yassouali / pytorch-segmentation Goto Github PK
View Code? Open in Web Editor NEW:art: Semantic segmentation models, datasets and losses implemented in PyTorch.
License: MIT License
:art: Semantic segmentation models, datasets and losses implemented in PyTorch.
License: MIT License

![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")































































































































Hi Yassine,
I trained Deeplab V3+ (80 epochs) and got Mean_IoU 0.6310 (Pixel_Accuracy : 0.828).
I trained PSPNet (75 epochs so far) and got Mean_IoU 0.6330 (Pixel_Accuracy : 0.827).
All with with ResNet101 and "base_size": 1024, "crop_size": 512. It seems lower than the performance they reported in the paper (PSPNet, DeepLabV3+).
If I remove "base_size": 1024, will it use the original input size for training? I got Deeplab V3+ in this case with Mean_IoU 0.6470 (Pixel_Accuracy : 0.83).
Do you think this performance is right? And how can I continue training with coarse mode? Thanks!
I run the experiment on DeepLabV3Plus and use the same configuration as the PSPNet(resnet50) provided in the project. The mIoU only reach 70.899 after 80 epoch . After checking for several times, I still can't locate the error. Do you have any advice? Besides, could you share the reproducible configuration of the DeepLabV3Plus?
deer author:
your library is very cool! I have reproduced the voc and ade data using this library.But I have a lot of problems when training with my own data set.
VOC data set format:(it show me this)
Detected GPUs: 1 Requested: 1
0%| | 0/100 [00:00<?, ?it/s]
ADE:can not study the charactor of the object.that only study the charactor of the background
Can I use resent50 pretrained model for training on custom dataset
Hi,I trianed my own dataset using deeplab. I got AssertionError, but I don't how to fix it.

Thank you!
How can I modify config.json for monitor a validation loss or metric in the earlystop in training process?
Hello, recently I meet the some problem My research is a two class segmentation. I've changed dataset from voc.py.
My problem is,Even if the losses keep going down,but the Pixel_acc and mean_Iou didn't change from 5th epoch to 50th epoch.The evaluation didn't change too much.I don't know why.Could you tell me this a bug of code or I do something wrong ?
Waiting for your reply.Thank you!
Sorry to bother you again. I want to call the model trained by your code in c++,when I use traced to exchange .pth to .pt,code in figure1,it always report the error that Missing key(s) in state_dict and Unexpected key(s) in state_dict in figure 2 and figure 3.I guess it is because of the config.json,but I don’t know how to call the config.json in traced,could you please teach me if you know about that,thank you very much.Looking forward to your reply.



I used the checkpoint of PSPNet downloaded from this repository, but the val mIoU as following is quite low at the beginning.

Does anyone share the same problem with me?
After configuring the environement as required (win10, anaconda3, python3.6.9, pytorch1.1.0, cuda9.0, torchvision0.3.0, etc.), I want to use the command "python train.py --config config.json" to train a PSP model on the dataset VOC (I have not changed the config.json), but with the following bug:
(There are many informations about PSPNet and config file...)
Detected GPUs: 1 Requested: 1
0%| | 0/1323 [00:00<?, ?it/s]Traceback (most recent call last):
File "train.py", line 61, in
main(config, args.resume)
File "train.py", line 42, in main
trainer.train()
File "C:\Users\USTC\capstone\dl frame\pytorch_segmentation\base\base_trainer.py", line 101, in train
results = self._train_epoch(epoch)
File "C:\Users\USTC\capstone\dl frame\pytorch_segmentation\trainer.py", line 49, in _train_epoch
for batch_idx, (data, target) in enumerate(tbar):
File "C:\Anaconda3\envs\pytorch\lib\site-packages\tqdm_tqdm.py", line 1017, in iter
for obj in iterable:
File "C:\Users\USTC\capstone\dl frame\pytorch_segmentation\base\base_dataloader.py", line 76, in iter
self.preload()
File "C:\Users\USTC\capstone\dl frame\pytorch_segmentation\base\base_dataloader.py", line 64, in preload
self.next_input, self.next_target = next(self.loaditer)
File "C:\Anaconda3\envs\pytorch\lib\site-packages\torch\utils\data\dataloader.py", line 582, in next
return self._process_next_batch(batch)
File "C:\Anaconda3\envs\pytorch\lib\site-packages\torch\utils\data\dataloader.py", line 608, in _process_next_batch
raise batch.exc_type(batch.exc_msg)
TypeError: Traceback (most recent call last):
File "C:\Anaconda3\envs\pytorch\lib\site-packages\torch\utils\data_utils\worker.py", line 99, in _worker_loop
samples = collate_fn([dataset[i] for i in batch_indices])
File "C:\Anaconda3\envs\pytorch\lib\site-packages\torch\utils\data_utils\worker.py", line 99, in
samples = collate_fn([dataset[i] for i in batch_indices])
File "C:\Users\USTC\capstone\dl frame\pytorch_segmentation\base\base_dataset.py", line 132, in getitem
label = torch.from_numpy(np.array(label, dtype=np.int32)).long()
TypeError: can't convert np.ndarray of type numpy.int32. The only supported types are: float64, float32, float16, int64, int32, int16, int8, and uint8.
so, what can I do to solve this? I am a beginner...
I want to train my own data.But it often meet some problem.
"split": "train_aug", // Split to use, depend of the dataset and "split": "val", i dont know how to set it.that make me meet a lot questions.Hope you will me some suggestions!my data just like ade20k.
Hi, is it possible to make support for image and labels data stored in numpy arrays (like (n, imwidth, imheight, channels) and (n, imwidth, imheight, classes))? It will be good for smooth migration from tensorflow.

no predict.py on github
especially well ordered models and all written in readable format. Thanks
Hi, follow issue #39 , there are some new issues when run the models deeplabv3, fcn, and gcn. It seems there is a common problem, so I wonder if you know something about it, I'll appreciate it a lot.
/home/notegeek/anaconda3/envs/semantic/lib/python3.6/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:541: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_qint8 = np.dtype([("qint8", np.int8, 1)])
/home/notegeek/anaconda3/envs/semantic/lib/python3.6/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:542: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_quint8 = np.dtype([("quint8", np.uint8, 1)])
/home/notegeek/anaconda3/envs/semantic/lib/python3.6/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:543: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_qint16 = np.dtype([("qint16", np.int16, 1)])
/home/notegeek/anaconda3/envs/semantic/lib/python3.6/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:544: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_quint16 = np.dtype([("quint16", np.uint16, 1)])
/home/notegeek/anaconda3/envs/semantic/lib/python3.6/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:545: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_qint32 = np.dtype([("qint32", np.int32, 1)])
/home/notegeek/anaconda3/envs/semantic/lib/python3.6/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:550: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
np_resource = np.dtype([("resource", np.ubyte, 1)])
Traceback (most recent call last):
File "train.py", line 62, in
main(config, args.resume)
File "train.py", line 27, in main
model = get_instance(models, 'arch', config, train_loader.dataset.num_classes)
File "train.py", line 17, in get_instance
return getattr(module, config[name]['type'])(*args, **config[name]['args'])
TypeError: 'module' object is not callable
I want to test on my own data(images). Can I achieve this?
Hi.
I want to train from the checkpoint of PSPnet.pth on my dataset. However, it is a matter that the size of output is 21 and that of my data is 4. Can I load the model and change the output size?
There are some error in gcn.py:
1、 in BottleneckGCN, when stride != 1 : x += identity got wrong ;
2、 self.layer4 must set channel==2048 like "*[BottleneckGCN(2048, 2048, kernel_sizes[1], out_channels_gcn[1])"
could you show the more data directory messages ? just like what files in the data directory ,the list of train data.
Hi
Iam not able to train on multiple gpus. Even though I mention "n_gpu": 4 and args.device='0,1,2,3', it only considers gpu 0 and trains the model on gpu 0.
Line no 90 in base_trainer.py is given like this
"device = torch.device('cuda:0' if n_gpu > 0 else 'cpu')"
Thanks
Hello, I have already trained a model with PSPNet and ADE20K dataset, now I want to turn to other models like SegNet. But I got the error as follows, I have only changed the 'name' and 'arch/type' in the config.json from 'PSPNet' to 'SegNet'(same for UperNet and GCN), so could you please help me with that?
{
"name": "SegNet",
"n_gpu": 2,
"use_synch_bn": true,
"arch": {
"type": "SegNet",
"args": {
"backbone": "resnet50",
"freeze_bn": false,
"freeze_backbone": false
}
},
"train_loader": {
"type": "ADE20K",
"args":{
"data_dir": "data/ADEChallengeData2016",
"batch_size": 8,
"base_size": 400,
"crop_size": 380,
"augment": true,
"shuffle": true,
"scale": true,
"flip": true,
"rotate": true,
"blur": false,
"split": "training",
"num_workers": 8
}
},
"val_loader": {
"type": "ADE20K",
"args":{
"data_dir": "data/ADEChallengeData2016",
"batch_size": 8,
"crop_size": 480,
"val": true,
"split": "validation",
"num_workers": 4
}
},
"optimizer": {
"type": "SGD",
"differential_lr": true,
"args":{
"lr": 0.01,
"weight_decay": 1e-4,
"momentum": 0.9
}
},
"loss": "CrossEntropyLoss2d",
"ignore_index": -1,
"lr_scheduler": {
"type": "Poly",
"args": {}
},
"trainer": {
"epochs": 40,
"save_dir": "saved/",
"save_period": 10,
"monitor": "max Mean_IoU",
"early_stop": 10,
"tensorboard": true,
"log_dir": "saved/runs",
"log_per_iter": 20,
"val": true,
"val_per_epochs": 5
}
}
/home/notegeek/anaconda3/envs/semantic/lib/python3.6/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:541: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_qint8 = np.dtype([("qint8", np.int8, 1)])
/home/notegeek/anaconda3/envs/semantic/lib/python3.6/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:542: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_quint8 = np.dtype([("quint8", np.uint8, 1)])
/home/notegeek/anaconda3/envs/semantic/lib/python3.6/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:543: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_qint16 = np.dtype([("qint16", np.int16, 1)])
/home/notegeek/anaconda3/envs/semantic/lib/python3.6/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:544: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_quint16 = np.dtype([("quint16", np.uint16, 1)])
/home/notegeek/anaconda3/envs/semantic/lib/python3.6/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:545: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_qint32 = np.dtype([("qint32", np.int32, 1)])
/home/notegeek/anaconda3/envs/semantic/lib/python3.6/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:550: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
np_resource = np.dtype([("resource", np.ubyte, 1)])
Downloading: "https://download.pytorch.org/models/vgg16_bn-6c64b313.pth" to /home/notegeek/.cache/torch/checkpoints/vgg16_bn-6c64b313.pth
Traceback (most recent call last):
File "/home/notegeek/anaconda3/envs/semantic/lib/python3.6/urllib/request.py", line 1318, in do_open
encode_chunked=req.has_header('Transfer-encoding'))
File "/home/notegeek/anaconda3/envs/semantic/lib/python3.6/http/client.py", line 1254, in request
self._send_request(method, url, body, headers, encode_chunked)
File "/home/notegeek/anaconda3/envs/semantic/lib/python3.6/http/client.py", line 1300, in _send_request
self.endheaders(body, encode_chunked=encode_chunked)
File "/home/notegeek/anaconda3/envs/semantic/lib/python3.6/http/client.py", line 1249, in endheaders
self._send_output(message_body, encode_chunked=encode_chunked)
File "/home/notegeek/anaconda3/envs/semantic/lib/python3.6/http/client.py", line 1036, in _send_output
self.send(msg)
File "/home/notegeek/anaconda3/envs/semantic/lib/python3.6/http/client.py", line 974, in send
self.connect()
File "/home/notegeek/anaconda3/envs/semantic/lib/python3.6/http/client.py", line 1415, in connect
server_hostname=server_hostname)
File "/home/notegeek/anaconda3/envs/semantic/lib/python3.6/ssl.py", line 407, in wrap_socket
_context=self, _session=session)
File "/home/notegeek/anaconda3/envs/semantic/lib/python3.6/ssl.py", line 817, in init
self.do_handshake()
File "/home/notegeek/anaconda3/envs/semantic/lib/python3.6/ssl.py", line 1077, in do_handshake
self._sslobj.do_handshake()
File "/home/notegeek/anaconda3/envs/semantic/lib/python3.6/ssl.py", line 689, in do_handshake
self._sslobj.do_handshake()
ssl.SSLError: [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed (_ssl.c:852)
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "train.py", line 61, in
main(config, args.resume)
File "train.py", line 26, in main
model = get_instance(models, 'arch', config, train_loader.dataset.num_classes)
File "train.py", line 16, in get_instance
return getattr(module, config[name]['type'])(*args, **config[name]['args'])
File "/home/notegeek/pytorch_segmentation/models/segnet.py", line 12, in init
vgg_bn = models.vgg16_bn(pretrained= pretrained)
File "/home/notegeek/anaconda3/envs/semantic/lib/python3.6/site-packages/torchvision/models/vgg.py", line 154, in vgg16_bn
return _vgg('vgg16_bn', 'D', True, pretrained, progress, **kwargs)
File "/home/notegeek/anaconda3/envs/semantic/lib/python3.6/site-packages/torchvision/models/vgg.py", line 92, in _vgg
progress=progress)
File "/home/notegeek/anaconda3/envs/semantic/lib/python3.6/site-packages/torch/hub.py", line 433, in load_state_dict_from_url
_download_url_to_file(url, cached_file, hash_prefix, progress=progress)
File "/home/notegeek/anaconda3/envs/semantic/lib/python3.6/site-packages/torch/hub.py", line 349, in _download_url_to_file
u = urlopen(url)
File "/home/notegeek/anaconda3/envs/semantic/lib/python3.6/urllib/request.py", line 223, in urlopen
return opener.open(url, data, timeout)
File "/home/notegeek/anaconda3/envs/semantic/lib/python3.6/urllib/request.py", line 526, in open
response = self._open(req, data)
File "/home/notegeek/anaconda3/envs/semantic/lib/python3.6/urllib/request.py", line 544, in _open
'_open', req)
File "/home/notegeek/anaconda3/envs/semantic/lib/python3.6/urllib/request.py", line 504, in _call_chain
result = func(*args)
File "/home/notegeek/anaconda3/envs/semantic/lib/python3.6/urllib/request.py", line 1361, in https_open
context=self._context, check_hostname=self._check_hostname)
File "/home/notegeek/anaconda3/envs/semantic/lib/python3.6/urllib/request.py", line 1320, in do_open
raise URLError(err)
urllib.error.URLError: <urlopen error [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed (_ssl.c:852)>
Added a custom data loader script and trained it using PSPNet with resnet50 backbone. mIOU on validation data is around 67.05.
When trying to test the model on test images, Im getting below error while loading the checkpoint
"Traceback (most recent call last):
File "/home/cognomine/Documents/workspace_caffetwopython36/yassouali_Segmentation/inference.py", line 164, in
main()
File "/workspace_caffetwopython36/yassouali_Segmentation/inference.py", line 123, in main
model.load_state_dict(checkpoint)
File ".conda/envs/pytorchpy36/lib/python3.6/site-packages/torch/nn/modules/module.py", line 777, in load_state_dict
self.class.name, "\n\t".join(error_msgs)))
RuntimeError: Error(s) in loading state_dict for DataParallel:
Missing key(s) in state_dict: "module.initial.0.0.weight", "module.initial.0.1.weight", "module.initial.0.1.bias", "module.initial.0.1.running_mean", "module.initial.0.1.running_var", "module.initial.0.3.weight", "module.initial.0.4.weight", "module.initial.0.4.bias", "module.initial.0.4.running_mean", "module.initial.0.4.running_var", "module.initial.0.6.weight", "module.initial.1.weight", "module.initial.1.bias", "module.initial.1.running_mean", "module.initial.1.running_var", "module.layer1.0.conv1.weight", "module.layer1.0.bn1.weight", "module.layer1.0.bn1.bias", "module.layer1.0.bn1.running_mean", "module.layer1.0.bn1.running_var", "module.layer1.0.conv2.weight", "module.layer1.0.bn2.weight", "module.layer1.0.bn2.bias", "module.layer1.0.bn2.running_mean", "module.layer1.0.bn2.running_var", "module.layer1.0.conv3.weight", "module.layer1.0.bn3.weight", "module.layer1.0.bn3.bias", "module.layer1.0.bn3.running_mean", "module.layer1.0.bn3.running_var", "module.layer1.0.downsample.0.weight", "module.layer1.0.downsample.1.weight", "module.layer1.0.downsample.1.bias", "module.layer1.0.downsample.1.running_mean", "module.layer1.0.downsample.1.running_var", "module.layer1.1.conv1.weight", "module.layer1.1.bn1.weight", "module.layer1.1.bn1.bias", "module.layer1.1.bn1.running_mean", "module.layer1.1.bn1.running_var", "module.layer1.1.conv2.weight", "module.layer1.1.bn2.weight", "module.layer1.1.bn2.bias", "module.layer1.1.bn2.running_mean", "module.layer1.1.bn2.running_var", "module.layer1.1.conv3.weight", "module.layer1.1.bn3.weight", "module.layer1.1.bn3.bias", "module.layer1.1.bn3.running_mean", "module.layer1.1.bn3.running_var", "module.layer1.2.conv1.weight", "module.layer1.2.bn1.weight", "module.layer1.2.bn1.bias", "module.layer1.2.bn1.running_mean", "module.layer1.2.bn1.running_var", "module.layer1.2.conv2.weight", "module.layer1.2.bn2.weight", "module.layer1.2.bn2.bias", "module.layer1.2.bn2.running_mean", "module.layer1.2.bn2.running_var", "module.layer1.2.conv3.weight", "module.layer1.2.bn3.weight", "module.layer1.2.bn3.bias", "module.layer1.2.bn3.running_mean", "module.layer1.2.bn3.running_var", "module.layer2.0.conv1.weight", "module.layer2.0.bn1.weight", "module.layer2.0.bn1.bias", "module.layer2.0.bn1.running_mean", "module.layer2.0.bn1.running_var", "module.layer2.0.conv2.weight", "module.layer2.0.bn2.weight", "module.layer2.0.bn2.bias", "module.layer2.0.bn2.running_mean", "module.layer2.0.bn2.running_var", "module.layer2.0.conv3.weight", "module.layer2.0.bn3.weight", "module.layer2.0.bn3.bias", "module.layer2.0.bn3.running_mean", "module.layer2.0.bn3.running_var", "module.layer2.0.downsample.0.weight", "module.layer2.0.downsample.1.weight", "module.layer2.0.downsample.1.bias", "module.layer2.0.downsample.1.running_mean", "module.layer2.0.downsample.1.running_var", "module.layer2.1.conv1.weight", "module.layer2.1.bn1.weight", "module.layer2.1.bn1.bias", "module.layer2.1.bn1.running_mean", "module.layer2.1.bn1.running_var", "module.layer2.1.conv2.weight", "module.layer2.1.bn2.weight", "module.layer2.1.bn2.bias", "module.layer2.1.bn2.running_mean", "module.layer2.1.bn2.running_var", "module.layer2.1.conv3.weight", "module.layer2.1.bn3.weight", "module.layer2.1.bn3.bias", "module.layer2.1.bn3.running_mean", "module.layer2.1.bn3.running_var", "module.layer2.2.conv1.weight", "module.layer2.2.bn1.weight", "module.layer2.2.bn1.bias", "module.layer2.2.bn1.running_mean", "module.layer2.2.bn1.running_var", "module.layer2.2.conv2.weight", "module.layer2.2.bn2.weight", "module.layer2.2.bn2.bias", "module.layer2.2.bn2.running_mean", "module.layer2.2.bn2.running_var", "module.layer2.2.conv3.weight", "module.layer2.2.bn3.weight", "module.layer2.2.bn3.bias", "module.layer2.2.bn3.running_mean", "module.layer2.2.bn3.running_var", "module.layer2.3.conv1.weight", "module.layer2.3.bn1.weight", "module.layer2.3.bn1.bias", "module.layer2.3.bn1.running_mean", "module.layer2.3.bn1.running_var", "module.layer2.3.conv2.weight", "module.layer2.3.bn2.weight", "module.layer2.3.bn2.bias", "module.layer2.3.bn2.running_mean", "module.layer2.3.bn2.running_var", "module.layer2.3.conv3.weight", "module.layer2.3.bn3.weight", "module.layer2.3.bn3.bias", "module.layer2.3.bn3.running_mean", "module.layer2.3.bn3.running_var", "module.layer3.0.conv1.weight", "module.layer3.0.bn1.weight", "module.layer3.0.bn1.bias", "module.layer3.0.bn1.running_mean", "module.layer3.0.bn1.running_var", "module.layer3.0.conv2.weight", "module.layer3.0.bn2.weight", "module.layer3.0.bn2.bias", "module.layer3.0.bn2.running_mean", "module.layer3.0.bn2.running_var", "module.layer3.0.conv3.weight", "module.layer3.0.bn3.weight", "module.layer3.0.bn3.bias", "module.layer3.0.bn3.running_mean", "module.layer3.0.bn3.running_var", "module.layer3.0.downsample.0.weight", "module.layer3.0.downsample.1.weight", "module.layer3.0.downsample.1.bias", "module.layer3.0.downsample.1.running_mean", "module.layer3.0.downsample.1.running_var", "module.layer3.1.conv1.weight", "module.layer3.1.bn1.weight", "module.layer3.1.bn1.bias", "module.layer3.1.bn1.running_mean", "module.layer3.1.bn1.running_var", "module.layer3.1.conv2.weight", "module.layer3.1.bn2.weight", "module.layer3.1.bn2.bias", "module.layer3.1.bn2.running_mean", "module.layer3.1.bn2.running_var", "module.layer3.1.conv3.weight", "module.layer3.1.bn3.weight", "module.layer3.1.bn3.bias", "module.layer3.1.bn3.running_mean", "module.layer3.1.bn3.running_var", "module.layer3.2.conv1.weight", "module.layer3.2.bn1.weight", "module.layer3.2.bn1.bias", "module.layer3.2.bn1.running_mean", "module.layer3.2.bn1.running_var", "module.layer3.2.conv2.weight", "module.layer3.2.bn2.weight", "module.layer3.2.bn2.bias", "module.layer3.2.bn2.running_mean", "module.layer3.2.bn2.running_var", "module.layer3.2.conv3.weight", "module.layer3.2.bn3.weight", "module.layer3.2.bn3.bias", "module.layer3.2.bn3.running_mean", "module.layer3.2.bn3.running_var", "module.layer3.3.conv1.weight", "module.layer3.3.bn1.weight", "module.layer3.3.bn1.bias", "module.layer3.3.bn1.running_mean", "module.layer3.3.bn1.running_var", "module.layer3.3.conv2.weight", "module.layer3.3.bn2.weight", "module.layer3.3.bn2.bias", "module.layer3.3.bn2.running_mean", "module.layer3.3.bn2.running_var", "module.layer3.3.conv3.weight", "module.layer3.3.bn3.weight", "module.layer3.3.bn3.bias", "module.layer3.3.bn3.running_mean", "module.layer3.3.bn3.running_var", "module.layer3.4.conv1.weight", "module.layer3.4.bn1.weight", "module.layer3.4.bn1.bias", "module.layer3.4.bn1.running_mean", "module.layer3.4.bn1.running_var", "module.layer3.4.conv2.weight", "module.layer3.4.bn2.weight", "module.layer3.4.bn2.bias", "module.layer3.4.bn2.running_mean", "module.layer3.4.bn2.running_var", "module.layer3.4.conv3.weight", "module.layer3.4.bn3.weight", "module.layer3.4.bn3.bias", "module.layer3.4.bn3.running_mean", "module.layer3.4.bn3.running_var", "module.layer3.5.conv1.weight", "module.layer3.5.bn1.weight", "module.layer3.5.bn1.bias", "module.layer3.5.bn1.running_mean", "module.layer3.5.bn1.running_var", "module.layer3.5.conv2.weight", "module.layer3.5.bn2.weight", "module.layer3.5.bn2.bias", "module.