sisteran / blog Goto Github PK
View Code? Open in Web Editor NEW瓶博:每日更新,前端前进
瓶博:每日更新,前端前进






































































































































































主要是为了弥补当前JS没有标准的缺陷,以达到像Python、Ruby和Java具备开发大型应用的基础能力。CommonJS API是以在浏览器环境之外构建 JS 生态系统为目标而产生的项目,比如服务器端JS应用程序、命令行工具、桌面图形界面应用程序等。如今,规范涵盖了模块、二进制、Buffer、字符集编码、I/O流、进程环境、文件系统、套接字,单元测试、Web服务器网管接口、包管理等。
CommonJS对模块的定义主要分为模块引用、模块定义和模块标识3个部分
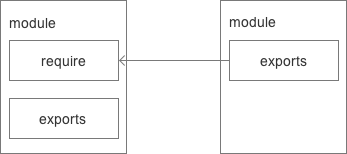
var math = require('math')在CommonJS规范中,存在一个require()方法,这个方法接收模块标识,一次引入一个模块的API到当前上下文中。
在模块中,上下文提供require()方法引入外部模块。对应引入的功能,上下文提供一个exports对象导出当前模块的方法或变量,并且它是唯一的导出出口,同时模块中还存在一个module对象,它代表的是当前模块,exports是module的属性。所以,在Node中,一个文件就是一个模块,将方法或属性挂载在exports对象上作为属性即可定义导出的方式。
// math.js
exports.add = function () {
var sum = 0,
i = 0,
args = arguments,
l = args.length
while (i < 1) {
sum += args[i++]
}
return sum
}在其他文件中,通过require()方法引入模块
// program.js
var math = require('math')
exports.increment = function (val) {
return math.add(val, 1)
}模块标识就是传递给require()方法的参数,采用小驼峰命名,或者以.、..开头的相对路径或绝对路径。它可以不加文件后缀.js。
CommonJS对模块的定义意义主要在于将类聚的方法或变量等限定在私有的作用域内,同时支持引入和导出功能以顺畅的连接上下游依赖。
CommonJS构建的这套模块导出或引用机制使得用户完全不必考虑变量污染,命名空间等方案与之相比相形见绌。
通常一个module有以下几个属性
module.id 模块的识别符,通常是带有绝对路径的模块文件名
module.filename 模块文件名,带有绝对路径
module.loaded 返回一个boolean值,标识模块是否已经加载完成
module.parent 返回调用该模块的对象
module.children 返回该模块调用的其他模块数组
module.exports 返回该模块对外的输出
module.paths 模块的搜索路径
例如:
// math.js
exports.add = function () {
var sum = 0,
i = 0,
args = arguments,
l = args.length
while (i < 1) {
sum += args[i++]
}
return sum
}
console.log(module)它的输出是:
Module {
id: '/Users/a123/Desktop/Study/wx/server/math.js',
exports: { add: [Function] },
parent:
Module {
id: '.',
exports: {},
parent: null,
filename: '/Users/a123/Desktop/Study/wx/server/app.js',
loaded: false,
children: [ [Module], [Module], [Module], [Module], [Module], [Circular] ],
paths:
[ '/Users/a123/Desktop/Study/wx/server/node_modules',
'/Users/a123/Desktop/Study/wx/node_modules',
'/Users/a123/Desktop/Study/node_modules',
'/Users/a123/Desktop/node_modules',
'/Users/a123/node_modules',
'/Users/node_modules',
'/node_modules' ] },
filename: '/Users/a123/Desktop/Study/wx/server/math.js',
loaded: false,
children: [],
paths:
[ '/Users/a123/Desktop/Study/wx/server/node_modules',
'/Users/a123/Desktop/Study/wx/node_modules',
'/Users/a123/Desktop/Study/node_modules',
'/Users/a123/Desktop/node_modules',
'/Users/a123/node_modules',
'/Users/node_modules',
'/node_modules' ] }当 Node.js 直接运行一个文件时,require.main 会被设为它的 module。 这意味着可以通过 require.main === module 来判断一个文件是否被直接运行:
// node app.js
math---require.main === module : false
app---require.main === module : truemodule.exports 对象是由模块系统创建的,表示当前文件对外输出的接口。
注意,对 module.exports 的赋值必须立即完成。 不能在任何回调中完成。
// 创建a.js文件
const EventEmitter = require('events')
module.exports = new EventEmitter() // 赋值
// 处理一些工作,并在一段时间后从模块自身触发 'ready' 事件。
setTimeout(() => {
module.exports.emit('ready')
}, 1000)// 创建b.js文件
setTimeout(() => {
module.exports = {a: 'hello'}
}, 0)// app.js 文件中分别调用a、b模块
// 引入a模块
const a = require('./a')
a.on('ready', () => {
console.log('模块 a 已准备好')
})
// 引入b模块
const b = require('./b')
console.log(b.a)执行app.js结果是:
undefined
模块 a 已准备好exports 变量是在模块的文件级别作用域内有效的,它在模块被执行前被赋予 module.exports 的值。
例如: module.exports.fun = …,相当于exports.fun = ...
但注意,不能将一个值赋值给exports,这样它将不在绑定到module.exports
module.exports.hello = true; // 从对模块的引用中导出
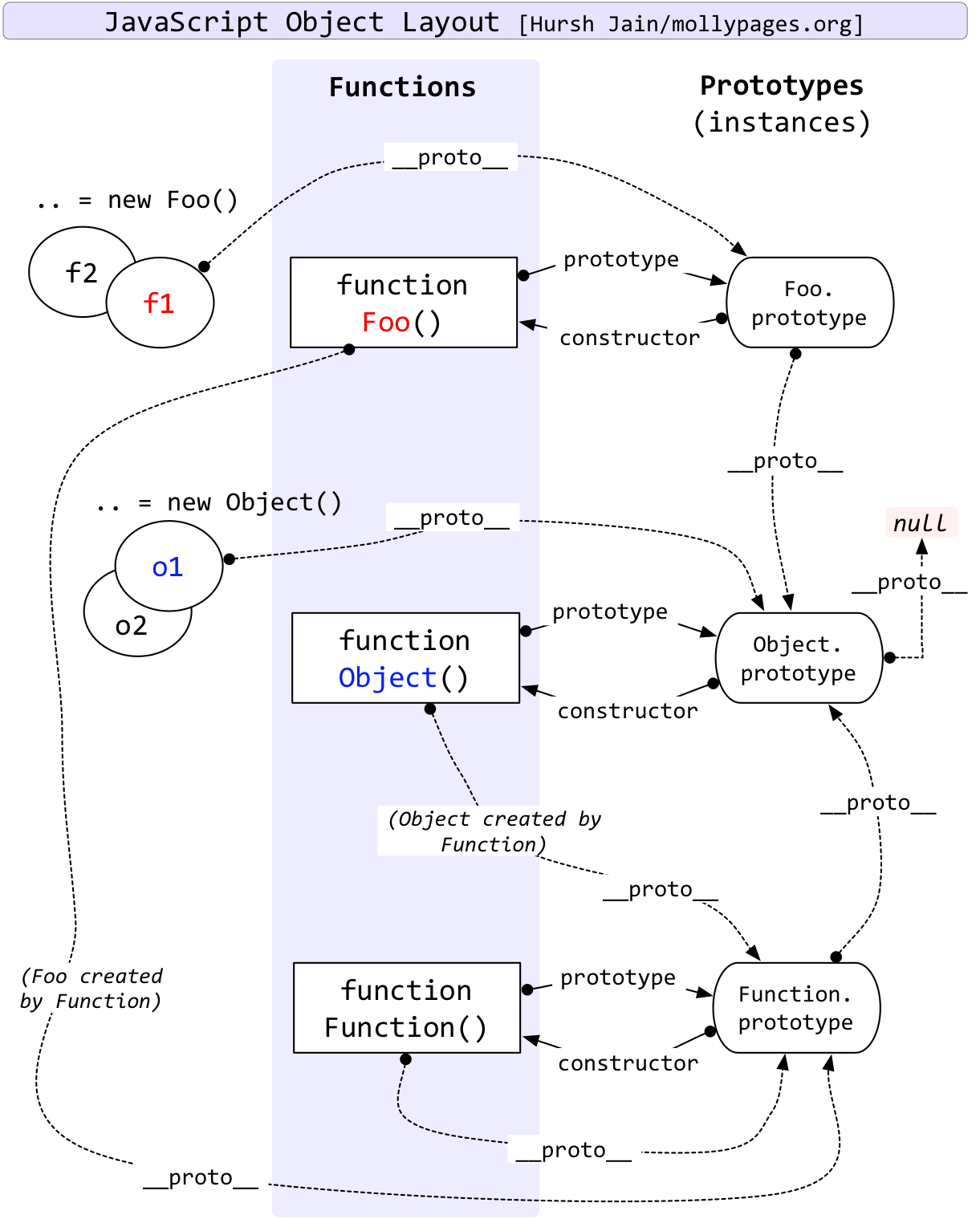
exports = { hello: false }; // 不导出,只在模块内有效在上述介绍中,module.exports 与exports很容易混淆,下面介绍module.exports 与exports内部的实现:
// 1. 模块引用
var module = require('./a')
module.a // 重要的是 module 这里,module 是 Node 独有的一个变量
// 2. 模块定义
module.exports = {
a: 1
}
// 3.模块内部实现
function require(/* ... */) {
const module = {
exports: {} // exports 就是一个空对象
}
// 这里其实就是包装了一层立即执行函数,这样就不会污染全局变量了
((module, exports) => {
// 模块代码在这
var a = 1 // 如果定义了一个函数。则为 function someFunc() {}
exports = a;
// 此时,exports 不再是一个 module.exports 的快捷方式,
// 且这个模块依然导出一个空的默认对象。
module.exports = a; // 这个是为什么 exports 和 module.exports 用法相似的原因
// 此时,该模块导出 a,而不是默认对象。
})(module, module.exports);
return module.exports;
}require命令的功能是,引入模块。
require命令用于加载文件,后缀名默认为.js。
require的加载顺序是:
以/开头,加载绝对路径模块文件
以./开头,加载相对路径模块文件
除以上两种情况外,加载的是一个默认提供的核心模块(位于Node的系统安装目录中),或者一个位于各级node_modules目录的已安装模块(全局安装或局部安装)。
举例来说,脚本/Users/a123/projects/foo.js执行了require('bar.js')`命令,Node会依次搜索以下文件。
如果指定的模块文件没有发现,Node会尝试为文件名添加.js、.json、.node后,再去搜索。.js件会以文本格式的JavaScript脚本文件解析,.json文件会以JSON格式的文本文件解析,.node文件会以编译后的二进制文件解析。
如果想得到require命令加载的确切文件名,使用require.resolve()方法。
通常,我们会把相关的文件放在一个目录里面,便于组织,这就需要给该目录设置一个入口文件,可以让require方法通过这个入口文件,加载整个目录,例如package.json:
{
"name": "wx_backend",
"version": "1.0.0",
"description": "",
"main": "app.js",
"scripts": {
"start:node-dev": "pm2 start process.prod.json --no-daemon --env development",
"start:node-prod": "pm2 start process.prod.json --no-daemon --env production",
"dev": "nodemon --config nodemon.json app.js",
"initdb": "npm install && node tools/initdb.js"
},
...
}require发现参数字符串指向一个目录时,就会自动查看该目录下的package.json文件,然后加载main指定的入口文件,如果package.json中没有main字段,或者根本没有package.json文件,则会加载该目录下的index.js文件或index.node文件。
前后端 JS 分别搁置在 HTTP 的两端,它们扮演的角色不同,侧重点也不一样。 浏览器端的 JS 需要经历从一个服务器端分发到多个客户端执行,而服务器端 JS 则是相同的代码需要多次执行。前者的瓶颈在于宽带,后者的瓶颈则在于 CPU 等内存资源。前者需要通过网络加载代码,后者则需要从磁盘中加载, 两者的加载速度也不是在一个数量级上的。
纵观 Node 的模块引入过程,几乎全都是同步的,尽管与 Node 强调异步的行为有些相反,但它是合理的,但前端如果也用同步方式引入,试想一下,在 UI 加载的过程中需要花费很多时间来等待脚本加载完成,这会造成用户体验的很大问题。
鉴于网络的原因, CommonJS 为后端 JS 制定的规范并不完全适合与前端的应用场景,下面来介绍 JS 前端的规范。
AMD是由RequireJS提出的,相对于CommonJS同步加载来说,AMD是"Asynchronous Module Definition"(异步模块定义)的缩写。是为浏览器环境专门设计的。
RequireJS即为遵循AMD规范的模块化工具。 RequireJS的基本**是,通过一个函数来将所有所需要的或者说所依赖的模块实现装载进来,然后返回一个新的函数(模块),我们所有的关于新模块的业务代码都在这个函数内部操作,其内部也可无限制的使用已经加载进来的以来的模块。
define(id?, dependencies?, factory)
定义模块
定义无依赖模块
define( {
sum : function( x, y ){
return x + y ;
}
} );定义有依赖模块
define(["some"], function( alpha ){
return {
add : function(){
return some.sum() + 1 ;
}
}
});定义数据对象模块
define({
add: [],
sub: []
});具名模块
define("alpha", [ "require", "exports", "beta" ], function( require, exports, beta ){
export.verb = function(){
return beta.verb();
// or:
return require("beta").verb();
}
});包装模块
define(function(require, exports, module) {
var a = require('a'),
b = require('b');
exports.action = function() {};
} );不考虑多了一层函数外,格式和Node.js是一样的:使用require获取依赖模块,使用exports导出API。
除了define外,AMD还保留一个关键字require。require 作为规范保留的全局标识符,可以实现为 module loader,也可以不实现。
模块加载
require([module], callback)
require(['math'], function(math) {
math.add(2, 3);
});CMD 的规范由国内的玉伯提出,与 AMD 的区别主要在于 定义模块与依赖引入 的部分。
CMD 更接近与 Node 对 CommonJS 规范的定义:
define(factory)
在依赖部分,CMD 支持动态引入
define(function(require, exports, module) {
// 模块内容
}require、exports、module 通过形参传递给模块,在需要依赖模块时,可以通过 require() 引入。
ES6正式提出了内置的模块化语法。
ES6 的模块自动采用严格模式,不管你有没有在模块头部加上"use strict";。
模块功能主要由两个命令构成:export和import。export命令用于规定模块的对外接口,import命令用于输入其他模块提供的功能。
export
//导出变量
export var a = 1;
//导出函数
export function fun(){
...
}
//导出类
export class Rectangle {
...
}
function fun1() { ... }
function fun2() { ... }
//导出对象,即导出引用
export {fun1 as f1, fun2 as f2} // 重命名模块
// 导出默认值
export default function fun3() { ... }
// 错误, 后面不能跟变量声明语句。
export default var a = 1
// 正确
export default 42另外,export语句输出的接口,与其对应的值是动态绑定关系,即通过该接口,可以取到模块内部实时的值。
export var foo = 'bar';
setTimeout(() => foo = 'baz', 500);上面代码输出变量foo,值为bar,500毫秒之后变成baz。
import
// 第一组 example.js
export default function fun() { // 输出
// ...
}
// app.js
import fun from './example';
// 第二组 example.js
export function fun() { // 输出
// ...
};
// app.js
import {fun} from './example'; // 输入
// 或
import * as allFun from './example';
//allFun.funexport default命令用于指定模块的默认输出。显然,一个模块只能有一个默认输出,因此export default命令只能使用一次。所以,import命令后面才不用加大括号,因为只可能对应一个方法。
本质上,export default就是输出一个叫做default的变量或方法,然后系统允许你为它取任意名字。所以,下面的写法是有效的。
// modules.js
function fun() {
...
}
export {fun as default};
// 等同于
// export default fun;
// app.js
import { default as fun } from './modules';
// 等同于
// import fun from 'modules';CommonJS和ES6中模块化的两者区别
require(${path}/xx.js),后者目前不支持,但是已有提案require/exports 来执行的在前端开发过程中,源码解读是必不可少的一个环节,我们直接进入主题,注意当前 React 版本号 16.8.6。
注意:react 包文件仅仅是 React components 的必要的、功能性的定义,它必须要结合 React render一起使用(web下是 react-dom,原生app环境下是react-native)。即 react 仅仅是定义节点与表现行为的包,具体如何渲染、如何更新这是与平台相关的,都是放在react-dom、react-native 包里的。这是我们只分析 web 环境的,即我们不会只分析 react 包文件,会结合 react 包与 react-dom、react-reconciler 及其他相关包一起分析。
React 16.8.6 使用 FlowTypes 静态类型检查器,我们需要在开发工具中支持 Fow(以 vscode 为例):
安装 Flow Language Support 插件
配置 workspace/.vscode/settings.json
{
"flow.useNPMPackagedFlow": true,
"javascript.validate.enable": false
}关于 Flow 更多请看 Flow官网。
首先,从 react 入口,打开 react 源码库 index.js:
'use strict';
const React = require('./src/React');
// TODO: 决定顶层文件导出格式
// 虽然是旁门左道,但它可以使 React 在 Rollup 和 Jest 上运行
module.exports = React.default || React;进入 ./src/React。
其中 React 完整内容是:
const React = { // React 暴露出来的 API
...
};
// Note: some APIs are added with feature flags.
// Make sure that stable builds for open source
// don't modify the React object to avoid deopts.
// Also let's not expose their names in stable builds.
if (enableStableConcurrentModeAPIs) {
React.ConcurrentMode = REACT_CONCURRENT_MODE_TYPE;
React.unstable_ConcurrentMode = undefined;
}
if (enableJSXTransformAPI) {
if (__DEV__) {
React.jsxDEV = jsxWithValidation;
React.jsx = jsxWithValidationDynamic;
React.jsxs = jsxWithValidationStatic;
} else {
React.jsx = jsx;
// we may want to special case jsxs internally to take advantage of static children.
// for now we can ship identical prod functions
React.jsxs = jsx;
}
}
export default React;其中,React 暴露出来的 API:
const React = {
/**
* 提供处理 props.children 的方法,
* 由于 props.children 是一个类数组的类型,可以用 React.Children 来处理
*/
Children: {
...
},
/**
* Component: React 组件类
* PureComponent: React 纯组件,和 React.Component类似,都是定义一个组件类。不同是 React.Component 没有实现 shouldComponentUpdate(),而 React.PureComponent 通过props和state的浅比较实现了。
* createRef: 创建 ref 函数, React.createRef()
* forwardRef: 用来解决 HOC 组件传递 ref 的问题
*/
Component,
PureComponent,
createRef,
forwardRef,
/**
* createContext: context 创建方法
* lazy: 实现异步加载的功能模块
* memo: 也是一个高阶组件,类似于React.PureComponent,不同于React.memo是function组件,React.PureComponent是class组件。
*/
createContext,
lazy,
memo,
error,
warn,
/**
* Hooks是React v16.7.0-alpha开始加入的新特性,可以让你在class以外使用state和其他React特性
* 其中 useState、useEffect、useContext 是 Hooks 三个最主要的API
* useState: 状态钩子,可以在一个函数式组件中调用它,为这个组件增加一些内部的状态
* useEffect: 副作用钩子,为函数式组件带来执行副作用的能力
* useContext: 可以订阅 React context 而不用引入嵌套
* useCallback: 回调钩子,当输入对象改变时调用
* useImperativeHandle: 自定义使用 ref 时,公开给父组件的实例值,应和 forwardRef 一起使用
* useDebugValue: 用于在 React 开发者工具中显示自定义 hook 的标签
* useLayoutEffect: api与useEffect相同,使用它从DOM读取布局并同步重新渲染
* useMemo: 当输入对象改变时,返回一个 memoized 值
* useReducer: useState的替代方案,允许你使用一个reducer来管理一个复杂组件的局部状态
* useRef: 返回 ref 对象,可以通过 .current 访问 ref 实例的属性方法
*/
useState,
useEffect,
useContext,
useCallback,
useImperativeHandle,
useDebugValue,
useLayoutEffect,
useMemo,
useReducer,
useRef,
/**
* 用 Symbol 来表示 React 的 Fragment、StrictMode、Suspense 组件
* Fragment: 可以聚合一个子元素列表,并且不在DOM中增加额外节点,(简写模式 <></>)
* StrictMode: 可以在开发阶段开启严格模式,发现应用存在的潜在问题,提升应用的健壮性
* Suspense: 在 React.lazy 时,import 失败或者异常时,就需要使用 Suspense 给出错误提示
*/
Fragment: REACT_FRAGMENT_TYPE,
Profiler: REACT_PROFILER_TYPE,
StrictMode: REACT_STRICT_MODE_TYPE,
Suspense: REACT_SUSPENSE_TYPE,
/**
* ReactElement 相关
* createElement: 创建 ReactElement
* cloneElement: 克隆 ReactElement
* createFactory: 创建一个专门用来创建某一类 ReactElement 的工厂
* isValidElement: 验证是否是一个 ReactElement
*/
createElement: __DEV__ ? createElementWithValidation : createElement,
cloneElement: __DEV__ ? cloneElementWithValidation : cloneElement,
createFactory: __DEV__ ? createFactoryWithValidation : createFactory,
isValidElement: isValidElement,
/**
* React 功能版本号
*/
version: ReactVersion,
unstable_ConcurrentMode: REACT_CONCURRENT_MODE_TYPE,
/**
* 顾名思义: React 内部元素,不要使用
*/
__SECRET_INTERNALS_DO_NOT_USE_OR_YOU_WILL_BE_FIRED: ReactSharedInternals,
};这些就是 React 最主要的 API,下面 逐个击破,从应用到源码,一一吃透 React 。
附 V16 个个版本的更新内容:
React v16.0
React v16.1
React v16.2
React v16.3
React v16.4
React v16.5
React v16.6
React v16.7
React v16.8
React v16.9(~mid 2019)
作为最流行的编程语言和最重要的 Web 开发语言之一,JavaScript 不断演变,每次迭代都会得到一些新的内部更新。让我们来看看 ES2019 有哪些新的特性,并加入到我们日常开发中:
Array.prototype.flat() 递归地将嵌套数组拼合到指定深度。默认值为 1,如果要全深度则使用 Infinity 。此方法不会修改原始数组,但会创建一个新数组:
const arr1 = [1, 2, [3, 4]];
arr1.flat();
// [1, 2, 3, 4]
const arr2 = [1, 2, [3, 4, [5, 6]]];
arr2.flat(2);
// [1, 2, 3, 4, 5, 6]
const arr3 = [1, 2, [3, 4, [5, 6, [7, 8]]]];
arr3.flat(Infinity);
// [1, 2, 3, 4, 5, 6, 7, 8]flat() 方法会移除数组中的空项:
const arr4 = [1, 2, , 4, 5];
arr4.flat(); // [1, 2, 4, 5]flatMap() 方法首先使用映射函数映射每个元素,然后将结果压缩成一个新数组。它与 Array.prototype.map 和 深度值为 1的 Array.prototype.flat 几乎相同,但 flatMap 通常在合并成一种方法的效率稍微高一些。
const arr1 = [1, 2, 3];
arr1.map(x => [x * 4]);
// [[4], [8], [12]]
arr1.flatMap(x => [x * 4]);
// [4, 8, 12]更好的示例:
const sentence = ["This is a", "regular", "sentence"];
sentence.map(x => x.split(" "));
// [["This","is","a"],["regular"],["sentence"]]
sentence.flatMap(x => x.split(" "));
// ["This","is","a","regular", "sentence"]
// 可以使用 归纳(reduce) 与 合并(concat)实现相同的功能
sentence.reduce((acc, x) => acc.concat(x.split(" ")), []);除了能从字符串两端删除空白字符的 String.prototype.trim() 之外,现在还有单独的方法,只能从每一端删除空格:
const test = " hello ";
test.trim(); // "hello";
test.trimStart(); // "hello ";
test.trimEnd(); // " hello";trimStart() :别名 trimLeft(),移除原字符串左端的连续空白符并返回,并不会直接修改原字符串本身。trimEnd() :别名 trimRight(),移除原字符串右端的连续空白符并返回,并不会直接修改原字符串本身。将键值对列表转换为 Object 的新方法。
它与已有 Object.entries() 正好相反,Object.entries()方法在将对象转换为数组时使用,它返回一个给定对象自身可枚举属性的键值对数组。
但现在您可以通过 Object.fromEntries 将操作的数组返回到对象中。
下面是一个示例(将所有对象属性的值平方):
const obj = { prop1: 2, prop2: 10, prop3: 15 };
// 转化为键值对数组:
let array = Object.entries(obj);
// [["prop1", 2], ["prop2", 10], ["prop3", 15]]将所有对象属性的值平方:
array = array.map(([key, value]) => [key, Math.pow(value, 2)]);
// [["prop1", 4], ["prop2", 100], ["prop3", 225]]我们将转换后的数组 array 作为参数传入 Object.fromEntries ,将数组转换成了一个对象:
const newObj = Object.fromEntries(array);
// {prop1: 4, prop2: 100, prop3: 225}新提案允许您完全省略 catch() 参数,因为在许多情况下,您并不想使用它:
try {
//...
} catch (er) {
//handle error with parameter er
}
try {
//...
} catch {
//handle error without parameter
}description 是一个只读属性,它会返回 Symbol 对象的可选描述的字符串,用来代替 toString() 方法。
const testSymbol = Symbol("Desc");
testSymbol.description; // "Desc"
testSymbol.toString(); // "Symbol(Desc)"现在,在函数上调用 toString() 会返回函数,与它的定义完全一样,包括空格和注释。
之前:
function /* foo comment */ foo() {}
foo.toString(); // "function foo() {}"现在:
foo.toString(); // "function /* foo comment */ foo() {}"行分隔符 (\u2028) 和段落分隔符 (\u2029),现在被正确解析,而不是报一个语法错误。
var str = '{"name":"Bottle\u2028AnGe"}'
JSON.parse(str)
// {name: "Bottle
AnGe"}在 React.createRef 中已经介绍过,有三种方式可以使用 React 元素的 ref
ref 是为了获取某个节点的实例,但是 函数式组件(PureComponent) 是没有实例的,不存在 this的,这种时候是拿不到函数式组件的 ref 的。
为了解决这个问题,由此引入 React.forwardRef, React.forwardRef 允许某些组件接收 ref,并将其向下传递给 子组件
const ForwardInput = React.forwardRef((props, ref) => (
<input ref={ref} />
));
class TestComponent extends React.Component {
constructor(props) {
super(props);
this.inputRef = React.createRef(); // 创建 ref 存储 textRef DOM 元素
}
componentDidMount() {
this.inputRef.current.value = 'forwardRef'
}
render() {
return ( // 可以直接获取到 ForwardInput input 的 ref:
<ForwardInput ref={this.inputRef}>
)
}
}只在使用 React.forwardRef 定义组件时,第二个参数 ref 才存在
在项目中组件库中尽量不要使用 React.forwardRef ,因为它可能会导致子组件被 破坏性更改
函数组件 和 class 组件均不接收 ref 参数 ,即 props 中不存在 ref,ref 必须独立 props 出来,否则会被 React 特殊处理掉。
通常在 高阶组件 中使用 React.forwardRef
function enhance(WrappedComponent) {
class Enhance extends React.Component {
componentWillReceiveProps(nextProps) {
console.log('Current props: ', this.props);
console.log('Next props: ', nextProps);
}
render() {
const {forwardedRef, ...others} = this.props;
// 将自定义的 prop 属性 “forwardedRef” 定义为 ref
return <WrappedComponent ref={forwardedRef} {...others} />;
}
}
// 注意 React.forwardRef 回调的第二个参数 “ref”。
// 我们可以将其作为常规 prop 属性传递给 Enhance,例如 “forwardedRef”
// 然后它就可以被挂载到被 Enhance 包裹的子组件上。
return React.forwardRef((props, ref) => {
return <Enhance {...props} forwardedRef={ref} />;
});
}
// 子组件
class MyComponent extends React.Component {
focus() {
// ...
}
// ...
}
// EnhancedComponent 会渲染一个高阶组件 enhance(MyComponent)
const EnhancedComponent = enhance(MyComponent);
const ref = React.createRef();
// 我们导入的 EnhancedComponent 组件是高阶组件(HOC)Enhance。
// 通过React.forwardRef 将 ref 将指向了 Enhance 内部的 MyComponent 组件
// 这意味着我们可以直接调用 ref.current.focus() 方法
<EnhancedComponent
label="Click Me"
handleClick={handleClick}
ref={ref}
/>;export default function forwardRef<Props, ElementType: React$ElementType>(
render: (props: Props, ref: React$Ref<ElementType>) => React$Node,
) {
if (__DEV__) {
if (render != null && render.$$typeof === REACT_MEMO_TYPE) {
warningWithoutStack(
false,
'forwardRef requires a render function but received a `memo` ' +
'component. Instead of forwardRef(memo(...)), use ' +
'memo(forwardRef(...)).',
);
} else if (typeof render !== 'function') {
warningWithoutStack(
false,
'forwardRef requires a render function but was given %s.',
render === null ? 'null' : typeof render,
);
} else {
warningWithoutStack(
// Do not warn for 0 arguments because it could be due to usage of the 'arguments' object
render.length === 0 || render.length === 2,
'forwardRef render functions accept exactly two parameters: props and ref. %s',
render.length === 1
? 'Did you forget to use the ref parameter?'
: 'Any additional parameter will be undefined.',
);
}
if (render != null) {
warningWithoutStack(
render.defaultProps == null && render.propTypes == null,
'forwardRef render functions do not support propTypes or defaultProps. ' +
'Did you accidentally pass a React component?',
);
}
}
/**
* REACT_FORWARD_REF_TYPE 并不是 React.forwardRef 创建的实例的 $$typeof
* React.forwardRef 返回的是一个对象,而 ref 是通过实例的参数形式传递进去的,
* 实际上,React.forwardRef 返回的是一个 ReactElement,它的 $$typeof 也就是 REACT_ELEMENT_TYPE
* 而 返回的对象 是作为 ReactElement 的 type 存在
*/
return { // 返回一个对象
$$typeof: REACT_FORWARD_REF_TYPE, // 并不是 React.forwardRef 创建的实例的 $$typeof
render, // 函数组件
};
}Promise就是为了解决callback的问题而产生的。
Promise 本质上就是一个绑定了回调的对象,而不是将回调传回函数内部。
开门见山,Promise解决的是回调函数处理异步的第2个问题:控制反转。
我们把上面那个多层回调嵌套的例子用Promise的方式重构:
let getPromise1 = function () {
return new Promsie(function (resolve, reject) {
$.ajax({
url: 'XXX1',
success: function (data) {
let key = data;
resolve(key);
},
error: function (err) {
reject(err);
}
});
});
};
let getPromise2 = function (key) {
return new Promsie(function (resolve, reject) {
$.ajax({
url: 'XXX2',
data: {
key: key
},
success: function (data) {
resolve(data);
},
error: function (err) {
reject(err);
}
});
});
};
let getPromise3 = function () {
return new Promsie(function (resolve, reject) {
$.ajax({
url: 'XXX3',
success: function (data) {
resolve(data);
},
error: function (err) {
reject(err);
}
});
});
};
getPromise1()
.then(function (key) {
return getPromise2(key);
})
.then(function (data) {
return getPromise3(data);
})
.then(function (data) {
// todo
console.log('业务数据:', data);
})
.catch(function (err) {
console.log(err);
}); Promise 在一定程度上其实改善了回调函数的书写方式;另外逻辑性更明显了,将异步业务提取成单个函数,整个流程可以看到是一步步向下执行的,依赖层级也很清晰,最后需要的数据是在整个代码的最后一步获得。
所以,Promise在一定程度上解决了回调函数的书写结构问题,但回调函数依然在主流程上存在,只不过都放到了then(...)里面,和我们大脑顺序线性的思维逻辑还是有出入的。
Promise是什么,无论是ES6的Promise也好,jQuery的Promise也好,不同的库有不同的实现,但是大家遵循的都是同一套规范,所以,Promise并不指特定的某个实现,它是一种规范,是一套处理JavaScript异步的机制。
Promise的规范会多,如Promise/A、Promise/B、Promise/D以及Promise/A的升级版Promise/A+,其中ES6遵循Promise/A+规范,有关Promise/A+,你可以参考一下:
这里只简要介绍下几点与接下来内容相关的规范:
首先,我们看一下Promise的简单使用:
var p = new Promise(function(resolve, reject) {
// Do an async task async task and then...
if(/* good condition */) {
resolve('Success!');
}
else {
reject('Failure!');
}
});
p.then(function() {
/* do something with the result */
}).catch(function() {
/* error :( */
})我们通过这种使用构建Promise实现的第一个版本
function MyPromise(callback) {
var _this = this
_this.value = void 0 // Promise的值
var onResolvedCallbacks // Promise resolve回调函数
var onRejectedCallback // Promise reject回调函数
// resolve 处理函数
_this.resolve = function (value) {
onResolvedCallbacks()
}
// reject 处理函数
_this.reject = function (error) {
onRejectedCallback()
}
callback(_this.resolve, _this.reject) // 执行callback并传入相应的参数
}
// 添加 then 方法
MyPromise.prototype.then = function(resolve, reject) {}大致框架已经出来了,但我们看到Promise状态、reslove函数、reject函数以及then等都没有处理。
首先,举个例子:
new Promise(function (resolve, reject) {
setTimeout(function () {
var a=1;
resolve(a);
}, 1000);
}).then(function (res) {
console.log(res);
return new Promise(function (resolve, reject) {
setTimeout(function () {
var b=2;
resolve(b);
}, 1000);
})
}).then(function (res) {
console.log(res);
return new Promise(function (resolve, reject) {
setTimeout(function () {
var c=3
resolve(c);
}, 1000);
})
}).then(function (res) {
console.log(res);
})上例结果是每间隔1s打印一个数字,顺序为1、2、3。
这里保证了:
Promise一个常见的需求就是连续执行两个或者多个异步操作,这种情况下,每一个后来的操作都在前面的操作执行成功之后,带着上一步操作所返回的结果开始执行。这里用setTimeout来处理
function MyPromise(callback) {
var _this = this
_this.value = void 0 // Promise的值
// 用于保存 then 的回调, 只有当 promise
// 状态为 pending 时才会缓存,并且每个实例至多缓存一个
_this.onResolvedCallbacks = [] // Promise resolve时的回调函数集
_this.onRejectedCallbacks = [] // Promise reject时的回调函数集
_this.resolve = function (value) {
setTimeout(() => { // 异步执行
_this.onResolvedCallbacks.forEach(cb => cb())
})
} // resolve 处理函数
_this.reject = function (error) {
setTimeout(() => { // 异步执行
_this.onRejectedCallbacks.forEach(cb => cb())
})
} // reject 处理函数
callback(_this.resolve, _this.reject) // 执行callback并传入相应的参数
}
// 添加 then 方法
MyPromise.prototype.then = function() {}为了保证Promise的异步操作时的顺序执行,这里给Promise加上状态机制
// 三种状态
const PENDING = "pending"
const FULFILLED = "fulfilled"
const REJECTED = "rejected"
function MyPromise(callback) {
var _this = this
_this.currentState = PENDING // Promise当前的状态
_this.value = void 0 // Promise的值
// 用于保存 then 的回调, 只有当 promise
// 状态为 pending 时才会缓存,并且每个实例至多缓存一个
_this.onResolvedCallbacks = [] // Promise resolve时的回调函数集
_this.onRejectedCallbacks = [] // Promise reject时的回调函数集
_this.resolve = function (value) {
setTimeout(() => { // 异步执行,保证顺序执行
if (_this.currentState === PENDING) {
_this.currentState = FULFILLED // 状态管理
_this.value = value
_this.onResolvedCallbacks.forEach(cb => cb())
}
})
} // resolve 处理函数
_this.reject = function (value) {
setTimeout(() => { // 异步执行,保证顺序执行
if (_this.currentState === PENDING) {
_this.currentState = REJECTED // 状态管理
_this.value = value
_this.onRejectedCallbacks.forEach(cb => cb())
}
})
} // reject 处理函数
callback(_this.resolve, _this.reject) // 执行callback并传入相应的参数
}
// 添加 then 方法
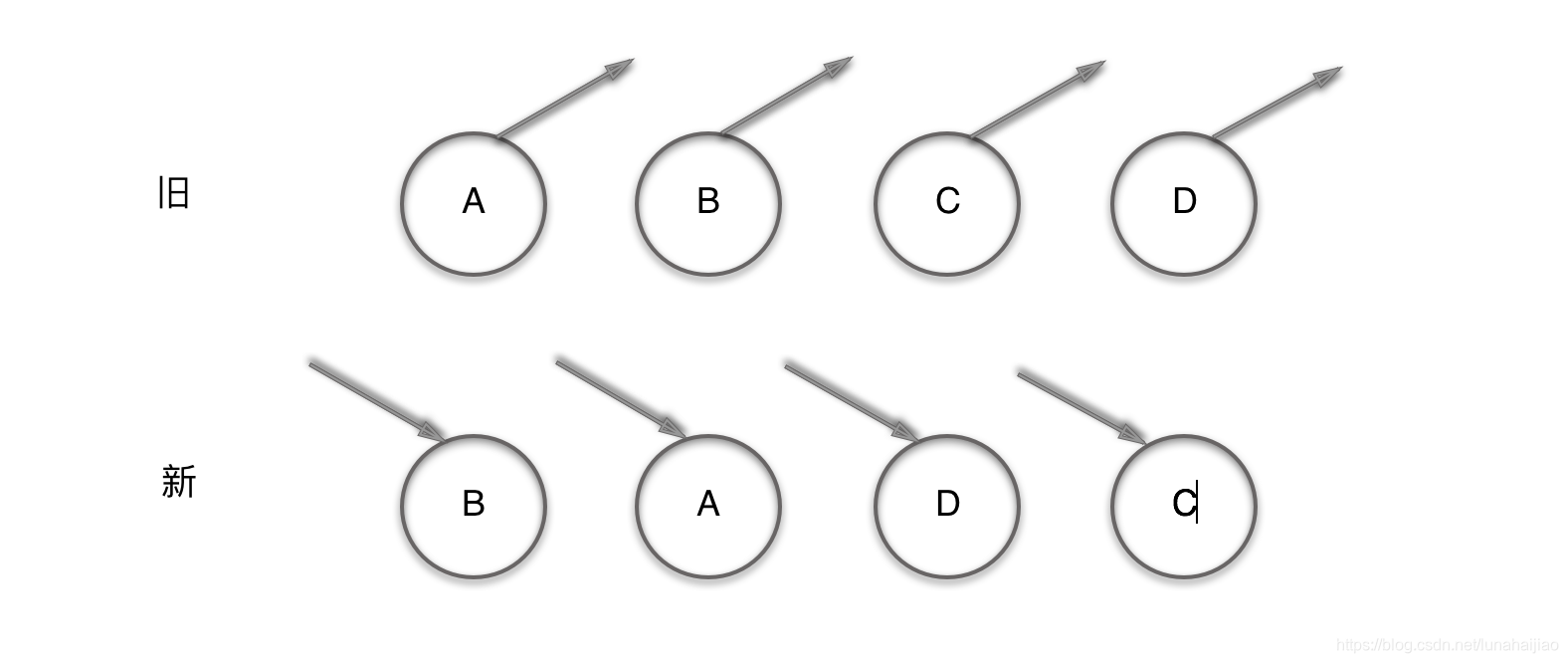
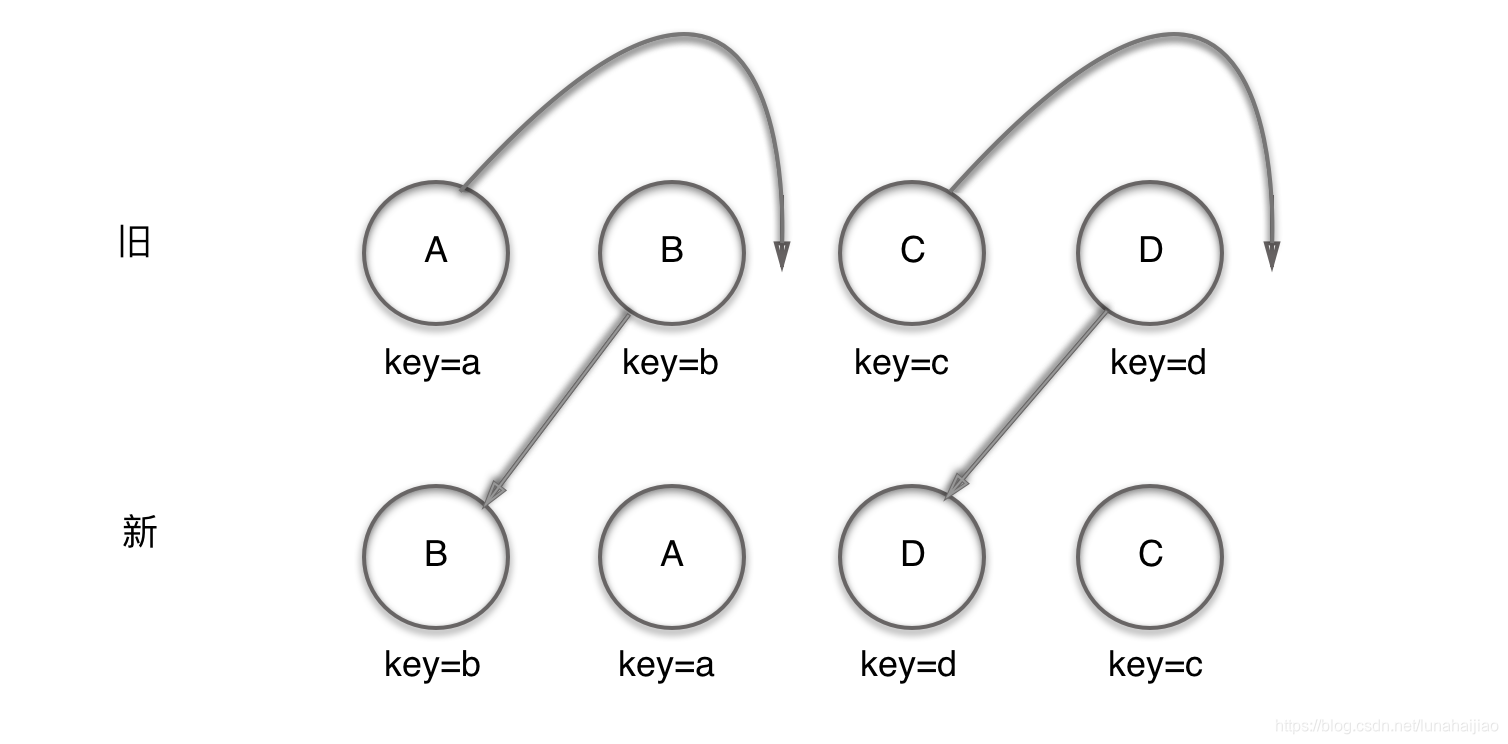
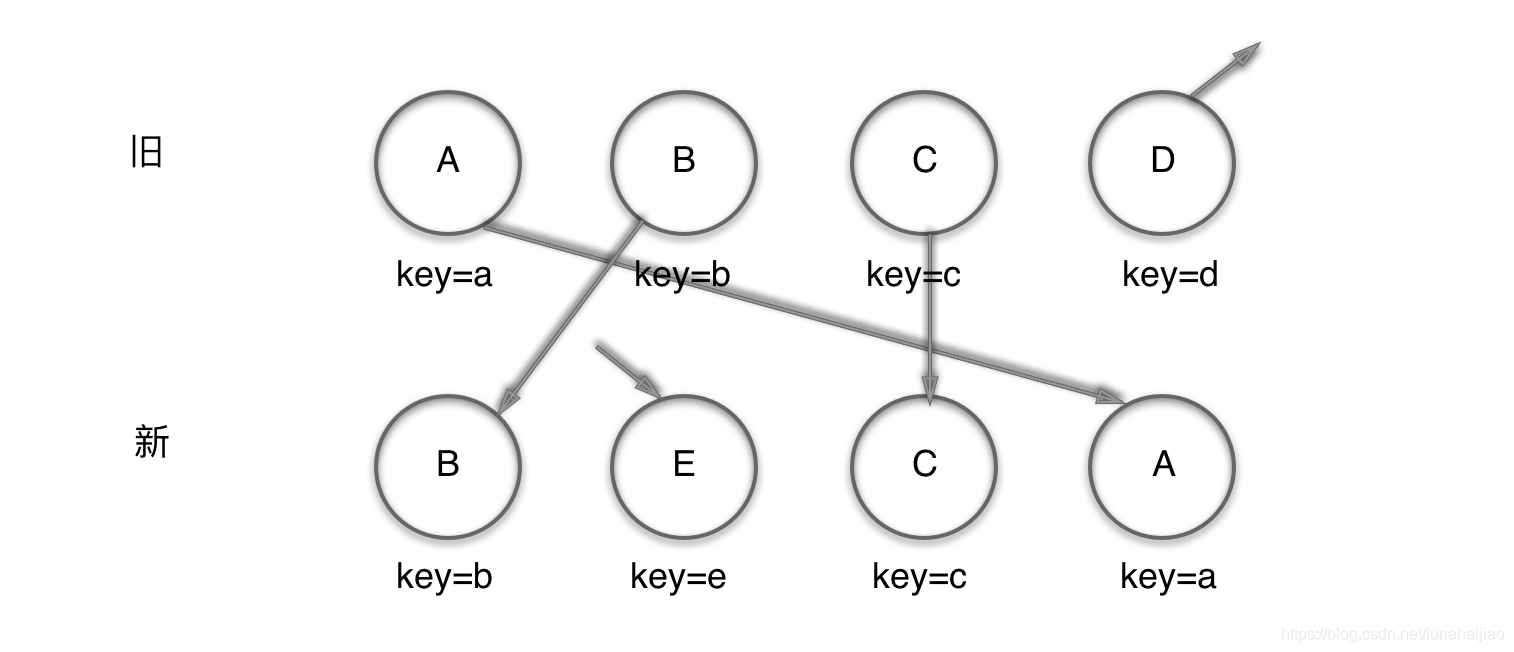
MyPromise.prototype.then = function() {}每个Promise后面链接一个对象,该对象包含onresolved,onrejected,子promise三个属性.
