xiaomuzhu / blog Goto Github PK
View Code? Open in Web Editor NEW个人博客(部分从掘金迁移而来),关注前端编辑器技术和图形学,喜欢的话点star,想订阅点watch
个人博客(部分从掘金迁移而来),关注前端编辑器技术和图形学,喜欢的话点star,想订阅点watch












































本文于2019年首发于掘金
设计前端组件是最能考验开发者基本功的测试之一,因为调用Material design、Antd、iView 等现成组件库的 API 每个人都可以做到,但是很多人并不知道很多常用组件的设计原理。
能否设计出通用前端组件也是区分前端工程师和前端api调用师的标准之一,那么应该如何设计出一个通用组件呢?
下文中提到的组件库通常是指单个组件,而非集合的概念,集合概念的组件库是 Antd iView这种,我们所说的组件库是指集合中的单个组件,集合性质的组件库需要考虑的要更多.
我们在学习设计模式的时候会遇到很多种设计原则,其中一个设计原则就是单一职责原则,在组件库的开发中同样适用,我们原则上一个组件只专注一件事情,单一职责的组件的好处很明显,由于职责单一就可以最大可能性地复用组件,但是这也带来一个问题,过度单一职责的组件也可能会导致过度抽象,造成组件库的碎片化。
举个例子,一个自动完成组件(AutoComplete),他其实是由 Input 组件和 Select 组件组合而成的,因此我们完全可以复用之前的相关组件,就比如 Antd 的AutoComplete组件中就复用了Select组件,同时Calendar、 Form 等等一系列组件都复用了 Select 组件,那么Select 的细粒度就是合适的,因为 Select 保持的这种细粒度很容易被复用.
那么还有一个例子,一个徽章数组件(Badge),它的右上角会有红点提示,可能是数字也可能是 icon,他的职责当然也很单一,这个红点提示也理所当然也可以被单独抽象为一个独立组件,但是我们通常不会将他作为独立组件,因为在其他场景中这个组件是无法被复用的,因为没有类似的场景再需要小红点这个小组件了,所以作为独立组件就属于细粒度过小,因此我们往往将它作为 Badge 的内部组件,比如在 Antd 中它以ScrollNumber的名称作为Badge的内部组件存在。
所以,所谓的单一职责组件要建立在可复用的基础上,对于不可复用的单一职责组件我们仅仅作为独立组件的内部组件即可。
我们要设计的本身就是通用组件库,不同于我们常见的业务组件,通用组件是与业务解耦但是又服务于业务开发的,那么问题来了,如何保证组件的通用性,通用性高一定是好事吗?
比如我们设计一个选择器(Select)组件,通常我们会设计成这样
这是一个我们最常见也最常用的选择器,但是问题是其通用性大打折扣
当我们有一个需求是长这样的时候,我们之前的选择器组件就不符合要求了,因为这个 Select 组件的最下部需要有一个可拓展的条目的按钮
这个时候我们难道要重新修改之前的选择器组件,甚至再造一个符合要求的选择器组件吗?一旦有这种情况发生,那么只能说明之前的选择器组件通用性不够,需要我们重新设计.
Antd 的 Select 组件预留了dropdownRender来进行自定义渲染,其依赖的 rc-select组件中的代码如下
Antd 依赖了大量以
rc-开头的底层组件,这些组件被react-component团队(同时也就是Antd 团队)维护,其主要实现组件的底层逻辑,Antd 则是在此基础上添加Ant Design设计语言而实现的
当然类似的设计还有很多,通用性设计其实是一定意义上放弃对 DOM 的掌控,而将 DOM 结构的决定权转移给开发者,dropdownRender其实就是放弃对 Select 下拉菜单中条目的掌控,Antd 的 Select 组件其实还有一个没有在文档中体现的方法getInputElement应该是对 Input 组件的自定义方法,Antd整个 Select 的组件设计非常复杂,基本将所有的 DOM 结构控制权全部暴露给了开发者,其本身只负责底层逻辑和最基本的 DOM 结构.
这是 Antd 所依赖的 re-select 最终 jsx 的结构,其 DOM 结构很简单,但是暴露了大量自定义渲染的接口给开发者.
return (
<SelectTrigger
onPopupFocus={this.onPopupFocus}
onMouseEnter={this.props.onMouseEnter}
onMouseLeave={this.props.onMouseLeave}
dropdownAlign={props.dropdownAlign}
dropdownClassName={props.dropdownClassName}
dropdownMatchSelectWidth={props.dropdownMatchSelectWidth}
defaultActiveFirstOption={props.defaultActiveFirstOption}
dropdownMenuStyle={props.dropdownMenuStyle}
transitionName={props.transitionName}
animation={props.animation}
prefixCls={props.prefixCls}
dropdownStyle={props.dropdownStyle}
combobox={props.combobox}
showSearch={props.showSearch}
options={options}
multiple={multiple}
disabled={disabled}
visible={realOpen}
inputValue={state.inputValue}
value={state.value}
backfillValue={state.backfillValue}
firstActiveValue={props.firstActiveValue}
onDropdownVisibleChange={this.onDropdownVisibleChange}
getPopupContainer={props.getPopupContainer}
onMenuSelect={this.onMenuSelect}
onMenuDeselect={this.onMenuDeselect}
onPopupScroll={props.onPopupScroll}
showAction={props.showAction}
ref={this.saveSelectTriggerRef}
menuItemSelectedIcon={props.menuItemSelectedIcon}
dropdownRender={props.dropdownRender}
ariaId={this.ariaId}
>
<div
id={props.id}
style={props.style}
ref={this.saveRootRef}
onBlur={this.onOuterBlur}
onFocus={this.onOuterFocus}
className={classnames(rootCls)}
onMouseDown={this.markMouseDown}
onMouseUp={this.markMouseLeave}
onMouseOut={this.markMouseLeave}
>
<div
ref={this.saveSelectionRef}
key="selection"
className={`${prefixCls}-selection
${prefixCls}-selection--${multiple ? 'multiple' : 'single'}`}
role="combobox"
aria-autocomplete="list"
aria-haspopup="true"
aria-controls={this.ariaId}
aria-expanded={realOpen}
{...extraSelectionProps}
>
{ctrlNode}
{this.renderClear()}
{this.renderArrow(!!multiple)}
</div>
</div>
</SelectTrigger>
);那么这么多需要自定义的地方,这个 Select 组件岂不是很难用?因为好像所有地方都需要开发者自定义,通用性设计在将 DOM 结构决定权交给开发者的同时也保留了默认结构,在开发者没有显示自定义的时候默认使用默认渲染结构,其实 Select 的基本使用很方便,如下:
<Select defaultValue="lucy" style={{ width: 120 }} disabled>
<Option value="lucy">Lucy</Option>
</Select>组件的形态(DOM结构)永远是千变万化的,但是其行为(逻辑)是固定的,因此通用组件的秘诀之一就是将 DOM 结构的控制权交给开发者,组件只负责行为和最基本的 DOM 结构
由于CSS 本身的众多缺陷,如书写繁琐(不支持嵌套)、样式易冲突(没有作用域概念)、缺少变量(不便于一键换主题)等不一而足。为了解决这些问题,社区里的解决方案也是出了一茬又一茬,从最早的 CSS prepocessor(SASS、LESS、Stylus)到后来的后起之秀 PostCSS,再到 CSS Modules、Styled-Components 等。
Antd 选择了 less 作为 css 的预处理方案,Bootstrap 选择了 Scss,这两种方案孰优孰劣已经争论了很多年了:
但是不管是哪种方案都有一个很烦人的点,就是需要额外引入 css,比如 Antd 需要这样显示引入:
import Button from 'antd/lib/button';
import 'antd/lib/button/style'; 为了解决这种尴尬的情况,Antd 用 Babel 插件将这种情况 Hack 掉了
而material-ui并不存在这种情况,他不需要显示引入 css,这个最流行的 React 前端组件库里面只有 js 和 ts 两种代码,并不存在 css 相关的代码,为什么呢?
他们用 jss 作为css-in-js 的解决方案,jsx 的引入已经将 js 和 html 耦合,css-in-js将 css 也耦合进去,此时组件便不需要显示引入 css,而是直接引用 js 即可.
这不是退化到史前前端那种写内联样式的时代了吗?
并不是,史前前端的内联样式是整个项目耦合的状态,当然要被抛弃到历史的垃圾堆中,后来的样式和逻辑分离,实际上是以页面为维度将 js css html 解耦的过程,如今的时代是组件化的时代了,jsx 已经将 js 和 html 框定到一个组件中,css 依然处于分离状态,这就导致了每次引用组件却还需要显示引入 css,css-in-js 正式彻底组件化的解决方案.
当然,我个人目前在用 styled-components,其优点引用如下:
首先,styled-components 所有语法都是标准 css 语法,同时支持 scss 嵌套等常用语法,覆盖了所有 css 场景。
在样式复写场景下,styled-components 支持在任何地方注入全局 css,就像写普通 css 一样
styled-components 支持自定义 className,两种方式,一种是用 babel 插件, 另一种方式是使用 styled.div.withConfig({ componentId: "prefix-button-container" }) 相当于添加 className="prefix-button-container"
className 语义化更轻松,这也是 class 起名的初衷
更适合组件库使用,直接引用 import "module" 即可,否则你有三条路可以走:像 antd 一样,单独引用 css,你需要给 node_modules 添加 css-loader;组件内部直接 import css 文件,如果任何业务项目没有 css-loader 就会报错;组件使用 scss 引用,所有业务项目都要配置一份 scss-loader 给 node_modules;这三种对组件库来说,都没有直接引用来的友好
当你写一套组件库,需要单独发包,又有统一样式的配置文件需求,如果这个配置文件是 js 的,所有组件直接引用,对外完全不用关注。否则,如果是 scss 配置文件,摆在面前还是三条路:每个组件单独引用 scss 文件,需要每个业务项目给 node_modules 添加 scss-loader(如果业务用了 less,还要装一份 scss 是不);或者业务方只要使用了你的组件库,就要在入口文件引用你的 scss 文件,比如你的组件叫 button,scss 可能叫 common-css,别人听都没听过,还要查文档;或者业务方在 webpack 配置中单独引用你的 common-css,这也不科学,如果用了3个组件库,天天改 webpack 配置也很不方便。
当 css 设置了一半样式,另一半真的需要 js 动态传入,你不得不 css + css-in-js 混合使用,项目久了,维护的时候发现某些 css-in-js 不变了,可以固化在 css 里,css 里固定的值又因为新去求变得可变了,你又得拿出来放在 css-in-js 里,实践过就知道有多么烦心。
选 Typescript ,因为巨硬大法好...
可以看看知乎问题下我的回答你为什么不用 Typescript
或者看此文TypeScript体系调研报告
组件的具体实现部分当然是组件库的核心,但是在现代前端库中其他部分也必不可少,我们需要一堆工具来辅助我们开发,例如编译工具、代码检测工具、打包工具等等。
市面上打包工具数不胜数,最火爆的当然是需要配置工程师专门配置的webpack,但是在类库开发领域它有一个强大的对手就是 rollup。
现代市面上主流的库基本都选择了 rollup 作为打包工具,包括Angular React 和 Vue, 作为基础类库的打包工具 rollup 的优势如下:
虽然上面部分功能已经被 webpack 实现了,但是 rollup 明显引入得更早,而Scope Hoisting更是杀手锏,由于 webpack 不得不在打包代码中构建模块系统来适应 app 开发(模块系统对于单一类库用处很小),Scope Hoisting将模块构建在一个函数内的做法更适合类库的打包.
由于 JavaScript 各种诡异的特性和大型前端项目的出现,代码检测工具已经是前端开发者的标配了,Douglas Crockford最早于2002创造出了 JSLint,但是其无法拓展,具有极强的Douglas Crockford个人色彩,Anton Kovalyov由于无法忍受 JSLint 无法拓展的行为在2011年发布了可拓展的JSHint,一时之间JSHint成为了前端代码检测的流行解决方案.
随后的2013年,Nicholas C. Zakas鉴于JSHint拓展的灵活度不够的问题开发了全新的基于 AST 的 Lint 工具 ESLint,并随着 ES6的流行**了前端界,ESLint 基于Esprima进行 JavaScript 解析的特性极易拓展,JSHint 在很长一段时间无法支持 ES6语法导致被 ESLint 超越.
但是在 Typescript 领域 ESLint 却处于弱势地位,TSLint 的出现要比 ESLint 正式支持 Typescript 早很多,目前 TSLint 似乎是 TS 的事实上的代码检测工具.
注: 文章成文较早,我也没想到前阵子 TS 官方钦点了 ESLint,TSLint 失宠了,面向未来的官方标配的代码检测工具肯定是 ESLint 了,但是 TSLint 目前依然被大量使用,现在仍然可以放心使用
代码检测工具是一方面,代码检测风格也需要我们做选择,市面上最流行的代码检测风格应该是 Airbnb 出品的eslint-config-airbnb,其最大的特点就是极其严格,没有给开发者任何选择的余地,当然在大型前端项目的开发中这种严格的代码风格是有利于协作的,但是作为一个类库的代码检测工具而言并不适合,所以我们选择了eslint-config-standard这种相对更为宽松的代码检测风格.
以下两种 commit 哪个更严谨且易于维护?
最开始使用 commit 的时候我也经常犯下图的错误,直到看到很多明星类库的 commit 才意识到自己的错误,写好 commit message 不仅有助于他人 review, 还可以有效的输出 CHANGELOG, 对项目的管理实际至关重要.
目前流行的方案是 Angular 团队的规范,其关于 head 的大致规范如下:
当然规范人们不一定会遵守,我最初知道此类规范的时候也并没有严格遵循,因为人总会偷懒,直到用commitizen将此规范集成到工具流中,每个 commit 就不得不遵循规范了.
我具体参考了这篇文章: 优雅的提交你的 Git Commit Message
业务开发中由于前端需求变动频繁的特性,导致前端对测试的要求并没有后端那么高,后端业务逻辑一旦定型变动很少,比较适合测试.
但是基础类库作为被反复依赖的模块和较为稳定的需求是必须做测试的,前端测试库也可谓是种类繁多了,经过比对之后我还是选择了目前最流行也是被三大框架同时选择了的 Jest 作为测试工具,其优点很明显:
当然以上是主要工具的选择,还有一些比如:
那么以上这么多配置难道要我们每次都自己写吗?组件的具体实现才是组件库的核心,我们为什么要花这么多时间在配置上面?
我们在建立 APP 项目时通常会用到框架官方提供的脚手架,比如 React 的 create-react-app,Angular 的 Angular-Cli 等等,那么能不能有一个专门用于组件开发的快速启动的脚手架呢?
有的,我最近开发了一款快速启动组件库开发的命令行工具--create-component
利用
create-component init <name>来快速启动项目,我们提供了丰富的可选配置,只要你做好技术选型后,根据提示去选择配置即可,create-component 会自动根据配置生成脚手架,其灵感就来源于 vue-cli和 Angular-cli.
说了很多理论,那么实战如何呢?设计一个通用组件试试吧!
轮播图(Carousel),在 Antd 中被称为走马灯,可能是前端开发者最常见的组件之一了,不管是在 PC 端还是在移动端我们总能见到他的身影.
那么我们通常是如何使用轮播图的呢?Antd 的代码如下
<Carousel>
<div><h3>1</h3></div>
<div><h3>2</h3></div>
<div><h3>3</h3></div>
<div><h3>4</h3></div>
</Carousel>问题是我们在Carousel中放入了四组div为什么一次只显示一组呢?
图中被红框圈住的为可视区域,可视区域的位置是固定的,我们只需要移动后面div的位置就可以做到1 2 3 4四个子组件轮播的效果,那么子组件2目前在可视区域是可以被看到的,1 3 4应该被隐藏,这就需要我们设置overflow 属性为 hidden来隐藏非可视区域的子组件.
复制查看动图: https://images2015.cnblogs.com/blog/979044/201707/979044-20170710105934040-1007626405.gif
因此就比较明显了,我们设计一个可视窗口组件Frame,然后将四个 div共同放入幻灯片组合组件SlideList中,并用SlideItem分别将 div包裹起来,实际代码应该是这样的:
<Frame>
<SlideList>
<SlideItem>
<div><h3>1</h3></div>
</SlideItem>
<SlideItem>
<div><h3>2</h3></div>
</SlideItem>
<SlideItem>
<div><h3>3</h3></div>
</SlideItem>
<SlideItem>
<div><h3>4</h3></div>
</SlideItem>
</SlideList>
</Frame>我们不断利用translateX来改变SlideList的位置来达到轮播效果,如下图所示,每次轮播的触发都是通过改变transform: translateX()来操作的
搞清楚基本原理那么实现起来相对容易了,我们以移动端的实现为例,来实现一个基础的移动端轮播图.
首先我们要确定可视窗口的宽度,因为我们需要这个宽度来计算出SlideList的长度(SlideList的长度通常是可视窗口的倍数,比如要放三张图片,那么SlideList应该为可视窗口的至少3倍),不然我们无法通过translateX来移动它.
我们通过getBoundingClientRect来获取可视区域真实的长度,SlideList的长度那么为:
slideListWidth = (len + 2) * width(len 为传入子组件的数量,width 为可视区域宽度)
至于为什么要+2后面会提到.
/**
* 设置轮播区域尺寸
* @param x
*/
private setSize(x?: number) {
const { width } = this.frameRef.current!.getBoundingClientRect()
const len = React.Children.count(this.props.children)
const total = len + 2
this.setState({
slideItemWidth: width,
slideListWidth: total * width,
total,
translateX: -width * this.state.currentIndex,
startPositionX: x !== undefined ? x : 0,
})
}获取到了总长度之后如何实现轮播呢?我们需要根据用户反馈来触发轮播,在移动端通常是通过手指滑动来触发轮播,这就需要三个事件onTouchStart onTouchMove onTouchEnd.
onTouchStart顾名思义是在手指触摸到屏幕时触发的事件,在这个事件里我们只需要记录下手指触摸屏幕的横轴坐标 x 即可,因为我们会通过其横向滑动的距离大小来判断是否触发轮播
/**
* 处理触摸起始时的事件
*
* @private
* @param {React.TouchEvent} e
* @memberof Carousel
*/
private onTouchStart(e: React.TouchEvent) {
clearInterval(this.autoPlayTimer)
// 获取起始的横轴坐标
const { x } = getPosition(e)
this.setSize(x)
this.setState({
startPositionX: x,
})
}onTouchMove顾名思义是处于滑动状态下的事件,此事件在onTouchStart触发后,onTouchEnd触发前,在这个事件中我们主要做两件事,一件事是判断滑动方向,因为用户可能向左或者向右滑动,另一件事是让轮播图跟随手指移动,这是必要的用户反馈.
/**
* 当触摸滑动时处理事件
*
* @private
* @param {React.TouchEvent} e
* @memberof Carousel
*/
private onTouchMove(e: React.TouchEvent) {
const { slideItemWidth, currentIndex, startPositionX } = this.state
const { x } = getPosition(e)
const deltaX = x - startPositionX
// 判断滑动方向
const direction = deltaX > 0 ? 'right' : 'left'
this.setState({
direction,
moveDeltaX: deltaX,
// 改变translateX来达到轮播组件跟随手指移动的效果
translateX: -(slideItemWidth * currentIndex) + deltaX,
})
}onTouchEnd顾名思义是滑动完毕时触发的事件,在此事件中我们主要做一个件事情,就是判断是否触发轮播,我们会设置一个阈值threshold,当滑动距离超过这个阈值时才会触发轮播,毕竟没有阈值的话用户稍微触碰轮播图就造成轮播,误操作会造成很差的用户体验.
/**
* 滑动结束处理的事件
*
* @private
* @memberof Carousel
*/
private onTouchEnd() {
this.autoPlay()
const { moveDeltaX, slideItemWidth, direction } = this.state
const threshold = slideItemWidth * THRESHOLD_PERCENTAGE
// 判断是否轮播
const moveToNext = Math.abs(moveDeltaX) > threshold
if (moveToNext) {
// 如果轮播触发那么进行轮播操作
this.handleSwipe(direction!)
} else {
// 轮播不触发,那么轮播图回到原位
this.handleMisoperation()
}
}我们常见的轮播图肯定不是生硬的切换,一般在轮播中会有一个渐变或者缓动的动画,这就需要我们加入动画效果.
