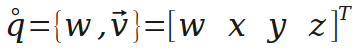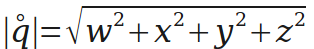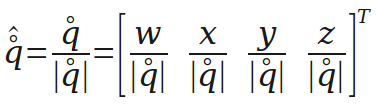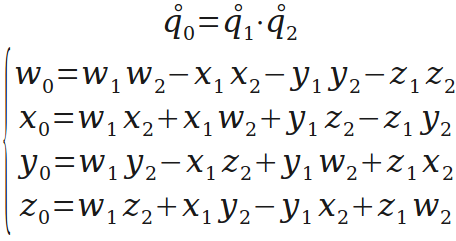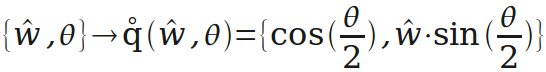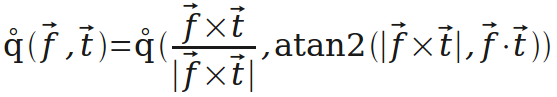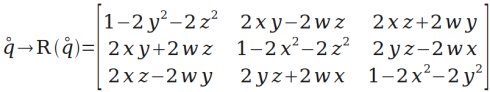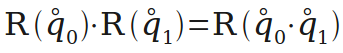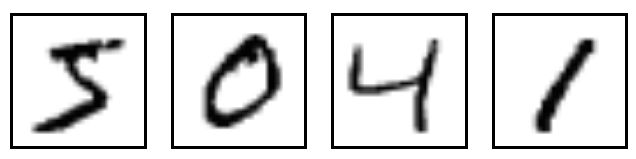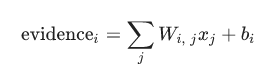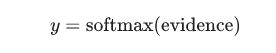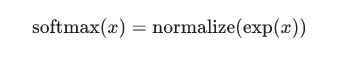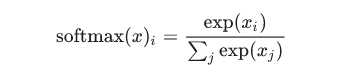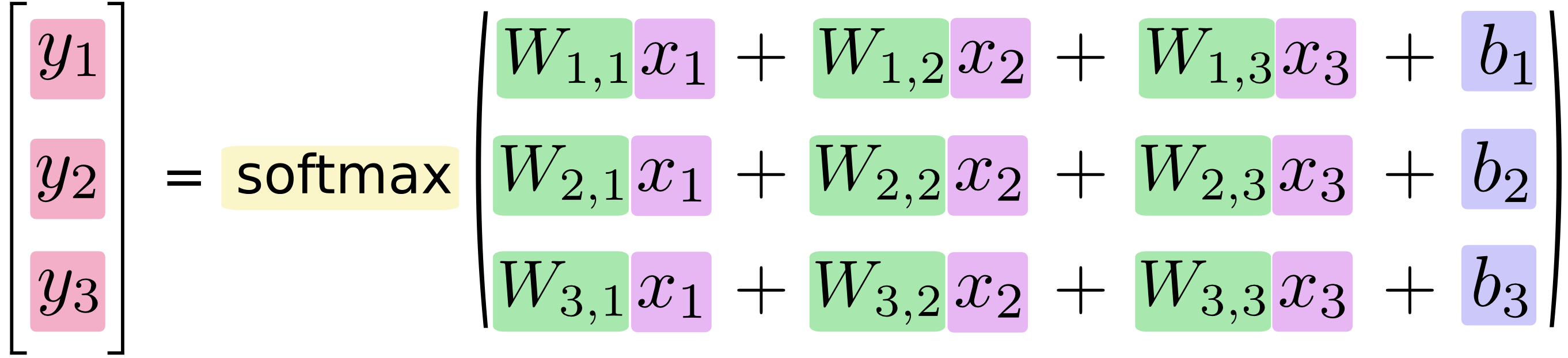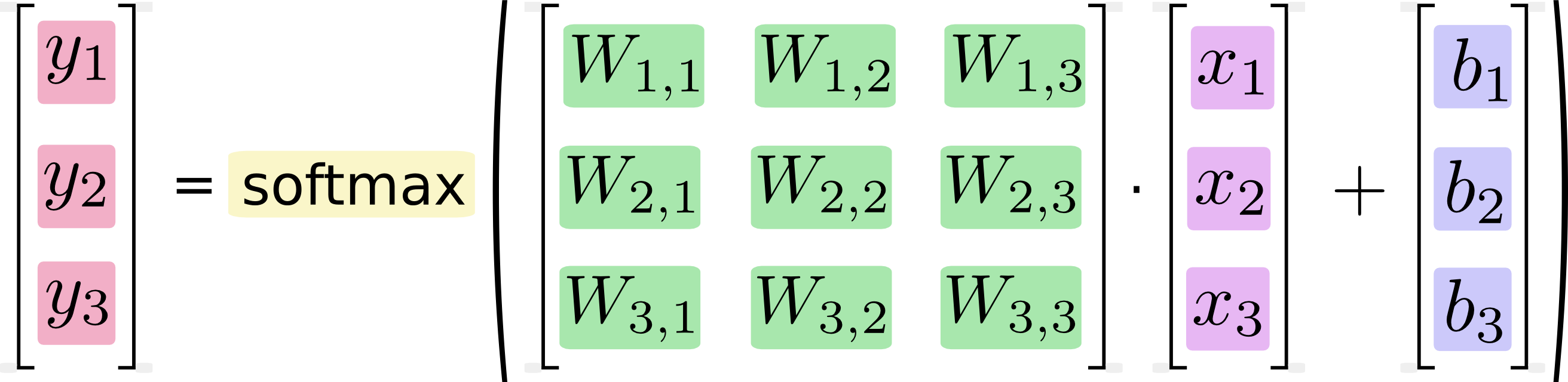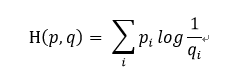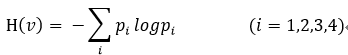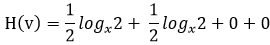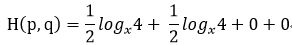wwminger / learningnote Goto Github PK
View Code? Open in Web Editor NEWmy own learning notes
my own learning notes








稳压二极管是一个特殊的面接触型的半导体硅二极管,其V-A特性曲线与普通二极管相似,但反向击穿曲线比较陡。稳压二极管工作于反向击穿区,由于它在电路中与适当电阴配合后能起到稳定电压的作用,故称为稳压管。稳压管反向电压在一定范围内变化时,反向电流很小,当反向电压增高到击穿电压时,反向电流突然猛增,稳压管从而反向击穿,此后,电流虽然在很大范围内变化,但稳压管两端的电压的变化却相当小,利于这一特性,稳压管访问就在电路到起到稳压的作用了。而且,稳压管与其它普能二极管不同之反向击穿是可逆性的,当去掉反向电压稳压管又恢复正常,但如果反向电流超过允许范围,二极管将会发热击穿,所以,与其配合的电阻往往起到限流的作用。
稳压二极管的参数:
(1)稳定电压
(2)电压温度系数
(3)动态电阻
(4)稳定电流 ,最大、最小稳定电流
(5)最大允许功耗
不同种类二极管如何选用
美标稳压二极管型号
1N4727 3V0
1N4728 3V3
1N4729 3V6
1N4730 3V9
1N4731 4V3
1N4732 4V7
1N4733 5V1
1N4734 5V6
1N4735 6V2
1N4736 6V8
1N4737 7V5
1N4738 8V2
1N4739 9V1
1N4740 10V
1N4741 11V
1N4742 12V
1N4743 13V
1N4744 15V
1N4745 16V
1N4746 18V
1N4747 20V
1N4748 22V
1N4749 24V
1N4750 27V
1N4751 30V
1N4752 33V
1N4753 36V
1N4754 39V
1N4755 43V
1N4756 47V
1N4757 51V
需要规格书请到以下地址下载,
http://www.dccomponents.com/products/Rectifiers/Diode/Zener/
经常看到很多板子上有M记的铁壳封装的稳压管,都是以美标的1N系列型号标识的,没有具体的电压值,刚才翻手册查了以下3V至51V的型号与电压的对照值,希望对大家有用
1N4727 3V0
1N4728 3V3
1N4729 3V6
1N4730 3V9
1N4731 4V3
1N4732 4V7
1N4733 5V1
1N4734 5V6
1N4735 6V2
1N4736 6V8
1N4737 7V5
1N4738 8V2
1N4739 9V1
1N4740 10V
1N4741 11V
1N4742 12V
1N4743 13V
1N4744 15V
1N4745 16V
1N4746 18V
1N4747 20V
1N4748 22V
1N4749 24V
1N4750 27V
1N4751 30V
1N4752 33V
1N4753 36V
1N4754 39V
1N4755 43V
1N4756 47V
1N4757 51V
DZ是稳压管的电器编号,是和1N4148和相近的,其实1N4148就是一个0.6V的稳压管,下面是稳压管上的编号对应的稳压值,有些小的稳压管也会在管体上直接标稳压电压,如5V6就是5.6V的稳压管。
1N4728A 3.3
1N4729A 3.6
1N4730A 3.9
1N4731A 4.3
1N4732A 4.7
1N4733A 5.1
1N4734A 5.6
1N4735A 6.2
1N4736A 6.8
1N4737A 7.5
1N4738A 8.2
1N4739A 9.1
1N4740A 10
1N4741A 11
1N4742A 12
1N4743A 13
1N4744A 15
1N4745A 16
1N4746A 18
1N4747A 20
1N4748A 22
1N4749A 24
1N4750A 27
1N4751A 30
1N4752A 33
1N4753A 36
1N4754A 39
1N4755A 43
1N4756A 47
1N4757A 51
1N4758A 56
1N4759A 62
1N4760A 68
1N4761A 75
摩托罗拉IN47系列1W稳压管
IN4728 3.3v
IN4729 3.6v
IN4730 3.9v
IN4731 4.3
IN4732 4.7
IN4733 5.1
IN4734 5.6
IN4735 6.2
IN4736 6.8
IN4737 7.5
IN4738 8.2
IN4739 9.1
IN4740 10
IN4741 11
IN4742 12
IN4743 13
IN4744 15
IN4745 16
IN4746 18
IN4747 20
IN4748 22
IN4749 24
IN4750 27
IN4751 30
IN4752 33
IN4753 34
IN4754 35
IN4755 36
IN4756 47
IN4757 51
摩托罗拉IN52系列 0.5w精密稳压管
IN5226 3.3v
IN5227 3.6v
IN5228 3.9v
IN5229 4.3v
IN5230 4.7v
IN5231 5.1
IN5232 5.6
IN5233 6
IN5234 6.2
IN5235 6.8
IN5236 7.5
IN5237 8.2
IN5238 8.7
IN5239 9.1
IN5240 10
IN5241 11
IN5242 12
IN5243 13
IN5244 14
IN5245 15
IN5246 16
IN5247 17
IN5248 18
IN5249 19
IN5250 20
IN5251 22
IN5252 24
IN5253 25
IN5254 27
IN5255 28
IN5256 30
IN5257 33
IN5730 5.6
IN5731 6.2
IN5732 6.8
IN5733 7.5
IN5734 8.2
IN5735 9.1
IN5736 10
IN5737 11
IN5738 12
IN5739 13
IN5740 15
IN5741 16
IN5742 18
IN5743 20
IN5744 22
IN5745 24
IN5746 27
IN5747 30
IN5748 33
IN5749 36
IN5750 39
IN5985 2.4
IN5986 2.7
IN5987 3
IN5988 3.3
IN5989 3.6
IN5990 3.9
IN5991 4.3
IN5992 4.7
IN5993 5.1
IN5994 5.6
IN5995 6.2
IN5996 6.8
IN5997 7.5
IN5998 8.2
IN5999 9.1
IN6000 10
IN6001 11
IN6002 12
IN6003 13
IN6004 15
IN6005 16
IN6006 18
IN6007 20
IN6008 22
贴片型SOD-123穏压二极管
型号规格标示法
Marking Code SINLOON
SMD SOD-123 Zener Diode
型号 电压 代码标示
Type /Voltage / Marking Code
HZD5221B 2.4V Z21
HZD5222B 2.5V Z22
HZD5223B 2.7V Z23
HZD5224B 2.8V Z24
HZD5225B 3.0V Z25
HZD5226B 3.3V Z26
HZD5227B 3.6V Z27
HZD5228B 3.9V Z28
HZD5229B 4.3V Z29
HZD5230B 4.7V Z30
HZD5231B 5.1V Z31
HZD5232B 5.6V Z32
HZD5233B 6.0V Z33
HZD5234B 6.2V Z34
HZD5235B 6.8V Z35
HZD5236B 7.5V Z36
HZD5237B 8.2V Z37
HZD5238B 8.7V Z38
HZD5239B 9.1V Z39
HZD5240B 10V Z40
HZD5241B 11V Z41
HZD5242B 12V Z42
HZD5243B 13V Z43
HZD5244B 14V Z44
HZD5245B 15V Z45
吴恩达:
深度学习之所以风靡全球,一个重要的因素就是在大数据时代,这种新型人工智能算法表现出来输入数据越多,精度越高的特征,至少比老式的要好,使得数据越多,产品越好,吸引用户越多的良性循环得以实现

互信息量I(xi;yj): 收到消息yj后获得关于xi的信息量。

表示先验的不确定性减去尚存的不确定性, 就是单次通信过程中收信者获得的信息量。

WiFi ESP-1s 采用ai-thinker公司提供的固件。总共有8个管脚,支持多种协议输出,但是UART比较方便。
芯片通过GPIO口上电分为多个模式
下载模式 通过下载模式可以更新固件具体操作参考官网资料
值得注意的是遇到固件写入到99%失败情况,按照售后提供方案,使用2.4版本的软件与低波特率成功刷入新的固件
UART模式 [必须在结尾发送/n即每条指令都是发送新行]可以使用UART发送at指令,并且设置透传,直连微信,通过mtqt连接服务器,发送HTTP请求等功能
HTTP请求
首先通过at指令连接WiFi加入互联网,注意由于字符集的问题,连接不了中文字符的WiFi(或者说涉及中文字符的都出现乱码导致错误应该是utf-8的关系)
配置一系列(依照官网例程)设置后可以启用post与get
注意每次发送都需要按照既定格式,对于HTTP协议,UID,host,字符集选择,发送内容字符长度,一个[空行]
加上HTTP的页面
结束服务器透传使用+++

它表示在输出端收到输出变量Y的符号后对于输入端的变量X尚存在的平均不确定性(存在疑义)。
由于声音分辨的基础是不同的频率,因此在调整速度的同时,频率同时也出现了巨大的变化,提速为2倍的同时频率提升为两倍,对音音高变化非常之大
同时想到了对于演奏的音乐尤其是乐器,交响乐,调节速度会导致音高不准这样的现象,确实是一个问题
lcddisplay.axf: Error: L6218E: Undefined symbol SystemInit (referred from startup_stm32f10x_hd.o).
最近学习STM32,使用软件为KEIL,库使用ST的3.5版本的。在进行编译时出现如上红色字体形式的很多L6218E错误。
通过搜索看到了[一切皆浮云][1](<http: blog.sina.com.cn="" u="" 1412148625="">)博主的《STM32_TEST.axf: Error: L6218E: Undefined symbol SystemInit (referred from startup_stm32f10x_md.o)》文章。 下为其文章全文(有问题原因分析及解决方法):
此问题错误提示已经十分清楚的告诉你错在哪里了,Undefined symbol SystemInit ,翻译过来就是:SystemInit 这个符号没有定义,随后的小括号告诉你了,是在startup_stm32f10x_md.o这个文件里面被提及的,这个.o文件在工程里面并没有,它是一个在编译的时候根据.c/.s文件生成的。所以我们只需要找到工程里面的.s或者.c即可,这里对应这个名字的就是startup_stm32f10x_md.s了。
在此文件里面可以找到SystemInit的所在:
Reset_Handler PROC
EXPORT Reset_Handler [WEAK]
IMPORT __main
IMPORT SystemInit
LDR R0, =SystemInit
BLX R0
LDR R0, =__main
BX R0
ENDP
原来在复位中断服务函数里面,调用了SystemInit这个函数,而这个函数在.s文件里面没有定义。
所以解决的办法有两个。
1,在外部(其他任何.c文件里面)定义SystemInit这个函数,哪怕是个空函数也可以。
2,把** LDR R0, =SystemInit
BLX R0**
这两句话去掉。
如果按上方式不能解决问题,你可按下面的方法尝试解决(下面的问题仍以
出现lcddisplay.axf: Error: L6218E: Undefined symbol SystemInit (referred from startup_stm32f10x_hd.o错误来说明。
1.根据问题提示,我们可知SystemInit 未定义,随后的小括号告诉你了,是在startup_stm32f10x_hd.o这个文件里面被提及的,这个.o文件在工程里面并没有,它是一个在编译的时候根据.c/.s文件生成的。所以我们只需要找到工程里面的.s或者.c即可,这里对应这个名字的就是startup_stm32f10x_hd.s了.我们使用的startup_stm32f10x_hd.s为ST公司提供的标准文件,基本可排除其文件出现问题,同时ST提供的库中会包含所有的的定义,因此我们可以得出问题的原因:定义SystemInit的文件没有包含在工程中。
2.确认未包含的文件。
通过ST提供的库中的帮助文件,我们可以快速的确定具体的文件。
2.1打开帮助文档
2.2使用索引工具,输入SystemInit
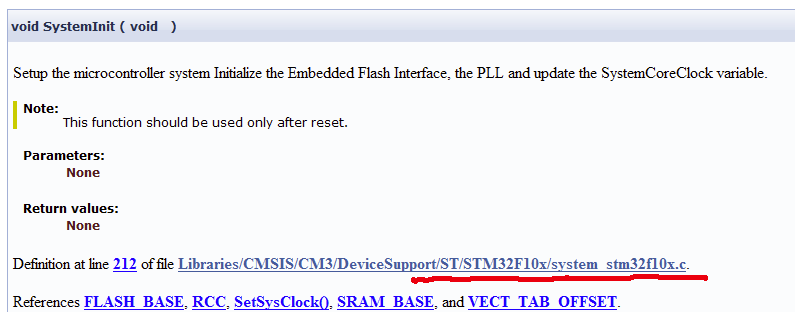
2.3进入相应的项,可以得到SystemInit的定义信息及涉及的文件及其路径
3.将文件加入工程中。
4.问题解决。

通常情况下,“交叉熵”(cross-entropy)是非常适用于评估模型的损益值大小。交叉熵的概念来自于信息论的中关于信息压缩与编码的讨论,但是在博弈论、机器学习等其他许多领域也是重要的**。他的数学定义是:

q表示预测的概率分布,p表示真实分布(图片标签的分布)。简单的说,交叉熵就是描述当前模型距离真实的数据值还有多少差距。


锁相环路是一种反馈控制电路,简称锁相环(PLL,Phase-Locked Loop)。锁相环的特点是:利用外部输入的参考信号控制环路内部振荡信号的频率和相位。
DLL:一般在altera公司的产品上出现PLL的多,而xilinux公司的产品则更多的是DLL,开始本人也以为是两个公司的不同说法而已,后来在论坛上见到有人在问两者的不同,细看下,原来真是两个不一样的家伙。DLL是基于数字抽样方式,在输入时钟和反馈时钟之间插入延迟,使输入时钟和反馈时钟的上升沿一致来实现的。又称数字锁相环。
PLL:使用了电压控制延迟,用VCO来实现和DLL中类试的延迟功能。又称模拟锁相环。功能上都可以实现倍频、分频、占空比调整,但是PLL调节范围更大,比如说:XILINX使用DLL,只能够2、4倍频;ALTERA的PLL可以实现的倍频范围就更大毕竟一个是模拟的、一个是数字的。两者之间的对比:对于PLL,用的晶振存在不稳定性,而且会累加相位错误,而DLL在这点上做的好一些,抗噪声的能力强些;但PLL在时钟的综合方面做得更好些。总的来说PLL的应用多,DLL则在jitter power precision等方面优于PLL。
目前大多数FPGA厂商都在FPGA内部集成了硬的DLL(Delay-Locked Loop)或者PLL(Phase-Locked Loop),用以完成时钟的高精度、低抖动的倍频、分频、占空比调整移相等。目前高端FPGA产品集成的DLL和PLL资源越来越丰富,功能越来越复杂,精度越来越高(一般在ps的数量级)。Xilinx芯片主要集成的是DLL,而Altera芯片集成的是PLL。Xilinx芯片DLL的模块名称为CLKDLL,在高端FPGA中,CLKDLL的增强型模块为DCM(Digital Clock Manager)。
Altera芯片的PLL模块也分为增强型PLL(Enhanced PLL)和高速(Fast PLL)等。这些时钟模块的生成和配置方法一般分为两种,一种是在HDL代码和原理图中直接实例化,另一种方法是在IP核生成器中配置相关参数,自动生成IP。Xilinx的IP核生成器叫Core Generator,另外在Xilinx ISE 5.x版本中通过Archetecture Wizard生成DCM模块。Altera的IP核生成器叫做MegaWizard。另外可以通过在综合、实现步骤的约束文件中编写约束属性完成时钟模块的约束。
PLL是英文Phase Lock Loop的缩写,中文名称为“锁相环”。说到频率信号的产生我们知道有很多种方法,其中在固定形状和大小的石英晶体上加电压就可以产生一个非常稳定的频率信号,因此常常用于高精度仪器上作为基准频率使用,早期电脑主板上的外频通常是由石英晶体直接产生的,通过倍频或分频电路来获得不同频率的信号让主板各个电路协调工作,因此在Pentium时代之前的前辈们在给CPU超频时往往需要采用更换晶体的方式,费力而麻烦。
为了能够在很宽的范围内随意产生任何高精度的频率信号,PLL电路诞生了。PLL电路的工作原理比较简单,它由**鉴相器、充电泵、环路滤波器和一个振荡器(VCO)**构成。PLL电路刚接通电源时,VCO内部由变容二极管组成的RCL电路开始振荡而产生一个并不规范的频率,该频率经过分频电路降频后被送到鉴相器与石英晶体产生的基准频率进行相位的对比,发现VCO产生的频率偏离电路设定时就根据偏差的方向由充电泵产生一个矫正电压,该电压经过环路滤波器后送入VCO内的可变二极管上,随着可变二极管上工作电压的变化,其内部电容容量也会发生变化,VCO的振荡频率开始改变并趋近电路设定的频率,一旦两者频率信号的相位同步,鉴相器检测出来的相位误差就接近0,VCO内变容二极管两端的电压就固定不变,PLL电路就开始输出设定的频率信号并开始正常工作了。
由于PLL电路输出的时钟信号的频率可以在很大范围内变化,而且调整速度快,信号稳定,我们只要改变基准频率的大小或加入不同的修正电压就能随意的改变VCO输出的频率大小,也正是因为PLL电路灵活方便的特性,现在很多需要产生高质量频率信号的电路中都能见到PLL的身影。
DLL和PLL是两个完全不同的东西,用在不同的地方。
DLL-Delay locked loop用在数字电路中,用来自动调节一路信号的延时,使两路信号的相位一致(边沿对齐),在需要某些数字信号(比如data bus上的信号)与系统时钟同步的情况下,DLL将两路clock的边沿对齐(实际上是使被调节的clock滞后系统clock 整数个周期),用被调节的clock做控制信号,就可以产生与系统时钟严格同步的信号(比如输出数据data跟输入clock同步,边沿的延时不受到电压、温度、频率影响)。PLL--Phase locked loop除了用作相位跟踪(输出跟输入同频同相,这种情况下跟DLL有点相似)外,可以用来做频率综合(frequency synthesizer),输出频率稳定度跟高精度低漂移参考信号(比如温补晶振)几乎相当的高频信号,这时,它是一个频率源。利用PLL,可以方便地产生不同频率的高质量信号,PLL输出的信号抖动(频域上表现为相噪)跟它的环路带宽,鉴相频率大小有关。总的说来,PLL的环路带宽越小,鉴相频率越高,它的相位噪声越小(时域上抖动也越小)。
由于在实际ADC系统中,采样系统总的动态特性主要取决于采样时钟的抖动特性,如果对频率要求不是太高,VCXO是比较好的选择。
如果确实需要可变频率低抖动时钟,则基于PLL的时钟发生器是最好选择。
锁相环的基本组成
锁相环路是一种反馈控制电路,简称锁相环(PLL,Phase-Locked Loop)。锁相环的特点是:利用外部输入的参考信号控制环路内部振荡信号的频率和相位。因锁相环可以实现输出信号频率对输入信号频率的自动跟踪,所以锁相环通常用于闭环跟踪电路。锁相环在工作的过程中,当输出信号的频率与输入信号的频率相等时,输出电压与输入电压保持固定的相位差值,即输出电压与输入电压的相位被锁住,这就是锁相环名称的由来。锁相环通常由鉴相器(PD,Phase Detector)、环路滤波器(LF,Loop Filter)和压控振荡器(VCO,Voltage Controlled Oscillator)三部分组成
锁相环电路的特点:
H(Y|X)
已知X后,对Y仍然存在的平均不确定度,如果信道不存在任何噪声,发送端和接收端必然存在确定的对因故干系,发出X后必能确定对应的Y,而现在不能完全确定对应的Y,这显然是由信道噪声引起的。
解释最小错误概率译码准则,最大似然译码准则和最小距离译码准则,说明三者的关答:
最小错误概率译码准则下,将接收序列译为后验概率最大时所对应的码字。
最大似然译码准则下,将接收序列译为信道传递概率最大时所对应的码字。
最小距离译码准则下,将接收序列译为与其距离最小的码字。
三者关系为:输入为等概率分布时,最大似然译码准则等效于最小错误概率译码准则。在二元对称无记忆信道中,最小距离译码准则等效于最大似然译码准则。
稳态概率计算

计算例子:



马尔可夫的信息熵应该是其平均符号熵的极限植,即计算

对于一阶马尔科夫有

对于一般的时齐、遍历马尔可夫信源有

在唯一可译码中,如果u是一信号字母串,由码元C={C1,C2,C3,…}中的码元前后排列而成,把字母串u从左到右来读,当码元一出现,就可以确定该码元所对应的消息字符,那么这个码称为即时码。
头文件:#include <stdio.h>
sprintf()函数用于将格式化的数据写入字符串,其原型为:
int sprintf(char *str, char * format [, argument, ...]);
【参数】str为要写入的字符串;format为格式化字符串,与printf()函数相同;argument为变量。
除了前两个参数类型固定外,后面可以接任意多个参数。而它的精华,显然就在第二个参数--格式化字符串--上。 printf()和sprintf()都使用格式化字符串来指定串的格式,在格式串内部使用一些以“%”开头的格式说明符(format specifications)来占据一个位置,在后边的变参列表中提供相应的变量,最终函数就会用相应位置的变量来替代那个说明符,产生一个调用者想要的字符串。
sprintf()最常见的应用之一莫过于把整数打印到字符串中,如:
sprintf(s, "%d", 123); //把整数123打印成一个字符串保存在s中
sprintf(s, "%8x", 4567); //小写16进制,宽度占8个位置,右对齐
sprintf的作用是将一个格式化的字符串输出到一个目的字符串中,而printf是将一个格式化的字符串输出到屏幕。sprintf的第一个参数应该是目的字符串,如果不指定这个参数,执行过程中出现 "该程序产生非法操作,即将被关闭...."的提示。
sprintf()会根据参数format 字符串来转换并格式化数据,然后将结果复制到参数str 所指的字符串数组,直到出现字符串结束('\0')为止。关于参数format 字符串的格式请参考printf()。
【返回值】成功则返回参数str 字符串长度,失败则返回-1,错误原因存于errno 中。
注意:C语言对数组进行操作时并不检测数组的长度,如果str的长度不够,sprintf()很容易造成缓冲区溢出,带来意想不到的后果,黑客经常利用这个弱点攻击看上去安全的系统。请看下面的代码:
#include <stdio.h>
main()
{
char buf[10];
sprintf(buf, "The length of the string is more than 10");
printf("%s", buf);
}
编译并运行,屏幕上输出”The length of the string is more than 10“,同时系统提示程序已经停止。原因就是要写入的字符串的长度超过了buf的长度,造成缓冲区溢出。
使用snprintf()来代替sprintf()将能够很好的解决这个问题。
【实例】打印字母a的ASCII值。
#include <stdio.h>
main()
{
char a = 'a';
char buf[80];
sprintf(buf, "The ASCII code of a is %d.", a);
printf("%s", buf);
}
运行结果:
The ASCII code of a is 97.
又如,产生10个100以内的随机数并输出。
#include<stdio.h>
#include<stdlib.h>
#include<time.h>
int main(void)
{
char str[100];
int offset =0;
int i=0;
srand(time(0)); // *随机种子
for(i = 0;i<10;i++)
{
offset+=sprintf(str+offset,"%d,",rand()%100); // 格式化的数据写入字符串
}
str[offset-1]='\n';
printf(str);
return 0;
}
运行结果:
74,43,95,95,44,90,70,23,66,84
例子使用了一个新函数srand(),它能产生随机数。例子中最复杂的部分是for循环中每次调用函数sprintf()往字符数组写数据的时候,str+foffset为每次写入数据的开始地址,最终的结果是所有产生的随机数据都被以整数的形式存入数组中。
过采样频率: 增加一位分辨率或每减小6dB 的噪声,需要以4 倍的采样频率fs 进行过采样.
假设一个系统使用12 位的ADC,每秒输出一个温度值(1Hz),为了将测量分辨率增加到16 位,按下式计算过采样频率: fos=4^4*1(Hz)=256(Hz)。
下面简要介绍常用的几种类型的基本原理及特点:积分型、逐次逼近型、并行比较型/串并行型、Σ-Δ调制型、电容阵列逐次比较型及压频变换型。
?
1)积分型(如TLC7135)
积分型AD工作原理是将输入电压转换成时间(脉冲宽度信号)或频率(脉冲频率),然后由定时器/计数器获得数字值。其优点是用简单电路就能获得高分辨率,抗干扰能力强(为何抗干扰性强?原因假设一个对于零点正负的白噪声干扰,显然一积分,则会滤掉该噪声), 但缺点是由于转换精度依赖于积分时间,因此转换速率极低。初期的单片AD转换器大多采用积分型,现在逐次比较型已逐步成为主流。
2)逐次比较型SAR(如TLC0831)
逐次比较型AD由一个比较器和DA转换器通过逐次比较逻辑构成,从MSB开始,顺序地对每一位将输入电压与内置DA转换器输出进行比较,经n次比较而输出 数字值。其电路规模属于中等。其优点是速度较高、功耗低,在低分辩率(<12位)时价格便宜,但高精度(>12位)时价格很高。
3)并行比较型/串并行比较型(如TLC5510)
并行比较型AD采用多个比较器,仅作一次比较而实行转换,又称FLash(快速)型。由于转换速率极高,n位的转换需要2n-1个比较器,因此电路规模也极大,价格也高,只适用于视频AD转换器等速度特别高的领域。 串并行比较型AD结构上介于并行型和逐次比较型之间,最典型的是由2个n/2位的并行型AD转换器配合DA转换器组成,用两次比较实行转换,所以称为 Half flash(半快速)型。还有分成三步或多步实现AD转换的叫做分级(Multistep/Subrangling)型AD,而从转换时序角度 又可称为流水线(Pipelined)型AD,现代的分级型AD中还加入了对多次转换结果作数字运算而修正特性等功能。这类AD速度比逐次比较型高,电路 规模比并行型小。
4)Σ-Δ(Sigma delta)调制型(如AD7705)
Σ-Δ型AD由积分器、比较器、1位DA转换器和数字滤波器等组成。原理上近似于积分型,将输入电压转换成时间(脉冲宽度)信号,用数字滤波器处理后得到数字值。电路的数字部分基本上容易单片化,因此容易做到高分辨率。主要用于音频和测量。
5)电容阵列逐次比较型
电容阵列逐次比较型AD在内置DA转换器中采用电容矩阵方式,也可称为电荷再分配型。一般的电阻阵列DA转换器中多数电阻的值必须一致,在单芯片上生成高 精度的电阻并不容易。如果用电容阵列取代电阻阵列,可以用低廉成本制成高精度单片AD转换器。最近的逐次比较型AD转换器大多为电容阵列式的。
6)压频变换型(如AD650)
压频变换型(Voltage-Frequency Converter)是通过间接转换方式实现模数转换的。其原理是首先将输入的模拟信号转换成频率,然 后用计数器将频率转换成数字量。从理论上讲这种AD的分辨率几乎可以无限增加,只要采样的时间能够满足输出频率分辨率要求的累积脉冲个数的宽度。其优点是 分辩率高、功耗低、价格低,但是需要外部计数电路共同完成AD转换。
1)分辩率(Resolution)
指数字量变化一个最小量时模拟信号的变化量,定义为满刻度与2n的比值。分辩率又称精度,通常以数字信号的位数来表示。
- 转换速率(Conversion Rate)
是指完成一次从模拟转换到数字的AD转换所需的时间的倒数。**积分型AD的转换时间是毫秒级属低速AD,逐次比 较型AD是微秒级属中速AD,全并行/串并行型AD可达到纳秒级。**采样时间则是另外一个概念,是指两次转换的间隔。为了保证转换的正确完成,采样速率 (Sample Rate)必须小于或等于转换速率。因此有人习惯上将转换速率在数值上等同于采样速率也是可以接受的。常用单位是ksps和Msps,表 示每秒采样千/百万次(kilo / Million Samples per Second)。
3)量化误差 (Quantizing Error)
由于AD的有限分辩率而引起的误差,即有限分辩率AD的阶梯状转移特性曲线与无限分辩率AD(理想AD)的转移特 性曲线(直线)之间的最大偏差。通常是1 个或半个最小数字量的模拟变化量,表示为1LSB、1/2LSB。
4)偏移误差(Offset Error)
输入信号为零时输出信号不为零的值,可外接电位器调至最小。
5)满刻度误差(Full Scale Error)
满度输出时对应的输入信号与理想输入信号值之差。
6)线性度(Linearity)
实际转换器的转移函数与理想直线的最大偏移,不包括以上三种误差。
说精度之前,首先要说分辨率。最近已经有贴子热门讨论了这个问题,结论是分辨率决不等同于精度。比如一块精度0.2%(或常说的准确度0.2级)的四位半万用表,测得A点电压1.0000V,B电压1.0005V,可以分辨出B比A高0.0005V,但A点电压的真实值可能在0.9980~1.0020之间不确定。
那么,既然数字万用表存在着精度和分辨率两个指标,那么,对于ADC和DAC,除了分辨率以外,也存在精度的指标。
模数器件的精度指标是用积分非线性度(Interger NonLiner)即INL值来表示。也有的器件手册用 Linearity error 来表示。**INL表示了ADC器件在所有的数值点上对应的模拟值,和真实值之间误差最大的那一点的误差值。**也就是,输出数值偏离线性最大的距离。单位是LSB(即最低位所表示的量)。
比如12位ADC:TLC2543,INL值为1LSB。那么,如果基准4.095V,测某电压得的转换结果是1000,那么,真实电压值可能分布在0.999~1.001V之间。对于DAC也是类似的。比如DAC7512,INL值为8LSB,那么,如果基准4.095V,给定数字量1000,那么输出电压可能是0.992~1.008V之间。
下面再说DNL值。理论上说,模数器件相邻量个数据之间,模拟量的差值都是一样的。就相一把疏密均匀的尺子。但实际并不如此。一把分辨率1毫米的尺子,相邻两刻度之间也不可能都是1毫米整。那么,ADC相邻两刻度之间最大的差异就叫差分非线性值(Differencial NonLiner)。 DNL值如果大于1,那么这个ADC甚至不能保证是单调的,输入电压增大,在某个点数值反而会减小。 这种现象在SAR(逐位比较)型ADC中很常见。
举个例子,某12位ADC,INL=8LSB,DNL=3LSB(性能比较差),基准4.095V,测A电压读数1000,测B电压度数1200。那么,可判断B点电压比A点高197~203mV。而不是准确的200mV。对于DAC也是一样的,某DAC的DNL值3LSB。那么,如果数字量增加200,实际电压增加量可能在197~203mV之间。
**很多分辨率相同的ADC,价格却相差很多。除了速度、温度等级等原因之外,就是INL、DNL这两个值的差异了。**比如AD574,贵得很,但它的INL值就能做到0.5LSB,这在SAR型ADC中已经很不容易了。换个便宜的2543吧,速度和分辨率都一样,但INL值只有1~1.5LSB,精度下降了3倍。
另外,工艺和原理也决定了精度。比如SAR型ADC,由于采用了R-2R或C-2C型结构,使得高权值电阻的一点点误差,将造成末位好几位的误差。在SAR型ADC的2^n点附近,比如128、1024、2048、切换权值点阻,误差是最大的。1024值对应的电压甚至可能会比1023值对应电压要小。这就是很多SAR型器件DNL值会超过1的原因。但SAR型ADC的INL值都很小,因为权值电阻的误差不会累加。
和SAR型器件完全相反的是阶梯电阻型模数/数模器件。比如TLC5510、DAC7512等低价模数器件。比如7512,它由4095个电阻串联而成。每个点阻都会有误差,一般电阻误差5%左右,当然不会离谱到100%,更不可能出现负数。因此这类器件的DNL值都很小,保证单调。但是,每个电阻的误差,串联后会累加,因此INL值很大,线性度差。
这里要提一下双积分ADC,它的原理就能保证线性。比如ICL7135,它在40000字的量程内,能做到0.5LSB的INL值(线性度达到1/80000 !!)和0.01LSB的DNL值.这两个指标在7135的10倍价钱内,是不容易被其他模数器件超越的。所以7135这一类双积分ADC特别适合用在数字电压表等需要线性误差非常小的场合。
还要特别提一下基准源。**基准源是测量精度的重要保证。基准的关键指标是温飘,一般用ppm/K(ppm百万分之一)来表示。**假设某基准30ppm/K,系统在20~70度之间工作,温度跨度50度,那么,会引起基准电压30*50=1500ppm的漂移,从而带来0.15%的误差。温漂越小的基准源越贵,比如30ppm/K的431,七毛钱;20ppm/K的385,1块5;10ppm/K的MC1403,4块5;1ppm/K的LM399,14元;0.5ppm/K的LM199,130元。
该死的教科书害了一代学生。说起来好笑的一个现象:我这边新来的学生大多第一次设计ADC电路的时候,基准直接连VCC,还理直气壮的找来N本教科书,书上的基准写了个网标:+5V。天下的书互相抄,也就所有的学校的教科书都是基准接5V。教科书把5V改成5.000V多好?学生就会知道,这个5V不是VCC。或者提一下基准需要高稳定度,也好啊!看完全文了吗?喜欢就一起来点个 赞 吧!
大家都是用计算机做音乐的高手了……呃,那位同学!别紧张嘛~看你激动的,高手其实也没什么了不起的……不信?那我问问你几个问题,你答得上来,算你了不起!我们用电脑做音乐的时候,经常会接触到各种各样的表,无论是测量什么的表,它们都离不开一个单位——分贝(dB),我的问题就和它有关,听好了:
20dB和60dB究竟差多少?(不要回答我60-20=40(dB),我抽你呀!你告诉我40dB究竟是多响,难道用手指在峰值表上测量距离吗?)
72dB和66dB的声音合在一起有多响?(停!看你的口型我就知道——138dB,对不对?拜托~这可相当于一架喷气式战斗机从你身边一米处远的距离飞过啊!Are you nuts?而我说的两个数值相当于一个鼓手和一个吉他手在一起演奏而已,你认为一个乐队演出就像空军基地里飞战斗机那么吵么?)
经常听人说一些设备的各种指标,-10dBV和+4dBu,这个很熟悉吧?他们说,+4dBu的设备属于“专业级”,-10dBV属于“民用级”,你知道这是为什么吗?
为什么有些文章说数字设备不会超过0dB,而模拟设备就可以超过呢?
16bit数字音频的动态范围是多少?24bit呢?如果让你说出21bit的,你能说出来吗?
100瓦的吉他音箱能比50瓦的吉他音箱响多少?
以上的问题如果你觉得对你来说是小事一桩,那你可以不用看这篇文章了,你是真正的高人!如果你使劲抠头皮……拜托,抠头皮解决不了问题的,你至少需要一个科学计算器呢!怎样,还觉得简单吗?
我知道,大家都能用电脑做出歌来,但这要归功于先进的技术和傻瓜式的操作,如果把你放在上个世纪30年代,你觉得就凭你懂的这些可以做今天做的事情吗?我见过有很多“高手”就是这样,他们或许根本就不知道分贝究竟是怎么一回事情!当然,有人也持反对态度,认为重要的是结果,而不是过程。道理不懂没关系,能做出来就可以了。我想说的是,那些真正的录音工程师们是绝对不会这样想的,因为他们真正懂得录音的艺术——不仅仅是扳动一堆按钮就完事了——你要想创造出前所未有的声音,你就必须了解所有的奥秘。所以我说,那些仅仅满足于模仿,甚至连模仿都不伦不类的“高手”其实是没有什么了不起的。
我很高兴你能坚持看到这里,这说明你绝对不是一个能够轻易满足的家伙,你的脑袋充满了无穷的求知欲望。也许你会把你能找到的所有器材的说明书和帮助文档都看一遍,你也经常会看到诸如:dBSPL、dBu、dBV、dBm、dBVU、dBFS等等和分贝有关的名词。但遗憾的是,几乎没有这方面的详细说明,搞得你经常一头雾水:它们是谁?它们究竟是什么关系?不要责怪那些厂商不在说明书里对这些家伙们做出解释,因为他们只想让你当我刚才说的那种“高手”,这样你才会一代接一代的购买他们的产品/软件,如果你慢慢的都懂了,也许你就不用了。^^当然,这些的确不是很容易就明白的,因为他们牵扯到数学、物理等相关的专业知识。(我也就这么一说,其实没那么夸张,只要你高中会考能及格,你就能看得懂)下面就让我们来看看分贝究竟是个什么东西?
通常表示两个声音信号或电力信号在功率或强度方面的相对差别的单位,相当于两个水平的比率的常用对数的十倍。"
这是我在一本专业词典上找到的关于分贝的科学的概括的定义。分贝就是这么回事!
“可是……等等!‘相对差别……两个水平的比率……常用对数……’
这……这都是什么跟什么啊?我看不懂!”呵呵,别急嘛,我当然不会让你看了半天就得到这么一个结论,请你听我慢慢说。
首先我们根据上面的定义,找出主语、谓语和宾语,把其他的部分先省略掉,我们可以得到“分贝是一种单位”,这个结论很明确吧?我们的常识告诉我们,单位都是用来度量的,用某一种仪器或是一个算式,我们可以得到这个单位的具体数值。那么分贝用什么测量呢?实践告诉我们峰值表等等可以测量它,只是我们不清楚测量的数据对我们来说具有什么样的意义,哪怕是一个抽象的意义也可以啊!所以这个问题我们需要数学来帮助我们。科学家们选择了用对数。
为什么要用对数?因为他们懒……我没有开玩笑哦!当你深入到分贝的奥秘当中去,你会发现你需要对付一大堆令人头疼的数字,科学家们——有点像器乐演奏家——的特点就是用尽一切可能的办法让问题变得简单点。我们来看看分贝究竟怎样复杂和怎样简单(拜托,已经看到这里了,再给点耐心和支持吧,马上就到正题了):
声音的响度是指在单位时间内通过指定大小的面积内的能量的总和(这个你知道吧?不过不知道也没关系,嘿嘿):
响度 = 能量 / (时间*面积)
我们知道能量和时间的比就是功率(这个总该知道了吧?还不知道?我*……真的都还给亲爱的老师了),so:
响度 = 功率 / 面积
功率的单位是瓦特咯,面积我们用平方米,那么响度的单位就是:瓦 / 米^(论坛上不好写特殊符号,我用^代替平方,下同)
现在我们假设你知道普通人能听见的最小的声音响度是0.000000000001瓦 / 米^,而让人开始感到痛苦的声音响度是1 瓦 / 米^,那么在这两个数字之间,我们会得到一大堆值,比如0.000792710162 瓦 / 米^,还有0.000006288415 瓦 / 米^等等,试试迅速比较这两个数字,算出它们的差!怎么样,开始头晕了吧?你能想象我们的峰值表用这种单位做表示吗?天啊……
我们可爱的科学家们可不会做这种愚蠢的事情,于是他们写下了这样的公式:
log (0.000792710162) = -3.1
log (0.000006288415) = -5.2
这个差好算多了吧?是2.1嘛……啊?你说什么?这个2.1是什么?就是音量的差啊,聪明的你可能一下子想起来它叫什么了——对,就是贝尔!
不过呢,这还不是分贝,因为贝尔之后的科学家继承了他的传统,并且又将之发扬光大(什么传统?懒呗!)……这一次,他们连小数点都不想看见,所以他们又乘了10,变成了这样:
10 * log(0.000792710162) = -31
10 * log(0.000006288415) = -52
答案从2.1变成了21,这个"21"就是我们今天的主角——分贝。
怎么样,科学家们聪明吧?同学们,大家要学习他们胡乱使用各类公式的好办法……呃呃,我的意思是:勇于探索!他们也真够懒的,是不是?还有更懒的呢!对数有一个特性,它可以把减法变成除法,所以,我们可以再简单一点:
10log(x) - 10log(y) = 10*log(x/y)
这样,对于刚才的问题,我们就不用分开来算了,用一条公式就可以解决问题:
10*log(0.000792710162/0.000006288415)=21dB
这就是为什么要用对数的原因,有了这个简便的方法,我们终于可以对分贝进行更深入的研究了。
还有一个小问题,如果我们得到的测量数据不全是以声音响度为单位的,那该怎么办?如果两个数据的单位不一样,我们得到的公式不就毁了吗?想想看,我们通常用什么方法来让不同单位的数值进行计算,并且得到同样单位的结果的?其实我们只需要找一个固定的常数带入这个公式就可以解决这问题了,我们把这个常数叫做“参照数”。用什么来作参照数呢?刚才我们好像提到过普通人能听见的最小的声音响度是0.000000000001 瓦 / 米^,我们就用这个吧!(别的数也一样,我们只是为了统一单位)我们用字母"N"来表示这个常数,所以:
10log(x/N)-10log(y/N)
= 10*log [(x/ N)/(y/N)]
= 10*log(x/y)
保险起见我们来检查一下这个公式有没有问题,还是用刚才的那个例子:
10*log(0.000792710162/0.000000000001) = 89dB
10*log(0.000006288415/0.000000000001) = 68dB
89 dB - 68 dB = 21 dB
OK,大功告成!这个方法可以让我们比较不同单位的数值。(这个例子的两个数据单位是相同的,所以看起来“参照数”没什么作用)
经常使用的测量单位有声音的功率(瓦特),声音的响度(瓦 / 米^),声音的压强是(帕斯卡)——嘿!你可要注意我接下来说的话了,这是最容易让人对分贝产生混淆的地方。
以功率或响度为单位测量的数据,我们用上面的公式都可以很好的计算。然而,通常情况下,当人们说到“分贝”的时候,却指的是压强。毕竟是声波的压力压迫我们的耳鼓膜来让我们分辨出声音究竟有多“响”的。所以,我们通常所谈到的分贝应该是dBSPL(Sound Pressure Levels)。
压强是作用于单位面积的力,力的单位是牛顿(看见你猛力的点头,我真得很无奈……),所以压强的单位是 牛 / 米^。另一种常用的单位是帕斯卡,1 帕等于1 牛 / 米^。
声响(I)和声压(P)之间的关系我们可以用下面的公式来表示:
I = P^ / ρ
ρ是希腊字母,读作:“肉”,它代表空气的阻力,是一个常量。这个值取决于大气压强、空气温度等等因素。通常情况下,在室温中,空气阻力的值大约是400。因此,普通人能听见的最小的声音响度换算成声压就是:
0.000000000001W/m2 = (0.00002 Pa)^ / 400
不过呢,刚才的公式里P的后面还有一个平方,也就是说声压翻两倍,声响就翻了四倍;声压翻四倍,声响就翻了十六倍……这样的话,我们把声压作为测量单位的时候,之前得到的公式不就出现问题了吗?
不妨,我们来稍微计算一下:
dB = 10 * log (x / y) --- 此时的X,Y是用声响作测量单位的,我们将P^ / ρ带入公式,则:
dBspl = 10*log[(Px^ / ρ) / (Py^ / ρ)]
= 10 * log (Px^ / Py^)
= 10 * log (Px / Py)^
= 20 * log (Px / Py)
就这样,问题解决了,和前面的公式不同之处,就是乘了20。
这就是dBSPL的公式,当我们谈论“分贝”的时候,99%说的都是它;我们在各种测量表上看见的dB,其实就是dBSPL,只不过没人说这个的时候总是带上SPL三个字母。(有的可能是怕麻烦,但多数恐怕是不知道,嘿嘿……不过你现在知道了)
那么当我们使用声压作为测量单位的时候,我们选用的“参照数”就是0.00002帕斯卡了,接近于我们所说的普通人能听见的最小的声音响度,带入刚才得到的公式,我们来看看:
dBSPL = 20 * (P / 0.00002 Pa)
因为log1 = 0,所以:
20 * log(0.00002 Pa / 0.00002 Pa) = 0 dBSPL
请注意,你应该注意到了,如果我们取一个和参照数相同的值,那么我们总会得到“0dB”,无论是什么类型——dBm, dBu, dBV, dBFS...都是如此!还有,你可能会有疑问0.00002帕不是几乎听不到么?怎么是0dB呢?对呀!0不就是等于没有么?哦,我明白你的意思了,你在计算机里经常看见0dB代表的是峰值表的最高值吧?嗬嗬,那是因为数字电路和我们现在所说的情况是有区别的,别着急,我等一下会讲到。
我们能忍受的最强的声压大约是20帕,你试试用分贝表示一下看看?应该如下:
20 * log(20Pa / .00002Pa) = 120dB
怎样,还记得物理课说过的吧?超过120分贝的声音,我们就无法忍受了,这个值就是这么算的。
讲到这里,我们应该复习一下,我相信一大堆的公式和计算已经让你头昏昏了吧?没办法,为了说清楚,我只能这样做,然而你只需要看明白就可以了,你需要记住的也就是下面这两个:
dB = 10 * log (x / y) ---- 以声响作度量单位时计算分贝的公式,单位应该是 W / m^
dB = 20 * log (x / y) ---- 以声压作度量单位时计算分贝的公式,单位应该是 Pa
太棒了,到此为止,你已经知道分贝到底是个什么东西了,然而我们今天的这一课却还没有结束,因为我们还不知道dBu, dBv, dBV, dBm, dBVU, dBFS这些东东的意思。不过有了以上的基础,你明白这些小东西只是时间的问题,让我们先从原理开始:
我们已经明白了分贝的含义,应当特别注意的是:分贝表示的是两个相同类型的数据之间的比(类型要相同,这一点很重要,你不能拿瓦特和伏特直接进行比较)。在这两个数据里,其中的一个我们把它叫做“参照数”,我们即是通过把测量到的数值和参照数代入公式进行计算来得到相应的分贝值的。比如之前我们已经使用过声压作为测量单位,那是我们选取的参照数是0.00002帕斯卡。我们最后得到的分贝值,我们称之为"dBSPL"。也就是说,dB后面不同的字母指示的就是我们用什么作为测量单位来得到这个分贝值的。用声压,那么就是SPL(Sound Pressure Levels)。这样解释应该非常明确吧?如果你看懂了,那么我就来一个一个地解释其他和dB有关的单位。
dBm 和 dBVU
我们已经讨论过用功率测量得到分贝值的方法,那时我们说的是声音的功率,单位是瓦特。不过我们知道,除了声音之外,还有很多现象可以产生功率的,比如说电。
很久以前,在发光二极管和液晶显示屏尚未诞生的“古代”,工程师们依赖一种叫做VU表的设备来完成他们的工作。VU表看起来就像一个驾驶室里的速度表,用一个指针以顺时针方向指示通过此题的电流增量。VU是"Volume Unit"的简写,意即:音量计量单位。
VU表的问题是每一个VU表都不一样!直到上世纪30年代末,一群工程师们坐在一起决定统一一下VU表的计量规范,这个问题才得以解决。他们确定的标准是:当电流的功率为1毫瓦(1 mW),VU表指示0dB。换句话说:0dBm = 0dBVU。dB后面的m就代表毫瓦。dBm也是以功率为单位测量的,参照数是1mW。
dBm = 10 * log (功率 / 1mW)
这样,我们就可以很容易得用dBm来表示电流功率的变化了。还记得么?当测量值和参照物相等的时候,dB值总是为0吗?所以了:
10 * log(1mW / 1mW) = 10 * log(1) = 0dBm
当VU表的指针指向+3dBm的时候,功率增加了一倍,怎么算的?这样:
10 * log(2mW / 1mW) = 10 * log(2) = 3dBm ---- 我说过了,至少你要准备一个科学计算器,对数是不好心算的。
那要是指向-6dBm呢?
10 * log(0.25mW / 1mW) = 10 * log(0.25) = -6dBm
dBu(也叫做dBv)
再回忆一下高中物理吧。功率(P)还可以用电压(V)和电阻(R)之间的关系来表示:
P = V^ / R ---- 电阻的单位是欧姆(Ω)
刚才讨论dBm的时候,参照数是1mW。这个标准是在上个世纪三十年代设立的。在那个时候,所有音频设备的输入阻抗都是600欧姆,磁带录音机,调音台,前置功率放大器……只要有插头,那么从火线到接地之间的电阻就是600欧姆。
那么,当电阻为600欧姆的时候,需要多大的电压才能产生1mW的功率呢?用刚才的公式计算一下:
P = V^ / R
0.001 W = V^ / 600 Ω
V2 = 0.001 W * 600 Ω
V = sqrt (0.001 W * 600 Ω) ---- sqrt是开平方,我不知道怎么打这个符号。
V = 0.775 V
答案是0.775伏特。那么,当所有的设备的输入阻抗还是600欧姆的那个年代,计算dBu时所用到的参照数就是0.775 V,也就是说,dBu就是以电压为测量单位是计算出的分贝值。不过我们又注意到,刚才的公式里电压是平方数的哦。根据前面的经验,我们知道怎么处理这个问题:
dBu = 20 * log(被测电压 / 0.775V)
如果你很仔细的话,大概你会觉得奇怪:为什么是dBu而不是dBv呢?其实呀,很早以前人们是直接用dBv来表示的,只不过后来人们发现dBv和dBV太容易让人混淆了,于是就用小写字母"u"来代替小写字母"v"了。如果你还能看到dBv,那么它的意思就是我们今天讲到的dBu——除非写dBv的人搞不清楚他到底想说什么!
那么,和dBv混淆的dBV又是怎么回事呢?
很长一段时间以来,人们所用到的音频设备都是输入阻抗为600欧姆的,到了今天我们才会遇见一些更高阻抗的设备,比如说10000Ω。电阻越高,电路耗费的功率就越低。(根据上面的公式,我们知道功率和电阻成反比)
还记得dBu使用的参照数是0.775V吧?很多工程师认为这个数字实在是太麻烦了,但因为那时候所有的设备都是固定的输入阻抗,因此使用0.775V作为参照数也就顺理成章了。设备不改进,这个参照数也就不能变,但是为了使用方便,一个新的参照数还是很快发展了出来——顺带产生了新的分贝单位dBV。这个参照数是1V:
dBV = 20 * log(被测电压 / 1V)
其实dBV和dBu非常相似,只是参照数不同罢了。
现在顺便说说所谓“专业级”和“用户级”设备之间的差别。你可能早就知道了,专业级设备是+4dBu而用户级设备是-10dBV,当然这其实是很荒谬的,哈哈。我们刚才已经看到了dBu和dBV都是通过比较电压来计算分贝值的,除了参照数不同,它们没有任何区别。所谓专业级,是指这些设备的使用者多是一些“大叔”(因为标准早嘛,使用的人当然大多数“资格”也都比较老)。事实上,仅凭这两个参数就断定设备的“级别”未免太过武断了,在任何场合这两种规格的设备都可以很好地完成工作要求。我觉得吧,在这方面我们应当多多发挥人的主观能动性。设备之间的硬性差别我们心中有数就可以了,但如何使用我们掌握的知识让你手中的设备发挥最大的潜能才是我们应该追求的境界。设备不好是个钱的问题,有了好设备做不好音乐那就是人的问题了,钱的问题可以解决,人的问题不好解决呀!在我们海峡对面有个小岛,上面的人虽然不多,但是搞音乐的却不少,我们承认他们的音乐发展得不错,但并代表他们搞音乐的人水平就都很高,在他们那里有个鸟论坛,上面就有些鸟人大言不惭的就“专业”和“用户”设备的差别大放狗——那个什么气!让我这个海峡另外一边的菜鸟(顺便说一句,那里有很多人都认为海峡这边的人比他们差的远了)都有些看不下去了……本是同根生啊~但谁让现在是这么个形势呢?为了让海峡这边的同志不要也像他们一样看起来“专业”,其实很“操蛋”,所以我才写下这一段话——应该说,促成我写这篇文章,有很大的原因也是为了这个!
好了好了,话题扯远了,我们来看看+4dBu和-10dBV到底有什么区别吧:
被测电压 = 1.228 V
被测电压 = 0.3162 V
20 * log(1.228V / 0.3162V) = 11.79dB
如果你有这两种设备,你可以做一个检测:连接-10dBV的输出到+4dBu的输入,然后读一下+4dBU的VU表,是不是11.79dBVU?
dBFS
最后我们来看看和我们联系最密切的dBFS。dBFS的全称是"Decibels Full Scale"(全分贝刻度)——是一种为数字音频设备创立的分贝值表示方法。
这个家伙和其他几个弟兄不太一样了,它的参照数不是最小的一个,也不是中间的某一个,而是最大的一个!也就是说"0 dBFS"是数字设备能够到达的最高响度水平。此外所有的值都会小于这个数值——都是负数。这就是为什么我们在电脑上看到的峰值表的最高刻度都是"0",并且指针永远不会读出更高的数字。
但是,为什么会这样呢?要解释这个问题,我们要简单说一下数字音频的存储原理。我们用16bit的数字音频为例:"16bit"的意思是,采样信号以16位二进制数字来存储。二进制数字就两个:"0"和"1"。所以,最大的值就是1111 1111 1111 1111(二进制,换算成十进制是65536),因此,计算dBFS的公式就是:
dBFS = 20 * log(采样信号 / 1111 1111 1111 1111)
这样就很容易解释为什么不能超过"0"了,因为dBFS的参照数是最大值,所以:
20 * log(1111 1111 1111 1111 / 1111 1111 1111 1111) = 0dBFS
那么最小的呢?除了0之外,16位二进制最小的数字是:0000 0000 0000 0001,那么:
20 * log(0000 0000 0000 0001 / 1111 1111 1111 1111) = -96dBFS
知道为什么你看见的峰值表都是从0 dB到-96 dB了吧?接下来,你可以自己算出24bit,32bit数字音频的动态范围了,我告诉你一个,24bit数字音频的动态范围是144dB。还是你自己试试吧?(别忘了要先把二进制转换成十进制,我可不会用二进制算对数!^^)
至此,这篇文章的内容就差不多都写完了,时间仓促,有疏漏之处在所难免,欢迎大家指正……然而,我回过头去看看前面的内容,总觉得还有一些东西可以写的,但是又不能操之过急。诚然,这篇文章不是很好读懂,但希望大家能够花点心思读读看,我敢向你保证:有百利而无一害!如果你认为你已经读懂了,麻烦你把文章最前面的几个问题试着解一下,如果大家都能解出来,说明我写得还算清楚,那我就不用再多做解释了;如果有很多问题,那我的担心还是有道理的,我会写关于分贝的另外一篇文章,解决这些问题,就算是一篇补遗吧。(究竟是什么问题,我先不说,免得大家偷懒,不自己发现自己的问题,嘎嘎)
最后我要感谢我刚才说的那个鸟论坛,还有上面的一些鸟人,是你们给了我写下这篇文字的原动力;同样还要感谢某效果器(忘了,好像是PSP Vintage)的说明文档,正因为这篇文档解释的不全面,才让我有机会拜读Lionel Dumond的文章(大家可以去ProRec搜一下,E文的);最后才要感谢(这次是真正感谢)Lionel Dumond,没有你的好文字,我也不会懂得分贝究竟是个什么东西!嗬嗬~~~
作者:nieyong
姿态解算的英文是attitude algorithm,也叫做姿态分析,姿态估计,姿态融合。姿态解算是指把陀螺仪、加速度计、罗盘等的数据融合在一起,得出飞行器的空中姿态。
飞行器从陀螺仪的三轴角速度通过四元数法得到的俯仰、偏航和滚转角,这是快速解算,结合三轴地磁和三轴加速度得到漂移补偿和深度解算。
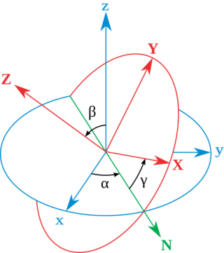
姿态是用来描述一个刚体的固连坐标系和参考坐标系之间的角位置关系,有一些数学表示方法。很常见的就是欧拉角,四元数,矩阵,轴角。
姿态解算需要解决的是四轴飞行器和地球的相对姿态问题。地球的坐标系又叫做地理坐标系,是固定不变的。正北,正东,正向上构成了这个坐标系的X,Y,Z轴,我们用坐标系R表示。四轴飞行器上固定着一个坐标系,用坐标系r表示。那么我们就可以用欧拉角,四元数等来描述r和R的角位置关系。这就是四轴飞行器姿态解算的数学模型和基础。
如上所说,地球坐标系R是固定的。四轴飞行器上固定一个坐标系r,这个坐标系r在坐标系R中运动。那么如何知道坐标系r和坐标系R的角位置关系呢,也就是怎么知道飞行器相对于地球这个固定坐标系R转动了一下航向,或者侧翻了一下机身,或者掉头下栽。这就是传感器需要测量的数据,传感器包括陀螺仪,加速度计,磁力计。通过获得这些测量数据,得到坐标系r和坐标系R的角位置关系,这就是姿态解算。
作者:nieyong
姿态有多种数学表示方式,常见的是四元数,欧拉角,矩阵和轴角。他们各自有其自身的优点,在不同的领域使用不同的表示方式。在四轴飞行器中使用到了四元数和欧拉角。
四元数是由爱尔兰数学家威廉·卢云·哈密顿在1843年发现的数学概念。从明确地角度而言,四元数是复数的不可交换延伸。如把四元数的集合考虑成多维实数空间的话,四元数就代表着一个四维空间,相对于复数为二维空间。
四元数大量用于电脑绘图(及相关的图像分析)上表示三维物件的旋转及方位。四元数亦见于控制论、信号处理、姿态控制、物理和轨道力学,都是用来表示旋转和方位。
相对于另几种旋转表示法(矩阵,欧拉角,轴角),四元数具有某些方面的优势,如速度更快、提供平滑插值、有效避免万向锁问题、存储空间较小等等。
以上部分摘自维基百科-四元数。
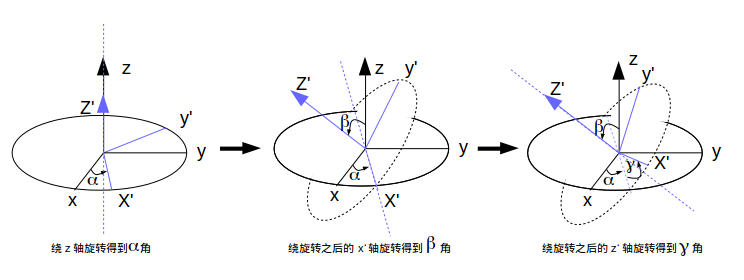
莱昂哈德·欧拉用欧拉角来描述刚体在三维欧几里得空间的取向。对于在三维空间里的一个参考系,任何坐标系的取向,都可以用三个欧拉角来表现。参考系又称为实验室参考系,是静止不动的。而坐标系则固定于刚体,随着刚体的旋转而旋转。
以上部分摘自维基百科-欧拉角。下面我们通过图例来看看欧拉角是如何产生的,并且分别对应哪个角度。
姿态解算的核心在于旋转,一般旋转有4种表示方式:矩阵表示、欧拉角表示、轴角表示和四元数表示。矩阵表示适合变换向量,欧拉角最直观,轴角表示则适合几何推导,而在组合旋转方面,四元数表示最佳。因为姿态解算需要频繁组合旋转和用旋转变换向量,所以采用四元数保存组合姿态、辅以矩阵来变换向量的方案。
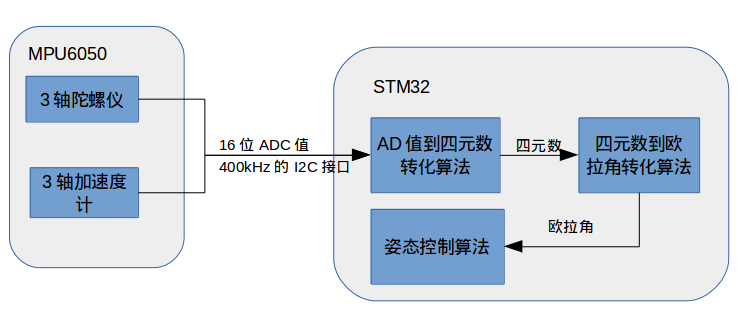
总结来说,在crazepony中,姿态解算中使用四元数来保存飞行器的姿态,包括旋转和方位。在获得四元数之后,会将其转化为欧拉角,然后输入到姿态控制算法中。
姿态控制算法的输入参数必须要是欧拉角。AD值是指MPU6050的陀螺仪和加速度值,3个维度的陀螺仪值和3个维度的加速度值,每个值为16位精度。AD值必须先转化为四元数,然后通过四元数转化为欧拉角。这个四元数可能是软解,主控芯片(STM32)读取到AD值,用软件从AD值算得,也可能是通过MPU6050中的DMP硬解,主控芯片(STM32)直接读取到四元数。具体参考《MPU60x0的四元数生成方式介绍》。
下面就是四元数软解过程,可以由下面这个框图表示:
下面介绍一下四元数,然后给出几种旋转表示的转换。这些运算在crazepony的代码中都会遇到。
四元数可以理解为一个实数和一个向量的组合,也可以理解为四维的向量。这里用一个圈表示q是一个四元数(很可能不是规范的表示方式)。
四元数的长度(模)与普通向量相似。
下面是对四元数的单位化,单位化的四元数可以表示一个旋转。
四元数相乘,旋转的组合就靠它了。
旋转的"轴角表示"转"四元数表示"。这里创造一个运算q(w,θ),用于把绕单位向量w转θ角的旋转表示为四元数。
通过q(w,θ),引伸出一个更方便的运算q(f,t)。有时需要把向量f的方向转到向量t的方向,这个运算就是生成表示对应旋转的四元数的(后面会用到)。
然后是"四元数表示"转"矩阵表示"。再次创造运算,用R(q)表示四元数q对应的矩阵(后面用到)。
多个旋转的组合可以用四元数的乘法来实现。
"四元数表示"转"欧拉角表示"。用于显示。
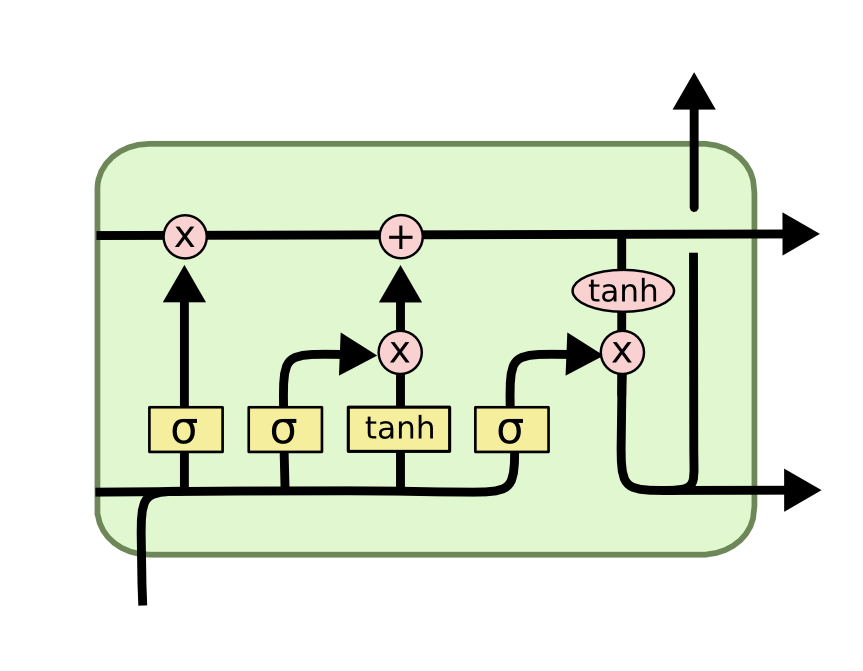
作者:nieyong
陀螺仪,测量角速度,具有高动态特性,但是它是一个间接测量角度的器件,它测量的是角度的导数,角速度,要将角速度对时间积分才能得到角度。
如果这个世界是理想的,美好的,那我们的问题到此就解决了,不过很遗憾,现实是残酷的,误差的引入,使得积分出现了问题。
假设陀螺仪固定不动,理想角速度值是0dps(degree per second),但是有一个偏置0.1dps加在上面,于是测量出来是0.1dps,积分一秒之后,得到的角度是0.1度,1分钟之后是6度,还能忍受,一小时之后是360度,转了一圈,也就是说,陀螺仪在短时间内有很大的参考价值。
陀螺仪就是内部有一个陀螺,它的轴由于陀螺效应始终与初始方向平行,这样就可以通过与初始方向的偏差计算出实际方向。传感器MPU6050实际上是一个结构非常精密的芯片,内部包含超微小的陀螺。陀螺仪运转一段时间以后,noise和offset会导致数据偏差,需要借助其它传感器进行较正。
使用陀螺仪获得角度,一定要考虑积分误差的问题。
加速度计可以测量加速度,包括重力加速度,于是在静止或匀速运动的时候,加速度计仅仅测量的是重力加速度,而重力加速度与刚才所说的R坐标系是固连的,通过这种关系,可以得到加速度计所在平面 与 地面 的角度关系.
但是加速度计若是绕着重力加速度的轴转动,则测量值不会改变,也就是说无法感知这种水平旋转。
MPU-60x0是全球首例9轴运动处理传感器。它集成了3轴MEMS陀螺仪,3轴MEMS加速度计,以及一个可扩展的数字运动处理器DMP(Digital Motion Processor),可用I2C接口连接一个第三方的数字传感器,比如磁力计。扩展之后就可以通过其I2C或SPI接口输出一个9轴的信号(SPI接口仅在MPU-6000可用)。MPU-60x0也可以通过其I2C接口连接非惯性的数字传感器,比如压力传感器。
MPU-60x0对陀螺仪和加速度计分别用了三个16位的ADC,将其测量的模拟量转化为可输出的数字量。为了精确跟踪快速和慢速的运动,传感器的测量范围都是用户可控的,陀螺仪可测范围为±250,±500,±1000,±2000°/秒(dps),加速度计可测范围为±2,±4,±8,±16g。一个片上1024 字节的FIFO,有助于降低系统功耗。和所有设备寄存器之间的通信采用400kHz的I2C接口或1MHz 的SPI接口(SPI仅MPU-6000可用)。对于需要高速传输的应用,对寄存器的读取和中断可用20MHz的SPI。另外,片上还内嵌了一个温度传感器和在工作环境下仅有±1%变动的振荡器。
在crazepony上,MPU6050,HMC5883传感器之间的连接如下图所示。

在Crazepony-II上,测试了软件解算四元素,然后通过四元素解算姿态角这种实现方式,其实总的来说,并没感觉36MHz的主控压力有多大,没有出现机身不稳,卡死的情况。
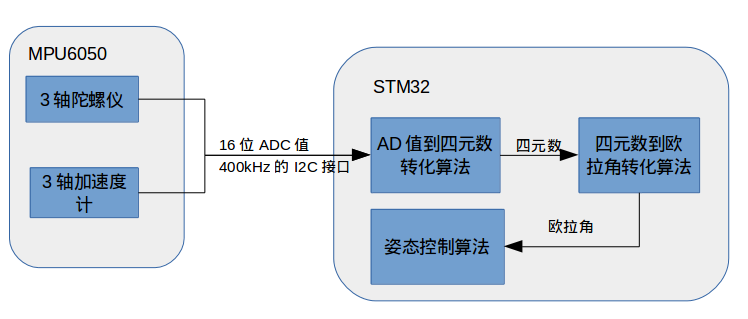
同时,本着务实他的态度,我们也测试了MPU6050的硬解四元素,即从IIC总线上读到的数据不再是MPU60x0的AD值,而是通过初始化对DMP引擎的配置,从IIC总线上读到的直接就是四元素的值,从而跳过了程序通过AD值计算四元素这个看起来繁琐的步骤。测试结果是,机身反应的确要比之前反应灵活,最关键的一点是,这样得出的偏航角(Yaw)很稳很稳,基本不会漂移或者说漂移小到了可以容忍的地步。
最后,MPU60x0的强大之处不仅于此,它支持一个从IIC接口,可以外部接上一个磁力计,如HMC5883,这样一来,DMP引擎可以直接输出一个绝对的方向姿态,即能够输出一个带东西南北的姿态数据包,很厉害的样子。在Crazepony-II第四版将会加上这样一个磁力计,相信它再也不会迷路了~~

disp(['Average of QRS Width(ms): ',int2str(QRSWidth_ave)]);
放之四海而皆准,在matlab中涉及字符串,在方括号[ ]内每个字符串用,隔开
对于数字需要用int2str()函数转化为字符串,否则被当作ascii码 当然还有num2str()与mat2str()根据需求选用
根据我们从小受到的教育中我们知道,这首先要求我们对于知识要理解透彻,越深入越好,对于任何一个知识点,通过基本公式,用数学工具推导到最后来验证高级定律和公式。我想对于这一点,高考物理是达到了极点,高中物理知识其实不难,但是我们为了选拔的目的,把物理各种定律糅合在一起,结合一些脑筋急转弯,复杂的运算,造成高考物理是最难的科目了。
但如果我们拿着解高考物理难题的精神来解决硬件问题,当然精神可嘉,工作之余还是值得鼓励这种学习和探索精神的;可是这样对于项目开发却是没有多少好处,毕竟硬件工程师的工作是工程开发,在规定的时间和预算之内完成硬件项目,而不是你在这个时间呢自己推导出来了什么公式和计算结果,那是科学家的工作,那是Research的工作。
工程开发一个重要特点就是“踩在前人的足迹”,就是通过过去几十上百年的工程实践,对于各种情况有了很多经验数据和经验方法,比如对于PCB layout来说,基本上每个公司都有自己的design guidelines/check list,这就是公司在过去很多项目中总结出来的,每一条可以说都付出了“血”的代价,这是对于板级设计来说了;对于核心芯片和器件,就更是如此了,芯片或器件公司几十数百人历时数年搞出来的一款芯片和器件,又岂是你通过几百页datasheet可以彻底理解的。
大多数情况下,知道主要接口,参数,功能和性能就足够了,尤其是芯片/器件公司提供的design guidelines或者application notes,里面一般都是芯片/器件工程师的肺腑之言,经验之谈,一般来说没有个十年二十年工作经验的工程师是写不了这些东西的。
看起来虽然很简单,看起来像是废话,但是细细分析,结合电路定理和电磁定律,略微分析,就会发现简直字字珠玑。刚毕业的好学生(一般来说学习好,喜欢啃难题,学习能力强,求知欲强)初干硬件设计,就会发现涉及的知识点和技术要点太多了,如果这个知识点想要理解透彻,那个知识点也要理解透彻,会发现一天24小时根本不够用,但是对不起,公司请你过来不是让你学习的,是要干硬件设计的,过一个月就要见原理图了,你还在这捧着OrCAD手册一个命令一个命令学习OrCAD使用技巧,研究为啥要有串行电阻呢,研究这个电容是取0.1uF还是0.01uF.。
有求知欲是好事,但是那是在工作之余,项目之余,虚心向前辈学习,尽量利用各种design guidelines,尽快完成设计工作,记录自己的知识缺点,在业余时间努力学习,理解透彻,通过设计验证/测试,加深对于知识点的了解,这才是正确的工作方法。
我在刚毕业的时候欣喜的发现传输线理论太重要了,遂花了一个月把传输线理论努力了一把,并推导了大量公式进行验证,其实总结起来就是几句话,阻抗匹配,如果接收端阻抗大于发送端,信号会怎么样;如果小于,信号会怎么样;如果开路,会怎么样;如果短路,会怎么样,这几条基本每本信号完整性的书上都会介绍,也不会有很复杂的数学公式推导,知道就行了,然后就是如何平衡发射端的阻抗,串行电阻,PCB阻抗,匹配阻抗等等,都是简单的数学公式。
所以说,对于求知欲特别强的人(比如我),有时候一定要学会“浅尝辄止”,充分利用前辈经验,避免陷入技术的误区,比如放着公式不用,非得自己用二重积分推导一遍。硬件开发最主要的特点就是“广博”,什么东西都要知道,一个好的硬件工程师就要什么都要懂一点,当然对于某些方面能够深入一些到原理层次就更好了。
关于硬件设计的各种技术/标准/芯片/器件都要知道,需要的时候,能够信手拈来,功能性能,参数特性,优点缺点。
那一个好的硬件工程师应该具备哪些基本知识和能力呢?
一方面,通信技术,标准,芯片更新的太快了,快到你根本来不及系统的了解它,只能通过特定的项目,需求进行了解;另一方面对于公司来说,需要做的硬件产品也是变化很快,客户需要T1, E1, PDH, SDH,Ethernet, VoIP, Switch, Router, 没有人是什么都懂的,都需要能够结合客户的需求,选择的芯片方案进行详细了解,尤其对于接口协议和电气特性。
假设你是做电源的,同理,你也需要对电源相关的知识和客户的需求进行深入的理解和学习吧?
通信设备,顾名思义,就是用来实现多种通信协议(比如T1, E1, V.35,PDH, SDH/SONET, ATM, USB, VoIP, WiFi, Ethernet, TCP/IP,RS232等等常用协议)实现通信的设备,各种电路,PCB板,电源都是为了通信协议服务的。
通信协议一般都是由芯片实现,要么是成熟的 ASIC,要么是自己开发的FPGA/CPLD,芯片工程师或者FPGA工程师比硬件工程师跟靠近通信协议,他们需要对于通信协议理解很透彻,实现各种逻辑上的状态机以及满足协议规定的电气参数标准。按照OSI的七层模型,硬件工程师尤其需要专注于一层物理层和二层数据链路层的协议标准,以 Ethernet距离,物理层是由PHY/transceiver芯片完成,数据链路层是由MAC/switch 芯片完成,对于从事Ethernet相关开发的硬件工程师来说,需要对于PHY和Switch芯片理解透彻,从编码方式,电气参数,眼图标准,模板,信号频率到帧格式,转发处理逻辑,VLAN等等。
对于传统PDH/SDH/SONET设备就更是如此,PDH/SDH/SONET是更硬件的设备,就是说主要协议都是通过ASIC实现的,软件的功能主要是管理,配置,监视,告警,性能,对于硬件工程师来说,必须要熟悉使用的相关协议和接口标准,尤其对于电气规范,眼图模板,这样在设计验证的时候才能胸有成竹。
如果你做智能家居的,你对蓝牙、WIFI、Zigbee的新标准应该要深入了解吧,各自的优劣势也应该了如指掌吧,最新的标准有啥提升和缺点也可以信手拈来,说不定这样你就能做出符合消费者需求的全新产品呢!也指不定在跳槽的时候,因为你掌握了一个别人还没有了解的技术,而获得成功呢!
对于硬件工程师来说,最重要的文档有两个:一个是硬件设计规范(HDS : hardware design specification)和硬件测试报告(一般叫EVT:Engineering Validation& Test report或者DVT: Design Validation & Test report),对于HDS的要求是内容详实,明确,主芯片的选择/硬件初始化,CPU的选择和初始化,接口芯片的选择/初始化/管理,各芯片之间连接关系框图(Block Diagram),DRAM类型/大小/速度,FLASH类型/大小/速度,片选,中断,GPIO的定义,复位逻辑和拓扑图,时钟/晶振选择/拓扑,RTC的使用,内存映射(Memory map)关系, I2C器件选择/拓扑,接口器件/线序定义,LED的大小/颜色/驱动,散热片,风扇,JTAG,电源拓扑/时序/电路等等。
对于DVT来说,要求很简单也很复杂:板卡上有什么接口,芯片,主要器件,电路,就要测试什么,尤其在板卡正常工作的情况下的电源/电压/纹波/时序,业务接口的眼图/模板,内部数据总线的信号完整性和时序(如MII, RGMII, XAUI, PCIe,PCM bus, Telecom Bus, SERDES, UART等等),CPU子系统(如时钟,复位,SDRAM/DDR,FLASH接口)。
好的硬件工程师无论是做的文档还是报道都是令人一目了然,这个硬件系统需要用什么方案和电路,最后验证测试的结果如何。内容详实,不遗漏各种接口/电路;简单名了,不说废话;图文并茂,需要的时候一个时序图,一个示波器抓图就很能说明问题了。
无论仪表还是软件,在政治经济学里说都是生产工具,都是促进生产力提高的,作为硬件工程师来说,这些仪表和软件就是手中的木。仓炮,硬件工程师很大一部分能力的体现都在与仪表和软件的使用上,尤其对于原理图软件和示波器的使用,更是十分重要,原理图软件的使用是硬件设计的具体实现,通过一个个器件的摆放,一个个NET的连接,构成了是十分复杂的硬件逻辑软件,是整个硬件设计的核心工作,任何一个原理图上的失误和错误造成的损失都是巨大的,真是“如履薄冰,战战兢兢”。
另外,原理图软件的使用还体现在原理图的美观上,好的设计,简单明了,注释明确,无论是谁,顺着思路就能很快搞清楚设计意图,需要特别注意之处,不好的设计,东一个器件,西一个器件,没有逻辑,命名怪异,难以理解,日后维护起来相当麻烦;示波器在所有测试仪表之中,对于硬件工程师是最重要的,无论原理图还是PCB都是设计工作,但是任何设计都需要仔细的验证测试,尤其在信号方面,都需要大量的示波器工作,不会正确的使用示波器根本谈不上正确的验证,接地有没有接好,测试点的选择,触发的选择,延时的选择,幅度、时间的选择,都决定着测试的结果。如果错误的使用示波器必然带来错误的测试结果,这种情况下,有可能本来是错误的设计被误认为是正确的,带来巨大的隐患;本来是正确的设计被误认为是错误的,带来大量的时间精力浪费。
尤其对于电源电路设计上,现在芯片电压多样化,电压越来越低,电流越来越大,运营商对于通信设备功耗的严格要求,散热要求,对于电源设计的挑战越来越大。可以说,对于一个硬件设计来说,40%的工作都是在于电源电路的原理图/PCB设计和后期测试验证,电源电路设计是硬件工程师电路能力的集中体现,各种被动器件、半导体器件、保护器件、DC/DC转换典型拓扑,都有很多参数,公式需要考虑到,计算到。
对于外部来说,硬件工程师还要与芯片的分销商,FAE处理好关系,争取获得更大的技术支持和帮助;与EMC实验室,外部实验室打好交道,获得更灵活的测试时间和更多的整改意见。
近年来,无线技术在音频传输领域得到越来越多的关注,包括蓝牙、WIFI 以及2.4GHz 技术等得到了迅猛的发展。在众多无线音频传输技术中,目前被看好的,而且最有可能在普通音频设备中、大面积使用的是2.4GHz 技术。2.4GHz,全名叫做"2.4GHz 非联网解决方案"。它和蓝牙、WiFi 一样,都是工作在2.4-2.485GHz ISM 无线频段上。而该频段在全世界几乎都是免费授权使用的。因此,在产品成本上面天生会有一些优势,有助于产品的大面积普及。目前,蓝牙技术在无线音频产品中 使用的最多,技术也最成熟,但它具有先天性的缺点,比如说:带宽窄,达不到传输高品质音频信号的要求;传输距离近,10 米左右;还有被人们广为诟病的抗干扰问题。WIFI 技术具有带宽宽,传输距离远的优势,具有相当不错的前景,但其弊病还是在于抗干扰且技术相对不成熟。2.4GHz 技术在对比与蓝牙、Wifi 的优势在于1) 带宽宽,能够传输CD 品质的无线信号。2) 抗干扰强,2.4G 技术使用的是自动调频技术,设备在工作时,如果发现频段被占用,它就会自动跳到一个无人使用的频段。3) 功耗低,2.4GHz 技术在发射和接收时不需要连续工作。 本文提出了基于TI 公司CC8520 系列芯片无线音频传输方案,该方案采用目前最热门且有发展前景的2.4GHz 短距离无线传输技术;无需进行软件开发,只需通过TI 提供的免费PurePath 无线配置器设置目标系统的期望功能及参数,显著减少了开发时间和开发难度,并且提高了系统的可靠性。CC8520内部集成了微控制器,无需额外的控制器或DSP 即可完成对系统的控制,如音量调节、网络配对等操作,并且提供数据旁路通道,即可以在传输音频的同时,对接受端发送额外数据,降低了整体的成本。 经实际测试,该方案在使用9V 干电池的情况下可持续工作22 小时;可传输多路采样率达(44.1/48KHz)及采样位数(16/24 位)的高品质立体声;无障碍开阔地传输距离达130 米,在拥挤、多障碍的环境下传输半径仍可达35 米。 1 系统概述 1.1 CC8520 芯片介绍 CC8520 芯片采用TI 公司"PurePath Wireless"的专有技术1.该芯片可以在各种复杂环境中提供无缝和可靠的音频流式传输。运用先进的误差校正及隐藏技术的嵌入式音频网络协议,CD 品质未压缩音频品质采样,采用I2S 和I2C 接口来实现与音频编解码器、DAC/ADC 和数字音频放大器的无缝连接和控制,无线数据传输速率5Mbps,音频延迟小于16ms,具有高达+4dBm 的可编程功率输出和-83dBm的灵敏度)。需要很少的外围器件,故CC8520 完全适合于无线音频系统传输的设计。 1.2 工作原理 如图1 所示,在发送端,通过传声器(俗称话筒、麦克风)或模拟音频接口将声音或音频信号转换为模拟电信号;将模拟电信号传送到音频编解码芯片TLV320AIC3204 的音频接口IN1_L、IN2_R 端,模拟电信号通过芯片内部的前置放大,A/D 处理后转换为I2S 格式的数字音频信号,并传送至CC8520的I2S 接口;CC8520 将接收到的数字音频信号进行载波发射,通过与射频扩展器CC2590 的RF_N 和RF_P 端连接,将射频信号通过芯片并经由天线将音频信号发射出去。
*图1 系统发射端原理框图。
*
如图2 所示,在接收端另一CC8520 芯片通过CC2590 将接收到载波信号进行解调,将解调的数字音频信号传送至音频编解码芯片TLV320AIC3204 进行D/A 转换,输出模拟音频信号。因该芯片内部的音频放大增益较小,所以将模拟信号通过方向放大器进行放大,通过功放或耳机输出。
*图2 系统接收端原理框图。
*
2 系统硬件设计及PurePath无线适配器设置 2.1 发射部分设计 无线音频发射端可采取便携式手持设计,主要由无线数字音频芯片CC8520 、音频编解码芯片TLV320AIC3204、射频扩展芯片CC2590 等低功耗微型贴片芯片组成,可全部装配在便携式设备狭小空间的电路板内,其发射端电路原理如图1 所示,当CC8520 和TLV320AIC3204 作为发射端时,首先在PurePath 无线适配器Projects 中选择"CC85XXDKdemo AIC3204 ", 打开后, 选择" Analog Inputmaster(AIC3204)"作为发射端配置。 考虑到在其在室内使用,并且要发挥CC8520 高品质CD 音质的性能,音频传输系统的主信号源1)选用良好声学性能的麦克风,连接至TLV320AIC3204的IN1_L 和IN1_R 端,进行前置放大与A/D 转换: 《电子设计技术》网站版权所有,谢绝转载 2)自带CD 机或通过电脑播放的音乐等其他任何标准的立体声音源可由TLV320AIC3204 的IN2_L 和IN2_R 端进行前置放大和A/D 转换, 因为TLV320AIC3204 支持麦克风输入和立体声输入两种模式。 音频编解码芯片TLV320AIC3204 的I2S 接口与主芯片CC8520 相连接,并根据本系统传输音频的特点,在PurePath 无线适配器设置,如图3 所示。
*图3 PurePath 无线适配器音频接口设置
*
接口形式:选择I2S;最大处理位数:选择16 位。 在本设计中TLV320AIC3204 使用CC8520 的 MCLK作为自己的系统时钟,因此在时钟源的选择上使用"Internal with MCLK".选择完成后,系统 自动生成控制指令,不需用户进行编程。 CC8520 内置了微控制器,因此系统不需要额外的微控制器, 将芯片CC8520 通过I2C 接口与与TLV320AIC3204 连接,对TLV320AIC3204 进行初始化和发送控制命令。 偏置电压设置:音源的输入在采用麦克风输入或立体声输时入,需设置偏置电压。在硬件中,由R1和R2 构成偏置网络;在PurePath 无线适配器"AudioDevice Customization"中进行设置,根据查看数据手册和本设计的特点,选择2.5V 偏置电压,故在该设置框中输入"W 51 05". 按键输入:PurePath 无线适配器提供以下事件发生方式1.click 2.hold 3.repeat 4.click+repeat.这样的好处是使设计者根据用户的需求或者是产品的需要灵活地选择按键样式,比如推拉式、触发式、自锁式等。 本次设计中在发射端,使用了三个按键,分别是网络配对键、远程音量控制+键、远程音量控制-键。网络配对键采用"hold"方式,即"按住"方式,音量控制键采用"hold+repeat"方式,即"可按住可轻点". 网络配对,音量+和-分别端接至CC8520 的CSN 端、GIO1 端、GIO3 端。这些均可在PurePath 无线适配器进行简单的选择。 状态灯提示:在PurePath 无线适配器中设置的状态显示方式,在本设计中,选择闪烁为网络配对进行,常亮为配对完成,如图4 所示,为设置好的I/O 映射图。
*图4 设置完的CC8520 的I/O 端口映射图。
*
2.2 接收部分设计 无线音频传输系统的接收端为固定形式,与发送端相类似,由无线数字音频芯片CC8520、音频编解码芯片TLV320AIC3204、射频扩展芯片CC2590,功率放大电路组成,接收端的电路主体部分与接收端相似,芯片CC8520 的I2C 接口与TLV320AIC3204 的I2C端连接,对其进行初始化和发送控制命令。在PurePath无线适配器中选择"Analog Output Slave(AIC3204)"作为接收端配置。 音频编解码芯片TLV320AIC3204 的I2S 接口与主芯片CC8520 相连接,将接收到的模拟音频信号进行A/D 转换、后置放大等一系列处理,将数字音频信号通过 1.送至功放从LOL、LOR 输出 2.耳机或小型扩音设备从HPL、HPR 输出。考虑到音频编解码芯片TLV320AIC3204 音频放大作用有限,故在LOL、LOR模拟音频信号输出端设计放大器,将音频信号再次放大,以便于连接至功放设备,原理如图5 所示,设计采用性价比较高的4558 功放芯片作为主体,由+、-9伏电源进行供电。放大后,通过卡侬接口,可连接至功放进行进一步的放大处理。
*图5 模拟信号放大电路原理图。
*
《电子设计技术》网站版权所有,谢绝转载 3 系统配置流程 图6 给出了在PurePath 无线配置器中的配置流程,工程师可根据硬件电路的特点以及设计实现的功能进行配置。定制方式,当设计者认为默认设置不满足设计产品的要求,如:需要更高级的功能时;需要改变外部音频接口的形式时,比如原本音频接口是I2s,现在要以I2C 作为音频传输接口;降低设备功耗,关闭在默认设置中不需要的功能。
*图6 设计配置流程图
*
4 网络拓补及设备识别 在建立网络配对时,由发送端的CC8520 建立网络,作为该网络主机,如图7 所示。这里需要注意到的是,该片CC8520 的设备ID 号就是所建立网络的ID号,因此需要自动固定配对时,需在PurePath 无线适配器"Netwok pairing"中"Default network ID"选项里将设备ID 号输入。设备ID 号是独一无二的,不能改变,这点与厂商ID 和产品ID 可自行定义不同。 本设计中音频发射端(主机)可挂接多个接收端(从机),其音频数据流向、旁路数据通道、建立网络信号流如图7 所示。 PurePath 无线适配器提供两种自定义设备识别方式:1)厂商ID 2)产品ID.厂商ID 作用是设备自动识别同一厂商生产的设备并进行网络配对,当其他厂商也采用CC8520 系列产品时,进行过滤,不与之进行网络配对。产品ID 是同一家厂商有不同的 "CC8520"的产品时,比如:该厂商同时有无线耳机和无线话筒等产品时,防止不同产品间产生配对串扰。
*图7 网络拓补结构。
*
5 结束语 本文提出了基于TI 最新芯片CC8520 无线音频传输系统的设计方案,采用当今热门的2.4GHz 无线技术,无需进行软件开发,提高了系统的可靠性。经实际测试表明:可以有效地提高音质,降低功耗,可持续使用22 小时,传输距离130 米,满足设计要求,为设计无线音频传输系统提供了一种新的思路。 《电子设计技术》网站版权所有,谢绝转载
在随机过程理论中,有两个地方会涉及这三个概念。
为给出这三个概念的定义,我们先引入相关函数和协方差函数的定义。
设有随机过程X(t)和Y(t),令pX和pY分别为X和Y这两个随机变量的概率分布。我们定义
Rx(t1,t2)=E{X(t1)X(t2)}
为自相关函数
再定义
Kx(t1,t2)=E{[X(t1)-Mx(t1)][X(t2)-Mx(t2)]}
为自协方差函数
其中Mx(t1)]和Mx(t2)]为两个时间点处随机变量的期望值。这两个函数之间存在下列关系:
Kx(t1,t2)= Rx(t1,t2)- Mx(t1)]Mx(t2)]
相应地,也可建立不同的随机过程在不同时刻的随机变量之间的互关联函数:
RxY(t1,t2)=E{X(t1)Y(t2)};
互 互协方差函数:
KxY(t1,t2)=E{[X(t1)-Mx(t1)][Y(t2)-MY(t2)]}
其中MY(t2)为Y在t2时刻的期望值。
这两个函数之间也存在下列关系:
KxY(t1,t2)= RxY(t1,t2)- Mx(t1)]MY(t2)]
现在我们给出两个随机过程相互独立的定义:
若pXY(x,y,t1,t2)=pX(x,t1)p(y,t2),则称随机过程X(t)和Y(t)相互统计独立。且有下式成立:
RxY(t1,t2)=E[X(t1)]E[Y(t2)]=MX(t1)MY(t2)
KxY(t1,t2)= RxY(t1,t2)- Mx(t1)]MY(t2)]=0
若 RxY(t1,t2)=E{X(t1)Y(t2)}=0,则称这两个随机过程相互正交。
若
KxY(t1,t2)=E{[X(t1)-Mx(t1)][Y(t2)-MY(t2)]}=0
则称这两个随机过程互不相关。
上述结论同样可以描述两个随机过程在同一时刻的关系;并且也可以描述同一随机过程在同一或不同时刻的关系。
KxY(t1,t2)=0,所以相互独立的随机过程必不相关。但由于这个时候的互相关函数RxY(t1,t2)=E[X(t1)]E[Y(t2)]=MX(t1)MY(t2)不一定为零,故尽管相互独立的随机过程必定不相关,但未必正交。仅当随机过程X(t)在t1或随机过程Y(t)在t2的期望值等于零的时候,相互独立的随机过程才不仅不相关,且正交。KxY(t1,t2)=0,且RxY(t1,t2)=MX(t1)MY(t2)。可见,两个随机过程不相关并非一定能推得独立和正交的结论。仅当MX(t1)或MY(t2)等于零的时候,这两个不相关的随机过程才会正交。RxY(t1,t2)=0,且有 KxY(t1,t2)= -Mx(t1)]MY(t2)]。可见,两个正交的随机过程并非一定能推得不相关或独立的结论。仅当MX(t1)或MY(t2)等于零的时候,这两个正交的随机过程才会不相关。可见,由于两个随机过程x(t)与Y(t)相互独立的充要条件就是它们的联合分布等于各自分布的乘积,而两个随机变量X与Y相关指的是在这两随机变量间存在线性关系(也就是式Y=aX+b成立),换句话说,相关性描述的是两个随机变量之间是否存在线性关系,而独立性考察的则是两个随机变量间是否存在某种关系,因此独立的条件要比不相关严格。如果两个随机变量独立,就是说它们之间不存在任何关系,自然也就不会有线性关系了,所以相互独立的随机变量一定不相关。反过来说,如果两个随机过程不相关,仅是说二者之间不存在线性关系,但二者之间不一定不存在非线性关系,所以不相关的随机过程不一定相互独立。例如,随机变量X与X^2之间不存在线性关系,亦即不相关,但显然不独立。不过,如果两个随机变量相关,也就是说它们之间存在线性关系,则二者之间一定不独立了。
当然,如果两个随机变量服从正态分布,则不相关与相互独立等价。
<!doctype html>
例如
3+2=13+2=13+2=1 //用在行中,不会居中
或者
图片可以用剪贴板复制到文档中,github会提供空间储存图片
也可以使用上传的方式,在编辑框的下方有一个button。
编辑默认使用markdown语言,规则与用法参考git上的项目给出发的翻译文档
https://github.com/riku/Markdown-Syntax-CN
项目主页为http://wowubuntu.com/markdown/
钽电容有一横的那边是正极...