当父Promise 状态改变完毕,执行完相应的onresolved/onrejected的时候,拿到子promise,在等待这个子promise状态改变,在执行相应的onresolved/onrejected。依次循环直到当前promise没有子promise。
// 三种状态
const PENDING = "pending"
const FULFILLED = "fulfilled"
const REJECTED = "rejected"
function MyPromise(callback) {
var _this = this
_this.currentState = PENDING // Promise当前的状态
_this.value = void 0 // Promise的值
// 用于保存 then 的回调, 只有当 promise
// 状态为 pending 时才会缓存,并且每个实例至多缓存一个
_this.onResolvedCallbacks = [] // Promise resolve时的回调函数集
_this.onRejectedCallbacks = [] // Promise reject时的回调函数集
_this.resolve = function (value) {
if (value instanceof MyPromise) {
// 如果 value 是个 MyPromise, 递归执行
return value.then(_this.resolve, _this.reject)
}
setTimeout(() => { // 异步执行,保证顺序执行
if (_this.currentState === PENDING) {
_this.currentState = FULFILLED // 状态管理
_this.value = value
_this.onResolvedCallbacks.forEach(cb => cb())
}
})
} // resolve 处理函数
_this.reject = function (value) {
setTimeout(() => { // 异步执行,保证顺序执行
if (_this.currentState === PENDING) {
_this.currentState = REJECTED // 状态管理
_this.value = value
_this.onRejectedCallbacks.forEach(cb => cb())
}
})
} // reject 处理函数
callback(_this.resolve, _this.reject) // 执行callback并传入相应的参数
}
// 添加 then 方法
MyPromise.prototype.then = function() {}// 三种状态
const PENDING = "pending"
const FULFILLED = "fulfilled"
const REJECTED = "rejected"
function MyPromise(callback) {
var _this = this
_this.currentState = PENDING // Promise当前的状态
_this.value = void 0 // Promise的值
// 用于保存 then 的回调, 只有当 promise
// 状态为 pending 时才会缓存,并且每个实例至多缓存一个
_this.onResolvedCallbacks = [] // Promise resolve时的回调函数集
_this.onRejectedCallbacks = [] // Promise reject时的回调函数集
_this.resolve = function (value) {
if (value instanceof MyPromise) {
// 如果 value 是个 MyPromise, 递归执行
return value.then(_this.resolve, _this.reject)
}
setTimeout(() => { // 异步执行,保证顺序执行
if (_this.currentState === PENDING) {
_this.currentState = FULFILLED // 状态管理
_this.value = value
_this.onResolvedCallbacks.forEach(cb => cb())
}
})
} // resolve 处理函数
_this.reject = function (error) {
setTimeout(() => { // 异步执行,保证顺序执行
if (_this.currentState === PENDING) {
_this.currentState = REJECTED // 状态管理
_this.value = value
_this.onRejectedCallbacks.forEach(cb => cb())
}
})
} // reject 处理函数
// 异常处理
// new Promise(() => throw Error('error'))
try {
callback(_this.resolve, _this.reject) // 执行callback并传入相应的参数
} catch(e) {
_this.reject(e)
}
}
// 添加 then 方法
MyPromise.prototype.then = function() {}then 方法是 Promise 的核心,这里做一下详细介绍。
promise.then(onFulfilled, onRejected)一个 Promise 的then接受两个参数: onFulfilled和onRejected(都是可选参数,并且为函数,若不是函数将被忽略)
onFulfilled 特性:
onRejected 特性
调用时机
onFulfilled 和 onRejected 只有在执行环境堆栈仅包含平台代码时才可被调用(平台代码指引擎、环境以及 promise 的实施代码)
调用要求
onFulfilled 和 onRejected 必须被作为函数调用(即没有 this 值,在 严格模式(strict) 中,函数 this 的值为 undefined ;在非严格模式中其为全局对象。)
多次调用
then 方法可以被同一个 promise 调用多次
promise 成功执行时,所有 onFulfilled 需按照其注册顺序依次回调promise 被拒绝执行时,所有的 onRejected 需按照其注册顺序依次回调返回
then方法会返回一个Promise,关于这一点,Promise/A+标准并没有要求返回的这个Promise是一个新的对象,但在Promise/A标准中,明确规定了then要返回一个新的对象,目前的Promise实现中then几乎都是返回一个新的Promise(详情)对象,所以在我们的实现中,也让then返回一个新的Promise对象。
promise2 = promise1.then(onFulfilled, onRejected);
onFulfilled 或者 onRejected 返回一个值 x ,则运行下面的 Promise 解决过程:[[Resolve]](promise2, x)onFulfilled 或者 onRejected 抛出一个异常 e ,则 promise2 必须拒绝执行,并返回拒因 eonFulfilled 不是函数且 promise1 成功执行, promise2 必须成功执行并返回相同的值onRejected 不是函数且 promise1 拒绝执行, promise2 必须拒绝执行并返回相同的拒因不论 promise1 被 reject 还是被 resolve , promise2 都会被 resolve,只有出现异常时才会被 rejected。
每个Promise对象都可以在其上多次调用then方法,而每次调用then返回的Promise的状态取决于那一次调用then时传入参数的返回值,所以then不能返回this,因为then每次返回的Promise的结果都有可能不同。
下面代码实现:
// then 方法接受两个参数,onFulfilled,onRejected,分别为Promise成功或失败的回调
MyPromise.prototype.then = function(onFulfilled, onRejected) {
var _this = this
// 规范 2.2.7,then 必须返回一个新的 promise
var promise2
// 根据规范 2.2.1 ,onFulfilled、onRejected 都是可选参数
// onFulfilled、onRejected不是函数需要忽略,同时也实现了值穿透
onFulfilled = typeof onFulfilled === 'function' ? onFulfilled : value => value
onRejected = typeof onRejected === 'function' ? onRejected : error => {throw error}
if (_this.currentState === RESOLVED) {
return promise2 = new MyPromise(function(resolve, reject) {
})
}
if (_this.currentState === REJECTED) {
return promise2 = new MyPromise(function(resolve, reject) {
})
}
if (_this.currentState === PENDING) {
return promise2 = new MyPromise(function(resolve, reject) {
})
}
}附:值穿透解读
MyPromise.prototype.then = function (onFulfilled, onRejected) {
...
onFulfilled = typeof onFulfilled === 'function' ? onFulfilled : value => value
onRejected = typeof onRejected === 'function' ? onRejected : error => {throw error}
...
}上面提到值穿透,值穿透即:
var promise = new MyPromise((resolve, reject) => {
setTimeout(() => {
resolve('1')
}, 1000)
})
promise.then('2').then(console.log)最终打结果是1而不是2
再例如:
new MyPromise(resolve => resolve('1'))
.then()
.then()
.then(function foo(value) {
alert(value)
})
// output: alert 出 1通过 return this 只实现了值穿透的一种情况,其实值穿透有两种情况:
promise 已经是 FULFILLED/REJECTED 时,通过 return this 实现的值穿透:
var promise = new Promise(function (resolve) {
setTimeout(() => {
resolve('1')
}, 1000)
})
promise.then(() => {
promise.then().then((res) => { // 状况A
console.log(res) // output: 1
})
promise.catch().then((res) => { // 状况B
console.log(res) // output: 1
})
console.log(promise.then() === promise.catch()) // output: true
console.log(promise.then(1) === promise.catch({name: 'anran'})) // output: true
})状况A与B处 promise 已经是 FULFILLED 了符合条件,所以执行了 return this。
注意:原生的Promise实现里并不是这样实现的,会打印出两个false
promise 是 PENDING时,通过生成新的 promise 加入到父 promise 的 queue,父 promise 有值时调用 callFulfilled->doResolve 或 callRejected->doReject(因为 then/catch 传入的参数不是函数)设置子 promise 的状态和值为父 promise 的状态与值。如:
var promise = new Promise((resolve) => {
setTimeout(() => {
resolve('1')
}, 1000)
})
var a = promise.then()
a.then((res) => {
console.log(res) // output: 1
})
var b = promise.catch()
b.then((res) => {
console.log(res) // output: 1
})
console.log(a === b) // output: falsePromise 有三种状态,我们分3个if块来处理,每块都返回一个new Promise。
根据标准,我们知道,对于一下代码,promise2的值取决于then里面的返回值:
promise2 = promise1.then(function(value) {
return 1
}, function(err) {
throw new Error('error')
})如果promise1被resolve了,promise2的被1resolve,如果promise1 被reject了,promise2将被new Error('error')reject。
所以,我们需要在then里面执行onFulfilled或者onRejected,并根据返回着(标记中记为x)来确定promise2的结果,并且,如果onFulfilled/onRejected返回的是一个Promise,promise将直接取这个Promise的结果。
// then 方法接受两个参数,onFulfilled,onRejected,分别为Promise成功或失败的回调
MyPromise.prototype.then = function(onFulfilled, onRejected) {
var _this = this
// 规范 2.2.7,then 必须返回一个新的 promise
var promise2
// 根据规范 2.2.1 ,onFulfilled、onRejected 都是可选参数
// onFulfilled、onRejected不是函数需要忽略,同时也实现了值穿透
onFulfilled = typeof onFulfilled === 'function' ? onFulfilled : value => value
onRejected = typeof onRejected === 'function' ? onRejected : error => {throw error}
if (_this.currentState === FULFILLED) {
// 如果promise1(此处为self/this)的状态已经确定并且为fulfilled,我们调用onFulfilled
// 如果考虑到有可能throw,所以我们将其包在try/catch块中
return promise2 = new MyPromise(function(resolve, reject) {
// 规范 2.2.4,保证 onFulfilled,onRjected 异步执行
// 所以用了 setTimeout 包裹下
setTimeout(function() {
try {
var x = onFulfilled(_this.value)
// 如果 onFulfilled 的返回值是一个 Promise 对象,直接取它的结果作为 promise2 的结果
if (x instanceof MyPromise) {
x.then(resolve, reject)
}
resolve(x) // 否则,以它的返回值为 promise2 的结果
} catch (err) {
reject(err) // 如果出错,以捕获到的错误作为promise2的结果
}
})
})
}
// 此处实现与FULFILLED相似,区别在使用的是onRejected而不是onFulfilled
if (_this.currentState === REJECTED) {
return promise2 = new MyPromise(function(resolve, reject) {
setTimeout(function() {
try {
var x = onRejected(_this.value)
if (x instanceof Promise){
x.then(resolve, reject)
}
} catch(err) {
reject(err)
}
})
})
}
if (_this.currentState === PENDING) {
// 如果当前的Promise还处于PENDING状态,我们并不能确定调用onFulfilled还是onRejected
// 只有等待Promise的状态确定后,再做处理
// 所以我们需要把我们的两种情况的处理逻辑做成callback放入promise1(此处即self/this)的回调数组内
// 处理逻辑和以上相似
return promise2 = new MyPromise(function(resolve, reject) {
_this.onResolvedCallbacks.push(function() {
try {
var x = onFulfilled(_this.value)
if (x instanceof MyPromise) {
x.then(resolve, reject)
}
resolve(x)
} catch(err) {
reject(err)
}
})
_this.onRejectedCallbacks.push(function() {
try {
var x = onRejected(_this.value)
if (x instanceof MyPromise) {
x.then(resolve, reject)
}
} catch (err) {
reject(err)
}
})
})
}
}// catch 的实现
MyPromise.prototype.catch = function (onRejected) {
return this.then(null, onRejected)
}至此,我们大致实现了Promise标准中所涉及到的内容。
不同的Promise实现之间需要无缝的可交互,如ES6的Promise,和我们自己实现的Promise之间以及其他的Promise实现,必须是无缝调用的。
new MyPromise(function(resolve, reject) {
setTimeout(function() {
resolve('1')
}, 1000)
}).then(function() {
return new Promise.reject('2') // ES6 的 Promise
}).then(function() {
return Q.all([ // Q 的 Promise
new MyPromise(resolve => resolve('3')) // 我们实现的Promise
new Promise.eresolve('4') // ES6 的 Promise
Q.resolve('5') // Q 的 Promise
])
})我之前实现的代码只是判断OnFullfilled/onRejected的返回值是否为我们自己实现的实例,并没有对其他类型Promise的判断,所以,上面的代码无法正常运行。
接下来,我们解决这个问题
关于不同Promise之间的交互,其实Promise/A+标准中有介绍,其中详细的指定了如何通过then的实参返回的值来决定promise2的状态,我们只需要按照标准把标准的内容转成代码即可。
即我们要把onFulfilled/onRejected的返回值x。当成是一个可能是Promise的对象,也即标准中的thenable,并以最保险的姿势调用x上的then方法,如果大家都按照标准来实现,那么不同的Promise之间就可以交互了。
而标准为了保险起见,即使x返回了一个带有then属性但不遵循Promise标准的对象(不如说这个x把它then里的两个参数都调用了,同步或者异步调用(PS,原则上then的两个参数需要异步调用,下文会讲到),或者是出错后又调用了它们,或者then根本不是一个函数),也能尽可能正确处理。
关于为何需要不同的Promise实现能够相互交互,我想原因应该是显然的,Promise并不是JS一早就有的标准,不同第三方的实现之间是并不相互知晓的,如果你使用的某一个库中封装了一个Promise实现,想象一下如果它不能跟你自己使用的Promise实现交互的场景。。。
代码实现:
// 规范 2.3
/*
resolutionProcedure函数即为根据x的值来决定promise2的状态的函数
也即标准中的[Promise Resolution Procedure](https://promisesaplus.com/#point-47)
x 为 promise2 = promise1.then(onFulfilled, onRejected)里onFulfilled/onRejected的返回值
resolve 和 reject 实际上是 promise2 的executor的两个实参,因为很难挂在其他地方,所以一并传过来。
相信各位一定可以对照标准转换成代码,这里就只标出代码在标准中对应的位置,只在必要的地方做一些解释。
*/
function resolutionProcedure(promise2, x, resolve, reject) {
// 规范 2.3.1,x 不能和 promise2 相同,避免循环引用
if (promise2 === x) {
return reject(new TypeError("Chaining cycle detected for promise!"))
}
// 规范 2.3.2
// 如果 x 为 Promise,状态为 pending 需要继续等待否则执行
if (x instanceof MyPromise) {
// 2.3.2.1 如果x为pending状态,promise必须保持pending状态,直到x为fulfilled/rejected
if (x.currentState === PENDING) {
x.then(function(value) {
// 再次调用该函数是为了确认 x resolve 的
// 参数是什么类型,如果是基本类型就再次 resolve
// 把值传给下个 then
resolutionProcedure(promise2, value, resolve, reject)
}, reject)
} else { // 但如果这个promise的状态已经确定了,那么它肯定有一个正常的值,而不是一个thenable,所以这里可以取它的状态
x.then(resolve, reject)
}
return
}
let called = false
// 规范 2.3.3,判断 x 是否为对象或函数
if (x !== null && (typeof x === "object" || typeof x === "function")) {
// 规范 2.3.3.2,如果不能取出 then,就 reject
try {
// 规范2.3.3.1 因为x.then可能是一个getter,这种情况下多次读取就有可能产生副作用
// 既要判断它的类型,又要调用它,这就是两次读取
let then = x.then
// 规范2.3.3.3,如果 then 是函数,调用 x.then
if (typeof then === "function") {
// 规范 2.3.3.3
// reject 或 reject 其中一个执行过的话,忽略其他的
then.call(
x,
y => { // 规范 2.3.3.3.1
if (called) return // 规范 2.3.3.3.3,即这三处谁先执行就以谁的结果为准
called = true
// 规范 2.3.3.3.1
return resolutionProcedure(promise2, y, resolve, reject)
},
r => {
if (called) return // 规范 2.3.3.3.3,即这三处谁先执行就以谁的结果为准
called = true
return reject(r)
}
)
} else {
// 规范 2.3.3.4
resolve(x)
}
} catch (e) { // 规范 2.3.3.2
if (called) return // 规范 2.3.3.3.3,即这三处谁先执行就以谁的结果为准
called = true
return reject(e)
}
} else {
// 规范 2.3.4,x 为基本类型
resolve(x)
}
}然后,我们使用resolutionProcedure函数替换MyPromise.prototype.then里面几处判断x是否为MyPromise对象的位置即可。即:
if (x instanceof MyPromise) {
x.then(resolve, reject)
}
// resolve(x) // 否则,以它的返回值为 promise2 的结果替换为:
resolutionProcedure(promise2, x, resolve, reject)总共四处,不要遗漏了
// 三种状态
const PENDING = "pending"
const FULFILLED = "fulfilled"
const REJECTED = "rejected"
function MyPromise(callback) {
var _this = this
_this.currentState = PENDING // Promise当前的状态
_this.value = void 0 // Promise的值
// 用于保存 then 的回调, 只有当 promise
// 状态为 pending 时才会缓存,并且每个实例至多缓存一个
_this.onResolvedCallbacks = [] // Promise resolve时的回调函数集
_this.onRejectedCallbacks = [] // Promise reject时的回调函数集
_this.resolve = function (value) {
if (value instanceof MyPromise) {
// 如果 value 是个 Promise, 递归执行
return value.then(_this.resolve, _this.reject)
}
setTimeout(() => { // 异步执行,保证顺序执行
if (_this.currentState === PENDING) {
_this.currentState = FULFILLED // 状态管理
_this.value = value
_this.onResolvedCallbacks.forEach(cb => cb())
}
})
} // resolve 处理函数
_this.reject = function (value) {
setTimeout(() => { // 异步执行,保证顺序执行
if (_this.currentState === PENDING) {
_this.currentState = REJECTED // 状态管理
_this.value = value
_this.onRejectedCallbacks.forEach(cb => cb())
}
})
} // reject 处理函数
// 异常处理
// new Promise(() => throw Error('error'))
try {
callback(_this.resolve, _this.reject) // 执行callback并传入相应的参数
} catch(e) {
_this.reject(e)
}
}
// then 方法接受两个参数,onFulfilled,onRejected,分别为Promise成功或失败的回调
MyPromise.prototype.then = function(onFulfilled, onRejected) {
var _this = this
// 规范 2.2.7,then 必须返回一个新的 promise
var promise2
// 根据规范 2.2.1 ,onFulfilled、onRejected 都是可选参数
// onFulfilled、onRejected不是函数需要忽略,同时也实现了值穿透
onFulfilled = typeof onFulfilled === 'function' ? onFulfilled : value => value
onRejected = typeof onRejected === 'function' ? onRejected : error => {throw error}
if (_this.currentState === FULFILLED) {
// 如果promise1(此处为self/this)的状态已经确定并且为fulfilled,我们调用onFulfilled
// 如果考虑到有可能throw,所以我们将其包在try/catch块中
return promise2 = new MyPromise(function(resolve, reject) {
try {
var x = onFulfilled(_this.value)
// 如果 onFulfilled 的返回值是一个 Promise 对象,直接取它的结果作为 promise2 的结果
resolutionProcedure(promise2, x, resolve, reject)
} catch (err) {
reject(err) // 如果出错,以捕获到的错误作为promise2的结果
}
})
}
// 此处实现与FULFILLED相似,区别在使用的是onRejected而不是onFulfilled
if (_this.currentState === REJECTED) {
return promise2 = new MyPromise(function(resolve, reject) {
try {
var x = onRejected(_this.value)
resolutionProcedure(promise2, x, resolve, reject)
} catch(err) {
reject(err)
}
})
}
if (_this.currentState === PENDING) {
// 如果当前的Promise还处于PENDING状态,我们并不能确定调用onFulfilled还是onRejected
// 只有等待Promise的状态确定后,再做处理
// 所以我们需要把我们的两种情况的处理逻辑做成callback放入promise1(此处即_this/this)的回调数组内
// 处理逻辑和以上相似
return promise2 = new MyPromise(function(resolve, reject) {
_this.onResolvedCallbacks.push(function() {
try {
var x = onFulfilled(_this.value)
resolutionProcedure(promise2, x, resolve, reject)
} catch(err) {
reject(err)
}
})
_this.onRejectedCallbacks.push(function() {
try {
var x = onRejected(_this.value)
resolutionProcedure(promise2, x, resolve, reject)
} catch (err) {
reject(err)
}
})
})
}
// 规范 2.3
/*
resolutionProcedure函数即为根据x的值来决定promise2的状态的函数
也即标准中的[Promise Resolution Procedure](https://promisesaplus.com/#point-47)
x 为 promise2 = promise1.then(onFulfilled, onRejected)里onFulfilled/onRejected的返回值
resolve 和 reject 实际上是 promise2 的executor的两个实参,因为很难挂在其他地方,所以一并传过来。
相信各位一定可以对照标准转换成代码,这里就只标出代码在标准中对应的位置,只在必要的地方做一些解释。
*/
function resolutionProcedure(promise2, x, resolve, reject) {
// 规范 2.3.1,x 不能和 promise2 相同,避免循环引用
if (promise2 === x) {
return reject(new TypeError("Chaining cycle detected for promise!"))
}
// 规范 2.3.2
// 如果 x 为 Promise,状态为 pending 需要继续等待否则执行
if (x instanceof MyPromise) {
// 2.3.2.1 如果x为pending状态,promise必须保持pending状态,直到x为fulfilled/rejected
if (x.currentState === PENDING) {
x.then(function(value) {
// 再次调用该函数是为了确认 x resolve 的
// 参数是什么类型,如果是基本类型就再次 resolve
// 把值传给下个 then
resolutionProcedure(promise2, value, resolve, reject)
}, reject)
} else { // 但如果这个promise的状态已经确定了,那么它肯定有一个正常的值,而不是一个thenable,所以这里可以取它的状态
x.then(resolve, reject)
}
return
}
let called = false
// 规范 2.3.3,判断 x 是否为对象或函数
if (x !== null && (typeof x === "object" || typeof x === "function")) {
// 规范 2.3.3.2,如果不能取出 then,就 reject
try {
// 规范2.3.3.1 因为x.then可能是一个getter,这种情况下多次读取就有可能产生副作用
// 既要判断它的类型,又要调用它,这就是两次读取
let then = x.then
// 规范2.3.3.3,如果 then 是函数,调用 x.then
if (typeof then === "function") {
// 规范 2.3.3.3
// reject 或 reject 其中一个执行过的话,忽略其他的
then.call(
x,
y => { // 规范 2.3.3.3.1
if (called) return // 规范 2.3.3.3.3,即这三处谁先执行就以谁的结果为准
called = true
// 规范 2.3.3.3.1
return resolutionProcedure(promise2, y, resolve, reject)
},
r => {
if (called) return // 规范 2.3.3.3.3,即这三处谁先执行就以谁的结果为准
called = true
return reject(r)
}
)
} else {
// 规范 2.3.3.4
resolve(x)
}
} catch (e) { // 规范 2.3.3.2
if (called) return // 规范 2.3.3.3.3,即这三处谁先执行就以谁的结果为准
called = true
return reject(e)
}
} else {
// 规范 2.3.4,x 为基本类型
resolve(x)
}
}
}
// catch 的实现
MyPromise.prototype.catch = function (onRejected) {
return this.then(null, onRejected)
}
// finally 的实现
MyPromise.prototype.finally = function (callback) {
return this.then(function (value) {
return MyPromise.resolve(callback()).then(function () {
return value
})
}, function (err) {
return MyPromise.resolve(callback()).then(function () {
throw err
})
})
}额外,附加 Promise.race 、 Promise.all 、 Promise.allSettled 的实现,有兴趣的可以了解一下
// race
MyPromise.race = function(values) {
return new MyPromise(function(resolve, reject) {
values.forEach(function(value) {
MyPromise.resolve(value).then(resolve, reject)
})
})
}
// all
MyPromise.all = function(arr) {
var args = Array.prototype.slice.call(arr)
return new MyPromise(function (resolve, reject) {
if (args.length === 0) return resolve([])
var remaining = args.length
for (var i = 0; i < args.length; i++) {
res(i, args[i])
}
function res(i, val) {
if (val && (typeof val === 'object' || typeof val === 'function')) {
if (val instanceof MyPromise && val.then === MyPromise.prototype.then) {
if (val.currentState === FULFILLED) return res(i, val.value)
if (val.currentState === REJECTED) reject(val.value)
val.then(function (val) {
res(i, val)
}, reject)
return
} else {
var then = val.then
if (typeof then === 'function') {
var p = new MyPromise(then.bind(val))
p.then(function(val) {
res(i, val)
}, reject)
return
}
}
}
args[i] = val
if (--remaining === 0) {
resolve(args)
}
}
})
}
// allSettled
MyPromise.allSettled = function (promises) {
return new MyPromise((resolve, reject) => {
promises = Array.isArray(promises) ? promises : []
let len = promises.length
const argslen = len
// 如果传入的是一个空数组,那么就直接返回一个resolved的空数组promise对象
if (len === 0) return resolve([])
// 将传入的参数转化为数组,赋给args变量
let args = Array.prototype.slice.call(promises)
// 计算当前是否所有的 promise 执行完成,执行完毕则resolve
const compute = () => {
if(--len === 0) {
resolve(args)
}
}
function resolvePromise(index, value) {
// 判断传入的是否是 promise 类型
if(value instanceof MyPromise) {
const then = value.then
then.call(value, function(val) {
args[index] = { status: 'fulfilled', value: val}
compute()
}, function(e) {
args[index] = { status: 'rejected', reason: e }
compute()
})
} else {
args[index] = { status: 'fulfilled', value: value}
compute()
}
}
for(let i = 0; i < argslen; i++){
resolvePromise(i, args[i])
}
})
}Promise.all、Promise.allSettled 简写
由于 Promise.all、Promise.allSettled 判断数组元素太过于繁琐,所以这里可以直接使用 Promise.reslove 包装
MyPromise.all = function(values) {
let promises = [].slice.call(values)
return new MyPromise((resolve, reject) => {
let result = [], count = 0
promises.forEach(promise => {
MyPromise.resolve(promise).then(value=>{
result.push(value)
if(++count === promise.length) {
resolve(result)
}
}).catch(err=>{
reject(err)
})
})
})
}
MyPromise.allSettled = function(values) {
let promises = [].slice.call(values)
return new MyPromise((resolve, reject) => {
let result = [], count = 0
promises.forEach(promise => {
MyPromise.resolve(promise).then(value=>{
result.push({status: FULFILLED, value})
}).catch(err=>{
result.push({status: REJECTED, value: err})
}).finally(()=>{
if(++count === promise.length) {
resolve(result)
}
})
})
})
}终于实现搞定了,继续加油
看一道面试题:
已知如下数组:var arr = [ [1, 2, 2], [3, 4, 5, 5], [6, 7, 8, 9, [11, 12, [12, 13, [14] ] ] ], 10];
编写一个程序将数组扁平化去并除其中重复部分数据,最终得到一个升序且不重复的数组
答案:
var arr = [ [1, 2, 2], [3, 4, 5, 5], [6, 7, 8, 9, [11, 12, [12, 13, [14] ] ] ], 10]
// 扁平化
let flatArr = arr.flat(4)
// 去重
let disArr = Array.from(new Set(flatArr))
// 排序
let result = disArr.sort(function(a, b) {
return a-b
})
console.log(result)
// [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14]关于 Set 请查阅 Set、WeakSet、Map及WeakMap
React 生命周期很多人都了解,但通常我们所了解的都是 单个组件 的生命周期,但针对 Hooks 组件、多个关联组件(父子组件和兄弟组件) 的生命周期又是怎么样的喃?你有思考和了解过吗,接下来我们将完整的了解 React 生命周期。
关于 组件 ,我们这里指的是 React.Component 以及 React.PureComponent ,但是否包括 Hooks 组件喃?
函数组件 的本质是函数,没有 state 的概念的,因此不存在生命周期一说,仅仅是一个 render 函数而已。
但是引入 Hooks 之后就变得不同了,它能让组件在不使用 class 的情况下使用 state 以及其他的 React特性,相比与 class 的生命周期概念来说,它更接近于实现状态同步,而不是响应生命周期事件。但我们可以利用 useState、 useEffect() 和 useLayoutEffect() 来模拟实现生命周期。
即:Hooks 组件更接近于实现状态同步,而不是响应生命周期事件。
下面,是具体的 生命周期 与 Hooks 的对应关系:
constructor:函数组件不需要构造函数,我们可以通过调用 useState 来初始化 state。如果计算的代价比较昂贵,也可以传一个函数给 useState。
const [num, UpdateNum] = useState(0)getDerivedStateFromProps:一般情况下,我们不需要使用它,我们可以在渲染过程中更新 state,以达到实现 getDerivedStateFromProps 的目的。
function ScrollView({row}) {
let [isScrollingDown, setIsScrollingDown] = useState(false);
let [prevRow, setPrevRow] = useState(null);
if (row !== prevRow) {
// Row 自上次渲染以来发生过改变。更新 isScrollingDown。
setIsScrollingDown(prevRow !== null && row > prevRow);
setPrevRow(row);
}
return `Scrolling down: ${isScrollingDown}`;
}React 会立即退出第一次渲染并用更新后的 state 重新运行组件以避免耗费太多性能。
shouldComponentUpdate:可以用 React.memo 包裹一个组件来对它的 props 进行浅比较
const Button = React.memo((props) => {
// 具体的组件
});注意:React.memo 等效于 PureComponent,它只浅比较 props。这里也可以使用 useMemo 优化每一个节点。
render:这是函数组件体本身。
componentDidMount, componentDidUpdate: useLayoutEffect 与它们两的调用阶段是一样的。但是,我们推荐你一开始先用 useEffect,只有当它出问题的时候再尝试使用 useLayoutEffect。useEffect 可以表达所有这些的组合。
// componentDidMount
useEffect(()=>{
// 需要在 componentDidMount 执行的内容
}, [])
useEffect(() => {
// 在 componentDidMount,以及 count 更改时 componentDidUpdate 执行的内容
document.title = `You clicked ${count} times`;
return () => {
// 需要在 count 更改时 componentDidUpdate(先于 document.title = ... 执行,遵守先清理后更新)
// 以及 componentWillUnmount 执行的内容
} // 当函数中 Cleanup 函数会按照在代码中定义的顺序先后执行,与函数本身的特性无关
}, [count]); // 仅在 count 更改时更新请记得 React 会等待浏览器完成画面渲染之后才会延迟调用 useEffect,因此会使得额外操作很方便
componentWillUnmount:相当于 useEffect 里面返回的 cleanup 函数
// componentDidMount/componentWillUnmount
useEffect(()=>{
// 需要在 componentDidMount 执行的内容
return function cleanup() {
// 需要在 componentWillUnmount 执行的内容
}
}, [])componentDidCatch and getDerivedStateFromError:目前还没有这些方法的 Hook 等价写法,但很快会加上。
为方便记忆,大致汇总成表格如下。
| class 组件 | Hooks 组件 |
|---|---|
| constructor | useState |
| getDerivedStateFromProps | useState 里面 update 函数 |
| shouldComponentUpdate | useMemo |
| render | 函数本身 |
| componentDidMount | useEffect |
| componentDidUpdate | useEffect |
| componentWillUnmount | useEffect 里面返回的函数 |
| componentDidCatch | 无 |
| getDerivedStateFromError | 无 |
我们可以将生命周期分为三个阶段:
分开来讲:
constructor:避免将 props 的值复制给 statecomponentWillMountrender:react 最重要的步骤,创建虚拟 dom,进行 diff 算法,更新 dom 树都在此进行componentDidMountcomponentWillReceivePropsshouldComponentUpdatecomponentWillUpdaterendercomponentDidUpdatecomponentWillUnMount这种生命周期会存在一个问题,那就是当更新复杂组件的最上层组件时,调用栈会很长,如果在进行复杂的操作时,就可能长时间阻塞主线程,带来不好的用户体验,Fiber 就是为了解决该问题而生。
Fiber 本质上是一个虚拟的堆栈帧,新的调度器会按照优先级自由调度这些帧,从而将之前的同步渲染改成了异步渲染,在不影响体验的情况下去分段计算更新。
对于异步渲染,分为两阶段:
reconciliation:
componentWillMountcomponentWillReceivePropsshouldConmponentUpdatecomponentWillUpdatecommit
componentDidMountcomponentDidUpdate其中,reconciliation 阶段是可以被打断的,所以 reconcilation 阶段执行的函数就会出现多次调用的情况,显然,这是不合理的。
所以 V16.3 引入了新的 API 来解决这个问题:
static getDerivedStateFromProps: 该函数在挂载阶段和组件更新阶段都会执行,即每次获取新的props 或 state 之后都会被执行,在挂载阶段用来代替componentWillMount;在组件更新阶段配合 componentDidUpdate,可以覆盖 componentWillReceiveProps 的所有用法。
同时它是一个静态函数,所以函数体内不能访问 this,会根据 nextProps 和 prevState 计算出预期的状态改变,返回结果会被送给 setState,返回 null 则说明不需要更新 state,并且这个返回是必须的。
getSnapshotBeforeUpdate: 该函数会在 render 之后, DOM 更新前被调用,用于读取最新的 DOM 数据。
返回一个值,作为 componentDidUpdate 的第三个参数;配合 componentDidUpdate, 可以覆盖componentWillUpdate 的所有用法。
注意:V16.3 中只用在组件挂载或组件 props 更新过程才会调用,即如果是因为自身 setState 引发或者forceUpdate 引发,而不是由父组件引发的话,那么static getDerivedStateFromProps也不会被调用,在 V16.4 中更正为都调用。
即更新后的生命周期为:
constructorstatic getDerivedStateFromPropsrendercomponentDidMountstatic getDerivedStateFromPropsshouldComponentUpdaterendergetSnapshotBeforeUpdatecomponentDidUpdatecomponentWillUnmount误解一:getDerivedStateFromProps 和 componentWillReceiveProps 只会在 props 改变 时才会调用
实际上,只要父级重新渲染,getDerivedStateFromProps 和 componentWillReceiveProps 都会重新调用,不管 props 有没有变化。所以,在这两个方法内直接将 props 赋值到 state 是不安全的。
// 子组件
class PhoneInput extends Component {
state = { phone: this.props.phone };
handleChange = e => {
this.setState({ phone: e.target.value });
};
render() {
const { phone } = this.state;
return <input onChange={this.handleChange} value={phone} />;
}
componentWillReceiveProps(nextProps) {
// 不要这样做。
// 这会覆盖掉之前所有的组件内 state 更新!
this.setState({ phone: nextProps.phone });
}
}
// 父组件
class App extends Component {
constructor() {
super();
this.state = {
count: 0
};
}
componentDidMount() {
// 使用了 setInterval,
// 每秒钟都会更新一下 state.count
// 这将导致 App 每秒钟重新渲染一次
this.interval = setInterval(
() =>
this.setState(prevState => ({
count: prevState.count + 1
})),
1000
);
}
componentWillUnmount() {
clearInterval(this.interval);
}
render() {
return (
<>
<p>
Start editing to see some magic happen :)
</p>
<PhoneInput phone='call me!' />
<p>
This component will re-render every second. Each time it renders, the
text you type will be reset. This illustrates a derived state
anti-pattern.
</p>
</>
);
}
}当然,我们可以在 父组件App 中 shouldComponentUpdate 比较 props 的 email 是不是修改再决定要不要重新渲染,但是如果子组件接受多个 props(较为复杂),就很难处理,而且 shouldComponentUpdate 主要是用来性能提升的,不推荐开发者操作 shouldComponetUpdate(可以使用 React.PureComponet)。
我们也可以使用 在 props 变化后修改 state。
class PhoneInput extends Component {
state = {
phone: this.props.phone
};
componentWillReceiveProps(nextProps) {
// 只要 props.phone 改变,就改变 state
if (nextProps.phone !== this.props.phone) {
this.setState({
phone: nextProps.phone
});
}
}
// ...
}但这种也会导致一个问题,当 props 较为复杂时,props 与 state 的关系不好控制,可能导致问题
解决方案一:完全可控的组件
function PhoneInput(props) {
return <input onChange={props.onChange} value={props.phone} />;
}完全由 props 控制,不派生 state
解决方案二:有 key 的非可控组件
class PhoneInput extends Component {
state = { phone: this.props.defaultPhone };
handleChange = event => {
this.setState({ phone: event.target.value });
};
render() {
return <input onChange={this.handleChange} value={this.state.phone} />;
}
}
<PhoneInput
defaultPhone={this.props.user.phone}
key={this.props.user.id}
/>当 key 变化时, React 会创建一个新的而不是更新一个既有的组件
误解二:将 props 的值直接复制给 state
应避免将 props 的值复制给 state
constructor(props) {
super(props);
// 千万不要这样做
// 直接用 props,保证单一数据源
this.state = { phone: props.phone };
}挂载阶段
分 两个 阶段:
render,解析其下有哪些子组件需要渲染,并对其中 同步的子组件 进行创建,按 递归顺序 挨个执行各个子组件至 render,生成到父子组件对应的 Virtual DOM 树,并 commit 到 DOM。componentDidMount,最后触发父组件的。注意:如果父组件中包含异步子组件,则会在父组件挂载完成后被创建。
所以执行顺序是:
父组件 getDerivedStateFromProps —> 同步子组件 getDerivedStateFromProps —> 同步子组件 componentDidMount —> 父组件 componentDidMount —> 异步子组件 getDerivedStateFromProps —> 异步子组件 componentDidMount
更新阶段
React 的设计遵循单向数据流模型 ,也就是说,数据均是由父组件流向子组件。
第 一 阶段,由父组件开始,执行
static getDerivedStateFromPropsshouldComponentUpdate更新到自身的 render,解析其下有哪些子组件需要渲染,并对 子组件 进行创建,按 递归顺序 挨个执行各个子组件至 render,生成到父子组件对应的 Virtual DOM 树,并与已有的 Virtual DOM 树 比较,计算出 Virtual DOM 真正变化的部分 ,并只针对该部分进行的原生DOM操作。
第 二 阶段,此时 DOM 节点已经生成完毕,组件挂载完成,开始后续流程。先依次触发同步子组件以下函数,最后触发父组件的。
getSnapshotBeforeUpdate()componentDidUpdate()React 会按照上面的顺序依次执行这些函数,每个函数都是各个子组件的先执行,然后才是父组件的执行。
所以执行顺序是:
父组件 getDerivedStateFromProps —> 父组件 shouldComponentUpdate —> 子组件 getDerivedStateFromProps —> 子组件 shouldComponentUpdate —> 子组件 getSnapshotBeforeUpdate —> 父组件 getSnapshotBeforeUpdate —> 子组件 componentDidUpdate —> 父组件 componentDidUpdate
卸载阶段
componentWillUnmount(),顺序为 父组件的先执行,子组件按照在 JSX 中定义的顺序依次执行各自的方法。
注意 :如果卸载旧组件的同时伴随有新组件的创建,新组件会先被创建并执行完 render,然后卸载不需要的旧组件,最后新组件执行挂载完成的回调。
挂载阶段
若是同步路由,它们的创建顺序和其在共同父组件中定义的先后顺序是 一致 的。
若是异步路由,它们的创建顺序和 js 加载完成的顺序一致。
更新阶段、卸载阶段
兄弟节点之间的通信主要是经过父组件(Redux 和 Context 也是通过改变父组件传递下来的 props 实现的),满足React 的设计遵循单向数据流模型, 因此任何两个组件之间的通信,本质上都可以归结为父子组件更新的情况 。
所以,兄弟组件更新、卸载阶段,请参考 父子组件。
走在最后:走心推荐一个在线编辑工具:StackBlitz,可以在线编辑 Angular、React、TypeScript、RxJS、Ionic、Svelte项目
预告:后续将加入高阶组件的生命周期,敬请期待小瓶子的下次更新。
PureComponent 最早在 React v15.3 版本中发布,主要是为了优化 React 应用而产生。
class Counter extends React.PureComponent {
constructor(props) {
super(props);
this.state = {count: 1};
}
render() {
return (
<button
color={this.props.color}
onClick={() => this.setState(state => ({count: state.count + 1}))}>
Count: {this.state.count}
</button>
);
}
}在这段代码中, React.PureComponent 会浅比较 props.color 或 state.count 是否改变,来决定是否重新渲染组件。
实现
React.PureComponent 和 React.Component 类似,都是定义一个组件类。不同是 React.Component 没有实现 shouldComponentUpdate(),而 React.PureComponent 通过 props 和 state 的 浅比较 实现了。
使用场景
当 React.Component 的 props 和 state 均为基本类型,使用 React.PureComponent 会节省应用的性能
可能出现的问题及解决方案
当props 或 state 为 复杂的数据结构 (例如:嵌套对象和数组)时,因为 React.PureComponent 仅仅是 浅比较 ,可能会渲染出 错误的结果 。这时有 两种解决方案 :
注意
React.PureComponent 中的 shouldComponentUpdate() 将跳过所有子组件树的 prop 更新(具体原因参考 Hooks 与 React 生命周期:即:更新阶段,由父至子去判断是否需要重新渲染),所以使用 React.PureComponent 的组件,它的所有 子组件也必须都为 React.PureComponent 。
如果你在 render 方法里创建函数,那么使用 props 会抵消使用 React.PureComponent 带来的优势。因为每次渲染运行时,都会分配一个新函数,如果你有子组件,即使数据没有改变,它们也会重新渲染,因为浅比较 props 的时候总会得到 false。
例如:
// FriendsItem 在父组件引用样式
<FriendsItem
key={friend.id}
name={friend.name}
id={friend.id}
onDeleteClick={() => this.deleteFriends(friend.id)}
/>
// 在父组件中绑定
// 父组件在 props 中传递了一个箭头函数。箭头函数在每次 render 时都会重新分配(和使用 bind 的方式相同)其中,FriendsItem 为 PureComponent:
// 其中 FriendsItem 为 PureComponent
class FriendsItem extends React.PureComponent {
render() {
const { name, onDeleteClick } = this.props
console.log(`FriendsItem:${name} 渲染`)
return (
<div>
<span>{name}</span>
<button onClick={onDeleteClick}>删除</button>
</div>
)
}
}
// 每次点击删除操作时,未删除的 FriendsItem 都将被重新渲染这种在 FriendsItem 直接调用 () => this.deleteFriends(friend.id),看起来操作更简单,逻辑更清晰,但它有一个有一个最大的弊端,甚至打破了像 shouldComponentUpdate 和 PureComponent 这样的性能优化。
这是因为:父组件在 render 声明了一个函数onDeleteClick,每次父组件渲染都会重新生成新的函数。因此,每次父组件重新渲染,都会给每个子组件 FriendsItem 传递不同的 props,导致每个子组件都会重新渲染, 即使 FriendsItem 为 PureComponent。
避免在 render 方法里创建函数并使用它。它会打破了像 shouldComponentUpdate 和 PureComponent 这样的性能优化。
要解决这个问题,只需要将原本在父组件上的绑定放到子组件上即可。FriendsItem 将始终具有相同的 props,并且永远不会导致不必要的重新渲染。
// FriendsItem 在父组件引用样式
<FriendsItem
key={friend.id}
id={friend.id}
name={friend.name}
onClick={this.deleteFriends}
/>FriendsItem:
class FriendsItem extends React.PureComponent {
onDeleteClick = () => {
this.props.onClick(this.props.id)
} // 在子组件中绑定
render() {
const { name } = this.props
console.log(`FriendsItem:${name} 渲染`)
return (
<div>
<span>{name}</span>
<button onClick={this.onDeleteClick}>删除</button>
</div>
)
}
}
// 每次点击删除操作时,FriendsItem 都不会被重新渲染通过此更改,当单击删除操作时,其他 FriendsItem 都不会被重新渲染了 👍
考虑一个文章列表,您的个人资料组件将从中显示用户最喜欢的 10 个作品。
render() {
const { posts } = this.props
// 在渲染函数中生成 topTen,并渲染
const topTen = [...posts].sort((a, b) =>
b.likes - a.likes).slice(0, 9)
return //...
}
// 这会导致组件每次重新渲染,都会生成新的 topTen,导致不必要的渲染topTen每次组件重新渲染时都会有一个全新的引用,即使 posts 没有更改,派生 state 也是相同的。
这个时候,我们应该将 topTen 的判断逻辑提取到 render 函数之外,通过缓存派生 state 来解决此问题。
例如,在组件的状态中设置派生 state,并仅在 posts 已更新时更新。
componentWillMount() {
this.setTopTenPosts(this.props.posts)
}
componentWillReceiveProps(nextProps) {
if (this.props.posts !== nextProps.posts) {
this.setTopTenPosts(nextProps.posts)
}
}
// 每次 posts 更新时,更新派生 state,而不是在渲染函数中重新生成
setTopTenPosts(posts) {
this.setState({
topTen: [...posts].sort((a, b) => b.likes - a.likes).slice(0, 9)
})
}在使用 PureComponent 时,请注意:
PureComponent 时,问题会更加复杂。对于 React 开发人员来说,知道何时在代码中使用 Component,**PureComponent ** 和 Stateless Functional Component 非常重要。
首先,让我们看一下无状态组件。
输入输出数据完全由 props 决定,而且不会产生任何副作用。
const Button = props =>
<button onClick={props.onClick}>
{props.text}
</button>无状态组件可以通过减少继承 Component 而来的生命周期函数而达到性能优化的效果。从本质上来说,无状态组件就是一个单纯的 render 函数,所以无状态组件的缺点也是显而易见的。因为它没有 shouldComponentUpdate 生命周期函数,所以每次 state 更新,它都会重新绘制 render 函数。
React 16.8 之后,React 引入 Hooks 。它可以让你在不编写 class 的情况下使用 state 以及其他的 React 特性。
PureComponent?PureComponent 提高了性能,因为它减少了应用程序中的渲染操作次数,这对于复杂的 UI 来说是一个巨大的胜利,因此建议尽可能使用。此外,还有一些情况需要使用 Component 的生命周期方法,在这种情况下,我们不能使用无状态组件。
无状态组件易于实施且快速实施。它们适用于非常小的 UI 视图,其中重新渲染成本无关紧要。它们提供更清晰的代码和更少的文件来处理。
React.memo 为高阶组件。它实现的效果与 React.PureComponent 相似,不同的是:
React.memo 用于函数组件React.PureComponent 适用于 class 组件React.PureComponent 只是浅比较 props、state,React.memo 也是浅比较,但它可以自定义比较函数function MyComponent(props) {
/* 使用 props 渲染 */
}
// 比较函数
function areEqual(prevProps, nextProps) {
/*
如果把 nextProps 传入 render 方法的返回结果与
将 prevProps 传入 render 方法的返回结果一致则返回 true,
否则返回 false
返回 true,复用最近一次渲染
返回 false,重新渲染
*/
}
export default React.memo(MyComponent, areEqual);React.memo 通过记忆组件渲染结果的方式实现 ,提高组件的性能props 浅比较,如果相同,React 将跳过渲染组件的操作并直接复用最近一次渲染的结果。shouldComponentUpdate() 方法不同的是,如果 props 相等,areEqual会返回 true;如果 props 不相等,则返回 false。这与 shouldComponentUpdate 方法的返回值相反。// 新建了空方法ComponentDummy ,ComponentDummy 的原型 指向 Component 的原型;
function ComponentDummy() {}
ComponentDummy.prototype = Component.prototype;
/**
* Convenience component with default shallow equality check for sCU.
*/
function PureComponent(props, context, updater) {
this.props = props;
this.context = context;
// If a component has string refs, we will assign a different object later.
this.refs = emptyObject;
this.updater = updater || ReactNoopUpdateQueue;
} // 解析同 React.Component,详细请看上一章
/**
* 实现 React.PureComponent 对 React.Component 的原型继承
*/
/**
* 用 ComponentDummy 的原因是为了不直接实例化一个 Component 实例,可以减少一些内存使用
*
* 因为,我们这里只需要继承 React.Component 的 原型,直接 PureComponent.prototype = new Component() 的话
* 会继承包括 constructor 在内的其他 Component 属性方法,但是 PureComponent 已经有自己的 constructor 了,
* 再继承的话,造成不必要的内存消耗
* 所以会新建ComponentDummy,只继承Component的原型,不包括constructor,以此来节省内存。
*/
const pureComponentPrototype = (PureComponent.prototype = new ComponentDummy());
// 修复 pureComponentPrototype 构造函数指向
pureComponentPrototype.constructor = PureComponent;
// Avoid an extra prototype jump for these methods.
