 时的回调。
task.options({
error: function(e) {
fail.warn(e, fail.code.TASK_FAILURE);
},
done: function() {
process.removeListener('uncaughtException', uncaughtHandler);
// 任务执行结束相关逻辑,代码略。
}
});
// run 这里在 API 语义上稍微有些歧义,它只是将各个任务详细信息(name, fn, info, args等)放入 task 实例的任务队列`_queue`中,并没有运行。
// 详见 /lib/util/task.js Task.prototype.run 函数定义.
// 备注: task 的实例化在 /lib/grunt/task.js 中进行
tasks.forEach(function(name) { task.run(name); });
// 开始执行任务
task.start({asyncDone:true});
};有一个部分,很关键,但上面一笔带过了,就是加载task。这一切以 Gruntfile.js 为切入点来看一看。
上面提到了 Gruntfile.js 是在 task.init(tasks); 这里加载并执行的。那么现在看看这个函数。
task.init = function(tasks, options) {
// 如果当前需要执行的任务队列都是通过 registerInitTask 来注册的
// 那么可以不需要加载执行 gruntfile。
var allInit = tasks.length > 0 && tasks.every(function(name) {
var obj = task._taskPlusArgs(name).task;
return obj && obj.init;
});
// 查找 gruntfile
var gruntfile = allInit ? null : grunt.option('gruntfile') ||
grunt.file.findup('Gruntfile.{js,coffee}', {nocase: true});
if (gruntfile && grunt.file.exists(gruntfile)) {
// 设置当前工作目录,来保证所有的路径信息都是相对于 Gruntfile.j这个文件的
process.chdir(grunt.option('base') || path.dirname(gruntfile));
loadTask(gruntfile);
} else if (options.help || allInit) {
} else {
// 其他分支。
}
(grunt.option('npm') || []).forEach(task.loadNpmTasks);
(grunt.option('tasks') || []).forEach(task.loadTasks);
};不要停,继续跟 loadTask 。
var loadTaskStack = [];
function loadTask(filepath) {
// 暂存之前最后一个 registry, 并重置 registry
loadTaskStack.push(registry);
registry = {tasks: [], untasks: [], meta: {info: lastInfo, filepath: filepath}};
var filename = path.basename(filepath);
var fn;
try {
// 加载 taskfile 并执行。
fn = require(path.resolve(filepath));
if (typeof fn === 'function') {
fn.call(grunt, grunt);
}
// log 相关
} catch(e) {}
// 恢复 registry
registry = loadTaskStack.pop() || {};
}所以说,不管在命令行实际调用时执行哪个 task,在 Gruntfile.js 中,只要写了类似 loadNpmTasks 或者 loadTasks这样的代码,这个阶段它都会将这个任务加载进来。m(_ _)m。
还记得自定义任务 grunt.loadTasks 吗,也是通过 loadTask 来加载的(/lib/grunt/task.js),代码略过。
到这里了,接下来让任务 真正 执行起来吧,入口在Task.prototype.start 这里。
Task.prototype.start = function(opts) {
var nextTask = function() {
var thing; // 获取接下来需要执行的任务
do {
thing = this._queue.shift();
} while (thing === this._placeholder || thing === this._marker);
// 如果没有 thing,就返回吧,通知注册好的 done 函数 任务执行结束。代码略
// this._placeholder作为一个占位符,目的是为了动态修改当前执行的任务队列。
// 当在 task 的 factory 中手动调用grunt.task.run(['foo'])时
// 能将 foo 插入到一个"合适"的位置而不是被 push 到队尾。
// 具体插入操作看 `Task.prototype._push` API.
this._queue.unshift(this._placeholder);
var context = {
nameArgs: thing.nameArgs,
name: thing.task.name,
args: thing.args,
flags: thing.flags
};
this.runTaskFn(context, function() {
return thing.task.fn.apply(this, this.args);
}, nextTask, !!opts.asyncDone);
}.bind(this);
// 开始执行
nextTask();
};寻找脉路,看runTaskFn。
// done 参数为任务执行完毕的 callback,也就是上面的 nextTask 的化身。
Task.prototype.runTaskFn = function(context, fn, done, asyncDone) {
var async = false; // 是否为异步任务 标志位
var complete = function(success) {
// 处理 success 信息 ...
// 然后传递参数,执行 done(err, success);
process.nextTick(function () {
done(err, success);
});
}.bind(this);
// 处理异步任务的奥秘所在。
// 这里就是 task 中调用的 async 的函数声明。调用后返回一个函数,当异步执行任务完毕后,
// 主动调用传递任务执行结果,通过上面的 complete 来拉起队列里面的下一个任务继续执行。
context.async = function() {
async = true;
return function(success) {
setTimeout(function() { complete(success); }, 1);
};
};
this.current = context; // 注册当前任务的相关信息
try {
var success = fn.call(context);
// 如果标志位设置为 true 了,回调就不会通过这里来继续执行下一步了.
if (!async) {
complete(success);
}
} catch (err) {complete(err); }
};到此,核心代码和一个完整的流程就介绍完了。
这个环节结束,现在,我想你应该知道为什么有两个 grunt 模块了吧。简单来说就是 grunt-cli 为了查找 local-grunt 模块同时启动它。
看到这里,大家对 grunt 的核心代码应该是有一个轮廓性的大致了解。使用的话,估计是没问题了。
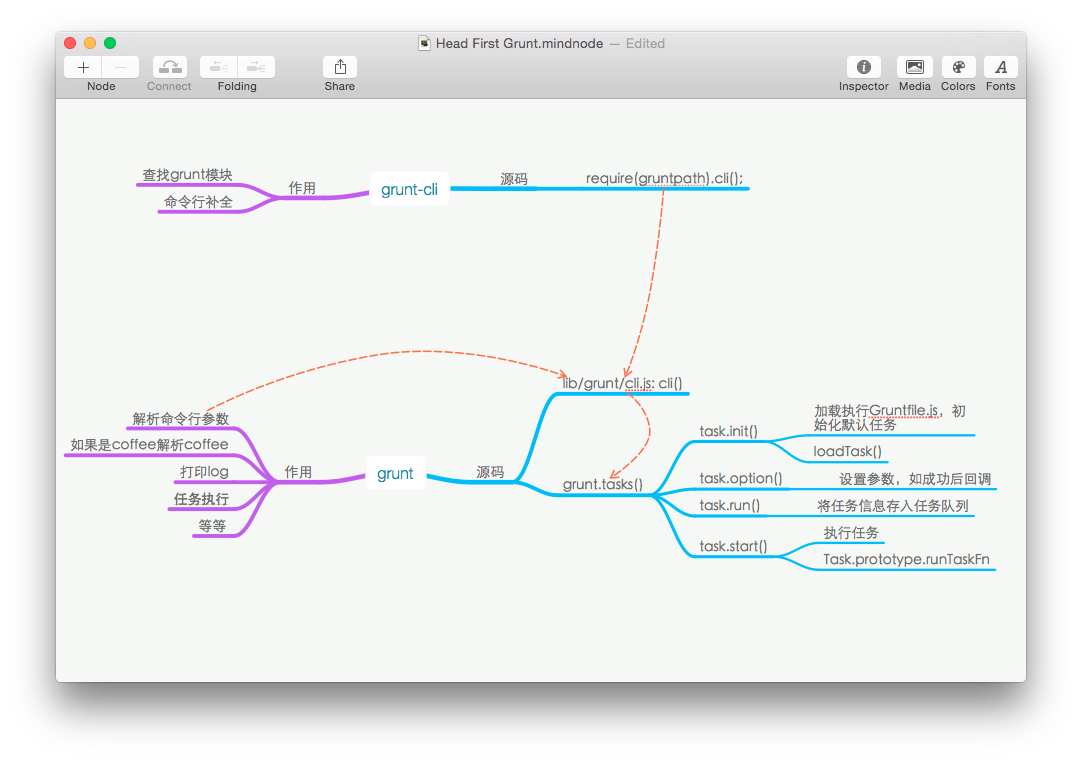
附一张图来帮助理解 Grunt 的整体结构。
如果你还想为 grunt 提点速的话,请继续往下看。否则可以关了这篇文章干别的去。
上面一部分其实埋了一个伏笔,提到了关于 grunt 的加载插件的时机。试想如下场景
当我们的 Gruntfile.js 是这样写:
grunt.initConfig({
// ...
});
// 加载一堆 grunt 插件
grunt.loadNpmTasks('grunt-contrib-uglify');
grunt.loadNpmTasks('grunt-contrib-jshint');
grunt.loadNpmTasks('grunt-contrib-cssmin');
grunt.loadNpmTasks('grunt-contrib-watch');
grunt.loadNpmTasks('grunt-contrib-connect');
// 可能还有...
