-
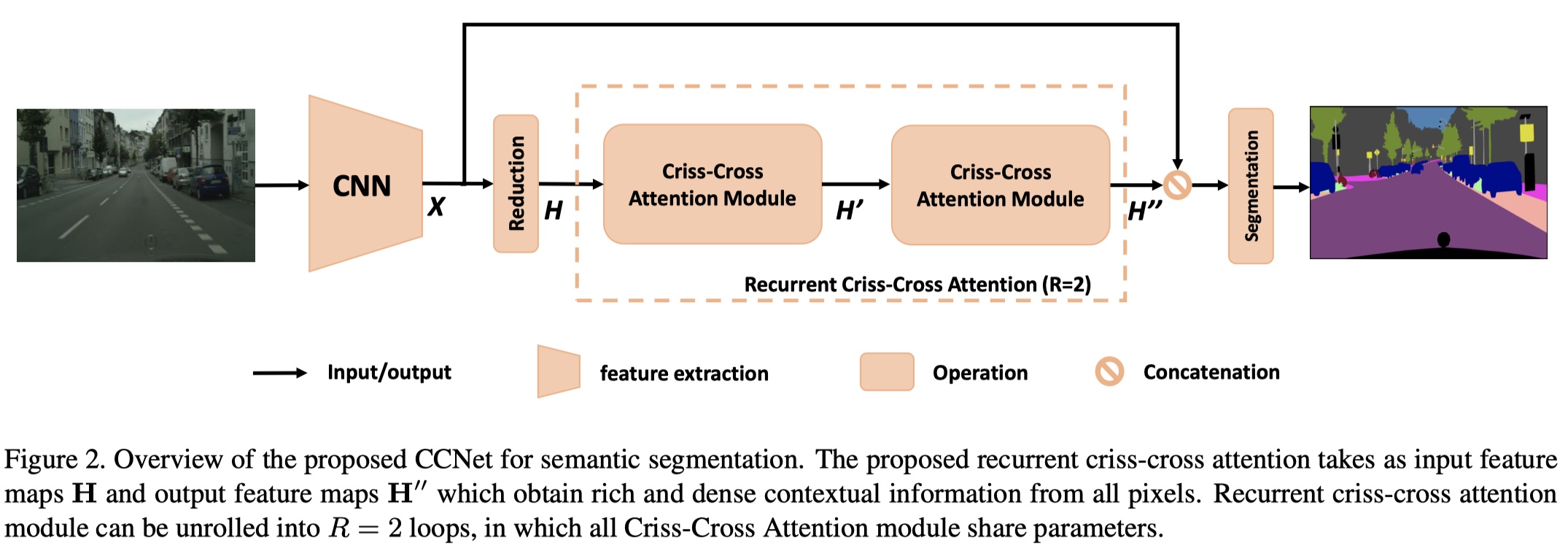
CCNet网络结构图:
- 环境: Python3.6, Pytorch1.0
- 各版本通用代码: MyData_kfold.py, MIouv0217.py, predict.py
- CCNet0403代码: CC.py, ccnet.py, train_kfold.py
- CCNet0509代码: CC.py, ccnet.py, ccnet_v3_0509.py, train_cc_v3_0509.py
- 一副无人机拍摄的高分辨率矿区影像图
- 实验室进行标注的对应label
- 进行裁剪后的320 x 320的图像与label数据
- MyData_kfold.py:数据载入代码,采用k折交叉验证载入数据
- CC.py:CCNet中Criss-Cross Attention模块的实现
- ccnet.py: 整个CCNet的实现代码,基于resnet
- ccnet_v3_0509.py:实现CCA模块与aspp模块并行,CCA模块加入deeplabv3
- train_kfold.py:CCNet0403版本训练代码,5折交叉验证方式读取训练
- train_cc_v3_0509.py:CCNet0509版本训练代码,5折交叉验证方式训练
- MIoUData.py:为计算MIoU载入label和预测数据
- MIouv0217.py:计算Acc、MIoU等指标的代码,需使用MIoUData.py载入的数据
- predict.py:使用训练好的模型进行预测,给预测结果涂色
- CCNet参考版本:参考代码,使用了辅助loss,对结果的两个输出拼接成list,分别求loss,得到的模型效果很差。