// 虽然上面两句已经让PureComponent继承了Component
// 但多加一个 Object.assign(),能有效的避免多一次原型链查找
Object.assign(pureComponentPrototype, Component.prototype);
// 唯一的区别,原型上添加了 isPureReactComponent 属性去表示该 Component 是 PureComponent
// 在后续组件渲染的时候,react-dom 会去判断 isPureReactComponent 这个属性,来确定是否浅比较 props、status 实现更新
/** 在 ReactFiberClassComponent.js 中,有对 isPureReactComponent 的判断
if (ctor.prototype && ctor.prototype.isPureReactComponent) {
return (
!shallowEqual(oldProps, newProps) || !shallowEqual(oldState, newState)
);
}
*/
pureComponentPrototype.isPureReactComponent = true;这里只是 PureComponent 的声明创建,至于如何实现 shouldComponentUpdate() ,核心代码在:
// ReactFiberClassComponent.js
function checkShouldComponentUpdate(
workInProgress,
ctor,
oldProps,
newProps,
oldState,
newState,
nextContext,
) {
// ...
if (ctor.prototype && ctor.prototype.isPureReactComponent) {
// 如果是纯组件,比较新老 props、state
// 返回 true,重新渲染,
// 即 shallowEqual props 返回 false,或 shallowEqual state 返回 false
return (
!shallowEqual(oldProps, newProps) || !shallowEqual(oldState, newState)
);
}
return true;
}shallowEqual.js
/**
* 通过遍历对象上的键并返回 false 来执行相等性
* 在参数列表中,当任意键对应的值不严格相等时,返回 false。
* 当所有键的值严格相等时,返回 true。
*/
function shallowEqual(objA: mixed, objB: mixed): boolean {
// 通过 Object.is 判断 objA、objB 是否相等
if (is(objA, objB)) {
return true;
}
if (
typeof objA !== 'object' ||
objA === null ||
typeof objB !== 'object' ||
objB === null
) {
return false;
}
// 参数列表
const keysA = Object.keys(objA);
const keysB = Object.keys(objB);
// 参数列表长度不相同
if (keysA.length !== keysB.length) {
return false;
}
// 比较参数列表每一个参数,但仅比较一层
for (let i = 0; i < keysA.length; i++) {
if (
!hasOwnProperty.call(objB, keysA[i]) ||
!is(objA[keysA[i]], objB[keysA[i]])
) {
return false;
}
}
return true;
}Object.is() 判断两个值是否相同。
这种相等性判断逻辑和传统的 == 运算不同,== 运算符会对它两边的操作数做隐式类型转换(如果它们类型不同),然后才进行相等性比较,(所以才会有类似 "" == false 等于 true 的现象),但 Object.is 不会做这种类型转换。
这与 === 运算符的判定方式也不一样。=== 运算符(和== 运算符)将数字值 -0 和 +0 视为相等,并认为 Number.NaN 不等于 NaN。
如果下列任何一项成立,则两个值相同:


JS系列暂定 27 篇,从基础,到原型,到异步,到设计模式,到架构模式等,
本篇是JS系列中第 4 篇,文章主讲 JS instanceof ,包括 instanceof 作用、内部实现机制,以及 instanceof 与 typeof、Symbol.hasInstance、isPrototype、Object.prototype.toString、[[Class]] 等的对比使用 ,深入了解 JS instanceof。
在 JS 中,判断一个变量的类型,常常会用到 typeof 运算符,但当用 typeof 来判断引用类型变量时,无论是什么类型的变量,它都会返回 Object 。
// 基本类型
console.log(typeof 100); // number
console.log(typeof 'bottle'); // string
console.log(typeof true); // boolean
// 引用类型
console.log(typeof {}); // object
console.log(typeof [1, 2, 3]); // object为此,引入了instanceof。
instanceof 操作符用于检测对象是否属于某个 class,同时,检测过程中也会将继承关系考虑在内。
// 类
class Bottle {}
// bottle 是 Bottle 类的实例对象
let bottle = new Bottle();
console.log(bottle instanceof Bottle); // true
// 也可以是构造函数,而非 class
function AnGe() {}
let an = new AnGe();
console.log(an instanceof AnGe); // trueinstanceof 与 typeof 相比,instanceof 方法要求开发者明确的确认对象为某特定类型。即 instanceof 用于判断引用类型属于哪个构造函数的方法。
var arr = []
arr instanceof Array // true
typeof arr // "object"
// typeof 是无法判断类型是否为数组的另外,更重的一点是 instanceof 可以在继承关系中用来判断一个实例是否属于它的父类型。
// 判断 f 是否是 Foo 类的实例 , 并且是否是其父类型的实例
function Aoo(){}
function Foo(){}
//JavaScript 原型继承
Foo.prototype = new Aoo();
var foo = new Foo();
console.log(foo instanceof Foo) // true
console.log(foo instanceof Aoo) // truef instanceof Foo 的判断逻辑是:
__proto__一层一层往上,是否对应到 Foo.prototypeAoo.prototypef instanceof Object即 instanceof 可以用于判断多层继承关系。
下面看一组复杂例子
console.log(Object instanceof Object) //true
console.log(Function instanceof Function) //true
console.log(Number instanceof Number) //false
console.log(String instanceof String) //false
console.log(Array instanceof Array) // false
console.log(Function instanceof Object) //true
console.log(Foo instanceof Function) //true
console.log(Foo instanceof Foo) //false在这组数据中,Object、Function instanceof 自己均为 true, 其他的 instanceof 自己都为 false,这就要从 instanceof 的内部实现机制以及 JS 原型继承机制讲起。
instanceof 的内部实现机制是:通过判断对象的原型链上是否能找到对象的 prototype,来确定 instanceof 返回值
// instanceof 的内部实现
function instance_of(L, R) {//L 表左表达式,R 表示右表达式,即L为变量,R为类型
// 取 R 的显示原型
var prototype = R.prototype
// 取 L 的隐式原型
L = L.__proto__
// 判断对象(L)的类型是否严格等于类型(R)的显式原型
while (true) {
if (L === null) {
return false
}
// 这里重点:当 prototype 严格等于 L 时,返回 true
if (prototype === L) {
return true
}
L = L.__proto__
}
}instanceof 运算符用来检测 constructor.prototype 是否存在于参数 object 的原型链上。
看下面一个例子,instanceof 为什么会返回 true?很显然,an 并不是通过 Bottle() 创建的。
function An() {}
function Bottle() {}
An.prototype = Bottle.prototype = {};
let an = new An();
console.log(an instanceof Bottle); // true这是因为 instanceof 关心的并不是构造函数,而是原型链。
an.__proto__ === An.prototype; // true
An.prototype === Bottle.prototype; // true
// 即
an.__proto__ === Bottle.prototype; // true即有 an.__proto__ === Bottle.prototype 成立,所以 an instanceof Bottle 返回了 true。
所以,按照 instanceof 的逻辑,真正决定类型的是 prototype,而不是构造函数。
图片来自于 JS原型链
由其本文涉及显示原型 prototype 和隐式原型 __proto__ ,所以下面对这两个概念作一下简单说明。
在 JavaScript 原型继承结构里面,规范中用 [Prototype]] 表示对象隐式的原型,在 JavaScript 中用 __proto__ 表示,并且在 Firefox 和 Chrome 浏览器中是可以访问得到这个属性的,但是 IE 下不行。所有 JavaScript 对象都有 __proto__ 属性,但只有 Object.prototype.__proto__ 为 null,前提是没有在 Firefox 或者 Chrome 下修改过这个属性。这个属性指向它的原型对象。 至于显示的原型,在 JavaScript 里用 prototype 属性表示,这个是 JavaScript 原型继承的基础知识,如果想进一步了解,请参考 JS 基础之: 深入 constructor、prototype、__proto__、[[Prototype]] 及 原型链
下面介绍几个例子(及其推演过程),加深你的理解:
// 为了方便表述,首先区分左侧表达式和右侧表达式
ObjectL = Object, ObjectR = Object;
// 下面根据规范逐步推演
O = ObjectR.prototype = Object.prototype
L = ObjectL.__proto__ = Function.prototype
// 第一次判断
O != L
// 循环查找 L 是否还有 __proto__
L = Function.prototype.__proto__ = Object.prototype
// 第二次判断
O === L
// 返回 true// 为了方便表述,首先区分左侧表达式和右侧表达式
FunctionL = Function, FunctionR = Function;
// 下面根据规范逐步推演
O = FunctionR.prototype = Function.prototype
L = FunctionL.__proto__ = Function.prototype
// 第一次判断
O === L
// 返回 true// 为了方便表述,首先区分左侧表达式和右侧表达式
FooL = Foo, FooR = Foo;
// 下面根据规范逐步推演
O = FooR.prototype = Foo.prototype
L = FooL.__proto__ = Function.prototype
// 第一次判断
O != L
// 循环再次查找 L 是否还有 __proto__
L = Function.prototype.__proto__ = Object.prototype
// 第二次判断
O != L
// 再次循环查找 L 是否还有 __proto__
L = Object.prototype.__proto__ = null
// 第三次判断
L == null
// 返回 falseSymbol.hasInstance 用于判断某对象是否为某构造器的实例。因此你可以用它自定义 instanceof 操作符在某个类上的行为。
你可实现一个自定义的instanceof 行为,例如:
class MyArray {
static [Symbol.hasInstance](instance) {
return Array.isArray(instance);
}
}
console.log([] instanceof MyArray); // trueisPrototypeOf 也是用来判断一个对象是否存在与另一个对象的原型链上。
// 判断 f 是否是 Foo 类的实例 ,
// 并且是否是其父类型的实例
function Aoo(){}
function Foo(){}
// JavaScript 原型继承
Foo.prototype = new Aoo();
var foo = new Foo();
console.log(Foo.prototype.isPrototypeOf(foo)) //true
console.log(Aoo.prototype.isPrototypeOf(foo)) //true需要注意的是:
instanceof :foo 的原型链是针对 Foo.prototype 进行检查的isPrototypeOf:foo 的原型链是针对 Foo 本身instanceof 在多个全局作用域下,判断会有问题,例如:
// parent.html
<iframe src="child.html" onload="test()">
</iframe>
<script>
function test(){
var value = window.frames[0].v;
console.log(value instanceof Array); // false
}
</script>// child.html
<script>
window.name = 'child';
var v = [];
</script>严格上来说 value 就是数组,但 parent 页面中打印输出: false ;
这是因为 Array.prototype !== window.frames[0].Array.prototype ,并且数组从前者继承。
出现问题主要是在浏览器中,当我们的脚本开始开始处理多个 frame 或 windows 或在多个窗口之间进行交互。多个窗口意味着多个全局环境,不同的全局环境拥有不同的全局对象,从而拥有不同的内置类型构造函数。
可以通过使用
Array.isArray(myObj) 或者
Object.prototype.toString.call(myObj) === "[object Array]"
来安全的检测传过来的对象是否是一个数组
默认情况下(不覆盖 toString 方法前提下),任何一个对象调用 Object 原生的 toString 方法都会返回 "[object type]",其中 type 是对象的类型;
let obj = {};
console.log(obj); // {}
console.log(obj.toString()); // "[object Object]"每个实例都有一个 [[Class]] 属性,这个属性中就指定了上述字符串中的 type (构造函数名)。 [[Class]] 不能直接地被访问,但通常可以间接地通过在这个值上借用默认的 Object.prototype.toString.call(..) 方法调用来展示。
Object.prototype.toString.call("abc"); // "[object String]"
Object.prototype.toString.call(100); // "[object Number]"
Object.prototype.toString.call(true); // "[object Boolean]"
Object.prototype.toString.call(null); // "[object Null]"
Object.prototype.toString.call(undefined); // "[object Undefined]"
Object.prototype.toString.call([1,2,3]); // "[object Array]"
Object.prototype.toString.call(/\w/); // "[object RegExp]"Object.prototype.toString.call(..) 检测对象类型可以通过 Object.prototype.toString.call(..) 来获取每个对象的类型。
function isFunction(value) {
return Object.prototype.toString.call(value) === "[object Function]"
}
function isDate(value) {
return Object.prototype.toString.call(value) === "[object Date]"
}
function isRegExp(value) {
return Object.prototype.toString.call(value) === "[object RegExp]"
}
isDate(new Date()); // true
isRegExp(/\w/); // true
isFunction(function(){}); //true或者可写为:
function generator(type){
return function(value){
return Object.prototype.toString.call(value) === "[object "+ type +"]"
}
}
let isFunction = generator('Function')
let isArray = generator('Array');
let isDate = generator('Date');
let isRegExp = generator('RegExp');
isArray([])); // true
isDate(new Date()); // true
isRegExp(/\w/); // true
isFunction(function(){}); //trueObject.prototype.toString 方法可以使用 Symbol.toStringTag 这个特殊的对象属性进行自定义输出。
举例说明:
let bottle = {
[Symbol.toStringTag]: "Bottle"
};
console.log(Object.prototype.toString.call(bottle)); // [object Bottle]大部分和环境相关的对象也有这个属性。以下输出可能因浏览器不同而异:
// 环境相关对象和类的 toStringTag:
console.log(window[Symbol.toStringTag]); // Window
console.log(XMLHttpRequest.prototype[Symbol.toStringTag]); // XMLHttpRequest
console.log(Object.prototype.toString.call(window)); // [object Window]
console.log(Object.prototype.toString.call(new XMLHttpRequest())); // [object XMLHttpRequest]输出结果和 Symbol.toStringTag(前提是这个属性存在)一样,只不过被包裹进了 [object ...] 里。
所以,如果希望以字符串的形式获取内置对象类型信息,而不仅仅只是检测类型的话,可以用这个方法来替代 instanceof。
| 适用于 | 返回 | |
|---|---|---|
| typeof | 基本数据类型 | string |
| instanceof | 任意对象 | true/false |
Object.prototype.toString |
基本数据类型、内置对象以及包含 Symbol.toStringTag 属性的对象 |
string |
Object.prototype.toString 基本上就是一增强版 typeof。
instanceof 在涉及多层类结构的场合中比较实用,这种情况下需要将类的继承关系考虑在内。
一道面试题引发的血案,下面进入主题:
// 今日头条面试题
async function async1() {
console.log('async1 start')
await async2()
console.log('async1 end')
}
async function async2() {
console.log('async2')
}
console.log('script start')
setTimeout(function () {
console.log('settimeout')
})
async1()
new Promise(function (resolve) {
console.log('promise1')
resolve()
}).then(function () {
console.log('promise2')
})
console.log('script end')题目的本质,就是考察setTimeout、promise、async await的实现及执行顺序,以及JS的事件循环的相关问题。
答案:
script start
async1 start
async2
promise1
script end
async1 end
promise2
settimeout再看一个经典的例子:
const p = Promise.resolve();
(async () => {
await p;
console.log('await end');
})();
p.then(() => {
console.log('then 1');
}).then(() => {
console.log('then 2');
});答案:
then 1
then 2
await end你答对了吗?这里涉及到Microtasks、Macrotasks、event loop 以及 JS 的异步运行机制。
JS主线程不断的循环往复的从任务队列中读取任务,执行任务,其中运行机制称为事件循环(event loop)。
在高层次上,JavaScript 中有 microtasks 和 macrotasks(task),它们是异步任务的一种类型,Microtasks的优先级要高于macrotasks,macrotasks 用于处理 I/O 和计时器等事件,每次执行一个。microtask 为 async/await 和 Promise 实现延迟执行,并在每个 task 结束时执行。在每一个事件循环之前,microtask 队列总是被清空(执行)。
图1: 微任务和任务之间的区别
下面是它们所包含的api:
注意:
我们已知, JS 是单线程的,至于为什么,详见 JS 基础之异步(一)。
下面看一个例子:
// 1. 开始执行
console.log(1) // 2. 打印 1
setTimeout(function () { // 6. 浏览器在 0ms 后,将该函数推入任务队列
console.log(2) // 7. 打印 2
Promise.resolve(1).then(function () { // 8. 将 resolve(1) 推入任务队列 9. 将 function函数推入任务队列
console.log('ok') // 10. 打印 ok
})
}) // 3.调用 setTimeout 函数,并定义其完成后执行的回调函数
setTimeout(function (){ // 11. 浏览器 0ms 后,将该函数推入任务队列
console.log(3) // 12. 打印 3
}) // 4. 调用 setTimeout 函数,并定义其完成后执行的回调函数
// 5. 主线程执行栈清空,开始读取 任务队列 中的任务
// output: 1 2 ok 3JS 主线程拥有一个 执行栈(同步任务) 和 一个 任务队列(microtasks queue),主线程会依次执行代码,
这就是 JS的异步执行机制
setTimeout
console.log('script start') //1. 打印 script start
setTimeout(function(){
console.log('settimeout') // 4. 打印 settimeout
}) // 2. 调用 setTimeout 函数,并定义其完成后执行的回调函数
console.log('script end') //3. 打印 script start
// 输出顺序:script start->script end->settimeoutPromise
Promise本身是同步的立即执行函数, 当在 executor 中执行 resolve 或者 reject 的时候, 此时是异步操作, 会先执行 then/catch 等,当主栈完成后,才会去调用 resolve/reject 中存放的方法执行,打印 p 的时候,是打印的返回结果,一个 Promise 实例。
console.log('script start')
let promise1 = new Promise(function (resolve) {
console.log('promise1')
resolve()
console.log('promise1 end')
}).then(function () {
console.log('promise2')
})
setTimeout(function(){
console.log('settimeout')
})
console.log('script end')
// 输出顺序: script start->promise1->promise1 end->script end->promise2->settimeout当JS主线程执行到Promise对象时,
回到文章开头经典的例子:
const p = Promise.resolve(); // 1. p 的状态为 resolve;
(async () => {
await p; // 2. 返回,并将 函数体后面的语句 console.log('await end') 放入下一个事件循环的 microtask queue 中
console.log('await end'); // 6. 执行,打印 await end
})();
p.then(() => { // 3. p 的状态为 resolve,会把 p.then() 放入当前事件循环的 microtask queue中。
console.log('then 1'); // 4. 执行,打印 then 1
}).then(() => {
console.log('then 2'); // 5. 执行,打印 then 2,当前 microtask queue 结束,运行下一个 microtask queue
});
// 输出结果:then 1->then 1->await end例如:
console.log('script start');
setTimeout(function() {
console.log('setTimeout');
}, 0);
Promise.resolve().then(function() {
console.log('promise1');
}).then(function() {
console.log('promise2');
});
console.log('script end');
// 输出结果:script start->script end->promise1->promise2->setTimeoutasync await
async function async1(){
console.log('async1 start');
await async2();
console.log('async1 end')
}
async function async2(){
console.log('async2')
}
console.log('script start');
async1();
console.log('script end')
// 输出顺序:script start->async1 start->async2->script end->async1 endasync 函数返回一个 Promise 对象,当函数执行的时候,一旦遇到 await 就会先返回,等到触发的异步操作完成,再执行函数体内后面的语句。可以理解为,是让出了线程,跳出了 async 函数体。
举个例子:
async function func1() {
return 1
}
console.log(func1())
很显然,func1的运行结果其实就是一个 Promise 对象。因此我们也可以使用 then 来处理后续逻辑。
func1().then(res => {
console.log(res); // 1
})
await 的含义为等待,也就是 async 函数需要等待 await 后的函数执行完成并且有了返回结果( Promise 对象)之后,才能继续执行下面的代码。await通过返回一个Promise对象来实现同步的效果。
在JS中,我们可以使用 setTimeout 和 setIntarval 实现动画,但是 H5 的出现,让我们又多了两种实现动画的方式,分别是 CSS 动画(transition、animation)和 H5的canvas 实现。除此以外,H5还提供了一个专门用于请求动画的API,让 DOM 动画、canvas动画、svg动画、webGL动画等有一个专门的刷新机制。
requestAnimationFrame 方法会告诉浏览器希望执行动画并请求浏览器在下一次重绘之前调用回调函数来更新动画。
window.requestAnimationFrame(callback)cancelAnimationFrame() 以取消动画。在使用和实现上, requestAnimationFrame 与 setTimeout 类似。举个例子:
let count = 0;
let rafId = null;
/**
* 回调函数
* @param time requestAnimationFrame 调用该函数时,自动传入的一个时间
*/
function requestAnimation(time) {
console.log(time); // 打印执行requestAnimation函数的时刻
// 动画没有执行完,则递归渲染
if (count < 5) {
count++;
// 渲染下一帧
rafId = window.requestAnimationFrame(requestAnimation);
}
}
// 渲染第一帧
window.requestAnimationFrame(requestAnimation);首先判断 document.hidden 属性是否可见(true),可见状态下才能继续执行以下步骤
浏览器清空上一轮的动画函数
requestAnimationFrame 将回调函数追加到动画帧请求回调函数列表的末尾
注意:当执行 requestAnimationFrame(callback)的时候,不会立即调用 callback 回调函数,只是将其放入回调函数队列而已,同时注意,每个 callback回调函数都有一个 cancelled 标志符,初始值为 false,并对外不可见。
当页面可见并且动画帧请求callback回调函数列表不为空时,浏览器会定期将这些回调函数加入到浏览器 UI 线程的队列中(由系统来决定回调函数的执行时机)。当浏览器执行这些 callback 回调函数的时候,会判断每个元组的 callback 的cancelled标志符,只有 cancelled 为 false 时,才执行callback回调函数。
requestAnimationFrame 自带函数节流功能,采用系统时间间隔,保持最佳绘制效率,不会因为间隔时间的过短,造成过度绘制,增加页面开销,也不会因为间隔时间过长,造成动画卡顿,不流程,影响页面美观。
浏览器的重绘频率一般会和显示器的刷新率保持同步。大多数采用 W3C规范,浏览器的渲染页面的标准频率也为 60 FPS(frames/per second)即每秒重绘60次,requestAnimationFrame的基本**是 让页面重绘的频率和刷新频率保持同步,即每 1000ms / 60 = 16.7ms执行一次。
通过 requestAnimationFrame 调用回调函数引起的页面重绘或回流的时间间隔和显示器的刷新时间间隔相同。所以 requestAnimationFrame 不需要像 setTimeout 那样传递时间间隔,而是浏览器通过系统获取并使用显示器刷新频率。例如在某些高频事件(resize,scroll 等)中,使用 requestAnimationFrame 可以防止在一个刷新间隔内发生多次函数执行,这样保证了流程度,也节省了开销
另外,该函数的延时效果是精确的,没有setTimeout或setInterval不准的情况(JS是单线程的,setTimeout 任务被放进异步队列中,只有当主线程上的任务执行完以后,才会去检查该队列的任务是否需要开始执行,造成时间延时)。
setTimeout的执行只是在内存中对图像属性进行改变,这个改变必须要等到下次浏览器重绘时才会被更新到屏幕上。如果和屏幕刷新步调不一致,就可能导致中间某些帧的操作被跨越过去,直接更新下下一帧的图像。即 掉帧
使用 requestAnimationFrame 执行动画,最大优势是能保证回调函数在屏幕每一次刷新间隔中只被执行一次,这样就不会引起丢帧,动画也就不会卡顿
节省资源,节省开销
在之前介绍requestAnimationFrame执行过程,我们知道只有当页面激活的状态下,页面刷新任务才会开始,才执行 requestAnimationFrame,当页面隐藏或最小化时,会被暂停,页面显示,会继续执行。节省了 CPU 开销。
注意:当页面被隐藏或最小化时,定时器setTimeout仍在后台执行动画任务,此时刷新动画是完全没有意义的(实际上 FireFox/Chrome 浏览器对定时器做了优化:页面闲置时,如果时间间隔小于 1000ms,则停止定时器,与requestAnimationFrame行为类似。如果时间间隔>=1000ms,定时器依然在后台执行)
// 在浏览器开发者工具的Console页执行下面代码。
// 当开始输出count后,切换浏览器tab页,再切换回来,可以发现打印的值从离开前的值继续输出
let count = 0;
function requestAnimation() {
if (count < 100) {
count++;
console.log(count);
requestAnimationFrame(requestAnimation);
}
}
requestAnimationFrame(requestAnimation);能够在动画流刷新之后执行,即上一个动画流会完整执行
我们可以使用 requestAnimationFrame 实现setInterval及 setTimeout
// setInterval实现
function setInterval(callback, interval) {
let timer
const now = Date.now
let startTime = now()
let endTime = startTime
const loop = () => {
timer = window.requestAnimationFrame(loop)
endTime = now()
if (endTime - startTime >= interval) {
startTime = endTime = now()
callback(timer)
}
}
timer = window.requestAnimationFrame(loop)
return timer
}
let a = 0
setInterval(timer => {
console.log(a)
a++
if (a === 3) window.cancelAnimationFrame(timer)
}, 1000)
// 0
// 1
// 2// setTimeout 实现
function setTimeout(callback, interval) {
let timer
const now = Date.now
let startTime = now()
let endTime = startTime
const loop = () => {
timer = window.requestAnimationFrame(loop)
endTime = now()
if (endTime - startTime >= interval) {
callback(timer)
window.cancelAnimationFrame(timer)
}
}
timer = window.requestAnimationFrame(loop)
return timer
}
let a = 0
setTimeout(timer => {
console.log(a)
a++
}, 1000)
// 0Creact React App(CRA)是创建React应用的一个构建脚本,并不处理后端逻辑及数据库,它与其他构建脚本不同的一点就是,它使用了 Babel 和 Webpack 这样的构建工具,使开发者不用单独去配置这些工具,从而降低了开发人员的学习难度。
但对于一些高阶的开发人员,想要对Webpack做一些修改,包括对less、跨域访问的支持以及antd的配置等,下面就是我的具体做法。
注意当前webpack的版本"webpack": "4.19.1",时基于此给出的解决方案,webpack至少是4以上版本。
按照React 官网创建你的React项目,这里就不在讲解。
使用CRA创建好项目之后,打开package.json文件:
{
...
"scripts": {
"start": "react-scripts start",
"build": "react-scripts build",
"test": "react-scripts test",
"eject": "react-scripts eject"
},
...
}执行yarn eject将封装到CRA中的全部配置反编译到当前项目,由此webpack的配置全部暴露给了开发者。
// eject 后项目根目录下会出现 config 文件夹,里面就包含了 webpack 配置
config
├── env.js
├── jest
│ ├── cssTransform.js
│ └── fileTransform.js
├── paths.js
├── webpack.config.dev.js // 开发环境配置
├── webpack.config.prod.js // 生产环境配置
└── webpackDevServer.config.js
// eject 后项目根目录下会出现 scripts 文件夹,里面就包含了 项目启动文件
├── build.js //生产环境
├── start.js // 开发环境
├── test.js // 测试环境
CRA和其他构建脚本不同的是,它可以通过升级react-scripts来升级CRA特性,但是如果使用eject命令后,就无法使用了,因为react-scripts已经是以文件的形式存在于你的项目,而不是以包的形式,所以无法对其升级。
这时,一个简单的项目已经可以运行成功了并且webpack配置暴露了出来,下面安装antd,配置antd
yarn add antd安装后,你可以使用antd的组件,官网提供了两种配置方案,我们这里只介绍eject配置。
yarn add less及yarn add less-loaderyarn babel-plugin-import 是一个用于按需加载组件代码和样式的 babel 插件...
// style files regexes
const cssRegex = /\.css$/;
const cssModuleRegex = /\.module\.css$/;
const sassRegex = /\.(scss|sass)$/;
const sassModuleRegex = /\.module\.(scss|sass)$/;
//--------------------注意:这里需要增加less的相关配置--------------------
const lessRegex = /\.less$/;
const lessModuleRegex = /\.module\.less$/;
// common function to get style loaders
const getStyleLoaders = (cssOptions, preProcessor) => {
...
// --------------------注意,在此处修改了判断语句的代码,增加对less的支持--------------------
if (preProcessor) {
if (preProcessor === 'less-loader') {
loaders.push({
loader:require.resolve(preProcessor),
options: {
modules: false,
modifyVars: {
"@primary-color": "#1890ff" // 这里配置antd的自定义主题色
},
javascriptEnabled: true
}
})
} else {
loaders.push(require.resolve(preProcessor));
}
}
return loaders;
};
// This is the development configuration.
// It is focused on developer experience and fast rebuilds.
// The production configuration is different and lives in a separate file.
module.exports = {
...
module: {
strictExportPresence: true,
rules: [
...
{
// "oneOf" will traverse all following loaders until one will
// match the requirements. When no loader matches it will fall
// back to the "file" loader at the end of the loader list.
oneOf: [
...
// Process application JS with Babel.
// The preset includes JSX, Flow, and some ESnext features.
{
test: /\.(js|mjs|jsx|ts|tsx)$/,
include: paths.appSrc,
loader: require.resolve('babel-loader'),
options: {
customize: require.resolve(
'babel-preset-react-app/webpack-overrides'
),
plugins: [
[
require.resolve('babel-plugin-named-asset-import'),
{
loaderMap: {
svg: {
ReactComponent: '@svgr/webpack?-prettier,-svgo![path]',
},
},
},
],
// --------------------注意此处增加:实现按需加载--------------------:
['import', { libraryName: 'antd', style: true }], // import less
],
// This is a feature of `babel-loader` for webpack (not Babel itself).
// It enables caching results in ./node_modules/.cache/babel-loader/
// directory for faster rebuilds.
cacheDirectory: true,
// Don't waste time on Gzipping the cache
cacheCompression: false,
},
},
...
// --------------------注意此处在cssRegex配置之上增加--------------------
// "postcss" loader applies autoprefixer to our CSS.
// "css" loader resolves paths in CSS and adds assets as dependencies.
// "style" loader turns CSS into JS modules that inject <style> tags.
// In production, we use a plugin to extract that CSS to a file, but
// in development "style" loader enables hot editing of CSS.
// By default we support CSS Modules with the extension .module.css
{
test: lessRegex,
exclude: lessModuleRegex,
use: getStyleLoaders({
importLoaders: 2,
}, 'less-loader'),
},
// Adds support for CSS Modules (https://github.com/css-modules/css-modules)
// using the extension .module.css
{
test: lessModuleRegex,
use: getStyleLoaders({
importLoaders: 2,
modules: true,
getLocalIdent: getCSSModuleLocalIdent,
}, 'less-loader'),
},
// "postcss" loader applies autoprefixer to our CSS.
// "css" loader resolves paths in CSS and adds assets as dependencies.
// "style" loader turns CSS into JS modules that inject <style> tags.
// In production, we use a plugin to extract that CSS to a file, but
// in development "style" loader enables hot editing of CSS.
// By default we support CSS Modules with the extension .module.css
{
test: cssRegex,
exclude: cssModuleRegex,
use: getStyleLoaders({
importLoaders: 1,
}),
},
// Adds support for CSS Modules (https://github.com/css-modules/css-modules)
// using the extension .module.css
{
test: cssModuleRegex,
use: getStyleLoaders({
importLoaders: 1,
modules: true,
getLocalIdent: getCSSModuleLocalIdent,
}),
},
...
],
},
...
// ** STOP ** Are you adding a new loader?
// Make sure to add the new loader(s) before the "file" loader.
],
},
...
};同样,对webpack.config.prod.js做相同的调整。
至此,antd配置结束。
webpack-dev-server 为你提供了一个简单的 web 服务器,并且能够实时重新加载(live reloading)。
在eject之后暴露出来的scripts/start.js, 找到
...
const paths = require('../config/paths');
...
// We require that you explictly set browsers and do not fall back to
// browserslist defaults.
const { checkBrowsers } = require('react-dev-utils/browsersHelper');
checkBrowsers(paths.appPath, isInteractive)
.then(() => {
// We attempt to use the default port but if it is busy, we offer the user to
// run on a different port. `choosePort()` Promise resolves to the next free port.
// 获取端口号
return choosePort(HOST, DEFAULT_PORT);
})
.then(port => {
if (port == null) {
// We have not found a port.
return;
}
// 获取协议类型
const protocol = process.env.HTTPS === 'true' ? 'https' : 'http';
// 获取名称
const appName = require(paths.appPackageJson).name;
// 获取url
const urls = prepareUrls(protocol, HOST, port);
// 根据惯用的信息创建一个webpack编译器
const compiler = createCompiler(webpack, config, appName, urls, useYarn);
// **加载代理**-----------
const proxySetting = require(paths.appPackageJson).proxy;
const proxyConfig = prepareProxy(proxySetting, paths.appPublic);
// 创建WebpackDevServer服务器
const serverConfig = createDevServerConfig(
proxyConfig,
urls.lanUrlForConfig
);
const devServer = new WebpackDevServer(compiler, serverConfig);
// 启动WebpackDevServer服务器
devServer.listen(port, HOST, err => {
if (err) {
return console.log(err);
}
if (isInteractive) {
clearConsole();
}
console.log(chalk.cyan('Starting the development server...\n'));
openBrowser(urls.localUrlForBrowser);
});
['SIGINT', 'SIGTERM'].forEach(function(sig) {
process.on(sig, function() {
devServer.close();
process.exit();
});
});
})
.catch(err => {
if (err && err.message) {
console.log(err.message);
}
process.exit(1);
});注意 加载代理配置项proxySetting,它是由paths.appPackageJson加载来的,我们向上找到const paths = require('../config/paths');
...
// config after eject: we're in ./config/
module.exports = {
dotenv: resolveApp('.env'),
appPath: resolveApp('.'),
appBuild: resolveApp('build'),
appPublic: resolveApp('public'),
appHtml: resolveApp('public/index.html'),
appIndexJs: resolveModule(resolveApp, 'src/index'),
appPackageJson: resolveApp('package.json'),
appSrc: resolveApp('src'),
appTsConfig: resolveApp('tsconfig.json'),
yarnLockFile: resolveApp('yarn.lock'),
testsSetup: resolveModule(resolveApp, 'src/setupTests'),
// -------加载代理配置栏------
proxySetup: resolveApp('src/setupProxy.js'),
appNodeModules: resolveApp('node_modules'),
publicUrl: getPublicUrl(resolveApp('package.json')),
servedPath: getServedPath(resolveApp('package.json')),
};
...查找当前src文件夹
src
├── App.css
├── App.js
├── App.test.js
├── index.css
├──index.js
├── logo.svg
└── serviceWorker.js
并没有setupProxy.js文件,我们创建src/setupProxy.js,并安装yarn add http-proxy-middleware,设置相应的代理
// src/setupProxy.js 配置代理
const proxy = require('http-proxy-middleware');
module.exports = function(app) {
app.use(proxy('/api/',
{
target: 'https://api.dev.com',// 后端服务器地址
changeOrigin: true,
secure: false
}
));
}更多devServer的配置,详见开发中 Server(devServer),这里不在详细介绍。
至此,若后续有修改,将继续更新。
co 函数库是 TJ 大神基于ES6 generator 的异步解决方案。要理解 co ,你必须首先理解 ES6 generator,可以看我之前的文章JS 基础之异步(五):Generator,这里不在赘述。
co 现在已经不怎么使用了,一些老版本的库里可能使用它,我是在看 koa 源码的时候看到它的。
co 最大的好处在于通过它可以把异步的流程以同步的方式书写出来,并且可以使用 try/catch。
废话少说,上实例:
var co = require('co')
var fs = require('fs')
// wrap the function to thunk
function readFile(filename) {
return new Promise(function(resolve, reject) {
fs.readFile(filename, function(err, date) {
if (err) reject(err)
resolve(data)
})
})
}
// generator 函数
function *gen() {
var file1 = yield readFile('./file/1.txt') // 1.txt内容为:content in 1.txt
var file2 = yield readFile('./file/2.txt') // 2.txt内容为:content in 2.txt
console.log(file1)
console.log(file2)
return 'done'
}
// co
co(gen).then(function(err, result) {
console.log(result)
})
// content in 1.txt
// content in 2.txt
// done在上例中,co 函数库可以让你不用编写 generator 函数的执行器,generator 函数只要放在 co 函数里,就会自动执行。
所以,我们可以模拟 co 的实现:
function myCo(generator) {
var gen = generator()
function next(data) {
var result = gen.next(data)
if (result.done) return result.value
result.value.then(function (data) {
next(data)
})
}
next()
}
myCo(gen)再看一个例子:
co(function *(){
try {
var res = yield get('http://baidu.com');
console.log(res);
} catch(e) {
console.log(e.code)
}
})co 函数库其实就是将两种自动执行器(Thunk 函数和 Promise 对象),包装成一个库。但用 co 的一个代价是 Generator 函数的 yield 命令后面必须返回一个 Thunk 或者一个 Promise。
源码实现:
function co(gen) { // co 接受一个 generator 函数
var ctx = this
var args = slice.call(arguments, 1)
return new Promise(function(resolve, reject) { // co 返回一个 Promise 对象
if(typeof gen === 'function') gen = gen.apply(ctx, args) // gen 为 generator 函数,执行该函数
if(!gen || typeof gen.next !== 'function') return resolve(gen) // 不是则返回并更新 Promise状态为 resolve
onFulfilled() // 将generator 函数的 next 方法包装成 onFulfilled,主要是为了能够捕获抛出的异常
/**
* @param {Mixed} res
* @return {Promise}
* @api private
*/
function onFulfilled(res) {
var ret;
try {
ret = gen.next(res)
} catch (err) {
return reject(err)
}
next(ret)
}
/**
* @param {Error} err
* @return {Promise}
* @api private
*/
function onRejected(err) {
var ret
try {
ret = gen.throw(err)
} catch (err) {
return reject(err)
}
next(ret)
}
/**
* Get the next value in the generator,
* return a promise.
*
* @param {Object} ret
* @return {Promise}
* @api private
*/
function next(ret) {
if(ret.done) return resolve(ret.value)
var value = toPromise.call(ctx, ret.value) // if (isGeneratorFunction(obj) || isGenerator(obj)) return co.call(this, obj);
if(value && isPromise(value)) return value.then(onFulfilled, onRejected)
return onRejected(new TypeError('You may only yield a function, promise, generator, but the following object was passed: ' + String(ret.value) + '"'))
}
})
}注意:onFulfilled这个函数只在两种情况下被调用,一种是调用co的时候执行,还有一种是当前promise中的所有逻辑都执行完毕后执行
本篇从 React Refs 的使用场景、使用方式、注意事项,到 createRef 与 Hook useRef 的对比使用,最后以 React createRef 源码结束,剖析整个 React Refs,关于 React.forwardRef 会在下一篇文章深入探讨。
React 的核心**是每次对于界面 state 的改动,都会重新渲染整个Virtual DOM,然后新老的两个 Virtual DOM 树进行 diff(协调算法),对比出变化的地方,然后通过 render 渲染到实际的UI界面,
使用 Refs 为我们提供了一种绕过状态更新和重新渲染时访问元素的方法;这在某些用例中很有用,但不应该作为 props 和 state 的替代方法。
在项目开发中,如果我们可以使用 声明式 或 提升 state 所在的组件层级(状态提升) 的方法来更新组件,最好不要使用 refs。
管理焦点(如文本选择)或处理表单数据: Refs 将管理文本框当前焦点选中,或文本框其它属性。
在大多数情况下,我们推荐使用受控组件来处理表单数据。在一个受控组件中,表单数据是由 React 组件来管理的,每个状态更新都编写数据处理函数。另一种替代方案是使用非受控组件,这时表单数据将交由 DOM 节点来处理。要编写一个非受控组件,就需要使用 Refs 来从 DOM 节点中获取表单数据。
class NameForm extends React.Component {
constructor(props) {
super(props);
this.input = React.createRef();
}
handleSubmit = (e) => {
console.log('A name was submitted: ' + this.input.current.value);
e.preventDefault();
}
render() {
return (
<form onSubmit={this.handleSubmit}>
<label>
Name:
<input type="text" ref={this.input} />
</label>
<input type="submit" value="Submit" />
</form>
);
}
}因为非受控组件将真实数据储存在 DOM 节点中,所以再使用非受控组件时,有时候反而更容易同时集成 React 和非 React 代码。如果你不介意代码美观性,并且希望快速编写代码,使用非受控组件往往可以减少你的代码量。否则,你应该使用受控组件。
**媒体播放:**基于 React 的音乐或视频播放器可以利用 Refs 来管理其当前状态(播放/暂停),或管理播放进度等。这些更新不需要进行状态管理。
**触发强制动画:**如果要在元素上触发过强制动画时,可以使用 Refs 来执行此操作。
集成第三方 DOM 库
Refs 有 三种实现:
createRef 是 **React v16.3 ** 新增的API,允许我们访问 DOM 节点或在 render 方法中创建的 React 元素。
Refs 是使用 React.createRef() 创建的,并通过 ref 属性附加到 React 元素。
Refs 通常在 React 组件的构造函数中定义,或者作为函数组件顶层的变量定义,然后附加到 render() 函数中的元素。
export default class Hello extends React.Component {
constructor(props) {
super(props);
// 创建 ref 存储 textRef DOM 元素
this.textRef = React.createRef();
}
componentDidMount() {
// 注意:通过 "current" 取得 DOM 节点
// 直接使用原生 API 使 text 输入框获得焦点
this.textRef.current.focus();
}
render() {
// 把 <input> ref 关联到构造器里创建的 textRef 上
return <input ref={this.textRef} />
}
} 使用 React.createRef() 给组件创建了 Refs 对象。在上面的示例中,ref被命名 textRef,然后将其附加到 <input> DOM元素。
其中, textRef 的属性 current 指的是当前附加到 ref 的元素,并广泛用于访问和修改我们的附加元素。事实上,如果我们通过登录 myRef 控制台进一步扩展我们的示例,我们将看到该 current 属性确实是唯一可用的属性:
componentDidMount = () => {
// myRef 仅仅有一个 current 属性
console.log(this.textRef);
// myRef.current
console.log(this.textRef.current);
// component 渲染完成后,使 text 输入框获得焦点
this.textRef.current.focus();
}在 componentDidMount 生命周期阶段,myRef.current 将按预期分配给我们的 <input> 元素; componentDidMount 通常是使用 refs 处理一些初始设置的安全位置。
我们不能在 componentWillMount 中更新 Refs,因为此时,组件还没渲染完成, Refs 还为 null。
不同于传递 createRef() 创建的 ref 属性,你会传递一个函数。这个函数中接受 React 组件实例或 HTML DOM 元素作为参数,以使它们能在其他地方被存储和访问。
import React from 'react';
export default class Hello extends React.Component {
constructor(props) {
super(props);
this.textRef = null; // 创建 ref 为 null
}
componentDidMount() {
// 注意:这里没有使用 "current"
// 直接使用原生 API 使 text 输入框获得焦点
this.textRef.focus();
}
render() {
// 把 <input> ref 关联到构造器里创建的 textRef 上
return <input ref={node => this.textRef = node} />
}
} React 将在组件挂载时将 DOM 元素传入ref 回调函数并调用,当卸载时传入 null 并调用它。在 componentDidMount 或 componentDidUpdate 触发前,React 会保证 refs 一定是最新的。
像上例, ref 回调函数是以内联函数的方式定义的,在更新过程中它会被执行两次,第一次传入参数 null,然后第二次会传入参数 DOM 元素。
这是因为在每次渲染时会创建一个新的函数实例,所以 React 清空旧的 ref 并且设置新的。我们可以通过将 ref 的回调函数定义成 class 的绑定函数的方式可以避免上述问题,但是大多数情况下它是无关紧要的。
export default class Hello extends React.Component {
constructor(props) {
super(props);
}
componentDidMount() {
// 通过 this.refs 调用
// 直接使用原生 API 使 text 输入框获得焦点
this.refs.textRef.focus();
}
render() {
// 把 <input> ref 关联到构造器里创建的 textRef 上
return <input ref='textRef' />
}
}尽管字符串 stringRef 使用更方便,但是它有一些缺点,因此严格模式使用 stringRef 会报警告。官方推荐采用回调 Refs。
ref 属性被用于一个普通的 HTML 元素时,React.createRef() 将接收底层 DOM 元素作为它的 current 属性以创建 ref ,我们可以通过 Refs 访问 DOM 元素属性。ref 属性被用于一个自定义 class 组件时,ref 对象将接收该组件已挂载的实例作为它的 current,与 ref 用于 HTML 元素不同的是,我们能够通过 ref 访问该组件的props,state,方法以及它的整个原型 。stringRef 将会废弃(严格模式下使用会报警告),React.createRef() API 是 React v16.3 引入的更新。useRef 返回一个可变的 ref 对象,其 .current 属性被初始化为传入的值。返回的 ref 对象在组件的整个生命周期内保持不变。
function Hello() {
const textRef = useRef(null)
const onButtonClick = () => {
// 注意:通过 "current" 取得 DOM 节点
textRef.current.focus();
};
return (
<>
<input ref={textRef} type="text" />
<button onClick={onButtonClick}>Focus the input</button>
</>
)
}####区别
useRef() 比 ref 属性更有用。useRef() Hook 不仅可以用于 DOM refs, useRef() 创建的 ref 对象是一个 current 属性可变且可以容纳任意值的通用容器,类似于一个 class 的实例属性。
function Timer() {
const intervalRef = useRef();
useEffect(() => {
const id = setInterval(() => {
// ...
});
intervalRef.current = id;
return () => {
clearInterval(intervalRef.current);
};
});
// ...
}这是因为它创建的是一个普通 Javascript 对象。而 useRef() 和自建一个 {current: ...}对象的唯一区别是,useRef 会在每次渲染时返回同一个 ref 对象。
请记住,当 ref 对象内容发生变化时,useRef 并不会通知你。变更 .current 属性不会引发组件重新渲染。如果想要在 React 绑定或解绑 DOM 节点的 ref 时运行某些代码,则需要使用回调 ref 来实现。
// ReactCreateRef.js 文件
import type {RefObject} from 'shared/ReactTypes';
// an immutable object with a single mutable value
export function createRef(): RefObject {
const refObject = {
current: null,
};
if (__DEV__) {
// 封闭对象,阻止添加新属性并将所有现有属性标记为不可配置。当前属性的值只要可写就可以改变。
Object.seal(refObject);
}
return refObject;
}其中 RefObject 为:
export type RefObject = {|
current: any,
|};这就是的 createRef 源码,实现很简单,但具体的它如何使用,如何挂载,将在后面的 React 渲染中介绍,敬请期待。
问题:
export与import语法
/* util1.js*/
export default {
a: 1
}
/* util2.js */
export function fun1() {}
export function fun2() {}
/* index.js */
import util1 from './util1'
import {fun1, fun2} from 'util2'模块化
node环境安装
创建项目工程文件:es-test
在项目根目录下,npm init
npm install —save-dev babel-core babel-preset-env babel-preset-latest
在项目根目录下,创建.babelrc文件,这是babel的配置文件
// .babelrc
{
"presets": ["env", "latest"],
"plugins": []
}npm install —global babel-cli
babel —version,可以查看当前版本号
创建./src/index.js
.
└── src
└── index.js// index.js
[1, 2, 3].map(item => item + 1)运行 babel ./src/index.js
// 控制台打印
[1, 2, 3].map(function (item) {
return item + 1;
});npm install webpack babel-loader —save-dev
配置 webpack.config.js
module.exports = {
entry: "./src/index.js",
output: {
path: __dirname,
filename: "./build/bundle.js"
},
module: {
rules: [{
test: /\.js?$/,
exclude: /(node_modules)/,
loader: "babel-loader"
}]
}
}配置 package.json 中的 scripts
"scripts": {
"start": "webpack",
"test": "echo \"Error: no test specified\" && exit 1"
},运行 npm start
总结
时间轴
Babel是将ES6语法转换成浏览器可识别的向后兼容版本的JS代码。
从低版本到babel7,有几项变化:
Babel-upgrade
babel-upgrade 是一个用于自动升级的新工具,具体可见https://github.com/babel/babel-upgrade
建议直接在git仓库上运行 npx babel-upgrade,或者使用 npm i babel-upgrade -g 进行全局安装。若是想修改文件,可是使用参数 --write 和--install
npx babel-upgrade --write --install安装配置
npm install --save-dev @babel/core @babel/cli @babel/preset-env
npm install --save @babel/polyfill
// 注意 --save 选项而不是 --save-dev,因为这是一个需要在源代码之前运行的 polyfill。配置Babel,你可以使用.babelrc文件方式,同时Babel 7 引入了 babel.config.js,
babel.config.js 的配置解析方式与.babelrc 不同。它始终会解析该文件中的配置,而不会从每个文件向上查找,直到找到配置为止。这样就可以利用 overrides 特性。
.babelrc
{
"presets": [
["@babel/env", {
"targets": {
"edge": "17",
"firefox": "60",
"chrome": "67",
"safari": "11.1"
},
"useBuiltIns": "usage",
"debug": true // 可以看到打包的文件。
}
]
],
"plugins": []
}babel.config.js
const presets = [
["@babel/env", {
targets: {
edge: "17",
firefox: "60",
chrome: "67",
safari: "11.1"
},
useBuiltIns: "usage"
}]
];
var env = process.env.NODE_ENV;
module.exports = {
presets,
plugins: [
env === "production" && "babel-plugin-that-is-cool"
].filter(Boolean)
};使用 overrides进行选择性配置
module.exports = {
presets: [
// defeault config...
],
overrides: [{
test: ["./node_modules"],
presets: [
// config for node_modules
],
}, {
test: ["./tests"],
presets: [
// config for tests
],
}]
};
有些应用程序需要针对测试、客户端代码和服务器代码使用不同的编译配置选项,通过这种方式就不需要在每个文件夹下创建.babelrc 文件了。
我们使用的是 env preset,其中有一个 "useBuiltIns" 选项,当设置为 "usage" 时,实际上将应用上面提到的最后一个优化,只包括你需要的 polyfill。
例如Promise.resolve().finally()会变成这个require("core-js/modules/es.promise.finally"); Promise.resolve().finally();如果我们没有将 env preset 的 "useBuiltIns" 选项的设置为 "usage" ,就必须在其他代码之前 require 一次完整的 polyfill。
运行./node_modules/.bin/babel src --out-dir lib将所有代码从 src 目录编译到 lib
我们使用 @babel/cli 从终端运行 Babel,@babel/polyfill 来实现所有新的 JavaScript 功能,useBuiltIns:entry 会根据target环境加载polyfill,需要手动import polyfill,不能多次引入。@babel/preset-env会将把@babel/polyfill根据实际需求打散,只留下必须的。做的只是打散。仅引入有浏览器不支持的polyfill。这样也会提高一些性能,减少编译后的polyfill文件大小。env preset 只包含我们使用的功能的转换,实现我们的目标浏览器中缺少的功能。
JS 构造函数
// 构造函数
function MathHandle(x, y) {
this.x = x
this.y = y
}
// 原型扩展
MathHandle.prototype.add = function() {
return this.x + this.y
}
// 实例化
var m = new MathHAndle(1, 2)
console.log(m.add()) // 3
typeof MathHandle // function
MathHandle/prototype.constructor === MathHandle // true
m.__proto__ === MathHandle.prototype // trueClass 基本语法
class Ad extends Rect.Component {
constructor(props) {
super(props)
this.state = {
data: []
}
}
componentDidMount() {}
render() {
return (
<div>hello world</div>
)
}
}
语法糖
class MathHandle {
// ...
