blog's People
Contributors

Stargazers




















































































Watchers








Forkers
daisyfeng128128 pouringrain0628 winnerbe sun2008mt live0717 coffeygit soulmate2015 xiaoxiaoshuoblog's Issues
关于团队nodejs生态建设的计划.md
WEB框架(种子项目)
- 约束规范
- 沉淀/扩展模式
- 模块依赖管理
- 集成typescript开发环境
- 集成API文档输出方案
- 环境配置
- 多节点/cluster解决方案
- socket.io
- schedule
- 集成常用插件功能
- logger
- cookie
- session
- security
- i18n
- redis
- sequelize
- multipart
- oauth
- onerror
- passport
- view
- role
- crypto
- 定义控制流/数据流约束规范
- schema
- pipe
- interceptor
- guard
- migration
- 微服务
- 错误分级
- 测试用例/代码覆盖率
- 调试
- 压力测试: apache jmeter
npm库
- npm包种子项目(发包规范)
- 公有npm库
- 私有npm库搭建
- 私有npm库使用推广
git/jenkins, 开发/测试环境
- git commit 规范推广和执行
- git flow 规范推广和执行
- 约定分支变更后自动部署到相应环境(jenkins)
- 约定分支变更后自动提测(邮件)
版本控制
- 开发流程
- 提测流程
- 发版流程
- 提测前checklist
- 发版前checklist
- 发版后checklist
文档
- 需求文档
- 需求实现方案公开化
- 在线知识库
- 新人指引
- 面试知识点
- 面试题库
Docker
- 推广及执行
性能监控
- alinode(免费, 暂定)
实时日志分析平台
- ELK(ElasticSearch, Logstash, Kibana)
在线接口测试工具
- 小幺鸡
告警通知
- 邮件
- 微信
2020,重新审视 Egg 和 Nest
现在已经是2020年了,看到大佬两年前的专业态度,很湿佩服,如今再看 Nest 貌似已经赶超了 Egg。想听听大佬的见解。
关于nodejs-web框架的调研.md
以下内容其实是补漏, 算是对1月份一点工作的总结。
加入了新团队, 初次接触, 粗略的查看了一些项目(nodejs server端), 发现存在几个问题:
对于新成立的团队,存在以上问题可以理解, 本次是讨论和解决第一个问题。
对于集团范围内而言,同种技术存在多种不同规范和框架很正常, 但是对于一个几十人的团队而言, 资源有限,还是集中力量统一一下效率高些, 有鉴于此, 觉得做一个种子项目比较合适: 一个企业定制框架, 共同维护, 同步更新, 信息共享和沉淀最佳实践。
跟领导聊了一下, 总结了一下当前状态团队对于这块内容的一些主观诉求:
- 框架实现够简单, 团队能全面掌控, 低风险。
- 给新手从基础开始学习的机会, 就是希望除了满足业务需求之外, 团队也能得到成长。
- 一个企业基础框架应满足的基本要求: 约束规范、扩展机制、安全、高效业务开发
- 最终还是希望能沉淀出一套自己的轮子
根据上面的要求, 筛选出了eggjs和nestjs2个web框架, 其中nestjs是团队一部分同学比较喜欢和尝试使用了的。
首先从外层信息做些调查。
我通读了eggjs和nestjs的文档,查阅了一些资料, 简单对比如下:
| -- | eggjs | nestjs |
|---|---|---|
| github stars | 7014 | 4291 |
| github forks | 720 | 250 |
| gitHub dependents | 1591/305 | 0/0 |
| npm search results | 565 | 53+ |
| github contributors | 101 | 31 |
| github core contributors | 4(10+) | 1(2+) |
| github releases | 49 | 19 |
| github issues | 86/1416 | 20/347 |
| 基础框架依赖 | koa2 | express |
| 文档 | 业界良心 | 一般 |
| 核心原理 | 载入-挂载 | 模块容器-依赖注入(通过装饰器和元数据实现) |
| 核心理念 | 微内核-插件机制 | 组件树-装饰器-流程控制 |
eggjs的特点和解决的主要问题:
- 通过载入代码-自动挂载代码到对象的方式解决了到处写import/require的问题, 不再需要手动维护模块之间的依赖关系, 核心就是一个loader, 虽然官方没有提及, 但是本人开下脑洞猜测, 这个模块的实现灵感有可能来自于坟头草已经一人高了的seajs, -_-, 这种挂载模式实现起来简单粗暴直接高效, 但是一个小问题就是在使用TS编写代码的时候, 会影响书写体验的流畅度, 毕竟不很OOP。
- 微核心 + 插件机制(这个理念其实一直以来都是代码组织的核心手段, 本人在以前开发播放器和IM客户端这块时感同身受), 大部分功能通过插件实现, 从而剥离非核心生命周期功能代码, 达到解耦/降低思维负担的目的; 另外一点就是跨模块API调用比较自由没有限制, 这个地方带来便捷的同时也有可能需要一定约束。
- 统一约束和规范, 对开发人员强约束, 保证不会出现千人千面的代码风格和设计。
- 种子项目 + 渐进式开发, 可以沉淀出自己的插件和业务框架、最佳实践
- 针对业务中遇到的常见问题基本都给出了解决方案, 插件丰富, 配套齐全
- 内部实现了进程间管理和通信功能
- 文档可是说是比较细致了, 基本把web这块涉及到的点都涵盖了, 仅仅通读文档对新手而言都会有不少收获
- 核心开发者较多, 属于团队项目, 整体看来比较严谨
- 沉淀时间较长, 正式发版2年, 实际发展了4年
- 明确定义了agent和app模式, 也实现了schedule功能
nestjs的特点和解决的主要问题:
- 通过模块容器-依赖注入维护组件树的模式解决了到处写import/require的问题, 不再需要手动维护模块之间的依赖关系, 另外编码方式与java十分相似。
- 组件树容器模式也达到了解耦效果, 实现方式上很大程度上受angular-module影响, 但是需要指定节点component的依赖关系, 跨模块调用严格依赖于声明. 其实这块功能github有独立的项目专做这个东西, 例如: InversifyJS | bottlejs, nestjs 自己实现了这个模块。
- 统一约束和规范, 对开发人员强约束
- 大量使用装饰器, 这个未支持的特性需要编译, 对代码阅读上可能会提高一些难度
- 流程控制上比较细致, 提出了filter、pipe、guard、interceptor这些明确的概念, 虽然这些工作在正常开发时也会做, 但是明确提出来并制定规范还是很有必要的
- 明确了Exception Layer的概念
- 默认使用/推荐TS开发
- 自带微服务实现
- 自带swagger接口文档生成功能
- 核心开发基本就作者一人, 属于个人项目, 提交记录比较难看, 前期的提交非常随便, 到后期才慢慢改善
- 2017年1月立项, 2017年5月发布第一个正式版本, 尚需时日印证
从上述情况来看, 2个框架都在123这几项做了工作, 完成了一个框架所应具备的基本诉求; 总体上看eggjs更加成熟和全面, 配套/生态相对完善的多, 低风险; nestjs则比较青涩和单一, 但是在组件树、流程控制、错误层级处理上有自己的特色, 理念上更加OOP,学习并吸收这些理念是很可取的, 但暂时不建议在核心产品线上投入使用。
接下来做深入调查, 阅读源码.
eggjs
详细阅读了核心相关代码, 粗略阅读了cluster等一些模块和插件的代码, 代码读起来总体比较流畅, 发现框架的核心实现非常简单明了:
-
框架基础依赖一个非常独立的loader模块, 功能就是加载代码文件和挂载函数到指定对象。
-
框架本身核心类只有6个: koa本身的application, context, response, request, egg自身新增的controller, service 这2个类, 后续所有的挂载动作都在这几个类上面进行
-
框架明确了app, framework, plugin3个概念, 依赖方式大概是这样:

