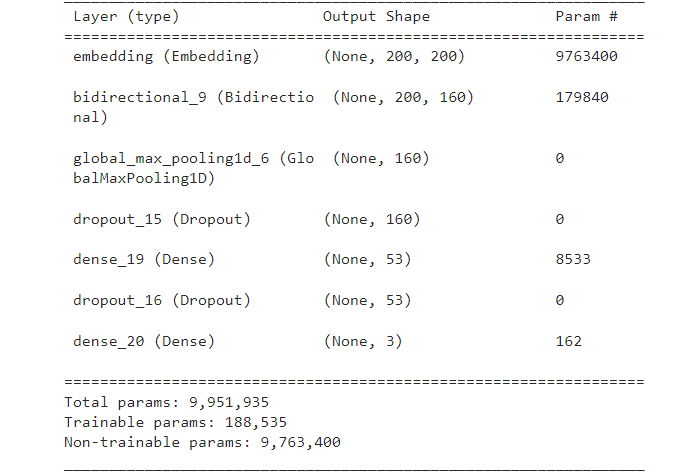
Covid 19 is a highly contagious disease caused by a virus known as SARS-CoV-2. The task of this project is to build a model for Text Classification task based on sentiments from Twitter data about Covid19. The dataset used contains 4 attributes, one of them being the sentiment associated with the tweets.The final model with the best performance for this multiclass classification task is Bidirectional LSTM with dense layers with a test accuracy of 80%. The model summary is as follows-
- First 10 rows
- Last 10 rows
- Information about data
- Number of missing values in data
- Number of duplicate values in data
- Number of unique values in columns
- Count of unique values for the column Sentiment
- Places of missing values in data
- Barplot for the top 20 places with most tweets
- Percentage distribution of tweets from top 20 locations
- Countplot for different classes
- Countplot for tweets on different dates
- Countplot for different classes of tweets on different days
- Merging five classes into three prominent classes
- Removing all links,mentions and special characters
- Removing stop words
- Generating wordcloud to see the most frequent words for each class
- Lemmatizing the data
- Tokenizing the text
- Replacing each word with its corresponding integer value from the word_index and padding it to make the data equal in length
- One hot encoding the classes
- Getting embeddings from GloVe model for our data
- Bidirectional LSTM
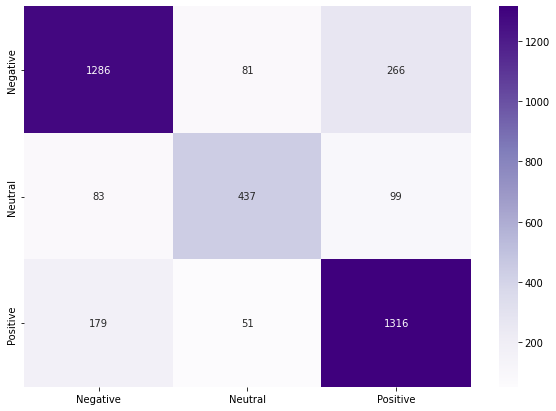
Accuracy: 0.8001579778830964
precision recall f1-score support
Negative 0.83 0.79 0.81 1633
Neutral 0.77 0.71 0.74 619
Positive 0.78 0.85 0.82 1546
micro avg 0.80 0.80 0.80 3798 macro avg 0.79 0.78 0.79 3798 weighted avg 0.80 0.80 0.80 3798 samples avg 0.80 0.80 0.80 3798