Perception and expression of emotion are key factors to the success of dialogue systems or conversational agents. However, this problem has not been studied in large-scale conversation generation so far. In this paper, we propose Emotional Chatting Machine (ECM) that can generate appropriate responses not only in content (relevant and grammatical) but also in emotion (emotionally consistent). The overview of ECM is shown in Figure 1.
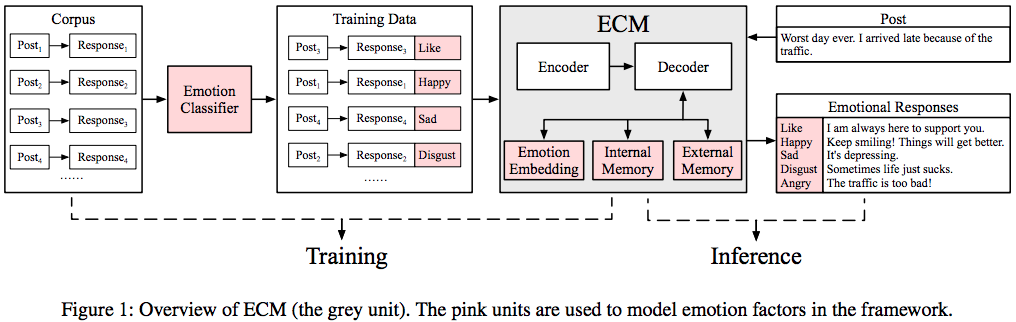
This project is a tensorflow implement of our work, ECM.
- Python 2.7
- Numpy
- Tensorflow 0.12
- Dataset
Due to the copyright of the STC dataset, you can ask Lifeng Shang ([email protected]) for the STC dataset (Neural Responding Machine for Short-Text Conversation), and build the ESTC dataset follow the instruction in the Data Preparation Section of our paper, ECM.
The basic format of the sample data is:
[[[post, emotion tag1, emotion tag2], [[response1, emotion tag1, emotion tag2], [response2, emotion tag1, emotion tag2], ...], ...]
where emotion tag1 is generated by neural network classifier which is used in our model, and emotion tag2 is generated by rule-based classifier which is not used.
The basic format of the ememory file used in our model is:
[[word1_of_emotion1, word2_of_emotion1,…], [word1_of_emotion2, word2_of_emotion2, …], …]
which is built according to the vocabulary and the emotion dictionary.
For your convenience, we also recommand you implement your model using the NLPCC2017 dataset, which has more than 1 million Weibo post-response pairs with emotional labels.
-
Train
python baseline.py --use_emb --use_imemory --use_ememory
You can remove "--use_emb", "--use_imemory", "--use_ememory" to remove the embedding, internal memory, and external memory module respectively. The model will achieve the expected performance after 20 epochs.
-
Test
python baseline.py --use_emb --use_imemory --use_ememory --decode
You can test and apply the ecm model using this command. Note: the input words should be splitted by ' ', for example, '我 很 喜欢 你 !', or you can add the chinese text segmentation module in split() function.
You can change the model parameters using:
--size xxx the hidden size of each layer
--num_layers xxx the number of RNN layers
--batch_size xxx batch size to use during training
--steps_per_checkpoint xxx steps to save and evaluate the model
--train_dir xxx training directory
--use_emb xxx whether to use the embedding module
--use_imemory xxx whether to use the internal memory module
--use_ememory xxx whether to use the external memory module
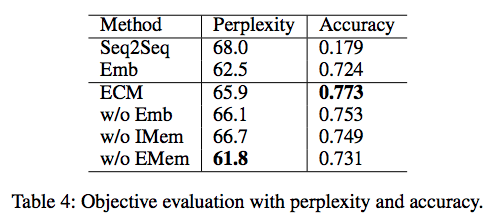
The automatic evaluation is shown as:
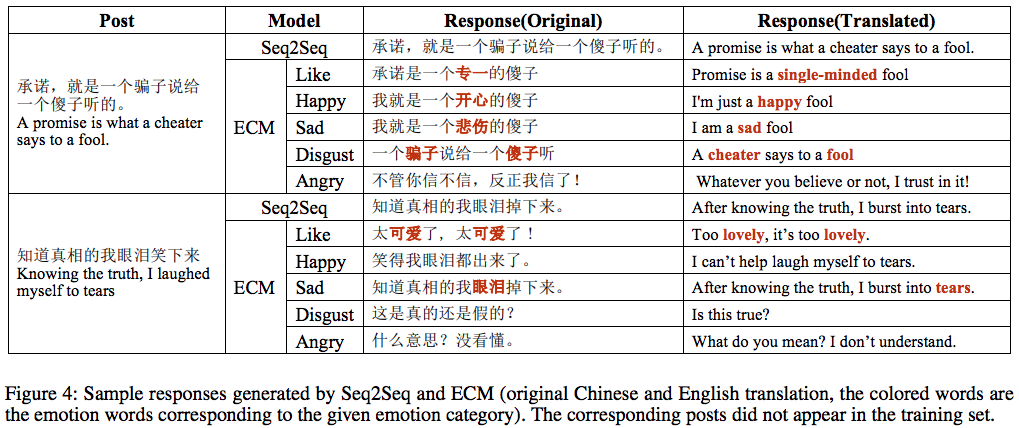
The sample responses generated by Seq2Seq and ECM is shown as:
Hao Zhou, Minlie Huang, Tianyang Zhang, Xiaoyan Zhu, Bing Liu.
Emotional Chatting Machine: Emotional Conversation Generation with Internal and External Memory.
AAAI 2018, New Orleans, Louisiana, USA.
Please kindly cite our paper if this paper and the code are helpful.
Thanks for the kind help of Prof. Minlie Huang and Prof. Xiaoyan Zhu. Thanks for the support of my teammates.
Apache License 2.0















































































