我们制作动画通常有两个选择,一个是用 css3自带的动画效果,另一个是用浏览器提供的requestAnimationFrame API
孰优孰劣?css3简单易用上手快,兼容性好,requestAnimationFrame 灵活性更高,能实现 css3实现不了的动画,比如众多缓动动画 css3都束手无策,因此我们毫无疑问地选择了requestAnimationFrame.
双方对比请看张鑫旭大神的CSS3动画那么强,requestAnimationFrame还有毛线用?
想用requestAnimationFrame实现缓动效果就需要特定的缓动函数,下面就是典型的缓动函数
type tweenFunction = (t: number, b: number, _c: number, d: number) => number
const easeInOutQuad: tweenFunction = (t, b, _c, d) => {
const c = _c - b;
if ((t /= d / 2) < 1) {
return c / 2 * t * t + b;
} else {
return -c / 2 * ((--t) * (t - 2) - 1) + b;
}
}缓动函数接收四个参数,分别是:
通过这个函数我们能算出每一帧轮播图所在的位置, 如下:
在获取每一帧对应的位置后,我们需要用requestAnimationFrame不断递归调用依次移动位置,我们不断调用animation函数是其触发函数体内的 this.setState({ translateX: tweenQueue[0], })来达到移动轮播图位置的目的,此时将这数组内的30个位置依次快速执行就是一个缓动动画效果.
/**
* 递归调用,根据轨迹运动
*
* @private
* @param {number[]} tweenQueue
* @param {number} newIndex
* @memberof Carousel
*/
private animation(tweenQueue: number[], newIndex: number) {
if (tweenQueue.length < 1) {
this.handleOperationEnd(newIndex)
return
}
this.setState({
translateX: tweenQueue[0],
})
tweenQueue.shift()
this.rafId = requestAnimationFrame(() => this.animation(tweenQueue, newIndex))
}但是我们发现了一个问题,当我们移动轮播图到最后的时候,动画出现了问题,当我们向左滑动最后一个轮播图div4时,这种情况下应该是图片向左滑动,然后第一张轮播图div1进入可视区域,但是反常的是图片快速向右滑动div1出现在可是区域...
因为我们此时将位置4设置为了位置1,这样才能达到不断循环的目的,但是也造成了这个副作用,图片行为与用户行为产生了相悖的情况(用户向左划动,图片向右走).
目前业界的普遍做法是将图片首尾相连,例如图片1前面连接一个图片4,图片4后跟着一个图片1,这就是为什么之前计算长度时要+2
slideListWidth = (len + 2) * width(len 为传入子组件的数量,width 为可视区域宽度)
当我们移动图片4时就不会出现上述向左滑图片却向右滑的情况,因为真实情况是:
图片4 -- 滑动为 -> 伪图片1 也就是位置 5 变成了位置 6
当动画结束之后,我们迅速把伪图片1的位置设置为真图片1,这其实是个障眼法,也就是说动画执行过程中实际上是图片4到伪图片1的过程,当结束后我们偷偷把伪图片1换成真图片1,因为两个图一模一样,所以这个转换的过程用户根本看不出来...
如此一来我们就可以实现无缝切换的轮播图了
我们实现了轮播图的基本功能,但是其通用性依然存在缺陷:
以上都是可以对轮播图进行拓展的方向,相关的还有性能优化方面
我们的具体代码中有一个相关实现,我们的轮播图其实是有自动轮播功能的,但是很多时候页面并不在用户的可视页面中,我们可以根据是否页面被隐藏来取消定时器终止自动播放.
github项目地址
以上 demo 仅供参考,实际项目开发中最好还是使用成熟的开源组件,要有造轮子的能力和不造轮子的觉悟
本文于2019年首发于掘金
对于不少开发者而言,链表(linked list)这种数据结构既熟悉又陌生,熟悉是因为它确实是非常基础的数据结构,陌生的原因是我们在业务开发中用到它的几率的确不大.
在很多情况下,我们用数组就能很好的完成工作,而且不会产生太多的差异,那么链表存在的意义是什么?链表相比于数组有什么优势或者不足吗?
链表是一种常见的基础数据结构,是一种线性表,但是并不会按线性的顺序存储数据,而是在每一个节点里存到下一个节点的指针(Pointer).
从本质上来讲,链表与数组的确有相似之处,他们的相同点是都是线性数据结构,这与树和图不同,而它们的不同之处在于数组是一块连续的内存,而链表可以不是连续内存,链表的节点与节点之间通过指针来联系.
当然,链表也有不同的形态,主要分为三种:单向链表、双向链表、循环链表.
单向链表的节点通常由两个部分构成,一个是节点储存的值val,另一个就是节点的指针next.
链表与数组类似,也可以进行查找、插入、删除、读取等操作,但是由于链表与数组的特性不同,导致不同操作的复杂度也不同.
单向链表的查找操作通常是这样的:
链表的查找性能与数组一样,都是时间复杂度为O(n).
链表与数组最大的不同就在于删除、插入的性能优势,由于链表是非连续的内存,所以不用像数组一样在插入、删除操作的时候需要进行大面积的成员位移,比如在a、b节点之间插入一个新节点c,链表只需要:
这个插入操作仅仅需要移动一下指针即可,插入、删除的时间复杂度只有O(1).
链表的插入操作如下:
链表的删除操作如下:
链表相比之下也有劣势,那就是读取操作远不如数组,数组的读取操作之所以高效,是因为它是一块连续内存,数组的读取可以通过寻址公式快速定位,而链表由于非连续内存,所以必须通过指针一个一个节点遍历.
比如,对于一个数组,我们要读取第三个成员,我们仅需要arr[2]就能快速获取成员,而链表则需要从头部节点进入,在通过指针进入后续节点才能读取.
由于双向链表的存在,单向链表的应用场景比较少,因为很多场景双向链表可以更出色地完成.
但是单向链表并非无用武之地,在以下场景中依然会有单向链表的身影:
我们上文已经提到,单向链表的应用场景并不多,而真正在生产环境中被广泛运用的正是双向链表.
双向链表与单向链表相比有何特殊之处?
我们看到双向链表多了一个新的指针prev指向节点的前一个节点,当然由于多了一个指针,所以双向链表要更占内存.
别小看双向链表多了一个前置指针,在很多场景里由于多了这个指针,它的效率更高,也更加实用.
比如编辑器的「undo/redo」操作,双向链表就更加适用,由于拥有前后指针,用户可以自由得进行前后操作,如果这个是一个单向链表,那么用户需要遍历链表这时的时间复杂度是O(n).
真正生产级应用中的编辑器采用的数据结构和设计模式更加复杂,比如Word就是采用Piece Table数据结构加上Command queue模式实现「undo/redo」的,不过这是后话了.
循环链表,顾名思义,他就是将单向链表的尾部指针指向了链表头节点:
循环链表一个应用场景就是操作系统的分时问题,比如有一台计算机,但是有多个用户使用,CPU要处理多个用户的请求很可能会出现抢占资源的情况,这个时候计算机会采取分时策略来保证每个用户的使用体验.
每个用户都可以看成循环链表上的节点,CPU会给每个节点分配一定的处理时间,在一定的处理时间后进入下一个节点,然后无限循环,这样可以保证每个用户的体验,不会出现一个用户抢占CPU而导致其他用户无法响应的情况.
当然,约瑟夫环的问题是单向循环链表的代表性应用,感兴趣的可以深入了解下.
当然如果是双向链表首尾相接呢?这就是双向循环链表.
在Node中有一类场景,没有查询,但是却有大量的插入和删除,这就是Timer模块。
几乎所有的网络I/O请求,都会提供timeout操作控制socket的超时状况,这里就会大量使用到setTimeout,并且这些timeout定时器,绝大部分都是用不到的(数据按时正常响应),那么又会有响应的大量clearTimeout操作,因此node采用了双向循环链表来提高Timer模块的性能,至于其中的细节就不再赘述了.
插入!
TimersList <-----> timer1 <-----> timer2 <-----> timer4 <-----> timer3 <-----> ......
1000ms后执行 1050ms后执行 1100ms后执行 1200ms后执行
至此,我们对链表这个数据结构有了一定的认知,由于其非连续内存的特性导致链表非常适用于频繁插入、删除的场景,而不见长于读取场景,这跟数组的特性恰好形成互补,所以现在也可以回到题目中的问题了,链表的特性与数组互补,各有所长,而且链表由于指针的存在可以形成环形链表,在特定场景也非常有用,因此链表的存在是很有必要的。
那么,现在有一个非常常见的一个面试向的思考题:
我们平时在用的微信小程序会有最近使用的功能,时间最近的在最上面,按照时间顺序往后排,当用过的小程序大于一定数量后,最不常用的小程序就不会出现了,你会如何设计这个算法?
本文于2019年首发于掘金
我们在学习 React 的过程中经常会碰到一个概念,那就是数据的不可变性(immutable),不可变数据是函数式编程里的重要概念,因为可变数据在提供方便的时候会带了很多棘手的副作用,那么我们应该如何处理这些棘手的问题,如何实现不可变数据呢?
我们应该都知道的基本知识,在JavaScript中分为原始类型和引用类型.
JavaScript原始类型:Undefined、Null、Boolean、Number、String、Symbol
JavaScript引用类型:Object
同时引用类型在使用过程中经常会产生副作用.
const person = {player: {name: 'Messi'}};
const person1 = person;
console.log(person, person1);
//[ { name: 'Messi' } ] [ { name: 'Messi' } ]
person.player.name = 'Kane';
console.log(person, person1);
//[ { name: 'Kane' } ] [ { name: 'Kane' } ]我们看到,当修改了person中属性后,person1的属性值也随之改变,因为这两个变量的指针指向了同一块内存,当一个变量被修改后,内存随之变动,而另一个变量由于指向同一块内存,自然也随之变化了,这就是引用类型的副作用.
可是绝大多数情况下我们并不希望person1的属性值也发生改变,我们应该如何解决这个问题?
在ES6中我们可以用Object.assign 或者 ...对引用类型进行浅复制.
const person = [{name: 'Messi'}];
const person1 = person.map(item =>
({...item, name: 'Kane'})
)
console.log(person, person1);
// [{name: 'Messi'}] [{name: 'Kane'}]person的确被成功复制了,但是之所以我们称它为浅复制,是因为这种复制只能复制一层,在多层嵌套的情况下依然会出现副作用.
const person = [{name: 'Messi', info: {age: 30}}];
const person1 = person.map(item =>
({...item, name: 'Kane'})
)
console.log(person[0].info === person1[0].info); // true上述代码表明当利用浅复制产生新的person1后其中嵌套的info属性依然与原始的person的info属性指向同一个堆内存对象,这种情况依然会产生副作用.
我们可以发现浅复制虽然可以解决浅层嵌套的问题,但是依然对多层嵌套的引用类型无能为力.
既然浅复制(克隆)无法解决这个问题,我们自然会想到利用深克隆的方法来实现多层嵌套复制的问题.
我们之前已经讨论过如何实现一个深克隆,在此我们不做深究,深克隆毫无疑问可以解决引用类型产生的副作用.
实现一个在生产环境中可以用的深克隆是非常繁琐的事情,我们不仅要考虑到_正则_、Symbol、_Date_等特殊类型,还要考虑到_原型链_和_循环引用_的处理,当然我们可以选择使用成熟的开源库进行深克隆处理.
可是问题就在于我们实现一次深克隆的开销太昂贵了,如何实现深克隆中我们展示了一个勉强可以使用的深克隆函数已经处理了相当多的逻辑,如果我们每使用一次深克隆就需要一次如此昂贵的开销,程序的性能是会大打折扣.
const person = [{name: 'Messi', info: {age: 30}}];
for (let i=0; i< 100000;i++) {
person.push({name: 'Messi', info: {age: 30}});
}
console.time('clone');
const person1 = person.map(item =>
({...item, name: 'Kane'})
)
console.timeEnd('clone');
console.time('cloneDeep');
const person2 = lodash.cloneDeep(person)
console.timeEnd('cloneDeep');
// clone : 105.520ms
// cloneDeep : 372.839ms我们可以看到深克隆的的性能相比于浅克隆大打折扣,但是浅克隆又不能从根本上杜绝引用类型的副作用,我们需要找到一个兼具性能和效果的方案.
immutable.js是正是兼顾了使用效果和性能的解决方案
原理如下:
Immutable实现的原理是Persistent Data Structur(持久化数据结构),对Immutable对象的任何修改或添加删除操作都会返回一个新的Immutable对象, 同时使用旧数据创建新数据时,要保证旧数据同时可用且不变。
为了避免像 deepCopy一样 把所有节点都复制一遍带来的性能损耗,Immutable 使用了 Structural Sharing(结构共享),即如果对象树中一个节点发生变化,只修改这个节点和受它影响的父节点,其它节点则进行共享。请看下面动画
我们看到动画中右侧的子节点由于发生变化,相关父节点进行了重建,但是左侧树没有发生变化,最后形成的新的树依然复用了左侧树的节点,看起来真的是无懈可击.
immutable.js 的实现方法确实很高明,毕竟是花了 Facebook 工程师三年打造的全新数据结构,相比于深克隆,带来的 cpu 消耗很低,同时内存占用也很小.
但是 immutable.js 就没有弊端吗?
在使用过程中,immutable.js也存在很多问题.
我目前碰到的坑有:
toJS()转化为原生数据结构再进行调试,这让人很崩溃.toJS转化为正常的 js 数据结构,这个时候新旧 props 就永远不会相等了,就导致了大量重复渲染,严重降低性能.immutable.js在某种程度上来说,更适合于对数据可靠度要求颇高的大型前端应用(需要引入庞大的包、额外的学习成本甚至类型检测工具对付immutable.js与原生js类似的api),中小型的项目引入immutable.js的代价有点高昂了,可是我们有时候不得不利用immutable的特性,那么如何保证性能和效果的情况下减少immutable相关库的体积和提高api友好度呢?
我们的原则已经提到了,要尽可能得减小体积,这就注定了我们不能像immutable.js那样自己定义各种数据结构,而且要减小使用成本,所以要用原生js的方式,而不是自定义数据结构中的api.
这个时候需要我们思考如何实现上述要求呢?
我们要通过原生js的api来实现immutable,很显然我们需要对引用对象的set、get、delete等一系列操作的特性进行修改,这就需要defineProperty或者Proxy进行元编程.
我们就以Proxy为例来进行编码,当然,我们需要事先了解一下Proxy的使用方法.
我们先定义一个目标对象
const target = {name: 'Messi', age: 29};我们如果想每访问一次这个对象的age属性,age属性的值就增加1.
const target = {name: 'Messi', age: 29};
const handler = {
get: function(target, key, receiver) {
console.log(`getting ${key}!`);
if (key === 'age') {
const age = Reflect.get(target, key, receiver)
Reflect.set(target, key, age+1, receiver);
return age+1
}
return Reflect.get(target, key, receiver);
}
};
const a = new Proxy(target, handler);
console.log(a.age, a.age);
//getting age!
//getting age!
//30 31是的Proxy就像一个代理器,当有人对目标对象进行处理(set、has、get等等操作)的时候它会拦截操作,并用我们提供的代码进行处理,此时Proxy相当于一个中介或者叫代理人,当然Proxy的名字也说明了这一点,它经常被用于代理模式中,例如字段验证、缓存代理、访问控制等等。
我们的目的很简单,就是利用Proxy的特性,在外部对目标对象进行修改的时候来进行额外操作保证数据的不可变。
在外部对目标对象进行修改的时候,我们可以将被修改的引用的那部分进行拷贝,这样既能保证效率又能保证可靠性.
function createState(target) {
this.modified = false; // 是否被修改
this.target = target; // 目标对象
this.copy = undefined; // 拷贝的对象
}createState.prototype = {
// 对于get操作,如果目标对象没有被修改直接返回原对象,否则返回拷贝对象
get: function(key) {
if (!this.modified) return this.target[key];
return this.copy[key];
},
// 对于set操作,如果目标对象没被修改那么进行修改操作,否则修改拷贝对象
set: function(key, value) {
if (!this.modified) this.markChanged();
return (this.copy[key] = value);
},
// 标记状态为已修改,并拷贝
markChanged: function() {
if (!this.modified) {
this.modified = true;
this.copy = shallowCopy(this.target);
}
},
};
// 拷贝函数
function shallowCopy(value) {
if (Array.isArray(value)) return value.slice();
if (value.__proto__ === undefined)
return Object.assign(Object.create(null), value);
return Object.assign({}, value);
}createState接受目标对象state生成对象store,然后我们就可以用Proxy代理store,producer是外部传进来的操作函数,当producer对代理对象进行操作的时候我们就可以通过事先设定好的handler进行代理操作了.const PROXY_STATE = Symbol('proxy-state');
const handler = {
get(target, key) {
if (key === PROXY_STATE) return target;
return target.get(key);
},
set(target, key, value) {
return target.set(key, value);
},
};
// 接受一个目标对象和一个操作目标对象的函数
function produce(state, producer) {
const store = new createState(state);
const proxy = new Proxy(store, handler);
producer(proxy);
const newState = proxy[PROXY_STATE];
if (newState.modified) return newState.copy;
return newState.target;
}producer并没有干扰到之前的目标函数.const baseState = [
{
todo: 'Learn typescript',
done: true,
},
{
todo: 'Try immer',
done: false,
},
];
const nextState = produce(baseState, draftState => {
draftState.push({todo: 'Tweet about it', done: false});
draftState[1].done = true;
});
console.log(baseState, nextState);
/*
[ { todo: 'Learn typescript', done: true },
{ todo: 'Try immer', done: true } ]
[ { todo: 'Learn typescript', done: true ,
{ todo: 'Try immer', done: true },
{ todo: 'Tweet about it', done: false } ]
*/没问题,我们成功实现了轻量级的 immutable.js,在保证 api友好的同时,做到了比 immutable.js 更小的体积和不错的性能.
实际上这个实现就是不可变数据库immer
的迷你版,我们阉割了大量的代码才缩小到了60行左右来实现这个基本功能,实际上除了get/set操作,这个库本身有has/getOwnPropertyDescriptor/deleteProperty等一系列的实现,我们由于篇幅的原因很多代码也十分粗糙,深入了解可以移步完整源码.
在不可变数据的技术选型上,我查阅了很多资料,也进行过实践,immutable.js 的确十分难用,尽管我用他开发过一个完整的项目,因为任何来源的数据都需要通过 fromJS()将他转化为 Immutable 本身的结构,而我们在组件内用数据驱动视图的时候,组件又不能直接用 Immutable 的数据结构,这个时候又需要进行数据转换,只要你的项目沾染上了 Immutable.js 就不得不将整个项目全部的数据结构用Immutable.js 重构(否则就是到处可见的 fromjs 和 tojs 转换,一方面影响性能一方面影响代码可读性),这个解决方案的侵入性极强,不建议大家轻易尝试.
本文标题的题目是由其他问题延伸而来,面试中面试官的常用套路,揪住一个问题一直深挖,在产生这个问题之前一定是这个问题.
React/Vue不同组件之间是怎么通信的?
Vue
$dispatch(已经废除)和$broadcast(已经废除)React
我们大体上都会有以上回答,接下来很可能会问到如何实现Event(Bus),因为这个东西太重要了,几乎所有的模块通信都是基于类似的模式,包括安卓开发中的Event Bus,Node.js中的Event模块(Node中几乎所有的模块都依赖于Event,包括不限于http、stream、buffer、fs等).
我们仿照Node中Event API实现一个简单的Event库,他是发布订阅模式的典型应用.
提前声明: 我们没有对传入的参数进行及时判断而规避错误,仅仅对核心方法进行了实现.
我们利用ES6的class关键字对Event进行初始化,包括Event的事件清单和监听者上限.
我们选择了Map作为储存事件的结构,因为作为键值对的储存方式Map比一般对象更加适合,我们操作起来也更加简洁,可以先看一下Map的基本用法与特点.
class EventEmeitter {
constructor() {
this._events = this._events || new Map(); // 储存事件/回调键值对
this._maxListeners = this._maxListeners || 10; // 设立监听上限
}
}触发监听函数我们可以用apply与call两种方法,在少数参数时call的性能更好,多个参数时apply性能更好,当年Node的Event模块就在三个参数以下用call否则用apply.
当然当Node全面拥抱ES6+之后,相应的call/apply操作用Reflect新关键字重写了,但是我们不想写的那么复杂,就做了一个简化版.
// 触发名为type的事件
EventEmeitter.prototype.emit = function(type, ...args) {
let handler;
// 从储存事件键值对的this._events中获取对应事件回调函数
handler = this._events.get(type);
if (args.length > 0) {
handler.apply(this, args);
} else {
handler.call(this);
}
return true;
};
// 监听名为type的事件
EventEmeitter.prototype.addListener = function(type, fn) {
// 将type事件以及对应的fn函数放入this._events中储存
if (!this._events.get(type)) {
this._events.set(type, fn);
}
};我们实现了触发事件的emit方法和监听事件的addListener方法,至此我们就可以进行简单的实践了.
// 实例化
const emitter = new EventEmeitter();
// 监听一个名为arson的事件对应一个回调函数
emitter.addListener('arson', man => {
console.log(`expel ${man}`);
});
// 我们触发arson事件,发现回调成功执行
emitter.emit('arson', 'low-end'); // expel low-end似乎不错,我们实现了基本的触发/监听,但是如果有多个监听者呢?
// 重复监听同一个事件名
emitter.addListener('arson', man => {
console.log(`expel ${man}`);
});
emitter.addListener('arson', man => {
console.log(`save ${man}`);
});
emitter.emit('arson', 'low-end'); // expel low-end是的,只会触发第一个,因此我们需要进行改造.
我们的addListener实现方法还不够健全,在绑定第一个监听者之后,我们就无法对后续监听者进行绑定了,因此我们需要将后续监听者与第一个监听者函数放到一个数组里.
// 触发名为type的事件
EventEmeitter.prototype.emit = function(type, ...args) {
let handler;
handler = this._events.get(type);
if (Array.isArray(handler)) {
// 如果是一个数组说明有多个监听者,需要依次此触发里面的函数
for (let i = 0; i < handler.length; i++) {
if (args.length > 0) {
handler[i].apply(this, args);
} else {
handler[i].call(this);
}
}
} else { // 单个函数的情况我们直接触发即可
if (args.length > 0) {
handler.apply(this, args);
} else {
handler.call(this);
}
}
return true;
};
// 监听名为type的事件
EventEmeitter.prototype.addListener = function(type, fn) {
const handler = this._events.get(type); // 获取对应事件名称的函数清单
if (!handler) {
this._events.set(type, fn);
} else if (handler && typeof handler === 'function') {
// 如果handler是函数说明只有一个监听者
this._events.set(type, [handler, fn]); // 多个监听者我们需要用数组储存
} else {
handler.push(fn); // 已经有多个监听者,那么直接往数组里push函数即可
}
};是的,从此以后可以愉快的触发多个监听者的函数了.
// 监听同一个事件名
emitter.addListener('arson', man => {
console.log(`expel ${man}`);
});
emitter.addListener('arson', man => {
console.log(`save ${man}`);
});
emitter.addListener('arson', man => {
console.log(`kill ${man}`);
});
// 触发事件
emitter.emit('arson', 'low-end');
//expel low-end
//save low-end
//kill low-end我们会用removeListener函数移除监听函数,但是匿名函数是无法移除的.
EventEmeitter.prototype.removeListener = function(type, fn) {
const handler = this._events.get(type); // 获取对应事件名称的函数清单
// 如果是函数,说明只被监听了一次
if (handler && typeof handler === 'function') {
this._events.delete(type, fn);
} else {
let postion;
// 如果handler是数组,说明被监听多次要找到对应的函数
for (let i = 0; i < handler.length; i++) {
if (handler[i] === fn) {
postion = i;
} else {
postion = -1;
}
}
// 如果找到匹配的函数,从数组中清除
if (postion !== -1) {
// 找到数组对应的位置,直接清除此回调
handler.splice(postion, 1);
// 如果清除后只有一个函数,那么取消数组,以函数形式保存
if (handler.length === 1) {
this._events.set(type, handler[0]);
}
} else {
return this;
}
}
};我们已经基本完成了Event最重要的几个方法,也完成了升级改造,可以说一个Event的骨架是被我们开发出来了,但是它仍然有不足和需要补充的地方.
- 鲁棒性不足: 我们没有对参数进行充分的判断,没有完善的报错机制.
- 模拟不够充分: 除了
removeAllListeners这些方法没有实现以外,例如监听时间后会触发newListener事件,我们也没有实现,另外最开始的监听者上限我们也没有利用到.
当然,这在面试中现场写一个Event已经是很够意思了,主要是体现出来对发布-订阅模式的理解,以及针对多个监听状况下的处理,不可能现场撸几百行写一个完整Event.
索性Event库帮我们实现了完整的特性,整个代码量有300多行,很适合阅读,你可以花十分钟的时间通读一下,见识一下完整的Event实现.
本文于2019年首发于掘金
数组几乎可以是所有软件工程师最常用到的数据结构,正是因为如此,很多开发者对其不够重视.
而面试中经常有这样一类问题: 「100万个成员的数组取第一个和最后一个有性能差距吗?为什么?」
除此之外,我们在平时的业务开发中会经常出现数组一把梭的情况,大多数情况下我们都会用数组的形式进行操作,而有读源码习惯的开发者可能会发现,在一些底层库中,我们可能平时用数组的地方,底层库却选择了另外的数据结构,这又是为什么?
希望大家带着以上的问题我们进行讨论.
数组是计算机科学中最基本的数据结构了,绝大多数编程语言都内置了这种数据结构,也是开发者最常见的数据结构.
数组(英语:Array),是由相同类型的元素(element)的集合所组成的数据结构,分配一块连续的内存来存储.
当然,在一些动态语言中例如Python的列表或者JavaScript的数组都可能是非连续性的内存,也可以存储不同类型的元素.
比如我们有如下一个数组:
arr = [1, 2, 3, 4, 5]其在内存中的表现应该是这样的:
我们可以看到,这个数组在内存中是以连续线性的形式储存的,这个连续线性的储存形式既有其优势又有其劣势,只有我们搞清楚优劣才能在以后的开发中更好地使用数组.
一个数据结构通常都有「插入、查找、删除、读取」这四种基本的操作,我们会逐一分析这些操作带来的性能差异.
首先我们要辨析一个概念--性能.
这里的性能并不是绝对意义上速度的快慢,因为不同的设备其硬件基础就会产生巨大的速度差异,这里的性能是我们在算法分析中的「复杂度」概念.
复杂度的概念可以移步算法分析
我们已经知道数组是一段连续储存的内存,当我们要将新元素插入到数组k的位置时呢?这个时候需要将k索引处之后的所有元素往后挪一位,并将k索引的位置插入新元素.
我们看到这个时候需要进行操作的工作量就大多了,通常情况下,插入操作的时间复杂度是O(n).
删除操作其实与插入很类似,同样我要删除数组之内的k索引位置的元素,我们就需要将其删除后,为了保持内存的连续性,需要将k之后的元素通通向前移动一位,这个情况的时间复杂度也是O(n).
比如我们要查找一个数组中是否存在一个为2的元素,那么计算机需要如何操作呢?
如果是人的话,在少量数据的情况下我们自然可以一眼找到是否有2的元素,而计算机不是,计算机需要从索引0开始往下匹配,直到匹配到2的元素为止.
这个查找的过程其实就是我们常见的线性查找,这个时候需要匹配的平均步数与数组的长度n有关,这个时间复杂度同样是O(n).
我们已经强调过数组的特点是拥有相同的数据类型和一块连续的线性内存,那么正是基于以上的特点,数组的读取性能非常的卓越,时间复杂度为O(1),相比于链表、二叉树等数据结构,它的优势非常明显.
那么数组是如何做到这么低的时间复杂度呢?
假设我们的数组内存起始地址为start,而元素类型的长度为size,数组索引为i,那么我们很容易得到这个数组内存地址的寻址公式:
arr[i]_address = start + size * i
比如我们要读取arr[3]的值,那么只需要把3代入寻址公式,计算机就可以一步查询到对应的元素,因此数组读取的时间复杂度只有O(1).
我们已经知道除了「读取」这一个操作以外,其他操作的时间复杂度都在O(n),那么有没有有效的方法进行性能优化呢?
当数组的元素是无序状态下,我们只能用相对不太快的线性查找进行查找,当元素是有序状态(递增或者递减),我们可以用另一种更高效的方法--二分查找.
假设我们有一个有int类型组成的数组,以递增的方式储存:
arr = [1, 2, 3, 4, 5, 6, 7]
如果我们要查找值为6元素,按照线性查找的方式需要根据数组索引从0依次比对,直到碰到索引5的元素.
而二分查找的效率则更高,由于我们知道此数组的元素是有序递增排列的:
4<6,那么此时由于是递增数组,目标值一定在索引3之后的元素中我们可以发现这样的操作每一次对比都能排除当前元素数量一半的元素,整体下来的时间复杂度只有O(log n),这表示此方法的效率极高.
这种高效的方法在数据量越大的情况下,越能体现出来,比如目前有一个10亿成员的数组是有序递增,如果按照线性查找,最差的情况下需要10亿此查找操作才能找到结果,而二分查找仅仅需要7次.
比如有以下数组,我们要将一个新成员orange插入索引1的位置,通常情况下需要后三位成员后移,orange占据索引1的位置.
但是如果我们的需求并不一定需要索引的有序性呢?也就是说,我们可以把数组当成一个集合概念,我们可以在索引1的位置插入orange并在数组的尾部开辟一个新内存将原本在1位置的banana存入新内存中,这样虽然索引的乱了,但是整个操作仅仅需要O(1)的时间复杂度.
arr = ['apple', 'banana', 'grape', 'watermelon']
删除操作需要将产出位置后的元素集体向前移动,这非常消耗性能,尤其是在频繁的删除、插入操作中更是如此。
我们可以先记录下相关的操作,但是并不立即进行删除,当到一定的节点时我们再一次性依据记录对数组进行操作,这样数组成员的反复频繁移动变成了一次性操作,可以很大程度上提高性能.
这个**应用非常广泛:
回到题目中的问题,我们现在已经可以很清楚地知道「100万个成员的数组取第一个和最后一个是否有性能差距」,答案显然是没有,因为数组是一块线性连续的内存,我们可以通过寻址公式一步取出对应的成员,这跟成员的位置没有关系.
最后我们经常在面试或者LeetCode中碰到这样一类问题,即数组中的子元素问题.
比如: 给定一个整数数组,计算长度为 'k' 的连续子数组的最大总和。
什么方法可以尽可能地降低时间复杂度?说出你的思路即可.
本文于2019年首发于掘金
很多时候虽然我们了解了TypeScript相关的基础知识,但是这不足以保证我们在实际项目中可以灵活运用,比如现在绝大部分前端开发者的项目都是依赖于框架的,因此我们需要来讲一下React与TypeScript应该如何结合运用。
如果你仅仅了解了一下TypeScript的基础知识就上手框架会碰到非常多的坑(比如笔者自己),如果你是React开发者一定要看过本文之后再进行实践。
使用TypeScript编写react代码,除了需要typescript这个库之外,还至少需要额外的两个库:
yarn add -D @types/{react,react-dom}可能有人好奇@types开头的这种库是什么?
由于非常多的JavaScript库并没有提供自己关于TypeScript的声明文件,导致TypeScript的使用者无法享受这种库带来的类型,因此社区中就出现了一个项目DefinitelyTyped,他定义了目前市面上绝大多数的JavaScript库的声明,当人们下载JavaScript库相关的@types声明时,就可以享受此库相关的类型定义了。
当然,为了方便我们选择直接用TypeScript官方提供的react启动模板。
create-react-app react-ts-app --scripts-version=react-scripts-ts我们用初始化好了上述模板之后就需要进行正式编写代码了。
无状态组件是一种非常常见的react组件,主要用于展示UI,初始的模板中就有一个logo图,我们就可以把它封装成一个Logo组件。
在JavaScript中我们往往是这样封装组件的:
import * as React from 'react'
export const Logo = props => {
const { logo, className, alt } = props
return (
<img src={logo} className={className} alt={alt} />
)
}但是在TypeScript中会报错:
原因就是我们没有定义props的类型,我们用interface定义一下props的类型,那么是不是这样就行了:
import * as React from 'react'
interface IProps {
logo?: string
className?: string
alt?: string
}
export const Logo = (props: IProps) => {
const { logo, className, alt } = props
return (
<img src={logo} className={className} alt={alt} />
)
}这样做在这个例子中看似没问题,但是当我们要用到children的时候是不是又要去定于children类型?
比如这样:
interface IProps {
logo?: string
className?: string
alt?: string
children?: ReactNode
}
其实有一种更规范更简单的办法,type SFC<P>其中已经定义了children类型。
我们只需要这样使用:
export const Logo: React.SFC<IProps> = props => {
const { logo, className, alt } = props
return (
<img src={logo} className={className} alt={alt} />
)
}
我们现在就可以替换App.tsx中的logo组件,可以看到相关的props都会有代码提示:
如果我们这个组件是业务中的通用组件的话,甚至可以加上注释:
interface IProps {
/**
* logo的地址
*/
logo?: string
className?: string
alt?: string
}
这样在其他同事调用此组件的时候,除了代码提示外甚至会有注释的说明:
现在假设我们开始编写一个Todo应用:
首先需要编写一个todoInput组件:
如果我们按照JavaScript的写法,只要写一个开头就会碰到一堆报错
有状态组件除了props之外还需要state,对于class写法的组件要泛型的支持,即Component<P, S>,因此需要传入传入state和props的类型,这样我们就可以正常使用props和state了。
import * as React from 'react'
interface Props {
handleSubmit: (value: string) => void
}
interface State {
itemText: string
}
export class TodoInput extends React.Component<Props, State> {
constructor(props: Props) {
super(props)
this.state = {
itemText: ''
}
}
}
细心的人会问,这个时候需不需要给Props和State加上Readonly,因为我们的数据都是不可变的,这样会不会更严谨?
其实是不用的,因为React的声明文件已经自动帮我们包装过上述类型了,已经标记为readonly。
如下:
接下来我们需要添加组件方法,大多数情况下这个方法是本组件的私有方法,这个时候需要加入访问控制符private。
private updateValue(value: string) {
this.setState({ itemText: value })
}
接下来也是大家经常会碰到的一个不太好处理的类型,如果我们想取某个组件的ref,那么应该如何操作?
比如我们需要在组件更新完毕之后,使得input组件focus。
首先,我们需要用React.createRef创建一个ref,然后在对应的组件上引入即可。
private inputRef = React.createRef<HTMLInputElement>()
...
<input
ref={this.inputRef}
className="edit"
value={this.state.itemText}
/>
需要注意的是,在createRef这里需要一个泛型,这个泛型就是需要ref组件的类型,因为这个是input组件,所以类型是HTMLInputElement,当然如果是div组件的话那么这个类型就是HTMLDivElement。
再接着讲TodoInput组件,其实此组件也是一个受控组件,当我们改变input的value的时候需要调用this.setState来不断更新状态,这个时候就会用到『事件』类型。
由于React内部的事件其实都是合成事件,也就是说都是经过React处理过的,所以并不原生事件,因此通常情况下我们这个时候需要定义React中的事件类型。
对于input组件onChange中的事件,我们一般是这样声明的:
private updateValue(e: React.ChangeEvent<HTMLInputElement>) {
this.setState({ itemText: e.target.value })
}当我们需要提交表单的时候,需要这样定义事件类型:
private handleSubmit(e: React.FormEvent<HTMLFormElement>) {
e.preventDefault()
if (!this.state.itemText.trim()) {
return
}
this.props.handleSubmit(this.state.itemText)
this.setState({itemText: ''})
}
那么这么多类型的定义,我们怎么记得住呢?遇到其它没见过的事件,难道要去各种搜索才能定义类型吗?其实这里有一个小技巧,当我们在组件中输入事件对应的名称时,会有相关的定义提示,我们只要用这个提示中的类型就可以了。
React中有时候会运用很多默认属性,尤其是在我们编写通用组件的时候,之前我们介绍过一个关于默认属性的小技巧,就是利用class来同时声明类型和创建初始值。
再回到我们这个项目中,假设我们需要通过props来给input组件传递属性,而且需要初始值,我们这个时候完全可以通过class来进行代码简化。
// props.type.ts
interface InputSetting {
placeholder?: string
maxlength?: number
}
export class TodoInputProps {
public handleSubmit: (value: string) => void
public inputSetting?: InputSetting = {
maxlength: 20,
placeholder: '请输入todo',
}
}
再回到TodoInput组件中,我们直接用class作为类型传入组件,同时实例化类,作为默认属性。
用class作为props类型以及生产默认属性实例有以下好处:
这种方法虽然不错,但是之后我们会发现问题了,虽然我们已经声明了默认属性,但是在使用的时候,依然显示inputSetting可能未定义。
在这种情况下有一种最快速的解决办法,就是加!,它的作用就是告诉编译器这里不是undefined,从而避免报错。
如果你觉得这个方法过于粗暴,那么可以选择三目运算符做一个简单的判断:
如果你还觉得这个方法有点繁琐,因为如果这种情况过多,我们需要额外写非常多的条件判断,而更重要的是,我们明明已经声明了值,就不应该再做条件判断了,应该有一种方法让编译器自己推导出这里的类型不是undefined,这就涉及到一些高级类型了。
我们现在需要先声明defaultProps的值:
const todoInputDefaultProps = {
inputSetting: {
maxlength: 20,
placeholder: '请输入todo',
}
}
接着定义组件的props类型
type Props = {
handleSubmit: (value: string) => void
children: React.ReactNode
} & Partial<typeof todoInputDefaultProps>
Partial的作用就是将类型的属性全部变成可选的,也就是下面这种情况:
{
inputSetting?: {
maxlength: number;
placeholder: string;
} | undefined;
}
那么现在我们使用Props是不是就没有问题了?
export class TodoInput extends React.Component<Props, State> {
public static defaultProps = todoInputDefaultProps
...
public render() {
const { itemText } = this.state
const { updateValue, handleSubmit } = this
const { inputSetting } = this.props
return (
<form onSubmit={handleSubmit} >
<input maxLength={inputSetting.maxlength} type='text' value={itemText} onChange={updateValue} />
<button type='submit' >添加todo</button>
</form>
)
}
...
}
我们看到依旧会报错:
其实这个时候我们需要一个函数,将defaultProps中已经声明值的属性从『可选类型』转化为『非可选类型』。
我们先看这么一个函数:
const createPropsGetter = <DP extends object>(defaultProps: DP) => {
return <P extends Partial<DP>>(props: P) => {
type PropsExcludingDefaults = Omit<P, keyof DP>
type RecomposedProps = DP & PropsExcludingDefaults
return (props as any) as RecomposedProps
}
}
这个函数接受一个defaultProps对象,<DP extends object>这里是泛型约束,代表DP这个泛型是个对象,然后返回一个匿名函数。
再看这个匿名函数,此函数也有一个泛型P,这个泛型P也被约束过,即<P extends Partial<DP>>,意思就是这个泛型必须包含可选的DP类型(实际上这个泛型P就是组件传入的Props类型)。
接着我们看类型别名PropsExcludingDefaults,看这个名字你也能猜出来,它的作用其实是剔除Props类型中关于defaultProps的部分,很多人可能不清楚Omit这个高级类型的用法,其实就是一个语法糖:
type Omit<P, keyof DP> = Pick<P, Exclude<keyof P, keyof DP>>而类型别名RecomposedProps则是将默认属性的类型DP与剔除了默认属性的Props类型结合在一起。
其实这个函数只做了一件事,把可选的defaultProps的类型剔除后,加入必选的defaultProps的类型,从而形成一个新的Props类型,这个Props类型中的defaultProps相关属性就变成了必选的。
这个函数可能对于初学者理解上有一定难度,涉及到TypeScript文档中的高级类型,这算是一次综合应用。
完整代码如下:
import * as React from 'react'
interface State {
itemText: string
}
type Props = {
handleSubmit: (value: string) => void
children: React.ReactNode
} & Partial<typeof todoInputDefaultProps>
const todoInputDefaultProps = {
inputSetting: {
maxlength: 20,
placeholder: '请输入todo',
}
}
export const createPropsGetter = <DP extends object>(defaultProps: DP) => {
return <P extends Partial<DP>>(props: P) => {
type PropsExcludingDefaults = Omit<P, keyof DP>
type RecomposedProps = DP & PropsExcludingDefaults
return (props as any) as RecomposedProps
}
}
const getProps = createPropsGetter(todoInputDefaultProps)
export class TodoInput extends React.Component<Props, State> {
public static defaultProps = todoInputDefaultProps
constructor(props: Props) {
super(props)
this.state = {
itemText: ''
}
}
public render() {
const { itemText } = this.state
const { updateValue, handleSubmit } = this
const { inputSetting } = getProps(this.props)
return (
<form onSubmit={handleSubmit} >
<input maxLength={inputSetting.maxlength} type='text' value={itemText} onChange={updateValue} />
<button type='submit' >添加todo</button>
</form>
)
}
private updateValue(e: React.ChangeEvent<HTMLInputElement>) {
this.setState({ itemText: e.target.value })
}
private handleSubmit(e: React.FormEvent<HTMLFormElement>) {
e.preventDefault()
if (!this.state.itemText.trim()) {
return
}
this.props.handleSubmit(this.state.itemText)
this.setState({itemText: ''})
}
}
关于在TypeScript如何使用HOC一直是一个难点,我们在这里就介绍一种比较常规的方法。
我们继续来看TodoInput这个组件,其中我们一直在用inputSetting来自定义input的属性,现在我们需要用一个HOC来包装TodoInput,其作用就是用高阶组件向TodoInput注入props。
我们的高阶函数如下:
import * as hoistNonReactStatics from 'hoist-non-react-statics'
import * as React from 'react'
type InjectedProps = Partial<typeof hocProps>
const hocProps = {
inputSetting: {
maxlength: 30,
placeholder: '请输入待办事项',
}
}
export const withTodoInput = <P extends InjectedProps>(
UnwrappedComponent: React.ComponentType<P>,
) => {
type Props = Omit<P, keyof InjectedProps>
class WithToggleable extends React.Component<Props> {
public static readonly UnwrappedComponent = UnwrappedComponent
public render() {
return (
<UnwrappedComponent
inputSetting={hocProps}
{...this.props as P}
/>
);
}
}
return hoistNonReactStatics(WithToggleable, UnwrappedComponent)
}
如果你搞懂了上一小节的内容,这里应该没有什么难度。
这里我们的P表示传递到HOC的组件的props,React.ComponentType<P> 是 React.FunctionComponent<P> | React.ClassComponent<P>的别名,表示传递到HOC的组件可以是类组件或者是函数组件。
其余的地方Omit as P等都是讲过的内容,读者可以自行理解,我们不再像上一小节那样一行行解释了。
只需要这样使用:
const HOC = withTodoInput<Props>(TodoInput)
我们总结了最常见的几种组件在TypeScript下的编写方式,通过这篇文章你可以解决在React使用TypeScript绝大部分问题了.