}
typeof MathHandle // function
MathHandle/prototype.constructor === MathHandle // true
m.__proto__ === MathHandle.prototype // true
继承
// 动物
function Animal() {
this.eat = function() {
console.log('animal eat')
}
}
// 狗
function Dog() {
this.dark = function() {
console.log('dog dark')
}
}
Dog.prototype = new Animal()
var d = new Dog()class Animal {
constructor(name) {
this.name = name
}
eat() {
console.log(`${this.name} eat`)
}
}
class Dog extends Animal {
constructor(name) {
super(name)
this.name = name
}
say() {
console.log(`${this.name} say`)
}
}
var dog = new Dog('hashiqi')
dog.say()
dog.eat()
总结
function loadImg(src, callback, fail) {
var img = document.createElement('img')
img.onload = function () {
callback(img)
}
img.onerror = function () {
fail()
}
img.src = src
}
var src= 'http://www.imooc.com/static/img/index/logo_new.png'
loadImg(src, function (img) {
console.log(img.width)
}, function () {
console.log('failed')
})function loadImg(src) {
return new Promise(function (resolve, reject) {
var img = document.createElement('img')
img.onload = function () {
resolve(img)
}
img.onerror = function () {
reject()
}
img.src= src
})
}
var src = 'http://www.imooc.com/static/img/index/logo_new.png'
var result = loadImg(src)
result.then(function (img) {
console.log(img.width)
}, function () {
console.log('failed')
})
result.then(function (img) {
console.log(img.height)
})let/const
// js
var i = 10
i = 100
// es6
let i = 10
i = 100
const j = 20
j = 200 // 报错多行字符串/模板变量
// js
var name = 'an'
var html + = '<div>'
html += name
html += '</div>'
//es6
var name = 'an'
const html = `<div>${name}</div>`解构赋值
//js
var obj = {a:1, b: 2}
obj.a
var arr = [1, 2, 3]
arr[0]
//es6
const obj = {a:1, b: 2}
const {a, b} = obj
a
const arr = [1, 2, 3]
const [a, b, c] = arr
x块级作用域
//js
var obj = {a: 1, b: 2}
for (var item in obj) {
console.log(item)
}
console.log(item) // output: b
// es6
const obj = {a: 1, b: 2}
for (let item in obj) {
console.log(item)
}
console.log(item) // output: undefined函数默认参数
// js
function(a, b) {
if (b == null) b = 0
}
// es6
function(a, b=0) {}箭头函数
//js
var arr = [1, 2, 3]
arr.map(function(item) {
return item + 1
})
// es6
const arr = [1, 2, 3]
arr.map(item =>item + 1)
arr.map((item, index) => {
console.log(index)
return item +1
})function fun() {
console.log(this) // output: {a: 100}
var arr = [1, 2, 3]
// js
arr.map(function(item) {
console.log(this) // output: window
return item + 1
})
// 箭头函数:对普通JS的补充
arr.map(item =>{
console.log(this) // output: {a: 100}
return item + 1
})
}
fun.call({a: 100})注意:箭头函数
JS 系列暂定 27 篇,从基础,到原型,到异步,到设计模式,到架构模式等。
本篇是JS系列中第 5 篇,文章主讲 JS 中 call 、 apply 、 bind 、箭头函数以及柯里化,着重介绍它们之间的区别、对比使用,深入了解 call 、 apply 、 bind 。
call() 方法调用一个函数, 其具有一个指定的 this 值和多个参数(参数的列表)。
func.call(thisArg, arg1, arg2, ...)它运行 func,提供的第一个参数 thisArg 作为 this,后面的作为参数。
先看一个例子:
func(1, 2, 3);
func.call(obj, 1, 2, 3)他们都调用的是 func,参数是 1,2 和 3。
唯一的区别是 func.call 也将 this 设置为 obj。
需要注意的是,设置的 thisArg 值并不一定是该函数执行时真正的 this 值,如果这个函数处于非严格模式下,则指定为 null 和 undefined 的 this 值会自动指向全局对象(浏览器中就是 window 对象),同时值为原始值(数字,字符串,布尔值)的 this 会指向该原始值的自动包装对象。
例如,在下面的代码中,我们在对象的上下文中调用 sayWord.call(bottle) 运行 sayWord ,并 bottle 传递为 sayWord 的 this:
function sayWord() {
var talk = [this.name, 'say', this.word].join(' ');
console.log(talk);
}
var bottle = {
name: 'bottle',
word: 'hello'
};
// 使用 call 将 bottle 传递为 sayWord 的 this
sayWord.call(bottle);
// bottle say hello// 非严格模式下
var bottle = 'bottle'
function say(){
// 注意:非严格模式下,this 为 window
console.log('name is %s',this.bottle)
}
say.call()
// name is bottle// 严格模式下
'use strict'
var bottle = 'bottle'
function say(){
// 注意:在严格模式下 this 为 undefined
console.log('name is %s',this.bottle)
}
say.call()
// Uncaught TypeError: Cannot read property 'bottle' of undefined基本**:在子类型的构造函数内部调用父类型构造函数。
注意:函数只不过是在特定环境中执行代码的对象,所以这里使用 apply/call 来实现。
使用父类的构造函数来增强子类实例,等于是复制父类的实例属性给子类(没用到原型)
// 父类
function SuperType (name) {
this.name = name; // 父类属性
}
SuperType.prototype.sayName = function () { // 父类原型方法
return this.name;
};
// 子类
function SubType () {
// 调用 SuperType 构造函数
// 在子类构造函数中,向父类构造函数传参
SuperType.call(this, 'SuperType');
// 为了保证子父类的构造函数不会重写子类的属性,需要在调用父类构造函数后,定义子类的属性
this.subName = "SubType";
// 子类属性
};
// 子类实例
let instance = new SubType();
// 运行子类构造函数,并在子类构造函数中运行父类构造函数,this绑定到子类var bottle = [
{name: 'an', age: '24'},
{name: 'anGe', age: '12'}
];
for (var i = 0; i < bottle.length; i++) {
// 匿名函数
(function (i) {
setTimeout(() => {
// this 指向了 bottle[i]
console.log('#' + i + ' ' + this.name + ': ' + this.age);
}, 1000)
}).call(bottle[i], i);
// 调用 call 方法,同时解决了 var 作用域问题
}打印结果:
#0 an: 24
#1 anGe: 12在上面例中的 for 循环体内,我们创建了一个匿名函数,然后通过调用该函数的 call 方法,将每个数组元素作为指定的 this 值立即执行了那个匿名函数。这个立即执行的匿名函数的作用是打印出 bottle[i] 对象在数组中的正确索引号。
apply() 方法调用一个具有给定 this 值的函数,以及作为一个数组(或[类似数组对象)提供的参数。
func.apply(thisArg, [argsArray])它运行 func 设置 this = context 并使用类数组对象 args 作为参数列表。
例如,这两个调用几乎相同:
func(1, 2, 3);
func.apply(context, [1, 2, 3])两个都运行 func 给定的参数是 1,2,3。但是 apply 也设置了 this = context。
call 和 apply 之间唯一的语法区别是 call 接受一个参数列表,而 apply 则接受带有一个类数组对象。
需要注意:Chrome 14 以及 Internet Explorer 9 仍然不接受类数组对象。如果传入类数组对象,它们会抛出异常。
我们已经知道了JS 基础之: var、let、const、解构、展开、函数 一章中的扩展运算符 ...,它可以将数组(或任何可迭代的)作为参数列表传递。因此,如果我们将它与 call 一起使用,就可以实现与 apply 几乎相同的功能。
这两个调用结果几乎相同:
let args = [1, 2, 3];
func.call(context, ...args); // 使用 spread 运算符将数组作为参数列表传递
func.apply(context, args); // 与使用 call 相同如果我们仔细观察,那么 call 和 apply 的使用会有一些细微的差别。
... 允许将 可迭代的 参数列表 作为列表传递给 call。apply 只接受 类数组一样的 参数列表。apply 最重要的用途之一是将调用传递给另一个函数,如下所示:
let wrapper = function() {
return anotherFunction.apply(this, arguments);
};wrapper 通过 anotherFunction.apply 获得了上下文 this 和 anotherFunction 的参数并返回其结果。
当外部代码调用这样的 wrapper 时,它与原始函数的调用无法区分。
array.push.apply 将数组添加到另一数组上:
var array = ['a', 'b']
var elements = [0, 1, 2]
array.push.apply(array, elements)
console.info(array) // ["a", "b", 0, 1, 2]Function.prototype.constructor = function (aArgs) {
var oNew = Object.create(this.prototype);
this.apply(oNew, aArgs);
return oNew;
};/* 找出数组中最大/小的数字 */
let numbers = [5, 6, 2, 3, 7]
/* 应用(apply) Math.min/Math.max 内置函数完成 */
let max = Math.max.apply(null, numbers)
/* 基本等同于 Math.max(numbers[0], ...) 或 Math.max(5, 6, ..) */
let min = Math.min.apply(null, numbers)
console.log('max: ', max)
// max: 7
console.log('min: ', min)
// min: 2它相当于:
/* 代码对比: 用简单循环完成 */
let numbers = [5, 6, 2, 3, 7]
let max = -Infinity, min = +Infinity
for (var i = 0; i < numbers.length; i++) {
if (numbers[i] > max)
max = numbers[i]
if (numbers[i] < min)
min = numbers[i]
}
console.log('max: ', max)
// max: 7
console.log('min: ', min)
// min: 2但是:如果用上面的方式调用 apply,会有超出 JavaScript 引擎的参数长度限制的风险。更糟糕的是其他引擎会直接限制传入到方法的参数个数,导致参数丢失。
所以,当数据量较大时
function minOfArray(arr) {
var min = Infinity
var QUANTUM = 32768 // JavaScript 核心中已经做了硬编码 参数个数限制在65536
for (var i = 0, len = arr.length; i < len; i += QUANTUM) {
var submin = Math.min.apply(null, arr.slice(i, Math.min(i + QUANTUM, len)))
min = Math.min(submin, min)
}
return min
}
var min = minOfArray([5, 6, 2, 3, 7])
// max 同样也是如此JavaScript 新手经常犯的一个错误是将一个方法从对象中拿出来,然后再调用,希望方法中的 this 是原来的对象(比如在回调中传入这个方法)。如果不做特殊处理的话,一般 this 就丢失了。
例如:
let bottle = {
nickname: "bottle",
sayHello() {
console.log(`Hello, ${this.nickname}!`)
},
sayHi(){
setTimeout(function(){
console.log('Hello, ', this.nickname)
}, 1000)
}
};
// 问题一
bottle.sayHi();
// Hello, undefined!
// 问题二
setTimeout(bottle.sayHello, 1000);
// Hello, undefined!问题一的 this.nickname 是 undefined ,原因是 this 指向是在运行函数时确定的,而不是定义函数时候确定的,再因为 sayHi 中 setTimeout 在全局环境下执行,所以 this 指向 setTimeout 的上下文:window。
问题二的 this.nickname 是 undefined ,是因为 setTimeout 仅仅只是获取函数 bottle.sayHello 作为 setTimeout 回调函数,this 和 bottle 对象分离了。
问题二可以写为:
// 在这种情况下,this 指向全局作用域
let func = bottle.sayHello;
setTimeout(func, 1000);
// 用户上下文丢失
// 浏览器上,访问的实际上是 Window 上下文那么怎么解决这两个问题喃?
解决方案一: 缓存 this 与包装
首先通过缓存 this 解决问题一 bottle.sayHi(); :
let bottle = {
nickname: "bottle",
sayHello() {
console.log(`Hello, ${this.nickname}!`)
},
sayHi(){
var _this = this // 缓存this
setTimeout(function(){
console.log('Hello, ', _this.nickname)
}, 1000)
}
};
bottle.sayHi();
// Hello, bottle那问题二 setTimeout(bottle.sayHello, 1000); 喃?
let bottle = {
nickname: "bottle",
sayHello() {
console.log(`Hello, ${this.nickname}!`);
}
};
// 加一个包装层
setTimeout(() => {
bottle.sayHello()
}, 1000);
// Hello, bottle!这样看似解决了问题二,但如果我们在 setTimeout 异步触发之前更新 bottle 值又会怎么样呢?
var bottle = {
nickname: "bottle",
sayHello() {
console.log(`Hello, ${this.nickname}!`);
}
};
setTimeout(() => {
bottle.sayHello()
}, 1000);
// 更新 bottle
bottle = {
nickname: "haha",
sayHello() {
console.log(`Hi, ${this.nickname}!`)
}
};
// Hi, haha!bottle.sayHello() 最终打印为 Hi, haha! ,那么怎么解决这种事情发生喃?
解决方案二: bind
bind() 最简单的用法是创建一个新绑定函数,当这个新绑定函数被调用时,this 键值为其提供的值,其参数列表前几项值为创建时指定的参数序列,绑定函数与被调函数具有相同的函数体(ES5中)。
let bottle = {
nickname: "bottle",
sayHello() {
console.log(`Hello, ${this.nickname}!`);
}
};
// 未绑定,“this” 指向全局作用域
let sayHello = bottle.sayHello
console.log(sayHello())
// Hello, undefined!
// 绑定
let bindSayHello = sayHello.bind(bottle)
// 创建一个新函数,将 this 绑定到 bottle 对象
console.log(bindSayHello())
// Hello, bottle!所以,从原来的函数和原来的对象创建一个绑定函数,则能很漂亮地解决上面两个问题:
let bottle = {
nickname: "bottle",
sayHello() {
console.log(`Hello, ${this.nickname}!`);
},
sayHi(){
// 使用 bind
setTimeout(function(){
console.log('Hello, ', this.nickname)
}.bind(this), 1000)
// 或箭头函数
setTimeout(() => {
console.log('Hello, ', this.nickname)
}, 1000)
}
};
// 问题一:完美解决
bottle.sayHi()
// Hello, bottle
// Hello, bottle
let sayHello = bottle.sayHello.bind(bottle); // (*)
sayHello();
// Hello, bottle!
// 问题二:完美解决
setTimeout(sayHello, 1000);
// Hello, bottle!
// 更新 bottle
bottle = {
nickname: "haha",
sayHello() {
console.log(`Hi, ${this.nickname}!`)
}
};问题一,可以通过 bind 或箭头函数完美解决。
最终更新 bottle 后, setTimeout(sayHello, 1000); 打印依然是 Hello, bottle!, 问题二完美解决!
再看一个例子:
this.nickname = 'window'
let bottle = {
nickname: 'bottle'
}
function sayHello() {
console.log('Hello, ', this.nickname)
}
let bindBottle = sayHello.bind(bottle) // this 指向 bottle
console.log(bindBottle())
// Hello, bottle
console.log(new bindBottle()) // this 指向 sayHello {}
// Hello, undefined上面例子中,运行结果 this.nickname 输出为 undefined ,这不是全局 nickname , 也不是 bottle 对象中的 nickname ,这说明 bind 的 this 对象失效了,new 的实现中生成一个新的对象,这个时候的 this 指向的是 sayHello 。
注意 :绑定函数也可以使用 new 运算符构造:这样做就好像已经构造了目标函数一样。提供的 this 值将被忽略,而前置参数将提供给模拟函数。
function sayHello() {
console.log('Hello, ', this.nickname)
}
sayHello = sayHello.bind( {nickname: "Bottle"} ).bind( {nickname: "AnGe" } );
sayHello();
// Hello, Bottle输出依然是 Hello, Bottle ,这是因为 func.bind(...) 返回的外来的绑定函数对象仅在创建的时候记忆上下文(如果提供了参数)。
一个函数不能作为重复绑定。
当我们确定一个函数的一些参数时,返回的函数(更加特定)被称为偏函数。我们可以使用 bind 来获取偏函数:
function list() {
return Array.prototype.slice.call(arguments);
}
var list1 = list(1, 2, 3); // [1, 2, 3]
var leadingThirtysevenList = list.bind(undefined, 37);
var list2 = leadingThirtysevenList(); // [37]
var list3 = leadingThirtysevenList(1, 2, 3); // [37, 1, 2, 3]当我们不想一遍又一遍重复相同的参数时,偏函数很方便。
function Bottle(nickname) {
this.nickname = nickname;
}
Bottle.prototype.sayHello = function() {
console.log('Hello, ', this.nickname)
};
let bottle = new Bottle('bottle');
let BindBottle = Bottle.bind(null, 'bindBottle');
let b1 = new BindBottle('b1');
b1 instanceof Bottle; // true
b1 instanceof BindBottle; // true
new Bottle('bottle1') instanceof BindBottle; // true
b1.sayHello()
// Hello, bindBottle在计算机科学中,柯里化(Currying)是把接受多个参数的函数变换成接受一个单一参数(最初函数的第一个参数)的函数,并且返回接受余下的参数且返回结果的新函数的技术。这个技术由 Christopher Strachey 以逻辑学家 Haskell Curry 命名的,尽管它是 Moses Schnfinkel 和 Gottlob Frege 发明的。
var add = function(x) {
return function(y) {
return x + y;
};
};
var increment = add(1);
var addTen = add(10);
increment(2);
// 3
addTen(2);
// 12
add(1)(2);
// 3这里定义了一个 add 函数,它接受一个参数并返回一个新的函数。调用 add 之后,返回的函数就通过闭包的方式记住了 add 的第一个参数。所以说 bind 本身也是闭包的一种使用场景。
柯里化是将 f(a,b,c) 可以被以 f(a)(b)(c) 的形式被调用的转化。JavaScript 实现版本通常保留函数被正常调用和在参数数量不够的情况下返回偏函数这两个特性。
let bottle = {
nickname: "bottle",
sayHi(){
setTimeout(function(){
console.log('Hello, ', this.nickname)
}, 1000)
// 或箭头函数
setTimeout(() => {
console.log('Hi, ', this.nickname)
}, 1000)
}
};
bottle.sayHi()
// Hello, undefined
// Hi, bottle报错是因为 Hello, undefined 是因为运行时 this=Window , Window.nickname 为 undefined。
但箭头函数就没事,因为箭头函数没有 this。在外部上下文中,this 的查找与普通变量搜索完全相同。this 指向定义时的环境。
不具有 this 自然意味着另一个限制:箭头函数不能用作构造函数。他们不能用 new 调用。
箭头函数 => 和正常函数通过 .bind(this) 调用有一个微妙的区别:
.bind(this) 创建该函数的 “绑定版本”。=> 不会创建任何绑定。该函数根本没有 this。在外部上下文中,this 的查找与普通变量搜索完全相同。箭头函数也没有 arguments 变量。
因为我们需要用当前的 this 和 arguments 转发一个调用,所有这对于装饰者来说非常好。
例如,defer(f, ms) 得到一个函数,并返回一个包装函数,以 毫秒 为单位延迟调用:
function defer(f, ms) {
return function() {
setTimeout(() => f.apply(this, arguments), ms)
};
}
function sayHi(who) {
alert('Hello, ' + who);
}
let sayHiDeferred = defer(sayHi, 2000);
sayHiDeferred("John"); // 2 秒后打印 Hello, John没有箭头功能的情况如下所示:
function defer(f, ms) {
return function(...args) {
let ctx = this;
setTimeout(function() {
return f.apply(ctx, args);
}, ms);
};
}在这里,我们必须创建额外的变量 args 和 ctx,以便 setTimeout 内部的函数可以接收它们。
节流和防抖在开发项目过程中很常见,例如 input 输入实时搜索、scrollview 滚动更新了,等等,大量的场景需要我们对其进行处理。我们由 Lodash 来介绍,直接进入主题吧。
防抖 (debounce) :多次触发,只在最后一次触发时,执行目标函数。
lodash.debounce(func, [wait=0], [options={}])节流(throttle):限制目标函数调用的频率,比如:1s内不能调用2次。
lodash.throttle(func, [wait=0], [options={}])lodash 在 opitons 参数中定义了一些选项,主要是以下三个:
根据 leading 和 trailing 的组合,可以实现不同的调用效果:
{leading: true, trailing: false}:只在延时开始时调用
{leading: false, trailing: true}:默认情况,即在延时结束后才会调用函数
{leading: true, trailing: true}:在延时开始时就调用,延时结束后也会调用
deboucne 还有 cancel 方法,用于取消防抖动调用
防抖 (debounce):
addEntity = () => {
console.log('--------------addEntity---------------')
this.debounceFun();
}
debounceFun = lodash.debounce(function(e){
console.log('--------------debounceFun---------------');
}, 500,{
leading: true,
trailing: false,
})首次点击时执行,连续点击且时间间隔在500ms之内,不再执行,间隔在500ms之外再次点击,执行。
节流(throttle):
addEntity = () => {
console.log('--------------addEntity---------------');
this.throttleFun();
}
throttleFun = lodash.throttle(function(e){
console.log('--------------throttleFun---------------');
}, 500,{
leading: true,
trailing: false,
})首次点击时执行,连续点击且间隔在500ms之内,500ms之后自动执行一次(注:连续点击次数时间之后小于500ms,则不会自动执行),间隔在500ms之外再次点击,执行。
// 这个是用来获取当前时间戳的
function now() {
return +new Date()
}
/**
* 防抖函数,返回函数连续调用时,空闲时间必须大于或等于 wait,func 才会执行
*
* @param {function} func 回调函数
* @param {number} wait 表示时间窗口的间隔
* @param {boolean} immediate 设置为ture时,是否立即调用函数
* @return {function} 返回客户调用函数
*/
function debounce (func, wait = 50, immediate = true) {
let timer, context, args
// 延迟执行函数
const later = () => setTimeout(() => {
// 延迟函数执行完毕,清空缓存的定时器序号
timer = null
// 延迟执行的情况下,函数会在延迟函数中执行
// 使用到之前缓存的参数和上下文
if (!immediate) {
func.apply(context, args)
context = args = null
}
}, wait)
// 这里返回的函数是每次实际调用的函数
return function(...params) {
// 如果没有创建延迟执行函数(later),就创建一个
if (!timer) {
timer = later()
// 如果是立即执行,调用函数
// 否则缓存参数和调用上下文
if (immediate) {
func.apply(this, params)
} else {
context = this
args = params
}
// 如果已有延迟执行函数(later),调用的时候清除原来的并重新设定一个
// 这样做延迟函数会重新计时
} else {
clearTimeout(timer)
timer = later()
}
}
}/**
* underscore 节流函数,返回函数连续调用时,func 执行频率限定为 次 / wait
*
* @param {function} func 回调函数
* @param {number} wait 表示时间窗口的间隔
* @param {object} options 如果想忽略开始函数的的调用,传入{leading: false}。
* 如果想忽略结尾函数的调用,传入{trailing: false}
* 两者不能共存,否则函数不能执行
* @return {function} 返回客户调用函数
*/
_.throttle = function(func, wait, options) {
var context, args, result;
var timeout = null;
// 之前的时间戳
var previous = 0;
// 如果 options 没传则设为空对象
if (!options) options = {};
// 定时器回调函数
var later = function() {
// 如果设置了 leading,就将 previous 设为 0
// 用于下面函数的第一个 if 判断
previous = options.leading === false ? 0 : _.now();
// 置空一是为了防止内存泄漏,二是为了下面的定时器判断
timeout = null;
result = func.apply(context, args);
if (!timeout) context = args = null;
};
return function() {
// 获得当前时间戳
var now = _.now();
// 首次进入前者肯定为 true
// 如果需要第一次不执行函数
// 就将上次时间戳设为当前的
// 这样在接下来计算 remaining 的值时会大于0
if (!previous && options.leading === false) previous = now;
// 计算剩余时间
var remaining = wait - (now - previous);
context = this;
args = arguments;
// 如果当前调用已经大于上次调用时间 + wait
// 或者用户手动调了时间
// 如果设置了 trailing,只会进入这个条件
// 如果没有设置 leading,那么第一次会进入这个条件
// 还有一点,你可能会觉得开启了定时器那么应该不会进入这个 if 条件了
// 其实还是会进入的,因为定时器的延时
// 并不是准确的时间,很可能你设置了2秒
// 但是他需要2.2秒才触发,这时候就会进入这个条件
if (remaining <= 0 || remaining > wait) {
// 如果存在定时器就清理掉否则会调用二次回调
if (timeout) {
clearTimeout(timeout);
timeout = null;
}
previous = now;
result = func.apply(context, args);
if (!timeout) context = args = null;
} else if (!timeout && options.trailing !== false) {
// 判断是否设置了定时器和 trailing
// 没有的话就开启一个定时器
// 并且不能不能同时设置 leading 和 trailing
timeout = setTimeout(later, remaining);
}
return result;
};
};asyncFunction(function(value) {
// todo
})这种回调函数,大家是最熟悉的。一般是需要在某个耗时操作之后执行某个回调函数。
例如:
setTimeout(function() {
console.log('Time out')
}, 1000)其中,我们称setTimeout为发起函数,fn为回调函数。都是在主线程上调用的,其中发起函数用来发动异步过程,回调函数用来处理结果。在执行setTimeout1s后,执行function函数。
下面,我们再看一种情况。
$.ajax({
url:'XXX1',
success: function(res) {
$.ajax({
url:'XXX2',
success: function(res) {
$.ajax({
url: 'XXX3',
success: function(res) {
// todo
},
fail: function(err) {
console.log(err)
}
})
},
fail: function(err) {
console.log(err)
}
})
},
fail: function(err) {
console.log(err)
}
})在上例中,我们看到这段回调函数,不断的在回调,这只是三层回调,在实际应用中,我们遇到的需求会更复杂,回调也许更多,调试起来也就更麻烦,代码也更不美观,这就是我们要引入的第一个问题:回调地狱。
问题1: 回调地狱
回调地狱是JS里一个约定俗成的名称,一般情况下,一个业务依赖于上层业务,上层业务又依赖于更上一层的业务,以此类推,如果我们使用回调函数来处理异步的话,就会出现回调地狱。
主要是因为:大脑对业务的逻辑处理是线性的、阻塞的、单线程的,但是回调表达异步的方式是非线形的、非顺序的,这使得正确推导这类代码的难度很大,很容易出bug。
再例如:
// A
$.ajax({
...
success: function (...) {
// C
}
});
// BA和B发生于现在,在JavaScript主程序的直接控制之下,而C会延迟到将来发生,并且是在第三方的控制下,在本例中就是函数$.ajax(...)。从根本上来说,这种控制的转移通常不会给程序带来很多问题。
但是,请不要被这个小概率迷惑而认为这种控制切换不是什么大问题。实际上,这是回调驱动设计最严重(也是最微妙)的问题。它以这样一个思路为中心:有时候ajax(...),也就是你交付回调函数的第三方不是你编写的代码,也不在你的直接控制之下,它是某个第三方提供的工具。
这种情况称为控制反转,也就是把自己程序一部分的执行控制交给某个第三方,在你的代码和第三方工具直接有一份并没有明确表达的契约。
既然是无法控制的第三方在执行你的回调函数,那么就有可能存在以下问题,当然通常情况下是不会发生的:
这种控制反转会导致信任链的完全断裂,如果你没有采取行动来解决这些控制反转导致的信任问题,那么你的代码已经有了隐藏的Bug,尽管我们大多数人都没有这样做。
这里,我们引出了回调函数处理异步的第二个问题:控制反转。
问题2:控制反转
综上,回调函数处理异步流程存在2个问题:
1. 缺乏顺序性: 回调地狱导致的调试困难,和大脑的思维方式不符
2. 缺乏可信任性: 控制反转导致的一系列信任问题
那么如何来解决这两个问题,先驱者们开始了探索之路......
已知,JavaScript 是单线程的,天生异步,适合 IO 密集型,不适合 CPU 密集型,但是,为什么是异步的喃,异步由何而来的喃,我们将在这里逐渐讨论实现。
它主要包括以下进程:
浏览器的渲染进程是多线程的,页面的渲染,JavaScript 的执行,事件的循环,都在这个进程内进行:
setInterval 与 setTimeout 所在线程,注意,W3C 在 HTML 标准中规定,规定要求 setTimeout 中低于 4ms 的时间间隔算为 4ms 。XMLHttpRequest 连接后通过浏览器新开一个线程请求,将检测到状态变更时,如果设置有回调函数,异步线程就产生状态变更事件,将这个回调再放入事件队列中。再由 JavaScript 引擎执行。注意,GUI 渲染线程与 JavaScript 引擎线程是互斥的,当 JavaScript 引擎执行时 GUI 线程会被挂起(相当于被冻结了),GUI 更新会被保存在一个队列中等到 JavaScript 引擎空闲时立即被执行。所以如果 JavaScript 执行的时间过长,这样就会造成页面的渲染不连贯,导致页面渲染加载阻塞。
所谓单线程,是指在 JavaScript 引擎中负责解释和执行 JavaScript 代码的线程唯一,同一时间上只能执行一件任务。
问题:首先为什么要引入单线程喃?
我们知道:
如果 JavaScript 引擎线程不是单线程的,那么可以同时执行多段 JavaScript,如果这多段 JavaScript 都修改 DOM,那么就会出现 DOM 冲突。
你可能会说,web worker 就支持多线程,但是 web worker 不能访问 window 对象,document 对象等。
原因:避免 DOM 渲染的冲突
当然,我们可以为浏览器引入锁 的机制来解决这些冲突,但其大大提高了复杂性,所以 JavaScript从诞生开始就选择了单线程执行。
引入单线程就意味着,所有任务需要排队,前一个任务结束,才会执行后一个任务。这同时又导致了一个问题:如果前一个任务耗时很长,后一个任务就不得不一直等着。
// 实例1
let i, sum = 0
for(i = 0; i < 1000000000; i ++) {
sum += i
}
console.log(sum)在实例1中,sum 并不能立刻打印出来,必须在 for 循环执行完成之后才能执行 console.log(sum) 。
// 实例2
console.log(1)
alert('hello')
console.log(2)在实例2中,浏览器先打印 1 ,然后弹出弹框,点击确定后才执行 console.log(2) 。
总结:
为了解决这个问题,JavaScript 语言将任务的执行模式分为两种:同步和异步
func(args...)如果在函数 func 返回的时候,调用者就能够得到预期结果(即拿到了预期的返回值或者看到了预期的效果),那么这个函数就是同步的。
let a = 1
Math.floor(a)
console.log(a) // 1如果在函数 func 返回的时候,调用者还不能够得到预期结果,而是需要在将来通过一定的手段得到,那么这个函数就是异步的。
fs.readFile('foo.txt', 'utf8', function(err, data) {
console.log(data);
});总结:
JavaScript 采用异步编程原因有两点,
fs.readFile('data.json', 'utf8', function(err, data) {
console.log(data)
})在执行这段代码时,fs.readFile 函数返回时,并不会立刻打印 data ,只有 data.json 读取完成时才打印。也就是异步函数 fs.readFile 执行很快,但后面还有工作线程执行异步任务、通知主线程、主线程回调等操作,这个过程就叫做异步过程。
主线程发起一个异步操作,相应的工作线程接受请求并告知主线程已收到(异步函数返回);主线程继续执行后面的任务,同时工作线程执行异步任务;工作线程完成任务后,通知主线程;主线程收到通知后,执行一定的动作(调用回调函数)。
工作线程在异步操作完成后通知主线程,那么这个通知机制又是如何显现喃?答案就是就是消息队列与事件循环。
工作线程将消息放在消息队列,主线程通过事件循环过程去取消息。
主线程不断的从消息队列中取消息,执行消息,这个过程称为事件循环,这种机制叫事件循环机制,取一次消息并执行的过程叫一次循环。
大致实现过程如下:
while(true) {
var message = queue.get()
execute(message)
}例如:
$.ajax({
url: 'xxxx',
success: function(result) {
console.log(1)
}
})
setTimeout(function() {
console.log(2)
}, 100)
setTimeout(function() {
console.log(3)
})
console.log(4)
// output:4321 或 4312其中,主线程:
// 主线程
console.log(4)异步队列:
// 异步队列
function () {
console.log(3)
}
function () { // 100ms后
console.log(2)
}
function() { // ajax加载完成之后
console.log(1)
}事件循环是JavaScript实现异步的具体解决方案,其中同步代码,直接执行;异步函数先放在异步队列中,待同步函数执行完毕后,轮询执行 异步队列 的回调函数。
其中,消息就是注册异步任务时添加的回调函数。
$.ajax('XXX', function(res) {
console.log(res)
})
...主线程在发起 AJAX 请求后,会继续执行其他代码,AJAX 线程负责请求 XXX,拿到请求后,会封装成 JavaScript 对象,然后构造一条消息:
// 消息队列里的消息
var message = function () {
callback(response)
}其中 callback 是 AJAX 网络请求成功响应时的回调函数。
主线程在执行完当前循环中的所有代码后,就会到消息队列取出这条消息(也就是 message 函数),并执行它。到此为止,就完成了工作线程对主线程的 通知 ,回调函数也就得到了执行。如果一开始主线程就没有提供回调函数,AJAX 线程在收到 HTTP 响应后,也就没必要通知主线程,从而也没必要往消息队列放消息。
异步过程中的回调函数,一定不在当前这一轮事件循环中执行。
消息队列中的每条消息实际上都对应着一个事件。
其中一个重要的异步过程就是: DOM事件
var button = document.getElementById('button')
button.addEventLister('click', function(e) {
console.log('事件')
})从异步的角度看,addEventLister 函数就是异步过程的发起函数,事件监听器函数就是异步过程的回调函数。事件触发时,表示异步任务完成,会将事件监听器函数封装成一条消息放在消息队列中,等待主线程执行。
事件的概念实际上并不是必须的,事件机制实际上就是异步过程的通知机制。
另外,所有的异步过程也都可以用事件来描述。例如:
setTimeout(func, 1000)
// 可以看成:
timer.addEventLister('timeout', 1000, func)其中关于事件的详细描述,可以看这篇文章: 事件绑定、事件监听、事件委托,这里不再深入介绍。
生产者和消费者问题是线程模型中的经典问题:生产者和消费者在同一时间段内共用同一个存储空间,生产者往存储空间中添加数据,消费者从存储空间中取走数据,当存储空间为空时,消费者阻塞,当存储空间满时,生产者阻塞。
从生产者与消费者的角度看,异步过程是这样的:
工作线程是生产者,主线程是消费者(只有一个消费者)。工作线程执行异步任务,执行完成后把对应的回调函数封装成一条消息放到消息队列中;主线程不断地从消息队列中取消息并执行,当消息队列空时主线程阻塞,直到消息队列再次非空。
那么异步的实现方式有哪些喃?
这是今天在 Advanced-Frontend组织 看到一个比较有意思的题目。
主要是讲JS的映射与解析
早在 2013年, 加里·伯恩哈德就在微博上发布了以下代码段:
['10','10','10','10','10'].map(parseInt);
// [10, NaN, 2, 3, 4]parseInt() 函数解析一个字符串参数,并返回一个指定基数的整数 (数学系统的基础)。
const intValue = parseInt(string[, radix]);string 要被解析的值。如果参数不是一个字符串,则将其转换为字符串(使用 ToString 抽象操作)。字符串开头的空白符将会被忽略。
radix 一个介于2和36之间的整数(数学系统的基础),表示上述字符串的基数。默认为10。
返回值 返回一个整数或NaN
parseInt(100); // 100
parseInt(100, 10); // 100
parseInt(100, 2); // 4 -> converts 100 in base 2 to base 10注意:
在radix为 undefined,或者radix为 0 或者没有指定的情况下,JavaScript 作如下处理:
更多详见parseInt | MDN
map() 方法创建一个新数组,其结果是该数组中的每个元素都调用一个提供的函数后返回的结果。
var new_array = arr.map(function callback(currentValue[,index[, array]]) {
// Return element for new_array
}[, thisArg])可以看到callback回调函数需要三个参数, 我们通常只使用第一个参数 (其他两个参数是可选的)。
currentValue 是callback 数组中正在处理的当前元素。
index可选, 是callback 数组中正在处理的当前元素的索引。
array可选, 是callback map 方法被调用的数组。
另外还有thisArg可选, 执行 callback 函数时使用的this 值。
const arr = [1, 2, 3];
arr.map((num) => num + 1); // [2, 3, 4]更多详见Array.prototype.map() | MDN
回到我们真实的事例上
['1', '2', '3'].map(parseInt)对于每个迭代map, parseInt()传递两个参数: 字符串和基数。
所以实际执行的的代码是:
['1', '2', '3'].map((item, index) => {
return parseInt(item, index)
})即返回的值分别为:
parseInt('1', 0) // 1
parseInt('2', 1) // NaN
parseInt('3', 2) // NaN, 3 不是二进制所以:
['1', '2', '3'].map(parseInt)
// 1, NaN, NaN由此,加里·伯恩哈德例子也就很好解释了,这里不再赘述
['10','10','10','10','10'].map(parseInt);
// [10, NaN, 2, 3, 4]如果您实际上想要循环访问字符串数组, 该怎么办? map()然后把它换成数字?使用编号!
['10','10','10','10','10'].map(Number);
// [10, 10, 10, 10, 10]JS系列暂定 27 篇,从基础,到原型,到异步,到设计模式,到架构模式等,
本篇是 JS系列中第 3 篇,文章主讲 JS 继承,包括原型链继承、构造函数继承、组合继承、寄生组合继承、原型式继承以及 ES6 继承 。
先定义一个父类
function SuperType () {
// 属性
this.name = 'SuperType';
}
// 原型方法
SuperType.prototype.sayName = function() {
return this.name;
};将父类的实例作为子类的原型
// 父类
function SuperType () {
this.name = 'SuperType'; // 父类属性
}
SuperType.prototype.sayName = function () { // 父类原型方法
return this.name;
};
// 子类
function SubType () {
this.subName = "SubType"; // 子类属性
};
SubType.prototype = new SuperType(); // 重写原型对象,代之以一个新类型的实例
// 这里实例化一个 SuperType 时, 实际上执行了两步
// 1,新创建的对象复制了父类构造函数内的所有属性及方法
// 2,并将原型 __proto__ 指向了父类的原型对象
SubType.prototype.saySubName = function () { // 子类原型方法
return this.subName;
}
// 子类实例
let instance = new SubType();
// instanceof 通过判断对象的 prototype 链来确定对象是否是某个类的实例
instance instanceof SubType; // true
instance instanceof SuperType; // true
// 注意
SubType instanceof SuperType; // false
SubType.prototype instanceof SuperType ; // true
特点:利用原型,让一个引用类型继承另一个引用类型的属性及方法
优点:继承了父类的模板,又继承了父类的原型对象
缺点:
可以在子类构造函数中,为子类实例增加实例属性。如果要新增原型属性和方法,则必须放在 SubType.prototype = new SuperType('SubType'); 这样的语句之后执行。
无法实现多继承
来自原型对象的所有属性被所有实例共享
// 父类
function SuperType () {
this.colors = ["red", "blue", "green"];
this.name = "SuperType";
}
// 子类
function SubType () {}
// 原型链继承
SubType.prototype = new SuperType();
// 实例1
var instance1 = new SubType();
instance1.colors.push("blcak");
instance1.name = "change-super-type-name";
console.log(instance1.colors); // ["red", "blue", "green", "blcak"]
console.log(instance1.name); // change-super-type-name
// 实例2
var instance2 = new SubType();
console.log(instance2.colors); // ["red", "blue", "green", "blcak"]
console.log(instance2.name); // SuperType
注意:更改 SuperType 引用类型属性时,会使 SubType 所有实例共享这一更新。基础类型属性更新则不会。
创建子类实例时,无法向父类构造函数传参,或者说是,没办法在不影响所有对象实例的情况下,向超类的构造函数传递参数
基本**:在子类型的构造函数内部调用父类型构造函数。
注意:函数只不过是在特定环境中执行代码的对象,所以这里使用 apply/call 来实现。
使用父类的构造函数来增强子类实例,等于是复制父类的实例属性给子类(没用到原型)
// 父类
function SuperType (name) {
this.name = name; // 父类属性
}
SuperType.prototype.sayName = function () { // 父类原型方法
return this.name;
};
// 子类
function SubType () {
// 调用 SuperType 构造函数
SuperType.call(this, 'SuperType'); // 在子类构造函数中,向父类构造函数传参
// 为了保证子父类的构造函数不会重写子类的属性,需要在调用父类构造函数后,定义子类的属性
this.subName = "SubType"; // 子类属性
};
// 子类实例
let instance = new SubType(); // 运行子类构造函数,并在子类构造函数中运行父类构造函数,this绑定到子类
顾名思义,组合继承就是将原型链继承与构造函数继承组合在一起,从而发挥两者之长的一种继承模式。
基本**:使用原型链继承使用对原型属性和方法的继承,通过构造函数继承来实现对实例属性的继承。这样既能通过在原型上定义方法实现函数复用,又能保证每个实例都有自己的属性。
通过调用父类构造,继承父类的属性并保留传参的优点,然后通过将父类实例作为子类原型,实现函数复用
// 父类
function SuperType (name) {
this.colors = ["red", "blue", "green"];
this.name = name; // 父类属性
}
SuperType.prototype.sayName = function () { // 父类原型方法
return this.name;
};
// 子类
function SubType (name, subName) {
// 调用 SuperType 构造函数
SuperType.call(this, name); // ----第二次调用 SuperType----
this.subName = subName;
};
// ----第一次调用 SuperType----
SubType.prototype = new SuperType(); // 重写原型对象,代之以一个新类型的实例
SubType.prototype.constructor = SubType; // 组合继承需要修复构造函数指向
SubType.prototype.saySubName = function () { // 子类原型方法
return this.subName;
}
// 子类实例
let instance = new SubType('An', 'sisterAn')
instance.colors.push('black')
console.log(instance.colors) // ["red", "blue", "green", "black"]
instance.sayName() // An
instance.saySubName() // sisterAn
let instance1 = new SubType('An1', 'sisterAn1')
console.log(instance1.colors) // ["red", "blue", "green"]
instance1.sayName() // An1
instance1.saySubName() // sisterAn1
第一次调用 SuperType 构造函数时,SubType.prototype 会得到两个属性name和colors;当调用 SubType 构造函数时,第二次调用 SuperType 构造函数,这一次又在新对象属性上创建了 name和colors,这两个属性就会屏蔽原型对象上的同名属性。
// instanceof:instance 的原型链是针对 SuperType.prototype 进行检查的
instance instanceof SuperType // true
instance instanceof SubType // true
// isPrototypeOf:instance 的原型链是针对 SuperType 本身进行检查的
SuperType.prototype.isPrototypeOf(instance) // true
SubType.prototype.isPrototypeOf(instance) // true
在组合继承中,调用了两次父类构造函数,这里 通过通过寄生方式,砍掉父类的实例属性,这样,在调用两次父类的构造的时候,就不会初始化两次实例方法/属性,避免的组合继承的缺点
主要**:借用 构造函数 继承 属性 ,通过 原型链的混成形式 来继承 方法
// 父类
function SuperType (name) {
this.colors = ["red", "blue", "green"];
this.name = name; // 父类属性
}
SuperType.prototype.sayName = function () { // 父类原型方法
return this.name;
};
// 子类
function SubType (name, subName) {
// 调用 SuperType 构造函数
SuperType.call(this, name); // ----第二次调用 SuperType,继承实例属性----
this.subName = subName;
};
// ----第一次调用 SuperType,继承原型属性----
SubType.prototype = Object.create(SuperType.prototype)
SubType.prototype.constructor = SubType; // 注意:增强对象
let instance = new SubType('An', 'sisterAn')
优点:
SuperType 构造函数,只创建一份父类属性instanceof 与 isPrototypeOf实现思路就是将子类的原型设置为父类的原型
// 父类
function SuperType (name) {
this.colors = ["red", "blue", "green"];
this.name = name; // 父类属性
}
SuperType.prototype.sayName = function () { // 父类原型方法
return this.name;
};
/** 第一步 */
// 子类,通过 call 继承父类的实例属性和方法,不能继承原型属性/方法
function SubType (name, subName) {
SuperType.call(this, name); // 调用 SuperType 的构造函数,并向其传参
this.subName = subName;
}
/** 第二步 */
// 解决 call 无法继承父类原型属性/方法的问题
// Object.create 方法接受传入一个作为新创建对象的原型的对象,创建一个拥有指定原型和若干个指定属性的对象
// 通过这种方法指定的任何属性都会覆盖原型对象上的同名属性
SubType.prototype = Object.create(SuperType.prototype, {
constructor: { // 注意指定 SubType.prototype.constructor = SubType
value: SubType,
enumerable: false,
writable: true,
configurable: true
},
run : {
value: function(){ // override
SuperType.prototype.run.apply(this, arguments);
// call super
// ...
},
enumerable: true,
configurable: true,
writable: true
}
})
/** 第三步 */
// 最后:解决 SubType.prototype.constructor === SuperType 的问题
// 这里,在上一步已经指定,这里不需要再操作
// SubType.prototype.constructor = SubType;
var instance = new SubType('An', 'sistenAn')
如果希望能 多继承 ,可使用 混入 的方式
// 父类 SuperType
function SuperType () {}
// 父类 OtherSuperType
function OtherSuperType () {}
// 多继承子类
function AnotherType () {
SuperType.call(this) // 继承 SuperType 的实例属性和方法
OtherSuperType.call(this) // 继承 OtherSuperType 的实例属性和方法
}
// 继承一个类
AnotherType.prototype = Object.create(SuperType.prototype);
// 使用 Object.assign 混合其它
Object.assign(AnotherType.prototype, OtherSuperType.prototype);
// Object.assign 会把 OtherSuperType 原型上的函数拷贝到 AnotherType 原型上,使 AnotherType 的所有实例都可用 OtherSuperType 的方法
// 重新指定 constructor
AnotherType.prototype.constructor = AnotherType;
AnotherType.prototype.myMethod = function() {
// do a thing
};
let instance = new AnotherType()最重要的部分是:
SuperType.call 继承实例属性方法Object.create() 来继承原型属性与方法SubType.prototype.constructor 的指向首先,实现一个简单的 ES6 继承:
class People {
constructor(name) {
this.name = name
}
run() { }
}
// extends 相当于方法的继承
// 替换了上面的3行代码
class Man extends People {
constructor(name) {
// super 相当于属性的继承
// 替换了 People.call(this, name)
super(name)
this.gender = '男'
}
fight() { }
}extends 继承的核心代码如下,其实现和上述的寄生组合式继承方式一样
function _inherits(subType, superType) {
// 创建对象,Object.create 创建父类原型的一个副本
// 增强对象,弥补因重写原型而失去的默认的 constructor 属性
// 指定对象,将新创建的对象赋值给子类的原型 subType.prototype
subType.prototype = Object.create(superType && superType.prototype, {
constructor: { // 重写 constructor
value: subType,
enumerable: false,
writable: true,
configurable: true
}
});
if (superType) {
Object.setPrototypeOf
? Object.setPrototypeOf(subType, superType)
: subType.__proto__ = superType;
}
}注: 考虑到JavaScript的工作方式,由于原型链等特性的存在,在不同对象之间功能的共享通常被叫做 委托 - 特殊的对象将功能委托给通用的对象类型完成。这也许比将其称之为继承更为贴切,因为“被继承”了的功能并没有被拷贝到正在“进行继承”的对象中,相反它仍存在于通用的对象中。
new 关键字创建的对象实际上是对新对象 this 的不断赋值,并将 prototype 指向类的 prototype 所指向的对象。
var SuperType = function (name) {
var nose = 'nose' // 私有属性
function say () {} // 私有方法
// 特权方法
this.getName = function () {}
this.setName = function () {}
this.mouse = 'mouse' // 对象公有属性
this.listen = function () {} // 对象公有方法
// 构造器
this.setName(name)
}
SuperType.age = 10 // 类静态公有属性(对象不能访问)
SuperType.read = function () {} // 类静态公有方法(对象无法访问)
SuperType.prototype = { // 对象赋值(也可以一一赋值)
isMan: 'true', // 公有属性
write: function () {} // 公有方法
}
var instance = new SuperType()
所以类的构造函数内定义的 私有变量或方法 ,以及类定义的 静态公有属性及方法 ,在 new 的实例对象中都将 无法访问 。
关于继承机制的设计**,请参见 Javascript继承机制的设计** 。
最近,工作加班写小程序,虽然之前也写了不少小程序,但大多是使用小程序原生来写,也使用过wepy框架,风格和vue差不多,这次尝试使用taro框架。今天小程序告一断落,特此总结一波。
npm install -g @tarojs/cli$ taro init myApp$ npm run dev:weapp
$ npm run build:weapp主要详见官网Taro安装及使用,重要的事情说三遍,一定要认真看官方文档、官方文档、官方文档,做好基础的入门。
若使用 微信小程序预览模式 ,则需下载并使用微信开发者工具添加项目进行预览,此时需要注意微信开发者工具的项目设置
.
├── dist 编译结果目录
├── config 配置目录
| ├── dev.js 开发时配置
| ├── index.js 默认配置
| └── prod.js 打包时配置
├── src 源码目录
| ├── pages 页面文件目录
| | ├── index index 页面目录
| | | ├── index.js index 页面逻辑
| | | └── index.css index 页面样式
| ├── app.css 项目总通用样式
| └── actions redux actions
| └── constants
| └── libs
| └── net
| └── asset
| └── reducers
| └── store
| └── utils
└── package.json在微信小程序端的自定义组件中,只有在 properties 中指定的属性,才能从父组件传入并接收
Component({
properties: {
myProperty: { // 属性名
type: String, // 类型(必填),目前接受的类型包括:String, Number, Boolean, Object, Array, null(表示任意类型)
value: '', // 属性初始值(可选),如果未指定则会根据类型选择一个
observer: function (newVal, oldVal, changedPath) {
// 属性被改变时执行的函数(可选),也可以写成在 methods 段中定义的方法名字符串, 如:'_propertyChange'
// 通常 newVal 就是新设置的数据, oldVal 是旧数据
}
},
myProperty2: String // 简化的定义方式
}
...
