soda-x / blog Goto Github PK
View Code? Open in Web Editor NEWHere is my blog
Here is my blog























































































































































































































webpack 是什么? 可以用来吃的吗?那么这篇文章可能并不适合你。
随着 webapp 的复杂程度不断地增加,同时 node 社区的崛起也让前端在除了浏览器之外各方面予以强力衍生与渗透,不得不承认目前的前端开发已然是一个庞大和复杂的体系,慢慢的前端工程化这个概念开始逐渐被强调和重视。
在支付宝,前端工程化应该是先驱者,我们有一套配套工具和脚手架来交代项目的初始,调试与打包;有成熟的线上部署和迭代系统交代每一行代码的始与终;有智能化的监控系统来交代代码的优与劣。
如上这么做好处是显然的,让所有的事情变得可控与规范,但前端开发的灵活与便捷性却带来不少影响,代码不管是否本地经过验证,要发布必须重新全量构建整个项目,而有些同学的把预发调试当成和本地调试一样使用,先不提这种做法是否正确但衍生而来的问题是用户必须忍受每次全量构建的时长,另外也由于项目复杂的增大,通常一个中型的项目业务模块都会有上百个,加上应用架构所包含的内容,已经是一个不小的体量,即使进行单次构建,也可能让开发者足足等上几分钟,甚至几十分钟。
本文的重点就是想要让开发者尽量缩小带薪的痛苦等待。
想知道 webpack 优化技巧,想要提升构建速度。
本机硬件环境:
2 GHz Intel Core i7 / 4 核
8 GB 1600 MHz DDR3
项目数据:
457 个项目文件,项目依赖 40 个
运行数据:
在 node@4 npm3 下整个全量构建耗时达 192s
在埋头开始优化前,首先我们必须理清楚知道一次全量构建他所包含的时间分别由什么组成,这可能让我们更加全面的去评估一个问题。
T总 = T下载依赖 + Twebpack
Twebpack = Tloaders + Tplugins
在如上粗略的评估中我们可以把时间归结在两大部分,一个是下载依赖耗时,还有一个是 webpack 构建耗时,而这一部分耗时可能包含了各类 loader 和 plugin 的耗时,css-loader ? babel-loader ? UglifyJsPlugin ?现在我们并不清楚。
基于如上的评估我们大概可以从四大方面来着手处理
一般碰到问题我们最容易想到的是升级一下依赖,把涉及构建的工具在 break change 版本之前都升级到最新,往往能带来意向不到的收益,这和机器出现问题重启往往能解决有异曲同工之处。
而事实上,也确实如此,在该项目中升级项目构建模块后提升了 10s 左右,暂时先不提其中的原由。
另外不得不吐槽 npm3 中安装依赖实在是龟速,那如何压榨安装依赖所需要的时间呢,是否有方案?或许大家已经听到过 pnpm,这里需要介绍下更为好用和极速的 npminstall。
先来看看项目在不同版本的 npm 以及在 npmintall 场景下的差异:
[email protected] | tnpm@2 (npm2)
修正后共计耗时 284s
依赖安装时长 182s
构建时长 Time: 102768ms 约为 102s
node@4 | tnpm@3 (npm3)
共计耗时 192s
依赖安装时长 64s
初始构建所需 Time: 128027ms 约为 128s
[email protected] | tnpm@4 (npminstall)
共计耗时 140s
依赖安装时长 15s
初始构建所需 Time: 125271ms 约为 125s
使用 tnpm@4/npminstall 能够达到立竿见影的效果,优化幅度达 70% - 90%
司内
npm install -g tnpm@4 --registry=http://registry.npm.alibaba-inc.com司外
npm install npminstall --g
npminstall
在未压缩的情况下脚本大于 1MB 变得非常普遍,甚者达到 3-4MB,这到底是因为什么?!
在这个过程中我分析了项目中的依赖,以及代码使用的状况。有几个案例非常的普遍。
在 package.json 中
"lodash": "^4.13.1",
"lodash.clonedeep": "^3.0.2",
在这个案例中根据需求只需要保留其一即可
很多时候我们业务变更很快,人员变动也很快,多人协同,这在项目中很容易被窥探出来
import xx from 'xxx';然后在业务实现中并没有使用 xx
必须及时删除已经停止使用的相关库,无论是 deps 还是 devdeps,都使用 uninstall 的方式把相关依赖从 package.json 中移除,并千万记得也从源码中移除相关依赖。
webpack 强大的混淆能力,让 web 开发 和 node 开发的界线变得模糊,依赖的滥用问题异常凸显。
moment(key).format('YYYY-MM-DD HH:mm:ss')
// 只是使用了 moment 的format 何必引入 moment
// 如果不想简单实现就可以使用更为专一的库来实现
// https://github.com/taylorhakes/fecha Lightweight date formatting and parsing (~2KB). Meant to replace parsing and formatting functionality of moment.js.
import isequal from 'lodash/isequal'
// 这样会导致整个 lodash 都被打入到包内
// 为何不直接使用
// import isequal from 'lodash.isequal'等等等等。
引入一个第三方 lib 的时候,请再三思量,问自己是否有必要,是否能简单实现,是否可以有更优的 lib 选择
这个项目是使用 antd-init 脚手架工具初始化而来的项目,所以在构建工具层面使用了 ant-tool/atool-build. 对于已经熟悉 ant-design 的同学而言,以上这些应该都已熟悉。
在查阅项目代码时候碰到了又一个很典型的案例
在 webpack.config.js 中引用了优化引用的插件 babel-plugin-antd
webpackConfig.babel.plugins.push(['antd', {
style: 'css',
}]);该插件会在 babel 语法解析层面对引用关系梳理即用什么的组件就只会引用什么样组件的代码以及样式。
// import js and css modularly, parsed by babel-plugin-antd
import { DatePicker } from 'antd';但是很让人忧心的是我们很容易在原始代码里面找到这样的踪迹
import 'antd/lib/index.css';一个错用可能就会让包的体积大上一个量级。
如上这类优化插件比如在 babel-plugin-lodash 中也有相关实现。
如果三方库有提供优化类插件,那么请合理的使用这类插件,此外之后 atool-build 也会升级到 webpack2,在 webpack2 中已经支持 tree-shaking 特性,那么如上优化插件可能就并不需要了。
由于历史的原因 babel@5 到 babel@6,polyfill 推荐的形式也并不一样。但是在项目中我们可以发现一点是,开发人员并不清楚这其中的原委。以至于代码中我们经常可以看到的一种情形是以下两种方式共存:
//js文件
require('babel-pollyfill');"dependencies": {
"babel-runtime": "*"
},
"devDependencies": {
"babel-plugin-transform-runtime": "*"
},
"babel": {
"presets": [
"es2015",
"stage-0"
],
"plugins": [
"add-module-exports",
"transform-runtime"
]
}
两种方式只需要一种即可,更加推荐下一种方式,在压缩的情况下至少能给代码减少 50KB 的体积
在 atool-build 中默认会对 *.module.less 和 *.module.css 的文件使用 css-module 来处理
而 css-module 这一块的处理由 css-loader 完成。css-loader 关于 css-module
对 css-module 还不清楚的同学可以移步至 阮一峰老师的 blog
简单来说使用 css-module 后可以保证某个组件的样式,不会影响到其他组件
在日常中经常有同学会跑过来问,为什么我的样式变成有 hash 后缀了,为什么构建文件变大了,原因就在于此。
如果你的项目使用 ant-design, 并且通过 antd-init 脚手架来生成项目,那么你所有的 less 文件都会被应用 css-module,代码
这本应是一种好的方式,但是在实际项目中开发者并不清楚其中的逻辑,并且在使用在也不规范,如手动直接调用大型组件的 less 文件的同时也调用其 css 文件。
应用 css-module 后会导致构建的文件体积变大,如果小项目,并且能自己管理好命名空间的情况下可以不开启,反之请开启。
另外关于 css-loader 自从版本 0.14.5 之后压缩耗时增加几十倍的问题,其实之前在本地做过相应的测试,
css-loader 分别尝试过 0.14.5 和 0.23.x
然后并没有在这个业务项目中发现问题,但不保证别的业务项目中会复现这个问题,基于此记录一笔。
目前在 atool-build 中处理 jsx 时并不会像处理 js 一样对 node_modules 目录下的内容进行屏蔽。
而现在在内部项目中可以看到大量的场景借 jsx 核没有 es5 化,这无疑是构建性能中巨大瓶颈的一块。
发布至 npm 的包,请全部 es5 化
综上开源世界的选择很多很精彩,但回过来头来想想我们是不是有点过分的利用了这份便捷,少了些对前端本身的敬畏呢。我们要合理适度的使用三方依赖,并认真思考每一步选择背后所需要承担的结果。
通过依赖的精简,使用上的规范,在构建速度上提升了 12秒,在代码压缩的情况下省下了约 900KB 的空间
在蚂蚁内部我们使用 atool-build 来进行前端资源文件的构建,如果并不清楚 atool-build 的同学可以前往 ant-tool/atool-build 文档 来进行了解。
笼统的说 atool-build 是基于 webpack 的构建工具,在其内部内置了一套通用型的 webpack 配置,同时这套配置通过 webpack.config.js 来进行重写。
在讲 CommonsChunkPlugin 前,可能大家需要理清楚一点是 entry 的概念,entry 在 atool-build 中更多意义上指的是一个页面的入口,这个入口对应一个 html 一个 js 一个 css,(这里并不排除不是这么做的,比如在 OLD IE 中对一个样式文件长度有限制,可能需要人为不得不进行拆分,这个时候借助 entry 或许是一种方式)如果在 multiple page 方案中就会有多个 entry,而 CommonsChunkPlugin 的作用是,在如上这些 entry 涉及的 chunk 中抽取公共部分的 module 合并进入一个 chunk;这里可能很多人有误区是认为抽取公共部分指的是能抽取某个代码片段,其实并不是,它是以 module 为单位的。
举几个典型的案例
现在有 entryA, entryB, entryC 和 entryD。
1)抽取 entryA, entryB, entryC, entryD 中所有公共部分的 modules(该 modules 必须都被所有 entry 所引用到) 进入一个 chunk
webpackConfig.plugins.push(
new webpack.optimize.CommonsChunkPlugin('common', 'common.js')
)2)抽取 entryA, entryB, entryC, entryD 中公共部分的 modules(该 modules 必须都被指定个数的 entry 所引用到) 进入一个 chunk
webpackConfig.plugins.push(
new webpack.optimize.CommonsChunkPlugin({
name: "commonOfAll",
minChunks: 3
})
)3)只抽取 entryA, entryB 的公共部分
webpackConfig.plugins.push(
new webpack.optimize.CommonsChunkPlugin({
name: "commonOfAB",
chunks: ['entryA', 'entryB']
})
)4)把 entry 中一些 lib 抽取到 vendor
首先可以在 entry 中设定一个 entry 名叫 vendor,并把 vendor 设置为所需要的 lib
webpackConfig.entry = {
vendor: ['jquery']
}
webpackConfig.plugins.push(
new CommonsChunkPlugin({
name: "vendor",
minChunks: Infinity,
})
)DedupePlugin 在 atool-build 中的应用 代码定位
这个插件中可以在打包的时候删除重复或者相似的文件,实际测试中应该是文件级别的重复的文件,相似没测出来。这个优化对于还在使用 npm2 的同学会特别有用,因为 npm2 不像 npm3 对整体的依赖进行拍平。
举例
在 npm2 目录结构下直接打包如图依赖关系,并且 d 没有被 a 直接依赖,会出现 d 重复打包问题:
a
|--b
|--d
|--c
|--d
该插件的功能是会在 resolve 所有的 module 后,对所有的 module 根据调用的次数重新给模块分配更短的 ids,从而减小最终构建产物的文件大小。该插件在 webpack2 中有类似的默认已经内置。在 atool-build 该插件默认内置。
在 webpack 官方站点 关于构建性能优化还提到了关于
文中所说
Only use
resolve.modulesDirectoriesfor nested paths. Most paths should useresolve.root. This can give significant performance gains. See also this discussion.
resolve.root 一般情况下指向的是项目的根目录,是一个绝对路径;而 modulesDirectories 则是用以模块解析的目录名,一般情况下是相对路径。
简单来说把 resolve.modulesDirectories 设置为 ["node_modules", "bower_components"]
那么在项目中 foo/bar 的文件下依赖一个模块 a
那么 webpack 会通过如下的顺序去寻找依赖
foo/bar/node_modules/a
foo/bar/bower_components/a
foo/node_modules/a
foo/bower_components/a
node_modules/a
bower_components/a
反观我们的的 atool-build 中相关的设置是有优化空间的
尝试调整如下:
resolve: {
- modulesDirectories: ['node_modules', join(__dirname, '../node_modules')],
+ modulesDirectories: ['node_modules'],
}调整完毕后,整体构建时长降低了 7s
第一次接触这个插件来源于在 stackoverflow 上看到的一个问题 how-to-optimize-webpacks-build-time-using-prefetchplugin-analyse-tool
随后翻看了相关的文档,文档中提到可以用来 boost performance 听上去很诱人,但在实际使用中并没有那么顺利。
要使用 PrefetchPlugin 插件,首先需要了解清楚哪些依赖或者模块需要被 prefetch。而这些就需要衍生出 webpack cli 和 其 analyse 工具。
由 webpack ci json 把构建输出的日志生成到一个 json 文件中,然后通过 analyse 工具分析。
atool-build 目前已经内置了协助分析所需的 stats.json
$ atool-build --json之后会在构建结果的目标目录会生成一个 build-bundle.json 基于数据安全原因建议大家自己搭建 analyse 平台,上传这个 json 文件查看效果。
上传完毕后,可以在页面最右侧的导航栏中可以看到 hints 这一级。点击之后便可以看到,Long module build chains 而 prefetch 的用意就在于实现 prefetch 一些文件或者模块以缩短 build chain。
举例在该项目中一处冗长构建链:

在这个案例中就可以把 babel-runtime 给 prefetch
new webpack.PrefetchPlugin('babel-runtime/core-js')
优化后,构建提速在毫秒级,效果不明显。
结论: preFetch 这类优化需贴合具体的应用场景,所以并不具有普遍性。对于构建速度的性能提升可能都不会明显。它的作用个人觉得是让你发现可能存在的性能问题,并通过 webpack 其他手段,比如之后会提到的 noParse 手段来解决其中的瓶颈
在此非常推荐一款 webpack 的插件,该插件可以让你清楚的看到代码的组成部分,以及在项目中可能存在的多版本引用的问题。
在 atool-build 中使用只需要在 webpack.config.js 中做对应设置即可
var Visualizer = require('webpack-visualizer-plugin');
module.exports = function(webpackConfig) {
webpackConfig.plugins.push(new Visualizer());
return webpackConfig;
}
简单来说 external 就是把我们的依赖申明为一个外部依赖,外部依赖通过 <script> 外链脚本引入。
在 atool-build 使用上
在 webpack.config.js 中
module.exports = function(webpackConfig) {
...
+ webpackConfig.externals = ['react', 'react-dom', 'react-router', 'classnames', 'immutable', 'g2']
...
return webpackConfig;
};并在对应的 entry 页面中通过 script 的方式传入这些库 cdn 的地址。
结论:提升整体构建时间 20s 以上,并在压缩代码的情况下省下约 1MB 的空间,个人比较推荐这种方式,因为有更好的 cdn 缓存加持。
如上我们已经知道如何声明一个外部依赖并通过 cdn 的方式来优化构建,这种方式是把依赖脱离了整个 bundle,可能有些情况下你需要把这个外部依赖打包进入到你的 bundle 但是你又不想为此而花费很长时间,如何做呢?
在 webpack.config.js 中
module.exports = function(webpackConfig) {
...
+ webpackConfig.resolve.alias = {
+ 'react': 'react/dist/react.min'
+ }
+ webpackConfig.module.noParse.push(
+ /react.min/
+ )
...
return webpackConfig;
};经过如上设置,那么 require('react'); 等价于于 require('react/dist/react.min.js')
而 noParse 则会让 webpack 忽略对其进行文件的解析,直接会进入最后的 bundle
在项目中合理使用 alias 和 noParse 可以提升效率,但该选择更适合生产环境,否则调试时会比较尴尬
在正常项目中我们会发现除了自身代码外,我们的 deps 中也引用了大量的 npm 包,而这些包在正常的开发过程中并不会进行修改,但是在每一次构建过程中却需要反复的将其分析,如何来规避此类内耗呢?这两个插件就是干这个用的。
简单来说 DllPlugin 的作用是预先编译一些模块,而 DllReferencePlugin 则是把这些预先编译好的模块引用起来。这边需要注意的是 DllPlugin 必须要在 DllReferencePlugin 执行前,执行过一次。
那在 atool-build 中如何使用呢
给项目新增一个 dll.config.js
var join = require('path').join;
var webpack = require('atool-build/lib/webpack');
var pkg = require(join(__dirname, 'package.json'));
var dependencyNames = Object.keys(pkg.dependencies);
var uniq = require('lodash.uniq');
var pullAll = require('lodash.pullall');
var autoprefixer = require('autoprefixer');
var exclude = []
var deps = uniq(dependencyNames);
var entry = pullAll(deps, exclude);
var outputPath = join(process.cwd(), 'dll/');
module.exports = function(webpackConfig, env) {
var babelQuery = webpackConfig.babel
webpackConfig = {};
webpackConfig = {
context: __dirname,
entry: {
vendor: entry
},
devtool: 'eval',
output: {
filename: '[name].dll.js',
path: outputPath,
library: '[name]',
},
resolve: {
modulesDirectories: ['node_modules'],
extensions: ['', '.web.tsx', '.web.ts', '.web.jsx', '.web.js', '.ts', '.tsx', '.js', '.jsx', '.json']
},
resolveLoader: {
modulesDirectories: ['node_modules'],
},
module: {
loaders: [
{
test: /\.js$/,
exclude: /node_modules/,
loader: 'babel',
query: babelQuery
},
{
test: /\.jsx$/,
loader: 'babel',
query: babelQuery
},
{
test: /\.tsx?$/,
loaders: ['babel', 'ts'],
},
{
test(filePath) {
return /\.css$/.test(filePath) && !/\.module\.css$/.test(filePath);
},
loader: 'css?sourceMap&-restructuring!postcss',
},
{
test: /\.module\.css$/,
loader: 'css?sourceMap&-restructuring&modules&localIdentName=[local]___[hash:base64:5]!postcss',
},
{
test(filePath) {
return /\.less$/.test(filePath) && !/\.module\.less$/.test(filePath);
},
loader: 'css?sourceMap!' +
'postcss!' +
'less-loader?{"sourceMap":true}',
},
{
test: /\.module\.less$/,
loader: 'css?sourceMap&modules&localIdentName=[local]___[hash:base64:5]!!' +
'postcss!' +
'less-loader?{"sourceMap":true}'
},
{ test: /\.woff(\?v=\d+\.\d+\.\d+)?$/, loader: 'url?limit=10000&minetype=application/font-woff' },
{ test: /\.woff2(\?v=\d+\.\d+\.\d+)?$/, loader: 'url?limit=10000&minetype=application/font-woff' },
{ test: /\.ttf(\?v=\d+\.\d+\.\d+)?$/, loader: 'url?limit=10000&minetype=application/octet-stream' },
{ test: /\.eot(\?v=\d+\.\d+\.\d+)?$/, loader: 'file' },
{ test: /\.svg(\?v=\d+\.\d+\.\d+)?$/, loader: 'url?limit=10000&minetype=image/svg+xml' },
{ test: /\.(png|jpg|jpeg|gif)(\?v=\d+\.\d+\.\d+)?$/i, loader: 'url?limit=10000' },
{ test: /\.json$/, loader: 'json' },
{ test: /\.html?$/, loader: 'file?name=[name].[ext]' },
]
},
postcss: [
autoprefixer({
browsers: ['last 2 versions', 'Firefox ESR', '> 1%', 'ie >= 8', 'iOS >= 8', 'Android >= 4'],
}),
],
plugins: [
new webpack.DllPlugin({ name: '[name]', path: join(outputPath, '[name].json') })
]
}
return webpackConfig;
}如上是把一个项目中的 deps 全部放入了 dll 中,运行如下命令后
atool-build --config dll.config.js会在项目中生成一个 dll 文件夹其中包含了 vendor.dll.js 和 vendor.json
并在原有 webpack.config.js 中添如下代码片段
if (env === 'development') {
webpackConfig.plugins.some(function(plugin, i){
if(plugin instanceof webpack.optimize.CommonsChunkPlugin) {
webpackConfig.plugins.splice(i, 1);
return true;
}
});
webpackConfig.plugins.push(
new webpack.DllReferencePlugin({
context: __dirname,
manifest: require('./dll/vendor.json')
})
)
}大功告成。
*请注意:dllPlugin 和 commonChunkPlugin 是二选一的,并且在启用 dll 后和 external、common 一样需要在页面中引用对应的脚本,在 dll 中就是需要手动引用 vendor.dll.js *
在实际使用中,dllPlugin 更加倾向于 开发环境,而对开发环境的整体提速非常明显。如下图所示,初次构建的速度优化约 20%,再次构建速度优化为 40%,hot-reload 约为50%

在 webpack 中虽然所有的 loader 都会被 async 并发调用,但是从实质上来讲它还是运行在单个 node 的进程中,以及在同一个事件循环中。虽然单进程在处理 IO 效率上要强于 多进程,但是在一些同步并且非常耗 cpu 过程中,多进程应该是优于单进程的,比如现在的项目中会用 babel 来 transform 大量的文件。所以 happypack 的性能提升大概就来源于此。 当然也可以预见到,如果你的项目并不复杂,没有大量的 ast 语法树解析层的事情要做,那么即使用了 happypack 成效基本可视为无。
在我这次尝试的优化项目中,400多模块都需要涉及 babel 加载,并且还存在 npm 包并没有 es5 的情况(bad),所以可以预见到的是会有不错的结果。
在 webpack.config.js 中添加如下代码片段
var babelQuery = webpackConfig.babel;
var happyThreadPool = HappyPack.ThreadPool({ size: 25 });
function createHappyPlugin(id, loaders) {
console.log('id', id)
return new HappyPack({
id: id,
loaders: loaders,
threadPool: happyThreadPool,
// disable happy caching with HAPPY_CACHE=0
cache: true,
// make happy more verbose with HAPPY_VERBOSE=1
verbose: process.env.HAPPY_VERBOSE === '1',
});
}
webpackConfig.module = {};
webpackConfig.module = {
loaders: [
{
test: /\.js$/,
exclude: /node_modules/,
loader: 'happypack/loader?id=js',
},
{
test: /\.jsx$/,
loader: 'happypack/loader?id=jsx',
},
{
test(filePath) {
return /\.css$/.test(filePath) && !/\.module\.css$/.test(filePath);
},
loader: ExtractTextPlugin.extract('style', 'happypack/loader?id=cssWithoutModules')
},
{
test: /\.module\.css$/,
loader: ExtractTextPlugin.extract('style', 'happypack/loader?id=cssWithModules')
},
{
test(filePath) {
return /\.less$/.test(filePath) && !/\.module\.less$/.test(filePath);
},
loader: ExtractTextPlugin.extract('style', 'happypack/loader?id=lessWithoutModules')
},
{
test: /\.module\.less$/,
loader: ExtractTextPlugin.extract('style', 'happypack/loader?id=lessWithModules')
}
],
}
if (!!handleFontAndImg) {
webpackConfig.module.loaders.concat([
{ test: /\.woff(\?v=\d+\.\d+\.\d+)?$/, loader: 'happypack/loader?id=woff' },
{ test: /\.woff2(\?v=\d+\.\d+\.\d+)?$/, loader: 'happypack/loader?id=woff2' },
{ test: /\.ttf(\?v=\d+\.\d+\.\d+)?$/, loader: 'happypack/loader?id=ttf' },
{ test: /\.eot(\?v=\d+\.\d+\.\d+)?$/, loader: 'happypack/loader?id=eot' },
{ test: /\.svg(\?v=\d+\.\d+\.\d+)?$/, loader: 'happypack/loader?id=svg' },
{ test: /\.(png|jpg|jpeg|gif)(\?v=\d+\.\d+\.\d+)?$/i, loader: 'happypack/loader?id=img' },
{ test: /\.json$/, loader: 'happypack/loader?id=json' },
{ test: /\.html?$/, loader: 'happypack/loader?id=html' }
])
} else {
webpackConfig.module.loaders.concat([
{ test: /\.woff(\?v=\d+\.\d+\.\d+)?$/, loader: 'url?limit=10000&minetype=application/font-woff' },
{ test: /\.woff2(\?v=\d+\.\d+\.\d+)?$/, loader: 'url?limit=10000&minetype=application/font-woff' },
{ test: /\.ttf(\?v=\d+\.\d+\.\d+)?$/, loader: 'url?limit=10000&minetype=application/octet-stream' },
{ test: /\.eot(\?v=\d+\.\d+\.\d+)?$/, loader: 'file' },
{ test: /\.svg(\?v=\d+\.\d+\.\d+)?$/, loader: 'url?limit=10000&minetype=image/svg+xml' },
{ test: /\.(png|jpg|jpeg|gif)(\?v=\d+\.\d+\.\d+)?$/i, loader: 'url?limit=10000' },
{ test: /\.json$/, loader: 'json' },
{ test: /\.html?$/, loader: 'file?name=[name].[ext]' }
])
}
webpackConfig.plugins.push(createHappyPlugin('js', ['babel?'+JSON.stringify(babelQuery)]))
webpackConfig.plugins.push(createHappyPlugin('jsx', ['babel?'+JSON.stringify(babelQuery)]))
webpackConfig.plugins.push(createHappyPlugin('cssWithoutModules', ['css?sourceMap&-restructuring!postcss']))
webpackConfig.plugins.push(createHappyPlugin('cssWithModules', ['css?sourceMap&-restructuring&modules&localIdentName=[local]___[hash:base64:5]!postcss']))
webpackConfig.plugins.push(createHappyPlugin('lessWithoutModules', ['css?sourceMap!postcss!less-loader?sourceMap']))
webpackConfig.plugins.push(createHappyPlugin('lessWithModules', ['css?sourceMap&modules&localIdentName=[local]___[hash:base64:5]!postcss!less-loader?sourceMap']))
if (!!handleFontAndImg) {
webpackConfig.plugins.push(createHappyPlugin('woff', ['url?limit=10000&minetype=application/font-woff']))
webpackConfig.plugins.push(createHappyPlugin('woff2', ['url?limit=10000&minetype=application/font-woff']))
webpackConfig.plugins.push(createHappyPlugin('ttf', ['url?limit=10000&minetype=application/octet-stream']))
webpackConfig.plugins.push(createHappyPlugin('eot', ['file']))
webpackConfig.plugins.push(createHappyPlugin('svg', ['url?limit=10000&minetype=image/svg+xml']))
webpackConfig.plugins.push(createHappyPlugin('img', ['url?limit=10000']))
webpackConfig.plugins.push(createHappyPlugin('json', ['json']))
webpackConfig.plugins.push(createHappyPlugin('html', ['file?name=[name].[ext]']))
}
总结来说,在需要大量 cpu 计算的场景下,使用 happypack 能给项目带来不少的性能提升。从本次优化项目来看,在建立在 dll 的基础上,初次构建能再提升 40% 以上,重新构建也会提升 40% 以上。所以 dllPlugin 和 happypack 的结合可以大大优化开发环节的时间。
uglify 过程应该是整个构建过程中除了 resolve and parse module 外最为耗时的一个环节。之前一直想要尝试在这个过程的优化,最近看社区新闻的时候,发现了 webpack-uglify-parallel 深入看了这个库的组织和实现,完全就是我需要的,因为它就是基于 uglifyPlugin 修改而来。
在 webpack.config.js 中启用 webpack-uglify-parallel 多核并行压缩
webpackConfig.plugins.some(function(plugin, i) {
if (plugin instanceof webpack.optimize.UglifyJsPlugin) {
webpackConfig.plugins.splice(i, 1);
return true;
}
});
var os = require('os');
var options = {
workers: os.cpus().length,
output: {
ascii_only: true,
},
compress: {
warnings: false,
},
sourceMap: false
}
var UglifyJsParallelPlugin = require('webpack-uglify-parallel');
webpackConfig.plugins.push(
new UglifyJsParallelPlugin(options)
);由于在 atool-build 中我们已经内置了 UglifyJsPlugin,所以一开始我们对该插件予以了删除。

结论:初次构建速度优化至少 40% 本地 8 核心 而服务端达到 20 核心。但是问题是在多核平行压缩中 cpu 负载非常高,如果服务端多项目并发构建,结果可能很难讲。需要有节制使用多核的并行能力。