本文2018年首发于掘金
双向绑定其实已经是一个老掉牙的问题了,只要涉及到MVVM框架就不得不谈的知识点,但它毕竟是Vue的三要素之一.
Vue三要素
可以实现双向绑定的方法有很多,KnockoutJS基于观察者模式的双向绑定,Ember基于数据模型的双向绑定,Angular基于脏检查的双向绑定,本篇文章我们重点讲面试中常见的基于数据劫持的双向绑定。
常见的基于数据劫持的双向绑定有两种实现,一个是目前Vue在用的Object.defineProperty,另一个是ES2015中新增的Proxy,而Vue的作者宣称将在Vue3.0版本后加入Proxy从而代替Object.defineProperty,通过本文你也可以知道为什么Vue未来会选择Proxy。
严格来讲Proxy应该被称为『代理』而非『劫持』,不过由于作用有很多相似之处,我们在下文中就不再做区分,统一叫『劫持』。
我们可以通过下图清楚看到以上两种方法在双向绑定体系中的关系.
基于数据劫持的当然还有已经凉透的
Object.observe方法,已被废弃。
提前声明: 我们没有对传入的参数进行及时判断而规避错误,仅仅对核心方法进行了实现.
数据劫持比较好理解,通常我们利用Object.defineProperty劫持对象的访问器,在属性值发生变化时我们可以获取变化,从而进行进一步操作。
// 这是将要被劫持的对象
const data = {
name: '',
};
function say(name) {
if (name === '古天乐') {
console.log('给大家推荐一款超好玩的游戏');
} else if (name === '渣渣辉') {
console.log('戏我演过很多,可游戏我只玩贪玩懒月');
} else {
console.log('来做我的兄弟');
}
}
// 遍历对象,对其属性值进行劫持
Object.keys(data).forEach(function(key) {
Object.defineProperty(data, key, {
enumerable: true,
configurable: true,
get: function() {
console.log('get');
},
set: function(newVal) {
// 当属性值发生变化时我们可以进行额外操作
console.log(`大家好,我系${newVal}`);
say(newVal);
},
});
});
data.name = '渣渣辉';
//大家好,我系渣渣辉
//戏我演过很多,可游戏我只玩贪玩懒月目前业界分为两个大的流派,一个是以React为首的单向数据绑定,另一个是以Angular、Vue为主的双向数据绑定。
其实三大框架都是既可以双向绑定也可以单向绑定,比如React可以手动绑定onChange和value实现双向绑定,也可以调用一些双向绑定库,Vue也加入了props这种单向流的api,不过都并非主流卖点。
单向或者双向的优劣不在我们的讨论范围,我们需要讨论一下对比其他双向绑定的实现方法,数据劫持的优势所在。
data.name = '渣渣辉'后直接触发变更,而比如Angular的脏检测则需要显示调用markForCheck(可以用zone.js避免显示调用,不展开),react需要显示调用setState。newVal,因此在这部分不需要额外的diff操作,否则我们只知道数据发生了变化而不知道具体哪些数据变化了,这个时候需要大量diff来找出变化值,这是额外性能损耗。数据劫持是双向绑定各种方案中比较流行的一种,最著名的实现就是Vue。
基于数据劫持的双向绑定离不开Proxy与Object.defineProperty等方法对对象/对象属性的"劫持",我们要实现一个完整的双向绑定需要以下几个要点。
Proxy或Object.defineProperty生成的Observer针对对象/对象的属性进行"劫持",在属性发生变化后通知订阅者Directive(指令),收集指令所依赖的方法和数据,等待数据变化然后进行渲染我们看到,虽然Vue运用了数据劫持,但是依然离不开发布订阅的模式,之所以在系列2做了Event Bus的实现,就是因为我们不管在学习一些框架的原理还是一些流行库(例如Redux、Vuex),基本上都离不开发布订阅模式,而Event模块则是此模式的经典实现,所以如果不熟悉发布订阅模式,建议读一下系列2的文章。
关于Object.defineProperty的文章在网络上已经汗牛充栋,我们不想花过多时间在Object.defineProperty上面,本节我们主要讲解Object.defineProperty的特点,方便接下来与Proxy进行对比。
对
Object.defineProperty还不了解的请阅读文档
两年前就有人写过基于Object.defineProperty实现的文章,想深入理解Object.defineProperty实现的推荐阅读,本文也做了相关参考。
上面我们推荐的文章为比较完整的实现(400行代码),我们在本节只提供一个极简版(20行)和一个简化版(150行)的实现,读者可以循序渐进地阅读。
我们都知道,Object.defineProperty的作用就是劫持一个对象的属性,通常我们对属性的getter和setter方法进行劫持,在对象的属性发生变化时进行特定的操作。
我们就对对象obj的text属性进行劫持,在获取此属性的值时打印'get val',在更改属性值的时候对DOM进行操作,这就是一个极简的双向绑定。
const obj = {};
Object.defineProperty(obj, 'text', {
get: function() {
console.log('get val');
},
set: function(newVal) {
console.log('set val:' + newVal);
document.getElementById('input').value = newVal;
document.getElementById('span').innerHTML = newVal;
}
});
const input = document.getElementById('input');
input.addEventListener('keyup', function(e){
obj.text = e.target.value;
})在线示例 极简版双向绑定 by Iwobi (@xiaomuzhu) on CodePen.
我们很快会发现,这个所谓的双向绑定貌似并没有什么乱用。。。
原因如下:
那么如何解决上述问题?
Vue的操作就是加入了发布订阅模式,结合Object.defineProperty的劫持能力,实现了可用性很高的双向绑定。
首先,我们以发布订阅的角度看我们第一部分写的那一坨代码,会发现它的监听、发布和订阅都是写在一起的,我们首先要做的就是解耦。
我们先实现一个订阅发布中心,即消息管理员(Dep),它负责储存订阅者和消息的分发,不管是订阅者还是发布者都需要依赖于它。
let uid = 0;
// 用于储存订阅者并发布消息
class Dep {
constructor() {
// 设置id,用于区分新Watcher和只改变属性值后新产生的Watcher
this.id = uid++;
// 储存订阅者的数组
this.subs = [];
}
// 触发target上的Watcher中的addDep方法,参数为dep的实例本身
depend() {
Dep.target.addDep(this);
}
// 添加订阅者
addSub(sub) {
this.subs.push(sub);
}
notify() {
// 通知所有的订阅者(Watcher),触发订阅者的相应逻辑处理
this.subs.forEach(sub => sub.update());
}
}
// 为Dep类设置一个静态属性,默认为null,工作时指向当前的Watcher
Dep.target = null;现在我们需要实现监听者(Observer),用于监听属性值的变化。
// 监听者,监听对象属性值的变化
class Observer {
constructor(value) {
this.value = value;
this.walk(value);
}
// 遍历属性值并监听
walk(value) {
Object.keys(value).forEach(key => this.convert(key, value[key]));
}
// 执行监听的具体方法
convert(key, val) {
defineReactive(this.value, key, val);
}
}
function defineReactive(obj, key, val) {
const dep = new Dep();
// 给当前属性的值添加监听
let chlidOb = observe(val);
Object.defineProperty(obj, key, {
enumerable: true,
configurable: true,
get: () => {
// 如果Dep类存在target属性,将其添加到dep实例的subs数组中
// target指向一个Watcher实例,每个Watcher都是一个订阅者
// Watcher实例在实例化过程中,会读取data中的某个属性,从而触发当前get方法
if (Dep.target) {
dep.depend();
}
return val;
},
set: newVal => {
if (val === newVal) return;
val = newVal;
// 对新值进行监听
chlidOb = observe(newVal);
// 通知所有订阅者,数值被改变了
dep.notify();
},
});
}
function observe(value) {
// 当值不存在,或者不是复杂数据类型时,不再需要继续深入监听
if (!value || typeof value !== 'object') {
return;
}
return new Observer(value);
}那么接下来就简单了,我们需要实现一个订阅者(Watcher)。
class Watcher {
constructor(vm, expOrFn, cb) {
this.depIds = {}; // hash储存订阅者的id,避免重复的订阅者
this.vm = vm; // 被订阅的数据一定来自于当前Vue实例
this.cb = cb; // 当数据更新时想要做的事情
this.expOrFn = expOrFn; // 被订阅的数据
this.val = this.get(); // 维护更新之前的数据
}
// 对外暴露的接口,用于在订阅的数据被更新时,由订阅者管理员(Dep)调用
update() {
this.run();
}
addDep(dep) {
// 如果在depIds的hash中没有当前的id,可以判断是新Watcher,因此可以添加到dep的数组中储存
// 此判断是避免同id的Watcher被多次储存
if (!this.depIds.hasOwnProperty(dep.id)) {
dep.addSub(this);
this.depIds[dep.id] = dep;
}
}
run() {
const val = this.get();
console.log(val);
if (val !== this.val) {
this.val = val;
this.cb.call(this.vm, val);
}
}
get() {
// 当前订阅者(Watcher)读取被订阅数据的最新更新后的值时,通知订阅者管理员收集当前订阅者
Dep.target = this;
const val = this.vm._data[this.expOrFn];
// 置空,用于下一个Watcher使用
Dep.target = null;
return val;
}
}那么我们最后完成Vue,将上述方法挂载在Vue上。
class Vue {
constructor(options = {}) {
// 简化了$options的处理
this.$options = options;
// 简化了对data的处理
let data = (this._data = this.$options.data);
// 将所有data最外层属性代理到Vue实例上
Object.keys(data).forEach(key => this._proxy(key));
// 监听数据
observe(data);
}
// 对外暴露调用订阅者的接口,内部主要在指令中使用订阅者
$watch(expOrFn, cb) {
new Watcher(this, expOrFn, cb);
}
_proxy(key) {
Object.defineProperty(this, key, {
configurable: true,
enumerable: true,
get: () => this._data[key],
set: val => {
this._data[key] = val;
},
});
}
}看下效果:
在线示例 双向绑定实现---无漏洞版 by Iwobi (@xiaomuzhu) on CodePen.
至此,一个简单的双向绑定算是被我们实现了。
其实我们升级版的双向绑定依然存在漏洞,比如我们将属性值改为数组。
let demo = new Vue({
data: {
list: [1],
},
});
const list = document.getElementById('list');
const btn = document.getElementById('btn');
btn.addEventListener('click', function() {
demo.list.push(1);
});
const render = arr => {
const fragment = document.createDocumentFragment();
for (let i = 0; i < arr.length; i++) {
const li = document.createElement('li');
li.textContent = arr[i];
fragment.appendChild(li);
}
list.appendChild(fragment);
};
// 监听数组,每次数组变化则触发渲染函数,然而...无法监听
demo.$watch('list', list => render(list));
setTimeout(
function() {
alert(demo.list);
},
5000,
);在线示例 双向绑定-数组漏洞 by Iwobi (@xiaomuzhu) on CodePen.
是的,Object.defineProperty的第一个缺陷,无法监听数组变化。
然而Vue的文档提到了Vue是可以检测到数组变化的,但是只有以下八种方法,vm.items[indexOfItem] = newValue这种是无法检测的。
push()
pop()
shift()
unshift()
splice()
sort()
reverse()
其实作者在这里用了一些奇技淫巧,把无法监听数组的情况hack掉了,以下是方法示例。
const aryMethods = ['push', 'pop', 'shift', 'unshift', 'splice', 'sort', 'reverse'];
const arrayAugmentations = [];
aryMethods.forEach((method)=> {
// 这里是原生Array的原型方法
let original = Array.prototype[method];
// 将push, pop等封装好的方法定义在对象arrayAugmentations的属性上
// 注意:是属性而非原型属性
arrayAugmentations[method] = function () {
console.log('我被改变啦!');
// 调用对应的原生方法并返回结果
return original.apply(this, arguments);
};
});
let list = ['a', 'b', 'c'];
// 将我们要监听的数组的原型指针指向上面定义的空数组对象
// 别忘了这个空数组的属性上定义了我们封装好的push等方法
list.__proto__ = arrayAugmentations;
list.push('d'); // 我被改变啦! 4
// 这里的list2没有被重新定义原型指针,所以就正常输出
let list2 = ['a', 'b', 'c'];
list2.push('d'); // 4由于只针对了八种方法进行了hack,所以其他数组的属性也是检测不到的,其中的坑很多,可以阅读上面提到的文档。
我们应该注意到在上文中的实现里,我们多次用遍历方法遍历对象的属性,这就引出了Object.defineProperty的第二个缺陷,只能劫持对象的属性,因此我们需要对每个对象的每个属性进行遍历,如果属性值也是对象那么需要深度遍历,显然能劫持一个完整的对象是更好的选择。
Object.keys(value).forEach(key => this.convert(key, value[key]));Proxy在ES2015规范中被正式发布,它在目标对象之前架设一层“拦截”,外界对该对象的访问,都必须先通过这层拦截,因此提供了一种机制,可以对外界的访问进行过滤和改写,我们可以这样认为,Proxy是Object.defineProperty的全方位加强版,具体的文档可以查看此处;
我们还是以上文中用Object.defineProperty实现的极简版双向绑定为例,用Proxy进行改写。
const input = document.getElementById('input');
const p = document.getElementById('p');
const obj = {};
const newObj = new Proxy(obj, {
get: function(target, key, receiver) {
console.log(`getting ${key}!`);
return Reflect.get(target, key, receiver);
},
set: function(target, key, value, receiver) {
console.log(target, key, value, receiver);
if (key === 'text') {
input.value = value;
p.innerHTML = value;
}
return Reflect.set(target, key, value, receiver);
},
});
input.addEventListener('keyup', function(e) {
newObj.text = e.target.value;
});在线示例 Proxy版 by Iwobi (@xiaomuzhu) on CodePen.
我们可以看到,Proxy直接可以劫持整个对象,并返回一个新对象,不管是操作便利程度还是底层功能上都远强于Object.defineProperty。
当我们对数组进行操作(push、shift、splice等)时,会触发对应的方法名称和length的变化,我们可以借此进行操作,以上文中Object.defineProperty无法生效的列表渲染为例。
const list = document.getElementById('list');
const btn = document.getElementById('btn');
// 渲染列表
const Render = {
// 初始化
init: function(arr) {
const fragment = document.createDocumentFragment();
for (let i = 0; i < arr.length; i++) {
const li = document.createElement('li');
li.textContent = arr[i];
fragment.appendChild(li);
}
list.appendChild(fragment);
},
// 我们只考虑了增加的情况,仅作为示例
change: function(val) {
const li = document.createElement('li');
li.textContent = val;
list.appendChild(li);
},
};
// 初始数组
const arr = [1, 2, 3, 4];
// 监听数组
const newArr = new Proxy(arr, {
get: function(target, key, receiver) {
console.log(key);
return Reflect.get(target, key, receiver);
},
set: function(target, key, value, receiver) {
console.log(target, key, value, receiver);
if (key !== 'length') {
Render.change(value);
}
return Reflect.set(target, key, value, receiver);
},
});
// 初始化
window.onload = function() {
Render.init(arr);
}
// push数字
btn.addEventListener('click', function() {
newArr.push(6);
});在线示例 Proxy列表渲染 by Iwobi (@xiaomuzhu) on CodePen.
很显然,Proxy不需要那么多hack(即使hack也无法完美实现监听)就可以无压力监听数组的变化,我们都知道,标准永远优先于hack。
Proxy有多达13种拦截方法,不限于apply、ownKeys、deleteProperty、has等等是Object.defineProperty不具备的。
Proxy返回的是一个新对象,我们可以只操作新的对象达到目的,而Object.defineProperty只能遍历对象属性直接修改。
Proxy作为新标准将受到浏览器厂商重点持续的性能优化,也就是传说中的新标准的性能红利。
当然,Proxy的劣势就是兼容性问题,而且无法用polyfill磨平,因此Vue的作者才声明需要等到下个大版本(3.0)才能用Proxy重写。
本文于2019年首发于掘金
2019年下半年即将到来,上半年狂风骤雨般的裁员浪潮让每一位从业者背脊发凉,在经历了五六年黄金发展期之后,前端开发这个行业似乎也进入了转折点。
我一边听开发者在网络上抱怨工作难找,前端开发早已经饱和了,又在另一边听大厂的朋友们抱怨,招了很久的人,四处出击却填不满HC,前端人才市场就是这么充满了矛盾与反常。
其实仔细想想,出现上述的情况很容易理解,实际上前端开发单纯从数量上已经饱和了,所以大量的初级前端工程师找不到活干,但是从另一方面,高级前端工程师依然是凤毛麟角,高级岗的HC永远是不饱和的。
前不久民工叔发的动态:
目前前端人员的分布是金字塔形的,而且是底部比较长的金字塔形状:
所以进阶是大部分前端开发必须要面对的事情,现在已经不是能写几个页面就能找到工作的时代了,只有往上进阶才能保持职业竞争力,否则我们谁都不能保证下次裁员潮来临的时候,我们会不会成为沙滩上裸泳的人。
前端社区是非常活跃的社区,几乎每过一段时间都会有新的技术或者新的开发方式变成了热点,因此前端开发者才会有了『学不动了』的梗,以及毕竟丢人的Deno留言事件。
以我自己为例,因为想自己开发一个APP,所以面临技术选型,也面临将来要投入大量时间选择学习的技术,摆在我面前的有三个选项:
到底选择哪一个技术既能满足开发APP的需求,又值得投入时间进行学习呢?
如果你去知乎或者其他技术类的社区去问,绝大多数的回答是Flutter(虽然从回答来看很多答主似乎都没用过Flutter),Flutter作为正式发布才刚刚半年的新技术已经席卷了整个大前端圈子,成为了当之无愧的第一热点,真是佩服谷歌的布道能力。
关于Flutter的事情我思考了很久,也用它快速开发了一个demo,它有很吸引人的地方:
这门技术确实很吸引人,加上社区各个会Flutter不会Flutter的人义务宣传下,我甚至快决定好好学习一下Flutter了。
但是,大家有没有想过,通过学习Flutter,你的技术就提升了吗?
很多人第一反应是『当然了,学了一门新技术,学了一门新语言,难道技术不是提升了吗?』。
但是我觉得并没有,我其实依然在原地打转,一个Java开发者学会了用Ruby增删改查并不能代表能力提高了,一个前端开发者用RN或者Flutter开发了简单的APP也不能说明水平提高了,只不过是用另一种语言再写了一遍UI而已,会用三种框架写页面,并不是什么高技术含量的事情,会三种不如深入一种。
Flutter跟RN一样,想玩得转必须深入到原生开发中,因为这两个技术都不是真正的跨平台,他们仅仅是UI跨平台,如果你仅仅学一个Flutter写写UI,意义不大,也不存在能力的提升。
我们或者再功利一点地思考,就算你学会了用Flutter写UI又怎么样呢?你们公司内部有Flutter项目吗?即使有轮得到你施展拳脚吗?毕竟你没有原生平台的知识储备,仅仅写个UI又有什么呢?
