
ttop5 / blog Goto Github PK
View Code? Open in Web Editor NEW博客仓库,用于记录一些幼稚的想法和脑残的瞬间,写在 issues 当中。
Home Page: https://ttop5.net/issue-blog
博客仓库,用于记录一些幼稚的想法和脑残的瞬间,写在 issues 当中。
Home Page: https://ttop5.net/issue-blog















眼看 2019 马上过去 1/12,勤快的大佬们早就在18年年底写完了自己的年终总结。而我,还在继续着我的咸鱼生活:博客已经停更大半年。失去了学习的动力自然也就没啥可写的内容。
最近时间多了,翻了很多大佬的博客感觉不错,也想把自己的一些或成熟或幼稚的想法记录下来。或发泄或成长,把以前写博客的习惯捡起来。偶尔去翻翻以前写的内容,感觉很幼稚也很真实。
称不上总结,姑且算是简单的回顾一下这过去的一年。
"不工作就没有钱呀,如果有钱谁还愿意工作,反正我不愿意。" —— 鲁迅

毕业后就一直在上家公司了,公司的同事老板什么的都挺不错的,特别老板是个很有意思的人。唯一让我不满足的是昆明分公司这边的技术氛围和受重视程度,还有工资(这是废话,工资肯定是永远都不能满足的)。
在社区大佬的帮助下顺利来到了现在的公司。工资还可以,公司规模也不小(100多人),前端技术也很潮。两家公司在昆明来说都是比较不错的公司了,纯正的互联网公司,也有自己的产品,管理宽松等等,跟昆明这片IT荒漠上其他的小外包电商的公司形成了鲜明的对比。在昆明一毕业就遇到这种公司需要上天眷顾的,然而好运没有一直眷顾我呀。
在上家公司的时候就一直在做后台管理系统,在做数据可视化的东西,这些都是我实习的时候就做过的东西,唯一不同的是以前用的是React,这次用的是Vue。当然因为没有大佬带,所以很多东西靠自己摸索,这段时间也大大提升了自己解决问题的能力,也让自己自信了一些(以前实习的时候表现得太依赖别人了)。难受的是跳槽后虽然到了一家技术很潮的公司,然而我被派去维护老的Vue项目去了,也是后台管理的23333。
更糟糕的是,从我入职开始就一直听到各种公司危机的传闻,然后各种公司完蛋之前的征兆就陆续在现在的公司都出现了。最近一段时间离职了好多人,公司上下也是人心惶惶。我常常跟同事们开玩笑说我有种49年加入国军的感觉呀,哎,总之一言难尽。
18年总共读了26本书,没记错的话连17年的一半都不到,技术书更是少之又少,可以说下半年几乎没看书。不想承认是自己懒,这是病,难治。
技能方面,熟悉了Vue全家桶,后面在深入就感觉到我的瓶颈了,很少有一开始那种解决了问题,感觉到进步的快乐了,这也是我要跳槽的很大原因:我想去做新东西,还是不想太安逸。另外一个,受前女友的影响,看了一些经济学基础的书。其他的,日语荒废,法律基础还没开工,英语停滞不前。总之,失败。
"是生活,生活强奸了所有人!" —— 沙雕网友

大环境在**,人文关怀、法律环境还有人权各种,我改变不了,羡慕那些肉翻大佬们,自己暂时能选择的就是城市和生活方式。
昆明这座城市,生活节奏比较慢,空气好(相对于国内其他城市),气候好四季如春,很适合人生活养老。作为从小长大的地方,不管是饮食还是气候,我已经很难再找到更适合的地方了。当年毕业回来昆明有部分原因家里人的强烈要求,当时内心是非常抗拒的,不过现在已经真香了。这破地方除了IT环境真的差以外,其他我都没啥要求了。没办法🤷♀️,云南人都是家乡宝。

今年除了换公司,住的地方也换了,从不足15平的小单间转到了一个占地面积小50平的一个复式楼里,上下楼加起来有小100平。和朋友一起租的,挺宽敞的,挺长一段时间也在家做饭吃,生活幸福感明显提升了。这个房子找了一个月,房租对比昆明的其他同样条件的来说也挺便宜了,而且房子还是在商业中心,啥都有很方便,目前为止都很满意。
我一直是个享乐主义,二十多年来一直被教育现在要努力奋斗为以后的生活。已经够了,享受当下吧,以后的事情以后再说吧。

这一年各种理由和借口,跑步基本荒废,其他的运动项目也没有坚持下来。身体素质明显不行了,小病生了好几次,家里全是感冒药,昨天打了半小时小半场的篮球就给我喘的要死。唯一的好事可能就是上大学落下的鼻炎感觉好多了,想想当年呼吸不畅、起床就突然止不住的清鼻涕和每天不少于半包纸的痛苦经历我真的是怕了,空气好真是太重要了。
马拉松报了好几个,昆明、成都、北京、青岛,都是在感情上出现问题的时候才想起来要找点事情做。但最后只参加了北京长城马拉松,浪费了好多钱和时间。昆明高原半马纯粹是因为头天晚上看剧太晚第二天不想起没去;成都的那个因为朋友训练受伤不去了,我也不去了;青岛的是因为差那么几分钟错过了航班,啊我的钱... 本来打算18年多参加几次半马,再练练然后19年直接挑战全马,看来计划又要至少推迟半年了,总之这一年在跑步这件事上非常失败。
现在好了,又有大把的时间了。跑步要拾起来了,外加中学之后就再也没有打的篮球,俯卧撑也做起来。19年的运动数据不能再这么难看了。

这一年的娱乐活动不算多也不算少,游戏看剧直播等宅的娱乐已经很多了,和朋友喝酒烧烤吹逼的也常有,遗憾的就在今年没去啥地方旅游,身体和心灵的旅行都没做好。出门最远的好像除了北京马拉松以外就是南京杭州的出差了,下半年基本都只是在市内走走,快发霉了。原先打算的去香港去日本都没了动静,港澳台通行证办了吃灰,隔壁泰国越南什么的今年看看有没有机会找人一起去吧。
18年封了好多主播,卢姥爷、发姐...... 每周必看的暴漫系列全部GG。真是服了,作为一个P民我还能说点啥呢,活生生的文字狱,可悲。
今年看了不少剧,106部其中有很多都是是10h+的啊,除了一直爱看的美剧和各段时间新上映的新片(楼下有电影院),今年更多的看了一些番剧,基本上就是B站番剧索引列表顺着看了。
国产辣鸡电视剧一直不屑于去看,所以今年也没去浪费时间,只看一些口碑还不错的院线电影和番剧。
印象最深的几部应该是《海王》、《血小板》、《我不是药神》,其他的就是看的时候爽一爽,然后就没了,想不起来了。
由于之前游戏一打折就买买买,导致到现在很多游戏都还在吃灰,我发誓了不把手里的游戏玩完就不买了,所以今年买的游戏不多。但是玩的游戏不少,玩了很多游戏但通关的不多,很多游戏也不了了之。
新添置了一台游戏电脑主机,拾起了LOL。也买了一些小游戏,好多还没通关。这一年里花了很多时间在主机游戏《怪物猎人世界》、网游《英雄联盟》和手游《绝地求生·刺激战场》。
怪猎是目前为止这个世界上最好的游戏之一,200+小时的游戏时间不到100级,和那些999级的大佬们肯定是比不了的,然而作为体验的游戏的我来说,和朋友联机玩耍到最后参加渣渣辉活动、打败这片新大陆上的最强怪物极贝并获得腾龙套,这个游戏对我来说已经结束了。LOL的话看看比赛,爬爬黑铁坑。刺激战场是找不到合适的和朋友联机游戏的情况下的选择,马上皇冠了,想上分也比较容易,苟就完事了。
”想结婚的就赶紧去结婚,想单身的就继续单着,反正你们早晚都会后悔的。“ —— 鲁迅

以前总觉得只要有感情加一些努力什么问题都可以解决,年轻!总之三观不合的话还是不要白费力气了。
很失败,失败的一塌糊涂。感谢好朋友,让我在新年的第一个月里见识了一些东西,刷新了一些三观,看开了一些事情,但同时也对感情这种事情更加的恐惧了。也在逼乎上看了好久"嫁/娶现在的老公/老婆后悔了没"的话题,心里感慨万千呀,这个东西太复杂了。
"改变就是好事" —— 虚空掠夺者·卡兹克

人总是会变的,不管是变好还是变坏。
改变是需要很大的勇气的,我很佩服那些敢于做出改变的人。

不管愿不愿意,新的一年已经来临,新的期盼也已开启:
工作
生活
好了,断断续续零零散散的写了一大堆,暂时就这些了,祝猪年大吉吧😉!

一台双网卡电脑拥有两个网关是不可能的,因为默认网关(default gateway)只能是一个!
我们将其中一块网卡(比如外网网卡 eth0)设置成默认网关,另外一块网卡eth1设置网关。
sudo vim /etc/network/interfaces配置如下:
auto eth0
iface eth0 inet static
address 210.44.185.75
netmask 255.255.255.0
gateway 210.44.185.10
auto eth1
iface eth1 inet static
address 10.6.0.248
netmask 255.255.255.0
sudo /etc/init.d/networking restart这时我们的第一条需求已经实现了,但是由于没有设置内网网关,第二条需求还实现不了,我们需要分别给这三个网段设置路由。
注意:一块网卡只能设置一个网关,多个网关会发生冲突而无法成功配置。
操作如下:
sudo route add -net 10.6.0.0/24 gw 10.6.0.254 dev eth1
sudo route add -net 10.6.1.0/24 dev eth1
sudo route add -net 10.6.4.0/24 dev eth1
sudo route add -net 10.6.15.0/24 dev eth1最后使用 ip route 查看路由设置情况:
ttop5@ubuntu:~$ ip route
default via 210.44.185.10 dev eth0 metric 100
10.6.0.0/24 dev eth1 proto kernel scope link src 10.6.0.248
10.6.1.0/24 dev eth1 scope link
10.6.4.0/24 dev eth1 scope link
10.6.15.0/24 dev eth1 scope link
210.44.185.0/24 dev eth0 proto kernel scope link src 210.44.185.75如有多余的配置,可使用下面的命令进行删除,祝你好运!:grinning:
sudo route del -net *.*.*.*/* dev eth*/* example 1-1 */
function test1(num) {
if (num) {
var val = 'color'
console.log(val + '1'); // 这里可以访问val
}
console.log(val + '2'); // 这里也可以访问val
}
test1(5);
// color1
// color2/* example 1-2 */
function test1(num) {
if (num) {
let val = 'color'
console.log(val + '1'); // 这里可以访问val
}
console.log(val + '2'); // 这里不可以访问val
}
test1(5);
// color1
// val is not defined让我们先来看一下这样两个例子:
(1). 变量a先使用后声明,输出undefined,不报错。
/* example 2-1 */
console.log(a); // undefined
var a = 2;(2). 把var换成const就报错了。
/* example 2-2 */
console.log(a); // Uncaught TypeError: Identifier 'a' has already been declared
const a = 2;为什么会出现这种情况呢?
事实上,在ES6之前由于变量声明总是在任意代码执行之前处理的,所以在代码中的任意位置的变量声明是等效于在代码开头声明,这个行为称之为"变量声明提升"(var hoisting)。即代码 example 2-1 等效如下代码:
/* example 2-1-1 */
var a;
console.log(a); // undefined
a = 2;(想过没有,为什么是undefine而不是null呢?两者有什么区别呢?)
而在代码 example 2-2 中,由于使用了let来声明变量,从一开始就形成了块级的封闭作用域,在声明之前使用这些变量是会报错的,这在语法上称之为"暂时性死区"(temporal dead zone,简称TDZ)。即等效于如下代码:
/* example 2-2-1 */
console.log(a); // Uncaught TypeError: Identifier 'a' has already been declared
let a;
a = 2;/* example 3-1 */
var x = 0;
function testf(){
var x = y = 1;
}
testf();
console.log(x, y); // 0, 1是不是有点懵,为什么结果不是 1, 1 ? 事实上,这里出现了三个变量,分别是全局变量x,局部变量x和隐式全局变量y。也就是说y其实不是在testf函数内部声明的,而是js默认在外层作用域默认给它进行了声明。它等效于以下代码:
/* example 3-1-1 */
var x = 0; // 声明并初始化全局变量x为0
function testf(){
var x; // 声明局部变量x
y = 1; // 将变量y初始化为1(并未声明,js隐式声明)
x = y; // 将y的值赋值给x
}
testf();
console.log(x, y); // 0, 1
// x是全局变量
// y是隐式声明的全局变量就这样我们无意中添加了一个全局变量,而如果使用ES6推荐的let或者const就不会出现上面的情况。
由于其不允许同时声明多个变量,暂时性死区和块级作用域等特性,就能避免了很多我们在无意间引入一些问题,这也是ES6极力的推荐使用let和const而非var的原因所在。
JS中变量的作用域无非两种:全局变量和局部变量。由于JS特有的“链式作用域”(chain scope)结构,父对象的变量对子对象是可见的,反之则不行,即:函数内部可以读取全局变量,在函数外部却无法读取函数内部的局部变量。
/* example 4-1 */
function f1(){
var n = 1;
}
alert(n); // error那么我们如何从外部读取局部变量?答案就是闭包
/* example 4-2 */
function f1(){
var n = 1;
function f2() {
alert(n);
}
return f2;
}
var result = f1();
result(); // 1上面代码中的f2函数,就是闭包。所以闭包就可以理解为能够读取其他函数内部变量的函数,它就是将函数内部和函数外部连接起来的一座桥梁。闭包在许多地方都非常实用,它允许将函数与其所操作的某些数据(环境)关联起来并是这些数据始终保持在内存中。当然了,在非必要的情况下还是要谨慎使用闭包,否则会造成一些性能问题。
客户端能访问外部的web,但是不能访问目标web,目标web所在的网络内一台机器充当目标web的代理,客户端直接访问代理就像访问目标web一样(此代理对客户端透明,即客户端不用做如何设置,并不知道实际访问的只是代理而已,以为就是访问的目标)。
第一步,首先是要打开apache的相关功能。
sudo a2enmod rewrite #打开 url 重写
sudo a2enmod proxy
sudo a2enmod proxy_http
sudo a2enmod proxy_balancer第二步,设置网站的配置文件,在 /etc/apache2/sites-available/ 目录下 新建文件 a.com, 写入如下内容
ServerName a.com
ProxyPreserveHost On
ProxyRequests Off
Order deny,allow
Allow from all
ProxyPass / http://192.168.0.10/
ProxyPassReverse / http://192.168.0.10/第三步,在/etc/apache2/sites-enabled/目录下把刚才建的文件做个软链接过来
sudo ln -s ../sites-available/a.com a.cm第四步,执行、启用这个站点
sudo a2ensite a.com
sudo service apache2 reload或者直接重启apache服务
sudo service apache2 restart这样所有来自 a.com 的请求都会转发到 http://192.168.0.10, 祝你好运!

去年夏天在杭州出差,应Feng(老板)的要求住在了他家所在的富人区的一个青年旅社里(感受了有钱人的生活环境),他每天开车上班会捎上我们。你问我Feng开什么车?我不知道只知道很贵。每天车里都会想起Feng的”帝国摇滚珍藏“(他把自己开的公司称之为”帝国“)。Feng是个很有意思的人。
”...... 相爱吧终有一散的人们 .......“。伴随着悲伤又愉悦的节奏,情不自禁之中拿起手机使用听歌识曲功能:《优美的低于生活》。你问我为什么喜欢,我不知道只知道就是喜欢,因为喜欢是不需要理由的。
到了公司跟小伙伴们说起早上车上听到的歌时,发现他们在后排也都用了听歌识曲并收藏了这首歌2333...
把歌声还给夜晚
把道路还给尽头
把果实还给种子
把飞翔还给天空
剩下的,让它们美好
从容的埋藏得更深
最后让这纷乱的一切
都单纯的低于生活
只有内心远过空旷
梦到了丰饶的草原
相爱吧,终有一散的人们
你失去的不过是童贞
等时光用尽了青春
你早已优美的在大街上溶化
只有内心远过空旷
梦到了丰饶的草原
只有内心远过空旷
梦到了丰饶的草原
我听歌有一个习惯,就是一直把喜欢的个单曲循环循环循环,一直循环到觉得听够了为止,然后再换下一首。出差的那阵子我几乎每天都在循环这首《优美的低于生活》,至于去了解歌手乐队就是后面的事情了。
那么这首歌想表达什么呢?

生活才是重要的,你要让你的生命愉快,因为生命只有一次,所以我想要先学会生活,再去做别的.....
这是声音碎片给出的答案。
在我看来,何谓低于生活?就是向生活低头,屈服于生活。生活高于一切,一切都是为了生活(至少这个世界上90%的人都是这样的)。想想这世间忙碌的人们,为的是什么呢,就是生活。但至于什么是生活,一百个人有一百种答案,每个人都是正确答案,无论完整或者残缺,都是对生活的一种理解,再优美也不过生活。为什么要优美的低于生活?我认为在没法高于生活的情况下尽可能的让自己优雅一些。
想当初年少轻狂的我们,野心勃勃,拥有远大理想和抱负,曾不止一次的励志要改变一切自己认为不美好的东西。然而岁月抹平了我们的棱角,现在剩下的也就是日复一日苟活。跟在长长的所谓社会潮流中队伍中,沉默、屈服、麻木。经历的越多越是感到乏力,越是麻木不仁,犹如行尸走肉般的活着。
是生活,生活强奸了所有人!

“声音碎片”,2002年以来最重要的**摇滚乐队之一。这是一支由彝族流浪诗人、山东三流神医、东北夜行骑士、西南原始摩登人、淄博长发小贝所建立的乐队,他们来自不同的地方,有着不同的经历,他们的音乐中从平静到狂躁、从孤独到幸福,从自恋自伤到纵情高歌,听者往往会将自身最隐秘的情感释放出来,进入一种宣泄状态...... ——【百度百科】

我的大学时光基本上都是在老许的音乐声中度过的。这四五年来,许巍在我心里的音乐地位是最高的。人称“摇滚诗人”的许巍,他的歌给我最大感觉就两个字:生活。他的所有歌曲基本都是在感受生活,体验生活的各种感觉。
当年刚到异地上学的我就被一首《旅行》迅速圈粉,而后沉迷于《星空》等。在错过了济南的演唱会一年后,在成都实习时终于赶上了一次有老许压轴出场并连唱五首的音乐节上,现场感受许巍的魅力和众多巍迷热情。那次我比较靠前,最近离许巍不到五米的位置,那天玩的很嗨。依稀记得那天下午好像前女友打电话来说做了个噩梦,然后我们说着说着就和好了2333。
老许的歌属于越听越耐听的那种,以至于我重复播放了这么多年。我认为他的歌偏民谣摇滚和流行摇滚,当然其实分不清这些这些类别。总之,“爱许巍,爱生活”。
声音碎片的出现,我听到了不一样的旋律,触动到了我不一样的内心深处,使我的另一部分感情得到了宣泄。还是会去听老许的歌,至于是什么歌,当情绪来临的时候就会自然想起那首歌。
摇滚(英语:rock and roll/rock 'n' roll/ rock & roll)是一种音乐类型,起源于1940年代末期的美国,1950年代早期开始流行,迅速风靡全球。摇滚乐结合了当时流行的非裔美国人蓝调、乡村音乐、爵士乐、以及福音音乐。虽然一些20年代的蓝调和30年代的爵士乐已经具有摇滚元素,摇滚乐直到50年代才定型成一种独立音乐流派。摇滚乐以其灵活大胆的表现形式和富有激情的音乐节奏表达情感,受到了全世界年轻人的喜爱。摇滚乐的力量已经远远超出了一种音乐形式,它影响了一代人的生活方式、时尚品味、处世态度,甚至语言。由摇滚乐发展出的其它音乐流派,通常不具有摇滚乐标志性的强劲打击乐器(backbeat)的节奏...... ——【维基百科】

摇滚的分类有很多,我根本也分不清。我目前为止听过最多的摇滚歌手/乐队就三个:许巍、声音碎片和德国战车。许巍的民谣摇滚居多,声音碎片后摇居多,而德国战车就是浓浓的重金属味道,我都很喜欢。前两者的是对内心和生活的震撼,需要细听才能区别开来;后者较前两者区别就很明显了,听过后绝对是对感官的震撼。
记得是高中同学带我入的德国战车,在当时周围人满大街都是听什么周杰伦、许嵩等一众软弱无力的流行歌曲的时候,简直就是一股清流啊。
流行歌的流行是与这个时代息息相关的。这是一个娱乐至死的年代,高度分工的现代社会,人们日复一日的做着重复的劳动,疲惫不堪的人们需要各种各样的娱乐活动来缓解这些东西,而流行音乐就是其中的一种。流行音乐的风格创作不受约束,接受着也不需要费尽心思的的去揣摩和品味,生活已经够辛苦了,谁还愿意在听首歌上费神啊。就像电影和小说书籍一样,大家更愿意走进电影院而不是捧起书籍细细品味。
并不是说看书就比看电影好,也不是说摇滚就比流行音乐好。科技的进步和多元文化的出现是时代进步的标志,我们应该去开放心态包容这一切。你看,隔壁刷抖音快手的不也很快乐,开心就好。但是话又说回来,如果有一天摇滚也跟今天的流行音乐烂大街的时候,或许我也就不那么感兴趣了。看来我不是真正的喜欢摇滚,而只是想追求一点与众不同和小众。但是这又有什么问题呢,开心就好。
在团队开发中,commit message(提交说明)就如同代码注释一样重要。良好的commit message能让团队中的其他成员对你的每次提交的目的、涉及的代码范围及作用一目了然,方便日常的查询和帮助其他成员更好的帮你Code Review,必要时还能方便的生成Change log。

上图是著名的前端项目Angular的commit message截图,对比一下与你平时写的的有什么不同,有没有眼前一亮的感觉~_~。以下总结自部分Angular 规范。
格式:<type>(<scope>): <subject>
必填 用于说明commit的类型。总共7个标识:
- feat: 新增feature
- fix: 修复bug
- docs: 仅仅修改了文档,比如README, CHANGELOG, CONTRIBUTE等等
- style: 仅仅修改了空格、格式缩进、变量名等等,不改变代码逻辑
- refactor: 代码重构,没有加新功能或者修复bug
- perf: 优化相关,比如提升性能、体验
- test: 测试用例,包括单元测试、集成测试等
- chore: 改变构建流程、或者增加依赖库、工具等
- revert: 回滚到上一个版本
可选 scope用于说明 commit 影响的范围,比如数据层、控制层、视图层或者目录甚至文件等等,视项目不同而不同。
必填 subject是 commit 目的的简短描述,不超过50个字符。
- 约定好commit message的语言,对我们来说最好使用中文
- 最好以动词开头(如使用英文请使用第一人称现在时,并且第一个字母小写)
<scope>之后的冒号后面留一个英文输入法的空格- 结尾不加句号或其他标点符号
- 若此次commit是解决某个issue应该在行末尾注明并加链接,如:...(#101)
(1). commitizen: 一个撰写合格 Commit message 的工具;
(2). validate-commit-msg: 用于检查 Node 项目的 Commit message 是否符合格式。
最近看到网上一个比较有意思的运动:抵制if运动,他们的口号是:Less IFs, more power。于是找了一些相关文章看了一下,略有启发,以下是其中的一篇。(非全文翻译)
原文链接:https://edgecoders.com/coding-tip-try-to-code-without-if-statements-d06799eed231
..... (略去废话)
假设有一个整数数组,我们想要统计奇数的个数,以下是测试用例:
const arrayOfIntegers = [1, 4, 5, 9, 0, -1, 5];使用if语句:
let counter = 0;
arrayOfIntegers.forEach((integer) => {
const remainder = Math.abs(integer % 2);
if (remainder === 1) {
counter++;
}
});
console.log(counter);不用if语句:
let counter = 0;
arrayOfIntegers.forEach((integer) => {
const remainder = Math.abs(integer % 2);
counter += remainder;
});
console.log(counter);在不用if语句时,我们巧妙的利用了奇数和偶数的特性:奇数%2等于1,偶数%2等于0。
给定个日期(如:new Date()),判断是周末还是工作日,分别返回“weekend”或者“weekday”。
使用if语句:
const weekendOrWeekday = (inputDate) => {
const day = inputDate.getDay();
if (day === 0 || day === 6) {
return 'weekend';
}
return 'weekday';
// 或使用三元表达式:
// return (day === 0 || day === 6) ? 'weekend' : 'weekday';
};
console.log(weekendOrWeekday(new Date()));不用if语句:
const weekendOrWeekday = (inputDate) => {
const day = inputDate.getDay();
return weekendOrWeekday.labels[day] ||
weekendOrWeekday.labels['default'];
};
weekendOrWeekday.labels = {
0: 'weekend',
6: 'weekend',
default: 'weekday'
};
console.log(weekendOrWeekday(new Date()));再不用if语句时,我们需要把哪天是周末哪天是工作日这些信息写入一个对象中,然后直接使用它。
写一个doubler函数,它会根据参数的类型,进行不同的操作:
使用switch语句:
const doubler = (input) => {
switch (typeof input) {
case 'number':
return input + input;
case 'string':
return input
.split('')
.map((letter) => letter + letter)
.join('');
case 'object':
Object.keys(input)
.map((key) => (input[key] = doubler(input[key])));
return input;
case 'function':
input();
input();
}
};
console.log(doubler(-10));
console.log(doubler('hey'));
console.log(doubler([5, 'hello']));
console.log(doubler({ a: 5, b: 'hello' }));
console.log(
doubler(function() {
console.log('call-me');
}),
);不用switch语句:
const doubler = (input) => {
return doubler.operationsByType[typeof input](input);
};
doubler.operationsByType = {
number: (input) => input + input,
string: (input) =>
input
.split('')
.map((letter) => letter + letter)
.join(''),
function: (input) => {
input();
input();
},
object: (input) => {
Object.keys(input)
.map((key) => (input[key] = doubler(input[key])));
return input;
},
};
console.log(doubler(-10));
console.log(doubler('hey'));
console.log(doubler([5, 'hello']));
console.log(doubler({ a: 5, b: 'hello' }));
console.log(
doubler(function() {
console.log('call-me');
}),
);同理,在不用switch语句时,我们依然是不用的类型和对应操作存到对象当中,然后该对象用于选择正确的操作并使用原始输入调用它。
不要去研究什么区块链技术,直接去买比特币。 —— 周树人


比特币(BitCoin)的概念最初由中本聪在2009年在 《比特币:一种点对点电子货币系统》一文中提出。
比特币是一种P2P形式的数字货币,是目前为止应用最广泛的一种数字货币,人称“数字黄金”;比特币是区块链技术的第一个应用,也是到目前为止最落地、最庞大、最稳定、最成功的一个区块链应用。
事实上,区块链技术的概念就是通过比特币带到了世人的面前的,而且世人对区块链技术的关注也是随着比特币价格的上涨而火热(2017年BTC价格曾一度涨到20000美元左右)。

比特币是一个点对点的网络系统,每个运行的全节点的地位都是独立平等的,节点之间不存在任何依赖关系。
比特币设计中的一种共识算法,通过这个竞争机制来解决异步网络中数据一致性的问题。
UTXO,全称Unspent Transaction Output,翻译为“未花费交易输出”。一个账户地址拥有一的所有可用的剩余“输出”就是UTXO。
依托于强大的区块链账本结构和分布式网络共识机制实现了数据不可篡改。
在比特币网络中想到得到比特币,要么靠挖矿获得,要么靠其他地址转账,任何人是无法凭空伪造出一个比特币的。
比特币在技术本质上其实就是一个网络软件,主要有钱包、挖矿节点(矿工)、完全节点和网络路由节点组成。

其中,完全节点是比特币网络的骨干组成,其数量的多少以及分布的广泛程度,对比特币网络的安全性、可用性都是有影响的。在完全节点上,对于任何比特币的交易数据以及区块等,都是可以进行最全面完整的验证的,而且在节点本机就可以独立的验证。
从bitnodes网站我们可以清楚的看到比特币全节点的全球地域分布:

各个比特币的全节点版本之间并非是完全兼容的。
比特币网络中主要处理的就是交易事物。一笔交易从签发开始,然后广播到网络中,网络中的其他节点会接收交易数据并且进行验证,验证通过后会继续广播到网络中的其他节点。当然,这个阶段是交易事物还没有被写入到区块中,等到被挖矿节点打包进区块后会再次同步给其他节点,直到被全网中的绝大部分的节点写入自己本地的账本,即是得到了全网的共识。

1.接收并验证交易事物,并将交易事务放入交易池中;
2.将交易池中的每笔交易按照规则分配优先级;
3.从交易池中取出交易事务构建区块;
4.进行挖矿算法的计算,抢夺打包记账权;
5.挖矿成功后组装完整的区块并广播给相邻的节点;
比特币中的账号系统的设计完全不同于通常软件中的用户账号模型,而是使用了公开密钥算法的私钥和公钥来表示。
比特币地址可由公钥经过单向的加密哈希算法得到。哈希算法是一种单向函数,接收任意长度的输入产生指纹摘要。

比特币账号生成的目的是使其在使用时能够有效的校验持有者的合法性,不通前缀类型的比特币地址的校验方法不同。常见的账号校验格式有两种:p2pkh校验和p2sh校验。
p2pkh校验是Pay-to-pubkey-hash校验的缩写,针对于版本前缀为1的账号类型的校验; p2sh是Pay-to-script-hash校验的缩写,针对于版本前缀为3的账号类型的校验。

区块链,可能是当下最有前景又充满分歧的技术与经济趋势。它给数字世界带来了“价值表示”和“价值转移”两项全新的基础功能。

现在的区块链技术可能带来互联网的二次革命,把互联网从“信息互联网”带向“价值互联网”。
综上,来吧少年,区块链未来就靠你了!

使用 React.createClass 构建组件是 React 最传统、也是兼容性最好的方法。在 0.14 版本发布之前,这一直都是 React 官方唯一指定的组件写法。
const Button = React.createClass({
getDefaultProps() {
return {
color: 'blue',
text: 'Confirm',
};
},
render() {
const { color, text } = this.props;
return (
<button className={`btn btn-${color}`}>
<em>{text}</em>
</button>
);
}
});React.createClass 方法就是构建一个组件 对象。当另一个组件需要调用 Button 组件时,只用写成 ,就可以被解析成 React.createElement(Button) 方法来创建 Button 实例,这意味着 在一个应用中调用几次 Button,就会创建几次 Button 实例。
ES6 class 的写法是通过 ES6 标准的类的语法的方式来构建:
import React, { Component } from 'react';
class Button extends Component {
constructor(props) {
super(props);
}
static defaultProps = {
color: 'blue',
text: 'Confirm',
}
render() {
return (
<button className={`btn btn-${color}`}
<em>{text}</em>
</button>
);
}
}这种方式给我们的直观感受就是从调用内部方法变成了用 类 来实现。与上一中方式相同的是,调用类实现的组件会创建实例对象。
使用无状态函数构建的组件称为无状态组件,这种构建方式是 0.14 版本之后新增的,且官方颇为推崇。
function Button({ color = 'blue', text = 'Confirm' }) {
return (
<button className={`btn btn-${color}`}>
<em>{text}</em>
</button>
);
}无状态组件只传入 props 和 context 两个人参数,不存在 state,组件本身就是上面两种 React 组件构建方法中的 render 方法。不过,像 propTypes 和defaultProps 还是可以通过向方法设置静态属性来实现的。
如果可以的话,我们还是应该尽量使用无状态组件。无状态组件不像上述两种方法在调用时会创建新的实例,它创建时始终保持了一个实例,避免了不必要的检查和内存分配,做到了内部优化。
在使用不同的方式来构建组件时,生命周期会有所不同,下面是三种构建方式的生命周期比较:

无状态组件既然没有生命周期,也就意味着没有 shouldComponentUpdate 方法,所以渲染该类型的组件时每次都会重新渲染。为了解决这个问题,我们可以引用 Recompose 库的 pure 方法,这里不做详述。
参考资料:《深入React技术栈》陈屹 著
Ag和Ack,用Ag来进行搜索,使用Ack用来展示结果。
# OSX
brew install the_silver_searcher
# Archlinux
pacman -S the_silver_searcher
# Ubuntu
apt-get install silversearcher-ag在~/.vimrc中加入:
Plugin 'mileszs/ack.vim'
let g:ackprg = 'ag --nogroup --nocolor --column'然后在vim中使用:PluginInstall进行安装(已经安装Vundle)
:Ack {搜索内容}
常用快捷键如下:
?帮助,显示所有快捷键Enter/o打开文件O打开文件并关闭Quickfixgo预览文件,焦点仍然在Quickfixt新标签页打开文件q关闭Quickfix
随着越来越多的人通过PC、手机等设备相互连接,现代互联网蓬勃发展使得人们的生活发生了翻天覆地的变化。很多人预测将会有更多其他的设备相互连接,这些设备的数量将远远超过人类的数量,到时候形成的网络将是现有网络的N个量级,这个网络带给世界的变化将是无法估量的。
不像人接入互联网的简单方便,由于物联网设备大多都是资源限制型的,有限的CPU、RAM、Flash、网络宽带等。对于这类设备来说,想要直接使用现有网络的TCP和HTTP来实现设备实现信息交换是不现实的。于是为了让这部分设备能够顺利接入网络,CoAP协议就被设计出来了。
Constrained Application Protocol (CoAP) is a specialized Internet Application Protocol for constrained devices, as defined in RFC 7252.It enables those constrained devices called "nodes" to communicate with the wider Internet using similar protocols. CoAP is designed for use between devices on the same constrained network (e.g., low-power, lossy networks), between devices and general nodes on the Internet, and between devices on different constrained networks both joined by an internet. CoAP is also being used via other mechanisms, such as SMS on mobile communication networks.
以上是来自维基百科对CoAP的定义。简言之,CoAP是受约束设备的专用Internet应用程序协议。
CoAP是一个完整的二进制应用层协议,消息格式紧凑,默认运行在UDP上。

【Ver】版本编号。
【T】报文类型,CoAP协议定了4种不同形式的报文,CON报文,NON报文,ACK报文和RST报文。
【TKL】CoAP标识符长度。CoAP协议中具有两种功能相似的标识符,一种为Message ID(报文编号),一种为Token(标识符)。其中每个报文均包含消息编号,但是标识符对于报文来说是非必须的。
【Code】功能码/响应码。Code在CoAP请求报文和响应报文中具有不同的表现形式,Code占一个字节,它被分成了两部分,前3位一部分,后5位一部分,为了方便描述它被写成了c.dd结构。其中0.XX表示CoAP请求的某种方法,而2.XX、4.XX或5.XX则表示CoAP响应的某种具体表现。
【Message ID】报文编号。
【Token】标识符具体内容,通过TKL指定Token长度。
【Option】报文选项,通过报文选项可设定CoAP主机,CoAP URI,CoAP请求参数和负载媒体类型等等。
【1111 1111B】CoAP报文和具体负载之间的分隔符。
这一类型的状态码,代表请求已成功被服务器接收、理解、并接受。
这类的状态码代表了客户端看起来可能发生了错误,妨碍了服务器的处理。
这类状态码代表了服务器在处理请求的过程中有错误或者异常状态发生,也有可能是服务器的软硬件资源无法完成对请求的处理。

【text/plain】 编号为0,表示负载为字符串形式,默认为UTF8编码。
【application/link-format】编号为40,CoAP资源发现协议中追加定义,该媒体类型为CoAP协议特有。
【application/xml】编号为41,表示负载类型为XML格式。
【application/octet-stream】编号为42,表示负载类型为二进制格式。
【application/exi】编号为47,表示负载类型为“精简XML”格式。
【applicaiton/cbor】编号为50,可以理解为二进制JSON格式。
CoAP参考了很多HTTP的设计思路,同时也根据受限资源限制设备的具体情况改良了诸多的设计细节,增加了很多实用的功能。
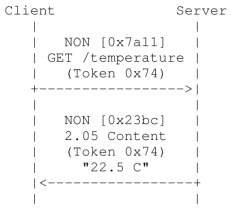
CON:需要被确认的请求,如果CON请求被发送,那么对方必须做出响应。
NON:不需要被确认的请求,如果NON请求被发送,那么对方不必做出回应。
ACK:应答消息,接受到CON消息的响应。
RST:复位消息,当接收者接收到的消息包含一个错误,接收者解析消息或者不再关心发送者发送的内容,那么复位消息将会被发送。

分离模式

非确认模式
CoAP协议的设计参考了HTTP,CoAP和MQTT都是行之有效的物联网协议,以下为它们之间的异同。
持续更新...
小米的物联网生态链还是挺好玩的哈~

vim-mode-plus 简直酸爽[2018/07/27] 新增:

m lock)
<C-Space> 快速选择打开文件git diff 内容




[2018/07/27] 新增:
说明:请确保在你开始前,Mi4 LTE 已充满电。在开始进行更新到 Windows 10 移动版的过程时,你将无法对其充电,并且在此过程中耗尽电池电量将会损坏手机。
【启用开发人员模式】:在 Mi4 LTE 上,依次点击设置->关于手机,然后点击MIUI 版本 5 次。
【 启用 USB 调试】:将 Mi4 LTE 插入电脑。在设备上,依次点击设置->其他设置->开发人员选项->USB 调试-> 并接受要求确认的提示。
【将设备置于刷写模式】:在电脑上,打开 cmd 提示并导航到安装 MiFlash 工具的文件夹,例如 C:\Program Files (x86)\Xiaomi\MiPhone\Google\Android。在 cmd 提示符中输入以下内容并按 Enter:adb reboot edl (完成此步骤后,Mi4 LTE 将会黑屏,直到安装了 Windows 10 移动版。这是正常情况。)
【安装 Windows 10 移动版】:在电脑上启动 MiFlash,然后在工具 UI 中单击刷新以连接 Mi4 LTE。你将看到在名为COM的工具中出现行项,后面跟有数字。单击浏览并导航到保存已解压的 Windows 10 移动版文件的文件夹,然后单击刷机。
当工具显示“刷写完成”时,表示你已完成。长按 Mi4 LTE 上的电源键来开始使用 Windows 10 移动版。
win10刷机包是12月3号(也就是昨天)刚出的,当初4月份的时候买mi4有一半的原因就是因为微软和小米合作win10要适配小米,所以12月2号的晚上(也就是前天)我就把所有数据备份好了,3号的时候第一时间刷了win10,哈哈!
以上便是我的使用体验,我尽量多用一段时间再刷回MIUI,哈哈哈:smiley::smiley::smiley:!



公司里的很多沟通都是通过邮件的方式来进行的,一封电子邮件可以让人看出你的职业素养和专业水平。上周听了 ZZM 同学的分享,觉得这种职场礼仪还是很重要的,特此总结。
如:一封请假邮件,应将你的部门领导(部门总监)和直接领导(研发组长)放在收件人栏,因为你需要他们回复同意或者不同意;你还需要将统计工时的HR和一些最几天可能与你联系的人(如正在开发的统一个项目中的其他人员),因为他们需要知道你上班的情况,以便统计工时和对项目中的一些事情做出相应的安排。

前天晚上大概十二点半左右,我刚洗漱完在卧室收拾东西的时候,啪的一声家里所有的灯都熄灭了。家里顿时黑压压一片,我耳机电还没充满,手机也没充电明天怕是不够用了。
我立马就想到了前两天贴在门口的缴费通知单。”肯定是他没交电费“,我心里嘀咕道。因为家里宽带每个月都是我在缴费,而且上个月的电费也是我交的,所以我想朋友 (室友)LY应该会自己主动去交这个月电费的吧。
我拿起手机拨通了LY的电话:
“你前两天是不是没有交电费?”,我问道。
“我还没去交,单子还在我这里,怎么了?”,他疑惑道。
“停电了,肯定是欠费了。还好我没开游戏,不然得被你给害死。”
“我擦,不会吧,一般都是月底才会停的吧。”
“应该通知单发出后三天之内吧,我记得是这么写的。”
“应该是月底才停才对。刚刚下雨打雷了,你去看看是不是家里总开关跳闸了。”
一分钟之后。
“我看了,没问题,就是没钱了。”
“好嘛,我错了。”
第二天早上出门的时候发现有电了,以为他把电费交了,实际上那时候他还没去交电费。
下午LY去交电费在物业那里了解到,他们昨晚没有给哪个片区停电,说可能是昨晚打雷的缘故导致我们这栋楼跳闸了。

以下是一些我遇到过/经历过的常见的对话:
“你这接口是不是有问题呀?”
“你参数没传对...”
“你这接口是不是有问题呀?”
“参数格式错了...”
“你这接口是不是有问题呀?”
“你的请求地址错了,后台没收到你的请求数据...”
......
开发联调的过程中类似的情况还有很多,绝大多数都是由于我们的粗心和浮躁造成的。

在新年的开工大会上,别的部门的同事当场表扬了我部门的产品经理XD。有句话我记得很清楚,原话是这么说的:“别人那里来的问题不一定是问题(有可能是他们自己的问题或者是用户操作的问题),但是XD那里来的问题就肯定是问题。”我想这可能是对一个同事认真负责的最高评价了吧。
XD作为一个非技术出生的产品,能把区块链相关特别是我们部门负责的钱包这块吃透摸熟,甚至还学会了很多技术相关的问题排查方法,让我很是佩服。
每当有问题出现,XD总是能排查出是哪里出了问题,然后解决掉问题或者去找相关的人解决问题。他会把问题进行过滤,确认这确实是一个问题,然后进行排查定位问题出现在哪儿,然后找到对应的人只到问题得到解决。
每当在日常的工作和生活中出现问题时,我们总是随便一想可能是哪里出的问题,然后就急于把问题抛向别人,然后就事不关己高高挂起。这是很不负责任的做法。
JS中的sort函数是可以接收排序方法作为参数的,所以我们就利用这点来进行自定义排序。
const array = [1, 5, 2, 4, 3];
array.sort();const array = [1, 5, 2, 4, 3];
function compare(a, b) {
return b - a;
}
array.sort(compare);将下面的对象根据年龄进行排序:
const friends = [
{ name: 'John', age: 30 },
{ name: 'Ana', age: 20 },
{ name: 'Tom', age: 25 },
];
function comparePerson(a, b) {
return a.age - b.age;
}
friends.sort(comparePerson);const names = ['Ana', 'ana', 'john', 'John'];
names.sort();上面的代码得到的结果是 ["Ana", "John", "ana", "john"],这是因为js在做字符比较的时候是根据字符对应的ASCII值来进行比较的,如:A, J, a, j 对应的ASCII值分别是 65, 75, 97, 106。
想要得到我们想要的 ["Ana", "ana", "John", "john"],只需要给sort传入一个忽略大小写的比较函数即可:
function stringCompare(a, b) {
if (a.toLowerCase() < b.toLowerCase()) {
return -1;
}
if (a.toLowerCase() > b.toLowerCase()) {
return 1;
}
return 0;
}
names.sort(stringCompare);为了开阔视野我们花很多时间去看新闻。但是这些时间花的值么?根据新闻的定义,新闻一般不会持续太久。而且由于现在新闻变得很容易发布和生产成本更低,其质量也下降了很多。
我们很少停下来问自己关于我们所花费时间的事物:这个东西真的重要么?是否经得起时间的考验 —— 一周或者一年之内?写这个东西的人是否对此问题了如指掌?
“[W]e’re surrounded by so much information that is of immediate interest to us that we feel overwhelmed by the never-ending pressure of trying to keep up with it all.”
— Nicolas Carr
我们当今所阅读的新闻有以下几个问题:
第一,新闻的传播速度大大提高。
曾经我们不得不通过等着报纸或者与镇上的人一起八卦来获取新闻,但是现在不一样了。感谢快讯、文章和其他一些终端,新闻几乎在它被发布的那一刻就找上了我们。
第二,新闻的生产成本大幅下降。
有人一天就能为主流报纸写12篇文章。能在一个主题下写上出一些有深度的东西都是很难的,更别说12个了。一年一个人就能产出2880篇文章(假设每年有四周的假期)。写文章给你看的那些人对文章相关的东西的熟悉程度很低,因此,你甚至都能对其中的某个主题发表你的意见。由于成本几乎为0,因此存在很多竞争者。
第三,新闻行业企图给读者洗脑。
现在的新闻都是各种震惊体,不再强调客观性,而是通过各种主观个性的内容来吸引你。这类新闻你看得越多,你做其他事的时间就越少了。
第四,点击量成了主要目标。
在某种程度上,由于竞争激烈,大多数新闻媒体不得不提供免费的新闻内容。没办法,因为其他人都这么干。但是,当新闻免费时,他们就只能通过广告的方式来获得收入了。而此时点击量这个东西就变得很重了,越多越好。对于很多"创造"新闻的人(这里我不会使用"记者"一词,因为我很尊重这个称呼),他们的点击量越多获得的收入就越高。不仅仅是展示广告,他们也向广告商提供你的个人信息。当然,这又是另一个故事了。
“What information consumes is rather obvious: it consumes the attention of its recipients. Hence a wealth of information creates a poverty of attention, and a need to allocate that attention efficiently among the overabundance of information sources that might consume it.”
— Herbert Simon
很关键的一点,如今你在网上阅读的大部分内容都是毫无意义的。它对你的生活无关紧要,它不能帮助你更好的做决定;不能帮助你更好的理解这个世界;不能帮助你与周围人建立深刻而有意义的联系。它唯一真正做的就是改变你的心情,或者可能是行为。
迪士尼的酒店、交通和票务系统都是为了让你进入主题公园,而不是在奥兰多的其他地方观光。同理,一旦你进入脸书,它就会尽可能的接管你的电脑,以防止你离开。但是像脸书这样的平台在此过程中发挥这很大的作用,我们并不是无辜的。退一步讲,是我们自己希望了解情况(更准确的说,我们希望看起来很了解情况)这就是被操控的弱点。
“To be completely cured of newspapers, spend a year reading the previous week’s newspapers.”
— Nassim Taleb
我有一个朋友,她看《纽约人》、《纽约时报》、《经济人》、《华尔街日报》、她当地的报纸和其他一些出版物。她看上瘾了。她想知道所有地方正在发生的事情并获得明智的意见。她就跟我们大多数人一样——我们都想知道在发生什么事情,并且有一个明智的意见。如果我们不了解情况,那我们算什么呢?我不想愚昧无知,而这个正是让我感觉我没有跟上别人的步伐的原因。
尽管如此,我还是停止了看新闻。一开始我感觉很困难。当我的朋友开始跟慷慨激昂的跟我谈论某个话题并问我怎么看时,我不得不说我不知道。紧随而来的是“啥?”和“你真的应该看看这个”,然他们就会拿出手机给我发某篇文章的连接,但是我从来不去看。这中情况比较搞笑的就是他们常常希望我停下谈话并且立马去看文章,以便能与他们一起感受愤怒。真不用了,谢谢。
二十二岁没什么生活经验的见识并不能告诉我该怎样想或者多么愤怒。我们对某件事情的第一个想法通常并不是你自己的,而是别人的。当你在看新闻时,你不仅是在让别人给你洗脑并且吸引你的注意,你也是在让他们替你思考。
我们应该避免干扰。你的注意力是有价值的,那么我们为什么要花那么多的时间在几天之内无关紧要的东西上呢?读一些经得起时间考验的东西;读一些尊重和重视时间的出版物,这些东西的带来的价值超过了它们的消费价值;读一些能激励你进行自我思考的东西;少看文章多读书,阅读那些经得起时间考验的书籍,经过二十年左右仍在印刷的书。
我们害怕沉默,害怕孤独的思考。这就是为什么我们在咖啡店或者杂货铺排队时拿出手机的原因。我们害怕问自己深刻而又有意思的问题。我们害怕感到无聊,为了避免它我们会疯狂的将时间浪费在无意义的信息上。
让我们用 Winifred Gallagher 的一句话来结束吧:“很少有东西对你的生活质量和你如何使用你的空闲时间如此宝贵资源的选择同样重要。”
如果我不是一直在为你生活带来价值,你应该立马取消订阅。然而有意思的是,如果你取消订阅了,也就证明了我在给你带来价值。
在向别人提出一个技术问题之前,请尝试从以下几个途径去寻找答案:
以上尝试无果的情况下向别人提出问题时:
留下你的解决方案并加以必要的说明,方便后人(我深受其害);哪怕是问的身边的人,有价值的问题也要在博客上做记录参考资料:
https://github.com/ryanhanwu/How-To-Ask-Questions-The-Smart-Way/blob/master/README-zh_CN.md

相关代码及具体使用说明:https://github.com/ttop5/douban-status-push-to-wechat
本篇文主要讲述一下这个小项目的实现思路和前因后果,顺便探讨一下相关的一些话题。
你是否也像我一样,脑海中总有一个心心念念挥之不去的人,对 ta 所在经历的事情,你都想第一时间知道,但是因为各种原因你又不好得直接关注人家。
于是你每天不知疲倦的一遍又一遍的刷新着人家的主页,希望能第一时间看到 ta 的最新动态。啊,这样手动舔也太累了吧,还是用程序去完成这种重复性劳动吧。

主动接收信息,实时性不高。适合 RSS 重度用户(我算是半个重度用户)并且由于种种原因没法直接关注此人的情况。此方式相当于变相关注了这个用户,之所以借助 RSSHub 是因为豆瓣官方没有提供用户动态的 Feed,只提供了用户收藏的 Feed。

被动接收消息,实时性很高。适合所有使用微信的用户(几乎大部分国人),可以关注的不可以关注的人都适合,想第一时间知道某人动态及时跪舔的必备工具。
以上两种我均做了实践,由于第一种没什么好讲的,这里就主要介绍一下第二种方案的一些细节。
代码:https://github.com/ttop5/douban-status-push-to-wechat/blob/master/src/douban.js
不必使用 cookie 爬虫,直接调用接口:
https://m.douban.com/rexxar/api/v2/status/user_timeline/${USERID}?max_id=&ck=eUUA&for_mobile=1
由于豆瓣接口对请求源进行了限制,所以需要在 HTTP 请求头部加上:
Referer: `https://m.douban.com/people/${USERID}/statuses`,
这里我们借助 Server 酱来完成,就不多做赘述。
为了简化,爬取到的数据不进行持久化保存(感觉没必要),随之而来的我们面临着以下的问题。
因为怕爬取对象在短时间内连续发表多条动态,从而导致漏推送的情况出现。我把周期时间设置为5s,但在实际部署的时候我改成了10s,怕请求太频繁官方封我 ip 。
请求太过于频繁除了怕被封 ip 外,如果服务量变大了还会外增加服务器的负担,在考虑是否可以通过爬取对象的时区进行间歇性爬取(比如白天爬取,半夜凌晨不爬)。
因为 Server 酱提供的免费推送次数的限制,加上我们不想看到重复的推送,所以我们需要对数据进行过滤后再进行推送。
由于数据不保存到数据库,于是我们将其存在临时变量中,把爬到的数据创建时间和上一次爬到的数据创建时间作对比,不一致则认为爬取对象更新了动态,将数据推送到用户微信。




“一切不平等的关系都是从舔狗开始的;舔狗舔到最后一无所有;舔狗不得好死!” —— 鲁迅



结论:舔狗,必将自食其果!老哥,我劝你还是不要当舔狗🐶。
几个月前半路出家于前端,一直想给自己的老 wp 博客写一个主题,可是苦于一直搬砖没时间。最近工地活少一些开始着手弄这个,但是一直苦于没有好的设计思路。最近看见国外很多大神的博客都是没有样式的那种(很有逼格),于是我就做了这样一个东西。把这个主题做到了最简(真的简洁到什么都没有),发现用 W3M 正好很合适,体验还不错。 Just for fun. 哈哈~
为了做到最简,整个主题只留下了最重要的功能,不适用任何样式,完全使用HTML标签完成显示。为了在w3m下的最佳浏览效果,去掉所有多余的链接和评论功能。
https://github.com/ttop5/nothing




主要难点在于自定义部分和 element-ui 组件国际化的结合使用
$ yarn add vue-i18n --save-dev
export function setLocalStorage(key, value) {
if (!key) { return }
window.localStorage.setItem(key, value)
}
export function getLocalStorage(key) {
if (!key) { return }
return window.localStorage.getItem(key)
}import enLan from './en'
import zhLan from './zh_CN'
export default {
en: enLan,
zh: zhLan,
}import enLocale from 'element-ui/lib/locale/lang/en'
export default {
...enLocale,
// leftbar
leftbar: {
websocket: 'Websocket',
api: 'HTTP API',
users: 'Users',
},
}import zhLocale from 'element-ui/lib/locale/lang/zh-CN'
export default {
...zhLocale,
// leftbar
leftbar: {
websocket: 'Websocket',
api: 'HTTP接口',
users: '用户管理',
},
}import VueI18n from 'vue-i18n'
import ElementLocale from 'element-ui/lib/locale'
import lang from './common/lang'
import { getLocalStorage } from './common/storage'
Vue.use(VueI18n) // 通过插件的形式挂载
const i18n = new VueI18n({
locale: getLocalStorage('language') || 'en', // 默认语言标识
messages: lang,
})
ElementLocale.i18n((key, value) => i18n.t(key, value))
new Vue({
el: '#app',
i18n,
render: h => h(App),
})<template>
<div class="select-language">
<a @click="switchLanguage('language', 'zh')" href="javascript:;">中文</a>
<span> / </span>
<a @click="switchLanguage('language', 'en')" href="javascript:;">EN</a>
</div>
</template>
<script>
import { setLocalStorage, getLocalStorage } from '../common/storage'
export default {
name: 'nav-bar',
methods: {
switchLanguage(key, value) {
if (getLocalStorage(key) !== value) {
setLocalStorage(key, value)
location.reload();
}
},
},
}
</script><template>
<div class="left-bar">
<div class="page-title">{{ $t('leftbar.websocket') }}</div>
<div class="page-title">{{ $t('leftbar.api') }}</div>
<div class="page-title">{{ $t('leftbar.users') }}</div>
</div>
</template>公司原本打算再香港举办的区块链大会因为香港大规模的游行示威活动取消了,于是我们跟随公司去香港吃喝玩乐的计划就泡汤了。
活动改成在深圳举办了,而且规模小了很多,于是之前很多打算去的同事也取消了计划不去了。也因为活动规模小了很多导致会场安排不下,于是随行的同事就不用去会场了改成了自由行,公司提供报销交通和住宿,体验了一把高级酒店233(四星还是五星级酒店不记得了)。
这样的话我们当然更开心了233。

深证的天气也说变就变,一场暴雨立过后还没安静几分钟又下起了另一场暴雨,搞得我们有点猝不及防。
办理完入住手续后,马上五点了饿的不行了,去找家店吃饭。让我们纳闷的是,五点了很多餐馆居然还不营业???特别是有一家店,我们都要进去了,店员跟我们说他们还没开张,让我们去别家店里吃???
在我们这边这个点是吃饭高峰期呀,也没遇到过有生意不做的情况,就算你下午两三点去吃,人家照样很开心的招待你。
好不容易找到一家开门也愿意做生意的店,店里也还没一个客人。这一顿吃下来给我的感觉就是锅小、量小菜也少,没吃饱。我们七个人这么小一个锅怎么够吃,问店员有没有更大的锅,店员答:没有。

酒店在世界之窗附近,那世界之窗肯定是要逛逛的。这里主要就是一些世界各地的著名建筑的缩小版:






由于最近香港比较乱,所以本来是打算从深圳去澳门玩的,所以出发之前我只签注了澳门个人旅游签。但是到了以后他们都觉得从深圳去澳门太远了时间来不及,另外一个是深圳到香港的入港线路的班车啊各种通道都还没有关闭,说明应该影响不大,于是我们合计最终决定第二天还是出发去香港。
于是,就一个没加香港签注的人屁颠屁颠的跑去南山区出入境管理大厅加香港签注。不是本地户口只能加团队旅游签,不过也没关系,没啥影响。

回来后大家合计着买了车票,讨论好行程和一些注意事项。
第二天,我们分两批准时出发:

过边检大厅的时候有一个同事因为穿的白衣服,被警察拉到“小黑屋”里单独仔细检查了233。

很早之前就一直想来香港看看这个特殊的地方,港澳台通行证的签注都过期了还没去,这次来也算是圆了一个小心愿。
又热又潮湿,走路都顶不住的天气还有人踢球,我是服气的:



找个地方吃饭:



车牌、房价、云南菜:



香港地铁:



游行痕迹:



必不可少的购物:



维多利亚港、星光大道、突如其来的暴雨:



本来最后一站是要去铜锣湾寻找同年记忆中的“浩南哥”的,但是由于暴雨耽误了一段时间,等到我们再想出发的时候,香港的同事告诉我们今天游行的人群正在往我们所在的这个方向过来。
为了避开游行人群(正好时间也不早了),于是我们临时决定立马撤退回程。我们立马买了最近的一班回去的车票,然后以最快的速度乘坐地铁转移到另一个位置,然后去赶车。
期间地铁站人很多,有个女同事在排队等待进入地铁的过程中看到几个黑衣人(游行人员),直接就吓哭了。

返程过边境大厅的时候,两个穿黑衣服的同事被搜了233。翻包翻手机(看来网上的传闻是真的),还要求删除了一些敏感的照片(比如上面游行相关的照片)。

回来后看了下相关的新闻,才得知当天的游行规模是这么多年来最大的一次,170W人(香港总人口才700W)。看了一些视频,庆幸还好我们当时溜得快呀。
最后附一张朋友圈截图:

最近在看Webpack相关的一些东西,这是官网推荐的一篇文章,主要讲的是项目打包后关于错误追踪调试的实现原理,根据我的理解翻译了一下。
原文链接:http://blog.teamtreehouse.com/introduction-source-maps
我们都知道为网站进行性能优化最简单的一招就是合并和压缩项目的JavaScript和CSS代码。但是当你需要去调试这些压缩后的代码的时候会发生什么?这简直就是噩梦(因为浏览器只会将错误指向直接运行代码,所以就你很难在原文件中定位错误代码)。不过不用担心,现在已经有一个成熟的解决方案了,它就是source maps。
source maps提供了一种从压缩文件代码到原始文件代码位置的映射。这就意味着在一些软件的帮助下,你可以很容易的去调试你的应用程序即使是在你的代码已经被优化的情况下。Chrome和Firefox的开发者工具都内建支持source maps。
在这篇文章中,你将学习到source maps的工作原理并了解如何生成它们。我们将主要关注JavaScript代码的source maps,当然这些原理也同样适用于CSS的source maps。
顾名思义,一个source map是由一大堆可用于将压缩文件中的代码映射回源代码的信息组成。你可以为不同的压缩文件指定不同的source map。
你可以向优化后的文件底部添加一行特殊的注释来告诉浏览器source map可用:
//# sourceMappingURL=/path/to/script.js.map
该语句通常由生成source map的程序来自动添加。开发者工具只是在支持source maps并且开发者工具被打开时才加载此文件。
你还可以通过在压缩JavaScript文件的响应中发送X-SourceMap HTTP来指定source map可用:
X-SourceMap: /path/to/script.js.map
source map包含一个关于它自身和原始JavaScript文件信息的JSON对象。例如:
{
version: 3,
file: "script.js.map",
sources: [
"app.js",
"content.js",
"widget.js"
],
sourceRoot: "/",
names: ["slideUp", "slideDown", "save"],
mappings: "AAA0B,kBAAhBA,QAAOC,SACjBD,OAAOC,OAAO..."
}
让我们来看看这些字段分别表示什么:
version – 这个属性标识了source map的版本;file – source map文件名;sources – 包含该源文件URL的数组;sourceRoot – (可选)sources数组中源文件所在的目录;names – 一个包含源文件中所有变量和函数名的数组;mappings – 一串包含实际代码映射的Base64 VLQs字符串(这就是魔法发生的地方)。UglifyJS是一个受欢迎的能让你合并和压缩JavaScript文件的命令行程序。2.0版本支持了一些有助于生成source maps的参数:
--source-map – source map输出文件;--source-map-root – (可选)用于填充映射文件中的sourceRoot属性 ;--source-map-url – (可选)你服务器上source map的路径。这个将被放在优化后的文件的注释中使用 //# sourceMappingURL=/path/to/script.js.map--in-source-map – (可选)输入source map。如果你要压缩已经从其他地方的源文件生成JavaScript文件,这个会很有用。比如JavaScript库;--prefix or -p – (可选)删除sources属性中出现的n个目录。例如-p 3将从路径中删除前三个目录,于是one/two/three/file.js将变成file.js。使用-p relative就能让UglifyJS为你找出source map和源文件之间的相对路劲;这是一个使用示例:
uglifyjs [input files] -o script.min.js --source-map script.js.map --source-map-root http://example.com/js -c -m
还有一些其他的程序也同样支持生成source maps:

如果你的source maps配置正确,你应该在浏览器的Source下看到列出的每个原始JavaScript文件。
检查页面的HTML确认只引用了压缩后的JavaScript文件。开发者工具为你加载源映射文件,然后获取每个原始文件。

Firefox用户可以直接在开发者工具的Debugger下看到各个源文件。开发者工具再次确认source maps可用,然后获取每个引用的源文件。
如果你希望查看压缩版本,点击此窗口右上角齿轮状图标然后取消选择Show original sources。
使用source maps能让开发人员在兼顾网站性能的同时保持一个直接的代码调试环境。
你在本文中学习了source maps的工作原理并了解了如何使用UglifyJS生成它们。如果你曾通过压缩资源来优化网站(你确实应该这样做),那么你很值得花时间来将source maps整合到你的工作流当中。
| 算法(用于数组) | 时间复杂度 |
|---|---|
| 冒泡排序 | O(n^2) |
| 选择排序 | O(n^2) |
| 插入排序 | O(n^2) |
| 归并排序 | O(n * log(n)) |
| 快速排序 | O(n * log(n)) |
比较任何两个相邻的项,如果第一个比第二个大,则交换他们,最后得到一个升序数组。
function modifiedBubbleSort(array) {
const len = array.length;
for (let i=0; i<len; i++) {
for (let j=0; j<len-1-i; j++) {
if (array[j] > array[j+1]) {
[array[j], array[j+1]] = [array[j+1], array[j]];
}
}
}
return array;
}每次找出最小值,与最小索引进行交换,最终得到一个升序数组。
function selectionSort(array) {
const len = array.length;
let indexMin;
for (let i=0; i<len-1; i++) {
indexMin = i;
for (let j=i; j<len; j++) {
if (array[indexMin] > array[j]) {
indexMin = j;
}
}
if (i !== indexMin) {
[array[i], array[indexMin]] = [array[indexMin], array[i]];
}
}
return array;
}每次排一个数组项,以此方式构建最后的排序数组,默认第一项已经排序了。
function insertionSort(array) {
const len = array.length;
for (let i=1; i<len; i++) {
let j = i;
const tmp = array[i];
while (j>0 && array[j-1] > tmp) {
array[j] = array[j-1];
j--;
}
array[j] = tmp;
}
return array;
}首先将原始数组分割直至只有一个元素的子数组,然后开始归并。归并过程也会完成排序,直至原始数组完全合并并完成排序。
/* 排序并合并 */
function merge(left, right) {
const result = [];
while (left.length > 0 && right.length > 0) {
if (left[0] < right[0]) {
result.push(left.shift());
} else {
result.push(right.shift());
}
}
/* 当左右数组长度不等.将比较完后剩下的数组项链接起来即可 */
return result.concat(left).concat(right);
}
function mergeSort(array) {
if (array.length == 1) return array;
/* 首先将无序数组划分为两个数组 */
const mid = Math.floor(array.length / 2);
const left = array.slice(0, mid);
const right = array.slice(mid);
/* 递归分别对左右两部分数组进行排序合并 */
return merge(mergeSort(left), mergeSort(right));
}和归并排序一样,快速排序也使用分治的方法,将原始数组分为较小的数组(但它没有像归并排序那样将它们分割开)。
function quickSort(array){
//如果数组<=1,则直接返回
if (array.length <= 1) {
return array;
}
const pivotIndex = Math.floor(array.length / 2);
//找基准,并把基准从原数组删除
const pivot = array.splice(pivotIndex, 1)[0];
const left = [];
const right = [];
//比基准小的放在left,比基准大的放在right
for (let i=0; i<array.length; i++) {
if (array[i] <= pivot) {
left.push(array[i]);
} else {
right.push(array[i]);
}
}
//递归
return quickSort(left).concat([pivot],quickSort(right));
}这是我坚定不移的使用yarn替换npm的最大原因,只因一次对老项目的问题排查(说多了都是泪 😭 )。
一般使用如 npm install lodash 的时候package.json里面写入的是类似于 "lodash": "^2.4.0",默认项目的依赖包每次安装都取最新版,依赖包的更新避免不了的会对我们自己的项目造成巨大的影响,所以我们需要锁定版本。
当然,对此npm官方推出了 shrinkwrap 用来锁定你的依赖版本,你页可以在 package.json 中手动锁定版本(不使用 ^ 的宽泛版本管理),但是由于npm的安装包的层次结构,你对你项目所依赖的三方包的依赖没办法进行控制,任何一个三方包不严谨的版本依赖就可能破坏你的依赖管理。使用yarn这些问题就不复存在!


扁平化模式 — 对于不匹配的依赖版本的包创立一个独立的包,避免创建重复的包。
yarn 缓存了每次你下载的模块,所以同样模块同样的版本不会发送第二次下载请求,对于没有缓存的模块, yarn 也可以通过并行的网络请求最大限度利用网络资源。现在真的是没有什么几十秒安装不完的依赖的。一个 50 个依赖的 webpack + babel 项目可以在 20 秒左右安装完成。有人拿 lockfile 说事,这。。。去掉一个默认的特性还有什么好对比的,你可以参考官方对比 npm 的区别 Compare Yarn Performance
yarn 在开始安装一个包之前会先用 checksums 来验证,你不用担心本地的缓存的包被破坏了导致安装失败。FB开发、使用和维护,靠谱~
最近被一个同样做前端的好朋友问了一个关于几个前端比较流行的HTTP请求库的主要区别,于是发现了一篇好文章完美回答了这个问题,顺便产生了将这篇文章翻译成中文的想法。
原文链接:http://andrewhfarmer.com/ajax-libraries/
JavaScript中的网络分为两大类:AJAX(浏览器)和HTTP客户端(服务器)。
有时候你只需要它们之中的一种,有时候两者都需要(比如在同构/通用的应用程序中)。
不管怎样,你都会希望拥有简洁的语法来编写,大多数的开发者都发现XMLHttpRequest的API太冗长了。
很多开发者选择使用jQuery,但是如果你只用AJAX却引入了整个库,这似乎太浪费了。
我整理了一个列表来帮助你为你的项目选择一个最合适的JavaScript网络请求库。之后,我会举几个具体的场景来推荐相应库。

- Chrome & Firefox:单独列出这两个浏览器是因为它们支持fetch():caniuse.com/fetch
- Native:意思是原生支持,你可以直接使用而不需要为此引入一个库
- Single Purpose:意思是这个库或者这个技术仅仅用于AJAX/HTTP网络通信,没有其他功能
fetch()是一个新的标准。它已经在Chrome和Firefox中原生支持了,你完全不用引入任何库就能直接使用它了 —— 所有如果你的项目不需要考虑IE和Safari的话,我建议你马上就开始使用它。
如果你需要支持更多浏览器的话我推荐GitHub的Fetch polyfill.你可以使用这些新特性,等到浏览器原生支持了你再来删掉这些库;
如果你使用node.js的话你仍然可以使用Fetch,但是你需要node-fetch库;
如果你的代码是通用的,同样也有一个库可选:isomorphic-fetch,它包含了node-fetch和Fetch polyfill;
如果你已经使用jQuery,你只需要使用$.get或$.ajax即可。不必额外引入新的库,而且你还将很好的支持绝大多数的浏览器,如果使用Fetch polyfill的话反而造成你的项目不必要的负担。
这是JavaScript的典型 —— 我罗列出了解决同一个问题的11种方法,它包括了最流行的选择。
研究JavaScript库是很花费时间的 —— 需要大量的时间。这种事情让我来为你做就好了,我会第一时间告诉你适合你项目的最新最好的JavaScript库。
我,战狼PTSD患者。《流浪地球》电影的几个主演的尴尬演技实在太让我出戏了,于是就去找了原著看看。这一看可不得了,被刘的硬科幻想象力深深征服了,立马路转粉。陆续把《流浪地球》、《带上她的眼睛》、《乡村教师》以及《三体》三部曲看了一遍。

其中最令我震撼的就是《三体》,特别是后面两部。看完感慨万千呀,除了“牛逼”我也找不到什么更好的词语来形容(吃了没文化的亏)。因为科幻部分可以说的东西太多了,我就从每部主人公的爱情作为切入点,简单的理一理整部作品。

叶文洁,大学教授、天体物理学家、CTO(三体神教)统帅。第一个地球叛徒,人类毁灭的元凶。
叶文洁在**时期被诬陷遭受折磨,后被杨卫宁救出并进入红岸基地,而后两人结婚。在此期间,叶文洁首次进行了Ⅱ型文明能级的发射。
八年后,她收到了来自三体文明的警告:“不要回答!不要回答!不要回答!”可是她经历太多:**时期,她亲眼目睹了父亲被母亲出卖而被活活批斗至死;而自己也被人陷害,遭受凌辱。这时候的她已经对人类绝望了,也对这个世界绝望了,于是她回复到:“到这里来吧,我将帮助你们获得这个世界,我的文明已无力解决自己的问题,需要你们的力量来介入”。
后来她发现雷志成也收到了信息,于是为了保密设计杀害了雷志成。由于丈夫杨卫宁当时也一同下悬崖工作,所以也被她害死了。同一天,叶文洁被确诊怀孕。
感觉叶文洁这个人和丈夫其实是没有什么爱情的,她和杨卫宁的结合也是轻描淡写顺其自然的。似乎她只是想随便找个人组建家庭,而杨卫宁又正好是同行而且救过他。以至于最后丈夫死在她手里也没有多少难过和悲伤,这种人是真的可怕。
这个故事告诉我们:广大男同胞们找媳妇儿要多留意,经历过重度心里创伤的、对某件事物特别迷恋执着甚至可以用疯狂形容的,遇到这类型的女孩子你最好慎重考虑,否则你读不知道哪天会成为牺牲品。


罗辑,第四位面壁者、宇宙社会学创立者之一、初代执剑人。建立黑暗森林威慑,坚守执剑换来人类半个多世纪的和平时期。
罗辑的一生,充满了传奇色彩。他起初是一个玩世不恭的享乐派混子学者。而后因偶然得到叶文洁关于研究宇宙社会学的建议,被三体文明追杀,然后被选为面壁者。
起初的罗辑并不知道自己为什么莫名其妙会被选为救世主面壁者的,他也不想做什么救世主。但是没办法,这个身份摆脱不掉,而且拥有可以调动地球上任何资源的权利。于是,他想到了泡妞:他调用大批的人员去帮他找女神。
这是一个罗辑虚构出来的人,是一个不存在的人,是罗辑对最完美女性的幻想而创造出来的,是一个天使。而就是这样一位完美的虚构的天使,还真在现实中找着了你敢信,她只比“她”多了点淡淡忧伤,她就是庄颜。随后,两人坠入爱河,组建家庭,并在北欧某庄园度过了快乐的五年。
之后,他参透了黑暗森林法则,并建立了黑暗森林威慑,成为执剑人,开启威慑纪元,使人类迎来了62年的和平。在地球被三体人攻占后成为地球抵抗组织的精神领袖;黑暗森林打击来临,他默默成为地球文明的守墓人。
罗辑,本是一个登徒浪子,至于什么世界毁灭对他来说完全不关心,他只想享受当下,而庄颜就是那个塑造了他人格的人。从某种意义上来说,罗辑找到了生活的意义:他想让庄颜母子生活得更好。可以说他后面所做的一切,都只是为了这个目的。
作为一个咸鱼肥宅,看这部的时候简直不要太爽,因为自己和初期的罗辑很像,代入感贼强。而且后期的罗辑太传奇了,简直就是每个肥宅的梦想:拥有至高的权利;梦中女神追到手;拯救过地球,还差点拯救了全人类!
我也想要这样的生活!认真总结了一下:我和罗辑的距离就差一个庄颜了,嗯(严肃脸)!