// 这里还有自定义插件
grunt.loadTasks('ultraman');
// 可能还有...而我们在使用的时候,并不一定每次都会调用全部加载进来的插件,大部分情景可能是只使用其中一个,比如说这样:
$ grunt uglify其实在内部逻辑上,不管你使用的是哪个插件, Grunt 都会为你默认加载所有写在 Gruntfile.js 中的组件。(备注,这么说不太严格,但是目前绝大多数Gruntfile.js 写法都是会被加载,譬如说下面这种情况就不会被加载,但是这种写法的使用太少。)
// foo 函数是定义在 Gruntfile.js 中,并且在 grunt 初始化执行 gruntfile.js 时,foo 函数并没有被调用到,总之遵循 js 的执行就是了。
module.exports = function(grunt) {
// ... 其他部分
function foo(){
grunt.loadNpmTasks('grunt-contrib-watch');
}
}这个问题,也是我在使用的过程中发现,当任务数稍微多些,此时在命令行执行 grunt taskname 时都会有一定的卡顿才会由执行任务过程和结果的输出。
为了确定这个问题是由 Grunt 引起,所以就找来了这么一个工具 time-grunt,它能显示出 Grunt 在执行任务的时候各个阶段的耗时,大概是这样样子:
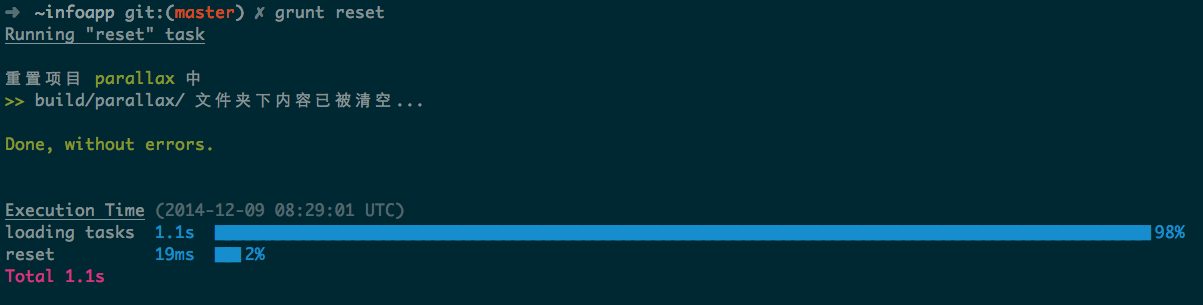
明显能对比, load 阶段的时间大于执行任务的时间,当任务数越多,load 就会越耗时间(取决于 task 的数目和复杂度,task 一多这个耗时非常明显),问题确定了就开始改造 Grunt 吧。
问题提炼一下,在初始化执行 Gruntfile.js 时已经加载了全部的任务,而大多数情况都用不上。
怎么解决呢,所以第一步,不要让它在初始化的时候加载插件,换句话说就是全部去掉出现在 Gruntfile.js 中 grunt.loadNpmTasks这样的语句。
第二步 在任务执行阶段的前期来加载该任务相关 js 代码。
上面在核心源码分析这一部分,提到了 /lib/grunt.js 文件中这样一行代码以及相关它的注释。
tasks.forEach(function(name) { task.run(name); });该函数的作用:将各个任务的详细信息放入 task 实例的任务队列 _queue。
所以就选择这里作为切入点,通过劫持 Task.prototype.run函数 来实现加速 Grunt 的需求。
代码如下:
// 先劫持原有的 run 函数。
var run = grunt.util.task.Task.prototype.run;
grunt.util.task.Task.prototype.run = function() {
var args = [].slice.call(arguments, 0);
this.parseArgs(arguments).forEach((function(item) {
var taskname = item.split(':')[0];
// 如果该任务还没有被注册,这个时候再加载
if (!this._tasks[taskname]) {
load(taskname);
}
}).bind(this));
// 最后调用原有 run 函数
run.apply(this, args);
};
function load(name) {
// 根据 name 和一定规则在本地查找相关 task 的代码了。
// 比如说 'grunt-contrib-' + name
// 比如说有可能是用户自定义的插件,那就在相关目录下查找 name + '.js' 文件是不是存在之类的。
// 代码略。
}现在,再来通过 time-grunt 来看一下时间消耗情况。

明显降少了 load task 阶段的时间消耗,其实就是只 load 本次任务需要用到的插件。
对了,最好不要修改 Grunt 的源代码,和 time-grunt 类似,尽量以插件的形式修改,这同时就要求这样的插件的执行时机要尽量“早一些”。