})而在 Taro 中,对于在组件代码中使用到的来自 props 的属性,会在编译时被识别并加入到编译后的 properties 中,暂时支持到了以下写法
this.props.property
const { property } = this.props
const property = this.props.property但是一千个人心中有一千个哈姆雷特,不同人的代码写法肯定也不尽相同,所以 Taro 的编译肯定不能覆盖到所有的写法,而同时可能会有某一属性没有使用而是直接传递给子组件的情况,这种情况是编译时无论如何也处理不到的,这时候就需要大家在编码时给组件设置 defaultProps 来解决了。
export default class LGLine extends Component {
static propTypes = {
value: string,
};
static defaultProps = {
value: '',
};
render () {
const { value } = this.props
return (
<View className='height-1 base-width-12'>
</View>
)
}
}组件设置的 defaultProps 会在运行时用来弥补编译时处理不到的情况,里面所有的属性都会被设置到 properties 中初始化组件,正确设置 defaultProps 可以避免很多异常的情况的出现。
在 Taro 中,JS 代码里必须书写单引号,特别是 JSX 中,如果出现双引号,可能会导致编译错误。
不要以解构的方式来获取通过 env 配置的 process.env 环境变量,请直接以完整书写的方式 process.env.NODE_ENV 来进行使用
// 错误写法,不支持
const { NODE_ENV = 'development' } = process.env
if (NODE_ENV === 'development') {
...
}
// 正确写法
if (process.env.NODE_ENV === 'development') {
}cover-view经常使用到换行,设置文本内容换行 white-space: normal;
由于我们在滚动页面中经常会使用到textarea,video等原生组件,这些原生组件在scroll-view中的支持并不友好,所有有时我们有时无法使用scroll-view,也就无法去获取scrollTop,例如Taro 拖拽排序,这时,可以这样做:
onPageScroll () {
let that = this;
var query = Taro.createSelectorQuery()
query.select('.content-view').boundingClientRect()
query.selectViewport().scrollOffset()
query.exec(function(res) {
that.setState({
scrollPosition: {
scrollTop: res[1].scrollTop,
scrollY: that.state.scrollPosition.scrollY
},
})
})
}小程序项目中遇到的性能问题,大多是频繁地调用 setData 造成的,这是由于每调用一次 setData,小程序内部都会将该部分数据在逻辑层(运行环境 JSCore)进行类似序列化的操作,将数据转换成字符串形式传递给视图层(运行环境 WebView),视图层通过反序列化拿到数据后再进行页面渲染,这个过程下来有一定性能开销。
所以开发过程中,我们建议尽量对 setData 进行合并,减少调用次数,例如:
this.setData({ foo: 'Strawberry' })
this.setData({ foo: 'Strawberry', bar: 'Fields' })
this.setData({ baz: 'Forever' })以上代码调用了 3 次 setData,造成不必要的性能开销,应对其进行合并:
this.setData({
foo: 'Strawberry',
bar: 'Fields',
baz: 'Forever',
})而使用 Taro 之后,更新数据时调用的 setState 为异步方法,它会自动地对同一事件循环里的多次 setState 调用进行合并处理,此外还会进行数据 diff 优化,自动剔除那些未变更的数据,从而有效避免了此类性能问题。例如:
// 初始时
this.state = {
foo: '1967',
bar: {
foo: 'Strawberry',
bar: 'Fields',
baz: 'Forever',
}
}
// 第一次更新
this.setState({
bar: {
foo: 'Norwegian',
bar: 'Fields',
baz: 'Forever',
}
})
// 紧接着进行第二次更新
this.setState({
foo: '1967',
bar: {
foo: 'Norwegian',
bar: 'Wood',
baz: 'Forever',
}
})以上代码虽然经过两次 setState,但只有 bar.foo 和 bar.bar 的数据更新了,此时 Taro 内部会自动对数据进行合并、并剔除重复数据,最终执行代码为:
// this.$scope 在小程序环境中为 page 实例
this.$scope.setData({
'bar.foo': 'Norwegian',
'bar.bar': 'Wood',
})其他的问题,请看下面:
Taro event handler 传递参数有问题
Taro 阻止事件冒泡
Taro 对接腾讯云对象存储服务COS
本文参考了Taro 在京东购物小程序上的实践及最佳实践
Taro 是一套遵循 React 语法规范的 多端开发 解决方案,所以一开始打算使用cos-js-sdk-v5,结果发现一直userAgent报错,代理出错,查看源码cos-js-sdk-v5/lib/request.js,才发现了自己忽略了一个致命错误。
cos-js-sdk-v5使用的是jquery请求,而小程序是无法使用jquery的,主要是因为:小程序的页面逻辑是在JsCore中运行,JsCore是一个没有窗口对象的环境,所以脚本中不能使用window对象,也无法在脚本中操作组件,而jquery会使用到window对象和document对象,所以无法使用。
进而,使用腾讯云对象储存服务对接小程序的cos-wx-sdk-v5,按照文档直接拖到项目了,运行正确,文件成功上传到腾讯云,但回调function (err, data)始终不运行。怎么办,只有一点点排查,在原生中是正常的,那么只能是Taro编译的时候出问题了,所以我们这样解决,在Taro编译时,忽略cos-wx-sdk-v5文件,我们在config/index.js配置如下:
...
weapp: {
compile: {
exclude:['src/libs/cos-wx-sdk-v5.js'] // 忽略的文件位置数组
},
module: {
postcss: {
autoprefixer: {
enable: true,
config: {
browsers: [
'last 3 versions',
'Android >= 4.1',
'ios >= 8'
]
}
},
pxtransform: {
enable: true,
config: {
}
},
url: {
enable: true,
config: {
limit: 10240 // 设定转换尺寸上限
}
},
cssModules: {
enable: false, // 默认为 false,如需使用 css modules 功能,则设为 true
config: {
namingPattern: 'module', // 转换模式,取值为 global/module
generateScopedName: '[name]__[local]___[hash:base64:5]'
}
}
}
}
},
...同时奉上部分代码实现:
import { UPLOADER_SERVER_URL } from "../vendor/lib/urls";
import net from '../vendor/index'
import {log, GUID, get_suffix, showLoading} from "./utils";
import COS from '../libs/cos-wx-sdk-v5'
var Bucket = 'XXX'
var Region = 'ap-shanghai'
var getAuthorization = function (options, callback) {
net.request({
url:UPLOADER_SERVER_URL,
method: 'GET',
success (res) {
log('getAuthorization', res)
let token = res.token
callback({
TmpSecretId: token.credentials.tmpSecretId,
TmpSecretKey: token.credentials.tmpSecretKey,
XCosSecurityToken: token.credentials.sessionToken,
ExpiredTime: parseInt(token.expiredTime)*1000, // SDK 在 ExpiredTime 时间前,不会再次调用 getAuthorization
})
}, fail (err) {
log('getAuthorization err', err)
}
})
}
let cos = new COS({
// path style 指正式请求时,Bucket 是在 path 里,这样用途相同园区多个 bucket 只需要配置一个园区域名
// ForcePathStyle: true,
getAuthorization: getAuthorization,
})
const cosUploader = {
cos,
uploaderFile (filePath) {
return new Promise((resolve, reject) => {
var filename = 'product-images/' + GUID(32, 62) + get_suffix(filePath)
showLoading('上传中')
cos.postObject({
Bucket: Bucket,
Region: Region,
Key: filename,
FilePath: filePath,
onProgress: function (info) {
console.log(JSON.stringify(info));
}
}, function (err, data) {
log('err || data', err || data)
if (err) {
reject(err)
} else {
resolve(data)
}
})
})
},
uploaderFiles (files, callback) {
let arr = files.map((item) => {
return this.uploaderFile(item)
})
Promise.all(arr).then(function (res) {
callback(null, res)
}, function (err) {
callback(err, null)
})
return arr
}
}
export default cosUploaderReact 官网上定义:
React 是一个用于构建用户界面的 JavaScript 库。
首先,让我们看一下这个定义的两个不同部分:
这意味着它不完全是一个 框架 。它不是一个完整的解决方案,你经常需要使用更多的库来辅助 React 形成一套完整的解决方案。React 不对解决方案中的其他部分作任何假设。
框架是一个伟大的目标,特别是对于年轻的团队和初创公司。在使用框架时,已经为你做出了许多明智的设计决策,这为你提供了一条清晰的道路,可以专注于编写良好的应用程序逻辑。但是,框架存在一些缺点。对于从事大型代码库开发工作的,并且经验丰富的开发人员来说,这些缺点有时会极具破坏性的。
尽管有些人声称,框架并不灵活。框架通常希望你以某种方式编码所有内容。如果你试图偏离这种方式,框架经常会为此与你发生冲突。框架通常很大并且功能齐全,如果你只需要使用它们中的一小部分,你必须要引入整个框架。不可否认今天这一点正在改变,但仍然不理想,一些框架正在模块化,我认为这很棒,但我是纯 Unix 哲学的忠实粉丝:
编写做一件事并做得好的程序。编写程序以协同工作。 - 道格麦克罗伊
React 遵循 Unix 哲学,因为它是一个小型库,专注于一件事并且非常好地完成这件事。“一件事” 是React定义的第二部分:构建用户界面。
用户界面(UI)是展现在用户面前,用于与机器交互的媒介。用户界面无处不在,从微波炉上的简单按钮到航天飞机的仪表板。如果我们尝试连接的设备可以识别 JavaScript ,我们就可以使用 React 来描述它的 UI 。由于 Web 浏览器识别 JavaScript ,我们可以使用 React 来描述 Web UI 。
我们只需要告诉浏览器我们想要什么!React 将代表我们在 Web 浏览器中构建实际的 UI。如果没有React或类似的库,我们需要使用原生 Web API 和 JavaScript 手动构建 UI,这并不容易。
当你听到 React 是声明 的陈述时,这正是它的含义。我们用 React 描述 UI 并告诉它我们想要什么(而不是如何做)。React将负责“how”并将我们的声明性描述(我们用React语言编写)转换为浏览器中的实际UI。React 与 HTML 本身共享这种简单的声明能力,但是使用React,我们可以声明代表动态数据的HTML UI,而不仅仅是静态数据。
当 React 发布时,有很多关于它性能的质疑,因为它引入了一个虚拟 DOM 的聪明想法,可以用来协调实际的DOM(我们将在下一节讨论)。
DOM是文档对象模型(Document Object Model)。它是HTML(和XML)文档的浏览器编程接口,将它们视为树结构。DOM API可用于更改文档结构,样式和内容。
虽然今天 React 非常流行的最重要原因之一就是 React 的高性能,但我并没有把它归类为 React 的最好的一点。我认为 React 是一个游戏规则改变者,因为它在开发人员和浏览器之间创建了一种通用语言,允许开发人员以声明方式描述UI并管理其状态(state)上的操作,而不是对 DOM 元素的操作。它只是用户界面“结果”的语言。开发人员只是根据“最终”状态(如函数)来描述接口,而不是采用步骤来描述接口上的操作。当更新该状态时,React会根据它来更新 DOM 中的 UI(高效更新)。
如果有人要求你给出一个 React 为什么值得学习的原因,就是它是一个基于结果的 UI 语言。我们可以将这种语言称为 React语言 。
假设我们有一个像这样的 todos 列表:
const todos: [
{ body: 'Learn React Fundamentals', done: true },
{ body: 'Build a TODOs App', done: false },
{ body: 'Build a Game', done: false },
];此 todos 数组是 UI 的起始状态。你需要构建一个 UI 来显示和管理。在这个页面上有三个操作,风别是一个添加新 todo 的表单 ,一个将 todo 标记为已完成,以及删除所有已完成的 todo 。

这些操作中的每一个都将要求应用程序执行DOM操作以创建,插入,更新或删除 DOM 节点。使用 React ,你不必担心所有这些 DOM 操作。你不必担心何时需要发生或如何有效地执行它们。你只需将 todos 数组置于应用程序的 state 中,然后使用 React 语言命令 React 在 UI 中以某种方式显示该状态:
<header>TODO List</header>
<ul>
{todos.map(todo =>
<li>{todo.body}</li>
)}
</ul>
// Other form elements...之后,你可以专注于对该todos 数组进行数据操作!你可以添加,删除和更新该数组,React 会将你对该对象所做的更改渲染到浏览器上。
这种基于最终状态建模 UI 的心理模型更易于理解和使用,尤其是当视图具有大量数据转换时。例如,考虑一下可以告诉你有多少朋友在线的视图。该视图的 state 只是目前有多少朋友在线的一个数字。它并不关心刚才三个朋友上网,然后其中一个断线,然后两个加入。它只知道在这个时刻,有四个朋友在线。
在 React 之前,当我们需要使用浏览器的API(DOM API)时,我们尽可能避免遍历 DOM 树,那是因为 DOM 上的任何操作都在同一个线程中完成,该线程负责浏览器中发生的所有事情,包括对用户事件的反应:如打字,滚动,调整大小等。
对 DOM 的任何昂贵的操作都可能给用户带来缓慢的操作体验。非常重要的是,你的应用程序执行最小的操作时,应尽可能地批量处理。React 就提出了一个独特的概念来帮助我们做到这一点!
当我们告诉 React 在浏览器中渲染元素树时,它首先生成该树的虚拟表示并将其保存在内存中以供日后使用。然后它将继续执行DOM操作,使树显示在浏览器中。
当我们告诉 React 更新之前渲染的元素树时,它会生成树的新的虚拟表示。现在React在内存中有2个版本的树!
要在浏览器中呈现更新的树,React 不会丢弃已呈现的内容。相反,它将比较它在内存中的2个虚拟版本,计算它们之间的差异,找出主树中需要更新的子树,并且只在浏览器中更新这些子树。
这个过程就是所谓的树协调算法,它是 React 渲染浏览器 DOM 树的一种非常有效的方法。
除了基于声明结果的语言和有效的树协调之外,以下是我认为React获得其广泛流行的其他一些原因:
为了看到树协调算法的实际好处及其所带来的巨大差异,让我们看一个只关注该概念的简单示例。让我们生成并更新两次HTML元素树,一次使用本机Web API,然后使用React API(及其协调工作)。为了简化这个例子,我不会使用组件或 JSX(与React一起使用的 JavaScript 扩展)。我还将在 JavaScript 间隔计时器内执行更新操作。这不是我们编写React应用程序的方式,而是让我们一次关注一个概念。
在此会话中,使用2种方法将简单的HTML元素呈现给显示:
方法1:直接使用 Web DOM API
document.getElementById('mountNode').innerHTML = `
<div>
Hello HTML
</div>
`;方法2:使用 React API
ReactDOM.render(
React.createElement(
'div',
null,
'Hello React',
),
document.getElementById('mountNode2'),
);该 ReactDOM.render 方法和 React.createElement 方法是 React 应用程序中的核心 API 方法。事实上,如果不使用这两种方法,React Web 应用程序就不可能存在。简要介绍一下:
是 React 应用程序渲染到浏览器 DOM 的入口点。它有两个参数:
mountNode2元素,该元素存在于playground 的显示区域中(第一个 mountNode 用于本机版本)。React元素究竟是什么?它是用来描述 Actual DOM 元素的 Virtual 元素。也就是 React.createElement API方法返回的内容。
在 React 中,我们不使用字符串来表示 DOM 元素(如上面的 DOM 示例中),而是使用对方法的调用来表示带有对象的 DOM 元素 React.createElement 。这些对象称为 React 元素。
该 React.createElement 函数有很多参数:
div 在此示例中。id,href,title,等),如果没有属性,可以使用 null 。Hello React 字符串。可选的第三个参数以及它后面的所有可选参数,形成渲染元素的子列表。元素可以包含0个或更多子元素。React.createElement 也可用于从 React 组件创建元素。
React 元素在内存中创建。为了实际在真实 DOM 中显示一个 React 元素,我们使用 ReactDOM.render 来实现将 React 元素的状态映射到浏览器中的真实 DOM 树中。
我们有两个节点:一个用 DOM API 直接控制,另一个用 React API 控制。
我们在浏览器中构建这两个节点的方式之间唯一的区别是,在 HTML 版本中,我们使用字符串来表示 DOM 树,而在 React 版本中,我们使用纯 JavaScript 调用并使用对象表示 DOM 树。
无论 HTML UI 有多复杂,使用 React 时,每个 HTML 元素都将用 React 元素表示。
对于 HTML 版本,你可以直接在模板中注入新元素的标记:
document.getElementById('mountNode').innerHTML = `
<div>
Hello HTML
<input />
</div>
`;而对 React 执行相同操作,就需要在 React.createElement 上面的第三个参数之后添加更多参数。为了匹配到在原生 DOM 示例中的内容,我们可以添加第四个参数,这是另一个 React.createElement 呈现 input 元素的调用:
ReactDOM.render(
React.createElement(
"div",
null,
"Hello React ",
React.createElement("input")
),
document.getElementById('mountNode2'),
);可以使用它 new Date().toLocaleTimeString() 来显示简单的时间字符串,并把它放在一个 pre 标签中。
原生 DOM 版本执行的操作:
document.getElementById('mountNode1').innerHTML = `
<div>
Hello HTML
<input />
<pre>${new Date().toLocaleTimeString()}</pre>
</div>
`;在 React 中,我们需要在顶层 div 元素中添加第五个参数。并且,这个新的第五个参数是另一个 React.createElement 调用,创建一个 pre 标签,并且内容为 Date().toLocaleTimeString() :
ReactDOM.render(
React.createElement(
'div',
null,
'Hello React ',
React.createElement('input'),
React.createElement(
'pre',
null,
new Date().toLocaleTimeString()
)
),
document.getElementById('mountNode2')
);因此,你可能认为使用 React 比使用简单熟悉的原生方式要困难得多。那么为什么我们要放弃熟悉的 HTML 并且必须学习 React API 来编写可以用 HTML 编写实现的内容喃?
答案不在于渲染第一个 HTML 视图,这是在于我们如何更新已渲染的 DOM 视图。
我们对 DOM 树进行更新操作。例如:简单地让时间字符串每秒更新。
我们可以使用 setInterval Web 计时器 API 轻松地在浏览器中重复 JavaScript 函数调用。将两个版本的所有 DOM 操作放入一个函数中,命名它 render ,并在 setInterval 调用中使用它以使其每秒重复一次。
以下是此示例的完整代码:
const render = () => {
// HTML DOM
document.getElementById('mountNode').innerHTML = `
<div>
Hello HTML
<input />
<pre>${new Date().toLocaleTimeString()}</pre>
</div>
`;
// React DOM
ReactDOM.render(
React.createElement(
'div',
null,
'Hello React',
React.createElement('input', null),
React.createElement('pre', null, new Date().toLocaleTimeString())
),
document.getElementById('mountNode2')
);
};
// 每秒更新一次
setInterval(render, 1000);请注意两个版本中的时间字符串如何每秒更新。我们现在正在更新 DOM 中的 UI 。
**这是React可能会让你大吃一惊的时刻。**如果你尝试在原生 DOM 版本的文本框中键入内容,则无法执行此操作。这是因为我们每秒都会抛弃原有的整个DOM节点并重新生成它。
但是,如果你尝试在 React 版本中的文本框中键入内容,却可以执行。
虽然整个 React 渲染代码都在计时器内,但 React只更改 pre 元素的内容而不是整个 DOM 树。这就是文本输入框没有重新生成的原因,我们可以输入它。
如果你检查 Chrome DevTools 元素面板中的两个DOM节点,你可以看到这两种方式更新 DOM 的不同。
div#mountNode 每秒重新生成其整个 DOM 树div#mountNode2 容器中仅 pre 每秒重新生成这是 React 的智能差异算法。它只在主 DOM 树中更新实际需要更新的内容,同时保持其他所有内容相同。这种差异化过程是可行的,因为它在内存中保留了 React 的虚拟 DOM 表示。无论 UI 视图需要重新生成多少次, React 将只向浏览器提供所需的更新部分。
这种方法不仅效率更高,而且消除了我们考虑更新 UI 的方式的复杂性。让 React 处理关于是否需要更新 DOM 的所有计算模块,使我们能够专注于思考我们的数据(state 状态)以及 UI 展示。
然后,我们根据需要管理数据状态的更新,而不必担心在浏览器的实际 UI 中渲染这些更新所需的步骤(因为我们知道 React 将完全执行此操作并且以更有效的方式执行!)
在 Taro 中另一个不同是你不能使用 catchEvent 的方式阻止事件冒泡。你必须明确的使用 stopPropagation。例如,阻止事件冒泡你可以这样写:
class Toggle extends Component {
constructor (props) {
super(props)
this.state = {isToggleOn: true}
}
onClick = (e) => {
e.stopPropagation() // 阻止事件冒泡
this.setState(prevState => ({
isToggleOn: !prevState.isToggleOn
}))
}
render () {
return (
<button onClick={this.onClick}>
{this.state.isToggleOn ? 'ON' : 'OFF'}
</button>
)
}
}作为一个开发人员,我们每天都会花大量的时间来处理前后端间的数据请求与响应,这就需要我们有足够的 HTTP 知识,本节将针对 HTTP status code 展开探讨。
Fernando Doglio在他的书中 - 使用NodeJS的REST API开发将状态代码定义为:
一个数字,总结了与之相关的响应。
当客户端向服务器发出请求时,服务器提供HTTP(超文本传输协议)响应状态代码,这使我们能够了解网站后端发生的情况,确定需要修复的错误。
1xx 的状态会被浏览器 HTTP 库直接处理掉,不会让上层应用知晓
请求成功
资源已创建,服务器已确认。它对POST或PUT请求的响应很有用。此外,新资源可以作为响应正文的一部分返回。
该操作请求成功,但没有返回任何内容。对于不需要响应主体的操作很有用,例如 DELETE 操作。
表示请求成功,但响应报文不含实体的主体部分,但是与 204 响应不同在于要求请求方重置内容
3xx: 当服务器通知客户端请求的目标有变化,希望客户端进一步处理,将使用这些。
用于通知浏览器所请求的文件已被移动,并且它应该从服务器提供的位置请求文件,并记住该新位置以供将来参考。这只能用于HTTP GET和HEAD请求。
此资源已移至另一个位置,并返回该位置。当URL随着时间的推移而变化时(尤其是由于版本,迁移或其他一些破坏性更改),此标头特别有用,保留旧标头并将重定向返回到新位置允许旧客户端更新其引用自己的时间。
相似301; 但它是临时重定向。它将客户端从旧资源引导到新资源,但它不会告诉搜索引擎更新页面的索引。告诉客户端浏览另一个URL。
产生的前提:客户端本地已经有缓存的版本,并且在 Request 中告诉了服务端,当服务端通过时间或 tag,发现没有更新的时候,就会返回一个不含 body 的 304 状态码
临时重定向,和302含义类似,但是期望客户端保持请求方法不变向新的地址发出请求
4xx: 定义客户端错误,这是服务器认为Web浏览器出错的地方。
发出的请求有问题(例如,可能缺少一些必需的参数)。对400响应的良好补充可能是开发人员可用于修复请求的错误消息
当拥有请求的用户无法访问所请求的资源时,对身份验证特别有用
通常在请求的文件有效但文件无法提供时发出,这通常是由于服务器端权限问题导致Web服务器不允许将文件提供给客户端。
401 与 403 的区别:
这可能是最常见且经常出现的错误。当Web浏览器请求服务器上不存在的文件时,会发生此问题。
不允许在资源上使用HTTP动词**(例如POST,GET,PUT等)** - 例如,在只读资源上执行PUT。
418 :It's a teapot,来自 ietf 的一个愚人节玩笑 😈
5xx: 定义服务器端错误。尽管客户端提供了有效请求,但这些都是服务器部分发生的错误。
这是一个不幸的模糊通用错误代码。只要认为服务器遇到与任何更具体的错误代码不匹配的错误,就会发出它。
服务器要么不识别请求方法,要么不支持请求。
当Web浏览器联系充当另一个服务器的代理的Web服务器并且从另一个服务器获得无效响应时,会发生这种情况。
这通常在服务器暂时性错误(暂时处于超负载或正在停机维护)的情况下遇到,此时服务器无法处理请求,可以一会再试
React 是通过管理状态来实现对组件的管理,即使用 this.state 获取 state,通过 this.setState() 来更新 state,当使用 this.setState() 时,React 会调用 render 方法来重新渲染 UI。
首先看一个例子:
class Example extends React.Component {
constructor() {
super();
this.state = {
val: 0
};
}
componentDidMount() {
this.setState({val: this.state.val + 1});
console.log(this.state.val); // 第 1 次 log
this.setState({val: this.state.val + 1});
console.log(this.state.val); // 第 2 次 log
setTimeout(() => {
this.setState({val: this.state.val + 1});
console.log(this.state.val); // 第 3 次 log
this.setState({val: this.state.val + 1});
console.log(this.state.val); // 第 4 次 log
}, 0);
}
render() {
return null;
}
};答案是: 0 0 2 3,你做对了吗?
setState 通过一个队列机制来实现 state 更新,当执行 setState() 时,会将需要更新的 state 浅合并后放入 状态队列,而不会立即更新 state,队列机制可以高效的批量更新 state。而如果不通过setState,直接修改this.state 的值,则不会放入状态队列,当下一次调用 setState 对状态队列进行合并时,之前对 this.state 的修改将会被忽略,造成无法预知的错误。
React通过状态队列机制实现了 setState 的异步更新,避免重复的更新 state。
setState(nextState, callback)在 setState 官方文档中介绍:将 nextState 浅合并到当前 state。这是在事件处理函数和服务器请求回调函数中触发 UI 更新的主要方法。不保证 setState 调用会同步执行,考虑到性能问题,可能会对多次调用作批处理。
举个例子:
// 假设 state.count === 0
this.setState({count: state.count + 1});
this.setState({count: state.count + 1});
this.setState({count: state.count + 1});
// state.count === 1, 而不是 3本质上等同于:
// 假设 state.count === 0
Object.assign(state,
{count: state.count + 1},
{count: state.count + 1},
{count: state.count + 1}
)
// {count: 1}但是如何解决这个问题喃,在文档中有提到:
也可以传递一个签名为 function(state, props) => newState 的函数作为参数。这会将一个原子性的更新操作加入更新队列,在设置任何值之前,此操作会查询前一刻的 state 和 props。...setState() 并不会立即改变 this.state ,而是会创建一个待执行的变动。调用此方法后访问 this.state 有可能会得到当前已存在的 state(译注:指 state 尚未来得及改变)。
即使用 setState() 的第二种形式:以一个函数而不是对象作为参数,此函数的第一个参数是前一刻的state,第二个参数是 state 更新执行瞬间的 props。
// 正确用法
this.setState((prevState, props) => ({
count: prevState.count + props.increment
}))这种函数式 setState() 工作机制类似:
[
{increment: 1},
{increment: 1},
{increment: 1}
].reduce((prevState, props) => ({
count: prevState.count + props.increment
}), {count: 0})
// {count: 3}关键点在于更新函数(updater function):
(prevState, props) => ({
count: prevState.count + props.increment
})
这基本上就是个 reducer,其中 prevState 类似于一个累加器(accumulator),而 props 则像是新的数据源。类似于 Redux 中的 reducers,你可以使用任何标准的 reduce 工具库对该函数进行 reduce(包括 Array.prototype.reduce())。同样类似于 Redux,reducer 应该是 纯函数 。
注意:企图直接修改
prevState通常都是初学者困惑的根源。
相关源码:
// 将新的 state 合并到状态队列
var nextState = this._processPendingState(nextProps, nextContext)
// 根据更新队列和 shouldComponentUpdate 的状态来判断是否需要更新组件
var shouldUpdate = this._pendingForceUpdate ||
!inst.shouldComponentUpdate ||
inst.shouldComponentUpdate(nextProps, nextState, nextContext)当调用 setState 时,实际上是会执行 enqueueSetState 方法,并会对 partialState 及 _pendingStateQueue 队列进行合并操作,最终通过 enqueueUpdate 执行 state 更新。
而 performUpdateIfNecessary 获取 _pendingElement、 _pendingStateQueue、_pendingForceUpdate,并调用 reaciveComponent 和 updateComponent 来进行组件更新。
** 但,如果在 shouldComponentUpdate 或 componentWillUpdate 方法里调用 this.setState 方法,就会造成崩溃。 **这是因为在 shouldComponentUpdate 或 componentWillUpdate 方法里调用 this.setState 时,this._pendingStateQueue!=null,则 performUpdateIfNecessary 方法就会调用 updateComponent 方法进行组件更新,而 updateComponent 方法又会调用 shouldComponentUpdate和componentWillUpdate 方法,因此造成循环调用,使得浏览器内存占满后崩溃。
图 2-1 循环调用
setState 源码:
// 更新 state
ReactComponent.prototype.setState = function(partialState, callback) {
this.updater.enqueueSetState(this, partialState)
if (callback) {
this.updater.enqueueCallback(this, callback, 'setState')
}
}
enqueueSetState: function(publicInstance, partialState) {
var internalInstance = getInternalInstanceReadyForUpdate(
publicInstance,
'setState'
)
if (!internalInstance) {
return
}
// 更新队列合并操作
var queue = internalInstance._pendingStateQueue || (internalInstance._pendingStateQueue=[])
queue.push(partialState)
enqueueUpdate(internalInstance)
}
// 如果存在 _pendingElement、_pendingStateQueue、_pendingForceUpdate,则更新组件
performUpdateIfNecessary: function(transaction) {
if (this._pendingElement != null) {
ReactReconciler.receiveComponent(this, this._pendingElement, transaction, this._context)
}
if (this._pendingStateQueue != null || this._pendingForceUpdate) {
this.updateComponent(transaction, this._currentElement, this._currentElement, this._context, this._context)
}
}既然 setState 是通过 enqueueUpdate 来执行 state 更新的,那 enqueueUpdate 是如何实现更新 state 的喃?
图3-1 setState 简化调用栈
上面这个流程图是一个简化的 setState 调用栈,注意其中核心的状态判断,在源码(ReactUpdates.js)中
function enqueueUpdate(component) {
// ...
if (!batchingStrategy.isBatchingUpdates) {
batchingStrategy.batchedUpdates(enqueueUpdate, component);
return;
}
dirtyComponents.push(component);
}
若 isBatchingUpdates 为 false 时,所有队列中更新执行 batchUpdate,否则,把当前组件(即调用了 setState 的组件)放入 dirtyComponents 数组中。先不管这个 batchingStrategy,看到这里大家应该已经大概猜出来了,文章一开始的例子中 4 次 setState 调用表现之所以不同,这里逻辑判断起了关键作用。
那么 batchingStrategy 究竟是何方神圣呢?其实它只是一个简单的对象,定义了一个 isBatchingUpdates 的布尔值,和一个 batchedUpdates 方法。下面是一段简化的定义代码:
var batchingStrategy = {
isBatchingUpdates: false,
batchedUpdates: function(callback, a, b, c, d, e) {
// ...
batchingStrategy.isBatchingUpdates = true;
transaction.perform(callback, null, a, b, c, d, e);
}
};
注意 batchingStrategy 中的 batchedUpdates 方法中,有一个 transaction.perform 调用。这就引出了本文要介绍的核心概念 —— Transaction(事务)。
在 Transaction 的源码中有一幅特别的 ASCII 图,形象的解释了 Transaction 的作用。
/*
* <pre>
* wrappers (injected at creation time)
* + +
* | |
* +-----------------|--------|--------------+
* | v | |
* | +---------------+ | |
* | +--| wrapper1 |---|----+ |
* | | +---------------+ v | |
* | | +-------------+ | |
* | | +----| wrapper2 |--------+ |
* | | | +-------------+ | | |
* | | | | | |
* | v v v v | wrapper
* | +---+ +---+ +---------+ +---+ +---+ | invariants
* perform(anyMethod) | | | | | | | | | | | | maintained
* +----------------->|-|---|-|---|-->|anyMethod|---|---|-|---|-|-------->
* | | | | | | | | | | | |
* | | | | | | | | | | | |
* | | | | | | | | | | | |
* | +---+ +---+ +---------+ +---+ +---+ |
* | initialize close |
* +-----------------------------------------+
* </pre>
*/
简单地说,一个所谓的 Transaction 就是将需要执行的 method 使用 wrapper 封装起来,再通过 Transaction 提供的 perform 方法执行。而在 perform 之前,先执行所有 wrapper 中的 initialize 方法;perform 完成之后(即 method 执行后)再执行所有的 close 方法。一组 initialize 及 close 方法称为一个 wrapper,从上面的示例图中可以看出 Transaction 支持多个 wrapper 叠加。
具体到实现上,React 中的 Transaction 提供了一个 Mixin 方便其它模块实现自己需要的事务。而要使用 Transaction 的模块,除了需要把 Transaction 的 Mixin 混入自己的事务实现中外,还需要额外实现一个抽象的 getTransactionWrappers 接口。这个接口是 Transaction 用来获取所有需要封装的前置方法(initialize)和收尾方法(close)的,因此它需要返回一个数组的对象,每个对象分别有 key 为 initialize 和 close 的方法。
下面是一个简单使用 Transaction 的例子
var Transaction = require('./Transaction');
// 我们自己定义的 Transaction
var MyTransaction = function() {
// do sth.
};
Object.assign(MyTransaction.prototype, Transaction.Mixin, {
getTransactionWrappers: function() {
return [{
initialize: function() {
console.log('before method perform');
},
close: function() {
console.log('after method perform');
}
}];
};
});
var transaction = new MyTransaction();
var testMethod = function() {
console.log('test');
}
transaction.perform(testMethod);
// before method perform
// test
// after method perform
当然在实际代码中 React 还做了异常处理等工作,这里不详细展开。有兴趣的同学可以参考源码中 Transaction 实现。
说了这么多 Transaction,它到底是怎么导致上文所述 setState 的各种不同表现的呢?
那么 Transaction 跟 setState 的不同表现有什么关系呢?首先我们把 4 次 setState 简单归类,前两次属于一类,因为他们在同一次调用栈中执行;setTimeout 中的两次 setState 属于另一类,原因同上。让我们分别看看这两类 setState 的调用栈:
图 5-1 componentDidMount 里的 setState 调用栈
图 5-2 setTimeout 里的 setState 调用栈
很明显,在 componentDidMount 中直接调用的两次 setState,其调用栈更加复杂;而 setTimeout 中调用的两次 setState,调用栈则简单很多。让我们重点看看第一类 setState 的调用栈,有没有发现什么熟悉的身影?没错,就是batchedUpdates 方法,原来早在 setState 调用前,已经处于 batchedUpdates 执行的 transaction 中!
那这次 batchedUpdate 方法,又是谁调用的呢?让我们往前再追溯一层,原来是 ReactMount.js 中的**_renderNewRootComponent** 方法。也就是说,整个将 React 组件渲染到 DOM 中的过程就处于一个大的 Transaction 中。
接下来的解释就顺理成章了,因为在 componentDidMount 中调用 setState 时,batchingStrategy 的 isBatchingUpdates 已经被设为 true,所以两次 setState 的结果并没有立即生效,而是被放进了 dirtyComponents 中。这也解释了两次打印this.state.val 都是 0 的原因,新的 state 还没有被应用到组件中。
再反观 setTimeout 中的两次 setState,因为没有前置的 batchedUpdate 调用,所以 batchingStrategy 的 isBatchingUpdates 标志位是 false,也就导致了新的 state 马上生效,没有走到 dirtyComponents 分支。也就是,setTimeout 中第一次 setState 时,this.state.val 为 1,而 setState 完成后打印时 this.state.val 变成了 2。第二次 setState 同理。
在上文介绍 Transaction 时也提到了其在 React 源码中的多处应用,想必调试过 React 源码的同学应该能经常见到它的身影,像 initialize、perform、close、closeAll、notifyAll 等方法出现在调用栈里时,都说明当前处于一个 Transaction 中。
既然事务那么有用,那我们可以用它吗?
答案是不能,但在 React 15.0 之前的版本中还是为开发者提供了 batchedUpdates 方法,它可以解决针对一开始例子中 setTimeout 里的两次 setState 导致 rendor 的情况:
import ReactDom, { unstable_batchedUpdates } from 'react-dom';
unstable_batchedUpdates(() => {
this.setState(val: this.state.val + 1);
this.setState(val: this.state.val + 1);
});在 React 15.0 之后的版本已经将 batchedUpdates 彻底移除了,所以,不再建议使用。
在React中, 如果是由React引发的事件处理(比如通过onClick引发的事件处理),调用setState不会同步更新this.state,除此之外的setState调用会同步执行this.state 。所谓“除此之外”,指的是绕过React通过addEventListener直接添加的事件处理函数,还有通过setTimeout/setInterval产生的异步调用。
原因: 在React的setState函数实现中,会根据一个变量isBatchingUpdates判断是直接更新this.state还是放到队列中回头再说,而isBatchingUpdates默认是false,也就表示setState会同步更新this.state,但是,有一个函数batchedUpdates,这个函数会把isBatchingUpdates修改为true,而当React在调用事件处理函数之前就会调用这个batchedUpdates,造成的后果,就是由React控制的事件处理过程setState不会同步更新this.state 。
对于异步渲染,我们应在 getSnapshotBeforeUpdate 中读取 state、props, 而不是 componentWillUpdate。但调用forceUpdate() 强制 render 时,会导致组件跳过 shouldComponentUpdate(),直接调用 render()。
注意: setState的“异步”并不是说内部由异步代码实现,其实本身执行的过程和代码都是同步的,只是合成事件和钩子函数的调用顺序在更新之前,导致在合成事件和钩子函数中没法立马拿到更新后的值,形式了所谓的“异步”,当然可以通过第二个参数 setState(partialState, callback) 中的callback拿到更新后的结果。
本文是《深入React技术栈》解密setState读书笔记以及自己的一些补充理解
React.PureComponent ,和 React.Component 类似,都是定义一个组件类。不同是 React.Component 没有实现 shouldComponentUpdate(),而 React.PureComponent 通过 props 和 state 的浅比较实现了。
// React.PureComponent 纯组件
class Counter extends React.PureComponent {
constructor(props) {
super(props);
this.state = {count: 0};
}
render() {
return (
<button onClick={() => this.setState(state => ({count: state.count + 1}))}>
Count: {this.state.count}
</button>
);
}
}在下一节中将会详细介绍。
定义React组件的最简单方式就是定义一个函数组件,它接受单一的 props 并返回一个React元素。
// 函数组件
function Counter(props) {
return <div>Counter: {props.count}</div>
}
// 类组件
class Counter extends React.Component {
render() {
return <div>Counter: {this.props.count}</div>
}
}受控和非受控主要是取决于组件是否受父级传入的 props 控制
用 props 传入数据的话,组件可以被认为是受控(因为组件被父级传入的 props 控制)。
数据只保存在组件内部的 state 的话,是非受控组件(因为外部没办法直接控制 state)。
export default class AnForm extends React.Component {
state = {
name: ""
}
handleSubmitClick = () => {
console.log("非受控组件: ", this._name.value);
console.log("受控组件: ", this.state.name);
}
handleChange = (e) => {
this.setState({
name: e.target.value
})
}
render() {
return (
<form onSubmit={this.handleSubmitClick}>
<label>
非受控组件:
<input
type="text"
defaultValue="default"
ref={input => this._name = input}
/>
</label>
<label>
受控组件:
<input
type="text"
value={this.state.name}
onChange={this.handleChange}
/>
</label>
<input type="submit" value="Submit" />
</form>
);
}
}与 html 不同的是,在 React 中,<input>或<select>、<textarea> 等这类组件,不会主动维持自身状态,并根据用户输入进行更新。它们都要绑定一个onChange事件;每当状态发生变化时,都要写入组件的 state 中,在 React 中被称为受控组件。
export default class AnForm extends React.Component {
constructor(props) {
super(props);
this.state = {value: ""};
this.handleChange = this.handleChange.bind(this);
}
handleChange(event) {
this.setState({value: event.target.value});
}
render() {
return <input
type="text"
value={this.state.value}
onChange={this.handleChange}
/>;
}
}onChange & value 模式(单选按钮和复选按钮对应的是 checked props)
react通过这种方式消除了组件的局部状态,使得应用的整个状态可控。
注意 <input type="file" />,它是一个非受控组件。
可以使用计算属性名将多个相似的操作组合成一个。
this.setState({
[name]: value
});非受控组件不再将数据保存在 state,而使用 refs,将真实数据保存在 DOM 中。
export default class AnForm extends Component {
handleSubmitClick = () => {
const name = this._name.value;
}
render() {
return (
<div>
<input type="text" ref={input => this._name = input} />
<button onClick={this.handleSubmitClick}>Sign up</button>
</div>
);
}
}非受控组件是最简单快速的实现方式,项目中出现极简的表单时,使用它,但受控组件才是是最权威的。
通常指定一个 defaultValue/defaultChecked 默认值来控制初始状态,不使用 value。
非受控组件相比于受控组件,更容易同时集成 React 和非 React 代码。
使用场景
| 特征 | 非受控组件 | 受控组件 |
|---|---|---|
| one-time value retrieval (e.g. on submit) | ✅ | ✅ |
| validating on submit | ✅ | ✅ |
| instant field validation | ❌ | ✅ |
| conditionally disabling submit button | ❌ | ✅ |
| enforcing input format | ❌ | ✅ |
| several inputs for one piece of data | ❌ | ✅ |
| dynamic inputs | ❌ | ✅ |
通过 state 管理状态
export default class Counter extends React.Component {
constructor(props) {
super(props)
this.state = { clicks: 0 }
this.handleClick = this.handleClick.bind(this)
}
handleClick() {
this.setState(state => ({ clicks: state.clicks + 1 }))
}
render() {
return (
<Button
onClick={this.handleClick}
text={`You've clicked me ${this.state.clicks} times!`}
/>
)
}
}输入输出数据完全由props决定,而且不会产生任何副作用。
const Button = props =>
<button onClick={props.onClick}>
{props.text}
</button>展示组件指不关心数据是怎么加载和变动的,只关注于页面展示效果的组件。
class TodoList extends React.Component{
constructor(props){
super(props);
}
render(){
const {todos} = this.props;
return (<div>
<ul>
{todos.map((item,index)=>{
return <li key={item.id}>{item.name}</li>
})}
</ul>
</div>)
}
}容器组件只关心数据是怎么加载和变动的,而不关注于页面展示效果。
//容器组件
class TodoListContainer extends React.Component{
constructor(props){
super(props);
this.state = {
todos:[]
}
this.fetchData = this.fetchData.bind(this);
}
componentDidMount(){
this.fetchData();
}
fetchData(){
fetch('/api/todos').then(data =>{
this.setState({
todos:data
})
})
}
render(){
return (<div>
<TodoList todos={this.state.todos} />
</div>)
}
}高阶函数的定义:接收函数作为输入,或者输出另一个函数的一类函数,被称作高阶函数。
对于高阶组件,它描述的便是接受 React 组件作为输入,输出一个新的 React 组件的组件。
更通俗的描述为,高阶组件通过包裹(wrapped)被传入的 React 组件,经过一系列处理,最终返回一个相对增强(enhanced)的 React 组件,供其他组件调用。使我们的代码更具有复用性、逻辑性和抽象特性,它可以对 render 方法做劫持,也可以控制 props 、state。
实现高阶组件的方法有以下两种:
// 属性代理
export default function withHeader(WrappedComponent) {
return class HOC extends React.Component { // 继承与 React.component
render() {
const newProps = {
test:'hoc'
}
// 透传props,并且传递新的newProps
return <div>
<WrappedComponent {...this.props} {...newProps}/>
</div>
}
}
}
// 反向继承
export default function (WrappedComponent) {
return class Inheritance extends WrappedComponent { // 继承于被包裹的 React 组件
componentDidMount() {
// 可以方便地得到state,做一些更深入的修改。
console.log(this.state);
}
render() {
return super.render();
}
}
}WrappedComponent.displayName || WrappedComponent.name || 'Component';Hook 是 React 16.8 的新增特性。它可以让你在不编写 class 的情况下使用 state 以及其他的 React 特性。
但与 class 生命周期不同的是,Hook 更接近于实现状态同步,而不是响应生命周期事件。
import React, { useState, useEffect } from 'react';
function Example() {
// 声明一个叫 "count" 的 state 变量
const [count, setCount] = useState(0);
useEffect(()=>{
// 需要在 componentDidMount 执行的内容
return function cleanup() {
// 需要在 componentWillUnmount 执行的内容
}
}, [])
useEffect(() => {
// 在 componentDidMount,以及 count 更改时 componentDidUpdate 执行的内容
document.title = 'You clicked ' + count + ' times';
return () => {
// 需要在 count 更改时 componentDidUpdate(先于 document.title = ... 执行,遵守先清理后更新)
// 以及 componentWillUnmount 执行的内容
} // 当函数中 Cleanup 函数会按照在代码中定义的顺序先后执行,与函数本身的特性无关
}, [count]); // 仅在 count 更改时更新
return (
<div>
<p>You clicked {count} times</p>
<button onClick={() => setCount(count + 1)}>
Click me
</button>
</div>
);
}useLayoutEffect 与 componentDidMount、componentDidUpdate 的调用阶段是一样的。但是,我们推荐你一开始先用 useEffect,只有当它出问题的时候再尝试使用 useLayoutEffectcomponentDidMount 或 componentDidUpdate 不同的是,Hook 在浏览器完成布局与绘制之后,传给 useEffect 的函数会延迟调用,但会保证在任何新的渲染前执行useEffect 的思维模型中,默认都是同步的。副作用变成了 React 数据流的一部分。对于每一个 useEffect 调用,一旦你处理正确,你的组件能够更好地处理边缘情况。首先看一下 React.Component 结构
// ReactBaseClasses.js 文件
/**
* Base class helpers for the updating state of a component.
*/
function Component(props, context, updater) {
this.props = props; // 属性 props
this.context = context; // 上下文 context
// If a component has string refs, we will assign a different object later.
// 初始化 refs,为 {},主要在 stringRef 中使用,将 stringRef 节点的实例挂载在 this.refs 上
this.refs = emptyObject;
// We initialize the default updater but the real one gets injected by the
// renderer.
this.updater = updater || ReactNoopUpdateQueue; // updater
}
Component.prototype.isReactComponent = {};
/**
* 设置 state 的子集,使用该方法更新 state,避免 state 的值为可突变的状态
* `shouldComponentUpdate`只是浅比较更新,
* 可突变的类型可能导致 `shouldComponentUpdate` 返回 false,无法重新渲染
* Immutable.js 可以解决这个问题。它通过结构共享提供不可突变的,持久的集合:
* 不可突变: 一旦创建,集合就不能在另一个时间点改变。
* 持久性: 可以使用原始集合和一个突变来创建新的集合。原始集合在新集合创建后仍然可用。
* 结构共享: 新集合尽可能多的使用原始集合的结构来创建,以便将复制操作降至最少从而提升性能。
*
* 并不能保证 `this.state` 通过 `setState` 后不可突变的更新,它可能还返回原来的数值
* 不能保证 `setrState` 会同步更新 `this.state`
* `setState` 是通过队列形式来更新 state ,当 执行 `setState` 时,
* 会把 state 浅合并后放入状态队列,然后批量执行,即它不是立即更新的。
* 不过,你可以在 callback 回调函数中获取最新的值
*
* 注意:对于异步渲染,我们应在 `getSnapshotBeforeUpdate` 中读取 `state`、`props`,
* 而不是 `componentWillUpdate`
*
* @param {object|function} partialState Next partial state or function to
* produce next partial state to be merged with current state.
* @param {?function} callback Called after state is updated.
* @final
* @protected
*/
Component.prototype.setState = function(partialState, callback) {
// 当 partialState 状态为 object 或 function类型 或 null 时,
// 执行 this.updater.enqueueSetState 方法,否则报错
invariant(
typeof partialState === 'object' ||
typeof partialState === 'function' ||
partialState == null,
'setState(...): takes an object of state variables to update or a ' +
'function which returns an object of state variables.',
);
// 将 `setState` 事务放入队列中
this.updater.enqueueSetState(this, partialState, callback, 'setState');
};
/**
* 强制更新,当且仅当当前不处于 DOM 事物(transaction)中才会被唤起
* This should only be invoked when it is known with
* certainty that we are **not** in a DOM transaction.
*
* 默认情况下,当组件的state或props改变时,组件将重新渲染。
* 如果你的`render()`方法依赖于一些其他的数据,
* 你可以告诉React组件需要通过调用`forceUpdate()`重新渲染。
* 调用`forceUpdate()`会导致组件跳过 `shouldComponentUpdate()`,
* 直接调用 `render()`。但会调用 `componentWillUpdate` 和 `componentDidUpdate`。
* 这将触发组件的正常生命周期方法,包括每个子组件的 shouldComponentUpdate() 方法。
* forceUpdate 就是重新 render 。
* 有些变量不在 state 上,当时你又想达到这个变量更新的时候,刷新 render ;
* 或者 state 里的某个变量层次太深,更新的时候没有自动触发 render 。
* 这些时候都可以手动调用 forceUpdate 自动触发 render
*
* @param {?function} callback 更新完成后的回调函数.
