This repository is for work by the W3C Cognitive AI Community Group.
- Introduction
- Webinars
- Background materials
- Program of work
- Positioning relative to existing approaches to AI
- Historical context
- Cognitive Architecture
- Long Term Aims
According to wikipedia:
Cognitive science is the interdisciplinary, scientific study of the mind and its processes. It examines the nature, the tasks, and the functions of cognition. Cognitive scientists study intelligence and behavior, with a focus on how nervous systems represent, process, and transform information.
Cognitive AI can be defined as AI based upon insights from the cognitive sciences, including cognitive neuroscience, and cognitive sociology. To put it another way, the brain has evolved over hundreds of millions of years, and we would do well to borrow from nature when it comes to building AI systems.
The W3C Cognitive AI Community Group seeks to demonstrate the potential of Cognitive AI through:
- Collaboration on defining use cases, requirements and datasets for use in demonstrators
- Work on open source implementations and scaling experiments
- Work on identifying and analysing application areas, e.g.
- Helping non-programmers to work with data
- Cognitive agents in support of customer services
- Smart chatbots for personal healthcare
- Assistants for detecting and responding to cyberattacks
- Teaching assistants for self-paced online learning
- Autonomous vehicles
- Smart manufacturing
- Smart web search
- Outreach to explain the huge opportunities for Cognitive AI
- Participation is open to all, free of charge: join group
We are using GitHub for documents, issue tracking and open source components. We have a public mailing list, and an IRC channel #cogai.
This is a series of recorded webinars, see webinar planning
- 7 March 2024, The role of symbolic knowledge at the dawn of AGI, as presented to the Estes Park Group: slides, and video recording
- Talks
- 04 July 2023 Combining Digital Twins with Cognitive Agents, talk at ETSI IoT Week 2023
- 14 June 2023 Human-like AI: from logic to argumentation, reasoning with imperfect knowledge in the era of AGI, see video recording talk for Darmstadt Ontology Group
- 18 April 2023 Human-Like AI for Artificial General Intelligence, as part of the Special day on Human-AI interaction, DATE 2023
- 20 February 2023 - Human-like AI for Artificial General Intelligence - research challenges for the Intelligent Web of Things)
- 14 November 2022 - Cognitive Agents, Plausible Reasoning and Scalable Knowledge Engineering, Workshop on Computing across the Continuum for the US NSF and the European Commission
- 12 September 2022 - Plausible reasoning and artificial minds, Workshop on Analogies: from Theory to Applications
- 16 February 2022 - Imperfect Knowledge, Distributed Knowledge Graphs workshop
- 06 September 2021 - Digital Transformation using chunks as a simple abstraction above triples and property graphs - talk at the Semantics2021 workshop on squaring the circle on graphs
- 17 March 2021 - Digital Transformation and the Knowledge Economy, an invited keynote for the Siemens conference on the IoT
- 17 March 2021 - Roadmap for realising general purpose AI
- 14-19 February 2021 - Human-like AI and the Sentient Web for Dagstuhl seminar on autonomous agents on the Web - slides, paper
- 11 January 2021 - Presentation and discussion of work on Cognitive Natural Language Processing
- 25 November 2020 - Seminar on Cognitive AI for Centre for Artificial Intelligence, Robotics and Human-Machine Systems, Cardiff University: slides, video
- 06 November 2020 - Seminar on Cognitive AI for Knowledge Media Institute, Open University - video and slides
- 08 June 2020 - Cognitive AI and the Sentient Web for ISO/TC 211 50th Plenary meeting, WG4 Geospatial Services
- Chunks format for declarative and procedural knowledge
- Common Sense Reasoning
- Demonstrators
- Frequently asked questions
- Longer treatise on Cognitive AI
- Contributing to the Cognitive AI Community Group
The initial focus is to describe the aims for a sequence of demonstrators, to collaborate on the scenarios, detailed use cases, and associated datasets, and to identify and discuss questions that arise in this work. In relation to this, we are working on a formal specification of the chunk data and rules format with a view to its standardisation.
A further line of work deals with the means to express and reason with imperfect knowledge, that is, everyday knowledge subject to uncertainty, imprecision, incompleteness and inconsistencies. See the draft specifcation for the plausible knowledge notation (PKN), and the web-based PKN demonstrator. This is based upon work on guidelines for effective argumentation by a long line of philosophers since the days of Ancient Greece. In place of logical proof, we have multiple lines of argument for and against the premise in question just like in courtrooms and everyday reasoning.
Both PKN and chunks & rules can be considered in relation to RDF. RDF is a framework for symbolic graphs based upon labelled directed graph edges (aka triples). Compared to RDF, PKN and chunks & rules are higher level with additional semantics, and designed for use in human-like AI applications. Furthermore, both notations are designed to be easy to read and author compared with RDF serialisations such as RDF/XML, Turtle and even JSON-LD. See also the Notation3 (N3) Language which is an assertion and logic language defined as a superset of RDF.
Work is now underway on vector-space representations of knowledge using artificial neural networks. Advances with generative AI have shown the huge potential of vector-space representations in combination with deep learning. However, there is a long way to go to better model many aspects of human cognition, e.g. continual learning using a blend of type 1 and type 2 cognition, episodic memory, and the role of emotions and feelings in directing cognition. Symbolic models will continue to serve an important role for semantic interoperability. Neurosymbolic systems combine the complementary strengths of vector space and symbolic approaches.
Traditional AI focuses on symbolic representations of knowledge and on mathematical logic, e.g. Expert Systems and the Semantic Web. Deep Learning, by contrast, focuses on statistical models implemented as multi-layer neural networks. Both approaches have their weaknesses. Symbolic AI has difficulties with the ambiguities, uncertainties and inconsistencies commonplace in everyday situations. Furthermore, the reliance on manual knowledge engineering is a big bottleneck. Deep Learning has problems with recognising what’s salient, providing transparent explanations, the need for very large data sets for training, and difficulties with generalisation. Symbolic AI and Deep Learning are associated with siloed communities that typify modern science in which researchers are discouraged from interdisciplinary studies and the breadth of views that those encompass.
Cognitive AI seeks to address these weaknesses through mimicking human thought, taking inspiration from over 500 million years of neural evolution and decades of work across the cognitive sciences. This involves the combination of symbolic and statistical approaches using functional models of the human brain, including the cortex, basal ganglia, cerebellum and limbic system. Human memory is modelled in terms of symbolic graphs with embedded statistics reflecting prior knowledge and past experience. Human reasoning is not based upon logic, nor on the laws of probability, but rather on mental models of what is possible, along with the use of metaphors and analogies.
Research challenges include mimicry, emotional and social intelligence, natural language and common sense reasoning. Mimicry is key to social interaction, e.g. a baby learning to smile at its mother, and young children learning to speak. As a social species, we pay attention to social interaction and models of ourselves and others, including beliefs, desires, judgements and behaviours. Emotional control of cognition determines what is important, and plays a key role in how we learn, reason and act. Natural language is important for both communication and for learning and the means to break free from the manual programming bottleneck. Common sense is everyday knowledge and key to natural language understanding, and is learned through experience.
AI lacks a precise agreed definition, but loosely speaking, it is about replicating intelligent behaviour, including perception, reasoning and action. There are many sub-fields of AI, e.g. logic and formal semantics, artificial neural networks, rule-based approaches including expert systems, statistical approaches including Bayesian networks and Markov chains, and a wide variety of approaches to search, pattern recognition and machine learning. Cognitive AI seeks to exploit work across the cognitive sciences on the organising principles of the human mind.
Chunk rules are a form of production rules as introduced by Allen Newell in 1973 in his production system theory of human cognition, which he subsequently developed as the SOAR project. John Anderson published his theory of human associative memory (HAM) in 1973, and inspired by Newell, went on to combine it with a production system to form the ACT system in 1976, and developed it further into ACT-R in 1993. ACT-R stands for adaptive control of thought - rational and has been widely applied to cognitive science experiments as a theory for simulating and understanding human cognition. For more details see An Integrated Theory of the Mind. Chunks, in turn, was inspired by ACT-R, and the realisation that the approach could be adapted for general use in artificial intelligence as the combination of graphs, statistics, rules and graph algorithms.
Credit is also due to Marvin Minsky for his work on frames, metacognition, self-awareness and appreciation of the importance of emotions for controlling cognition, to Philip Johnson-Laird for his work on mental models and demonstrating that humans don't reason using logic and probability, but rather by thinking about what is possible, to George Lakoff for his work on metaphors, Dedre Gentner for her work on reasoning with analogies, and to Allan Collins for his work on plausible reasoning. Cognitive AI has a broader scope than ACT-R and seeks to mimic the human brain as a whole at a functional level, inspired by advances across the cognitive sciences. As such, Cognitive AI can be contrasted with approaches that focus on logic and formal semantics. Cognitive AI can likewise be decoupled from the underlying implementation, as the phenomenological requirements are essentially independent of whether they are realised as explicit graphs, vector spaces or pulsed neural networks, see David Marr's three levels of analysis.