-
框架启动的核心流程主要是这样:
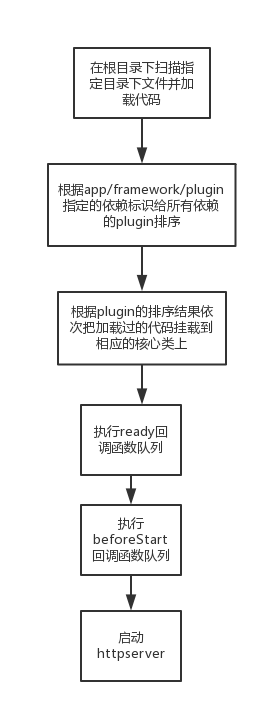
由于eggjs自己实现了cluster, 自带进程管理和进程间通信功能, 所以egg自身部署时并不需要pm2这个工具, 官方文档上也对此做了解释。不过由于这块内容的引入(cluster还涉及到schedule、socket等功能),给框架本身带来了大量额外的代码和逻辑, 总体提升了框架的复杂度。
但是有些时候由于某些原因并不希望直接使用框架提供的cluster解决方案, 另外我查看了下pm2的API, 也是有进程间通信的API的, 当然用起来可能没有自定义实现时那样自由, 也尚未听说该API有被广泛使用过, 不过, cluster相关的内容能否作为一个扩展包, 而不是强耦合进框架核心流程中? 这样框架本身更加简单纯洁, 或者更容易被接受一些?
为此尝试抽离了eggjs的核心代码, 目标是仅保留最最核心的代码(移除cluster等周边代码), 具备egg的扩展机制和能正常直接使用eggjs的周边插件, 结果最后只需要几百行代码, 很少几个文件即可完成。后续在此基础上整理了一个上层框架, 预想作为业务项目的基础框架使用,主要涉及以下一些方面:
-
抽离eggjs的核心代码, 仅保留其插件机制和对应的约束规范
-
集成常用扩展函数、中间件、插件
-
集成多节点/进程下消息推送解决方案示例
-
集成schedule定时任务模块
之后花了点时间用这个上层框架开发了一个抽奖小项目, 开发体验还算流畅, 虽说是草量级项目, 不过也是五脏俱全, 作为example还挺适合。
nestjs
粗略查看了下nestjs的源码, nestjs的核心其实就是一个IoC模块管理容器的实现, 这块内容的逻辑实现作者处理的还是相对复杂的多, 这里吐槽下作者的代码组织方式和略显随意的注释大量的接口引用和糟糕的历史提交记录...,真是额外提高了阅读的难度. TypeScript的加持和作者本人的光环也不能阻挡这一点。言归正传, 这里说下它的核心原理和流程。
要想理解nestjs的源码先要理解和掌握以下知识:
- ES6的proxy,reflect
- TypeScript的decorator
- inversion of control (IoC)的基本概念
- 一定TypeScript基础.
- 如何通过decorator和元数据实现依赖注入
- container类: 用于存储所有模块
- scanner类: 递归提取出所有模块并存储到容器中; 提取出模块间的关联关系和模块自身的各种类以及内部联系,并存储到模块中;
- module类: 存储自身的关联模块、组件、可注入类、控制器类
- injector类: 依赖注入的核心环节, 在所有模块的内容和关系都被扫描出后, 来创建实例,
- instanceLoader类: 使用Injector来加载模块的各种实例, 这个过程很复杂, 伴随递归和各种判断
这个IoC容器实现的核心流程是这样:
scanner扫描所有module并提取关系存入module->module存入 container-> injector创建实例(依赖注入)-> instanceLoader加载实例
我们再拿nestjs实现上面eggjs版本lottery的例子, 大概是这样:
结合源码和实际开发体验来说:
-
eggjs框架本身的模块管理(扩展机制)非常简单, 复杂度主要在于cluster这块内容和为此配套的周边设施(命令行工具、调试工具),但是这个复杂度是脱离于核心之外的东西。
-
nestjs的复杂度主要在于IoC模块管理器这块的实现上, 实际上这个东西理论上可以独立出来, 以此降低框架本身逻辑的复杂度。
从总体上讲, eggjs相对成熟, 更贴合实际开发需求。 nestjs的优势就是在一些细节上的约束和控制以及理念上的新颖(仅相对node-web框架而言), 但是这些并不是核心诉求。
另外eggjs团队做的工作内容相对于nestjs而言相当的多, 这些与人力、时间资源的投入是分不开的。
最后, 对于想要的新框架的处理结论已经有了:
1 社区模式(节省资源)
- 直接在eggjs基础上做一个上层框架, 吸收nestjs的一些优点, 作为插件/扩展内容去完善框架本身.
2 造轮子模式
- eggjs插件机制 + nestjs流程控制 + component模式(可选) => 新轮子
3 所应具备的特性
- 约束规范
- 沉淀/扩展模式
- 模块依赖管理
- 集成typescript开发环境
- 集成API文档输出方案
- 环境配置
- 多节点/cluster解决方案
- socket.io
- schedule
- 集成常用插件功能
- logger
- cookie
- session
- security
- i18n
- redis
- sequelize
- multipart
- oauth
- onerror
- passport
- view
- role
- crypto
- 定义控制流/数据流约束规范
- schema
- pipe
- interceptor
- guard
- migration
- 微服务
- 错误分级
- 监控
- 测试用例/代码覆盖率
- 调试
- 压力测试
补充:
随着各种工具的发展, 加上eggjs使用也有一段时日,最初一些模糊的预感变得清晰:
1 egg内置cluster模式带来的额外麻烦太多, 现在各种配套工具逐渐完善, 这个功能并没有什么用
2 egg模块隔离度不够但矛盾的是有时候又有限制, 简单的说就是代码组织模式上作为框架不够好, 需要自行定制上层规范; egg的是plugin模式, 相对于nest的component模式还是不够用;
3 egg的ts开发的流畅度差那么一点
4 实际的项目, 需要各种配套设施、工具、系统的协作联合,框架只是一个组成部分, 就应该只做它应该做的事就可以了
各有优劣, 诉求不一样, 选择就不一样:
1 eggjs: 短平快稳,上手极快, 文档完善,配套齐全, 能极大缩短工期。
2 nestjs: 有点追求, 复杂度高的协作项目, 核心诉求是代码组织模式的
之前egg很好的满足了我们的诉求, 但是下一个项目, 会考虑使用nestjs或者自行开发框架(足够闲的话)。
分支管理.md
版本
版本号必须符合semver,其的形式为{major}.{minor}.{patch}
其中major、minor、patch必须为十进制数字,且随版本发布递增。