程心,又称程圣母,航天发动机专业博士、阶梯计划提出者、二代执剑人。圣母婊,又一个人类毁灭的元凶。
程心在行星防御理事会战略情报局(PIA)提出了阶梯计划,需要把一颗人脑发送给三体探舰队。而此时,暗恋她多年的云天明因确诊为肺癌而准备安乐死。云天明死前唯一牵挂的就是大学相识的程心,于是他利用意外之财买了一个恒星 DX3906 匿名送给了程心。
就在安乐死被执行前一秒,被专程赶来的程心阻止了。程心说明了此次来的目的:希望云天明加入阶梯计划。日思夜想的女神,唯一牵挂的女神要自己的脑袋,他又怎能拒绝呢?于是云天明答应了。
人类发现 DX3906 是颗类地行星,于是被联合国回收,程心也因此成为二代执剑人。然而,心慈手软的程圣母早已被三体人看透,她不忍心进行黑暗森林威慑操作,最终地球被三体人占领。之后的很长一段时间吃了很多苦,直到发现万有引力号启动广播。
广播纪元,他们终于再次相见。这时候的程心已经经历了太多,她也知道了云天明为她所做的一切。这时候的她对云天明的感情已经发生了巨大的变化。云天明向程心讲述了三个童话故事,人类躲避黑暗森林打击的情报就隐藏于其中。
而后,程心阻止了星环公司对光速飞船的研究,人类最有希望的一个方案就此终结。在黑暗森林打击来临后,程心和艾AA作为幸存者来到 DX3906 恒星。就在程心即将于云天明重聚之时,她和关一帆落入了黑域。再次降落蓝星时,已然是一千万年以后,沧海桑田啊。此时的云天明已经死去,好在他和艾AA度过了幸福的一生,死前还送了个小宇宙给程心和关一帆......
程心和云天明的故事,就很像女神和舔狗剧,特别是前期。比大多数舔狗备胎强的是,云天明是宇宙大天狗,舔狗中的 NO.1。在后期女神注意也到了她,也因为种种重大是事件,女神慢慢对他有了感情,也能算得上是舔狗转正了吧。
这个故事告诉我们:圣母婊是真的害人不浅啊。但是话又说回来,绝大多数的舔狗的下场我们都是知道的,所以好自为之,老哥。

你可能已经注意到在项目结构中我们有两个静态资源目录:src/assets 和 static/,那么他们有什么区别呢?
为了回答这个问题,我们首先需要了解一下Webpack是如何处理静态资源的。在 *.vue 的组件中,所有的模板和CSS都由 vue-html-loader 和 css-loader 来解析并查找资源URL。例如,在 <img src="./logo.png"> 和 background: url(./logo.png) 中,"./logo.png" 是相对的资源路径,将由Webpack解析为模块依赖。
因为 ./logo.png 不是JavaScript,当被视为模块依赖时,我们就需要用 url-loader 和 file-loader 来处理它。此脚手架已经为你配置了这些loader,因此你基本上可以免费获得文件名指纹和base64条件内联功能,同时可以使用相对/模块路径而不必在部署的时候为此担忧。
由于这些资源在构建时能被内联/复制/重命名,所以它们本质上是你源码的一部分。这就是为什么建议将Webpack处理的静态资源放置在 /src 中和其他源文件放在一起的原因。实际上,你甚至不必将它们全部放在 /src/assets 中:你可以根据使用它们的模块/组件进行组织。例如,你可以在每个放置组件的目录中存放自己的静态资源。
./assets/logo.png 将被解析为模块依赖。它们将被基于Webpack输出配置的自动生成的URL替换。assets/logo.png 将被视为与相对URL相同并转换为 ./assets/logo.png。require('some-module/image.png')。如果想要使用Webpack的模块解析配置,则需要使用此前缀。例如,如果你有 assets 的解决别名,你需要使用 <img src="~assets/logo.png"> 来确保别名符合要求、/assets/logo.png 完全不处理。为了使Webpack返回正确的资源路径,你需要使用 require('./relative/path/to/file.jpg'),这将由 file-loader 处理并返回已解析的URL。例如:
computed: {
background () {
return require('./bgs/' + this.id + '.jpg')
}
}
注意上面的例子将包括最终构建的中的
./bgs/
下的每个图像。这是因为Webpack无法猜测其中哪些将在运行时被使用,所以它包括所有的。
相比之下,放在 static/ 目录下的文件并不会被Webpack处理:它们会直接被复制到最终目录(默认是 dist/static)下。你必须使用绝对路径来引用这些文件,这是通过在 config.js 文件中的 build.assetsPublicPath 和 build.assetsSubDirectory 连接来确定的。
例如,使用下面的默认值:
// config.js
module.exports = {
// ...
build: {
assetsPublicPath: '/',
assetsSubDirectory: 'static'
}
}
任何放在 static/ 中的文件需要以绝对路径的形式引用:/static/[filename]。如果更改 assetSubDirectory 的值为 assets,那么路径需改为 /assets/[filename]。
原文链接:http://vuejs-template.github.io/webpack/static.html (vue-cli 的 webpack 模板文档)

上大学的时候,刘老师就告诉我们一定要有个自己的博客,记录好自己的学习和进步的过程。博客不仅能记录并监督自己的学习,还能在将来的在面试的时候展示在自己的简历当中,是加分项。
于是跟实验室里众多小伙伴一样选择了在 CSDN 博客上开了一个账号,并在上面记流水账一样的写下了自己的一些解题代码和学习过程。
刚开始的时候写博客还是比较积极的,基本每天都至少有一篇产出。虽然都没啥营养:或是解题记录、或是碎碎念的流水账、或是学到的某个知识点...

一段时间后,周围有小伙伴开始有自己买域名,买服务器折腾自己的 WordPress 博客。一开始我不以为然,因为觉得太麻烦了,为了写个博文折腾这么一大圈太累了。
我又继续在 CSDN 上继续写了小半年左右,慢慢开始发现一些我不满意的地方:比如不能定制自己想要的样式,不能加入很多好玩的小插件... 最重要的一个是我发现它的广告越来越多,多到开始让我有点不能忍受了。
于是,我彻底放弃了 CSDN,从零开始,开始买域名、备案、学生认证买虚拟主机、搭建 WordPress 博客。之后开始了一些列的折腾:折腾服务器、折腾样式、插件、SEO、友链...
期间也因为种种原因重新部署了好几次,数据丢了不少,还好也没啥觉得重要的数据。虽然还是没啥营养,但是折腾的间隙偶尔还是会去记录一下这个过程,这让我乐在其中。

折腾一段时间的 WordPress 之后,我感觉累了,插件样式各种折腾了一大堆没多少用,一个真正吸引人的博客最主要的是内容,形式并不重要。我应该把时间花在如何写出一篇好文章上面,于是我又开始考虑博客迁移的问题了。
我发现有大佬直接在 GitHub Issue 上写文章,感觉这是个很不错的主意。简单的分析了下利弊:
于是,我又再一次抛弃之前的所有数据从零开始,愉快的开始了 GitHub Issue Blog 之旅。
为了解决上面的一些不足,我尝试过一些基于 GitHub Issue 的一些博客生成工具,比如:Mirror 就是其中很不错的一个,它很简洁我很喜欢。

v1.0.0 啦,非常想用它来造个轮子来看看手感如何。从6月份开始,感觉墙又双叒叕突然高了很多,原因大家自然都懂。很多飞机场关门跑路,搬瓦工ip被封了一大片,现在换ip也要钱了(坑)...
手里没有梯子可用了,干啥都不方便了。于是我打算暂时祭出吃灰多年的双十一买的阿里云香港服务器来顶一阵子度过难关。
奈何阿里云官方的系统里监控软件一大堆,不想受到警告邮件不想账户被封的话,还是老老实实重装一下纯净系统。
详情请看这里:https://moeclub.org/2018/04/03/603/?spm=88.9
- 不支持OpenVZ构架;
- 适用于由GRUB引导的CentOS,Ubuntu,Debian系统;
- 需要使用root权限;
- 全自动安装默认用户:root 密码:MoeClub.org;
- 重装需要20-40分钟不等的时间,期间无法连接服务器,请耐心等待。
#Debian/Ubuntu:
apt-get update
apt-get install -y xz-utils openssl gawk file
#RedHat/CentOS:
yum update
yum install -y xz openssl gawk file#默认安装64位的debian8,其他版本请查阅配置详情
bash <(wget --no-check-certificate -qO- 'https://moeclub.org/attachment/LinuxShell/InstallNET.sh') -d 8 -v 64 -a详情请看这里: https://flyzyblog.com/install-ss-ssr-bbr-in-one-command/
#Debian/Ubuntu:
apt-get update
apt-get install -y git
#RedHat/CentOS:
yum update
yum install -y gitgit clone -b master https://github.com/flyzy2005/ss-fly#passwd为密码 443为端口号
ss-fly/ss-fly.sh -i passwd 443注意:这里用到的端口需要在阿里云服务器实例中的[更多]-> [网络和安全组]中进行配置,否则将出现ss服务无法使用的情况。
#修改配置文件:
vim /etc/shadowsocks.json
#停止ss服务:
ssserver -c /etc/shadowsocks.json -d stop
#启动ss服务:
ssserver -c /etc/shadowsocks.json -d start
#重启ss服务:
ssserver -c /etc/shadowsocks.json -d restart
#卸载ss服务:
ss-fly/ss-fly.sh -uninstallBBR是Google开源的一套内核加速算法,可以让你搭建的shadowsocks/shadowsocksR速度上一个台阶。
ss-fly/ss-fly.sh -bbr
#如果以下命令返回值中含有bbr则说明已经开启成功
sysctl net.ipv4.tcp_available_congestion_control

componentWillMount()在初始化渲染之前(render之前)执行,并且永远只会执行一次;
如果在这里定义了setState方法之后,页面永远都只会在加载前更新一次。
componentDidMount()在组件挂载完成后立即执行,这时候组件已经生成了对应的DOM结构,可以通过this.getDOMNode()来进行访问;
如果想和其它 JavaScript 框架集成,使用 setTimeout 或者 setInterval 来设置定时器,或者发送 AJAX 请求,可以在该方法中执行这些操作。
componentWillReceiveProps(object nextProps)在组件接收到新的props的时候调用;
在初始化渲染(render)的时候,该方法不会调用;
用此函数可以作为 react 在 prop 传入之后, render() 渲染之前更新 state 的机会;
旧的props可以使用this.props来获取;
在该函数中调用 this.setState() 将不会引起第二次渲染。
boolean shouldComponentUpdate(object nextProps, object nextState)在接收到新的props或者state,将要渲染之前调用。
该方法在初始化渲染的时候不会调用,在使用forceUpdate方法的时候也不会。
该方法默认返回true,在没有必要重新渲染的情况下可以设置成false,优化组件性能的关键。
componentWillUpdate(object nextProps, object nextState)在组件接收到新的props或者state,render之前被执行,但是初始化渲染的时候不会被调用。
componentDidUpdate(object prevProps, object prevState)组件更新完成到DOM后立即执行,但在初始化渲染时不执行。
componentWillUnmount()在组件从DOM中移除时立即执行;
在该方法中可以执行一些必要的清理,如无效的定时器、或者清除在 componentDidMount 中创建的 DOM 元素。
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.