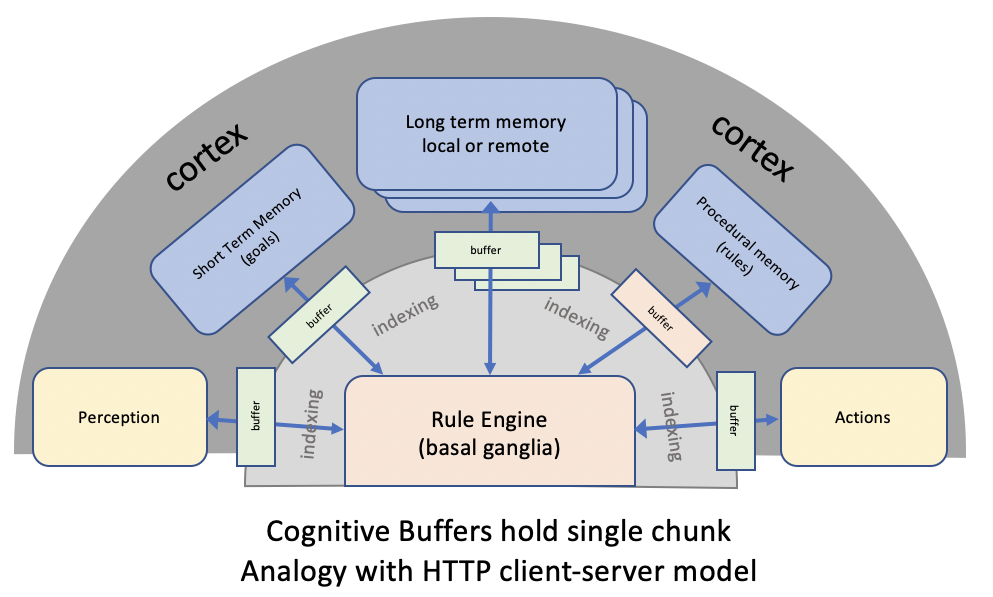
The following diagram depicts how cognitive agents can be built as a collection of different building blocks that connect via the cortex, which functions as a collection of cognitive databases and associated algorithms. Semantic integration across the senses mimics the Anterior Temporal Lobe's role as a hub for the unimodal spokes. The initial focus of work was on a chunk rule engine inspired by John Anderson's ACT-R. Current work is focusing on plausible reasoning and belief revision. Future work will look at the other building blocks.

Image of cognitive architecture as a set of modules connected via the cortex
- Perception interprets sensory data and places the resulting models into the cortex, e.g. scene graphs. Cognitive rules can set the context for perception, and direct attention as needed. Events are signalled by queuing chunks to cognitive buffers to trigger rules describing the appropriate behaviour. A prioritised first-in first-out queue is used to manage events that are closely spaced in time.
- Emotion is about cognitive control and prioritising what’s important. The limbic system provides rapid assessment of past, present and imagined situations without the delays incurred in deliberative thought. Emotions are perceived as positive or negative, and associated with passive or active responses, involving actual and perceived threats, goal-directed drives and soothing/nurturing behaviours.
- Cognition is slower and more deliberate thought, involving sequential execution of rules to carry out particular tasks, including the means to invoke graph algorithms in the cortex, and to invoke operations involving other cognitive systems. Thought can be expressed at many different levels of abstraction, and is subject to control through metacognition, emotional drives, internal and external threats.
- Action is about carrying out actions initiated under conscious control, leaving the mind free to work on other things. An example is playing a musical instrument where muscle memory is needed to control your finger placements as thinking explicitly about each finger would be far too slow. The Cerebellum provides real-time coordination of muscle activation guided by perception, computing smooth functions over time.
Zooming in on cognition and the role of the basal ganglia as a sequential rule engine, the architecture looks like:

Image of cognitive architecture for deliberative reasoning (System 2)
This has been implemented as an open source JavaScript library and used as the basis for an evolving suite of demos.
New work is underway on vector space approaches inspired by human cognition and the advances in generative AI. This will mimic human language processing (sequential, hierarchical and predictive), implicit and explicit memory, continual learning, and Type 1 and 2 cognition. This is being implemented in Python and PyTorch. Language processing uses retained feedback connections in conjunction with a small sliding window to mimic the buffering limitations of the phonological loop. Type 2 cognition features a vector based implementation of chunks and rules. Explicit memory (episodic and encyclopaedic) is based upon a vector database designed to mimic characteristics of human memory (forgetting curve, spreading activation and spacing effect). The different modules are integrated through shared access to the latent semantics (loosely equivalent to the buffers in the above diagram).
In the long run, the mission of the Cognitive AI Community Group is to enable cognitive agents that:
- Are knowledgeable, general purpose, creative, collaborative, empathic, sociable and trustworthy
- Can apply metacognition and past experience to reason about new situations
- Support continual learning based upon curiosity about the unexpected
- Have a level of self awareness in respect to current state, goals and actions
- Have an awareness of others in respect to their beliefs, desires and intents
- Are multilingual and can interact with people using their own language
These topics can be divided into areas for study and exploration with an emphasis on identifying use cases and building demonstrators that advance the overall mission. There is plenty to exploit along the way, with many opportunities to spin off practical applications as work proceeds.
![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")