layer3.5.bn2.running_mean", "module.layer3.5.bn2.running_var", "module.layer3.5.conv3.weight", "module.layer3.5.bn3.weight", "module.layer3.5.bn3.bias", "module.layer3.5.bn3.running_mean", "module.layer3.5.bn3.running_var", "module.layer4.0.conv1.weight", "module.layer4.0.bn1.weight", "module.layer4.0.bn1.bias", "module.layer4.0.bn1.running_mean", "module.layer4.0.bn1.running_var", "module.layer4.0.conv2.weight", "module.layer4.0.bn2.weight", "module.layer4.0.bn2.bias", "module.layer4.0.bn2.running_mean", "module.layer4.0.bn2.running_var", "module.layer4.0.conv3.weight", "module.layer4.0.bn3.weight", "module.layer4.0.bn3.bias", "module.layer4.0.bn3.running_mean", "module.layer4.0.bn3.running_var", "module.layer4.0.downsample.0.weight", "module.layer4.0.downsample.1.weight", "module.layer4.0.downsample.1.bias", "module.layer4.0.downsample.1.running_mean", "module.layer4.0.downsample.1.running_var", "module.layer4.1.conv1.weight", "module.layer4.1.bn1.weight", "module.layer4.1.bn1.bias", "module.layer4.1.bn1.running_mean", "module.layer4.1.bn1.running_var", "module.layer4.1.conv2.weight", "module.layer4.1.bn2.weight", "module.layer4.1.bn2.bias", "module.layer4.1.bn2.running_mean", "module.layer4.1.bn2.running_var", "module.layer4.1.conv3.weight", "module.layer4.1.bn3.weight", "module.layer4.1.bn3.bias", "module.layer4.1.bn3.running_mean", "module.layer4.1.bn3.running_var", "module.layer4.2.conv1.weight", "module.layer4.2.bn1.weight", "module.layer4.2.bn1.bias", "module.layer4.2.bn1.running_mean", "module.layer4.2.bn1.running_var", "module.layer4.2.conv2.weight", "module.layer4.2.bn2.weight", "module.layer4.2.bn2.bias", "module.layer4.2.bn2.running_mean", "module.layer4.2.bn2.running_var", "module.layer4.2.conv3.weight", "module.layer4.2.bn3.weight", "module.layer4.2.bn3.bias", "module.layer4.2.bn3.running_mean", "module.layer4.2.bn3.running_var", "module.master_branch.0.stages.0.1.weight", "module.master_branch.0.stages.0.2.weight", "module.master_branch.0.stages.0.2.bias", "module.master_branch.0.stages.0.2.running_mean", "module.master_branch.0.stages.0.2.running_var", "module.master_branch.0.stages.1.1.weight", "module.master_branch.0.stages.1.2.weight", "module.master_branch.0.stages.1.2.bias", "module.master_branch.0.stages.1.2.running_mean", "module.master_branch.0.stages.1.2.running_var", "module.master_branch.0.stages.2.1.weight", "module.master_branch.0.stages.2.2.weight", "module.master_branch.0.stages.2.2.bias", "module.master_branch.0.stages.2.2.running_mean", "module.master_branch.0.stages.2.2.running_var", "module.master_branch.0.stages.3.1.weight", "module.master_branch.0.stages.3.2.weight", "module.master_branch.0.stages.3.2.bias", "module.master_branch.0.stages.3.2.running_mean", "module.master_branch.0.stages.3.2.running_var", "module.master_branch.0.bottleneck.0.weight", "module.master_branch.0.bottleneck.1.weight", "module.master_branch.0.bottleneck.1.bias", "module.master_branch.0.bottleneck.1.running_mean", "module.master_branch.0.bottleneck.1.running_var", "module.master_branch.1.weight", "module.master_branch.1.bias", "module.auxiliary_branch.0.weight", "module.auxiliary_branch.1.weight", "module.auxiliary_branch.1.bias", "module.auxiliary_branch.1.running_mean", "module.auxiliary_branch.1.running_var", "module.auxiliary_branch.4.weight", "module.auxiliary_branch.4.bias".
Unexpected key(s) in state_dict: "arch", "epoch", "logger", "state_dict", "optimizer", "monitor_best", "config". "
I have trained the PSPnet on the VOC datasets according to your steps, and now I need to test the trained model, so I run the command python inference.py --config config.json --model ./saved/PSPNet/10-28_05-10/best_model.pth --images test_images, there are 10 images named *.jpg to be tested, however the outputs is empty, do you know the reason?
`(torch110) jenny@ubuntn:~/pytorch_segmentation$ python inference.py --config config.json --model ./saved/PSPNet/10-28_05-10/best_model.pth --images test_images/
0it [00:00, ?it/s]
`
Hi,
Thanks for building this cool library. I've been trying to run some benchmarks and reproduce the results of existing papers from your code. So far I've tested FCN8s and PSPNet and here's what I've obtained:
Here is a snapshot of final evaluation after 100 epochs:

Here is the config file I've used to train the PSPNet:
{
"name": "PSPNet",
"n_gpu": 4,
"use_synch_bn": true,
"arch": {
"type": "PSPNet",
"args": {
"backbone": "resnet101",
"freeze_bn": false,
"freeze_backbone": false
}
},
"train_loader": {
"type": "VOC",
"args":{
"data_dir": "/path/to/VOC/",
"batch_size": 8,
"base_size": 400,
"crop_size": 380,
"augment": true,
"shuffle": true,
"scale": true,
"flip": true,
"rotate": true,
"blur": false,
"split": "train_aug",
"num_workers": 8
}
},
"val_loader": {
"type": "VOC",
"args":{
"data_dir": "/path/to/VOC",
"batch_size": 8,
"crop_size": 480,
"val": true,
"split": "val",
"num_workers": 4
}
},
"optimizer": {
"type": "SGD",
"differential_lr": true,
"args":{
"lr": 0.001,
"weight_decay": 1e-4,
"momentum": 0.9
}
},
"loss": "CrossEntropyLoss2d",
"ignore_index": 255,
"lr_scheduler": {
"type": "Poly",
"args": {}
},
"trainer": {
"epochs": 100,
"save_dir": "saved/",
"save_period": 10,
"monitor": "max Mean_IoU",
"early_stop": 10,
"tensorboard": true,
"log_dir": "saved/runs",
"log_per_iter": 20,
"val": true,
"val_per_epochs": 5
}
}Following #26, I kept the batch size to 8 and decreased the learning rate to 1e-3. I also checked that the loss correctly weights the auxiliary loss. I'm willing to help debug and reproduce the performance, if you can take a look into it.