- ps:应该是自己对该代码实验的理解有误,后期改为论文中的样例,将x与x_dsn进行cat,再分割
- CCNet_0403版本:放弃辅助loss,将两个输出cat,再进行分割,效果还算可以,实验结果如下表
- CCNet_v3_0509版本:将CCA模块加入deeplabv3模块,与aspp模块并行,cat两者的输出,再分割,结果如下
- CCNet0607: deeplabv3-ccnet-resnet152 + 5折交叉验证 + dataset3数据调整 + 使用weight减轻样本不均衡
| 版本&指标 | Acc | MIoU | Kappa | 地面 | 房屋 | 道路 | 车辆 |
|---|---|---|---|---|---|---|---|
| CCnet0403 | 0.9412 | 0.6846 | 0.7845 | 0.9876 | 0.7803 | 0.9252 | 0.4353 |
| CCnet0509 | 0.9593 | 0.7947 | 0.8593 | 0.9863 | 0.8818 | 0.8856 | 0.6740 |
| CCNet0607 | 0.9603 | 0.8057 | 0.8684 | 0.9722 | 0.8907 | 0.9216 | 0.7745 |
-
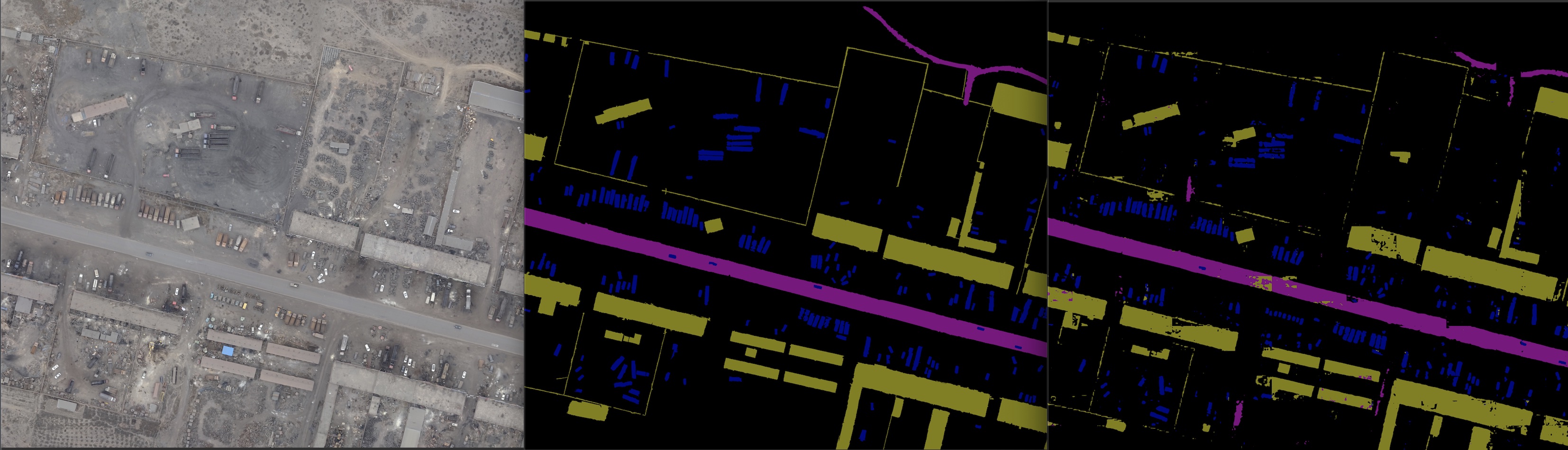
CCNet0403版本,左至右为原图、GT、predict
-
CCNet_v3_0509版本,左至右为原图、GT、predict
-
- CCNet-v3-0607版本(在0509版本加入样本权重且调整数据)实验预测图:

- CCNet-v3-0607版本(在0509版本加入样本权重且调整数据)实验预测图: