数据结构、算法、设计模式 -- Java 描述
创建型模式:
结构型模式:
行为型模式:
设计模式总结:
数组的特点是:数据是连续的,随机访问速度很快
缺点是:插入删除涉及到元素位置的移动,开销较大;如果设计为自动扩容的数组,当剩余空间不足时,需要重新申请空间。
单向链表(单链表)由结点组成,每个结点都包含下一个结点的指针。
单链表的特点:结点的链接方向是单向的,插入删除速度很快
但是相对于数组来说,随机访问速度较慢。
双向链表(双链表)是链表的一种。和单链表一样,双链表也是由结点组成,不过它的每个结点中有两个指针,分别指向直接后继结点和直接前驱结点。
Java 中 LinkedList 的实现是双向链表。
循环链表与单链表相比,其末尾结点的后继结点是表头结点。
栈是一种线性存储结构,它有以下几个特点:
- 栈中数据按照“后进先出”(LIFO, Last In First Out)的方式进出栈。
- 向栈中添加/删除数据时,只能从栈顶进行操作。
栈通常包括三种操作:push、peek、pop:
- push: 向栈中添加元素
- peek: 返回栈顶元素
- pop: 返回并删除栈顶元素
栈的实现可以通过数组也可以通过链表,数组实现有空间限制,而链表实现没有。
队列也是一种线性存储结构,它有以下几个特点:
- 队列中的数据按照“先进先出”(FIFO, First In First Out)的方式进出队列。
- 队列只允许在队首进行删除操作,在队尾进行插入操作。
队列通常包括三种操作:add、peek、poll:
- add: 向队列中添加元素
- peek: 返回队首元素
- poll: 返回并删除队首元素
队列也可以通过数组、链表实现。
二叉树T:一个有穷的结点集合。这个集合可以为空。若不为空,则它是由根结点和称为左子树TL和右子树TR的两个不相交的二叉树组成。
二叉树有几个重要的性质:
- 一个二叉树第 i 层的最大结点数为 2^(i-1), i >= 1
- 深度为 k 的二叉树有最大结点数为 2^k - 1, k >= 1
- 对任何非空二叉树 T,若 n0 表示叶结点的个数、n2 表示度为 2 的非叶结点的个数,那么两者满足关系 n0 = n2 + 1
对于第三条性质,通过边来证明:
从树底往上看,每个结点都往上有一条边,根结点往上没有边。
从树顶往下看,n0 往下没有边,n1 往下有一条边,n2 往下有两条边。
故有:n0 + n1 + n2 -1 = 0 * n0 + 1 * n1 + 2 * n2
得:n0 = n2 + 1
二叉树通常包括几种操作:前序遍历、中序遍历、后序遍历、层次遍历。
有一个结论:
在任何一次遍历过程中,对于某一个结点总会访问三次。前序遍历就是在第一次访问的时候输出结点中信息,中序遍历则是在第二次访问的时候输出,后序遍历是在第三次访问的时候进行输出。
前序遍历和中序遍历也可以利用栈来进行非递归遍历,后序遍历的非递归实现比较复杂。
层次遍历利用队列实现,每次从队列中取出一个结点访问,然后将该结点的左右儿子(非空)放入队列。
问题1:输出二叉树的叶结点
在二叉树的前序、中序、后序遍历的时候加一个判断:
if (node.left == null && node.right == null) {
System.out.print(node.data + " ");
}问题2:输出二叉树的高度
递归计算树的高度,每次返回左子树和右子树高度的最大值+1:
private int height(Node node) {
int highLeft, highRight;
if (node != null) {
highLeft = height(node.left);
highRight = height(node.right);
return (Math.max(highLeft, highRight) + 1);
}
return 0;
}完全二叉树:有 n 个结点的二叉树,对树中结点按从上至下、从左到右的顺序进行编号,编号为 i(1 <= i <= n)结点与满二叉树中编号为 i 结点在二叉树中位置相同。
完全二叉树有以下几个重要的性质:
- 非根结点(序号 i > 1)的父结点的序号是 [i/2] (向下取整)
- 结点 i 的左孩子的序号是 2i。如果 2i > n,则没有左孩子
- 结点 i 的右孩子的序号是 2i+1。如果 2i+1 > n,则没有右孩子
二叉搜索树(Binary Search Tree)是特殊的二叉树:对于二叉树,假设 x 为二叉树中任意一个结点,x 结点包含关键字 key,结点 x 的 key 值记为 key[x]。如果 y 是 x 的左子树中的一个结点,则 key[y] <= key[x];如果 y 是 x 右子树的一个结点,则 key[y] >= key[x]。那么,这棵树就是二叉搜索树。
在二叉搜索树中:
- 若任意结点的左子树不空,则左子树上所有结点的值均小于它的根结点的值
- 若任意结点的右子树不空,则右子树上所有结点的值均大于它的根结点的值
- 任意结点的左、右子树也分别为二叉搜索树
- 没有键值相等的结点
二叉搜索树常用的操作有:插入、删除、查找、查找最大值、查找最小值。
public void insert(E element) {
this.root = this.insert(this.root, element);
}
private Node insert(Node node, E element) {
if (node == null) {
// 结点为空,创建并插入数据
node = new Node();
node.data = element;
} else {
if (element.compareTo(node.data) > 0)
node.right = insert(node.right, element);
else if (element.compareTo(node.data) < 0)
node.left = insert(node.left, element);
}
return node;
}public boolean delete(E element) {
try {
this.root = this.delete(this.root, element);
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* 分三种情况:
* 1、删除的结点是叶子节点。将其父结点的指针为 null
* 2、删除的结点只有一个儿子。将其父结点的指针指向要删除结点的儿子结点
* 3、删除的结点有两个儿子。用右子树的 最小元素 或者左子树的 最大元素 替代要删除的结点
*/
private Node delete(Node node, E element) throws Exception {
if (node == null) {
throw new Exception("Not Found!");
} else if (element.compareTo(node.data) < 0) {
node.left = delete(node.left, element);
} else if (element.compareTo(node.data) > 0) {
node.right = delete(node.right, element);
} else {
if (node.left != null && node.right != null) {
// 要删除的结点有两个儿子结点
Node tmp = findMin(node.right); // 找到右子树的最小结点
node.data = tmp.data;
node.right = delete(node.right, (E) node.data);
} else {
node = (node.left != null) ? node.left : node.right;
}
/*
if (node.left != null) {
// 要删除的结点有左儿子结点
node = node.left;
} else if (node.right != null) {
// 要删除的结点有右儿子结点
node = node.right;
} else {
// 要删除的结点没有儿子结点
node = null;
}
*/
}
return node;
}/**
* 递归实现查找
*/
private Node find(Node node, E element) {
if (node == null)
return null;
if (element.compareTo(node.data) > 0)
return find(node.right, element);
else if (element.compareTo(node.data) < 0)
return find(node.left, element);
else
return node;
}
/**
* 迭代实现查找
*/
private Node findIter(Node node, E element) {
while (node != null) {
if (element.compareTo(node.data) > 0)
node = node.right;
else if (element.compareTo(node.data) < 0)
node = node.left;
else
return node;
}
return null;
}AVL 树是高度平衡的二叉树。它的特点是:AVL 树中任何两个子树的高度最大差别为 1。
AVL 树中一个重要的操作就是旋转,在每次插入删除后都要检测 AVL 树的平衡是否被打破,如果被打破就要进行相应的旋转来保持平衡。
AVL 树的高度:
按照维基百科上的定义:树的高度为最大层次。即空二叉树的高度为 0,非空二叉树的高度为根结点左右子树的最大高度 + 1:
private int height(Node node) {
if (node != null)
return node.height;
return 0;
}AVL 树中主要涉及到了四种旋转:LL旋转(右旋)、RR旋转(左旋)、LR旋转(先左旋,再右旋)、RL旋转(先右旋,再左旋)。
- LL 即左子树的左子结点导致失衡,需要右旋恢复平衡
- RR 即右子树的右子结点导致失衡,需要左旋恢复平衡
- LR 即左子树的右子结点导致失衡,需要先左旋成为 LL 失衡,再右旋恢复平衡
- RL 即右子树的左子结点导致失衡,需要先右旋成为 RR 失衡,再左旋恢复平衡
RR旋转(左旋):
private Node rightRightRotation(Node node) {
Node tmp = node.right;
node.right = tmp.left;
tmp.left = node;
node.height = Math.max(height(node.left), height(node.right)) + 1;
tmp.height = Math.max(height(tmp.left), height(tmp.left)) + 1;
return tmp;
}LL旋转(右旋):
// LL 旋转。T 结点的左子树的左子树插入结点导致平衡因子改变。
private Node leftLeftRotation(Node node) {
// 定义临时结点,指向 node 的左孩子,旋转后替代 node 的位置
Node tmp = node.left;
// 将 node(失衡结点)的左孩子指向 tmp 的右孩子上
node.left = tmp.right;
// 将 tmp 的右孩子指向 node
tmp.right = node;
// 以上,旋转完成
// 重新计算高度
node.height = Math.max(height(node.left), height(node.right)) + 1;
tmp.height = Math.max(height(tmp.left), height(tmp.right)) + 1;
return tmp;
}LR旋转:
// LR 旋转,首先进行 RR 旋转使其变为 LL 失衡状态,然后进行 LL 旋转
private Node leftRightRotation(Node node) {
node.left = rightRightRotation(node.left);
return leftLeftRotation(node);
}RL 旋转:
// RL 旋转,首先进行 LL 旋转使其变为 RR 失衡状态,然后进行 RR 旋转
private Node rightLeftRotation(Node node) {
node.right = leftLeftRotation(node.right);
return rightRightRotation(node);
}public void insert(E element) {
this.root = this.insert(this.root, element);
}
private Node insert(Node node, E element) {
if (node == null) {
node = new Node(element);
} else {
if (element.compareTo(node.data) < 0) {
node.left = insert(node.left, element);
// 检测在左子树插入节点后,AVL 树是否失去平衡
if (height(node.left) - height(node.right) == 2) {
if (element.compareTo(node.left.data) < 0) {
// 说明插入的位置是左儿子的左子节点,需要进行 LL 旋转
node = this.leftLeftRotation(node);
} else {
// 说明插入的位置是右儿子的右子节点,需要进行 LR 旋转
node = this.leftRightRotation(node);
}
}
} else if (element.compareTo(node.data) > 0) {
node.right = insert(node.right, element);
// 检测在右子树插入节点后,AVL 树是否失去平衡
if (height(node.right) - height(node.left) == 2) {
if (element.compareTo(node.right.data) > 0) {
// 说明插入位置是右儿子的右子节点,需要进行 RR 旋转
node = rightRightRotation(node);
} else {
// 说明插入位置是右儿子的左子节点,需要进行 RL 旋转
node = rightLeftRotation(node);
}
}
}
// 忽略相同结点
}
// 重新计算 height
node.height = Math.max(height(node.left), height(node.right)) + 1;
return node;
}public void remove(E element) throws Exception {
this.root = this.remove(this.root, element);
}
private Node remove(Node node, E element) throws Exception {
if (node == null) {
return null;
}
if (element.compareTo(node.data) < 0) {
node.left = this.remove(node.left, element);
// 删除左子树结点,可能导致 AVL 失衡。需要根据情况进行右旋
if (height(node.right) - height(node.left) == 2) {
if (height(node.right.left) > height(node.right.right)) {
// 这一层判断是为了选择要进行的旋转。如果 右子树的左子树的高度 高于 右子树的右子树的高度,则进行 RL 旋转
node = rightLeftRotation(node);
} else {
// 否则,即 右子树的右子树 高于或者等于 右子树的左子树,则进行 RR 旋转
node = rightRightRotation(node);
}
}
} else if (element.compareTo(node.data) > 0) {
node.right = this.remove(node.right, element);
// 删除右子树结点,可能导致 AVL 失衡。需要根据情况进行左旋
if (height(node.left) - height(node.right) == 2) {
if (height(node.left.left) >= height(node.left.right)) {
// 这一层判断是为了选择要进行的旋转。如果 左子树的左子树的高度 高于或等于 左子树的右子树的高度,则进行 LL 旋转
node = leftLeftRotation(node);
} else {
// 否则,即 左子树的右子树 高于 左子树的左子树,则进行 LR 旋转
node = leftRightRotation(node);
}
}
} else {
// 删除结点
if (node.left != null && node.right != null) {
if (height(node.left) > height(node.right)) {
node.data = findMax(node.left);
node.left = remove(node.left, (E) node.data);
} else {
node.data = findMin(node.right);
node.right = remove(node.right, (E) node.data);
}
} else {
node = (node.left != null) ? node.left : node.right;
}
}
return node;
}伸展树是特殊的二叉搜索树。它的特殊之处在于:当某个结点被访问时,伸展树会通过旋转使该结点成为树根。
伸展树保证从空树开始任意连续 M 次对树的操作最多花费 O(M log N) 时间。
伸展树最重要的操作是旋转:
/**
* 算法**参考了《数据结构与算法分析 —— C语言描述》中伸展树自底向上展开
* 以下注释中,
* <strong>根结点</strong>指的是调用 splay 时传入的 node 结点
* <strong>目标结点</strong>是程序中调用 splay 函数的语句返回的结点
*/
private Node splay(Node node, E key) {
if (node == null) {
// 如果结点为空,返回 null
return null;
}
if (key.compareTo(node.key) < 0) {
// 处理左侧,key < root.key
if (node.left == null) {
// 如果根结点没有左儿子,说明不存在值为 key 的结点,将根结点返回作为新的根。
return node;
}
if (key.compareTo(node.left.key) < 0) {
// 如果 key 小于根结点的左儿子,则对根结点的左儿子的左儿子进行 splay 调用
node.left.left = splay(node.left.left, key);
// 调用结束后对根结点进行一次右旋,根结点指向其原左儿子,目标结点((原根结点的左儿子的左儿子)旋转到根结点的左儿子
// A B
// B => C A
//C 目标结点是 C
node = rightRotation(node);
} else if (key.compareTo(node.left.key) > 0) {
// 如果 key 大于根结点的左儿子,则对根结点的左儿子的右儿子进行 splay 调用
node.left.right = splay(node.left.right, key);
if (node.left.right != null)
// 如果调用结束目标结点(根结点的左儿子的右儿子)非空,则在左儿子处进行一次左旋,将目标结点旋转到根结点的左儿子
node.left = leftRotation(node.left);
// A A
// B => C C 是目标结点
// C B
}
// 最后如果根结点左儿子为空,则不存在 key 结点,返回当前根结点
if (node.left == null) {
return node;
} else {
// 如果左儿子非空,则说明 key 结点存在,并且就在根结点的左儿子,进行一次右旋将其旋转为新的根结点
return rightRotation(node);
}
} else if (key.compareTo(node.key) > 0) {
// 处理右侧,key > root.key
if (node.right == null) {
// 如果根结点没有右儿子,说明不存在值为 key 的结点,将当前结点返回作为根。
return node;
}
if (key.compareTo(node.right.key) < 0) {
// 如果 key 小于根结点的右儿子,则对根结点的右儿子的左儿子进行 splay 调用
node.right.left = splay(node.right.left, key);
if (node.right.left != null)
// 如果调用结束并且目标结点(根结点的右儿子的左儿子)非空,则对根结点的右儿子进行一次右旋,将目标结点旋转为根结点的右儿子
node.right = rightRotation(node.right);
// A A
// B => C C是目标结点
// C B
} else if (key.compareTo(node.right.key) > 0) {
// 如果 key 大于根结点的右儿子,则对根结点的右儿子的右儿子进行 splay 调用
node.right.right = splay(node.right.right, key);
// 调用结束后对根结点进行一次左旋,根结点指向其右儿子,现在根结点的右儿子是目标结点(原根结点的右儿子的右儿子)
node = leftRotation(node);
// A B
// B => A C
// C C是目标结点
}
// 最后如果根结点右儿子为空,则不存在 key 结点,返回当前根结点
if (node.right == null) {
return node;
} else {
// 如果右儿子非空,则说明 key 结点存在,并且就在根结点的右儿子,进行一次左旋将其旋转为新的根结点
return leftRotation(node);
}
} else {
// 如果找到,直接返回
return node;
}
}哈夫曼树,又称最优二叉树。
定义:给定 n 个权值作为 n 个叶子结点,构造一颗二叉树,若树的带权路径长度达到最小,则这棵树称为哈夫曼树。
路径和路径长度:在一棵树中,从一个结点往下可以达到的孩子或孙子结点之间的通路,称为路径。通路中分支的数目称为路径长度。若规定根结点的层数为 1,则从根结点到第 L 层结点的路径长度为 L-1。
结点的权:若将树中结点赋给一个有着某种含义的数值,则这个数值称为该结点的权。
结点的带权路径长度:从根结点到该结点之间的路径长度与该结点的权的乘积。
树的带权路径长度:所有叶子结点的带权路径长度之和。
可以利用优先队列(最大堆)来创建哈夫曼树:
public HuffmanTree(int... elements) {
Node parent = null;
PriorityQueue<Node> queue = new PriorityQueue<>(Comparator.comparingInt(o -> o.key));
for (int element : elements) {
queue.add(new Node(element));
}
while (queue.size() > 1) {
// 当最后两个结点被取出计算 parent 后,parent 又放入队列中,此时应该停止循环。
// 停止的条件就是 size > 1
Node left = queue.poll();
Node right = queue.poll();
parent = new Node(left.key + right.key, left, right);
queue.add(parent);
}
this.root = parent;
}Red-Black Tree,又称红黑树,是一种特殊的二叉搜索树。红黑树上的每个结点都有存储位表示结点的颜色,可以是红(Red)或黑(Black)。
红黑树的着色性质:
- 每个结点或者是红色,或者是黑色
- 根是黑色的
- 如果一个结点是红色的,那么它的子结点必须是黑色的
- 从一个结点到一个 null 指针的每一条路径必须包含相同数目的黑色结点
着色法则的一个推论是,红黑树的高度最多为 2log(N + 1)。因此,查找保证是一种对数的操作。事实上,最红黑树的操作在最坏情况下花费 O(logN) 时间。
红黑树的应用比较广泛,主要是用它来存储有序的数据,它的时间复杂度是 O(logN),效率非常之高。例如,Java集合中的 TreeSet 和 TreeMap,C++ STL 中的 set、map,以及 Linux 虚拟内存的管理,都是通过红黑树实现的。
红黑树实现起来太复杂了,容后再做 😢
堆(heap),这里说的堆是数据结构中的堆,而不是内存模型中的堆。堆通常可以被看作一棵树,他满足以下性质:
- 堆中任意结点的值总是不大于(不小于)其子结点的值
- 堆总是一颗完全树
将任意结点不大于其子结点的堆叫做最小堆,而将任意结点不小于其子结点的堆叫做最大堆。常见的堆有二叉堆、左倾堆、斜堆、二项堆、斐波那契堆等等。
二叉堆是完全二元树或者是近似完全二元树,它分为两种:最大堆或最小堆。
二叉堆一般都通过数组实现。数组实现的二叉堆,父结点和子结点的位置存在一定的关系。有时候,我们将二叉堆的第一个元素放在索引 0 的位置,有时候放在 1 的位置。当然,它们的本质一样,只是实现上稍微有一丁点的区别。
假设第一个元素在数组中索引为 0,则父结点和子结点的位置关系如下:
- 索引 i 结点的左孩子的索引是 (2i + 1)
- 索引 i 结点的右孩子的索引是 (2i + 2)
- 索引 i 结点的父结点的索引是 (i - 1) / 2 取整数
假设第一个元素在数组中索引为 1,则父结点和子结点的位置关系如下:
- 索引 i 结点的左孩子的索引是 2i
- 索引 i 结点的右孩子的索引是 2i + 1
- 索引 i 结点的父结点的索引是 i / 2 取整数
我的代码实现里统统采用二叉堆的第一个元素在数组索引为 0 的方式
最大堆的添加:
private List<T> heap;
public void add(T t) {
this.heap.add(t);
int current = this.heap.size() - 1;
int parent = (current - 1) / 2;
while (current > 0) {
if (this.heap.get(parent).compareTo(t) < 0) {
// 父结点位置元素小于新插入结点元素的值
// 交换小的元素到新插入的位置
this.heap.set(current, this.heap.get(parent));
// current 移动到父结点的位置继续比较
current = parent;
// parent 移动到现在 current 的父结点
parent = (current - 1) / 2;
} else {
// 父结点位置元素大于等于新插入结点元素的值,无需移动
break;
}
}
this.heap.set(current, t);
}最大堆删除元素:
private List<T> heap;
public void remove(T t) {
if (this.heap.isEmpty()) {
// 堆为空,返回
return;
}
int index = this.heap.indexOf(t);
int size = this.heap.size();
if (-1 == index) {
// 堆中没有要删除的元素,返回
return;
}
// 用最后的元素填补要删除元素的位置
this.heap.set(index, this.heap.get(size - 1));
// 删除最后的元素
this.heap.remove(size - 1);
if (this.heap.size() > 1) {
// 进行调整
int left = 2 * index + 1; // 左孩子
int end = this.heap.size() - 1;
T tmp = this.heap.get(index);
while (left <= end) {
if (left < end && this.heap.get(left).compareTo(this.heap.get(left + 1)) < 0) {
left++; // left 指向左右孩子中较大者
}
if (tmp.compareTo(this.heap.get(left)) < 0) {
// 填补的元素比左右孩子中较大者小
// 将较大者交换到填补位置
this.heap.set(index, this.heap.get(left));
// index 指向较大者位置
index = left;
// left 指向 index 的左儿子
left = 2 * index + 1;
} else {
// 调整结束
break;
}
}
this.heap.set(index, tmp);
}
}添加元素从下往上修正,删除元素从上往下修正。
左倾堆(leftist tree 或 leftist heap),又称为左偏树、左偏堆、最左堆等。它和二叉堆一样,都是优先队列的实现方式,当优先队列中涉及到对两个优先队列进行合并的问题时,二叉堆的效率就无法令人满意了,而左倾堆则可以很好的解决这类问题。
左倾堆的结点除了和二叉堆一样具有左右儿子键值之外,还有一个属性:零距离。
- 零距离(NPL,Null Path Length):从一个结点到一个最近的不满结点的长度。
- 不满结点:该结点左右孩子至少有一个为 NULL。
叶结点的 NPL 为 0,NULL结点的 NPL 为 -1
左倾堆有以下几个基本性质:
- 结点的键值小于或等于它的左右子结点的键值
- 结点的左孩子的 NPL >= 右孩子的 NPL
- 结点的 NPL = 它的右孩子的 NPL + 1
左倾堆中最重要的操作是合并,其基本**如下:
- 如果一个空左倾堆和一个非空左倾堆合并,返回非空左倾堆
- 如果两个左倾堆都非空,比较两个根结点,取较小堆的根结点为新的根结点。将较小堆的根结点的右孩子和较大堆进行合并
- 如果新堆的右孩子的 NPL > 左孩子的 NPL,则交换左右孩子
- 设置新堆的根结点的 NPL = 右孩子的 NPL + 1
相关代码实现:
private Node merge(Node<T> x, Node<T> y) {
if (x == null) {
return y;
}
if (y == null) {
return x;
}
// 合并 x 和 y 时,将 x 作为合并后的根
if (x.key.compareTo(y.key) > 0) {
Node node = x;
x = y;
y = node;
}
// 将 x 的右孩子和 y 合并,**合并后树的根**是 x 的右孩子
x.right = this.merge(x.right, y);
// 如果 x 的左孩子为空或者 x 的左孩子的 npl < 右孩子的 npl,交换左右孩子
if (x.left == null || x.left.npl < x.right.npl) {
Node node = x.left;
x.left = x.right;
x.right = node;
}
if (x.right == null || x.left == null) {
// 如果为叶子结点,则 npl 为 0
x.npl = 0;
} else {
// 否则,npl 为
x.npl = x.left.npl > x.right.npl ? x.right.npl + 1 : x.left.npl + 1;
}
return x;
}斜堆(skew heap)也叫自适应堆(self-adjusting heap),它是左倾堆的一个变种。和左倾堆一样,它通常也适用于优先队列;作为一种自适应的左倾堆,它的合并操作的时间复杂度也是 O(log N)。
斜堆和左倾堆的差别是:
- 斜堆的结点没有零距离这个属性
- 斜堆的合并操作和左倾堆的合并算法不同
斜堆的合并操作:
- 如果一个空斜堆与一个非空斜堆合并,返回非空斜堆
- 如果两个斜堆都非空,那么比较两个根结点,取较小堆的根结点为新的根结点。并将较小堆的根结点的右孩子和较大堆进行合并
- 合并后,交换新根结点的左孩子和右孩子
第三步是斜堆和左倾堆合并操作的关键所在,如果是左倾堆,合并后要比较左右孩子的零距离大小,若左孩子零距离 < 右孩子零距离,则需要交换左右孩子。而斜堆无论任何情况都交换左右孩子。
斜堆的合并算法:
private Node merge(Node<T> x, Node<T> y) {
if (x == null) {
return y;
}
if (y == null) {
return x;
}
// 合并 x 和 y 时,将 x 作为合并后的树根
if (x.key.compareTo(y.key) > 0) {
Node<T> node = x;
x = y;
y = node;
}
// 将 x 的右孩子和 y 合并,合并后直接交换 x 的左右孩子
Node tmp = merge(x.right, y);
x.right = x.left;
x.left = tmp;
return x;
}二项堆是二项树的集合。在了解二项堆之前,先对二项树进行介绍。
二项树是一种递归定义的有序树:
- 二项树 B0 只有一个结点
- 二项树 Bk 由两颗二项树 B(k-1) 组成,其中一颗树是另一棵树的最左孩子
具体实现太过复杂 😢
😢
图的几个概念:
- 图的种类:根据边是否有方向,将图分为无向图和有向图
- 邻接点:一条边上的两个顶点叫邻接点
- 度:在无向图中,某个顶点的度是邻接到该顶点的边的数目
- 路径:如果顶点 v1 和顶点 v2 之间存在一个顶点序列,则表示 v1 到 v2 是一条路径
- 路径长度:路径中边的数目
- 简单路径:一条路径上的顶点不重复出现
- 回路:路径的第一个顶点和最后一个顶点相同
- 简单回路:第一个顶点和最后一个顶点相同,且其他顶点不重复的路径
- 连通图:对于无向图,任意两个顶点之间都存在一条无向路径,则称无向图为连通图
- 连通分量:无向图的极大连通子图
主要有两个条件:
1、极大顶点数:再加一个顶点就不连通了
2、极大边数:包含子图中所有顶点相连的所有边
图的存储:
- 邻接矩阵:容易判断两个顶点之间是否有边,耗费空间
- 邻接表:相对节省空间,但是不容易判断两个顶点之间是否有边
相关算法(均基于领接矩阵无向图,其他图实现方式类似):
private List<Integer> adjacent(int v) {
List<Integer> list = new ArrayList<>();
if (v < 0 || v > graph.vertices.length - 1) {
// v 的索引不合法
return list;
}
for (int i = 0; i < graph.vertexCount; i++) {
if (graph.edges[v][i] > 0) {
// 说明 v 到 i 有一条边
list.add(i);
}
}
return list;
}/**
* 深度优先遍历 —— Depth First Search
*
* 和树的先序遍历类似。
*
* 它的**:假设初始状态所有顶点均未被访问,则从某个顶点 v 出发,首先访问该顶点,然后依次从它的各个邻接点出发进行深度优先搜索,直至途中所有和 v 有路径连通的顶点都被访问到。若此时还有其他顶点没有被访问到,则另选一个未被访问的顶点作为起始点,重复上述过程,直至图中所有的顶点都被访问到。
*
* 显示,深度优先遍历是一个递归的过程。
*/
public void DFS() {
boolean[] visited = new boolean[graph.vertexCount];
for (int i = 0; i < graph.vertexCount; i++) {
visited[i] = false;
}
System.out.println("Depth First Search: ");
for (int i = 0; i < graph.vertices.length; i++) {
if (!visited[i]) {
this.depthFirstSearch(i, visited);
}
}
System.out.println();
}
private void depthFirstSearch(int v, boolean[] visited) {
visited[v] = true;
System.out.print(graph.vertices[v] + " ");
for (Integer integer : this.adjacent(v)) {
if (!visited[integer]) {
this.depthFirstSearch(integer, visited);
}
}
}/**
* 广度优先遍历 —— Breadth First Search
*
* 外层 for 循环的作用是完全访问这种图(不连通图):A-B C-D
* 内层使用队列,队列中的元素始终是访问过的,每次我们从队列中取出元素,访问其邻接点,然后再把访问过的邻接点放入队列。循环直到队列为空。
*/
public void BFS() {
boolean[] visited = new boolean[graph.vertexCount];
Queue<Integer> queue = new ArrayDeque<>();
for (int i = 0; i < graph.vertexCount; i++) {
visited[i] = false;
}
System.out.println("Breadth First Search: ");
for (int i = 0; i < graph.vertices.length; i++) {
if (!visited[i]) {
visited[i] = true;
System.out.print(graph.vertices[i] + " ");
queue.add(i);
}
while (!queue.isEmpty()) {
int v = queue.poll();
for (Integer integer : this.adjacent(v)) {
if (!visited[integer]) {
visited[integer] = true;
System.out.print(graph.vertices[integer] + " ");
queue.add(integer);
}
}
}
}
}拓扑排序(Topological Order)是指,将一个有向无环图(Directed Acyclic Graph,简称 DAG)进行排序进而得到一个有序的线性序列。
拓扑排序的基本步骤:
- 构造一个队列 Q 和拓扑排序结果队列 T
- 将所有没有依赖顶点的结点放入 Q
- 当 Q 中还有顶点的时候,执行下面的步骤:
- 从 Q 中取出一个顶点 M,放入 T
- 对 m 的每一个邻接点 n(m 是起点,n 是终点):
去掉边
<m, n>如果 n 没有依赖顶点,把 n 放入 Q
邻接表有向图中代码实现:
public void topologicalSort() {
Map<String, Integer> inDegree = new HashMap<>(); // 入度
Queue<Integer> queue = new ArrayDeque<>(); // 保存入度为 0 的顶点
List<Integer> result = new ArrayList<>(); // 结果序列
// 计算每个顶点的入度
for (int i = 0; i < vertexCount; i++) {
Node node = vertices[i].firstNode;
while (node != null) {
// 初次初始化,使用 getOrDefault 来避免 NullPointerException
inDegree.put(node.vertex, inDegree.getOrDefault(node.vertex, 0) + 1);
node = node.next;
}
}
// 入度为 0 的顶点入队列
for (int i = 0; i < vertexCount; i++) {
// 因为可能存在入度为 0 的顶点,所以这里也是用 getOrDefault 在未设置值的时候返回默认值
if (inDegree.getOrDefault(vertices[i].vertex, 0) == 0) {
queue.add(i);
}
}
while (!queue.isEmpty()) {
int v = queue.poll(); // 弹出入度为 0 的顶点
result.add(v); // 加入结果序列
Node node = vertices[v].firstNode; // 获得其邻接序列
while (node != null) {
// 更新 v 邻接序列的入度
// v 的邻接序列的入度一定非 0,所以不需要设置 map 默认值
inDegree.put(node.vertex, inDegree.get(node.vertex) - 1);
if (inDegree.get(node.vertex) == 0) {
queue.add(valueOf(node.vertex));
}
node = node.next;
}
}
if (result.size() != vertexCount) {
System.out.println("Graph has a cycle!");
return;
}
for (Integer integer : result) {
System.out.print(vertices[integer].vertex + " ");
}
System.out.println();
}Dijkstra 算法是典型的最短路径算法,用于计算一个结点到其他结点的最短路径。它的主要特点是以起始点为中心向外层层层扩展(广度优先算法**),直到扩展到终点为止。
基本**:
通过 Dijkstra 算法计算最短路径的时候需要指定起点 s。
同时,引进两个集合 S 和 U。S 的作用是记录已求出最短路径的顶点(以及相应的最短路径长度),U 则是记录还未求出最短路径的顶点(以及该顶点到起点 s 的距离)。
初始时,S 中只有 s;U 中是除 s 之外的顶点,并且 U 中顶点的路径是 “起点 s 到该顶点的路径”。然后,从 U 中找出路径最短的顶点,并将其加入 S 中;接着,更新 U 中的顶点和顶点对应的路径。然后,再从 U 中找出路径最短的顶点,并将其加入 S 中;接着,...。重复该操作,直到遍历完所有顶点
操作步骤:
- 初始时,S 只包含 s,U 包含除 s 之外的其他定点,且 U 中顶点的距离为 “起点 s 到该顶点的距离”(例如:U 中顶点 v 的距离为 (s, v) 的长度。如果 s 和 v 不相邻,则 v 的距离为 ∞)。
- 从 U 中选出“距离最短的顶点 k”,并将顶点 k 加入 S 中,同时从 U 中移除 k。
- 更新 U 中各个顶点到起点 s 的距离。之所以更新,是因为上一步中确定了 k 是最短距离,从而可以利用 k 来更新其他顶点的距离。
- 重复步骤 2 和 3,直到遍历完所有顶点。
邻接矩阵无向图的代码实现:
public void Dijkstra(int v) {
boolean[] flag = new boolean[this.vertexCount]; // flag[i] = true 表示顶点 v 到顶点 i 的最短路径已经成功找到
int[] distance = new int[this.vertexCount]; // 长度数组,distance[i] 是顶点 v 到顶点 i 的最短路径长度
int k = 0; // k 位置顶点是已获得的最短路径
for (int i = 0; i < this.vertexCount; i++) {
flag[i] = false; // 顶点 i 的最短路径还没找到
distance[i] = edges[v][i]; // 顶点 i 的最短路径为顶点 v 到顶点 i 的权,权值的默认值为 Integer.MAX_VALUE
}
// 对顶点 v 进行初始化
flag[v] = true;
distance[v] = 0;
System.out.println("Dijkstra: ");
System.out.println(vertices[v] + " 到 " + vertices[v] + " 的最短路径是:" + distance[v]);
// 进行 vertexCount - 1 次循环
for (int i = 1; i < this.vertexCount; i++) {
int min = INF;
// 获取未找到最短路径顶点中最小值及其索引
for (int j = 0; j < this.vertexCount; j++) {
if (!flag[j] && distance[j] < min) {
min = distance[j];
k = j;
}
}
// 标记顶点 k 为已经获得的最短路径
flag[k] = true;
System.out.println(vertices[v] + " 到 " + vertices[k] + " 的最短路径是:" + distance[k]);
// 修正未获得最短路径的顶点集合中的路径长度
for (int j = 0; j < this.vertexCount; j++) {
// tmp 此处的判断是:如果从顶点 k 到顶点 j 有边,那么暂存 min+边的权值
int tmp = (edges[k][j] == INF ? INF : (min + edges[k][j]));
if (!flag[j] && tmp < distance[j]) {
// 如果 tmp 比 distance[j] 大,说明 j 到 v 之间有较短路径
// 如果 tmp 比 distance[j] 小,说明需要更新 distance[j]
distance[j] = tmp;
}
}
}
}最小生成图:
在含有 n 个顶点的连通图中选择 n - 1 条边,构成一颗极小连通子图,并使该连通子图中 n - 1 条边上权值之和最小,则称其为连通网(网,带权值的图)的最小生成树。
Kruskal 算法是用来求加权连通图的最小生成树的算法。
基本**:
按照权值从小到大的顺序选择 n - 1 条边,并保证这 n - 1 条边不构成回路。
具体做法:
首先构造一个只含 n 个结点的森林,然后依权值大小从连通网中选择边加入森林中,并使森林不产生回路,直至森林变成一棵树为止。
算法分析:
Kruskal 算法重点需要解决以下两个问题:
- 对图中的边按照权值大小进行排序
- 将边添加到最小生成树中时,怎样判断是否形成了回路
第一个问题很好解决,采用排序算法即可。
第二个问题的处理方式是:记录顶点再最小生成树中的终点,顶点的终点是“在最小生成树中与它连通的最大顶点”。然后每次需要将一条边添加到最小生成树时,判断该边的两个终点是否重合,重合的话则构成回路。
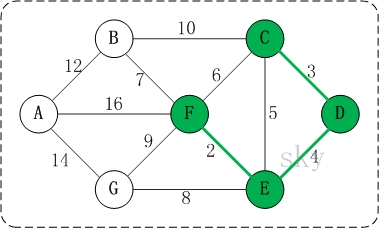
在将 <E, F>, <C, D>, <D, E> 加入到最小生成树中之后,这几条边的顶点都有了终点:
C 的终点是 F D 的终点是 F E 的终点是 F F 的终点是 F
关于终点,就是将所有顶点按照从小到大的顺序排列好之后,某个顶点的终点就是“与它连通的最大顶点”
Kruskal 算法的邻接矩阵代码实现:
public void Kruskal() {
int[] vEnds = new int[this.edgeCount];
// 使用优先队列保存边,创建优先队列时设置比较器为从小到大
PriorityQueue<Edge> edges = new PriorityQueue<>(Comparator.comparing(e -> e.weight));
// 结果列表
List<Edge> edgeList = new ArrayList<>();
int resultWeight = 0;
// 初始化边
for (int i = 0; i < this.vertexCount; i++) {
for (int j = 0; j < i; j++) {
if (this.edges[i][j] != INF) {
// 因为创建边的时候 i 为第一下标,j 为第二下标,所以数组中应该是
// A B C
// A
// B
// C
// ...
// 因为使用邻接矩阵保存,为避免加入队列的时候出现一条边加入两次的情况,内次循环只循环 i 次
// 但是如果循环 i 次,会造成只访问了左下半部分元素,如果我们需要 A B 形式而不是 B A 形式的边,我们必须在保存的时候交换 i j 位置
edges.add(new Edge(j, i, this.edges[i][j]));
}
}
}
Edge edge;
int start, end; // 边开始顶点位置,结束顶点位置
int sEnd, eEnd; // 开始顶点的终点,结束顶点的终点
while (!edges.isEmpty()) {
edge = edges.poll(); // 权值最小的边出队列
start = edge.start;
end = edge.end;
sEnd = this.getEnd(vEnds, start); // 获取 start 的终点
eEnd = this.getEnd(vEnds, end); // 获取 end 的终点
if (sEnd != eEnd) { // 如果两个终点相同,则说明可能产生回路
vEnds[sEnd] = eEnd;
edgeList.add(edge);
resultWeight += edge.weight;
}
}
System.out.println("Kruskal 最小生成树的权值:" + resultWeight);
System.out.println("Kruskal 最小生成树的边: ");
for (Edge edge1 : edgeList) {
System.out.println(this.vertices[edge1.start] + ", " + this.vertices[edge1.end]);
}
}Prim 算法和 Kruskal 算法一样,是用来求加权连通图的最小生成树的算法。
基本**:
对于图 G,V 是所有顶点的集合。现在,设置两个新的集合 U 和 T,其中 U 用于存放 G 的最小生成树中的顶点,T 存放 G 的最小生成树的边。从所有 u ∈ U,v ∈ (V-U) 的边中选取权值最小的边(u, v),将顶点 v 加入集合 U 中,将边 (u, v) 加入集合 T 中,如此不断重复,直至 U=V 为止,最小生成树构造完毕,这时,集合 T 中包含了最小生成树的所有边。
Prim 算法的邻接矩阵代码实现:
public void Prim(int start) {
int[] weight = new int[vertexCount]; // 权值数组,权值为 0 视为已加入最小生成树
List<String> list = new ArrayList<>();
int resultWeight = 0;
// prim 最小生成树的第一个数是 start 顶点
list.add(this.vertices[start]);
// 初始化权值列表
System.arraycopy(edges[start], 0, weight, 0, vertexCount);
// 初始化顶点 start 的权值
weight[start] = 0;
for (int i = 0; i < vertexCount; i++) {
if (i == start) {
// 不需要再处理 start 顶点
continue;
}
int k = 0, min = INF;
// 找到未被加入最小生成树的顶点中权值最小的顶点
for (int j = 0; j < vertexCount; j++) {
if (weight[j] != 0 && weight[j] < min) {
// weight[j] == 0 代表着 j 已经加入最小生成树
min = weight[j];
k = j;
}
}
// 将第 k 个顶点加入最小生成树的结果数组
list.add(this.vertices[k]);
// 将 k 顶点的权值标记为 0,意味着第 k 个顶点已经加入最小生成树
weight[k] = 0;
resultWeight += min;
// 更新剩下顶点的权值
for (int j = 0; j < vertexCount; j++) {
if (weight[j] != 0 && weight[j] > this.edges[k][j]) {
weight[j] = this.edges[k][j];
}
}
}
System.out.println("Prim 最小生成树的权值:" + resultWeight);
System.out.println("Prim 最小生成树的边:");
for (String s : list) {
System.out.print(s + " ");
}
System.out.println();
}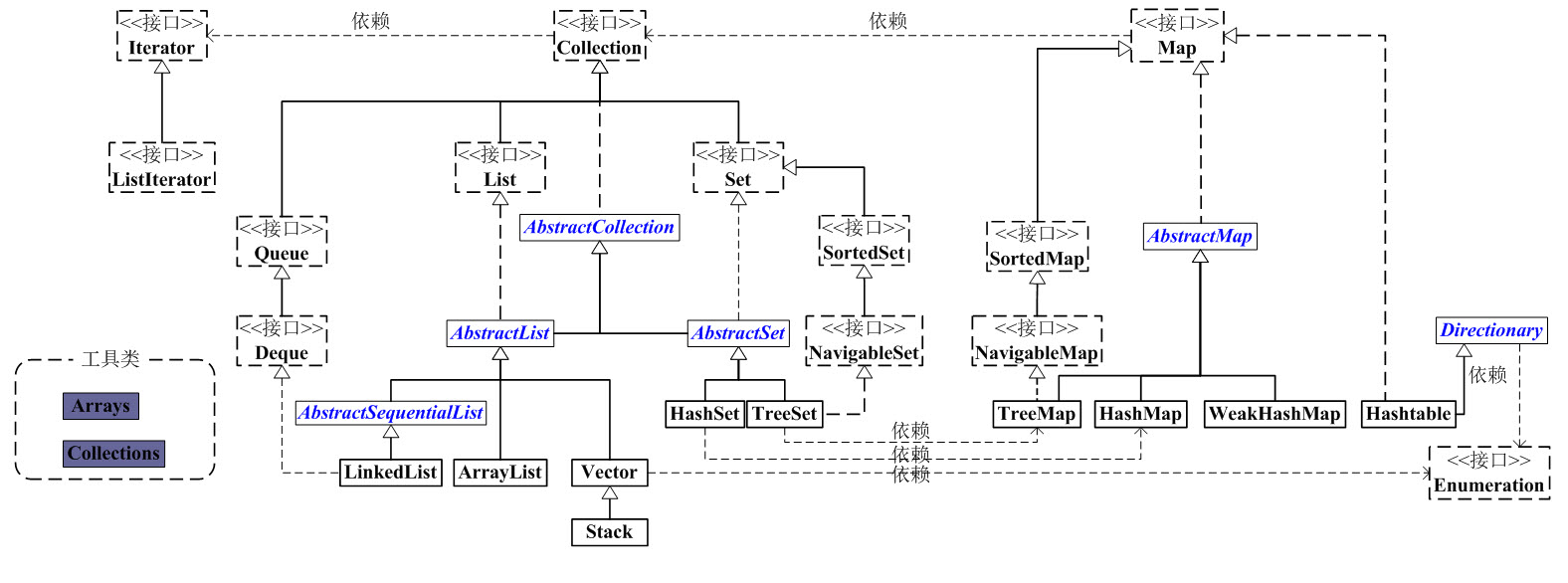
Collection 是一个接口,是高度抽象出来的集合,它包括了集合的基本操作和属性。
package java.util;
public interface Collection<E> extends Iterable<E> {
int size();
boolean isEmpty();
boolean contains(Object o);
Iterator<E> iterator();
Object[] toArray();
<T> T[] toArray(T[] a);
boolean add(E e);
boolean remove(Object o);
boolean containsAll(Collection<?> c);
boolean addAll(Collection<? extends E> c);
boolean removeAll(Collection<?> c);
boolean retainAll(Collection<?> c);
void clear();
boolean equals(Object o);
int hashCode();
}Collection 包括了 List 和 Set 两大分支:
- List 是有序的序列,每一个元素都有它的索引。List 的实现类有 LinkedList,ArrayList,Vector,Stack
- Set 是一个不允许有重复元素的集合。Set 的实现类有 HashSet 和 TreeSet。HashSet 依赖于 HashMap,它实际上通过 HashMap 实现;TreeSet 依赖与 TreeMap,它实际上通过 TreeMap 实现。
Map 是一个映射接口,即 key-value 键值对。Map 中的每一个元素包含 “一个 key” 和 “key 对应的 value”。
AbstractMap 是一个抽象类,它实现了 Map 接口中的大部分 API。而 HashMap,TreeMap,WeakHashMap 等都是继承于 AbstractMap。
Hashtable 虽然继承于 Dictionary,但它实现了 Map 接口。
Iterator 是遍历集合的工具,即我们通常通过 Iterator 迭代器来遍历集合。Collection 继承于 Iterable,所有 Collection 的实现类都要实现 iterator() 函数,返回一个 Iterator 对象。
ListIterator 是专门为遍历 List 而存在的。
Enumeration 的作用和 Iterator 一样,也是遍历集合。但是 Enumeration 的功能要比 Iterator 少。
Arrays 和 Collections 是用来操作数组、集合的两个工具类。提供了非常多方便的函数。
List 是有序的序列,List 中可以有重复的元素。
Set 是数学概念中的集合,Set 中没有重复元素。
ArrayList 是一个数组实现的 List,是动态数组。与 Java 中的数组相比,它的容量能动态增长,初始值为 10。它继承于 AbstractList,实现了 List, RandomAccess, Cloneable, java.io.Serializable 这些接口。
和 Vector 不同,ArrayList 的操作不是同步的!所以,建议在单线程中才使用 ArrayList,而在多线程中可以选择 Vector 或者 CopyOnWriteArrayList。
当 ArrayList 的容量不足以容纳全部元素时,ArrayList 会重新设置容量(扩大三倍):
int newCapacity = oldCapacity + (oldCapacity >> 1);fail-fast 是 Java 集合(Collection)中的一种错误机制。当多个线程对同一集合的内容进行操作时,就可能产生 fail-fast 事件。
例如:当某一个线程A通过iterator去遍历某集合的过程中,若该集合的内容被其他线程所改变了;那么线程A访问集合时,就会抛出 ConcurrentModificationException 异常,产生 fail-fast 事件。
ArrayList 每次调用 next() 和 remove() 等方法时,都会执行 checkForComodification():
if (expectedModCount != ArrayList.this.modCount)
throw new ConcurrentModificationException();如果 modCount 不等于 expectedModCount,则抛出 ConcurrentModificationException 异常,产生 fail-fast 事件。
而 java.util.concurrent.CopyOnWriteArrayList 则使用了 volatile 关键字保证内存一致性。CopyOnWriteArrayList 通过在写的时候将原数组的内容拷贝到新数组进行写,写操作完成时,将原数组的引用指向新数组。为了避买并发写时出现多份不同数据,CopyOnWriteArrayList 的整个 add 操作都是在 ReentrantLock 锁的保护下进行的。而对于读不作限制。CopyOnWriteArrayList 保证了数据的最终一致性,而不保证实时读(即写操作完成后读取到的数据不一定是最新的数据,因为还需要更改引用指向)。
fail-fast 机制,是一种错误检测机制。它只能被用来检测错误,因为 JDK 并不保证 fail-fast 机制一定会发生。若在多线程环境下使用 fail-fast 机制的集合,建议使用 java.util.concurrent 包下的类去取代 java.util 包下的类。
LinkedList 是一个继承于 AbstractSequentialList 的双向链表。它也可以被当作堆栈、队列、或双端队列进行操作。LinkedList 实现了 List, Deque, Cloneable, java.io.Serializable 接口。
LinkedList 是非同步的。
LinkedList 实际上是通过双向链表实现的,它包含一个非常重要的内部类 Entry。Entry 是双向链表结点所对应的数据结构。
Vector 是矢量队列,继承于 AbstractList,实现了 List, RandomAccess, Cloneable, java.io.Serializable 接口。
和 ArrayList 不同,Vector 中的操作是同步(单线程低效)的。
Vector 默认容量大小为 10。
当 Vector 的容量不够时,会根据增长因子的情况增加容量:
int newCapacity = oldCapacity + ((capacityIncrement > 0) ?
capacityIncrement : oldCapacity);Stack 是栈,它的特性是:先进后出(FILO, First In Last Out)
Stack 继承于 Vector(非常愚蠢的设计),而 Vector 是通过数组实现的,这就意味着,Stack 也是通过数组实现的,而非链表。当然,我们也可以把 LinkedList 当作栈来使用(推荐)。
如果涉及到 “栈”、“队列”、“链表” 等操作,应该考虑 List,具体选择哪个 List,以下有几条标准:
- 对于需要快速插入、删除元素,应该使用 LinkedList
- 对于需要快速随机访问的元素,应该使用 ArrayList
- 对于“单线程环境”或者“多线程环境,但是 List 只会被单个线程操作”,应该使用非同步的类(如 ArrayList)
- 对于“多线程环境,且 List 可能同时被多个线程操作”,此时应该使用同步的类(如 Vector)
HashMap 继承自 AbstractMap,实现了 Map, Cloneable, Serializable 接口。
HashMap 的实现是不同步的,这意味着它不是线程安全的。
HashMap 的 key、value 都可以为 null。
HashMap 中的映射不是有序的。
HashMap 中有两个参数影响其性能:初始容量和加载因子。初始容量是哈希表在创建时的容量。加载因子是哈希表在其容量自动增加之前可以达到多满的一种尺度。通常,默认的加载因子是 0.75
在 jdk1.8 HashMap 在某一个表项的结点数到达 8 的时候会将该链表转换为红黑树。
和 HashMap 一样,Hashtable 也是一个散列表,它存储的内容是键值对(key-value)映射。
Hashtable 继承于 Dictionary,实现了 Map, Cloneable, java.io.Serializable 接口。
Hashtable 的函数都是同步的,这意味着它是线程安全的(单线程低效)。
Hashtable 的 key、value 都不可以为 null。
Hashtable 中的映射不是有序的。
和 HashMap 一样,Hashtable 中也有两个参数影响其性能:初始容量和加载因子。加载因子默认是 0.75。
TreeMap 是一个有序的 key-value 集合,它的内部是通过红黑树实现的。
TreeMap 继承于 AbstractMap,实现了 NavigableMap, Cloneable, java.io.Serializable 接口。实现 NavigableMap 意味着它支持一系列的导航方法。
TreeMap 是基于红黑树实现的。该映射根据其键的自然顺序进行排序,或者根据创建映射时提供的 Comparator 进行排序。
TreeMap 是非同步的。多线程情况下考虑 ConcurrentHashMap,它利用分段锁来保证安全的高并发访问。
WeakHashMap 继承于 AbstractMap,实现了 Map 接口。
和 HashMap 一样,WeakHashMap 也是一个散列表,它存储的内容也是键值对映射,而且键和值都可以是 null。
不过,WeakHashMap 中的键是弱键。在 WeakHashMap 中,当某个键不再正常使用时,会被从 WeakHashMap 中自动移除。更准确的说,对于一个给定的键,其映射的存在并不组织垃圾回收器对其键的丢弃,这就是该键称为可终止的,被终止,然后被回收。某个键被终止时,它对应的键值对也就从映射中有效地移除了。
弱键的原理,大致上是通过WeakReference和ReferenceQueue实现的。WeakHashMap 的 key 时弱键,即是 WeakReference 类型的;ReferenceQueue 是一个队列,它会保存被 GC 回收的弱键。实现步骤是:
- 新建 WeakHashMap,将键值对添加到 WeakHashMap 中。
- 当某弱键不再被其他对象引用,并被GC回收时,在 GC 回收该弱键时,这个弱键也同样会被添加到 ReferenceQueue 队列中。
- 当下一次我们需要操作 WeakHashMap 时,会先同步内部的 table 和 ReferenceQueue,也即,删除 table 中被 GC 回收的键值对。
WeakHashMap 是不同步的。
- HashMap 是基于拉链(分离链接)法实现的散列表,一般用于单线程程序中
- Hashtable 也是基于拉链法实现的散列表(任何时候不建议使用)
- WeakHashMap 也是基于拉链法实现的散列表,它一般也用于单线程程序中
- TreeMap 是有序的 Map,它是通过红黑树实现的,一般用于单线程中存储有序的映射
HashSet 是一个没有重复元素的集合,它是由 HashMap 实现的,不保证元素顺序,并且允许使用 null 元素。
HashSet 是非同步的,可以通过 Collections.synchronizedSet 方法来包装 set。
TreeSet 是一个有序的集合,继承于 AbstractSet 类,实现了 NavigableSet, Cloneable, java.io.Serializable 接口。
TreeSet 是基于 TreeMap 实现的。TreeSet 中的元素支持两种排序方式:自然排序或者根据创建 TreeSet 时提供的 Comparator 进行排序。TreeSet 为基本操作(add、remove等)提供受保证的 log (N) 时间开销。
TreeSet 是非线程安全的。
Enumeration 是一个接口:
public interface Enumeration<E> {
boolean hasMoreElements();
E nextElement();
}Iterator 也是一个接口:
public interface Iterator<E> {
boolean hasNext();
E next();
default void remove() {
throw new UnsupportedOperationException("remove");
}
default void forEachRemaining(Consumer<? super E> action) {
Objects.requireNonNull(action);
while (hasNext())
action.accept(next());
}
}他们之间主要的区别有:
- 函数接口不同
- Iterator 支持 fail-fast 机制,而 Enumeration 不支持
Enumeration 是 JDK 1.0 添加的接口,使用它的类包括 Vector、Hashtable 等,这些类都是 JDK 1.0 中加入的,Enumeration 存在的目的就是为他们提供遍历接口。Enumeration 本身并没有支持同步,而在 Vector、Hashtable 实现 Enumeration 时,添加了同步。
Iterator 是 JDK 1.2 添加的接口,它也是为了 HashMap、ArrayList 等集合提供遍历接口。Iterator 是支持 fail-fast 机制的:当多个线程对同一个集合的内容进行操作时,就可能会产生 fail-fast 事件。
分治算法,字面上的解释是“分而治之”,就是把一个复杂的问题分成两个或者更多的相同或者相似的子问题,再把子问题分成更小的子问题......直到最后子问题可以简单的直接求解,原问题的解即子问题的解的合并。这个技巧是很多高效算法的基础,如排序算法(快速排序、归并排序),傅里叶变换(快速傅里叶变换)......
分治法的设计**是:将一个难以直接解决的大问题,分割成一些规模较小的相同问题,以使各个击破,分而治之。
分治策略是:对于一个规模为 n 的问题,若该问题可以容易地解决(例如 n 较小)则直接解决,否则将其分解成 k 个规模较小的子问题,这些子问题互相独立且与原问题形式相同,递归地解这些子问题,然后将各子问题的解合并得到原问题的解。
- 该问题的规模缩小到一定程度就可以很容易地解决
- 该问题可以分解为若干个规模较小的相同问题,即该问题具有最优子结构性质
- 利用该问题分解出的子问题的解可以合并为该问题的解
- 该问题所分解出的各个子问题是相互独立的,即子问题之间不包含公共的子子问题
第二条特征是应用分治法的前提,此特征反映了递归**的应用。
第三条特征是关键,能否利用分治法完全取决于问题是否具有第三条特征。如果具备了一、二条特征,而不具备第三条特征,则可以考虑贪心算法或者动态规划。
第四条特征涉及到分治法的效率。如果不满足,即子问题有公共子子问题,使用动态规划会更好。
分治法在每一层递归上都有三个步骤:
- 分解:将原问题分解为若干个规模较小,相互独立,与原问题形式相同的子问题
- 解决:将子问题规模较小而容易解决的直接解决,否则递归地解各个子问题
- 合并:将各个子问题的解合并为原问题的解
动态规划过程是:每次决策依赖于当前状态,又随即引起状态的转移。一个决策序列就是在变化的状态中产生出来的,所以,这种多阶段最优化决策解决问题的过程就成为动态规划。
基本**与分治法类似,也是将待求解的问题分成若干子问题(阶段),按顺序求解子阶段,前一子问题的解,为后一子问题的求解提供了有用的信息。在求解任一子问题时,列出所有可能的局部解,通过决策保留那些有可能达到最优的局部解,丢弃其他局部解。依次解决各子问题,最后一个字问题就是初始问题的解。
由于动态规划解决的问题多数有重叠子问题这个特点,为减少重复计算,对每个子问题只解一次,将其不同阶段的不同状态保存在一个二维数组中。
与分治法最大的差别是:适合于动态规划求解的问题,经分解后得到的子问题往往不是互相独立的(即下一个子阶段的求解是建立在上一个子阶段的解的基础上,进行进一步的求解)。
- 最优化原理:如果问题的最优解包含的子问题的解也是最优的,就称该问题具有最优子结构,即满足最优化原理
- 无后性:即某阶段一旦确定,就不受这个状态以后的决策的影响。也就是说,某状态以后的过程不会影响以前的状态,只与当前状态有关
- 有重叠子问题:即子问题之间不是独立的,一个子问题在下一阶段的决策中可能被多次用到(该性质不是动态规划适用的必要条件,但是如果没有这条性质,动态规划算法同其他算法相比就不具备优势)
- 划分阶段:按照问题的时间或空间特征,将问题分为若干阶段。在划分阶段时,注意划分后的阶段一定要是有序的或者是可排序的,否则问题就无法求解。
- 确定状态和状态变量:将问题发展到各个阶段时所处于的各种客观情况用不同的状态表示出来。当然,状态的选择要满足无后性。
- 确定决策并写出状态转移方程:因为决策和状态转移有着天然的联系,状态转移就是根据上一阶段的状态和决策来导出本状态的阶段。所以如果确定了决策,状态转移方程也就可以写出。但事实上常常是反过来做,**根据相邻两阶段的状态之间的关系来确定决策方法和状态转移方程。
- 寻找边界条件:给出的状态转移方程是一个递推式,需要一个递推的终止条件或边界条件。
实际应用中可以按照以下几个简化的步骤进行设计:
- 分析最优解的性质,并刻画其结构特征
- 递归地定义最优解
- 以自底向上或者自顶向下的记忆化方式计算出最优值
- 根据计算最优值时得到的信息,构造问题的最优解
使用动态规划求解问题,最重要的就是确定动态规划三要素:
- 问题的阶段
- 每个阶段的状态
- 从前一阶段转化到后一阶段之间的递推关系
递推关系必须是从次小问题开始到较大问题之间的转化,从这个角度来说,动态规划往往可以用递归程序来实现,不过因为递推可以充分利用前面保存的子问题的解来减少重复计算,所以对于大规模问题来说,有递归不可比拟的优势,这也是动态规划的核心之处。
所谓贪心算法是指,在对问题求解时,总是做出在当前看来是最好的选择。也就是说,不从整体最优上加以考虑,它做出的仅仅是某种意义上的局部最优解。
贪心算法没有固定的算法框架,算法设计的关键是贪心策略的选择。必须注意的是,贪心算法不是对所有问题都能得到整体最优解,选择贪心策略必须具备无后效性,即某个状态以后的过程不会影响以前的状态,只与当前状态有关。
- 建立数学模型来描述问题
- 把求解的问题分成若干个子问题
- 把每一子问题求解,得到子问题的局部最优解
- 把子问题的局部最优解合成原来问题的一个解
贪心算法适用的前提是:局部最优策略能导致产生全局最优解
事实上,贪心算法适用的情况很少。一般,对于一个问题是否适用于贪心算法,可以先选择该问题下的几个实际数据进行分析,就可做出判断。
[背包问题]有一个背包,背包容量是M=150。有7个物品,物品可以分割成任意大小。要求尽可能让装入背包中的物品总价值最大,但不能超过总容量。
物品:A B C D E F G 重量:35 30 60 50 40 10 25 价值:10 40 30 50 35 40 30 分析:目标函数 ∑pi 最大,约束条件是装入物品的总重量不超过背包重量:∑wi <= M(M = 150)
- 根据贪心的策略,每次挑选价值最大的物品装入背包,得到的结果是否最优?
- 每次挑选所占重量最小的物品装入是否能得到最优解?
- 每次选取单位重量价值最大的物品,成为本题的最优策略。
值得注意的是,贪心算法并不是完全不可以使用,贪心策略一旦证明成立后,它就是一种高效的算法。
贪心算法还是很常见的算法之一,这是由于它简单易行,构造贪心策略不是很困难。
一般来说,贪心算法的证明围绕着:整个问题的最优解一定由贪心策略中存在的子问题的最优解得来的。
回溯算法实际上是一个类似枚举的搜索尝试过程,主要是在搜索尝试过程中寻找问题的解,当发现条件已不满足求解条件时,就“回溯”返回,尝试别的路径。
回溯法是一种选优搜索法,按照选优条件向前搜索,以达到目标,但当探索到某一步时,发现原先选择并不优或者达不到目标,就退一步重新选择,这种走不通就退回再走的技术称为回溯法,而满足回溯条件的某个状态的点称为“回溯点”。
许多复杂的、规模较大的问题都可以使用回溯法。回溯法有“通用解题方法”之美称。
在包含问题的所有解的解空间树中,按照深度优先搜索的策略,从根结点出发深度探索解空间树。当探索到某一结点时,要先判断该结点是否包含问题的解,如果包含,就从该结点出发继续探索下去,如果该结点不包含问题的解,则逐层向其祖先结点回溯。(其实回溯法就是对隐式图的深度优先搜索算法)。
若用回溯法求问题的所有解时,要回溯到根,且根结点的所有可行的子树都要已被搜索遍才结束。
而若使用回溯法求任一个解时,只要搜索到问题的一个解就可以结束。
- 针对所给问题,确定问题的解空间
- 确定结点的扩展搜索规则
- 以深度优先方式搜索解空间,并在搜索过程中用剪枝函数避免无效搜索
分支限界法类似于回溯法,也是一种在问题的解空间树 T 上搜索问题解的算法。但在一般情况下,分支限界法与回溯法的求解目标不同。
回溯法的求解目标是找出 T 中满足约束条件的所有解,而分支限界法的求解目标则是找出满足约束条件的一个解,或是在满足约束条件的解中找出使某一目标函数值达到极大或极小的解,即在某种意义下的最优解。
所谓“分支”就是采用广度优先的策略,依次搜索 E-结点 的所有分支,也就是所有相邻结点,抛弃不满足约束条件的结点,其余结点加入活结点表。然后从表中选择一个结点作为下一个 E-结点,继续搜索。
选择下一个 E-结点 的方式不同,则会有几种不同的分支搜索方式:
- FIFO搜索
- 优先队列式搜索
由于求解目标不同,导致分支限界法与回溯法在解空间树T上的搜索方式也不相同。回溯法以深度优先的方式搜索解空间树T,而分支限界法则以广度优先或以最小耗费优先的方式搜索解空间树T。
分支限界法的搜索策略是:在扩展结点处,先生成其所有的儿子结点(分支),然后再从当前的活结点表中选择下一个扩展对点。为了有效地选择下一扩展结点,以加速搜索的进程,在每一活结点处,计算一个函数值(限界),并根据这些已计算出的函数值,从当前活结点表中选择一个最有利的结点作为扩展结点,使搜索朝着解空间树上有最优解的分支推进,以便尽快地找出一个最优解。
分支限界法常以广度优先或以最小耗费(最大效益)优先的方式搜索问题的解空间树。问题的解空间树是表示问题解空间的一棵有序树,常见的有子集树和排列树。在搜索问题的解空间树时,分支限界法与回溯法对当前扩展结点所使用的扩展方式不同。
在分支限界法中,每一个活结点只有一次机会成为扩展结点。活结点一旦成为扩展结点,就一次性产生其所有儿子结点。在这些儿子结点中,那些导致不可行解或导致非最优解的儿子结点被舍弃,其余儿子结点被子加入活结点表中。此后,从活结点表中取下一结点成为当前扩展结点,并重复上述结点扩展过程。这个过程一直持续到找到所求的解或活结点表为空时为止。
给定整数 A1, A2, ..., An(可能有负数),求 ∑(k=i, j)Ak 的最大值(为方便起见,如果所有整数均为负数,则最大子序列和为 0)
public static int maxSubSequenceSum(int[] sequence) {
int max = 0, this_sum = 0;
for (int i = 0; i < sequence.length; i++) {
for (int j = i; j < sequence.length; j++) {
this_sum = 0;
for (int k = i; k <= j; k++) {
this_sum += sequence[k];
}
if (this_sum > max) {
max = this_sum;
}
}
}
return max;
}算法的时间复杂度 O(N³)
public static int maxSubSequenceSum(int[] sequence) {
int max = 0, this_sum = 0;
for (int i = 0; i < sequence.length; i++) {
this_sum = 0;
// 相对一算法 1 的改进,直接计算和,没必要再遍历一次
for (int j = i; j < sequence.length; j++) {
this_sum += sequence[j];
if (this_sum > max) {
max = this_sum;
}
}
}
return max;
}算法的时间复杂度:O(N²)
分治算法,将序列分为左右两个子序列,分别计算 左、右、中间 的子序列和,比较最大的并返回。
public static int maxSubSequenceSum(int[] sequence, int left, int right) {
int center;
int maxLeftSum, maxRightSum;
int leftBorderSum, rightBorderSum;
int maxLeftBorderSum, maxRightBorderSum;
if (left == right) {
if (sequence[left] > 0) {
return sequence[left];
} else {
return 0;
}
}
center = left / 2 + right / 2;
// 计算左侧的最大子序列和
maxLeftSum = maxSubSequenceSum(sequence, left, center);
// 计算右侧的最大子序列和
maxRightSum = maxSubSequenceSum(sequence, center + 1, right);
// 计算包括中间的最大子序列和
leftBorderSum = 0;
maxLeftBorderSum = 0;
for (int i = center; i >= left; i--) {
leftBorderSum += sequence[i];
if (leftBorderSum > maxLeftBorderSum) {
maxLeftBorderSum = leftBorderSum;
}
}
rightBorderSum = 0;
maxRightBorderSum = 0;
for (int i = center + 1; i < right; i++) {
rightBorderSum += sequence[i];
if (rightBorderSum > maxRightBorderSum) {
maxRightBorderSum = rightBorderSum;
}
}
return Math.max(Math.max(maxLeftSum, maxRightSum), maxLeftBorderSum + maxRightBorderSum);
}算法的时间复杂度 O(N log N)
只对数据进行一次扫描即可。
public static int maxSubSequenceSum(int[] sequence) {
int max = 0, this_sum = 0;
for (int i : sequence) {
this_sum += i;
if (this_sum > max) {
max = this_sum;
} else if (this_sum < 0) {
this_sum = 0;
}
}
return max;
}算法的时间复杂度 O(N)
对于一个排序好的序列,如果要查找其中是否有某个元素,遍历的做法是十分低效的,我们可以使用二分查找法。
二分查找的**是每次比较序列的中间值,大于中间值就比较右半序列,小于就比较左半序列,直到找到元素或者找不到循环退出。
public class BinarySearch {
public static void main(String[] args) {
int[] sequence = new int[]{1, 3, 4, 5, 6, 7, 9, 14, 17};
System.out.println(binarySearch(sequence, 4));
}
public static int binarySearch(int[] sequence, int n) {
int low = 0, high = sequence.length - 1;
int mid;
while (low <= high) {
mid = (low + high) / 2;
System.out.println("Try " + sequence[mid]);
if (n < sequence[mid]) {
high = mid;
} else if (n > sequence[mid]) {
low = mid + 1;
} else {
return mid;
}
}
return -1;
}
}算法的时间复杂度 O(log N)
辗转相除法,又名欧几里得算法,是计算两个数的最大公约数的简便算法
public class EuclidGCD {
public static void main(String[] args) {