-
major版本,第1位数字变化表示一个major版本,此类版本通常是完全的重新设计的版本,可自由做任意更改
-
minor版本,第2位数字变化表示一个minor版本,此类版本会有新功能的引入,但应该(SHOULD)保持向后兼容性,如有向后兼容性问题,必须(MUST)在发布的时候说明,并必须(MUST)提供升级指导
-
patch版本,第3位数字变化表示一个patch版本,此类版本不得(MUST NOT)引入新的功能或接口,仅能包含重构或功能修复,不得(MUST NOT)引入不向后兼容的变化
分支
要求:
-
master上永远对应最新的主流版本
-
所有release和master的代码都是绝对可用的
-
分支分为开发分支、发布分支、功能分支、修复分支和master分支
-
实际的分支以版本号为前缀,开发分支的形式为{version}/dev,例如2.1.0/dev, 此类分支用于维护一个版本的开发过程
-
发布分支的形式为{version}/release,例如2.1.0/release, 此类分支用于维护每一个发布版本的状态,不得将功能或修复直接合并至此分支
-
功能分支的形式为{version}/feat/{feature-desc},例如2.1.0/feat/support-xd, 此类分支用于开发单一的原子性的功能
-
修复分支的形式为{version}/fix/{bug-desc},例如2.1.0/fix/jira1150, 此类分支用于修复一个已有的BUG
-
master分支即master,此分支用于维护当前主流版本的稳定状态,不得将任何功能、修复、开发分支合并至此分支
开发
1 新建新版本: 每次有新的版本, 就必须(MUST)从master上切出新的开发分支和发布分支
2 jira单驱动开发: 开发任何功能前,应该(SHOULD)有一个jira单对应其功能
3 新建功能|修复分支: 每次开发新功能|修复,都应该新建一个单独的分支, 从对应版本的开发分支中拉取功能|修复分支
4 提交commit: 提交commit时应该(SHOULD)提交完整扼要的提交信息, 格式参考 Angular format, 其中包含 形如Fix jira#xxx的信息对应jira单号
5 与开发分支同步: 分支的开发过程中,要经常与开发分支保持同步。
6 合并commit: 分支开发完成后,很可能有一堆commit,但是合并到开发分支的时候,往往希望只有一个(或最多两三个)commit,这样不仅清晰,也容易管理。
7 开发完成后,推送到远程, 发起pull request,需注意pull request的对应目标为开发分支, @相关人员或者团队
8 相关人员进行Code Review,通过后merge并删除功能|修复分支
提测
1 从开发分支 向对应的 发布分支 发起Merge Request
2 code review 和 merge
3 自动提测(触发Jenkins任务和邮件通知)
发布
1 生产环境上线成功后, 合并发布分支到master
2 在master上 创建一个tag,tag的命名必须(MUST)为符合semver的当前发布的版本号
3 删除开发分支
目前需要改进的问题.md
统一性
目前各个项目互相独立, 百花齐放, 没有统一的约束和规范, 统一的技术选型, 统一的架构设计,统一的流程。约束混乱的同时提升他人阅读和理解代码的成本。
例如: 每一个项目都有自己维护的独特“框架”, 每个项目一套轮子。这将导致资源浪费和降低效率的问题, 非常明显。这块需要统一一个企业框架, 一套技术方案和规范。
信息共享和同步(文档)
个人掌握的信息没有有效的输出途径, 他人的信息获取变得困难和低效率, 尤其在业务开发上体现尤甚, 非常影响开发的流畅性. 这个主要靠主动输出、同步文档和周知他人。
新人指引(文档)
缺乏这块的建设将会提高新人快速上手的成本
没有技术沉淀机制
个人踩过的坑,耗费过的资源, 取得的成果没有有效的输出和迭代机制, 不能有效的扩大影响范围和效率提升。可以建设公用模块库和种子项目。
基础建设
基础建设配套不完善, 非常影响开发的流畅性
例如: 开发一个新项目时很多工作都要从0开始做一遍, 测试/发布/部署这块的自动化工作尚未做。
版本控制
从需求立项到版本上线之间的流程不够明确和精细, 需求迭代控制的粒度较大, 对开发周期的稳定性会有影响。解决办法是完善相关流程规范。
NODE多节点&进程下websocket消息推送和定时任务解决方案.md
js异步总结.md
JS核心之异步
- 新手向: 基础普及, 这是一篇分享记录。
Save your time, dude!
- 这次是一次系统总结, 让你更加理解JS。
- 网上有很多资料会讲异步相关的知识, 但这次我打算自己总结一遍。
- 本篇文章主要涉及JS的异步运行机制以及它的应用场景。
老生长谈么?
- UI卡顿的时候发生了什么?
- 浏览器的渲染时机?
- React fiber的增量渲染是怎么回事?
- Vue里面的nextTick API是怎么回事?
- Electron中如何完成计算密集性工作?
- RequestAnimationFrame为什么流畅?
- Promise, setTimeout, await, nextTick打印N连面试题都做对了么?
- WebWorker?
如果上面这些问题在你心中都有清晰的答案和认知, 那么我想这篇文章对你帮助不大。
提到JS的异步, 你会想到什么?
- 单线程
- 事件驱动
- nodejs: 异步非阻塞IO
- event loop
- setTimeout, setInterval,requestAnimationFrame
- Promise, await, nextTick, setImmediate
- IndexDB/WebSocket, mutationObserver
- addEventListener & onClick
- XMLHttpRequest & FileReader
- UI渲染
- web worker
- ...
单线程
-
为什么js做成单线程?
js最早在浏览器中执行,在GUI编程里, 单线程控制GUI是一个普遍的做法
js对于开发者是单线程的(js代码的解释和执行是在一个线程里进行), 但是异步操作是在运行时环境中用多线程实现的;
-
js分为js引擎和js运行时: nodejs 是运行时, chrome 包含一个运行时, 它们都使用v8这个js引擎
事件驱动

- 这个是最精简的样子, 实际情况当然要比这个复杂
(配图自《深入浅出nodejs》第三章)
异步非阻塞io
(配图来自《深入浅出nodejs》第三章)

- 由图可见, nodejs中的异步操作是通过一个线程池中的多个线程去处理的, 实际上在浏览器中也是这样: 除了运行js代码的的线程外, 还会有另外的请求线程、timer线程、IO线程、渲染线程等线程帮助处理相应操作。
- 这里面有个核心概念: 事件循环, 就是人人皆知的event Loop。
异步vs非异步
实际上, 大部分语言都是同步的, js作为异步语言算是少数民族了
很明显, 和传统的非异步处理方式对比, 实际上就是串行(Sequential)和并行(Parallel)的区别
- 大多时候耗时的操作都属于io类操作
- 并行能耗费更少的资源处理更多的io类请求
- 单线程开发变得简单多了
所以, js具体是怎样实现异步的呢? 那就是 event loop
event loop 作为js异步实现的核心机制, 对理解和解决很多问题十分重要
event loop
理解event loop, 需要理解下面这些概念
- heap
- callstack | Excution context stack
- Tasks
- task source
- MicroTasks
- Multiple task queue
调用栈
调用栈是解析器(如浏览器中的的javascript解析器)的一种机制,可以在脚本调用多个函数时,跟踪每个函数在完成执行时应该返回控制的点。(如什么函数正在执行,什么函数被这个函数调用,下一个调用的函数是谁)
当脚本要调用一个函数时,解析器把该函数添加到栈中并且执行这个函数。
任何被这个函数调用的函数会进一步添加到调用栈中,并且运行到它们被上个程序调用的位置。
当函数运行结束后,解释器将它从堆栈中取出,并在主代码列表中继续执行代码。
如果栈占用的空间比分配给它的空间还大,那么则会导致“栈溢出”错误。

可以自己尝试运行一下这个demo, 帮助理解调用栈的概念
理解了调用栈的概念, 那么递归时候出现的爆栈问题也就很容易理解了: 每层栈的上下文都将被存储直到整个函数调用结束, 将占用大量内存直到溢出。
浏览器中的event loop 模型图

(配图来自how javascript works)
需明白event loop是运行时的一部分, 所以不同环境下的实现细节可能是有区别的, 比如nodejs, 但核心机制是一样的
再看官方文档怎么说的
文档中有很多定义和规则, 篇幅很长, 而且网上讲event loop的文章很多, 但是很多太boring, 有时候耐心度有限, 希望走走便捷通道, 所以这里我想尝试换一种方式.
面对任何新事物时, 最先要做的是: 刨除细枝末节, 找出它的核心生命周期。
伪代码实现event loop(浏览器实现)
step 1: 先模拟处理异步任务
// 一个任务队列, 其中每个节点是一个回调函数
// 比如当用户点击了一个提交按钮, 触发了一个ajax请求, 当请求完成时会将回调函数push到这个队列
let taskQueue: Array<Task> = []
while (true) {
debug('生命周期开始')
task = taskQueue.shift();
execute(task);
// 当浏览器觉得需要渲染时(这里是黑箱的)
if (isRepaintTime()) repaint();
debug('生命周期结束')
}
step 2: 模拟多类别异步任务
- 事件,用户交互,脚本,渲染,网络等任务会根据触发来源(taskSource)被添加到对应类别的任务队列里, 这样就方便runtime自行调度任务执行顺序
// 有多个不同类别的任务队列, 它们是有次序的
let allTaskQueues =[
taskQueueA: Array<TaskA>,
taskQueueB: Array<TaskB>,
taskQueueC: Array<TaskC>,
...
]
while (true) {
debug('生命周期开始')
// 取最旧的任务队列
queue = getNextQueue();
task = queue.shift();
execute(task);
// 当浏览器觉得需要渲染时(这里是黑箱的)
if (isRepaintTime()) repaint();
debug('生命周期结束')
}
step 3: 希望某些任务能提前执行
// 有多个不同类别的任务队列, 它们是有次序的
let allTaskQueues =[
taskQueueA: Array<TaskA>,
taskQueueB: Array<TaskB>,
taskQueueC: Array<TaskC>,
...
]
// 为了某些任务能提前执行, 这里单独定义了一个新的队列类别
// 微任务队列, 其中每个节点是一个回调函数
let microTaskQueue: Array<MicroTask> = []
while (true) {
debug('生命周期开始')
// 取最旧的任务队列
queue = getNextQueue();
task = queue.shift();
execute(task);
// 将微任务队列中的回调函数全部执行完毕
while (microtaskQueue.hasTasks()) {
doMicrotask();
}
// 当浏览器觉得需要渲染时(这里是黑箱的)
if (isRepaintTime()) repaint();
debug('生命周期结束')
}
step 4: 模拟RequestAnimateFrame
- 浏览器的渲染时机没法控制和感知, 所以靠纯js渐变法做动画掉帧很正常, 为了解决这个问题, 通过RequestAnimateFrame引入一个新类别的任务队列AnimateTaskQueue
// 有多个不同类别的宏任务队列, 它们是有次序的
let allTaskQueues =[
taskQueueA: Array<TaskA>,
taskQueueB: Array<TaskB>,
taskQueueC: Array<TaskC>,
...
]
// 为了某些任务能提前执行, 这里单独定义了一个新的队列类别
// 微任务队列, 其中每个节点是一个回调函数
let microTaskQueue: Array<MicroTask> = []
while (true) {
debug('生命周期开始')
// 取最旧的宏任务队列
queue = getNextQueue();
task = queue.shift();
execute(task);
// 将微任务队列中的回调函数全部执行完毕
while (microtaskQueue.hasTasks()) {
doMicrotask();
}
// 当浏览器觉得需要渲染时(这里是黑箱的)
if (isRepaintTime()) {
// 执行完所有动画任务队列里的回调函数
while (animateTaskQueue.hasTasks()) {
execute(animateTaskQueue.shift());
}
repaint()
};
debug('生命周期结束')
}
小例子
可以尝试运行一下这个demo, 帮助理解event loop的运行机制

浏览器的渲染时机

微任务 在浏览器中的表现
const btn = document.getElementById('btn')
btn.onclick = function () {
let html = ''
for (let i = 0; i < 100; i++) {
html += `<div></div>`
}
const output = document.getElementById('output')
Promise.resolve().then(function promise1() {
output.innerHTML = html
})
};

- 微任务是在当前循环周期中执行的, 且发生在渲染之前
宏任务 在浏览器中表现
function buildItems(num) {
let html = ''
for (let i = 0; i < num; i++) {
html += `<div></div>`
}
return html
}
const btn = document.getElementById('btn')
const output = document.getElementById('output')
btn.onclick = function () {
setTimeout(function setTimeout1 () {
output.innerHTML = buildItems(100)
}, 0)
};

- 宏任务是在下个循环周期中执行的, 且发生在渲染之前
多个宏任务
function buildItems(num) {
let html = ''
for (let i = 0; i < num; i++) {
html += `<div></div>`
}
return html
}
const btn = document.getElementById('btn')
const output = document.getElementById('output')
btn.onclick = function () {
let html = buildItems(100)
setTimeout(function setTimeout1 () {
output.innerHTML = html
}, 0)
setTimeout(function setTimeout2 () {
output.innerHTML = html
}, 0)

- 宏任务每次都被分到下一次循环周期中执行
- 不是每次循环浏览器都会渲染
注意: 这里用了setTimeout作为宏任务例子, 实际上这个现象在浏览器和nodejs中是不一样的: 在nodejs中会把当前执行栈中触发的timer统一放到下一个循环周期中执行
多个微任务
- 在一轮event loop中多次修改dom,只有最后一次会进行绘制。
主线程和渲染线程是互斥的: 在主线程执行事件循环时渲染线程是不work的, 反之亦然。
nodejs event loop的生命周期
- nextTick也是微任务, 且执行在Promise之前
- setImmediate 放在下次下次循环周期的最前面
微任务有如下几种(其它默认为宏任务)
- process.nextTick
- promises
- Object.observe(废弃的)
- MutationObserver
Vue里面的nextTick API是怎么回事?
- 其实就是微任务和宏任务的应用
React fiber中的增量渲染?
fiber 之前
- 实际上是递归渲染, 不能中断
- 单次大量计算: Freeze Rendering
function drawMany(limit) {
const output = document.getElementById('output')
for (let i = 0; i < limit; i++) {
output.appendChild(document.createElement('div'))
}
}
drawMany(200000)
可以看下运行下这个demo看效果

fiber
- 非递归渲染, 可以中断和控制
- 分割: Allows Rendering
var LIMIT = 200000;
var CHUNK = 1000;
function drawFew(start, callback) {
for (var i = 0; i < CHUNK; i++) {
output.appendChild(document.createElement('div'));
}
if (start >= LIMIT) return callback();
setTimeout(function() {
drawFew(start + CHUNK, callback);
}, 0);
}
drawFew(0, function() {})

可以看下这个demo
Electron中如何完成计算密集性工作
- 在主进程和渲染进程里处理很明显会造成卡死, 新开一个背景渲染进程处理即可。
Web Workers
- 有自己的event Loop
- 通过json传递消息
- 不能操作 DOM等API
实际上主线程完成高并发的前提是主线程自身作为一个任务调度者存在, 需要等待的异步任务或者重型任务必须交给其它进程|线程去处理, 一旦调度者本身被具体事务的执行占住, 就会造成整个进程阻塞, 什么也处理不了了
结论
- 不要阻塞渲染(确保每次循环 消耗时间小于 16ms)
- 大量节点: 分割排队渲染
- 把繁重的dom操作放到队列里分割操作(多个帧)
- 用背景进程 | 子进程 | web worker 处理cpu 重型操作
- 使用Chrome DevTools的Timeline来分析JavaScript的性能
- 动画实现,避免使用setTimeout或setInterval,尽量使用requestAnimationFrame 或者 css3
- promise 比 setTimeout 先执行
- 使用负载均衡开启多个app实例, 充分利用资源
参考
聊聊代码质量.md
背景
这次的主题是代码质量, 其实不太知道该从何说起, 重点讲什么, 如何讲。编码指导规范, 错误/整洁代码示例, 原则, 设计模式, 领域模型什么的, 要么网上都有现成的, 要么知识点太多, 对于这么一次短时间的分享来说没啥意义,网上关于代码质量的文章也是大把。所以这次我只想结合自身的经历, 聊一聊感想,只说自己想说的那部分: 仅代表个人观点, 由于自身局限性,偏见在所难免, 欢迎大家纠正和补缺。
首先, 前端/后端工作的难点在哪里?
- 不同阶段, 不同项目, 遇到的难点会不断变化
初期: 技术难点
- 其实不是真的很难(大部分)
- 再难也有攻克的一天
- 大部分时间其实没什么技术难点
- 点状
初中期
- 纯靠个人技术成长收益最高的时期
- 要分清知识和工具的区别
中后期: 项目难点
- 高扩展性/可维护性
- 快速迭代
- 高自动化
- 工程复杂, 面状
中后期: 人的难点
- 沟通/协作
- 跨部门沟通/协作
- 业务理解
程序的目的是要解决现实中的问题, 最终还是人的问题
前端
- 本质适配端, 解决状态与UI的同步问题
后端
- 本质上解决数据管理和流动的问题
前端的难点在哪
- 数据 + UI + 交互: 状态管理复杂, 变更频繁,难抽象
- 垂直领域解决方案各不相同, 分析、设计、开发、落地难, 重用度低
- 个人成长: 不稳定的环境容易让人迷失方向
后端的难点在哪
- 高稳定性
- 高安全性
- 高伸缩性
职业生涯
- 持续学习总结
- 做很多项目: 开荒的, 重构的, 接手维护的
- 接触不同的人, 不同的团队
- 面临很多挑战
其实我想说的是, 高质量代码也是重要难点之一, 且全方位贯穿始终, 是基石。代码质量体现了很多问题。
框架, 某项技术, 知识点, 可以短时间学习并投入使用
而代码质量不能, 需要长时间有意识的学习训练和提高
在日常工作中, 无论在何种阶段, 何种境遇, 做什么项目, 面临何种挑战, 代码质量将是贯穿始终不得不面对的一环。
什么是代码质量
代码质量指的是代码内在的非功能性的质量,用户不能直接体验到这种质量的好坏,代码质量不好,最直接的“受害者”是开发者或组织自身.
为什么需要好的代码质量
背景: 熵增定律
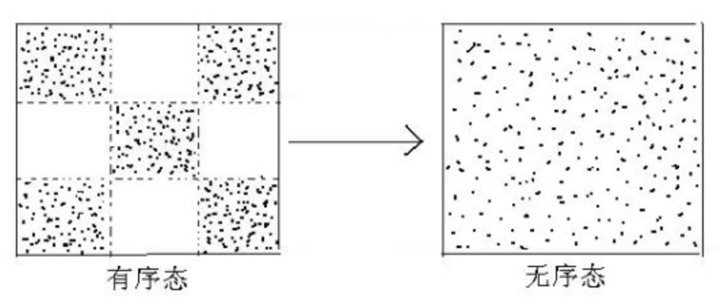
在无外力影响的情况下,烂代码只会原来越多。
为了维持系统有序,需要外界向系统不断输入能量
从组织/团体角度上讲
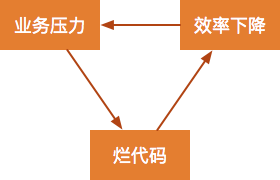
烂代码产生的常见原因是业务压力大,导致没有时间或意愿讲究代码质量。因为向业务压力妥协而生产烂代码之后,开发效率会随之下降,导致业务压力更大,形成一种典型的恶性循环。
为了应对业务压力,常见的做法就是向项目中增加人力,但是单纯地增加人力的话,会因为风格不一致、沟通成本上升等原因导致烂代码更多。
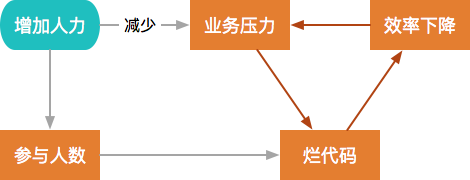
要遏制这种恶性循环,需要多管齐下,主动对代码质量进行管控,并且持续进行技术升级,系统性地解决问题。
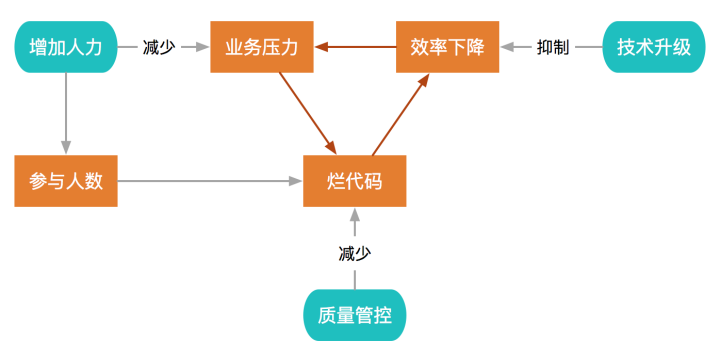
现实中实际上很多情况是这样: 质量不够, 人力来凑。
这招确实有效, 毕竟初期要抢占市场, 必须要快, 毕竟有些项目总共也存活不了多长时间。
然而人力只能在一定程度上解决问题。
人力是有限的,也不太可能在短时间内爆发, 而业务的发展就不受控制了。
当人力增加跟不上业务发展的时候,就不是一个好坏的问题了, 是无和有的问题。这个时条件允许的话只能重构/推倒重来, 否则积重难返, 项目就回天乏术了。
每个项目都有自己的生命周期, 烂代码越多, 越离崩解不远了。
有人会说靠更新架构支撑业务发展, 这个当然没错, 然而这建立在良性循环、条件、成本之上, 并不是万能的。
从个人角度上讲
-
好的代码, 容易理解/掌握, 情绪可以保持稳定
-
好的代码, 容易修改/扩展, 效率高, 少加班
-
好的代码, 容易定位bug, 故障少, 少挨喷
-
好的代码, 让人信赖, 更有机会负责更大的事
总结: 保命保平安, 有前途

我之前曾经接手一个IM项目, 当时的情景是这样:
- 1 开发新功能困难, 进度慢, 不能支撑业务发展
- 2 四处冒烟, 出了bug难定位, 很多蜜汁bug
- 3 开发本人都不清楚自己写过的功能都有啥逻辑
- 4 完美的实践了怎么写出无法维护代码的准则
最后没有办法, 只能抽丝剥茧, 一块块拆, 重新设计和重构, 耗费了大量成本填补技术债务,那就是另外一个关于如何重构的故事了。
代码中常见的问题
不好的味道太多, 我这里只总结了自己在各个项目中碰到的写代码中出现频次很高的一些问题.
这里面有些是个人可以规避的, 有些需要靠团队共同努力。
硬编码
- 不愿意写枚举/用常量
- '04', '04', '04': 我喜欢这个数字, 没人知道这个数字的秘密
全局变量
- 临时图省事, 维护泪两行
没有边界
- 不分上下文/层级, 模块间随意互相调用, 交叉污染
- 一个功能的代码可以分散到世界的各个角落
- 本来只需要依赖几个模块, 结果引用一大堆
所谓架构师, 就是一个很会拆的人。
过程式编程
- 企图用一个函数解决所有问题, 动辄几百行
- 拆分是不可能的, 这辈子都不会拆的
- 面向对象语言愣是写出C语言的范来
异常处理缺失或者混乱
- 从不验证外源数据
- 不管异常
- 不打日志
- 日志不写上下文
复制粘贴
- 复制自己: 1, 2, 3, 跑起来了!
- 复制别人: 完全不用理解代码, 就可以'高效'的编程了
- 从不封装: 调用者需要知道被调用的所有的细节
大量条件嵌套
- 里三圈, 外三圈, 脖子扭扭, 屁股扭扭...

长代码行
- 有助于治疗鼠标手: 别人阅读的时候需要来来回回的拖
随意的命名
- 抽象到跟没说一样
- 没有人能根据我的关键字搜索
注释
- 写了完全没用, 除了碍眼
- 不注释机关陷阱
- 假注释: 改代码但是不改注释
无用的代码
- git history 的存在是有意义的
- 你的代码没有想象中那么值钱
没有代码保护
- 任何外部模块都可以随意访问和修改, 你在写公用库/API时尤其要重视这一点
参数个数巨多的函数
- 修改和调用都将是噩梦
- 写单元测试将是一项无法完成的工作
参数结构不写清楚(弱类型语言通病)
- 靠人肉在线推导类型
- ts不写类型, 关键地方 any
没有一致性
- 同样的对象在A模块叫c, 在B模块叫d
总结一句话: 没有设计和架构的概念, 低内聚, 高耦合, 用复杂的代码解决简单的问题, 说句实话, 前端在这块普遍意识薄弱一些
工作中你可能遇到的问题
代码质量和工作效率怎么平衡
- 立项初期, 团队不成熟的时候, 两者成反比
- 项目中后期, 团队成熟后, 两者成正比
- 无论何种时期, 代码质量有要有一个下限
- 一次性代码就随便了, 这种应该自动化
如何看待宁可拷贝大段代码也不调整/优化原有代码的行为
改:
- 可能带来大量的修改点和工作量
- 可能对些奇怪的点理解错误,导致已正常运行的功能出错(单元测试是个好东西)
- 高风险
不改:
- 代码负债增加
- 影响心情
- 破窗效应
- 传染性
问题:
- 值不值?
基本原则:
- 不能出错
- 按时交付
- 遵守团队规范
想重构怎么办
重构不是推倒重写
- 要理解清楚现有业务逻辑
- 在不改变现有功能表现的前提下做内部优化
- 不能丢失细节
重构要做好CI防护: 兜底
- 要做好测试, 保证现有功能不受影响
重构是要针对性的解决问题
- 要有明确的目标, 有关键性的问题要解决
- 不是用一坨烂代码替换另一坨烂代码
重构是一个持续的过程
- 小步慢跑, 细水长流
- 贵在坚持
重构不是憋大招
- 不是憋个一年半载搞爆破
Code Review 难落地怎么办, 总是不了了之
关于Code Review
Code Review不只是一种方法,也是开发者特有的沟通方式,更是一种团队文化。
Code Review的意义
- 交叉排查缺陷 - 绝大多数BUG都可以在代码层面被发现,甚至测试难以覆盖到的深层次BUG也可以通过团队成员相互审核而避免
- 提高代码质量 - Code Review意味着开发者要接受团队成员的建议与监督,在完成功能的基础之上不断完善代码结构
- 加强团队协作 - 团队成员在相互督促与改进**同成长
国外一流的公司都是有完备的Code Review流程的, 国内只要把这块能做起来的, 随便就可以拿出来吹一吹了
有这些好处, 为啥 Code Review 还是难执行?
我本人这方面也遇到过不少问题, 也有很多困扰.
大致是这几种:
- 不能被看到直接产出
- 不能提升绩效
- 代码变更频繁投入时间review没意义
- 进行review的人还要花精力了解对应的功能需求, 耗费时间
- 代码不规范, 太多无意义review
- commit方式不规范: 让review变得困难
总结一句话: 总是投入没有回报的事让人坚持真的是强人所难。
所以得想个办法,因地制宜,讲究个方式。
措施
- 做需求前先讨论, 定好方案, 定好后方案要持久化
- 提交规范要落地(standard-version): 一个commit对应一个需求, 杜绝一次提交夹带无关联改动或者几个需求一次提交的情况。
- 代码规范(clean-code-typescript + ts-lint + sonar): 自动化流程解决规范不统一和基础质量问题, 不过自动检查的代码不得合并, 进不到code review这一步, 能自动的就不要人肉。
- 到了code review这一步,主要关心代码有没有按照既定方案实现, 有没有明显的bug, 代码组织有没有改善空间?
- 重点代码: 每个迭代/双周/月度对具有代表性的代码集体评审,重点在于解决团队共性问题,讨论改进方法
- 新人重点review
意识
- 代码是团队共有的知识财富,而不是个人的私有地
- 所有人对所有代码的最终质量负责,而非某个人对某些代码负责
- 完成功能只是开始,代码需要持续改进以符合团队标准
- Code Review对于团队中的新人来说是很好的锻炼机会
注意事项
- Code Review不能形式化,没看过PR、没改进意见不能通过
- PR被打回不是丢面子的事情,被提改进建议也不是批评,对事不对人
- 将别人提交的代码视作自己将维护的代码,个人标准与集体标准对齐
总结
Code Review体现的是团队对于代码质量的追求,对于团队内部协作的重视。对于新手来讲,对于日常工作的钻研与打磨比偶尔一次的技术培训或分享更有学习价值。
如何提高代码质量
基本原则
- 代码不是私人的, 是公共财产
- 程序员大部分时间是在阅读代码
- 写代码要保证可读性, 尽量降低思维负担
扎实基础
- 对语言特性的理解
- 专业背景知识的掌握
- 数据结构和算法
- 设计模式和原则
- 英语姿势水平
前端工程师首先是工程师, 然后才是前端。
不要总觉得数据结构,算法,设计模式是后端的东西, 这都是基本素质, 和前后端无关。
随着5G、AI、AR/VR等技术的落地普及, 前端领域很可能切换新的开发方式, 有新的要求,对人员的基本素养要求将会越来越高。
下面是个人觉得实用的入门资料:






模仿优秀的代码
再忙, 停下来, 抬头看天, 多总结, 多思考
代码标准
强类型检测(针对动态语言)
- typescript
自动检测
- 代码规范检查 - 包括风格规范、实践规范、业务规范
- 重复率 - 重复出现的代码区块占比,通常要求在5%以下
- 复杂度 - 总行数,模块大小,循环复杂度等
- 检查覆盖度 - 经过检查的行数占代码库总行数的比例
- tslint + sonar + jenkins
想好再写
善用开源
持续重构
代码审查
单元测试
充分自测
技术升级
流程标准
- git flow·改
进阶
自我保护能力
伸缩能力
资源限制
详细的日志
Reference
Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.