- 写一些自己想写的代码
- 做一些自己想做的需求
- ❤️ ❤️
stack-wuh / blog Goto Github PK
View Code? Open in Web Editor NEW接入vitepress, 做碎片化的知识管理,记录一些日常遇到的问题和解决方案,有时间就写一写前端范围的研究文档
Home Page: https://stack-wuh.github.io/blog/
接入vitepress, 做碎片化的知识管理,记录一些日常遇到的问题和解决方案,有时间就写一写前端范围的研究文档
Home Page: https://stack-wuh.github.io/blog/




curl -O https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-3.0.6.tgz # 下载
tar -zxvf mongodb-linux-x86_64-3.0.6.tgz # 解压
mv mongodb-linux-x86_64-3.0.6/ /usr/local/mongodb 在远程服务器,准备mongo需要的几个文件和文件夹
cd /
mkdir mongo
cd mongo
mkdir data
mkdir log
cd data && mkdir db # 数据库
cd log
vi mongob.log # 日志文件
vi mongo.cfg # mongodb的配置文件cd /mongo/bin/
mongo --config '/mongo/mongod.cfg'以我自己的服务器配置为例,在**/lib/systemd/system/** 目录下新建 mongodb.service文件,内容如下
[Unit]
Description=mongodb
After=network.target remote-fs.target nss-lookup.target
[Service]
Type=forking
ExecStart=/mongo/mongodb/bin/mongod --config /mongo/mongodb/bin/mongodb.conf
ExecReload=/bin/kill -s HUP $MAINPID
ExecStop=/mongo/mongodb/bin/mongod --shutdown --config /mongo/mongodb/bin/mongodb.conf
PrivateTmp=true
[Install]
WantedBy=multi-user.target 使用:
systemctl start mongodb.service # 开启mongodb服务
systemctl reload mongodb.service # 重启mongodb服务
systemctl stop mongodb.service # 停止mongodb服务如图:
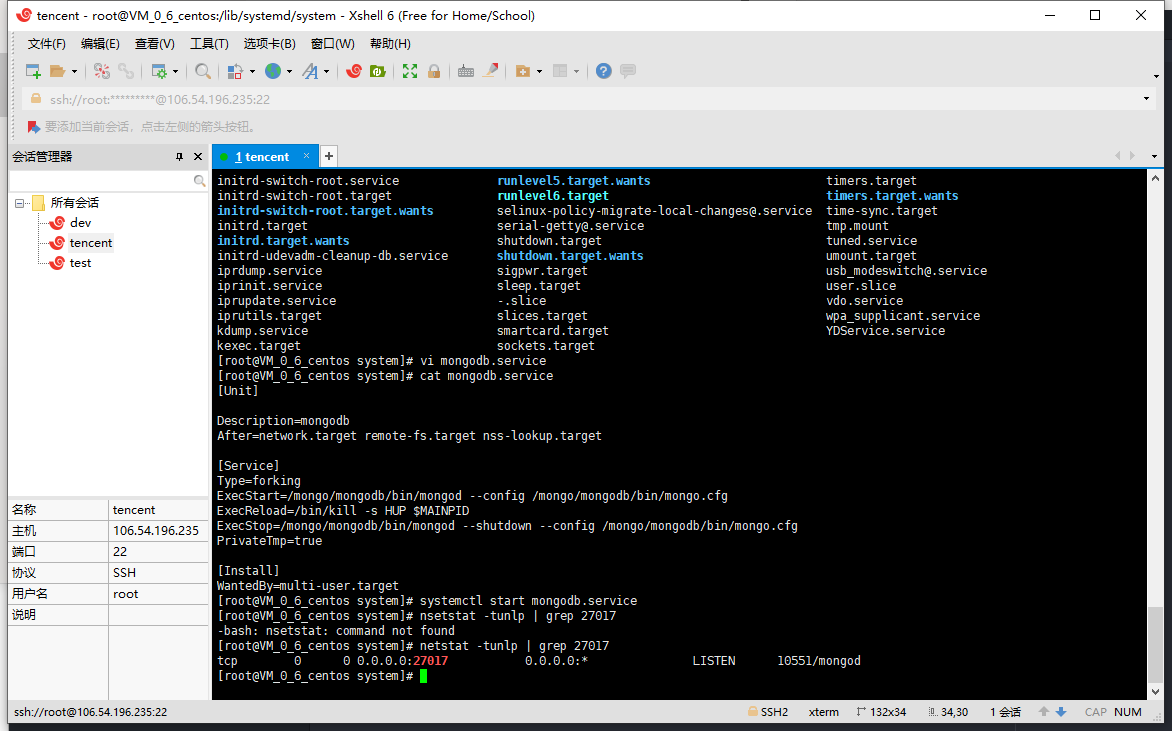
启动服务之后, 执行命令 netstat -tunlp | grep 27017 查看一下端口的占用情况, 端口号为mongo.cfg的配置文件中配置的端口号
使用mongo的时候,需要把mongod安装的位置暴露到全局环境
export PATH=‘<mongodb filepath>/bin:$PATH’开启--auth 或者是mongo.cfg中设置auth=true之后,数据库的操作就有了权限控制,在没有权限的情况下会报一个没有权限的错误,
就像下面这个没有写入权限的错误类似
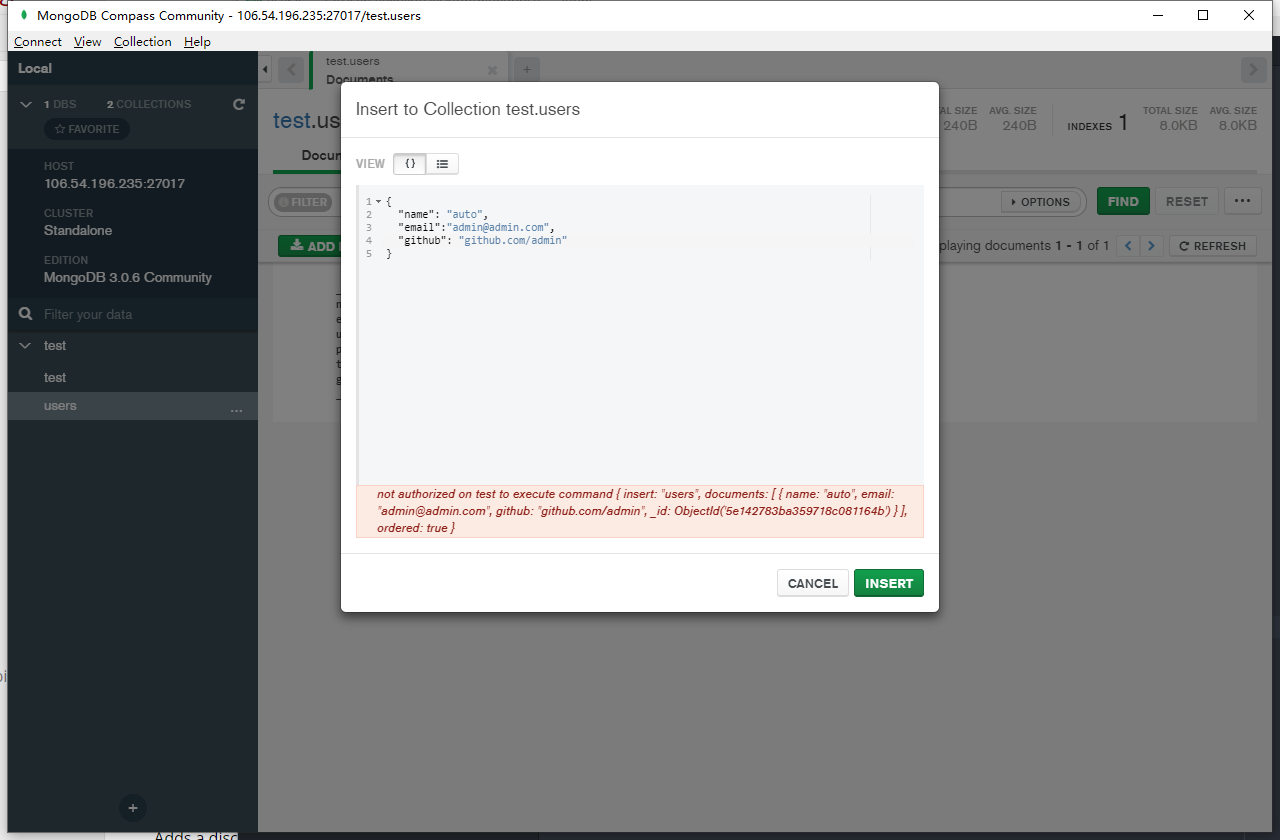
解决如下:
打开mongo的shell
use admin
> switched admin
db.createUser({
user: 'root',
pwd: 'root'
roles: [
{
role: 'userAdminAnyDatabase', # 添加数据库管理员
db: 'admin'
}
]
})
db.auth('root', 'root') # 验证账户
db.createUser({ # 给数据库添加可操作账号
user: 'admin',
pwd: 'admin',
roles: [
{ role: 'read', db: 'test' }, # 只读权限
]
})
配置之后继续验证一下权限
use test
db.auth('admin', 'admin')
db.createUser({ # 给数据库添加可操作账号
user: 'admin_rw',
pwd: 'admin_rw',
roles: [
{ role: 'readWrite', db: 'test' } # 读写权限
]
})
use test
db.auth('admin_rw', 'admin_rw')在开始之前我先介绍一个Antd的扩展组件库 ProTable,
将所有的数据源维护在一个JSON数据中,用函数去处理筛选的逻辑,从而得到我们在当前页所需要的数据结构。Antd中的有一个仓库ProTable,ProTable是一个集合了查询、表格和分页的多功能复合型组件,它将Search部分以及Table部分的数据都维护在一份JSON数据中,用不同的参数去驱动UI,其基本配置如下:
从ProTable的配置表上可以展现出来, ProTable几乎满足一般中后台的表格操作和属性配置的, 从这一种配置型的Schema可以简单分析一下, 将后台管理中的查询表单以及表格属性栏全部集中到一个JSON对象中去管理. 通过两个自定义的字段 hideInSearch、hideInForm 和 hideInTable 来区分该配置项目的所在的模块渲染. 如下: 下列Column定义地就是以上三个模块全部不渲染, 类似于权限控制:
[
{
title: 'A',
dataIndex: 'A',
hideInSearch: true,
hideInForm: true,
hideInTable: true
}
]现在可以使用数组Api: Array.prototype.filter, 就可以轻易的完成以上的筛选操作, 让我们来实现一个组合筛选功能函数.
现在, 我越来越认识到, 定义的每一个函数都有着这个函数独有的功能, 不要将多个任务放到一个函数里, 如果需要处理的数据上的问题, 可以将函数留一个入口, 通过一个回调函数去处理我们需要的数据结构, 就如同JS的数组Api一样.
例如, 在JS中的数组Filter, Array.prototype.filter(cb(element, index, arr)), 就可以根据我们在回调函数中定义的条件, 快速的将数据做一次筛选.
组合函数可以仿写一下Redux的函数, 函数很简单不超过十行, 但是其实现的功能非常强大, 我们现在的多条件组合查询筛选都用它.
function compose (...fn) {
if (fn.length === 0) {
return args => args
}
if (fn.length === 1) {
return fn[0]
}
return fn.reduce((f, g) => (...args) => f(g(args)))
}运用compose函数的方法及其简单, 现在定义以下情景, 按步骤实现:
先将一个Emnu类型的对象, 转换为数组;
将转换的数组, 做一次权限控制;
将权限控制的数组, 根据不同字段, 动态添加一些不同的属性;
...
以上情景根据你的业务逻辑, 无限扩展
在日常业务中, 我们极有可能遇到一些及其复杂的逻辑, 通常我们将它们全部在一个函数内部全部实现, 随着业务的升级以及业务逻辑的升级, 原来控制逻辑的代码越来越多, 越来越不好控制. 由此, 我们可以得出一个结论: 必须将复杂的业务逻辑, 一点一点拆分出去, 这样我们就可以实现, 业务环节状态的流转越多, 代码越好控制.
在Redux中, 有一个及其有意思的combineReduce函数, 可以将我们定义的多个Reducer集中为一个Reducer. 所以, 我们可以仿写Reducer的流程控制, 来实现复杂的业务逻辑.
// 将一个Emnu转换为 Array
// @params {obj} Object
// {
// 1: { label: '便签1', value: '0' },
// 2: { label: '便签2', value: '2' }
// }
function emnuConvertToArray (obj = {}) {
try {
if (obj === null && obj === undefined && obj !== 'object') return obj
return Object.entries(obj).map(([key, value]) => ({ [value.label]: key, ...value }))
} catch (error) {
Error(error)
}
}
const ops = {
getProto: item => item.value === 2 ? ({ ...item, name: 'yes' }) : ({ ...item, name: 'no' })
}
function filterColumnsBy (arr = [], cb) {
if (!Array.isArray(arr)) return arr
return [arr.filter(item => cb ? cb(item) : (item.value > 1)), ops]
}
// 如果value 等于2, 添加一些字段
function appendProtoBy (args) {
const [arr, ops] = args
if (!Array.isArray(arr)) return arr
return arr.map(item => ({ ...item, extend: ops.getProto(item) }))
}
// 组合三个条件分支, 返回需要的数据结构
var composeColumns = compose(appendProtoBy, filterColumnsBy, emnuConvertToArray)
var obj = {
1: { label: 'aaa', value: 1 },
2: { label: 'bbb', value: 2 },
3: { label: 'ccc', value: 3 }
}
var columns = composeColumns(obj)
console.log('current is columns: ', columns)如上, 如果任意环节需要改变逻辑, 就可以直接找到对应的逻辑函数, 改掉对应的逻辑就可以啦.
依次将筛选hideInTable, hideInSearch 的函数定义, 然后组合外部传入的函数, 将自定义筛选的函数留一个入口, 如下:
function filterSearch (origin = [], cb) {
return origin.filter((item, index, arr) => cb ? cb(item, index, arr) : !item.hideInTable)
}filter的筛选功能极其简单快捷, 也是我们常用的过滤功能的手段. 但是, 在目前看来很多的前端还没有积极的使用ES6中的api, 还在固执的, 守旧的使用着落后的手段去处理极其简单的筛选+挑选功能.
比如, 同一个管理后台的订单列表页, 不同的身份有着不同的查询条件, 或者是不同的渲染表格, 我看过一段代码, 差点把我看吐了. 是这么处理的:
// 定义公共部分的 查询条件
const commonQuery = [
{ label: 'AAA', field: 'AAA' },
{ label: 'BBB', field: 'BBB' }
]
// 定义客服身份的查询
const serviceQuery = [
{ label: 'service', field: 'service' }
]
// 定义商务身份的查询
const businessQuery = [
{ label: 'business', field: 'business' }
]
const composeQuery = []
if (type === 'service') {
composeQuery = commonQuery.concat(serviceQuery)
} else if (type === 'business') {
composeQuery = commonQuery.concat(businessQuery)
}以上代码的优化手段有很多, 每一个人都有不一样的解法, 下面列出我的解决方法:
const agreevQuery = [
{ label: 'AAA', field: 'AAA', auth: ['service'] },
{ label: 'BBB', field: 'BBB', auth: ['business'] },
{ label: 'CCC', field: 'CCC', auth: ['type'] }
]
const AUTH_TYPE = 'business'
const filterColumns = (origin = []) => origin.filter(item => item.auth.indexOf(AUTH_TYPE) > -1)当然如果对页面的表单项的排序有着强烈的需求, 我们还可以定义一个字段, 去定义数组项目的Index索引, 其配置如下:
const agreevQuery = [
{ label: 'AAA', field: 'AAA', auth: ['service'], index: 1 },
{ label: 'BBB', field: 'BBB', auth: ['business'], index: 3 },
{ label: 'CCC', field: 'CCC', auth: ['type'], index: 2 }
]
const AUTH_TYPE = 'business'
// 控制排序
const sortColumns = (origin = []) => origin.sort((a, b) => a - b)
// 处理Index序号
const filterIndexColumns = (origin = []) => origin.map(item => ({ ...item, index: typeof item.index === 'function' ? item.index(item) : item.index }))
// 权限过滤
const filterColumns = (origin = []) => origin.filter(item => item.auth.indexOf(AUTH_TYPE) > -1)
const composeColumns = compose(sortColumns, filterIndexColumns, filterColumns)
const columns = composeColumns(agreevQuery)
console.log('current is columns: ', columns)当我们慢慢地尝试将复杂的, 复合式的逻辑一条一条的抽离, 然后将这一些逻辑函数, 一个一个的组合, 那我们得出的结果就是我们需要的数据. 这样去维护逻辑和接口, 数据的流转就变得清晰透明起来, 我们可以很快速的排查到错误位置.
我们现在只是实现了表格的多条件渲染以及查询表单的多条件渲染, 在业务中还存在各种条件渲染, 以及各种各样的需求去实现, 我们不可能定义实现一个百分百匹配的模型, 所以我们设计模型的时候, 需要将一些变动的模块或者的方法, 留出一个入口, 允许外部传入函数, 组合模型内部的方法去实现需求.
在我接触使用Nginx之前, 并不太了解Nginx是什么, 做什么用的. 它给我印象最深的就是反向代理与负载均衡, 因为办公室的后台开发一直所津津乐道的就是这两个'概念'.
我在2019年年底开始接触Nginx, 起因就是腾讯云做活动, 我买了一台服务器. 就在这个时候我开始敲击Linux的一些命令, 尽管我对他们的原理并不太了解.
我一直认为, 要认识一个技术最快的方法就是直接上手一个项目.
不要害怕开发过程中会遇到无法解决的问题, 现在的网络太发达了, 可以获取到有效资料的来源非常的多, 身边的同事队友也可以一起研究, 所以别害怕直接上.
一款轻量级的Web服务器, 静态资源服务器和反向代理服务器. 启动极快, 配置上手极其简单. 网上的资料也极其丰富, 几乎不同担心遇到了解决不了的问题. 如果遇到了, 那说明我们已经不是一个位面的了.
我在配置反向代理时遇到的一个最大的问题就是并没有理解什么叫做'反向代理'. 与之相反的那就是'正向代理'了, 那什么又是'正向代理'呢?
我在知乎上看到了一种简单的理解: '正向代理'就是代理的客户端, 服务器其实不知道请求来自于哪一台客户端. '反向代理'恰恰相反, 客户端发起的请求不知道被哪一台服务器处理. 共同之处就是中间都有一个服务器器, 起到一个转发的作用.
反向代理的示意图:
正向代理示意图:
我只实现了反向代理, 下面我介绍一下我是怎么实现的反向代理.
在服务器安装了Nginx之后, 可以执行如下命令, 用于查看Nginx的安装位置:
whereis nginx
# /usr/local/nginx 这个就是我的安装位置
在进入了nginx安装文件夹之后, 会看到以.conf结尾的文件, 那就是nginx的配置文件.
如下图:
我有四个项目需要配置, 如果写在一个nginx.conf文件中不方便, 查找起来未免太过麻烦, 所以我使用了nginx中include属性, 所有的配置文件以.nginx.conf结尾, 在include中引入所有以.nginx.conf结尾的文件.
正如上图反向代理示意图, 在项目正式打包上线之后, 访问的接口就是线上的正式环境的接口啦. 而我们的请求访问的是: https://wuh.site/api/articles. 在没有代理之前, 这个地址访问的结果应该是一个你的项目网页, 又或者是一个404网页.
其配置脚本如下:
主要就是location的拦截处理, 匹配所有有/api/的地址, 与项目的路由地址区分开, 命中规则的转发请求至localhost:3100中. 而转发的关键就是: proxy_pass 属性.
是不是很好奇, 我为什么会代理到3100端口呢, 小可爱? 因为我把express项目部署到了3100端口, 所以现在访问 https://wuh.site/api/articles, 实际访问的就是: http://localhost:3100
端口详情如下图:
好啦, 终于说完了反向代理了, 可以看得出来, 到目前为止nginx的配置还是很简单的. 所以我应该算是踏进了nginx应用的大门了, 因为我已经独立发布了一个项目啦.
下面讲一下我是怎么配置的SSL.
安全套接字层(SSL)数字证书, 用于客户端与服务器建立加密链接, 保护客户端与服务端之间的交换敏感数据不会被劫持篡改.
我使用的是腾讯云的服务器, 在控制台中有SSL证书下载的入口, 申请之后需要将已下载的证书上传到自己的服务器中, 这里我特意创建了一个文件夹, 存放所有的网站的证书.
nginx默认的https协议的端口是443, 所以配置时就监听443端口, 如下:
server {
listen 443 ssl;
server_name domain;
ssl_certificate /path/domain.crt;
ssl_certificate_key /path/domain.key;
........
}配置完成之后, 可以打开浏览器, 输入域名以验证ssl是否已经生效. 但是需要自己手动修改协议为https, 所以还需要重定向一下由http跳转至https.
使用时相当的简单, 还是在location中使用, 命中规则之后就返回, 如下:
location ~ /re/ {
return 301 https://$host$request_uri;
}语法: rewrite reg replace flag
rewrite的使用就稍微复杂一点, 需要一个正则表达式, 到现在我愈来愈发现正则表达式确实是一个好东西呀, 其使用如下:
server {
location /re/ {
rewrite (.?\/re\/) https://baidu.com permanent;
}
}flag 列表如下:
| 属性名 | 说明 | 备注 |
|---|---|---|
| last | 不再向下执行rewrite操作 | 与break不同, last会立即发起新一轮的location |
| break | 不再向下执行rewrite操作 | 只能终结rewrite模块, 而不能终结其他模块 |
| permanent | 301 永久重定向 | |
| redirect | 302 临时重定向 |
配置之后, 打开浏览器验证一下, 看一下自动跳转是否成功, 如果不成功, 可以按照以下几个方向排查:
针对第四点我就遇到过这个问题, 配置重定向之后始终不生效, 但是在我睡了一觉之后, 它自动跳转了. 我当时就跪了, 有啥可说的呢, 它就是这么的可爱!!!
我在这里使用一下, antd-pro: https://pro.ant.design/docs/deploy-cn的部署配置, 我的配置差不多, 需要配置的属性如下:
| 属性名 | 属性值 | 说明 |
|---|---|---|
| root | absolute_path | 静态文件的绝对地址, 指定dist文件夹的绝对地址 |
| index | 指定项目的入口文件 | .html/.htm |
| location | Object | 用于匹配静态文件和错误页面 |
| ^gzip | none | 配置加载使用gzip文件 |
部署前端项目其实是很简单的啦, 比较困难的或者是说可以玩出花儿来的就是, 怎么使浏览器加载的速度更快. 可以看我的另一篇文章: 优化网页加载速度, 现在只写了三种优化, 后边慢慢会补齐我是咋玩的.
可以在express的官网中看到一篇Express应用中的进程管理, 它推荐了好几个进程管理工具, 如下:
我使用的就是其中之一的PM2, 具体的使用可以看我的另一篇博客: 使用PM2部署node应用
最后还是总结一下吧:
1. 多看文档, 多读书, 就算记不住概念, 大致上要把某一个概念出现的位置记住, 方便遇到问题时快速定位查找
2. 勤快动手, 有目标的验证, 带着问题去验证会收获更多
3. 将想法赋予实现
在10.1的假期中,我用TS重写了博客的前端应用,同时用sass改写了全部组件的样式。对于组件的设计,全部借鉴于ant design的设计规范和开发规范。
第一版的Next应用写的不是很满意,很多代码和实现都不是我喜欢的那一种。恰逢10.1假期,改写了大部分的组件的代码。
由于近期的工作比较多,平时又很累一直没顾得上写一写,这一次重写遇到的问题和解决的方法,以及对整个应用工程化的实现的记录。现在已经过去了两个多月了,很多细节已经回想不起来了。没办法,只能看着现在的代码总结一下。
无论我们做任何项目,从规范代码提交的开始,应该是对整个项目最负责的体现。
不知道从什么时候开始,我个人的提交规范就朝着angular的方向了。我记得当时我看了一篇讲述angular提交规范的博客,当时一看顿时觉得仪式感太强了,整个commit记录一眼看过去相当整齐,从那时起,我觉得angular规范是最好的。
代码规范和样式美化选用 prettier 和 eslint 。代码的样式美化和统一,给我的感觉就是舒服。这里没什么可以说的,网上的教程一大把,但是我偷懒了,对于react的规则,我用是的umijs的规则,当然nextjs自身的规则继续保留。
只要是严格的遵循了angular的提交规范,就可以使用 conventional-changelog 工具,快速的生成本次发布的版本的更新日志,这里附上近期的更新日志。大致就是以下这个样子,看起来就是满满的仪式感。
Github Actions用起来的感觉就是一个字,太爽了!之前一直不会用,一直在研究到底是怎么玩的。直到看阮老师的博客,发现了一个新的工具act,可以在本地调试github actions。可以监听git的merge事件,来做一些自动化操作。
所以现在,我把主分支切成了main分支,每一次的功能迭代改为pull merge操作。因为我看到了next的官网上有推荐,可以使用Vercel持续集成应用,这样每一次的merge操作就可以自动发布到Vercel容器了。
基本原则还是遵照我之前的总结《浅尝一下UI设计》,基本的设计不变,但是改成sass函数之后,整个css部分变得更加地整齐、清晰和简单。
这里不得不提到sass中的函数和混入,在sass的官网中有它们相当具体地实现。这次我用到的基本都是Map类型操作。我举一个相当简单的用例,实现组件的大中小三种类型的样式函数。文件名: vars.scss
$font-size-base: 14px;
$compose-base: 8px;
$sizes: ((small, $font-size-base - 2px, $compose-base * 0.5),
(middle, $font-size-base, $compose-base),
(large, $font-size-base+2px, $compose-base*2));
@mixin getSizes () {
@each $size,
$fontsize,
$padding in $sizes {
.is-#{$size} {
font-size: $fontsize;
padding: $padding;
}
}
}在调用getSizes函数之后,自动生成了.is-small、.is-middle和.is-large三个类名,对应着组件的三种大小状态。在此处我只定义了基本字体大小和内边距两种属性,如果需要扩展属性,可以很轻易地实现。
其编译之后的代码如下:
所以,我们可以借助类似的一些自定义函数,在快速完成我们样式代码的同时减少代码量。less和sass其功能相差不大,基本功能都可以实现,具体的一些功能函数可以参考ant的代码实现。
完全舍弃类组件,全部由函数式组件构建。
如果你不会做,不妨跟着会做的人做。
在本次更新中,很多组件都是模仿ant。包括对于TS的使用下的React组件定义,自定义组件对外暴露的属性,组件内部classname的命名和条件渲染,大量代码都借鉴了ant。
Hooks的实现借鉴了另一个开源库ahooks,但是hooks文件的规则还是沿用umijs。
当然,audio的单例模式实现也发生了一些变化。在init阶段的单例实现没有任何变化,但是我创建了一个全局的context,在这个context中新建了ref来保存audio实例。整个应用似乎不太需要Redux。
主题切换,不再使用原方案,改为使用脚本实现。同时,bubble泡泡也改为使用脚本实现。你可以直接下载bubble.js(https://src.wuh.site/scripts/bubble.js)脚本体验。
在google浏览器的性能测试工具中,就有_Accessibility_指标。在ant的实现中,我们可以发现role 和 aria-* 属性。当时我看到的时候很迷惑,因为我从来没见到过html元素的属性中,有role这个属性。知道后来我听了_《重学前端》_这门课,我才知道原来是这么回事。
除此之外,还有键盘的可访问性,那就是tabindex。其对应的键盘按件就是tab键。在对一个html元素配置该属性之后,就可以通过tab键聚焦。如下:
<div tabindex='0'>hello</div>我们都知道在Html5 中发布了一些新的元素,这一些元素被称之为语义化标签,我记得在当时,我是完全用section标签取代了div标签。现在我的大部分标签改回了div。
所以,在一轮的重构中,我对大量的元素加入了role属性,覆盖率大致上达到了80%。只要是涉及到了可交互的组件基本上完成了配置。页面可点击按钮全部换成button元素和a元素。
或许,我们都应该听老师傅的话:如果你不知道的怎么用语义化标签,那就不要用
一个网站的SEO是极其重要的,所以在一次的重构中,我选择了NextSEO库,不再使用自己维护的代码实现。这个仓库满足了我全部的需求,因为我只需要配置google结构化,标题,关键字这一些属性,其他的我并不需要。
Gtag可以完成满足我的上报需求。首先我对页面的按钮进行了基础分类,大致分为了: normal、loadmore、link、share、behivor。这样,我完成了页面点击按钮的事件上报。
接口上报还没来得及做,现在我的服务后台换成了Nest应用,很多功能都没有时间去做。
我优化了Dockerfile构建文件,改成了分段式构建。
早前我是自己的野路子,能把应用跑起来就行,但是后来我发现,构建的Docker镜像太大了,感觉告诉我有点点不太对劲儿。在我改了构建文件之后,现在我的镜像的体积是91M。
构建步骤大致分为三个阶段: 初始化、构建、运行时。
本次升级内容,如下:
jq一个json文件的解析工具# ==================== Deps ==============
# =================== 安装依赖 =============
FROM mhart/alpine-node as deps
LABEL maintainer = "shadow [[email protected]][6]"
WORKDIR /usr/src/app
COPY package.json yarn.lock /usr/src/app/
RUN apk add jq
RUN npm config set registry https://registry.npmmirror.com
RUN yarn
# ================== Builder ================
# ================= 编译 ===================
FROM mhart/alpine-node as builder
WORKDIR /usr/src/app
.......
# ============== Runing ===========
# ============== 运行时 ===========
FROM mhart/alpine-node AS runner
WORKDIR /usr/src/app
ENV NODE\_ENV production
...
USER nextjs
EXPOSE 3000
CMD ["yarn", "start"]更为关键的是自动构建,自动升级和镜像清理脚本,结合一下github actions,一切都变得舒服了起来。
只要有优质的订阅源,我们完全可以只使用RSS阅读器,就可以享受阅读的乐趣。它是一个信息板,只关注我想关注的内容。所以现在的一些博客网站都会配置rss。
怎么配置实现rss就成了我们需要关注的内容啦。
在这里我推荐使用Feed(https://www.npmjs.com/package/feed),但是我的实现稍有不同。
每一次更新博客之后,都需要更新维护的rss.xml文件,只有这个文件更新了,订阅器才会有更新推送。现在我把这个功能集成到了我的管理后台,我的feed文件托管在aliOSS,这个是我的feed(https://src.wuh.site/common/rss.xml)。
我用 web worker 注册一个时间轮询器,用于获取当前设备的时间。白天使用light模式,晚上变为dark模式。怎么让它们实现自动切换就是一个比较指的研究的问题啦。
难道要在主线程中加一个定时器,让它每次30分钟更新一次吗?
或许,有别的方式。在不占用主线程的资源的前提下,还可以监听时间的变化,在满足条件的前提下,切换网站的主题模式。
这是一个相当简单的实现,如果你感兴趣,可以在项目的源文件里面,查看相关的代码。
.webp类型的文件,从文件可压缩的大小的比率上看具有相当的优势。但是目前为止,我只是把网站的背景图片和部分封面图改为了.wepb,大部分文件仍然还是.png。
来自于h5的新标签picture,提供了非常棒的降级方案,只需要配置额外的基础源就可以放心使用webp文件。
看起来,需要实现一下转换图片的格式了
思来想去也不知道写一点什么东西好,那就简简单单随便来一篇日记吧,作为我个人网站的静态数据库.
作为一个前端开发工程师(菜鸟),我们可能都有一个共同的偶像,那就是阮一峰老师,他的博客太高产了,平均是每周两篇当然还不算他的翻译作品.所有以后我将尽可能的每一周写两篇,或者是技术文档或者是读书笔记,我个人是比较喜欢推理小说和历史小说类.
既然说起了技术文档,行业内公认的走向全栈最快的技术栈:React + react-router + redux/mobx/flux/react-redux + mongodb + nodejs.
React
React框架,前端三驾马车之一,MV?型框架,他的核心就是React app是一个状态机,state数据变了view模型也要改变;一个state对应一个view,若果view受到了多个state的影响,就应该抽离成为一个新的view.
React-router
官方的路由库,构建单页面应用即只有一个index.html入口文件,再无其他的html文件,所以我们要通过router地址把组件分开,根据浏览器路由地址跳转至对应组件页面.
Redux/Mobx/Fulx/React-redux
可用于React应用的store,即状态管理器或者是状态管理仓库,用于同一个state作用于多个view.state是不能直接改变的,而是要显示的提交,actions?,reducer?,store?
MongoDB
NoSql 非关系型数据库,js语言的最佳拍档,数据流入流出都是collection即集合,mongo中的集合与js中的对象格式之间无须转换,省去了Sql中的二联表数据转换操作
Nodejs
现在的前端再也离不开nodejs了,从npm到webpack全部是基于nodejs构建,nodejs社区越来越好,用户越来越多,坚定了我学习nodejs的恒心.而且nodejs是基于javascript,这代表着只需要一门javascript既可以游走于前端后台中间件.
从刚开始工作至今,我们所用的技术栈就是Vuejs + vue-router + vuex + php?java? + sql
Vuejs(2.0)
一个MVVM型框架,以组件化开发为基础,渐进式后台开发框架,什么是组件化?就是堆积木一样,假设有100块积木拼图,我们分开拼,最后再将分开的拼图合到一起,组成一个大的拼图!Vue的文档极为良心,我们可以把它的文档成为渐进式文档!!!!
Vue-Router
官方的路由库,为vue量身定做,文档都是渐进式,多看几遍就熟悉了
Vuex
官方为vue量身打造的状态管理器,借鉴Flux架构,与Redux极为相似,但是却大有不同,同为单一状态管理树,事件触发,显示提交,getter与reducers返回state.不同的是vuex可能使用更为简单,你只需要全局注入就行了,但是在React中,数据仅仅在容器型组件中流动,不会到展示型组件.所以在React中需要connect关联一下!
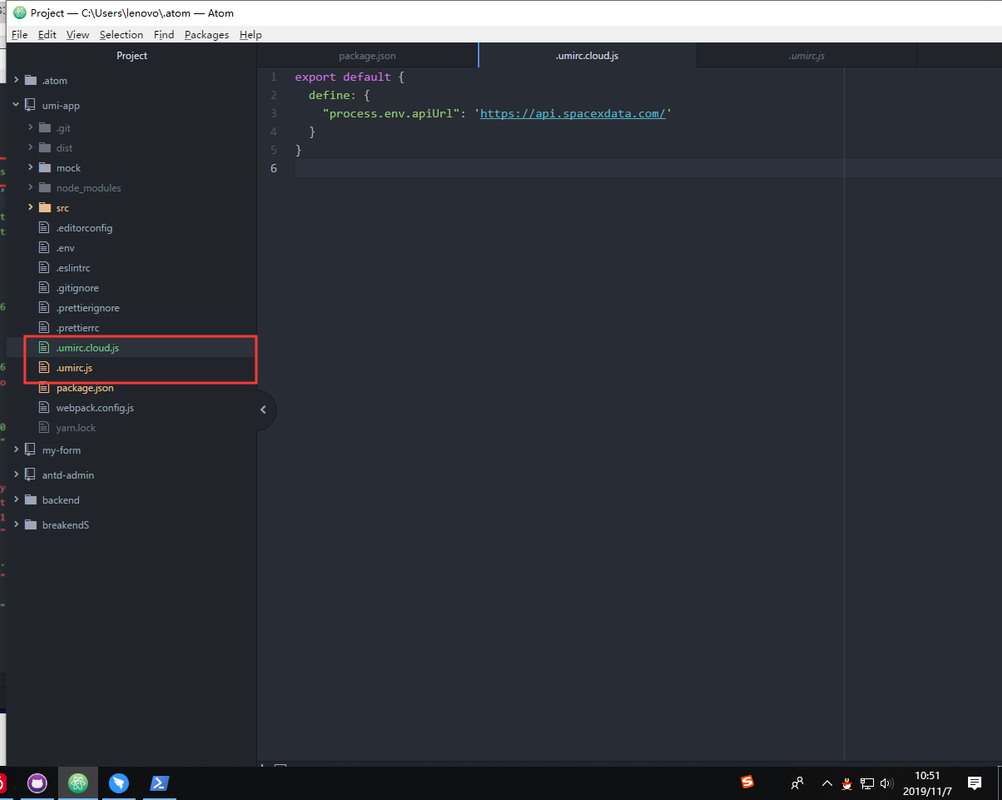
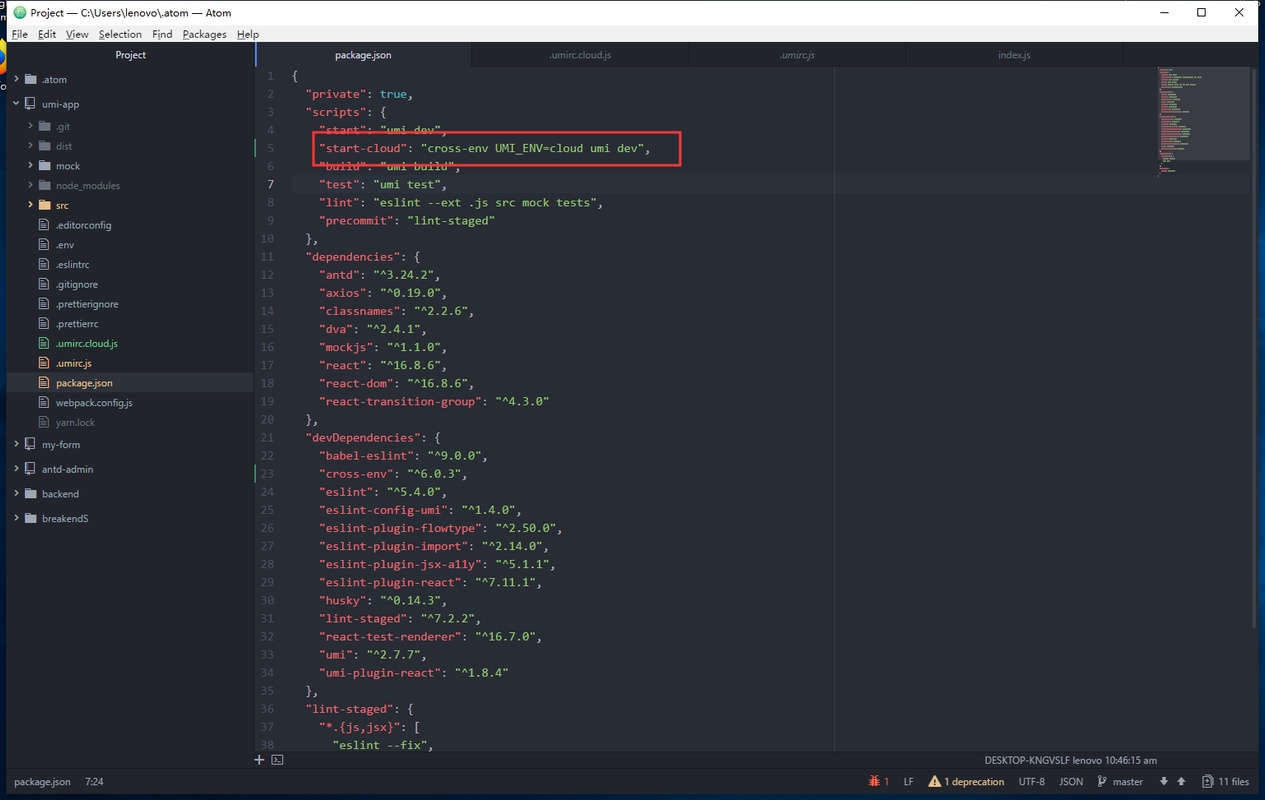
配置多环境打包的方法:
corss-env npm install cross-env -Dor
yarn add cross-env
命名: .umirc.XXX.js, 所命名的环境名与脚本下的UMI_ENV=XXX一致
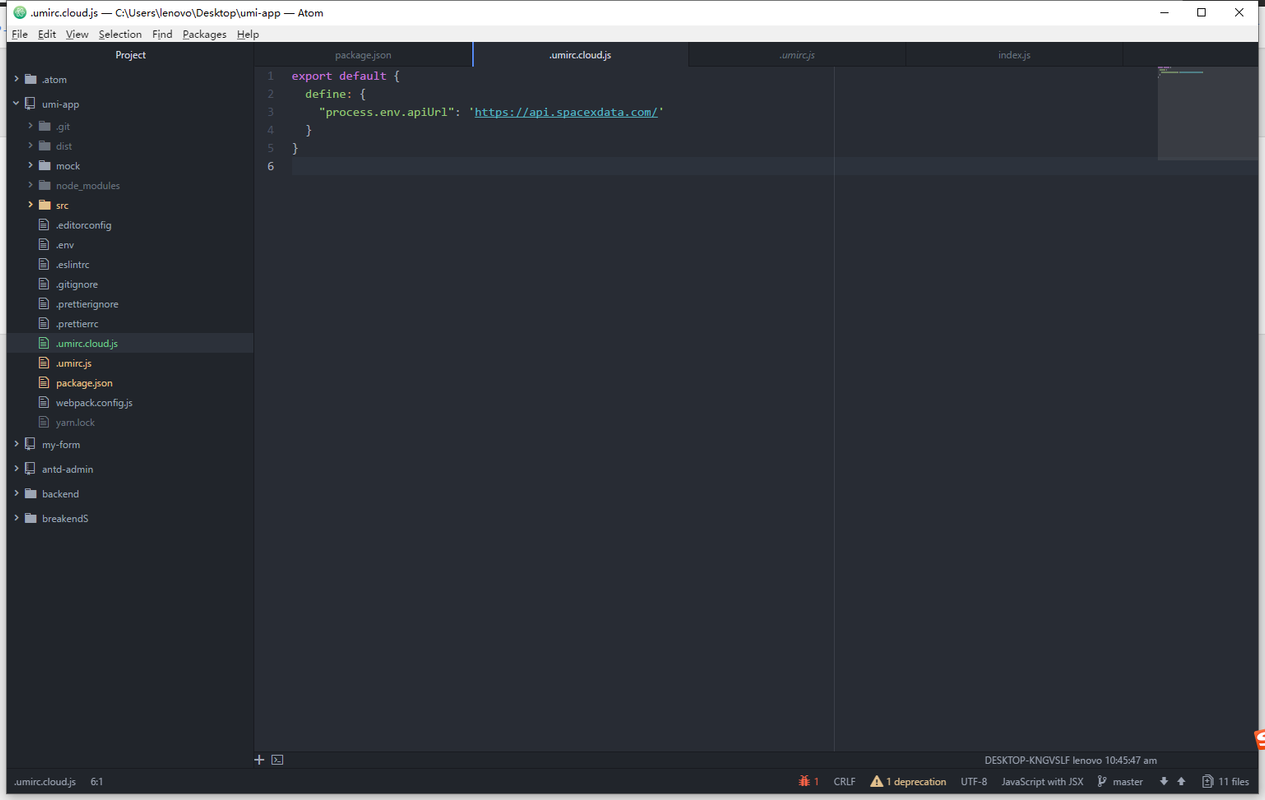
在package.json文件中配置
"script": {
"start": "umi dev",
"start:cloud": "cross-env UMI_ENV=cloud umi dev"
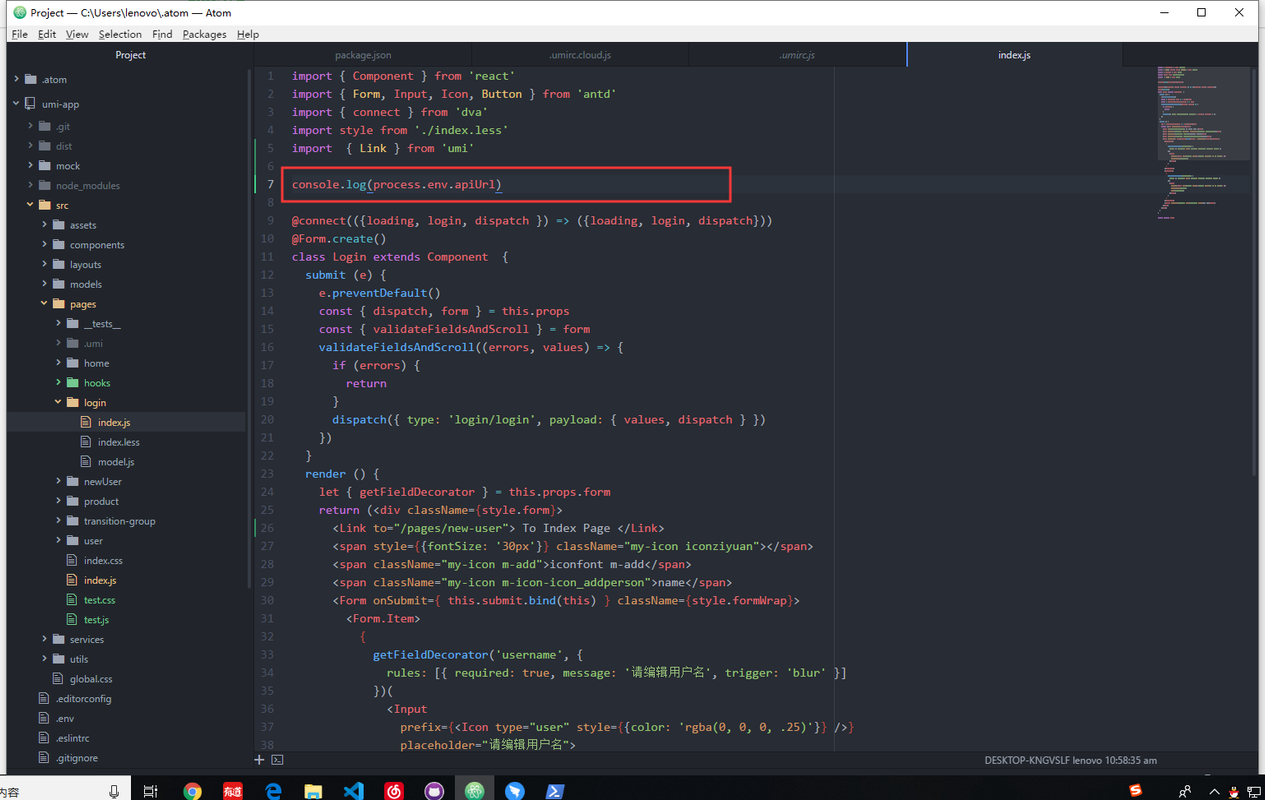
}在index.js文件中使用
console.log(process.env.apiUrl)昨天下了一天的雨,闲着实在没什么事情做,就在微信阅读里面找了一本书《长安的荔枝》来读,读的正在兴头上呢,结果出现了下面这个恶心的东西。不得不说,现在的微信读书没有之前好用了,腾讯总是习惯于把一款优秀的产品做成垃圾。
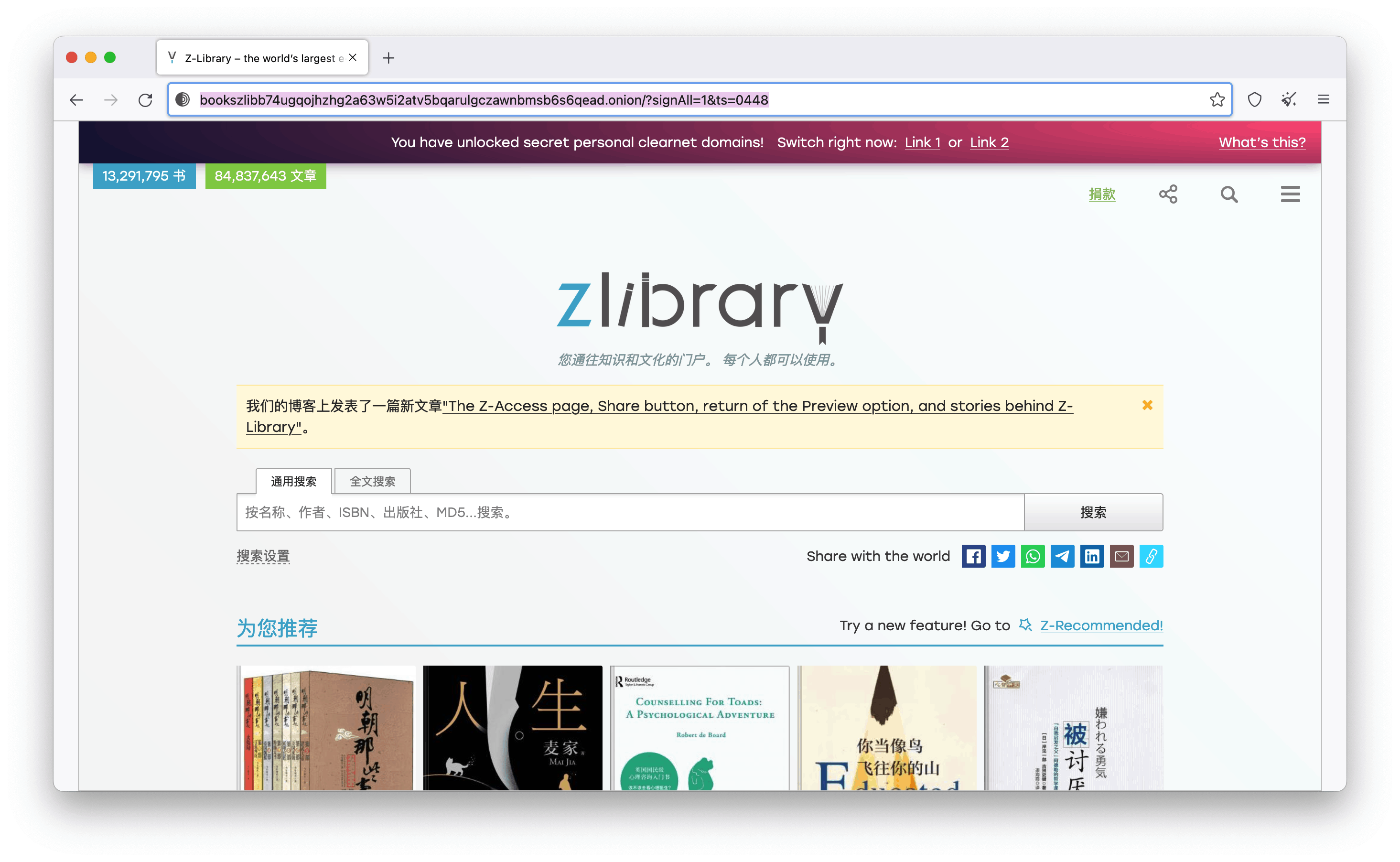
实在是受不了这种,我是提倡知识付费的,但是白嫖还是快乐的。我想起了之前看到的一个视频里面提到过一个免费的在线图书馆,资源贼拉多,它就是大名鼎鼎的**[zlibrary](https://lib-boxnfxb7fl57xmwt2nd5h4gx.1lib.fr/)**。
这个网站的官网已经被封了,一些镜像站也被封了。我是在telegram里面找到了一些组群,在里面找到了一个可以使用的机器人:https://t.me/fbooki。
这个机器人会发一些可以使用链接地址,大家可以自行点击使用。下面我贴一个镜像站:https://lib-boxnfxb7fl57xmwt2nd5h4gx.1lib.fr/。
除此之外,还有一种的暗网访问的方法,这里贴一个教程链接:https://www.youtube.com/watch?v=pK3LzbT271E
其使用方式是一样一样的,点击书籍链接进入明细就可以看到下载按钮了,我们直接使用默认的下载类型,然后在微信读书里面导入本地文件,就也可以继续阅读了。
注意:

今天我想写一写关于生活的感想, 没有别的原因, 只是想写一写, 也没有什么主题, 单纯地聊一聊这两天的见闻.
我还没开始投简历, 就有hr主动地联系着我, 帮我安排着面试, 我一想反正是没事, 那就去面一面吧.
首先我说明一下, 对于外包与自研我都不拒绝, 我只是一个普通的程序员, 在现在看起来我似乎还没有资格去挑选, 因为我还不够强.
首先这位面试官跟我聊了一个多小时, 具体的聊了很多的内容, 与JS相关的、与Css相关的、与Webpakc相关的, 但是更多的我们在关于职业规划的问题上发生了共鸣.
首先他的年纪比我大, 工作年限比我久, 也是平安的一位编制人员. 我们在说起30岁以后的程序员的优劣势这个话题时, 出乎意料的语气转变, 让我意识到似乎存在于这个大的环境下, 不管你是谁, 不管你是什么职务, 都会有这么一种忧患的意识.
在聊天的时候他还时不时地给我来了一点小插曲, 比如 html元素中的tabindex 与 accesskey. 但是就是这一些插曲, 让我学到了一些比较冷门的知识, 而且后来听说他对我的印象很不错.
但是今天不谈技术.
我今天看了一部老电影《时光倒流七十年》, 不知道为什么我就是想看一看. 在这一部电影中我看到了过去与未来的交叉, 一方面在过去憧憬着未来, 另一方面在未来后悔.
未来是多变地, 多彩地.
相反地是不是也代表着未来是绝望地.
站在房顶, 看着一座座的高楼, 车水马龙的街道, 多好! 但是当我想到在这么大的一座城市里, 没有我的一处立身之地, 感觉就像是给我交了一桶冰水, 让我彻底冷静下来, 脸上也没有了一丁点的笑容.
我开始变得孤独, 孤独地走在一条崎岖的山路上.
我记得在我出发去武汉上大学之前, 我爸爸带着银行卡, 带着现金, 带着行李送我去武汉. 我在武汉待了两年之后, 开始使用移动支付, 那时我开始使用淘宝.
我的专业是计算机软件基础, 我们的专业课有C, C++, Java, DW. 而这些让我安身立命的东西, 在当时有效的环境下没有好好的珍惜, 所以直到今天我仍然时常的后悔, 后悔着当初的不该.
后来移动支付兴起了, 然而在相当长的一段时间里我是使用的现金, 每一个星期在学校的提款机里面提200块. 我开逛一逛学校的几个超市, 把在学校超市付款之后找给我的零钱回寝室, 然后把他们放在一个瓶子里, 几年的时间我存满了两大瓶.
现在我开始敲代码, 我敲了多久的代码了? 大概四年了吧.
我开始写的jquery, 然后开始做公众号, 然后开始做小程序, 然后就是Vue, 然后React, 然后Node. 一路走来我只能说走得太累, 太辛苦!
每一年都有新的改变! 而我正在被这个技术世界打造的面目全非, 因为我开始有白头发, 开始掉头发!
而在此之前, 我的亲戚朋友没有一个不拿我的秀发开玩笑!
自我批判, 才给我带来了学习地动力, 因为我不要在40岁的时候再次后悔.
现在回首, 我回头看过去, 看见的全部是失败. 看见的是那个孤独地, 落寞的, 萧条的自己! 我曾不止一次的回头问他: "嘿, 兄弟, 当时你是咋想的, 咋弄的, 怎么就弄成这样了".
我开始补救, 我开始看书, 我爱看推理小说, 因为我认为推理小说可以使我的大脑一直运转. 就这样我开始读《心理罪》、《余罪》、《十宗罪》、《高智商犯罪》.
我也看历史小说《明朝那些事儿》、《万历十五年》、《资治通鉴》
我还喜欢古龙, 喜欢那快意江湖的恩仇, 我羡慕陆小凤, 楚留香, 沈浪, 李寻欢, 他们有那么多的朋友, 他们总是不孤独, 他们都是那么地喜欢喝酒, 或许他们喜欢的是一起喝酒的感觉而不是酒.
我期待着在多年之后, 我们可以不那么的孤独, 可以自信地谈论着未来.
我: "嘿, 你最近好吗?"
他: “很累, 但是我很快乐, 因为我再也不会孤独!”
我看着他自信地脸, 甚至那早已不见的光彩也出现在他的眼睛之中, 慢慢地他的面庞和我重叠, 而那时的我早已热泪盈眶!
我: “嘿, 兄弟不赖嘛, 我看见了你眼睛里的光!”
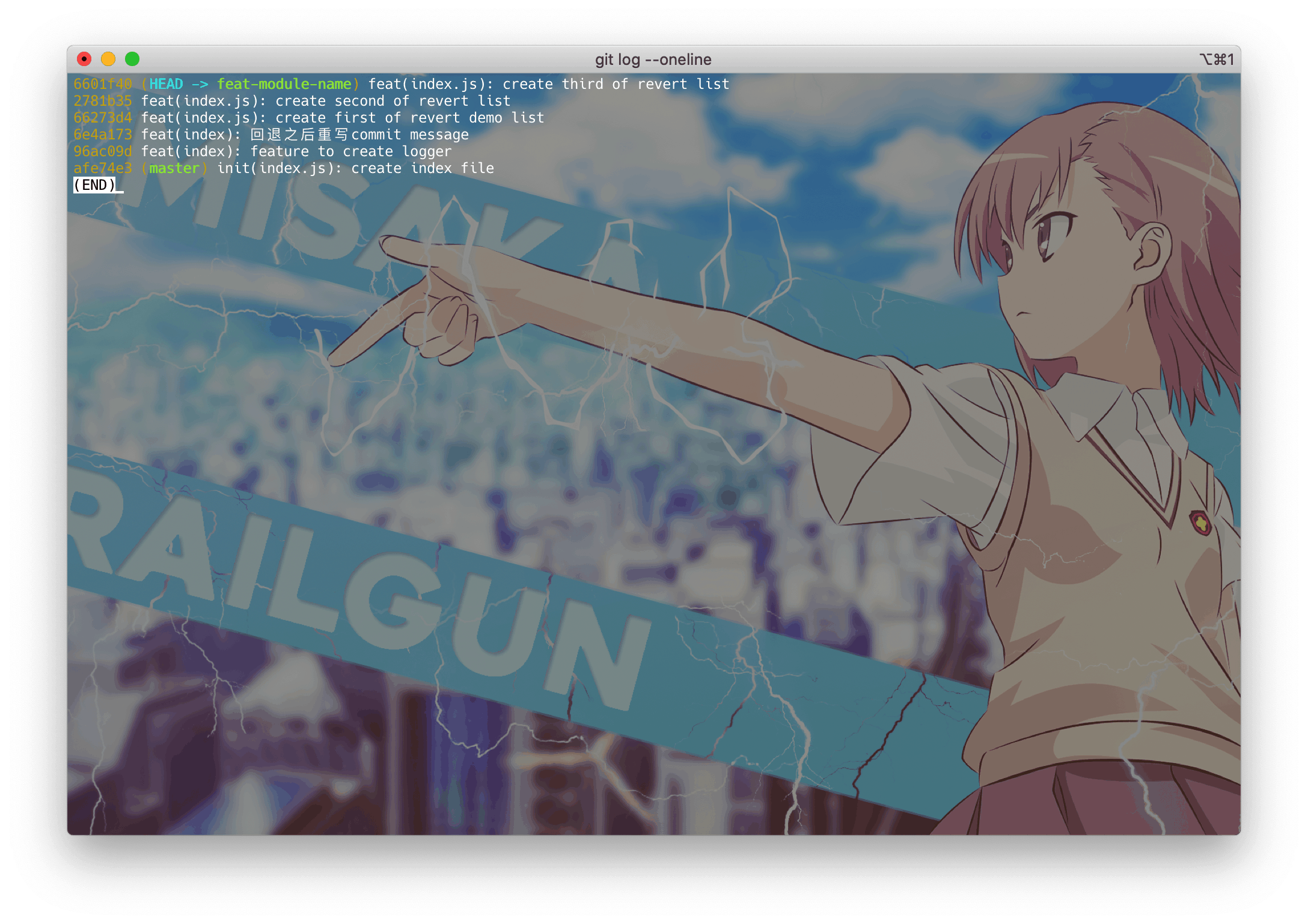
git log # 查看当前分支的全部提交记录
git reflog # 查看所有分支的全部提交记录
git log/reflog -10 # 查看前10条记录
git log -10 --oneline # 展示前10条提交记录的大概记录
git shortlog # 按提交的作者分类
git log --pretty=format:"%cn committed %h on %cd" # cn会替换成作者姓名, h 换成标志符, cd 换成提交时间
git log --author=shadow # 按提交用户查看
git log --before='2019-04-15' # 按提交时间
git log --grep='feat' # 按提交信息
git show # 追踪最近一次提交的文件更改
git show commit_id # 追踪指定提交的文件更改
git log -- fielname # 查看指定文件的历史提交记录
git log -p filename # 查看指定文件的每次提交diff
git diff # 追踪文件工作区与暂存区的差别git commit -m'feat(application): feat component for test feat#01' # 提交添加注释
git commit --amend # 修改最近一次提交的注释git branch dev # 新建一个dev分支
git branch --move devs # 重命名一个分支
git branch -d dev # 删除指定分支
git checkout -- filename # 放弃工作区文件的追踪
git chekout -- '*.js' # 放弃工作区所有.js文件的更改
git checkout -- [path] # 放弃工作区全部文件的追踪
git checkout -b dev # 切换指定分支
git cherry-pick bug ee883aa # 拉取指定分支的指定提交
git cherry-pick bug eeaas33...aa2233a # 拉取指定分支的区间提交
git remote get-url origin # 获取指定远程连接的url
gir remote add origin git@gitssh # 添加一个指定的源参考链接:
在我接触使用Nginx之前, 并不太了解Nginx是什么, 做什么用的. 它给我印象最深的就是反向代理与负载均衡, 因为办公室的后台开发一直所津津乐道的就是这两个'概念'.
我在2019年年底开始接触Nginx, 起因就是腾讯云做活动, 我买了一台服务器. 就在这个时候我开始敲击Linux的一些命令, 尽管我对他们的原理并不太了解.
我一直认为, 要认识一个技术最快的方法就是直接上手一个项目.
不要害怕开发过程中会遇到无法解决的问题, 现在的网络太发达了, 可以获取到有效资料的来源非常的多, 身边的同事队友也可以一起研究, 所以别害怕直接上.
一款轻量级的Web服务器, 静态资源服务器和反向代理服务器. 启动极快, 配置上手极其简单. 网上的资料也极其丰富, 几乎不同担心遇到了解决不了的问题. 如果遇到了, 那说明我们已经不是一个位面的了.
我在配置反向代理时遇到的一个最大的问题就是并没有理解什么叫做'反向代理'. 与之相反的那就是'正向代理'了, 那什么又是'正向代理'呢?
我在知乎上看到了一种简单的理解: '正向代理'就是代理的客户端, 服务器其实不知道请求来自于哪一台客户端. '反向代理'恰恰相反, 客户端发起的请求不知道被哪一台服务器处理. 共同之处就是中间都有一个服务器器, 起到一个转发的作用.
反向代理的示意图:
正向代理示意图:
我只实现了反向代理, 下面我介绍一下我是怎么实现的反向代理.
在服务器安装了Nginx之后, 可以执行如下命令, 用于查看Nginx的安装位置:
whereis nginx
# /usr/local/nginx 这个就是我的安装位置
在进入了nginx安装文件夹之后, 会看到以.conf结尾的文件, 那就是nginx的配置文件.
如下图:
我有四个项目需要配置, 如果写在一个nginx.conf文件中不方便, 查找起来未免太过麻烦, 所以我使用了nginx中include属性, 所有的配置文件以.nginx.conf结尾, 在include中引入所有以.nginx.conf结尾的文件.
正如上图反向代理示意图, 在项目正式打包上线之后, 访问的接口就是线上的正式环境的接口啦. 而我们的请求访问的是: https://wuh.site/api/articles. 在没有代理之前, 这个地址访问的结果应该是一个你的项目网页, 又或者是一个404网页.
其配置脚本如下:
主要就是location的拦截处理, 匹配所有有/api/的地址, 与项目的路由地址区分开, 命中规则的转发请求至localhost:3100中. 而转发的关键就是: proxy_pass 属性.
是不是很好奇, 我为什么会代理到3100端口呢, 小可爱? 因为我把express项目部署到了3100端口, 所以现在访问 https://wuh.site/api/articles, 实际访问的就是: http://localhost:3100
端口详情如下图:
好啦, 终于说完了反向代理了, 可以看得出来, 到目前为止nginx的配置还是很简单的. 所以我应该算是踏进了nginx应用的大门了, 因为我已经独立发布了一个项目啦.
下面讲一下我是怎么配置的SSL.
安全套接字层(SSL)数字证书, 用于客户端与服务器建立加密链接, 保护客户端与服务端之间的交换敏感数据不会被劫持篡改.
我使用的是腾讯云的服务器, 在控制台中有SSL证书下载的入口, 申请之后需要将已下载的证书上传到自己的服务器中, 这里我特意创建了一个文件夹, 存放所有的网站的证书.
nginx默认的https协议的端口是443, 所以配置时就监听443端口, 如下:
server {
listen 443 ssl;
server_name domain;
ssl_certificate /path/domain.crt;
ssl_certificate_key /path/domain.key;
........
}配置完成之后, 可以打开浏览器, 输入域名以验证ssl是否已经生效. 但是需要自己手动修改协议为https, 所以还需要重定向一下由http跳转至https.
使用时相当的简单, 还是在location中使用, 命中规则之后就返回, 如下:
location ~ /re/ {
return 301 https://$host$request_uri;
}语法: rewrite reg replace flag
rewrite的使用就稍微复杂一点, 需要一个正则表达式, 到现在我愈来愈发现正则表达式确实是一个好东西呀, 其使用如下:
server {
location /re/ {
rewrite (.?\/re\/) https://baidu.com permanent;
}
}flag 列表如下:
| 属性名 | 说明 | 备注 |
|---|---|---|
| last | 不再向下执行rewrite操作 | 与break不同, last会立即发起新一轮的location |
| break | 不再向下执行rewrite操作 | 只能终结rewrite模块, 而不能终结其他模块 |
| permanent | 301 永久重定向 | |
| redirect | 302 临时重定向 |
配置之后, 打开浏览器验证一下, 看一下自动跳转是否成功, 如果不成功, 可以按照以下几个方向排查:
针对第四点我就遇到过这个问题, 配置重定向之后始终不生效, 但是在我睡了一觉之后, 它自动跳转了. 我当时就跪了, 有啥可说的呢, 它就是这么的可爱!!!
我在这里使用一下, antd-pro: https://pro.ant.design/docs/deploy-cn的部署配置, 我的配置差不多, 需要配置的属性如下:
| 属性名 | 属性值 | 说明 |
|---|---|---|
| root | absolute_path | 静态文件的绝对地址, 指定dist文件夹的绝对地址 |
| index | 指定项目的入口文件 | .html/.htm |
| location | Object | 用于匹配静态文件和错误页面 |
| ^gzip | none | 配置加载使用gzip文件 |
部署前端项目其实是很简单的啦, 比较困难的或者是说可以玩出花儿来的就是, 怎么使浏览器加载的速度更快. 可以看我的另一篇文章: 优化网页加载速度, 现在只写了三种优化, 后边慢慢会补齐我是咋玩的.
可以在express的官网中看到一篇Express应用中的进程管理, 它推荐了好几个进程管理工具, 如下:
我使用的就是其中之一的PM2, 具体的使用可以看我的另一篇博客: 使用PM2部署node应用
最后还是总结一下吧:
勿忧勿忧,欲说还休;不休不休,至死方休。
此刻,我一边喝着酒,一边想着一些*话。
先来一口,开摆。
也不知道为什么起了这样一个标题,可能是忽然之间想起来这么一本书,内容是什么一时之间也想不起更多了。既然内容想不起来了,那就直接用他的标题吧。
如果非要给未来定义一个颜色,那我的未来一定是灰色,或者我认为我的未来是灰色。矛盾的对立统一在我的身上得到了相当明显的体现,换一种描述,那就叫它“纠缠”吧,再也不用纠结它的实体了,它就是抽象的存在。
我的生活轨迹就像是齿轮一样,每天都在重复做一样的事情,我很想改变他,最后却发现我无能为力,能改变的只能是我自己。
就这样,我在生活的漩涡中越陷越深。同时,我很庆幸我还没有结婚,还没有孩子,还没有家庭,还没有那如山的压力。我毫不怀疑,我可以想象出这样的一种压力可以把一个家庭家长的腰彻底压垮。
我已在漩涡中,挣扎太久,我变老了,我想我快失去动力了。
在辛苦忙碌了两个多月之后,我终于有时间来写一写博客啦,尽管我当初给自己规定的目标是每一个星期出一篇。在业务工作当中我透支了全部精力,没办法静心去写,现在终于有时间啦。
毫无疑问,现在市场上的公司用的不是Vue就是React,这里的Vue当然指的是Vue2.0。除此之外,Ng的市场份额远不及Vue以及React,所以目前前端的技术栈就大致上分为:以React为主导的React技术栈和以Vue为主导的Vue技术栈。
我是由Vue技术栈转的React技术栈的前端开发工程师。
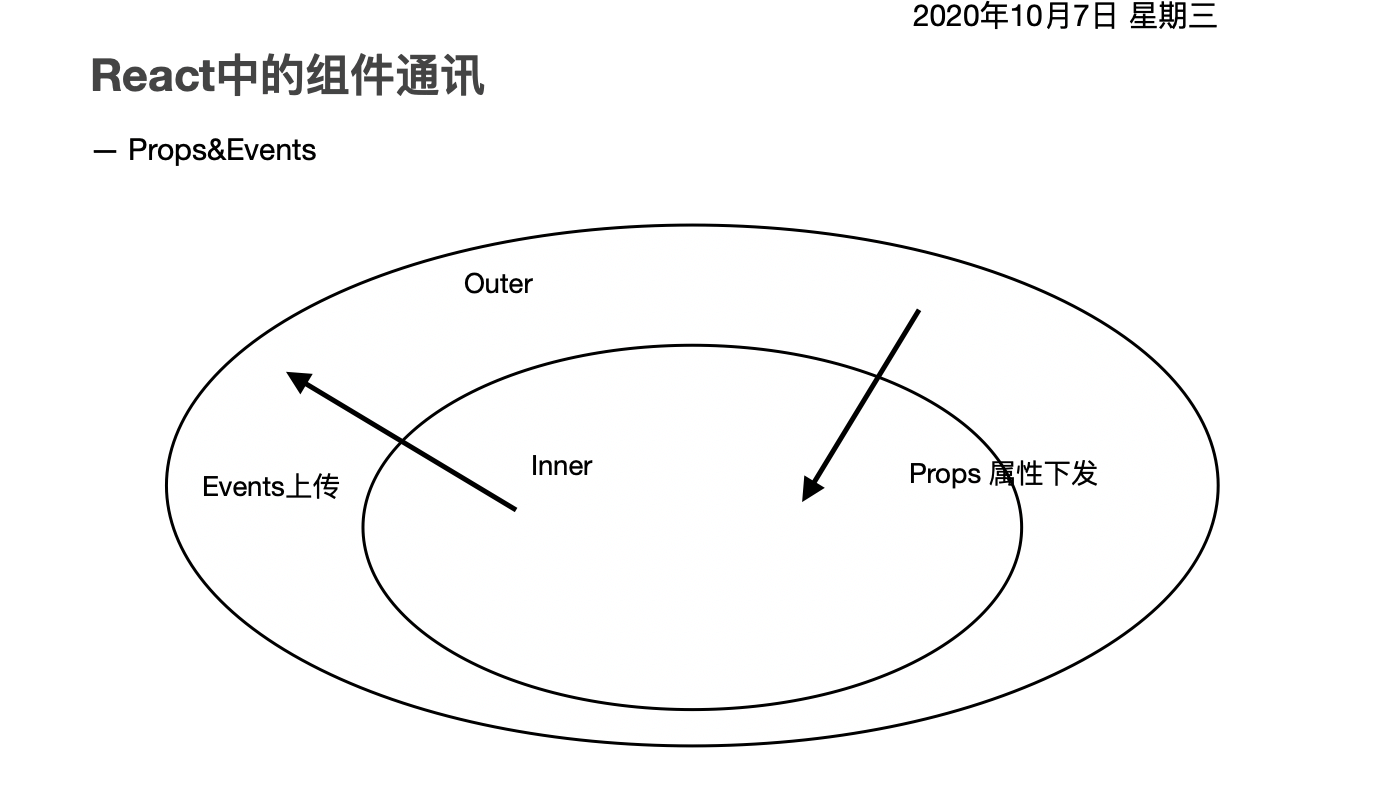
我使用React的时间其实真的不太久,不过一年时间。我个人认为对于React的深刻了解以及学习方式都来自于我使用Vue时的经验,它使我快速精进,下面我们就从最常用的组件通讯作为入口,做一个分析。
如上图: 其父级组件Outer与子组件Inner的通讯,通过在outer中注册一些属性下发给Inner组件,这种方式就是React以及Vue中最普通的通讯方式:Props 。
通常,我们会在父组件中定义一些属性或者是事件,然后将这一些属性作为Inner的属性赋值,类似于原html标签中的data-*。在原生的html或者是Jquery中我们可以将一些数据缓存在html标签的data- * 属性中。这样可以通过DOM或者是BOM的事件获取目标元素之后,访问缓存在目标对象中的data-*值。
到了React中可以这样使用,其实现如下:
const Inner = ({
name,
onClick
}) => {
const currentMode = 'inner'
return (<>
<h5>current is Inner</h5>
use father's props:
<ul>
<li onClick={() => onClick(currentMode)}>name: {name}</li>
</ul>
</>)
}
const Outer = () => {
const handleClick = data => {
console.log('current has data: ', data)
}
const innerProps = {
name: 'Inner',
onClick: handleClick
}
return (<>
<h5>current is Outer</h5>
<Inner {...innerProps} />
</>)
}如上,我简单的实现了一个Props通讯。我们将一些通用到同一个组件的属性,统一到一个对象innerProps内部去管理,然后通过解构赋值到Inner组件中。Inner组件上传了带着自身状态的onClick事件到父组件中,这样它们通过onClick事件搭建了一个桥梁,就形成了Inner向Outer传递的事件。这个就是Props的下发以及Events事件的上传。
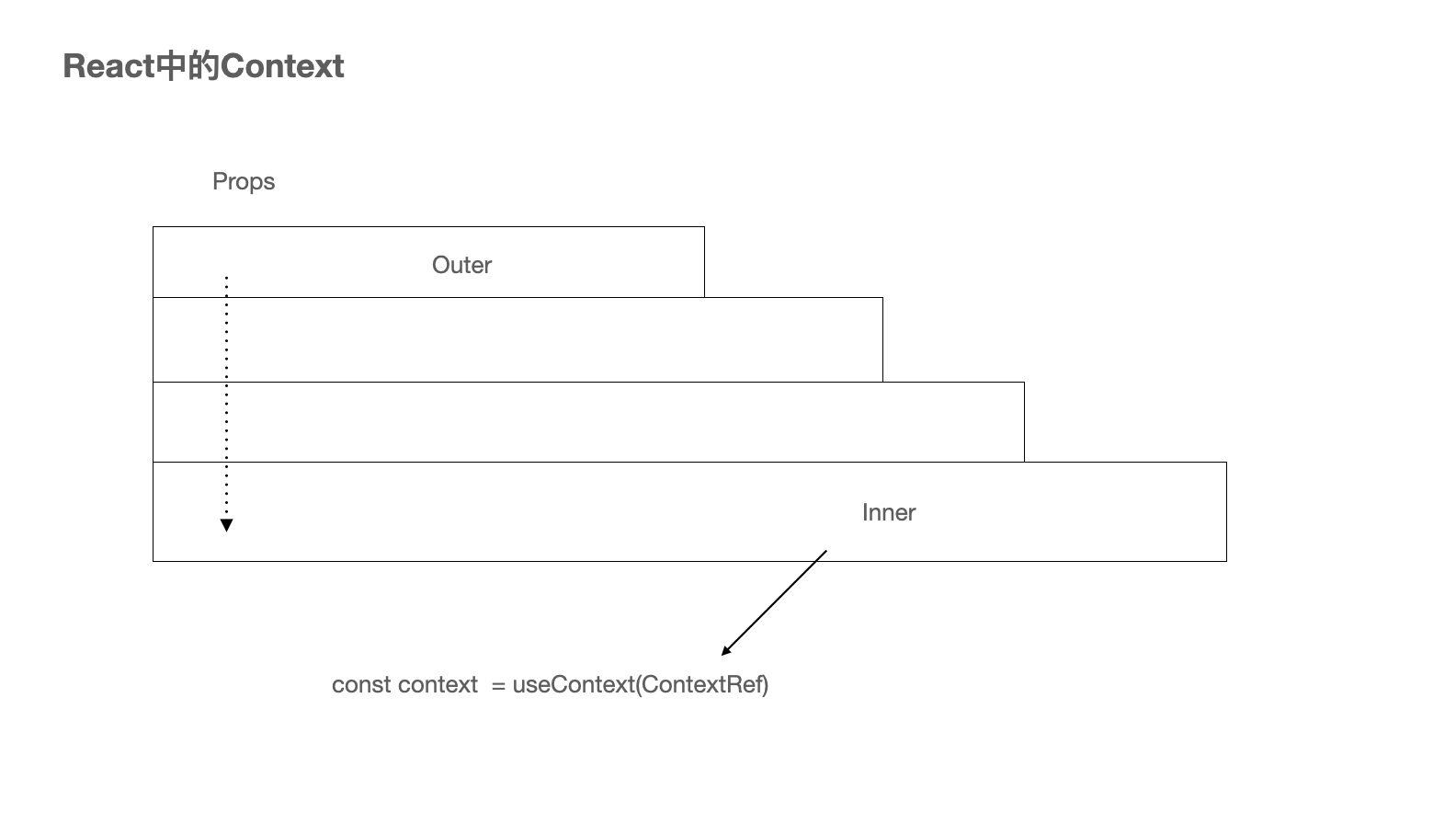
Context是React中相当特殊的一个属性,使用它可以跨层级传递我们提前定义的属性,在其包裹中的子组件就可以访问和使用这些属性啦,其示意图如下:
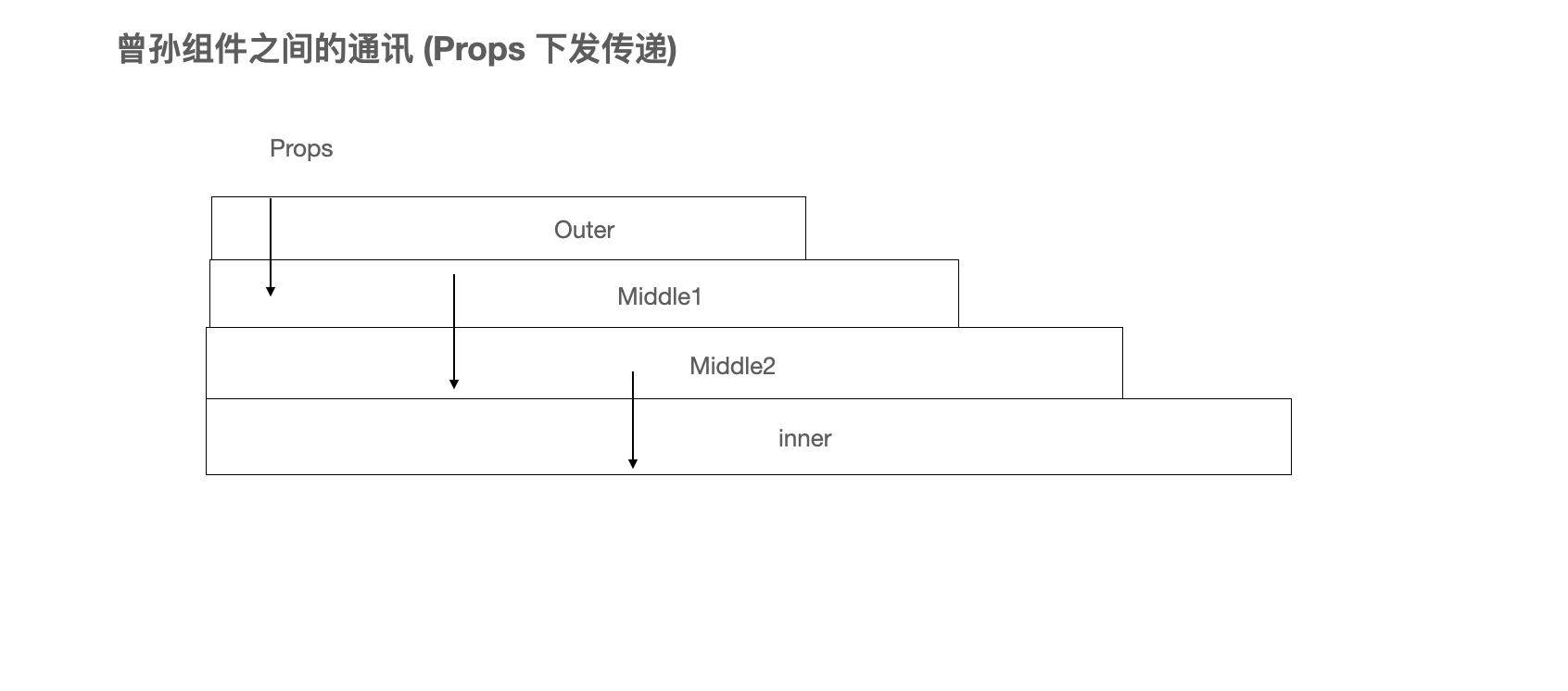
普通的下发模式下,只能通过将Props一层一层的向下传递,一直传递到需要使用的组件Inner中,此时就可以在Inner中的Props中访问到数据,其嵌套层数越深我们需要传递的次数就越多,为了解决这样的场景,我们可以引入React中的准备的Context,在应用了Context之后,其模型变为如下:
在定义使用了Context之后,我们改变了传递的模型,不再将数据层层下发,改为一次下发,随用随取。在需要的组件中,获取在Outer中定义的元数据。
关于Context的使用又有多种方式,比如在16.8之后的Hooks和Provider&Consumer,我将会独立一个章节介绍其使用模式。
在16.8中我们可以使用一些React的顶层API,其中有一个好玩的钩子:useRef。在ProTable中有一个相当酷的玩法,如下:
import React, { useRef, useEffect } from 'react'
const Inner = ({
ref
}) => {
const currentMode = 'Inner'
useEffect(() => {
const actions = {
mode: currentMode,
onChange () {
console.log('currnet has changed')
}
}
if (ref && typeof ref === 'function') {
ref(actions)
}
if (ref && typeof ref !== 'function') {
ref.current = actions
}
}, [])
return (<>
<h5>current is Inner</h5>
</>)
}
const Outer = () => {
const innerRef = useRef()
const handleClick = () => {
innerRef.current.onChange()
}
return (<>
<Inner ref={innerRef} />
<button onClick={handleClick}>calling inner Change</button>
</>)
}如上,这时我们不再拘束于ref属性的类型,它可以定义为一个函数,也可以是一个ref对象。现在我们将事件绑定到了button元素上,同时可以将Inner组件的状态通过ref.current 访问到。
他们关注的都是横切关注点的问题,例如Redux中的connect函数就是一个高阶组件,在引入了HOC之后,又会存在额外的问题,比如在使用同一个HOC时,有同名的变量存在时,会造成属性丢失的问题。
而在使用Render Props模式时,同样面临着一个棘手的问题,如果组件的嵌套层数过多,就会造成类似于回调地狱的问题。如下:
const Inner = ({ children, ...props }) => {
return children(props)
}
const Outer = () => {
return (<>
<Inner>
{
children => (<p>
current is Inner
<Inner children={() => (<p>current is children inner</p>)}>
</p>)
}
</Inner>
</>)
}更多的可以查看React官网中关于Render Props的例子,github上有一个基于Render props的动画库ReactMotion
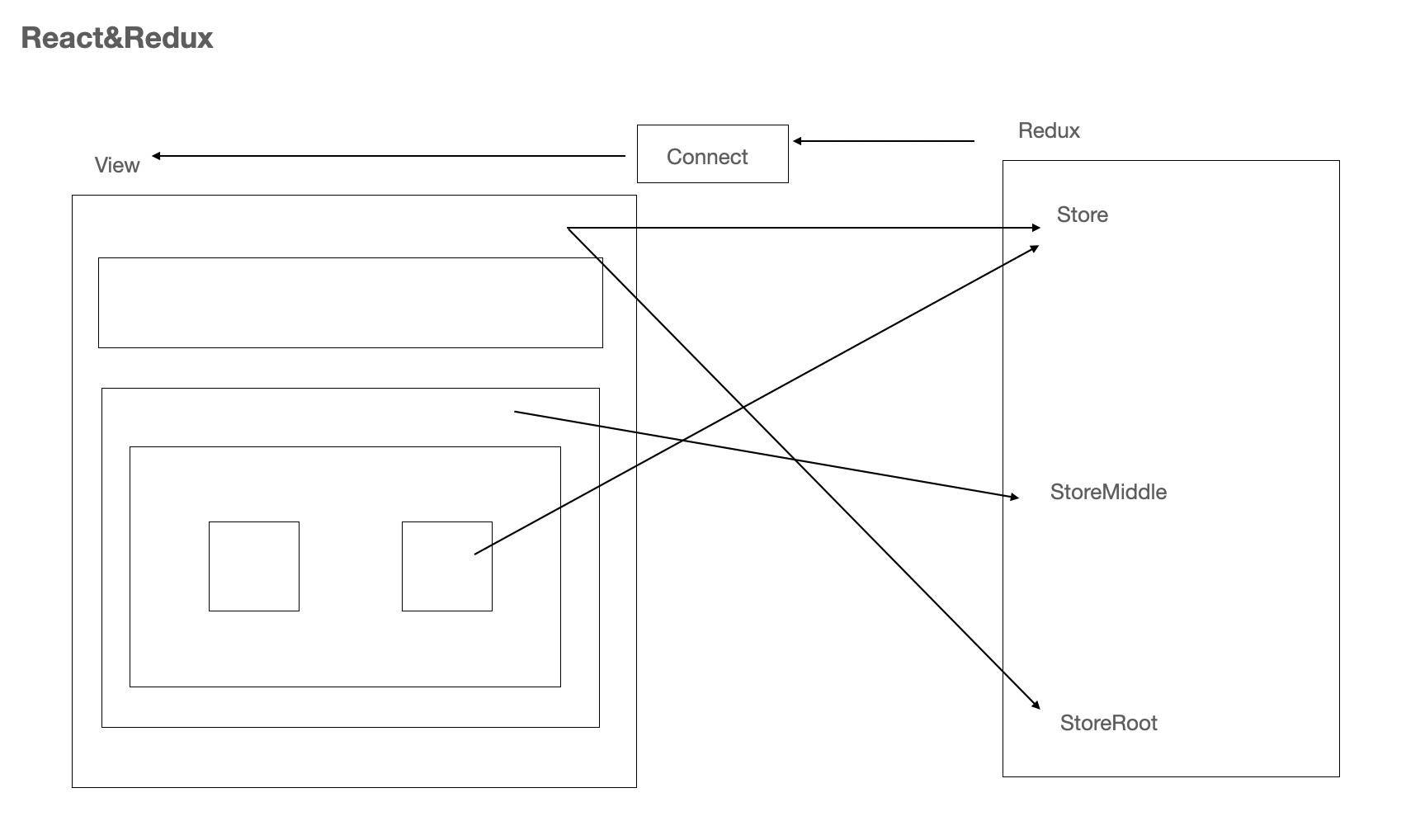
在16.8之后,React推出了useReducer,useReducer 的使用于 Redux 的使用相同。在日常的业务中我们使用的最多的应该还是Redux,Redux与React没有直接的关联,我们在React应用中的使用的类库是基于Redux封装的react-redux,它暴露了一个connect沟通数据层与视图层,这样不管我们的视图层中的组件嵌套多少层,我们都可以将数据托管到Redux中,其使用方式也与Context相似。
示意图如下:
我们将数据存储到每一个Store中,每一个视图都有与之对应的一个Store或者是多个Store,而沟通二者的桥梁就是connect函数,其实现如下:
const Inner = ({
store
}) => {
const { Store } = store
return null
}
const mapStateToProps = ({ Store, StoreRoot }) => ({
store: {
Store,
StoreRoot
}
})
const mapDispatchToProps = dispatch => ({ dispatch })
const combineCm = connect(mapStateToProps, mapDispatchToProps)(Inner)
export default combineCm随着业务的处理越来越复杂,我们定义的Reducer越来越多,数据也会变得越来越难以管理,所以我们一定要在一个迭代周期结束之后,整理我们的redux,以便于后期的维护和迭代。
在使用react开发的时候,一般是使用Create-react-app脚手架生成reactApp。当需要自定义webpack配置的时候,有以下几种方法:
npm install customize-cra react-app-rewired -Sconst { override, fixBabelImports, addLessLoader, addPostcssPlugins, overrideDevServer } = require('customize-cra')
const { resolve } = require('path')
// 打包配置
const addCustomize = () => config => {
config.resolve.alias = {
...config.resolve.alias,
'@': resolve(__dirname, './src')
}
if (process.env.NODE_ENV === 'production') {
// 关闭sourceMap
config.devtool = false;
// 配置打包后的文件位置
config.output.path = __dirname + '../dist/demo/';
config.output.publicPath = './demo';
// 添加js打包gzip配置
config.plugins.push(
new CompressionWebpackPlugin({
test: /\.js$|\.css$/,
threshold: 1024,
}),
)
}
return config;
}
// 跨域配置
const devServerConfig = () => config => {
return {
...config,
// 服务开启gzip
compress: true,
proxy: {
'/api': {
target: 'xxx',
changeOrigin: true,
pathRewrite: {
'^/api': '/api',
},
}
}
}
}
module.exports = {
webpack: override(
fixBabelImports('import', {
libraryName: 'antd-mobile',
style: 'css',
}),
addLessLoader(),
addCustomize(),
),
devServer: overrideDevServer(
devServerConfig()
)
}然后还需要下载一个react-app-rewired 包,将pakeage.json中的启动脚本文件,更换为react-app-rewired ***
参考链接如下:
REACTAPPREWIRED(create-react-app custom webpack config)
yarn eject
or
npm eject会在根目录下生成一个config文件夹
剩下的就全部是webpack的内容啦, 官网链接:CREATEREACTAPP
这几天一直在研究React应用,与React搭配的就是react-router,而且还支持了与VueRouter相同的集中型配置型路由表。其配置步骤如下:
npm install react-router react-router-dom react-router-configrouter
router.js
import React from 'react'
import {
Home,Books,Electronics,Mobile,Desktop,Laptop
} from '../pages/pages.js'
import Root from '../App.js'
const routes = [
{
component: Root,
routes: [
{
path: '/',
label: '首页',
exact: true,
component: Home
},
{
path: '/books',
label: '书籍',
component: Books
},
{
path: '/elec',
label: '商城',
component: Electronics,
routes: [
{
path: '/elec/mobile',
label: '移动',
component: Mobile
},
{
path: '/elec/desktop',
label: '桌面',
component: Desktop
},
{
path: '/elec/laptop',
label: '笔记本',
component: Laptop
}
]
}
]
}
]
export default routes路由表的内容大概就是这个样子啦
把App.js作为路由的主出口, 其他的path,exact属性同react-router的属性。label属性是为了配置面包屑。如果子组件下还有子组件就用routes数组包含起来。
src
index.js
import React from 'react';
import ReactDOM from 'react-dom';
import { BrowserRouter as Router, Switch } from 'react-router-dom';
import './index.css';
import App from './App';
import * as serviceWorker from './serviceWorker';
import routes from './router/router.js'
import { renderRoutes } from 'react-router-config'
ReactDOM.render(<Router>
{renderRoutes(routes)}
</Router>, document.getElementById('root'));
// If you want your app to work offline and load faster, you can change
// unregister() to register() below. Note this comes with some pitfalls.
// Learn more about service workers: https://bit.ly/CRA-PWA
serviceWorker.unregister();把路由挂载到App下, 现在整个app就有了router对象了
在组件的使用很简单,App组件中会在声明的路由中传递一个route参数,route是一个对象, 以上面的配置的路由表为例:
//home.jsx
import { renderRoutes } from 'react-router-config'
function Home ({ route }) {
return (<>
{renderRoutes(route.routes)}
</>)
}route对象形如:

就这样哪一个组件有子组件了, 就在哪一个页面下配置一下。
react-router-config 官方例子
react-router-config 搭建一个面包屑组件
react-router-config 的鉴权**
现在ERP以及支持通过Element面板查找使用组件的文件地址,但是还有一种情景是比较特殊的。在批量改完cooHttp优化需求之后,还可以通过发起的ajax的请求来查找发起请求的文件路径。
如下图,即为ERP支持的使用组件的文件地址:

如何通过ajax反查调用文件位置
打开NewWork面板中的Initiator栏
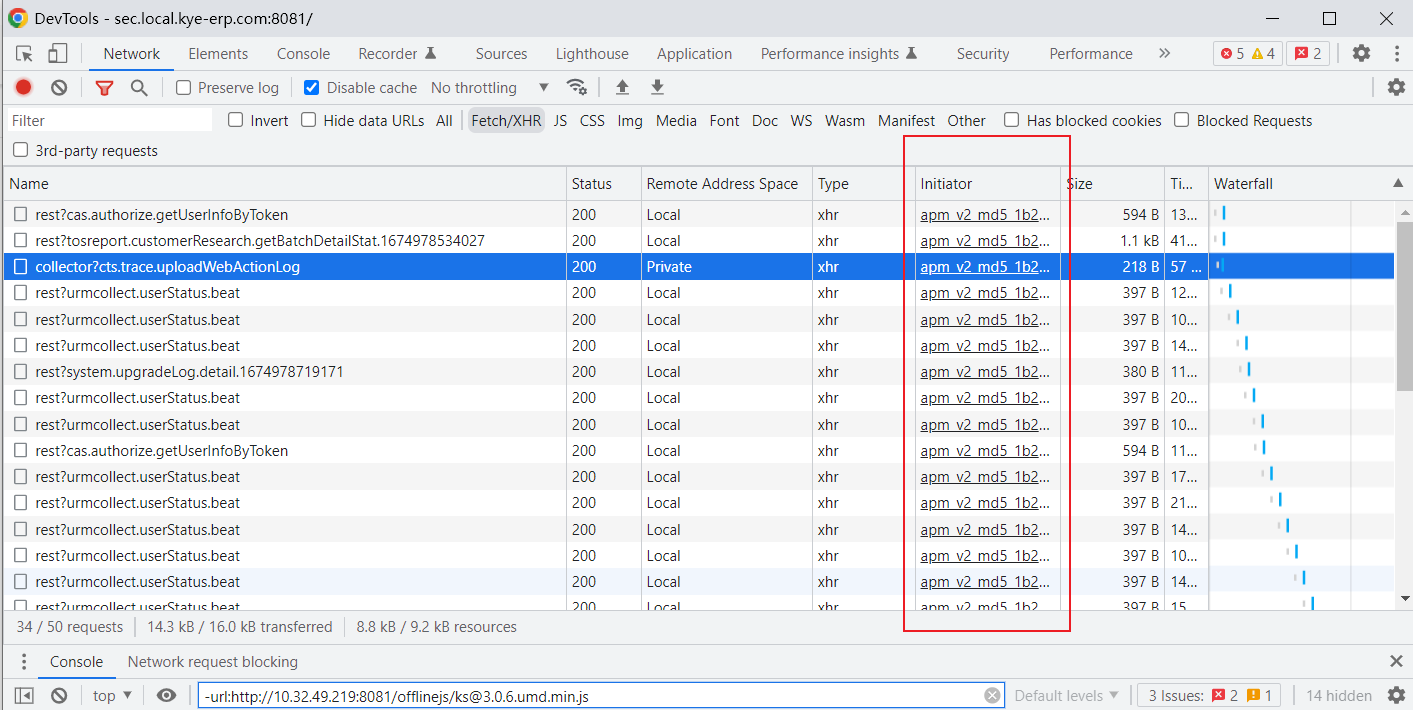
鼠标移入对应的接口处,就可以看到请求的执行栈,标红处是依次触发的方法,标蓝处是执行方法时对应的文件位置
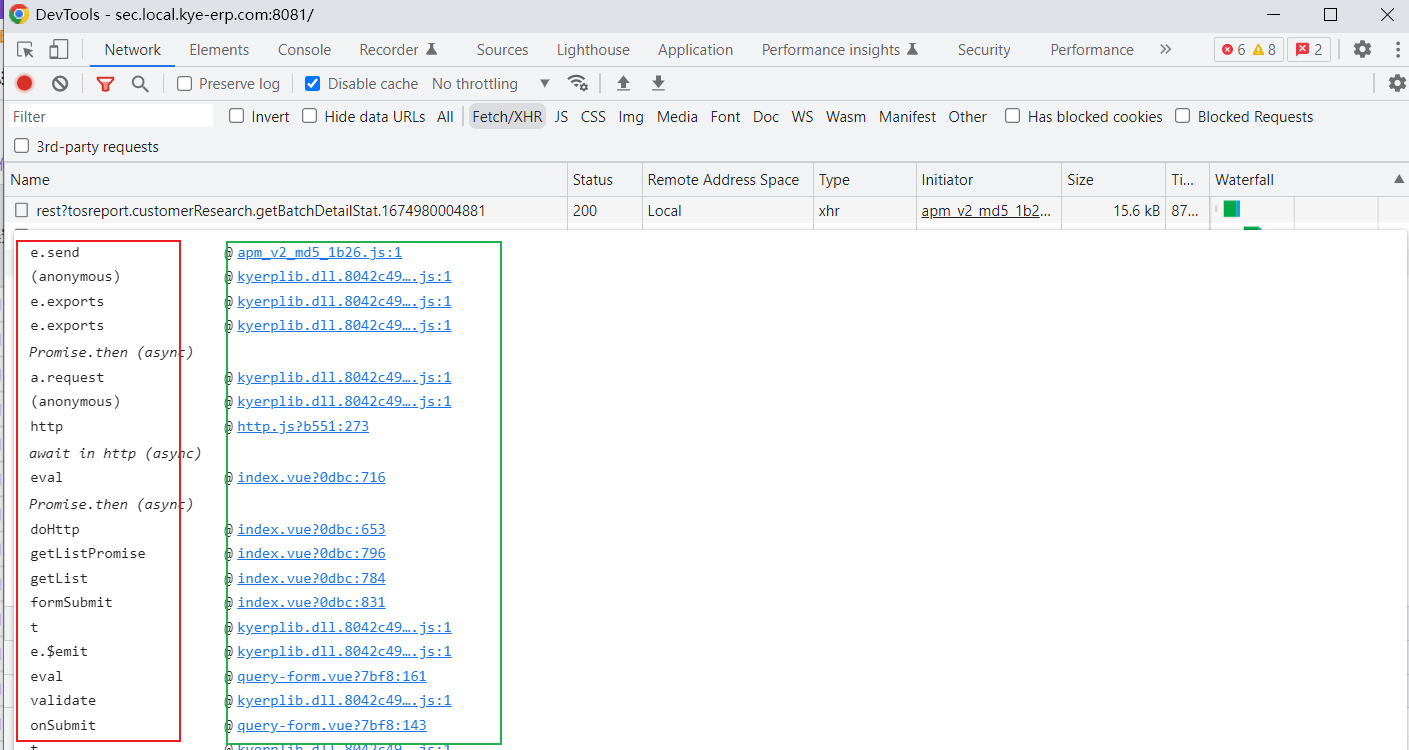
我之前用的是google浏览器的的一个插件,大多数朋友可能都有用过,就是GHelper。
但是在公司内部,不知道出于什么原因,也可能是内网的原因,这个插件失效了。所以只能另寻他法,终于找到了一个几乎不用啥配置的工具,但是也需要交一点点保护费。
在Mac上使用特别的简单,因为我本身的意愿就是找一个零配置的工具。
而且,Clashx在Mac上的表现也相当的亮眼,颜值还是不错的。
在交保护费的平台拿到clash的订阅地址,点开菜单栏的猫头,找到配置->托管配置->管理。把你的clash订阅地址贴到管理里面,之后更新列表,不出意外的话,在成功更新之后就可以看到代理服务器列表了。
我选择的代理模式是规则模式,打开系统代理之后。打开浏览器输入google看一下,不出意外现在是可以访问外网了。
这是不同于win10平台的一点,在window平台上,用浏览器的无痕模式可以直接访问外网,但是普通模式不可以,还需要用switchomage这个插件做转发。真是有够麻烦的。
最后,附上clashx在Mac平台的下载地址clashX,版本号是1.72.0。在Mac上使用极其简单的,几乎没有费什么工夫就成功的跑了起来,完全没有遇到什么麻烦。
在window平台的上的客户端不再是ClashX,而是Clash。都是一家人没什么太大的区别,都是基于go。不得不说,在各个平台使用Clash都很简单,几乎没遇到什么大的麻烦,但是在window上需要多处理一点。
在这里附上Clash的下载地址clash_for_window(https://github.com/Fndroid/clash\_for\_windows\_pkg/releases)。该链接来自于**github**,请放心使用。
首先,如果没有买飞机票,请先交保护费买一张飞机票,获得clash的订阅地址。另外还需要给google浏览器装一个插件Proxy switchyOmega。
第一贴上clash_for_android的下载地址:https://github.com/Kr328/ClashForAndroid/releases,该链接来自于**github**,请放心使用。
在进入app之后,引入眼帘还是熟悉的一个黑色的猫头。接下来的操作还是老一套,点开配置进入配置页之后,点击右上角**+**图标,会进入“创建配置”页。进入”创建配置”页之后,选择从URL导出,这里就是贴上clash的订阅地址。
完成这些操作之后,回到首页。看一下第一栏的文案,如果是“运行中”就表示已经正常代理了,打开手机浏览器,进入google浏览器,或者是打开twitter。如果是“已停止”就点击启动,不出什么以外,就可以正常使用了。
手机上的操作就这么简单。
只要是找的源足够靠谱,那代理的网速应该差不了多少,足够日常的使用。
注意:

在过去的一年时间里,自己除了工作就是工作,现在是时候做出一点点改变了,去玩生活去。
每一个人的身上的优缺点都是他的“闪光点“,而这些”闪光点“无时无刻不在反映着他自身。他永远也无法将这些闪光点抹除,不管它是积极的还是消极的。虽然无法消除消极的闪光点,但是可以隐藏,这一个过程给它命名一个名字——"搬山计划"。
整个人体,我把它当做一座山。你的优点和缺点全部集中在山顶之中,所以它们最显眼。而山脚处,则是普通地不能普通的个人因素。
现在我加入一个思考,当你接触观察一个新朋友的时候,你首先是关注他的优点,还是缺点?或者说,彻底影响你对他的个人看法是什么因素?
所以,我说:”自身修炼改造,犹如搬山。你永远也不能彻底改变沉疴旧疾,只能将山顶最引人注目的土往下搬。“
对于我而言,普普通通,平平凡凡,无人关注才是一种最佳的生活状态。
写字,读书,玩一些从未接触过的事物。
每一晚,我给自己安排了200字的控笔。
每一天,我给自己安排了2小时的阅读。
每一周,我给自己安排去逛一逛周边。
每一月,我给自己安排去见一见我在深圳的朋友。
现在,我对无人机很感兴趣,我似乎应该去买一个无人机玩一玩。
博客的前端项目基础功能终于做的差不多了,现在就差设计一下UI了,奈何我不是专业的UI,只能从前端的角度和一些专业的设计文档,去实现一下。
在我们构建网站的布局时,前端会依据设计图,设计网页。在开始工作前,我们会确认一些基础值,比如:
我对设计的初级了解主要来自于Antd Design的设计**,它们的组件设计的真的很棒!现在先用原生css实现一次,以后再考虑改为less。如下:
:root {
/** Base **/
--padding-base: 8px;
--margin-base: 8px;
--font-size-base: 14px;
--border-radius-base: 3px;
--line-height-base: 22px;
--transition-base: all .5s ease;
}基础属性可以配置的有很多,我先定义一些比较常规的属性,然后根据这些基础属性,延伸出一些派生属性, 比如:
:root {
/** Base **/
--padding-base: 8px;
--margin-base: 8px;
--font-size-base: 14px;
--border-radius-base: 3px;
--line-height-base: 22px
--transition-base: all .5s ease;
/** Margin **/
--margin-base-2: calc(2 * var(--margin-base));
--margin-base-3: calc(3 * var(--margin-base));
/** Border **/
--border-radius-2: calc(2 * var(--border-radius-base));
/** Line Height **/
--line-height-default: calc(var(--font-size-base) + 10 - 2);
}将这些派生属性的配置全部集中到一个样式文件当中,不要在组件中再次定义样式,以保证全局样式的整体一致性。
当然,派生属性的倍数设置,并不是简简单单的乘于整数倍这么简单,有一些相关的公式或者是规范,详情可以参考antd的设计文档。例如:
字号: 对于字号与行高的定义就是:lineHeight = fontSize+10 - 2。在Antd中基础字号为14px,相对应的行高为 22px,字阶的选择在3-5中之间,保持克制原则。
字重: 对于字重只建议使用3种,400、500和600。具体效果可以研究Antd的Typograph组件,赶紧按照标准实现一下自己的个人网站试一试。
字体颜色:个人认为,色彩还是很考验一个设计师的,因为需要搭配,整体搭配的色彩需要和谐,所以对于色彩的把握才是整个体系的重中之重。对于不同的应用场景有不一样的实现,需要提前定义好网站的主,次,辅助和标题的色彩。

暗黑模式: 给自己的网站准备一套暗黑模式是一个不错的功能,现在我们可以直接使用Antd的工具生成,站在巨人的肩膀上扩展,让我们的自定义开发快乐起来。
现在先试着将我们的基础属性定义出来。就用Antd官网的工具生成一系列的色彩值,在此之前我们需要定义一个主题色彩。除此之外,需要定义字体色彩、border色彩和shadow阴影。
最为关键的是,我们需要设计一下页面的布局结构。从我个人的项目来分,可以分为:
从「克制」方向来看,我做出了调整:
首先给文案类配置主题,达到一种视觉上的层次感。可以通过主题色系的不同的色彩,然后在页面上使用。
在上图中,定义了8种类型,可以按照上面的顺序,将生成的色彩,一一对应。但是可能也会有特殊的位置需要额外定义。比如我们现在需要生成两套文字色,以对应light和dark模式下的展示。
/** Light **/
--color-base: #ebecec;
--color-base-10: #0d0d0d;
--color-base-9: #333333;
--color-base-8: #595959;
--color-base-7: #808080;
--color-base-6: #a6a6a6;
--color-base-5: #b3b3b3;
--color-base-4: #bfbfbf;
--color-base-3: #cccccc;
--color-base-2: #d9d9d9;
--color-base-1: #e6e6e6;
/** Dark **/
--color-base: #141313;
--color-base-10: #fafafa;
--color-base-9: #f8f8f8;
--color-base-8: #f3f3f3;
--color-base-7: #e8e7e7;
--color-base-6: #dcdcdc;
--color-base-5: #adacac;
--color-base-4: #7e7d7d;
--color-base-3: #5b5a5a;
--color-base-2: #454545;
--color-base-1: #2c2b2b;一共生成10种色彩,用于对应上图的8种类型,可用的色彩还是比较多的,先定义一套最普通的样式出来。
--title-normal-color: var(--color-base-10);
--title-less-color: var(--color-base-9);
--text-primary-color: var(--color-base-8);
--text-less-color: var(--color-base-7);
--text-second-color: var(--color-base-6);
--disabled-color: var(--color-base-5);
--border-color: var(--color-base-4);
--divider-color: var(--color-base-3);
--background-color: var(--color-base-2);
--table-head-color: var(--color-base-1);偷个懒,直接用Antd的中性色,以color-7为基准,大于7的为Dark模式下的色彩,小于7的为Light模式下的色彩。
生成这些中性色有什么用呢?
我把它搭配使用在Card组件当中,中性色是以Gray色彩为基准生成的,灰色是百搭色彩,没有什么色彩能够比中性色更适合做背景色彩了。除非你需要自定义一些Alert或者的Message类型的样式,才会去给这些组件定义一些不同状态下的背景色彩。
在选择辅助色时,需要考虑到的是辅助色和背景色以及字色的搭配,需要好好准备一下色彩,最好是从选择的主题色出发,去选择相近的色系。
我们最少需要准备两套动画,即入场动画和出场动画。举一个例子,我们给一个标签做hover特效时,定义在hover类中的就是入场动画,比如使用ease-in,那么定义在当前标签类中的即为出场动画,比如使用ease-out,这个样子给用户的体验是不是有了一点点趣味呢。
如果需要将我们的页面细节做起来,我们可以给每一个属性都指定一个特有的出场和入场动画,那看起来就更美妙了,但是我觉得用两个动画就可以了。
现在我们的基础都是基于8px,几何倍数的增加或者是减少,这样看起来的页面的间距值就全部统一起来啦,从结构上确实好看,具体去看Antd的组件。我是觉得好看的~
除了8n这一种写法,还可以使用em单位和rem单位,em相对于父级标签的字号,rem相对于根标签的字号,也是一种结构性的写法。但是使用场景上有差异,用em单位我们通过Fontsize属性轻松实现自适应的组件,比如在项目中的AudioContronl组件和Button组件组,就是通过Fontsize来控制Audio按钮组的样式。
查询结果结构化是我在做google查询优化时接触到概念,我认为这个概念也可以用到我们的构建个人网站的查询结果中。
举个例子404页面,我个人认为:在类博客项目这种内容型项目中,我并不是想看一个枯燥的404提示,我更想看的是我查询的关键字在没有反馈的内容时,开发者给用户的交互是一种什么样的实现,才能吸引用户停留在我的网站中。
比如,我查询一个色彩关键字,我的网站上没有相关的博客内容,但是我不能给你一个简简单单的404,而是给用户一些推荐内容的快捷入口,引导用户点击进入博客内容页面,留住流量。
而资源类的404,可以给一些动画,或者是引入腾讯404服务的交互,让服务器端的错误或者是资源缺失,给用户一种丰富、有趣的体验。
在最近有一个主题卖疯了,就是华为商城的宇航人主题,它不就是靠着有趣才吸引了消费者吗,在短视频中火了后,不知道多少人为了一个主题去买了一块手表。可见,现在C端产品考虑趣味性的比重应该是比较大的。
为了弥补我们网站内容的缺失和资源缺失,给用户带来的不良体验,我们需要优化的点就是做一个有意思的Empty 空状态展示页。
在Empty中,我设计的结构是,一个简单的动画吸引用户视线,一组类bilibili中的火星文,一组引流快捷入口,如下图:

我们在写作时,工具会提示让我们选择是否启用专注模式,专注模式就是一种定制型设计。再类比一下,我们使用网易云App时有精简模式和普通模式,精简模式下,只有控制按钮组其他的什么都没有。
所以,一个网站能不能够吸引用户长时间停留,最为关键的点大概就是有意义的丰富内容和有意思的交互。让用户觉得好玩,让他自己去浏览、去玩。这样的网站才能够保证回访率。
单从设计结构来看,开发者可以给用户提供两套布局模式,比如:菜单固定在左的模型和菜单固定在顶部的模型。给用户提供两套视觉模型,Light型和Dark型,然后我们可以根据系统时间,默认给用户切换主题色。
或者,定义精简模式,在阅读模式下,减少系统相关的交互和按钮入口,新增一些阅读类型的按钮,比如:自定义行高、字号,自定义阅读模式下网站字色和背景色,有耐心的话,还可以给出一些国际化方案,例如,中英文切换或者是简繁体切换。
总之,需要我们动用一些时间和心血去做一些不一样的细节出来,把网站打磨的漂漂亮亮的,就可以比较大方的拿出去拉外快项目啦。
一个开发者的个人网站大概就是他的一个比较有特色的个人名片啦。我们前端开发者还是占据了大量的优势的,我们可以自己做一些自己想要的效果出来,我们自己就是自己项目的产品经理。
在Antd的设计文档中,始终在着重描述三个设计**:自然、高效和克制。始终在表达一种简简单单才是美。
在理想状态下,我们不太需要关注更多的细节,比如那个经典的撕逼话题:”你这个1像素能不能细一点点, 我看着就不像1像素“。相反我们需要去做减法,但是此减法非彼减法。视觉上的细节少了但是给开发的工作却多了。单是色彩就至少准备40多个,其看不见的工作就给了视觉上的简单赋予了另外的一种不简单。
做好一份设计并不是我以上描述的这么简单,有很多内容我们都不知道,毕竟不是专业的设计师,我了解的相关知识全部来自于书本。但是我们现在是从前端角度去分析一下下怎么去做设计,让我们的项目做得更好一点,更快一点,更简单一点。
简洁而不简单,把背后的工作留给自己慢慢品,把清新留给用户。
我在开发的过程中有了这么一个想法,可以一键推送至微信,qq空间,知乎还有twitter,但是一个微信公众平台的富文本编辑器的兼容就让我绝望了,我用的react-quill,跟我之前用过的wangeditor编辑器差不太多,要不是为了配合各个平台,我才懒得换呢,跟我之前用过的wangeditor差不太多,简单配置一下就可以使用。我还是决定换回Markdown,因为我发现了一个可以在线编辑online-markdown的网站可以完美兼容微信公众平台,现在我使用react-markdown。
react-markdown是一个编译器,它可以将字符串翻译成Markdown语法。使用起来很简单:
import ReactMarkdown from 'react-markdown'
const Markdown = source => (<ReactMarkdown source={source} />)现在就可以在组件中使用这个markdown的组件啦。当然这个就是最简单的使用,react-markdown还有很多的配置没有加上去,比如日常写文档需要的语法高亮。
在没有配置之前,react-markdow的背景是灰色,当然可以自己写一个样式表去配置所有的markdown中的所有标签,那就不需要这个插件啦。
yarn add react-syntax-highligher里面提供了两种模式,Prism和hljs两种,有一点点不同的差异,大概就是样式上和markdown支持的语言上有差别,其他的就没啥了。我用的prism,下面就是我的配置内容,当然才开始比较简单的配置,所有的功能都可以自己加上去。如下:
template这个只是react-markdown的展示型组件,使用提供的一个属性:renderers, 如下:
这个就是基本的为react-markdown的配置theme主题,我比较喜欢atom的主题,我的vscode也用的atom,所以我选了atomDrak作为我的主题啦。
下面介绍一下怎么在Antd的Fom组件中使用已经封装好的ReactMarkdownEditor,有很多种方法去在Antd.Form中实现双向绑定, 我个人理解就是全局始终一个form对象,v4版本中引入了Form的hooks,可以这么使用:
import Form from 'antd'
const CustomForm = () => {
const [form] = Form.useForm()
const { setFieldValues } = form //就是这个方法去绑定value
}区别一下受控组件与非受控组件,textarea的value--htmlString值就是依赖于外部传入的value字段,
所以在初始化时将它映射一下,通过的组件内部的onChange事件上传value值。回到Form的双向绑定。
可以看到我实现双向绑定的做法就是form对象中的setFieldValues与getFieldValue。
作为Form.Item的children,它会有一个id字段作为props传递给后代元素。这个id值就是Form.Item中的name字段的值
这里我思考了一下,Form.Item是不是一个高阶组件呢?如果是一个高阶组件,为什么只给子组件下发了一个id字段?
如果有更好的实现双向绑定的方法可以联系我,我想了解一下更多的更秀的写法
同样的代码到了前台展示的时候,会遇到一个比较的扯淡的问题,那就是全局引入的样式
,暂且叫global.css吧,这个文件就是项目全部模块样式的入口。样式覆盖了咋办呢?可以看到的是react-syctax-highlighter的样式没有做模块化,标签全部被global.css 覆盖了。
小可爱们,那就只有再写一个markdown.css 去自定义美化你的样式啦
不要停步不前,每一天都要做出一点改变。
在开始分析之前,我想是不是需要一些数据模型来判断,在2021-2022年度我的个人发展是曲折向前的呢,还是原地踏步呢?
回头一想,还是算了吧。没有必要这么卷自己了,下面的数据留给阅读者自己对比吧。
书本之外的世界很大,书本之内的乾坤也不小。
现在,我不爱和人谈论的内容之一就是: ”你最爱看什么的类型的小说“,那没有意义。
和去年一样的套路,还是先列出今年的书单吧:
人的耐心是有上限的,每一个人的上限都会不一样,甚至于每一个人在不同的时期面对相同的事情,其承受度都是弹性的,比如我对《剑来》的耐心已经消磨完了,越来越看不下去了。作者对其热门IP产品的消费是不是也要考虑一下读者的想法呀。
我喜欢古龙小说,他对笔下的大侠们战斗方式和战斗场景的描写极其简洁,往往几十个字就描述了一段精彩的战斗或者是前文铺下的伏笔,最后揭露出来让人大呼过瘾,只叫痛快。武侠小说和这种玄幻小说又有什么差异呢?这么多年过去了,我们仍然爱着古龙,和他笔下的那些大侠。
《基督山伯爵》是本年度内耗时最长的小说。不得不说作者设计的一些场景起承转合,尤其是终章善有善报的结局,当然最让人受不了的是那种不缺钱的“钞能力”。
等待和希望就是基督山伯爵一生的写照,他的上半生经历了被人陷害入狱,陷入了无尽的黑暗与等待之中。出狱后获得宝藏,在逍遥与复仇之间抉择,当然最后的结局是他复仇成功,那他呢?在复仇过程中,他的得与失孰多孰少呢?他失去的是那一个青春与活力的少年之心,在谋划复仇的过程中已经不复存在了。那他得到的呢?
所以他的上半生的关键字就是等待。
伯爵是一个善良的人,他宽恕了他的敌人,他原谅了背叛了他的恋人,他挽救了另一对陷入热恋的男女,同时他也拯救了自己。他不敢想一个高高在上的公主居然爱上了自己,当他带着公主乘帆远航,又回到了无边无垠的大海时,他在上半生失去的,在下半生重新得到了。人世间最幸福的事情莫过于失而复得。
所以他的下半生的关键字就是希望。
朋友们不要失去希望。
我发现日本特别喜欢三国题材,不信你去看一看《银河英雄传说》。其故事架构计划和《三国演义》一毛一样,不同的是,其故事时代在未来,将战场嫁接到了太空。
刚开始我想看一看他能写出什么不一样的故事,现在一看,还是别了吧。看《三国演义》更加的原滋原味。
我在看电视剧”一计害三贤“时,看到了一条弹幕,汉大将军起于卫青而终于姜维,姜维别号“天水麒麟”。多酷啊!!!
而在姜维出场之前,那么多的风流人物,俱往矣!
我在回乡的途中读完了《夜谭十记》的前五篇,在返程途中读完了后五篇。是巧合还是有意为之?我说不清了。
一群科员,一群无所事事的科员,一群喜欢乱扯谈的无所事事的科员,一群喜欢乱扯谈的无所事事的坐冷板凳的科员,最后留下了十记。
他们是那一个时代的缩影,流水的官老爷,铁打的科员,一成不变的是底层的劳苦大众。
峨眉山人,羌江钓徒,三家村夫,无是楼主,不第秀才,山城走卒,巴陵野老,穷通道士,野狐禅师,砚耕斋主,我还记得的这些科员的雅号,仿佛我也身在其中,他们带着令人心酸的往事,迎面走进屋来。
各位,容我先泡上一壶茶,再摆上几条板凳。来吧,开摆。
“搬山计划”一直在继续,但是执行地断断续续。
我越来越喜欢写字,但是字一直写得不好看,以前信笺上的开头都写一句“见字如面”,如果我给一些朋友写信,那他们一定看不下去。
我知道字的结构要合理了,字才好看。用笔的力与势要中庸协调了,字的结构就合理了。但是我却不得入其门,我反思得出结果,其一练得少,其二路子野,其三任意潇洒,不循其法,不得其势,其四我再也没有那么多的精力了。
过刚者易折,善柔者不败。
“搬山计划”的最终目的就是训练自己,以中正平和为目标,磨练自己的冲动随性。半年多过去了,我个人认为还是得到了一些矫正。
一阴一阳之谓道,典出《易经》。我仔细地回味了一下,决定随意发挥一下,一撇一捺之谓道,以合方寸之间。
动与静两种态,就好比是阴与阳。互相成就,互相印证,此消彼长。
在自我磨练的过程中,我的“动”态慢慢地被消磨掉了,我的熵变低了,变得相对稳定了,换一句话说,我变得成熟了。
今年,我27岁了,我还很年轻,还有很多人没有遇见,很多事情没有经历。或许在不久的将来,我会选择冲冠一怒,也会选择沉默不言。
这是合理的,人不可能永远是被理性武装的动物,“动”和“静”就是一种动态的,互相**和互相抵御的过程。我甚至认为理性都是动态存在的状态,时间的不同,空间的不同,场景的不同,都是影响调整状态的元素。
redux家族中又多了一个新朋友,rematch。结构与dva相似,打算在三月份做一个音乐播放页面,与网页顶部的播放器控件联动。
express阵营中也多了一个新朋友,nest。号称是nodejs化的spring boot,用了一下确实很简单,让我想起了很久之前的用过的angular,写起来很爽。
简单的玩了一下AST转换,玩的很吃力,不是很懂,有很多的问题没有解决,最大的问题就是,有很多问题出现了都不知道怎么描述我的问题,这才是最大的问题。
github actions让自动化变得简单。github官网有一个菜单入口MarketPlace,没错里面就是一些常用的actions,具体怎么玩可以看github官方案例,也可以先看一下我的Github Actions 自动部署应用实现笔记。
docker让我的应用部署起飞。我的应用已经全部docker化了,可以先看一下我的实现Docker镜像的制作与使用。
NeteaseCloudMusicApi支持了音乐播放列表的后台动态控制。我的播放列表终于不再裸奔了。
mongodb嗯~~暂时没什么,好像有一些新的比较好玩的工具,没时间去试。
nginx-js可以用js的语法去配置nginx了,这个不错,我想去尝试一下,刚好马上证书到期了,这个很期待。
webComponent仔细看了一下github的网站结构,我发现好像github早就开始使用webcomponent了。试玩了一下,感觉还是很不错的,要是可以把组件的事件代理解决一下就好啦,如同react一般地去使用component元素。
preact相当舒服的react mini版本,基本适配了react的全部api,使用起来还是不错的。
webpack5 和 vite今年的明星项目莫过于vite了,试了一下vite+v3感觉相当棒,顺便把之前搭过的微前端的基座应用换成了vite。
在去年我看过了一系列的纪录片,相比现在的一些电视剧,纪录片都比他们有意思。
卸载抖音我丝毫没有犹豫,那没什么大不了,但是b站让我很难做呀。
我几乎每天都混迹在B站,今年的我很幸运见证了最快百万王冰冰,可鸽可泣小约翰。美食主播盗月社带给我的是快乐,嘉佑生宣让我重新认识了那些课本上的熟人,想不到短短的一句“庆历四年春”的背后居然还有这么多的波折。
我喜欢《深夜食堂》,也说不出究竟喜欢哪里,或者是喜欢哪一些人,可能只是喜欢日剧夏日午后般的平淡。尤其推荐《凡人修仙传》,看的很爽,真的很不错。
《肖申克的救赎》是我每年必看的电影,他提醒着我无论在什么环境里面生活多久也不要放弃自己,永远保持希望,不要被环境同化。
《怦然心动》令人触动,我到哪里去找我的初恋,你大爷的,为什么我现在才看这部电影~~
《戚继光》短短的六集所展现的内容比起那些三十几集连续剧强太多了,我觉得电视剧可以退出历史舞台了,把钱拿来做方块人都比他强。
《湮灭》根据《遗落的南境》改编,说实话很受震撼,但是电影最后所表达的究竟是什么意思,顶塔消失了,他们已经是新人类了,始终牢记是反射而非复制。
更离谱的是,可以看到各大高校的课程分享,我已经在b站看过了好几个up主赏析《红楼梦》,而且讲起来条条是道,很感慨啊,我还是书读少了。因为我看到的和别人看到的差别居然这么大。
除此之外,我还在b站里面找到了一些专业相关的课程,有关于nodejs、mongodb、flutter和docker。学习的平台已经搭建好了,接下来就是看自己寻找靠谱的视频资料了。
直播行业将会是这个娱乐时代中最普遍的职业,门槛最低的职业。只需要一台手机就可以开启直播了,我试着玩了一下B站的直播,操作很简单。当然有时间会看一下游戏直播,我最近很喜欢iwanna这个游戏,注意可不是喜欢玩,是喜欢看别人玩。
如何开启自我保护机制?如果没有答案,那就戴上耳机。
每天早上醒来,已经形成了一种习惯,首先打开网抑云,随机播放。出门时戴上耳机,隔绝了整个世界。如果可以打字交流,绝不会说话。
我沉迷在《金风玉露》当中无法自拔,它真的很好听~~
笛声悠长,散播这无尽的缠绵哀怨。我看到歌名就联想到了“金风玉露一相逢,便胜却人间无数”,不知道他在期待着什么,只知道留下的是如汉水般连绵不绝的遗憾。
来,拿出笛子,先来一个欢快的,让大家折磨一下。
遇到问题不暴露,暴露之后不解决,解决之后不总结,总结之后不记录,等于这个问题我从未经历,从未解决。
各位客官,别太相信自己的大脑,它的存储保质期真不太长~~
现在真实地发生在自己的身上,是因为年纪的关系还是其他的问题,很多东西长时间不去接触,再次谈论的时候我发现,我的记忆是一片空白。很多问题分明之前已经解决过,但是一些重复问题还是需要去google一下。
所以现在遇到问题了,我会提前把问题截图记下来,相关的google链接也会记下来,提供一些简洁的描述,增强自己的记忆力。它就是我的问题检索索引,最重要的是,不要简单的复制粘贴,手敲一下增强记忆。
不求甚解的理念不适合专业性较强的问题。业务相关、专业相关的文章应该持有的态度应该是庖丁解牛,而不是不求甚解。我现在一直在看之前群里发的一些面试题,并不是为了准备面试,而是面试题里面体现出了很多我不会,不了解的东西。我认为专精是专业性文章的指导方针。
记录和归类貌似也是一个学科,每一个人都需要自己去寻找适合自己的方式,以达到构建一种高效的储存和读取模型。我曾经在b站上面看到了一个分类的视频,看到之后很受教育,但是我现在仍然在摸索的过程中。
分析问题,一般我是围绕几个点:“是什么?为什么?怎么做?”。首先分析一下他是什么类型的问题,我之前是不是也遇到过类似的问题,那样就可以快速检索得出结果。既然是与之前遇到的问题相似,那它为什么表现出了一个独有的特性,那是不是也有其他的问题延伸出来。最后已经列出了全部的线索,结合一下前期的遇到的问题和解答步骤,尝试做出针对当前问题的解答。
从分析问题到得出结果,它是一个过程。能不能分析出什么问题是前期准备,能不能解决问题是最终结果。也许很多情景下,我的能力不足以解决我分析出来的结果,但是我相信一定有解决这些问题的高人存在。所以,有没有解决问题的能力,并不影响我尝试分析问题。
又一年结束了。
我还是一如往常,没有长进,没有改变,孤身一人。
乾上坤下,又一年开始了。
下面是用Mixin混入函数玩的一个*操作

现在的应用虽然看着页面很多, 但是很多的相似的页面实质上用的是同一个Component页面, 里面可能写满了v-if, v-else或者是v-else-if. 业务逻辑越复杂, 条件判断越多, 看的眼花缭乱. 页面不变改变的其实是写满了alias路由别名, 就像这样:

为了配合这种写法, mixin可以玩的飞起, 上面就是mixin的一个http请求插件, 搭配浏览器的地址栏配置一下执行事件,搭配promise.all 可以轻易的完成一个Promise队列,完全满足平时写的fetch类型的请求, 因为他也是Promise, 相互依赖的多个接口可以很好的在队列中实现。
下面是实现的效果图
既然是请求, 肯定会有这样那样的参数, 怎么破?
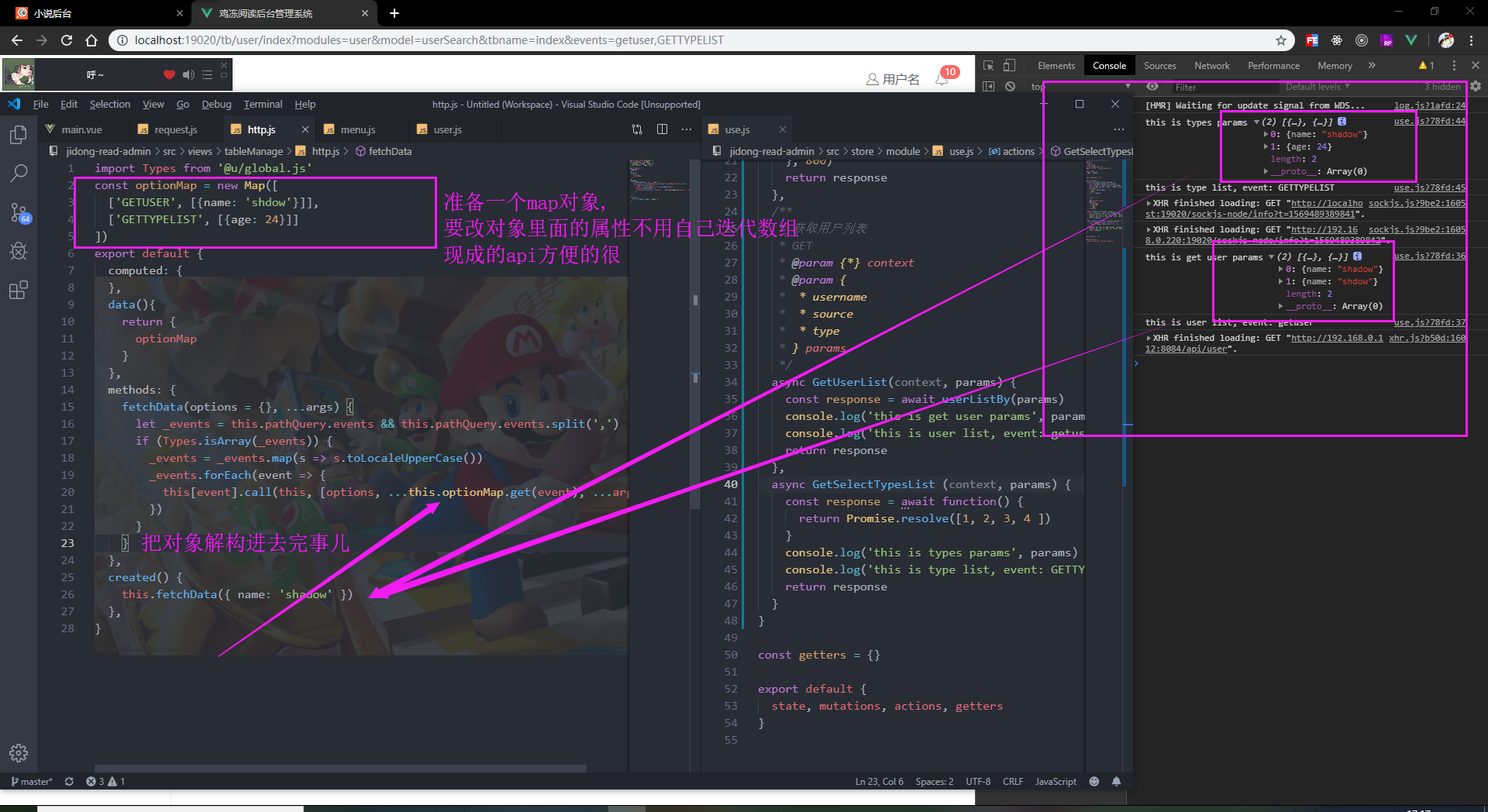
Map对象可以完美的解决任何问题, 他的键值对不受到拘束, 可以是任何类型, 你甚至完全可以使用正则表达式来适配你映射出来的事件名, 这样就要求你的事件名非常有规律, 形如:
// 导出事件
export const handleGetSome = () => { to do }
export const fetchSomeBy = () => { to do }
export const export2Excel = () => { to do }
// reg
var handle = /^handle?[Get|Post|Any]*/gi
var feat = /^(fetch|export)?By$/gi是不是很easy
代表源, 可以通过 git remote 获取该项目下的全部源, 如下:
所以命令可以这样敲:
git pull origin与push的指令相反, 推送的时候冒号前面的指的是本地分支名,冒号后指的是远程分支名如下:
# 如果分支同名可以省略冒号后面的远程分支名
git push -u dev[,:master] remote 表示远程分支名
git pull origin remotelocale表示本地分支名
git pull origin:locale上面代码表示拉取远程的remote分支的更新至本地的locale分支
四天之前我开始迁移我的Github中的issue, 把我之前的日记迁移到了微信公众号和服务器, 中间遇到了富文本迁移的时候, 样式差异大的问题, 于是我换回了Markdown.
所以有了之前几篇的关于Markdown的踩坑记录, 自定义处理了一下前台渲染时的样式. 第一期的开发到这里基本就全部结束了, 现在它们上线了.
后台我用的是Node, 搭配的是node社区常见的技术, 如下:
为什么选择了Express这么一个框架呢? 我的考虑有以下几点, 总结一下:
Nodejs与前端息息相关, 比如说: npm, webpack. 为什么我说我一直在使用着Node, 因为脚手架里面那几条经典的命令:
npm install vuex
npm view vuex
npm run start
npm build慢慢的我了解到了一个名词叫做环境变量NODE_ENV, 于是我开始自定义脚本, 我想开启Mock服务器我就可以敲 npm run start:mock, 现在我需要发布测试包我可以敲 npm run build:test
再后来打包的体积太大了, 严重的影响了网站的加载速度, 我需要优化打包我的项目包, 于是我开始使用webpack提供的插件了.
所以每一个前端都离不开Nodejs, 既然离不开那就好好学习它!!!
既然是后台开发肯定是离不开数据库的, 因为我做的并不是云应用, 没有给我那种技术支持, 使我不用自己开发Api. 那么对于数据库, 我选择了MongoDB.
Mongodb是什么? 它是一个NoSql, not only sql. 底层基于c++, 是不是有点眼熟呢?
当然使用原生的api写起来稍微有一点点繁琐, 比如对于一个文档的查询:
db.collection.find(query)
db.collection.find({ name: 'shadow', age: 20 })
db.collection.find({ gendor: 1, age: { $gt: 20 } })在设计文档的结构时缺少了sql中对value的强限制, api的操作过于繁琐, 于是乎有了类似于mongoose的驱动, 让我们可以在Nodejs通过npm直接使用.
在开始学习时我使用的原生api, 现在我使用mongoose. 为什么使用mongoose, 有几点原因:
我就不过多的描述了, 已经贴上了官网的地址, 可点击链接去查看一下它提供的api. 以后也会一边学习mongoose的玩法, 一边更新文档, 有兴趣的可以一起学习, 共同进步.
一种鉴权的实现, 现在的鉴权大概有这么几种:
前端在于服务器端交互时, 在涉及到访问权限时, 处理的方式也有以下几种:
现在我用的就是jwt, 说到这里我一定要正式向一个老哥道谢, 他是一个老外Andela, 他写了一篇博客就是介绍JWT Authorization, 但是不仅仅是JWT, 而是介绍了Express+Mongoose+JWT用法, 而且非常用心的分析了代码, 标注了使用步骤.
如果碰巧你也是一个node新手, 也想写一写后台应用, 应该去看一看JWTAuthorization
既然是一个后台, 怎么可能没有文件上传这个必不可缺的功能呢. 社区里面使用的比较多的文件上传中间件那就是multer.
我从未接触过后台, 我印象中的文件上传是一个很复杂的功能, 比如说: 上传文件类型的限制, 进度条的实现, 大文件的分片上传, 以及前端的断点续传. 你看其实文件上传的内容并不少吧.
但是有了这么一个中间件以后, 我所需要的工作就是, 配置一下上传的文件夹, 然后按照我的想法重置一下文件名, 之后结束.
我为了文件上传这么一个功能准备了一天, 我一直在社区里面看文档, 比较不同中间件的玩法, 让我没想到的是收尾原来这么简单.
这个没有好讲啦, 我只用在了一个位置, user_password加密.
现在终于讲完了后台系统的基本结构, 做一个总结吧:
1. 在没有尝试的前提下, 不要小瞧任意一种技术, 不要轻谈它的难易程度
2. 在没有尝试的前提下, 不要请看任意一个功能点
3. talk is cheap, show me code
最后贴上几篇博客:
还分不清 Cookie、Session、Token、JWT?
我深信,独立开发模式下的开发者们是不需要过多操心我们的代码管理的,更不会担心我这一次的合并会不会有冲突? 有冲突了我怎么去改? 代码改乱了我怎么办?之类的问题。
代码的版本管理工具有很多,它们从性质上分为:商用与开源,从管理方式上分为:集中式与分布式。商业以BitKeeper为代表,开源首推SVN与Git。而现在Git成为最受欢迎的代码管理工具之一,离不开我们熟知的Linux之父Linus以及全世界为开源工作的开发工程师们的共同努力。
在两个星期之内,Linus用C语言完成了Git的初代版本,一个月之后Linux的源码由Git接管。
Git的快速风靡为开源世界带来的变化,在我们现在的日常工作中深有体现,比如:Github、GitLab、Gitee、GitBook。从命名上看来,我们可以猜测它们都与Git有关,实际上它们都是基于Git。尤其是Github,上面聚集着大量的开源项目,为开源项目提供着免费的托管服务。
一切的一切都让我对开源才是未来这个观点深信不疑。
既然使用了Git,我们的代码管理还是遵循Git的工作流吧。Git与Linux一样,随处体现着开源项目的无限魅力,让每一个开发者心中都有了一个属于自己的Git或者是Linux,其魅力主要体现在多样性、扩展性。
workflow工作流有以下三种:
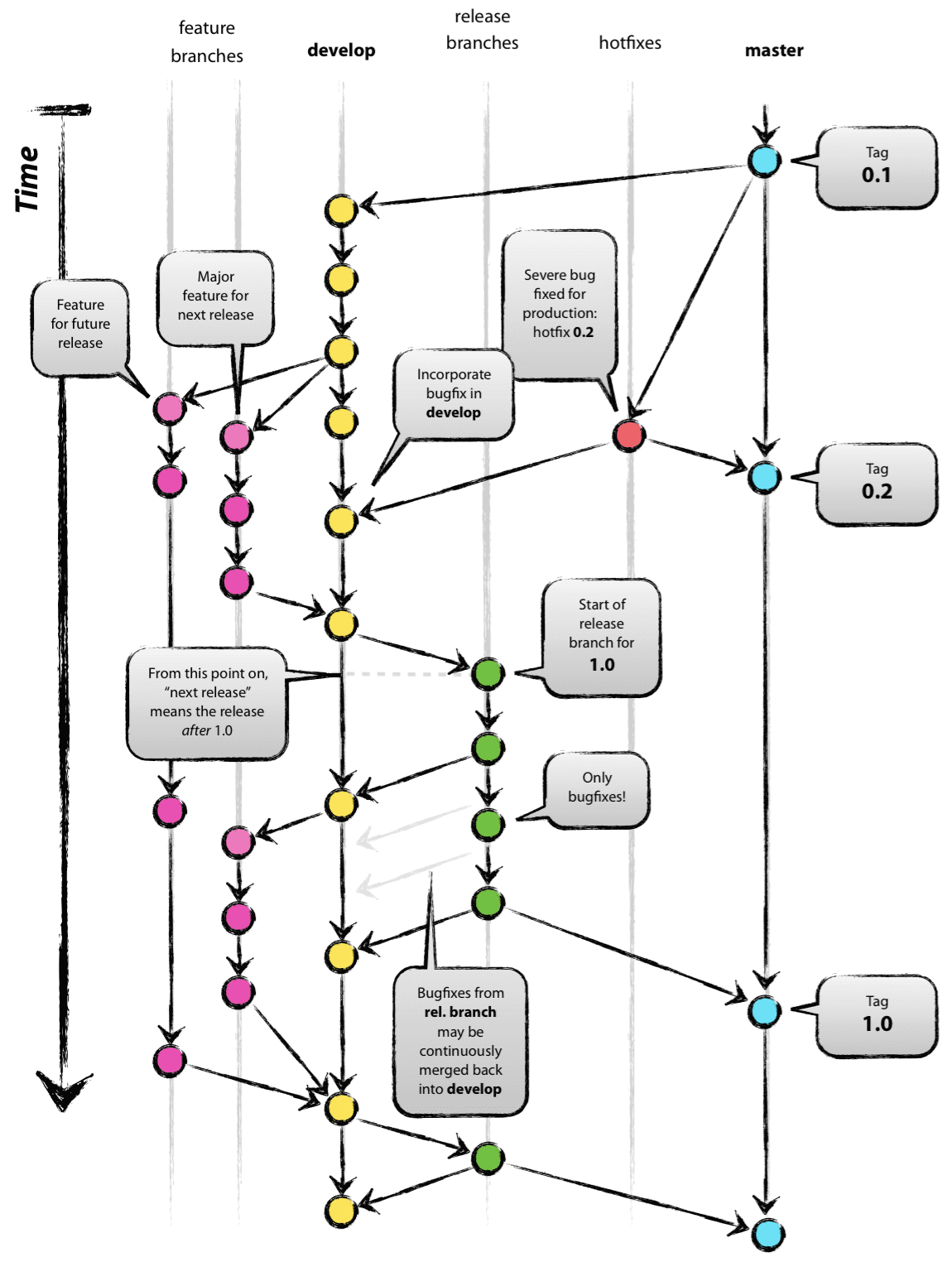
既然在git中存在着多种管理方式,那么每一个团队都需要寻找适合自己团队的代码工作流。我们前端团队选择的是gitflow工作流,其示意图如下:
其特征是:始终保持两个常驻分支,其他分支即为辅助分支,辅助分支合并之后可以随时删除,并不影响其常驻分支。
GithubFlow工作流的管理方式相当特殊,它只有一个分支master,而且受到了保护,有一个专门维护的开发者负责核查合并每一个pr。每一次pr操作之后,设置的github actions自动触发进行CI操作,通过后即可发布relaese版本。
Gitlab Flow工作流是一个混合了GitFlow与GithubFlow特性的新生代工作流,从常驻分支Master和Dev中检出一个release预发布分支,业务代码发布上线之后稳定之后将代码合并入Master分支,并且打上一个Tag版本号。于是我们的代码终于可以配合一些管理平台,快速部署了。
现在我们亲手实现一个简单的GitFlow工作流,一起动手吧~~
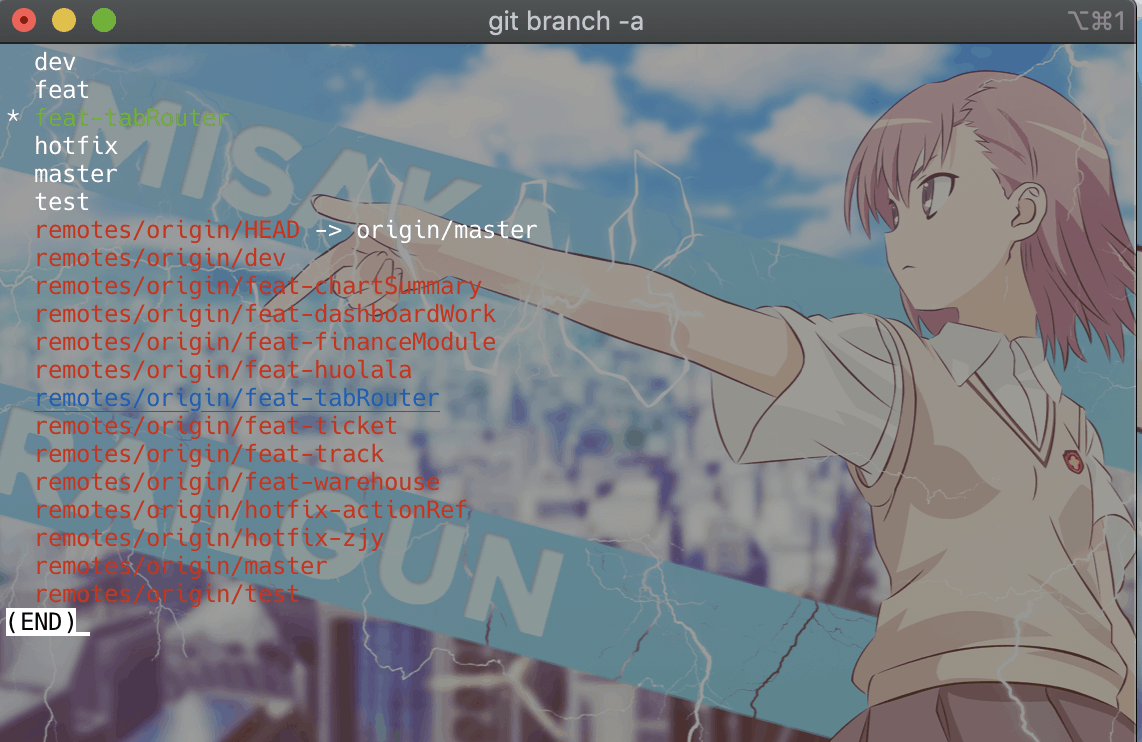
git branch
git branch -agit branch 可以查看本地的全部分支,git branch -a 可以查看该源上的全部分支,若要查看远程的全部分支可以使用, 如下图所示,前缀以remote/origin开头的即为远程分支名。
git branch -rorigin为当前代码的远程源之一,如果要查看全部源可以使用
# 查询关联源
git remote
#$ origin
# 查询源信息
git remote get-url origin
#$ [email protected]
由上图可见,我们本地已经有了master分支了,gitflow规范dev分支的上游源只有master,所以我们需要从master分支检出一个dev分支
git checkout master
# parent branch master
git checkout -b dev好啦,现在我们的常驻分支已经全部在我们的工作区啦,现在我们需要管理我们的团队代码啦,我们的前端代码以功能模块区分,新功能以feat-*开头, 其操作如下:
git checkout dev
git checkout -b feat-module-name现在我们组内的一个前端开发人员在feat-module-name下开发一个混合查询功能,另外一个前端开发需要开发一个新增以及编辑的表单,所以他需要从dev检出一个feat-module-form
现在我们以这两个功能作为我们工作流的示范。
开发混合查询的前端工作的效率很高,功能很快就开发完成,通过了内测现在进行到了提测阶段,所以我们需要一个辅助分支test用来配合测试环境。现在我们需要将查询功能合并进入test分支啦。
初始版本的test分支应该由dev分支检出
现在我们将第一个新功能进入测试环境
git checkout test
# 不要使用快速合并
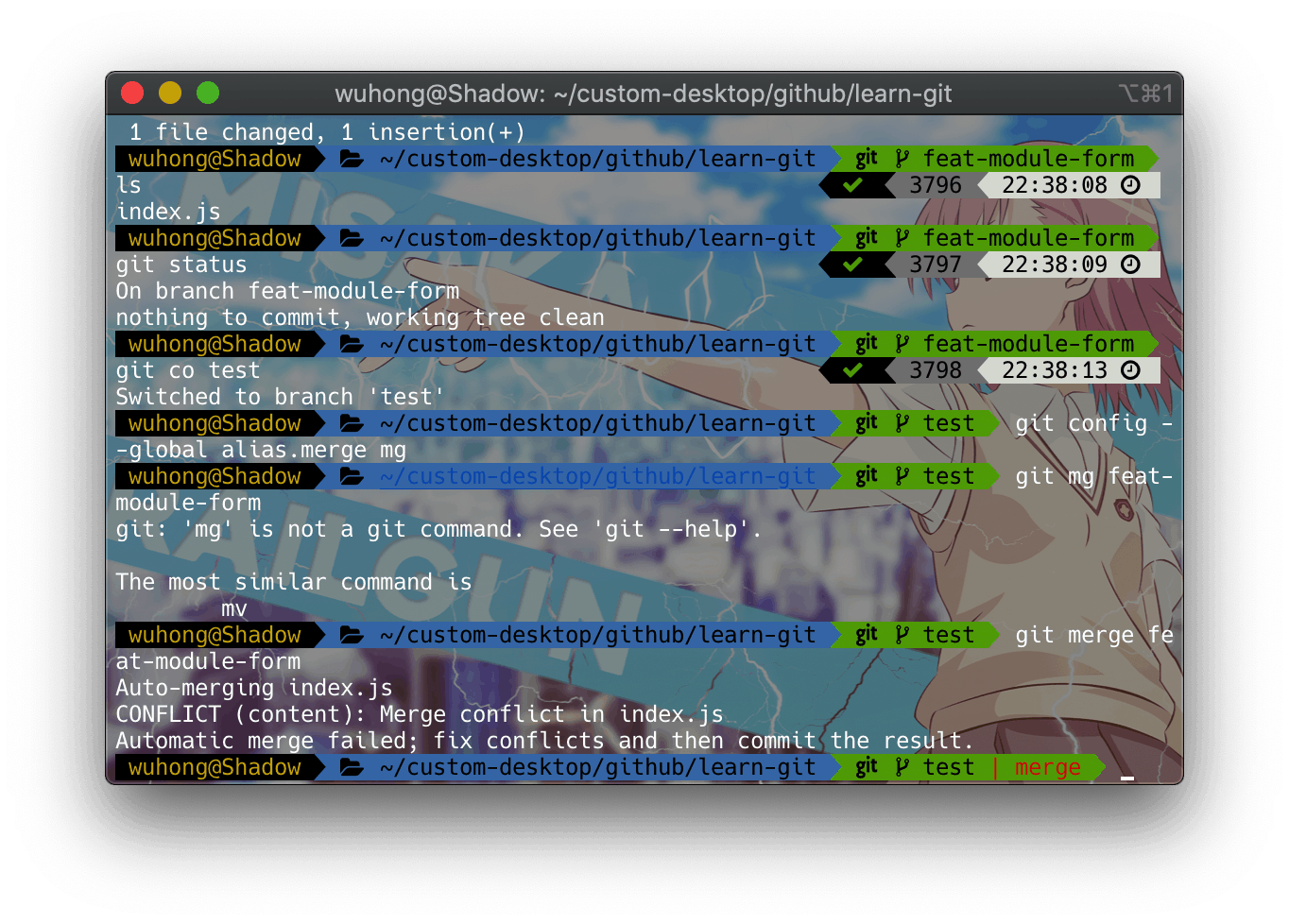
git merge feat-module-name --no-ff现在我们的另一个功能的开发也开发完成啦,也需要进测试分支啦,同理我们合并进入test
git checkout test
git merge feat-module-form --no-ff成功合并的提示并没有如期的出现,反而是出现了一串英文,我们可能不认识全部,但是绝对认识一个单词, 它就是团队开发的口头禅: 卧槽 又冲突了, 没错它就是 CONFLICT, 翻译一下就是冲突
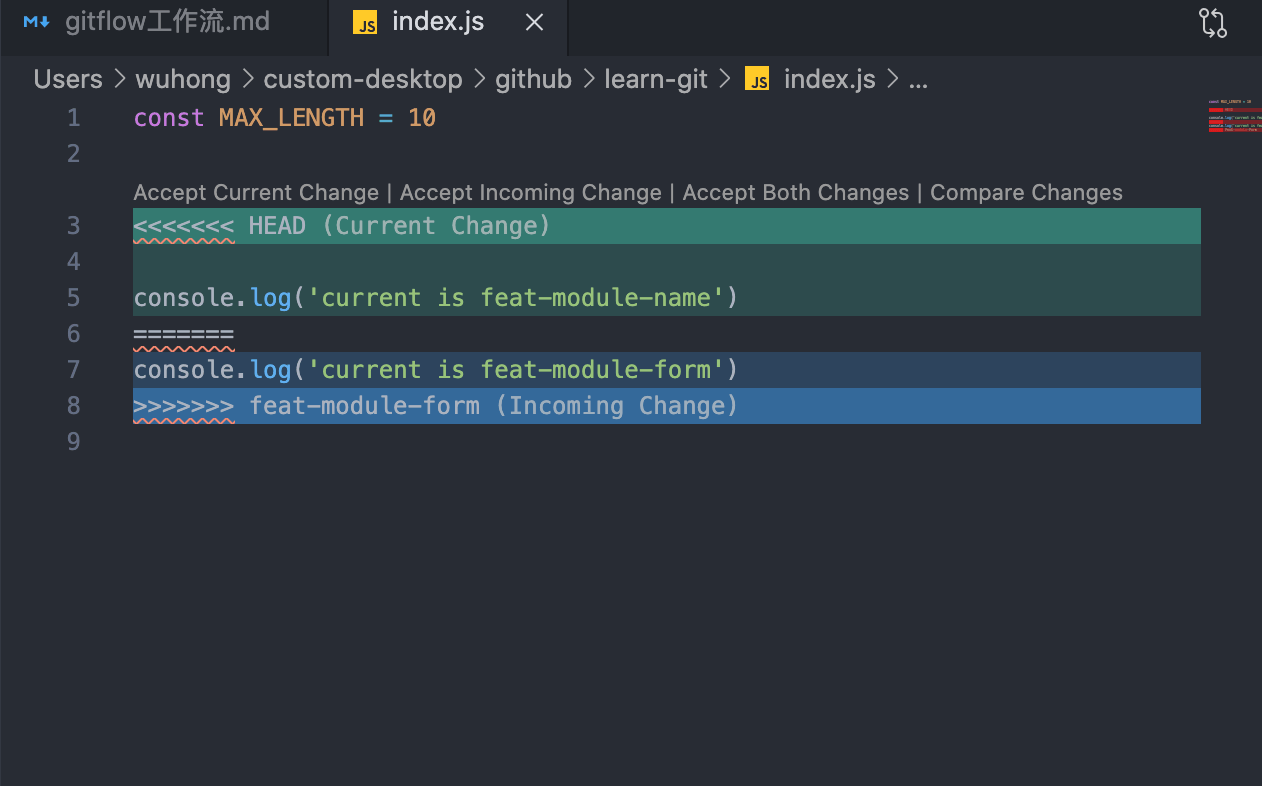
如上图: 是由于我们两个前端在两个分支中同时修改了index.js文件,命令行中也指出了我们冲突的文件位置,那么我们应该怎么修复冲突才算是正确操作呢?
首先不要轻易的选择Accept Current Change / Accept InComing Change / Accept Both Change。
我们必须有相当清晰思路,现在我们是两个新功能先不考虑Bug修复的代码冲突,查看一下冲突代码前后文是否有相关联的代码,再决定怎么解决我们的冲突。
现在我们将模拟代码全部保留, 记住解决冲突之后一定要将冲突文件再次提交,最后才是推送远程。
我们回到测试分支,现在的测试分支有了两个新功能了,我们可以通知测试工程师们,可以跑一下脚本啦,代码已经上测试啦。
经过第一轮功能测试之后,测试工程师们提交了好几个Bug,首先是feat-module-name 有一个条件查询无效,其次feat-module-form 表单重新编辑提交报错啦。
好吧有了bug了,我们再次回到我们的工作分支feat-module-name 处理了bug之后合并测试,feat-module-form 也处理完成了,合并之后推送远程测试分支,进行第二轮测试。这一次测试很顺利,我们的功能通过了测试,我们的代码也要合并进入dev分支啦。
操作与发布测试环境相同,代码成功进入了dev分支。现在我们的测试工程师需要进行回归测试,针对于全部功能点来一次回归。
但是现在出了一点状况, 我们的混合查询功出问题了,时间上已经来不及了,所以我们选择这一次部署,要移除这个查询功能。
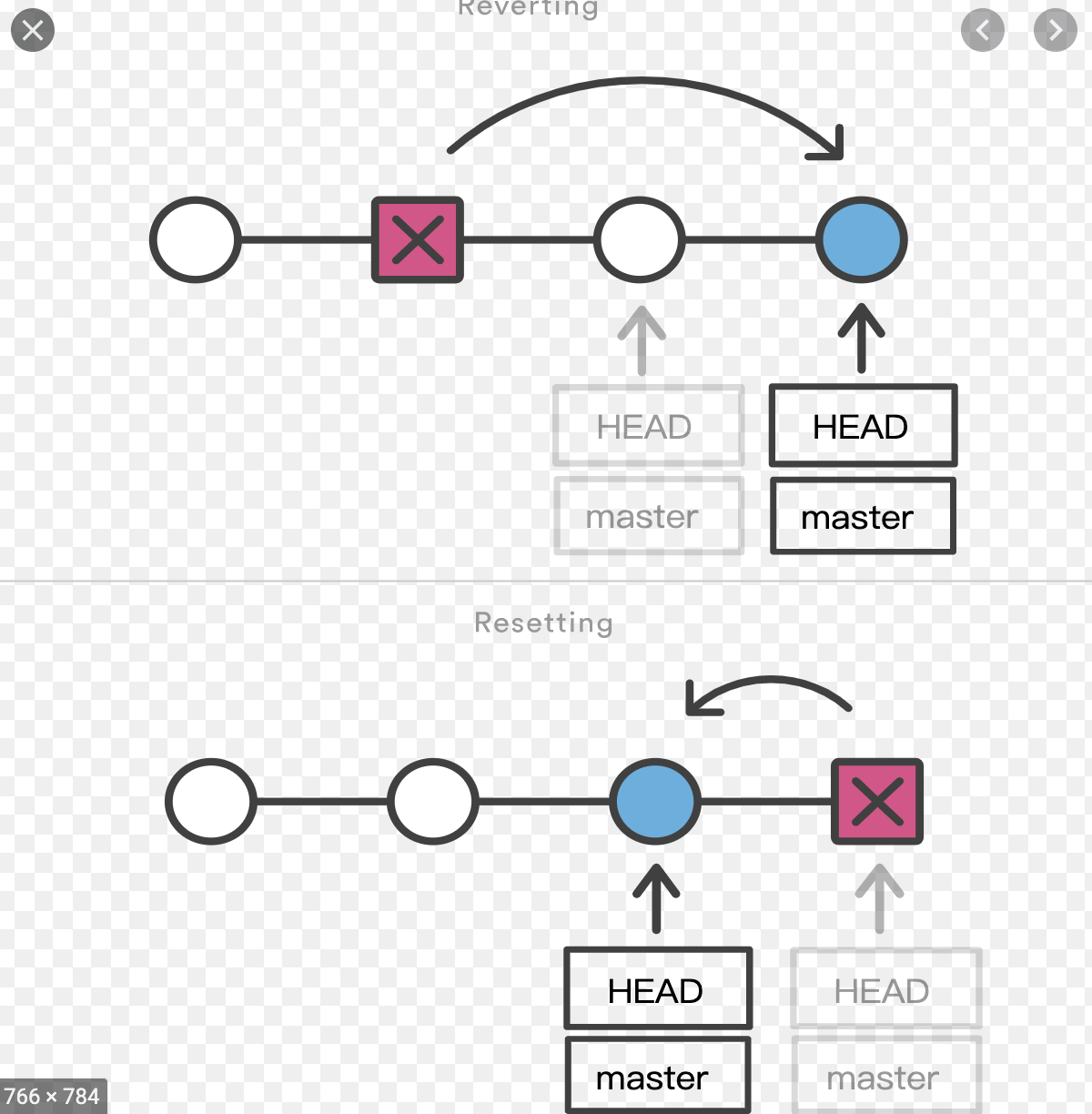
要实现这样的一个功能,就需要使用Git的版本回退指令,Git的版本回退操作,基本上有以下三种:
那我们一次介绍一下它们对应的操作说明。
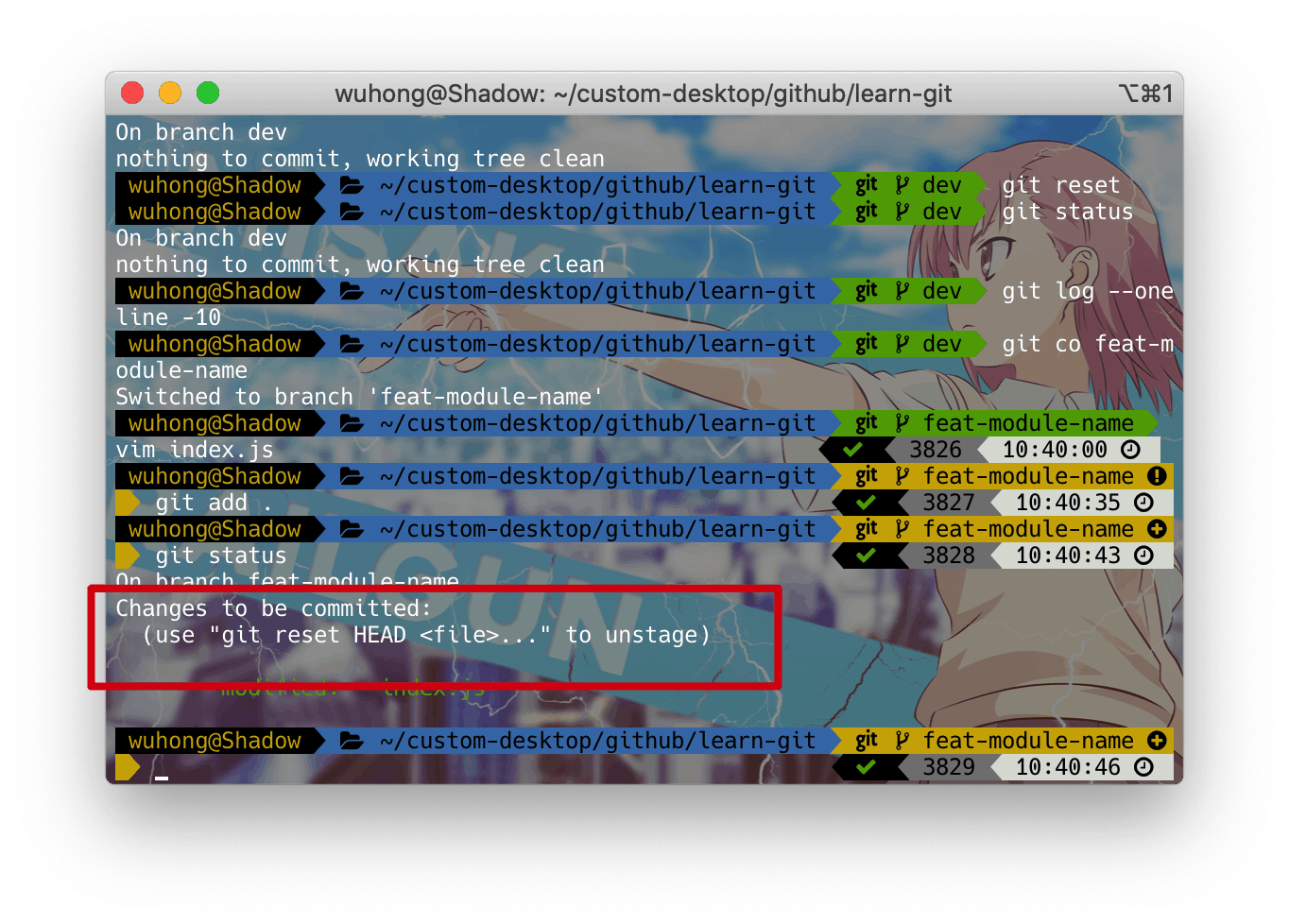
reset 指令应该是我们日常用到的最多的一个指令,它可以快速撤销已提交到暂存区的文件到工作区 git reset [path],如果指定了文件地址,就只会撤回该文件地址相对应的文件,不指定就会将暂存区文件全部撤回。 如图标红区:
# 回退两个提交
git reset --hard HEAD~~
执行--hard,然后commit之后会将当前指针之后的全部commit舍弃,而--soft不会,在修改commit之后,它仍然会在保留提交的历史记录。
同为reset指令,但是它们的使用情景不相同, 比如:
commit到了本地暂存区,你已经确认不再需要这一次的代码提交了,可以直接选择 --hard 丢弃本次commit_id,回到工作区的代码将会是 HEAD~~ 指针的代码--soft 回到工作区,此时本次HEAD的代码更改仍然存在,修改之后提交,完美。rebase翻译一下是重定、变基的意思。使用rebase指令我们可以完成一些比较*气的操作,比如将我们开发分支的全部提交合并为一次指定提交。除了可以合并多次提交丢弃一些无用的提交记录之外,还可以帮助我们将我们的提交历史整个变为一条时间提交线。下面我们分开演示一下:
git rebase -igit rebase -i HEAD~~~~我pick了最近的一次提交,将其他的commit 全部改为f后,现在提交已经全部合并进入了pick的top_commit_id了。这样我们可以将我们的功能分支全部管理起来,在合并进入dev分支之前将我们的代码处理的干干净净。
其操作结果如下图:
将代码处理干净了,没有多余提交了,我们可以来美化一下我们的master以及dev分支上面的历史提交记录啦。
在开始之前我们查看一下官网的描述, 关键的流程图已经做出了标记,如下图:
上图的表达的意思是在E节点检出了一个分支,功能开发完成之后merge进入master分支就会有一个分叉,而使用了rebase之后,将原A、B、C节点隐去,将A'、B'、C'直接合并到master分支的G提交后。结合节点图二,表达的是如果两个分支中同时存在一个相同提交,变基之后原节点被隐藏,改为该节点副本,其他提交依次拼接到master最近一次提交。
操作一下,这个时候我们需要格式化一下我们的log日志,试一下吧。
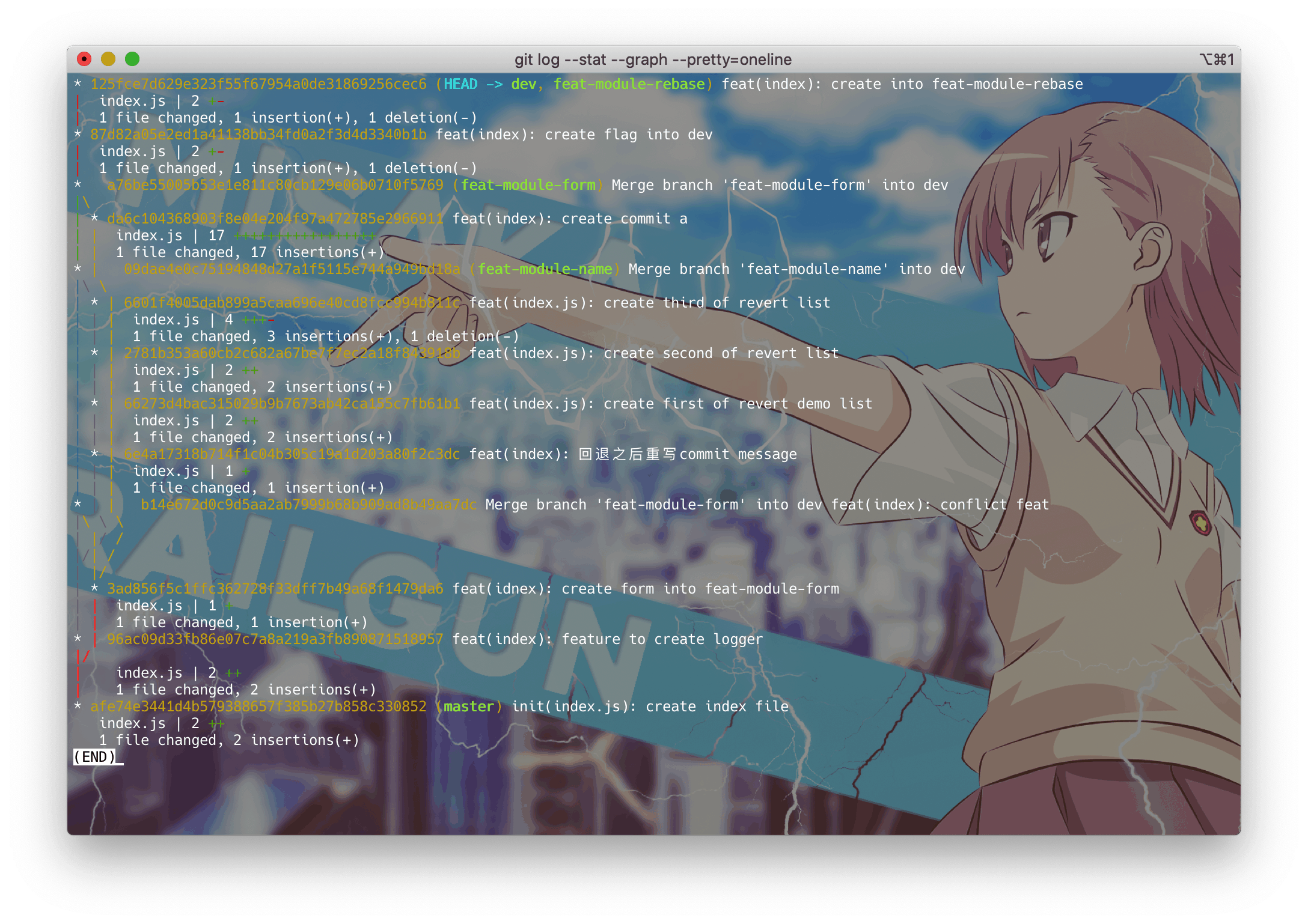
git log --graph --pretty=oneline进入主题,我们直接进入变基操作,看我操作
# 先回到dev 分支进行一个检出
git checout -b feat-module-rebase
# 修改文件之后提交
git add .
git commit -m'feat(index): create rebase flag'
# 进入 feat-module-rebase 分支后立即进行变基
git rebase dev
git merge feat-module-rebase其操作结果如下图:
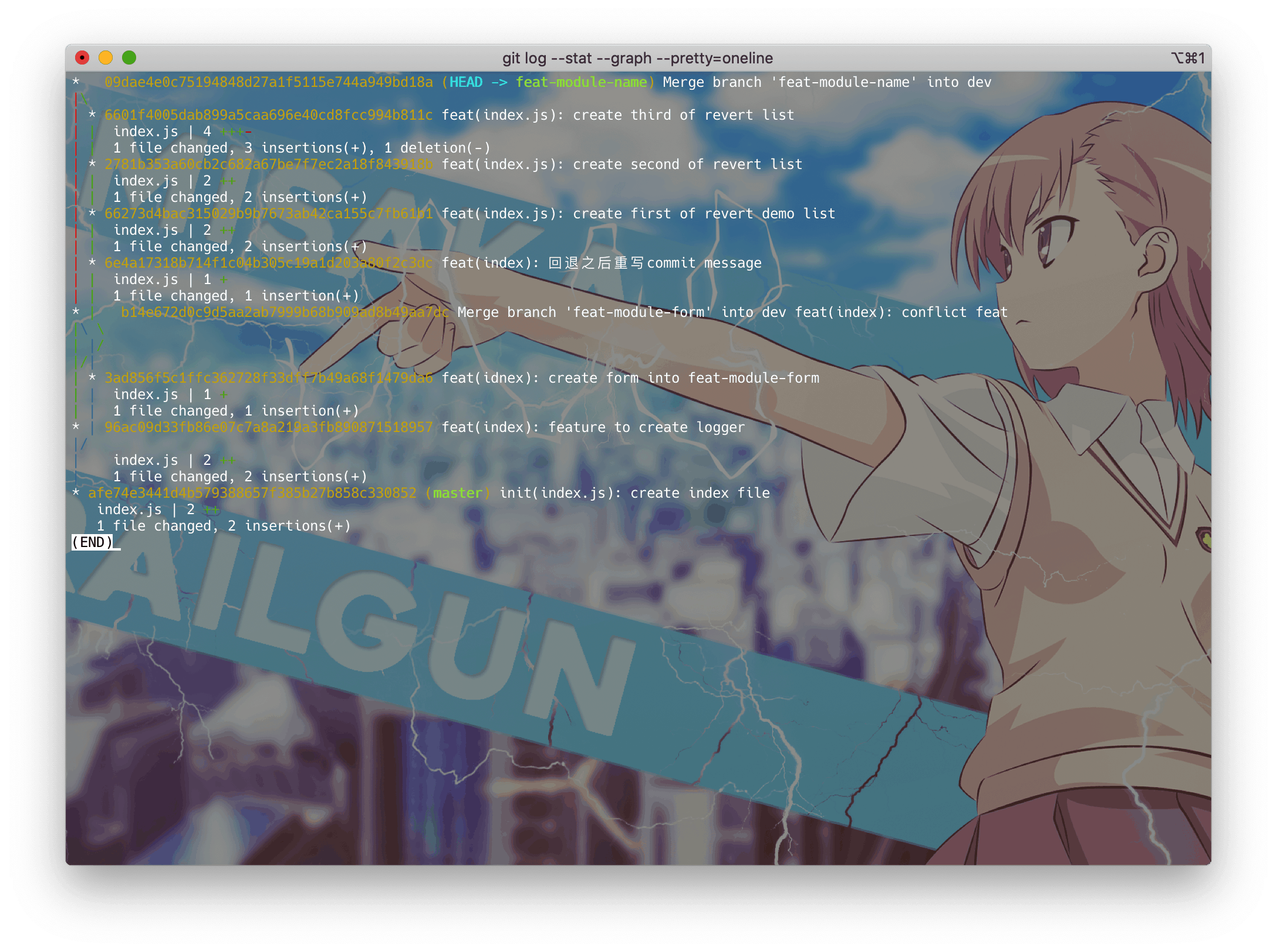
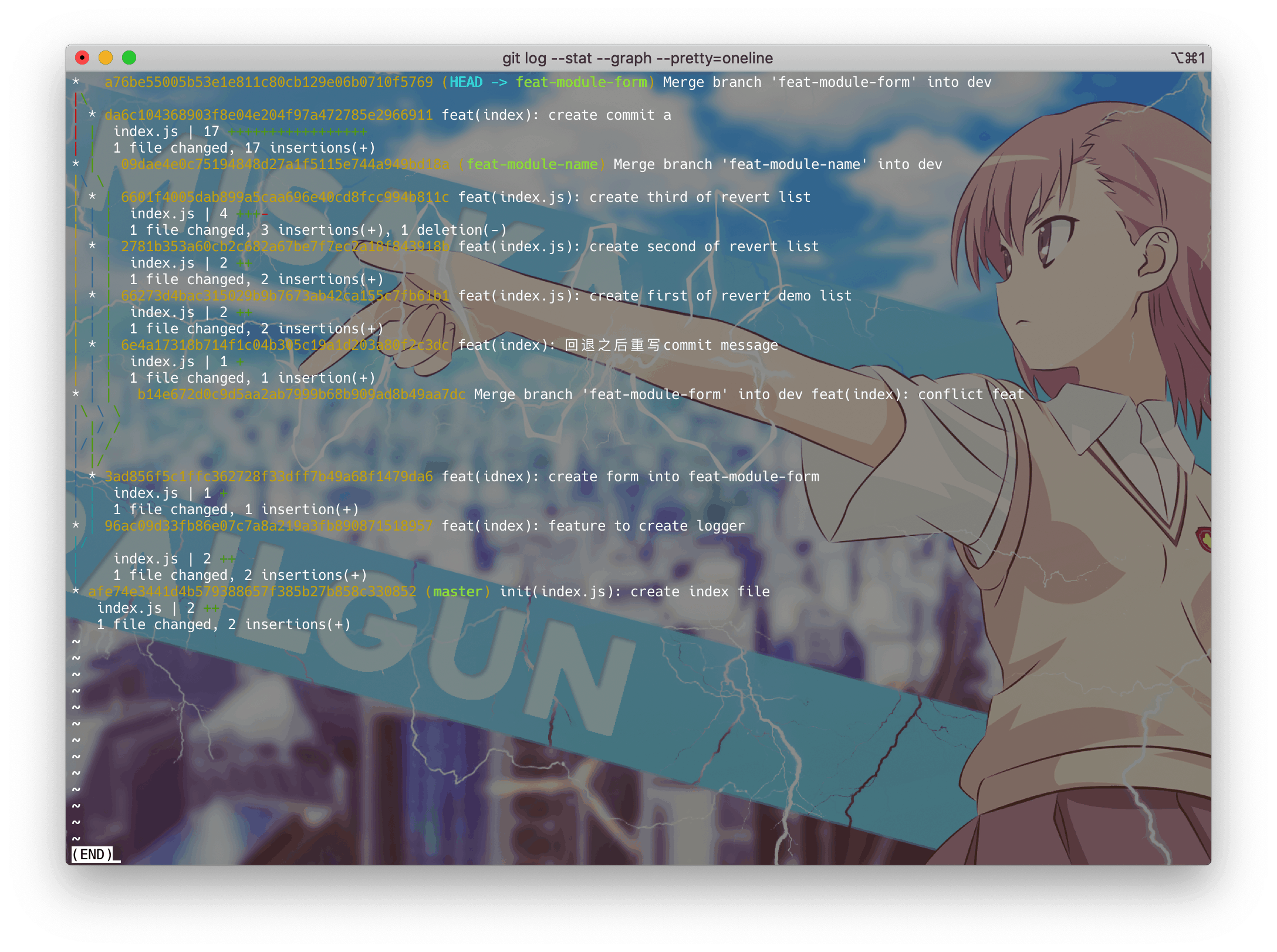
我们分别看一下变基的feat-module-name分支与未变基的feat-module-form分支
feat-module-name
feat-module-form
由图上可以看出,我的rebase操作是基于dev分支,所以feat-module-name以及feat-module-form 两个分支的提交全部合并到了dev分支上,它们没有了分叉,是一条笔直的直线。
rebase 操作与reset操作都会改变仓库的提交记录,对日志都是毁灭性的打击,所以这个指令是不太推荐使用的。
revert操作其指针永远是前进的,其翻译是反转,它只会生成一个全新的commit去假回退对应指针, 修改之后提交其历史提交记录不会更改,不会像 reset --hard 直接移除提交记录,而是与 reset --soft 类似,所以它的操作永远是安全的,我们对于远程仓库的管理比较推崇 git revert
我们看一下revert的操作示意图:
让我们来试一下revert操作吧,我已经提前准备好了三次提交,如下如,我们将每一次的提交标记清楚:
现在我认为第一次提交有错误代码,我需要注释它,操作如下:
```bash
git revert HEAD~~
```没想到吧,报了一个冲突,没关系前后多次版本的提交有冲突是很正常的,修复之后提交,然后再次执行一次revert操作,可以看下面的历史记录,多次以First为基准进行revert操作,修改之后提交,会有一条新的commit提交记录,所以它的指针永远是向前走,以此来达到一种反转效果的回退。
Revert还可以执行一个*操作,我们Revert了一次,达到了移除指定commit_id的操作,现在推迟发布上线,已经有时间去改了,我又需要将commit_id 的操作加上去。我们可以执行对一个Revert执行一次Revert,将指定的反转再一次反转,这样我们的代码不就还原啦。操作如下:
```bash
git log --oneline -10
# 查找全部提交记录, 找出其中的需要revert的revert_id
git revert revert_commit_id
```执行之后查看一下代码,如果顺利的话,指定revert_commit_id的提交应该已经还原了。
相当不巧,现在线上出现了一点点小问题,需要紧急修复一下,按照规范,我们需要从dev分支检出一个新的分支以hotfix-*命名。操作如下:
git checkout dev
git checkout -b hotfix-form代码修复完成之后我们按照提测流程,将代码再次合并入test分支测试,测试环境通过后代码进入dev分支,这一次的代码将在预发布环境再次测试,预发布环境测试通过后紧急部署到生产环境。
一个完整的gitflow工作流到此就已经闭环,在多次流程之后,各个团队的测试通过的功能代码就已经全部进入了dev分支。而未通过测试功能代码依旧停留在test分支上,我们可以在预发布决断这一次迭代需要发布哪一些功能,因为我们可以在dev分支合并选择需要的功能分支的代码。
注意:
1. 以master分支为主分支,受到分支保护,不允许任何人提交,由专人维护
2. 全部分支以dev分支为上游源
相关文章:
Git协同与提交规范(蚂蚁金服前端九部)
Rebase(变基)(跟着廖雪峰学习Git)
Rebase变基(Git官网)
为什么变基操作是危险的?
商城项目遇见了一个发布商品的操作, 大致上是这样

指的是获得所有可能的有序对组成的集合, 下面我列出了搜索查到的比较好的blog
algorithm - JavaScript中多个数组的笛卡尔积
JavaScript小算法!(这个没看懂,,写的太麻烦了)
JavaScript中多个数组的笛卡尔积超简单的实现(这个写了多了一步)
Cartesian Product of Multiple Arrays(我推荐这个, 这个最秀)
需要处理的数据大概是这样的
var arr = new Array(new Array(1,2,3), new Array(1), new Array(5,6,7))N个二维数组去获取他们的笛卡尔积, 一般的处理方法大概就是forEach循环, 以得到结果
arr = [[1,1,5], [1,1,6], [1,1,7]...]笛卡尔积的结果依赖于你的数组大小, 当你的数组个数达到4个, 每个数组里面都有4个子元素, 那他的结果就是 4 * 4 * 4 * 4
吾日三省吾身,为人谋而不忠乎?与朋友交而不信乎?传不习乎?
最近,准确地说是昨天,发生了一件值得让我深思的事情。“我并没有学会珍惜”是我思考之后得出的结果。
我想我必须把这件事情记录一下,留给未来的自己,值得反复体会。
首先我家没什么底子,就是一个普普通通的农民家庭,从小到大没什么依仗都是靠我爸一个人独立奋斗,唯二的就是我的亲人们时不时地帮助,什么帮助呢?帮你做一做耗时的农活。
棉花,一种经济作物,但是现在它越来越廉价。
种棉花是体力活,它不像插秧苗直接插到水地里,唯一的相同点就是人必须得弯着腰,直到把家里的棉花田里全部种满,那个时候人才能得到一点点的休息时间。
有一种棉是开心棉,很好摘。还有一种,是闭口的,是淋了雨,打了风,掉落在地里的。这种不好搞,要暴晒之后,才能剥开外壳。
我印象中最深刻的画面就是我爸一个人,一台电视机,两大筐闭口棉,干到半夜1点过,而明天他早上5点又要早起下地了。
太阳,太炽热了,太残酷了,太无情了。
我能体会到,那段时间,准确地说是那十年,他很累。
现在,他在工厂里面上班,他终于脱离了面朝黄土背朝天的日子。
我陷入了一种虚无,精神上的虚无。整整一个月的迟到,扣了2000块。刚开始我觉得没什么,就这样,它只是我工资的一小部分,更何况那段时间我确实感觉很累很累,早上睡不醒,晚上睡不着,头痛胃痛啥都有。
想吃啥吃啥,想买啥买啥,美其名曰太累,身体不好,需要搞点好东西改善一下伙食,现在回过头去看,简直是浪费,我忘记了过去的我了,我忘记了那一段艰苦的日子。
我很久没有读书了,最近沉迷上了王者荣耀,连胜让我觉得很过瘾,吸引我一直打下去。唯一让我欣慰地是,我没有染上一些陋习。
不赌不嫖不偷不抢,我还是我。迷失的是那个积极进取、热爱读书的我,我已经不再是我了。
我可以把一些客观因素归结到繁重的工作吗?是天天加班导致的心力交瘁?还是自己已经甘于沉沦了,甘愿躲在过去的阴影里面?
我忘记了我们小学时候学过的《论语》了,还记得“吾日三省吾身”吗?还记得《劝学》吗?
我怎么可以把一切问题推给外部环境,我忘记了“适者生存”的丛林法则。如果我一直抱着这种想法,我终将被社会淘汰,成为优秀的猎食者的晚餐。
我突然之间想起了《人间失格》,自我催眠的弱者,怎么可能在这个社会丛林正常的生存。如果能在一些文学作品中看到自己的样子,说明这本小说是一个最基础的社会缩影,它是现实的。
试着通过这类文学作品去反推,看看自己在小说中的结局,它又是魔幻的。
魔幻的现实是残酷的,是悲剧的,是无法挣脱的枷锁,是禁锢自己的牢笼。
不去主动地打破牢笼,就失去了向上的阶梯, 将被永远的困在地牢,不见光明。失去了阳光,失去了一切。
我想起了刚上班的那段时间,上下班的路上我在思考怎么写那些业务代码,因为我接手的第一个项目就做砸了,当时是我的领导保了我,给了我第二次机会。那真是一段令人无法忘记的回忆。
我觉得思考的东西应该是要深刻的。写到这里我想先停一下。
越是深刻的东西越是简单。归根究底,就是我进入社会的这5年,过的太顺利了。顺利到我还没有学会珍惜。
回顾了一下我的履历,我是在大佬的爱护下成长的。我的每一位领导年龄都比我大,我想他们对我的这种爱护之情,包容之心和同事之谊,就是我成长的养分。
我听说,我的同事们私底下对我的评价还不错,他们都认为我的业务水平还可以,但其实我已经在原地踏步了一年,我想我已经很落后了。
技术是个很容易替代的东西。我认为,一个刚毕业的大学生,给他足够的训练时间,外加一位负责的领导指导一下,可以极大地减少他上手的代价。
所以,遇到了这样的一个领导或者是同事,他又愿意和你交流,愿意给你分析一些问题,是一件幸福的事情,是一件值得珍惜的事情。同时,这样的同事是值得深交的,很多事情,有高人指点可以免去你很多的时间。
同时,在自己力所能及的范围内,对后浪们也要有一种爱护之情。他们只是比我入行晚而已,我的优势只是比他们提前入行,见过的东西多一些,见过套路多一些,除此以外,我没有任何优势。
无言是最好的告白。
最近我很忙碌,忙碌于工作,没有时间去学习实践。
这样不太对。
这个星期我们部门的一个小兄弟辞职了,高强度的工作使他的身体承受不了工作的压力,最终他离职了。我知道他一定很累,因为我也一样。
今年由于疫情的影响,我匆匆忙忙的从家来到了深圳,面试一天订了一家公司。原因就一个离我住的地方近,我可以很方便的上下班,刚开始我觉得在哪儿上班都一样。但是现在我改变了自己的看法,现在我陷入了忙碌的泥沼,在我以往的工作经历中从来没有这样地忙碌。
在过去我工作地很愉快,或者在某一种意义上说我的工作很轻松,我有时间去学习接收其他的一些新鲜的事务和知识。技术的爆炸带来了太多的业务变革,所以我们有太多的业务需要去实现。我一直认为技术人进步的最快方式就是动手实践,纸上得来终觉浅,绝知此事要躬行。
距离上一次我发布的日志已经过去了60多天,换一句话说我已经60多天没有写一写学习的笔记和想法了,也代表着这一段时间我停止学习了。在这样的一种强度的工作之下我停止了学习,从我的角度看来: 它表示了我能力的缺失与不足。在总的工作量不变的前提下,时间与产出成反比,比重越大说明能力越强。如下图:
随着现在前端工具软件的开发和缤纷灿烂的工具函数,似乎前端的开发工作应该越来越简单快速,但是事实却与我们的理论推导相反。现在前端的开发工作越来越注重用户体验,而我们口口声声挂在嘴边的用户体验又涉及到了前后端的交互,人机交互。人机交互浮在水面之上是冰山一角,前后端的交互才是经济基础,支撑着人机交互。
我们的工作就是尽量使人机交互更加稳定自然。
在这段时间的工作经历使我深刻认识到了团队的力量是无限大的,个人的力量极其渺小。若以一人之力去挑起整个团队的工作任务,最后得到的结果一定是一个苦果,至少它不会是你快乐。在一定程度上我能保证的是大的方向流程上的任务不出问题,保证主流程的稳定。但是随之带来的苦果就是大的方向得到了支持,小的方向自然就没有办法兼顾,鱼和熊掌安可兼得!
团队的分工使我们的工作更加高效,但是遇到了一个不重视技术的上级或者是老板,这一份工作是痛苦的。他们太天真、太理想,将我们的工作想当然地评估为“简单”级别,于是我们陷入了另外一个泥潭。我们的工作毁于“理想”,这个带着引号的理想,我把它理解为天真,或者是呆傻,又或者是蠢。
有多少工作毁于乌托邦式的想法!在这样一种想法之下,他们的项目“流产”了。换而言之他们失败了,可悲的是击败他们的不是对手而是他们自己。
我喜欢写日报,尽管公司不要求。日报实际上是我们自己对我们自己一天工作的总结,每一天下班我都会花一段时间看一下今天git的提交记录,看一下我的代码,更多的是看一下我自己的想法。之前我走路上下班,除了走路我什么事情都做不了,所以我开始回顾今天看了一些什么文章,遇到了什么问题,有没有什么更好地解决方案,有很多的习惯就在这个时候慢慢养成了。比如:每天打开手机刷一刷公众号里面的文章,增长一下见闻。
后来我发现,看与做是一回事,会看与会做是另外一回事儿。技术上的事情一定要去动手实践,它需要时间的积累与经验的总结,所以我给自己定了一个计划,不管有没有接触到新东西,每一个星期都要写一篇日志,它可以与技术相关,也可以是生活感悟,没有界限的区分。
我讨厌忙于工作的自己,他让我没有了自己的想法,我的一天被工作填满了。最近,我在地铁上不能沉浸下来去看书了,我开始刷抖音。我不喜欢这样的自己,我认为是劳累的工作消费了我的注意力,使我无法再去集中精神去做另外的事情了。我想如果工作压力再得不到缓解,我会离开这里。
它使我没有了进步的空间与时间,在注意力过度消费的前提下,用再多的工夫去学去看也不过是无用之功。
就这样,我开始讨厌自己了,越来越讨厌。

转眼之间都快到2021年的年中了, 突然回味过来了, 想要写一写我的2020.
在2020年4月中旬,我终于回到了深圳,在一个星期后我入职了现在就职的公司。从工作的时间维度看,现在的时间刚好一年,恰到好处。
正正经经读完的小说没有几本,好多的小说我没办法一直读下去,因为他们太耗费精力和时间。对于我而言,我可能需更多的时间去阅读和研究。比如说: 《时间简史》和《**通史》。
以下是我整理的一份书单: 我的常读书。
它们是:
《时间简史》和《**通史》似乎更加适合比较专业的读者、研究员去研究学习。我推荐去看在B站里的一部同名记录片《**通史》。视频接受地速度更快,也许更加适合现在我们的生活节奏。
《**通史》里面有一个观点:”以今观古,可乎?“。
所以我们去看历史类读物时,就别太认真了。做一个旁观者,看作者讲好一个故事,就可以啦!
与此同时,并不影响你有自己的猜想和判断。比如:如果王莽的运气好一点点,新朝继续发展,历史会怎样?杨广东征高句丽时,那个冬天如果没那么冷,现在又是什么样的世界格局?如果赤壁的那一把火点不起来?如果把李自成在某一个不知名的山头干掉?
不同的猜想,不同的发展,写一本短篇小说也没什么难事。比如写一写《穿越到XX朝做一个XXXX》。
20年初,一本小说火爆全网,它就是《人间失格》。说是什么魔幻现实主义的又一代表。特点就是虚虚实实,真假难辨。其实,我真的看不出什么,可能是水平不够吧。
在年初,在B站上,看了一个栏目,李健主持的一个拉美地区的主题音乐会。里面提到了马尔克斯,热情桑巴,拉美音乐。他们提起了伦巴舞,动作极其热情,气氛很是旖旎。大家可以找一段伦巴看一下,验证一下。
我大胆地描绘一下场景:水手们上岸了,在这一个港口,他们看到了热情如吉普赛女郎的哥伦比亚少女,站在街边。随手拿了一杯啤酒,拉上了一个女郎,在道路的中心跳起了舞。那少女也舞动着身体,脸上布满了笑容。伴随着手鼓的节奏,肢体摆动的幅度越来越大,她的身体也越来越放松。慢慢地,跳舞的男女一对一对地加入进来,少女们如同提线木偶,听从摆动。音乐声混杂着笑声、吆喝声和叫骂声,在无尽的夜色中越传越远...
我看《三体》大概有四五年了,每一年都会翻一翻,看一看。每一次翻感觉都不一样,今年看《三体》的起因是因为,我在B站刷完了一部动画《我的三体之章北海传》。
官僚游戏在明朝嘉靖时期迎来了一波高潮,嘉靖的一生就是斗争、斗争,再斗争。帝国权利高层的工作就是斗争、斗争,再斗争。但是基层的权利斗争也同样精彩; 《大明王朝1566》结合《显微镜下的大明王朝》一起看,最好再加上《那些事儿》。
举一个例子,海瑞在做县令时,除了要跟上司斗争还要和底下的小弟们斗争。做好一个官已经很困难了,更别说做一个有作为的清官了。
《黑客与画家》是阮一峰老师的翻译作品,在前端范围内,应该无人不识阮老师。
互联网产品的生命周期极其短暂,在旧金山奋斗的打工人们,每一个月都会涌出各种各样的创意,新生力量在不断冲击着硅谷的各种行业,各种职业。从目前的局势看起来,在未来相当长的一段时间内,世界的中心仍然是旧金山,因为那里可以制造出源源不断的新鲜血液。
布局这一发展模式的奠基人大概就是本书的作者保罗了吧。“天使投资计划”给创业者基本的创业资金和技术支持,似乎是真正做到了前浪带动后浪。
我们在github读源码的时候经常会看到一些注释,是这个样子:
/**
* Hack
* create somthing for build chore
*/书中对Hack的解释是,对某一个问题做出了一个优秀的解答。做出这个优秀解答的作者就是Hacker,音译过来就是”黑客“。
我自认为够不上优秀。
大唐并不是全时期都是盛世,但是每一个盛世之前都有一段血腥的历史。我不知道这是不是书名的本意,我只知道大唐帝国的光辉,也曾照耀中亚的大地和东南亚的海湾,阴影中躺着无数的白骨和箭矢。
在落日的余晖中,唐明皇回想起自己的一生。如果当时少听一听音乐,多看一看奏本,提前宰了安禄山。现在是不是在太液池和自己心爱的杨贵妃一起跳那支霓裳羽衣舞。
大明宫中,久已不闻破阵乐。
似乎是为了弥补在家里待的三个月的时间,自四月开始,我就像上了发条的手表,想停下来都停不下来了。
生活轨迹如同机械表般的规律,上班下班,上班加班下班,后来就更过分了,开始熬夜加班了。现在正好反思一下,为什么加班?什么样的工作量积压才会像我们这样的加班?加班是否真的有效?
首先我们的系统功能很多,单独拿一个业务线出去,就是一个管理系统。
项目开始...
在我正式接手开发之后,我终于意识到,我进了一个深坑。试想一下,我给你一个大概的日期,你准备一下,到时候我找你要结果,安排项目上线。当时我就懵了。当我看到原型图上密密麻麻的功能之后,我发誓,我懵早了。
活着干,死了算,时间不够,加班干。两个月后,项目上线了!
当时的开发人力就两个人,一个前端,一个后台。在那一段时间里,面对前端的工作积压,加班消费接口的选择无疑是正确的。但是在项目实际上线运营的前夜,我们还在更改需求。在当时看来,这是一段备受折磨的日子,但是我绝对想象不到,在后期还有一个折磨之王。
三级复核的审核功能可以有多复杂?54个节点的审核功能见过吗,兄弟?
在这个功能开发过程中,我们的团队逐渐成型稳定,功能全部分出去了,我开始全力做这个复核功能。我的第一次熬夜加班献给了这个项目。到现在我终于明白,通宵加班只有0次和无数次。
我接了一个最不应该接的功能多页签。现在回想,我有好几种方式可以无侵入解决需求,但是覆水难收,终成困局。现在我只想说一句:”我干~“。
折磨之王上线了!
在我进组开发财务系统后,我完全没有意识到,这将会是一个什么样的折磨项目,一直到现在都是我极力逃避的项目。整个开发时间达到了惊人的2个月,功能通过率不过10%。在这个数据的背后,没有一个人是轻松的,每一个开发都是疲倦的,沧桑的,崩溃的。
”加班“是这个项目的主题词,在这两个月的时间里,我们能做的就是”加班,加班,再加班“。而造成这个局面的是一个”折磨之王“。长叹一口气后,就这样吧都过去了。
我们度过的一段最美好的时光就是现在,终于进入正轨了,迭代中的项目才是最美好的项目。因为我们控制住了功能,在规定时长内能够完成预定的工作,但是有人不开心了,是谁我不想说。
我常开玩笑地说,如果经常加班,那水平一定不咋样,牛逼的人是不加班的。但是我们认真工作在预期内完成的工作,却被认定为工作不饱和。进入迭代后,功能质量被牢牢地控制住了,难道非要让我们做一些超量的工作,但是质量却得不到保障的功能吗?
究竟是量者取胜,还是质者为王?
判定一个男人成熟的标准,是以生理维度为上,还是心智维度最佳?
我不得不承认:冲动的一面将在相当长的一段时间里陪伴着我,同时我将长期与他同行。能改变的是缺点,而改变不了的是弱点。性格缺陷的修补能力大概就是决定心智发育程度的短板。
一时兴起,来练字吧,我总得给自己找一个填补的入口。
不爱正楷爱行书,不爱唐诗爱宋词,找了一套宋词字帖就开始了!
我想,当我进行到离开了田字格,在一页空白的纸上,心静手稳地写出了行列对齐的汉字后,我大概就取得了阶段性的成功了吧!那时的我应该是极其内敛,水波不兴。
初初练字,手抖的极为厉害,可能是因为长时间不正经写字了。正经起来,重新去学写字表现的极为痛苦。第一,心有牵挂,难以平静;第二,长期形成的写字习惯也是重学的阻力;第三,临摹字帖的滋味不太好受。
我练字的最终目的,并不是为了写一手漂亮的汉字,其目的是为了控制,即为**“克己”**。一个汉字能否写的好看是控制它的结构,类推一下,是否成人是看能否控制自我心智,慢慢地我发现写好一个字还真不简单!正如做好一个人是那么的困难!
不用刻意地去计较时间,不用刻意地去计较字体,随心而动,随意而发,大概就是《人间词话》中的”气“了吧。
方寸之中,也有大道。
关山难越, 谁悲失路之人。萍水相逢, 尽是他乡之客。
来深圳一年多了,这里很大也很好。它离我家两千里。
那一天我特意早起去海边,朝霞平铺在海平面上,我看着旁边经过的路人和依稀的汽车,沉睡中的城市又开始躁动了。那一刻我强烈的希望回家。
免密登录,用到的就是一个公钥。如果之前在机器上用过github的ssh模式,那你一定还记得,秘钥生成到哪一个文件夹下了。
用到的指令就一个 ssh-keygen,几乎可以不用加任何参数,直接生成一对key文件: id_rsa.pub和id_rsa
ssh-keygen --help
usage: ssh-keygen [-q] [-b bits] [-C comment] [-f output_keyfile] [-m format]
[-N new_passphrase] [-t dsa | ecdsa | ed25519 | rsa]
ssh-keygen -p [-f keyfile] [-m format] [-N new_passphrase]
[-P old_passphrase]
ssh-keygen -i [-f input_keyfile] [-m key_format]
ssh-keygen -e [-f input_keyfile] [-m key_format]
ssh-keygen -y [-f input_keyfile]
ssh-keygen -c [-C comment] [-f keyfile] [-P passphrase]
ssh-keygen -l [-v] [-E fingerprint_hash] [-f input_keyfile]
ssh-keygen -B [-f input_keyfile]
ssh-keygen -D pkcs11
ssh-keygen -F hostname [-lv] [-f known_hosts_file]
ssh-keygen -H [-f known_hosts_file]
ssh-keygen -R hostname [-f known_hosts_file]
ssh-keygen -r hostname [-g] [-f input_keyfile]
ssh-keygen -G output_file [-v] [-b bits] [-M memory] [-S start_point]
ssh-keygen -f input_file -T output_file [-v] [-a rounds] [-J num_lines]
[-j start_line] [-K checkpt] [-W generator]
ssh-keygen -I certificate_identity -s ca_key [-hU] [-D pkcs11_provider]
[-n principals] [-O option] [-V validity_interval]
[-z serial_number] file ...
ssh-keygen -L [-f input_keyfile]
ssh-keygen -A [-f prefix_path]
ssh-keygen -k -f krl_file [-u] [-s ca_public] [-z version_number]
file ...
ssh-keygen -Q -f krl_file file ...
ssh-keygen -Y check-novalidate -n namespace -s signature_file
ssh-keygen -Y sign -f key_file -n namespace file ...
ssh-keygen -Y verify -f allowed_signers_file -I signer_identity
-n namespace -s signature_file [-r revocation_file]在本地生成的key文件,推送到服务器上,在此之前先看下服务器的ssh服务开启了没有,没有开启的打开就好。
systemctl status sshd
systemctl start sshd在服务器上,设置一下.ssh和authorized_keys的权限,网上有部分资料将权限设置之后,免密登录才生效。
sudo chmod 700 ~/.ssh
sudo chmod 600 ~/.ssh/authrized_keys设置之后,测试一下,看看免密登录能不能成功:
只要可以正常进入云服务器就说明已经生效了,如果还不行的,检查一下配置文件的路径或者是权限。
最后,在本地的.ssh目录,新增一个配置文件config:
Host aliyun
user root
hostname 192.168.1.1
IdentityFile /Users/root/.ssh/id_rsa (密钥的本地地址)执行一下ssh aliyun,就可以登录云服务器了。

这两天没事,在翻看红宝书的继承篇,重新学习了一下下js中的继承。出于对Es6中class 类继承的好奇,我在babel里面试了一下,才发现Es6中class类继承,实际是寄生组合式继承,也是一下我要介绍的一种, 如图:
在红宝书中主要介绍了一下5中实现继承的方案:
以下,我只记录它们主要的设计代码和基本原理,其实例可以访问我的codesandbox,里面有继承篇详细的例子。
基本**就是利用原型,让一个引用类型可以继承使用另一个引用类型的属性和方法。详情查看例子原型链继承。
每一个构造函数都有一个原型对象,而原型对象中又有一个指针指向构造函数,实例也有一个指向原型对象的指针。如果让原型对象等于另一个类型的实例,那该原型对象就具有了另一个类型的构造函数。如果另一个类型的原型中又有另一个类型的实例,层层递进就有形成了一种实例与原型的链条,这个就是原型链。
对SubType的原型对象改写为SuperType的实例,此时可以将SuperType称之为SubType的超类,那SubType即为子类。
如果继续将SubType作为超类,对SubType2改写原型对象,那SubType2将同时具有SuperType和SubType的属性和方法,尽管SupType2不是SuperType的子类。这个就是继承链最简单的一个实现例子,
function SuperType () {
this.name = 'super'
}
SuperType.prototype.getName = function () { return this.name }
function SubType () {
this.name = 'sub'
}
Sub.prototype = new SuperType()
Sub.prototype.getSubName = function () { return this.name }
function SubType2 () {}
SubType2.prototype = new SubType()注意:
在子类的构造函数中调用超类的构造函数,即为借用构造函数的基本原理。详情查看例子借用构造函数
借用构造函数方法的出现就是为了解决原型链继承的复杂类型值会被各个实例共享的问题。
在子类的构造函数中调用超类的构造函数,其实质是将超类绑定在this中的属性复制到子类中,只有在调用子类的构造函数时,才执行超类的构造函数,所以现在的参数问题得以解决,各个实例间不会互相影响。
function Super (name) {
this.name = 'super' || name
}
function Sub (name) {
Super.call(this, name)
this.name = 'sub'
}注意:
利用原型链实现方法的基础和利用构造函数实现属性的继承,就是组合继承的基本原理。结合了原型链和借用构造函数的技术,同时具有了它们的优点。详情查看例子组合继承
在重写了子类的原型后,Sup.prototype实质上指向了Super.prototype,在Sup.prototype.constructor指向的是Super,这里需要手动将Sub.prototype.constructor指向Sub。
function Super (name) {
this.name = 'super' || name
}
Super.prototype.getName = function () {
return this.name
}
function Sub () {
Super.call(this)
this.age = 20
}
Sub.prototype = new Super()
Sub.prototype.constructor = Sub注意:
没有严格意义的构造函数,原型可以基于一个对象生成另外一个新对象,还不必为它声明额外的类型,就是原型式继承的基本原理。详情查看例子原型式继承
原型继承的实现特别简单,公式一样的三句代码。object函数实际是创建基于传入的对象o,生成的副本。每一个由object函数生成的副本,其状态都被共享了。
但是对实例进行扩展的方法是不会被共享的。
function object (o) {
function F () {}
F.prototype = o
return new F()
}注意:
寄生式继承,是与原型式继承密不可分的。其基本**就是,仅创建一个封装继承过程的函数,在函数内部对新对象进行增强,然后返回增强的新对象。详情查看例子寄生式继承
就这样在由寄生式继承的函数返回的新对象,就有了源对象origin的属性和增强的属性。
所以,寄生式继承和原型式继承,主要针对的是对象间的继承,而非自定义构造函数。
function inherit (o) {
var prototype = object(o)
prototype.getName = function () {
return this.name
}
return prototype
}注意:
寄生组合式继承,指的是通过构造函数来继承属性,通过原型链的混成形式来继承方法。其基本原理就是: 不必为了子类的原型而调用超类的构造函数,我们需要的就是超类原型的一个副本。详情查看例子寄生组合式继承
可以使用寄生式继承来继承超类的原型,再将结果指定给子类的原型。
寄生组合继承,可以减去一步在子类外部调用的超类构造函数,避免将一些额外的属性附加到子类的原型链中,而且原型链还能保持不变。
所以,开发人员一致认为寄生组合式继承是引用类型最理想的继承范式。
function Super () {
this.name = 'super'
}
Super.ptototype.getName = function () { return this.name }
function Sub () {
this.subname = 'sub'
}
function inherit (subType, SuperType) {
const prototype = object(SuperType)
prototype.constructor = subType
subType.prototype = prototype
return prototype
}
inherit(Sub, Super)可以回到顶部,查看babel对class类继承实现的转换,仔细一对比,发现其实没有什么大的不同,从实现**上来说是一致的。
ES6终于实现了基于类继承的方案了。可以使用extends关键字实现继承, 但是在子类中必须使用super关键字,因为子类没有自己的this。
class Parent {}
class Child extends Parent {
constructor (props) {
super(props)
}
}在ES5中,先创建的是子类的this,然后将父类的属性和方法添加到子类的this当中。 在ES6中,先将父类的实例添加到this中,然后用子类的构造函数去修改this。
注意:
__proto__属性,该属性总是指向对应构造函数的prototype属性。Class作为构造函数的语法糖,同时具有__proto__与prototype两条继承链。__proto__属性,表示构造函数的继承,总是指向父类。 Child.__proto__ === Parent__proto__,表示方法的继承,总是指向父类的prototype。 Child.prototype.__proto__ === Parent.prototype__proto__属性是层层嵌套的,子类的__proto__属性的__proto__属性指向的就是父类的__proto__。 Child.__proto__.__proto__ === Parent.__proto__寄生组合继承是基于类型继承最有效的方式。
关于网站优化的事情都是老生常谈的事情了,尤其是在面试的时候,我估计这个问题也是出现的频率比较高的热门问题之一。下面就是稍微介绍一下,我是怎么优化我的个人网站的。
科普一下
这个就是http资源加载的分析图,在请求完全结束之后,计时结束进度条不再变化。它的几个属性代表的意思如下:
优化: 这里的优化就是将资源分散到不同的域名下,大文件需要压缩,似乎项目打包出来dist文件下的文件都可以发布到cdn,可以使用webpack下的public指定发布的静态资源地址,例如:
module.export = {
public: 'https://src.**.com/static/js/[hash:8].js
}我在服务器端开了一个src开头的二级域名,作为我的静态文件服务器,现在我全部的图片文件就全部放在了这个服务器里面,所以全部的静态资源可以通过src这个资源域名访问。
注意: 需要前后端配合
webpack有一个插件: compression-webpack-plugin, 在webpack.config.js的文件中做如下配置:
const CompressionWebpackPlugin = require('compression-webpack-plugin')
module.export = {
plugins: [
new CompressionWebpack({
test: /\.(js|css|png|svg)$/,
threshold: 10240,
minRatio: 0.9
})
]
}太小的文件就不要压缩呀,小文件压缩有可能比源文件更大,别问我为什么,因为我也是听说的没有具体实践。
执行打包的命令之后,如果你配置成功的话,就可以看到已经压缩的文件了。
下面配置一下服务器 我用的是Nginx
http { # http模块
gzip on;
gzip_http_version 1.1; #有的不支持gzip哦
gzip_min_length 1k;
gzip_comp_level 5; # 最高为9,最低为1,取中间
gzip_types application/javascript image/bmp text/css; # 可以配置很多类型
}配置以后记得重启服务器
nginx -t # 检查一下语法
# nginx: the configuration file /usr/local/nginx/conf/nginx.conf syntax is ok
# nginx: configuration file /usr/local/nginx/conf/nginx.conf test is successful
nginx -s reload
ps -el|grep nginx # 看一下nginx启动了没有如果你配置成功了,并且重启了服务器,再次打开你的网站应该可以看到的大文件加载使用了gzip文件
如下图:
在React的某一次更新之后,它有了一个方法React.lazy(),就是动态的引入静态文件,类似于Vue中的路由懒加载,但是最大的区别就是,在react中任意模块都可以使用,使用的时候需要配合一下 标签,它必须有一个fallback函数返回一个Jsx,具体的看官网。
import React from 'react'
const LazyCompoennt = React.lazy(() => import('....'))
export default () => {
<Suspense fallback={<div>Loading...</div>}>
<LazyComponent />
</Suspense>
}npm上各种懒加载的插件,可以自己搜了用,这里我贴一个我的实现。其原理就是准备一张压缩过的小图片,作为ScrollWrapper里面的全部图片src源,其真实的url资源地址保存在data-src属性中, 监听scrollWrapper的滚动事件,图片进入视窗的时候就用data-src去替换src。如下:
<img src='https://src.***.com/cover.png' data-src='target_url' />下面是我的实现**lazy.js**,很简单不过50行代码
npm install -g pm2 # 下载pm2包
pm2 -v # 查看pm2的版本号, 如果能查看说明安装成功如果出现 pm2 no command 的提示,是由于路径的问题,可以做如下配置:
whereis pm2
# /home/node/bin/pm2
ln -s /home/node/bin/pm2 /usr/local/bin # 前一个地址代表pm2的安装地址,后一个地址代表全局如果运行指令只出现PM2 Spawning PM2 daemon with pm2_home=/root/.pm2,可能是nodejs的版本号太低了, 可以做如下操作
npm install n -g
n -v # 出现 no command 可以照pm2配置地址
n latest # 安装最新版nodeNode的版本管理器 N
安装完成之后再次运行指令
pm2 -v # 出现版本号接就表示可以使用了在nodejs的应用中使用pm2,可以使用脚本,在package.json文件中配置
{
"scripts: "pm2 start pm2.yml"
}然后使用 npm run pm2
当然在此之前需要新建一个pm2.yml文件,简单的配置如下:
apps:
- script : "/home/data/apps/my-app-name/bin/www"
name : "my-app-name"
watch : true
env :
NODE_ENV : 'development'
port : 3100其余配置可以去Pm2官网查询
上一种介绍的是在一个node应用中使用pm2的脚本,现在介绍一下服务器端的脚本文件配置,其配置项跟上面没有什么太大的差别。如下:
apps:
- script : "/home/data/apps/my-app-name/bin/www"
name : "my-app-name"
watch : true
env :
NODE_ENV : 'development'
port : 3200
- script : "/home/data/apps/my-app-name/bin/www"
name : "my-app-name"
watch : true
env :
NODE_ENV : 'development'
port : 3300注意: 端口号一定不能重复,其配置由单个转换为多个,运行就很简单了,一键启动全部node应用
whereis pm2.yml
# /opt/node/scripts/pm2.yml
pm2 start /opt/node/scripts
pm2 list官网介绍的配置方法不止一种,剩余的可以慢慢玩慢慢补
这几天一直在看三国志,当然啦还有三国演绎, 我发现了一个相当有意思的事情,那就是张飞究竟是一个什么样子的人。
前期普普通通,后期直接爆发,粗中有细,有胆有谋。他对士人很好,但是经常打骂士兵,所以最后他被自己的侍卫杀了。
关羽张飞跟诸葛亮都不对付,但是徐庶可以跟他们很好的沟通交流,我查了一下原来徐庶爱喝酒,还杀过人,性格上跟张飞很对付,因为徐庶还会舞剑,说不定喝多了还较量一下。
在项目中,经常会遇到的一种情况,就是大段大段的逻辑代码,各种各样的逻辑全局集中到了主函数的内部,在上一次的【盘活运力】的review中,我给大家描述了一下,我是怎么处理大段逻辑代码的,这里是记录性质的博客。
对于可复用性要求较高的公共函数、公共文件的封装或者是逻辑的处理。可以对比去看一下重构之前的代码,大段的逻辑代码集中在一个函数内部,导致一个函数的逻辑杂糅,一个方法甚至有几百行,这都是需要优化的地方。
从我个人的经验来看,对于公共方法,有以下几个关键点:
高灵活性
高区块性
高责任性
高灵活性
其实,灵活性就是可扩展性。
我们在写公共的函数的时候,无论是mixin文件还是utils工具文件,都要做到的一点就是,一定要操作空间,一旦这个函数内部的逻辑不满足了,还可以通过外部传入的逻辑,来实现我的最终目的,而不用改动公共函数的内部代码。
怎么留足操作空间呢?就是在关键的逻辑位置提供一个函数,可以满足外部传入的需求。
高区块性
区块性,就是说将一大段函数逻辑,拆分为若干个逻辑片段。
既然是逻辑杂糅了,那就必然可以将一段杂糅的逻辑切片成多段逻辑,然后按照执行的顺序依次执行,到了最后的结果就是将多段函数的执行结果就是大函数的执行结果,这种方法就叫分治。
高责任性
指函数职责的单一性要强,对于公共函数一定要做到,一个方法一个功能。
对于单一职责我们一直放在嘴边,但是完成的力度一直不够,我们可以回想一下现在的代码,很多情景下,对于多个地方用到了相同的公共函数的位置,经常会来新声明一个函数。而这个新函数的作用就是将多个公共函数放在一起,然后在页面上就调用这个新函数。
对于这个新函数,你能说它职责单一了吗?
一旦遇到了特殊场景,大部分开发人员就会在新函数内部,使用各种if/else的逻辑判断来执行对应的函数,随着迭代次数越来越多,逻辑越来越复杂,新函数就成了另一个杂糅函数,换一句话说,它不纯了。
分治法
分治法,是一种经典的数学算法,取分而治之之意。目的是将一个复杂的问题划分为多个相同或者是相似的小问题,分开解决。
对于具体实现可以看下图代码,文件地址:

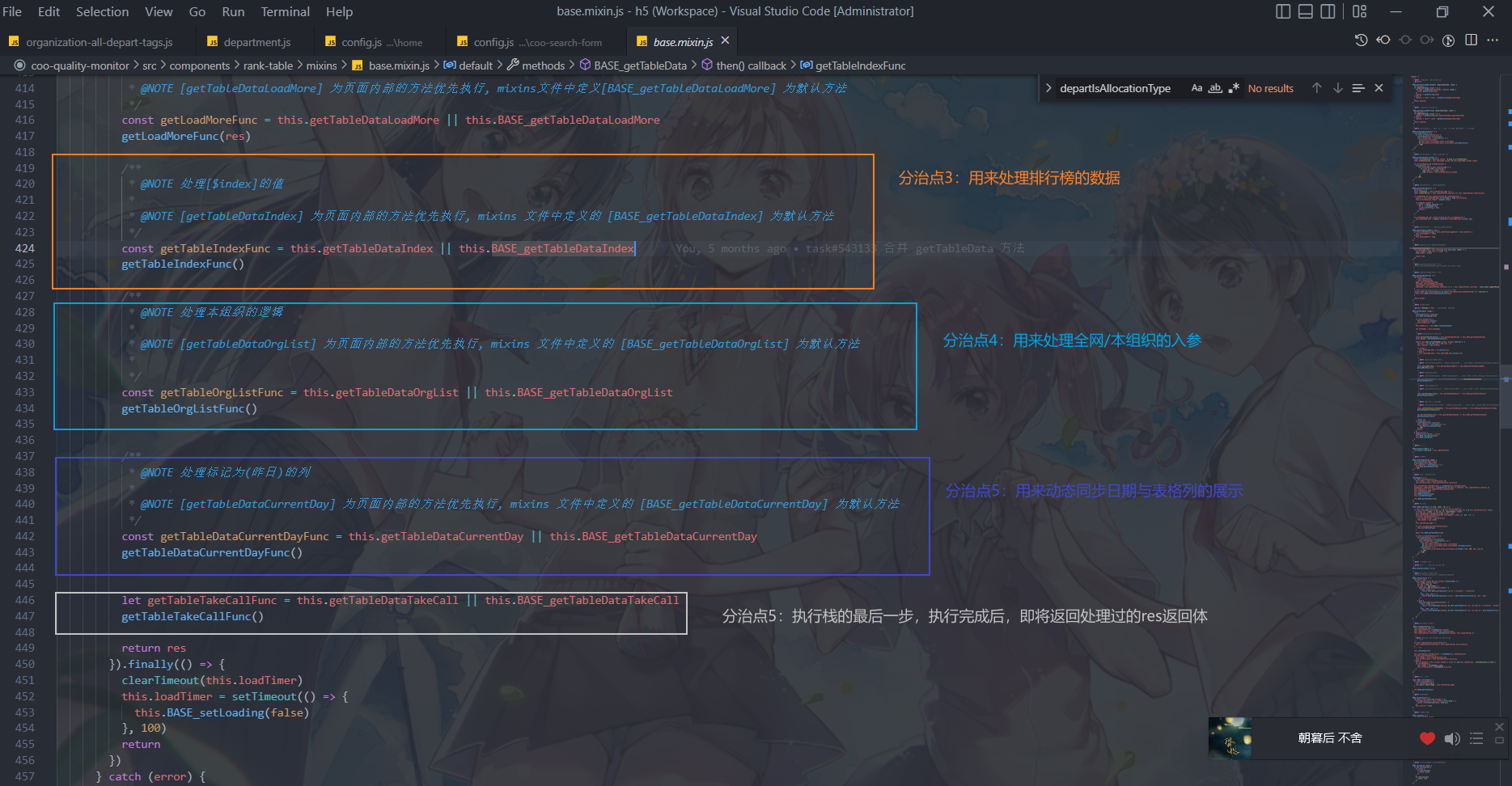
这一段是我们经常遇到的处理表格的请求逻辑,它是一个非常典型的、可复用性要求较高的、可分治的案例。
它是一个mixin混入文件,给9个表格业务组件提供了全部的逻辑支持,基本没有出现什么问题。分治点已经标出,大家可以点击文件链接进去自由查看细节。
大家可以仔细看一下,上面说的三点在这个案例中已经全部体现出来了。
对于一个区块内部的逻辑,可以将它分成两块,一部分由函数体内部提供一个默认函数,同时支持外部传入函数,留足了操作空间,灵活性极佳。
每一个区块内部的函数,只管理它负责部分的功能,可以清晰的看到我标出的5个分治点,就是其区块性最好的体现。
现在项目中有大量的业务代码,可以提供给大家练手的机会,可以尽情地去使用分治法。

在去年我上线了一个前后端分离的博客项目, 后台服务用的是Express, 在当时我选择了PM2来启动我的Node服务. 为什么会需要PM2呢?
NodeJS是一个基于V8的运行时环境, 当我们打开一个shell面板, 输入启动指令 npm run start, 程序开始运行在机器后台, 这个时候我们可以通过服务占用的端口号, 找到这个进程. 例如:

但是, 在我们关掉这个shell面板后, 我们的Node运行时也被终结了, 所以我需要一个工具, 对运行的进程守卫, 使它永远存在, 除非我使用指令结束NodeJS进程, 这个就是PM2的作用. 它的驱动命令就是我经常用到的:
pm2 list
# ===============
pm2 start app-name
pm2 stop app-name
pm2 restart app-name对比一下Nginx的操作命令:
# =========== 启动Nginx ========
systemctl start nginx
# ========== 重启Nginx ============
systemctl restart nginx
# =========== 结束Nginx ============
systemctl stop nginx以及 Docker的操作命令:
# ============= 查看docker的状态 ============
systemctl status docker
# ============ 启动docker ===========
systemctl start docker
# ============= 结束docker ============
systemctl stop docker我们似乎总结出了一个规律: 在linux下的指令, 工具包的指令都是高度相似的存在, 查询工具包的存在 可以使用 search 关键字, 安装工具包可以使用 install, 更新可以使用 update 或者是 upgrade.
在迁移数据到阿里云的过程中, 我遗失了我的文章数据库, 现在的文章全部是来自于Github的Issues, 还好部分文章还能恢复, 但是我永远地丢失了我的封面图, 似乎我可以从公众号平台抓取一次-_-.
现在, 我开始使用Docker了, MongoDB、Express应用和NextJs应用全部改为了docker镜像, container在某一些方面似乎与PM2的作用相似, 那就是只要Docker的进程存在, 那它的下属container不会熄火, 它的结构如下图:
-------| |
| | ======== image1-container1 ======= port:port
| | ======== image1-container2 ======= port:port
|====== image1 |
remote | |
store | |
| |
| | ======= image2-container1 ======= port:port
|====== image2 | ======= image2-container2
| |
------- |上图表示: 远程仓库可以上传多个镜像仓库, 形如Github, 在宿主机检出任意个Image镜像, Image就是Github上的项目, Container由Image生成驱动. 在Container成功启动后, 作为一个服务, 它被运行在后台. 其结果如下:

可以看到的是, 现在docker一共启动了三个容器, 一共有4个镜像, 3个容器.
github上有一个很不错的一个仓库awesome-compose, 我选择的就是其中的一个模型, 在实际上线部署的时候, 慢慢的加入自己的配置. 现在Nextjs的官网都发布了Docker的示例, 实际用起来其实并不困难. 下面我贴一个Next的配置, 文件名 Dockerfile:
FROM mhart/alpine-node
LABEL maintainer = "shadow <[email protected]>"
WORKDIR /usr/src/app
COPY package.json /usr/src/app
RUN yarn install
COPY . /usr/src/app
ENV NODE_ENV production
# COPY ./app/public /usr/src/app/public
# COPY ./app/.next /usr/src/app/.next
# COPY ./app/node_modules /usr/src/app/node_modules
RUN addgroup -g 1001 -S nodejs
RUN adduser -S nextjs -u 1001
RUN chown -R nextjs:nodejs /usr/src/app/.next
USER nextjs
EXPOSE 3000
# EXPOSE 3100
# CMD npm run build
CMD npm run build
CMD ["node_modules/.bin/next", "start"]
Dockerfile文件是制作Image镜像的一个配置文件, 启动image 可以使用docker-compose包, 用起来是真的很简单, 很方便. 也可以使用官方提供的一些原生的指令集. 我贴一个docker-cn的中文文档.
更多具体的配置可以访问Nextjs的官网提供的示例next-js.
Next应用的部署分为几种模式, 支持静态导出, 也支持持续启用, Next应用其实际也是启动一个Nodejs进程, 但是Node应用启动后, 没有办法支持端口的代理, 什么意思呢? 比如: 我的应用启动的端口是4000, 正式上线后, 我必须访问: wuh.site:4000 才能正确地访问web应用, 为了丢掉这个丑陋的端口号, 只能使用Nginx.
还是老一套, 在阿里云平台免费拿了20张SSL证书, 给自己的域名申请一下证书, 将我们的服务升级为https, 升级为https后, 就可以升级http版本到http2. 下面是一张升级为http2的站点请求瀑布图:

HTTP2的其中一个优势完全体现了出来: 多路复用. 面对如此多的请求, 在HTTP2中, HTTP1.1的排队阻塞问题得到了缓解, 从这两条进度条看起来, 它们几乎在同一时间开始, 同一时间结束.
影响静态资源访问速度的因素, 不外乎:
一方面http2解决了文件数量的问题, 另一方面, 我启用Nginx的gzip, 使用压缩文件, 减少静态资源的体积.

下一步就是用webpack提取公共部分代码, 将common.bundle放入CDN服务中, 进一步优化资源的请求.
另外, 我们需要减少初次请求的接口返回体的大小, 如图:
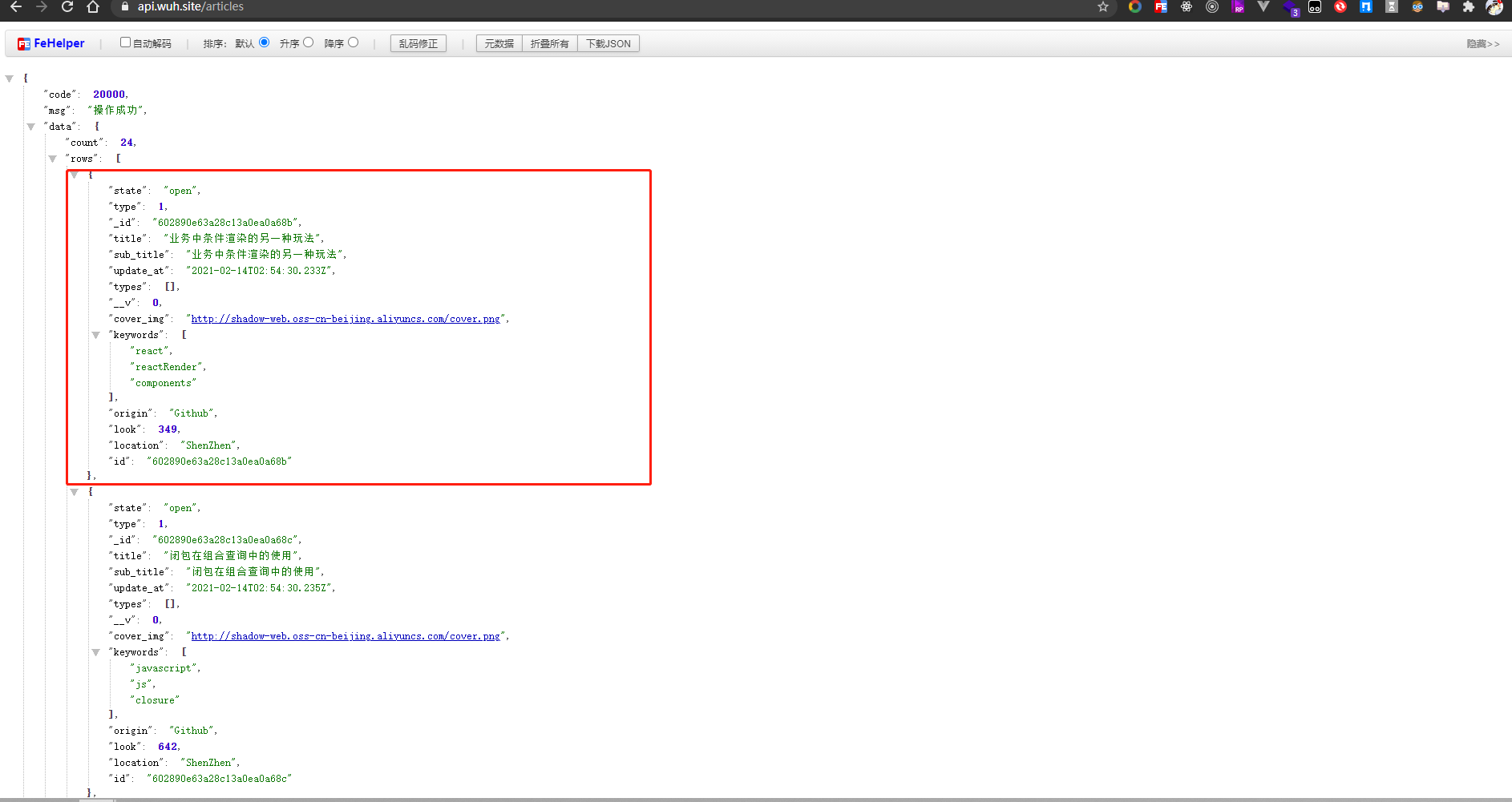
目的就是控制第一屏加载的数量和返回体的字段, 只返回首页需要的关键字段, 让接口的响应速度变快, 富余字段放进详情接口中返回.
我记得我之前写过一篇《技术世界的打造》, 但是这一篇已经丢失了, 再也找不回来了.
技术的升级过程中, 陈旧的技术会被一个又一个新兴的技术所替代, 新兴的技术又会被下一个时代的技术所更换. 就像是一个车轮, 来回旋转不断向前, 谁也不能让它停下了.
接触一个或者是一些, 自己从未经历过的事务, 是一个痛苦又自豪的过程.
我对于Docker的使用和了解都是相当初级的存在, 我曾经坐在一个大佬的旁边, 看他表演如何使用docker发布更新webapp, 看他如何操作自签证书, 看了很多, 也听了很多. 那个时候我只是一个观众, 现在我想做一个演员, 做一个好演员, 做好一个演员.
在升级Http2时, 我提前做了很多准备, 我了解到nginx的版本需要制定版本以上的才可以直接配置 http2, 但是我在升级时, 什么都没做, 只是加上listen 443 ssl http2配置, 居然成功升级了, 这也算是给我的一个小小的惊喜.
现在我用docker-compose来进行构建Image镜像和启动Container容器, 困难处在于宿主机和容器之间的内部访问, COPY指令与WORKDIR之间的联系.
MongoDB换成镜像而不再是宿主机的服务, 给我带来的更直接的影响是几乎没有什么影响, 更加简单, 更加快捷, 我不用自己写一个service文件, 用systemctl来托管服务, 得益于Container的进程守卫, 很多工作省下来了.
我用Nextjs重写了前端应用, 替换了原React-App的生产包. SSR服务侧渲染似乎让网站的更加容易被搜索引擎抓取, 但是在我仔细了解Google的SEO优化指南后, 我发现真正的SEO优化并不是写一写meta头这么简单. 它需要一个sitemap网站地图, 需要一个robots来告诉爬虫不用爬取无效地址, 需要接入一些三方追踪服务帮我做优化, 比如: Google Analyze.
如果你需要做SEO优化, 可以参考Google SEO优化指南. 在优化了搜索引擎的爬取结构后, 从三方平台可以得到结果.
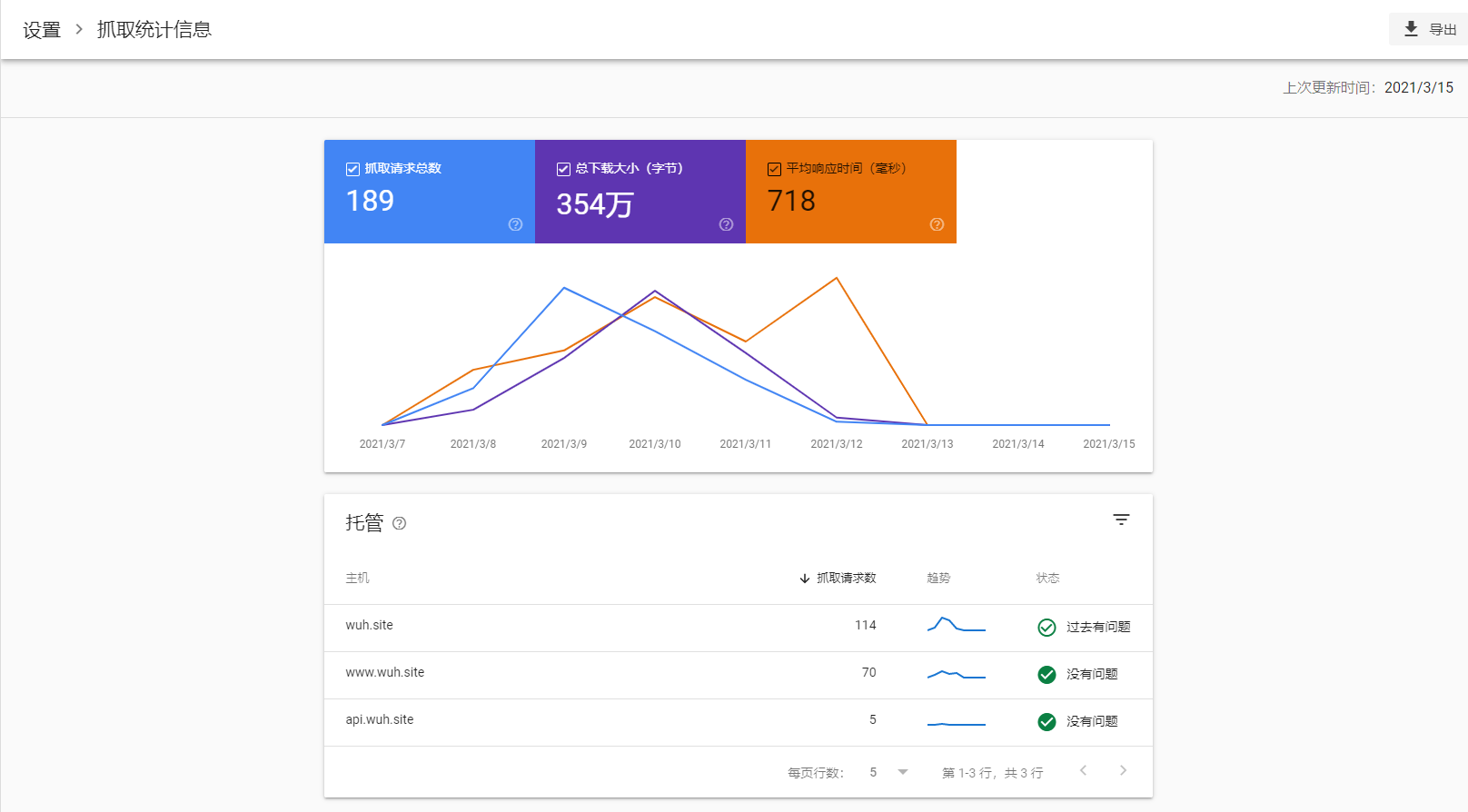
SEO最快速的方式就是打广告, 在门户网站推广你的网站, 开启SRR, 配置sitemap或者是其他一些优化手段.
WEBApp的性能优化也有一些关键指标, 依靠google的分析系统, 我们将持续优化WEBAPP

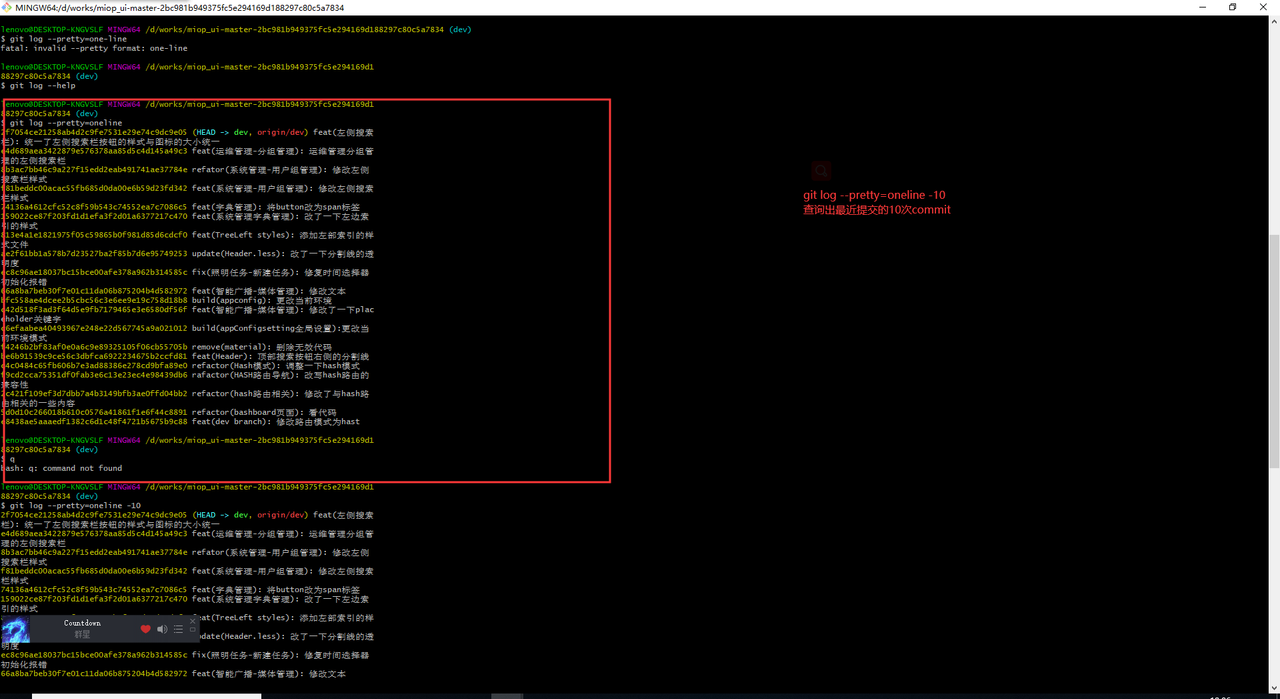
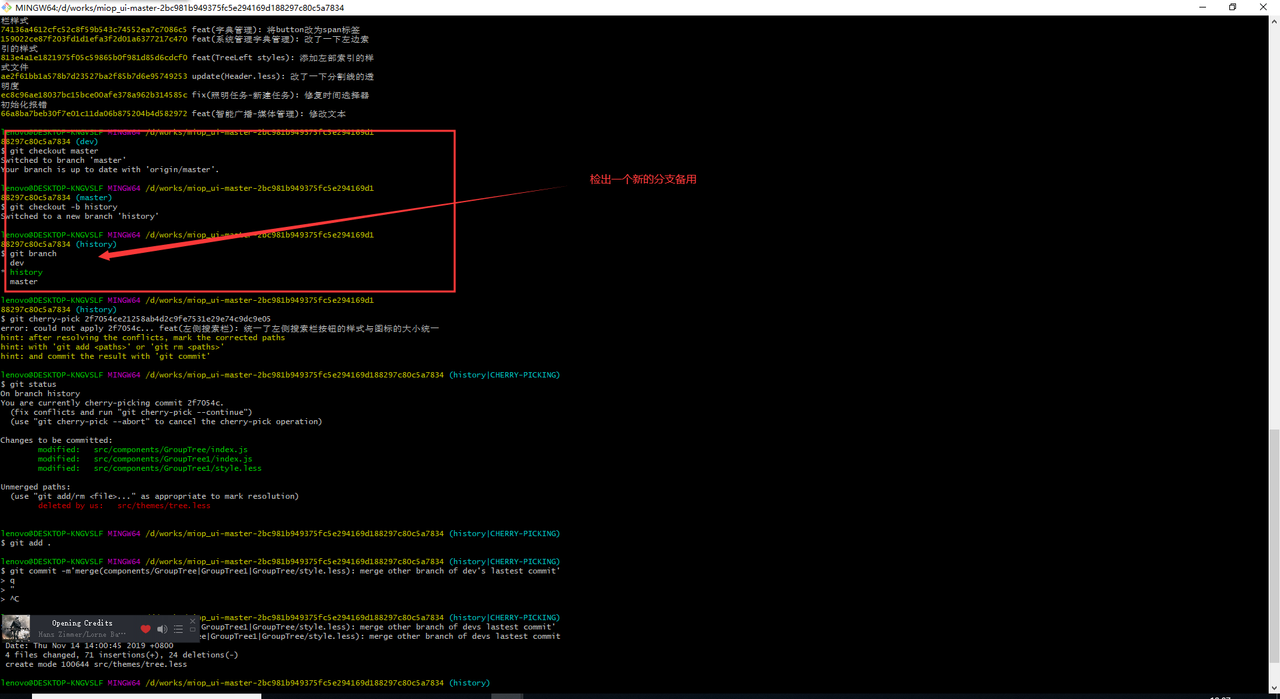
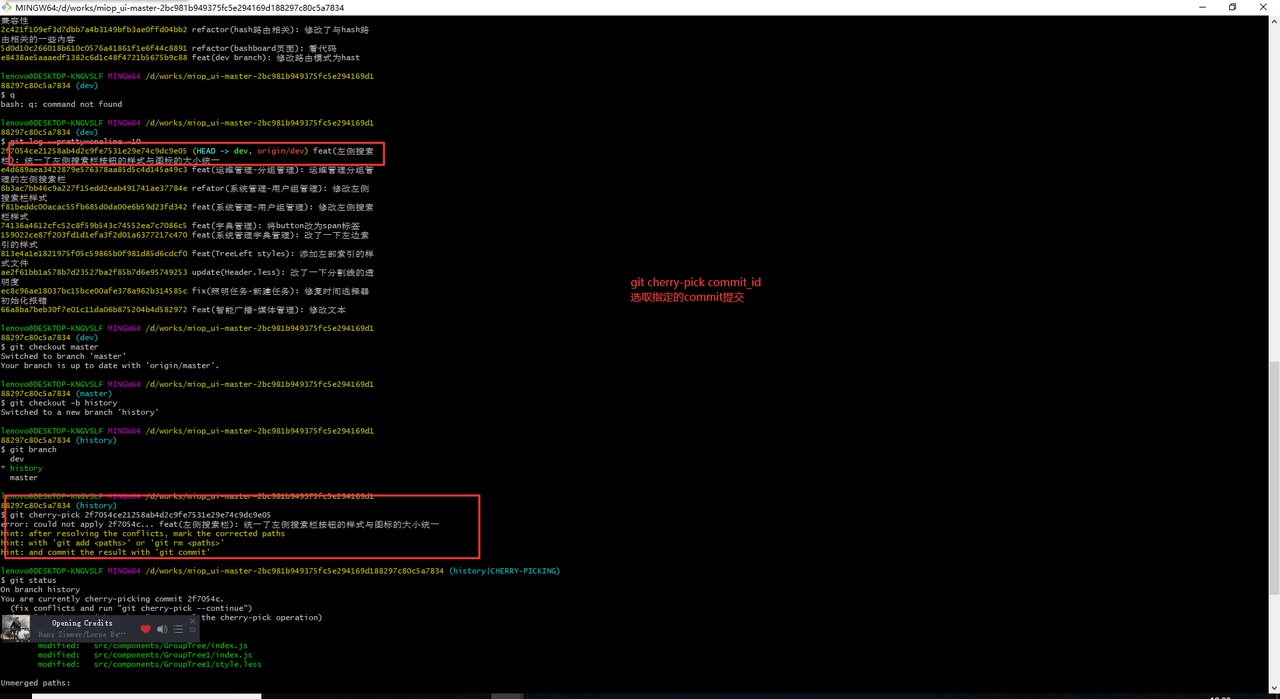
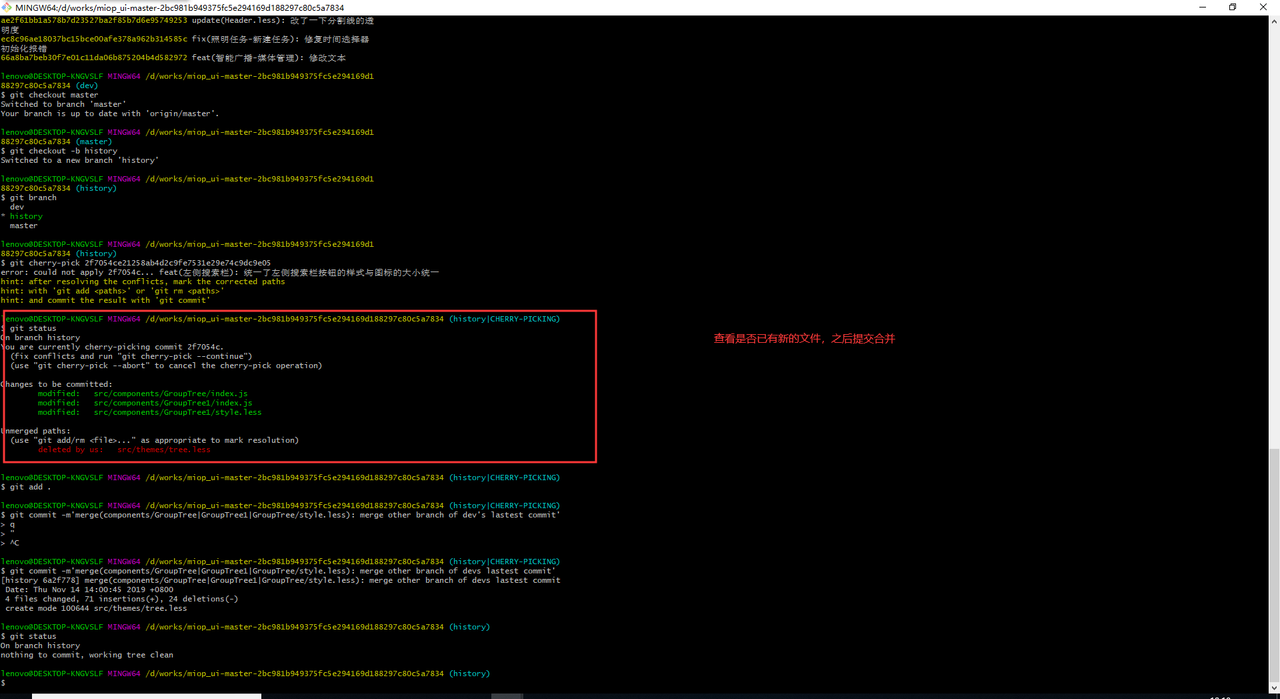
尝试一下多分支开发, 合并某个分支的某一个commit或者是多个commit,下面是具体的步骤:
git log --help可以调出git的文档, 对着文档的敲一下
git log -10 --pretty=oneline只看每一次commit的Header部信息, 获取到每次commit的Id
git checkout -b pre新检出一个分支, 在pre分支上拉取合并其他的分支的commit, 消除冲突之后再合并到主支
git cherry-pick commit_id获取某一个commit只写一个commit_id
git cherry-pick commit_id...commit_id_2中间加上...表示一个左半开区间(A, B]
git cherry-pick commit^...commit_id_2加上匹配符'^', 表示一个闭合区间[A, B]
合并之后提交
什么是github actions? 我们可以使用github actions做一些什么事情?怎么实现我们的需求?
我们在日常的开发过程中,部署过程中或者是更新日志的发布,一定会重复地执行一些操作。我一直在寻找和尝试一些简单、自动化的操作,免去一些重复操作。
首先说明,我也是头一次运用github actions,不过是在完成了一些操作之后,反过头来记录一些我是怎么做的。
先从一个简单的配置文件,来认识一下github actions。.github/workflows/first.yml
name: Github Actions Demo First
on: [push]
jobs:
logger:
runs-on: ubuntu-latest
steps:
- name: 'runner task1'
run: echo 'actions runner task1'
- run: echo 'actions runner task2'
- run: echo 'actions runner task3'首先文件的类型是yaml,文件名的后缀是yml,所以我们需要提前学习一下yml的语法。其语法和json的语法很相似,上面的yml文件翻译为json,其实就是这个样子:
{
"name": "Github Actinon Demo First",
"on": ["push"],
"jobs": {
"logger": {
"runs-on": "ubuntu-latest",
"steps": [
{
"name": "runner task1",
"run": "echo 'actions runner task1'"
},
{
"run": "echo 'actions runner task1'"
},
{
"run": "echo 'actions runner task1'"
}
]
}
}
}只要是在语句之前加上-号,那么它的父级会自动解析为数组,在:之后的换行符会解析为对象。其语法对比json来讲,更加简单。
不出意外,其执行成功的结果就是这个样子:
在github官方对github actions的文档描述看,上面的例子虽然简单,但是已经包含了事件流的基础元素。
现在对比这么一看,跟我之前写过的docker-compose的文件结构相当相似。要知道上面的元素全部是复数,就是说可以有一个也可以有多个,只要保证了基本的结构不错误,那你可以随意的加多个任务。
需要注意的是,对于Jobs下的子任务,都需要指定runs-on属性,要不然会抛出:
ERRO[0000] 'runs-on' key not defined in Github Actions Demo First/tags Workflows文件一般是放在.github/workflows文件夹内部,我看了好几个开源项目的文件目录大致上都是这样,因为github会自动拉取这个文件目录下以.yml结尾的文件作为任务文件。
Events是一个关键点。下面我贴上两个地址,是github actions的官网上对于Events模块的描述。events-that-trigger-workflows,workflow-syntax-for-github-actions。on可以监听到的事件官网上提供了一个索引表,和它们相关的写法和用法。同时不单单是对事件,还可以针对单独的分支进行事件监听。
name: Github Actions Demo Second
on:
push:
branches:
- main
pull_request:
branches:
- main
schedule:
- cron: '/5 * * *'
jobs:
reb:
runs-on: ubuntu-latest
steps:
- name: 'push main'
run: echo 'push events'Events.schedule定时任务。在文档上schedule出现的位相当靠前,估计这个是一个相当不错的特性。它的函数是一些云函数,官网给出了一些例子,但是我目前还没有测试,所以先放着,以后再玩。
Jobs和它的一系列参数列表和语法。Jobs是Github Actions最核心的元素了吧,我们需要的各种各样的功能能不能实现,怎么实现就依赖于怎么实现。其中,我们比较关注就是一些环境变量问题。env提供了这一功能,另外use和with成对使用。
其中,介绍Jobs任务的另一种使用,串联。任务可以是单行,也可以是多个任务有先后、互相依赖的关系存在。所以在github actions中提供了jobs.jobs_id.needs 这个配置项,让我们可以个性化配置。使用方法也简单
jobs:
reb:
runs-on: ubuntu-latest
needs:
- first_task
_ second_task
steps:
- name: 'thrid_task'
- run: echo 'thrid_task'jobs.jobs_id.runs-on表示在哪一个虚拟机执行任务。 现在提供的虚拟机,可能我们日常使用ubuntu就够了。它有以下几个选项,可能以后还会再增加。
| 虚拟机 | Runs-on label |
|---|---|
| Windows Server 2022 | windows-2022 |
| Windows Server 2019 | windows-latest |
| Windows Server 2016 | windows-2016 |
| Ubuntu 20.04 | ubuntu-latest |
| Ubunti 18.04 | ubuntu-18.04 |
| macOS Big Sur 11 | macos-11 |
| macOS Catalina 10.15 | macos-latest |
这是一个github 官方提供的例子,actions来自于docker官方仓库。
可以查看我的编译yml,也可以直接查看github官方例子。对比一下,你就会发现没有什么太大的差异,只是我换成了分支名,而github例子使用的hashid。
因为需要上传Docker Image镜像到Docker Hub,可以使用由docker官方提供的几个actions:
不得不承认,有很多的工作或者是操作都可以用一些工具自动生成。比如,我现在项目的更新日志,仍然还是在本地执行脚本,生成日志之后再推送到github。
每一次更新,发布release版本时,还需要把本次更新的内容复制粘贴到版本说明中。看起来可以改变一下,让这一步工作自动化进行。
版本更新CI/CD的一个重要环节,其价值不可谓不巨大,可以极其方便地控制一些手动操作。尽管现在有一个工具可以了本地测试,但是还是有缺陷,在我做完了全部的流程之后,我回过头来仔细分析了一下。我之所以干的这么不顺利,就是因为我不太了解linux和虚拟机相关的知识。
另外不太熟悉github actions相关的进阶的玩法。由此可见,我这种英语不行,我看着文档上面例子,也可以做出一些我想要的功能。另外也归功于github actions的仓库,里面准备了一大批日常使用的功能,完全解决了我的需求。
现在介绍使用的actions:
+ **actions/checkout@v2** 应该算是使用频率最高的actions了吧,只要是涉及到了git相关的操作就离不开它
+ actions/setup-node@v1 选择任务执行的nodejs版本,可以控制其版本号
+ **release-drafter/release-drafter@v5** 生成release notes的一个actions,可以生成这个版本号的提交日志
+ **appleboy/ssh-action@master** 服务器登录执行指令
注意:
1. 在使用release-drafter的过程中,必须使用pull_request 这样才可以拿到每一次分支的更新日志
1. appleboy/ssh-action 需要注意的是有多种连接服务器的方式,如果使用的用户名+密码,需要查看远程服务器的是否支持连接
1. 如果条件允许,还是拆分多个任务比较好,不要都写在一个任务里面
最近github的速度是在是太慢了,实在是受不了了,所以只好把镜像的编译工作放在了本地。在本地制作镜像然后托管到dockerhub,直接使用线上镜像了。
换一句话描述: 之前在服务器做镜像,现在在本地做镜像。
首先,介绍一下,这次更换部署方式用了哪一些工具和一些使用的坑,更多关于使用的方法和问题的排查。
基本的流水线节点大致如下:
连接服务器更新的脚本,没有提交到github,但是我会讲一下我是怎么做的。
具体的安装流程可以百度一下,网上有很多的教程,就不具体说了。这里贴上一些我经常查看的一些网站,当然都是关于docker的。
简单列一下我用的比较多的一些docker的指令:
首先,我是将镜像文件托管到了docker的官方网站,所以login是必须要执行的一个指令。除此之外,每一个镜像文件必须指定两个版本号。docker pull指令默认拉取的是docker-image:latest版本号,同时我必须将这个镜像打上另一个版本号,以防需要镜像回退。
首先,在bin目录下创建一个脚本文件,执行环境指定为node,docker-push.sh
#!/usr/src/env node所以,在push操作之前必须先只执行一句代码,docker-push.sh:
docker build -t 'shadowu/wuh.site:latest' -t 'shadowu/wuh.site:1.6.0'另外一个版本号,来自于package.json文件中的version字段,基于这个文件可以更新一下执行的脚本:
version=$(node -e "(function () {
const path = require('path')
const pathname = path.resolve(__dirname, './package.json')
console.log(require(pathname).version)
})()")
docker build -t 'shadowu/wuh.site:latest' -t 'shadowu/wuh.site:'$version执行环境指定为node了,我才可以用nodejs的模块化拿到package.json文件里面的version,这个是我能想到的最简单的方法。
然后,在脚本指令里面,为这个脚本加上一个命令:
"scripts": {
"build:docker": "./bin/docker-push.sh"
}镜像的文件制作``Dockerfile`,可以访问我之前写过的一篇《从PM2到docker, 离不开的Nginx》,不用写太多,简单制作一下,先让项目可以用docker跑起来,其他的再说。
在很早之前,docker-compose还是需要单独安装,但在更新了docker的版本后,docker-cli里面集成了docker-compose,相当的方便,我在项目的描述文件里面记录了两种启动容器的方式。一种是用docker-compose 启动本地制作镜像,另一种是docker启动线上镜像。
在项目里面我提供了docker-compose.yml的执行文件,在不考虑其他优化的前提下,用docker-compose启动镜像是如此的简单。
version: "3"
services:
nextjs_app:
build: ./
ports:
- 3100:3000必须的配置项就这么简单,但是优化镜像体积的时候,我们还需要用到volume挂载卷,和一个针对node_modules的专用镜像。两个镜像之间的网络桥接用到的network。
目前我遇到的,比较麻烦的处理就是这两个,因为也是头一次做,很多东西都需要慢慢摸索。
在之前版本中,服务器端的执行脚本是这个样子:
frontend:
build: frontend
ports:
- 3100:3000
stdin_open: true
container_name: frontend
restart: always
depends_on:
- backend
networks:
- react-express
- mongo-db现在不用执行编译过程,简单改一下,直接使用镜像名+版本号就好:
frontend:
image: shadowu/wuh.site:latest
ports:
- 3100:3000
stdin_open: true
container_name: frontend
restart: always
depends_on:
- backend
networks:
- react-express
- mongo-db你永远可以使用且可以只使用 docker-compose up -d 指令,来完成你想完成的任意操作。
首先,介绍一下有关bash相关的教程《Bash脚本教程》(来自于阮老师的教程,链接地址直接指向了Bash的启动环境篇)。
教程的内容很多,但是我用到的实际上也没几个,目前只会写一点相当基础的语句,但是没关系,可以慢慢来。
现在使用的一个source指令,用来加载同步服务器端的脚本文件。
ssh username@ip
$ password这个是比较常用,使用ssh登录服务器的操作。输入密码是必不可少的一步。只有密码正确了才可以操作服务器,我已经将一些基础的操作全部做成了脚本,现在只差服务器的同步。那么有没有一种方法可以免去输密码的这一步?
我用到的一种就是安全证书。
能力有限,原理我说不清,感兴趣的自己百度。
执行脚本之后,能够正常的走到这一步说明没有遇到问题,而且已经推送成功了。
初次制作的时间还是比较长的达到了43s,别慌,之后的编译过程会快一点。有些问题需要注意下:
看一下执行过程,停留在yarn install 的过程特别耗时,有一次达到了200s+,只好改成淘宝的镜像源了。
volume的配置项,不管我放到哪里都感觉没用,也不知道是不是使用的姿势不对。但是我看到了一种方法就是将node_modules单独做成一个镜像,容器之间是可以互相访问,免去每一次制作镜像都需要安装依赖,后面实践一下。
启动容器一定要加上端口号,容器默认端口是3000,但是浏览器访问3000端口是没办法正常访问的,这里我测试过,加上一个映射端口就没问题。
docker-hub设置为公共源,才可以用到一些三方工具,比如生成一个icon标签放在github上面。
注意nodejs的版本,有很多莫名的问题是nodejs的版本带来的问题,linux上可以使用的n这个工具,可以快速的切换nodejs的版本
WORKDIR是指app在容器里面运行的文件目录,在遇到镜像可以正常制作,但是容器死活起不来的时候,可以减掉一些镜像文件的配置项,进入到容器里面去看一下究竟遇到了什么问题
docker container ls -a docker image ls -a docker stop container_id & rm contaier_id``docker image rm image_id
以上是使用的频率最多的一些指令,同时我们还会用到 docker container inspect和docker image inspect,它们是用来查询容器和镜像的基础配置的。
docker run和docker create 在创建容器的时候,其实没啥大区别,需要注意的是,最好加上-it配置,在容器正常启动后会返回容器iddocker-compose,有了它一切变得简单起来官方提供的一个工具,使用简单。
可以看到目前容器占用的资源
可以看到一些变量属性
======= 分割线以下是更新内容 =======
已经在深圳待了一个星期了,与武汉最大的差别就是:快;
下班之后跟朋友回家的路上讲了起来,深圳的快节奏就体现在路上形形色色的路人,走的速度快,吃饭的速度快,我不知道他们是不是上厕所也是同样的快。
谈到工作处,讲起了一起工作日常中的事情,就是到哪里都有自己不喜欢的人,回来了我仔细想了一想,环境是不可能适应个人的,反而是个人要积极的适应环境。就这样一个人走进了我的视野,他是谁?
万历首辅申时行,到了万历十五年之际,朝堂上面的党争已经十分激烈了,就是凭借着申时行一个人沟通着万历皇帝和百官,打酱油将明朝经营了下去,他是一个有意思的人,一个将混派玩的极致的人,同时也是一个优秀的政治家,官僚。
我似乎应该改变了,千人千面是我讨厌的样子,而又不得不去对应个人去作出改变,我怎么了?我们怎么了?我们似乎都在变成自己讨厌的样子,这就是成长?不是这不是,这只是生活的无奈,因为我们都要在这个世界上生存。
我在写博客的这几天意识到了一个相当严重的问题, 就是文档样式在各个平台的差异性导致视觉效果太low. 痛定思痛之下我把我总结的几点记录下来, 方便大家不要再次踩坑.
大纲如下:
书写时一律采用英文符号
hello, my friends, welcome
你好, 我的胖友, 欢迎你的到来
使用符号后一定要空格
Hello, world! buteaful
世界, 你好
markdown 中对图片的引用包括以下几种:
注意: 我推荐第二种
原因无它, 结构清晰, 一目了然, 定位准确, 文档美观. 将所有的图片变量全部放在文档底部, 包括网址链接
注意: 不要使用img标签去设置图片的大小
markdown 中使用外链接也有多种方式, 如下:
注意: 我推荐使用第四种
markdown 中也分为有序和无序列表两种, 分别对应了html中的ol与ul
注意: 这个要结合使用, 第一级别尽量使用有序列表
| 字段 | 说明 | 默认值 |
|---|---|---|
| name | 用户名 | none: string |
注意: 使用表格做到职责分明, 有子属性的字段尽可能的拆分, 放到下一个表格之中
注意: 表格样式居中, 这个不强求, 我是觉得居中对齐好看
你也许会遇到这么一种情况, 在一个段落之中, 使用了标题, 有普通的文本, 还有图片, 怎么处理一下, 样式上才会更好的兼容, 或者说是融洽. 如下:
# 标题
这是对这个标题的一段说明, 只是一段普通的文本, 但是下面我需要引入图片了
<img src='https://baidu.com' alt='preview' />
这里的文本我接着写对这一个标题的或者是图片的描述这一段的结构不好, 太粗糙了. 我试过在微信公众平台和前台的渲染中使用, 样式上的问题还是比较多, 比如我在博客里面提到了, 全局样式覆盖的问题.
改进:
## 标题
另起一行写第一段描述: 这里是描述
换行
现在要插入图片了!
插入图片的意图, 简单说明, 十个字以内, 手机的屏幕最小的展示10em左右

再次换行
这里写第二段描述
注意: 使用标题后一定要换行
提示性语句的重点在于提示, 所以一定要醒目, 老外的醒目是大写, 这里我就用加粗吧. 例如: **注意: **, 所以除了提示性质之外的语句, 不要轻易的使用加粗, 如果目的是为了醒目, 可以使用 斜体
注意: 为了演示效果, 我加了转义符, 使用的语法可以直接看清楚
我记得前人给我总结闭包的时候说过: 口口相传的闭包拥有三个特性,有函数,有内部变量,有返回值, 其目的就是为了绕过浏览器的垃圾回收机制, 令闭包对象及其相关的引用值长期留在浏览器中.
但是现在对闭包有了一点点自己的理解.
首先看一下MDN的对于闭包的定义: 一个函数和对其周围状态(lexical environment,词法环境)的引用捆绑在一起(或者说函数被引用包围),这样的组合就是闭包(closure)。也就是说,闭包让你可以在一个内层函数中访问到其外层函数的作用域。在 JavaScript 中,每当创建一个函数,闭包就会在函数创建的同时被创建出来。
从以上定义可以看出,在闭包形成后它会形成一个声明该函数的词法环境组合,这个环境包含了这个函数执行时引用的局部变量。
其常规写法如下:
function f1 () {
let a = 0
function f2 () {
a ++
console.log(a)
}
return f2
}
var ff = f1()
ff () // a = 1
ff () // a = 2
ff () // a = 3以上代码中, ff 就是 f1函数执行 f2 时形成的一个函数实例的引用, f2维持了一个对它的词法环境的引用 a, 所以在调用ff时, a 依然存在.
闭包的写法种类有很多, 可以参考闭包的多种写法, 由此可见实现一个闭包的方式, 在js中并不只有一种.
在日常的业务开发过程中,我们使用闭包的场景更多的是处理请求的缓存值,如果命中的缓存就取缓存值,如果没有就重新发起请求。
但是鲜有对函数调用时,缓存函数形参的实现,这个我找了很多的资料,最多的还是对于请求结果的缓存,却忽略了对于多区块条件查询时,函数执行的参数的处理。
其示意图如下:
这个是我们在中后台应用中经常遇见的条件查询示意图, Table部分负责渲染数据,所以我们需要一个Request方法来获取数据,其他部分的查询表单就是Request方法的形参.
最为常见的搜索模式就是 Search + Pagenation 组合查询. 为了应对这种情景下我的组合查询,我们会提前定义一个SearchObj用于储存Search Change 和 Pagenation Change 后的值。所以它一定会有如下操作: 1. 在Pagenation 改变后 更新 SearchObj中的pagenation值; 2. 发起Request请求;
其代码实现如下:
import { useState, useEffect } from 'react'
const Demo = () => {
const [searchArgv, setsearchArgv] = useState({ pageNum: 1, pageSize: 7 })
const handleRequest = (params) => {
return fetch(api, params)
}
const handleSearchChange = (params) => {
setsearchArgv(params)
}
useEffect(() => handleRequest(searchArgv), [searchArgv])
return (<>
<Search onChange={handleSearchChange} />
<Table onChange={handleSearchChange} />
<Pagenation onChange={handleSearchChange} />
</>)
}这个是比较常规的处理联合查询的业务, 其实现过程还算是比较简单, 但是一旦遇到了Search部分拆分了太多的UI, 或者是多个Search组合的情景下, 每一个Search变动之后都需要重复经历上面两步,赋值和请求.
现在我们是不是可以考虑一下, 将以上步骤简化一下, 就利用闭包的特性, 始终调用memo函数, 将函数执行的形参缓存下来, 从而达到免去重复操作的步骤.
首先我们要实现一个memo函数, 其次结合我们的技术栈React, 我们还要实现一个Memo Hooks。
引用之前实现的一个简易版本:
function memo(fn) {
let store = {};
// eslint-disable-next-line func-names
return function (params, isFresh = false) {
if (isFresh) {
store = {};
} else {
store = Object.assign(store, params);
}
if (fn) {
fn.call(this, store);
}
return store;
};
}分析一下:
上面的代码也有其问题:
改写一下上面的代码, 将一些属性定义在原型上, 使用Map或者是WeakMap数据结构, 其进阶版本的实现如下:
const KEY_FIELD = `@@`
function memoQuery (fn, {
key = KEY_FIELD,
initialValues = {}
}) {
const cache = new Map()
if (initialValues) {
cache.set(Symbol(key), initialValues)
}
const update = (key, val) => {
const origin = cache.has(key) ? cache.get(key) : {}
cache.set(key, { ...origin, ...val })
}
function call (params = {}) {
update(key, params)
fn.call(this, cache.get(key))
this.get = key => cache.get(key)
}
call.prototype = new call()
// 查询闭包内部缓存的 Store
call.get = call.prototype.get
// 原 Map 方法, 查看Store中是否有对应的 Key
call.has = key => cache.has(key)
// 原Map方法, 清空当前Key下全部缓存的值
call.clear = () => cache.clear()
// 原Map方法, 清空对应的Key的Map
call.delete = key => cache.delete(key)
// 根据Key更新 对应的值
call.update = update
// 原Map方法, 查询size
call.size = cache.size
// 对象销毁, 用于生命周期的注销阶段, 注销后为空
call.unmounted = () => {
call = new Object(null)
cache.clear()
}
return call
}
const logger = (params) => console.log(`current is params: ${JSON.stringify(params)}`)
const memof1 = memoQuery(logger, { key: 'logger' })上面的代码似乎是好了一点点, 它的api全部是Map对象的api, 基于Map的扩展是不是比自己半斤八两的封装好的太多了.
这里将一个注销接口暴露出来, 专门用于组件销毁后其词法环境的引用值无法被浏览器回收的问题, 从而避免内存泄漏问题.
我可以将返回的方法做成一个AOP或者是一个Promise, 这样用户可以自定义一些行为, 可以处理参数的类型问题或者是接口返回的数据接口问题,AOP就可以轻易的实现。
持续更新中
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.