Batch 1/1
0%| | 0/50 [00:01<?, ?it/s]
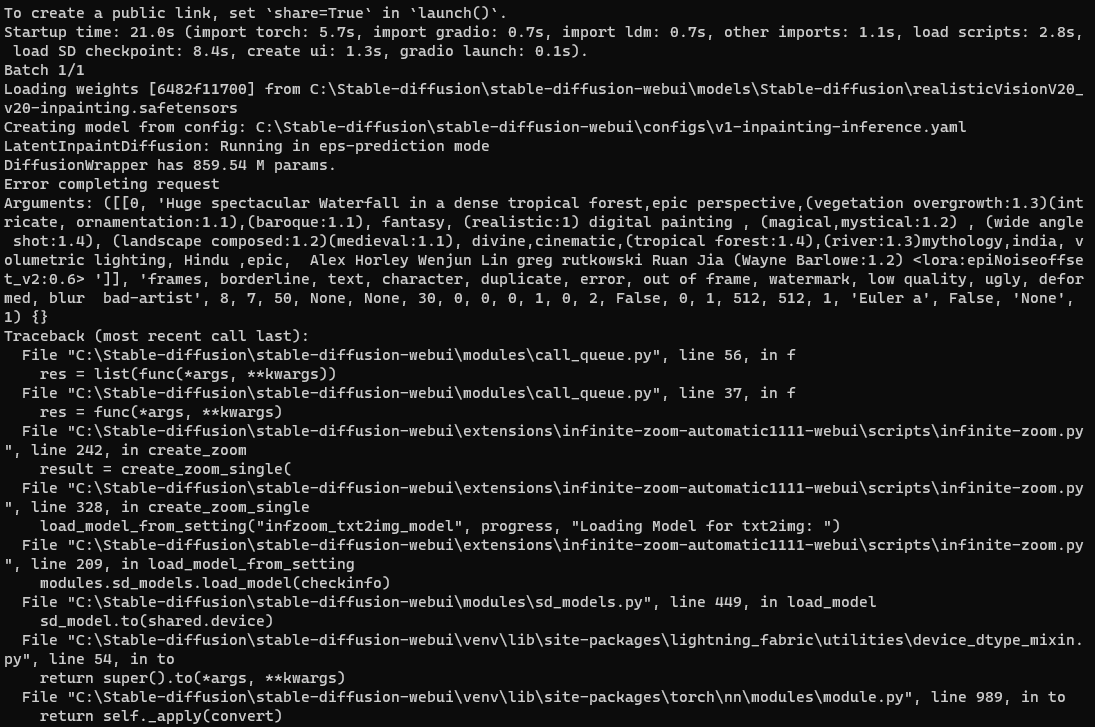
Error completing request
Arguments: ([[0, 'Huge spectacular Waterfall in a dense tropical forest,epic perspective,(vegetation overgrowth:1.3)(intricate, ornamentation:1.1),(baroque:1.1), fantasy, (realistic:1) digital painting , (magical,mystical:1.2) , (wide angle shot:1.4), (landscape composed:1.2)(medieval:1.1), divine,cinematic,(tropical forest:1.4),(river:1.3)mythology,india, volumetric lighting, Hindu ,epic, Alex Horley Wenjun Lin greg rutkowski Ruan Jia (Wayne Barlowe:1.2) <lora:epiNoiseoffset_v2:0.6> ']], 'frames, borderline, text, character, duplicate, error, out of frame, watermark, low quality, ugly, deformed, blur bad-artist', 8, 7, 50, None, None, 30, 0, 0, 0, 1, 0, 2, False, 0, 1, 512, 512, 1, 'Euler a', False, 'None', 1) {}
Traceback (most recent call last):
File "D:\Graphics\stable-diffusion-webui\stable-diffusion-webui\modules\call_queue.py", line 56, in f
res = list(func(*args, **kwargs))
File "D:\Graphics\stable-diffusion-webui\stable-diffusion-webui\modules\call_queue.py", line 37, in f
res = func(*args, **kwargs)
File "D:\Graphics\stable-diffusion-webui\stable-diffusion-webui\extensions\infinite-zoom-automatic1111-webui\scripts\infinite-zoom.py", line 242, in create_zoom
result = create_zoom_single(
File "D:\Graphics\stable-diffusion-webui\stable-diffusion-webui\extensions\infinite-zoom-automatic1111-webui\scripts\infinite-zoom.py", line 330, in create_zoom_single
processed = renderTxt2Img(
File "D:\Graphics\stable-diffusion-webui\stable-diffusion-webui\extensions\infinite-zoom-automatic1111-webui\scripts\infinite-zoom.py", line 132, in renderTxt2Img
processed = process_images(p)
File "D:\Graphics\stable-diffusion-webui\stable-diffusion-webui\modules\processing.py", line 503, in process_images
res = process_images_inner(p)
File "D:\Graphics\stable-diffusion-webui\stable-diffusion-webui\extensions\sd-webui-controlnet\scripts\batch_hijack.py", line 42, in processing_process_images_hijack
return getattr(processing, '__controlnet_original_process_images_inner')(p, *args, **kwargs)
File "D:\Graphics\stable-diffusion-webui\stable-diffusion-webui\modules\processing.py", line 653, in process_images_inner
samples_ddim = p.sample(conditioning=c, unconditional_conditioning=uc, seeds=seeds, subseeds=subseeds, subseed_strength=p.subseed_strength, prompts=prompts)
File "D:\Graphics\stable-diffusion-webui\stable-diffusion-webui\modules\processing.py", line 869, in sample
samples = self.sampler.sample(self, x, conditioning, unconditional_conditioning, image_conditioning=self.txt2img_image_conditioning(x))
File "D:\Graphics\stable-diffusion-webui\stable-diffusion-webui\modules\sd_samplers_kdiffusion.py", line 358, in sample
samples = self.launch_sampling(steps, lambda: self.func(self.model_wrap_cfg, x, extra_args={
File "D:\Graphics\stable-diffusion-webui\stable-diffusion-webui\modules\sd_samplers_kdiffusion.py", line 234, in launch_sampling
return func()
File "D:\Graphics\stable-diffusion-webui\stable-diffusion-webui\modules\sd_samplers_kdiffusion.py", line 358, in <lambda>
samples = self.launch_sampling(steps, lambda: self.func(self.model_wrap_cfg, x, extra_args={
File "d:\Graphics\stable-diffusion-webui\stable-diffusion-webui\venv\lib\site-packages\torch\autograd\grad_mode.py", line 27, in decorate_context
return func(*args, **kwargs)
File "D:\Graphics\stable-diffusion-webui\stable-diffusion-webui\repositories\k-diffusion\k_diffusion\sampling.py", line 145, in sample_euler_ancestral
denoised = model(x, sigmas[i] * s_in, **extra_args)
File "d:\Graphics\stable-diffusion-webui\stable-diffusion-webui\venv\lib\site-packages\torch\nn\modules\module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "D:\Graphics\stable-diffusion-webui\stable-diffusion-webui\modules\sd_samplers_kdiffusion.py", line 126, in forward
x_out = self.inner_model(x_in, sigma_in, cond=make_condition_dict([cond_in], image_cond_in))
File "d:\Graphics\stable-diffusion-webui\stable-diffusion-webui\venv\lib\site-packages\torch\nn\modules\module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "D:\Graphics\stable-diffusion-webui\stable-diffusion-webui\repositories\k-diffusion\k_diffusion\external.py", line 167, in forward
return self.get_v(input * c_in, self.sigma_to_t(sigma), **kwargs) * c_out + input * c_skip
File "D:\Graphics\stable-diffusion-webui\stable-diffusion-webui\repositories\k-diffusion\k_diffusion\external.py", line 177, in get_v
return self.inner_model.apply_model(x, t, cond)
File "D:\Graphics\stable-diffusion-webui\stable-diffusion-webui\modules\sd_hijack_utils.py", line 17, in <lambda>
setattr(resolved_obj, func_path[-1], lambda *args, **kwargs: self(*args, **kwargs))
File "D:\Graphics\stable-diffusion-webui\stable-diffusion-webui\modules\sd_hijack_utils.py", line 28, in __call__
return self.__orig_func(*args, **kwargs)
File "D:\Graphics\stable-diffusion-webui\stable-diffusion-webui\repositories\stable-diffusion-stability-ai\ldm\models\diffusion\ddpm.py", line 858, in apply_model
x_recon = self.model(x_noisy, t, **cond)
File "d:\Graphics\stable-diffusion-webui\stable-diffusion-webui\venv\lib\site-packages\torch\nn\modules\module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "D:\Graphics\stable-diffusion-webui\stable-diffusion-webui\repositories\stable-diffusion-stability-ai\ldm\models\diffusion\ddpm.py", line 1335, in forward
out = self.diffusion_model(x, t, context=cc)
File "d:\Graphics\stable-diffusion-webui\stable-diffusion-webui\venv\lib\site-packages\torch\nn\modules\module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "D:\Graphics\stable-diffusion-webui\stable-diffusion-webui\repositories\stable-diffusion-stability-ai\ldm\modules\diffusionmodules\openaimodel.py", line 797, in forward
h = module(h, emb, context)
File "d:\Graphics\stable-diffusion-webui\stable-diffusion-webui\venv\lib\site-packages\torch\nn\modules\module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "D:\Graphics\stable-diffusion-webui\stable-diffusion-webui\repositories\stable-diffusion-stability-ai\ldm\modules\diffusionmodules\openaimodel.py", line 84, in forward
x = layer(x, context)
File "d:\Graphics\stable-diffusion-webui\stable-diffusion-webui\venv\lib\site-packages\torch\nn\modules\module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "D:\Graphics\stable-diffusion-webui\stable-diffusion-webui\repositories\stable-diffusion-stability-ai\ldm\modules\attention.py", line 334, in forward
x = block(x, context=context[i])
File "d:\Graphics\stable-diffusion-webui\stable-diffusion-webui\venv\lib\site-packages\torch\nn\modules\module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "D:\Graphics\stable-diffusion-webui\stable-diffusion-webui\repositories\stable-diffusion-stability-ai\ldm\modules\attention.py", line 269, in forward
return checkpoint(self._forward, (x, context), self.parameters(), self.checkpoint)
File "D:\Graphics\stable-diffusion-webui\stable-diffusion-webui\repositories\stable-diffusion-stability-ai\ldm\modules\diffusionmodules\util.py", line 121, in checkpoint
return CheckpointFunction.apply(func, len(inputs), *args)
File "D:\Graphics\stable-diffusion-webui\stable-diffusion-webui\repositories\stable-diffusion-stability-ai\ldm\modules\diffusionmodules\util.py", line 136, in forward
output_tensors = ctx.run_function(*ctx.input_tensors)
File "D:\Graphics\stable-diffusion-webui\stable-diffusion-webui\repositories\stable-diffusion-stability-ai\ldm\modules\attention.py", line 273, in _forward
x = self.attn2(self.norm2(x), context=context) + x
File "d:\Graphics\stable-diffusion-webui\stable-diffusion-webui\venv\lib\site-packages\torch\nn\modules\module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "D:\Graphics\stable-diffusion-webui\stable-diffusion-webui\modules\sd_hijack_optimizations.py", line 332, in xformers_attention_forward
k_in = self.to_k(context_k)
File "d:\Graphics\stable-diffusion-webui\stable-diffusion-webui\venv\lib\site-packages\torch\nn\modules\module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "D:\Graphics\stable-diffusion-webui\stable-diffusion-webui\extensions-builtin\Lora\lora.py", line 305, in lora_Linear_forward
lora_apply_weights(self)
File "D:\Graphics\stable-diffusion-webui\stable-diffusion-webui\extensions-builtin\Lora\lora.py", line 273, in lora_apply_weights
self.weight += lora_calc_updown(lora, module, self.weight)
RuntimeError: The size of tensor a (1024) must match the size of tensor b (768) at non-singleton dimension 1
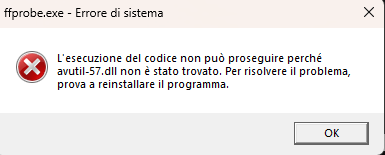
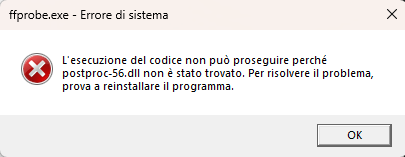
Traceback (most recent call last):
File "d:\Graphics\stable-diffusion-webui\stable-diffusion-webui\venv\lib\site-packages\gradio\blocks.py", line 987, in postprocess_data
if predictions[i] is components._Keywords.FINISHED_ITERATING:
IndexError: tuple index out of range
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "d:\Graphics\stable-diffusion-webui\stable-diffusion-webui\venv\lib\site-packages\gradio\routes.py", line 394, in run_predict
output = await app.get_blocks().process_api(
File "d:\Graphics\stable-diffusion-webui\stable-diffusion-webui\venv\lib\site-packages\gradio\blocks.py", line 1078, in process_api
data = self.postprocess_data(fn_index, result["prediction"], state)
File "d:\Graphics\stable-diffusion-webui\stable-diffusion-webui\venv\lib\site-packages\gradio\blocks.py", line 991, in postprocess_data
raise ValueError(
ValueError: Number of output components does not match number of values returned from from function f