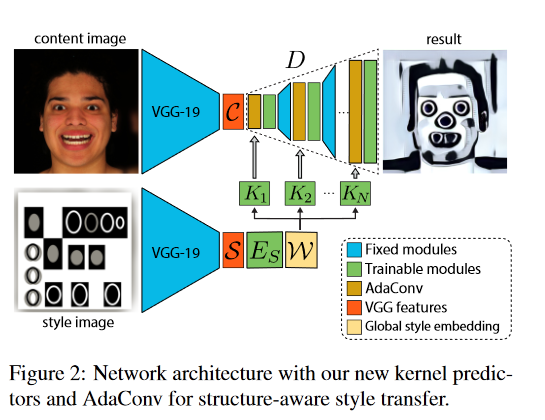
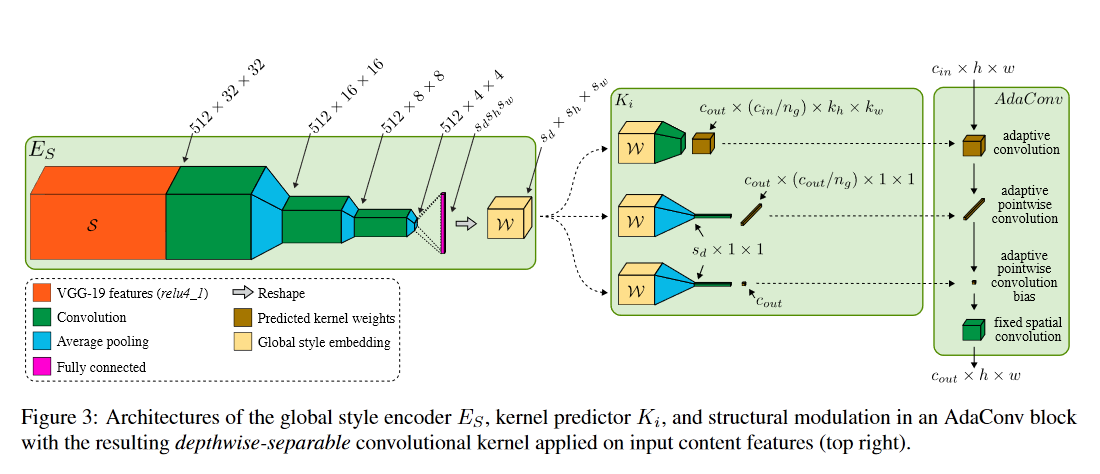
Unofficial PyTorch implementation of the Adaptive Convolution architecture for image style transfer from "Adaptive Convolutions for Structure-Aware Style Transfer". I tried to be as faithful as possible to the what the paper explains of the model, but not every training detail was in the paper so I had to make some choices regarding that. If something was unclear I tried to do what AdaIn does instead. Results are at the bottom of this page.
Direct link to the adaconv module.
Direct link to the kernel predictor module.
The parameters in the commands below are the default parameters and can thus be omitted unless you want to use different options. Check the help option (-h or --help) for more information about all parameters. To train a new model:
python train.py --content ./data/MSCOCO/train2017 --style ./data/WikiArt/trainTo resume training from a checkpoint (.ckpt files are saved in the log directory):
python train.py --checkpoint <path-to-ckpt-file>To apply the model on a single style-content pair:
python stylize.py --content ./content.png --style ./style.png --output ./output.png --model ./model.ckptTo apply the model on every style-content combination in a folder and create a table of outputs:
python test.py --content-dir ./test_images/content --style-dir ./test_images/style --output-dir ./test_images/output --model ./model.ckptPretrained weights can be downloaded here. Move model.ckpt to the root directory of this project and run stylize.py or test.py. You can finetune the model further by loading it as a checkpoint and increasing the number of iterations. To train for an additional 40k (200k - 160k) iterations:
python train.py --checkpoint ./model.ckpt --iterations 200000The model is trained with the MS COCO train2017 dataset for content images and the WikiArt train dataset for style images. By default the content images should be placed in ./data/MSCOCO/train2017 and the style images in ./data/WikiArt/train. You can change these directories by passing arguments when running the script. The test style and content images in the ./test_images folder are taken from the official AdaIn repository.
Judging from the results I'm not convinced everything is as the original authors did, but without an official repository it's hard to compare implementations. Results after training 160k iterations:

Comparison with reported results in the paper: