ttaoretw / tacotron-pytorch Goto Github PK
View Code? Open in Web Editor NEWA Pytorch Implementation of Tacotron: End-to-end Text-to-speech Deep-Learning Model
License: MIT License
A Pytorch Implementation of Tacotron: End-to-end Text-to-speech Deep-Learning Model
License: MIT License








































































































Exactly what the title says - how do I use the pretrained model?
Hello!
I'm trying training my spanish voice, but i have problems with especials characters (for example: ñ)
But i try my own wavs files and metadata without any special character but i have the same problem, when i strart training (main.py) i have this error:
[INFO] Load data
[INFO] Build model
Traceback (most recent call last):
File "main.py", line 36, in
solver.build_model()
File "/content/Tacotron-pytorch/src/solver.py", line 80, in build_model
self.model = Tacotron(**self.config['model']['tacotron']).to(device=self.device)
File "/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py", line 386, in to
return self._apply(convert)
File "/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py", line 193, in _apply
module._apply(fn)
File "/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py", line 193, in _apply
module._apply(fn)
File "/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py", line 193, in _apply
module._apply(fn)
File "/usr/local/lib/python3.6/dist-packages/torch/nn/modules/rnn.py", line 127, in _apply
self.flatten_parameters()
File "/usr/local/lib/python3.6/dist-packages/torch/nn/modules/rnn.py", line 123, in flatten_parameters
self.batch_first, bool(self.bidirectional))
RuntimeError: cuDNN error: CUDNN_STATUS_EXECUTION_FAILED
I'm using default config:
tacotron:
n_vocab: 250 # Use a larger vocab size is ok.
embedding_size: 256
mel_size: 80
linear_size: 1025
r: 5
The self.device it's correct because with LJSpeech work fine.
Have you any idea about this error?
Thanks man!
PD: excellents result with LJSpeech
def txt2seq(txt):
txt = ''.join([t for t in txt if t in _characters])
txt = english_cleaners(txt) + _eos
seq = [symbol2id[s] for s in txt]
return seq
I guess 'english_cleaners' function should be called ahead because first line erases numbers.
Hello!
Have you think about developper a code for export this model to coffee2 or anything for use in app android?
Thanks!
Hello!
I see that you don't save the .pth if linear_loss is bigger than the rest of steeps. I think is good idea but i use the google colab (TeslaGPU) for training and i only have sessions of 12hours.
When i use --checkpoint-path i can see that the best-linear-loss start in 1e10 and i created new param for load last best-linear-loss, you can see:
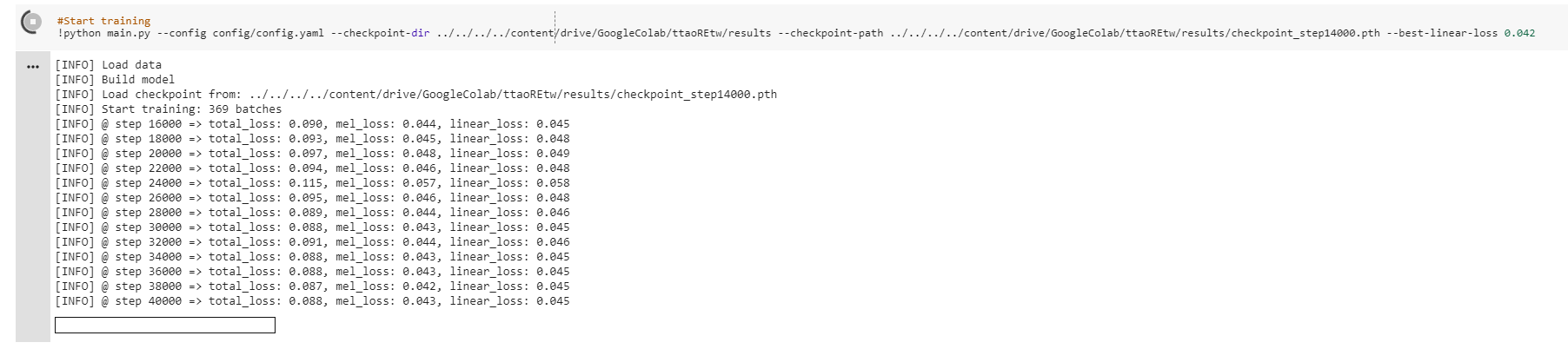
is normal in step 16K linear_loss: 0.042?
My problem is that i can't give less than 0.042 in 12 hours and i don't know if is good save step 40K even though the linear_loss is bigger?
Thanks for your help!
Good code!
I have a model with 100k in spanish and work ok.
Need make any change in config for continue this .pth with news wavs for make other people voice?
thanks!
模型的输入是 Word Embedding 还是 Character Embedding ? 。 “TACOTRON: TOWARDS END-TO-END SPEECH SYN- THESIS” 论文里面输入的 Character Embedding 。 我大概看了一下代码好像找不到关于Character Embedding 的部分
Hi tao,
Thank you for your effort to code the Tacotron. I would like to ask why do we get different results in tmp/results and eval/results even if we use the same sentences for eval ?
The train results in tmp sounds very good, but in eval, it sounds like it doesn't work. Shouldn't it be the same if we use same sentences ?
Thanks in advance
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.