* @final
* @protected
*/
Component.prototype.forceUpdate = function(callback) {
// updater 强制更新
this.updater.enqueueForceUpdate(this, callback, 'forceUpdate');
};其中 this.refs 值 emptyObject 为:
// 设置 refs 初始值为 {}
const emptyObject = {};
if (__DEV__) {
Object.freeze(emptyObject); // __DEV__ 模式下, 冻结 emptyObject
}
// Object.freeze() 冻结一个对象,被冻结的对象不能被修改(添加,删除,
// 修改已有属性的可枚举性、可配置性、可写性与属性值,原型);返回和传入的参数相同的对象。ReactNoopUpdateQueue 为:
// ReactNoopUpdateQueue.js 文件
/**
* 这是一个关于 更新队列(update queue) 的抽象 API
*/
const ReactNoopUpdateQueue = {
/**
* 检查复合组件是否装载完成(被插入树中)
* @param {ReactClass} publicInstance 测试实例单元
* @return {boolean} 装载完成为 true,否则为 false
* @protected
* @final
*/
isMounted: function(publicInstance) {
return false;
},
/**
* 强制更新队列,当且仅当当前不处于 DOM 事物(transaction)中才会被唤起
*
* 当 state 里的某个变量层次太深,更新的时候没有自动触发 render 。
* 这些时候就可以调用该方法强制更新队列
*
* 该方法将跳过 `shouldComponentUpdate()`, 直接调用 `render()`, 但它会唤起
* `componentWillUpdate` 和 `componentDidUpdate`.
*
* @param {ReactClass} publicInstance 将被重新渲染的实例
* @param {?function} callback 组件更新后的回调函数.
* @param {?string} callerName 在公共 API 调用该方法的函数名称.
* @internal
*/
enqueueForceUpdate: function(publicInstance, callback, callerName) {
warnNoop(publicInstance, 'forceUpdate');
},
/**
* 完全替换state,与 `setState` 不同的是,`setState` 是以修改和新增的方式改变 `state `的,
* 不会改变没有涉及到的 `state`。
* 而 `enqueueReplaceState` 则用新的 `state` 完全替换掉老 `state`
* 使用它或 `setState` 来改变 state,并且应该把 this.state 设置为不可突变类型对象,
* 并且this.state不会立即更改
* 我们应该在回调函数 callback 中获取最新的 state
*
* @param {ReactClass} publicInstance The instance that should rerender.
* @param {object} completeState Next state.
* @param {?function} callback Called after component is updated.
* @param {?string} callerName name of the calling function in the public API.
* @internal
*/
enqueueReplaceState: function(
publicInstance,
completeState,
callback,
callerName,
) {
warnNoop(publicInstance, 'replaceState');
},
/**
* 设置 state 的子集
* 它存在的唯一理由是 _pendingState 是内部方法。
* `enqueueSetState` 实现浅合并更新 `state`
*
* @param {ReactClass} publicInstance The instance that should rerender.
* @param {object} partialState Next partial state to be merged with state.
* @param {?function} callback Called after component is updated.
* @param {?string} Name of the calling function in the public API.
* @internal
*/
enqueueSetState: function(
publicInstance,
partialState,
callback,
callerName,
) {
warnNoop(publicInstance, 'setState');
},
};
export default ReactNoopUpdateQueue;注意,React API 只是简单的功能介绍,具体的实现是在 react-dom 中,这是因为不同的平台,React API 是一致的,但不同的平台,渲染的流程是不同的,具体的 Component 渲染流程不一致,会根据具体的平台去定制。
组件生命周期请参考 Hooks 与 React 生命周期的关系
JS 系列暂定 27 篇,从基础,到原型,到异步,到设计模式,到架构模式等,
本篇是 JS 系列中最重要的一章,花费 3 分钟即可理解,如果你已了解,快速浏览即可。
本篇文章主讲构造函数、原型以及原型链,包括 Symbol 是不是构造函数、constructor 属性是否只读、prototype 、__proto__ 、[[Prototype]] 、原型链。
在JS中,万物皆对象,对象又分为普通对象和函数对象,其中 Object、Function 为 JS 自带的函数对象。
let obj1 = {};
let obj2 = new Object();
let obj3 = new fun1()
function fun1(){};
let fun2 = function(){};
let fun3 = new Function('some','console.log(some)');
// JS自带的函数对象
console.log(typeof Object); //function
console.log(typeof Function); //function
// 普通对象
console.log(typeof obj1); //object
console.log(typeof obj2); //object
console.log(typeof obj3); //object
// 函数对象
console.log(typeof fun1); //function
console.log(typeof fun2); //function
console.log(typeof fun3); //function 凡是通过 new Function() 创建的对象都是函数对象,其他的都是普通对象,Function Object 是通过 New Function() 创建的。
function Foo(name, age) {
// this 指向 Foo
this.name = name
this.age = age
this.class = 'class'
// return this // 默认有这一行
}
// Foo 的实例
let f = new Foo('aa', 20)每个实例都有一个 constructor(构造函数)属性,该属性指向对象本身。
f.constructor === Foo // true构造函数本身就是一个函数,与普通函数没有任何区别,不过为了规范一般将其首字母大写。构造函数和普通函数的区别在于,使用 new 生成实例的函数就是构造函数,直接调用的就是普通函数。
JS 本身不提供一个 class 实现。(在 ES2015/ES6 中引入了 class 关键字,但只是语法糖,JavaScript 仍然是基于原型的)。
let a = {} 其实是 let a = new Object() 的语法糖let a = [] 其实是 let a = new Array() 的语法糖function Foo(){ ... } 其实是 var Foo = new Function(...)instanceof 判断一个函数是否为一个变量的构造函数Symbol 是基本数据类型,它并不是构造函数,因为它不支持 new Symbol() 语法。我们直接使用Symbol() 即可。
let an = Symbol("An");
let an1 = new Symbol("An");
// Uncaught TypeError: Symbol is not a constructor但是,Symbol() 可以获取到它的 constructor 属性
Symbol("An").constructor;
// ƒ Symbol() { [native code] }这个 constructor 实际上是 Symbol 原型上的,即
Symbol.prototype.constructor;
// ƒ Symbol() { [native code] }对于 Symbol,你还需要了解以下知识点:
Symbol() 返回的 symbol 值是唯一的Symbol("An") === Symbol("An");
// falseSymbol.for(key) 获取全局唯一的 symbolSymbol.for('An') === Symbol.for("An"); // true它从运行时的 symbol 注册表中找到对应的 symbol,如果找到了,则返回它,否则,新建一个与该键关联的 symbol,并放入全局 symbol 注册表中。
// 实现可迭代协议,使迭代器可迭代:Symbol.iterator
function createIterator(items) {
let i = 0
return {
next: function () {
let done = (i >= items.length)
let value = !done ? items[i++] : undefined
return {
done: done,
value: value
}
},
[Symbol.iterator]: function () {
return this
}
}
}
const iterator = createIterator([1, 2, 3]);
[...iterator]; // [1, 2, 3]// Symbol.toPrimitive 来实现拆箱操作(ES6 之后)
let obj = {
valueOf: () => {console.log("valueOf"); return {}},
toString: () => {console.log("toString"); return {}}
}
obj[Symbol.toPrimitive] = () => {console.log("toPrimitive"); return "hello"}
console.log(obj + "")
// toPrimitive
// hello// Symbol.toStringTag 代替 [[class]] 属性(ES5开始)
let o = { [Symbol.toStringTag]: "MyObject" }
console.log(o + "");
// [object MyObject]对于引用类型来说 constructor 属性值是可以修改的,但是对于基本类型来说是只读的。
function An() {
this.value = "An";
};
function Anran() {};
Anran.prototype.constructor = An;
// 原型链继承中,对 constructor 重新赋值
let anran = new Anran();
// 创建 Anran 的一个新实例
console.log(anran);
这说明,依赖一个引用对象的 constructor 属性,并不是安全的。
function An() {};
let an = 1;
an.constructor = An;
console.log(an.constructor);
// ƒ Number() { [native code] }这是因为:原生构造函数(native constructors)是只读的。
JS 对于不可写的属性值的修改静默失败(silently failed),但只会在严格模式下才会提示错误。
'use strict';
function An() {};
let an = 1;
an.constructor = An;
console.log(an.constructor); 
注意:null 和 undefined 是没有 constructor 属性的。
首先,贴上
图片来自于http://www.mollypages.org/tutorials/js.mp,请根据下文仔细理解这张图
在JS中,每个对象都有自己的原型。当我们访问对象的属性和方法时,JS 会先访问对象本身的方法和属性。如果对象本身不包含这些属性和方法,则访问对象对应的原型。
// 构造函数
function Foo(name) {
this.name = name
}
Foo.prototype.alertName = function() {
alert(this.name)
}
// 创建实例
let f = new Foo('some')
f.printName = function () {
console.log(this.name)
}
// 测试
f.printName()// 对象的方法
f.alertName()// 原型的方法所有函数都有一个 prototype (显式原型)属性,属性值也是一个普通的对象。对象以其原型为模板,从原型继承方法和属性,这些属性和方法定义在对象的构造器函数的 prototype 属性上,而非对象实例本身。
但有一个例外: Function.prototype.bind(),它并没有 prototype 属性
let fun = Function.prototype.bind();
// ƒ () { [native code] }当我们创建一个函数时,例如
function Foo () {}
prototype 属性就被自动创建了
从上面这张图可以发现,Foo 对象有一个原型对象 Foo.prototype,其上有两个属性,分别是 constructor 和 __proto__,其中 __proto__ 已被弃用。
构造函数 Foo 有一个指向原型的指针,原型 Foo.prototype 有一个指向构造函数的指针 Foo.prototype.constructor,这就是一个循环引用,即:
Foo.prototype.constructor === Foo; // true
__proto__每个实例对象(object )都有一个隐式原型属性(称之为 __proto__ )指向了创建该对象的构造函数的原型。也就时指向了函数的 prototype 属性。
function Foo () {}
let foo = new Foo()
当 new Foo() 时,__proto__ 被自动创建。并且
foo.__proto__ === Foo.prototype; // true即:

__proto__ 发音 dunder proto,最先被 Firefox使用,后来在 ES6 被列为 Javascript 的标准内建属性。
[[Prototype]] 是对象的一个内部属性,外部代码无法直接访问。
遵循 ECMAScript 标准,someObject.[[Prototype]] 符号用于指向 someObject 的原型
__proto__ 属性在 ES6 时才被标准化,以确保 Web 浏览器的兼容性,但是不推荐使用,除了标准化的原因之外还有性能问题。为了更好的支持,推荐使用 Object.getPrototypeOf()。
通过现代浏览器的操作属性的便利性,可以改变一个对象的
[[Prototype]]属性, 这种行为在每一个JavaScript引擎和浏览器中都是一个非常慢且影响性能的操作,使用这种方式来改变和继承属性是对性能影响非常严重的,并且性能消耗的时间也不是简单的花费在obj.__proto__ = ...语句上, 它还会影响到所有继承来自该[[Prototype]]的对象,如果你关心性能,你就不应该在一个对象中修改它的 [[Prototype]]。相反, 创建一个新的且可以继承[[Prototype]]的对象,推荐使用Object.create()。
如果要读取或修改对象的 [[Prototype]] 属性,建议使用如下方案,但是此时设置对象的 [[Prototype]] 依旧是一个缓慢的操作,如果性能是一个问题,就要避免这种操作。
// 获取(两者一致)
Object.getPrototypeOf()
Reflect.getPrototypeOf()
// 修改(两者一致)
Object.setPrototypeOf()
Reflect.setPrototypeOf()如果要创建一个新对象,同时继承另一个对象的 [[Prototype]] ,推荐使用 Object.create()。
function An() {};
var an = new An();
var anran = Object.create(an);这里 anran 是一个新的空对象,有一个指向对象 an 的指针 __proto__。
新生成了一个对象
链接到原型
绑定 this
返回新对象
function new_object() {
// 创建一个空的对象
let obj = new Object()
// 获得构造函数
let Con = [].shift.call(arguments)
// 链接到原型 (不推荐使用)
obj.__proto__ = Con.prototype
// 绑定 this,执行构造函数
let result = Con.apply(obj, arguments)
// 确保 new 出来的是个对象
return typeof result === 'object' ? result : obj
}// 优化后 new 实现
function create() {
// 1、获得构造函数,同时删除 arguments 中第一个参数
Con = [].shift.call(arguments);
// 2、创建一个空的对象并链接到原型,obj 可以访问构造函数原型中的属性
let obj = Object.create(Con.prototype);
// 3、绑定 this 实现继承,obj 可以访问到构造函数中的属性
let ret = Con.apply(obj, arguments);
// 4、优先返回构造函数返回的对象
return ret instanceof Object ? ret : obj;
};__proto__ 属性,属性值是一个普通的对象,该原型对象也有一个自己的原型对象(__proto__) ,层层向上直到一个对象的原型对象为 null。根据定义,null 没有原型,并作为这个原型链 中的最后一个环节。__proto__ (即它的构造函数的 prototype )中寻找。每个对象拥有一个原型对象,通过 __proto__ 指针指向上一个原型 ,并从中继承方法和属性,同时原型对象也可能拥有原型,这样一层一层,最终指向 null,这种关系被称为原型链(prototype chain)。根据定义,null 没有原型,并作为这个原型链中的最后一个环节。
原型链的基本**是利用原型,让一个引用类型继承另一个引用类型的属性及方法。
// 构造函数
function Foo(name) {
this.name = name
}
// 创建实例
let f = new Foo('some')
// 测试
f.toString()
// f.__proto__.__proto__中寻找f.__proto__=== Foo.prototype,Foo.prototype 也是一个对象,也有自己的__proto__ 指向 Object.prototype, 找到toString()方法。
也就是
Function.__proto__.__proto__ === Object.prototype
下面是原型链继承的例子
function Elem(id) {
this.elem = document.getElementById(id)
}
Elem.prototype.html = function(val) {
let elem = this.elem
if (val) {
elem.innerHtml = val
return this // 链式操作
} else {
return elem.innerHtml
}
}
Elem.prototype.on = function( type, fn) {
let elem = this.elem
elem.addEventListener(type, fn)
}
let div1 = new Elem('div1')
// console.log(div1.html())
div1.html('<p>hello</p>').on('click', function() {
alert('clicked')
})// 链式操作Symbol 是基本数据类型,并不是构造函数,因为它不支持语法 new Symbol(),但其原型上拥有 constructor 属性,即 Symbol.prototype.constructor。constructor 是可以修改的,但对于基本类型来说它是只读的, null 和 undefined 没有 constructor 属性。__proto__ 是每个实例对象都有的属性,prototype 是其构造函数的属性,在实例上并不存在,所以这两个并不一样,但 foo.__proto__ 和 Foo.prototype 指向同一个对象。__proto__ 属性在 ES6 时被标准化,但因为性能问题并不推荐使用,推荐使用 Object.getPrototypeOf()。__proto__ 指针指向上一个原型 ,并从中继承方法和属性,同时原型对象也可能拥有原型,这样一层一层向上,最终指向 null,这就是原型链。null)暂时就这些,后续我将持续更新
{
"name": "hello world", // 项目名称
"version": "0.0.1", // 版本号:大版本.次要版本.小版本
"author": "张三",
"description": "第一个node.js程序",
"keywords":["node.js","javascript"], // 关键词,有助于 npm search 发现
"repository": { // 存储库,指定代码所在位置(如果git repo在GitHub上,那么该npm docs 命令将能够找到文件位置。)
"type": "git",
"url": "https://path/to/url"
},
"license":"MIT", // 指定包许可证,详细可见[SPDX许可证ID的完整列表](https://spdx.org/licenses/)
"engines": {"node": "0.10.x"}, // 指定该模块运行的平台,可以指定 node 版本、npm 版本等
"bugs":{"url":"http://path/to/bug","email":"[email protected]"}, // 项目问题跟踪器的URL和应报告问题的电子邮件地址。
"contributors":[{"name":"李四","email":"[email protected]"}],
"bin": { // 指定内部命令对应的可执行文件的位置,在 scripts 中就可以简写
"webpack": "./bin/webpack.js"
},
"main": "lib/webpack.js", // 指定加载的模块入口文件,require('moduleName')就会加载这个文件。这个字段的默认值是模块根目录下面的index.js。
"config" : { "port" : "8080" }, // 用于添加命令行的环境变量(用户在运行 scripts 命令时,就默认在脚本文件中添加 process.env.npm_package_config_port,用户可以通过 npm config set foo:port 80 命令更改这个值)
"scripts": { // 指定运行脚本的 npm 命令行缩写
"start": "node index.js"
},
"peerDependencies": { // 指定项目安装必须一起安装的模块及其版本号,(注意:从 npm 3.0 开始,peerDependencies不会再默认安装)
"chai": "1.x"
},
"dependencies": { // 指定项目运行所依赖的模块
"express": "latest",
"mongoose": "~3.8.3",
"handlebars-runtime": "~1.0.12",
"express3-handlebars": "~0.5.0",
"MD5": "~1.2.0"
},
"devDependencies": { // 指定项目开发所需要的模块
"bower": "~1.2.8",
"grunt": "~0.4.1",
"grunt-contrib-concat": "~0.3.0",
"grunt-contrib-jshint": "~0.7.2",
"grunt-contrib-uglify": "~0.2.7",
"grunt-contrib-clean": "~0.5.0",
"browserify": "2.36.1",
"grunt-browserify": "~1.3.0",
},
"browser": { // 指定该模板供浏览器使用的版本
"tipso": "./node_modules/tipso/src/tipso.js"
},
"preferGlobal": true, // 表示当用户不将该模块安装为全局模块时(即不用–global参数),要不要显示警告,表示该模块的本意就是安装为全局模块。
}package.json 在 node 和 npm 环节都要使用,node 在调用 require 的时候去查找模块,会按照一个次序去查找,package.json 会是查找中的一个环节。npm 用的就比较多,其中的 dependencies 字段就是本模块的依赖的模块清单。每次npm update的时候,npm会自动的把依赖到的模块也下载下来。当npm install 本模块的时候,会把这里提到的模块都一起下载下来。通过package.json,就可以管理好模块的依赖关系。
关于更多规范,请看官方npm-package.json
- 指定版本:比如
1.2.2,遵循“大版本.次要版本.小版本”的格式规定,安装时只安装指定版本。- 波浪号(tilde)+指定版本:比如
~1.2.2,表示安装1.2.x的最新版本(不低于1.2.2),但是不安装1.3.x,也就是说安装时不改变大版本号和次要版本号。- 插入号(caret)+指定版本:比如ˆ1.2.2,表示安装1.x.x的最新版本(不低于1.2.2),但是不安装2.x.x,也就是说安装时不改变大版本号。需要注意的是,如果大版本号为0,则插入号的行为与波浪号相同,这是因为此时处于开发阶段,即使是次要版本号变动,也可能带来程序的不兼容。
- latest:安装最新版本。
node_modules 已安装,再次执行 install 不会更新包版本, 执行 update 才会更新; 而如果本地 node_modules 为空时,执行 install/update 都会直接安装更新包;npm update 总是会把包更新到符合 package.json 中指定的 semver(语义化版本) 的最新版本号——本例中符合 ^1.8.0 的最新版本为 1.15.0package.json, 无论后面执行 npm install 还是 update, package.json 中的 webpack 版本一直顽固地保持 一开始的 ^1.8.0 岿然不动实际使用的区别点主要如下:
npm i安装的模块无法用npm uninstall删除,用npm un才卸载掉npm i会帮助检测与当前 node 版本最匹配的 npm 包版本号,并匹配出来相互依赖的 npm 包应该提升的版本号npm-debug.log 文件,npm i不一定--save-dev
或
—save
首先需要说明的是 Dependencies一词的中文意思是依赖和附属的意思,而dev则是 develop(开发)的简写。
所以它们的区别在 package.json 文件里面体现出来的就是,使用 --save-dev 安装的 插件,被写入到 devDependencies 域里面去,而使用 —save 安装的插件,则是被写入到 dependencies 区块里面去。
那 package.json 文件里面的 devDependencies 和 dependencies 对象有什么区别呢?
devDependencies 里面的插件只用于开发环境,不用于生产环境,而 dependencies 是需要发布到生产环境的。
比如我们写一个项目要依赖于jQuery,没有这个包的依赖运行就会报错,这时候就把这个依赖写入dependencies
通过 -g 来安装的包,将包安装成全局可用的可执行命令。
// 全局安装 babel-cli
babel app.js// 本地安装 babel-cli
node_modules/.bin/babel app.js设置自定义的全局安装路径
npm config set prefix "/usr/local/npm" // 自定义的全局安装路径
npm config set cache "/usr/local/npm" // 自定义的全局安装路径设置环境变量
切到 ~/.bash_profile 文件中配置路径:
GNPM_PATH=/usr/local/npm
export GNPM_PATH
export PATH=$PATH:$GNPM_PATH/bin // 将 /usr/local/npm/bin 追加到 PATH 变量中
export NODE_PATH=$PATH:$GNPM_PATH/lib/node_modules // 指定 NODE_PATH 变量操作系统中都会有一个PATH环境变量,想必大家都知道,当系统调用一个命令的时候,就会在PATH变量中注册的路径中寻找,如果注册的路径中有就调用,否则就提示命令没找到。
而 NODE_PATH 就是NODE中用来 寻找模块所提供的路径注册环境变量 。我们可以使用上面的方法指定NODE_PATH 环境变量。
使用 npm config list 查看配置
npm list -g --depth 0 // 查看全局安装过的包 -g:全局的安装包 list:已安装的node包 –depth 0:深度0
npm view <packageName> // 查看npm服务器中包版本号
npm info <packageName> // npm服务器更多信息,更多版本号
npm ls <packageName> // 本地包
npm ls <packageName> -g // 全局安装包
npm docs // 打开包git目录
// 注意:npm build 与 npm start 是项目中常用的命令,注意它们有什么不同
npm start [--<args>] // 在 package.json 文件中定义的 "scripts" 对象中查找 "start" 属性,执行该属性定义的命令,如果没有定义,默认执行 node server.js 命令
npm build [<package-folder>] // 其中,<package-folder> 为其根目录中包含一个 package.json 文件的文件夹,这是由 npm link 命令和 npm install 命令组成的管道命令,通常在安装过程中被调用。如果想要直接运行它,则运行 npm run build还有其他的 钩子命令,具体项目中我还没用到,你可以自行了解。
package.json 中 scripts 常用命令:
// 删除目录
"clean": "rimraf dist/*",
// 本地搭建一个 HTTP 服务
"serve": "http-server -p 9090 dist/",
// 打开浏览器
"open:dev": "opener http://localhost:9090",
// 实时刷新
"livereload": "live-reload --port 9091 dist/",
// 构建 HTML 文件
"build:html": "jade index.jade > dist/index.html",
// 只要 CSS 文件有变动,就重新执行构建
"watch:css": "watch 'npm run build:css' assets/styles/",
// 只要 HTML 文件有变动,就重新执行构建
"watch:html": "watch 'npm run build:html' assets/html",
// 部署到 Amazon S3
"deploy:prod": "s3-cli sync ./dist/ s3://example-com/prod-site/",
// 构建 favicon
"build:favicon": "node scripts/favicon.js",npm start // 是 npm run start 的简写
npm stop // 是 npm run stop 的简写
npm test // 是 npm run test 的简写
npm restart // 是 npm run stop && npm run restart && npm run start 的简写我们可以通过环境变量process.env对象,拿到 npm 所有的配置变量。其中 npm 脚本可以通过npm_config_前缀,拿到 npm 的配置变量。通过npm_package_前缀,拿到package.json里面的字段。
console.log(process.env.npm_package_name); // chejianer
console.log(process.env.npm_package_version); // 1.0.0
console.log(process.env); // ... 对于 全局模式安装的包(通过 -g 来安装的包,将包安装成全局可用的可执行命令,并不意味着任何地方都可以通过 require() 来引用它):它会通过 bin 字段配置,将实际脚本链接到 Node 可执行目录下,例如
"bin": {
"webpack": "./bin/webpack.js"
},通过全局安装的包都安装到一个统一的目录下,可以通过以下方式获得:
path.resolve(process.execPath, "..", "..", "lib", "node_modules")
// 例如:/usr/local/lib/node_modules// lib/index.js
exports.sayHello = function () {
return "Hello An!";
};npm initpackage name: (module) hello-an
version: (1.0.0) 0.1.0
description: a hello-an package
entry point: (hello.js)
test command:
git repository:
keywords: hello an
author: sisterAn
license: (ISC) MIT
About to write to /Users/lianran777/Study/node/chejianer_node/module/package.json:
{
"name": "hello-an",
"version": "1.0.0",
"description": "a hello-an package",
"main": "hello.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [
"hello",
"an"
],
"author": "sisterAn",
"license": "MIT"
}
Is this OK? (yes) npm addusernpm publish . // package.json 所在目录在这个过程中,npm 会将目录打包成一个存档文件,然后上传到官方源仓库中
npm owner add <user> [<@scope>/]<pkg>
npm owner rm <user> [<@scope>/]<pkg>
npm owner ls [<@scope>/]<pkg>在自己的项目中安装包 npm install,通过 npm ls 分析模块路径找到的所有包,并生成依赖树。
JS 系列暂定 27 篇,从基础,到原型,到异步,到设计模式,到架构模式等,此为第一篇:是对 var、let、const、解构、展开、函数 的总结。
let在很多方面与 var 是相似的,但是 let 可以帮助大家避免在 JavaScript 里常见一些问题。const 是对 let 的一个增强,它能阻止对一个变量再次赋值。
var 声明一直以来我们都是通过 var 关键字定义 JavaScript 变量。
var num = 1;定义了一个名为 num 值为 1 的变量。
我们也可以在函数内部定义变量:
function f() {
var message = "Hello, An!";
return message;
}并且我们也可以在其它函数内部访问相同的变量。
function f() {
var num = 10;
return function g() {
var b = num + 1;
return b;
}
}
var g = f();
g(); // 11;上面的例子里,g 可以获取到 f 函数里定义的 num 变量。 每当 g 被调用时,它都可以访问到 f 里的 num 变量。 即使当 g 在 f 已经执行完后才被调用,它仍然可以访问及修改 num 。
function f() {
var num = 1;
num = 2;
var b = g();
num = 3;
return b;
function g() {
return num;
}
}
f(); // 2对于熟悉其它语言的人来说,var 声明有些奇怪的作用域规则。 看下面的例子:
function f(init) {
if (init) {
var x = 10;
}
return x;
}
f(true); // 10
f(false); // undefined在这个例子中,变量 x 是定义在 if 语句里面,但是我们却可以在语句的外面访问它。
这是因为 var 声明可以在包含它的函数,模块,命名空间或全局作用域内部任何位置被访问,包含它的代码块对此没有什么影响。 有些人称此为 var 作用域或函数作用域 。 函数参数也使用函数作用域。
这些作用域规则可能会引发一些错误。 其中之一就是,多次声明同一个变量并不会报错:
function sumArr(arrList) {
var sum = 0;
for (var i = 0; i < arrList.length; i++) {
var arr = arrList[i];
for (var i = 0; i < arr.length; i++) {
sum += arr[i];
}
}
return sum;
}这里很容易看出一些问题,里层的 for 循环会覆盖变量 i,因为所有 i 都引用相同的函数作用域内的变量。 有经验的开发者们很清楚,这些问题可能在代码审查时漏掉,引发无穷的麻烦。
快速的思考一下下面的代码会返回什么:
for (var i = 0; i < 10; i++) {
setTimeout(function() { console.log(i); }, 100 * i);
}介绍一下,setTimeout 会在若干毫秒的延时后执行一个函数(等待其它代码执行完毕)。
好吧,看一下结果:
10
10
10
10
10
10
10
10
10
10很多 JavaScript 程序员对这种行为已经很熟悉了,但如果你很不解,你并不是一个人。 大多数人期望输出结果是这样:
0
1
2
3
4
5
6
7
8
9还记得我们上面提到的捕获变量吗?
我们传给
setTimeout的每一个函数表达式实际上都引用了相同作用域里的同一个i。
让我们花点时间思考一下这是为什么。 setTimeout 在若干毫秒后执行一个函数,并且是在 for 循环结束后。for 循环结束后,i 的值为 10。 所以当函数被调用的时候,它会打印出 10!
一个通常的解决方法是使用立即执行的函数表达式(IIFE)来捕获每次迭代时i的值:
for (var i = 0; i < 10; i++) {
(function(i) {
setTimeout(function() { console.log(i); }, 100 * i);
})(i);
}这种奇怪的形式我们已经司空见惯了。 参数 i 会覆盖 for 循环里的 i ,但是因为我们起了同样的名字,所以我们不用怎么改 for 循环体里的代码。
let 声明现在你已经知道了 var 存在一些问题,这恰好说明了为什么用 let 语句来声明变量。 除了名字不同外, let 与 var 的写法一致。
let hello = "Hello,An!";主要的区别不在语法上,而是语义,我们接下来会深入研究。
当用 let 声明一个变量,它使用的是词法作用域或块作用域。 不同于使用 var 声明的变量那样可以在包含它们的函数外访问,块作用域变量在包含它们的块或 for 循环之外是不能访问的。
function f(input) {
let a = 100;
if (input) {
// a 被正常引用
let b = a + 1;
return b;
}
return b;
}这里我们定义了2个变量 a 和 b 。 a 的作用域是 f 函数体内,而 b 的作用域是 if 语句块里。
在 catch 语句里声明的变量也具有同样的作用域规则。
try {
throw "oh no!";
}
catch (e) {
console.log("Oh well.");
}
// Error: 'e' doesn't exist here
console.log(e);拥有块级作用域的变量的另一个特点是,它们不能在被声明之前读或写。 虽然这些变量始终“存在”于它们的作用域里,但在直到声明它的代码之前的区域都属于 暂时性死区。 它只是用来说明我们不能在 let 语句之前访问它们:
a++;
// Uncaught ReferenceError: Cannot access 'a' before initialization
let a;注意一点,我们仍然可以在一个拥有块作用域变量被声明前获取它。 只是我们不能在变量声明前去调用那个函数。
function foo() {
return a;
}
// 不能在'a'被声明前调用'foo'
// 运行时应该抛出错误
foo();
// Uncaught ReferenceError: Cannot access 'a' before initialization
let a;关于暂时性死区的更多信息,查看这里Mozilla Developer Network.
我们提过使用 var 声明时,它不在乎你声明多少次;你只会得到1个。
function f(x) {
var x;
var x;
if (true) {
var x;
}
}在上面的例子里,所有 x 的声明实际上都引用一个相同的 x,并且这是完全有效的代码。 这经常会成为 bug 的来源。 好的是, let 声明就不会这么宽松了。
let x = 10;
let x = 20;
// Uncaught SyntaxError: Identifier 'x' has already been declared并不是要求两个均是块级作用域的声明才会给出一个错误的警告。
function f(x) {
let x = 100;
// Uncaught SyntaxError: Identifier 'x' has already been declared
}
function g() {
let x = 100;
var x = 100;
// Uncaught SyntaxError: Identifier 'x' has already been declared
}并不是说块级作用域变量不能用函数作用域变量来声明。 而是块级作用域变量需要在明显不同的块里声明。
function f(condition, x) {
if (condition) {
let x = 100;
return x;
}
return x;
}
f(false, 0); // 0
f(true, 0); // 100在一个嵌套作用域里引入一个新名字的行为称做 屏蔽 。 它是一把双刃剑,它可能会不小心地引入新问题,同时也可能会解决一些错误。 例如,假设我们现在用 let 重写之前的 sumArr 函数。
function sumArr(arrList) {
let sum = 0;
for (let i = 0; i < arrList.length; i++) {
var arr = arrList[i];
for (let i = 0; i < arr.length; i++) {
sum += arr[i];
}
}
return sum;
}此时将得到正确的结果,因为内层循环的 i 可以屏蔽掉外层循环的 i 。
通常来讲应该避免使用屏蔽,因为我们需要写出清晰的代码。 同时也有些场景适合利用它,你需要好好打算一下。
在我们最初谈及获取用 var 声明的变量时,我们简略地探究了一下在获取到了变量之后它的行为是怎样的。 直观地讲,每次进入一个作用域时,它创建了一个变量的环境。 就算作用域内代码已经执行完毕,这个环境与其捕获的变量依然存在。
function theCityThatAlwaysSleeps() {
let getCity;
if (true) {
let city = "Seattle";
getCity = function() {
return city;
}
}
return getCity();
}因为我们已经在 city 的环境里获取到了 city ,所以就算 if 语句执行结束后我们仍然可以访问它。
回想一下前面 setTimeout 的例子,我们最后需要使用立即执行的函数表达式来获取每次 for 循环迭代里的状态。 实际上,我们做的是为获取到的变量创建了一个新的变量环境。
当 let 声明出现在循环体里时拥有完全不同的行为。 不仅是在循环里引入了一个新的变量环境,而是针对每次迭代都会创建这样一个新作用域。 这就是我们在使用立即执行的函数表达式时做的事,所以在 setTimeout 例子里我们仅使用 let 声明就可以了。
for (let i = 0; i < 10 ; i++) {
setTimeout(function() {console.log(i); }, 100 * i);
}会输出与预料一致的结果:
0
1
2
3
4
5
6
7
8
9const 声明const 声明是声明变量的另一种方式。
const numLivesForCat = 9;它们与 let 声明相似,但是就像它的名字所表达的,它们被赋值后不能再改变。 换句话说,它们拥有与 let 相同的作用域规则,但是不能对它们重新赋值。
这很好理解,它们引用的值是不可变的。
const numLivesForCat = 9;
const kitty = {
name: "Aurora",
numLives: numLivesForCat,
}
// Error
kitty = {
name: "Danielle",
numLives: numLivesForCat
};
// all "okay"
kitty.name = "Rory";
kitty.name = "Kitty";
kitty.name = "Cat";
kitty.numLives--;除非你使用特殊的方法去避免,实际上 const 变量的内部状态是可修改的。
let vs. const现在我们有两种作用域相似的声明方式,我们自然会问到底应该使用哪个。 与大多数泛泛的问题一样,答案是:依情况而定。
使用最小特权原则,所有变量除了你计划去修改的都应该使用const。 基本原则就是如果一个变量不需要对它写入,那么其它使用这些代码的人也不能够写入它们,并且要思考为什么会需要对这些变量重新赋值。 使用 const也可以让我们更容易的推测数据的流动。
跟据你的自己判断,如果合适的话,与团队成员商议一下。
最简单的解构莫过于数组的解构赋值了:
let input = [1, 2];
let [first, second] = input;
console.log(first); // 1
console.log(second); // 2这创建了2个命名变量 first 和 second。 相当于使用了索引,但更为方便:
first = input[0];
second = input[1];解构作用于已声明的变量会更好:
[first, second] = [second, first];作用于函数参数:
function f([first, second]) {
console.log(first);
console.log(second);
}
f(input);你可以在数组里使用 ... 语法创建剩余变量:
let [first, ...rest] = [1, 2, 3, 4];
console.log(first); // 1
console.log(rest); // [ 2, 3, 4 ]当然,由于是JavaScript, 你可以忽略你不关心的尾随元素:
let [first] = [1, 2, 3, 4];
console.log(first); // 1或其它元素:
let [, second, , fourth] = [1, 2, 3, 4];你也可以解构对象:
let o = {
a: "foo",
b: 12,
c: "bar"
};
let { a, b } = o;这通过 o.a and o.b 创建了 a 和 b 。 注意,如果你不需要 c 你可以忽略它。
就像数组解构,你可以用没有声明的赋值:
({ a, b } = { a: "baz", b: 101 });注意,我们需要用括号将它括起来,因为 Javascript 通常会将以 { 起始的语句解析为一个块。
你可以在对象里使用 ... 语法创建剩余变量:
let { a, ...passthrough } = o;
let total = passthrough.b + passthrough.c.length;展开操作符正与解构相反。 它允许你将一个数组展开为另一个数组,或将一个对象展开为另一个对象。 例如:
let first = [1, 2];
let second = [3, 4];
let bothPlus = [0, ...first, ...second, 5];这会令 bothPlus 的值为 [0, 1, 2, 3, 4, 5] 。 展开操作创建了 first 和 second 的一份浅拷贝。 它们不会被展开操作所改变。
你还可以展开对象:
let defaults = { food: "spicy", price: "$$", ambiance: "noisy" };
let search = { ...defaults, food: "rich" };search 的值为 { food: "rich", price: "$$", ambiance: "noisy" } 。 对象的展开比数组的展开要复杂的多。 像数组展开一样,它是从左至右进行处理,但结果仍为对象。 这就意味着出现在展开对象后面的属性会覆盖前面的属性。 因此,如果我们修改上面的例子,在结尾处进行展开的话:
let defaults = { food: "spicy", price: "$$", ambiance: "noisy" };
let search = { food: "rich", ...defaults };那么,defaults 里的 food 属性会重写 food: "rich" ,在这里这并不是我们想要的结果。
对象展开还有其它一些意想不到的限制。 首先,它仅包含对象 自身的可枚举属性。 大体上是说当你展开一个对象实例时,你会丢失其方法:
class C {
p = 12;
m() {
}
}
let c = new C();
let clone = { ...c };
clone.p; // ok
clone.m(); // error!new 关键字创建的对象实际上是对新对象 this 的不断赋值,并将 __proto__ 指向类的 prototype 所指向的对象。
var SuperType = function (name) {
var nose = 'nose' // 私有属性
function say () {} // 私有方法
// 特权方法
this.getName = function () {}
this.setName = function () {}
this.mouse = 'mouse' // 对象公有属性
this.listen = function () {} // 对象公有方法
// 构造器
this.setName(name)
}
SuperType.age = 10 // 类静态公有属性(对象不能访问)
SuperType.read = function () {} // 类静态公有方法(对象无法访问)
SuperType.prototype = { // 对象赋值(也可以一一赋值)
isMan: 'true', // 公有属性
write: function () {} // 公有方法
}
var instance = new SuperType()在函数调用前增加 new,相当于把 SuperType 当成一个构造函数(虽然它仅仅只是个函数),然后创建一个 {} 对象并把 SuperType 中的 this 指向那个对象,以便可以通过类似 this.mouse 的形式去设置一些东西,然后把这个对象返回。
具体来讲,只要在函数调用前加上 new 操作符,你就可以把任何函数当做一个类的构造函数来用。
在上例中,我们可以看到:在构造函数内定义的 私有变量或方法 ,以及类定义的 静态公有属性及方法 ,在 new 的实例对象中都将 无法访问 。
如果你调用 SuperType() 时没有加 new,其中的 this 会指向某个全局且无用的东西(比如,window 或者 undefined),因此我们的代码会崩溃,或者做一些像设置 window.mouse 之类的傻事。
let instance1 = SuperType();
console.log(instance1.mouse);
// Uncaught TypeError: Cannot read property 'mouse' of undefined
console.log(window.mouse);
// mousefunction Bottle(name) {
this.name = name;
}
// + new
let bottle = new Bottle('bottle'); // ✅ 有效: Bottle {name: "bottle"}
console.log(bottle.name) // bottle
// 不加 new
let bottle1 = Bottle('bottle'); // 🔴 这种调用方法让人很难理解
console.log(bottle1.name); // Uncaught TypeError: Cannot read property 'name' of undefined
console.log(window.name); // bottleclass Bottle {
constructor(name) {
this.name = name;
}
sayHello() {
console.log('Hello, ' + this.name);
}
}
// + new
let bottle = new Bottle('bottle');
bottle.sayHello(); // ✅ 依然有效,打印:Hello, bottle
// 不加 new
let bottle1 = Bottle('bottle'); // 🔴 立即失败
// Uncaught TypeError: Class constructor Bottle cannot be invoked without 'new'let fun = new Fun();
// ✅ 如果 Fun 是个函数:有效
// ✅ 如果 Fun 是个类:依然有效
let fun1 = Fun(); // 我们忘记使用 `new`
// 😳 如果 Fun 是个长得像构造函数的方法:令人困惑的行为
// 🔴 如果 Fun 是个类:立即失败即
| new Fun() | Fun | |
|---|---|---|
| class | ✅ this 是一个 Fun 实例 |
🔴 TypeError |
| function | ✅ this 是一个 Fun 实例 |
😳 this 是 window 或 undefined |
function Bottle() {
return 'Hello, AnGe';
}
Bottle(); // ✅ 'Hello, AnGe'
new Bottle(); // 😳 Bottle {}对于箭头函数,使用 new 会报错🔴
const Bottle = () => {console.log('Hello, AnGe')};
new Bottle(); // Uncaught TypeError: Bottle is not a constructor这个行为是遵循箭头函数的设计而刻意为之的。箭头函数的一个附带作用是它没有自己的 this 值 —— this 解析自离得最近的常规函数:
function AnGe() {
this.name = 'AnGe'
return () => {console.log('Hello, ' + this.name)};
}
let anGe = new AnGe();
console.log(anGe()); // Hello, AnGe所以**箭头函数没有自己的 this。**但这意味着它作为构造函数是完全无用的!
总结:箭头函数
new 调用的函数返回另一个对象以 覆盖 new 的返回值先看一个例子:
function Vector(x, y) {
this.x = x;
this.y = y;
}
var v1 = new Vector(0, 0);
var v2 = new Vector(0, 0);
console.log(v1 === v2); // false
v1.x = 1;
console.log(v2); // Vector {x: 0, y: 0}对于这个例子,一目了然,没什么可说的。
那么再看下面一个例子,思考一下为什么 b === c 为 true 喃😲:
let zeroVector = null;
// 创建了一个懒变量 zeroVector = null;
function Vector(x, y) {
if (zeroVector !== null) {
// 复用同一个实例
return zeroVector;
}
zeroVector = this;
this.x = x;
this.y = y;
}
var v1 = new Vector(0, 0);
var v2 = new Vector(0, 0);
console.log(v1 === v2); // true
v1.x = 1;
console.log(v2); // Vector {x: 1, y: 0}这是因为,JavaScript 允许一个使用 new 调用的函数返回另一个对象以 覆盖 new 的返回值。这在我们利用诸如「对象池模式」来对组件进行复用时可能是有用的。
Flow Based Layout)HTML解析成DOM,把CSS解析成CSSOM,DOM和CSSOM合并就产生了渲染树(Render Tree)。RenderTree,我们就知道了所有节点的样式,然后计算他们在页面上的大小和位置,最后把节点绘制到页面上。Render Tree的计算通常只需要遍历一次就可以完成,但table及其内部元素除外,他们可能需要多次计算,通常要花3倍于同等元素的时间,这也是为什么要避免使用table布局的原因之一。由于节点的几何属性发生改变或者由于样式发生改变而不会影响布局的,称为重绘,例如outline, visibility, color、background-color等,重绘的代价是高昂的,因为浏览器必须验证DOM树上其他节点元素的可见性。
回流是布局或者几何属性需要改变就称为回流。回流是影响浏览器性能的关键因素,因为其变化涉及到部分页面(或是整个页面)的布局更新。一个元素的回流可能会导致了其所有子元素以及DOM中紧随其后的节点、祖先节点元素的随后的回流。
<body>
<div class="error">
<h4>我的组件</h4>
<p><strong>错误:</strong>错误的描述…</p>
<h5>错误纠正</h5>
<ol>
<li>第一步</li>
<li>第二步</li>
</ol>
</div>
</body>在上面的HTML片段中,对该段落(<p>标签)回流将会引发强烈的回流,因为它是一个子节点。这也导致了祖先的回流(div.error和body – 视浏览器而定)。此外,<h5>和<ol>也会有简单的回流,因为其在DOM中在回流元素之后。大部分的回流将导致页面的重新渲染。
回流必定会发生重绘,重绘不一定会引发回流。
现代浏览器大多都是通过队列机制来批量更新布局,浏览器会把修改操作放在队列中,至少一个浏览器刷新(即16.6ms)才会清空队列,但当你获取布局信息的时候,队列中可能有会影响这些属性或方法返回值的操作,即使没有,浏览器也会强制清空队列,触发回流与重绘来确保返回正确的值。
主要包括以下属性或方法:
offsetTop、offsetLeft、offsetWidth、offsetHeightscrollTop、scrollLeft、scrollWidth、scrollHeightclientTop、clientLeft、clientWidth、clientHeightwidth、heightgetComputedStyle()getBoundingClientRect()所以,我们应该避免频繁的使用上述的属性,他们都会强制渲染刷新队列。
CSS
使用 transform 替代 top
使用 visibility 替换 display: none ,因为前者只会引起重绘,后者会引发回流(改变了布局
避免使用table布局,可能很小的一个小改动会造成整个 table 的重新布局。
尽可能在DOM树的最末端改变class,回流是不可避免的,但可以减少其影响。尽可能在DOM树的最末端改变class,可以限制了回流的范围,使其影响尽可能少的节点。
避免设置多层内联样式,CSS 选择符从右往左匹配查找,避免节点层级过多。
<div>
<a> <span></span> </a>
</div>
<style>
span {
color: red;
}
div > a > span {
color: red;
}
</style>对于第一种设置样式的方式来说,浏览器只需要找到页面中所有的 span 标签然后设置颜色,但是对于第二种设置样式的方式来说,浏览器首先需要找到所有的 span 标签,然后找到 span 标签上的 a 标签,最后再去找到 div 标签,然后给符合这种条件的 span 标签设置颜色,这样的递归过程就很复杂。所以我们应该尽可能的避免写过于具体的 CSS 选择器,然后对于 HTML 来说也尽量少的添加无意义标签,保证层级扁平。
将动画效果应用到position属性为absolute或fixed的元素上,避免影响其他元素的布局,这样只是一个重绘,而不是回流,同时,控制动画速度可以选择 requestAnimationFrame,详见探讨 requestAnimationFrame。
避免使用CSS表达式,可能会引发回流。
将频繁重绘或者回流的节点设置为图层,图层能够阻止该节点的渲染行为影响别的节点,例如will-change、video、iframe等标签,浏览器会自动将该节点变为图层。
CSS3 硬件加速(GPU加速),使用css3硬件加速,可以让transform、opacity、filters这些动画不会引起回流重绘 。但是对于动画的其它属性,比如background-color这些,还是会引起回流重绘的,不过它还是可以提升这些动画的性能。
JavaScript
style属性,或者将样式列表定义为class并一次性更改class属性。DOM,创建一个documentFragment,在它上面应用所有DOM操作,最后再把它添加到文档中。diff 作为 Virtual DOM 的加速器,其算法上的改进优化是React页面渲染的基础和性能保障,本节从源码入手,深入剖析diff算法。
React 中醉值得称道的莫过于Virtual DOM与diff的完美结合,尤其是其高效的diff算法,可以帮助我们在页面蔌渲染的时候,计算出Virtual DOM真正变化的部分,并只针对该部分进行的原生DOM操作,而不是渲染整个页面,从而保证了每次操作后,页面的高效渲染。
计算一个树形结构转换成另一个树形结构的最少操作,是一个复杂且值得研究的问题,传统 diff 算法通过循环递归的方法对节点进行操作,算法复杂度 为O(n^3),其中n为树中节点的总数,这效率太低了,如果 React 只是单纯的引入 diff 算法,而没有任何的优化的话,其效率远远无法满足前端渲染所需要的性能。那么React 是如何实现一个高效、稳定的 diff 算法。
React 将 Virtual DOM 树转换为 actual DOM 树的最小操作的过程称为调和, diff 算法便是调和的结果,React 通过制定大胆的策略,将 O(n^3)的时间复杂度转换成 O(n)。
下面是 React diff 算法的 3 个策略:
基于以上三个策略,React 分别对 tree diff、component diff 以及 element diff 进行算法优化。
对于策略一,React 对树的算法进行了简单明了的优化,即对树进行分层比较,两颗树只会对同一层级的节点进行比较。
既然 DOM 节点跨层级的移动,可以少到忽略不计,针对这种现象,React 通过 updateDepth 对 Virtual DOM 树进行层级控制,只对相同层级的DOM节点进行比较,即同一父节点下的所有子节点,当发现该节点已经不存在时,则该节点及其子节点会被完全删除掉,不会用于进一步的比较。这样只需要对树进行一次遍历,便能完成整个DOM树的比较。
// updateChildren 源码
updateChildren: function (nextNestedChildrenElements, transaction, context) {
updateDepth ++;
var errorThrown = true;
try {
this._updateChildren(nextNestedChildrenElements, transaction, context);
errorThrown = false;
} finally {
updateDepth --;
if (!updateDepth) {
if (errorThrown) {
clearQueue();
} else {
processQueue();
}
}
}
}那么就会有这样的问题:
如果出现了 DOM 节点跨层级的移动操作,diff 会有怎样的表现喃?
我们举个例子看一下:
如下图2-1,A节点(包括其子节点)整个需要跨层级移动到D节点下,React会如何操作喃?
图2-1 DOM层级变换
由于 React 只会简单的考虑同层级节点的位置变换,对于不同层级的节点,只有创建和删除操作。当根节点R发现子节点中A消失了,就会直接销毁A;当D节点发现多了一个子节点A,就会创建新的A子节点(包括其子节点)。执行的操作为:
create A —> create B —> create C —> delete A
所以。当出现节点跨级移动时,并不会像想象中的那样执行移动操作,而是以 A 为根节点的整个树被整个重新创建,这是影响 React 性能的操作,所以 官方建议不要进行 DOM 节点跨层级的操作。
在开发组件中,保持稳定的 DOM 结构有助于性能的提升。例如,可以通过CSS隐藏或显示节点,而不是真正的移除或添加 DOM 节点。
React 是基于组件构建应用的,对于组件间的比较所采取的策略也是非常简洁、高效的。
shouldComponentUpdate()来判断该组件是否需要大量 diff 算法分析。
图3-1 component diff
如上图3-1,当 D 组件变成 G 时,即使这两个组件结构相似,但一旦 React 判断D和G是两个不同类型的组件时,就不会再比较这两个组件的结构,直接进行删除组件D, 重新创建组件G及其子组件。虽然这两个组件是不同类型单结构类似,diff 算法会影响性能,正如 React 官方博客所言:
不同类型的组件很少存在相似 DOM 树的情况,因此,这种极端因素很难在实际开发过程中造成重大影响。
当节点处于同一层级时,diff 提供三种节点操作:
// INSERT_MARKUP
function makeInsertMarkup(markup, afterNode, toIndex) {
return {
type: ReactMultiChildUpdateTypes.INSERT_MARKUP,
content: markup,
fromIndex: null,
fromNode: null,
toIndex: toIndex,
afterNode: afterNode
}
}
// MOVE_EXISTING
function makeMove(child, afterNode, toIndex) {
return {
type: ReactMultiChildUpdateTypes.MOVE_EXISTING,
content: null,
fromIndex: child._mountIndex,
fromNode: ReactReconciler.getNativeNode(child),
toIndex: toIndex,
afterNode: afterNode
}
}
// REMOVE_NODE
function makeRemove(child, node) {
return {
type: ReactMultiChildUpdateTypes.REMOVE_NODE,
content: null,
fromIndex: child._mountIndex,
fromNode: node,
toIndex: null,
afterNode: null
}
}下面由三个例子加深我们的理解
例1:旧集合A、B、C、D四个节点,更新后的新集合为B、A、D、C节点,对新旧集合进行 diff 算法差异化对比,发现 B!=A,则创建并插入B节点到新集合,并删除旧集合中A,以此类推,创建A、D、C,删除 B、C、D。如下图4-1
图4-1 节点 diff
React发现这样操作非常繁琐冗余,因为这些集合里含有相同的节点,只是节点位置发生了变化而已,却发生了繁琐的删除、创建操作,实际上只需要对这些节点进行简单的位置移动即可。
针对这一现象,React 提出了优化策略:
允许开发者对同一层级的同组子节点,添加唯一key进行区分,虽然只是小小的改动,但性能上却发生了翻天覆地的变化。
例2:看下图
进行对新旧集合的 diff 差异化对比,通过 key 发现新旧集合中包含的节点是一样的,所以可以通过简单的位置移动就可以更新为新集合,React 给出的 diff 结果为:B、D不做任何操作,A、C移动即可。
图4-2 对节点进行 diff 差异化对比
步骤:
初始化,lastIndex = 0, nextIndex = 0
从新集合取出节点B,发现旧集合中也有节点B,并且B.__mountIndex = 1,lastIndex = 0,不满足 B._mountIndex < lastIndex,则不对B操作,并且更新 lastIndex= Math.max(prevChild._mountIndex, lastIndex),并将B的位置更新为新集合中的位置prevChild._mountIndex = nextIndex,即B._mountIndex = 0, nextIndex ++ 进入下一步
从新集合取出节点A,发现旧集合中也有节点A,并且A.__mountIndex = 0,lastIndex = 1,满足 A._mountIndex < lastIndex,则对A进行移动操作,enqueue( updates, makeMove(prevChild, lastPlacedNode, nextIndex))并且更新 lastIndex= Math.max(prevChild._mountIndex, lastIndex),并将A的位置更新为新集合中的位置prevChild._mountIndex = nextIndex,即A._mountIndex = 1, nextIndex ++ 进入下一步
依次进行操作,可以根据下面代码执行的步骤实现,这里不再赘述
操作为:
updateChildren1: function(prevChildren, nextChildren) { // 旧集合 新集合
var updates = null
var name
// lastIndex 是 prevChildren 中最后一个索引,nextIndex 是 nextChildren 中每个节点的索引
var lastIndex = 0
var nextIndex = 0
for (name in nextChildren) { // 对新集合的节点进行循环遍历
if (!nextChildren.hasOwnProperty(name)) {
continue
}
var prevChild = prevChildren && prevChildren[name]
var nextChild = nextChildren[name]
// 通过唯一的key判断新旧集合是否有相同的节点
if (prevChild === nextChild) { // 新旧集合有相同的节点
// 如果子节点的 index 小于 lastIndex 则移动该节点
if (prevChild._mountIndex < lastIndex) {
// 获取移动节点
let moveNode = makeMove(prevChild, lastPlacedNode, nextIndex)
// 存入差异队列
updates = enqueue(
updates,
moveNode
)
} // 这是一种顺序优化手段,lastIndex 一直在更新表示访问过的节点一直在prevChildren最大的位置,如果当前访问的节点比 lastIndex 大,说明当前访问的节点在旧结合中就比上一个节点靠后,则该节点不会影响其它节点的位置,因此不插入差异队列,不要执行移动操作,只有访问的节点比 lastIndex 小时,才需要进行移动操作。
// 更新lastIndex
lastIndex= Math.max(prevChild._mountIndex, lastIndex)
// 将prevChild的位置更新为在新集合中的位置
prevChild._mountIndex = nextIndex
} else {
if (prevChild) {// 如果没有相同节点且prevChild存在
// 更新lastIndex
lastIndex = Math.max(prevChild._mountIndex, lastIndex)
}
}
// 进入下一个节点的判断
nextIndex ++
}
// 如果存在更新,则处理更新队列
if (updates) {
processQueue(this, updates)
}
// 更新 DOM
this._renderedChildren = nextChildren
}
function enqueue(queue, update) {
// 如果有更新,将其存入 queue
if (update) {
queue = queue || []
queue.push(update)
}
return queue
}
// 处理队列的更新
function processQueue (inst, updateQueue) {
ReactComponentEnvironment.processChildrenUpdates(
inst,
updateQueue
)
}例3:看下图
图4-3 创建、移动、删除节点
可以看出在这个例子中,有新增的节点,还有需要删除的节点,具体怎么操作,请大胆的尝试一下吧
_updateChildren: function(nextNestedChildrenElements, transaction, context) {
var prevChildren = this._renderedChildren // 旧集合
var removedNodes = {} // 需要删除的节点集合
var nextChildren = this._reconcilerUpdateChildren(prevChildren, nextNestedChildrenElements, removedNodes, transaction, context) // 新集合
// 如果不存在 prevChildren 及 nextChildren,则不做 diff 处理
if (!prevChildren && !nextChildren) {
return
}
var updates = null
var name
// lastIndex 是 prevChildren 中最后一个索引,nextIndex 是 nextChildren 中每个节点的索引
var lastIndex = 0
var nextIndex = 0
var lastPlacedNode = null
for (name in nextChildren) { // 对新集合的节点进行循环遍历
if (!nextChildren.hasOwnProperty(name)) {
continue
}
var prevChild = prevChildren && prevChildren[name]
var nextChild = nextChildren[name]
// 通过唯一的key判断新旧集合是否有相同的节点
if (prevChild === nextChild) { // 新旧集合有相同的节点
// 如果子节点的 index 小于 lastIndex 则移动该节点,并加入差异队列
updates = enqueue(
updates,
this.moveChild(prevChild, lastPlacedNode, nextIndex, lastIndex)
)// 这是一种顺序优化手段,lastIndex 一直在更新表示访问过的节点一直在prevChildren最大的位置,如果当前访问的节点比 lastIndex 大,说明当前访问的节点在旧结合中就比上一个节点靠后,则该节点不会影响其它节点的位置,因此不插入差异队列,不要执行移动操作,只有访问的节点比 lastIndex 小时,才需要进行移动操作。
// 更新lastIndex
lastIndex= Math.max(prevChild._mountIndex, lastIndex)
// 将prevChild的位置更新为在新集合中的位置
prevChild._mountIndex = nextIndex
} else {
if (prevChild) {// 如果没有相同节点且prevChild存在
// 更新lastIndex
lastIndex = Math.max(prevChild._mountIndex, lastIndex)
// 通过遍历 removedNodes 删除子节点 prevChild
}
// 初始化并创建节点
updates = enqueue(
updates,
this._mountChildAtIndex(nextChild, lastPlacedNode, nextIndex, transaction, context)
)
}
// 进入下一个节点的判断
nextIndex ++
lastPlacedNode = ReactReconciler.getNativeNode(nextChild)
}
// 如果父节点不存在,则将其子节点全部移除
for (name in removedNodes) {
if (removedNodes.hasOwnProperty(name)) {
updates = enqueue(
updates,
this._unmountChild(prevChildren[name], removedNodes[name])
)
}
}
// 如果存在更新,则处理更新队列
if (updates) {
processQueue(this, updates)
}
this._renderedChildren = nextChildren
}
function enqueue(queue, update) {
// 如果有更新,将其存入 queue
if (update) {
queue = queue || []
queue.push(update)
}
return queue
}
// 处理队列的更新
function processQueue (inst, updateQueue) {
ReactComponentEnvironment.processChildrenUpdates(
inst,
updateQueue
)
}
// 移动节点
moveChild: function(child, afterNode, toIndex, lastIndex) {
// 如果子节点的 index 小于 lastIndex 则移动该节点
if (child._mountIndex < lastIndex) {
return makeMove(child, afterNode, toIndex)
}
}
// 创建节点
createChild: function(child, afterNode, mountIndex) {
return makeInsertMarkup(mountIndex, afterNode, child._mountIndex)
}
// 删除节点
removeChild: function(child, node) {
return makeRemove(child, node)
}
// 卸载已经渲染的子节点
_unmountChild: function(child, node) {
var update = this.removeChild(child, node)
child._mountIndex = null
return update
}
// 通过提供的名称,实例化子节点
_mountChildAtIndex: function(child, afterNode, index, transaction, context) {
var mountIndex = ReactReconciler.mountComponent(child, transaction, this, this._nativeContainerInfo, context)
child._mountIndex = index
return this._createChild(child, afterNode, mountIndex)
}本节是对《深入React技术栈》中关于 diff 算法的理解和总结
如果,你在开发过程中,发现event handler 传递参数有问题,例如:代码里使用onClick={this.handleClick.bind(this, 1)}的方式绑定事件处理程序,并且传递值,其定义是
// 方法
handleClick (params , e) {
console.log('params:', params)
console.log('e:', e)
}// render
<View className='flexDirection-c'>
<View className='base-width-12 lh-22 tx-c fs-14' onClick={this.handleClick.bind(this, -1)}>全部商品</View>
<View className='base-width-12 lh-22 tx-c fs-14' onClick={this.handleClick.bind(this, 0)}>在售商品</View>
<View className='lh-22 tx-c fs-14' onClick={this.handleClick.bind(this, 1)}>下架商品</View>
</View>打印结果你如果看到:
而我们所期望的结果是:
这是因为你项目中的taro-cli与依赖的版本不同,升级依赖即可,
项目中必须确保 CLI 和项目依赖是相同版本。
图是一种复杂的非线性结构,它由边(边Edge)和点(顶点Vertex)组成。一条边连接的两个点称为相邻顶点。
G = (V, E)图分为:
本文探讨的是无向图
图的表示一般有以下两种:
arr[i][j] = 1表示节点 i 与节点 j 之间有边,arr[i][j] = 0表示节点 i 与节点 j 之间没有边下面声明图类,Vertex 用数组结构表示,Edge 用 map结构表示
function Graph() {
this.vertices = [] // 顶点集合
this.edges = new Map() // 边集合
}
Graph.prototype.addVertex = function(v) { // 添加顶点方法
this.vertices.push(v)
this.edges.set(v, [])
}
Graph.prototype.addEdge = function(v, w) { // 添加边方法
let vEdge = this.edges.get(v)
vEdge.push(w)
let wEdge = this.edges.get(w)
wEdge.push(v)
this.edges.set(v, vEdge)
this.edges.set(w, wEdge)
}
Graph.prototype.toString = function() {
var s = ''
for (var i=0; i<this.vertices.length; i++) {
s += this.vertices[i] + ' -> '
var neighors = this.edges.get(this.vertices[i])
for (var j=0; j<neighors.length; j++) {
s += neighors[j] + ' '
}
s += '\n'
}
return s
}测试:
var graph = new Graph()
var vertices = [1, 2, 3, 4, 5]
for (var i=0; i<vertices.length; i++) {
graph.addVertex(vertices[i])
}
graph.addEdge(1, 4); //增加边
graph.addEdge(1, 3);
graph.addEdge(2, 3);
graph.addEdge(2, 5);
console.log(graph.toString())
// 1 -> 4 3
// 2 -> 3 5
// 3 -> 1 2
// 4 -> 1
// 5 -> 2测试成功
两种遍历算法:
深度优先遍历(Depth-First-Search),是搜索算法的一种,它沿着树的深度遍历树的节点,尽可能深地搜索树的分支。当节点v的所有边都已被探寻过,将回溯到发现节点v的那条边的起始节点。这一过程一直进行到已探寻源节点到其他所有节点为止,如果还有未被发现的节点,则选择其中一个未被发现的节点为源节点并重复以上操作,直到所有节点都被探寻完成。
简单的说,DFS就是从图中的一个节点开始追溯,直到最后一个节点,然后回溯,继续追溯下一条路径,直到到达所有的节点,如此往复,直到没有路径为止。
DFS 可以产生相应图的拓扑排序表,利用拓扑排序表可以解决很多问题,例如最大路径问题。一般用堆数据结构来辅助实现DFS算法。
注意:深度DFS属于盲目搜索,无法保证搜索到的路径为最短路径,也不是在搜索特定的路径,而是通过搜索来查看图中有哪些路径可以选择。
步骤:
实现:
Graph.prototype.dfs = function() {
var marked = []
for (var i=0; i<this.vertices.length; i++) {
if (!marked[this.vertices[i]]) {
dfsVisit(this.vertices[i])
}
}
function dfsVisit(u) {
let edges = this.edges
marked[u] = true
console.log(u)
var neighbors = edges.get(u)
for (var i=0; i<neighbors.length; i++) {
var w = neighbors[i]
if (!marked[w]) {
dfsVisit(w)
}
}
}
}测试:
graph.dfs()
// 1
// 4
// 3
// 2
// 5测试成功
广度优先遍历(Breadth-First-Search)是从根节点开始,沿着图的宽度遍历节点,如果所有节点均被访问过,则算法终止,BFS 同样属于盲目搜索,一般用队列数据结构来辅助实现BFS
BFS从一个节点开始,尝试访问尽可能靠近它的目标节点。本质上这种遍历在图上是逐层移动的,首先检查最靠近第一个节点的层,再逐渐向下移动到离起始节点最远的层
步骤:
实现:
Graph.prototype.bfs = function(v) {
var queue = [], marked = []
marked[v] = true
queue.push(v) // 添加到队尾
while(queue.length > 0) {
var s = queue.shift() // 从队首移除
if (this.edges.has(s)) {
console.log('visited vertex: ', s)
}
let neighbors = this.edges.get(s)
for(let i=0;i<neighbors.length;i++) {
var w = neighbors[i]
if (!marked[w]) {
marked[w] = true
queue.push(w)
}
}
}
}测试:
graph.bfs(1)
// visited vertex: 1
// visited vertex: 4
// visited vertex: 3
// visited vertex: 2
// visited vertex: 5测试成功
JS 异步已经告一段落了,这里来一波小总结
setTimeout(() => {
// callback 函数体
}, 1000)缺点:回调地狱,不能用 try catch 捕获错误,不能 return
回调地狱的根本问题在于:
ajax('XXX1', () => {
// callback 函数体
ajax('XXX2', () => {
// callback 函数体
ajax('XXX3', () => {
// callback 函数体
})
})
})优点:解决了同步的问题(只要有一个任务耗时很长,后面的任务都必须排队等着,会拖延整个程序的执行。)
Promise就是为了解决callback的问题而产生的。
Promise 实现了链式调用,也就是说每次 then 后返回的都是一个全新 Promise,如果我们在 then 中 return ,return 的结果会被 Promise.resolve() 包装
优点:解决了回调地狱的问题
ajax('XXX1')
.then(res => {
// 操作逻辑
return ajax('XXX2')
}).then(res => {
// 操作逻辑
return ajax('XXX3')
}).then(res => {
// 操作逻辑
})缺点:无法取消 Promise ,错误需要通过回调函数来捕获
特点:可以控制函数的执行,可以配合 co 函数库使用
function *fetch() {
yield ajax('XXX1', () => {})
yield ajax('XXX2', () => {})
yield ajax('XXX3', () => {})
}
let it = fetch()
let result1 = it.next()
let result2 = it.next()
let result3 = it.next()async、await 是异步的终极解决方案
优点是:代码清晰,不用像 Promise 写一大堆 then 链,处理了回调地狱的问题
缺点:await 将异步代码改造成同步代码,如果多个异步操作没有依赖性而使用 await 会导致性能上的降低。
async function test() {
// 以下代码没有依赖性的话,完全可以使用 Promise.all 的方式
// 如果有依赖性的话,其实就是解决回调地狱的例子了
await fetch('XXX1')
await fetch('XXX2')
await fetch('XXX3')
}下面来看一个使用 await 的例子:
let a = 0
let b = async () => {
a = a + await 10
console.log('2', a) // -> '2' 10
}
b()
a++
console.log('1', a) // -> '1' 1
对于以上代码你可能会有疑惑,让我来解释下原因
b 先执行,在执行到 await 10 之前变量 a 还是 0,因为 await 内部实现了 generator ,generator 会保留堆栈中东西,所以这时候 a = 0 被保存了下来await 是异步操作,后来的表达式不返回 Promise 的话,就会包装成 Promise.reslove(返回值),然后会去执行函数外的同步代码a = 0 + 10上述解释中提到了 await 内部实现了 generator,其实 await 就是 generator 加上 Promise的语法糖,且内部实现了自动执行 generator。如果你熟悉 co 的话,其实自己就可以实现这样的语法糖。

一般代码提交流程为:工作区 -> git status 查看状态 -> git add . 将所有修改加入暂存区-> git commit -m "提交描述" 将代码提交到 本地仓库 -> git push 将本地仓库代码更新到 远程仓库
当你改乱了工作区某个文件的内容,想直接丢弃工作区的修改时,用命令 git checkout -- file。
// 丢弃工作区的修改
git checkout -- <文件名>当你不但改乱了工作区某个文件的内容,还 git add 添加到了暂存区时,想丢弃修改,分两步,第一步用命令 git reset HEAD file,就回到了场景1,第二步按场景1操作。
git reset HEAD <文件名> // 把暂存区的修改撤销掉(unstage),重新放回工作区。更改 commit 信息
git commit --amend -m“新提交消息”commit 时,遗漏提交部分更新,有两种解决方案:
方案一:再次 commit
git commit -m“提交消息”此时,git 上会出现两次 commit
方案二:遗漏文件提交到之前 commit 上
git add missed-file // missed-file 为遗漏提交文件
git commit --amend --no-edit--no-edit 表示提交消息不会更改,在 git 上仅为一次提交
删除指定的 commit
// 修改版本库,保留暂存区,保留工作区
// 将版本库软回退1个版本,软回退表示将本地版本库的头指针全部重置到指定版本,且将这次提交之后的所有变更都移动到暂存区。
git reset --soft HEAD~1
// 修改版本库,修改暂存区,修改工作区
//将版本库回退1个版本,不仅仅是将本地版本库的头指针全部重置到指定版本,也会重置暂存区,并且会将工作区代码也回退到这个版本
git reset --hard HEAD~1
// git版本回退,回退到特定的commit_id版本,可以通过git log查看提交历史,以便确定要回退到哪个版本(commit 之后的即为ID);
git reset --hard commit_id 撤销 某次操作,此次操作之前和之后的commit和history都会保留,并且把这次撤销
作为一次最新的提交
// 撤销前一次 commit
git revert HEAD
// 撤销前前一次 commit
git revert HEAD^
// (比如:fa042ce57ebbe5bb9c8db709f719cec2c58ee7ff)撤销指定的版本,撤销也会作为一次提交进行保存。
git revert commitgit revert是提交一个新的版本,将需要revert的版本的内容再反向修改回去,
版本会递增,不影响之前提交的内容
git revert 和 git reset 的区别git revert是用一次新的commit来回滚之前的commit,git reset是直接删除指定的commit。git revert是用一次逆向的commit“中和”之前的提交,因此日后合并老的branch时,导致这部分改变不会再次出现,但是git reset是之间把某些commit在某个branch上删除,因而和老的branch再次merge时,这些被回滚的commit应该还会被引入。git reset 是把HEAD向后移动了一下,而git revert是HEAD继续前进,只是新的commit的内容和要revert的内容正好相反,能够抵消要被revert的内容。git clone 地址git branch 分支名git branchgit branch -agit checkout 分支名 (一般修改未提交则无法切换,大小写问题经常会有,可强制切换 git checkout 分支名 -f 非必须慎用)git push <远程仓库> <本地分支>:<远程分支>将某个远程主机的更新,全部/分支 取回本地(此时之更新了Repository)它取回的代码对你本地的开发代码没有影响,如需彻底更新需合并或使用git pull
拉取远程主机某分支的更新,再与本地的指定分支合并(相当与fetch加上了合并分支功能的操作)
将本地分支的更新,推送到远程主机,其命令格式与git pull相似
git clone -b 分支名仓库地址git checkout -b serverfix origin/serverfixgit merge hotfix:(将 hotfix 分支合并到当前分支)git merge origin/serverfixgit branch -d hotfix:(删除本地 hotfix 分支)git push origin --delete serverfixgit push origin newName;git branch branchName:(创建名为 branchName 的本地分支)git checkout branchName:(切换到 branchName 分支)git checkout -b branchName:(相当于以上两条命令的合并)git branchgit branch -agit branch -m oldName newNamegit branch -m oldName newNamegit branch --set-upstream-to origin/newName在团队协作过程中,假设你和你的同伴在本地中分别有各自的新提交,而你的同伴先于你 push 了代码到远程分支上,所以你必须先执行 git pull 来获取同伴的提交,然后才能 push 自己的提交到远程分支。
而按照 Git 的默认策略,如果远程分支和本地分支之间的提交线图有分叉的话(即不是 fast-forwarded),Git 会执行一次 merge 操作,因此产生一次没意义的提交记录,从而造成了像上图那样的混乱。
其实在 pull 操作的时候,,使用 git pull --rebase 选项即可很好地解决上述问题。 加上 --rebase 参数的作用是,提交线图有分叉的话,Git 会 rebase 策略来代替默认的 merge 策略。
假设提交线图在执行 pull 前是这样的:
A---B---C remotes/origin/master
/
D---E---F---G master
如果是执行 git pull 后,提交线图会变成这样:
A---B---C remotes/origin/master
/ \
D---E---F---G---H master
结果多出了 H 这个没必要的提交记录。如果是执行 git pull --rebase 的话,提交线图就会变成这样:
remotes/origin/master
|
D---E---A---B---C---F'---G' master
F G 两个提交通过 rebase 方式重新拼接在 C 之后,多余的分叉去掉了,目的达到。
大多数时候,使用 git pull --rebase 是为了使提交线图更好看,从而方便 code review。
不过,如果你对使用 git 还不是十分熟练的话,我的建议是 git pull --rebase 多练习几次之后再使用,因为 rebase 在 git 中,算得上是『危险行为』。
另外,还需注意的是,使用 git pull --rebase 比直接 pull 容易导致冲突的产生,如果预期冲突比较多的话,建议还是直接 pull。
注意:
git pull = git fetch + git merge
git pull --rebase = git fetch + git rebase
上述的 git pull --rebase 策略目的是修整提交线图,使其形成一条直线,而即将要用到的 git merge --no-ff <branch-name> 策略偏偏是反行其道,刻意地弄出提交线图分叉出来。
假设你在本地准备合并两个分支,而刚好这两个分支是 fast-forwarded 的,那么直接合并后你得到一个直线的提交线图,当然这样没什么坏处,但如果你想更清晰地告诉你同伴:这一系列的提交都是为了实现同一个目的,那么你可以刻意地将这次提交内容弄成一次提交线图分叉。
执行 git merge --no-ff <branch-name> 的结果大概会是这样的:
中间的分叉线路图很清晰的显示这些提交都是为了实现 complete adjusting user domains and tags
往往我的习惯是,在合并分支之前(假设要在本地将 feature 分支合并到 dev 分支),会先检查 feature 分支是否『部分落后』于远程 dev 分支:
git checkout dev
git pull # 更新 dev 分支
git log feature..dev
如果没有输出任何提交信息的话,即表示 feature 对于 dev 分支是 up-to-date 的。如果有输出的话而马上执行了 git merge --no-ff 的话,提交线图会变成这样:
所以这时在合并前,通常我会先执行:
git checkout feature
git rebase dev
这样就可以将 feature 重新拼接到更新了的 dev 之后,然后就可以合并了,最终得到一个干净舒服的提交线图。
再次提醒:像之前提到的,rebase 是『危险行为』,建议你足够熟悉 git 时才这么做,否则的话是得不偿失啊。
使用 git pull --rebase 和 git merge --no-ff 其实和直接使用 git pull git merge 得到的代码应该是一样。
使用 git pull --rebase 主要是为是将提交约线图平坦化,而 git merge --no-ff 则是刻意制造分叉。
$ cd ~/.ssh
$ ls
id_rsa id_rsa.pub known_hosts
其中 id_rsa 是私钥,id_rsa.pub 是公钥。
git config --list // 查看是否设置了user.name与user.email,没有的话,去设置
// 设置全局的user.name与user.email
git config --global user.name "XX"
git config --global user.email "XX"ssh-keygen -t rsa -C "email")$ ssh-keygen
Generating public/private rsa key pair.
Enter file in which to save the key (/Users/schacon/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /Users/schacon/.ssh/id_rsa.
Your public key has been saved in /Users/schacon/.ssh/id_rsa.pub.
The key fingerprint is:
$ cat ~/.ssh/id_rsa.pub
ssh-rsa AAAAB3NzaC1yc2EAAAABIwAAAQEAklOUpkDHrfHY17SbrmTIpNLTGK9Tjom/BWDSU
GPl+nafzlHDTYW7hdI4yZ5ew18JH4JW9jbhUFrviQzM7xlELEVf4h9lFX5QVkbPppSwg0cda3
Pbv7kOdJ/MTyBlWXFCR+HAo3FXRitBqxiX1nKhXpHAZsMciLq8V6RjsNAQwdsdMFvSlVK/7XA
t3FaoJoAsncM1Q9x5+3V0Ww68/eIFmb1zuUFljQJKprrX88XypNDvjYNby6vw/Pb0rwert/En
mZ+AW4OZPnTPI89ZPmVMLuayrD2cE86Z/il8b+gw3r3+1nKatmIkjn2so1d01QraTlMqVSsbx
NrRFi9wrf+M7Q== [email protected]
git stash 可用来暂存当前正在进行的工作,比如想 pull 最新代码又不想 commit , 或者另为了修改一个紧急的 bug ,先 stash,使返回到自己上一个 commit,,改完 bug 之后再 stash pop , 继续原来的工作;
git stash ;git stash list ;git stash pop ;git stash apply stash@{1} ;Filename too long warning: Clone succeeded, but checkout failed.
git config --system core.longpaths true
git config user.name
git config user.email
git config --global user.name "username"
git config --global user.email "email"
git rm -r --cached .
git add .
git commit -m ".gitignore is now working”
1、配置remote,指向原始仓库
git remote add upstream https://github.com/InterviewMap/InterviewMap.git
2、上游仓库获取到分支,及相关的提交信息,它们将被保存在本地的 upstream/master 分支
git fetch upstream
# remote: Counting objects: 75, done.
# remote: Compressing objects: 100% (53/53), done.
# remote: Total 62 (delta 27), reused 44 (delta 9)
# Unpacking objects: 100% (62/62), done.
# From https://github.com/ORIGINAL_OWNER/ORIGINAL_REPOSITORY
# * [new branch] master -> upstream/master
3、切换到本地的 master 分支
git checkout master
# Switched to branch 'master'
4、把 upstream/master 分支合并到本地的 master 分支,本地的 master 分支便跟上游仓库保持同步了,并且没有丢失本地的修改。
git merge upstream/master
# Updating a422352..5fdff0f
# Fast-forward
# README | 9 -------
# README.md | 7 ++++++
# 2 files changed, 7 insertions(+), 9 deletions(-)
# delete mode 100644 README
# create mode 100644 README.md
5、上传到自己的远程仓库中
git push
这一块不是难点,主要是movable-view,movable-area及一些页面逻辑的计算(当前拖拽的控件,拖拽到什么地步进行排序)。
需要注意:排序时setState/setData的延时,可能会引起多次排序错乱
在简单的拖拽排序基本实现后,我们需要关注它的性能及流畅度。
由于我们的contents(拖拽排序数组)中设计textarea、video等原生控件。
- 页面滑动的时候,可能出现
textarea、video凌驾于navigator或其他高层级组件上
这是因为textarea、video为原生组件,脱离在 WebView 渲染流程外,原生组件的层级是最高的,所以页面中的其他组件无论设置 z-index 为多少,都无法盖在原生组件上,
为了解决原生组件层级最高的限制,小程序专门提供了 cover-view 、 cover-image组件,可以覆盖在部分原生组件上面。我们需要把在textarea、video层次上的组件写到cover-view中。
- 滑动页面的时候,当滑动落在
textarea上时,可能出现页面卡顿的现象
这是因为我们把contents(拖拽排序数组)写在了scroll-view 中,而滑动手势落在textarea上时,textarea的层级在scroll-view之上,操作会被textarea拦截,就不会作用到scroll-view滚动上,这时,两者只能选其一,textarea是我们必须要有的功能,如果用伪多行输入又会造成更多的性能问题,如果你有更好的方案,可以试一下,这里我们去除scroll-view
由于我们通过页面的clientY以及scrollY来得到当前拖拽控件及拖拽路径,而不使用scroll-view后无法scroll-view滚动的距离,这时,需要使用页面的onPageScroll方法
onPageScroll () {
let that = this;
var query = Taro.createSelectorQuery()
query.select('.content-view').boundingClientRect()
query.selectViewport().scrollOffset()
query.exec(function(res) {
that.setState({
scrollPosition: {
scrollTop: res[1].scrollTop,
scrollY: that.state.scrollPosition.scrollY
},
})
})
}
- 文本控件拖拽时,textarea没有跟随移动
由于textarea不是position: fixed的,所以fixed={true}无效,我这里的解决方法是把拖拽的时movable-view的文本框设为text组件。
后续如果继续优化,我会不断更新,感谢你的阅读
使用 React Native 替代基于 WebView 的框架来开发 App 的一个强有力的理由,就是为了使 App 可以达到每秒 60 帧(足够流畅),并且能有类似原生 App 的外观和手感。因此我们也尽可能地优化 React Native 去实现这一目标,使开发者能集中精力处理 App 的业务逻辑,而不用费心考虑性能。但是,总还是有一些地方有所欠缺,以及在某些场合 React Native 还不能够替你决定如何进行优化(用原生代码写也无法避免),因此人工的干预依然是必要的。 本文的目的是教给你一些基本的知识,来帮你排查性能方面的问题,以及探讨这些问题产生的原因和推荐的解决方法。
React Native为我们提供了JS的运行环境,开发者们只需要关心如何编写JS代码,画UI只需要画到virtual DOM 中,不需要特别关心具体的平台
至于JS转换为native代码,由React Native实现
React Native的本质是把中间的这个桥Bridge搭建好,使JS和Native可以相互调用
老一辈人常常把电影称为“移动的画”,是因为视频中逼真的动态效果其实是一种幻觉,这种幻觉是由一组静态的图片以一个稳定的速度快速变化所产生的。我们把这组图片中的每一张图片叫做一帧,而每秒钟显示的帧数直接的影响了视频(或者说用户界面)的流畅度和真实感。iOS 设备提供了每秒 60 的帧率,这就留给了开发者和 UI 系统大约 16.67ms 来完成生成一张静态图片(帧)所需要的所有工作。如果在这分派的 16.67ms 之内没有能够完成这些工作,就会引发‘丢帧’的后果,使界面表现的不够流畅。
console.log语句
在运行打好了离线包的应用时,控制台打印语句可能会极大的拖累JavaScript线程。注意第三方调试库,如redux-logger
if (!__DEV__) {
global.console = {
info: () => {},
log: () => {},
warn: () => {},
debug: () => {},
error: () => {}
};
}
或使用babel 插件移除,首先yarn add —dev babel-plugin-transform-remove-console来安装,然后在项目根目录下编辑或新建.babelrc的文件
// .babelrc文件
{
"env": {
"production": {
"plugins": ["transform-remove-console"]
}
}
}
这样在打包发布时,所有的控制台语句就会被自动移除,而在调试时它们仍然会被正常调用。
开发模式(dev=true)
JavaScript 线程的性能在开发模式下是很糟糕的。这是不可避免的,因为有许多工作需要在运行的时候去做,譬如使你获得良好的警告和错误信息,又比如验证属性类型(propTypes)以及产生各种其他的警告。
缓慢的导航器(Navigator)切换
如之前所说,Navigator的动画是由JavaScript线程控制。想象一下“从右边推入”这个场景的切换:每一帧中,新的场景从右向左移动,从屏幕右边开始,最终移动到x轴偏移为0的屏幕位置。切换过程中的每一帧,JavaScript线程都需要发送一个新的x轴偏移量给主线程。如果JavaScript线程卡住了,它就无法处理这项事情,因而这一帧就无法更新,动画就卡住了。
长远的解决方法,其中一部分是要允许基于 JavaScript 的动画从主线程分离。同样是上面的例子,我们可以在切换动画开始的时候计算出一个列表,其中包含所有的新的场景需要的 x 轴偏移量,然后一次发送到主线程以某种优化的方式执行。由于 JavaScript 线程已经从更新 x 轴偏移量给主线程这个职责中解脱了出来,因此 JavaScript 线程中的掉帧就不是什么大问题了 —— 用户将基本上不会意识到这个问题,因为用户的注意力会被流畅的切换动作所吸引。
新的React Navigation库的一大目标就是为了解决这个问题。React Navigation 中的视图是原生组件,同时用到了运行在原生线程上的Animated动画库,因而性能表现十分流畅
ListView初始化渲染太慢以及列表过长时滚动性能太差
这是一个频繁出现的问题。因为 iOS 配备了 UITableView,通过重用底层的 UIViews 实现了非常高性能的体验(相比之下 ListView 的性能没有那么好)。用 React Native 实现相同效果的工作仍正在进行中,但是在此之前,我们有一些可用的方法来稍加改进性能以满足我们的需求。
我的组件渲染太慢,我不需要立即显示全部
这在初次浏览 ListView 时很常见,适当的使用它是获得稳定性能的关键。就像之前所提到的,它可以提供一些手段在不同帧中来分开渲染页面,稍加改进就可以满足你的需求。此外要记住的是,ListView 也可以横向滚动。
在重绘一个几乎没什么变化的页面时,JS帧率严重降低
如果你正在使用一个 ListView,你必须提供一个rowHasChanged函数,它通过快速的算出某一行是否需要重绘,来减少很多不必要的工作。如果你使用了不可变的数据结构,这项工作就只需检查其引用是否相等。
同样的,你可以实现shouldComponentUpdate函数来指明在什么样的确切条件下,你希望这个组件得到重绘。如果你编写的是纯粹的组件(返回值完全由 props 和 state 所决定),你可以利用PureComponent来为你做这个工作。再强调一次,不可变的数据结构在提速方面非常有用 —— 当你不得不对一个长列表对象做一个深度的比较,它会使重绘你的整个组件更加快速,而且代码量更少。
由于在JavaScript线程中同时做很多事情,导致JS线程掉帧
“导航切换极慢”是该问题的常见表现。在其他情形下,这种问题也可能会出现。使用InteractionManager是一个好的方法,但是如果在动画中,为了用户体验的开销而延迟其他工作并不太能接受,那么你可以考虑一下使用LayoutAnimation。
Animated的接口一般会在 JavaScript 线程中计算出所需要的每一个关键帧,而LayoutAnimation则利用了Core Animation,使动画不会被 JS 线程和主线程的掉帧所影响。
举一个需要使用这项功能的例子:比如需要给一个模态框做动画(从下往上划动,并在半透明遮罩中淡入),而这个模态框正在初始化,并且可能响应着几个网络请求,渲染着页面的内容,并且还在更新着打开这个模态框的父页面。
注意:
在屏幕上移动视图(滚动,切换,旋转)时,UI线程掉帧
当具有透明背景的文本位于一张图片上时,或者在每帧重绘视图时需要用到透明合成的任何其他情况下,这种现象尤为明显。设置shouldRasterizeIOS或者renderToHardwareTextureAndroid属性可以显著改善这一现象。 注意不要过度使用该特性,否则你的内存使用量将会飞涨。在使用时,要评估你的性能和内存使用情况。如果你没有需要移动这个视图的需求,请关闭这一属性。
使用动画改编图片的尺寸时,UI线程掉帧
在 iOS 上,每次调整 Image 组件的宽度或者高度,都需要重新裁剪和缩放原始图片。这个操作开销会非常大,尤其是大的图片。比起直接修改尺寸,更好的方案是使用transform: [{scale}]的样式属性来改变尺寸。比如当你点击一个图片,要将它放大到全屏的时候,就可以使用这个属性。
Touchable系列组件不能很好的响应
有些时候,如果有一项操作与点击事件所带来的透明度或者高亮效果发生在同一帧中,那么有可能在onPress函数结束之前我们都不看不到这些效果,比如在onPress执行一个setState的操作,这个操纵需要大量的计算操作并且导致了掉帧。对此,一个解决方案就是将onPress处理函数中操作封装到rquestAnimationFrame中:
handleOnPress() {
// 谨记在使用requestAnimationFrame、setTimeout以及setInterval时
// 要使用TimerMixin(其作用是在组件unmount时,清除所有定时器)
this.requestAnimationFrame(() => {
this.doExpensiveAction();
});
}
InteractionManager和requestAnimationFrame(fn)的作用类似,都是为了避免动画卡顿,具体的原因是边渲染边执行动画,或者有大量的code计算阻塞页面进程。
InteractionManager.runAfterInteractions是在动画或者操作结束后执行
InteractionManager.runAfterInteractions(() => {
// ...long-running synchronous task...
});
总结
你可以利用内置的分析器来同时获取 JavaScript 线程和主线程中代码执行情况的详细信息。
对于 iOS 来说,Instruments 是一个宝贵的工具库,Android 的话,你可以使用 systrace。
React Native的加载流程主要为几个阶段
初始React Native环境
下载JS Bundle
运行JS Bundle
渲染页面
通过对FaceBook的ios版进行性能测试,得到上面的耗时图 可以看到,绿色的JS Init + Require占据了一大半的时间,这部分主要的操作是初始化JS环境:下载JS Bundle、运行JS Bundle
JS Bundle 是由 RN 开发工具打包出来的 JS 文件,其中包含了RN 页面组件的 JS 代码,还有 react、react-native 的JS代码,还有我们经常会用上的redux、react-navigation等的代码,所以 JS Bundle文件大小是性能优化的瓶颈,如果你有一个较为庞大的应用程序,你就要考虑使用拆分和内联引用。这对于具有大量页面的应用程序是非常有用的,这些页面在应用程序的典型使用过程中可能不会被打开。通常对于启动后一段时间内不需要大量代码的应用程序来说是非常有用的。例如应用程序包含复杂的配置文件屏幕或较少使用的功能,但大多数会话只涉及访问应用程序的主屏幕更新。我们可以通过使用打包器的unbundle特性来优化bundle的加载,并且内联引用这些功能和页面(当它们被实际使用时)。
Loading JavaScript
在react-native执行JS代码之前,必须将所有的代码加载到内存并进行解析。如果你加载了一个50MB的bundle,那么所有的50MB都必须被加载和解析才能执行。拆分后的优化是,启动时值加载50MB中实际需要的部分,并随着需要的部分逐渐加载更多的包。
内联引用
内联引用(require代替import)可以延迟模块或文件的加载,直到实际需要该文件。例如:
// 优化前
import React, {Component} from 'react'
import {Text} from 'react-native'
// ... import some very exponsive modules
// You may want to log at the file level to verify when this is happening
console.log('VeryExpensive component loaded.')
export default class VeryExpensive extends Component {
// lots and lots of code
render() {
return <Text>Very Expensive Component</Text>
}
}
// 优化后
import React,{Component} from 'react'
import {RouchableOpacity, View, Text} from 'react-native'
let VeryExpensive = null
export default class Optimized extends Component {
state = {needExpensive: false}
didPress = () => {
if (VeryExpensive == null)
VeryExpensive = require('./VeryExpensive').default
this.setState(() => {
needExpensive: true
})
}
render() {
return (
<View style={{marginTop: 20}}>
<TouchableOpacity onPress={this.didPress}>
<Text>Load</Text>
</TouchableOpacity>
{this.state.needsExpensive ? <VeryExpensive /> : null}
</View>
)
}
}
即使没有使用拆包,内联引用也会使启动时间减少,因为优化后的代码只有第一次require时才会执行
启动拆包
在iOS上unbundling将创建一个简单的索引文件,React Native将一次加载一个模块。在 Android 上,默认情况下它会为每个模块创建一组文件。你可以像 iOS 一样,强制 Android 只创建一个文件,但使用多个文件可以提高性能,并降低内存占用。
通过编辑 build phase "Bundle React Native code and images",在 Xcode 中启用 unbundling。在../node_modules/react-native/packager/react-native-xcode.sh 添加 export BUNDLE_COMMAND="unbundle":
export BUNDLE_COMMAND="unbundle"
export NODE_BINARY=node
../node_modules/react-native/packager/react-native-xcode.sh
在 Android 上,通过编辑你的 android/app/build.gradle 文件启用 unbundling。在apply from: "../../node_modules/react-native/react.gradle"之前修改或添加project.ext.react:
project.ext.react = [
bundleCommand: "unbundle",
]
如果在 Android 上,你想使用单个索引文件(如前所述),请在 Android 上使用以下行:
project.ext.react = [
bundleCommand: "unbundle",
extraPackagerArgs: ["--indexed-unbundle"]
]
配置预加载与内联引用
现在我们拆分了代码,然而调用require会造成额外的开销。当遇到尚未加载的模块时,现在需要通过桥发送消息。这主要会影响到启动速度,因为在应用程序加载初始模块时可能触发相当大量的请求调用。幸运的是,我们可以配置一部分模块进行预加载。为了做到这一点,你将需要实现某种形式的内联引用。
添加packager配置文件
在项目中创建一个名为packager的文件夹,并创建一个名为config.js的文件,添加一下内容
const config = {
getTransformOptions: () => {
return {
transform: { inlineRequires: true },
};
},
};
module.exports = config;
在 Xcode 的 Build phase 中添加export BUNDLE_CONFIG="packager/config.js"
export BUNDLE_COMMAND="unbundle"
export BUNDLE_CONFIG="packager/config.js"
export NODE_BINARY=node
../node_modules/react-native/packager/react-native-xcode.sh
编辑 android/app/build.gradle 文件,添加bundleConfig: "packager/config.js",
project.ext.react = [
bundleCommand: "unbundle",
bundleConfig: "packager/config.js"
]
最后,在 package.json 的“scripts”下修改“start”命令来启用配置文件:
"start": "node node_modules/react-native/local-cli/cli.js start --config ../../../../packager/config.js",
此时用npm start启动你的 packager 服务即会加载配置文件。请注意,如果你仍然通过 xcode 或是 react-native run-android 等方式自动启动 packager 服务,则由于没有使用上面的参数,不会加载配置文件。
调试预加载模块
在您的根文件 (index.(ios|android).js) 中,您可以在初始导入(initial imports)之后添加以下内容:
const modules = require.getModules();
const moduleIds = Object.keys(modules);
const loadedModuleNames = moduleIds
.filter(moduleId => modules[moduleId].isInitialized)
.map(moduleId => modules[moduleId].verboseName);
const waitingModuleNames = moduleIds
.filter(moduleId => !modules[moduleId].isInitialized)
.map(moduleId => modules[moduleId].verboseName);
// make sure that the modules you expect to be waiting are actually waiting
console.log(
'loaded:',
loadedModuleNames.length,
'waiting:',
waitingModuleNames.length
);
// grab this text blob, and put it in a file named packager/moduleNames.js
console.log(`module.exports = ${JSON.stringify(loadedModuleNames.sort())};`);
当你运行你的应用程序时,你可以查看 console 控制台,有多少模块已经加载,有多少模块在等待。你可能想查看 moduleNames,看看是否有任何意外。注意在首次 import 时调用的内联引用。你可能需要检查和重构,以确保只有你想要的模块在启动时加载。请注意,您可以根据需要修改 Systrace 对象,以帮助调试有问题的引用。
require.Systrace.beginEvent = (message) => {
if(message.includes(problematicModule)) {
throw new Error();
}
}
虽然每个 App 各有不同,但只加载第一个页面所需的模块是有普适意义的。当你满意时,把 loadedModuleNames 的输出放到 packager/moduleNames.js 文件中。
转化模块路径
得到了需要预加载的模块名还不够,我们还需要模块的绝对路径,所以接下来将会搞定它。添加 packager/generatemodulepaths.js 文件:
// @flow
/* eslint-disable no-console */
const execSync = require('child_process').execSync;
const fs = require('fs');
const moduleNames = require('./moduleNames');
const pjson = require('../package.json');
const localPrefix = `${pjson.name}/`;
const modulePaths = moduleNames.map(moduleName => {
if (moduleName.startsWith(localPrefix)) {
return `./${moduleName.substring(localPrefix.length)}`;
}
if (moduleName.endsWith('.js')) {
return `./node_modules/${moduleName}`;
}
try {
const result = execSync(
`grep "@providesModule ${moduleName}" $(find . -name ${moduleName}\\\\.js) -l`
)
.toString()
.trim()
.split('\n')[0];
if (result != null) {
return result;
}
} catch (e) {
return null;
}
return null;
});
const paths = modulePaths
.filter(path => path != null)
.map(path => `'${path}'`)
.join(',\n');
const fileData = `module.exports = [${paths}];`;
fs.writeFile('./packager/modulePaths.js', fileData, err => {
if (err) {
console.log(err);
}
console.log('Done');
});
你可以通过node packager/modulePaths.js来运行这段脚本。
此脚本尝试从模块名称映射到模块路径,但它不是万无一失的。例如,它忽略了平台特定的文件(_ ios.js 和_ .android.js)。然而根据最初的测试,它处理了 95%的情况。当它运行一段时间后,它应该完成并输出一个名为packager/modulePaths.js的文件。它应该包含相对于你的项目根目录的模块文件路径。您可以将 modulePaths.js 提交到您的代码仓库,以便它可以被传递。
更新配置文件
Returning to packager/config.js we should update it to use our newly generated modulePaths.js file.
const modulePaths = require('./modulePaths');
const resolve = require('path').resolve;
const fs = require('fs');
const config = {
getTransformOptions: () => {
const moduleMap = {};
modulePaths.forEach(path => {
if (fs.existsSync(path)) {
moduleMap[resolve(path)] = true;
}
});
return {
preloadedModules: moduleMap,
transform: { inlineRequires: { blacklist: moduleMap } },
};
},
};
module.exports = config;
配置文件中的 preloadedModules 条目指示哪些模块应被标记为由 unbundler 预加载。当 bundle 被加载时,这些模块立即被加载,甚至在任何 requires 执行之前。blacklist 表明这些模块不应该被要求内联引用,因为它们是预加载的,所以使用内联没有性能优势。实际上每次解析内联引用 JavaScript 都会花费额外的时间。
今天我们发布了 React 16.9。它包含了一些新特性、bug修复以及新的弃用警告,以便与筹备接下来的主要版本。
一年前,我们宣布 unsafe 生命周期方法重命名为:
componentWillMount → UNSAFE_componentWillMountcomponentWillReceiveProps → UNSAFE_componentWillReceivePropscomponentWillUpdate → UNSAFE_componentWillUpdateReact v16.9 不包含破坏性更改,而且旧的生命周期方法在此版本依然沿用。但是,当你在新版本中使用旧的生命周期方法时,会提示如下警告:
正如警告所示,对于每种 unsafe 的方法,通常有更好的解决方案。但你可能没有过多时间去迁移或测试这些组件。在这种情况下,我们建议运行一个自动重命名它们的 codemod 脚本:
cd your_project
npx react-codemod rename-unsafe-lifecycles(注意:这里使用的是 npx,不是 npm ,npx 是 Node 6+ 默认提供的实用程序。)
运行 codemod 将会替换旧的生命周期,如 componentWillMount 将会替换为 UNSAFE_componentWillMount :
新命名的生命周期(例如:UNSAFE_componentWillMount)在 React 16.9 和 React 17.x 继续使用,但是,新的 UNSAFE_ 前缀将帮助具有问题的组件在代码 review 和 debugging 期间脱颖而出。(如果你不喜欢,你可以引入 严格模式(Strict Mode)来进一步阻止开发人员使用它 。)
点击此链接,学习更多关于 版本策略以及稳定性承诺
以 javascript: 开头的 URL 很容易遭受攻击,因为它很容易意外在标签中(<a href>)引入未经处理的输出,造成安全漏洞。
const userProfile = {
website: "javascript: alert('you got hacked')",
};
// This will now warn:
<a href={userProfile.website}>Profile</a>在 React 16.9 中,这种模式将继续有效,但它将输出一个警告,如果你逻辑上需要使用 javascript: 开头的 URL,请尝试使用 React 事件处理程序代替。(万不得已,你可以使用 dangerouslySetInnerHTML 来规避保护,但仍然是不鼓励使用的并且往往会导致安全漏洞。)
在未来的主要版本中,如果遇到 javascript: 形式的 URL,React 将抛出错误。
在用 Babel 编译 JavaScript 类流行前,React 支持 “factory” 组件,它使用 render 方法返回一个对象。
function FactoryComponent() {
return { render() { return <div />; } }
}这种模式令人困惑,因为它看起来太像一个函数组件,但它不是一个。(函数组件只会返回像上述示例中的 <div /> )。
这种模式几乎从未在外部使用过,并且支持它会导致 React 变大、变慢。因此,我们在 16.9 中弃用此模式,并且遇到时,输出警告。如果你在项目中依赖此组件,可以添加 FactoryComponent.prototype = React.Component.prototype 作为解决方法。或者,你可以将它转换为 class 组件或函数组件。
我们预计大多数代码库不会受此影响。
act()React 16.8 引入了名为 act() 的新测试实用程序来帮助你编写更匹配浏览器行为的测试代码。例如,对单个 act() 中的多个状态更新进行批处理。这与 React 已有的处理真实浏览器事件时的工作方式相匹配,并有助于为将来 React 组件更频繁地批处理更新做准备。
然而,React v16.8 中的 act() 仅支持同步函数,有时,你可能在测试环境下看到以下警告,但无法轻易修复:
An update to SomeComponent inside a test was not wrapped in act(...).在 React 16.9 中 act() 支持异步函数 ,你可以在调用它时,使用 await :
await act(async () => {
// ...
});这将解决以前无法使用 act() 的情况,例如当 state 更新位于异步函数中时。因此,你现在应该能够测试中修复所有关于 act() 的警告了 。
我们听说,现在还没有足够的信息关于如何使用 act() 编写测试用例。新的测试技巧指南介绍了一些常见方案,以及 act() 如何帮助您编写良好的测试。这些示例使用原生 DOM API,但您也可以使用 React Testing Library 来减少样板代码。它的许多方法已经在内部使用 act() 。
如果你遇到 act() 的相关问题,请在问题跟踪器上告知我们,我们会尽力提供帮助。
<React.Profiler> 进行性能评估在 React 16.5 中,我们介绍了新的 React Profiler for DevTools 来帮助开发人员发现项目中的性能瓶颈。在 React 16.9 中,我们提供了一种编程的方式来收集测量你的代码,这就是 <React.Profiler> ,我们预计大多数较小的应用不会使用它,但在大型应用中跟踪性能回归会很方便。
<Profiler> 测量 React 应用程序渲染的频率以及渲染的 "成本" 。其目的是帮助识别应用程序中渲染缓慢的部分,并且可能更益与 memoization 等优化 。
可以将 <Profiler> 添加到 React 项目中的任意一个子树上,来测量该子树的渲染成本。它需要两个 props :id (string) 和 onRender 回调(function),当树中的组件"提交"更新时,React 将调用它。
render(
<Profiler id="application" onRender={onRenderCallback}>
<App>
<Navigation {...props} />
<Main {...props} />
</App>
</Profiler>
);要了解关于 Profiler 和传递给 onRender 回调的参数的更多详细信息,请查看 Profiler 文档。
注意:
Profiling会增加一些额外的开销,因此在生产构建中禁止使用它。如果想要在生产环境中进行性能分析,React 提供了特殊的生产构建,并启用了分析模式。在 fb.me/react-profiling 阅读更多关于如何使用此构建的更多信息。
此版本包含一些一些其他显著的提升:
<Suspense> 组件中调用 findDOMNode() 造成崩溃,已修复useEffect 中,使用 setState 引起的循环引用,现在会输出错误(这与在 class 组件中的 componentDidUpdate 使用 setState 导致的错误一致)感谢所有帮助解决这些问题的贡献者,你可以在此处找到完整的日志。
本文翻译自:https://reactjs.org/blog/2019/08/08/react-v16.9.0.html
在典型的 React 应用中, 数据 是通过 props 属性显式的由父及子进行 传递 的,但这种方式,对于复杂情况(例如,跨多级传递,多个组件共享)来说,是极其繁琐的。
第一种解决方式是: 组件的封装与组合,将组件自身传递下去
在项目中,我们在父层获取数据,不同层级的子组件访问时,我们可以使用 将子组件的公共组件封装,将公共组件传递下去 。例如
function Page(props) {
// 你可以传递多个子组件,甚至会为这些子组件(children)封装多个单独的接口(slots)
const localeCom = (
<span>{ props.locale }</span>
)
return (
<Content localeCom={localeCom} />
);
} // 这种情况下,只有顶层 Page 才知道 localeCom 的具体实现,实现了组件的控制反转
function Content(props) {
return (
<div>
<FirstComponent localeCom={localeCom} />
</div>
);
}
class FirstComponent extends React.Component {
render() {
return (
<div>FirstComponent: {this.props.localeCom}</div>
);
}
}这种对组件的 控制反转 减少了在应用中要传递的 props 数量,这在很多场景下会使得你的 代码更加干净 ,使你对根组件有更多的把控。但是,这并不适用于每一个场景: 将逻辑提升到组件树的更高层次来处理,会使得这些高层组件变得更复杂,并且会强行将低层组件提到高层实现,这很多时候有违常理。
第二种解决方式是:context
context 提供了一种在 组件之间共享此类值 的方式,使得我们无需每层显式添加 props 或传递组件 ,就能够实现在 组件树中传递数据 。
// Context 可以让我们无须显式地传遍每一个组件,就能将值深入传递进组件树。
// 为当前的 locale 创建一个 context(默认值为 anan)。
// context 会在每一个创建或使用 context 的组件上引入,所以,最好在单独一个文件中定义
// 这里只做演示
const LocaleContext = React.createContext('anan');
class App extends React.Component {
render() {
// 使用一个 Provider 来将当前的 name 传递给以下的组件树。
// 无论多深,任何组件都能读取这个值。
// 在这个例子中,我们将 “ananGe” 作为当前的值传递下去。
return ( // Provider 接收一个 value 属性,传递给消费组件
<LocaleContext.Provider value="ananGe">
<Content />
</LocaleContext.Provider>
);
}
}
// 中间的组件再也不必指明往下传递 locale 了。
// LocaleContext 分别在 FirstComponent 组件与 SecondComponent 的子组件 SubComponent 中使用
function Content(props) {
return (
<div>
<FirstComponent />
<SecondComponent />
</div>
);
}
// 第一个子组件
class FirstComponent extends React.Component {
// 指定 contextType 读取当前的 locale context。
// React 会往上找到最近的 locale Provider,然后使用它的值。
// 在这个例子中,当前的 locale 值为 ananGe
static contextType = LocaleContext;
render() {
return (
<div>FirstComponent: <span>{ this.context }</span></div>
);
}
}
// 第二个子组件(中间件)
function SecondComponent(props) {
return (
<div>
<SubComponent />
</div>
);
}
// SecondComponent 的子组件
class SubComponent extends React.Component {
static contextType = LocaleContext;
render() {
return (
<div>SubComponent: <span>{ this.context }</span></div>
); // this.context 为传递过来的 value 值
}
}注意:在大多数情况下,context 一般用来做 中间件 的方式使用,例如 redux。
React.createContext
const LocaleContext = React.createContext(defaultValue);
// 创建一个 Context 对象。当 React 渲染一个订阅了这个 Context 对象的组件,这个组件会从组件树中 离自身最近 的那个匹配的 Provider 中读取到当前的 context 值。Context.Provider
<LocaleContext.Provider value={/* 某个值 */}>Class.contextType
// 挂载在 SubComponent 上的 contextType 属性会被重赋值为 LocaleContext
SubComponent.contextType = LocaleContext;
// 使用 this.context 来消费最近 Context 上的那个值
let value = this.context;
// 你可以使用这种方式来获取 context value,也可以使用 Context.Consumer 函数式订阅获取Context.Consumer
// 在函数式组件中完成订阅 context
<LocaleContext.Consumer>
{value => /* 基于 context 值进行渲染*/}
</LocaleContext.Consumer><LocaleProvider.Provider value={{name: 'AnGe'}}>),因为这样会导致,每次 Provider 的父组件进行重渲染时,都会导致 Consumer 组件中重新渲染,因为 value 属性总是被赋值为新的对象(Object.is 新旧值检测)locale-context.js
export const locales = {
An: {
name: 'an',
color: 'red',
},
AnGe: {
name: 'anGe',
color: 'green',
},
}
export const LocaleContext = React.createContext(
locales.An // 默认值
)
// 确保传递给 createContext 的默认值数据结构是调用的组件(consumers)所能匹配的!
export const AddressContext = React.createContext({
address: 'Shanghai',
updateAddress: () => {}, // Consumer 更新 Provider value 函数
})app.js
import { locales, LocaleContext, AddressContext } from './locale-context';
import SubComponent from './SubComponent';
class App extends React.Component {
state = {
locale: locales.An,
address: 'Beijing',
}
// 更新 locale 函数
changePerson = () => {
this.setState(state => ({
locale:
state.locale === locales.An
? locales.AnGe
: locales.An,
}));
}
// 更新 address 函数
updateAddress = () => {
this.setState(state => ({
address:
state.address === 'Beijing'
? 'Shanghai'
: 'Beijing',
}));
}
render() {
const {
locale,
address,
} = this.state
// addressValue 包含了 updateAddress 更新函数
const addressValue = {
address: 'Beijing',
updateAddress: this.updateAddress
}
return (
<div>
// 在 LocaleProvider 内部的 SubComponent 组件使用 state 中的 locale 值
// 当 LocaleProvider 的 value 值发生变化时,它内部的所有消费组件都会重新渲染
<LocaleProvider.Provider value={locale}>
// addressValue 都被传递进 AddressContext.Provider
<AddressContext.Provider value={addressValue}>
<Toolbar changePerson={this.changePerson} />
</AddressContext.Provider>
</LocaleProvider.Provider>
// 而外部的组件,没有被 LocaleProvider.Provider 包裹,则使用默认的 locale 值
<div>
<SubComponent />
</div>
</div>
);
}
}
// 一个使用 SubComponent 的中间组件
function Toolbar(props) {
return (
<SubComponent onClick={props.changePerson}>
Change Person
</SubComponent>
);
}
ReactDOM.render(<App />, document.root);SubComponent.js
import { LocaleContext, AddressContext } from './locale-context';
class SubComponent extends React.Component {
render() {
const props = this.props;
return ( // 一个组件可能会消费多个 context
<LocaleContext.Consumer>
{locale => (
<div
{...props}
style={{color: locale.color}}
>
{locale.name}
<AddressContext.Consumer> // AddressContext.Consumer 可以从 context 中获取到 address 值 与 updateAddress 函数
{(address, updateAddress) => ( // 点击 button,执行 AddressContext.Provider 的 updateAddress 函数,更新 address
<button onClick={updateAddress}>{address}</button>
)}
</AddressContext.Consumer>
</div>
)}
</LocaleContext.Consumer>
);
}
}
export default SubComponent;export function createContext<T>(
defaultValue: T, // context 默认值
calculateChangedBits: ?(a: T, b: T) => number, // 计算新老 context 变化函数
): ReactContext<T> {
if (calculateChangedBits === undefined) {
calculateChangedBits = null;
} else {
if (__DEV__) {
warningWithoutStack(
calculateChangedBits === null ||
typeof calculateChangedBits === 'function',
'createContext: Expected the optional second argument to be a ' +
'function. Instead received: %s',
calculateChangedBits,
);
}
}
// 声明了一个 context 对象
const context: ReactContext<T> = {
$$typeof: REACT_CONTEXT_TYPE,
_calculateChangedBits: calculateChangedBits,
// As a workaround to support multiple concurrent renderers, we categorize
// some renderers as primary and others as secondary. We only expect
// there to be two concurrent renderers at most: React Native (primary) and
// Fabric (secondary); React DOM (primary) and React ART (secondary).
// Secondary renderers store their context values on separate fields.
_currentValue: defaultValue, // 用来记录 context 最新值,当 Provider value 更新时,同步到 _currentValue 上
_currentValue2: defaultValue,
// Used to track how many concurrent renderers this context currently
// supports within in a single renderer. Such as parallel server rendering.
_threadCount: 0,
// These are circular
Provider: (null: any), // context Provider
Consumer: (null: any), // context Consumer
};
context.Provider = { // context.Provider 的 _context 为 context
$$typeof: REACT_PROVIDER_TYPE,
_context: context,
};
let hasWarnedAboutUsingNestedContextConsumers = false;
let hasWarnedAboutUsingConsumerProvider = false;
if (__DEV__) {
// A separate object, but proxies back to the original context object for
// backwards compatibility. It has a different $$typeof, so we can properly
// warn for the incorrect usage of Context as a Consumer.
const Consumer = { //Consumer 的 _context 也为 context
$$typeof: REACT_CONTEXT_TYPE,
_context: context,
_calculateChangedBits: context._calculateChangedBits,
};
// $FlowFixMe: Flow complains about not setting a value, which is intentional here
Object.defineProperties(Consumer, {
Provider: {
get() {
if (!hasWarnedAboutUsingConsumerProvider) {
hasWarnedAboutUsingConsumerProvider = true;
warning(
false,
'Rendering <Context.Consumer.Provider> is not supported and will be removed in ' +
'a future major release. Did you mean to render <Context.Provider> instead?',
);
}
return context.Provider;
},
set(_Provider) {
context.Provider = _Provider;
},
},
_currentValue: {
get() {
return context._currentValue;
},
set(_currentValue) {
context._currentValue = _currentValue;
},
},
_currentValue2: {
get() {
return context._currentValue2;
},
set(_currentValue2) {
context._currentValue2 = _currentValue2;
},
},
_threadCount: {
get() {
return context._threadCount;
},
set(_threadCount) {
context._threadCount = _threadCount;
},
},
Consumer: {
get() {
if (!hasWarnedAboutUsingNestedContextConsumers) {
hasWarnedAboutUsingNestedContextConsumers = true;
warning(
false,
'Rendering <Context.Consumer.Consumer> is not supported and will be removed in ' +
'a future major release. Did you mean to render <Context.Consumer> instead?',
);
}
return context.Consumer;
},
},
});
// $FlowFixMe: Flow complains about missing properties because it doesn't understand defineProperty
context.Consumer = Consumer;
} else {
context.Consumer = context;
}
// Provider 与 Consumer 均指向 context,也就是说,Provider 与 Consumer 使用同一个变量 _currentValue,当 Consumer 需要渲染时,直接从自身取得 context 最新值 _currentValue 去渲染
if (__DEV__) {
context._currentRenderer = null;
context._currentRenderer2 = null;
}
return context;
}**生成器(Generator)**对象是ES6中新增的语法,和Promise一样,都可以用来异步编程。但与Promise不同的是,它不是使用JS现有能力按照一定标准制定出来的,而是一种新型底层操作,async/await就是在它的基础上实现的。
generator对象是由generator function返回的,符合可迭代协议和迭代器协议。
generator function 可以在JS单线程的背景下,使JS的执行权与数据自由的游走在多个执行栈之间,实现协同开发编程,当项目调用generator function时,会在内部开辟一个单独的执行栈,在执行一个generator function 中,可以暂停执行,或去执行另一个generator function,而当前generator function并不会销毁,而是处于一种被暂停的状态,当执行权回来的时候,再继续执行。
可迭代协议和迭代器协议都是ES6的补充
顾名思义,所谓迭代器对象就是满足迭代器协议的对象。
迭代器协议
迭代器协议定义了一种标准的方式来产生一个有限或无限序列的值。使的迭代器对象拥有一个next()对象,并有以下含义:
为了加深一下理解,下面贴出
迭代器构建版本一:Iterator的源码实现
// 源码实现
function createIterator(items) {
var i = 0
return {
next: function() {
var done = (i >= items.length)
var value = !done ? items[i++] : undefined
return {
done: done,
value: value
}
}
}
}
// 应用
var iterator = createIterator([1, 2, 3])
console.log(iterator.next()) // {value: 1, done: false}
console.log(iterator.next()) // {value: 2, done: false}
console.log(iterator.next()) // {value: 3, done: false}
console.log(iterator.next()) // {value: undefined, done: true}满足可迭代协议的对象就是可迭代对象。
可迭代协议:允许JS对象去定义或定制它们的迭代行为。
可迭代对象:该对象必须实现@@iterator方法,即这个对象或它原型链(prototype chain)上的某个对象必须有一个名字是Symbol.iterator的属性。
Symbol.iterator:返回一个对象的无参函数,被返回对象符合迭代器协议
在ES6中,所有的集合对象(Array、Set与Map)以及String、TypedArray、arguments都是可迭代对象,它们都有默认的迭代器。
当一个对象被迭代的时候,它的@@iterator方法被调用并且无参数,并返回一个值迭代器
扩展运算符
[...'abc'] // ["a", "b", "c"]
...['a', 'b', 'c'] // ["a", "b", "c"]yield*
function* generator() {
yield* ['a', 'b', 'c']
}
generator().next() // { value: "a", done: false }解构赋值
let [a, b, c] = new Set(['a', 'b', 'c'])
a // 'a'这里以for ...of为例子,加深对可迭代对象的理解
for...of接受一个可迭代对象(Iterable),或者能强制转换/包装成一个可迭代对象的值(如'abc')。遍历时,for...of会获取可迭代对象的[Symbol.iterator](),对该迭代器逐次调用next(),直到迭代器返回对象的done属性为true时,遍历结束,不对该value处理。
for...of循环实例:
var a = ['a', 'b', 'c', 'd', 'e']
for (var val of a) {
console.log(val)
}
// 'a' 'b' 'c' 'd' 'e'转换成普通的for循环实例,等价于上面for...of循环
var a = ["a", "b", "c", "d", "e"]
for (var val, ret, it = a[Symbol.iterator]();
(ret = it.next()) && !ret.done;
) {
val = ret.value
console.log(val)
}
// "a" "b" "c" "d" "e"在迭代器部分我们定义了一个简单的迭代器函数createIterator,但是该函数生成的迭代器部分并没有实现可迭代协议,所以不能在for...of等语法中使用。需要为该对象实现可迭代协议,
在[Symbol.iterator]函数中返回该迭代器自身。
function createIterator(items) {
var i = 0
return {
next: function () {
var done = (i >= items.length)
var value = !done ? items[i++] : undefined
return {
done: done,
value: value
}
}
[Symbol.iterator]: function () {
return this
}
}
}
var iterator = createIterator([1, 2, 3])
...iterator // 1, 2, 3添加[Symbol.iterator]使Object可迭代
根据可迭代协议,给Object的原型添加[Symbol.iterator],值为返回一个对象的无参函数,被返回对象符合迭代器协议。
Object.prototype[Symbol.iterator] = function () {
var i = 0
var items = Object.entries(this)
return {
next: function () {
var done = (i >= items.length)
var value = !done ? items[i++] : undefined
return {
done: done,
value: value
}
}
}
}使用生成器简化代码
Object.prototype[Symbol.iterator] = function* () {
for (const key in this) {
if (this.hasOwnPrototype(key)) {
yield [key, this[key]]
}
}
}接着上一部分继续了解JS 基础之异步(四):Generator(生成器、迭代器源码实现)
function *会定义一个生成器函数,并返回一个Generator(生成器)对象,其内部可以通过 yield 暂停代码,通过调用 next 恢复执行。
调用一个生成器对象并不会马上执行里面的代码语句,而是返回一个这个生成器的迭代器(iterator)对象。当这个迭代器对象的next() 方法被调用时,其内部的语句就会被执行到yield的位置,yield后紧跟需要返回的值(可以是函数或表达式)。如果遇到的yield为yield*的话,则表示将执行权交给另一个生成器函数(当前生成器暂停执行)。
注意:
yield/yield*命令,而generator function内部调用的或声明的其他普通函数是不能调用yield/yield*命令的。yield,即箭头函数不能用做generator function(但可以用做async function)// 声明式
function* generator() {}
// 表达式
let generator = function* (){}
// 作为对象属性
let obj = {
generator: function* (){}
}
// 箭头函数不能用做generator function,报错
let obj = {
generator: *() => {}
}
// 箭头函数可以用做 async 函数
let obj = {
generator: async () => {}
}在生成器中return
遍历返回对象的done值为true时迭代即结束,不对该value处理。
function* createIterator() {
yield 'a'
return 1
yield 'b'
}
let iterator = createIterator()
iterator.next() // {value: "a", done: false}
iterator.next() // {value: 1, done: true}
iterator.next() // {value: undefined, done: true}所以对这个迭代器遍历,不会对值1处理。当在生成器函数中显式 return 时,会导致生成器立即变为完成状态,即调用 next() 方法返回的对象的 done 为 true。如果 return 后面跟了一个值,那么这个值会作为当前调用 next() 方法返回的 value 值,若 return 后面没有跟任何值,则返回 undefined,相当于默认 return undefined。
注意:生成器函数不能当构造函数使用
function* f() {}
var obj = new f; // throws "TypeError: f is not a constructor"Generator对象(生成器对象)既是迭代器,又是可迭代对象。
function* generator() {
yield 'a'
yield 'b'
yield 'c'
}
var gen = generator()
// 满足迭代器协议,是迭代器
gen.next() // {value: "a", done: false}
gen.next() // {value: "b", done: false}
gen.next() // {value: "c", done: false}
gen.next() // {value: undefined, done: true}
// [Symbol.iterator]是一个无参函数,该函数执行后返回生成器对象本身(是迭代器),所以是可迭代对象
gen[Symbol.iterator]() === gen // true
// 可以被迭代
var gen1 = generator()
[...gen1] // ["a", "b", "c"]先看一个例子
function* generator() {
var val = yield 1
return val + 1
}
var gen = generator()
var gen1 = gen.next
console.log('1: ', gen1.value)
gen1 = gen.next
console.log('2: ', gen1.value)
gen1 = gen.next
console.log('3: ', gen1.value)
// output: 1 NaN undefined为什么会这样喃?这是因为调用 next()方法时,如果传入了参数,那么这个参数会作为上一条执行的 yield 语句的返回值。如果没有,则上一条执行的 yield 语句的返回值默认为 NaN,因为在处理的时候,我们没有给 next 函数传值,导致 yield 语句返回值为 NaN,则 val 为NaN,NaN + 1 当然也是 NaN了。
yield * 也称为 yield 委托。作用是将执行权交给另一个生成器或可迭代对象。(当前生成器暂停执行)。yield* 表达式迭代操作数,并产生它返回的每个值。
下面看一个例子:
function* generator(index) {
yield index + 1
yield index + 2
yield index + 3
}
function* mainGenerator(index) {
yield index
yield* generator(index)
yield index + 100
}
var gen = mainGenerator(1)
console.log(gen.next().value) // 1
console.log(gen.next().value) // 2
console.log(gen.next().value) // 3
console.log(gen.next().value) // 4
console.log(gen.next().value) // 101注意:yield* 是一个表达式,不是语句,所以它会有自己的值,即为当前迭代器关闭时返回的值(即done为true时)。
function* gnerator1() {
yield* [1, 2, 3];
return "gnerator1";
}
var result;
function* gnerator2() {
result = yield* gnerator1();
}
var iterator = gnerator2();
console.log(iterator.next()); // { value: 1, done: false }
console.log(iterator.next()); // { value: 2, done: false }
console.log(iterator.next()); // { value: 3, done: false }
console.log(iterator.next()); // { value: undefined, done: true },
// 此时 g4() 返回了 { value: "foo", done: true }
console.log(result); // "foo"下面看一个例子:
function asyncFun() {
return new Promise((resolve, reject) => {
setTimeout(()=>{
resolve('promise')
}, 3000)
})
}
function *generator() {
var result = yield asyncFun()
console.log(result)
}在这个例子中,yield 后跟着一个异步函数 asyncFun ,我们如何操作才能使整个流程顺序执行喃?
var gen = generator()
var afun = gen.next()
afun.value.then( res => {
console.log(res)
}).then( res => {
gen.next('success')
})
// 3s后打印:promise success上面代码中,首先执行 Generator 函数,获取遍历器对象 gen,然后使用next方法 ,执行异步任务的第一阶段。由于 asyncFun 函数返回的是一个 Promise 对象,因此要用then方法调用下一个next方法。
// cb 也就是编译过的 test 函数
function generator(cb) {
return (function() {
var object = {
next: 0,
stop: function() {}
}
return {
next: function() {
var ret = cb(object)
if (ret === undefined) return {value: undefined, done: true}
return {
value: ret,
done: false
}
}
}
})()
}
// 如果你使用babel编译后,可以发现 test 函数变成了这样
function test() {
var a
return generator(function(_context) {
while (1) {
switch ((_context.prev = _context.next)) {
// 可以发现通过 yield 将代码分割成几块
// 每次执行 next 函数就执行一块代码
// 并且表明下次需要执行那块代码
case 0:
a = 1 + 2
_context.next = 4
return 2
case 4:
_context.next = 6
return 3
// 执行完毕
case 6:
case "end":
return _context.stop()
}
}
})
}使用CSS实现背景色渐变、边框渐变,字体渐变的效果。
.bg-block {
background: linear-gradient(to bottom, #F80, #2ED);
}效果如图:
image.png
linear-gradient: ([ | to , ]? [, + ])
angle | side-to corner 定义了渐变线,to-bottom 等同于180deg, to-top 等同于0deg。
color-stop 定义渐变的颜色,可以使用百分比指定渐变长度。比如:
background: linear-gradient(180deg, #F80 70%, #2ED);
则变成了酱子:
image.png
背景色渐变非常简单,但上面的css代码中,linear-gradient是加在background属性上的。于是测试下具体是加在了哪个属性上,首先感性上就觉得是加在了background-color上,修改代码background为background-color之后,果然,渐变色没有了。
仔细看下linear-gradient的定义:
Thelinear-gradient()function creates an image consisting of a progressive transition between two or more colors along a straight line. Its result is an object of the data type, which is a special kind of []
于是,这应该是个image了,修改代码background为background-image,结果渐变色保持如上图。
字体渐变
字体渐变没那么容易想到了,参考了张鑫旭大神的文章,实现如下:
.font-block {
font-size: 48px;
background-image: linear-gradient(to bottom,#F80, #2ED);
-webkit-background-clip: text;
-webkit-text-fill-color: transparent;
}
效果如下:
image.png
这种字体渐变的方法可以这么理解:字体本身是有颜色的,先让字体本身的颜色变透明(text-fill-color为transparent),然后添加渐变的背景色(background-image: line-gradient...),但是得让背景色作用在字体上(background-clip: text)。
要注意的是:
text-fill-color 是个非标准属性,但多数浏览器支持带-webkit前缀,所以使用时需要带上-webkit前缀。
background-clip属性虽然多数浏览器已经支持,但text属性值浏览器支持还需要加-webkit前缀。(参考这里:https://developer.mozilla.org...)
以上两条,通常使用postcss时是不会自动加前缀的,所以也就不能偷懒。
要注意-webkit-text-fill-color: transparent对字体带来的影响,因为设置了透明,笔者在使用时踩了坑,同时使用了text-overflow: ellipsis; 这个时候是看不到点点点的。
边框渐变
.border-block {
border: 10px solid transparent;
border-image: linear-gradient(to top, #F80, #2ED);
border-image-slice: 10;
}
实现效果如下:
image.png
给border-image加linear-gradient不难理解,但是如果单纯使用border-image,会发现效果是这样的:
image.png
所以关键作用是border-image-slice属性。
先看下border-image属性。
border-image是border-image-source, border-image-slice, border-image-width, border-image-outset, border-image-repeat的简写。
border-image-source 属性可以给定一个url作为边框图像,类似background-image: url的用法;
border-image-slice是指将边框图片切成9份,四个角四个边,和一个中心区域。被切割的9个部分分布在边框的9个区域。
image.png
当盒子宽度和被切图像的宽度不相等时,四个顶角的变化具有一定的拉伸效果。border-image-slice属性默认值是100%,这个百分比是相对于边框图像的宽高来的,当左右切片宽度之和>100%时,5号7号就显示空白,因此使用默认值无法看到被填满的边框图片。关于boder-image具体可以参考这篇References第一篇文章,讲的比较详细。
References
1.CSS3边框图片详解:http://www.360doc.com/content...
2.linear-gradient MDN:
https://developer.mozilla.org...
众所周知,微信的wxml页面不支持html标签,现有的插件如wxParse只能进行富文本的解析。那么如何构建一个富文本编辑器喃,这里,我简单的写了一个。
其中包括,添加文本、语音、图片、图片集 以及 视频。
功能操作包括上移下移与删除
git地址wxRichEditor,暂定这些,后期会不断更新
React的官方介绍是这样的:
In the typical React dataflow, props are the only way that parent components interact with their children. To modify a child, you re-render it with new props. However, there are a few cases where you need to imperatively modify a child outside of the typical dataflow. The child to be modified could be an instance of a React component, or it could be a DOM element. For both of these cases, React provides an escape hatch.
其中提到了这几个概念:
在典型的React数据流理念中,父组件跟子组件的交互都是通过传递属性(properties)实现的。如果父组件需要修改子组件,只需要将新的属性传递给子组件,由子组件来实现具体的绘制逻辑。
在特殊的情况下,如果你需要命令式(imperatively)的修改子组件,React也提供了应急的处理办法--Ref。
Ref 既支持修改DOM元素,也支持修改自定义的组件。
值得一提的是当中声明式编程(Declarative Programming)和命令式编程(Imperative Programming)的区别。声明式编程的特点是只描述要实现的结果,而不关心如何一步一步实现的,而命令式编程则相反,必须每个步骤都写清楚。我们可以根据语义直观的理解代码的功能是:针对数组的每一个元素,将它的值打印出来。不必关心实现其的细节。而命令式编程必须将每行代码读懂,然后再整合起来理解总体实现的功能。
React有2个基石设计理念:一个是声明式编程,一个是函数式编程。函数式编程以后有机会再展开讲。声明式编程的特点体现在2方面:
组件定义的时候,所有的实现逻辑都封装在组件的内部,通过state管理,对外只暴露属性。
组件使用的时候,组件调用者通过传入不同属性的值来达到展现不同内容的效果。一切效果都是事先定义好的,至于效果是怎么实现的,组件调用者不需要关心。
因此,在使用React的时候,一般很少需要用到Ref。那么,Ref的使用场景又是什么?
React官方文档是这么说的:
There are a few good use cases for refs: Managing focus, text selection, or media playback.Triggering imperative animations.Integrating with third-party DOM libraries. Avoid using refs for anything that can be done declaratively.
简单理解就是,控制一些DOM原生的效果,如输入框的聚焦效果和选中效果等;触发一些命令式的动画;集成第三方的DOM库。最后还补了一句:如果要实现的功能可以通过声明式的方式实现,就不要借助Ref。
通常我们会利用 render 方法得到一个 App 组件的实例,然后就可以对它做一些操作。但在组件内,JSX 是不会返回一个组件的实例的,它只是一个ReactElement,只是告诉你,React被挂载的组件应该涨什么样:
const myApp = <App />refs就是由此而生,它是React组件中非常特殊的props, 可以附加到任何一个组件上,从字面意思上看,refs即reference,组件被调用时会创建一个该组件的实例,而refd就会指向这个实例。
如果作用在原生的DOM元素上,通过Ref获取的是DOM元素,可以直接操作DOM的API:
class CustomTextInput extends React.Component {
constructor(props) {
super(props);
this.focusTextInput = this.focusTextInput.bind(this);
}
focusTextInput() {
if(this.myTextInput !== null) {
this.textInput.current.focus();
}
}
render() {
return (
<div>
<input type="text" ref={(ref) => this.myTextInput = ref} />
<input type="button" value="Focus the text input" onClick={this.focusTextInput}/>
</div>
);
}
}如果作用在自定义组件,Ref获取的是组件的实例,可以直接操作组件内的任意方法:
class AutoFocusTextInput extends React.Component {
constructor(props) {
super(props);
this.textInput = React.createRef();
}
componentDidMount() {
this.textInput.current.focusTextInput();
}
render() {
return (
<CustomTextInput ref={this.textInput} />
);
}
}为了防止内存泄漏,当卸载一个组件时,组件里所有的refs就会变成null。
值得注意的是,findDOMNode 和 refs 都无法用于无状态组件中。因为,无状态组件挂载时只是方法调用,并没有创建实例。
对于 React 组件来讲,refs 会指向一个组件类实例,所以可以调用该类定义的任何方法。如果需要访问该组件的真实 DOM ,可以用 ReactDOM 。 findDOMNode来找到 DOM 节点,但并不推荐这样做,因为这大部分情况下都打破了封装性,而且通常都能用更清晰的方法在React中构建代码。
Proxy,代理,是ES6新增的功能,可以理解为代理器(即由它代理某些操作)。
Proxy 对象用于定义或修改某些操作的自定义行为,可以在外界对目标对象进行访问前,对外界的访问进行改写。
var proxy = new Proxy(target, handler)new Proxy()表示生成一个 Proxy 实例
注意:要实现拦截操作,必须是对 Proxy 实例进行操作,而不是针对目标对象 target 进行操作。
首先,看个例子:
let handler = {
get: function(target, key, receiver) {
console.log(`getter ${key}!`)
return Reflect.get(target, key, receiver)
},
set: function(target, key, value, receiver) {
console.log(`setter ${key}=${value}`)
return Reflect.set(target, key, value, receiver)
}
}
var obj = new Proxy({}, handler)
obj.a = 1 // setter a=1
obj.b = undefined // setter b=undefined
console.log(obj.a, obj.b)
// getter a!
// getter b!
// 1 undefined
console.log('c' in obj, obj.c)
// getter c!
// false undefined在这个例子中,proxy 拦截了get和set操作。
再看一个例子:
let handler = {
get: function(target, key, receiver) {
return 1
},
set: function (target, key, value, receiver) {
console.log(`setting ${key}!`);
return Reflect.set(target, key, value, receiver);
}
}
var obj = new Proxy({}, handler)
obj.a = 5 // setting a!
console.log(obj.a) // 1则由上面代码看出:Proxy 不仅是拦截了行为,更是用自己定义的行为覆盖了组件的原始行为。
**若handler = {},则代表 Proxy 没有做任何拦截,访问 Proxy 实例就相当于访问 target 目标对象。**这里不再演示,有兴趣的可以自己举例尝试。
get(target, key, receiver):拦截 target 属性的读取set(target, key, value, receiver):拦截 target 属性的设置has(target, key):拦截 key in proxy 的操作,并返回是否存在(boolean值)deleteProperty(target, key):拦截 delete proxy[key]的操作,并返回结果(boolean值)ownKeys(target):拦截Object.getOwnPropertyName(proxy)、Object.getOwnPropertySymbols(proxy)、Object.keys(proxy)、for ... in循环。并返回目标对象所有自身属性的属性名数组。注意:Object.keys()的返回结果数组中只包含目标对象自身的可遍历属性getOwnPropertyDescriptor(target, key):拦截 Object.getOwnPropertyDescriptor(proxy, key),返回属性的描述对象defineProperty(target, key, desc):拦截Object.defineProperty(proxy, key, desc)、Object.defineProperties(proxy, descs),返回一个 boolean 值preventExtensions(target):拦截Object.preventExtensions(proxy),返回一个 boolean 值getPrototypeOf(target):拦截Object.getPrototypeOf(proxy),返回一个对象isExtensible(target):拦截Object.isExtensible(proxy),返回一个 boolean 值setPrototypeOf(target, key):拦截Object.setPrototypeOf(proxy, key),返回一个 boolean 值。如果目标对象是函数,则还有两种额外操作可以被拦截apply(target, object, args):拦截 Proxy 实例作为函数调用的操作,比如proxy(...args)、proxy.call(object, ...args)、proxy.apply(...)construct(target, args):拦截 Proxy 实例作为构造函数调用的操作,比如new proxy(...args)总共 13 个拦截方法,下面进行简要举例说明,更多可见阮一峰老师的 《ECMAScript 6 入门》
get方法用于拦截某个属性的读取操作,可以接受三个参数,依次为目标对象、属性名和 proxy 实例本身(严格地说,是操作行为所针对的对象),其中最后一个参数可选。
set拦截 target 属性的设置,可以接受四个参数,依次为目标对象、属性名、value和 proxy 实例本身(严格地说,是操作行为所针对的对象),其中最后一个参数可选。
let target = {foo: 1}
let proxy = new Proxy(target, {
get(target, key, receiver) {
console.log(`getter ${key}!`)
return target[key]
},
set: function(target, key, value, receiver) {
console.log(`setter ${key}!`)
target[key] = value;
}
})
let obj = Object.create(proxy)
console.log(obj.foo)
// getter foo!
// 1拦截 propKey in proxy 的操作,返回一个布尔值。
// 使用 has 方法隐藏某些属性,不被 in 运算符发现
var handler = {
has (target, key) {
if (key.startsWith('_')) {
return false;
}
return key in target;
}
};
var foo = { _name: 'foo', name: 'foo' };
var proxy = new Proxy(foo, handler);
console.log('_name' in proxy); // false
console.log('name' in proxy); // true拦截自身属性的读取操作。并返回目标对象所有自身属性的属性名数组。具体返回结果可结合 MDN 属性的可枚举性和所有权
Object.getOwnPropertyName(proxy)Object.getOwnPropertySymbols(proxy)Object.keys(proxy)for ... in循环let target = {
_foo: 'foo',
_bar: 'bar',
name: 'An'
};
let handler = {
ownKeys (target) {
return Reflect.ownKeys(target).filter(key => key.startsWith('_'));
}
};
let proxy = new Proxy(target, handler);
for (let key of Object.keys(proxy)) {
console.log(target[key]);
}
// "An"apply 拦截 Proxy 实例作为函数调用的操作,比如函数的调用(proxy(...args))、call(proxy.call(object, ...args))、apply(proxy.apply(...))等。
var target = function () { return 'I am the target'; };
var handler = {
apply: function () {
return 'I am the proxy';
}
};
var proxy = new Proxy(target, handler);
proxy();
// "I am the proxy"Proxy 方法太多,这里只是将常用的简要介绍,更多请看阮一峰老师的 《ECMAScript 6 入门》
Set 和 Map 主要的应用场景在于 数据重组 和 数据储存
Set 是一种叫做集合的数据结构,Map 是一种叫做字典的数据结构
ES6 新增的一种新的数据结构,类似于数组,但成员是唯一且无序的,没有重复的值。
Set 本身是一种构造函数,用来生成 Set 数据结构。
new Set([iterable])举个例子:
const s = new Set()
[1, 2, 3, 4, 3, 2, 1].forEach(x => s.add(x))
for (let i of s) {
console.log(i) // 1 2 3 4
}
// 去重数组的重复对象
let arr = [1, 2, 3, 2, 1, 1]
[... new Set(arr)] // [1, 2, 3]Set 对象允许你储存任何类型的唯一值,无论是原始值或者是对象引用。
向 Set 加入值的时候,不会发生类型转换,所以5和"5"是两个不同的值。Set 内部判断两个值是否不同,使用的算法叫做“Same-value-zero equality”,它类似于精确相等运算符(===),主要的区别是** Set 认为NaN等于自身,而精确相等运算符认为NaN不等于自身。**
let set = new Set();
let a = NaN;
let b = NaN;
set.add(a);
set.add(b);
set // Set {NaN}
let set1 = new Set()
set1.add(5)
set1.add('5')
console.log([...set1]) // [5, "5"]Set 实例属性
constructor: 构造函数
size:元素数量
let set = new Set([1, 2, 3, 2, 1])
console.log(set.length) // undefined
console.log(set.size) // 3Set 实例方法
add(value):新增,相当于 array里的push
delete(value):存在即删除集合中value
has(value):判断集合中是否存在 value
clear():清空集合
let set = new Set()
set.add(1).add(2).add(1)
set.has(1) // true
set.has(3) // false
set.delete(1)
set.has(1) // falseArray.from 方法可以将 Set 结构转为数组
const items = new Set([1, 2, 3, 2])
const array = Array.from(items)
console.log(array) // [1, 2, 3]
// 或
const arr = [...items]
console.log(arr) // [1, 2, 3]keys():返回一个包含集合中所有键的迭代器
values():返回一个包含集合中所有值得迭代器
entries():返回一个包含Set对象中所有元素得键值对迭代器
forEach(callbackFn, thisArg):用于对集合成员执行callbackFn操作,如果提供了 thisArg 参数,回调中的this会是这个参数,没有返回值
let set = new Set([1, 2, 3])
console.log(set.keys()) // SetIterator {1, 2, 3}
console.log(set.values()) // SetIterator {1, 2, 3}
console.log(set.entries()) // SetIterator {1, 2, 3}
for (let item of set.keys()) {
console.log(item);
} // 1 2 3
for (let item of set.entries()) {
console.log(item);
} // [1, 1] [2, 2] [3, 3]
set.forEach((value, key) => {
console.log(key + ' : ' + value)
}) // 1 : 1 2 : 2 3 : 3
console.log([...set]) // [1, 2, 3]Set 可默认遍历,默认迭代器生成函数是 values() 方法
Set.prototype[Symbol.iterator] === Set.prototype.values // true所以, Set可以使用 map、filter 方法
let set = new Set([1, 2, 3])
set = new Set([...set].map(item => item * 2))
console.log([...set]) // [2, 4, 6]
set = new Set([...set].filter(item => (item >= 4)))
console.log([...set]) //[4, 6]因此,Set 很容易实现交集(Intersect)、并集(Union)、差集(Difference)
let set1 = new Set([1, 2, 3])
let set2 = new Set([4, 3, 2])
let intersect = new Set([...set1].filter(value => set2.has(value)))
let union = new Set([...set1, ...set2])
let difference = new Set([...set1].filter(value => !set2.has(value)))
console.log(intersect) // Set {2, 3}
console.log(union) // Set {1, 2, 3, 4}
console.log(difference) // Set {1}WeakSet 对象允许你将弱引用对象储存在一个集合中
WeakSet 与 Set 的区别:
属性:
constructor:构造函数,任何一个具有 Iterable 接口的对象,都可以作参数
const arr = [[1, 2], [3, 4]]
const weakset = new WeakSet(arr)
console.log(weakset)
方法:
var ws = new WeakSet()
var obj = {}
var foo = {}
ws.add(window)
ws.add(obj)
ws.has(window) // true
ws.has(foo) // false
ws.delete(window) // true
ws.has(window) // false集合 与 字典 的区别:
const m = new Map()
const o = {p: 'haha'}
m.set(o, 'content')
m.get(o) // content
m.has(o) // true
m.delete(o) // true
m.has(o) // false任何具有 Iterator 接口、且每个成员都是一个双元素的数组的数据结构都可以当作Map构造函数的参数,例如:
const set = new Set([
['foo', 1],
['bar', 2]
]);
const m1 = new Map(set);
m1.get('foo') // 1
const m2 = new Map([['baz', 3]]);
const m3 = new Map(m2);
m3.get('baz') // 3如果读取一个未知的键,则返回undefined。
new Map().get('asfddfsasadf')
// undefined
注意,只有对同一个对象的引用,Map 结构才将其视为同一个键。这一点要非常小心。
const map = new Map();
map.set(['a'], 555);
map.get(['a']) // undefined
上面代码的set和get方法,表面是针对同一个键,但实际上这是两个值,内存地址是不一样的,因此get方法无法读取该键,返回undefined。
由上可知,Map 的键实际上是跟内存地址绑定的,只要内存地址不一样,就视为两个键。这就解决了同名属性碰撞(clash)的问题,我们扩展别人的库的时候,如果使用对象作为键名,就不用担心自己的属性与原作者的属性同名。
如果 Map 的键是一个简单类型的值(数字、字符串、布尔值),则只要两个值严格相等,Map 将其视为一个键,比如0和-0就是一个键,布尔值true和字符串true则是两个不同的键。另外,undefined和null也是两个不同的键。虽然NaN不严格相等于自身,但 Map 将其视为同一个键。
let map = new Map();
map.set(-0, 123);
map.get(+0) // 123
map.set(true, 1);
map.set('true', 2);
map.get(true) // 1
map.set(undefined, 3);
map.set(null, 4);
map.get(undefined) // 3
map.set(NaN, 123);
map.get(NaN) // 123
Map 的属性及方法
属性:
constructor:构造函数
size:返回字典中所包含的元素个数
const map = new Map([
['name', 'An'],
['des', 'JS']
]);
map.size // 2操作方法:
遍历方法
const map = new Map([
['name', 'An'],
['des', 'JS']
]);
console.log(map.entries()) // MapIterator {"name" => "An", "des" => "JS"}
console.log(map.keys()) // MapIterator {"name", "des"}Map 结构的默认遍历器接口(Symbol.iterator属性),就是entries方法。
map[Symbol.iterator] === map.entries
// true
Map 结构转为数组结构,比较快速的方法是使用扩展运算符(...)。
对于 forEach ,看一个例子
const reporter = {
report: function(key, value) {
console.log("Key: %s, Value: %s", key, value);
}
};
let map = new Map([
['name', 'An'],
['des', 'JS']
])
map.forEach(function(value, key, map) {
this.report(key, value);
}, reporter);
// Key: name, Value: An
// Key: des, Value: JS在这个例子中, forEach 方法的回调函数的 this,就指向 reporter
与其他数据结构的相互转换
Map 转 Array
const map = new Map([[1, 1], [2, 2], [3, 3]])
console.log([...map]) // [[1, 1], [2, 2], [3, 3]]Array 转 Map
const map = new Map([[1, 1], [2, 2], [3, 3]])
console.log(map) // Map {1 => 1, 2 => 2, 3 => 3}Map 转 Object
因为 Object 的键名都为字符串,而Map 的键名为对象,所以转换的时候会把非字符串键名转换为字符串键名。
function mapToObj(map) {
let obj = Object.create(null)
for (let [key, value] of map) {
obj[key] = value
}
return obj
}
const map = new Map().set('name', 'An').set('des', 'JS')
mapToObj(map) // {name: "An", des: "JS"}Object 转 Map
function objToMap(obj) {
let map = new Map()
for (let key of Object.keys(obj)) {
map.set(key, obj[key])
}
return map
}
objToMap({'name': 'An', 'des': 'JS'}) // Map {"name" => "An", "des" => "JS"}Map 转 JSON
function mapToJson(map) {
return JSON.stringify([...map])
}
let map = new Map().set('name', 'An').set('des', 'JS')
mapToJson(map) // [["name","An"],["des","JS"]]JSON 转 Map
function jsonToStrMap(jsonStr) {
return objToMap(JSON.parse(jsonStr));
}
jsonToStrMap('{"name": "An", "des": "JS"}') // Map {"name" => "An", "des" => "JS"}WeakMap 对象是一组键值对的集合,其中的键是弱引用对象,而值可以是任意。
注意,WeakMap 弱引用的只是键名,而不是键值。键值依然是正常引用。
WeakMap 中,每个键对自己所引用对象的引用都是弱引用,在没有其他引用和该键引用同一对象,这个对象将会被垃圾回收(相应的key则变成无效的),所以,WeakMap 的 key 是不可枚举的。
属性:
方法:
let myElement = document.getElementById('logo');
let myWeakmap = new WeakMap();
myWeakmap.set(myElement, {timesClicked: 0});
myElement.addEventListener('click', function() {
let logoData = myWeakmap.get(myElement);
logoData.timesClicked++;
}, false);Object 与 Set
// Object
const properties1 = {
'width': 1,
'height': 1
}
console.log(properties1['width']? true: false) // true
// Set
const properties2 = new Set()
properties2.add('width')
properties2.add('height')
console.log(properties2.has('width')) // trueObject 与 Map
JS 中的对象(Object),本质上是键值对的集合(hash 结构)
const data = {};
const element = document.getElementsByClassName('App');
data[element] = 'metadata';
console.log(data['[object HTMLCollection]']) // "metadata"但当以一个DOM节点作为对象 data 的键,对象会被自动转化为字符串[Object HTMLCollection],所以说,Object 结构提供了 字符串-值 对应,Map则提供了 值-值 的对应
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.