EDIT: I am using the augmented Pascal VOC dataset, following the instructions in your Readme and the DeepLabv1 readme.
Best,
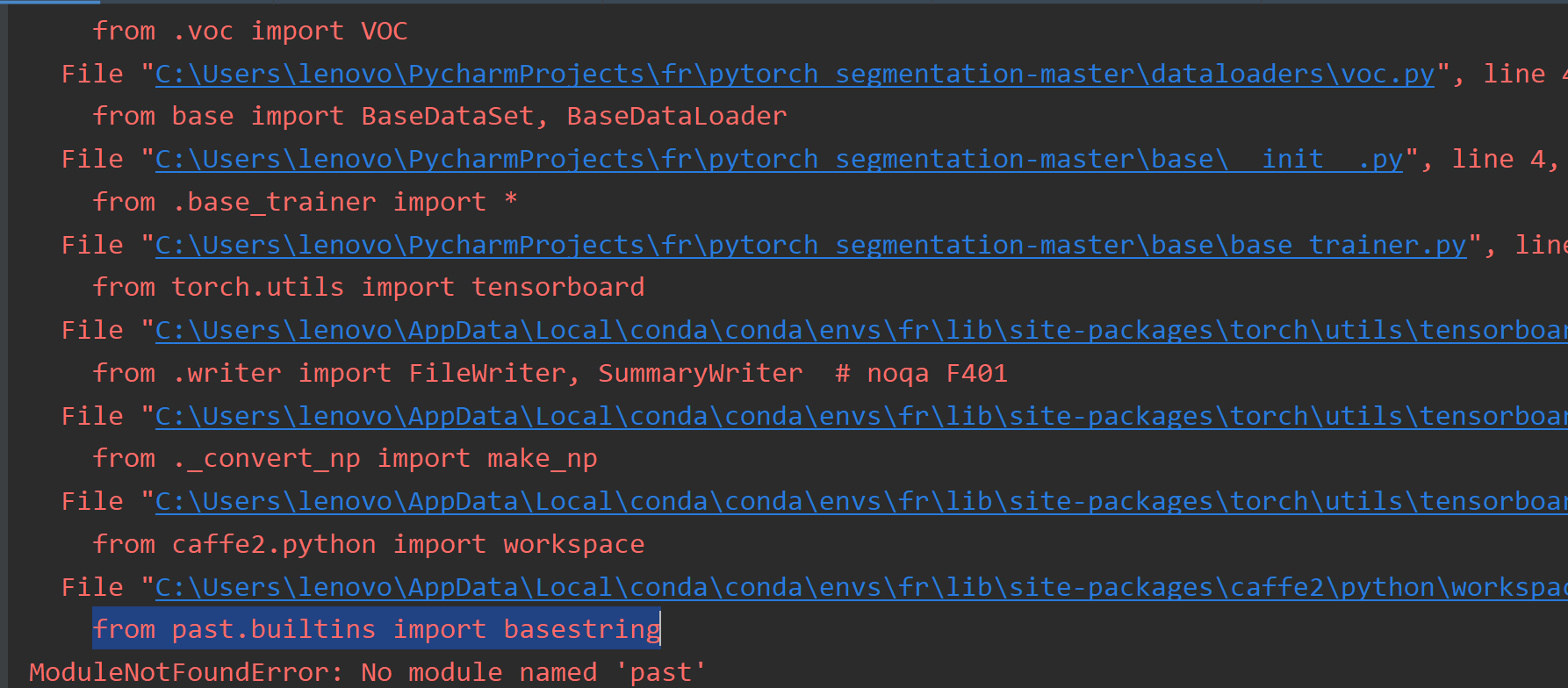
When training on VOC, I met this error.
I want to know how to solve it, does anybody know it?
Maybe my batchsize=4 is not suitable, but 8 or 16 is too large for my gpu...
I trained the PSPNet model from scratch for 80 epochs and saved a checkpoint whose training and validating mIoU were about 0.6.

After that, I didn't change any setting, but when I resumed from the checkpoint, the training and validating mIoU were just about 0.5.

I have no idea how this could have happened :(
Is it because of the 'lr_scheduler' that commented by you?

Looking forward to your reply, and thanks very much. :)
Hi Yassine,
The file related to synch batch norm seems to be changed, so does the requirement for config file. What does the new config need related to this change?
Hello,Could you please tell me the difference between multiscale and sliding when run inference?
In line 181 in segnet.py, I think it may be encoder[0].in_channels = in_channels or encoder[0] = nn.Conv2d(in_channels, 64, kernel_size=3, stride=1, padding=1)
Hi.
I have a my own custom dataset that contains images and coresponding masks, and there are five classes.
How can I select type of train_loader?
I saw this repository give four kind of dataloader but I don't know how to select a proper one.
Hi, I missed a problem when first ran this code. The Model printed successfully

But Problems happened during training
Detected GPUs: 1 Requested: 1
0%| | 0/1323 [00:00<?, ?it/s]Traceback (most recent call last):
File "train.py", line 61, in
main(config, args.resume)
File "train.py", line 42, in main
trainer.train()
File "G:\pytorch_segmentation\base\base_trainer.py", line 101, in train
results = self._train_epoch(epoch)
File "G:\pytorch_segmentation\trainer.py", line 49, in _train_epoch
for batch_idx, (data, target) in enumerate(tbar):
File "C:\Users\Administrator\AppData\Roaming\Python\Python37\site-packages\tqdm_tqdm.py", line 1017, in iter
for obj in iterable:
File "G:\pytorch_segmentation\base\base_dataloader.py", line 76, in iter
self.preload()
File "G:\pytorch_segmentation\base\base_dataloader.py", line 64, in preload
self.next_input, self.next_target = next(self.loaditer)
File "C:\Users\Administrator\Anaconda3\lib\site-packages\torch\utils\data\dataloader.py", line 346, in next
data = self.dataset_fetcher.fetch(index) # may raise StopIteration
File "C:\Users\Administrator\Anaconda3\lib\site-packages\torch\utils\data_utils\fetch.py", line 44, in fetch
data = [self.dataset[idx] for idx in possibly_batched_index]
File "C:\Users\Administrator\Anaconda3\lib\site-packages\torch\utils\data_utils\fetch.py", line 44, in
data = [self.dataset[idx] for idx in possibly_batched_index]
File "G:\pytorch_segmentation\base\base_dataset.py", line 132, in getitem
label = torch.from_numpy(np.array(label, dtype=np.int32)).long()
TypeError: can't convert np.ndarray of type numpy.int32. The only supported types are: float64, float32, float16, int64, int32, int16, int8, uint8, and bool.

Looking forward to your reply.Thanks
Thank you very much for your code. Could you please tell me how to continue the training on the existing model.It's a waste of time to start from scratch every time.waiting for your answer ,Thank you very much
The official dataset does not have the annotations/ directory where as the current ade20k dataset file needs that structure.
Do you have any scripts to convert the official dataset folder to the required directory structure?
0%| | 0/291 [00:00<?, ?it/s]/home/caffe/anaconda3/envs/pytorch/lib/python3.6/site-packages/torch/nn/functional.py:2539: UserWarning: Default upsampling behavior when mode=bilinear is changed to align_corners=False since 0.4.0. Please specify align_corners=True if the old behavior is desired. See the documentation of nn.Upsample for details.
"See the documentation of nn.Upsample for details.".format(mode))
TRAIN (1) | Loss: 0.334 | Acc 0.92 mIoU 0.69 | B 0.62 D 0.03 |: 27%|███████▋ | 80/291 [00:49<01:51, 1.90it/s]Traceback (most recent call last):
File "train.py", line 61, in
main(config, args.resume)
File "train.py", line 42, in main
trainer.train()
File "/home/caffe/语义分割/pytorch_segmentation/base/base_trainer.py", line 101, in train
results = self._train_epoch(epoch)
File "/home/caffe/语义分割/pytorch_segmentation/trainer.py", line 49, in _train_epoch
for batch_idx, (data, target) in enumerate(tbar):
File "/home/caffe/anaconda3/envs/pytorch/lib/python3.6/site-packages/tqdm/_tqdm.py", line 1017, in iter
for obj in iterable:
File "/home/caffe/语义分割/pytorch_segmentation/base/base_dataloader.py", line 81, in iter
self.preload()
File "/home/caffe/语义分割/pytorch_segmentation/base/base_dataloader.py", line 64, in preload
self.next_input, self.next_target = next(self.loaditer)
File "/home/caffe/anaconda3/envs/pytorch/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 582, in next
return self._process_next_batch(batch)
File "/home/caffe/anaconda3/envs/pytorch/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 608, in _process_next_batch
raise batch.exc_type(batch.exc_msg)
FileNotFoundError: Traceback (most recent call last):
File "/home/caffe/anaconda3/envs/pytorch/lib/python3.6/site-packages/torch/utils/data/_utils/worker.py", line 99, in _worker_loop
samples = collate_fn([dataset[i] for i in batch_indices])
File "/home/caffe/anaconda3/envs/pytorch/lib/python3.6/site-packages/torch/utils/data/_utils/worker.py", line 99, in
samples = collate_fn([dataset[i] for i in batch_indices])
File "/home/caffe/语义分割/pytorch_segmentation/base/base_dataset.py", line 126, in getitem
image, label, image_id = self._load_data(index)
File "/home/caffe/语义分割/pytorch_segmentation/dataloaders/voc.py", line 37, in _load_data
image = np.asarray(Image.open(image_path), dtype=np.float32)
File "/home/caffe/anaconda3/envs/pytorch/lib/python3.6/site-packages/PIL/Image.py", line 2770, in open
fp = builtins.open(filename, "rb")
FileNotFoundError: [Errno 2] No such file or directory: 'data/VOC-200-200-0/VOCdevkit/VOC2012/JPEGImages/.jpg'
Hi, yassouali:
I am a beginner in the computer version. I download this project and try to run it on my laptop. Followed by README.md, I download Pascal VOC dataset, and I entered "python train.py --config config.json" command in Pycharm terminal. However, it returns that: can't open file 'train.py': [Errno 2] No such file or directory.
The software I used is Pycharm and in configuration setting, the script path is the location of "train.py".
How to use the get weights function with the cross entropy loss in multiclass problem?
I am using this repository with my dataset that has some images that contain only one class and that could be labeled as zero. I was facing a very strange error that even didn't pop up any message. After some time debugging I found that in the file base_dataset.py the method _augmentation has an while statement that only finish if label_new.sum() != 0. So, in some cases this go forever.
When I use the LovaszSoftmax loss function,that show me this:
Traceback (most recent call last):
File "train.py", line 61, in
main(config, args.resume)
File "train.py", line 30, in main
loss = getattr(losses, config['loss'])(ignore_index = config['ignore_index'])
TypeError: init() got an unexpected keyword argument 'ignore_index'
I want to use my own dataset and made myloader.py.
However, I cannot figure out what self.STD and self.MEAN mean.
I need your help about these values and how I can calculate those.
Hi,I think your code is nice and detailed, but when I run it , a error was happend as follow:
Traceback (most recent call last):
File "train.py", line 61, in
main(config, args.resume)
File "train.py", line 42, in main
trainer.train()
File "/home/lilier/code/pytorch_segmentation/base/base_trainer.py", line 101, in train
results = self._train_epoch(epoch)
File "/home/lilier/code/pytorch_segmentation/trainer.py", line 60, in _train_epoch
loss = self.loss(output[0], target)
File "/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py", line 477, in call
result = self.forward(*input, **kwargs)
File "/home/lilier/code/pytorch_segmentation/utils/losses.py", line 30, in forward
loss = self.CE(output, target)
File "/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py", line 477, in call
result = self.forward(*input, **kwargs)
File "/usr/local/lib/python3.6/dist-packages/torch/nn/modules/loss.py", line 862, in forward
ignore_index=self.ignore_index, reduction=self.reduction)
File "/usr/local/lib/python3.6/dist-packages/torch/nn/functional.py", line 1550, in cross_entropy
return nll_loss(log_softmax(input, 1), target, weight, None, ignore_index, None, reduction)
File "/usr/local/lib/python3.6/dist-packages/torch/nn/functional.py", line 1409, in nll_loss
return torch._C._nn.nll_loss2d(input, target, weight, _Reduction.get_enum(reduction), ignore_index)
File "/usr/local/lib/python3.6/dist-packages/torch/nn/functional.py", line 30, in get_enum
raise ValueError(reduction + " is not a valid value for reduction")
ValueError: mean is not a valid value for reduction
How can I solve it,thank you!
Dear maintainer:
When using resumes to reload training process, your code failed to run due to a bug in base_trainer.py:
At line 145, state should also save ‘logger’: self.train_logger
Hi Yassine,
Did you train on CityScapes and what the config file should be? Thanks!
in models/segnet.py, line
if in_channels != 3:
encoder[0].in_channels = nn.Conv2d(
in_channels, 64, kernel_size=3, stride=1, padding=1)
should be
if in_channels != 3:
encoder[0] = nn.Conv2d(
in_channels, 64, kernel_size=3, stride=1, padding=1)
I have two class in my task. And I have revised your code suggested by this link
PROBLEM: After I train the network with my own database and run inference.py. I got the prediction map with all black pixels.
CHECK: In this line, I print the variable prediction.sum() and get the big negative number (e.g., prediction=-15624.34)
How can I solve this issue? please help me. Thanks
This is my dataloader file with python:
from base import BaseDataSet, BaseDataLoader
from utils import palette
import numpy as np
import os
import torch
import cv2
from PIL import Image
from glob import glob
from torch.utils.data import Dataset
from torchvision import transforms
class COD10KDataset(BaseDataSet):
def __init__(self, **kwargs):
self.num_classes = 2
self.palette = palette.COD10K_palette
super(COD10KDataset, self).__init__(**kwargs)
def _set_files(self):
if self.split in ["training", "validation"]:
# self.image_dir = os.path.join(self.root, 'images', self.split)
# self.label_dir = os.path.join(self.root, 'annotations', self.split)
self.image_dir = os.path.join(self.root, 'images')
self.label_dir = os.path.join(self.root, 'annotations')
self.files = [os.path.basename(path).split('.')[0] for path in glob(self.image_dir + '/*.jpg')]
print(len(self.files))
else:
raise ValueError(f"Invalid split name {self.split}")
def _load_data(self, index):
image_id = self.files[index]
image_path = os.path.join(self.image_dir, image_id + '.jpg')
label_path = os.path.join(self.label_dir, image_id + '.png')
image = np.asarray(Image.open(image_path).convert('RGB'), dtype=np.float32)
label = np.asarray(Image.open(label_path), dtype=np.int32)
return image, label, image_id
class COD10K(BaseDataLoader):
def __init__(self, data_dir, batch_size, split, crop_size=None, base_size=None, scale=True, num_workers=1, val=False,
shuffle=False, flip=False, rotate=False, blur= False, augment=False, val_split= None, return_id=False):
self.MEAN = [0.48897059, 0.46548275, 0.4294]
self.STD = [0.22861765, 0.22948039, 0.24054667]
kwargs = {
'root': data_dir,
'split': split,
'mean': self.MEAN,
'std': self.STD,
'augment': augment,
'crop_size': crop_size,
'base_size': base_size,
'scale': scale,
'flip': flip,
'blur': blur,
'rotate': rotate,
'return_id': return_id,
'val': val
}
self.dataset = COD10KDataset(**kwargs)
super(COD10K, self).__init__(self.dataset, batch_size, shuffle, num_workers, val_split)
Dear Author,
I have labeled my own datasets, now I have RGB images and the label png data, how can I generate the SegmentationClassAug files as the VOC datasets? Hope for your quick reply, thank you
I keep getting this error when train
Traceback (most recent call last):
File "train.py", line 61, in <module>
main(config, args.resume)
File "train.py", line 42, in main
trainer.train()
File "/home/vltanh/pytorch_segmentation/base/base_trainer.py", line 101, in train
results = self._train_epoch(epoch)
File "/home/vltanh/pytorch_segmentation/trainer.py", line 92, in _train_epoch
self.batch_time.average, self.data_time.average))
TypeError: unsupported format string passed to dict.__format__
I am using Python 3.5.
Thank you.
Edit: It works or doesn't work randomly.
epoch, self.total_loss.average,
pixAcc, mIoU,
self.batch_time.average, self.data_time.average
I think sometimes it will get weird value making it not suitable for printing?
Edit 2: When I print them out, pixAcc is a dictionary of mean IoU for each class? Also sometimes when I train the pixAcc got swapped with the mean IoU.
Edit 3: Found the problem. It's because you do
pixAcc, mIoU, _ = self._get_seg_metrics().values()
This is undefined behaviour since the value is extracted randomly from the dict (chances, maybe 2/3, is that you will get the class_iou as one of the two, or mix them up like I said above. You should fix this.
Edit 4: When I fixed it I also got error from
for k, v in list(seg_metrics_.items())[:-1]
Same problem, you wouldn't know the order of the item in the list. Consider checking this also.
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.
{kind=link}