srarod / ithome2022 Goto Github PK
View Code? Open in Web Editor NEWiThome Ironman 2022 - 30 days Challenge
iThome Ironman 2022 - 30 days Challenge


本日將介紹另一個Learning Rate的技巧,也就是Warmup,並整合到Lightning-module當中。
Warmup的本質,實際上就是一種Learning Rate的使用策略。最早是在Deep Residual Learning for Image Recognition內有討論到「過大的Learning Rate似乎不易於收斂」這樣的可能性,後來才在Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour中作為一個Learning Rate策略廣為人知。
主要是為了避免初期Learning Rate過大,導致收斂的狀態不好(不收斂、或是收斂到Local Optimal之類的)。warmup主要採取的策略就是在訓練初期時,使用比較小的learning rate,在指定的epoch之後才恢復成原先的learning rate這樣的一個策略。也就是所謂訓練前要先暖身(warm-up)這樣的一個概念。
在論文中主要分成,下列兩種:
$$
\text{- constant warmup : } \alpha_t =
\begin{cases}
\alpha/n,& \text{if } t < n\
\alpha, & t \geq n
\end{cases}
$$
精神上都差不多,主要就是gradual是屬於一個緩步上升的版本,逐漸暖升。下圖則是論文中的實驗結果,主要是展示在不同的batch size底下,有warmup相對會比較穩定收斂:
那麼在Lightning-Module內該如何實作這個warm-up的機制呢?實際上有很多種方法都可行,最簡單的方法就是設置一個learning rate scheduler去達成這個功能,例如依上面的式子直接設置一個lr_scheduler.LambdaLR就也可以達成。不過依照epoch、step的單位變化就稍微要調整一下,而且若要跟其他Scheduler一併使用也會讓lambda function的定義上更為複雜。
因此另外一個實作方法則是,利用lightning-module內的optimization_step(參考文件)。首先在超參數內新增一個:
train:
optimizer:
name: 'Adam'
learning_rate: 0.001
warmup_epochs: 5
這邊參照論文中一樣設定為5個epoch,沒有太多額外的理由。
接著定義具有warm-up功能的optimization_step:
# learning rate warm-up
def optimizer_step(
self,
epoch,
batch_idx,
optimizer,
optimizer_idx,
optimizer_closure,
on_tpu=False,
using_native_amp=False,
using_lbfgs=False,):
# update params
optimizer.step(closure=optimizer_closure)
# skip the first epochs
if self.CONFIG['train']['optimizer']['warmup_epochs'] > 0:
if (self.trainer.global_step < self.CONFIG['train']['optimizer']['warmup_epochs'] * self.trainer.num_training_batches) :
lr_scale = min(1.0, float(self.trainer.global_step + 1) / float(self.CONFIG['train']['optimizer']['warmup_epochs'] * self.trainer.num_training_batches))
for pg in optimizer.param_groups:
pg["lr"] = lr_scale * self.trainer.lr_scheduler_configs[0].scheduler._get_closed_form_lr()[0]
其中主要就是利用先找到每個epoch內batch的數量self.trainer.num_training_batches接著就能計算出該step應當的變化量,在乘上根據初始learning rate以及scheduler當下本該有的learning rateself.trainer.lr_scheduler_configs[0].scheduler._get_closed_form_lr()[0],就能scale出warm-up所需要設定的量了!
接著我們進實作面,改好的檔案可以參考model.py,之後在同個commit之下便可以執行train.py。一樣參考wandb的結果圖,可以看到Learning的變化囉!
那一樣的有使用pretrained的情況可以看一下Loss與AUC的表現:
是不是相對來說有warm-up的版本平穩了許多呢?而且即使過度訓練,AUC的表顯距離上個峰值的差距也來的比較小了一些!
一樣承襲前幾日的主題,繼續討論資料前處理優化的方式。同樣是Cached到記憶體內,今天會利用比較土法煉鋼的方式來進一步優化效能。
實際上有跑前一篇利用Monai來進行Cached的朋友應該有發現,每次的訓練前,都需要花費一段時間進行Cached。於是就會發生「80M的東西要讀取好幾分鐘」這樣十分不合理的事情。於是我本身在實驗的時候,對於前一篇所提到的「monai.data.CacheDataset與直接把mednist的.npz讀進來的效率差不多」這件事情開始懷疑,經過測試以後發現果然還有優化的空間,因此意外誕生了這一篇。
.npz直接讀取.npz其實會發現,不過就是幾秒鐘的事情,而且已經直接把三個切分全部讀進來了。
>>> npz_files = np.load('data/chestmnist.npz')
>>> for key in npz_files.files:
>>> print(key, f'shape {npz_files[key].shape}')
train_images shape (78468, 28, 28)
val_images shape (11219, 28, 28)
test_images shape (22433, 28, 28)
train_labels shape (78468, 14)
val_labels shape (11219, 14)
test_labels shape (22433, 14)
上一篇情況中,會比較久,主要是因為需要把10多萬張png分別進行讀取,再整成檔案花費了許多時間。而.npz的狀況,則是因為是單一個連續的檔案,因此可以只進行一次的I/O直接全部讀取進來。
所以若是原始比較大型的檔案,如果前處理以後的影像不大(例如把X光壓成224x224),再壓成像.npz這樣的array實際上應該是可行的。
為了讓先前dict-based的Transforms以及Dataloader可以延續使用,首先我們要把資料點從整個大矩陣切個出來,像是train set就是把78468x28x28 切成 78,468個28x28,可以利用np.split直接進行快速的分割:
for key in npz_files.files:
sliced_data[key] = np.split(npz_files[key], len(npz_files[key]))
[npz_files[key][i] for i in range(len(npz_files[key]))] 很慢,可以體驗看看...),會受到python慢的原罪影響,要跑非常久。矩陣運算的任務可以的話一定要交給優化過效能的numpy來執行。接著把slice後的array製程dict就完成了!
datasets = {
split : [{
'img' : sliced_data[f'{split_mapping[split]}_images'][i].transpose(0,2,1),
'labels' : sliced_data[f'{split_mapping[split]}_labels'][i][0]}
for i in range(len(sliced_data[f'{split_mapping[split]}_images']))]
具體可以參考preprocess.py,執行後可以得到下圖,基本上與先前無異。
在修改了前處理以後,可以實際跑一次train.py看看。這邊大概要注意幾點是:
一樣只訓練5個epoch,大概跑個幾分鐘就可以得到結果了:
monai.data.CacheDataset有進行更多一些meta data的I/O,或是讀取Cached的機制沒有這麼直接,造成實際上產生資料的速度會花上更多的時間。前幾日的文章,已經利用scheduler訓練出在Validation上還不錯的結果,今天就來test一下,順帶討論一下test的一些哲學吧!
一般在我們進行訓練模型的任務時,大致上就是分成Train、Validation以及Test的三個階段。讓我們回顧一下,其各自的角色分別是
在我們前面已經介紹、並建構用來做實驗的Lightning-Module之中,除了我們先前用過train_step跟validation_step功能以外,自然也有相應的test_step。
具體只要一樣在module的class內加上:
def test_step(self, batch: Any, batch_idx: int):
inputs, preds, labels, loss = self.step(batch)
self.log('test/loss', loss.item(), on_step=False, on_epoch=True, batch_size = inputs.shape[0])
return {
'loss' : loss,
'preds' : preds,
'labels' : labels
}
接著一樣加上對應的epoch_end,就可以計算metrics了:
def test_epoch_end(self, validation_step_outputs: List[Any]):
preds = torch.cat([output['preds'] for output in validation_step_outputs], dim=0).float()
labels = torch.cat([output['labels'] for output in validation_step_outputs], dim=0).long()
probs = torch.nn.Sigmoid()(preds)
# compute metrics and log
acc_score = torchmetrics.functional.accuracy(probs, labels, mdmc_average = 'global')
auc_score = monai.metrics.compute_roc_auc(probs, labels, average='macro')
self.log('test/acc', acc_score.item())
self.log('test/auroc', auc_score.item())
之後重新build model的物件,把訓練好的權重讀進來,使用lightning-module對應的test函式,就可以進行test set的計算了:
# build model and load trained model
net = model.MultiLabelsModel(CONFIG)
net = net.load_from_checkpoint(CONFIG['evaluate']['weights_path'])
# initialize the Trainer
trainer = pl.Trainer(**CONFIG['evaluate']['tester'])
# test the model
trainer.test(net, dataloaders=data_generator)
具體可以參考 evaluation.py,一樣可以用
# python src/evaluate.py --config=hparams.yaml
GPU available: True (cuda), used: True
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
Testing DataLoader 0: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 44/44 [00:06<00:00, 6.89it/s]
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━┓
┃ Test metric ┃ DataLoader 0 ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━┩
│ test/acc │ 0.9475677013397217 │
│ test/auroc │ 0.7314980626106262 │
│ test/loss │ 0.16936460137367249 │
└───────────────────────────┴───────────────────────────┘
結果跟驗證集的結果十分的接近,算是一個相當不錯的結果。
另外注意一下是,我這裡test時的batch size = 512,純粹就是比較快。而且正常情況下test時不論batch size多少都不應該影響計算結果。覺得結果怪怪時,不妨可以試試看,如果不同的話可能就是程式出現了什麼問題。
雖然這樣下小標題可能誇張了!但其實我認為在實務上,Test Set其實隱藏著很多的巧思。
首先是第一種常見的狀況就是,開發者過多且反覆的對Test Set計算結果。這個情況在各種資料的比賽跟以準確度為驗收標準的專案上尤其常見,大部分都會演變成Test Set儼然已經變成另外一個Validation set,在資料有限的狀況下,很難知道準確度的上升到底只是hyperparameter fit on test set還是真的找到了什麼insignt。有些團隊則會利用類似Cross-validation的方式來驗證模型的好壞以避免此情形,也不失一個好方法。
另一種狀況則是更根本的問題,被挑選的Test set其究竟代表什麼?是否與訓練樣本具有相同的分佈?是否與未來真實要處理的問題有相同分佈?種種的問題。分佈問題這一點在像是ChestMNIST資料量很龐大的資料集通常不是大問題,畢竟量大,抽樣基本上誤差也不會大到哪裡去,但小樣本就必須要很注意這東西。尤其是label的分佈,會直接影響到模型對label precition的偏好,不可不慎。
還有就是一些實務上會遇到的準確度下降的問題,這邊簡稱是各種Drifting,這個會在最後一天作為收尾來介紹。
承襲前幾日的主題,今天繼續討論Preprocess優化的方式。今天處要討論的是針對I/O重複性優化的問題。
一樣我們先上架構圖,但稍微改一下。假設是在大量的訓練過程中,自然而然我們就需要做非常多次Preprocess + model computation (forward + backward),大概會變得像是下面這張圖一樣:
flowchart LR
subgraph Main[ ]
CPU <-->|preprocess| RAM
end
subgraph GPU[ ]
gpu_core[GPU Cores] <-->|training+validation| gpu_m[GPU Memory]
end
Storage --> Main --> GPU
Storage --> Main --> GPU
Storage --> Main --> GPU
Storage --> Main --> GPU
Storage --> Main --> GPU
那這裡頭還有沒有什麼優化空間呢?有的,簡單一句,空間換取時間。
理論上來說,同樣的影像(或是原始資料)在經過預處理以後,會是相同的衍生物(即使加入augmentation,至少在augment之前也是相同的東西)。於是這裡就有個可以介入的空間了,即是把預期會被重複執行的Preprocess結果儲存起來以便重複利用。
概念上就可以畫成下面這張圖:
flowchart LR
subgraph Main[ ]
CPU <-->|preprocess| RAM
end
subgraph Temp
temp[Process Data]
end
subgraph GPU[ ]
gpu_core[GPU Cores] <-->|training+validation| gpu_m[GPU Memory]
end
Storage --> Main --> Temp --> GPU
Temp --> GPU
Temp --> GPU
Temp --> GPU
Temp --> GPU
而把整個Processed暫存的位置,具體而言又可以分成下列兩種:
monai.data.CacheDataset直接實作,傳送門monai.data.PersistentDataset,傳送門由於MedMNIST非常的小,Persistent的作法不太顯著。我們這邊直接比較Cached到RAM的作法,可以看到訓練時間又更加的縮短了!Cached的實作可以參考這個commit,見下圖:
看起來似乎沒有差很多,但這些操作隨著前處理計算量跟資料量大小的增加而更加的效果顯著,尤其像是在醫療影像內動輒幾萬張解析度2000x2000的x光、有時間維度的超音波甚至是CT跟MRI。
.npz的格式把整個資料集讀進來,直接使用差不多就是這個cached後的效率。.pt的cache檔案,不小,注意你的硬碟量本日的文章將介紹幾個常見的Deep Learning Log system,然後嘗試解決目前模型所看到的問題。
在前一日的實作中,除了為了讓Callback可以參考metrics作為模型儲存的依據,而增加在validation_epoch_end的self.log(val/puroc)以外,相信眼尖的讀者應該有發現,我們也分別在train_step與validation_step內新增了self.log('train/loss', loss.item())以及self.log('val/loss', loss.item()),如此一來便能開啟Lightning-Module在訓練的途中紀錄LOSS的功能。
另外可以在PyTorch-Lightning文件當中,可以看到其實預設是會使用TensorBoard的logger。所以其實先前訓練完會在/home/$USER/workspace/artefacts/weights內的就包含有TensorBoard的Log檔唷!(主要就是那個event檔)
此時可以使用Jupyter Lab已經設定好的Tensorboard:
就可以看到先前訓練模型的紀錄囉!
TensorBoard可說是最老牌的開源工具,且當然,也有不少可以替代他的工具。在這邊我介紹一個我個人滿喜歡的一個服務WandB(Weights & Biaes)。
有興趣的人可以直接到官網申請帳號,只要在Terminal打入
wandb login
然後輸入辦好帳號以後獲得的API KEY就完成初步的設置了。
接著只要在加到Trainer後就可以使用了
wandb_logger = pl.loggers.WandbLogger(project="iThome2022")
# set trainer
trainer = pl.Trainer(
callbacks = checkpoint_callback,
logger = wandb_logger, # 加在這裡
default_root_dir = CONFIG['train']['weights_folder'],
max_epochs = CONFIG['train']['max_epochs'],
limit_train_batches = CONFIG['train']['steps_in_epoch'],
accelerator = 'cuda',
devices = 1,
profiler="simple")
一樣到這次對應的commit底下,執行
python src/train.py --config=hparams.yaml
(註:這次有更新一些Dockerfile及Docker-compose的內容,建議重新Build,不然可能會有bug)
訓練完以後,登入以後可以在首頁看到目前有跑得實驗們的紀錄
點進去以後就可以到處看看囉!個人覺得最方便的則是可以互動式的去新增自己想看的圖
從上面這張比較Training與Validation的圖當中可以看到,Training很穩定的下降,而validation一開始上升,但後續就跟training十分接近了!評估起來應該是沒有Overfitting的問題。但考慮到auroc還不夠高,而且似乎尚未收斂的狀況,我想應該是太早就停下來訓練所導致。
下次可以訓練多一點Epoch來看看成效!
本篇開始之後的幾天,預計將介紹模型訓練的最後一個章節,正規化(Regularization)。本篇會先給一些Overview的介紹,後續的幾篇則會有實作。
首先定義一下,台灣因為翻譯滿亂的關係,有時候Normalization也會翻成正規化,這兩個term在Deep Learning幾乎可以說是完全不同的東西,而今天這篇介紹的正規化指得就是Regularization。
先借用一下Ian Goodfellow大神出版的Deep Learning教科書中的定義:
we defined regularization as “any modification we make to a learning algorithm that is intended to reduce its generalization error but not its training error.”
Training Error的角色很顯而易見,就是我們在訓練途中,訓練集內的loss或是準確度。我們先前所作的optimizer、learning rate,無異就是為了要去減少我們訓練時的所產生的Training error。
Generalization Error (可參考wiki),一般會翻譯成泛化誤差,意思是指我們所訓練出來的模型,針對從未見過的資料,進行估計或預測時的誤差。這一概念其實很玄,從未見過那又要怎麼去計算?所以一般的情況下,我們也只能對泛化誤差進行某種程度上的估計。
常見的估計便是Testing Error,畢竟Test Set是模型從未看過的資料,因此是一個合理的估計。但問題是開發人員一旦反覆的對測試集進行計算,其實人看過自然會影響模型的選擇,因此某種程度上可以說測試集進行計算的次數越多,使用Testing Error對Generalization Error就很可能越不准。(可能啦...)這也是我先前在介紹Test時,所說的盡量不要一直對測試集進行計算的主因。
另一個term則是Validation Error,它的角色則是比較接近我們找一個與test set分佈接近的validation set,然後以能夠去得到Validation Error最小的方式,來去盡量獲得一個可能是Testing Error最小的模型。
那回到主題的部份,也就是說,一切我們為了降低generalization error的那些事情,就可以說是Regularization!也因此或許換個語言說,那些可以減緩Overfitting的方法或技術,就可以稱作Regularization。
在一般不進行任何限制底下,只要模型的參數越多,網路的結構越複雜,幾乎都可以訓練到Training Error接近0的狀態,但套用到Test set甚至僅在Validation Set的狀況下,很可能就已經不好了,這種情況下就是所謂的Overfitting。概念圖(來源):
這時候所謂Regularization之稱的技巧,就有空間可以進入了。手法基本上有千千百百種,常見的Dropout Layer(基本上已經是每個模型必備,這邊就不介紹),甚至連early stopping(一種在若觀測到validation error不再下降便停止訓練的手法)也是一種Regularization。這個手法在Pytorch-Lightning上實作也十分容易:
from pytorch_lightning.callbacks.early_stopping import EarlyStopping
early_stopping_callback = EarlyStopping(monitor="val_loss", mode="min", min_delta=0.00, patience=3)
trainer = pl.Trainer(...,
callbacks = [early_stopping_callback])
但這個手法難的主要是怎樣叫做下降變慢?有沒有可能在訓練一些又下降了?基本上也是要實驗才會知道。
而後續的幾篇主要則主要會介紹下列幾種Regularization的方法,並進行實作:
總之,無意外的話,後續三天會實作這三項,並比較結果。
本篇將延伸上一篇討論的L2 Regularization,延伸到所謂的Lp Regualrization,及其在Deep Learning中比較粗暴的作法。是作者本人覺得很喜歡的一個技術,不過實務上提昇通常很有限就是(汗)。
顧名思義,Lp Regularization,是利用Lp去進行Regularization的方式。而除了前一篇提過的L2是歐基理德距離以外,所謂的Lp指得便是線性代數中的Lp-norm:
$$
{\left|x\right|}p = \left(\sum{i=1}^n |x_i|^p\right)^{1/p} \text{, vector } x = (x_1, x_2, ..., x_n)
$$
具體限制的方式一樣是把沒有開根號版本的Lp-norm加入loss,(僅是為了比較好算梯度、以及避免rounding error)再進行學習,可以寫成類似下面的概念式:
$$
\begin{align}
L &= L_{class}(f(x, w), y) + \lambda |w|p^p, \
&= L{class}(f(x, w), y) + \lambda \sum_{i=1}^{n} w_i^p,
\end{align}
$$
如此一來,除了可以達到對權重的限制以外,也可以根據p這個超參數的設置,進一步進行不同的限制效果。
具體實例可以參考上一篇也有提到Google爸爸的這個視覺化工具。裡面有L1跟L2的比較,大約總結底下幾項:
上一篇文章有提過,只要使用Optimizer中的weight decay就可以達到類似L2 Regularization的限制效果。但其實還有一個差異尚未提到的則是,由於weight decay是直接實作在整個梯度,因此整個Regularization的範圍是模型內所有的參數。傳統的迴歸僅作用在乘法項的權重,而不作用在截距項的BIAS,因此實際上還是不大一樣。
由於筆者是統計出身的,總覺得連帶截距項也懲罰很奇怪。因此本作為本篇文章的目標,決定自刻一個只作用在乘法項的權重的Lp Regularization實作。
實作方法一樣可以透過增加lightning-module內的函數來作到,首先新增對應的超參數到hparma.yaml
train:
weight_decay:
p: 2
lambda: 0.00001 # 0.01 * 0.001
然後新增計算lp power sum的函數:
def lp_power_sum(tensor, p):
if p == 2:
return (tensor ** 2).sum()
else:
return (tensor.abs() ** p).sum()
將利用lp power sum計算懲罰項的函數到增加lightning-module內:
def lp_penalty(self):
reg_loss = 0
for name, weight in self.named_parameters():
if 'weight' in name:
reg_loss += lp_power_sum(weight, p = self.CONFIG['train']['weight_decay']['p'])
return reg_loss
最後更改train_step內計算loss的方式:
def training_step(self, batch: Any, batch_idx: int):
inputs, preds, labels, loss = self.step(batch)
self.log('train/loss', loss.item(), on_step=True, on_epoch=True, batch_size = inputs.shape[0])
reg_loss = self.lp_norm()
self.log('train/reg_loss', reg_loss.item(), on_step=True, on_epoch=True, batch_size = inputs.shape[0])
reg_loss = self.lp_penalty()
self.log('train/reg_psum_loss', reg_loss.item(), on_step=True, on_epoch=True, batch_size = inputs.shape[0])
if self.CONFIG['train']['weight_decay']['lambda'] > 0:
loss += reg_loss * self.CONFIG['train']['weight_decay']['lambda']
self.log('train/total_loss', loss.item(), on_step=True, on_epoch=True, batch_size = inputs.shape[0])
return loss
基本上就大功告成了!
另外解釋幾點:
lp_norm,純粹是希望log能與作比較。一樣請參考這個commit進行實驗。
跟前幾次相比的結果如下圖:
前一日我們將原始影像檔案都抓下來到資料夾內了,本日將接續繼續進行資料的處理。依照個人的習慣主要會建立一個對應的長表格(long table or narrow data, 可參考wiki)進行管理,主要優點有下列兩點:
延續前一日的我們抓取來使用的ChestMNIST,資料集的詳細都可以透過該套件的函式得到,如下:
>>> from medmnist.info import INFO
>>> INFO['chestmnist']
{'python_class': 'ChestMNIST',
'description': 'The ChestMNIST is based on the NIH-ChestXray14 dataset, a dataset comprising 112,120 frontal-view X-Ray images of 30,805 unique patients with the text-mined 14 disease labels, which could be formulized as a multi-label binary-class classification task. We use the official data split, and resize the source images of 1×1024×1024 into 1×28×28.',
'url': 'https://zenodo.org/record/6496656/files/chestmnist.npz?download=1',
'MD5': '02c8a6516a18b556561a56cbdd36c4a8',
'task': 'multi-label, binary-class',
'label': {'0': 'atelectasis',
'1': 'cardiomegaly',
'2': 'effusion',
'3': 'infiltration',
'4': 'mass',
'5': 'nodule',
'6': 'pneumonia',
'7': 'pneumothorax',
'8': 'consolidation',
'9': 'edema',
'10': 'emphysema',
'11': 'fibrosis',
'12': 'pleural',
'13': 'hernia'},
'n_channels': 1,
'n_samples': {'train': 78468, 'val': 11219, 'test': 22433},
'license': 'CC BY 4.0'}
看到輸出後可以得知,這主要是一個總共112,120個樣本的資料集,且具有下列性質的任務:
而這些類別則分別是:
先讓大家有個初步的認識,翻譯全部是透過GOOGLE再個人挑選,有錯誤請指正,感謝!
基本上後續的工作就是根據資料的不同狀況,進行一些理解再整理,也可以一併進行抽樣。
此部份會很根據實際的樣本情形。
本文案例的話,由於MedMNIST已經整理的差不多了,基本上進行以下的小處理就可以得到結果
df = pd.read_csv('data/chestmnist.csv', header = None)
cols = ['split', 'img'] + list(INFO['chestmnist']['label'].values())
df = df.rename(columns={ i: col for i, col in enumerate(cols)})
df['img'] = df['img'].apply(lambda x: os.path.join('data/chestmnist/', x))
此外,整段可以參考該commit的src/make_dataset.py,一樣在workspace執行就可以了!
python src/make_dataset.py
執行以後就可以得到該csv囉
在實際進入真正的建模之前,還是先多解資料一點吧!
先畫個圖理解一下概況,大概可以掌握有幾類是比較好發於資料集中的疾病
import pandas as pd
import plotnine as p9
df = pd.read_csv('data/dataset.csv')
df_long = pd.melt(df, id_vars=['split', 'img'])
df_long = df_long[df_long['value'] != 0]
(p9.ggplot(df_long)
+ p9.geom_bar(p9.aes(x='variable', fill = 'split'))
+ p9.theme(axis_text_x=p9.element_text(angle=45))
)
另外也可以看一下各個切分的樣本分佈是不是夠接近,以免發生分佈差異,而預測不准的常見問題。
看起來是還好,應該可以安心的進入下一步囉!
本日將深入介紹並實作第一個Regularization的技巧--Label Smooth,翻譯的話,好像可以稱作標籤平滑吧。
在前一日的文章內已經簡介提到,Label Smooth是一種在訓練時,將loss在與label進行計算時進行模糊化的技巧。這裡我們以最單純的Binary Classification為例,在只有兩類的情況下,label通常就是陽性(y=1)以及陰性(y=0)。
而Label Smooth的技術就是類似把這個0跟1,視為機率的概念,加入一個允許模糊的參數α,讓模型可以進行一個不會太極端狀態的學習,具體就是把label的定義改成類似下者:
$$
y^{*} =
\begin{cases}
1 - \alpha, & \text{ if } y = 1 \
\alpha, & \text{ if } y = 0
\end{cases}
$$
因此α便是一個可以自訂來調整模糊空間的超參數,理論上也是需要Tune的。(Multiclass的情況可以參考這篇)
前一日也有提到,這是一個Regularization的方法,為的是降低Generalization Error。但思路是怎麼做的呢?在訓練反覆迭代的過程中,其實是會讓模型對於訓練集中的陽性樣本給出的結果越來越趨近1,而陰性樣本的結果則是越來越趨近於0。聽起來很不錯,但對嗎?這是不是也意味著,模型很有可能只能輸出很接近0跟1的結果?是不是模型在0到1之間的變化幅度會非常劇烈、鮮少出現中間值的情形?即使是未來的資料出現模型不存在的特徵,沒辦法給出不確定的中間機率值,而給出一個極端值呢?
Label Smooth便是一個處理這樣問題的技術,藉由調整label在計算loss時的數值,允許某一程度的模糊空間,進一步的避免訓練出來的模型變得只會去預測接近0與1的極端值。
另外補充,To Smooth or Not? When Label Smoothing Meets Noisy Labels有討論到noise rate的大小與label smooth與否及程度大小的研究,算是一個滿適合延伸的閱讀,有興趣的讀者可以再看看。
實作的部份則需要土法煉鋼一些東西,首先定義一個調整label的函數:
def label_smoother(tensor, label_smooth_fact):
return tensor * (1 - 2 * label_smooth_fact) + label_smooth_fact
然後讓我們在step內設定成,如果要做label smooth的話會進行更動:
def step(self, batch: Any):
inputs, labels = batch['img'].to(self.device, non_blocking=True), batch['labels'].to(self.device, non_blocking=True)
preds = self.forward(inputs)
if self.CONFIG['train']['label_smooth'] > 0:
smooth_label = label_smoother(labels, self.CONFIG['train']['label_smooth'])
loss = self.loss_function(preds, smooth_label.float())
else:
loss = self.loss_function(preds, labels.float())
return inputs, preds, labels, loss
接著就可以進入訓練環節了!
而另外補充,常見的Cross Entropy實作上比較容易,可藉由直接調整參數來達到,可參考文件)
一樣可以參考這個Commit進行實作,這裡設定的α=0.05。
首先讓我們看看loss,可以看到Label Smooth的緣故,會使得BCE計算loss的方式跟預測的方式都會改變,也因此會造成一個很大的格差。
另外來看看AUC的部份,個人是猜測可能由於

最後可以來看一下對outcome的影響,可以發現確實大部分的結果從接近0,被移動到了
α=0.05的部份了。
本日會開始進入最主體的Classification的部份,首先就從資料集開始介紹吧!這次會使用的是MedMNIST這個資料集,差不多就是Medical版的MNIST的意思。
MedMNIST基本上是個包含了各種不同類型的醫療影像的資料集,分別由12個不同的2D醫療影像集與6個不同的3D醫療影像集所組成。所對應的Task基本上也都是Classification問題,其中的RetinaMNIST雖說是Ordinal Regression,但其實本質上也是一種Classification。影像的解析度部份則都壓縮到了28x28(x28),都非常小,所以非常適合新手作為練習使用。目前已經出到第二版,所以才會加個v2,主要差異是新增3D的6個資料集。
簡單看這張來自官網的Overview其實應該就可以理解整個資料集的概況:
其餘詳細的部份,有興趣建議直接參考官網,本日的文章則會著重講解實際抓取下來使用的部份。
pip install medmnist
或是先前透過我提供的docker-compose.yml安裝環境的朋友們應該也都已經有了(請參考requirements.txt)。
MedMNIST的函式庫內提供不少東西可以使用,尤其是還可以直接使用PyTorch的DataLoader,基本上直接套用再加上常見的訓練框架就可以開始做模型,可說是十分方便。
但實務上其實真正耗費大量時間的,往往是資料的準備及處理,撇除不太可能在這裡進行的標注,本系列文希望盡量模擬實際資料獲得的情形。
現在讓我們模擬較接近真實的情況,因此我們後續會採用一大筆影像檔再加上一個對照的csv檔案,這樣的形式開始。
所幸只要利用靈活的MedMNIST,以取得chestmnist為例,輸入以下的程式碼
import medmnist
from medmnist.info import INFO, DEFAULT_ROOT
DATASET = 'chestmnist'
TEMP = '/tmp'
FOLDER = 'data'
POSTFIX = 'png'
def make_dataset() -> None:
for split in ["train", "val", "test"]:
print(f"Saving {DATASET} {split}...")
dataset = getattr(medmnist, INFO[DATASET]['python_class'])(
split=split, root=TEMP, download=True)
dataset.save(FOLDER, POSTFIX)
也可以直接在workspace底下執行檔案
python src/make_dataset.py
等待片刻,執行好以後,就可以獲得像這樣的結構
如此一來,就準備好資料了!
接續上一篇討論的Optimizer與Learning Rate,今天來討論關於Learning Rate以及其Scheduler的挑選。
上一篇我們有提及Learning Rate的挑選是個重要的問題,太小會訓練太慢,太大則怕梯度爆炸。但要到底要怎麼挑選呢?是否有任何的依據?
這裡介紹一個十分熱門的參考方法,就是所謂的Learning Rate Finder。透過一個有限次數內的step,每個step使用不同的Learning Rate進行模型的訓練,觀察其Loss的變化程度,依照變化程度去尋找收斂較快的Learning Rate。
具體的作法Pytorch-Lightning的Tuner,可以直接實作,例如下面的例子:
# set tunner
trainer = pl.Trainer(**CONFIG['train']['trainer'])
# tunner
lr_finder = trainer.tuner.lr_find(net, data_generator)
跑出來以後就會得到類似這張圖,以及其建議的Learning Rate:
那麼這次實驗的結果是建議 0.0058,就可以考慮從這個周圍去選取並開始訓練囉!
實作部份可以參考這個tuner.py,一樣只要打下列就能跑:
python src/tuner.py --config=hparam.yaml
另外關於Learning Rate Finder的來源我沒有查到,最早看到是在Deeplearning.ai的課程當中。若有讀者知道的話,也請告訴我,感謝!
那麼拿到 0.0058 以後,其實也是有不少作法,可以就直接用這個值開始訓練。我個人的習慣則是會設置一個在這個值周圍的Scheduler,例如我個人的策略就會是,下降速度稍微慢一點沒關係,畢竟大多的情況通常都是必須要decay learning rate才比較有好結果,因此我會稍微再縮小一點,然後再下調某個range,用週期型的learning rate進行訓練。
所以我這邊使用的是CosineAnnealingLR,從0.001開始,然後最小值到0.00003,具體變化如下圖:
那麼接下來就讓我們進入訓練環節,明天來收菜吧!
經過前面的文章,目前在單一個訓練的節點內,能做的優化已經做的差不多了。接下來大概就是訓練次數以及一些超參數的調整。讓我們先回到一組很基礎但又很重要的超參數「Learning Rate」&「Optimizer」。
讓我們首先回想一下,所謂的「用資料訓練模型」,具體而言到是作什麼事情?以大多的Deep Learning模型來說,不外乎就是在Backward-Propagation的大框架下,利用資料產生梯度,然後更新模型參數,接著再驗證準確度,直至有滿意(或可接受)的準確為止。
在這樣的框架底下,Learning Rate與Optimizer就有點男女主角的味道在。大致上每一個更新參數的Step可以寫作下面的式子:
其中
根據上面的式子,Learning Rate好比是,每一步(每次迭代)步伐的大小。而Optimizer則是,每一步走路的pattern。
一般大多關於Optimizer的文章及實驗結果都還是根據某一個情況實驗下得到的結果,暫且沒有最佳解,也因此不少人也會花時間在上面進行調整。比較有人用的optimizer,基本上在Pytorch裡頭都有實作,具體可以參考torch.optim。
而Optimizer事實上非常難仔細描述,想視覺化理解的話,可以參考Alec Radford大神當年在reddit文章po的圖:
看能不能感知出些什麼?
在不少探討Optimizer到底是幹了些什麼事的文章中,其中滿經典的是The Marginal Value of Adaptive Gradient Methods in Machine Learning,主要在討論adaptive家族的optimizer(像是 AdaGrad、RMSProp、以及最常見的Adam)比起傳統的SGD,範化性(generalization)的能力差很多,算是值得一看,下圖是裡頭的實驗結果:
現在Adam由於其快速收斂的特性,仍是最受歡迎的演算法。不過也因為上述說的這個性質,曾聽說過有團隊的工作方式是先用Adam做實驗,產品化的模型則利用SGD再產出。
Learning Rate也是一項藝術,太小不動,太大則亂飄甚至爆炸。概念上大概可以參考下圖(來源傳送門):
但大部分的情況,你問我要怎麼挑,老實說我也不知道,很多時候其實都是用1e-3或1e-4這種magic number開始慢慢tune,或是另外一種滿實際的方法是去找類似資料的文獻,參考他們的超參數選擇也是很好的出發點。另外也有一種自動挑選Learning Rate的方式,會在明日的文章做一起實作。
再者,即使挑到了好的初始Learning Rate,其實也很難確保後續是不是真的表現一樣好?由此因應而生的便是Learning Rate Scheduler,藉由在訓練的途中對learning rate進行變化,進而達到比較理想的訓練結果。不同的Scheduler可以參考下面這張圖(來源傳送門):
跟optimizer一樣,比較熱門的Pytorch都有實作,可參考torch.optim.lr_scheduler。
本日的文章打算來講一些資料讀取的機制以及優化的方式。
先上一個目前所採用的Training/Validation,在每一次進行時的資料流簡易流程圖。
flowchart LR
subgraph Main[ ]
CPU <-->|preprocess| RAM
end
subgraph GPU[ ]
gpu_core[GPU Cores] <-->|training+validation| gpu_m[GPU Memory]
end
Storage --> Main --> GPU
主要的流程,大概可以分為以下幾個步驟:
不同的硬體在其中扮演的角色可以得到不同的優化:
因此,硬體的選用($$$$$$$)與實驗的效率,有很直接的關聯!但卻也不是唯一。
接下來讓我們一項一項的介紹以及給一些例子:
講這麼多,嘴巴都是泡。其實不外乎就是就是希望做Deep Learning Engineering的人,也可以對所使用的硬體們有更多的認識,進而知道可能會遇到的問題並進一步去解決。
綜合上面所說,舉一些實際可能發生的狀況:
以上都是很常見的情形,有了一些硬體的先備知識以後,可以幫助我們解決一些軟體無法解決的問題!
本日將簡單介紹Pytorch-Lightning,而在包含今日的未來幾天內,會將先前構築的程式碼,分段整合成Pytorch-Lightning的格式。本日的部份是forward propogation的部份。
Pytorch Lightning是一個標榜同時可以簡化工程作業量,又同時具備高擴充性的Pytorch相容框架。
其與Pytorch的關係,有點類似TensorFlow與Keras。
(註:筆者本人也用過一陣子Keras跟TensorFlow 2,Keras的操作更加簡易,但是Flexibility就不太令人滿意,尤其是要客製一些框架或是訓練策略的時候,反倒是TensorFlow 2還順手一些)
主要的概念跟作法,可以直接參考下列這個來自Pytorch Lightning官方文件 LIGHTNING IN 15 MINUTES的簡介影片:
簡單看完影片以後,相信大概能有個概念。現在來舉一個最簡單的例子,讓我們先來回顧前幾日的train.py裡頭每個epoch的training跟validation是怎麼做的?
Training Phase:
inputs, labels = batch['img'].to(device), batch['labels'].float().to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = loss_function(outputs, labels)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
Validation Phase:
for batch in pbar:
step += 1
val_images, val_labels = batch['img'].to(device), batch['labels'].to(device)
y_pred = torch.cat([y_pred, model(val_images)], dim=0)
y = torch.cat([y, val_labels], dim=0)
pbar.set_description('Validating ...')
y_prob = torch.nn.Sigmoid()(y_pred)
loss = loss_function(y_pred, y.float()).item()
有沒有發現驚人的重工之處?
基本上都是在forward propogation以後在計算loss,只是差在有沒有梯度下降的差異而已。而且其實重複的且類似但又不太一樣的程式碼,也是增加進行小修改時出錯的風險。
Pytorch Lightning 裡最核心的api就屬 Lightning Module,只要把模型整合成這個物件,基本上就可以開啟 Pytorch Lightning內的各種強大的支援。
根據文件中的內容,可以透過這個api把上一段落內的training跟validation大致整成下面的架構如下:
import pytorch_lightning as pl
class MultiLabelsModel(pl.LightningModule):
"""
Lightning Module of Multi-Labels Classification for ChestMNIST
"""
def __init__(self, CONFIG):
self.backbone = get_backbone(CONFIG)
... # 可以網羅各種的初始設定,通常我會把大部分的超參數
... # 還有一些實驗過程需要的額外物件放在這個地方
def forward(self, x):
y = self.backbone(x) # model inference 的主體,使用很自由
return y # 不論是要加層,增加input或output都可以簡單實現
def step(self, batch: Any):
inputs, labels = batch['img'].to(self.device), batch['labels'].to(self.device)
preds = self.forward(inputs)
loss = self.loss_function(preds, labels.float())
return inputs, preds, labels, loss
def training_step(self, batch: Any, batch_idx: int):
inputs, preds, labels, loss = self.step(batch)
return loss
def validation_step(self, batch: Any, batch_idx: int):
inputs, preds, labels, loss = self.step(batch)
return {
'preds' : outputs,
'labels' : labels
}
def validation_epoch_end(self, validation_step_outputs: List[Any]):
preds = torch.cat([output['preds'] for output in validation_step_outputs], dim=0)
labels = torch.cat([output['labels'] for output in validation_step_outputs], dim=0)
probs = torch.nn.Sigmoid()(preds)
# compute metrics and log
acc_score = torchmetrics.functional.accuracy(probs, labels, mdmc_average = 'global')
auc_score = monai.metrics.compute_roc_auc(probs, labels, average='macro')
...
透過呼叫共用的step,就可以讓分別對應的training_step與validation_step都能實現與原先相同的forward propogation。而要蒐集整個validation結果,進而計算accuracy與auc的部份,則可以在validation_epoch_end內,會自動將每個validation_step的output作為input輸入,就可以計算整個驗證集的指標了。
如此切割各個功能後,除了可讀性上比較好一些,要debug也會比較容易一些,可說是好處多多。後續還有許多設計檔的瑣碎工作需要做,就讓我們挪到後續幾天再來慢慢完成!
前一日已經開始進行模型的訓練。本日將討論要如何確認或挑選訓練出來的模型是否真的好?真的朝著正確的方向在邁進呢?
在訓練的過程當中,很多情況只要是Training Code沒有異常的bugs的情況底下,在訓練集上的loss通常只會不斷下降。
這是否表示,我訓練出來的模型正在不斷變好呢? 這個答案,你知、我知、獨眼龍也知道,當然是不! 主因是在機械學習越來越發展以來,模型內的參數也隨之越來越多。在這種情況底下,模型很有可能會去把某些樣本或是巧合硬是記下來,換句人話就是模型把答案硬背下來了!(尤其是在Deep Learning時代下,參數又多,訓練集的樣本又每張都看過幾十幾百次的狀況下,更加的容易發生。)
上圖則是參考Wiki Overfitting條目當中的圖,其中綠色的線就是想表達一個過擬合的圖。
雖然它完全正確分出紅色藍色了,但我們事實上很害怕這樣的模型,如同上面所說的,它只是用極端的狀況去硬記訓練資料,進而在實際上無法套用到新的或實際的資料上。
為了去驗證我們的模型套用沒有學習過的資料時的效果,一般我們會保留一份資料用來檢查模型表現,這個資料子集通常我們就稱作為驗證集。(另外還有測試集,後續會再介紹。)
常見的具體實作,通常我們每次訓練模型到一個段落的時候,會使用當下的模型針對驗證集內的所有資料進行推論,並紀錄當下的模型在驗證集上各種metric的表現,進而評估模型的好壞。
以我們的Multi-Label Classification來說,我們最主要就是比較準確率(Accuracy)以及AUROC(Area Under the Receiver Operating Characteristic),這部份在Torchmetrics跟MONAI上都可以找到對應的函數可以使用。
本次的具體實作可以在每一個epoch的後面加上:
model.eval()
with torch.no_grad():
y_pred = torch.tensor([], dtype=torch.float32, device=device)
y = torch.tensor([], dtype=torch.long, device=device)
pbar = tqdm.tqdm(data_generators['VALIDATION'], total = len(processed_datasets['VALIDATION']) // data_generators['VALIDATION'].batch_size)
for batch in pbar:
val_images, val_labels = batch['img'].to(device), batch['labels'].to(device)
y_pred = torch.cat([y_pred, model(val_images)], dim=0)
y = torch.cat([y, val_labels], dim=0)
pbar.set_description('Validating ...')
y_prob = torch.nn.Sigmoid()(y_pred)
loss = loss_function(y_pred, y.float()).item()
acc_score = torchmetrics.functional.accuracy(y_prob, y, mdmc_average = 'global').item()
auc_score = monai.metrics.compute_roc_auc(y_prob, y, average='macro').item()
這裡要注意幾個重要的小細節,分別是
model.eval():做推論的模式切換,沒有做的話像是Dropout或是Batch Normalization就會根據訓練的模式跑出不正確的結果。with torch.no_grad():使用沒有梯度的模式進行運算,節省運算資源。新增了Validation以後的實作一樣放在Github對應的commit內,簡單執行,等待一下就可以得到結果:
# python src/train.py
----------
----------
epoch 24/25
Training Epoch 50/50train_loss: 0.2043: 98%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████▋ | 49/50 [00:31<00:00, 1.57it/s]
epoch 24 average loss: 0.1974
Validating ...: : 88it [00:10, 8.11it/s]
current epoch: 24 current loss : 0.1849 current AUC: 0.5837 current accuracy: 0.9489 best AUC: 0.5849 at epoch: 23
----------
epoch 25/25
Training Epoch 50/50train_loss: 0.2136: 98%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████▋ | 49/50 [00:29<00:00, 1.68it/s]
epoch 25 average loss: 0.1972
Validating ...: : 88it [00:11, 7.84it/s]
saved new best metric model
current epoch: 25 current loss : 0.1843 current AUC: 0.5866 current accuracy: 0.9490 best AUC: 0.5866 at epoch: 25
train completed, best_metric(AUC): 0.5866at epoch: 25
這裡可以注意到幾點分別為:
本篇是 Regularization的第二篇,講得是DATA Augmentation。是一個非常常見的技巧!
Data Augmentation是一個非常常用的技巧,大致上就是利用一些Computer Vision的技巧,對影像進行小幅度的修改,確保修改後的影像仍能具有原先希望辨別的特徵,以期望模型即使在圖片加入這些變化間,仍能具有判別影像特徵的能力。
具體實例可以參考albumentation函式庫中的展示圖:
大致上的重點便是同一張圖經過變化以後,還是要能看得出他是一隻鸚鵡(試想,如果連你都看不太懂了,要什麼都不會的模型學習是不是太強人所難了呢?),而我們同時也可使用不同的處理方法來疊合,創造出千變萬化的圖片出來讓模型學習!
這個方法同時也非常常見於資料量不大的專案中。但別忘了他的本質仍是一種Regularization,實際上資料量不大的模型訓練中,效果不好的結果,主要的問題是來自於小型的訓練集無法代表整體樣本,因此收斂於小樣本的模型,自然無法適應到整個宏觀世界。此時Data Augmentation的介入,便是盡可能的透過讓資料更接近整個宏觀世界的方式,來去增加模型訓練時收斂的難度,進而去讓模型能有更好的generalization error。
但這東西卻也不是加越多越好,它一樣是個需要tune的超參數組。常見的謬誤有做了過多不合理的變化,使得訓練資料變得已經有點過度扭曲,已經脫離宏觀世界的長相時(宏觀世界的借鑒則是驗證集及測試集),類似像下面這張圖(來源),有一張貓貓的頭已經完全被切掉了,這種難以辨識的東西如果一兩百張有1-2張還沒什麼關係,但太多可就不好了,所以實際也要注意一下。
另外補充一下,還有一個借鑒則是Data Augmentation也要符合資料與domain的知識。例如醫療影像中,由於人體骨頭的生理結構不會差異太大,不宜做過度的扭曲,如果跑出個斜的頭骨那還真不知道該如何是好?
這邊推薦幾個我個人比較常用的函式庫:
另外如果要把非monai的Augmentation整合起來一起使用的話,可以善用monai.transforms.Lambdad。
實作基本上不難,基本上一樣是準備一組monai.transforms
def prepare_data_aug(CONFIG: Dict) -> monai.transforms.transform:
prob = CONFIG['train']['data_aug']['prob']
transforms_data_aug = [
monai.transforms.RandAffined(keys = ['img'],
prob=prob,
rotate_range = [-0.1, 0.1],
translate_range = [-3, 3],
scale_range = 0.1),
monai.transforms.RandGaussianNoised(keys = ['img'],
prob=prob,
mean=0.0, std=0.1),
monai.transforms.RandFlipd(keys = ['img'],
prob=prob,
spatial_axis = [0])]
transforms_data_aug = monai.transforms.Compose(transforms_data_aug)
return transforms_data_aug
然後在做成dataloader前,套上dataset就可以了!
transforms_data_aug = prepare_data_aug(CONFIG)
processed_datasets['TRAIN'] = monai.data.Dataset(data = processed_datasets['TRAIN'],
transform = transforms_data_aug)
然後我們可以試跑看看,一張圖片可能有的變化性:
一樣參考這個commit訓練,讓我們直接看結果:
增加了一點幅度的訓練難度,一開始上升的比較少一些。但並沒有脫離宏觀世界太多,一樣是獲得了差不多0.76左右的auroc結果!
滿多預計要討論的其他Task最後都沒有實作到,居然意外變成是純粹以Classification為例的深度學習實作範例了!在此作為系列篇的最後一篇,打算分享一下這段時間作Deep Learning的一些心得及想法。
其實這個小標同時也是在告誡自己,大家可以看到在[Day21]當中,其實我們的AUROC已經達到0.731,距離我們最後的0.772其實也僅是提升了0.041。但這0.041我們卻使用了大約構築第一次實驗結果的好幾倍時間來進行實驗才得到。
先分享一個非常寫實、也讓人又氣又好笑的深度學習迷因(出處):
身為一個理工宅出身的人,我個人認為深度學習的技術是迷人的。有趣的數學性質、各種實驗的曲線、以及加入各種調整以後的改善結果,那種「我再試一些超參數是不是就會變好」的心態,真的很可怕!我覺得裡面應該已經有一些多巴胺陷阱的成分。不過總歸來說,一切仍需要適度而止。尤其是不要陷入把Test Set當作另外一個Validation Set來不斷優化的無底洞陷阱中,一來是能改善的幅度有限,二來則是所見也可能並非是真正的改善。
那麼,這些操作,究竟值不值得呢?我的回答是:要看目標。
目標的話,個人的經驗目前可以粗分成兩種:
深度學習或是機械學習,最重要的一點其實是後面共通的那兩個字「學習」(Learning)。向什麼學習?資料(DATA)。
由於很多技術實施者大多都是從被整理好的公開資料集開始進行學習,因此這一點其實很常被遺忘。整個系列的MedMNIST其實就屬於這類已經經過大量資料清理、驗證的標準資料集,而且又有模型預測的標準可供參考,供學習者能專注在演算法的學習與開發上。
但大多的AI專案做不出來,其實問題不外乎都是出現在根本的資料問題上,而這個問題又可以分成幾個層次討論,我這邊依嚴重度高到低依序討論:
以上大概是綜觀個人在職場上幾年的一些小心得。
在系列文的最後,感謝細心讀到最後一篇的觀眾們,如果有什麼想法也都歡迎在討論串提出來互相討論,或是也可以mail到我個人信箱進行交流。
本系列文的實作一律都放在 https://github.com/SraRod/iThome2022
有興趣的讀者可以直接上去抓下來實作,有什麼issue也都可以直接在上面提出來。在此感謝你的閱讀!
前幾日的文章,討論到了在訓練過程中,從資料的I/O、前處理到放入GPU之前的優化方式。今天將討論在GPU內的優化方式。
我們在先前的訓練時,預設的狀況下,從讀取資料到模型的訓練以及驗證,全部的數值都是使用float32(單精度浮點數,可參考wiki)。
數值部份的資料格式,除了最常見的float32以外,其實還存在很多不同的種,例如:只有01的Boolean、整數常用的Int16以及今天要討論到的主角-----大小只有Float32一半的半精度浮點數Flost16。
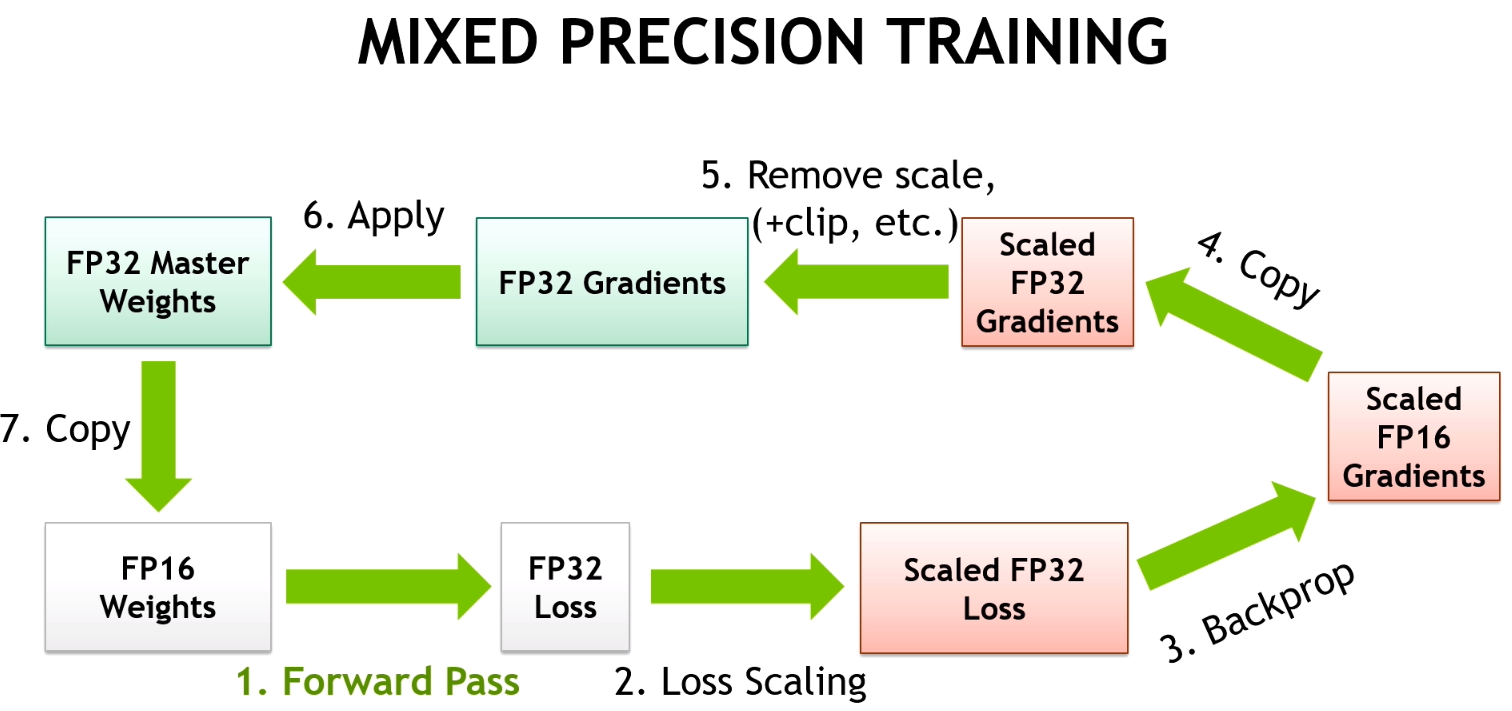
所謂的AMP(automatic mixed precision,即自動混和精度),就是一種利用相同數值能以不同格式儲存所帶來的記憶體容量差異優勢來進行訓練的技術。更詳細的介紹可以觀看這篇文章,這裡截一張裡頭的重點圖:
其運作方式大致上是:
除了今天主要介紹的AMP以外,還有一個個人覺得比較有感的加速則是Cudnn的Benchmark Mode。
詳細內容可以參考這篇討論,主要是由於cudnn內其實有多套不同的Convolution演算法實作,開啟這個功能主要是訓練時,cudnn會去自動調整針對當下tensor大小的最快最適合的演算法,來藉以加速。
實際實作很簡單,在pytroch裡面只要加上:
torch.backends.cudnn.benchmark = True
而Pytorch-Lightning則只要在Trainer內加上:
trainer = pl.Trainer(...,
benchmark = True)
就可以開啟這項功能了。
現在讓我們實際來比較差異,這次主要針對有無AMP跟有無開啟CUDNN benchmark來做四組的比較:
左圖為訓練時的使用記憶體變化量,右圖是整體的計算時間
大概可以歸納出下列幾點:
flowchart LR
Image --> Reader --> preprocess[all kinds of preprocess] --> tensor --> training/testing/serving
在進行模型訓練之前,通常需要透過一連串的行為,將資料轉換成適合訓練的格式。前一日的文章構建了長資料來管理資料,本日的文章將透過PyTorch與MONAI來進行前處理。
一般來說資料準備好,要進入模型之前大致上會經歷以下流程:
這邊也分享一下每一個環節的大觀念:
在monai裡頭,我們可以寫成像是下面這樣一個function的list,之後直接以pipeline的形式對所有資料作完整的前處理:
import monai
transforms = [
monai.transforms.LoadImageD(keys = ['img']),
monai.transforms.EnsureChannelFirstD(keys = ['img']),
monai.transforms.ScaleIntensityD(keys = ['img']),
monai.transforms.ToTensorD(keys = ['img'])
]
transforms = monai.transforms.Compose(transforms)
以上述的函式例子,我們假設每個進來的資料點都是一個dict(這些都是屬於monai.transfroms函數的DICT版,才會每個函數名稱後面都有一個D)。
而這個transforms則是可以針對每個dict裡頭img這個key,依序進行decode、調整channel、正規化pixel value到[0, 1]以及轉換成tensor。
有了前處理的函數以後,接著就可以讀取我們前一日進行的資料進來,接著轉換成list of dicts:
SPLITS = ['TRAIN', 'VALIDATION', 'TEST']
df = pd.read_csv('data/dataset.csv')
datasets = {split : df[df['split'] == split].to_dict('records') for split in SPLITS}
再下來,把資料點們跟上一段準備好的transforms進行結合成一個monai的dataset物件:
processed_datasets = {
split : monai.data.Dataset(data = datasets[split], transform = transforms)
for split in SPLITS
}
最後,為dataset建立PyTorch的dataloader:
data_generators = {
split : torch.utils.data.DataLoader(processed_datasets[split],
batch_size = BATCH_SIZE,
shuffle = True,
collate_fn = monai.data.utils.pad_list_data_collate,
pin_memory=torch.cuda.is_available())
for split in SPLITS
}
接著就大功告成了!
補充:
collate_fn = monai.data.utils.pad_list_data_collate 是個很有趣的東西,他可以幫你把各種前處理以後如果有少掉大小的圖檔pad成一致的大小,避免在製造batch的時候不會出錯。接著根據上述三個dataloader,可以簡單進行sampling並製圖:
看起來還不錯,詳細的產生方式可以參考這個檔案,一樣使用
python src/preprocess.py
就能得到結果。
flowchart LR
Image --> Model
Model --> P1("Prob(atelectasis)")
Model --> P2("Prob(cardiomegaly)")
Model --> P3("...")
Model --> P4("Prob(hernia)")
基礎的資料生成模組已經有了,那接下來今天會介紹基礎的模型定義方式。
在設計模型之前,要先體認到最根本的問題:我們要執行怎麼樣的任務?
根據我們前幾天資料的介紹,可以得知ChestMNIST是一項具有下列特徵的資料集:
根據以上,可以進行一個基礎的設計來達成這個目標:
一個image in,然後會output出14個對應症狀機率值的模型。
這邊採用最常見的摺積神經網路(Convolutional Neural Network, CNN/ConvNet)作為開發,骨幹(backbone)的部份則是選取近年來很紅很高效的Efficient Net,是一個Google爸爸花了很多錢燒出來的框架,要好好的站在巨人的肩膀上。
現在很多地方都有 Efficient Net的實作可以直接採用,也包括MONAI。
這邊我們修改最小的B0來做使用。不過首先會發現一件問題是B0的設計是設計給ImageNet使用的,因此輸入的維度是常見的224x224:
>>> import monai
>>> monai.networks.nets.efficientnet.efficientnet_params['efficientnet-b0']
(1.0, 1.0, 224, 0.2, 0.2)
於是我們這裡稍微做一個小修改後再建立骨幹,以確保整個骨幹能夠正常運行:
monai.networks.nets.efficientnet.efficientnet_params['efficientnet-b0'] = (1.0, 1.0, 28, 0.2, 0.2)
model = monai.networks.nets.EfficientNetBN('efficientnet-b0',
spatial_dims = 2, # 表示2D 或 3D影像
in_channels = 1, # 採用灰階 所以設定1
num_classes = 14) # 14個不同的症狀
這邊介紹一個好用的工具TorchInfo,可以用來觀看模型的各階層:
>>> import torchinfo
>>> torchinfo.summary(model, input_size=(16,1,28,28))
====================================================================================================
Layer (type:depth-idx) Output Shape Param #
====================================================================================================
EfficientNetBN [16, 14] --
├─ConstantPad2d: 1-1 [16, 1, 29, 29] --
├─Conv2d: 1-2 [16, 32, 14, 14] 288
├─BatchNorm2d: 1-3 [16, 32, 14, 14] 64
├─MemoryEfficientSwish: 1-4 [16, 32, 14, 14] --
├─Sequential: 1-5 [16, 320, 1, 1] --
│ └─Sequential: 2-1 [16, 16, 14, 14] --
│ │ └─MBConvBlock: 3-1 [16, 16, 14, 14] 1,448
│ └─Sequential: 2-2 [16, 24, 7, 7] --
│ │ └─MBConvBlock: 3-2 [16, 24, 7, 7] 6,004
│ │ └─MBConvBlock: 3-3 [16, 24, 7, 7] 10,710
│ └─Sequential: 2-3 [16, 40, 4, 4] --
│ │ └─MBConvBlock: 3-4 [16, 40, 4, 4] 15,350
│ │ └─MBConvBlock: 3-5 [16, 40, 4, 4] 31,290
│ └─Sequential: 2-4 [16, 80, 2, 2] --
│ │ └─MBConvBlock: 3-6 [16, 80, 2, 2] 37,130
│ │ └─MBConvBlock: 3-7 [16, 80, 2, 2] 102,900
│ │ └─MBConvBlock: 3-8 [16, 80, 2, 2] 102,900
│ └─Sequential: 2-5 [16, 112, 2, 2] --
│ │ └─MBConvBlock: 3-9 [16, 112, 2, 2] 126,004
│ │ └─MBConvBlock: 3-10 [16, 112, 2, 2] 208,572
│ │ └─MBConvBlock: 3-11 [16, 112, 2, 2] 208,572
│ └─Sequential: 2-6 [16, 192, 1, 1] --
│ │ └─MBConvBlock: 3-12 [16, 192, 1, 1] 262,492
│ │ └─MBConvBlock: 3-13 [16, 192, 1, 1] 587,952
│ │ └─MBConvBlock: 3-14 [16, 192, 1, 1] 587,952
│ │ └─MBConvBlock: 3-15 [16, 192, 1, 1] 587,952
│ └─Sequential: 2-7 [16, 320, 1, 1] --
│ │ └─MBConvBlock: 3-16 [16, 320, 1, 1] 717,232
├─Identity: 1-6 [16, 320, 1, 1] --
├─Conv2d: 1-7 [16, 1280, 1, 1] 409,600
├─BatchNorm2d: 1-8 [16, 1280, 1, 1] 2,560
├─MemoryEfficientSwish: 1-9 [16, 1280, 1, 1] --
├─AdaptiveAvgPool2d: 1-10 [16, 1280, 1, 1] --
├─Dropout: 1-11 [16, 1280] --
├─Linear: 1-12 [16, 14] 17,934
====================================================================================================
Total params: 4,024,906
Trainable params: 4,024,906
Non-trainable params: 0
Total mult-adds (M): 128.06
====================================================================================================
Input size (MB): 0.05
Forward/backward pass size (MB): 31.48
Params size (MB): 16.10
Estimated Total Size (MB): 47.63
====================================================================================================
最後以Batch Size = 16來實際測試 Forward Propogation:
>>> device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
>>> model = model.to(device)
>>> test_input = torch.rand([16,1,28,28]).to(device)
>>> test_output = model(test_input)
>>> print(test_output.shape)
torch.Size([16, 14])
一切大功告成!
從本日的文章開始的幾天內會介紹一些額外還沒介紹到的訓練技巧,今天會先從Transfer Learning開始。
讓我們先參考wikipedia的定義:
很好,十分的General。如果有一點的數學底子的朋友千萬不要覺得這麼general是在講什麼鬼?因為它就是這麼如此的General,所以利用Transfer Learning概念實作的方式可說是包山包海。
那讓我們說回人話,基本上就是有個主要的task與domain組合是T需要學習時,如果能利用到任何一個task與domain組合S的知識,就可說是遷移學習(Transfer Learning)。
好吧!這聽起來還是很抽象。這邊舉兩個目前我實務上也比較常用到的例子:
更多關於Transfer Learning,有興趣的朋友可以參考台大李宏毅老師的線上課程。
那回到我們系列文的實作,這裡主要會使用ImageNet Pretrained Weight的Fine-tune為例。不過回到一個重點,要去哪裡找這些pre-trained呢?以下推薦幾個相容PyTorch的套件:
以我們系列文實驗的monai.networks.nets.EfficientNetBN來說,只要將pretrained = True就可使用imagenet的pretrained來進行fine-tune了!(具體請參考文件)
具體修改過的code可以參這個commit,跑完以後讓我們來參考一下wandb上的結果。
使用Pre-trained的模型是不是訓練成效更快,而且獲得了更好效果呢!
(另外第二個cosine效果不太好,可能就是這組超參數在後面不太適合pretrained了呢!)
本日將利用前一篇建立好的模型,結合先前的資料前處理,利用基礎的PyTorch語法,進行模型的訓練。
根據先前的文章,我們可以藉由以下語法,得到Pytorch的Data Loader:
# prepare dataset
df = pd.read_csv('data/dataset.csv')
datasets = {split : df[df['split'] == split].to_dict('records') for split in SPLITS}
transforms = preprocess.prepare_transform()
processed_datasets = {
split : monai.data.Dataset(data = datasets[split], transform = transforms)
for split in SPLITS
}
data_generators = {
split : torch.utils.data.DataLoader(processed_datasets[split],
batch_size = BATCH_SIZE,
shuffle = True,
collate_fn = monai.data.utils.pad_list_data_collate,
pin_memory=torch.cuda.is_available())
for split in SPLITS
}
但從前一篇當中,我們預計模型的輸出會是14維的一個向量,因此會需要把每個label全部Concat起來。對應到transforms,就必須先做以下的修改,而當中的labels就會是我們想要預測的14個症狀的Ground Truth:
LABEL_LIST = ['atelectasis', 'cardiomegaly', 'effusion', 'infiltration', 'mass', 'nodule', 'pneumonia', 'pneumothorax', 'consolidation', 'edema', 'emphysema', 'fibrosis', 'pleural', 'hernia']
transforms = [
monai.transforms.LoadImageD(keys = ['img']),
monai.transforms.EnsureChannelFirstD(keys = ['img']),
monai.transforms.ScaleIntensityD(keys = ['img']),
monai.transforms.ToTensorD(keys = ['img'] + LABEL_LIST), # 把label們也轉換成tensor
monai.transforms.AddChanneld(keys = LABEL_LIST), # 整理他們的維度
monai.transforms.ConcatItemsd(keys = LABEL_LIST, name = 'labels'), # 將整理後維度後的label進行疊合
]
接著進行抽樣就可以得到:
>>> for batch in data_generators['TEST']:
>>> break;
>>> batch['labels'].shape
(256, 14)
由於我們針對14個症狀,每一個類別都是二元分類問題,因此我這裡採用Torch中的BCEWithLogitsLoss作為Loss Function。
這裡做一下簡介,主要是由Binary Cross Entropy (基本上,其實也等同是Binomial Distribution的log-likelihood函數,不過差個負號跟常數倍)
$$
L_{BCE}(x, y) = - \frac{1}{k} \sum_{}
w_n \left[ y_n \cdot \log \sigma(x_n)
+ (1 - y_n) \cdot \log (1 - \sigma(x_n)) \right]
$$
與 Sigmoid Function (大多時候,在統計內也稱為Logistic Function)
$$
Sigmoid(x) = \frac{1}{1+\exp^{-x}}
$$
所組成。
比起先對model的結果取Sigmoid再算BCE,放在一起的好處主要是有數值計算上的好處。(試想,分開等於先取exponetial再取log ...)另外,除了資料以外,損失函數幾乎是整個機械學習領域水最深的一塊,因此這邊就不再多做什麼贅述。
另外,optimizer的部份則選用常見於實驗中的Adam,好處是收斂快速,不過實務上有一些研究表示Generalization error比起其他慢的匯差一些就是。
結合在一起也很容易,輸入以下即可:
loss_function = torch.nn.BCEWithLogitsLoss()
optimizer = torch.optim.Adam(model.parameters(), 1e-3)
建立好以上以後,就可以利用PyTorch透過反向傳播法(back-propogation)對模型進行訓練,參考語法如下:
inputs, labels = batch['img'].to(device), batch['labels'].float().to(device)
optimizer.zero_grad() # 初始化這次傳播的梯度
outputs = model(inputs) # 進行forward propogation
loss = loss_function(outputs, labels) # 計算當前的loss
loss.backward() # 利用loss計算梯度
optimizer.step() # 利用這次算出來的梯度,對模型的weights進行更新
一樣本次的實作有放在Github內,簡單執行就可以得到結果:
# python src/train.py
----------
epoch 1/1
1/515, train_loss: 1.8068
2/515, train_loss: 1.6626
3/515, train_loss: 1.5855
4/515, train_loss: 1.4236
5/515, train_loss: 1.4121
6/515, train_loss: 1.3223
7/515, train_loss: 1.2272
8/515, train_loss: 1.1468
9/515, train_loss: 1.0351
10/515, train_loss: 1.0378
簡單執行了10個step。很好,loss有在穩定下降,這代表模型是有在訓練集當中學習到東西的!
transforms 來符合模型的設計本日要介紹的是透過Configuration的方式來管理Deep Learning中的超參數。
在前面的實作中,我們目前已經可以進行完整的資料前處理、模型訓練以及模型驗證。
在後續模型表現性的調教中,超參數的調整是一種很常見方式,也是十分多的學術論文在研究探討的議題。
那麼,什麼是超參數呢?既然有個超,是不是也有參數(parameters)?以下給一些簡要的介紹:
那我們先前的實作中,已經出現了哪些超參數呢?以下為大家簡介:
... 不勝枚舉。
上述這些都是超參數的一部分,也因此管理好超參數,事實上就是深度學習開發當中很重要的一項工作。
個人則習慣透過一個YAML的設定檔,來對整個開發工作管理。其中除了超參數以外,也會用來管理一些整套程式碼運行途中需要用到的變數。
yaml檔的設定可以設定成這樣,第一層是功能層,然後才是變數層:
base:
project: 'iThome2022'
make_dataset:
dataset_from: 'chestmnist'
tmp_folder: '/tmp'
save_folder: 'data'
img_subfilename: 'png'
dataset_file: 'data/dataset.csv'
train:
backbone: 'efficientnet-b0'
batch_size: 128
max_epochs: 25
steps_in_epoch: 50
data_loader:
num_workers: 8
prefetch_factor: 166
loss_function: 'BCEWithLogitsLoss'
optimizer: 'Adam'
learning_rate: 0.0001
具體變更可以參考這個commit。
接著只要在新的commit底下,加一行使用設定好的hparams.yaml,就可以開始train model了:
# python src/train.py --config=hparams.yaml
----------
epoch 1/25
Training Epoch 14/50 train_loss: 1.8244: 28%|█▋ | 14/50 [00:14<00:28, 1.28it/s]
根據前一篇的Learning Rate設定後,實際進行了訓練。獲得了結果後,今天的文章將實際解釋實驗產出。
除了上一篇最後提及的CosineAnnealingLR以外,這裡也額外進行了兩個實驗進行對比,具體Learning Rate,隨著訓練過程的變化可以參考下圖:
optimizer一樣都使用Adam,依序分別是
Machine Learning大多的方法都是圍繞在Loss的優化上,因此廢話不多說,先上loss圖:
看圖時大概可以搭配下列幾點服用:
其實上述的這些實驗結果,類似的情況反覆被我遇見,所以也是我個人近年來偏好使用CosineAnnealingLR的原因。
最後讓我們看一下,最主要的Metrics -- AUROC :
最好的那一個結果是在CosineAnnealingLR找到的AUROC = 0.7333。目前結果看起來還不錯了,雖然只是Validation set,但也十分接近MedMNIST裡頭最好的一樣也是使用28x28的0.769!
那到底Test的結果會如何?欲知後事如何,且待下回分解!
接續前一日的文章,我們簡介了PyTorch Lightning以及如何利用Lightning Module將forward propagation進行簡單的封裝。今天我們將把Lightning Module完成,並利用新的格式進行模型訓練。
先前已經利用YAML的方式進行超參數管理(詳見hparam.yaml),進一步,這裡可以把整個Configuration當作是整個Lightning Module的輸入,直接在模組內搭建模型的超參數。
# initialize
def __init__(self, CONFIG : Dict, **kwargs):
super().__init__()
self.CONFIG = CONFIG # 把整個CONFIG放到CLASS內的一個property,以利其他函式可以重複利用。
self.save_hyperparameters() # PL內建的儲存當次實驗超參數的函數
self.backbone = get_backbone(CONFIG) # 用之前創立的函數,建立backbone
self.loss_function = getattr(torch.nn, CONFIG['train']['loss_function'])() # 利用CONFIG設定需要的loss functiondef configure_optimizers(self):
opt = getattr(torch.optim, self.CONFIG['train']['optimizer'])
opt = opt(params=self.parameters(),
lr = self.CONFIG['train']['learning_rate'])
return opt這些都建立好以後,初步的一個lightning module就完成啦!
詳細可以看一下model.py,一樣可以使用下列指令來進行測試整個模型的建立狀況:
python src/model.py --config=hparams.yaml 在建立好Lightning-Module以後, 下一個問題便是怎麼使用它來訓練以及儲存結果了。這裡介紹兩個最常用的功能,分別是trainer以及callback。
在先前的PyTorch實作當中,我們使用了每個EPOCH訓練後,驗證集的AUROC來作為挑選模型的標準,進而儲存要選擇的模型。在PL當中,我們會利用一個Callback的物件,在模型過程中紀錄各式各樣的事情,例如下列的ModelCheckpoint就可以用來儲存模型的結果:
checkpoint_callback = pl.callbacks.ModelCheckpoint(dirpath=CONFIG['train']['weights_folder'],
monitor= 'val/auroc',
mode='max',
save_top_k=3,
filename = 'epoch_{epoch:02d}_val_loss_{val/loss:.2f}_val_acc_{val/acc:.2f}_val_auroc_{val/auroc:.2f}',
auto_insert_metric_name = False)
這邊用白話來講就是,利用指定的名稱,根據validation set的auroc,去儲存最高的三個權重組到指定的資料夾內。另外是為了在訓練途中,callback能夠認識到val\auroc,我們需要利用Lightning-Module本身的log功能,在訓練的時紀錄所需要的metrics:
def validation_epoch_end(self, validation_step_outputs: List[Any]):
preds = torch.cat([output['preds'] for output in validation_step_outputs], dim=0)
labels = torch.cat([output['labels'] for output in validation_step_outputs], dim=0)
probs = torch.nn.Sigmoid()(preds)
# compute metrics and log
acc_score = torchmetrics.functional.accuracy(probs, labels, mdmc_average = 'global')
auc_score = monai.metrics.compute_roc_auc(probs, labels, average='macro')
self.log('val/acc', acc_score.item())
self.log('val/auroc', auc_score.item())
最後是設置Trainer,以及要訓練的模型與對應的相關參數:
from src import model
net = model.MultiLabelsModel(CONFIG)
trainer = pl.Trainer(
callbacks = checkpoint_callback,
default_root_dir = CONFIG['train']['weights_folder'],
max_epochs = CONFIG['train']['max_epochs'],
limit_train_batches = CONFIG['train']['steps_in_epoch'],
accelerator = 'cuda',
devices = 1)
# model training
trainer.fit(net,
data_generators['TRAIN'],
data_generators['VALIDATION'])
接著就可以開始進行模型訓練了!
一樣這次的實作有放到這個commit內,只要執行:
# python src/train.py --config=hparams.yaml
...
Epoch 24: 100%|█████████████████████████████████████████████| 138/138 [00:40<00:00, 3.42it/s, loss=0.194, v_num=16]
可以看到相同的參數底下,pl所訓練+驗證一個epoch的時間約是40秒。這項與先前在DAY08所實作的PyTorch訓練約30秒及驗證10秒加起來的數值相近,可見目前為止的效率而言是幾乎一樣的!
另一方面,以這次筆者實際訓練的結果為例,可以看到Callback所儲存的結果如下圖:
也與DAY08所得到的模型結果,auroc=0.58十分接近!
本篇將討論第三個預計介紹的Weight Decay Regularization技術,會先從L2開始講再帶到目前使用Optimizer的Weight Decay實作方式。
在講Weight Decay之前,首先先介紹其關係緊密相連的L2 Regularization。是一種利用L2-Norm(也就是所謂很常見的歐基理德距離):
$$
{\left|x\right|}2 = \sqrt{\left(\sum{i=1}^n x_i^2\right)} \text{, vector } x = (x_1, x_2, ..., x_n)
$$
來進行Regularization的方式。
那怎麼利用這個norm去作到Regularization呢?中心私路是這樣,一個overfitting的模型,一般被認為可能具有過度複雜以及不具無意義的pattern。而過度複雜的權重則很可能是這些過於取巧的pattern呈現的方式之一,L2 Regularization則是一種在學習時,利用L2-norm去限制權重的,進而避免overfitting的技術。另外,還有一種很常見的說法會說這個限制項,是對使用過大權重的懲罰(Penalty)項。
具體限制的方式則是把L2-norm混和加入loss再進行學習,可以寫成類似下面的概念式:
如此一來在模型訓練的過程時,就會考量到權重的大小,避免使用過大,通常可以降低很多無意義的權重。還是不太懂的朋友可以參考Google爸爸的這個視覺化工具。
那有了新的Loss函數後,下一步自然便是計算梯度並優化了。那是否有任何可以簡化梯度計算的方式呢?由於L2所增加的項,具有解析解,因此是有的:
簡化後的式子是原始LOSS所計算出的梯度、第二項則是原先權重的倍數,新增的第二項會讓有點權重逐漸衰變的意味在,也因此被稱作Weight Decay(起碼我是這樣理解的...)。
在實作的部分,如果是最單純的SGD,想實作L2 Regularization的話,基本上便等同於在每次迭代時進行梯度的修改。因此可以看到文件中是有一個weight decay可以進行調整,便能直接實作。
但我們最常用的Adam呢?雖然裡頭一樣也有weight decay這個參數,可以進行類似SGD的方式來進行訓練,但Adam所採用的是Adaptive Gradient的方式,實質上與L2 Regularization並不等價,而且其表現也不佳,實驗結果可以參考這篇DECOUPLED WEIGHT DECAY REGULARIZATION。
所幸的是,這篇論文提出了一種新的優化器叫AdamW,是一種修正了上述問題的方法。並且也有實作於PyTorch當中,我們也可以直接使用。文件參考,要注意的是這個優化器,預設weight decay rate是0.02,大部分優化器則是0。
基本上一樣參考這個commit,我們也寫入新的config:
optimizer:
name: 'AdamW'
learning_rate: 0.001
weight_decay: 0.02
warmup_epochs: 5
經過訓練後,變可以得到下列的結果:
另外這裡我也有紀錄權重的L2-norm結果:
可以看到確實其L2-norm有不斷在下降,確實是有正常在工作。
[Day29] Model Serving with Triton Inference Server
在一般的模型開發流程中,我們經歷過了Training、Testing之後。如果順利完成了一個不錯的模型,但那之後呢?今天要介紹的就是所謂的Serving,即模型佈署之道。
在先前諸多的實驗中,最後選用上一篇所訓練出來的L2的參數。經過驗證src/evaluate.py以後可以得到下面的Testing結果:
Testing DataLoader 0: 100%|███████████████████████████████████████████████████████████████████████████████████| 44/44 [00:05<00:00, 7.58it/s]
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━┓
┃ Test metric ┃ DataLoader 0 ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━┩
│ test/acc │ 0.9476282000541687 │
│ test/auroc │ 0.772826611995697 │
│ test/loss │ 0.16255274415016174 │
└───────────────────────────┴───────────────────────────┘
基本上結果已經跟MedMNIST網站內的BenchMark差不多囉!可以放心應該已經適合結束實驗的階段。
(一般Task的允收標準除了BenchMark以外、還可以參考High Performance之類的)
對於版本與框架錯綜複雜的深度學習,佈署長久以來一直是個很棘手的問題。 Open Neural Network Exchange又簡稱ONNX,是一個嘗試將深度學習的模型進行標準化的格式。基本上任何模型如果能轉成這個格式,在佈署上便可以省掉不少麻煩。接著就讓我們來進行模型的格式轉換吧!
基本上PyTorch與PyTorch-Lightning對於onnx已經有相當不錯的支援了,只要下列幾行就便可轉檔:
net = model.MultiLabelsModel.load_from_checkpoint(CONFIG['evaluate']['weights_path'])
net.to_onnx('model.onnx',
input_sample = torch.rand([1,3,28,28]),
export_params=True)
接著事前的準備便完成啦!
早期滿多實作都是架一個Flask API來作為serving的服務使用,使用上是容易上手,但其實裡頭使用Python來抓取模型、進行推論的主要媒介,其實對於記憶體跟運算速度都不是很有效率。
所謂站在巨人的肩膀上,這裡選用的是NVIDIA家出廠的Triton Inference Server來作為基礎Serving的服務,效能很不錯,不過東西很新,使用上很多小問題需要依靠社群的力量解決。也有不少家其他的Inference Server,例如TensorFlow Serving,不過我個人沒有用過,各位有興趣可以再嘗試看看。
具體的設定有點繁瑣,可以參考下列要點:
docker network create ithome_network
networks:
default:
external:
name: ithome_network
version: "3.7"
networks:
default:
external:
name: ithome_network
services:
triton:
container_name: "iThome2022_Triton"
image: nvcr.io/nvidia/tritonserver:22.08-py3
runtime: nvidia
shm_size: '32GB'
command:
- tritonserver
- --model-repository=/models
- --log-verbose=1
- --model-control-mode=explicit
- --load-model=chestmnist_net
volumes:
- ./deploy:/models
ports:
- 8000:8000
然後按下:
docker-compose -f docker-compose-triton.yml up
就可以開啟了,另外要注意的是開啟GPU模式時triton的版本根本機的CUDA可能會有相容性問題,要稍微挑一下版本,由於個人用11.7所以選22.08。
以上都沒跳錯的話,一切就都設置完成囉!
那設定好API以後,就可以開始測試結果啦!只使用Python的朋友需要先裝一個triton開發的client可以進行測試:
pip install tritonclient[all]
接著可以利用這個工具,進行以下的post:
import tritonclient.grpc as grpcclient
import tritonclient.http as httpclient
def triton_run(processed_img, module_name, triton_api_path):
with httpclient.InferenceServerClient(triton_api_path) as client:
# initial inputs format
inputs = [
httpclient.InferInput("input", processed_img.shape, 'FP32')
]
outputs = [
httpclient.InferRequestedOutput("output"),
]
inputs[0].set_data_from_numpy(processed_img.numpy())
response = client.infer(module_name,
inputs,
model_version = '1',
request_id=str(1),
outputs=outputs)
result = response.get_response()
output = response.as_numpy("output")
return output
仔細的內容可以參考src/evaluate_with_triton.py,一樣可以執行:
# python src/evaluate_with_triton.py --config=hparams.yaml
100%|████████████████████████████████████████████████████████████████████████| 44/44 [00:04<00:00, 9.65it/s]
Inference Result : AUC = 0.7728351871517246
基本上結果大概在小數點四位內都與原生Pytorch的結果相同,看起來是個合理的模型佈署!
前一日的文章,以硬體面討論了訓練的效率。但有了適當的硬體以後,要如何利用軟體去使用這些硬體呢?從今天開始的幾天內將介紹一些優化的方式。
先複習一下,上一篇文章內說的訓練流程:
flowchart LR
subgraph Main[ ]
CPU <-->|preprocess| RAM
end
subgraph GPU[ ]
gpu_core[GPU Cores] <-->|training+validation| gpu_m[GPU Memory]
end
Storage --> Main --> GPU
今天將以橫向及縱向的兩種方向,來介紹增加Preprocess的方法,分別是:
正常情形的程式,其實都是使用單一個執行序(thread)在執行程式。但在某些情況下,有些任務是可以被平行處理(詳見平行計算)進而加快計算效率的。
例如,資料的預處理就是個很好的例子。以影像為例,每一張影像我們需要讀取、解碼、然後進行前處理,這是一個執行序能為我們做到的事情。那理論上而言,在同一時間單位下,有多少個的執行序,便能完成多少倍的資料預處理(但實際上會有個增幅極限,因為考慮到storage、cpu以及ram在單位時間內的存取極限),大致上概念上就會是下圖的模樣:
flowchart LR
subgraph Main[ ]
subgraph CPU
thread1
thread2
thread3
thread4
end
thread1 <-->|preprocess| RAM
thread2 <-->|preprocess| RAM
thread3 <-->|preprocess| RAM
thread4 <-->|preprocess| RAM
end
subgraph GPU[ ]
gpu_core[GPU Cores] <-->|training+validation| gpu_m[GPU Memory]
end
Storage --> Main --> GPU
另一個可以考量的方式則是,GPU計算跟CPU前處理都需要時間對吧?那麼如果CPU前處理時,GPU閒置,GPU處理時,CPU閒置。這樣不是很浪費嗎?(慣老闆心態...)
Prefetch(或許可以譯作預取?),便是一個更加利用資源的方式。在GPU計算時,讓原本閒置的CPU先行進行下一個批次計算需要用到的預處理,透過同時壓榨CPU與GPU的計算能力來增加效能。概念大概就會長得像下面這張圖:
flowchart LR
subgraph Main[ ]
CPU <-->|preprocess| RAM
end
Storage --> Main --> GPU
subgraph SameTime
subgraph GPU[ ]
gpu_core[GPU Cores] <-->|training+validation| gpu_m[GPU Memory]
end
subgraph Main2[ ]
CPU2[CPU] <-->|preprocess| RAM2[CPU]
end
end
subgraph GPU2[ ]
gpu_core2[GPU Cores] <-->|training+validation| gpu_m2[GPU Memory]
end
Storage2[Storage] --> Main2 --> GPU2
classDef bk fill:#fff,stroke:#333,stroke-width:4px
class SameTime bk
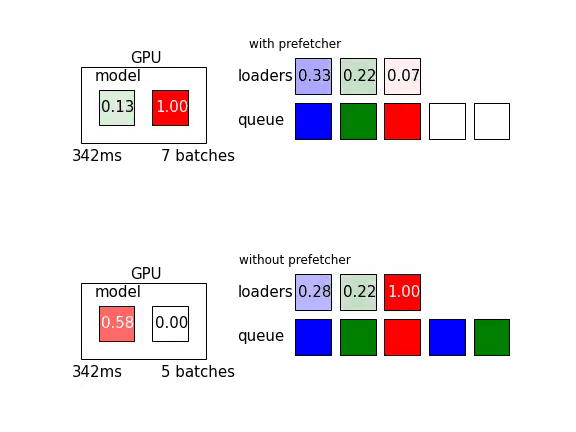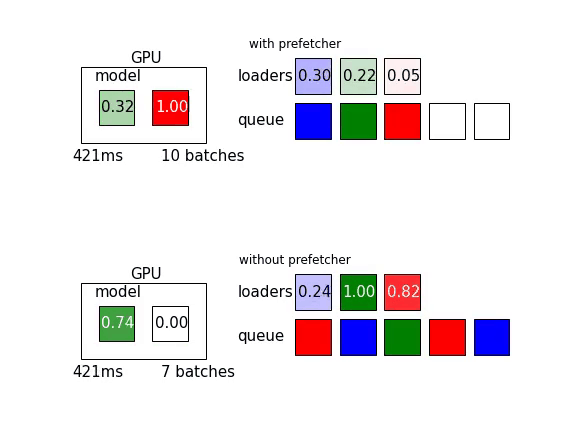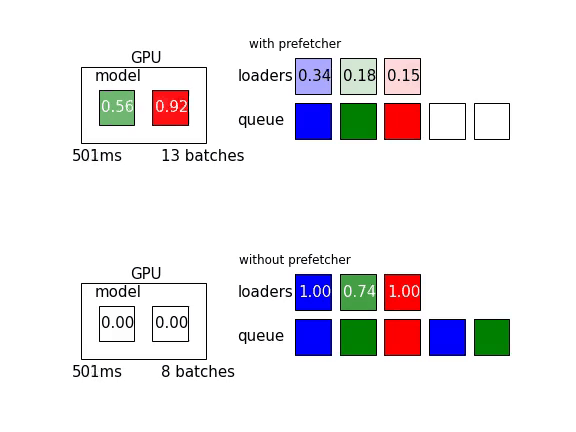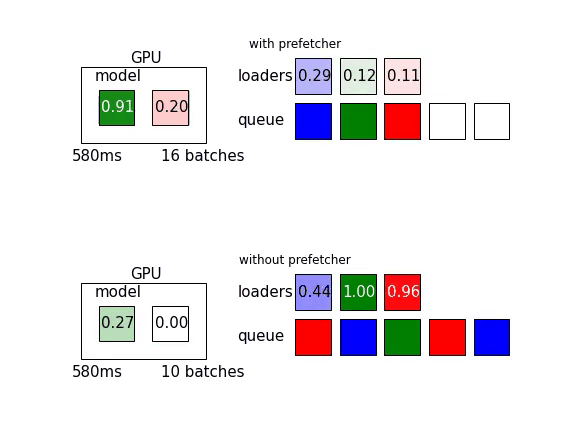
另外可以參考參考這篇文章,裡頭有以下這張動態圖,讓人更好理解Prefetch能增加多少效率:
說的嘴巴都泡,但具體怎麼做呢?所幸,歸功於強大的社群功能,Torch內的DataLoader已經同時實作了這兩樣東西。參考官方文件
可以透過其中下列的參數進行設置:
具體實例如下:
torch.utils.data.DataLoader(dataset,
num_workers = 8,
prefetch_factor = 4)
那麼實際差異到底有多少呢?讓我們實際各跑5個epoch比較看看。實驗結果如下表
進行了平行預處理以及prefetch的結果是原本的43%(245ms/579ms)唷!詳細設置可以參考無優化以及有優化的這兩個commit。
本日的重點就是介紹個人所使用的Containerized Development框架,說穿了就是分享個人所使用的DockerFile與Docker Compose設定檔。
Docker是一套現在非常火紅、以容器為基礎的虛擬化框架,但比起傳統的虛擬機器使,使用上也十分的輕易近人,而且更重要的是有許多第三方已經建立好的Image,可以直接pull下來做使用,也算是一種站在巨人肩膀上的方式。Docker Compose則是一種使用Docker時的設置檔案,主要用來簡化Docker的使用方式以及再利用性。詳細就不多做介紹,建議可以直接參考官方文件:
談這件事之前想先問下列兩種讀者問題:
其實這兩個問題都環繞著一個相同的核心,就是模型的再現性問題。而再現性又可以分兩個層面:
而 Containerized Development 便是一個對這兩種再現性都具有相當程度幫助的一個方式。(當然也有例外就是,但就是後話了)
https://github.com/SraRod/iThome2022/tree/aa33395073d0e0dbf3321521f08415c41fbd7d9a
(註:原則上這幾個檔案應該會持續更新,各位也可以選擇main的最新檔案)
Docker基本上在做的事情就是把已經建立好的Image,展開成一個Container再來運行。
而DockerFile的作用,基本上就是用來製作我們自己需要的Image!
可以參考我在連結中的DockerFile
首先我們一樣站在巨人的肩膀上,運用MONAI所提供的Image作為基礎
FROM projectmonai/monai:0.9.1
但實際使用會發現這位巨人的視力好像有點狀況,於是重裝一下opencv。
(註:應該是因為MONAI大部分都用PIL,所以裡頭沒有OPENCV)
(註:也可以在requirement裡面裝 opencv-headless,比較方便但Performance上有些許差異,看個人抉擇)
# install opencv dependency
RUN apt update &&\
apt install libgl1-mesa-glx -y &&\
conda install -c conda-forge nodejs=16.12.0 -y
# for nodejs > 12...
接著則是利用requirements.txt安裝裡頭Python所需要的套件以及固定好的版本。
# specify version if you could...
COPY requirements.txt .
# install pyton dependency
RUN pip install --upgrade pip &&\
pip install -r requirements.txt
最後就是同步一下內外跟專案的Python路徑,會讓一些小操作上更加順暢。就大功告成啦!
# set workspace to python path
ENV PYTHONPATH $PYTHONPATH
下一步則是 docker-compose 的設定檔,請參考我寫好的檔案。
首先介紹一下,以下是基礎設定,解說寫在後面
version: '3.7' # 採用的Confiuguration版本
services:
jupyter:
container_name: "iThome2022" # build起來以後的container name,沒有也可以,會根據資料夾跟service name自己命名
build: . # 根據我們剛剛建立好的Dockerfile來build Image,預設檔名就是Dockerfile,可以不同,需加額外參數
shm_size: '32GB' # Share Memory的設定,太低的話,PyTorch有些操作會出錯
runtime: nvidia # 讓Container可以吃到NVIDIA的GPU
user: root # 用root權限執行
working_dir: /home/$USER/workspace # 設定workspace
environment: # 一些環境變數,基本上跟在LINUX相同
NVIDIA_VISIBLE_DEVICES: 0 # 只吃第一張 GPU ,跟同事同主機多張GPU怕誤搶到時可以使用
JUPYTER_ENABLE_LAB: 'yes' # 把Jupyter LAB 打開
PYTHONPATH: /home/$USER/workspace # 同working_dir
這裡則是把container內部的空間作一個連動,類似ln -s。
值得注意的是除了把repo的資料夾就投到workspace以外,這裡還分別做了與local user共享ssh key、git設定檔以及把jupyter放到外部的小巧思。可以讓使用者直接打開jupyter lab開發的時候更加順暢一些。
volumes:
- .:/home/$USER/workspace
- ~/.ssh:/home/$USER/.ssh # for ssh
- ~/.gitconfig:/home/$USER/.gitconfig # for git
- ./.jupyter:/root/.jupyter
這邊就是port跟外部的連動,我是都會把juyter用的8888打到5566(得第一,不解釋)。
5000就是預留給額外服務用的,例如開發很常用到的Tensorboard 或是 MLFlow。
ports:
- 5566:8888
- 5000:5000
最後則是container建立好以後,需要執行的指令。這邊主要就是作jupyter的一些初始設定,然後再把服務架起來(以危險的方式,好孩子在佈署非個人化的服務時千萬不要學)。
command: bash -c '
cd /home/$USER/workspace
&& jupyter lab build
&& jupyter labextension install jupyterlab-plotly
&& jupyter labextension install @jupyter-widgets/jupyterlab-manager
&& jupyter lab --no-browser --allow-root --ip=0.0.0.0 --ContentsManager.allow_hidden=True --NotebookApp.token="" --NotebookApp.password=""'
基本上就是把整個repo clone下來以後
docker-compose up -d
等待image拉下來跟build好以後,就是一套完整可以使用的jupyter lab啦!
PyTorch是目前產學界都十分活耀的深度學習框架,其中很大的一個原因來自於他豐富的生態鏈。本系列文將以醫療影像為例,介紹多個套件所共同組合出的實戰運用。
本系列文預計將整理目前筆者所使用的深度學習框架,採用一步一步慢慢堆疊的方式,並搭配到時候會發佈的github repository,將所採用的技術環節,以手把手的方式一個個commit加入並完整整個開發模組。
基本上每日的文章大致上會分成兩種概念文與實作文兩種,概念文主會要講述所採用套件或技術的觀念及其所被採用的理由,實作的部分則會有實際的coding內容,以及對應的git commit可以直接讓讀者去比較差異。
系列文會從開發環境以及Configuration開始介紹,具體上是希望各個學習深度學習的工程師或是資料科學家們,能夠對於自己所開發出來的東西有比較細步的掌握。
整個系列文基本上會環繞在下列的三個套件:
作為基礎框架來進行實作。會採用Deep Learning中最基本的任務Classification來做為系列文章的主體,接著一步一步加入不同Pytorch的生態系套件及訓練技巧,以此提升整個開發的效率跟嚴謹度,最後也會把開發好的模型佈署成API,進行所謂的Model Serving。資料上則會採用醫療影像相關的公開資料集,目前選定會是MedMNIST v2。
另外依照實際進度,可能還會有一些3D Segmentation 甚至是 Registration的實例。
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.