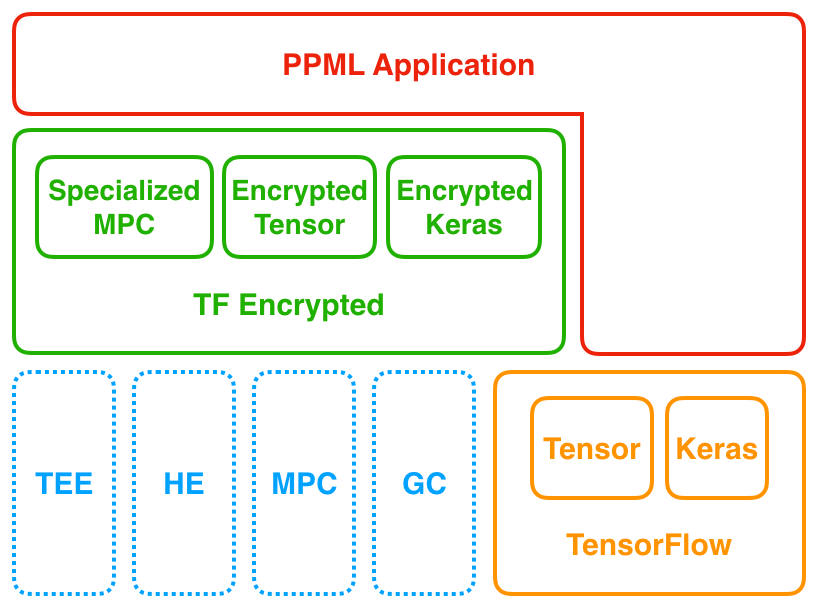
TF Encrypted is a framework for encrypted machine learning in TensorFlow. It looks and feels like TensorFlow, taking advantage of the ease-of-use of the Keras API while enabling training and prediction over encrypted data via secure multi-party computation and homomorphic encryption. TF Encrypted aims to make privacy-preserving machine learning readily available, without requiring expertise in cryptography, distributed systems, or high performance computing.
See below for more background material, explore the examples, or visit the documentation to learn more about how to use the library.



TF1 execute computation by building a graph first, then run this graph in a session.
This is hard to use for a lot of developers, especially for researchers not major in computer science.
Therefore, TF1 has very few users and is not maintained any more.
Since TF Encrypted based on TF1, it face the same problem that TF1 has encountered.
So we update TF Encrypted, to rely on TF2 to support eager execution which makes development on TF Encrypted more easier.
At the same time, it also supports building graph implicitly by tfe.function to realize nearly the same performance as TF Encrypted based on TF1.
Unfortunately, after updated, TF1 features like session and placeholder are not supported by TFE any more.
For those developers who want to use TF1 like TFE, we suggest them to use version 0.8.0.
TF Encrypted is available as a package on PyPI supporting Python 3.8+ and TensorFlow 2.9.1+:
pip install tf-encryptedCreating a conda environment to run TF Encrypted code can be done using:
conda create -n tfe python=3.8
conda activate tfe
conda install tensorflow notebook
pip install tf-encrypted
Alternatively, installing from source can be done using:
git clone https://github.com/tf-encrypted/tf-encrypted.git
cd tf-encrypted
pip install -e .
make buildThis latter is useful on platforms for which the pip package has not yet been compiled but is also needed for development. Note that this will get you a working basic installation, yet a few more steps are required to match the performance and security of the version shipped in the pip package, see the installation instructions.
The following is an example of simple matmul on encrypted data using TF Encrypted based on TF2,
you could execute matmul in eager mode or building a graph by @tfe.function.
import tensorflow as tf
import tf_encrypted as tfe
@tfe.local_computation('input-provider')
def provide_input():
# normal TensorFlow operations can be run locally
# as part of defining a private input, in this
# case on the machine of the input provider
return tf.ones(shape=(5, 10))
# provide inputs
w = tfe.define_private_variable(tf.ones(shape=(10,10)))
x = provide_input()
# eager execution
y = tfe.matmul(x, w)
res = y.reveal().to_native()
# build graph and run graph
@tfe.function
def matmul_func(x, w)
y = tfe.matmul(x, w)
return y.reveal().to_native()
res = matmul_func(x, w)For more information, check out the documentation or the examples.
All tests are performed by using the ABY3 protocol among 3 machines, each with 4 cores (Intel Xeon Platinum 8369B CPU @ 2.70GHz), Ubuntu 18.04 (64bit), TensorFlow 2.9.1, Python 3.8.13 and pip 21.1.2. The LAN environment has a bandwidth of 40 Gbps and a RTT of 0.02 ms, and the WAN environment has a bandwidth of 352 Mbps and a RTT of 40 ms.