其实,这个例子说了这么久,我只是在说两件事情:
我以这种思考模式仔细研究了近一段时间热点的技术,有几门技术我可以比较确信在未来会在前端开发领域大展拳脚。
我从2017年就开始使用TypeScript了,可以说正当时,在使用过程中踩了很多坑,也总结出很多经验,知乎上的问题『你为什么不使用TypeScript?』中的最高票回答就是笔者本人。
在2019年的年中,我可以非常确信TypeScript会在一年内大规模流行,怎么定义大规模流行?
超过30%基于前端框架的新项目会以TypeScript为主要语言开发。
原因我总结了三点。
大量重量级前端开源项目采用TypeScript开发,包括不限于:Angular、VScode、Vue3.0、Rxjs、TypeScript(对,它自举)、Mobx、deno、Antd,而且这个趋势越来越明显,包括Facebook自家的Jest也宣布从flowType转向TypeScript。
这些重量级的开源项目有非常强得带动作用,我不止一次见过有的前端开发者说,为了看懂Antd的源码,特地学了TypeScript。
可以说,TypeScript的开源生态已经非常完善了,公司完全可以放心大胆得进行TypeScript化开发。
请问前端开发中,引起错误的最多的三种报错是什么?
你不会想到,是:
居然是三种非常非常低级的错误,原因就是JavaScript是动态语言,只有运行时才会报错,这些低级错误在类型定义完整的TypeScript中不会发生,这就是TypeScript的优势之一,编码时就能规避大量的类型错误。
TypeScript完整定义接口,可以减少非常多的沟通成本和文档编写成本,最好的文档就是类型,除此之外,有了TypeScript的支持前后端的协作也会非常方便,有了TypeScript我们完全可以开发一个工具把后端Java Swagger的信息映射到TypeScript中,方便我们取数并最大程度规避错误。
现在已经有了这么一款前端取数库pont.
总而言之,TypeScript解决了前端的两大问题,规避错误和提升效率。
阿里 MidwayJs Team的负责人在GMTC上就说到过『 TypeScript,来帮助我们解决这些质量,习惯,方法上的问题,就拿 midway 团队来说,自从使用了 TypeScript,质量提升的非常明显,平常需要测试很久的代码,几乎不会出现低级的问题,反而暴露出的大多都是逻辑问题。』并提到『而今年,我们希望新应用全量使用 TS。』
Vue3.0将在下半年的发布,虽然尤雨溪确认Vue3.0支持JavaScript和TypeScript两种语言,但是vue2.x那种残疾级别的支持到现在原生支持TypeScript,势必会引起大量以vue为技术栈的公司进行TypeScript化运动。
届时三大框架都可以完美支持TypeScript,甚至其中有两个是由TypeScript直接开发的,而vue在国内的用户量最多,也最能影响TypeScript在国内的走势。
而据我所知美团、饿了么等一大批vue技术栈的前端团队也已经大量实践了TypeScript,至少在大厂层面,TypeScript已经开始大规模普及了。
图形技术不会在短时间内席卷前端,也永远不可能成为前端的热门技术,但是却是前端开发者进阶必学的技术。
为什么说图形技术不会在前端大火?
要火早就火了,今年年内都要发布webGPU了,绝大部分前端连webgl1.x都搞不清楚,归根到底是技术栈不匹配,前端开发和移动端开发虽然很大一部分工作是实现UI,但是这个实现方式几乎都是调用宿主内置组件,极少有用图形接口画UI的情况。
为什么又说是进阶必备?
图形技术可能是仅有的与前端有密切联系的计算机底层技术了,因为所谓的UI就是靠图形接口调用GPU绘制而成的,这样就意味着掌握图形技术就能更深度地定制UI。
未来的前端UI不仅仅是简单的Input、Table、List等粗颗粒的组件构成的,而是更加多元化、更加细粒度,就拿笔者最近研究的可视化大屏项目来说,它几乎用不到任何传统的前端组件,一部分2D组件是调用Canvas绘图接口,一部分3D组件是靠webgl绘制而成。
今年下半年5G开始在国内大面积铺开,普遍的一个观点是认为5G的到来会让AR、VR等虚拟技术重新焕发生机,这些技术也无一例外不与图形技术相关联,毕竟你总不会认为在AR中绘制一个input组件吧。
从去年开始关注图形技术,我也惊喜的发现跟一些前端专家们的观点不谋而合。
一个是年初奇舞团的leader月影在知乎的回答:
另一个也是年初winter的前端技术预测:
这里的编辑器指的是各种编辑器的总称,例如:代码编辑器(WebIDE)、图形编辑器(在线的3d建模或者ps)、文本编辑器等。
编辑器领域技术不会像TypeScript一样蔓延到几乎所有的前端团队,但是一定是会在局部火起来的技术。
为什么说只会在局部火起来?
这是个非常小众的领域,但是复杂度和重要性却与日俱增,首先绝大部分公司的绝大部分业务场景中对编辑器的需求很小,其次,编辑器的通用性很大,每个网站的具体业务场景的实现千差万别,但是说到用户输入的文本编辑器,那可能用的都是同一款开源软件。
说完了局部,我们在谈谈为什么会火,最重要的一点就是云端开发的普及,大量的开发者服务被移植到云上,包括最近比较火的FaaS、小程序服务等等,云厂商一方面为了给开发者提供更好的服务,比如开发FaaS的调试服务,所以需要定制符合自己业务的webIDE,另一方面也更重要,一个开发者的开发环境轻易是不会变的,webIDE就是这个环境,webIDE就是云厂商开发者争夺战的入口。
另一个原因就是,大规模的团队十分需要将各个团队的能力整合在一起,而整合开发的钥匙就是IDE。
虽然很多公司招编辑器相关的工程师都是挂着前端的Title,但是普通的前端工程师如果没有相关经验,完全拿不下这种场景,这就造成了虽然这是个小众领域,但是人才却很缺失的情况。
下图为圆心在GMTC上展示的阿里前端委员会布局的四大方向:
Serverless肯定会火,而且也是生产力上的直接提升,前端可以不考虑部署、运维、环境等场景,直接编写函数来实现后端逻辑,可能以后人人都是所谓的全干工程师了。
但是为什么没有重点拿来将,首先serverless的适用场景还比较轻量,他不是银弹,现在的serverless热在一定程度上夸大了它的实际作用。
还有一点,对于前端而言Serverless其实是工具,你只能拿来用,本身的开发需要云原生的专业开发者,所以前端根本无法深度参与,他反而把前端对node的要求降低了(因为只要会代码,不需要后端知识),但是对于企业和团队是好事,对于个人而言并不是非常有助于成长的一门技术。
5G来临,万物互联的说法又随之而来,IOT会不会在5G时代火,我并不确定,但是前端在IOT上想大展身手我觉得这几年内看不到进展。
有人会说不是有人把js移植到嵌入式领域了吗?是的,甚至三星还为IOT设备定制了js虚拟机。
IOT是低性能低功耗低内存的设备,越是在这种场景下,低运行时高性能偏底层的编程语言越强大,可惜js与此恰恰相反,这门语言天生不适合IOT,而C语言却如鱼得水。
ps:我之前听过一个专门搞IOT的技术专家说过,js最大的问题就是功耗,很多便携式的IOT设备上js根本没办法商用(充电五分钟,待机5秒钟)
那为什么还有那么多人在炒js in IOT这个话题?
感兴趣的可以听Ruff的作者郑晔的电台采访。
原因就是js开发者多。。。有技术难度的底层技术都会被专业的嵌入式开发者搞定,js开发者只需要写业务即可,所以又回到关于Flutter的问题了,你在IOT写业务比浏览器写业务有啥技术提升呢?
当然了,从职场角度搞IOT还是有前途的,一旦IOT火起来,先进入这个领域的人可以更轻松地摘桃子,但是我个人不推荐现在就入坑,风险远大于收益,如果真的对js in any感兴趣,不如去研究js runtime,比如node和deno,这是真正有助于提升能力的技术。
GraphQL已经被炒了好几年了,但是依旧动静不大,不是技术本身又有问题,是这门技术严重损害了后端开发利益。
GraphQL对于前端开发者是真的好用,从此不用求后端大哥搞新接口了,完全可以自给自足,但是这个让前端开发爽到天的技术,付出的代价就是大量的改造工作需要后端来做,后端团队累死累活搞了GraphQL,得利最大的却是前端,出了错锅得后端背,这种技术推动的阻力可想而知。
这门技术考验的是跨团队沟通协作能力,不是技术本身,当然很多时候前者比后者更重要,但是与本文主题不符,按下不表。
这几年炒的最火的技术就是AI,虽然这个领域跟前端可以说没有任何交集,但是依然有很多人想往这方面靠。
先说tfjs的问题,基于浏览器的深度学习框架,其实应用范围非常非常窄,笔者在调研的时候没有发现什么有商业价值的案例,在浏览器中跑深度学习本来就很小众,再加上js本身的性能问题和浏览器没有支持GPU加速的API,导致tfjs更像是个残次品,实际上一些前端团队虽然在开发AI应用,但是基本用的都是正宗TensorFlow。
目前算是比较靠谱的前端+AI的场景就是自动化UI,将设计师的设计稿自动生成UI组件,还原UI是非常机械重复性的工作,早日干掉还原设计稿可以充分解放前端,目前闲鱼的大前端团队已经有相关的成果了。
前端就算涉及AI,也最多是停留在工具使用阶段,也就是所谓的『调包侠』,当然,即使这样你能帮助团队解决生产力问题,那么已经是大功一件了,建议有能力的同学可以布局一下这方面的技术,但是对于绝大多数人而言,玩转深度学习即使是调参也是很遥远的事情。
这是笔者看完圆心的分享之后的一点感受,圆心的格局很高,谈到的都是技术形态、技术影响力和技术生态,本文格局还很小,只停留在技术成长上,只不过对于当下的笔者这种小格局似乎更实用。
这就是笔者站在2019年年中对未来前端技术发展的思考。
本文于2018年首发于掘金
自 Backbone 之后前端框架就如同雨后春笋般出现,我们已经习惯了用各种框架进行开发,但是前端框架出现的意义是什么?我们为什么要选择前端框架进行开发呢?
提前声明: 我们没有对传入的参数进行及时判断而规避错误,仅仅对核心方法进行了实现.
最开始学习前端框架的时候(我第一个框架是 React)并不理解框架能带来什么,只是因为大家都在用框架,最实际的一个用途就是所有企业几乎都在用框架,不用框架就 out 了.
随着使用的深入我逐渐理解到框架的好处:
上一节我们只说了前端框架的好处,但是并没有指出根本问题,直到我看到这篇文章(中文版)。
简单来说,前端框架的根本意义是解决了UI 与状态同步问题。
在 Vue 中我们如果要在todos中添加一条,只需要app4.todos.push({ text: '新项目' }),这时由于 Vue 内置的响应式系统会自动帮我们进行 UI 与状态的同步工作.
<div id="app-4">
<ol>
<li v-for="todo in todos">
{{ todo.text }}
</li>
</ol>
</div>var app4 = new Vue({
el: '#app-4',
data: {
todos: [
{ text: '学习 JavaScript' },
{ text: '学习 Vue' },
{ text: '整个牛项目' }
]
}
})如果我们用 JQuery 或者 JS 进行操作,免不了一大堆li.appendChild、document.createElement等 DOM 操作,我们需要一长串 DOM 操作保证状态与 UI 的同步,其中一个环节出错就会导致 BUG,手动操作的缺点如下:
不管是 vue 的数据劫持、Angular 的脏检测还是 React 的组件级 reRender都是帮助我们解决 ui 与状态同步问题的利器。
这也解释了Backbone作为前端框架鼻祖在之后落寞的原因,Backbone只是引入了 MVC 的**,并没有解决 View 与 Modal 同步的问题,相比于现代的三大框架直接操作 Modal 就可以同步 UI 的特性, Backbone 仍然与 JQuery 绑定,在 View 里操作 Dom来达到同步 UI 的目的,这显然是不符合现代前端框架设计要求的。
UI 在 MVVM 中指的是 View,状态在 MVVM 中指的是 Modal,而保证 View 和 Modal 同步的是 View-Modal。
Vue 通过一个响应式系统保证了View 与 Modal的同步,由于要兼容IE,Vue 选择了 Object.defineProperty作为响应式系统的实现,但是如果不考虑 IE 用户的话, Object.defineProperty并不是一个好的选择,具体请看面试官系列(4): 基于Proxy 数据劫持的双向绑定优势所在。
我们将用 Proxy 实现一个响应式系统。
建议阅读之前看一下面试官系列(4): 基于Proxy 数据劫持的双向绑定优势所在中基于
Object.defineProperty的大致实现。
一个响应式系统离不开发布订阅模式,因为我们需要一个 Dep保存订阅者,并在 Observer 发生变化时通知保存在 Dep 中的订阅者,让订阅者得知变化并更新视图,这样才能保证视图与状态的同步。
发布订阅模式请阅读面试官系列(2): Event Bus的实现
/**
* [subs description] 订阅器,储存订阅者,通知订阅者
* @type {Map}
*/
export default class Dep {
constructor() {
// 我们用 hash 储存订阅者
this.subs = new Map();
}
// 添加订阅者
addSub(key, sub) {
// 取出键为 key 的订阅者
const currentSub = this.subs.get(key);
// 如果能取出说明有相同的 key 的订阅者已经存在,直接添加
if (currentSub) {
currentSub.add(sub);
} else {
// 用 Set 数据结构储存,保证唯一值
this.subs.set(key, new Set([sub]));
}
}
// 通知
notify(key) {
// 触发键为 key 的订阅者们
if (this.subs.get(key)) {
this.subs.get(key).forEach(sub => {
sub.update();
});
}
}
}我们在订阅器 Dep 中实现了一个notify方法来通知相应的订阅这们,然而notify方法到底什么时候被触发呢?
当然是当状态发生变化时,即 MVVM 中的 Modal 变化时触发通知,然而Dep 显然无法得知 Modal 是否发生了变化,因此我们需要创建一个监听者Observer来监听 Modal, 当 Modal 发生变化的时候我们就执行通知操作。
vue 基于Object.defineProperty来实现了监听者,我们用 Proxy 来实现监听者.
与Object.defineProperty监听属性不同, Proxy 可以监听(实际是代理)整个对象,因此就不需要遍历对象的属性依次监听了,但是如果对象的属性依然是个对象,那么 Proxy 也无法监听,所以我们实现了一个observify进行递归监听即可。
/**
* [Observer description] 监听器,监听对象,触发后通知订阅
* @param {[type]} obj [description] 需要被监听的对象
*/
const Observer = obj => {
const dep = new Dep();
return new Proxy(obj, {
get: function(target, key, receiver) {
// 如果订阅者存在,直接添加订阅
if (Dep.target) {
dep.addSub(key, Dep.target);
}
return Reflect.get(target, key, receiver);
},
set: function(target, key, value, receiver) {
// 如果对象值没有变,那么不触发下面的操作直接返回
if (Reflect.get(receiver, key) === value) {
return;
}
const res = Reflect.set(target, key, observify(value), receiver);
// 当值被触发更改的时候,触发 Dep 的通知方法
dep.notify(key);
return res;
},
});
};
/**
* 将对象转为监听对象
* @param {*} obj 要监听的对象
*/
export default function observify(obj) {
if (!isObject(obj)) {
return obj;
}
// 深度监听
Object.keys(obj).forEach(key => {
obj[key] = observify(obj[key]);
});
return Observer(obj);
}我们目前已经解决了两个问题,一个是如何得知 Modal 发生了改变(利用监听者 Observer 监听 Modal 对象),一个是如何收集订阅者并通知其变化(利用订阅器收集订阅者,并用notify通知订阅者)。
我们目前还差一个订阅者(Watcher)
// 订阅者
export default class Watcher {
constructor(vm, exp, cb) {
this.vm = vm; // vm 是 vue 的实例
this.exp = exp; // 被订阅的数据
this.cb = cb; // 触发更新后的回调
this.value = this.get(); // 获取老数据
}
get() {
const exp = this.exp;
let value;
Dep.target = this;
if (typeof exp === 'function') {
value = exp.call(this.vm);
} else if (typeof exp === 'string') {
value = this.vm[exp];
}
Dep.target = null;
return value;
}
// 将订阅者放入待更新队列等待批量更新
update() {
pushQueue(this);
}
// 触发真正的更新操作
run() {
const val = this.get(); // 获取新数据
this.cb.call(this.vm, val, this.value);
this.value = val;
}
}我们在上一节中实现了订阅者( Watcher),但是其中的update方法是将订阅者放入了一个待更新的队列中,而不是直接触发,原因如下:
因此这个队列需要做的是异步且去重,因此我们用 Set作为数据结构储存 Watcher 来去重,同时用Promise模拟异步更新。
// 创建异步更新队列
let queue = new Set()
// 用Promise模拟nextTick
function nextTick(cb) {
Promise.resolve().then(cb)
}
// 执行刷新队列
function flushQueue(args) {
queue.forEach(watcher => {
watcher.run()
})
// 清空
queue = new Set()
}
// 添加到队列
export default function pushQueue(watcher) {
queue.add(watcher)
// 下一个循环调用
nextTick(flushQueue)
}我们梳理一下流程, 一个响应式系统是如何做到 UI(View)与状态(Modal)同步的?
我们首先需要监听 Modal, 本文中我们用 Proxy 来监听了 Modal 对象,因此在 Modal 对象被修改的时候我们的 Observer 就可以得知。
我们得知Modal发生变化后如何通知 View 呢?要知道,一个 Modal 的改变可能触发多个 UI 的更新,比如一个用户的用户名改变了,它的个人信息组件、通知组件等等组件中的用户名都需要改变,对于这种情况我们很容易想到利用发布订阅模式来解决,我们需要一个订阅器(Dep)来储存订阅者(Watcher),当监听到 Modal 改变时,我们只需要通知相关的订阅者进行更新即可。
那么订阅者来自哪里呢?其实每一个组件实例对应着一个订阅者(正因为一个组件实例对应一个订阅者,才能利用 Dep 通知到相应组件,不然乱套了,通知订阅者就相当于间接通知了组件)。
当订阅者得知了具体变化后它会进行相应的更新,将更新体现在 UI(View)上,至此UI 与 Modal 的同步完成了。
完整代码已经在 github 上,目前只实现了一个响应式系统,接下来会逐步实现一个完整的迷你版 mvvm 框架,所以你可以 star 或者 watch 来关注进度.
响应式系统虽然是 Vue 的核心概念,但是一个响应式系统并不够.
响应式系统虽然得知了数据值的变化,但是当值不能完整映射 UI 时,我们依然需要进行组件级别的 reRender,这种情况并不高效,因此 Vue 在2.0版本引入了虚拟 DOM, 虚拟 DOM进行进一步的 diff 操作可以进行细粒度更高的操作,可以保证 reReander 的下限(保证不那么慢)。
除此之外为了方便开发者,vue 内置了众多的指令,因此我们还需要一个 vue 模板解析器.
本文于2020年发布于掘金
动态规划(Dynamic programming,简称DP)是一种通过把原问题分解为相对简单的子问题的方式求解复杂问题的方法。
从面试的角度看,动态规划是正规算法面试中无论如何都逃不掉的必考题,曾经有一个伟人说过这样一句话:
那么为什么动态规划会在面试中这么重要?
其实最主要的原因就是动态规划非常适合面试,因为动态规划没办法「背」。
我们很多求职者其实是通过背题来面试的,而之前这个做法屡试不爽,什么翻转二叉树、翻转链表,快排、归并、冒泡一顿背,基本上也能在面试中浑水摸鱼过去,其实这哪是考算法能力、算法思维,这就是考谁的备战态度好,愿意花时间去背题而已,把连背都懒得背的筛出去就完事了。
但是随着互联网遇冷,人才供给进一步过热,背题的人越来越多,面试的门槛被增加了,因此这个时候需要一种非常考验算法思维、变化多端而且容易设计的题目类型,动态规划就完美符合这个要求。
比如 LeetCode 中有1261道算法类题目,其中动态规划题目占据了近200道,动态规划能占据总题目的 1/6 的比例,可见其火热程度。
更重要的是,动态规划的题目难度以中高难度为主:
所以,既然我们已经知道这是算法面试的必考题了,我们怎么准备都不为过,本文尽笔者最大努力把动态规划讲清楚。
我们在前面内容了解到了贪心算法可以解决「硬币找零问题」,但是那只是在部分情况下可以解决而已,因为题目中给出的钱币面值为 1、5、25,我们现实生活中我们现行的第五套人民币面值分别为100、50、20、10、5、1,我们的人民币是可以用贪心算法找零的。
那么有什么情况下不能用贪心算法吗?比如一个算法星球的央行发行了奇葩币,币值分别为1、5、11,要凑够15元,这个时候贪心算法就失效了。
我们可以算一下,按照贪心算法的策略,我们先拿出最大面值的11,剩下的4个分别对应四个1元的奇葩币,这总共需要五个奇葩币才能凑够15元。
而实际上我们简单一算,就知道最少情况是拿出3个五元的奇葩币才能凑够15元。
这里就有问题了,贪心算法的弊端在这种特殊面值钱币面前展露无疑,原因就在于「只顾眼前,无大局观」,在先拿出最大的 11 面值的奇葩币后就彻底把周旋余地堵死了,因为剩下的 4 要想凑足付出的代价是非常高的,我们需要依次拿出4个面值为1的奇葩币。
那么既然贪心算法已经不适用于这种场景了,我们应该如何改变计算策略呢?
当我们面试过程中遇到这种问题时,如果一时没有思路,也要想到一种万能算法--暴力破解。
我们分析一下上述题目,它的问题其实是「给定一组面额的硬币,我们用现有的币值凑出n最少需要多少个币」。
我们要凑够这个 n,只要 n 不为0,那么总会有处在最后一个的硬币,这个硬币恰好凑成了 n,比如我们用 {11,1,1,1,1} 来凑15,前面我们拿出 {11,1,1,1},最后我们拿出 {1} 正好凑成 15。
如果用 {5,5,5} 来凑15,最后一个硬币就是5,我们按照这个思路捋一捋,:
大家发现了没有,我们的问题提可以不断被分解为「我们用现有的币值凑出 n 最少需要多少个币」,比如我们用 f(n) 函数代表 「凑出 n 最少需要多少个币」.
把「原有的大问题逐渐分解成类似的但是规模更小的子问题」这就是最优子结构,我们可以通过自底向上的方式递归地从子问题的最优解逐步构造出整个问题的最优解。
这个时候我们分别假设 1、5、11 三种面值的币分别为最后一个硬币的情况:
这个时候大家发现问题所在了吗?最少找零 min 与 f(4)、f(10)、f(14) 三个函数解中的最小值是有关的,毕竟后面的「+1」是大家都有的。
假设凑的硬币总额为 n,那么 f(4) = f(n-11)、f(10) = f(n-5)、f(14) = f(n-1),我们得出以下公式:
f(n) = min{f(n-1), f(n-5), f(n-11)} + 1
我们再具体到上面公式中 f(n-1) 凑够它的最小硬币数量是多少,是不是又变成下面这个公式:
f(n-1) = min{f(n-1-1), f(n-1-5), f(n-1-11)} + 1
以此类推...
这真是似曾相识,这不就是递归吗?
是的,我们可以通过递归来求出最少找零问题的解,代码如下:
function f(n) {
if(n === 0) return 0
let min = Infinity
if (n >= 1) {
min = Math.min(f(n-1) + 1, min)
}
if (n >= 5) {
min = Math.min(f(n-5) + 1, min)
}
if (n >= 11) {
min = Math.min(f(n-11) + 1, min)
}
return min
}
console.log(f(15)) // 3Math.min 求最小值min = Math.min(f(n-1) + 1, min),求此种情况下的最小找零min = Math.min(f(n-5) + 1, min),求此种情况下的最小找零min = Math.min(f(n-11) + 1, min),求此种情况下的最小找零我们看似已经把问题解决了,但是别着急,我们继续测试,当n=70的时候,我们测试要凑出这个数最少我们需要多少个硬币。
答案是8,但是我们的耗时如下:
如果n=270呢?在八代i7处理器和node.js 12.x版本的加持下我跑了这么长时间都没算出来:
当n=27000的时候,我们成功的爆栈了:
所以为什么会造成如此长的执行耗时?归根到底是递归算法的低效导致的,我们看如下图:
我们如果计算f(70)就需要分别计算最后一个币为1、5、11三种面值时的不同情况,而这三种不同情况作为子问题又可以被分解为三种情况,依次类推...这样的算法复杂度有 O(3ⁿ),这是极为低效的。
我们再仔细看图:
我们用红色标出来的都是相同的计算函数,比如有两个f(64)、f(58)、f(54),这些都是重复的,这些只是我们整个计算体系下的冰山一角,我们还有非常多的重复计算没办法在图中展示出来。
可见我们重复计算了非常多的无效函数,浪费了算力,到底有多浪费我们已经从上面函数执行时间测试上有了一定的认识。
我们不妨再举一个简单的例子,比如我们要计算 「1 + 1 + 1 + 1 + 1 + 1 + 1 + 1」的和。
我们开始数数...,直到我们数出上面计算的和为 8,那么,我们再在上述 「1 + 1 + 1 + 1 + 1 + 1 + 1 + 1」 后面 「+ 1」,那么和是多少?
这个时候你肯定数都不会数,脱口而出「9」。
为什么我们在后面的计算这么快?是因为我们已经在大脑中记住了之前的结果 「8」,我们只需要计算「8 + 1」即可,这避免了我们重复去计算前面的已经计算过的内容。
我们用的递归像什么?像继续数「1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1」来计算出「9」,这是非常耗时的。
我们假设用 m 种面值的硬币凑 n 最少需要多少硬币,在上述问题下递归的时间复杂度是惊人的O(nᵐ),指数级的时间复杂度可以说是最差的时间复杂度之一了。
我们已经发现问题所在了,大量的重复计算导致时间复杂度奇高,我们必须想办法解决这个问题。
既然已经知道存在大量冗余计算了,那么我们可不可以建立一个备忘录,把计算过的答案记录在备忘录中,再有我们需要答案的时候,我们去备忘录中查找,如果能查找到就直接返回答案,这样就避免了重复计算,这就是算法中典型的空间换时间的思维,我们用备忘录占用的额外内存换取了更高效的计算。
有了思路后,其实代码实现非常简单,我们只需要建立一个缓存备忘录,在函数内部校验校验是否存在在结果,如果存在返回即可。
function f(n) {
function makeChange(amount) {
if(amount <= 0) return 0
// 校验是否已经在备忘录中存在结果,如果存在返回即可
if(cache[amount]) return cache[amount]
let min = Infinity
if (amount >= 1) {
min = Math.min(makeChange(amount-1) + 1, min)
}
if (amount >= 5) {
min = Math.min(makeChange(amount-5) + 1, min)
}
if (amount >= 11) {
min = Math.min(makeChange(amount-11) + 1, min)
}
return (cache[amount] = min)
}
// 备忘录
const cache = []
return makeChange(n)
}
console.log(f(70)) // 8public class Cions {
public static void main(String[] args) {
int a = coinChange(70);
System.out.println(a);
}
private static HashMap<Integer,Integer> cache = new HashMap<>();
public static int coinChange(int amount) {
return makeChange(amount);
}
public static int makeChange(int amount) {
if (amount <= 0) return 0;
// 校验是否已经在备忘录中存在结果,如果存在返回即可
if(cache.get(amount) != null) return cache.get(amount);
int min = Integer.MAX_VALUE;
if (amount >= 1) {
min = Math.min(makeChange(amount-1) + 1, min);
}
if (amount >= 5) {
min = Math.min(makeChange(amount-5) + 1, min);
}
if (amount >= 11) {
min = Math.min(makeChange(amount-11) + 1, min);
}
cache.put(amount, min);
return min;
}
}我们的执行时间只有:
实际上利用备忘录来解决递归重复计算的问题叫做「记忆化搜索」。
这个方法本质上跟回溯法的「剪枝」是一个目的,就是把上图中存在重复的节点全部剔除,只保留一个节点即可,当然上图没办法把所有节点全部展示出来,如果剔除全部重复节点最后只会留下线性的节点形式:
这个带备忘录的递归算法时间复杂度只有O(n),已经跟动态规划的时间复杂度相差不大了。
那么这不就可以了吗?为什么还要搞动态规划?
还记得我们上面提到递归的另一大问题吗?
爆栈!
这是我们备忘录递归计算 f(27000) 的结果:
编程语言栈的深度是有限的,即使我们进行了剪枝,在五位数以上的情况下就会再次产生爆栈的情况,这导致递归根本无法完成大规模的计算任务。
这是递归的计算形式决定的,我们这里的递归是「自顶向下」的计算思路,即从 f(70) f(69)...f(1) 逐步分解,这个思路在这里并不完全适用,我们需要一种「自底向上」的思路来解决问题。
「自底向上」就是 f(1) ... f(70) f(69)通过小规模问题递推来解决大规模问题,动态规划通常是用迭代取代递归来解决问题。
「自顶向下」的思路在另一种算法**中非常常见,那就是分治算法
除此之外,递归+备忘录的另一个缺陷就是再没有优化空间了,因为在最坏的情况下,递归的最大深度是 n。
因此,我们需要系统递归堆栈使用 O(n) 的空间,这是递归形式决定的,而换成迭代之后我们根本不需要如此多的的储存空间,我们可以继续往下看。
还记得上面我们利用备忘录缓存之后各个节点的形式是什么样的吗,我们把它这个「备忘录」作为一张表,这张表就叫做 DP table,如下:
注意: 上图中
f[n]代表凑够 n 最少需要多少币的函数,方块内的数字代表函数的结果
我们不妨在上图中找找规律?
我们观察f[1]: f[1] = min(f[0], f[-5], f[-11]) + 1
由于f[-5] 这种负数是不存在的,我们都设为正无穷大,那么f[1] = 1。
再看看f[5]: f[1] = min(f[4], f[0], f[-6]) + 1,这实际是在求f[4] = 4、f[0] = 0、f[-6]=Infinity中最小的值即0,最后加上1,即1,那么f[5] = 1。
发现了吗?我们任何一个节点都可以通过之前的节点来推导出来,根本无需再做重复计算,这个相关的方程是:
f[n] = min(f[n-1], f[n-5], f[n-11]) + 1
还记得我们提到的动态规划有更大的优化空间吗?递归+备忘录由于递归深度的原因需要 O(n) 的空间复杂度,但是基于迭代的动态规划只需要常数级别的复杂度。
看下图,比如我们求解 f(70),只需要前面三个解,即 f(59) f(69) f(65) 套用公式即可求得,那么 f(0)f(1) ... f(58) 根本就没有用了,我们可以不再储存它们占用额外空间,这就留下了我们优化的空间。
上面的方程就是动态转移方程,而解决动态规划题目的钥匙也正是这个动态转移方程。
当然,如果你只推导出了动态转移方程基本上可以把动态规划题做出来了,但是往往很多人却做不对,这是为什么?这就得考虑边界问题。
部分的边界问题其实我们在上面的部分已经给出解决方案了,针对这个找零问题我们有以下边界问题。
处理f[n]中n为负数的问题: 针对这个问题我们的解决方案是凡是n为负数的情况,一律将f[n]视为正无穷大,因为正常情况下我们是不会有下角标为负数的数组的,所以其实 n 为负数的 f[n] 根本就不存在,又因为我们要求最少找零,为了排除这种不存在的情况,也便于我们计算,我们直接将其视为正无穷大,可以最大程度方便我们的动态转移方程的实现。
处理f[n]中n为0的问题:n=0 的情况属于动态转移方程的初始条件,初始条件也就是动态转移方程无法处理的特殊情况,比如我们如果没有这个初始条件,我们的方程是这样的: f[0] = min(f[-1], f[-5], f[-11]) + 1,最小的也是正无穷大,这是特殊情况无法处理,因此我们只能人肉设置初始条件。
处理好边界问题我们就可以得到完整的动态转移方程了:
f[0] = 0 (n=0)
f[n] = min(f[n-1], f[n-5], f[n-11]) + 1 (n>0)
那么我们再回到这个找零问题中,这次我们假设给出不同面额的硬币 coins 和一个总金额 amount。编写一个函数来计算可以凑成总金额所需的最少的硬币个数。如果没有任何一种硬币组合能组成总金额,返回 -1。
比如:
输入: coins = [1, 2, 5], amount = 11
输出: 3
解释: 11 = 5 + 5 + 1
其实上面的找零问题就是我们一直处理的找零问题的通用化,我们的面额是定死的,即1、5、11,这次是不定的,而是给了一个数组 coins 包含了相关的面值。
有了之前的经验,这种问题自然就不再话下了,我们再整理一下思路。
确定最优子结构: 最优子结构即原问题的解由子问题的最优解构成,我们假设最少需要k个硬币凑足总面额n,那么f(n) = min{f(n-cᵢ)}, cᵢ 即是硬币的面额。
处理边界问题: 依然是老套路,当n为负数的时候,值为正无穷大,当n=0时,值也为0.
得出动态转移方程:
f[0] = 0 (n=0)
f[n] = min(f[n-cᵢ]) + 1 (n>0)
我们根据上面的推导,得出以下代码:
const coinChange = (coins, amount) => {
// 初始化备忘录,用Infinity填满备忘录,Infinity说明该值不可以用硬币凑出来
const dp = new Array(amount + 1).fill(Infinity)
// 设置初始条件为 0
dp[0] = 0
for (var i = 1; i <= amount; i++) {
for (const coin of coins) {
// 根据动态转移方程求出最小值
if (coin <= i) {
dp[i] = Math.min(dp[i], dp[i - coin] + 1)
}
}
}
// 如果 `dp[amount] === Infinity`说明没有最优解返回-1,否则返回最优解
return dp[amount] === Infinity ? -1 : dp[amount]
}class Solution {
public int coinChange(int[] coins, int amount) {
// 初始化备忘录,用amount+1填满备忘录,amount+1 表示该值不可以用硬币凑出来
int[] dp = new int[amount + 1];
Arrays.fill(dp,amount+1);
// 设置初始条件为 0
dp[0]=0;
for (int coin : coins) {
for (int i = coin; i <= amount; i++) {
// 根据动态转移方程求出最小值
if(coin <= i) {
dp[i]=Math.min(dp[i],dp[i-coin]+1);
}
}
}
// 如果 `dp[amount] === amount+1`说明没有最优解返回-1,否则返回最优解
return dp[amount] == amount+1 ? -1 : dp[amount];
}
}我们总结一下学习历程:
其实动态规划本质上就是被一再优化过的暴力破解,我们通过动态规划减少了大量的重叠子问题,此后我们讲到的所有动态规划题目的解题过程,都可以从暴力破解一步步优化到动态规划。
本文我们学习了动态规划到底是怎么来的,在此后的解题过程中我们如果没有思路可以在脑子里把这个过程再过一遍,但是我们之后的题解就不会再把整个过程走一遍了,而是直接用动态规划来解题。
可能你会问面试题这么多,到底哪一道应该用动态规划?如何判断?
其实最准确的办法就是看题目中的给定的问题,这个问题能不能被分解为子问题,再根据子问题的解是否可以得出原问题的解。
当然上面的方法虽然准确,但是需要一定的经验积累,我们可以用一个虽然不那么准确,但是足够简单粗暴的办法,如果题目满足以下条件之一,那么它大概率是动态规划题目:
本文于2018年首发于掘金,后面的代码有一些bug,我基于栈写了一个新版路由:
在线预览:https://codepen.io/xiaomuzhu/pen/MWYKxKB
前端路由是现代SPA应用必备的功能,每个现代前端框架都有对应的实现,例如vue-router、react-router。
我们不想探究vue-router或者react-router们的实现,因为不管是哪种路由无外乎用兼容性更好的hash实现或者是H5 History实现,与框架几个只需要做相应的封装即可。
提前声明: 我们没有对传入的参数进行及时判断而规避错误,也没有考虑兼容性问题,仅仅对核心方法进行了实现.
hash路由一个明显的标志是带有#,我们主要是通过监听url中的hash变化来进行路由跳转。
hash的优势就是兼容性更好,在老版IE中都有运行,问题在于url中一直存在#不够美观,而且hash路由更像是Hack而非标准,相信随着发展更加标准化的History API会逐步蚕食掉hash路由的市场。
我们用Class关键字初始化一个路由.
class Routers {
constructor() {
// 以键值对的形式储存路由
this.routes = {};
// 当前路由的URL
this.currentUrl = '';
}
}在初始化完毕后我们需要思考两个问题:
class Routers {
constructor() {
this.routes = {};
this.currentUrl = '';
}
// 将path路径与对应的callback函数储存
route(path, callback) {
this.routes[path] = callback || function() {};
}
// 刷新
refresh() {
// 获取当前URL中的hash路径
this.currentUrl = location.hash.slice(1) || '/';
// 执行当前hash路径的callback函数
this.routes[this.currentUrl]();
}
}那么我们只需要在实例化Class的时候监听上面的事件即可.
class Routers {
constructor() {
this.routes = {};
this.currentUrl = '';
this.refresh = this.refresh.bind(this);
window.addEventListener('load', this.refresh, false);
window.addEventListener('hashchange', this.refresh, false);
}
route(path, callback) {
this.routes[path] = callback || function() {};
}
refresh() {
this.currentUrl = location.hash.slice(1) || '/';
this.routes[this.currentUrl]();
}
}对应效果如下:
完整示例
点击这里 hash router by 寻找海蓝 (@xiaomuzhu) on CodePen.
上一节我们只实现了简单的路由功能,没有我们常用的回退与前进功能,所以我们需要进行改造。
我们在需要创建一个数组history来储存过往的hash路由例如/blue,并且创建一个指针currentIndex来随着后退和前进功能移动来指向不同的hash路由。
class Routers {
constructor() {
// 储存hash与callback键值对
this.routes = {};
// 当前hash
this.currentUrl = '';
// 记录出现过的hash
this.history = [];
// 作为指针,默认指向this.history的末尾,根据后退前进指向history中不同的hash
this.currentIndex = this.history.length - 1;
this.refresh = this.refresh.bind(this);
this.backOff = this.backOff.bind(this);
window.addEventListener('load', this.refresh, false);
window.addEventListener('hashchange', this.refresh, false);
}
route(path, callback) {
this.routes[path] = callback || function() {};
}
refresh() {
this.currentUrl = location.hash.slice(1) || '/';
// 将当前hash路由推入数组储存
this.history.push(this.currentUrl);
// 指针向前移动
this.currentIndex++;
this.routes[this.currentUrl]();
}
// 后退功能
backOff() {
// 如果指针小于0的话就不存在对应hash路由了,因此锁定指针为0即可
this.currentIndex <= 0
? (this.currentIndex = 0)
: (this.currentIndex = this.currentIndex - 1);
// 随着后退,location.hash也应该随之变化
location.hash = `#${this.history[this.currentIndex]}`;
// 执行指针目前指向hash路由对应的callback
this.routes[this.history[this.currentIndex]]();
}
}我们看起来实现的不错,可是出现了Bug,在后退的时候我们往往需要点击两下。
点击查看Bug示例 hash router by 寻找海蓝 (@xiaomuzhu) on CodePen.
问题在于,我们每次在后退都会执行相应的callback,这会触发refresh()执行,因此每次我们后退,history中都会被push新的路由hash,currentIndex也会向前移动,这显然不是我们想要的。
refresh() {
this.currentUrl = location.hash.slice(1) || '/';
// 将当前hash路由推入数组储存
this.history.push(this.currentUrl);
// 指针向前移动
this.currentIndex++;
this.routes[this.currentUrl]();
}如图所示,我们每次点击后退,对应的指针位置和数组被打印出来
我们必须做一个判断,如果是后退的话,我们只需要执行回调函数,不需要添加数组和移动指针。
class Routers {
constructor() {
// 储存hash与callback键值对
this.routes = {};
// 当前hash
this.currentUrl = '';
// 记录出现过的hash
this.history = [];
// 作为指针,默认指向this.history的末尾,根据后退前进指向history中不同的hash
this.currentIndex = this.history.length - 1;
this.refresh = this.refresh.bind(this);
this.backOff = this.backOff.bind(this);
// 默认不是后退操作
this.isBack = false;
window.addEventListener('load', this.refresh, false);
window.addEventListener('hashchange', this.refresh, false);
}
route(path, callback) {
this.routes[path] = callback || function() {};
}
refresh() {
this.currentUrl = location.hash.slice(1) || '/';
if (!this.isBack) {
// 如果不是后退操作,且当前指针小于数组总长度,直接截取指针之前的部分储存下来
// 此操作来避免当点击后退按钮之后,再进行正常跳转,指针会停留在原地,而数组添加新hash路由
// 避免再次造成指针的不匹配,我们直接截取指针之前的数组
// 此操作同时与浏览器自带后退功能的行为保持一致
if (this.currentIndex < this.history.length - 1)
this.history = this.history.slice(0, this.currentIndex + 1);
this.history.push(this.currentUrl);
this.currentIndex++;
}
this.routes[this.currentUrl]();
console.log('指针:', this.currentIndex, 'history:', this.history);
this.isBack = false;
}
// 后退功能
backOff() {
// 后退操作设置为true
this.isBack = true;
this.currentIndex <= 0
? (this.currentIndex = 0)
: (this.currentIndex = this.currentIndex - 1);
location.hash = `#${this.history[this.currentIndex]}`;
this.routes[this.history[this.currentIndex]]();
}
}查看完整示例 Hash Router by 寻找海蓝 (@xiaomuzhu) on CodePen.