这个环节介绍的其实就是 grunt-task-loader 插件的由来。
最后,填一个坑,**为什么一个是 -g, 一个是--save-dev?**这里面其实涉及到两个点,一个是 npm 包的安装方式,一个是 npm 包的依赖管理方式,这俩问题又存在一些交叉,因为都是在安装 npm 包。
当安装一个npm 包时,与 -g 对应的选项是不带 -g 的形式,前者是全局安装,后者会根据情况决定是安装在当前项目目录下或者用户目录下。
另一个问题,npm 包的依赖,常见的存在三种形式:
require('grunt')的代码来,即使这些插件的 node_modules 目录下存在着一份 grunt 的拷贝,也不会被实际应用到。摘一段官方的描述:What we need is a way of expressing these "dependencies" between plugins and their host package. Some way of saying, "I only work when plugged in to version 1.2.x of my host package, so if you install me, be sure that it's alongside a compatible host." We call this relationship a peer dependency
via: Peer Dependencies ,这篇文章从该依赖诞生的原因,要解决的问题说的很清楚了。
其实还有两个,optionalDependencies 和 bundledDependencies。 前者是可选,即使依赖包出错,npm 也可以继续初始化。后者是一组包名,他们会在发布的时候被打包进去,不太常用,我对这俩者的了解也只局限于此了。
EOF
今天,前端的重要性是不容置疑的。但是这个职位的重要性,在十多年前,却并不如今天这般肩负产品成败的使命,甚至不存在这样的分工。这篇文章简要回顾了这十多年的前端变迁,以及今天的web开发前端为什么愈来愈重要。此外,也会当前非常流行的四大前端框架做一简单对比,帮助我们更好得针对未来项目做出更合适的技术选型。

谈到前端的发展及重要性的,不可脱离三大因素:
二和三可能做技术的人们都会有所了解,为什么第一点互联网对人们生活影响力的不断深入 也会影响前端 的发展?这里谈谈我的理解,互联网在不断入侵及深入普通人的生活所带来的情况是,从技术的角度来看这个问题是,用户体验的地位在不断被强调,产品的易用性愈来愈重要(尤其是在同类型产品的竞争中),界面的简洁,美观,交互是否能够对用户产生持续性吸引,再具体一些,产品性能表现如何,页面在用户交互的感官体验中是否良好,能够带给用户轻松愉悦的使用感受,等等,这些都交叉性得指向了一个技术岗位: 前端。
大约在90年代至2000年初的时间轴里,可以称为早期的web开发,是不分前后端的,HTML 片段大多由 Server 端生成,直接渲染到浏览中,甚至包括了表现,就是 table 满天飞的那个年代。Javascript 在其中也只是充当了玩具的角色,充其量做个表单校验,“这个脚本语言还能干点什么呢?估计也就这点用途吧”。这是那个时代开发者对 Javascript 的印象。整个 web 开发可能也没有应用起 MVC 的模式来。
这样的好处是什么呢?试想在那个年代,浏览器所呈现的页面绝大多数是一个简单的页面,文本/图片可能是呈现最多的媒介,也不存在太过复杂的页面交互,在这样的项目背景下,后端自然也是可以充当一定的前端开发任务。少量的大型 web 项目,前端也并没有太多的开发量。
坏处呢,当新的时代来临,项目日益复杂的情况下,项目难以维护,甚至难以正常开发出来。
团队成员的配置上,也没有前端后端的分工,因为不需要。
这是互联网 web 初期的一个缩影。
当我们谈论用户体验的时候,我们在讲什么。这是绕不过去的一个点:前端。
当 Amazon 绞尽脑汁想如何提高网站交易量的时候,他们发现网站每慢100ms,将导致收入下降1%。
...
当 Google 的 Gmail 上线的时候,人们惊呆了,Javascript 原来可以这么酷。
回头看国内,淘宝的崛起,始终有一个团队功不可没,UED。
前端渐渐浮出水面,于此同时伴随着的是,前后端分离的开发理念,web开发中的MVC最佳实践。后端掌控着 Mmodel,Controller。前端在 View 的领域里深耕,代码的可维护性明显得到了质的提升。后端只需要处理好 逻辑 相关就可以了,再也不用管美观,易用等产品可用,易用性方面的问题了。而这些恰恰是一个合格的前端应该具备的素养,大的方面来看:
(不止于此,我想的肯定没有概括全。)
有时候我讲,前端还应该至少是半个产品(保证和产品的沟通,和产品协商如何让产品更好用),半个后端(知道哪些东西后端做合理,哪些应该放在前端),还有对美,对细节的追求(更是必不可少,否则还是去做后端吧)。
这个时代的前端开发人员,大多是备受摧残的一代,虽然 IE6 已经有了数年的历史,但依然稳坐浏览器份额的半壁江山,尤其是在国内,面对无数个 IE 系的坑,前端开发人员是有苦也得硬撑着,也开始了一些工程化方面的积累。
HTML5,CSS3,ES2015还没有到来,前端在隐忍着,有的时候,前端也会自我调侃,“我们是页面仔。”
当 Ryan Dahl 创造出独门武功 Node.js 然后隐退江湖的时候,不知道他是否能想到今天 Node.js 的发展。
当HTML5,CSS3,ECMA2015 被支持越来越好,越来越好的时候。
当 V8 的开发团队为了挑战 Javascript 引擎执行效率而剑走偏锋跳过了字节码生成直接从抽象语法树生成本地代码的时候,Safari 也在不断为 squirrelFish 注入多层优化机制来提升 Javascript 的时候。
当移动端开发大潮来临的时候。
当 Javascript 被应用在硬件开发的时代来临的时候。
等等。
前端工程师觉得他们的舞台,越来越大了。这个时候的前端工程师,也应该是面临着自身技术栈的转型阶段,从之前的需要懂点jQuery,CSS 各种 Hack,浏览器兼容性,YUI,Extjs,文件combo,代码压缩混淆,无模式过渡到 ES5,Backbone,Knockout,LESS,SASS,Spine,Grunt,Gulp,RequireJS,AMD,依赖管理到现在的 React,Angular,Vue,响应式,数据可视化,自动化测试,新的调试方式,SPA,离线, Postcss,cssnext, JSX, Flow等。围绕着 Javascript/前端 的技术发展愈演愈烈,发展愈来愈快。举个栗子,Grunt 的兴起,到新贵 Gulp 的出现,再到 Browserify 进入人们的视野,今天的 webpack 俨然成为了新的宠儿,可能也就是一年一换代而已,他们都代表着在新的时间里,解决问题的更先进的生产力。

图示: 今年常见库/框架/工具
当然了,今天的前端需要了解的远远不止这些,从这一阶段初始的大前端到 Node.js 带来的全栈开发,业界一些团队也在跃跃欲试。React Native 的开源也让前端插足本应该是 Native 的领域。MVVM 的模式重新刷新了前端开发人员的思维模式,还有 Flux 架构。Webpack 团队甚至还在考虑着将 HMR 投入到生产阶段。
前端已经不是一个小小的领域,越来越多的开发需要工程化方面的思考。项目也从最初的 web page 过渡到了 web app,前端承担的职责也越来越多,势必对架构提出了新的挑战。组件化,组件之间的通讯,全局事件模型,ES2015中的模块系统,不可变数据结构, JSX,数据在 app 中的流向,函数响应式编程在前端的应用。
有人说,前端社区的活跃是因为目前还比较混乱,都还在尝试摸索着最佳实践,试图寻找最适合前端这一特殊领域的开发,这让部分普通的开发者会觉得追这些技术很痛苦,或者质疑学习他们的收益。我倒不这么认为,前端社区的活跃加之Javascript语言的活跃也正是它吸引人的原因,这也是它本身复杂,独有魅力的地方,这也是多方面决定,其次变化同时也意味着可能性,意味着这个行业在成长,身处其中,环境也会促人成长,当然了,如果在这趟知识的漩涡中只停留在了皮毛,也没多大意义。
Angular 是 MV* 的,Google 推出的前端框架,核心是依赖注入,借助于该特性,可以非常自由得声明组件,在想使用的地方就像写 HTML 标签一样使用组件,正如官网给出的 slogon 一般: HTML enhanced for web apps!,从这一点来说,增强了 HTML 的自描述能力。举个栗子来说明这一特性。
<slider items="items"></slider>
That's it. 它在号称专注于未来 web app 开发的同时,也带来了大量新的概念**,比如 Services,Directive,Scope,Model等,这些设计如同一把双刃剑,在吸引来部分开发者的同时,也让更多传统的前端开发者久久不能转变至此。
前不久,Google 也推出了 Angular 2 的 beta 版本,这一次,他们向其他几个框架库以及 web components 靠拢了一些,但依然保持了非常激进的血脉。强调了组件化这一大的趋势,同时在大幅度提升了 Angular 1 中被开发者抱怨多次的脏检查的性能问题。
这篇文章我意在提及四个具有代表性的框架,而 React 是我主观最喜欢的,我甚至一度认为究其原因,想来应该是 React 背后团队对 React 的野心所向:当 React 在 0.14 版本中将 react-dom API 从核心库中剥离开来的时候,便似乎看到了这个团队的高瞻远瞩,他们想要统一界面编程。换句话说,只要涉及 UI 的编程实践,都可以通过 React 来实现,比如常见的 web,以及深入到移动端 iOS,Android的实现,这可不是简单的 Webview,而是让前端开发者借助于 React 来开发 Native 应用,想想这是多么兴奋且有挑战的一件事,从商业的角度来看,如果在 React 这条技术栈能够胜任产品需求的情况下,如果公司能够拥有一个精通 React 的团队,那这个团队便是可以同时胜任 Web + iOS + Android 端的 开发任务, 很棒,是吧。
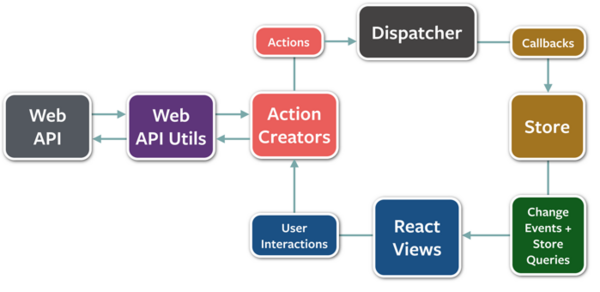
图示: React 和 Flux 模式架构图。
此外,React 还有一些别的更被业界所熟知的特点:
还有常常与它结伴出现的 Webpack 工具,给开发者带来了创新性的调试特性:HMR。
如果对其中两点以上都感兴趣,那一定得亲自尝试下 React 为开发者带来的魅力,我坚信选择一条好的酷的技术栈能够增加开发者 coding 的愉悦感,肯定是这样。
Vue 是国人开发的一个非常具有国际范的开发框架,非常出色。单纯的性能对比,Vue 比 React 快10倍,React 比 Angular 快 10 倍(备注:10是一个概数,和场景有关,但借助于底层的实现方式,Vue 确实表现得足够让人爱不释手)。
图示:vue 和 vuex 数据流。
Vue 给我的感觉是又可爱又可口的感觉,不知道有没有别人注意到,Vue 的 API 设计非常非常得简约,能用单个单词表现的,决不用多个单词去表现,在 API 层面也保证了框架给人的整体印象,小巧可爱简约。可能很多人觉得这是无足轻重的事情,但我不这么认为,这恰恰是我喜欢 Vue 的一个原因,一个不可忽视的重要原因。想想很多年之前的 jQuery,它的 API 不也是这样的风格吗,在议论着YUI太过于理想国教条化的实现同时也在赞美着 jQuery 的精巧,使用简单,上手容易。
在最初,Vue 的设计是借鉴了 Angular 的一些 MVVM 的特点,比如双向绑定,但又没有 Angular 那么陡峭的学习曲线。可以说,扫一遍 Api 和官方文档,就可以开始开发了。
这次冰箱项目,本来是想使用 React + Redux 的技术栈的,但因为硬件 pad 性能表现实在太差的原因,所以最终采用了 Vue。我想如果没有外界原因,这一决定将会一直持续下去。
在提到了学习曲线,脑里突然蹦出了 Ember 这个怪兽,因为它的学习曲线算得是更陡峭,官方的开发团队甚至调侃称之为 Learning cliff 而不是 learning curve。之前在 ThoughtWorks 时有过一段短暂的使用 Ember 的经历,还谈不上自己充分掌握了 Ember ,只是觉得这是个巨无霸,迫不得已的情况下,我不会在自己和自己团队中的项目中主动青睐它,毕竟一个原因是核心文件动辄压缩后也几百K再加一个必须使用的 Ember-data也是几百 K 的大小;其次它比 Angular 还不稳定(现在稳定下来没还不太清楚)。