You can find source code of the following benchmarks in ./examples/benchmark/ and corresponding guidelines of how to reproduce them.
Graph building is a one-time cost, while LAN or WAN timings are average running time across multiple runs. For example, it takes 152.5 seconds to build the graph for Resnet50 model, and afterwards, it only takes 19.1 seconds to predict each image.
| Build graph (seconds) |
LAN (seconds) |
WAN (seconds) |
|
|---|---|---|---|
| Sort/Max (2^10)1 | 5.26 | 0.14 | 10.37 |
| Sort/Max (2^16)1 | 14.06 | 7.37 | 41.97 |
| Max (2^10 |
5.63 | 0.01 | 0.55 |
| Max (2^16 |
5.81 | 0.29 | 1.14 |
1 Max is implemented by using a sorting network, hence its performance is essentially the same as Sort. Sorting network can be efficiently constructed as a TF graph. The traditional way of computing Max by using a binary comparison tree does not work well in a TF graph, because the graph becomes huge when the number of elements is large.
2 This means 2^10 (respectively, 2^16) invocations of max on 4 elements, which is essentially a MaxPool with pool size of 2 x 2.
We show the strength of TFE by loading big TF models (e.g. RESNET50) and run private inference on top of it.
| Build graph |
LAN |
WAN |
|
|---|---|---|---|
| VGG19 inference time (seconds) | 105.18 | 49.63 | 139.63 |
| RESNET50 inference time (seconds) | 150.47 | 19.071 | 84.29 |
| DENSENET121 inference time (seconds) | 344.55 | 33.53 | 151.43 |
1 This is currently one of the fastest implementation of secure RESNET50 inference (three-party). Comparable with CryptGPU , SecureQ8, and faster than CryptFLOW.
We benchmark the performance of training several neural network models on the MNIST dataset (60k training images, 10k test images, and batch size is 128).
The definitions of these models can be found in examples/models.
| Accuracy (epochs) | Accuracy (epochs) | Seconds per Batch (LAN) | Seconds per Batch (LAN) | Seconds per Batch (WAN) | Seconds per Batch (WAN) | |
|---|---|---|---|---|---|---|
| MP-SPDZ | TFE | MP-SPDZ | TFE | MP-SPDZ | TFE | |
| A (SGD) | 96.7% (5) | 96.5% (5) | 0.098 | 0.167 | 9.724 | 4.510 |
| A (AMSgrad) | 97.8% (5) | 97.4% (5) | 0.228 | 0.717 | 21.038 | 15.472 |
| A (Adam ) | 97.4% (5) | 97.4% (5) | 0.221 | 0.535 | 50.963 | 15.153 |
| B (SGD) | 97.5% (5) | 98.6% (5) | 0.571 | 5.332 | 60.755 | 18.656 |
| B (AMSgrad) | 98.6% (5) | 98.7% (5) | 0.680 | 5.722 | 71.983 | 21.647 |
| B (Adam) | 98.8% (5) | 98.8% (5) | 0.772 | 5.733 | 98.108 | 21.130 |
| C (SGD) | 98.5% (5) | 98.7% (5) | 1.175 | 8.198 | 91.341 | 27.102 |
| C (AMSgrad) | 98.9% (5) | 98.9% (5) | 1.568 | 10.053 | 119.271 | 66.357 |
| C (Adam) | 99.0% (5) | 99.1% (5) | 2.825 | 9.893 | 195.013 | 65.320 |
| D (SGD) | 97.6% (5) | 97.1% (5) | 0.134 | 0.439 | 15.083 | 5.465 |
| D (AMSgrad) | 98.4% (5) | 97.4% (5) | 0.228 | 0.900 | 26.099 | 14.693 |
| D (Adam) | 98.2% (5) | 97.6% (5) | 0.293 | 0.710 | 54.404 | 14.515 |
We also give the performance of training a logistic regression model in the following table. This model is trained to classify two classes: small digits (0-4) vs large digits (5-9). Dataset can be found in examples/benchmark/training/lr_mnist_dataset.py
| Accuracy (epochs) | Seconds per Batch (LAN) | Seconds per Batch (WAN) | |
|---|---|---|---|
| LR (SGD) | 84.8% (5) | 0.010 | 0.844 |
| LR (AMSgrad) | 85.0% (5) | 0.023 | 1.430 |
| LR (Adam) | 85.2% (5) | 0.019 | 1.296 |
-
High-level APIs for combining privacy and machine learning. So far TF Encrypted is focused on its low-level interface but it's time to figure out what it means for interfaces such as Keras when privacy enters the picture.