System.out.println(euclid(1989, 1590)); // 3
}
public static int euclid(int number1, int number2) {
// 欧几里得 -- 辗转相除法,求两个数的最大公约数
int remainder;
while (number2 > 0) {
remainder = number1 % number2;
number1 = number2;
number2 = remainder;
}
return number1;
}
}算法的时间复杂度 O(log N)
选择排序(Selection Sort)是一种简单直观的排序算法。
它的基本**是:首先在未排序的数列中找到最小(或最大)的元素,然后将其存放到数列的起始位置;接着,再从剩余未排序的元素中继续寻找最小(或最大)元素,然后放到已排序序列的末尾。以此类推,直到所有的元素排序完毕。
public static void sort(int[] numbers) {
int min;
for (int i = 0, len = numbers.length; i < len; i++) {
min = i;
for (int j = i + 1; j < len; j++) {
// 获取未排序元素中的最小值
if (numbers[j] < numbers[min])
min = j;
}
// 若 min != i,则交换 numbers[i] 和 numbers[min]
if (min != i) {
int tmp = numbers[i];
numbers[i] = numbers[min];
numbers[min] = tmp;
}
}
}选择排序算法的平均时间复杂度:O(N²),最坏情况下的时间复杂度:O(N²),额外的空间复杂度:O(1),稳定性:不稳定。
冒泡排序(Bubble Sort),又称为起泡排序或者泡沫排序。
它是一种较简单的排序算法。它会遍历若干次要排序的序列,每次遍历时,它都会比较相邻两个数的大小;如果前者比后者大,则交换它们的位置。这样,一次遍历结束,最大的元素就在数列的末尾。采用相同的方法再次遍历时,第二大的元素就在最大元素之前。重复此操作,直到整个序列有序。
public static void sort(int[] numbers) {
// 从后往前开始遍历,每次外层循环结束,i 位置(当前最后)的元素为 0 - i 中最大的元素
for (int i = numbers.length - 1; i > 0; i--) {
for (int j = 0; j < i; j++) {
if (numbers[j] > numbers[i]) {
int tmp = numbers[j];
numbers[j] = numbers[i];
numbers[i] = tmp;
}
}
}
}
/**
* 优化策略:如果一趟排序中没有发生任何数据交换,说明数据已经是有序的了,直接终止循环。
*/
public static void optimize_sort(int[] numbers) {
boolean flag;
for (int i = numbers.length - 1; i > 0; i--) {
flag = true;
for (int j = 0; j < i; j++) {
if (numbers[j] > numbers[i]) {
int tmp = numbers[j];
numbers[j] = numbers[i];
numbers[i] = tmp;
flag = false;
}
}
if (flag) {
break;
}
}
}对冒泡排序还可以做一次优化:如果一趟遍历中没有发生过元素交换,则说明数列已经有序,跳出循环。
冒泡排序算法的平均时间复杂度:O(N²),最坏情况下的时间复杂度:O(N²),额外的空间复杂度:O(1),稳定性:稳定。
插入排序(Insertion Sort)类似于起牌,每次起到手里的牌都是有序的。
基本**是:将 n 个待排序序列的元素看成一个有序表和一个无序表。开始有序表只包含一个元素,无序表包含 n - 1 个元素,排序过程中每次从无序表中取出第一个元素,将它插入到有序表中的适当位置,使之成为新的有序表,重复 n - 1 次即可完成排序过程。
public static void sort(int[] numbers) {
int j;
for (int i = 1, len = numbers.length; i < len; i++) {
// i 位置元素是待排序元素,i 前元素是有序序列
int tmp = numbers[i];
for (j = i; j > 0 && numbers[j - 1] > tmp; j--) {
// 进行比较,移动元素,空出合适的位置
// numbers[j - 1] > tmp 说明应将 numbers[j - 1] 后移
// 如果 numbers[j - 1] < tmp,说明应插入元素位置为 j
numbers[j] = numbers[j - 1];
}
numbers[j] = tmp;
}
}插入排序算法的平均时间复杂度:O(N²),最坏情况下的时间复杂度:O(N²),额外的空间复杂度:O(1),稳定性:稳定。
希尔排序(Shell Sort)是插入排序的一种,它是针对插入排序算法的一种改进。该方法又称为缩小增量排序。
希尔排序实质上是一种分组插入方法,它的基本**是:对于 n 个元素的待排序序列,取一个小于 n 的整数 gap 将待排序序列分为若干个子序列,所有距离为 gap 的倍数的记录放在同一个组中。然后,对各组内的元素进行插入排序。这一趟排序完成后,每一个组的元素都是有序的。然后减小 gap 的值,并重复执行上述分组和排序。重复这样的操作,当 gap 为 1 的时候,整个数列就是有序的。
public static void sort(int[] numbers) {
int k;
for (int i = numbers.length / 2; i > 0; i /= 2) {
for (int j = i; j < numbers.length; j++) {
int tmp = numbers[j];
for (k = j; k >= i && numbers[k - i] > tmp; k -= i) {
numbers[k] = numbers[k - i];
}
numbers[k] = tmp;
}
}
}希尔排序的时间复杂度与增量序列的选取有关。例如,当增量选为 1 的时候,希尔排序直接退化为直接插入排序,此时的时间复杂度为 O(N²);而 Hibbard 增量序列的希尔排序的时间复杂度为 O(N^3/2)。
希尔排序算法的平均时间复杂度:O(N^d),最坏情况下的时间复杂度:O(N²),额外的空间复杂度:O(1),稳定性:不稳定。
堆排序(Heap Sort)是指利用堆这种数据结构所设计的一种排序算法。
堆分为最大堆和最小堆,最大堆通常被用来进行升序排序,最小堆通常被用来进行降序排序。
Java 中优先队列内部就是堆实现,我们只需要在创建的时候传入一个比较器即可指定最大堆或者最小堆。
public static void sort(int[] numbers) {
PriorityQueue<Integer> heap = new PriorityQueue<Integer>(Comparator.comparing(Integer::intValue));
for (int number : numbers) {
heap.add(number);
}
for (int i = 0; i < numbers.length; i++) {
numbers[i] = heap.poll();
}
}堆排序算法的平均时间复杂度:O(N log N),最坏情况下的时间复杂度:O(N log N),额外的空间复杂度:O(1),稳定性:不稳定。
将两个有序数列合并成一个有序树列,我们称之为“归并”。
归并排序(Merge Sort)就是利用归并**对数列进行排序。根据具体实现,归并排序包括“从下往上”和“从上往下”两种方式。
- 从下往上的归并排序
将待排序的数列分成若干个长度为 1 的子数列,然后将这些数列两两合并,得到若干长度为 2 的数列,再将这些数列两两合并;直到合并为一个数列为止。这样就得到了我们想要的排序结果。
- 从上往下的归并排序
第一步:将当前区间一分为二
第二步:递归地对两个区间进行归并排序,递归的终结条件是子区间的长度为 1
第三步:将已排序的两个子区间归并为一个有序的区间
// 自顶向下排序
public static void sortUp2Down(int[] numbers) {
sortUp2Down(numbers, 0, numbers.length - 1);
}
// 自底向上排序
public static void sortDown2Up(int[] numbers) {
if (numbers == null) {
return;
}
for (int i = 1, len = numbers.length; i < len; i *= 2) {
sortDown2Up(numbers, len, i);
}
}
private static void sortUp2Down(int[] numbers, int start, int end) {
if (numbers == null || start >= end) {
return;
}
int mid = start / 2 + end / 2;
sortUp2Down(numbers, start, mid);
sortUp2Down(numbers, mid + 1, end);
merge(numbers, start, mid, end);
}
private static void sortDown2Up(int[] numbers, int len, int gap) {
int twoLen = gap * 2;
int i;
// 将每两个相邻的子数组进行归并
for (i = 0; i + twoLen - 1 < len; i += twoLen) {
merge(numbers, i, i + gap - 1, i + twoLen - 1);
}
// 若 i + gap - 1 < len - 1,则剩余一个子数组没有配对
// 将该子数组归并到已排序的数组中
if (i + gap - 1 < len - 1) {
merge(numbers, i, i + gap - 1, len - 1);
}
}
// 合并一个数组中的两个相邻有序区间
private static void merge(int[] numbers, int start, int mid, int end) {
int[] tmp = new int[end - start + 1];
int t = 0; // tmp 数组的索引
int i = start;
int j = mid + 1;
while (i <= mid && j <= end) {
if (numbers[i] <= numbers[j]) {
tmp[t++] = numbers[i++];
} else {
tmp[t++] = numbers[j++];
}
}
while (i <= mid) {
tmp[t++] = numbers[i++];
}
while (j <= end) {
tmp[t++] = numbers[j++];
}
System.arraycopy(tmp, 0, numbers, start, t);
}归并排序算法的平均时间复杂度:O(N log N),最坏情况下的时间复杂度:O(N log N),额外的空间复杂度:O(N),稳定性:稳定。
快速排序(Quick Sort)使用分治策略。
它的基本**是:选择一个基准数,通过一趟排序,将要排序的数据分割成独立的两部分。其中一部分的所有数据都比基准数大,而另一部分的所有数据都比基准数小。然后,再按照此方法对两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数列都变为有序序列。
快速排序流程:
- 从数列中选出一个基准值
- 将所有比基准值小的数放在基准值前面,所有比基准值大的元素放在基准值后面(相同的数可以放到任一边);在这个分区退出后,该基准值就处于数列的中间位置(正确位置)
- 递归的对“基准值前的子数列”和“基准值后的子序列”进行快速排序
public static void sort(int[] numbers) {
sort(numbers, 0, numbers.length - 1);
}
private static void sort(int[] numbers, int left, int right) {
if (left < right) {
int i = left, j = right;
int pivot = pivot(numbers, left, right);
while (true) {
// 从左往右找第一个大于 pivot 的数
while (numbers[i] < numbers[pivot])
i++;
// 从右向左找第一个小于 pivot 的数
while (numbers[j] > numbers[pivot])
j--;
if (i < j) {
// 找到且符合条件,交换两元素
swap(numbers, i, j);
} else {
break;
}
}
swap(numbers, i, pivot);
sort(numbers, left, i - 1);
sort(numbers, i + 1, right);
}
}
private static void swap(int[] nums, int i, int j) {
int tmp = nums[i];
nums[i] = nums[j];
nums[j] = tmp;
}
// 获取头、中、尾的中位数
private static int pivot(int[] numbers, int start, int end) {
int n1 = numbers[start], n2 = numbers[start / 2 + end / 2], n3 = numbers[end];
return n1 < n2 ? (n2 < n3 ? n2 : (n1 < n3 ? n3 : n1)) : (n2 > n3 ? n2 : (n3 > n1 ? n1 : n3));
// List<Integer> list = new ArrayList<>(Arrays.asList(numbers[start], numbers[start / 2 + end / 2], numbers[end]));
// list.sort(Integer::compareTo);
// return list.get(1);
}快速排序算法的平均时间复杂度:O(N log N),最坏情况下的时间复杂度:O(N²),额外的空间复杂度:O(log N),稳定性:不稳定。
桶排序(Bucket Sort)的原理很简单,它是将数组分到有限数量的桶里去。
假设待排序数列**有 N 个元素,并且已知数组中元素的范围[0, MAX)。创建容量为 MAX 的桶数组,并将桶数组元素初始化为 0,将容量为 MAX 的桶数组中的每一个元素都看作一个 “桶”。
在排序时,逐个遍历数列,用数列元素的值,作为桶数组的下标。当数列中元素被读取时,将桶的值加 1。
private static final int MAX = 100;
public static void sort(int[] numbers) {
int[] buckets = new int[MAX];
Arrays.fill(buckets, 0);
// 计数
for (int i = 0, len = numbers.length; i < len; i++) {
buckets[numbers[i]]++;
}
// 排序
for (int i = 0, j = 0; i < MAX; i++) {
while ((buckets[i]--) > 0) {
numbers[j++] = i;
}
}
}桶排序算法的平均时间复杂度是:O(MAX + N)
基数排序(Radix Sort)是桶排序的扩展,它的基本**是:将整数按位分割为不同的数字,然后按每个位数进行比较。
具体做法是:将所有待比较的值统一为同样的数位长度,数位短的前面补 0。然后,从最低位开始,依次进行依次排序,这样从最低位排序一直到最高位排序完成以后,数列就变成了一个有序序列。
public static void sort(int[] numbers) {
int max = max(numbers);
// 使用队列来作为桶数组中的桶,桶数组的大小为 10,因为有十个数字
List<Queue<Integer>> buckets = new ArrayList<>(10);
for (int i = 0; i < 10; i++) {
// 初始化队列
buckets.add(new ArrayDeque<>());
}
for (int exp = 1; max / exp > 0; exp *= 10) {
for (int number : numbers) {
// 获得 number 的最低位,存入队列
int mod = (number / exp) % 10;
buckets.get(mod).add(number);
}
int j = 0;
// 从队列中取出元素到 numbers 数组
for (Queue<Integer> bucket : buckets) {
while (!bucket.isEmpty()) {
numbers[j++] = bucket.poll();
}
}
}
}
private static int max(int[] numbers) {
int max = numbers[0];
for (int number : numbers) {
if (number > max) {
max = number;
}
}
return max;
}基数排序算法的平均时间复杂度:O(P(N + B)),最坏情况下的时间复杂度:O(P(N + B)),额外的空间复杂度:O(N + B),稳定性:稳定。
Hash 最重要的就是 Hash函数 和 冲突解决
- 直接定址法
取关键词的某个线性函数值为散列地址,即:
h(key) = a * key + b (a, b 为常数)
- 除留余数法
h(key) = key mod p (一般取 p 为素数)
- 数字分析法
分析数字关键字在各位上的变化情况,取比较随机的位数作为散列地址
例如,取 11 位手机号码 key 的后 4 位作为地址:
h(key) = atoi(key + 7)
- 折叠法
把关键词分割为位数相同的几部分,然后叠加
例如:56793542 => 542 + 793 + 056 = 1391 => h(key) = 391
- 平方取中法
将关键词平方,然后取中间的某几位
例如:56793542² = 3225506412905764 => h(key) = 641
- ASCII 码加和法
h(key) = (∑key[i]) mid TableSize
- 前三字符移位法
h(key) = (key[0]*27² + key[1]*27 + key[2]) mod TableSize
- 移位法
h(key) = (∑(i=0, ... , n-1) key(n - i - 1) * 32^i) mod TableSize
- 开放定址法
若发生了第 i 次冲突,试探的下一个地址将增加 di, 基本公式是:
hi(key) = (h(key) + di) mod TableSize
di 决定了不同的解决方案:线性探测、平方探测、双散列
- 线性探测:di = i
- 平方探测:di = ±i²
- 双散列:di = i * h2(key)
- 分离链接法
将相应位置上冲突的所有关键词存储在同一个单链表中。
- 再散列
如果表过大(即装填因子α太大),查找效率会下降。实际测试证明,装填因子一般取:
0.5 <= α <= 0.85
解决方法是 再散列:新建一个更大的表,将原来的表中的元素重新 hash 到新表。
单例模式保证了一个类只有一个实例,并提供一个访问它的全局访问点。
何时使用:
想控制实例数目,节省系统资源
应用实例:
- 一个党只能有一个主席
- Windows 是多进程多线程的,在操作一个文件的时候,就不可避免地出现多个进程或线程同时操作一个文件的现象,所以所有文件的处理必须通过唯一的实例来进行
- 一些设备管理器常常设计为单例模式,比如一个电脑有两台打印机,在输出的时候就要处理不能两台打印机打印同一个文件
优点:
- 在内存里只有一个实例,减少了内存开销,尤其是频繁的创建和销毁实例
- 避免对资源的多重占用
缺点:
没有接口,不能继承,与单一职责原则冲突,一个类应该只关心内部逻辑,而不关心外面怎么样来实例化
工厂方法模式定义了一个创建对象的接口,但由子类决定要实例化的类是哪一个,也就是说工厂方法模式让实例化推迟到子类。
何时使用:
我们明确地计划不同条件下创建不同实例时
应用示例:
- 您需要一辆汽车,可以直接从工厂里面提货,而不用去管汽车是怎么做出来的,以及这个汽车里面的具体实现
- Hibernate 换数据库只需要换方言和驱动就可以
优点:
- 一个调用者想创建一个对象,只需要知道其名称就可以了
- 扩展性高,如果想增加一个产品,只需要扩展一个工厂类就可以
- 屏蔽产品的具体实现,调用者只关心产品的接口
缺点:
- 每次增加一个产品时,都需要增加一个具体的类和对象实现工厂,使得系统中类的个数成倍增加,在一定程度上增加了系统的复杂度,同时也增加了系统具体类的依赖
抽象工厂模式提供了一个创建一系列相关或者互相依赖的对象的接口,而无需指定它们具体的类。
何时使用:
系统的产品有多于一个的产品族,而系统只消费其中某一族的产品
应用实例:
工作了,为了参加一些聚会,肯定有两套或多套衣服吧,比如说有商务装(成套,一系列具体产品)、时尚装(成套,一系列具体产品),甚至对于一个家庭来说,可能有商务女装、商务男装、时尚女装、时尚男装,这些也都是成套的,即一系列具体产品。假设一种情况(现实中是不存在的,要不然,没法进入共产主义了,但有利于说明抽象工厂模式),在您的家中,某一个衣柜(具体工厂)只能存放某一种这样的衣服(成套,一系列具体产品),每次拿这种成套的衣服时也自然要从这个衣柜中取出了。用 OO 的**去理解,所有的衣柜(具体工厂)都是衣柜类的(抽象工厂)某一个,而每一件成套的衣服又包括具体的上衣(某一具体产品),裤子(某一具体产品),这些具体的上衣其实也都是上衣(抽象产品),具体的裤子也都是裤子(另一个抽象产品)。
优点:
当一个产品族中的多个对象被设计成一起工作时,它能保证客户端始终只使用同一个产品族中的对象
缺点:
产品族扩展十分困难,要增加一个一个系列的某一个产品,既要在抽象的 Creator 里加代码,也要在具体的实现里加代码
将一个复杂的构建过程与其表示相分离,使得同样的构建过程可以构建不同的表示。
何时使用:
一些基本部件不会变,而其组合经常变化的时候
应用实例:
- 去肯德基,汉堡、可乐、薯条、炸鸡翅等是不变的,而其组合是经常变化的
- Java 中的 StringBuilder
优点:
- 建造者独立,易于扩展
- 便于控制细节风险
缺点:
- 产品必须有共同点,范围有限制
- 如内部变化复杂,会有很多的建造类
在我们应用程序可能有某些对象的结构比较复杂,但是我们又需要频繁的使用它们,如果这个时候我们来不断的新建这个对象势必会大大损耗系统内存的,这个时候我们需要使用原型模式来对这个结构复杂又要频繁使用的对象进行克隆。所以原型模式就是用原型实例指定创建对象的种类,并且通过复制这些原型创建新的对象。
何时使用:
- 当一个系统应该独立于它的产品创建、构成和表示时
- 当要实例化的类是在运行时刻指定时,例如,通过动态装载
- 为了避免创建一个与产品类层次平行的工厂类层次时
- 当一个类的实例只能有几个不同状态组合中的一种时,建立相应的原型并克隆他们可能比每次用合适的状态手工实例化该类更方便
应用实例:
- 细胞分裂
- Java 中的
Object.clone()方法
优点:
- 性能提高
- 逃避构造函数的约束
缺点:
- 配备克隆方法需要对类的功能进行通盘考虑,这对全新的类不是很难,但对已有的类不一定很容易,特别当一个类引用不支持串行化的简介对象,或者引用含有循环结构的时候
- 必须实现 Cloneable 接口
在我们的应用程序中我们可能需要将两个不同接口的类来进行通信,在不修改这两个的前提下我们可能会需要某个中间件来完成这个衔接的过程。这个中间件就是适配器。所谓适配器模式就是将一个类的接口,转换成客户期望的另一个接口。它可以让原本两个不兼容的接口能够无缝完成对接。
作为中间件的适配器将目标类和适配者解耦,增加了类的透明性和可复用性。
何时使用:
- 系统需要使用现有的类,而此类的接口不符合系统的需要
- 想要建立一个可以重复使用的类,用于与一些彼此之间没有太大关联的一些类,包括一些可能在将来引进的类一起工作,这些源类不一定有一致的接口
- 通过接口转换,将一个类插入另一个类系中
应用实例:
- 美国电器 110V,** 220V,就要有一个适配器将 110V 转化为 220V
- 在 Linux 运行 Windows 程序需要 Wine
- Java 中的 jdbc
优点:
- 可以让任何两个没有关联的类一起运行
- 提高了类的复用
- 增加了类的透明度
- 灵活性好
缺点:
- 过多地使用适配器,会让系统非常凌乱
- 由于 Java 至多继承一个类,所以至多只能适配一个适配者类,而且目标类必须是抽象类
如果说某个系统能够从多个角度来分类,且每一种分类都可能会变化,那么我们需要做的就是将这多个角度分离出来,使得他们能独立变化,减少他们之间的耦合,这个分离的过程就用到了桥接模式。
何时使用:
- 实现系统可能有多个角度分类,每一种角度都可能变化
应用实例:
- 墙上的开关,可以看到的开关是抽象的,而不用管里面是怎么实现的
优点:
- 抽象和实现的分离
- 优秀的扩展能力
- 实现细节对客户透明
缺点:
- 桥接模式的引入会增加系统的理解和设计难度,由于聚合关联关系建立在抽象层,要求开发者针对抽象层进行设计与编程
组合模式组合多个对象形成树形结构以表示“整体-部分”的结构层次。组合模式使得用户对单个对象和组合对象的使用具有一致性。
何时使用:
- 想表示对象的部分-整体层次结构(树形结构)
- 希望用户忽略组合对象与单个对象的不同,用户将统一地使用组合结构中的所有对象
应用实例:
- 算术表达式包括操作数、操作符和另一个操作数,其中另一个操作符也可以是操作数、操作符和另一个操作数
- 在 Java AWT 和 Swing 中,对于 Button 和 Checkbox 是树叶,Container 是树枝
优点:
- 高层模块调用简单
- 节点自由增加
缺点:
在使用组合模式时,其叶子和树枝的声明都是实现类,而不是接口,违反了依赖倒置原则
我们可以通过继承和组合的方式给一个对象添加行为,虽然使用继承能够很好拥有父类的行为,但是它存在几个缺陷:
- 对象之间的关系复杂的话,系统变得复杂不利于维护
- 容易产生“类爆炸”现象
- 是静态的
我们使用装饰器模式来动态的给一个对象添加一些额外的职责,就增加功能来说,装饰器模式相比生成子类更灵活。
何时使用:
- 在不想增加很多子类的情况下扩展类
应用实例:
- 不论一幅画有没有画框,都可以挂在墙上。但是通常都是有画框的,并且实际上是画框被挂在墙上。在被挂在墙上之前,画可以被蒙上玻璃,撞到框子里
优点:
- 装饰类和被装饰类可以独立发展,不会相互耦合,装饰器模式是继承的一个替代模式,装饰器模式可以动态扩展一个实现类的功能
缺点:
- 多层装饰比较复杂
为子系统中的一组接口提供一个一致的界面,外观模式定义了一个高层接口,这个接口使得这一子系统更加容易使用。
何时使用:
- 客户端不需要知道系统内部的复杂联系,整个系统只需要提供一个接待员即可
- 定义系统的入口
应用实例:
- 去医院看病,可能要去挂号、门诊、划价、取药,让患者或者家属觉得很复杂,如果有提供接待人员,只让接待人员处理,就很方便
- Java 的三层开发模式
- 电脑启动:按电源键,自动启动CPU,自动启动内存,自动启动硬盘
优点:
- 减少系统相互依赖
- 提高灵活性
- 提高了安全性
缺点:
- 不符合开闭原则,如果要改东西很麻烦,继承重写都不合适
运用共享技术有效地支持大量细粒度的对象
何时使用:
- 系统中有大量对象
- 这些对象消耗大量内存
- 这些对象的状态大部分可以外部化
- 这些对象可以按内蕴状态分为很多组,当把外蕴对象从对象中剔除出来时,每一组对象都可以用一个对象来代替
- 系统不依赖于这些对象的身份,这些对象是不可辨的
应用实例:
- Java 中的 String,如果有则返回,如果没有则创建一个字符串保存在字符串缓存池里面
- 数据库的数据池
优点:
- 大大减少了对象的创建,降低系统的内存,使效率提高
缺点:
- 提高了系统的复杂度,需要分离出外部状态和内部状态,而且外部状态也具有固化的性质,不应该随着内部状态的变化而变化,否则会造成系统混乱
代理模式就是给一个对象提供一个代理,并由代理对象控制对原对象的引用。它使得客户不能直接与真正目标对象通信。代理对象是目标对象的代表,其他需要与这个目标对象打交道的操作都是和这个代理对象在交涉。
何时使用:
- 想在访问一个类时做一些控制
应用实例:
- Windows 里面的快捷方式
- 在代售点买火车票
- Spring AOP
优点:
- 职责清晰
- 高扩展性
- 智能化
缺点:
- 由于在客户端和真实对象之间增加了代理对象,因此有些类型的代理模式可能造成请求处理速度变慢
- 实现代理模式需要额外的工作,有些代理模式实现起来非常复杂