Ember 团队是这样宣称的,它为开发者做了更全面的事情,只要按照 Ember 框架的那一套哲学来,写出来的项目是可以做到应用结构清晰,易于维护,保证项目质量,正如用 Java 语言开发项目一般,一个良莠不一的开发团队也可以做出漂亮的项目。如果说之前是个 Rails 程序员的话,上手 Ember 估计会很快,因为它从 Rails 项目借鉴了一些优秀的理念。
为项目选择一个框架/库/工具永远不会是一个公平的事情,这里面涉及了方方面面的因素权衡:
上面看起来因素很多,但每个因素可能都有一定的权重,或者在某些场景下权重会变更高。但在正常情况下,坦白得来讲,这其中个人主观应该是会占据了相对很大的比重,当然个人主观也可以理解为,决策者一定是是先行结合了以上各个因素,然后看似用主观的方式表达出自己的思考结果“咱们就用这个吧”,突然想起了《程序员的思维修炼》一书中关于对专家分析问题的内容。
暂且不论项目方面的考虑,只谈论这些框架的异同。
正如 OSX,Windows和 Linux 之间,Android 和 iOS 之间他们在长期的演进过程中,不断提升自身优势,也不断得在吸取对方的优势,拿来己用,求同存异。
React 的虚拟 DOM 因为另辟蹊径解决了困扰前端界多年的渲染性能的难题,而赢得了超越了其他几个框架的好评,但之后 Ember 也借鉴了此引入了 Glimmer 模板渲染引擎,再到最近的 Vue 2.0 的版本更新,也宣布了引入一个轻量级类似的 Virtual-DOM 的实现,从这个角度来看,Facebook 团队也算是为前端界贡献了一个非常漂亮的 idea,Virtual-DOM 借此风生水起。
从另一个角度编程范式上来说,大家可能会感受到近几年来函数式编程的热度有所升温,原因是众多方面的,但我觉得这其中应该是有这些框架的推波助澜。React 将函数式编程带入到 UI 编程的世界里来,在它的设计哲学中,一个组件就是一个状态机,改变了组件的输入就可以得到不同的输出,这是相对应的,这不正是函数式编程的根本要领吗,想想又像大学时所学的电子电路。如果厌倦了命令式编程,对声明式抱有好感时,那很可能会因此对 Angular 的关注度有所上升,借助依赖注入,将复杂的逻辑隐藏起来,专注于干什么,让 HTML 更具有语义化。
那么 Vue 呢,最初它从 Angular 处获得一些灵感,但因为厌倦它的庞大而诞生,所以 Vue 一开始注定是一个小巧的框架,也还是可以从 Vue 中看到一些 Angular 的影子,比如 directive,filter 等。最大的不同在于 Vue 从一开始就倡导组件化的,Component-oriented,视图是一棵组件树,页面应该像搭积木一般通过搭建组件而构成,恩,这是它和 React 非常相似的地方,也是 web components 的设计趋势。
因为底层的实现迥异,响应式编程在 Vue 也和和 React 中也是完全不同的实现原理,前者中,需要一个对象/数组是 mutable 的,当改变一个对象的属性时,只需要简单得给该属性赋值就可以通过对应的getter/setter触发与之相关联的 watchers,性能在这里基本不会有任何的损失。而 React 采用的是 immutable data的形式,当需要改变对象属性的时候,必须将该对象重新设置, 这样在之后重绘时只需要简单比较两次前后两个数据对象是否一致就可以了 this.props.data !== this.nextProps.data,而如果在 React 中采用 mutable 的 data,那必然会丢掉 React 高性能的一大优势。Angular 的 dirty checking 就不提起了。
Ember这个怪兽,还没有提及,其实他们都还有一些特性,比如计算属性,比如对 DOM 操作的批量异步更新,Vue 如此,React 中也有同类似的策略实现,在batchingStrategy 中。(这一点 Angular 中是否有实现,我目前还没有了解到。)
前端以它独有的特性(混合了GUI编程及逻辑编程,同时编写三门语言)和 Javascript at everywhere (浏览器端,服务器端,还有目前正处于前期的硬件编程)都吸引了大批开发者,这是一个非常cool的岗位,我有幸经历了其中的第二阶段的末期到第三阶段。这篇文章是我对此的一个简要回顾及当前阶段几个框架的一个简要对比。其中每一个技术点都值得再花费大量的时间调研深入探索研究。
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.