-
Tighter integration with TensorFlow. This includes aligning with the upcoming TensorFlow 2.0 as well as figuring out how TF Encrypted can work closely together with related projects such as TF Privacy and TF Federated.
-
Support for third party libraries. While TF Encrypted has its own implementations of secure computation, there are other excellent libraries out there for both secure computation and homomorphic encryption. We want to bring these on board and provide a bridge from TensorFlow.
Blog posts:
-
Introducing TF Encrypted walks through a simple example showing two data owners jointly training a logistic regression model using TF Encrypted on a vertically split dataset (by Alibaba Gemini Lab)
-
Federated Learning with Secure Aggregation in TensorFlow demonstrates using TF Encrypted for secure aggregation of federated learning in pure TensorFlow (by Justin Patriquin at Cape Privacy)
-
Encrypted Deep Learning Training and Predictions with TF Encrypted Keras introduces and illustrates first parts of our encrypted Keras interface (by Yann Dupis at Cape Privacy)
-
Growing TF Encrypted outlines the roadmap and motivates TF Encrypted as a community project (by Morten Dahl)
-
Experimenting with TF Encrypted walks through a simple example of turning an existing TensorFlow prediction model private (by Morten Dahl and Jason Mancuso at Cape Privacy)
-
Secure Computations as Dataflow Programs describes the initial motivation and implementation (by Morten Dahl)
Papers:
-
Privacy-Preserving Collaborative Machine Learning on Genomic Data using TensorFlow outlines the iDASH'19 winning solution built on TF Encrypted (by Cheng Hong, et al.)
-
Crypto-Oriented Neural Architecture Design uses TF Encrypted to benchmark ML optimizations made to better support the encrypted domain (by Avital Shafran, Gil Segev, Shmuel Peleg, and Yedid Hoshen)
-
Private Machine Learning in TensorFlow using Secure Computation further elaborates on the benefits of the approach, outlines the adaptation of a secure computation protocol, and reports on concrete performance numbers (by Morten Dahl, Jason Mancuso, Yann Dupis, et al.)
Presentations:
-
Privacy-Preserving Machine Learning with TensorFlow, TF World 2019 (by Jason Mancuso and Yann Dupis at Cape Privacy); see also the slides
-
Privacy-Preserving Machine Learning in TensorFlow with TF Encrypted, O'Reilly AI 2019 (by Morten Dahl at Cape Privacy); see also the slides
Other:
-
Privacy Preserving Deep Learning – PySyft Versus TF Encrypted makes a quick comparison between PySyft and TF Encrypted, correctly hitting on our goal of being the encryption backend in PySyft for TensorFlow (by Exxact)
-
Bridging Microsoft SEAL into TensorFlow takes a first step towards integrating the Microsoft SEAL homomorphic encryption library and some of the technical challenges involved (by Justin Patriquin at Cape Privacy)
TF Encrypted is open source community project developed under the Apache 2 license and maintained by a set of core developers. We welcome contributions from all individuals and organizations, with further information available in our contribution guide. We invite any organizations interested in partnering with us to reach out via email.
Don't hesitate to send a pull request, open an issue, or ask for help! We use ZenHub to plan and track GitHub issues and pull requests.
We appreciate the efforts of all contributors that have helped make TF Encrypted what it is! Below is a small selection of these, generated by sourcerer.io from most recent stats:








We are very grateful for the significant contributions made by the following organizations!
TF Encrypted is experimental software not currently intended for use in production environments. The focus is on building the underlying primitives and techniques, with some practical security issues postponed for a later stage. However, care is taken to ensure that none of these represent fundamental issues that cannot be fixed as needed.
- Elements of TensorFlow's networking subsystem does not appear to be sufficiently hardened against malicious users. Proxies or other means of access filtering may be sufficient to mitigate this.
Please open an issue, or send an email to [email protected].
Licensed under Apache License, Version 2.0 (see LICENSE or http://www.apache.org/licenses/LICENSE-2.0). Copyright as specified in NOTICE.




![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")

































































































































