前进的部分就不实现了,思路我们已经讲得比较清楚了,可以看出来,hash路由这种方式确实有点繁琐,所以HTML5标准提供了History API供我们使用。
我们可以直接在浏览器中查询出History API的方法和属性。
当然,我们常用的方法其实是有限的,如果想全面了解可以去MDN查询History API的资料。
我们只简单看一下常用的API
window.history.back(); // 后退
window.history.forward(); // 前进
window.history.go(-3); // 后退三个页面history.pushState用于在浏览历史中添加历史记录,但是并不触发跳转,此方法接受三个参数,依次为:
state:一个与指定网址相关的状态对象,popstate事件触发时,该对象会传入回调函数。如果不需要这个对象,此处可以填null。
title:新页面的标题,但是所有浏览器目前都忽略这个值,因此这里可以填null。
url:新的网址,必须与当前页面处在同一个域。浏览器的地址栏将显示这个网址。
history.replaceState方法的参数与pushState方法一模一样,区别是它修改浏览历史中当前纪录,而非添加记录,同样不触发跳转。
popstate事件,每当同一个文档的浏览历史(即history对象)出现变化时,就会触发popstate事件。
需要注意的是,仅仅调用pushState方法或replaceState方法 ,并不会触发该事件,只有用户点击浏览器倒退按钮和前进按钮,或者使用 JavaScript 调用back、forward、go方法时才会触发。
另外,该事件只针对同一个文档,如果浏览历史的切换,导致加载不同的文档,该事件也不会触发。
以上API介绍选自history对象,可以点击查看完整版,我们不想占用过多篇幅来介绍API。
上一节我们介绍了新标准的History API,相比于我们在Hash 路由实现的那些操作,很显然新标准让我们的实现更加方便和可读。
所以一个mini路由实现起来其实很简单
class Routers {
constructor() {
this.routes = {};
// 在初始化时监听popstate事件
this._bindPopState();
}
// 初始化路由
init(path) {
history.replaceState({path: path}, null, path);
this.routes[path] && this.routes[path]();
}
// 将路径和对应回调函数加入hashMap储存
route(path, callback) {
this.routes[path] = callback || function() {};
}
// 触发路由对应回调
go(path) {
history.pushState({path: path}, null, path);
this.routes[path] && this.routes[path]();
}
// 监听popstate事件
_bindPopState() {
window.addEventListener('popstate', e => {
const path = e.state && e.state.path;
this.routes[path] && this.routes[path]();
});
}
}点击查看H5路由 H5 Router by 寻找海蓝 (@xiaomuzhu) on CodePen.
我们大致探究了前端路由的两种实现方法,在没有兼容性要求的情况下显然符合标准的History API实现的路由是更好的选择。
想更深入了解前端路由实现可以阅读vue-router代码,除去开发模式代码、注释和类型检测代码,核心代码并不多,适合阅读。
虽然前端开发作为 GUI 开发的一种,但是存在其特殊性,前端的特殊性就在于“动态”二字,传统 GUI 开发,不管是桌面应用还是移动端应用都是需要预先下载的,只有先下载应用程序才会在本地操作系统运行,而前端不同,它是“动态增量”式的,我们的前端应用往往是实时加载执行的,并不需要预先下载,这就造成了一个问题,前端开发中往往最影响性能的不是什么计算或者渲染,而是加载速度,加载速度会直接影响用户体验和网站留存。
《Designing for Performance》的作者 Lara Swanson在2014年写过一篇文章《Web性能即用户体验》,她在文中提到“网站页面的快速加载,能够建立用户对网站的信任,增加回访率,大部分的用户其实都期待页面能够在2秒内加载完成,而当超过3秒以后,就会有接近40%的用户离开你的网站”。
值得一提的是,GUI 开发依然有一个共同的特殊之处,那就是 体验性能 ,体验性能并不指在绝对性能上的性能优化,而是回归用户体验这个根本目的,因为在 GUI 开发的领域,绝大多数情况下追求绝对意义上的性能是没有意义的.
比如一个动画本来就已经有 60 帧了,你通过一个吊炸天的算法优化到了 120 帧,这对于你的 KPI 毫无用处,因为这个优化本身没有意义,因为除了少数特异功能的异人,没有人能分得清 60 帧和 120 帧的区别,这对于用户的体验没有任何提升,相反,一个首屏加载需要 4s 的网站,你没有任何实质意义上的性能优化,只是加了一个设计姐姐设计的 loading 图,那这也是十分有意义的优化,因为好的 loading 可以减少用户焦虑,让用户感觉没有等太久,这就是用户体验级的性能优化.
因此,我们要强调即使没有对性能有实质的优化,通过设计提高用户体验的这个过程,也算是性能优化,因为 GUI 开发直面用户,你让用户有了性能快的 错觉,这也叫性能优化了,毕竟用户觉得快,才是真的快...
首屏加载是被讨论最多的话题,一方面web 前端首屏的加载性能的确普遍较差,另一方面,首屏的加载速度至关重要,很多时候过长的白屏会导致用户还没有体验到网站功能的时候就流失了,首屏速度是用户留存的关键点。
以用户体验的角度来解读首屏的关键点,如果作为用户我们从输入网址之后的心里过程是怎样的呢?
当我们敲下回车后,我们第一个疑问是:
"它在运行吗?"
这个疑问一直到用户看到页面第一个绘制的元素为止,这个时候用户才能确定自己的请求是有效的(而不是被墙了...),然后第二个疑问:
"它有用吗?"
如果只绘制出无意义的各种乱序的元素,这对于用户是不可理解的,此时虽然页面开始加载了,但是对于用户没有任何价值,直到文字内容、交互按钮这些元素加载完毕,用户才能理解页面,这个时候用户会尝试与页面交互,会有第三个疑问:
"它能使用了吗?"
直到用户成功与页面互动,这才算是首屏加载完毕了.
在第一个疑问和第二个疑问之间的等待期,会出现白屏,这是优化的关键.
不管是我们如何优化性能,首屏必然是会出现白屏的,因为这是前端开发这项技术的特点决定的。
那么我们先定义一下白屏,这样才能方便计算我们的白屏时间,因为白屏的计算逻辑说法不一,有人说要从首次绘制(First Paint,FP)算起到首次内容绘制(First Contentful Paint,FCP)这段时间算白屏,我个人是不同意的,我个人更倾向于是从路由改变起(即用户再按下回车的瞬间)到首次内容绘制(即能看到第一个内容)为止算白屏时间,因为按照用户的心理,在按下回车起就认为自己发起了请求,而直到看到第一个元素被绘制出来之前,用户的心里是焦虑的,因为他不知道这个请求会不会被响应(网站挂了?),不知道要等多久才会被响应到(网站慢?),这期间为用户首次等待期间。
白屏时间 = firstPaint - performance.timing.navigationStart
以webapp 版的微博为例(微博为数不多的的良心产品),经过 Lighthouse(谷歌的网站测试工具)它的白屏加载时间为 2s,是非常好的成绩。
在现代前端应用开发中,我们往往会用 webpack 等打包器进行打包,很多情况下如果我们不进行优化,就会出现很多体积巨大的 chunk,有的甚至在 5M 左右(我第一次用 webpack1.x 打包的时候打出了 8M 的包),这些 chunk 是加载速度的杀手。
浏览器通常都有并发请求的限制,以 Chrome 为例,它的并发请求就为 6 个,这导致我们必须在请求完前 6 个之后,才能继续进行后续请求,这也影响我们资源的加载速度。
当然了,网络、带宽这是自始至终都影响加载速度的因素,白屏也不例外.
我们先梳理下白屏时间内发生了什么:
如果你用的是以 webpack 为基础的前端框架工程体系,那么你的index.html 文件一定是这样的:
<div id="root"></div>我们将打包好的整个代码都渲染到这个 root 根节点上,而我们如何渲染呢?当然是用 JavaScript 操作各种 dom 渲染,比如 react 肯定是调用各种 _React_._createElement_(),这是很耗时的,在此期间虽然 html 被加载了,但是依然是白屏,这就存在操作空间,我们能不能在 js 执行期间先加入提示,增加用户体验呢?
是的,我们一般有一款 webpack 插件叫html-webpack-plugin ,在其中配置 html 就可以在文件中插入 loading 图。
webpack 配置:
const HtmlWebpackPlugin = require('html-webpack-plugin')
const loading = require('./render-loading') // 事先设计好的 loading 图
module.exports = {
entry: './src/index.js',
output: {
path: __dirname + '/dist',
filename: 'index_bundle.js'
},
plugins: [
new HtmlWebpackPlugin({
template: './src/index.html',
loading: loading
})
]
}那么既然在 HTML 加载到 js 执行期间会有时间等待,那么为什么不直接服务端渲染呢?直接返回的 HTML 就是带完整 DOM 结构的,省得还得调用 js 执行各种创建 dom 的工作,不仅如此还对 SEO 友好。
正是有这种需求 vue 和 react 都支持服务端渲染,而相关的框架Nuxt.js、Next.js也大行其道,当然对于已经采用客户端渲染的应用这个成本太高了。
于是有人想到了办法,谷歌开源了一个库Puppeteer,这个库其实是一个无头浏览器,通过这个无头浏览器我们能用代码模拟各种浏览器的操作,比如我们就可以用 node 将 html 保存为 pdf,可以在后端进行模拟点击、提交表单等操作,自然也可以模拟浏览器获取首屏的 HTML 结构。
prerender-spa-plugin就是基于以上原理的插件,此插件在本地模拟浏览器环境,预先执行我们的打包文件,这样通过解析就可以获取首屏的 HTML,在正常环境中,我们就可以返回预先解析好的 HTML 了。
我们看到在获取 html 之后我们需要自上而下解析,在解析到 script 相关标签的时候才能请求相关资源,而且由于浏览器并发限制,我们最多一次性请求 6 次,那么有没有办法破解这些困境呢?
http2 是非常好的解决办法,http2 本身的机制就足够快:
例如:下图中的两个请求, 请求一发送了所有的头部字段,第二个请求则只需要发送差异数据,这样可以减少冗余数据,降低开销
我们可以点击此网站 进行 http2 的测试
我曾经做个一个测试,http2 在网络通畅+高性能设备下的表现没有比 http1.1有明显的优势,但是网络越差,设备越差的情况下 http2 对加载的影响是质的,可以说 http2 是为移动 web 而生的,反而在光纤加持的高性能PC 上优势不太明显.
既然 http 请求如此麻烦,能不能我们避免 http 请求或者降低 http 请求的负载来实现性能优化呢?
利用浏览器缓存是很好的办法,他能最大程度上减少 http 请求,在此之前我们要先回顾一下 http 缓存的相关知识.
我们先罗列一下和缓存相关的请求响应头。
响应头,代表该资源的过期时间。
请求/响应头,缓存控制字段,精确控制缓存策略。
请求头,资源最近修改时间,由浏览器告诉服务器。
响应头,资源最近修改时间,由服务器告诉浏览器。
响应头,资源标识,由服务器告诉浏览器。
请求头,缓存资源标识,由浏览器告诉服务器。
配对使用的字段:
当无本地缓存的时候是这样的:
当有本地缓存但没过期的时候是这样的:
当缓存过期了会进行协商缓存:
了解到了浏览器的基本缓存机制我们就好进行优化了.
通常情况下我们的 WebApp 是有我们的自身代码和第三方库组成的,我们自身的代码是会常常变动的,而第三方库除非有较大的版本升级,不然是不会变的,所以第三方库和我们的代码需要分开打包,我们可以给第三方库设置一个较长的强缓存时间,这样就不会频繁请求第三方库的代码了。
那么如何提取第三方库呢?在 webpack4.x 中, SplitChunksPlugin 插件取代了 CommonsChunkPlugin 插件来进行公共模块抽取,我们可以对SplitChunksPlugin 进行配置进行 拆包 操作。
SplitChunksPlugin配置示意如下:
optimization: {
splitChunks: {
chunks: "initial", // 代码块类型 必须三选一: "initial"(初始化) | "all"(默认就是all) | "async"(动态加载)
minSize: 0, // 最小尺寸,默认0
minChunks: 1, // 最小 chunk ,默认1
maxAsyncRequests: 1, // 最大异步请求数, 默认1
maxInitialRequests: 1, // 最大初始化请求书,默认1
name: () => {}, // 名称,此选项课接收 function
cacheGroups: { // 缓存组会继承splitChunks的配置,但是test、priorty和reuseExistingChunk只能用于配置缓存组。
priority: "0", // 缓存组优先级,即权重 false | object |
vendor: { // key 为entry中定义的 入口名称
chunks: "initial", // 必须三选一: "initial"(初始化) | "all" | "async"(默认就是异步)
test: /react|lodash/, // 正则规则验证,如果符合就提取 chunk
name: "vendor", // 要缓存的 分隔出来的 chunk 名称
minSize: 0,
minChunks: 1,
enforce: true,
reuseExistingChunk: true // 可设置是否重用已用chunk 不再创建新的chunk
}
}
}
}SplitChunksPlugin 的配置项很多,可以先去官网了解如何配置,我们现在只简单列举了一下配置元素。
如果我们想抽取第三方库可以这样简单配置
splitChunks: {
chunks: 'all', // initial、async和all
minSize: 30000, // 形成一个新代码块最小的体积
maxAsyncRequests: 5, // 按需加载时候最大的并行请求数
maxInitialRequests: 3, // 最大初始化请求数
automaticNameDelimiter: '~', // 打包分割符
name: true,
cacheGroups: {
vendor: {
name: "vendor",
test: /[\\/]node_modules[\\/]/, //打包第三方库
chunks: "all",
priority: 10 // 优先级
},
common: { // 打包其余的的公共代码
minChunks: 2, // 引入两次及以上被打包
name: 'common', // 分离包的名字
chunks: 'all',
priority: 5
},
}
},这样似乎大功告成了?并没有,我们的配置有很大的问题:
下图示意了如何将第三方库进行拆包,基础型的 react 等库与工具性的 lodash 和特定库 Echarts 进行拆分
cacheGroups: {
reactBase: {
name: 'reactBase',
test: (module) => {
return /react|redux/.test(module.context);
},
chunks: 'initial',
priority: 10,
},
utilBase: {
name: 'utilBase',
test: (module) => {
return /rxjs|lodash/.test(module.context);
},
chunks: 'initial',
priority: 9,
},
uiBase: {
name: 'chartBase',
test: (module) => {
return /echarts/.test(module.context);
},
chunks: 'initial',
priority: 8,
},
commons: {
name: 'common',
chunks: 'initial',
priority: 2,
minChunks: 2,
},
}我们对 chunk 进行 hash 化,正如下图所示,我们变动 chunk2 相关的代码后,其它 chunk 都没有变化,只有 chunk2 的 hash 改变了
output: {
filename: mode === 'production' ? '[name].[chunkhash:8].js' : '[name].js',
chunkFilename: mode === 'production' ? '[id].[chunkhash:8].chunk.js' : '[id].js',
path: getPath(config.outputPath)
}我们通过 http 缓存+webpack hash 缓存策略使得前端项目充分利用了缓存的优势,但是 webpack 之所以需要传说中的 webpack配置工程师 是有原因的,因为 webpack 本身是玄学,还是以上图为例,如果你 chunk2的相关代码去除了一个依赖或者引入了新的但是已经存在工程中依赖,会怎么样呢?
我们正常的期望是,只有 chunk2 发生变化了,但是事实上是大量不相干的 chunk 的 hash 发生了变动,这就导致我们缓存策略失效了,下图是变更后的 hash,我们用红圈圈起来的都是 hash 变动的,而事实上我们只变动了 chunk2 相关的代码,为什么会这样呢?
原因是 webpack 会给每个 chunk 搭上 id,这个 id 是自增的,比如 chunk 0 中的id 为 0,一旦我们引入新的依赖,chunk 的自增会被打乱,这个时候又因为 hashchunk 根据内容生成 hash,这就导致了 id 的变动致使 hashchunk 发生巨变,虽然代码内容根本没有变化。
这个问题我们需要额外引入一个插件HashedModuleIdsPlugin,他用非自增的方式进行 chunk id 的命名,可以解决这个问题,虽然 webpack 号称 0 配置了,但是这个常用功能没有内置,要等到下个版本了。
webpack hash缓存相关内容建议阅读此文章 作为拓展
在白屏结束之后,页面开始渲染,但是此时的页面还只是出现个别无意义的元素,比如下拉菜单按钮、或者乱序的元素、导航等等,这些元素虽然是页面的组成部分但是没有意义.
什么是有意义?
对于搜索引擎用户是完整搜索结果
对于微博用户是时间线上的微博内容
对于淘宝用户是商品页面的展示
那么在FCP 和 FMP 之间虽然开始绘制页面,但是整个页面是没有意义的,用户依然在焦虑等待,而且这个时候可能出现乱序的元素或者闪烁的元素,很影响体验,此时我们可能需要进行用户体验上的一些优化。
Skeleton是一个好方法,Skeleton现在已经很开始被广泛应用了,它的意义在于事先撑开即将渲染的元素,避免闪屏,同时提示用户这要渲染东西了,较少用户焦虑。
比如微博的Skeleton就做的很不错
在不同框架上都有相应的Skeleton实现
React: antd 内置的骨架图Skeleton方案
Vue: vue-skeleton-webpack-plugin
以 vue-cli 3 为例,我们可以直接在vue.config.js 中配置
//引入插件
const SkeletonWebpackPlugin = require('vue-skeleton-webpack-plugin');
module.exports = {
// 额外配置参考官方文档
configureWebpack: (config)=>{
config.plugins.push(new SkeletonWebpackPlugin({
webpackConfig: {
entry: {
app: path.join(__dirname, './src/Skeleton.js'),
},
},
minimize: true,
quiet: true,
}))
},
//这个是让骨架屏的css分离,直接作为内联style处理到html里,提高载入速度
css: {
extract: true,
sourceMap: false,
modules: false
}
}然后就是基本的 vue 文件编写了,直接看文档即可。
当有意义的内容渲染出来之后,用户会尝试与页面交互,这个时候页面并不是加载完毕了,而是看起来页面加载完毕了,事实上这个时候 JavaScript 脚本依然在密集得执行.
我们看到在页面已经基本呈现的情况下,依然有大量的脚本在执行
这个时候页面并不是可交互的,直到TTI 的到来,TTI 到来之后用户就可以跟页面进行正常交互的,TTI 一般没有特别精确的测量方法,普遍认为满足**FMP && DOMContentLoader事件触发 && 页面视觉加载85%**这几个条件后,TTI 就算是到来了。
在页面基本呈现到可以交互这段时间,绝大部分的性能消耗都在 JavaScript 的解释和执行上,这个时候决定 JavaScript 解析速度的无非一下两点:
JavaScript 的体积问题我们上一节交代过了一些,我们可以用SplitChunksPlugin拆库的方法减小体积,除此之外还有一些方法,我们下文会交代。
Tree Shaking虽然出现很早了,比如js基础库的事实标准打包工具 rollup 就是Tree Shaking的祖师爷,react用 rollup 打包之后体积减少了 30%,这就是Tree Shaking的厉害之处。
Tree Shaking的作用就是,通过程序流分析找出你代码中无用的代码并剔除,如果不用Tree Shaking那么很多代码虽然定义了但是永远都不会用到,也会进入用户的客户端执行,这无疑是性能的杀手,Tree Shaking依赖es6的module模块的静态特性,通过分析剔除无用代码.
目前在 webpack4.x 版本之后在生产环境下已经默认支持Tree Shaking了,所以Tree Shaking可以称得上开箱即用的技术了,但是并不代表Tree Shaking真的会起作用,因为这里面还是有很多坑.
