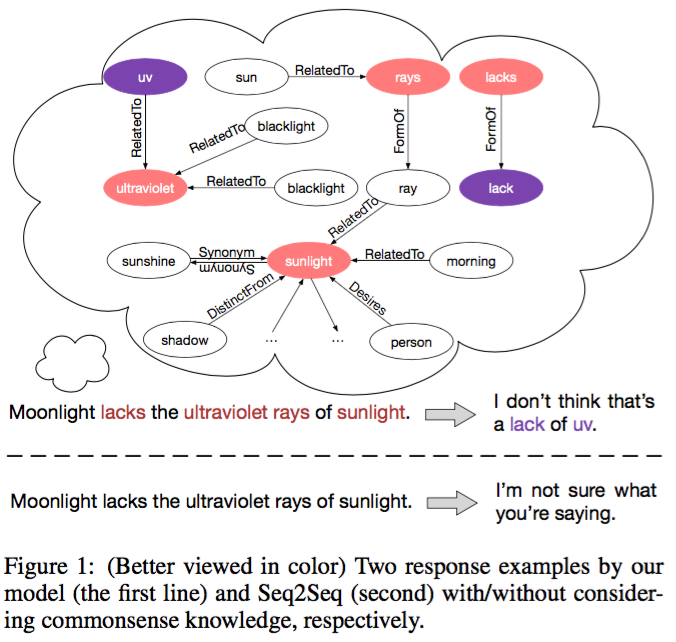
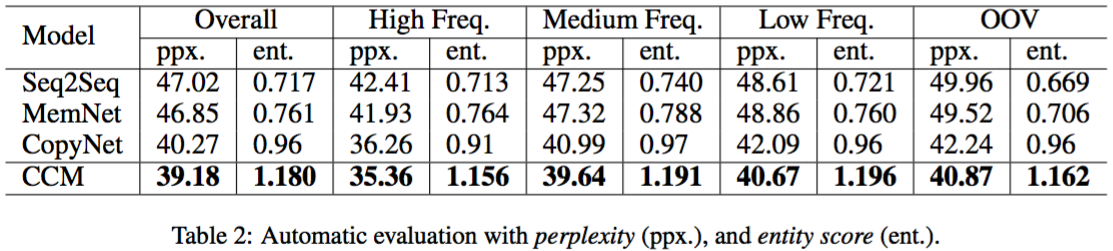
Not the author but I'm working on extending this paper for my master's thesis so I've done some work to decode the input data and be able to recreate it so I think I can provide some insight.
Match_triples are the triples where an entity from the post and an entity from the response appear in the same commonsense knowledge triple.
Match_index is the list of response entities matched with post entities in the following format: the first index is the number of the entity in post_triples that matches the current word (the list is the length of the response), the second index is the index of the entity that matches in all_entities. [-1,-1] is appended if the response word is not an entity or the entity doesn't match anything in the post.
Post_triples is a list of the entities that appear in the post, with 0 representing an entity is not found in the list of entities and >0 indicating an index of entities starting with 1 and incrementing each time a new entity is found.
all_entities is a list of all the matching entities on the other end of a csk triple for the entities found in the post.
response_triples is either -1 if a word is not an entity or the entity doesn't match a triple in csk or the index of the matched triple where the current word is an entity and that entity is part of a triple in both the post and response.
all_triples is simply a list of all the matched triples between the post and response entities.
Below is the script I've written to recreate the training data. It seems to output extra entities in all_entities for some reason, at least more than what the authors found but that shouldn't break anything I think. If you find a bug in the script please let me know so I can update it on my end.
import json
test = {"post": ["you", "mean", "the", "occupation", "that", "did", "happen", "?"], "response": ["no", "i", "mean", "the", "fighting", "invasion", "that", "the", "military", "made", "so", "many", "purple", "hearts", "for", "in", "anticipation", "for", "that", "we", "have", "n't", "used", "up", "to", "this", "day", "."]}
f = open('resource.txt')
data = json.load(f)
f.close()
data['postEntityToCSKTripleIndex'] = {}
data['postEntityToOtherCSKTripleEntities'] = {}
index = 0
for triple in data['csk_triples']:
firstEntity = triple.split(',')[0]
secondEntity = triple.split(',')[2].strip()
if(not firstEntity in data['postEntityToCSKTripleIndex']):
data['postEntityToCSKTripleIndex'][firstEntity] = []
data['postEntityToCSKTripleIndex'][firstEntity].append(index)
if(not secondEntity in data['postEntityToCSKTripleIndex']):
data['postEntityToCSKTripleIndex'][secondEntity] = []
data['postEntityToCSKTripleIndex'][secondEntity].append(index)
if (not firstEntity in data['postEntityToOtherCSKTripleEntities']):
data['postEntityToOtherCSKTripleEntities'][firstEntity] = []
data['postEntityToOtherCSKTripleEntities'][firstEntity].append(data['dict_csk_entities'][secondEntity])
if (not secondEntity in data['postEntityToOtherCSKTripleEntities']):
data['postEntityToOtherCSKTripleEntities'][secondEntity] = []
data['postEntityToOtherCSKTripleEntities'][secondEntity].append(data['dict_csk_entities'][firstEntity])
index += 1
data['indexToCSKTriple'] = {v: k for k,v in data['dict_csk_triples'].items()}
post_triples = []
all_triples = []
all_entities = []
post = test['post']
index = 0
for word in post:
try:
entityIndex = data['dict_csk_entities'][word]
index += 1
post_triples.append(index)
all_triples.append(data['postEntityToCSKTripleIndex'][word])
all_entities.append(data['postEntityToOtherCSKTripleEntities'][word])
except:
post_triples.append(0)
test['post_triples'] = post_triples
test['all_triples'] = all_triples
test['all_entities'] = all_entities
response_triples = []
match_index = []
match_triples = []
for word in test['response']:
try:
found = False
entityIndex = data['dict_csk_entities'][word]
for index,entitiesList in enumerate(test['all_entities']):
for subindex,entity in enumerate(entitiesList):
if(entity == entityIndex):
match_index.append([index+1,subindex])
response_triples.append(test['all_triples'][index][subindex])
match_triples.append(test['all_triples'][index][subindex])
found = True
break
if not found:
response_triples.append(-1)
match_index.append([-1,-1])
except:
response_triples.append(-1)
match_index.append([-1,-1])
test['response_triples'] = response_triples
test['match_index'] = match_index
test['match_triples'] = match_triples
print(str(test))Originally posted by @andrewtackett in https://github.com/tuxchow/ccm/issues/3#issuecomment-461907771