刚接触 Visual Studio的时候大多数人会写个Hello World的程序试一下,有的人会发现执行结束后输出窗口会一闪而过,并没有出现Press any key to continue的字样。无论是在Visual Studio 2008、2010还是2012中都有这种情况出现,有些人可能会用下面两种方法中的一种:
类比理解
n个人掷一次骰子 和 其中一个人掷n次骰子的数字特征相同。
抗干扰设计的基本任务是系统或装置既不因外界电磁干扰影响而误动作或丧失功能,也不向外界发送过大的噪声干扰,以免影响其他系统或装置正常工作。因此提高系统的抗干扰能力也是该系统设计的一个重要环节。
抗干扰问题是现代电路设计中一个很重要的环节,它直接反映了整个系统的性能和工作的可靠性。在飞轮储能系统的电力电子控制中,由于其高压和低压控制信号同时并存,而且功率晶体管的瞬时开关也产生很大的电磁干扰,因此提高系统的抗干扰能力也是该系统设计的一个重要环节。
形成干扰的主要原因有如下几点:
1)干扰源,是指产生干扰的元件、设各或信号,用数字语言描述是指du/dt、di/dt大的地方。干扰按其来源可分为外部干扰和内部干扰:外部干扰是指那些与仪表的结构无关,由使用条件和外界环境因素决定的干扰,如雷电、交流供电、电机等;内部干扰是由仪表结构布局及生产工艺决定的,如多点接地选成的电位差引起的干扰、寄生振荡引起的干扰、尖峰或振铃噪声引起的干扰等。
2)敏感器件,指容易被干扰的对象,如微控制器、存贮器、A/D转换、弱信号处理电路等。
3)传播路径,是干扰从干扰源到敏感器件传播的媒介,典型的干扰传播路径是通过导线的传导、电磁感应、静电感应和空间的辐射。
抗干扰设计的基本任务是系统或装置既不因外界电磁干扰影响而误动作或丧失功能,也不向外界发送过大的噪声干扰,以免影响其他系统或装置正常工作。
其设计一般遵循下列三个原则:
抑制噪声源,直接消除干扰产生的原因;
切断电磁干扰的传播途径,或者提高传递途径对电磁干扰的衰减作用,以消除噪声源和受扰设各之间的噪声耦合;
加强受扰设各抵抗电磁干扰的能力,降低噪声敏感度。
目前,对系统的采用的抗干扰技术主要有硬件抗干扰技术和软件抗干扰技术。
**1)硬件抗干扰技术的设计。**飞轮储能系统的逆变电路高达20kHz的载波信号决定了它会产生噪声,这样系统中电力电子装置所产生的噪声和谐波问题就成为主要的干扰,它们会对设备和附近的仪表产生影响,影响的程度与其控制系统和设各的抗干扰能力、接线环境、安装距离及接地方法等因素有关。
转换器产生的PWM信号是以高速通断DC电压来控制输出电压波形的。急剧的上升或下降的输出电压波包含许多高频分量,这些高频分量就是产生噪声的根源。虽然噪声和谐波都对电子设各运行产生不良影响,但是两者还是有区别的:谐波通常是指50次以下的高频分量,频率为2~3kHz;而噪声却为10kHz甚至更高的高频分量。噪声一般要分为两大类:一类是由外部侵入到飞轮电池的电力电子装置,使其误动作:另一类是该装置本身由于高频载波产生的噪声,它对周围电子、电信设各产生不良影响。
减低噪声影响的一般办法有改善动力线和信号线的布线方式,控制信号用的信号线必须选用屏蔽线,屏蔽线外皮接地。为防止外部噪声侵入,可以采取以下的措施:使该电力电子装置远离噪声源、信号线采取数字滤波和屏蔽线接地。
噪声的衰减技术有如下几点:
①电线噪声的衰减的方法:在交流输入端接入无线电噪声滤波器;在电源输入端和逆变器输出端接入线噪声滤波器,该滤波器可由铁心线圈构成;将无线电噪声滤波器和线噪声滤波器联合使用;在电源侧接人LC滤波器。
②逆变器至电机配线噪声辐射衰减,可采取金属导线管和金属箱通过接地来切断噪声辐射。
③飞轮电力电子装置的辐射噪声的衰减,通常其噪声辐射是很小的,但是如果周围的仪器对噪声很敏感,则应把该装置装入金属箱内屏蔽起来。
对于模拟电路干扰的抑制,由于电路中有要测量的电流、电压等模拟量,其输出信号都是微弱的模拟量信号,极易受干扰影响,在传输线附近有强磁场时,信号线将有较大的交流噪声。可以通过在放大器的输入、输出之间并联一个电容,在输入端接入有源低通滤波器来有效地抑制交流噪声。此外,在A/D变换时,数字地线和模拟电路地线分开,在输入端加入箝位二极管,防止异常过压信号。
而数字电路常见的干扰有电源噪声、地线噪声、串扰、反射和静电放电噪声。为抑制噪声,应注意输入与输出线路的隔离,线路的选择、配线、器件的布局等问题。输入信号的处理是抗干扰的重要环节,大量的干扰都是从此侵入的。
一般可以从以下几个方面采取措施:
①接点抖动干扰的抑制;多余的连接线路要尽量短,尽量用相互绞合的屏蔽线作输入线,以减少连线产生的杂散电容和电感;避免信号线与动力线、数据线与脉冲线接近。
②采用光电隔离技术,并且在隔离器件上加RC电路滤波。
③认真妥善处理好接地问题,如模拟电路地与数字电路地要分开,印制板上模拟电路与数字电路应分开,大电流地应单独引至接地点,印制板地线形成网格要足够宽等。
除了硬件上要采取一系列的抗干扰措施外,在软件上也要采取数字滤波、设置软件陷阱、利用看门狗程序冗余设计等措施使系统稳定可靠地运行。特别地,当储能飞轮处于某一工作状态的时间较长时,在主循环中应不断地检测状态,重复执行相应的操作,也是增强可靠性的一个方法。
由于DSP、CPU等芯片工作频率较高,即使电路原理图设计正确,若印制电路板设计不当,也会对芯片的可靠性产生不利影响。例如,如果印制板两条细平行线靠得很近,则会形成信号波形的延迟,在传输线的终端形成反射噪声。因此,在设计印制电路板时,应注意采用正确的方法。
1)地线设计。在电路中,接地是控制干扰的重要方法,如能将接地和屏蔽正确结合起来使用,可解决大部分干扰问题。在一块电路板上,DSP、CPU同时集成了数字电路和模拟电路,设计电路板时,应使它们尽量分开,而两者的地线不要相混,分别与电源端地线相连。尽量加粗接地线,同时将接地线构成闭环路。
2)配置去耦电容。在直流电源回路中,负载的变化会引起电源噪声。例如在数字电路中,当电路从一个状态转换为另一种状态时,就会在电源线上产生一个很大的尖峰电流,形成瞬变的噪声电压。配置去耦电容可以抑制因负载变化而产生的噪声,是DSP电路板的可靠性设计的一种常规做法:电源输人端可跨接一个10~100μF的电解电容器;为每个集成电路芯片配置一个0.01 μF的陶瓷电容器;对于关断时电流变化大的器件和ROM、RAM等存储型器件,应在芯片的电源线和地线间直接接入去耦电容。注意去耦电容的引线不能过长,特别是高频旁路电容不能带引线。
大多数资料有提到过,去耦电容就近放置,是从减小回路电感的角度去谈及摆放问题,其实还有一个原则就是去耦半径的问题,如果电容离着芯片位置较远,超过去耦半径,会起不到去耦效果。
考虑去耦半径的最好办法就是考察噪声源和电容补偿电流之间的相位关系。当芯片对电流的需求发生变化时,会在电源平面的一个很小的局部区域内产生电压扰动,电容要补偿这一电流(电压),就必须感知到这一电压扰动。信号在介质中传播需要一定的时间,因此发生局部电压扰动到电容感知到需要有一定的时间延迟,因此必然造成噪声源和电容补偿电流之间的相位上的不一致。特定的电容,对与它自谐振频率相同的噪声补偿效果最好,我们以这个频率来衡量这种相位关系。当扰动区到电容的距离到达时,补偿电流的相位为和噪声源相位刚好差180°,即完全反相,此时补偿电流不再起作用,去耦作用失效,补偿的能量无法及时送达,为了能有效传递补偿能量,应使噪声源和补偿电流之间的相位差尽可能的小,最好是同相位的。距离越近,相位差越小,补偿能量传递越多,如果距离为0,则补偿能量百分之百传递到扰动区,这就要求噪声源距离电容尽可能得近。
对于大电容,因为其谐振频率很低,对应的波长非常长,因为去耦半径很大,所以不用去怎么关心大电容在电路板上的放置位置的原因,对于小电容,因为去耦半径很小,需要靠近去耦的芯片。
3)电路板器件的布置。在器件布置方面与其他逻辑电路一样,应把相互有关的器件尽量放得靠近些,这样可以获得较好的抗噪声效果。时钟发生器、晶振和CPU的时钟输人端都易产生噪声,这些器件要相互靠近些,同时远离模拟器件。
(1) 选择合适的电源
(2) 尽量加宽电源线
(3) 保证电源线、底线走向和数据传输方向一致
(4) 使用抗干扰元器件
(5) 电源入口添加去耦电容(10~100uf)
(1) 模拟地和数字地分开
(2) 尽量采用单点接地
(3) 尽量加宽地线
(4) 将敏感电路连接到稳定的接地参考源
(5) 对pcb板进行分区设计,把高带宽的噪声电路与低频电路分开
(6) 尽量减少接地环路(所有器件接地后回电源地形成的通路叫"地线环路")的面积
(1) 不要有过长的平行信号线
(2) 保证pcb的时钟发生器、晶振和cpu的时钟输入端尽量靠近,同时远离其他低频器件
(3) 元器件应围绕核心器件进行配置,尽量减少引线长度
(4) 对pcb板进行分区布局
(5) 考虑pcb板在机箱中的位置和方向
(6) 缩短高频元器件之间的引线
(1) 每10个集成电路要增加一片充放电电容(10uf)
(2) 引线式电容用于低频,贴片式电容用于高频
(3) 每个集成芯片要布置一个0.1uf的陶瓷电容
(4) 对抗噪声能力弱,关断时电源变化大的器件要加高频去耦电容
(5) 电容之间不要共用过孔
(6) 去耦电容引线不能太长
(1) 尽量采用45°折线而不是90°折线(尽量减少高频信号对外的发射与耦合)
(2) 用串联电阻的方法来降低电路信号边沿的跳变速率
(3) 石英晶振外壳要接地
(4) 闲置不用的们电路不要悬空
(5) 时钟垂直于IO线时干扰小
(6) 尽量让时钟周围电动势趋于零
(7) IO驱动电路尽量靠近pcb的边缘
(8) 任何信号不要形成回路
(9) 对高频板,电容的分布电感不能忽略,电感的分布电容也不能忽略
(10) 通常功率线、交流线尽量在和信号线不同的板子上
(1)CMOS的未使用引脚要通过电阻接地或电源
(2)用RC电路来吸收继电器等原件的放电电流
(3)总线上加10k左右上拉电阻有助于抗干扰
(4)采用全译码有更好的抗干扰性
(5)元器件不用引脚通过10k电阻接电源
(6)总线尽量短,尽量保持一样长度
(7)两层之间的布线尽量垂直
(8)发热元器件避开敏感元件
(9)正面横向走线,反面纵向走线,只要空间允许,走线越粗越好(仅限地线和电源线)
(10)要有良好的地层线,应当尽量从正面走线,反面用作地层线
(11)保持足够的距离,如滤波器的输入输出、光耦的输入输出、交流电源线和弱信号线等
(12)长线加低通滤波器。走线尽量短截,不得已走的长线应当在合理的位置插入C、RC、或LC低通滤波器。
(13)除了地线,能用细线的不要用粗线。
一般宽度不宜小于0.2.mm(8mil)
在高密度高精度的pcb上,间距和线宽一般0.3mm(12mil)
当铜箔的厚度在50um左右时,导线宽度1~1.5mm(60mil) = 2A
公共地一般80mil,对于有微处理器的应用更要注意
首先,要考虑PCB尺寸大小。PCB尺寸过大时,印制线条长,阻抗增加,抗噪声能力下降,成本也增加;过小,则散热不好,且邻近线条易受干扰。
在确定PCB尺寸后.再确定特殊元件的位置。最后,根据电路的功能单元,对电路的全部元器件进行布局。
在确定特殊元件的位置时要遵守以下原则:
(1)尽可能缩短高频元器件之间的连线,设法减少它们的分布参数和相互间的电磁干扰。易受干扰的元器件不能相互挨得太近,输入和输出元件应尽量远离。
(2)某些元器件或导线之间可能有较高的电位差,应加大它们之间的距离,以免放电引出意外短路。带高电压的元器件应尽量布置在调试时手不易触及的地方。
(3)重量超过15g的元器件、应当用支架加以固定,然后焊接。那些又大又重、发热量多的元器件,不宜装在印制板上,而应装在整机的机箱底板上,且应考虑散热问题。热敏元件应远离发热元件。
(4)对于电位器、可调电感线圈、可变电容器、微动开关等可调元件的布局应考虑整机的结构要求。若是机内调节,应放在印制板上方便于调节的地方;若是机外调节,其位置要与调节旋钮在机箱面板上的位置相适应。
(5)应留出印制扳定位孔及固定支架所占用的位置。
根据电路的功能单元.对电路的全部元器件进行布局时,要符合以下原则:
(1)按照电路的流程安排各个功能电路单元的位置,使布局便于信号流通,并使信号尽可能保持一致的方向。
(2)以每个功能电路的核心元件为中心,围绕它来进行布局。元器件应均匀、整齐、紧凑地排列在PCB上.尽量减少和缩短各元器件之间的引线和连接。
(3)在高频下工作的电路,要考虑元器件之间的分布参数。一般电路应尽可能使元器件平行排列。这样,不但美观.而且装焊容易.易于批量生产。
(4)位于电路板边缘的元器件,离电路板边缘一般不小于2mm。电路板的最佳形状为矩形。长宽比为3:2成4:3。电路板面尺寸大于200x150mm时.应考虑电路板所受的机械强度。
布线的原则如下:
(1)输入输出端用的导线应尽量避免相邻平行。最好加线间地线,以免发生反馈藕合。
(2)印制摄导线的最小宽度主要由导线与绝缘基扳间的粘附强度和流过它们的电流值决定。当铜箔厚度为0.05mm、宽度为 1 ~ 15mm 时.通过 2A的电流,温度不会高于3℃,因此.导线宽度为1.5mm可满足要求。对于集成电路,尤其是数字电路,通常选0.02~0.3mm导线宽度。当然,只要允许,还是尽可能用宽线.尤其是电源线和地线。导线的最小间距主要由最坏情况下的线间绝缘电阻和击穿电压决定。对于集成电路,尤其是数字电路,只要工艺允许,可使间距小至5~8mm。
(3)印制导线拐弯处一般取圆弧形,而直角或夹角在高频电路中会影响电气性能。此外,尽量避免使用大面积铜箔,否则.长时间受热时,易发生铜箔膨胀和脱落现象。必须用大面积铜箔时,最好用栅格状.这样有利于排除铜箔与基板间粘合剂受热产生的挥发性气体。
焊盘中心孔要比器件引线直径稍大一些。焊盘太大易形成虚焊。焊盘外径D一般不小于(d+1.2)mm,其中d为引线孔径。对高密度的数字电路,焊盘最小直径可取(d+1.0)mm。
印制电路板的抗干扰设计与具体电路有着密切的关系,这里仅就PCB抗干扰设计的几项常用措施做一些说明。
根据印制线路板电流的大小,尽量加租电源线宽度,减少环路电阻。同时、使电源线、地线的走向和数据传递的方向一致,这样有助于增强抗噪声能力。
地线设计的原则是:
(1)数字地与模拟地分开。若线路板上既有逻辑电路又有线性电路,应使它们尽量分开。低频电路的地应尽量采用单点并联接地,实际布线有困难时可部分串联后再并联接地。高频电路宜采用多点串联接地,地线应短而租,高频元件周围尽量用栅格状大面积地箔。
(2)接地线应尽量加粗。若接地线用很纫的线条,则接地电位随电流的变化而变化,使抗噪性能降低。因此应将接地线加粗,使它能通过三倍于印制板上的允许电流。如有可能,接地线应在2~3mm以上。
(3)接地线构成闭环路。只由数字电路组成的印制板,其接地电路布成团环路大多能提高抗噪声能力。
PCB设计的常规做法之一是在印制板的各个关键部位配置适当的退耦电容。
退耦电容的一般配置原则是:
(1)电源输入端跨接10~100uf的电解电容器。如有可能,接100uF以上的更好。
(2)原则上每个集成电路芯片都应布置一个0.01pF的瓷片电容,如遇印制板空隙不够,可每4~8个芯片布置一个1 ~ 10pF的但电容。
(3)对于抗噪能力弱、关断时电源变化大的器件,如 RAM、ROM存储器件,应在芯片的电源线和地线之间直接接入退耦电容。
(4)电容引线不能太长,尤其是高频旁路电容不能有引线。
此外,还应注意以下两点:
(1)在印制板中有接触器、继电器、按钮等元件时.操作它们时均会产生较大火花放电,必须采用附图所示的 RC 电路来吸收放电电流。一般 R 取 1 ~ 2K,C取2.2 ~47UF。
(2)CMOS的输入阻抗很高,且易受感应,因此在使用时对不用端要接地或接正电源。
来源:硬件十万个为什么
严格平稳 Strict(ly) stationary process【强平稳过程Strong(ly) stationary process】
信号处理中常用的弱平稳也被称为广义平稳(Wide-sense stationary,WSS)或者协方差平稳。WSS 随机过程仅仅要求一阶和二阶矩不随时间变化。
当使用线性、时不变(线性时不变系统)滤波器处理广义平稳随机信号的时候,将相关函数作为线性算子是很有帮助的。由于它是循环矩阵运算,只与两个变量之间的差值有关,所以它的特征函数是傅里叶级数复数指数函数。另外,由于线性时不变系统算子也是复指数函数,广义平稳随机信号的线性非时变处理非常易于操作——所有的运算都可以在频域进行。另外,根据线性非时变系统的特征,也可以知道,当输入信号是一个广义平稳过程时,输出信号也会是一个广义平稳过程。因此,广义平稳假设在信号处理算法中得到了广泛应用。
均值与相关函数按照周期变化
本文是为既没有机器学习基础也没了解过TensorFlow的码农、序媛们准备的。如果已经了解什么是MNIST和softmax回归本文也可以再次帮助你提升理解。在阅读之前,请先确保在合适的环境中安装了TensorFlow(windows安装请点这里,其他版本请官网找),适当编写文章中提到的例子能提升理解。
首先我们需要了解什么是"MNIST"?
每当我们学习一门新的语言时,所有的入门教程官方都会提供一个典型的例子——"Hello World"。而在机器学习中,入门的例子称之为MNIST。
MNIST是一个简单的视觉计算数据集,它是像下面这样手写的数字图片:
每张图片还额外有一个标签记录了图片上数字是几,例如上面几张图的标签就是:5、0、4、1。
本文将会展现如何训练一个模型来识别这些图片,最终实现模型对图片上的数字进行预测。
首先要明确,我们的目标并不是要训练一个能在实际应用中使用的模型,而是通过这个过程了解如何使用TensorFlow完成整个机器学习的过程。我们会从一个非常简单的模型开始——Softmax回归。
然后要明白,例子对应的源代码非常简单,所有值得关注的信息仅仅在三行代码中。然而,这对于理解TensorFlow如何工作以及机器学习的核心概念非常重要,因此本文除了说明原理还会详细介绍每一行代码的功用。
阅读之前请先获取 mnist_softmax.py 的代码,文中会一步一步的介绍每一行代码的内容。建议读者分为2种方式去学习后面的内容:
mnist_softmax.py 的代码,之后回来继续阅读以解惑不明部分。本文包含以下内容:
MINIST数据集的官网是 Yann LeCun's website。下面这2行代码的作用是从MINIST官网自动下载并读取数据:
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
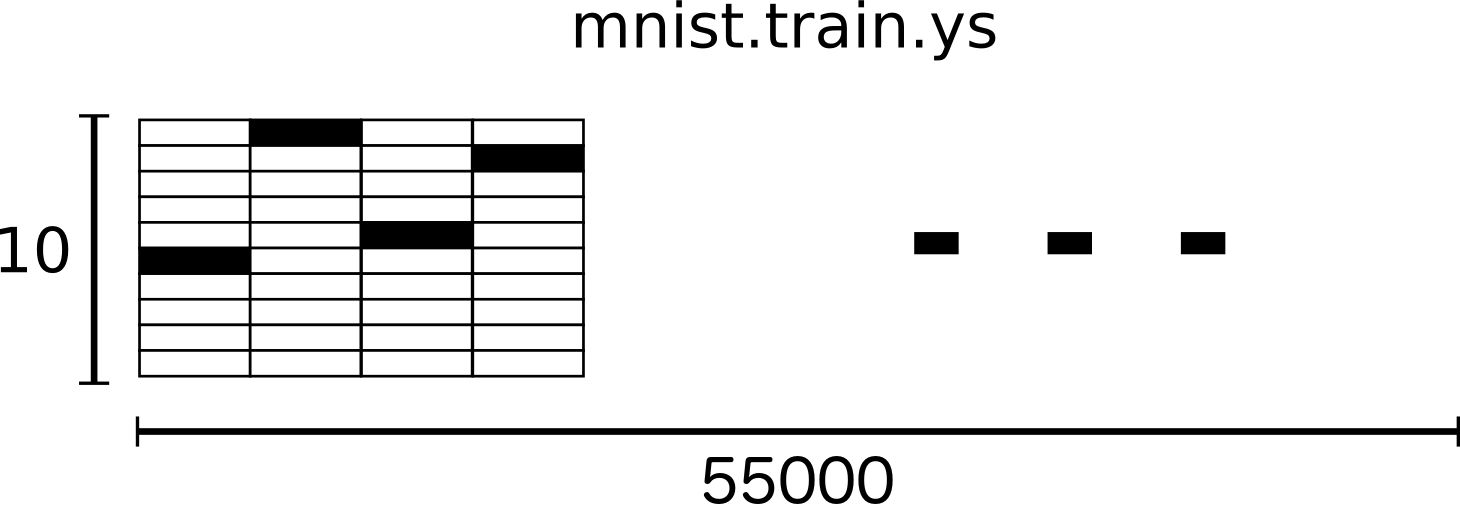
MINIST的数据分为2个部分:55000份训练数据(mnist.train)和10000份测试数据(mnist.test)。这个划分有重要的象征意义,他展示了在机器学习中如何使用数据。在训练的过程中,我们必须单独保留一份没有用于机器训练的数据作为验证的数据,这才能确保训练的结果是可以在所有范围内推广的(可泛化)。
前面已经提到,每一份MINIST数据都由图片以及标签组成。我们将图片命名为"x",将标记数字的标签命名为"y"。训练数据集和测试数据集都是同样的结构,例如:训练的图片名为 mnist.train.images 而训练的标签名为 mnist.train.labels。
每一个图片均为28×28像素,我们可以将其理解为一个二维数组的结构:
然后将这个数组扁平化成由784(28×28)个数字组成的一维数组。怎么扁平化数组并不重要,关键在于我们要保证所有的图片都使用一致的扁平化方法。因此,在数学意义上可以把MINIST图片看成是在784维度向量空间中的点,关于这个数据结构的复杂性可以参看这篇论文加以了解——Visualizing MNIST: An Exploration of Dimensionality Reduction。
扁平化会丢失图片的二维结构信息,优秀的图形结构算法都会利用二维结构信息,但是为了简化过程便于理解,这里先使用这种一维结构来进行softmax回归。
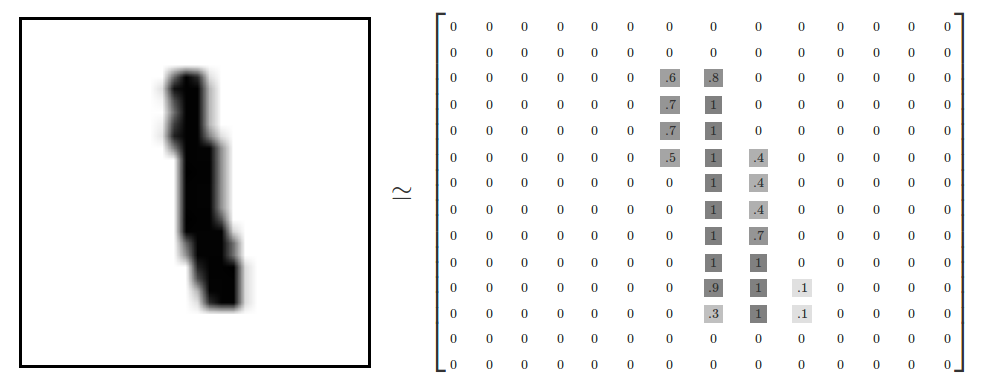
mnist.train.images 是一个形态为 [55000, 784] 的张量(tensor)。第一个维度表示图片个数的索引,第二个维度表示图片中每一个像素的索引。每一个像素的取值为0或1,表示该像素的亮度。 mnist.train.images 可以理解为下图这样的空间结构:
MNIST的每一张图片都有一个数值0~9的标记。教程中,我们将标签数据设置为"one-hot vectors"。"one-hot vectors"是指一个向量只有一个维度的数据是1,其他维度的数据都是0。在本文例子中,标记数据的维度将设置为1,而其他维度设置为0。例如3的向量结构是[0,0,0,1,0,0,0,0,0]。所以 mnist.train.labels 是一个结构为 [55000, 10] 的张量。
然后开始实际创建前面描述的模型。
MNIST中每一张图片表示一个手写体0到9的数字,所以每一张图片所要表达的内容只有10种可能性。我们希望得到图片代表某个数字的概率。举个例子,一个模型当图片上的手写体数字是9时有80%的可能性识别的结果是9,还有5%的可能性识别出的结果是8。因这2者并没有覆盖100%的可能性,所有还有其他数字可能会出现。这是一个典型的softmax回归案例。softmax回归的作用是可以将概率分配给几个不同的对象,softmax提供了一个值处于0到1之间的列表,而列表中的值加起来为1。
一个softmax回归包含2步:首先根据输入的数据提取该输入属于各个分类的"证据"(evidence),然后将这个证据转换成一个概率值。
为了收集证据(evidence)以便将给定的图片划定到某个固定分类,我们对图片的像素值进行加权求和。如果有很明显的证据表明某个像素点会导致图片不属于该类,则加权值为负值反之为正。
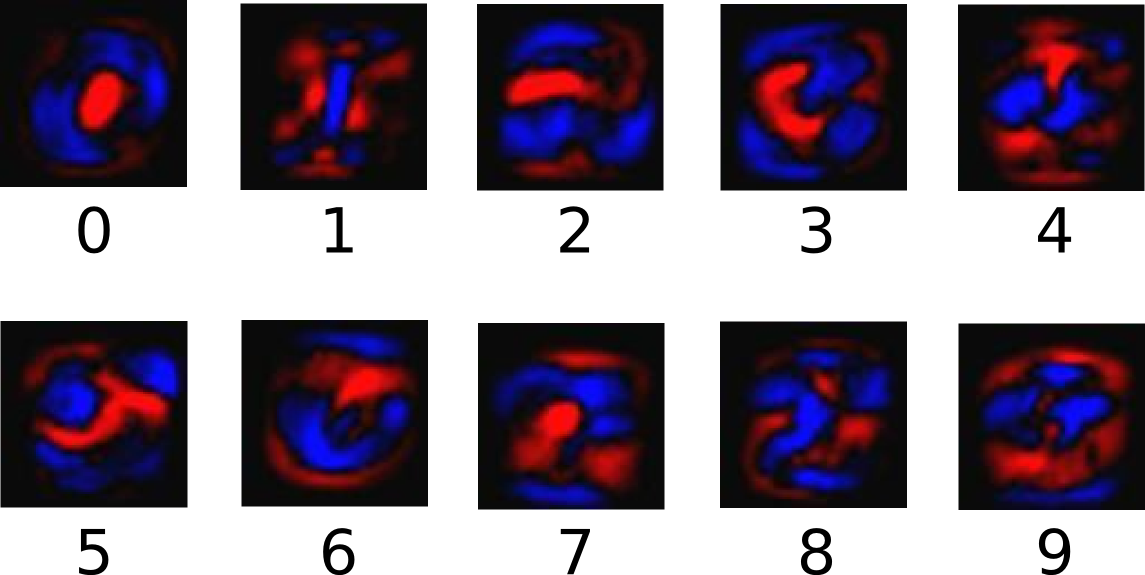
下面的图片展示了一个模型经过学习后,图片上的每个像素点对于特定数字的权值。红色表示负数权值、蓝色表示正数权值:
在训练的过程中,我们需要设定额外的偏置量(bias)以排除在输入中引入的干扰数据。下面图表示证据的提取计算公示,对于分类i给定一个x的输入得到:
这里i表示分类(i=[0...9]),j表示图片x的像素索引(j=[0...784])、Wij表示分类i在像素点j的加权值、xj表示图片x在j像素点的值(xj=[0,1]),bi表示分类i的偏移量。然后用softmax函数将这些证据转换成一个概率值:
这里的softmax可以看成是一个转换函数,把线性函数的输出转换成需要的格式。在本文的例子中输出的就是图片在0~9这10个数字上的概率分布。因此,整个过程就是给定一个图片x,softmax最终会转化输出成一个对应每个分类概率值。它的定义是:
展开等式的子等式:
这个公式可以理解为:图片x在i分类中的加权值在所有加权值中的占比,exp()是e为底的指数计算公式。
上面的2个公示展示了softmax函数的计算过程:
如果想了解更多关于softmax回归的细节,请阅读Michael Nieslen书中关于softmax的说明。
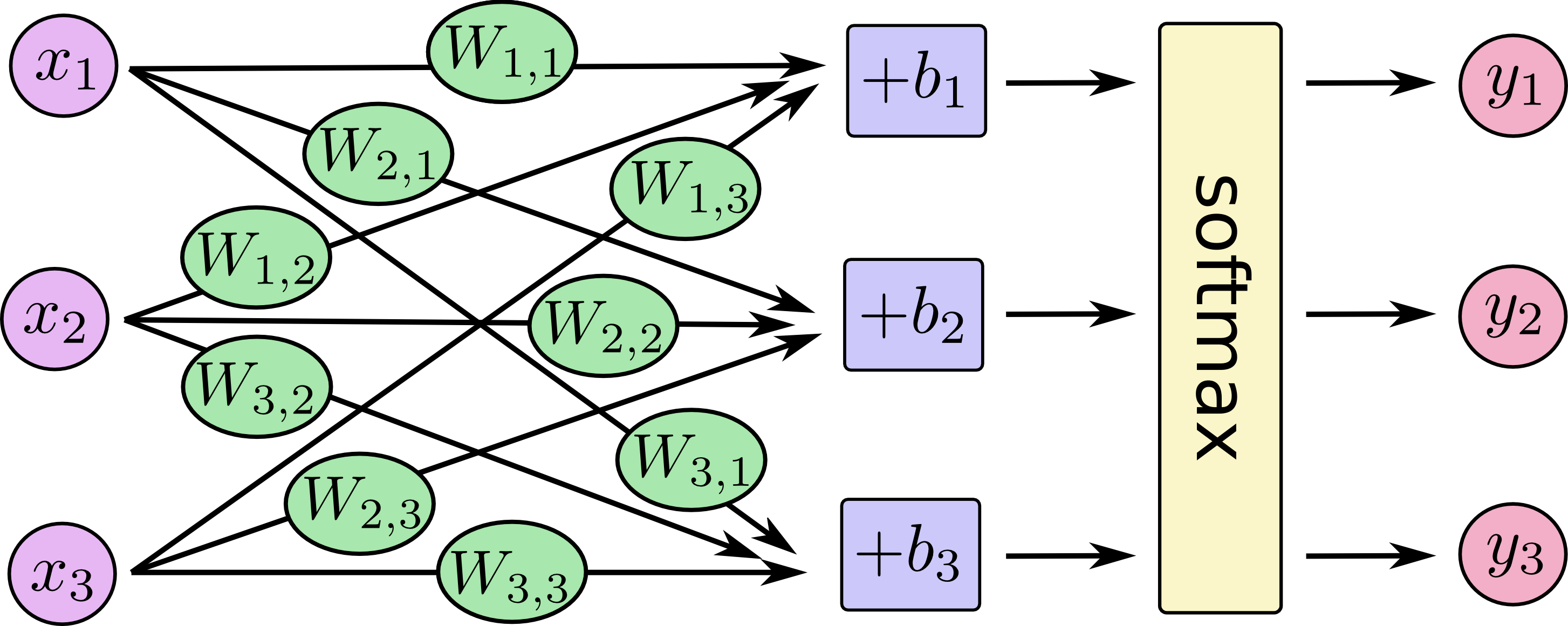
下图形象的展示了softmax回归的过程。Xj表示一个像素点(下图中j=[1,2,3])。然后通过像素点与权重Wij的乘积求和(下图中i=[1,2,3])再加上偏移量bi得到模型值,最后将模型进行softmax运算。
如果将其转换成线性方程式,得到:
还可以用向量矩阵来表述这个过程。下图的结果将上面的方程式转换成向量矩阵,这样有助于提升计算效率。
最后可以使用下面的等式形象的表示这个过程:
y=softmax(Wx+b)
接下来,我们将把这个过程使用TensorFlow实现。
为了在python中实现高效的数字运算建议用 NumPy 这一类第三方库进行复杂的数学运算(比如下文会用到的矩阵乘法运算),因为它们使用了其他更高效的语言(C++)提升运算速度。使用外部库还是会存在一些效率问题:计算操作在python和其他语言之间来回切换会导致许多额外的性能开销,在使用GPU运算时这个问题尤为明显,在集群环境下同样存在这个问题。
TensorFlow同样使用C++等语言实现高效的运算,但是为了避免前面说到的问题,TensorFlow进行了一些完善。在 TensorFlow入门部分 已经说明,它的执行过程是先构建模型然后再执行模型,所以TensorFlow会在模型执行期间一次性使用外部语言进行所有的计算然后再切换回python返回结果(绝大部分机器学习库都以这种方式实现)。
首先,导入TensorFlow:
import tensorflow as tf
声明变量x:
x = tf.placeholder(tf.float32, [None, 784])
x表示所有的手写体图片。它并不是一个固定值而是一个占位符,只有在TensorFlow运行时才会被设定真实值。根据前文描述的模型,输入是任意数量的MNIST图片,每张图片的像素值被扁平化到一个784维度的向量中([784]),我们用一个二维浮点数张量来记录所有图片的输入,这个张量的形状就是 [None, 784] 。这里的 None 表示任意维度的向量。
我们的模型还有 **权重 **和 偏移量。由于是可训练数据,我们将这些值指定为一个附加输入,在 TensorFlow入门部分 我们称之为 变量。变量就是可修改的张量,他在图中是一个可操作的节点。在计算的过程中,变量是样本训练的基础,通过不断调整变量来实现一个收敛过程找到变量的最佳值。
# tf.zeros表示所有的维度都为0
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
使用 tf.Variable 创建一个变量,然后使用 tf.zeros 将变量 W 和 b 设为值全为0的张量(就是将张量中的向量维度值设定为0)。由于我们在后续的过程中要使用大量的数据来训练 W 和 b 的值,因此他们的初始值是什么并不重要。
下面解释下W和b的意义:
在TensorFlow中仅仅一行代码就可以实现整个运算过程:
y = tf.nn.softmax(tf.matmul(x, W) + b)
解释一下这行代码:
tf.matmul(x, W) 表达式表示W和x的乘积运算,对应之前等式(y=softmax(Wx+b))的Wx,这个计算结果会得到一个y1=[None, 10]的张量,表示每个图片在10个分类下权重计算结果。tf.matmul(x, W) + b 表示执行y2=y1+b的运算,它计算每个分类的偏移量。y2还是一个[None,10]的张量。tf.nn.softmax 进行归一计算,得到每张图片在每个分类下概率。到止为止,使用TensorFlow完成了计算模型的创建。回忆下做了什么事:先用几行代码创建了数据(占位和变量),然后用一行代码创建了运算模型,代码非常的简短。简短并不是因为TensorFlow特意为softmax回归计算做了什么特别的设计,而是因为无论是机器学习建模还是物理仿真运算,使用TensorFlow描述数值计算都非常灵活。模型一旦定义好就可以在不同的设备上运行,例如电脑的CPU、GPU甚至手机。
为了训练模型,需要针对模型定义一个指标来衡量模型"有多好"。不过事实上在机器学习中典型的方法是定义某个指标来衡量模型"有多差"。这个指标称为"成本"(cost)或"损益"(loss),它表示某个模型与期望的结果有多远。训练的目的就是不断的减少损益值,损益值越小证明我们的模型越好。
通常情况下,"交叉熵"(cross-entropy)是非常适用于评估模型的损益值大小。交叉熵的概念来自于信息论的中关于信息压缩与编码的讨论,但是在博弈论、机器学习等其他许多领域也是重要的**。他的数学定义是:
q表示预测的概率分布,p表示真实分布(图片标签的分布)。简单的说,交叉熵就是描述当前模型距离真实的数据值还有多少差距。
> TensorFlow官网在对应的教程中并没有解释什么是交叉熵,这里根据我对信息论相关的数学知识理解说明什么是交叉熵。如果对数学符号所代表的含义没有兴趣,可以跳过本小节
信息论中的熵是指信息不确定性的度量。熵越高代表为了呈现某个事物所需要的信息量就越多。熵的值都是基于概率的,其概率解释是:当某些事物在样本空间中的占比率越高,则需要将他描述出来的信息量越少。若占比率越少,则描述他的信息就越多。根据这个理论,熵值实质上衡量是信息量大小的数值,加上单位后的数量就是实际中常用于标记数据量大小的值,通常情况下用1位信息表示2个信号来表述,这个单位我们称之为bit。
数学上对于均匀分布的信息,其熵可以用:
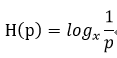
来表示。假设26个英文字符是均匀分布的,那么这里的p=1/26。若使用bit为运算单位,那么低x取值为2,所以计算得出26个英文字母需要4.7004bit信息来表述,取上界就是5bit的信息量。
但是在现实世界中,绝大部分事物都不是均匀分布的。比如英文单词,通常字母e出现的频率比z就高很多,所以这种情况需要分别对不同事物的"统计特征"逐个计算,在这种情况下,熵的计算公式为:
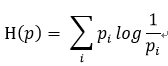
数学含义是:对于i个事物X,每个事物X的概率分布为Pi,其熵值为每个独立事物熵值占比的合计。
公式(1)是公式(2)在均匀分布下的推导:若P1=P2=P3=....=Pn且均分同一概率空间,那么可以推导出公式(1)。
举个例子。架设有4个英文字母集合v=[A,B,C,D],其对应的概率分布p=[1/2,1/2,0,0],那么:
将公式展开:
若取bit作为度量单位,那么x=2,则得到的结果是H=1。所以如果按照这样的分布,只需要1bit的信息就可以表述所有的信息(因为C和D根本就不会出现,而A或B只需要一位[0,1]来表述)。
在公式(2)中p表示所有事物的真实分布,但是在实际情况中并不一定准确的清晰所有样本的真实分布,信息论中用交叉熵来表示这种情况,其表达式就是前面出现的公式:
q是预测分布,而p是真实分布。
还是使用上面的例子:集合v=[A,B,C,D,E]、p=[1/2,1/2,0,0],预测分布我们使用均匀分布p=[1/4,1/4,1/4,1/4],所以带入公式:
若取bit作为度量单位,那么x=2,则交叉熵的值H(p,q)=2。
H(p,q)>=H(p)恒成立,当q等于真实分布q时取等号。因此在机器学习中,若p表示真实标记的分布,q为训练后的模型的预测标记分布,交叉熵损失函数可以衡量p与q的相似性。交叉熵作为损失函数还有一个好处是使用sigmoid函数在梯度下降时能避免均方误差损失函数学习速率降低的问题,因为学习速率可以被输出的误差所控制。
为了在编码中实现交叉熵,首先需要增加一个占位符来输入真实分布值:
y_ = tf.placeholder(tf.float32, [None, 10])
然后我们实现交叉熵功能:
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y), reduction_indices=[1]))
这一行代码的含义:
tf.log 对y进行对数计算。tf.log 相乘。tf.reduce_sum 根据 reduction_indices=[1] 指定的参数,计算y中第二个维度所有元素的总和。tf.reduce_mean 用于计算该批次的一个平均值。需要注意的是,这里的cross_entropy仅仅用于示例以便于理解。在源代码中,不推荐使用这个公式,因为在数值上非常不稳定。推荐使用tf.nn.softmax_cross_entropy_with_logits 方法直接训练 tf.matmul(x, W) + b) 的结果。因为他在内部计算softmax,数值更加稳定。
现在,我们已经定义好模型和训练方式,TensorFlow接下来会使用"反转传播算法"逐步修改变量以找到能使损益值最小化的变量值。现在定义所需的优化器:
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)
上面的代码设定梯度递减算法为训练的优化器,每次变量的调整范围为0.01。梯度递减是非常快捷高效的算法,TensorFlow需要做的是将每个变量一点点的向损益值变小的方向逐渐移动。TensorFlow提供了非常多的优化算法,只需要修改这行代码即可将优化器修改为其他算法。
整个过程TensorFlow都做了什么呢?在另外一篇 TensorFlow入门 的博文中介绍了TensorFlow的计算过程就是一个图。在后台运算时,TensorFlow会向这个图增加额外的操作以实现"反转传播算法"和"梯度递减算法"。最后TensorFlow返回一个独立的操作入口(就是上面代码中的train_step),这个入口会用梯度下降算法训练你的模型、微调你的变量、不断减少损益值。
现在可以在 InteractiveSession 中启用该模型:
sess = tf.InteractiveSession()
在运行之前需要初始化所有的变量:
tf.global_variables_initializer().run()
然后就可以开始训练了,我们允许一次执行1000次训练。
for _ in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})
循环中的每一步,我们都会从训练图片分类的集合中(回想一下,前面提到每一个图片包含图片自身的像素值以及一个标记数值的标签)中随机取出100条随机数据,然后执行train_step将占位数据替换成从测试图片库mnist.train中获取的参数。
使用一个小批量的随机数称为随机训练(stochastic training),在这个例子中可以叫随机梯度递减训练。理想状态下,当然期望所有的数据都用于每一步训练,这样可以覆盖到所有样本,但是所带来的负面影响是计算成本太高。所以,每次训练都随机使用不同的数据子集,这样既降低计算成本又有效最大化利用数据。
现在我们来到了所有工作的最后一步,验证所设计的模型是否足够好。
首先找出那些被模型预测正确的图标。 tf.argmax 是一个非常有用的方法,它能够找到张量中某个列表最高数值的条目索引。例如 tf.argmax(y,1) 是找到张量y第二个向量的最大值(图标标签是0~9,softmax计算完成后会得到一个分布概率,argmax方法就是找到每一个图片对应的最高概率),而 tf.argmax(y_,1) 设定的参数就是真实标签。然后使用 tf.equal 方法检查预测是否和真实情况一样。
correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1))
比较的结果会返回一个boolean列表,为了确定正确预测的占比,我们用float类型来表示boolean类型。例如对于boolean类型的列表[true,false,true,true]可以转换成[1,0,1,1],然后正确占比是75%。下面的代码完成了这一步工作。
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
最后,运行它测试模型预测图片数据的准确率。
# 这里使用的是整个mnist.test的数据
print(sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels}))
输出的结果应该是92%左右。
最后我们说说这个结果。从严格意义上来说,92%的正确率是非常差的。因为我们所使用的模型不仅非常简单而且数据也非常规范。不过不必灰心,只要经过小小的跳转,可以让这个正确率立刻达到97%,而现在最好的模型达到了99.7%。关于模型准确性的讨论,可以看 这里。
本文的价值并不是正确率,而是了解如何进行机器学习建模。当然,对于机器学习这仅仅是一个开始,后续会在这篇文章的基础上继续介绍如何使用TensorFlow搭建更复杂更有价值的模型。
在写本文时,正好在微信朋友圈和OC都看到传得正火爆的《自动编程是不可能的 我为什么不在乎人工智能》一文。关于人工智能是否值得在乎每个人都有自己的看法谈下去没什么价值,不过自动编程这一点倒是在这一代AI技术上不太可能做得比普通工程师做得更好。原因很简单,本文提到的一个数学公式就说明了这个问题:
这是信息交叉熵公式,也是机器学习常用的损益评估公式。当期望分布p=q时,获得最少信息量或最少损益值,收敛学习结果的过程,其实就是在找p=q或让q逐渐接近p的过程。
从信息论的角度来看,所有用户通过自然语言描述的需求对于机器来说熵值是非常高的,因为大段的自然语言中有用的内容在整体信息中的分布非常低。而通过产品人和研发工程师的转换最终成为熵值非常低的源码。所以靠不懂编程开发的人去实现有价值的程序个人认为几乎不可能。
不过AI对于编程肯定有增益效果。比如当年用C#写windows界面,妥妥拽拽代码就生成好了,码农下一步活就是在各种回调事件中写业务、写DAO、写调用。AI也可以通过大数据观察各种功能的实现方式,最终帮码农快速生成一个60~70%可用的代码,然后序员们在以后的基础上继续写逻辑。个人觉得这个思路可以推广到很多行业——减少重复劳动,增加有特定意义的劳动时间,最终实现提升生产率。
-将码C 中所有码字可能的尾随后缀组成一个集合F, 当且仅当集合F中没有包含任一码字,则可判断此码C为唯一可译变长码。
-集合F 的构造:
之前觉得有问题的方式
只能说判断是不是即时码
来源与百度知道
高配信号很容易由于辐射产生干扰,高速变化的信号会导致振铃、反射、串扰最重要的提供一个稳定的电源分配网络,同时为电路板上所有产生或接受的信号提供信号回路
一般情况下分电源层与总线,我们实验室条件有限,不好做多层PCB,因此只能选择总线