坑 1: Babel 转译,我们已经提到用Tree Shaking的时候必须用 es6 的module,如果用 common.js那种动态module,Tree Shaking就失效了,但是 Babel 默认状态下是启用 common.js的,所以需要我们手动关闭.
坑 2: 第三方库不可控,我们已经知道Tree Shaking的程序分析依赖 ESM,但是市面上很多库为了兼容性依然只暴露出了ES5 版本的代码,这导致Tree Shaking对很多第三方库是无效的,所以我们要尽量依赖有 ESM 的库,比如之前有一个 ESM 版的 lodash(lodash-es),我们就可以这样引用了import { dobounce } from 'lodash-es'
polyfill是为了浏览器兼容性而生,是否需要 polyfill 应该有客户端的浏览器自己决定,而不是开发者决定,但是我们在很长一段时间里都是开发者将各种 polyfill 打包,其实很多情况下导致用户加载了根本没有必要的代码.
解决这个问题的方法很简单,直接引入 <script src="https://cdn.polyfill.io/v2/polyfill.min.js"></script> 即可,而对于 Vue 开发者就更友好了,vue-cli 现在生成的模板就自带这个引用.
这个原理就是服务商通过识别不同浏览器的浏览器User Agent,使得服务器能够识别客户使用的操作系统及版本、CPU 类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等,然后根据这个信息判断是否需要加载 polyfill,开发者在浏览器的 network 就可以查看User Agent。
既然 polyfill 能动态加载,那么 es5 和 es6+的代码能不能动态加载呢?是的,但是这样有什么意义呢?es6 会更快吗?
我们得首先明确一点,一般情况下在新标准发布后,浏览器厂商会着重优化新标准的性能,而老的标准的性能优化会逐渐停滞,即使面向未来编程,es6 的性能也会往越来越快的方向发展.
其次,我们平时编写的代码可都es6+,而发布的es5是经过babel 或者 ts 转译的,在大多数情况下,经过工具转译的代码往往被比不上手写代码的性能,这个性能对比网站 的显示也是如此,虽然 babel 等转译工具都在进步,但是仍然会看到转译后代码的性能下降,尤其是对 class 代码的转译,其性能下降是很明显的.
最后,转译后的代码体积会出现代码膨胀的情况,转译器用了很多奇技淫巧将 es6 转为 es5 导致了代码量剧增,使用 es6就代表了更小的体积.
那么如何动态加载 es6 代码呢?秘诀就是<script type="module">这个标签来判断浏览器是否支持 es6,我之前在掘金上看到了一篇翻译的文章 有详细的动态打包过程,可以拓展阅读.
体积大小对比
执行时间对比
双方对比的结果是,es6 的代码体积在小了一倍的同时,性能高出一倍.
我们在上文中已经通过SplitChunksPlugin将第三方库进行了抽离,但是在首屏加载过程中依然有很多冗余代码,比如我们的首页是个登录界面,那么其实用到的代码很简单
登录界面的代码是很少的,为什么不只加载登录界面的代码呢?
这就需要我们进行对代码在路由级别的拆分,除了基础的框架和 UI 库之外,我们只需要加载当前页面的代码即可,这就有得用到Code Splitting技术进行代码分割,我们要做的其实很简单.
我们得先给 babel 设置plugin-syntax-dynamic-import这个动态import 的插件,然后就可以就函数体内使用 import 了.
对于Vue 你可以这样引入路由
export default new Router({
routes: [
{
path: '/',
name: 'Home',
component: Home
},
{
path: '/login',
name: 'login',
component: () => import('@components/login')
}
]你的登录页面会被单独打包.
对于react,其内置的 React.lazy() 就可以动态加载路由和组件,效果与 vue 大同小异,当然 lazy() 目前还没有支持服务端渲染,如果想在服务端渲染使用,可以用React Loadable.
路由其实是一个大组件,很多时候人们忽略了路由跳转之间的加载优化,更多的时候我们的精力都留在首屏加载之上,但是路由跳转间的加载同样重要,如果加载过慢同样影响用户体验。
我们不可忽视的是在很多时候,首屏的加载反而比路由跳转要快,也更容易优化。
比如石墨文档的首页是这样的:
一个非常常见的官网首页,代码量也不会太多,处理好第三方资源的加载后,是很容易就达到性能要求的页面类型.
加载过程不过几秒钟,而当我跳转到真正的工作界面时,这是个类似 word 的在线编辑器
我用 Lighthouse 的测试结果是,可交互时间高达17.2s
这并不是石墨做得不够好,而是对于这种应用型网站,相比于首屏,工作页面的跳转加载优化难度更大,因为其工作页面的代码量远远大于一个官网的代码量和复杂度.
我们看到在加载过程中有超过 6000ms 再进行 JavaScript 的解析和执行
Code Splitting不仅可以进行路由分割,甚至可以进行组件级别的代码分割,当然是用方式也是大同小异,组件的级别的分割带来的好处是我们可以在页面的加载中只渲染部分必须的组件,而其余的组件可以按需加载.
就比如一个Dropdown(下拉组件),我们在渲染初始页面的时候下拉的Menu(菜单组件)是没必要渲染的,因为只有点击了Dropdown之后Menu 才有必要渲染出来.
路由分割 vs 组件分割
我们可以以一个demo 为例来分析一下组件级别分割的方法与技巧.
我们假设一个场景,比如我们在做一个打卡应用,有一个需求是我们点击下拉菜单选择相关的习惯,查看近一周的打卡情况.
我们的 demo 是这样子:
我们先对比一下有组件分割和无组件分割的资源加载情况(开发环境下无压缩)
无组件分割,我们看到有一个非常大的chunk,因为这个组件除了我们的代码外,还包含了 antd 组件和 Echarts 图表以及 React 框架部分代码
组件分割后,初始页面体积下降明显,路由间跳转的初始页面加载体积变小意味着更快的加载速度
其实组件分割的方法跟路由分割差不多,也是通过 lazy + Suspense 的方法进行组件懒加载
// 动态加载图表组件
const Chart = lazy(() => import(/* webpackChunkName: 'chart' */'./charts'))
// 包含着图表的 modal 组件
const ModalEchart = (props) => (
<Modal
title="Basic Modal"
visible={props.visible}
onOk={props.handleOk}
onCancel={props.handleCancel}
>
<Chart />
</Modal>
)我们通过组件懒加载将页面的初始渲染的资源体积降低了下来,提高了加载性能,但是组件的性能又出现了问题,还是上一个 demo,我们把初始页面的 3.9m 的体积减少到了1.7m,页面的加载是迅速了,但是组件的加载却变慢了.
原因是其余的 2m 资源的压力全部压在了图表组件上(Echarts 的体积缘故),因此当我们点击菜单加载图表的时候会出现 1-2s 的 loading 延迟,如下:
我们能不能提前把图表加载进来,避免图表渲染中加载时间过长的问题?这种提前加载的方法就是组件的预加载.
原理也很简单,就是在用户的鼠标还处于 hover 状态的时候就开始触发图表资源的加载,通常情况下当用户点击结束之后,加载也基本完成,这个时候图表会很顺利地渲染出来,不会出现延迟.
/**
* @param {*} factory 懒加载的组件
* @param {*} next factory组件下面需要预加载的组件
*/
function lazyWithPreload(factory, next) {
const Component = lazy(factory);
Component.preload = next;
return Component;
}
...
// 然后在组件的方法中触发预加载
const preloadChart = () => {
Modal.preload()
}对于使用 vue 的开发者 keep-alive 这个 API 应该是最熟悉不过了,keep-alive 的作用是在页面已经跳转后依然不销毁组件,保存组件对应的实例在内存中,当此页面再次需要渲染的时候就可以利用已经缓存的组件实例了。
如果大量实例不销毁保存在内存中,那么这个 API 存在内存泄漏的风险,所以要注意调用deactivated销毁
但是在 React 中并没有对应的实现,而官方 issue 中官方也明确不会添加类似的 API,但是给出了两个自行实现的方法
style={{display: 'none'}} 进行控制如果你看了这两个建议就知道不靠谱,redux 已经足够啰嗦了,我们为了缓存状态而利用 redux 这种全局方案,其额外的工作量和复杂度提升是得不偿失的,用 dispaly 控制显示是个很简单的方法,但是也足够粗暴,我们会损失很多可操作的空间,比如动画。
react-keep-alive 在一定程度上解决这个问题,它的原理是利用React 的 Portals API 将缓存组件挂载到根节点以外的 dom 上,在需要恢复的时候再将缓存组件挂在到相应节点上,同时也可以在额外的生命周期 componentWillUnactivate 进行销毁处理。
当然还有很多常见的性能优化方案我们没有提及:
我们着重整理了前端加载阶段的性能优化方案,很多时候只是给出了方向,真正要进行优化还是需要在实际项目中根据具体情况进行分析挖掘才能将性能优化做到最好.
参考链接:
笔者于2018年首发于掘金的文章。
实现一个深克隆是面试中常见的问题的,可是绝大多数面试者的答案都是不完整的,甚至是错误的,这个时候面试官会不断追问,看看你到底理解不理解深克隆的原理,很多情况下一些一知半解的面试者就原形毕漏了.
我们就来看一下如何实现一个深克隆,当然面试中没有让你完整实现的时候,但是你一定要搞清楚其中的坑在哪里,才可以轻松应对面试官的追问.
在要实现一个深克隆之前我们需要了解一下javascript中的基础类型.
JavaScript原始类型:Undefined、Null、Boolean、Number、String、Symbol
JavaScript引用类型:Object
浅克隆之所以被称为浅克隆,是因为对象只会被克隆最外部的一层,至于更深层的对象,则依然是通过引用指向同一块堆内存.
// 浅克隆函数
function shallowClone(o) {
const obj = {};
for ( let i in o) {
obj[i] = o[i];
}
return obj;
}
// 被克隆对象
const oldObj = {
a: 1,
b: [ 'e', 'f', 'g' ],
c: { h: { i: 2 } }
};
const newObj = shallowClone(oldObj);
console.log(newObj.c.h, oldObj.c.h); // { i: 2 } { i: 2 }
console.log(oldObj.c.h === newObj.c.h); // true我们可以看到,很明显虽然oldObj.c.h被克隆了,但是它还与oldObj.c.h相等,这表明他们依然指向同一段堆内存,这就造成了如果对newObj.c.h进行修改,也会影响oldObj.c.h,这就不是一版好的克隆.
newObj.c.h.i = 'change';
console.log(newObj.c.h, oldObj.c.h); // { i: 'change' } { i: 'change' }我们改变了newObj.c.h.i 的值,oldObj.c.h.i也被改变了,这就是浅克隆的问题所在.
当然有一个新的apiObject.assign()也可以实现浅复制,但是效果跟上面没有差别,所以我们不再细说了.
前几年微博上流传着一个传说中最便捷实现深克隆的方法,JSON对象parse方法可以将JSON字符串反序列化成JS对象,stringify方法可以将JS对象序列化成JSON字符串,这两个方法结合起来就能产生一个便捷的深克隆.
const newObj = JSON.parse(JSON.stringify(oldObj));我们依然用上一节的例子进行测试
const oldObj = {
a: 1,
b: [ 'e', 'f', 'g' ],
c: { h: { i: 2 } }
};
const newObj = JSON.parse(JSON.stringify(oldObj));
console.log(newObj.c.h, oldObj.c.h); // { i: 2 } { i: 2 }
console.log(oldObj.c.h === newObj.c.h); // false
newObj.c.h.i = 'change';
console.log(newObj.c.h, oldObj.c.h); // { i: 'change' } { i: 2 }果然,这是一个实现深克隆的好方法,但是这个解决办法是不是太过简单了.
确实,这个方法虽然可以解决绝大部分是使用场景,但是却有很多坑.
主要的坑就是以上几点,我们一一测试下:
// 构造函数
function person(pname) {
this.name = pname;
}
const Messi = new person('Messi');
// 函数
function say() {
console.log('hi');
};
const oldObj = {
a: say,
b: new Array(1),
c: new RegExp('ab+c', 'i'),
d: Messi
};
const newObj = JSON.parse(JSON.stringify(oldObj));
// 无法复制函数
console.log(newObj.a, oldObj.a); // undefined [Function: say]
// 稀疏数组复制错误
console.log(newObj.b[0], oldObj.b[0]); // null undefined
// 无法复制正则对象
console.log(newObj.c, oldObj.c); // {} /ab+c/i
// 构造函数指向错误
console.log(newObj.d.constructor, oldObj.d.constructor); // [Function: Object] [Function: person]我们可以看到在对函数、正则对象、稀疏数组等对象克隆时会发生意外,构造函数指向也会发生错误。
const oldObj = {};
oldObj.a = oldObj;
const newObj = JSON.parse(JSON.stringify(oldObj));
console.log(newObj.a, oldObj.a); // TypeError: Converting circular structure to JSON对象的循环引用会抛出错误.
我们知道要想实现一个靠谱的深克隆方法,上一节提到的序列/反序列是不可能了,而通常教程里提到的方法也是不靠谱的,他们存在的问题跟上一届序列反序列操作中凸显的问题是一致的.
(这个方法也会出现上一节提到的问题)
由于要面对不同的对象(正则、数组、Date等)要采用不同的处理方式,我们需要实现一个对象类型判断函数。
const isType = (obj, type) => {
if (typeof obj !== 'object') return false;
const typeString = Object.prototype.toString.call(obj);
let flag;
switch (type) {
case 'Array':
flag = typeString === '[object Array]';
break;
case 'Date':
flag = typeString === '[object Date]';
break;
case 'RegExp':
flag = typeString === '[object RegExp]';
break;
default:
flag = false;
}
return flag;
};这样我们就可以对特殊对象进行类型判断了,从而采用针对性的克隆策略.
const arr = Array.of(3, 4, 5, 2);
console.log(isType(arr, 'Array')); // true对于正则对象,我们在处理之前要先补充一点新知识.
我们需要通过正则的扩展了解到flags属性等等,因此我们需要实现一个提取flags的函数.
const getRegExp = re => {
var flags = '';
if (re.global) flags += 'g';
if (re.ignoreCase) flags += 'i';
if (re.multiline) flags += 'm';
return flags;
};做好了这些准备工作,我们就可以进行深克隆的实现了.
/**
* deep clone
* @param {[type]} parent object 需要进行克隆的对象
* @return {[type]} 深克隆后的对象
*/
const clone = parent => {
// 维护两个储存循环引用的数组
const parents = [];
const children = [];
const _clone = parent => {
if (parent === null) return null;
if (typeof parent !== 'object') return parent;
let child, proto;
if (isType(parent, 'Array')) {
// 对数组做特殊处理
child = [];
} else if (isType(parent, 'RegExp')) {
// 对正则对象做特殊处理
child = new RegExp(parent.source, getRegExp(parent));
if (parent.lastIndex) child.lastIndex = parent.lastIndex;
} else if (isType(parent, 'Date')) {
// 对Date对象做特殊处理
child = new Date(parent.getTime());
} else {
// 处理对象原型
proto = Object.getPrototypeOf(parent);
// 利用Object.create切断原型链
child = Object.create(proto);
}
// 处理循环引用
const index = parents.indexOf(parent);
if (index != -1) {
// 如果父数组存在本对象,说明之前已经被引用过,直接返回此对象
return children[index];
}
parents.push(parent);
children.push(child);
for (let i in parent) {
// 递归
child[i] = _clone(parent[i]);
}
return child;
};
return _clone(parent);
};我们做一下测试:
function person(pname) {
this.name = pname;
}
const Messi = new person('Messi');
function say() {
console.log('hi');
}
const oldObj = {
a: say,
c: new RegExp('ab+c', 'i'),
d: Messi,
};
oldObj.b = oldObj;
const newObj = clone(oldObj);
console.log(newObj.a, oldObj.a); // [Function: say] [Function: say]
console.log(newObj.b, oldObj.b); // { a: [Function: say], c: /ab+c/i, d: person { name: 'Messi' }, b: [Circular] } { a: [Function: say], c: /ab+c/i, d: person { name: 'Messi' }, b: [Circular] }
console.log(newObj.c, oldObj.c); // /ab+c/i /ab+c/i
console.log(newObj.d.constructor, oldObj.d.constructor); // [Function: person] [Function: person]当然,我们这个深克隆还不算完美,例如Buffer对象、Promise、Set、Map可能都需要我们做特殊处理,另外对于确保没有循环引用的对象,我们可以省去对循环引用的特殊处理,因为这很消耗时间,不过一个基本的深克隆函数我们已经实现了。
实现一个完整的深克隆是由许多坑要踩的,npm上一些库的实现也不够完整,在生产环境中最好用lodash的深克隆实现.
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.



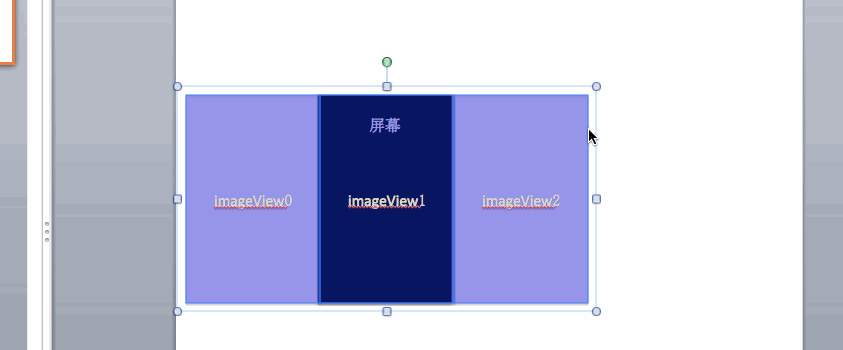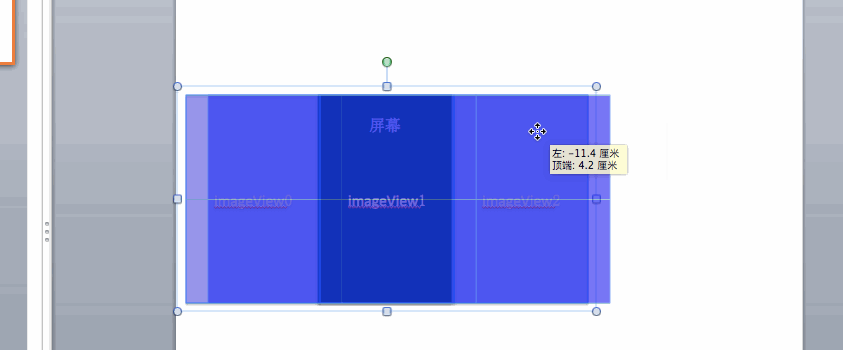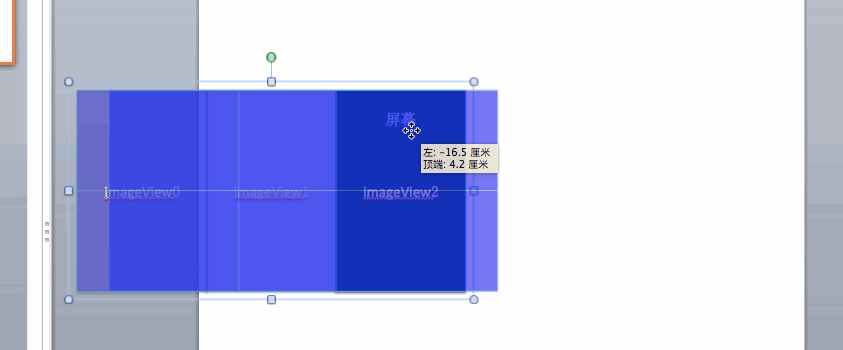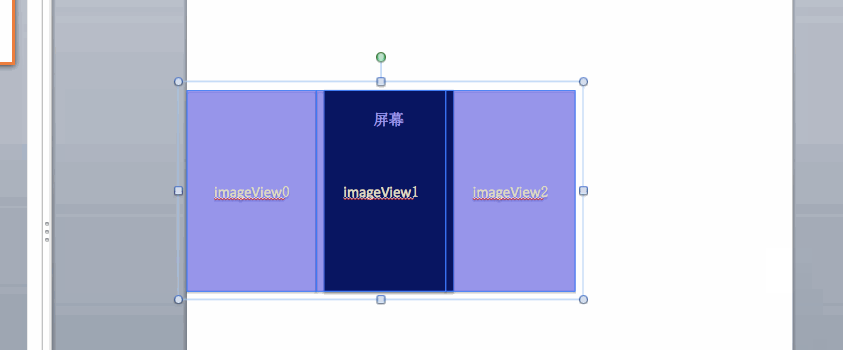{kind=link}