如上这个组合拳非常适合在生成环节下使用,而 dll + happypack 则更加适合在开发环节。
本地构建时长 从原先的 125s 优化到了 36s,优化幅度为 70% 左右
本地调试时长从原先的 22s 优化到了 7s,优化幅度也为 70% 左右
webpack-uglify-parallel 和 happypack 和 external 的混搭非常适合在生产环节
dll + happypack 的混搭非常适合在开发环节
如上这个 emoji commit message 指引感觉非常好,所以大致翻译了下和大家分享
出发点源于最近在梳理和制定一套标准化且规范化开发细则,其中如何管理 commit 就是其中很重要的一个环节
借鉴了 angular 开发的规范,目前也是比较大规模使用的。
在指引文档中其中有一点涉及
Subject
The subject contains succinct description of the change:
- use the imperative, present tense: "change" not "changed" nor "changes"
- don't capitalize first letter
- no dot (.) at the end
其中就有 use the imperative, present tense,回过头想其实平时开发中很少有同学能把一些关键信息用简易且关键的英文动词来描述清楚此次 commit 的动机,而这篇指引一方面用了 emoji 这种形象化的方式外,关键多了解释说明,让我们这种英文不好的同学也能快速掌握到要领,同时可以把这些点,适用到 Subject 中。
🎨 :art: Improving structure / format of the code. 改进目录或代码结构 / 格式化代码
⚡ :zap: Improving performance. 提升性能
🔥 :fire: Removing code or files. 移除代码或文件
🐛 :bug: Fixing a bug. 修复 bug
🚑 :ambulance: Critical hotfix. 紧急修复
✨ :sparkles: Introducing new features. 新 feature
📝 :memo: Writing docs. 书写文档
🚀 :rocket: Deploying stuff. 部署相关
💄 :lipstick: Updating the UI and style files. 更新 UI 和 样式文件
🎉 :tada: Initial commit. 首次提交
✅ :white_check_mark: Adding tests. 新增测试用例
🔒 :lock: Fixing security issues. 修复安全性问题
🍎 :apple: Fixing something on macOS. 修复 macOS 平台上的缺陷
🐧 :penguin: Fixing something on Linux. 修复 Linux 平台上的缺陷
🏁 :checkered_flag: Fixing something on Windows. 修复 Windows 平台上的缺陷
🤖 :robot: Fixing something on Android. 修复 Android 上的缺陷
🍏 :green_apple: Fixing something on iOS. 修复 iOS 上的缺陷
🔖 :bookmark: Releasing / Version tags. 发布 / 给代码打版本化的 tag
🚨 :rotating_light: Removing linter warnings. 移除 linter 的警告
🚧 :construction: Work in progress. 开发进行时
💚 :green_heart: Fixing CI Build. 修复 CI 问题
⬇️ :arrow_down: Downgrading dependencies. 降级依赖版本
⬆️ :arrow_up: Upgrading dependencies. 升级依赖版本
📌 :pushpin: Pinning dependencies to specific versions. 锁死依赖版本
👷 :construction_worker: Adding CI build system. 添加 CI
📈 :chart_with_upwards_trend: Adding analytics or tracking code. 添加分析或埋点代码
♻️ :recycle: Refactoring code. 代码重构
➖ :heavy_minus_sign: Removing a dependency. 移除依赖
🐳 :whale: Work about Docker. Docker 相关事由
➕ :heavy_plus_sign: Adding a dependency. 添加一个依赖
🔧 :wrench: Changing configuration files. 修改一个配置文件
🌐 :globe_with_meridians: Internationalization and localization. 国际化和本地化
✏️ :pencil2: Fixing typos. 修正拼写错误
💩 :hankey: Writing bad code that needs to be improved. 需要改进的代码,先上后续再重构
⏪ :rewind: Reverting changes. 回滚变更
🔀 :twisted_rightwards_arrows: Merging branches. 分支合并
📦 :package: Updating compiled files or packages. 更新打包后的文件或者包
👽 :alien: Updating code due to external API changes. 外部依赖 API 变更导致的代码变更
🚚 :truck: Moving or renaming files. 移动或重命名文件
📄 :page_facing_up: Adding or updating license. 添加或者更新许可
💥 :boom: Introducing breaking changes. 不兼容变更
🍱 :bento: Adding or updating assets. 新增或更新 assets 资源
👌 :ok_hand: Updating code due to code review changes. 更新由 CR 引起的代码变更
♿ :wheelchair: Improving accessibility. 提升无障碍体验
💡 :bulb: Documenting source code. 书写源码文档
🍻 :beers: Writing code drunkenly.
💬 :speech_balloon: Updating text and literals. 更新文案以及字面量
🗃️ :card_file_box: Performing database related changes. 执行数据库相关变更
🔊 :loud_sound: Adding logs. 增加日志
🔇 :mute: Removing logs. 移除日志
👥 :busts_in_silhouette: Adding contributor(s). 新增贡献者
🚸 :children_crossing: Improving user experience / usability. 提升用户体验 / 可用性
🏗️ :building_construction: Making architectural changes. 架构变更
📱 :iphone: Working on responsive design. 真在进展响应式设计的相关事由
🤡 :clown_face: Mocking things. Mock 相关
🥚 :egg: Adding an easter egg. 彩蛋
🙈 :see_no_evil: Adding or updating a .gitignore file 新增或者更新 .gitignore 文件
在我的理解中支付宝小程序构建经历了两大过程
webpack 化
去 webpack 化
看上去就好像走错了路,但话说回来任何的技术变更其实都没有清晰的界限来判定是对的还是错的,因为所有的决定都是基于当时的状态下决定的。
先来说一说为什么 webpack 化。
个人觉得 webpack 最大的魅力是有视万物为 module 的能力,它高阶的扩展能力,可以有极高的个性化能力;极其活跃的社区氛围或多或少可以让我们少走路,也少走弯路;另外不得不单独提一下 CRA,CRA 在开发体验优化这块上下的功夫非常深,目前很多基于 webpack 的上层封装,绝大多数都会有 CRA 的影子。
总结来说 webpack :
这些对于新生业务来说有着致命的诱惑力。
另外基于对原先 ant tool 的维护,使我成为了 webpack 死忠粉。所以自然而然我们采用了 webpack 做为构建的内核,另外基于它的 add-on 能力做了足够多的个性化能力输出。
确实一切看上去没什么大问题,除了 webpack 内置的缓存优化方案让我们坑了一次外没有任何的意外。
然而凡是都有个但是,随着小程序的一步步铺开,自然而然开发者的个性化需求开始见涨。正如大家所料到的越来越多的同学希望能开放核心的构建能力,更多的参数配置,webpack.config.js 又被搬上了台面。如果业务取向稳定,可控,那么 webpack.config.js 它绝对是滋生恶魔的来源,关于这一块探讨我在差不多2年前写过一篇文章构建工具的发展和未来的选择,这里就不再展开了,根本性问题我是担忧这给后续带来的维护性、稳定性、安全性问题。
由于 webpack 内置支持 pollyfill nodejs buildin 的模块,另外社区大库也不难发现他们也会很自然而然使用一些 module,但通常很多他们都会提供一个 dist 目录是纯可以跑在浏览器端的文件,而作为开发者,从我看到上千的项目使用中,我能保障90%的开发者没有这个意识,拿来即用成为了一种习惯。
这边扯出来另外一个话题,很有趣,我应该曾经2次在对外分享中问大家一个问题,如下代码,涉及了几种模块规范
import a from 'a';
const hello = require('./hello');
const d = {
x: 1,
};
module.exports.c = function c() {};
exports.b = {};
export { d };让人惊讶的是,能回答上来的人寥寥无几。
不知道大家有没有想过元罪是什么?是 webpack 这一类 universal 方案么? 还是 npm 把前端模块也引入了进来了?这是一个开放的命题没有标准答案。
回到正题,因为 webpack 巨大的包容性,当然这也怪我们当初没限死,慢慢的我们看到了在小程序业务中,居然出现了一类 cheerio 的依赖,看到越来越多的案例把传统 pc,node 开发思路慢慢的衍生到了小程序之上。做为我个人的观点,这是我不想看到的。
另外在调试环节下,小程序研发流程中用户会设置编译模式(即只调试固定页),webpack 这种贪婪式的编译模式(全量构建)是否真的契合小程序的调试模式。
于此之外,随着 WEB-IDE 的盛行,我们也琢磨着把编译流程整合到浏览器端,webpack 的厚重让可能性显得比较渺茫。
不过最最最重要的原因还是,webpack 在效率上还是显得有些局促,特别是在对比友商后,不过在这里要给 webpack 抱不平的是,webpack 的能力远大于友商的,而这种能力,就像现在的手机,它的算力是过剩的,而这种过剩的算力导致了时间的上累。
友商在安全的防护上做的还是相当到位的,我很难通过 hack 的方式来窥视整个流程。
探究的过程中留给我最大的印象是对于克制的理解,产品层是克制的,功能是克制的,开放度是克制的。要真正在浮躁的互联网中做到还是挺难的。
接下来我们单纯从技术层面来说一说,以下都是我个人的理解,未必对。
友商的技术选型,按我的理解应该遵循四点:轻,快,可管控,够用就好。
这些方面可以体现在他们他们的任何一方面,框架、DSL、构建服务等。框架层友商相比蚂蚁,做的还是很薄的,蚂蚁背靠 react 生态,但这很有可能是把双刃剑,小程序真的 “小” 吗?我们是否做好了开放所带来的的管控问题?我觉得这些都是棘手的问题。而友商的轻薄,虽然在管控性上做的比较极致,但是面对开发者天马行空的需求,或许他们的问题更多的是如何来支持,典型的有一个案例就是 npm 支持,在蚂蚁这套技术体系下,我们是纯天然就支持现有的前端研发链路,所以在开发习惯的延续性上基本没有任何问题,但友商最初的做法是,让开发者在小程序生态外自己创建一个 npm 使用流程,这也就是为什么在社区里面为什么会有很多这类方案的原因,而后续友商发布支持 npm,但仔细琢磨,其实友商 npm 更加偏向于是 component 而不是非标准前端意义上模块,比如不支持 nodejs module shim 就可以看出。反观我们的 npm 目前已被玩坏。
另外在梳理过程中发现,友商的比如在处理 *xml 文件和 *css 文件时,它是解耦的,贪婪的。稍微深入一点就可以看到TA有专门的二进制编译工具在负责此类文件的编译,利用编译工具可以批处理诸如 *xml 和 *css 文件。这和我们之前基于 webpack 有着巨大的差异的,我们的编译本质上是有上下文的,即比如 component 样式会有作用域提升,进而影响 page,另外这当中大量依赖了 webpack 的语法分析 和 loader 机制,同此同时我们还依赖了一个让不属于构建但却又能影响构建的外部过程,所以从根本上我们在现有的技术架构上很难从真正意义上超越友商。
另外友商在框架层应该就考虑了模块加载,但我们在这一层依赖 webpack 提供的 runtime,所以友商对于模块的加载模式优化或者内部模块间的管控,比如控制 exports 有着更加灵活的空间,正因为这种模式,如果友商想要往比如 web-ide 靠其实有着更高的可行性。对于这一层的认知主要是我接触到了 Stackblitz,以及之后慢慢了解到了 Systemjs。这部分内容我放到下节。
通过友商的学习,更多的是让我感受到了小而美的力量,没有厚重的堆积感,确实能称得上 “小程序”。
对于我来说,我的命题就是尽可能的让开发者以最快的速度来完成开发环境的初始化。我做过非常多的基于 webpack 的尝试,熟人常知的 happypack,cache-loader,thread-loader,hardsource,以及如何尽可能的让缓存增加有效性,以及甚至基于 webpack 的 memory fs hack 了一套自己的逻辑等等等等,但效果并不让人满意,甚至很多优化反而会导致很奇怪的问题。
很神奇有一次无意看到了友商在 worker 端代码的加载过程,可以看到的是 Ta 并没有真正意义上的 bundle 过程,对所有的 worker 进行了全量的 http 请求,我的第一个反应是 http 同源策略为什么他们还敢这样做,难道并发量不会成为瓶颈吗,这种方式我见不到对于webpack 的优势到底是什么?!很长时间带着这样的困惑,但这时 Stackblitz 走入到了我的眼前,最初就是他那篇 turboCDN 文章。我基本上挖坟了所有有关 Stackblitz 的 Issue Twitter。实际上 CodeSandbox 在这一块上也用着类似的方案,但 CodeSandbox 的问题是他在这块的实现在那会儿和其业务实现耦合非常深,所以我更加倾向的投向了 systemjs,至少它是独立的,且有自己的生态。随着更多的深入了解渐渐的我对他如何在浏览器内实现伪 bundle 和 npm 如何跑在浏览器端有了一定的了解。当时我的最大想法就是,我可以基于 systemjs 来实现一套动态和按需的加载方案,在本地开发阶段省去所有 bundle 过程,文件只有在真正用到时再进行编译,甚至通过一些方式比如在浏览器端实现 fs 那么这套方案就可以被移植到 web-ide 上。基于这样的构想,我开始了很长时间的尝试,从 18 年 10 月初我写下了第一行代码,代号被取为 Gravity,更多 Gravity 设计的内容我会放在下一段 。但在浏览器端实现 fs 和 利用 web worker 来实现 compile 上我碰到了很多壁,因为浏览器端没有 nodejs 环境,我要解决所有的 pollyfill 的问题,以及 文件 resolve 的差异性。然而时间上并不允许我做过多的技术性探究,所以在第一阶段我退而求其次,把这部分内容架设在了本地,通过启动一个 koajs 实例来解决,即浏览器端发生资源请求时,通过中间件(所处 nodejs 环境)来实现真正的编译过程。但是仅仅只是这一步尝试我把原先在 mac 上需要花 40s+ 的应用降到了 8s 左右,说实话我自己都没法相信。
通过学习 CodeSandbox、Stackblitz 带来的启发是利用纯浏览器带来的架构上的变更或许是另外一种出路。
最近有一篇文章出现在社区,题目是:A Future Without Webpack。如文中所说在过去的几年中 JavaScript 打包过程,一个原先仅仅面向于生产环境优化到现在成为 web 应用开发必要的一个步骤。不管你是喜欢也好,厌恶也罢,都很难否定一个事实,那就是它增加了 web 应用开发大量新的复杂度。而 web 领域一直来它所引以为傲的的点是,view-source 和 easy-to-get-started。这或许现在成为了一种讽刺。
为什么我们需要 bundler?
把时间倒退到六年前,那会儿我们对于打包的概念应该还是在 grunt 或 gulp 流式的任务处理,对资源文件的处理也仅仅是压缩和拼接。而后前端界兴起了模块化浪潮,模块化后的代码放在哪儿,又如何被引入相信这个问题是那会儿前端们最为关注的事情,所以又要翻翻老账 - seajs 有自己的源服务器来承载模块化后的模块也是非常自然的事情。但大家也都知道,世界上最大的代码源服务是 NPM,但如上文中提到的起始时 NPM = “Node.js Package Manager”,它并不真正意义上服务于前端浏览器。但是开发者对这一块的诉求实在是太大了,但 Node.js 众所周知使用的是 CJS 模块规范,所以不经过打包根本不可能运行于浏览器中,而诸多的模块定义,也给了像 Browserify, Webpack 空间,特别是 Webpack universal 的概念非常棒的契合了大家的诉求。
当然作者观点更多是当下已然是 2019 了,我们应该往前看,因为在浏览器端已经支持了 ESM。对我而言我觉得这种想要跳出困局寻求突破的精神是更加值得学习的。另外也抛给我一个问题,撇开作者的提供的思路或实现,是否本地 bundle 基于现有的技术架构,能否有所破局。
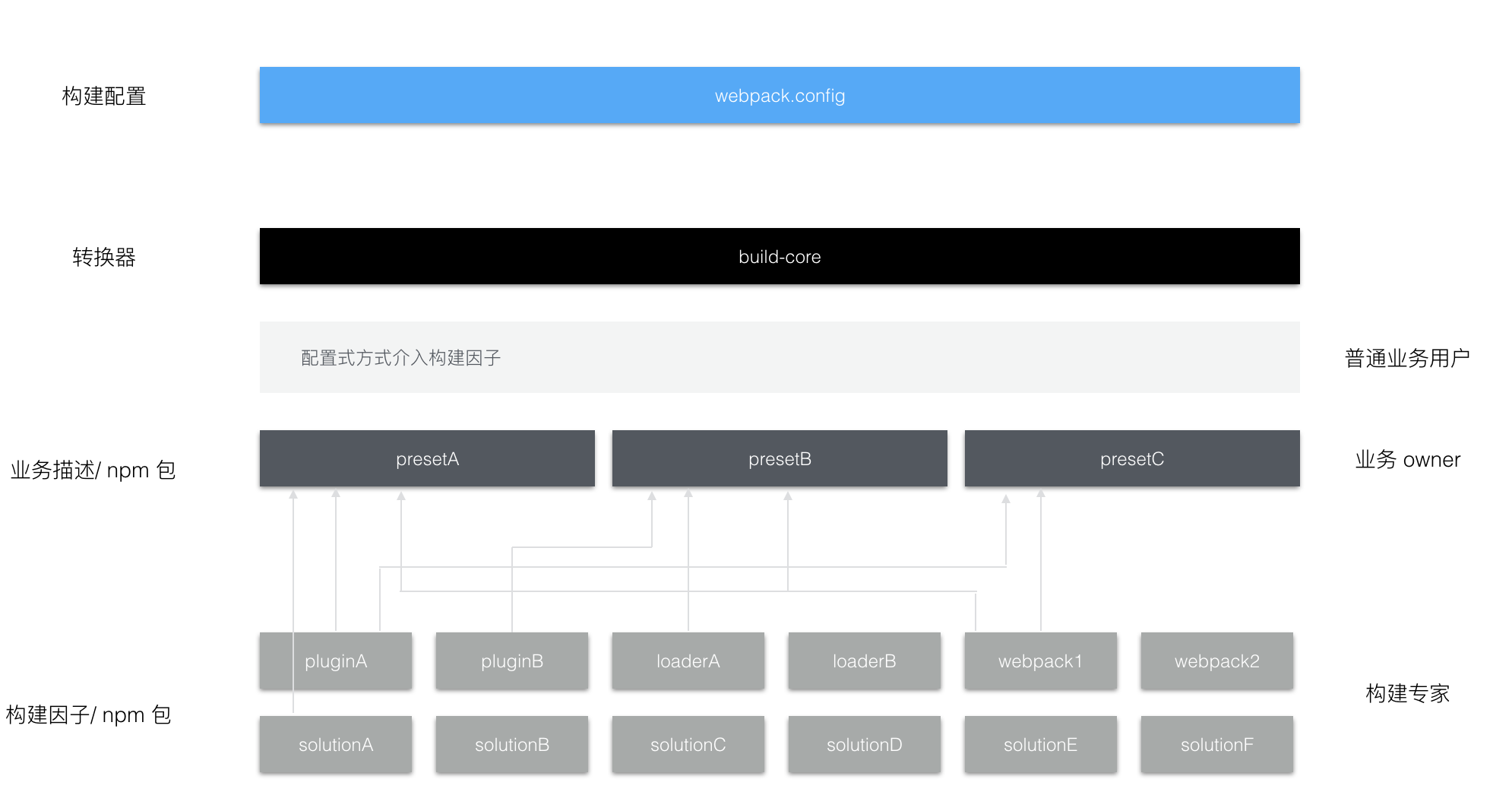
在谈 Gravity 前,还要来回首下我在几年前写的一篇文章 - 支付宝前端构建工具的发展和未来的选择,那会儿我们最大的困扰是配置带来的不可控性。所以那会儿我提出了构建因子以及 preset 的想法。基于对配置的敬畏所以在 Gravity 中我把这一套想法完全实现了出来(其实在那篇文章几个月后就有一版实现,但不幸的是没有继续深入流产了,另外也因为我工作内容被被动调整了)。
另外对于我看到了市面上各个公司都想往小程序上走,大家在小程序架构上都是大同小异,是不是有一种可能性能做一套构建底层来适配所有的小程序业务。这是我做 Gravity 的第二个念想。
所以 Gravity 的最 base 的架构思路是让 Gravity 变成构建工具的工厂,让各种业务形态的小程序构建变成 Gravity 的一种上层实现。要实现如上这个想法也就意味着,Gravity 必须要有好的插件机制。这个时候 tapable 自然而然成为了我的最佳选择,对于 tapable 渊源还要从我解析 webpack watch 实现说起,当然这不是我们今天的重点。重点是 webpack 就是基于 tapable 实现出来的,它的灵活性健壮性毋庸置疑,另外我彻彻底底研究过 tapable,真的是喜欢到不行。还有非常重要的一点是,我用 tapable 来设计插件机制,可以对开发者非常友好,因为基本没有学习的过程。
另外还有一个好处是基于 tapable 我可以非常轻松去实现一种时序,比如说我现在要实现一个 css 文件的加载 loader,在上文中我大概说了因为在时间上的原因我并未在一期就尝试把所有流程都丢到浏览器内完成,而是把一部分工作丢给了 koa 的中间件,所以在文件处理上(webpack 中叫 loader),我实现了一套动态生成中间件的方案,原因在于实现一个 css 文件的加载可能需要经过多个加载器,比如 post-css,css,style,这其中就有时序的问题,所以借由 tapable 我可以很方便来根据描述文件(类 webpack rules 设计)动态创建一个时序转而变成一个中间件。
在设计 gravity loader 时,和 CodeSandbox 一样,我们把 API 尽可能的往 webpack 靠了。原因就在于我想要有复用 webpack loader 的可能性。另外对于上层实现,也会更加友好,因为基本可以做到和 webpack 长得一样,用的一样。
另外还有很多细节我这里就不在阐述了。
Gravity 会进一步维护,也会在合适的时候开源。它的目标也非常明确,成为真正意义上浏览器端方案,在上层实现层可以对接到更多的业务场景。最终通过一个 web-ide 把所有的事情都串联起来。
抛弃偏见,我相信 Cloud IDE 一定是未来,而面向 web 的架构一定是当务之急。
最近调研了所有 atool-build 使用方的代码,大概近千个项目,总结了一些常用的 webpack 方式,记录如下:
entry 是描述一个 bundle 的入口文件是什么。在具体在业务中使用的方式有如下三种:
output 的作用在于告知 webpack 该如何把构建编译后的文件放入到磁盘。
在具体业务中使用的方式有如下种:
output.filename: 修改构建后文件的命名,业务中会存在 4 种情况。
output.path: 修建构建后文件输出到磁盘的目录,业务中会存在 1 种情况。
传入一个相对于当前 cwd 的路径,这种自定义情况非常普遍
output.publicPath: 申明构建后的资源文件的引入地址,业务中会存在 1 种情况
https://xxxx.xx.com/assets/ 这种方式,这种方式的出现在于 webpack 默认在引用资源时都是从根目录开始,然后现实中 assets 资源 和 html 会随不同的发布平台发布。output.chunkFilename:声明非 entry chunks 的资源文件的命名,一般它发生的场景在 code split 即按需加载的业务场景,例如 require.ensure,在这种场景下,会对 require.ensure 的模块进行独立的打包,文件命名也会有四种情况。
require.ensure(dependencies: String[], callback: function(require), errorCallback: function(error), chunkName: String)output.library:一旦设置后该 bundle 将被处理为 library。
output.libraryTarget:export 的 library 的规范,有支持 var, this, commonjs,commonjs2,amd,umd。
resolve.alias:为模块设置别名。这种方案通常使用在两种情况下:
../ 等这种路径操作,另外也可以提升 webpack 在 resolve 模块时的速度;resolve.alias.a = isTest ? 'moduleTestA' : 'moduleA',如上这种方式使用最大的好处在于能根据当前所属代码所需情况构建产物中只会有 moduleTestA 或者 moduleA。以上这种方式可以在所有资源文件应用。当然也可以使用 babel-plugin-module-resolver 和 less-plugin-rewrite-import 予以解决。resolve.root:添加个人目录到 webpack 查找模块的路径里,这种需求比如发生在当前某个项目所依赖某个文件并不在该项目中。
resolve.modulesDirectories:模块解析方式,在项目中我看到一般会有两种使用的场景,
一种主要针对开发者,需要新增一种模块的解析方式。比如设置为 ["node_modules", "bower_components"] 那么在项目中 foo/bar 的文件下依赖一个模块 a, 那么 webpack 会通过如下的顺序去寻找依赖
foo/bar/node_modules/a
foo/bar/bower_components/a
foo/node_modules/a
foo/bower_components/a
node_modules/a
bower_components/a
另外一种则是想要申明模块 resolve 的优先级,比如在一个项目中有依赖 A,B,依赖的 A,B 同时依赖了 C,如果在构建过程中,你想明确表示我只想要某个 C 的话,则就可以通过这种方式。
resolve.extensions:设置解析模块的拓展名。默认为 ["", ".webpack.js", ".web.js", ".js"]。比如新增一种文件扩展名,["", ".webpack.js", ".web.js", ".web.ts", ".web.tsx", ".js"]
resolve.packageMains:设置 main 的入口文件。这种方式目前会在 webpack@2 中使用 resolve.mainFields 来解决 tree-shaking,目前支持的有 redux 等。
resolveLoader.modulesDirectories:同 resolve.modulesDirectories 只不过针对 loader,这边需要注意的是在 resolve.modulesDirectories 中关于优先级的,在工具被二次封装时会用到比较多。resolveLoader.moduleTemplates: ["*-webpack-loader", "*-web-loader", "*-loader", "*"] webpack@1 中内置的模板,但是在 webpack@2 是并不会补齐。resolve.root, resolve.fallback, resolve.modulesDirectories 这三个属性在 webpack@2 中被合并到了 resolve.modules
module.loaders:对应模块的加载器。在 webpack@2 中使用 module.rules 予以取代。以下会罗列目前常用文件类型的模块加载处理方式。
babel-loader 处理 .js 和 .jsx 文件,由于历史原因 atool-build 在处理 .jsx 文件时会处理 node_modules 下内容。
babel-preset-es2015-ie,babel-preset-react,babel-preset-stage-0,plugins 有 babel-plugin-add-module-exports 和 babel-plugin-transform-decorators-legacy。babel-plugin-import 构建资源大小提供优化,babel-plugin-transform-runtime 实现按需加载 pollyfill 需要与 babel-runtime 结合使用,babel-plugin-module-resolver 实现诸如 webpack 中 resolve.alias 功能,babel-plugin-dva-hmr 和 babel-plugin-dev-expression 实现 dva hot module replacement 功能,babel-plugin-react-intl 实现 react 多语言方案, babel-plugin-es6-promise 覆盖原有 promise; preset: babel-preset-env 实现根据浏览器支持情况自动打包 pollyfill 等功能,babel-preset-es2016 等。**在实际过程中,都可能需要对 preset 传入参数的需求。**一般设置如下
presets: [[require.resolve('xxx-preset'), { options: hi }]]cacheDirectory:缓存支持,一般默认就开启babelrc:一般需要禁用掉,防止用户端的 babel 配置影响内置配置tsx-loader: 处理 ts 文件,内置参数 target: 'es6', jsx: 'preserve',moduleResolution: 'node', declaration: false, sourceMap: true,需要注意的是在使用 ts 项目时必须要人为引入一个 ts config.json 的文件,如果没有内容,内部设置为一个空对象即可。style-loader: 通过 js 方式 inject style 节点来注入样式,一般用于开发环境css-loader: 处理 css 文件,一般现有项目中都会使用 ExtractTextPlugin 把样式文件抽取出来,但是在本地开发环境下一般不会 extract 出来,因为一旦 extract 出来会导致 hmr 对样式失效。所以一般在开环环境下会 style-loader!css-loader!postcss-loader 而在 production 下采用 ExtractTextPlugin,另外在每个 loader 都有对应的参数,postcss 还有专门的插件集。除此之外,常用的 css-loader 参数有 modules autoprefix indentName 等postcss-loader: 目前在 postcss 中内置的 plugin 有 rucksack-css - 可废弃 和 autoprefixer 用以实现 autoprefix。一般针对适配的不同的浏览器,需要对 autoprefixer 配置 browsers 参数。一般在无线业务中为了适配高清方案也会引入 postcss-plugin-pxtorem, 同时也需要设置一些参数。less-loader: 处理 less 文件,一般情况下需要配置 modifyVars 参数,用以覆盖 less 变量值sass-loader: 处理 sass 文件,也有使用 fast-sass-loader 和 @ali/sass-loaderfile-loader: 处理 html 文件,当前 atool-build 内置的方式,在实际业务中,很多并不希望 html 是拍平的结构,所以他们会自定义 fileloader 的参数,比如 file?name=[path][name].[ext]&context=./src/pages,但是也有不少业务中对 html 处理引入了新的 loader, 有 ejs-html-loader,html-minify-loader,还有直接使用插件 HtmlWebpackPlugin 来处理的情况,经过研究,根本上其实是想要解决 html 的自动化生成,以及内部资源文件的引用可以自动化生成。url-loader: 处理 woff woff2 ttf eot svg png jpg jpeg gif 文件,目前业务中会有变更的点有,需要设置 limit 的大小,以及 svg 的处理可能需要存在多个 loader 处理,因为在使用 antd-mobile 业务中需要新增一个 svg-sprite-loader 来把 svg 文件当成一个 componentsvg-sprite-loader, 已在 url-loader 中予以说明HtmlWebpackPlugin, 已在 file-loader 中予以说明ejs-html-loader, 已在 file-loader 中予以说明html-minify-loader, 已在 file-loader 中予以说明handlebars-loader, 处理 .handlebars 文件,并未内置,业务中自行引入aptl-loader, 处理 .atpl 文件raw-loader, 处理 tpl 文件,也有使用 html-loader 来处理的scss-loader, 处理 scss 文件vue-loader, 处理 vue 文件json-loader, 处理 json 文件test,exclude,include,loader,loaders属性module.preLoaders:istanbul-instrumenter,此方式在 webpack@2 中被弃用,可以直接在对应的应用规则的文件中启用 enforce: 'pre'module.postLoaders:es3ify-loader,提升 ie 兼容性,此方式在 webpack@2 中被弃用,可以直接在对应的应用规则的文件中启用 enforce: 'post'module.noParse: 指明 webpack 不去解析某些内容,该方式有助于提升 webpack 的构建性能,配置内容可以是目前业务中使用都为声明外部依赖,这种方式有益于加速 webpack 构建,但是需要开发者额外引入被 external 库的 cdn 地址,常见的有 React 和 ReactDom。
目前内置如下内容为 empty
[
'child_process',
'cluster',
'dgram',
'dns',
'fs',
'module',
'net',
'readline',
'repl',
'tls',
];
大部分插件都有需要参数传入
大部分插件都有需要参数传入
前一阵子和 @sorrycc 聊天,我们都谈到了自己很久没有写文章了,差不多有半年了吧,罪恶感油然而生。我们的 CC 同学对自己更狠一些,他建了一个监督群,没有按时完成任务会罚钱。
第一个中心点: gravity
gravity 是一个架设于魔改 systemjs 之上的调试构建工具。为什么会做他,为什么不用 webpack 可能订阅了我的 blog 的同学会有这样的疑问,我也是经过了非常多的考虑和实践之后才做的决定。这些内容都会在后面一一来回答大家。
gravity 这个方案让我非常激动,做了几年的工具,终于有机会把所有的想法付诸于这个方案上了,目前我们已经在内部获得了还算不错的效果,达到足够稳定之时,秉着开源的精神,也秉着让这个方案拥有更强的通用性,我也会逐步开源。
第二个中心点:猪罐头
猪罐头是我的个人公众号,里面主要讲讲我的业余生活,在这里无关代码,只有诗和远方。

第三个中心点:铿锵三人行
这个事情是我,@sorrycc 还有 范公子我们三个人在杭州南山路酒吧 - ink 墨水,拍脑袋的决定。我们想要做一个访谈,比较轻松的形式,地点也会选在咖啡厅,酒吧等一些比较轻松的位置。大家邀请一个嘉宾,围绕一个主题,各自谈谈自己的想法。
但是,目前我们的 @sorrycc 反悔了,大家赶紧去说服他!😁
Hi,你现在看到的内容是一篇充满诚意的前端紧急招聘公告。我们团队来自 蚂蚁金服-微贷事业部,目前业务战略重大升级,急切需要大量前端人才加入,P5、P6(资深)、P7(专家/TL)、P8(高级专家/TL) 不限!
我们的业务明星产品线有:花呗、借呗、网商银行。
**花呗、借呗 **是国民普惠级的消费信贷产品,下设核心产品、规模、场景、用户粘性、市场等多条产品线和子产品,拥有数亿级的消费者群体,深受广大用户喜爱。
**网商银行 **是国内第一家云上的银行,包含了转账、存款、融资、理财等各类金融服务,致力于成为**小微企业首选综合金融服务商。
部门从诞生开始就梦想着『让信用等于财富』,实践着『每个认真生活的人,都值得被认真对待』。微贷技术的伙伴们用多年的时间诠释了『理想、行动、坚持』这六个字。在未来,我们还有更长的路要走,我们希望用金融科技+数据智能化的开放创新,让普惠金融真正的触手可及。
作为蚂蚁金服最具明星气质的金融业务,必须要有一支具备明星气质的前端团队。
我们有太多的事情想做,不能缺少你。
我们还会提供什么?
我们有太多的快乐要分享,不能缺少你。
在上述基础要求的基础上,设置六大方向:
杭州/北京 (人数不限!)
简历投递至我的个人邮箱:[email protected]
在讲 lerna workflow 前我们先粗话来谈下当今主流的项目代码管理方式
multiRepos 它是一种管理 organisation 代码的方式,在这种方式下,独立功能会拆分成独立的 repo
这是最常见的项目管理方式
优点:
缺点:
Monorepo 它是一种管理 organisation 代码的方式,在这种方式下会摒弃原先一个独立功能一个 repo 的方式,取而代之的是把所有的 modules 都放在一个 repo 内来管理,而 lerna 是基于此种理念在工具端集合 git 和 npm 的实现。
优点:
缺点:
^项目开发中使用 multiRepos 和 monoRepo 都可以,问题在于项目合不合适。
个人角度上:
合适的项目需要有以下特征
符合以上条件我个人比较建议采用 monoRepo,以及与之带来的 lerna workflow。
当前使用 lerna确实还会有些小问题,这也是我们需要解决的点。
先再次简单的介绍下 lerna
Lerna is a tool that optimizes the workflow around managing multi-package repositories with git and npm.
在初始化一个项目之前我们必须要清楚,lerna 对管理 monoRepo 有两种模式
Fixed/Locked 模式: 官方默认推荐模式,当前 babel 的项目管理模式,在该模式下所有的 packages 都会遵循一个版本号,该版本号维护在 lerna.json 的 version 字段中,当需要版本发布时 lerna publish 时,如果一个模块和上一次 release 相比有过变更的话,会自动发布一个新版本。
这种模式的问题在于:当有一个 major 变更的时候,所有 packages 都会都会有一个新的 major 版本。
维护团队认为:版本是一种非常 cheap 的东西,所以不必纠结。
Independent 模式: 在该模式下所有 packages 新版本的生成将会由开发者决定,lerna.json 的 version 字段也会随之失效。这种模式的弊端非常明显,开发者必须要非常清晰该发什么版本,事实上在多人协作项目上很难做到这一点。
init
$ lerna init初始化一个 lerna 项目
add
$ lerna add <package>[@version] [--dev]默认给当前所有的 packages 添加一个依赖
这边需要推荐一个比较有用的命令
$ lerna add module-1 --scope=module-2 # Install module-1 to module-2
$ lerna add babel-core # Install babel-core in all modules这种方式是可以快速建立 packages 的依赖关系,而不用人为手动建立
bootstrap
$ lerna bootstrap这个命令会安装好所有 packages 的依赖,以及建立好 packages 相互依赖的软连接
正式流程为:
publish
$ lerna publish发布一个版本。
正式流程为:
caret (^).较为有用的附加参数
--npm-tag
$ lerna publish --npm-tag=beta使用传入的 tag 把包发布至 npm 对应的 dist-tag
--conventional-commits
$ lerna publish --conventional-commits遵从 Conventional Commits Specification 进行版本生成和 changlog 生成。
--skip-git
$ lerna publish --skip-npm跳过 git 打标
--skip-npm
$ lerna publish --skip-npm跳过 npm 发布
--cd-version
$ lerna publish --cd-version (major | minor | patch | premajor | preminor | prepatch | prerelease)
# uses the next semantic version(s) value and this skips `Select a new version for...` prompt指定发包的时的语义版本
clean
$ lerna clean移除所有 package 下的 node_modules 目录.
import
$ lerna import <path-to-external-repository>从现有仓库导入一个 package,这种方式下会保留原有的 commit 的信息
run
$ lerna run <script> -- [..args] # runs npm run my-script in all packages that have it
$ lerna run test
$ lerna run build
# watch all packages and transpile on change, streaming prefixed output
$ lerna run --parallel watch执行 package 下 npm script
exec
$ lerna exec -- <command> [..args] # runs the command in all packages
$ lerna exec -- rm -rf ./node_modules在任何 package 下执行任意的命令
step 1:
$ npm install --global lernastep 2:
$ mkdir lerna-example
$ cd lerna-examplestep 3:
$ lerna init运行完后在 terminal 中执行 tree 后我们可以看到此时的目录结构为
➜ lerna-example git:(master) ✗ tree
.
├── lerna.json
├── package.json
└── packagesstep 4:
$ packages git:(master) ✗ mkdir module-a && cd module-a && touch index.js && tnpm init
$ packages git:(master) ✗ mkdir module-b && cd module-b && touch index.js && tnpm init
$ packages git:(master) ✗ mkdir module-base && cd module-base && touch index.js && tnpm init运行完后在 terminal 中执行 tree 后我们可以看到此时的目录结构为
➜ lerna-example git:(master) ✗ tree
.
├── lerna.json
├── package.json
└── packages
├── module-a
│ ├── index.js
│ └── package.json
├── module-b
│ ├── index.js
│ └── package.json
└── module-base
├── index.js
└── package.jsonstep 5:
如果已知 module-base 被 module-a 和 module-b 共同依赖,同时 module-a 又 依赖 module-b
➜ lerna-example git:(master) ✗ lerna add @alipay/module-base
➜ lerna-example git:(master) ✗ lerna add @alipay/module-b --scope=@alipay/module-a在协同开发时,假设如果开发人员在 module-base 上发布了一个并不兼容的提交,此时做为 pm 的同学很难在没有提前沟通的情况下获知此次变更,所以在选择版本发布时也很容易出现,因为 lerna 默认对依赖的描述是 ^,所以这在信息不对称的情况下很容易造成线上故障。
如何破局呢?
--conventional-commits,来自动化生成版本以及 changelog关于 commitzen 相关的可以看我另外一篇文章 用工具思路来规范化 git commit message
第二种方案也是目前我们项目中应用最多的。
应用 commitizen 方案后, package.json 变更为
{
"private": true,
"scripts": {
"ct": "git-cz",
"changelog": "./tasks/changelog.js",
"publish": "./tasks/publish.js"
},
"config": {
"commitizen": {
"path": "./node_modules/cz-lerna-changelog"
}
},
"husky": {
"hooks": {
"commit-msg": "commitlint -e $GIT_PARAMS",
"pre-commit": "lint-staged"
}
},
"lint-staged": {
"*.js": [
"prettier --trailing-comma es5 --single-quote --write",
"git add"
]
},
"devDependencies": {
"@alipay/config-conventional-volans": "^0.1.0",
"@commitlint/cli": "^6.1.3",
"commitizen": "^2.9.6",
"cz-lerna-changelog": "^1.2.1",
"husky": "v1.0.0-rc.4",
"lerna": "^2.10.2",
"lint-staged": "^7.0.4",
"prettier": "^1.11.1"
},
"dependencies": {
"fs-extra": "^6.0.0",
"inquirer": "^5.2.0",
"shelljs": "^0.8.1"
}
}
packages 目录下存放的是所有的子仓库
tasks 目录下存放一些全局的任务脚本,当前有用的是 publish.js 和 changelog.js
changelog.js,当有发布任务时,请事先执行 npm run changelog,此举意为生成本次版本发布的 changelog,执行脚本时会提醒,本次发布是正式版还是 beta,会予以生成不同版本信息供予发布publish.js,当 changelog 生成并调整相关内容完毕后,执行 npm run publish,会对如上所有的子 packages 进行版本发布,执行脚本时会提醒,本次发布是正式版还是 beta,会予以不同 npm dist-tag 进行发布在常规开发中,我们的操作方式会变更为如下:
第一步:使用 commitizen 替代 git commit
即当我们需要 commit 时,请使用如下命令
$ npm run ct如果你在全局安装过 commitizen 那么,直接在项目目录下执行
$ git ct执行时,会有引导式的方式让你书写 commit 的 message 信息
如果你是 sourceTree 用户,其实也不用担心,你完全可以可视化操作完后,再在命令行里面执行 npm run ct 命令,这一部分确实破坏了整体的体验,当前并没有找到更好的方式来解决。
关于为什么需要 commitizen,可以参考 这篇文章
当前我们遵循的是 angular 的 commit 规范。
具体格式为:
<type>(<scope>): <subject>
<BLANK LINE>
<body>
<BLANK LINE>
<footer>
type: 本次 commit 的类型,诸如 bugfix docs style 等
scope: 本次 commit 波及的范围
subject: 简明扼要的阐述下本次 commit 的主旨,在原文中特意强调了几点 1. 使用祈使句,是不是很熟悉又陌生的一个词,来传送门在此 祈使句 2. 首字母不要大写 3. 结尾无需添加标点
body: 同样使用祈使句,在主体内容中我们需要把本次 commit 详细的描述一下,比如此次变更的动机,如需换行,则使用 |
footer: 描述下与之关联的 issue 或 break change,详见案例
第二步:格式化代码
这一步,并不需要人为干预,因为 precommit 中的 lint-staged 会自动化格式,以保证代码风格尽量一致
第三步:commit message 校验
这一步,同样也不需要人为介入,因为 commitmsg 中的 commitlint 会自动校验 msg 的规范
第四步:当有发布需求时,先生成 changelog
使用
$ npm run changelog在这一步中我们借助了 commitizen 标准化的 commit-msg 以及 lerna 中 publish 的 --conventional-commits 来自动化生成了版本号以及 changelog,但过程中我们忽略了 git tag 以及 npm publish ( --skip-git --skip-npm),原因是我们需要一个时机去修改自动化生成的 changelog。
第五步:再发布
由于第四步中,我们并没有实质意义上做版本发布,而是借以 lerna 的 publish 功能,生成了 changelog,所以后续的 publish 操作被实现在了自定义脚本中,即 publish.js 中。
$ npm run publish> 第六步:打 tag
给当前分支打好对应的 git tag 信息,推送到开发分支
本个系列的文章会被分成两篇文章
(一)主要描述下问题的表现,并 dive into webpack watch system
(二)解决问题,从根本上解决 webpack 的 bug
最近做一个内部工具时碰到了一个很有意思的问题
当首次动态创建 webpack 入口文件后,入口文件新增依赖时,会导致数十次的重新编译过程。
搜了下,发现 webpack 可追溯的 issue 记录为 Files created right before watching starts make watching go into a loop
该问题不论你是在使用 webpack-dev-middleware 或者 webpack --watch 又或者 webpack-dev-server 都可以复现。
webpack 作者 @sokra 对其解释为:
The watching may loop in a unlucky case, but this should not result in a different compilation hash. I. e. the webpack-dev-server doesn't trigger a update if the hash is equal.
白话理解为:确实有问题,但是呢,最关键的 compilation hash 不会变,所以上层使用时,自己内部处理下这个逻辑。
但实际情况呢, webpack-dev-server 等作者不认这一说!
至于不想刨根问底,这里也有狗皮膏药的解决方案:
// Webpack startup recompilation fix. Remove when @sokra fixes the bug.
// https://github.com/webpack/webpack/issues/2983
// https://github.com/webpack/watchpack/issues/25
const timefix = 11000;
compiler.plugin('watch-run', (watching, callback) => {
watching.startTime += timefix;
callback()
});
compiler.plugin('done', (stats) => {
stats.startTime -= timefix
})当然狗皮膏药并不是本文的重点,刚好借此一窥,webpack 中整体的 watch 机制。
如果不想看那么多代码片段,也可以看我在梳理代码逻辑时做的笔记,笔记中红色流程为初始化时的调用链路,蓝色部分为文件变更后事件回调链路。

首先我们可以确定一点的是,不管是 webpack 自身的 cli 工具还是 webpack-dev-middleware 和 webpack-dev-server 都是通过 Compiler.prototype.watch 来实现了 watch 的功能,进而来实现调试阶段的高性能需求。
为了比较清晰的知道整一个流程,我们从创建一个 Compiler 实例开始说起
总所周知我们通过 const compiler = webpack(webpackConfig); 这种方式来创建一个 Compiler 的实例,一般也叫做 webpack 的实例,compiler 实例对象中包含着和打包相关的所有参数,plugins loaders 等等。这种情况下 webpack 并不会默认进行构建编译的过程,如果想要启动编译则需要执行一下 compiler.run(callback)。 另外我们也可以通过 webpack(webpackConfig, callback); 默认来启动构建编译流程。
对于今天我们想要了解的 watch 过程我们这边只需要知道,当构建参数中含有明确开启 watch 配置项时整个流程的走向是 compiler.watch(watchOptions, callback); 而非 compiler.run(callback);。
题外话: 或许你比较好奇 compilation 是什么,它包含着 chunks modules 等信息,构建依赖文件变更时都会重新生成 compilation,而 compiler 只有一个。
// compiler 的 watch 方法
class Compiler extends Tapable {
watch(watchOptions, handler) {
...
const watching = new Watching(this, watchOptions, handler);
return watching;
}
}// Watch 类
class Watching {
constructor(compiler, watchOptions, handler) {
this.startTime = null;
...
this.compiler = compiler;
this.compiler.readRecords(err => {
if(err) return this._done(err);
this._go();
});
}
}在这边需要注意的是 startTime 每次编译执行时 _go 方法将被调用,调用时会赋值编译启动时间,该时刻在认定文件是否需要再次编译或者是否变更时非常非常重要!
当如上 this._go() 被执行时,即开始了首次的编译过程
_go() {
this.startTime = Date.now();
this.running = true;
this.invalid = false;
this.compiler.applyPluginsAsync("watch-run", this, err => {
if(err) return this._done(err);
const onCompiled = (err, compilation) => {
...
this.compiler.emitAssets(compilation, err => {
...
return this._done(null, compilation);
});
};
this.compiler.compile(onCompiled);
});
}敲黑板: 注意此时 startTime 被正式赋值为 首次构建编译开始的时间,同时 compile 的执行标志着首次编译的开始。
此次文章并不会涉及 webpack 的事件流,以及编译过程中 loaders 和 plugins 等的流转过程,这边我们只需要知道,执行 compile 后进入了编译流程即可。
由代码可以看出在正常流程下正常编译流程完毕后,调用 _done 方法。
_done(err, compilation) {
...
const stats = compilation ? this._getStats(compilation) : null;
...
this.compiler.applyPlugins("done", stats);
...
if(!this.closed) {
this.watch(compilation.fileDependencies, compilation.contextDependencies, compilation.missingDependencies);
}
}在 compilation 对象中我们可以获取到和构建相关所有的依赖,而这些依赖正是需要去监听的内容。
上个过程中我们可以看到最后我们把构建依赖,传递给了 watch 的方法。
watch(files, dirs, missing) {
this.pausedWatcher = null;
this.watcher = this.compiler.watchFileSystem.watch(files, dirs, missing, this.startTime, this.watchOptions, (err, filesModified, contextModified, missingModified, fileTimestamps, contextTimestamps) => {
...
this.invalidate();
}, (fileName, changeTime) => {
this.compiler.applyPlugins("invalid", fileName, changeTime);
});
}这里我们注意到 watch 实际调用的是 compiler.watchFileSystem.watch。看过源码的可能会很好奇,因为在 Compiler 的源码中没有定义过这个原型链上的方法。原因很简单,因为在 webpack(webpackConfig) 的阶段中,webpack 注入很多内部的自有插件,webpack 源码非常让人值得学习的一点就是插件机制应用的炉火纯青。具体我们可以看到这 webpack.js,而通过这个线索我们找到了NodeEnvironmentPlugin,开始有所眉目我们看到了熟悉的 watch 字眼 NodeWatchFileSystem,通过它进而我们终于找到了 NodeWatchFileSystem 兴奋之余 watch 服务最终的启动者 watchpack 也浮出水面。
题外话: 这边比较有趣的是 NodeEnvironmentPlugin 这个 plugin,在这个 plugin 中默认设置了 NodeOutputFileSystem NodeJsInputFileSystem CachedInputFileSystem,以 NodeOutputFileSystem 为例,在 webpack 默认情况下编译完成后文件内容都会通过 io 输出到实际的文件目录中,但是毕竟涉及 io 操作这种性能并不能满足调试的需求,所以在 webpack-dev-middleware 中会将 NodeOutputFileSystem 原本默认的 fs 替换为 memory-fs 进而 boost performance。另外 CachedInputFileSystem 等也是通过本地构建的缓存文件物理加速。由于这些内容并不是本文重点,所以不再展开,有兴趣的同学可以继续深挖。
const Watchpack = require("watchpack");
class NodeWatchFileSystem {
constructor(inputFileSystem) {
this.inputFileSystem = inputFileSystem;
this.watcherOptions = {
aggregateTimeout: 0
};
this.watcher = new Watchpack(this.watcherOptions);
}
watch(files, dirs, missing, startTime, options, callback, callbackUndelayed) {
...
const oldWatcher = this.watcher;
this.watcher = new Watchpack(options);
...
if(callbackUndelayed)
this.watcher.once("change", callbackUndelayed);
this.watcher.once("aggregated", (changes, removals) => {
...
const times = this.watcher.getTimes();
callback(null,
changes.filter(file => files.indexOf(file) >= 0).sort(),
changes.filter(file => dirs.indexOf(file) >= 0).sort(),
changes.filter(file => missing.indexOf(file) >= 0).sort(), times, times);
});
...
this.watcher.watch(files.concat(missing), dirs.concat(missing), startTime);
if(oldWatcher) {
oldWatcher.close();
}
...
}
}基于 webpack 的源码不难发现最终 watch 交由的是 Watchpack 实例的 watch 方法。
接下来我们看到
Watchpack.prototype.watch = function watch(files, directories, startTime) {
this.paused = false;
var oldFileWatchers = this.fileWatchers;
var oldDirWatchers = this.dirWatchers;
this.fileWatchers = files.map(function(file) {
return this._fileWatcher(file, watcherManager.watchFile(file, this.watcherOptions, startTime));
}, this);
this.dirWatchers = directories.map(function(dir) {
return this._dirWatcher(dir, watcherManager.watchDirectory(dir, this.watcherOptions, startTime));
}, this);
oldFileWatchers.forEach(function(w) {
w.close();
}, this);
oldDirWatchers.forEach(function(w) {
w.close();
}, this);
};这边对 webpack 不是很熟悉的同学可能会比较困惑为什么 file 和 dir 需要进行区分 watch,默认情况下,通过 webpack resolve 后我们能拿到每个模块精确的路径地址,但是在一些特别的用法下,比如使用 require.context(path) 就会对该 path 所对应的目录加以监听。
所以在一般业务场景下只会涉及到 this._fileWatcher。
Watchpack.prototype._fileWatcher = function _fileWatcher(file, watcher) {
watcher.on("change", function(mtime, type) {
this._onChange(file, mtime, file, type);
}.bind(this));
watcher.on("remove", function(type) {
this._onRemove(file, file, type);
}.bind(this));
return watcher;
};根据如上代码我们可以获知 watcherManager.watchFile(file, this.watcherOptions, startTime) 返回了 一个 watcher
而 _fileWather 根本上是对返回的 watcher 做了一次事件绑定。
那我们看看 watcherManager.watchFile(file, this.watcherOptions, startTime) 到底创建了一个怎么样的 watcher。
WatcherManager.prototype.getDirectoryWatcher = function(directory, options) {
var DirectoryWatcher = require("./DirectoryWatcher");
options = options || {};
var key = directory + " " + JSON.stringify(options);
if(!this.directoryWatchers[key]) {
this.directoryWatchers[key] = new DirectoryWatcher(directory, options);
this.directoryWatchers[key].on("closed", function() {
delete this.directoryWatchers[key];
}.bind(this));
}
return this.directoryWatchers[key];
};
WatcherManager.prototype.watchFile = function watchFile(p, options, startTime) {
var directory = path.dirname(p);
return this.getDirectoryWatcher(directory, options).watch(p, startTime);
};
WatcherManager.prototype.watchDirectory = function watchDirectory(directory, options, startTime) {
return this.getDirectoryWatcher(directory, options).watch(directory, startTime);
};Step1: this.getDirectoryWatcher(directory, options)
如上所知不管是传入的内容是 file 路径还是 directory 路径,都会被转到 getDirectoryWatcher
言下之意就是一个目录下所有的文件都会被对应到一个 directoryWatcher。
在新建一个 DirectoryWatcher 的实例时
function DirectoryWatcher(directoryPath, options) {
EventEmitter.call(this);
this.options = options;
this.path = directoryPath;
this.files = Object.create(null);
this.directories = Object.create(null);
this.watcher = chokidar.watch(directoryPath, {
ignoreInitial: true,
persistent: true,
followSymlinks: false,
depth: 0,
atomic: false,
alwaysStat: true,
ignorePermissionErrors: true,
ignored: options.ignored,
usePolling: options.poll ? true : undefined,
interval: typeof options.poll === "number" ? options.poll : undefined
});
this.watcher.on("add", this.onFileAdded.bind(this));
this.watcher.on("addDir", this.onDirectoryAdded.bind(this));
this.watcher.on("change", this.onChange.bind(this));
this.watcher.on("unlink", this.onFileUnlinked.bind(this));
this.watcher.on("unlinkDir", this.onDirectoryUnlinked.bind(this));
this.watcher.on("error", this.onWatcherError.bind(this));
this.initialScan = true;
this.nestedWatching = false;
this.initialScanRemoved = [];
this.doInitialScan();
this.watchers = Object.create(null);
}可以发现,webpack watch 文件夹变更的能力实际输出者为 chokidar
并且对 directoryPath 对应的 chokidar watcher,绑定 add,addDir, change,unlink,unlinkDir,error 等事件。
并执行了 this.doInitialScan();。
DirectoryWatcher.prototype.doInitialScan = function doInitialScan() {
fs.readdir(this.path, function(err, items) {
if(err) {
this.initialScan = false;
return;
}
async.forEach(items, function(item, callback) {
var itemPath = path.join(this.path, item);
fs.stat(itemPath, function(err2, stat) {
if(!this.initialScan) return;
if(err2) {
callback();
return;
}
if(stat.isFile()) {
if(!this.files[itemPath])
this.setFileTime(itemPath, +stat.mtime, true);
} else if(stat.isDirectory()) {
if(!this.directories[itemPath])
this.setDirectory(itemPath, true, true);
}
callback();
}.bind(this));
}.bind(this), function() {
this.initialScan = false;
this.initialScanRemoved = null;
}.bind(this));
}.bind(this));
};根据如上代码我们可以获知,在执行首次扫描时,会把当前文件夹下的内容读取出来。对文件则进行 this.setFileTime(itemPath, +stat.mtime, true);
这边不对 setFileTime 做过多阐述,他有两种使用场景。
一种来源于 initialScan 会把所有的文件的最新修改时间全部读取出来,为之后判断文件变更触发更新提供依据。另外一个场景就是触发更新了。
Step2: directoryWatcher.watch((p, startTime))
DirectoryWatcher.prototype.watch = function watch(filePath, startTime) {
this.watchers[withoutCase(filePath)] = this.watchers[withoutCase(filePath)] || [];
this.refs++;
var watcher = new Watcher(this, filePath, startTime);
watcher.on("closed", function() {
var idx = this.watchers[withoutCase(filePath)].indexOf(watcher);
this.watchers[withoutCase(filePath)].splice(idx, 1);
if(this.watchers[withoutCase(filePath)].length === 0) {
delete this.watchers[withoutCase(filePath)];
if(this.path === filePath)
this.setNestedWatching(false);
}
if(--this.refs <= 0)
this.close();
}.bind(this));
this.watchers[withoutCase(filePath)].push(watcher);
var data;
if(filePath === this.path) {
this.setNestedWatching(true);
data = false;
Object.keys(this.files).forEach(function(file) {
var d = this.files[file];
if(!data)
data = d;
else
data = [Math.max(data[0], d[0]), Math.max(data[1], d[1])];
}, this);
} else {
data = this.files[filePath];
}
process.nextTick(function() {
if(data) {
var ts = data[0] === data[1] ? data[0] + FS_ACCURACY : data[0];
if(ts >= startTime)
watcher.emit("change", data[1]);
} else if(this.initialScan && this.initialScanRemoved.indexOf(filePath) >= 0) {
watcher.emit("remove");
}
}.bind(this));
return watcher;
};该代码记录了一个 filepath 创建一个 Watcher 的过程,最后返回了该 wathcer。
所以再反观
Watchpack.prototype._fileWatcher = function _fileWatcher(file, watcher) {
watcher.on("change", function(mtime, type) {
this._onChange(file, mtime, file, type);
}.bind(this));
watcher.on("remove", function(type) {
this._onRemove(file, file, type);
}.bind(this));
return watcher;
};我们就可以知道,这边是对每个文件绑定了一个 change 和 remove 事件。
文件发生变更后,最初会被 directoryWatcher 监听到,进而触发对应的 fileWatcher 的 change 事件。
而 _onChange 会被调用
Watchpack.prototype._onChange = function _onChange(item, mtime, file) {
file = file || item;
this.mtimes[file] = mtime;
if(this.paused) return;
this.emit("change", file, mtime);
if(this.aggregateTimeout)
clearTimeout(this.aggregateTimeout);
if(this.aggregatedChanges.indexOf(item) < 0)
this.aggregatedChanges.push(item);
this.aggregateTimeout = setTimeout(this._onTimeout, this.options.aggregateTimeout);
};进而触发了 Watchpack 实例的 change 事件, 该事件由在 NodeWatchFileSystem 中绑定。
// 片段
if(callbackUndelayed)
this.watcher.once("change", callbackUndelayed);
this.watcher.once("aggregated", (changes, removals) => {
changes = changes.concat(removals);
if(this.inputFileSystem && this.inputFileSystem.purge) {
this.inputFileSystem.purge(changes);
}
const times = this.watcher.getTimes();
callback(null,
changes.filter(file => files.indexOf(file) >= 0).sort(),
changes.filter(file => dirs.indexOf(file) >= 0).sort(),
changes.filter(file => missing.indexOf(file) >= 0).sort(), times, times);
});那如何触发重编译呢?答案在 aggregated 事件中。
function example(err, filesModified, contextModified, missingModified, fileTimestamps, contextTimestamps) => {
this.pausedWatcher = this.watcher;
this.watcher = null;
if(err) return this.handler(err);
this.compiler.fileTimestamps = fileTimestamps;
this.compiler.contextTimestamps = contextTimestamps;
this.invalidate();
}触发 invalidate 事件,因为 _go 事件再次被执行。
invalidate(callback) {
if(callback) {
this.callbacks.push(callback);
}
if(this.watcher) {
this.pausedWatcher = this.watcher;
this.watcher.pause();
this.watcher = null;
}
if(this.running) {
this.invalid = true;
return false;
} else {
this._go();
}
}之前我们的网红 @sorrycc 说可以把自己在用的软件和硬件分享出来,爽快答应后发现都拖了快一年了, ORZ。
所以这是一篇还债贴,所以这几天趁着午休和晚上整理了下。
以下是我日常工作和生活中的一些装备,和 cc 不太一样的是,我一旦习惯了某个东西,基本不会去变更。
值不值不值不值不值值不值Mac: Instapaper -> IFTTT -> Github Private Repo
Mobile: Workflow -> Instapaper -> IFTTT -> Github Private Repo
所以的内容都会最后都会被归总到个人的 github 上的 private repo 的 issue,issue 的好处就不用多说。
值值不值 升级为 Apple M1 Pro 高配,都挺好,建议内存升级到最大,这样做视频更游刃有余不值值值不值值不值值不值值值,但是对画质有追求的想拿来当 vlog 相机的,在我多次尝试后,我放弃了值拍照值,视频不值拍照和视频都值16-35 F2.8 最值值值不值不值值值不值值不值值不值不值值推荐两家目前国内做的比较好的 dfrobot Seeed Studio

图片来自 New wave modularity with Lerna, monorepos, and npm organizations
前纪: 大概在 16 年初通过 babel 了解到了 lerna,同时也首次听到了 monorepo 这个概念。当时测试后的结果是,lerna 非常不稳定所以那会儿并没有使用。时隔近一年,在最近尝试中感觉各方面都做的不错了,所以已经开始在项目内使用。大概 google 了下国内似乎并没有文章介绍这一块内容,所以这篇文章的动力遍来源于此。
Monorepo is a unified source code repository used by an organisation to host as much of its code as possible.
Monorepo 它是一种管理 organisation 代码的方式,在这种方式下会摒弃原先一个 module 一个 repo 的方式,取而代之的是把所有的 modules 都放在一个 repo 内来管理。
目前诸如 Babel, React, Angular, Ember, Meteor, Jest 等等都采用了 Monorepo 这种方式来进行源码的管理。
Lerna 它是基于 Monorepo 理念在工具端的实现。
Lerna 出现的历史背景,其实就是 Monorepos 和 Multirepos 在进行项目管理时优与劣。
说说我个人的感触:
Multirepos
缺点:
在 Multirepos 方案中我们通常一个项目会有一个 repo 或者说是一个 module 一个 repo,事实上因为项目或者 module 因为功能或者属性或者历史的原因我们不得不拆分到不同的 organisation 中,这导致了后期如果涉及人员交接,或者自己项目管理时就会陷入到不知道哪里去找 repo 的境地。(这个问题对于涉及历史包袱的开发会特别痛苦)
issue 不知道往哪里提,导致项目管理混乱。(目前 atool-build、dora 都有这样的困境)
版本管理带来的日常开销,首先不得不说采用 semver 后确实给版本管理带来了很多便利之处,但是其偏向于于 patch 版本,当 core module 需要 发布 minor 或者 Major 版本时这就会变成一场灾难。举个例子,dora (插件化 server)的 core 需要变更时,我们得同步所有官方插件,这涉及到了 20 多个仓库,这完全是体力劳动。于此同时,在日常开发中,可能我们一次迭代会涉及多个 repo,一方面需要用 npm link 的方式 hack 到本地仓库,另外一方面,每次都需要手动切换到对应的各个仓库进行 lint test 等操作,要完成这些我们不得不在 terminal 中开启多个 tab,这绝对是个眼力和体力活
changelog 梳理又是一场灾难,在 Multirepos 管理项目的情况下,我们需要人工同步所有变动的仓库最终列出一个 changelog。如果全部是由一个人开发还能理得清楚,但实际上一般正常迭代都是多人开发协同开发的模式,这个情况下我们很难统计到仓库依赖的 module 是否有更新,做了什么样的工作。
等等。
使用 monorepo 以上问题都可以迎刃而解。
但使用 monorepo 方案也有相应的缺陷
以上只是个人的一些项目中的感触,也来看看 babel 为什么选择 monorepo Why is Babel a monorepo
step 1:
$ npm install --global lernastep 2:
$ git init monorepo-example
$ cd monorepo-examplestep 3:
$ lerna init运行完后在 terminal 中执行 tree 后我们可以看到此时的目录结构为
$ monorepo-example git:(master) ✗ tree
.
├── lerna.json
└── package.jsonstep 4:
$ monorepo-example git:(master) ✗ mkdir packages && cd packages创建 packages 目录,该目录内将会存放之后所有的官方维护的 module
step 5:
$ packages git:(master) ✗ mkdir monorepo-example-module-a && cd monorepo-example-module-a && npm init
$ packages git:(master) ✗ mkdir monorepo-example-module-core && cd monorepo-example-module-core && npm init新建两个 package,并通过 npm init 来初始化 package.json
此时我们的 packages 目录结构为
➜ packages git:(master) ✗ tree
.
├── monorepo-example-module-a
│ └── package.json
└── monorepo-example-module-core
└── package.json假设 module-a 依赖 module-core 详细参考 monorepo-example 案例
step 6:
$ monorepo-example git:(master) ✗ lerna bootstrap
Lerna v2.0.0-beta.31
Bootstrapping 2 packages
Preinstalling packages
Installing external dependencies
Symlinking packages and binaries
Postinstalling packages
Prepublishing packages
Successfully bootstrapped 2 packages.执行 lerna bootstrap 该操作会自动为 module-a 进行 npm install 和 npm link 操作. 如图

是不是非常方便呢!
step 7:
$ monorepo-example git:(master) lerna publish
Lerna v2.0.0-beta.31
Current version: 0.0.0
Checking for updated packages...
? Select a new version (currently 0.0.0) Patch (0.0.1)
Changes:
- monorepo-example-module-a: 0.0.1 => 0.0.1
- monorepo-example-module-core: 1.0.0 => 0.0.1
? Are you sure you want to publish the above changes? Yes
Publishing packages to npm...
npm WARN dist-tag add latest is already set to version 0.0.1
monorepo-example-module-a
npm WARN dist-tag add latest is already set to version 0.0.1
Pushing tags to git...
To [email protected]:pigcan/monorepo-example.git
0f8674c..2ecb064 master -> master
To [email protected]:pigcan/monorepo-example.git
* [new tag] v0.0.1 -> v0.0.1
Successfully published:
- [email protected]
- [email protected]执行 lerna publish 回答几个问题便可以把自己的包推送到 npm.
当然实际情况使用中,会更复杂一些,更多的内容就留给大家看官方使用说明了,基本都是简单明了的内容,如果有不清楚的地方欢迎大家提问 官方文档 commands
在现实开发中我们经常碰到一个老大难的问题就是 changelog 的梳理,在 lerna 中提供了一个非常有用的 lerna-changelog 的库,在一定的规范开发下会使得这个问题解决起来非常方便,在这边以这个仓库为例我给大家大概讲解下如何使用。
step 1:
$ monorepo-example git:(master) npm install lerna-changelog --save-dev安装 lerna-changelog 依赖
step 2:
修改 lerna.josn 需要新增相关 lerna-changelog 所需要的配置
+"changelog": {
+ "repo": "pigcan/monorepo-example",
+ "labels": {
+ "tag: bugfix": "Bug fix",
+ "tag: enhancement": "Enhancement"
+ },
+ "cacheDir": ".changelog"
+}在这边需要特别注意的是 labels 内的内容,labels 的 key 必须在 github 的仓库内定义好
可以通过以下链接 https://github.com/pigcan/monorepo-example/labels 来进行 labels 的创建,接下来我在 github 上分别新增 tag: bugfix 和 tag: enhancement
step 3:
$ export GITHUB_AUTH="..."GITHUB_AUTH 的 token 字段可以在github 申请 token 获得。
步骤到此结束了,但是这边要想要达到理想的效果必须要遵循一定的开发规则,其实就是需要有好的开发习惯,在此推荐个人的习惯。
如案例所示 https://github.com/pigcan/monorepo-example/issues 把项目碰到的 bug、需要增强的地方等等内容都记入到 issue中,并标记好相应的 label 标签。
创建对应的分支,来解决对应 issue 中记入的内容。
$ monorepo-example git:(bugfix-core) git branch
* bugfix-core
enhance-module-a
master例如我们在此修复 core 的问题,最终 commit 的日志推荐为
$ git commit -a -m "core-bugfix: the xxx problem had fixed, Close #1"
在 commit 的 message 中要把解决了什么问题和相应的 issue 进行关联,然后一目了然,如果后续需要对该部分代码进行回滚也会变得非常轻松。
一旦 bugfix-core 分支被提交后,我们可以在 github 上以该分支创建一个 pr ,
在创建 pr 时需要注意 ** 一定要选择对应的 label ** 在这个案例中我需要选择,tag: bugfix
具体可以参考 soda-x/monorepo-example#3
一旦分支的代码合并到主干后本地运行
$ monorepo-example git:(master) node_modules/.bin/lerna-changelog
## Unreleased (2017-01-05)
#### Bug fix
* `monorepo-example-module-core`
* [#3](https://github.com/pigcan/monorepo-example/pull/3) core-bugfix: the xxx problem had fixed, Closes [#1](https://github.com/pigcan/monorepo-example/issues/1). ([@pigcan](https://github.com/pigcan))
#### Committers: 1
- pigcan ([pigcan](https://github.com/pigcan))看是不是已经生成了绝妙的 changelog 日志。
在需要 publish 之前我们运行一次 lerna-changelog 以便拿到日志(publish 后之前的 commit 信息将会被清空)
一旦 publish 后我们便可以创建 release note https://github.com/pigcan/monorepo-example/releases
以下便是最终的效果,是不是很酷很方便呢!

最近一周在补前人留下的测试用例,然后碰到了一个 sinon 的使用问题困扰了一整天,特做此记录。
文章的前提是:你对 sinon 已经有了初步的使用经验。
// src.js
function add(a, b) {
return a + b;
}
function multiplication(a, b) {
return a * b;
}
export function complex(a, b) {
console.error('此处为 error 发生出');
return add(a, b) + multiplication(a, b);
}
export default function division(a, b) {
return add(a, b)/multiplication(a, b);
}//test.js
import test from 'ava'; // eslint-disable-line
import sinon from 'sinon'; // eslint-disable-line
import { complex }, division from '../src';
let sandbox;
test.before(() => {
sandbox = sinon.sandbox.create();
});
test.after(() => {
sandbox.restore();
});
test('complex', (t) => {
sandbox.stub(console, 'error');
// how to stub add or multiplication ?
});碰到第一个问题是:如何 stub 非 export 的方法呢 ?另外 stub 的 api 要求,method 需要挂载在相应的
object 下
无奈之下我选择了最偷懒的方式把 add 和 multiplication 都修改为 export 的方法,使用了 import * 的方式
即修改为了
// src.js
export function add(a, b) {
return a + b;
}
export function multiplication(a, b) {
return a * b;
}
export function complex(a, b) {
console.error('此处为 error 发生出');
return add(a, b) + multiplication(a, b);
}
export default function division(a, b) {
return add(a, b)/multiplication(a, b);
}//test.js
import test from 'ava'; // eslint-disable-line
import sinon from 'sinon'; // eslint-disable-line
import * as math from '../src';
let sandbox;
test.before(() => {
sandbox = sinon.sandbox.create();
});
test.after(() => {
sandbox.restore();
});
test('complex', (t) => {
sandbox.stub(console, 'error');
sandbox.stub(math, 'add').returns(2);
sandbox.stub(math, 'multiplication').returns(3);
t.true(console.error.called);
t.is(math.complex(2, 3), 5);
// 用例挂了 t.is(11, 5);
});偷懒方式破灭,发现 math.complex(2, 3) 返回的是 11,也就是 stub math add 和 multiplication 并没有生效!但是关键是 console.error 被正常改写。到底发生了什么!所以我猜想 stub 的 add 和 multiplication 方法并不是 complex 方式调用的 add 和 multiplication
由于并不清楚发生了什么,所以猜测是不是因为引用关系的问题
所以我开始尝试,改写 src.js 尽量保证引用关系
let math;
function add(a, b) {
return a + b;
}
function multiplication(a, b) {
return a * b;
}
function complex(a, b) {
console.error('此处为 error 发生出');
process.exit(1);
return math.add(a, b) + math.multiplication(a, b);
}
math = {
add,
multiplication,
complex,
};
export { math };然而答案居然是成功了!!!!但回过头必须要思考的事情是:1.这种处理方案并不完美,原因在于为了写测试需要变更源码本身相对优雅的写法,同时会暴露无关的内部函数 2. 为什么 直接 export 到具体的 function 不行,但是 export 到 对象就行了,这或许并不是引用关系的问题。
带着这个思考,我往这个方向 google 了下,非常有意思我发现了在 stackoverflow 上的提问 https://stackoverflow.com/questions/35240469/how-to-mock-the-imports-of-an-es6-module
其中在非常不显眼的地方我居然看到了问题最最最关键的内容,
@carpeliam This wont work with the ES6 module spec where the imports are readonly.
import 的内容是 readonly 的!!!!!!!但是其内部 child 不是 readonly 的!!!!!!!至此豁然开朗!!!!
接下来我就开始想,如果说这是因为 spec 的原因导致,那么万能的 babel 解决这个问题肯定易如反掌,所以我开始尝试搜索这方面的 babel-plugin 。结果当然是 wala babel-plugin-rewire
因为找对了方向,所以问题的解决方式也越合规。其中认为最合适的是how to stub ES6 module dependencies。
最佳实践
// src.js 不需要对 源码 文件作出任何的调整
function add(a, b) {
return a + b;
}
function multiplication(a, b) {
return a * b;
}
export function complex(a, b) {
console.error('此处为 error 发生出');
return add(a, b) + multiplication(a, b);
}
export default function division(a, b) {
return add(a, b)/multiplication(a, b);
}import test from 'ava'; // eslint-disable-line
import sinon from 'sinon'; // eslint-disable-line
import * as math from '../src';
let sandbox;
const rewire = (module, methodName, method) => {
module.__Rewire__(methodName, method);
return method;
};
test.before(() => {
sandbox = sinon.sandbox.create();
});
test.after(() => {
sandbox.restore();
});
test('complex', (t) => {
sandbox.stub(console, 'error');
rewire(math, 'add', sandbox.stub())
.returns(2);
rewire(math, 'multiplication', sandbox.stub())
.returns(3);
t.true(console.error.called);
t.is(math.complex(2, 3), 5);
});补充课外题
当如果 src.js 中我们 import 了 一个 util 的方法
// src.js
import { chalk } from 'util';
export default function log() {
console.log(chalk.yellow('yellow log'));
}请问如何测试 chalk.yellow 被正确调用了?

TLDR;
教条一:不管是 html 元素还是 body 元素,它们都是透明的。
教条二:如需全局背景色,请将背景色设置于 body 元素上。
教条三:UI Library 作者需要设置元素的背景色,同时最好在 body 元素上设置好基调色。
教条四:习惯设置背景色是个好习惯,嗯,你是个好孩子
既然事情总结的如此简单,那还有必要专门写一篇文章吗?! 答案是:有,经过测试这里还有不少坑
Riddle: 一个前端代码片段分享平台,支持但不限于 React 代码的在线编辑和演示,当前 Riddle 演示功能的实现依托于嵌入的 Gravity iframe,即 Riddle 加载到实例代码后会发消息给 Gravity,而 Gravity 会通过约定的消息拿到代码后开始编译,并加载对应的入口文件,最终由 Gravity 实现预览。
Gravity: 基于浏览器技术的 bundless 方案。
前一阵子,Riddle 联合 CloudIDE 的第一期合作发布,其中有一项变更是将原先的 Light 模式升级到了 Dark 模式。升级之后遭到了用户的投诉,原因是 Dark 模式影响了他们的展现。

起先我是感到委屈的,因为非常确定在完成编译之后我没有给嵌入的 iframe 设置颜色。第一反应就是,难道 HTML 默认是透明的,不是白色的?!内心飘过三个字。
出了问题肯定是要刨根问底的,那接下来就是弄明白时间。
编写测试案例。
注明:
Body区域: Body 以内,后简写为 B
HTML区域: HTML 以内,后简写为 H
ViewPort区域: 整个可视区域,后简写为 V
Drag区域: 由拖拽而展现出来的区域(通常是页面的最上端和最下端由于拖拽而展现区域),后简写为 D
(1) 没有设置背景色 html-none-body-none
(2) html 未设置背景色 body 设置红色 html-none-body-red
(3) html 设置黄色 body 未设置颜色 html-yellow-body-none
(4) html 设置黄色 body 设置红色 html-yellow-body-red
直接进入总结环节:
| 案例 | chrome 桌面 | chrome 移动 | Safari 桌面 | Safari 移动 |
|---|---|---|---|---|
| html-none-body-none | B: 白 H: 白 V: 白 D: 白 | B: 白 H: 白 V: 白 D: 白 | B: 白 H: 白 V: 白 D: 白 | B: 白 H: 白 V: 白 D: 白 |
| html-none-body-red | B: 红 H: 红 V: 红 D: 红 | B: 红 H: 红 V: 红 D: 红 | B: 红 H: 红 V: 红 D: 红 | B: 红 H: 红 V: 红 D: 红 |
| html-yellow-body-none | B: 黄 H: 黄 V: 黄 D: 黄 | B: 黄 H: 黄 V: 黄 D: 黄 | B: 黄 H: 黄 V: 黄 D: 黄 | B: 黄 H: 黄 V: 黄 D: 黄 |
| html-yellow-body-red | B: 红 H: 黄 V: 黄 D: 黄 | B: 红 H: 黄 V: 黄 D: 红 | B: 红 H: 黄 V: 黄 D: 红 | B: 红 H: 黄 V: 黄 D: 红 |
这里我们发现
1. body 的颜色优先级为 body -> html
2. html 的颜色优先级为 html -> body
3. viewport 的颜色优先级为 html -> body
4. drag 区域颜色在同时设置 html 和 body 背景色时存在兼容性问题。 如果移动为先的思路,优先级应该是 body > html
讨论完了第一 p,那我们再来看看第二 p,嵌套 iframe 也是一种非常常见的场景
注明:以下颜色记录均为 iframe
(1) html-none-body-none 嵌套 html-none-body-none 的 iframe
(2) html-none-body-red 嵌套 html-none-body-none 的 iframe
(3) html-none-body-none 嵌套 html-yellow-body-red 的 iframe
| 案例 (父/子) | chrome 桌面 | chrome 移动 | Safari 桌面 | Safari 移动 |
|---|---|---|---|---|
| html-none-body-none/html-none-body-none | B: 白 H: 白 V: 白 D: 白 | B: 白 H: 白 V: 白 D: 白 | B: 白 H: 白 V: 白 D: 白 | B: 白 H: 白 V: 白 D: 白 |
| html-none-body-red/html-none-body-none | B: 红 H: 红 V: 红 D: 红 | B: 红 H: 红 V: 红 D: 红 | B: 红 H: 红 V: 红 D: 红 | B: 红 H: 红 V: 红 D: 红 |
| html-none-body-none/html-yellow-body-red | B: 红 H: 黄 V: 黄 D: / | B: 红 H: 黄 V: 黄 D: 白 | B: 红 H: 黄 V: 黄 D: 白 | B: 红 H: 黄 V: 黄 D: 白 |
综合第一 P,这里我们发现:
1. html,body,viewport,drag 区域默认是透明的
2. iframe 中的 drag 区域是透明的,这里和 1 中有差别
这里产生困惑,iframe 区域的 drag 区域如何设置颜色呢
(1) html-none-body-none 嵌套 html-yellow-body-red 的 iframe,且设置 iframe 的 background-color: green
| 案例 (父/子) | chrome 桌面 | chrome 移动 | Safari 桌面 | Safari 移动 |
|---|---|---|---|---|
| html-none-body-none/html-yellow-body-red | B: 红 H: 黄 V: 黄 D: / | B: 红 H: 黄 V: 黄 D: 绿 | B: 红 H: 黄 V: 黄 D: 绿 | B: 红 H: 黄 V: 黄 D: 绿 |
从此可以得出
iframe 的 drag 区域颜色由 iframe 的颜色决定,当未设定时,其就是透明的。
(1) html 设置黄色和图梵高星空 body 设置红色和图梵高睡莲 html-yellow-image(记为星)-body-red-image(记为莲)
| 案例 | chrome 桌面 | chrome 移动 | Safari 桌面 | Safari 移动 |
|---|---|---|---|---|
| html-yellow-星-body-red-莲 | B: 莲 H: 星 V: 星 D: 黄 | B: 莲 H: 星 V: 星 D: 红 | B: 莲 H: 星 V: 星 D: 星 | B: 莲 H: 星 V: 星 D: 红 |
| html-yellow-body-red-莲 | B: 莲 H: 黄 V: 黄 D: 黄 | B: 莲 H: 黄 V: 黄 D: 红 | B: 莲 H: 黄 V: 黄 D: 红 | B: 莲 H: 黄 V: 黄 D: 红 |
| html-none-body-red-莲 | B: 莲 H: 莲 V: 莲 D: 红 | B: 莲 H: 莲 V: 莲 D: 红 | B: 莲 H: 莲 V: 莲 D: 莲 | B: 莲 H: 莲 V: 莲 D: 红 |
(2) 嵌套场景 html-none-body-none/html-yellow-星-body-red-莲
注明:以下颜色记录均为 iframe
| 案例 (父/子) | chrome 桌面 | chrome 移动 | Safari 桌面 | Safari 移动 |
|---|---|---|---|---|
| html-none-body-none/html-yellow-星-body-red-莲 | B: 莲 H: 星 V: 星 D: / | B: 莲 H: 星 V: 星 D: 白 | B: 莲 H: 星 V: 星 D: 白 | B: 莲 H: 星 V: 星 D: 白 |
从此可以得出
1. 当设置 background-image 时,兼容性问题依旧存在,html 的优先级为 html > body,body 的优先级为 body > html
2. viewport 区域的的优先级为 html > body,这里的意思是如果未对 html 做相关背景色或者背景图设置,viewport 的将被 body 的 html 颜色或者背景图填充
3. 嵌套模式下,drag 区域依旧为透明色
4. 由于存在兼容性问题需要谨慎设置背景图平铺
在做完上面的探索之后,其实内心有了个想法就是想要确定下,我们的标准到底是怎么样的。
于是我在 W3C 上找到了一些答案 -》 W3C
The document canvas is the infinite surface over which the document is rendered.
If the canvas background is not opaque, the canvas surface below it shows through. The texture of the canvas surface is UA-dependent (but is typically an opaque white).
The background of the root element becomes the canvas background and its background painting area extends to cover the entire canvas. However, any images are sized and positioned relative to the root element as if they were painted for that element alone. (In other words, the background positioning area is determined as for the root element.) The root element does not paint this background again, i.e., the used value of its background is transparent.
For documents whose root element is an HTML HTML element or an XHTML html element [HTML]: if the computed value of background-image on the root element is none and its background-color is transparent, user agents must instead propagate the computed values of the background properties from that element’s first HTML BODY or XHTML body child element. The used values of that BODY element’s background properties are their initial values, and the propagated values are treated as if they were specified on the root element. It is recommended that authors of HTML documents specify the canvas background for the BODY element rather than the HTML element.
这里其实可以总结为一个图:

但是这里要表达的是 W3C 制定的标准和浏览器厂商的实现是有一定的差距的,这里存在不少兼容性的问题。同时如果认真把文章读下来,或者有认真比对 DEMO 展现的话,这里其实有一个很迷的东西(viewport),这个概念在 W3C 的表述里是不存在的,在标准中更加倾向于把 viewport 理解为 canvas ,但是我们在测试过程中能比较明显感觉到 canvas 的表现并不能简简单单的把 viewport 画上等号 (典型案例:在移动端 html-yellow-body-red,如果我们限制了 html 元素的高度,但是可视区域依旧是会被渲染为黄色,但是可拖拽区显示为红色,这就非常不符合 canvas 层的定义,反而 chrome 的 pc 端反而更加符合标准)。
在翻阅资料的时候,看到了一个有趣的且容易掉坑的 CSS 属性 - mix-blend-mode,该CSS 属性描述了元素的内容应该与元素的直系父元素的内容和元素的背景如何混合。
这里为了说明问题,我们就讲一个 mix-blend-mode: difference,difference 的意思是取反,即反色。举例我们现在有一个色彩 色值为 rgb(255, 0, 255),紫色,那它在白色的反色就是 rgb(0, 255, 0) 绿色。
.div {color: rgb(255, 0, 255);mix-blend-mode: difference;font-weight: bold;font-size: 30px} <div class="div">文字颜色</div>| 案例 | chrome 桌面 | chrome 移动 | Safari 桌面 | Safari 移动 |
|---|---|---|---|---|
| html-none-body-none | 粉 | 绿 | 绿 | 绿 |
这里其实我们预期的是得到的是 粉,因为背景色为透明色,而 chrome 移动 Safari 桌面 Safari 移动显然是以白色为基础的反色了。
嵌套 iframe
注明一下颜色为,iframe 内文字颜色
| 案例 | chrome 桌面 | chrome 移动 | Safari 桌面 | Safari 移动 |
|---|---|---|---|---|
| html-none-body-none | 粉 | 粉 | 粉 | 粉 |
这里和上诉单纯的 html 一比较发现存在的差异,iframe 中的文字清一色的变为了粉色。
综上总结:
- mix-blend-mode: difference 兼容性存在很大的问题,甚至存在 position 的设定也会影响具体的表现。那如何避免呢,方案很简单,对自己所需的元素设置背景色,不要依赖外界。
Firefox 可以很轻松设置,CMD + ,,相信你可以很快找到。
为什么会有这种需求呢,我想了下,确实有这种场景,比如现在的 Dark Mode 并没有真正意义上的实现 Dark Mode,因为我们没法控制软件层的底色,根据这次测试来看,即使你操作系统设置了 Dark Mode,但是你的软件的背景色还是白色。所以在一些特殊场景下,你还是能看到那个白。
这里也衍生出了一种网站设计的流派,原先我也不太清楚,那就是透明派,比如 vimeo。我觉得初衷是好的,因为他们想要尊重用户的选择(我猜的),但是事实上,这绝对不是一个明智的方式,因为用户的偏好很可能违背你的设计(假设设计设计了 Light Mode,正常黑色字体,而如果用户偏好 Dark Mode,那么用户就啥也看不到了),因此我对透明的制作思路保留我自己的看法。
教条一:不管是 html 元素还是 body 元素,它们都是透明的。
教条二:如需全局背景色,请将背景色设置于 body 元素上。
教条三:UI Library 作者需要设置元素的背景色,同时最好在 body 元素上设置好基调色。
教条四:习惯设置背景色是个好习惯,嗯,你是个好孩子
以下是所有的测试 demo

同步一篇旧文,下文中的 Gravity 指的是浏览器的 Bundless 方案,可在 D2 分享 - 基于浏览器的实时构建探索之路 中找到相应的内容
之前犯了一个认知的错误,卡了很久,分享给大家.
在 webpack 中 less 文件可以通过 import 的方式引入三方样式文件,该样式文件可以是 npm 库中的文件(@import "~npm/a.css"),或者本地文件(@import "relative/to/a.less")。
这里我认知出错的地方是: 以为 less-loader 可以处理所有 import 的文件 (less-loader 本质是一个 附加了 webpack resolve 逻辑的 less plugin),即我原认为 less-loader 处理完之后是一个完全可用的 css 文件(事实不是如此)。
我的卡点就是: Gravity 中尝试实现 import npm 库发现,当我 @import "~npm/a.css" 时,less plugin 的 resolve 逻辑怎么都不会进入到我的自定义 resolve 逻辑中来(能注册成功插件,却不执行插件)。
恍然大悟的点是: 在 less 的设计中,不会对 css 文件做任何的处理,包括自定义插件,除非把 less 提供的 reference 强制把 css 设置为 less,即(@import (less) "~npm/a.css"),这种方式是强侵入性的,和 webpack 的方式相比需要我们感知更多的开发工具细节。 到目前我觉得 less 这一块设计是可以优化的,让插件开发者来决定是否走插件的逻辑,而不是现在的注册一个插件默认认定为是应用给 less 的,如果需要给该 css 应用 less 插件逻辑,得硬编码,这绝对不是面向用户的解决方式。
后来我发现,webpack 这一块处理是交给 css-loader 的, 即 less-loader 处理完 import less 逻辑后,其并不会处理 import css 逻辑,而 import css 逻辑交给了 css-loader 中的 postcss 去分析 import 的语法,再做进一步处理。
解决方案:
在 Gravity 中引入 postcss-loader
即实现链路 less-loader -> postcss-loader -> style-loader
如何基于 webpack 做持久化缓存似乎一直处于没有最佳实践的状态。网路上各式各样的文章很多,open 的 bug 反馈和建议成堆,很容易让人迷茫和心智崩溃。
作为开发者最大的诉求是:在 entry 内部内容未发生变更的情况下构建之后也能稳定不变。
拉到最后看总结 XD
想要做持久化缓存的首要一步是 hash,在 webpack 中提供了两种方式,hash 和 chunkhash
在此或许有不少同学就这两者之间的差别就模糊了:
hash:在 webpack 一次构建中会产生一个 compilation 对象,该 hash 值是对 compilation 内所有的内容计算而来的,
chunkhash:每一个 chunk 都根据自身的内容计算而来。
单从上诉描述来看,chunkhash 应该在持久化缓存中更为有效。
到底是否如此呢,接下来我们设定一个应用场景。
| entry | 入口文件 | 入口文件依赖链 |
|---|---|---|
| pageA | a.js | a.less <- a.css common.js <- common.less <- common.css lodash |
| pageB | b.js | b.less <- b.css common.js <- common.less <- common.css lodash |
hash 时:......
module.exports = {
entry: {
"pageA": "./a.js",
"pageB": "./b.js",
},
output: {
path: path.join(cwd, 'dist'),
filename: '[name]-[hash].js'
},
module: {
rules: ...
},
plugins: [
new ExtractTextPlugin('[name]-[hash].css'),
]
}构建结果:
Hash: 7ee8fcb953c70a896294
Version: webpack 3.8.1
Time: 6308ms
Asset Size Chunks Chunk Names
pageB-7ee8fcb953c70a896294.js 525 kB 0 [emitted] [big] pageB
pageA-7ee8fcb953c70a896294.js 525 kB 1 [emitted] [big] pageA
pageA-7ee8fcb953c70a896294.css 147 bytes 1 [emitted] pageA
pageB-7ee8fcb953c70a896294.css 150 bytes 0 [emitted] pageB如果细心一点,多尝试几次,可以发现即使在全部内容未变动的情况下 hash 值也会发生变更,原因在于我们使用了 extract,extract 本身涉及到异步的抽取流程,所以在生成 assets 资源时存在了不确定性(先后顺序),而 updateHash 则对其敏感,所以就出现了如上所说的 hash 异动的情况。另外所有 assets 资源的 hash 值保持一致,这对于所有资源的持久化缓存来说并没有深远的意义。
chunkhash 时:......
module.exports = {
entry: {
"pageA": "./a.js",
"pageB": "./b.js",
},
output: {
path: path.join(cwd, 'dist'),
filename: '[name]-[chunkhash].js'
},
module: {
rules: ...
},
plugins: [
new ExtractTextPlugin('[name]-[chunkhash].css'),
]
}构建结果:
Hash: 1b432b2e0ea7c80439ff
Version: webpack 3.8.1
Time: 1069ms
Asset Size Chunks Chunk Names
pageB-58011d1656e7b568204e.js 525 kB 0 [emitted] [big] pageB
pageA-5c744cecf5ed9dd0feaf.js 525 kB 1 [emitted] [big] pageA
pageA-5c744cecf5ed9dd0feaf.css 147 bytes 1 [emitted] pageA
pageB-58011d1656e7b568204e.css 150 bytes 0 [emitted] pageB此时可以发现,运行多少次,hash 的异动没有了,每个 entry 拥有了自己独一的 hash 值,细心的你或许会发现此时样式资源的 hash 值和 入口脚本保持了一致,这似乎并不符合我们的想法,冥冥之中告诉我们发生了某些坏事情。
然后尝试随意修改 b.css 然后重新构建得到以下日志,
Hash: 50abba81a316ad20f82a
Version: webpack 3.8.1
Time: 1595ms
Asset Size Chunks Chunk Names
pageB-58011d1656e7b568204e.js 525 kB 0 [emitted] [big] pageB
pageA-5c744cecf5ed9dd0feaf.js 525 kB 1 [emitted] [big] pageA
pageA-5c744cecf5ed9dd0feaf.css 147 bytes 1 [emitted] pageA
pageB-58011d1656e7b568204e.css 147 bytes 0 [emitted] pageB不可思议的恐怖的事情发生了,居然 PageB 脚本和样式的 hash 值均未发生改变。为什么?细想一下不难理解,因为在 webpack 中所有的内容都视为 js 的一部分,而当构建发生,extract 生效后,样式被抽离出 entry chunk,此时对于 entry chunk 来说其本身并未发生改变,因为改变的部分已经被抽离变成 normal chunk,而 chunkhash 是根据 chunk 内容而来,所以不变更应该是符合预期的行为。虽然原理和结果符合预期,但是这并不是持久化缓存所需要的。幸运的是,extract-text-plugin 为抽离出来的内容提供了 contenthash 即: new ExtractTextPlugin('[name]-[contenthash].css')
Hash: 50abba81a316ad20f82a
Version: webpack 3.8.1
Time: 1177ms
Asset Size Chunks Chunk Names
pageB-58011d1656e7b568204e.js 525 kB 0 [emitted] [big] pageB
pageA-5c744cecf5ed9dd0feaf.js 525 kB 1 [emitted] [big] pageA
pageA-3ebfe4559258be46a13401ec147e4012.css 147 bytes 1 [emitted] pageA
pageB-c584acc56d4dd7606ab09eb7b3bd5e9f.css 147 bytes 0 [emitted] pageB此时我们再修改 b.css 然后重新构建得到以下日志,
Hash: 08c8682f823ef6f0d661
Version: webpack 3.8.1
Time: 1313ms
Asset Size Chunks Chunk Names
pageB-58011d1656e7b568204e.js 525 kB 0 [emitted] [big] pageB
pageA-5c744cecf5ed9dd0feaf.js 525 kB 1 [emitted] [big] pageA
pageA-3ebfe4559258be46a13401ec147e4012.css 147 bytes 1 [emitted] pageA
pageB-0651d43f16a9b34b4b38459143ac5dd8.css 150 bytes 0 [emitted] pageB很棒!一切符合预期,只有 pageB 的样式 hash 发生了变更。你以为事情都结束了,然而总是会一波三折
接下来我们尝试在 a.js 中除去依赖 a.less,再进行一次构建,得到以下日志
Hash: 649f27b36d142e5e39cc
Version: webpack 3.8.1
Time: 1557ms
Asset Size Chunks Chunk Names
pageB-0ca5aed30feb05b1a5e2.js 525 kB 0 [emitted] [big] pageB
pageA-1a8ce6dcab969d4e4480.js 525 kB 1 [emitted] [big] pageA
pageA-f83ea969c4ec627cb92bea42f12b75d6.css 91 bytes 1 [emitted] pageA
pageB-0651d43f16a9b34b4b38459143ac5dd8.css 150 bytes 0 [emitted] pageB奇怪的事情再次发生,这边我们可以理解 pageA 的脚本和样式发生变化。但是对于 pageB 的脚本也发生变化感觉并不符合预期。
所以我们 pageB.js 去看一看到底是什么发生了变更。
通过如下命令我们可以获知具体的变更位置
$ git diff dist/pageB-58011d1656e7b568204e.js dist/pageB-0ca5aed30feb05b1a5e2.js结果为:
/******/ __webpack_require__.p = "";
/******/
/******/ // Load entry module and return exports
-/******/ return __webpack_require__(__webpack_require__.s = 75);
+/******/ return __webpack_require__(__webpack_require__.s = 74);
/******/ })
/************************************************************************/
/******/ ([/***/ }),
/* 73 */,
-/* 74 */,
-/* 75 */
+/* 74 */
/***/ (function(module, exports, __webpack_require__) {
"use strict";
console.log('bx');
-__webpack_require__(76);
+__webpack_require__(75);
__webpack_require__(38);
__webpack_require__(40);
/***/ }),
-/* 76 */
+/* 75 */
/***/ (function(module, exports) {
// removed by extract-text-webpack-plugin以上我们可以明确的知道,当 pageA 内移除 a.less 后整体的 id 发生了变更。那么可以推测的是 id 代表着具体的引用的模块。
其实在构建结束时,webpack 会给到我们具体的每个模块分配到的 id 。
case: pageA 移除 a.less 前
[73] ./a.js 93 bytes {1} [built]
[74] ./a.less 41 bytes {1} [built]
[75] ./b.js 94 bytes {0} [built]
[76] ./b.less 41 bytes {0} [built]case: pageA 移除 a.less 后
[73] ./a.js 72 bytes {1} [built]
[74] ./b.js 94 bytes {0} [built]
[75] ./b.less 41 bytes {0} [built]通过比较发现,在 pageA 移除 a.less 的依赖前,居然在其构建出来的代码中,隐藏着/* 73 */, 和 /* 74 */,,也就是说 pageB 的脚本中包含着 a.js, a.less 的模块 id 信息。这对于持久化来说并不符合预期。我们期待的是 pageB 中不会包含任何和它并不相关的内容。
这边衍生出两个命题
命题1:如何把不相关的 module id 或者说内容摒除在外
命题2:如何能让 module id 尽可能的保持不变
我们来一个一个看。
简单来说,我们的目标就是把这些不相关的内容摒除在 pageA 和 pageB 的 entry chunk 之外。
对 webpack 熟悉的人或多或少听说过 Code Splitting,本质上是对 chunk 进行拆分再组合的过程。那谁能完成此任务呢?
相信你已经猜到了 - CommonsChunkPlugin
接下来我们回退所有之前的变更。来检验我们的猜测是否正确。
在构建配置中我们加上 CommonsChunkPlugin
...
plugins: [
new ExtractTextPlugin('[name]-[contenthash].css'),
+ new webpack.optimize.CommonsChunkPlugin({
+ name: 'runtime'
+ }),
],
...case: pageA 移除 a.less 前
Hash: fc0f3a602209ca0adea9
Version: webpack 3.8.1
Time: 1182ms
Asset Size Chunks Chunk Names
pageB-ec1c1e788034e2312e56.js 316 bytes 0 [emitted] pageB
pageA-cd16b75b434f1ff41442.js 315 bytes 1 [emitted] pageA
runtime-3f77fc83f59d6c4208c4.js 529 kB 2 [emitted] [big] runtime
pageA-8c3d50283e85cb98eafa5ed6a3432bab.css 56 bytes 1 [emitted] pageA
pageB-64db1330bc88b15e8c5ae69a711f8179.css 59 bytes 0 [emitted] pageB
runtime-f83ea969c4ec627cb92bea42f12b75d6.css 91 bytes 2 [emitted] runtimecase: pageA 移除 a.less 后
Hash: 8881467bf592ceb67696
Version: webpack 3.8.1
Time: 1185ms
Asset Size Chunks Chunk Names
pageB-8e3a2584840133ffc827.js 316 bytes 0 [emitted] pageB
pageA-a5d2ad06fbaf6a0e42e0.js 190 bytes 1 [emitted] pageA
runtime-f8bc79ce500737007969.js 529 kB 2 [emitted] [big] runtime
pageB-64db1330bc88b15e8c5ae69a711f8179.css 59 bytes 0 [emitted] pageB
runtime-f83ea969c4ec627cb92bea42f12b75d6.css 91 bytes 2 [emitted] runtime此时我们再通过如下命令
$ git diff dist/pageB-8e3a2584840133ffc827.js dist/pageB-ec1c1e788034e2312e56.js对 pageB 的脚本来进行对比
webpackJsonp([0],{
-/***/ 74:
+/***/ 75:
/***/ (function(module, exports, __webpack_require__) {
"use strict";
console.log('bx');
-__webpack_require__(75);
+__webpack_require__(76);
__webpack_require__(27);
__webpack_require__(28);
/***/ }),
-/***/ 75:
+/***/ 76:
/***/ (function(module, exports) {
// removed by extract-text-webpack-plugin
/***/ })
-},[74]);
\ No newline at end of file
+},[75]);
\ No newline at end of file发现模块的内容终于不再包含和 pageB 不相关的其他的内容。换言之 CommonsChunkPlugin 达到了我们的预期,其实这部分内容即是 webpack 的 runtime,他存储着 webpack 对 module 和 chunk 的信息。另外有趣的是 pageA 和 pageB 在尺寸上也有了惊人的减小,原因在于默认行为的 CommonsChunkPlugin 会把 entry chunk 都包含的 module 抽取到这个名为 runtime 的 normal chunk 中。在持久化缓存中我们的目标是力争变更达到最小化。但是在如上两次变更中不难发现我们仅仅是变更了 pageA 但是 runtime pageB pageA 却都发生了变更,另外由于 runtime 中由于 CommonsChunkPlugin 的默认行为抽取了 lodash,我们有充分的理由相信 lodash 并未更新但却需要花费高昂的代价去更新,这并不符合最小化原则。
所以在这边需要谈到的另外一点便是 CommonsChunkPlugin 的用法并不仅仅局限于自动化的抽取,在持久化缓存的背景下我们也需要人为去干预这部分内容,真正意义上去抽取公共内容,并尽量保证后续不再变更。
在这里需要再迈出一步去自定义公共部分的内容。注意 runtime 要放在最后!
...
entry: {
"pageA": "./a.js",
"pageB": "./b.js",
+ "vendor": [ "lodash" ],
},
...
plugins: [
new ExtractTextPlugin('[name]-[contenthash].css'),
+ new webpack.optimize.CommonsChunkPlugin({
+ name: 'vendor',
+ minChunks: Infinity
+ }),
new webpack.optimize.CommonsChunkPlugin({
name: 'runtime'
}),
],
...我们再对所有的变更进行回退。再来看看是否会满足我们的期望!
case: pageA 移除 a.less 前
Hash: 719ec2641ed362269d4e
Version: webpack 3.8.1
Time: 4190ms
Asset Size Chunks Chunk Names
vendor-32e0dd05f48355cde3dd.js 523 kB 0 [emitted] [big] vendor
pageB-204aff67bf5908c0939c.js 559 bytes 1 [emitted] pageB
pageA-44af68ebd687b6c800f7.js 558 bytes 2 [emitted] pageA
runtime-77e92c75831aa5a249a7.js 5.88 kB 3 [emitted] runtime
pageA-3ebfe4559258be46a13401ec147e4012.css 147 bytes 2 [emitted] pageA
pageB-0651d43f16a9b34b4b38459143ac5dd8.css 150 bytes 1 [emitted] pageBcase: pageA 移除 a.less 后
Hash: 93ab4ab5c33423421e51
Version: webpack 3.8.1
Time: 4039ms
Asset Size Chunks Chunk Names
vendor-329a6b18e90435921ff8.js 523 kB 0 [emitted] [big] vendor
pageB-96f40d170374a713b0ce.js 559 bytes 1 [emitted] pageB
pageA-1d31b041a29dcde01cc5.js 433 bytes 2 [emitted] pageA
runtime-f612a395e44e034757a4.js 5.88 kB 3 [emitted] runtime
pageA-f83ea969c4ec627cb92bea42f12b75d6.css 91 bytes 2 [emitted] pageA
pageB-0651d43f16a9b34b4b38459143ac5dd8.css 150 bytes 1 [emitted] pageB到此为止,合理利用 CommonsChunkPlugin 我们解决了命题 1
module id 是一个模块的唯一性标识,且该标识会出现在构建之后的代码中,如以下 pageB 脚本片段
/***/ 74:
/***/ (function(module, exports, __webpack_require__) {
"use strict";
console.log('bx');
__webpack_require__(75);
__webpack_require__(13);
__webpack_require__(15);
/***/ }),
模块的增减肯定或者引用权重的变更肯定会导致 id 的变更(这边对 id 如何进行分配不做展开讨论,如有兴趣可以以 webpack@1 中的 OccurrenceOrderPlugin 作为切入,该插件在 webpack@2 中被默认内置)。所以不难想象如果要解决这个问题,肯定是需要再找一个能保持唯一性的内容,并在构建期间进行 id 订正。
所以命题二被拆分成两个部分。
直觉的第一反应肯定是路径,因为在一次构建中资源的路径肯定是唯一的,另外我们也可以非常庆幸在 webpack 中肯定在 resolve module 的环节中拿到资源的路径。
不过谈到路径,我们不得不担忧一下,windows 和 macos 下路径的 sep 是不一致的,如果我们把 id 生成这一块单独拿出来自己做了,会不会还要处理一大堆可能存在的差异性问题。带着这样的困惑我查阅了 webpack 的源码其中在 ContextModule#74 和 ContextModule#35 中 webpack 对 module 的路径做了差异性修复。
也就是说我们可以放心的通过 module 的 libIdent 方法来获取模块的路径
时机就不是难事了,在 webpack 中我一直认为最 NB 的地方在于其整体插件的实现全部基于它的 tapable 事件系统,在灵活性上堪称完美。事件机制这部分内容我会在后续着重写文章分享。
这边我们只需要知道的是,在整个 webpack 执行过程中涉及 moudle id 的事件有
before-module-ids -> optimize-module-ids -> after-optimize-module-ids
所以我们只需要在 before-module-ids 这个时机内进行 id 订正即可。
// 插件实现核心片段
apply(compiler) {
compiler.plugin("compilation", (compilation) => {
compilation.plugin("before-module-ids", (modules) => {
modules.forEach((module) => {
if(module.id === null && module.libIdent) {
module.id = module.libIdent({
context: this.options.context || compiler.options.context
});
}
});
});
});
}这部分内容,已经被 webpack 抽取为一个内置插件 NamedModulesPlugin
所以只需一小步在构建配置中添加该插件即可
...
entry: {
"pageA": "./a.js",
"pageB": "./b.js",
"vendor": [ "lodash" ],
},
...
plugins: [
new ExtractTextPlugin('[name]-[contenthash].css'),
+ new webpack.NamedModulesPlugin(),
new webpack.optimize.CommonsChunkPlugin({
name: 'vendor',
minChunks: Infinity
}),
new webpack.optimize.CommonsChunkPlugin({
name: 'runtime'
}),
],
...回滚之前所有的代码修改,我们再来做相应的比较
case: pageA 移除 a.less 前
Hash: 563971a30d909bbcb0db
Version: webpack 3.8.1
Time: 1271ms
Asset Size Chunks Chunk Names
vendor-a5620db988a639410257.js 539 kB 0 [emitted] [big] vendor
pageB-42b894ca482a061570ae.js 681 bytes 1 [emitted] pageB
pageA-b7d7de62392f41af1f78.js 680 bytes 2 [emitted] pageA
runtime-dc322ed118963cd2e12a.js 5.88 kB 3 [emitted] runtime
pageA-3ebfe4559258be46a13401ec147e4012.css 147 bytes 2 [emitted] pageA
pageB-0651d43f16a9b34b4b38459143ac5dd8.css 150 bytes 1 [emitted] pageBcase: pageA 移除 a.less 后
Hash: 0d277f49f54159bc7286
Version: webpack 3.8.1
Time: 950ms
Asset Size Chunks Chunk Names
vendor-a5620db988a639410257.js 539 kB 0 [emitted] [big] vendor
pageB-42b894ca482a061570ae.js 681 bytes 1 [emitted] pageB
pageA-bedb93c1db950da4fea1.js 539 bytes 2 [emitted] pageA
runtime-85b317d7b21588411828.js 5.88 kB 3 [emitted] runtime
pageA-f83ea969c4ec627cb92bea42f12b75d6.css 91 bytes 2 [emitted] pageA
pageB-0651d43f16a9b34b4b38459143ac5dd8.css 150 bytes 1 [emitted] pageB自此利用 NamedModulesPlugin 我们做到了 pageA 中的变更只引发了 pageA 的脚本、样式、和 runtime 的变更,而 vendor,pageB 的脚本和样式均未发生变更。
一窥 pageB 的代码片段
/***/ "./b.js":
/***/ (function(module, exports, __webpack_require__) {
"use strict";
console.log('bx');
__webpack_require__("./b.less");
__webpack_require__("./common.js");
__webpack_require__("./node_modules/[email protected]@lodash/lodash.js");
/***/ }),确实模块的 id 被替换成了模块的路径。但是不得不规避的问题是,尺寸变大了,因为 id 数字 和 路径的字符数不是一个量级,以 vendor 为例,应用方案前后尺寸上增加了 16KB。或许有同学已经想到,那我对路径做次 hash 然后取几位不就得了,是的没错,webpack 官方就是这么做的。NamedModulesPlugin 适合在开发环境,而在生产环境下请使用 HashedModuleIdsPlugin。
所以在生产环境下,为了获得最佳尺寸我们需要变更下构建的配置
...
entry: {
"pageA": "./a.js",
"pageB": "./b.js",
"vendor": [ "lodash" ],
},
...
plugins: [
new ExtractTextPlugin('[name]-[contenthash].css'),
- new webpack.NamedModulesPlugin(),
+ new webpack.HashedModuleIdsPlugin(),
new webpack.optimize.CommonsChunkPlugin({
name: 'vendor',
minChunks: Infinity
}),
new webpack.optimize.CommonsChunkPlugin({
name: 'runtime'
}),
],
...Hash: 80871a9833e531391384
Version: webpack 3.8.1
Time: 1230ms
Asset Size Chunks Chunk Names
vendor-2e968166c755a7385f9b.js 524 kB 0 [emitted] [big] vendor
pageB-68be4dda51b5b08538f2.js 595 bytes 1 [emitted] pageB
pageA-a70b7fa4d67cb16cb1f7.js 461 bytes 2 [emitted] pageA
runtime-6897b6cc7d074a5b2039.js 5.88 kB 3 [emitted] runtime
pageA-f83ea969c4ec627cb92bea42f12b75d6.css 91 bytes 2 [emitted] pageA
pageB-0651d43f16a9b34b4b38459143ac5dd8.css 150 bytes 1 [emitted] pageB在生产环境下把 NamedModulesPlugin 替换为 HashedModuleIdsPlugin,在包的尺寸增加幅度上上达到了可接受的范围,以 vendor 为例,只增加了 1KB。
事情到此我以为可以结束了,直到我 diff 了一下 runtime 才发现持久化缓存似乎还可以继续深挖。
$ diff --git a/dist/runtime-85b317d7b21588411828.js b/dist/runtime-dc322ed118963cd2e12a.js /******/ if (__webpack_require__.nc) {
/******/ script.setAttribute("nonce", __webpack_require__.nc);
/******/ }
-/******/ script.src = __webpack_require__.p + "" + chunkId + "-" + {"0":"a5620db988a639410257","1":"42b894ca482a061570ae","2":"bedb93c1db950da4fea1"}[chunkId] + ".js";
+/******/ script.src = __webpack_require__.p + "" + chunkId + "-" + {"0":"a5620db988a639410257","1":"42b894ca482a061570ae","2":"b7d7de62392f41af1f78"}[chunkId] + ".js";
/******/ var timeout = setTimeout(onScriptComplete, 120000);
/******/ script.onerror = script.onload = onScriptComplete;
/******/ function onScriptComplete() {我们发现在 3 个 entry 入口未改变的情况下,变更某个 entry chunk 的内容,对应 runtime 脚本的变更只是涉及到了 chunk id 的变更。基于 module id 的经验,自然想到了是不是有相应的唯一性内容来取代现有的 chunk id,因为数值型的 chunk id 总会存在不确定性。
所以至此问题又再次被拆分成两个命题:
接下来我们一个一个看
因为我们知道在 webpack 中 entry 其实是具有唯一性的,而 entry chunk 的 name 即来源于我们对 entry 名的设置。所以这里的问题变得很简单我们只需要把每个 chunk 对应的 id 指向到对应 chunk 的 name 即可。
在整个 webpack 执行过程中涉及 moudle id 的事件有
before-chunk-ids -> optimize-chunk-ids -> after-optimize-chunk-ids
所以我们只需要在 before-chunk-ids 这个时机内进行 chunk id 订正即可。
伪代码:
apply(compiler) {
compiler.plugin("compilation", (compilation) => {
compilation.plugin("before-chunk-ids", (chunks) => {
chunks.forEach((chunk) => {
if(chunk.id === null) {
chunk.id = chunk.name;
}
});
});
});
}非常简单。
在 webpack@2 时期作者把这个部分的实现引入到了官方插件,即 NamedChunksPlugin。
所以在一般需求下我们只需要在构建配置中添加 NamedChunksPlugin 的插件即可。
...
entry: {
"pageA": "./a.js",
"pageB": "./b.js",
"vendor": [ "lodash" ],
},
...
plugins: [
new ExtractTextPlugin('[name]-[contenthash].css'),
new webpack.NamedModulesPlugin(),
+ new webpack.NamedChunksPlugin(),
new webpack.optimize.CommonsChunkPlugin({
name: 'vendor',
minChunks: Infinity
}),
new webpack.optimize.CommonsChunkPlugin({
name: 'runtime'
}),
],
...runtime 的 diff
/******/
/******/ // objects to store loaded and loading chunks
/******/ var installedChunks = {
-/******/ 3: 0
+/******/ "runtime": 0
/******/ };
/******/
/******/ // The require function
@@ -91,7 +91,7 @@
/******/ if (__webpack_require__.nc) {
/******/ script.setAttribute("nonce", __webpack_require__.nc);
/******/ }
-/******/ script.src = __webpack_require__.p + "" + chunkId + "-" + {"0":"a5620db988a639410257","1":"42b894ca482a061570ae","2":"b7d7de62392f41af1f78"}[chunkId] + ".js";
+/******/ script.src = __webpack_require__.p + "" + chunkId + "-" + {"vendor":"45cd76029c7d91d6fc76","pageA":"0abd02f11fa4c29e99b3","pageB":"2b8c3672b02ff026db06"}[chunkId] + ".js";
/******/ var timeout = setTimeout(onScriptComplete, 120000);
/******/ script.onerror = script.onload = onScriptComplete;
/******/ function onScriptComplete() {可以看到标示 chunk 唯一性的 id 值被替换成了我们 entry 入口的名称。非常棒!感觉出岔子的机会又减小了不少。
讨论这个问题的另外一个原因是像 webpack@2 中的 dynamic import 或者 webpack@1 时的 require.ensure 会将代码抽离出来形成一个独立的 bundle,在 webpack 中我们把这种行为叫成 Code Splitting,一旦代码被抽离出来,最终在构建结果中会出现 0.[hash].js 1.[hash].js ,或多或少大家对此都有过困扰。
可以预想的是通过该 plugin 我们能比较好解决这个问题,一方面我们可以尝试定义这些被动态加载的模块的名称,另外一方面我们也可以遇见,假定一个构建场景会生成多个 [chunk-id].[chunkhash].js, 当 Code Splitting 的 chunk 需要变更时,比如减少了一个,此时你没法保证在新一个 compilation 中还继续分配到上一个 compilation 中的 [chunk-id],所以通过 name 命名的方式恰好可以顺带解决这个问题。
只是在这边我们需要稍微对 NamedChunksPlugin 做一些变更。
...
entry: {
"pageA": "./a.js",
"pageB": "./b.js",
"vendor": [ "lodash" ],
},
...
plugins: [
new ExtractTextPlugin('[name]-[contenthash].css'),
new webpack.NamedModulesPlugin(),
- new webpack.NamedChunksPlugin(),
+ new webpack.NamedChunksPlugin((chunk) => {
+ if (chunk.name) {
+ return chunk.name;
+ }
+ return chunk.mapModules(m => path.relative(m.context, m.request)).join("_");
+ }),
new webpack.optimize.CommonsChunkPlugin({
name: 'vendor',
minChunks: Infinity
}),
new webpack.optimize.CommonsChunkPlugin({
name: 'runtime'
}),
],
...要做到持久化缓存需要做好以下几点:
[chunkhash] 对 extractTextPlugin 应用的的文件应用 [contenthash];CommonsChunkPlugin 合理抽出公共库 vendor(包含社区工具库这些 如 lodash), 如果必要也可以抽取业务公共库 common(公共部分的业务逻辑),以及 webpack的 runtime;NamedModulesPlugin 来固化 module id,在生产环境下使用 HashedModuleIdsPlugin 来固化 module idNamedChunksPlugin 来固化 runtime 内以及在使用动态加载时分离出的 chunk 的 chunk id。CodeSandbox 是一个在线的代码编辑器,主要聚焦于创建 Web 应用项目。当前已经进化为可以同时支持浏览器端以及服务端的 web 应用。
先来看下目前 CodSandbox 它支持的 client 端的应用类型

server 端的应用类型

这个项目的起源来源于 Ives van Hoorne 当初在一家名为 Catawiki 公司工作,那会儿他们正在把 Ruby on Rails pages 迁移到 React 上来,某一天恰好他正在休假,然后公司的同事问他一个关于 React 的相关问题,而他又没带电脑,整个沟通过程全部建立在想象之上,所以沟通异常困难,所以 codesandbox 最初的想法就诞生了。
接下来看看这些年来如何一步步推进整个进程的:
Apr, 2017 - CodeSandbox — An online React editor
未来规划
发布后的两个月,改进 npm 体验
这里可以延伸得到的是 CodeSandbox 在发布之后,npm 的这块的支持在效率上是有缺陷的,同时期还有一个社区产品叫 Webpackbin ,因为他们同时都在做 npm 支持这块内容。所以 Ives van Hoorne 联系了Webpackbin 的作者 Christian Alfoni ,表达了想要合力来完成这块内容。所以自然而然他们走到了一起,建立了一个通用的项目来同时给 Webpackbin 和 CodeSandbox 提供包服务。Christian Alfoni 为此写过一篇文章。这边衍生出来另外两个库 webpackdll 和 webpack-packager。而这之后,Christian Alfoni 很快的废弃了 Webpackbin 方案。相信他们应该是合力开发 CodeSandbox 了。
Feature:
Aug 16, 2017 - CodeSandbox 1.5
重点:CodeSandbox 是如何基于浏览器创建一个能并行的,支持离线的,同时又有扩展能力的 bundler 的
以往的做法
这使得作者需要重新考虑整个的打包流程
作者第一个想到的是让 webpack 跑在浏览器里面,这应该是非常容易得出的结论,事实上他也这么做了,因为 webpack 从当前来看在市场占有率上来讲具有绝对的优势,另外任何的项目支持可能一个 webpack.config.js 都可以搞定。看上去非常美好。事实也这样,作者让 webpack 成功的跑在了浏览器端。但问题是被 uglify 后的 webpack 大小有 3.5MB,同时还需要提供大量的 pollyfill,由于动态引用的关系,compilation 还会报一堆的警告。在作者测试中他让一半的 loader 跑在了浏览器端。另外由于使用 webpack 时其实假定了一个 nodejs 环境,所以后期可能会需要消耗大量的经历在模拟 nodejs 环境中,关键效果还可能差强人意,作者觉得要做的事情实在太多了,收益又太小,另外,基于 CodeSandbox 本身平台的考虑(浏览器,动态加载等),或许去构造一个适合 CodeSandbox 的构建工具可能更加适合 ,因为所有优化都是可以基于这个平台来做的,所以最终他放弃了这个让 webpack 跑在浏览器的原始想法。
作者的第二个想法就是自己做一个打包工具,但是在 loader 的 API 设计时尽量接近 webpack,这一点和我在设计 Gravity 时不谋而合了。这种设计的优点是,就感觉像在用 webpack,甚至有些 webpack 的 loader 可以无痛移植过来,而有痛那些我们只要摘除了 SSR, Node, Production 的逻辑后基本都可以跑起来了。另外由于我们是浏览器的环境,所以 Web Workers, Service Workers 和 code splitting 我们就可以随意使用了。
最终作者在实现该打包工具时尽力做好了两件事情,第一件事情是 loader 的 API 设计尽量往 webpack 靠,第二件事情就是尽力优化在 CodeSandbox 中的表现。最终这个 bundler 分为了三个阶段:configuration, transpilation 和 evaluation.
Configuration:
在该方案中每一种项目类型都会被定义一个 preset,这个 preset 主要来描述一种文件类型是需要如何 resolve 以及这种文件类型的需要被什么 loader 加载。
Transpilation:
顾名思义,这个阶段主要做 transpilation,另外还有还会负责一件非常重要的事情 - 构建依赖树。每个被 transpile 的文件都会被进行语法分析 得到 AST,该 AST 便于我们找到 require 申明,并且把这些加到树结构中。这不操作不仅仅限制在 js 文件,对 typescript, sass, less 和 stylus 文件也会做同样的事情。在 Transpilation 阶段做构建依赖树的好处是,我们只需要要对文件构建一次 AST 语法树。编译后的内容会被存放在 TranspiledModule 这个对象中,另外需要了解的是,一个文件可能关联了多个 TranspiledModule,原因就在于 require(‘raw-loader!./Hello.js’) 并不等价于 require(‘./Hello.js’)。
另外这次重构,彻底释放了 web worker 的潜力,因为我们可以通过 web 端的 web worker 能力进行并发的编译流程,所以这里可以推断是作者在实现时,应该是有个 web worker pool 管理。这种做法也会大大加快 UI 端的渲染,因为 UI 层 和 编译层进行了分离。这部分来源初始于 reactjs - core- team 成员 bvaughn 的一次对 babel 的优化。 另外基于动态按需加载的特性,所有被加载的文件全部都是所需的内容,不过最终所有的内容,(比如 额外的 loader )还是会被 SW 下载到本地,以用来支持更好的 offline 体验。
Evaluation:
虽然作者把这个工具称之为 bundler 但实际上并没有真正意义上 bundle 的过程。这边的方式和 systemjs 其实基本是一致的。最后需要做的就是执行文件就可以了。另外和 webpack runtime 或者 systemjs 一样也提供了自己的 require 方法,该方法本质都是扩展到缓存,而 CodeSandbox 这边则是去获得 TranspiledModule。
另外关于 HMR,大家知道 module.hot 是 webpack 的方法,在这边要实现 hot reload 方法本质上是做不到的,看到作者做了一点小技巧,当文件变更后,促使关联文件失效,引发重新编译,最后其实他应该是重新执行了入口那个函数。这个处理和 systemjs 的处理方式如出一辙,在 systemjs 在内存链路里面需要手动引发一个 invalid 操作来标记失效文件,但 systemjs 不足的地方在于他们的文件数结构是扁平的,不是真正意义上的树形结构,所以在引发链路更新的时候,一个文件的副作用很难确定出来,或许我还没足够了解。
重点:CodeSandbox 是如何把 npm 在浏览器里面执行起来的
在作者描述中,起初他们并没有想要把 npm 考虑进来,因为他们觉得这不太可能。到现在来看 npm 支持应该说是 CodeSandbox 非常重要的一项特性。
首个版本:
严格意义上来讲并不算支持了 npm 了,作者做法是在本地下载了相关的依赖,然后把调用的依赖指向到了本地,这种方案显然是不可用的方式。
基于 webpack 的版本:
后续作者在偶然看到了 https://esnextb.in/ ,这个小产品对作者影响很大,因为他一直认为 npm 模块不可能真正意义上在浏览器里面使用起来,但这款小的产品做到了。所以作者开始回过头来重新思考里面的问题。

这是作者想到的第一种实现架构,有点过于复杂。而后他也意识到了当中的复杂性,然后机缘巧合,他看到了 webpack dll plugin,通过这种方式可以单独打包依赖文件,单独生成一个依赖文件,以及一个 manifest json 文件,该文件内描述了依赖文件的 module id,我们可以通过 module id 来得到某个文件的 exports。
基于如上这个想法作者对其进行了实现

这种方式应该比第一种想到架构会简单很多。
但是使用这种方案会有个缺陷,webpack 的依赖树是真正被引用到的文件才会出现在依赖树结构中,这意味着如果你需要依赖一个 npm 模块内的某个脚本,但是该模块并不在 main 的依赖树中,那么我们在实际使用中将无法 require 到这个脚本拿不到对应的 exports。后续才会有了CodeSandbox 作者和 WebpackBin 作者 Christian Alfoni 合作开发的事情,根本上他们想要一起合作解决这个限制。最终他们也解决了这个问题。
新系统的诞生也让他们对整体架构做了升级,他们把 dll 这个功能做成了一个 service,该 service 上跑了多个 npm 打包服务。更多这块内容被记录在了一篇博文中 。
这种方案看上去很棒,但也有一些限制和缺陷,当 CodeSandbox 越来越有名后,使用的人也越来越多,服务端的开销也就越来越多了。与此同时他们对缓存处理是对整个包的出发的,当添加一个文件后,原有的缓存全部会失效,因为他们需要重新构建,原因在于 module id 这些全部会发生变更。
Serverless 的出现:
作者受一篇 serverless 文章的影响,便在自己的系统中开始尝试使用 serverless 。通过 serverless 可以定义一个将在请求时执行的函数,该函数可以处理该请求,并在一段时间内终结自身。这种可伸缩性对 CodeSandbox 来说是比较有用的。后续作者通过一个名叫 Serverless framework 快速实现了三个 serverless 函数。
通过如上优化,大幅降低了 CodeSandbox 在服务端的支出,同时让响应速度提升了40% - 700%。
事情总是很曲折,在对这次重构跑了一段时间后发现了新的问题,一个 lambda 函数最多只能有 500 MB 的磁盘空间,这意味着有些 combination 将不能安装,这个问题是致命性的,会导致服务完全不可用。所以作者又重新开始了新的一轮优化。
因为架构设计的原因,bundler 和 packger 拆分处在不同的环境下,bundler 执行在浏览器端,处理真正依赖关系,而 packager 则是单纯对 npm 依赖进行了处理。基于 bundler 的设计,本质上 bundler 完全有能力去处理 npm 级的文件,而 packager 只是单纯去把 npm 依赖梳理清楚然后全部下发给浏览器端,而最后让 bundler 来处理最终如 resolve,执行等操作。这样一来,就会更加大幅度的提升性能,因为服务端的 webpack dll server 就可以被废弃掉了,废弃的好处还在于不用每次依赖更新时需要更新整个 compilation(受限于 webpack),而只需单单关注新增依赖的下发。

架构进一步得到了简化。但是知道 unpkg,或者 jsdeliver 的同学,或许有个困惑,因为还可以有更快的方式,比如如上这个流程完全可以拆分到 unpkg,或者 jsdeliver 来实现。其实说白了就是 stackblitz 的 turbo 方案。
作者还是想要保持这套架构的原因在于他想要离线化,当只有你有所有文件的的控制权时,这些才有可能实现。
结论:
当前一个组合 deps 发生请求时,事先会对这个组合进行确认,确认是否已经在 S3 上存在,如果不存在则会走到 API Service, 这个服务会对这个组合进行拆分形成独立的依赖,并对这个独立的依赖请求 Packager,Packager 会使用 yarn 进行依赖的安装,并且对基于入口文件的 AST 递归分析最终获取所有相关文件的依赖拓扑,最终 Packager 会把结果存储到 S3 上 。一旦 API Service 返回 200,那么就会再去 S3 上去获取最终的结果。
另外 Packager 做 AST 分析时额外做了附加做了一件事情就是把文件 resolve 关系也一并记录了,原因就在于浏览器端没有 nodejs resolve 算法,另外如需支持 bower 类型的模块,resolve 规则会更麻烦一点。这一点并不是不能通过浏览器端实现,而是能让整个过程更加顺畅,这一点我在做 Gravity resolve 时深有感触。
改造优点:
这一部分处理作者把它开源了,详见 https://github.com/CompuIves/dependency-packager。
Nov 17, 2017 CodeSandbox 2.0
Feb 7, 2018 CodeSandbox 2.5
Mar 27, 2018 实时协同编辑

为了解决潜在的冲突,作者使用了 operational transformation 这项技术。在前端上作者使用了 ot.js 而在后端实现上则是使用了 ot_ex. 当然这当中有很多的定制化的内容,作者表示这是他有史以来做过的最最有趣的需求,因为这当中有非常多的技术挑战以及需要解决很多竞争态。
Sep 28, 2018 支持 container
言下之意就是我们本地跑的任何的项目都可以使用 CodeSandbox Container 跑起来,因为在容器的沙箱环境下本质上和本地环境并无多大差异,这种方案也可以让我们肆无忌惮的使用 npm scripts,甚至我们也可以使用远端的 terminal。
Mar 19,2019 CodeSandbox 发布 3.0 版本
在团队协作中我们经常碰到的问题是每个人都有自己的开发习惯,这个习惯包含但不限于编码风格,工具使用等,所以往往协作中就会出现各种各样的问题。这篇文章将会从很小的切入点开始讲,即如标题所诉 Git Commit Message。
但在讲之前大家最好对如下的分支管理有一定的了解,原因在于,好的分支管理模型和好的 Git Commit Message 是规范化开发必不可少的内容。
衍生阅读 Git 分支管理模型 和 gitflow
在项目开发开发中或许我们能经常看到
相信或多或少大家都曾碰到过。一旦涉及代码回滚,issue 回溯,changelog,语义化版本发布等操作时,作为 PM 肯定一脸懵逼 即使 PM 参与了全程的 CR 环节。
那理想中的 Git Commit Message 应该是要能较好的解决如上问题
而 changelog,语义化版本发布这更像是合理化 commit 后水到渠成之事。
以个人来看,好的 commit 需要有以下特征
当前业界应用的比较广泛的是 Angular Git Commit Guidelines
具体格式为:
<type>(<scope>): <subject>
<BLANK LINE>
<body>
<BLANK LINE>
<footer>
type: 本次 commit 的类型,诸如 bugfix docs style 等
scope: 本次 commit 波及的范围
subject: 简明扼要的阐述下本次 commit 的主旨,在原文中特意强调了几点 1. 使用祈使句,是不是很熟悉又陌生的一个词,来传送门在此 祈使句 2. 首字母不要大写 3. 结尾无需添加标点
body: 同样使用祈使句,在主体内容中我们需要把本次 commit 详细的描述一下,比如此次变更的动机,如需换行,则使用 |
footer: 描述下与之关联的 issue 或 break change,详见案例
一方面我们可以通过 commit 模板,但是这对于整体管控而言比较难以把握。所以如标题所诉,我采取了工具化的方式。
问题将会被拆分成
如何利用工具协助
生成commit
commitizen 来格式化 git commit message 的工具,它提供了一种问询式的方式去获取所需信息,而在一个大框架下,我们肯定有自己想要遵循的范式(即个性化内容,比如 types 的类型),此时就由 commitizen 中的 adapter 来承载,例如如上提到的 angular 规范则是由 cz-conventional-changelog 来实现。
如何利用工具协助
校验commit
commitlint 来校验 git commit message 的工具,而所需要校验的内容是否符合规范则和 commitizen 一样需要一个 adapter,例如校验 angular 规范的则由 @commitlint/config-conventional 来呈现。
何时校验才算合理
在老版本中在 package.json 中
"scripts": {
"commitmsg": "commitlint -e $GIT_PARAMS"
}在新版本中
"husky": {
"hooks": {
"commit-msg": "commitlint -e $GIT_PARAMS"
}
}
依托于 commitizen 对 Git Commit Message 的规范化,我们非常容易依托 commit 信息来自动化生成 changelog。
正常情况下,我们可以使用 standard-version 或 semantic-release 来生成 changelog。
standard-version 与 semantic-release 的区别,总结来说就是 standard-version 只针对 local git repo 而 semantic-release 则会牵扯到代码 push 亦或 npm publish。
另外如果你的项目是 mono repo 的,即通过 lerna 来管理的,然后代码又托管在 github 上,那么 lerna 也给了一套自己的解决方案,一种基于 github tag 给 pr 和 issue 打标的方式。这一块可以见我之前的文章 monorepo 新浪潮 | introduce lerna。
在实际我们的业务项目中当前有两种场景,一种是普通的 repo,还有一种是 mono repo,如果还不知道 mono repo 是什么的,可以参考下我之前写的这篇文章 monorepo 新浪潮 | introduce lerna,这篇文章也在文章上面有所提到。
为了让读者可以快速上手,我已经把相关内容整理到一个示例 repo - normal repo,对它的解释是 Starter kit with zero-config for building a library in ES6, featuring Prettier, Semantic Release, and more! 这是一个还在进行中的 repo,当前还确少 babel 那个部分,如果是 ts 用户的话 还需要 ts 那个部分,这些都是需要后续补上的部分。
接下来说下关键部分,先上 package.json
"scripts": {
"ct": "git-cz",
"precommit": "lint-staged",
"commitmsg": "commitlint -e $GIT_PARAMS",
"release": "standard-version"
},
"config": {
"commitizen": {
"path": "./node_modules/cz-conventional-changelog"
}
},
"standard-version": {
"skip": {
"commit": true,
"tag": true
}
},
"lint-staged": {
"*.js": [
"prettier --trailing-comma es5 --single-quote --write",
"git add"
]
},在常规开发中,我们的操作方式会变更为如下:
第一步:使用 commitizen 替代 git commit
使用
$ npm run ct来替代原有的 git commit
如果你把 commitizen 安装在全局,即 -g
那么也可以使用
$ git ct来替代原有的 git commit
如果你是 sourceTree 用户,其实也不用担心,你完全可以可视化操作完后,再在命令行里面执行 ct 命令,这一部分确实破坏了整体的体验,当前并没有找到更好的方式来解决。
第二步:格式化代码
这一步,并不需要人为干预,因为 precommit 中的 lint-staged 会自动化格式,以保证代码风格尽量一致
第三步:commit message 校验
这一步,同样也不需要人为介入,因为 commitmsg 中的 commitlint 会自动校验 msg 的规范
第四步:当有发布需求时
使用
$ npm run release在这一步中,我们依托 standard-version 的能力,输出 changelog,细心的同学可以看到在配置 standard-version 时,我们忽略了相关的打标操作。 原因在于,我们会介入修改 changelog,因为依托 commit msg 的 changelog 对用户而言或许并不直观。 如果没有这种特殊需求的,可以选择打标。
"standard-version": {
"skip": {
"commit": true,
"tag": true
}
},
第五步:发布
$ npm publish
同上,这是一个使用 mono repo 的快速上手示例。 对它的解释是 Starter kit with lerna and zero-config for building a library in ES6, featuring Prettier, Semantic Release, and more!
mono repo 最大的差异是,需要用不同的 commiizen adapter 来适配 mono repo 这种特殊的项目结构,所以在这边我们也选用了 cz-lerna-changelog,最大原因在于我们想要根据 commit 生成 changelog 时 commit 能落实到对应的 package,以及有一份归总的 changelog,这份 changelog 能说明所有的子 packages 的 changelog。
同样说下关键部分,先上 package.json
"scripts": {
"ct": "git-cz",
"precommit": "lint-staged",
"commitmsg": "commitlint -e $GIT_PARAMS",
"release": "lerna publish --conventional-commits --skip-git --skip-npm",
"publish": "./tasks/publish.js"
},
"config": {
"commitizen": {
"path": "./node_modules/cz-lerna-changelog"
}
},
"lint-staged": {
"*.js": [
"prettier --trailing-comma es5 --single-quote --write",
"git add"
]
},
这边我只说下差异部分
第四步:当有发布需求时
使用
$ npm run release在这一步中我们借助了 lerna 自身的能力来根据 commit msg 来生成了 changelog,同样我们忽略了打标,以及发布流程,原因依旧是我们需要修改自动化生成的 changelog。但这个操作带来的问题是后续需要手动进行 publish 的操作。在实际业务项目里面,我们的选择是在项目根目录中新建一个 tasks 目录,该目录内放一些自动化脚本,比如这里有 publish.js
所以这边变成利用 release 来生成 changelog,继而我们修改,然后再到根目录中执行 npm run publish 来执行 tasks/publish.js。这部分当前我还没有同步到示例中,后续会添加。
第五步:发布
$ npm run publish
缘由如上诉。
前几天听 UCAN 分享,温伯华提到一点特别印象深刻,大意就是成长必定是上坡路,必定是艰辛的,其实没有如上工具照样可以开发,然而它的存在是让人养成良好的协作习惯,而好的习惯是可以让人受益终身的,所以希望作为读者的你,能踏上这个上坡路。
Ref: https://github.com/angular/angular.js/blob/master/DEVELOPERS.md
诞生的意义:web ide 的诞生提供了在浏览器端进行编码的可能性,到现在来看目前也并没有一个构建工具对 web 层进行构建有足够的兼容。
codesandbox 的 sandpack 并不是严格意义上的构建工具,它只是提供了一个 runtime 时的 transpile 流程。Transpile 层思路其实很简单,即进行依赖分析后,拿到依赖,把依赖给到专属 transpiler 进行代码转换。
这一块的优势我觉得有:
但最大的优势是:
缺点:
这个方案是之前我做小程序构建优化的根基,基于这一层我实现了配置式的 preset,类 webpack loader等等。
其诞生的意义:传统意义上在浏览器端只能通过类似 requirejs 等方案来实现模块加载,其只能加载特定规范的模块,而随着 npm 在前端界的铺开,一个项目中可能存在多种模块规范,所以我觉得 systemjs 最初的亮点来源于,在 client 端实现了对 CJS,AMD,UMD,ES,GLOBAL模块的加载。
systemjs 并不是构建工具而其只是一个通用模块的加载器,与之配套的 systemjs-builder 才是一个构建工具。
我觉得这套方案的优势有:
system.config.js 可用于描述模块的加载形式缺点也很明显:
当然如上这些缺陷我可以舍去 client 端,通过 server 中间件来介入到本地 nodejs 环境来解决,通过其他七七八八的插件来构建另外一个闭环。
这种方案仍然可以继续深挖,如作者所说,无需为 systemjs 版本升级而感焦虑。但根本问题让我感觉不安的是 systemjs-builder,其无法满足大而多需求的研发场景,简单来讲就是上面说的,他做的太简单了,很多 api 都是 low level 的,虽然这点对像我这类开发者其实是友好的我能接受,但无法接受的是其缓存策略,并发性,依赖树维护上有一些缺陷,需要花非常多经历去改造内核。
其实从 systemjs 2.0 开始,作者就已经放弃 systemjs-builder 了,另外也并没有继续往 universal loader 的方向继续做,而是专注在了构建一个最好的最轻量化的以及可被更好 hack 的浏览器端加载器上。为什么他可以这么做?这就是它诞生的意义了。
其诞生的意义:据统计约 85% 的用户 已经运行在了可支持 native-modules 的浏览器环境中了。所以作者认为我们可以进一步优化原有的应用开发和部署思路,甚至大有去除本地构建的势头。
来说一说优势,这 2.0 版本开始,systemjs 分为了三个部分:
s.js: 1.5KB,用以支持现有的 native-module 的工作流,并向下兼容到 IE11。
system.js: 3KB,在支持现有的 native-module 的工作流基础上进一步支持了即将发布的新标准,诸如import-maps 和 WASM
extras: 提供 0.21.x 上的一些功能,诸如 AMD、Named Exports 等等的支持,以及我认为可玩性较高的 transform loader,这个本质上就是利用 fetch 函数做出更加 high level 的 loader、 preset 的概念。
应该说如上三点,基本可以 fallback 0.21.x 时代。作者让我们不要有版本顾虑应该也来源于此吧。
优势其实很明显,通过拆分,用户可以根据自己需求引入自己想要的工作流,一种更加面向未来的方式。细心的同学有没有发现作者其实刻意在避开 build 这个概念,其实他是把这个流程抛给了 rollup 或者 webpack,而这一点也正应了 systemjs 想要去的方向,专注在浏览器加载,即运行时。
来细细琢磨下作者的小心思,或许工作流可以这样:
development: 纯 es module,采用 native-module 加载方案即可,这一点似乎在实际工程中不可能做到,比如还有 node_modules;如果,你还是有不可逾越的障碍,比如兼容性问题,但还是需要继续享受 es module 的 live bindings,动态 import 等等,所以 s.js 就出来了,s.js 对于一般业务也够用了。
production: systemjs + rollup format system / systemjs + webpack library target system / rollup iife,简单来讲就是在生产环境下你可以继续选择 systemjs 这一套 shim native module 的流程,也可以配合一些打包工具,完整输出一个 one bundle,取决于用户。
但这个方案下的缺点是什么:
jspm 2.0 目前所处 beta 阶段,这个应该是作者想要彻彻底底想要实现 bundless 一种实现方式。作者巧妙的把最不确定的 node_modules 做了一层移花接木。作者约定安装依赖需要通过 jspm 进行,jspm 在进行依赖安装的时候会把会把所有的安装模块转换成 es,并且生成一个 map 文件,而该 map 文件即可以是 systemjs 2.x 3.x 中 system.js 所面向的未来的模块家在方案。作者为什么可以这么任性呢?这又是诞生的背景了。
其诞生的背景和意义:接触过 native-module 的同学可能知道,在浏览器端要实现模块加载,必须要显示的申明模块的类型,即需要有完整的模块路径,这样或多或少会比较麻烦。而背景是 Import maps 在 Chrome 74 中可以以实验性质开启,Import maps 它是什么呢,其意义又在于哪里呢。本质上来讲,Import maps 就是一个配置文件,该配置文件描述了某个依赖的 resolve 方式,某种意义上来讲,Import maps 给浏览器端带来了包管理。
[email protected] 的出现应该是应运 systemjs 2.0 而来,这样的思路非常顺。
优点非常明显:
缺点亦非常明显:
对于 @pika 系工具的了解,完全出于其作者在社区的一篇文章 A Future Without Webpack,这篇文章引发了一众大佬的挑战,挑战的内容就是 one bundle 和 bundless 之间到底差在哪。比较典型的一篇讨论帖在这 Performance Breakdown and Bundler DX/UX/Perf Validations。各自相互举证甚是精彩。
@pika/web 的核心点也来源于浏览器端的 native-module 的加载方式,做法上和 jspm 2.0 类似但有差异,即 jspm 2.0 还有一个完整的 x_modules 结构,只不过内部是被转换了,另外可以轻松使用 link 或者 fallback 到 node_modules。但是 pika 则比较偏激,它是对依赖用 rollup 进行了一次打包输出为某些个 ESM 模块,这种方式简单高效,但这并不符合实际的项目开发,实际项目开发中我们或许需要 link 调试 component,需要 monkey-patch,最不能接受 @pika/web 的一点是,起完全看齐未来,不像 jspm 中,可以借由 systemjs 有一套 fallback 的方案。
所以我对 @pika/web 的看法
Gravity 底层原先采用 [email protected] + systemjs-builder,至于如何落地,大家可以参考下这篇文章 小程序构建重构我的一些个人思考 。这种方式下的一些不足已经在上诉中总结了。
那 Gravity 接下来如何去做呢?是保持现状完善还是继续突破。Vue-cli,Angular-cli 中 Modern Mode 给我了更多的启发。所谓 Modern Mode 就是 native-module 加载方案,但是是一种阉割版的 native-module 加载方式,如同我给 umi 提的 Modern Mode PR。Modern Mode 让我相信它绝对是一个方向,但当前社区或许有点剑走偏锋,在我看来或多或少是因为作者的某些执念与洁癖。业务本质上是骨感的,有很多的历史背景,技术禁锢,如何切合业务,去业务之痛,同时又能看齐未来,这是我给 Gravity 的下一个命题。
而我们又在 web-ide 的浪潮之下,静观四周,似乎我们找不到一个真正面向 browser 端的构建方案,基本上大家都在往 docker 上走,Gravity 如何能突破这套技术架构,占得先机,给到更加优质的开发体验,这是我对 Gravity 的理想。
在反复验证和思考下(很抱歉我真的花了很多时间),我计划基于 [email protected] 来构建一个全新的生态。
虽然文章前边已经讲了,但还是再总结下
总结成一个字,稳。
所以接下来会基于 [email protected] 重构一些实现,由于有 systemjs 0.21.x 的经验,相信会让这个流程变的可控和顺畅。
Gravity 后续会有三种形态,Modern Mode,Legacy Mode,One bundle Mode,这三种模式分别对焦到不同的用户需求场景。
Modern Mode 是完全面向未来的方式,即完全采用 native-module 的加载方案,一期中还是会使用打包方案来解决 node_modules 问题,以及通过约束来解决自身模块加载问题;而二期,则会采用诸如 jspm 中 CJS2ES 配合 import-map,以及其他一些轻量化动态分析的方式来解决人为约束被动感。这一步的终态将会实现真正意义上的 bundless。
Legacy Mode 是一套面向未来的方式下的 polyfill 方案,即通过 systemjs 来实现,目前 systemjs 整体处于比较 low api level 的状态,设计中我会尝试把当前在 webpack 开发体验完全移植到 gravity 中来,同时这一步的实现会借鉴 codesandbox sandpack 的思路。言简意赅的来讲就 是Gravity 会基于 systemjs hook 以及 WHATWG Fetch 来封装出一个 Compiler 基类,对应 sandpack 中的 Compiler,用来处理文件的编译,如 babel、sass、less 等都是 Compiler 的实例实现;与此同时会把原先那套 webpack-like 的 loader 机制迁移过来,但不是中间件实现,而是通过纯 web;再通过 tapable 把 compilers 有机结合到一起形成 Preset,并适量提供一些插件化的能力,该 Preset 用以描述一种项目开发时形态的描述,这也是也延续 sandpack 的想法;还有非常重要的一点是设计一套缓存方案,该缓存方案要把本地文件系统和浏览器的 BFS相通,这一块的链接直接决定了 gravity 面向 web 研发的延续;另外还有通用类的,比如计算型任务 web worker管理,错误管理,配置管理等。 如上完成,大概 Gravity 的理想就可以实现了。可以把本地的研发能力通过 Legacy Mode 表达出来,或许细心的同学要问了,怎么没有构建,其实 Legacy Mode 可以是生产环境的终态,但当前 HTTP2 并不普及,以及离线方案广泛应用,这种 Legacy Mode 方案,更加适合于开发环境,基本做到次时代的 bundless 的概念。Legacy mode 的玩法可以有很多,我们可以基于 webpack 去构建出 target 为 system 的模块 又或者基于 rollup 去构建出 format 为 system 的模块,从而把多个工具生态串联起来,应用到这个模式中来。
One bundle Mode 本质上是对现实的妥协,当然我们的业务体量来讲,one bundle 的方式在生产环境下更占优,dev 环境下有劣势。要实现 one bundle 其实非常简单,我们可以直接使用 rollup 把 format 设置为 self-excuting 的模式即可,通常也叫做 iife。而此时对应的编译系统则会走到 rollup 生态。到这里可能就有同学会有疑惑,如何保证 dev 环境下的 compiler 和 rollup 生态下的 plugin 拥有一致性。要解决这一点其实非常简单,我们使用同一个编译的内核就行,举例来讲,比如 rollup 的 babel 插件用的也是 babel-core 等,我们也使用同样的 babel-core 即可。话粗理不粗。否则 codesandbox 早翻车了不是。
在调试环境中我们通常会有如下需求:
更改一个非 webpack 构建 assets 内容,但希望引发重新构建。
这个场景就比如小程序中的 [page].json
以往我们的做法比较绕,大致可以归结为:
嗯,没毛病
但是这一次看 webpack watch 实现,让我对 watch 整体实现有了非常全面的了解。
如果仔细读过文章,可以知道 webpack 的监听是发生在 compile 之后的。
_done(err, compilation) {
...
const stats = compilation ? this._getStats(compilation) : null;
...
this.compiler.applyPlugins("done", stats);
...
if(!this.closed) {
this.watch(compilation.fileDependencies, compilation.contextDependencies, compilation.missingDependencies);
}
}另外 webpack 监听的内容发生变更终将引发新的 compile 过程,这个过程可以在文章 webpack watch 实现 的手稿笔记中,查看蓝色部分的回调链路。
带着这样的思路,我给出了一个假设:
compile 之后,只要保证
compilation中涵盖了额外的内容,那么额外文件变更也会引入重新 compile 过程。
比较庆幸的是在读 watch 机制的时候,大致看了下 webpack 的事件机制。 这一块后续必须要研读,非常具有借鉴意义。
在时间机制中有一个事件是 after-compile 就琢磨着,我就在这个时机修改下是否就可以了呢?
wala
于是就有了这个插件
插件实现非常简单,可以自行前往如上链接查看源码。
接下来大概说下如何使用这个插件吧
npm install --save extra-watch-webpack-pluginfiles: string or array, defualt [], attach extra files to webpack's watch system
dirs: string or array, defualt [], attach extra dirs to webpack's watch system
// webpack.config.js
import ExtraWathWebpackPlugin from 'extra-watch-webpack-plugin';
......
{
plugins: [
new ExtraWathWebpackPlugin({
fies: [ 'path/to/file' ],
dirs: [ 'path/to/dir' ]
}),
],
}
作为工具开发者,我想最常收到的反馈就是
为啥昨天还好好的,今天就挂了。
说实话这个问题同样也很困扰我。
背后的原因绝大部分都是依赖发生了不兼容的更新,这种问题非常让人头疼,主要牵扯出两个方面的问题:
举例我最近看到的三个因为 babel 升级引发的 bug
要解这个问题的第一条出路:锁依赖。
目前云谦 @sorrycc 同学也在积极尝试锁依赖这条路。
具体可以参考下
https://github.com/umijs/deps
umijs/umi#6148
要解这个问题的第二条出路:走 PR。
今天我主要和大家分享下解决 issue babel 锁死 semver 7.0.0 导致 Gravity 无法浏览器实时编译 这个 PR 的由来,以及我在这个过程中感受到内容。

时间回到 2021/02/25 开始有同学和我反馈利用 Gravity 开发时,页面出现报错,报错信息如下:

起先我的怀疑是 babel preset 可能有变更,导致编译之后的内容出现其他第三方库的内容(比如 core-js)。排查了一会儿之后很快发现错误来源是 babel 自身引用的 semver 引起的,所以接下来我去查看 babel 官方仓库,想要找找 semver 的 blame 信息,果不其然,让我找到了这个升级的 PR。
因为并不清楚 semver 被锁死在 7.0.0 的原因,所以第一时间,我给这个 PR 的作者留了言,PR 作者回复非常快,详细背景点这里 这边我大概和大家分享下原因。
祸因大佬 isaacs 发布了
[email protected],而该版本是个 breaking change 版本(不再支持 node-10 以下)。很多大佬纷纷追讨,为什么一个 breaking change 发生在 minor release 上,声讨作者知不知道该操作会害死一片开发者,因为大部分基础库都需要支持 node-8 极其以下,而很多库也已经升到^[email protected]。可是 isaacs 态度也很强硬,他坚决不认为这个锅应该让他来背,他的出发点是发生在 EOL 软件平台的 breaking change 并不算 breaking change (因为他在 7.0 时就已经不再支持老的 node 版本,现在他只是做了个 engines 标记而已)。自此,大伙儿似乎都把这件事情当成一个笑话来看。
个人觉得 isaacs 的行为并不太负责。那么在了解了这个背景后,我大概看了下 semver 的历史代码
semver@5
semver@6
[email protected]
semver@latest
其实发现 7.0.0 的代码初衷是好的,作者想要实现一个 lazy require 的效果,某种程度来提升执行效率,但是诸如 Gravity 作为构建,如果我需要打包 semver,这肯定就会出现问题,因为依赖的分析其实是静态化解析的过程,像 webpack 根本没法感知到这一层的逻辑(除非自写逻辑)。在翻看 smever 的历史 PR Remove the fancy preload logic in index.js #311
时也看到了作者对于这段 fancy logic (😹) 的无奈。
在明白了这些事情,以及看了 babel 历史版本对 semver 的诉求后,我提议能否把 semver 固定在 6.3.0,6.3.0 在是一个更为合理的选择。结果没想到,官方同意了这个提议,所以就有了这个 PR.
简单盘一下
近期,我们在内部做了一个类似 IDE 性质的应用,基于 electron 和 dva,由于之前一直只关注 node 相关的开发者工具,并未太多接触 React 等内容,所以这段时间过的有点煎熬同时也很兴奋,煎熬来源于非舒适区,而兴奋来源于发现基于 dva + electron 给开发者工具带来了更多的可能性。
此次开发 IDE 项目组织方式已由 sorrycc 同学整理成脚手架 dva-boilerplate-electron。
初识 dva 是此次总结的第一篇文章,第二篇文章我会记录下在 electron 中的相关沉淀。
回归正题,如何在几天内玩好 React、Dva、Electron。
React 的核心目的是创建 UI 组件,也就是说它是 MVC 架构中的 V 层,所以 React 和你的技术架构并没有关系。
打个比方来说在 AngularJS 1.x 中它通过扩展 html 标签,注入一些结构性的东西(比如 Controllers, Services),所以 AngularJS 1.x 是会侵入到你整个技术的架构,从某些方面来说这些抽象确实能解决一些业务问题,但由此而来的是塔缺乏了灵活性。
React 这种仅仅关注在 Components 的库,给了开发者非常强的灵活度,因为我不并不会被束缚在某一个技术架构。
总结来讲
从最上层来说 React Component 生命周期可以落入到以下三个环节:
在这三个类别下分别对应着一些 React 的抽象方法,这些方法都是在组件特定生命周期中的钩子,这些钩子会在组件整个生命周期中执行一次或者多次。明白了这些钩子的调用时机,可以有助于更好的书写组件。
比如:
componentWillMount: 在组件 render 之前执行且永远只执行一次。
componentDidMount: 组件加载完毕之后立即执行,并且此时才在 DOM 树中生成了对应的节点,因此我们通过 this.getDOMNode() 来获取到对应的节点。
等等详细请看 文档。
import React, { PropTypes } from 'react';
import ReactDOM from 'react-dom'
var SayHi = React.createClass({
getInitialState(){
return {};
},
getDefaultProps(){
return { from: 'pigcan' };
}
propTypes:{
name: PropTypes.string.isRequired,
},
render(){
var name=this.props.name;
return(
<p>{from} says: hello {name}! </p>
);
}
})
ReactDOM.render(
<SayHi name='pigcan'/>,
document.getElementById('demo')
)import React, { Component, PropTypes } from 'react';
import { Popover, Icon } from 'antd';
class PreviewQRCodeBar extends Component { // 组件的声明方式
constructor(props) { // 初始化的工作放入到构造函数
super(props); // 在 es6 中如果有父类,必须有 super 的调用用以初始化父类信息
this.state = { // 初始 state 设置方式
visible: false,
};
}
// 因为是类,所以属性与方法之间不必添加逗号
hide() {
this.setState({
visible: false,
});
}
handleVisibleChange(visible) {
this.setState({ visible });
}
render() {
const { dataurl } = this.props;
return (
<Popover
placement="rightTop"
content={<img src={dataurl} alt="二维码" />}
trigger="click"
visible={this.state.visible}
onVisibleChange={this.handleVisibleChange.bind(this)} // 通过 .bind(this) 来绑定
>
<Icon type="qrcode" />
</Popover>
);
}
}
// 在 react 写法中,直接通过 propTypes {key:value} 来约定
PreviewQRCodeBar.proptypes = {
dataurl: PropTypes.string.isRequired,
};
// 在 ES6 类声明中无法设置 props 只能在类的驻外使用 defaultProps 属性来完成默认值的设定
// 而在 react 中则通过 getDefaultProps(){} 方法来设定
PreviewQRCodeBar.defaults = {
// obj
}
export default PreviewQRCodeBar;import React, { PropTypes } from 'react';
// 组件无 state,pure function
const PreviewDevToolWebview = ({ remoteUrl }) => // 箭头函数,结构赋值
<webview className={devToolWebview.devToolWebview} src={remoteUrl} />;
PreviewDevToolWebview.proptype = {
remoteUrl: PropTypes.string.isRequired,
};
export default PreviewDevToolWebview;
// 此类组件不支持 ref 属性,没有组件生命周期的相关的时候和方法,仅支持 propTypes
// 此类组件用以简单呈现数据如果想了解更多的基础
简而言之 Flux 是一种架构**,和 MVC 一样,用以解决软件结构的问题,如上所说 React 只是涉及了 UI 层所以在搭建大型应用时必须要有与之配套的应用架构。在 React 社区大家普遍使用 Flux 架构的**来搭建应用,目前 flux 前端框架。
Flux 中最为显著的特点就是它的单向数据流,核心目的是为了在多组件交互时能避免数据的污染。
在 flux 模式中 Store 层是所有数据的权利中心,任何数据的变更都需要发生在 store 中,Store 层发生的数据变更随后都会通过事件的方式广播给订阅该事件的 View,随后 View 会根据接受到的新的数据状态来更新自己。任何想要变更 Store 层数据都需要调用 Action,而这些 Action 则由 Dispatcher 集中调度,在使用 Actions 时需要确保每个 action 对应一个数据更新,并同一时刻只触发一个 action。
说一说我个人的感受,在以往 MVC 架构中,某一个 Model 的数据可能被多个 View 共享,而每个 View 在通常情况下都会有自己的 Controller 层来代理 Model 和 View,那样子很显著的一个问题就出现了,任何一个 Controller 都可能会引发 Model 的数据更新,在现实中我们的应用通常拥有更为复杂的 UI 层,所以使用稍有不当我们的数据流将乱如麻,在调试中我们也会越来越难以调试,因为我们很难确定数据变更发生的确切位置。
如何来理解呢?
在 web 应用中,数据的改变通常发生在用户交互行为或者浏览器行为(如路由跳转等),当此类行为改变数据的时候可以通过 dispatch 发起一个 action,如果是同步行为会直接通过 Reducers 改变 State ,如果是异步行为会先触发 Effects 然后流向 Reducers 最终改变 State,所以在 dva 中,数据流向非常清晰简明,并且思路基本跟开源社区保持一致。
简而言之 dva 是基于现有应用架构 (redux + react-router + redux-saga 等)的一层轻量封装
dva 的基本概念有哪些?
以下内容基本摘自 Dva Concepts
State 表示 Model 的状态数据,通常表现为一个 javascript 对象(immutable data)。
Action 是一个普通 javascript 对象,它是改变 State 的唯一途径。无论是从 UI 事件、网络回调,还是 WebSocket 等数据源所获得的数据,最终都会通过 dispatch 函数调用一个 action,从而改变对应的数据。** 需要注意的是 dispatch 是在组件 connect Models以后,通过 props 传入的。**
dispatch({
type: 'user/add', // 如果在 model 外调用,需要添加 namespace
payload: {}, // 需要传递的信息
});以上调用函数内的对象就是一个 action。
用于触发 action 的函数,action 是改变 State 的唯一途径,但是它只描述了一个行为,而 dipatch 可以看作是触发这个行为的方式,而 Reducer 则是描述如何改变数据的。
在 dva 中,reducers 聚合积累的结果是当前 model 的 state 对象。通过 actions 中传入的值,与当前 reducers 中的值进行运算获得新的值(也就是新的 state)。需要注意的是 Reducer 必须是纯函数。
app.model({
namespace: 'todos', //model 的 namespace
state: [], // model 的初始化数据
reducers: {
// add 方法就是 reducer,可以看到它其实非常简单就是把老的 state 和接收到的数据处理下,返回新的 state
add(state, { payload: todo }) {
return state.concat(todo);
},
},
};Effect 被称为副作用,在我们的应用中,最常见的就是异步操作,Effects 的最终流向是通过 Reducers 改变 State。
核心需要关注下 put, call, select。
app.model({
namespace: 'todos',
effects: {
*addRemote({ payload: todo }, { put, call, select }) {
const todos = yield select(state => state.todos); // 这边的 state 来源于全局的 state,select 方法提供获取全局 state 的能力,也就是说,在这边如果你有需要其他 model 的数据,则完全可以通过 state.modelName 来获取
yield call(addTodo, todo); // 用于调用异步逻辑,支持 promise 。
yield put({ type: 'add', payload: todo }); // 用于触发 action 。这边需要注意的是,action 所调用的 reducer 或 effects 来源于本 model 那么在 type 中不需要声明命名空间,如果需要触发其他非本 model 的方法,则需要在 type 中声明命名空间,如 yield put({ type: 'namespace/fuc', payload: xxx });
},
},
});Subscriptions 是一种从 源 获取数据的方法,它来自于 elm。
Subscription 语义是订阅,用于订阅一个数据源,然后根据条件 dispatch 需要的 action。数据源可以是当前的时间、服务器的 websocket 连接、keyboard 输入、geolocation 变化、history 路由变化等等。
import key from 'keymaster';
...
app.model({
namespace: 'count',
subscriptions: {
keyEvent(dispatch) {
key('⌘+up, ctrl+up', () => { dispatch({type:'add'}) });
},
}
});这里的路由通常指的是前端路由,由于我们的应用现在通常是单页应用,所以需要前端代码来控制路由逻辑,通过浏览器提供的 History API 可以监听浏览器url的变化,从而控制路由相关操作。
dva 实例提供了 router 方法来控制路由,使用的是react-router。
import { Router, Route } from 'dva/router';
app.router(({history}) =>
<Router history={history}>
<Route path="/" component={HomePage} />
</Router>
);详见 react-router
在 dva 中我们通常以页面维度来设计 Container Components。
所以在 dva 中,通常需要 connect Model的组件都是 Route Components,组织在/routes/目录下,而/components/目录下则是纯组件(Presentational Components)。
** 通过 connect 绑定数据 **
比如:
import { connect } from 'dva';
function App() {}
function mapStateToProps(state, ownProps) { // 该方法名已经非常形象的说明了 connect 的作用在于 State -> Props 的转换,同时自动注册一个 dispatch 的方法,用以触发 action
return {
users: state.users,
};
}
export default connect(mapStateToProps)(App);然后在 App 里就有了 dispatch 和 users 两个属性。
好了,如上就是 dva 中的一些核心概念,起初看的时候可能一下子接收到的信息量颇大,但是不要着急,后续业务中的使用会让你对于如上概念越来越清晰。
那么如何来启动一个 dva 应用呢
// Install dva-cli
$ npm install dva-cli -g
// Create app and start
$ dva new myapp
$ cd myapp
$ npm install
$ npm startDone o.o
让我们来一窥 dva 项目 src 目录结构,尝试来明白整体的代码的组织方式
.
├── assets
│ └── yay.jpg
├── components
│ └── Example.js
├── index.css
├── index.html
├── index.js
├── models
│ └── example.js
├── router.js
├── routes
│ ├── IndexPage.css
│ └── IndexPage.js
├── services
│ └── example.js
├── tests
│ └── models
│ └── example-test.js
└── utils
└── request.jsassets: 我们可以把项目 assets 资源丢在这边
components: 纯组件,在 dva 应用中 components 目录中应该是一些 logicless 的 component, logic 部分均由对应的 route-component 来承载。在安装完 dva-cli 工具后,我们可以通过 dva g component componentName 的方式来创建一个 component。
index.css: 首页样式
index.html: 首页
index.js: dva 应用启动 五部曲,这点稍后再展开
models: 该目录结构用以存放 model,在通常情况下,一个 model 对应着一个 route-component,而 route-component 则对应着多个 component,当然这取决于你如何拆分,个人偏向于尽可能细粒度的拆分。在安装完 dva-cli 工具后,我们可以通过 dva g model modelName 的方式来创建一个 model。该 model 会在 index.js 中自动注册。
router.js: 页面相关的路由配置,相应的 route-component 的引入
routes: route-component 存在的地方,在安装完 dva-cli 工具后,我们可以通过 dva g route route-name 的方式去创建一个 route-component,该路由配置会被自动更新到 route.js 中。route-component 是一个重逻辑区,一般业务逻辑全部都在此处理,通过 connect 方法,实现 model 与 component 的联动。
services: 全局服务,如发送异步请求
tests: 测试相关
utils: 全局类公共函数
import './index.html';
import './index.css';
import dva from 'dva';
// 1. Initialize
const app = dva();
// 2. Plugins - 该项为选择项
//app.use({});
// 3. Model 的注册
//app.model(require('./models/example'));
// 4. 配置 Router
app.router(require('./router'));
// 5. Start
app.start('#root');好了,以上便是五部曲,看了 dva 官方文档的可能说还少一步
// 4. Connect components and models
const App = connect(mapStateToProps)(Component);原因是在实际业务中,我们的 connect 行为通常在 route-component 中进行设置。
以上。
对了,人为新增 model 后记得 model 要在 index.js 中予以注册,当然使用脚手架功能并不存在这个问题。 XD。
作为工具开发者,babel 关联问题是难绕过去的砍。
在 babel@6 时候,最常收到反馈之一就是 regeneratorRuntime is not defined
而到了 babel@7,最常收到反馈之一 Cannot find module 'core-js/library/fn/**'.
那是什么问题导致这些问题的出现呢,我觉得有一个 issue 特别能代表这一类的开发者。大家不要笑,我们内部一些基础模块也有这个问题
总结来讲:Babel 在编译大家的代码时候,会依据大家配置的 preset or plugin 注入一些模块依赖,而这些模块依赖是大家需要在 pkg.dependencies 里面体现出来的,否则很可能出现的问题就是加载不到具体的文件或者加载错误的版本的文件。
根本的原因是什么:其实大家对
@babel/preset-env@babel/plugin-transform-runtime@babel/runtimecore-js@babel/polyfillsbabel-polyfills等等这些熟悉但又陌生的原因。
那今天我想大概和大家分享一下使用 babel@7 的心得,如有不对,欢迎大家及时指出。
开讲之前我们有必要先来看看各个包到底是干啥的
@babel/preset-env在 babel@7 推出之际,babel 官方把 babel preset stage 以及 es2015 es2016 等等都废弃了,取而代之的是 @babel/preset-env。
@babel/preset-env is a smart preset that allows you to use the latest JavaScript without needing to micromanage which syntax transforms (and optionally, browser polyfills) are needed by your target environment(s). This both makes your life easier and JavaScript bundles smaller!
通过官方文档的描述,preset-env 主要做的是转换 JavaScript 最新的 Syntax(指的是 const let ... 等), 而作为可选项 preset-env 也可以转换 JavaScript 最新的 API (指的是比如 数组最新的方法 filter 、includes,Promise 等等)。
这里细心的同学估计发现了我刻意在强调 Syntax 和 API, 是的,babel 在实现编译 或者我们在组合使用各个 preset 或者 plugin 时,其实有隐含这一层的关系的,同时这里也有一些历史背景,为了不给大家增加负担,我们只需要点到为止就好,需要了解的自行深挖也行。
说到这,我需要给大家一些 tips:
综上我想小伙伴们会有几个困惑
要解释清楚这几个问题,首先需要大概知道 preset-env 的三个关键参数
Describes the environments you support/target for your project.
简单讲,该参数决定了我们项目需要适配到的环境,比如可以申明适配到的浏览器版本,这样 babel 会根据浏览器的支持情况自动引入所需要的 polyfill。
"usage" | "entry" | false, defaults to false
This option configures how @babel/preset-env handles polyfills.
这个参数决定了 preset-env 如何处理 polyfills。
false: 这种方式下,不会引入 polyfills,你需要人为在入口文件处import '@babel/polyfill';
但如上这种方式在 @[email protected] 之后被废弃了,取而代之的是在入口文件处自行 import 如下代码
import 'core-js/stable';
import 'regenerator-runtime/runtime';
// your code不推荐采用 false,这样会把所有的 polyfills 全部打入,造成包体积庞大
usage:
我们在项目的入口文件处不需要 import 对应的 polyfills 相关库。 babel 会根据用户代码的使用情况,并根据 targets 自行注入相关 polyfills。
entry:
我们在项目的入口文件处 import 对应的 polyfills 相关库,例如
import 'core-js/stable';
import 'regenerator-runtime/runtime';
// your code此时 babel 会根据当前 targets 描述,把需要的所有的 polyfills 全部引入到你的入口文件(注意是全部,不管你是否有用到高级的 API)
String or { version: string, proposals: boolean }, defaults to "2.0".
注意 corejs 并不是特殊概念,而是浏览器的 polyfill 都由它来管了。
举个例子
const one = Symbol('one');==Babel==>
"use strict";
require("core-js/modules/es.symbol.js");
require("core-js/modules/es.symbol.description.js");
require("core-js/modules/es.object.to-string.js");
var one = Symbol('one');这里或许有人可能不太清楚,2 和 3 有啥区别,可以看看官方的文档 core-js@3, babel and a look into the future
简单讲 corejs-2 不会维护了,所有浏览器新 feature 的 polyfill 都会维护在 corejs-3 上。
总结下:用 corejs-3,开启 proposals: true,proposals 为真那样我们就可以使用 proposals 阶段的 API 了。
使用 preset-env 注入的 polyfill 是会污染全局的,但是如果是自己的应用其实是在可控的。
所以这里推荐业务项目这么使用 .babelrc
{
"presets": [
[
"@babel/preset-env",
{
"targets": {
"chrome": "58" // 按自己需要填写
},
"useBuiltIns": "entry",
"corejs": {
"version": 3,
"proposals": true
}
}
]
],
"plugins": []
}import 'core-js/stable';
import 'regenerator-runtime/runtime';
// 入口文件代码这样配置的原因是:targets 下设置我们业务项目所需要支持的最低环境配置,useBuiltIns 设置为 entry,将最低环境不支持的所有 polyfill 都引入到入口文件(即使你在你的业务代码中并未使用)。这是一种兼顾最终打包体积和稳妥的方式,为什么说稳妥呢,因为我们很难保证引用的三方包有处理好 polyfill 这些问题。当然如果你能充分保证你的三方依赖 polyfill 处理得当,那么也可以把 useBuiltIns 设置为 usage。
针对大众普通项目,可能如上方式的配置(撇开个性化)应该够用了,
但追求极致的同学会有两个问题:
问题一:还是会有一定程度的代码重复,举个例子:
import a from 'a';
export default a;==Babel==>
"use strict";
Object.defineProperty(exports, "__esModule", {
value: true
});
exports.default = void 0;
var _a = _interopRequireDefault(require("a"));
function _interopRequireDefault(obj) { return obj && obj.__esModule ? obj : { default: obj }; }
var _default = _a.default;
exports.default = _default;
_interopRequireDefault 这个方法,明显是可以变成一个独立模块,这样打包体积会变更小(再少也是爱)。
问题二:针对项目,polyfill 会污染全局可以接受,但是作为 Library 我更希望它不会污染全局环境
两个都是好问题,那么接下来就是 @babel/plugin-transform-runtime 的出场机会了。
@babel/plugin-transform-runtime@babel/plugin-transform-runtime
官方描述是这样的
A plugin that enables the re-use of Babel's injected helper code to save on codesize.
很明显该插件的出现就是复用 babel 注入的关联代码。
具体 @babel/plugin-transform-runtime 做了什么,官方也有明确的解释,相信大家都能看明白:
The transform-runtime transformer plugin does three things:
Automatically requires @babel/runtime/regenerator when you use generators/async functions (toggleable with the regenerator option).
Can use core-js for helpers if necessary instead of assuming it will be polyfilled by the user (toggleable with the corejs option)
Automatically removes the inline Babel helpers and uses the module @babel/runtime/helpers instead (toggleable with the helpers option).
举个例子:
import a from 'a';
export default a;"use strict";
var _interopRequireDefault = require("@babel/runtime/helpers/interopRequireDefault");
Object.defineProperty(exports, "__esModule", {
value: true
});
exports.default = void 0;
var _a = _interopRequireDefault(require("a"));
var _default = _a.default;
exports.default = _default;这是不是解决了上面提到的问题一。
至于问题二,关于 polyfill 全局污染,不打算展开,因为涉及源码讲解,大家只需要知道 通过 @babel/plugin-transform-runtime 插件实现的 polyfill 是不会影响全局的,所以更适合 Library 作者使用
另外也肯定会有好奇宝宝 @babel/plugin-transform-runtime 开启 corejs 并且 @babel/preset-env 也开启 useBuiltIns 会咋样。结论是:被使用到的高级 API polyfill 将会采用 runtime 的不污染全局方案(注意:@babel/preset-env targets 设置将会失效),而不被使用到的将会采用污染全局的。
所以总结下:
如果针对组件开发者,无需关注 @babel/preset-env 的 targets, 并开启 @babel/plugin-transform-runtime 的 corejs,此时对于 polyfill 的注入相当于是 @babel/preset-env useBuiltIns usage 的形式
如果针对业务开发者,请开启 @babel/preset-env 的 targets,并关闭 @babel/plugin-transform-runtime 的 corejs
| corejs option | Install command |
|---|---|
| false | npm install --save @babel/runtime |
| 2 | npm install --save @babel/runtime-corejs2 |
| 3 | npm install --save @babel/runtime-corejs3 |
根据如上 option,@babel/runtime 要做为项目的 dependencies
根据如上 option,@babel/runtime 要做为项目的 dependencies
根据如上 option,@babel/runtime 要做为项目的 dependencies
@babel/plugin-transform-runtime ,建议关闭 corejs,polyfill 的引入由 @babel/preset-env 完成,即开启 useBuiltIns(如需其他配置,自行根据诉求配置)。{
"presets": [
[
"@babel/preset-env",
{
"targets": {
"chrome": 58
},
"useBuiltIns": "entry",
"corejs": {
"version": 3,
"proposals": true
}
}
]
],
"plugins": [
[
"@babel/plugin-transform-runtime",
{
"corejs": false
}
]
]
}并在入口文件处 import 如下内容
import 'core-js/stable';
import 'regenerator-runtime/runtime';
// 入口文件代码@babel/plugin-transform-runtime ,建议开启 corejs,polyfill 由 @babel/plugin-transform-runtime 引入。 @babel/preset-env 关闭 useBuiltIns。{
"presets": [
[
"@babel/preset-env",
]
],
"plugins": [
[
"@babel/plugin-transform-runtime",
{
"corejs": {
"version": 3,
"proposals": true
}
}
]
]
}但心细的同学,肯定又发现了新的问题
为什么 @babel/preset-env 不能使用不污染全局的 polyfill(请注意不污染全局的 polyfill 必须由 @babel/plugin-transform-runtime 引入);
为什么要使用不污染全局的 polyfill 就必须要使用 @babel/plugin-transform-runtime,而与此同时我必须妥协掉preset-env targets 带来的体积优势(请注意,由于是不污染全局的前提,我们默认是由 runtime 引入 polyfill )
如何解决呢?
抱歉在现有的 babel 正式体系下还没好办法来解决这个问题,当然 babel 也意识到了这个问题,于是有了 babel-polyfills。
注意是 babel-polyfills 不是 @babel/polyfills,我们移到文章最后。
@babel/runtime不需要深入研究它,请结合 @babel/plugin-transform-runtime 来看。
core-js不需要深入研究它,请结合 @babel/preset-env 来看。
@babel/polyfills已经在 [email protected] 废弃,请结合 @babel/preset-env 来看。
babel-polyfills这个库的动机就是我们在 @babel/plugin-transform-runtime 小节下最后提出的问题:
Motivation
但是目前这个库处于 experimental 即试验性的阶段,按我对 babel 的了解,并不推荐大家当前在生产中引入,我们可以开放的心态保持关注即可。
至于想要尝鲜的,官方也给了 升级方式。
ps: 自己尝鲜自己负责(我是求生欲极强的作者 o.o)
这篇文章没有 TLDR; 不管你是工具开发者、Library 开发者还是业务开发者,多一点耐心,好好把这篇文章捋一捋,因为就我观察 99% 的开发者都弄不明白。
「蚂蚁 RichLab 前端团队」致力于与你共享高质量的技术文章,欢迎关注我们的知乎/掘金专栏,将文章分享给你的好友,共同成长 :-)
我们团队正在急招前端工程师以及 22 届实习生:前端/全栈开发、互动图形技术、低代码/工程化、前端架构、数据算法 等技术方向任选。团队技术氛围好,上升空间大,简历可以直接砸给我 [email protected]
由于是 Youtube 重度中毒患者所以在 Youtube 上关注了很多自己感兴趣的 Vloger. 然后经常被问关注了哪些能不能共享下,所以整理了下分享给大家。
对 spm 历史不感兴趣的同学可以直接从 ant tool 段落读起
下文说说我理解的支付宝前端构建工具发展史,从 spm 到 ant tool,再到未来我们可能会走的路。
在谈及 spm1 spm2 时,我们不得不回过头去看当时的历史背景,时间大概是 2012 年左右,当时前端模块化非常火热,伴随模块化的浪潮,模块加载器就不约而同成成为不得不做的命题。所以那会儿出现了 seajs 等一系列的模块加载器。所以起初 spm 的定位是 sea.js 配套的打包工具。但是新的问题又来了,模块化进程其实非常快,但是这些模块要何去何从呢,由于当时 npm 并不接受浏览器的包发布在其上,所以 spm 源服务器就应运而生了,现在骂声很多,但是那个时候源服务器的产生是有其历史价值的。
所以那会儿 spm 演变为一个前端组件包管理器,和 npm 托管 node 包一样,它实际管理着各类 module 的生命周期。所以那会儿它不包含实际的构建功能,而具体的构建功能,当时是写了扩展交由 gulp,或者衍生的 spm-build 等处理。
从这演变可以得到的结论是,spm 那会儿更看重的是遵从 CMD 规范的模块生态圈。但是比较可惜的是,没过多久 npm 开始接受了浏览器的包,并且 CommonJS 规范也越来越得到公众的认可,npm 的活跃度、 CommonJS 的广泛度、和 seajs 之间的复杂度一度让 spm 淹没在吐槽声中。这时 spm 3 应运而生。
spm3 应该是 一个 all in one 的大跨步,它涵盖了浏览器模块生命周期,包括初始化、本地化调试、文档、发布、单元测试、构建、源服务等功能。spm 3 解决了很多以往 seajs 项目中的构建问题
但是在我看来那会儿最重要的事情是 编码书写规范从 CMD 规范全面转向 CommonJS。可以窥探出的是 CMD 真在逐步退出历史舞台。拥抱社区的进程真在一步一步的推进。
但是那会儿 spm 和 seajs 还是存在着屡不清的关系。
工具在业务内的复杂度开始初步显现,spm 2 和 spm 3 共存一度让大家头疼,我认为这也是工具收敛最初的来源。
在这个系列的版本进程中,最重要的事情是撇开了 seajs 这个历史包袱,把 sea.js 的功能合并进入 spm-sea,构建工具开始全面拥抱社区的解决方案。
但 all in one 的配置方式,也把维护人员带入到了另一个深渊,因为配置会存在互斥性,同时配置达到一定量级和复杂度后,要想要新增一个配置,或者某个配置会引发群体效应时,我们都不敢动了,即使有严格的用例。
随着业务项目的复杂度的提升,性能这个词开始被广大的开发者所注重,从最原先几秒的构建时间上升到了分钟,甚至几十分钟。这些点都是我们那会儿无法预计的。
但也就那时 15 年初,webpack 开始进入大家的视线,一时间所有开发人员都对 webpack 宠宠欲动,但 webpack 高度的学习成本,函数式的配置方式,也让大家望而却步,但不乏开发同学对其尝鲜。
所以那会儿出现了 spm2 spm3 spm3.4 spm3.6 spm-sea 。
基于 webpack 的大火,和其优异的生态圈,spm 3.6.x 的 build 核心变更为了 webpack,但依旧提供配置式的方式来介入具体的构建过程。我也在这个时间段开始进入 spm 的维护。
受益于 webpack 天然生态,我们在各方面得到了一劳永逸的效果。然后好景并没有很长,由于 react 生态圈的兴起,大量优异的模块在社区涌动,而众所周知, spm 其实绑定了 spmjs.io 这个模块生态圈,所以开源生态和闭源生态之间的矛盾越发的开始变得激烈。
无奈之下,spmjs.io 源服务开始能同步社区的模块到其生态圈,在这个过程中,虽然放缓了矛盾,但是源服务器因此而频频出现故障也让我们苦恼不已。进而源稳定性越来越成为其中的一个话题。
所以后续才有了放弃 spm 源进驻 npm 源的一系列事情。
spm 源进驻 npm 源这是一个看似简单的命题,就是把 spm 上所有的包全部在 npm 上发布一遍。 然后我们却花了大量的精力,1. 首先我们必须把所有包所有版本全部需要发布一次;2. 包需要做内外网的隔离;3. 包存在同名情况;4. 需要重写原有包的部分内容,但之后如何同步给包所对应的仓库,因为有些模块并不存在实际仓库 等等。
当然所有问题都会被解决,最终我们顺利迁移 2000 + 模块,上万个版本,spmjs.io 源服务器也如期下线。
在以上进程中,作为开发者,我最大的感触是,想要去维护好自己的一个生态圈是一件多么难的事情,特别是在通用领域上,比如构建、调试、源等和社区保持好良好关系的重要性。当然每个时期都会有一定的局限性,所以大家都是在跌跌撞撞中得到成长。
在经历了,spm 一系列的变更后,构建工具已经完全是放射性了,如何在构建层的收敛成为了我们不得不面对的问题。
另外在如上所说,spm 配置式的方式,达到一定量级和复杂度后,要想要新增一个配置,或者修改某个配置经常会引发群体效应,有时根本没法改,工具对于维护人员的束缚日趋明显,而随着业务类型的增加,比如 H5 开发的井喷,导致开发人员的个性化需求猛增,变革变得更加急迫。
在这个过程中我们经过了很长时间的讨论,围绕的点可以归结为工具 **中心化和去中心化 **。
什么是中心化:
中心化的思路本质上是 all in one, 即我们基本上需要去覆盖开发人员的整个工作流,从项目初始化,开发,构建,调试和联调,以及发布,可能还会衍生测试,proxy,文档等其他服务。中心化的思路好处是,用户体验度高,入口具有唯一性。但缺点也很明显,all in one 就是大,另外由于内置了什么可能的方案,用户个性化需求基本不能满足,同时达到一定程度后,工具会变得没法维护。
什么是去中心化:
去中心化思路本质上是工具模块化开发,即我们去落实用户在整个工作流中可能会需要的解决方案,在用户在特定业务场景中需要某个功能时,加载和选择对应的模块即可。这种方式的好处是,让各个解决方案成为了单点模块,用户在最终使用时可以选择性使用,缺点是成本相对较高。为此我们通过脚手架来解决相关问题。
基于这个场景下 ant tool 的历史使命出现了,ant tool 想要达到一个非常灵活的状态,同时把所有的业务场景通过某种扩展配置的方式收敛到一种形态的工具上。
ant tool 只是一个 代号,在 ant tool 体系下有很多下沉至开源社区的职责单一的模块,而这些模块具备了:构建、调试等所有功能。
所以 ant tool 对于开发者的视图是一个一个的散点,而散点是我们给出的解决方案,诸如
与此同时我们也尝试给前端工具下了一个定义:前端开发工具是一个把 规范化输入内容 转化为 规范化输出内容 的转化器。
在这个定义下,我们细化了各类业务场景做为规范化的输入,但是如何规范化呢,答案是 细分业务类型脚手架。
脚手架很好的解决了工具有点到面的过程,相对降低了工具的门槛。
所以要用一句话来概括 ant tool 可以归结为 ** 一套更加 面向社区 的、更加 轻薄灵活 的,并以 脚手架做为输出口径 的解决方案 **。
但随着脚手架方案的普及,弊端也随之而来了。
总结来说使用脚手架的问题是:
灵活的 webpack.config.js 带来的配置灾难
因为 atool-build 只是针对共性业务,实际业务场景下可能并不能满足,所以为了灵活性,我们在 atool-build 中引入了 webpack.config.js,这个配置的作用在于给用户一个时机覆盖 atool-build 内的配置。
这是一个看似合情合理的需求,但为何我现在把它描述为一种灾难呢?
atool-build 的定位是通用性的,所以到具体业务场景 100% 会出现不够用的情况进而使用扩展,目前基本所有的业务类型脚手架全部需要基于 atool-build 的配置,在做一层业务化,这个情况同样也发生在 doc site chair-atool fengdie 等基于 atool-build 做二次封装的。小规模使用情况下问题都不会显露,当大规模使用后,问题就越来越显现了。这种思路下,atool-build 将很难新增 feature 或者 修改内置参数。原因是在用户配置中很可能已经对其进行了修改,而再当有内置配置发生更新时,很多业务配置中的相关判断将会失效。从而影响整体用户配置的生效,从而影响构建结果的正确性。
举例来说之前 atool-build 在 0.10.x 版本时尝试对 .icon.svg 的 svg 应用 svg-sprite-loader, 同时对原有的 .svg 配置的 test 变更为 .svg 非 .icon.svg 。就这样的改动,业务线非常多的项目就出问题了,原因在于,用户端对 .svg 文件的 test 进行了强行的依赖。
atool-build 给到的启示是,一旦开了灵活度极高的 webpack.config.js 都很可能让构建的主体变得难以升级,但个性化需求永远存在,如何解开这个难题是关键的关键。另外大量脚手架都需要在 atool-build 的基础上自定义配置,这种集中式的看似通用性的通用配置,是否真的合适与实际多变的业务场景。
转而我们再来看看其他的解决思路。
create-react-app 是 fb 家创建 react 应用的工具。使用它可以很方便的创建一个 fb 推荐的 react 应用,其内部会包含构建所需的所有配置内容。那它是是如何看待,要在内置配置上做修改这个需求呢,fb 的答案很明确,这就是我们的最佳实践,你要改,那么使用 eject 功能吧。 eject 本质是把 cra 中内置的 webpack 配置一口气全部给到用户,同时也很抱歉,你的项目已经脱离于 cra。
反问我们能那么做吗? 我们面对的不单单只是 pc react 应用场景,还有 mobile 等其他使用业务场景。
但是 cra 的优点也非常凸显,它能把其中的体验做到极致。
由于 create-react-app 的默认配置不能满足需求,而他又不提供定制的功能,于是云谦同学基于 cra 现有代码的基础上实现了一个可配置内置配置的版本 roadhog,roadhog 针对 dva 做过很多优化,所以这也是云谦把 roadhog 定位服务于 dva 应用的很重要一部分原因。另外所谓的可配置就是对已有的内置的 loader 或者 plugin 传递一些参数,或者功能的开启或者关闭等。这某种程度上解决了既要 create-react-app 的优雅体验,又想定制配置的需求。
但是问题还是不得不需要面对,对于新增配置的业务场景呢?
从最开始的不支持这种使用场景,到逐步开放一些内部配置,再到支持通过 webpack.config.js 以编码的方式进行配置,可以看出这是一个相当纠结的过程。其实大家都知道,支持通过 webpack.config.js 的方式基本可以肯定是后续想要暗箱升级,是不太可能了。本质上这和 atool-build 是一模一样的情况。
经过那么多年的发展,各类方式的长和短差不多都已心知肚明。那如何根本上解决这个问题呢?
个人观点:
要放弃特定业务脚手架针对通用型构建配置进一步修改或者封装的这种方式。原因在于,一做为构建主体会很难升级,二业务会强绑定死某个版本,三业务很可能在某个阶段需要构建配置,目前脚手架这种一旦初始化生命周期就被终止的情况,很难把新的内容给予到老的业务。
抹杀 webpack.config.js 这种形式,至少要在所有正常归属业务中抹杀掉。
实现语义配置,用户只需要知道语义化的配置来实现配置的自定义。
那如何达成以上这三点呢?
我想到了 m-init 无线端脚手架的演化,以及 babel 的 preset.
分别来说说这两个看似没有关系事情。
m-init 诞生之初都由我一个人在维护,内部包含了通用型的离线包业务,react-native 业务,component 等,但是随着业务方自己在各方面的沉淀,在应用架构也好,在工具端的认知度也好,我慢慢开始享受 pr/mr 的过程。到目前 m-init 已经不再托管实际脚手架,而只是作为标准化业务脚手架输出的管理工具。简单的来说我的角色变成了审核以及 code review。
而 babel 的 preset 只是针对了特定的技术选型或者 transform 条件而集合在一起的一堆 babel-plugin。方便记忆和管理,便把它通过 preset 这种方式告知于用户。
所以我相信未来的配置应该是属于 preset 这种方式和方向的,而基于 m-init 中演化,我并不担心这整一套机制的在业务中落地的可行性。
那问题又来了,preset 到底是什么?如何看待 preset 和 普通开发者之间的关系呢?又如何实现 preset 这种机制呢?
我尝试用一些图来说明
构建因子:在这边额外引入了一个概念叫构建因子,白话来说它是可以被沉淀的一种针对某种构建场景的最小单元解决方案。而在具体实现中,构建因子需要符合因子的规范。在这边大家可以理解为所有的因子都是某个基础因子的 extension,在这些 extension 中需要用户实现对应的 hook 即钩子,如 pre、post、main、和 service。前三者应该不用过多解释,而 service 即提供了从用户端读取特定配置的功能,即语义化配置的最终来源。
preset: 业务 owner 即目前脚手架维护者,从构建因子中挑选已有的解决方案,形成一个业务级别的 preset,该 preset 会以 npm 包的形式存在,并最终被业务脚手架所引用。而作为业务普通开发者可以在约定配置文件中,针对 preset 做出选择性调整。任何不能适应当前 preset 的情况,都需要基于当前 preset 创建新的 preset。这么做的原因在于,业务一旦稳定,配置也会稳定,如果需要变更,可以理解为 1. 新的类型,那么创建新的 preset 2. 如果是新增 feature,则 告知维护当前业务 preset 成员新增因子,并由开发人员决定是否将其开启。
通过以上这些我相信能更好的解决如上提到的这些问题,业务也会从配置这个泥潭中出来。
同时这种处理方案还能解决:
2017/5/8 更新
虽然上文中已经提到了中心化和非中心化,但总感觉没讲彻底,所以故予以补充。
在我的理解中,中心化是 AllInOne 的代表,具体表现在工具时,当工具需要支持的业务类型足够多时,那需要内置的内容即解决方案就要足够多,如此一来,工具本身在尺寸上就会显得臃肿一些(比如当初 spm 尺寸达到了 400MB 以上),这是我想要表达的缺陷1: 尺寸大。由于要做到一面千用,那么势必可配置的内容也要足够的多,用户的灵活度提升了,但背后牺牲的是工具本身的灵活度和可维护性,因为往往配置到了一定程度后,就会存在配置同步与配置互斥的问题,这往往是面对后续新需求,但又无从下手的导火索,这是缺陷2:开发者维护性会越来越差。另外配置足够多是否意味着用户用的越 high 呢?在 spm 时代,对于构建我们大概有 20 多个 配置项,这是一个看起来并不起眼的数字,即使在文档充裕的情况下,用户也经常被配置困惑,很多时候一个字段很难把事情描述明白,另外在往常项目中,配置文件往往是收敛在 package.json 或者某个 .rc 文件下,时间一长项目一交接工具一升级,等等这之后就没有人感动项目内的配置文件了,这都是发生的真实案例,这是我要表达的 缺陷3:可配置并不意味高用户体验度。
所以在个人观点中,我并不建议把需要面向多种业务形态的工具 - 构建和调试工具,做成 AllInOne 的形式。如果你的工具就面向一种业务形态,那么中心化或许可以提供更好的用户体验,甚至可以内置脚手架。
但是在面向多业务形态时,对于中心化,我们现在的做法是脚手架进行输出,也就是我们的脚手架内容其实是中心化的。它的作用并不单单初始化一个项目,而同时也输出了衔接各类其他前端工程类产品方式。
在如上图的架构设计中,构建因子是离散的即所谓的非中心化,它是单个功能的解决方案,用户可以在各个方案选择中可以实现热替换,而 preset 本质上是中心化的,它是规定某个业务对构建的完全描述。
在线下沟通中,很多同学并不能理解未来工具体系如何做到收敛,如何做到更新,作为原有的构建实体 atool-build 又该承担怎么样的角色。在这里再重新梳理一下。
在上图的分层结构中,作为开发者应该活跃在构建因子层,而业务 owner 应该主要活跃在 preset 函数式配置层,而普通开发者应该主要活跃在 rc 语义层配置。在目标态中,一旦业务层 preset 确定 后普通业务开发者应该去动语义层配置的机会会很少。
如何理解 preset 层是需要函数式的呢,原因在于构建因子层在设计中本质是一个函数块,钩子的方法集,另外确保一定的灵活性,所以这里不得不是函数式的。同时 preset 对构建因子的组合方式也决定了用户 rc 语义层的配置,原因在于,构建因子存在对特定构建配置的读取权。
而 preset 要作为 npm 包它的出发点其实来源于收敛和更新。众所周知在以往我们把配置完完全全留在了项目端,而且该配置还是函数式的,这样太高灵活度导致的是构建实体没法升级,于此同时,一旦某一类业务发生变更那么就需要手动通知所有的该业务类型进行升级,如果没有很好的监控体系,这几乎是一个不可能完成的任务。而 preset 作为一个 npm 包由业务 owner 来进行维护,一旦该包发布版本,那么就可以普惠到所有的业务开发者。另外由于 preset 的形式本身就约束了用户端的灵活性所以在升级阻力上基本可以视为 0 阻力。
那又如何理解原有的 atool-build 将来会承担怎么样的角色呢?
在原先 atool-build 只是一个中性的构建工具,而往后由于实际描述构建能力的内容已经被 preset 替代,它更多程度上会转换为一个壳的角色,可以让自己的版本维持在一个相对稳定的版本。得益于 preset 机制,在壳上我们可以做到一些基于配置的性能优化分析。另外 atool-build 也将承载调度 preset,提醒 preset 升级等,一系列围绕在 preset 周边的功能。
首先先自我介绍下,我是来自 RichLab 花呗借呗前端团队 的同学。在公司大家喊我玄寂,生活中大家称呼我 pigcan 或者猪罐头。除了是一个程序员,我现在也在尝试做一名 YouTuber 和 up 主,也在微信公众号中分享我的生活,我自己的方式践行快乐工作,认真生活。

首先为了让大家有更好的体感,我们先来看一个案例。这个案例是使用code mirror 加 antd tab 组件加 gravity 做的一个实时预览。大家可以通过这个 gif 能看到,我变更js文件或者样式文件的时候,在右侧这个预览区域可以进行实时的更新,那这部分的能力完全由浏览器作为支撑在提供出来,并不涉及本地 server 或者 远程 server 能力的输出。
在有了这个体感之后,大家可能会更容易理解我之后讲的内容。
那接下来我会从5个方面来切入来谈一谈基于浏览器的实时构建探索之路。
第一点是背景,从历史来看构建工具每次发生大的变更时,都和前端的技术风潮息息相关,那 2019 年前端界发生的变化,也可以说是促使我做这个技术探索的原因。
有了这些变化,通常情况下现有的技术架构就会可能出现不满足现状的情形,这就是机遇了,这也就是我第二部分想要来说的,基于这些变化对于我们的构建会有哪些机遇,而面对这些机遇,我们在技术上又会有哪些挑战。
第三点我会来谈一下在面对这些机遇和挑战时,我们在技术上的做出的选择,也就是我们如何来架构整个技术方案。
第四点我会来谈一谈基于这种技术架构下会需要克服的技术难点,主要是要抛一些我的解决思路。
第五点也是最后一点,我会来谈一谈这个技术方案可以有的未来,其实更多的是我对他的期待。
时间回到2011年,那会儿我们前端一直在强调复用性,基于复用性的考虑,我们会把所有的文件尽可能的按照功能维度进行拆分,拆的越小越好,这种追求我称它为粒子化。粒子化的结果是工程的文件会非常非常碎,所以那个时候的构建工具,更多的思路是化零为整,典型工具有 grunt 和 gulp。
随着粒子化时代的到来,到 13 年左右很快新的问题出现了,在我看来主要集中在了两个部分:第一个是,传统的拼接脚本的方式开始并不能满足模块化的需求,因为模块之间存在依赖关系,再者还有动态化载入的需求;第二个是那么多功能模块被划分出来了我们放哪里是一个问题,最初 npm 是并没有向前端模块开放的。 所以接下来便出现了模块加载器,和包管理之战。这场战役让我们的前端模块规范变得五花八门,最后好在所有的包落在了 npm 了。所以这个时候的构建工具更多的是抹平模块规范,典型工具 webpack 的出现意义很大一部分就在于此(当然在这个过程中其实还出现了各种基于加载器去做的的定向构建工具和包管理,这里就先不谈了)。
那时间再次回到 2019 年,我们听到了不一样的声音,这些声音都在对抗 bundler 的理念。
比较典型的有两篇文章:
为什么会有这些声音,这些声音背后的原因是什么?一方面是因为会新的技术标准的出现,另外一方面也来源于日益陡峭的学习曲线。
现在的前端开发要运行一个项目通常我们需要知道:
反正就是一个字,“南”
再来看看我们的包管理,以 CRA 为例现在我们要运行起一个 react 应用,我们居然需要附加如此复杂的依赖。

在网上也有一些调侃,前端的依赖比黑洞造成的时间扭曲还要大。

回过头再来看,2019 的趋势是什么,相信大家都感觉到了云这个词,我们很多的流程都在上云。那面向上云的这种场景,我们如此复杂的 bundler 和包管理是否符合这种趋势呢?
归根结底,其实是要探讨一个问题:前端资源的加载和分发是不是还会有更好的形式。
面对这个问题,我觉得是有空间的,正是这种笃定,才有了接下来的内容。
在上一小节中我们已经谈到了 2019 年不管是 pro / low code 都在朝着上云的趋势在变化,那应对这些变化,我们先来看看现有的一些平台,他们对于构建的态度是什么。
| 类型 | 代表 |
|---|---|
| 专业 | Codesandbox、Stackbiltz、Gitlab Web IDE、Ali Cloud IDE |
| 辅助 | Outsystems、Mendix、云凤蝶 |
从这些平台中我们可以总结出三种态度:
总结下这三种态度,本质上是使用了两种技术方案
最终其实可以总结为:
云时代的来临,我认为配套的构建也来到了十字路口,到底是继续维持现有的技术架构走下去,还是说另辟蹊径,寻找一条更加轻薄的方式来配合上云。
我们再回过来看看,2019 年为什么在社区能释放出这些声音来(Luke Jackson - Don’t Build That App!、Fred K. Schott - A Future Without Webpack),为什么会有人敢说,我们可以有一个没有 webpack 的未来,为什么 Bundless 的想法能够成立,支撑他们这些说法的技术依据到底是什么。
归纳总结下:
比较典型的产品有:systemjs 0.21.x & JSPM 1.x 、stackblitz 、codesandbox
比较典型的产品有:systemjs >= 3.x & JSPM 2.x 、@pika/web
再看了这些产品和技术实现后,我内心其实非常笃定,我觉得机会来了,未来肯定会是轻薄的方式来配合上云,只是这一块目前还没有人来专心突破这些点。
所以我觉得未来肯定是 云 + Browser Based Bundless + Web NPM,这就是 Gravity 这套技术方案出现的背景了。
所有的挑战其实来源于我们从 nodejs 抽出来之后,在浏览器内的适配问题。
可以罗列下我们会碰到的问题:
总结下其实是四个方面的问题:


从这个图中其实可以归纳出,我们就是在解决上面提到四个问题,即:
这里会提几个名词,方便之后大家理解。
Transpiler: 代码 A 转换为代码 B 转换器

Preset: 是一份构建描述集合,该集合包含了模块加载器文件加载的描述,
转换器的描述,插件的描述等。

Ruleset: 具体一个文件应该被怎么样的 transpilers 来转换。

这里可以衍生出来说一说为什么要设计 Preset 的概念。在文章的最前面我提到了现在要构建一个前端的项目学习曲线非常陡峭。在社区我们能看到两种解法:
通过以上两者不难发现,他们都在做一件事情:解耦应用开发者和工具开发者。
再回到 Preset,我的角色是工具专家,提供一系列的底层能力,而 Preset 则是垂直业务专家,他们基于我的底层能力去做的业务抽象,然后把业务输出为一个 preset。而真正的应用用户其实无需感知这部分的内容,对他们而言或许只需要知道一些扩展配置。

在 Gravity的设计中,Core 层其实没有耦合任何的具体业务逻辑(这个逻辑指的是,比如 react 应用要怎么执行,vue 应用要怎么执行等),Core 层简单来讲,它是实现浏览器实时构建的事件流注册、分发、执行的集合。而具体的业务场景,比如 React,Vue,小程序等则是通过具体的 Preset 来实现整合。而我们的 Preset 会再交给对应的垂直场景的载体,比如 WebIDE 等。

事先我们来看一看 Gravity 是如何运作的,上图只是一个流程示意,但也能说明一下流程上的设计。注意看我们在 Plugin 类上定义了一些事件,而这些事件是允许被用户订阅的,那 Gravity 在执行时,会对这些事件先尝试绑定。在进入到相关的流程时,会分发这些事件,订阅了该事件的订阅者,就会在第一时间收到信息。举例来说,Plugin 中的 Code 描述了如何来获取代码的方式,而在 Gravity Core 的整个生命周期中,会调用 fetch-data 去分发 Code 事件,如果说用户订阅了该事件,那么就会马上响应去执行用户定义的获取代码的方式,并得到代码进而告诉内核。
所以不难看出,Gravity 本质上是事件流机制,它的核心流程就是将插件连接起来。
既然如此,其实我们要解决的重点就是:
说到这里不知道大家是不是有一种似曾听闻的感觉,没错,其实这些思路都是来自于 webpack 的设计理念,webpack 是由一堆插件来驱动的,而背后的驱动这些插件的底层能力,来源于一个名叫 Tapable 的库。
Tapable 这个库我个人非常非常非常喜欢。原因在于它解决了很多我们在处理事件时会碰到的问题,比如有序性。另外要做一个插件系统的设计其实很简单,但后果是对用户会有额外的负担来学习如何书写,所以我选择 Tapable 来做还有另外很重要的一个原因,用户可以继续延续 webpack 插件写法到 Gravity 中来。

这里我罗列一下 Tapable 所拥有的能力。并用伪代码的方式为例来讲一讲我们在核心层如何定义一个插件(定义可被订阅的事件),业务专家如何来使用这个自定义插件(订阅该事件),以及我们在核心层如何来执行这个插件(绑定,分发)。



所以 Gravity-Core 重在事件的编排和分发,Plugin 则重在事件的申明,而 Custom plugins 则是订阅这些事件来达到个性化的目的。
在讲如何实现前,我们再回过来看下 Ruleset,在架构大图小节中我说明了下,Ruleset 是用来描述一个文件应该被怎么样的 transpilers 来转换。而 Ruleset 的生成其实是依赖于 preset 中 rule 的配置,这一点,其实 Gravity 和 webpack 是一致的,这种设计原因有两点:1. 用户可以沿用 webpack 的 rule 配置习惯到 Gravity 中来;2. 我们甚至可以复用一些现有的 webpack loader,或者说让改造量变得更小。

在这里我们以小程序中的 axml 文件为例,假设现在有一个 index.axml 需要被被编译,此时会通过 Preset 中 rule 描述,最终被拆解为一个 ruleset,在这个 set 信息中我们可以获取到 index.axml 文件需要经过怎么样的转换流程(也可以理解为该 index.axml 文件需要什么 transpiler 来进行编译)。该示例中我们可以看到,index.axml 需要经过一层 appx 小程序编译后再把对应的结果交给 babel 进行编译,而 babel 编译的结果再交给下级的消费链路。
暂时抛开复杂的业务层实现,我们想一想要实现这条串行的编译链路的本质是什么。相信大家都能找到这个答案,答案就是如何保证事件的有序性。既然又是事件,是不是我们又可以回过来看一看 Tapable,没错,在 Tapable 中就有这样一个 hook - AsyncSeriesWaterfallHook,异步串行,上一个回调函数的返回的内容可以作为下一回调函数的参数。说到这是不是很多问题就迎刃而解了。没错,那么在 Tapable 中实现编译链是不是就被简化为如何基于 ruleset 动态创建 AsyncSeriesWaterfallHook 事件,以及如何分发的问题。
如果我们在浏览器中没有文件系统的支撑,其实可以想象本地的文件的依赖将无法被解析出来(即无法完成 resolve 过程),所以实现浏览器内的文件系统是实现浏览器编译的前提条件。这里幸运的是 John Vilk 前辈有一个项目叫做 BrowserFS,这个库在浏览器内实现了一个文件系统,同时这个文件系统模拟了 Nodejs 文件系统的 API,这样的好处就是,我们所有的 resolve 算法就可以在浏览器内实现了。同时这个库最棒的一点是提出了 backends 的概念。这个概念的背后是,我们可以自定义文件的存储和读取过程,这样文件系统的概念和思路一下子就被打开了,因为这个文件系统其实本质上并不局限于本地。
在这里我们可以大概看下如何使用 BFS。

是不是很简单。但实际情况下大家在使用过程中,如果使用深入的话还会碰到很多问题,这些问题来自于多个文件系统间进行数据同步,会碰到不少 bug 和性能问题。这里我就不展开了。
有了文件系统我们再来想一想前端不可分割的一个部分,包管理。
思路一:浏览器内实现 NPM
这个思路是最容易想到的,通常做法是我们会拉取包信息,然后对包进行依赖分析,然后安装对应的包,最后把安装的包内容存储到对应的文件系统,编译器会对这些文件进行具体的编译,最后把编译结果存在文件系统里面。浏览器加执行文件时,模块加载器会加载这些编译后的文件。思路很通畅。但是这种方式的问题是原模原样照搬了 npm 到浏览器中,复杂度还是很高。
缺点:
思路二:服务化 NPM
这一块的思路其实来自于对我影响最大的两篇文章
非常精彩,我也写过一些文章来分析他们。但是 stackblitz 和 codesandbox 在 npm 思路上各自都有一些缺陷,比如 stackblitz 的资源分发形式,codesandbox 的服务端缓存策略。
服务化的 NPM 本质是基于网络的本地文件系统。怎么来理解这句话呢?我们来举个例子,一起来构想一下如何基于 unpkg / jsdelivr 做一个的文件系统。
假设我们现在依赖 lodash 这个库,那么在我们对接的文件系统里面会发一个请求(https://unpkg.com/[email protected]/?meta)给远程的 unpkg,该请求可以获取到完整的目录结构(数据结构),那么在得到这份数据后,我们便可以初始化一个文件系统了,因为我们可以通过接口返回的数据完整的知道目录内会有什么,以及这个文件的尺寸,虽然没有内容。所以此时文件系统内包含了一整个完整的树结构。 假设此时我们通过 resolve 发现,我们的文件中确切依赖了一个文件是 lodash/upperCase.js,这个文件系统事先需要做的事情是先在本地文件数里面找下是否存在 upperCase.js,这里毫无疑问是存在的,因为我们在这个接口中 https://unpkg.com/[email protected]/?meta 能找到对应的 upperCase.js 这个文件,能确定肯定是在文件系统里面是有标记的但是如之前所说 meta 信息只是一种标记,他是没有内容的,那么接下来我们就会去往 unpkg 服务器上那固定的文件,发送请求获取该文件内容 https://unpkg.com/[email protected]/upperCase.js,至此我们的基于 unpkg / jsdelivr 的文件系统就设计好了。
所以服务化 NPM 的关键是:
需要我们抽象
需要我们包装
注明:下发逻辑指的是我们按什么规则去下发用户的 dependencies。
服务化 NPM 的要点是:
对于 Gravity 的未来,其实更多的是我对他的憧憬,总结一下可以是三个要点。
垂直业务场景所对应的 Preset 的产出,可以按着某个流程,用极少的成本自由组合一下就可以使用。
所有搭建 Preset 、以及 Preset 内配置都可以通过可视化方式露出。
Gravity 服务化。
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.