对于某一信源的某一符号集,若存在一个唯一可译码,其平均长度小于所有其他唯一可译码的平均长度,则该码称为紧致码。
D(x) 方差
E(x) 均值
对于Y=aX+b;
D[Y]=a^2 D[X]+b ;
E[Y]=aE[X]+b ;
D(X)=E[X^2]-E[x]^2 ;
E[X^2]=sum(pi*Xi^2) ;
Posted on August 31, 2015
Backpropagation is the key algorithm that makes training deep models computationally tractable. For modern neural networks, it can make training with gradient descent as much as ten million times faster, relative to a naive implementation. That's the difference between a model taking a week to train and taking 200,000 years.
Beyond its use in deep learning, backpropagation is a powerful computational tool in many other areas, ranging from weather forecasting to analyzing numerical stability – it just goes by different names. In fact, the algorithm has been reinvented at least dozens of times in different fields (see Griewank (2010)). The general, application independent, name is "reverse-mode differentiation."
Fundamentally, it's a technique for calculating derivatives quickly. And it's an essential trick to have in your bag, not only in deep learning, but in a wide variety of numerical computing situations.
Computational graphs are a nice way to think about mathematical expressions. For example, consider the expression (e=(a+b)*(b+1)). There are three operations: two additions and one multiplication. To help us talk about this, let's introduce two intermediary variables, (c) and (d) so that every function's output has a variable. We now have:
[c=a+b]
[d=b+1]
[e=c*d]
To create a computational graph, we make each of these operations, along with the input variables, into nodes. When one node's value is the input to another node, an arrow goes from one to another.
These sorts of graphs come up all the time in computer science, especially in talking about functional programs. They are very closely related to the notions of dependency graphs and call graphs. They're also the core abstraction behind the popular deep learning framework Theano.
We can evaluate the expression by setting the input variables to certain values and computing nodes up through the graph. For example, let's set (a=2) and (b=1):
The expression evaluates to (6).
If one wants to understand derivatives in a computational graph, the key is to understand derivatives on the edges. If (a) directly affects (c), then we want to know how it affects (c). If (a) changes a little bit, how does (c) change? We call this the partial derivative of (c) with respect to (a).
To evaluate the partial derivatives in this graph, we need the sum rule and the product rule:
[frac{partial}{partial a}(a+b) = frac{partial a}{partial a} + frac{partial b}{partial a} = 1]
[frac{partial}{partial u}uv = ufrac{partial v}{partial u} + vfrac{partial u}{partial u} = v]
Below, the graph has the derivative on each edge labeled.
What if we want to understand how nodes that aren't directly connected affect each other? Let's consider how (e) is affected by (a). If we change (a) at a speed of 1, (c) also changes at a speed of (1). In turn, (c) changing at a speed of (1) causes (e) to change at a speed of (2). So (e) changes at a rate of (1*2) with respect to (a).
The general rule is to sum over all possible paths from one node to the other, multiplying the derivatives on each edge of the path together. For example, to get the derivative of (e) with respect to (b) we get:
[frac{partial e}{partial b}= 12 + 13]
This accounts for how b affects e through c and also how it affects it through d.
This general "sum over paths" rule is just a different way of thinking about the multivariate chain rule.
The problem with just "summing over the paths" is that it's very easy to get a combinatorial explosion in the number of possible paths.
In the above diagram, there are three paths from (X) to (Y), and a further three paths from (Y) to (Z). If we want to get the derivative (frac{partial Z}{partial X}) by summing over all paths, we need to sum over (3*3 = 9) paths:
[frac{partial Z}{partial X} = alphadelta + alphaepsilon + alphazeta + betadelta + betaepsilon + betazeta + gammadelta + gammaepsilon + gammazeta]
The above only has nine paths, but it would be easy to have the number of paths to grow exponentially as the graph becomes more complicated.
Instead of just naively summing over the paths, it would be much better to factor them:
[frac{partial Z}{partial X} = (alpha + beta + gamma)(delta + epsilon + zeta)]
This is where "forward-mode differentiation" and "reverse-mode differentiation" come in. They're algorithms for efficiently computing the sum by factoring the paths. Instead of summing over all of the paths explicitly, they compute the same sum more efficiently by merging paths back together at every node. In fact, both algorithms touch each edge exactly once!
Forward-mode differentiation starts at an input to the graph and moves towards the end. At every node, it sums all the paths feeding in. Each of those paths represents one way in which the input affects that node. By adding them up, we get the total way in which the node is affected by the input, it's derivative.
Though you probably didn't think of it in terms of graphs, forward-mode differentiation is very similar to what you implicitly learned to do if you took an introduction to calculus class.
Reverse-mode differentiation, on the other hand, starts at an output of the graph and moves towards the beginning. At each node, it merges all paths which originated at that node.
Forward-mode differentiation tracks how one input affects every node. Reverse-mode differentiation tracks how every node affects one output. That is, forward-mode differentiation applies the operator (frac{partial}{partial X}) to every node, while reverse mode differentiation applies the operator (frac{partial Z}{partial}) to every node.
At this point, you might wonder why anyone would care about reverse-mode differentiation. It looks like a strange way of doing the same thing as the forward-mode. Is there some advantage?
Let's consider our original example again:
We can use forward-mode differentiation from (b) up. This gives us the derivative of every node with respect to (b).
We've computed (frac{partial e}{partial b}), the derivative of our output with respect to one of our inputs.
What if we do reverse-mode differentiation from (e) down? This gives us the derivative of (e) with respect to every node:
When I say that reverse-mode differentiation gives us the derivative of e with respect to every node, I really do mean every node. We get both (frac{partial e}{partial a}) and (frac{partial e}{partial b}), the derivatives of (e) with respect to both inputs. Forward-mode differentiation gave us the derivative of our output with respect to a single input, but reverse-mode differentiation gives us all of them.
For this graph, that's only a factor of two speed up, but imagine a function with a million inputs and one output. Forward-mode differentiation would require us to go through the graph a million times to get the derivatives. Reverse-mode differentiation can get them all in one fell swoop! A speed up of a factor of a million is pretty nice!
When training neural networks, we think of the cost (a value describing how bad a neural network performs) as a function of the parameters (numbers describing how the network behaves). We want to calculate the derivatives of the cost with respect to all the parameters, for use in gradient descent. Now, there's often millions, or even tens of millions of parameters in a neural network. So, reverse-mode differentiation, called backpropagation in the context of neural networks, gives us a massive speed up!
(Are there any cases where forward-mode differentiation makes more sense? Yes, there are! Where the reverse-mode gives the derivatives of one output with respect to all inputs, the forward-mode gives us the derivatives of all outputs with respect to one input. If one has a function with lots of outputs, forward-mode differentiation can be much, much, much faster.)
When I first understood what backpropagation was, my reaction was: "Oh, that's just the chain rule! How did it take us so long to figure out?" I'm not the only one who's had that reaction. It's true that if you ask "is there a smart way to calculate derivatives in feedforward neural networks?" the answer isn't that difficult.
But I think it was much more difficult than it might seem. You see, at the time backpropagation was invented, people weren't very focused on the feedforward neural networks that we study. It also wasn't obvious that derivatives were the right way to train them. Those are only obvious once you realize you can quickly calculate derivatives. There was a circular dependency.
Worse, it would be very easy to write off any piece of the circular dependency as impossible on casual thought. Training neural networks with derivatives? Surely you'd just get stuck in local minima. And obviously it would be expensive to compute all those derivatives. It's only because we know this approach works that we don't immediately start listing reasons it's likely not to.
That's the benefit of hindsight. Once you've framed the question, the hardest work is already done.
Derivatives are cheaper than you think. That's the main lesson to take away from this post. In fact, they're unintuitively cheap, and us silly humans have had to repeatedly rediscover this fact. That's an important thing to understand in deep learning. It's also a really useful thing to know in other fields, and only more so if it isn't common knowledge.
Are there other lessons? I think there are.
Backpropagation is also a useful lens for understanding how derivatives flow through a model. This can be extremely helpful in reasoning about why some models are difficult to optimize. The classic example of this is the problem of vanishing gradients in recurrent neural networks.
Finally, I claim there is a broad algorithmic lesson to take away from these techniques. Backpropagation and forward-mode differentiation use a powerful pair of tricks (linearization and dynamic programming) to compute derivatives more efficiently than one might think possible. If you really understand these techniques, you can use them to efficiently calculate several other interesting expressions involving derivatives. We'll explore this in a later blog post.
This post gives a very abstract treatment of backpropagation. I strongly recommend reading Michael Nielsen's chapter on it for an excellent discussion, more concretely focused on neural networks.
Thank you to Greg Corrado, Jon Shlens, Samy Bengio and Anelia Angelova for taking the time to proofread this post.
Thanks also to Dario Amodei, Michael Nielsen and Yoshua Bengio for discussion of approaches to explaining backpropagation. Also thanks to all those who tolerated me practicing explaining backpropagation in talks and seminar series!
[
本文简要介绍了Windows 64位和32位构架的区别,并给出了使用某些NI软件时的最佳Windows构架建议。
64位构架有如下几项优势。 最主要的优势在于它能利用更多的计算机内存。 运行32位Windows操作系统的计算机最多只能使用4 GB的RAM, 而64位构架则无此限制。 根据操作系统版本的不同(家庭版、专业版和企业版),64位Windows 7和Windows Vista的最大内存使用量可达8至192 GB。 关于Windows不同版本内存限制的详细信息,请参阅Microsoft网站文档Memory Limits for Windows Releases 。
如在64位硬件上运行应用程序,则使用64位操作系统性能更优,因为它可使用32位系统无法使用的更多物理内存。 更多可用内存意味着降低了使用存储在硬盘上的页面文件的需求(页面文件是读写速度远远低于物理内存和缓存的内存设备),从而使系统性能得到提高。
除物理内存更大之外,64位处理器还有更多的寄存器,最多可使应用程序的执行速度提高20%。
尽管64位操作系统有诸多好处,但如当前软件是为32位系统设计的,则迁移至64位系统或许并非最佳。 迁移至64位构架意味着要运行一个不同的Windows内核,因而所有已安装驱动必须与64位构架兼容。#160;绝大多数NI软件和驱动程序兼容64位,但用户需明白兼容64位操作系统与本身是为64位系统而设计的区别,后者才能完全利用该构架的优势和可用内存。
为说明这种区别,我们可以把一个NI驱动程序分为两个组件: 用户模式和内核模式。 驱动程序内核模式组件的构架与操作系统的构架相一致。 驱动程序用户模式组件的构架可以与操作系统的构架不一致, 因此,以用户模式运行的软件既可创建成32位也可创建成64位的。#160;大部分NI驱动程序的内核模式组件只能在64位或32位操作系统上运行, 而只有部分NI驱动程序有64位的用户模式组件。 因此,尽管驱动程序可以在64位Windows上运行,但可能无法充分利用64位构架的优势。
对于使用用户模式架构而非内核模式架构的驱动程序,通过软件层将32位架构转换为64位。#160;这种转换需要一定的处理时间和资源。 Windows 7和Windows Vista中提供这一软件层的是叫做Windows-on-Windows (WOW64)的操作系统子系统。 在牺牲性能的条件下该子系统允许32位应用程序在64位环境中运行。
Windows-on-Windows子系统专为将32位Windows应用程序转换至64位环境而设计。 它负责处理因操作系统构架不同而必须进行的结构转换。 WOW64的主要作用是模拟一个32位系统环境,提供32位Windows应用程序在无需修改的情况下,运行在64位操作系统上的所需接口。 尽管它是Windows操作系统中相对轻量级的层,但仍会造成一些性能下降, 因此,如要实现32位应用程序的最佳性能,应选择32位操作系统。因为此时无需执行Windows-on-Windows转换。
大部分NI驱动程序对32位和64位构架均支持。 此外,自LabVIEW 2009发布起,NI开始提供分开发行的32位和64位软件版本。 分开发行的版本只针对英文版的LabVIEW基础版、 完整版和专业版,不包含模块和工具包(NI Vision模块除外)。 LabVIEW 2009 64位与其他NI软件产品不兼容,如LabVIEW RT、LabVIEW FPGA、NI TestStand和LabVIEW工具包。 NI将密切关注市场需求,未来将把其他产品的64位迁移置于优先考虑。 除LabVIEW 2009外,下列软件也有64位版本: NI-VISA、NI-GPIB、NI-DAQmx和NI-IMAQ。
关于可兼容软件的完整列表,请参阅 National Instruments Product Compatibility for Microsoft Windows 7.
请参考下表选择最利于应用程序性能优化的最佳Windows构架。
本文将初步向码农和程序媛们介绍如何使用TensorFlow进行编程。在阅读之前请先 安装TensorFlow,此外为了能够更好的理解本文的内容,阅读之前需要了解一点以下知识:
TensorFlow提供种类繁多的API接口,其中TensorFlow Core是最低层级的接口,为开发TensorFlow提供基础支持。官方推荐把TensorFlow Core用作机器学习研究以及相关的数据建模。除了TensorFlow Core之外还有更高抽象的API接口,这些API接口比TensorFlow Core更易于使用、更易于快速实现业务需求。例如 tf.contrib.learn 接口,它提供管理数据集合、进行数据评估、训练、推演等功能。在使用TensorFlow开发的过程中需要特别注意,以 contrib 开头的API接口依然还在不断完善中,很有可能在未来某个发行版本中进行调整或者直接取消。
本文首先介绍TensorFlow Core,然后会演示如何使用 tf.contrib.learn 实现简单的建模。了解TensorFlow Core是为了让开发者理解在使用抽象接口时底层是如何工作的,以便于在训练数据时创建更合适的模型。
TensorFlow的基础数据单元是张量(tensor)。一个张量认为是一组向量的集合,从数据结构的角度来理解这个集合等价于一组数值存储在1到多个队列中(张量没办法几句话说得清楚,想要了解去谷哥或者度妞搜索"张量分析",可以简单想象成一个多维度的数组)。一个张量的阶表示了张量的维度,下面是一些张量的例子:
>
> 3 # 0阶张量,可以用图形[]来表示
> [1. ,2., 3.] # 1阶张量,是一个图形为3的向量
> [[1., 2., 3.], [4., 5., 6.]] # 2阶张量,是一个图形为[2,3]的矩阵
> [[[1., 2., 3.]], [[7., 8., 9.]]] # 图形为[2,1,3]的三阶张量
下面是导入TensorFlow包的标准方式:
import tensorflow as tf
通过python的方式导入之后, tf 提供了访问所有TensorFlow类、方法和符号的入口。
TensorFlow Core的编程开发可以看就做2个事:
> 图(graph,也可以叫连接图)表示由多个点链接而成的图。本文中的图指的是TensorFlow建模后运算的路径,可以使用TensorBoard看到图的整个形态。
>
> 节点(node)表示图中每一个点,这些点都代表了一项计算任务。
所以简而言之:编程 TensorFlow Core 就是事先安排好一系列节点的计算任务,然后运行这些任务。
下面我们先构建一个简单的图,图中的节点(node)有0或多个张量作为输入,并产生一个张量作为输出。一个典型的节点是"常量"(constant)。TensorFlow的常量在构建计算模型时就已经存在,在运行计算时并不需要任何输入。下面的代码创建了2个浮点常量值常量 node1 和 node2:
node1 = tf.constant(3.0, tf.float32)
node2 = tf.constant(4.0) # also tf.float32 implicitly
print(node1, node2)
运行后会打印输出:
Tensor("Const:0", shape=(), dtype=float32) Tensor("Const_1:0", shape=(), dtype=float32)
观察这个打印的结果会发现,它并不是按照预想的那样输出 3.0 或_ 4.0 的值。这里输出的是一个节点的对象信息。因为到这里还没有执行第二项工作——运行计算模型图。只有在运行时,才会使用到节点真实的值 3.0 和_4.0。为了进行图运算需要创建一个会话(session),一个会话封装了TensorFlow运行库的各种控制方法和状态量(context)。
下面的代码会创建一个会话(session)对象实例,然后执行 run 方法来进行模型计算:
sess = tf.Session()
print(sess.run([node1, node2]))
运行后我们会发现,打印的结果是3.0和4.0:
[3.0, 4.0]
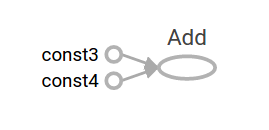
然后,对 node1 和 node2 进行和运算,这个和运算就是图中的运算模型。下面的代码是构建一个 node1 、 node2 进行和运算, node3 代表和运算的模型,构建完毕后使用 sess.run 运行:
node3 = tf.add(node1, node2)
print("node3: ", node3)
print("sess.run(node3): ",sess.run(node3))
运行后会输出了以下内容:
node3: Tensor("Add_2:0", shape=(), dtype=float32)
sess.run(node3): 7.0
到此,完成了TensorFlow创建图和执行图的过程。
前面提到TensorFlow提供了一个名为TensorBoard的工具,这个工具能够显示图运算的节点。下面是一个TensorBoard可视化看到计算图的例子:
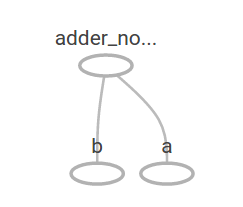
这样的常量运算结果并没有什么价值,因为他总是恒定的产生固定的结果。图中的节点能够以参数的方式接受外部输入——比如使用占位符。占位符可以等到模型运行时再使用动态计算的数值:
a = tf.placeholder(tf.float32)
b = tf.placeholder(tf.float32)
adder_node = a + b # + 可以代替tf.add(a, b)构建模型
上面这3行代码有点像用一个function或者一个lambda表达式来获取参数输入。我们可以在运行时输入各种各样的参数到图中进行计算:
print(sess.run(adder_node, {a: 3, b:4.5}))
print(sess.run(adder_node, {a: [1,3], b: [2, 4]}))
输出结果为:
7.5
[ 3. 7.]
在TensorBoard中,显示的计算图为:
我们可以使用更复杂的表达式来增加计算的内容:
add_and_triple = adder_node * 3.
print(sess.run(add_and_triple, {a: 3, b:4.5}))
计算输出:
22.5
TensorBoard中的显示:
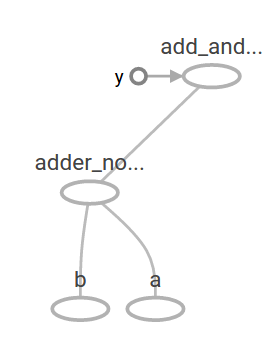
在机器学习中一个模型通常需要接收各种类型的数据作为输入。为了使得模型可以不断的训练通常需要能够针对相同的输入修改图的模型以获取新的输出。**变量(Variables)**可以增加可训练的参数到图中,他们由指定一个初始类型和初始值来创建:
W = tf.Variable([.3], tf.float32)
b = tf.Variable([-.3], tf.float32)
x = tf.placeholder(tf.float32)
linear_model = W * x + b
前面已经提到在调用 tf.constant 时会初始化不可变更的常量。 而这里通过调用 tf.Variable 创建的变量不会被初始化,为了在TensorFlow运行之前(sess.run执行模型运算之前)初始化所有的变量,需要增加一步 init 操作:
init = tf.global_variables_initializer()
sess.run(init)
可以通过重载 init 方式来全局初始化所有TensorFlow图中的变量。在上面的代码中,在我们调用 sess.run 之前,所有的变量都没有初始化。
下面的 x 是一个占位符,{x:[1,2,3,4]} 表示在运算中把x的值替换为[1,2,3,4]:
print(sess.run(linear_model, {x:[1,2,3,4]}))
输出:
[ 0. 0.30000001 0.60000002 0.90000004]
现在已经创建了一个计算模型,但是并不清晰是否足够有效,为了让他越来越有效,需要对这个模型进行数据训练。下面的代码定义名为 y 的占位符来提供所需的值,然后编写一个"损益功能"(loss function)。
一个"损益功能"是用来衡量当前的模型对于想达到的输出目标还有多少距离的工具。下面的例子使用线性回归作为损益模型。回归的过程是:计算模型的输出和损益变量(y)的差值,然后再对这个差值进行平方运算(方差),然后再把方差的结果向量进行和运算。下面的代码中, linear_model - y 创建了一个向量,向量中的每一个值表示对应的错误增量。然后调用 tf.square 对错误增量进行平方运算。最后将所有的方差结果相加创建一个数值的标量来抽象的表示错误差异,使用 tf.reduce_sum来完成这一步工作。如下列代码:
# 定义占位符
y = tf.placeholder(tf.float32)
# 方差运算
squared_deltas = tf.square(linear_model - y)
# 定义损益模型
loss = tf.reduce_sum(squared_deltas)
# 输出损益计算结果
print(sess.run(loss, {x:[1,2,3,4], y:[0,-1,-2,-3]}))
运算之后的差异值是:
23.66
可以通过手动将 W 和 b 的值修改为-1和1降低差异结果。TensorFlow中使用 tf.Variable 创建变量,使用 tf.assign 修改变量。例如 W=-1 、b=1 才是当前模型最佳的值,可以像下面这样修改他们的值:
fixW = tf.assign(W, [-1.])
fixb = tf.assign(b, [1.])
sess.run([fixW, fixb])
print(sess.run(loss, {x:[1,2,3,4], y:[0,-1,-2,-3]}))
修改之后的最终输出结果为:
0.0
机器学习的完整过程超出了本文的范围,这里仅说明训练的过程。TensorFlow提供了很多优化器来逐渐(迭代或循环)调整每一个参数,最终实现损益值尽可能的小。最简单的优化器之一是"梯度递减"(gradient descent),它会对损益计算模型求导,然后根据求导的结果调整输入变量的值(W和b),最终目的让求导的结果逐渐趋向于0。手工进行编写求导运算非常冗长且容易出错,TensorFlow还提供了函数 tf.gradients 实现自动求导过程。下面的例子展示了使用梯度递减训练样本的过程:
# 设定优化器,这里的0.01表示训练时的步进值
optimizer = tf.train.GradientDescentOptimizer(0.01)
train = optimizer.minimize(loss)
sess.run(init) # 初始化变量值.
for i in range(1000): # 遍历1000次训练数据,每次都重新设置新的W和b值
sess.run(train, {x:[1,2,3,4], y:[0,-1,-2,-3]})
print(sess.run([W, b]))
这个模式的运算结果是:
[array([-0.9999969], dtype=float32), array([ 0.99999082], dtype=float32)]
现在我们已经完成机器学习的整个过程。虽然进行简单的线性回归计算并不需要用到太多的TensorFlow代码,但是这仅仅是一个用于实例的案例,在实际应用中往往需要编写更多的代码实现复杂的模型匹配运算。TensorFlow为常见的模式、结构和功能提供了更高级别的抽象接口。
下面是根据前文的描述,编写的完整线性回归模型:
import numpy as np
import tensorflow as tf
# 模型参数
W = tf.Variable([.3], tf.float32)
b = tf.Variable([-.3], tf.float32)
# 模型输入
x = tf.placeholder(tf.float32)
# 模型输出
linear_model = W * x + b
# 损益评估参数
y = tf.placeholder(tf.float32)
# 损益模式
loss = tf.reduce_sum(tf.square(linear_model - y)) # 方差和
# 优化器
optimizer = tf.train.GradientDescentOptimizer(0.01)
train = optimizer.minimize(loss)
# 训练数据
x_train = [1,2,3,4]
y_train = [0,-1,-2,-3]
# 定义训练的循环
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init) # reset values to wrong
for i in range(1000):
sess.run(train, {x:x_train, y:y_train})
# 评估训练结果的精确性
curr_W, curr_b, curr_loss = sess.run([W, b, loss], {x:x_train, y:y_train})
print("W: %s b: %s loss: %s"%(curr_W, curr_b, curr_loss))
运行后会输出:
W: [-0.9999969] b: [ 0.99999082] loss: 5.69997e-11
这个复杂的程序仍然可以在TensorBoard中可视化呈现:
前面已经提到,TensorFlow除了TensorFlow Core之外,为了便于业务开发还提供了很多更抽象的接口。tf.contrib.learn 是TensorFlow的一个高级库,他提供了更加简化的机器学习机制,包括:
tf.contrib.learn 定义了一些通用模块。
先看看使用 tf.contrib.learn 来实现线性回归的方式。
import tensorflow as tf
# NumPy常用语加载、操作、预处理数据.
import numpy as np
# 定义一个特性列表features。
# 这里仅仅使用了real-valued特性。还有其他丰富的特性功能
features = [tf.contrib.layers.real_valued_column("x", dimension=1)]
# 一个评估者(estimator)是训练(fitting)与评估(inference)的开端。
# 这里预定于了许多类型的训练评估方式,比如线性回归(linear regression)、
# 逻辑回归(logistic regression)、线性分类(linear classification)和回归(regressors)
# 这里的estimator提供了线性回归的功能
estimator = tf.contrib.learn.LinearRegressor(feature_columns=features)
# TensorFlow提供了许多帮助类来读取和设置数据集合
# 这里使用了'numpy_input_fn'。
# 我们必须告诉方法我们许多多少批次的数据,以及每次批次的规模有多大。
x = np.array([1., 2., 3., 4.])
y = np.array([0., -1., -2., -3.])
input_fn = tf.contrib.learn.io.numpy_input_fn({"x":x}, y, batch_size=4,
num_epochs=1000)
# 'fit'方法通过指定steps的值来告知方法要训练多少次数据
estimator.fit(input_fn=input_fn, steps=1000)
# 最后我们评估我们的模型价值。在一个实例中,我们希望使用单独的验证和测试数据集来避免过度拟合。
estimator.evaluate(input_fn=input_fn)
运行后输出:
{'global_step': 1000, 'loss': 1.9650059e-11}
tf.contrib.learn 并不限定只能使用它预设的模型。假设现在需要创建一个未预设到TensorFlow中的模型。我们依然可以使用tf.contrib.learn保留数据集合、训练数据、训练过程的高度抽象。我们将使用我们对较低级别TensorFlow API的了解,展示如何使用LinearRegressor实现自己的等效模型。
使用 tf.contrib.learn 创建一个自定义模型需要用到它的子类 tf.contrib.learn.Estimator 。而 tf.contrib.learn.LinearRegressor 是 tf.contrib.learn.Estimator 的子类。下面的代码中为 Estimator 新增了一个 model_fn 功能,这个功能将告诉 tf.contrib.learn 如何进行评估、训练以及损益计算:
import numpy as np
import tensorflow as tf
# 定义一个特征数组,这里仅提供实数特征
def model(features, labels, mode):
# 构建线性模型和预设值
W = tf.get_variable("W", [1], dtype=tf.float64)
b = tf.get_variable("b", [1], dtype=tf.float64)
y = W*features['x'] + b
# 损益子图
loss = tf.reduce_sum(tf.square(y - labels))
# 训练子图
global_step = tf.train.get_global_step()
optimizer = tf.train.GradientDescentOptimizer(0.01)
train = tf.group(optimizer.minimize(loss),
tf.assign_add(global_step, 1))
# ModelFnOps方法将创建我们自定义的一个抽象模型。
return tf.contrib.learn.ModelFnOps(
mode=mode, predictions=y,
loss=loss,
train_op=train)
estimator = tf.contrib.learn.Estimator(model_fn=model)
# 定义数据集
x = np.array([1., 2., 3., 4.])
y = np.array([0., -1., -2., -3.])
input_fn = tf.contrib.learn.io.numpy_input_fn({"x": x}, y, 4, num_epochs=1000)
# 训练数据
estimator.fit(input_fn=input_fn, steps=1000)
# 评估模型
print(estimator.evaluate(input_fn=input_fn, steps=10))
运行后输出:
{'loss': 5.9819476e-11, 'global_step': 1000}
阅读了到这里,你应该初步了解如何在TensorFlow中进行开发和编码。但是如果你刚踏入机器学习的领域,就算很仔细的看了本文,对于如何使用TensorFlow进行机器学习基本上还是懵逼的。请继续阅读《MNIST 机器学习入门》,文章给出了一个完整的机器学习建模案例,适合零知识入门机器学习。
发现目前除了一些特殊的芯片外,一般可以使用0-10v稳压输出的芯片,GND接-5V Vout接+5V 在GND与Vout之间用电阻分压产生新的GND2
所以当需要进行线形度很高的精确DA转换时必须使用较小的滤波电容,且尽量避免使用电解类电容 。而为了得到较强的信号输出,_RC惯性环节_之后还必须加一级高性能的电压跟随,然后在跟随器输出的地方加上一个滤波用的电解电容,用于平滑RC惯性环节的纹波。但是这还不够,因为这时的输出电压里可能含有较多的交流谐波成分,如果处理不当,跟随器有可能自激。解决的办法就是使用一个小的去藕电容。而且这里电容的放置顺序必须是电解电容在前,去藕电容在后!
如果输出电压精度和线形度要求不高,但是对纹波要求却很高,或者这个电压比较固定时,可以使用电容较大的滤波组合。因为,虽然大电容的直流损耗较大,但是我们可以通过调节PWM占空比来达到要求的输出电压,或者通过一级AD转换的反馈来实现精确的固定电压输出。只是这里仍然要加一级电压跟随器,以便于后级采集电路使用,且AD采集点放置在跟随器输出处。
由于想把自己多年的印象笔记里的技术笔记都转成markdown导出,但目前印象笔记不支持直接导出evernote,怎么办?google了一下,发现还没有直接导出的,只发现马克飞象可以直接绑定印象笔记和evernote国际版,绑定了以后可以直接在马克飞象上面写文章,然后同步到evernote上去,但是我需要的是把原来evernote上的笔记全部导出为markdown格式,目前evernote只支持导出为html和enex格式,看来只能从这里入手了。
我是mac电脑,安装的是印象笔记客户端,直接在文件–>导出笔记(格式选html),但是问题来了,导出的是批量的html,目前我们也没有看到有可以批量将html转成markdown的工具,所以就只能自己用脚本摸索一个了。
目前我知道的比较流行的将html转为markdown的工具有:
1.MarkdownRules.
这款工具将html转markdown是在线上的,美中不足的是,它不支持 < pre> 这类的标记
2.Pandoc.
这款工具是就非常强大了,它不公可以转html到markdown,还可以对markdown, reStructuredText, textile, HTML, DocBook, LaTeX, MediaWiki markup, TWiki markup, OPML, Emacs Org-Mode, Txt2Tags, Microsoft Word docx, LibreOffice ODT, EPUB, or Haddock markup 等十几种格式文档相互转换。但是,同样的,对< pre >标记的支持不足,mac用户可以通过home brew 进行安装
这是一款python写的工具,它相比前两款对< pre >标记解析有着更出色的表现,但也有些情况解析不了
我选择了pandoc对我的东西进行转换
Pandoc真的是个好东西!能迅速在很多种文件格式之间转来转去!超级方便!转换速度超级快!超级漂亮!
然而我只用到了Markdown转html和markdown而已……
好像Pandoc并不支持批量转换啊,一直敲命令我也受不了。那就现学现卖写了个sh文件来玩。
#!/bin/sh
function ergodic(){
for fullname in `ls $1`
do
name=${fullname%.*}
ext=${fullname##*.}
if [ "$ext"x = "html"x ]
then
echo $name
pandoc $name.html -o $name.md
fi
done
}
IFS=$'\n'
INIT_PATH=".";
ergodic $INIT_PATH
想学bash编程,可以参考这里,有比较全的bash语法
如果只是想和我一样,想速学速用,那就看这里吧
逻辑是这样的:首先用ls命令找出文件夹下所有文件名,获取文件名部分和后缀名部分。如果后缀名为html,就让pandoc进行转换去。
其他的么……sh语法我也不会啊……
另外,这里是pandoc参考手册,如果需要转换成其他格式的话可以参考这里进行配置。
例如写成pandoc -f markdown -t docx $name.md -o $name.docx。默认就是markdown to docx
导出的md文件有以下两问题需要解决:
---
title: 如何将印象笔记导为markdown
date: {{ date }}
categories: 专业技术(印象笔记)
tags: 从印象笔记导入
---
我的解决方案是用sed工具
这个工具在linux和unix环境上的用法是有些差异的,稍后会说明
再次用bash解决:
#!/bin/sh
function ergodic(){
for fullname in `ls $1`
do
name=${fullname%.*}
ext=${fullname##*.}
if [ "$ext"x = "md"x ]
then
echo $name
# grep -o 输出匹配的字符串
#echo $name | grep -o [^][,_%$\“\ ]
lineStr="---"
title="title: $name"
dateStr="date: {{ date }}"
categories="categories: 专业技术(印象笔记)"
tags="tags: 从印象笔记导入"
# titlePost="--- title: $name <br/> categories: 专业技术 印象笔记 tags: 从印象笔记导入 <br/> ---"
echo "categories is" $categories
# 在内容第一行前面插入文本
sed -i "" -e $'1 i\\\n'"$lineStr" $fullname
# 在内容第一行后面插入文本
sed -i "" -e $'1 a\\\n'"$title" $fullname
sed -i "" -e $'2 a\\\n'"$dateStr" $fullname
sed -i "" -e $'3 a\\\n'"$categories" $fullname
sed -i "" -e $'4 a\\\n'"$tags" $fullname
sed -i "" -e $'5 a\\\n'"$lineStr" $fullname
sed -i "" -e $'6 a\\\n'"# $name" $fullname
sed -i "" -e $'40 a\\\n'"<!--more-->" $fullname
fi
done
}
IFS=$'\n'
INIT_PATH=".";
ergodic $INIT_PATH
可能看了sed的使用语法后,发现我的写法跟语法不太一样,这是因为我是mac电脑,是unix内核,使用的时候不管是插入还是替换,都必须要在sed -i 后面加空""号和 -e $,至于为什么,请参考这里
好了,新年要棒棒的,现在要开始找工作了。。。。。
来自汇承公司开发的蓝牙芯片
电压范围2.0~3.6
可以直接四个引出管脚接UART
也可以采用周围的管脚直接连接PCB电路板
采用at指令控制[每个指令介绍不能回车或选发送新行],具体可以登录官网hc01.com查询指令表
配对完成,两个蓝牙LED一起常亮
未配对蓝牙主机快闪,从机慢闪
需要注意如下
hc08没有密码pin,默认为000000,在配对时凭借三个UUID识别设备,分别为
主从设备设置透传仅仅用于配对时收发角色的控制,配对完成后启动透传,双方可以自由相互发送数据[蓝牙是全双工通信]
遇到配对不了的蓝牙试着使用at+clear,清除之前的配对记录
连接密码:就是指与其他蓝牙设备连接时需要对方输入匹配的密码,可支持至少8位的长度,字母与数字混合;
本文你可以获得什么?
晶体管或许可以说是整个电子信息系统以及集成电路的基石。三极管电路也是最为常见的电路模块,其应用也极为灵活。我记得前几年看过晶体管设计一书中,有一段话我一直印象很深刻,大致意思是说,如果想制作一个电路,只需要将几个IC组合起来,起振复位上电源大体就可以简单地完成了。
但是,如果掌握了晶体管和MOS管的相关知识后,对于电路系统的认识将会大为不同。因为,以IC为单位作为黑盒子来考虑,此时IC被一定程度上认为是理想器件,但是,以单个晶体管放大电路为例,电压增益是有限的,输入电流是以基极电流的形式存在并不是理想放大器的0电流,但是我们懂得晶体管后,我们可以知道其内部结构,通过内部结构,我们结合外部电路,能够帮助我们更好的理解分析,调试电路。
1. 三极管的开关电路
开关电路应用的普遍性就不用我多讲了。输入电压Vin控制三极管开关的开启(open) 与闭合(closed) 动作,当三极管呈开启状态时,负载电流便被阻断,反之,当三极管呈闭合状态时,电流便可以流通。详细的说,当Vin为低电压时,由于基极没有电流,因此集电极亦无电流,致使连接于集电极端的负载亦没有电流,而相当于开关的开启,此时三极管工作在截止(cut off)区。
同理,当Vin为高电压时,由于有基极电流流动,因此使集电极流过更大的放大电流,因此负载回路便被导通,而相当于开关的闭合,此时三极管工作在饱和区(saturation)。
图1 基本三极管开关
一般而言,可以假设当三极管开关导通时,其基极与射极之间是完全短路的。
应用实例:
下图是英特尔公司某块主板中电路图的一部分,就是一个典型的三极管应用电路。
图2 三极管开关电路应用实例
电路分析:
当A为高电平时,三极管1导通,所以输出B点跟发射极电平相同,为低电平;因为B为低电平,所以三极管2截止,输出C为高电平。
当A为低电平时,三极管1截止,所以输出B点为高电平;因为B为高电平,所以三极管2导通,输出C为低电平。
2. 三极管的推挽型射极跟随器
由于射极带负载电阻的射极跟随器,在输出很大电流时也就是阻抗较低情况时,输出波形的负半轴会被截去,不能得到完整的输出最大电压而失真。为提升性能并改善这个缺点将发射极负载电阻换成PNP管的射极跟随器电路称之为推挽射极跟随器。
【电路分析】
由于上边的NPN晶体管将电流"吐出来"给负载(对应推,source current),PNP晶体管从负载将电流"吸进来"(对应挽,sink current),所以称为推挽(push-pull)。但是此电路的缺点是在0V附近晶体管都截止,会产生交越失真。推挽电路以及拉电流、灌电流是实际工程系统中非常重要的概念,通过此电路学习理解此概念非常易懂。
交越失真是指正弦波的上下侧没有连接上的那部分,此失真的原因在于晶体管的基极都是连在一起的,所以基极电位是一样的。当输入信号在0V附近时,基极-发射极间没有电位差,因此没有基极电流的流动。也就是,此时两个晶体管都是截止的,并没有工作。
另外,即便是基极上加上了输入信号,对上侧在基极电位比发射极电位高0.6V以前,也不会工作。反之,对于下侧晶体管的基极只有比发射极低0.6V以后才能工作。所以,体现在波形上就会产生一个交越失真的盲区。
不过,此电流稍加修改就是一个很好用的电路了,思路很简单,用两个二极管在每个晶体管的基极上加上大概0.6V的二极管的正向压降--补偿电压,就可以抵消晶体管的盲区了。如下图所示:
此电路用两个二极管的压降抵消晶体管的基极-发射极间的电压Vbe,可以认为晶体管的空载电流几乎为0。所以当不存在信号时,就也没有晶体管的发热问题。顺便提一下,这个电路中在输出状态总有一个晶体管处于截止状态的电路称之为B类放大器,举一反三的,如果只有一个管子且晶体管常进行工作的电路称之为A类放大器。
这样一来,射极跟随器-推挽电路-拉电流,灌电流-A类放大器,B类放大器,这些知识就可以串起来了,那么有没有想过同样非常常用的D类放大器?又有什么样的特点呢?
tm4c123gxl的ADC分ADC0与ADC1两块寄存器,ain0到ain11等12条通道


A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.