主要将数据结构与数据操作相分离。
何时使用:
- 需要对一个对象结构中的对象进行很多不同的并且不相关的操作,而需要避免让这些操作“污染”这些对象的类,使用访问者模式将这些封装到类中
应用实例:
- 你在朋友家做客,你是访问者,朋友接收你的访问,你通过朋友的描述,然后对朋友的描述做一个判断,这就是访问者模式
优点:
- 符合单一指责原则
- 优秀的扩展性
- 灵活性
缺点:
- 具体元素对访问者公布细节,违反了迪米特原则
- 具体元素变更比较困难
- 违反了依赖倒置原则,依赖了具体类,没有依赖抽象
定义一个操作中的算法的骨架,而将一些步骤延迟到子类中。模板方法使得子类可以不改变一个算法的结构即可重定义该算法的某些特定步骤
何时使用:
- 有一些通用的方法
应用实例:
- 造房子的时候,地基、走线、水管都一样,只有在建筑后期才有加壁橱加栅栏等差异
- Spring 中对 Hibernate 的支持,将一些已经定义好的方法封装起来,比如开启事务、获取 Session、关闭 Session 等
优点:
- 封装不可变部分,扩展可变部分
- 提取公共代码,便于维护
- 行为由父类控制,子类实现
缺点:
- 每一个不同的实现都需要一个子类来实现,导致类的个数增加,使得系统变得庞大
定义一系列算法,把它们一个一个封装起来,并且使他们可相互替换。
何时使用:
- 一个系统中有许多许多类,而区分它们的只是他们直接的行为
应用实例:
- 诸葛亮的锦囊妙计,一个锦囊就是一个策略
- 旅行的出游方式,选择骑自行车、坐汽车,每一种方式就是一种策略
- Java AWT 的 LayoutManager
优点:
- 算法可以自由切换
- 避免使用多重条件判断
- 扩展性良好
缺点:
- 策略类会增多
- 所有策略类都需要对外暴露
允许对象在内部状态发生改变时改变它的行为,对象看起来好像修改了它的类。
何时使用:
- 代码中包含大量与对象状态相关的条件语句
应用实例:
- 打篮球的时候运动员可以有正常状态、不正常状态和超常状态
优点:
- 封装了转换规则
- 枚举可能的状态,在枚举状态之前需要确定状态种类
- 将所有与某个状态有关的行为放到一个类中,并且可以方便的增加新的状态,只需要改变对象状态即可改变对象的行为
- 允许状态转换逻辑与状态对象合成一体,而不是某一个巨大的条件语句块
- 可以让多个环境共享一个状态对象,从而减少系统中对象的个数
缺点:
- 状态模式的使用必然会增加系统中类和对象的个数
- 状态模式的结构与实现都较为复杂,如果使用不当将导致程序结构和代码的混乱
定义对象间的一种一对多的依赖关系,当一个对象发生改变时,所有依赖于它的对象都得到通知并被自动更新。
何时使用:
- 一个对象的状态发生改变,所有的依赖对象都将得到通知,进行广播通知
应用实例:
- 拍卖时,拍卖师观察最高标价,然后通知给其他竞价者竞价
优点:
- 观察者和被观察者是抽象耦合的
- 建立一套触发机制
缺点:
- 如果一个被观察者对象有很多的直接和简接的观察者的话,将所有的观察者都通知会花费很多时间
- 如果在观察者和观察目标之间有循环依赖的话,观察目标会触发他们之间进行循环调用,可能导致系统崩溃
- 观察者模式没有相应的机制让观察者知道所观察的对象是怎么发生变化的,而仅仅是知道目标对象发生了变化
在不破坏封装性的前提下,捕获一个对象的内部状态,并在该对象之外保存这个状态
何时使用:
- 很多时候我们总是需要记录一个对象的内部状态,这样做的目的是为了允许用户取消不确定或者错误的操作,能够恢复到他原先的条件,使得他有后悔药可吃
应用实例:
- 后悔药
- 打游戏时的存档
- Windows 里的 ctrl+z
- IE 中的后退
优点:
- 给用户提供了一种可以恢复状态的机制,可以使用户能够比较方便地回到某个历史的状态
- 实现了信息的封装,使得用户不需要关心状态的保存细节
缺点:
- 消耗资源。如果类的成员变量过多,势必会占用比较大的资源,而且每一次保存都会消耗一定的内存
用一个中介对象来封装一系列的对象交互,中介者使各对象不需要显式地相互引用,从而使其耦合松散,而且可以独立地改变它们之间的交互
何时使用:
- 多个类相互耦合,形成了网状结构
应用实例:
- 机场调度系统
- MVC框架,其中 Controller 是 Model 和 View 的中介者
优点:
- 降低了类的复杂度,将一对多转换成了一对一
- 各个类之间解耦
- 符合迪米特原则
缺点:
- 中介者会庞大,变得复杂难以维护
提供一种方法顺序访问一个聚合对象中的各个元素,而又无需暴露该对象的内部表示
何时使用:
- 遍历一个聚合对象
应用实例:
- Java 中的 Iterator
优点:
- 支持以不同的方式遍历聚合对象
- 迭代器简化了聚合类
- 在同一个聚合上可以有多个遍历
- 在迭代器模式中,增加新的聚合类和迭代器类都很方便,无需修改原有代码
缺点:
由于迭代器模式将存储数据和遍历数据的职责分离,增加新的聚合类需要对应增加新的迭代器类,类的个数成对增加,一定程度上增加了系统的复杂性
给定一个语言,定义它的文法表示,并定义一个解释器,这个解释器使用该标识来解释语言中的句子
何时使用:
- 如果一种特定类型的问题发生的频率足够高,那么可能就值得将该问题的各个实例表述为一个简单语言中的句子,这样就可以构建一个解释器,该解释器通过解释这些句子来解决该问题
应用实例:
- 编译器
- 运算表达式计算
优点:
- 可扩展性比较好
- 增加了新的解释表达式的方式
- 易于实现简单文法
缺点:
- 可利用场景比较少
- 对于复杂的文法比较难维护
- 解释器模式会引起类膨胀
- 解释器模式采用递归调用方法
将一个请求封装成一个对象,从而可以使用不同的请求对客户进行参数化
何时使用:
- 某些场合,比如要对行为进行“记录、撤销、事务”等处理,这种无法抵御变化的紧耦合是不合适的。在这种情况下,如何将“行为请求者”与“行为实现者”解耦?将一组行为抽象为对象,可以实现二者之间的松耦合
应用实例:
- struts1 中的 action 核心控制器 ActionServlet 只有一个,相当于 Invoker,而模型层的类会随着不同的应用有不同的模型类,相当于具体的 Command
优点:
- 降低了系统的耦合度
- 新的命令可以很容易添加到系统中
缺点:
- 使用命令模式可能会导致某些系统有过多的命令类
避免请求发送者与接收者耦合在一起,让多个对象都有可能接收请求,将这些对象连接成一条链,并且沿着这条链传递请求,直到有对象处理它为止
何时使用:
- 在处理消息的时候可以过滤很多道
应用实例:
- JS 中的事件冒泡
- Java Web 中 Apache Tomcat 对 Encoding 的处理,Struts2 的拦截器,Servlet JSP 中的 Filter
优点:
- 降低耦合度,将请求的发送者和接收者解耦
- 简化了对象,使得对象不需要直到链的结构
- 增强给对象指派职责的灵活性,动过改变链内成员或者调动它们的次序,允许动态地新增或者删除责任
- 增加新的请求处理类很方便
缺点:
- 不能保证请求一定被接受
- 系统性能受一定影响
- 可能不容易观察运行时的特征

给定链表的头指针和一个结点指针,在 O(1)的时间删除该结点
思路:使用下一个结点的数据覆盖要删除的结点,然后删除下一个结点
public void deleteNode(Node node) {
assert node != null;
assert node.next != null; // 不能是尾结点
Node nextNode = node.next;
node.data = nextNode.data;
node.next = nextNode.next;
}使用快慢指针:
- 如果遇到 null,则退出,说明没有环
- 如果快指针遇到慢指针或者快指针跑到慢指针后面,说明有环
public boolean hasCircle(Node head) {
Node fast = head;
Node slow = head;
while (true) {
if (fast == null || fast.next == null) {
// 如果链表中有空,即到尽头
return false;
} else {
fast = fast.next.next;
slow = slow.next;
}
if (fast == slow || fast.next == slow) {
// 如果快慢指针相遇或者快指针跑到慢指针后边,说明有环
return true;
}
}
}循环方式:
public Node reverseByLoop(Node head) {
if (head == null || head.next == null) {
return head;
}
Node ret = null, next = null;
while (head != null) {
next = head.next; // 保存下一个结点的位置
head.next = ret; // 现在的结点接到新链表的头部
ret = head; // 重置新链表的头部指针
head = next; // head 往后移动
}
return ret;
}思路是:每次断开一个结点,接到新链表上。
递归方式:
public Node reverseByRecursion(Node head) {
if (head == null || head.next == null) {
return head;
}
Node node = head.next;
// 将 head 结点断开
head.next = null;
// 对剩下的结点递归调用反转
Node reverse = reverseByRecursion(node);
// 将 head 结点接到转置后链表的末尾
node.next = head;
// 返回转置后的链表
return reverse;
}思路是:每次断开头结点,对剩下的结点递归调用转置函数,然后再将头结点接到转置后的链表末尾。
实例:
a + b * c + (d * e + f) * g 转换为 a b c * + d e * f + g * +
转换的逻辑:
- 遇到操作数,直接输出
- 遇到 左括号,进栈
- 遇到 右括号,将栈中元素弹出,直到遇到左括号为止。左括号不输出
- 遇到其他操作符,从栈中弹出元素直到遇到更低优先级的元素(或栈为空),然后将操作符入栈
- 左括号 直到遇到 右括号 的时候才弹出,遇到普通操作符不弹出
- 读到输入的末尾,将栈中剩余的元素依次弹出
/**
* 入栈判断。
* 1、栈顶是左括号,直接入栈
* 2、输入是乘除,栈顶是加减,入栈
* 3、其他情况,栈顶元素出栈
*/
private static boolean compare(String input, String top) {
return "(".equals(top) || ("*".equals(input) || "/".equals(input)) && ("+".equals(top) || "-".equals(top));
}
public static void convert(String input) {
String[] strings = input.split(" ");
Stack<String> stack = new Stack<>();
for (String string : strings) {
if ("(".equals(string)) {
// 遇到左括号,直接入栈
stack.push(string);
} else if (")".equals(string)) {
// 遇到右括号,弹出元素直到弹出对应的左括号
String top;
while (!stack.isEmpty()) {
top = stack.pop();
if (top.equals("("))
// 弹出了左括号,停止循环
break;
else
System.out.print(top + " ");
}
} else if ("+-*/".contains(string)) {
// 普通操作符
if (stack.isEmpty()) {
// 栈为空时直接入栈
stack.push(string);
} else {
String top = stack.peek();
if (compare(string, top)) {
// 判断栈顶元素优先级比操作符低,直接入栈
stack.push(string);
} else {
// 栈顶元素优先级比操作符高,依次弹出
while (!stack.isEmpty()) {
top = stack.peek();
if (!compare(string, top)) {
// 先取栈顶元素进行比较,再弹出的原因是避免 左括号( 被误弹出
System.out.print(stack.pop() + " ");
} else {
break;
}
}
// 现在栈顶元素的优先级比操作符低,操作符入栈
stack.push(string);
}
}
} else {
// 数字,直接输出
System.out.print(string + " ");
}
}
// 输出栈中剩余元素
while (!stack.isEmpty()) {
System.out.print(stack.pop() + " ");
}
}直接弹出元素计算,然后重新压入栈即可。其中需要注意的一点是左右操作数的顺序:左操作数先入栈,右操作数后入栈;右操作数先出栈,左操作数后出栈。
public static int compute(String suffix) {
String[] strings = suffix.split(" ");
Stack<Integer> stack = new Stack<>();
for (String string : strings) {
if (string.matches("\\d+")) {
stack.push(Integer.valueOf(string));
} else {
if (stack.isEmpty()) {
return -1;
}
int num1 = stack.pop();
int num2 = stack.pop();
int result = 0;
switch (string) {
// 其中 num2 和 num1 的顺序不能乱。因为中缀表达式转后缀表达式的时候,左操作数(操作符左侧)先入栈,右操作数后入栈。所以 pop 的时候右操作数先出栈,左操作数后出栈
case "+":
result = num2 + num1;
break;
case "-":
result = num2 - num1;
break;
case "*":
result = num2 * num1;
break;
case "/":
result = num2 / num1;
break;
}
stack.push(result);
}
}
if (stack.size() == 1) {
return stack.pop();
} else {
return -1;
}
}
